Заявляемое изобретение относится к методам и системам цифровых вычислений и обработки данных, предназначенным для обеспечения интеграции проектно-конструкторских данных об изделии в условиях дискретного многономенклатурного производства.
Известен метод обеспечения интероперабельности данных в распределенной сети данных и система для его осуществления [патент на изобретение США US 9497283 В2, МПКН04b 29/08200601, H04L 29/06200601, опубл. 15.11.2016]. Представленная система включает: внутренний клиент с последовательно соединенными источником данных и преобразователем данных, распределенную сеть данных с последовательно соединенными первым акцептором данных, кэшем бинарных данных, преобразователем данных и вторым акцептором данных, внешний клиент с источником данных. При этом преобразователь данных внутреннего клиента связан с первым акцептором данных, а источник данных внешнего клиента - со вторым акцептором данных. Преобразователи данных внутреннего клиента и распределенной сети данных реализую механизм сериализации данных с использованием формата POF распределенной сети данных Oracle Coherence (Oracle Corporation, США).
Реализация метода обеспечения интероперабельности данных в распределенной сети данных предполагает выполнение следующих операций:
1) реализацию акцепторов данных в распределенной сети данных, при этом первый и второй акцепторы данных связаны с кэшем бинарных данных распределенной сети данных;
2) прием от внутреннего клиента через преобразователь данных и первый акцептор данных входящих элементов данных;
3) предоставление внешнему клиенту, связанному посредством второго акцептора данных и преобразователя данных распределенной сети данных с распределенным кэшем бинарных данных, совместного использования входящих элементов данных с внутренним клиентом.
Недостатками данной системы является то, что она не обеспечивает:
- поиск и визуализацию данных по запросам от внутреннего и внешнего клиентов;
- адаптацию формата представления данных в соответствии с изменением среды функционирования данной системы.
Известен метод семантической интеграции данных и система, его реализующая [патент на изобретение США US 9406018 В2, МПК G06F 15/182006 01, G06N 5/022006 01, G06K 9/622006 01, G06N 99/00201001, G06N 7/002006 01, опубл. 02.08.2016]. Данный метод включает следующие операции, реализуемые семантическим интегратором данных, входящим в состав известной системы:
1) создание онтологии верхнего уровня, включающей один или несколько словарей понятий и семантических карт заданной предметной области;
2) создание одной или нескольких процессных онтологий и их внедрение в онтологию верхнего уровня;
3) сопоставление одного или нескольких процессов, семантических карт или словарей понятий заданной предметной области с одним или несколькими источниками данных;
4) прием входных запросов к данным посредством графического интерфейса пользователя;
5) сопоставление входного запроса к данным с одним или несколькими понятиями онтологии верхнего уровня, формирование соответствующих подзапросов к данным;
6) запрос содержимого одного или нескольких источников данных в соответствии с подзапросами к данным, сформированными ранее.
Система, обеспечивающая реализацию данного метода, включает:
- процессор со встроенным семантическим интегратором данных;
- графический интерфейс запросов к данным;
- хранилище данных, обеспечивающее хранение и доступ к онтологии верхнего уровня, процессным онтологиям, словарям понятий и семантическим картам заданной предметной области;
- массив статических и динамических источников данных. Недостатками данной системы является то, что она не обеспечивает:
- адаптацию онтологии верхнего уровня и процессных онтологий в соответствии с изменением среды функционирования данной системы;
- визуализацию элементов онтологии верхнего уровня, процессных онтологий и элементов данных;
Наиболее близким по технической сущности к заявляемому изобретению является метод интеграции и валидации данных с использованием промежуточного хранилища данных [патент на изобретение США US 10102229 В2, МПК G06F 7/002006 01, G06F 17/302006.01, опубл. 16.10.2018]. Предложенный метод включает следующие операции:
1) извлечение исходных элементов данных из источников данных;
2) применение правил предварительной обработки и очистки данных к исходным элементам данных с получение очищенных элементов данных;
3) формирование базовой онтологии данных;
4) применение базовой онтологии данных к очищенным элементам данных с получением массива структурированных данных;
5) выгрузка массива структурированных данных в промежуточное хранилище данных подсистемы валидации данных;
6) проверка на соответствие структуры и семантики массива структурированных данных и исходных элементов данных;
7) при отрицательном результате проверки (6) формируется схема модификации базовой онтологии данных с последующей модификацией онтологии данных;
8) по результатам модификации базовой онтологии данных промежуточное хранилище данных подсистемы валидации данных очищается с повторным получением массива структурированных данных;
9) при положительном результате проверки (6) выполняется загрузка массива структурированных данных и базовой онтологии данных в производственную подсистему.
Реализация метода интеграции и валидации данных с использованием промежуточного хранилища данных обеспечивается системой интеграции данных, включающей следующие компоненты:
- не менее двух интеллектуальных рабочих мест с соответствующими источниками данных, при этом источник данных может включать файловую систему, систему управления реляционной базой данных, нереляционную базу данных, распределенную файловую систему или любое другое хранилище данных на одном или нескольких вычислительных устройствах;
- модуль предварительной обработки и очистки данных, коммуникативно связанный с источниками данных интеллектуальных рабочих мест;
-генератор структурированных данных, коммуникативно связанный с модулем предварительной обработки и очистки данных, подсистемой валидации данных и производственной подсистемой;
- хранилище базовой онтологии данных, коммуникативно связанное с генератором структурированных данных, подсистемой валидации данных и производственной подсистемой;
- подсистему валидации данных с модулем поиска данных и промежуточным хранилищем данных;
- производственную подсистему.
Недостатками данной системы является то, что она не обеспечивает:
- автоматическое формирование базовой онтологии данных;
- поиск по массиву структурированных данных производственной подсистемы;
- визуализацию данных и элементов базовой онтологии данных подсистемы валидации данных и производственной подсистемы.
Техническим результатом заявленного изобретения является расширение функциональных возможностей системы интеграции проектно-конструкторских данных, а именно обеспечение возможности автоматического формирования, адаптации и визуального представления базовой онтологии проектно-конструкторских данных, поиска и визуализации как проектно-конструкторских данных, так и элементов базовой онтологии проектно-конструкторских данных непосредственно с интеллектуальных рабочих мест с выдачей полученных результатов в тексто-графическом формате, что способствует повышению надежности хранения, представления проектно-конструкторских данных и обеспечению информационной интеграции средств обеспечения дискретного многономенклатурного производства.
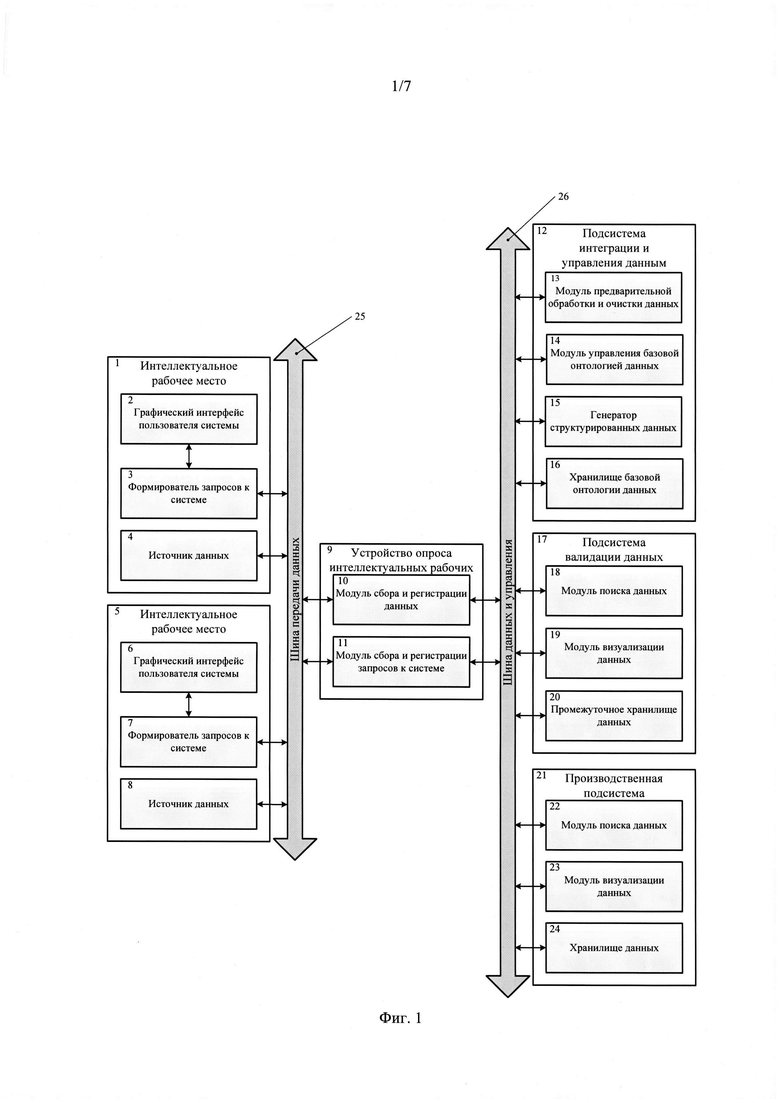
Указанный технический результат достигается тем, что в системе интеграции проектно-конструкторских данных, включающей два интеллектуальных рабочих места с источниками данных, модуль предварительной обработки и очистки данных, генератор структурированных данных, хранилище базовой онтологии данных, производственную подсистему, подсистему валидации данных с модулем поиска данных и промежуточным хранилищем данных, новым является то, что дополнительно содержит устройство опроса интеллектуальных рабочих мест со встроенными модулем сбора и регистрации данных, модулем сбора и регистрации запросов к системе, модуль предварительной обработки и очистки данных, генератор структурированных данных и хранилище онтологии данных формируют подсистему интеграции и управления данными, которая дополнительно включает модуль управления базовой онтологией данных, производственная подсистема дополнительно включает модуль поиска данных, модуль визуализации данных и хранилище данных, подсистема валидации данных дополнительно включает модуль визуализации данных, при этом взаимодействие модулей и генератора структурированных данных подсистемы интеграции и управления данными, модулей и промежуточного хранилища данных подсистемы валидации данных, модулей и хранилища данных производственной подсистемы с модулями устройства опроса интеллектуальных рабочих мест обеспечивается шиной данных и управления, интеллектуальные рабочие места дополнительно содержат графический интерфейс пользователя и связанным с ним формирователь запросов к системе, при этом взаимодействие формирователя запросов к системе и источника данных с модулями устройства опроса интеллектуальных рабочих мест обеспечивается шиной передачи данных.
