Область техники, к которой относится изобретение
Настоящее изобретение относится к компьютерным и сетевым технологиям, а именно к технологиям, используемым для выявления аудио и/или видео потоков, вещание которых осуществляется в масштабе реального времени.
Изобретение может быть использовано, например, для построения эффективной системы поиска веб-сайтов, имеющих общие отличительные признаки, с последующим обнаружением целевого контента, размещенного в сети. Изобретение может быть применено как для поиска специфических медиа-объектов (он-лайн радио, потоков с веб-камер, видео потоков), так и для поиска объектов в виде ссылок на внешние источники определенного вида, сигнализирующие о наличии целевого аудио и/или видео контента реального времени, например схемы передачи данных - rtmp, rtsp, mms, sop и т.д. Предлагаемый в изобретении принцип построения модели характерных для веб-страниц признаков позволяет использовать изобретение также и для поиска прочего контента (помимо «живых» медиа-потоков), обладающего общими признаками, что позволит создавать новые продукты/сервисы как развлекательно-медийного, так и аналитического характера.
Предшествующий уровень техники
В традиционных системах поиск целевого контента в веб-страницах базируется на определенном наборе признаков наличия данного контента на веб-странице. Набор признаков формируется разработчиками систем в зависимости от конкретного контента. В силу высокой динамики среды размещения в интернете аудио и/или видео потоков, вещание которых осуществляется в масштабе реального времени («живых» потоков), такой принцип не является оптимальным для их поиска, так как требует времени и усилий разработчиков на распознавание нового признака или комбинации признаков и реализации механизма анализа этого признака для поиска целевого контента.
Известные из уровня техники поисковые системы проводят только быстрый поверхностный анализ содержимого веб-страницы и далеко не всегда способны отыскать динамически создаваемые объекты.
В настоящее время в мире широко известны и массово используются поисковые машины, которые обеспечивают пользователям возможность осуществлять в Интернете поиск веб-страниц, содержащих нужную для них информацию по вводимым ими поисковым запросам. Популярными поисковыми машинами являются, в частности, Yahoo!, Google, Yandex, Rambler.
Общий принцип работы известных поисковых машин основан на сборе информации по веб-страницам в Интернете, ее обработке и индексировании для дальнейшего предоставления пользователю возможности поиска необходимой информации в том объеме, который был обработан поисковой машиной. В состав каждой поисковой машины входят поисковые роботы, целью которых является сканирование веб-страниц Интернета и их загрузка. После обращения поискового робота по указанному адресу веб-страницы он просматривает, например, http-заголовки, проверяя, когда в последний раз была модифицирована эта страница. Если поисковый робот уже просматривал данную веб-страницу, а дата последней модификации страницы изменилась, тогда он загрузит ее для обработки вновь, если же просматриваемая им веб-страница вообще не просматривалась, тогда она сразу будет загружена для обработки.
Веб-страницы, загруженные поисковым роботом, обрабатываются соответствующими программно-аппаратными компонентами поисковой машины. Целью такой обработки является анализ страницы: как правило, вначале из веб-страницы извлекается заголовок (Title), поскольку он несет в себе общую информацию о веб-странице. Далее извлекается и обрабатывается весь текст, который так или иначе выделен, например, курсивом, подчеркиванием или размером (в частности, размер его шрифта больше размера шрифта основного текста), поскольку поисковая машина предполагает, что это ключевые места в тексте и на них сделан акцент.
Некоторые поисковые машины просматривают метатеги веб-страниц, предполагая, что в них имеются ключевые слова или словосочетания страницы. В то же время, поскольку в содержимом метатегов зачастую дается недостоверная информация, некоторые поисковые машины не используют их для определения ключевых слов страницы.
Также весь текст веб-страницы подвергается полной обработке. Например, те поисковые машины, которые не используют метатеги для определения ключевых слов веб-страницы, ищут ключевые слова путем выполнения проверки на предмет того, как часто встречается то или иное слово в тексте, и для этого из текста удаляются все "стоп-слова", такие как <а>, <он>, <ты>, <в>, а также все символы и цифры, поскольку они создают шум при поиске ключевых слов.
Наконец, обработанный текст веб-страницы индексируется поисковой системой надлежащим образом, так чтобы предоставить пользователю посредством веб-интерфейса (например, браузера) возможность удобного поиска по базе данных поисковой машины на основе ввода поисковых запросов.
Более подробно структура и базовые принципы функционирования поисковых машин изложены, в частности, в "The anatomy of a large-scale hypertextual Web search engine", Brin, S., Page, L., Computer Networks and ISDN Systems, 30(1-7):107-117, 1998; "Effective Web Crawling", Castillo, C, PhD thesis, University of Chile, 2004; "Crawling the Web". Web Dynamics: Adapting to Change in Content, Size, Topology and Use, ed. by M. Levene, A. Poulovassilis, 153-178, Pant, G., Srinivasan, P., Menczer, F., 2004.
Однако построенные таким образом поисковые машины перестают отвечать требованиям сегодняшнего дня в силу все увеличивающегося объема и разнообразия информации, представляемой в Интернете. В частности, при проведении такого основывающегося на тексте поиска веб-страниц, где содержались бы интересующие пользователя картинки или видео, выдается обширный результирующий список веб-страниц, в котором доля страниц, действительно отвечающих требованиям и запросам пользователя, оказывается невелика, поскольку в данный список, в силу специфики описываемых поисковых машин, также попадут те веб-страницы, которые содержат упоминания, обсуждения, рекламу, отзывы и т.п., касающиеся требующихся картинок или видео, но непосредственно не содержат самих требующихся картинок или видео. По мере же роста совокупного объема и разнообразия веб-контента в Интернете доля релевантных веб-страниц при такого рода специфических поисках будет лишь снижаться, и, как следствие, пользователи вынуждены строить хитроумные, скорее всего неоднократные поисковые запросы и тратить время на просеивание больших массивов результатов поиска.
Этой проблемой обуславливается актуальность создания специализированных (так называемых, вертикальных) поисковых систем, строго ориентированных на поиск по тематическим ресурсам Интернета.
В частности, из уровня техники известны технические решения, обеспечивающие выявление аудио и/или видео потоков, вещание которых осуществляется в масштабе реального времени. Выявление таких потоков может осуществляться в процессе интернет-поиска ссылок на данные потоки, в том числе, с использованием поисковых роботов, или с использованием специализированных (так называемых вертикальных) поисковых систем, ориентированных на поиск по тематическим ресурсам Интернета, в которых предусмотрена возможность проверки ссылок на мультимедийные потоки на предмет их соответствия критерию «живого» потока. При этом в качестве объекта обработки, как правило, выступают веб-страницы Интернета. Результатом обработки является обширный результирующий список веб-страниц с низким процентом релевантности на соответствие критерию «живой поток».
Из уровня техники известно решение, представленное в заявке на изобретение US 2003028896 - «Video and digital multimedia aggregator remote content crawler», в котором представлен способ проверки медиа контента как составной части более общей системы для поиска мультимедийных материалов. Для проверки контента используют процессор критериев проверки (контента), базу данных критериев проверки, процессор сбора метаданных. Проверка критериев может быть основана на типе контента, формате, и способе доставки. Процессор критериев может идентифицировать поисковые параметры посредством анализа и импорта метаданных стандартизированных и собственных форматов контента, парсинга имен полей метаданных, описательных терминов с последующим добавлением их в базу данных критериев. Процессор критериев может также идентифицировать критерии поиска обратным способом, анализируя гипертекст, связанный с требуемыми гиперссылками и, анализируя текст, ближайший к гиперссылке. Типы данных контента, которые будут включены в базу данных, могут включать все доступные промышленные стандарты и собственные форматы подачи. Обработка критериев происходит в модуле проверки критериев, который определяет, удовлетворяет ли содержание гипертекстовых файлов условиям критериев проверки. Выполняется алгоритм сравнения, чтобы определить, содержат ли гипертекстовые файлы элементы, перечисленные в базе данных критериев, такие как ключевые слова, описания типа данных, и дескрипторы метаданных. Сбор метаданных может быть выполнен несколькими способами, включая передачу или загрузку всех, или части файлов, и анализа файловой структуры для известных полевых дескрипторов метаданных и содержания полей.
Однако известное решение не ориентировано на определение живых потоков. Определение потоков подобного рода происходит исключительно по ограниченному набору ключевых элементов (слов), поиск которых осуществляется в гипертекстовых файлах. В случае, если в гипертекстовом файле отсутствуют ключевые элементы из известного набора, тип потока не будет определен.
Из уровня техники известно также решение, представленное в заявке на изобретение US 2009216758 «Method and apparatus for an application crawler», в котором представлены способ и устройство для поиска видеофайлов и извлечения подробной информации из веб-страниц и веб-приложений. С помощью данного изобретения осуществляют проверку функционирующего приложения. Поисковый робот, может загрузить и инсталлировать компоненты так, что веб-приложение будет представлено тем же самым способом, что было бы создано в браузере. Метод может включать инсталлирование видеофайлов, видеопотоков. Поисковый робот приложения может индексировать контент, используя многочисленные поля метаданных. В одном из вариантов исполнения изобретения поисковый робот приложения может достигнуть видеопотока или видеоплеера и «вытащить» соответствующие данные.
Однако для поиска медиа потоков необходима инсталляция приложения с вебстраницы. При этом индексация контента происходит после инсталляции контента и анализа метаданных. Таким образом, в известном техническом решении идет процесс, «обратный» процессу, представленному в заявляемом техническом решении, в котором вывод о содержимом контента - «живой» поток или нет, делают на основе анализа метаданных. Кроме того, данное изобретение не ориентированно на выявление аудио и видео источников, вещание которых осуществляется в масштабе реального времени. Изобретение позволяет находить на веб-страницах аудио или видео файл и определять их описание и технические характеристики.
