1. Область техники
Настоящее изобретение относится к области контента объемного видео. Настоящее изобретение также следует понимать в контексте кодирования и/или форматирования данных, представляющих объемный контент, например, для визуализации на устройствах конечного пользователя, таких как мобильные устройства или Дисплеи, Устанавливаемые на Голове.
2. Уровень техники
Данный раздел предназначен для ознакомления читателя с различными аспектами области техники, которые могут быть связаны с различными аспектами настоящего изобретения, которые описаны и/или заявлены ниже. Предполагается, что данное обсуждение будет полезно при предоставлении читателю информации об уровне техники, чтобы способствовать более хорошему пониманию различных аспектов настоящего изобретения. Соответственно, эти утверждения следует читать в этом свете, а не в качестве допущений предшествующего уровня техники.
В последнее время наблюдается рост доступного контента с большим полем обзора (вплоть до 360°). Такой контент потенциально не полностью виден пользователю, просматривающему контент на устройствах демонстрации с погружением, таких как Дисплеи, Устанавливаемые на Голове, интеллектуальные очки, экраны ПК, планшеты, интеллектуальные телефоны и аналогичное. Это означает, что в заданный момент пользователь может просматривать только часть контента. Однако обычно пользователь может перемещаться по контенту с помощью различных средств, таких как перемещение головы, перемещение мыши, сенсорный экран, голос и аналогичное. Обычно желательно кодировать и декодировать этот контент.
Видео с погружением, также называемое 360° плоским видео, позволяет пользователю просматривать все вокруг себя посредством поворотов его головы вокруг неподвижной точки зрения. Повороты обеспечивают только восприятие с 3 Степенями Свободы (3DoF). Даже если 3DoF видео является достаточным для первого всенаправленного восприятия видео, например, с использованием устройства Дисплея, Устанавливаемого на Голове (HMD), то 3DoF видео может быстро стать разочарованием для зрителя, который бы ожидал большей свободы, например, путем восприятия параллакса. В дополнение, 3DoF также может вызывать головокружение, потому что пользователь никогда не осуществляет только поворот своей головы, а перемещает свою голову также в трех направлениях, причем эти перемещения не воспроизводятся в восприятии 3DoF видео.
Контент с большим полем обзора может, среди прочего, быть сценой трехмерного видеоряда компьютерной графики (3D CGI сцена), облаком точек или видео с погружением. Для создания таких видеороликов с погружением может быть использовано много понятий: Виртуальная Реальность (VR), 360, панорамное, 4π стерадиан, с погружением, всенаправленное или с большим полем зрения, например.
Объемное видео (также известное как видео с 6 Степенями Свободы (6DoF)) является альтернативой 3DoF видео. При просмотре 6DoF видео, в дополнение к поворотам, пользователь также может перемещать свою голову, и даже свое тело, внутри просматриваемого контента и воспринимать параллакс и даже объемы. Такие видеоролики значительно увеличивают ощущение погружения и восприятие глубины сцены, и не допускают головокружения путем обеспечения согласующейся визуальной обратной связи во время перемещений головы. Контент создается посредством специальных датчиков, обеспечивающих одновременную запись цвета и глубины сцены интереса. Использование установки из цветных камер, объединенной с методиками фотограмметрии, является распространенным способом выполнения такой записи.
При том, что 3DoF видеоролики содержат последовательность изображений, полученных в результате отмены отображения изображений текстуры (например, сферические изображения, кодированные в соответствии с проекционным отображением по широте/долготе или равнопрямоугольным проекционным отображением), 6DoF видеокадры содержат информацию с нескольких точек зрения. Их можно рассматривать в качестве временных рядов из облаков точек, полученных в результате трехмерного захвата. Может рассматриваться два вида объемных видеороликов в зависимости от условий просмотра. Первый (т.е. полный 6DoF) обеспечивает полную свободную навигацию по видеоконтенту, тогда как второй (также известный как 3DoF+) ограничивает пространство просмотра пользователя ограниченным объемом, обеспечивая ограниченное перемещение головы и восприятие параллакса. Этот второй контекст является ценным компромиссом между свободной навигацией и условиями пассивного просмотра сидящего члена аудитории.
3DoF видеоролики могут быть кодированы в потоке в качестве последовательности прямоугольных цветных изображений, сформированных в соответствии с выбранным проекционным отображением (например, кубическое проекционное отображение, пирамидальное проекционное отображение или равнопрямоугольное проекционное отображение). Преимущество данного кодирования заключается в использовании общепринятых стандартов обработки изображения и видео. 3DoF+ и 6DoF видеоролики требуют дополнительных данных для кодирования глубины цветных точек облаков точек. Вид визуализации (т.е. 3DoF или объемная визуализация) для объемной сцены неизвестен заранее при кодировании сцены в потоке. На сегодняшний день потоки кодируются для того или иного вида визуализации. Отсутствует поток, и ассоциированные способы и устройства, который может нести данные, представляющие собой объемную сцену, который может быть кодирован один раз и декодирован либо в качестве 3DoF видео, либо в качестве объемного видео (3DoF+ или 6DoF).
Более того, объем данных, которые должны быть транспортированы для, например, визуализации на устройствах конечного пользователя, может быть очень важен, значительно увеличивая потребности в полосе пропускания по сетям.
3. Сущность изобретения
Обращения в техническом описании к «одному варианту осуществления», «варианту осуществления», «примерному варианту осуществления», «конкретному варианту осуществления» указывают то, что описанный вариант осуществления может включать в себя конкретный признак, структуру или характеристику, но каждый вариант осуществления не обязательно может включать в себя конкретный признак, структуру или характеристику. Более того, такие фразы не обязательно обращаются к одному и тому же варианту осуществления. Кроме того, когда конкретный признак, структура или характеристика описываются в связи с вариантом осуществления, предполагается, что специалист в соответствующей области техники может повлиять на такой признак, структуру или характеристику в связи с другими вариантами осуществления, описано или нет это в явной форме.
Настоящее изобретение относится к способу кодирования данных, представляющих собой 3D сцену, причем способ, содержащий этапы, на которых:
- кодируют, в, по меньшей мере, первую дорожку, первые данные, представляющие собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов (tile) первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- кодируют, в, по меньшей мере, вторую дорожку, вторые данные, представляющие собой глубину, связанную с точками 3D сцены, причем вторые данные размещаются во множестве вторых сегментов второго кадра, при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, при этом для каждого первого сегмента по меньшей мере части из множества первых сегментов:
набор вторых сегментов, содержащий по меньшей мере один второй сегмент из множества вторых сегментов, распределяется каждому первому сегменту по меньшей мере части из множества первых сегментов;
набор по меньшей мере фрагмента (patch) размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в части 3D сцены, связанной с каждым первым сегментом, и содержит вторые данные, представляющие собой глубину, связанную с 3D точками группы;
- кодируют, в, по меньшей мере, третью дорожку, по меньшей мере инструкцию для извлечения по меньшей мере части первых данных и вторых данных из по меньшей мере части по меньшей мере первой дорожки и по меньшей мере второй дорожки.
Настоящее изобретение относится к устройству, выполненному с возможностью кодирования данных, представляющих собой 3D сцену, причем устройство содержит память, связанную по меньшей мере с одним процессором, выполненным с возможностью:
- кодирования, в, по меньшей мере, первую дорожку, первых данных, представляющих собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- кодирования, в, по меньшей мере, вторую дорожку, вторых данных, представляющих собой глубину, связанную с точками 3D сцены, причем вторые данные размещаются во множестве вторых сегментов второго кадра, при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, при этом для каждого первого сегмента по меньшей мере части из множества первых сегментов:
набор вторых сегментов, содержащий по меньшей мере один второй сегмент из множества вторых сегментов, распределяется каждому первому сегменту по меньшей мере части из множества первых сегментов;
набор по меньшей мере фрагмента размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в части 3D сцены, связанной с каждым первым сегментом, и содержит вторые данные, представляющие собой глубину, связанную с 3D точками группы;
- кодирования, в, по меньшей мере, третью дорожку, по меньшей мере инструкции для извлечения по меньшей мере части первых данных и вторых данных из по меньшей мере части по меньшей мере первой дорожки и по меньшей мере второй дорожки.
Настоящее изобретение относится к устройству, выполненному с возможностью кодирования данных, представляющих собой 3D сцену, причем устройство содержит:
- кодер, выполненный с возможностью кодирования, в, по меньшей мере, первую дорожку, первых данных, представляющих собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- кодер, выполненный с возможностью кодирования, в, по меньшей мере, вторую дорожку, вторых данных, представляющих собой глубину, связанную с точками 3D сцены, причем вторые данные размещаются во множестве вторых сегментов второго кадра, при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, при этом для каждого первого сегмента по меньшей мере части из множества первых сегментов:
набор вторых сегментов, содержащий по меньшей мере один второй сегмент из множества вторых сегментов, распределяется каждому первому сегменту по меньшей мере части из множества первых сегментов;
набор по меньшей мере фрагмента размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в части 3D сцены, связанной с каждым первым сегментом, и содержит вторые данные, представляющие собой глубину, связанную с 3D точками группы;
- кодер, выполненный с возможностью кодирования, в, по меньшей мере, третью дорожку, по меньшей мере инструкции для извлечения по меньшей мере части первых данных и вторых данных из по меньшей мере части по меньшей мере первой дорожки и по меньшей мере второй дорожки.
Настоящее изобретение относится к устройству, выполненному с возможностью кодирования данных, представляющих собой 3D сцену, причем устройство содержит:
- средство для кодирования, в, по меньшей мере, первую дорожку, первых данных, представляющих собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- средство для кодирования, в, по меньшей мере, вторую дорожку, вторых данных, представляющих собой глубину, связанную с точками 3D сцены, причем вторые данные размещаются во множестве вторых сегментов второго кадра, при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, при этом для каждого первого сегмента по меньшей мере части из множества первых сегментов:
набор вторых сегментов, содержащий по меньшей мере один второй сегмент из множества вторых сегментов, распределяется каждому первому сегменту по меньшей мере части из множества первых сегментов;
набор по меньшей мере фрагмента размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в части 3D сцены, связанной с каждым первым сегментом, и содержит вторые данные, представляющие собой глубину, связанную с 3D точками группы;
- средство для кодирования, в, по меньшей мере, третью дорожку, по меньшей мере инструкции для извлечения по меньшей мере части первых данных и вторых данных из по меньшей мере части по меньшей мере первой дорожки и по меньшей мере второй дорожки.
В соответствии с конкретным отличительным свойством, каждый фрагмент дополнительно содержит третьи данные, представляющие собой текстуру, связанную с 3D точками группы, причем третьи данные кодируются в, по меньшей мере, вторую дорожку.
В соответствии с особым отличительным свойством, набор третьих сегментов третьего кадра, содержащий по меньшей мере один третий сегмент, распределяется каждому первому сегменту, и набор по меньшей мере фрагмента, содержащий третьи данные, представляющие собой текстуру, связанную с 3D точками группы, размещается в наборе третьих сегментов, причем по меньшей мере фрагмент соответствует двумерной параметризации группы 3D точек, причем третьи данные кодируются в, по меньшей мере, третью дорожку.
В соответствии с другим особым отличительным свойством, когда размер фрагмента набора больше размера второго сегмента, в который должен быть размещен фрагмент, тогда фрагмент разбивается на множество суб-фрагментов, причем размер каждого меньше размера второго сегмента.
В соответствии с дополнительным особым отличительным свойством, фрагменты набора размещаются в приоритетном порядке в зависимости от визуальной важности фрагментов, причем визуальная важность зависит от вторых данных, связанных с фрагментами.
В соответствии с дополнительным особым отличительным свойством, вторые сегменты имеют один и тот же размер, который является фиксированным для множества следующих друг за другом по времени вторых кадров.
Настоящее изобретение относится к способу декодирования данных, представляющих собой 3D сцену, причем способ, содержащий этапы, на которых:
- декодируют, по меньшей мере из третьей дорожки, по меньшей мере инструкцию для извлечения первых данных и вторых данных из по меньшей мере первой дорожки и по меньшей мере второй дорожки;
- декодируют первые данные из по меньшей мере первой дорожки, причем первые данные представляют собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- декодируют вторые данные из по меньшей мере второй дорожки, причем вторые данные представляют собой глубину, связанную с точками 3D сцены, причем вторые данные, представляющие собой глубину, содержатся по меньшей мере в фрагменте, который размещен по меньшей мере в наборе вторых сегментов второго кадра, причем набор вторых сегментов распределяется каждому первому сегменту, причем по меньшей мере фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся по меньшей мере в части 3D сцены, связанной с каждым первым сегментом, причем вторые данные представляют собой глубину, связанную с 3D точками группы.
Настоящее изобретение относится к устройству, выполненному с возможностью декодирования данных, представляющих собой 3D сцену, причем устройство содержит память, связанную по меньшей мере с одним процессором, выполненным с возможностью:
- декодирования, по меньшей мере из третьей дорожки, по меньшей мере инструкции для извлечения первых данных и вторых данных из по меньшей мере первой дорожки и по меньшей мере второй дорожки;
- декодирования первых данных из по меньшей мере первой дорожки, причем первые данные представляют собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- декодирования вторых данных из по меньшей мере второй дорожки, причем вторые данные представляют собой глубину, связанную с точками 3D сцены, причем вторые данные, представляющие собой глубину, содержатся по меньшей мере в фрагменте, который размещен по меньшей мере в наборе вторых сегментов второго кадра, причем набор вторых сегментов распределяется каждому первому сегменту, причем по меньшей мере фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся по меньшей мере в части 3D сцены, связанной с каждым первым сегментом, причем вторые данные представляют собой глубину, связанную с 3D точками группы.
Настоящее изобретение относится к устройству, выполненному с возможностью декодирования данных, представляющих собой 3D сцену, причем устройство содержит:
- декодер, выполненный с возможностью декодирования, по меньшей мере из третьей дорожки, по меньшей мере инструкции для извлечения первых данных и вторых данных из по меньшей мере первой дорожки и по меньшей мере второй дорожки;
- декодер, выполненный с возможностью декодирования первых данных из по меньшей мере первой дорожки, причем первые данные представляют собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- декодер, выполненный с возможностью декодирования вторых данных из по меньшей мере второй дорожки, причем вторые данные представляют собой глубину, связанную с точками 3D сцены, причем вторые данные, представляющие собой глубину, содержатся по меньшей мере в фрагменте, который размещен по меньшей мере в наборе вторых сегментов второго кадра, причем набор вторых сегментов распределяется каждому первому сегменту, причем по меньшей мере фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся по меньшей мере в части 3D сцены, связанной с каждым первым сегментом, причем вторые данные представляют собой глубину, связанную с 3D точками группы.
Настоящее изобретение относится к устройству, выполненному с возможностью декодирования данных, представляющих собой 3D сцену, причем устройство содержит:
- средство для декодирования, по меньшей мере из третьей дорожки, по меньшей мере инструкции для извлечения первых данных и вторых данных из по меньшей мере первой дорожки и по меньшей мере второй дорожки;
- средство для декодирования первых данных из по меньшей мере первой дорожки, причем первые данные представляют собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные размещаются во множестве первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- средство для декодирования вторых данных из по меньшей мере второй дорожки, причем вторые данные представляют собой глубину, связанную с точками 3D сцены, причем вторые данные, представляющие собой глубину, содержатся по меньшей мере в фрагменте, который размещен по меньшей мере в наборе вторых сегментов второго кадра, причем набор вторых сегментов распределяется каждому первому сегменту, причем по меньшей мере фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся по меньшей мере в части 3D сцены, связанной с каждым первым сегментом, причем вторые данные представляют собой глубину, связанную с 3D точками группы.
В соответствии с конкретным отличительным свойством третьи данные, представляющие собой текстуру, связанную с 3D точками группы, которые содержатся в каждом фрагменте, дополнительно декодируются из по меньшей мере второй дорожки.
В соответствии с особым отличительным свойством третьи данные, представляющие собой текстуру, дополнительно декодируются из по меньшей мере третьей дорожки, причем третьи данные размещаются во множестве третьих сегментов третьего кадра, причем набор третьих сегментов, содержащий по меньшей мере один третий сегмент, распределяется каждому первому сегменту, причем набор по меньшей мере фрагмента, содержащий третьи данные, связанные с 3D точками группы, размещается в наборе третьих сегментов, причем по меньшей мере фрагмент соответствует двумерной параметризации группы 3D точек.
В соответствии с другим отличительным свойством визуализация по меньшей мере части 3D сцены осуществляется в соответствии с первыми и вторыми данными.
Настоящее изобретение также относится к битовому потоку, несущему данные, представляющие собой 3D сцену, причем данные содержат, по меньшей мере в первом элементе синтаксиса, первые данные, представляющие собой текстуру 3D сцены, которая видна в соответствии с первой точкой обзора, причем первые данные связаны со множеством первых сегментов первого кадра, причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов; по меньшей мере во втором элементе синтаксиса, вторые данные, представляющие собой глубину, связанную с точками 3D сцены, причем вторые данные связаны со множеством вторых сегментов второго кадра, причем общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, причем набор вторых сегментов содержит по меньшей мере один второй сегмент, распределенный упомянутому каждому первому сегменту, причем набор по меньшей мере фрагмента размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в части 3D сцены, связанной с каждым первым сегментом, и содержит вторые данные, представляющие собой глубину, связанную с 3D точками группы; причем битовый поток дополнительно несет по меньшей мере в третьем элементе синтаксиса по меньшей мере инструкцию для извлечения по меньшей мере части первых данных и вторых данных.
Настоящее изобретение также относится к компьютерному программному продукту, содержащему инструкции программного кода для исполнения этапов способа кодирования или декодирования данных, представляющих собой 3D сцену, когда данная программа исполняется на компьютере.
Настоящее изобретение также относится к (долговременному) читаемому процессором носителю информации, с хранящимися на нем инструкциями для предписания процессору выполнять по меньшей мере вышеупомянутый способ кодирования или декодирования данных, представляющих собой 3D сцену.
