ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Данная заявка заявляет приоритет по предварительной заявке на патент США № 62/705897, поданной 21 июля 2020 г., предварительной заявке на патент США № 62/705410, поданной 25 июня 2020 г., предварительной заявке на патент США № 62/971421, поданной 7 февраля 2020 г., предварительной заявке на патент США № 62/950004, поданной 18 декабря 2019 г., предварительной заявке на патент США № 62/880122, поданной 30 июля 2019 г., предварительной заявке на патент США № 62/880113, поданной 30 июля 2019 г., заявке на европейский патент № 19212391.7, поданной 29 ноября 2019 г., и заявке на патент Испании № P201930702, поданной 30 июля 2019 г., все из которых полностью включены в данный документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к системам и способам координации (организации) и реализации аудиоустройств (например, интеллектуальных аудиоустройств) и управления рендерингом аудио с помощью аудиоустройств.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Аудиоустройства, включающие, но без ограничения, интеллектуальные аудиоустройства, широко распространились и становятся общими признаками многих домов. Хотя существующие системы и способы управления аудиоустройствами обеспечивают преимущества, были бы целесообразными усовершенствованные системы и способы.
УСЛОВНЫЕ ОБОЗНАЧЕНИЯ И ТЕРМИНОЛОГИЯ
По всему этому документу, включая формулу изобретения, термины «динамик» и «громкоговоритель» используются как синонимы для обозначения любого излучающего звук преобразователя (или набора преобразователей), приводимого в действие одним сигналом, подаваемым на динамик. Обычный набор наушников содержит два динамика. Динамик может быть реализован так, что он содержит ряд преобразователей (например, низкочастотный громкоговоритель и высокочастотный громкоговоритель), которые могут приводиться в действие одним общим сигналом, подаваемым на динамик, или рядом сигналов, подаваемых на динамик. В некоторых примерах сигнал (сигналы), подаваемый (подаваемые) на динамик, может (могут) претерпевать различную обработку в разных ветвях схемы, соединенных с разными преобразователями.
По всему этому документу, включая формулу изобретения, выражение выполнения операции «над» сигналом или данными (например, фильтрация, масштабирование, преобразование или применение коэффициента усиления к сигналу или данным) используется в широком смысле для обозначения выполнения операции непосредственно над сигналом или данными или над обработанной версией сигнала или данных (например, над версией сигнала, который был подвергнут предварительной фильтрации или предварительной обработке перед выполнением над ним операции).
По всему этому документу, включая формулу изобретения, выражение «система» используется в широком смысле для обозначения устройства, системы или подсистемы. Например, подсистема, которая реализует декодер, может называться системой декодера, и система, содержащая такую подсистему (например, система, которая генерирует Х выходных сигналов в ответ на ряд входных сигналов, в которой подсистема генерирует М из входных сигналов, а остальные X − M входных сигналов принимаются из внешнего источника), также может называться системой декодера.
По всему этому документу, включая формулу изобретения, термин «процессор» используется в широком смысле для обозначения системы или устройства, запрограммированного или иным образом выполненного (например, с использованием программного обеспечения или программно-аппаратного обеспечения) с возможностью выполнения операций над данными (например, аудио, или видео, или других данных изображений). Примеры процессоров включают программируемую пользователем вентильную матрицу (или другую настраиваемую интегральную схему или набор микросхем), процессор цифровой обработки сигналов, запрограммированный и/или иным образом выполненный с возможностью выполнения конвейерной обработки над аудио или другими звуковыми данными, программируемый процессор общего назначения или компьютер и программируемую микропроцессорную интегральную схему или набор микросхем.
По всему этому документу, включая формулу изобретения, термин «соединяет» или «соединенный» используется для обозначения либо непосредственного, либо косвенного соединения. Таким образом, если первое устройство соединено со вторым устройством, данное соединение может быть осуществлено через непосредственное соединение или через косвенное соединение посредством других устройств или соединений.
В контексте данного документа «интеллектуальное устройство» представляет собой электронное устройство, в целом выполненное с возможностью осуществления связи с одним или более другими устройствами (или сетями) с помощью различных беспроводных протоколов, таких как Bluetooth, Zigbee, связь ближнего радиуса действия, Wi-Fi, Light Fidelity (Li-Fi), 3G, 4G, 5G и т. д., которые могут действовать в некоторой степени интерактивно и/или автономно. Некоторыми заслуживающими внимания типами интеллектуальных устройств являются смартфоны, интеллектуальные автомобили, интеллектуальные терморегуляторы, интеллектуальные дверные звонки, интеллектуальные замки, интеллектуальные холодильники, планшетофоны и планшеты, умные часы, интеллектуальные браслеты, интеллектуальные цепочки для ключей и интеллектуальные аудиоустройства. Термин «интеллектуальное устройство» может также относиться к устройству, проявляющему некоторые свойства повсеместных вычислений, таких как искусственный интеллект.
В контексте данного документа выражение «интеллектуальное аудиоустройство» используется для обозначения интеллектуального устройства, представляющего собой либо аудиоустройство специального назначения, либо многоцелевое аудиоустройство (например, аудиоустройство, реализующее по меньшей мере некоторые аспекты функциональных возможностей виртуального помощника). Аудиоустройство специального назначения представляет собой устройство (например, телевизор (TV) или мобильный телефон), содержащее или соединенное с по меньшей мере одним микрофоном (а также необязательно содержащее или соединенное с по меньшей мере одним динамиком и/или по меньшей мере одной камерой) и выполненное в значительной степени или в первую очередь для достижения единственной цели. Например, хотя TV обычно может проигрывать (и рассматривается как способный проигрывать) звук из материала программы, в большинстве случаев современный TV запускает какую-либо операционную систему, в которой локально запускаются приложения, в том числе приложение для просмотра телевизионных передач. Аналогично аудиовход и аудиовыход в мобильном телефоне могут осуществлять многое, но они обслуживаются приложениями, запущенными на телефоне. В этом смысле аудиоустройство специального назначения, содержащее динамик (динамики) и микрофон (микрофоны), часто выполнено с возможностью запуска локального приложения и/или службы для непосредственного использования динамика (динамиков) и микрофона (микрофонов). Некоторые аудиоустройства специального назначения могут быть выполнены с возможностью группировки друг с другом с целью выполнения проигрывания аудио в некоторой зоне или настраиваемой пользователем области.
Одним общеизвестным типом многоцелевого аудиоустройства является аудиоустройство, реализующее по меньшей мере некоторые аспекты функциональных возможностей виртуального помощника, хотя другие аспекты функциональных возможностей виртуального помощника могут быть реализованы одним или более другими устройствами, такими как один или более серверов, с возможностью осуществления связи с которыми выполнено многоцелевое аудиоустройство. Такое многоцелевое аудиоустройство в данном документе может называться «виртуальным помощником». Виртуальный помощник представляет собой устройство (например, интеллектуальный динамик или устройство со встроенным голосовым помощником), содержащее или соединенное с по меньшей мере одним микрофоном (а также необязательно содержащее или соединенное с по меньшей мере одним динамиком и/или по меньшей мере одной камерой). В некоторых примерах виртуальный помощник может обеспечивать возможность использования ряда устройств (отличных от виртуального помощника) для применений, которые в той или иной мере являются доступными в облаке или иначе не полностью реализованными в или на самом виртуальном помощнике. Иначе говоря, по меньшей мере некоторые аспекты функциональных возможностей виртуального помощника, например, функциональные возможности распознавания речи, могут быть (по меньшей мере частично) реализованы одним или более серверами или другими устройствами, с которыми виртуальный помощник может осуществлять связь через такую сеть, как Интернет. Виртуальные помощники могут иногда действовать совместно, например, обособленным и условно заданным образом. Например, два или более виртуальных помощников могут действовать совместно в том смысле, что один из них, например, тот, который наиболее уверен в том, что услышал пробуждающее слово, откликается на пробуждающее слово. В некоторых реализациях соединенные виртуальные помощники могут образовывать своего рода группу, которой может управлять одно главное приложение, возможно, представляющее собой (или реализующее) виртуальный помощник.
В контексте данного документа термин «пробуждающее слово» используется в широком смысле для обозначения любого звука (например, слова, произносимого человеком, или какого-либо другого звука), при этом интеллектуальное аудиоустройство выполнено с возможностью пробуждения в ответ на обнаружение («слышимость») звука (с использованием по меньшей мере одного микрофона, содержащегося в интеллектуальном аудиоустройстве или соединенного с ним, или по меньшей мере одного другого микрофона). В этом контексте «пробуждение» означает вхождение устройства в состояние, в котором оно ожидает (иначе говоря, старается расслышать) звуковую команду. В некоторых случаях то, что может называться в данном документе «пробуждающим словом», может содержать более одного слова, например, фразу.
