Область техники, к которой относится изобретение
Настоящее изобретение относится к системам параллельной обработки и в частности к системам параллельной обработки, которые имеют повышенную эффективность с точки зрения производительности/энергопотребления.
Уровень техники
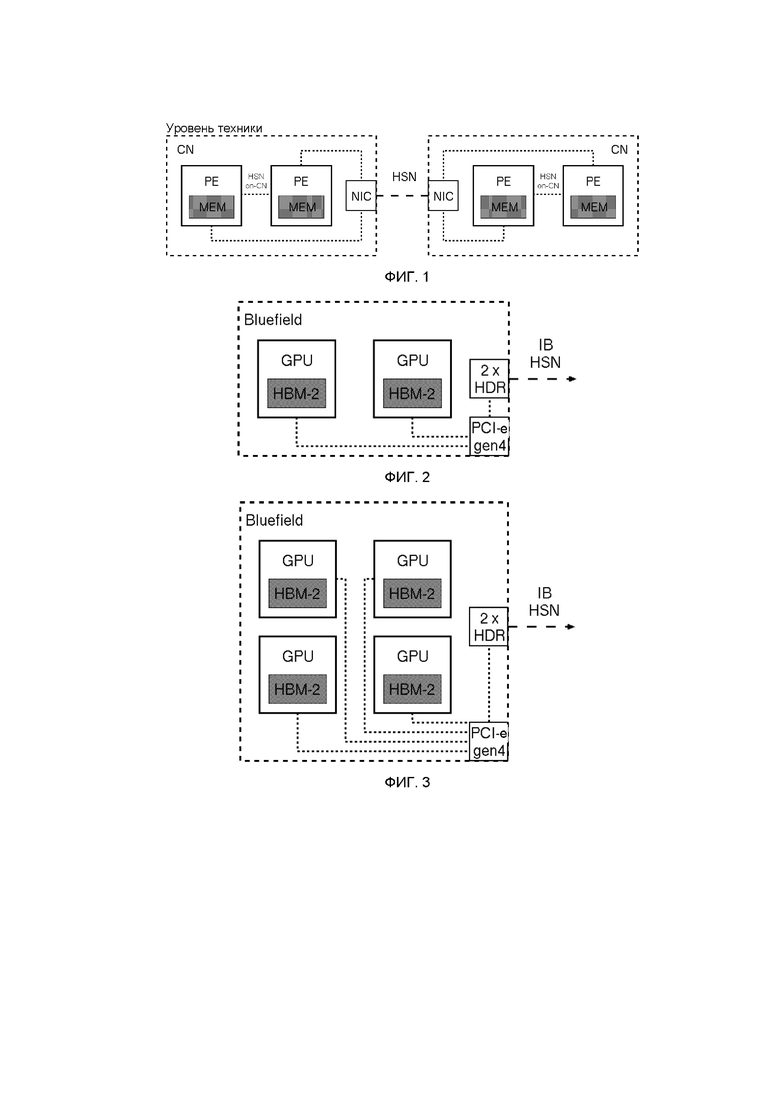
В типичной системе параллельной обработки многочисленные вычислительные узлы, каждый из которых содержит один или более элементов обработки, соединены с помощью высокоскоростной сети. Каждый из элементов обработки вычислительного узла имеет внутреннюю память. Элементы обработки подключены в пределах своего вычислительного узла. Эта связность на вычислительном узле может быть реализована с помощью технологии высокоскоростной сети, отдельной высокоскоростной сети на вычислительном узле или общей памяти (как, например, в системах с симметричной многопроцессорной обработкой (SMP)). Такое размещение показано на фиг.1.
На фиг.1 показано размещение нескольких вычислительных узлов CN, причем каждый вычислительный узел включает в себя множество элементов обработки (PE), каждый из которых имеет соответствующую память (MEM). Вычислительные узлы соединены друг с другом через высокоскоростную сеть (HSN), причем каждый вычислительный узел включает в себя контроллер сетевого интерфейса (NIC) для подключения к высокоскоростной сети. Отдельные элементы обработки соединены вместе и также подключены к контроллеру сетевого интерфейса.