Сущность предлагаемого технического решения иллюстрируется графическими материалами, на которых показаны:
фиг. 1 - структурная схема заявляемой системы интеграции проектно-конструкторских данных;
фиг. 2 - блок-схема метода интеграции и управления данными;
фиг. 3 - блок-схема процедуры семантической интеграции данных;
фиг. 4 - блок-схема процедуры формирования базовой онтологии данных;
фиг. 5 - блок-схема процедуры адаптации базовой онтологии данных;
фиг. 6 - блок-схема процедуры поиска данных;
фиг. 7 - блок-схема процедуры визуализации данных.
Предлагаемая система интеграции проектно-конструкторских данных включает два интеллектуальных рабочих места (1, 5), каждое из которых включает графический интерфейс пользователя системы (2, 6), формирователь запросов к системе (3, 7) и источник данных (4, 8); устройство опроса интеллектуальных рабочих мест (9) с модулем сбора и регистрации данных (10) и модулем сбора и регистрации запросов к системе (11); подсистему интеграции и управления данными (12) с модулем предварительной обработки и очистки данных (13), модулем управления базовой онтологией данных (14), генератором структурированных данных (15) и хранилищем базовой онтологии данных (16); подсистему валидации данных (17) с модулем поиска данных (18), модулем визуализации данных (19) и промежуточным хранилищем данных (20); производственную подсистему (21) с модулем поиска данных (22), модулем визуализации данных (23) и хранилищем данных (24); шину передачи данных (25); шину данных и управления (26).
Взаимодействие модуля сбора и регистрации данных (10), модуля сбора и регистрации запросов к системе (11) устройства опроса интеллектуальных рабочих мест (9), а также формирователей запросов к системе (3, 7) и источников данных (4, 8), входящих в состав интеллектуальных рабочих мест (1, 5) обеспечивается шиной передачи данных (25).
Взаимодействие следующих компонентов подсистем (12, 17, 21) и модулей (10, 11) устройства опроса интеллектуальных рабочих мест (9) обеспечивается шиной данных и управления (26):
- подсистема интеграции и управления данными (12): модуль предварительной обработки и очистки данных (13), модуль управления базовой онтологией данных (14), генератор структурированных данных (15), хранилище базовой онтологии данных (16);
- подсистема валидации данных (17): модуль поиска данных (18), модуль визуализации данных (19), промежуточное хранилище данных (20);
- производственная подсистема (21): модуль поиска данных (22), модуль визуализации данных (23), хранилище данных (24).
Графический интерфейс пользователя системы (2, 6) и формирователь запросов к системе (3, 7) взаимодействуют путем соответствующих линий связи в рамках интеллектуальных рабочих мест (1, 5).
Техническая реализация компонентов предлагаемой системы интеграции проектно-конструкторских данных может быть осуществлена с использованием следующих известных из уровня техники технических средств (производитель - Huawei Technologies Co. Ltd., КНР):
- устройство опроса интеллектуальных рабочих мест (9) - персональный компьютер в моноблочном исполнении Huawei MateStation X 2023 с дополнительным управляемым коммутатором Huawei S5700-SI
- подсистема интеграции и управления данными (12)-сервер Huawei FS2488V5 с дополнительной KVM-консолью Huawei 6040109
- подсистема валидации данных (17) и производственная подсистема (21)-сервер Huawei FS2488V5 с дополнительным сетевым хранилищем данных Huawei OceanStor 5310 V6.
Модуль сбора и регистрации данных (10), модуль сбора и регистрации запросов к системе (11), модуль предварительной обработки и очистки данных (13), модуль управления базовой онтологией данных (14), модули поиска данных (18, 22), модули визуализации данных (19, 23) и генератор структурированных данных (15) могут быть реализованы в виде программных компонентов, разработанных в кросс-платформенной интегрированной среде разработки прикладного программного обеспечения Qt Creator на базе кросс-платформенного инструментария разработчика прикладного программного обеспечения Qt. Данные программные компоненты загружаются в исполняемую среду технических средств, реализующих устройство опроса интеллектуальных рабочих мест (9), подсистему интеграции и управления данными (12), подсистему валидации данных (17) и производственную подсистему (21).
В качестве интеллектуального рабочего места (1, 5) может рассматриваться известное из уровня техники многофункциональное автоматизированное рабочее место тестирования радиоэлектронной аппаратуры [патент на изобретение Российской Федерации RU 2740546 С1, МПК G05B 23/022006 01, опубл. 15.01.2021]. При этом графический интерфейс пользователя системы (2, 6), формирователь запросов к системе (3, 7) и источник данных (4, 8), входящие в состав интеллектуальных рабочих мест (1,5) могут быть реализованы в виде программных компонентов, разработанных в кросс-платформенной интегрированной среде разработки прикладного программного обеспечения Qt Creator на базе кросс-платформенного инструментария разработчика прикладного программного обеспечения Qt. Данные программные компоненты загружаются в исполняемую среду управляющего компьютера известного из уровня техники многофункционального автоматизированного рабочего места тестирования радиоэлектронной аппаратуры.