В контексте данного документа выражение «детектор пробуждающего слова» обозначает устройство, выполненное (или программное обеспечение, содержащее инструкции для конфигурирования устройства) с возможностью непрерывного поиска совпадения между признаками звука (например, речи) в реальном времени и обученной моделью. Обычно событие пробуждающего слова инициируется всякий раз, когда детектор пробуждающего слова определяет, что вероятность обнаружения пробуждающего слова превышает предварительно заданный порог. Например, порог может представлять собой предварительно заданный порог, настроенный на предоставление рационального компромисса между коэффициентами ложного доступа и ложного отказа. После наступления события пробуждающего слова устройство может входить в состояние (которое можно называть «пробужденным» состоянием или состоянием «концентрации внимания»), в котором оно слушает команду и при приеме команды переходит к большему средству распознавания с большим объемом вычислений.
В контексте данного документа выражение «местоположение микрофона» обозначает местоположение одного или более микрофонов. В некоторых примерах одно местоположение микрофона может соответствовать массиву микрофонов, находящемуся в одном аудиоустройстве. Например, местоположение микрофона может представлять собой одно местоположение, которое соответствует всему аудиоустройству, содержащему один или более микрофонов. В некоторых таких примерах местоположение микрофона может представлять собой одно местоположение, соответствующее средней точке массива микрофонов одного аудиоустройства. Однако в некоторых случаях местоположение микрофона может представлять собой местоположение одного микрофона. В некоторых таких примерах аудиоустройство может содержать только один микрофон.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Некоторые раскрытые варианты осуществления предоставляют подход для управления взаимодействием со слушателем или «пользователем» с целью улучшения ключевого критерия для успешной полнодуплексной связи в одном или более аудиоустройствах. Этот критерий известен как «отношение сигнал-эхо» (SER), также называемое в данном документе «отношение речь-эхо», которое можно задать как отношение между голосовым (или другим желательным) сигналом, подлежащим захвату из среды (например, помещения) с помощью одного или более микрофонов, и эхом, которое присутствует в аудиоустройстве, содержащем один или более микрофонов, из выходного содержимого программы, интерактивного содержимого и т. д. Предполагается, что многие аудиоустройства аудиосреды могут содержать встроенные громкоговорители и микрофоны, одновременно выполняющие и другие функции. Однако другие аудиоустройства аудиосреды могут содержать один или более громкоговорителей, но не содержать микрофон (микрофоны), или содержать один или более микрофонов, но не содержать громкоговоритель (громкоговорители). В некоторых вариантах осуществления применение (или использование в первую очередь) ближайшего к пользователю громкоговорителя (громкоговорителей) в некоторых вариантах или сценариях использования преднамеренно исключено. Альтернативно или дополнительно некоторые варианты осуществления могут вызывать один или более других типов изменений аудиообработки для аудиоданных, подвергаемых рендерингу с помощью одного или более громкоговорителей аудиосреды, с целью увеличения SER на одном или более микрофонах среды.
Некоторые варианты осуществления выполнены с возможностью реализации системы, содержащей скоординированные (организованные) аудиоустройства, которые в некоторых реализациях могут включать интеллектуальные аудиоустройства. Согласно некоторым таким реализациям два или более из интеллектуальных аудиоустройств представляют собой детектор пробуждающего слова (или выполнены с возможностью его реализации). Соответственно, в таких примерах доступен ряд микрофонов (например, асинхронных микрофонов). В некоторых случаях каждый из микрофонов может быть включен в или выполнен с возможностью осуществления связи с по меньшей мере одним из интеллектуальных аудиоустройств. Например, по меньшей мере некоторые из микрофонов могут представлять собой обособленные микрофоны (например, в бытовых приборах), которые не включены в любое из интеллектуальных аудиоустройств, но выполнены с возможностью осуществления связи с по меньшей мере одним из интеллектуальных аудиоустройств (так, что их выходные сигналы могут быть им захвачены). В некоторых вариантах осуществления каждый детектор пробуждающего слова (или каждое интеллектуальное аудиоустройство, содержащее детектор пробуждающего слова) или другая подсистема (например, классификатор) системы выполнены с возможностью оценки зоны человека путем применения классификатора, который приводится в действие с помощью ряда акустических признаков, полученных из по меньшей мере некоторых из микрофонов (например, асинхронных микрофонов). В некоторых реализациях целью может являться не оценка точного местоположения человека, но, вместо этого, формирование робастной оценки обособленной зоны, содержащей текущее местоположение человека.
В некоторых реализациях человек (который в данном документе также может называться «пользователем»), интеллектуальные аудиоустройства и микрофоны находятся в аудиосреде (например, по месту жительства, в автомобиле или по месту работы пользователя), в которой звук может распространяться от пользователя к микрофонам, и аудиосреда может содержать предварительно определенные зоны. Согласно некоторым примерам среда может содержать по меньшей мере следующие зоны: область приготовления пищи; область столовой; открытую область жилой площади; TV-область (содержащую диван для просмотра TV) жилой площади; и т. д. В ходе эксплуатации системы предполагается, что пользователь в любой момент времени физически расположен в одной из этих зон («зоне пользователя»), и что зона пользователя может время от времени изменяться.
В некоторых примерах микрофоны могут являться асинхронными (например, с цифровой выборкой, в которой применяются разные тактовые сигналы выборки) и случайно расположенными (или по меньшей мере не расположенными в предварительно определенных положениях, в симметричном расположении, по сетке и т. д.). В некоторых случаях зону пользователя можно оценить с помощью подхода, основанного на анализе данных, который приводится в действие множеством высокоуровневых признаков, по меньшей мере частично получаемых из по меньшей мере одного из детекторов пробуждающего слова. Эти признаки (например, достоверность и принятый уровень пробуждающего слова) в некоторых примерах могут потреблять очень небольшую часть полосы пропускания и могут передаваться (например, асинхронно) в устройство, реализующее классификатор, с очень небольшой нагрузкой на сеть.
Аспекты некоторых вариантов осуществления относятся к реализации интеллектуальных аудиоустройств и/или к координации интеллектуальных аудиоустройств.
Аспекты некоторых раскрытых реализаций включают систему, выполненную (например, запрограммированную) с возможностью выполнения одного или более раскрытых способов или их этапов, и материальный постоянный машиночитаемый носитель данных, на котором реализовано постоянное хранение данных (например, диск или другой материальный носитель данных), и на котором хранится код для выполнения (например, код, исполняемый для выполнения) одного или более раскрытых способов или их этапов. Например, некоторые раскрытые варианты осуществления могут представлять собой или содержать программируемый процессор общего назначения, процессор цифровой обработки сигналов или микропроцессор, запрограммированный с использованием программного обеспечения или программно-аппаратного обеспечения и/или иным образом выполненный с возможностью выполнения любой из множества операций над данными, включая один или более раскрытых способов или их этапов. Такой процессор общего назначения может представлять собой или содержать компьютерную систему, содержащую устройство ввода, запоминающее устройство и подсистему обработки, запрограммированную (и/или иным образом выполненную) с возможностью выполнения одного или более раскрытых способов (или их этапов) в ответ на передаваемые в нее данные.
В некоторых реализациях система управления может быть выполнена с возможностью реализации одного или более способов, раскрытых в данном документе, таких как один или более способов управления аудиосеансом. Некоторые такие способы включают прием (например, системой управления) выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде. В некоторых примерах каждый микрофон из множества микрофонов находится в местоположении микрофона в аудиосреде. В некоторых случаях выходные сигналы включают сигналы, соответствующие текущему фрагменту речи человека. Согласно некоторым примерам выходные сигналы включают сигналы, соответствующие неречевым аудиоданным, таким как шум и/или эхо.
Некоторые такие способы включают определение (например, системой управления) на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку. В некоторых примерах контекстная информация содержит оценочное текущее местоположение человека и/или оценочную текущую близость человека к одному или более местоположениям микрофонов. Некоторые такие способы включают выбор двух или более аудиоустройств аудиосреды по меньшей мере частично на основе одного или более аспектов контекстной информации. В некоторых реализациях каждое из двух или более аудиоустройств содержит по меньшей мере один громкоговоритель.
Некоторые такие способы включают определение (например, системой управления) одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств. В некоторых примерах результатом изменений аудиообработки является увеличение отношения речь-эхо на одном или более микрофонах. Некоторые такие способы включают обеспечение применения одного или более типов изменений аудиообработки.
Согласно некоторым реализациям один или более типов изменений аудиообработки могут вызывать снижение уровня воспроизведения громкоговорителя для громкоговорителей двух или более аудиоустройств. В некоторых реализациях по меньшей мере одно из изменений аудиообработки для первого аудиоустройства может отличаться от изменения аудиообработки для второго аудиоустройства. В некоторых примерах выбор двух или более аудиоустройств аудиосреды (например, системой управления) может включать выбор N оснащенных громкоговорителями аудиоустройств аудиосреды, где N – целое число, превышающее 2.
