Подробное описание изобретения и предпочтительные варианты осуществления
Настоящее изобретение относится к обработке аудиосигналов и может применяться, например, в стереообработке MDCT, например, IVAS.
Кроме того, настоящее изобретение может применяться при объединенном кодировании параметров формирования спектрального стереошума.
Формирование спектрального шума формирует шум квантования в частотной области таким образом, что шум квантования минимально воспринимается посредством человеческого уха, и в силу этого может быть максимизировано перцепционное качество декодированного выходного сигнала.
Формирование спектрального шума представляет собой технологию, используемую в большинстве аудиокодеков на основе преобразования из уровня техники.
Усовершенствованное кодирование аудиоданных (AAC)
В этом подходе [1][2] спектр MDCT сегментируется на определенное число полос частот с неравномерными коэффициентами масштабирования. Например, при 48 кГц, MDCT имеет 1024 коэффициента, и он сегментируется на 49 полос частот коэффициентов масштабирования. В каждой полосе частот коэффициент масштабирования используется для масштабирования коэффициентов MDCT этой полосы частот. Затем используется модуль скалярного квантования с постоянным размером шага для квантования масштабированных коэффициентов MDCT. На стороне декодера в каждой полосе частот выполняется обратное масштабирование, формируя шум квантования, внесенный модулем скалярного квантования.
49 коэффициентов масштабирования кодируются в поток битов в качестве вспомогательной информации. Это обычно требует очень высокого числа битов для кодирования коэффициентов масштабирования, вследствие относительно высокого числа коэффициентов масштабирования и требуемой высокой точности. Это может становиться проблемой при низкой скорости передачи битов и/или при низкой задержке.
TCX на основе MDCT
В TCX на основе MDCT, аудиокодеке на основе преобразования, используемом в стандартах MPEG-D USAC [3] и 3GPP EVS [4], формирование спектрального шума выполняется с помощью перцепционных фильтров на основе LPC, аналогичного перцепционного фильтра с используемым в последних речевых кодеках на основе ACELP (например, AMR-WB).
В этом подходе, набор из 16 коэффициентов линейного прогнозирования (LPC) сначала оценивается во входном сигнале с коррекцией предыскажений. LPC затем взвешиваются и квантуются. Частотный отклик взвешенных и квантованных LPC затем вычисляется в 64 равномерно разнесенных полосах частот. Коэффициенты MDCT после этого масштабируются в каждой полосе частот с использованием вычисленного частотного отклика. Масштабированные коэффициенты MDCT затем квантуются с использованием модуля скалярного квантования с размером шага, управляемым посредством глобального усиления. В декодере, обратное масштабирование выполняется в каждых 64 полосах частот, формируя шум квантования, внесённый модулем скалярного квантования.
Этот подход имеет явное преимущество по сравнению с подходом AAC: он требует кодирования только 16 (LPC)+1 (глобальное усиление) параметров в качестве вспомогательной информации (в отличие от 49 параметров в AAC). Кроме того, 16 LPC могут эффективно кодироваться с небольшим числом битов посредством использования представления LSF и модуля векторного квантования. Следовательно, подход TCX на основе MDCT требует меньшего количества вспомогательных информационных битов по сравнению с подходом AAC, что может существенно изменять ситуацию при низкой скорости передачи битов и/или низкой задержке.
Улучшенное TCX на основе MDCT (психоакустический LPC)
Улучшенная TCX-система на основе MDCT публикуется в [5]. В этом новом подходе, автокорреляция (для оценки LPC) более не выполняется во временной области, но она вместо этого вычисляется в области MDCT с использованием обратного преобразования энергий коэффициентов MDCT. Это обеспечивает возможность использования неравномерной шкалы частот посредством простой группировки коэффициентов MDCT в 64 неравномерных полосы частот и вычисления энергии каждой полосы частот. Это также уменьшает сложность, требуемую для того, чтобы вычислять автокорреляцию.
Новое формирование спектрального шума (SNS)
В улучшенной технологии для формирования спектрального шума, описанной в [6] и реализованной в кодеке по стандарту связи с низкой сложностью (LC3/LC3plus), низкая скорость передачи битов без значительной потери качества может получаться посредством масштабирования, на стороне кодера, с более высоким числом коэффициентов масштабирования и посредством понижающей дискретизации параметров масштабирования на стороне кодера во второй набор из 16 параметров масштабирования (параметров SNS). Таким образом, получается вспомогательная информация при низкой скорости передачи битов, с одной стороны, и при этом высококачественная спектральная обработка спектра аудиосигнала вследствие точного масштабирования, с другой стороны.
Линейное стереопрогнозирование (SLP)
В тезисе, описанном в [7], набор коэффициентов линейного прогнозирования вычисляется не только с учетом межкадрового прогнозирования, но также и с учетом прогнозирования между каналами. Двумерный набор вычисленных коэффициентов затем квантуется и кодируется с использованием аналогичных технологий с одноканальным LP, но без учета квантования остатка в контексте тезиса. Тем не менее, описанная реализация обладает высокой задержкой и существенной сложностью, и в силу этого она является довольно неподходящей для варианта применения в реальном времени, которое требует низкой задержки, например, для систем связи.
В стереосистеме, такой как система на основе MDCT, которая описана в [8], предварительная обработка дискретных канальных сигналов L, R выполняется для масштабирования спектров с использованием формирования шума в частотной области в «отбеленную область». После этого объединенная стереообработка выполняется для квантования и кодирования отбеленных спектров оптимальным способом.
Параметры масштабирования для технологий формирования спектрального шума, описанных выше, кодируются с квантованием независимо для каждого канала. Это приводит к двойной скорости передачи битов вспомогательной информации, которая должна отправляться в декодер через поток битов.
Задача настоящего изобретения состоит в создании улучшенной или более эффективной концепции кодирования/декодирования.
Данная задача решается посредством аудиодекодера по пункту 1 формулы, аудиокодера по пункту 17 формулы, способа декодирования по пункту 35 формулы, способа декодирования по пункту 36 формулы или компьютерной программы по пункту 37 формулы.
Настоящее изобретение основано на таких выявленных сведениях, что сокращение скорости передачи битов может получаться для случаев, в которых сигналы L, R или, в общем, два или более каналов многоканального сигнала коррелируются. В таком случае, извлеченные параметры для обоих каналов вместо этого являются аналогичными. Следовательно, объединенное кодирование с квантованием параметров применяется, что приводит к значительному сокращению скорости передачи битов. Это сокращение скорости передачи битов может использоваться в нескольких различных направлениях. Одно направление может заключаться в том, чтобы расходовать сокращенную скорость передачи битов на кодирование базового сигнала таким образом, что полное перцепционное качество стерео- или многоканального сигнала повышается. Другое направление заключается в том, чтобы достигать более низкой полной скорости передачи битов в случае, если кодирование базового сигнала и в силу этого полное перцепционное качество не повышается, а остается неизменным качеством.
В предпочтительном варианте осуществления, в соответствии с первым аспектом, аудиокодер содержит модуль вычисления параметров масштабирования для вычисления первой группы объединенно кодированных параметров масштабирования и второй группы объединенно кодированных параметров масштабирования для первого набора параметров масштабирования для первого канала многоканального аудиосигнала и для второго набора параметров масштабирования для второго канала многоканального аудиосигнала. Аудиокодер дополнительно содержит процессор сигналов для применения первого набора параметров масштабирования к первому каналу и для применения второго набора параметров масштабирования ко второму каналу многоканального аудиосигнала. Процессор сигналов дополнительно извлекает многоканальные аудиоданные из первых и вторых данных каналов, полученных посредством применения первых и вторых наборов параметров масштабирования, соответственно. Аудиокодер дополнительно имеет модуль формирования кодированных сигналов для использования многоканальных аудиоданных и информации относительно первой группы объединенно кодированных параметров масштабирования и информации относительно второй группы объединенно кодированных параметров масштабирования для получения кодированного многоканального аудиосигнала.
Предпочтительно, модуль вычисления параметров масштабирования выполнен с возможностью адаптивности таким образом, что для каждого кадра или субкадра многоканального аудиосигнала, выполняется определение в отношении того, должно выполняться объединенное кодирование параметров масштабирования или отдельное кодирование параметров масштабирования. В дополнительном варианте осуществления, это определение основано на анализе подобий между каналами рассматриваемого многоканального аудиосигнала. В частности, анализ подобий осуществляется посредством вычисления энергии объединенно кодированных параметров и, в частности, энергии одного набора параметров масштабирования из первой группы и второй группы объединенно кодированных параметров масштабирования. В частности, модуль вычисления параметров масштабирования вычисляет первую группу в качестве суммы между соответствующими первыми и вторыми параметрами масштабирования и вычисляет вторую группу в качестве разности между первыми и вторыми соответствующими параметрами масштабирования. В частности, вторая группа и, предпочтительно, параметры масштабирования, которые представляют разность, используются для определения показателя подобия для принятия решения в отношении того, следует ли выполнять объединенное кодирование параметров масштабирования или отдельное кодирование параметров масштабирования. Эта ситуация может передаваться в служебных сигналах через стерео- или многоканальный флаг.
Кроме того, предпочтительно конкретно квантовать параметры масштабирования с помощью двухступенчатого процесса квантования. Модуль векторного квантования первой ступени квантует множество параметров масштабирования или, в общем, информационных аудиоэлементов для определения результата векторного квантования первой ступени и определять множество промежуточных квантованных элементов, соответствующих результату векторного квантования первой ступени. Кроме того, модуль квантования содержит модуль определения остаточных элементов для вычисления множества остаточных элементов из множества промежуточных квантованных элементов и множества информационных аудиоэлементов. Кроме того, предусмотрен модуль векторного квантования второй ступени для квантования множества остаточных элементов для получения результата векторного квантования второй ступени, при этом результат векторного квантования первой ступени и результат векторного квантования второй ступени вместе представляют квантованное представление множества информационных аудиоэлементов, которые, в одном варианте осуществления, представляют собой параметры масштабирования. В частности, информационные аудиоэлементы могут представлять собой либо объединенно кодированные параметры масштабирования, либо отдельно кодированные параметры масштабирования. Кроме того, другие информационные аудиоэлементы могут представлять собой любые информационные аудиоэлементы, которые являются полезными для векторного квантования. В частности, помимо параметров масштабирования или коэффициентов масштабирования в качестве конкретных информационных аудиоэлементов, другие информационные аудиоэлементы, полезные для векторного квантования, представляют собой спектральные значения, такие как линии MDCT или FFT. Еще дополнительные информационные аудиоэлементы, которые могут подвергаться векторному квантованию, представляют собой аудиозначения во временной области, такие как значения аудиодискретизации или группы аудиовыборок временной области или группы частотных линий спектральной области либо данные LPC или другие данные огибающей, независимо от спектрального или временного представления данных огибающей.
В предпочтительной реализации, модуль определения остаточных элементов вычисляет, для каждого остаточного элемента, разность между соответствующими информационными аудиоэлементами, такими как параметр масштабирования, и соответствующим промежуточным квантованным элементом, таким как квантованный параметр масштабирования или коэффициент масштабирования. Кроме того, модуль определения остаточных элементов выполнен с возможностью усиления или взвешивания для каждого остаточного элемента разности между соответствующим информационным аудиоэлементом и соответствующим промежуточным квантованным элементом таким образом, что множество остаточных элементов больше соответствующей разности, либо усиливать или взвешивать множество информационных аудиоэлементов и/или множество промежуточных квантованных элементов перед вычислением разности между усиленными элементами для получения остаточных элементов. Посредством этой процедуры может осуществляться полезное управление ошибкой квантования. В частности, когда вторая группа информационных аудиоэлементов, таких как различные параметры масштабирования, является довольно небольшой, что типично имеет место, когда первый и второй каналы коррелируются друг с другом таким образом, что объединенное квантование определено, остаточные элементы типично являются довольно небольшими. Следовательно, когда остаточные элементы усиливаются, результат квантования должен содержать большее число значений, которые не квантуются до 0, по сравнению со случаем, когда это усиление не выполнено. Следовательно, усиление на стороне кодера или квантования может быть полезным.
Это, в частности, имеет место, когда, как в другом предпочтительном варианте осуществления, квантование объединенно кодированной второй группы параметров масштабирования, таких как разностные параметры масштабирования, выполняется. Вследствие того факта, что эти боковые параметры масштабирования в любом случае являются небольшими, может возникать такая ситуация, что, без усиления, большинство различных параметров масштабирования квантуется до 0 в любом случае. Следовательно, чтобы исключать эту ситуацию, которая может приводить к потере стереовпечатления и в силу этого к потере психоакустического качества, усиление выполняется таким образом, что только небольшое количество либо почти нуль боковых параметров масштабирования квантуются до 0. Это, конечно, уменьшает сокращение скорости передачи битов. Тем не менее вследствие этого факта, квантованные элементы остаточных данных в любом случае являются только небольшими, т.е. приводят к индексам квантования, которые представляют небольшие значения, и увеличение скорости передачи битов не является слишком высоким, поскольку индексы квантования для небольших значений кодируются эффективнее индексов квантования для больших значений. Это может еще улучшаться посредством дополнительного выполнения операции энтропийного кодирования, которая в еще большей степени предпочитает небольшие индексы квантования относительно скорости передачи битов по сравнению с более высокими индексами квантования.
В другом предпочтительном варианте осуществления, модуль векторного квантования первой ступени представляет собой модуль векторного квантования, имеющий определенную таблицу кодирования, и модуль векторного квантования второй ступени представляет собой алгебраический модуль векторного квантования, приводящий в результате, в качестве индекса квантования, к номеру таблицы кодирования, векторному индексу в базовой таблице кодирования и индексу Вороного. Предпочтительно, и модуль векторного квантования и алгебраический модуль векторного квантования выполнены с возможностью выполнения векторного квантования с разбиением на уровни, при этом оба модуля квантования имеют одинаковую процедуру разбиения на уровни. Кроме того, модули векторного квантования первого и второй ступени конфигурированы таким образом, что число битов и в силу этого точность результата модуля векторного квантования первой ступени больше числа битов или точности результата модуля векторного квантования второй ступени, либо число битов и в силу этого точность результата модуля векторного квантования первой ступени отличается от числа битов или точности результата модуля векторного квантования второй ступени. В других вариантах осуществления модуль векторного квантования первой ступени имеет фиксированную скорость передачи битов, и модуль векторного квантования второй ступени имеет переменную скорость передачи битов. Таким образом, в общем, характеристики модулей векторного квантования первой ступени и второй ступени отличаются друг от друга.
В предпочтительном варианте осуществления аудиодекодера для декодирования кодированного аудиосигнала в соответствии с первым аспектом, аудиодекодер содержит декодер параметров масштабирования для декодирования информации относительно объединенно кодированных параметров масштабирования. Кроме того, аудиодекодер имеет процессор сигналов, в котором декодер параметров масштабирования выполнен с возможностью комбинирования объединенно кодированного параметра масштабирования первой группы и объединенно кодированного параметра масштабирования второй группы с использованием различных правил комбинирования для получения параметров масштабирования для первого набора параметров масштабирования и параметров масштабирования для второго набора параметров масштабирования, которые затем используются процессором сигналов.
В соответствии с дополнительным аспектом настоящего изобретения предложено устройство деквантования аудиоданных, которое содержит модуль векторного деквантования первой ступени, модуль векторного деквантования второй ступени и модуль комбинирования для комбинирования множества промежуточных квантованных информационных элементов, полученных посредством модуля векторного деквантования первой ступени, и множества остаточных элементов, полученных из модуля векторного деквантования второй ступени, для получения деквантованного множества информационных аудиоэлементов.
Первый аспект объединенного кодирования параметров масштабирования может комбинироваться со вторым аспектом, связанным с двухступенчатым векторным квантованием. С другой стороны, аспект двухступенчатого векторного квантования может применяться к отдельно кодированным параметрам масштабирования, таким как параметры масштабирования для левого канала и правого канала, либо может применяться к средним параметрам масштабирования в качестве другого вида информационного аудиоэлемента. Таким образом, второй аспект двухступенчатого векторного квантования может применяться независимо от первого аспекта или вместе с первым аспектом.
Далее обобщенно поясняются предпочтительные варианты осуществления настоящего изобретения.
В стереосистеме, в которой используется кодирование на основе преобразования (MDCT), параметры масштабирования, которые извлекаются из любой из технологий, описанных во вводном разделе для выполнения формирования шума в частотной области на стороне кодера, должны подвергаться квантованию и кодироваться для включения в качестве вспомогательной информации в поток битов. После этого, на стороне декодера, параметры масштабирования декодируются и используются для масштабирования спектра каждого канала для формирования шума квантования таким способом, который минимально воспринимается.
Независимое кодирование параметров формирования спектрального шума двух каналов: левого и правого, может применяться.
Параметры масштабирования формирования спектрального шума кодируются адаптивно независимо или объединенно, в зависимости от степени корреляции между двумя каналами. В общих словах:
- Среднее/боковое представление параметров масштабирования вычисляется.
- Энергия боковых параметров вычисляется.
- В зависимости от энергии, указывающей степень корреляции между двумя сигналами, параметры кодируются:
- Независимо: аналогично текущему подходу, с использованием, для каждого канала, например, двухступенчатого векторного квантования (VQ).
- Объединенно:
- Средний вектор кодируется с использованием, например, двухступенчатого векторного квантования. Боковой вектор кодируется с использованием более приблизительной схемы квантования, например, посредством такого предположения, что -вывод VQ первой ступени содержит квантованные значения в нуль, и применения только квантования второй ступени, например, алгебраического модуля векторного квантования (AVQ).
- Один дополнительный бит используется для передачи в служебных сигналах того, является ли квантованный боковой вектор нулевым.
- Дополнительный один бит для передачи в служебных сигналах того, кодируются ли два канала объединенно или независимо, отправляется в декодер.
На фиг. 24 показана стереореализация кодера MDCT, как подробно описано в [8]. Существенная часть стереосистемы, описанной в [8], заключается в том, что стереообработка выполняется для «отбеленных» спектров. Следовательно, каждый канал подвергается предварительной обработке, в которой, для каждого кадра, после кодирования со взвешиванием, блок во временной области преобразуется в область MDCT, после чего формирование временного шума (TNS) применяется адаптивно, либо до, либо после формирования спектрального шума (SNS) в зависимости от характеристик сигналов. После формирования спектрального шума, объединенная стереообработка выполняется, а именно, адаптивное решение M-S, L/R для каждой полосы частот для квантования и кодирования отбеленных спектральных коэффициентов эффективным способом. В качестве следующего этапа, стереоанализ на основе интеллектуального заполнения интервалов отсутствия сигнала (IGF) проводится, и соответствующие информационные биты записываются в поток битов. В завершение, обработанные коэффициенты квантуются и кодируются. Добавлены ссылочные позиции, аналогичные ссылочным позициям на фиг. 1. Вычисление и обработка коэффициентов масштабирования осуществляются в блоках "SNS" между двумя блоками TNS на фиг. 24. Блок «кодирование со взвешиванием» иллюстрирует операцию кодирования со взвешиванием. Блок "MCLT" означает модифицированное комплексное перекрывающееся преобразование. Блок "MDCT" означает модифицированное дискретное косинусное преобразование. Блок «спектр мощности» означает вычисление спектра мощности. Блок «решение по блочному переключению» означает анализ входного сигнала для определения длин блоков, которые должны использоваться для кодирования со взвешиванием. Блок "TNS" означает формирование временного шума, и этот признак выполняется до или после масштабирования спектра в блоке "SNS".
В стереореализации MDCT кодека, описанной в [7], на стороне кодера предварительная обработка дискретных каналов L-R выполняется для масштабирования спектров с использованием формирования шума в частотной области в «отбеленную область». После этого, объединенная стереообработка выполняется для квантования и кодирования отбеленных спектров оптимальным способом.
На стороне декодера, как проиллюстрировано на фиг. 25 и описано в [8], кодированный сигнал декодируется, и выполняется обратное квантование и обратная стереообработка. Затем «устраняется отбеливание» спектра каждого канала посредством параметров формирования спектрального шума, которые извлекаются из потока битов. Добавлены ссылочные позиции, аналогичные ссылочным позициям на фиг. 1,. Декодирование и обработка коэффициентов масштабирования осуществляются в блоках 220 на фиг. 25. Блоки, указываемые на чертеже, связаны с блоками в кодере на фиг. 24 и типично выполняют соответствующие обратные операции. Блок «кодирование со взвешиванием и OLA» выполняет операцию синтезирующего кодирования со взвешиванием и последующую операцию сложения с перекрытием для получения выходных сигналов L и R временной области.
Формирование шума в частотной области (FDNS), применяемое в системе в [8], здесь заменяется SNS, как описано в [6]. Блок-схема тракта обработки SNS показана на блок-схемах по фиг. 1 и фиг. 2 для кодера и декодера, соответственно.
Предпочтительно, низкая скорость передачи битов без значительной потери качества может получаться посредством масштабирования, на стороне кодера, с более высоким числом коэффициентов масштабирования и посредством понижающей дискретизации параметров масштабирования на стороне кодера во второй набор параметров масштабирования или коэффициентов масштабирования, причем параметры масштабирования во втором наборе, который затем кодируется и передается или сохраняется через выходной интерфейс, ниже первого числа параметров масштабирования. Таким образом, точное масштабирование, с одной стороны, и низкая скорость передачи битов, с другой стороны, получаются на стороне кодера.
На стороне декодера, передаваемое небольшое число коэффициентов масштабирования декодируется посредством декодера коэффициентов масштабирования для получения первого набора коэффициентов масштабирования, причем число коэффициентов масштабирования или параметров масштабирования в первом наборе больше числа коэффициентов масштабирования или параметров масштабирования второго набора, и после этого, снова, точное масштабирование с использованием более высокого числа параметров масштабирования выполняется на стороне декодера в спектральном процессоре, чтобы получать точно масштабированное спектральное представление.
Таким образом, получается низкая скорость передачи битов, с одной стороны, и при этом высококачественная спектральная обработка спектра аудиосигнала, с другой стороны.
Формирование спектрального шума, выполняемом в предпочтительных вариантах осуществления, реализуется только с использованием очень низкой скорости передачи битов. Таким образом, это формирование спектрального шума может представлять собой важнейшее инструментальное средство даже в аудиокодеке на основе преобразования с низкой скоростью передачи битов. Формирование спектрального шума формирует шум квантования в частотной области таким образом, что шум квантования минимально воспринимается посредством человеческого уха, и в силу этого перцепционное качество декодированного выходного сигнала может максимизироваться.
Предпочтительные варианты осуществления базируются на спектральных параметрах, вычисленных из связанных с амплитудой показателей, таких как энергии спектрального представления. В частности, энергии для каждой полосы частот или, в общем, связанные с амплитудой показатели для каждой полосы частот вычисляются как основание для параметров масштабирования, причем полосы пропускания, используемые при вычислении связанных с амплитудой показателей для каждой полосы частот, увеличиваются от полос нижних к полосам верхних частот, чтобы приближаться к характеристике человеческого слуха в максимально возможной степени. Предпочтительно, разделение спектрального представления на полосы частот выполняется в соответствии с известной шкалой в барках.
В дополнительных вариантах осуществления, параметры масштабирования в линейной области вычисляются и, в частности, вычисляются для первого набора параметров масштабирования с высоким числом параметров масштабирования, и это высокое число параметров масштабирования преобразуется в логарифмическую область. Логарифмическая область, в общем, представляет собой область, в которой небольшие значения расширяются, а высокие значения сжимаются. Далее, операция понижающей дискретизации или прореживания параметров масштабирования выполняется в логарифмической области, которая может представлять собой логарифмическую область с основанием 10 или логарифмическую область с основанием 2, при этом вторая является предпочтительной для целей реализации. Второй набор коэффициентов масштабирования затем вычисляется в логарифмической области, и, предпочтительно, векторное квантование второго набора коэффициентов масштабирования выполняется, при этом коэффициенты масштабирования находятся в логарифмической области. Таким образом, результат векторного квантования указывает параметры масштабирования в логарифмической области. Второй набор коэффициентов масштабирования или параметров масштабирования имеет, например, число коэффициентов масштабирования в половину от числа коэффициентов масштабирования первого набора или даже в одну треть или, еще более предпочтительно, в одну четверть. После этого, квантованное небольшое число параметров масштабирования во втором наборе параметров масштабирования переводится в поток битов и затем передается из стороны кодера в сторону декодера либо сохраняется в качестве кодированного аудиосигнала вместе с квантованным спектром, который также обработан с использованием этих параметров, причем эта обработка дополнительно заключает в себе квантование с использованием глобального усиления. Тем не менее, предпочтительно, кодер извлекает из этих квантованных вторых коэффициентов масштабирования в логарифмической области снова набор коэффициентов масштабирования линейной области, который представляет собой третий набор коэффициентов масштабирования, и число коэффициентов масштабирования в третьем наборе коэффициентов масштабирования больше второго числа и предпочтительно даже равно первому числу коэффициентов масштабирования в первом наборе первых коэффициентов масштабирования. Затем на стороне кодера, эти интерполированные коэффициенты масштабирования используются для обработки спектрального представления, причем обработанное спектральное представление в конечном счете квантуется и в любом случае энтропийно кодируется, к примеру, посредством кодирования кодом Хаффмана, арифметического кодирования либо кодирования на основе векторного квантования и т.д.
В декодере, который принимает кодированный сигнал, имеющий низкое число спектральных параметров, вместе с кодированным представлением спектрального представления, низкое число параметров масштабирования интерполируется в высокое число параметров масштабирования, т.е. для получения первого набора параметров масштабирования, причем число параметров масштабирования коэффициентов масштабирования из второго набора коэффициентов масштабирования или параметров масштабирования меньше числа параметров масштабирования из первого набора, т.е. набора, вычисленного посредством декодера коэффициентов/параметров масштабирования. Затем спектральный процессор, расположенный в устройстве для декодирования кодированного аудиосигнала, обрабатывает декодированное спектральное представление с использованием этого первого набора параметров масштабирования для получения масштабированного спектрального представления. Преобразователь для преобразования масштабированного спектрального представления затем работает с возможностью получения в конечном счете декодированного аудиосигнала, который предпочтительно находится во временной области.
Дополнительные варианты осуществления приводят к дополнительным преимуществам, изложенным ниже. В предпочтительных вариантах осуществления, формирование спектрального шума выполняется с помощью 16 параметров масштабирования, аналогичных коэффициентам масштабирования, используемым в [6] или в [8], или в [1]. Эти параметры получаются в кодере посредством вычисления сначала энергии спектра MDCT в 64 неравномерных полосах частот (аналогичных 64 неравномерным полосам частот документа 3 из уровня техники), затем посредством применения некоторой обработки к 64 энергиям (сглаживания, коррекции предыскажений, минимального уровня шума, логарифмического преобразования), затем посредством понижающей дискретизации 64 обработанных энергий на коэффициент 4, чтобы получать 16 параметров, которые в конечном счете нормализуются и масштабируются. Эти 16 параметров затем квантуются с использованием векторного квантования (с использованием векторного квантования, аналогичного векторному квантованию, используемому в документах 2/3 из уровня техники). Квантованные параметры затем интерполируются, чтобы получать 64 интерполированных параметра масштабирования. 64 параметра масштабирования затем используются для непосредственного формирования спектра MDCT в 64 неравномерных полосах частот. Аналогично документам 2 и 3 из уровня техники, масштабированные коэффициенты MDCT затем квантуются с использованием модуля скалярного квантования с размером шага, управляемым посредством глобального усиления.
В дополнительном варианте осуществления, информация относительно объединенно кодированных параметров масштабирования для одной из двух групп, к примеру, для второй группы, предпочтительно связанной с боковыми параметрами масштабирования, не содержит индексы квантования или другие биты квантования, а содержит только информацию, такую как флаг или один бит, указывающий, что все параметры масштабирования для второй группы являются нулевыми для части или кадра аудиосигнала. Эта информация определяется кодером посредством анализа или другим средством и используется декодером для синтеза второй группы параметров масштабирования на основе этой информации, к примеру, посредством формирования нулевых параметров масштабирования для временной части или кадра аудиосигнала, либо используется декодером для вычисления первого и второго набора параметров масштабирования только с использованием первой группы объединенно кодированных параметров масштабирования.
В дополнительном варианте осуществления, вторая группа объединенно кодированных параметров масштабирования квантуется только с использованием второй ступени квантования двухступенчатого модуля квантования, который предпочтительно представляет собой ступень модуля квантования с переменной скоростью. В этом случае, предполагается, что первая ступень приводит в результате ко всем нулевым квантованным значениям, так что только вторая ступень является эффективной. В еще одном дополнительном варианте осуществления, применяется только первая ступень квантования двухступенчатого модуля квантования, который предпочтительно представляет собой ступень квантования с фиксированной скоростью, а вторая ступень вообще не используется для временной части или кадра аудиосигнала. Этот случай соответствует ситуации, в которой все остаточные элементы предположительно равны нулю либо меньше наименьшего или первого размера шага квантования второй ступени квантования.
