[0001] По данной заявке испрашивается приоритет на основе заявки США № 16/816,016, поданной 11 марта 2020 г., по которой испрашивается приоритет на основе предварительной заявки США № 62/817,475, поданной 12 марта 2019 г., предварительной заявки США № 62/834,297, поданной 15 апреля 2019 г. и предварительной заявки США № 62/871,519, поданной 08 июля 2019 г., полное содержимое каждой из которых включено в настоящее описание путем ссылки.
ОБЛАСТЬ ТЕХНИКИ
[0002] Данное изобретение относится к кодированию видео и декодированию видео.
УРОВЕНЬ ТЕХНИКИ
[0003] Возможности цифрового видео могут быт включены в широкий диапазон устройств, включая цифровые телевизоры, системы прямого цифрового вещания, системы беспроводного вещания, персональные цифровые помощники (PDA), настольные компьютеры или компьютеры класса лэптоп, планшетные компьютеры, устройства для чтения электронных книг, цифровые камеры, цифровые записывающие устройства, цифровые мультимедийные проигрыватели, устройства видеоигр, игровые видеоприставки, сотовые или спутниковые радиотелефоны, так называемые «интеллектуальные телефоны», устройства для видеоконференцсвязи, устройства потоковой передачи видео и аналогичное. Цифровые видеоустройства реализуют методики видеокодирования, такие как те, что описываются в стандартах, определенных в MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, Усовершенствованное Видеокодирование (AVC), ITU-T H.265/Высокоэффективное Видеокодирование (HEVC), и расширениях таких стандартов. Видеоустройства могут передавать, принимать, кодировать, декодировать и/или хранить цифровую видеоинформацию более эффективно путем реализации таких методик кодирования видео.
[0004] Методики кодирования видео включают в себя пространственное (внутри картинки) предсказание и/или временное (между картинками) предсказание, чтобы уменьшать или удалять избыточность, присущую видеопоследовательностям. Применительно к видеокодированию на основе блоков, видеослайс (например, видеокартинка или участок видеокартинки) может быть разбит на видеоблоки, которые также могут упоминаться как единицы дерева кодирования (CTU), единицы кодирования (CU) и/или узлы кодирования. Видеоблоки в слайсе с внутрикадровым кодированием (I) картинки кодируются с использованием пространственного предсказания относительно опорных выборок в соседних блоках в той же самой картинке. Видеоблоки в слайсе с межкадровым кодированием (P или B) картинки могут использовать пространственное предсказание относительно опорных выборок в соседних блоках в той же самой картинке или временное предсказание относительно опорных выборок в других опорных картинках. Картинки могут упоминаться как кадры, а опорные картинки могут упоминаться как опорные кадры.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] В целом, данное изобретение описывает методики для инициализации вероятности для арифметического кодирования для сжатия видео. Например, кодировщик видео может устанавливать первоначальное вероятностное состояние(ия) каждой контекстной модели, используемой в двоичном арифметическом кодировщике. Процесс может быть вызван в начале энтропийного кодирования или декодирования независимо декодируемой единицы, такой как слайс или тайл.
[0006] В качестве одного примера, способ для энтропийного кодирования видеоданных включает в себя этапы, на которых: получают предопределенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса для независимо кодируемой единицы видеоданных; определяют, на основе предопределенного значения инициализации и в линейной области, первоначальное вероятностное состояние контекста; и энтропийно кодируют, на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса.
[0007] В качестве другого примера, устройство включает в себя память, хранящую видеоданные; и один или несколько процессоров, реализованных в схеме и выполненных с возможностью: получения предопределенного значения инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса для независимо кодируемой единицы видеоданных; определения, на основе предопределенного значения инициализации и в линейной области, первоначального вероятностного состояния контекста; и энтропийного кодирования, на основе первоначального вероятностного состояния контекста, бина значения для элемента синтаксиса.
[0008] В качестве другого примера, устройство включает в себя: средство для получения предопределенного значения инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса для независимо кодируемой единицы видеоданных; средство для определения, на основе предопределенного значения инициализации и в линейной области, первоначального вероятностного состояния контекста; и средство для энтропийного кодирования, на основе первоначального вероятностного состояния контекста, бина значения для элемента синтаксиса.
[0009] В качестве другого примера, машиночитаемый запоминающий носитель информации хранит инструкции, которые, когда исполняются, предписывают одному или нескольким процессорам кодировщика видео: получать предопределенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса для независимо кодируемой единицы видеоданных; определять, на основе предопределенного значения инициализации и в линейной области, первоначальное вероятностное состояние контекста; и энтропийно кодировать, на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса.
[0010] Подробности одного или нескольких аспектов изобретения изложены в сопроводительных чертежах и описании ниже. Прочие признаки, цели и преимущества методик, описанных в данном изобретении, станут очевидны из описания и чертежей, и из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0011] Фиг. 1 является структурной схемой, иллюстрирующей систему кодирования и декодирования видео, которая может выполнять методики данного изобретения.
[0012] Фиг. 2A и 2B являются концептуальными схемами, иллюстрирующими процесс обновления диапазона в двоичном арифметическом кодировании.
[0013] Фиг. 3 является концептуальной схемой, иллюстрирующей процесс вывода в двоичном арифметическом кодировании.
[0014] Фиг. 4A и 4B являются концептуальными схемами, иллюстрирующими примерную структуру квадродерево-двоичное дерево (QTBT), и соответствующую единицу дерева кодирования (CTU).
[0015] Фиг. 5 является структурной схемой, иллюстрирующей примерный видеокодер, который может выполнять методики данного изобретения.
[0016] Фиг. 6 является структурной схемой, иллюстрирующей контекстно-адаптивный двоичный арифметический кодировщик в видеокодере.
[0017] Фиг. 7 является структурной схемой, иллюстрирующей примерный видеодекодер, который может выполнять методики данного изобретения.
[0018] Фиг. 8 является структурной схемой, иллюстрирующей контекстно-адаптивный двоичный арифметический кодировщик в видеодекодере.
[0019] Фиг. 9 является графиком, иллюстрирующим вероятностные состояния, чтобы представить вероятности быть 1, как в HEVC.
[0020] Фиг. 10A и 10B являются графиками, иллюстрирующими вероятностного состояния, чтобы представить вероятности быть 1, как в VVC, причем Фиг. 10A с 1024 вероятностными состояниями (10-битная точность), а Фиг. 10B с 16384 вероятностными состояниями (14-битная точность).
[0021] Фиг. 11A и 11B являются графиками, иллюстрирующими отображение из InitProbState в вероятностное состояние, которое может быть использовано в машине арифметического кодирования Универсального Видеокодирования (VVC), причем Фиг. 11A с 1024 вероятностными состояниями (10-битная точность), а Фиг. 11B с 16384 вероятностными состояниями (14-битная точность).
[0022] Фиг. 12 является графиком, иллюстрирующим априорные знания по распределению вероятности элемента SaoMergeFlag синтаксиса (1 бин) в I слайсе.
[0023] Фиг. 13A является графиком, иллюстрирующим априорные знания по распределению вероятности на Фиг. 12, представленные посредством вероятностного состояния в логарифмической области, а Фиг. 13B является графиком, иллюстрирующим вероятностное состояние модели и SliceQPY с линейной функцией.
[0024] Фиг. 14A является графиком, иллюстрирующим априорные знания по распределению вероятности на Фиг. 12, представленные посредством вероятностного состояния в линейной области; Фиг. 14B является графиком, иллюстрирующим вероятностное состояние модели и SliceQPY с линейной функцией без увеличения диапазонов наклона и смещения, определенных в HEVC и текущем VVC, а Фиг. 14C является графиком, иллюстрирующим вероятностное состояние модели и SliceQPY с линейной функцией с увеличением диапазонов наклона и смещения.
[0025] Фиг. 15A является графиком, иллюстрирующим априорные знания по распределению вероятности элемента SplitFlag синтаксиса, который используется в B слайсе; Фиг. 15B является графиком, иллюстрирующим логарифмическое вероятностное состояние модели и SliceQPY с линейной функцией; Фиг. 15C является графиком, иллюстрирующим линейное вероятностное состояние модели и SliceQPY с линейной функцией с использованием наклонов и смещений, определенных в HEVC и текущем VVC, а Фиг. 15D является графиком, иллюстрирующим линейное вероятностное состояние модели и SliceQPY с пересечением, определенным при SliceQPY равным 32.
[0026] Фиг. 16A-16С являются графиками, иллюстрирующими кусочно-линейную функцию, определенную посредством нескольких пересечений, чтобы осуществлять подгонку распределений вероятности.
[0027] Фиг. 17A и 17B являются графиками, иллюстрирующими пример отображения InitProbState квадратичной области в вероятностном состоянии, которое может быть использовано в машине арифметического кодирования VVC, причем Фиг. 17A с 1024 вероятностными состояниями (10-битная точность), а Фиг. 17B с 16384 вероятностными состояниями (14-битная точность).
[0028] Фиг. 18A и 18B являются графиками, иллюстрирующими примеры экстремальных распределений вероятности.
[0029] Фиг. 19 является блок-схемой, иллюстрирующей примерный способ для кодирования текущего блока.
[0030] Фиг. 20 является блок-схемой, иллюстрирующей примерный процесс для выполнения энтропийного кодирования на основе контекста, в соответствии с одной или несколькими методиками данного изобретения.
[0031] Фиг. 21 является блок-схемой, иллюстрирующей способ для декодирования текущего блока.
[0032] Фиг. 22 является блок-схемой, иллюстрирующей примерный процесс для выполнения энтропийного декодирования на основе контекста, в соответствии с одной или несколькими методиками данного изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0033] В целом, данное раскрытие описывает методики для инициализации вероятности для арифметического кодирования для сжатия видео. Например, кодировщик видео может устанавливать первоначальное вероятностное состояние(ия) каждой контекстной модели, используемой в двоичном арифметическом кодировщике. Процесс может быть вызван в начале энтропийного кодирования или декодирования независимо от декодируемой единицы, такой как слайс.
[0034] Чтобы выполнить инициализацию, кодировщик видео может получать предопределенное значение инициализации (например, initValue) для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса для слайса видеоданных. Кодировщик видео может определять, на основе предопределенного значения инициализации и в логарифмической области, первоначальное вероятностное состояние контекста (например, pStateIdx). Кодировщик видео может энтропийно кодировать, на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса.
[0035] При кодировании видеоданных в соответствии с некоторыми видеостандартами, кодировщик видео может поддерживать вероятностные состояния в линейной области. Например, как обсуждается более подробно ниже, Контекстно-Адаптивный Двоичный Арифметический Кодировщик (CABAC), используемый в Универсальном Видеокодировании (VVC), может поддерживать вероятностные состояния контекстов в линейной области. В тех случаях, когда первоначальное вероятностное состояние определяется в логарифмической области, кодировщики видео могут выполнять различные операции, чтобы преобразовывать определенные первоначальные вероятностные состояния в линейную область. Например, кодировщик видео может использовать таблицу поиска (LUT) чтобы преобразовывать первоначальное вероятностное состояние из логарифмической области в линейную область.
[0036] В соответствии с одной или несколькими методиками данного изобретения, кодировщик видео может непосредственно определять первоначальное вероятностное состояние в линейной области. Например, кодировщик видео может определять, на основе предопределенного значения инициализации, первоначальное вероятностное состояние контекста (например, pStateIdx) в линейной области без использования LUT, чтобы преобразовывать первоначальное вероятностное состояние из логарифмической области в линейную область. Таким образом кодировщик видео может избежать необходимости в хранении и/или в доступе к LUT, которая осуществляет перевод между первоначальными вероятностными состояниями в линейной и логарифмической областях.
[0037] Фиг. 1 является структурной схемой, иллюстрирующей примерную систему 100 кодирования и декодирования видео, которая может выполнять методики данного изобретения. Методики данного изобретения в целом направлены на кодирование (кодирование и/или декодирование) видеоданных. В целом видеоданные включают в себя любые данные для обработки видео. Таким образом, видеоданные могут включать в себя необработанное, не кодированное видео, кодированное видео, декодированное (например, реконструированное) видео и метаданные видео, такие как данные сигнализации.
[0038] Как показано на Фиг. 1, система 100 включает в себя устройство-источник 102, которое предоставляет кодированные видеоданные, которые должны быть декодированы и продемонстрированы устройством-получателем 116, в данном примере. В частности, устройство-источник 102 предоставляет видеоданные устройству-получателю 116 через машиночитаемый носитель 110 информации. Устройство-источник 112 и устройство-получатель 116 могут быть выполнены в виде широкого диапазона устройств, включая настольные компьютеры, компьютеры класса ноутбук (т.е. лэптоп), планшетные компьютеры, телевизионные приставки, телефонные трубки, такие как интеллектуальные телефоны, телевизоры, камеры, дисплейные устройства, цифровые мультимедийные проигрыватели, игровые видеоприставки, устройства потоковой передачи видео или аналогичное. В некоторых случаях, устройство-источник 102 и устройство-получатель 116 могут быть оборудованы для беспроводной связи, и, следовательно, могут упоминаться как устройства беспроводной связи.
[0039] В примере Фиг. 1 устройство-источник 102 включает в себя видеоисточник 104, память 106, видеокодер 200 и интерфейс 108 вывода. Устройство-получатель 116 включает в себя интерфейс 122 ввода, видеодекодер 300, память 120 и дисплейное устройство 118. В соответствии с данным изобретением, видеокодер 200 устройства-источника 102 и видеодекодер 300 устройства-получателя 116 могут быть выполнены с возможностью применения методик для инициализации вероятности для арифметического кодирования для сжатия видео. Таким образом, устройство-источник 102 представляет собой пример устройства кодирования видео при том, что устройство-получатель 116 представляет собой пример устройства декодирования видео. В других примерах, устройство-источник и устройство-получатель могут включать в себя другие компоненты или компоновки. Например, устройство-источник 102 может принимать видеоданные от внешнего видеоисточника, такого как внешняя камера. Аналогичным образом, устройство-получатель 116 может взаимодействовать с внешним дисплейным устройством, а не включать в себя интегрированное дисплейное устройство.
[0040] Система 100, как показано на Фиг. 1, является лишь одним примером. В целом, любое цифровое устройство кодирования и/или декодирования видео может выполнять методики для инициализации вероятности для арифметического кодирования для сжатия видео. Устройство-источник 102 и устройство-получатель 116 являются лишь примерами таких устройств кодирования, в которых устройство-источник 102 формирует кодированные видеоданные для передачи устройству-получателю 116. Данное изобретение относится к устройству «кодирования» как к устройству, которое выполняет кодирование (кодирование и/или декодирование) данных. Таким образом видеокодер 200 и видеодекодер 300 представляют собой примеры устройств кодирования, в частности, видеокодер и видеодекодер, соответственно. В некоторых примерах, устройства 102, 116 могут работать в основном симметричным образом так, что каждое из устройств 102, 116 включает в себя компоненты кодирования и декодирования видео. Следовательно, система 100 может поддерживать одностороннюю или двухстороннюю передачу видео между видеоустройствами 102, 116, например, для потоковой передачи видео, воспроизведения видео, трансляции видео или видеотелефонии.
[0041] В целом, видеоисточник 104 представляет собой источник видеоданных (т.е. необработанных, не кодированных видеоданных) и предоставляет последовательный ряд картинок (также упоминаемых как «кадры») видеоданных видеокодеру 200, который кодирует данные для картинок. Видеоисточник 104 устройства-источника 102 может включать в себя устройство захвата видео, такое как видеокамера, видеоархив, содержащий ранее захваченное необработанное видео, и/или интерфейс подачи видео, чтобы принимать видео от поставщика видеоконтента. В качестве дополнительной альтернативы, видеоисточник 104 может формировать данные на основе компьютерной графики в качестве исходного видео, или сочетания видео прямого эфира, архивного видео и сформированного компьютером видео. В каждом случае, видеокодер 200 кодирует захваченные, предварительно захваченные или сформированные компьютером видеоданные. Видеокодер 200 может осуществлять перестановку картинок из принятой очередности (иногда упоминаемой как «очередность демонстрации») в очередность кодирования для кодирования. Видеокодер 200 может формировать битовый поток, включающий в себя кодированные видеоданные. Устройство-источник 102 затем может выводить кодированные видеоданные через интерфейс 108 вывода на машиночитаемый носитель 110 информации для приема и/или извлечения посредством, например, интерфейса 122 ввода устройства-получателя 116.
[0042] Память 106 устройства-источника 102 и память 120 устройства-получателя 116 представляют собой памяти общего назначения. В некоторых примерах, памяти 106, 120 могут хранить необработанные видеоданные, например, необработанное видео от видеоисточника 104 и необработанные, декодированные видеоданные от видеодекодера 300. Дополнительно или в качестве альтернативы, памяти 106, 120 могут хранить инструкции программного обеспечения исполняемые, например, видеокодером 200 и видеодекодером 300, соответственно. Несмотря на то, что показаны отдельно от видеокодера 200 и видеодекодера 300 в данном примере, следует понимать, что видеокодер 200 и видеодекодер 300 также могут включать в себя внутренние памяти для функционально аналогичных или эквивалентных целей. Кроме того, памяти 106, 120 могут хранить кодированные видеоданные, например, которые выводятся из видеокодера 200 и вводятся в видеодекодер 300. В некоторых примерах, участки памятей 106, 120 могут быть распределены в качестве одного или нескольких видеобуферов, например, чтобы хранить необработанные, декодированные и/или кодированные видеоданные.
[0043] Машиночитаемый носитель 110 информации может представлять собой любой тип носителя информации или устройства, выполненного с возможностью транспортировки кодированных видеоданных от устройства-источника 102 к устройству-получателю 116. В одном примере, машиночитаемый носитель 110 информации представляет собой средство связи, позволяющее устройству-источнику 102 передавать кодированные видеоданные непосредственно устройству-получателю 116 в режиме реального времени, например, через радиочастотную сеть или сеть на основе компьютеров. Интерфейс 108 вывода может модулировать сигнал передачи, включающий в себя кодированные видеоданные, а интерфейс 122 ввода может демодулировать принятый сигнал передачи, в соответствии со стандартом связи, таким как протокол беспроводной связи. Средство связи может содержать любое беспроводное или проводное средство связи, такое как радиочастотный (RF) спектр или одна, или несколько физических линий передачи. Средство связи может формировать часть сети на основе пакетов, такой как локальная сеть, широкомасштабная сеть или глобальная сеть, такая как Интернет. Средство связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть полезно для обеспечения связи от устройства-источника 102 к устройств-получателю 116.
[0044] В некоторых примерах, машиночитаемый носитель 110 информации может включать в себя запоминающее устройство 112. Устройство-источник 102 может выводить кодированные данные из интерфейса 108 вывода на запоминающее устройство 112. Аналогичным образом, устройство-получатель 116 может осуществлять доступ к кодированным данным в запоминающем устройстве 112 через интерфейс 122 ввода. Запоминающее устройство 112 может включать в себя любой из многообразия носителей информации для хранения данных с распределенным или локальным доступом, таких как накопитель на жестком диске, диски Blu-ray, DVD, CD-ROM, флэш-память, энергозависимая или энергонезависимая память, или любые другие подходящие цифровые запоминающие носители информации для хранения кодированных видеоданных.
[0045] В некоторых примерах, машиночитаемый носитель 110 информации может включать в себя файловый сервер 114 или другое промежуточное запоминающее устройство, которое может хранить кодированные видеоданные, сформированные устройством-источником 102. Устройство-источник 102 может выводить кодированные видеоданные на файловый сервер 114 или другое промежуточное запоминающее устройство, которое может хранить кодированные видеоданные, сформированные устройством-источником 102. Устройство-получатель 116 может осуществлять доступ к сохраненным видеоданным на файловом сервере 114 через потоковую передачу или загрузку. Файловый сервер 114 может быть любым типом серверного устройства, выполненного с возможностью хранения кодированных видеоданных и передачи этих кодированных видеоданных устройству-получателю 116. Файловый сервер 114 может представлять собой веб-сервер (например, для веб-сайта), сервер Протокола Передачи Файлов (FTP), сетевое устройство доставки контента или устройство подключаемого к сети накопителя (NAS). Устройство-получатель 116 может осуществлять доступ к кодированным видеоданным на файловом сервере 114 через любое стандартное соединение для передачи данных, включая Интернет-соединение. Это может включать в себя беспроводной канал (например, Wi-Fi соединение), проводное соединение (например, DSL, кабельный модем и т.д.) или сочетание двух видов, которое пригодно для осуществления доступа к кодированным видеоданным, которые хранятся на файловом сервере 114. Файловый сервер 114 и интерфейс 122 ввода могут быть выполнены с возможностью работы в соответствии с протоколом потоковой передачи, протоколом передачи загрузки или их сочетанием.
[0046] Интерфейс 108 вывода и интерфейс 122 ввода могут представлять собой беспроводной передатчик/приемник, модемы, компоненты проводной организации сети (например, карты Ethernet), компоненты беспроводной связи, которые работают в соответствии с любым из многообразия стандартов IEEE 802.11, или другими физическими компонентами. В примерах, в которых интерфейс 108 вывода и интерфейс 122 ввода содержат беспроводные компоненты, интерфейс 108 вывода и интерфейс 122 ввода могут быть выполнены с возможностью переноса данных, таких как кодированные видеоданные, в соответствии со стандартом сотовой связи, таким как 4G, 4G-LTE (Долгосрочное Развитие), Усовершенствованное LTE, 5G или аналогичное. В некоторых примерах, в которых интерфейс 108 вывода содержит беспроводной передатчик, интерфейс 108 вывода и интерфейс 122 ввода могут быть выполнены с возможностью переноса данных, таких как кодированные видеоданные, в соответствии с другими беспроводными стандартами, такими как техническое описание IEEE 802.11, техническое описание IEEE 802.15 (например, ZigBee™), стандарт Bluetooth™ или аналогичное. В некоторых примерах, устройство-источник 102 и/или устройство-получатель 116 может включать в себя соответствующие устройства системы-на-кристалле (SoC). Например, устройство-источник 102 может включать в себя устройство SoC для выполнения функциональных возможностей, приписываемых видеокодеру 200 и/или интерфейсу 108 вывода, а устройство-получатель 116 может включать в себя устройство SoC для выполнения функциональных возможностей, приписываемых видеодекодеру 300 и/или интерфейсу 122 ввода.
[0047] Методики данного изобретения могу быть применены к видеокодированию в поддержку любых из многообразия мультимедийных приложений, таких как эфирное телевизионное вещание, передачи кабельного телевидения, передачи спутникового телевидения, передачи потокового видео через Интернет, такие как динамическая адаптивная потоковая передача через HTTP (DASH), цифровому видео которое кодируется на носители информации для хранения данных, декодированию цифрового видео, которое хранится на носители информации для хранения данных, или другим приложениям.
[0048] Интерфейс 122 ввода устройства-получателя 116 принимает кодированный битовый поток видео от машиночитаемого носителя 110 информации (например, запоминающего устройства 112, файлового сервера 114 или аналогичного). Кодированный битовый поток видео может включать в себя информацию сигнализации, определенную видеокодером 200, которая также используется видеодекодером 300, такую как элементы синтаксиса со значениями, которые описывают характеристики и/или обработку видеоблоков или других кодированных единиц (например, слайсов, картинок, групп картинок, последовательностей или аналогичного). Дисплейное устройство 118 демонстрирует декодированные картинки декодированных видеоданных пользователю. Дисплейное устройство 118 может представлять собой любое из многообразия дисплейных устройств, таких как дисплей с электронно-лучевой трубкой (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светоизлучающих диодах (OLED) или другой тип дисплейного устройства.
[0049] Несмотря на то, что не показано на Фиг. 1, в некоторых примерах, видеокодер 200 и видеодекодер 300 каждый может быть интегрирован с аудиокодером и/или аудиодекодером, и может включать в себя соответствующие блоки MUX-DEMUX, или другое аппаратное обеспечение и/или программное обеспечение, чтобы обрабатывать мультиплексированные потоки, включающие в себя как аудио, так и видео в общем потоке данных. Если применимо, блоки MUX-DEMUX могут быть согласованы с протоколом мультиплексора ITU H.223, или другими протоколами, такими как протокол пользовательских дейтаграмм (UDP).
[0050] Каждый из видеокодера 200 и видеодекодера 300 может быть реализован в качестве любой из многообразия подходящих схем кодера и/или декодера, таких как один или несколько микропроцессоров, цифровых сигнальных процессоров (DSP), проблемно-ориентированных интегральных микросхем (ASIC), программируемых вентильных матриц (FPGA), дискретной логики, программного обеспечения, аппаратного обеспечения, встроенного программного обеспечения или любого их сочетания. Когда методики реализуются частично в программном обеспечении, устройство может хранить инструкции для программного обеспечения в подходящем, не временном машиночитаемом носителе информации и исполнять инструкции в аппаратном обеспечении с использованием одного или нескольких процессоров, чтобы выполнять методики данного изобретения. Каждый из видеокодера 200 и видеодекодера 300 может быть включен в один или несколько кодеров, или декодеров, любой из которых может быть интегрирован, как часть объединенного кодера/декодера (КОДЕКА), в соответствующее устройство. Устройство, включающее в себя видеокодер 200 и/или видеодекодер 300, может содержать интегральную микросхему, микропроцессор и/или устройство беспроводной связи, такое как сотовый телефон.
[0051] Видеокодер 200 и видеодекодер 300 могут работать в соответствии со стандартом видеокодирования, таким как ITU-T H.265, также упоминаемый как Высокоэффективное Видеокодирование (HEVC), или его расширениями, такими как расширения для многовидового и/или масштабируемого видеокодирования. В качестве альтернативы, видеокодер 200 и видеодекодер 300 могут работать в соответствии с другими собственными или промышленными стандартами, такими как Тестовая Модель Совместного Изучения (JEM) или ITU-T H.266, также упоминаемого как Универсальное Видеокодирование (VVC). Последний проект стандарта VVC описывается в документе автора Bross и др. «Versatile Video Coding (Draft 4)», Совместная Группа Экспертов по Кодированию Виде из ITU-T SG 16 WP 3 и ISO/IEC JTC 1/SC 29/WG 11, 13е Заседание: Марракеш, Марокко 09-18 января 2019 г., JVET-M1001-v6 (далее «VVC Проект 4»). Однако методики данного изобретения не ограничиваются каким-либо конкретным стандартом кодирования.
[0052] В целом видеокодер 200 и видеодекодер 300 могут выполнять кодирование на основе блока картинок. Понятие «блок» в целом относится к структуре, включающей в себя данные, которые должны быть обработаны (например, кодированы, декодированы или иным образом использованы в процессе кодирования и/или декодирования). Например, блок может включать в себя двумерную матрицу из выборок данных яркости и/или цветности. В целом, видеокодер 200 и видеодекодер 300 могут кодировать видеоданные, представленные в формате YUV (например, Y, Cb, Cr). Т.е. вместо того, чтобы кодировать данные красного, зеленого и синего (RGB) цветов для выборок картинки, видеокодер 200 и видеодекодер 300 могут кодировать составляющие яркости и цветности, причем составляющие цветности могут включать в себя составляющие цветности как красного оттенка, так и синего оттенка. В некоторых примерах, видеокодер 200 преобразует принятые данные в формате RGB в YUV представление перед кодированием, а видеодекодер 300 преобразует YUV представление в формат RGB. В качестве альтернативы, эти преобразования могут выполнять блоки предварительной обработки и постобработки (не показано).
[0053] Данное изобретение может в целом относиться к кодированию (например, кодированию и декодированию) картинок, чтобы включать в себя процесс кодирования или декодирования данных картинки. Аналогичным образом, данное изобретение может относиться к кодированию блоков картинки, чтобы включать в себя процесс кодирования или декодирования данных для блоков, например, кодирование с предсказанием и/или кодирование остатка. Кодированный битовый поток видео в целом включает в себя ряд значений для элементов синтаксиса, представляющих собой решения кодирования (например, режимы кодирования) и разбиения картинок на блоки. Таким образом, обращения к кодированию картинки или блоку следует в целом понимать, как кодирование значений для элементов синтаксиса, формирующих картинку или блок.
[0054] Стандарт HEVC определяет различные блоки, включая единицы кодирования (CU), единицы предсказания (PU) и единицы преобразования (TU). В соответствии со стандартом HEVC кодировщик видео (такой как видеокодер 200) разбивает единицу дерева кодирования (CTU) на CU в соответствии со структурой квадродерева. Т.е. кодировщик видео разбивает CTU и CU на четыре равных не перекрывающихся квадрата и каждый узел квадродерева имеет либо ноль, либо четыре узла-потомка. Узлы без узлов-потомков могут упоминаться как «краевой узел», и CU таких краевых узлов могут включать в себя одну или несколько PU и/или одну или несколько TU. Кодировщик видео может дополнительно разбивать PU и TU. Например, в стандарте HEVC, остаточное квадродерево (RQT) представляет собой разбиение TU. В стандарте HEVC, PU представляют собой данные межкадрового предсказания при том, что TU представляют собой остаточные данные. CU, которые являются с внутрикадровым предсказанием, включают в себя информацию внутрикадрового предсказания, такую как указание внутрикадрового режима.