Наиболее близким к заявляемому решению является способ определения медиа потоков, вещание которых осуществляется в масштабе реального времени, и система для реализации способа, представленные в контексте описания технологии интернет-поиска мультимедийного контента реального времени (RU 2399090 (C2); МПК: G06F 17/30). Способ содержит этапы, на которых: A) заранее задают в поисковой системе расширяемый и модифицируемый набор признаков наличия на Web-страницах вещания AV контента реального времени; B) осуществляют анализ загруженной Web-страницы на предмет присутствия в ней признаков, свидетельствующих о наличии на данной Web-странице вещания AV контента реального времени, из упомянутого их набора; C) если такие признаки выявлены в Web-странице при анализе, сохраняют адрес данной Web-страницы в базе данных из состава поисковой системы. Если же на этапе C) такие признаки не выявлены, то переходят на этап D), на котором загружают новую Web-страницу и повторяют в отношении нее этапы B) и C). При этом этап B) осуществляют посредством разбора текстового содержимого файлов Web-страницы сначала на предмет обнаружения в нем по меньшей мере одного признака, указывающего на средство или технологию воспроизведения AV контента, и затем, при успешном обнаружении, на предмет присутствия в нем по меньшей мере одного признака, указывающего на то, что воспроизводимый AV контент является именно AV контентом реального времени. Признак может представлять собой некоторой символ или набор символов. В частности, признак может представлять собой элемент разметки Web-страницы, такой как тег, параметр или атрибут.
В материалах описания данного изобретения (RU 2399090) также предоставлена компьютерно-реализуемая поисковая система, включающая модуль поиска признаков, выполненный с возможностью анализа загруженной Web-страницы на предмет присутствия в ней признаков, свидетельствующих 6 наличии на данной Web-странице вещания AV контента реального времени, из упомянутого их набора; базу данных, приспособленную для сохранения адресов Web-страниц, в которых модулем поиска признаков по результатам анализа установлено наличие вещания AV контента реального времени.
В техническом решении по патенту RU 2399090 в процессе поиска ссылок на мультимедийные потоки предусмотрена возможность проверки данных ссылок на предмет их соответствия критерию «живой» поток. При этом в качестве объекта обработки выступают веб-страницы Интернета. В данном техническом решении не предусмотрена возможность подключения непосредственно к серверу по ссылке для получения результирующего списка ссыпок с высоким процентом релевантности на соответствие критерию «живой поток». Таким образом, набор ссылок, предоставляемый конечному пользователю, в большинстве своем, включает ссылки, находящиеся в «выключенном» состоянии или представляющие собой статические файлы фиксированной продолжительности, т.е. не удовлетворяющие критерию «живого» потока.
Сущность изобретения
Задачей настоящего изобретения является создание системы и способа, ориентированных на поиск веб-страниц, на которых присутствует целевой аудио и/или видео контент реального времени на основе анализа признаков и/или наборов признаков наличия целевого контента, содержащихся в исходном коде веб-страниц.
Техническим результатом изобретения является повышение эффективности обнаружения целевого контента, содержащегося в проверяемых веб-страницах, а также снижение количества ресурсоемких операций, применяемых к веб-страницам, которые такой контент не содержат, при повышении достоверности получаемых результатов. Таким образом, заявляемый способ может быть реализован со значительно меньшими затратами, в т.ч. временными (по сравнению с известными аналогами), необходимыми для поиска веб-страниц с целевым контентом при повышении степени релевантности обнаруженных веб-страниц на наличие в них целевого контента.
Поставленная задача решается за счет создания определенного алгоритма формирования признаков или набора признаков (ключей), используемых в процессе проверки веб-страниц на содержание в них целевого контента реального времени за счет добавления эффективных признаков и вырождения неэффективных. При этом формирование таких признаков осуществляется по итогам анализа веб-страниц, который реализуется в два этапа - на этапе быстрого анализа веб-страниц (на основе внешних характерных для целевого контента признаков) и этапе глубокого анализа веб-страниц (с выполнением всего программного кода страницы с целью получения конечных и скрытых объектов, исполняемых в браузере на стороне клиента). Повышение эффективности способа обеспечивается посредством распространения гипотезы о наличии ряда признаков «живого» потока, выявленных на одной странице, на другие страницы со схожими признаками после определенного алгоритма проверки. При этом отличительной особенностью заявляемого способа является разработанная оригинальная технология построения набора характерных признаков (которые с высокой степенью вероятности указывают на наличие или отсутствие на веб-странице целевого контента), по которым «сырой» html-текст главной страницы сайта либо отбрасывается, либо отправляется на более глубокий анализ. Степень вероятности определения наличия или отсутствия на веб-странице целевого контента определяется из показателей результативности признаков, которые вычисляются в процессе работы системы. Наличие обратной связи в случае обнаружения целевого контента на этапе глубокого анализа веб-страниц позволяет значительно повысить эффективность анализа веб-страниц на этапе их быстрого анализа. Таким образом, при помощи значительного сокращения объема анализируемых данных достигается максимальная эффективность поиска целевого контента.
Актуальность решения поставленной задачи обусловлена возрастающими вычислительными затратами на поиск и определение контента, который в общем случае не представлен в исходном коде веб-страниц явным образом, что не позволяет сделать однозначный вывод о наличии или отсутствии целевого контента без исполнения ресурсоемких операций - построения модели веб-документа, интерпретации программного кода страницы, загрузки внешних объектов и анализа полученного контента на принадлежность к целевому. Подобные операции требуют ресурсных затрат, эквивалентных работе веб-браузера, и в отличие от поиска признаков в исходном коде, отнимают значительные вычислительные ресурсы. Таким образом, в отличие от классических поисковых систем, которые анализируют только текстовое содержимое исходного кода, вычислительные затраты поиска специфического контента значительно возрастают, что является одной из ключевых проблем при работе поисковой системы в сети Интернет, особенно учитывая непрерывный рост количества Интернет-ресурсов.
Поставленная задача решается тем, что способ проверки веб-страниц на содержание в них целевого аудио и/или видео (AV) контента реального времени, включает следующие этапы и операции:
A. формирование расширяемого и модифицируемого набора базовых признаков, свидетельствующих о наличии на веб-страницах целевого контента реального времени с последующим сохранением базовых признаков в БД признаков,
B. быстрый анализ веб-страниц посредством анализа исходного кода веб-страницы на предмет присутствия в исходном коде базовых признаков,
C. в случае выявления в исходном коде базовых признаков, сохраняют найденный на странице набор признаков в качестве ключа в БД ключей, а также веб-страницу и/или ссылку на веб-страницу, ассоциированную с данным ключом, а в случае отсутствия базовых признаков в исходном коде, веб-странице присваивают статус «пропущенная»,
D. из БД ключей выбирают ключ и осуществляют глубокий анализ ассоциированных с данным ключом веб-страниц на наличие в них целевого контента посредством исполнения всего или части программного кода и загрузки всех или части объектов, при этом веб-страницам, прошедшим глубокий анализ присваивают статус «результативная», либо «пустая», в зависимости от наличия или отсутствия в ней целевого контента,
E. по итогам выполнения этапа D в отношении каждого из ключей в БД ключей сохраняют статистическую информацию о количестве проверенных веб-страниц, а также количестве «результативных» и «пустых» веб-страниц,
F. по итогам накопленной на этапе E статистической информации определяют для каждого ключа показатель результативности ключа, либо по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ (качественный показатель), либо по соответствию ключу наибольшего количества ассоциированных веб-страниц (количественный показатель),
G. по показателям результативности ключей, полученных на этапе F составляют рейтинг результативности ключей, находящихся в БД ключей, при этом выборку ключей из БД ключей для глубокой проверки ассоциированных с ключом веб-страниц осуществляют с учетом рейтингового номера ключа, построенного по показателям результативности ключей,
при этом этапы B и C повторяют для каждой проверяемой веб-страницы, по итогам которых обновляют БД ключей, с получением списка ключей и набора вебстраниц и/или ссылок на веб-страницы, ассоциированных с каждым ключом из списка, а этап D повторяют для каждого ключа, сохраненного в БД ключей.
Глубокий анализ (этап D) в способе может быть осуществлен сначала для заданного ограниченного количества проверяемых страниц из набора, и в случае, если, по крайней мере, одна страница содержит целевой контент, глубокому анализу подвергают все остальные страницы из набора, проассоциированные с данным ключом; в случае, если в заданном количестве проверяемых страниц по итогам глубокого анализа страницы с целевым контентом выявлены не будут, всем остальным страницам набора, проассоциированным с данным ключом, присваивают статус «пропущенные» и глубокому анализу не подвергают. Заданное ограничение для количества проверяемых страниц из набора в процессе глубокого анализа определяют эмпирическим путем по итогам анализа массива веб-страниц, при этом количество проверяемых страниц выбирают не менее трех, принадлежащих различным доменам.
По итогам глубокого анализа (этап D) выявляют ссылки на медиа серверы, а определение наличия целевого контента осуществляют посредством подключения к медиа серверам, с последующим получением от них информации о медиа потоках, включающей характеристики потока в заданном формате и/или части потока, предназначенного для воспроизведения веб-браузером, анализом полученной информации о медиа потоке и/или части потока, заключающимся в поиске признаков, свидетельствующих о том, что анализируемый поток является источником мультимедиа, вещание которого осуществляется в масштабе реального времени. Глубокий анализ веб-страницы может быть осуществлен посредством эмуляции работы веб-браузера через построение модели веб-документа и создание всех объектов, потенциально содержащих целевой контент. Созданные объекты анализируют на наличие ссылок на мультимедийный контент, при этом каждую ссылку проверяют на соответствие контенту вещания реального времени.