Элемент обработки имеет пиковую производительность (PP), которая является верхним пределом по количеству операций (с плавающей запятой), которые может выполнить элемент обработки в секунду и могут быть измерены как операции с плавающей запятой в секунду или сокращенно "флопс" (хотя в данном случае упоминаются операции с плавающей запятой, операции в равной степени могут быть целочисленными). Пиковая производительность вычислительного узла (PPCN) представляет собой сумму пиковых показателей его элементов обработки. Данное приложение A, как правило, позволяет реализовать только часть ηA пиковой производительности, при этом 0<η< 1, η называется устойчивой эффективностью. Причина этого состоит в том, что скорость передачи данных, то есть полоса пропускания памяти (MBW) между памятью элемента обработки и его вычислительными регистрами, является конечной и, таким образом, будет снижать использование пиковой производительности до ηA для данного приложения. Аналогичный аргумент может быть представлен для скорости передачи входных/выходных данных, то есть для полосы пропускания связи (CBW) одного элемента обработки в другом вычислительном узле вне вычислительного узла элемента обработки, что потенциально дополнительно снижает использование пиковой производительности.
Как показывает практика, специалисты в области высокопроизводительных вычислений считают отношение R = MBW/PP, равное 1 байт/флопс, необходимым требованием для достижения η, близкого к 1, для большинства приложений с интенсивным использованием данных. В зависимости от скорости передачи данных, необходимой для данного приложения A для достижения пиковой производительности, фактическая полоса пропускания памяти элемента обработки определяет ηA, который может быть достигнут для приложения A.
Современные высокопроизводительные CPU сталкиваются с R всего лишь от 0,05 до 0,1 байт/флопс, число которых непрерывно уменьшалось в последнее десятилетие с увеличением количества вычислительных ядер элемента обработки. Современные высокопроизводительные GPU достигают R ниже 0,15 байт/флопс, в основном они предназначены для удовлетворения требований к данным графических приложений и, в последнее время, к приложениям глубокого обучения. Как неблагоприятное последствие, приложения, интенсивно использующие данные, априори достигают ηA ниже 5-10% на современных процессорах и около 15% на современных GPU, независимо от какого-либо дальнейшего уменьшения выполняемого алгоритма или параллелизма с точки зрения необходимых элементов обработки. Чем больше данных требует приложение, тем ниже становится эффективность ηA для данного R элемента обработки.
Эта проблема была выявлена другими, например, Элом Вегнером (Al Wegner) в статье, опубликованной в журнале Electronic Design в 2011 году под названием "The Memory Wall is Ending Multicore Scaling", доступной на сайте http://www.electronicdesign.com/analog/memory-wall-ending-multicore-scaling.
Аналогичное рассмотрение может быть сделано для полосы пропускания связи данного элемента обработки, описывающей скорость передачи данных в другой элемент обработки на вычислительном узле и вне вычислительного узла. Важное значение в данном случае имеет влияние пропускной способности канала связи на масштабируемость кода.
Что касается полосы пропускания связи на вычислительном узле, то можно выделить три случая: вычислительные узлы, где элементы обработки подключены через высокоскоростную сеть, вычислительные узлы, где элементы обработки подключены к отдельной сети на вычислительном узле, который снова подключен к высокоскоростной сети, и на вычислительных узлах, которые обмениваются данными на вычислительном узле через общую память.
Что касается узла связи вне вычислительного узла, специалисты по высокопроизводительным вычислениям рассматривают отношение r = CBW/MBW > 0,1-0,2, что подходит для достижения масштабируемости для множества приложений. Очевидно, что чем ближе пропускная способность связи к пропускной способности памяти, тем лучше условия для масштабируемости.
Теоретически возможная полоса пропускания связи определяется количеством последовательных линий, доступных от элемента обработки до высокоскоростной сети (это справедливо как для CPU, так и для GPU). Это количество ограничено реализацией сериализатора-десериализатора, которая ограничена современной технологией микросхем.
