Изобретение относится к области цифровой вычислительной техники, а именно к способам параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле (СнК) и может применяться при построении многопроцессорных и многомашинных вычислительных и управляющих систем, а также кластеров.
Известен способ повышения пропускной способности модуля за счет обеспечения параллельной обработки сообщений, поступающих на разные входы, а также путем организации конвейерного режима, при котором прием на обработку новых сообщений выполняют без ожидания выдачи всех обработанных сообщений.
Из уровня техники известен способ, в котором для взаимодействия модулей на базе центрального процессора (CPU-CPU) используют принцип прямой работы с памятью, отображенной через непрозрачный мост на другую шину PCI Express. А при помощи библиотек OpenCL и CUDA SDK может быть реализовано взаимодействие модулей на базе центрального процессора с модулями на базе графического процессора (CPU-GPU) в равноправном режиме. Для взаимодействия модулей на базе центрального процессора с модулями на базе ПЦОС (процессор цифровой обработки сигналов, CPU-DSP) используется принцип отображения ресурсов модуля на базе ПЦОС на шину PCI Express.
Дополнительно существует способ, в котором используется технология открытого языка вычислений (OpenCL), позволяющая процессорам с различной архитектурой центрального процессора (CPU) и графического процессора (GPU) выполнять совместные вычисления, центральный процессор выполняет логическое управление и последовательные вычисления, множество рабочих элементов графического процессора выполняют одну и ту же программу ядра для получения траекторий инструмента бикубической В-сплайновой изогнутой поверхности путем параллельного решения, и реализуется параллелизм гетерогенной системы.
Существует изобретение, раскрывающее структуру планирования, основанную на задачах ядра OpenCL. Фреймворк включает в себя извлечение функций и выбор функций задач ядра OpenCL компилятором LLVM, а также статические функции кода ядра во время компиляции и во время выполнения. Выбранные функции используются для прогнозирования соотношения разделов задач между процессором и графическим процессором с помощью статического классификатора в машинном обучении. Изобретение реализует автоматическое планирование максимального использования вычислительных ресурсов в гетерогенной системе за счет сочетания машинного обучения и алгоритма планирования и улучшает коэффициент использования ресурсов гетерогенной системы.
Существует способ обработки потока данных с высокой размерностью, основанный на гетерогенной платформе CPU-MIC, который имеет преимущества, заключающиеся в том, что для обработки совместно используются сопроцессоры CPU и MIC, снижается нагрузка на процессор, что позволяет процессору лучше сосредоточиться на обработке транзакций с высокой логичностью и последовательных вычислениях, повышается скорость высокопроизводительных вычислений, а также улучшается производительность обработки потока данных и общая производительность алгоритма.
Известен из патента на изобретение CN 105893151 В способ обработки многомерного потока данных, основанный на гетерогенной платформе CPU-MIC, который имеет преимущества, заключающиеся в том, что для обработки совместно используют сопроцессоры CPU и MIC, при этом снижается нагрузка на процессор, что позволяет процессору лучше сосредоточиться на обработке транзакций с высокой логичностью и последовательных вычислениях, повышается скорость высокопроизводительных вычислений, а также улучшается производительность обработки потока данных и общая производительность алгоритма. Данный способ обработки реализуется с помощью высокопроизводительного сервера, загруженного сопроцессорами MIC, системный узел использует гетерогенный смешанный режим CPU-MIC, и узел содержит микросхему центрального процессора и дополнительно содержит по меньшей мере один сопроцессор MIC; центральный процессор служит ядром логического суждения и управления и отвечает за последовательные вычисления; сопроцессоры MIC концентрируются на задаче многопоточной параллельной обработки, то есть часть плотных вычислений и плотных данных передается сопроцессорам MIC для вычисления, поэтому производительность обработки потока данных оптимизируется, а обработка данных является общей.
Недостаток данного способа заключается в том, что сопроцессор MIC не является самостоятельным вычислительным ядром, поэтому степень масштабируемости значительно ограничена. Существенным недостатком такой системы является отсутствие возможности у сопроцессора самостоятельно принимать и передавать данные от других подсистем с использованием портов ввода/вывода. Все функции управления и координации данных возложены на центральный процессор.
