Настоящее изобретение относится, в числе прочего, к формированию комфортного шума (CNG) для обеспечения прерывистой передачи (DTX) в стереокодеках. Изобретение также относится к генератору многоканальных сигналов, к аудиокодеру и к связанным способам, например, на базе шумового сигнала микширования. Изобретение может быть реализовано в устройстве, в системе, в способе, в постоянном модуле хранения, сохраняющем инструкции, которые, при выполнении посредством компьютера (процессора, контроллера), предписывают компьютеру (процессору, контроллеру) осуществлять конкретный способ, и в кодированном многоканальном аудиосигнале.
Введение
Генераторы комфортного шума обычно используются в прерывистой передаче (DTX) аудиосигналов, в частности, аудиосигналов, содержащих речь. В таком режиме, аудиосигнал сначала классифицируется на активные и неактивные кадры посредством детектора голосовой активности (VAD). На основе результата VAD, только активные речевые кадры кодируются и передаются с номинальной скоростью передачи битов. В течение длинных пауз, в которых присутствует только фоновый шум, скорость передачи битов понижается или обнуляется, и фоновый шум кодируется параметрически с использованием кадров дескриптора вставки молчания (кадров SID). Средняя скорость передачи битов в таком случае значительно уменьшается.
Шум формируется в течение неактивных кадров на стороне декодера посредством генератора комфортного шума (CNG). Размер кадра SID очень ограничен на практике. Следовательно, число параметров, описывающих фоновый шум, должно сохраняться максимально возможно малым. С этой целью, оценка шума не применяется непосредственно к выводу спектральных преобразований. Вместо этого, она применяется при более низком спектральном разрешении за счет усреднения входного спектра мощности между группами полос частот, например, согласно шкале в барках. Усреднение может достигаться посредством средних арифметических или геометрических. К сожалению, ограниченное число параметров, передаваемых в кадрах SID, не позволяет захватывать точную спектральную структуру фонового шума. Следовательно, только сглаженная спектральная огибающая шума может воспроизводиться посредством CNG. Когда VAD инициирует кадр CNG, расхождение между сглаженным спектром восстановленного комфортного шума и спектром фактического фонового шума может становиться очень слышимым при переходах между активными кадрами (предусматривающими регулярное кодирование и декодирование зашумленной речевой части сигнала) и кадрами CNG.
Некоторые примерные технологии CNG содержатся в рекомендациях ITU-T G.729B [1], G.729.1C [2], G.718 [3] либо в спецификациях 3GPP для AMR [4] и AMR-WB [5]. Все эти технологии формируют комфортный шум (CN) посредством использования подхода анализа/синтеза с использованием линейного прогнозирования (LP).
Для дополнительного уменьшения скорости передачи кодек связи 3GPP для улучшенных голосовых услуг (EVS) LTE [6] оснащается режимом прерывистой передачи (DTX), применяющим формирование комфортного шума (CNG) для неактивных кадров, т.е. для кадров, которые определяются как состоящие только из фонового шума. Для этих кадров, низкоскоростное параметрическое представление сигнала передается посредством кадров дескриптора вставки молчания (SID) самое большее каждые 8 кадров (160 мс). Это обеспечивает возможность CNG в декодере формировать искусственный шумовой сигнал, напоминающий фактический фоновый шум. В EVS, CNG может достигаться с использованием либо линейной прогнозирующей схемы (LP-CNG), либо схемы в частотной области (FD-CNG), в зависимости от спектральных характеристик фонового шума.
Подход LP-CNG в EVS [7] работает на основе разбиения полосы частот с кодированием, состоящим из ступени аналитического/синтезирующего кодирования в полосе низких частот и в полосе высоких частот. В отличие от кодирования в полосе низких частот, параметрическое моделирование спектра шума полосы высоких частот не выполняется для сигнала полосы высоких частот. Только энергия сигнала полосы высоких частот кодируется и передается в декодер, и спектр шума полосы высоких частот формируется исключительно на стороне декодера. CN полосы низких частот и полосы высоких частот синтезируются посредством фильтрации возбуждения через синтезирующий фильтр. Возбуждение в полосе низких частот извлекается из принимаемой энергии возбуждения в полосе низких частот и частотной огибающей возбуждения в полосе низких частот. Синтезирующий фильтр полосы низких частот извлекается из принимаемых параметров LP в форме частотных коэффициентов спектральных линий (LSF). Возбуждение в полосе высоких частот получается с использованием энергии, которая экстраполируется из энергии полосы низких частот, и синтезирующий фильтр полосы высоких частот извлекается из интерполяции LSF на стороне декодера. Синтез полосы высоких частот спектрально переворачивается и добавляется в синтез полосы низких частот для формирования конечного сигнала CN.
Подход FD-CNG [8],[9] использует алгоритм оценки шума в частотной области, а затем векторное квантование сглаженной спектральной огибающей фонового шума. Декодированная огибающая детализируется в декодере посредством выполнения второго модуля оценки шума в частотной области. Поскольку чисто параметрическое представление используется в течение неактивных кадров, шумовой сигнал не доступен в декодере в этом случае. В FD-CNG, оценка шума выполняется в каждом кадре (активном и неактивном) на сторонах кодера и декодера на основе минимального статистического алгоритма.
Способ формирования комфортного шума в случае двух (или более) каналов описан в [10]. В [10] описана система для стерео-DTX и CNG, которая комбинирует моно-SID с показателем когерентности для каждой полосы частот, вычисленным для двух входных стереоканалов в кодере. В декодере моноинформация CNG и значения когерентности декодируются из потока битов, и целевая когерентность в числе полос частот синтезируется. Чтобы понижать скорость передачи битов результирующего стереокадра SID, значения когерентности кодируются с использованием прогнозирующей схемы и после этого энтропийного кодирования с переменной скоростью передачи битов. Комфортный шум формируется для каждого канала с помощью способов, описанных в предыдущих параграфах, и затем два CN микшируются для каждой полосы частот с использованием формулы со взвешиванием на основе передаваемых значений когерентности полос частот, включенных в кадр SID.
Обуславливание/недостатки уровня техники
В стереосистеме, отдельное формирование фонового шума приводит к полностью декоррелированному шуму, который звучит неприятно и существенно отличается от фактического фонового шума, вызывающего резкие слышимые переходы, при переключении в/из фона активного режима в фоны режима DTX. Кроме того, невозможно сохранять стереоизображение фона с использованием только двух полностью декоррелированных источников шума. В завершение, если имеется источник фонового шума, и говорящий перемещается с карманным устройством вокруг источника, то пространственное изображение фонового шума должно изменяться во времени, то, что не может реплицироваться при независимом восстановлении фонового шума для каждого канала. Следовательно, необходимо создать новый подход для решения данной проблемы для стереофонических сигналов.
Это также решается в [10]; тем не менее, в вариантах осуществления, вставка общего источника шума для двух каналов для имитации коррелированного шума для формирования конечного комфортного шума, играет важную роль при имитации стереофонической записи фонового шума.
Существующие речевые кодеки связи обычно кодируют только моносигналы. Следовательно, большинство существующих систем DTX проектируются для моно-CNG. Простое применение режима DTX работы независимо для обоих каналов стереосигнала кажется несложным, но включает в себя несколько проблем. Во-первых, этот подход требует передачи двух наборов параметров, описывающих два фоновых шумовых сигнала в двух каналах. Это должно увеличивать скорость передачи данных, необходимую для передачи кадров SID, что уменьшает преимущество уменьшения нагрузки на сеть. Другой проблематичный аспект заключается в решении VAD, которое должно синхронизироваться между каналами, чтобы не допускать странностей и искажений пространственного изображения стереосигнала, а также оптимизировать уменьшение скорости передачи битов системы. Кроме того, при применении CNG к стороне приемного устройства независимо для обоих каналов, два независимых алгоритма CNG обычно должны формировать два сигнала случайного шума с нулевой или очень низкой когерентностью. Это должно приводить к очень широкому стереоизображению в сформированном комфортном шуме. С другой стороны, применение только к генератору шума и использование одинакового комфортного шумового сигнала в обоих каналах приводит к очень высокой когерентности и к очень узкому стереоизображению. Тем не менее, для большинства стереосигналов, стереоизображение и его пространственное впечатление должны находиться где-то между этими двумя экстремальными значениями. Переключение на или из активных кадров в режим DTX в силу этого должно вводить резкие слышимые переходы. Кроме того, если имеется источник фонового шума, и говорящий перемещается с карманным устройством вокруг источника, то пространственное изображение фонового шума должно изменяться во времени, то, что не может реплицироваться при независимом восстановлении фонового шума для каждого канала. Следовательно, необходим новый подход для решения данной проблемы для стереофонических сигналов.
Система, описанная в [10], разрешает эти проблемы посредством передачи информации для моно-CNG наряду со значениями параметров, которые используются для повторного синтеза стереоизображения фонового шума в декодере. Этот тип системы DTX оптимально подходит для параметрических стереокодеров, которые применяют понижающее микширование к двум входным каналам перед кодированием и передачей, из которых могут извлекаться монопараметры CNG. Тем не менее, в схеме дискретного стереокодирования обычно по-прежнему два канала кодируются объединенно, и параметры повышающего микширования, такие как высокодетализированный показатель когерентности, обычно не извлекаются. Таким образом, для подобных стереокодеров, требуется другой подход.
Аспекты настоящего изобретения
Настоящие примеры обеспечивают эффективную передачу речевых стереосигналов. Передача стереосигнала может улучшать возможности работы пользователей и понятность речи по сравнению с (моно-)передачей только одного канала аудио, в частности, в ситуациях с налагаемым фоновым шумом или другими звуками. Стереосигналы могут кодироваться параметрически, при этом понижающее мономикширование двух стереоканалов применяется, и этот один канал понижающего микширования кодируется и передается в приемное устройство наряду со вспомогательной информацией, которая используется для аппроксимации исходного стереосигнала в декодере. Другой подход заключается в использовании дискретного стереокодирования, которое направлено на удаление избыточности между каналами, чтобы достигать более компактного двухканального представления исходного сигнала посредством некоторой предварительной обработки сигналов. Два обработанных канала затем кодируются и передаются. В декодере, обратная обработка применяется. Однако, вспомогательная информация, релевантная для стереообработки, может передаваться вдоль двух каналов. Основное различие между способами параметрического и дискретного стереокодирования в силу этого заключается в числе передаваемых каналов.
Типично, в разговоре возникают периоды, в которые не все говорящие активно говорят. Входной сигнал в речевой кодер в эти периоды в силу этого состоит главным образом из фонового шума или (практически) молчания. Чтобы снижать скорость передачи данных и понижать нагрузку на сеть передачи, речевые кодеры пытаются отличать между кадрами, которые содержат речь (активными кадрами), и кадрами, которые содержат главным образом фоновый шум или молчание (неактивными кадрами). Для неактивных кадров, скорость передачи данных может значительно уменьшаться за счет не кодирования аудиосигнала, как в активных кадрах, а вместо этого извлечения параметрического описания с низкой скоростью передачи битов текущего фонового шума в форме кадра дескриптора вставки молчания (SID). Этот кадр SID периодически передается в декодер, чтобы обновлять параметры, описывающие фоновый шум, тогда как для неактивных кадров в промежутке скорость передачи битов уменьшается, либо даже информация вообще не передается. В декодере, фоновый шум ремоделируется с использованием параметров, передаваемых в кадре SID посредством алгоритма формирования комфортного шума (CNG). Таким образом, скорость передачи может понижаться или даже обнуляться для неактивных кадров без интерпретации пользователем этого как прерывания или конца соединения.
Описана система DTX для дискретно кодированных стереосигналов, состоящая из стерео-SID и способа CNG, которое формирует комфортный стереошум за счет моделирования спектральных характеристик фонового шума в обоих каналах, а также степени корреляции между ними, при поддержании средней скорости передачи битов сравнимой с моновариантами применения.
Раскрытие изобретения
В соответствии с аспектом, предусмотрен генератор многоканальных сигналов для формирования многоканального сигнала, имеющего первый канал и второй канал, содержащий:
- первый аудиоисточник для формирования первого аудиосигнала;
- второй аудиоисточник для формирования второго аудиосигнала;
- источник шума при микшировании для формирования шумового сигнала микширования; и
- микшер для микширования шумового сигнала микширования и первого аудиосигнала для получения первого канала, и для микширования шумового сигнала микширования и второго аудиосигнала для получения второго канала.
Согласно аспекту, первый аудиоисточник представляет собой первый источник шума, и первый аудиосигнал представляет собой первый шумовой сигнал, или второй аудиоисточник представляет собой второй источник шума, и второй аудиосигнал представляет собой второй шумовой сигнал,
- при этом первый источник шума или второй источник шума выполнен с возможностью формирования первого шумового сигнала или второго шумового сигнала таким образом, что первый шумовой сигнал или второй шумовой сигнал декоррелируется относительно шумового сигнала микширования.
Согласно аспекту, микшер выполнен с возможностью формирования первого канала и второго канала таким образом, что величина шумового сигнала микширования в первом канале равна величине шумового сигнала микширования во втором канале или составляет в пределах диапазона в 80-120 процентов относительно величины шумового сигнала микширования во втором канале.
Согласно аспекту, микшер содержит управляющий ввод для приема управляющего параметра, и при этом микшер выполнен с возможностью управления величиной шумового сигнала микширования в первом канале и втором канале в ответ на управляющий параметр.
Согласно аспекту, каждый из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании представляет собой источник гауссова шума.
Согласно аспекту, первый аудиоисточник содержит первый генератор шума для формирования первого аудиосигнала в качестве первого шумового сигнала, при этом второй аудиоисточник содержит декоррелятор для декорреляции первого шумового сигнала для формирования второго аудиосигнала в качестве второго шумового сигнала, и при этом источник шума при микшировании содержит второй генератор шума, или
- при этом первый аудиоисточник содержит первый генератор шума для формирования первого аудиосигнала в качестве первого шумового сигнала, при этом второй аудиоисточник содержит второй генератор шума для формирования второго аудиосигнала в качестве второго шумового сигнала, и при этом источник шума при микшировании содержит декоррелятор для декорреляции первого шумового сигнала или второго шумового сигнала для формирования шумового сигнала микширования, или
- при этом один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит генератор шума для формирования шумового сигнала, и при этом другой из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит первый декоррелятор для декорреляции шумового сигнала, и при этом еще один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит второй декоррелятор для декорреляции шумового сигнала, при этом первый декоррелятор и второй декоррелятор отличаются друг от друга таким образом, что выходные сигналы первого декоррелятора и второго декоррелятора декоррелируются друг от друга, или
- при этом первый аудиоисточник содержит первый генератор шума, при этом второй аудиоисточник содержит второй генератор шума, и при этом источник шума при микшировании содержит третий генератор шума, при этом первый генератор шума, второй генератор шума и третий генератор шума выполнены с возможностью формирования взаимно декоррелированных шумовых сигналов.
Согласно аспекту, один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит генератор псевдослучайных числовых последовательностей, выполненный с возможностью формирования псевдослучайной числовой последовательности в ответ на начальное число, и при этом по меньшей мере два из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании выполнены с возможностью инициализации генератора псевдослучайных числовых последовательностей с использованием различных начальных чисел.
Согласно аспекту по меньшей мере один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании выполнен с возможностью работы с использованием предварительно сохраненной таблицы шумов, или
- при этом по меньшей мере один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании выполнен с возможностью формирования комплексного спектра для кадра с использованием первого значения шума для действительной части и второго значения шума для мнимой части,
- при этом, при необходимости, по меньшей мере один генератор шума выполнен с возможностью формирования комплексного спектрального значения шума для частотного элемента k разрешения с использованием, для одной из действительной части и мнимой части, первого случайного значения с индексом k, и с использованием, для другой из действительной части и мнимой части, второго случайного значения с индексом (k+M), при этом первое значение шума и второе значение шума включаются в шумовой массив, например, извлекаемый из генератора последовательности случайных чисел или из таблицы шумов, или из шумового процесса, в диапазоне от начального индекса до конечного индекса, причем начальный индекс меньше M, и причем конечный индекс равен или меньше 2M, при этом M и k являются целыми числами.
Согласно аспекту, микшер содержит:
- первый амплитудный элемент для воздействия на амплитуду первого аудиосигнала;
- первый сумматор для суммирования выходного сигнала первого амплитудного элемента и по меньшей мере части шумового сигнала микширования;
- второй амплитудный элемент для воздействия на амплитуду второго аудиосигнала;
- второй сумматор для суммирования вывода второго амплитудного элемента и по меньшей мере части шумового сигнала микширования,
- при этом величина воздействия, выполняемого посредством первого амплитудного элемента, и величина воздействия, выполняемого посредством второго амплитудного элемента, равны друг другу, или величина воздействия, выполняемого посредством второго амплитудного элемента, отличается менее чем на 20 процентов относительно величины, выполняемой посредством первого амплитудного элемента.
Согласно аспекту, микшер содержит третий амплитудный элемент для воздействия на амплитуду шумового сигнала микширования,
- при этом величина воздействия, выполняемого посредством третьего амплитудного элемента, зависит от величины воздействия, выполняемого посредством первого амплитудного элемента или второго амплитудного элемента таким образом, что величина воздействия, выполняемого посредством третьего амплитудного элемента, становится больше, когда величина воздействия, выполняемого посредством первого амплитудного элемента, или величина воздействия, выполняемого посредством второго амплитудного элемента, становится меньше.
Согласно аспекту, величина воздействия, выполняемого посредством третьего амплитудного элемента, представляет собой квадратный корень значения cq, и величина воздействия, выполняемого посредством первого амплитудного элемента, и величина воздействия, выполняемого посредством второго амплитудного элемента, представляет собой квадратный корень разности между единицей и cq.
Согласно аспекту, входной интерфейс для приема кодированных аудиоданных в последовательности кадров, содержащих активный кадр и неактивный кадр после активного кадра; и
- аудиодекодер для декодирования кодированных аудиоданных для активного кадра для формирования декодированного многоканального сигнала для активного кадра,
- при этом первый аудиоисточник, второй аудиоисточник, источник шума при микшировании и микшер являются активными в неактивном кадре для формирования многоканального сигнала для неактивного кадра.
Согласно аспекту, кодированный аудиосигнал для активного кадра имеет первое множество коэффициентов, описывающих первое число частотных элементов разрешения; и
- кодированный аудиосигнал для неактивного кадра имеет второе множество коэффициентов, описывающих второе число частотных элементов разрешения,
- при этом первое число частотных элементов разрешения больше второго числа частотных элементов разрешения.
Согласно аспекту, кодированные аудиоданные для неактивного кадра содержат данные дескриптора вставки молчания, содержащие данные комфортного шума, указывающие энергию сигналов для каждого канала двух каналов или для каждой из первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов для неактивного кадра и указывающие когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом микшер выполнен с возможностью микширования шумового сигнала микширования и первого аудиосигнала или второго аудиосигнала на основе данных комфортного шума, указывающих когерентность, и
- при этом генератор многоканальных сигналов дополнительно содержит модуль модификации сигналов для модификации первого канала и второго канала либо первого аудиосигнала, либо второго аудиосигнала, либо шумового сигнала микширования, при этом модуль модификации сигналов выполнен с возможностью управления посредством данных комфортного шума, указывающих энергии сигналов для первого аудиоканала и второго аудиоканала либо указывающих энергии сигналов для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов.
Согласно аспекту, аудиоданные для неактивного кадра содержат:
- первый кадр дескриптора вставки молчания для первого канала и второй кадр дескриптора вставки молчания для второго канала, при этом первый кадр дескриптора вставки молчания содержит:
- данные параметров комфортного шума для первого канала и/или для первой линейной комбинации первого и второго каналов, и
- вспомогательную информацию формирования комфортного шума для первого канала и второго канала, и
- при этом второй кадр дескриптора вставки молчания содержит:
- данные параметров комфортного шума для второго канала и/или для второй линейной комбинации первого и второго каналов, и
- информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала в неактивном кадре с использованием вспомогательной информации формирования комфортного шума для первого кадра дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала и второго канала и/или для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов, с использованием информации когерентности во втором кадре дескриптора вставки молчания для задания когерентности между первым каналом и вторым каналом в неактивном кадре, и с использованием данных параметров комфортного шума из первого кадра дескриптора вставки молчания, и с использованием данных параметров комфортного шума из второго кадра дескриптора вставки молчания для задания энергетической ситуации первого канала и энергетической ситуации второго канала.
Согласно аспекту, аудиоданные для неактивного кадра содержат:
- по меньшей мере один кадр дескриптора вставки молчания для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов,
- при этом по меньшей мере один кадр дескриптора вставки молчания содержит:
- данные (p_noise) параметров комфортного шума для первой линейной комбинации первого и второго каналов, и
- вспомогательную информацию формирования комфортного шума для второй линейной комбинации первого и второго каналов,
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала в неактивном кадре с использованием вспомогательной информации формирования комфортного шума для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов, с использованием информации когерентности во втором кадре дескриптора вставки молчания для задания когерентности между первым каналом и вторым каналом в неактивном кадре, и с использованием данных параметров комфортного шума по меньшей мере из одного кадра дескриптора вставки молчания, и с использованием данных параметров комфортного шума по меньшей мере из одного кадра дескриптора вставки молчания для задания энергетической ситуации первого канала и энергетической ситуации второго канала.
Согласно аспекту, спектрально-временной преобразователь для преобразования результирующего первого канала и результирующего второго канала, спектрально регулируемых и когерентно регулируемых, в соответствующие представления во временной области, которые должны комбинироваться или конкатенироваться с представлениями во временной области соответствующих каналов декодированного многоканального сигнала для активного кадра.
Согласно аспекту, аудиоданные для неактивного кадра содержат:
- кадр дескриптора вставки молчания, при этом кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого и второго канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала и/или для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала в неактивном кадре с использованием вспомогательной информации формирования комфортного шума для кадра дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала и второго канала, с использованием информации когерентности в кадре дескриптора вставки молчания для задания когерентности между первым каналом и вторым каналом в неактивном кадре, и с использованием данных параметров комфортного шума из кадра дескриптора вставки молчания для задания энергетической ситуации первого канала и энергетической ситуации второго канала.
Согласно аспекту, кодированные аудиоданные для неактивного кадра содержат данные дескриптора вставки молчания, содержащие данные комфортного шума, указывающие энергию сигналов для каждого канала в среднем/боковом представлении, и данные когерентности, указывающие когерентность между первым каналом и вторым каналом в левом/правом представлении, при этом генератор многоканальных сигналов выполнен с возможностью преобразования среднего/бокового представления энергии сигналов в левое/правое представление энергии сигналов в первом канале и втором канале,
- при этом микшер выполнен с возможностью микширования шумового сигнала микширования в первый аудиосигнал и второй аудиосигнал на основе данных когерентности для получения первого канала и второго канала, и
- при этом генератор многоканальных сигналов дополнительно содержит модуль модификации сигналов, выполненный с возможностью модификации первого и второго канала посредством формирования первого и второго канала на основе энергии сигналов в левой/правой области.
Согласно аспекту, генератор многоканальных сигналов выполнен с возможностью, в случае, если аудиоданные содержат передачу служебных сигналов, указывающую, что энергия в боковом канале меньше заданного порогового значения, обнуления коэффициентов бокового канала.
Согласно аспекту, аудиоданные для неактивного кадра содержат:
- по меньшей мере один кадр дескриптора вставки молчания, при этом по меньшей мере один кадр дескриптора вставки молчания содержит данные параметров комфортного шума для среднего и бокового канала и вспомогательную информацию формирования комфортного шума для среднего и бокового канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала в неактивном кадре с использованием вспомогательной информации формирования комфортного шума для кадра дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала и второго канала, с использованием информации когерентности в кадре дескриптора вставки молчания для задания когерентности между первым каналом и вторым каналом в неактивном кадре, и с использованием данных параметров комфортного шума либо их обработанной версии из кадра дескриптора вставки молчания для задания энергетической ситуации первого канала и энергетической ситуации второго канала.
Согласно аспекту, генератор многоканальных сигналов выполнен с возможностью масштабирования энергетических коэффициентов сигналов для первого и второго канала посредством информации усиления, кодированной с помощью данных параметров комфортного шума для первого и второго канала.
Согласно аспекту, генератор многоканальных сигналов выполнен с возможностью преобразования сформированного многоканального сигнала из версии в частотной области в версию во временной области.
Согласно аспекту, первый аудиоисточник представляет собой первый источник шума, и первый аудиосигнал представляет собой первый шумовой сигнал, или второй аудиоисточник представляет собой второй источник шума, и второй аудиосигнал представляет собой второй шумовой сигнал,
- при этом первый источник шума или второй источник шума выполнен с возможностью формирования первого шумового сигнала или второго шумового сигнала таким образом, что первый шумовой сигнал или второй шумовой сигнал по меньшей мере частично коррелируются, и
- источник шума при микшировании выполнен с возможностью формирования шумового сигнала микширования с первой частью шума при микшировании и второй частью шума при микшировании, причем вторая часть шума при микшировании по меньшей мере частично декоррелируется относительно первой части шума при микшировании; и
- микшер служит для микширования первой части шума при микшировании шумового сигнала микширования и первого аудиосигнала для получения первого канала, и для микширования второй части шума при микшировании шумового сигнала микширования и второго аудиосигнала для получения второго канала.