Важно, чтобы контроллер сетевого интерфейса (NIC) вычислительного узла имел соответствующие размеры для поддержания потока данных из и в элементы обработки вычислительного узла.
В документе US 2005/0166073 A1 описано использование переменной рабочей частоты системных процессоров для того, чтобы максимизировать пропускную способность системной памяти.
В документе US 2011/0167229 A1 описана вычислительная система, содержащая несколько вычислительных устройств, каждое из которых подключено к запоминающему устройству, такому как жесткий диск, в отличие от памяти. Целью системы является согласование скорости извлечения сохраненных данных и скорости обработки. В этом документе предложено использовать блоки запоминающего устройства с более высокой скоростью передачи данных, то есть твердотельный накопитель вместо жесткого диска или в дополнение к нему, в сочетании с конкретными процессорами с низким энергопотреблением, которые работают на более низкой тактовой частоте.
В документе US 3025/0095620 описана технология оценки масштабируемости рабочей нагрузки в вычислительной системе. Система имеет один многоядерный процессор.
Раскрытие сущности изобретения
Настоящее изобретение обеспечивает вычислительный блок для функционирования в параллельной вычислительной системе, причем вычислительный блок содержит множество элементов обработки и интерфейс для подключения вычислительного блока к другим компонентам вычислительной системы, при этом каждый элемент обработки имеет номинальную максимальную скорость обработки NPR, и каждый элемент обработки включает в себя соответствующий блок памяти, так что данные могут передаваться из блока памяти с заданной максимальной скоростью передачи данных MBW, и интерфейс обеспечивает максимальную скорость передачи данных CBW, при этом для того, чтобы обеспечить заданную максимальную производительность вычислений для вычислительного блока PP, получаемую с помощью числа n элементов обработки, работающих с номинальной максимальной скоростью обработки, так что PP = n × NPR операций в секунду, вычислительный блок включает в себя целое кратное f, умноженное на n элементов обработки, где f больше единицы, и каждый элемент обработки ограничен для работы со скоростью обработки NPR/f.
В дополнительном аспекте изобретение обеспечивает способ функционирования вычислительного блока, содержащего многоядерный процессор и множество графических процессоров (GPU), причем каждый GPU имеет номинальную пиковую производительность операций PPG в секунду, причем способ содержит функционирование GPU при доле 1/f от их номинальной пиковой производительности, при этом вычислительный блок обеспечивает заданную пиковую производительность вычислений PP операций в секунду, и вычислительный блок имеет n раз f GPU, так что PP равно n раз PPG.
Настоящее изобретение относится к тому факту, что уменьшение тактовой частоты ν элемента обработки на коэффициент F позволяет уменьшить энергопотребление элемента обработки на коэффициент f или более. Этот процесс называется "разгоном".
Для потребляемой мощности устройства элемента обработки справедлива следующая приблизительная формула: P ∝ CV2ν, где C – емкость, V – напряжение, и P – потребляемая мощность. Это означает, что P масштабируется по линейному закону в зависимости от ν и по квадратичному закону в зависимости от V.
Что касается, например, тактовой частоты GPU, в последние годы было опубликовано большое количество статей по моделированию мощности, в которых, помимо прочего, делается попытка распределить энергопотребление между отдельными частями элемента обработки. Новейшие GPU NVIDIA позволяют изменять частоту потоковых мультипроцессоров (SM). Они все чаще проектируются с возможностью динамического и автономного управления с помощью аппаратных средств для того, чтобы обеспечить оптимальное использование доступного бюджета мощности. Насколько это известно из литературы, частоту подсистемы памяти нельзя изменить, и в современных версиях она синхронизируется автономно. Это позволяет приложениям, производительность которых ограничена пропускной способностью памяти, улучшить энергетический баланс за счет некоторого снижения частоты SM. Таким образом, можно ожидать эффекта около 10%.