Известен описанный в патенте RU 2360283 С2 коммутационный модуль с параллельно-конвейерной обработкой и вещанием сообщений, особенностью которого является возможность с аналогичными модулями совместного функционирования в составе коммутатора (коммутационной сети). Коммутатор обладает ориентированной матричной структурой, в которой каждый модуль связан по входам с соседними модулями слева и снизу, а по выходам - с соседними модулями справа и сверху. Каждый модуль коммутатора обслуживает соответствующее операционное устройство (например, процессорный элемент в многопроцессорной вычислительной системе), принимая от него информацию, подлежащую передаче другим устройствам, и передавая ему информацию от других устройств. Взаимодействие модулей коммутатора осуществляют на основе обмена сообщениями через другие (транзитные) модули. Каждое сообщение при этом включает информационную и адресную части. В информационной части сообщения размещается информация (данные), подлежащая передаче, а адресная часть содержит адресную информацию, которая определяет порядок передачи сообщения.
Недостатком данной схемы является необходимость использования данных модулей в качестве коммутирующих устройств между операционными устройствами, что ведет к усложнению общей схемы, и, следовательно, к снижению ее надежности коммутационного модуля в целом. Дополнительным недостатком служит отсутствие способа совместной обработки информации, полученной из разных источников, что бывает необходимым для принятия комплексного решения.
В патенте RU 2635896 С1 описана высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой, предназначенная для параллельной обработки больших объемов информации от специальных систем в режиме реального времени. Технический результат заключается в повышении надежности системы при формировании вычислительных задач и повышении эффективности при их выполнении на центральном компьютере. Указанный технический результат достигают за счет применения вычислительной платформы на базе процессоров с разнородной архитектурой, содержащей установочный блок высотой 4U, предназначенный для установки в телекоммуникационную стойку и выполненный в виде корпуса, разделенного на две секции. В одной из секций смонтирована система питания, а во второй размещена объединительная плата со слотами, для размещения в них помещаемых через указанный проем модуля коммутации и вычислительных модулей на базе разнородных процессоров, объединенных через высокоскоростную шину стандарта CompactPCI Serial для образования многопроцессорной конфигурации. Для взаимодействия модулей на базе центрального процессора (CPU-CPU) используют принцип прямой работы с памятью, отображенной через непрозрачный мост на другую шину PCI Express. А при помощи библиотек OpenCL и CUDA SDK реализуют взаимодействие модулей на базе центрального процессора с модулями на базе графического процессора (CPU-GPU) в равноправном режиме. Для взаимодействия модулей на базе центрального процессора с модулями на базе ПЦОС (CPU-DSP) используют принцип отображения ресурсов модуля на базе ПЦОС на шину PCI Express. Изобретение может применяться в различных областях техники, где требуется обеспечить высокую вычислительную производительность, используя возможности одновременного задействования модулей с разной архитектурой для решения общей прикладной задачи.
Недостатком данной системы является не достаточная компактность и энергоэффективность. Другим недостатком является требование по размещению оборудования в составе телекоммуникационной стойки, что не всегда приемлемо в конечных продуктах.
В патенте CN 108345503 А описывается основанный на CPU-GPU способ параллельного планирования траектории инструмента криволинейной поверхности В-сплайна. В соответствии со способом изобретения используется технология открытого языка вычислений (OpenCL), позволяющая процессорам с различной архитектурой центрального процессора (CPU) и графического процессора (GPU) выполнять совместные вычисления, центральный процессор выполняет логическое управление и последовательные вычисления, множество рабочих элементов графического процессора выполняют одну и ту же программу ядра для получения траекторий инструмента бикубической В-сплайновой изогнутой поверхности путем параллельного решения, и реализуется параллелизм гетерогенной системы. Недостатком данного способа является отсутствие унификации для широкого круга задач.
Наиболее близкой к заявленному изобретению является система планирования, описанная в патенте CN 109542596, которая основана на задачах ядра OpenCL. Фреймворк включает в себя извлечение функций и выбор функций задач ядра OpenCL компилятором LLVM, а также статические функции кода ядра во время компиляции и во время выполнения. В процессе извлечения объектов алгоритм выбора объектов используют для выбора наиболее важных объектов, чтобы избежать чрезмерной подгонки. Затем выбранные функции используют для прогнозирования соотношения разделов задач между процессором и графическим процессором с помощью статического классификатора в машинном обучении. Наконец, алгоритм планирования используют для разделения задач на пропорции и доступную информацию об оборудовании платформы. Данная система завершает детали проектирования функций, реализует работу алгоритма и кодирования, реализует автоматическое планирование максимального использования вычислительных ресурсов в гетерогенной системе за счет сочетания машинного обучения и алгоритма планирования и улучшает коэффициент использования ресурсов гетерогенной системы. Данная система выбрана в качестве прототипа заявленного изобретения.
