Перекрестная ссылка на родственные заявки
[0001] Согласно настоящей заявке испрашивается приоритет согласно заявке на патент Китайской Народной Республики №201911051711.0, поданной 31 октября 2019 г., содержание которой полностью включено в настоящий документ посредством ссылки.
Область техники, к которой относится настоящее изобретение
[0002] Настоящее раскрытие относится к области технологий модерации видеоматериалов и, в частности, относится к способу и устройству для обучения модели модерации контента, способу и устройству модерации видеоконтента, и вычислительному устройству и запоминающему устройству.
Предшествующий уровень техники настоящего изобретения
[0003] В последние годы с развитием интернет-технологий трафик видеоматериалов в Интернете резко возрастает, и пользовательский контент (UGC), например, короткие видеоматериалы, онлайн трансляции и т.п., приводит к тому, что Интернет все более насыщается видеоматериалами.
[0004] Также в этой ситуации создают и пытаются распространять в Интернете множество видеоматериалов с недопустимым контентом, например, видеоматериалы терроризма, насилия, порнографии, азартных игр и т.п.
[0005] Поэтому до или после публикации видеоматериала контент этого видеоматериала необходимо модерировать и отфильтровывать видеоматериалы с недопустимым контентом.
[0006] В одном варианте видеоресурс, загруженный в Интернет, модерируют вручную, чтобы определить содержит ли он недопустимый контент. Однако при увеличении количества видеоресурсов в Интернете модерация видеоконтента вручную занимает много времени и менее эффективна. Поэтому подходом к решению задачи модерирования видеоконтента может быть подход машинного обучения. Согласно этому подходу, если видеоданные (кадр изображения) в обучающем видеоматериале являются недопустимыми, эти видеоданные вначале помечают как относящиеся к категории нарушения, а затем видеоданные и соответствующую категорию недопустимого контента вводят в модель машинного обучения для обучения, и при помощи обученной модели выявляют другой видеоконтент.
[0007] Однако когда видеоданные для обучения помечают в каждом видеоматериале, количество видеоданных велико, операция присвоения меток может быть трудоемкой, это приводит к низкой эффективности обучения модели и модерирования видеоматериала при помощи этого модуля, а также к повышению затрат на обучение модели из-за присвоения меток вручную.
Краткое описание настоящего изобретения
[0008] Варианты осуществления настоящего изобретения обеспечивают способ и устройство для обучения модели модерации контента, способ и устройство для модерации видеоконтента, и вычислительное устройство и запоминающее устройство, с тем чтобы решить проблему низкой эффективности обучения модели и модерации видеоматериала при помощи этой модели, и высоких затрат на обучение модели, связанных с присвоением меток видеоданным вручную.
[0009] Предлагается способ обучения модели модерации контента. Способ предусматривает:
[0010] извлечение части видеоданных из образца видеофайла в качестве образца видеоданных;
[0011] установление момента времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент;
[0012] извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[0013] обучение модели модерации контента, исходя из участка видеоданных и образца видеоданных.
[0014] Также предлагается способ модерации видеоконтента. Способ предусматривает:
[0015] извлечение части видеоданных из проверяемого видеофайла в качестве целевых видеоданных;
[0016] установление момента времени в проверяемых видеоданных проверяемого видеофайла в случае, когда проверяемые видеоданные содержат недопустимый контент;
[0017] извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[0018] модерация контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации контента.
[0019] Также предлагается устройство для обучения модели модерации контента. Способ предусматривает:
[0020] модуль извлечения образца видеоданных, рассчитанный на извлечения части видеоданных из образца видеофайла в качестве образца видеоданных;
[0021] модуль установления момента времени, рассчитанный на установление момента времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент;
[0022] модуль извлечения участка видеоданных, рассчитанный на извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[0023] модуль обучения модели, рассчитанный на обучение модели модерации контента, исходя из участка видеоданных и образца видеоданных.
[0024] Также предлагается устройство для модерации видеоконтента. Способ предусматривает:
[0025] модуль извлечения проверяемых видеоданных, рассчитанный на извлечение части видеоданных из проверяемого видеофайла в качестве проверяемых видеоданных;
[0026] модуль установления момента времени, рассчитанный на установление момента времени проверяемых видеоданных в проверяемом видеофайле в случае, когда проверяемые видеоданные содержат недопустимый контент;
[0027] модуль извлечения участка видеоданных, рассчитанный на извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[0028] модуль модерации видеоматериала, рассчитанный на модерацию контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации контента.
[0029] Также предлагается вычислительное устройство. Вычислительное устройство предусматривает:
[0030] один или несколько процессоров;
[0031] накопительное устройство, рассчитанное на хранение одной или нескольких программ;
[0032] при этом запуск одним или несколькими процессорами одной или нескольких программ приводит к выполнению описанного выше способа обучения модели модерации контента или описанного выше способа модерации видеоконтента.
[0033] Также предлагается машиночитаемое запоминающее устройство. На машиночитаемом запоминающем устройстве хранят компьютерную программу, при этом запуск компьютерной программы процессором вычислительного устройства приводит к тому, что вычислительное устройство выполняет описанный выше способ обучения модели модерации контента или описанный выше способ модерации видеоконтента.
Краткое описание фигур
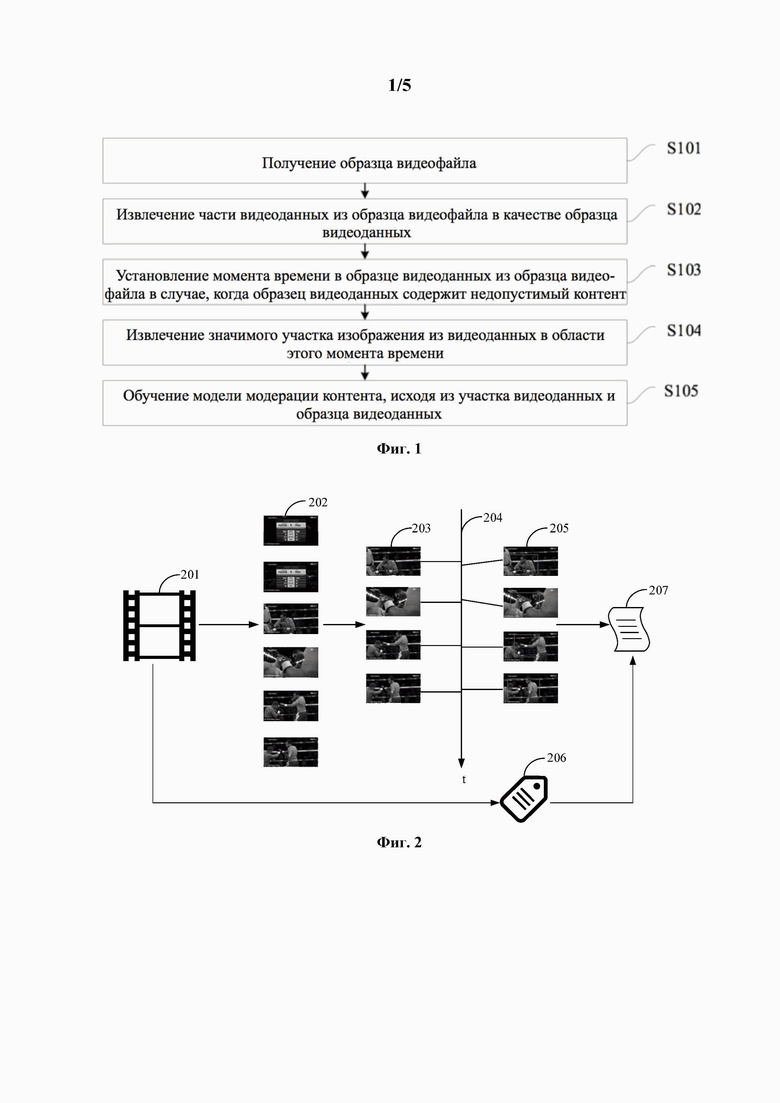
[0034] На фиг. 1 представлена блок-схема способа обучения модели модерации контента согласно первому варианту осуществления настоящего изобретения.