Производительность машины с пониженной тактовой частотой часто бывает лучше, чем ожидается. При нормальном использовании рабочего стола редко требуется полная производительность элемента обработки. Даже когда система занята, обычно много времени тратится на ожидание данных из памяти или других устройств.
Этот факт позволяет, в принципе, заменять элемент обработки, установленный на вычислительном узле, работающий на частоте ν, на ряд из f элементов обработки, работающих на частоте ν/f, без изменения накопленной вычислительной мощности PPCN вычислительного узла. Кроме того, энергопотребление вычислительного узла сохраняется или потенциально снижается. На практике можно выбрать f = 2, или f = 3.
Ключевой аспект изобретения состоит в том, что для элементов обработки, таких как современные CPU и GPU, частота f вычислений может быть уменьшена без одновременного уменьшения пропускной способности памяти элемента обработки. Как следствие, отношение R увеличивается в f раз при данной модификации. Следует отметить, что невозможно увеличить рабочую частоту вычислительных ядер без адаптации скорости памяти.
Во-вторых, увеличение количества элементов обработки вычислительного узла на коэффициент f увеличивает общее количество доступных последовательных линий на вычислительном узле на коэффициент f. Таким образом, отношение r для операций ввода/вывода вне вычислительного узла также повышается в f раз.
Эти улучшения повышают параллелизм на вычислительный узел в f раз. Это требует настройки алгоритмических подходов для различных высокомасштабируемых приложений, но в принципе это не создает проблем.
Хотя ожидается, что энергопотребление останется постоянным, увеличенное количество элементов обработки сможет, на первый взгляд, увеличить инвестиционные затраты. Однако большая часть этих затрат будет связана с памятью, которую можно уменьшить для каждого элемента обработки на коэффициент f при сохранении постоянного общего объема памяти на постоянную вычислительного узла. Более того, использование высокопроизводительных элементов обработки на более низкой частоте позволяет использовать гораздо менее дорогостоящий сектор выхода продукции, которая не может работать на пиковой частоте.
В качестве второй меры может быть выполнено снижение рабочего напряжения V элемента обработки, что приведет к дальнейшему снижению энергопотребления. Зависимость от напряжения может быть значительной, так как потребляемая мощность пропорциональна напряжению. Это "пониженное напряжение" может использоваться отдельно или в дополнение к понижению частоты и является другим элементом стратегии настоящего изобретения для улучшения энергопотребления вычислительной секции элемента обработки.
Настоящее изобретение обеспечивает устройство, которое позволяет увеличить эффективность систем параллельной обработки с точки зрения производительности и энергопотребления. Внесены технические модификации, которые позволяют снизить рабочую частоту элементов обработки и, соответственно, увеличить количество элементов обработки для достижения одинаковых пиковых характеристик всей системы при увеличенной производительности приложений. Эти модификации влияют на два параметра системы, которые влияют на общую эффективность; пропускная способность памяти для регистрации данных, деленная на пиковую производительность узлов обработки, и пропускная способность передачи данных узлов обработки в высокоскоростной сети параллельной системы, деленная на пиковую производительность узлов обработки. Это позволяет увеличить параллельность узлов при постоянном или даже меньшем энергопотреблении узла. Таким образом, система может быть настроена на оптимальную производительность приложения. Оптимум может быть выбран для любого желаемого показателя, например, для средней производительности определенного набора приложений или оптимальной производительности для определенного приложения. Ожидается, что общие инвестиционные затраты останутся аналогичными, так как используемые элементы обработки будут работать на более низкой рабочей частоте вычислительных ядер своих процессорных блоков, сохраняя при этом память и производительность ввода/вывода.
Представленное изобретение позволяет выбрать коэффициент f, который определяет уменьшение частоты элемента обработки и соответствующее увеличение количества элементов обработки на вычислительном узле в соответствии с выбранными желаемыми критериями, например, средняя максимальная мощность для определенного набора приложений или максимальная мощность для определенного приложения. Фактически, обе модификации могут также применяться независимо в зависимости от влияния критических для системы параметров, таких как энергопотребление и инвестиционные затраты, а также оптимальной производительности, особенно в части взаимодействия архитектуры, и приложения в части масштабируемости.