В соответствии с аспектом, предусмотрен способ формирования многоканального сигнала, имеющего первый канал и второй канал, содержащий:
- формирование первого аудиосигнала с использованием первого аудиоисточника;
- формирование второго аудиосигнала с использованием второго аудиоисточника;
- формирование шумового сигнала микширования с использованием источника шума при микшировании; и
- микширование шумового сигнала микширования и первого аудиосигнала для получения первого канала, и микширование шумового сигнала микширования и второго аудиосигнала для получения второго канала.
В соответствии с аспектом, предусмотрен аудиокодер для формирования кодированного многоканального аудиосигнала для последовательности кадров, содержащих активный кадр и неактивный кадр, причем аудиокодер содержит:
- детектор активности для анализа многоканального сигнала для определения кадра последовательности кадров как представляющего собой неактивный кадр;
- модуль вычисления параметров шума для вычисления первых параметрических данных шума для первого канала многоканального сигнала и для вычисления вторых параметрических данных шума для второго канала многоканального сигнала;
- модуль вычисления когерентности для вычисления данных когерентности, указывающих ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре; и
- выходной интерфейс для формирования кодированного многоканального аудиосигнала, имеющего кодированные аудиоданные для активного кадра и, для неактивного кадра, первые параметрические данные шума, вторые параметрические данные шума или первую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума и вторую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума, и данных когерентности.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью вычисления значения когерентности и квантования значения когерентности для получения квантованного значения когерентности, при этом выходной интерфейс выполнен с возможностью использования квантованного значения когерентности в качестве данных когерентности в кодированном многоканальном сигнале.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью:
- вычисления действительного промежуточного значения и мнимого промежуточного значения из комплексных спектральных значений для первого канала и второго канала в неактивном кадре;
- вычисления первого значения энергии для первого канала и второго значения энергии для второго канала в неактивном кадре; и
- вычисления данных когерентности с использованием действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии, или
- сглаживания по меньшей мере одного из действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии и вычислять данные когерентности с использованием по меньшей мере одного сглаженного значения.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью вычисления действительного промежуточного значения в качестве суммы по действительным частям произведений комплексных спектральных значений для соответствующих частотных элементов разрешения первого канала и второго канала в неактивном кадре, или
- вычисления мнимого промежуточного значения в качестве суммы по мнимым частям произведений комплексных спектральных значений для соответствующих частотных элементов разрешения первого канала и второго канала в неактивном кадре.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью возведения в квадрат сглаженного действительного промежуточного значения и возведения в квадрат сглаженного мнимого промежуточного значения и суммирования возведенных в квадрат значений для получения первого компонентного числа,
- при этом модуль вычисления когерентности выполнен с возможностью умножения сглаженных первого и второго значений энергии для получения второго компонентного числа, и комбинирования первого и второго компонентных чисел для получения результирующего числа для значения когерентности, на котором основаны данные когерентности.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью вычисления квадратного корня результирующего числа для получения значения когерентности, на котором основаны данные когерентности.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью квантования значения когерентности с использованием равномерного квантователя для получения квантованного значения когерентности в качестве n битов в качестве данных когерентности.
Согласно аспекту, выходной интерфейс выполнен с возможностью формирования первого кадра дескриптора вставки молчания для первого канала и второго кадра дескриптора вставки молчания для второго канала, при этом первый кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала, и при этом второй кадр дескриптора вставки молчания содержит данные параметров комфортного шума для второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, или
- при этом выходной интерфейс выполнен с возможностью формирования кадра дескриптора вставки молчания, при этом кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого и второго канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре,
- или при этом выходной интерфейс выполнен с возможностью формирования первого кадра дескриптора вставки молчания для первого канала и второго канала и второй кадр дескриптора вставки молчания для первого канала и второго канала, при этом первый кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого канала и второго канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала, и при этом второй кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого канала и второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре.
Согласно аспекту, равномерный квантователь выполнен с возможностью вычисления n битов таким образом, что значение для n равно значению битов, занимаемых посредством вспомогательной информации формирования комфортного шума для первого кадра дескриптора вставки молчания.
Согласно аспекту, детектор активности выполнен с возможностью:
- анализа первого канала многоканального сигнала для классификации первого канала как активного или неактивного, и
- анализа второго канала многоканального сигнала для классификации второго канала как активного или неактивного, и
- определения кадра последовательности кадров как представляющего собой неактивный кадр, если как первый канал, так и второй канал классифицированы как неактивные.
Согласно аспекту, модуль вычисления параметров шума выполнен с возможностью вычисления первой информации усиления для первого канала и второй информации усиления для второго канала и обеспечения параметрических данных шума в качестве первой информации усиления для первого канала и второй информации усиления.
Согласно аспекту, модуль вычисления параметров шума выполнен с возможностью преобразования по меньшей мере некоторых из первых параметрических данных шума и вторых параметрических данных шума из левого/правого представления в среднее/боковое представление со средним каналом и боковым каналом.
Согласно аспекту, модуль вычисления параметров шума выполнен с возможностью повторного преобразования среднего/бокового представления по меньшей мере некоторых из первых параметрических данных шума и вторых параметрических данных шума в левое/правое представление,
- при этом модуль вычисления параметров шума выполнен с возможностью вычисления из повторно преобразованного левого/правого представления первой информации усиления для первого канала и второй информации усиления для второго канала и обеспечения первой информации усиления для первого канала, включенной в первые параметрические данные шума, и второй информации усиления, включенной во вторые параметрические данные шума.
Согласно аспекту, модуль вычисления параметров шума выполнен с возможностью вычисления:
- первой информации усиления посредством сравнения:
- версии первых параметрических данных шума для первого канала, повторно преобразованной из среднего/бокового представления в левое/правое представление; с
- версией первых параметрических данных шума для первого канала до преобразования из среднего/бокового представления в левое/правое представление; и/или
- второй информации усиления посредством сравнения:
- версии вторых параметрических данных шума для второго канала, повторно преобразованной из среднего/бокового представления в левое/правое представление; с
- версией вторых параметрических данных шума для второго канала до преобразования из среднего/бокового представления в левое/правое представление.
Согласно аспекту, модуль вычисления параметров шума выполнен с возможностью сравнения энергии второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума с заданным пороговым значением энергии и:
- в случае, если энергия второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума больше заданного порогового значения энергии, коэффициенты вектора форм бокового канального шума обнуляются; и
- в случае, если энергия второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума меньше заданного порогового значения энергии, коэффициенты вектора форм бокового канального шума сохраняются.
Согласно аспекту, аудиокодер выполнен с возможностью кодирования второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума с меньшим количеством битов, чем количество битов, через которые кодируется первая линейная комбинация между первыми параметрическими данными шума и вторыми параметрическими данными шума.
Согласно аспекту, выходной интерфейс выполнен с возможностью:
- формирования кодированного многоканального аудиосигнала, имеющего кодированные аудиоданные для активного кадра с использованием первого множества коэффициентов для первого числа частотных элементов разрешения; и
- формирования первых параметрических данных шума, вторых параметрических данных шума или первой линейной комбинации первых параметрических данных шума и вторых параметрических данных шума и второй линейной комбинации первых параметрических данных шума и вторых параметрических данных шума с использованием второго множества коэффициентов, описывающих второе число частотных элементов разрешения,
- при этом первое число частотных элементов разрешения больше второго числа частотных элементов разрешения.
В соответствии с аспектом, предусмотрен способ кодирования аудио для формирования кодированного многоканального аудиосигнала для последовательности кадров, содержащих активный кадр и неактивный кадр, при этом способ содержит:
- анализ многоканального сигнала для определения кадра последовательности кадров как представляющего собой неактивный кадр;
- вычисление первых параметрических данных шума для первого канала многоканального сигнала и/или для первой линейной комбинации первого и второго каналов многоканального сигнала и вычисление вторых параметрических данных шума для второго канала многоканального сигнала и/или для второй линейной комбинации первого и второго каналов многоканального сигнала;
- вычисление данных когерентности, указывающих ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре; и
- формирование кодированного многоканального аудиосигнала, имеющего кодированные аудиоданные для активного кадра и, для неактивного кадра, первые параметрические данные шума, вторые параметрические данные шума и данные когерентности.
Согласно аспекту, предусмотрена компьютерная программа для осуществления, при выполнении на компьютере или процессоре, вышеприведенного или нижеприведенного способа.
В соответствии с аспектом, предусмотрен кодированный многоканальный аудиосигнал, организованный в последовательности кадров, причем последовательность кадров содержит активный кадр и неактивный кадр, причем кодированный многоканальный аудиосигнал содержит:
- кодированные аудиоданные для активного кадра;
- первые параметрические данные шума для первого канала в неактивном кадре;
- вторые параметрические данные шума для второго канала в неактивном кадре; и
- данные когерентности, указывающие ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре.
Согласно аспекту, первый аудиоисточник представляет собой первый источник шума, и первый аудиосигнал представляет собой первый шумовой сигнал, или второй аудиоисточник представляет собой второй источник шума, и второй аудиосигнал представляет собой второй шумовой сигнал,
- при этом первый источник шума или второй источник шума выполнен с возможностью формирования первого шумового сигнала или второго шумового сигнала таким образом, что первый шумовой сигнал или второй шумовой сигнал декоррелирован относительно шумового сигнала микширования.
Согласно аспекту, микшер выполнен с возможностью формирования первого канала и второго канала таким образом, что величина шумового сигнала микширования в первом канале равна величине шумового сигнала микширования во втором канале или составляет в пределах диапазона в 80-120 процентов относительно величины шумового сигнала микширования во втором канале.
Согласно аспекту, микшер содержит управляющий ввод для приема управляющего параметра, и при этом микшер выполнен с возможностью управления величиной шумового сигнала микширования в первом канале и втором канале в ответ на управляющий параметр.
Согласно аспекту, каждый из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании представляет собой источник гауссова шума.
Согласно аспекту, первый аудиоисточник содержит первый генератор шума для формирования первого аудиосигнала в качестве первого шумового сигнала, при этом второй аудиоисточник содержит декоррелятор для декорреляции первого шумового сигнала для формирования второго аудиосигнала в качестве второго шумового сигнала, и при этом источник шума при микшировании содержит второй генератор шума, или
- при этом первый аудиоисточник содержит первый генератор шума для формирования первого аудиосигнала в качестве первого шумового сигнала, при этом второй аудиоисточник содержит второй генератор шума для формирования второго аудиосигнала в качестве второго шумового сигнала, и при этом источник шума при микшировании содержит декоррелятор для декорреляции первого шумового сигнала или второго шумового сигнала для формирования шумового сигнала микширования, или
- при этом один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит генератор шума для формирования шумового сигнала, и при этом другой из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит первый декоррелятор для декорреляции шумового сигнала, и при этом еще один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит второй декоррелятор для декорреляции шумового сигнала, при этом первый декоррелятор и второй декоррелятор отличаются друг от друга таким образом, что выходные сигналы первого декоррелятора и второго декоррелятора декоррелируются друг от друга, или
- при этом первый аудиоисточник содержит первый генератор шума, при этом второй аудиоисточник содержит второй генератор шума, и при этом источник шума при микшировании содержит третий генератор шума, при этом первый генератор шума, второй генератор шума и третий генератор шума выполнены с возможностью формирования взаимно декоррелированных шумовых сигналов.
Согласно аспекту, один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании содержит генератор псевдослучайных числовых последовательностей, выполненный с возможностью формирования псевдослучайной числовой последовательности в ответ на начальное число, и
- при этом по меньшей мере два из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании выполнены с возможностью инициализации генератора псевдослучайных числовых последовательностей с использованием различных начальных чисел.
Согласно аспекту по меньшей мере один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании выполнен с возможностью работы с использованием предварительно сохраненной таблицы шумов, или
- при этом по меньшей мере один из первого аудиоисточника, второго аудиоисточника и источника шума при микшировании выполнен с возможностью формирования комплексного спектра для кадра с использованием первого значения шума для действительной части и второго значения шума для мнимой части,
- при этом, при необходимости, по меньшей мере один генератор шума выполнен с возможностью формирования комплексного спектрального значения шума для частотного элемента k разрешения с использованием для одной из действительной части и мнимой части первого случайного значения с индексом k, и с использованием для другой из действительной части и мнимой части второго случайного значения с индексом (k+M),
- при этом первое значение шума и второе значение шума включаются в шумовой массив, например, извлекаемый из генератора последовательности случайных чисел или из таблицы шумов, или из шумового процесса, в диапазоне от начального индекса до конечного индекса, причем начальный индекс меньше M, и причем конечный индекс равен или меньше 2M, при этом M и k являются целыми числами.
Согласно аспекту, микшер содержит:
- первый амплитудный элемент для воздействия на амплитуду первого аудиосигнала;
- первый сумматор для суммирования выходного сигнала первого амплитудного элемента и по меньшей мере части шумового сигнала микширования;
- второй амплитудный элемент для воздействия на амплитуду второго аудиосигнала;
- второй сумматор для суммирования вывода второго амплитудного элемента и по меньшей мере части шумового сигнала микширования,
- при этом величина воздействия, выполняемого посредством первого амплитудного элемента, и величина воздействия, выполняемого посредством второго амплитудного элемента, равны друг другу или отличаются менее чем на 20 процентов относительно величины, выполняемой посредством первого амплитудного элемента.
Согласно аспекту, микшер содержит третий амплитудный элемент для воздействия на амплитуду шумового сигнала микширования, при этом величина воздействия, выполняемого посредством третьего амплитудного элемента, зависит от величины воздействия, выполняемого посредством первого амплитудного элемента или второго амплитудного элемента таким образом, что величина воздействия, выполняемого посредством третьего амплитудного элемента, становится больше, когда величина воздействия, выполняемого посредством первого амплитудного элемента, или величина воздействия, выполняемого посредством второго амплитудного элемента, становится меньше.
Согласно аспекту, генератор многоканальных сигналов дополнительно содержит:
- входной интерфейс для приема кодированных аудиоданных в последовательности кадров, содержащих активный кадр и неактивный кадр после активного кадра; и
- аудиодекодер для декодирования кодированных аудиоданных для активного кадра для формирования декодированного многоканального сигнала для активного кадра,
- при этом первый аудиоисточник, второй аудиоисточник, источник шума при микшировании и микшер являются активными в неактивном кадре для формирования многоканального сигнала для неактивного кадра.
Согласно аспекту, кодированные аудиоданные для неактивного кадра содержат данные дескриптора вставки молчания, содержащие данные комфортного шума, указывающие энергию сигналов для каждого канала двух каналов для неактивного кадра и указывающие когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом микшер выполнен с возможностью микширования шумового сигнала микширования и первого аудиосигнала или второго аудиосигнала на основе данных комфортного шума, указывающих когерентность, и при этом генератор многоканальных сигналов дополнительно содержит модуль модификации сигналов для модификации первого канала и второго канала либо первого аудиосигнала, либо второго аудиосигнала, либо шумового сигнала микширования,
- при этом модуль модификации сигналов выполнен с возможностью управления посредством данных комфортного шума, указывающих энергии сигналов для первого аудиоканала и второго аудиоканала.
Согласно аспекту, аудиоданные для неактивного кадра содержат:
- первый кадр дескриптора вставки молчания для первого канала и второй кадр дескриптора вставки молчания для второго канала, при этом первый кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала, и при этом второй кадр дескриптора вставки молчания содержит данные параметров комфортного шума для второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала в неактивном кадре с использованием вспомогательной информации формирования комфортного шума для первого кадра дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала и второго канала, с использованием информации когерентности во втором кадре дескриптора вставки молчания для задания когерентности между первым каналом и вторым каналом в неактивном кадре, и с использованием данных формирования комфортного шума из первого кадра дескриптора вставки молчания, и с использованием данных параметров формирования комфортного шума из второго кадра дескриптора вставки молчания для задания энергетической ситуации первого канала и энергетической ситуации второго канала.
Согласно аспекту, дополнительно содержащий спектрально-временной преобразователь для преобразования результирующего первого канала и результирующего второго канала, спектрально регулируемых и когерентно регулируемых, в соответствующие представления во временной области, которые должны комбинироваться или конкатенироваться с представлениями во временной области соответствующих каналов декодированного многоканального сигнала для активного кадра.
Согласно аспекту, аудиоданные для неактивного кадра содержат:
- кадр дескриптора вставки молчания, при этом кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого и второго канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, и
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала в неактивном кадре с использованием вспомогательной информации формирования комфортного шума для кадра дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала и второго канала, с использованием информации когерентности во втором кадре дескриптора вставки молчания для задания когерентности между первым каналом и вторым каналом в неактивном кадре, и с использованием данных формирования комфортного шума из кадра дескриптора вставки молчания для задания энергетической ситуации первого канала и энергетической ситуации второго канала.
Согласно аспекту, первый аудиоисточник представляет собой первый источник шума, и первый аудиосигнал представляет собой первый шумовой сигнал, или второй аудиоисточник представляет собой второй источник шума, и второй аудиосигнал представляет собой второй шумовой сигнал,
- при этом первый источник шума или второй источник шума выполнен с возможностью формирования первого шумового сигнала или второго шумового сигнала таким образом, что первый шумовой сигнал или второй шумовой сигнал по меньшей мере частично коррелированы, и
- при этом источник шума при микшировании выполнен с возможностью формирования шумового сигнала микширования с первой частью шума при микшировании и второй частью шума при микшировании, причем вторая часть шума при микшировании по меньшей мере частично декоррелируется относительно первой части шума при микшировании; и
- при этом микшер выполнен с возможностью микширования первой части шума при микшировании шумового сигнала микширования и первого аудиосигнала для получения первого канала, и микширования второй части шума при микшировании шумового сигнала микширования и второго аудиосигнала для получения второго канала.
Согласно аспекту, способ формирования многоканального сигнала, имеющего первый канал и второй канал содержит:
- формирование первого аудиосигнала с использованием первого аудиоисточника;
- формирование второго аудиосигнала с использованием второго аудиоисточника;
- формирование шумового сигнала микширования с использованием источника шума при микшировании; и
- микширование шумового сигнала микширования и первого аудиосигнала для получения первого канала, и микширование шумового сигнала микширования и второго аудиосигнала для получения второго канала.
Согласно аспекту, предусмотрен аудиокодер для формирования кодированного многоканального аудиосигнала для последовательности кадров, содержащих активный кадр и неактивный кадр, причем аудиокодер содержит:
- детектор активности для анализа многоканального сигнала для определения кадра последовательности кадров как представляющего собой неактивный кадр;
- модуль вычисления параметров шума для вычисления первых параметрических данных шума для первого канала многоканального сигнала и для вычисления вторых параметрических данных шума для второго канала многоканального сигнала;
- модуль вычисления когерентности для вычисления данных когерентности, указывающих ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре; и
- выходной интерфейс для формирования кодированного многоканального аудиосигнала, имеющего кодированные аудиоданные для активного кадра и, для неактивного кадра, первые параметрические данные шума, вторые параметрические данные шума и данные когерентности.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью вычисления значения когерентности и квантования значения когерентности для получения квантованного значения когерентности, при этом выходной интерфейс выполнен с возможностью использования квантованного значения когерентности в качестве данных когерентности в кодированном многоканальном сигнале.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью:
- вычисления действительного промежуточного значения и мнимого промежуточного значения из комплексных спектральных значений для первого канала и второго канала в неактивном кадре;
- вычисления первого значения энергии для первого канала и второго значения энергии для второго канала в неактивном кадре; и
- вычисления данных когерентности с использованием действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии, или
- сглаживания по меньшей мере одного из действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии и вычислять данные когерентности с использованием по меньшей мере одного сглаженного значения.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью вычисления действительного промежуточного значения в качестве суммы по действительным частям произведений комплексных спектральных значений для соответствующих частотных элементов разрешения первого канала и второго канала в неактивном кадре, или
- вычисления мнимого промежуточного значения в качестве суммы по мнимым частям произведений комплексных спектральных значений для соответствующих частотных элементов разрешения первого канала и второго канала в неактивном кадре.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью возведения в квадрат сглаженного действительного промежуточного значения и возведения в квадрат сглаженного мнимого промежуточного значения и суммирования возведенных в квадрат значений для получения первого компонентного числа,
- при этом модуль вычисления когерентности выполнен с возможностью умножения сглаженных первого и второго значений энергии для получения второго компонентного числа, и комбинирования первого и второго компонентных чисел для получения результирующего числа для значения когерентности, на котором основаны данные когерентности.
Согласно аспекту, предусмотрен аудиокодер, при этом модуль вычисления когерентности выполнен с возможностью вычисления квадратного корня результирующего числа для получения значения когерентности, на котором основаны данные когерентности.
Согласно аспекту, модуль вычисления когерентности выполнен с возможностью квантования значения когерентности с использованием равномерного квантователя для получения квантованного значения когерентности в качестве N битов в качестве данных когерентности.
Согласно аспекту, предусмотрен аудиокодер,
- при этом выходной интерфейс выполнен с возможностью формирования первого кадра дескриптора вставки молчания для первого канала и второго кадра дескриптора вставки молчания для второго канала, при этом первый кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала, и при этом второй кадр дескриптора вставки молчания содержит данные параметров комфортного шума для второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре, или
- при этом выходной интерфейс выполнен с возможностью формирования кадра дескриптора вставки молчания, при этом кадр дескриптора вставки молчания содержит данные параметров комфортного шума для первого и второго канала и вспомогательную информацию формирования комфортного шума для первого канала и второго канала и информацию когерентности, указывающую когерентность между первым каналом и вторым каналом в неактивном кадре.
Согласно аспекту, равномерный квантователь выполнен с возможностью вычисления N битов таким образом, что значение для N равно значению битов, занимаемых посредством вспомогательной информации формирования комфортного шума для первого кадра дескриптора вставки молчания.
Согласно аспекту, способ кодирования аудио для формирования кодированного многоканального аудиосигнала для последовательности кадров, содержащих активный кадр и неактивный кадр, при этом способ содержит:
- анализ многоканального сигнала для определения кадра последовательности кадров как представляющего собой неактивный кадр;
- вычисление первых параметрических данных шума для первого канала многоканального сигнала и вычисление вторых параметрических данных шума для второго канала многоканального сигнала;
- вычисление данных когерентности, указывающих ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре; и
- формирование кодированного многоканального аудиосигнала, имеющего кодированные аудиоданные для активного кадра и, для неактивного кадра, первые параметрические данные шума, вторые параметрические данные шума и данные когерентности.
Согласно аспекту, кодированный многоканальный аудиосигнал, организованный в последовательности кадров, причем последовательность кадров содержит активный кадр и неактивный кадр, причем кодированный многоканальный аудиосигнал содержит:
- кодированные аудиоданные для активного кадра;
- первые параметрические данные шума для первого канала в неактивном кадре;
- вторые параметрические данные шума для второго канала в неактивном кадре; и
- данные когерентности, указывающие ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре.
Краткое описание чертежей
Фиг. 1 показывает пример в кодере, в частности, для классификации кадра как активного или неактивного.
Фиг. 2 показывает пример кодера и декодера.
Фиг. 3a-3f показывают примеры генераторов многоканальных сигналов, которые могут использоваться в декодере.
Фиг. 4 показывает пример кодера и декодера.
Фиг. 5 показывает пример ступени квантования параметров шума.
Фиг. 6 показывает пример ступени деквантования параметров шума.
Осуществление изобретения
В настоящем документе описана, в числе прочего, новая технология, например, для DTX и CNG для дискретно кодированных стереосигналов. Вместо работы с понижающим мономикшированием стереосигнала, параметры шума для обоих каналов извлекаются, объединенно кодируются и передаются. В декодере (или если обобщать, в многоканальном генераторе), три независимых комфортных шумовых сигнала могут микшироваться на основе одного широкополосного значения межканальной когерентности, которое передается, например, вдоль двух наборов параметров шума. Некоторые аспекты примеров могут охватывать, в некоторых примерах по меньшей мере один из следующих аспектов:
- CNG в декодере посредством микширования, например, трех независимых шумовых сигналов. После декодирования стерео-SID и восстановления параметров шума для левого и правого канала, два шумовых сигнала могут формироваться, например, в качестве смешения коррелированного и декоррелированного шума. Для этого, один общий источник шума для обоих каналов (служащий в качестве источника коррелированного шума) и два отдельных источника шума (обеспечивающих декоррелированный шум) могут микшироваться между собой. Процесс микширования может управляться посредством значения межканальной когерентности, передаваемого в стерео-SID. После микширования, два микшированных шумовых сигнала спектрально формируются с использованием восстановленных параметров шума для левого и правого каналов, соответственно.