4. Список фигур
Настоящее изобретение будет лучше понятно, и будут выяснены другие особые признаки и преимущества, после прочтения нижеследующего описания, причем описание обращается к приложенным чертежам, на которых:
- Фигура 1 показывает изображение, представляющее собой трехмерную сцену, содержащую поверхностное представление нескольких объектов, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 2 иллюстрирует примерное размещение точек зрения в сцене фигуры 1 и видимые точки данной сцены с разных точек зрения данного размещения, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 3 иллюстрирует восприятие параллакса путем показа разных видов сцены фигуры 1 в соответствии с точкой зрения фигуры 2, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 4 показывает изображение текстуры точек сцены фигуры 1, которые видны с точки зрения фигуры 2 в соответствии с равнопрямоугольным проекционным отображением, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 5 показывает изображение тех же самых точек сцены, как на фигуре 4, представленных в кубическом проекционном отображении, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 6 показывает изображение глубины (также называемое картой глубины) 3D сцены фигуры 1 в соответствии с точкой зрения фигуры 2, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 7 показывает трехмерную (3D) модель объекта 3D сцены фигуры 1 и точки облака точек, соответствующего 3D модели, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 8 показывает изображение фигуры 4 разбитое на множество сегментов, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 9 показывает 2D параметризацию части 3D сцены фигуры 1, связанную с одним сегментом изображения фигуры 4, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 10 показывает двумерный вид углового сектора обзора части сцены, проиллюстрированной на фигуре 9, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 11 показывает пример групп фрагментов 3D сцены, полученных путем 2D параметризации частей сцены, связанных с сегментами фигуры 8, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 12 показывает пример кодирования, передачи и декодирования последовательности 3D сцены в формате, который является, одновременно, совместимым с 3DoF визуализацией и совместимым с 3DoF+ визуализацией, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 13 показывает пример размещения фрагментов фигуры 11 в сегментах кадра, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 14 показывает пример процесса для размещения фрагментов фигуры 11 в разделенном на сегменты кадре фигуры 13, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 15 показывает примеры четвертых кадров, полученных из сегментов разделенного на сегменты кадра фигуры 13, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 16 показывает пример синтаксиса битового потока, несущего информацию и данные, представляющие собой 3D сцену фигуры 1, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 17 показывает пример процесса, чтобы кодировать 3D сцену фигуры 1, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 18 показывает пример процесса, чтобы декодировать 3D сцену фигуры 1, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 19 показывает примерную архитектуру устройства, которое может быть выполнено с возможностью реализации способа или процесса, описанного по отношению к фигурам 14, 17, 18, 20 и/или 21, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 20 иллюстрирует пример способа для кодирования данных, представляющих собой 3D сцену фигуры 1, реализованный, например, в устройстве фигуры 19, в соответствии с неограничивающим вариантом осуществления настоящих принципов;
- Фигура 21 иллюстрирует способ для декодирования данных, представляющих собой 3D сцену фигуры 1, реализованный, например, в устройстве фигуры 19, в соответствии с неограничивающим вариантом осуществления настоящих принципов.
5. Подробное описание вариантов осуществления
Теперь предмет изобретения описывается при обращении к чертежам, на которых аналогичные номера позиций используются для обращения к аналогичным элементам на всем протяжении. В нижеследующем описании, в целях объяснения, изложены многочисленные особые подробности для того, чтобы обеспечить исчерпывающее понимание предмета изобретения. Однако, может быть очевидно, что варианты осуществления предмета изобретения могут быть реализованы на практике без этих особых подробностей.
Настоящее описание иллюстрирует принципы настоящего изобретения. Таким образом, будет понятно, что специалисты в соответствующей области техники могут разработать различные компоновки, которые, несмотря на то, что в явной форме не описано или не показано в данном документе, воплощают принципы изобретения.
В соответствии с неограничивающими вариантами осуществления настоящего изобретения раскрываются способы и устройства, чтобы кодировать изображения объемного видео (также называемого 3DoF+ или 6DoF видео), например, в одном или более кадрах, в контейнере и/или в битовом потоке. Также раскрываются способы и устройства, чтобы декодировать изображения объемного видео из потока и/или кадров. Также раскрываются примеры синтаксиса битового потока для кодирования одного или более изображений/кадров объемного видео.
В соответствии с неограничивающим аспектом, настоящие принципы будут описаны при обращении к первому конкретному варианту осуществления способа (и устройства, выполненного с возможностью) кодирования данных, представляющих собой 3D сцену (представленную с помощью объемного контента, также называемого видео с погружением), в один или несколько кадров контейнера и/или битового потока.
Для достижения этой цели первые данные, представляющие собой текстуру (например, информацию о цвете, связанную с элементами, например, точками, 3D сцены) 3D сцены, которая видна в соответствии с первой точкой обзора, кодируются в одной или более первых дорожках, связанных по меньшей мере с частью первых сегментов первого кадра. Первые данные соответствует информации о текстуре 3DoF вида/изображения сцены, т.е. вида сцены в соответствии с центральной точкой обзора только с текстурой и без геометрии (т.е. глубины или 3D информации), т.е. «плоского» вида/изображения 3D сцены. Первый кадр разбивается на множество первых сегментов (сегмент, соответствующий суб-зоне кадра, и является, например, определенным в стандарте HEVC (Высокоэффективное Кодирование Видео) или в VP9 от Google с различной аббревиатурой), причем часть 3D сцены связана с каждым первым сегментом первого кадра.
Второй кадр разбивается на множество вторых сегментов, причем общее количество вторых сегментов больше общего количества первых сегментов первого кадра. Применительно по меньшей мере к части первых сегментов, набор вторых сегментов распределяется для каждого первого сегмента. Что касается каждого первого сегмента, фрагменты части 3D сцены, соответствующие каждому первому сегменту, размещаются в распределенных вторых сегментах. Фрагмент соответствует двумерной (2D) параметризации 3D части сцены и содержит по меньшей мере вторые данные, представляющие собой глубину по меньшей мере некоторых точек, которые содержатся в 3D части.
Вторые данные кодируются в одной или более вторых дорожках, связанных со вторыми сегментами.
Инструкции, адаптированные для извлечения по меньшей мере части первых данных (из по меньшей мере части первых дорожек) и по меньшей мере части вторых данных (из по меньшей мере части вторых дорожек) кодируются в одну или более третьих дорожек.
2D параметризация 3D части 3D сцены соответствует 2D представлению 3D части (например, точек 3D сцены, которые содержатся в 3D части). 2D параметризация может быть получена различными путями, как будет объяснено более подробно в описании.
Кадр соответствует изображению (например, у последовательности следующих один за другим по времени неподвижных изображений, формирующих видео) и соответствует массиву пикселей, причем атрибут (например, информация о глубине и/или информация о текстуре) связан с пикселями кадра.
Соответствующий способ (и устройство, выполненное с возможность) декодирования данных, представляющих собой 3D сцену, также описывается в отношении неограничивающего аспекта настоящих принципов.
Фигура 1 показывает изображение, представляющее собой трехмерную (3D) сцену 10, содержащую поверхностное представление нескольких объектов. Сцена могла быть получена с использованием любой подходящей технологии. Например, она могла быть создана с использованием инструментов интерфейса компьютерной графики (CGI). Она могла быть получена с помощью устройств получения цветного изображения и изображения глубины. В таком случае возможно, что одна или несколько частей объектов, которые не видны с устройств получения (например, камер), могут быть не представлены в сцене, как описано по отношению к фигуре 2. Примерная сцена, проиллюстрированная на фигуре 1, содержит дома, двух персонажей и колодец. Куб 11 иллюстрирует пространство зрения, из которого пользователь может наблюдать 3D сцену. Пространство 11 зрения, например, является с центром в первой точке обзора. 3D сцена (или ее часть) может, например, быть представлена с помощью плоского изображения (или плоского видео, также называемого всенаправленным изображением/видео), представляющего собой 3D сцену в соответствии с первой точкой обзора, и позволяющего пользователю (например, с надетым HMD) просматривать сцену в соответствии с 3 степенями свободы (3Dof), т.е. с поворотами вокруг продольной, вертикальной и поперечной оси. 3D сцена (или дополнительные части 3D сцены) могут быть представлены с помощью дополнительных данных (в дополнение к данным текстуры/цвета плоского изображения), связанных с частями 3D сцены, просматриваемой с точек обзора куба 11, за исключением первой точки обзора для данных текстуры. Дополнительные данные, например, могут содержать одну или любое сочетание из следующей информации:
- информация о глубине, связанная с точками 3D сцены, просматриваемой с первой точки обзора;
- информация о глубине, связанная с частями 3D сцены, просматриваемой с точек обзора куба 11, исключая первую точку обзора;
- информация о текстуре (также называемая информация о цвете), связанная с частями 3D сцены, просматриваемой с точек обзора куба 11, исключая первую точку обзора.
Дополнительные данные в сочетании с плоским видео обеспечивают 3DoF+ и/или 6DoF просмотр в представлении 3D сцены.
Фигура 2 показывает примерное размещение точек зрения в сцене, например, 3D сцене 10 фигуры 1. Фигура 2 также показывает точки данной 3D сцены 10, которые видны с/в соответствии с разными точками зрения данного размещения. Для обеспечения визуализации и демонстрации посредством устройства визуализации с погружением (например, CAVE или устройство Монитора, Устанавливаемого на Голове (HMD)), 3D сцена рассматривается с первой точки обзора (также называемой первой точкой зрения), например, первой точки 20 зрения. Точка 21 сцены, соответствующая правому локтю первого персонажа, видна с первой точки 20 обзора, поскольку отсутствует какой-либо непрозрачный объект, лежащий между первой точкой 20 зрения и точкой 21 сцены. В противоположность, точка 22 3D сцены 10, которая соответствует, например, левому локтю второго персонажа, не видна с первой точки 20 зрения, поскольку она закрыта точками первого персонажа.
Применительно к 3DoF визуализации, рассматривается только одна точка зрения, например, первая точка 20 обзора. Пользователь может поворачивать свою голову в трех степенях свободы вокруг первой точки зрения, чтобы просматривать различные части 3D сцены, но пользователь не может перемещать первую точку обзора. Точки сцены, которые должны быть кодированы в потоке, являются точками, которые видны с данной первой точки зрения. Не нужно кодировать точки сцены, которые не видны с данной первой точки зрения, поскольку пользователь не может осуществить к ним доступ путем перемещения первой точки обзора.
В отношении 6DoF визуализации, пользователь может перемещать точку обзора в любое место в сцене. В данном случае, важно кодировать каждую точку сцены в битовом потоке контента, поскольку каждая точка является потенциально доступной пользователю, который может перемещать его/ее точку зрения. На стадии кодирования, нет никаких средств заранее знать, с какой точки зрения пользователь будет смотреть 3D сцену 10.
В отношении визуализации 3DoF+, пользователь может перемещать точку зрения в рамках ограниченного пространства вокруг точки зрения, например, вокруг первой точки 20 обзора. Например, пользователь может перемещать свою точку зрения в рамках куба 11 с центром в первой точке 20 обзора. Это позволяет воспринимать параллакс, как проиллюстрировано по отношению к фигуре 3. Данные, представляющие собой часть сцены, которая видна с любой точки пространства зрения, например, куба 11, должны быть кодированы в поток, включая данные, представляющие собой 3D сцену, которая видна в соответствии с первой точкой 20 обзора. Размер и форма пространства зрения могут, например, быть решены и определены на этапе кодирования и могут быть кодированы в битовом потоке. Декодер может получать данную информацию из битового потока и визуализатор ограничивает пространство зрения до пространства, определенного полученной информации. В соответствии с другим примером, визуализатор определяет пространство зрения в соответствии с ограничениями аппаратного обеспечения, например, по отношению к возможностям датчика(ов), которые обнаруживают перемещения пользователя. В таком случае, если, на фазе кодирования, точка, которая видна с точки в рамках пространства зрения визуализатора, не была кодирована в битовом потоке, то не будет осуществлена визуализация данной точки. В соответствии с дополнительным примером, данные (например, текстура и/или геометрия), представляющие собой каждую точку 3D сцены, кодируются в потоке без учета пространства зрения визуализации. Чтобы оптимизировать размер потока, может быть кодировано лишь подмножество точек сцены, например, подмножество точек, которые могут быть видны в соответствии с пространством зрения визуализации.
Фигура 3 иллюстрирует восприятие параллакса, которое обеспечивается объемным (т.е. 3DoF+ и 6DoF) визуализацией. Фигура 3B иллюстрирует часть сцены, которую пользователь может видеть с первой точки 20 обзора фигуры 2. С данной первой точки 20 обзора два персонажа находятся в заданной пространственной конфигурации, например, левый локоть второго персонажа (в белой рубашке) спрятан телом первого персонажа при том, что видна его голова. Когда пользователь поворачивает его/ее голову в соответствии с тремя степенями свободы вокруг первой точки 20 обзора, данная конфигурация не меняется. Если точка обзора фиксирована, левый локоть второго персонажа не виден. Фигура 3A иллюстрирует ту же самую часть сцены, которая видна с точки обзора, расположенной с левой стороны пространства 11 зрения фигуры 2. С такой точки обзора, точка 22 фигуры 2 видна из-за эффекта параллакса. Вследствие этого, применительно к объемному визуализации, точка 22 должна быть кодирована в поток. Если не кодируется, то не будет осуществляться визуализация данной точки 22. Фигура 3C иллюстрирует ту же самую часть сцены, которая наблюдается с точки обзора, расположенной с правой стороны пространства 11 зрения фигуры 3. С данной точки обзора второй персонаж почти полностью скрыт первым персонажем.
Путем перемещения точки обзора в 3D сцене пользователь может воспринимать эффект параллакса.
Фигура 4 показывает изображение 40 текстуры (также называемое цветным изображением), содержащее информацию о текстуре (например, данные RGB или данные YUV) точек 3D сцены 10, которые видны с первой точки 20 обзора фигуры 2, причем данная информация о текстуре получается в соответствии с равнопрямоугольным проекционным отображением. Равнопрямоугольное проекционное отображение является примером сферического проекционного отображения.
Фигура 5 показывает изображение 50 точек 3D сцены, полученное или кодированное в соответствии с кубическим проекционным отображением. Существуют разные кубические проекционные отображения. Например, грани куба могут быть размещены по-другому в изображении 50 фигуры 5 и/или грани могут быть сориентированы другим образом.
Проекционное отображение, использованное для получения/кодирования точек сцены, которые видны с определенной точки обзора, выбирается, например, в соответствии с критериями сжатия или, например, в соответствии с опцией стандарта. Специалисту в соответствующей области техники известно, что можно преобразовать изображение, полученное путем проецирования, например, облака точек в соответствии с проекционным отображением в эквивалентное изображение того же самого облака точек в соответствии с другим проекционным отображением. Такое преобразование может все же повлечь за собой некоторую потерю в разрешении проекции.
Фигуры 4 и 5 показаны в оттенках серого. Естественно понятно, что они являются примерами (цветных) изображений текстуры (кодирующих текстуру (цвет) точек сцены), например, в RGB или в YUV. Каждое из изображений 40 и 50 содержит данные, необходимые для 3DoF визуализации 3D сцены. Декодер, принимающий битовый поток или поток данных, содержащий, в первом элементе синтаксиса, изображение, как примерные изображения 40 и/или 50 фигуры 4 и/или фигуры 5, декодирует изображение с использованием способа, который коррелирует со способом, использованным для кодирования изображения. Поток может быть кодирован в соответствии со стандартными способами сжатия изображения и видео и стандартным форматом для транспортировки изображения и видео, например, MPEG-2, H.264 или HEVC. Декодер может передавать декодированное изображение (или последовательность изображений) 3DoF визуализатору или модулю для переформатирования, например. 3DoF визуализатор будет сначала выполнять отмену проецирования декодированного изображения с проекционной поверхности (например, сферы применительно к ERP изображению 40 фигуры 4 или куба применительно к изображению 50 фигуры 5) и затем формировать прямоугольное окно просмотра, запрошенное просматривающим устройством конечного пользователя. В варианте, визуализатор преобразует изображение в соответствии с другим отличным проекционным отображением перед его проецированием.
Изображение совместимо с 3DoF визуализацией, когда изображение кодирует точки 3D сцены в соответствии с проекционным отображением. Сцена может содержать точки под углом 360°. Проекционные отображения, которые обычно используются чтобы кодировать изображения, совместимые с 3DoF визуализацией, соответствуют, например, среди сферических отображений: равнопрямоугольной проекции; проекции по долготе/широте; или разным схемам расположения кубических проекционных отображений или пирамидальных проекционных отображений.
Фигура 6 показывает изображение глубины (также называемое картой глубины) 3D сцены 10 в соответствии с первой точкой 20 обзора. Информация о глубине требуется для объемной визуализации. В примере кодирования изображения фигуры 6, чем темнее пиксель, тем ближе точка, которая проецируется в данный пиксель, от точки обзора. Например, глубина может быть кодирована двенадцатью битами, т.е. глубина представляется целым числом в диапазоне от 0 до 212-1 (= 4095). Если, например, самая близкая точка располагается на 1 метре от определенной точки обзора, а наиболее удаленная точка на 25 метрах от определенной точки обзора, то линейное кодирование глубины будет выполнено с шагами в 0,586 сантиметров (=(2500-100)/4096). Глубина также может быть кодирована в соответствии с логарифмической шкалой, поскольку неточность значения глубины точки, которая находится дальше от точки обзора, менее важна, чем неточность значения глубины для точки, которая находится ближе к точке обзора. В примерном варианте осуществления фигуры 6 глубина точек сцены, которые видны с точки обзора, кодируется в карте глубины в соответствии с тем же самым проекционным отображением, как проекционное отображение, используемое для кодирования карты цветов фигуры 5. В другом варианте осуществления глубина может быть кодирована в соответствии с другим проекционным отображением. Визуализатор преобразует карту глубины и/или цветное изображение в де-проекционные точки сцены, кодированные в этих данных.
Фигура 7 показывает трехмерную (3D) модель объекта 70 и точки облака 71 точек, соответствующие 3D модели 70. Модель 70 может быть 3D представлением сетки, а точки облака 71 точек могут быть вершинами сетки. Точки облака 71 точек также могут быть точками, рассеянными по поверхности граней сетки. Модель 70 также может быть представлена в качестве полученной посредством сплэттинга (splatting) версии облака 71 точек, причем поверхность модели 70 создается путем сплэттинга точек облака 71 точек. Модель 70 может быть представлена посредством множества разных представлений, таких как в вокселях или сплайнах. Фигура 7 иллюстрирует тот факт, что облако точек может быть определено с помощью представления поверхности 3D объекта и что представление поверхности 3D объекта может быть сформировано из точки облака. Используемые в данном документе проецирование точек 3D объекта (путем продления точек 3D сцены) на изображение является эквивалентным проецированию любого представления изображения данного 3D объекта для создания объекта.