Вычисление показателя результативности ключей проводят при достижении количества ассоциированных веб-страниц, прошедших глубокий анализ, определенного порогового значения, например, 10000, или при достижении определенного порогового значения для доменов (например, 10), которым принадлежат ассоциированные вебстраницы, прошедшие глубокий анализ. В отношении всех веб-страниц, ассоциированных с ключами, имеющими показатель результативности ключей в виде отношения количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, превышающий пороговое значение, равное 10%, применяют глубокий анализ.
По итогам накопленной статистической информации дополнительно может быть определен показатель результативности признака как отношение количества «результативных» веб-страниц к общему количеству ассоциированных веб-страниц, прошедших глубокую проверку для всех ключей, в которые входит данный признак, составляют рейтинг результативности базовых признаков, и с учетом рейтингового номера признака обновляют БД признаков, например, посредством исключения признаков, имеющих наименьшие показатели результативности (например, менее 1%). При обновлении базовых признаков в БД признаков всем веб-страницам, имеющим статус «пропущенные», может быть установлен статус «на быстрый анализ», при этом веб-страницы направляют на этап их быстрого анализа. Обновление БД ключей может происходить посредством блокировки ключей, в случае обнаружения на этапе С заблокированного ключа ассоциированной с ним веб-странице присваивают статус «пропущенная». Блокировка ключей может происходить автоматически в случае достижения показателя результативности ключа, составленного по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, минимального порогового значения, например, 1%.
В качестве базового признака могут выступать символы или наборы символов (например, представляющие собой элемент разметки веб-страницы в виде тега, параметра или атрибута). Базовый признак может быть представлен частью программного кода страницы, выполняемого в процессе построения веб-страницы в веб-браузере (например, swfobject, flowplayer, uppod, rtmp, swf, object, moyea, flv, wimpy, player, embed, flow, offeecup, xspf, xmoov, applet). Базовый признак может представлять собой внешнюю ссылку, например, на внешний программный код, выполняемый в процессе построения веб-страницы в веб-браузере. В качестве таких ссылок могут быть использованы схемы передачи данных, например, mms, mmsu, mmst, rtmp, pnm, pna, rtsp, rtspu, rtspt, icyx, rtpx, htpx, uvxx, rtp. Базовый признак также может быть представлен в виде внешней ссылки на мультимедийный контент, имеющий заданное расширение, например, .asx, .pls, .plc, .m3u, .m3u8, .m4u, .b4s, .fpl, .smil, .smi, .vlc, .wpl, .wax, .wmx, .xspf, .zpl, .rmp, .qtl, .asf, .aa, .aac, аа3, .a52, .amr, .aacp, .wma, .wmv, .dvr-ms, .rm, .ra, .ram, .rv, .rmj, .mp4, .m4a, .m4p, .m4b, .m4r, .m4v, .mpg, .mpe, .mpg2, .mpeg, .mp1, .mp2, .mp3, .mj2, .mjp, .mjp2, .mjpg, .ogg, .ogv, .ts, .flv, .f4v, .f4p, .f4a, .h264, .vp3, .nsv, .nsa, .qt, или заданный тип мультимедийного контента - MIME type, например, audio/aac, audio/aacp, audio/3gpp, audio/3gpp2, audio/mp4, udio/mp4a-latm, audio/mpeg4-generic, audio/audible, audio/x-pn-audibleaudio, audio/atrac3, audio/x-oma, audio/asf, application/asx, video/x-ms-asf-plugin, application/x-mplayer2, video/x-ms-asf, application/vnd.ms-asf, video/x-ms-wm, video/x-ms-wmx, audio/x-ms-wma, video/x-ms-wmv, video/x-ms-dvr, application/vnd.rn-realmedia, audio/vnd.rn-realaudio, audio/x-pn-realaudio, audio/x-realaudio, video/vnd.rn-realvideo, audio/wav, audio/x-wav, audio/wave, udio/x-pn-wav, video/quicktime, video/x-quicktime, audio/aiff, audio/x-midi, audio/x-wav, video/x-flv, video/mp4, video/mpeg, video/mpg, video/x-mpg, video/mpeg2, application/x-pn-mpg, video/x-mpeg, video/x-mpeg2a, audio/x-mpeg, audio/mpa, audio/mpeg, audio/mpa-robust, udio/mp3, audio/x-mp3, audio/mpeg3, audio/mpg, audio/x-mpegaudio, audio/x-mpg, audio/x-mpeg3, video/mp4v-es, audio/x-m4a, audio/x-m4b, audio/x-ms-wax, video/x-ms-wvx, application/vnd.rn-realsystem-rmj, application/vnd.rn-rn-taiko-real-rmj, audio/ogg, application/ogg, audio/x-ogg, application/x-ogg, application/x-winamp, video/x-nsv, video/ogg, ideo/mj2, video/x-motion-jpeg, video/mjpeg, video/mp2t, video/h264, application/x-nsv-vp3-mp3, audio/amr, application/vnd.ms-wpl, application/xspf+xml, audio/mpeg-url, audio/x-mpegurl, application/x-winamp-playlist, audio/scpls, audio/x-scpls, application/vnd.rn-rn_music_package, application/x-smil, application/smil, application/smil+xml, application/videolan, application/vnd.mpegurl, video/x-mpegurl.
Базовые признаки могут формироваться в независимые группы по типу целевого контента таким образом, что один признак принадлежит только одной группе, при этом в случае обнаружения для одной веб-страницы признаков из разных групп, для данной веб-страницы формируют несколько ключей. Веб-страница представляет собой файл, непосредственно содержащий текст веб-страницы, и/или скрипт-файл, ассоциированный с данной веб-страницей.
Поставленная задача решается также тем, что компьютерно-реализуемая поисковая система, предназначенная для проверки веб-страниц на содержание в них целевого аудио и/или видео (AV) контента реального времени, включает следующие базы данных (БД) и модули:
- БД признаков с расширяемым и модифицируемым набором базовых признаков, свидетельствующих о наличии на веб-страницах аудио и/или видео контента реального времени,
- БД веб-страниц для анализа,
- модуль быстрого анализа веб-страниц, выполненный с возможностью анализа исходного кода веб-страницы, взятой из БД веб-страниц на предмет присутствия в исходном коде базовых признаков и формирования ключа из найденных признаков, с последующим сохранением их в БД ключей,
- БД ключей со списком ключей и ассоциированных с ними веб-страниц,
- модуль глубокого анализа веб-страниц, выполненный с возможностью выбора ключа из БД ключей и глубокого анализа ассоциированных с данным ключом веб-страниц на наличие в них целевого контента посредством исполнения всего программного кода и загрузки всех объектов, при этом веб-страницам, прошедшим глубокий анализ присваивают в БД веб-страниц статус «результативная», либо «пустая», в зависимости от наличия или отсутствия в ней целевого контента,
- модуль статистической обработки результатов глубокого анализа веб-страниц, выполненный с возможностью сохранения информации о количестве проверенных веб-страниц, количестве «результативных» и «пустых» веб-страниц, построения показателя результативности ключа, либо по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, либо по соответствию ключу наибольшего количества ассоциированных веб-страниц, а также построения рейтинга результативности ключей,
при этом модуль статистической обработки связан с БД ключей и БД признаков.
Перечисленные модули и БД могут быть также снабжены дополнительным функционалом, реализующим различные варианты заявляемого способа (представленные выше).
Описание чертежей
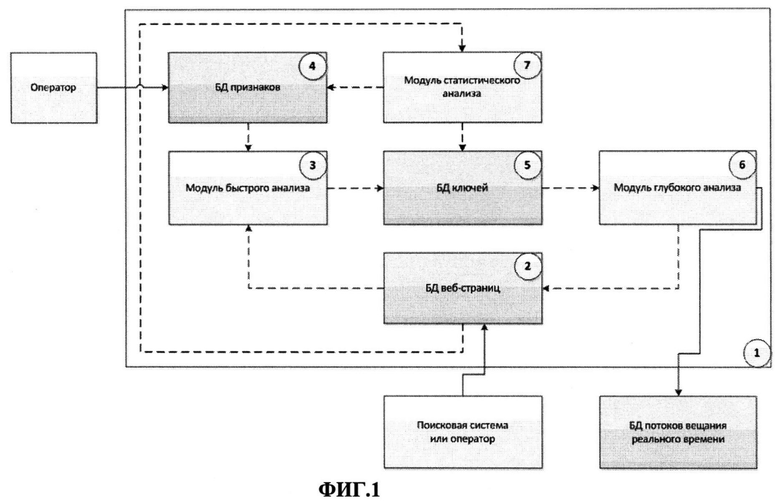
Изобретение поясняется чертежами, где на фиг.1 представлена блок-схема заявляемой системы, на фиг.2 представлена высокоуровневая архитектура заявляемой системы, демонстрирующая алгоритм реализации заявляемого способа; на фиг.3 и 4 представлены схемы работы модулей быстрого и глубокого анализа, соответственно, реализованные согласно настоящему изобретению. Позициями на фиг.1 обозначены: 1 - заявляемая система, которая включает следующие модули: 2 - БД веб-страниц, 3 - модуль быстрого анализа веб-страниц, 4 - БД признаков, 5 - БД ключей, 6 - модуль глубокого анализа веб-страниц, 7 - модуль статистического анализа.
Подробное описание изобретения.
Способ проверки веб-страниц на содержание в них целевого аудио и/или видео (AV) контента реального времени включает этап быстрого анализа веб-страниц на наличие в них признаков целевого контента, этап глубокого анализа веб-страниц на наличие в них целевого контента и этап статистического анализа данных. При этом последовательность выполнения этапов не является строго детерминированной, в частности, этапы быстрого анализа, глубокого анализа и статистического анализа могут выполняться параллельно друг другу.
Под целевым контентом, согласно настоящему изобретению, понимают мультимедийные потоки реального времени, воспроизведение которых может быть осуществлено на стороне клиента с помощью веб-браузера.