- Объединенное кодирование параметров шума может извлекаться из двух каналов стереосигнала. Для поддержания скорости передачи битов стерео-SID низкой, параметры шума дополнительно могут сжиматься перед их кодированием в стерео-SID. Это может достигаться, например, посредством преобразования левого/правого канального представления параметров шума в среднее/боковое представление и кодирования боковых параметров шума с меньшим числом битов, чем средние параметры шума.
- SID для двухканальной DTX (стерео-SID). Этот SID может содержать параметры шума для обоих каналов стереосигнала наряду с одним широкополосным значением межканальной когерентности и флагом, указывающим равные параметры шума для обоих каналов.
Показано, что нижеприведенные примеры могут быть реализованы в устройствах, системах, способах, контроллерах и постоянных модулях хранения, сохраняющих инструкции, которые, при выполнении посредством процессора, предписывают процессору выполнять раскрытые технологии (например, способы, такие как последовательности операций).
В частности по меньшей мере один из нижеприведенных блоков может управляться посредством контроллера.
Примеры
Перед подробным пояснением аспектов настоящих примеров приведено краткое общее представление некоторых наиболее важных из них.
1) Фиг. 3a-3f показывают примеры генераторов многоканальных сигналов (например, сформированных по меньшей мере посредством одного первого сигнала или канала и одного второго аудиосигнала или канала), которые формируют многоканальный аудиосигнал (например, в декодере). Многоканальный аудиосигнал (первоначально в форме нескольких, декоррелированных каналов) может воздействоваться (например, масштабироваться) посредством амплитудного элемента(ов). Величина воздействия может быть основана на данных когерентности между первым и вторым аудиосигналами, оцененных в кодере. Первый и второй аудиосигналы могут подвергаться микшированию с общим сигналом микширования (который также может декоррелироваться и воздействоваться, например, масштабироваться, посредством данных когерентности). Величина воздействия для сигнала микширования может быть такой, что первый и второй аудиосигналы масштабируются посредством высокого весового коэффициента (например, в 1 или менее, но, например, близкого к 1), когда сигнал микширования масштабируется посредством низкого весового коэффициента (например, в 0 или более, но, например, близкого к 0), и наоборот. Величина воздействия для сигнала микширования может быть такой, что высокая когерентность, измеренная в кодере, предписывает масштабирование первого и второго аудиосигналов посредством низкого весового коэффициента (например, в 0 или более, но, например, близкого к 0), и высокая когерентность, измеренная в кодере, предписывает масштабирование первого и второго аудиосигналов посредством высокого весового коэффициента (например, в 1 или менее, но, например, близкого к 1). Технологии по фиг. 3a-3f могут использоваться для реализации генератора комфортного шума (CNG).
2) Фиг. 1, 2 и 4 показывают примеры кодеров. Кодер может классифицировать аудиокадр как активный или неактивный. Если аудиокадр является неактивным, то только некоторые параметрические данные шума кодируются в потоке битов (например, для обеспечения параметрической формы шума, которая обеспечивает параметрическое представление формы шума без необходимости обеспечения самого шумового сигнала), и также могут быть обеспечены данные когерентности между двумя каналами.
3) Фиг. 2 и 4 показывают примеры декодеров. Декодер может формировать аудиосигнал (комфортный шум), например, посредством следующего:
a. использование одной из технологий, показанных на фиг. 3a-3f (вышеприведенный пункт 1)) (в частности, с учетом значения когерентности, обеспеченного кодером, и его применения в качестве весового коэффициента в амплитудном элементе(ах)); и
b. формирование сформированного аудиосигнала (комфортного шума) с использованием параметрических данных шума, кодированных в потоке битов.
В частности, для кодера не обязательно обеспечивать полный аудиосигнал для неактивного кадра, а можно только значение когерентности и параметрическое представление формы шума, за счет этого уменьшая количество битов, которые должны кодироваться в потоке битов.
Генератор сигналов (например, сторона декодера), CNG
Фиг. 3a-3f показывают примеры CNG или, если обобщать, генератора 200 многоканальных сигналов для формирования многоканального сигнала 204, имеющего первый канал 201 и второй канал 203. (В настоящем описании, сформированные аудиосигналы 221 и 223 считаются шумом, но также являются возможными другие виды сигналов, которые не представляют собой шум). Первоначально следует обратиться к на фиг. 3f, который является общим, тогда как фиг. 3a-3e показывают конкретные примеры.
Первый аудиоисточник 211 может представлять собой первый источник шума и может указываться здесь как формирующий первый аудиосигнал 221, который может представлять собой первый шумовой сигнал. Источник 212 шума при микшировании может формировать шумовой сигнал 222 микширования. Второй аудиоисточник 213 может формировать второй аудиосигнал 223, который может представлять собой второй шумовой сигнал. Генератор 200 многоканальных сигналов может микшировать первый аудиосигнал 221 (первый шумовой сигнал) с шумовым сигналом 222 микширования и второй аудиосигнал 223 (второй шумовой сигнал) с шумовым сигналом 222 микширования. (Помимо этого или альтернативно, первый аудиосигнал 221 может микшироваться с версией 221a шумового сигнала 222 микширования, и второй аудиосигнал 223 может микшироваться с версией 221b шумового сигнала 222 микширования, при этом версии 221a и 221b могут отличаться, например, на 20% друг от друга; каждая из версий 221a и 221b может, например, представлять собой повышающе масштабированную и/или понижающе масштабированную версию общего сигнала 222). Соответственно, первый канал 201 многоканального сигнала 204 может получаться из первого аудиосигнала 221 (первого шумового сигнала) и шумового сигнала 222 микширования. Аналогично, второй канал 203 многоканального сигнала 204 может получаться из второго аудиосигнала 223, микшированного с шумовым сигналом 222 микширования. Также следует отметить, что сигналы здесь могут находиться в частотной области, и k означает конкретный индекс или коэффициент (ассоциированный с конкретным частотным элементом разрешения).
Как видно из фиг. 3a-3f, первый аудиосигнал 221, шумовой сигнал 222 микширования и второй аудиосигнал 223 могут декоррелироваться друг с другом. Это может получаться, например, посредством декорреляции того же сигнала (например, в декорреляторе) и/или посредством независимого формирования шума (примеры приведены ниже).
Микшер 208 может быть реализован для микширования первого аудиосигнала 221 и второго аудиосигнала 223 с шумовым сигналом 222 микширования. Микширование может иметь тип суммирования сигналов (например, в ступенях 206-1 и 206-3 сумматора) после того, как первый аудиосигнал 221, шумовой сигнал 222 микширования и второй аудиосигнал 223 взвешены посредством масштабирования (например, в амплитудных элементах 208-1, 208-2, 208-3). Микширование имеет тип «суммирование после взвешивания». Фиг. 3a-3f показывают фактическую обработку сигналов, которая применяется для формирования шумовых сигналов Nl[k] и Nr[k], при этом элемент суммирования (+) обозначает суммирование по выборкам двух сигналов (k является индексом частотного элемента разрешения).
Амплитудные элементы 208-1, 208-2 и 208-3 (либо весовые элементы или масштабирующие элементы) могут получаться, например, посредством масштабирования первого аудиосигнала 221, шумового сигнала 222 микширования и второго аудиосигнала 223 посредством подходящих коэффициентов и могут выводить взвешенную версию 221' первого аудиосигнала 221, взвешенную версию 222' шумового сигнала 222 микширования и взвешенную версию 223' второго аудиосигнала 223. Подходящие коэффициенты могут представлять собой sqrt(coh) и sqrt(1-coh) и могут получаться, например, из информации когерентности, кодированной в передаче в служебных сигналах конкретного кадра дескриптора (см. также ниже) (sqrt относится здесь к операции вычисления квадратного корня). Когерентность "coh" подробно поясняется ниже и, например, может представлять собой то, что указывается с помощью "c" или "cind" или "cq" ниже, например, кодироваться в информации 404 когерентности потока 232 битов (см. ниже, в комбинации с фиг. 2 и 4). В частности, шумовой сигнал 222 микширования может быть подвергнут, например, масштабированию посредством весового коэффициента, который представляет собой квадратный корень значения когерентности, в то время как первый аудиосигнал 221 и второй аудиосигнал 222 могут масштабироваться посредством весового коэффициента, который представляет собой квадратный корень значения, комплементарного одной из когерентности coh. Несмотря на это, шумовой сигнал 222 микширования может считаться общим сигналом режима, часть которого микшируется во взвешенную версию 221' первого аудиосигнала 221 и взвешенную версию 223' второго аудиосигнала 223 таким образом, чтобы получать первый канал 201 многоканального сигнала 204 и второй канал 203 многоканального сигнала 204, соответственно. В некоторых случаях, первый источник 211 шума или второй источник 213 шума может быть выполнен с возможностью формирования первого шумового сигнала 221 или второго шумового сигнала 223 таким образом, что первый шумовой сигнал 221 и/или второй шумовой сигнал 223 декоррелированы относительно шумового сигнала 222 микширования (см. ниже с обращением к фиг. 3b-3e).
По меньшей мере один (либо каждый) из первого аудиоисточника 211, второго аудиоисточника 213 и источника 212 шума при микшировании может представлять собой источник гауссова шума.
В примере по фиг. 3a, первый аудиоисточник 211 (здесь указываемый с помощью 211a) может содержать или соединяться с первым генератором шума, и второй аудиоисточник 213 (213a) может содержать или соединяться со вторым генератором шума. Источник 212 (212a) шума при микшировании может содержать или соединяться с третьим генератором шума. Первый генератор 211 (211a) шума, второй генератор 213 (213a) шума и третий генератор 212 (212a) шума могут формировать взаимно декоррелированные шумовые сигналы.
В примерах по меньшей мере один из первого аудиоисточника 211 (211a), второго аудиоисточника 213 (213a) и источника 212 (212a) шума при микшировании может работать с использованием предварительно сохраненной таблицы шумов, которая может в силу этого обеспечивать случайную последовательность.
В некоторых примерах по меньшей мере один из первого аудиоисточника 211, второго аудиоисточника 213 и источника 212 шума при микшировании может формировать комплексный спектр для кадра с использованием первого значения шума для действительной части и второго значения шума для мнимой части. При необходимости, по меньшей мере один генератор шума может формировать комплексное спектральное значение шума (например, коэффициент) для частотного элемента k разрешения с использованием, для одной из действительной части и мнимой части, первого случайного значения с индексом k, и с использованием, для другой из действительной части и мнимой части, второго случайного значения с индексом (k+M). Первое значение шума и второе значение шума могут включаться в шумовой массив, например, извлекаемый из генератора последовательности случайных чисел или из таблицы шумов, или из шумового процесса, в диапазоне от начального индекса до конечного индекса, причем начальный индекс меньше M, и причем конечный индекс равен или меньше 2xM (который в два раза больше M). M и k могут быть целыми числами (при этом k является индексом конкретного частотного элемента разрешения битов в представлении в частотной области сигнала).
Каждый аудиоисточник 211, 212, 213 может включать в себя по меньшей мере один генератор аудиоисточника (генератор шума), который формирует шум, например, с точки зрения N1[k], N2[k], N3[k].
Генератор 200 многоканальных сигналов по фиг. 3a-3f может использоваться, например, для декодера 200a, 200b (200''). В частности, генератор 200 многоканальных сигналов может рассматриваться в качестве части генератора 220 комфортного шума (CNG) на фиг. 4. Декодер 200 может использоваться, в общем, для декодирования сигналов, которые кодированы посредством кодера, либо посредством формирования сигналов, которые должны формироваться посредством информации энергии, полученной из потока битов, с тем чтобы формировать аудиосигнал, который соответствует исходному входному аудиосигналу, вводимому в кодер. В некоторых примерах, предусмотрена классификация между кадрами с речью (или в общем непустыми аудиосигналами) и кадрами дескриптора вставки молчания. Как пояснено выше и ниже, кадры дескриптора вставки молчания (SID) (так называемые «неактивные кадры 308», которые могут кодироваться, например, как -кадры 241 и/или 243 SID) предусматриваются в общем под информацией скорости передачи битов и в силу этого предусматриваются реже, чем нормальные речевые кадры (так называемые «активные кадры 306», см. также ниже). Кроме того, информация, которая присутствует в кадрах дескриптора вставки молчания (SID, неактивных кадрах 308), в общем ограничена (и может практически соответствовать информации энергии в отношении сигнала).
Несмотря на это, следует понимать, что можно дополнять контент кадров SID с многоканальным шумом 204, сформированным посредством генератора многоканальных сигналов. По существу, аудиоисточники 211, 212, 213 могут обрабатывать сигналы (например, шум), которые могут быть независимыми и декоррелироваться друг с другом. Несмотря на это, первый аудиосигнал 221, шумовой сигнал 222 микширования и второй аудиосигнал 223могут масштабироваться посредством информации когерентности, обеспеченной кодером и вставленной в поток битов. Как видно из фиг. 3a-3f, значение когерентности может быть равным для шумового сигнала 222 микширования, вводит общий сигнал режима как в первый аудиосигнал 221, так и во второй аудиосигнал 223, в силу этого обеспечивая возможность получения первого канала 201 и второго канала 203 многоканального сигнала 204. Сигнал когерентности в общем составляет значение от 0 до 1:
- Когерентность, равная 0, означает, что исходный первый аудиоканал (например, L, 301) и второй аудиоканал (например, R, 303) полностью декоррелированы друг с другом, и амплитудный элемент 208-2 шумового сигнала 222 микширования должен масштабировать посредством 0 шумовой сигнал 222 микширования, что приводит к тому, что первый аудиосигнал 221 и второй аудиосигнал 223 вообще не должны микшироваться с общим сигналом режима (посредством микширования с сигналом, который постоянно равен 0), и выходные каналы 201, 203 должны быть практически равными первому шумовому сигналу 221 и второму шумовому сигналу 223 многоканального сигнала 204.
- Когерентность, равная 1, означает, что исходный первый аудиоканал (например, L, 301) и второй аудиоканал (например, R, 303) должны быть одинаковыми, и амплитудные элементы 208-1 и 208-3 должны масштабировать посредством 0 входные сигналы, и первый и второй каналы в таком случае равны шумовому сигналу 222 микширования (который масштабируется посредством 1 в амплитудном элементе 208-2).
- Когерентности, промежуточные между 0 и 1, должны приводить к промежуточным микшированиям между двумя вышеописанными ситуациями.
Ниже поясняются некоторые аспекты и варианты микшера 206 и/или CNG 220.
Первый аудиоисточник (211) может представлять собой первый источник шума, и первый аудиосигнал (221) может представлять собой первый шумовой сигнал, или второй аудиоисточник (213) представляет собой второй источник шума, и второй аудиосигнал (223) представляет собой второй шумовой сигнал. Первый источник (211) шума или второй источник (213) шума может быть выполнен с возможностью формирования первого шумового сигнала (221) или второго шумового сигнала (223) таким образом, что первый шумовой сигнал (221) или второй шумовой сигнал (223) декоррелированы относительно шумового сигнала (222) микширования.
Микшер (206) может быть выполнен с возможностью формирования первого канала (201) и второго канала (203) таким образом, что величина шумового сигнала (222) микширования в первом канале (201) равна величине шумового сигнала (222) микширования во втором канале (203) или составляет в пределах диапазона в 80-120 процентов относительно величины шумового сигнала (222) микширования во втором канале (203) (например, его части 221a и 221b отличаются в диапазоне в 80-120 процентов друг от друга и от исходного шумового сигнала 222 микширования).
В некоторых случаях:
- величина воздействия, выполняемого посредством первого амплитудного элемента (208-1), и величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), равны друг другу (например, когда отсутствует различение между частями 221a и 221b), или
- величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), отличается менее чем на 20 процентов относительно величины, выполняемой посредством первого амплитудного элемента (208-1) (например, когда разность между частями 221a и 221b меньше 20%).
Микшер (206) и/или CNG 220 могут содержать управляющий ввод для приема управляющего параметра (404, c). Микшер (206) может в силу этого быть выполнен с возможностью управления величиной шумового сигнала (222) микширования в первом канале (201) и втором канале (203) в ответ на управляющий параметр (404, c).
На фиг. 3a-3f показано, что шумовой сигнал 222 микширования подвергается коэффициенту sqrt(coh), и первый и второй аудиосигналы 221, 223 подвергаются коэффициенту sqrt(1-coh).
Как пояснено выше, фиг. 3a показывает CNG 220a, в котором первый источник 211a (211), второй источник 213a (213) и источник 212a (212) шума при микшировании содержат различные генераторы. Это не является строго обязательным, и возможны несколько вариантов.
В качестве обобщения:
1. Первый вариантный CNG 220b (фиг. 3b):
a. первый аудиоисточник 211b (211) может содержать первый генератор шума для формирования первого аудиосигнала (221) в качестве первого шумового сигнала,
b. второй аудиоисточник 213b (213) может содержать декоррелятор для декорреляции первого шумового сигнала (221) для формирования второго аудиосигнала (213) в качестве второго шумового сигнала (например, второй аудиосигнал получается из первого аудиосигнала после декорреляции), и
c. источник 212b (212) шума при микшировании может содержать второй генератор шума (который исходно декоррелируется относительно первого генератора шума);
2. Второй вариантный CNG 220c (фиг. 3c):
a. первый аудиоисточник 211c (211) может содержать первый генератор шума для формирования первого аудиосигнала (221) в качестве первого шумового сигнала,
b. второй аудиоисточник 213c (213) может содержать второй генератор шума для формирования второго аудиосигнала (223) в качестве второго шумового сигнала (например, второй генератор шума исходно декоррелируется относительно первого генератора шума), и
c. источник 212c (212) шума при микшировании может содержать декоррелятор для декорреляции первого шумового сигнала (221) или второго шумового сигнала (223) для формирования шумового сигнала (222) микширования;
3. Третий вариантный CNG 220d (фиг. 3d и 3e):
a. один из первого аудиоисточника 211d или 211e (211), второго аудиоисточника 213d или 213e (213) и источника 212d или 212e (212) шума при микшировании может содержать генератор шума для формирования шумового сигнала,
b. другой из первого аудиоисточника 211d или 211e (211), второго аудиоисточника 213d или 213e (213) и источника 212d или 212e (212) шума при микшировании может содержать первый декоррелятор для декорреляции шумового сигнала, и
c. еще один из первого аудиоисточника 211d или 211e (211), второго аудиоисточника 213d или 213e (213) и источника 212d или 212e (212) шума при микшировании может содержать второй декоррелятор для декорреляции шумового сигнала,
d. первый декоррелятор и второй декоррелятор могут отличаться друг от друга, так что выходные сигналы первого декоррелятора и второго декоррелятора декоррелируются друг от друга;
4. Четвертый вариантный CNG 220 (фиг. 3a):
a. первый аудиоисточник 211a (211) содержит первый генератор шума,
b. второй аудиоисточник 213a (213) содержит второй генератор шума,
c. источник 212a (212) шума при микшировании содержит третий генератор шума,
d. первый генератор шума, второй генератор шума и третий генератор шума могут представлять собой сформированные взаимно декоррелированные шумовые сигналы (например, древовидные генераторы исходно декоррелируются друг от друга).
5. Пятый вариант:
a. один из первого аудиоисточника (211) второго аудиоисточника (213) и источника (212) шума при микшировании может содержать генератор псевдослучайных числовых последовательностей для формирования псевдослучайной числовой последовательности в ответ на начальное число,
b. по меньшей мере два из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании могут инициализировать генератор псевдослучайных числовых последовательностей с использованием различных начальных чисел.
6. Шестой вариант:
a. по меньшей мере один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании может работать с использованием предварительно сохраненной таблицы шумов,
b. при необходимости, по меньшей мере один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании может формировать комплексный спектр для кадра с использованием первого значения шума для действительной части и второго значения шума для мнимой части,
c. при необходимости, по меньшей мере один генератор шума может формировать комплексное спектральное значение шума для частотного элемента k разрешения с использованием, для одной из действительной части и мнимой части, первого случайного значения с индексом k, и с использованием, для другой из действительной части и мнимой части, второго случайного значения с индексом (k+M) (первое значение шума и второе значение шума включаются в шумовой массив, например, извлекаемый из генератора последовательности случайных чисел или из таблицы шумов, или из шумового процесса, в диапазоне от начального индекса до конечного индекса, причем начальный индекс меньше M, и причем конечный индекс равен или меньше 2xM, M и k являются целыми числами),
Как видно из фиг. 4 декодер 200'' (200a, 200b) может включать в себя, помимо CNG 220 по фиг. 3, также входной интерфейс 210 для приема кодированных аудиоданных в последовательности кадров, содержащих активный кадр и неактивный кадр после активного кадра; и аудиодекодер для декодирования кодированных аудиоданных для активного кадра для формирования декодированного многоканального сигнала для активного кадра, при этом первый аудиоисточник 211, второй аудиоисточник 213, источник 212 шума при микшировании и микшер 206 являются активными в неактивном кадре для формирования многоканального сигнала для неактивного кадра.
В частности, активные кадры представляют собой кадры, которые классифицируются посредством кодера как имеющие речь (или любой другой вид нешумового звука), и неактивные кадры представляют собой кадры, которые классифицируются как имеющие молчание или только шум.
Любые из примеров CNG 220 (220a-220e) могут управляться посредством подходящего контроллера.
Кодер
Ниже поясняется кодер. Кодер может кодировать активные кадры и неактивные кадры. Для неактивных кадров, кодер может кодировать параметрические данные шума (например, форму шума и/или значение когерентности) без кодирования аудиосигнала полностью. Следует отметить, что кодирование неактивных аудиокадров может уменьшаться относительно активных аудиокадров, таким образом, чтобы уменьшить объем информации, которая должна кодироваться в потоке битов. Также параметрические данные шума (например, форма шума) для неактивных кадров могут иметь меньший объем информации для каждой полосы частот и/или могут иметь меньшее количество элементов разрешения, чем данные, кодированные в активных кадрах. Параметрические данные шума могут определяться в левой/правой области или в другой области (например, в средней/боковой области), например, посредством обеспечеения первой линейной комбинации между параметрическими данными шума первого и второго каналов и второй линейной комбинации между параметрическими данными шума первого и второго каналов (в некоторых случаях также можно предусмотреть информацию усиления, которая не ассоциирована с первой и второй линейными комбинациями, а определяется в левой/правой области). Первая и вторая линейные комбинации в общем являются линейно независимыми друг от друга.
Кодер может включать в себя детектор активности, который классифицирует, является ли кадр активным или неактивным.
Фиг. 1, 2 и 4 показывают примеры кодеров 300a и 300b (которые также указаны позицией 300, если не обязательно различать кодер 300a и кодер 300b). Каждый аудиокодер 300 может формировать кодированный многоканальный аудиосигнал 232 для последовательности кадров входного сигнала 304. Входной сигнал 304 здесь считается разделенным между первым каналом 301 (также указываемым в качестве левого канала или "l", где "l" является буквой, прописная версия которой представляет собой "L" и является первой буквой слова «левый» на английском языке) и вторым каналом 303 (или "r", где "r" является буквой, прописная версия которой представляет собой "R" и является первой буквой слова «правый» на английском языке).
Кодированный многоканальный аудиосигнал 232 может задаваться в последовательности кадров, которые, например, могут находиться во временной области (например, каждая выборка "n" может означать конкретный момент времени, и выборки одного кадра могут формировать последовательность, например, последовательность дискретизации входного аудиосигнала или последовательность после фильтрации входного аудиосигнала).
Кодер 300 (300a, 300b) может включать в себя детектор 380 активности, который не показывается на фиг. 2 и 4 (хотя быть в некоторых примерах реализован в нем), но показывается на фиг. 1. Фиг. 1 показывает, что каждый кадр входного сигнала 304 может быть классифицирован либо как «активный кадр 306», либо как «неактивный кадр 308». Неактивный кадр 308 является таким, что сигнал считается молчанием (и, например, имеется только молчание или шум), тогда как активный кадр 306 может иметь некоторое обнаружение бесшумного аудиосигнала (например, речи, музыки и т.д.).
В кодированном многоаудиосигнале 232, кодированном (например, в потоке битов) посредством кодера 300, информация относительно того, представляет кадр собой активный кадр 306 или кадр 308 молчания, может передаваться в служебных сигналах, например, в так называемой «вспомогательной информации 402 (p_frame) формирования комфортного шума», также называемой «вспомогательной информацией».
Фиг. 1 показывает ступень 360 предварительной обработки, которая может определять (например, классифицировать), является ли кадр активным кадром 306 или кадром 308 молчания. Здесь следует отметить, что каналы 301 и 303 входного сигнала 304 указаны прописными буквами, такими как L (301, левый канал) и R (303, правый канал) для указания того, что они находятся в частотной области. Как можно видеть на фиг. 1, может применяться ступень 370 этапа спектрального анализа (первый спектральный анализ 370-1 к первому каналу 301, L; и вторая ступень 370-3 для второго канала 303, R). Ступень 370 спектрального анализа может выполняться для каждого кадра входного сигнала 304 и может быть основана, например, на измерениях гармоничности. В частности, в некоторых примерах, спектральный анализ выполняется посредством ступени 370 для первого канала 301, и может выполняться отдельно от спектрального анализа, выполняемого для второго канала 303 того же кадра.