Далее предпочтительные варианты осуществления настоящего изобретения поясняются с обращением к сопровождающим чертежам, на которых:
Фиг. 1 иллюстрирует декодер в соответствии с первым аспектом;
Фиг. 2 иллюстрирует кодер в соответствии с первым аспектом;
Фиг. 3a иллюстрирует другой кодер в соответствии с первым аспектом;
Фиг. 3b иллюстрирует другую реализацию кодера в соответствии с первым аспектом;
Фиг. 4a иллюстрирует дополнительный вариант осуществления декодера в соответствии с первым аспектом;
Фиг. 4b иллюстрирует другой вариант осуществления декодера;
Фиг. 5 иллюстрирует дополнительный вариант осуществления кодера;
Фиг. 6 иллюстрирует дополнительный вариант осуществления кодера;
Фиг. 7a иллюстрирует предпочтительную реализацию модуля векторного деквантования в соответствии с первым или вторым аспектом;
Фиг. 7b иллюстрирует дополнительный модуль квантования в соответствии с первым или вторым аспектом;
Фиг. 8a иллюстрирует декодер в соответствии с первым аспектом настоящего изобретения;
Фиг. 8b иллюстрирует кодер в соответствии с первым аспектом настоящего изобретения;
Фиг. 9a иллюстрирует кодер в соответствии со вторым аспектом настоящего изобретения;
Фиг. 9b иллюстрирует декодер в соответствии со вторым аспектом настоящего изобретения;
Фиг. 10 иллюстрирует предпочтительную реализацию декодера в соответствии с первым или вторым аспектом;
Фиг. 11 является блок-схемой устройства для кодирования аудиосигнала;
Фиг. 12 является схематичным представлением предпочтительной реализации модуля вычисления коэффициентов масштабирования по фиг. 1;
Фиг. 13 является схематичным представлением предпочтительной реализации модуля понижающей дискретизации по фиг. 1;
Фиг. 14 является схематичным представлением кодера коэффициентов масштабирования по фиг. 4;
Фиг. 15 является схематичной иллюстрацией спектрального процессора по фиг. 1;
Фиг. 16 иллюстрирует общее представление кодера, с одной стороны, и декодера, с другой стороны, реализующих формирование спектрального шума (SNS);
Фиг. 17 иллюстрирует более подробное представление стороны кодера, с одной стороны, и стороны декодера, с другой стороны, в котором формирование временного шума (TNS) реализуется вместе с формированием спектрального шума (SNS);
Фиг. 18 иллюстрирует блок-схему устройства для декодирования кодированного аудиосигнала;
Фиг. 19 является схематичной иллюстрацией, представляющей подробности декодера коэффициентов масштабирования, спектрального процессора и спектрального декодера по фиг. 8;
Фиг. 20 иллюстрирует подразделение спектра на 64 полосы частот;
Фиг. 21 приводит схематичную иллюстрацию операции понижающей дискретизации, с одной стороны, и операции интерполяции, с другой стороны;
Фиг. 22a иллюстрирует аудиосигнал временной области с перекрывающимися кадрами;
Фиг. 22b иллюстрирует реализацию преобразователя по фиг. 1;
Фиг. 22c приводит схематичную иллюстрацию преобразователя по фиг. 8;
Фиг. 23 иллюстрирует гистограмму, сравнивающую различные процедуры согласно изобретению;
Фиг. 24 иллюстрирует вариант осуществления кодера; и
Фиг. 22c иллюстрирует вариант осуществления декодера.
Фиг. 8 иллюстрирует аудиодекодер для декодирования кодированного аудиосигнала, содержащего многоканальные аудиоданные, содержащие данные для двух или более аудиоканалов и информацию относительно объединенно кодированных параметров масштабирования. Декодер содержит декодер 220 параметров масштабирования и процессор 210, 212, 213 сигналов, проиллюстрированные на фиг. 8a в качестве одного элемента. Декодер 220 параметров масштабирования принимает информацию относительно объединенно кодированной первой группы и второй группы параметров масштабирования, причем, предпочтительно, первая группа параметров масштабирования представляет собой средние параметры масштабирования, и вторая группа параметров масштабирования представляет собой боковые параметры масштабирования. Предпочтительно, процессор сигналов принимает первое канальное представление многоканальных аудиоданных и второе канальное представление многоканальных аудиоданных и применяет первый набор параметров масштабирования к первому канальному представлению, извлекаемому из многоканальных аудиоданных, и применяет второй набор параметров масштабирования к второму канальному представлению, извлекаемому из многоканальных аудиоданных, с тем чтобы получать первый канал и второй канал декодированного аудиосигнала в выводе блока 210, 212, 213 по фиг. 8a. Предпочтительно, объединенно кодированные параметры масштабирования содержат информацию относительно первой группы объединенно кодированных параметров масштабирования, такую как средние параметры масштабирования, и информацию относительно второй группы объединенно кодированных параметров масштабирования, такую как боковые параметры масштабирования. Кроме того, декодер 220 параметров масштабирования выполнен с возможностью комбинирования объединенно кодированного параметра масштабирования первой группы и объединенно кодированного параметра масштабирования второй группы с использованием первого правила комбинирования для получения параметра масштабирования из первого набора параметров масштабирования, и комбинирования тех же обоих из объединенно кодированных параметров масштабирования первой и второй групп с использованием второго правила комбинирования, отличного от первого правила комбинирования, для получения параметра масштабирования из второго набора параметров масштабирования. Таким образом, декодер 220 параметров масштабирования применяет два различных правила комбинирования.
В предпочтительном варианте осуществления, два различных правила комбинирования представляют собой правило комбинирования в форме сложения или суммы, с одной стороны, и правило комбинирования в форме вычитания или разности, с другой стороны. Тем не менее, в других вариантах осуществления, первое правило комбинирования может представлять собой правило комбинирования в форме умножения, и второе правило комбинирования может представлять собой правило комбинирования в форме частного или деления. Таким образом, все другие пары правил комбинирования являются полезными также в зависимости от представления соответствующих параметров масштабирования первой группы и второй группы или первого набора и второго набора параметров масштабирования.
Фиг. 8b иллюстрирует соответствующий аудиокодер для кодирования многоканального аудиосигнала, содержащего два или более каналов. Аудиокодер содержит модуль 140 вычисления параметров масштабирования, процессор 120 сигналов и модуль 1480, 1500 формирования кодированных сигналов. Модуль 140 вычисления параметров масштабирования выполнен с возможностью вычисления первой группы объединенно кодированных параметров масштабирования и второй группы объединенно кодированных параметров масштабирования из первого набора параметров масштабирования для первого канала многоканального аудиосигнала и из второго набора параметров масштабирования для второго канала многоканального аудиосигнала. Кроме того, процессор сигналов выполнен с возможностью применения первого набора параметров масштабирования к первому каналу многоканального аудиосигнала и применения второго набора параметров масштабирования ко второму каналу многоканального аудиосигнала для извлечения кодированных многоканальных аудиоданных. Многоканальные аудиоданные извлекаются из масштабированных первых и вторых каналов, и многоканальные аудиоданные используются посредством модуля 1480, 1500 формирования кодированных сигналов вместе с информацией относительно первой и второй группы объединенно кодированных параметров масштабирования для получения кодированного многоканального аудиосигнала в выводе блока 1500 на фиг. 8b.
Фиг. 1 иллюстрирует дополнительную реализацию декодера по фиг. 8a. В частности, поток битов вводится в процессор 210 сигналов, который выполняет, типично, энтропийное декодирование и обратное квантование вместе с процедурами на основе интеллектуального заполнения интервалов отсутствия сигнала (процедурами IGF) и обратной стереообработкой масштабированных или отбеленных каналов. Вывод блока 210 представляет собой масштабированные или отбеленные декодированные левый и правый либо, в общем, несколько декодированных каналов многоканального сигнала. Поток битов содержит вспомогательные информационные биты для параметров масштабирования для левого и правого в случае раздельного кодирования и вспомогательные информационные биты для масштабированных объединенно кодированных параметров масштабирования, проиллюстрированных в качестве M-, S-параметров масштабирования на фиг. 1. Эти данные вводятся в декодер 220 параметров масштабирования или коэффициентов масштабирования, который в выводе, формирует декодированные левые коэффициенты масштабирования и декодированные правые коэффициенты масштабирования, которые затем применяются в блоке 212, 230 формирования спектра, чтобы в конечном счете получать предпочтительно спектр MDCT для левого и правого, который затем может быть преобразован во временную область с использованием определенной обратной операции MDCT.
Соответствующая реализация на стороне кодера приводится на фиг. 2. Фиг. 2 начинается со спектра MDCT, имеющего левый и правый канал, которые вводятся в модуль 120a формирования спектра, и вывод модуля 120a формирования спектра вводится в процессор 120b, который, например, выполняет операции стереообработки, интеллектуального заполнения интервалов отсутствия сигнала на стороне кодера и соответствующие операции квантования и (энтропийного) кодирования. Таким образом, блоки 120a, 120b вместе представляют процессор 120 сигналов по фиг. 8b. Кроме того, для целей вычисления коэффициентов масштабирования, которое выполняется в блоке 120b для вычисления коэффициентов масштабирования при SNS (формировании спектрального шума), также предусмотрены спектр MDST, и спектр MDST вместе со спектром MDCT перенаправляется в модуль 110a вычисления спектра мощности. В качестве альтернативы, модуль 110a вычисления спектра мощности может работать непосредственно для входного сигнала без процедуры вычисления спектра MDCT или MDST. Другой способ, например, заключается в том, чтобы вычислять спектр мощности из DFT-операции, а не из операции MDCT и MDST. Кроме того, коэффициенты масштабирования вычисляются посредством модуля 140 вычисления параметров масштабирования, который проиллюстрирован на фиг. 2 в качестве блока кодирования с квантованием коэффициентов масштабирования. В частности, блок 140 выводит, в зависимости от подобия между первым и вторым каналом, отдельно кодированные коэффициенты масштабирования для левого и правого либо объединенно кодированные коэффициенты масштабирования для M и S. Это проиллюстрировано на фиг. 2 справа от блока 140. Таким образом, в этой реализации, блок 110b вычисляет коэффициенты масштабирования для левого и правого, и блок 140 затем определяет то, лучше или хуже раздельное кодирование, т.е. кодирование для левых и правых коэффициентов масштабирования, чем кодирование объединенно кодированных коэффициентов масштабирования, т.е. M- и S-коэффициентов масштабирования, извлекаемых из отдельных коэффициентов масштабирования, посредством двух различных правил комбинирования, таких как сложение, с одной стороны, и вычитание, с другой стороны.
Результат блока 140 представляет собой вспомогательные информационные биты для L, R или M, S, которые, вместе с результатом блока 120b, вводятся в выходной поток битов, проиллюстрированный посредством фиг. 2.
Фиг. 3a иллюстрирует предпочтительную реализацию кодера по фиг. 2 или по фиг. 8b. Первый канал вводится в блок 1100a, который определяет отдельные параметры масштабирования для первого канала, т.е. для канала L. Кроме того, второй канал вводится в блок 1100b, который определяет отдельные параметры масштабирования для второго канала, т.е. для R. Затем параметры масштабирования для левого канала и параметры масштабирования для правого канала, соответственно, дискретизируются с понижением посредством модуля 130a понижающей дискретизации для первого канала и модуля 130b понижающей дискретизации для второго канала. Результаты представляют собой дискретизированные с понижением параметры (DL) для левого канала и дискретизированные с понижением параметры для правого канала (DR).
Затем эти данные DL и DR вводятся в модуль 1200 определения объединенных параметров масштабирования. Модуль 1200 определения объединенных параметров масштабирования формирует первую группу объединенно кодированных параметров масштабирования, таких как средние или M-параметры масштабирования и вторую группу объединенно кодированных параметров масштабирования, таких как боковые или S-параметры масштабирования. Обе группы вводятся в соответствующие модули 140a, 140b векторного квантования для получения квантованных значений, которые затем передаются в конечный энтропийный кодер 140c и должны кодироваться для получения информации в отношении объединенно кодированных параметров масштабирования.
Энтропийный кодер 140c может быть реализован с возможностью выполнения алгоритма арифметического энтропийного кодирования или алгоритма энтропийного кодирования с помощью одномерных либо с помощью одно- или более мерных кодовых таблиц Хаффмана.
Другая реализация кодера проиллюстрирована на фиг. 3b, в которой понижающая дискретизация не выполняется с отдельными параметрами масштабирования, к примеру, с левым и правым, как проиллюстрировано в 130a, 130b на фиг. 3a. Вместо этого, порядок операций определения объединенных параметров масштабирования и последующей понижающей дискретизации посредством соответствующих модулей 130a, 130b понижающей дискретизации изменяется. То, используется реализация по фиг. 3a или по фиг. 3b, зависит от конкретной реализации, причем реализация по фиг. 3a является предпочтительной, поскольку определение 1200 объединенных параметров масштабирования уже выполняется для дискретизированных с понижением параметров масштабирования, т.е. два различных правила комбинирования, выполняемые посредством модуля 140 вычисления параметров масштабирования, типично выполняются для меньшего числа вводов по сравнению со случаем на фиг. 3b.
Фиг. 4a иллюстрирует реализацию декодера для декодирования кодированного аудиосигнала, имеющего многоканальные аудиоданные, содержащие данные для двух или более аудиоканалов и информацию относительно объединенно кодированных параметров масштабирования. Тем не менее, декодер на фиг. 4a представляет собой только часть целого декодера по фиг. 8a, поскольку только часть процессора сигналов, и, в частности, соответствующие модули 212a, 212b канального масштабирования проиллюстрированы на фиг. 4a. Относительно декодера 220 параметров масштабирования, этот элемент содержит энтропийный декодер 2200, осуществляющий в обратном порядке процедуру, выполняемую посредством соответствующего блока 140c на фиг. 3a. Кроме того, энтропийный декодер выводит квантованные объединенно кодированные параметры масштабирования, такие как квантованные M-параметры масштабирования и квантованные S-параметры масштабирования. Соответствующие группы параметров масштабирования вводятся в модули 2202 и 2204 деквантования для получения деквантованных значений для M и S. Эти деквантованные значения затем вводятся в модуль 2206 определения отдельных параметров масштабирования, который выводит параметры масштабирования для левого и правого, т.е. отдельные параметры масштабирования. Эти соответствующие параметры масштабирования вводятся в интерполяторы 222a, 222b, чтобы получать интерполированные параметры масштабирования для левого (IL) и интерполированные параметры масштабирования для правого (IR). Эти данные вводятся в модуль 212a и 212b канального масштабирования, соответственно. Кроме того, модули канального масштабирования, соответственно, например, принимают первое канальное представление после полной процедуры, выполненной посредством блока 210 на фиг. 1. Соответственно, модуль 212b канального масштабирования также получает свое соответствующее второе канальное представление в качестве вывода посредством блока 210 на фиг. 1. Затем конечное канальное масштабирование или «формирование спектра», как оно называется на фиг. 1, осуществляется для получения спектрального канала определенной формы для левого и правого, который проиллюстрирован в виде «спектра MDCT» на фиг. 1. После этого, конечное преобразование из частотной области во временную область для каждого канала, проиллюстрированное на 240a, 240b, может выполняться для получения в конечном итоге декодированного первого канала и декодированного второго канала многоканального аудиосигнала в представлении во временной области.
В частности, декодер 220 параметров масштабирования, проиллюстрированный в левой части по фиг. 4a, может включаться в аудиодекодер, как показано на фиг. 1 либо как совместно показано на фиг. 4a, но также может включаться в качестве локального декодера в кодер, как показано относительно фиг. 5, явно показывающего локальный декодер 220 параметров масштабирования в выводе кодера 140 параметров масштабирования.
Фиг. 4b иллюстрирует дополнительную реализацию, в которой по сравнению с фиг. 4a изменён порядок интерполяции и определения параметров масштабирования для определения отдельных параметров масштабирования. В частности, интерполяция осуществляется с объединенно кодированными параметрами M и S масштабирования с использованием интерполяторов 222a, 222b по фиг. 4b, и интерполированные объединенно кодированные параметры масштабирования, такие как IM и IS, вводятся в модуль 2206 определения отдельных параметров масштабирования. Затем вывод блока 2206 представляют собой дискретизированные с повышением параметры масштабирования, т.е. параметры масштабирования, например, для каждой из 64 полос частот, проиллюстрированных на фиг. 21.
Фиг. 5 иллюстрирует дополнительную предпочтительную реализацию кодера по фиг. 8b, по фиг. 2 либо по фиг. 3a, фиг. 3b. Первый канал и второй канал вводятся в факультативный преобразователь из временной области в частотную область, к примеру, в 100a, 100b по фиг. 5. Спектральное представление, выводимое посредством блоков 100a, 100b, вводится в модуль 120a канального масштабирования, который отдельно масштабирует спектральное представление для левого и правого канала. Таким образом, модуль 120a канального масштабирования выполняет операцию формирования спектра, проиллюстрированную в 120a по фиг. 2. Вывод модуля канального масштабирования вводится в процессор 120b каналов по фиг. 5, и обработанный канальный вывод блока 120b вводится в модуль 1480, 1500 формирования кодированных сигналов для получения кодированного аудиосигнала.
Кроме того, для целей определения отдельно или объединенно кодированных параметров масштабирования предусмотрен модуль 1400 вычисления подобий, который принимает, в качестве ввода, первый канал и второй канал непосредственно во временной области. В качестве альтернативы, модуль вычисления подобий может принимать первый канал и второй канал в выводе преобразователей 100a, 100b из временной области в частотную область, т.е. в спектральном представлении.
Хотя относительно фиг. 6 следует подчеркнуть, что подобие между двумя каналами вычисляется на основе второй группы объединенно кодированных параметров масштабирования, т.е. на основе боковых параметров масштабирования, следует отметить, что это подобие также может вычисляться на основе каналов временной области или спектральной области непосредственно без явного вычисления объединенно кодированных параметров масштабирования. В качестве альтернативы, подобие также может определяться на основе первой группы объединенно кодированных параметров масштабирования, т.е. на основе средних параметров масштабирования. В частности, когда энергия боковых параметров масштабирования ниже порогового значения, затем определяется то, что объединенное кодирование может выполняться. Аналогично, например, энергия средних параметров масштабирования в кадре также может измеряться, и определение для объединенного кодирования может выполняться, когда энергия средних параметров масштабирования больше другого порогового значения. Таким образом, может быть реализовано много различных способов определения подобия между первым каналом и вторым каналом для принятия решения по объединенному кодированию параметров масштабирования или отдельному кодированию параметров масштабирования. Тем не менее, следует отметить, что определение для объединенного или отдельного кодирования параметров масштабирования не обязательно должно быть таким же, что и определение объединенного стереокодирования для каналов, т.е. если два канала кодируются объединенно с использованием среднего/бокового представления или кодируются отдельно в L-, R-представлении. Определение объединенного кодирования параметров масштабирования выполняется независимо от определения стереообработки для фактических каналов, поскольку определение любого вида стереообработки, выполняемой в блоке 120b на фиг. 2, осуществляется исключительно после масштабирования или формирования спектра с использованием коэффициентов масштабирования для среднего и бокового. В частности, как проиллюстрировано на фиг. 2, блок 140 может определять объединенное кодирование. Таким образом, как проиллюстрировано посредством стрелки на фиг. 2, указывающей на блок 140, коэффициенты масштабирования для M и S могут возникать в этом блоке. В случае применения локального декодера 220 параметров масштабирования в кодере по фиг. 5, в таком случае фактически используемые параметры масштабирования для формирования спектра, хотя и представляют собой параметры масштабирования для левого и параметры масштабирования для правого, тем не менее, извлекаются из кодированных и декодированных параметров масштабирования для среднего и бокового.
Обращаясь к фиг. 5, предусмотрен модуль 1402 принятия решений по выбору режима. Модуль 1402 принятия решений по выбору режима принимает вывод модуля 1400 вычисления подобий и принимает решение по отдельному кодированию параметров масштабирования, когда каналы не являются аналогичными в достаточной степени. Тем не менее, если определено, что каналы являются аналогичными, затем объединенное кодирование параметров масштабирования определяется посредством блока 1402, и информация в отношении того, применяется ли отдельное или измененное объединенное кодирование параметров масштабирования, передается в служебных сигналах посредством соответствующей вспомогательной информации или флага 1403, проиллюстрированного на фиг. 5, который передаётся из блока 1402 в модуль 1480, 1500 формирования кодированных сигналов. Кроме того, кодер содержит кодер 140 параметров масштабирования, который принимает параметры масштабирования для первого канала и параметры масштабирования для второго канала и кодирует параметры масштабирования отдельно или объединенно, что управляется посредством модуля 1402 принятия решений по выбору режима. Кодер 140 параметров масштабирования может, в одном варианте осуществления, выводить параметры масштабирования для первого и второго канала, как указано посредством пунктирных линий, так что модуль 120a канального масштабирования выполняет масштабирование с соответствующими параметрами масштабирования первого и второго канала. Тем не менее, предпочтительно применять локальный декодер 220 параметров масштабирования в кодере таким образом, что канальное масштабирование осуществляется с локально кодированными и декодированными параметрами масштабирования, так что деквантованные параметры масштабирования применяются для канального масштабирования в кодере. Это имеет такое преимущество, что совершенно одинаковая ситуация реализуется в модуле канального масштабирования в кодере и декодере по меньшей мере относительно используемых параметров масштабирования для канального масштабирования или формирования спектра.
Фиг. 6 иллюстрирует дополнительный предпочтительный вариант осуществления настоящего изобретения относительно аудиокодера. Предусмотрен модуль 100 вычисления спектра MDCT, который, например, может представлять собой преобразователь из временной области в частотную область, применяющий алгоритм MDCT. Кроме того, предусмотрен модуль 110a вычисления спектра мощности, как проиллюстрировано на фиг. 2. Отдельные параметры масштабирования вычисляются посредством соответствующего модуля 1100 вычисления и, для целей вычисления объединенно кодированных параметров масштабирования, блока 1200a сложения и блока 1200b вычитания. После этого, для целей определения подобия, выполняется вычисление энергии в расчете на кадр с боковыми параметрами, т.е. со второй группой объединенно кодированных параметров масштабирования. В блоке 1406, выполняется сравнение с пороговым значением, и этот блок, аналогичный модулю 1402 принятия решений по выбору режима для кадра по фиг. 5, выводит флаг режима или стереофлаг для соответствующего кадра. Кроме того, информация передаётся в управляемый кодер, который выполняет отдельное или объединенное кодирование в текущем кадре. С этой целью, управляемый кодер 140 принимает параметры масштабирования, вычисленные посредством блока 1100, т.е. отдельные параметры масштабирования и, кроме того, принимает объединенно кодированные параметры масштабирования, т.е. параметры масштабирования, определенные посредством блока 1200a и 1200b.
Блок 140 предпочтительно формирует нулевой флаг для кадра, когда блок 140 определяет то, что все боковые параметры кадра квантуются до 0. Этот результат должен возникать, когда первый и второй канал находятся очень близко друг к другу, и разности между каналами и в силу этого разности между коэффициентами масштабирования являются такими, что эти разности меньше наименьшего порогового значения квантования, применяемого модулем квантования, включенным в блок 140. Блок 140 выводит информацию относительно объединенно кодированных или отдельно кодированных параметров масштабирования для соответствующего кадра.
Фиг. 9a иллюстрирует устройство квантования аудиоданных для квантования множества информационных аудиоэлементов. Устройство квантования аудиоданных содержит модуль 141, 143 векторного квантования первой ступени для квантования множества информационных аудиоэлементов, таких как коэффициенты масштабирования или параметры масштабирования либо спектральные значения и т.д., чтобы определять результат 146 векторного квантования первой ступени. Кроме того, блок 141, 143 формирует множество промежуточных квантованных элементов, соответствующих результату векторного квантования первой ступени. Промежуточные квантованные элементы, например, представляют собой значения, ассоциированные с результатом первой ступени. Когда результат первой ступени идентифицирует определенную таблицу кодирования, например, с 16 определенных (квантованных) значений, в таком случае промежуточные квантованные элементы представляют собой 16 значений, ассоциированных с векторным индексом таблицы кодирования, представляющим собой результат 146 первой ступени. Промежуточные квантованные элементы и информационные аудиоэлементы во вводе в модуль 141, 143 векторного квантования первой ступени вводятся в модуль определения остаточных элементов для вычисления множества остаточных элементов из множества промежуточных квантованных элементов и множества информационных аудиоэлементов. Это, например, выполняется посредством вычисления разности для каждого элемента между исходным элементом и квантованным элементом. Остаточные элементы вводятся в модуль 145 векторного квантования второй ступени для квантования множества остаточных элементов для получения результата векторного квантования второй ступени. В таком случае, результат векторного квантования первой ступени в выводе блока 141, 143 и результата второй ступени в выводе блока 145 вместе представляет квантованное представление множества информационных аудиоэлементов, которое кодируется посредством факультативного модуля 1480, 1500 формирования кодированных сигналов, который выводит квантованные информационные аудиоэлементы, которые, в предпочтительном варианте осуществления, не только квантуются, но и дополнительно энтропийно кодируются.
Соответствующее устройство деквантования аудиоданных проиллюстрировано на фиг. 9b. Устройство деквантования аудиоданных содержит модуль 2220 векторного деквантования первой ступени для деквантования результата квантования первой ступени, включенного в квантованное множество информационных аудиоэлементов для получения множества промежуточных квантованных информационных аудиоэлементов. Кроме того, предусмотрен модуль 2260 векторного деквантования второй ступени, выполненный с возможностью деквантования результата векторного квантования второй ступени, включенного в квантованное множество информационных аудиоэлементов для получения множества остаточных элементов. Как промежуточные элементы из блока 2220, так и остаточные элементы из блока 2260 комбинируются модулем 2240 комбинирования для комбинирования множества промежуточных квантованных аудиоэлементов и множества остаточных элементов для получения деквантованного множества информационных аудиоэлементов. В частности, промежуточные квантованные элементы в выводе блока 2220 представляют собой отдельно кодированные параметры масштабирования, такие как для L и R или первую группу объединенно кодированных параметров масштабирования, например, для M, и остаточные элементы могут представлять объединенно кодированные боковые параметры масштабирования, например, т.е. вторую группу объединенно кодированных параметров масштабирования.
Фиг. 7a иллюстрирует предпочтительную реализацию модуля 141, 143 векторного квантования первой ступени по фиг. 9a. На этапе 701, векторное квантование первого поднабора параметров масштабирования выполняется для получения первого индекса квантования. На этапе 702 выполняется векторное квантование второго поднабора параметров масштабирования для получения второго индекса квантования. Кроме того, в зависимости от реализации, выполняется векторное квантование третьего поднабора параметров масштабирования, как проиллюстрировано в блоке 703, для получения третьего индекса квантования, который представляет собой факультативный индекс. Процедура на фиг. 7a применяется, когда возникает квантование с разбиением на уровни. В качестве примера, входной аудиосигнал разделяется на 64 полосы частот, проиллюстрированные на фиг. 21. 64 полосы частот дискретизируются с понижением до 16 полос частот/коэффициентов масштабирования, так что полная полоса частот покрывается 16 коэффициентами масштабирования. Эти 16 коэффициентов масштабирования квантуются посредством модуля 141, 143 векторного квантования первой ступени в режиме с разбиением на уровни, проиллюстрированном на фиг. 7a. Первые 8 коэффициентов масштабирования из 16 коэффициентов масштабирования по фиг. 21, которые получаются посредством понижающей дискретизации исходных 64 коэффициентов масштабирования, векторно квантуются посредством этапа 701 и в силу этого представляют первый поднабор параметров масштабирования. Оставшиеся 8 параметров масштабирования для 8 полос верхних частот представляют второй поднабор параметров масштабирования, которые векторно квантуются на этапе 702. В зависимости от реализации, отделение полного набора параметров масштабирования или информационных аудиоэлементов не обязательно должно выполняться точно в двух поднаборах, но также может выполняться в трех поднаборах либо в еще большем количестве поднаборов.
Независимо от того, сколько разбиений выполняется, индексы для каждого уровня вместе представляют результат первой ступени. Как пояснено относительно фиг. 14, эти индексы могут комбинироваться через модуль комбинирования индексов на фиг. 14 таким образом, чтобы иметь один индекс первой ступени. В качестве альтернативы, результат первой ступени может состоять из первого индекса и второго индекса и потенциального третьего индекса и вероятно еще большего количества индексов, которые не комбинируются, но которые энтропийно кодируются как есть.
В дополнение к соответствующим индексам, формирующим результат первой ступени, этап 701, 702, 703 также предусматривает промежуточные параметры масштабирования, которые используются в блоке 704 для целей вычисления остаточных параметров масштабирования для кадра. Следовательно, этап 705, который выполняется, например, посредством блока 142 по фиг. 9a, приводит к остаточным параметрам масштабирования, которые затем обрабатываются посредством (алгебраического) векторного квантования, выполняемого посредством этапа 705, чтобы формировать результат второй ступени. Таким образом, результат первой ступени и результат второй ступени формируются для отдельных параметров L масштабирования, отдельных параметров R масштабирования и первой группы объединенных параметров M масштабирования. Тем не менее, как проиллюстрировано на фиг. 7b, (алгебраическое) векторное квантование второй группы объединенно кодированных параметров масштабирования или боковых параметров масштабирования выполняется только посредством этапа 706, который в предпочтительной реализации является одинаковым с этапом 705 и вновь выполняется посредством блока 142 по фиг. 9a.