Особенностью заявляемой системы, реализующей алгоритм способа является то, что функционирование этапов зависит от режимов работы системы - обучения или производственного. Предполагается, что на этапе обучения в качестве исходных данных в систему поступают подготовленные оператором веб-страницы, содержащие целевой контент, что позволяет выявить наиболее результативные (по сути указывающие на наличие целевого контента) признаки и наборы признаков. Показатели результативности признаков и наборов признаков (ключей), сформированные на этапе обучения, влияют на работу системы в производственном режиме, позволяя применять ресурсоемкие операции к веб-страницам, имеющим наибольшую вероятность наличия целевого контента.
Этап быстрого анализа представляет собой высокопроизводительный цикл операций, применяемый ко всему массиву веб-страниц, подлежащих проверке.
Исходными данными для проверки могут являться как обнаруженные в сети Интернет веб-страницы, поступающие с течением времени из поисковой системы, так и заданные иным способом (например, оператором) наборы веб-страниц. В последнем случае набор может служить эталоном для проверки эффективности способа и последующей регулировки параметров, влияющих на дальнейшее принятие решений о необходимости применения последующих этапов.
Группировка веб-страниц в массивы для проверки на последующих этапах происходит путем ассоциации веб-страницы с ключом, который представляет собой набор обнаруженных в исходном коде веб-страницы базовых признаков, указывающих на возможность нахождения на веб-странице целевого контента. Ключи могут содержаться в единой общей базе данных, где также могут храниться показатели результативности ключа, вычисляемые на последующих этапах, и наборы веб-страниц, имеющих эквивалентный ключ. Таким образом, все веб-страницы разделяются на группы по условию принадлежности к одному и тому же ключу и попадают на следующий этап проверки (глубокого анализа) только в случае выбора соответствующего ключа.
Выбор ключа происходит исходя из соответствующего рейтинга (построенного либо качественным показателям, либо количественным), выбор которого происходит в зависимости от режима работы. В случае работы системы в режиме обучения выбирают рейтинг, построенный по количественному показателю, в случае работы в производственном режиме выбирают рейтинг, построенный по качественному показателю. Рейтинги вычисляют в процессе работы посредством этапа статистического анализа, который описан далее. Ключ, имеющий наибольший рейтинговый номер, и ассоциированные с данным ключом веб-страницы, имеющие статус «на глубокий анализ», направляют на следующий этап - глубокого анализа.
Этап глубокого анализа представляет собой набор ресурсоемких операций по выявлению целевого контента на веб-странице, применяемых к выбранной части массива веб-страниц, ассоциированных с выбранным ключом.
По результатам глубокого анализа выбранной части массива веб-страниц принимается решение о необходимости применения ресурсоемких операций к оставшейся части массива, либо принимается решение о том, что дальнейшее выполнение ресурсоемких операций нецелесообразно, в связи с тем, что они не выявят целевого контента. В общем случае весь массив проходит глубокий анализ, если хотя бы одна веб-страница из выбранной для анализа части содержит целевой контент, в противоположной ситуации оставшаяся часть массива не проверяется.
Выбор части массива веб-страниц для глубокого анализа происходит исходя из режима работы системы и заданных параметров. В случае работы в режиме обучения глубокий анализ проводится в отношении всего массива ассоциированных страниц с целью накопления качественных показателей результативности ключей, достоверность которых напрямую зависит от объема веб-страниц, прошедших полноценный анализ на предмет наличия целевого контента. В случае работы в производственном режиме выбор веб-страниц из массива происходит исходя из принадлежности к различным доменам и в количестве, определяемом внешним параметром, который задается оператором (например, не менее 10 страниц, принадлежащих как минимум 3 различным доменам).
По итогам выполнения первого и второго этапов веб-страницам присваивают один из следующих статусов:
- «на быстрый анализ» - веб-страница, в отношение которой должен быть осуществлен этап быстрого анализа (предполагается, что изначально все веб-страницы имеют статус «на быструю проверку»);
- «на глубокий анализ» - веб-страница, в отношение которой уже осуществлен быстрый анализ, но еще не применен глубокий анализ;
- «пустая» - прошедшая этап глубокого анализа, в результате которого не выявлено наличия целевого контента;
- «результативная» - прошедшая этап глубокого анализа, в результате которого выявлен целевого контент;
- «пропущенная» - веб-страница, в отношении которой реализован быстрый анализ, но не реализован глубокий анализ, вследствие принятия решения о низкой степени вероятности наличия целевого контента.
Количество обработанных веб-страниц с присвоенным определенным статусом является основой для построения рейтинга ключей и базовых признаков, вычисление которых происходит на этапе статистического анализа.
Этап статистического анализа представляет собой независимый этап по обработке количественных показателей, связанных с ключами и признаками, а именно количества страниц, прошедших этап глубокого анализа на наличие целевого контента (веб-страниц в состояниях «пустая» или «результативная»), ассоциированных с ключами и признаками.
Количественным показателем результативности ключа является параметр в виде количества ассоциированных с ключом веб-страниц, прошедших этап быстрого анализа. Качественным показателем результативности ключа является параметр, определяемый как отношение количества веб-страниц, содержащих целевой контент, по итогам этапа глубокого анализа, к общему объему прошедших глубокий анализ веб-страниц. По полученным количественным и/или качественным показателям результативности строят рейтинги для ключей и в зависимости от режима работы выбирают один из рейтингов.
Количественным показателем результативности признака является параметр в виде количества ассоциированных с ключами, в состав которых входит признак веб-страниц, прошедших этап быстрого анализа. Качественным показателем результативности признака является параметр, определяемый как отношение количества веб-страниц, ассоциированных с ключами, в состав которых входит признак, и при этом содержащих целевой контент (состояние «результативная»), к общему объему прошедших глубокий анализ веб-страниц, ассоциированных с ключами, в состав которых входит признак. По полученным количественным и/или качественным показателям результативности строят рейтинги для признаков, которые аналитически оцениваются оператором и могут быть исключены из списка базовых признаков с целью снижения ресурсных затрат на этапе быстрого анализа.
Этап проводится в отношение ключей, с которыми проассоциировано достаточное количество страниц, принадлежащих определенному количеству различных доменов (например, не менее 10000 страниц, которые принадлежат, по крайней мере, 10 различным доменам), а также в отношение признаков, которые входят в определенное количество ключей (например, признак входит не менее чем в 10 ключей). Параметры, определяющие ограничения для выбора ключей и признаков, задаются оператором.
В результате работы этапа статистического анализа ключам присваиваются показатели результативности, оказывающие влияние на процесс быстрого и глубокого анализа:
- ключам, имеющим низкие качественные показатели результативности (менее заданного порогового значения, например, 0,1%), присваивают статус «заблокирован», что исключает ассоциацию веб-страниц с такими ключами на этапе быстрого анализа;
- показатели результативности ключей влияют на выбор ключа (определяют порядок выбора) и ассоциированных с ним веб-страниц для проведения этапа глубокого анализа.
Таким образом способ реализует обратную связь, позволяющую регулировать применение ресурсоемких операций к веб-страницам, и выявлять веб-страницы с наибольшей вероятностью содержащие целевой контент, и не тратить ресурсы на веб-страницы, не содержащие целевой контент, снижая затраты на определение целевого контента в общем массиве веб-страниц.
Блок схема заявляемой системы проверки веб-страниц на содержание в них целевого аудио и/или видео контента реального времени представлена на фиг.1.
Система 1 включает следующие БД и модули:
2 - БД веб-страниц для последующего анализа;
3 - модуль быстрого анализа веб-страниц, выполненный с возможностью анализа исходного кода веб-страницы, взятой из БД веб-страниц на предмет присутствия в исходном коде базовых признаков и формирования ключа из найденных признаков, с последующим сохранением их в БД ключей,
4 - БД признаков с расширяемым и модифицируемым набором базовых признаков, свидетельствующих о наличии на веб-страницах аудио и/или видео контента реального времени;
5 - БД ключей со списком ключей и ассоциированных с ними веб-страниц,
6 - модуль глубокого анализа веб-страниц, выполненный с возможностью выбора ключа из БД ключей и глубокого анализа ассоциированных с данным ключом веб-страниц на наличие в них целевого контента посредством исполнения всего программного кода и загрузки всех объектов, при этом веб-страницам, прошедшим глубокий анализ присваивают в БД веб-страниц статус «результативная», либо «пустая», в зависимости от наличия или отсутствия в ней целевого контента,
7 - модуль статистического анализа результатов глубокого анализа веб-страниц, выполненный с возможностью сохранения информации о количестве прошедших анализ веб-страниц, количестве «результативных» и «пустых» веб-страниц, построения показателя результативности ключа, либо по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, либо по соответствию ключу наибольшего количества ассоциированных веб-страниц, а также построения рейтинга результативности ключей.
Модуль быстрого анализа связан с БД веб-страниц, из которой выбирается страница для быстрого анализа, и БД признаков, из которой выбираются признаки для поиска в исходном коде веб-страницы. В результате работы модуля происходит обновление БД ключей, где хранятся ключи и ассоциированные с ними страницы.
Модуль глубокого анализа выбирает ключ из БД ключей, проводит глубокий анализ набора ассоциированных с данным ключом веб-страниц и по результатам анализа присваивает веб-страницам определенный статус.
Модуль статистического анализа анализирует БД ключей и БД веб-страниц и по результатам проверки ассоциированных с ключами страниц определяет показатели результативности, обновляя БД ключей и БД признаков.
Алгоритм работы системы представлен на фиг.2-4.
Проверка веб-страниц на содержание в них целевого контента начинается с того, что в модуль 2, представляющий собой базу данных веб-страниц, поступают исходные данные в виде исходного кода веб-страниц и адреса их размещения в сети Интернет (URL). Поступающие извне веб-страницы имеют заранее заданный статус «на быстрый анализ», что выделяет их среди прочих данных как исходные данные для анализа. По сути, функции модуля 2 аналогичны любой известной базе данных (MySQL, Oracle и аналогичных им), предоставляющей интерфейс для выбора набора данных по определенному критерию (SELECT), т.е. имеющих определенный статус, и обновлению данных (UPDATE), т.е. изменению статуса.