Недостаток системы прототипа заключается в раскрытии только сути программной реализации алгоритма планирования, без учета особенностей аппаратного обеспечения. Кроме того, не описано, каким образом достигают наилучшую эффективность при планировании задач.
Техническим результатом является создание способа параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле (СнК) с улучшенной производительностью путем увеличения скорости обработки данных, за счет выполнения вычислений одновременно на всех доступных вычислительных ресурсах, таких как процессорные ядра и сопроцессоры.
Поставленный технический результат достигнут путем создания способа параллельной обработки информации в гетерогенных многопроцессорной системе на кристалле (СнК), состоящей из нескольких наборов симметричных процессоров разной архитектуры, связанных внутренней высокоскоростной сетью, в котором
- служебным процессом, с помощью интерфейса OpenCL и драйвера вычислительного процессорного ядра в операционной системе Linux, запускают параллельные вычислительный процесс центрального ядра и вычислительный процесс процессорного ядра;
- служебным процессом каждой СнК устанавливают соединение с другими служебными процессами соответствующих СнК;
- выполняют обмен сообщениями и синхронизацию глобальных процессов служебным процессом с помощью механизма локальных сетевых сокетов, локальных процессов - напрямую между вычислительными процессами с использованием разделяемой памяти в рамках СнК;
- осуществляют межпроцессное взаимодействие вычислительных процессов с помощью библиотек, реализующих интерфейс передачи сообщений для данного процессорного ядра, которые эмулируют обмен MPI-сообщениями между различными процессами;
- в рамках каждой СнК организуют свою общую циклическую очередь локальных и глобальных сообщений.
В предпочтительном варианте осуществления способа число процессов не превышает число вычислительных ядер в системе.
В предпочтительном варианте осуществления способа процессы, выполняемые на ядрах одной СнК, являются локальными, а процессы, выполняемые на ядрах разных СнК, являются глобальными.
В предпочтительном варианте осуществления способа осуществляют межпроцессное взаимодействие вычислительных процессов с помощью библиотек, реализующих интерфейс передачи сообщений для данного процессорного ядра, которые эмулируют обмен MPI-сообщениями между различными процессами, причем вычислительные процессы, выполняемые на гетерогенных процессорных ядрах, также используют библиотеку, содержащую функции, необходимые для корректной работы процессов. Способ по п. 1, отличающийся тем, что в рамках каждой СнК организуют свою общую циклическую очередь локальных и глобальных сообщений, при этом очередь сообщений делят на две части, кэшируемую часть для данных и некэшируемую часть для заголовков.
В предпочтительном варианте осуществления способа обмен сообщениями между локальными процессами А и В, запущенными на одной СнК, осуществляют следующим образом: процесс А вызывает MPI-функцию, при этом в очереди сообщений появляется соответствующий заголовок и блок данных; процесс В вызывает парную MPI-функцию, и при обнаружении в очереди сообщения с информацией для процесса В, сообщение копируют в локальную память, а счетчик процессов, для которых предназначено сообщение, уменьшают на единицу; процесс В анализирует счетчик, при этом, если значение счетчика равно нулю, сообщение удаляют из очереди.
В предпочтительном варианте осуществления способа обмен сообщениями между глобальными процессами А и В, работающими на разных СнК, осуществляют следующим образом: процесс А вызывает MPI-функцию, при этом в очереди сообщений появляется соответствующий заголовок и блок данных; при обнаружении служебным процессом в очереди сообщений заголовка, предназначенного для процессорного ядра, находящегося в другой СнК, сообщение отправляют в соответствующую СнК через сокет; служебный процесс в рамках СнК с идентификатором dstHost копирует полученное сообщение в свою очередь; процесс В вызывает парную MPI-функцию, и при обнаружении в очереди сообщения с информацией для процесса В, сообщение копируют в локальную память; процесс В анализирует счетчик, при этом, если значение счетчика равно нулю, сообщение удаляют из очереди.