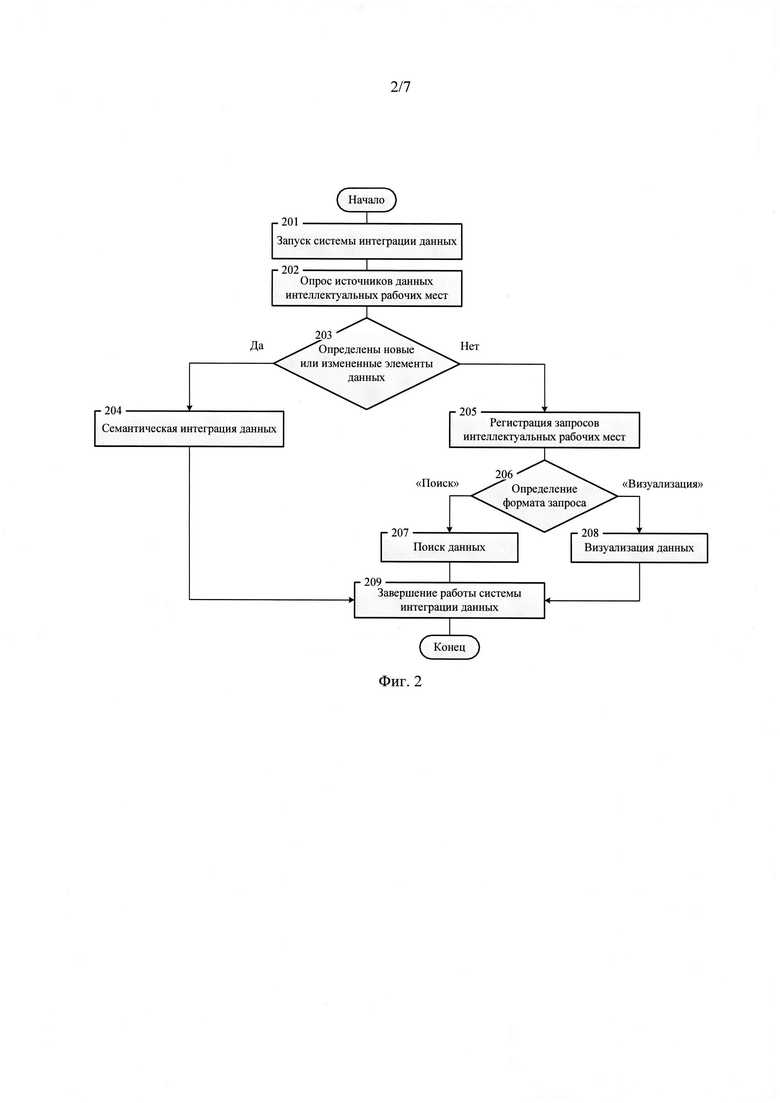
Заявляемая система интеграции проектно-конструкторских данных обеспечивает реализацию метода интеграции и управления проектно-конструкторскими данными, который предполагает выполнение ряда процедур в последовательности, представленной на фиг. 2. Реализация процедур семантической интеграции данных (фиг. 2, поз. 204), формирования базовой онтологии данных (фиг. 3, поз. 306), адаптации базовой онтологии данных (фиг. 3, поз. 314), поиска данных (фиг. 2, поз. 207) и визуализации данных (фиг. 2, поз. 208) представлены на фиг. 3, фиг. 4, фиг. 5, фиг. 6 и фиг. 7 соответственно.
Под проектно-конструкторскими данными в соответствии с определением ГОСТ Р 58300-2018 понимается массив систематизированной информации об изделии, представленной в формализованном виде, пригодном для обработки автоматическими средствами. Проектно-конструкторские данные представлены в форме структурированных электронных конструкторских документов, включающих в соответствии с ГОСТ Р ИСО 15489-1-2019 две ключевых составляющих: метаданные о документе и собственно проектно-конструкторские данные (содержательная часть документа).
На фиг. 2-фиг. 7 для обозначения базовой онтологии данных принята аббревиатура БОД.
Ниже перечислены процедуры реализуемого заявляемой системой интеграции проектно-конструкторских данных метода интеграции и управления данными:
1. Запуск системы интеграции проектно-конструкторских данных (фиг. 2, поз. 201).
2. Опрос (фиг. 2, поз. 202) источников данных (4, 8) интеллектуальных рабочих мест (1, 5).
3. Проверка на наличие новых или измененных элементов данных (фиг. 2, поз. 203).
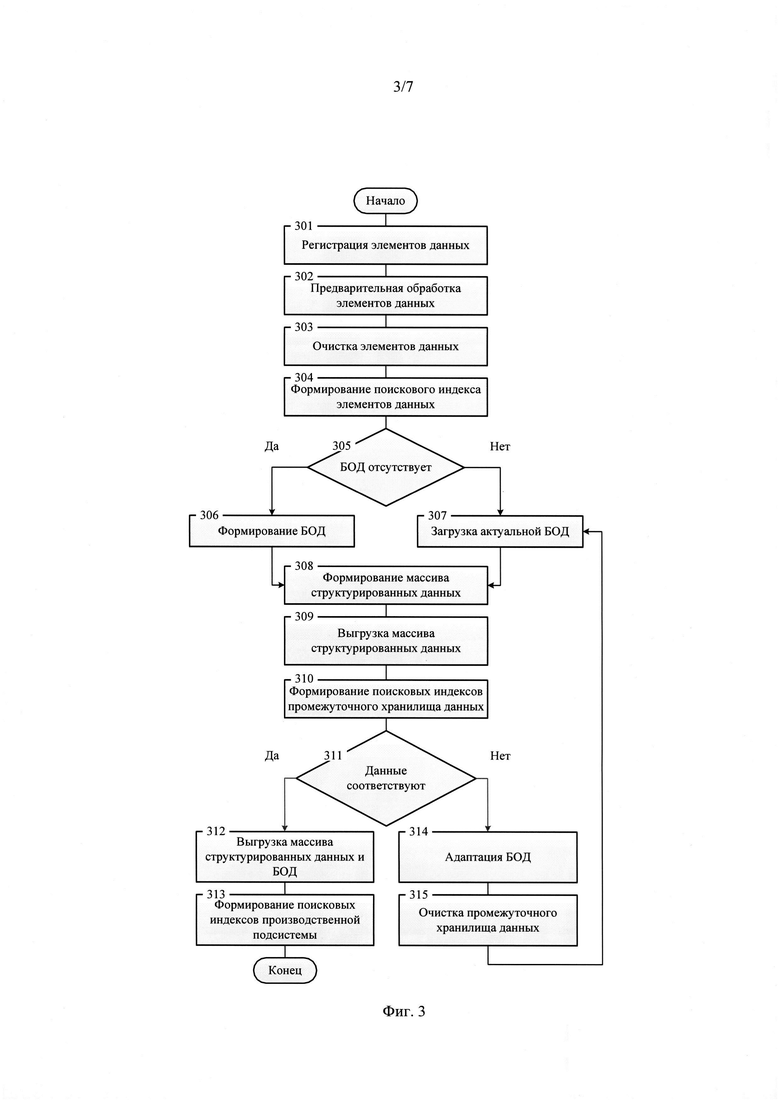
4. В том случае, если по результатам проверки на наличие новых или измененных элементов данных (фиг. 2, поз. 203) выявлены соответствующие элементы данных, то выполняется процедура семантической интеграции данных (фиг. 2, поз. 204), предполагающая выполнение следующих процедур и операций, последовательность выполнения которых представлена на фиг. 3:
- регистрация элементов данных (фиг. 3, поз. 301);
- предварительная обработка элементов данных (фиг. 3, поз. 302);
- очистка элементов данных (фиг. 3, поз. 303);
- формирование поискового индекса элементов данных (фиг. 3, поз. 304);
- проверка на наличие базовой онтологии данных в системе интеграции проектно-конструкторских данных (фиг. 3, поз. 305);
- в том случае, если базовая онтология данных отсутствует, выполняется процедура формирования базовой онтологии данных (фиг. 3, поз. 306), последовательность операций которой дана в пункте 5 настоящего перечня процедур рассматриваемого метода, в противном случае выполняется операция загрузки актуальной версии базовой онтологии данных (фиг. 3, поз. 307);
- формирование массива структурированных данных (фиг. 3, поз. 308);
- выгрузка массива структурированных данных (фиг. 3, поз. 309) в подсистему валидации данных (17);
- формирование поисковых индексов (фиг. 3, поз. 310) промежуточного хранилища данных (20) подсистемы валидации данных (17);
- в том случае, если структура и семантика массива структурированных данных в промежуточном хранилище данных (20) подсистемы валидации данных (17) соответствуют содержательной части и метаданным элементов данных (фиг. 3, поз. 311), то выполняется выгрузка массива структурированных данных и базовой онтологии данных (фиг. 3, поз. 312) в хранилище данных (24) производственной подсистемы (21);
- формирование поисковых индексов производственной подсистемы (фиг. 3, поз. 313): поискового индекса структурированных данных и поискового индекса базовой онтологии данных, включающего элементы словаря понятий, семантической карты заданной предметной области и объекты базовой онтологии данных;
- в том случае, если структура и семантика массива структурированных проектно-конструкторских данных в промежуточном хранилище данных (20) не соответствуют содержательной части и метаданным элементов данных (фиг. 3, поз. 311), то выполняется процедура адаптации базовой онтологии данных (фиг. 3, поз. 314), последовательность операций которой дана в пункте 6 настоящего перечня процедур рассматриваемого метода;
- после выполнения процедуры адаптации базовой онтологии данных (фиг. 3, поз. 314) производится очистка (фиг. 3, поз. 315) промежуточного хранилища данных (20) подсистемы валидации данных (17) с последующей загрузкой (фиг. 3, поз. 307) актуальной версии базовой онтологии данных.
