Область техники
[0001] Настоящее изобретение относится, в общем, к обработке изображений на основе искусственного интеллекта (AI) и, в частности, к способу создания 3D портрета с изменяемым освещением с использованием глубокой нейронной сети, а также к вычислительному устройству, реализующему данный способ.
Уровень техники
[0002] Рост использования мобильной фотографии тесно связан с повсеместным применением двумерных дисплеев. По мере того как все более широкое распространение получают устройства трехмерного отображения, такие как гарнитуры виртуальной реальности (VR), очки дополненной реальности (AR), 3D мониторы, все более востребованной областью развития технологии становится расширение мобильной фотографии на получение и обработку 3D контента. Большинство 3D дисплеев проецируют 3D модели либо в окружение пользователя (очки AR), либо в виртуальную среду (гарнитуры VR, 3D мониторы). Поэтому для повышения реалистичности таких моделей необходимо обеспечить возможность изменения их освещения реалистичным образом в соответствии с окружающей их средой (реальной или синтетической).
[0003] Создание реалистичных 3D моделей с возможностью изменения освещения является намного менее изученной областью исследований. Известные решения либо фокусируются на реконструкции одного вида с возможностью изменения освещения (что существенно ограничивает качественные характеристики получаемой модели), либо на построении переосвещаемых моделей с использованием специализированного оборудования (Light Stage). Работы "Deep single-image portrait relighting", H. Zhou, S. Hadap, K. Sunkavalli, D. W. Jacobs (In Proceedings of the IEEE International Conference on Computer Vision, 2019) и "Neural Light Transport for Relighting and View Synthesis" version 1 (v1), X. Zhang, S. Fanello, Y.-T. Tsai, T. Sun, T. Xue, R. Pandey, S. Orts-Escolano, P. Davidson, C. Rhemann, P. Debevec, J. Barron, R. Ramamoorthi, W. Freeman (In Proceedings of ACM Transactions on Graphics, August 2020) можно считать наиболее близкими решениями предшествующего уровня техники.
Сущность изобретения
[0004] В настоящей заявке предложены способы, вычислительные устройства и системы для получения фотореалистичных 3D моделей головы или верхней части тела человека (именуемых как "3D портрет человека") из видео, снятых обычными камерами существующих в настоящее время портативных устройств с ограниченными ресурсами, например, снимков, сделанных камерой смартфона.
[0005] Для предложенной системы (термин "система" используется в данном контексте взаимозаменяемо с терминами "способ" и "устройство" и означает комбинацию существенных признаков предложенного способа и всех необходимых аппаратных частей) требуется всего лишь видео человека, состоящее из чередующихся изображений (кадров), снятых камерой смартфона со вспышкой и без вспышки. При наличии такого видео предложенная система может подготовить модель с изменяемым освещением и визуализировать 3D портрет человека с измененным освещением с произвольной точки обзора. Таким образом, предложенную систему можно успешно использовать в устройствах отображения AR, VR и 3D.
[0006] В предложенной системе в качестве геометрических промежуточных представлений используются нейросетевая точечная графика и 3D облака точек. При этом фотометрическая информация кодируется в этих облаках в виде скрытых дескрипторов отдельных точек. Точки и их скрытые дескрипторы можно затем растеризовать для новых точек обзора камеры (например, для точки обзора, которую запросил пользователь соответствующими манипуляциями в среде VR), и эти растеризации обрабатываются глубокой нейронной сетью, обученной прогнозировать, для каждого пикселя, альбедо, нормали (нормальные направления), карты теней окружающей среды и маску сегментации, наблюдаемые из новой позы камеры, и визуализировать 3D портрет человека на основе этой спрогнозированной информации.
[0007] В процессе реконструкции сцены модель подгоняется к видеоизображениям, и заодно оцениваются вспомогательные параметры освещения сцены и вспышки камеры. Для разделения факторов освещения сцены и альбедо используются априорные параметры, специфичные для лица человека. Хотя эти априорные параметры измеряются только в лицевой части сцены, они облегчают разделение по всему 3D портрету. После реконструкции данную сцену (портрет) можно визуализировать из новых точек обзора и с новым освещением на скоростях, соответствующих интерактивному режиму.
[0008] Таким образом, первым аспектом настоящего изобретения является способ визуализации 3D портрета человека с измененным освещением, заключающийся в том, что принимают ввод, определяющий позу камеры и условия освещения; осуществляют растеризацию скрытых дескрипторов 3D облака точек с различными разрешениями в соответствии с позой камеры для получения растеризованных изображений, причем 3D облако точек создают на основе последовательности изображений, отснятых камерой с мигающей вспышкой при перемещении камеры по меньшей мере частично вокруг верхней части тела человека, при этом последовательность изображений содержит набор изображений, снятых со вспышкой, и набор изображений, снятых без вспышки; обрабатывают растеризованные изображения глубокой нейронной сетью для прогнозирования альбедо, нормалей, карт теней окружающей среды и маски сегментации для принятой позы камеры, и объединяют спрогнозированные альбедо, нормали, карты теней окружающей среды и маску сегментации в 3D портрет с измененным освещением в соответствии с условиями освещения.
[0009] Вторым аспектом настоящего изобретения является вычислительное устройство, содержащее процессор и память, в которой хранятся выполняемые процессором инструкции и веса глубокой нейронной сети, скрытые дескрипторы и вспомогательные параметры, полученные на стадии обучения, при этом при выполнении процессором выполняемых процессором инструкций процессор предписывает вычислительному устройству выполнять способ визуализации 3D портрета человека с измененным освещением согласно первому аспекту или любой дальнейшей реализации первого аспекта.
[0010] Техническим результатом предлагаемых изобретений являются: (1) новая модель нейросетевой визуализации, которая поддерживает изменение освещения и основана на геометрии 3D облака точек; (2) новый подход к разделению альбедо и освещения, в котором используются априорные параметры лица. Посредством объединения этих результатов была получена система, способная создавать реалистичный 3D портрет человека на основе всего лишь последовательности изображений, снятых обычной камерой, которая поддерживает визуализацию в реальном времени. Таким образом, предлагаемое изобретение позволяет получать в реальном времени на вычислительных устройствах, имеющих ограниченные ресурсы обработки, 3D портреты с реалистично измененным освещением, качество которых выше или, по меньшей мере, сопоставимо с качеством, достигаемым известными решениями, но без использования сложного и дорогостоящего оборудования для получения изображений (например, Light Stage). При этом вычислительное устройство (например, смартфон, планшет или устройство отображения/очки VR/AR/3D или удаленный сервер), имеющее функциональные возможности предложенной системы, обеспечивает значительно лучшее взаимодействие с пользователем и способствует внедрению технологий VR и AR.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - полный конвейер обработки согласно варианту осуществления настоящего изобретения.
Фиг. 2 - блок-схема способа визуализации 3D портрета человека с измененным освещением согласно варианту осуществления настоящего изобретения.
Фиг. 3 - детали этапа создания 3D облака точек на основе последовательности изображений согласно варианту осуществления настоящего изобретения.
Фиг. 4 - блок-схема стадии обучения системы согласно варианту осуществления настоящего изобретения.
Фиг. 5 - структурная схема вычислительного устройства, выполненного с возможностью визуализации 3D портрета человека согласно варианту осуществления настоящего изобретения
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
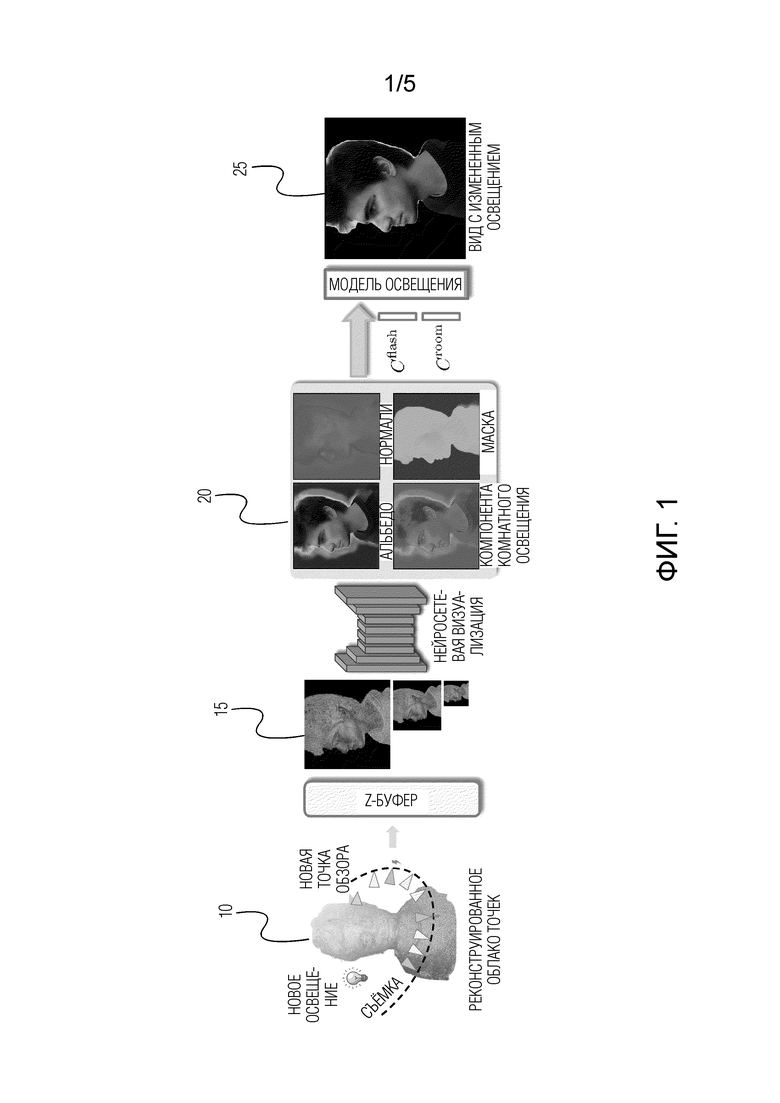
[0011] На фиг.1 изображен полный конвейер обработки согласно одному варианту осуществления настоящего изобретения. Показанный конвейер обработки можно реализовать полностью или частично в существующих вычислительных устройствах, таких как смартфон, планшет, устройство отображения VR (виртуальной реальности), устройство отображения AR (дополненной реальности), устройство отображения 3D. Устройства отображения VR, AR и 3D могут иметь форму интеллектуальных очков. При частичной реализации наиболее ресурсоемкие операции (например, операции стадии обучения) могут выполняться в облаке, например, сервером.
[0012] Для создания 3D портрета человека с измененным освещением предложенной системе требуется последовательность изображений человека. Выполнять съемку такой последовательности изображений могут обычные камеры существующих портативных устройств (например, камера смартфона). В качестве альтернативы можно предоставить конвейеру последовательность изображений из галереи пользователя (при условии разрешения пользователем доступа к галерее) или загрузить с веб-ресурса.