В некоторых реализациях выбор двух или более аудиоустройств аудиосреды может по меньшей мере частично основываться на оценочном текущем местоположении человека относительно по меньшей мере одного из местоположения микрофона или местоположения оснащенного громкоговорителем аудиоустройства. Согласно некоторым таким реализациям способ может включать определение ближайшего оснащенного громкоговорителем аудиоустройства, которое является ближайшим к оценочному текущему местоположению человека или к местоположению микрофона, ближайшему к оценочному текущему местоположению человека. В некоторых таких примерах два или более аудиоустройств могут включать ближайшее оснащенное громкоговорителем аудиоустройство.
В некоторых примерах один или более типов изменений аудиообработки включают изменение процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения человека. В некоторых реализациях один или более типов изменений аудиообработки могут включать спектральную модификацию. Согласно некоторым таким реализациям спектральная модификация может включать снижение уровня аудиоданных в полосе частот от 500 Гц до 3 кГц.
В некоторых реализациях один или более типов изменений аудиообработки могут включать вставку по меньшей мере одного промежутка в по меньшей мере одну выбранную полосу частот сигнала аудиопроигрывания. В некоторых примерах один или более типов изменений аудиообработки могут включать сжатие динамического диапазона.
Согласно некоторым реализациям выбор двух или более аудиоустройств может по меньшей мере частично основываться на оценке отношения сигнал-эхо для одного или более местоположений микрофонов. Например, выбор двух или более аудиоустройств может по меньшей мере частично основываться на определении того, является ли оценка отношения сигнал-эхо меньшей, чем порог отношения сигнал-эхо, или равной ему. В некоторых случаях определение одного или более типов изменений аудиообработки может основываться на оптимизации функции стоимости, по меньшей мере частично основанной на оценке отношения сигнал-эхо. Например, функция стоимости может по меньшей мере частично основываться на выполнении рендеринга. В некоторых реализациях выбор двух или более аудиоустройств может по меньшей мере частично основываться на оценке близости.
В некоторых примерах способ может включать определение (например, системой управления) ряда текущих акустических признаков из выходных сигналов каждого микрофона и применение классификатора к ряду текущих акустических признаков. Согласно некоторым реализациям применение классификатора может включать применение модели, обученной на ранее определенных акустических признаках, которые были получены из множества предыдущих фрагментов речи, произнесенных человеком во множестве пользовательских зон в среде.
В некоторых таких примерах определение одного или более аспектов контекстной информации, относящейся к человеку, может включать определение, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой человек расположен в настоящий момент. Согласно некоторым реализациям оценка пользовательской зоны может быть определена без отсылки к геометрическим местоположениям множества микрофонов. В некоторых случаях текущий фрагмент речи и предыдущие фрагменты речи могут представлять собой или могут содержать фрагменты речи, содержащие пробуждающее слово.
Согласно некоторым реализациям один или более микрофонов могут находиться в ряде аудиоустройств аудиосреды. Однако в других случаях один или более микрофонов могут находиться в одном аудиоустройстве аудиосреды. В некоторых примерах по меньшей мере одно из одного или более местоположений микрофонов может соответствовать ряду микрофонов одного аудиоустройства. Некоторые раскрытые способы могут включать выбор по меньшей мере одного микрофона согласно одному или более аспектам контекстной информации.
По меньшей мере некоторые аспекты настоящего изобретения могут быть реализованы с помощью таких способов, как способы управления аудиосеансом. Как отмечено в другом месте данного документа, в некоторых случаях способы могут быть по меньшей мере частично реализованы системой управления, например, описанной в данном документе. Некоторые такие способы включают прием выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде. В некоторых примерах каждый микрофон из множества микрофонов находится в местоположении микрофона в аудиосреде. В некоторых случаях выходные сигналы включают сигналы, соответствующие текущему фрагменту речи человека. Согласно некоторым примерам выходные сигналы включают сигналы, соответствующие неречевым аудиоданным, таким как шум и/или эхо.
Некоторые такие способы включают определение на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку. В некоторых примерах контекстная информация содержит оценочное текущее местоположение человека и/или оценочную текущую близость человека к одному или более местоположениям микрофонов. Некоторые такие способы включают выбор двух или более аудиоустройств аудиосреды по меньшей мере частично на основе одного или более аспектов контекстной информации. В некоторых реализациях каждое из двух или более аудиоустройств содержит по меньшей мере один громкоговоритель.
Некоторые такие способы включают определение одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств. В некоторых примерах результатом изменений аудиообработки является увеличение отношения речь-эхо на одном или более микрофонах. Некоторые такие способы включают обеспечение применения одного или более типов изменений аудиообработки.
Согласно некоторым реализациям один или более типов изменений аудиообработки могут вызывать снижение уровня воспроизведения громкоговорителя для громкоговорителей двух или более аудиоустройств. В некоторых реализациях по меньшей мере одно из изменений аудиообработки для первого аудиоустройства может отличаться от изменения аудиообработки для второго аудиоустройства. В некоторых примерах выбор двух или более аудиоустройств аудиосреды может включать выбор N оснащенных громкоговорителями аудиоустройств аудиосреды, где N – целое число, превышающее 2.
В некоторых реализациях выбор двух или более аудиоустройств аудиосреды может по меньшей мере частично основываться на оценочном текущем местоположении человека относительно по меньшей мере одного из местоположения микрофона или местоположения оснащенного громкоговорителем аудиоустройства. Согласно некоторым таким реализациям способ может включать определение ближайшего оснащенного громкоговорителем аудиоустройства, которое является ближайшим к оценочному текущему местоположению человека или к местоположению микрофона, ближайшему к оценочному текущему местоположению человека. В некоторых таких примерах два или более аудиоустройств могут включать ближайшее оснащенное громкоговорителем аудиоустройство.
В некоторых примерах один или более типов изменений аудиообработки включают изменение процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения человека. В некоторых реализациях один или более типов изменений аудиообработки могут включать спектральную модификацию. Согласно некоторым таким реализациям спектральная модификация может включать снижение уровня аудиоданных в полосе частот от 500 Гц до 3 кГц.
В некоторых реализациях один или более типов изменений аудиообработки могут включать вставку по меньшей мере одного промежутка в по меньшей мере одну выбранную полосу частот сигнала аудиопроигрывания. В некоторых примерах один или более типов изменений аудиообработки могут включать сжатие динамического диапазона.
Согласно некоторым реализациям выбор двух или более аудиоустройств может по меньшей мере частично основываться на оценке отношения сигнал-эхо для одного или более местоположений микрофонов. Например, выбор двух или более аудиоустройств может по меньшей мере частично основываться на определении того, является ли оценка отношения сигнал-эхо меньшей, чем порог отношения сигнал-эхо, или равной ему. В некоторых случаях определение одного или более типов изменений аудиообработки может основываться на оптимизации функции стоимости, по меньшей мере частично основанной на оценке отношения сигнал-эхо. Например, функция стоимости может по меньшей мере частично основываться на выполнении рендеринга. В некоторых реализациях выбор двух или более аудиоустройств может по меньшей мере частично основываться на оценке близости.
В некоторых примерах способ может включать определение ряда текущих акустических признаков из выходных сигналов каждого микрофона и применение классификатора к ряду текущих акустических признаков. Согласно некоторым реализациям применение классификатора может включать применение модели, обученной на ранее определенных акустических признаках, которые были получены из множества предыдущих фрагментов речи, произнесенных человеком во множестве пользовательских зон в среде.
В некоторых таких примерах определение одного или более аспектов контекстной информации, относящейся к человеку, может включать определение, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой человек расположен в настоящий момент. Согласно некоторым реализациям оценка пользовательской зоны может быть определена без отсылки к геометрическим местоположениям множества микрофонов. В некоторых случаях текущий фрагмент речи и предыдущие фрагменты речи могут представлять собой или могут содержать фрагменты речи, содержащие пробуждающее слово.
Согласно некоторым реализациям один или более микрофонов могут находиться в ряде аудиоустройств аудиосреды. Однако в других случаях один или более микрофонов могут находиться в одном аудиоустройстве аудиосреды. В некоторых примерах по меньшей мере одно из одного или более местоположений микрофонов может соответствовать ряду микрофонов одного аудиоустройства. Некоторые раскрытые способы могут включать выбор по меньшей мере одного микрофона согласно одному или более аспектам контекстной информации.
Некоторые или все из операций, функций и/или способов, описанных в данном документе, могут быть выполнены посредством одного или более устройств в соответствии с инструкциями (например, программным обеспечением), хранящимися на одном или более постоянных носителях данных. Такие постоянные носители данных могут содержать запоминающие устройства, такие как описанные в данном документе, включая, но без ограничения, оперативные запоминающие устройства (RAM), постоянные запоминающие устройства (ROM) и т. д. Соответственно, некоторые изобретательские аспекты объекта изобретения, описанные в данном документе, могут быть реализованы в постоянном носителе данных, содержащем хранящееся в нем программное обеспечение.