В некоторых случаях, ступень 370 спектрального анализа может включать в себя вычисление энергозависимых параметров, таких как средняя энергия для диапазона предварительно заданных полос частот и полная средняя энергия.
Может применяться ступень 380 обнаружения активности (что может считаться обнаружением голосовой активности в случае поиска голоса). Первая ступень 380-1 обнаружения активности может применяться к первому каналу 301 (и, в частности, к измерениям, выполняемым для первого канала), и вторая ступень 380-3 обнаружения активности может применяться ко второму каналу 303 (и, в частности, к измерениям, выполняемым для второго канала). В примерах, ступень 380 обнаружения активности может оценивать энергию фонового шума во входном сигнале 304 и использовать эту оценку для вычисления отношения сигнала к шуму, которое сравнивается с пороговым значением отношения сигнала к шуму, для определения, классифицируется ли кадр как активный или неактивный (т.е. вычисленное отношение сигнала к шуму выше порогового значения отношения сигнала к шуму, что подразумевает, что кадр классифицируется как активный; и вычисленное отношение сигнала к шуму ниже порогового значения отношения сигнала к шуму, что подразумевает, что кадр классифицируется как неактивный). В примерах, ступень 380 может сравнивать гармоничность, полученную посредством ступеней 370-1 и 370-3 спектрального анализа, соответственно, с одним или двумя пороговыми значениями гармоничности (например, с первым пороговым значением для первого канала 301 и со вторым пороговым значением для второго канала 303). В обоих случаях, может быть возможным классифицировать не только каждый кадр, но также и каждый канал каждого кадра как активный канал или неактивный канал.
Решение 381 может выполняться, и на его основе можно принимать решение в (что идентифицируется посредством переключателя 381'') в отношении того, следует выполнять дискретную стереообработку 306a или стереообработку 306b прерывистой передачи (стерео-DTX). В частности, в случае активного кадра (и дискретной стереообработки 306a), кодирование может выполняться согласно любой стратегии либо стандарту или процессу обработки и в силу этого здесь не анализируется более подробно. Большая часть нижеприведенного пояснения относится к стерео-DTX 306b.
В частности, в примерах кадр классифицируется (в ступени 381) как неактивный кадр, только если оба канала 301 и 303 классифицированы как неактивные ступенями 380-1 и 380-3, соответственно. Следовательно, исключаются проблемы в решении по обнаружению активности, как пояснено выше. В частности, не обязательно передавать в служебных сигналах классификацию активных/неактивных для каждого канала для каждого кадра (за счет этого уменьшая передачу служебных сигналов) и синхронизация между каналами внутренне получается. Кроме того, если декодер является таким, как пояснено в настоящем документе, можно использовать когерентность между первым и вторым каналами 301 и 303 и формировать некоторые шумовые сигналы, которые коррелируются/декоррелируются согласно когерентности, полученной для сигнала 304. Ниже подробно поясняются элементы кодера 300 (300a, 300b), которые используются для кодирования неактивного кадра. Как пояснено, любая другая технология может использоваться для кодирования активных кадров 308 и в силу этого не поясняется здесь.
В общих чертах, кодер 300a, 300b (300) может включать в себя модуль 3040 вычисления параметров шума для вычисления параметрических данных 401, 403 шума для первого и второго каналов 301, 303. Модуль 3040 вычисления параметров шума может вычислять параметрические данные 401, 403 шума (например, индексы и/или усиления) для первого канала 301 и второго канала 303. Модуль 3040 вычисления параметров шума может, таким образом, обеспечивать кодированные аудиоданные 232 в последовательности кадров, которые могут содержать активные кадры 306 и неактивные кадры 308 (которые могут идти после активных кадров 306). В частности, в случае неактивных кадров 308, кодированные аудиоданные 232 могут кодироваться как один или два кадра 241 дескриптора вставки молчания (SID), 243. В некоторых примерах (например, на фиг. 2), предусмотрен только один отдельный кадр SID, в некоторых других, предусмотрено два кадра SID (например, на фиг. 4).
Неактивный кадр 308 может включать в себя, в частности по меньшей мере одно из следующего:
- вспомогательную информацию формирования комфортного шума (например, 402, p_frame);
- данные 401 параметров комфортного шума для первого канала 301 либо первую линейную комбинацию данных параметров комфортного шума для первого канала 301 и данных параметров комфортного шума для второго канала (vl, ind, vm, ind, p_noise, усиление gl, q);
- данные 403 параметров комфортного шума для второго канала 303 либо вторую линейную комбинацию данных параметров комфортного шума для первого канала 301 и данных (vr, ind, vs, ind, p_noise, усиление gr, q) параметров комфортного шума для второго канала;
- информацию (c, 404) когерентности (данные когерентности).
В некоторых примерах, первый кадр 241 дескриптора вставки молчания может включать в себя первые два пункта вышеприведенного списка, и второй кадр 243 дескриптора вставки молчания может включать в себя последние два признака в конкретных полях данных. Несмотря на это, различные протоколы могут предусматривать различные поля данных или другую организацию потока битов. Тем не менее, в некоторых случаях (например, на фиг. 2), может быть предусмотрен только один отдельный неактивный кадр для параметров шума для обоих каналов.
Показано, что информация когерентности (например, часть «дескриптора вставки молчания») может включать в себя одно отдельное значение (например, кодированное в небольшом количестве битов, к примеру, в четырех битах), которое указывает информацию когерентности (например, корреляционные данные), например, когерентность между первым каналом 301 и вторым каналом 303 того же неактивного кадра 308. С другой стороны, данные 401, 403 параметров комфортного шума могут указывать, для каждого канала 301, 303, энергию сигналов для неактивного кадра 308 (например, они могут фактически обеспечивать огибающую) либо в любом случае могут обеспечивать информацию формы шума. Огибающая или информация формы шума может иметь форму нескольких коэффициентов для частотных элементов разрешения и усиления для каждого канала. Информация формы шума может получаться в ступени 312 (см. ниже) с использованием исходных входных каналов (301, 303), и после этого среднее/боковое кодирование выполняется для векторов параметров формы шума. Показано, что в декодере может быть возможным формировать некоторые шумовые каналы (например, 201, 203, как указано на фиг. 3), которые могут воздействоваться посредством информации 404 когерентности. Шумовые каналы 201, 203, сформированные посредством CNG 220 (220a-220), могут в силу этого модифицироваться посредством модуля 250 модификации сигналов, управляемого посредством данных шума управления (данных 401, 403, 2312 параметров комфортного шума), которые указывают энергии сигналов для первого аудиоканала Lout и второго аудиоканала Rout.
Аудиокодер 300 (300a, 300b) может включать в себя модуль 320 вычисления когерентности, который может получать информацию (404) когерентности, которая должна кодироваться в потоке битов (например, в сигнале 232, в кадре 241 или 243). Информация (c, 404) когерентности может указывать ситуацию когерентности между первым каналом 301 (например, левым каналом) и вторым каналом 303 (например, правым каналом) в неактивном кадре 308. В дальнейшем поясняются примеры означенного.
Кодер 300 (300a, 300b) может включать в себя выходной интерфейс 310, выполненный с возможностью формирования многоканального аудиосигнала 232 (потока битов) с кодированными аудиоданными для активного кадра 306 и, для неактивного кадра 308, первыми параметрическими данными 401 (p_noise, left) (параметрическими данными комфортного шума) вторыми параметрическими данными (p_noise, right 403) шума и данными c (404) когерентности. Первые параметрические данные 401 могут представлять собой параметрические данные первого канала (например, левого канала) либо первой линейной комбинации первого и второго канала (например, среднего канала). Вторые параметрические данные 403 могут представлять собой параметрические данные второго канала (например, правого канала) либо вторую линейную комбинацию первого и второго канала (например, бокового канала), отличающуюся от первой линейной комбинации.
В потоке 232 битов, также может быть предусмотрена вспомогательная информация 402, включающая в себя индикатор для того, представляет текущий кадр собой активный кадр 306 или неактивный кадр 308, например, чтобы информировать декодер в отношении технологий декодирования, которые должны использоваться.
В частности, на фиг. 4 показан модуль 3040 вычисления параметров шума (каскад вычисления параметров шума), включающий в себя первую ступень 304-1 модуля вычисления параметров шума, в котором могут вычисляться данные 401 параметров комфортного шума для первого канала 301, и вторую ступень 304-3 модуля вычисления параметров шума, в которой может вычисляться второй параметр 403 комфортного шума для второго канала 303. На фиг. 2 показан пример, в котором параметры шума обрабатываются и квантуются объединенным образом. Внутренние части (например, преобразование векторов форм шума в представление M/S) показаны на фиг 5. По существу, можно иметь форму шума первого канала M и форму шума второго канала S, которые могут кодироваться как средние индексы и боковые индексы, тогда как усиление для формы шума левого канала 301 и усиления для формы шума правого канала 303 также могут кодироваться.
Модуль 320 вычисления когерентности может вычислять данные c (404) когерентности (информацию когерентности), которые указывают ситуацию когерентности между первым каналом L и вторым каналом R. В этом случае, модуль 320 вычисления когерентности может работать в частотной области.
Как можно видеть, модуль 320 вычисления когерентности может включать в себя ступень 320'' вычисления канальной когерентности, в которой получается значение c (404) когерентности. После неё может использоваться ступень 320'' равномерного квантования. Следовательно, может быть получена квантованная версия cind значения c когерентности.
Ниже приведены некоторые пояснения в отношении того, каким образом следует получить когерентность, и того, каким образом следует квантовать ее.
Модуль 320 вычисления когерентности может, в некоторых примерах:
- вычислять действительное промежуточное значение и мнимое промежуточное значение из комплексных спектральных значений для первого канала и второго канала (303) в неактивном кадре;
- вычислять первое значение энергии для первого канала и второе значение энергии для второго канала (303) в неактивном кадре; и
- вычислять данные (404, c) когерентности с использованием действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии, и/или
- сглаживать по меньшей мере одно из действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии и вычислять данные когерентности с использованием по меньшей мере одного сглаженного значения.
Модуль 320 вычисления когерентности может возводить в квадрат сглаженное действительное промежуточное значение и возводить в квадрат сглаженное мнимое промежуточное значение и суммировать возведенные в квадрат значения для получения первого компонентного числа. Модуль 320 вычисления когерентности может умножать сглаженные первое и второе значения энергии для получения второго компонентного числа, и комбинировать первое и второе компонентные числа для получения результирующего числа для значения когерентности, на котором основаны данные когерентности. Модуль 320 вычисления когерентности может вычислять квадратный корень результирующего числа для получения значения когерентности, на котором основаны данные когерентности. Ниже приведены примеры формул.
Ниже поясняется то, каким образом получается форма формы шума (или другой энергии сигналов), которая должна подготавливаться посредством рендеринга в декодере. Кодируется, по существу, форма (или другая информация, связанная с энергией) шума исходного входного сигнала 302, который в декодере должен применяться к шуму 252 и должен формировать его, с тем чтобы выполнять рендеринг шума 252 (выходного аудиосигнала), который напоминает исходный шум сигнала 304.
Сначала следует отметить, что сигнал 304 как таковой не кодируется в потоке 232 битов посредством кодера. Тем не менее, информация шума (например, информация энергии, информация огибающей) может кодироваться в потоке 232 битов, с тем чтобы затем формировать шумовой сигнал, который имеет форму шума, кодированную посредством кодера.
Блок 312 получения формы шума может применяться к входному сигналу 304 кодера. Блок 312 «получения формы шума» может вычислять параметрическое представление 1312 низкого разрешения спектральной огибающей шума во входном сигнале 304. Это может осуществляться, например, посредством вычисления значений энергии в полосах частот представления в частотной области входного сигнала 304. Значения энергии могут быть преобразованы в логарифмическое представление (при необходимости) и могут уплотняться в меньшее число (N) параметров, которые впоследствии используются в декодере для формирования комфортного шума. Эти представления низкого разрешения шума здесь называются «формами 1312 шума». Следовательно, то, что находится после блока 312 «получения формы шума», следует понимать не как представляющее входной сигнал 304, а как представляющее его форму шума (параметрические представления спектральных огибающих шума в соответствующих каналах). Это является важным, поскольку кодер может передавать только это представление более низкого разрешения спектральной огибающей шума в -кадре SID. Таким образом, на фиг. 2, вся часть (3040) «модуля вычисления параметров шума» может пониматься как работающая только с этими векторами связанных с шумом параметров (например, идентифицированными как vl, vr, vm, ind и vs, ind) а не с представлениями сигналов для сигнала 304.
Фиг. 5 показывает пример части 3040 «модуля вычисления параметров шума» (объединенного квантования по форме шума). Ступень 314 преобразователя L/R-M/S может применяться для получения среднего канального представления vm формы 1312 шума (первой линейной комбинации форм шума каналов L и R) и бокового канального представления vr формы 1312 шума (второй линейной комбинации форм шума для форм шума каналов L и R). Ниже показан способ их получения. Соответственно, форма шума 304 может в результате разделяться на два канала vm и vr.
Затем, в ступени 316 нормализации может быть нормализовано по меньшей мере одно из среднего канального представления vm формы 1312 шума и бокового канального представления vr формы 1312 шума для получения нормализованной версии vm, n среднего канального представления vm формы 1312 шума и/или нормализованной версии vr, n бокового канального представления vr формы 1312 шума.
Затем ступень 318 квантования (например, векторное квантование, VQ) может применяться к нормализованной версии сигнала 1304, например, в форме квантованной версии vm, ind нормализованного среднего канального представления vm, n формы 1312 шума и квантованной версии vs, ind нормализованного бокового канального представления vs, n формы 1312 шума. Может использоваться векторное квантование (например, через многоступенчатый векторный квантователь). Следовательно, индексы vm, ind[k] (k является индексом конкретного частотного элемента разрешения) могут описывать среднее представление формы шума, и индексы vs, ind[k] могут описывать боковое представление формы шума. Индексы vm, ind[k] и vs, ind[k] в силу этого могут кодироваться в потоке 232 битов в качестве первой линейной комбинации данных параметров комфортного шума для первого канала и данных параметров комфортного шума для второго канала и второй линейной комбинации данных параметров комфортного шума для первого канала и данных параметров комфортного шума для второго канала.
В ступени 322 деквантования может выполняться деквантование для квантованной версии vm, ind нормализованного среднего канального представления vm, n формы 1312 шума и квантованной версии vs, ind нормализованного бокового канального представления vs, n формы 1312 шума.
Преобразователь 324 M/S-L/R может применяться к деквантованным версиям деквантованных среднего и бокового представлений vm, q и vs, q формы 1312 шума для получения версии v'l и v'r формы 1312 шума в исходных (левом и правом) каналах.
Затем в ступени 326 могут вычисляться усиления gl и gr. В частности, усиления являются допустимыми для всех выборок формы (v'l и v'r) шума одинакового канала одинакового неактивного кадра 306. Усиления gl и gr могут получаться с учетом совокупности (или почти совокупности) частотных элементов разрешения в представлениях v'l и v'r формы шума.
Усиление gl может получаться посредством сравнения:
- значений частотных элементов разрешения формы шума первого канала 301 в области L/R (перед -преобразователем 314 L/R-M/S);
- со значениями частотных элементов разрешения формы 1312 шума, после повторного преобразования в области L/R, первого канала 301 (после преобразователя 324 M/S-L/R).
Аналогично, усиление gr может получаться посредством сравнения:
- значений коэффициентов формы шума второго канала 303 в области L/R (перед преобразователем 314 L/R-M/S);
- со значениями коэффициентов формы 1312 шума, после повторного преобразования в области L/R, второго канала 303 (после преобразователя 324 M/S-L/R).
Ниже предложен пример того, каким образом следует получать усиления. Тем не менее, усиление, в линейной области, например, может быть пропорциональным среднему геометрическому кратности долей, при этом каждая доля представляет собой долю между коэффициентами формы шума конкретного канала в области L/R (перед преобразователем 314 L/R-M/S) и коэффициентами того же канала после повторного преобразования в области L/R после преобразователя 324 M/S-L/R. В логарифмической области, для каждого канала усиление может быть получено как пропорциональное алгебраическому среднему между разностями между коэффициентами коэффициенты версии FD формы шума в области L/R (перед преобразователем 314 L/R-M/S) и коэффициентами формы шума после повторного преобразования в области L/R после преобразователя 324 M/S-L/R. В общем, в логарифмической или скалярной области, усиление может обеспечивать взаимосвязь между версией формы шума левого или правого канала перед преобразованием L/R-M/S и квантованием с версией формы шума левого или правого канала после деквантования и обратного преобразования M/S-L/R.
Ступень 328 квантования может применяться к усилению gl для получения его квантованной версии, указываемой gl, q, к усилению gr для получения его квантованной версии, указываемуой gr, q, которая может быть получена из неквантованного усиления gr. Усиления gl, q и gr, q могут кодироваться в потоке 232 битов (например, в качестве данных 401 и/или 403 параметров комфортного шума), который должен считываться декодером.
В некоторых примерах также можно сравнивать энергию вектора форм бокового канального шума (например, перед нормализацией, например, между ступенями 314 и 316) с заданным пороговым значением α энергии (которое может быть положительным действительным значением) (которое в этом случае составляет 0,1, но также может составлять другое значение, например значение от 0,05 до 0,15). В блоке 435 сравнения можно определять, имеет ли боковое представление vs формы шума неактивного кадра 308 достаточно энергии. Если энергия бокового представления vs формы шума меньше порогового значения α энергии, то двоичные результаты («флаг no-side»), в качестве вспомогательной информации 402 передаются в служебных сигналах в потоке 232 битов. Здесь предполагается, что флаг no-side=1, если энергия бокового представления vs формы шума меньше порогового значения α энергии, и флаг no-side=0, если энергия бокового представления vs формы шума больше порогового значения α энергии. В некоторых случаях, флаг может быть равным 1 или 0 согласно конкретному варианту применения в случае, если энергия точно равна пороговому значению энергии. Блок 436 отрицает двоичное значение флага 436 no-side (если ввод блока 436 равен 1, то вывод 436'' равен 0; если ввод блока 436 равен 0, то вывод 436'' равен 1). Блок 436 показан как выдающий в качестве вывода 436'' противоположное значение флага. Соответственно, если энергия бокового представления vs формы шума больше порогового значения энергии, то значение 436'' может быть равным 1, и если энергия бокового представления vs формы шума меньше заданного порогового значения, то значение 436'' равно 0. Следует отметить, что деквантованное значение vs, q может умножаться на двоичное значение 436''. Это представляет собой просто один возможный способ получения того, что если энергия бокового представления vs формы шума меньше заданного порогового значения α энергии, то элементы разрешения деквантованного бокового представления vs, q формы шума искусственно обнуляются (вывод 437'' блока 437 должен быть равен 0). С другой стороны, если энергия бокового представления vs формы шума является достаточно большой (>α), то вывод 437'' блока 437 (умножителя) может быть точно равным vs, q. Соответственно, если энергия бокового представления vs формы шума меньше заданного порогового значения α энергии, боковое представление vs формы шума (и, в частности, ее деквантованной версии vs, q) не учитывается при получении левого/правого представлений формы шума. (Показано, что помимо этого или альтернативно, декодер также может иметь аналогичный механизм, который обнуляет коэффициенты бокового представления формы шума). Следует отметить, что флаг no-side также может кодироваться в потоке 232 битов в качестве части вспомогательной информации 402.
Следует отметить, что энергия бокового представления формы шума показана как измеряемая (посредством блока 435) перед нормализацией формы шума (в блоке 316), и энергия не нормализуется до ее сравнения с пороговым значением. В принципе, она также может измеряться посредством блока 435 после нормализации формы шума (например, блок 435 может вводиться посредством vs, n вместо vs).
Со ссылкой на пороговое значение α, используемое для сравнения энергии бокового представления формы шума, значение 0,1, в некоторых примерах, может произвольно выбираться. В примерах, пороговое значение α может выбираться после экспериментирования и тонкой подстройки (например, посредством калибровки). В некоторых примерах, в принципе, может использоваться любое число, которое работает для числового формата (с плавающей запятой или с фиксированной запятой) либо точности отдельной реализации. Следовательно, пороговое значение α может представлять собой конкретный для реализации параметр, который может вводиться после калибровки.
Следует отметить, что выходной интерфейс (310) может быть выполнен с возможностью:
- формирования кодированного многоканального аудиосигнала (232), имеющего кодированные аудиоданные для активного кадра (306) с использованием первого множества коэффициентов для первого числа частотных элементов разрешения; и
- формирования первых параметрических данных шума, вторых параметрических данных шума или первой линейной комбинации первых параметрических данных шума и вторых параметрических данных шума и второй линейной комбинации первых параметрических данных шума и вторых параметрических данных шума с использованием второго множества коэффициентов, описывающих второе число частотных элементов разрешения,
- при этом первое число частотных элементов разрешения больше второго числа частотных элементов разрешения.
Фактически, уменьшенное разрешение может использоваться для неактивных кадров, за счет этого дополнительное уменьшая количество битов, используемых для кодирования потока битов. То же применимо к декодеру.
Любой из примеров кодера может управляться посредством подходящего контроллера.
Декодер
Ниже поясняются декодеры согласно примерам. Декодер может включать в себя, например, генератор 220 (220a-220e) комфортного шума, поясненный выше, например, показанный на фиг. 3a-3f. Комфортный шум 204 (многоканальный аудиосигнал) может формироваться в модуле 250 модификации сигналов для получения выходного сигнала 252. Здесь интересна демонстрация операций для формирования шума в неактивных кадрах 308, а не операций для активных кадров 206.
Фиг. 4 показывает первый пример декодера 200'', здесь указываемого с помощью 200'' (200b). Следует отметить, что декодер 200' включает в себя генератор 220 комфортного шума, который может включать в себя генератор 220 (220a-220e) согласно любому по фиг. 3a-3f. После генератора 220 (220a-220e) может присутствовать модуль 250 модификации сигналов (не показан, но показан на фиг. 4) для формирования сформированного многоканального шума 204 согласно энергетическим параметрам, кодированным в данных (401, 403) параметров комфортного шума. Через входной интерфейс 210 декодера декодер 200'' может получать из потока 232 битов данные (401, 403) параметров комфортного шума, которые могут включать в себя данные параметров комфортного шума, описывающие энергию сигнала (например, для первого канала и второго канала либо для первой линейной комбинации и второй линейной комбинации первого и второго каналов, причем первая и вторая линейные комбинации являются линейно независимыми друг от друга). Через входной интерфейс 210 декодера, декодер 200'' может получать данные 404 когерентности, которые указывают когерентность между различными каналами Фиг. 4 показывает то, что в потоке 232 битов для кодирования неактивных кадров, предусмотрены два различных кадра 241 и 243 дескриптора молчания, соответственно, но имеется возможность использования более чем двух кадров дескриптора или только одного отдельного кадра дескриптора. Вывод декодера 200b представляет собой многоканальный вывод.
Обращаясь к фиг. 2, ниже поясняется декодер 200'' (здесь указанный позицией 200a), который представляет собой пример декодера 200, который может использоваться для формирования выходного сигнала 252, например, в форме шума.
Сначала, например, декодер 200a (200'') может включать в себя входной интерфейс 210 для приема кодированных аудиоданных 232 (потока битов) в последовательности кадров 306, 308, кодированных посредством кодера 300a или 300b. Декодер 200a (200''), например, может представлять собой либо, если обобщать, представлять собой часть генератора 200 многоканальных сигналов, который может представлять собой или включать в себя генератор 220 (220a-220e) комфортного шума по любому из фиг. 3a-3f.
Сначала, фиг. 2 показывает стереогенератор 220 (220a-220e) комфортного шума (CNG). В частности, генератор 220 (220a-220e) комфортного шума может быть похожим на генератор комфортного шума по фиг. 3a-3f либо на один из его вариантов. Здесь, информация 404 когерентности (например, c или более точно cq, также указываемая с помощью "coh" или cind), полученная из кодера 300a или 300b, может использоваться для формирования многоканального сигнала 204 (в каналах 201, 203), который пояснен выше. Многоканальный сигнал 204, сформированный посредством CNG 220 (220a-220e), может фактически дополнительно модифицироваться, например, за счет учета данных 401 и 403 параметров комфортного шума, например, информации формы шума для первого (левого) канала и второго (правого) канала многоканального сигнала, который должен формироваться. В частности, показано, что имеется возможность получения средних индексов vm, ind (401) и боковых индексов vs, ind (403), сформированных посредством кодера 300a (и, в частности, посредством модуля 3040 вычисления параметров шума) в ступени 316 и/или 318, и усилений gl, q и gr, q, полученных в ступени 326 и/или 328.
Как показано на фиг. 2, вспомогательная информация 402 может позволить определить, является ли текущий кадр активным кадром 306 или неактивным кадром 308. Элементы по фиг. 2 означают обработку неактивных кадров 308, и подразумевается, что любая технология может использоваться для формирования выходного сигнала в активных кадрах 306, что в силу этого не представляет собой цель настоящего документа.