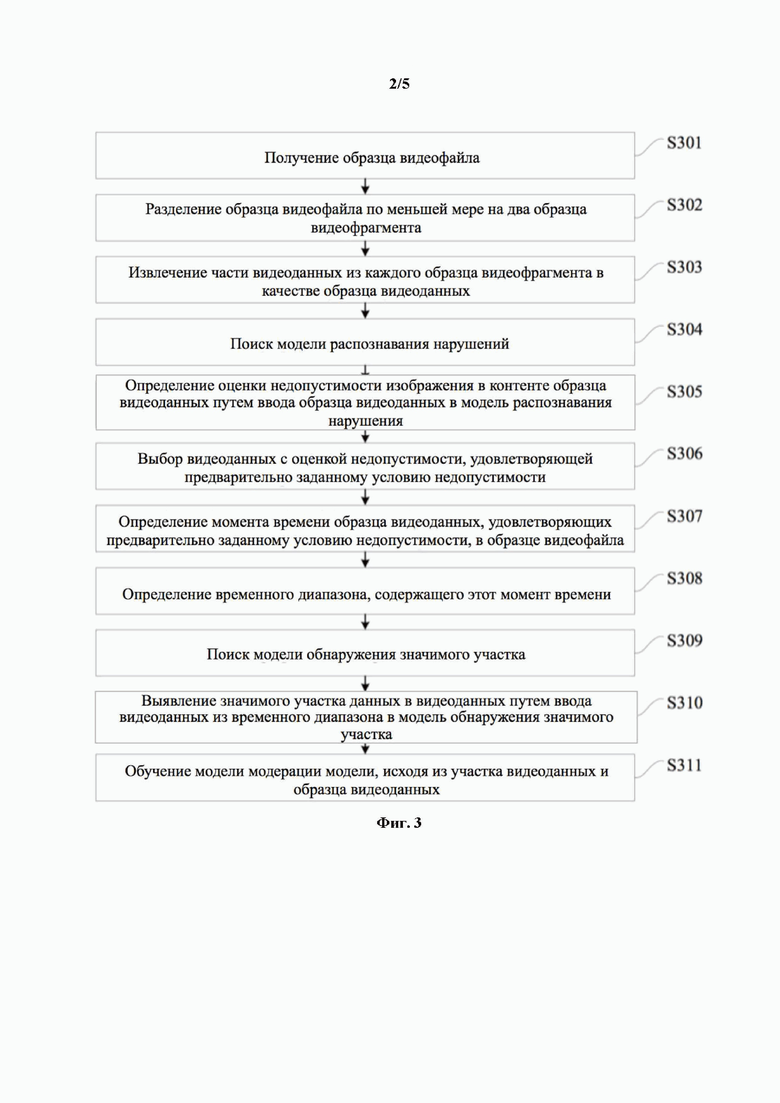
[0035] На фиг. 2 представлена принципиальная схема обучения модели модерации контента согласно первому варианту осуществления настоящего изобретения.
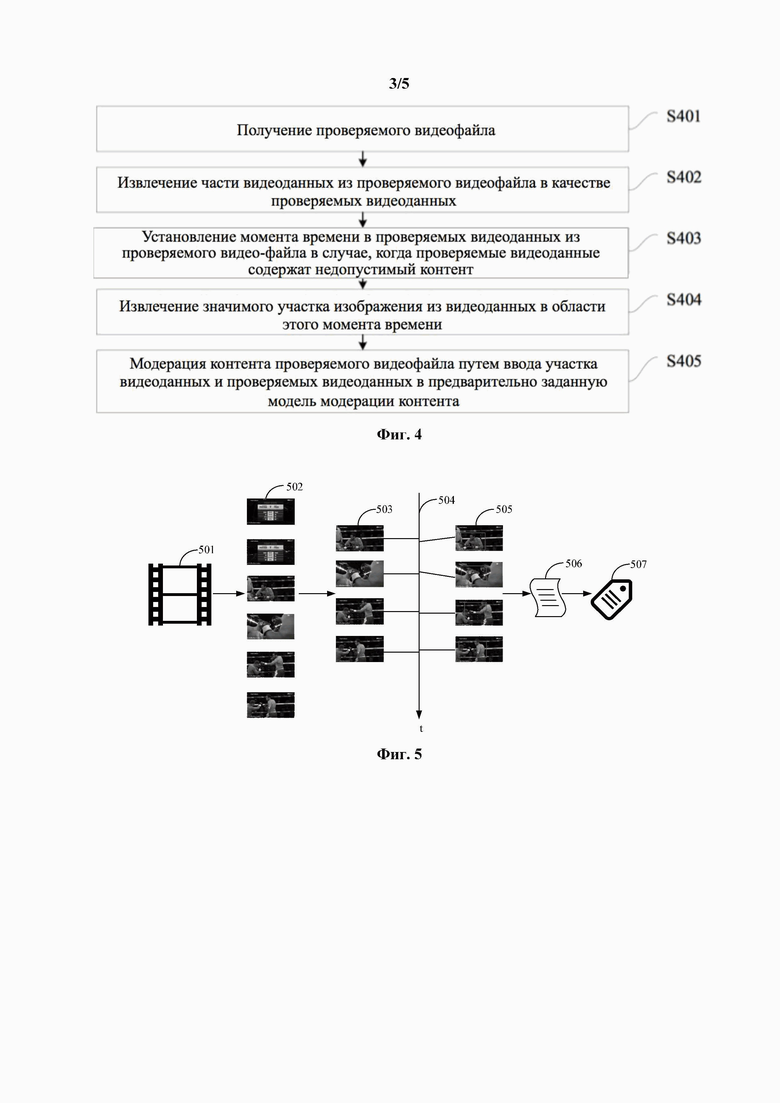
[0036] На фиг. 3 представлена блок-схема способа обучения модели модерации контента согласно второму варианту осуществления настоящего изобретения.
[0037] На фиг. 4 представлена блок-схема способа модерации видеоконтента согласно третьему варианту осуществления настоящего изобретения.
[0038] На фиг. 5 представлена принципиальная схема модерации видеоконтента согласно третьему варианту осуществления настоящего изобретения.
[0039] На фиг. 6 представлена блок-схема способа модерации видеоконтента согласно четвертому варианту осуществления настоящего изобретения.
[0040] На фиг. 7 представлена принципиальная структурная схема устройства для обучения модели модерации контента согласно пятому варианту осуществления настоящего изобретения.
[0041] На фиг. 8 представлена принципиальная структурная схема устройства для модерации видеоконтента согласно шестому варианту осуществления настоящего изобретения.
[0042] На фиг. 9 представлена принципиальная структурная схема вычислительного устройства согласно седьмому варианту осуществления настоящего изобретения.
Подробное раскрытие настоящего изобретения
[0043] Ниже представлено описание настоящего изобретения, связанное с прилагаемыми чертежами, и варианты его осуществления. На прилагаемых чертежах показаны не все, а только некоторые конструкции, связанные с настоящим изобретением. Варианты осуществления настоящего изобретения и признаки в вариантах осуществления могут быть объединены друг с другом. Следует понимать, что, хотя термины «первый», «второй», «третий» и т.п. могут быть использованы в настоящем документе для описания различной информации, эта информация не должна ограничиваться этими терминами. Эти термины использованы только для того, чтобы отличать одну категорию информации от другой. Формы единственного числа «а», «an» и «the» включают в себя как единственное, так и множественное число определяемых объектов, если контекст явно не указывает на иное.
[0044] Первый вариант осуществления
[0045] На фиг. 1 представлена блок-схема способа обучения модели модерации контента согласно первому варианту осуществления настоящего изобретения. Этот вариант осуществления применим в случаях, когда видеоданные автоматически помечены во времени, пространстве. Способ могут выполнять при помощи устройства для обучения модели модерации контента, и устройство для обучения модели модерации контента может быть реализовано на программном и/или аппаратном обеспечении и может быть включено в конфигурацию вычислительного устройства, например сервера, рабочей станции, персонального компьютера и т.п. Способ предусматривает следующие процедуры.
[0046] На стадии S101 получают образец видеофайла.
[0047] Образец видеофайла, будучи видеоматериалом, содержит некоторое количество кадров последовательных видеоданных. В случае, когда последовательная смена видеоданных происходит чаще, чем 24 раза в секунду, согласно принципу инерции зрения, глаз человека не может видеть единое статическое изображение и поэтому визуальный эффект является плавным и непрерывным.
[0048] Согласно этому варианту осуществления, видеофайл могут получать заблаговременно в качестве образца для обучения модели модерации контента путем перехвата файла в сети, накопления видеофайлов, загруженных пользователем, выгрузки видеофайла из опубликованной базы данных и т.п., и образец для обучения модели модерации контента также называют образцом видеофайла.
[0049] Для различных бизнес-сценариев форматы и виды образцов видеофайлов отличаются, в данном варианте осуществления они не ограничены.
[0050] Согласно одному примеру, форматы образца видеофайла могут включать в себя MPEG (формат Экспертной группы по кинематографии), RMVB (формат переменной скорости передачи данных RealMedia), AVI (формат файлов с чередованием аудио и видео), FLV (формат Flash Video) и т.п.
[0051] Образец видеофайла может быть, в том числе, в виде короткого видеоматериала, видеоматериала онлайн трансляции, фильма, телевизионного сериала и т.п.
[0052] На стадии S102 часть видеоданных из образца видеофайла извлекают в качестве образца видеоданных.
[0053] Согласно этому варианту осуществления, часть видеоданных могут выбирать изо всех видеоданных образца видеофайла в качестве образца видеоданных.
[0054] На стадии S103 момент времени в образце видеоданных устанавливают в образце видеофайла в случае, когда образец видеоданных содержит недопустимый контент.
[0055] Согласно этому варианту осуществления, могут определять контент образца видеоданных, чтобы определить является ли контент нежелательным контентом. Контент образца видеоданных может быть определен как недопустимый контент в случае, когда контент связан с терроризмом, насилием, порнографией, азартными играми и т.п., и контент образца видеоданных может быть определен как допустимый в случае, когда контент относится к природному ландшафту, зданию и т.п.