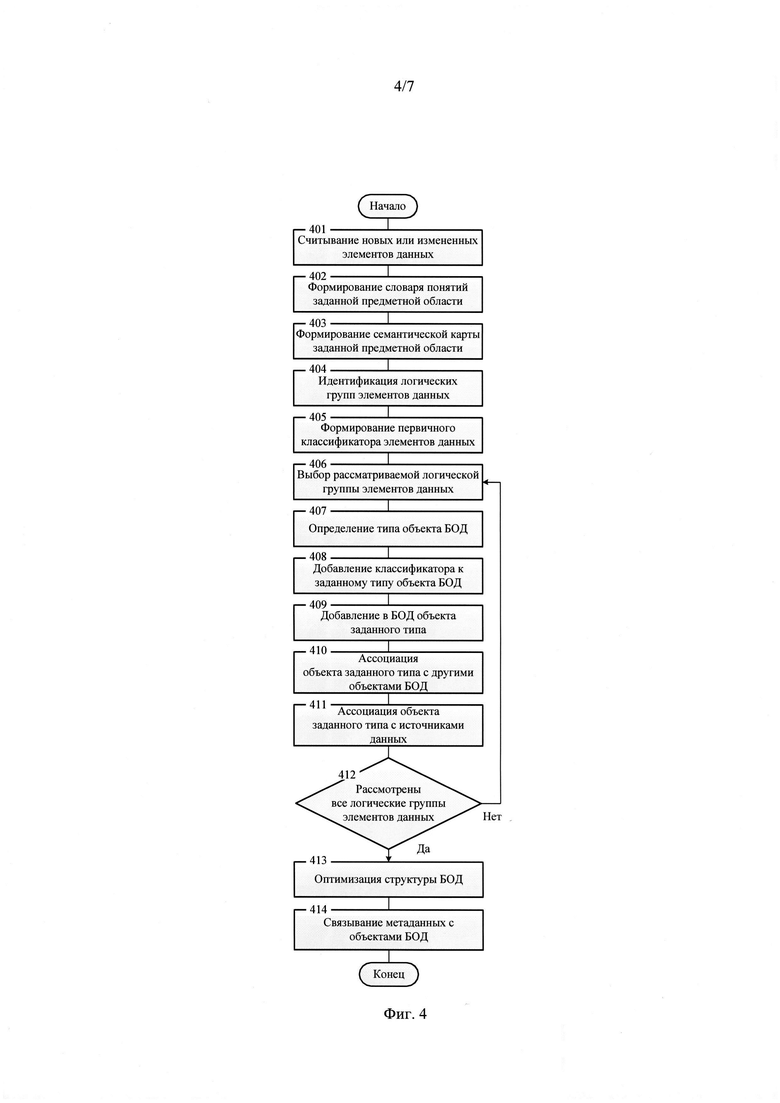
5. Процедура формирования базовой онтологии данных (фиг. 3, поз. 306) предполагает выполнение следующих операций, последовательность выполнения которых представлена на фиг. 4:
- считывание новых или измененных элементов данных (фиг. 4, поз. 401);
- формирование словаря понятий заданной предметной области (фиг. 4, поз. 402);
- формирование семантической карты заданной предметной области (фиг. 4, поз. 403);
- идентификация логических групп элементов данных, ассоциированных с ними метаданных и атрибутов элементов данных с использованием предварительно заданных правил логического вывода (фиг. 4, поз. 404);
- формирование первичного классификатора элементов данных на основе атрибутов элементов данных с использованием технологий глубокого обучения и предварительно заданных правил классификации элементов данных (фиг. 4, поз. 405);
- выбор рассматриваемой логической группы элементов данных (фиг. 4, поз. 406);
- определение типа объекта базовой онтологии данных (фиг. 4, поз. 407), свойства которого соответствуют атрибутам рассматриваемой логической группы элементов данных;
- добавление классификатора к заданному типу объекта базовой онтологии данных (фиг. 4, поз. 408);
- добавление в базовую онтологию данных объекта заданного типа, ассоциированных с ним классификатора и свойств объекта (фиг. 4, поз. 409);
- ассоциация объекта заданного типа с другими объектами базовой онтологии данных (фиг. 4, поз. 410) путем обнаружения возможных сематических связей объектов с использованием предварительно заданных синтаксических шаблонов элементов данных;
- ассоциация объекта заданного типа (фиг. 4, поз. 411) с источниками данных (4, 8) интеллектуальных рабочих мест (1, 5);
- проверка на рассмотрение всех доступных логических групп элементов данных (фиг. 4, поз. 412), в том случае, если рассмотрены не все доступные логические группы элементов данных, то осуществляется переход к операции выбора логической группы элементов данных (фиг. 4, поз. 406);
- в том случае, если рассмотрены все доступные логические группы элементов данных, то выполняется оптимизация структуры базовой онтологии данных (фиг. 4, поз. 413);
- связывание метаданных элементов данных с объектами базовой онтологии данных (фиг. 4, поз. 414).
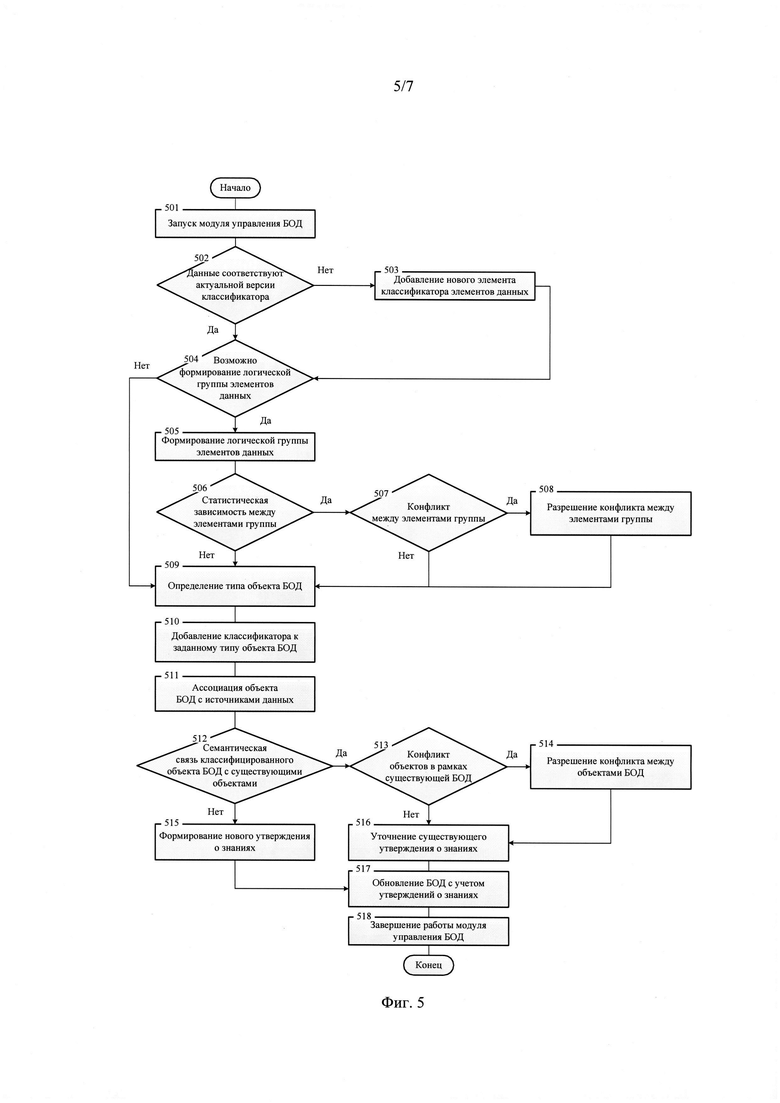
6. Процедура адаптации базовой онтологии данных (фиг. 3, поз. 314) предполагает выполнение следующих операций, последовательность выполнения которых представлена на фиг. 5:
-запуск (фиг. 5, поз. 501) модуля управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12);
- проверка на соответствие новых или измененных элементов данных актуальной версии классификатора элементов данных (фиг. 5, поз. 502);
- в том случае, если по результатам проверки (фиг. 5, поз. 502) выявлено несоответствие элементов данных и актуальной версии классификатора элементов данных, то в классификатор добавляется новый элемент данных (фиг. 5, поз. 503);
- при соответствии элементов данных актуальной версии классификатора элементов данных выполняется проверка на возможность формирования логической группы элементов данных (фиг. 5, поз. 504), положительный результат которой устанавливается в том случае, если число новых элементов данных более одного и возможно формирование как минимум одной связанной логической группы элементов данных;
- при положительном результате проверки на возможность формирования логической группы элементов данных (фиг. 5, поз. 504), выполняется операция формирования логической группы элементов данных (фиг. 5, поз. 505);
-для сформированной логической группы элементов данных последовательно выполняются проверки на наличие статистической зависимости между элементами группы (фиг. 5, поз. 506) и наличия конфликтов между элементами группы (фиг. 5, поз. 507);
- в случае положительного результата проведения проверок на наличие статистической зависимости между элементами группы (фиг. 5, поз. 506) и наличия конфликтов между элементами группы (фиг. 5, поз. 507) проводится процедура разрешения конфликта между элементами группы (фиг. 5, поз. 508) с использованием методов снижения размерности данных;
-в случае отрицательного результата проведения проверок на наличие статистической зависимости между элементами группы (фиг. 5, поз. 506) и наличия конфликтов между элементами группы (фиг. 5, поз. 507) или завершения операции разрешения конфликта между элементами группы (фиг. 5, поз. 508) последовательно выполняются операции определения типа объекта базовой онтологии данных (фиг. 5, поз. 509), свойства которого соответствуют атрибутам рассматриваемой логической группы элементов данных, добавления классификатора к заданному типу объекта базовой онтологии данных (фиг. 5, поз. 510) и ассоциации объекта базовой онтологии данных (фиг. 5, поз. 511) с соответствующими источниками данных (4, 8) интеллектуальных рабочих мест (1,5);
- при отрицательном результате проверки на возможность формирования логической группы элементов данных (фиг. 5, поз. 504) последовательно выполняются операции определения типа объекта базовой онтологии данных (фиг. 5, поз. 509), добавления классификатора к заданному типу объекта базовой онтологии данных (фиг. 5, поз. 510) и ассоциации объекта базовой онтологии данных (фиг. 5, поз. 511) с соответствующими источниками данных (4, 8) интеллектуальных рабочих мест (1, 5);
-для заданного классифицированного объекта базовой онтологии данных последовательно осуществляются проверки на наличие семантической связи классифицированного объекта с существующими объектами базовой онтологии данных (фиг. 5, поз. 512) и наличия конфликта объектов в рамках существующей базовой онтологии данных (фиг. 5, поз. 513);