Модуль быстрого анализа 3, функцией которого является анализ исходного кода веб-страницы с целью выявления в нем признаков, свидетельствующих о том, что в данной веб-странице может содержаться источник целевого контента, выбирает из модуля 2 веб-страницу, имеющую статус «на быстрый анализ».
Перед тем как начать анализ веб-страницы, модуль 3 быстрого анализа загружает из БД признаков 4 набор базовых признаков, которые известны на данный момент. Данный набор известных признаков в БД 4 может быть расширен в любое время посредством добавления новых признаков, прямо или косвенно свидетельствующих о наличии на веб-странице источника AV контента реального времени, по мере их появления. Также из данного набора могут, по необходимости, исключаться признаки, утратившие актуальность. По сути, функции модуля 4 аналогичны функциям модуля 2. Каждый признак в БД 4 имеет уникальный идентификатор (ID), который используется модулем 3 для построения ключа веб-страницы, который представляет собой набор (вектор) идентификаторов признаков, обнаруженных в исходном коде веб-страницы.
Каждому признаку в БД 4 может быть поставлена в соответствие группа, к которой данный признак принадлежит, причем один признак может принадлежать только одной группе. Признаки могут быть сгруппированы по принципу отношения к целевому контенту различного типа и/или формата (Macromedia Flash, Windows Media, RealAudio, RealVideo и так далее) с целью формирования нескольких ключей в случае наличия на веб-странице нескольких различных источников мультимедиа. Для каждой из групп признаков построение ключа происходит независимо, таким образом, одна веб-страница может иметь несколько ключей. В простейшем варианте исполнения все признаки могут принадлежать одной общей группе и веб-страница может иметь только один ключ.
Подробное описание одного из вариантов реализации изобретения, связанного с поиском признаков AV контента реального времени в полученной на проверку веб-странице с использованием набора базовых (известных) признаков и формированием ключа в модуле быстрого анализа 3 представлено в Примере 1.
При наличии признаков и сформированных из них ключей модуль 3 обращается к БД ключей 5 с целью проверки статуса ключей и их наличия в БД 5. По сути, функции модуля 5 аналогичны функциям модуля 2.
Следующие действия выполняются для каждого ключа: в случае, если ключ в БД 5 отсутствует, модуль 3 добавляет полученный ключ в БД 5, получая в качестве ответа из БД 5 идентификатор (ID) созданного ключа. При наличии идентификатора ключа и идентификатора веб-страницы модуль 3 добавляет в БД 5 ассоциацию ключ-страница в виде пары: (идентификатор ключа)-(идентификатор веб-страницы), а в БД веб-страниц 2 назначает веб-странице статус «на глубокий анализ». В дальнейшем пара (идентификатор ключа)-(идентификатор веб-страницы) всегда имеет статус, эквивалентный статусу веб-страницы.
В случае, если все построенные ключи в БД 5 имеют состояние (статус) «заблокирован», модуль 3 назначает текущей веб-странице статус «пропущенная», обновляя статус веб-страницы в БД 2, и переходит к следующей веб-странице.
Далее модуль 3 выбирает следующую страницу из БД 2 и повторяет вышеописанные операции, таким образом реализуя быстрый производительный цикл (этап быстрого анализа), который в силу низкой вычислительной сложности способен обрабатывать значительный объем данных при небольших ресурсных затратах.
Модуль 6 глубокого анализа выбирает один из ключей и набор ассоциированных с ключом страниц из БД 5, для дальнейшей проверки, согласно установленному критерию выбора. Возможные критерии выбора (в зависимости от режима работы системы) подробно представлены в Примере 2.
Модуль 6 осуществляет в отношении набора веб-страниц глубокий анализ, который для каждой веб-страницы из набора заключается в построении модели веб-документа, исполнении расположенного на странице, а также загружаемого извне, программного кода (например, JavaScript), выделении всех ссылок на источники мультимедиа и определении принадлежности ссылок к целевому AV контенту. Механизм реализации построения модели документа, создания объектов и извлечения ссылок на источники аудио и видео контента не является предметом настоящего изобретения и может быть реализован в системе посредством эмуляции веб-браузера с помощью известных средств (WebCore, JavaScriptCore их аналоги), механизм определения принадлежности мультимедийного контента к контенту вещания реального времени может быть реализован в системе по Примеру 4. В случае обнаружения целевого контента модуль 6 сохраняет все характеристики AV контента в БД потоков вещания реального времени.
Ключевой задачей модуля 6 в контексте данного изобретения является определение статуса ассоциированного с ключом массива веб-страниц в зависимости от наличия AV контента на веб-странице, что представляет собой изменение статуса каждой веб-страницы из массива в БД 2, а также изменение статуса пары (ключ)-(страница) в БД ключей 5. Описание возможных статусов подробно представлено в Примере 2.
Модуль 7 статистического анализа выбирает из БД 5 ключ в зависимости от установленного оператором порогового значения количества ассоциированных с ключом страниц. Затем модуль 7 путем запросов к БД 5 определяет актуальные на данный момент времени количественные характеристики ключа: общее количество ассоциированных с ключом страниц, что эквивалентно количеству пар (ключ)-(страница) в БД 5, а также количество пар, имеющих различные статусы, которые эквивалентны статусам веб-страниц по итогам глубокого анализа («результативная», «пустая» или «пропущенная»). Показатель результативности вычисляется путем применения математических операций к статистическим показателям. Суть операций состоит в определении и сохранении в БД 5 характеристик ключа, которые непосредственно влияют на функционирование модулей 3 и 6 с целью повышения эффективности работы системы. Алгоритм вычисления показателей результативности представлен в Примере 3.
Подобные операции модуль 7 проводит и в отношении признаков, при этом количественные характеристики признака определяются как суммарные значения количественных характеристик всех ключей, при построении который данный признак был использован. Суть операций состоит в определении характеристик признака и сохранения их в БД 4 для дальнейшего анализа оператором системы. По итогам анализа оператор может принять решение об исключении низкорезультативных признаков, что снизит вычислительную нагрузку и общий объем сохраненных данных. Примеры вычислений приведены в Примере 3 ниже.
Следует также отметить, что формирование и сохранение модулем 6 описаний AV контента в соответствующей БД, является в высокой степени предпочтительным и выгодным в контексте настоящего изобретения, однако оно может быть реализовано и без задействования данной БД, по-прежнему обеспечивая вышеуказанные преимущества.
Предлагаемая система может быть воплощена на одном или более серверных компьютерах, объединенных для совместной реализации предписанной функциональности, при этом вышеуказанные ее модули могут быть реализованы программными и аппаратными составляющими этих серверных компьютеров, известными специалистам и широко применяемыми в технике. В частности, вышеуказанные базы данных могут быть реализованы на одном или более широко известных машиночитаемых носителях, например накопителях на жестких дисках, RAID-массивах, твердотельной памяти и т.п. Модуль глубокого анализа может быть подключен и может взаимодействовать с Интернет на основе широко известных проводных и/или беспроводных сетевых технологий и оборудования, в частности на основе стека протоколов http/tcp/ip. Для взаимодействия с модулями баз данных оператор может использовать любое известное терминальное оборудование, поддерживающее возможность исполнения команд взаимодействия с базой данных (например SQL). Таковым оборудованием может быть, например, соответствующим образом сконфигурированный персональный/переносной/наладонный компьютер.
Пример 1. Пример поиска признаков AV контента реального времени в полученной на проверку веб-странице с использованием набора базовых (известных) признаков и формированием ключа в модуле быстрого анализа 3.
На Фиг.3 представлена блок-схема последовательности операций предпочтительного варианта осуществления заявляемого способа, реализуемого в модуле быстрого анализа 3, согласно настоящему изобретению.
Из БД 2 выбирают веб-страницу, которая имеет статус «на быстрый анализ», в виде ее идентификатора (PAGEID), ссылки (URL) и исходного кода (HTML), при этом критерий выбора одной страницы из множества страниц с таким же статусом реализован в БД 2, например, при помощи хранимой процедуры (stored procedure), которая может возвращать страницу с самой ранней датой создания в БД 2. Ключевого влияния на изобретение данный критерий не оказывает.
Для проверки наличия базовых признаков выполняют следующие действия для каждой группы признаков из БД 4: осуществляют прямой текстовый поиск признака, при этом признак может представлять собой как текстовый элемент (например «player», «embed», «flow»), так и регулярное выражение (например «http://.*/.asx», «codebase=\"http://.*mplayer.*», «document.write(.*mjpg/video\.cgi.*» и подобные). В случае обнаружения признака в исходном коде добавляют его идентификатор (ID) в список обнаруженных признаков (ID1, ID2, …, IDx).
В случае, если список обнаруженных признаков пуст, назначают веб-странице статус «пропущенная» в БД 2 и переходят на начальный этап данного цикла. В противном случае формируют ключи, представляющие собой наборы обнаруженных признаков, дополнительно сгруппированных по принадлежности к разным группам. Например, если при проверке наличия признака обнаружены признаки (ID101, ID234, ID870), при этом признак ID101 принадлежит группе признаков 1, a ID234 и ID870 группе признаков 5, то в результате получают два ключа - (ID101) и (ID234, ID870).
Затем запрашивают идентификаторы (KEYID) и статус построенных ключей в БД 5 и в случае, если все ключи существуют, то есть имеют непустой идентификатор, и имеют статус «заблокирован», назначают веб-странице статус «пропущенная» в БД 2 и переходят на начальный этап данного цикла. В случае отсутствия найденного ключа в БД 5 добавляют ключ и получают его идентификатор (KEYID) в качестве результата.