[0056] Для образца видеоданных с недопустимым контентом могут устанавливать момент времени в образце видеоданных из образца видеофайла.
[0057] На стадии S104 значимый участок видеоданных извлекают из видеоданных в области этого момента времени.
[0058] Значимость, как визуальная особенность изображения, представляет собой внимание человеческого взгляда к некоторым участкам изображения.
[0059] В кадре изображения пользователя интересует элемент изображения, и интересующий элемент отражает намерение пользователя. Большинство остальных участков не связаны с намерением пользователя, то есть, значимый участок представляет собой участок изображения, который с наибольшей вероятностью вызовет интерес у пользователя и представляет контент изображения.
[0060] На самом деле, выбор значимости субъективен, и на одном и том же кадре изображения разные пользователи могут выбирать разные участки в качестве значимых участков в силу различных задач и знаний пользователей.
[0061] Для расчета значимости участка используют механизм внимания человека. Исследования в области когнитивной психологии показали, что некоторые участки изображения могут сильно привлекать внимание человека, и эти участки содержат больший объем информации. Таким образом, механизм внимания человека могут моделировать, исходя из математической модели, и извлеченные значимые участки больше соответствуют субъективной оценке человека, поскольку в процессе познания изображения используют общее правило.
[0062] На временной шкале образца видеофайла в области момента времени в образце видеоданных присутствует некоторое количество кадров. Согласно этому варианту осуществления, значимые участки могут извлекать из видеоданных в качестве участков видеоданных.
[0063] В образце видеофайла объект съемки обычно не изменяется за короткий промежуток времени. То есть, другие видеоданные в области образца видеоданных по существу аналогичны контенту образца видеоданных. В случае, когда образец видеоданных содержит недопустимый контент, очень вероятно, что контент видеоданных является недопустимым, и таким образом, контент видеоданных также считают недопустимым. Поэтому, исходя из чувствительности пользователя к недопустимому контенту, связанному с терроризмом, насилием, порнографией, азартным играм и т.п., значимый участок видеоданных в видеоданных сосредоточен в первую очередь на терроризме, насилии, порнографии, азартных играх и т.п.
[0064] На стадии S105 модель модерации контента обучают, исходя из участка видеоданных и образца видеоданных.
[0065] Согласно этому варианту осуществления, образец видеофайла могут заранее помечать как относящийся к категории нарушения. Модель модерации контента получают путем обучения по предварительно заданной сети с обучающей выборкой участка видеоданных и образца видеоданных различных образцов видеофайлов и тега категории нарушения, в случае завершения обучения.
[0066] Согласно одному примеру, сеть может включать в себя компьютерную модель, например, SVM (машину опорных векторов), модель случайного леса, библиотеку Xgboost, и нейронную сеть, например, CNN (сверточную нейронную сеть), DNN (глубокую нейронную сеть) и RNN (рекуррентную нейронную сеть), что не представляет собой ограничения этого варианта осуществления.
[0067] Согласно этому варианту осуществления, DNN приведена в качестве примера модели модерации контента.
[0068] Согласно этому варианту осуществления, определяют категорию нарушения (например, терроризм, насилие, порнография и т.п.), которой помечен образец видеофайла и которая представляет недопустимый контент.
[0069] Получают глубокую нейронную сеть и предварительно обученную модель. Предварительно обученная модель представляет собой структуру глубокого обучения, которая обучена выполнять конкретные задачи (например, определять классификацию по фотографии) на большом объеме данных, и предусматривает архитектуры сетей VGG, Inception, ResNet, MobileNet, NasNet и т.п.
[0070] Глубокую нейронную сеть инициализируют с применением предварительно обученной модели. То есть путем применения предварительно обученной модели, которая до применения обучена на большом наборе данных, соответствующую конфигурацию и вес могут напрямую применять к глубокой нейронной сети с целью реализации миграционного обучения.
[0071] Путем обратного распространения, глубокую нейронную сеть обучают как модель модерации контента, исходя из участка видеоданных, образца видеоданных и категории нарушения.
[0072] Согласно одному примеру, участок видеоданных и образец видеоданных вводят в глубокую нейронную сеть, исходную пиксельную информацию объединяют между нейронами при помощи нелинейного отображения, и оценки различных категорий недопустимости получают с помощью регрессионного слоя функции Softmax, они выступают в качестве оценки недопустимости. Потерю классификации всей глубокой нейронной сети получают путем вычисления перекрестной энтропии оценки недопустимости и тэга обучающей выборки.
[0073] Согласно одному примеру, в котором образец видеофайла принадлежит к разным категориям недопустимости, модель модерации контента может быть рассчитана на выявление различных категорий недопустимости. Когда образец видеофайла принадлежит к той же категории нарушения, модель модерации контента может быть рассчитана на выявление этой категории нарушения.
[0074] Способ обучения модели модерации контента согласно этому варианту осуществления проиллюстрирован следующими примерами.
[0075] Например, как показано на фиг. 2, для образца 201 видеофайла, контент которого представляет собой соревнование по боксу, шесть кадров видеоданных извлекли из образца видеофайла в качестве образца видеоданных 202, четыре кадра видеоданных 202, содержащих недопустимый контент, определили как образец 203 видеоданных, и образец 203 видеоданных, содержащий недопустимый контент, содержит насилие. Момент времени в образце 203 видеоданных, содержащих недопустимый контент, располагают на временной шкале 204 образца 201 видеофайла, значимый участок видеоданных извлекают из видеоданных 205 в области этого момента времени (часть блока). Модель 207 модерации контента обучают на обучающем образце значимого участка видеоданных в образце 202 видеоданных и видеоданных 205, и тэге 206 категории нарушения образца 201 видеофайла, так что модель 207 модерации контента могут настраивать на классификацию видеоданных, и рассматриваемые факторы классификации соответствуют категории 206 нарушения.
[0076] Согласно этому варианту осуществления, получают образец видеофайла. Образец видеофайла содержит некоторое количество кадров видеоданных, часть видеоданных извлекают в качестве образца видеоданных, и устанавливают момент времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент. Значимый участок видеоданных извлекают из видеоданных в области этого момента времени, и модель модерации контента обучают, исходя из участка видеоданных и образца видеоданных. Устанавливают местоположение образца видеоданных, содержащего недопустимый контент, по времени, а местоположение значимого участка видеоданных - в пространстве, таким образом определяют пространственно-временное местоположение образца видеофайла, то есть, получают самоопределение местоположения недопустимого контента образца видеофайла во времени и пространстве. Таким образом, признак недопустимого контента могут быстро получать из образца видеофайла для определения его характеристик, качество признака возрастает в аспектах времени и пространства с точки зрения модерации контента, и эффективность модели модерации контента могут обеспечивать путем такого способа обучения модели модерации контента. Кроме того, автоматическую расстановку тэгов в образце видеоданных выполняют без дополнительных действий по аннотированию, путем установления местоположения образца видеоданных и области видеоданных с недопустимым контентом, что легко выполнить и что исключает необходимость расстановки тэгов вручную, повышает эффективность обучения модели модерации контента и снижает затраты на обучение модели модерации контента.
[0077] Второй вариант осуществления
[0078] На фиг. 3 представлена блок-схема способа обучения модели модерации контента согласно второму варианту осуществления настоящего изобретения. Этот вариант осуществления иллюстрирует действия по извлечению образца видеоданных, установлению местоположения момента времени и извлечению области видеоданных, исходя из описанного выше варианта осуществления. Способ предусматривает следующие процедуры.
[0079] На стадии S301 получают образец видеофайла.
[0080] Образец видеофайла содержит некоторое количество кадров видеоданных.
[0081] На стадии S302 образец видеофайла разделяют по меньшей мере на два видеофрагмента образца.
[0082] На стадии S303 часть видеоданных извлекают из каждого видеофрагмента образца в качестве образца видеоданных.
[0083] Согласно одному примеру, образец видеофайла могут разделять на фрагменты по интервалу времени, то есть, образец видеофайла разделяют по меньшей мере на два видеофрагмента образца.
[0084] Из каждого видеофрагмента образца случайным образом извлекают n кадров видеоданных в качестве образца видеоданных, и таким образом формируют последовательность видеокадров для обработки.
[0085] Параметры t и n представляют собой регулируемые параметры.
[0086] Согласно одному примеру, за исключением усредненного разделения образца видеофайла на части и случайного извлечения изображения, образец видеоданных могут извлекать другими способами согласно фактическим потребностям. Так, для образца видеофайла, содержащего плотины, плотина может в определенной степени представлять для пользователя интерес в контенте образца видеофайла, и образец видеофайла разделяют на части относительно заграждений так, чтобы содержание плотин в каждом видеофрагменте образца (количество на единицу времени) находилась в заданном диапазоне. В качестве альтернативы, видеоданные извлекают из каждого видеофрагмента образца так, чтобы интервалу времени между двумя кадрами видеоданных был одинаковым, и т.п., что не ограничено в настоящем варианте осуществления.