Краткое описание чертежей
Предпочтительные варианты осуществления изобретения будут теперь описаны только в качестве примера со ссылкой на сопроводительные чертежи, на которых:
на фиг.1 показано упрощенное схематичное представление традиционной системы параллельной обработки;
на фиг.2 показано схематичное представление вычислительного узла, включающего в себя два графических процессора (GPU) и максимальную скорость 25 терафлопс; и
на фиг.3 показано схематичное представление вычислительного узла, включающего в себя в два раза больше графических процессоров в размещении, показанном на фиг.2, но с одной и той же скоростью при пиковой производительности.
Осуществление изобретения
Настоящее изобретение может быть реализовано с помощью существующих на сегодняшний день технологий. В качестве примера, это может быть способ повышения производительности приложений в модуле повышения мощности в рамках модульной суперкомпьютерной системы, которая предназначена для получения пиковой эксафлопсной производительности к 2021 году, как описано в документе WO 2012/049247 A1 и последующих документах EP 16192430.3 и EP 18152903.3, которые включены сюда путем ссылки для всех целей. Задача изобретения состоит в том, чтобы повысить производительность приложения на вычислительном узле для вычислений с интенсивным использованием данных по сравнению с любым другим архитектурным проектом на коэффициент f и, кроме того, увеличить пропускную способность связи, чтобы не отставать от пропускной способности памяти для лучшего масштабирования многих приложений с большими требованиями к связи вне вычислительного узла.
Реализация обеспечивается набором вычислительных узлов, использующих многоядерную систему на кристалле BlueField (BF) Mellanox. Плата BlueField может содержать несколько графических процессоров (GPU) PCIe, коммутатор 4-ой версии и один или несколько коммутаторов с высокой скоростью передачи данных (HDR). Каждая плата BlueField может быть оснащена до четырех GPU. Каждая плата BF содержит два адаптера канала хоста (HCA) Mellanox, таким образом, производительность HDR может быть увеличена до двух раз вне вычислительного узла.
GPU AMD Radeon Vega 20 рассматривается в качестве конкретного примера элемента обработки, который ожидается в середине 2018 года. GPU Vega-20 может быть подключен к интерфейсу PCI-e на BF-вычислительном узле по 16 линиям PCIe 4-ой версии. Ожидается, что GPU будет оснащен 32-гигабайтной памятью HBM-2, разделенной на четыре блока памяти по 8 гигабайт каждый. Кроме того, возможен также вариант 16 Гб HBM-2, снова организованный в четыре блока памяти по 4 гигабайта каждый. Таким образом, скорость памяти может быть одинаковой для обеих конфигураций.
При ожидаемой пропускной способности памяти 1,28 терабайта в секунду и ожидаемой пиковой производительности 12,5 терафлопса в секунду (удвоенной точностью) R = 0,1. Хотя это в 10 отличается от правила специалист-практика 1 байт/флопс, это по-прежнему считается одним из лучших доступных отношений R.
Пропускная способность связи ограничена 16 линиями PCIe 4-ой версии, каждая из которых имеет 2 гигабайта на линию и направление. При r = 64 гигабайта/1,28 терабайта = 0,05, безусловно, придется бороться с серьезными проблемами масштабируемости для приложений, интенсивно использующих данные. В этом отношении поможет любое улучшение R и r.
Это схематично проиллюстрировано фиг.2 и 3.
Пусть стандартная конфигурация содержит два GPU в качестве элементов обработки на каждый BF-CN, работающих на пиковой частоте ν, достигая максимальной производительности. Начальная конфигурация изображена на фиг.2. Что касается вычислительного узла, то заданы или ожидаются следующие параметры системы:
• Количество GPU на один вычислительный узел: 2
• f: 1
• Энергопотребление на один вычислительный узел: 2 × 150 Вт = 300 Вт.
• Память на один вычислительный узел: 64 Гб
• Пропускная способность памяти на один вычислительный узел: 2,56 терабайта в секунду.