Как показано на фиг. 2, несколько примеров данных комфортного шума получаются из потока 232 битов. Данные комфортного шума могут включать в себя, как пояснено выше, информацию 404 (данные) когерентности, параметры 401 и 403 (vm, ind и vs, ind), указывающие форму шума, и/или усиления (gl, q и gr, q).
Ступень 212-C может деквантовать квантованную версию cind информации 404 когерентности для получения деквантованной информации cq когерентности.
Ступень 2120 (объединенное деквантование по форме шума) может позволить деквантовать другие данные комфортного шума, полученные из потока 232 битов. Можно обратиться к фиг. 6. Ступень 212 деквантования образована другими ступенями деквантования, указанными в настоящем документе позициями 212-M, 212-S, 212-R, 212-L. Ступень 212-M может деквантовать параметры 401 и 403 формы среднего канального шума для получения деквантованных параметров vm, q и vs, q формы шума. Ступень 212-S может обеспечивать деквантованную версию vs, q параметров 403 (vs, ind) формы бокового канального шума. В некоторых примерах можно использовать флаг no-side таким образом, чтобы обнулить вывод ступени 212-S в случае, если блок 435 в кодере 300a распознает энергию вектора vs форм шума как меньшую, чем заданное пороговое значение α. В случае, если энергия меньше заданного порогового значения α и флаг no-side передает это в служебных сигналах, деквантованная версия vs, q вектора vs форм шума может обнуляться (что концептуально показано как умножение на флаг 536', полученный из блока 536, который имеет ту же функцию, что и блок 436 кодера, даже если блок 536 фактически считывает флаг no-side, кодированный во вспомогательной информации потока 232 битов, вообще без выполнения сравнения с пороговым значением α). Следовательно, если энергия бокового канала в кодере определена как меньшая, чем заданное пороговое значение α, деквантованная версия vs, q вектора vs форм шума искусственно обнуляется, и значение в выводе 537'' блока 537 модуля масштабирования равно нулю. В противном случае, если энергия больше заданного порогового значения, то вывод 537'' является равным квантованной версии vs, q боковых индексов 403 (vs, ind) формы шума бокового канала. Другими словами, значениями вектора vs, ind форм шума пренебрегают в случае, если энергия бокового канала ниже заданного порогового значения α энергии.
В ступени 516 M/S-L/R выполняется преобразование M/S-L/R таким образом, чтобы получить версию L/R v'l, v'r параметрических данных (формы шума). Затем может использоваться усилительная ступень 518 (образованная ступенями 518-L и 518-L) таким образом, что в ступени 518-L, канал v'l масштабируется посредством усиления gl, d, тогда как в ступени 518-R, канал v'r масштабируется посредством усиления gr, q. Следовательно, энергетические каналы vl, q и vr, q могут быть получены в виде вывода усилительного каскада 518. Блоки 518-L и 518-R ступеней показаны с «+», поскольку передача значений предположительно выполняется в логарифмической области, и масштабирование значений в силу этого указывается в суммировании. Тем не менее, усилительная ступень 518 указывает то, что восстановленные векторы vl, q и vr, q форм шума масштабируются. Восстановленные векторы vl, q и vr, q форм шума здесь комплексно указываются с помощью 2312 и представляют собой восстановленную версию формы 1312 шума, первоначально полученной посредством блока 312 «получения формы шума» в кодере. В общих чертах, каждое усиление является постоянным для всех индексов (коэффициентов) того же канала того же неактивного кадра.
Следует отметить, что индексы vm, ind, vs, ind и усиления gl, q, gr, q представляют собой коэффициенты формы шума и выдают информацию относительно энергии кадра. Они по существу означают параметрические данные, ассоциированные с входным сигналом 304, которые используются для формирования сигнала 252, но они не представляют сигнал 304 или сигнал 252, который должен формироваться. Иначе говоря, шумовые каналы vr, q и vl, q описывают огибающую, которая должна применяться к многоканальному сигналу 204, сформированному посредством CNG 220.
Возвращаясь к фиг. 2, восстановленные векторы vl, q и vr, q форм шума (2312) используются в модуле 250 модификации сигналов для получения модифицированного сигнала 252 посредством формирования шума 204. В частности, первый канал 201 сформированного шума 204 может быть образован каналом vl, q в ступени 250-L и каналом 203 сформированного шума 204 в ступени 250-R для получения выходного многоканального аудиосигнала 252 (Lout и Rout).
В примерах, непосредственно комфортный шумовой сигнал 204 не формируется в логарифмической области: только формы шума могут использовать логарифмическое представление. Преобразование из логарифмической области в линейную область может выполняться (хотя не показано).
Также преобразование из частотной области во временную область может выполняться (хотя не показано).
Декодер 200'' (200a, 200b) также может содержать спектрально-временной преобразователь (например, модуль 250 модификации сигналов) для преобразования результирующего первого канала 201 и результирующего второго канала 203, спектрально регулируемых и когерентно регулируемых, в соответствующие представления во временной области, которые должны комбинироваться или конкатенироваться с представлениями во временной области соответствующих каналов декодированного многоканального сигнала для активного кадра. Это преобразование сформированного комфортного шума в сигнал временной области происходит после блока 250 модификации сигналов на фиг. 2. «Комбинация или конкатенация» с частью, по существу, означает, что до или после неактивного кадра, который использует одну из этих технологий CNG, также могут быть предусмотрены активные кадры (другой тракт обработки на фиг. 1), и для формирования непрерывного вывода вообще без перерывов или слышимых щелчков и т.д., кадры должны корректно конкатенироваться.
В некоторых примерах:
- кодированный аудиосигнал (232) для активного кадра (306) имеет первое множество коэффициентов, описывающих первое число частотных элементов разрешения; и
- кодированный аудиосигнал (232) для неактивного кадра (308) имеет второе множество коэффициентов, описывающих второе число частотных элементов разрешения.
Первое число частотных элементов разрешения может быть больше второго числа частотных элементов разрешения.
Любой из примеров декодера может управляться посредством подходящего контроллера.
Этапы обработки: первая версия
Параметры шума, кодированные в двух кадрах SID для двух каналов, вычисляются так, как указано в EVS [6], к примеру, согласно LP-CNG или FD-CNG либо обоим из означенного. Формирование энергии шумов в декодере также является одинаковым с EVS, к примеру, согласно LP-CNG или FD-CNG либо обоим из них.
В кодере, дополнительно когерентность двух каналов вычисляется, равномерно квантуется с использованием четырех битов и отправляется в потоке 232 битов. В декодере, работа в режиме CNG затем может управляться посредством передаваемого значения 404 когерентности. Три источника N1, N2, N3 (211a, 212a, 213a; 211b, 212b, 213b; 211c, 212c, 213c; 211d, 212d, 213d; 211e, 212e, 213e) гауссова шума могут использоваться, как показано на фиг. 3a-3f. Когда канальная когерентность является высокой, главным образом коррелированный шум может добавляться в оба канала 221' и 223', тогда как больше декоррелированного шума добавляется, если когерентность 404 является низкой.
Для всех неактивных кадров 306, параметры для формирования комфортного шума (параметры шума) могут постоянно оцениваться в кодере (например, 300, 300a, 300b). Это может осуществляться, например, посредством применения алгоритма оценки шума в частотной области (например, [8]), например, как описано в [6] отдельно для обоих входных каналов (например, 301, 303) для вычисления двух наборов параметров шума (например, 401, 403), которые также поясняются в качестве параметрических данных шума. Кроме того, когерентность (c, 404) двух каналов может вычисляться (например, в модуле 320 вычисления когерентности) следующим образом: С учетом M-точечных DFT-спектров двух входных каналов 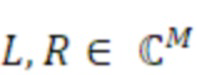 (L, R могут представлять собой 301, 303), могут вычисляться четыре промежуточных значения, например:
(L, R могут представлять собой 301, 303), могут вычисляться четыре промежуточных значения, например:
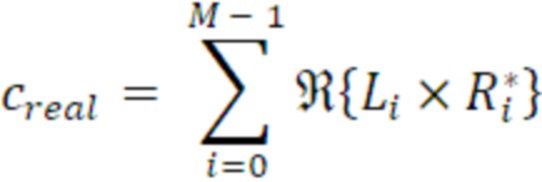
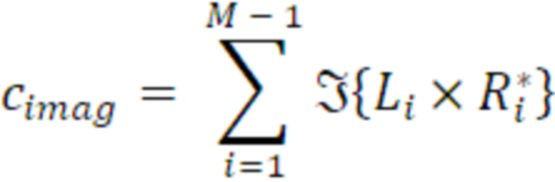 ,
,
и энергии двух каналов:

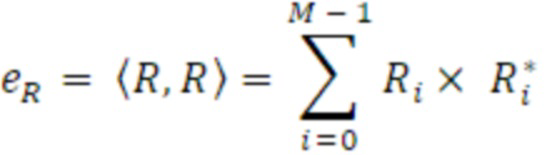
Здесь, оно может составлять M=256, 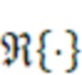 обозначает действительную часть комплексного числа,
обозначает действительную часть комплексного числа, 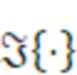 обозначает мнимую часть комплексного числа, и
обозначает мнимую часть комплексного числа, и  обозначает комплексное сопряжение. Эти промежуточные значения затем могут сглаживаться, например, с использованием соответствующих значений из предыдущего кадра:
обозначает комплексное сопряжение. Эти промежуточные значения затем могут сглаживаться, например, с использованием соответствующих значений из предыдущего кадра:
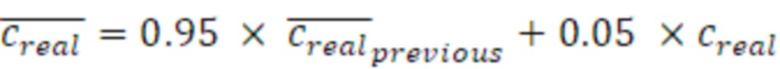
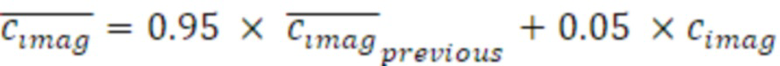


Этот проход может представлять собой часть блока 320'' «вычисления канальной когерентности» в кодере. Он представляет собой временное сглаживание внутренних параметров, чтобы не допустить больших внезапных перескоков в параметрах между кадрами. Другими словами, фильтр нижних частот применяется здесь к параметрам.
Вместо констант 0,95 и 0,05, могут использоваться другие константы в интервале 0,95±0,03 и 0,05±0,03.
В альтернативе, можно задавать:
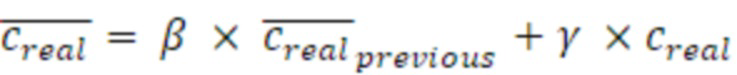
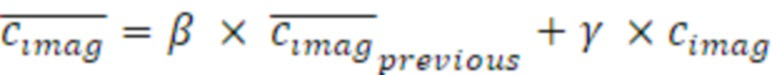
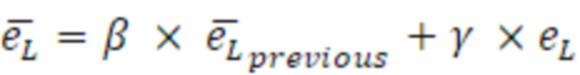
 ,
,
где 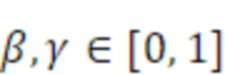 , и β+γ=1, например, β=0,95 и γ=0,05.
, и β+γ=1, например, β=0,95 и γ=0,05.
Когерентность (c, 404) (которая может составлять между 0 и 1) затем может вычисляться (например, в модуле (320) вычисления) когерентности следующим образом:
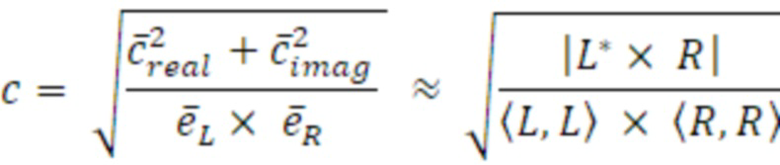 ,
,
и равномерно квантоваться (например, в квантователе 320'') с использованием, например, четырех битов следующим образом:
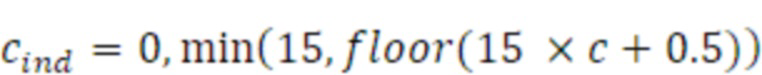
Кодирование оцененных параметров 1312, 2312 шума для обоих каналов может выполняться отдельно, например, как указано в [6]. Два кадра 241, 243 SID затем могут кодироваться и отправляться в декодер. Первый кадр 241 SID может содержать оцененные параметры 401 шума канала L и (например, четыре) бита вспомогательной информации 402, например, как описано в [6]. Во втором кадре 243 SID, параметры 403 шума канала R могут отправляться наряду с четырехбитовым квантованным значением c, 404 когерентности (различные количества битов могут выбираться в других примерах).
В декодере (например, 200'', 200a, 200b), как параметры (401, 403) шума кадра SID, так и вспомогательная информация 402 первого кадра могут декодироваться, например, как описано в [6]. Значение 404 когерентности во втором кадре может деквантоваться в ступени 212-C следующим образом:
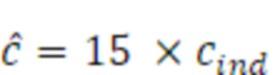
(на фиг. 2,  заменяется на cq).
заменяется на cq).
Для формирования комфортного шума (например, в генераторе 220 либо в любом из генераторов 220a-220e, которые могут включать в себя генератор по любому из фиг. 3a-3e), согласно примеру, три источника 211, 212, 213 гауссова шума могут использоваться, как показано на фиг. 3. Источники 211, 212, 213 шума могут адаптивно суммироваться между собой (например, в ступенях 206-1 и 206-3 сумматора), например, на основе значения (c, 404) когерентности. DFT-спектры левого и правого канальных шумовых сигналов Nl[k], Nr[k] могут вычисляться следующим образом:

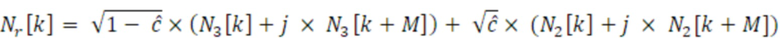 ,
,
где 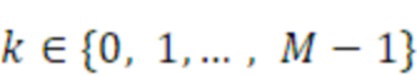 (что является индексом конкретного частотного элемента разрешения, в тогда как каждый канал имеет M частотных элементов разрешения), и j 2=-1 (т.е. j является мнимой единицей), и "x" является нормальным умножением. Здесь, «частотный элемент разрешения» означает число комплексных значений в спектрах Nl и Nr, соответственно. M является длиной преобразования FFT или DFT, которое используется, так что длина спектров составляет M. Следует отметить, что шум, вставленный в действительную часть, и шум, вставленный в мнимую часть, может отличаться. Таким образом, для длины спектра M, требуется 2xM значений (одно действительное и одно мнимое), сформированных из каждого источника шума. Либо, другими словами: Nl и Nr являются комплекснозначными векторами с длиной M, тогда как N1, N2 и N3 являются действительнозначными векторами с длиной 2xM.
(что является индексом конкретного частотного элемента разрешения, в тогда как каждый канал имеет M частотных элементов разрешения), и j 2=-1 (т.е. j является мнимой единицей), и "x" является нормальным умножением. Здесь, «частотный элемент разрешения» означает число комплексных значений в спектрах Nl и Nr, соответственно. M является длиной преобразования FFT или DFT, которое используется, так что длина спектров составляет M. Следует отметить, что шум, вставленный в действительную часть, и шум, вставленный в мнимую часть, может отличаться. Таким образом, для длины спектра M, требуется 2xM значений (одно действительное и одно мнимое), сформированных из каждого источника шума. Либо, другими словами: Nl и Nr являются комплекснозначными векторами с длиной M, тогда как N1, N2 и N3 являются действительнозначными векторами с длиной 2xM.
Впоследствии, шумовой сигнал 204 в двух каналах спектрально формируется (например, в ступенях 250-L, 250-R на фиг. 2) с использованием соответствующих параметров (2312) шума, декодированных из соответствующего кадра SID и затем преобразованных обратно во временную область (например, как описано в [6]) для формирования комфортного шума частотной области.
Любой из примеров обработки может выполняться посредством подходящего контроллера.
Этапы обработки: вторая версия
Аспекты этапов обработки, как пояснено выше, могут интегрироваться по меньшей мере с одним из нижеприведенных аспектов. Здесь главным образом необходимо обратиться к фиг. 2 и 5, но также можно обратиться к фиг. 4.
Блок-схема общей инфраструктуры кодера проиллюстрирована на фиг. 1. Для каждого кадра в кодере, текущий сигнал может классифицироваться как активный или как неактивный посредством отдельного выполнения VAD для каждого канала, как описано в [6]. VAD-решение затем может синхронизироваться между двумя каналами. В примерах, кадр классифицируется как неактивный кадр 308, только если оба канала классифицируются как неактивные. В противном случае, он классифицируется как активный, и оба канала объединенно кодируются в системе на основе MDCT с использованием M/S для каждой полосы частот, как описано в [10]. При переключении из активного кадра на неактивный кадр, сигналы могут входить в тракт кодирования SID, как показано на фиг. 3.
Параметры (например, 1312, 401, 403, ql, q, gr, q) для формирования комфортного шума (например, параметры шума) могут постоянно оцениваться в кодере (например, 300, 300a, 300b) для активных и неактивных кадров (306, 308). Это может осуществляться, например, посредством применения процесса оценки шума в частотной области, такого как процесс, поясненный в [8], и/или как описано в [6], например, отдельно для обоих входных каналов 301, 303 для вычисления двух наборов параметров шума, включающих в себя формы (Mi или 401 и/или Is или 403) спектрального шума, например, в логарифмической области для каждого канала.
Кроме того, когерентность (404, c) двух каналов может вычисляться (например, в модуле 320 вычисления когерентности) следующим образом: С учетом M-точечных DFT-спектров двух входных каналов , четыре промежуточных значения могут вычисляться как:
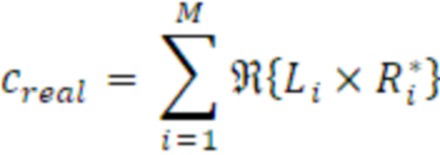
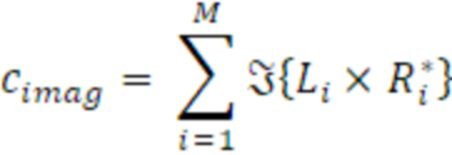 ,
,
и энергии двух каналов:
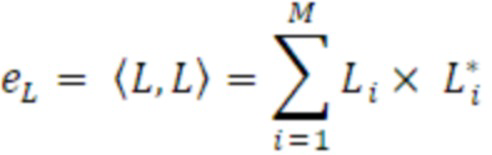
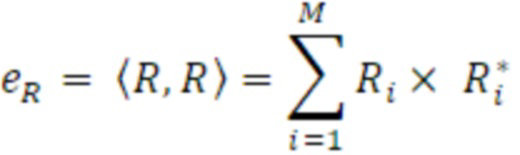
Здесь, оно может составлять M=256 (другие значения для M могут использоваться), обозначает действительную часть комплексного числа, обозначает мнимую часть комплексного числа, и обозначает комплексное сопряжение. Эти промежуточные значения затем сглаживаются на основе 10-миллисекундных субкадров. Если  обозначает соответствующее значение из предыдущего субкадра, сглаженные значения могут вычисляться следующим образом:
обозначает соответствующее значение из предыдущего субкадра, сглаженные значения могут вычисляться следующим образом:

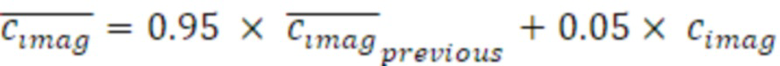

Вместо констант 0,95 и 0,05, могут использоваться другие константы в интервале 0,95±0,03 и 0,05±0,03.
В альтернативе, можно задавать:
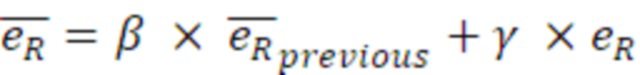 ,
,
где , β+xγ=1, например, β=0.95 и γ=0.95 (β> γ, например, β> 3xγ или β> 6xγ).
Когерентность 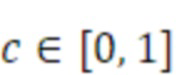 затем может вычисляться (например, в 320'') следующим образом:
затем может вычисляться (например, в 320'') следующим образом:
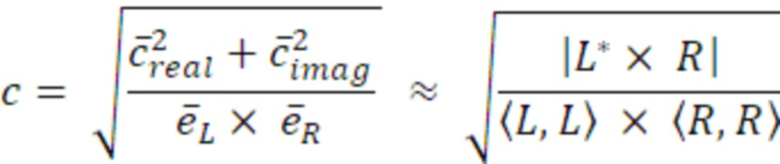 ,
,
и равномерно квантоваться (например, в 320'') с использованием четырех битов (но различные количества битов являются возможными) следующим образом:
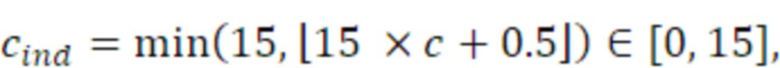 ,
,
где 
 обозначает округление в меньшую сторону до ближайшего целого числа (функцию минимального уровня)
обозначает округление в меньшую сторону до ближайшего целого числа (функцию минимального уровня)
Кодирование оцененных форм шума обоих каналов может выполняться объединенно. Из форм левого (vl) и правого (vr) канального шума, различные каналы могут получаться (например, через линейную комбинацию), к примеру, форма среднего канального (vm) шума и форма бокового канального (vs) шума могут вычисляться, (например, в блоке 314) следующим образом:
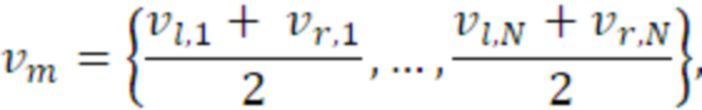
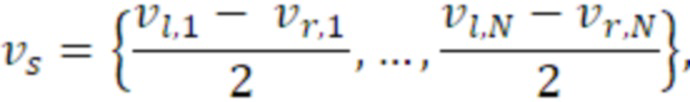 ,
,
где N обозначает длину векторов форм шума (например, для каждого неактивного кадра 308), например, в частотной области. N обозначает длину вектора форм шума, например, оцененную так, как указано в EVS [6], которая может составлять между 17 и 24. Векторы форм шума могут рассматриваться в качестве более компактного представления спектральной огибающей шума во входном кадре либо, более абстрактно, в качестве параметрического спектрального описания шумового сигнала с использованием N параметров. N не связано с длиной преобразования FFT или DFT.
Затем эти формы шума могут быть нормализованы (например, в ступени 316) и/или квантованы. Например, они могут быть векторно квантованы (например, в ступени 318), например, с использованием многокаскадных векторных квантователей (MSVQ) (пример описан в [6, стр. 442].
MSVQ, используемый в каскаде 318 для квантования формы vm (для получения vm, ind 401), может иметь 6 каскадов (но возможно и другое число каскадов) и/или использовать 37 битов (но возможно и другое количество битов), например, при реализации для моноканалов в [6], тогда как MSVQ, используемый, в каскаде 318, для квантования формы vs (для получения vs, ind 403) может быть уменьшен до 4 ступеней (либо, в любом случае, до числа ступеней, меньшего, чем число ступеней, используемых в ступени 318), и/или может использовать в сумме 25 битов (либо, в любом случае, количество битов, меньшее, чем количество битов, используемое в ступени 318 для кодирования формы vm).
Индексы таблиц кодирования MSVQ могут передаваться в потоке битов (например, в данных 232 и, более конкретно, в данных 401, 403 параметров комфортного шума). Индексы затем деквантуются, что приводит к деквантованным формам vm, q и vm, q шума.