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими графическими материалами.
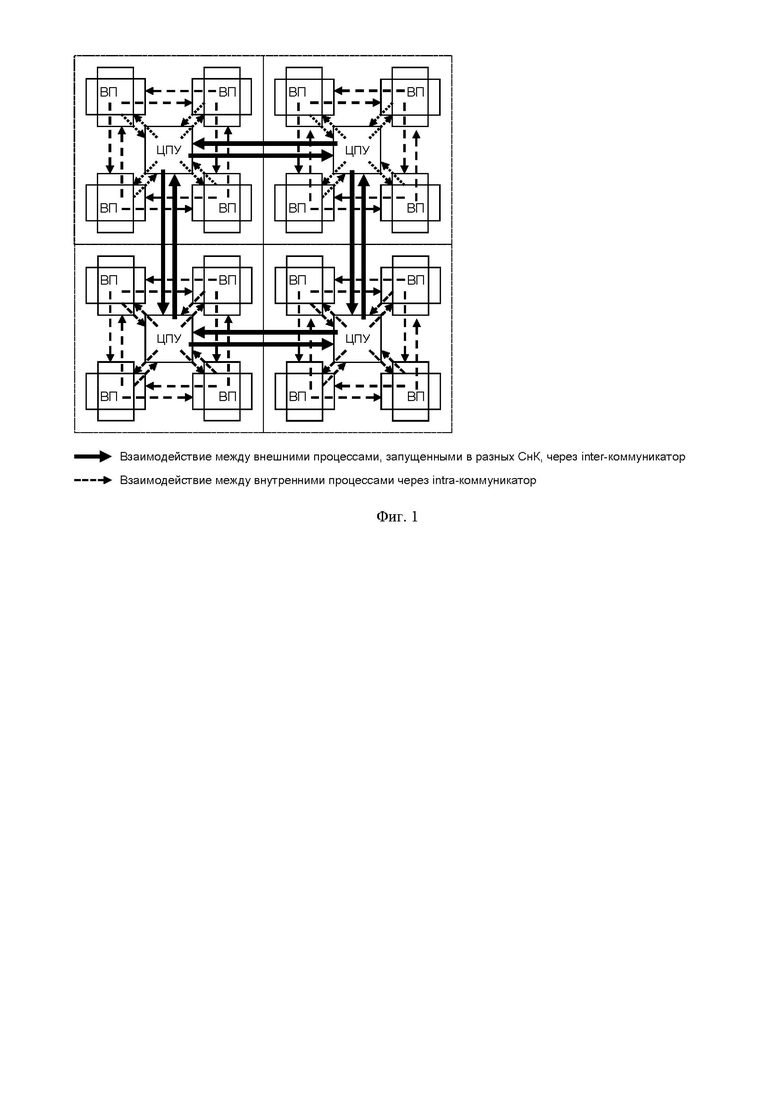
Фиг. 1. Схема способа параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле (СнК) с применением MPI-процессов, выполненного согласно изобретению.
Элементы:
ЦПУ - центральное процессорное устройство;
ВП - вычислительный процессор.