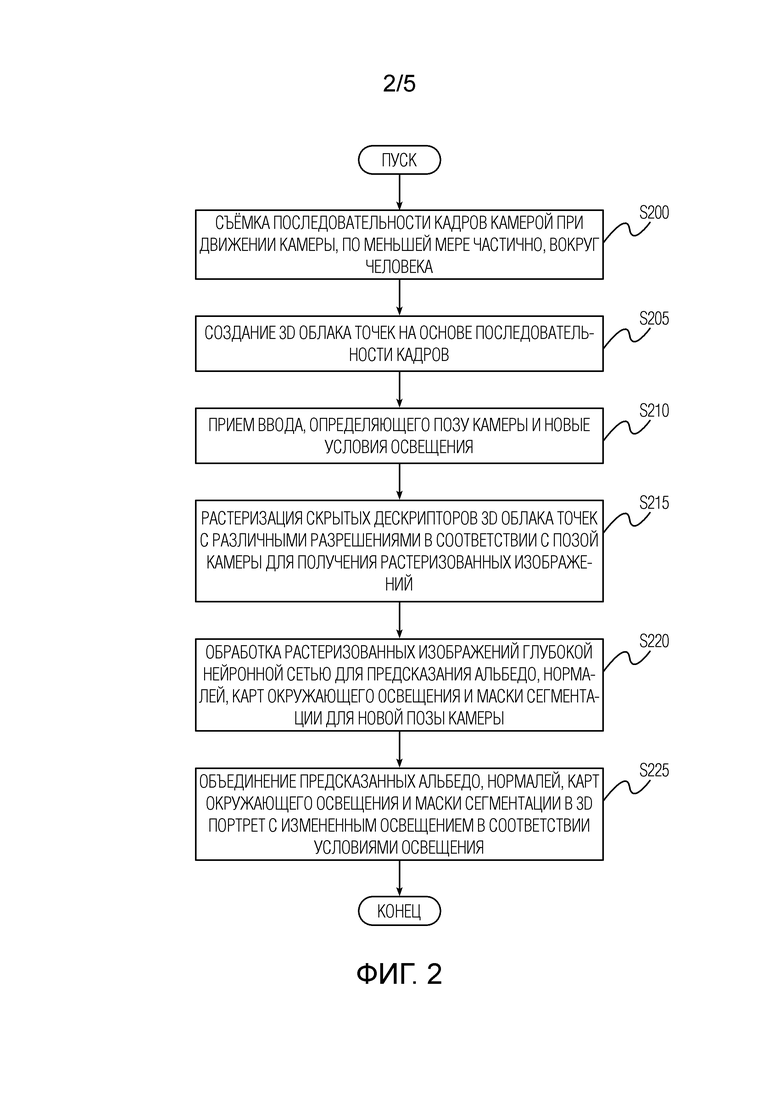
[0013] Важно отметить, что съемка последовательности изображений выполняется камерой с мигающей вспышкой при одновременном перемещении камеры, по меньшей мере частично, вокруг верхней части тела человека. Таким образом, последовательность изображений содержит набор изображений, снятых со вспышкой, и набор изображений, снятых без вспышки. Эти существенные признаки облегчают разделение альбедо и освещения для последующих модификаций освещения, включая случаи полного изменения освещения 3D портрета или частичного изменения освещения 3D портрета в соответствии с новой позой камеры. Изменение освещения можно осуществлять для совершенно новых условий освещения, то есть условий освещения, заменяющих освещение, имевшее место при съемке данной последовательности изображений, новыми произвольными условиями освещения. В качестве альтернативы, изменение освещения можно выполнять, например, для изменения освещения определенных частей 3D портрета путем корректной экстраполяции освещения, имевшего место при съемке данной последовательности изображений, на упомянутые части 3D портрета.
[0014] Съемку последовательности изображений можно выполнять с использованием мигающей вспышки, используя стандартные функции камеры вычислительного устройства или любое имеющееся программное обеспечение или приложение (например, приложение Open Camera), подходящие для получения изображения с мигающей вспышкой. Пунктирная кривая на фиг.1 показывает примерную траекторию движения камеры вокруг верхней части тела человека. Верхняя часть тела может включать в себя, без ограничения перечисленным, голову, плечи, руки и грудь человека. Например, съёмка может выполняться с контролируемым балансом белого, частотой 30 кадров в секунду, выдержкой 1/200 с и ISO примерно 200 (выбирается для каждой последовательности в соответствии с условиями освещения). Во время каждой записи вспышка камеры мигает, например, один раз в секунду, включаясь каждый раз, например, на 0,1 с. Мигание вспышки может быть регулярным или нерегулярным. Следует понимать, что отснятая последовательность изображений должна охватывать всю верхнюю часть тела человека, для которого создается 3D портрет с измененным освещением. Каждого человека фотографируют, например, в течение 15-25 секунд. Конкретные значения приведены в данном абзаце только для примера и не имеют ограничивающего значения. Понятно, что конкретные значения можно выбирать из соответствующих диапазонов, например +/-10-50% от заданных конкретных значений.
[0015] Предполагается, что в процессе съемки человек остается практически неподвижным. В частности, предполагается, что голова пользователя направлена вперед и остается практически неподвижной на протяжении всего перемещения камеры в процессе съемки. Перемещение камеры может осуществлять сам человек при съемке селфи или третье лицо. Перемещение камеры может охватывать 180° или меньше вокруг человека, например, двигаясь от левой стороны верхней части тела через лицевую сторону верхней части тела к правой стороне верхней части тела или в противоположном направлении.
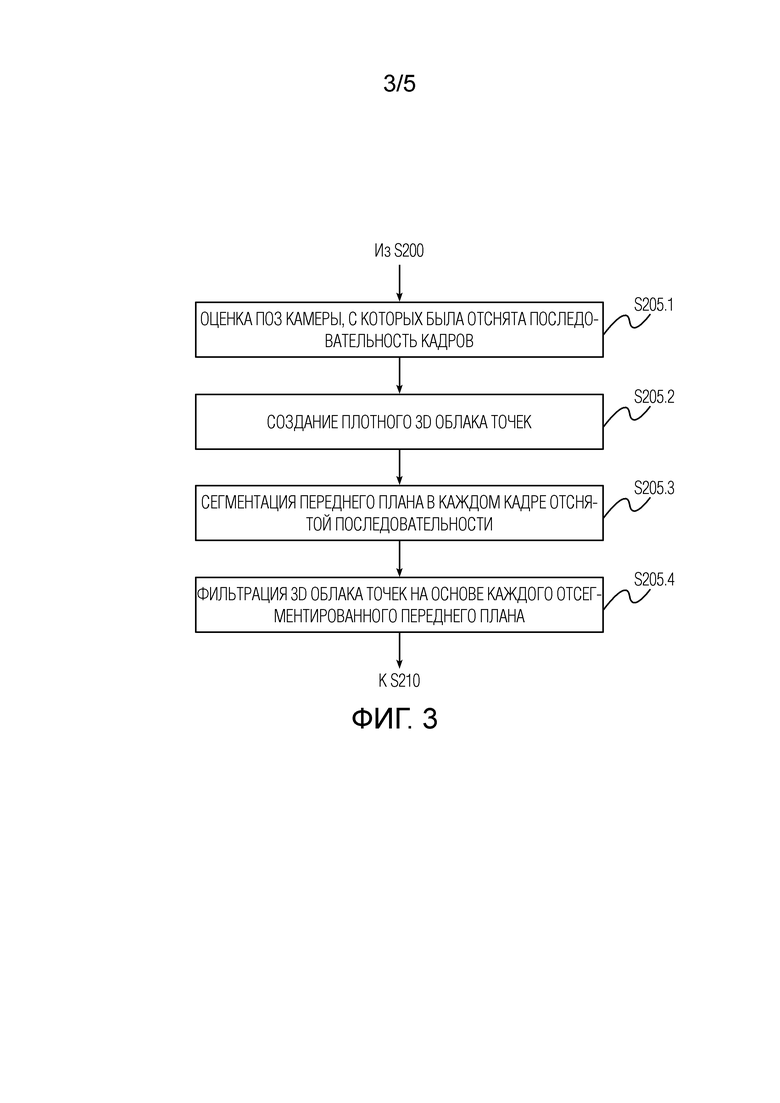
[0016] Затем на основе последовательности снятых изображений создается 3D облако 10 точек. 3D облако 10 точек можно создать, используя технологию "структура из движения" (SfM) или любую другую известную технологию, позволяющую реконструировать 3D структуру сцены или объекта на основе последовательности двумерных изображений этой сцены или объекта. Каждая точка в 3D облаке 10 точек дополнена скрытым дескриптором, представляющим собой многомерный скрытый вектор, характеризующий свойства данной точки. Скрытые дескрипторы выбираются из заранее определенного распределения вероятностей, например, поэлементно из стандартного нормального распределения, а затем подгоняются на стадии обучения. Каждый скрытый дескриптор служит вектором памяти для глубокой нейронной сети (также называемой сетью визуализации и подробно описанной ниже) и может использоваться этой сетью для вывода геометрических и фотометрических свойств каждой точки. Создается 3D облако точек, и позы камеры оцениваются на основе набора изображений, снятых со вспышкой, или набора изображений, снятых без вспышки.
[0017] Затем скрытые дескрипторы созданного 3D облака точек растеризуются с различными разрешениями в соответствии с запрошенной новой позы камеры, чтобы получить растеризованные изображения 15. Растеризацию можно выполнять с использованием метода Z-буферизации или любых других известных методов, позволяющих представлять изображения обнаруженных объектов в 3D пространстве из определенной позы камеры. Различные разрешения для растеризации могут включать в себя, например, 512х512, 256х256, 128х128, 64х64 и 32х32 (на стадии обучения). Во время использования может быть оценено исходное разрешение, например, заданное пользователем для новой позы камеры, и затем может быть построена пирамида растеризаций с постепенно уменьшающимися разрешениями (например, 1920х1080, 860х540, 430х270, 215х145, 107х72). Преимущество ввода в нейронную сеть пирамиды растеризаций с различными разрешениями (от высокого к низкому) позволяет нейросети учитывать как детали изображений (из растеризаций с более высоким разрешением), так и близость точек к камере (из растеризаций с более низким разрешением, которые не содержат "просветов" между проецируемыми точками ближайшей к камере поверхности 3D облака точек и точками дальней поверхности данного облака).
[0018] Позу камеры можно задать непосредственно во вводе, например в виде конкретных координат в среде AR/VR, направления камеры, фокусного расстояния и других внутренних параметров камеры, или косвенно, например, с помощью сенсорного ввода для соответствующей позы в среде AR/VR, ввода, соответствующего позе на основе положения и ориентации вычислительного устройства (например, смартфона, интеллектуальных очков AR/VR), используемых для управления в AR/VR среде или для отображения в ней определенной информации. Этот ввод может приниматься соответствующим образом.