[0055] В качестве другого примера, видеокодер 200 и видеодекодер 300 могут быть выполнены с возможностью работы в соответствии с JEM или VVC. В соответствии с JEM или VVC, кодировщик видео (такой как видеокодер 200) разбивает картинку на множество единиц дерева кодирования (CTU). Видеокодер 200 может разбивать CTU в соответствии с древовидной структурой, такой как структура квадродерево-двоичное дерево (QTBT) или структура Многотипного Дерева (MTT). Структура QTBT удаляет концепции нескольких типов разбиения, такое как разделение на CU, PU и TU в стандарте HEVC. Структура QTBT включает в себя два уровня: первый уровень, разбитый в соответствии с разбиением квадродерева, и второй уровень, разбитый в соответствии с разбиением двоичного дерева. Корневой узел структуры QTBT соответствует CTU. Краевые узлы двоичных деревьев соответствуют единицам кодирования (CU).
[0056] В структуре разбиения MTT блоки могут быть разбиты с использованием разбиения квадродерева (QT), разбиения двоичного дерева (BT) и одного или нескольких типов разбиений троичного дерева (TT). Разбиение троичного дерева является разбиением, в котором блок дробится на три субблока. В некоторых примерах, разбиение троичного дерева делит блок на три субблока без разделения исходного блока через центр. Типы разбиения в MTT (например, QT, BT и TT) могут быть симметричными или несимметричными.
[0057] В некоторых примерах, видеокодер 200 и видеодекодер 300 могут использовать единственную структуру QTBT или MTT для представления каждой из составляющих яркости и цветности при том, что в других примерах видеокодер 200 и видеодекодер 300 могут использовать две или несколько структур QTBT или MTT, как, например, одна структура QTBT/MTT для составляющей яркости и другая структура QTBT/MTT для обеих составляющих цветности (или две структуры QTBT/MTT для соответствующих составляющих цветности).
[0058] Видеокодер 200 и видеодекодер 300 могут быть выполнены с возможностью использования разбиения квадродерева согласно HEVC, разбиения QTBT, разбиения MTT или других структур разбиения. В целях объяснения, описание методик данного изобретения представляется в отношении разбиения QTBT. Однако, следует понимать, что методики данного изобретения также могут быть применены к кодировщикам видео, выполненным с возможностью использования разбиения квадродерева, или также других типов разбиения.
[0059] Данное изобретение может использовать «N×N» и «N на N» взаимозаменяемым образом, чтобы обращаться к размерам в выборках блока (такого как CU или другой видеоблок), исходя из вертикальных и горизонтальных размеров, например, 16×16 выборок или 16 на 16 выборок. В целом, 16×16 CU будет иметь 16 выборок в вертикальном направлении (y=16) и 16 выборок в горизонтальном направлении (x=16). Аналогичным образом, N×N CU в целом имеет N выборок в вертикальном направлении и N выборок в горизонтальном направлении, где N представляет собой не отрицательное целочисленное значение. Выборки в CU могут быть скомпонованы в строках и столбцах. Более того, не требуется чтобы CU имели такое же количество выборок в горизонтальном направлении, как в вертикальном направлении. Например, CU могут содержать N×M выборок, где M не обязательно равно N.
[0060] Видеокодер 200 кодирует видеоданные для CU, представляющие собой информацию предсказания и/или остаточную информацию и другую информацию. Информация предсказания указывает то, каким образом CU должна быть разбита для того, чтобы сформировать блок предсказания для CU. Остаточная информация в целом представляет собой разность выборка за выборкой между выборками CU перед кодированием и блоком предсказания.
[0061] Чтобы предсказать CU видеокодер 200 может в целом формировать блок предсказания для CU посредством межкадрового предсказания или внутрикадрового предсказания. Межкадровое предсказание в целом относится к предсказанию CU из данных ранее кодированной картинки, тогда как внутрикадровое предсказание в целом относится к предсказанию CU из ранее кодированных данных той же самой картинки. Чтобы выполнить межкадровое предсказание видеокодер 200 может формировать блок предсказания с использованием одного или нескольких векторов движения. Видеокодер 200 может в целом выполнять поиск движения, чтобы идентифицировать опорный блок, который наиболее близко совпадает с CU, например, исходя из отличий между CU и опорным блоком. Видеокодер 200 может вычислять метрику разности с использованием суммы абсолютных разностей (SAD), суммы квадратов разностей (SSD), средней абсолютной разности (MAD), средней квадратичной разности (MSD) или другие такие вычисления разности, чтобы определять, совпадает ли опорный блок с текущей CU. В некоторых примерах, видеокодер 200 может предсказывать текущую CU с использованием однонаправленного предсказания или двунаправленного предсказания.
[0062] Некоторые примеры JEM и VVC также обеспечивают режим аффинной компенсации движения, который может считаться режимом межкадрового предсказания. В режиме аффинной компенсации движения видеокодер 200 может определять два или несколько векторов движения, которые представляют собой непоступательное движение, такое как увеличение или уменьшение масштаба, поворот, перспективное движение или другие неправильные типы движения.
[0063] Чтобы выполнить внутрикадровое предсказание видеокодер 200 может выбирать режим внутрикадрового предсказания, чтобы формировать блок предсказания. Некоторые примеры JEM и VVC обеспечивают шестьдесят семь режимов внутрикадрового предсказания, включая различные направленные режимы, как, впрочем, и планарный режим и DC режим. В целом, видеокодер 200 выбирает режим внутрикадрового предсказания, который описывает соседние выборки для текущего блока (например, блока CU), по которым нужно предсказывать выборки текущего блока. Такие выборки в целом могут быть выше, выше и слева, или слева от текущего блока в той же картинке, что и текущий блок, в предположении, что видеокодер 200 кодирует CTU и CU в растровом порядке сканирования (слева направо, сверху вниз).
[0064] Видеокодер 200 кодирует данные, представляющие собой режим предсказания для текущего блока. Например, применительно к режимам межкадрового предсказания, видеокодер 200 может кодировать данные, представляющие собой то, какой из различных доступных режимов межкадрового предсказания используется, как, впрочем, и информацию о движении для соответствующего режима. Применительно к однонаправленному или двунаправленному межкадровому предсказанию, например, видеокодер 200 может кодировать векторы движения с использованием режима усовершенствованного предсказания вектора движения (AMVP) или режима слияния. Видеокодер 200 может использовать аналогичные режимы для кодирования векторов движения для режима аффинной компенсации движения.
[0065] Вслед за предсказанием, таким как внутрикадровое предсказание или межкадровое предсказание блока, видеокодер 200 может вычислять остаточные данные для блока. Остаточные данные, такие как остаточный блок, представляют собой разности выборка за выборкой между блоком и блоком предсказания для блока, который формируется с использованием соответствующего режима предсказания. Видеокодер 200 может применять одно или несколько преобразований к остаточному блоку, чтобы создавать преобразованные данные в области преобразований вместо области выборок. Например, видеокодер 200 может применять дискретное косинусное преобразование (DCT), целочисленное преобразование, вейвлет преобразование или концептуально аналогичное преобразование к остаточным видеоданным. Дополнительно, видеокодер 200 может применять вторичное преобразование, следующее за первым преобразованием, такое как зависимое от режима неразделимое вторичное преобразование (MDNSST), зависимое от сигнала преобразование, преобразование Карунена-Лоэва (KLT) или аналогичное. Видеокодер 200 создает коэффициенты преобразования вслед за применением одного или нескольких преобразований.
[0066] Как отмечалось выше, вслед за любыми преобразованиями для создания коэффициентов преобразования, видеокодер 200 может выполнять квантование коэффициентов преобразования. Квантование в целом относится к процессу, при котором коэффициенты преобразования квантуются, чтобы возможно уменьшить объем данных, которые используются для представления коэффициентов, обеспечивая дальнейшее сжатие. Путем выполнения процесса квантования, видеокодер 200 может уменьшать битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Например, видеокодер 200 может округлять n-битное значение вниз до m-битного значения во время квантования, где n больше m. В некоторых примерах, чтобы выполнить квантование, видеокодер 200 может выполнять побитовый сдвиг вправо значения, которое должно быть квантовано.
[0067] Вслед за квантованием видеокодер 200 может осуществлять сканирование коэффициентов преобразования, создавая одномерный вектор из двумерной матрицы, включающей в себя квантованные коэффициенты преобразования. Сканирование может быть предназначено для того, чтобы помещать коэффициенты с более высокой энергией (и вследствие этого с более низкой частотой) в передней части вектора и, чтобы помещать коэффициенты преобразования с более низкой энергией (и вследствие этого с более высокой частотой) в задней части вектора. В некоторых примерах, видеокодер 200 может использовать предопределенный порядок сканирования, чтобы осуществлять сканирование квантованных коэффициентов преобразования, чтобы создавать преобразованный в последовательную форму вектор, и затем энтропийно кодировать квантованные коэффициенты преобразования вектора. В других примерах, видеокодер 200 может выполнять адаптивное сканирование. После сканирования квантованных коэффициентов преобразования, чтобы сформировать одномерный вектор, видеокодер 200 может энтропийно кодировать одномерный вектор, например, в соответствии с контекстно-адаптивным двоичным арифметическим кодированием (CABAC). Видеокодер 200 также может энтропийно кодировать значения для элементов синтаксиса, описывающих метаданные, ассоциированные с кодированными видеоданными, для использования видеодекодером 300 при декодировании видеоданных.
[0068] Чтобы выполнить CABAC, видеокодер 200 может назначать контекст в рамках контекстной модели символу, который должен быть передан. Контекст может относиться к, например, тому, являются или нет значения, соседние для символа, с нулевым значением или нет. Определение вероятности может быть основано на контексте, назначенном символу.
[0069] Видеокодер 200 может дополнительно формировать данные синтаксиса, такие как данные синтаксиса на основе блока, данные синтаксиса на основе картинки и данные синтаксиса на основе последовательности, для видеодекодера 300, например, в заголовке картинки, заголовке блока, заголовке слайса, или другие данные синтаксиса, такие как набор параметров последовательности (SPS), набор параметров картинки (PPS) или набор видеопараметров (VPS). Видеодекодер 300 может аналогичным образом декодировать данные синтаксиса, чтобы определять, каким образом декодировать соответствующие видеоданные.
[0070] Таким образом видеокодер 200 может формировать битовый поток, включающий в себя кодированные видеоданные, например, элементы синтаксиса, описывающие разбиение картинки на блоки (например, CU) и информацию предсказания и/или остаточную информацию для блоков. В конечном счете видеодекодер 300 может принимать битовый поток и декодировать кодированные видеоданные.
[0071] Нижеследующий раздел будет описывать методики двоичного арифметического кодирования (BAC) и CABAC более подробно. BAC в целом является рекурсивной процедурой подразделения интервала. BAC используется чтобы кодировать бины в процессе CABAC в стандартах видеокодирования H.264/AVC и H.265/HEVC. Вывод кодировщика BAC является двоичным потоком, который представляет собой значение или указатель на вероятность в рамках итогового кодированного интервала вероятности. Интервал вероятности указывается диапазоном (‘диапазон’) (range) и нижним конечным значением (‘минимум’) (low). Диапазон является расширением интервала вероятности. Минимум является нижней границей интервала кодирования/вероятности.
[0072] Применение арифметического кодирования к видеокодированию описывается в документе авторов D. Marpe, H. Schwarz и T. Wiegand «Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video Compression Standard» IEEE Trans. Circuits and Systems for Video Technology, том 13, № 7, июль 2003 г. CABAC включает три основные функции, а именно, бинаризацию, контекстное моделирование и арифметическое кодирование. Бинаризация относится к функции отображения элементов синтаксиса в двоичных символах (или «бинах»). Двоичные символы также могут упоминаться как «строки бинов». Контекстное моделирование относится к функции оценки вероятности различных бинов. Арифметическое кодирование относится к последующей функции сжатия бинов в биты, на основе оцененной вероятности. Различные устройства и/или их модули, такие как двоичный арифметический кодировщик, могут выполнять функцию арифметического кодирования.
[0073] В HEVC используется несколько разных процессов бинаризации, включая унарный (U), усеченный унарный (TU), Экспоненциальный-Голомба k-ого порядка (EGk) и фиксированной длины (FL). Подробности различных процессов бинаризации описываются в документе авторов V. Sze и M. Budagavi, «High throughput CABAC entropy coding in HEVC», IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), том 22, № 12, стр. 1778-1791, декабрь 2012 г.
[0074] Каждый контекст (т.е. вероятностная модель) в CABAC представляется состоянием. Каждое состояние (σ) неявным образом представляет собой вероятность (pσ) того, что конкретный символ (например, бин) является Наименее Вероятным Символом (LPS). Символ может быть LPS или Наиболее Вероятным Символом (MPS). Символы являются двоичными, и раз так, то MPS и LPS могут быть 0 или 1. Вероятность оценивается для соответствующего контекста и используется (неявным образом) чтобы энтропийно кодировать символ с использованием арифметического кодировщика.
[0075] Процесс BAC обрабатывается конечным автоматом, который меняет свои внутренние значения ‘диапазон’ и ‘минимум’ в зависимости от контекста для кодирования и значения кодируемого бина. В зависимости от состояния контекста (т.е. его вероятности), диапазон делится на rangeMPSσ (диапазон наиболее вероятного символа в состоянии σ) и rangeLPSσ (диапазон наименее вероятного символа в состоянии σ). В теории, значение rangeLPSσ вероятности состояния σ выводится путем умножения:
rangeLPSσ=range × pσ,
где pσ является вероятностью выбора LPS. Конечно, вероятность MPS составляет 1-pσ. Эквивалентно, rangeMPSσ равен range минус rangeLPSσ. BAC итерационно обновляет диапазон в зависимости от состояния бина контекста для кодирования, текущего диапазона и значения кодируемого бина (т.е. равен ли бин LPS или MPS).
[0076] Фиг. 2A и 2B показывают примеры данного процесса в бине n. В примере 201 на Фиг. 2A, диапазон в бине n включает в себя RangeMPS и RangeLPS, который задается вероятностью LPS (pσ) при заданном определенном состоянии (σ) контекста. Пример 201 показывает обновление диапазона в бине n+1, когда значение бина n равно MPS. В данном примере, минимум остается тем же самым, но значение диапазона в бине n+1 уменьшается до значения RangeMPS в бине n. Пример 203 на Фиг. 2B показывает обновление диапазона в бине n+1, когда значение бина n не равно MPS (т.е. равно LPS). В данном примере, минимум перемещается к нижнему значению диапазона RangeLPS в бине n. В дополнение, значение диапазона в бине n+1 уменьшается до значения RangeLPS в бине n.
[0077] В HEVC диапазон выражается с помощью 9 битов, а минимум с помощью 10 битов. Присутствует процесс ренормализации, чтобы сохранить значения диапазона и минимума с достаточной точностью. Ренормализация происходит всякий раз, когда диапазон меньше 256. Вследствие этого, диапазон всегда равен или больше 256 после ренормализации. В зависимости от значений диапазона и минимума, BAC выводит в битовый поток ‘0’ или ‘1’, или обновляет внутреннюю переменную (называемую BO: биты-невыполненные (bits-outstanding)), чтобы сохранить для будущих выводов. Фиг. 3 показывает примеры вывода BAC в зависимости от диапазона. Например, ‘1’ выводится в битовый поток, когда диапазон и минимум находятся выше определенной пороговой величины (например, 512). ‘0’ выводится в битовый поток, когда диапазон и минимум находятся ниже определенной пороговой величины (например, 512). В битовый поток ничего не выводится, когда диапазон и минимум находятся между определенными пороговыми величинами. Вместо этого увеличивается значение BO и кодируется следующий бин.
[0078] Методики, описанные в данном изобретении, могут быть выполнены, например, в рамках видеокодера, видеодекодера или объединенного видео кодера-декодера (КОДЕКА). В частности, такие методики могут быть выполнены в блоке энтропийного кодирования видеокодера и/или блоке энтропийного декодирования видеодекодера. Методики могут быть выполнены, например, в рамках процесса CABAC, который может быть сконфигурирован, чтобы поддерживать видеокодирование, такое как видеокодирование в соответствии с аспектами стандарта HEVC. Блоки энтропийного кодирования и декодирования могут применять процессы кодирования противоположным или обратным образом, например, чтобы кодировать или декодировать любые из многообразия видеоданных, такие как квантованные коэффициенты преобразования, ассоциированные с остаточными видеоданными, информацию о векторе движения, элементы синтаксиса и другие типы информации, которая может быть полезна в процессе кодирования видео и/или декодирования видео.
[0079] В целом, видеодекодер 300 выполняет процесс, противоположный процессу, который выполняется видеокодером 200, чтобы декодировать кодированные видеоданные битового потока. Например, видеодекодер 300 может декодировать значения для элементов синтаксиса битового потока с использованием CABAC образом, который в основном аналогичен, хотя и противоположен, процессу кодирования CABAC видеокодера 200. Элементы синтаксиса могут определять информацию разбиения картинки на CTU, и разбиение каждой CTU в соответствии с соответствующей структурой разбиения, такой как структура QTBT, чтобы определять CU у CTU. Элементы синтаксиса могут дополнительно определять информацию предсказания и остаточную информацию для блоков (например, CU) видеоданных.
[0080] Остаточная информация может быть представлена, например, квантованными коэффициентами преобразования. Видеодекодер 300 может осуществлять обратное квантование и обратное преобразование квантованных коэффициентов преобразования блока, чтобы воссоздавать остаточный блок для блока. Видеодекодер 300 использует просигнализированный режим предсказания (внутрикадровое или межкадровое предсказание) и связанную информацию предсказания (например, информацию о движении для межкадрового предсказания), чтобы сформировать блок предсказания для блока. Видеодекодер 300 затем может объединять блок предсказания и остаточный блок (на основе выборка за выборкой), чтобы воссоздавать исходный блок. Видеодекодер 300 может выполнять дополнительную обработку, такую как выполнение процесса устранения блочности, чтобы уменьшить визуальные искажения на границах блока.
[0081] В соответствии с методиками данного изобретения, видеокодер 200 и/или видеодекодер 300 может: получать предопределенный индекс наклона (например, SlopeIdx) и предопределенный индекс смещения (например, OffsetIdx) для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса в слайсе видеоданных; определять, на основе предопределенного индекса наклона и предопределенного индекса смещения, первоначальное вероятностное состояние контекста для слайса видеоданных в линейной области; и энтропийно кодировать, на основе первоначального вероятностного состояния контекста, бин значения элемента синтаксиса.
[0082] Данное изобретение в целом может относиться к «сигнализации» определенной информации, такой как элементы синтаксиса. Понятие «сигнализация» может в целом относиться к сообщению значений элементов синтаксиса и/или других данных, которые используются, чтобы декодировать кодированные видеоданные. Т.е. видеокодер 200 может сигнализировать значения для элементов синтаксиса в битовом потоке. В целом, сигнализация относится к формированию значения в битовом потоке. Как отмечалось выше, устройство-источник 102 может транспортировать битовый поток устройству-получателю 116 в основном в режиме реального времени, или не в режиме реального времени, так, как это может происходить при сохранении элементов синтаксиса в запоминающем устройстве 112 для извлечения позже устройством-получателем 116.
[0083] Методики данного изобретения подходят для двоичных арифметических кодировщиков, в которых вероятностное состояние представляет собой действительную вероятность в линейной области, таких как Контекстно-Адаптивный Двоичный Арифметический Кодировщик (CABAC), используемый в Универсальном Видеокодировании (VVC).
[0084] В двоичном арифметическом кодировании, видеопоследовательность сначала преобразуется в элементы данных (или элементы синтаксиса) с удаленной пространственно-временной избыточностью; затем элементы синтаксиса преобразуются с потерей в двоичные представления (или битовые потоки) путем энтропийного кодирования. Последние стандарты видеокодирования (например, HEVC и VVC) могут использовать двоичное арифметическое кодирование чтобы выполнять энтропийное кодирование.
[0085] Процесс двоичного арифметического кодирования имеет три основные стадии, т.е. бинаризацию, адаптивную оценку вероятности и арифметическое кодирование. На стадии бинаризации, каждый не двоичный элемент синтаксиса, который должен быть кодирован, преобразуется в строку двоичных символов данных (или бинов).
[0086] На стадии адаптивной оценки вероятности, каждый бин, неважно, является ли он двоичным элементом синтаксиса или одним элементом двоичной строки, преобразованной из не двоичного элемента синтаксиса, имеет оценку своего распределения вероятности (т.е. вероятности того, что является 0 или 1). Распределения могут быть классифицированы на две категории: (1) стационарное и равномерное распределение (т.е. всегда p=0.5) и (2) изменяющееся по времени или неравномерное распределение. Бину с распределением Категории (2) может быть назначена вероятностная модель (или контекстная модель), отслеживающая это распределение бина в режиме реального времени на основе его предыдущих значений бина и других статистических данных контекста.
[0087] На стадии арифметического кодирования, бин с распределением Категории (1) может быть кодирован в режиме обхода, режиме низкой сложности и высокого параллелизма; бин с распределением Категории (2) кодируется в обычном режиме, при котором используются значение бина и его вероятность, оцененная ассоциированной контекстной моделью.
[0088] При использовании в двоичных арифметических кодировщиках для видеокодирования, вероятность, теоретически с действительным значением и в диапазоне от 0 до 1, приводится в цифровую форму, и вследствие этого обычно упоминается как вероятностное состояние. Например, в HEVC, вероятность иметь 7-битную точность, соответствующую 128 вероятностным состояниям. Фиг. 9 показывает отображение между вероятностью и вероятностным состоянием. Как может быть видно, вероятностное состояние в HEVC представляет действительную вероятность в логарифмической области. В качестве другого примера, в VVC, оценка вероятности определенного бина является средним двух вероятностей, которые отслеживаются в ассоциированной с бином контекстной модели и обновляются с высокой скоростью и низкой скоростью, соответственно. Та, что обновляется с высокой скоростью, имеет 10-битную точность, соответствующую 1024 вероятностным состояниям; другая, которая обновляется с низкой скоростью, имеет 14-битную точность, соответствующую 16384 вероятностным состояниям. В отличие от HEVC, VVC использует линейное отображение между вероятностным состоянием и вероятностью (см. Фиг. 10A и 10B).
[0089] В HEVC и VVC, битовый поток видео содержит или состоит из нескольких независимо декодируемых единиц (например, слайсов), подразумевая, что в начале такой единицы, вероятностные состояния всех контекстных моделей должны быть сброшены до некоторых предопределенных значений. Обычно, без каких-либо априорных знаний о статистической природе источника, каждая контекстная модель должна предполагать равномерное распределение (p=0.5). Однако, чтобы связать фазы обучения адаптивной оценки вероятности и обеспечения возможности предварительной адаптации при разных условиях кодирования, было обнаружено полезным предоставление некоторого более подходящего первоначального вероятностного состояния (процесс инициализации), чем равновероятное состояние для каждой вероятностной модели.
[0090] CABAC в HEVC имеет зависимый от параметра квантования (QP) процесс инициализации, который вызывается в начале каждого слайса. При заданном первоначальном значении QP яркости для слайса, SliceQPY, первоначальное вероятностное состояние определенной контекстной модели, обозначенное как InitProbState, формируется посредством Уравнений с (1) по (3),
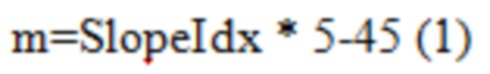
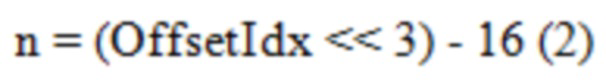
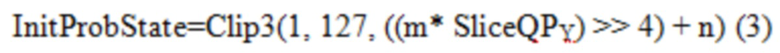
где SlopeIdx и OffsetIdx (оба целые числа в диапазоне от 0 до 15 включительно) являются параметрами инициализации, которые предопределены и сохранены для каждой контекстной модели. Уравнение (3) означает, что InitProbState моделируется посредством линейной функции SliceQPY, с наклоном приблизительно m>>4 и пересечением n при SliceQPY=0. Отображение из SlopeIdx в наклон и из OffsetIdx в пересечение можно найти в Таблицах 1 и 2, соответственно.
Другими словами, контекстная модель может не хранить непосредственно первоначальное вероятностное состояние; вместо этого, она хранит два параметра инициализации, которые совместно определяют линейную функцию, которая, в начале каждого слайса, использует SliceQPY в качестве аргумента для извлечения вероятностного состояния.
[0091] SlopeIdx и OffsetIdx, оба с 4-битной точностью, упаковываются в единое 8-битное значение инициализации, в котором верхний и нижний полубайт является SlopeIdx и OffsetIdx, соответственно.
[0092] CABAC текущего VVC использует в основном такой же способ извлечения InitProbState, как в HEVC, за исключением того, что в Уравнении (3) отсечение осуществляется от 0 до 127. Однако после извлечения InitProbState, которое представляет собой вероятность в логарифмической области (см. Фиг. 9), процессу инициализации в VVC требуется еще один этап, чтобы преобразовывать InitProbState в вероятностное состояние, которое представляет собой вероятность в линейной области (см. Фиг. 10A и 10B), для того, чтобы использовать его в машине арифметического кодирования VVC. Преобразование (или отображение), показанное на Фиг. 11A и 11B, реализуется путем использования таблицы поиска (LUT) (см. Таблицу 3), как описано ниже:
1. Используют InitProbState в качестве поискового индекса, чтобы найти соответствующее значение probability_state (вероятностное состояние) в LUT.
2. - Вероятностное состояние с более низкой точностью (10-битной), обозначенное как ProbabilityStateL, извлекается в Уравнении (4).
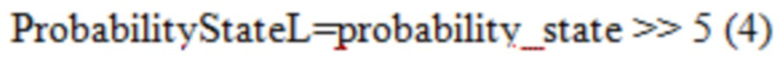
Вероятностное состояние с более высокой точностью (14-битной), обозначенное как ProbabilityStateH, извлекается в Уравнении (5).
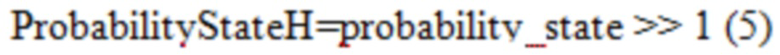
[0093] Как обсуждалось выше, CABAC в текущем VVC использует вероятностные состояния, представляющие собой вероятности в линейной области (см. Фиг. 10A и 10B), но по-прежнему использует унаследованный процесс инициализации из HEVC, в котором извлеченные первоначальные вероятностные состояния представляют собой вероятности в логарифмической области. Чтобы связать вывод процесса инициализации и ввод машины арифметического кодирования, для отображения используется LUT со 128 записями.
[0094] В соответствии с одной или несколькими методиками данного изобретения, процесс инициализации может быть модифицирован для VVC (например, эти методики могут улучшать данный процесс поиска по таблице путем надлежащего модифицирования процесса инициализации в VVC). Для модификации предлагаются два способа. В одном способе, выходное вероятностное состояние InitProbState представляет собой вероятность в линейной области. Посредством этого, процесс отображения уменьшается до операций сдвига, только для точной регулировки. В другом способе, выходное вероятностное состояние InitProbState представляет собой вероятность в квадратичной области, и отображение реализуется путем использования уравнений, а не LUT.
[0095] Увеличить диапазон наклона и пересечения. Чтобы найти подходящие параметры инициализации для заданной контекстной модели, требуется получить априорные знания о распределении вероятности бинов, которые используют контекстную модель, некоторым образом, таким как статистический анализ источника. Фиг. 12 показывает пример бина элемента синтаксиса SaoMergeFlag, который используется в I слайсе.
[0096] В HEVC и текущем VVC, априорные знания о вероятности преобразуются в вероятностное состояние в логарифмической области (Фиг. 13A преобразуется из Фиг. 12), и оптимальные параметры инициализации, при которых определенная линейная функция наилучшим образом осуществляет подгонку корреляции между вероятностным состоянием и SliceQPY, находятся путем поиска методом перебора или некоторыми другими более интеллектуальными путями. Применительно к тому же самому примеру, SlopeIdx и OffsetIdx соответствуют 13 и 6, соответственно (наклон приблизительно 1.25 и пересечение 32), и соответствующая линейная функция наилучшей подгонки нанесена на Фиг. 13B.
[0097] В соответствии с методиками данного изобретения, первоначальное вероятностное состояние находится в линейной области, чтобы быть согласованным с машиной арифметического кодирования. Применительно к тому же самому примеру, априорные знания, представленные вероятностным состоянием в линейной области, показаны на Фиг. 14A, которая является просто представленной в масштабе версией Фиг. 12. Обратите внимание на то, что 7-битная точность используется как для логарифмических, так и линейных вероятностных состояний для простоты пояснения. Однако, в других примерах, могут быть использованы другие битовые точности.