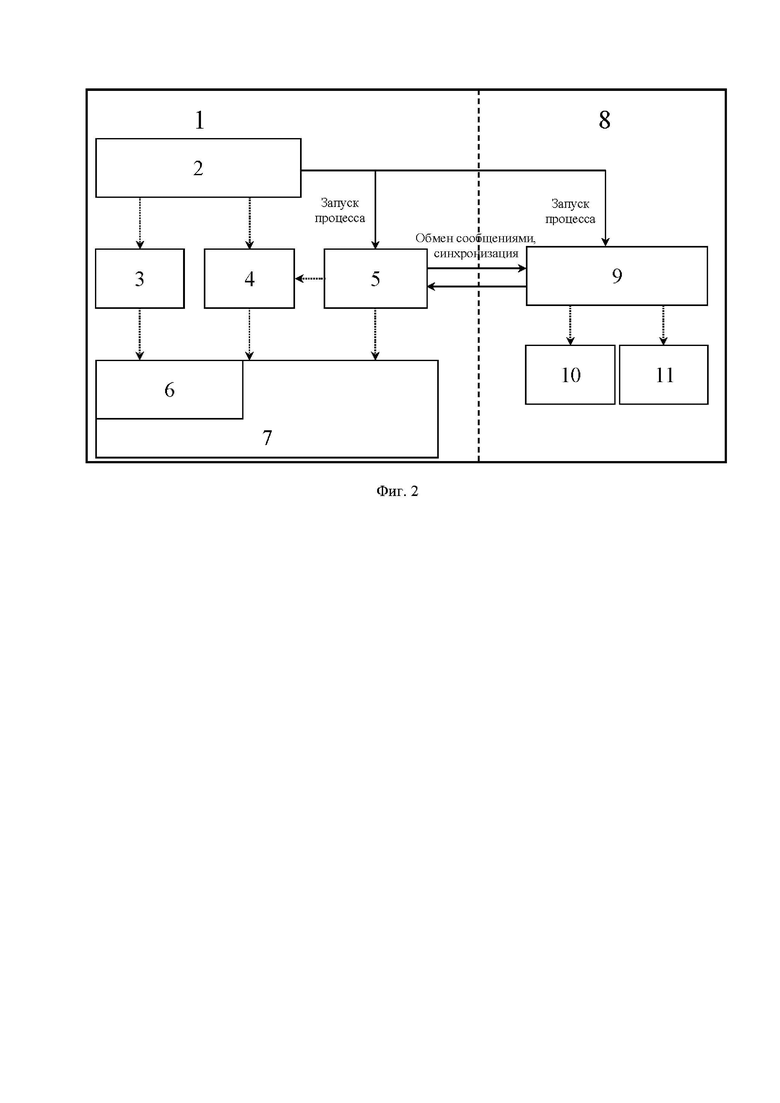
Фиг. 2. Программная модель способа параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле (СнК), выполненного согласно изобретению.
Элементы:
1 - центральный процессор (CPU);
2 - служебный процесс, обеспечивающий запуск процессов и их взаимодействие;
3 - интерфейс OpenCL, обеспечивающий параллелизм на уровне инструкций и на уровне данных;
4 - библиотека OpenMPI интерфейсов передачи сообщений;
5 - вычислительный процесс центрального ядра;
6 - драйвер вычислительного процессорного ядра в ОС Linux;
7 - операционная система на основе ядра Linux;
8 - вычислительное процессорное ядро;
9 - вычислительный процесс процессорного ядра;
10 - библиотека, эмулирующая обмен MPI-сообщениями между внутренними и внешними процессами и обеспечивающая взаимодействие процессами, запущенными на других СнК через очередь сообщений;
11 - основной процесс вычислительного процессорного ядра.
Фиг. 3. Схема способа взаимодействия программных вычислительных единиц и организации очереди сообщений, выполненная согласно изобретению.
Принцип работы заявленного способа заключается в реализации стандарта MPI (Message Passing Interface) для гетерогенного вычислителя. Программа MPI состоит из автономных процессов, выполняющих свой собственный код в стиле MIMD на вычислительных ядрах разной архитектуры по правилам стека MPI технологий. Процессы взаимодействуют через вызовы примитивов связи MPI. Процессы, запущенные на одном гетерогенном вычислителе, используют механизмы работы с общей памятью при реализации стандарта MPI. Процессы поддерживают POSIX-потоки, удовлетворяющих ограничениям стандарта MPI.
В качестве целевой платформы используют вычислительную систему, состоящую из нескольких гетерогенных СнК. Каждая гетерогенная СнК состоит из нескольких наборов симметричных ядер или процессоров разной архитектуры (symmetric multiprocessing, SMP). Вычислительные ядра/процессоры СнК связаны внутренней высокоскоростной сетью.
Технологии на основе MPI парадигмы позволяют осуществлять масштабирование как на уровне процессоров/СнК, так и на уровне процессорных ядер, обеспечивая выполнение крупноблочных, среднеблочных и мелкозернистых алгоритмов. Технология OpenCL обеспечивает поддержку, доступ и управление гетерогенными IP-ядрами в одном программном приложении, тем самым являясь эффективным средством гибридного программирования гетерогенных СнК. Каждое ядро/процессор СнК является OpenCL-устройством, которые обладают преимуществами для обработки информации различного уровня. Каждое OpenCL-устройство в реальном времени обслуживает не менее одного потока данных, тем самым осуществляет обработку информации с использованием различных алгоритмов, включая алгоритмы машинного обучения и нейросетевые алгоритмы. Фреймворк OpenCL реализуют поверх драйверов вычислительных устройств. Фреймворк OpenCL является частью операционной системы Linux и выполняет следующие функции:
- управление жизненным циклом процессов: создание, постановка в очередь, запуск, завершение;
- управление жизненным циклом объектов памяти: создание, настройка виртуального адресного пространства, удаление;
- реализация механизма zero сору для избегания копирования данных между вычислительными ядрами;
- поддержка системных вызовов;
- поддержка профилирования и отладки процессов.