[0019] Затем можно осуществить нейросетевую визуализацию. Нейросетевая визуализация может выполняться путем обработки растеризованных изображений 15 глубокой нейронной сетью, обученной прогнозировать альбедо, нормали, карты теней окружающей среды и маску сегментации для принятой позы камеры. Архитектура глубокой нейронной сети соответствует структуре U-Net с маскируемыми свертками. Стадия обучения предлагаемой системы и архитектура используемой глубокой нейронной сети подробно описаны ниже со ссылкой на фиг.4. Прогнозируемые альбедо, нормали, карты теней окружающей среды и маска сегментации показаны все вместе позицией 20 на фиг.1. Спрогнозированное альбедо описывает пространственно изменяющиеся свойства отражения (альбедо 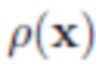 ) поверхности головы (кожа, волосы или другие части). Спрогнозированные нормали содержат векторы
) поверхности головы (кожа, волосы или другие части). Спрогнозированные нормали содержат векторы 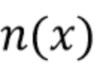 нормалей точек на поверхности головы в мировом пространстве. Спрогнозированные карты теней окружающей среды представлены одноканальной группой, которая использует сигмоидную нелинейность и соответствует затемнению в градациях серого
нормалей точек на поверхности головы в мировом пространстве. Спрогнозированные карты теней окружающей среды представлены одноканальной группой, которая использует сигмоидную нелинейность и соответствует затемнению в градациях серого 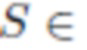
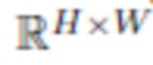 , вызванному различиями в освещении помещения и, как следствие, возникающими окклюзиями. И наконец, спрогнозированная маска сегментации представлена одноканальной группой, которая также использует сигмоидную нелинейность и определяет маску сегментации
, вызванному различиями в освещении помещения и, как следствие, возникающими окклюзиями. И наконец, спрогнозированная маска сегментации представлена одноканальной группой, которая также использует сигмоидную нелинейность и определяет маску сегментации 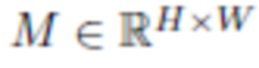 , в которой каждый пиксель содержит спрогнозированную вероятность того, что этот пиксель принадлежит голове, а не фону.
, в которой каждый пиксель содержит спрогнозированную вероятность того, что этот пиксель принадлежит голове, а не фону.
[0020] И наконец, спрогнозированные альбедо, нормали, карты теней окружающей среды и маска сегментации объединяются в 3D портрет 25 с освещением, измененным в соответствии с условиями освещения. Поскольку первоначально отснятая последовательность изображений включает в себя набор изображений, снятых без вспышки, передающих условия освещения, с которыми была отснята данная последовательность изображений, освещение объединенного 3D портрета можно при желании изменить путем полной замены условий освещения, с которыми была отснята данная последовательность изображений, новыми условиями освещения, в которых заинтересован пользователь.
[0021] Типы освещения могут включать в себя, без ограничения перечисленным, окружающее освещение, направленное освещение и освещение на основе сферических гармоник. Ввод условий освещения может приниматься любым подходящим способом. Вспомогательные параметры, относящиеся к освещению, также могут включать в себя, без ограничения, цветовую температуру освещения в помещении Croom и цветовую температуру вспышки Cflash. Croom определяет цветовую температуру теней в освещении сцены (также называемой помещением), а Cflash определяет интенсивность и цветовую температуру вспышки. Как Croom, так и Cflash могут быть представлены векторами, например 3 числами, общими для всей сцены. Они обучаются (настраиваются) вместе со всей системой. Эти параметры будут подробно описаны ниже. Тип нового освещения, необходимого для пользователя, определяет выражение, с помощью которого создается 3D портрет с измененным освещением из спрогнозированных попиксельных альбедо, нормалей, карт теней окружающей среды, маски сегментации, вспомогательных параметров, относящихся к освещению, и параметров новых условий освещения. Это выражение проиллюстрировано как "Модель освещения" на фиг.1 и будет подробно описано ниже в разделе "Детали реализации способа".
[0022] На фиг.2 показана блок-схема способа визуализации 3D портрета человека с измененным освещением согласно варианту осуществления настоящего изобретения. На этапе S200 камерой с мигающей вспышкой снимают последовательность изображений верхней части тела человека. Во время съемки (например, фотографирования или видеосъемки) камера перемещается этим человеком или третьим лицом, по меньшей мере частично, вокруг верхней части тела человека. Таким образом, полученная последовательность изображений содержит набор изображений, снятых со вспышкой, и набор изображений, снятых без вспышки.
[0023] На основе отснятой последовательности изображений на этапе S205 создают 3D облако точек. 3D облако точек можно создать, используя технологию "структура из движения" (SfM) или любую другую известную технологию, позволяющую реконструировать 3D структуру сцены или объекта на основе последовательности двумерных изображений этой сцены или объекта. На стадии обучения, который будет подробно описан ниже, способ включает в себя дополнение каждой точки в 3D облаке 10 точек скрытым дескриптором, который является многомерным скрытым вектором, характеризующим свойства данной точки.
[0024] На этапе S210 принимают один или несколько вводов, определяющих позу камеры и/или условия освещения. Затем на этапе S215 растеризуются скрытые дескрипторы 3D облака точек, полученные ранее на стадии обучения, с различными разрешениями в соответствии с позой камеры для получения растеризованных изображений. После этого, на этапе S220, выполняют нейросетевую визуализацию путем обработки растеризованных изображений глубокой нейронной сетью для прогнозирования альбедо, нормалей, карт теней окружающей среды и маски сегментации для принятой позы камеры. Перед стадией использования глубокую нейронную сеть обучают, как будет описано со ссылкой на фиг.4. И наконец, на этапе S225 визуализируют 3D портрет с измененным освещением путем объединения спрогнозированных альбедо, нормалей, карт теней окружающей среды и маски сегментации в 3D портрет с измененным освещением в соответствии с полученными условиями освещения.
[0025] На фиг.3 представлены детали этапа S205 создания 3D облака точек на основе последовательности изображений согласно варианту осуществления настоящего изобретения. Создание 3D облака точек на этапе S205 дополнительно включает в себя этап S205.1 оценки точек обзора камеры, с которых осуществляется съёмка данной последовательности изображений. Позы камеры, оцененные на этапе S205.1, используются для создания 3D облака точек, а также для обучения глубокой нейронной сети, скрытых дескрипторов для 3D облака точек и вспомогательных параметров на стадии обучения. Следует понимать, что поза камеры и условия освещения, полученные через ввод на этапе S210 (т.е. новая или произвольная поза камеры и условия освещения, запрошенные пользователем), отличаются от поз камеры, оцененных на этапе S205.1, и условий освещения, при которых осуществлена съёмка последовательности изображений (т.е. текущие позы камеры и условия освещения во время съёмки). На этапе S205.1 позы камеры оценивают с помощью SfM. Точки первоначально созданного 3D облака точек, по меньшей мере частично, соответствуют верхней части тела человека.
[0026] Этап создания S205 3D облака точек дополнительно включает в себя этап S205.2 фактического создания 3D облака точек, обработку каждого изображения последовательности на этапе S205.3 сегментации переднего плана и этап S205.4 фильтрации 3D облака точек на основе переднего плана, отсегментированного нейронной сетью сегментации, для получения отфильтрованного 3D облака точек. 3D облако 10 точек, созданное в результате обработки на этапах S205.3 и S205.4, включает в себя только точки верхней части тела человека (т.е. исключены точки, относящиеся к фону). Нейронная сеть сегментации - это глубокая нейронная сеть, которая получает изображение и создает попиксельную маску сегментации с реальными значениями от 0 до 1. Для заданного порогового скалярного значения от 0 до 1 все значения в этой маске ниже порога считаются фоном, а остальные считаются передним планом (объектом). Такую сеть можно, например, обучить, используя большую коллекцию изображений и соответствующих масок с функцией потерь, которая учитывает расхождение спрогнозированной маски с истинной маской. Для каждого изображения снятого видео оценивается сегментируемый передний план, и для каждого из изображений и соответствующих точек обзора камеры создается её поле зрения в 3D путем пропускания лучей из камеры через пиксели, принадлежащие отсегментированному переднему плану. Точки 3D облака точек, которые не принадлежат пересечению усеченных пирамид, отфильтровываются, и, таким образом, строится отфильтрованное 3D облако точек.
[0027] Описанные сегментация и фильтрация могут улучшить качественные характеристики созданного 3D портрета за счет повышения точности прогнозов 20 альбедо, нормалей, карт теней окружающей среды и маски сегментации, выполняемых глубокой нейронной сетью.
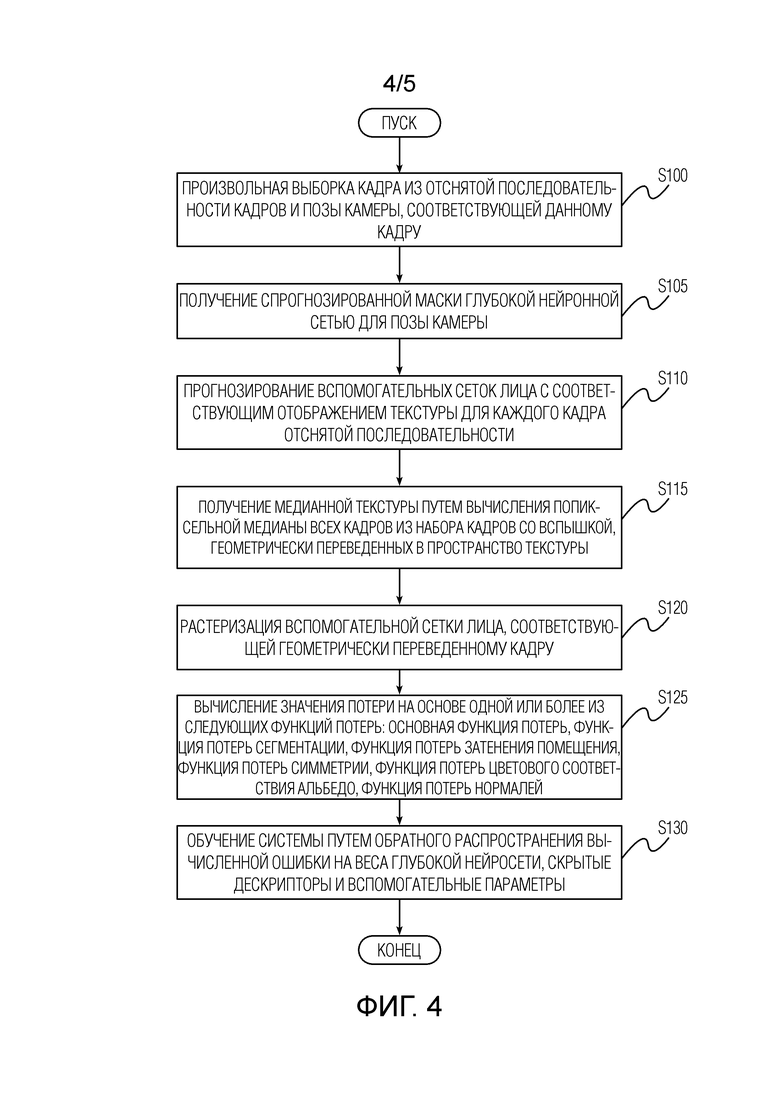
[0028] На фиг.4 изображена блок-схема стадии обучения системы согласно варианту осуществления настоящего изобретения. Обучение может выполняться на том же вычислительном устройстве 50 (см. фиг.5), на котором визуализируется 3D портрет с измененным освещением, или вне этого устройства, например, на сервере (не показан). Если обучение выполняется на сервере, последовательность изображений, отснятых на этапе S200, и вся другая информация, используемая в данном контексте в качестве обучающей информации, может быть передана на сервер. После этого сервер может выполнять обучение, а также любые операции преобразования обучающих данных, как раскрыто в данном документе, и передавать обученную глубокую нейронную сеть, скрытые дескрипторы 3D облака точек и вспомогательные параметры обратно в вычислительное устройство для использования на стадии использования. Для этого вычислительное устройство может быть снабжено блоком связи. Обучение выполняется итеративно, одна итерация показана на фиг.4. Перед началом обучения случайным образом инициализируются веса и другие параметры глубокой нейронной сети, значения скрытых дескрипторов, значения вспомогательных параметров. Вспомогательные параметры включают в себя один или несколько параметров из цветовой температуры освещения в помещении, цветовой температуры вспышки и полутекстуру альбедо.