[0098] Сравнение Фиг. 13A и Фиг. 14A показывает то, что вероятностное состояние меняется гораздо мягче в зависимости от SliceQPY в логарифмической области, чем это происходит в линейной области, что означает, что ровная прямая, хорошо подгоняющая вероятностные состояния в логарифмической области, может становиться довольно крутой в линейной области. Касательно вероятностного состояния, показанного на Фиг. 14A, без изменения процесса инициализации, определенного в HEVC и текущем VVC (см. Уравнения с (1) по (3)), наилучшими параметрами инициализации, которые можно найти путем поиска методом перебора, являются SlopeIdx равный 15 и OffsetIdx равный 4, при которых достигается наибольший действительный наклон в 1.88, как показано на Фиг. 14B. Однако, линия может быть недостаточно крутой для обеспечения хорошей подгонки. С помощью увеличенных диапазонов поиска наклона и пересечения, может быть найдена более хорошая подгонка, как показано на Фиг. 14C, на которой наклон составляет 3.25 и пересечение составляет -23, причем оба значения превышают пределы, допустимые в HEVC и текущем VVC.
[0099] Обратите внимание на то, что пример (Фиг. с 12 по 14C) является типичным, а не исключительным - большое количество бинов имеет такой вид распределений вероятности. Вследствие этого, диапазоны наклона и смещения должны быть увеличены для того, чтобы использовать линейную модель для осуществления подгонки корреляции SliceQPY и вероятностного состояния, которые сейчас находятся в линейной области.
[0100] В одном примере, количества возможных значений наклона и пересечения не меняются (т.е. SlopeIdx и OffsetIdx по-прежнему находятся в диапазоне от 0 до 15), но увеличивается размер шага между ними, что означает, что постоянная a в Уравнении (6) больше 5 в Уравнении (1) и b в Уравнении (7) больше 3 в Уравнении (2), соответственно.
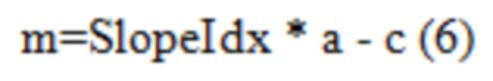
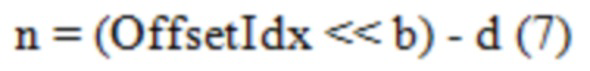
[0101] В другом примере, увеличивается количество возможных значений наклона и пересечения. Например, SlopeIdx может находиться в диапазоне от 0 до 31, приводя к 32 возможным значениям наклона. Вышеупомянутые два примера могут быть использованы вместе, или могут быть использованы независимо.
[0102] Определение Пересечения в SliceQPY не Равном 0. Помимо удовлетворения линейного вероятностного состояния с помощью увеличенных диапазонов наклона и смещения, определение пересечения при SliceQPY не равном 0 является альтернативным или дополнительным способом. Например, Фиг. 15A показывает распределение вероятности SplitFlag, используемого в B слайсе. В логарифмической области, как показано на Фиг. 15B, вероятностное состояние относительно SliceQPY может быть хорошо смоделировано посредством линейной функции с наклоном равным -0.63 и пересечением равным 88 (т.е. SlopeIdx 7 и OffsetIdx 13, как определено в HEVC и текущем VVC). Однако, в линейной области, вероятностное состояние не может быть хорошо смоделировано посредством действительных сочетаний наклона/пересечения, определенных в HEVC и текущем VVC. Фиг. 15C показывает наиболее близкую подгонку, найденную путем поиска методом перебора, при которой наклон равен -0.94 и пересечение равно 104 (т.е. SlopeIdx 6 и OffsetIdx 15). Как показано на Фиг. 15D, другой действительный наклон -1.88 (SlopeIdx 3) добивается более хорошей подгонки, но проекция на ось y (т.е. пересечение при SliceQPY равно 0) соответствует 130, что далеко за пределами верхнего лимита в 104.
[0103] Как показано выше в Уравнении (3), в некоторых примерах, первоначальное вероятностное состояние может быть определено частично путем умножения переменной m на SliceQPY. В примере Уравнения (3), линейная модель вероятностного состояния определяется в точке, в которой SliceQPY равно нулю.
[0104] В соответствии с одной или несколькими методиками данного изобретения, кодировщик видео может использовать такое смещение, при котором линейная модель вероятностного состояния определяется при значении SliceQPY отличном от нуля. Точка на линейной модели, при которой определяется вероятностное состояние, может упоминаться как точка привязки параметра квантования (QPanchor). Например, кодировщик видео может вычитать смещение из SliceQPY, и умножать результат на переменную m. В одном примере, это может быть осуществлено путем модифицирования Уравнения (3) на Уравнение (8), как показано ниже.
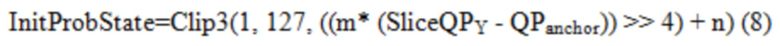
где QPanchor является значение QP, при котором определяется пересечение. Таким образом, пересечение не может превышать действительный диапазон вероятностных состояний (от 1 до 127 в данном примере), и исключается рассмотрение большой проекции на ось y, особенно когда наклон крутой. На Фиг. 15D, SlopeIdx равен 3, QPanchor равен 32 и пересечение при QPanchor равно 72. Другие значения для QPanchor включают в себя, но не ограничиваются, 8, 16, 64, 128 и т.д.
[0105] Использование Альтернативного Представления для Линейной Функции. В примерах, которые обсуждались выше, линейная функций, используемая для моделирования вероятностного состояния с помощью SliceQPY, определяется парой из наклона и пересечения, что является точно таким же, как HEVC и текущем VVC. Данный раздел предлагает альтернативные представления для линейных функций, в которых линейная функция определяется двумя пересечениями при двух разных QP. В сравнении с представлением в виде наклон/пересечение, данное представление в виде двойного пересечения обеспечивает большую гибкость при подгонке, так как обеспечивает много больше значений наклона, которые не представлены в форме арифметической последовательности.
[0106] Обозначим два пересечения и два соответствующих QP как int1, int2, QP1 и QP2, соответственно. QP1 и QP2 могут быть произвольными, при условии, что они находятся в рамках действительного диапазона, определенного в текущем VVC (от 0 до 63). Однако, поскольку InitProbState вычисляется посредством Уравнения (9) или Уравнения (10), как показано ниже (обратите внимание на то, что для простоты пояснения, здесь не рассматриваются промежуточные операции отсечения и сдвига),
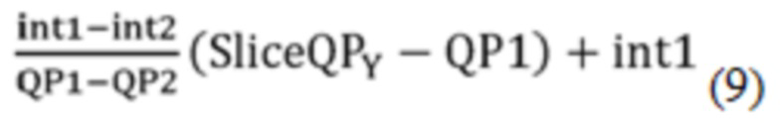
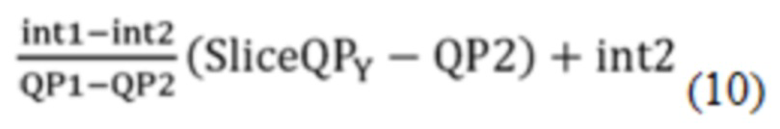
лучше, чтобы разность между QP1 и QP2 была целым числом кратным 2 так, чтобы деления в Уравнении (9) и Уравнении (10) могли быть замещены сдвигом вправо.
[0107] Представление в виде двойного пересечения может быть дополнительно расширено на представление в виде множественного пересечения, определяющего кусочно-линейные функции. Одним таким примером является бин из SigFlag яркости, см. Фиг. 16A-16C, где точка перелома возникает при QP около 30 или 31 и прямая линия, которая определяется парой наклон/пересечение или двойными пересечениями, является недостаточной для подгонки (см. Фиг. 16A). В данном случае предлагается представление в виде тройного пересечения, которое использует три параметра инициализации: пересечение при QP равном 31 и два других пересечения при QP меньшем и большем 31, соответственно (см. Фиг. 16B). Чтобы осуществлять подгонку распределения вероятности даже еще более точнее, может быть использовано представление в виде четверки пересечений, в котором дополнительный параметр инициализации, представляющий собой пересечение при QP равном 37, используется для захвата другой незначительной точки перелома (см. Фиг. 16C).
[0108] Сохранять Более Высокую Промежуточную Точность. Вышеприведенные примеры вносят модификации в Уравнения с (1) по (3) и извлекают InitProbeState в линейной области. InitProbState по-прежнему имеет 7-битную точность (от 0 до 127), из-за наследования HEVC, и должно быть сдвинуто влево на 3 бита и 7 битов для того, чтобы быть выровненным с точностями Probability StateL и ProbabilityStateH, которые определены в текущем VVC, как в Уравнениях (11) и (12).
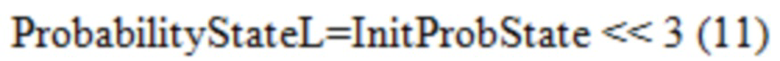
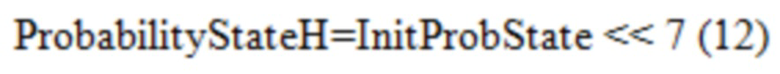
[0109] Обратите внимание на то, что в данной методике этап поиска по таблице сохраняется непосредственно до Уравнений (4) и (5).
[0110] Применение сдвига вправо для извлечения InitProbState (см. Уравнение (3)), за которым следуют сдвиги влево (см. Уравнения (11) и (12)), естественно сопровождается потерей больше информации, чем перемещение всех (или части) сдвигов вправо на последний этап, поскольку последнее сохраняет более высокую промежуточную точность. Нижеследующие два примера перемещают все сдвиги вправо на последний этап.
В одном примере:
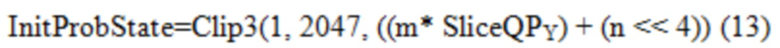
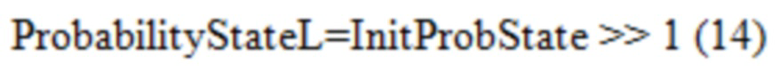
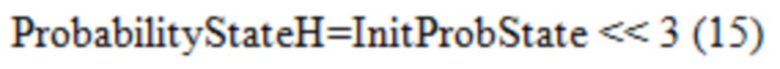
В другом примере:
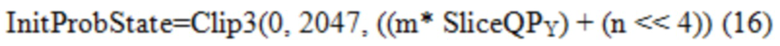
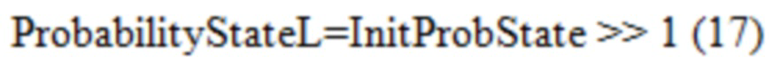
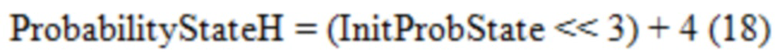
[0111] Документ «CE1-related: Simplification of JVET-O0191 using 4 or 6 bit per initialization value», JVET-O0946, Гетеборг, Швеция, 03-12 июля 2019 г. (далее «JVET-O0946») предлагает следующую методику для инициализации:
q=Clip3(9, 23, SliceQPY >> 1) - 8
a = (initValue >> 3) * 9
b = (initValue & 7) * 9
ProbabilityStateL=16 * a + (b - a) * q+8
ProbabilityStateH=ProbabilityStateL << 4
[0112] Однако, методика, предложенная в JVET-O0946 может демонстрировать один или несколько недостатков. Например, методика, предложенная в JVET-O0946, может терять некоторую промежуточную точность.
[0113] В соответствии с одной или несколькими методиками данного изобретения, кодировщик видео может выполнять инициализацию следующим образом:
q=Clip3(18, 46, SliceQPY) - 16
a = (initValue >> 3) * 9
b = (initValue & 7) * 9
ProbabilityStateL=16 * a + ((b - a) * q >> 1) + 8
ProbabilityStateH=ProbabilityStateL << 4
[0114] Как может быть видно выше, путем перемещения сдвига вправо до последнего этапа (т.е. вычисления ProbabilityStateL), вышеприведенная методика обеспечивает высокую промежуточную точность.
[0115] Инициализация в Квадратичной Области. Вышеприведенные примеры могут быть для сценариев, в которых вывод процесса инициализации представляет собой вероятностное состояние в линейной области. Однако, применительно к некоторым источникам ввода, может быть желательно, чтобы вероятностное состояние представляло собой вероятность в логарифмической области, соответствующую представлению энтропии в линейной области. Для достижения представления в логарифмической области, данное изобретение предлагает использовать вероятностные состояния в квадратичной области. Фиг. 17A и 17B показывают пример отображения из квадратичной области InitProbState в линейные вероятности, используемые в машине арифметического кодирования VVC, которое похоже на отображение для логарифмического InitProbState (см. Фиг. 11A-11B), но может быть реализовано путем умножений (отметим, что LUT, хранящая все возможные результаты умножения, может быть сформирована заранее для использования, если это предпочтительно для определенной реализации). Ниже приводится пример.
slope=int(initId & 0×0F) - 8;
offset=int(initId & 0xF0) - 128;
shp=offset + ((slope * (qp - 32)) >> 1);
idx=Clip3(-127, 127, shp);
val=128 - abs(idx);
p1 = (idx < 0 ? 32768 - val2 : val2);
ProbabilityStateL=p1 >> 1
ProbabilityStateH=p1 >> 5
где initId является значением инициализации с верхним и нижним полубайтом, представляющими собой наклон и смещение, соответственно, и idx означает вероятностное состояние с 8-битной точностью и с центрированием при 0.
[0116] Отметим, что способ, предложенный в данном разделе, может быть объединен с использованием более высокой промежуточной точности, как представлено выше.
[0117] Инициализация для Экстремальных Распределений Вероятности. Большое количество бинов может иметь экстремальные распределения вероятности, означая то, что эти бины имеют очень высокую вероятность соответствия 1 или 0, независимо от SliceQPY. Фиг. 18A и 18B являются графиками, иллюстрирующими примеры экстремальных распределений вероятности.
[0118] Для моделирования таких экстремальных распределений вероятности, наклон может быть 0, и первоначальное вероятностное состояние может зависеть только от n (см. Уравнения (2) и (7)). Раз так, то первоначальное вероятностное состояние может не меняться по параметру квантования (QP). Формула, извлекающая n, как в Уравнении (2) или Уравнении (7), может быть разработана таким образом, что обе вероятности, приближающиеся к 0 и 1, могут быть представлены эффективно. Нижеследующие примеры основаны на 7-битном представлении (от 0 до 127) вероятностных состояний и могут быть расширены на другие точности.
[0119] Возьмем в качестве примера Уравнение (2). При OffsetIdx, находящемся в диапазоне от 0 до 15, максимальное значение n, которое может быть достигнуто, составляет 104, представляющее собой вероятность 0.8189 (т.е. 104/128), которая далека от 1.0.
[0120] В документе «Simplification of the initialization process for context variables», JVETN0301, Женева, Швейцария, 19-27 марта, 2019 г., n извлекается с 10-битной точностью, при OffsetIdx, находящимся в диапазоне от 0 до 7, как в Уравнении (19).
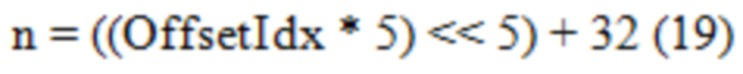
[0121] Его эквивалентное 7-битное представление n показано в Уравнении (20),
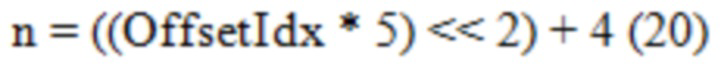
где наиболее близкая к 0 вероятность, которую оно может достигать, составляет 0.0313 (OffsetIdx равно 0 и n равно 4, 4/128=0.0313), а наиболее близкая к 1.0 вероятность, которую оно может достигать, составляет 0.9688 (OffsrtIdx равно 6 и n равно 124, 124/128=0.9688). Однако, такие аппроксимации могут быть недостаточно точными, чтобы представлять экстремальные распределения вероятности.
[0122] В соответствии с одной или несколькими методиками данного изобретения, кодировщик видео может использовать одну или несколько из следующих формул для извлечения параметра инициализации (например, n).
1. Если OffsetIdx является 3-битным (от 0 до 7), n может быть извлечено, как показано в Уравнении (21).
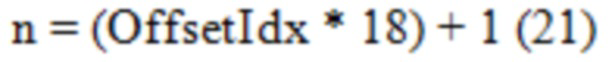
2. Если OffsetIdx является 4-битным (от 0 до 15), n может быть извлечено, как показано в Уравнении (22).
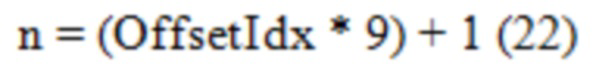
[0123] Как может быть видно, в любом случае, n может достигать 1 и 127, означая, что могут быть достигнуты вероятности в 0.0078 (т.е. 1/128) и 0.9922 (т.е. 127/128). Такие вероятности могут быть достаточно близкими к 0 и 1, соответственно. Таким образом, методики данного изобретения позволяют кодировщику видео инициализировать экстремальные распределения вероятности более точно, что может уменьшить скорость передачи битов кодированных видеоданных.
[0124] В некоторых примерах, m, n и/или initState могут быть определены в соответствии с одним из следующих уравнений:
(23)
m=slopeIdx * 4-36
n=OffsetIdx * 9+1
initState = (m * (qp - 24) >> 4) + n
(24)
m=slopeIdx * 8-32
n=OffsetIdx * 18+1
initState = (m * (qp - 16) >> 4) + n
(25)
m=slopeIdx * 5-45
n=OffsetIdx * 8+7
initState = (m * (qp - 32) >> 4) + n
[0125] Фиг. 4A и 4B являются концептуальной схемой, иллюстрирующей примерную структуру 130 квадродерево-двоичное дерево (QTBT), и соответствующую единицу 132 дерева кодирования (CTU). Сплошные линии представляют собой дробление квадродерева, а пунктирные линии указывают дробление двоичного дерева. В каждом узле дробления (т.е. не краевом) двоичного дерева, один флаг сигнализируется, чтобы указывать, какой используется тип дробления (т.е. горизонтальный или вертикальный), где 0 указывает горизонтальное дробление, а 1 указывает вертикальное дробление в данном примере. Применительно к дроблению квадродерева, отсутствует необходимость в указании типа дробления, поскольку узлы квадродерева дробят блок горизонтально и вертикально на 4 субблока одинакового размера. Соответственно, видеокодер 200 может кодировать, а видеодекодер 300 может декодировать, элементы синтаксиса (такие как информацию о дроблении) для уровня дерева области (т.е. первого уровня) структуры 130 QTBT (т.е. сплошные линии) и элементы синтаксиса (такие как информация о дроблении) для уровня дерева предсказания (т.е. второго уровня) структуры 130 QTBT (т.е. пунктирные линии). Видеокодер 200 может кодировать, а видеодекодер 300 может декодировать, видеоданные, такие как данные предсказания и преобразования, для CU, представленных конечными краевыми узлами структуры 130 QTBT.
[0126] В целом, CTU 132 на Фиг. 4B может быть ассоциирована с параметрами, определяющими размеры блоков, соответствующих узлам структуры 130 QTBT на первом и втором уровнях. Эти параметры могут включать в себя размер CTU (представляющий собой размер CTU 132 в выборках), минимальный размер квадродерева (MinQTSize, представляющий собой минимальный допустимый размер краевого узла квадродерева), максимальный размер двоичного дерева (MaxBTSize, представляющий собой максимальный допустимый размер корневого узла двоичного дерева), максимальную глубину двоичного дерева (MaxBTDepth, представляющую собой максимальную допустимую глубину двоичного дерева) и минимальный размер двоичного дерева (MinBtSize, представляющий собой минимальный допустимый размер краевого узла двоичного дерева).
[0127] Корневой узел структуры QTBT, соответствующий CTU, может иметь четыре узла-потомка на первом уровне структуры QTBT, каждый из которых может быть разбит в соответствии с разбиением квадродерева. Т.е. узлы первого уровня являются либо краевыми узлами (без узлов-потомков), либо имеют четыре узла-потомка. Пример структуры 130 QTBT представляет такие узлы, как включающие в себя узел-родитель и узлы-потомки со сплошными линиями для ветвей. Если узлы первого уровня не больше максимального допустимого размера корневого узла двоичного дерева (MaxBTSize), они могут быть дополнительно разбиты посредством соответствующих двоичных деревьев. Дробление двоичного дерева одного узла может повторяться до тех пор, пока узлы, полученные в результате дробления, не достигают минимального допустимого размера краевого узла двоичного дерева (MinBTSize) или максимальной допустимой глубины двоичного дерева (MaxBTDepth). Пример структуры 130 QTBT представляет такие узлы, как с пунктирными линиями для ветвей. Краевой узел двоичного дерева упоминается как единица кодирования (CU), которая используется для предсказания (например, предсказания внутри картинки или между картинками) и преобразования, без какого-либо дальнейшего разбиения. Как обсуждалось выше, CU также могут упоминаться как «видеоблоки» или «блоки».
[0128] В одном примере структуры разбиения QTBT, размер CTU устанавливается как 128×128 (выборок яркости и двух соответствующих 64×64 выборок цветности), MinQTSize устанавливается как 16×16, MinBTSize устанавливается как 64×64, MinBTSize (как для ширины, так и высоты) устанавливается как 4, и MaxBTDepth устанавливается как 4. Сначала разбиение квадродерева применяется к CTU, чтобы сформировать краевые узлы квадродерева. Краевые узлы квадродерева могут иметь размер от 16×16 (т.е. MinQTSize) до 128×128 (т.е. размер CTU). Если краевой узел квадродерева соответствует 128×128, то он не будет далее дробиться посредством двоичного дерева, поскольку размер превышает MaxBTSize (т.е. 64×64 в данном примере). В противоположном случае, краевой узел квадродерева будет дополнительно разбиваться посредством двоичного дерева. Вследствие этого, краевой узел квадродерева также является корневым узлом для двоичного дерева и имеет глубину двоичного дерева равную 0. Когда глубина двоичного дерева достигает MaxBTDepth (4 в данном примере), никакое дальнейшее дробление не разрешено. Когда узел двоичного дерева имеет ширину равную MinBTSize (4 в данном примере), это подразумевает то, что никакое дальнейшее горизонтальное дробление не разрешено. Аналогичным образом, узел двоичного узла с высотой равной MinBTSize подразумевает то, что никакое дальнейшее вертикальное дробление не разрешено для этого узла двоичного дерева. Как отмечено выше, краевые узлы двоичного дерева упоминаются как CU, и дополнительно обрабатываются в соответствии с предсказанием и преобразованием без дальнейшего разбиения.
[0129] Фиг. 5 является структурной схемой, иллюстрирующей примерный видеокодер 200, который может выполнять методики данного изобретения. Фиг. 5 предоставляется в целях объяснения и не должна рассматриваться, как ограничивающая методики, широко приведенные в качестве примера и описанные в данном изобретении. В целях объяснения, данное изобретение описывает видеокодер 200 в контексте стандартов видеокодирования, таких как стандарт видеокодирования HEVC и разрабатываемый стандарт видеокодирования H.266. Однако, методики данного изобретения не ограничиваются этими стандартами видеокодирования, и могут быть применены в целом к кодированию и декодированию видео.
[0130] В примере Фиг. 5, видеокодер 200 включает в себя память 230 видеоданных, блок 202 выбора режима, блок 204 формирования остатка, блок 206 обработки преобразования, блок 208 квантования, блок 210 обратного квантования, блок 212 обработки обратного преобразования, блок 214 реконструкции, блок 216 фильтра, буфер 218 декодированной картинки (DPB) и блок 220 энтропийного кодирования. Любые или все из памяти 230 видеоданных, блока 202 выбора режима, блока 204 формирования остатка, блока 206 обработки преобразования, блока 208 квантования, блока 210 обратного квантования, блока 212 обработки обратного преобразования, блока 212 реконструкции, блока 216 фильтра, DPB 218 и блока 220 энтропийного кодирования, может быть реализовано в одном или нескольких процессорах, или в схеме обработки. Более того, видеокодер 200 может включать в себя дополнительные или альтернативные процессоры, или схемы обработки, чтобы выполнять эти и другие функции.
[0131] Память 230 видеоданных может хранить видеоданные, которые должны быть кодированы компонентами видеокодера 200. Видеокодер 200 может принимать видеоданные, которые сохраняются в памяти 230 видеоданных, от, например, видеоисточника 104 (Фиг. 1). DPB 218 может действовать в качестве памяти опорной картинки, которая хранит опорные видеоданные для использования при предсказании последующих видеоданных видеокодером 200. Память 230 видеоданных и DPB 218 могут быть сформированы посредством любого из многообразия устройств памяти, таких как память с динамическим произвольным доступом (DRAM), включая синхронную DRAM (SDRAM), магниторезистивную RAM (MRAM), резистивную RAM (RRAM), или другие типы устройств памяти. Память 230 видеоданных и DPB 218 могут быть обеспечены одним и тем же устройством памяти или отдельными устройствами памяти. В различных примерах, память 230 видеоданных может быть на кристалле с другими компонентами видеокодера 200, как проиллюстрировано, или вне кристалла по отношению к этим компонентам.
[0132] В данном изобретении, обращение к памяти 230 видеоданных не следует интерпретировать, как ограниченное памятью, которая является внутренней для видеокодера 200, при условии, что конкретно не описана как таковая, или памятью, которая является внешней для видеодекодера 200, при условии, что конкретно не описана как таковая. Наоборот, обращение к памяти 230 видеоданных следует понимать, как обращение к памяти, которая хранит видеоданные, которые видеокодер 200 принимает для кодирования (например, видеоданные для текущего блока, который должен быть кодирован). Память 106 на Фиг. 1 также может обеспечивать временное хранилище для выводов из различных блоков видеокодера 200.
[0133] Различные блоки на Фиг. 5 иллюстрируются с тем, чтобы помочь в понимании операций, выполняемых видеокодером 200. Блоки могут быть реализованы в качестве схем с фиксированной функцией, программируемых схем или их сочетания. Схемы с фиксированной функцией относятся к схемам, которые обеспечивают конкретную функциональную возможность, и являются предварительно установленными на операции, которые могут быть выполнены. Программируемые схемы относятся к схемам, которые могут быть запрограммированы на выполнение различных задач, и обеспечивают гибкие функциональные возможности в операциях, которые могут быть выполнены. Например, программируемые схемы могут исполнять программное обеспечение или встроенное программное обеспечение, которое предписывает программируемым схемам работать образом, который определяется инструкциями программного обеспечения или встроенного программного обеспечения. Схемы с фиксированной функцией могут исполнять инструкции программного обеспечения (например, чтобы принимать параметры или выводить параметры), но типы операций, которые выполняют схемы с фиксированной функцией, в целом неизменны. В некоторых примерах, один или несколько блоков могут быть отдельными блоками схемы (с фиксированной функцией или программируемой), и в некоторых примерах, один или несколько блоков могут быть интегральными микросхемами.
[0134] Видеокодер 200 может включать в себя арифметико-логические устройства (ALU), устройства элементарной функции (EFU), цифровые схемы, аналоговые схемы и/или программируемые ядра, сформированные из программируемых схем. В примерах, в которых операции видеокодера 200 выполняются с использованием программного обеспечения, которое исполняется программируемыми схемами, память 106 (Фиг. 1) может хранить объектный код программного обеспечения, который видеокодер 200 принимает и исполняет, или другая память в видеокодере 200 (не показано) может хранить такие инструкции.
[0135] Память 230 видеоданных выполнена с возможностью хранения принятых видеоданных. Видеокодер 200 может извлекать картинку видеоданных из памяти 230 видеоданных и предоставлять видеоданные блоку 204 формирования остатка и блоку 202 выбора режима. Видеоданные в памяти 230 видеоданных могут быть необработанными видеоданными, которые должны быть кодированы.
[0136] Блок 202 выбора режима включает в себя блок 222 оценки движения, блок 224 компенсации движения и блок 226 внутрикадрового предсказания. Блок 202 выбора режима может включать в себя дополнительные функциональные блоки, чтобы выполнять предсказание видео в соответствии с другими режимами предсказания. В качестве примеров, блок 202 выбора режима может включать в себя блок палитры, блок копирования внутрикадрового блока (который может быть частью блока 222 оценки движения и/или блока 224 компенсации движения), аффинный блок, блок линейной модели (LM) или аналогичное.
[0137] Блок 202 выбора режима в целом координирует несколько проходов кодирования, чтобы протестировать сочетания параметров кодирования и результирующие значения скорость-искажение для таких сочетаний. Параметры кодирования могут включать в себя разбиение CTU на CU, режимы предсказания для CU, типы преобразования для остаточных данных CU, параметры квантования для остаточных данных CU и т.п. Блок 202 выбора режима может в итоге выбирать сочетание параметров кодирования со значениями скорость-искажение, которые лучше, чем другие протестированные сочетания.
[0138] Видеокодер 200 может разбивать картинку, извлеченную из памяти 230 видеоданных на ряд CTU, и инкапсулировать одну или несколько CTU в слайс. Блок 202 выбора режима может разбивать CTU картинки в соответствии с древовидной структурой, такой как структура QTBT или структура квадродерева в HEVC, описанные выше. Как описано выше, видеокодер 200 может формировать одну или несколько CU из разбиения CTU в соответствии с древовидной структурой. Такая CU также может упоминаться в целом как «видеоблок» или «блок».