[0087] Кроме того, образец видеоданных могут масштабировать до предварительно заданного размера и образец видеоданных могут дополнительно упорядочивать по времени, тем самым облегчая обучение модели модерации контента.
[0088] На стадии S304 выполняют поиск модели распознавания нарушений.
[0089] Согласно этому варианту осуществления, видеоданные, содержащие недопустимый контент, могут предварительно использовать в качестве обучающей выборки, и сеть (например, CNN) обучают с тегом категории нарушения. В случае, когда обучение завершено, можно получить модель распознавания нарушений. То есть, модель распознавания нарушений может быть рассчитана на определение оценки недопустимости изображения в контенте видеоданных.
[0090] При необходимости для разных категорий нарушений могут обучать разные модели распознавания нарушений. То есть, модель распознавания нарушений может быть рассчитана на определение оценки недопустимости изображения в видеоданных, контент которых принадлежит к той же категории нарушения.
[0091] Как правило, образец видеофайла соответствует категории нарушения в образце видеоданных. Таким образом, могут определять категорию нарушения, которой помечен образец видеофайла и которая представляет недопустимый контент, находить модель распознавания нарушения, которая соответствует категории нарушения, причем модель распознавания нарушения рассчитана на определение оценки недопустимости изображения в видеоданных, контент которых принадлежит к этой категории нарушения.
[0092] Типичную модель распознавания нарушения могут также обучать по разным категориям нарушений, то есть, одна модель распознавания нарушений может быть рассчитана на определение оценки недопустимости изображения в видеоданных, контент которых принадлежит к другой категории нарушения, что не ограничено в настоящем варианте осуществления.
[0093] На стадии S305 оценку недопустимости изображения в контенте образца видеоданных определяют путем ввода образца видеоданных в модель распознавания нарушения.
[0094] В случае, когда определена модель распознавания нарушения, образцы видеоданных образца видеофайла могут последовательно вводить в модель распознавания нарушения для обработки, и модель распознавания нарушения на выходе последовательно дает оценку недопустимости изображения образца видеоданных.
[0095] На стадии S306 выбирают образец видеоданных с оценкой недопустимости, которая удовлетворяет предварительно заданному условию недопустимости.
[0096] Согласно этому варианту осуществления, условие недопустимости могут задавать предварительно, и это условие недопустимости используют для определения образца видеоданных, содержащего недопустимый контент.
[0097] В случае, когда определена оценка недопустимости изображения, определяют образец видеоданных с оценкой недопустимости изображения, который удовлетворяет условию недопустимости.
[0098] Согласно одному примеру, условие недопустимости заключается в том, что оценка недопустимости изображения превышает пороговое значение оценки изображения, либо значение оценки недопустимости изображения является наибольшим.
[0099] Согласно этому варианту осуществления, оценку недопустимости образца видеоданных могут определять согласно тому, превышает ли она предварительно заданное пороговое значение оценки изображения.
[00100] В случае, когда оценка недопустимости изображения образца видеоданных больше предварительно заданного порогового значения оценки изображения, определяют, что оценка недопустимости изображения удовлетворяет предварительно заданному условию недопустимости.
[00101] В случае, когда оценка недопустимости изображения образца видеоданных больше предварительно заданного порогового значения оценки изображения, определяют, что оценка недопустимости изображения удовлетворяет предварительно заданному условию недопустимости.
[00102] Приведенное выше условие недопустимости представляет собой только пример, и когда этот вариант осуществления реализуют, согласно фактической потребности могут задавать другое условие недопустимости, например, верхнее значение m оценки недопустимости изображения и т.п., что не ограничено в вариантах осуществления настоящего изобретения. Кроме того, согласно фактическим потребностям могут применять другие условия недопустимости помимо указанного выше условия недопустимости, что не ограничено в вариантах осуществления настоящего изобретения.
[00103] На стадии S307 в образце видеоданных определяют момент времени, отвечающий предварительно заданному условию недопустимости образца видеофайла.
[00104] В случае, когда для удовлетворения условия недопустимости определен кадр образца видеоданных, этот момент времени определяют в образце видеоданных из образца видеофайла.
[00105] На стадии S308 определяют временной диапазон, который содержит этот момент времени.
[00106] Исходя из этого момента времени, на временной шкале образца видеофайла создают временной диапазон, содержащий этот момент.
[00107] Согласно одному примеру, предполагают, что момент времени - это Т, тогда могут создавать временной диапазон продолжительностью F[T-F/2, T+F/2], где F представляет собой регулируемый параметр.
[00108] Описанный выше способ создания временного диапазона представляет собой только пример, и когда этот вариант осуществления реализуют, могут использовать другие способы создания временного диапазона согласно фактическим потребностям, например [Т-F/3, T+2F/3], [Т-3F/4, T+F/4] и т.п., что не ограничено в вариантах осуществления настоящего изобретения. Кроме того, согласно фактическим потребностям могут применять другие условия недопустимости помимо указанного выше условия недопустимости, что не ограничено в вариантах осуществления настоящего изобретения.
[00109] На стадии S309 находят модель обнаружения значимого участка.
[00110] Согласно этому варианту осуществления, модель обнаружения значимого участка также является предварительно заданной, и модель обнаружения значимого участка может быть рассчитана на выявление значимого участка изображения в видеоданных.
[00111] Согласно одному примеру, модель обнаружения значимого участка могут следующим образом применять в трех классах алгоритмов.
[00112] Первый класс представляет собой алгоритм анализа значимости, исходя из низкоуровневой обработки изображения, например, алгоритм визуальной значимости (алгоритм ITTI), который представляет собой алгоритм избирательного внимания, при помощи которого моделируют механизм визуального внимания организма, и приспособлен для обработки естественных изображений.
[00113] Второй класс представляет собой способ исключительно математических вычислений, который не исходит ни из какого визуального биологического принципа, например, алгоритм полного разрешения (алгоритм Ахо-Корасик, АС алгоритм), алгоритм спектральной остаточности (алгоритм SR), которые основаны на области пространственных частот.
[00114] Третий класс сочетает два вышеописанных класса алгоритмов, например, алгоритм, основанный на теории графов (алгоритм GBVS), который моделирует визуальный принцип, аналогичный алгоритму ITTI в процедуре извлечения признаков, и вводит марковские цепи в процедуру создания значимого изображения и получает значение значимости при помощи способа исключительно математических вычислений.
[00115] На стадии S310 значимый участок видеоданных выявляют в видеоданных путем ввода видеоданных из временного диапазона в модель обнаружения значимого участка.
[00116] Видеоданные в пределах временного диапазона извлекают из образца видеофайла, эти видеоданные последовательно вводят в модель обнаружения значимого участка, и модель обнаружения значимого участка выдает на выходе значимый участок видеоданных из видеоданных.
[00117] На стадии S311 модель модерации контента обучают, исходя из участка видеоданных и образца видеоданных.
[00118] Согласно этому варианту осуществления, для образца видеоданных, содержащего недопустимый контент, временной диапазон определяют, исходя из момента времени, и весьма вероятно, что контент видеоданных в этом временном диапазоне недопустимый. Таким образом, извлечение значимого участка видеоданных может быстро повысить надежность обучающей выборки, тем самым повышая эффективность модели модерации контента за счет обучения модели модерации контента.
[00119] Третий вариант осуществления
[00120] На фиг. 4 представлена блок-схема способа модерации видеоконтента согласно третьему варианту осуществления настоящего изобретения. Этот вариант осуществления применим в случаях, когда видеоданные модерируют во времени и пространстве. Способ могут выполнять при помощи устройства для модерации видеоконтента, и устройство для обучения модели модерации контента может быть реализовано на программном и/или аппаратном обеспечении и может быть включено в конфигурацию вычислительного устройства, например сервера, рабочей станции, персонального компьютера и т.п. Способ предусматривает следующие процедуры.
[00121] На стадии S401 получают проверяемый видеофайл.
[00122] Проверяемый видеофайл, будучи видеоматериалом, содержит некоторое количество кадров последовательных видеоданных. В случае, когда последовательная смена видеоданных происходит чаще, чем 24 раза в секунду, согласно принципу инерции зрения, глаз человека не может видеть единое статическое изображение и поэтому визуальный эффект является плавным и непрерывным.
[00123] Для различных бизнес-сценариев форматы и виды проверяемых видеофайлов отличаются, в данном варианте осуществления они не ограничены.
[00124] Формат проверяемого видеофайла может представлять собой MPEG, RMVB, AVI, FLV и т.п.
[00125] Проверяемый видеофайл может быть, в том числе, в виде короткого видеоматериала, видеоматериала онлайн трансляции, фильма, телевизионного сериала и т.п.
[00126] Пользователь загружает проверяемый видеофайл в вычислительное устройство и намеревается опубликовать целевой видеофайл для публичного просмотра.