[0029] На этапе S100 из отснятой последовательности изображений произвольно выбираются изображение и поза камеры, соответствующие данному изображению. Затем на этапе S105 с помощью глубокой нейронной сети получают спрогнозированное изображение (т.е. спрогнозированные альбедо, нормали, карты теней окружающей среды и маска сегментации) для данной позы камеры. На этапе S110 сеть реконструкции 3D сетки лица прогнозирует вспомогательные сетки лица с соответствующим отображением текстуры для каждого из изображений в снятой последовательности, включая изображение, выбранное произвольно на этапе S100. Отображение соответствующей текстуры определяется набором двумерных координат в фиксированном, заранее определенном пространстве текстуры для каждой вершины сетки. Сеть реконструкции 3D сетки лица представляет собой глубокую нейронную сеть, которая прогнозирует треугольную сетку лица, найденного на входном изображении, которая совмещается с лицом на входном изображении. Такую сеть можно обучить, используя различные методы - основанные на обучении с учителем, на частично размеченных данных или на обучении без учителя. Неограничивающими примерами являются модель PRNet и модель 3DDFA_v2.
[0030] На этапе S115 получают медианную эталонную текстуру путем вычисления попиксельных медиан всех изображений из набора изображений, снятых со вспышкой, геометрически переведенных в пространство текстуры посредством билинейной интерполяции. Пространство текстуры - это прямоугольник на 2D плоскости, в котором каждая точка имеет фиксированную семантику, относящуюся к области лица (например, точка (0,3, 0,3) может всегда соответствовать левому глазу, а точка (0,5, 0,5) может всегда соответствовать кончику носа). Чем точнее прогнозирование вспомогательной сетки лица с отображением текстуры, тем ближе спрогнозированные двумерные координаты каждой вершины сетки к их соответствующей семантике в пространстве текстуры. Вспомогательные сетки лица, спрогнозированные на этапе S110, растеризуются на этапе S120 с использованием цветового кодирования вершин сетки лица с их геометрическими нормалями и Z-буферизацией. Цветовое кодирование вершин с их геометрическими нормалями - это процесс присвоения каждой точке цветовых каналов R, G, B соответственно координатам X, Y, Z вектора нормали в этой точке. Затем присвоенные цвета RGB растеризуются с помощью Z-буферизации.
[0031] На этапе S125 вычисляют значения потерь на основе комбинации одной или нескольких из следующих функций потерь: основная функция потерь, функция потерь сегментации, функция потерь затенения помещения, функция потерь симметрии, функция потерь цветового соответствия альбедо, функция потерь нормалей. Основная функция потерь вычисляется как несоответствие между спрогнозированным изображением (из этапа S105) и выбранным изображением (из этапа S100) посредством комбинации неперцептивных и перцептивных функций потерь. Функция потерь сегментации вычисляется как несоответствие между спрогнозированной маской сегментации и отсегментированным передним планом. Функция потерь затенения помещения вычисляется как штраф за резкость спрогнозированных карт теней окружающей среды, причем штраф увеличивается по мере увеличения резкости. Функция потерь симметрии вычисляется как несоответствие между зеркально-отображенной полутекстурой альбедо и спрогнозированным альбедо (из S105), геометрически переведенным в пространство текстуры с помощью билинейной интерполяции.
[0032] Функция потерь цветового соответствия альбедо вычисляется как несоответствие между медианной эталонной текстурой (из S115) и спрогнозированным альбедо (из S105), геометрически переведенным в пространство текстуры посредством билинейной интерполяции. Функция потерь нормалей вычисляется как несоответствие между спрогнозированными нормалями (из S105) и растеризованными изображениями (из S120) вспомогательной сетки лица, соответствующей выбранному изображению. После вычисления значений потерь на этапе S125 эти значения потерь распространяют на этапе S130 обратно на веса глубокой нейронной сети, скрытые дескрипторы и вспомогательные параметры. Иными словами, веса глубокой нейронной сети, скрытые дескрипторы и вспомогательные параметры обновляются на основе значений потерь, вычисленных на этапе S125. Затем выполняется следующая итерация, начиная с этапа S100. Глубокая нейронная сеть обучается фиксированное (заранее определенное) количество итераций (80000 итераций в неограничивающем примере).
Детали реализации способа
Модель освещения
[0033] Для данной точки x в пространстве, которое принадлежит поверхности объемного объекта, уровень яркости излучения света в положении x в направлении 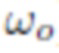 обычно описывается уравнением визуализации_(рендеринга):
обычно описывается уравнением визуализации_(рендеринга):
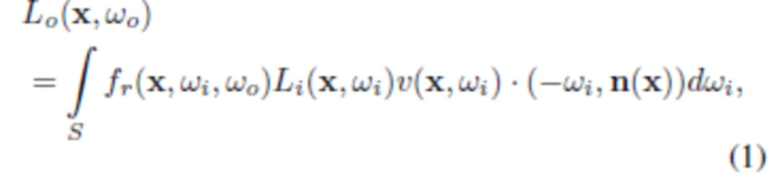
где 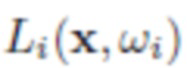 определяет яркость входящего излучения к x в направлении ω1, S означает верхнюю полусферу по отношению к касательной плоскости поверхности в точке x с единичной нормалью n(x). Также,
определяет яркость входящего излучения к x в направлении ω1, S означает верхнюю полусферу по отношению к касательной плоскости поверхности в точке x с единичной нормалью n(x). Также, 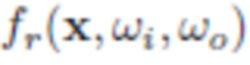 - отношение интенсивности рассеянного света в направлении и входящего в направлении
- отношение интенсивности рассеянного света в направлении и входящего в направлении 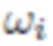 , которое обычно называют функцией распределения двунаправленного отражения (BRDF). Кроме того,
, которое обычно называют функцией распределения двунаправленного отражения (BRDF). Кроме того, 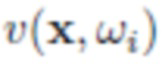 - это член видимости (равен 1, если точка x достижима для света с направления
- это член видимости (равен 1, если точка x достижима для света с направления 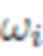 , или 0, если в этом направлении имеется окклюзия), и
, или 0, если в этом направлении имеется окклюзия), и 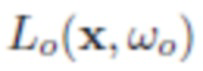 характеризует общую яркость излучения, исходящую из x в направлении
характеризует общую яркость излучения, исходящую из x в направлении 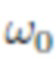 . В терминах этой модели BRDF - это свойство материала, которое описывает его характеристики рассеяния света, изменяющиеся в пространстве. Поскольку отснятые изображения являются изображениями RGB, все значения , , находятся в
. В терминах этой модели BRDF - это свойство материала, которое описывает его характеристики рассеяния света, изменяющиеся в пространстве. Поскольку отснятые изображения являются изображениями RGB, все значения , , находятся в 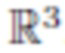 и каждый компонент (канал) вычисляется отдельно.
и каждый компонент (канал) вычисляется отдельно.
[0034] В варианте осуществления настоящего изобретения съемка человека (объекта) осуществляется с использованием набора изображений, снятых с окружающим освещением, и другого набора изображений в той же самой окружающей среде, дополнительно освещенной вспышкой камеры. Как было описано выше, можно использовать мигающую вспышку. Чтобы смоделировать эти два набора изображений, яркость входящего излучения можно разложить с учетом видимости на два члена:
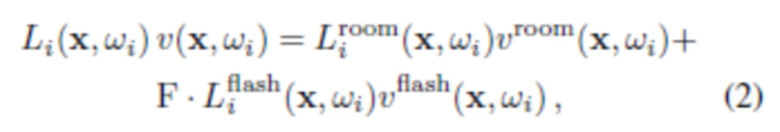
где 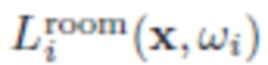 - окружающее освещение (в помещении),
- окружающее освещение (в помещении), 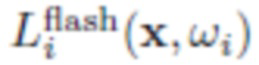 - освещение вспышкой, и F указывает, было ли сделано фото с включенной вспышкой (F=1) или выключенной вспышкой (F=0). В данном случае
- освещение вспышкой, и F указывает, было ли сделано фото с включенной вспышкой (F=1) или выключенной вспышкой (F=0). В данном случае  и
и  , соответственно, моделируют окклюзию света для окружающего освещения и вспышки.
, соответственно, моделируют окклюзию света для окружающего освещения и вспышки.
[0035] Также предполагается, что BRDF является ламбертовской (т.е. постоянной в каждой точке),  (с отброшенной нормирующей постоянной), т.е. соответствует диффузной поверхности, и p(x) обозначает альбедо поверхности в точке x. Следует отметить, что с помощью нейросетевой визуализации система может смоделировать некоторое количество неламбертовских эффектов, поскольку альбедо в модели можно фактически сделать зависимым от вида. Применив модификации к (1), получаем следующее:
(с отброшенной нормирующей постоянной), т.е. соответствует диффузной поверхности, и p(x) обозначает альбедо поверхности в точке x. Следует отметить, что с помощью нейросетевой визуализации система может смоделировать некоторое количество неламбертовских эффектов, поскольку альбедо в модели можно фактически сделать зависимым от вида. Применив модификации к (1), получаем следующее:
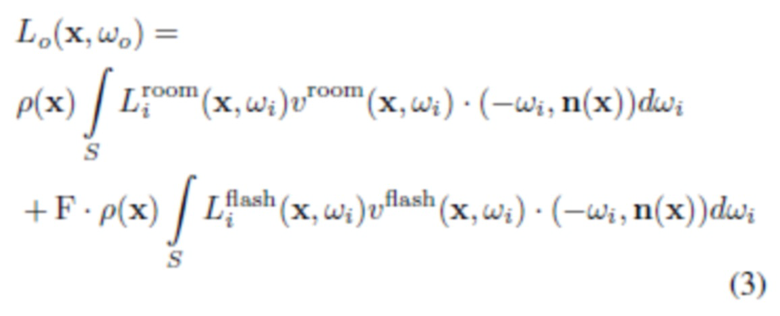 .
.