В дополнительном варианте осуществления, информация относительно объединенно кодированных параметров масштабирования для одной из двух групп, к примеру, для второй группы, предпочтительно связанной с боковыми параметрами масштабирования, не содержит индексы квантования или другие биты квантования, а содержит только информацию, такую как флаг или один бит, указывающий, что все параметры масштабирования для второй группы являются нулевыми для части или кадра аудиосигнала либо имеют определенное значение, к примеру, небольшое значение. Эта информация определяется посредством кодера посредством анализа либо посредством другого средства и используется посредством декодера для синтеза второй группы параметров масштабирования на основе этой информации, к примеру, посредством формирования нулевых параметров масштабирования для временной части или кадра аудиосигнала либо посредством формирования параметров масштабирования с определенным значением, либо посредством формирования небольших случайных параметров масштабирования, все из которых меньше наименьшего или первой ступени квантования, либо используется декодером для вычисления первого и второго набора параметров масштабирования только с использованием первой группы объединенно кодированных параметров масштабирования. Следовательно, вместо выполнения ступени 705 на фиг. 7a, только флаг всех нулевых значений для второй группы объединенно кодированных параметров масштабирования записывается в качестве результата второй ступени. Вычисление в блоке 704 также может опускаться в этом случае и может заменяться посредством модуля решения для принятия решения в отношении того, должен ли активироваться и передаваться флаг всех нулевых значений. Этот модуль решения может управляться посредством пользовательского ввода, указывающего вообще пропуск кодирования параметров S, или информации скорости передачи битов, либо может фактически выполнять анализ остаточных элементов. Следовательно, для кадра, имеющего бит всех нулевых значений, декодер параметров масштабирования не выполняет комбинирование, а вычисляет второй набор параметров масштабирования только с использованием первой группы объединенно кодированных параметров масштабирования, к примеру, посредством деления кодированных параметров масштабирования первой группы на два или посредством взвешивания с использованием другого заданного значения.
В дополнительном варианте осуществления, вторая группа объединенно кодированных параметров масштабирования квантуется только с использованием второй ступени квантования двухступенчатого модуля квантования, который предпочтительно представляет собой ступень модуля квантования с переменной скоростью. В этом случае, предполагается, что первая ступень приводит в результате ко всем нулевым квантованным значениям, так что только вторая ступень является эффективной. Этот случай проиллюстрирован на фиг. 7b.
В еще одном дополнительном варианте осуществления, только применяется первая ступень квантования, такая как 701, 702, 703, из двухступенчатого модуля квантования на фиг. 7a, который предпочтительно представляет собой ступень квантования с фиксированной скоростью, а вторая ступень 705 вообще не используется для временной части или кадра аудиосигнала. Этот случай соответствует ситуации, в которой все остаточные элементы предположительно равны нулю либо меньше наименьшего или первого размера шага квантования второй ступени квантования. Далее, на фиг. 7b, элемент 706 соответствует элементам 701, 702, 703 по фиг. 7a, и элемент 704 также может опускаться и может заменяться посредством модуля решения для принятия решения в отношении того, используется ли только квантование первой ступени. Этот модуль решения может управляться посредством пользовательского ввода или информации скорости передачи битов либо может фактически выполнять анализ остаточных элементов для определения, что остаточные элементы являются достаточно небольшими, таким образом, что точность второй группы объединенно кодированных параметров масштабирования, квантованных посредством только одной ступени, является достаточной.
В предпочтительной реализации настоящего изобретения, которая дополнительно иллюстрируется на фиг. 14, алгебраический модуль 145 векторного квантования дополнительно выполняет вычисление с разбиением на уровни и, предпочтительно, выполняет операцию с разбиением на уровни, одинаковую с операцией, которая выполняется посредством модуля векторного квантования. Таким образом, поднаборы остаточных значений соответствуют, относительно номера полосы частот, поднабору параметров масштабирования. Для случая наличия двух уровней разбиения, т.е. для первых 8 дискретизированных с понижением полос частот по фиг. 21, алгебраический модуль 145 векторного квантования формирует результат первого уровня. Кроме того, алгебраический модуль 145 векторного квантования формирует результат второго уровня для верхних 8 дискретизированных с понижением коэффициентов масштабирования или параметров масштабирования либо, в общем, информационных аудиоэлементов.
Предпочтительно, алгебраический модуль 145 векторного квантования реализован как алгебраический модуль векторного квантования, определённый в разделе 5.2.3.1.6.9 документа ETSI TS 126 445 V13.2.0 (2016-08), упомянутого в качестве справочного документа (4), в котором результат соответствующего многоскоростного решетчатого векторного квантования с разбиением представляет собой номер таблицы кодирования для каждых 8 элементов, векторный индекс в базовой таблице кодирования и 8-мерный индекс Вороного. Тем не менее, только в случае наличия одной таблицы кодирования, номер таблицы кодирования может исключаться, и только векторный индекс в базовой таблице кодирования и соответствующий n-мерный индекс Вороного являются достаточными. Таким образом, эти элементы, которые представляют собой элемент a, элемент b и элемент c либо только элемент b и элемент c для каждого уровня для результата алгебраического векторного квантования, представляют результат квантования второй ступени.
Далее следует обратиться к фиг. 10, иллюстрирующему соответствующую операцию декодирования, совпадающую с кодированием по фиг. 7a, 7b или кодированием по фиг. 14, в соответствии с первым или вторым аспектом настоящего изобретения либо в соответствии с обоими аспектами.
На этапе 2221 по фиг. 10, квантованные средние коэффициенты масштабирования, т.е. вторая группа объединенно кодированных коэффициентов масштабирования извлекаются. Это выполняется, когда флаг стереорежима или элемент 1403 по фиг. 5 указывает истинное значение. Далее, декодирование 2223 в первой ступени и декодирование 2261 во второй ступени выполняются для выполнения заново процедур, выполненных кодером по фиг. 14 и, в частности, алгебраическим модулем 145 векторного квантования, описанным с обращением к фиг. 14 или описанным с обращением к фиг. 7a. На этапе 2225 предполагается, что все боковые коэффициенты масштабирования равны 0. На этапе 2261, посредством значения нулевого флага проверяется, поступают ли фактически ненулевые квантованные коэффициенты масштабирования для кадра. В случае если значение нулевого флага указывает то, что имеются ненулевые боковые коэффициенты масштабирования для кадра, то квантованные боковые коэффициенты масштабирования извлекаются и декодируются с использованием декодирования 2261 во второй ступени либо выполнения только блока 706 по фиг. 7b. В блоке 2207, объединенно кодированные параметры масштабирования преобразуются обратно в отдельно кодированные параметры масштабирования для последующего вывода квантованных левых и правых параметров масштабирования, которые далее могут использоваться для обратного масштабирования спектра в декодере.
Когда значение флага стереорежима указывает значение в нуль, или когда определяется то, что отдельное кодирование использовано в кадре, в таком случае только декодирование 2223 в первой ступени и декодирование 2261 во второй ступени выполняется для левых и правых коэффициентов масштабирования, и поскольку левые и правые коэффициенты масштабирования уже находятся в отдельно кодированном представлении, преобразование, такое как блок 2207, вообще не требуется. Процесс эффективного кодирования и декодирования коэффициентов SNS масштабирования, которые необходимы для масштабирования спектра перед стереообработкой на стороне кодера и после обратной стереообработки на стороне декодера, описан ниже, чтобы показать предпочтительную реализацию настоящего изобретения в качестве примерного псевдокода с комментариями.
Объединенное квантование и кодирование коэффициентов масштабирования

Любой вид квантования, например, равномерное или неравномерное скалярное квантование и энтропийное или арифметическое кодирование, может использоваться для представления параметров. В описанной реализации, как можно видеть в описании алгоритма, реализуется двухступенчатая схема векторного квантования:
- Первая ступень: 2 разбиения (по 8 размерностей) с 5 битами каждый, в силу чего кодирование с 10 битами.
- Вторая ступень: алгебраическое векторное квантование (AVQ), снова с 2 разбиениями с масштабированием остатка, при этом индексы таблиц кодирования энтропийно кодируются, и в силу этого использует переменную скорость передачи битов.
Поскольку боковой сигнал для высококоррелированных каналов может считаться небольшим, использование, например, только AVQ второй ступени уменьшенного масштаба является достаточным для представления соответствующих параметров SNS. За счет пропуска VQ первой ступени для этих сигналов, может достигаться значительное снижение сложности и числа битов для кодирования параметров SNS.
Ниже приводится описание в форме псевдокода каждой ступени реализованного квантования. Первая ступень с векторным квантованием с 2 разбиениями с использованием 5 битов для каждого разбиения:


Алгебраическое векторное квантование второй ступени:

Индексы, которые выводятся из процесса кодирования, в конечном счете пакетируются в поток битов и отправляются в декодер.
Процедура AVQ, раскрытая выше для второй ступени, предпочтительно реализуется так, как указано в EVS, указывающем на высокоскоростной LPC (подраздел 5.3.3.2.1.3) в главе «TCX на основе MDCT». В частности, для используемого алгебраического модуля векторного квантования второй ступени указано, что "5.3.3.2.1.3.4. Algebraic vector quantizer and the algebraic VQ used for quantizing the refinement" описан в подразделе 5.2.3.1.6.9. В варианте осуществления для каждого индекса имеется набор кодовых слов для индекса базовой таблицы кодирования и набор кодовых слов для индекса Вороного, и все это энтропийно кодируется и в силу этого имеет переменную скорость передачи битов. Следовательно, параметры AVQ в каждой подполосе j частот состоят из номера таблицы кодирования, векторного индекса в базовой таблице кодирования и n-(к примеру, 8-)мерного индекса Вороного.
Декодирование коэффициентов масштабирования
На стороне декодера индексы извлекаются из потока битов и используются для декодирования и получения квантованных значений коэффициентов масштабирования. Ниже приведен пример псевдокода процедуры.
Процедура двухступенчатого декодирования подробно описана в нижеприведенном псевдокоде.


Процедура двухступенчатого декодирования подробно описана в нижеприведенном псевдокоде.

Квантованные коэффициенты SNS масштабирования, извлеченные из первой ступени, детализируются посредством декодирования остатка во второй ступени. Процедура обеспечивается в нижеприведенном псевдокоде:

Относительно масштабирования или усиления/взвешивания остатка на стороне кодера и масштабирования или ослабления/взвешивания на стороне декодера, весовые коэффициенты не вычисляются отдельно для каждого значения или разбиения, но один весовой коэффициент или небольшое число различных весовых коэффициентов (в качестве аппроксимации для исключения сложности) используются для масштабирования всех параметров. Это масштабирование представляет собой фактор, который определяет компромисс, например, сокращения скорости передачи битов при приблизительном квантовании (с большим количеством квантований до нуля) и точности квантования (с соответствующим спектральным искажением), и может быть задан в кодере таким образом, что это заданное значение не должно обязательно передаваться в декодер, а может задаваться фиксированно либо инициализироваться в декодере, чтобы сокращать число передаваемых битов. Следовательно, более высокое масштабирование остатка требует большего числа битов, но имеет минимальное спектральное искажение, тогда как уменьшение масштаба должно сокращать дополнительное число битов, и если спектральное искажение поддерживается в приемлемом диапазоне, это может служить в качестве средства дополнительного сокращения скорости передачи битов.
Преимущества предпочтительных вариантов осуществления
- Существенное сокращение числа битов, когда два канала коррелируются, и параметры SNS кодируются объединенно.
Ниже показывается пример сокращения числа битов в расчете на кадр, достигаемого в системе, описанной в предыдущем разделе:
-- Независимый: 88,1 бита в среднем
-- Новый независимый: 72,0 бита в среднем
-- Новый объединенный: 52,1 бита в среднем
- где:
- «Независимый» представляет собой стереореализацию MDCT, описанную в [8] с использованием SNS [6] для кодирования FDNS только двух каналов независимо с двухступенчатым VQ
- Первая ступень: 8-битовая обученная таблица кодирования (16 размерностей)
- Вторая ступень: AVQ остатка, масштабируемого с коэффициентом 4 (переменная скорость передачи битов)
- «Новый независимый» означает вышеописанный вариант осуществления изобретения, в котором корреляция двух каналов не является достаточно высокой, и они кодируются отдельно, с использованием нового двухступенчатого подхода VQ, как описано выше, и остаток масштабируется с уменьшенным коэффициентом в 2,5
- «Новый объединенный» означает объединенно кодированный случай (также описанный выше), в котором снова во второй ступени остаток масштабируется с уменьшенным коэффициентом в 2,5.
- Другое преимущество предложенного способа заключается в снижении вычислительной сложности. Как показано в [6], новый SNS является более оптимальным с точки зрения вычислительной сложности из FDNS на основе LPC, описанного в [5], вследствие вычислений автокорреляции, которые необходимы для оценки LPC. Следовательно, при сравнении вычислительной сложности стереосистемы на основе MDCT из [8], в которой используется улучшенное FDNS на основе LPC [5], с реализацией, в которой новый SNS [6] заменяет подход на основе LPC, предусмотрено сокращение приблизительно в 6 WMOPS на частоте дискретизации в 32 кГц.
Кроме того, новое двухступенчатое квантование с VQ для первой ступени и AVQ с уменьшенным масштабом для второй ступени достигает некоторого дополнительного уменьшения вычислительной сложности. Для варианта осуществления, описанного в предыдущем разделе, вычислительная сложность уменьшается дополнительно приблизительно на 1 WMOPS на частоте дискретизации в 32 кГц с компромиссом в отношении приемлемого спектрального искажения.
Сущность предпочтительных вариантов осуществления или аспектов
1. Объединенное кодирование параметров формирования спектрального шума, в котором среднее/боковое представление параметров вычисляется, и средний кодируется с использованием квантования и энтропийного кодирования, а боковой кодируется с использованием более приблизительной схемы квантования.
2. Адаптивное определение того, должны параметры формирования шума кодироваться независимо или объединенно, на основе канальной корреляции или когерентности.
3. Служебный бит, отправленный для определения, кодированы ли параметры независимо или объединенно.
4. Варианты применения на основе стереореализации MDCT:
- передача служебных сигналов с битами, в которых боковые коэффициенты являются нулевыми,
- в которых используется SNS,
- в которых спектр мощности используется для вычисления SNS,
- в которых 2 разбиения с 5 битами используются в первой ступени.
- Регулирование масштабирования остатка AVQ второй ступени дополнительно может уменьшать число битов для квантования второй ступени.
Фиг. 23 иллюстрирует сравнение в числе битов для обоих каналов в соответствии с текущей реализацией из уровня техники (описанного как «независимый» выше), новой независимой реализацией в соответствии со вторым аспектом настоящего изобретения и для новой объединенной реализации в соответствии с первым аспектом настоящего изобретения. Фиг. 23 иллюстрирует гистограмму, на которой вертикальная ось представляет частоту появления, и горизонтальная ось иллюстрирует элементы разрешения общего числа битов для кодирования параметров для обоих каналов.
Далее проиллюстрированы дополнительные предпочтительные варианты осуществления, в которых конкретный акцент придается вычислению коэффициентов масштабирования для каждого аудиоканала, и в которых дополнительно конкретный акцент придается конкретному применению понижающей дискретизации и повышающей дискретизации параметров масштабирования, которая применяется до или после вычисления объединенно кодированных параметров масштабирования, как проиллюстрировано относительно фиг. 3a, фиг. 3b.
Фиг. 11 иллюстрирует устройство для кодирования аудиосигнала 160. Аудиосигнал 160 предпочтительно доступен во временной области, хотя другие представления аудиосигнала, таки как область прогнозирования или любая другая область, преимущественно также должны быть полезными. Устройство содержит преобразователь 100, модуль 110 вычисления коэффициентов масштабирования, спектральный процессор 120, модуль 130 понижающей дискретизации, кодер 140 коэффициентов масштабирования и выходной интерфейс 150. Преобразователь 100 выполнен с возможностью преобразования аудиосигнала 160 в спектральное представление. Модуль 110 вычисления коэффициентов масштабирования выполнен с возможностью вычисления первого набора параметров масштабирования или коэффициентов масштабирования из спектрального представления. Другой канал принимается в блоке 120, и параметры масштабирования из других каналов принимаются посредством блока 140.
Во всем подробном описании термин «коэффициент масштабирования» или «параметр масштабирования» используется для указания на одинаковый параметр или значение, т.е. значение или параметр, который, после некоторой обработки, используется для взвешивания некоторых спектральных значений. Это взвешивание, при выполнении в линейной области, фактически представляет собой операцию умножения с коэффициентом масштабирования. Тем не менее, когда взвешивание выполняется в логарифмической области, в таком случае операция взвешивания с коэффициентом масштабирования осуществляется посредством фактической операции сложения или вычитания. Таким образом, в отношении настоящей заявки, масштабирование означает не только умножение или деление, но также означает, в зависимости от определенной области, сложения или вычитание либо, в общем, означает каждую операцию, посредством которой спектральное значение, например, взвешивается или модифицируется с использованием коэффициента масштабирования или параметра масштабирования.
Модуль 130 понижающей дискретизации выполнен с возможностью понижающей дискретизации первого набора параметров масштабирования для получения второго набора параметров масштабирования, при этом второе число параметров масштабирования во втором наборе параметров масштабирования ниже первого числа параметров масштабирования в первом наборе параметров масштабирования. Это также приводится в поле на фиг. 11, указывающем то, что второе число ниже первого числа. Как проиллюстрировано на фиг. 11, кодер коэффициентов масштабирования выполнен с возможностью формирования кодированного представления второго набора коэффициентов масштабирования, и это кодированное представление перенаправляется в выходной интерфейс 150. Вследствие того факта, что второй набор коэффициентов масштабирования имеет меньшее число коэффициентов масштабирования, чем первый набор коэффициентов масштабирования, скорость передачи битов для передачи или сохранения кодированного представления второго набора коэффициентов масштабирования является более низкой по сравнению с ситуацией, в которой понижающая дискретизация коэффициентов масштабирования, выполняемая в модуле130 понижающей дискретизации, не выполнена.
Кроме того, спектральный процессор 120 выполнен с возможностью обработки спектрального представления, выводимого посредством преобразователя 100 на фиг. 11, с использованием третьего набора параметров масштабирования, причем третий набор параметров масштабирования или коэффициентов масштабирования имеет третье число коэффициентов масштабирования, большее второго числа коэффициентов масштабирования, при этом спектральный процессор 120 выполнен с возможностью использования для целей спектральной обработки первого набора коэффициентов масштабирования, доступный из блока 110 через линию 171. В качестве альтернативы, спектральный процессор 120 выполнен с возможностью использования второго набора коэффициентов масштабирования в качестве вывода посредством модуля 130 понижающей дискретизации для вычисления третьего набора коэффициентов масштабирования, как проиллюстрировано посредством линии 172. В дополнительной реализации, спектральный процессор 120 использует кодированное представление, выводимое посредством кодера 140 коэффициента/параметра масштабирования, для целей вычисления третьего набора коэффициентов масштабирования, как проиллюстрировано посредством линии 173 на фиг. 11. Предпочтительно, спектральный процессор 120 не использует первый набор коэффициентов масштабирования, но использует либо второй набор коэффициентов масштабирования, вычисленный посредством модуля понижающей дискретизации, либо, еще более предпочтительно, использует кодированное представление или, в общем, квантованный второй набор коэффициентов масштабирования и после этого выполняет операцию интерполяции для интерполяции квантованного второго набора спектральных параметров, чтобы получить третий набор параметров масштабирования, который имеет более высокое число параметров масштабирования вследствие операции интерполяции.
Таким образом, кодированное представление второго набора коэффициентов масштабирования, который выводится посредством блока 140, содержит либо индекс таблицы кодирования для предпочтительно используемой таблицы кодирования параметров масштабирования, либо набор соответствующих индексов таблиц кодирования. В других вариантах осуществления, кодированное представление содержит квантованные параметры масштабирования квантованных коэффициентов масштабирования, которые получаются, когда индекс таблицы кодирования или набор индексов таблиц кодирования или, в общем, кодированное представление вводится в векторный декодер на стороне декодера или любой другой декодер.
Предпочтительно, спектральный процессор 120 использует тот же набор коэффициентов масштабирования, который также доступен на стороне декодера, т.е. использует квантованный второй набор параметров масштабирования вместе с операцией интерполяции, чтобы в конечном счете получать третий набор коэффициентов масштабирования.
В предпочтительном варианте осуществления, третье число коэффициентов масштабирования в третьем наборе коэффициентов масштабирования равно первому числу коэффициентов масштабирования. Тем не менее, меньшее число коэффициентов масштабирования также является полезным. В качестве примера, например, можно извлекать 64 коэффициента масштабирования в блоке 110, и можно затем дискретизировать с понижением 64 коэффициента масштабирования до 16 коэффициентов масштабирования для передачи. После этого, можно выполнять интерполяцию не обязательно в 64 коэффициента масштабирования, а в 32 коэффициента масштабирования в спектральном процессоре 120. В качестве альтернативы, можно выполнять интерполяцию в еще более высокое число, к примеру, более чем в 64 коэффициента масштабирования, в зависимости от обстоятельств, при условии, что число коэффициентов масштабирования, передаваемых в кодированном выходном сигнале 170, меньше числа коэффициентов масштабирования, вычисленных в блоке 110 либо вычисленных и используемых в блоке 120 по фиг. 11.
Предпочтительно, модуль 110 вычисления коэффициентов масштабирования выполнен с возможностью выполнения нескольких операций, проиллюстрированных на фиг. 12. Эти операции означают вычисление 111 связанного с амплитудой показателя в расчете на полосу частот, при этом спектральное представление для одного канала вводится в блок 111. Вычисление для другого канала должно осуществляться аналогичным образом. Предпочтительный связанный с амплитудой показатель в расчете на полосу частот представляет собой энергию в расчете на полосу частот, но также могут использоваться другие связанные с амплитудой показатели, например, сложение абсолютных величин амплитуд в расчете на полосу частот или сложение возведенных в квадрат амплитуд, которое соответствует энергии. Тем не менее, помимо степени 2, используемой для вычисления энергии в расчете на полосу частот, также могут использоваться другие степени, к примеру, степень 3, которая отражает уровень громкости сигнала, и также могут использоваться степени, отличающиеся от целых чисел, к примеру, степени в 1,5 или 2,5, для вычисления связанных с амплитудой показателей в расчете на полосу частот. Даже степени, меньшие 1,0, могут использоваться при условии, что необходимо удостовериться, что значения, обработанные посредством таких степеней, имеют положительные значения.
Дополнительная операция, выполняемая посредством модуля вычисления коэффициентов масштабирования, может представлять собой межполосное сглаживание 112. Это межполосное сглаживание предпочтительно используется для сглаживания возможных нестабильностей, которые могут появляться в векторе связанных с амплитудой показателей, полученных посредством этапа 111. Если нельзя выполнять это сглаживание, эти нестабильности должны усиливаться при преобразовании в логарифмическую область впоследствии, как проиллюстрировано в 115, в частности, в спектральных значениях, в которых энергия составляет близко к 0. Тем не менее, в других вариантах осуществления, межполосное сглаживание не выполняется.
Дополнительная предпочтительная операция, выполняемая посредством модуля 110 вычисления коэффициентов масштабирования, представляет собой операцию 113 коррекции предыскажений. Эта операция коррекции предыскажений имеет аналогичное назначение с операцией коррекции предыскажений, используемой в перцепционном фильтре на основе LPC для обработки TCX на основе MDCT, как пояснено выше относительно уровня техники. Эта процедура увеличивает амплитуду спектра определенной формы на низких частотах, что приводит к уменьшенному шуму квантования на низких частотах.
Тем не менее, в зависимости от реализации, операция коррекции предыскажений - в качестве других конкретных операций - не должна выполняться обязательно.
Дополнительная факультативная операция обработки представляет собой обработку 114 сложения минимального уровня шума. Эта процедура повышает качество сигналов, содержащих очень высокую спектральную динамику, таких как, например, глокеншпиль, в силу ограничения усиления амплитуды спектра определенной формы во впадинах, что имеет косвенный эффект уменьшения шума квантования в пиках, за счет увеличения шума квантования во впадинах, при этом шум квантования в любом случае не является воспринимаемым вследствие маскирующих свойств человеческого уха, таких как абсолютное пороговое значение прослушивания, премаскирование, постмаскирование или общее пороговое значение маскирования, указывающее то, что типично, тон достаточно низкой громкости, относительно близкий по частоте к тону высокой громкости, вообще не является воспринимаемым, т.е. полностью маскируется либо только грубо воспринимается посредством механизма человеческого слуха таким образом, что эта спектральная доля может квантоваться достаточно приблизительно.
Тем не менее, операция 114 сложения минимального уровня шума не должна выполняться обязательно.
Кроме того, блок 115 указывает преобразование в логарифмической области. Предпочтительно, преобразование вывода одного из блоков 111, 112, 113, 114 на фиг. 12 выполняется в логарифмической области. Логарифмическая область представляет собой область, в которой значения, близкие к 0, расширяются, а высокие значения сжимаются. Предпочтительно, логарифмическая область представляет собой область с основанием в 2, но также могут использоваться другие логарифмические области. Тем не менее, логарифмическая область с основанием в 2 лучше для реализации в процессоре сигналов с фиксированной запятой.
Вывод модуля 110 вычисления коэффициентов масштабирования представляет собой первый набор коэффициентов масштабирования.
Как проиллюстрировано на фиг. 12, каждый из блоков 112-115 может быть организован, т.е. вывод блока 111, например, может уже представлять собой первый набор коэффициентов масштабирования. Тем не менее, все операции обработки и, в частности, преобразование в логарифмической области являются предпочтительными. Таким образом, например, можно даже реализовать модуль вычисления коэффициентов масштабирования посредством выполнения только этапов 111 и 115 без процедур на этапах 112-114. В выводе блока 115, получается набор параметров масштабирования для канала (к примеру, L), и набор параметров масштабирования для другого канала (к примеру, R) также может получаться посредством аналогичного вычисления.
Таким образом, модуль вычисления коэффициентов масштабирования выполнен с возможностью выполнения одной либо двух или более из процедур, проиллюстрированных на фиг. 12, как указано посредством входных/выходных линий, соединяющих несколько блоков.
Фиг. 13 иллюстрирует предпочтительную реализацию модуля 130 понижающей дискретизации по фиг. 11 снова для одного канала. Данные для другого канала вычисляются аналогично. Предпочтительно, фильтрация нижних частот или, в общем, фильтрация с определенной функцией w(k) кодирования со взвешиванием выполняется на этапе 131, и после этого выполняется операция понижающей дискретизации/прореживания результата фильтрации. Вследствие того факта, что фильтрация 131 нижних частот, и в предпочтительных вариантах осуществления, операция 132 понижающей дискретизации/прореживания представляют собой арифметических операции, фильтрация 131 и понижающая дискретизация 132 могут выполняться в пределах одной операции, как указано далее. Предпочтительно, операция понижающей дискретизации/прореживания выполняется таким образом, что перекрытие между отдельными группами параметров масштабирования из первого набора параметров масштабирования выполняется. Предпочтительно, перекрытие одного коэффициента масштабирования в операции фильтрации между двумя прореженными вычисленными параметрами выполняется. Таким образом, этап 131 выполняет фильтрацию нижних частот для вектора параметров масштабирования перед прореживанием. Эта фильтрация нижних частот имеет эффект, аналогичный эффекту функции разброса, используемой в психоакустических моделях. Она уменьшает шум квантования в пиках, за счет увеличения шума квантования вокруг пиков, когда он в любом случае перцепционно маскируется по меньшей мере в более высокой степени относительно шума квантования в пиках.
Кроме того, модуль понижающей дискретизации дополнительно выполняет удаление 133 средних значений и дополнительный этап 134 масштабирования. Тем не менее, операция 131 фильтрации нижних частот, этап 133 удаления средних значений и этап 134 масштабирования представляют собой только факультативные этапы. Таким образом, модуль понижающей дискретизации, проиллюстрированный на фиг. 13 или проиллюстрированный на фиг. 11, может быть реализован с возможностью выполнения только этапа 132 либо выполнения двух этапов, проиллюстрированных на фиг. 13, к примеру, этап 132 и один из этапов 131, 133 и 134. В качестве альтернативы, модуль понижающей дискретизации может выполнять все четыре этапа или только три этапа из четырех этапов, проиллюстрированных на фиг. 13, при условии, что операция 132 понижающей дискретизации/прореживания выполняется.
Как указано на фиг. 13, аудиооперации на фиг. 13, выполняемые посредством модуля понижающей дискретизации, выполняются в логарифмической области, чтобы получать лучшие результаты.
Фиг. 15 иллюстрирует предпочтительную реализацию спектрального процессора. Спектральный процессор 120, включенный в кодер по фиг. 11, содержит интерполятор 121, который принимает квантованный второй набор параметров масштабирования для каждого канала или, в качестве альтернативы, для группы объединенно кодированных параметров масштабирования, и который выводит третий набор параметров масштабирования для канала для группы объединенно кодированных параметров масштабирования, причем третье число больше второго числа и предпочтительно равно первому числу. Кроме того, спектральный процессор содержит преобразователь 120 в линейную область. В таком случае, формирование спектра выполняется в блоке 123 с использованием линейных параметров масштабирования, с одной стороны, и спектрального представления, с другой стороны, которое получается посредством преобразователя 100. Предпочтительно, последующая операция формирования временного шума, т.е. прогнозирование по частоте выполняется для получения остаточных спектральных значений в выводе блока 124, тогда как вспомогательная информация TNS перенаправляется в выходной интерфейс, как указано посредством стрелки 129.