Облако точек может быть рассмотрено в качестве векторной структуры, при этом каждая точка имеет свои координаты (например, трехмерные координаты XYZ, или глубину/расстояние от заданной точки обзора) и один или несколько атрибутов, также называемых составляющей. Примером составляющей является цветовая составляющая, которая может быть выражена в различных цветовых пространствах, например, RGB (Красный, Зеленый и Синий) или YUV (Y является составляющей яркости, а UV двумя составляющими цветности). Облако точек является представлением объекта с заданной точки обзора или диапазона точек обзора. Облако точек может быть получено посредством множества способов, например:
из захвата реального объекта, снятого установкой из камер, необязательно дополненного активным устройством регистрации глубины;
из захвата виртуального/искусственного объекта, снятого установкой из виртуальных камер в инструменте моделирования;
из смеси как реальных, так и виртуальных объектов.
Объемные части 3D сцены могут, например, быть представлены с помощью одного или более облаков точек, таких как облако 71 точек.
Фигура 8 показывает разбиение на сегменты изображения 40 (также называемого первым кадром 40 в нижеследующем), в соответствии с неограничивающим вариантом осуществления настоящих принципов. Первый кадр 40 соответствует плоскому представлению большого поля обзора (вплоть до 360°) 3D сцены, т.е. 2D представлению только с информацией о текстуре (цвете) и без глубины. Контент большого поля обзора (также называемый всенаправленным контентом) является контентом с полем обзора, которое, как правило, больше окна просмотра устройства конечного пользователя, т.е. только суб-часть первого кадра 40 демонстрируется за раз на устройстве конечного пользователя. Первый кадр 40 разбит на множество суб-частей или суб-зон с 81 по 88, которые могут соответствовать сегментам в смысле HEVC, VP9 или AV1 (разработанного Альянсом за Открытые Медиа), например. Сегменты могут, например, быть получены путем использования разбиение на сегменты HEVC с ограничением движения (MCTS).
В соответствии с неограничивающим примером первый кадр (после того, как было выполнено равнопрямоугольное проецирование (EPR)) делится на 8 сегментов HEVC с 81 по 88. Сегменты HEVC соответствуют неперекрывающимся прямоугольным областям, содержащим целое количество CTU (Единица Дерева Кодирования, CTU соответствует наибольшему блоку кодирования, например, размера 64×64) и организованным в шаблоне сетки со строками и столбцами фиксированного или переменного размера (например, Основной профиль 10 уровня 5.1 в HEVC устанавливает максимальное количество строк и столбцов сегментов в 11×10). Контент первого кадра может, например, быть кодирован в одном или более разрешениях с использованием наборов сегментов с ограничением движения (MCTS), т.е. при отсутствии другого предсказания из других сегментов. Каждая кодированная последовательность MCTS может быть сохранена инкапсулированной в отдельную дорожку сегмента в рамках, например, контейнера ISOBMFF (Базовый Формат Файла Мультимедиа ISO). Количество сегментов не ограничено 8 и может быть любым целым числом, например, больше или равным 2 и меньше 110 (11×10), если основано на Основном профиле 10 уровня 5.1 HEVC.
Разная 3D часть или 3D секция 3D сцены связывается с каждым сегментом T1 81, T2 82, T3 83, T4 84, T5 85, T6 86, T7 87 и T8 88 первого кадра 40 (как объяснено более подробно в отношении фигуры 10), причем видеоконтент определенного сегмента первого кадра соответствует результату проецирования 3D части 3D сцены, связанной с данным определенным сегментом.
Фигура 9 показывает 2D параметризацию 3D части 3D сцены, связанной с одним сегментом T6 86 первого кадра, в соответствии с неограничивающим вариантом осуществления настоящего принципа. Точно такой же процесс может быть применен к каждой 3D части 3D сцены, связанной с сегментами T1, T2, T3, T4, T5, T7 и T8 первого кадра 40.
Точки 3D сцены, которые содержатся в 3D части 3D сцены, связанной с сегментом T6 86, могут быть сгруппированы, чтобы формировать одну или несколько групп из точек, причем точки, принадлежащие одной и той же группе, обладают, например, информацией о глубине, которая содержится в определенном диапазоне глубины (т.е. точки одной и той же группы являются согласованными по глубине). Диапазон точек обзора, которые содержатся в пространстве 11 зрения (например, кубе), например, получается путем дискретизации на множество точек обзора (например, 5, 10 или 20 точек обзора). В соответствии с другим примером множество точек обзора получается из пространства 11 зрения путем определения тетраэдра с центром в первой точке 20 обзора, причем каждая из четырех вершин тетраэдра определяет точку обзора из множества точек обзора в дополнение к первой точке 20 обзора. Точки 3D части 3D сцены, связанной с сегментом T6 86, группируются с учетом 3D части с каждой точки обзора из множества. Чтобы избежать того, что одна и та же точка принадлежит множеству групп, группирование может быть сначала выполнено для первой точки обзора, и точки, которые были сгруппированы в соответствии с первой точкой обзора, не рассматриваются для следующего группирования в соответствии с другой точкой обзора. Примеры групп точек иллюстрируются на фигуре 9, например, группы с 91 по 95, причем каждая группа содержит, например, точки с согласованной глубиной, например, группа 94 содержит точки с глубиной, которая находится между 2м и 2.5м (расстояние от первой точки обзора), группа 95 содержит точки с глубиной, которая находится между 3,2м и 3,9м, группа 93 содержит точки с глубиной, которая находится между 3,9м и 10м.
Применительно к каждой группе точек формируется фрагмент, причем фрагмент соответствует 2D параметризации группы точек. Например, фрагмент 904 формируется из группы 94 точек. Один или несколько фрагментов каждой группы точек 3D части формируются, чтобы представлять каждую группу точек в двух измерениях, т.е. в соответствии с 2D параметризацией. Одна или несколько 2D параметризаций могут быть получены для каждой группы 91, 92, 93, 94 и 95 точек. 2D параметризация может варьироваться от группы точек к другой. В соответствии с вариантом все 2D параметризации, связанные со всеми группами точек, являются одного и того же типа, например, линейным перспективным проецированием или ортогональным проецированием. В соответствии с вариантом разные 2D параметризации могут быть использованы для одной и той же группы точек.
2D параметризация, связанная с одной заданной группой точек, например, группой 94, соответствует просмотру в 2 измерениях заданной 3D группы точек облака точек, что позволяет осуществить выборку заданной 3D группы точек, т.е. 2D представление контента (т.е. точки(ек)) данной заданной 3D группы точек, содержащее множество выборок (которые могут соответствовать пикселям изображения фрагмента), количество который зависит от применяемого шага выборки. 2D параметризация может быть представлена с помощью набора параметров и может быть получена посредством множества способов, например, путем применения любого из следующих способов:
- равнопрямоугольное проецирование (EPR) точек у группы точек облака точек на сферу, связанную с точкой обзора, причем параметры, представляющие собой ERP проецирование, содержат местоположение сферы, ее ориентацию и шаг пространственной выборки;
- линейное перспективное проецирование точек у группы точек облака точек на плоскость, связанную с точкой обзора, причем параметры, представляющие собой линейное перспективное проецирование, содержат местоположение виртуальной камеры, фокусное расстояние, шаг пространственной выборки и поле зрения в 2 измерениях;
- ортогональное проецирование точек у группы точек облака точек на поверхность, причем параметры, представляющие собой ортогональное проецирование, содержат геометрию (форму, размер и ориентацию) проецирующей поверхности и шаг пространственной выборки;
- LLE (Локально-Линейное Вложение), которое соответствует математической операции уменьшения размерности, здесь применяется для конвертирования/преобразования из 3D в 2D, причем параметры, представляющие LLE, содержат коэффициенты преобразования.
Каждый фрагмент обладает преимущественно прямоугольной формой, чтобы упростить процесс упаковки, который будет объяснен ниже. Каждый фрагмент может содержать геометрическую информацию, полученную путем проецирования/2D параметризации точек у связанной группы точек. Геометрическая информация может соответствовать информации о глубине или информации о позиции вершин элемента сетки. Фрагмент может дополнительно содержать информацию о текстуре, связанную с точками у связанной группы точек, за исключением того, когда фрагмент получается из точек, которые видны с первой точки обзора. Применительно к точкам, которые видны с первой точки обзора, информация о текстуре может быть получена из первого кадра 40. В соответствии с вариантом формируются геометрические фрагменты, содержащие только геометрическую информацию, и дополнительно формируются фрагменты текстуры, содержащие только информацию о текстуре, при необходимости.
Может быть сформирована информация об отображении, которая связывает каждую 2D параметризацию с ее связанным фрагментом. Информация об отображении может быть сформирована для обеспечения связи между 2D параметризацией и связанным геометрическим фрагментом, и фрагментом текстуры в кадрах, в которые размещаются фрагменты. Информация об отображении может, например, быть в форме:
{параметры 2D параметризации; ID геометрического фрагмента; ID фрагмента текстуры}
при этом ID геометрического фрагмента может быть целочисленным значением или парой значений, содержащей индекс U столбца и индекс V строки, к которым принадлежит геометрический фрагмент в кадре, в котором он размещен; ID фрагмента текстуры может быть целочисленным значением или парой значений, содержащей индекс U’ столбца и индекс V’ строки, к которым принадлежит фрагмент текстуры в матрице фрагментов кадра(ов) (или сегментов кадра(ов)), к которому принадлежат фрагменты.
Точно такая же информация об отображении формируется для каждой 2D параметризации и связанного геометрического фрагмента, и фрагмента текстуры. Такая информация об отображении обеспечивает воссоздание соответствующих частей 3D сцены путем создания связки 2D параметризации с соответствующим геометрическим фрагментом и фрагментом текстуры. Если 2D параметризация является проецированием, то соответствующая часть 3D сцены может быть воссоздана путем де-проецирования (выполнения обратного проецирования) геометрической информации, которая содержится в связанном геометрическом фрагменте, и информации о текстуре в связанном фрагменте текстуры. Тогда информация об отображении соответствует списку информации об отображении:
{параметры 2D параметризации; ID геометрического и фрагмента текстуры}i,
Для i=1 до n, причем n количество 2D параметризаций.
Фигура 10 показывает двумерный вид углового сектора обзора, соответствующего 3D части 3D сцены, связанной с сегментом T6 80 первого кадра 40, в соответствии с неограничивающим вариантом осуществления настоящего принципа.
Как объяснено по отношению к фигуре 8, каждый первый сегмент с T1 81 по T8 88 связан с 3D частью 3D сцены. Когда первый кадр 40 получается путем равнопрямоугольного или по кубической карте проекционного отображения, 3D часть, связанная с заданным первым сегментом T (T∈[1,8] в неограничивающем примере фигуры 8) соответствует угловому диапазону 101 обзора с первой точки обзора, которая может быть определена с помощью 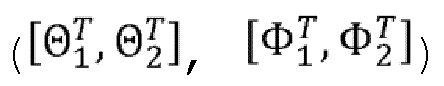 . Количество 3D-фрагментов может быть получено из 3D части, чтобы сформировать фрагменты, такие как фрагмент 904, путем 2D-параметризации 3D-фрагментов. 3D-фрагмент соответствует подмножеству 3D части, т.е. группе точек, полученной как объяснено в отношении фигуры 9. 3D-фрагмент 102 может, например, быть определен с помощью угла обзора и диапазона расстояний от определенной точки обзора (либо первой точки 20 обзора, либо любой из точек обзора, полученных из дискретизации пространства 11 зрения). 3D-фрагмент 102, например, определяется с помощью
. Количество 3D-фрагментов может быть получено из 3D части, чтобы сформировать фрагменты, такие как фрагмент 904, путем 2D-параметризации 3D-фрагментов. 3D-фрагмент соответствует подмножеству 3D части, т.е. группе точек, полученной как объяснено в отношении фигуры 9. 3D-фрагмент 102 может, например, быть определен с помощью угла обзора и диапазона расстояний от определенной точки обзора (либо первой точки 20 обзора, либо любой из точек обзора, полученных из дискретизации пространства 11 зрения). 3D-фрагмент 102, например, определяется с помощью 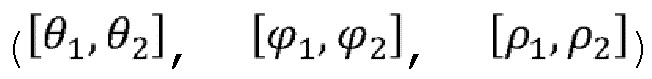 , при этом
, при этом  соответствуют угловому диапазону, соответствующему углу обзора, а
соответствуют угловому диапазону, соответствующему углу обзора, а 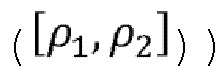 соответствует диапазону расстояний. Одно или несколько ограничений может быть применено при определении 3D-фрагментов (или групп точек). Например, сферический диапазон
соответствует диапазону расстояний. Одно или несколько ограничений может быть применено при определении 3D-фрагментов (или групп точек). Например, сферический диапазон 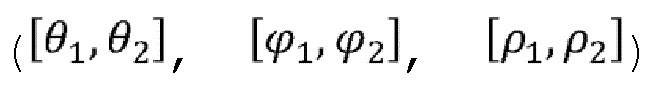 , связанный с 3D-фрагментом, должен содержаться или должен соответствовать диапазону угла обзора
, связанный с 3D-фрагментом, должен содержаться или должен соответствовать диапазону угла обзора 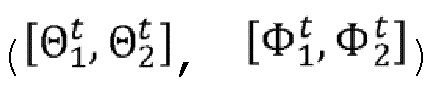 первого сегмента T6 86, определенного в первом кадре, чтобы избежать того, что один и тот же 3D-фрагмент охватывает два разных первых сегмента первого кадра (или эквивалентно два разных диапазона угла обзора, связанных с двумя разными сегментами). Фрагмент 904, содержащий информацию о глубине и/или информацию о текстуре, получается путем 2D-параметризации точек 3D-фрагмента 102, как объяснено в отношении фигуры 9. Как объяснено в отношении фигуры 9, может быть сформирован геометрический фрагмент 904, связанный с 3D-фрагментом 102, и дополнительно может быть сформирован геометрический фрагмент текстуры, связанный с 3D-фрагментом 102. Когда 3D-фрагмент 102 просматривается/определяется с первой точки 20 обзора, фрагмент 904 содержит только геометрическую информацию, причем информация о текстуре может быть извлечена из первого кадра 40.
первого сегмента T6 86, определенного в первом кадре, чтобы избежать того, что один и тот же 3D-фрагмент охватывает два разных первых сегмента первого кадра (или эквивалентно два разных диапазона угла обзора, связанных с двумя разными сегментами). Фрагмент 904, содержащий информацию о глубине и/или информацию о текстуре, получается путем 2D-параметризации точек 3D-фрагмента 102, как объяснено в отношении фигуры 9. Как объяснено в отношении фигуры 9, может быть сформирован геометрический фрагмент 904, связанный с 3D-фрагментом 102, и дополнительно может быть сформирован геометрический фрагмент текстуры, связанный с 3D-фрагментом 102. Когда 3D-фрагмент 102 просматривается/определяется с первой точки 20 обзора, фрагмент 904 содержит только геометрическую информацию, причем информация о текстуре может быть извлечена из первого кадра 40.
Фигура 11 показывает примеры групп фрагментов, полученных путем 2D параметризации 3D-фрагментов 3D частей сцены, связанной с первыми сегментами первого кадра, в соответствии с неограничивающим вариантом осуществления настоящего принципа.
Фигура 11 иллюстрирует некоторые из групп фрагментов, полученных путем 2D-параметризации групп точек, которые содержатся в частях сцены, связанных с некоторыми первыми сегментами первого кадра 40. Фигура 11 показывает, например, группу фрагментов S1, связанных с первым сегментом T1 81 первого кадра 40, группу фрагментов S3, связанных с первым сегментом T3 83 первого кадра 40, группу фрагментов S5, связанных с первым сегментом T5 85 первого кадра 40, группу фрагментов S6, связанных с первым сегментом T6 86 первого кадра 40 и группу фрагментов S8, связанных с первым сегментом T8 88 первого кадра 40. Даже если не проиллюстрировано, группы фрагментов S2, S4 и S7 могут быть получены из контента 3D частей сцены, связанных с соответствующими первыми сегментами T2 82, T4 84 и T7 87.
Группа фрагментов может содержать фрагменты, содержащие информацию о глубине и информацию о текстуре. В соответствии с вариантом группа фрагментов может содержать фрагменты, содержащие только информацию о глубине или только информацию о текстуре. Когда группа фрагментов содержит фрагменты, содержащие только информацию о глубине (соответственно информацию о текстуре), может быть сформирована соответствующая группа фрагментов, содержащая фрагменты, которые содержат только информацию о текстуре (соответственно информацию о глубине). В соответствии с последним вариантом количество фрагментов глубины, которые содержатся в соответствующей группе (например, группе S1, связанной с первым сегментом T1) может отличаться от (например, быть больше, чем) количества фрагментов текстуры, которые содержатся в соответствующей группе (например, в группе S1’, не проиллюстрировано, связанной с тем же самым первым сегментом T1, что и группа S1).
Количество фрагментов, которые содержатся в группе, может варьироваться от группы к другой группе. Например, количество фрагментов, которое содержится в группе S1, больше количества фрагментов, которое содержится в группах S5 и S8, но меньше, чем количество фрагментов, которое содержится в группах S3 и S6. Количество фрагментов, которое содержится в группе (например, группе S1), может зависеть от контента 3D части сцены, связанной с первым сегментом, связанным с упомянутой группой (например, первым сегментом T1). Количество фрагментов может, например, зависеть от количества согласованных по глубине групп точек, которые содержатся в 3D части сцены, соответствующей первому сегменту (например, первому сегменту T1), связанному с группой фрагментов (например, S1).
В соответствии с вариантом, количество фрагментов является одним и тем же в каждой из групп фрагментов. Количество фрагментов может быть определяемым пользователем значением или значением по умолчанию, которое хранится в устройстве, выполненном с возможностью формирования фрагментов и групп фрагментов.