[0139] В целом, блок 202 выбора режима также управляет своими компонентами (например, блоком 222 оценки движения, блоком 224 компенсации движения и блоком 226 внутрикадрового предсказания, чтобы формировать блок предсказания для текущего блока (например, текущей CU, или в HEVC, перекрывающегося участка PU и TU). Применительно к межкадровому предсказанию текущего блока, блок 222 оценки движения может выполнять поиск движения, чтобы идентифицировать один или несколько наиболее совпадающих опорных блоков в одной или нескольких опорных картинках (например, одной или нескольких ранее кодированных картинках, хранящихся в DPB 128). В частности, блок 222 оценки движения может вычислять значение, представляющее собой то, насколько похож потенциальный блок на текущий блок, например, в соответствии с суммой абсолютных разностей (SAD), суммой квадратичных разностей (SSD), средних абсолютных разностей (MAD), средних квадратичных разностей (MSD) и аналогичного. Блок 222 оценки движения может в целом выполнять эти вычисления с использованием разностей выборка за выборкой между текущим блоком и рассматриваемым опорным блоком. Блок 222 оценки движения может идентифицировать опорный блок с самым низким значением, полученным из этих вычислений, указывая опорный блок, который наиболее точно совпадает с текущим блоком.
[0140] Блок 222 оценки движения может формировать один или несколько векторов движения (MV), которые определяют положения опорных блоков в опорных картинках относительно положения текущего блока в текущей картинке. Блок 222 оценки движения затем может предоставлять векторы движения блоку 224 компенсации движения. Например, применительно к однонаправленному межкадровому предсказанию, блок 222 оценки движения может предоставлять один вектор движения, тогда как применительно к двунаправленному межкадровому предсказанию, блок 222 оценки движения может предоставлять два вектора движения. Блок 224 компенсации движения затем может формировать блок предсказания с использованием векторов движения. Например, блок 224 компенсации движения может извлекать данные опорного блока с использованием вектора движения. В качестве другого примера, если вектор движения имеет дробную точность выборки, то блок 224 компенсации движения может интерполировать значения для блока предсказания в соответствии с одним или несколькими фильтрами интерполяции. Более того, применительно к двунаправленному межкадровому предсказанию, блок 224 компенсации движения может извлекать данные для двух опорных блоков, идентифицированных соответствующими векторами движения, и объединять извлеченные данные, например, посредством усреднения или взвешенного усреднения выборка за выборкой.
[0141] В качестве другого примера, применительно к внутрикадровому предсказанию, или кодированию с внутрикадровым предсказанием, блок 226 внутрикадрового предсказания может формировать блок предсказания из выборок, которые являются соседними для текущего блока. Например, применительно к направленным режимам, блок 226 внутрикадрового предсказания может в целом математически объединять значения соседних выборок и заполнять этими вычисленными значениями в определенном направлении текущий блок, чтобы создавать блок предсказания. В качестве другого примера, применительно к DC режиму, блок 226 внутрикадрового предсказания может вычислять среднее соседних выборок для текущего блока и формировать блок предсказания, чтобы он включал в себя это результирующее среднее для каждой выборки блока предсказания.
[0142] Блок 202 выбора режима предоставляет блок предсказания блоку 204 формирования остатка. Блок 204 формирования остатка принимает необработанную, не кодированную версию текущего блока от памяти 230 видеоданных и блок предсказания от блока 202 выбора режима. Блок 204 формирования остатка вычисляет разности выборка за выборкой между текущим блоком и блоком предсказания. Результирующие разности выборка за выборкой определяют остаточный блок для текущего блока. В некоторых примерах, блок 204 формирования остатка также определяет разности между значениями выборки в остаточном блоке, чтобы сформировать остаточный блок с использованием остаточной дифференциальной импульсно-кодовой модуляции (RDPCM). В некоторых примерах, блок 204 формирования остатка может быть сформирован с использованием одной или нескольких схем вычитателя, которые выполняют двоичное вычитание.
[0143] В примерах, в которых блок 202 выбора режима разбивает CU на PU, каждая PU может быть ассоциирована с единицей предсказания яркости и соответствующими единицами предсказания цветности. Видеокодер 200 и видеодекодер 300 могут поддерживать PU различных размеров. Как указано выше, размер CU может относиться к размеру блока кодирования яркости у CU, а размер PU может относиться к размеру единицы предсказания яркости у PU. Предполагая, что размер конкретной CU составляет 2N×2N, видеокодер 200 может поддерживать размеры PU в виде 2N×2N или N×N для внутрикадрового предсказания, и размеры симметричной PU в виде 2N×2N, 2N×N, N×2N, N×N или аналогичное для межкадрового предсказания. Видеокодер 200 и видеодекодер 300 также могут поддерживать ассиметричное разбиение для размеров PU в виде 2N×nD, nL×2N и nR×2N применительно к межкадровому предсказанию.
[0144] В примерах, в которых блок выбора режима дополнительно не разбивает CU на PU, каждая CU может быть ассоциирована с блоком кодирования яркости и соответствующими блоками кодирования цветности. Как описано выше, размер CU может относиться к размеру блока кодирования яркости у CU. Видеокодер 200 и видеодекодер 300 могут поддерживать размеры CU в виде 2N×2N, 2N×N или N×2N.
[0145] Применительно к другим методикам видеокодирования, таким как кодирование в режиме копирования внутрикадрового блока, кодирования в аффинном режиме и кодирования в режиме линейной модели (LM), в качестве нескольких примеров, блок 202 выбора режима, через соответствующие блоки, ассоциированные с методиками кодирования, формирует блок предсказания для текущего кодируемого блока. В некоторых примерах, таком как кодирование в режиме палитры, блок 202 выбора режима может не формировать блок предсказания, а вместо этого формировать элементы синтаксиса, которые указывают способ, посредством которого следует реконструировать блок на основе выбранной палитры. В таких режимах, блок 202 выбора режима может предоставлять эти элементы синтаксиса блоку 220 энтропийного кодирования для кодирования.
[0146] Как описано выше, блок 204 формирования остатка принимает видеоданные для текущего блока и соответствующего блока предсказания. Блок 204 формирования остатка затем формирует остаточный блок для текущего блока. Чтобы сформировать остаточный блок, блок 204 формирования остатка вычисляет разности выборка за выборкой между блоком предсказания и текущим блоком.
[0147] Блок 206 обработки преобразования применяет одно или несколько преобразований к остаточному блоку, чтобы сформировать блок из коэффициентов преобразования (упоминаемый в данном документе как «блок коэффициентов преобразования»). Блок 206 обработки преобразования может применять различные преобразования к остаточному блоку, чтобы сформировать блок коэффициентов преобразования. Например, блок 206 обработки преобразования может применять дискретное косинусное преобразование (DCT), направленное преобразование, преобразование Карунена-Лоэва (KLT) или концептуально аналогичное преобразование к остаточному блоку. В некоторых примерах, блок 206 обработки преобразования может выполнять несколько преобразований над остаточным блоком, например, первичное преобразование и вторичное преобразование, такое как вращательное преобразование. В некоторых примерах, блок 206 обработки преобразования не применяет преобразования к остаточному блоку.
[0148] Блок 208 квантования может квантовать коэффициенты преобразования в блоке коэффициентов преобразования, чтобы создавать блок квантованных коэффициентов преобразования. Блок 208 квантования может квантовать коэффициенты преобразования блока коэффициентов преобразования в соответствии со значением параметра квантования (QP), ассоциированным с текущим блоком. Видеокодер 200 (например, через блок 202 выбора режима) может регулировать степень квантования, которая применяется к блокам коэффициентов преобразования, ассоциированную с текущим блоком, путем регулирования значения QP, ассоциированного с CU. Квантование может вносить потери информации, и, следовательно, квантованные коэффициенты преобразования могут иметь более низкую точность, чем исходные коэффициенты преобразования, созданные блоком 206 обработки преобразования.
[0149] Блок 210 обратного квантования и блок 212 обработки обратного преобразования могут применять обратное квантование и обратные преобразования к блоку квантованных коэффициентов преобразования, соответственно, чтобы реконструировать остаточный блок из блока коэффициентов преобразования. Блок 214 реконструкции может создавать реконструированный блок, соответствующий текущему блоку (хотя потенциально с некоторой степенью искажения) на основе реконструированного остаточного блока и блока предсказания, сформированного блоком 202 выбора режима. Например, блок 214 реконструкции может складывать выборки реконструированного остаточного блока с соответствующими выборками из блока предсказания, сформированного блоком 202 выбора режима, чтобы создавать реконструированный блок.
[0150] Блок 216 фильтра может выполнять одну или несколько операций фильтра над реконструированными блоками. Например, блок 216 фильтра может выполнять операции устранения блочности, чтобы уменьшать искажения блочности на краях CU. Операции блока 216 фильтра могут быть пропущены, в некоторых примерах.
[0151] Видеокодер 200 сохраняет реконструированные блоки в DPB 218. Например, в примерах, в которых операции блока 216 фильтра не требуются, блок 214 реконструкции может сохранять реконструированные блоки в DPB 218. В примерах, в которых операции блока 216 фильтра требуются, блок 216 фильтра может сохранять реконструированные блоки после фильтрации в DPB 218. Блок 222 оценки движения и блок 224 компенсации движения могут извлекать опорную картинку из DPB 218, сформированную из реконструированных (и потенциально после фильтрации) блоков, чтобы осуществлять межкадровое предсказание блоков последующих кодируемых картинок. В дополнение, блок 226 внутрикадрового предсказания может использовать реконструированные блоки в DPB 218 текущей картинки, чтобы осуществлять внутрикадровое предсказание других блоков в текущей картинке.
[0152] В целом, блок 220 энтропийного кодирования может энтропийно кодировать элементы синтаксиса, принятые от других функциональных компонентов видеокодера 200. Например, блок 220 энтропийного кодирования может энтропийно кодировать блоки квантованных коэффициентов преобразования от блока 208 квантования. В качестве другого примера, блок 220 энтропийного кодирования может энтропийно кодировать элементы синтаксиса предсказания (например, информацию о движении для межкадрового предсказания или информации о внутрикадровом режиме для внутрикадрового предсказания) от блока 202 выбора режима. Блок 220 энтропийного кодирования может выполнять одну или несколько операций энтропийного кодирования над элементами синтаксиса, которые являются другим примером видеоданных, чтобы формировать энтропийно-кодированные данные. Например, блок 220 энтропийного кодирования может выполнять операцию контекстно-адаптивного кодирования с переменной длиной кодового слова (CAVLC), операцию CABAC, операцию кодирования переменных с переменной длиной (V2V), операцию контекстно-адаптивного двоичного арифметического кодирования на основе синтаксиса (SBAC), операцию Энтропийного кодирования с Разбиением Интервала Вероятностей (PIPE), операцию Экспоненциального-Голомба кодирования или другой тип операции энтропийного кодирования над данными. В некоторых примерах, блок 220 энтропийного кодирования может работать в режиме обхода в случае, когда элементы синтаксиса энтропийно не кодируются.
[0153] Фиг. 6 является структурной схемой примерного блока 220 энтропийного кодирования, который может быть выполнен с возможностью выполнения CABAC в соответствии с методиками данного изобретения. Элемент 1180 синтаксиса вводится в блок 220 энтропийного кодирования. Если элемент синтаксиса уже является элементом синтаксиса с двоичным значением (например, флаг или элемент синтаксиса, который имеет значение только 0 и 1), то этап бинаризации пропускается. Если элемент синтаксиса является элементом синтаксиса не с двоичным значением (например, элемент синтаксиса, который имеет значения отличные от 1 или 0), то средство 1200 бинаризации осуществляет бинаризацию элемента синтаксиса не с двоичным значением. Средство 1200 бинаризации выполняет отображение элемента синтаксиса не с двоичным значением в последовательности из двоичных выборов. Эти двоичные выборы часто называются «бинами». Например, применительно к уровням коэффициента преобразования, значение уровня может быть разобрано на последовательные бины, причем каждый бин указывает, является или нет абсолютное значение уровня коэффициента больше некоторого значения. Например, бин 0 (иногда называется флагом значимости) указывает, является ли абсолютное значение уровня коэффициента преобразования больше 0 или нет. Бин 1 указывает, является ли абсолютное значение уровня коэффициента преобразования больше 1 или нет, и т.д. Уникальное отображение может быть разработано для каждого элемента синтаксиса не с двоичным значением.
[0154] Каждый бин, созданный средством 1200 бинаризации, подается стороне двоичного арифметического кодирования блока 220 энтропийного кодирования. Т.е., применительно к предварительно определенному набору из элементов синтаксиса с не двоичным значением, каждый тип бина (например, бин 0) кодируется перед следующим типом бина (например, бином 1). Кодирование может быть выполнен либо в обычном режиме, либо в режиме обхода. В режиме обхода, машина 1260 кодирования с обходом выполняет арифметическое кодирование с использованием фиксированной вероятностной модели, например, с использованием кодирования Голомба-Райса или экспоненциального-Голомба кодирования. Режим обхода в целом используется для более предсказуемых элементов синтаксиса.
[0155] Кодирование в обычном режиме включает выполнение CABAC. CABAC обычного режима служит для кодирования значений бина, в которых вероятность значения бина является предсказуемой при наличии значений ранее кодированных бинов. Вероятность того, что бин является LPS, определяется средством 1220 моделирования контекста. Средство 1220 моделирования контекста выводит значение бина и вероятностное состояние для контекста (например, вероятностное состояние σ, включающее в себя значение LPS и вероятность появления LPS). Контекст может быть первоначальным контекстом для ряда бинов или может быть определен на основе кодированных значений у ранее кодированных бинов. Как описано выше, средство 1220 моделирования контекста может обновлять состояние на основе того, был или нет принятый бин соответственно MPS или LPS. После того как контекст и вероятностное состояние σ определяются средством 1220 моделирования контекста, машина 1240 обычного кодирования выполняет BAC над значением бина.
[0156] Возвращаясь к Фиг. 5, видеокодер 200 может выводить битовый поток, который включает в себя энтропийно кодированные элементы синтаксиса, необходимые для реконструкции блоков слайса или картинки. В частности, блок 220 энтропийного кодирования может выводить битовый поток.
[0157] Операции, описанные выше, описаны в отношении блока. Такое описание следует понимать в качестве операций для блока кодирования яркости и/или блоков кодирования цветности. Как описано выше, в некоторых примерах, блок кодирования яркости и блоки кодирования цветности являются составляющими яркости и цветности у CU. В некоторых примерах, блок кодирования яркости и блоки кодирования цветности являются составляющими яркости и цветности у PU.
[0158] В некоторых примерах, операции, выполняемые в отношении блока кодирования яркости, не должны повторяться для блоков кодирования цветности. В качестве одного примера, операции для идентификации вектора движения (MV) и опорной картинки для блока кодирования яркости не должны повторяться для идентификации MV и опорной картинки для блоков цветности. Наоборот, MV для блока кодирования яркости может быть масштабирован, чтобы определять MV для блоков цветности, а опорная картинка может быть той же самой. В качестве другого примера, процесс внутрикадрового предсказания может быть одним и тем же для блоков кодирования яркости и блоков кодирования цветности.
[0159] Видеокодер 200 представляет собой пример устройства, выполненного с возможностью кодирования видеоданных, включающего в себя память, выполненную с возможностью хранения видеоданных, и один или несколько блоков обработки, реализованных в схеме и выполненных с возможностью: получения предопределенного индекса наклона (например, SlopeIdx) и предопределенного индекса смещения (например, OffsetIdx) для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса в слайсе видеоданных; определять, на основе предопределенного индекса наклона и предопределенного индекса смещения, первоначальное вероятностное состояние контекста для слайса видеоданных; и энтропийно кодировать, на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса.
[0160] Фиг. 7 является структурной схемой, иллюстрирующей примерный видеодекодер 300, который может выполнять методики данного изобретения. Фиг. 7 предоставляется для целей объяснения и не является ограничивающей методики, которые широко приведены в качестве примера и описаны в данном изобретении. В целях объяснения, данное изобретение описывает видеодекодер 300 в соответствии с методиками JEM, VVC и HEVC. Однако методики данного изобретения могут быть выполнены устройствами видеокодирования, которые сконфигурированы с другими стандартами видеокодирования.
[0161] В примере на Фиг. 7, видеодекодер 300 включает в себя память 320 буфера кодированной картинки (CPB), блок 302 энтропийного декодирования, блок 304 обработки предсказания, блок 306 обратного квантования, блок 308 обработки обратного преобразования, блок 310 реконструкции, блок 312 фильтра и буфер 314 декодированной картинки (DPB). Любое или все из памяти 320 CPB, блока 302 энтропийного декодирования, блока 304 обработки предсказания, блока 306 обратного квантования, блока 308 обработки обратного преобразования, блока 310 реконструкции, блока 312 фильтра и DPB 314, может быть реализовано в одном или нескольких процессорах, или в схеме обработки. Более того, видеодекодер 300 может включать в себя дополнительные или альтернативные процессоры, или схему обработки, чтобы выполнять эти и другие функции.
[0162] Блок 304 обработки предсказания включает в себя блок 316 компенсации движения и блок 318 внутрикадрового предсказания. Блок 304 обработки предсказания может включать в себя дополнительные блоки, чтобы выполнять предсказание в соответствии с другими режимами предсказания. В качестве примеров, блок 304 обработки предсказания может включать в себя блок палитры, блок копирования внутрикадрового блока (который может быть частью блока 316 компенсации движения), аффинный блок, блок линейной модели (LM) или аналогичное. В других примерах, видеодекодер 300 может включать в себя больше, меньше или другие функциональные компоненты.
[0163] Память 320 CPB может хранить видеоданные, такие как кодированный битовый поток видео, который должен быть декодирован компонентами видеодекодера 300. Видеоданные, хранящиеся в памяти 320 CPB, могут быть получены, например, из машиночитаемого носителя 110 информации (Фиг. 1). Память 320 CPB может включать в себя CPB, который хранит кодированные видеоданные (например, элементы синтаксиса) из кодированного битового потока видео. Также память 320 CPB может хранить видеоданные отличные от элементов синтаксиса кодированной картинки, такие как временные данные, представляющие собой выводы из различных блоков видеодекодера 300. DPB 314 в целом хранит декодированные картинки, которые видеодекодер 300 может выводить и/или использовать в качестве опорных видеоданных при декодировании последующих данных или картинок кодированного битового потока видео. Память 320 CPB и DPB 314 могут быть сформированы посредством любого из многообразия устройств памяти, таких как динамическая память с произвольным доступом (DRAM), включая синхронную DRAM (SDRAM), магниторезистивная RAM (MRAM), резистивная RAM (RRAM) или другие типы устройств памяти. Память 320 CPB и DPB 314 могут быть обеспечены одним и тем же устройством памяти или отдельными устройствами памяти. В различных примерах, память 320 CPB может быть на кристалле с другими компонентами видеодекодера 300 или вне кристалла по отношению к этим компонентам.
[0164] Дополнительно или в качестве альтернативы, в некоторых примерах, видеодекодер 300 может извлекать кодированные видеоданные из памяти 120 (Фиг. 1). Т.е. память 120 может хранить данные, как обсуждалось выше касательно памяти 320 CPB. Аналогичным образом, память 120 может хранить инструкции, которые должны быть исполнены видеодекодером 300, когда некоторые или все из функциональных возможностей видеодекодера 300 реализуются в программном обеспечении, которое должно быть исполнено схемой обработки видеодекодера 300.
[0165] Различные блоки, показанные на Фиг. 7, иллюстрируются, чтобы помочь в понимании операций, выполняемых видеодекодером 300. Блоки могут быть реализованы в качестве схем с фиксированной функцией, программируемых схем или их сочетания. Аналогично Фиг. 5, схемы с фиксированной функцией относятся к схемам, которые обеспечивают конкретную функциональную возможность, и являются предварительно установленными на операции, которые могут быть выполнены. Программируемые схемы относятся к схемам, которые могут быть запрограммированы на выполнение различных задач, и обеспечивают гибкие функциональные возможности в операциях, которые могут быть выполнены. Например, программируемые схемы могут исполнять программное обеспечение или встроенное программное обеспечение, которое предписывает программируемым схемам работать образом, который определяется инструкциями программного обеспечения или встроенного программного обеспечения. Схемы с фиксированной функцией могут исполнять инструкции программного обеспечения (например, чтобы принимать параметры или выводить параметры), но типы операций, которые выполняют схемы с фиксированной функцией, в целом неизменны. В некоторых примерах, один или несколько блоков могут быть отдельными блоками схемы (с фиксированной функцией или программируемой), и в некоторых примерах, один или несколько блоков могут быть интегральными микросхемами.
[0166] Видеодекодер 300 может включать в себя ALU, EFU, цифровые схемы, аналоговые схемы и/или программируемые ядра, сформированные из программируемых схем. В примерах, в которых операции видеодекодера 300 выполняются с использованием программного обеспечения, которое исполняется программируемыми схемами, память на кристалле или вне кристалла может хранить инструкции (например, объектный код) программного обеспечения, которые видеодекодер 300 принимает и исполняет.
[0167] Блок 302 энтропийного декодирования может принимать кодированные видеоданные от CPB и энтропийно декодировать видеоданные, чтобы создавать элементы синтаксиса. Блок 304 обработки предсказания, блок 306 обратного квантования, блок 308 обработки обратного преобразования, блок 310 реконструкции и блок 312 фильтра могут формировать декодированные видеоданные на основе элементов синтаксиса, извлеченных из битового потока.
[0168] Фиг. 8 является структурной схемой примерного блока 302 энтропийного декодирования, который может быть выполнен с возможностью выполнения CABAC в соответствии с методиками данного изобретения. Блок 302 энтропийного декодирования на Фиг. 8 выполняет CABAC образом обратным тому, как его выполняет блок 220 энтропийного кодирования, описанный на Фиг. 6. Кодированные биты из битового потока 2180 вводятся в блок 302 энтропийного декодирования. Кодированные биты подаются либо в средство 2200 моделирования контекста, либо в машину 2220 декодирования с обходом на основе того, были ли они энтропийно кодированы с использованием обычного режима или режима обхода. Если кодированные биты были кодированы в режиме обхода, машина декодирования с обходом будет использовать декодирование Голомба-Райса или экспоненциальное-Голомба декодирование, например, чтобы извлекать элементы синтаксиса с двоичным значением или бины элементов синтаксиса не с двоичным значением.
[0169] Если кодированные биты были кодированы в обычном режиме, средство 2200 моделирования контекста может определять вероятностную модель для кодированных битов, и машина 2240 обычного декодирования может декодировать кодированные биты, чтобы создавать бины элементов синтаксиса с не двоичным значением (или сами элементы синтаксиса, если они с двоичными значениями). После того, как контекст и вероятностное состояние σ определяются средством 2200 моделирования контекста, машина 2240 обычного декодирования выполняет BAC, чтобы декодировать значение бина. Другими словами, машина 2240 обычного декодирования может определять вероятностное состояние и контекст, и декодировать значение бина на основе ранее кодированных бинов и текущего диапазона. После декодирования бина, средство 2200 моделирования контекста может обновлять вероятностное состояние контекста на основе размера окна и значения декодированного бина.
[0170] Возвращаясь к Фиг. 7, видеодекодер 300 реконструирует картинку блок за блоком. Видеодекодер 300 может выполнять операцию реконструкции над каждым блоком отдельно (причем блок, который реконструируется в данный момент, т.е. декодируется, может упоминаться как «текущий блок»).
[0171] Блок 302 энтропийного декодирования может энтропийно декодировать элементы синтаксиса, определяющие квантованные коэффициенты преобразования блока квантованных коэффициентов преобразования, как, впрочем, и информацию преобразования, такую как параметры квантования (QP) и/или указание(ия) режима преобразования. Блок 306 обратного квантования может использовать QP, ассоциированный с блоком квантованных коэффициентов преобразования, чтобы определять степень квантования и, аналогичным образом, степень обратного квантования для блока 306 обратного квантования для применения. Блок 306 обратного квантования может, например, выполнять операцию побитового сдвига влево, чтобы осуществлять обратное квантование квантованных коэффициентов преобразования. Блок 306 обратного квантования может таким образом формировать блок коэффициентов преобразования, включающий в себя коэффициенты преобразования.
[0172] После того, как блок 306 обратного квантования формирует блок коэффициентов преобразования, блок 308 обработки обратного преобразования может применять одно или несколько обратных преобразований к блоку коэффициентов преобразования, чтобы формировать остаточный блок, ассоциированный с текущим блоком. Например, блок 308 обратного преобразования может применять обратное DCT, обратное целочисленное преобразование, обратное преобразование Карунена-Лоэва (KLT), обратное вращательное преобразование, обратное направленное преобразование или другое обратное преобразование к блоку коэффициентов преобразования.
[0173] Кроме того, блок 304 обработки предсказания формирует блок предсказания в соответствии с элементами синтаксиса информации предсказания, которые были энтропийно декодированы блоком 302 энтропийного декодирования. Например, если элементы синтаксиса информации предсказания указывают на то, что текущий блок является с межкадровым предсказанием, блок 316 компенсации движения может формировать блок предсказания. В данном случае, элементы синтаксиса информации предсказания могут указывать опорную картинку в DPB 314 из которой извлекать опорный блок, как, впрочем, и вектор движения, идентифицирующий местоположение опорного блока в опорной картинке относительно местоположения текущего блока в текущей картинке. Блок 316 компенсации движения может в целом выполнять процесс межкадрового предсказания образом, который в основном аналогичен тому, который описан в отношении блока 224 компенсации движения (Фиг. 5).
[0174] В качестве другого примера, если элементы синтаксиса информации предсказания указывают, что текущий блок является с внутрикадровым предсказанием, блок 318 внутрикадрового предсказания может формировать блок предсказания в соответствии с режимом внутрикадрового предсказания, указанным элементами синтаксиса информации предсказания. Вновь, блок 318 внутрикадрового предсказания может в целом выполнять процесс внутрикадрового предсказания образом, который в основном аналогичен тому, который описан в отношении блока 226 внутрикадрового предсказания (Фиг. 5). Блок 318 внутрикадрового предсказания может извлекать данные соседних выборок для текущего блока из DPB 314.
[0175] Блок 310 реконструкции может реконструировать текущий блок с использованием блока предсказания и остаточного блока. Например, блок 310 реконструкции может складывать выборки остаточного блока с соответствующими выборками блока предсказания, чтобы реконструировать текущий блок.
[0176] Блок 312 фильтра может выполнять одну или несколько операций фильтра над реконструированными блоками. Например, блок 312 фильтра может выполнять операции устранения блочности, чтобы уменьшать искажения блочности по краям реконструированных блоков. Операции блока 312 фильтра не обязательно выполняются во всех примерах.
[0177] Видеодекодер 300 может сохранять реконструированные блоки в DPB 314. Например, в примерах, в которых операции блока 312 фильтра не выполняются, блок 310 реконструкции может сохранять реконструированные блоки в DPB 314. В примерах, в которых операции блока 312 фильтра выполняются, блок 312 фильтра может сохранять реконструированные блоки после фильтрации в DPB 314. Как обсуждалось выше, DPB 314 может предоставлять опорную информацию, такую как выборки текущей картинки для внутрикадрового предсказания и ранее декодированных картинок для последующей компенсации движения, блоку 304 обработки предсказания. Более того, видеодекодер 300 может выводить декодированные картинки из DPB для последующего представления на дисплейном устройстве, таком как дисплейное устройство 118 на Фиг. 1.
[0178] Таким образом, видеодекодер 300 представляет собой пример устройства декодирования видео, включающего в себя память, выполненную с возможностью хранения видеоданных, и один или несколько блоков обработки, реализованных в схеме и выполненных с возможностью: получения предопределенного индекса наклона (например, SlopeIdx) и предопределенного индекса смещения (например, OffsetIdx) для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса в слайсе видеоданных; определения, на основе предопределенного индекса наклона и предопределенного индекса смещения, первоначального вероятностного состояния контекста для слайса видеоданных; и энтропийного декодирования, на основе первоначального вероятностного состояния контекста, бина значения для элемента синтаксиса.
[0179] Фиг. 19 является блок-схемой, иллюстрирующей примерный способ для кодирования текущего блока. Текущий блок может содержать текущую CU. Несмотря на то, что описано в отношении видеокодера 200 (Фиг. 1 и 5), следует понимать, что другие устройства могут быть выполнены с возможностью выполнения способа, аналогичного тому, что на Фиг. 19.
[0180] В данном примере, видеокодер 200 первоначально предсказывает текущий блок (350). Например, видеокодер 200 может формировать блок предсказания для текущего блока. Видеокодер 200 затем может вычислять остаточный блок для текущего блока (352). Для вычисления остаточного блока, видеокодер 200 может вычислять разность между исходным, не кодированным блоком и блоком предсказания для текущего блока. Видеокодер 200 затем может преобразовывать и квантовать коэффициенты остаточного блока (354). Далее, видеокодер 200 может осуществлять сканирование квантованных коэффициентов преобразования остаточного блока (356). Во время сканирования, или вслед за сканированием, видеокодер 200 может энтропийно кодировать коэффициенты (358). Например, видеокодер 200 может кодировать коэффициенты, и/или другие элементы синтаксиса, с использованием CAVLC или CABAC с использованием методик для инициализации вероятности, которые обсуждаются выше и при обращении к Фиг. 20. Видеокодер 200 затем может выводить энтропийно кодированные данные блока (360).