[00127] Вычислительное устройство может разработать критерии модерации согласно бизнес-факторам, факторам легальности и другим факторам. Перед публикацией проверяемого видеофайла контент проверяемого видеофайла модерируют, исходя из критериев модерации, некоторые проверяемые видеофайлы, которые не отвечают критериям оценки, отфильтровывают (например, контент проверяемого видеофайла содержит терроризм, насилие, порнографию, азартные игры и т.п.), а некоторые проверяемые видеофайлы, отвечающие критериям модерации, публикуют.
[00128] Для проверяемого видеофайла с более высокими требованиями к своевременности, например, короткого видеоматериала, видеоматериала онлайн трансляции и т.п., могут предусматривать систему потоковой передачи в режиме реального времени. Пользователь загружает проверяемый видеофайл в систему потоковой передачи в режиме реального времени через клиента, и система потоковой передачи в режиме реального времени может передавать проверяемый видеофайл на вычислительное устройство с целью модерации.
[00129] Для проверяемого видеофайла с более низкими требованиями к своевременности, например, фильмов, телесериалов и т.п., может быть предусмотрена база данных, например, распределенная база данных и т.п. Пользователь загружает базу данных на вычислительное устройство через клиента, и вычислительное устройство может читать проверяемый видеофайл из базы данных с целью модерации.
[00130] На стадии S402 часть видеоданных извлекают из проверяемого видеофайла в качестве проверяемых видеоданных.
[00131] Согласно этому варианту осуществления, часть видеоданных могут выбирать в качестве целевых видеоданных изо всех видеоданных целевого видеофайла.
[00132] На стадии S403 момент времени целевых видеоданных в целевом видеофайле устанавливают в случае, когда целевые видеоданные содержат недопустимый контент.
[00133] Согласно этому варианту осуществления, могут определять контент целевых видеоданных, чтобы определить является ли контент целевых видеоданных нежелательным контентом. Контент целевых видеоданных могут определять как недопустимый контент в случае, когда контент связан с терроризмом, насилием, порнографией, азартными играми и т.п., и контент целевых видеоданных могут определять как допустимый в случае, когда контент относится к природному ландшафту, зданию и т.п.
[00134] Для проверяемых видеоданных, содержащих недопустимый контент, могут устанавливать момент времени в проверяемых видеоданных проверяемого видеофайла.
[00135] На стадии S404 значимый участок видеоданных извлекают из видеоданных в области этого момента времени.
[00136] Значимость, как визуальная особенность изображения, представляет собой отражение внимания человеческого взгляда к некоторым участкам изображения.
[00137] В кадре изображения пользователя интересует элемент изображения, и интересующий элемент отражает намерение пользователя. Большинство остальных участков не зависят от намерения пользователя, то есть, значимый участок представляет собой участок изображения, который с наибольшей вероятностью вызовет интерес у пользователя и представляет контент изображения.
[00138] На самом деле, выбор значимости субъективен, и на одном и том же кадре изображения разные пользователи могут выбирать разные участки в качестве значимых участков в силу различных задач и знаний пользователей.
[00139] Для расчета значимости участка используют механизм внимания человека. Исследования в области когнитивной психологии показали, что некоторые участки изображения могут сильно привлекать внимание человека, и эти участки содержат больший объем информации. Таким образом, механизм внимания человека могут моделировать, исходя из математической модели, и извлеченные значимые участки лучше согласуются с субъективной оценкой человека, поскольку в процессе познания изображения используют общее правило.
[00140] На временной шкале целевого видеофайла в области момента времени в целевых видеоданных присутствует некоторое количество кадров. Согласно этому варианту осуществления, значимые участки могут извлекать из видеоданных в качестве участков видеоданных.
[00141] В целевом видеофайле объект съемки обычно не изменяется за короткий промежуток времени. То есть другие видеоданные в области целевых видеоданных по существу аналогичны контенту целевых видеоданных. В случае, когда целевые видеоданные содержат недопустимый контент, очень вероятно, что контент видеоданных является недопустимым, и таким образом, контент видеоданных также считают недопустимым контентом. Поэтому, исходя из чувствительности пользователя к недопустимым данным, связанным с терроризмом, насилием, порнографией, азартными играми и т.п., значимый участок видеоданных в видеоданных сосредоточен в первую очередь на терроризме, насилии, порнографии, азартных играх и недопустимом контенте.
[00142] На стадии S405 контент целевого видеофайла модерируют путем ввода участка видеоданных и целевых видеоданных в предварительно заданную модель модерации контента.
[00143] Согласно этому варианту осуществления, модель модерации контента могут предварительно обучать и модель модерации контента может быть рассчитана на определение оценки недопустимости файла в случае, когда контент проверяемого видеофайла принадлежит к предварительно заданной категории нарушения.
[00144] Поскольку способ обучения модели модерации контента по существу аналогичен применению описанных выше первого варианта осуществления и второго варианта осуществления, это описание краткое, и можно сослаться на части описания первого варианта осуществления, второго варианта осуществления, который не описан в данном варианте осуществления в этом документе.
[00145] Для проверяемого видеофайла участок видеоданных и проверяемые видеоданные могут вводить в модель модерации контента с целью обработки, и контент проверяемого видеофайла могут модерировать, исходя из результата на выходе модели модерации контента, чтобы определить представляет ли собой контент недопустимый контент.
[00146] Согласно одному примеру, участок видеоданных и проверяемые видеоданные вводят в предварительно заданную модель модерации контента для определения оценки недопустимости файла в случае, когда контент проверяемого видеофайла принадлежит к предварительно заданной категории нарушения.
[00147] Определяют пороговое значение оценки файла.
[00148] Оценку недопустимости файла сопоставляют с пороговым значением оценки файла.
[00149] В случае, когда оценка недопустимости файла ниже или равна пороговой оценке файла, вероятность того, что контент проверяемого видеофайла недопустимый, меньше, и контент проверяемого видеофайла определяют как допустимый.
[00150] В случае, когда оценка недопустимости файла выше пороговой оценки файла, весьма вероятно, что контент проверяемого видеофайла недопустимый, и проверяемый видеофайл могут передать специальному клиенту в качестве задания на модерацию. Клиентом управляет специальный модератор.
[00151] В случае, когда клиент получает задание на модерацию, модератор может просмотреть проверяемый видеофайл, чтобы вручную определить является ли контент проверяемого видеофайла недопустимым.
[00152] Контент проверяемого видеофайла определяют как допустимый в случае, когда от клиента получают первую информацию о модерации.
[00153] Контент проверяемого видеофайла определяют как недопустимый в случае, когда от клиента получают вторую информацию о модерации.
[00154] Путем определения порогового значения оценки файла определяют общее количество проверяемых видеофайлов за предыдущий промежуток времени (например, предыдущий день), и определяют оценку недопустимости проверяемого видеофайла.
[00155] Пороговое значение оценки файла создают таким образом, что отношение количества модераций к общему количеству совпадений соответствует предварительно заданному push-показателю (предполагаемому недопустимому push-показателю, SIPR), при этом количество модераций представляет собой количество проверяемых видеофайлов, для которых оценки недопустимости файла выше порогового значения оценки файла.
[00156] Как правило, отношение количества проверяемых видеофайлов с недопустимым контентом к количеству всех проверяемых видеофайлов относительно невелико, например, 1%. В этом способе определения могут задавать push-показатель выше показателя в 1% (например, 10%), чтобы обеспечить возможность ручной модерации как можно большего количества проверяемых видеофайлов с недопустимым контентом.
[00157] Если предположить, что количество всех проверяемых видеофайлов за предыдущий промежуток времени составляет 100 000, а push-показатель составляет 10%, тогда проверяемый видеофайл можно ранжировать, исходя из оценки недопустимости файла (от меньшей к большей) и в качестве порогового значения оценки задают оценку недопустимости файла для каждого 10000-го проверяемого видеофайла.
[00158] Описанный выше способ определения порогового значения оценки файла представляет собой только пример, и когда реализуют этот вариант осуществления, могут задавать другой способ определения порогового значения оценки файла согласно фактическим потребностям, например, в качестве порогового значения оценки файла могут задавать значение по умолчанию и т.п., что не ограничено в вариантах осуществления настоящего изобретения. Кроме того, согласно фактическим потребностям могут применять другой способ определения порогового значения оценки файла помимо указанного выше способа определения порогового значения оценки файла, что не ограничено в вариантах осуществления настоящего изобретения.
[00159] Способ модерации видеоконтента согласно этому варианту осуществления проиллюстрирован следующими вариантами осуществления.
[00160] Например, как показано на фиг. 5, для образца видеофайла 501, контент которого представляет собой соревнование по боксу, шесть кадров видеоданных извлекли из образца видеофайла в качестве проверяемых видеоданных 502, четыре кадра видеоданных 502, содержащих недопустимый контент, определили как проверяемые видеоданные 503, и проверяемые видеоданные 503, содержащие недопустимый контент, содержат насилие. Момент времени проверяемых видеоданных 503, содержащих недопустимый контент, располагают на временной шкале 504 проверяемого видеофайла 501, значимый участок видеоданных извлекают из видеоданных 505 в области этого момента времени (часть блока). Значимый участок видеоданных в проверяемых видеоданных 502 и видеоданные 505 вводят в модель 506 модерации контента, и тэг 507, то есть класс допустимости или недопустимости проверяемого видеофайла 501, определяют, исходя из результата на выходе модели 506 модерации контента.