Рассмотрим более подробно заявленный способ параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле (Фиг. 1-3). Особенность показанной на Фиг. 2 схемы межпроцессного взаимодействия в вычислительных системах на основе СнК заключается в следующем. Параллельные процессы 5, 9 запускают служебным процессом 2, используя интерфейс OpenCL и драйвер ОС Linux 3, 6. Служебный процесс 2 каждой СнК устанавливает соединение с другими служебными процессами соответствующих СнК. При этом число запускаемых процессов не должно превышать число вычислительных ядер в вычислительной системе. Процессы, выполняемые на ядрах одной СнК, являются локальными. Процессы, выполняемые на ядрах разных СнК, являются глобальными. Обмен сообщениями и синхронизацию глобальных процессов выполняют с привлечением служебного процесса 2 и с использованием механизма сетевых сокетов, локальных - напрямую между вычислительными процессами с использованием разделяемой памяти в рамках СнК. Для реализации межпроцессного взаимодействия вычислительные процессы используют библиотеки, реализующие интерфейс передачи сообщений 4,10 для данного процессорного ядра 1, 8, которые эмулируют обмен MPI-сообщениями между различными процессами. Вычислительные процессы, выполняемые на гетерогенных процессорных ядрах 10, также используют библиотеку, содержащую функции, необходимые для корректной работы процессов 11. В рамках каждой СнК организуют свою общую циклическую очередь сообщений (локальных и глобальных). Очередь сообщений (Фиг. 3) делится на две части: кэшируемую для данных и некэшируемую для заголовков. Использование некэшируемой памяти обусловлено необходимостью уменьшения времени на синхронизацию процессов при одновременной записи сообщений, при этом чтение происходит в безблокировочном режиме.
Обмен сообщениями между локальными процессами А и В, запущенными на одной СнК, осуществляют следующим образом.
- Процесс А вызывает MPI-функцию. В очереди сообщений появляется соответствующий заголовок и блок данных.
- Процесс В вызывает парную MPI-функцию. При обнаружении в очереди сообщения с информацией для процесса В, сообщение копируются в локальную память. Счетчик процессов, для которых предназначено сообщение, уменьшают на единицу.
- Процесс В анализирует счетчик. Если значение счетчика равно нулю, сообщение удаляют из очереди.
Обмен сообщениями между глобальными процессами А и В, работающими на разных СнК, осуществляют следующим образом.
- Процесс А вызывает MPI-функцию. В очереди сообщений появляется соответствующий заголовок и блок данных.
- При обнаружении служебным процессом в очереди сообщений заголовка, предназначенного для процессорного ядра, находящегося в другой СнК, сообщение отправляют в соответствующую СнК через сокет.
- Служебный процесс в рамках СнК с идентификатором dstHost копирует полученное сообщение в свою очередь.
- Процесс В вызывает парную MPI-функцию. При обнаружении в очереди сообщения с информацией для процесса В, сообщение копируют в локальную память.
- Процесс В анализирует счетчик. Если значение счетчика равно нулю, сообщение удаляют из очереди.
Заявленное изобретение позволяет повысить эффективность взаимодействия внутрисистемных процессов в гетерогенных системах на кристалле
Целью изобретения является решение задачи программирования многоядерных гетерогенных СнК путем предложения программной модели со стеком программного обеспечения для организации эффективной параллельно-конвейерной обработки информации. Кроме того, заявленное изобретение позволяет улучшить производительность системы на кристалле, за счет использования предложенного способа взаимодействия процессов, запущенных на вычислительных процессорах/ядрах разной архитектуры на гетерогенных системах на кристалле путем увеличения скорости обработки данных за счет расширения стандартного способа распараллеливания вычислений на все доступные вычислительные ресурсы (процессорные ядра и сопроцессоры).