[0036] Теперь через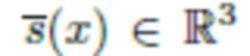 обозначим интеграл в первой части, который характеризует затенение, вызванное как комнатными лампами, так и окклюзиями (например, тень от носа на щеке в случае освещения головы человека). Это затенение можно смоделировать как произведение цветовой температуры и затенения в градациях серого
обозначим интеграл в первой части, который характеризует затенение, вызванное как комнатными лампами, так и окклюзиями (например, тень от носа на щеке в случае освещения головы человека). Это затенение можно смоделировать как произведение цветовой температуры и затенения в градациях серого 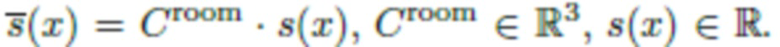 . Что касается второй части (вспышки), яркость входящего излучения прямо моделируется как
. Что касается второй части (вспышки), яркость входящего излучения прямо моделируется как 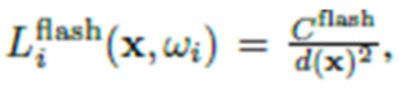 , где d(x) - расстояние от вспышки до x, а
, где d(x) - расстояние от вспышки до x, а 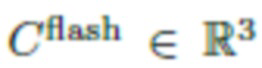 - постоянный вектор, пропорциональный цветовой температуре и интенсивности вспышки. Предполагается, что вспышка находится достаточно далеко, и это даёт возможность считать, что
- постоянный вектор, пропорциональный цветовой температуре и интенсивности вспышки. Предполагается, что вспышка находится достаточно далеко, и это даёт возможность считать, что 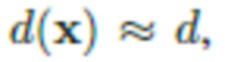 где d - расстояние от камеры до ближайшей точки в 3D облаке точек, а световые лучи от вспышки приблизительно параллельны. Так как на смартфоне вспышка и объектив камеры обычно расположены в непосредственной близости (в
где d - расстояние от камеры до ближайшей точки в 3D облаке точек, а световые лучи от вспышки приблизительно параллельны. Так как на смартфоне вспышка и объектив камеры обычно расположены в непосредственной близости (в 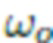 ), допускается, что
), допускается, что 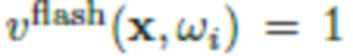 для всех x, видимых на изображении со вспышкой (изображении, освещенном вспышкой). Исходя из этого, можно выполнить преобразование (3) в (4):
для всех x, видимых на изображении со вспышкой (изображении, освещенном вспышкой). Исходя из этого, можно выполнить преобразование (3) в (4):
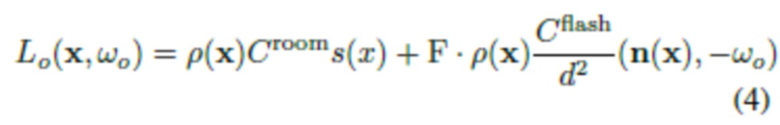
[0037] Следует отметить, что в (4) разложение интенсивности света 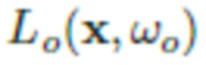 на отдельные компоненты неоднозначно, что является обычным явлением для большинства задач оценки альбедо и освещения. В частности, существует обратно пропорциональная зависимость между
на отдельные компоненты неоднозначно, что является обычным явлением для большинства задач оценки альбедо и освещения. В частности, существует обратно пропорциональная зависимость между 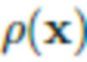 и обоими параметрами,
и обоими параметрами,  и
и  . Эта неоднозначность решается в настоящем изобретении с помощью соответствующих априорных параметров, как будет подробно описано ниже в разделе "Подгонка модели".
. Эта неоднозначность решается в настоящем изобретении с помощью соответствующих априорных параметров, как будет подробно описано ниже в разделе "Подгонка модели".
Геометрическое моделирование
[0038] После описания модели освещения описывается геометрическое моделирование. Предполагается, что 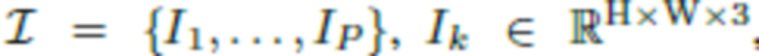 - это последовательность изображений верхней части тела человека, снятых камерой смартфона в одной и той же среде и характеризующих верхнюю часть тела, включая голову человека, под разными углами. Набор изображений, снятых со вспышкой, это
- это последовательность изображений верхней части тела человека, снятых камерой смартфона в одной и той же среде и характеризующих верхнюю часть тела, включая голову человека, под разными углами. Набор изображений, снятых со вспышкой, это 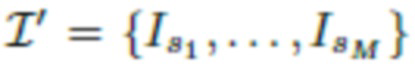 , т.е. в этот набор входят фотографии верхней части тела человека, дополнительно освещенные вспышкой камеры. Для оценки (реконструкции) точек обзора камеры
, т.е. в этот набор входят фотографии верхней части тела человека, дополнительно освещенные вспышкой камеры. Для оценки (реконструкции) точек обзора камеры 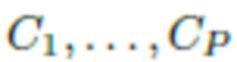 каждого изображения можно использовать методы построения структуры из движения (SfM),
каждого изображения можно использовать методы построения структуры из движения (SfM), 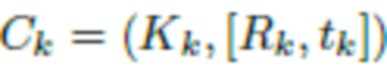 . Затем аналогичным образом оценивается (реконструируется) 3D облако точек P=
. Затем аналогичным образом оценивается (реконструируется) 3D облако точек P= 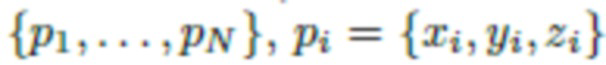 из всех изображений. Для оценки 3D облака точек можно использовать любой известный метод или программное обеспечение, например, SfM.
из всех изображений. Для оценки 3D облака точек можно использовать любой известный метод или программное обеспечение, например, SfM.
[0039] Сегментация и фильтрация. Поскольку моделирование человека осуществляется без фона, на этапе S205.3 сегментируется передний план, а на этапе S205.4 3D на основе отсегментированного переднего плана нейронной сетью сегментации фильтруется облако точек для получения отфильтрованного 3D облака точек. Для примера, но без ограничения, в качестве нейронной сети сегментации можно использовать сеть сегментации U2-Net, разработанную для задачи сегментации объектов переднего плана. Предобученную модель U2-Net можно дополнительно тонко настроить с помощью режима обучения с ускорением, например, на наборе данных изображений людей и соответствующих масок сегментации Supervisely, чтобы сделать ее более пригодной для данной задачи. После этого изображения 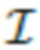 пропускают через тонко настроенную нейронную сеть сегментации и получают последовательность исходных "мягких" масок
пропускают через тонко настроенную нейронную сеть сегментации и получают последовательность исходных "мягких" масок 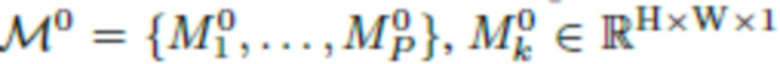 . И наконец, можно достичь многовидовой согласованности силуэтов посредством визуальной оценки корпуса с использованием 3D облака точек в качестве геометрического представителя и используя веса нейросети сегментации в качестве параметризации. Это реализуется путем тонкой настройки весов нейросети сегментации, чтобы минимизировать несогласованность сегментов между видами, что приводит к получению уточненных масок
. И наконец, можно достичь многовидовой согласованности силуэтов посредством визуальной оценки корпуса с использованием 3D облака точек в качестве геометрического представителя и используя веса нейросети сегментации в качестве параметризации. Это реализуется путем тонкой настройки весов нейросети сегментации, чтобы минимизировать несогласованность сегментов между видами, что приводит к получению уточненных масок 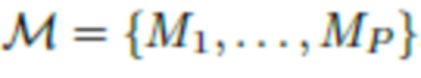 .
.
[0040] Нейросетевая визуализация (Neural rendering). Нейросетевая визуализация осуществляется на основе глубокой нейронной сети, которая прогнозирует альбедо, нормали и карты теней окружающей среды из 3D облака точек, растеризованного для каждого вида камеры. Каждая точка в 3D облаке точек дополняется скрытым (нейронным) дескриптором, то есть многомерным скрытым вектором, характеризующим свойства точки:
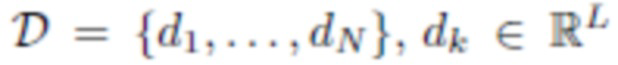 (L может быть равно 8, но это не является ограничением).
(L может быть равно 8, но это не является ограничением).
[0041] Этап нейросетевой визуализации начинается с растеризации скрытых дескрипторов на холсте, связанном с камерой Ck. Это можно осуществить следующим образом: с помощью Z-буферизации 3D облака точек формируется необработанное изображение (растеризованное изображение) 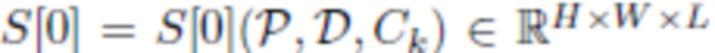 (для каждого пикселя находится ближайшая к камере точка, которая проецируется на этот пиксель). Скрытый дескриптор каждой из ближайших точек назначается соответствующему пикселю. При отсутствии точки, которая проецируется на какой-либо пиксель, этому пикселю назначается нулевой дескриптор. Аналогичным образом строится набор вспомогательных необработанных изображений
(для каждого пикселя находится ближайшая к камере точка, которая проецируется на этот пиксель). Скрытый дескриптор каждой из ближайших точек назначается соответствующему пикселю. При отсутствии точки, которая проецируется на какой-либо пиксель, этому пикселю назначается нулевой дескриптор. Аналогичным образом строится набор вспомогательных необработанных изображений  пространственных размеров
пространственных размеров 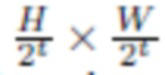 , и на этих изображениях выполняется растеризация скрытых дескрипторов по тому же алгоритму. Для покрытия 3D облака точек в нескольких масштабах (разрешениях) вводится пирамида необработанных изображений. Необработанное изображение с самым высоким разрешением
, и на этих изображениях выполняется растеризация скрытых дескрипторов по тому же алгоритму. Для покрытия 3D облака точек в нескольких масштабах (разрешениях) вводится пирамида необработанных изображений. Необработанное изображение с самым высоким разрешением  имеет наибольшую пространственную детализацию, в то время как изображения с более низким разрешением имеют меньшее просвечивание точек.
имеет наибольшую пространственную детализацию, в то время как изображения с более низким разрешением имеют меньшее просвечивание точек.
[0042] Затем набор необработанных изображений  обрабатывается глубокой нейронной сетью
обрабатывается глубокой нейронной сетью  , точно следуя структуре U-Net с маскируемыми свертками. Каждое из необработанных изображений может быть передано в качестве ввода (или присоединено) в первый уровень сетевого кодировщика соответствующего разрешения. Выходом глубокой нейронной сети является набор плотных карт. Эти карты могут содержать выходные значения RGB.
, точно следуя структуре U-Net с маскируемыми свертками. Каждое из необработанных изображений может быть передано в качестве ввода (или присоединено) в первый уровень сетевого кодировщика соответствующего разрешения. Выходом глубокой нейронной сети является набор плотных карт. Эти карты могут содержать выходные значения RGB.
[0043] На фиг.1 представлен в общих чертах полный конвейер обработки согласно варианту осуществления настоящего изобретения. В настоящем изобретении последний слой глубокой нейронной сети выдает восьмиканальный тензор с несколькими группами:
- Первая группа содержит три канала и использует сигмоидную нелинейность. Эти каналы содержат значения альбедо 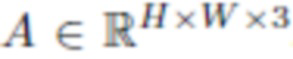 . Каждый пиксель A описывает пространственно изменяющиеся свойства отражения (альбедо ) поверхности головы (кожи, волос или других частей).
. Каждый пиксель A описывает пространственно изменяющиеся свойства отражения (альбедо ) поверхности головы (кожи, волос или других частей).
- Вторая группа также имеет три канала и в конце использует групповую нормализацию L2. Эта группа содержит растеризованные нормали 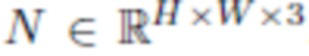 , причем каждый пиксель содержит вектор нормали n(x) точки на поверхности головы в мировом пространстве.
, причем каждый пиксель содержит вектор нормали n(x) точки на поверхности головы в мировом пространстве.
- Следующая одноканальная группа, использующая сигмоидную нелинейность, соответствует затенению в градациях серого , вызванному различиями в освещении помещения и, как следствие, возникающими окклюзиями.