[0181] Фиг. 20 является блок-схемой, иллюстрирующей примерный процесс для выполнения энтропийного кодирования на основе контекста, в соответствии с одной или несколькими методиками данного изобретения. Методики на Фиг. 20 могут быть выполнены видеокодером, таким как видеокодер 200, проиллюстрированный на Фиг. 1, 5 и 6. Для целей иллюстрации, методики Фиг. 20 описываются в контексте видеокодера 200 с Фиг. 1, 5 и 6, несмотря на то, что видеокодеры с конфигурациями отличными от той, что у видеокодера 200, могут выполнять методики Фиг. 20.
[0182] Видеокодер 200 может получать строку бинов (например, одномерный двоичный вектор), который должен быть кодирован с использованием энтропийного кодирования на основе контекста (например, CABAC) (2002). Например, блок 220 энтропийного кодирования видеокодера 200 может получать строку бинов путем бинаризации элемента синтаксиса, принятого от блока 202 выбора режима видеокодера 200.
[0183] Видеокодер 200 может получать предопределенное значение инициализации для контекста из множества контекстов (2004). Например, блок 220 энтропийного кодирования видеокодера 200 может получать значение initValue, которое может быть шестибитовой переменной.
[0184] Видеокодер 200 может определять, на основе предопределенного значения инициализации, первоначальное вероятностное состояние контекста для независимо кодируемой единицы (например, слайса, тайла и т.д.) видеоданных в линейной области (2006). Например, блок 220 энтропийного кодирования может определять первоначальное вероятностное состояние контекста в линейной области без промежуточного определения первоначального вероятностного состояния контекста в логарифмической области. В некоторых примерах, блок 220 энтропийного кодирования может определять первоначальное вероятностное состояние без использования LUT для преобразования первоначального вероятностного состояния из логарифмической области в линейную область.
[0185] Для определения первоначального вероятностного состояния, блок 220 энтропийного кодирования может получать первоначальное значение параметра квантования, ассоциированного с независимо кодируемой единицей (например, SliceQPY), и получать значение точки привязки параметра квантования, которое не является нулем (например, QPanchor). Блок 220 энтропийного кодирования может определять первоначальное вероятностное состояние на основе разности между первоначальным значением параметра квантования для слайса и значением точки привязки параметра квантования. Например, блок 220 энтропийного кодирования может определять первоначальное вероятностное состояние в соответствии со следующим уравнением:
InitProbState=((m*(SliceQPY - QPanchor))>>rshift)+n.
где InitProbState является первоначальным вероятностным состоянием, SliceQPY является первоначальным значением параметра квантования, QPanchor является точкой привязки параметра квантования, и rshift является значением сдвига вправо.
[0186] Как обсуждалось выше, в некоторых примерах, блок 220 энтропийного кодирования может быть выполнен с возможностью выполнения инициализации с увеличенной точностью для экстремальных распределений вероятности. Например, блок 220 энтропийного кодирования может определять, на основе предопределенного значения инициализации, значение индекса наклона и значение индекса смещения. Блок 220 энтропийного кодирования может определять, на основе значения индекса наклона, значение m; и определять, на основе значения индекса смещения, значение n. В некоторых примерах, блок 220 энтропийного кодирования может определять значение n, в соответствии со следующим уравнением n=(OffsetIdx*18)+1 где OffsetIdx является значением индекса смещения. Как показано выше, в некоторых примерах, блок 220 энтропийного кодирования может определять первоначальное вероятностное состояние на основе значения m и значения n.
[0187] Видеокодер 200 может кодировать, в битовый поток видео и на основе первоначального вероятностного состояния контекста, бин строки бинов (2008). Например, блок 220 энтропийного кодирования может выводить двоичный поток, который представляет собой значение или указатель на вероятность в итоговом кодированном интервале вероятности контекста.
[0188] Фиг. 21 является блок-схемой, иллюстрирующей примерный способ для декодирования текущего блока видеоданных. Текущий блок может содержать текущую CU. Несмотря на то, что описан в отношении видеодекодера 300 (Фиг. 1 и 7), следует понимать, что другие устройства могут быть выполнены с возможностью выполнения способа аналогичного тому, что на Фиг. 21.
[0189] Видеодекодер 300 может принимать энтропийно кодированные данные для текущего блока, такие как энтропийно кодированную информацию предсказания и энтропийно кодированные данные для коэффициентов остаточного блока, соответствующего текущему блоку (370). Видеодекодер 300 может энтропийно декодировать энтропийно кодированные данные, чтобы определять информацию предсказания для текущего блока и воссоздавать коэффициенты остаточного блока (372). Например, видеодекодер 300 может декодировать коэффициенты, и/или другие элементы синтаксиса, с использованием CAVLC или CABAC с использованием методик для инициализации вероятности, которые обсуждаются выше и при обращении к Фиг. 22. Видеодекодер 300 может предсказывать текущий блок (374), например, с использованием режима внутрикадрового или межкадрового предсказания, как указано информацией предсказания для текущего блока, чтобы вычислять блок предсказания для текущего блока. Видеодекодер 300 затем может осуществлять обратное сканирование воссозданных коэффициентов (376), чтобы создавать блок квантованных коэффициентов преобразования. Видеодекодер 300 затем может обратно квантовать и обратно преобразовывать коэффициенты, чтобы создавать остаточный блок (378). Видеодекодер 300 может в итоге декодировать текущий блок путем объединения блока предсказания и остаточного блока (380).
[0190] Фиг. 22 является блок-схемой, иллюстрирующей примерный процесс для выполнения энтропийного декодирования на основе контекста, в соответствии с одной или несколькими методиками данного изобретения. Методики на Фиг. 22 могут быть выполнены видеодекодером, таким как видеодекодер 300, проиллюстрированный на Фиг. 1, 7 и 8. Для целей иллюстрации, методики Фиг. 22 описываются в контексте видеодекодера 300 с Фиг. 1, 7 и 8, несмотря на то, что видеодекодеры с конфигурациями отличными от той, что у видеодекодера 300, могут выполнять методики Фиг. 22.
[0191] Видеодекодер 300 может получать, из битового потока, строку бинов (например, одномерный двоичный вектор), который должен быть декодирован с использованием энтропийного декодирования на основе контекста (2202). Например, блок 302 энтропийного декодирования видеодекодера 300 может получать, из памяти 320 CPB, строку бинов. В некоторых примерах, строка бинов может представлять собой значение или указатель на вероятность в итоговом кодированном интервале вероятности контекста. В некоторых примерах, энтропийное кодирование на основе контекста может содержать контекстно-адаптивное двоичное арифметическое кодирование (CABAC).
[0192] Видеодекодер 300 может получать предопределенное значение инициализации для контекста из множества контекстов (2204). Например, блок 302 энтропийного декодирования видеодекодера 300 может получать значение initValue, которое может быть шестибитовой переменной.
[0193] Видеодекодер 300 может определять, на основе предопределенного значения инициализации, первоначальное вероятностное состояние контекста для независимо кодируемой единицы видеоданных (например, слайса, тайла и т.д.) в линейной области (2206). Например, блок 302 энтропийного декодирования может определять первоначальное вероятностное состояние контекста в линейной области без промежуточного определения первоначального вероятностного состояния контекста в логарифмической области. В некоторых примерах, блок 302 энтропийного декодирования может определять первоначальное вероятностное состояние без использования LUT для преобразования первоначального вероятностного состояния из логарифмической области в линейную область.
[0194] Для определения первоначального вероятностного состояния, блок 302 энтропийного декодирования может получать первоначальное значение параметра квантования для независимо кодируемой единицы (например, SliceQPY) и получать значение точки привязки параметра квантования, которое не является нулем (например, QPanchor). Блок 302 энтропийного декодирования может определять первоначальное вероятностное состояние на основе разности между первоначальным значением параметра квантования для независимо кодируемой единицы и значением точки привязки параметра квантования. Например, блок 302 энтропийного декодирования может определять первоначальное вероятностное состояние в соответствии со следующим уравнением:
InitProbState=((m*(SliceQPY - QPanchor))>>rshift)+n.
где InitProbState является первоначальным вероятностным состоянием, SliceQPY является первоначальным значением параметра квантования, QPanchor является точкой привязки параметра квантования, и rshift является значением сдвига вправо.
[0195] Как обсуждалось выше, в некоторых примерах, блок 302 энтропийного декодирования может быть выполнен с возможностью выполнения инициализации с увеличенной точностью для экстремальных распределений вероятности. Например, блок 302 энтропийного декодирования может определять, на основе предопределенного значения инициализации, значение индекса наклона и значение индекса смещения. Блок 302 энтропийного декодирования может определять, на основе значения индекса наклона, значение m; и определять, на основе значения индекса смещения, значение n. В некоторых примерах, блок 302 энтропийного декодирования может определять значение n, в соответствии со следующим уравнением n=(OffsetIdx*18)+1, где OffsetIdx является значением индекса смещения. Как показано выше, в некоторых примерах, блок 302 энтропийного декодирования может определять первоначальное вероятностное состояние на основе значения m и значения n.
[0196] Видеодекодер 300 может декодировать, на основе первоначального вероятностного состояния контекста, бин строки бинов (2208). Видеодекодер 300 может определять, на основе декодированного бина и первоначального вероятностного состояния контекста, обновленное вероятностное состояние контекста. Видеодекодер 300 может декодировать, на основе обновленного вероятностного состояния контекста, другой бин (2206).
[0197] Нижеследующие пронумерованные примеры могут иллюстрировать один или несколько аспектов изобретения:
[0198] Пример 1A. Способ для энтропийного кодирования видеоданных, причем способ, содержащий этапы, на которых: получают предопределенный индекс наклона и предопределенный индекс смещения для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса в слайсе видеоданных; определяют, на основе предопределенного индекса наклона и предопределенного индекса смещения, первоначальное вероятностное состояние контекста для слайса видеоданных; и энтропийно кодируют, на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса.
[0199] Пример 2A. Способ примера 1A, в котором первоначальное вероятностное состояние представляет собой первоначальную вероятность в линейной области.
[0200] Пример 3A. Способ примера 1A, в котором первоначальное вероятностное состояние представляет собой первоначальную вероятность в квадратичной области.
[0201] Пример 4A. Способ примера 3A, в котором этап, на котором определяют первоначальное вероятностное состояние, выполняется без использования таблицы поиска (LUT) для отображения между предопределенным индексом наклона, предопределенным индексом смещения и первоначальным вероятностным состоянием.
[0202] Пример 5A. Способ любого сочетания примеров 1A-4A, в котором первоначальное вероятностное состояние представляется посредством InitProbState, индекс наклона представляется посредством SlopeIndx и индекс смещения представляется посредством OffsetIdx.
[0203] Пример 6A. Способ любого из примеров 1A-5A, в котором процесс контекстно-адаптивного энтропийного кодирования содержит процесс контекстно-адаптивного двоичного арифметического кодирования (CABAC) или процесс контекстно-адаптивного кодирования с переменной длиной кодового слова (CAVLC).
[0204] Пример 7A. Способ любого из примеров 1A-6A, в котором этап, на котором кодируют, содержит декодирование.
[0205] Пример 8A. Способ любого из примеров 1A-7A, в котором этап, на котором кодируют, содержит кодирование.
[0206] Пример 9A. Устройство для кодирования видеоданных, причем устройство, содержащее одно или несколько средств для выполнения способа любого из примеров 1A-8A.
[0207] Пример 10A. Устройство примера 9A, в котором одно или несколько средств содержат один или несколько процессоров, реализованных в схеме.
[0208] Пример 11A. Устройство любого из примеров 9A и 10A, дополнительно содержащее память, чтобы хранить видеоданные.
[0209] Пример 12A. Устройство любого из примеров 9A-11A, дополнительно содержащее дисплей, выполненный с возможностью демонстрации декодированных видеоданных.
[0210] Пример 13A. Устройство любого из примеров 9A-12A, при этом устройство выполнено в виде одного или нескольких из камеры, компьютера, мобильного устройства, устройства широковещательного приемника или телевизионной приставки.
[0211] Пример 14A. Устройство любого из примеров 9A-13A, при этом устройство содержит видеодекодер.
[0212] Пример 15A. Устройство любого из примеров 9A-14A, при этом устройство содержит видеокодер.
[0213] Пример 16A. Машиночитаемый запоминающий носитель информации с хранящимися на нем инструкциями, которые, когда исполняются, предписывают одному или нескольким процессорам выполнять способ любого из примеров 1A-8A.
[0214] Пример 1B. Способ для энтропийного кодирования видеоданных, причем способ, содержащий этапы, на которых: получают предопределенный индекс смещения для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса в слайсе видеоданных; определяют, на осознании предопределенного индекса смещения, первоначальное вероятностное состояние контекста для слайса видеоданных; и энтропийно кодируют, на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса.
[0215] Пример 2B. Способ примера 1B, в котором первоначальное вероятностное состояние представляет собой первоначальную вероятность в линейной области.
[0216] Пример 3B. Способ примера 1B, в котором первоначальное вероятностное состояние представляет собой первоначальную вероятность в квадратичной области.
[0217] Пример 4B. Способ примера 3B, в котором этап, на котором определяют первоначальное вероятностное состояние, выполняется без использования таблицы поиска (LUT) для отображения между предопределенным индексом смещения и первоначальным вероятностным состоянием.
[0218] Примере 5B. Способ любого сочетания примеров 1B-4B, в котором первоначальное вероятностное состояние представляется посредством InitProbeState, а индекс смещения представляется посредством OffsetIdx.
[0219] Пример 6B. Способ любого из примеров 1B-5B, в котором процесс контекстно-адаптивного энтропийного кодирования содержит процесс контекстно-адаптивного двоичного арифметического кодирования (CABAC) или процесс контекстно адаптивного кодирования с переменной длиной кодового слова (CAVLC).
[0220] Пример 7B. Способ любого из примеров 1B-6B, в котором этап, на котором кодируют содержит декодирование.
[0221] Пример 8B. Способ любого из примеров 1B-7B, в котором этап, на котором кодируют содержит кодирование.
[0222] Пример 9B. Устройство для кодирования видеоданных, причем устройство, содержащее одно или несколько средств для выполнения способа любого из примеров 1B-8B.
[0223] Пример 10B. Устройство примера 9B, в котором одно или несколько средств содержат один или несколько процессоров, реализованных в схеме.
[0224] Пример 11B. Устройство любого из примеров 9B и 10B, дополнительно содержащее память, чтобы хранить видеоданные.
[0225] Пример 12B. Устройство любого из примеров 9B-11B, дополнительно содержащее дисплей, выполненный с возможностью демонстрации декодированных видеоданных.
[0226] Пример 13B. Устройство любого из примеров 9B-12B, при этом устройство выполнено в виде одного или нескольких из камеры, компьютера, мобильного устройства, устройства широковещательного приемника или телевизионной приставки.
[0227] Пример 14B. Устройство любого из примеров 9B-13B, при этом устройство содержит видеодекодер.
[0228] Пример 15B. Устройство любого из примеров 9B-14B, при этом устройство содержит видеокодер.
[0229] Пример 16B. Машиночитаемый запоминающий носитель информации с хранящимися на нем инструкциями, которые, когда исполняются, предписывают одному или нескольким процессорам выполнять способ любого из примеров 1B-8B.
[0230] Пример 1C. Способ для энтропийного кодирования видеоданных, причем способ, содержащий этапы, на которых: определяют, на основе значения переменной, первое промежуточное значение; определяют, на основе первого промежуточного значения, значение вероятностного состояния низкой точности у контекстной модели, при этом этап, на котором определяют значение вероятностного состояния низкой точности, содержит этап, на котором осуществляют сдвиг вправо первого промежуточного значения; и кодируют, на основе значения вероятностного состояния низкой точности у контекстной модели, значение по меньшей мере одного бита элемента синтаксиса.
[0231] Пример 2C. Способ примера 1C, в котором этап, на котором определяют первое промежуточное значение, содержит этап, на котором определяют первое промежуточное значение в соответствии со следующим уравнением: q=Clip3(18, 46, SliceQPY) - 16, где q является первый промежуточным значением, а SliceQPY является значением переменной.
[0232] Пример 3C. Способ примера 1C или примера 2C, в котором этап, на котором определяют значение вероятностного состояния низкой точности у контекстной модели, содержит этап, на котором определяют значение вероятностного состояния низкой точности у контекстной модели в соответствии со следующим уравнением: ProbabilityStateL=16 * a + ((b - a) * q >> 1) + 8, где q является первым промежуточным значением, ProbabilityStateL является значением вероятностного состояния низкой точности у контекстной модели, a является вторым промежуточным значением и b является третьим промежуточным значением.
[0233] Пример 4C. Способ примера 3C, дополнительно содержащий этап, на котором определяют значения для a и b в соответствии со следующими уравнениями: a = (initValue >> 3) * 9 b = (initValue & 7) * 9, где initValue является значением инициализации.
[0234] Пример 5C. Способ любого из примеров 1C-4C, дополнительно содержащий этап, на котором определяют, на основе значения вероятностного состояния низкой точности у контекстной модели, значение вероятностного состояния высокой точности у контекстной модели.
[0235] Пример 6C. Способ примера 5C, в котором этап, на котором определяют значение вероятностного состояния высокой точности у контекстной модели, содержит этап, на котором определяют значение вероятностного состояния высокой точности у контекстной модели в соответствии со следующим уравнением: ProbabilityStateH = ProbabilityStateL << 4, где ProbabilityStateH является значением вероятностного состояния высокой точности у контекстной модели, а ProbabilityStateL является значением вероятностного состояния низкой точности у контекстной модели.
[0236] Пример 7C. Способ любого из примеров 1C-6C, в котором процесс контекстно-адаптивного энтропийного кодирования содержит процесс контекстно-адаптивного двоичного арифметического кодирования (CABAC) или процесс контекстно адаптивного кодирования с переменной длиной кодового слова (CAVLC).
[0237] Пример 8C. Способ любого из примеров 1C-7C, в котором этап, на котором кодируют содержит декодирование.
[0238] Пример 9C. Способ любого из примеров 1C-8C, в котором этап, на котором кодируют содержит кодирование.
[0239] Пример 10C. Устройство для кодирования видеоданных, причем устройство, содержащее одно или несколько средств для выполнения способа любого из примеров 1C-9C.
[0240] Пример 11C. Устройство примера 10C, в котором одно или несколько средств содержат один или несколько процессоров, реализованных в схеме.
[0241] Пример 12C. Устройство любого из примеров 10C и 11C, дополнительно содержащее память, чтобы хранить видеоданные.
[0242] Пример 13C. Устройство любого из примеров 10C-12C, дополнительно содержащее дисплей, выполненный с возможностью демонстрации декодированных видеоданных.
[0243] Пример 14C. Устройство любого из примеров 10C-13C, при этом устройство выполнено в виде одного или нескольких из камеры, компьютера, мобильного устройства, устройства широковещательного приемника или телевизионной приставки.
[0244] Пример 15C. Устройство любого из примеров 10C-14C, при этом устройство содержит видеодекодер.
[0245] Пример 16C. Устройство любого из примеров 10C-15C, при этом устройство содержит видеокодер.
[0246] Пример 17C. Машиночитаемый запоминающий носитель информации с хранящимися на нем инструкциями, которые, когда исполняются, предписывают одному или нескольким процессорам выполнять способ любого из примеров 1C-9C.
[0247] Следует понимать, что в зависимости от примера, определенные действия или события любой из методик, описанных в данном документе, могут быть выполнены в другой последовательности, могут быть добавлены, объединены или полностью исключены (например, не все описанные действия или события необходимы для воплощения методик на практике). Более того, в определенных примерах, действия или события могут быть выполнены параллельно, например, посредством многопоточной обработки, обработки прерываний или нескольких процессоров, а не последовательно.
[0248] В одном или нескольких примерах, описанные функции могут быть реализованы в аппаратном обеспечении, программном обеспечении, встроенном программном обеспечении или любом их сочетании. При реализации в программном обеспечении, функции могут быть сохранены, или переданы через, в качестве одной или нескольких инструкций, или кода, на машиночитаемом носителе информации и исполнены блоком обработки на основе аппаратного обеспечения. Машиночитаемые носители информации могут включать в себя машиночитаемые запоминающие носители информации, которые соответствуют вещественному носителю информации, такому как носители информации для хранения данных, или средствам связи, включающим в себя любое средство, которое способствует переносу компьютерной программы из одного места в другое, например, в соответствии с протоколом связи. Таким образом, машиночитаемые носители информации в целом соответствуют (1) вещественным машиночитаемым запоминающим носителям информации, которые являются не временными, или (2) средству связи, такому как сигнал или несущая волна. Носители информации для хранения данных могут быть любыми доступными носителями информации, доступ к которым может быть осуществлен посредством одного или нескольких компьютеров, или одного или нескольких процессоров, чтобы извлекать инструкции, код и/или структуры данных для реализации методик, описанных в данном изобретении. Компьютерный программный продукт может включать в себя машиночитаемый носитель информации.
[0249] В качестве примера, а не ограничения, такие машиночитаемые запоминающие носители информации могут содержать RAM, ROM, EEPROM, CD-ROM или другое хранилище на оптическом диске, хранилище на магнитном диске или другие магнитные запоминающие устройства, флэш-память или другой носитель информации, который может быть использован, чтобы хранить требуемый программный код в форме инструкций или структур данных, и доступ к которому может быть осуществлен посредством компьютера. Также, любое соединение правильно называть машиночитаемым носителем информации. Например, если инструкции передаются от веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, оптоволоконного кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасная, радио и микроволновая, тогда коаксиальный кабель, оптоволоконный кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасная, радио и микроволновая, включаются в определение носителя информации. Однако следует понимать, что машиночитаемые запоминающие носители информации и носители информации для хранения данных не включают в себя соединения, несущие волны, сигналы или другие временные средства, а вместо этого направлены на не временные, вещественные запоминающие носители информации. Магнитный диск и оптический диск, для целей данного документа, включают в себя компакт диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), гибкий диск и диск Blu-ray, причем магнитные диск обычно воспроизводят данные магнитным образом при том, что оптические диски воспроизводят данные оптическим образом с помощью лазеров. Сочетания вышеприведенного также должны быть включены в объем машиночитаемых носителей информации.
[0250] Инструкции могут быть исполнены одним или несколькими процессорами, такими как один или несколько цифровых сигнальных процессоров (DSP), микропроцессоров общего назначения, проблемно-ориентированных интегральных микросхем (ASIC), программируемых вентильных матриц (FPGA) или другой эквивалентной интегральной микросхемы или схемы с дискретной логикой. Соответственно, понятия «процессор» и «схема обработки», для целей данного документа, могут относиться к любой из вышеприведенных структур и любой другой структуре, подходящей для реализации методик, описанных в данном документе. В дополнение, в некоторых аспектах, функциональные возможности, описанные в данном документе, могут быть обеспечены в выделенном аппаратном обеспечении и/или модулях программного обеспечения, сконфигурированных для кодирования и декодирования, или включенных в объединенный кодек. Также методики могут быть полностью реализованы в одной или нескольких схемах, или логических элементах.
[0251] Методики данного изобретения могут быть реализованы в широком многообразии устройств или аппаратур, включая беспроводную телефонную трубку, интегральную микросхему (IC) или набор IC (например, чипсет). Различные компоненты, модули или блоки описаны в данном изобретении, чтобы подчеркнуть функциональные аспекты устройств, выполненных с возможностью выполнения раскрытых методик, но не обязательно требует реализации посредством разных аппаратных блоков. Наоборот, как описано выше, различные блоки могут быть объединены в аппаратный блок кодека или предоставлены совокупностью взаимодействующих аппаратных блоков, включая один или несколько процессоров, как описано выше, вместе с подходящим программным обеспечением и/или встроенным программным обеспечением.
[0252] Были описаны различные примеры. Эти и прочие примеры находятся в рамках объема нижеследующей формулы изобретения.