В завершение, спектральный процессор 125, 120b имеет по меньшей мере одно из модуля скалярного квантования/кодера, который выполнен с возможностью приема одного глобального усиления для целого спектрального представления, т.е. для целого кадра, и функциональности стереообработки и функциональности обработки IGF и т.д. Предпочтительно, глобальное усиление извлекается в зависимости от определенных учитываемых факторов скорости передачи битов. Таким образом, глобальное усиление задается таким образом, что кодированное представление спектрального представления, сформированного посредством блока 125, 120b, удовлетворяет определенным требованиям, таким как требование по скорости передачи битов, требование к качеству либо оба требования. Глобальное усиление может итеративно вычисляться или может вычисляться в показателе с прямой связью в зависимости от обстоятельств. В общем, глобальное усиление используется вместе с модулем квантования, и высокое глобальное усиление типично приводит к более приблизительному квантованию, при этом низкое глобальное усиление приводит к более точному квантованию. Таким образом, другими словами, высокое глобальное усиление приводит к более высокому размеру шага квантования, тогда как низкое глобальное усиление приводит к меньшему размеру шага квантования, когда получается модуль квантования с фиксированным шагом. Тем не менее также могут использоваться другие модули квантования вместе с функциональностью на основе глобального усиления, к примеру, модуль квантования, который имеет некоторую функциональность сжатия для высоких значений, т.е. некоторую функциональность нелинейного сжатия таким образом, что, например, большие значения сжимаются в большей степени, чем меньшие значения. Вышеуказанная зависимость между глобальным усилением и приблизительностью квантования является допустимой, когда глобальное усиление умножается на значения перед квантованием в линейной области, соответствующем сложению в логарифмической области. Тем не менее, если глобальное усиление применяется посредством деления в линейной области или посредством вычитания в логарифмической области, зависимость является обратной. Это справедливо, когда «глобальное усиление» представляет обратное значение.
Далее приводятся предпочтительные реализации отдельных процедур, описанных относительно фиг. 11 фиг. 15.
Детализированное пошаговое описание предпочтительных вариантов осуществления
Кодер:
Этап 1. Энергия в расчете на полосу частот (111)
Энергии в расчете на полосу частот EB(n) вычисляются следующим образом:
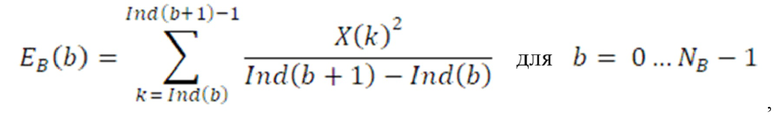
где X(k) являются коэффициентами MDCT, NB=64 является числом полос частот, и Ind(n) являются индексами полос частот. Полосы частот являются неравномерными и придерживаются перцепционно релевантной шкалы в барках (меньше на низких частотах, больше на высоких частотах).
Этап 2. Сглаживание (112)
Энергия EB(b) в расчете на полосу частот сглаживается с использованием:
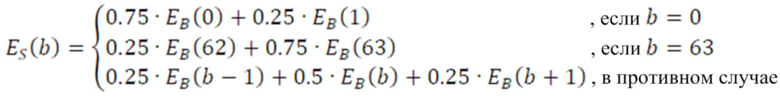
Комментарий: этот этап главным образом используется для сглаживания возможных нестабильностей, которые могут появляться в векторе EB(b). Если не сглаживаются, эти нестабильности усиливаются при преобразовании в логарифмическую область (см. этап 5), в частности, во впадинах, в которых энергия составляет близко к 0.
Этап 3. Коррекция предыскажений (113)
Сглаженная энергия ES(b) в расчете на полосу частот затем подвергается коррекции предыскажений с использованием:
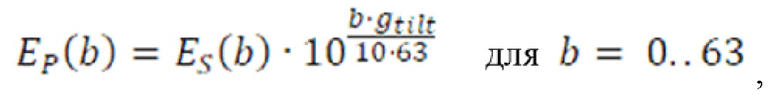
где gtilt управляет наклоном при коррекции предыскажений и зависит от частоты дискретизации. Она, например, составляет 18 при 16 кГц и 30 при 48 кГц. Коррекция предыскажений, используемая на этом этапе, имеет то же назначение с коррекцией предыскажений, используемой в перцепционном фильтре на основе LPC по документу 2 из уровня техники, она увеличивает амплитуду спектра определенной формы на низких частотах, приводя к уменьшенному шуму квантования на низких частотах.
Этап 4. Минимальный уровень шума (114)
Минимальный уровень шума в -40dB суммируется с EP(b) с использованием:
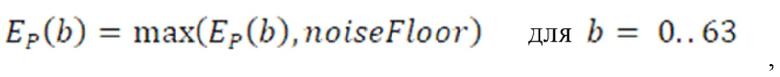
причем минимальный уровень шума вычисляется следующим образом:
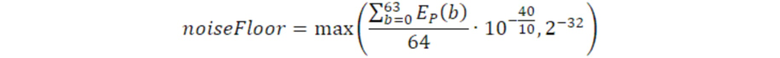
Этот этап повышает качество сигналов, содержащих очень высокую спектральную динамику, таких как, например, глокеншпиль, в силу ограничения усиления амплитуды спектра определенной формы во впадинах, что имеет косвенный эффект уменьшения шума квантования в пиках, за счет увеличения шума квантования во впадинах, в которых он является в любом случае не воспринимаемым.
Этап 5. Логарифм (115)
Преобразование в логарифмическую область затем выполняется с использованием:
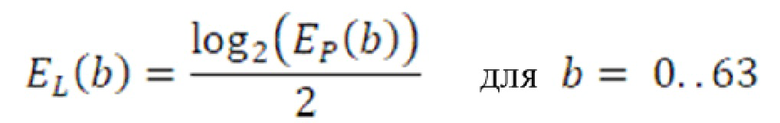
Этап 6. Понижающая дискретизация (131, 132)
Вектор EL(b) затем дискретизируется с понижением на коэффициент 4 с использованием:
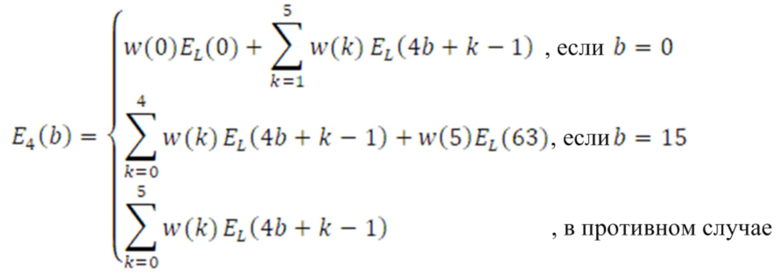
- где:
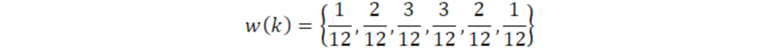
Этот этап применяет фильтрацию нижних частот (w(k)) к вектору EL(b) перед прореживанием. Эта фильтрация нижних частот имеет эффект, аналогичный эффекту функции разброса, используемой в психоакустических моделях: она уменьшает шум квантования в пиках, за счет увеличения шума квантования вокруг пиков, когда он в любом случае перцепционно маскируется.
Этап 7. Удаление средних и масштабирование (133, 134)
Конечные коэффициенты масштабирования получаются после удаления средних и масштабирования на коэффициент в 0,85:
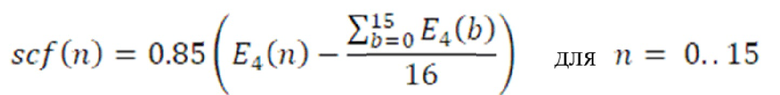
Поскольку кодек имеет дополнительное глобальное усиление, среднее значение может удаляться вообще без потерь информации. Удаление среднего значения также обеспечивает возможность более эффективного векторного квантования.
Масштабирование в 0,85 немного сжимает амплитуду кривой формирования шума. Оно имеет аналогичный перцепционный эффект с функцией разброса, упомянутой на этапе 6: уменьшенный шум квантования в пиках и увеличенный шум квантования во впадинах.
Этап 8. Квантование (141, 142)
Коэффициенты масштабирования квантуются с использованием векторного квантования, формируя индексы, которые затем пакетируются в поток битов и отправляются в декодер, и квантованные коэффициенты scfQ(n) масштабирования.
Этап 9. Интерполяция (121, 122)
Квантованные коэффициенты scfQ(n) масштабирования интерполируются с использованием:
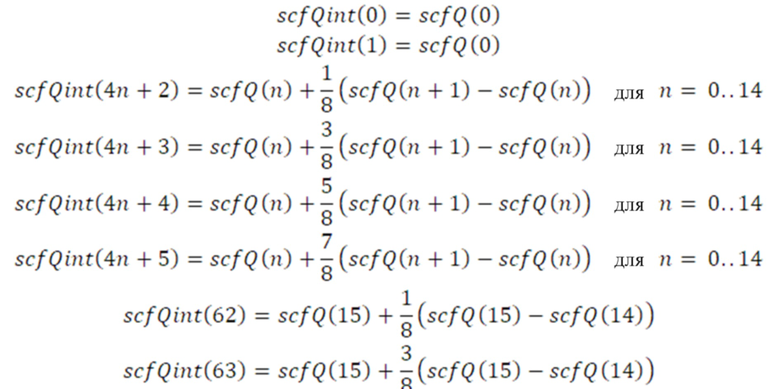
и преобразуются обратно в линейную область с использованием:
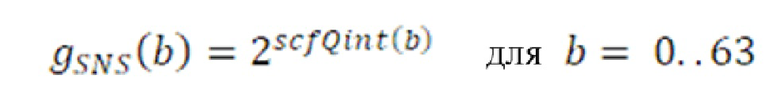
Интерполяция используется для получения сглаженной кривой формирования шума, и таким образом вообще для исключения больших скачков амплитуды между смежными полосами частот.
Этап 10. Формирование спектра (123)
Коэффициенты SNS gSNS(b) масштабирования применяются к частотным линиям MDCT для каждой полосы частот отдельно, чтобы формировать спектр Xs(k) определенной формы:
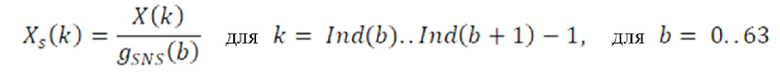
Фиг. 18 иллюстрирует предпочтительную реализацию устройства для декодирования кодированного аудиосигнала 250 (стереосигнала, кодированного в качестве L, R или M, S), содержащего информацию относительно кодированного спектрального представления и информацию относительно кодированного представления второго набора параметров масштабирования (отдельно объединенно кодированных). Декодер содержит входной интерфейс 200, спектральный декодер 210 (например, выполняющий обработку IGF либо обратную стереообработку или обработку деквантования), декодер 220 коэффициентов/параметров масштабирования, спектральный процессор 230 (например, для R, L) и преобразователь 240 (например, для R, L). Входной интерфейс 200 выполнен с возможностью приема кодированного аудиосигнала 250 и извлечения кодированного спектрального представления, которое перенаправляется в спектральный декодер 210, и извлечения кодированного представления второго набора коэффициентов масштабирования, который перенаправляется в декодер 220 коэффициентов масштабирования. Кроме того, спектральный декодер 210 выполнен с возможностью декодирования кодированного спектрального представления, чтобы получать декодированное спектральное представление, которое перенаправляется в спектральный процессор 230. Декодер 220 коэффициентов масштабирования выполнен с возможностью декодирования кодированного второго набора параметров масштабирования для получения первого набора параметров масштабирования, перенаправляемого в спектральный процессор 230. Первый набор коэффициентов масштабирования имеет число коэффициентов масштабирования или параметров масштабирования, которое больше числа коэффициентов масштабирования или параметров масштабирования во втором наборе. Спектральный процессор 230 выполнен с возможностью обработки декодированного спектрального представления с использованием первого набора параметров масштабирования для получения масштабированного спектрального представления. Затем масштабированное спектральное представление преобразуется преобразователем 240, чтобы в конечном счете получить декодированный аудиосигнал 260, представляющий собой стереосигнал или многоканальный сигнал более чем с двумя каналами.
Предпочтительно, декодер 220 коэффициентов масштабирования выполнен с возможностью работы практически таким же способом по сравнению с тем, что пояснено относительно спектрального процессора 120 по фиг. 11, связанного с вычислением третьего набора коэффициентов масштабирования или параметров масштабирования, как пояснено в связи с блоками 141 или 142 и, в частности, относительно блоков 121, 122 по фиг. 15. В частности, декодер коэффициентов масштабирования выполнен с возможностью выполнения по существу такой же процедуры для интерполяции и преобразования обратно в линейную область по сравнению с тем, что пояснено выше в отношении этапа 9. Таким образом, как проиллюстрировано на фиг. 19, декодер 220 коэффициентов масштабирования выполнен с возможностью применения таблицы 221 кодирования декодера к одному или более индексов в расчете на кадр, представляющих представление кодированного параметра масштабирования. После этого, интерполяция выполняется в блоке 222, которая представляет собой практически такую же интерполяцию, как та, что пояснена относительно блока 121 на фиг. 15. Далее используется преобразователь 223 в линейную область, который представляет собой практически такой же преобразователь 122 в линейную область по сравнению с тем, который пояснен относительно фиг. 15. Тем не менее, в других реализациях, блоки 221, 222, 223 могут работать отлично от того, что пояснено относительно соответствующих блоков на стороне кодера.
Кроме того, спектральный декодер 210, проиллюстрированный на фиг. 18 или 19, содержит блок модуля деквантования/декодера, который принимает в качестве ввода кодированный спектр и который выводит деквантованный спектр, который предпочтительно деквантуется с использованием глобального усиления, которое дополнительно передается из стороны кодера в сторону декодера в кодированном аудиосигнале в кодированной форме. Блок 210 также может выполнять обработку IGF или обратную стереообработку, такую как декодирование MS. Модуль деквантования/декодер 210, например, может содержать функциональность арифметического декодера или декодера Хаффмана, которая принимает, в качестве ввода, некоторые коды, и которая выводит индексы квантования, представляющие спектральные значения. После этого, эти индексы квантования вводятся в модуль деквантования вместе с глобальным усилением, и вывод представляет собой деквантованные спектральные значения, которые затем могут подвергаться обработке TNS, такой как обратное прогнозирование по частоте, в блоке 211 обработки декодера TNS, что, тем не менее, является факультативным. В частности, блок обработки декодера TNS дополнительно принимает вспомогательную информацию TNS, которая сформирована посредством блока 124 по фиг. 15, как указано посредством линии 129. Вывод этапа 211 обработки декодера TNS вводится в блок 212 формирования спектра, работающий для каждого канала отдельно с использованием отдельных коэффициентов масштабирования, причем первый набор коэффициентов масштабирования, вычисленный посредством декодера коэффициентов масштабирования, применяется к декодированному спектральному представлению, которое может или не может подвергаться обработке TNS в зависимости от обстоятельств, и вывод представляет собой масштабированное спектральное представление для каждого канала, которое затем вводится в преобразователь 240 по фиг. 18.
Далее поясняются дополнительные процедуры предпочтительных вариантов осуществления декодера.
Декодер:
Этап 1. Квантование (221)
Индексы модуля векторного квантования, сформированные на этапе 8 работы кодера, считываются из потока битов и используются для декодирования квантованных коэффициентов scfQ(n) масштабирования.
Этап 2. Интерполяция (222, 223)
Одинаков с этапом 9 работы кодера.
Этап 3. Формирование спектра (212)
Коэффициенты SNS gSNS(b) масштабирования применяются к квантованным частотным линиям MDCT для каждой полосы частот отдельно, чтобы формировать декодированный спектр 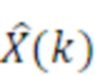 , как указано посредством следующего кода:
, как указано посредством следующего кода:
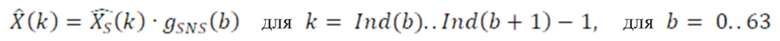
Фиг. 16 и фиг. 17 иллюстрируют общую компоновку кодера/декодера, при этом фиг. 16 представляет реализацию без обработки TNS, тогда как фиг. 17 иллюстрирует реализацию, которая содержит обработку TNS. Аналогичные функциональности, проиллюстрированные на фиг. 16 и фиг. 17, соответствуют аналогичным функциональностям на других чертежах, на которых указаны такие же ссылочные позиции. В частности, как проиллюстрировано на фиг. 16, входной сигнал 160, например, стереосигнал или многоканальный сигнал вводится в ступень 110 преобразования, и после этого выполняется спектральная обработка 120. В частности, спектральная обработка отражается посредством кодера SNS, указываемого ссылочными позициями 123, 110, 130, 140, указывающих, что блок «кодер SNS» реализует функциональности, указываемые этими ссылочными позициями. После блока кодера SNS, выполняется операция 120b, 125 кодирования с квантованием, и кодированный сигнал вводится в поток битов, как указано в 180 на фиг. 16. Поток 180 битов затем возникает на стороне декодера, и после обратного квантования и декодирования, проиллюстрированного ссылочной позицией 210, операция декодера SNS, проиллюстрированная блоками 210, 220, 230 по фиг. 18, выполняется таким образом, что в конечном счете, после обратного преобразования 240, получается декодированный выходной сигнал 260.
Фиг. 17 иллюстрирует представление, аналогичное представлению на фиг. 16, но указывается то, что, предпочтительно, обработка TNS выполняется после обработки SNS на стороне кодера, и, соответственно, обработка 211 TNS выполняется перед обработкой 212 SNS относительно последовательности обработки на стороне декодера.
Предпочтительно, используется дополнительное инструментальное средство TNS между формированием спектрального шума (SNS) и квантованием/кодированием (см. нижеприведенную блок-схему). TNS (формирование временного шума) также формирует шум квантования, но при этом выполняет формирование во временной области (в отличие от формирования в частотной области в SNS). TNS является полезным для сигналов, содержащим резкие атаки и для речевых сигналов.
TNS обычно применяется (например, в AAC) между преобразованием и SNS. Тем не менее, предпочтительно, предпочтительно применять TNS к спектру определенной формы. Это исключает некоторые артефакты, которые сформированы посредством декодера TNS при работе с кодеком на низких скоростях передачи битов.
Фиг. 20 иллюстрирует предпочтительное подразделение спектральных коэффициентов или спектральных линий, полученных посредством блока 100 на стороне кодера, на полосы частот. В частности, указывается то, что полосы нижних частот имеют меньшее число спектральных линий, чем полосы верхних частот.
В частности, ось X на фиг. 20 соответствует индексу полос частот и иллюстрирует предпочтительный вариант осуществления 64 полос частот, и ось Y соответствует индексу спектральных линий, иллюстрирующих 320 спектральных коэффициентов в одном кадре. В частности, фиг. 20 примерно иллюстрирует ситуацию сверхширокополосного (SWB) случая, в котором предусмотрена частота дискретизации в 32 кГц.
Для широкополосного случая, ситуация относительно отдельных полос частот является такой, что один кадр приводит к 160 спектральным линиям, и частота дискретизации составляет 16 кГц, так что, для обоих случаев, один кадр имеет длину во времени в 10 миллисекунд.
Фиг. 21 иллюстрирует дополнительные сведения по предпочтительной понижающей дискретизации, выполняемой в модуле 130 понижающей дискретизации по фиг. 11, либо по соответствующей повышающей дискретизации или интерполяции, выполняемой в декодере 220 коэффициентов масштабирования по фиг. 18 или так, как проиллюстрировано в блоке 222 по фиг. 19.
Вдоль оси X, приводится индекс для полос 0-63 частот. В частности, имеются 64 полосы частот в диапазоне от 0 до 63.
16 дискретизированных с понижением точек, соответствующих scfQ(i), проиллюстрированы в качестве вертикальных линий 1100. В частности, фиг. 21 иллюстрирует то, как определенная группировка параметров масштабирования выполняется для получения в конечном итоге дискретизированной с понижением точки 1100. В качестве примера, первый блок из четырех полос частот состоит из (0, 1, 2, 3), и средняя точка этого первого блока находится в 1,5, что указывается посредством элемента 1100 в индексе 1,5 вдоль оси X.
Соответственно, второй блок из четырех полос частот представляет собой (4, 5, 6, 7), и средняя точка второго блока составляет 5,5.
Функции 1110 кодирования со взвешиванием соответствуют функциям w(k) кодирования со взвешиванием, поясненным относительно понижающей дискретизации на этапе 6, описанной выше. Можно видеть, что эти функции кодирования со взвешиванием центрируются в дискретизированных с понижением точках, и возникает перекрытие одного блока в каждую сторону, как пояснено выше.
Этап 222 интерполяции по фиг. 19 восстанавливает 64 полосы частот после 16 дискретизированных с понижением точек. Это видно на фиг. 21 посредством вычисления позиции любой из линий 1120 в качестве функции двух дискретизированных с понижением точек, указываемых в 1100, вокруг определенной линии 1120. Нижеприведенный пример примерно иллюстрирует это.
Позиция второй полосы частот вычисляется в качестве функции от двух вертикальных линий вокруг нее (1,5 и 5,5):2=1,5+1/8x(5,5-1,5).
Соответственно, позиция третьей полосы частот в качестве функции от двух вертикальных линий 1100 вокруг нее (1,5 и 5,5): 3=1,5+3/8x(5,5-1,5).
Конкретная процедура выполняется для первых двух полос частот и последних двух полос частот. Для этих полос частот, интерполяция не может выполняться, поскольку не существуют вертикальные линии или значения, соответствующие вертикальным линиям 1100, за пределами диапазона, проходящего от 0 до 63. Таким образом, чтобы разрешать эту проблему, выполняется экстраполяция, как описано относительно этапа 9: интерполяция, как указано выше для двух полос частот 0, 1, с одной стороны, и 62 и 63, с другой стороны.
Далее поясняется предпочтительная реализация преобразователя 100 по фиг. 11, с одной стороны, и преобразователя 240 по фиг. 18, с другой стороны.
В частности, фиг. 22a иллюстрирует расписание для указания кадрирования, выполняемого на стороне кодера в преобразователе 100. Фиг. 22b иллюстрирует предпочтительную реализацию преобразователя 100 по фиг. 11 на стороне кодера, и фиг. 22c иллюстрирует предпочтительную реализацию преобразователя 240 на стороне декодера.
Преобразователь 100 на стороне кодера предпочтительно реализуется с возможностью выполнения кадрирования с перекрывающимися кадрами, к примеру, с 50%-м перекрытием, так что кадр 2 перекрывается с кадром 1, и кадр 3 перекрывается с кадром 2 и кадром 4. Тем не менее, также могут выполняться другие перекрытия или неперекрывающаяся обработка, но предпочтительно выполнять 50%-е перекрытие вместе с алгоритмом MDCT. С этой целью, преобразователь 100 содержит функцию 101 аналитического кодирования со взвешиванием и последующий соединенный спектральный преобразователь 102 для выполнения обработки FFT, обработки MDCT или любого другого вида обработки временно-спектрального преобразования, чтобы получать последовательность кадров, соответствующих последовательности спектральных представлений, вводимых на фиг. 11 в блоки после преобразователя 100.
Соответственно, масштабированное спектральное представление(я) вводятся в преобразователь 240 по фиг. 18. В частности, преобразователь содержит временной преобразователь 241, реализующий обратную операцию FFT, обратную операцию MDCT или соответствующую операцию спектрально-временного преобразования. Вывод вставляется в функцию 242 синтезирующего кодирования со взвешиванием, и вывод функции 242 синтезирующего кодирования со взвешиванием вводится в процессор 243 сложения с перекрытием, чтобы выполнять операцию сложения с перекрытием, с тем чтобы в конечном счете получать декодированный аудиосигнал. В частности, обработка сложения с перекрытием в блоке 243, например, выполняет последовательное выборочное сложение между соответствующими выборками второй половины, например, кадра 3 и первой половины кадра 4, так что получаются значения аудиодискретизации для перекрытия между кадром 3 и кадром 4, как указано посредством элемента 1200 на фиг. 22a. Аналогичные операции сложения с перекрытием последовательным выборочным способом выполняются для получения оставшихся значений аудиодискретизации декодированного выходного аудиосигнала.
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше, и все аспекты, заданные посредством независимых пунктов в нижеприведенной формуле изобретения, могут использоваться отдельно, т.е. без альтернатив или целей, отличных от предполагаемой альтернативы, цели или независимого пункта формулы изобретения. Тем не менее, в других вариантах осуществления, две или более из альтернатив или аспектов или независимых пунктов формулы изобретения могут комбинироваться друг с другом, и, в других вариантах осуществления, все аспекты или альтернативы и все независимые пункты формулы изобретения могут комбинироваться друг с другом.
Хотя выше описаны дополнительные аспекты, прилагаемая формула изобретения указывают два различных аспекта, т.е. аудиодекодер, аудиокодер и соответствующие способы с использованием объединенного кодирования параметров масштабирования для каналов многоканального аудиосигнала, либо устройство квантования аудиоданных, устройство деквантования аудиоданных или соответствующие способы. Эти два аспекта могут комбинироваться или использоваться отдельно, в зависимости от обстоятельств, и изобретения в соответствии с этими аспектами являются применимыми к другому варианту применения аудиообработки, отличающемуся от вышеописанных конкретных вариантов применения.
Кроме того, следует обратиться к дополнительным фиг. 3a, 3b, 4a, 4b, 5, 6, 8a, 8b, иллюстрирующим первый аспект, и фиг. 9a, 9b, иллюстрирующим второй аспект, и фиг. 7a, 7b, иллюстрирующим второй аспект, применяемый в первом аспекте.
Изобретательный кодированный сигнал может сохраняться на цифровом носителе хранения данных или постоянном носителе хранения данных или может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем случае, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на постоянном носителе хранения данных.
Другими словами, таким образом вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную на нём компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнять части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства аппаратного обеспечения.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Далее обобщаются дополнительные варианты осуществления/примеры:
1. Устройство квантования аудиоданных для квантования множества информационных аудиоэлементов, содержащее:
- модуль (141, 143) векторного квантования первой ступени для квантования множества информационных аудиоэлементов для определения результата векторного квантования первой ступени, и множества промежуточных квантованных элементов, соответствующих результату векторного квантования первой ступени;
- модуль (142) определения остаточных элементов для вычисления множества остаточных элементов из множества промежуточных квантованных элементов и множества информационных аудиоэлементов; и
- модуль (145) векторного деквантования второй ступени для квантования множества остаточных элементов для получения результата векторного квантования второй ступени, при этом результат векторного квантования первой ступени и результат векторного квантования второй ступени представляют собой квантованное представление множества информационных аудиоэлементов.
2. Устройство квантования аудиоданных по примеру 1, в котором модуль (142) определения остаточных элементов выполнен с возможностью вычисления для каждого остаточного элемента разности между соответствующим информационным аудиоэлементом и соответствующим промежуточным квантованным элементом.
3. Устройство квантования аудиоданных по примеру 1 или 2, в котором модуль (142) определения остаточных элементов выполнен с возможностью усиления или взвешивания для каждого остаточного элемента разности между соответствующим информационным аудиоэлементом и соответствующим промежуточным квантованным элементом таким образом, что множество остаточных элементов больше соответствующих разностей, либо усиливать или взвешивать множество информационных аудиоэлементов и/или множество промежуточных квантованных элементов перед вычислением разности между усиленными элементами для получения остаточных элементов.
4. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором модуль (142) определения остаточных элементов выполнен с возможностью деления соответствующих разностей между множеством промежуточных квантованных элементов и информационными аудиоэлементами на заданный коэффициент, меньший 1, либо умножения соответствующих разностей между множеством промежуточных квантованных элементов и информационными аудиоэлементами на заданный коэффициент больше 1.
5. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором модуль (141, 143) векторного квантования первой ступени выполнен с возможностью выполнения квантования с первой точностью квантования, при этом модуль (145) векторного квантования второй ступени выполнен с возможностью выполнения квантования со второй точностью квантования, и при этом вторая точность квантования меньше или больше первой точности квантования, или
- при этом модуль (141, 143) векторного квантования первой ступени выполнен с возможностью выполнения квантования с фиксированной скоростью, и при этом модуль (145) векторного квантования второй ступени выполнен с возможностью выполнения квантования с переменной скоростью.
6. Устройство квантования аудиоданных по одному из предшествующих примеров, в котором модуль (141, 143) векторного квантования первой ступени выполнен с возможностью использования таблицы кодирования первой ступени, имеющей первое число записей, при этом модуль (145) векторного квантования второй ступени выполнен с возможностью использования таблицы кодирования второй ступени, имеющей второе число записей, и при этом второе число записей меньше или больше первого числа записей.
7. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором информационные аудиоэлементы представляют собой параметры масштабирования для кадра аудиосигнала, применимого для масштабирования аудиовыборок временной области аудиосигнала во временной области или применимого для масштабирования аудиовыборок спектральной области аудиосигнала в спектральной области, при этом каждый параметр масштабирования является применимым для масштабирования по меньшей мере двух аудиовыборок временной области или спектральной области, при этом кадр содержит первое число параметров масштабирования,
- при этом модуль (141, 143) векторного квантования первой ступени выполнен с возможностью выполнения разбиения первого числа параметров масштабирования на два или более наборов параметров масштабирования, и при этом модуль (141, 143) векторного квантования первой ступени выполнен с возможностью определения индекса квантования для каждого набора параметров масштабирования для получения множества индексов квантования, представляющих первый результат квантования.
8. Устройство квантования аудиоданных по примеру 7, в котором модуль (141, 143) векторного квантования первой ступени выполнен с возможностью комбинирования первого индекса квантования для первого набора и второго индекса квантования для второго набора для получения одного индекса в качестве первого результата квантования.