- И наконец, последняя одноканальная группа, также использующая сигмоидную нелинейность, определяет маску сегментации , при этом каждый пиксель содержит спрогнозированную вероятность того, что данный пиксель принадлежит голове, а не фону.
[0044] На основании этого вывода глубокой нейронной сети определяется окончательное визуализированное изображение (то есть 3D портрет с измененным освещением) путем объединения (fusing) альбедо, нормалей и карт теней окружающей среды, а также маски сегментации, как предписано моделью освещения (4) (т.е. в зависимости от условий освещения):
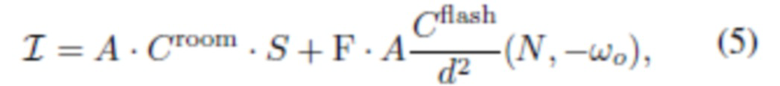
где скалярное произведение 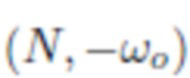 применяется к каждому пикселю по отдельности. Векторы цветовой температуры Croom и Cflash, оба в
применяется к каждому пикселю по отдельности. Векторы цветовой температуры Croom и Cflash, оба в 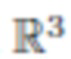 , считаются частью модели, общими для всех пикселей. Эти векторы можно оценить из обучающих данных, как обсуждается ниже. Во время использования карты признаков A и N, а также параметры Croom, Cflash можно использовать для визуализации верхней части тела человека при измененном освещении, таком как направленное освещение
, считаются частью модели, общими для всех пикселей. Эти векторы можно оценить из обучающих данных, как обсуждается ниже. Во время использования карты признаков A и N, а также параметры Croom, Cflash можно использовать для визуализации верхней части тела человека при измененном освещении, таком как направленное освещение 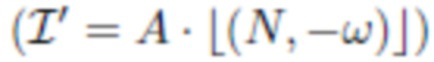 , или других моделях, например, сферических гармониках (SH). В последнем случае альбедо A умножается на нелинейную функцию от нормалей N пикселей и коэффициентов SH. При наличии панорамы 360° нового окружения можно получить значения коэффициентов SH (до заранее определенного порядка) путем интегрирования этой панорамы. Известно, что выбор порядка 3 или выше, приводящий к по меньшей мере 9 коэффициентам на цветовой канал, часто может создавать выразительные световые эффекты. В случае SH третьего порядка изображение с измененным освещением можно определить как квадратичную форму:
, или других моделях, например, сферических гармониках (SH). В последнем случае альбедо A умножается на нелинейную функцию от нормалей N пикселей и коэффициентов SH. При наличии панорамы 360° нового окружения можно получить значения коэффициентов SH (до заранее определенного порядка) путем интегрирования этой панорамы. Известно, что выбор порядка 3 или выше, приводящий к по меньшей мере 9 коэффициентам на цветовой канал, часто может создавать выразительные световые эффекты. В случае SH третьего порядка изображение с измененным освещением можно определить как квадратичную форму:
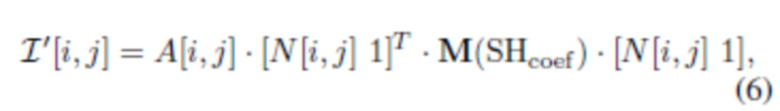
где матрица 4×4 M(SHcoef) линейно зависит от 27 коэффициентов SHCoef.
Подгонка модели
[0045] Общие потери сцены. Эта модель содержит большое число параметров, которые подгоняются к данным. Во время подгонки полученные изображения 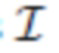 (5) сравниваются с истинными изображениями
(5) сравниваются с истинными изображениями 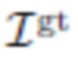 с помощью функции потерь, построенной как комбинация одного или более компонентов, описанных ниже.
с помощью функции потерь, построенной как комбинация одного или более компонентов, описанных ниже.
[0046] Основная функция потерь равна оцененному несоответствию между спрогнозированным изображением и истинным изображением :
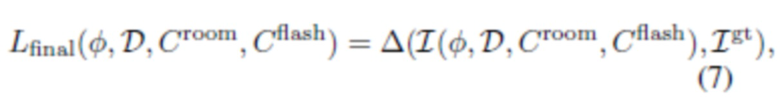
где для сравнения пары изображений используется функция несоответствия  :
:
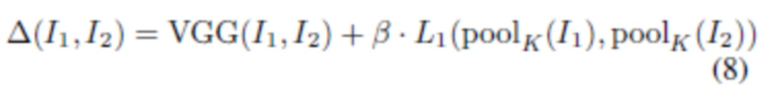
[0047] В данном случае 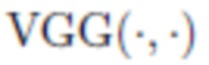 - перцептивное несоответствие, основанное на уровнях сети VGG-16,
- перцептивное несоответствие, основанное на уровнях сети VGG-16, 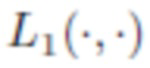 относится к среднему абсолютному отклонению,
относится к среднему абсолютному отклонению, 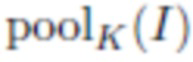 представляет собой уменьшение через усреднение (average pooling) изображения
представляет собой уменьшение через усреднение (average pooling) изображения 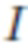 с ядром KxK (K может быть равно 4, но без ограничения) и
с ядром KxK (K может быть равно 4, но без ограничения) и 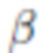 представляет собой коэффициент балансировки, введенный для выравнивания диапазона значений двух членов (например, может быть равно 2500). В то время как VGG поощряет соответствие высокочастотных деталей,
представляет собой коэффициент балансировки, введенный для выравнивания диапазона значений двух членов (например, может быть равно 2500). В то время как VGG поощряет соответствие высокочастотных деталей, 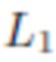 поощряет соответствие цветов. Так как наивная оптимизация может привести к размытию и потере деталей, член можно оценивать по изображениям с пониженной дискретизацией.
поощряет соответствие цветов. Так как наивная оптимизация может привести к размытию и потере деталей, член можно оценивать по изображениям с пониженной дискретизацией.
[0048] Поскольку в предложенном способе необходимо сегментировать визуализированную голову с произвольной точки обзора, можно ввести функцию потерь сегментации, ограничивающую спрогнозированную маску M:
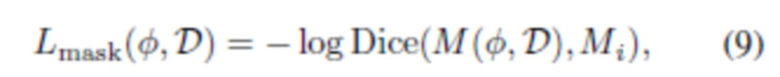
где функция Dice является распространенным выбором вида функции потерь для сегментации (оценивается как попиксельная оценка F1). Фактически, с помощью этой функции потерь глубокая нейронная сеть обучается экстраполировать предварительно вычисленные маски 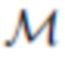 на новые точки обзора.
на новые точки обзора.
[0049] Согласно (5) визуализированное изображение для изображений, снятых без вспышки, равно 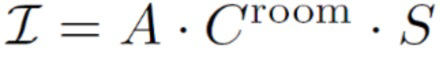 . На практике это создает определенную неоднозначность между обученными картами A и S. Поскольку A участвует в обоих членах (5), высокочастотный компонент этих визуализаций имеет тенденцию сохраняться по умолчанию в S. Следующая функция потерь затенения помещения неявно требует, чтобы вместо этого A была крайне точной:
. На практике это создает определенную неоднозначность между обученными картами A и S. Поскольку A участвует в обоих членах (5), высокочастотный компонент этих визуализаций имеет тенденцию сохраняться по умолчанию в S. Следующая функция потерь затенения помещения неявно требует, чтобы вместо этого A была крайне точной:
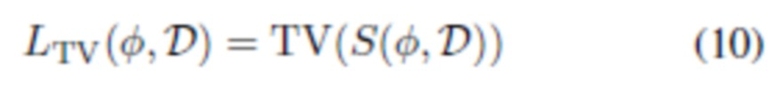 ,
,
где TV - потеря полной вариации на основе L1.
[0050] Потери, основанные на априорных знаниях о структуре лица. Для дополнительного упорядочения процесса обучения можно использовать особое свойство сцен, а именно наличие лицевых областей. С этой целью для каждого обучающего изображения выполняется выравнивание лица с использованием предварительно обученной сети реконструкции 3D сетки лица. В качестве сети реконструкции 3D сетки лица может использоваться известная система PRNet, но без ограничения. При наличии произвольного изображения 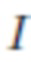 , содержащего лицо, сеть реконструкции 3D сетки лица может оценить карту выравнивания лица, то есть тензор Posmap размером 256×256 (конкретный размер указан в качестве примера, а не ограничения), которая отображает UV-координаты (в заранее определенном фиксированном пространстве текстуры, связанном с данным человеческим лицом) в координатах экранного пространства изображения .
, содержащего лицо, сеть реконструкции 3D сетки лица может оценить карту выравнивания лица, то есть тензор Posmap размером 256×256 (конкретный размер указан в качестве примера, а не ограничения), которая отображает UV-координаты (в заранее определенном фиксированном пространстве текстуры, связанном с данным человеческим лицом) в координатах экранного пространства изображения .
[0051] Пусть Posmap1,..., PosmapP определяют карты положения, вычисленные для каждого изображения в обучающей последовательности. Билинейная выборка (обратная деформация) изображения на Posmap обозначается операцией 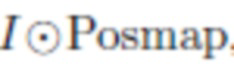 , которая приводит к отображению видимой части изображения в пространстве UV-текстуры. Таким образом, отображение создает цветную (частичную) текстуру лица.
, которая приводит к отображению видимой части изображения в пространстве UV-текстуры. Таким образом, отображение создает цветную (частичную) текстуру лица.
[0052] Собранные данные о геометрии лица используются двумя способами. Во-первых, на протяжении всей подгонки оценивается полутекстура альбедо 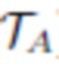 размером 256×128 (для левой или правой части альбедо). Конкретный размер (256×128) приведен в качестве примера и не является ограничением. Полутекстура альбедо инициализируется путем взятия попиксельной медианы проецируемых текстур для всех изображений со вспышкой
размером 256×128 (для левой или правой части альбедо). Конкретный размер (256×128) приведен в качестве примера и не является ограничением. Полутекстура альбедо инициализируется путем взятия попиксельной медианы проецируемых текстур для всех изображений со вспышкой 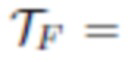
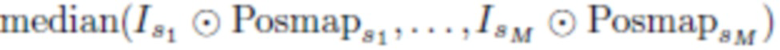 и усреднения левой и перевернутой правой половины или правой и перевернутой левой половины. Функция потерь симметрии - это функция потерь, использующая априорные знания о структуре лица, которые содействуют симметрии альбедо путем их сравнения с обученной текстурой альбедо:
и усреднения левой и перевернутой правой половины или правой и перевернутой левой половины. Функция потерь симметрии - это функция потерь, использующая априорные знания о структуре лица, которые содействуют симметрии альбедо путем их сравнения с обученной текстурой альбедо:
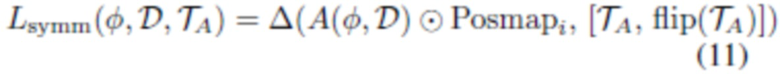
(эта функция несоответствия оценивается только в том случае, если определено 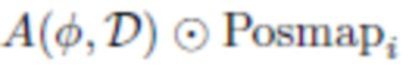 ).