Следующим этапом является обновление ключей и ассоциированных страниц для каждого ключа, полученного на этапе построения ключей. В БД 5 добавляют пару (KEYID)-(PAGEID) и назначают ей статус «на глубокий анализ» в БД 5, что может быть реализовано средствами БД 5. Веб-странице с идентификатором (PAGEID) также назначают статус «на глубокий анализ» в БД 2. Затем переходят на начальный этап данного цикла.
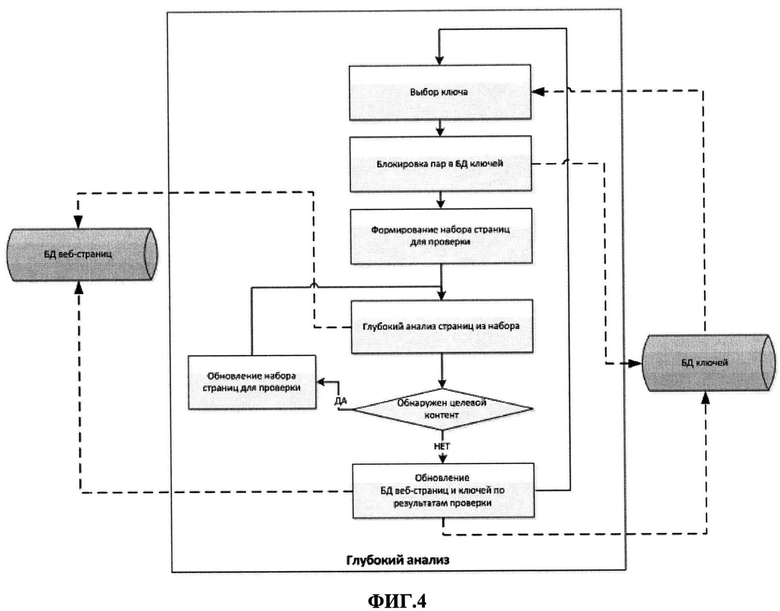
Пример 2. Пример выбора ключа из БД ключей, согласно критериям.
На Фиг.4 представлена блок-схема последовательности операций предпочтительного варианта осуществления заявляемого способа, реализуемого в модуле глубокого анализа 6, согласно настоящему изобретению.
Выбирают ключ из БД 5. В зависимости от режима функционирования системы выбор происходит одним из нижеперечисленных способов:
- в режиме обучения - выбирают из БД ключей ключ, которому соответствует наибольшее количество страниц, имеющих статус «на глубокий анализ»;
- в производственном режиме - выбирают из БД ключей ключ, которому соответствует как минимум ЛИМИТ количество пар (KEYID) (PAGEID) и имеющий при этом наивысший рейтинг.
Предпочтительным вариантом реализации выбора является способ, когда в случае отсутствия ключей в производственном режиме, происходит выбор по способу режима обучения. Механизм выбора ключа реализован в БД 5 как хранимая процедура, которая и возвращает в качестве результата идентификатор ключа (KEYID), используемый на следующем этапе.
На этапе блокировки пар производят изменение статуса пар (KEYID) (PAGEID) в БД 5. После выбора ключа все ассоциированные в данный момент пары, имеющие статус «на глубокий анализ», переводятся в состояние «заблокирован», что, по сути, означает, что эти пары в данный момент проходят этап глубокого анализа. Все заблокированные пары объединяют в массив данных для следующего этапа.
На этапе формирования набора страниц для проверки выделяют из полученного на этапе блокировки пар массив (набор), к которому будут применены ресурсоемкие операции. Если выбран режим работы «обучение», то глубокому анализу подвержен весь массив веб-страниц. В противоположном случае из массива выбирается подмножество веб-страниц по следующему критерию - как минимум ЛИМИТ2 веб-страниц, при этом они должны принадлежать как минимум ЛИМИТ3 различным доменам. Если данное условие невозможно осуществить, то анализу подвергаются все страницы.
На этапе глубокого анализа страниц из набора проводят ресурсоемкий анализ каждой страницы из полученного на предыдущем этапе набора на наличие AV контента. К каждой из выбранных веб-страниц применяется этап глубокого анализа, по итогам которого подсчитывается количество целевого контента. По результатам проверки помечают веб-страницы в БД веб-страниц как «пустые», если нет контента, либо «результативная», если обнаружен контент. Соответствующим образом изменяют статус пар (KEYID) (PAGEID) в БД ключей.
На этапе изменения набора страниц происходит принятие решения о необходимости проверки всего исходного массива веб-страниц. Если на предыдущем этапе хотя бы одной странице в результате глубокого анализа был присвоен статус «результативная», в этом случае предыдущий этап применяют ко всему массиву.
На последнем этапе обновления БД веб-страниц и ключей по результатам проверки всем «заблокированным» парам, соответствующим ключу, присваивают статус «пропущена». Такой же статус получают ассоциированные с ключом веб-страницы.
Таким образом, по итогам глубокого анализа, все веб-страницы из ассоциированного массива получают один из статусов - «результативная», «пустая», «пропущенная».
Ограничения ЛИМИТ, ЛИМИТ2 и ЛИМИТ3 определяются оператором системы и хранятся в соответствующих модулях. Изменение ограничений приводит к немедленному изменению поведения системы. В примерах конкретной реализации изобретения были использованы следующие значения указанных параметров: ЛИМИТ=10000, ЛИМИТ2=1000 и ЛИМИТ3=3, однако система функционирует и при иных ограничениях.
Пример 3. Пример построения показателя результативности ключа и признака.
Модуль статистического анализа выбирает из БД ключей ключ, обладающий достаточным количеством пар (ключ)-(веб-страница) в БД ключей, прошедших этап глубокого анализа, а именно имеющих один из статусов: «результативная», «пустая» или «пропущенная». Пороговое достаточное значение задается внешним параметром из соображений достаточного для анализа количества веб-страниц, по итогам анализа которых можно сделать вывод о результативности ключа, а именно вычислить показатель, по которому выстраивается рейтинг ключей. Авторы предлагают считать пороговым значением как минимум 1000 веб-страниц, прошедших этап глубокого анализа.
Наиболее достоверным показателем результативности для ключа в рамках данного изобретения является отношение количества результативных страниц, то есть страниц содержащих целевой контент, к общему количеству веб-страниц, ассоциированных с ключом.
Например, ключ, имеющий в БД ключей ассоциированных 10 000 пар, созданных на этапе быстрого анализа, среди них имеет 500 пар, имеющих статус «результативная», в таком случае показатель результативности данного ключа будет вычислен как 500/10 000=0,05. А ключ, имеющий 100000 пар и из них 1000 результативных, будет иметь показатель результативности 1000/100 000=0,01. Ключ, не имеющий результативных пар, будет всегда иметь показатель результативности = 0.
Пример 4. Пример определения потока вещания реального времени (общий случай).
Определение принадлежности мультимедийного контента, вещание которого осуществляется в масштабе реального времени, может быть реализовано подсистемой, состоящей из следующих блоков:
- мультимедийного клиента, выполненного с возможностью подключения к медиа серверу по ссылке и загрузки информации о медиа потоке, включающей характеристики потока в заданном формате и/или определенной части потока, предназначенной для воспроизведения на клиентской стороне и/или информации о заголовках протоколов, полученных от сервера,
- блока анализа информации о медиа потоке, выполненного с возможностью проверки полученной информации о медиа потоке, заключающейся в поиске признаков, свидетельствующих о том, что анализируемый поток является источником мультимедиа, вещание которого осуществляется в масштабе реального времени, где в качестве признаков использована любая последовательность символов или байт в медиа потоке, на основе которых делают вывод о том, что медиа поток соответствует критерию «живой» поток.
В качестве мультимедийного клиента могут быть использованы такие приложения как MPlayer или VLC media player, а также любой другой продукт, в том числе самостоятельно разработанный мультимедийный клиент, выполненный с возможностью коммуникации, обработки и предоставления необходимой информации.
Ниже представлены конкретные примеры анализа и определения типа потока.
Пример 5. Пример определения потока вещания реального времени (вариант 1 реализации)
На вход блока определения типа потока была получена медиа ссылка следующего формата http://Reference_1?MSWMExt=.asf(URL). После подключения к серверу загрузки передаваемой от сервера информации и определения характеристик, на выходе была получена структура с переменным набором характеристик (см. таблицу №1)
Данная структура была передана модулю определения «живых» потоков. Совместно с характеристиками из таблицы №1, данному модулю также были переданы заголовки протокола, по которому осуществлялась коммуникация с медиа сервером (см. таблицу №2).
В данном случае сначала системой рассмотрены характеристики потока, изначально проанализированы параметры, связанные с продолжительностью потока и позицией, относительно которой начинается воспроизведение медиа потока. Поскольку медиа сервер указал, что продолжительность потока равна нулю, а позиция, с которой воспроизводится поток, при этом начинается с сорок шестого дня, модуль определения «живых» потоков сделал вывод о том, что данный поток является потоком, вещание которого осуществляется в реальном времени.
Duration=0.00
Start Time=4041177.35 (4041177.35/86400=46.8 дней, где 86400 количество секунд в сутках)
При этом стоит учитывать, что сервер мог не сообщить значение продолжительности потока, что автоматически присваивает данному параметру нулевое значение, соответственно, если сервер не сообщил позицию воспроизведения, он также приравнивается нулю.
Пример 6. Пример определения потока вещания реального времени (вариант 2 реализации)
В рамках настоящего примера представлено три варианта реализации изобретения с измененными значениями параметра Duration при сохранении всех остальных значений параметров Примера 5. Для всех вариантов также можно сделать вывод о том, что поток является источником мультимедиа реального времени, если продолжительность потока задана достаточно большим интервалом или отрицательной величиной, что явно указывает в рамках одного признака на то, что данный поток является потоком реального времени. В таблице №3 приведены варианты значений продолжительности потока, которые явно указывают на его принадлежность к потокам реального времени.