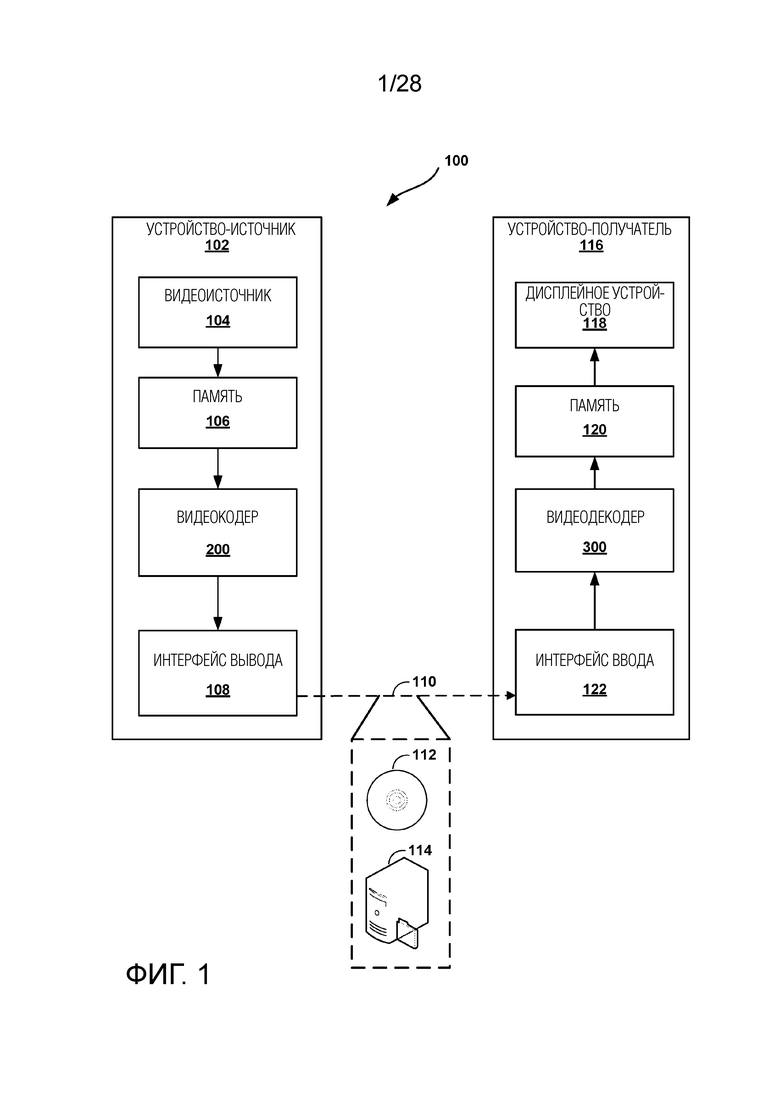
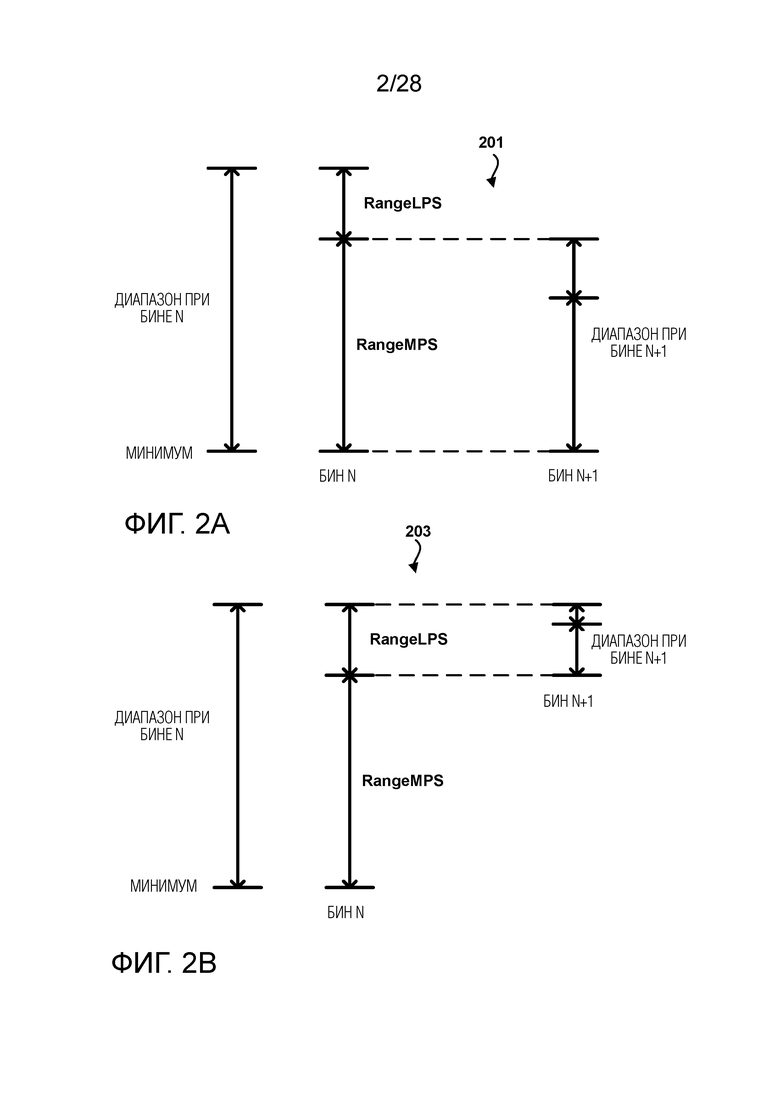
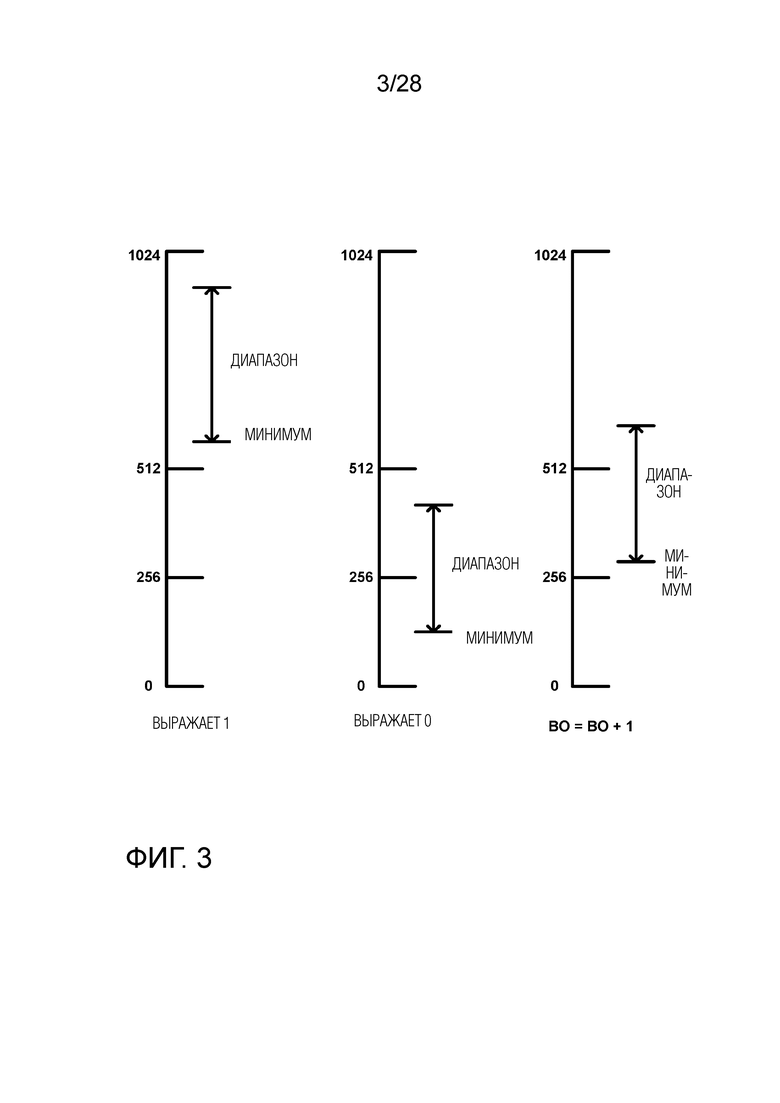
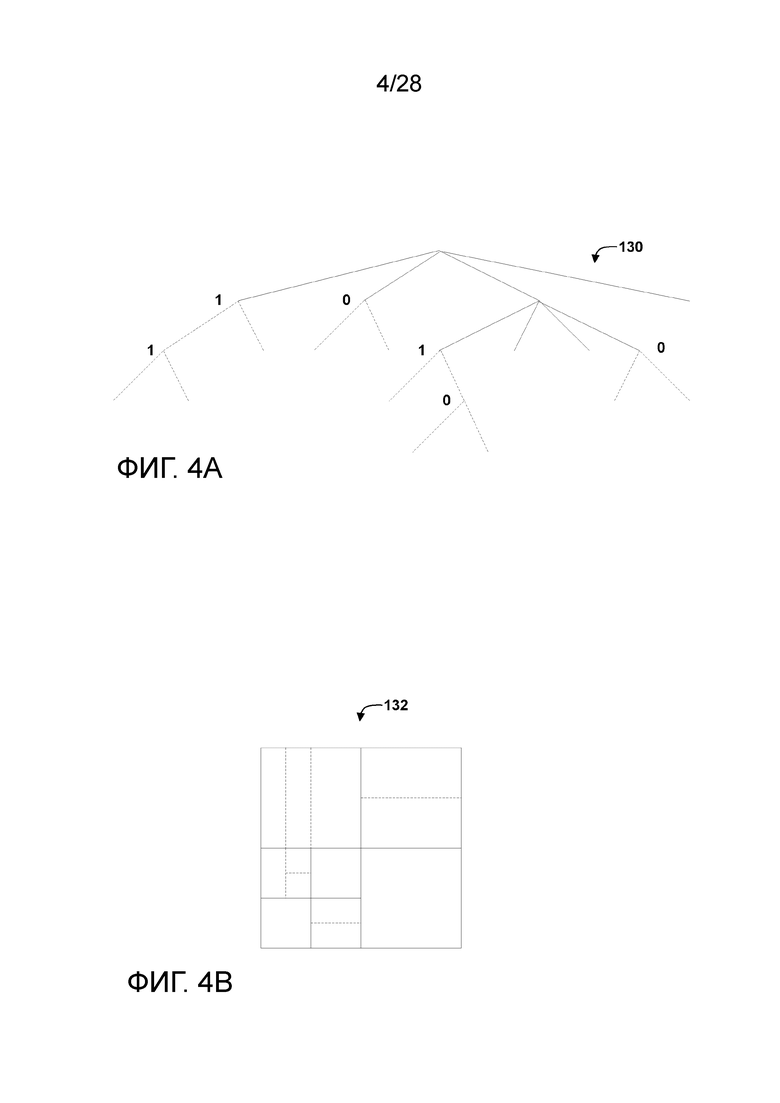
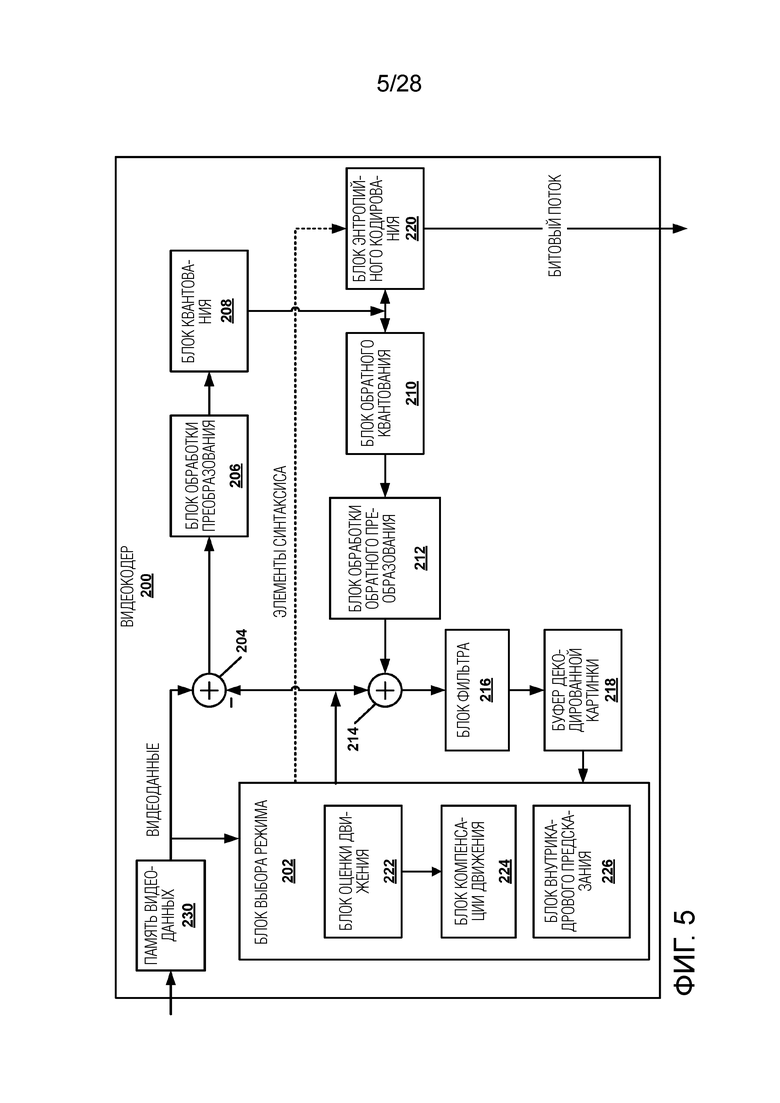
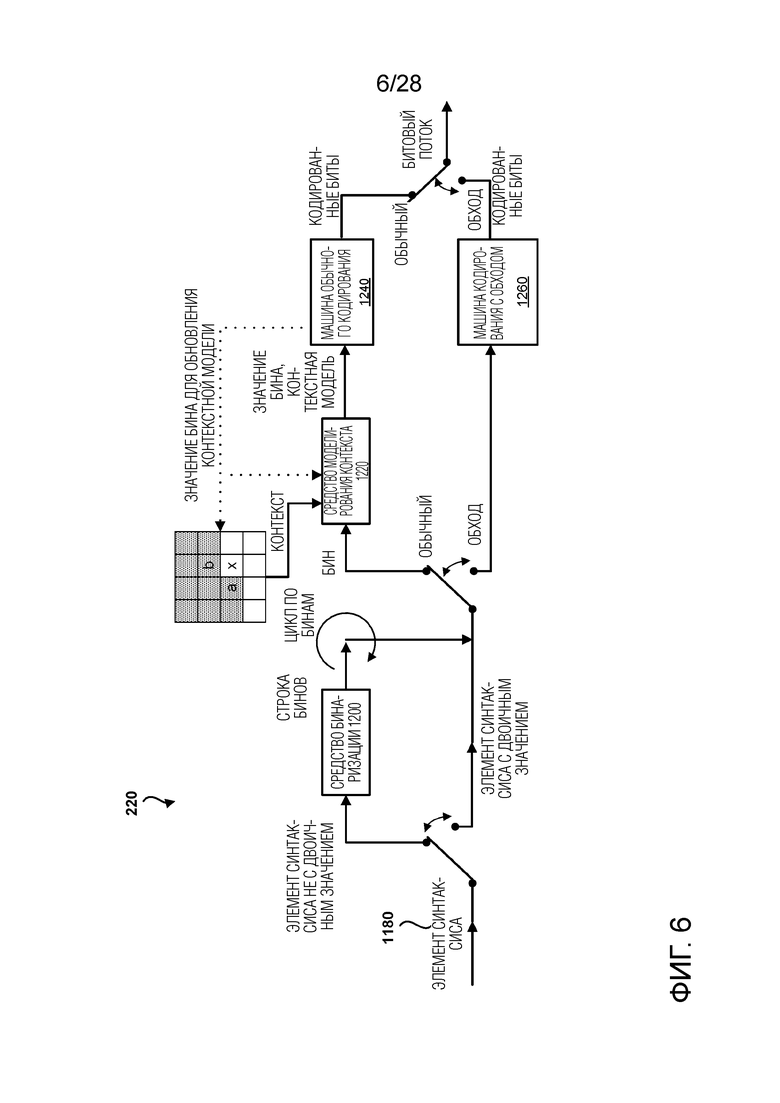
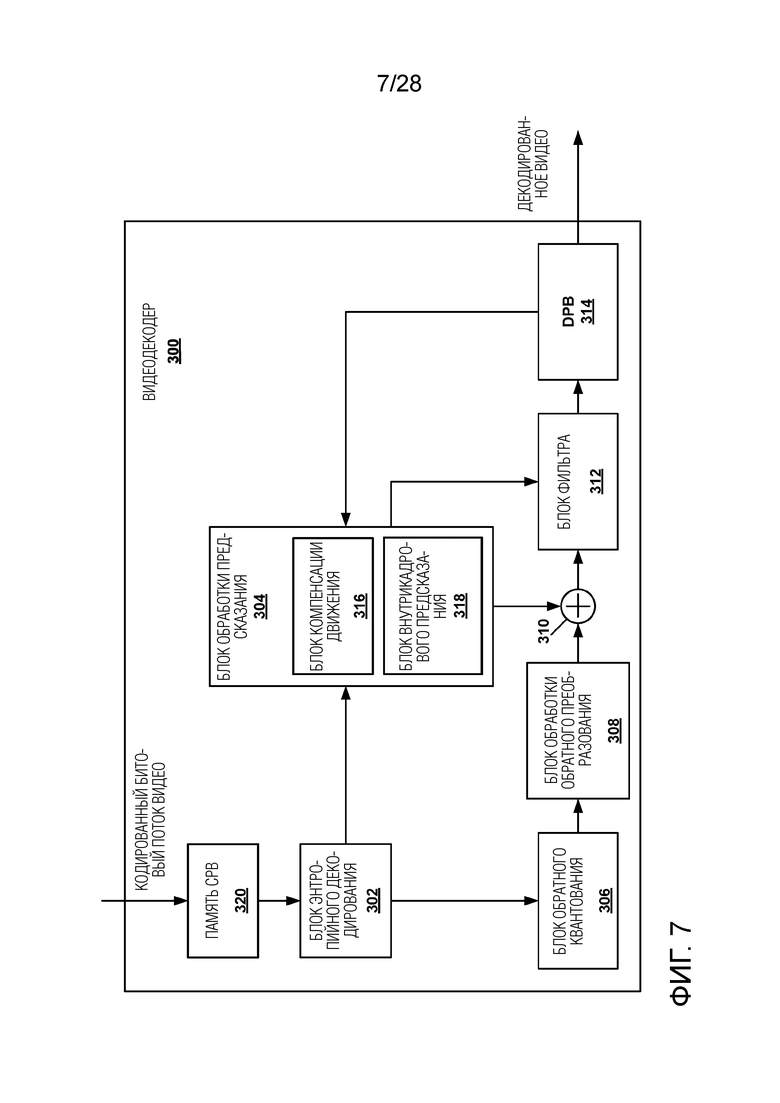
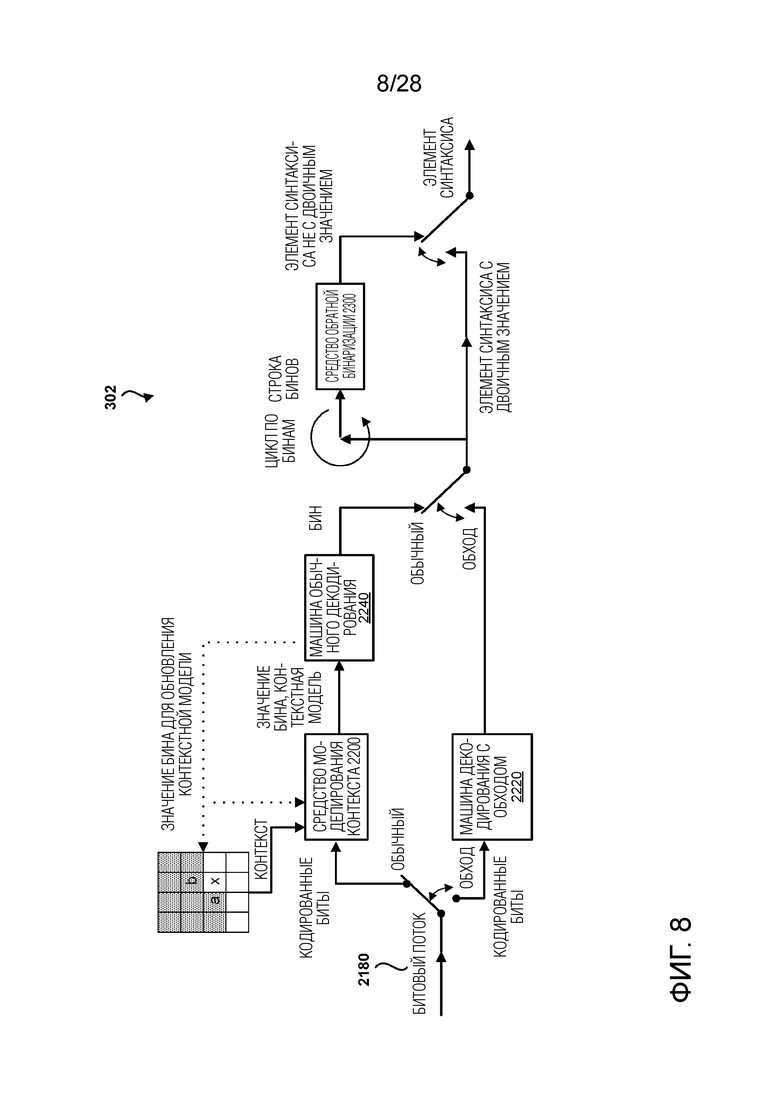
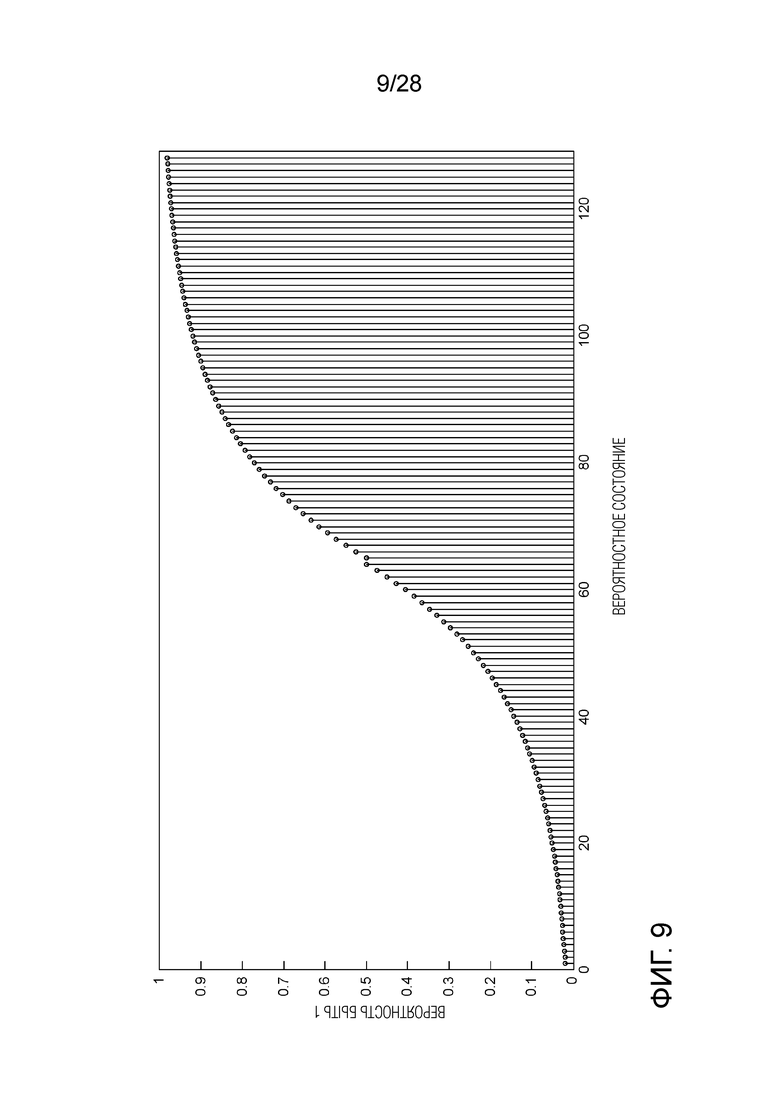
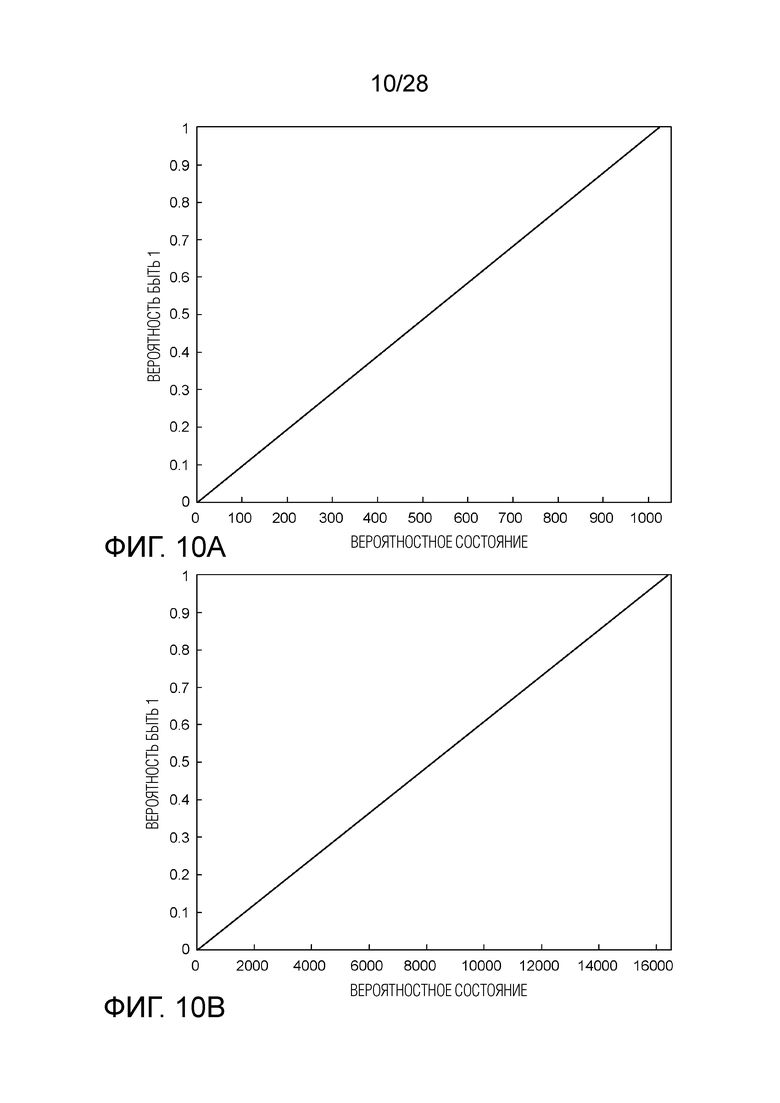
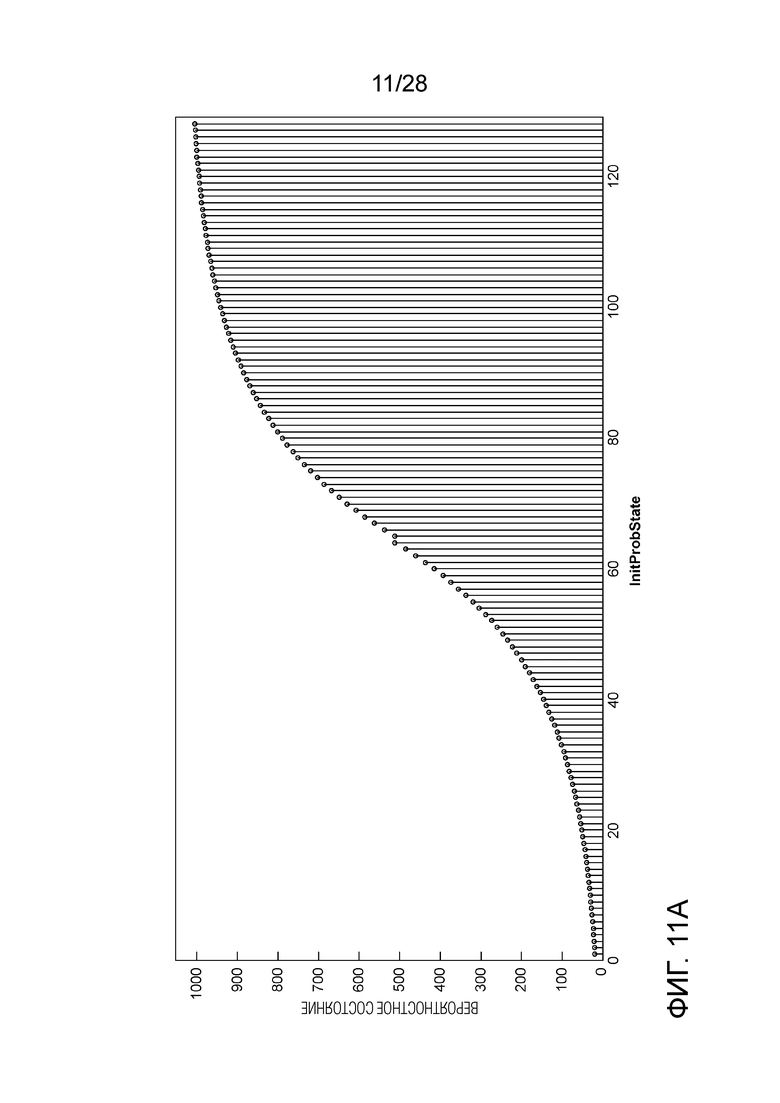
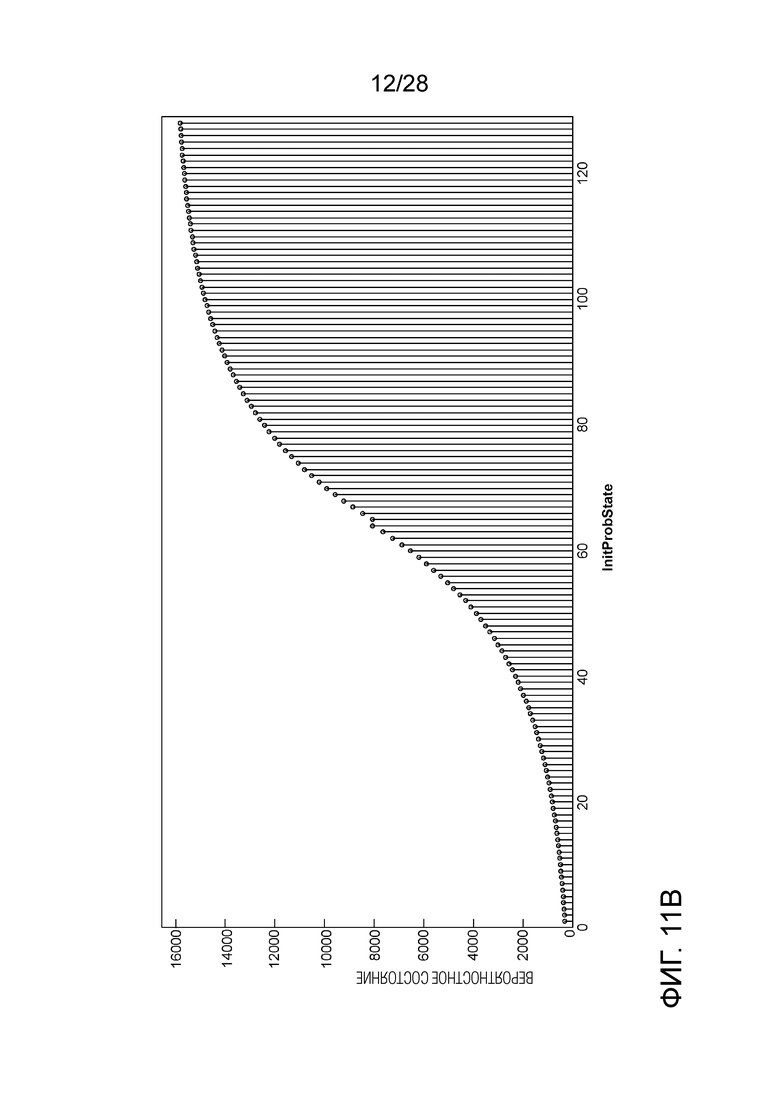
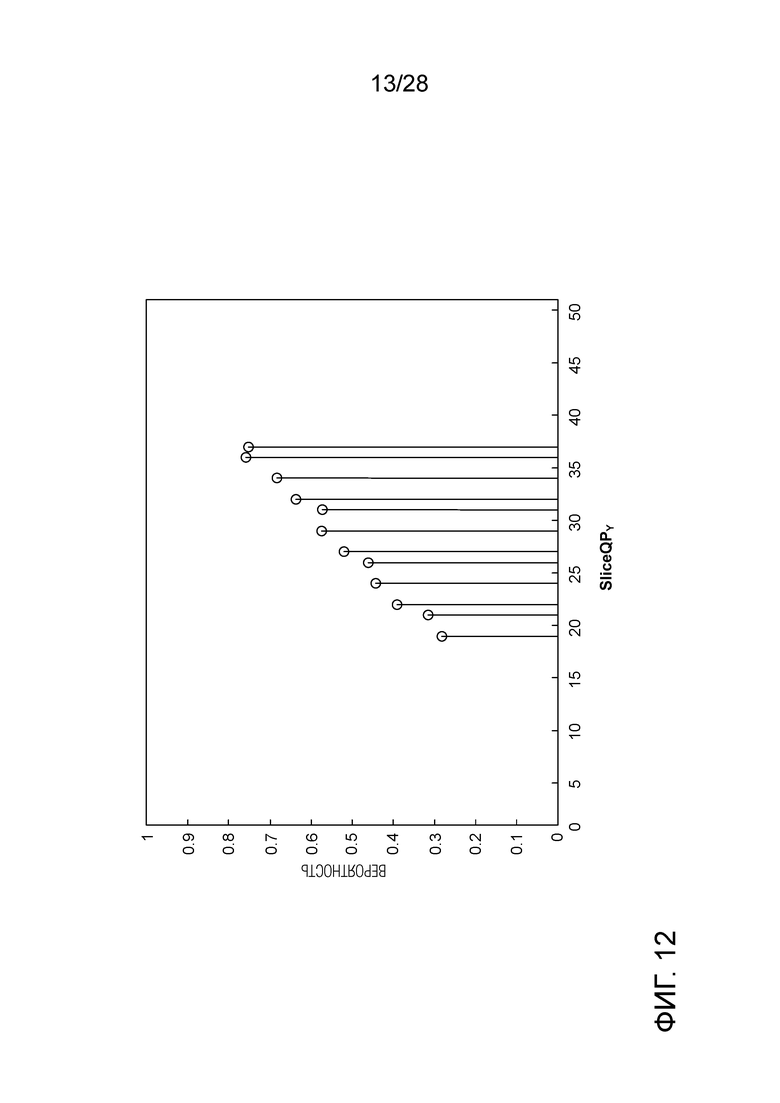
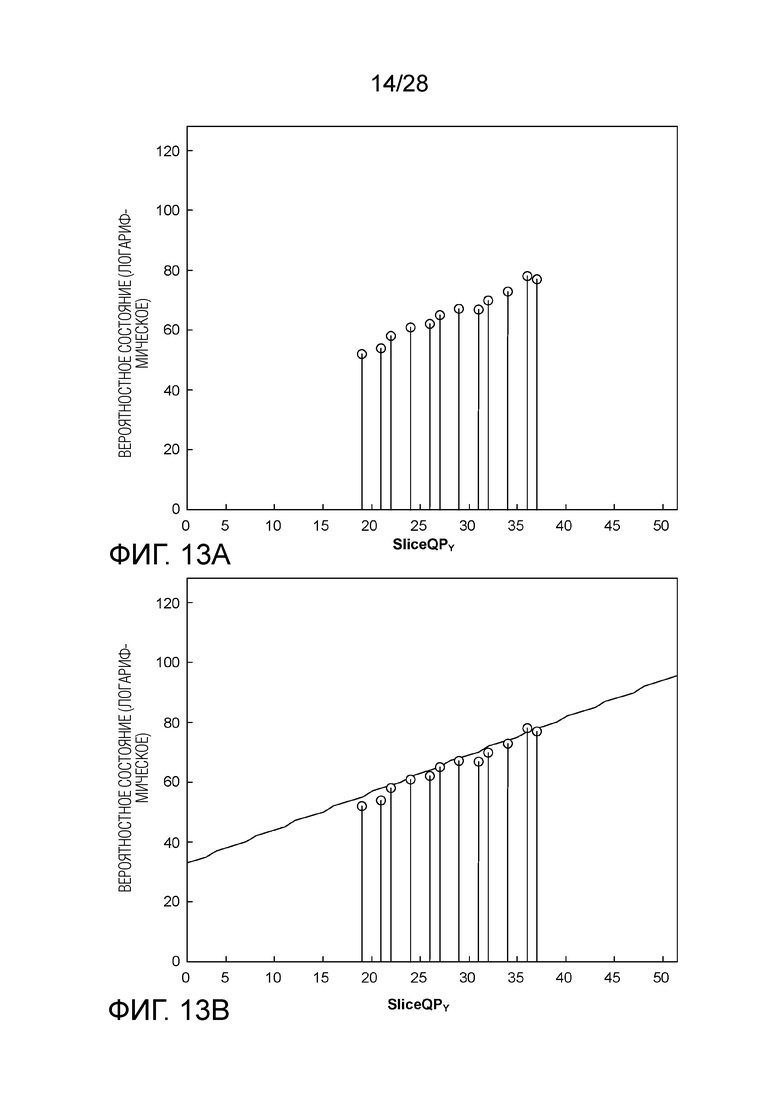
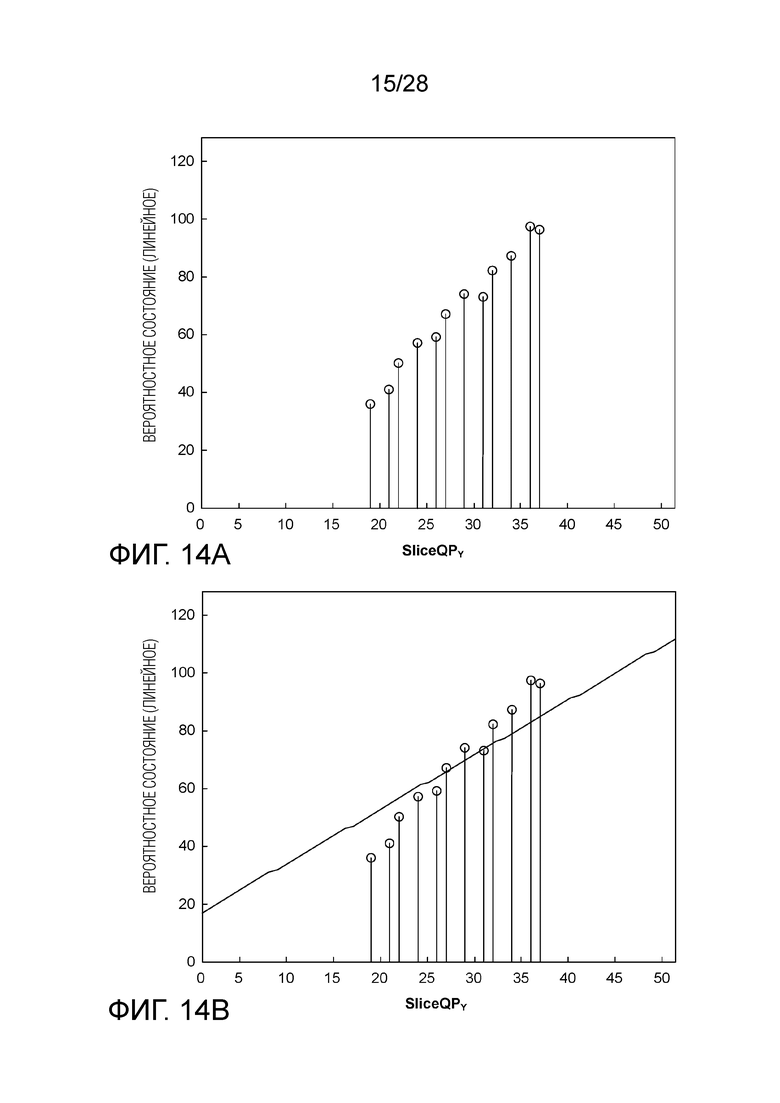
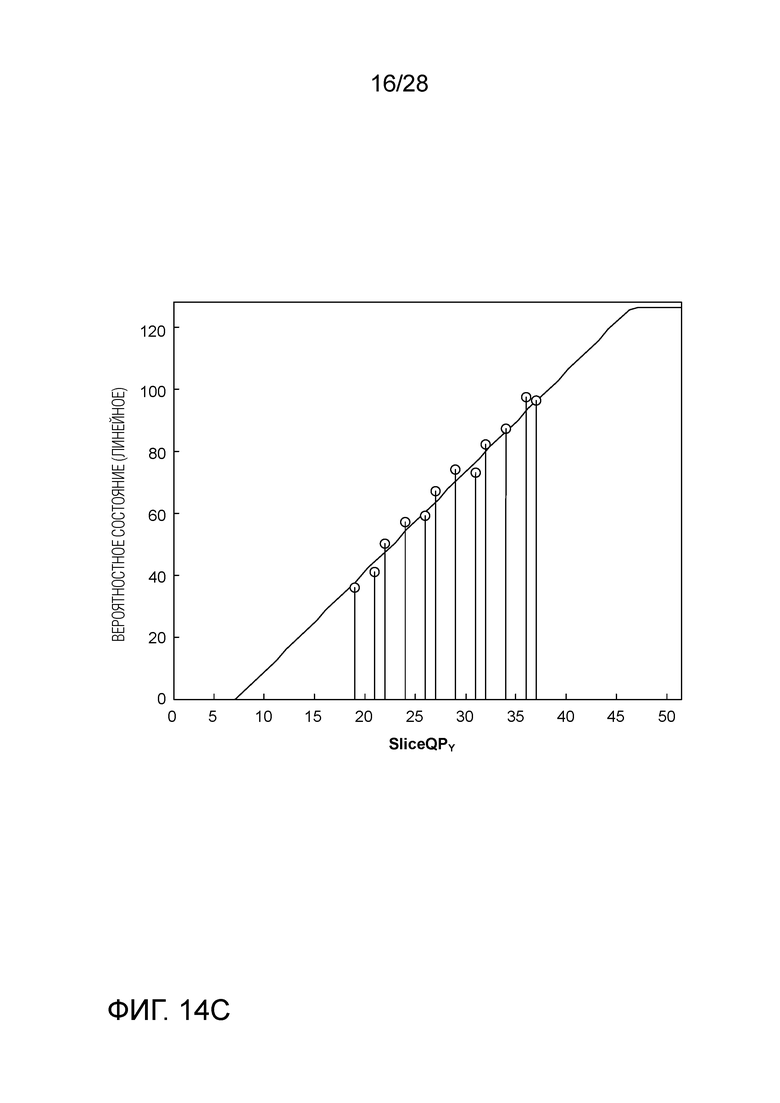
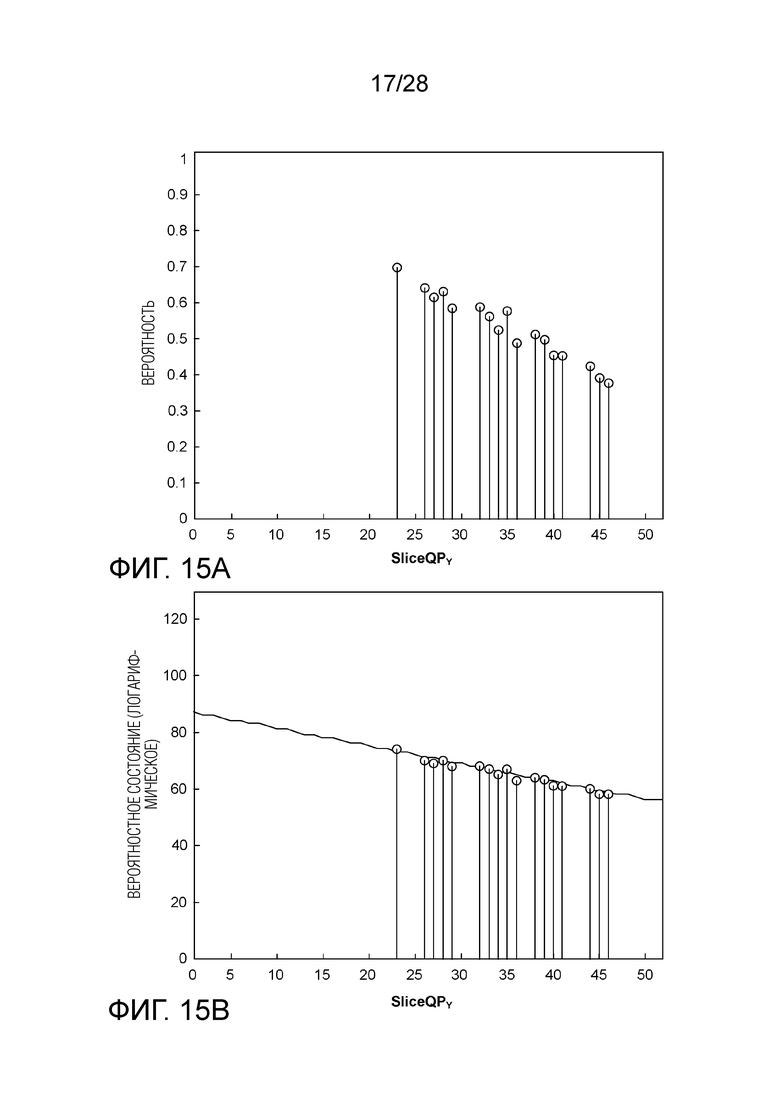
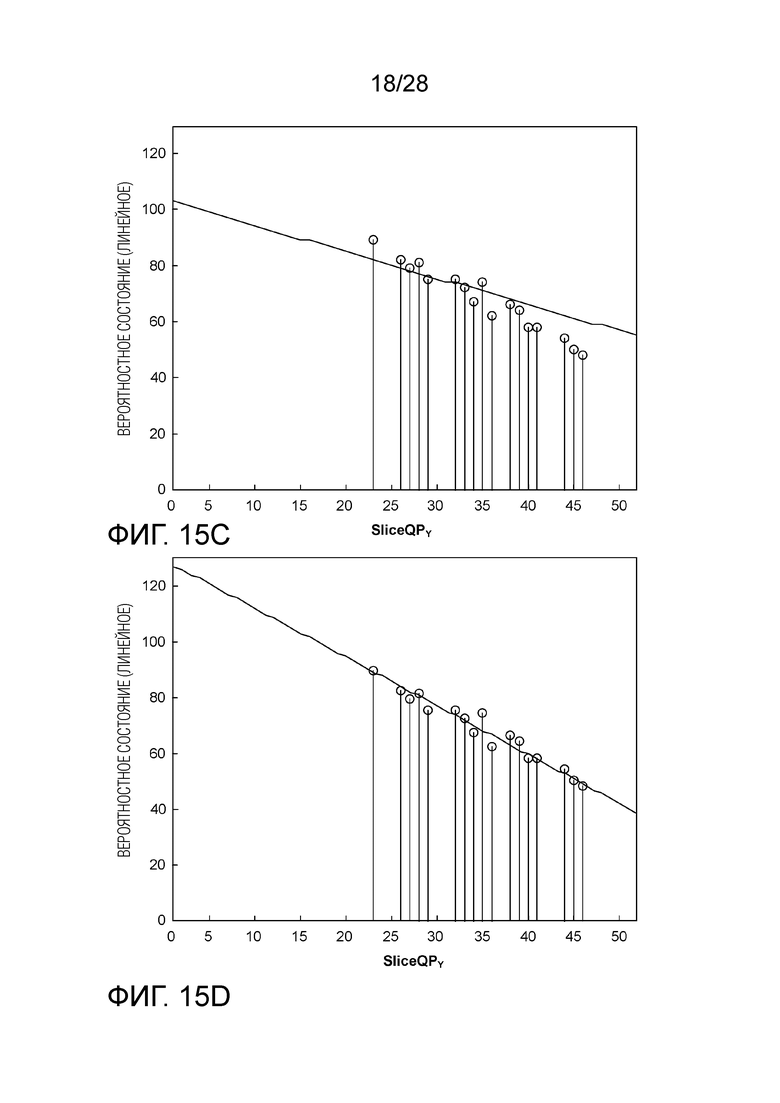
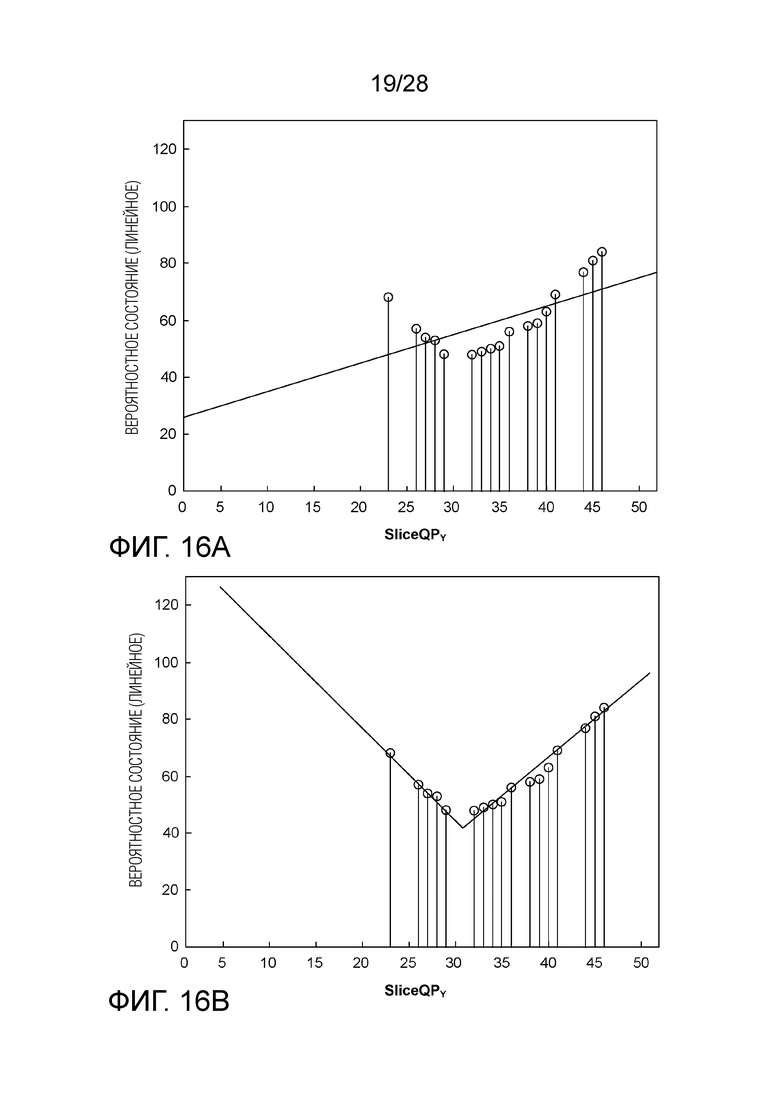
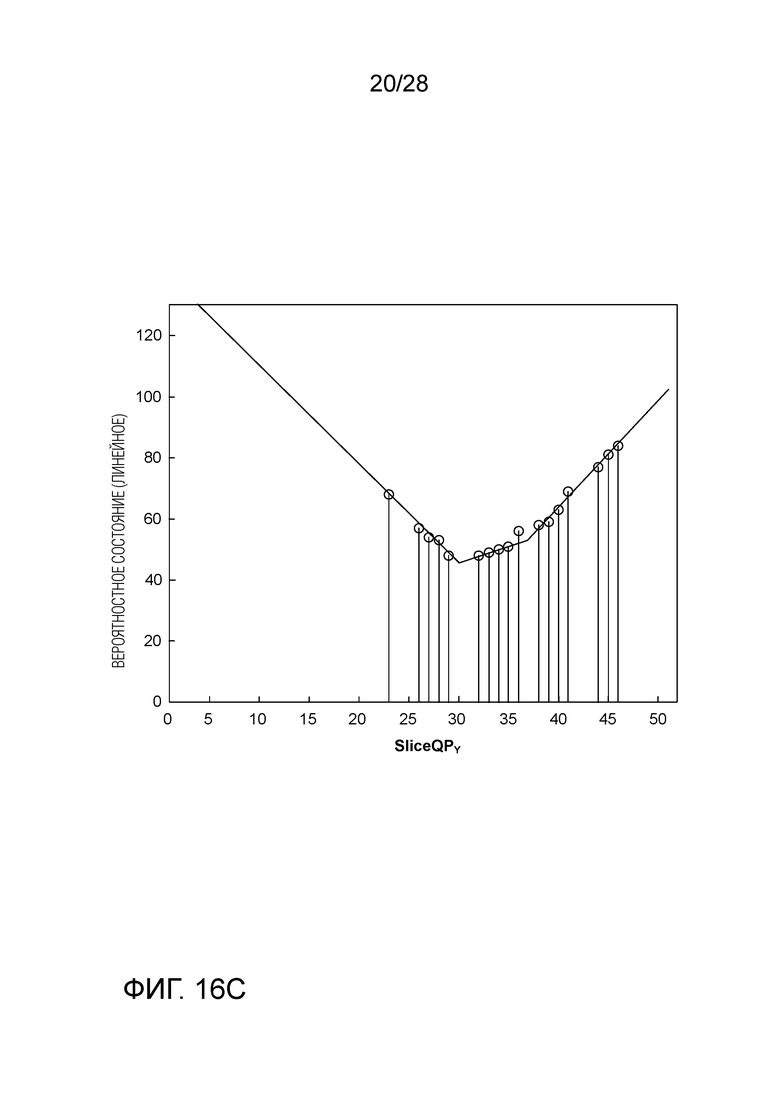
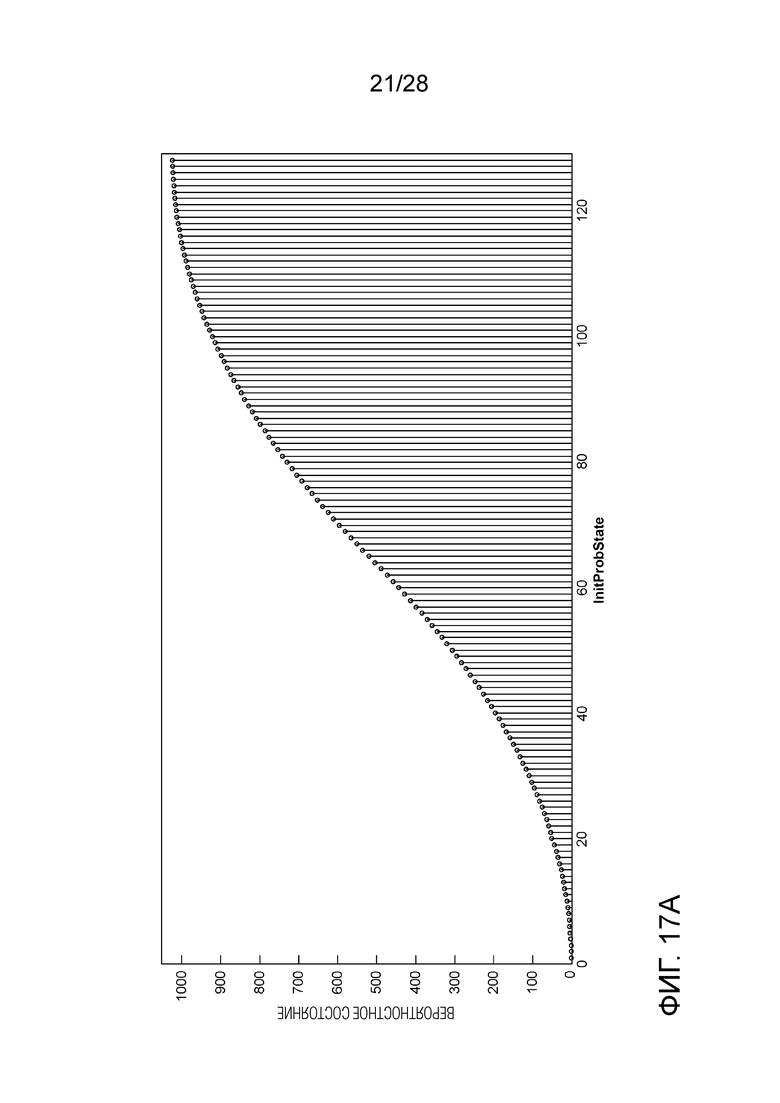
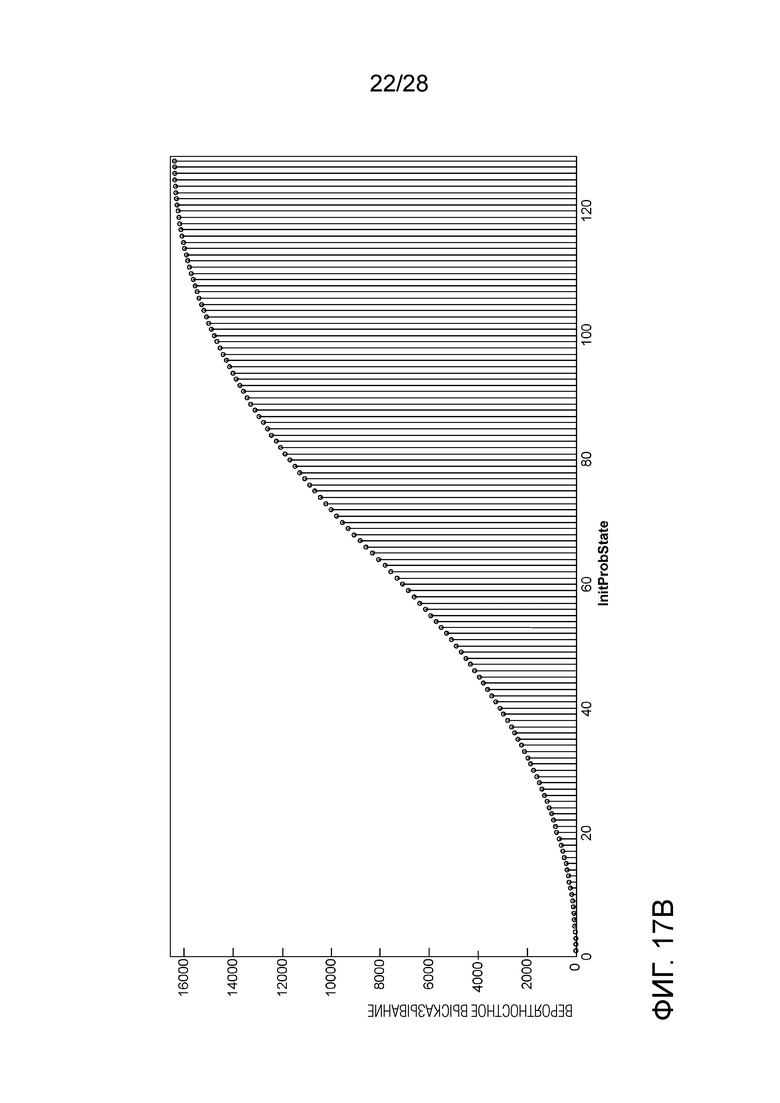
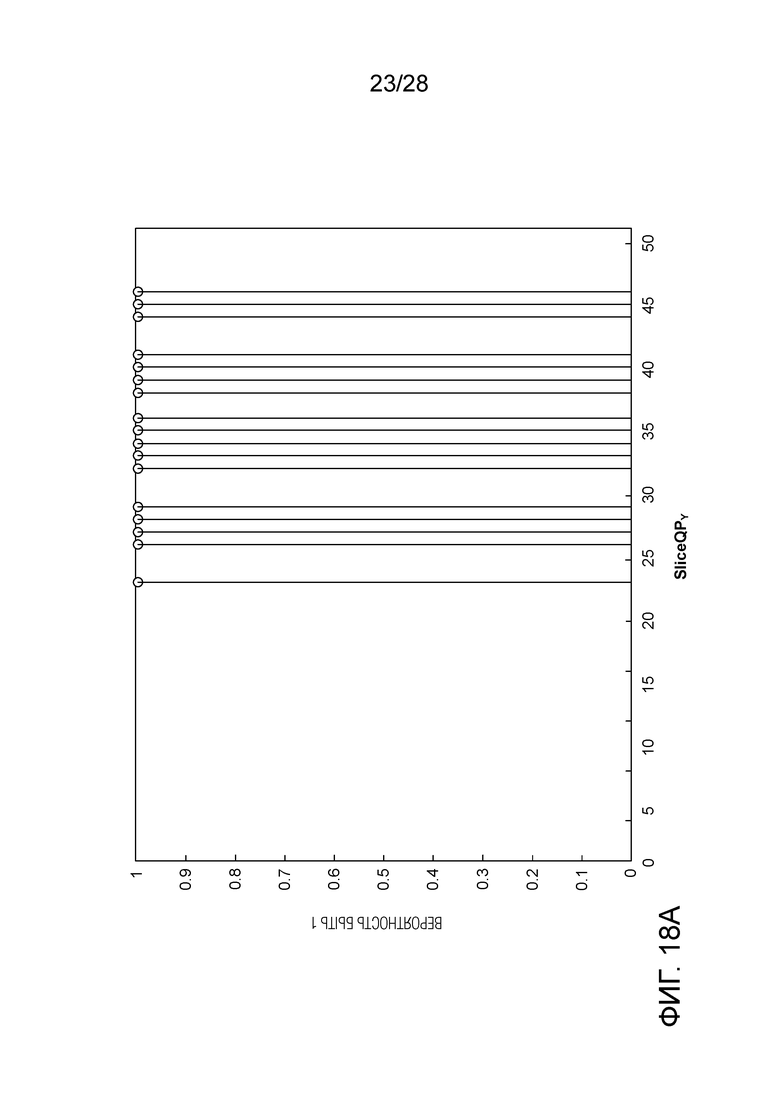
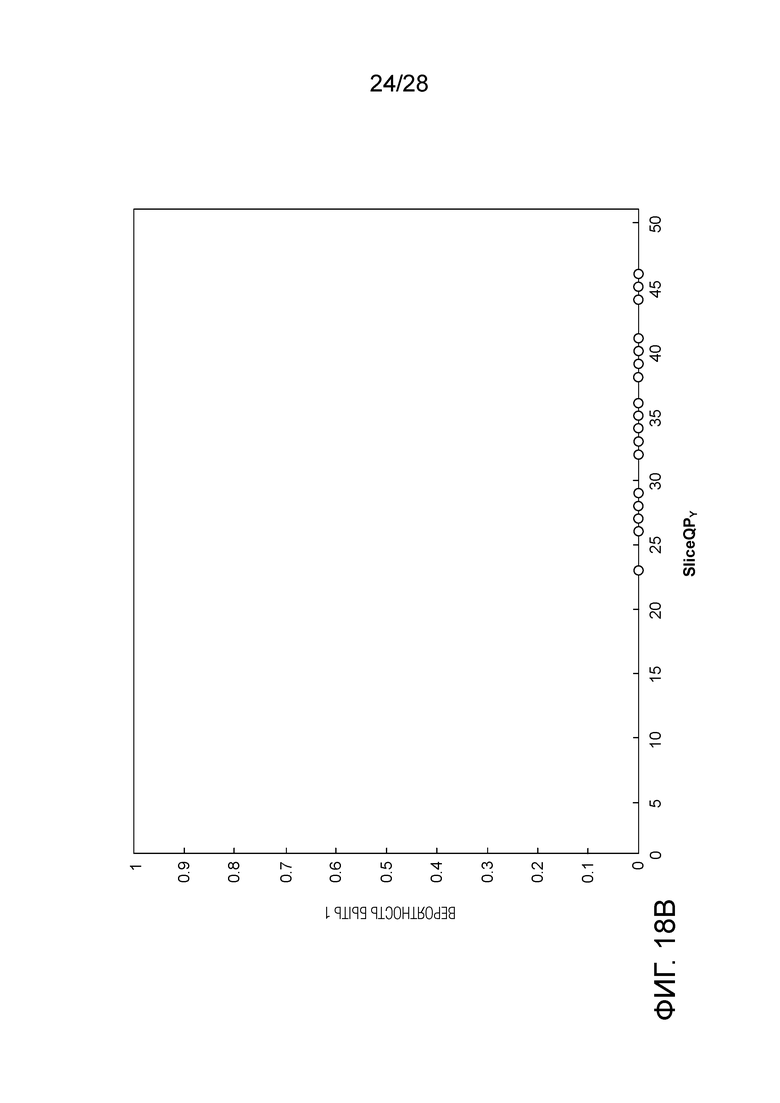
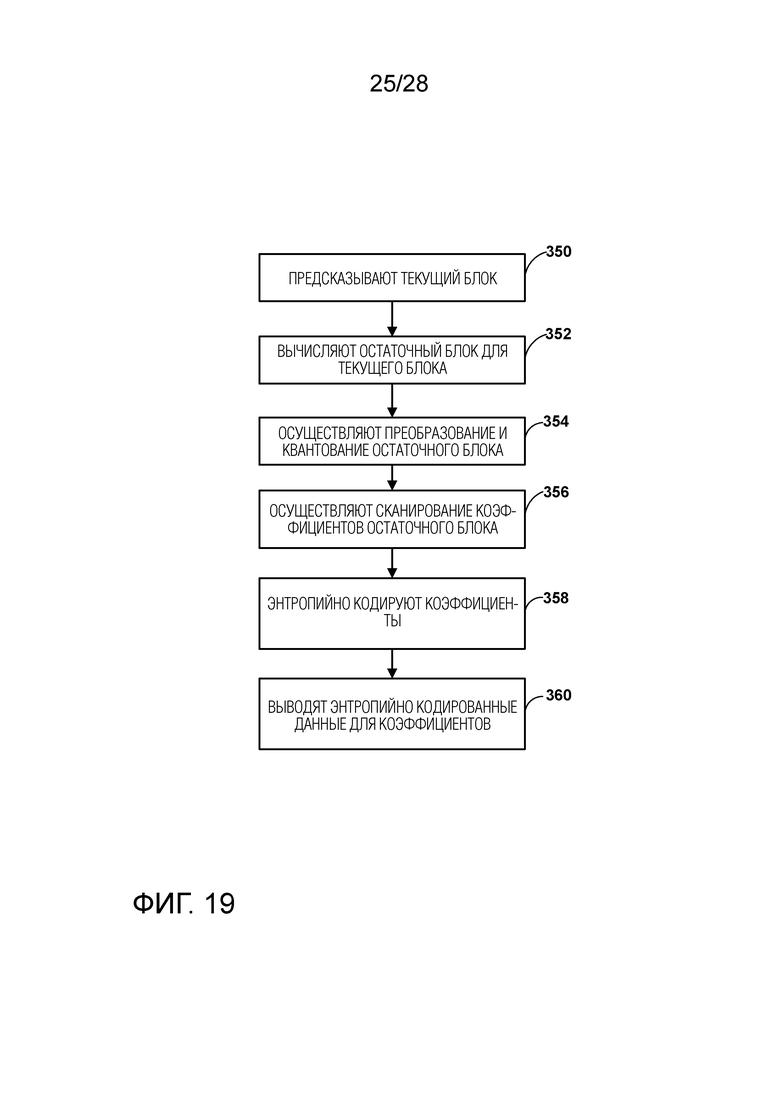
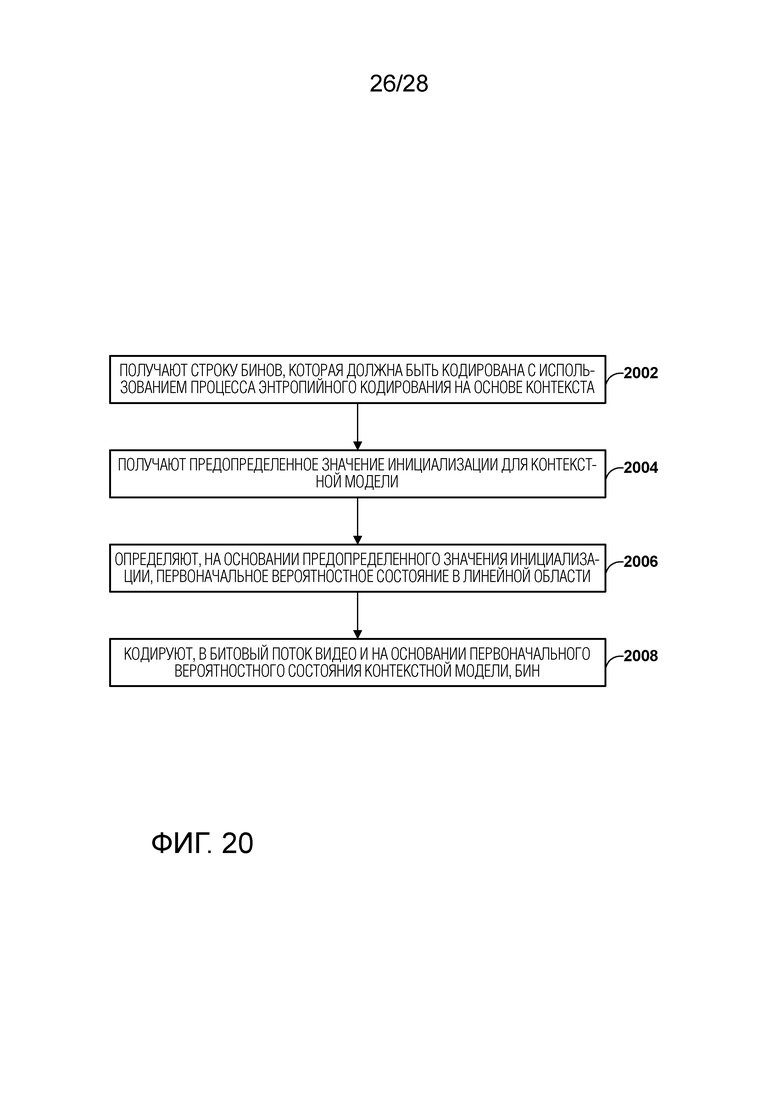
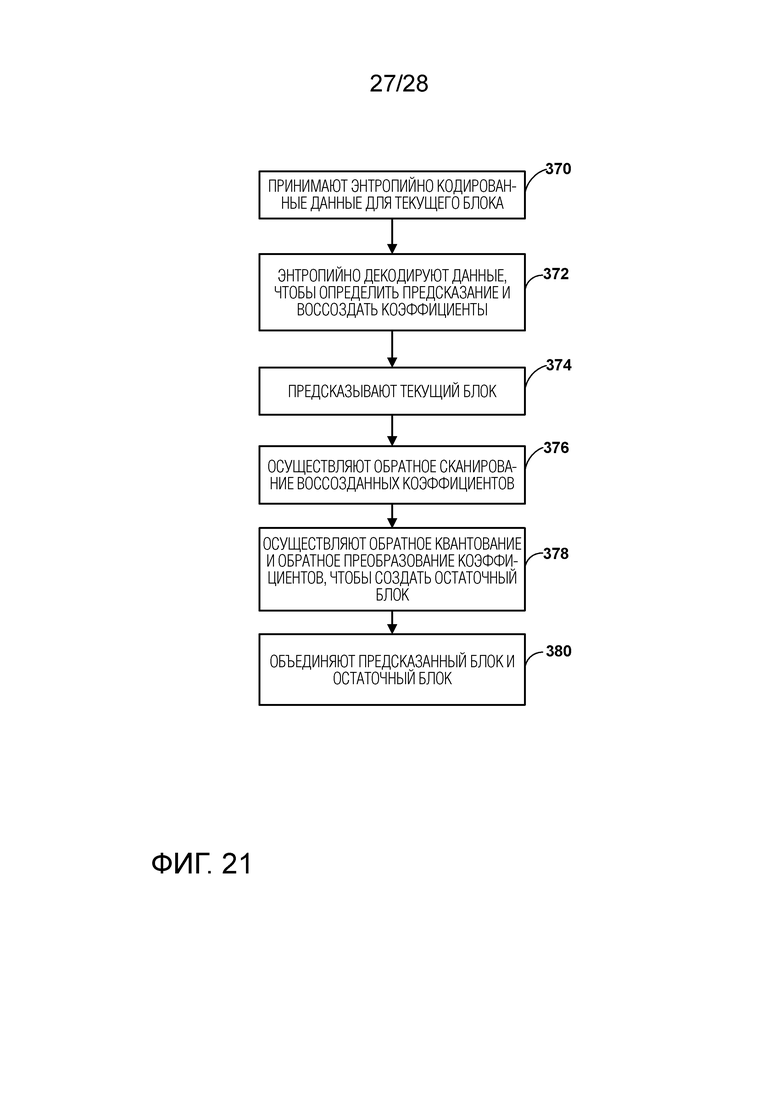
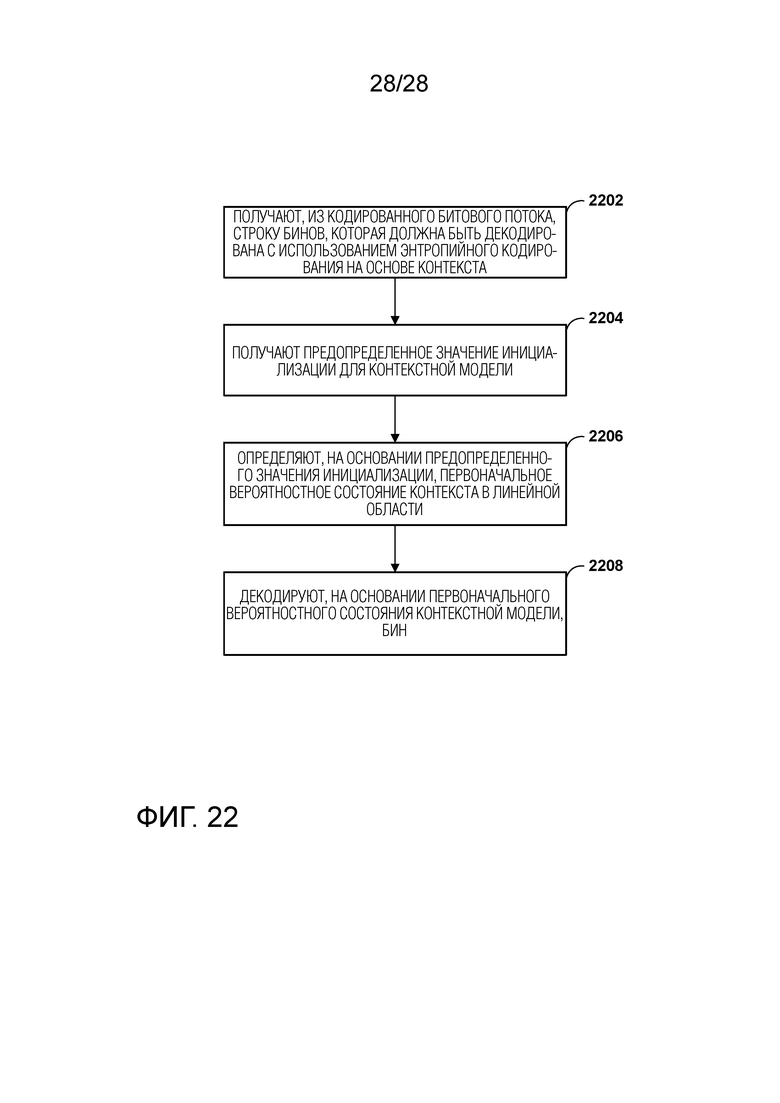
Изобретение относится к области кодирования/декодирования видео. Техническим результатом является повышение эффективности кодирования/декодирования. Предложен способ для энтропийного декодирования видеоданных, который включает этапы: извлекают предопределенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, чтобы энтропийно кодировать значение для элемента синтаксиса для независимо кодируемой единицы видеоданных; определяют, на основе предопределенного значения инициализации и в линейной области, первоначальное вероятностное состояние контекста; и энтропийно декодируют, из битового потока и на основе первоначального вероятностного состояния контекста, бин значения для элемента синтаксиса. 6 н. и 26 з.п. ф-лы, 36 ил., 3 табл.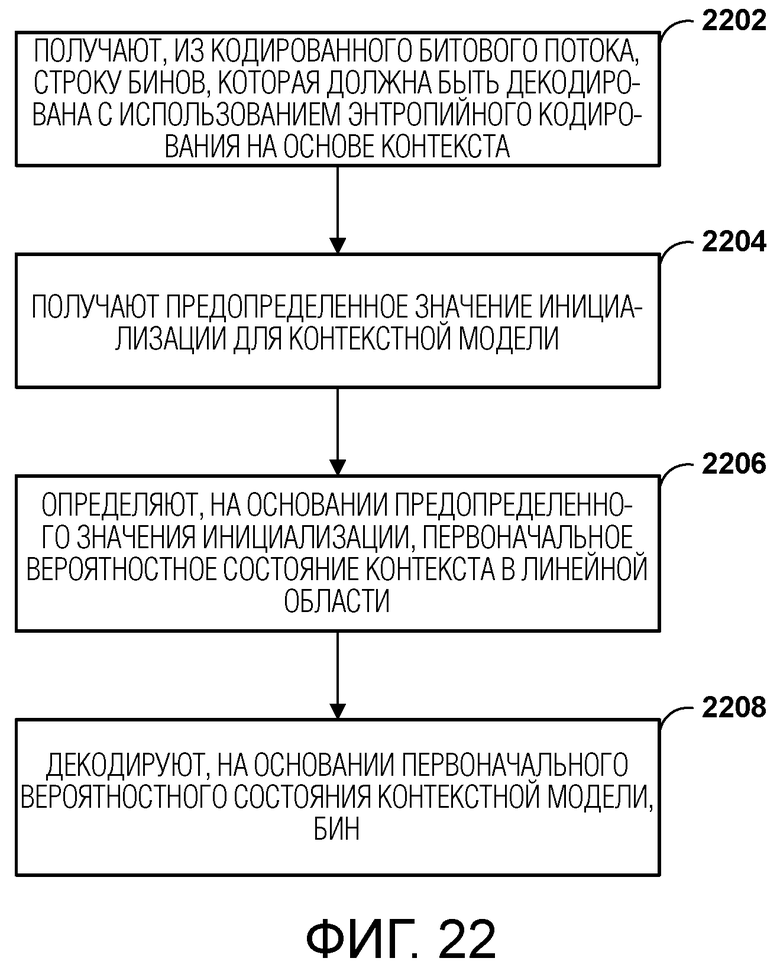
1. Способ энтропийного декодирования видеоданных, содержащий этапы, на которых:
извлекают из памяти заранее определенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, для энтропийного кодирования значения для элемента синтаксиса для независимо кодируемой единицы видеоданных;
определяют, на основе этого заранее определенного значения инициализации, значение индекса наклона и значение индекса смещения;
определяют, на основе значения индекса наклона, значение параметра m;
определяют, на основе значения индекса смещения, значение параметра n в соответствии со следующим уравнением
n = (OffsetIdx * 18) + 1,
где OffsetIdx - значение индекса смещения;
получают первоначальное значение параметра квантования, ассоциированного с упомянутой независимо кодируемой единицей;
определяют, на основе упомянутого заранее определенного значения инициализации, параметра m, параметра n и первоначального значения параметра квантования, первоначальное вероятностное состояние контекста, при этом определение первоначального вероятностного состояния дополнительно основывается на разности между первоначальным значением параметра квантования, ассоциированного с независимо кодируемой единицей, и ненулевым значением, которое задает точку привязки параметра квантования; и
выполняют энтропийное декодирование, из битового потока видео и на основе первоначального вероятностного состояния контекста, двоичного символа упомянутого значения для элемента синтаксиса.
2. Способ по п.1, в котором при упомянутом определении первоначального вероятностного состояния контекста первоначальное вероятностное состояние контекста определяют в линейной области без промежуточного определения первоначального вероятностного состояния контекста в логарифмической области.
3. Способ по п.1, в котором первоначальным значением параметра квантования является SliceQPY.
4. Способ по п.1, в котором значение точки привязки параметра квантования составляет 16.
5. Способ по п.1, в котором при упомянутом определении первоначального вероятностного состояния первоначальное вероятностное состояние определяют в соответствии со следующим уравнением:
InitProbState = clip3(1, 127, ((m * (SliceQPY - QPanchor)) >> rshift) + n),
где InitProbState - первоначальное вероятностное состояние, SliceQPY - первоначальное значение параметра квантования, QPanchor - точка привязки параметра квантования, а rshift - значение сдвига вправо.
6. Способ по п.1, в котором энтропийное декодирование содержит энтропийное декодирование с использованием контекстно-адаптивного двоичного арифметического кодирования (CABAC).
7. Устройство декодирования видео, содержащее:
память, хранящую видеоданные; и
один или более процессоров, реализованных в схеме и выполненных с возможностью:
извлекать из памяти заранее определенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, для энтропийного кодирования значения для элемента синтаксиса для независимо кодируемой единицы видеоданных;
определять, на основе этого заранее определенного значения инициализации, значение индекса наклона и значение индекса смещения;
определять, на основе значения индекса наклона, значение параметра m;
определять, на основе значения индекса смещения, значение параметра n в соответствии со следующим уравнением
n = (OffsetIdx * 18) + 1,
где OffsetIdx - значение индекса смещения;
получать первоначальное значение параметра квантования, ассоциированного с упомянутой независимо кодируемой единицей;