[00161] Согласно этому варианту осуществления, получают проверяемый видеофайл. Проверяемый видеофайл содержит некоторое количество кадров видеоданных, часть видеоданных извлекают в качестве проверяемых видеоданных, и момент времени для проверяемых видеоданных устанавливают в проверяемом видеофайле в случае, когда образец видеоданных содержит недопустимый контент. Характерный участок видеоданных извлекают из видеоданных в области этого момента времени, и участок видеоданных и проверяемые видеоданные вводят в предварительно заданную модель модерации контента с целью модерации контента проверяемого видеофайла. Устанавливают местоположение во времени проверяемых видеоданных, содержащих недопустимый контент, а местоположение значимого участка видеоданных - в пространстве, таким образом определяют пространственно-временное местоположение проверяемого видеофайла, то есть, получают самоопределение местоположения недопустимых данных в проверяемом видеофайле во времени и пространстве. Таким образом, признак недопустимого контента быстро получают из образца видеофайла с целью определения его характеристик, и для модерации контента качество признака повышают в аспектах времени и пространства, тем самым обеспечивают качество модерации контента, снижают показатель неверной модерации и повышают эффективность модерации видеоконтента.
[00162] Четвертый вариант осуществления
[00163] На фиг.6 представлена блок-схема способа модерации видеоконтента согласно четвертому варианту осуществления настоящего изобретения, и этот вариант осуществления иллюстрирует действия по извлечению проверяемых видеоданных, установлению местоположения момента времени и извлечению области видеоданных, исходя из описанных выше вариантов осуществления. Способ предусматривает следующие процедуры.
[00164] На стадии S601 получают проверяемый видеофайл.
[00165] Проверяемый видеофайл содержит некоторое количество кадров видеоданных.
[00166] На стадии S602 проверяемый видеофайл разделяют по меньшей мере на два проверяемых видеофрагмента.
[00167] На стадии S603 часть видеоданных извлекают из каждого проверяемого видеофрагмента в качестве проверяемых видеоданных.
[00168] Согласно одному примеру, проверяемый видеофайл могут разделять на сегменты по интервалу времени, то есть, проверяемый видеофайл разделяют по меньшей мере на два проверяемых видеофрагмента.
[00169] Из каждого проверяемого видеофрагмента случайным образом извлекают n кадров видеоданных в качестве проверяемых видеоданных, и таким образом формируют последовательность видеокадров для обработки.
[00170] Параметры t и n представляют собой регулируемые параметры.
[00171] За исключением усредненного разделения проверяемого видеофайла на части и случайного извлечения изображения, проверяемые видеоданные могут извлекать другими способами согласно фактическим потребностям. Так, когда проверяемый видеофайл разделен на части, продолжительность проверяемых видеофрагментов на обоих концах больше, а продолжительность среднего проверяемого видеофрагмента меньше. В качестве альтернативы, видеоданные извлекают из каждого проверяемого видеофрагмента так, чтобы интервал времени между каждыми двумя кадрами видеоданных был одинаковым, и т.п., что не ограничено в настоящем варианте осуществления.
[00172] Кроме того, целевые видеоданные могут масштабировать до предварительно заданного размера и проверяемые видеоданные могут дополнительно упорядочивать по времени, тем самым облегчая определение модели модерации контента.
[00173] На стадии S604 выполняют поиск модели распознавания нарушений.
[00174] Согласно этому варианту осуществления, видеоданные, содержащие недопустимый контент, могут предварительно использовать в качестве обучающей выборки, и сеть (например, CNN) обучают с тегом категории нарушения. В случае, когда обучение завершено, можно получить модель распознавания нарушений. То есть, модель распознавания нарушений может быть рассчитана на определение оценки недопустимости изображения в контенте видеоданных.
[00175] При необходимости для разных категорий нарушений могут обучать разные модели распознавания нарушений. То есть, модель распознавания нарушений может быть рассчитана на определение оценки недопустимости изображения в видеоданных, контент которых принадлежит к той же категории нарушения.
[00176] Типичную модель распознавания нарушения могут также обучать по разным категориям нарушений, то есть, одна модель распознавания нарушений может быть рассчитана на определение оценки недопустимости изображения в видеоданных, контент которых принадлежит к этой категории нарушения, что не ограничено в настоящем варианте осуществления.
[00177] На стадии S605 оценку недопустимости изображения в контенте проверяемых видеоданных определяют путем ввода проверяемых видеоданных в модель распознавания нарушения.
[00178] В случае, когда определена модель распознавания нарушения, проверяемые видеоданные проверяемого видеофайла могут последовательно вводить в эту модель распознавания нарушения для обработки, и эта модель распознавания нарушения на выходе последовательно дает оценку недопустимости изображения проверяемых видеоданных.
[00179] На стадии S606 выбирают проверяемые видеоданные с оценкой недопустимости, которая удовлетворяет предварительно заданному условию недопустимости.
[00180] Согласно этому варианту осуществления, условие недопустимости могут задавать предварительно, и это условие недопустимости используют для определения проверяемых видеоданных, содержащих недопустимый контент.
[00181] В случае, когда определена оценка недопустимости проверяемого изображения, определяют проверяемые видеоданные с оценкой недопустимости изображения, которая удовлетворяет условию недопустимости.
[00182] Согласно одному примеру, условие недопустимости заключается в том, что оценка недопустимости изображения превышает пороговое значение оценки изображения, либо значение оценки недопустимости изображения является наибольшим.
[00183] Согласно этому варианту осуществления, оценку недопустимости проверяемых видеоданных могут определять согласно тому, превышает ли она предварительно заданное пороговое значение оценки изображения.
[00184] В случае, когда оценка недопустимости изображения проверяемых видеоданных больше предварительно заданного порогового значения оценки изображения, определяют, что оценка недопустимости изображения удовлетворяет предварительно заданному условию недопустимости.
[00185] В случае, когда оценка недопустимости изображения проверяемых видеоданных больше предварительно заданного порогового значения оценки изображения, определяют, что оценка недопустимости изображения удовлетворяет предварительно заданному условию недопустимости.
[00186] Приведенное выше условие недопустимости представляет собой только пример, и когда этот вариант осуществления реализуют, согласно фактической потребности могут задавать другое условие недопустимости, например, верхнее значение m оценки недопустимости изображения и т.п., что не ограничено в вариантах осуществления настоящего изобретения. Кроме того, согласно фактическим потребностям могут применять другое условие недопустимости помимо указанного выше условия недопустимости, что не ограничено в вариантах осуществления настоящего изобретения.
[00187] На стадии S607 в проверяемых видеоданных определяют момент времени, отвечающий предварительно заданному условию недопустимости проверяемого видеофайла
[00188] В случае, когда для удовлетворения условия недопустимости определяют кадр проверяемых видеоданных, этот момент времени определяют в проверяемых видеоданных из проверяемого видеофайла.
[00189] На стадии S608 определяют временной диапазон, который содержит этот момент времени.
[00190] Исходя из этого момента времени, на временной шкале проверяемого видеофайла создают временной диапазон, содержащий этот момент.
[00191] Согласно одному примеру, предполагают, что момент времени - это Т, тогда могут создавать временной диапазон продолжительностью F[T-F/2, T+F/2], где F представляет собой регулируемый параметр.
[00192] Описанный выше способ создания временного диапазона представляет собой только пример, и когда этот вариант осуществления реализуют, могут задавать другие способы создания временного диапазона согласно фактическим потребностям, например [T-F/3, T+2F/3], [T-3F/4, T+F/4] и т.п., что не ограничено в вариантах осуществления настоящего изобретения. Кроме того, согласно фактическим потребностям могут применять другое условие недопустимости помимо указанного выше условия недопустимости, что не ограничено в вариантах осуществления настоящего изобретения.
[00193] На стадии S609 находят модель обнаружения значимого участка.
[00194] Согласно этому варианту осуществления, модель обнаружения значимого участка также является предварительно заданной, и модель обнаружения значимого участка может быть рассчитана на выявление значимого участка изображения в видеоданных.
[00195] Согласно одному примеру, модель обнаружения значимого участка могут применять в трех классах алгоритмов следующим образом.
[00196] Первый класс представляет собой алгоритм анализа значимости, исходя из низкоуровневой обработки изображения, например, алгоритм визуальной значимости (алгоритм ITTI), который представляет собой алгоритм избирательного внимания, при помощи которого моделируют механизм визуального внимания организма, и приспособлен для обработки естественных изображений.
[00197] Второй класс представляет собой способ исключительно математических вычислений, который не исходит ни из какого визуального биологического принципа, например, алгоритм полного разрешения (алгоритм Ахо-Корасик, АС алгоритм), алгоритм спектральной остаточности (алгоритм SR), которые основаны на области пространственных частот.
[00198] Третий класс сочетает два вышеописанных класса алгоритмов, например, алгоритм, основанный на теории графов (алгоритм GBVS), который моделирует визуальный принцип, аналогичный алгоритму ITTI в процедуре извлечения признаков, и вводит марковские цепи в процедуру создания значимого изображения и получает значение значимости при помощи способа исключительно математических вычислений.