Заявленный способ позволяет значительно улучшить производительность системы на кристалле, за счет увеличения объема и скорости обработки данных путем распараллеливания вычислений на все доступные вычислительные ресурсы (процессорные ядра различной архитектуры), при этом не требует наличия дополнительных коммутирующих устройств между операционными устройствами, т.к. взаимодействие между ними осуществляют по правилам стандарта MPI (Message Passing Interface - Взаимодействие через передачу сообщений) с использованием технологий OpenCL (Open Computing Language - открытый язык вычислений).
Основные преимущества заявленного способа параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле:
- использование синтеза стандартных технологий MPI и OpenCL на гетерогенных вычислительных ядрах;
- использование общих разделяемых ресурсов в виде памяти без использования дополнительных операций копирования;
- построение вычислительной системы на одном кристалле;
- построение вычислительной системы по принципу: гетерогенные задачи, гетерогенные вычислители;
- для графической обработки информации предназначен GPU, для управления и скалярной обработки CPU, для кодирования и декодирования информационных потоков VXE, VXD, DSP - для сигнальной обработки и другие вычислительные устройства специализированного назначения, включая вычислители для нейросетевой обработки.
Заявленного способа параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле имеет следующие особенности:
- позволяет запускать процессы на ядрах различной архитектуры в составе одного СнК;
- использует локальные процессы, запускаемые на одной СнК и глобальные процессы, запускаемые на разных СнК;
- для обмена между локальными процессами использует ОЗУ СнК, для обмена информацией между глобальными процессами использует сообщения, реализованные с помощью технологий обмена между распределенными вычислительными узлами, например, на основе сокетов;
- использует служебный процесс, запускаемый на ЦПУ, который контролирует обмены между процессами;
- использует счетчик сообщений, который контролирует жизненный цикл сообщений, при этом сообщение удаляют, если все адресаты получили локальные копии.
Хотя описанный выше вариант выполнения изобретения был изложен с целью иллюстрации настоящего изобретения, специалистам ясно, что возможны разные модификации, добавления и замены, не выходящие из объема и смысла настоящего изобретения, раскрытого в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой | 2016 |
|
RU2635896C1 |
| Малогабаритный высокопроизводительный вычислительный модуль на базе многопроцессорной Системы-на-Кристалле | 2021 |
|
RU2778213C1 |
| Программно-аппаратная платформа и способ ее реализации для беспроводных средств связи | 2016 |
|
RU2626550C1 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2618367C1 |
| ЗАПУСК ПРИЛОЖЕНИЯ НА ОСНОВЕ ИНТЕРФЕЙСА ПЕРЕДАЧИ СООБЩЕНИЯ (MPI) В ГЕТЕРОГЕННОЙ СРЕДЕ | 2014 |
|
RU2600538C2 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОПОТОКОВОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2708794C2 |
| Вычислительная система для научно-технических расчетов | 2018 |
|
RU2710890C1 |
| НЕОГРАНИЧЕННАЯ ТРАНЗАКЦИОННАЯ ПАМЯТЬ С ГАРАНТИЯМИ ПРОДВИЖЕНИЯ ПРИ ПЕРЕСЫЛКЕ, ИСПОЛЬЗУЯ АППАРАТНУЮ ГЛОБАЛЬНУЮ БЛОКИРОВКУ | 2014 |
|
RU2597506C2 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНАЯ КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ | 2017 |
|
RU2733058C1 |
| УСОВЕРШЕНСТВОВАНИЕ ИНТЕРФЕЙСА PCI EXPRESS | 2013 |
|
RU2645288C2 |

Изобретение относится к области цифровой вычислительной техники. Технический результат заключается в повышении скорости обработки данных. Технический результат достигается за счет распараллеливания вычислений на все доступные вычислительные ресурсы, такие как процессорные ядра различной архитектуры. Согласно способу запускают параллельные вычислительный процесс центрального ядра и вычислительный процесс процессорного ядра. Обмен сообщениями и синхронизацию процессов, выполняемых на ядрах разных систем на кристалле, осуществляют с помощью механизма локальных сетевых сокетов, а процессов, выполняемых на ядрах одной системы на кристалле - напрямую между вычислительными процессами с использованием разделяемой памяти. В рамках каждой системы на кристалле организуют свою общую циклическую очередь локальных и глобальных сообщений. Счетчик сообщений контролирует жизненный цикл сообщений. 6 з.п. ф-лы, 3 ил.