). 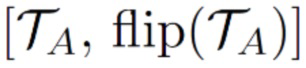 обозначает объединенную текстуру и ее перевернутую по горизонтали версию. Эта функция потерь делает альбедо более симметричным и приводит цвета текстуры альбедо в соответствие с цветами обученного альбедо. Баланс между этими двумя факторами регулируется скоростью обучения для . В настоящем изобретении функция потерь симметрии помогает разрешить разложение изображения на альбедо и тени, поскольку противоположные точки лица (например, левая и правая щека) могут иметь одинаковое альбедо, тогда как отбрасываемые тени чаще всего несимметричны.
обозначает объединенную текстуру и ее перевернутую по горизонтали версию. Эта функция потерь делает альбедо более симметричным и приводит цвета текстуры альбедо в соответствие с цветами обученного альбедо. Баланс между этими двумя факторами регулируется скоростью обучения для . В настоящем изобретении функция потерь симметрии помогает разрешить разложение изображения на альбедо и тени, поскольку противоположные точки лица (например, левая и правая щека) могут иметь одинаковое альбедо, тогда как отбрасываемые тени чаще всего несимметричны.
[0053] Кроме того, чтобы выбрать гамму для альбедо, можно ввести функцию потерь цветового соответствия альбедо 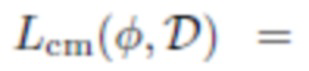
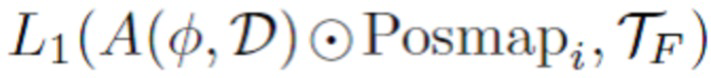 (также вычисленную только для действительных элементов текстуры
(также вычисленную только для действительных элементов текстуры 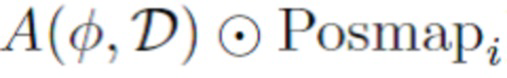 ).
).
[0054] Другой тип данных, который можно выводить из сети реконструкции 3D сетки лица (например, PRNet), это нормали для данной части лица. Каждая карта выравнивания лица вместе с оцененной глубиной (также с помощью PRNet) и набором треугольников определяет треугольную сетку. Сетки, оцененные для каждого вида, визуализируются и сглаживаются, вычисляются нормали лица, и спроецированные нормали визуализируются на соответствующем виде камеры (технически все операции могут выполняться, например, в системе рендеринга Blender). Затем визуализированные нормали поворачиваются матрицей поворота камеры для их преобразования в мировое пространство. Для оцененных изображений нормалей для лицевой части размером H x W вводится обозначение N1,..., NP. Нормали, спрогнозированные глубокой нейронной сетью, сопоставляются с нормалями сети реконструкции 3D сетки лица (например, PRNet) на лицевой области (определенной маской Mface) с помощью функции потерь нормалей:
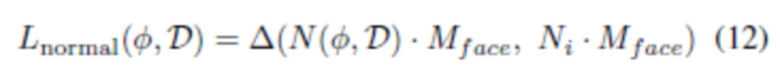
[0055] Суммарную (объединенную) функцию потерь можно выразить следующим образом:
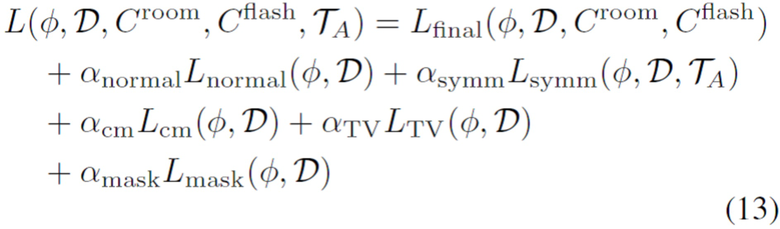
Отдельные функции потерь можно сбалансировать, например, следующим образом: 
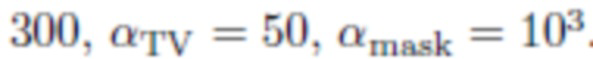 . Возможны и другие схемы балансировки, например:
. Возможны и другие схемы балансировки, например: 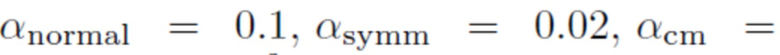
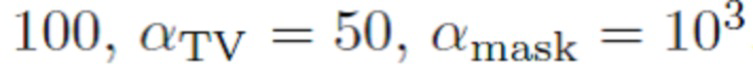 .
.
[0056] Оптимизация. Обучаемая часть системы обучается для одной сцены путем обратного распространения ошибки на параметры 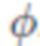 сети визуализации, точечные дескрипторы D и вспомогательные параметры
сети визуализации, точечные дескрипторы D и вспомогательные параметры  . Для и D можно использовать Adam с одинаковой скоростью обучения, а для остальных обучаемых параметров могут использоваться другие скорости обучения, выбранные эмпирически в соответствии с диапазоном их возможных значений. На каждом этапе отбирается образец обучающего изображения и выполняется прямой проход, за которым следует градиентный шаг. Улучшения во время обучения могут включать произвольное увеличение/уменьшение и последующее обрезание небольшого участка.
. Для и D можно использовать Adam с одинаковой скоростью обучения, а для остальных обучаемых параметров могут использоваться другие скорости обучения, выбранные эмпирически в соответствии с диапазоном их возможных значений. На каждом этапе отбирается образец обучающего изображения и выполняется прямой проход, за которым следует градиентный шаг. Улучшения во время обучения могут включать произвольное увеличение/уменьшение и последующее обрезание небольшого участка.
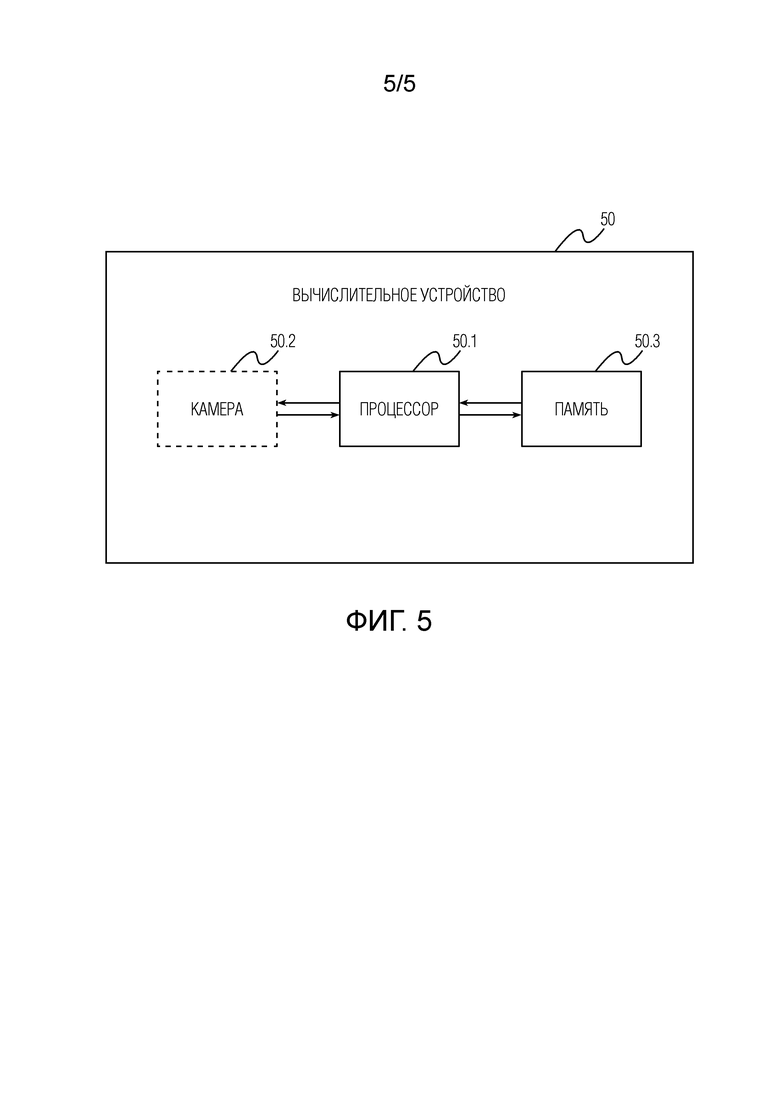
[0057] На фиг.5 представлена структурная схема вычислительного устройства 50, выполненного с возможностью визуализации 3D портрета человека согласно варианту осуществления настоящего изобретения. Вычислительное устройство 50 содержит взаимосвязанные друг с другом процессор 50.1, камеру 50.2 (камера 50.2 не является обязательной, поэтому на фиг.5 она обведена пунктирной линией) и память 50.3. Иллюстрацию взаимосвязей между процессором 50.1, камерой 50.2 и памятью 50.3 не следует считать ограничением, поскольку ясно, что процессор 50.1, камера 50.2 и память 50.3 могут быть взаимосвязаны друг с другом различным образом. Камера 50.2 выполнена с возможностью съёмки последовательности изображений человека с использованием мигающей вспышки. Память 50.3 выполнена с возможностью хранения инструкций, выполняемых процессором, которые побуждают вычислительное устройство 50 выполнять любой этап или подэтап предложенного способа, а также весовых коэффициентов глубокой нейронной сети, скрытых дескрипторов и вспомогательных параметров, полученных на стадии обучения. При исполнении выполняемых процессором инструкций процессор 50.1 выполнен с возможностью предписывать вычислительному устройству 50 выполнять предложенный способ визуализации 3D портрета человека с измененным освещением.
[0058] В альтернативном варианте осуществления, в котором для обучения раскрытой системы и обработки последовательности изображений человека используется удаленный сервер, вычислительное устройство может дополнительно содержать блок связи (не показан), предназначенный для обмена данными с удаленным сервером. Эти данные могут включать в себя запрос от вычислительного устройства на обучение предложенной системы и/или обработку последовательности изображений человека. Данные для удаленного сервера также могут включать в себя последовательность изображений, отснятых с использованием мигающей вспышки вычислительным устройством. Данные с удаленного сервера могут включать в себя веса и другие параметры обученной системы и/или 3D портрет человека с измененным освещением. Блок связи может использовать любую известную технологию связи, например, WiFi, WiMax, 4G (LTE), 5G и т.п. Блок связи взаимосвязан с другими компонентами вычислительного устройства или может быть часть процессора (например, как SoC).
[0059] Вычислительное устройство 50 может содержать другие, не показанные компоненты, например экран, камеру, блок связи, сенсорную панель, клавиатуру, малую клавишную панель, одну или несколько кнопок, динамик, микрофон, модуль Bluetooth, модуль NFC, модуль RF, модуль Wi-Fi, источник питания и т.д., а также соответствующие соединения. Предложенный способ визуализации 3D портрета человека с измененным освещением может быть реализован на широком ассортименте вычислительных устройств 50, таких как интеллектуальные очки виртуальной реальности (VR), интеллектуальные очки дополненной реальности (AR), системы 3D отображения, смартфоны, планшеты, ноутбуки, мобильные роботы и навигационные системы, но без ограничения перечисленным. Реализация предложенного способа поддерживает все виды устройств, способных производить вычисления на ЦП. Кроме того, вычислительное устройство 50 может содержать дополнительные компоненты для ускорения нейронной сети и растеризации, такие как GPU (блок обработки графики), NPU (нейронный процессор), TPU (блок обработки тензорных данных). Для реализации растеризации может применяться OpenGL. В случае включения этих дополнительных компонентов такие устройства могут реализовать предложенный способ быстрее, эффективнее и с более высокой производительностью (включая стадию обучения). В неограничивающих вариантах осуществления процессор 50.1 может быть реализован как вычислительное средство, включая, без ограничения, универсальный процессор, специализированную интегральную схему (ASIC), программируемую логическую интегральную схему (FPGA) или систему на кристалле (SoC).