Фигура 12 показывает неограничивающий пример кодирования, передачи и декодирования данных, представляющих собой 3D сцену в формате, который, одновременно, совместим с 3DoF и 3DoF+ визуализацией.
3D сцена 120 (или последовательность 3D сцен) кодируется в потоке 122 кодером 121. Поток 122 содержит первый элемент синтаксиса, несущий данные, представляющие собой 3D сцену для 3DoF визуализации (данные первого изображения 40 фигуры 8), и по меньшей мере второй элемент синтаксиса, несущий данные, представляющие собой 3D сцену для 3DoF+ визуализации (например, данные одного или более вторых/третьих изображений 130 фигуры 13 и/или данные одного или более четвертых изображений 151, 152 фигуры 15).
Кодер 121 является, например, совместимым с кодером, таким как:
HEVC (его спецификация находится на веб-сайте ITU, рекомендация T, выпуск H, h265, http://www.itu.int/rec/T-REC-H.265-201612-I/en);
3D-HEVC (расширение HEVC, спецификация которого находится на веб-сайте ITU, рекомендация T, выпуск H, h265, http://www.itu.int/rec/T-REC-H.265-201612-I/en приложение G и I);
VP9, разработанный Google; или
AV1 (AOMedia Video 1) разработанный Альянсом за Открытые Медиа.
Декодер 123 получает поток 122 от источника. Например, источник принадлежит к набору, содержащему:
- локальную память, например, видеопамять или RAM (или Память с Произвольным Доступом), флэш-память, ROM (или Постоянная Память), жесткий диск;
- интерфейс хранения, например, интерфейс с запоминающим устройством большой емкости, RAM, флэш-памятью, ROM, оптическим диском или магнитным средством обеспечения;
- интерфейс связи, например, проводной интерфейс (например, интерфейс шины, интерфейс глобальной сети, интерфейс локальной сети) или беспроводной интерфейс (такой как интерфейс IEEE 802.11 или интерфейс Bluetooth®); и
- интерфейс пользователя, такой как Графический Интерфейс Пользователя, позволяющий пользователю вводить данные.
Декодер 123 декодирует первый элемент синтаксиса потока 122 для 3DoF визуализации 124. Применительно к 3DoF+ визуализации 125 декодер декодирует как первый элемент синтаксиса, так и второй элемент синтаксиса потока 122.
Декодер 123 совместим с кодером 121, например, совместим с декодером, таким как:
HEVC;
3D-HEVC (расширение HEVC);
VP9; или
AV1.
Фигура 13 показывает пример размещения фрагментов, которые содержатся в группах фрагментов фигуры 11 во вторых сегментах с 1301 по 13032 второго кадра 130, в соответствии с неограничивающим вариантом осуществления настоящих принципов.
Второй кадр 130 делится на множество вторых сегментов с 1301 по 13032, например, 32 вторых сегмента в неограничивающем примере фигуры 13. Количество вторых сегментов не ограничено 32 и может быть любым количеством при условии, что количество вторых сегментов больше количества первых сегментов первого изображения 40. Как и для первых сегментов, размер (например, высота и ширина) каждого второго сегмента с 1301 по 13032 является таким, что второй сегмент может содержать целое количество (больше или равное 1) CTU (Единица Дерева Кодирования, CTU соответствует наибольшему блоку кодирования, например, размера 64×64), причем вторые сегменты с 1301 по 13032 организованы в шаблоне сетки, со строками и столбцами фиксированного или переменного размера (например, Основной профиль 10 уровень 5.1 HEVC устанавливает максимальное количество строк и столбцов сегментов в 11×10).
Вторые сегменты с 1301 по 13032 связаны с первыми сегментами с T1 по T8, причем один или несколько вторых сегментов связаны с каждым первым сегментом. Например, 2 вторых сегмента (например, вторые сегменты с 1301 по 1302) могут быть назначены первому сегменту T1, 4 вторых сегмента (например, вторые сегменты с 1303 по 1306) могут быть назначены первому сегменту T2, 5 вторых сегментов (например, вторые сегменты с 1307 по 13011) могут быть назначены первому сегменту T3, 5 вторых сегментов (например, вторые сегменты с 13012 по 13016) могут быть назначены первому сегменту T4, 3 вторых сегмента (например, вторые сегменты с 13017 по 13019) могут быть назначены первому сегменту T5, 5 вторых сегментов (например, вторые сегменты с 13020 по 13024) могут быть назначены первому сегменту T6, 5 вторых сегментов (например, вторые сегменты с 13025 по 13029) могут быть назначены первому сегменту T7 и 3 вторых сегмента (например, вторые сегменты с 13030 по 13032) могут быть назначены первому сегменту T8. Вторые сегменты используются, чтобы содержать и транспортировать фрагменты, полученные путем 2D-параметризации 3D частей сцены, связанных с первыми сегментами с T1 по T8. Фрагменты, которые содержатся в группе фрагментов S1, полученной путем 2D параметризации 3D части, связанной с первым сегментом T1, размещаются во вторых сегментах с 1301 по 1302, назначенных первому сегменту T1; фрагменты группы S2 размещаются во вторых сегментах с 1303 по 1306, назначенных первому сегменту T2; фрагменты группы S3 размещаются во вторых сегментах с 1307 по 13011, назначенных первому сегменту T3 и т.д.
Вторые сегменты получаются, например, путем подразделения первых сегментов. Первый сегмент может, например, быть подразделен на 2, 4 или 8 вторых сегментов.
Количество вторых сегментов, назначенных первому сегменту, может, например, зависеть от количества фрагментов, которые содержатся в группе фрагментов, связанной с первым сегментом. Данное количество может быть дополнительно ограничено максимальным значением так, что каждый первый сегмент может быть назначен по меньшей мере одному второму сегменту.
Второе изображение 130 может содержать фрагменты, содержащие информацию о глубине и текстуре. В соответствии с вариантом второе изображение 130 может содержать фрагменты, содержащие только информацию о глубине, и формируется третье изображение, чтобы содержать фрагменты, содержащие информацию о текстуре, связанные с первыми сегментами, за исключением фрагментов, полученных из первой точки обзора. Третье изображение содержит множество третьих сегментов, причем количество третьих сегментов больше количества первых сегментов.
Параметры, такие как размер кадра и количество сегментов, могут быть одними и теми же для первых и вторых изображений. В соответствии с вариантом один или несколько параметров отличаются для первого и второго изображений.
Фигура 14 показывает неограничивающий пример процесса для размещения фрагментов у группы фрагментов с S1 по S8 во вторых сегментах второго кадра 130 (и/или в третьем кадре).
Первоначальный бюджет по вторым сегментам составляет 32 в соответствии с примером Фигуры 14.
Ввод для процесса состоит из списка из 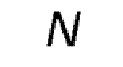 групп St из
групп St из 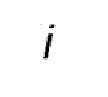 фрагментов
фрагментов 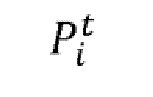 ( и целые числа, причем соответствует количеству фрагментов в группе, причем = 8 в соответствии с примером Фигуры 14), причем
( и целые числа, причем соответствует количеству фрагментов в группе, причем = 8 в соответствии с примером Фигуры 14), причем 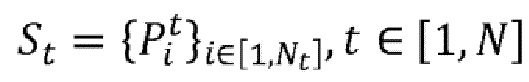 , каждая группа с S1 по S8 соответствует первому сегменту с T1 по T8 в первом кадре 40.
, каждая группа с S1 по S8 соответствует первому сегменту с T1 по T8 в первом кадре 40.
На первой операции проверяется, является ли размер каждого входного фрагмента не шире или выше размера второго сегмента. Например, с учетом того, что размер второго кадра 130 составляет 2048×1024 пикселей, и что 32 вторых сегмента имеют один и тот же размер, размер второго сегмента составляет 256×256 пикселей. Когда фрагмент не помещается в целевой размер второго сегмента, фрагмент дробится на более мелкие фрагменты, причем размер каждого меньше целевого размера второго сегмента.
На второй операции входные фрагменты сортируются по убыванию визуальной важности. Визуальная важность фрагмента может зависеть от его расстояния от точки просмотра (чем дальше, тем меньше важность), и/или его углового местоположения по отношению к основному направлению просмотра (крайние левые, правые, верхние или нижние фрагменты менее важны, чем центральные), и/или преград (фрагменты, которые закрыты с центральной точки просмотра являются менее важными). Сортировка в соответствии с визуальной важностью выполняется для всех входных фрагментов, т.е. путем обработки всех входных фрагментов всех групп фрагментов с S1 по S8 в одно и то же время и без параллельного рассмотрения групп фрагментов с S1 по S8 или одного после другого. Тем не менее информация, связанная с принадлежностью входных фрагментов к группам фрагментов, сохраняется для последующих операций.
алгоритмов упаковки могут, например, выполняться параллельно, причем один алгоритм упаковки для каждой группы фрагментов с S1 по S8. В качестве примеров, в качестве алгоритма упаковки могут быть использованы способы Шельфов, Гильотины, Максимальных Прямоугольников и Горизонта, со всеми их вариантами, описанные в документе «A thousand ways to pack the bin - A practical approach to two-dimensional rectangle bin packing», автор J. Jylänki.
На третьей операции входные фрагменты могут быть обработаны один за другим, начиная с наиболее визуально важного. Определяется группа фрагментов, к которой принадлежит входной фрагмент (например, извлекается из метаданных, связанных с входными фрагментами) и входные фрагменты направляются в ветвь упаковки (t=с 1 по 8), соответствующую группе фрагментов, к которой каждый из них принадлежит. Один или несколько вторых сегментов с 1301 по 13032 назначаются каждой ветви упаковки.
Когда в одной из ветвей упаковки больше нет места в текущем втором сегменте для текущего поступающего фрагмента, создается новый пустой второй сегмент и упаковка возобновляется до следующего раунда упаковки. Применительно к следующим фрагментам в той ветви упаковки, все вторые сегменты, созданные в течение предыдущего раунда упаковки, остаются в качестве потенциальных целевых вторых сегментов. Конечно, новый поступающий входной фрагмент может быть меньше предыдущего и может быть размещен в ранее созданном втором сегменте.
Процесс останавливается, когда все входные фрагменты были обработаны или, был использован бюджет вторых сегментов и все вторые сегменты заполнены. Если второй кадр 130 недостаточного размера и все входные фрагменты не могут быть упакованы, оставшиеся неупакованные фрагменты не пакуются и отбрасываются. Поскольку входные фрагменты были обработаны в соответствии с их визуальной важностью, то отброшенные входные фрагменты соответствуют наименее визуально важным входным фрагментам, что ограничивает проблемы при визуализации 3D сцены из фрагментов второго кадра 130.
Фигура 15 показывает неограничивающие примеры двух четвертых кадров 151, 152, полученных из вторых сегментов второго кадра 130 (и/или из третьих сегментов третьего кадра).
Каждый из четвертых кадров 151, 152 содержит фрагменты, которые содержатся в части вторых сегментов второго кадра 130. Вторые сегменты в четвертом кадре соответствуют выбору некоторых из первых сегментов в первом кадре, причем существует отображение между первыми сегментами и вторыми сегментами. На стороне визуализации может потребоваться только часть первого кадра, поскольку окно просмотра устройства конечного пользователя, которое используется для визуализации контента, может быть меньше поля обзора контента первого кадра 40. В соответствии с направлением просмотра, которое может быть определено на уровне устройства конечного пользователя, может быть продемонстрирована только суб-часть кадра 40 и должно быть осуществлено декодирование и визуализация только первых сегментов, соответствующих данной суб-части.
Четвертый кадр 151 содержит, например, 20 четвертых сегментов, размещенных в 5 столбцах и 4 строках (с, например, разрешением 1280×1024 пикселей). Четвертый кадр 151 содержит данные, соответствующие окну просмотра, которое охватывает 3D части 3D сцены, связанные с первыми сегментами T1, T2, T5 и T6, и содержит фрагменты, полученные путем 3D-параметризации 3D частей 3D сцены, связанной с этими первыми сегментами T1, T2, T5 и T6, т.е. фрагменты, которые содержатся во вторых сегментах 1301, 1302, 1033, 1034, 1305, 1306, 13017, 13018, 13019, 13020, 13021, 13022, 13023 и 13024. Сегмент данного четвертого кадра может соответствовать второму сегменту и содержать контент (фрагменты и данные, которые содержатся в фрагментах) соответствующего второго сегмента, причем второй сегмент идентифицируется своим индексом, т.е. с 1 по 32. Оставшиеся сегменты данного четвертого кадра, т.е. сегменты, заполненные диагональными полосами, являются пустыми и не содержат данные или содержат фиктивные данные.
Четвертые сегменты могут быть получены из вторых сегментов или непосредственно из процесса 2D параметризации, без формирования вторых сегментов второго кадра фигуры 13.
Каждый из первого, второго, третьего и четвертого кадров имеет фиксированный по времени размер и фиксированное по времени количество сегментов. Размер и/или количество сегментов могут быть либо одними и теми же для первого, второго, третьего и четвертого кадров, либо могут быть разными между первым, вторым, третьим и/или четвертым кадрами.
Четвертый кадр 152 содержит 20 четвертых сегментов, размещенных в 5 столбцах и 4 строках, как для четвертого кадра 151. Четвертый кадр 152 содержит данные, соответствующие окну просмотра, которое охватывает 3D части 3D сцены, связанной с первыми сегментами T2, T3, T6 и T7, и содержит фрагменты, полученные путем 3D-параметризации 3D частей 3D сцены, связанных в этими первыми сегментами T2, T3, T6 и T7, т.е. фрагменты, которые содержатся во вторых сегментах 1033, 1034, 1305, 1306, 1037, 1038, 1309, 13010, 13011, 13020, 13021, 13022, 13023, 13024, 13025, 13026, 13027, 13028 и 13029. Вторые сегменты, распределенные четвертому кадру, идентифицируются с помощью их индекса 3, 4, 5, 6, 7, 8, 9, 10, 11,20, 21, 22, 23, 24, 25, 26, 27, 28 и 29. Оставшийся сегмент четвертого кадра, т.е. сегмент, заполненный диагональными полосами, является пустым и не содержит данные или содержит фиктивные данные.
Вообще говоря, существует 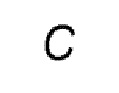 сочетаний первых сегментов в первом кадре 40, соответствующих всенаправленному плоскому изображению/видео сцены, причем каждое сочетание из
сочетаний первых сегментов в первом кадре 40, соответствующих всенаправленному плоскому изображению/видео сцены, причем каждое сочетание из 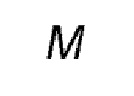 первых сегментов соответствует разной ориентации окна просмотра ( является целым числом, например, равным 4). Запрашивается только
первых сегментов соответствует разной ориентации окна просмотра ( является целым числом, например, равным 4). Запрашивается только  первых сегментов из полного набора из
первых сегментов из полного набора из 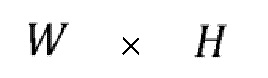 первых сегментов (
первых сегментов (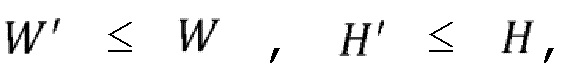 причем W равно 4 и H равно 2 в примере фигуры 8) и дорожка экстрактора выполняет их агрегацию в разделенный на сегментный совместимый с HEVC (или VP9 или AV1) битовый поток перед декодированием.
причем W равно 4 и H равно 2 в примере фигуры 8) и дорожка экстрактора выполняет их агрегацию в разделенный на сегментный совместимый с HEVC (или VP9 или AV1) битовый поток перед декодированием.
Аналогичный процесс агрегации выполняется для подмножества  вторых сегментов (из полного набора из
вторых сегментов (из полного набора из  вторых сегментов), соответствующих одному из сочетаний первых сегментов. Вторые сегменты все одного и того же размера, причем всегда возможна агрегация с разделением на сегменты в прямоугольный кадр (например, четвертый кадр 151, 152) из
вторых сегментов), соответствующих одному из сочетаний первых сегментов. Вторые сегменты все одного и того же размера, причем всегда возможна агрегация с разделением на сегменты в прямоугольный кадр (например, четвертый кадр 151, 152) из 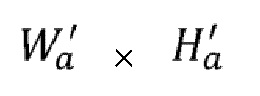 сегментов
сегментов 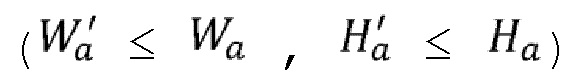 . Существует 3 возможности:
. Существует 3 возможности:
(i) 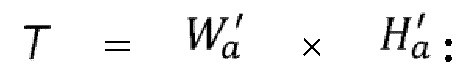 полная сетка деления на сегменты на стороне декодера (т.е. четвертый кадр) используется для агрегации;
полная сетка деления на сегменты на стороне декодера (т.е. четвертый кадр) используется для агрегации;
(ii) 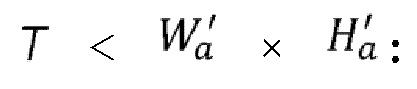 используется только часть сетки деления на сегменты на стороне декодера, и фиктивные значения заполняют неиспользованные сегменты (показаны с помощью диагональных полос);
используется только часть сетки деления на сегменты на стороне декодера, и фиктивные значения заполняют неиспользованные сегменты (показаны с помощью диагональных полос);
(iii) 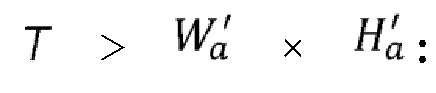 используется полная сетка деления на сегменты на стороне декодера (т.е. четвертый кадр), но некоторые вторые сегменты сбрасываются; поскольку каждому фрагменту назначается значение визуальной важности (в соответствии с алгоритмом упаковки, описанным по отношению к фигуре 14), то визуальная важность сегментов определяется как максимальная визуальная важность фрагментов в нем упакованных; приоритетно сбрасываются сегменты с наименьшей визуальной важностью.
используется полная сетка деления на сегменты на стороне декодера (т.е. четвертый кадр), но некоторые вторые сегменты сбрасываются; поскольку каждому фрагменту назначается значение визуальной важности (в соответствии с алгоритмом упаковки, описанным по отношению к фигуре 14), то визуальная важность сегментов определяется как максимальная визуальная важность фрагментов в нем упакованных; приоритетно сбрасываются сегменты с наименьшей визуальной важностью.