[00199] На стадии S610 значимый участок видеоданных выявляют в видеоданных путем ввода видеоданных в пределах временного диапазона в модель обнаружения значимого участка.
[00200] Видеоданные в пределах временного диапазона извлекают из проверяемого видеофайла, видеоданные последовательно вводят в модель обнаружения значимого участка, и модель обнаружения значимого участка выдает на выходе значимый участок видеоданных из видеоданных.
[00201] На стадии S611 контент целевого видеофайла модерируют путем ввода участка видеоданных и целевых видеоданных в предварительно заданную модель модерации контента.
[00202] Согласно этому варианту осуществления, для проверяемых видеоданных, содержащих недопустимый контент, временной диапазон определяют, исходя из момента времени, и весьма вероятно, что контент видеоданных в этом временном диапазоне недопустимый. Таким образом, извлечение значимого участка видеоданных может быстро повысить надежность обучающей выборки, тем самым повышая эффективность модели модерации контента за счет обучения модели модерации контента.
[00203] Пятый вариант осуществления
[00204] На фиг. 7 представлена принципиальная структурная схема устройства для обучения модели модерации контента согласно пятому варианту осуществления настоящего изобретения. Устройство предусматривает:
[00205] модуль 701 получения образца видеофайла, рассчитанный на получение образца видеофайла, при этом образец видеофайла содержит некоторое количество кадров видеоданных;
[00206] модуль 702 извлечения образца видеоданных, рассчитанный на извлечение части видеоданных из образца видеофайла в качестве образца видеоданных;
[00207] модуль 703 установления момента времени, рассчитанный на установление момента времени образца видеоданных в образце видеофайла в том случае, когда образец видеоданных содержит недопустимый контент;
[00208] модуль 704 извлечения участка видеоданных, рассчитанный на извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[00209] модуль 705 обучения модели, рассчитанный на обучение модели модерации контента, исходя из участка видеоданных и образца видеоданных.
[00210] Устройство для обучения модели модерации контента согласно вариантам осуществления настоящего изобретения может осуществлять способ обучения модели модерации контента согласно любому варианту осуществления настоящего изобретения, и имеет функциональные модули и преимущества в соответствии с этим способом.
[00211] Шестой вариант осуществления
[00212] На фиг. 8 представлена принципиальная структурная схема устройства для модерации видеоконтента согласно шестому варианту осуществления настоящего изобретения. Устройство предусматривает:
[00213] модуль 801 получения проверяемого видеофайла, рассчитанный на получение проверяемого видеофайла, при этом проверяемый видеофайл содержит некоторое количество кадров видеоданных;
[00214] модуль 802 извлечения проверяемых видеоданных, рассчитанный на извлечение части видеоданных из проверяемого видеофайла в качестве проверяемых видеоданных;
[00215] модуль 803 установления момента времени, рассчитанный на установление момента времени в проверяемых видеоданных из проверяемого видеофайла в случае, когда проверяемые видеоданные содержат недопустимый контент;
[00216] модуль 804 извлечения участка видеоданных, рассчитанный на извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[00217] модуль 805 модерации видеоматериала, рассчитанный на модерацию контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации контента.
[00218] Устройство для модерации видеоконтента согласно вариантам осуществления настоящего изобретения может осуществлять способ модерации видеоконтента согласно любому варианту осуществления настоящего изобретения, и имеет функциональные модули и преимущества в соответствии с этим способом.
[00219] Седьмой вариант осуществления
[00220] На фиг.9 представлена принципиальная структурная схема вычислительного устройства согласно седьмому варианту осуществления настоящего изобретения. Как видно из фиг. 9 вычислительное устройство предусматривает процессор 900, накопительное устройство 901, модуль 902 связи, устройство 903 ввода и устройство 904 вывода. Вычислительное устройство может содержать один или несколько процессоров 900, на фиг. 9 в качестве примера показан один процессор 900. Процессор 900, запоминающее устройство 901 и модуль 902 связи, устройство 903 ввода и устройство 904 вывода в компьютерном устройстве могут быть соединены шиной или другими средствами, и на фиг. 9 в качестве примера показано соединение шиной.
[00221] Вычислительное устройство согласно этому варианту осуществления может осуществлять способ обучения модели модерации контента или способ модерации видеоконтента согласно любому варианту осуществления настоящего изобретения, и имеет функциональные модули и преимущества в соответствии с этим способом.
[00222] Восьмой вариант осуществления
[00223] Этот вариант осуществления предусматривает машиночитаемое запоминающее устройство, на котором хранят компьютерную программу. Запуск компьютерной программы процессором вычислительного устройства приводит к тому, что вычислительное устройство осуществляет способ обучения модели модерации контента или способ модерации видеоконтента.
[00224] Способ обучения модели модерации контента предусматривает:
[00225] получение образца видеофайла, при этом образец видеофайла содержит некоторое количество кадров видеоданных;
[00226] извлечение части видеоданных в качестве образца видеоданных;
[00227] установление момента времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент;
[00228] извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[00229] обучение модели модерации контента, исходя из участка видеоданных и образца видеоданных.
[00230] Способ модерации видеоконтента предусматривает:
[00231] получение проверяемого видеофайла, при этом проверяемый видеофайл содержит некоторое количество кадров видеоданных;
[00232] извлечение части видеоданных в качестве проверяемых видеоданных;
[00233] установление момента времени в проверяемых видеоданных проверяемого видеофайла в случае, когда проверяемые видеоданные содержат недопустимый контент;
[00234] извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
[00235] модерация контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации контента.
[00236] Согласно этому варианту осуществления настоящего изобретения, для машиночитаемого запоминающего устройства компьютерная программа не ограничена описанным выше способом работы, и может также выполнять сопутствующие операции в способе обучения модели модерации контента или способе модерации видеоконтента согласно любому из вариантов осуществления настоящего изобретения.
[00237] Исходя из приведенного выше описания вариантов осуществления, настоящее изобретение могут осуществлять посредством программного обеспечения и необходимого обычного аппаратного обеспечения, или могут осуществлять посредством аппаратного обеспечения. Технические решения настоящего изобретения могут осуществлять в виде программного продукта, и программный продукт могут хранить на машиночитаемом запоминающем устройстве, например, на дискете, постоянном запоминающем устройстве (ROM), в оперативной памяти (RAM), флэш-памяти (FLASH), на жестком диске, оптическом диске компьютера и т.п. Машиночитаемое запоминающее устройство содержит различные команды, при помощи которых вычислительное устройство (это может быть персональный компьютер, сервер или сетевое устройство, и т.п.) выполняет способы, описанные в различных вариантах осуществления настоящего изобретения.
[00238] Согласно описанным выше вариантам осуществления устройства для обучения модели модерации контента и устройства для модерации видеоконтента, предусмотренные узлы и модули только разделены согласно функциональной логике, но не ограничены описанным выше разделением при условии, что могут быть реализованы соответствующие функции. Кроме того, названия функциональных узлов также носят только разграничительный характер и не преследуют цели ограничить объем настоящего изобретения.


Группа изобретений относится к области распознавания видеоизображений и может быть использована для модерации видеоматериалов. Техническим результатом является повышение эффективности модерации видеоматериала. Способ модерации видеоконтента содержит извлечение части видеоданных из проверяемого видеофайла в качестве целевых видеоданных; установление момента времени в проверяемых видеоданных проверяемого видеофайла в случае, когда проверяемые видеоданные содержат недопустимый контент; и извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и модерацию контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации видео контента; причем извлечение значимого участка видеоданных из видеоданных в области этого момента времени предусматривает: определение временного диапазона, который содержит этот момент времени; поиск модели обнаружения значимого участка, рассчитанной на определение значимого участка в видеоданных; и выявление значимого участка видеоданных в видеоданных путем ввода видеоданных в пределах временного диапазона в модель обнаружения значимого участка. 8 н. и 9 з.п. ф-лы, 9 ил.
1. Способ обучения модели модерации видеоконтента, предусматривающий:
извлечение части видеоданных из образца видеофайла в качестве образца видеоданных;
установление момента времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент;
извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
обучение модели модерации видеоконтента, исходя из участка видеоданных и образца видеоданных;
извлечение значимого участка видеоданных из видеоданных в области этого момента времени предусматривает:
определение временного диапазона, который содержит этот момент времени;
поиск модели обнаружения значимого участка, рассчитанной на определение значимого участка в видеоданных; и
выявление значимого участка видеоданных в видеоданных путем ввода видеоданных в пределах временного диапазона в модель обнаружения значимого участка.
2. Способ по п. 1, в котором извлечение части видеоданных из образца видеофайла в качестве образца видеоданных предусматривает:
разделение образца видеофайла по меньшей мере на два видеофрагмента образца; и
извлечение части видеоданных из каждого видеофрагмента образца в качестве образца видеоданных.