Например, программное обеспечение может содержать инструкции для управления одним или более устройствами с целью выполнения способа, включающего прием выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде. В некоторых примерах каждый микрофон из множества микрофонов находится в местоположении микрофона в аудиосреде. В некоторых случаях выходные сигналы включают сигналы, соответствующие текущему фрагменту речи человека. Согласно некоторым примерам выходные сигналы включают сигналы, соответствующие неречевым аудиоданным, таким как шум и/или эхо.
Некоторые такие способы включают определение на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку. В некоторых примерах контекстная информация содержит оценочное текущее местоположение человека и/или оценочную текущую близость человека к одному или более местоположениям микрофонов. Некоторые такие способы включают выбор двух или более аудиоустройств аудиосреды по меньшей мере частично на основе одного или более аспектов контекстной информации. В некоторых реализациях каждое из двух или более аудиоустройств содержит по меньшей мере один громкоговоритель.
Некоторые такие способы включают определение одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств. В некоторых примерах результатом изменений аудиообработки является увеличение отношения речь-эхо на одном или более микрофонах. Некоторые такие способы включают обеспечение применения одного или более типов изменений аудиообработки.
Согласно некоторым реализациям один или более типов изменений аудиообработки могут вызывать снижение уровня воспроизведения громкоговорителя для громкоговорителей двух или более аудиоустройств. В некоторых реализациях по меньшей мере одно из изменений аудиообработки для первого аудиоустройства может отличаться от изменения аудиообработки для второго аудиоустройства. В некоторых примерах выбор двух или более аудиоустройств аудиосреды может включать выбор N оснащенных громкоговорителями аудиоустройств аудиосреды, где N – целое число, превышающее 2.
В некоторых реализациях выбор двух или более аудиоустройств аудиосреды может по меньшей мере частично основываться на оценочном текущем местоположении человека относительно по меньшей мере одного из местоположения микрофона или местоположения оснащенного громкоговорителем аудиоустройства. Согласно некоторым таким реализациям способ может включать определение ближайшего оснащенного громкоговорителем аудиоустройства, которое является ближайшим к оценочному текущему местоположению человека или к местоположению микрофона, ближайшему к оценочному текущему местоположению человека. В некоторых таких примерах два или более аудиоустройств могут включать ближайшее оснащенное громкоговорителем аудиоустройство.
В некоторых примерах один или более типов изменений аудиообработки включают изменение процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения человека. В некоторых реализациях один или более типов изменений аудиообработки могут включать спектральную модификацию. Согласно некоторым таким реализациям спектральная модификация может включать снижение уровня аудиоданных в полосе частот от 500 Гц до 3 кГц.
В некоторых реализациях один или более типов изменений аудиообработки могут включать вставку по меньшей мере одного промежутка в по меньшей мере одну выбранную полосу частот сигнала аудиопроигрывания. В некоторых примерах один или более типов изменений аудиообработки могут включать сжатие динамического диапазона.
Согласно некоторым реализациям выбор двух или более аудиоустройств может по меньшей мере частично основываться на оценке отношения сигнал-эхо для одного или более местоположений микрофонов. Например, выбор двух или более аудиоустройств может по меньшей мере частично основываться на определении того, является ли оценка отношения сигнал-эхо меньшей, чем порог отношения сигнал-эхо, или равной ему. В некоторых случаях определение одного или более типов изменений аудиообработки может основываться на оптимизации функции стоимости, по меньшей мере частично основанной на оценке отношения сигнал-эхо. Например, функция стоимости может по меньшей мере частично основываться на выполнении рендеринга. В некоторых реализациях выбор двух или более аудиоустройств может по меньшей мере частично основываться на оценке близости.
В некоторых примерах способ может включать определение ряда текущих акустических признаков из выходных сигналов каждого микрофона и применение классификатора к ряду текущих акустических признаков. Согласно некоторым реализациям применение классификатора может включать применение модели, обученной на ранее определенных акустических признаках, которые были получены из множества предыдущих фрагментов речи, произнесенных человеком во множестве пользовательских зон в среде.
В некоторых таких примерах определение одного или более аспектов контекстной информации, относящейся к человеку, может включать определение, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой человек расположен в настоящий момент. Согласно некоторым реализациям оценка пользовательской зоны может быть определена без отсылки к геометрическим местоположениям множества микрофонов. В некоторых случаях текущий фрагмент речи и предыдущие фрагменты речи могут представлять собой или могут содержать фрагменты речи, содержащие пробуждающее слово.
Согласно некоторым реализациям один или более микрофонов могут находиться в ряде аудиоустройств аудиосреды. Однако в других случаях один или более микрофонов могут находиться в одном аудиоустройстве аудиосреды. В некоторых примерах по меньшей мере одно из одного или более местоположений микрофонов может соответствовать ряду микрофонов одного аудиоустройства. Некоторые раскрытые способы могут включать выбор по меньшей мере одного микрофона согласно одному или более аспектам контекстной информации.
Подробности одной или более реализаций объекта изобретения, описываемого в данном описании, изложены в сопроводительных графических материалах и в приведенном ниже описании. Другие признаки, аспекты и преимущества будут очевидны из описания, графических материалов и формулы изобретения. Следует отметить, что относительные размеры на нижеследующих фигурах могут быть приведены не в масштабе.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
На фиг. 1A представлена аудиосреда согласно одному примеру.
На фиг. 1B показан другой пример аудиосреды.
На фиг. 2A представлена структурная схема, на которой показаны примеры компонентов оборудования, способного реализовывать различные аспекты настоящего изобретения.
На фиг. 2B представлена блок-схема, содержащая этапы способа управления аудиосеансом согласно некоторым реализациям.
На фиг. 3A представлена структурная схема системы, выполненной с возможностью реализации отдельной логической схемы управления рендерингом и прослушивания или захвата для ряда устройств.
На фиг. 3B представлена структурная схема системы согласно другой раскрытой реализации.
На фиг. 3C представлена структурная схема варианта осуществления, выполненного с возможностью реализации сети балансировки энергии согласно одному примеру.
На фиг. 4 представлен график, на котором изображены примеры аудиообработки, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды.
На фиг. 5 представлен график, на котором изображена аудиообработка другого типа, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды.
На фиг. 6 изображена аудиообработка другого типа, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды.
На фиг. 7 представлен график, на котором изображена аудиообработка другого типа, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды.
На фиг. 8 представлена схема примера, в котором аудиоустройство, звук которого подлежит убавлению, может не являться аудиоустройством, ближайшим к говорящему человеку.
На фиг. 9 изображена ситуация, в которой устройство с очень высоким SER находится очень близко к пользователю.
На фиг. 10 представлена блок-схема, на которой описан один пример способа, который может выполняться таким оборудованием, как показанное на фиг. 2A.
На фиг. 11 представлена структурная схема элементов одного примера варианта осуществления, выполненного с возможностью реализации классификатора зон.
На фиг. 12 представлена блок-схема, на которой описан один пример способа, который может выполняться таким оборудованием, как оборудование 200, показанное на фиг. 2A.
На фиг. 13 представлена блок-схема, на которой описан другой пример способа, который может выполняться таким оборудованием, как оборудование 200, показанное на фиг. 2A.
На фиг. 14 представлена блок-схема, на которой описан другой пример способа, который может выполняться таким оборудованием, как оборудование 200, показанное на фиг. 2A.
На фиг. 15 и 16 представлены схемы, на которых изображено иллюстративное множество значений активации динамиков и положений рендеринга объектов.
На фиг. 17 представлена блок-схема, на которой описан один пример способа, который может выполняться таким оборудованием или такой системой, как показанные на фиг. 2A.
На фиг. 18 представлен график значений активации динамиков в иллюстративном варианте осуществления.
На фиг. 19 представлен график положений рендеринга объектов в иллюстративном варианте осуществления.
На фиг. 20 представлен график значений активации динамиков в иллюстративном варианте осуществления.
На фиг. 21 представлен график положений рендеринга объектов в иллюстративном варианте осуществления.
На фиг. 22 представлен график значений активации динамиков в иллюстративном варианте осуществления.
На фиг. 23 представлен график положений рендеринга объектов в иллюстративном варианте осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
В настоящее время разработчики обычно рассматривают аудиоустройства как единственную точку сопряжения для аудиоданных, которые могут представлять собой сочетание развлекательных, коммуникационных и информационных служб. Преимуществом использования аудиоданных для уведомлений и голосового управления является исключение визуального или физического вмешательства. Расширяющийся ландшафт устройств является фрагментированным, при этом за одну пару наших ушей конкурирует все больше систем.
Во всех формах интерактивного аудио проблемой остается увеличение способности к полнодуплексной аудиосвязи. Когда в помещении имеются выходные аудиоданные, не являющиеся подходящими для передачи или захвата на основе информации в этом помещении, эти аудиоданные требуется удалить из захватываемого сигнала (например, с помощью эхокомпенсации и/или эхоподавления). Некоторые раскрытые варианты осуществления предоставляют подход и управление взаимодействием с пользователем с целью увеличения отношения сигнал-эхо (SER), которое является ключевым критерием для успешной полнодуплексной связи в одном или более устройствах.