определять, на основе упомянутого заранее определенного значения инициализации, параметра m, параметра n и первоначального значения параметра квантования, первоначальное вероятностное состояние контекста, при этом для определения первоначального вероятностного состояния процессоры дополнительно выполнены с возможностью определять первоначальное вероятностное состояние на основе разности между первоначальным значением параметра квантования, ассоциированного с независимо кодируемой единицей, и ненулевым значением, которое задает точку привязки параметра квантования; и
выполнять энтропийное декодирование, из битового потока видео и на основе первоначального вероятностного состояния контекста, двоичного символа упомянутого значения для элемента синтаксиса.
8. Устройство по п.7, в котором для определения первоначального вероятностного состояния контекста один или более процессоров выполнены с возможностью определять первоначальное вероятностное состояния контекста в линейной области без промежуточного определения первоначального вероятностного состояния контекста в логарифмической области.
9. Устройство по п.7, при этом первоначальным значением параметра квантования является SliceQPY.
10. Устройство по п.7, при этом значение точки привязки параметра квантования составляет 16.
11. Устройство по п.7, в котором для определения первоначального вероятностного состояния один или более процессоров выполнены с возможностью определять первоначальное вероятностное состояние в соответствии со следующим уравнением:
InitProbState = clip3(1, 127, ((m * (SliceQPY - QPanchor)) >> rshift) + n).
где InitProbState - первоначальное вероятностное состояние, SliceQPY - первоначальное значение параметра квантования, QPanchor - точка привязки параметра квантования, а rshift - значение сдвига вправо.
12. Устройство по п.7, в котором для энтропийного декодирования двоичного символа один или более процессоров выполнены с возможностью декодирования двоичного символа с использованием контекстно-адаптивного двоичного арифметического кодирования (CABAC).
13. Способ энтропийного кодирования видеоданных, содержащий этапы, на которых:
извлекают из памяти заранее определенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, для энтропийного кодирования значения для элемента синтаксиса для независимо кодируемой единицы видеоданных;
определяют, на основе этого заранее определенного значения инициализации, значение индекса наклона и значение индекса смещения;
определяют, на основе значения индекса наклона, значение параметра m;
определяют, на основе значения индекса смещения, значение параметра n в соответствии со следующим уравнением
n = (OffsetIdx * 18) + 1,
где OffsetIdx - значение индекса смещения;
получают первоначальное значение параметра квантования, ассоциированного с упомянутой независимо кодируемой единицей;
определяют, на основе упомянутого заранее определенного значения инициализации, параметра m, параметра n и первоначального значения параметра квантования, первоначальное вероятностное состояние контекста, при этом определение первоначального вероятностного состояния дополнительно основывается на разности между первоначальным значением параметра квантования, ассоциированного с независимо кодируемой единицей, и ненулевым значением, которое задает точку привязки параметра квантования; и
выполняют энтропийное кодирование, в битовый поток видео и на основе первоначального вероятностного состояния контекста, двоичного символа упомянутого значения для элемента синтаксиса.
14. Способ по п.13, в котором при упомянутом определении первоначального вероятностного состояния контекста первоначальное вероятностное состояние контекста определяют в линейной области без промежуточного определения первоначального вероятностного состояния контекста в логарифмической области.
15. Способ по п.13, в котором первоначальным значением параметра квантования является SliceQPY.
16. Способ по п.13, в котором значение точки привязки параметра квантования составляет 16.
17. Способ по п.13, в котором при упомянутом определении первоначального вероятностного состояния первоначальное вероятностное состояние определяют в соответствии со следующим уравнением:
InitProbState = clip3(1, 127, ((m * (SliceQPY - QPanchor)) >> rshift) + n),
где InitProbState - первоначальное вероятностное состояние, SliceQPY - первоначальное значение параметра квантования, QPanchor - точка привязки параметра квантования, а rshift - значение сдвига вправо.
18. Устройство кодирования видео, содержащее:
память, хранящую видеоданные; и
один или более процессоров, реализованных в схеме и выполненных с возможностью:
извлекать из памяти заранее определенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, для энтропийного кодирования значения для элемента синтаксиса для независимо кодируемой единицы видеоданных;
определять, на основе этого заранее определенного значения инициализации, значение индекса наклона и значение индекса смещения;
определять, на основе значения индекса наклона, значение параметра m;
определять, на основе значения индекса смещения, значение параметра n в соответствии со следующим уравнением
n = (OffsetIdx * 18) + 1,
где OffsetIdx - значение индекса смещения;
получать первоначальное значение параметра квантования, ассоциированного с упомянутой независимо кодируемой единицей;