- в случае положительного результата проверок на наличие семантической связи классифицированного объекта с существующими объектами базовой онтологии данных (фиг. 5, поз. 512) и наличия конфликта объектов в рамках существующей базовой онтологии данных (фиг. 5, поз. 513) проводится операция разрешения конфликта между объектами базовой онтологии данных (фиг. 5, поз. 514) с использованием методов снижения объемов данных;
- в случае отрицательного результата проверки на наличие семантической связи классифицированного объекта с существующими объектами базовой онтологии данных (фиг. 5, поз. 512) формируется новое утверждение о знаниях (фиг. 5, поз. 515);
- в случае отрицательного результата проверки на наличие конфликта объектов в рамках существующей базовой онтологии данных (фиг. 5, поз. 513) или завершения процедуры разрешения конфликта между объектами базовой онтологии данных (фиг. 5, поз. 514), производится уточнение существующего утверждения о знаниях (фиг. 5, поз. 516);
- по результатам выполнения предыдущих операций обновляется базовая онтология данных с учетом новых или измененных утверждений о знания (фиг. 5, поз. 517) с последующим завершением работы (фиг. 5, поз. 518) модуля управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12).
7. В том случае, если по результатам проверки на наличие новых или измененных элементов данных (фиг. 2, поз. 203) выявлено, что соответствующие элементы данных отсутствуют, то осуществляется регистрация запросов интеллектуальных рабочих мест (фиг. 2, поз. 205) на поиск и визуализацию данных.
8. Определяется формат запроса (фиг. 2, поз. 206) от интеллектуального рабочего места с определением рассматриваемой области поиска и визуализации элементов данных или объектов базовой онтологии данных: промежуточного хранилища данных (20) подсистемы валидации данных (17) или хранилища данных (24) производственной подсистемы (21).
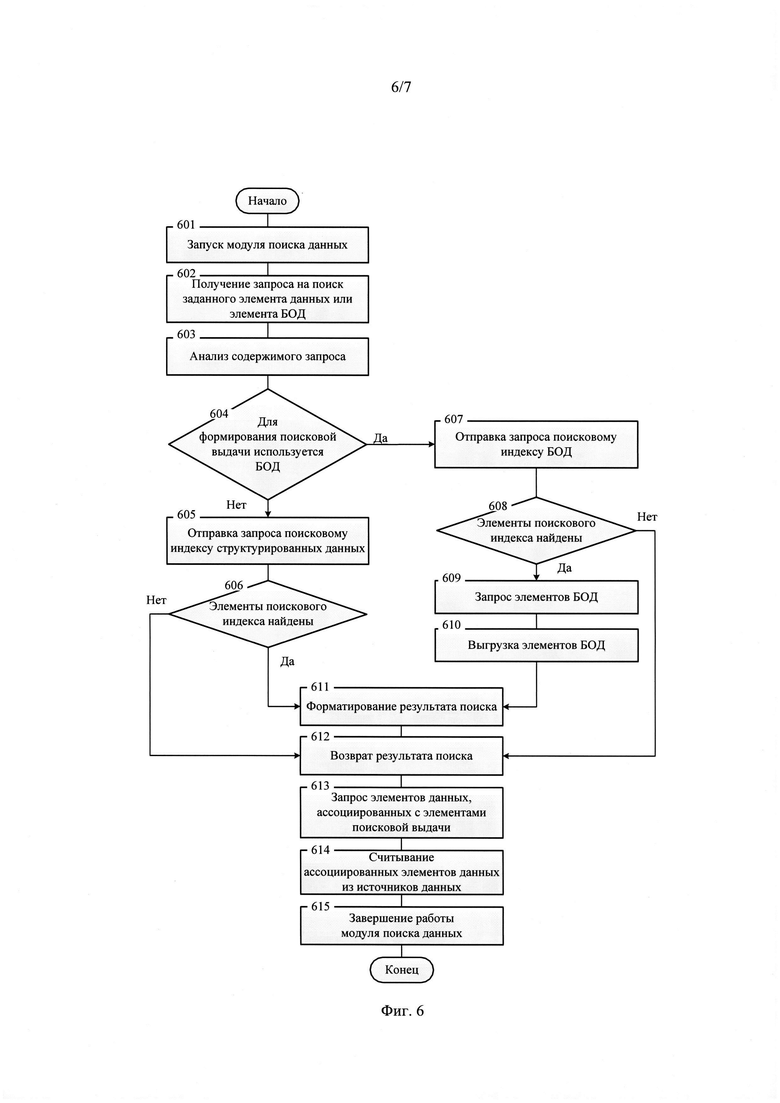
9. В том случае, если от интеллектуального рабочего места (1, 5) получен запрос на поиск данных, выполняется соответствующая процедура поиска данных (фиг. 2, поз. 207), предполагающая выполнение следующих операций, последовательность выполнения которых представлена на фиг. 6:
- запуск модуля поиска данных (фиг. 6, поз. 601);
- получение запроса на поиск заданного элемента данных или элемента базовой онтологии данных (фиг. 6, поз. 602);
- анализ содержимого запроса (фиг. 6, поз. 603) на поиск заданного элемента данных или элемента базовой онтологии данных;
- выбор поискового пространства, используемого при формировании поисковой выдачи: массива структурированных данных или базовой онтологии данных (фиг. 6, поз. 604). При этом определяется, используется ли базовая онтология данных как основа для формирования поисковой выдачи;
- в том случае, если по результатам проверки (фиг. 6, поз. 604) поисковая выдача формируется на основе массива структурированных данных, то выполняется отправка запроса поисковому индексу структурированных данных (фиг. 6, поз. 605);
- в том случае, если по результатам проверки (фиг. 6, поз. 606) элементы поискового структурированных данных найдены, то производится форматирование результата поиска (фиг. 6, поз. 611) с возвратом результата поиска (фиг. 6, поз. 612) и его выводом на графический интерфейс пользователя (2, 6) интеллектуального рабочего места (1, 5), с которого получен запрос на поиск данных;
- в том случае, если по результатам проверки (фиг. 6, поз. 606) элементы поискового структурированных данных не были найдены, возвращается результат поиска с соответствующим сообщением (фиг. 6, поз. 612) с выводом на графический интерфейс пользователя (2, 6) интеллектуального рабочего места (1, 5), с которого получен запрос на поиск данных;
- в том случае, если по результатам проверки (фиг. 6, поз. 604) для формирования поисковой выдачи используется базовая онтология данных, то выполняется отправка запроса поисковому индексу базовой онтологии данных (фиг. 6, поз. 607);
- если по результатам проверки (фиг. 6, поз. 608) соответствующие элементы поискового индекса базовой онтологии данных найдены, то последовательно выполняются запрос элементов базовой онтологии данных, соответствующих найденным элементам поискового индекса базовой онтологии данных (фиг. 6, поз. 609) с последующей выгрузкой элементов базовой онтологии данных, ассоциированных с ними классификаторов и свойств (фиг. 6, поз. 610);
- производится форматирование результата поиска элементов базовой онтологии данных (фиг. 6, поз. 611) с возвратом результата поиска (фиг. 6, поз. 612) и его выводом на графический интерфейс пользователя (2, 6) интеллектуального рабочего места (1, 5), с которого получен запрос на поиск данных;
- в том случае, если по результатам проверки (фиг. 6, поз. 608) элементы поискового индекса базовой онтологии данных не были найдены, возвращается соответствующее сообщение (фиг. 6, поз. 612) с выводом на графический интерфейс пользователя (2, 6) интеллектуального рабочего места (1, 5), с которого получен запрос на поиск данных;
- запрашиваются элементы данных, ассоциированные с соответствующими элементами поисковой выдачи (фиг. 6, поз. 613) с последующим считыванием ассоциированных элементов данных (фиг. 6, поз. 614) из соответствующих источников данных (4, 8) интеллектуальных рабочих мест (1, 5);
- после выполнения перечисленных выше операций (фиг. 6, поз. 601-614) модуль поиска данных завершает работу (фиг. 6, поз. 615).