• Пиковая производительность на один вычислительный узел: 25 терафлопс в секунду (dp)
• R на один вычислительный узел: 0,1
• Линии PCIe 4-ой версии на один вычислительный узел: 32
• Скорость двунаправленной передачи данных на один вычислительный узел: 128 Гбайт/с (1/2 для элемента обработки по отношению к элементу обработки, 1/2 для NIC)
• Возможно 2 × HDR Mellanox: 100 Гбайт в секунду в двух направлениях
• r на один вычислительный узел: 0,05
• NIC не сбалансирован со связью
Усовершенствованная конфигурация, показанная на фиг.3, содержит четыре GPU в качестве элементов обработки на каждый вычислительный узел BF, работающий на половине пиковой частоты ν, при f = 2, тем самым обеспечивая то же самое номинальное значение максимальной производительности вычислительного узла. В этом случае элемент обработки будет работать на половине максимальной производительности стандартной конфигурации. Что касается усовершенствованного вычислительного узла, то заданы или ожидаются следующие параметры системы:
• Количество GPU на один вычислительный узел: 4
• f: 2
• Ожидаемое энергопотребление на один вычислительный узел: 4 × 75 Вт = 300 Вт.
• Память на один вычислительный узел: 64 Гб и 16 Гб на GPU или 128 Гб и 32 Гб
• Пропускная способность памяти на один вычислительный узел: 5,12 терабайт в секунду.
• Пиковая производительность на один вычислительный узел: 25 терафлопс в секунду (dp)
• R на один вычислительный узел: 0,2
• Линии PCIe 4-ой версии на один вычислительный узел: 64
• Скорость двунаправленной связи на один вычислительный узел: 256 Гбайт/с (1/2 для элемента обработки по отношению к элементу обработки, 1/2 по отношению к NIC)
• Возможно 2 × HDR Mellanox: 100 Гбайт в секунду в двух направлениях
• r на один вычислительный узел: 0,05
• NIC сбалансирован для связи
К понижению частоты можно добавить пониженное напряжение для дальнейшего снижения энергопотребления. Стабильность элемента обработки при пониженном напряжении может быть меньше, чем в случае приложения полного напряжения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ДИНАМИЧЕСКОЙ ОПТИМИЗАЦИИ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ | 2020 |
|
RU2839361C2 |
| Вычислительная система для научно-технических расчетов | 2018 |
|
RU2710890C1 |
| Высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой | 2016 |
|
RU2635896C1 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНАЯ КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ | 2017 |
|
RU2733058C1 |
| РАСПРЕДЕЛЕННАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА ОПТИМАЛЬНЫХ РЕШЕНИЙ | 2010 |
|
RU2459239C2 |
| МНОГОРЕЖИМНЫЙ ИГРОВОЙ СЕРВЕР | 2014 |
|
RU2679978C1 |
| СПОСОБ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ИНФОРМАЦИИ В ГЕТЕРОГЕННОЙ МНОГОПРОЦЕССОРНОЙ СИСТЕМЕ НА КРИСТАЛЛЕ (СнК) | 2022 |
|
RU2790094C1 |
| ОСНОВАННАЯ НА ФРАГМЕНТАХ СИСТЕМА И СПОСОБ СЖАТИЯ ВИДЕО | 2008 |
|
RU2506709C2 |
| СИСТЕМА И СПОСОБ ЗАЩИТЫ ОПРЕДЕЛЕННЫХ ТИПОВ МУЛЬТИМЕДИЙНЫХ ДАННЫХ, ПЕРЕДАВАЕМЫХ ПО КАНАЛУ СВЯЗИ | 2008 |
|
RU2491756C2 |
| СИСТЕМА И СПОСОБ СЖАТИЯ ВИДЕО НА ОСНОВЕ ОБНАРУЖЕННОГО ВНУТРИКАДРОВОГО ДВИЖЕНИЯ | 2008 |
|
RU2493588C2 |
Изобретение относится к системам параллельной обработки и в частности к системам параллельной обработки, которые имеют повышенную эффективность с точки зрения производительности/энергопотребления. Изобретение обеспечивает вычислительный блок для функционирования в параллельной вычислительной системе, причем вычислительный блок содержит множество элементов обработки и интерфейс для подключения вычислительного блока к другим компонентам вычислительной системы, при этом каждый элемент обработки имеет номинальную максимальную скорость обработки NPR, и каждый элемент обработки включает в себя соответствующий