9. Устройство квантования аудиоданных по примеру 8,
- в котором модуль (141, 143) векторного квантования первой ступени выполнен с возможностью умножения одного из первого и второго индекса на число, соответствующее числу битов первого и второго индекса, и сложения умноженного индекса и неумноженного индекса для получения одного индекса.
10. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором модуль (145) векторного квантования второй ступени представляет собой алгебраический модуль векторного квантования, при этом каждый индекс содержит индекс базовой таблицы кодирования и индекс расширения Вороного.
11. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором модуль (141, 143) векторного квантования первой ступени выполнен с возможностью выполнения первого разбиения множества информационных аудиоэлементов,
- при этом модуль (145) векторного квантования второй ступени выполнен с возможностью выполнения второго разбиения множества остаточных элементов,
- при этом первое разбиение приводит к первому числу поднаборов информационных аудиоэлементов, и второе разбиение приводит к второму числу поднаборов остаточных элементов, при этом первое число поднаборов равно второму числу поднаборов.
12. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором первый модуль векторного квантования выполнен с возможностью вывода из первого поиска в таблице кодирования первого индекса, имеющего первое число битов,
- при этом второй модуль векторного квантования выполнен с возможностью вывода для поиска во второй таблице кодирования второго индекса, имеющего второе число битов, причем второе число битов меньше или больше первого числа битов.
13. Устройство квантования аудиоданных по примеру 12,
- в котором первое число битов представляет собой число битов между 4 и 7, и при этом второе число битов представляет собой число битов между 3 и 6.
14. Устройство квантования аудиоданных по одному из предшествующих примеров,
- в котором информационные аудиоэлементы содержат, для первого кадра многоканального аудиосигнала, первое множество параметров масштабирования для первого канала многоканального аудиосигнала и второе множество параметров масштабирования для второго канала многоканального аудиосигнала,
- при этом устройство квантования аудиоданных выполнено с возможностью применения модулей векторного квантования первого и второй ступени к первому множеству и второму множеству первого кадра,
- при этом информационные аудиоэлементы содержат, для второго кадра многоканального аудиосигнала, третье множество средних параметров масштабирования и четвертое множество боковых параметров масштабирования, и
- при этом устройство квантования аудиоданных выполнено с возможностью применения модулей векторного квантования первого и второй ступени к третьему множеству средних параметров масштабирования и применения второй ступени модуля векторного квантования к четвертому множеству боковых параметров масштабирования и неприменения модуля (141, 143) векторного квантования первой ступени к четвертому множеству боковых параметров масштабирования.
15. Устройство квантования аудиоданных по примеру 14,
- в котором модуль (142) определения остаточных элементов выполнен с возможностью усиления или взвешивания для второго кадра четвертого множества боковых параметров масштабирования, и при этом модуль (145) векторного квантования второй ступени выполнен с возможностью обработки усиленных или взвешенных боковых параметров масштабирования для второго кадра многоканального аудиосигнала.
16. Устройство деквантования аудиоданных для деквантования квантованного множества информационных аудиоэлементов, содержаще:
- модуль (2220) векторного деквантования первой ступени для деквантования результата векторного квантования первой ступени, включенного в квантованное множество информационных аудиоэлементов для получения множества промежуточных квантованных информационных аудиоэлементов;
- модуль (2260) векторного деквантования второй ступени для деквантования результата векторного квантования второй ступени, включенного в квантованное множество информационных аудиоэлементов для получения множества остаточных элементов; и
- модуль (2240) комбинирования для комбинирования множества промежуточных квантованных информационных элементов и множества остаточных элементов для получения деквантованного множества информационных аудиоэлементов.
17. Устройство деквантования аудиоданных по примеру 16, в котором модуль (2240) комбинирования выполнен с возможностью вычисления для каждого деквантованного информационного элемента суммы между соответствующим промежуточным квантованным информационным аудиоэлементом и соответствующим остаточным элементом.
18. Устройство деквантования аудиоданных по одному из примеров 16 или 17,
- в котором модуль (2240) комбинирования выполнен с возможностью обеспечения ослабления или взвешивания множества остаточных элементов таким образом, что остаточные элементы с ослаблением ниже соответствующих остаточных элементов до выполнения ослабления, и
- при этом модуль (2240) комбинирования выполнен с возможностью сложения остаточных элементов с ослаблением с соответствующими промежуточными квантованными информационными аудиоэлементами,
- или:
- при этом модуль (2240) комбинирования выполнен с возможностью использования значения ослабления или взвешивания ниже 1 для обеспечения ослабления множества остаточных элементов или объединенно кодированных параметров масштабирования до выполнения комбинирования, при этом комбинирование выполняется с использованием остаточных значений с ослаблением, и/или
- при этом, в качестве примера, значение взвешивания или ослабления используется для умножения параметра масштабирования на значение взвешивания или усиления, при этом значение взвешивания предпочтительно составляет между 0,1 и 0,9, или более предпочтительно, между 0,2 и 0,6, или еще более предпочтительно, между 0,25 и 0,4, и/или