1. Способ параллельной обработки информации в гетерогенной многопроцессорной системе на кристалле (СнК), состоящей из нескольких наборов симметричных процессоров разной архитектуры, связанных внутренней высокоскоростной сетью, в котором:
- служебным процессом, с помощью интерфейса OpenCL и драйвера вычислительного процессорного ядра в операционной системе Linux, запускают параллельные вычислительный процесс центрального ядра и вычислительный процесс процессорного ядра;
- служебным процессом каждой СнК устанавливают соединение с другими служебными процессами соответствующих СнК;
- выполняют обмен сообщениями и синхронизацию глобальных процессов служебным процессом с помощью механизма локальных сетевых сокетов, локальных процессов - напрямую между вычислительными процессами с использованием разделяемой памяти в рамках СнК;
- осуществляют межпроцессное взаимодействие вычислительных процессов с помощью библиотек, реализующих интерфейс передачи сообщений для данного процессорного ядра, которые эмулируют обмен MPI-сообщениями между различными процессами;
- в рамках каждой СнК организуют свою общую циклическую очередь локальных и глобальных сообщений.
2. Способ по п. 1, отличающийся тем, что число процессов не превышает число вычислительных ядер в системе.
3. Способ по п. 1, отличающийся тем, что процессы, выполняемые на ядрах одной СнК, являются локальными, а процессы, выполняемые на ядрах разных СнК, являются глобальными.
4. Способ по п. 1, отличающийся тем, что осуществляют межпроцессное взаимодействие вычислительных процессов с помощью библиотек, реализующих интерфейс передачи сообщений для данного процессорного ядра, которые эмулируют обмен MPI-сообщениями между различными процессами, причем вычислительные процессы, выполняемые на гетерогенных процессорных ядрах, также используют библиотеку, содержащую функции, необходимые для корректной работы процессов.
5. Способ по п. 1, отличающийся тем, что в рамках каждой СнК организуют свою общую циклическую очередь локальных и глобальных сообщений, при этом очередь сообщений делят на две части, кэшируемую часть для данных и некэшируемую часть для заголовков.
6. Способ по п. 1, отличающийся тем, что обмен сообщениями между локальными процессами А и В, запущенными на одной СнК, осуществляют следующим образом: процесс А вызывает MPI-функцию, при этом в очереди сообщений появляется соответствующий заголовок и блок данных; процесс В вызывает парную MPI-функцию, и при обнаружении в очереди сообщения с информацией для процесса В, сообщение копируют в локальную память, а счетчик процессов, для которых предназначено сообщение, уменьшают на единицу; процесс В анализирует счетчик, при этом, если значение счетчика равно нулю, сообщение удаляют из очереди.
7. Способ по п. 1, отличающийся тем, что обмен сообщениями между глобальными процессами А и В, работающими на разных СнК, осуществляют следующим образом: процесс А вызывает MPI-функцию, при этом в очереди сообщений появляется соответствующий заголовок и блок данных; при обнаружении служебным процессом в очереди сообщений заголовка, предназначенного для процессорного ядра, находящегося в другой СнК, сообщение отправляют в соответствующую СнК через сокет; служебный процесс в рамках СнК с идентификатором dstHost копирует полученное сообщение в свою очередь; процесс В вызывает парную MPI-функцию, и при обнаружении в очереди сообщения с информацией для процесса В, сообщение копируют в локальную память; процесс В анализирует счетчик, при этом, если значение счетчика равно нулю, сообщение удаляют из очереди.
| US 20140351551 A1, 27.11.2014 | |||
| US 20110179252 A1, 21.07.2011 | |||
| US 20080162873 A1, 03.07.2008 | |||
| US 20140281243 A1, 18.09.2014 | |||
| US 20050203988 A1, 15.09.2005 | |||
| US 20120311299 A1, 06.12.2012 | |||
| ЗАПУСК ПРИЛОЖЕНИЯ НА ОСНОВЕ ИНТЕРФЕЙСА ПЕРЕДАЧИ СООБЩЕНИЯ (MPI) В ГЕТЕРОГЕННОЙ СРЕДЕ | 2014 |
|
RU2600538C2 |
| СПОСОБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ ПРОЦЕССАМИ | 2014 |
|
RU2592461C2 |