Такие варианты осуществления, как ожидается, будут полезны в ситуациях, когда в акустическом диапазоне пользователя находится более одного аудиоустройства, для того чтобы каждое аудиоустройство могло иметь возможность представления материала аудиопрограммы, имеющего подходящую для пользователя громкость требуемой развлекательной, коммуникационной или информационной службы. Значение таких вариантов осуществления, как ожидается, является особенно высоким, когда в подобной близости к пользователю находятся три или более аудиоустройств.
Применение для рендеринга иногда является первичной функцией аудиоустройства, и поэтому иногда существует потребность в использовании максимально возможного количества устройств вывода аудиоданных. Если аудиоустройства находятся ближе к пользователю, аудиоустройства могут являться более преимущественными в том, что касается способности точного расположения звука или доставки пользователю конкретной аудиосигнализации и аудиовизуализации. Однако если эти аудиоустройства содержат один или более микрофонов, они также могут являться предпочтительными для приема голоса пользователя. При рассмотрении совместно с проблемой отношения сигнал-эхо видно, что отношение сигнал-эхо значительно увеличивается при реализации использования устройства, более близкого к пользователю, в симплексном режиме (только для ввода) или при переходе к нему.
В различных раскрытых вариантах осуществления аудиоустройства могут содержать встроенные динамики и микрофоны с одновременным выполнением других функций (например, представленных на фиг. 1A). В некоторых раскрытых вариантах осуществления реализована концепция преднамеренного неиспользования в первую очередь ближайшего к пользователю громкоговорителя (ближайших к пользователю громкоговорителей) в некоторых обстоятельствах.
Предполагается, что в соединенной операционной системе или при сокращении числа посредников между приложениями (например, приложений на облачной основе) могут быть предусмотрены устройства множества разных типов (обеспечивающие возможность ввода, вывода и/или взаимодействия в реальном времени с аудиоданными). Примеры таких устройств включают носимые устройства, бытовые аудиоустройства, мобильные устройства, автомобильные и мобильные вычислительные устройства и интеллектуальные динамики. Интеллектуальный динамик может содержать подключенный к сети динамик и микрофон для служб на облачной основе. Другие примеры таких устройств могут включать динамики и/или микрофоны, в том числе лампы, часы, телевизоры, устройства личного помощника, холодильники и урны для мусора. Некоторые варианты осуществления, в частности, относятся к ситуациям, когда имеется общая платформа для организации ряда аудиоустройств аудиосреды посредством такого организующего устройства, как концентратор умного дома или другое устройство, выполненное с возможностью управления аудиосеансом, и которое в данном документе может называться «администратором аудиосеанса». Некоторые такие реализации могут включать команды между администратором аудиосеанса и локально реализованными программными приложениями на языке, который не является специфичным для устройств, но вместо этого включает маршрутизацию организующим устройством аудиосодержимого к людям и от них и в места и из мест, которые точно определяются программными приложениями. В некоторых вариантах осуществления реализованы способы динамического управления рендерингом, например, включающие ограничение для отталкивания звука от ближайшего устройства и поддержания пространственной визуализации, и/или для определения местоположения пользователя в зоне, и/или для отображения и расположения устройств относительно друг друга и пользователя.
Обычно системе, содержащей ряд интеллектуальных аудиоустройств, требуется указать, где она услышала от пользователя «пробуждающее слово» (заданное выше), и где сконцентрировать внимание (иначе говоря, попытаться расслышать) команду от пользователя.
На фиг. 1A представлена аудиосреда согласно одному примеру. Некоторые раскрытые варианты осуществления могут являться, в частности, полезными в сценарии, где в среде (например, на жилой площади или в рабочем пространстве) имеется множество аудиоустройств, способных передавать звук и захватывать аудиоданные, например, как это описано в данном документе. Система, представленная на фиг. 1A, может быть выполнена в соответствии с различными раскрытыми вариантами осуществления.
На фиг. 1A представлена схема аудиосреды (жилой площади), которая содержит систему, содержащую набор интеллектуальных аудиоустройств (устройств 1.1) для взаимодействия с аудиоданными, динамики (1.3) для вывода аудиоданных и управляемое освещение (1.2). Как и в других раскрытых реализациях, тип, количество и компоновка элементов на фиг. 1A являются лишь примерами. В других реализациях может быть предусмотрено большее количество элементов, меньшее количество элементов и/или другие элементы. В некоторых случаях один или более из микрофонов 1.5 могут являться частью или быть связанными с одним из устройств 1.1, освещения 1.2 или динамиков 1.3. Альтернативно или дополнительно один или более из микрофонов 1.5 могут быть присоединены к другой части среды, например, к стене, к потолку, к мебели, к бытовому прибору или к другому устройству среды. В одном примере каждое из устройств 1.1 содержит по меньшей один микрофон 1.5 (и/или соединено с ним). И хотя это не показано на фиг. 1A, некоторые аудиосреды могут содержать одну или более камер. Согласно некоторым раскрытым реализациям одно или более устройств аудиосреды (например, устройство, выполненное с возможностью управления аудиосеансом, такое как одно или более из устройств 1.1, устройство, реализующее администратор аудиосеанса, концентратор умного дома и т. д.) могут иметь возможность оценки того, где (например, в какой зоне жилой площади) находится пользователь (1.4), подающий пробуждающее слово, команду и т. д. Одно или более устройств системы, показанной на фиг. 1A (например, ее устройств 1.1), могут быть выполнены с возможностью реализации различных раскрытых вариантов осуществления. С использованием различных способов можно совокупно получать информацию из устройств, представленных на фиг. 3, для предоставления оценки положения пользователя, произносящего пробуждающее слово. Согласно некоторым раскрытым способам информация может получаться совокупно из микрофонов 1.5 согласно фиг. 1A и доставляться в устройство (например, устройство, выполненное с возможностью управления аудиосеансом), которое реализует классификатор, выполненный с возможностью предоставления оценки положения пользователя, произносящего пробуждающее слово.
На жилой площади (например, представленной на фиг. 1A) имеется множество зон естественной активности, в которых человек мог бы выполнять задачу или действие или пересекать порог. Эти области, которые в данном документе могут называться «пользовательскими зонами», могут быть в некоторых примерах заданы пользователем без точного определения координат или других признаков геометрического местоположения. Согласно некоторым примерам «контекст» человека может включать или может соответствовать пользовательской зоне, в которой человек расположен в настоящий момент, или ее оценке. В примере согласно фиг. 1A пользовательские зоны включают:
1) кухонную мойку и область приготовления пищи (в верхнем левом участке жилой площади);
2) дверь холодильника (справа от мойки и области приготовления пищи);
3) область столовой (в нижнем левом участке жилой площади);
4) открытую область жилой площади (справа от мойки и области приготовления пищи, а также области столовой);
5) диван для просмотра телевизора (TV) (справа от открытой области);
6) сам TV;
7) столы; и
8) область двери или прихожую (в верхнем правом участке жилой площади). Другие аудиосреды могут содержать большее количество пользовательских зон, меньшее количество пользовательских зон и/или другие типы пользовательских зон, например, одну или более зон спальни, зон гаража, зон двора или веранды и т. д.
Согласно некоторым вариантам осуществления система, оценивающая (например, определяющая недостоверную оценку того), где появляется или возникает звук (например, пробуждающее слово или другой сигнал, требующий внимания), может характеризоваться некоторой определенной достоверностью (или рядом гипотез для) оценки. Например, если человек оказывается находящимся вблизи границы между пользовательскими зонами аудиосреды, недостоверная оценка местоположения человека может включать определенную достоверность того, что человек находится в каждой из зон. В некоторых традиционных реализациях голосовых интерфейсов требуется, чтобы голос голосового помощника издавался только из одного местоположения одновременно, что делает принудительным единственный выбор для одного местоположения (например, одного из восьми местоположений динамиков 1.1 и 1.3 на фиг. 1A). Однако на основе простой воображаемой ролевой игры очевидно, что (в таких традиционных реализациях) вероятность того, что выбранное местоположение источника голоса помощника (т. е. местоположение динамика, содержащегося в или соединенного с помощником) является точкой фокуса или естественным обратным ответом для выражения внимания, может являться низкой.
На фиг. 1B показан другой пример аудиосреды. На фиг. 1B изображена другая аудиосреда, содержащая пользователя 101, который произносит прямую речь 102, и систему, содержащую набор интеллектуальных аудиоустройств 103 и 105, динамики для вывода аудиоданных и микрофоны. Система может быть выполнена в соответствии с некоторыми раскрытыми реализациями. Речь, произносимая пользователем 101 (иногда называемым в данном документе «говорящим»), может распознаваться одним или более элементами системы как пробуждающее слово.