Пример 7. Пример определения потока вещания реального времени (вариант 3 реализации)
Этап получения и обработки данных в данном случае полностью аналогичен примеру 5. Так же загружаются данные, формируется структура с характеристиками потока и данные передаются модулю определения «живых» потоков для анализа. Модуль анализирует продолжительность потока и позицию воспроизведения (см. таблицу №4). В момент анализа модуль посчитал, что продолжительность является достаточно маленькой величиной, что явно указывает на то, что данный поток является файлом с фиксированной продолжительностью.
В случае получения подобных данных (короткая продолжительность) от сервера, модуль делает повторное подключение через небольшой интервал времени (от секунды до трех). После повторного подключения были получены характеристики продолжительности и позиции воспроизведения (см. таблицу №5). Новые характеристики сравнивались с данными, полученными при первом подключении.
При этом обнаружено, что при повторном соединении изменилась позиция воспроизведения в потоке. Для модуля это означает, что сервер передает трафик небольшими буферами переменной длины, при этом указывая с какой позиции в буфере следует начать воспроизведение. В некоторых случаях при повторном обращении может быть получен новый размер продолжительности (Duration), подобная ситуация возникает в том случае, если при первичном обращении позиция воспроизведения находилась в конце буфера (см., например, таблицу №6).
Основной сутью повторного запроса является определение изменений в характеристиках потока. Если при втором запросе изменяется продолжительность и (или) позиция, с которой надо начинать воспроизведение, модуль считает данный поток источником мультимедиа реального времени.
Пример 8. Пример определения потока вещания реального времени (вариант 4 реализации)
Для различных видов протоколов используется разный подход с целью определения типа потока, например, в случае подключения к потоку по протоколу RTMP в момент так называемого «рукопожатия», клиент отправляет запрос на воспроизведение конкретного потока, после чего сервер отправляет клиенту определенный набор метаинформации с характеристиками потока и сообщений о статусе обработки запроса. В случае с протоколом RTMP для файлов конечной длины сервер передает сообщение «Stream Is Recorded». Если такое сообщение получено, тогда поток считается файлом, если такое сообщение не получено, поток считает источником мультимедиа реального времени.
Пример 9. Пример определения потока вещания реального времени (вариант 5 реализации)
В некоторых случаях, проанализировав полученные характеристики потока, а также сам буфер для воспроизведения, не получается определить тип потока. В таких случаях анализируют различные косвенные признаки, полученные от медиа сервера. Модулем просматриваются заголовки протокола, переделанные серверам (заголовки ответа см. Таблицу №7).
В данном примере медиа сервер указал через особенные опции выполнения операции, что трансляция является broadcast (широковещательной). Используя вышеуказанную директиву, модуль определения «живых» потоков посчитает данный поток источником мультимедиа реального времени.
Таким образом, технология определения типа потока, является ли он потоком реального времени или статическим файлом фиксированной продолжительности, заключается в анализе метаинформации, получаемой из самого медиа потока. Медиа клиент подключается к медиа серверу, после чего получает от него метаинформацию о потоке в заданном формате, а также определенную часть потока, предназначенную для воспроизведения на клиентской стороне. Полученная метаинформация, а также переданный буфер медиа потока, проходят стадию проверки с целью определения типа потока. Основная цель проверки заключается в анализе данных и поиске признаков, свидетельствующих о том, что анализируемый поток является источником мультимедиа, вещание которого осуществляется в масштабе реального времени. Характерной чертой «живого» потока (контента) является невозможность выполнения в отношении него «перемотки вперед» с помощью средств клиентского воспроизводящего приложения.
Следует отметить, что представленные Примеры 1-9 не ограничивают возможности реализации настоящего изобретения. Для специалистов могут быть очевидны и иные варианты осуществления изобретения, не меняющие его сущности, как она раскрыта в настоящем описании. Соответственно, изобретение следует считать ограниченным по объему только нижеследующей формулой изобретения.

Изобретение относится к компьютерной технике, а именно, к технологиям, используемым для выявления целевого контента в виде аудио и/или видео потоков, вещание которых осуществляется в масштабе реального времени. Технический результат - повышение эффективности обнаружения целевого контента, содержащегося в проверяемых веб-страницах. Способ проверки веб-страниц на содержание в них целевого контента, включающий быстрый анализ веб-страниц посредством анализа исходного кода веб-страницы на предмет присутствия в нем базовых признаков, свидетельствующих о наличии на веб-страницах целевого контента, и формирование ключа из обнаруженных признаков; глубокий анализ ассоциированных с ключом веб-страниц на наличие в них целевого контента посредством исполнения программного кода, загрузки объектов и подключения к медиа серверам, загрузке и анализу технической и мета-информации из потоков, и присваивание веб-страницам статуса, в зависимости от наличия или отсутствия в ней целевого контента, при этом каждому ключу и признаку определяют показатель результативности на основе статистической информации о количестве и статусе проверенных веб-страниц. Полученные показатели результативности используются на этапах быстрого и глубокого анализа, позволяя применять ресурсоемкий глубокий анализ только к веб-страницам, имеющим высокую вероятность наличия целевого контента. 2 н. и 50 з.п. ф-лы, 9 пр., 4 ил. 
1. Способ проверки веб-страниц на содержание в них целевого аудио и/или видео (AV) контента реального времени, согласно которому:
A. формируют расширяемый и модифицируемый набор базовых признаков, свидетельствующих о наличии на веб-страницах целевого контента реального времени с последующим сохранением базовых признаков в БД признаков,
B. проводят быстрый анализ веб-страниц посредством анализа исходного кода веб-страницы на предмет присутствия в исходном коде базовых признаков,
C. при выявлении в исходном коде базовых признаков, сохраняют найденный на странице набор признаков в качестве ключа в БД ключей, а также веб-страницу и/или ссылку на веб-страницу, ассоциированную с данным ключом, а в случае отсутствия базовых признаков в исходном коде, веб-странице присваивают статус «пропущенная»,
D. из БД ключей выбирают ключ и осуществляют глубокий анализ ассоциированных с данным ключом веб-страниц на наличие в них целевого контента посредством исполнения программного кода и загрузки объектов, при этом веб-страницам, прошедшим глубокий анализ, присваивают статус «результативная», либо «пустая», в зависимости от наличия или отсутствия в ней целевого контента,
E. по итогам выполнения этапа D в отношении каждого из ключей в БД ключей сохраняют статистическую информацию о количестве проверенных веб-страниц, а также количестве «результативных» и «пустых» веб-страниц,
F. по итогам накопленной статистической информации определяют для каждого ключа показатель результативности ключа,
G. по показателям результативности ключей, полученных на этапе F, составляют рейтинг результативности ключей, находящихся в БД ключей, при этом выборку ключей из БД ключей для глубокой проверки ассоциированных с ключом веб-страниц осуществляют с учетом рейтингового номера ключа, построенного по показателям результативности ключей.
при этом этапы B и C повторяют для каждой проверяемой веб-страницы, по итогам которых обновляют БД ключей, с получением списка ключей и набора вебстраниц и/или ссылок на веб-страницы, ассоциированных с каждым ключом из списка, этап D повторяют для ключей, сохраненных в БД ключей.
2. Способ по п.1, характеризующийся тем, что показатель результативности определяют либо по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, либо по соответствию ключу наибольшего количества ассоциированных веб-страниц.
3. Способ по п.1, характеризующийся тем, что глубокий анализ осуществляют сначала для заданного ограниченного количества проверяемых страниц из набора, и в случае, если, по крайней мере, одна страница содержит целевой контент, глубокому анализу подвергают все остальные страницы из набора, проассоциированные с данным ключом; в случае, если в заданном количестве проверяемых страниц по итогам глубокого анализа страницы с целевым контентом выявлены не будут, всем остальным страницам набора, проассоциированным с данным ключом, присваивают статус «пропущенные» и глубокому анализу не подвергают.
4. Способ по п.1, характеризующийся тем, что по итогам накопленной статистической информации дополнительно определяют показатель результативности признака как отношение количества «результативных» веб-страниц к общему количеству ассоциированных веб-страниц, прошедших глубокую проверку для всех ключей, в которые входит данный признак, составляют рейтинг результативности базовых признаков, и с учетом рейтингового номера признака обновляют БД признаков.
5. Способ по п.3, характеризующийся тем, что заданное ограничение для количества проверяемых страниц из набора в процессе глубокого анализа определяют эмпирическим путем по итогам анализа массива веб-страниц, при этом количество проверяемых страниц выбирают не менее трех, принадлежащих различным доменам.
6. Способ по п.4, характеризующийся тем, что БД базовых признаков обновляют посредством исключения признаков, имеющих показатели результативности, менее 1%.
7. Способ по п.1, характеризующийся тем, что базовый признак представляет собой символ или набор символов.
8. Способ по п.7, характеризующийся тем, что символ или набор символов представляет собой элемент разметки веб-страницы.
9. Способ по п.8, характеризующийся тем, что элемент разметки веб-страницы представляет собой параметр или атрибут.
10. Способ по п.1, характеризующийся тем, что базовый признак представляет собой элемент в виде части программного кода страницы, выполняемого в процессе построения веб-страницы в веб-браузере.
11. Способ по п.1, характеризующийся тем, что базовый признак представляет собой ссылку на внешний программный код, выполняемый в процессе построения веб-страницы в веб-браузере.
12. Способ по п.1, характеризующийся тем, что базовый признак представляет собой внешнюю ссылку.
13. Способ по п.12, характеризующийся тем, что внешняя ссылка представляет собой схему передачи данных.
14. Способ по п.1, характеризующийся тем, что базовый признак представляет собой внешнюю ссылку на мультимедийный контент, имеющий заданное расширение или заданный тип мультимедийного контента - MIME type.