блок памяти, так что данные могут передаваться из блока памяти с заданной максимальной скоростью передачи данных MBW, и интерфейс обеспечивает максимальную скорость передачи данных CBW. Причем для того, чтобы обеспечить заданную максимальную производительность вычислений для вычислительного блока PP, получаемую числом n элементов обработки, работающих с номинальной максимальной скоростью обработки, так что PP = n × NPR операций в секунду, вычислительный блок включает в себя целое кратное f, умноженное на n элементов обработки, где f больше единицы, и каждый элемент обработки ограничен для работы со скоростью обработки NPR/f. Также предложен способ функционирования вычислительного блока. Технический результат - увеличение эффективности систем параллельной обработки с точки зрения производительности и энергопотребления. 2 н. и 5 з.п. ф-лы, 3 ил.
1. Вычислительный блок для функционирования в параллельной вычислительной системе, содержащий множество элементов обработки и интерфейс для соединения вычислительного блока с другими компонентами вычислительной системы, при этом каждый элемент обработки имеет номинальную максимальную скорость обработки (NPR), при этом каждый элемент обработки включает в себя соответствующий блок памяти с произвольным доступом, так что данные могут передаваться из блока памяти с заданной максимальной скоростью передачи данных (MBW), при этом интерфейс выполнен с возможностью обеспечения максимальной скорости передачи данных (CBW), причем для обеспечения заданной максимальной производительности вычислений (PP) вычислительного блока, получаемой числом n элементов обработки, работающих с номинальной максимальной скоростью обработки, так что PP = n × NPR операций в секунду, вычислительный блок включает в себя целое кратное f, умноженное на n элементов обработки, где f больше единицы, и каждый элемент обработки ограничен для работы со скоростью обработки NPR/f.
2. Вычислительный блок по п. 1, в котором блок демонстрирует полосу пропускания памяти, в f раз превышающую полосу пропускания памяти гипотетического вычислительного блока, имеющего n элементов обработки.
3. Вычислительный блок по п. 1 или 2, в котором элементы обработки вычислительного блока являются графическими процессорами.
4. Вычислительный блок по любому из пп. 1-3, в котором элементы обработки соединены вместе интерфейсным блоком, причем каждый элемент обработки соединен с интерфейсным блоком множеством S последовательных линий передачи данных.
5. Вычислительный блок по любому из пп. 1-4, в котором вычислительный блок представляет собой компьютерную плату, содержащую многоядерный процессор, выполненный с возможностью управления элементами обработки.
6. Вычислительный блок по любому из пп. 1-5, в котором максимальная скорость передачи данных находится в пределах 30% от скорости передачи данных элемента обработки.
7. Способ функционирования вычислительного блока, содержащего многоядерный процессор и множество графических процессоров (GPU), причем каждый GPU имеет номинальную пиковую производительность операций (PPG) в секунду и соответствующий блок памяти с произвольным доступом, отличающийся тем, что дополнительно содержит этап, на котором осуществляют функционирование GPU при доле 1/f от их номинальной пиковой производительности, при которой вычислительный блок обеспечивает заданную пиковую производительность вычислений для PP операций в секунду, где f больше единицы, и вычислительный блок включает в себя целое кратное f, умноженное на n GPU, так что PP равно n раз PPG.
| US 2011167229 A1, 07.07.2011 | |||
| US 2015095620 A1, 02.04.2015 | |||
| US 2005166073 A1, 28.07.2005 | |||
| WO 2012049247 A1, 19.04.2012 | |||
| US 2017212581 A1, 27.07.2017. |