Конкретнее, элементы системы согласно фиг. 1B включают:
102: направленный локальный голос (производимый пользователем 101);
103: устройство голосового помощника (соединенное с одним или более громкоговорителями). Устройство 103 расположено ближе к пользователю 101, чем устройство 105, поэтому устройство 103 иногда называется «ближним» устройством, а устройство 105 называется «дальним» устройством;
104: множество микрофонов в ближнем устройстве 103 (или соединенных с ним);
105: устройство голосового помощника (соединенное с одним или более громкоговорителями);
106: множество микрофонов в дальнем устройстве 105 (или соединенных с ним);
107: бытовой прибор (например, лампу); и
108: множество микрофонов в бытовом приборе 107 (или соединенных с ним). В некоторых примерах каждый из микрофонов 108 может быть выполнен с возможностью осуществления связи с устройством, выполненным с возможностью реализации классификатора, которое в некоторых случаях может представлять собой по меньшей мере одно из устройств 103 или 105. В некоторых реализациях устройство, выполненное с возможностью реализации классификатора, также может представлять собой устройство, выполненное с возможностью управления аудиосеансом, такое как устройство, выполненное с возможностью реализации CHASM или концентратора умного дома.
Система согласно фиг. 1B может также содержать по меньшей мере один классификатор (например, классификатор 1107, представленный на описанной ниже фиг. 11). Например, устройство 103 (или устройство 105) может содержать классификатор. Альтернативно или дополнительно классификатор можно реализовать с помощью другого устройства, которое может быть выполнено с возможностью осуществления связи с устройствами 103 и/или 105. В некоторых примерах классификатор может быть реализован с помощью другого локального устройства (например, устройства в среде 109), тогда как в других примерах классификатор может быть реализован удаленным устройством, расположенным вне среды 109 (например, сервером).
Согласно некоторым реализациям по меньшей мере два устройства (например, устройства 1.1 согласно фиг. 1A, устройства 103 и 105 согласно фиг. 1B и т. д.) некоторым образом действуют совместно (например, под управлением организующего устройства, такого как устройство, выполненное с возможностью управления аудиосеансом) для доставки звука так, чтобы аудиоданными для них можно было управлять совместно. Например, два устройства 103 и 105 могут проигрывать звук либо по отдельности, либо совместно. В простом случае устройства 103 и 105 действуют как совместная пара, при этом каждое из них выполняет рендеринг части аудиоданных (например, без потери общности, стереофонического сигнала, в котором одно устройство выполняет рендеринг по существу L, а другое – по существу R).
Бытовой прибор 107 (или другое устройство) может содержать один микрофон 108, который является ближайшим к пользователю 101 и не содержит никаких громкоговорителей, и в этом случае имеет место ситуация, в которой может уже иметься предпочтительное отношение сигнал-эхо или отношение речь-эхо (SER) для данной конкретной аудиосреды и данного конкретного местоположения пользователя 101, которое нельзя улучшить с помощью изменения аудиообработки для аудиоданных, воспроизводимых динамиком (динамиками) устройства 105 и/или 107. В некоторых вариантах осуществления такой микрофон отсутствует.
Некоторые раскрытые варианты осуществления обеспечивают обнаруживаемое и значимое воздействие на характеристики SER. Некоторые реализации обеспечивают такие преимущества и в отсутствие реализации аспектов расположения зон и/или динамического переменного рендеринга. Однако в некоторых вариантах осуществления реализованы изменения аудиообработки, которые включают рендеринг с отталкиванием или «деформацией» звуковых объектов (или аудиообъектов) в сторону от устройств. Причиной для деформации аудиообъектов относительно конкретных аудиоустройств, местоположений и т. д. в некоторых случаях может являться увеличение отношения сигнал-эхо на конкретном микрофоне, который используется для захвата человеческой речи. Такая деформация может включать, но без ограничения, убавление уровня проигрывания одного, двух, трех или более близлежащих аудиоустройств. В некоторых случаях изменения в аудиообработке с целью увеличения SER могут сообщаться с помощью технического решения для обнаружения зон так, что одним, двумя или более близлежащими аудиоустройствами, для которых реализуются изменения аудиообработки (например, убавление звука), являются устройства, ближайшие к пользователю, ближайшие к конкретному микрофону, который будет использоваться для захвата речи пользователя, и/или ближайшие к представляющему интерес звуку.
Аспекты некоторых вариантов осуществления включают контекст, решение и изменение аудиообработки, которое в данном документе может называться «изменением рендеринга». В некоторых примерах этими аспектами являются:
КОНТЕКСТ (такой как, местоположение и/или время). В некоторых примерах как положение, так и время являются частью контекста, и каждое из них может получаться из источника или определяться разными способами;
РЕШЕНИЕ (которое может содержать порог или непрерывную модуляцию изменения (изменений)). Этот компонент может являться простым или сложным в зависимости от конкретного варианта осуществления. В некоторых вариантах осуществления решение может приниматься на непрерывной основе, например, в соответствии с обратной связью. В некоторых случаях решение может создавать устойчивость системы, например, сильную устойчивость обратной связи, как описано ниже; и
РЕНДЕРИНГ (сущность изменения (изменений) аудиообработки). И хотя это обозначено в данном документе как «рендеринг», изменение (изменения) аудиообработки может (могут) включать или не включать изменение (изменения) рендеринга в зависимости от конкретной реализации. В некоторых реализациях существует несколько возможностей для изменений аудиообработки, в том числе реализация едва воспринимаемых изменений аудиообработки, путем реализации рендеринга резких и явных изменений аудиообработки.
В некоторых примерах «контекст» может включать информацию как о местоположении, так и о цели. Например, контекстная информация может содержать по меньшей мере приблизительный образ местоположения пользователя, такой как оценка пользовательской зоны, соответствующей текущему местоположению пользователя. Контекстная информация может соответствовать местоположению аудиообъекта, например, местоположению аудиообъекта, которое соответствует произнесению пользователем пробуждающего слова. В некоторых примерах контекстная информация может содержать информацию о расчете времени и вероятности издания звука объектом или человеком. Примеры контекста включают, но без ограничения, следующее:
A. Знание о том, где находится вероятное местоположение. Оно может быть основано на:
i) слабом обнаружении или обнаружении с низкой вероятностью (например, обнаружении звука, который потенциально может представлять интерес, но может являться или не являться достаточно четким для действия в соответствии с ним);
ii) конкретной активации (например, пробуждающее слово произнесено и четко обнаружено);
iii) поведенческой модели и образах (например, на основе распознавания образов, например, того, что некоторые местоположения, такие как диван вблизи телевизора, могут быть связаны с одним или более людьми, смотрящими видеоматериал по телевизору и слушающими связанные аудиоданные, сидя на диване);
iv) и/или присоединении некоторых других форм обнаружения близости на основе другой методики (такой как один или более инфракрасных (IR) датчиков, камер, емкостных датчиков, радиочастотных (RF) датчиков, термических датчиков, датчиков давления (например, в или на мебели аудиосреды), носимых радиомаяков и т. д.); и
B. Знание или оценку вероятности звука, который человек может хотеть услышать, например, с улучшенной возможностью обнаружения. Это может включать некоторое или все из:
i) события на основе некоторого обнаружения аудиоданных, такого как обнаружение пробуждающего слова;
ii) события или контекста на основе известного действия или последовательности событий, например, паузы в отображении видеосодержимого, пространства для взаимодействия в интерактивном содержимом типа заданного сценарием автоматического распознавания речи (ASR) или изменений в действиях и/или диалоговой динамике действий полнодуплексной связи (таких как пауза одного или более участников телеконференции);
iii) дополнительного сенсорного ввода других методик;
iv) выбора для получения постоянно улучшающегося некоторым образом прослушивания – повышенная подготовленность или улучшенное прослушивание.
Ключевым различием между A (знание о том, где находится вероятное местоположение) и B (знание или оценка вероятности звука, который мы хотим слышать, например, с улучшенной возможностью обнаружения) заключается в том, что A может включать конкретную информацию о положении или знание положения без необходимости в знании о том, существует ли что-либо для прослушивания, тогда как B может являться в большей мере сосредоточенным на конкретном расчете времени или информации о событии без необходимости в точном знании о том, где слушать. Разумеется, может существовать перекрытие между некоторыми аспектами A и B, при этом, например, слабое или полное обнаружение пробуждающего слова будет содержать информацию как о местоположении, так и о расчете времени.
Для некоторых вариантов использования важным может являться то, что «контекст» содержит информацию как о местоположении (например, местоположении человека и/или близлежащего микрофона), так и о расчете времени потребности в прослушивании. Эта контекстуальная информация может приводить в действие одно или более связанных решений и одно или более возможных изменений аудиообработки (например, одно или более возможных изменений рендеринга). Так, различные варианты осуществления допускают множество возможностей на основе различных типов информации, которую можно использовать для образования контекста.