В случае фонового шума, представляющего собой один источник шума в центре стереоизображения, оцененные формы vm, vs шума обоих каналов предположительно должны быть почти равными или даже равными. Результирующая форма шума S-канала в таком случае должна содержать только нули. Тем не менее, векторный квантователь (ступень 322), используемый для квантования текущей реализации vs, может быть таким, что он не может моделировать вектор со всеми нулями, и после деквантования, деквантованная форма (vs, q) шума vs в результате может более не быть со всеми нулями. Это может приводить к перцепционным проблемам с представлением таких центрированных фоновых шумов. Чтобы обходить этот недостаток VQ 322, значение no_side (флаг no_side) может вычисляться (и также может передаваться в служебных сигналах в потоке битов) в зависимости от энергии неквантованного вектора форм vs (например, энергии вектора форм шума vs после ступени 314 и/или перед ступенью 316). Флаг no_side может быть следующим:
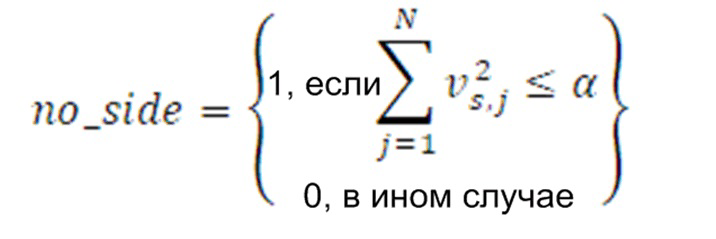
Пороговое значение α энергии может составлять, просто в качестве примера, 0,1 или другое значение в интервале [0,05, 0,15]. Тем не менее, пороговое значение α может быть произвольным, и в реализации может зависеть от используемого числового формата (например, с фиксированной запятой или с плавающей запятой) и/или от возможно используемых нормализаций сигналов. В примерах, положительное действительное значение может использоваться в зависимости от того, насколько резким является используемое определение S-канала «молчания». Следовательно, интервал может составлять (0, 1). Значение no_side может использоваться для указания того, должна ли форма шума vs использоваться для восстановления форм канального шума vl и vr (например, в декодере). Если no_side равно 1, деквантованная форма vs задается равной нулю (например, посредством масштабирования канала vs, q на значение 436'' на фиг. 2, которое представляет собой логическое значение NOT(no_side)); no_side передается (передается в служебных сигналах) в потоке 232 битов, например, в качестве вспомогательной информации 402. Затем, обратное преобразование M/S (например, ступень 324) может применяться к деквантованным векторам vm, q и vs, q форм шума (при этом второе может заменяться на 0 в случае, если энергия является низкой, в силу чего указывается с помощью 437'' на фиг. 2) для получения промежуточных векторов v'l и v'r следующим образом:
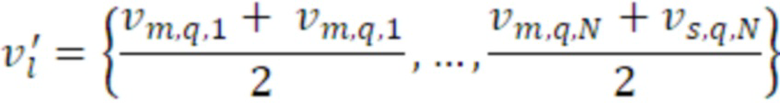
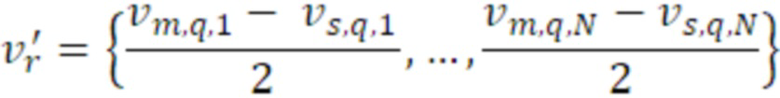
С использованием этих промежуточных векторов v'l и v'r и неквантованных векторов vl и vr форм шума, два значения усиления вычисляются следующим образом:
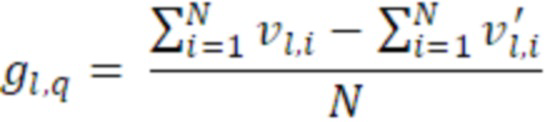
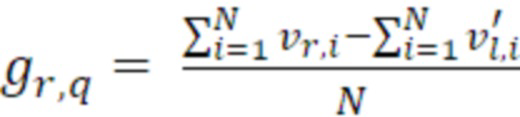 .
.
Два значения усиления затем могут линейно квантоваться (например, в ступени 328) следующим образом:
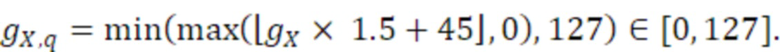 ,
,
(возможны другие квантования).
Квантованные усиления могут кодироваться в потоке битов SID (например, в качестве части данных 401 или 403 параметров комфортного шума, и более конкретно, gl, q может представлять собой часть первых параметрических данных шума, и gr, q может представлять собой часть вторых параметрических данных шума), например, с использованием семи битов для значения gl, q усиления и/или семи битов для значения gr, q усиления (различные величины также являются возможными для каждого значения усиления).
В декодере (например, 200'', 200a, 200b), квантованные векторы форм шума (например, часть данных 401 или 403 параметров комфортного шума и, более конкретно, первых параметрических данных шума и вторых параметрических данных шума) могут деквантоваться, например, в ступени 212 (в частности, в любой из частичных ступеней 212-M, 212-S).
Значения усиления могут деквантоваться, например, в ступени 212 (в частности, в любой из частичных ступеней 212-L, 212-R) следующим образом:
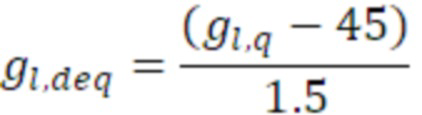

(значение 45 зависит от квантования и может отличаться для различных квантований). (На фиг. 2, gl, d и gr, d используются вместо gl, deq и gr, deq).
Значение 404 когерентности может деквантоваться (например, в ступени 212-C) следующим образом:
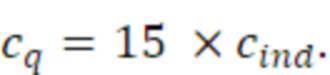
Если флаг no_side (во вспомогательной информации 402) равен 1, деквантованная форма vs, q vs задается равной нулю (значение 537'') до вычисления промежуточных векторов v'l и v'r (например, в ступени 516). Затем соответствующее значение усиления суммируется со всеми элементами соответствующего промежуточного вектора для формирования деквантованных форм vl, q и vr, q шума, комплексно указываемых позицией 522, следующим образом:
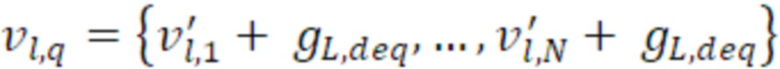
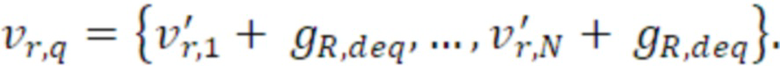
(Суммирование обусловлено тем, что мы находимся в логарифмической области, и соответствует умножению на коэффициент в линейной области).
Для формирования комфортного шума, три источника N1, N2, N3 гауссова шума (например, 211a, 212a, 213a на фиг. 3a, 211b, 212b, 212c на фиг. 3b и т.д.) могут использоваться, как показано на любом из фиг. 3a-3f (либо может использоваться любая из других технологий). Когда канальная когерентность является высокой, главным образом коррелированный шум добавляется в оба канала, тогда как больше декоррелированного шума добавляется, если когерентность является низкой.
С использованием трех источников шума, DFT-спектры левого и правого канальных шумовых сигналов Nl (201) и Nr (203) могут вычисляться следующим образом:
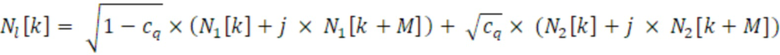
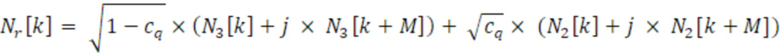 ,
,
где , и j2=-1. Здесь, M обозначает длину блока DFT. Чтобы формировать независимый шум в действительной и мнимой части комплексного спектра, 2xM значений (по два для одного частотного элемента разрешения) в расчете на кадр должны формироваться посредством каждого источника шума. Следовательно, N1, N2 и N3 (соответственно, в 211, 212, 213 на фиг. 3f) могут рассматриваться в качестве действительнозначных шумовых векторов, имеющих длину 2xM, тогда как Nr и Nk (соответственно, в 201, 203) являются комплекснозначными векторами с длиной M.
Впоследствии, шумовые сигналы в двух каналах могут быть спектрально сформированы (например, в модуле 252 модификации сигналов) с использованием соответствующей формы (vl, q или vr, q) шума, декодированной из потока 232 битов, и затем преобразованы обратно из логарифмической области в скалярную область и из частотной области во временную область, например, как описано в [6], чтобы формировать стереофонический комфортный шумовой сигнал.
Любой из примеров обработки может выполняться посредством подходящего контроллера.
Некоторые преимущества
Настоящее изобретение может обеспечивать технологию для формирования комфортного стереошума, в частности, подходящую для схем дискретного стереокодирования. Посредством объединенного кодирования и передачи параметров формы шума для обоих каналов, стерео-CNG может применяться без необходимости понижающего мономикширования.
Вместе с двумя отдельными наборами параметров шума, микширование одного общего и двух отдельных источников шума, управляемых посредством одного значения когерентности, обеспечивает возможность достоверного восстановления стереоизображения фонового шума без необходимости передавать высокодетализированные стереопараметры, которые типично присутствуют только в параметрических аудиокодерах. Поскольку только этот один параметр используется, кодирование SID является простым без необходимости сложных способов сжатия, при одновременном поддержании размера кадра SID малым.
Некоторые важные аспекты:
В некоторых примерах получается по меньшей мере один из следующих аспектов:
1. Формирование комфортного шума для стереофонического сигнала посредством микширования трех источников гауссова шума, по одному для каждого канала и третьего общего источника шума для создания коррелированного фонового шума.
2. Управление микшированием источников шума со значением когерентности, которое передается с кадром SID.
3. Передача отдельных параметров формы шума для обоих стереоканалов посредством объединенного кодирования форм шума способом M/S. Понижение скорости передачи в битах кадров SID посредством кодирования S-образной формы с меньшим числом битов, чем M.
Другие технологии
Также можно реализовать способ формирования многоканального сигнала, имеющего первый канал и второй канал, содержащий:
- формирование первого аудиосигнала с использованием первого аудиоисточника;
- формирование второго аудиосигнала с использованием второго аудиоисточника;
- формирование шумового сигнала микширования с использованием источника шума при микшировании; и
- микширование шумового сигнала микширования и первого аудиосигнала для получения первого канала, и микширование шумового сигнала микширования и второго аудиосигнала для получения второго канала.
Также может быть реализован способ кодирования аудио для формирования кодированного многоканального аудиосигнала для последовательности кадров, содержащих активный кадр и неактивный кадр, при этом способ содержит:
- анализ многоканального сигнала для определения кадра последовательности кадров как представляющего собой неактивный кадр;
- вычисление первых параметрических данных шума для первого канала многоканального сигнала и вычисление вторых параметрических данных шума для второго канала многоканального сигнала;
- вычисление данных когерентности, указывающих ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре; и
- формирование кодированного многоканального аудиосигнала, имеющего кодированные аудиоданные для активного кадра и, для неактивного кадра, первые параметрические данные шума, вторые параметрические данные шума и данные когерентности.
Изобретение также может быть реализовано в постоянном модуле хранения, сохраняющем инструкции, которые, при выполнении посредством компьютера (либо процессора или контроллера), предписывают компьютеру (либо процессору или контроллеру) осуществлять вышеприведенный способ.
Изобретение также может быть реализовано в многоканальном аудиосигнале, организованном в последовательность кадров, причем последовательность кадров содержит активный кадр и неактивный кадр, причем кодированный многоканальный аудиосигнал содержит:
- кодированные аудиоданные для активного кадра;
- первые параметрические данные шума для первого канала в неактивном кадре;
- вторые параметрические данные шума для второго канала в неактивном кадре; и
- данные когерентности, указывающие ситуацию когерентности между первым каналом и вторым каналом в неактивном кадре. Многоканальный аудиосигнал может получаться с помощью одной из технологий, раскрытых выше и/или ниже.
Преимущества вариантов осуществления
Вставка общего источника шума для двух каналов, чтобы имитировать коррелированный шум для формирования конечного комфортного шума, играет важную роль при имитации стереофонической записи фонового шума.
Варианты осуществления изобретения также могут считаться процедурой для формирования комфортного шума для стереофонического сигнала посредством микширования трех источников гауссова шума, по одному для каждого канала и третьего общего источника шума для создания коррелированного фонового шума либо, дополнительно или отдельно, управления микшированием источников шума со значением когерентности, которое передается с кадром SID, либо, дополнительно или отдельно, следующим образом: В стереосистеме, отдельное формирование фонового шума приводит к полностью декоррелированному шуму, который звучит неприятно и существенно отличается от фактического фонового шума, вызывающего резкие слышимые переходы, при переключении в/из фона активного режима в фоны режима DTX. В варианте осуществления, на стороне кодера, помимо параметров шума, когерентность двух каналов вычисляется, равномерно квантуется и суммируется с кадром SID. В декодере, работа в режиме CNG затем управляется посредством передаваемого значения когерентности. Используются три источника N_1, N_2, N_3 гауссова шума; когда канальная когерентность является высокой, главным образом коррелированный шум добавляется в оба канала, тогда как больше декоррелированного шума добавляется, если когерентность является низкой.
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше, и все аспекты, заданные посредством независимых пунктов в нижеприведенной формуле изобретения, могут использоваться отдельно, т.е. без альтернатив или целей, отличных от предполагаемой альтернативы, цели или независимого пункта формулы изобретения. Тем не менее, в других вариантах осуществления, две или более из альтернатив или аспектов или независимых пунктов формулы изобретения могут комбинироваться друг с другом, и, в других вариантах осуществления, все аспекты или альтернативы и все независимые пункты формулы изобретения могут комбинироваться друг с другом.
Кодированный сигнал согласно изобретению может сохраняться на цифровом носителе хранения данных или на постоянном носителе хранения данных либо может передаваться по передающей среде, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или позволяют взаимодействовать) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые позволяют взаимодействовать с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на постоянном носителе хранения данных.
Другими словами, вариант осуществления способа согласно изобретению, таким образом, представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Список литературы
[1] ITU-T G.729 Annex B "A silence compression scheme for G.729 optimized for terminals conforming to ITU-T Recommendation V.70. International Telecommunication Union (ITU)", серия G, 2007.
[2] ITU-T G.729.1 Annex C "DTX/CNG scheme: International Telecommunication Union (ITU)", серия G, 2008.
[3] ITU-T G.718 "Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s, International Telecommunication Union (ITU)", серия G, 2008.
[4] "Mandatory Speech Codec speech processing functions; Adaptive Multi-Rate (AMR) speech codec; Transcoding functions", 3GPP Technical Specification TS 26.090, 2014.
[5] "Adaptive Multi-Rate - Wideband (AMR-WB) speech codec; Transcoding functions", 3GPP, 2014.
[6] 3GPP TS 26.445 "Codec for Enhanced Voice Services (EVS); Detailed algorithmic description".
[7] Z. Wang и другие "Linear prediction based comfort noise generation in the EVS codec", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, 2015.
[8] A. Lombard, S. Wilde, E. Ravelli, S. Döhla, G. Fuchs и M. Dietz "Frequency-domain Comfort Noise Generation for Discontinuous Transmission in EVS", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, 2015.
[9] A. Lombard, M. Dietz, S. Wilde, E. Ravelli, P. Setiawan и M. Multrus "Generation of the comfort noise with high spectro-temporal resolution in discontinuous transmission of audio signals". Патент США № 9,583,114B2, 19 июня 2015 года.
[10] E. NORVELL и F. JANSSON "SUPPORT FOR GENERATION OF COMFORT NOISE. AND GENERATION OF COMFORT NOISE", публикация WO 2019/193149 A1, 5 апреля 2019 года.
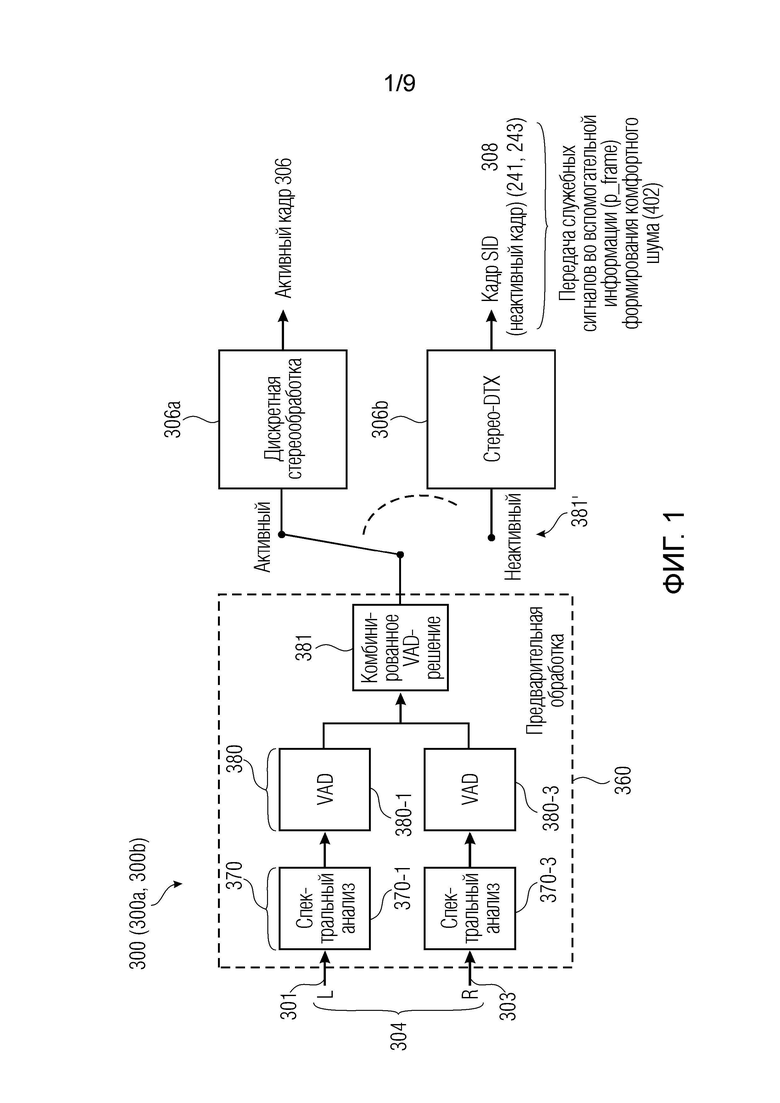
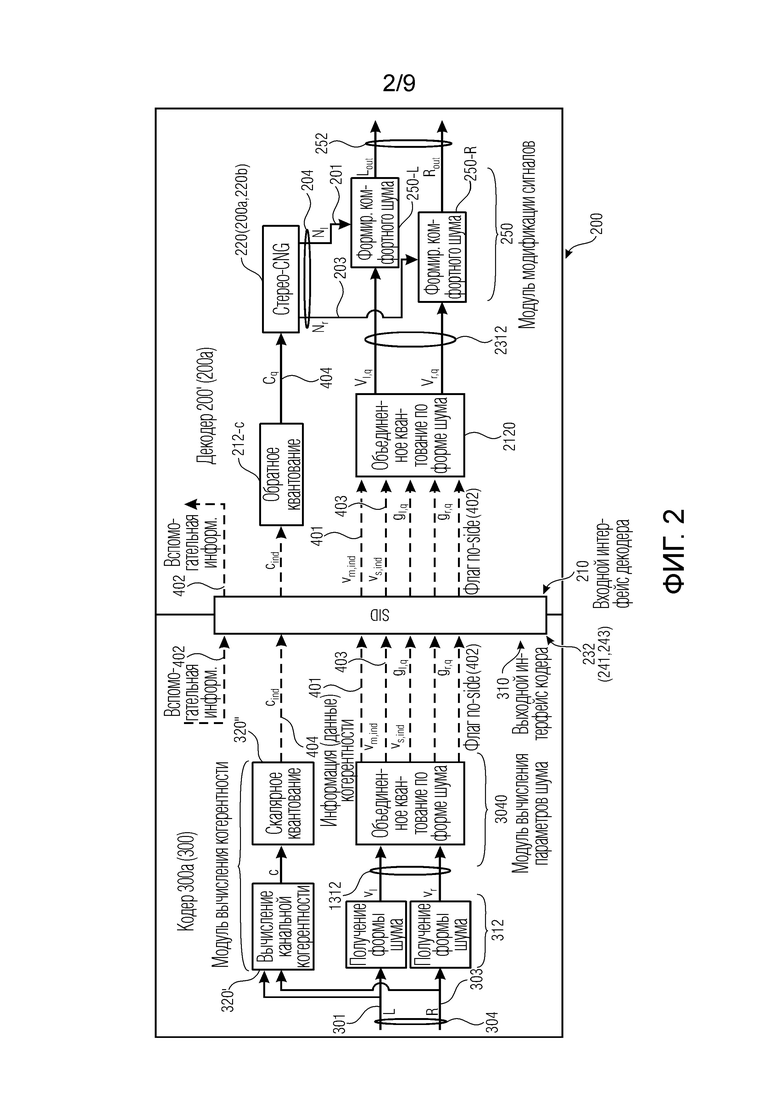
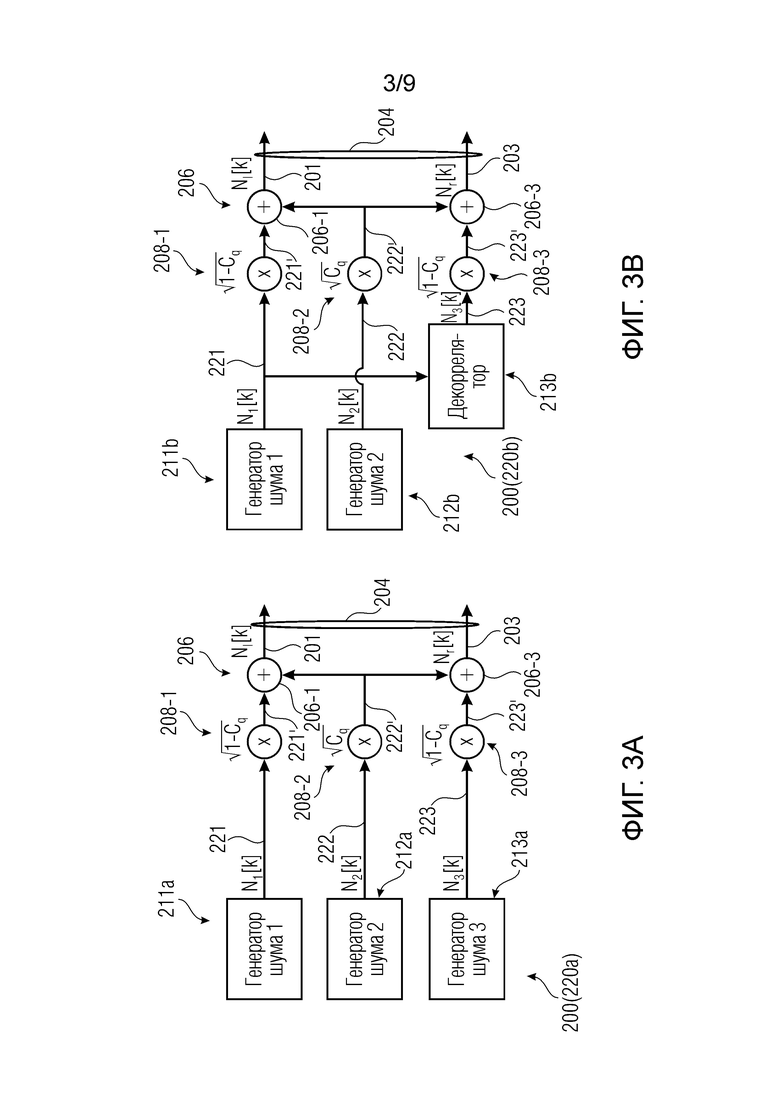
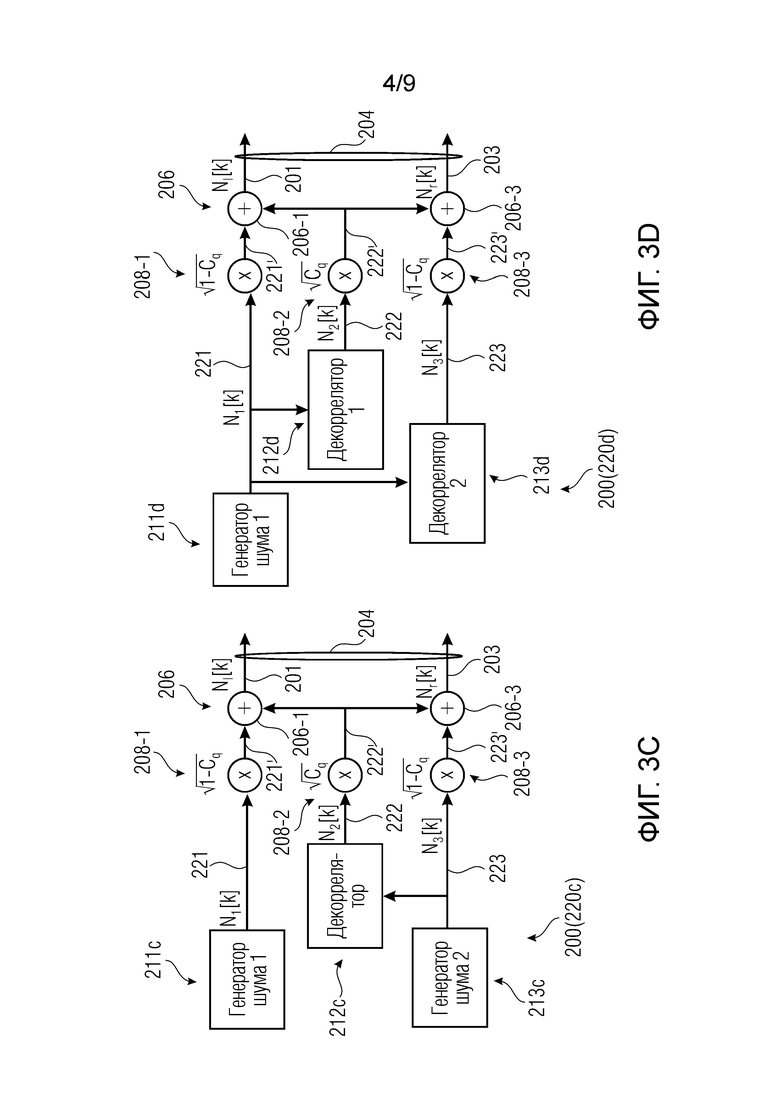
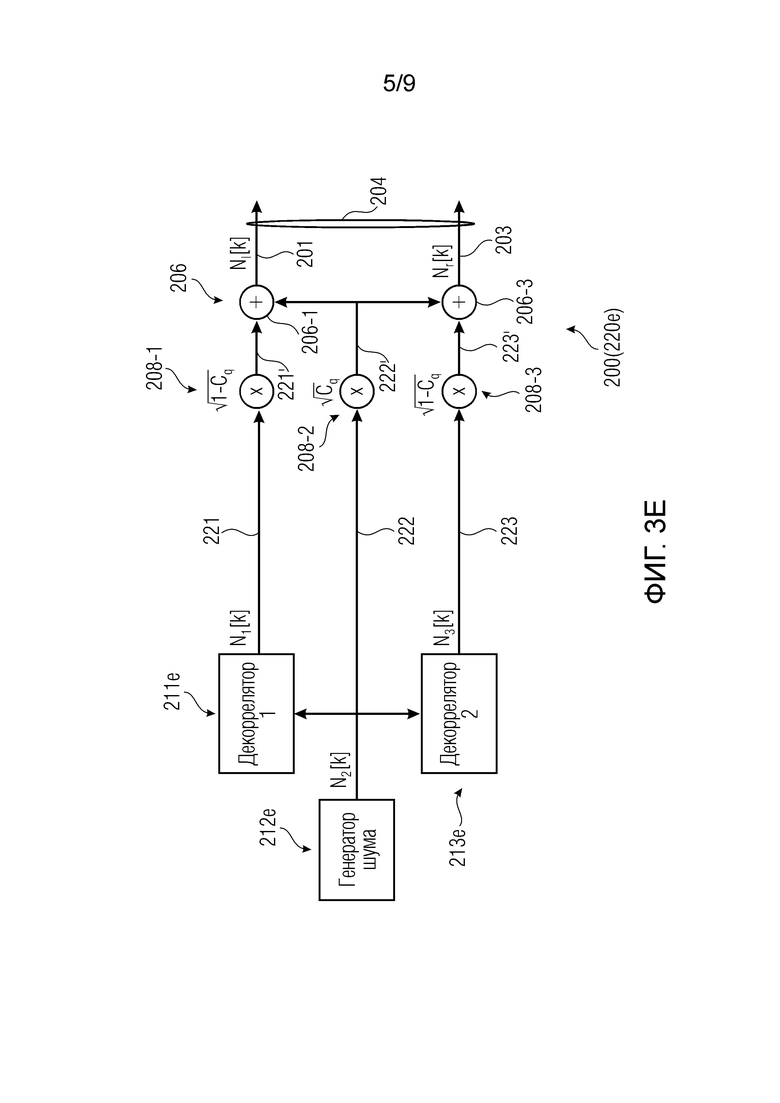
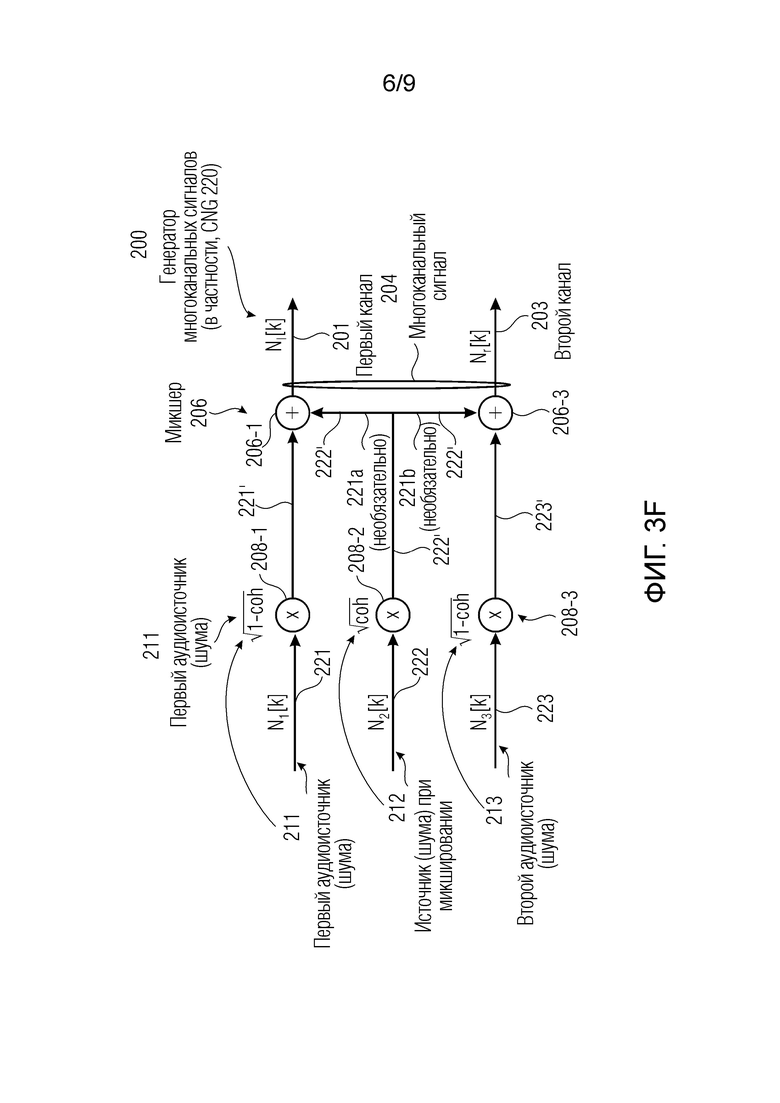

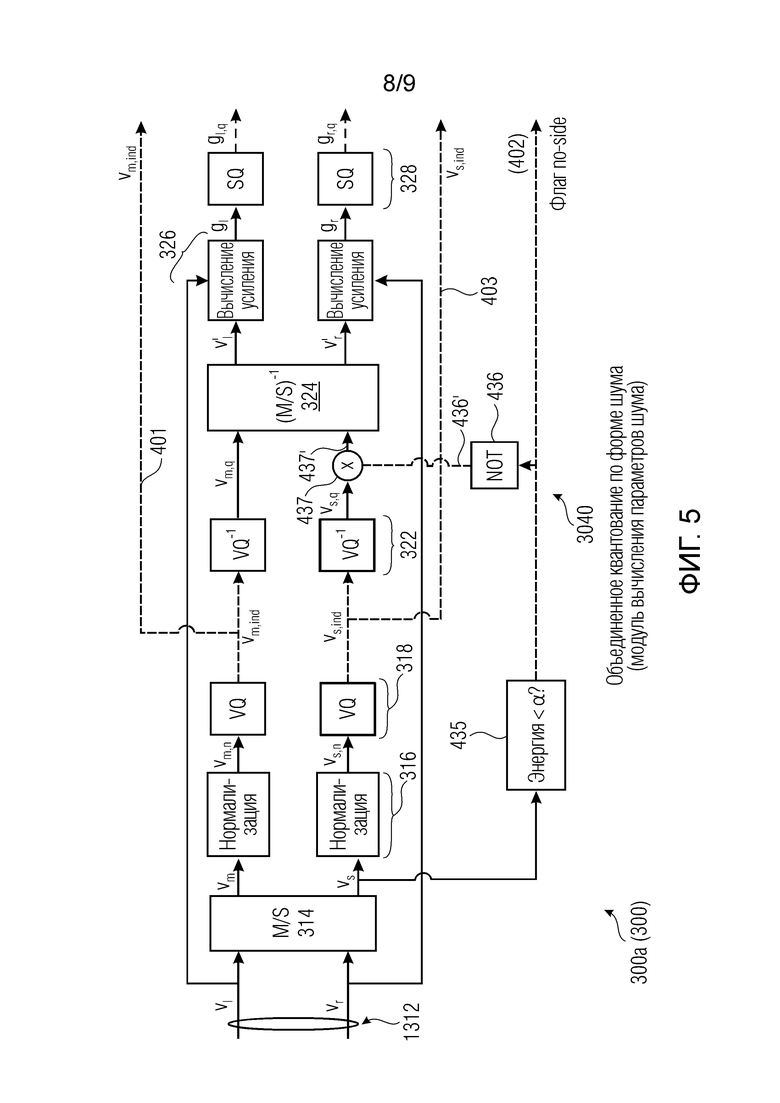
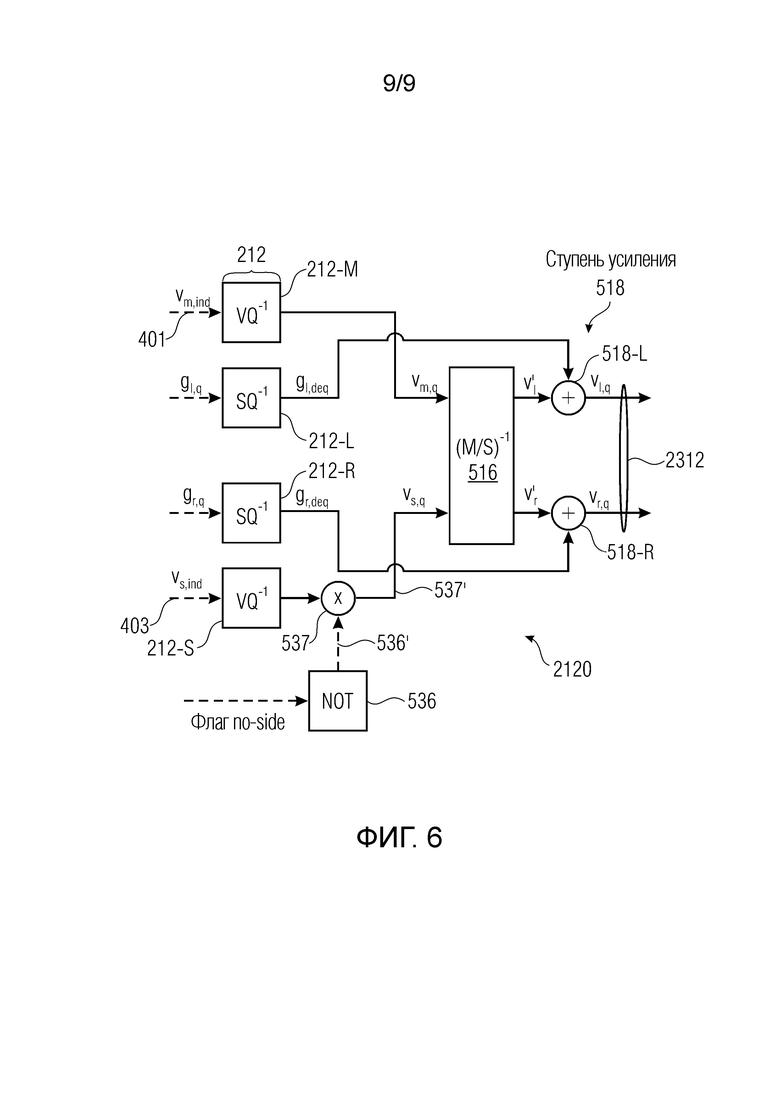