определять, на основе упомянутого заранее определенного значения инициализации, параметра m, параметра n и первоначального значения параметра квантования, первоначальное вероятностное состояние контекста, при этом для определения первоначального вероятностного состояния процессоры дополнительно выполнены с возможностью определять первоначальное вероятностное состояние на основе разности между первоначальным значением параметра квантования, ассоциированного с независимо кодируемой единицей, и ненулевым значением, которое задает точку привязки параметра квантования; и
выполнять энтропийное кодирование, в битовый поток видео и на основе первоначального вероятностного состояния контекста, двоичного символа упомянутого значения для элемента синтаксиса.
19. Устройство по п.18, в котором для определения первоначального вероятностного состояния контекста один или более процессоров выполнены с возможностью определять первоначальное вероятностное состояние контекста в линейной области без промежуточного определения первоначального вероятностного состояния контекста в логарифмической области.
20. Устройство по п.18, при этом первоначальным значением параметра квантования является SliceQPY.
21. Устройство по п.18, при этом значение точки привязки параметра квантования составляет 16.
22. Устройство по п.18, в котором для определения первоначального вероятностного состояния один или более процессоров выполнены с возможностью определять первоначальное вероятностное состояние в соответствии со следующим уравнением:
InitProbState = clip3(1, 127, ((m * (SliceQPY - QPanchor)) >> rshift) + n).
где InitProbState - первоначальное вероятностное состояние, SliceQPY - первоначальное значение параметра квантования, QPanchor - точка привязки параметра квантования, а rshift - значение сдвига вправо.
23. Устройство для энтропийного декодирования видеоданных, содержащее:
средство для получения заранее определенного значения инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, для энтропийного кодирования значения для элемента синтаксиса для независимо кодируемой единицы видеоданных;
средство для определения, на основе этого заранее определенного значения инициализации, значения индекса наклона и значения индекса смещения;
средство для определения, на основе значения индекса наклона, значения параметра m;
средство для определения, на основе значения индекса смещения, значения параметра n в соответствии со следующим уравнением
n = (OffsetIdx * 18) + 1,
где OffsetIdx - значение индекса смещения;
средство для получения первоначального значения параметра квантования, ассоциированного с упомянутой независимо кодируемой единицей;
средство для определения, основываясь на упомянутом заранее определенном значении инициализации, параметре m, параметре n и первоначальном значении параметра квантования, первоначального вероятностного состояния контекста, при этом средство для определения первоначального вероятностного состояния содержит средство для определения первоначального вероятностного состояния на основе разности между первоначальным значением параметра квантования, ассоциированного с независимо кодируемой единицей, и ненулевым значением, которое задает точку привязки параметра квантования; и
средство для энтропийного декодирования, из битового потока видео и на основе первоначального вероятностного состояния контекста, двоичного символа упомянутого значения для элемента синтаксиса.
32. Энергонезависимый машиночитаемый носитель информации, хранящий инструкции, которые при их исполнении предписывают одному или более процессорам кодировщика видео:
получать заранее определенное значение инициализации для контекста из множества контекстов, которые используются в процессе контекстно-адаптивного энтропийного кодирования, для энтропийного кодирования значения для элемента синтаксиса для независимо кодируемой единицы видеоданных;
определять, на основе этого заранее определенного значения инициализации, значение индекса наклона и значение индекса смещения;
определять, на основе значения индекса наклона, значение параметра m;
определять, на основе значения индекса смещения, значение параметра n в соответствии со следующим уравнением
n = (OffsetIdx * 18) + 1,
где OffsetIdx - значение индекса смещения;
получать первоначальное значение параметра квантования, ассоциированного с упомянутой независимо кодируемой единицей;
определять, на основе упомянутого заранее определенного значения инициализации, параметра m, параметра n и первоначального значения параметра квантования, первоначальное вероятностное состояние контекста, при этом для определения первоначального вероятностного состояния процессоры дополнительно выполнены с возможностью определять первоначальное вероятностное состояние на основе разности между первоначальным значением параметра квантования, ассоциированного с независимо кодируемой единицей, и ненулевым значением, которое задает точку привязки параметра квантования; и
выполнять энтропийное кодирование, в битовый поток видео и на основе первоначального вероятностного состояния контекста, двоичного символа упомянутого значения для элемента синтаксиса.
| ИНИЦИАЛИЗАЦИЯ ВЕРОЯТНОСТЕЙ И СОСТОЯНИЙ КОНТЕКСТОВ ДЛЯ КОНТЕКСТНО-АДАПТИВНОГО ЭНТРОПИЙНОГО КОДИРОВАНИЯ | 2012 |
|
RU2576587C2 |
| J | |||
| STEGEMANN еt al., CE5-related: Clean up of the context model initialization process for CE5.1.5 and CE5.1.6, Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, JVET-M0772, 13th Meeting: Marrakech, 9-18 Jan | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2013 |
|
RU2603531C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2595934C2 |
| RU | |||