Ниже описан аспект «решения». Этот аспект может включать, например, определение одного, двух, трех или более устройств вывода, для которых будет изменяться связанная аудиообработка. Одним простым способом выработки такого решения является следующее:
При наличии информации из контекста (например, местоположения и/или события (или в некотором смысле достоверности того, что в отношении данного местоположения имеется что-либо значимое или важное)), в некоторых примерах администратор аудиосеанса может определять или оценивать расстояние от этого местоположения до некоторых или всех аудиоустройств в аудиосреде. В некоторых реализациях администратор аудиосеанса также может создавать множество потенциалов активации для каждого громкоговорителя (или набора громкоговорителей) для некоторых или всех аудиоустройств аудиосреды. Согласно некоторым таким примерам множество потенциалов активации можно определить как [f_1, f_2, …, f_n] без потери общности, обычно лежащее в диапазоне [0..1]. В другом примере результат решения может описывать целевое увеличение отношения речь-эхо [s_1, s_2, …, s_n] для устройства в аспекте «рендеринг». В дополнительном примере как потенциалы активации, так и увеличения отношения речь-эхо можно получить с помощью аспекта «решение».
В некоторых вариантах осуществления потенциалы активации придают такую степень, что аспект «рендеринг» должен обеспечить SER, увеличенное в требуемом местоположении микрофона. В некоторых таких примерах максимальные значения f_n могут указывать, что подвергаемые рендерингу аудиоданные агрессивно приглушаются или деформируются, или, в случае предоставления значений s_n, что аудиоданные ограничиваются и приглушаются для достижения отношения речь-эхо, равного s_n. Средние значения f_n, близкие к 0,5, в некоторых вариантах осуществления могут указывать, что требуется лишь умеренная степень изменения рендеринга, и что может являться подходящей деформация аудиоисточников в эти местоположения. Кроме того, в некоторых реализациях низкие значения f_n можно считать некритичными для ослабления. В некоторых таких реализациях значения f_n, которые равны пороговому уровню или ниже него, могут не передаваться. Согласно некоторым примерам значения f_n, которые равны пороговому уровню или ниже него, могут соответствовать местоположениям для деформации в их направлении рендеринга аудиосодержимого. В некоторых случаях уровень проигрывания громкоговорителей, соответствующих значениям f_n, которые равны пороговому уровню или ниже него, может даже повышаться в соответствии с некоторыми процессами, которые будут описаны позднее.
Согласно некоторым реализациям предыдущий способ (или один из альтернативных способов, которые описаны ниже) можно использовать для создания параметра управления для каждого из выбранных изменений аудиообработки для всех выбранных аудиоустройств, например, для каждого устройства аудиосреды, для одного или более устройств аудиосреды, для двух или более устройств аудиосреды, для трех или более устройств аудиосреды и т. д. Выбор изменений аудиообработки может отличаться в соответствии с конкретной реализацией. Например, решение может включать определение:
- набора из двух или более громкоговорителей, для которых следует изменить аудиообработку; и
- степени изменения аудиообработки для набора из двух или более громкоговорителей. Степень изменения в некоторых примерах можно определить в контексте спроектированного или определенного диапазона, который может по меньшей мере частично основываться на функциональных возможностях одного или более громкоговорителей в наборе громкоговорителей. В некоторых случаях функциональные возможности каждого громкоговорителя могут включать частотную характеристику, ограничения уровня проигрывания и/или параметры одного или более алгоритмов динамической обработки громкоговорителей.
Например, проектное решение может являться таким, что наилучшей возможностью в конкретных обстоятельствах является убавление звука. В некоторых таких примерах максимальную и/или минимальную степень изменений аудиообработки можно определить, например, так, что степень, в которой будет убавляться звук любого громкоговорителя, ограничена конкретным порогом, например, 15 дБ, 20 дБ, 25 дБ и т. д. В некоторых таких реализациях решение может быть основано на эвристической модели или логической схеме, которая выбирает один, два, три или более громкоговорителей, и основано на достоверности представляющего интерес действия, местоположения громкоговорителя и т. д., при этом решением может являться приглушение аудиоданных, воспроизводимых одним, двумя, тремя или более громкоговорителями на величину в диапазоне от минимального до максимального значения, например, от 0 до 20 дБ. В некоторых случаях способ решения (или элемент системы) может создавать множество потенциалов активации для каждого оснащенного громкоговорителем аудиоустройства.
В одном простом примере процесс решения может являться настолько простым, как определение того, что все аудиоустройства, кроме одного, характеризуются изменением значения активации рендеринга, которое равно 0, и определение того, что одно аудиоустройство характеризуется изменением значения активации, которое равно 1. В некоторых примерах проектное решение изменения (изменений) аудиообработки (например, приглушения) и степени изменения (изменений) аудиообработки (например, постоянных времени и т. д.) могут не зависеть от логической схемы решения. Данный подход создает простое и эффективное проектное решение.
Однако альтернативные реализации могут включать выбор двух или более оснащенных громкоговорителями аудиоустройств и изменение аудиообработки для по меньшей мере двух, по меньшей мере трех (и в некоторых случаях всех) из двух или более оснащенных громкоговорителями аудиоустройств. В некоторых таких примерах по меньшей мере одно из изменений аудиообработки (например, снижение уровня проигрывания) для первого аудиоустройства может отличаться от изменения аудиообработки для второго аудиоустройства. Отличия между изменениями аудиообработки в некоторых примерах могут быть по меньшей мере частично основаны на оценочном текущем местоположении человека или местоположении микрофона относительно местоположения каждого аудиоустройства. Согласно некоторым таким реализациям изменения аудиообработки могут включать применение разных значений активации динамиков в разных местоположениях громкоговорителей в качестве части изменения процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения представляющего интерес человека. Отличия между изменениями аудиообработки в некоторых примерах могут по меньшей мере частично основываться на функциональных возможностях громкоговорителей. Например, если изменения аудиообработки включают снижение уровня аудиоданных в низкочастотном диапазоне, эти измерения могут более агрессивно применяться к аудиоустройству, которое содержит один или более громкоговорителей, способных к воспроизведению с высокой громкостью в низкочастотном диапазоне.
Ниже более подробно описан аспект изменений аудиообработки, который в данном документе может называться аспектом «изменения рендеринга». В настоящем изобретении этот аспект иногда может называться «убавлением звука ближайшего» (например, снижением громкости, с которой подвергается рендерингу аудиосодержимое, подлежащее проигрыванию ближайшим одним, двумя, тремя или более динамиками), хотя (как отмечено в другом месте данного документа), в более общем смысле, во многих реализациях может затрагиваться одно или более изменений аудиообработки, которое или которые направлено или направлены на улучшение общей оценки, меры и/или критерия отношения сигнал-эхо с целью обеспечения возможности захвата или опознавания требуемого излучателя звука (например, человека, произнесшего пробуждающее слово). В некоторых случаях изменения аудиообработки (например, «убавление» громкости звука подвергаемого рендерингу аудиосодержимого) регулируются или могут регулироваться с помощью некоторого непрерывного параметра величины эффекта. Например, в контексте убавления звука громкоговорителя некоторые реализации могут быть выполнены с возможностью применения регулируемой (например, непрерывно регулируемой) величины ослабления (дБ). В некоторых таких примерах регулируемая величина ослабления может характеризоваться первым диапазоном (например, 0–3 дБ) для едва различимого изменения, и вторым диапазоном (например, 0–20 дБ) – для особенно эффективного увеличения SER, который, однако, может являться весьма заметным для слушателя.