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в обеспечении комфортного стереошума за счет моделирования спектральных характеристик фонового шума в обоих каналах, а также степени корреляции между ними при поддержании средней скорости передачи битов, сравнимой с моновариантами применения. Технический результат достигается за счет формирования первого аудиосигнала с использованием первого аудиоисточника; формирования второго аудиосигнала с использованием второго аудиоисточника; формирования шумового сигнала микширования с использованием источника шума при микшировании; и микширования шумового сигнала микширования и первого аудиосигнала для получения первого канала, и микширования шумового сигнала микширования и второго аудиосигнала для получения второго канала, использования первого амплитудного элемента, воздействующего на амплитуду первого аудиосигнала; использования первого сумматора, суммирующего выходной сигнал первого амплитудного элемента и по меньшей мере часть шумового сигнала микширования; использования второго амплитудного элемента, воздействующего на амплитуду второго аудиосигнала; использования второго сумматора, суммирующего вывод второго амплитудного элемента и по меньшей мере часть шумового сигнала микширования. 10 н. и 39 з.п. ф-лы, 11 ил.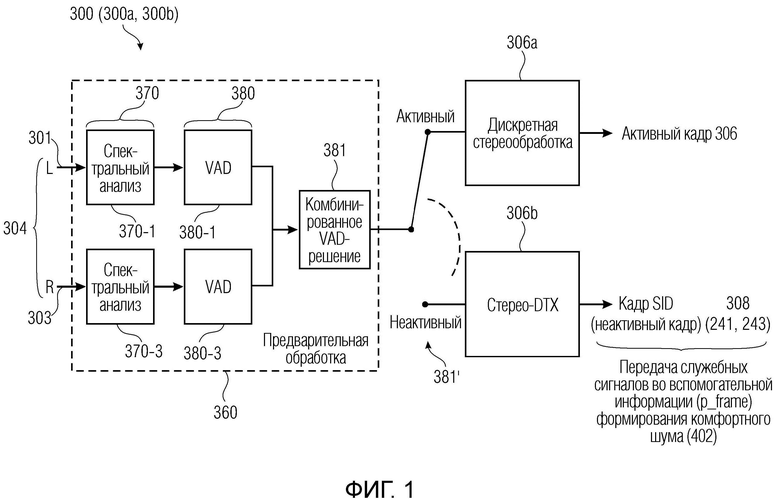
1. Генератор (200) многоканальных сигналов для формирования многоканального сигнала (204), имеющего первый канал (201) и второй канал (203), содержащий:
- первый аудиоисточник (211) для формирования первого аудиосигнала (221);
- второй аудиоисточник (213) для формирования второго аудиосигнала (223);
- источник (212) шума при микшировании для формирования шумового сигнала (222) микширования; и
- микшер (206) для микширования шумового сигнала (222) микширования и первого аудиосигнала (221) для получения первого канала (201), и для микширования шумового сигнала (222) микширования и второго аудиосигнала (222) для получения второго канала (203),
- при этом микшер (206) содержит:
- первый амплитудный элемент (208-1) для воздействия на амплитуду первого аудиосигнала (221);
- первый сумматор (206-1) для суммирования выходного сигнала (221) первого амплитудного элемента и по меньшей мере части шумового сигнала (222) микширования;
- второй амплитудный элемент (208-3) для воздействия на амплитуду второго аудиосигнала (223);
- второй сумматор (206-3) для суммирования вывода (223) второго амплитудного элемента (208-3) и по меньшей мере части шумового сигнала (222) микширования,
- при этом величина воздействия, выполняемого посредством первого амплитудного элемента (208-1), и величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), равны друг другу, или величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), отличается менее чем на 20 процентов относительно величины, выполняемой посредством первого амплитудного элемента (208-1),
- при этом микшер (206) содержит третий амплитудный элемент (208-2) для воздействия на амплитуду шумового сигнала (222) микширования,
- при этом величина воздействия, выполняемого посредством третьего амплитудного элемента (208-2), зависит от величины воздействия, выполняемого посредством первого амплитудного элемента (208-1) или второго амплитудного элемента (208-3) таким образом, что величина воздействия, выполняемого посредством третьего амплитудного элемента (208-2), становится больше, когда величина воздействия, выполняемого посредством первого амплитудного элемента, или величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), становится меньше.
2. Генератор канальных сигналов по п. 1, в котором первый аудиоисточник (211) представляет собой первый источник шума, и первый аудиосигнал (221) представляет собой первый шумовой сигнал, и/или второй аудиоисточник (213) представляет собой второй источник шума, и второй аудиосигнал (223) представляет собой второй шумовой сигнал,
- при этом первый источник (211) шума и/или второй источник (213) шума выполнены с возможностью формирования первого шумового сигнала (221) и/или второго шумового сигнала (223) таким образом, что первый шумовой сигнал (221) и/или второй шумовой сигнал (223) декоррелируются относительно шумового сигнала (222) микширования.
3. Генератор многоканальных сигналов по п. 1 или 2, в котором микшер (206) выполнен с возможностью формирования первого канала (201) и второго канала (203) таким образом, что величина шумового сигнала (222) микширования в первом канале (201) равна величине шумового сигнала (222) микширования во втором канале (203) или составляет в пределах диапазона в 80-120 процентов относительно величины шумового сигнала (222) микширования во втором канале (203).
4. Генератор многоканальных сигналов по одному из предшествующих пунктов, в котором микшер (206) содержит управляющий ввод для приема управляющего параметра (404, с), и при этом микшер (206) выполнен с возможностью управления величиной шумового сигнала (222) микширования в первом канале (201) и втором канале (203) в ответ на управляющий параметр (404, с).
5. Генератор многоканальных сигналов по одному из предшествующих пунктов, в котором каждый из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании представляет собой источник гауссова шума.
6. Генератор многоканальных сигналов по одному из предшествующих пунктов,
- в котором первый аудиоисточник (211) содержит первый генератор шума для формирования первого аудиосигнала (221) в качестве первого шумового сигнала, при этом второй аудиоисточник (213) содержит декоррелятор для декорреляции первого шумового сигнала (221) для формирования второго аудиосигнала (213) в качестве второго шумового сигнала, и при этом источник (212) шума при микшировании содержит второй генератор шума.
7. Генератор многоканальных сигналов по одному из пп. 1-5,
- в котором первый аудиоисточник (211) содержит первый генератор (211) шума для формирования первого аудиосигнала (221) в качестве первого шумового сигнала, при этом второй аудиоисточник (213) содержит второй генератор (213) шума для формирования второго аудиосигнала (223) в качестве второго шумового сигнала, и при этом источник (212) шума при микшировании содержит декоррелятор для декорреляции первого шумового сигнала (221) или второго шумового сигнала (223) для формирования шумового сигнала (222) микширования.
8. Генератор многоканальных сигналов по одному из пп. 1-5,
- в котором один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании содержит генератор шума для формирования шумового сигнала, и при этом другой из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании содержит первый декоррелятор для декорреляции шумового сигнала, и при этом еще один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании содержит второй декоррелятор для декорреляции шумового сигнала, при этом первый декоррелятор и второй декоррелятор отличаются друг от друга таким образом, что выходные сигналы первого декоррелятора и второго декоррелятора декоррелируются друг от друга.
9. Генератор многоканальных сигналов по одному из пп. 1-5, в котором первый аудиоисточник (211) содержит первый генератор шума, при этом второй аудиоисточник (213) содержит второй генератор шума, и при этом источник (212) шума при микшировании содержит третий генератор шума, при этом первый генератор шума, второй генератор шума и третий генератор шума выполнены с возможностью формирования взаимно декоррелированных шумовых сигналов.
10. Генератор многоканальных сигналов по одному из предшествующих пунктов,
- в котором один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании содержит генератор псевдослучайных числовых последовательностей, выполненный с возможностью формирования псевдослучайной числовой последовательности в ответ на начальное число, и при этом по меньшей мере два из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании выполнены с возможностью инициализации генератора псевдослучайных числовых последовательностей с использованием различных начальных чисел.
11. Генератор многоканальных сигналов по одному из пп. 1-6,
- в котором по меньшей мере один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании выполнен с возможностью работы с использованием предварительно сохраненной таблицы шумов.
12. Генератор многоканальных сигналов по одному из пп. 1-6,
- в котором по меньшей мере один из первого аудиоисточника (211), второго аудиоисточника (213) и источника (212) шума при микшировании выполнен с возможностью формирования комплексного спектра для кадра с использованием первого значения шума для действительной части и второго значения шума для мнимой части.
13. Генератор многоканальных сигналов по одному из пп. 11 и 12, в котором по меньшей мере один генератор шума выполнен с возможностью формирования комплексного спектрального значения шума для частотного элемента k разрешения с использованием, для одной из действительной части и мнимой части, первого случайного значения с индексом k, и с использованием, для другой из действительной части и мнимой части, второго случайного значения с индексом (k+М), при этом первое значение шума и второе значение шума включены в шумовой массив, например, извлекаемый из генератора последовательности случайных чисел или из таблицы шумов, или из шумового процесса, в диапазоне от начального индекса до конечного индекса, причем начальный индекс меньше М, и причем конечный индекс равен или меньше 2М, при этом М и k являются целыми числами.
14. Генератор многоканальных сигналов по одному из предшествующих пунктов,
- в котором величина воздействия, выполняемого посредством третьего амплитудного элемента (208-2), представляет собой квадратный корень заданного значения (cq), и величина воздействия, выполняемого посредством первого амплитудного элемента (208-1), и величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), представляет собой квадратный корень разности между 1 и заданное значение (cq).
15. Генератор многоканальных сигналов по одному из предшествующих пунктов, дополнительно содержащий:
- входной интерфейс (210) для приема кодированных аудиоданных (232) в последовательности кадров (306, 308), содержащих активный кадр (306) и неактивный кадр (308) после активного кадра (306); и
- аудиодекодер (200'', 200а, 200b) для декодирования кодированных аудиоданных для активного кадра (306) для формирования декодированного многоканального сигнала для активного кадра,
- при этом первый аудиоисточник (211), второй аудиоисточник (213), источник (212) шума при микшировании и микшер (206) являются активными в неактивном кадре (308) для формирования многоканального сигнала (204) для неактивного кадра.
16. Генератор многоканальных сигналов по п. 15, в котором:
- кодированные аудиоданные (232) для активного кадра (306) имеют первое множество коэффициентов, описывающих первое число частотных элементов разрешения; и
- кодированные аудиоданные (232) для неактивного кадра (308) имеют второе множество коэффициентов, описывающих второе число частотных элементов разрешения,
- при этом первое число частотных элементов разрешения больше второго числа частотных элементов разрешения.
17. Генератор (200) многоканальных сигналов для формирования многоканального сигнала (204), имеющего первый канал (201) и второй канал (203), содержащий:
- первый аудиоисточник (211) для формирования первого аудиосигнала (221);
- второй аудиоисточник (213) для формирования второго аудиосигнала (223);
- источник (212) шума при микшировании для формирования шумового сигнала (222) микширования;
- микшер (206) для микширования шумового сигнала (222) микширования и первого аудиосигнала (221) для получения первого канала (201), и для микширования шумового сигнала (222) микширования и второго аудиосигнала (222) для получения второго канала (203),
- входной интерфейс (210) для приема кодированных аудиоданных (232) в последовательности кадров (306, 308), содержащих активный кадр (306) и неактивный кадр (308) после активного кадра (306); и
- аудиодекодер (200'', 200а, 200b) для декодирования кодированных аудиоданных для активного кадра (306) для формирования декодированного многоканального сигнала для активного кадра,
- при этом первый аудиоисточник (211), второй аудиоисточник (213), источник (212) шума при микшировании и микшер (206) являются активными в неактивном кадре (308) для формирования многоканального сигнала (204) для неактивного кадра,
- при этом кодированные аудиоданные (232) для неактивного кадра (308) содержат данные (р_noise, с) дескриптора вставки молчания, содержащие данные (с, р_noise) комфортного шума, указывающие энергию (1312) сигналов для каждого канала двух каналов (301, 303) или для каждой из первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов для неактивного кадра и указывающие когерентность (404, с) между первым каналом (301) и вторым каналом (303) в неактивном кадре, и
- при этом микшер (206, 220) выполнен с возможностью микширования (206-1, 206-3) шумового сигнала (222) микширования и первого аудиосигнала (221) или второго аудиосигнала (223) на основе данных комфортного шума, указывающих когерентность (404, с), и
- при этом генератор (200, 220, 220а-220е) многоканальных сигналов дополнительно содержит модуль (250) модификации сигналов для модификации первого канала (201) и второго канала (203), либо первого аудиосигнала (221) или второго аудиосигнала (223), либо шумового сигнала (222) микширования,
- при этом модуль (250) модификации сигналов выполнен с возможностью управления посредством данных (р_noise) комфортного шума, указывающих энергии сигналов для первого аудиоканала (301) и второго аудиоканала (303) или указывающих энергии сигналов для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов.
18. Генератор многоканальных сигналов по любому из пп. 15-17, в котором аудиоданные (232) для неактивного кадра содержат:
- первый кадр (241) дескриптора вставки молчания для первого канала (201) и второй кадр (243) дескриптора вставки молчания для второго канала (203), при этом первый кадр (241) дескриптора вставки молчания содержит:
- данные (р_noise) параметров комфортного шума для первого канала (201) и/или для первой линейной комбинации первого и второго каналов, и
- вспомогательную информацию (р_frame) формирования комфортного шума для первого канала и второго канала (203), и
- при этом второй кадр (243) дескриптора вставки молчания содержит:
- данные (р_noise) параметров комфортного шума для второго канала (203) и/или для второй линейной комбинации первого и второго каналов, и
- информацию (404, с) когерентности, указывающую когерентность между первым каналом (201) и вторым каналом (203) в неактивном кадре, и
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала (204) в неактивном кадре с использованием вспомогательной информации (р_frame) формирования комфортного шума для первого кадра (241) дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала (201) и второго канала (203) и/или для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов, с использованием информации (404, с) когерентности во втором кадре (243) дескриптора вставки молчания для задания когерентности (404, с) между первым каналом (201) и вторым каналом (203) в неактивном кадре, и с использованием данных (р_noise) параметров комфортного шума из первого кадра (241) дескриптора вставки молчания, и с использованием данных (р_noise) параметров комфортного шума из второго кадра (243) дескриптора вставки молчания для задания энергетической ситуации (vl, q) первого канала (301) и энергетической ситуации (vr, q) второго канала (303).