Фигура 16 показывает неограничивающий пример варианта осуществления синтаксиса потока, несущего информацию и данные, представляющие собой 3D сцену, когда данные передаются через основанный на пакете протокол передачи. Фигура 16 показывает примерную структуру 16 потока объемного видео. Структура состоит из контейнера, который организует поток в независимых элементах синтаксиса. Структура может содержать часть 161 заголовка, которая является набором данных общих для каждого из элементов синтаксиса потока. Например, часть заголовка содержит метаданные об элементах синтаксиса, описывающие характер и роль каждого из них. Часть заголовка также может содержать координаты точки обзора, использованной для кодирования первого кадра для 3DoF визуализации, и информацию о размере и разрешении кадров. Структура содержит полезную нагрузку, содержащую первый элемент 162 синтаксиса и по меньшей мере один второй элемент 163 синтаксиса. Первый элемент 162 синтаксиса содержит данные, представляющие собой первый кадр, подготовленный для 3DoF визуализации, соответствующий, например, первой видеодорожке, связанной с данными текстуры первого кадра, кодированного в первом элементе синтаксиса.
Один или несколько вторых элементов 163 синтаксиса содержат геометрическую информацию и информацию о текстуре, связанные с, например, одной или несколькими вторыми видеодорожками. Один или несколько вторых элементов 163 синтаксиса содержат, например, данные, представляющие собой один или несколько вторых кадров и/или третьих кадров, описанных по отношению к фигуре 13.
В соответствии с вариантом один или несколько вторых элементов 163 синтаксиса содержат данные, представляющие собой один или несколько четвертых кадров, описанных по отношению к фигуре 15.
В соответствии с дополнительным вариантом поток дополнительно содержит по меньшей мере инструкцию для извлечения по меньшей мере части упомянутых первых данных и вторых данных в одном или более третьих элементах синтаксиса.
В целях иллюстрации в контексте стандарта формата файла ISOBMFF, обращение к фрагментам текстуры, геометрическим фрагментам и метаданным как правило будет осуществляться в дорожках ISOBMFF в блоке типа moov, причем сами данные текстуры и данные геометрии встроены в блок медиа-данных типа mdat.
Фигура 17 показывает неограничивающий пример процесса, чтобы кодировать 3D сцену. Процесс фигуры 17 соответствует основанному на сегментах кодированию (например, основанному на сегментах HEVC или основанному на сегментах AV1) и инкапсуляции в файл объемного видео.
Последовательность 171 первых кадров 40 может быть кодирована, чтобы получить:
Множество дорожек 1710 сегментов, которые переносят обратно совместимое всенаправленное видео, причем каждая дорожка сегментов содержит данные, которые содержатся в одном отличном первом сегменте из  первых сегментов с T1 по T8 (например, одна дорожка сегментов для переноса контента первого сегмента T1, одна дорожка сегментов для переноса контента первого сегмента T2, одна дорожка сегментов для переноса контента первого сегмента T3, … и одна дорожка сегментов для переноса контента первого сегмента T8); причем количество дорожек сегментов может находиться между, например, 2 и N, причем N соответствует количеству первых сегментов в первом кадре 40;
первых сегментов с T1 по T8 (например, одна дорожка сегментов для переноса контента первого сегмента T1, одна дорожка сегментов для переноса контента первого сегмента T2, одна дорожка сегментов для переноса контента первого сегмента T3, … и одна дорожка сегментов для переноса контента первого сегмента T8); причем количество дорожек сегментов может находиться между, например, 2 и N, причем N соответствует количеству первых сегментов в первом кадре 40;
Метаданные 1712, соответствующие проецированию, которое используется для получения первого кадра, сшиванию и упаковке по областям, чтобы осуществлять визуализацию всенаправленного видео;
Одну или несколько дорожек 1711 экстрактора, вплоть до максимального количества дорожек экстрактора, соответствующих количеству C возможных ориентаций окна просмотра; экстрактор содержит инструкции для воссоздания битового потока, который может быть декодирован одним декодером, причем воссозданный битовый поток является синтаксически корректным для декодирования посредством декодера.
Сигнал, полученный на выходе процесса кодирования, может содержать, например, 8 дорожек 1710 сегментов (8 соответствует количеству первых сегментов в примере фигуры 8), 4 дорожки 1711 экстрактора (4 соответствует количеству возможных сочетаний первых сегментов в соответствии с ориентацией окна просмотра на устройстве конечного пользователя, а именно первое сочетание, содержащее первые сегменты T1, T2, T5, T6; второе сочетание, содержащее первые сегменты T2, T3, T6, T7; третье сочетание, содержащее первые сегменты T3, T4, T7, T8; и четвертое сочетание, содержащее первые сегменты T4, T1, T8, T5), и метаданные 1712.
В соответствии с вариантом сигнал содержит только часть из 8 дорожек 1710 сегментов, только одну дорожку 1711 экстрактора и метаданные 1712. Например, декодер может передавать запрос, который запрашивает заданную ориентацию окна просмотра, соответствующую одному сочетанию первых сегментов, например, второму сочетанию, содержащему первые сегменты T2, T3, T6, T7. В ответ на запрос кодер может кодировать только дорожку экстрактора, соответствующую запросу с дорожками 2, 3, 6 и 7 сегментов, содержащими связанные первые сегменты T2, T3, T6 и T7, и передавать запрошенный экстрактор, 4 дорожки сегментов, необходимые для воссоздания битового потока для визуализации запрошенного окна просмотра, с связанными метаданными 1712. Такой вариант обеспечивает уменьшение затрат на кодирование и уменьшение полосы пропускания, которая необходима для транспортировки данных. Такая зависимая от окна просмотра доставка контента может быть реализована на основании механизма потоковой передачи DASH (документ «ISO/IEC 23009-1, Dynamic adaptive streaming over HTTP» (Динамическая адаптивная потоковая передача через HTTP)).
Кодирование последовательности 171 обеспечивает визуализацию всенаправленного видео после декодирования, причем дорожки, полученные из кодирования данной последовательности 171, совместимы, например, со стандартом OMAF (документ «ISO/IEC 23090-2 Information Technology - Coded representation of immersive media (MPEG-I) - Part 2: Omnidirectional media format» (Информационные Технологии - Кодированное представление мультимедиа с погружением (MPEG-I) - Часть 2: Формат всенаправленного мультимедиа).
Последовательность 172 вторых кадров 130 может быть кодирована, чтобы получить:
Множество дорожек 1720 сегментов, которые переносят вторые сегменты и связанные фрагменты, причем каждая дорожка сегментов содержит данные, которые содержатся в одном отличном втором сегменте из вторых сегментов с 1301 по 13032;
Метаданные 1722, содержащие, например, параметры отмены проецирования фрагментов, информацию, представляющую собой местоположение внутри вторых сегментов второго кадра (соответственно местоположение внутри третьих сегментов третьего кадра, если применимо); и
Одну или несколько дорожек 1721 экстрактора, вплоть до максимального количества дорожек экстрактора, соответствующего количеству C возможных ориентаций окна просмотра; экстрактор содержит одну или несколько инструкций для воссоздания битового потока, который может быть декодирован одним декодером, причем воссозданный битовый поток является синтаксически корректным для декодирования посредством декодера; экстрактор содержит инструкцию для извлечения данных из другой дорожки, которая связана с дорожкой, в которой находится экстрактор, как описано в документе «Information Technology - Coding of audiovisual objects - Part 15: carriage of NAL unit structured video in the ISO Base Media File Format, AMENDMENT 1: Carriage of Layered HEVC», ISO/IEC 14496-15:2014/PDAM 1, датированный 11 июля 2014 г.
Сигнал, полученный на выходе процесса кодирования может содержать, например, 32 дорожки 1720 сегментов (32 соответствует количеству вторых сегментов в примере фигуры 13), 4 дорожки 1721 экстрактора (4 соответствует количеству возможных сочетаний первых сегментов в соответствии с ориентацией окна просмотра устройства конечного пользователя, а именно первое сочетание, содержащее вторые сегменты, распределенные для первых сегментов T1, T2, T5, T6; второе сочетание, содержащее вторые сегменты, распределенные для первых сегментов T2, T3, T6, T7; третье сочетание, содержащее вторые сегменты, распределенные для первых сегментов T3, T4, T7, T8; и четвертое сочетание, содержащее вторые сегменты, распределенные для первых сегментов T4, T1, T8, T5), и метаданные 1722.
В соответствии с вариантом сигнал содержит только часть из 32 дорожек 1720 сегментов, только одну дорожку 1721 экстрактора и метаданные 1722. Например, декодер может передавать запрос, который запрашивает заданную ориентацию окна просмотра, соответствующую одному сочетанию первых сегментов, например, второму сочетанию, содержащему вторые сегменты, распределенные для первых сегментов T2, T3, T6, T7. В ответ на запрос кодер может формировать только дорожку экстрактора, соответствующую запросу, и кодировать дорожки сегментов, содержащие вторые сегменты, распределенные для первых сегментов T2, T3, T6 и T7, содержащих данные, связанные со вторыми сегментами, распределенными первым сегментам T2, T3, T6 и T7, и передавать запрошенный экстрактор, причем связанные дорожки сегментов необходимы для воссоздания битового потока для визуализации запрошенного окна просмотра с связанными метаданными 1722. Такой вариант обеспечивает уменьшение затрат на кодирование и уменьшение полосы пропускания, которая необходима для транспортировки данных. Такая зависимая от окна просмотра доставка контента может быть реализована на основании механизма потоковой передачи DASH (документ «ISO/IEC 23009-1, Dynamic adaptive streaming over HTTP»).
Кодирование последовательности 172 с последовательностью 171 обеспечивает визуализацию объемного видео.
Если последовательность 172 соответствует последовательности вторых изображений, содержащих только геометрическую информацию, то дополнительная последовательность из третьих кадров, содержащих информацию о текстуре, может быть кодирована точно таким же образом, как последовательность 172.
Фигура 18 показывает неограничивающий пример процесса, чтобы декодировать битовый поток, полученный с помощью процесса кодирования фигуры 17.
Процесс декодирования содержит два основных процесса, первый процесс, чтобы декодировать данные, представляющие собой всенаправленный контент (только информация о текстуре) для 3DoF визуализации, и второй процесс, чтобы декодировать данные, обеспечивающие визуализацию объемного контента применительно к 3DoF+ визуализации.
В первом процессе осуществляется синтаксический анализ дорожек 1810 сегментов, связанных с запрошенной ориентацией окна просмотра (дорожек, содержащих данные, связанные с первыми сегментами T2, T3, T6 и T7 в соответствии с неограничивающим примером фигуры 17) посредством синтаксического анализатора (парсера) 181 в соответствии с инструкциями, принятыми в дорожке экстрактора. Синтаксический анализатор 181 позволяет воссоздать битовый поток 1811, который совместим с декодером 183 (например, совместимый с HEVC битовый поток, если декодер 183 является HEVC-совместимым, или совместимый с AV1 битовый поток, если декодер 183 является AV1-совместимым). Данные, которые содержатся в битовом потоке 1811, декодируются декодером 183 и декодированные данные передаются визуализатору 185, который выполнен с возможностью визуализации всенаправленного контента с использованием метаданных 1712, которые содержатся в битовом потоке, полученном с помощью процесса кодирования фигуры 17.
Во втором процессе осуществляется синтаксический анализ дорожек 1820 сегментов, связанных с запрошенной ориентацией окна просмотра (дорожек, содержащих фрагменты, которые содержатся во вторых сегментах (или третьих сегментах для данных текстуры), связанных с первыми сегментами T2, T3, T6 и T7, в соответствии с неограничивающим примером фигуры 17) посредством синтаксического анализатора 182 в соответствии с инструкциями, принятыми в дорожке экстрактора. Синтаксический анализатор 182 позволяет воссоздать битовый поток 1821, который совместим с декодером 184 (например, совместимый с HEVC битовый поток, если декодер 184 является HEVC-совместимым, или совместимый с AV1 битовый поток, если декодер 184 является AV1-совместимым). Воссозданный битовый поток содержит, например, данные одного или более четвертых кадров, описанных по отношению к фигуре 15. Данные, которые содержатся в битовом потоке 1821, декодируются декодером 184 и декодированные данные передаются визуализатору 186, который выполнен с возможностью визуализации объемной части объемного контента с использованием метаданных 1722, которые содержатся в битовом потоке, полученном с помощью процесса кодирования фигуры 17. Второй процесс может быть выполнен для дорожек сегментов, содержащих информацию о глубине, и для дорожек сегментов, содержащих информацию о текстуре.
Фигура 19 показывает примерную архитектуру устройства 19, которое может быть выполнено с возможностью реализации способа, описанного по отношению к фигурам 17, 18, 20 и/или 21. Устройство 19 может быть выполнено в виде кодера 121 или декодера 123 фигуры 12.
Устройство 19 содержит следующие элементы, которые связаны вместе шиной 191 адресов и данных:
- микропроцессор 192 (или CPU), который является, например, DSP (или Цифровым Сигнальным Процессором);
- ROM 193 (или Постоянную Память);
- RAM 194 (или Память с Произвольным Доступом);
- интерфейс 195 хранения;
- интерфейс 196 I/O для приема данных для передачи, от приложения; и
- источник питания, например, батарею.
В соответствии с примером, источник питания является внешним для устройства. В каждой упомянутой памяти слово «регистр», используемое в спецификации, может соответствовать зоне небольшой емкости (в несколько битов) или очень большой зоне (например, целой программе или большому объему принятых или декодированных данных). ROM 193 содержит по меньшей мере программу и параметры. ROM 193 может хранить алгоритмы и инструкции, чтобы выполнять методики в соответствии с настоящими принципами. При включении CPU 192 выгружает программу в RAM и исполняет соответствующие инструкции.
RAM 194 содержит, в регистре, программу, исполняемую CPU 192 и выгружаемую после включения устройства 19, входные данные в регистре, промежуточные данные в разных состояниях способа в регистре и прочие переменные, которые используются для исполнения способа в регистре.
Реализации, описанные в данном документе, могут быть реализованы в, например, способе или процессе, устройстве, компьютерном программном продукте, потоке данных или сигнале. Даже при обсуждении только в контексте единственной формы реализации (например, при обсуждении только в качестве способа или устройства), реализация обсуждаемых признаков также может быть реализована в других формах (например, в программе). Устройство может быть реализовано в, например, надлежащем аппаратном обеспечении, программном обеспечении или встроенном программном обеспечении. Способы могут быть реализованы в, например, устройстве, таком как, например, процессор, который относится к устройствам обработки в целом, включая, например, компьютер, микропроцессор, интегральную микросхему или программируемое логическое устройство. Процессоры также включают в себя устройства связи, такие как, например, компьютеры, сотовые телефоны, портативные/персональные цифровые помощники («PDA») и прочие устройства, которые обеспечивают сообщение для передачи информации между конечными пользователями.
В соответствии с примером кодирования или кодера 121 фигуры 12, от источника получается трехмерная сцена. Например, источник принадлежит к набору, содержащему:
- локальную память (193 или 194), например, видеопамять или RAM (или Память с Произвольным Доступом), флэш-память, ROM (или Постоянную Память), жесткий диск;
- интерфейс (195) хранения, например, интерфейс с запоминающим устройством большой емкости, RAM, флэш-памятью, ROM, оптическим диском или магнитным средством обеспечения;
- интерфейс (196) связи, например, проводной интерфейс (например, интерфейс шины, интерфейс глобальной сети, интерфейс локальной сети) или беспроводной интерфейс (такой как интерфейс IEEE 802.11 или интерфейс Bluettoth®); и
- интерфейс пользователя, такой как Графический Интерфейс Пользователя, позволяющий пользователю вводить данные.
В соответствии с примерами декодирования или декодера(ов) 123 фигуры 12, поток отправляется получателю; в частности, получатель принадлежит к набору, содержащем:
- локальную память (193 или 194), например, видеопамять или RAM, флэш-память, жесткий диск;
- интерфейс (195) хранения, например, интерфейс с запоминающим устройством большой емкости, RAM, флэш-памятью, ROM, оптическим диском или магнитным средством обеспечения;
- интерфейс (196) связи, например, проводной интерфейс (например, интерфейс шины (например, USB (или Универсальная Последовательная Шина)), интерфейс глобальной сети, интерфейс локальной сети, интерфейс HDMI (Мультимедийный Интерфейс Высокой Четкости)) или беспроводной интерфейс (такой как интерфейс IEEE 802.11 или интерфейс WiFi® и Bluettoth®).
В соответствии с примерами кодирования или кодера битовый поток, содержащий данные, представляющие собой объемную сцену, отправляется получателю. В качестве примера битовый поток сохраняется в локальной или удаленной памяти, например, видеопамяти или RAM, на жестком диске. В варианте битовый поток отправляется интерфейсу хранения, например, интерфейсу с запоминающим устройством большой емкости, флэш-памятью, ROM, оптическим диском или магнитным средством обеспечения и/или передается через интерфейс связи, например, интерфейс с линией связи типа точка-точка, шиной связи, линией связи типа точка-многоточка или широковещательной сетью.
В соответствии с примерами декодирования или декодера, или визуализатора 123 фигуры 12 битовый поток получается от источника. В качестве примера битовый поток считывается из локальной памяти, например, видеопамяти, RAM, ROM, флэш-памяти или жесткого диска. В варианте битовый поток принимается от интерфейса хранения, например, интерфейса с запоминающим устройством большой емкости, RAM, ROM, флэш-памятью, оптическим диском или магнитным средством обеспечения и/или принимается от интерфейса связи, например, интерфейса с линией связи типа точка-точка, шиной, линией связи типа точка-многоточка или широковещательной сетью.
В соответствии с примерами устройство 19 выполнено с возможностью реализации способа, описанного по отношению к фигурам 17, 18, 20 и/или 21, и принадлежит к набору, содержащему:
- мобильное устройство;
- устройство связи;
- игровое устройство;
- планшет (или планшетный компьютер);
- лэптоп;
- камеру для неподвижных картинок;
- видеокамеру;
- чип кодирования;
- сервер (например, широковещательный сервер, сервер видео по запросу или веб-сервер).