- при этом одинаковое значение ослабления или взвешивания используется для всех параметров масштабирования множества остаточных элементов или любых объединенно кодированных параметров масштабирования.
19. Устройство деквантования аудиоданных по примеру 18, в котором модуль (2240) комбинирования выполнен с возможностью умножения соответствующего остаточного элемента на весовой коэффициент меньше единицы, или деления соответствующего остаточного элемента на весовой коэффициент больше единицы.
20. Устройство деквантования аудиоданных по одному из примеров 16-19,
- в котором модуль деквантования первой ступени выполнен с возможностью выполнения деквантования с первой точностью,
- при этом модуль деквантования второй ступени выполнен с возможностью выполнения деквантования со второй точностью, при этом вторая точность меньше или больше первой точности.
21. Устройство деквантования аудиоданных по одному из примеров 16-20,
- в котором модуль деквантования первой ступени выполнен с возможностью использования таблицы кодирования первой ступени, имеющую первое число записей, при этом модуль деквантования второй ступени выполнен с возможностью использования таблицы кодирования второй ступени, имеющей второе число записей, и при этом второе число записей меньше или больше первого числа записей, или
- при этом модуль деквантования первой ступени выполнен с возможностью приёма, для извлечения из первой таблицы кодирования первого индекса, имеющего первое число битов,
- при этом модуль (2260) векторного деквантования второй ступени выполнен с возможностью приёма для извлечения из второй таблицы кодирования, второго индекса, имеющего второе число битов, причем второе число битов меньше или больше первого числа битов, или при этом, в качестве примера, первое число битов представляет собой число битов между 4 и 7, и при этом, в качестве примера, второе число битов представляет собой число битов между 3 и 6.
22. Устройство деквантования аудиоданных по одному из примеров 16-21,
- в котором деквантованное множество информационных аудиоэлементов представляют собой параметры масштабирования для кадра аудиосигнала, применимого для масштабирования аудиовыборок временной области аудиосигнала во временной области или применимого для масштабирования аудиовыборок спектральной области аудиосигнала в спектральной области, при этом каждый параметр масштабирования является применимым для масштабирования по меньшей мере двух аудиовыборок временной области или спектральной области, при этом кадр содержит первое число параметров масштабирования,
- при этом модуль деквантования первой ступени выполнен с возможностью определения из двух или более результирующих индексов для результата векторного квантования первой ступени первого набора и второго набора параметров масштабирования, и
- при этом векторный модуль (2220) деквантования первой ступени или модуль (2240) комбинирования выполнен с возможностью сбора первого набора параметров масштабирования и второго набора параметров масштабирования в вектор для получения первого числа промежуточных квантованных параметров масштабирования.
23. Устройство деквантования аудиоданных по примеру 22,
- в котором модуль (2220) векторного деквантования первой ступени выполнен с возможностью извлечения в качестве результата деквантования первой ступени одного комбинированного индекса и обработки одного комбинированного индекса для получения двух или более результирующих индексов.
24. Устройство деквантования аудиоданных по примеру 23,
- в котором модуль деквантования первой ступени выполнен с возможностью извлечения первого результирующего индекса посредством определения остатка от деления и извлечения второго результирующего индекса посредством определения целочисленного результата из деления.
25. Устройство деквантования аудиоданных по одному из примеров 16 в 24, в котором модуль (2260) векторного деквантования второй ступени представляет собой алгебраический модуль векторного деквантования, при этом каждый индекс содержит индекс базовой таблицы кодирования и индекс расширения Вороного.
26. Устройство деквантования аудиоданных по одному из примеров 16-25,
- в котором модуль (2220) векторного деквантования первой ступени или модуль (2240) комбинирования выполнен с возможностью сбора первого набора параметров масштабирования и второго набора параметров масштабирования из разбиения квантования в кадре аудиосигнала,
- при этом модуль (2260) векторного деквантования второй ступени выполнен с возможностью сбора первого набора остаточных параметров и второго набора остаточных параметров из разбиения остаточных параметров, и
- при этом число разбиений, разрешаемое посредством модуля деквантования первого вектора, и другое число разбиений, разрешаемое посредством модуля (2260) векторного деквантования второй ступени, являются равными.
27. Устройство деквантования аудиоданных по одному из примеров 16-26,
- в котором модуль (2220) векторного деквантования первой ступени выполнен с возможностью использования первого индекса, имеющего первое число битов, для формирования множества промежуточных квантованных информационных аудиоэлементов, и
- при этом модуль (2260) векторного деквантования второй ступени выполнен с возможностью использования в качестве индекса второго индекса, имеющего второе число битов, для получения множества остаточных элементов, при этом второе число битов меньше или больше первого числа битов.
28. Устройство деквантования аудиоданных по примеру 27, в котором первое число битов составляет от четырёх и семи, и второе число битов составляет от трех и шести.
29. Устройство деквантования аудиоданных по одному из примеров 16-28,
- в котором квантованное множество информационных аудиоэлементов содержат, для первого кадра многоканального аудиосигнала, первое множество параметров масштабирования для первого канала многоканального аудиосигнала и второе множество параметров масштабирования для второго канала многоканального аудиосигнала,
- при этом устройство деквантования аудиоданных выполнено с возможностью применения модуля (2220) векторного деквантования первой ступени и модуля (2260) векторного деквантования второй ступени к первому множеству и второму множеству первого кадра,
- при этом квантованное множество информационных аудиоэлементов содержат, для второго кадра многоканального аудиосигнала, третье множество средних параметров масштабирования и четвертое множество боковых параметров масштабирования, и
- при этом устройство деквантования аудиоданных выполнено с возможностью применения модуля (2220) векторного деквантования первой ступени и модуля (2260) векторного деквантования второй ступени к третьему множеству средних параметров масштабирования и применения модуля (2260) векторного деквантования второй ступени к четвертому множеству боковых параметров масштабирования и неприменения модуля (2220) векторного деквантования первой ступени к четвертому множеству боковых параметров масштабирования.
30. Устройство деквантования аудиоданных по примеру 29,
- в котором модуль (2240) комбинирования выполнен с возможностью обеспечения ослабления для второго кадра четвертого множества боковых параметров масштабирования перед дополнительным использованием или дополнительной обработкой четвертого множества боковых параметров масштабирования.
31. Способ квантования множества информационных аудиоэлементов, содержащий:
- векторное квантование первой ступени для множества информационных аудиоэлементов для определения результата векторного квантования первой ступени, и множества промежуточных квантованных элементов, соответствующих результату векторного квантования первой ступени;
- вычисление множества остаточных элементов из множества промежуточных квантованных элементов и множества информационных аудиоэлементов; и
- векторное квантование второй ступени для множества остаточных элементов для получения результата векторного квантования второй ступени, при этом результат векторного квантования первой ступени и результат векторного квантования второй ступени представляют собой квантованное представление множества информационных аудиоэлементов.
32. Способ деквантования квантованного множества информационных аудиоэлементов, содержащий:
- векторное деквантование первой ступени для результата векторного квантования первой ступени, включенного в квантованное множество информационных аудиоэлементов для получения множества промежуточных квантованных информационных аудиоэлементов;
- векторное деквантование второй ступени для результата векторного квантования второй ступени, включенного в квантованное множество информационных аудиоэлементов для получения множества остаточных элементов; и
- комбинирование множества промежуточных квантованных информационных элементов и множества остаточных элементов для получения деквантованного множества информационных аудиоэлементов.
33. Компьютерная программа для осуществления способа по примеру 31 или способа по примеру 32 при выполнении на компьютере или в процессоре.
Список литературы
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО КВАНТОВАНИЯ АУДИОДАННЫХ, УСТРОЙСТВО ДЕКВАНТОВАНИЯ АУДИОДАННЫХ И СООТВЕТСТВУЮЩИЕ СПОСОБЫ | 2021 |
|
RU2807462C1 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2456682C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2019 |
|
RU2793725C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2562375C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕЙ ДИСКРЕТИЗАЦИИ ИЛИ ИНТЕРПОЛЯЦИИ МАСШТАБНЫХ ПАРАМЕТРОВ | 2018 |
|
RU2762301C2 |
| ГЕНЕРАТОР МНОГОКАНАЛЬНЫХ СИГНАЛОВ, АУДИОКОДЕР И СООТВЕТСТВУЮЩИЕ СПОСОБЫ, ОСНОВАННЫЕ НА ШУМОВОМ СИГНАЛЕ МИКШИРОВАНИЯ | 2021 |
|
RU2809646C1 |
| СИСТЕМА ОБРАБОТКИ АУДИО | 2014 |
|
RU2625444C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР И СВЯЗАННЫЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ ДВУХКАНАЛЬНОЙ ОБРАБОТКИ В ИНФРАСТРУКТУРЕ ИНТЕЛЛЕКТУАЛЬНОГО ЗАПОЛНЕНИЯ ИНТЕРВАЛОВ ОТСУТСТВИЯ СИГНАЛА | 2014 |
|
RU2646316C2 |
| ИНТЕГРАЛЬНОЕ ПАРАМЕТРИЧЕСКОЕ АУДИОКОДИРОВАНИЕ ДЛЯ КАЖДОЙ ПОЛОСЫ ЧАСТОТ | 2022 |
|
RU2834366C2 |
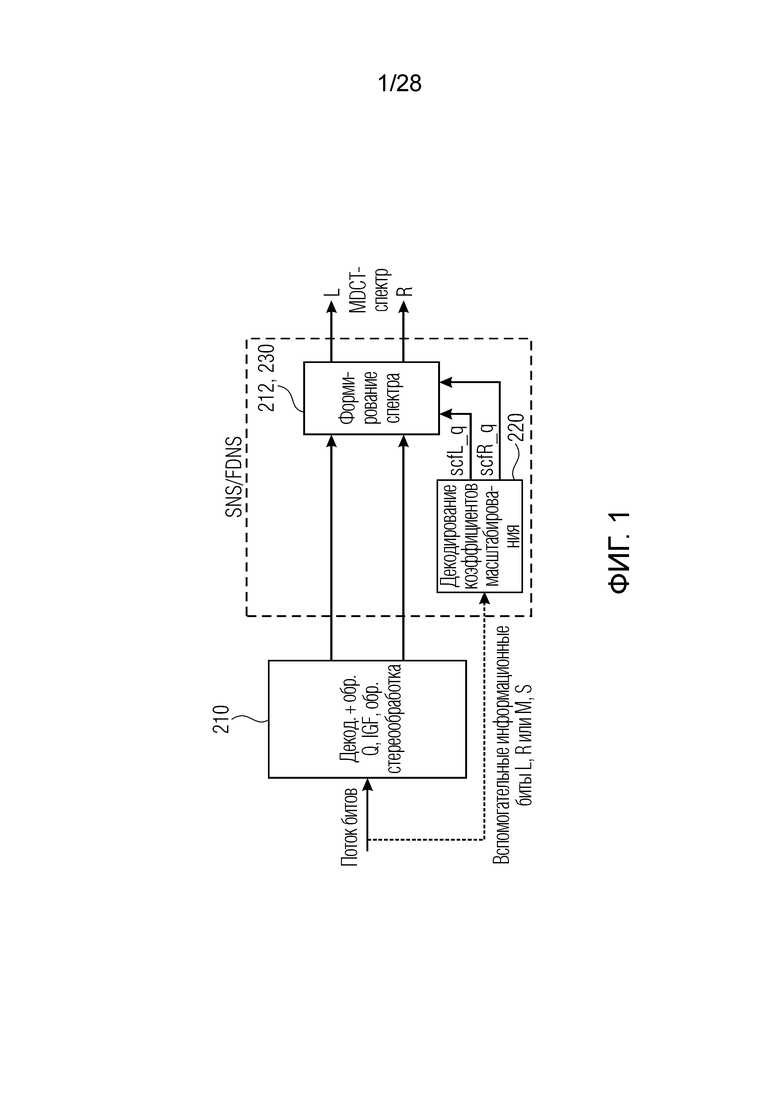
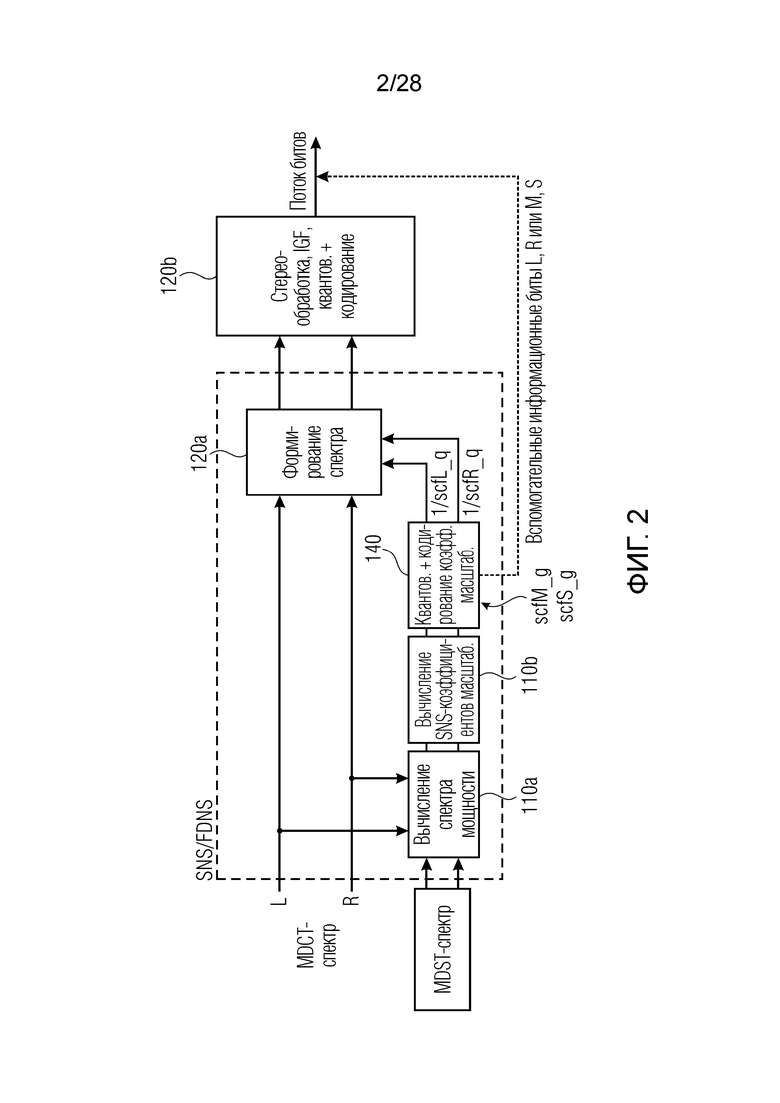
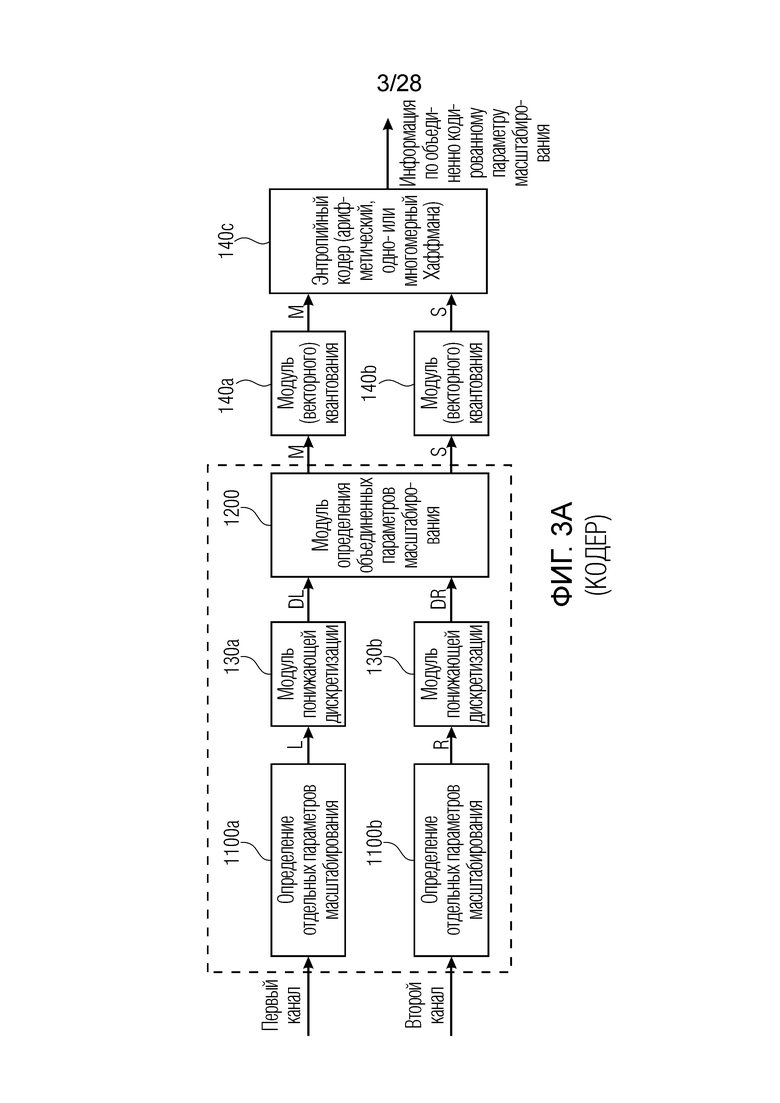
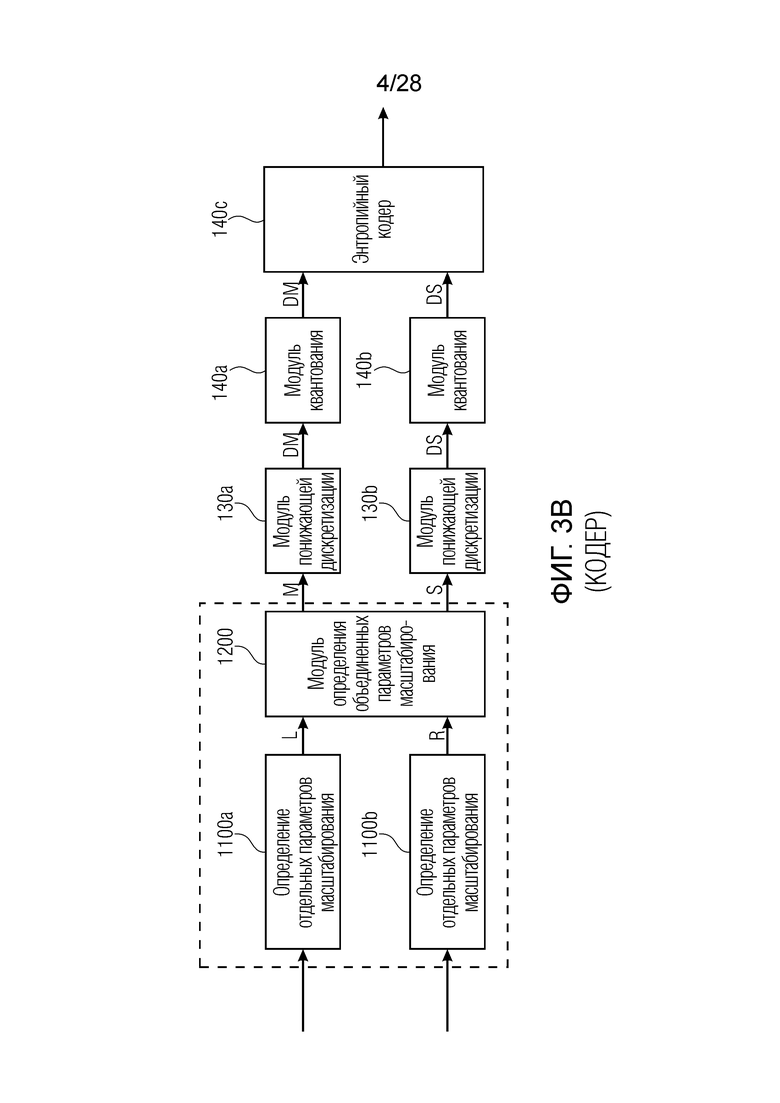
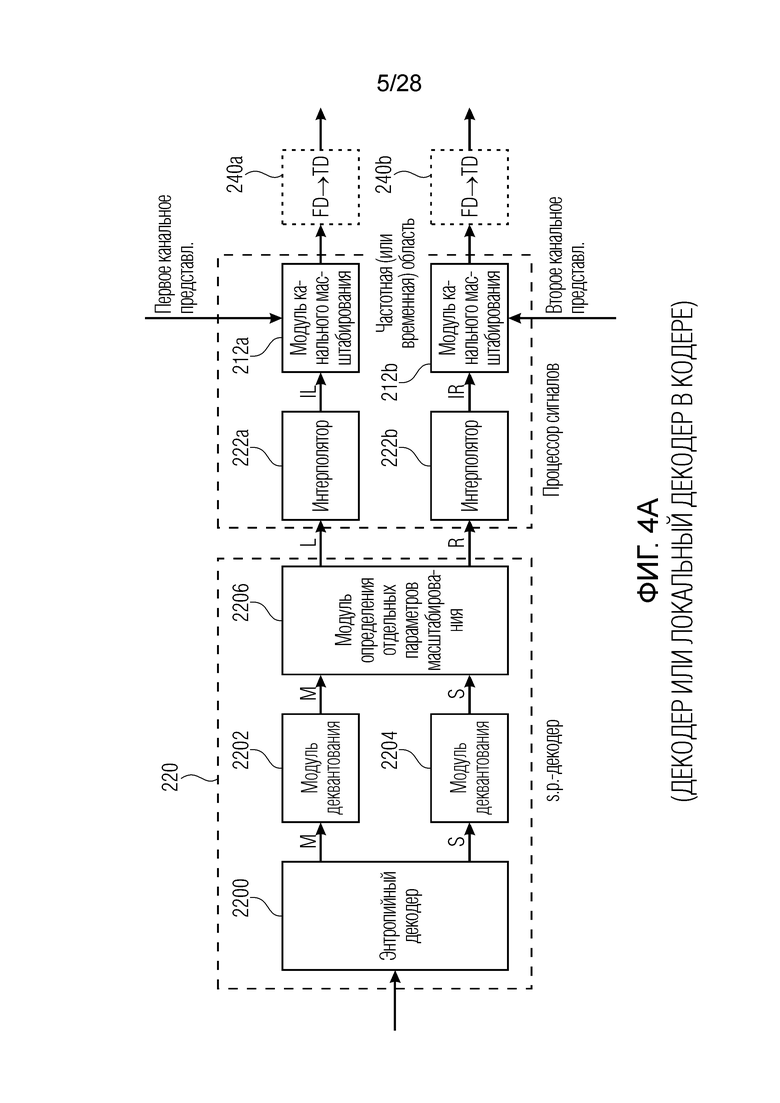
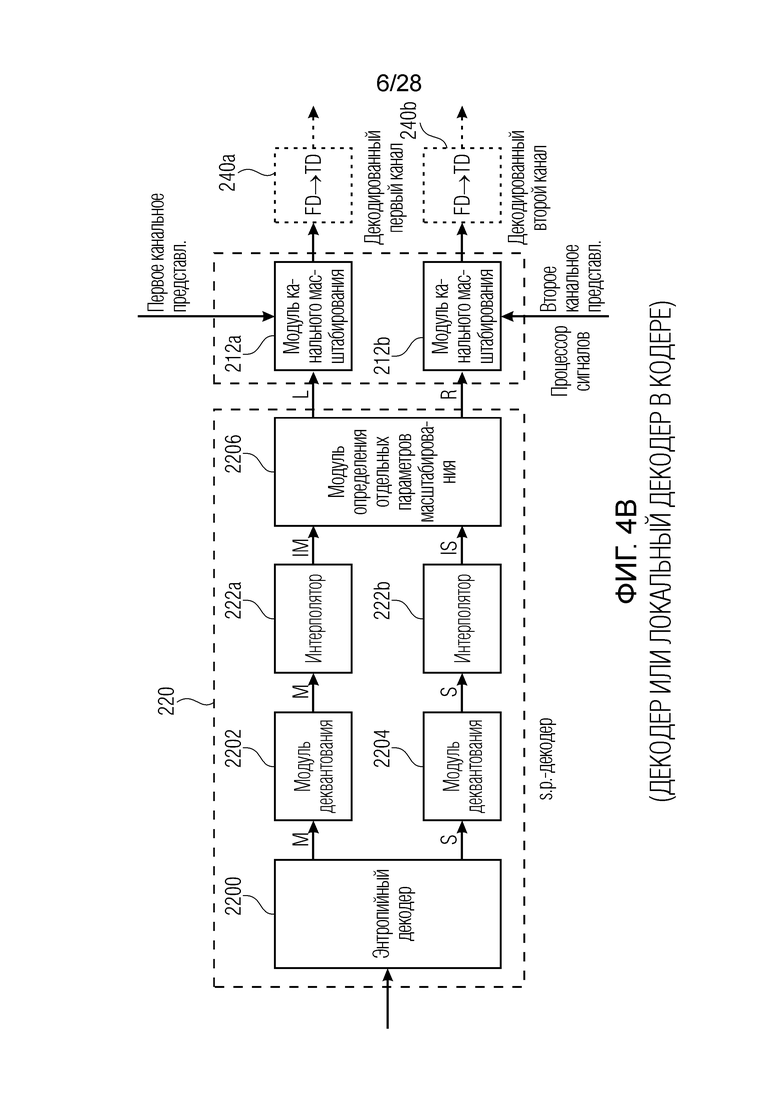
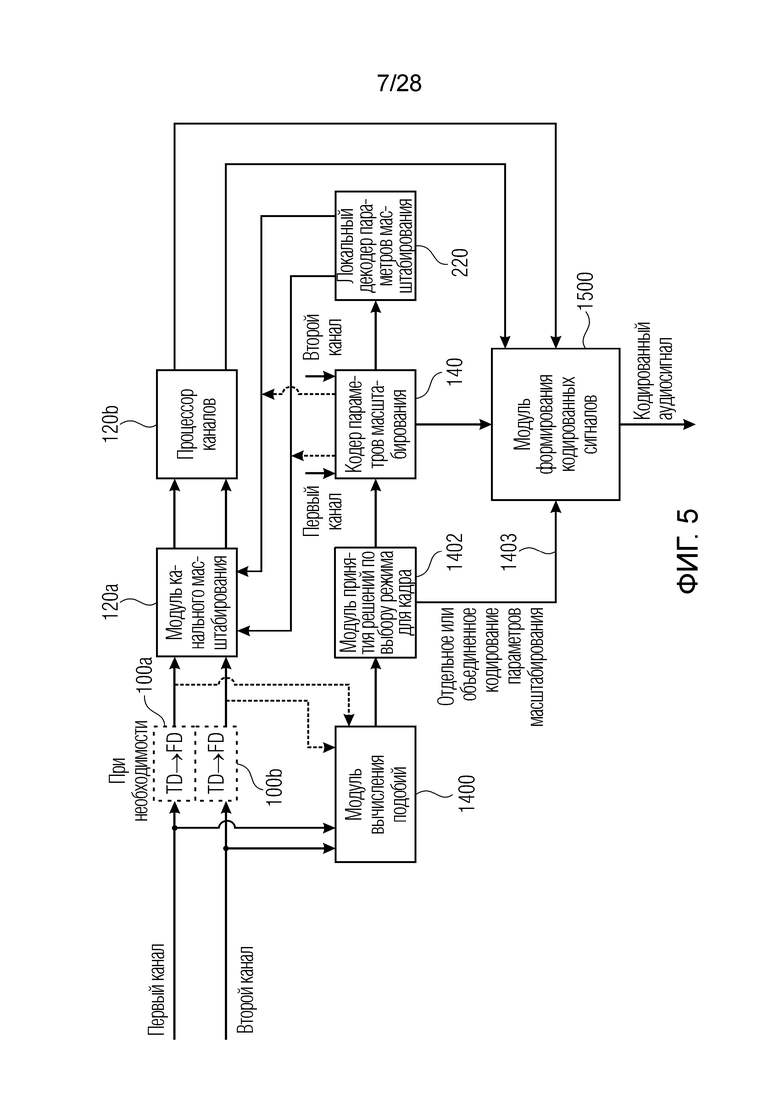
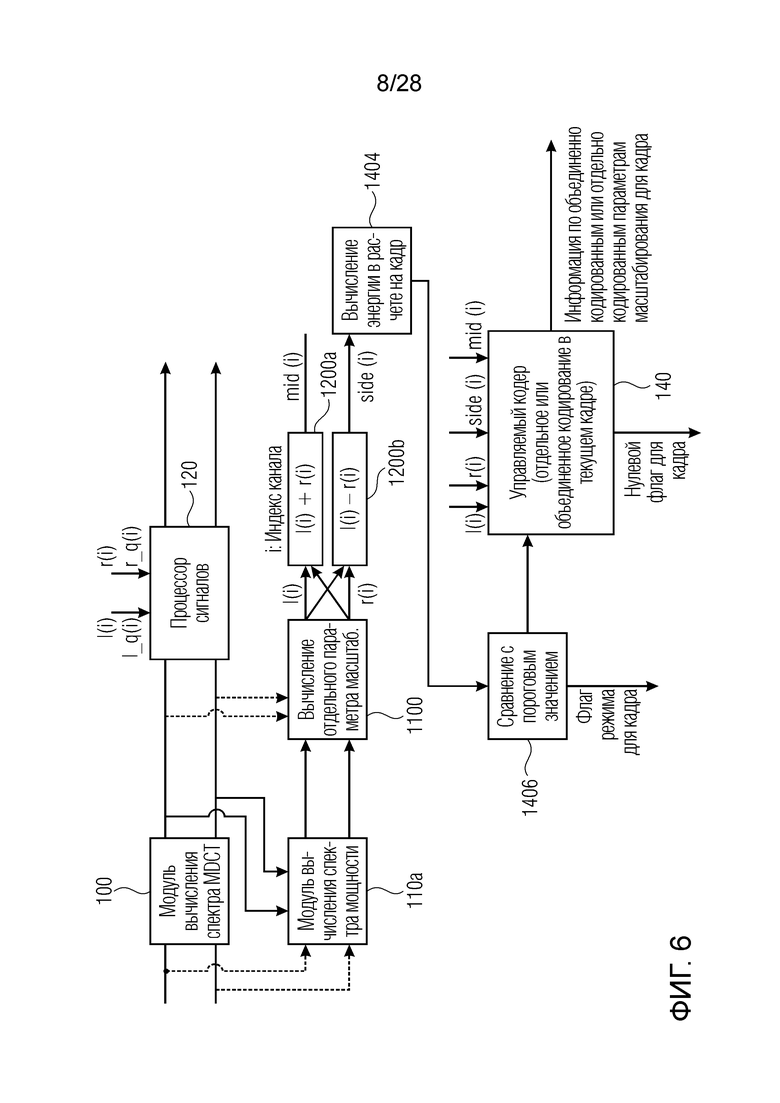
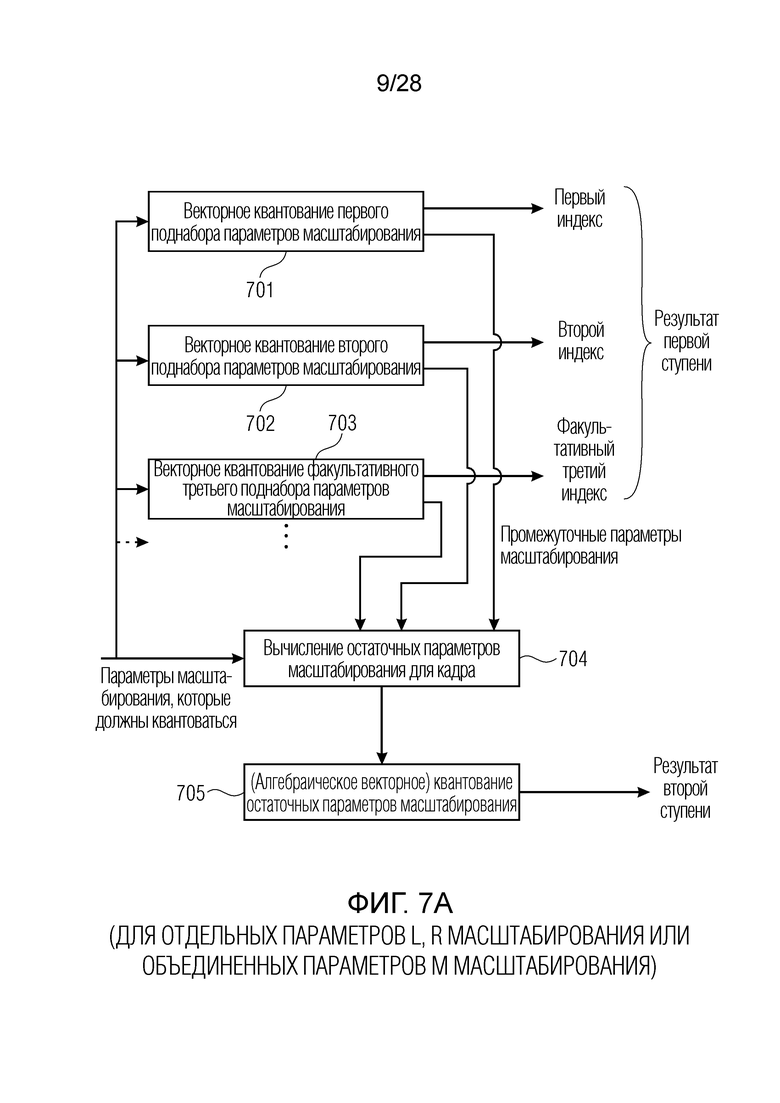
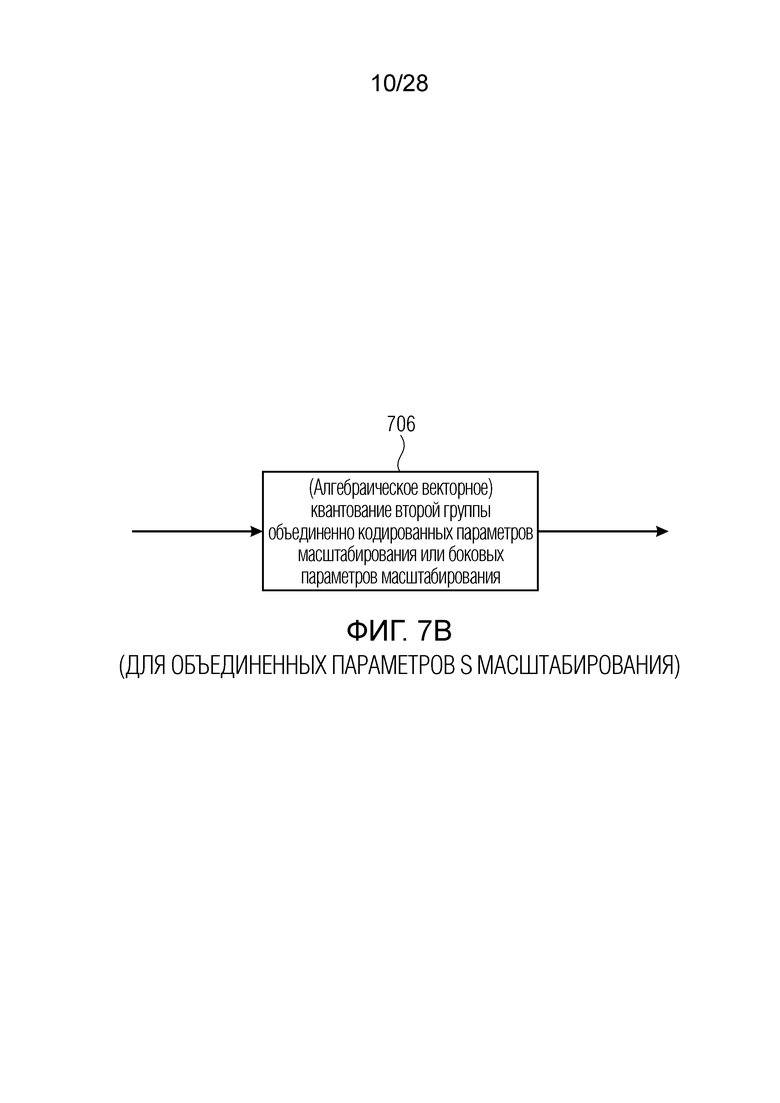
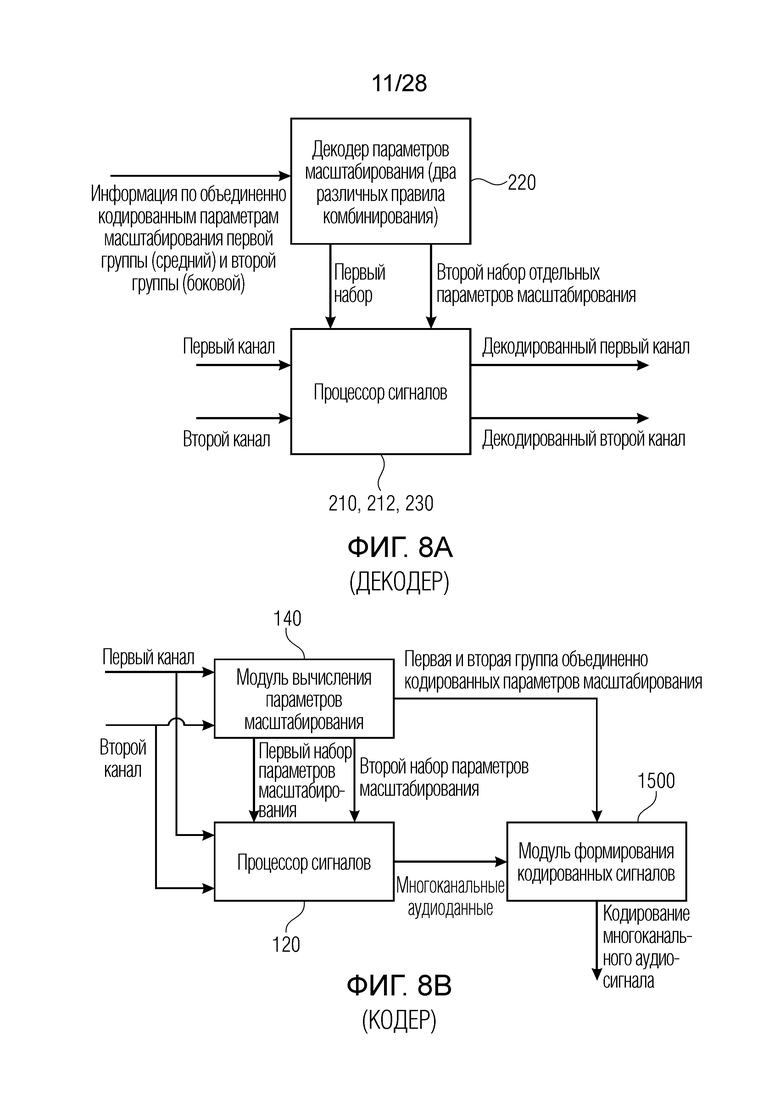
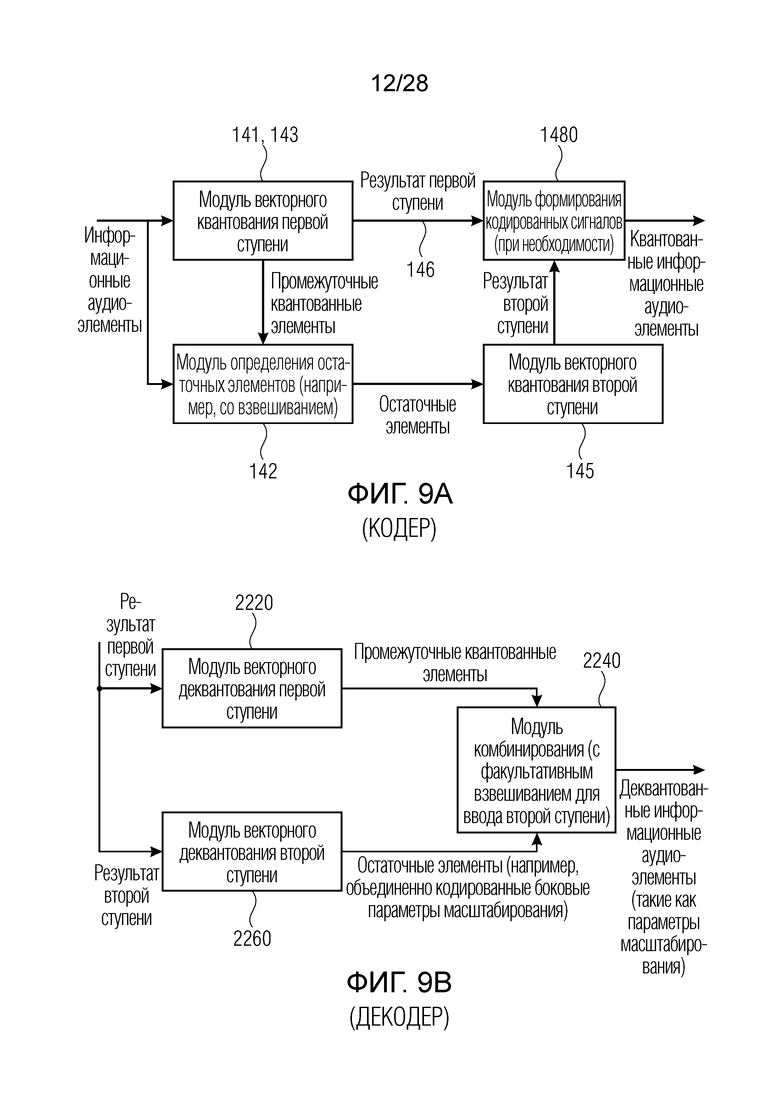
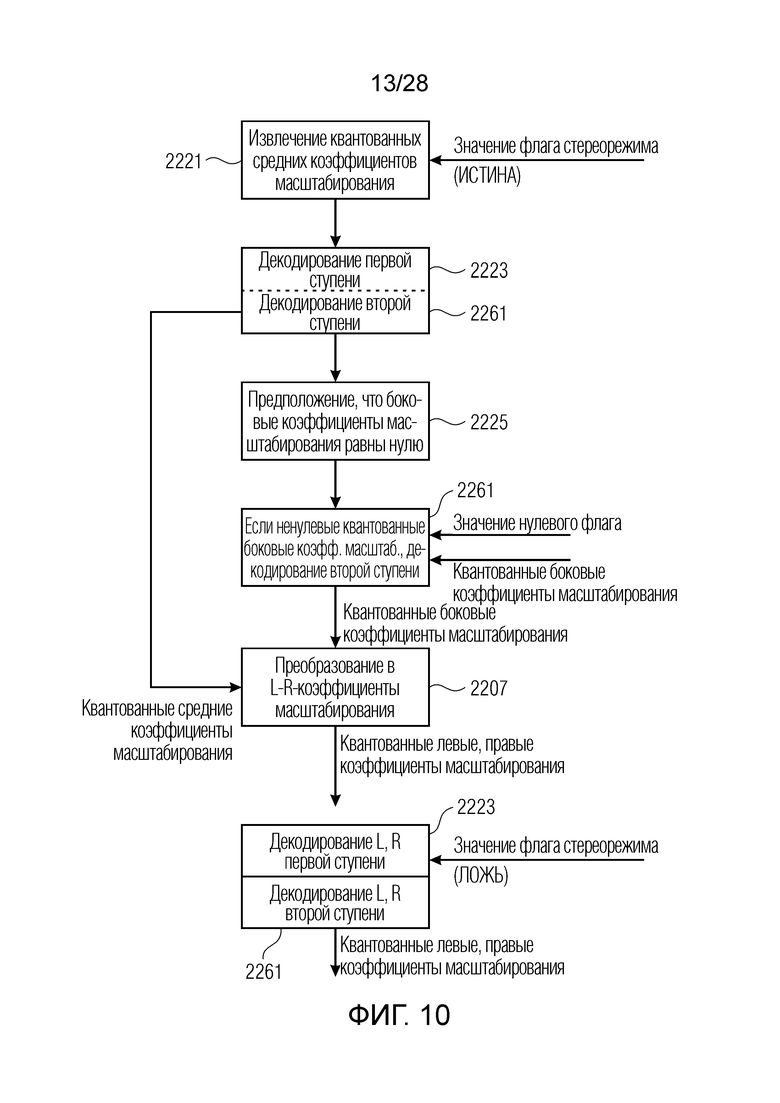
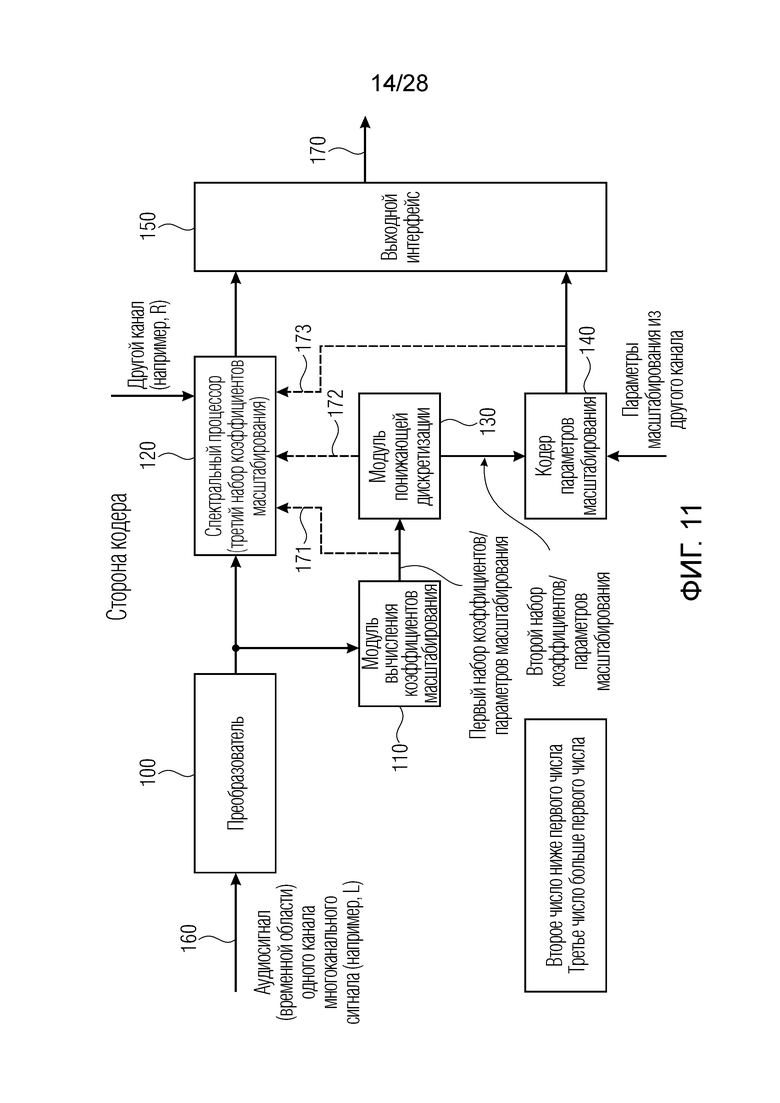
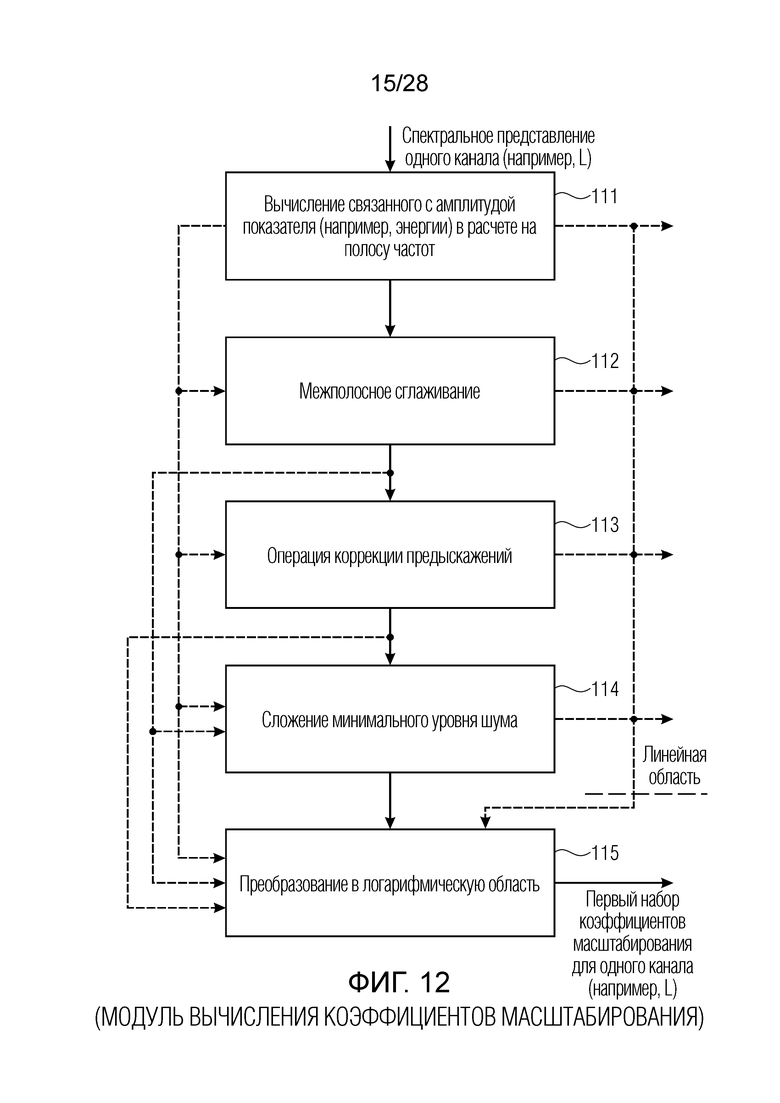
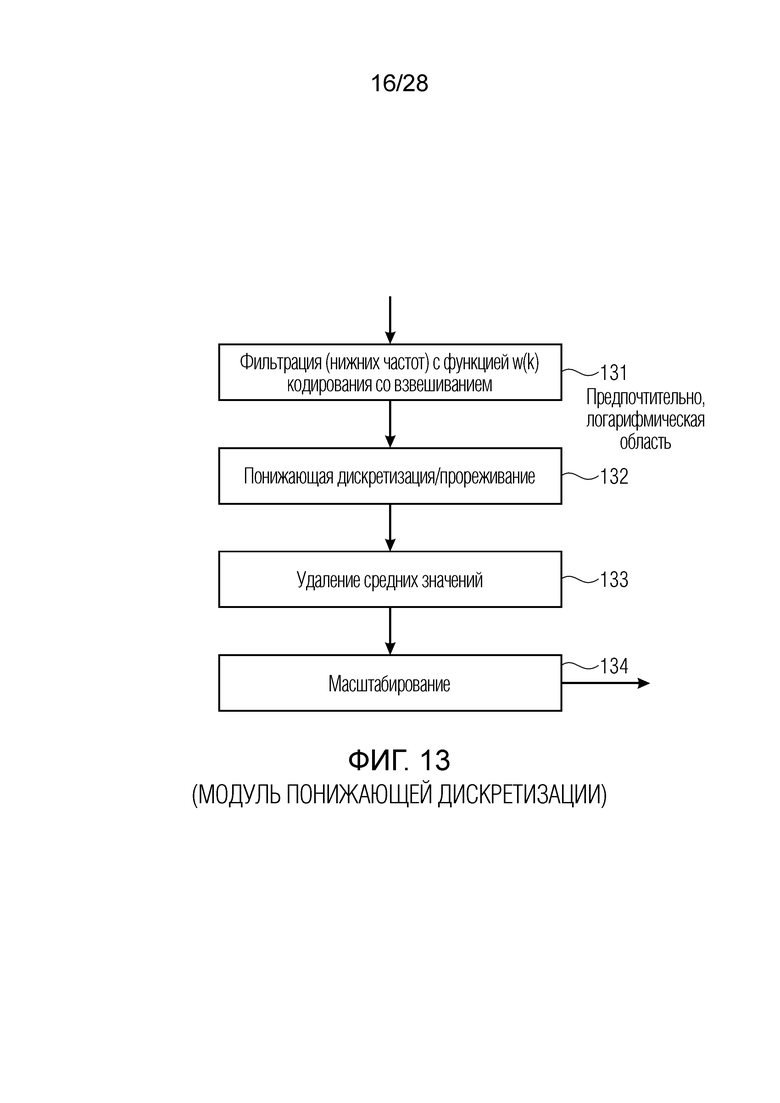
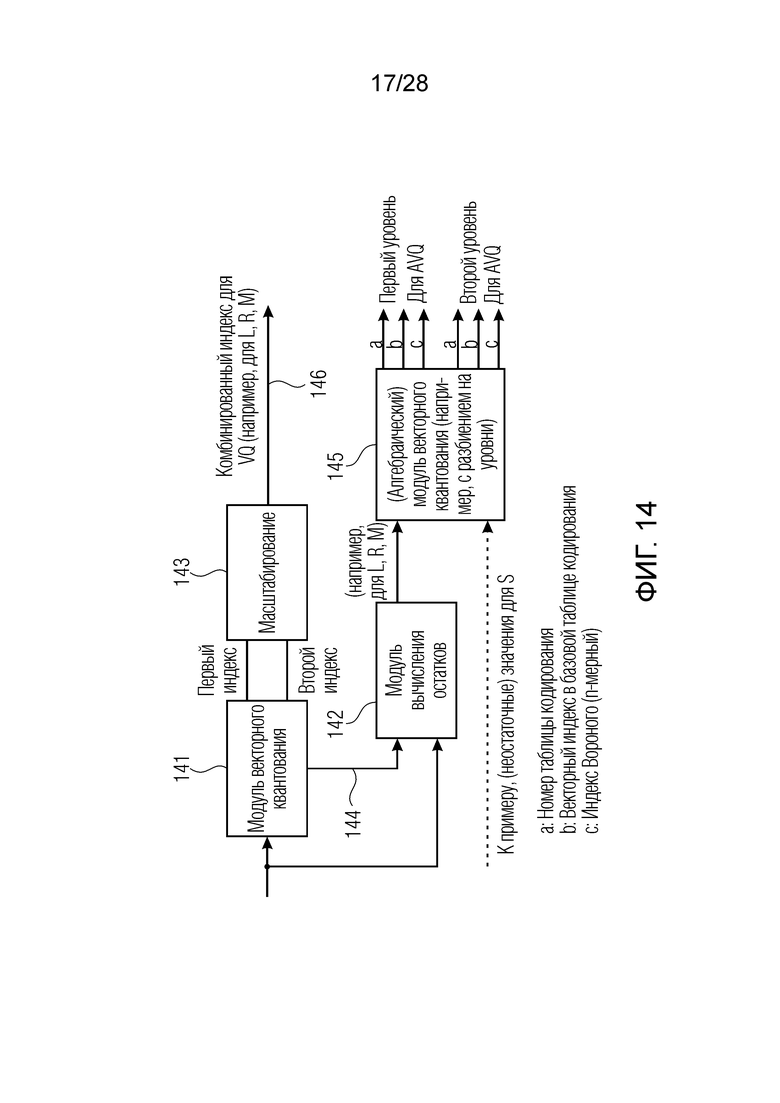
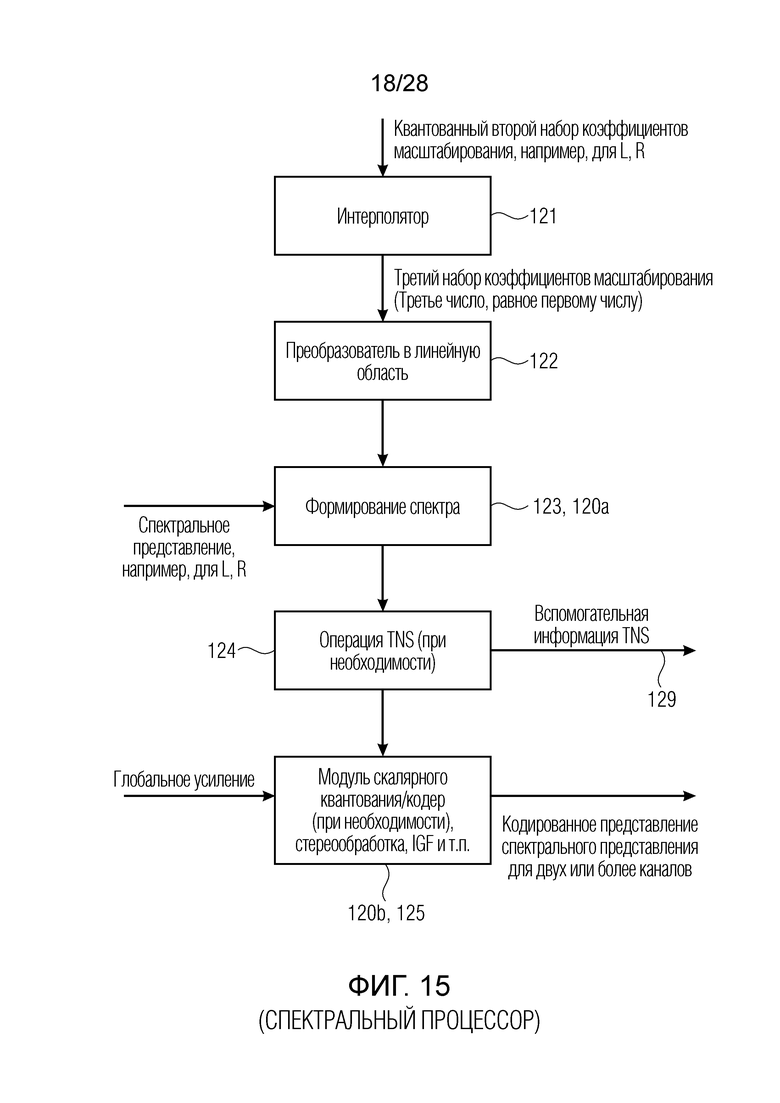
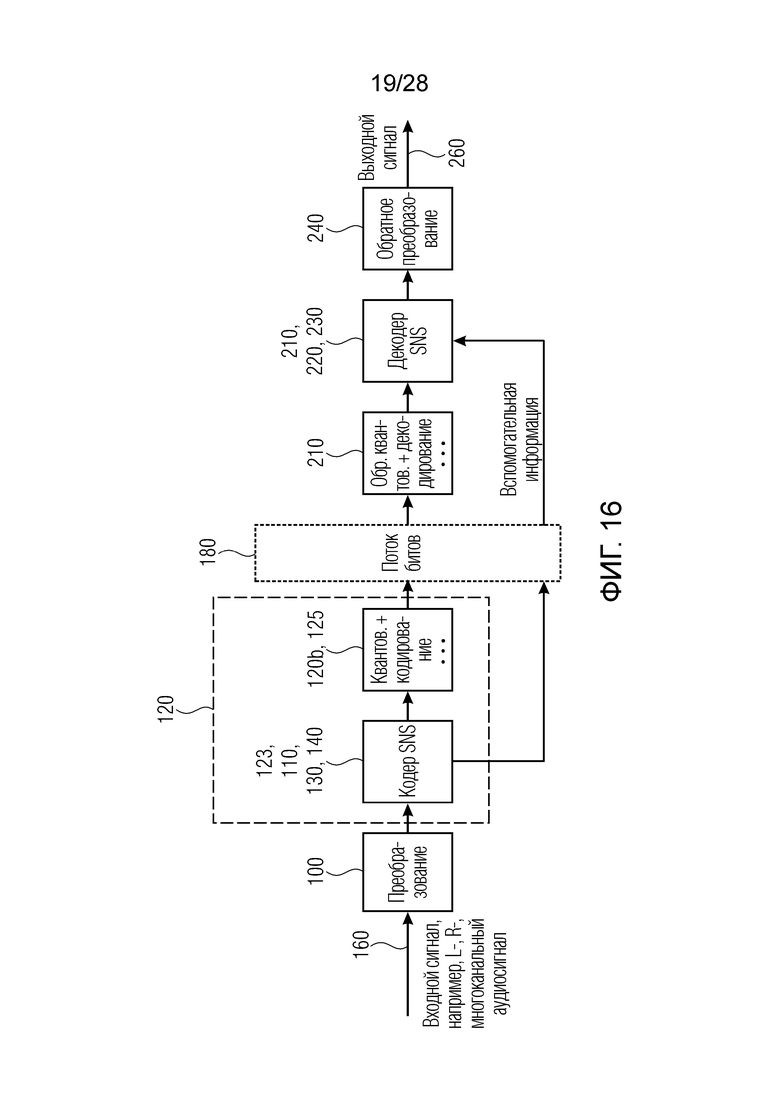
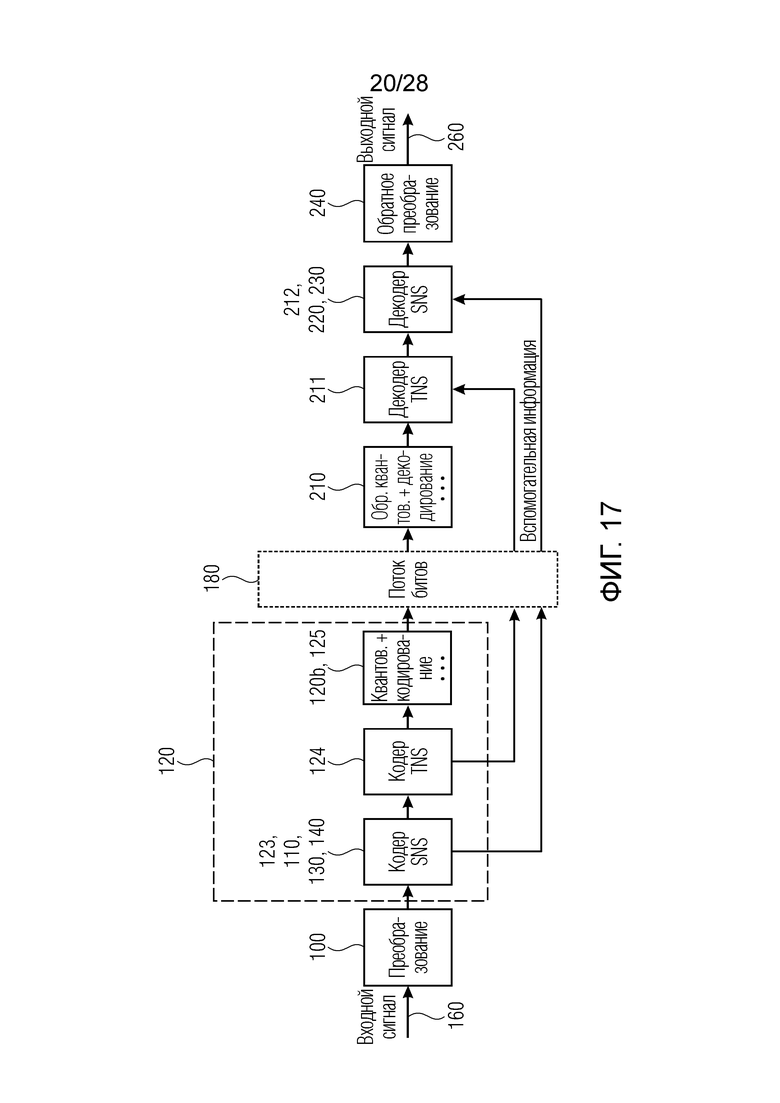
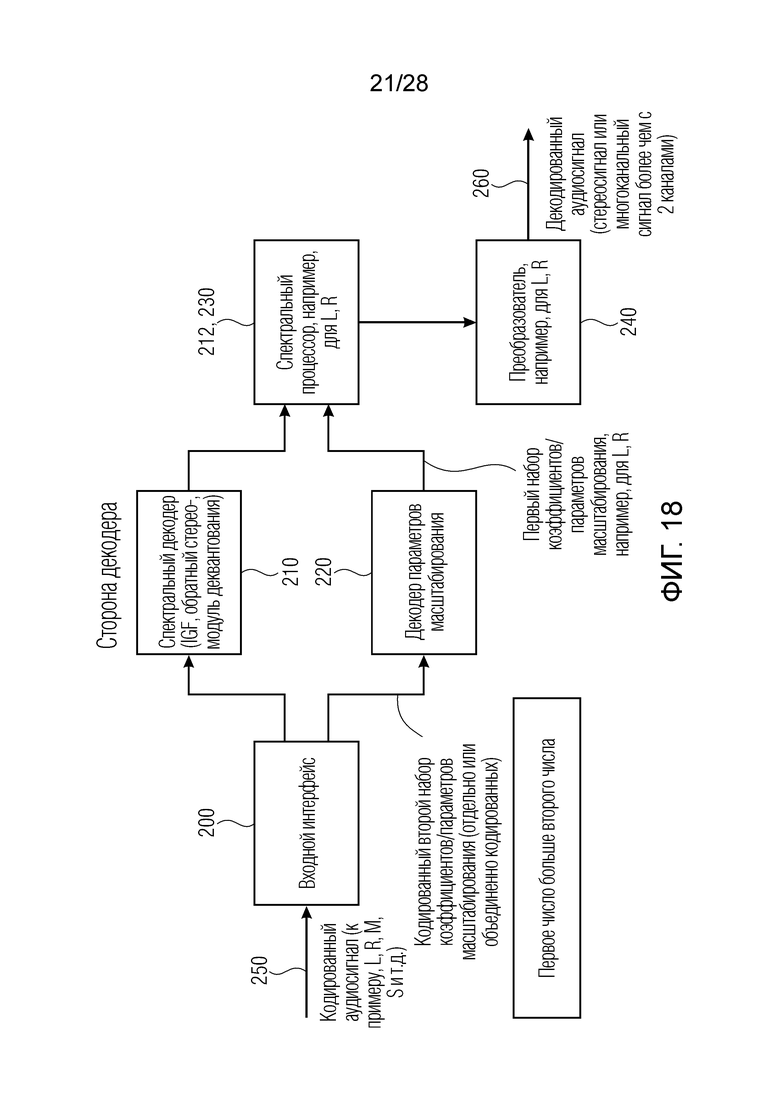
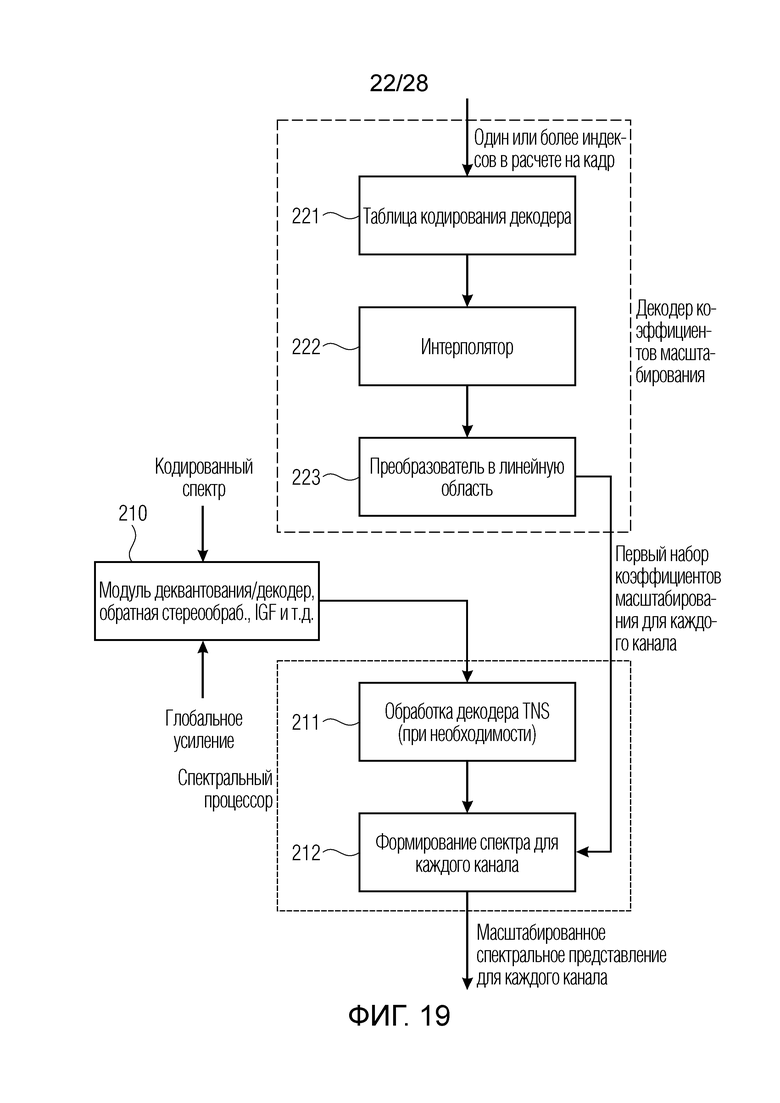
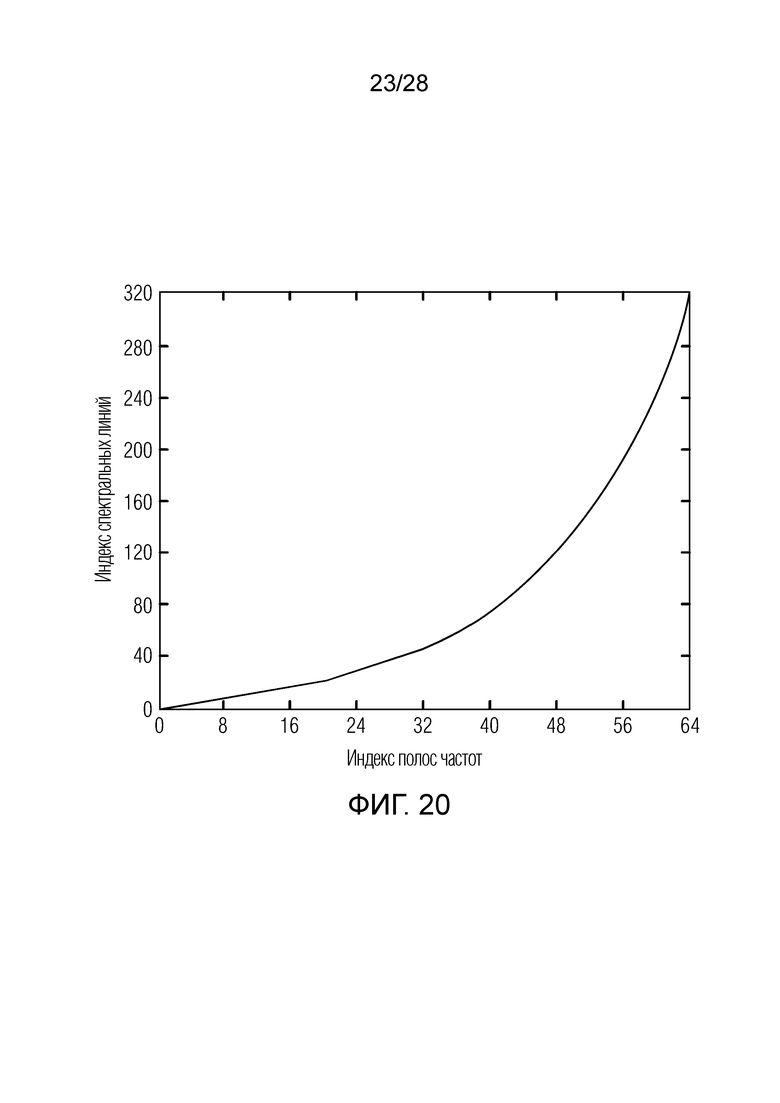
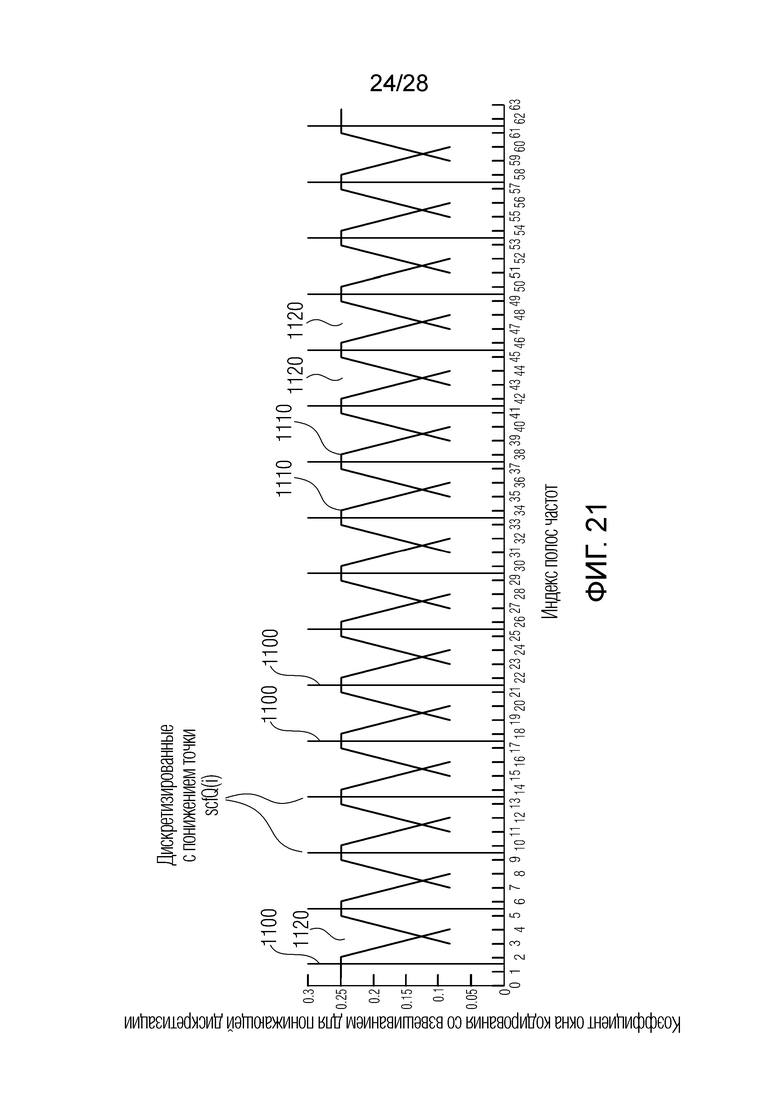
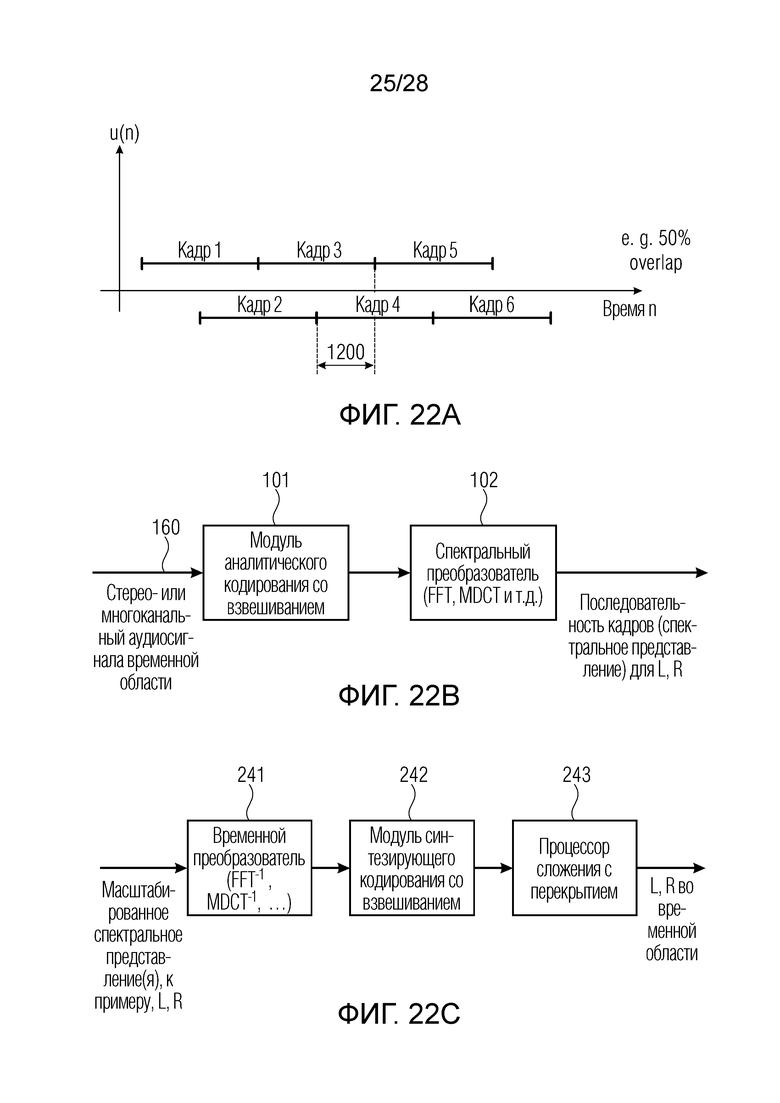
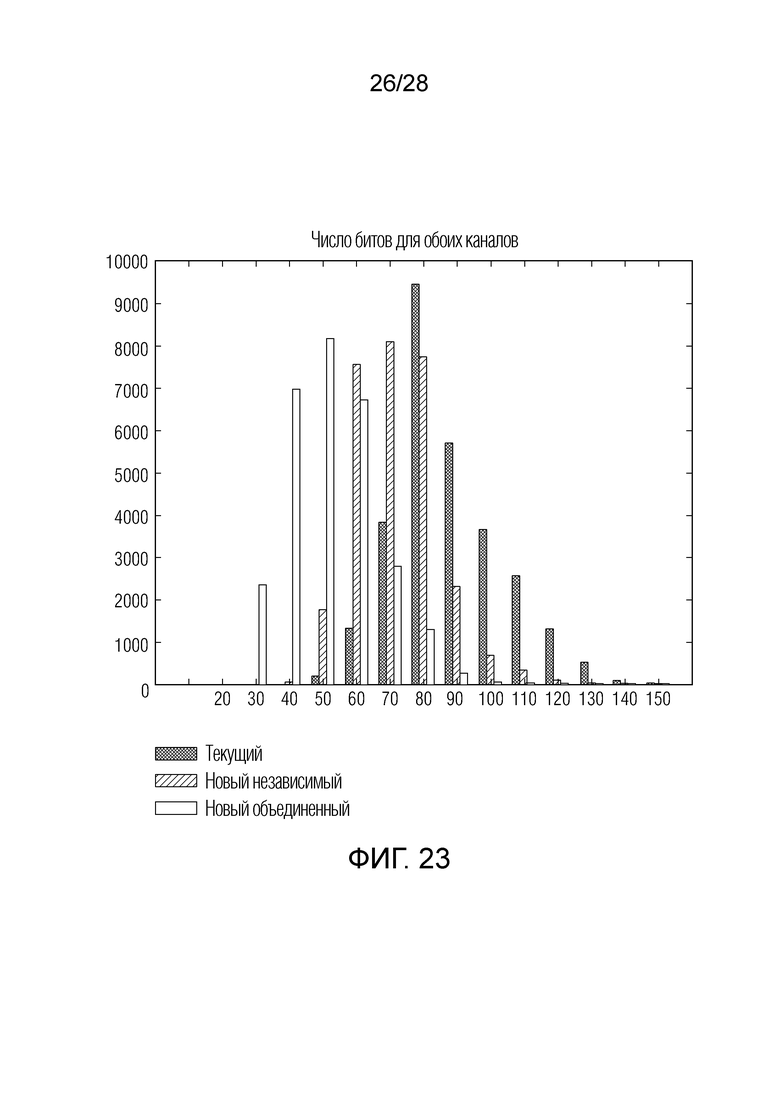
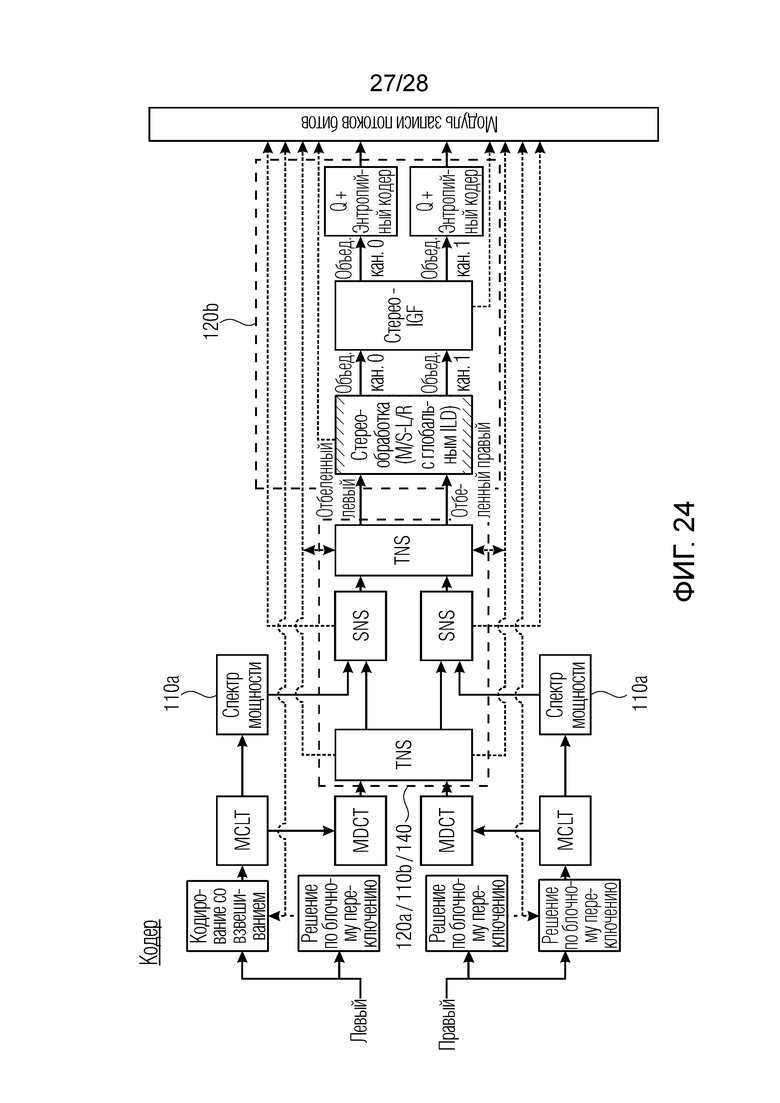
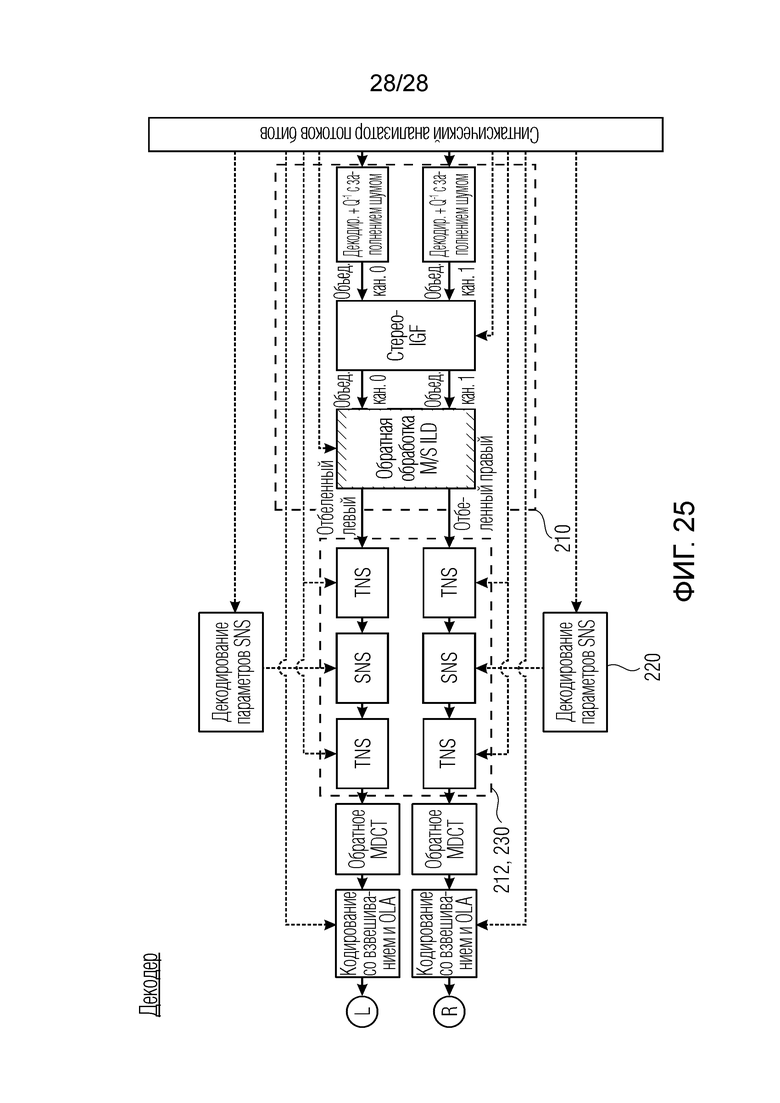
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в сокращении скорости передачи битов на кодирование базового сигнала для повышения полного перцепционного качества стерео- или многоканального сигнала. Технический результат достигается за счет применения первого набора параметров масштабирования к первому каналу многоканального аудиосигнала и применения второго набора параметров масштабирования ко второму каналу многоканального аудиосигнала и извлечения многоканальных аудиоданных; и использования многоканальных аудиоданных и информации относительно первой группы объединенно кодированных параметров масштабирования и информации относительно второй группы объединенно кодированных параметров масштабирования для получения кодированного многоканального аудиосигнала. 6 н. и 32 з.п. ф-лы, 32 ил.