19. Генератор многоканальных сигналов по любому из пп. 15-18, в котором аудиоданные (232) для неактивного кадра содержат:
- по меньшей мере один кадр (241) дескриптора вставки молчания для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов,
- при этом по меньшей мере один кадр (241) дескриптора вставки молчания содержит:
- данные (р_noise) параметров комфортного шума для первой линейной комбинации первого и второго каналов, и
- вспомогательную информацию (р_frame) формирования комфортного шума для второй линейной комбинации первого и второго каналов,
- при этом генератор многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала (204) в неактивном кадре с использованием вспомогательной информации (р_frame) формирования комфортного шума для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов, с использованием информации (404, с) когерентности во втором кадре (243) дескриптора вставки молчания для задания когерентности (404, с) между первым каналом (201) и вторым каналом (203) в неактивном кадре, и с использованием данных (р_noise) параметров комфортного шума по меньшей мере из одного кадра (241) дескриптора вставки молчания, и с использованием данных (р_noise) параметров комфортного шума по меньшей мере из одного кадра (243) дескриптора вставки молчания для задания энергетической ситуации (vl, q) первого канала (301) и энергетической ситуации (vr, q) второго канала (303).
20. Генератор многоканальных сигналов по любому из пп. 17-19, дополнительно содержащий спектрально-временной преобразователь для преобразования результирующего первого канала и результирующего второго канала, спектрально регулируемых и когерентно регулируемых, в соответствующие представления во временной области, которые должны комбинироваться или конкатенироваться с представлениями во временной области соответствующих каналов декодированного многоканального сигнала для активного кадра.
21. Генератор многоканальных сигналов по любому из пп. 15-20, в котором аудиоданные для неактивного кадра содержат:
- кадр (241, 243) дескриптора вставки молчания, при этом кадр (241, 243) дескриптора вставки молчания содержит данные (р_noise) параметров комфортного шума для первого и второго канала (201, 203) и вспомогательную информацию (р_frame) формирования комфортного шума для первого канала (203) и второго канала (203) и/или для первой линейной комбинации первого и второго каналов и второй линейной комбинации первого и второго каналов и информацию (404, с) когерентности, указывающую когерентность между первым каналом (201) и вторым каналом (203) в неактивном кадре, и
- при этом генератор (200) многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала (202) в неактивном кадре с использованием вспомогательной информации (р_frame) формирования комфортного шума для кадра (241, 243) дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала (201) и второго канала (203), с использованием информации (404, с) когерентности в кадре (241) дескриптора вставки молчания для задания когерентности (404, с) между первым каналом (201) и вторым каналом (203) в неактивном кадре, и с использованием данных (р_noise) параметров комфортного шума из кадра (241, 243) дескриптора вставки молчания для задания энергетической ситуации (vl, q) первого канала (301) и энергетической ситуации (vr, q) второго канала (303).
22. Генератор многоканальных сигналов по любому из пп. 15-21,
- в котором кодированные аудиоданные (232) для неактивного кадра содержат данные (р_noise, с) дескриптора вставки молчания, содержащие данные (с, р_noise) комфортного шума, указывающие энергию сигналов для каждого канала в среднем/боковом представлении, и данные (404, с) когерентности, указывающие когерентность между первым каналом и вторым каналом в левом/правом представлении, при этом генератор многоканальных сигналов выполнен с возможностью преобразования среднего/бокового представления энергии сигналов в левое/правое представление энергии сигналов в первом канале (301) и втором канале (303),
- при этом микшер (206, 220) выполнен с возможностью микширования (206-1, 206-3) шумового сигнала (222) микширования в первый аудиосигнал (221) и второй аудиосигнал (223) на основе данных (404, с) когерентности для получения первого канала (201) и второго канала (203), и
- при этом генератор многоканальных сигналов дополнительно содержит модуль (250) модификации сигналов, выполненный с возможностью модификации первого и второго канала (201, 203) посредством формирования первого и второго канала (201, 203) на основе энергии сигналов в левой/правой области.
23. Генератор многоканальных сигналов по п. 22, выполненный с возможностью, в случае, если аудиоданные содержат передачу служебных сигналов, указывающую то, что энергия в боковом канале меньше заданного порогового значения, обнуления (337) коэффициентов (vs, q) бокового канала.
24. Генератор многоканальных сигналов по п. 22 или 23, в котором аудиоданные для неактивного кадра содержат:
- по меньшей мере один кадр (241, 243) дескриптора вставки молчания, при этом по меньшей мере один кадр (241, 243) дескриптора вставки молчания содержит данные (р_noise, vm, ind, ql, q, qr, q, vs, ind) параметров комфортного шума для среднего и бокового канала (vm, q, vs, q) и вспомогательную информацию (р_frame) формирования комфортного шума для среднего и бокового канала (vm, q, vs, q) и информацию (404, с) когерентности, указывающую когерентность между первым каналом (201) и вторым каналом (203) в неактивном кадре, и
- при этом генератор (200) многоканальных сигналов содержит контроллер для управления формированием многоканального сигнала (202) в неактивном кадре с использованием вспомогательной информации (р_frame) формирования комфортного шума для кадра (241, 243) дескриптора вставки молчания для определения режима формирования комфортного шума для первого канала (201) и второго канала (203), с использованием информации (404, с) когерентности в кадре (241) дескриптора вставки молчания для задания когерентности (404, с) между первым каналом (201) и вторым каналом (203) в неактивном кадре, и с использованием данных (р_noise) параметров комфортного шума либо их обработанной версии из кадра (241, 243) дескриптора вставки молчания для задания энергетической ситуации (vl, q) первого канала (301) и энергетической ситуации (vr, q) второго канала (303).
25. Генератор многоканальных сигналов по любому из пп. 15-24, дополнительно выполненный с возможностью масштабирования энергетических коэффициентов (1312, v'l, v'r) сигналов для первого и второго канала посредством информации (gl, q, qr, q) усиления, кодированной с помощью данных (401, 403) параметров комфортного шума для первого и второго канала.
26. Генератор многоканальных сигналов по любому из предшествующих пунктов, выполненный с возможностью
преобразования сформированного многоканального сигнала (252) из версии в частотной области в версию во временной области.
27. Генератор канальных сигналов по любому из предшествующих пунктов, в котором первый аудиоисточник (211) представляет собой первый источник шума, и первый аудиосигнал (221) представляет собой первый шумовой сигнал, или второй аудиоисточник (213) представляет собой второй источник шума, и второй аудиосигнал (223) представляет собой второй шумовой сигнал,
- при этом первый источник шума или второй источник шума выполнен с возможностью формирования первого шумового сигнала (201) или второго шумового сигнала (203) таким образом, что первый шумовой сигнал (201) или второй шумовой сигнал (203) по меньшей мере частично коррелированы, и
- при этом источник (212) шума при микшировании выполнен с возможностью формирования шумового сигнала (222) микширования с первой частью (221а) шума при микшировании и второй частью (221b) шума при микшировании, причем вторая часть (221b) шума при микшировании по меньшей мере частично декоррелируется относительно первой части шума при микшировании (221b); и
- при этом микшер (206) выполнен с возможностью микширования первой части (221а) шума при микшировании шумового сигнала (222) микширования и первого аудиосигнала (221) для получения первого канала (201), и микширования второй части (221b) шума при микшировании шумового сигнала (222) микширования и второго аудиосигнала (223) для получения второго канала (203).
28. Генератор (200) многоканальных сигналов для формирования многоканального сигнала (204), имеющего первый канал (201) и второй канал (203), содержащий:
- первый аудиоисточник (211) для формирования первого аудиосигнала (221);
- второй аудиоисточник (213) для формирования второго аудиосигнала (223);
- источник (212) шума при микшировании для формирования шумового сигнала (222) микширования; и
- микшер (206) для микширования шумового сигнала (222) микширования и первого аудиосигнала (221) для получения первого канала (201), и для микширования шумового сигнала (222) микширования и второго аудиосигнала (222) для получения второго канала (203),
- при этом первый аудиоисточник (211) представляет собой первый источник шума, и первый аудиосигнал (221) представляет собой первый шумовой сигнал, или второй аудиоисточник (213) представляет собой второй источник шума, и второй аудиосигнал (223) представляет собой второй шумовой сигнал,
- при этом первый источник шума или второй источник шума выполнен с возможностью формирования первого шумового сигнала (201) или второго шумового сигнала (203) таким образом, что первый шумовой сигнал (201) или второй шумовой сигнал (203) по меньшей мере частично коррелированы, и
- при этом источник (212) шума при микшировании выполнен с возможностью формирования шумового сигнала (222) микширования с первой частью (221а) шума при микшировании и второй частью (221b) шума при микшировании, причем вторая часть (221b) шума при микшировании по меньшей мере частично декоррелируется относительно первой части шума при микшировании (221b); и
- при этом микшер (206) выполнен с возможностью микширования первой части (221а) шума при микшировании шумового сигнала (222) микширования и первого аудиосигнала (221) для получения первого канала (201), и микширования второй части (221b) шума при микшировании шумового сигнала (222) микширования и второго аудиосигнала (223) для получения второго канала (203).
29. Способ формирования многоканального сигнала, имеющего первый канал и второй канал (203), содержащий этапы, на которых:
- формируют первый аудиосигнал (221) с использованием первого аудиоисточника (211);
- формируют второй аудиосигнал (223) с использованием второго аудиоисточника (213);
- формируют шумовой сигнал (222) микширования с использованием источника (212) шума при микшировании; и
- микшируют (206) шумовой сигнал (222) микширования и первый аудиосигнал (221) для получения первого канала (201), и микшируют шумовой сигнал (222) микширования и второй аудиосигнал (223) для получения второго канала (202), при этом способ содержит этапы, на которых:
- используют первый амплитудный элемент (208-1), воздействующий на амплитуду первого аудиосигнала (221);
- используют первый сумматор (206-1), суммирующий выходной сигнал (221) первого амплитудного элемента и по меньшей мере часть шумового сигнала (222) микширования;
- используют второй амплитудный элемент (208-3), воздействующий на амплитуду второго аудиосигнала (223);
- используют второй сумматор (206-3), суммирующий вывод (223) второго амплитудного элемента (208-3) и по меньшей мере часть шумового сигнала (222) микширования,
- при этом величина воздействия, выполняемого посредством первого амплитудного элемента (208-1), и величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), равны друг другу, или величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), отличается менее чем на 20 процентов относительно величины, выполняемой посредством первого амплитудного элемента (208-1),
- при этом микширование (206) использует третий амплитудный элемент (208-2), воздействующий на амплитуду шумового сигнала (222) микширования,
- при этом величина воздействия, выполняемого посредством третьего амплитудного элемента (208-2), зависит от величины воздействия, выполняемого посредством первого амплитудного элемента (208-1) или второго амплитудного элемента (208-3) таким образом, что величина воздействия, выполняемого посредством третьего амплитудного элемента (208-2), становится больше, когда величина воздействия, выполняемого посредством первого амплитудного элемента, или величина воздействия, выполняемого посредством второго амплитудного элемента (208-3), становится меньше.
30. Аудиокодер (300, 300а, 300b) для формирования кодированного многоканального аудиосигнала (232) для последовательности кадров, содержащих активный кадр (306) и неактивный кадр (308), причем аудиокодер содержит:
- детектор (380) активности для анализа многоканального сигнала (304) для определения (381) кадра последовательности кадров как представляющего собой неактивный кадр (308);
- модуль (3040) вычисления параметров шума для вычисления первых параметрических данных (р_noise, vm, ind) шума для первого канала (301, 201) многоканального сигнала (304) и для вычисления вторых параметрических данных (р_noise, vs, ind) шума для второго канала (303) многоканального сигнала (320);
- модуль (320) вычисления когерентности для вычисления данных (404, с) когерентности, указывающих ситуацию когерентности между первым каналом (301, 201) и вторым каналом (303, 203) в неактивном кадре (308); и
- выходной интерфейс (310) для формирования кодированного многоканального аудиосигнала (232), имеющего кодированные аудиоданные для активного кадра (306) и для неактивного кадра (308), первые параметрические данные (р_noise, vm, ind) шума, вторые параметрические данные (р_noise, vs, ind) шума и/или первую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума и вторую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума и данных (с, 404) когерентности, при этом модуль (3040) вычисления параметров шума выполнен с возможностью преобразования по меньшей мере некоторых из первых параметрических данных шума и вторых параметрических данных шума из левого/правого представления в среднее/боковое представление со средним каналом и боковым каналом.
31. Аудиокодер по п. 30, в котором модуль (3040) вычисления параметров шума выполнен с возможностью повторного преобразования среднего/бокового представления (М, S) по меньшей мере некоторых из первых параметрических данных шума и вторых параметрических данных шума в левое/правое представление,
- при этом модуль (3040) вычисления параметров шума выполнен с возможностью вычисления из повторно преобразованного левого/правого представления первой информации (gl) усиления для первого канала (301) и второй информации усиления (gr) для второго канала (303) и обеспечения, первую информацию (gl) усиления для первого канала (301), включенной в первые параметрические данные шума, и второй информации усиления (gr), включенной во вторые параметрические данные шума.
32. Аудиокодер (300) по п. 31, в котором модуль (3040) вычисления параметров шума выполнен с возможностью вычисления:
- первой информации (gl) усиления посредством сравнения:
- версии (v'l) первых параметрических данных шума для первого канала (301), повторно преобразованной из среднего/бокового представления в левое/правое представление;
- с версией (vl) первых параметрических данных шума для первого канала (301) до преобразования из среднего/бокового представления в левое/правое представление; и/или
- второй информации усиления (gr) посредством сравнения:
- версии (v'r) вторых параметрических данных шума для второго канала (301), повторно преобразованной из среднего/бокового представления в левое/правое представление;
- с версией (vr) вторых параметрических данных шума для второго канала (301) до преобразования из среднего/бокового представления в левое/правое представление.
33. Аудиокодер (300, 300а, 300b) для формирования кодированного многоканального аудиосигнала (232) для последовательности кадров, содержащих активный кадр (306) и неактивный кадр (308), причем аудиокодер содержит:
- детектор (380) активности для анализа многоканального сигнала (304) для определения (381) кадра последовательности кадров как представляющего собой неактивный кадр (308);
- модуль (3040) вычисления параметров шума для вычисления первых параметрических данных (р_noise, vm, ind) шума для первого канала (301, 201) многоканального сигнала (304) и для вычисления вторых параметрических данных (р_noise, vs, ind) шума для второго канала (303) многоканального сигнала (320);
- модуль (320) вычисления когерентности для вычисления данных (404, с) когерентности, указывающих ситуацию когерентности между первым каналом (301, 201) и вторым каналом (303, 203) в неактивном кадре (308); и
- выходной интерфейс (310) для формирования кодированного многоканального аудиосигнала (232), имеющего кодированные аудиоданные для активного кадра (306) и для неактивного кадра (308), первые параметрические данные (р_noise, vm, ind) шума, вторые параметрические данные (р_noise, vs, ind) шума и/или первую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума и вторую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума, и данных (с, 404) когерентности, при этом модуль (320) вычисления когерентности выполнен с возможностью:
- вычисления действительного промежуточного значения и мнимого промежуточного значения из комплексных спектральных значений для первого канала и второго канала (303) в неактивном кадре;
- вычисления первого значения энергии для первого канала (301) и второго значения энергии для второго канала (303) в неактивном кадре; и
- вычисления данных (404, с) когерентности с использованием действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии, или
- сглаживания по меньшей мере одного из действительного промежуточного значения, мнимого промежуточного значения, первого значения энергии и второго значения энергии и вычисления данных когерентности с использованием по меньшей мере одного сглаженного значения,
- при этом модуль (320) вычисления когерентности выполнен с возможностью возведения в квадрат сглаженного действительного промежуточного значения и возведения в квадрат сглаженного мнимого промежуточного значения и суммирования возведенных в квадрат значений для получения первого компонентного числа,
- при этом модуль (320) вычисления когерентности выполнен с возможностью умножения сглаженных первого и второго значений энергии для получения второго компонентного числа и комбинирования первого и второго компонентных чисел для получения результирующего числа для значения когерентности, на котором основаны данные когерентности.
34. Аудиокодер (300, 300а, 300b) для формирования кодированного многоканального аудиосигнала (232) для последовательности кадров, содержащих активный кадр (306) и неактивный кадр (308), причем аудиокодер содержит:
- детектор (380) активности для анализа многоканального сигнала (304) для определения (381) кадра последовательности кадров как представляющего собой неактивный кадр (308);
- модуль (3040) вычисления параметров шума для вычисления первых параметрических данных (р_noise, vm, ind) шума для первого канала (301, 201) многоканального сигнала (304) и для вычисления вторых параметрических данных (р_noise, vs, ind) шума для второго канала (303) многоканального сигнала (320);
- модуль (320) вычисления когерентности для вычисления данных (404, с) когерентности, указывающих ситуацию когерентности между первым каналом (301, 201) и вторым каналом (303, 203) в неактивном кадре (308); и
- выходной интерфейс (310) для формирования кодированного многоканального аудиосигнала (232), имеющего кодированные аудиоданные для активного кадра (306) и для неактивного кадра (308), первые параметрические данные (р_noise, vm, ind) шума, вторые параметрические данные (р_noise, vs, ind) шума и/или первую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума и вторую линейную комбинацию первых параметрических данных шума и вторых параметрических данных шума и данных (с, 404) когерентности,
- при этом модуль (3040) вычисления параметров шума выполнен с возможностью сравнения энергии второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума с заданным пороговым значением (а) энергии и:
- в случае, если энергия второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума больше заданного порогового значения (а) энергии, коэффициенты вектора форм бокового канального шума обнуляются (437); и
- в случае, если энергия второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума меньше заданного порогового значения (ex) энергии, коэффициенты вектора форм бокового канального шума сохраняются.
35. Аудиокодер по любому из пп. 30-34, в котором модуль (320) вычисления когерентности выполнен с возможностью вычисления (320'') значения (404, с) когерентности и квантования (320'') значения (320'') когерентности для получения квантованного значения (cind) когерентности, при этом выходной интерфейс (310) выполнен с возможностью использования квантованного значения (cind) когерентности в качестве данных когерентности в кодированном многоканальном сигнале.
36. Аудиокодер по любому из пп. 30-35,
- в котором модуль (320) вычисления когерентности выполнен с возможностью вычисления действительного промежуточного значения в качестве суммы по действительным частям произведений комплексных спектральных значений для соответствующих частотных элементов разрешения первого канала и второго канала (303) в неактивном кадре, или
- вычисления мнимого промежуточного значения в качестве суммы по мнимым частям произведений комплексных спектральных значений для соответствующих частотных элементов разрешения первого канала и второго канала (303) в неактивном кадре.
37. Аудиокодер по п. 33, в котором модуль вычисления когерентности выполнен с возможностью вычисления квадратного корня результирующего числа для получения значения когерентности, на котором основаны данные когерентности.
38. Аудиокодер по одному из пп. 30-37,
- в котором модуль (320) вычисления когерентности выполнен с возможностью квантования значения (404, с) когерентности с использованием равномерного квантователя (320'') для получения квантованного значения (cind) когерентности в качестве n битов в качестве данных когерентности.
39. Аудиокодер по п. 38, в котором равномерный квантователь (320'') выполнен с возможностью вычисления n битов таким образом, что значение для n равно значению битов, занимаемых посредством вспомогательной информации (р_frame) формирования комфортного шума для первого кадра (241) дескриптора вставки молчания.
40. Аудиокодер по одному из пп. 30-39, в котором выходной интерфейс (310) выполнен с возможностью формирования первого кадра (241) дескриптора вставки молчания для первого канала (301, L) и второго кадра (243) дескриптора вставки молчания для второго канала (303, R), при этом первый кадр (241) дескриптора вставки молчания содержит данные (р_noise) параметров комфортного шума для первого канала (301, L) и вспомогательную информацию (р_frame) формирования комфортного шума для первого канала (301, L) и второго канала (303, R), и при этом второй кадр (243) дескриптора вставки молчания содержит данные (р_noise) параметров комфортного шума для второго канала (303) и информацию (404, с) когерентности, указывающую когерентность между первым каналом и вторым каналом (303) в неактивном кадре.
41. Аудиокодер по одному из пп. 30-39,
- в котором выходной интерфейс (310) выполнен с возможностью формирования кадра (241, 243) дескриптора вставки молчания, при этом кадр дескриптора вставки молчания содержит данные (р_noise) параметров комфортного шума для первого и второго канала (301, 303) и вспомогательную информацию (р_frame) формирования комфортного шума для первого канала (301, L) и второго канала (303, R) и информацию (404, с) когерентности, указывающую когерентность между первым каналом (301, L) и вторым каналом (303, R) в неактивном кадре.
42. Аудиокодер по одному из пп. 30-39,
- в котором выходной интерфейс (310) выполнен с возможностью формирования первого кадра (241) дескриптора вставки молчания для первого канала (301, L) и второго канала и второго кадра (243) дескриптора вставки молчания для первого канала и второго канала (303, R), при этом первый кадр (241) дескриптора вставки молчания содержит данные (р_noise) параметров комфортного шума для первого канала и второго канала и вспомогательную информацию (р_frame) формирования комфортного шума для первого канала (301, L) и второго канала (303, R), и при этом второй кадр (243) дескриптора вставки молчания содержит данные (р_noise) параметров комфортного шума для первого канала и второго канала (303) и информацию (404, с) когерентности, указывающую когерентность между первым каналом и вторым каналом (303) в неактивном кадре.
43. Аудиокодер (300) по одному из пп. 30-42, в котором детектор (380) активности выполнен с возможностью по меньшей мере для одного кадра последовательности кадров:
- анализа (370-1) первого канала (301, L) многоканального сигнала (304) для классификации первого канала (301, L) как активного или неактивного, и
- анализа (370-2) второго канала (303, R) многоканального сигнала (304) для классификации второго канала (303, R) как активного или неактивного, и
- определения (381) кадра как неактивного, если как первый канал (301, L), так и второй канал (303, R) классифицированы как неактивные, а в ином случае - как активного.
44. Аудиокодер (300) по одному из пп. 30-43, в котором модуль (3040) вычисления параметров шума выполнен с возможностью вычисления первой информации (gl) усиления для первого канала (301) и второй информации (gs) усиления для второго канала (gl) и обеспечения параметрических данных шума в качестве первой информации (gl) усиления для первого канала (301) и второй информации (gs) усиления.
45. Аудиокодер по одному из пп. 30-44, выполненный с возможностью кодирования второй линейной комбинации между первыми параметрическими данными шума и вторыми параметрическими данными шума с меньшим количеством битов, чем количество битов, через которые кодирована первая линейная комбинация между первыми параметрическими данными шума и вторыми параметрическими данными шума.
46. Аудиокодер по одному из пп. 30-45,
- в котором выходной интерфейс (310) выполнен с возможностью:
- формирования кодированного многоканального аудиосигнала (232), имеющего кодированные аудиоданные для активного кадра (306), с использованием первого множества коэффициентов для первого числа частотных элементов разрешения; и
- формирования первых параметрических данных шума, вторых параметрических данных шума или первой линейной комбинации первых параметрических данных шума и вторых параметрических данных шума и второй линейной комбинации первых параметрических данных шума и вторых параметрических данных шума с использованием второго множества коэффициентов, описывающих второе число частотных элементов разрешения,
- при этом первое число частотных элементов разрешения больше второго числа частотных элементов разрешения.
47. Способ кодирования аудио для формирования кодированного многоканального аудиосигнала для последовательности кадров, содержащих активный кадр и неактивный кадр, при этом способ содержит этапы, на которых:
- анализируют многоканальный сигнал для определения кадра последовательности кадров как представляющего собой неактивный кадр;
- вычисляют первые параметрические данные шума для первого канала многоканального сигнала и/или для первой линейной комбинации первого и второго каналов многоканального сигнала и вычисляют вторые параметрические данные шума для второго канала (303) многоканального сигнала и/или для второй линейной комбинации первого и второго каналов многоканального сигнала;
- вычисляют данные когерентности, указывающие ситуацию когерентности между первым каналом и вторым каналом (303) в неактивном кадре; и
- формируют кодированный многоканальный аудиосигнал, имеющий кодированные аудиоданные для активного кадра и, для неактивного кадра, первые параметрические данные шума, вторые параметрические данные шума и данные когерентности,
- при этом модуль (3040) вычисления параметров шума выполнен с возможностью преобразования по меньшей мере некоторых из первых параметрических данных шума и вторых параметрических данных шума из левого/правого представления в среднее/боковое представление со средним каналом и боковым каналом.
48. Постоянный модуль хранения, сохраняющий инструкции, которые при выполнении на компьютере или в процессоре реализуют способ по п. 29.
49. Постоянный модуль хранения, сохраняющий инструкции, которые при выполнении на компьютере или в процессоре, реализуют способ по п. 47.
| Токарный резец | 1924 |
|
SU2016A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ГЕНЕРАЦИИ МНОГОКАНАЛЬНОГО СИГНАЛА, ИСПОЛЬЗУЮЩИЕ ОБРАБОТКУ ГОЛОСОВОГО СИГНАЛА | 2008 |
|
RU2461144C2 |
| МИКШИРОВАНИЕ ВХОДЯЩИХ ИНФОРМАЦИОННЫХ ПОТОКОВ | 2009 |
|
RU2562395C2 |