Фигура 20 иллюстрирует способ для кодирования данных, представляющих собой 3D сцену, например, 3D сцену 10, в соответствии с неограничивающим вариантом осуществления настоящих принципов. Способ может, например, быть реализован в кодере 121 и/или в устройстве 19. Разные параметры устройства 19 могут быть обновлены. 3D сцена может, например, быть получена от источника, может быть определена одна или несколько точек зрения в пространстве 3D сцены, могут быть инициализированы параметры, связанные с проекционным отображением(ями).
На первой операции 201 первые данные, представляющие собой текстуру 3D сцены, кодируются или форматируются в одну или более первых дорожек контейнера или файла в соответствии с определенным форматом, например, в соответствии с документом HEVC/H265: «ITU-T H.265 TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU (10/2014), SERIES H: AUDIOVISUAL AND MULTIMEDIA SYSTEMS, Infrastructure of audiovisual services - Coding of moving video, High efficiency video coding, Recommendation ITU-T H.265» или в соответствии с AV1. Контейнер соответствует, например, файлу ISOBMFF (Базовый Формат Файла Мультимедиа ISO, документ ISO/IEC 14496-12-MPEG-4 Часть 12). Первые данные относятся к частям (например, точкам или элементам сетки) 3D сцены, которые видны в соответствии с одной первой точкой обзора. Первые данные содержат, например, метаданные и информацию сигнализации, указывающую на первый элемент синтаксиса битового потока, который содержит информацию о текстуре, кодированную в пикселях первого кадра, причем первый кадр разбит на множество сегментов. 3D часть 3D сцены 10 связана с каждым первым сегментом первого кадра 40. Каждая первая дорожка, например, связана с одним отличным первым сегментом и содержит первые данные связанного первого сегмента. Первые данные, как только декодированы или интерпретированы, обеспечивают получение 3DoF представления 3D сцены в соответствии с первой точкой обзора, т.е. представление без параллакса.
На второй операции 202 вторые данные, представляющие собой глубину, связанную с точками 3D сцены, кодируются в одну или более вторых дорожек контейнера или файла. Вторые данные размещаются во вторых сегментах второго кадра, который может соответствовать четвертому кадру 151, 152 фигуры 15. Разный набор вторых сегментов связывается с каждым первым сегментом и количество вторых сегментов, которые содержатся во втором кадре, больше количества первых сегментов первого кадра. Фрагменты вторых данных (вторые данные соответствуют, например, геометрической информации (глубине)) размещаются во вторых сегментах и кодируются в соответствующую вторую дорожку, например, в соответствии с форматом HEVC или AV1. Каждый фрагмент соответствует 2D параметризации части (т.е. группы точке) 3D сцены. Фрагменты, полученные путем 2D параметризации 3D части 3D сцены, связанной с заданными первыми сегментами, размещаются во вторых сегментах, распределенных для данного первого сегмента. Вторые данные, как только декодированы или интерпретированы, позволяют получить 3DoF+ представление 3D сцены в соответствии со множеством точек обзора, включая первую точку обзора, т.е. представление с параллаксом.
В соответствии с вариантом фрагменты содержат информацию о текстуре в дополнение к геометрической информации, за исключением фрагментов, полученных с учетом первой точки обзора. Другими словами, вторые данные содержат геометрические данные и данные текстуры.
В соответствии с дополнительным вариантом фрагменты содержат только геометрическую информацию. В соответствии с данным вариантом может быть получен один или несколько дополнительных вторых кадров, причем каждый дополнительный второй кадр разбивается на множество вторых сегментов, причем количество вторых сегментов больше общего количества первых сегментов. Один или несколько вторых сегментов связываются с каждым первым сегментом и фрагменты данных текстуры размещаются во вторых сегментах и кодируются в дополнительные дорожки, называемые четвертыми дорожками. Фрагменты, полученные путем 2D параметризации 3D части 3D сцены, связанной с заданными первыми сегментами, размещаются во вторых сегментах, распределенных данному первому сегменту.
На третьей операции 204 одна или несколько инструкций кодируются в одной или более третьих дорожках контейнера или файла. Инструкции выполнены с возможностью извлечения первых и вторых данных из первой и второй дорожек и размещения извлеченных первых и вторых данных в битовый поток, отформатированный для декодирования одним декодером. Третья дорожка соответствует, например, дорожке экстрактора в соответствии с HEVC. Вторые данные кодируются во второй кадр(ы). Количество третьих дорожек, например, равно числу величины C возможных ориентаций окна просмотра, описанных по отношению к фигуре 17.
В соответствии с дополнительным необязательным вариантом данные и инструкции первой, второй и третьей дорожек формируют битовый поток, который передается декодеру или визуализатору, содержащему декодер.
Фигура 21 иллюстрирует способ для декодирования данных, представляющих собой 3D сцену, например, 3D сцену 10, в соответствии с неограничивающим вариантом осуществления настоящих принципов. Способ может, например, быть реализован в декодере 123 и/или в устройстве 19.
На первой операции 211 одна или несколько инструкций декодируются из одной или более третьих дорожек контейнера или файла. Инструкции выполнены с возможностью извлечения первых и вторых данных из первой и второй дорожек и размещения извлеченных первых и вторых данных в битовый поток, отформатированный для декодирования одним декодером. Третья дорожка соответствует, например, дорожке экстрактора в соответствии с HEVC.
На второй операции 212 первые данные, представляющие собой текстуру части 3D сцены, которая видна в соответствии с первой точкой обзора, декодируются или интерпретируются из первых сегментов, которые содержатся в одной или более первых дорожках, как предписано инструкциями, полученными на операции 211. Первые данные позволяют получить 3DoF представление 3D сцены в соответствии с первой точкой обзора, т.е. представление без параллакса.
На третьей операции 213 вторые данные, представляющие собой геометрию 3D сцены, которая видна в соответствии с набором точек зрения, содержащих первую точку обзора, декодируются или интерпретируются из вторых сегментов, которые содержатся в одной или более вторых дорожках, как предписано инструкциями, полученными на операции 211. Вторые данные содержатся в фрагментах, полученных путем 2D параметризации группы точек 3D сцены. В соответствии с вариантом третьи данные, представляющие собой текстуру 3D сцены, которая видна в соответствии с упомянутым набором точек обзора, за исключением первой точки обзора, декодируются или интерпретируются из одного или более третьих сегментов дополнительных дорожек. Вторые данные с третьими данными обеспечивают получение 3DoF+ представления 3D сцены в соответствии с упомянутыми точками обзора, т.е. представление с параллаксом.
В соответствии с вариантом декодированные первые и вторые данные размещаются в битовом потоке, как предписано инструкциями, полученными на операции 211, чтобы сформировать битовый поток, который должен быть декодирован декодером. В соответствии с другим вариантом полученный битовый поток декодируется декодером для визуализации визуализатором. Полученный в результате визуализации контент может быть продемонстрирован на устройстве конечного пользователя для просмотра, таком как HMD, в соответствии с ориентацией точки обзора, соответствующей инструкциям.
Естественно настоящее изобретение не ограничивается ранее описанными вариантами осуществления.
В частности, настоящее изобретение не ограничивается способом и устройством для кодирования/декодирования данных, представляющих собой 3D сцену, а также расширяется на способ для формирования битового потока, содержащего кодированные данные, и устройство, реализующее данный способ и в особенности на любые устройства, содержащие по меньшей мере один CPU и/или по меньшей мере один GPU.
Настоящее изобретение также относится к способу (и устройству, выполненному с возможностью) для демонстрации изображений, полученных в результате визуализации из декодированных данных битового потока.
Настоящее изобретение также относится к способу (и устройству, выполненному с возможностью) для передачи и/или приема битового потока.
Реализации, описанные в данном документе, могут быть реализованы в, например, способе или процессе, устройстве, компьютерном программном продукте, потоке данных или сигнале. Даже при обсуждении только в контексте одной формы реализации (например, при обсуждении только в качестве способа или устройства), реализация признаков, которые обсуждались, также может быть реализована в других формах (например, программе). Устройство может быть реализовано в, например, надлежащем аппаратном обеспечении, программном обеспечении и встроенном программном обеспечении. Способы могут быть реализованы в, например, устройстве, таком как, например, процессор, который относится к устройствам обработки в целом, включая, например, компьютер, микропроцессор, интегральную микросхему или программируемое логическое устройство. Процессоры также включают в себя устройства связи, такие как, например, интеллектуальные телефоны, планшеты, компьютеры, мобильные телефоны, портативные/персональные цифровые помощники («PDA») и прочие устройства, которые обеспечивают сообщение для передачи информации между конечными пользователями.
Реализации различных процессов и признаков, описанных в данном документе, могут быть воплощены в многообразии разного оборудования или приложений, в частности, например, оборудовании или приложениях, связанных с кодированием данных, декодированием данных, формированием просмотра, обработкой текстуры и другой обработкой изображений, и связанной информации о текстуре и/или информации о глубине. Примеры такого оборудования включают кодер, декодер, постпроцессор, обрабатывающий выход с декодера, препроцессор, обеспечивающий ввод для кодера, кодер видео, декодер видео, кодек видео, веб-сервер, телевизионную абонентскую приставку, лэптоп, персональный компьютер, сотовый телефон, PDA и другие устройства связи. Как должно быть ясно, оборудование может быть мобильным или даже инсталлированным на мобильном транспортом средстве.
Дополнительно, способы могут быть реализованы посредством инструкций, выполняемых процессором, и такие инструкции (и/или значения данных, создаваемые путем реализации) могут быть сохранны на читаемом процессором носителе информации, таком как, например, интегральная микросхемы, носитель программного обеспечения или другое запоминающее устройство, такое как, например, жесткий диск, компакт-дискета («CD»), оптический диск (такой как, например, DVD, часто упоминаемый как цифровой универсальный диск или цифровой видеодиск), память с произвольным доступом («RAM») или постоянная память («ROM»). Инструкции могут формировать прикладную программу, которая вещественным образом воплощается на читаемом процессором носителе информации. Инструкции могут быть, например, в аппаратном обеспечении, встроенном программном обеспечении, программном обеспечении или сочетании. Инструкции можно найти, например, в операционной системе, отдельном приложении или сочетании двух видов. Вследствие этого процессор может быть охарактеризован в качестве, например, как устройства, выполненного с возможностью осуществления процесса, так и устройства, которое включает в себя читаемый процессором носитель информации (такой как запоминающее устройство) с инструкциями для осуществления процесса. Кроме того, читаемый процессором носитель информации может хранить, в дополнение к или вместо инструкций, значения данных, созданных путем реализации.
Как будет очевидно специалисту в соответствующей области техники, реализации могут создавать многообразие сигналов, отформатированных для переноса информации, которая может быть, например, сохранена или передана. Информация может включать в себя, например, инструкции для выполнения способа, или данные, созданные одной из описанных реализаций. Например, сигнал может быть отформатирован для переноса в качестве данных правил для записи или чтения синтаксиса описанного варианта осуществления, или переноса в качестве данных фактических синтаксических значений, записанных описанным вариантом осуществления. Такой сигнал может быть отформатирован, например, в качестве электромагнитной волны (например, с использованием радиочастотного сегмента спектра) или в качестве сигнала основной полосы частот. Форматирование может включать в себя, например, кодирование потока данных и модуляцию несущей с помощью потока кодированных данных. Информация, которую несет сигнал, может быть, например, аналоговой или цифровой информацией. Сигнал может быть передан через многообразие разных проводных или беспроводных линий связи, как известно. Сигнал может быть сохранен на читаемом процессором носителе информации.
Было описано некоторое количество реализаций. Тем не менее будет понятно, что могут быть выполнены различные модификации. Например, элементы разных реализаций могут быть объединены, дополнены, модифицированы или удалены, чтобы создавать другие реализации. Дополнительно, специалист в соответствующей области техники будет понимать, что в отношении раскрытых структур и процессов может быть осуществлено замещение на другие структуры и процессы, и результирующие реализации будут выполнять по меньшей мере практически ту же самую функцию(ии), по меньшей мере практически тем же самым образом, для достижения по меньшей мере практически того же самого результата(ов), как и раскрытие реализации. Соответственно, данная заявка предполагает эти и другие реализации.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ГЕНЕРАЦИИ ТОЧЕК ТРЕХМЕРНОЙ (3D) СЦЕНЫ | 2018 |
|
RU2788439C2 |
| СПОСОБ И АППАРАТУРА ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ГЛУБИНЫ | 2020 |
|
RU2809180C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕО | 2020 |
|
RU2784900C1 |
| СХЕМА КОДИРОВАНИЯ ДЛЯ ДАННЫХ О ГЛУБИНЕ | 2020 |
|
RU2829737C1 |
| ОБРАБОТКА ОБЛАКА ТОЧЕК | 2019 |
|
RU2767775C1 |
| СПОСОБЫ, УСТРОЙСТВО И СИСТЕМЫ ФОРМИРОВАНИЯ ЗВУКА 6DOF, И ПРЕДСТАВЛЕНИЕ ДАННЫХ, И СТРУКТУРЫ БИТОВЫХ ПОТОКОВ ДЛЯ ФОРМИРОВАНИЯ ЗВУКА 6DOF | 2019 |
|
RU2782344C2 |
| ТОЧКИ ВХОДА ДЛЯ УСКОРЕННОГО 3D-ВОСПРОИЗВЕДЕНИЯ | 2010 |
|
RU2552137C2 |
| ВЫБОР ТОЧЕК ОБЗОРА ДЛЯ ФОРМИРОВАНИЯ ДОПОЛНИТЕЛЬНЫХ ВИДОВ В 3D ВИДЕО | 2010 |
|
RU2551789C2 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| УНИВЕРСАЛЬНЫЙ ФОРМАТ 3-D ИЗОБРАЖЕНИЯ | 2009 |
|
RU2519057C2 |
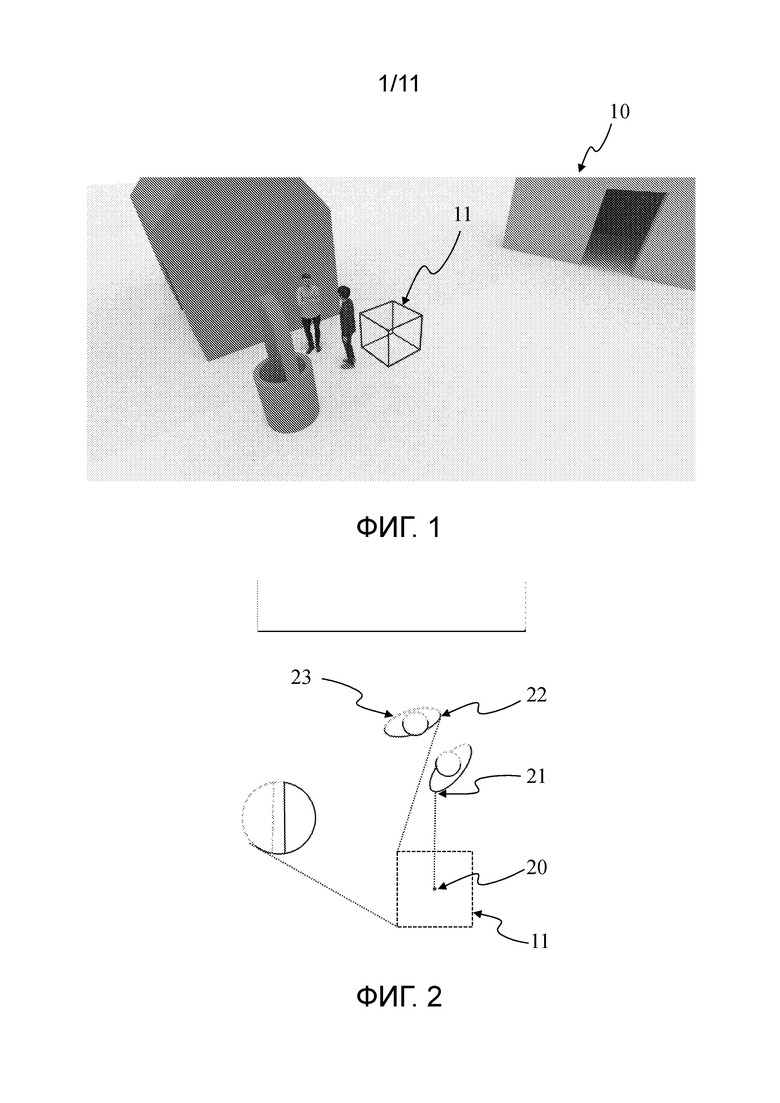
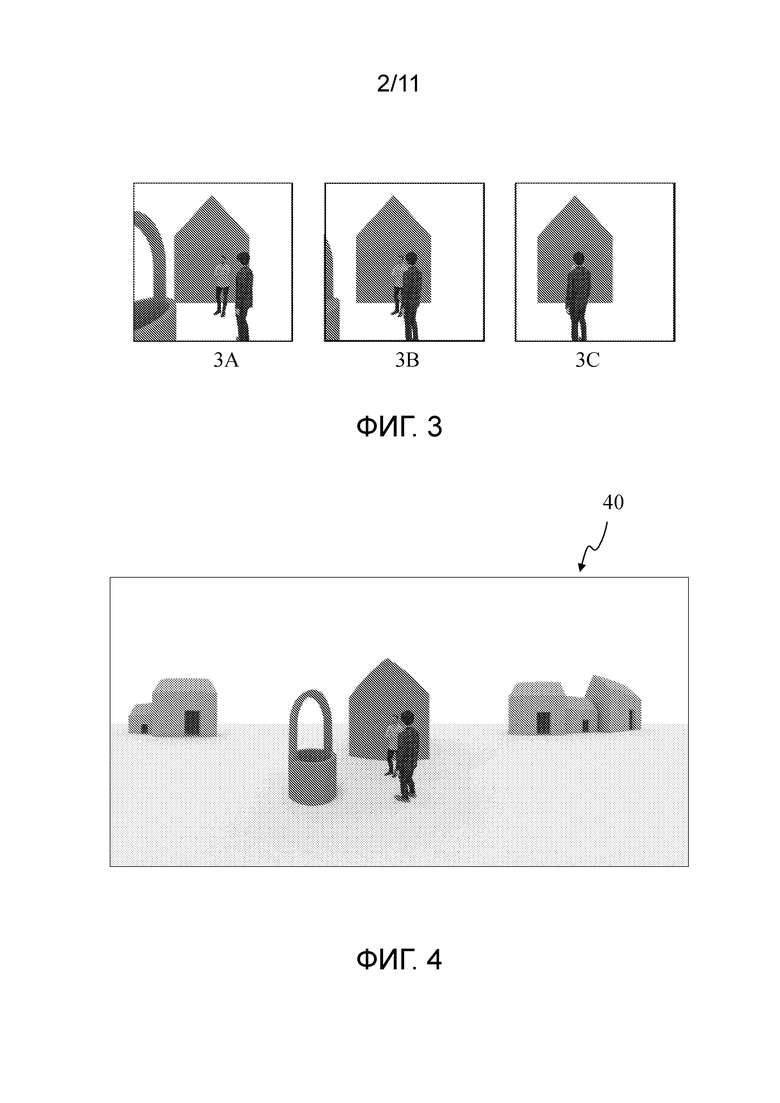
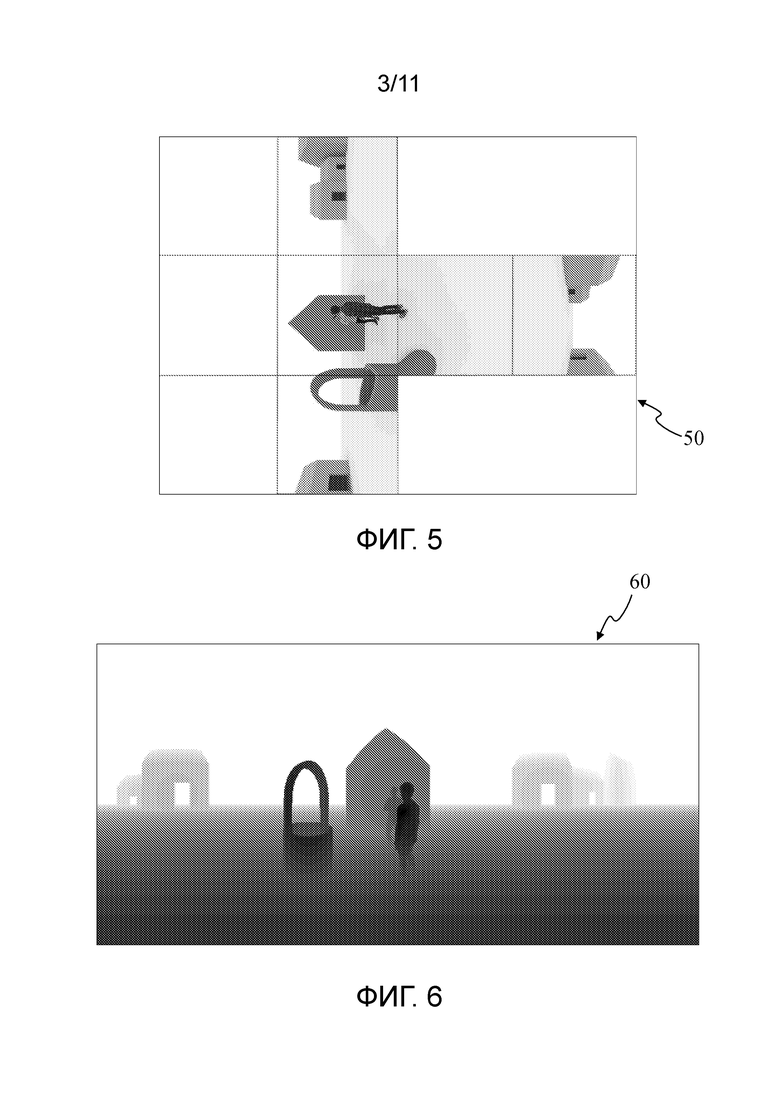
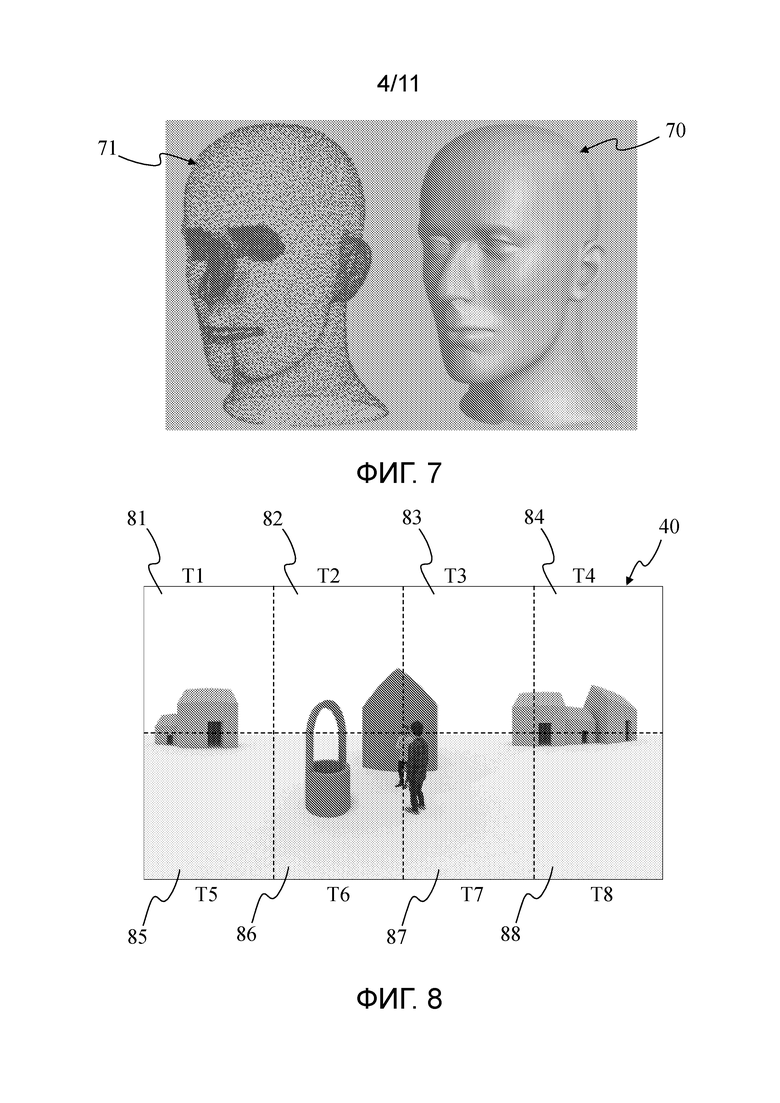
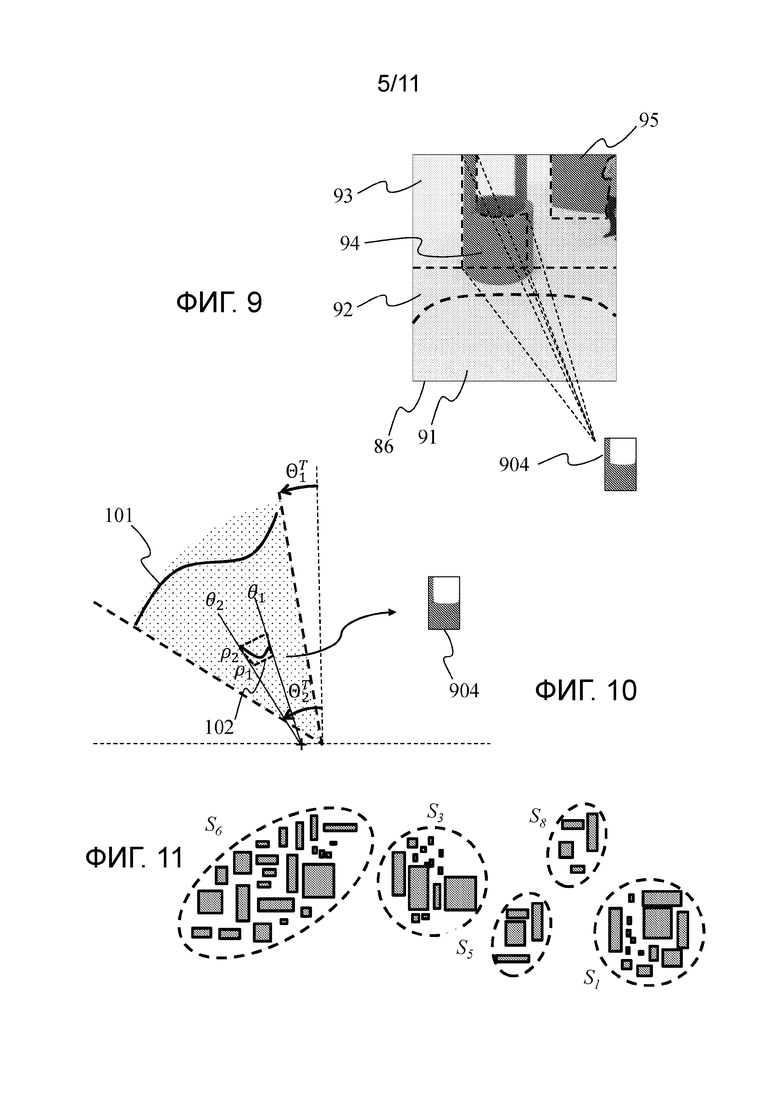
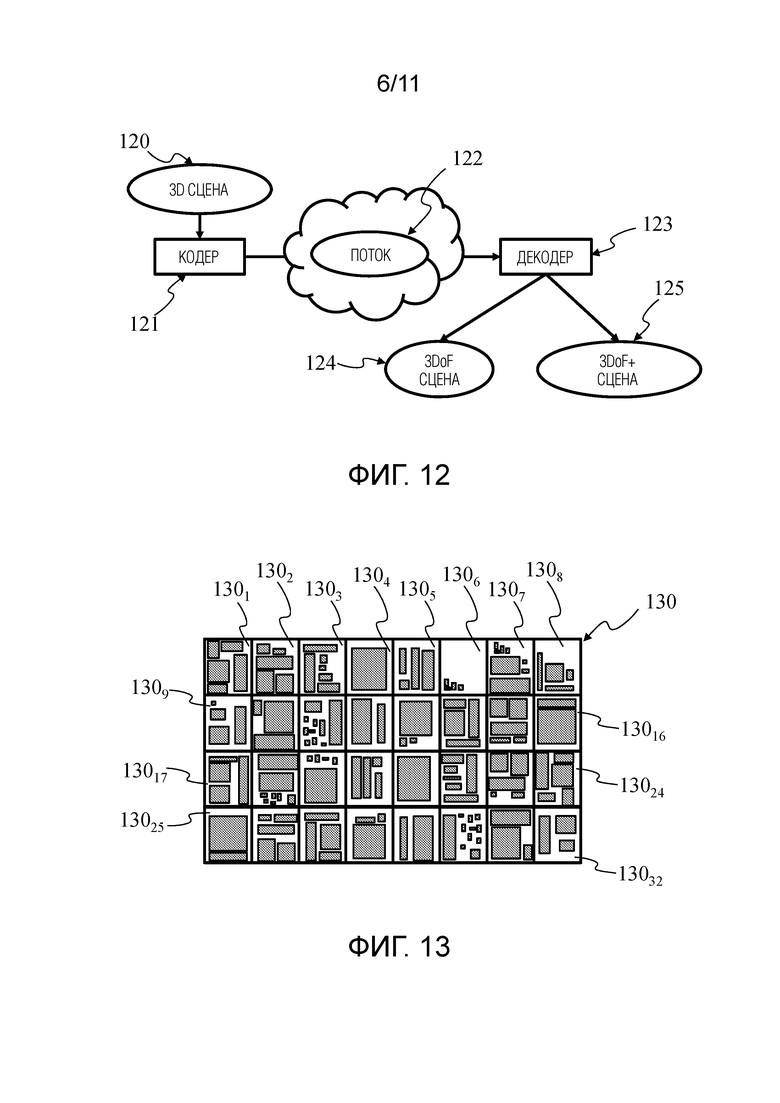
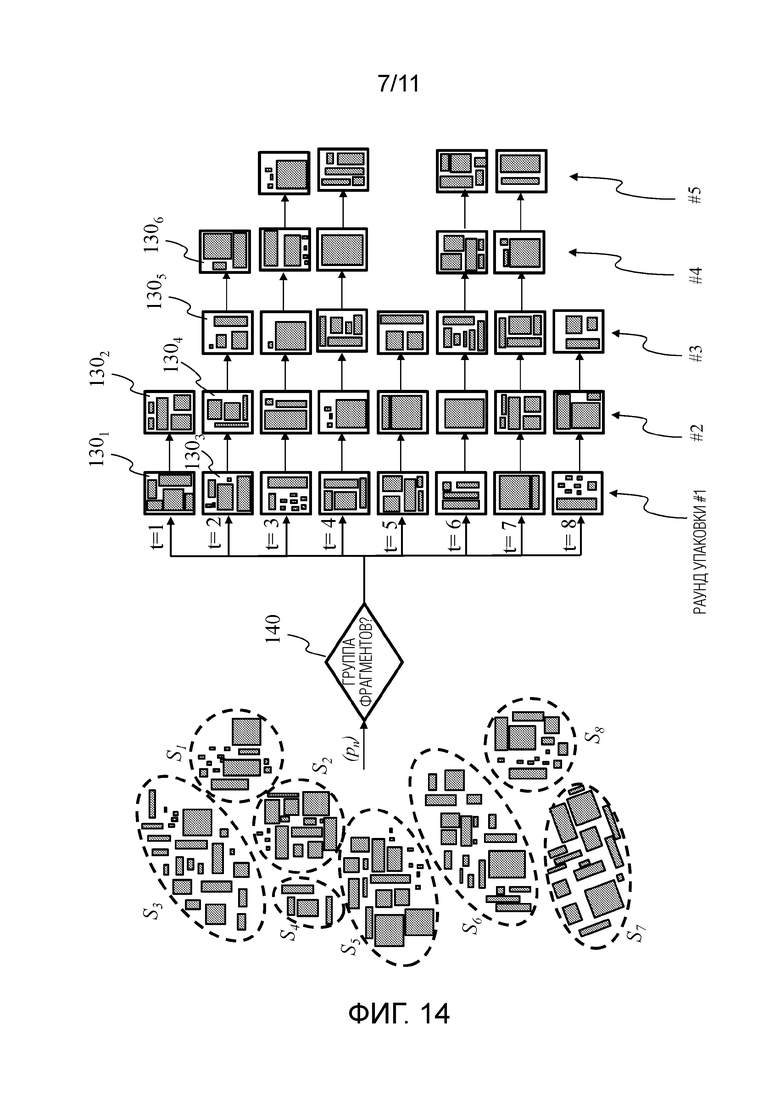
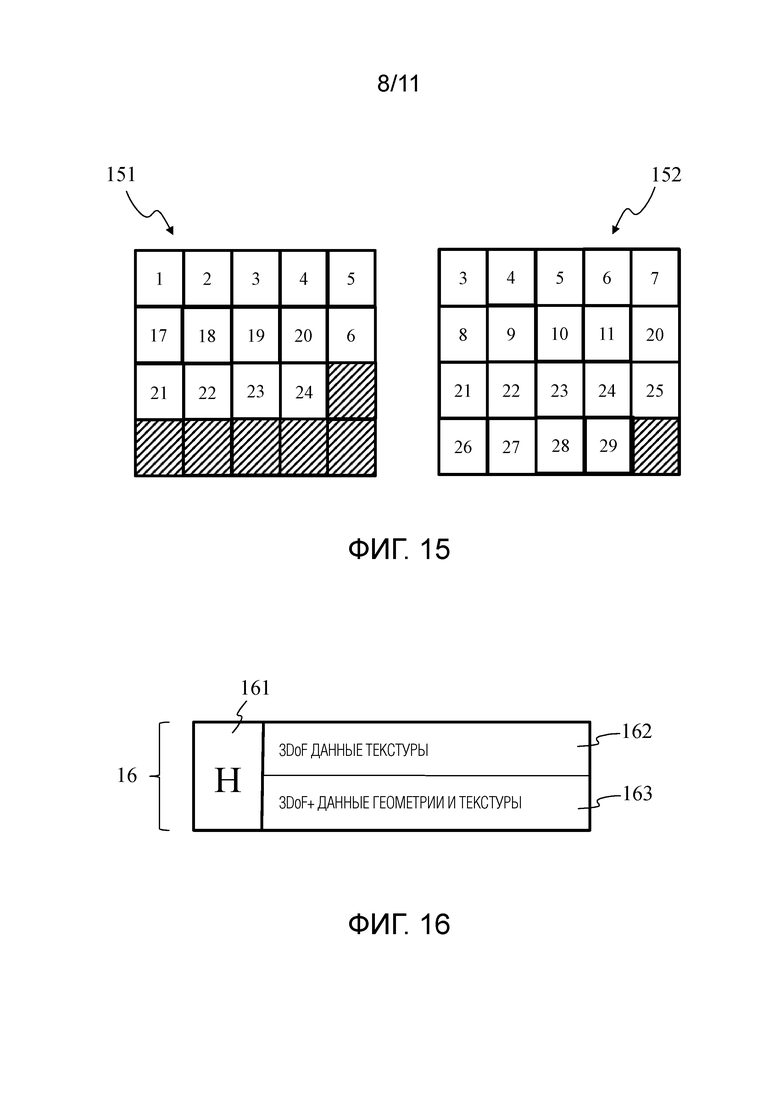
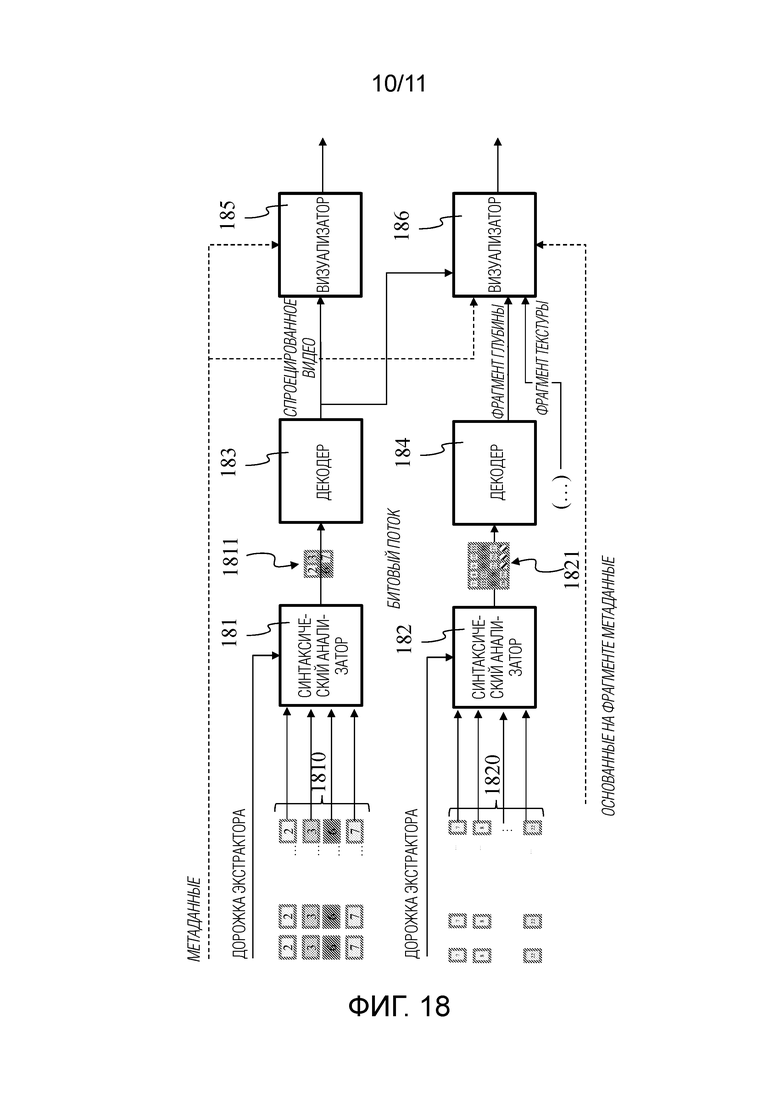
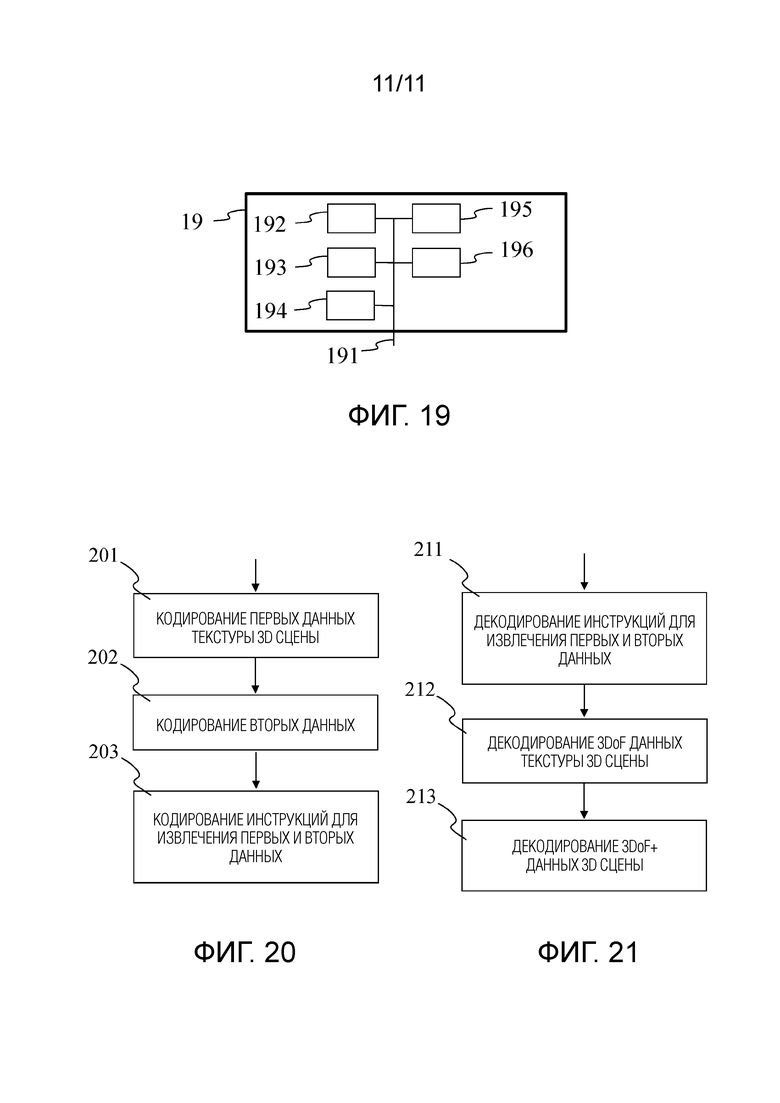
Изобретение относится к области контента объемного видео, в частности к кодированию и/или форматированию данных, представляющих объемный контент. Технический результат заключается в эффективном кодировании/декодировании данных, представляющих объемный контент. Согласно предложенному решению кодируют в, по меньшей мере, первую дорожку первые данные, представляющие текстуру 3D сцены, кодируют в, по меньшей мере, вторую дорожку вторые данные, представляющие глубину, связанную с точками 3D сцены, кодируют в, по меньшей мере, третью дорожку, по меньшей мере, инструкцию для извлечения, по меньшей мере, части упомянутых первых данных и вторых данных из, по меньшей мере, части упомянутой по меньшей мере первой дорожки и по меньшей мере второй дорожки. Первые данные размещаются во множестве первых сегментов, на которые разделен первый кадр, при этом часть 3D сцены связана с каждым первым сегментом из множества первых сегментов. Вторые данные размещаются во множестве вторых сегментов второго кадра, при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра. Полученный в результате визуализации контент может быть продемонстрирован на устройстве конечного пользователя для просмотра, таком как HMD, в соответствии с ориентацией точки обзора, соответствующей инструкциям. 4 н. и 16 з.п. ф-лы, 21 ил.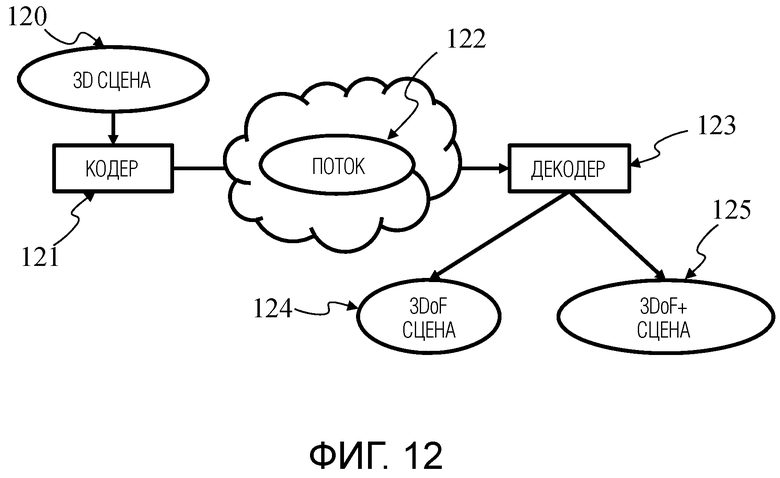
1. Способ кодирования данных, представляющих 3D сцену (10), причем способ содержит этапы, на которых:
- кодируют (201) в, по меньшей мере, первую дорожку первые данные, представляющие текстуру 3D сцены, которая видна в соответствии с первой точкой (20) обзора, причем первые данные размещаются во множестве первых сегментов, на которые разделен первый кадр (40), при этом часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- кодируют в, по меньшей мере, вторую дорожку вторые данные, представляющие глубину, связанную с точками 3D сцены, причем вторые данные размещаются во множестве вторых сегментов второго кадра (151, 152), при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, при этом для каждого первого сегмента из, по меньшей мере, части множества первых сегментов:
набор вторых сегментов, содержащий по меньшей мере один второй сегмент из множества вторых сегментов, распределяется каждому первому сегменту из, по меньшей мере, части множества первых сегментов,
набор содержащий, по меньшей мере, фрагмент (904), который размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек (94), которые содержатся в части 3D сцены, связанной с упомянутым каждым первым сегментом, и содержит вторые данные, представляющие глубину, связанную с 3D точками группы;
- кодируют в, по меньшей мере, третью дорожку, по меньшей мере, инструкцию для извлечения, по меньшей мере, части упомянутых первых данных и вторых данных из, по меньшей мере, части упомянутой по меньшей мере первой дорожки и по меньшей мере второй дорожки.
2. Устройство (19), сконфигурированное для кодирования данных, представляющих 3D сцену (10), причем устройство содержит память (194), связанную с по меньшей мере одним процессором (192), выполненным с возможностью:
- кодировать в, по меньшей мере, первую дорожку первые данные, представляющие текстуру 3D сцены, которая видна в соответствии с первой точкой (20) обзора, причем первые данные размещаются во множестве первых сегментов, на которые разделен первый кадр (40), при этом часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- кодировать в, по меньшей мере, вторую дорожку вторые данные, представляющие глубину, связанную с точками 3D сцены, причем вторые данные размещаются во множестве вторых сегментов второго кадра (151, 152), при этом общее количество вторых сегментов второго кадра больше общего количества первых сегментов первого кадра, при этом для каждого первого сегмента из, по меньшей мере, части множества первых сегментов:
набор вторых сегментов, содержащий по меньшей мере один второй сегмент из множества вторых сегментов, распределяется каждому первому сегменту из, по меньшей мере, части множества первых сегментов,
набор содержит, по меньшей мере, фрагмент (904), который размещается в наборе вторых сегментов, причем каждый фрагмент соответствует двумерной параметризации группы из 3D точек (94), которые содержатся в части 3D сцены, связанной с упомянутым каждым первым сегментом, и содержит вторые данные, представляющие глубину, связанную с 3D точками группы;
- кодировать в, по меньшей мере, третью дорожку, по меньшей мере, инструкцию для извлечения, по меньшей мере, части упомянутых первых данных и вторых данных из, по меньшей мере, части упомянутой по меньшей мере первой дорожки и по меньшей мере второй дорожки.
3. Способ по п.1, в котором упомянутый каждый фрагмент дополнительно содержит третьи данные, представляющие текстуру, связанную с 3D точками группы, причем третьи данные кодируются в упомянутую по меньшей мере вторую дорожку.
4. Способ по п.1, в котором набор третьих сегментов третьего кадра, содержащий по меньшей мере один третий сегмент, распределяется упомянутому каждому первому сегменту, и набор, по меньшей мере, фрагмента, содержащий третьи данные, представляющие текстуру, связанную с 3D точками группы, размещается в упомянутом наборе третьих сегментов, причем, по меньшей мере, фрагмент соответствует двумерной параметризации группы 3D точек, при этом третьи данные кодируются в, по меньшей мере, третью дорожку.
5. Способ по одному из пп.1, 3 и 4, в котором, когда размер фрагмента набора больше размера второго сегмента, в который должен быть размещен фрагмент, тогда фрагмент разбивается на множество субфрагментов, причем размер каждого меньше размера второго сегмента.
6. Способ по одному из пп.1, 3 и 4, в котором фрагменты набора размещаются в приоритетном порядке в зависимости от визуальной важности фрагментов, причем визуальная важность зависит от вторых данных, связанных с фрагментами.
7. Способ по одному из пп.1, 3 и 4, в котором вторые сегменты имеют один и тот же размер, который является фиксированным для множества следующих друг за другом по времени вторых кадров.
8. Способ декодирования данных, представляющих 3D сцену (10), причем способ содержит этапы, на которых:
- декодируют из, по меньшей мере, третьей дорожки, по меньшей мере, инструкцию для извлечения первых данных и вторых данных из, по меньшей мере, первой дорожки и, по меньшей мере, второй дорожки;
- декодируют упомянутые первые данные из упомянутой по меньшей мере первой дорожки, причем упомянутые первые данные представляют текстуру 3D сцены, которая видна в соответствии с первой точкой (20) обзора, причем первые данные размещаются во множестве первых сегментов, на которые разделен первый кадр (40), при этом часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- декодируют упомянутые вторые данные из упомянутой по меньшей мере второй дорожки, причем упомянутые вторые данные представляют глубину, связанную с точками 3D сцены, причем упомянутые вторые данные, представляющие глубину, содержатся в, по меньшей мере, фрагменте, который размещен в, по меньшей мере, наборе вторых сегментов второго кадра, при этом набор вторых сегментов распределяется упомянутому каждому первому сегменту, причем по меньшей мере фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в, по меньшей мере, части 3D сцены, связанной с упомянутым каждым первым сегментом, при этом вторые данные представляют глубину, связанную с 3D точками группы.
9. Устройство (19), сконфигурированное для декодирования данных, представляющих 3D сцену, причем устройство содержит память (194), связанную с по меньшей мере одним процессором (192), выполненным с возможностью:
- декодировать из, по меньшей мере, третьей дорожки, по меньшей мере, инструкцию для извлечения первых данных и вторых данных из, по меньшей мере, первой дорожки и, по меньшей мере, второй дорожки;
- декодировать упомянутые первые данные из упомянутой по меньшей мере первой дорожки, причем упомянутые первые данные представляют текстуру 3D сцены, которая видна в соответствии с первой точкой (20) обзора, при этом первые данные размещаются во множестве первых сегментов, на которые разделен первый кадр (40), причем часть 3D сцены связана с каждым первым сегментом из множества первых сегментов;
- декодировать упомянутые вторые данные из упомянутой по меньшей мере второй дорожки, причем упомянутые вторые данные представляют глубину, связанную с точками 3D сцены, причем упомянутые вторые данные, представляющие глубину, содержатся в, по меньшей мере, фрагменте, который размещен в, по меньшей мере, наборе вторых сегментов второго кадра, при этом набор вторых сегментов распределяется упомянутому каждому первому сегменту, причем, по меньшей мере, фрагмент соответствует двумерной параметризации группы из 3D точек, которые содержатся в, по меньшей мере, части 3D сцены, связанной с упомянутым каждым первым сегментом, при этом вторые данные представляют глубину, связанную с 3D точками группы.
10. Способ по п.8, в котором третьи данные, представляющие текстуру, связанную с 3D точками группы, которые содержатся в упомянутом каждом фрагменте, дополнительно декодируются из, по меньшей мере, второй дорожки.
11. Способ по п.8, в котором третьи данные, представляющие текстуру, дополнительно декодируются из, по меньшей мере, третьей дорожки, причем третьи данные размещаются во множество третьих сегментов третьего кадра, при этом набор третьих сегментов, содержащий по меньшей мере один третий сегмент, распределяется упомянутому каждому первому сегменту, причем набор, по меньшей мере, фрагмента, содержащий третьи данные, связанные с 3D точками группы, размещается в наборе третьих сегментов, при этом, по меньшей мере, фрагмент соответствует двумерной параметризации группы 3D точек.
12. Способ по одному из пп.8, 10 и 11, в котором визуализация, по меньшей мере, части 3D сцены осуществляется в соответствии с первыми и вторыми данными.
13. Устройство по п.2, при этом упомянутый каждый фрагмент дополнительно содержит третьи данные, представляющие текстуру, связанную с 3D точками группы, причем третьи данные кодируются в упомянутую по меньшей мере вторую дорожку.
14. Устройство по п.2, при этом набор третьих сегментов третьего кадра, содержащий по меньшей мере один третий сегмент, распределяется упомянутому каждому первому сегменту, и набор, по меньшей мере, фрагмента, содержащий третьи данные, представляющие текстуру, связанную с 3D точками группы, размещается в упомянутом наборе третьих сегментов, при этом, по меньшей мере, фрагмент соответствует двумерной параметризации группы 3D точек, причем третьи данные кодируются в, по меньшей мере, третью дорожку.
15. Устройство по одному из пп.2, 13 и 14, при этом, когда размер фрагмента набора больше размера второго сегмента, в который должен быть размещен фрагмент, тогда фрагмент разбивается на множество субфрагментов, причем размер каждого меньше размера второго сегмента.
16. Устройство по одному из пп.2, 13 и 14, при этом фрагменты набора размещаются в приоритетном порядке в зависимости от визуальной важности фрагментов, причем визуальная важность зависит от вторых данных, связанных с фрагментами.
17. Устройство по одному из пп.2, 13 и 14, при этом вторые сегменты имеют один и тот же размер, который является фиксированным для множества следующих друг за другом по времени вторых кадров.
18. Устройство по п.9, при этом третьи данные, представляющие текстуру, связанную с 3D точками группы, которые содержатся в упомянутом каждом фрагменте, дополнительно декодируются из, по меньшей мере, второй дорожки.
19. Устройство по п.9, при этом третьи данные, представляющие текстуру, дополнительно декодируются из, по меньшей мере, третьей дорожки, причем третьи данные размещаются во множество третьих сегментов третьего кадра, причем набор третьих сегментов, содержащий по меньшей мере один третий сегмент, распределяется упомянутому каждому первому сегменту, причем набор, по меньшей мере, фрагмента, содержащий третьи данные, связанные с 3D точками группы, размещается в наборе третьих сегментов, при этом, по меньшей мере, фрагмент соответствует двумерной параметризации группы 3D точек.
20. Устройство по одному из пп.9, 18 и 19, в котором визуализация, по меньшей мере, части 3D сцены осуществляется в соответствии с первыми и вторыми данными.
| US 20180035134 A1, 01.02.2018 | |||
| WO 2018050529 A1, 22.03.2018 | |||
| US 20170347084 A1, 30.11.2017 | |||
| WO 2009008864 A1, 15.01.2009 | |||
| US 20180045963 A1, 15.02.2018 | |||
| US 9674507 B2, 06.06.2017 | |||
| СПОСОБ И СИСТЕМА ОТОБРАЖЕНИЯ МАСШТАБНЫХ СЦЕН В РЕЖИМЕ РЕАЛЬНОГО ВРЕМЕНИ | 2015 |
|
RU2606875C2 |
| СПОСОБ ПРЕДСТАВЛЕНИЯ ИСХОДНОЙ ТРЕХМЕРНОЙ СЦЕНЫ ПО РЕЗУЛЬТАТАМ СЪЕМКИ ИЗОБРАЖЕНИЙ В ДВУМЕРНОЙ ПРОЕКЦИИ (ВАРИАНТЫ) | 2010 |
|
RU2453922C2 |