1. Аудиодекодер для декодирования кодированного аудиосигнала, содержащего многоканальные аудиоданные, содержащие данные для двух или более аудиоканалов и информацию относительно объединенно кодированных параметров масштабирования, содержащий:
- декодер (220) параметров масштабирования для декодирования информации относительно объединенно кодированных параметров масштабирования для получения первого набора параметров масштабирования для первого канала декодированного аудиосигнала и второй набор параметров масштабирования для второго канала декодированного аудиосигнала; и
- процессор (210, 212, 230) сигналов для применения первого набора параметров масштабирования к первому канальному представлению, извлекаемому из многоканальных аудиоданных, и для применения второго набора параметров масштабирования ко второму канальному представлению, извлекаемому из многоканальных аудиоданных, с тем чтобы получать первый канал и второй канал декодированного аудиосигнала,
- при этом объединенно кодированные параметры масштабирования содержат информацию относительно первой группы объединенно кодированных параметров масштабирования и информацию относительно второй группы объединенно кодированных параметров масштабирования, и
- при этом декодер (220) параметров масштабирования выполнен с возможностью комбинирования объединенно кодированного параметра масштабирования первой группы и объединенно кодированного параметра масштабирования второй группы с использованием первого правила комбинирования для получения параметра масштабирования из первого набора параметров масштабирования, и с использованием второго правила комбинирования, отличного от первого правила комбинирования, для получения параметра масштабирования из второго набора параметров масштабирования.
2. Аудиодекодер по п. 1, в котором первая группа объединенно кодированных параметров масштабирования содержит средние параметры масштабирования, и вторая группа объединенно кодированных параметров масштабирования содержит боковые параметры масштабирования, и при этом декодер (220) параметров масштабирования выполнен с возможностью использования сложения в первом правиле комбинирования и использования вычитания во втором правиле комбинирования.
3. Аудиодекодер по п. 1 или 2, в котором кодированный аудиосигнал организуется в последовательность кадров, при этом первый кадр содержит многоканальные аудиоданные и информацию относительно объединенно кодированных параметров масштабирования, и при этом второй кадр содержит информацию отдельно кодированных параметров масштабирования, и
- при этом декодер (220) параметров масштабирования выполнен с возможностью обнаружения, что второй кадр содержит информацию отдельно кодированных параметров масштабирования, и вычисления первого набора параметров масштабирования и второго набора параметров масштабирования.
4. Аудиодекодер по п. 3, в котором первый кадр и второй кадр содержат вспомогательную информацию состояния, указывающую в первом состоянии, что первый кадр содержит информацию относительно объединенно кодированных параметров масштабирования, и во втором состоянии - что второй кадр содержит информацию отдельно кодированных параметров масштабирования, и
- при этом декодер (220) параметров масштабирования выполнен с возможностью считывания вспомогательной информации состояния второго кадра, обнаружения, что второй кадр содержит информацию отдельно кодированных параметров масштабирования, на основе считанной вспомогательной информации состояния, либо считывания вспомогательной информации состояния первого кадра и обнаружения, что первый кадр содержит информацию относительно объединенно кодированных параметров масштабирования, с использованием считанной вспомогательной информации состояния.
5. Аудиодекодер по одному из предшествующих пунктов,
- в котором процессор (210, 212, 230) сигналов выполнен с возможностью декодирования многоканальных аудиоданных для извлечения первого канального представления и второго канального представления, при этом первое канальное представление и второе канальное представление являются представлениями в спектральной области, имеющими значения спектральной дискретизации, и
- при этом процессор (210, 212, 230) сигналов выполнен с возможностью применения каждого параметра масштабирования первого набора и второго набора к соответствующему множеству значений спектральной дискретизации для получения спектрального представления определенной формы первого канала и спектрального представления определенной формы второго канала.
6. Аудиодекодер по п. 5, в котором процессор (210, 212, 230) сигналов выполнен с возможностью преобразования спектрального представления определенной формы первого канала и спектрального представления определенной формы второго канала во временную область для получения представления во временной области первого канала и представления во временной области второго канала декодированного аудиосигнала.
7. Аудиодекодер по одному из предшествующих пунктов, в котором первое канальное представление содержит первое число полос частот, при этом первый набор параметров масштабирования содержит второе число параметров масштабирования, причем второе число ниже первого числа, и
- при этом процессор (210, 212, 230) сигналов выполнен с возможностью интерполяции второго числа параметров масштабирования для получения числа интерполированных параметров масштабирования, большего или равного первому числу полос частот, и при этом процессор (210, 212, 230) сигналов выполнен с возможностью масштабирования первого канального представления с использованием интерполированных параметров масштабирования,
- или:
- при этом первое канальное представление содержит первое число полос частот, при этом информация относительно первой группы объединенно кодированных параметров масштабирования содержит второе число объединенно кодированных параметров масштабирования, причем второе число ниже первого числа,
- при этом декодер (220) параметров масштабирования выполнен с возможностью интерполяции второго числа объединенно кодированных параметров масштабирования для получения числа интерполированных объединенно кодированных параметров масштабирования, большего или равного первому числу полос частот, и
- при этом декодер (220) параметров масштабирования выполнен с возможностью обработки интерполированных объединенно кодированных параметров масштабирования для определения первого набора параметров масштабирования и второго набора параметров масштабирования.
8. Аудиодекодер по одному из предшествующих пунктов, в котором кодированный аудиосигнал организуется в последовательность кадров, при этом информация относительно второй группы объединенно кодированных параметров масштабирования содержит, в определенном кадре, нулевую вспомогательную информацию, при этом декодер (220) параметров масштабирования выполнен с возможностью обнаружения нулевой вспомогательной информации для определения, что вся вторая группа объединенно кодированных параметров масштабирования является нулевой для определенного кадра, и
- при этом декодер (220) параметров масштабирования выполнен с возможностью извлечения параметров масштабирования из первого набора параметров масштабирования и из второго набора параметров масштабирования только из первой группы объединенно кодированных параметров масштабирования или задания при комбинировании объединенно кодированного параметра масштабирования первой группы и объединенно кодированного параметра масштабирования второй группы равными нулевым значениям или значениям, меньшим, чем пороговое значение шума.
9. Аудиодекодер по одному из предшествующих пунктов,
- в котором декодер (220) параметров масштабирования выполнен с возможностью:
- деквантования информации относительно первой группы объединенно кодированных параметров масштабирования с использованием первого режима деквантования, и
- деквантования информации относительно второй группы объединенно кодированных параметров масштабирования с использованием второго режима деквантования, причем второй режим деквантования отличается от первого режима деквантования.
10. Аудиодекодер по п. 9, в котором декодер (220) параметров масштабирования выполнен с возможностью использования второго режима деквантования, имеющего ассоциированную более низкую или более высокую точность квантования, чем первый режим деквантования.
11. Аудиодекодер по п. 9 или 10, в котором декодер (220) параметров масштабирования выполнен с возможностью использования в качестве первого режима деквантования первой ступени (2220) деквантования и второй ступени (2260) деквантования и модуля (2240) комбинирования, причем модуль (2240) комбинирования принимает в качестве ввода результат первой ступени (2220) деквантования и результат второй ступени (2260) деквантования, и
- использования в качестве второго режима деквантования второй ступени деквантования (2220) первого режима деквантования, принимающей в качестве ввода информацию относительно второй группы объединенно кодированных параметров масштабирования.
12. Аудиодекодер по п. 11, в котором первая ступень (2220) деквантования представляет собой ступень векторного деквантования, и в котором вторая ступень (2260) деквантования представляет собой ступень алгебраического векторного деквантования, либо в котором первая ступень (2220) деквантования представляет собой ступень деквантования с фиксированной скоростью, и в котором вторая ступень (2260) деквантования представляет собой ступень деквантования с переменной скоростью.
13. Аудиодекодер по п. 11 или 12, в котором информация относительно первой группы объединенно кодированных параметров масштабирования содержит, для кадра кодированного аудиосигнала, два или более индексов, и при этом информация относительно второй группы объединенно кодированных параметров масштабирования содержит один индекс либо меньшее число индексов или равное число индексов с первой группой, и
- при этом декодер (220) параметров масштабирования выполнен с возможностью определения в первой ступени (2220) деквантования, например, для каждого индекса из двух или более индексов, промежуточных объединенно кодированных параметров масштабирования первой группы, и при этом декодер (220) параметров масштабирования выполнен с возможностью вычисления во второй ступени (2260) деквантования остаточных объединенно кодированных параметров масштабирования первой группы, например, из одного либо из более низкого или равного числа индексов информации относительно первой группы объединенно кодированных параметров масштабирования, и вычисления посредством модуля (2240) комбинирования первой группы объединенно кодированных параметров масштабирования из промежуточных объединенно кодированных параметров масштабирования первой группы и остаточных объединенно кодированных параметров масштабирования первой группы.
14. Аудиодекодер по одному из пп. 11-13, в котором первая ступень (2220) деквантования содержит использование индекса для первой таблицы кодирования, имеющей первое число записей, либо использование индекса, представляющего первую точность, при этом вторая ступень (2260) деквантования содержит использование индекса для второй таблицы кодирования, имеющей второе число записей, либо использование индекса, представляющего вторую точность, и при этом второе число меньше или больше первого числа, или вторая точность меньше или больше первой точности.
15. Аудиодекодер по одному из предшествующих пунктов, в котором информация относительно второй группы объединенно кодированных параметров масштабирования указывает, что вся вторая группа объединенно кодированных параметров масштабирования является нулевой или имеет определенное значение для кадра кодированного аудиосигнала, и при этом декодер (220) параметров масштабирования выполнен с возможностью использования при комбинировании с использованием первого правила или второго правила объединенно кодированного параметра масштабирования, равного нулю или равного определенному значению, или представляющего собой синтезированный объединенно кодированный параметр масштабирования, или
- при этом для кадра, содержащего информацию всех нулевых или определенных значений, декодер (220) параметров масштабирования выполнен с возможностью определения второго набора параметров масштабирования только с использованием первой группы объединенно кодированных параметров масштабирования без операции комбинирования.
16. Аудиодекодер по одному из пп. 9 или 10, в котором декодер (220) параметров масштабирования выполнен с возможностью использования в качестве первого режима деквантования первой ступени (2220) деквантования и второй ступени (2260) деквантования и модуля (2240) комбинирования, причем модуль (2240) комбинирования принимает в качестве ввода результат первой ступени (2220) деквантования и результат второй ступени (2260) деквантования, и использования в качестве второго режима деквантования первой ступени (2220) деквантования первого режима деквантования.
17. Аудиокодер для кодирования многоканального аудиосигнала, содержащего два или более каналов, содержащий:
- модуль (140) вычисления параметров масштабирования для вычисления первой группы объединенно кодированных параметров масштабирования и второй группы объединенно кодированных параметров масштабирования из первого набора параметров масштабирования для первого канала многоканального аудиосигнала и из второго набора параметров масштабирования для второго канала многоканального аудиосигнала;
- процессор (120) сигналов для применения первого набора параметров масштабирования к первому каналу многоканального аудиосигнала и для применения второго набора параметров масштабирования ко второму каналу многоканального аудиосигнала и для извлечения многоканальных аудиоданных; и
- модуль (1480, 1500) формирования кодированных сигналов для использования многоканальных аудиоданных и информации относительно первой группы объединенно кодированных параметров масштабирования и информации относительно второй группы объединенно кодированных параметров масштабирования для получения кодированного многоканального аудиосигнала.
18. Аудиокодер по п. 17, в котором процессор (120) сигналов выполнен с возможностью, при применении:
- кодирования первой группы объединенно кодированных параметров масштабирования и второй группы объединенно кодированных параметров масштабирования для получения информации относительно первой группы объединенно кодированных параметров масштабирования и информации относительно второй группы объединенно кодированных параметров масштабирования,
- локального декодирования информации относительно первой и второй групп объединенно кодированных параметров масштабирования для получения локально декодированного первого набора параметров масштабирования и локально декодированного второго набора параметров масштабирования, и
- масштабирования первого канала с использованием локально декодированного первого набора параметров масштабирования и масштабирования второго канала с использованием локально декодированного второго набора параметров масштабирования,
- или:
- при этом процессор (120) сигналов выполнен с возможностью, при применении:
- квантования первой группы объединенно кодированных параметров масштабирования и второй группы объединенно кодированных параметров масштабирования для получения квантованной первой группы объединенно кодированных параметров масштабирования и квантованной второй группы объединенно кодированных параметров масштабирования,
- локального декодирования квантованных первой и второй групп объединенно кодированных параметров масштабирования для получения локально декодированного первого набора параметров масштабирования и локально декодированного второго набора параметров масштабирования, и
- масштабирования первого канала с использованием локально декодированного первого набора параметров масштабирования и масштабирования второго канала с использованием локально декодированного второго набора параметров масштабирования.
19. Аудиокодер по п. 17 или 18,
- в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью комбинирования параметра масштабирования из первого набора параметров масштабирования и параметра масштабирования из второго набора параметров масштабирования с использованием первого правила комбинирования для получения объединенно кодированного параметра масштабирования первой группы объединенно кодированных параметров масштабирования, и с использованием второго правила комбинирования, отличного от первого правила комбинирования, для получения объединенно кодированного параметра масштабирования второй группы объединенно кодированных параметров масштабирования.
20. Аудиокодер по п. 19, в котором первая группа объединенно кодированных параметров масштабирования содержит средние параметры масштабирования, и вторая группа объединенно кодированных параметров масштабирования содержит боковые параметры масштабирования, и при этом модуль (140) вычисления параметров масштабирования выполнен с возможностью использования сложения в первом правиле комбинирования и использования вычитания во втором правиле комбинирования.
21. Аудиокодер по одному из пп. 17-20, в котором модуль вычисления параметров масштабирования выполнен с возможностью обработки последовательности кадров многоканального аудиосигнала,
- при этом модуль (140) вычисления параметров выполнен с возможностью:
- вычисления первой и второй групп объединенно кодированных параметров масштабирования для первого кадра последовательности кадров, и
- анализа второго кадра из последовательности кадров для определения режима отдельного кодирования для второго кадра, и
- при этом модуль (1480, 1500) формирования кодированных сигналов выполнен с возможностью ввода в кодированный аудиосигнал вспомогательной информации состояния, указывающей режим раздельного кодирования для второго кадра или режим объединенного кодирования для первого кадра, и информации относительно первого набора и второго набора отдельно кодированных параметров масштабирования для второго кадра.
22. Аудиокодер по одному из пп. 17-21, в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью:
- вычисления первого набора параметров масштабирования для первого канала и второго набора параметров масштабирования для второго канала,
- дискретизации с понижением первого и второго наборов параметров масштабирования для получения дискретизированного с понижением первого набора и дискретизированного с понижением второго набора; и
- комбинировать параметр масштабирования из дискретизированного с понижением первого набора и дискретизированного с понижением второго набора с использованием различных правил комбинирования для получения объединенно кодированного параметра масштабирования первой группы и объединенно кодированного параметра масштабирования второй группы,
- или:
- при этом модуль (140) вычисления параметров выполнен с возможностью:
- вычисления первого набора параметров масштабирования для первого канала и второго набора параметров масштабирования для второго канала,
- комбинирования параметра масштабирования из первого набора и параметра масштабирования из второго набора с использованием различных правил комбинирования для получения объединенно кодированного параметра масштабирования первой группы и объединенно кодированного параметра масштабирования второй группы, и
- дискретизации с понижением первой группы объединенно кодированных параметров масштабирования для получения дискретизированной с понижением первой группы объединенно кодированных параметров масштабирования, и дискретизации с понижением второй группы объединенно кодированных параметров масштабирования для получения дискретизированной с понижением второй группы объединенно кодированных параметров масштабирования,
- при этом дискретизированная с понижением первая группа и дискретизированная с понижением вторая группа представляют информацию относительно первой группы объединенно кодированных параметров масштабирования и информацию относительно второй группы объединенно кодированных параметров масштабирования.
23. Аудиокодер по п. 21 или 22,
- в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью вычисления подобия первого канала и второго канала во втором кадре и определения режима раздельного кодирования в случае, если вычисленное подобие находится в первом отношении с пороговым значением, либо определения режима объединенного кодирования в случае, если вычисленное подобие находится в другом втором отношении с пороговым значением.
24. Аудиокодер по п. 23, в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью:
- вычисления для второго кадра разности между параметром масштабирования первого набора и параметром масштабирования второго набора для каждой полосы частот,
- обработки каждой разности для второго кадра таким образом, что отрицательные знаки удаляются для получения обработанных разностей второго кадра,
- комбинирования обработанных разностей для получения показателя подобия,
- сравнения показателя подобия с пороговым значением, и
- принятия решения в пользу режима отдельного кодирования, если показатель подобия больше порогового значения, либо принятия решения в пользу режима объединенного кодирования, если показатель подобия ниже порогового значения.
25. Аудиокодер по одному из пп. 17-24, в котором процессор (120) сигналов выполнен с возможностью:
- квантования первой группы объединенно кодированных параметров масштабирования с использованием функции (141, 143) квантования первой ступени для получения одного или более первых индексов квантования в качестве результата первой ступени и получения промежуточной первой группы объединенно кодированных параметров масштабирования,
- вычисления (142) остаточной первой группы объединенно кодированных параметров масштабирования из первой группы объединенно кодированных параметров масштабирования и промежуточной первой группы объединенно кодированных параметров масштабирования, и
- квантования остаточной первой группы объединенно кодированных параметров масштабирования с использованием функции (145) квантования второй ступени для получения одного или более индексов квантования в качестве результата второй ступени.
26. Аудиокодер по одному из пп. 17-25,
- в котором процессор (120) сигналов выполнен с возможностью квантования второй группы объединенно кодированных параметров масштабирования с использованием функции одноступенчатого квантования для получения одного или более индексов квантования в качестве одноступенчатого результата, или
- при этом процессор (120) сигналов выполнен с возможностью квантования первой группы объединенно кодированных параметров масштабирования с использованием по меньшей мере функции квантования первой ступени и функции квантования второй ступени, и при этом процессор (120) сигналов выполнен с возможностью квантования второй группы объединенно кодированных параметров масштабирования с использованием функции одноступенчатого квантования, при этом функция одноступенчатого квантования выбирается из функции квантования первой ступени и функции квантования второй ступени.
27. Аудиокодер по одному из пп. 21-26, в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью:
- квантования первого набора параметров масштабирования с использованием функции (141, 143) квантования первой ступени для получения одного или более первых индексов квантования в качестве результата первой ступени и получения промежуточного первого набора параметров масштабирования,
- вычисления (142) остаточного первого набора параметров масштабирования из первого набора параметров масштабирования и промежуточного первого набора параметров масштабирования, и
- квантования остаточного первого набора параметров масштабирования с использованием функции (145) квантования второй ступени для получения одного или более индексов квантования в качестве результата второй ступени,
- или:
- при этом модуль (140) вычисления параметров выполнен с возможностью:
- квантования второго набора параметров масштабирования с использованием функции (141, 143) квантования первой ступени для получения одного или более первых индексов квантования в качестве результата первой ступени и получения промежуточного второго набора параметров масштабирования,
- вычисления (142) остаточного второго набора параметров масштабирования из второго набора параметров масштабирования и промежуточного второго набора параметров масштабирования, и
- квантования остаточного второго набора параметров масштабирования с использованием функции (145) квантования второй ступени для получения одного или более индексов квантования в качестве результата второй ступени.
28. Аудиокодер по п. 25 или 27,
- в котором функция (145) квантования второй ступени использует значение усиления или взвешивания ниже 1 для увеличения остаточной первой группы объединенно кодированных параметров масштабирования либо остаточный первый или второй набор параметров масштабирования до выполнения векторного квантования, при этом векторное квантование выполняется с использованием увеличенных остаточных значений, и/или
- при этом, в качестве примера, значение взвешивания или усиления используется для деления параметра масштабирования на значение взвешивания или усиления, при этом значение взвешивания предпочтительно составляет между 0,1 и 0,9, или более предпочтительно, между 0,2 и 0,6, или еще более предпочтительно, между 0,25 и 0,4, и/или
- при этом одинаковое значение усиления используется для всех параметров масштабирования из остаточной первой группы объединенно кодированных параметров масштабирования либо остаточного первого или второго набора параметров масштабирования.
29. Аудиокодер по одному из пп. 25-28,
- в котором функция (141, 143) квантования первой ступени содержит по меньшей мере одну таблицу кодирования с первым числом записей, соответствующим первому размеру одного или более индексов квантования,
- при этом функция (145) квантования второй ступени или функция одноступенчатого квантования содержит по меньшей мере одну таблицу кодирования со вторым числом записей, соответствующим второму размеру одного или более индексов квантования, и
- при этом первое число больше или меньше второго числа, либо первый размер больше или меньше второго размера, или
- при этом функция (141, 143) квантования первой ступени представляет собой функцию квантования с фиксированной скоростью, и при этом функция (145) квантования второй ступени представляет собой функцию квантования с переменной скоростью.
30. Аудиокодер по одному из пп. 15-29, в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью:
- приема первого представления MDCT для первого канала и второго представления MDCT для второго канала,
- приема первого представления MDST для первого канала и второго представления MDST для второго канала,
- вычисления первого спектра мощности для первого канала из первого представления MDCT и первого представления MDST и второго спектра мощности для второго канала из второго представления MDCT и второго представления MDST, и
- вычисления первого набора параметров масштабирования для первого канала из первого спектра мощности и вычисления второго набора параметров масштабирования для второго канала из второго спектра мощности.
31. Аудиокодер по п. 30,
- в котором процессор (120) сигналов выполнен с возможностью масштабирования первого представления MDCT с использованием информации, извлекаемой из первого набора параметров масштабирования, и масштабирования второго представления MDCT с использованием информации, извлекаемой из второго набора параметров масштабирования.
32. Аудиокодер по одному из пп. 17-31,
- в котором процессор (120) сигналов выполнен с возможностью дополнительной обработки масштабированного первого канального представления и масштабированного второго канального представления с использованием объединенной многоканальной обработки для извлечения многоканального обработанного представления многоканального аудиосигнала, при необходимости - дополнительной обработки с использованием обработки репликации полос частот спектра или обработки интеллектуального заполнения интервалов отсутствия сигнала, или обработки улучшения полосы пропускания, и квантования и кодирования представления каналов многоканального аудиосигнала для получения многоканальных аудиоданных.
33. Аудиокодер по одному из пп. 17-31, выполненный с возможностью определения для кадра многоканального аудиосигнала информации относительно второй группы объединенно кодированных параметров масштабирования в качестве информации всех нулевых или всех определенных значений, указывающей равное значение или нулевое значение для всех объединенно кодированных параметров масштабирования кадра, и при этом модуль (1480, 1500) формирования кодированных сигналов выполнен с возможностью использования информации всех нулевых или всех определенных значений для получения кодированного многоканального аудиосигнала.
34. Аудиокодер по одному из пп. 17-31, в котором модуль (140) вычисления параметров масштабирования выполнен с возможностью:
- вычисления первой группы объединенно кодированных параметров масштабирования и второй группы объединенно кодированных параметров масштабирования для первого кадра,
- вычисления первой группы объединенно кодированных параметров масштабирования для второго кадра,
- при этом во втором кадре не вычисляются или кодируются объединенно кодированные параметры масштабирования, и
- при этом модуль (1480, 1500) формирования кодированных сигналов выполнен с возможностью использования флага в качестве информации относительно второй группы объединенно кодированных параметров масштабирования, указывающей, что во втором кадре любые объединенно кодированные параметры масштабирования второй группы не включены в кодированный многоканальный аудиосигнал.
35. Способ декодирования кодированного аудиосигнала, содержащего многоканальные аудиоданные, содержащие данные для двух или более аудиоканалов и информацию относительно объединенно кодированных параметров масштабирования, содержащий этапы, на которых:
- декодируют информацию относительно объединенно кодированных параметров масштабирования для получения первого набора параметров масштабирования для первого канала декодированного аудиосигнала и второго набора параметров масштабирования для второго канала декодированного аудиосигнала; и
- применяют первый набор параметров масштабирования к первому канальному представлению, извлекаемому из многоканальных аудиоданных, и применяют второй набор параметров масштабирования ко второму канальному представлению, извлекаемому из многоканальных аудиоданных, с тем чтобы получать первый канал и второй канал декодированного аудиосигнала,
- при этом объединенно кодированные параметры масштабирования содержат информацию относительно первой группы объединенно кодированных параметров масштабирования и информацию относительно второй группы объединенно кодированных параметров масштабирования, и
- при этом декодирование содержит этап, на котором комбинируют объединенно кодированный параметр масштабирования первой группы и объединенно кодированный параметр масштабирования второй группы с использованием первого правила комбинирования для получения параметра масштабирования из первого набора параметров масштабирования, и с использованием второго правила комбинирования, отличающегося от первого правила комбинирования, для получения параметра масштабирования из второго набора параметров масштабирования.
36. Способ кодирования многоканального аудиосигнала, содержащего два или более каналов, содержащий этапы, на которых:
- вычисляют первую группу объединенно кодированных параметров масштабирования и вторую группу объединенно кодированных параметров масштабирования из первого набора параметров масштабирования для первого канала многоканального аудиосигнала и из второго набора параметров масштабирования для второго канала многоканального аудиосигнала;
- применяют первый набор параметров масштабирования к первому каналу многоканального аудиосигнала и применяют второй набор параметров масштабирования ко второму каналу многоканального аудиосигнала и извлекают многоканальные аудиоданные; и
- используют многоканальные аудиоданные и информацию относительно первой группы объединенно кодированных параметров масштабирования и информацию относительно второй группы объединенно кодированных параметров масштабирования для получения кодированного многоканального аудиосигнала.
37. Носитель данных, на котором сохранена компьютерная программа для осуществления способа по п. 35 при выполнении на компьютере или в процессоре.
38. Носитель данных, на котором сохранена компьютерная программа для осуществления способа по п. 36 при выполнении на компьютере или в процессоре.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ И КОДИРОВАНИЯ МАТРИЦЫ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ, СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ АУДИОКОНТЕНТА, КОДЕР И ДЕКОДЕР ДЛЯ МАТРИЦЫ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ, АУДИОКОДЕР И АУДИОДЕКОДЕР | 2014 |
|
RU2648588C2 |
| МАСШТАБИРУЕМОЕ МНОГОКАНАЛЬНОЕ КОДИРОВАНИЕ ЗВУКА | 2006 |
|
RU2416129C2 |