15. Способ по п.1, характеризующийся тем, что базовые признаки формируют в независимые группы по типу целевого контента таким образом, что один признак принадлежит только одной группе, при этом в случае обнаружения для одной веб-страницы признаков из разных групп, для данной веб-страницы формируют несколько ключей.
16. Способ по п.1, характеризующийся тем, что веб-страница представляет собой файл, непосредственно содержащий текст веб-страницы, и/или скрипт-файл, ассоциированный с данной веб-страницей.
17. Способ по п.1, характеризующийся тем, что обновляют БД ключей посредством блокировки ключей, а на этапе C в случае обнаружения заблокированного ключа присваивают ассоциированной веб-странице статус «пропущенная».
18. Способ по п.17, характеризующийся тем, что блокировку ключей проводят автоматически в случае достижения показателя результативности ключа, составленного по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, минимального порогового значения, выбранного равным 1%.
19. Способ по п.1, характеризующийся тем, что по итогам глубокого анализа выявляют ссылки на медиа серверы, а определение наличия целевого контента осуществляют посредством подключения к медиа серверам, с последующим получением от медиа сервера информации о медиа потоке, включающей характеристики потока в заданном формате и/или части потока, предназначенного для воспроизведения веб-браузером, анализа полученной информации о медиа потоке и/или части потока, заключающейся в поиске признаков, свидетельствующих о том, что анализируемый поток является источником мультимедиа, вещание которого осуществляется в масштабе реального времени.
20. Способ по п.19, характеризующийся тем, что глубокий анализ веб-страницы осуществляют посредством эмуляции работы веб-браузера посредством построения модели веб-документа и создания всех объектов, потенциально содержащих целевой контент.
21. Способ по п.20, характеризующийся тем, что созданные объекты анализируют на наличие ссылок на мультимедийный контент, при этом каждую ссылку проверяют на соответствие контенту вещания реального времени.
22. Способ по п.1, характеризующийся тем, что вычисление показателя результативности ключей проводят по достижении задаваемого порогового количества ассоциированных веб-страниц, которые прошли глубокий анализ.
23. Способ по п.22, характеризующийся тем, что пороговое значение выбирают, равным 10000.
24. Способ по п.1, характеризующийся тем, что определение показателя результативности ключей проводят по достижении задаваемого порогового количества доменов, которым принадлежат ассоциированные веб-страницы, прошедшие глубокий анализ.
25. Способ по п.24, характеризующийся тем, что пороговое значение выбирают равным 10.
26. Способ по п.1, характеризующийся тем, что в отношении всех веб-страниц, ассоциированных с ключами, имеющими показатель результативности ключей в виде отношения количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, превышающий пороговое значение, равное 10%, применяют глубокий анализ.
27. Способ по п.5, характеризующийся тем, что при обновлении базовых признаков в БД признаков всем веб-страницам, имеющим статус «пропущенные», устанавливают статус «на быстрый анализ», при этом веб-страницы направляют на этап их быстрого анализа.
28. Компьютерно-реализуемая поисковая система, предназначенная для проверки веб-страниц на содержание в них целевого аудио и/или видео (AV) контента реального времени, включающая:
- БД признаков с расширяемым и модифицируемым набором базовых признаков, свидетельствующих о наличии на веб-страницах аудио и/или видео контента реального времени,
- БД веб-страниц для анализа,
- модуль быстрого анализа веб-страниц, выполненный с возможностью анализа исходного кода веб-страницы, взятой из БД веб-страниц на предмет присутствия в исходном коде базовых признаков и формирования ключа из найденных признаков, с последующим сохранением их в БД ключей,
- БД ключей со списком ключей и ассоциированных с ними веб-страниц,
- модуль глубокого анализа веб-страниц, выполненный с возможностью выбора ключа из БД ключей и глубокого анализа ассоциированных с данным ключом веб-страниц на наличие в них целевого контента посредством исполнения всего программного кода и загрузки всех объектов, при этом веб-страницам, прошедшим глубокий анализ, присваивают в БД веб-страниц статус «результативная», либо «пустая», в зависимости от наличия или отсутствия в ней целевого контента,
- модуль статистической обработки результатов глубокого анализа веб-страниц, выполненный с возможностью сохранения информации о количестве проверенных веб-страниц, количестве «результативных» и «пустых» веб-страниц, построения показателя результативности ключа, а также построения рейтинга результативности ключей;
при этом модуль статистической обработки связан с БД ключей и БД признаков.
29. Система по п.28, характеризующаяся тем, что построение показателя результативности ключа в модуле статистической обработки реализовано либо по отношению количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, либо по соответствию ключу наибольшего количества ассоциированных веб-страниц.
30. Система по п.28, характеризующаяся тем, что модуль статистической обработки выполнен с возможностью построения показателя результативности признака, определяемого в виде отношения количества «результативных» веб-страниц к общему количеству ассоциированных веб-страниц, прошедших глубокую проверку, для всех ключей, в которые входит данный признак.
31. Система по п.28, характеризующаяся тем, что БД веб-страниц формируют с использованием поисковых систем сети Интернет.
32. Система по п.28, характеризующаяся тем, что базовый признак в БД признаков представляет собой символ или набор символов.
33. Система по п.32, характеризующаяся тем, что символ или набор символов в БД признаков представляют собой элемент разметки веб-страницы.
34. Система по п.33, характеризующаяся тем, что элемент разметки веб-страницы в БД признаков представляет собой тег, параметр или атрибут.
35. Система по п.28, характеризующаяся тем, что базовый признак в БД признаков представляет собой элемент в виде части программного кода страницы, выполняемого в процессе построения веб-страницы в веб-браузере.
36. Система по п.28, характеризующаяся тем, что базовый признак в БД признаков представляет собой ссылку на внешний программный код, выполняемый в процессе построения веб-страницы в веб-браузере.
37. Система по п.28, характеризующаяся тем, что базовый признак в БД признаков представляет собой внешнюю ссылку.
38. Система по п.37, характеризующаяся тем, что внешняя ссылка в БД признаков представляет собой протокол передачи данных.
39. Система по п.28, характеризующаяся тем, что базовый признак в БД признаков представляет собой внешнюю ссылку на мультимедийный контент, имеющий заданное расширение.
40. Система по п.28, характеризующаяся тем, что БД признаков содержит базовые признаки, сформированные в независимые группы по типу целевого контента таким образом, что один признак принадлежит только одной группе, при этом в случае обнаружения для одной веб-страницы признаков из разных групп, для данной веб-страницы формируют несколько ключей.
41. Система по п.28, характеризующаяся тем, что веб-страница в БД веб-страниц, представляет собой файл, непосредственно содержащий текст веб-страницы, и/или скрипт-файл, ассоциированный с данной веб-страницей.
42. Система по п.28, характеризующаяся тем, что модуль статистической обработки выполнен с возможностью обновления БД ключей посредством блокировки ключей, при этом модуль быстрого анализа веб-страниц выполнен с возможностью присвоения ассоциированной веб-странице статус «пропущенная» в случае обнаружения заблокированного ключа.
43. Система по п.42, характеризующаяся тем, что модуль статистической обработки выполнен с возможностью автоматической блокировки ключей в случае достижения показателем результативности ключа, рассчитанного как отношение количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, минимального порогового значения, выбранного равным 1%.
44. Система по п.28, характеризующаяся тем, что модуль глубокого анализа выполнен с возможностью выявления ссылок на медиа серверы по итогам глубокого анализа, определения наличия целевого контента посредством подключения к медиа серверам, с последующим получением от медиа сервера информации о медиа потоке, включающей характеристики потока в заданном формате и/или части потока, предназначенного для воспроизведения веб-браузером, анализа полученной информации о медиа потоке и/или части потока, заключающейся в поиске признаков, свидетельствующих о том, что анализируемый поток является источником мультимедиа, вещание которого осуществляется в масштабе реального времени.
45. Система по п.44, характеризующаяся тем, что модуль глубокого анализа выполнен с возможностью эмуляции работы веб-браузера посредством построения модели веб-документа и создания всех объектов, потенциально содержащих целевой контент.
46. Система по п.45, характеризующаяся тем, что модуль глубокого анализа выполнен с возможностью анализа созданных объектов на наличие ссылок на мультимедийный контент, и проверки каждой ссылки на соответствие контенту вещания реального времени.
47. Система по п.28, характеризующаяся тем, что модуль статистической обработки выполнен с возможностью вычисления показателя результативности ключей по достижении задаваемого порогового количества ассоциированных веб-страниц, которые прошли глубокий анализ.
48. Система по п.47, характеризующаяся тем, что пороговое значение в модуле статистической обработки выбрано равным 10000.
49. Система по п.28, характеризующаяся тем, что модуль статистической обработки выполнен с возможностью определения показателя результативности ключей по достижении задаваемого порогового количества доменов, которым принадлежат ассоциированные веб-страницы, прошедшие глубокий анализ.
50. Система по п.49, характеризующаяся тем, что пороговое значение в модуле статистической обработки выбрано равным 10.
51. Система по п.28, характеризующаяся тем, что модуль глубокого анализа веб-страниц выполнен с возможностью применения глубокого анализа в отношении всех веб-страниц, ассоциированных с ключами, показатель результативности ключей которых, вычисленный в виде отношения количества «результативных» веб-страниц к общему количеству ассоциированных с данным ключом веб-страниц, прошедших глубокий анализ, превышает пороговое значение, равное 10%.
52. Система по п.28, характеризующаяся тем, что модуль статистической обработки выполнен с возможностью обновления базовых признаков в БД признаков, при котором всем веб-страницам, имеющим статус «пропущенные», устанавливают статус «на проверку», при этом веб-страницы направляют на этап их быстрого анализа.
| СИСТЕМА И СПОСОБ ДЛЯ ИНТЕРНЕТ-ПОИСКА МУЛЬТИМЕДИЙНОГО КОНТЕНТА РЕАЛЬНОГО ВРЕМЕНИ | 2008 |
|
RU2399090C2 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |