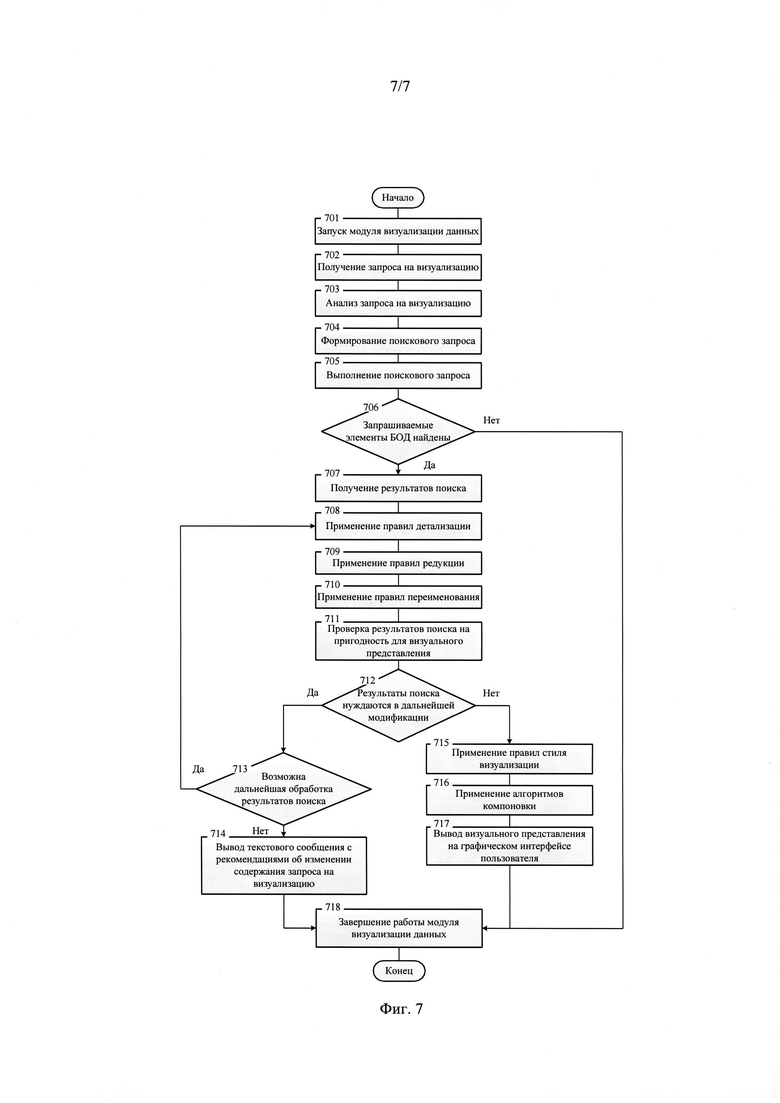
10. В том случае, если от интеллектуального рабочего места (1, 5) получен запрос на визуализацию данных, выполняется соответствующая процедура визуализации данных (фиг. 2, поз. 208), предполагающая выполнение следующих операций, последовательность выполнения которых представлена на фиг. 7:
- запуск модуля визуализации данных (фиг. 7, поз. 701);
- получение запроса на визуализацию (фиг. 7, поз. 702) заданного элемента базовой онтологии данных и его семантических связей;
- анализ запроса на визуализацию (фиг. 7, поз. 703), формирование поискового запроса (фиг. 7, поз. 704) с последующей передачей модулю поиска данных;
- выполнение поискового запроса модулем поиска данных (фиг. 7, поз. 705);
- в том случае, если запрашиваемые элементы базовой онтологии данных найдены (фиг. 7, поз. 706), модуль визуализации данных получает результаты поиска (фиг. 7, поз. 707), включающие перечень элементов базовой онтологии данных, подлежащих визуализации, их свойства и семантические связи с другими элементами базовой онтологии данных;
- к результатам выполнения поискового запроса применяются предварительно заданные правила детализации результатов поиска (фиг. 7, поз. 708);
- к результатам выполнения поискового запроса применяются предварительно заданные правила редукции результатов поиска (фиг. 7, поз. 709);
- к результатам выполнения поискового запроса применяются предварительно заданные правила переименования результатов поиска (фиг. 7, поз. 710);
- выполняется проверка результатов поиска на пригодность для визуального представления (фиг. 7, поз. 711) по результатам применения правил модификации результатов поиска (фиг. 7, поз. 708-710);
- в том случае, если по результатам проверки (фиг. 7, поз. 711) дальнейшая модификация результатов поиска не требуется (фиг. 7, поз. 712), к модифицированным результатам поиска последовательно применяются правила стиля визуализации (фиг. 7, поз. 715) и алгоритмы компоновки (фиг. 7, поз. 716) с последующим выводом визуального представления (фиг. 7, поз. 717) на графическом интерфейсе пользователя (2, 6) интеллектуального рабочего места (1, 5), с которого был получен запрос на визуализацию данных;
- если по результатам проверки (фиг. 7, поз. 711) результаты поиска признаны непригодными для визуализации (фиг. 7, поз. 712), то проверяется возможность дальнейшей обработки результатов поиска без потери содержания (фиг. 7, поз. 713). Если данная обработка возможна, то осуществляется возврат к операции (фиг. 7, поз. 708), в противном случае на графическом интерфейсе пользователя системы (2, 6) интеллектуального рабочего места (1, 5), с которого был получен запрос на визуализацию данных, выводится текстовое сообщение с рекомендациями об изменении содержания запроса на визуализацию (фиг. 7, поз. 714);
- при завершении операций (фиг. 7, поз. 714; фиг. 7, поз. 717), а также, если по результатам проверки (фиг. 7, поз. 706) запрашиваемые элементы базовой онтологии данных не были найдены, модуль визуализации данных завершает работу (фиг. 7, поз. 718).
11. Завершение работы системы интеграции проектно-конструкторских данных (фиг. 2, поз. 209).
Рассмотрим процесс функционирования заявляемой системы интеграции проектно-конструкторских данных.
Осуществляется запуск системы интеграции проектно-конструкторских данных (фиг. 2, поз. 201) с последующим последовательным опросом (фиг. 2, поз. 202) источников данных (4, 8) интеллектуальных рабочих мест (1, 5) посредством модуля сбора и регистрации данных (10) устройства опроса интеллектуальных рабочих мест (9) и шины передачи данных (25). При этом операция (фиг. 2, поз. 202) опроса источников данных (4, 8) интеллектуальных рабочих мест (1, 5) инициируется модулем управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12) посредством шины данных и управления (26).
Полученные с интеллектуальных рабочих мест (1, 5) элементы данных посредством шины передачи данных (25), модуля сбора и регистрации данных (10) устройства опроса интеллектуальных рабочих мест (9), шины данных и управления (26) выгружаются в промежуточное хранилище данных (20) подсистемы валидации данных (17). Далее модулем управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12) осуществляется проверка на наличие новых или измененных элементов данных (фиг. 2, поз. 203). В том случае, если по результатам проверки (фиг. 2, поз. 203) определено, что в промежуточном хранилище данных (20) подсистемы валидации данных (17) имеются элементы данных, метаданные которых отличаются от имеющихся элементов данных в хранилище данных (24) производственной подсистемы (21), инициируется процедура семантической интеграции данных (фиг. 2, поз. 204).
Семантическая интеграция данных предполагает предварительную подготовку элементов данных, а именно:
1) регистрацию элементов данных (фиг. 3, поз. 301);
2) предварительную обработку элементов данных (фиг. 3, поз. 302);
3) очистку элементов данных (фиг. 3, поз. 303).
Данные процедуры (фиг. 3, поз. 301-303) реализуются модулем предварительной обработки и очистки данных (13) подсистемы интеграции и управления данными (12), при этом исходные элементы данных перед выполнением процедуры регистрации элементов данных (фиг. 3, поз. 301) выгружаются из промежуточного хранилища данных (20) подсистемы валидации данных (17) во внутреннюю память модуля первичной обработки и очистки данных (13). Подготовленные элементы данных после выполнения процедуры очистки элементов данных (фиг. 3, поз. 303) выгружаются из внутренней памяти модуля предварительной обработки и очистки данных (13) в промежуточное хранилище данных (20) подсистемы валидации данных (17).
После завершения процедур предварительной подготовки элементов данных (фиг. 3, поз. 301-303), модулем поиска данных (18) подсистемы валидации данных (17) формируется поисковый индекс элементов данных (фиг. 3, поз. 304), выгруженных в промежуточное хранилище данных (20) подсистемы валидации данных (17) по результатам выполнения операции очистки элементов данных (фиг. 3, поз. 303). Полученный при этом поисковый индекс сохраняется в промежуточном хранилище данных (20).
Далее модулем управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12) выполняется проверка (фиг. 3, поз. 305) на наличие в хранилище данных (24) производственной подсистемы (21) базовой онтологии данных. В том случае, если базовая онтология данных отсутствует, модулем управления базовой онтологией данных (14) выполняется процедура формирования базовой онтологии данных (фиг. 3, поз. 306) и операции (фиг. 4, поз. 401-414), входящие в нее.
При этом во внутреннюю память модуля управления базовой онтологией данных (14) из промежуточного хранилища данных (20) подсистемы валидации данных (17) посредством шины данных и управления (26) выгружается массив подготовленных элементов данных, полученный в результате выполнения процедур предварительной подготовки элементов данных (фиг. 3, поз. 301-303) и, после завершения операции формирования базовой онтологии данных (фиг. 3, поз. 306), полученная базовая онтология данных выгружается в хранилище базовой онтологии данных (16) подсистемы интеграции и управления данными (12).
В том случае, если в хранилище данных (24) производственной подсистемы (21) имеется актуальная базовая онтология данных, она выгружается (фиг. 3, поз. 307) в хранилище базовой онтологии данных (16) подсистемы интеграции и управления данными (12).
Далее с использованием базовой онтологии данных генератором структурированных данных (15) подсистемы интеграции и управления данными (12) осуществляется формирование массива структурированных данных (фиг. 3, поз. 308) с последующей их выгрузкой (фиг. 3, поз. 309) в промежуточное хранилище данных (20) подсистемы валидации данных (17). После завершения процедур (фиг. 3, поз. 301-308), модулем поиска данных (18) подсистемы валидации данных (17) формируются поисковые индексы промежуточного хранилища данных (фиг. 3, поз. 310): поисковый индекс структурированных данных и поисковый индекс базовой онтологии данных, выгруженных в промежуточное хранилище данных (20) подсистемы валидации данных (17) по результатам выполнения процедуры выгрузки структурированных данных в подсистему валидации данных (фиг. 3, поз. 309). Полученные при этом поисковые индексы сохраняются в промежуточном хранилище данных (20).
Далее осуществляется проверка (фиг. 3, поз. 311) на соответствие структурной организации и семантики существующих элементов данных, сформированных по результатам выполнения операций (фиг. 3, поз. 301-303) и массива структурированных данных, полученного по результатам выполнения операций (фиг. 3, поз. 308-309), размещенных в промежуточном хранилище данных (20) подсистемы валидации данных (17). В случае положительного результата проверки (фиг. 3, поз. 311) осуществляется выгрузка (фиг. 3, поз. 312) массива структурированных данных из промежуточного хранилища данных (20) подсистемы валидации данных (17) в хранилище данных (24) производственной подсистемы (21), также производится выгрузка (фиг. 3, поз. 312) базовой онтологии данных из хранилища базовой онтологии данных (16) подсистемы интеграции данных и управления (12) в хранилище данных (24) производственной подсистемы (21).
После завершения процедур (фиг. 3, поз. 301-312), модулем поиска данных (22) производственной подсистемы (21) формируется (фиг. 3, поз. 313) поисковый индекс структурированных данных и поисковый индекс базовой онтологии данных, выгруженных в хранилище данных (24) производственной подсистемы (21) по результатам выполнения процедуры выгрузки структурированных данных и базовой онтологии данных в производственную подсистему (фиг. 3, поз. 312). Полученные при этом поисковые индексы сохраняются в хранилище данных (24).
В случае отрицательного результата проверки (фиг. 3, поз. 311) модулем управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12) выполняется процедура адаптации базовой онтологии данных (фиг. 3, поз. 314) и операции (фиг. 5, поз. 501-518), входящие в нее.
При этом во внутреннюю память модуля управления базовой онтологией данных (14) подсистемы интеграции и управления данными (12) из промежуточного хранилища данных (20) подсистемы валидации данных (17) посредством шины данных и управления (26) выгружаются массив подготовленных элементов данных, полученный в результате выполнения процедур предварительной подготовки элементов данных (фиг. 3, поз. 301-303). Также из хранилища данных (24) производственной подсистемы (20) во внутреннюю память модуля управления базовой онтологией данных (13) выгружается текущая версия базовой онтологии данных.
После завершения процедуры адаптации базовой онтологии данных (фиг. 3, поз. 314), промежуточное хранилище данных (20) подсистемы валидации данных (17) очищается (фиг. 3, поз. 315) и в него загружается (фиг. 3, поз. 307) актуальная версия базовой онтологии данных, полученная по результатам выполнения процедуры адаптации базовой онтологии данных (фиг. 3, поз. 314).
В том случае, если по результатам проверки (фиг. 2, поз. 203) новые или измененные элементы данных не найдены, модулем сбора и регистрации запросов к системе (11) устройства опроса интеллектуальных рабочих мест (9) посредством шины передачи данных (25) осуществляется последовательный сбор запросов интеллектуальных рабочих мест (1, 5) с последующей регистрацией запросов интеллектуальных рабочих мест (фиг. 2, поз. 205) модулем сбора и регистрации запросов к системе (11). При этом запросы интеллектуальных рабочих мест (1, 5), подлежащие регистрации, инициируются посредством графического интерфейса пользователя (2, 6) и преобразуются формирователем запросов к системе (3, 7) в формат, пригодный для использования модулями поиска данных (18, 22) и визуализации данных (19, 23) подсистемы валидации данных (17) и производственной подсистемы (21) заявляемой системы соответственно.
Для полученных запросов интеллектуальных рабочих мест модулем сбора и регистрации запросов к системе (11) устройства опроса интеллектуальных рабочих мест (9) определяется формат запроса, в зависимости от этого полученный запрос посредством шины данных и управления (26) передается соответственно в модули поиска данных (18, 22) или модули визуализации данных (19, 23) подсистемы валидации данных (17) и производственной подсистемы (21) заявляемой системы интеграции проектно-конструкторских данных для выполнения одной из соответствующих процедур:
- поиска данных (фиг. 2, поз. 207), включающей операции (фиг. 6, поз. 601-615);
- визуализации данных (фиг. 2, поз. 208), включающей операции (фиг. 7, поз. 701-718).
При этом по результатам анализа запроса определяется область поиска и визуализации данных и используемые при этом поисковые индексы структурированных данных или базовой онтологии данных, ранее сформированные (фиг. 3, поз. 310, 313) для промежуточного хранилища данных (20) подсистемы валидации данных (17) и хранилища данных (24) производственной подсистемы (21).
Процедура поиска данных (фиг. 2, поз. 207), включающая операции (фиг. 6, поз. 601-615) реализуется модулями поиска данных (18, 22) подсистемы валидации данных (17) и производственной подсистемы (21) соответственно. При этом операция считывания ассоциированных элементов данных (фиг. 6, поз. 614) из источников данных (4, 8) интеллектуальных рабочих мест (1, 5) реализуется модулем сбора и регистрации данных (10) устройства опроса интеллектуальных рабочих мест (9). В процессе выполнения операции считывания ассоциированных элементов данных из источников данных (фиг. 6, поз. 614) модулем сбора и регистрации данных (10) устройства опроса интеллектуальных рабочих мест (9) выполняется считывание элементов данных, соответствующих содержанию поисковой выдачи из источников данных (4, 8) интеллектуальных рабочих мест (1, 5) посредством шины передачи данных (25) с последующей передачей элементов данных соответствующему модулю поиска данных (18, 22) посредством шины данных и управления (26).
Процедура визуализации данных (фиг. 2, поз. 208), включающая операции (фиг. 7, поз. 701-718) реализуется модулями визуализации данных (19, 23) подсистемы валидации данных (17) и производственной подсистемы (21) соответственно. При этом операции вывода текстового сообщения с рекомендациями об изменении содержания запроса на визуализацию (фиг. 7, поз. 714) и вывода визуального представления на графическом интерфейсе пользователя (фиг. 7, поз. 717) выполняются графическим интерфейсом пользователя (2, 6) интеллектуального рабочего места (1, 5), с которого был получен запрос на визуализацию данных.
Таким образом, заявленная система интеграции проектно-конструкторских данных обеспечивает автоматическое формирование, адаптацию и визуальное представление базовой онтологии проектно-конструкторских данных, поиск и визуализацию как проектно-конструкторских данных, так и элементов базовой онтологии проектно-конструкторских данных непосредственно с интеллектуальных рабочих мест с выдачей полученных результатов в тексто-графическом формате, что способствует повышению надежности хранения, представления проектно-конструкторских данных и обеспечению информационной интеграции средств обеспечения дискретного многономенклатурного производства.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОСТРОЕНИЯ ЕДИНОГО ИНФОРМАЦИОННОГО ПРОСТРАНСТВА И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2016 |
|
RU2656841C2 |
| Геопортальная платформа для управления пространственно-распределенными ресурсами | 2023 |
|
RU2818866C1 |
| СПОСОБ ФОРМИРОВАНИЯ ЦИФРОВОЙ ПЛАН-СХЕМЫ ОБЪЕКТОВ СЕЛЬСКОХОЗЯЙСТВЕННОГО НАЗНАЧЕНИЯ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2015 |
|
RU2612326C2 |
| СЕМАНТИЧЕСКАЯ НАВИГАЦИЯ ПО ВЕБ-КОНТЕНТУ И КОЛЛЕКЦИЯМ ДОКУМЕНТОВ | 2007 |
|
RU2442214C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| БАЗА ЗНАНИЙ ПО ОБРАБОТКЕ, АНАЛИЗУ И РАСПОЗНАВАНИЮ ИЗОБРАЖЕНИЙ | 2003 |
|
RU2256224C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ ИНЖЕНЕРНЫМИ ДАННЫМИ | 2022 |
|
RU2787261C1 |
| ЦИФРОВАЯ КОМПЬЮТЕРНО-РЕАЛИЗУЕМАЯ ПЛАТФОРМА ДЛЯ СОЗДАНИЯ МЕДИЦИНСКИХ ПРИЛОЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА И СПОСОБ ЕЁ РАБОТЫ | 2020 |
|
RU2742261C1 |
| КОНТЕКСТНЫЕ ЗАПРОСЫ | 2011 |
|
RU2573764C2 |
Изобретение относится к области обработки данных и предназначено для обеспечения управления проектно-конструкторскими данными об изделии в условиях дискретного многономенклатурного производства. Техническим результатом является повышение надежности хранения, представления проектно-конструкторских данных и обеспечения информационной интеграции средств обеспечения дискретного многономенклатурного производства. Система содержит два интеллектуальных рабочих места, каждое из которых включает графический интерфейс пользователя системы, формирователь запросов к системе и источник данных; устройство опроса интеллектуальных рабочих мест с модулями сбора и регистрации данных, сбора и регистрации запросов к системе; подсистему интеграции и управления данными с модулями предварительной обработки и очистки, управления базовой онтологией данных, генератором структурированных данных и хранилищем базовой онтологии данных; подсистему валидации данных с промежуточным хранилищем данных и производственную подсистему с хранилищем данных, каждая из которых также включает модули поиска и визуализации данных. 7 ил.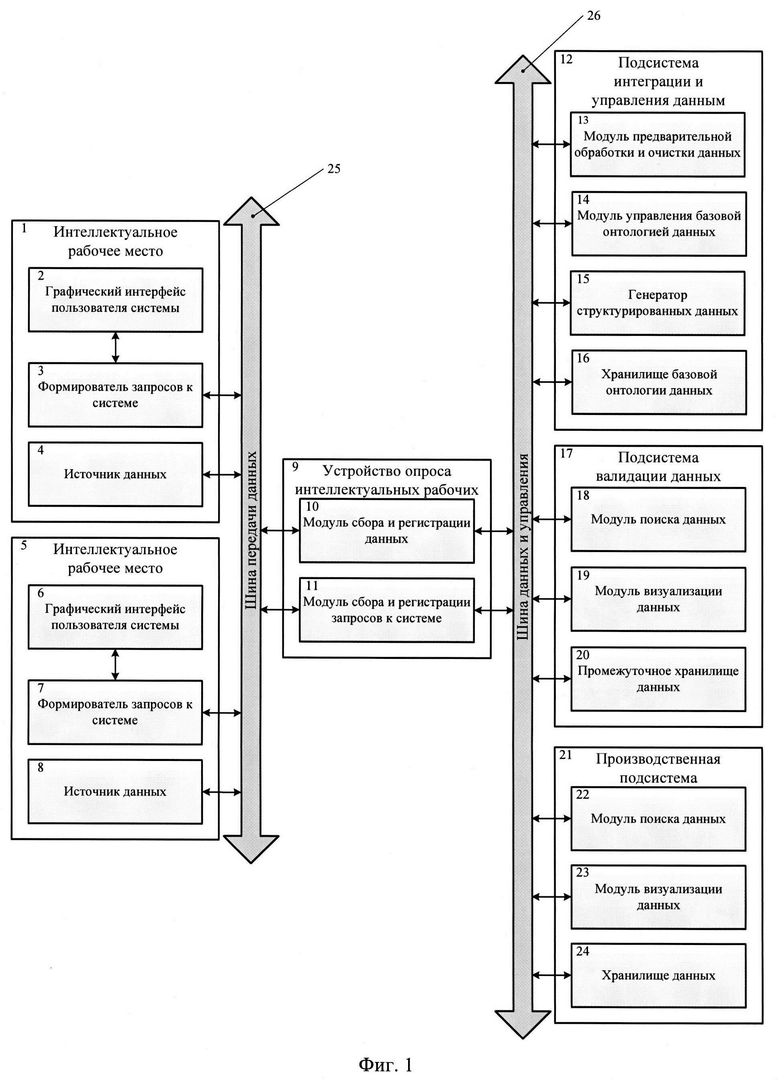
Система интеграции проектно-конструкторских данных, включающая два интеллектуальных рабочих места с источниками данных, модуль предварительной обработки и очистки данных, генератор структурированных данных, хранилище базовой онтологии данных, производственную подсистему, подсистему валидации данных с модулем поиска данных и промежуточным хранилищем данных, отличающаяся тем, что дополнительно содержит устройство опроса интеллектуальных рабочих мест со встроенными модулем сбора и регистрации данных, модулем сбора и регистрации запросов к системе, модуль предварительной обработки и очистки данных, генератор структурированных данных и хранилище онтологии данных формируют подсистему интеграции и управления данными, которая дополнительно включает модуль управления базовой онтологией данных, производственная подсистема дополнительно включает модуль поиска данных, модуль визуализации данных и хранилище данных, подсистема валидации данных дополнительно включает модуль визуализации данных, при этом взаимодействие модулей и генератора структурированных данных подсистемы интеграции и управления данными, модулей и промежуточного хранилища данных подсистемы валидации данных, модулей и хранилища данных производственной подсистемы с модулями устройства опроса интеллектуальных рабочих мест обеспечивается шиной данных и управления, интеллектуальные рабочие места дополнительно содержат графический интерфейс пользователя и связанный с ним формирователь запросов к системе, при этом взаимодействие формирователя запросов к системе и источника данных с модулями устройства опроса интеллектуальных рабочих мест обеспечивается шиной передачи данных.
| US 10102229 B2, 16.10.2018 | |||
| US 9406018 B2, 02.08.2016 | |||
| Многофункциональное автоматизированное рабочее место тестирования радиоэлектронной аппаратуры | 2020 |
|
RU2740546C1 |
| CN 104376077 B, 31.10.2017 | |||
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ, СПОСОБ ОБНОВЛЕНИЯ КАРТЫ, ПРОГРАММА И СИСТЕМА ОБРАБОТКИ ИНФОРМАЦИИ | 2011 |
|
RU2481625C2 |