[0060] По меньшей мере один из множества модулей, блоков, компонентов, этапов, подэтапов можно реализовать с помощью модели AI. Один или несколько этапов или подэтапов раскрытого способа могут быть реализованы как блоки/модули (т.е. как аппаратные компоненты) вычислительного устройства 50. Функция, связанная с AI, может выполняться через память 50.3, которая может включать в себя энергонезависимую память и энергозависимую память и процессор 50.1. Процессор 50.1 может включать в себя один или несколько процессоров. Один или несколько процессоров могут содержать универсальный процессор, такой как центральный процессор (CPU), процессор приложений (AP) и т.п., процессор только графической информации, такой как графический процессор (GPU), процессор визуальной информации (VPU) и/или специализированный процессор AI, такой как нейронный процессор (NPU). Один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным правилом работы или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Предварительно определенное рабочее правило или модель искусственного интеллекта предоставляется посредством обучения. В данном контексте предоставление посредством обучения означает, что заранее определенное рабочее правило или модель AI с желаемой характеристикой создается посредством применения алгоритма обучения к множеству обучающих данных. Обучение может выполняться в самом устройстве, в котором выполняется AI согласно варианту осуществления, и/или может быть реализовано через отдельный сервер/систему.
[0061] Модель AI может состоять из множества уровней нейронной сети. Каждый уровень имеет множество весовых значений и выполняет операцию уровня путем вычисления предыдущего уровня и операции с множеством весов. Примеры нейронных сетей включают в себя, без ограничения перечисленным, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративные состязательные сети (GAN) и глубокие Q-сети. Алгоритм обучения - это способ обучения заранее определенного целевого вычислительного устройства 50 с использованием множества обучающих данных, чтобы побудить, разрешить или контролировать выполнение определения, оценки или прогнозирования целевым вычислительным устройством 50. Примерами алгоритмов обучения являются, без ограничения перечисленным, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
[0062] Следует четко понимать, что не все технические эффекты, упомянутые в данном документе, необходимо использовать в каждом варианте осуществления настоящей технологии. Например, варианты осуществления данной технологии могут быть реализованы без использования пользователем некоторых из этих технических эффектов, в то время как другие варианты могут быть реализованы с использованием пользователем других технических эффектов или вообще без них.
[0063] Модификации и усовершенствования описанных выше реализаций настоящей технологии могут быть очевидными для специалистов в данной области техники. Например, конкретные значения параметров, указанные в приведенном выше описании, не следует рассматривать как ограничение, поскольку значения параметров можно выбирать экспериментальным путем из соответствующих диапазонов, например +/-10-50% от указанных конкретных значений параметров. Приведенное выше описание предназначено скорее для примера, чем для ограничения. Таким образом, объем настоящей технологии ограничивается исключительно объемом прилагаемой формулы изобретения.
[0064] Хотя представленные выше реализации были описаны и проиллюстрированы со ссылкой на конкретные этапы, выполняемые в определенном порядке, следует понимать, что эти этапы можно объединить, разделить на части или выполнить в другом порядке без отклонения от принципов настоящего изобретения. Соответственно, порядок и группирование этапов не являются ограничением настоящей технологии. Использование формы единственного числа по отношению к любому элементу, раскрытому в данном изобретении, не исключает того, что в фактической реализации может быть два или более таких элементов.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ получения информации о форме и размерах трехмерного объекта по его двухмерному изображению | 2022 |
|
RU2816504C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| ИНТЕРАКТИВНАЯ СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЙ | 2023 |
|
RU2833268C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
Настоящее изобретение относится области вычислительной техники для создания 3D портрета с изменяемым освещением. Технический результат заключается в улучшении качественных характеристик созданного 3D портрета. Предложен способ визуализации 3D портрета человека с измененным освещением, заключающийся в том, что принимают ввод, определяющий позу камеры и условия освещения; осуществляют растеризацию скрытых дескрипторов 3D облака точек, причем 3D облако точек создают на основе последовательности изображений, отснятых камерой с мигающей вспышкой при перемещении камеры вокруг верхней части тела человека, при этом последовательность изображений содержит набор изображений, снятых со вспышкой, и набор изображений, снятых без вспышки; обрабатывают растеризованные изображения глубокой нейронной сетью для прогнозирования альбедо, нормалей, карт теней окружающей среды и маски сегментации для принятой позы камеры, и объединяют спрогнозированные альбедо, нормали, карты теней окружающей среды и маску сегментации в 3D портрет с измененным освещением в соответствии с условиями освещения. 2 н. и 19 з.п. ф-лы, 5 ил.
1. Способ визуализации 3D портрета человека с измененным освещением, заключающийся в том, что:
принимают (S210) ввод, определяющий позу камеры и условия освещения;
осуществляют растеризацию (S215) скрытых дескрипторов 3D облака точек с различными разрешениями в соответствии с позой камеры для получения растеризованных изображений, причем 3D облако точек создают (S205) на основе последовательности изображений, отснятых (S200) камерой с мигающей вспышкой при перемещении камеры, по меньшей мере частично, вокруг верхней части тела человека, при этом последовательность изображений содержит набор изображений, снятых со вспышкой, и набор изображений, снятых без вспышки;
обрабатывают (S220) растеризованные изображения глубокой нейронной сетью для прогнозирования альбедо, нормалей, карт теней окружающей среды и маски сегментации для принятой позы камеры, и
объединяют (S225) спрогнозированные альбедо, нормали, карты теней окружающей среды и маску сегментации в 3D портрет с измененным освещением в соответствии с условиями освещения.
2. Способ по п.1, в котором на этапе создания (S205) 3D облака точек дополнительно осуществляют оценку (S205.1) точек обзора камеры, с которых снята данная последовательность изображений.
3. Способ по п.2, в котором поза камеры и условия освещения, полученные через ввод, отличаются от точек обзора камеры и условий освещения, с которых снята данная последовательность изображений.
4. Способ по п.2, в котором этап создания (S205) 3D облака точек и подэтап осуществления оценки (S205.1) точек обзора камеры выполняют с использованием структуры из движения (SfM), причем 3D облако точек содержит точки, по меньшей мере частично соответствующие верхней части тела человека.
5. Способ по п.1, в котором на этапе создания (S205) 3D облака точек дополнительно обрабатывают каждое изображение последовательности путем сегментации (S205.3) переднего плана и фильтрации (S205.4) 3D облака точек на основе переднего плана, отсегментированного нейронной сетью сегментации, для получения отфильтрованного 3D облака точек.
6. Способ по п.1, в котором этап растеризации (S215) 3D облака точек выполняют с использованием Z-буферизации.
7. Способ по п.1, в котором в указанной последовательности изображений изображения со вспышкой из набора изображений, снятых со вспышкой, чередуются с изображениями без вспышки из набора изображений, снятых без вспышки.
8. Способ по п.1, в котором скрытый дескриптор представляет собой многомерный скрытый вектор, характеризующий свойства соответствующей точки в 3D облаке точек.
9. Способ по любому из пп.1-8, в котором на стадии обучения осуществляют случайную выборку (S100) изображения из отснятой последовательности изображений, причем поза камеры соответствует данному изображению, и получают (S105) спрогнозированное изображение глубокой нейронной сетью для данной позы камеры, при этом стадию обучения выполняют итеративно.
10. Способ по п.9, в котором глубокую нейронную сеть обучают посредством обратного распространения (S130) потери на веса глубокой нейронной сети, скрытые дескрипторы и вспомогательные параметры,
причем значение потери вычисляют (S125) на основе одной или нескольких из следующих функций потерь: основная функция потерь, функция потерь сегментации, функция потерь затенения помещения, функция потерь симметрии, функция потерь цветового соответствия альбедо, функция потерь нормалей.
11. Способ по п.10, в котором вспомогательные параметры включают в себя один или несколько из следующих параметров: цветовая температура освещения в помещении, цветовая температура вспышки и полутекстура альбедо.
12. Способ по п.11, в котором дополнительно прогнозируют (S110) вспомогательные сетки лица с соответствующим отображением текстуры сетью реконструкции 3D сетки лица для каждого из изображений в отснятой последовательности;
причем соответствующее отображение текстуры определяется набором двумерных координат в фиксированном, предопределенном пространстве текстуры для каждой вершины сетки.
13. Способ по п.10, в котором основную функцию потерь вычисляют как несоответствие между спрогнозированным изображением и выбранным изображением посредством комбинации неперцептивных и перцептивных функций потерь.
14. Способ по п.10, в котором функцию потерь сегментации вычисляют как несоответствие между спрогнозированной маской сегментации и отсегментированным передним планом.
15. Способ по п.10, в котором функцию потерь затенения помещения вычисляют как штраф за резкость спрогнозированных карт теней окружающей среды, причем штраф возрастает по мере увеличения резкости.
16. Способ по п.10, в котором функцию потерь симметрии вычисляют как несоответствие между зеркально отображенной полутекстурой альбедо и спрогнозированным альбедо, геометрически переведенным в пространство текстуры посредством билинейной интерполяции.
17. Способ по п.10, в котором функцию потерь цветового соответствия альбедо вычисляют как несоответствие между медианной эталонной текстурой и спрогнозированным альбедо, геометрически переведенным в пространство текстуры посредством билинейной интерполяции,
при этом медианную эталонную текстуру получают (S115) путем вычисления попиксельной медианы всех изображений из набора изображений, снятых со вспышкой, геометрически переведенных в пространство текстуры посредством билинейной интерполяции.
18. Способ по п.10, в котором функцию потерь нормалей вычисляют как несоответствие между спрогнозированными нормалями и растеризованными изображениями вспомогательной сетки лица, соответствующей выбранному изображению,
при этом растеризацию (S120) выполняют путем цветового кодирования вершин сетки лица с их геометрическими нормалями и Z-буферизацией.
19. Вычислительное устройство (50), содержащее процессор (50.1) и память (50.3), в которой хранятся выполняемые процессором инструкции и веса глубокой нейронной сети, скрытые дескрипторы и вспомогательные параметры, полученные на стадии обучения, при этом при выполнении процессором (50.1) выполняемых процессором инструкций процессор (50.1) предписывает вычислительному устройству (50) выполнять способ визуализации 3D портрета человека с измененным освещением по любому из пп.1-18.
20. Вычислительное устройство (50) по п.19, дополнительно содержащее камеру (50.2), выполненную с возможностью съёмки последовательности изображений человека с мигающей вспышкой.
21. Вычислительное устройство (50) по п.19, дополнительно содержащее блок связи, выполненный с возможностью обмена данными с удаленным сервером.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| KR 20180004635 A, 12.01.2018 | |||
| СПОСОБ ГЕНЕРАЦИИ АНИМАЦИОННОЙ МОДЕЛИ ГОЛОВЫ ПО РЕЧЕВОМУ СИГНАЛУ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО, РЕАЛИЗУЮЩЕЕ ЕГО | 2019 |
|
RU2721180C1 |