3. Способ по п. 2, в котором извлечение части видеоданных из образца видеофайла в качестве образца видеоданных предусматривает по меньшей мере одно из перечисленных:
ранжирование образца видеоданных в хронологическом порядке; и/или
масштабирование образца видеоданных до предварительно заданного размера.
4. Способ по п. 1, в котором установление момента времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент, предусматривает:
поиск модели распознавания нарушений, рассчитанной на определение оценки недопустимости изображения в контенте видеоданных;
определение оценки недопустимости изображения в контенте образца видеоданных путем ввода образца видеоданных в модель распознавания нарушений;
выбор образца видеоданных с оценкой недопустимости изображения, соответствующей предварительно заданному условию недопустимости; и
определение момента времени в образце видеоданных, соответствующего предварительно заданному условию недопустимости, из образца видеофайла;
5. Способ по п. 4, в котором поиск модели распознавания нарушений предусматривает:
определение категории нарушения, которой помечен образец видеофайла, и представляющей недопустимый контент; и
поиск модели распознавания нарушений, соответствующей категории нарушения, при этом модель распознавания нарушений рассчитана на определение оценки недопустимости изображения в контенте, который в этих видеоданных принадлежит к категории нарушения.
6. Способ по п. 4, в котором выбор образца видеоданных с оценкой недопустимости изображения, соответствующей предварительно заданному условию недопустимости, предусматривает:
определение того, содержит ли образец видеоданных оценку недопустимости изображения, которая превышает предварительно заданное пороговое значение оценки изображения;
определение того факта, что оценка недопустимости изображения соответствует предварительно заданному условию нарушения в случае, когда образец видеоданных содержит оценку недопустимости изображения, которая превышает предварительно заданное пороговое значение оценки изображения; и
определение того факта, что максимальное значение оценки недопустимости изображения соответствует предварительно заданному условию нарушения в случае, когда образец видеоданных не содержит оценки недопустимости изображения, которая превышает предварительно заданное пороговое значение оценки изображения.
7. Способ по любому из пп. 1-6, в котором обучение модели модерации видеоконтента, исходя из участка видеоданных и образца видеоданных, предусматривает:
определение категории нарушения, которой помечен образец видеофайла и которая представляет недопустимый контент.
получение глубокой нейронной сети и предварительно обученной модели;
инициализацию глубокой нейронной сети при помощи предварительно обученной модели;
обучение глубокой нейронной сети путем обратного распространения ошибки в качестве модели модерации видеоконтента, исходя из участка видеоданных, образца видеоданных и категории нарушения.
8. Способ модерации видеоконтента, предусматривающий:
извлечение части видеоданных из проверяемого видеофайла в качестве целевых видеоданных;
установление момента времени в проверяемых видеоданных проверяемого видеофайла в случае, когда проверяемые видеоданные содержат недопустимый контент; и
извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
модерацию контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации видео контента;
причем извлечение значимого участка видеоданных из видеоданных в области этого момента времени предусматривает:
определение временного диапазона, который содержит этот момент времени;
поиск модели обнаружения значимого участка, рассчитанной на определение значимого участка в видеоданных; и
выявление значимого участка видеоданных в видеоданных путем ввода видеоданных в пределах временного диапазона в модель обнаружения значимого участка.
9. Способ по п. 8, в котором ввод участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации видеоконтента с целью модерации контента проверяемого видеофайла предусматривает:
определение оценки недопустимости файла для контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации контента в случае, когда видеоконтент проверяемого видеофайла принадлежит к предварительно заданной категории нарушения;
определение порогового значения оценки файла;
определение того, что проверяемый файл является допустимым в случае, когда оценка недопустимости файла меньше или равна пороговому значению оценки файла.
10. Способ по п. 9, в котором модерация контента проверяемого видеофайла путем ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации видеоконтента дополнительно предусматривает:
передачу проверяемого видеофайла клиенту в случае, когда оценка недопустимости файла выше, чем пороговое значение оценки файла;
определение контента проверяемого видеофайла как допустимого в случае, когда от клиента получают первую информацию о модерации; и
определение контента проверяемого видеофайла как недопустимого в случае, когда от клиента получают вторую информацию о модерации.
11. Способ по п. 9 или 10, в котором определение порогового значения оценки файла предусматривает:
определение общего количества проверяемых видеофайлов за предыдущий промежуток времени, в который была определена оценка недопустимости файла для проверяемого видеофайла;
создание порогового значения оценки файла таким образом, что отношение количества модераций к общему количеству совпадений соответствует предварительно заданному push-показателю, при этом количество модераций представляет собой количество проверяемых видеофайлов, для которых оценки недопустимости файла выше порогового значения оценки файла.
12. Устройство для обучения модели модерации видеоконтента, предусматривающее:
модуль извлечения образца видеоданных, рассчитанный на извлечения части видеоданных из образца видеофайла в качестве образца видеоданных;
модуль установления момента времени, рассчитанный на установление момента времени в образце видеоданных из образца видеофайла в случае, когда образец видеоданных содержит недопустимый контент;
модуль извлечения участка видеоданных, рассчитанный на извлечение значимого участка видеоданных из видеоданных в области этого момента времени; и
модуль обучения модели, рассчитанный на обучение модели модерации видеоконтента, исходя из участка видеоданных и образца видеоданных;
при этом модуль извлечения участка видеоданных предусматривает:
подмодуль определения временного диапазона, рассчитанный на определение временного диапазона, который содержит этот момент времени;
подмодуль поиска модели обнаружения значимого участка, рассчитанный на поиск модели обнаружения значимого участка, рассчитанный на выявление значимого участка изображения в видеоданных; и
подмодуль обработки модели обнаружения значимого участка, рассчитанный на выявление значимого участка видеоданных в видеоданных путем ввода видеоданных из временного диапазона в модель обнаружения значимого участка.
13. Устройство для модерации видеоконтента, предусматривающее:
модуль извлечения проверяемых видеоданных, рассчитанный на извлечение части видеоданных из проверяемого видеофайла в качестве проверяемых видеоданных;
модуль установления момента времени, рассчитанный на установление момента времени в проверяемых видеоданных из проверяемого видеофайла в случае, когда проверяемые видеоданные содержат недопустимый контент; и
модуль извлечения участка видеоданных, рассчитанный на извлечение значимого участка видеоданных из видеоданных в области этого момента времени;
модуль модерации видеоматериала, рассчитанный на модерацию контента проверяемого видеофайла после ввода участка видеоданных и проверяемых видеоданных в предварительно заданную модель модерации видеоконтента,
при этом модуль извлечения участка видеоданных предусматривает:
подмодуль определения временного диапазона, рассчитанный на определение временного диапазона, который содержит этот момент времени;
подмодуль поиска модели обнаружения значимого участка, рассчитанный на поиск модели обнаружения значимого участка, рассчитанный на выявление значимого участка изображения в видеоданных; и
подмодуль обработки модели обнаружения значимого участка, рассчитанный на выявление значимого участка видеоданных в видеоданных путем ввода видеоданных из временного диапазона в модель обнаружения значимого участка.
14. Вычислительное устройство для обучения модели модерации видеоконтента, предусматривающее:
один или несколько процессоров;
накопительное устройство, рассчитанное на хранение одной или нескольких программ;
при этом запуск одной или нескольких программ одним или несколькими процессорами приводит к выполнению способа обучения модели модерации видеоконтента согласно описанию в любом из пп.1-7.
15. Энергонезависимое машиночитаемое запоминающее устройство, на котором хранят компьютерную программу, при этом запуск компьютерной программы процессором вычислительного устройства приводит к тому, что вычислительное устройство выполняет способ обучения модели модерации видеоконтента согласно описанию в любом из пп. 1-7.
16. Вычислительное устройство для обучения модели модерации видеоконтента, предусматривающее:
один или несколько процессоров;
накопительное устройство, рассчитанное на хранение одной или нескольких программ;
при этом запуск одной или нескольких программ одним или несколькими процессорами приводит к выполнению способа модерации видеоконтента согласно описанию в любом из пп. 8-11.
17. Энергонезависимое машиночитаемое запоминающее устройство, на котором хранят компьютерную программу, при этом запуск компьютерной программы процессором вычислительного устройства приводит к тому, что вычислительное устройство выполняет способ модерации видеоконтента согласно описанию в любом из пп. 8-11.
| CN 109862394 A, 07.06.2019 | |||
| CN 109151499 A, 04.01.2019 | |||
| US 20190012568 A1, 10.01.2019 | |||
| WO 2017162919 A1, 28.09.2017 | |||
| CN 107341505 A, 10.11.2017 | |||
| СПОСОБ ПРОВЕРКИ ВЕБ-СТРАНИЦ НА СОДЕРЖАНИЕ В НИХ ЦЕЛЕВОГО АУДИО И/ИЛИ ВИДЕО (AV) КОНТЕНТА РЕАЛЬНОГО ВРЕМЕНИ | 2013 |
|
RU2530671C1 |
| СПОСОБ И СИСТЕМА ФИЛЬТРАЦИИ ВЕБ-КОНТЕНТА | 2010 |
|
RU2446460C1 |