В некоторых вариантах осуществления, реализующих отмеченную схему (КОНТЕКСТ, РЕШЕНИЕ и РЕНДЕРИНГ или ИЗМЕНЕНИЕ РЕНДЕРИНГА), может отсутствовать конкретная жесткая граница «ближайшего» (например, для громкоговорителя или устройства, являющегося «ближайшим» к пользователю или к другому человеку или элементу системы), и, без потери общности, «Изменение рендеринга» может представлять собой или включать изменение (например, непрерывное изменение) одного или более из следующего:
A. Режим изменения выходных данных с целью уменьшения выходного аудиосигнала из одного или более аудиоустройств, при этом изменение (изменения) в выходном аудиосигнале может (могут) включать одно или более из:
i) снижения общего уровня выходного сигнала аудиоустройства (убавления звука одного или более громкоговорителей, его или их выключения);
ii) формирования спектра выходного сигнала одного или более громкоговорителей, например, с помощью по существу линейного выравнивающего (EQ) фильтра, рассчитанного на получение выходного сигнала, который отличается от спектра аудиоданных, которые требуется обнаружить. В некоторых примерах, если выходной спектр подвергается формированию с целью обнаружения человеческого голоса, фильтр может убавлять звук на частотах в диапазоне приблизительно 500 Гц – 3 кГц (например, плюс или минус 5 % или 10 % на каждом конце диапазона частот) или формировать громкость для охвата низких и высоких частот с оставлением интервала в среднечастотных полосах (например, в диапазоне приблизительно 500 Гц – 3 кГц);
iii) изменения верхних пределов или пиковых значений выходного сигнала для снижения пикового уровня и/или уменьшения продуктов искажения, которые могут дополнительно снижать эффективность любой эхокомпенсации, являющейся частью всей системы, которая создает достигаемое SER для обнаружения аудиоданных, например, компрессора динамического диапазона во временной области или многополосного компрессора с зависимостью от частоты. Такие модификации аудиосигнала могут эффективно снижать амплитуду аудиосигнала и могут способствовать ограничению амплитуды полного колебания диффузора громкоговорителя;
iv) пространственного управления аудиоданными способом, который стремился бы понизить энергию или связь выходного сигнала одного или более громкоговорителей с одним или более микрофонами, на которых система (например, администратор аудиообработки) обеспечивает возможность более высокого SER, например, как в примерах «деформации», которые описаны в данном документе;
v) использования временного квантования времени или регулировок для создания «промежутков» или периодов разреженного по времени и частоте менее интенсивного выходного сигнала, достаточного для получения беглых набросков аудиоданных, как в примерах вставки промежутков, которые описаны ниже; и/или
vi) изменения аудиоданных в некоторой комбинации вышеупомянутых способов; и/или
B. Сохранение энергии и/или создание непрерывности в конкретном или широком множестве местоположений прослушивания, например, включая одно или более из следующего:
i) в некоторых примерах энергию, удаляемую из громкоговорителя, можно скомпенсировать путем доставки дополнительной энергии в или к другому громкоговорителю. В некоторых случаях общая громкость остается одинаковой или по существу одинаковой. Этот признак не является существенным, но может представлять собой эффективное средство обеспечения возможности внесения более резких изменений в аудиообработку «ближайшего» устройства или ближайшего набора устройств без потери содержимого. Однако непрерывность и/или сохранение энергии могут являться особенно значимыми при работе со сложным выходным аудиосигналом и аудиосценами; и/или
ii) постоянные времени активации, в частности, изменения, вносимые в аудиообработку, могут применяться несколько быстрее (например, 100–200 мс), чем они возвращаются к нормальному состоянию (например, 1000–10000 мс), так что изменение (изменения), вносимое (вносимые) в аудиообработку, если оно заметно (они заметны), кажется преднамеренным (кажутся преднамеренными), но последующее возвращение от изменения (изменений) может не казаться связанным с каким-либо фактическим событием или изменением (с точки зрения пользователя) и в некоторых случаях может являться достаточно медленным, чтобы быть едва заметным.
Ниже представлены дополнительные примеры того, как можно сформулировать и определить контекст и решение.
Вариант осуществления A
(КОНТЕКСТ) В качестве примера, контекстную информацию можно математически сформулировать следующим образом:
H(a, b), приблизительное физическое расстояние в метрах между устройствами a и b:
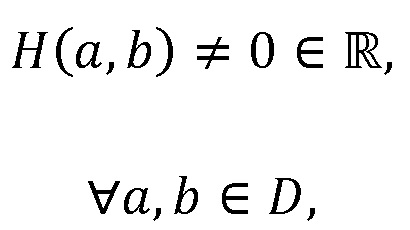
где D представляет множество всех устройств в системе. S, оценочное SER на каждом устройстве можно выразить следующим образом:
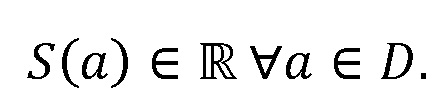
Определение H и S
H представляет собой свойство физического местоположения устройств, и поэтому его можно определить или оценить путем:
(1) Прямого указания пользователем, например, с использованием смартфона или планшетного устройства для отметки или указания приблизительных местоположений устройств на архитектурном плане или аналогичном схематическом представлении среды. Такие цифровые интерфейсы уже являются обычными при управлении конфигурацией, группировкой, наименованием, назначением и идентификаторами интеллектуальных бытовых устройств. Например, такое прямое указание можно предоставить с помощью приложения для смартфонов Amazon Alexa, приложения для контроллеров Sonos S2 или аналогичного приложения.
(2) Решение основной задачи трилатерации с использованием измеренного уровня сигнала (иногда называемой «Индикатором уровня принимаемого сигнала» или RSSI) согласно общепринятым технологиям беспроводной связи, таким как Bluetooth, Wi-Fi, ZigBee и т. д., для получения оценок физического расстояния между устройствами, например, как описано в публикации J. Yang и Y. Chen, «Indoor Localization Using Improved RSS-Based Lateration Methods» GLOBECOM 2009 - 2009 IEEE Global Telecommunications Conference, Honolulu, HI, 2009, pp. 1–6, doi: 10.1109/GLOCOM.2009.5425237, и/или как описано в публикации Mardeni, R. & Othman, Shaifull & Nizam, (2010) «Node Positioning in ZigBee Network Using Trilateration Method Based on the Received Signal Strength Indicator (RSSI)» 46, которые включены в данный документ посредством ссылки.
S(a) представляет собой оценку отношения речь-эхо на устройстве a. По определению, отношение речь-эхо в дБ имеет вид:
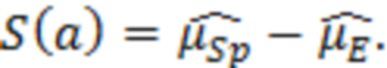
В предыдущем выражении 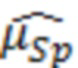 представляет оценку энергии речи в дБ, и
представляет оценку энергии речи в дБ, и 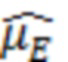 представляет оценку в дБ энергии остаточного эха после эхокомпенсации. Различные методологии оценки этих величин раскрыты в данном документе, например, далее.
представляет оценку в дБ энергии остаточного эха после эхокомпенсации. Различные методологии оценки этих величин раскрыты в данном документе, например, далее.
(1) Энергию речи и энергию остаточного эха можно оценить с помощью процесса автономного измерения, выполняемого для конкретного устройства, с учетом акустической связи между микрофоном и динамиками устройства, и характеристик встроенной схемы эхокомпенсации. В некоторых таких примерах средний уровень энергии речи «AvgSpeech» можно определить с помощью среднего уровня человеческой речи, измеренного устройством на номинальном расстоянии. Например, для получения AvgSpeech речь от небольшого количества людей, находящихся на расстоянии 1 м от оснащенного микрофоном устройства, можно записать с помощью устройства во время произнесения, а энергию можно усреднить. Согласно некоторым таким примерам, средний уровень энергии остаточного эха «AvgEcho» можно оценить путем проигрывания музыкального содержимого из устройства во время генерирования и запуска встроенной схемы эхокомпенсации с целью получения остаточного эхосигнала. Для оценки AvgEcho можно использовать усреднение энергии остаточного эхосигнала для небольшой выборки музыкального контента. Когда устройство не проигрывает аудиоданные, AvgEcho можно вместо этого приравнять к номинальному низкому значению, такому как
-96,0 дБ (dB). В некоторых таких реализациях энергию речи и энергию остаточного эха можно оценить следующим образом:
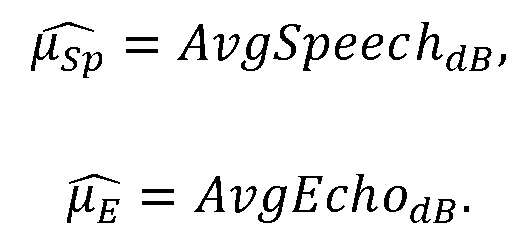
(2) Согласно некоторым примерам среднюю энергии речи можно определить путем взятия энергии сигналов микрофонов, соответствующих фрагменту речи пользователя, определенному с помощью детектора речевой активности (VAD). В некоторых таких примерах среднюю энергию остаточного эха можно оценить с помощью энергии сигналов микрофонов, когда VAD не указывает речь. Если x представляет отсчеты импульсно-кодовой модуляции (PCM) микрофона устройства a с некоторой частотой выборки, и V представляет флаг VAD, принимающий значение 1,0 для отсчетов, соответствующих голосовой активности, и 0,0 – в противном случае, энергию речи и энергию остаточного эха можно выразить следующим образом:
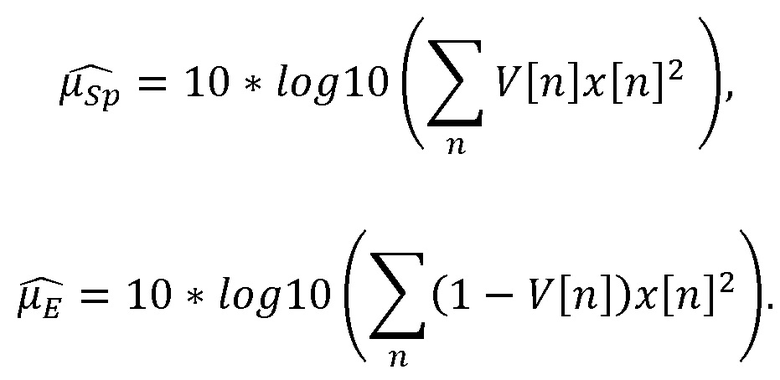
(3) В дополнение к предыдущим способам, в некоторых реализациях энергию микрофона можно обработать как случайную переменную и смоделировать отдельно на основе определения VAD. Статистические модели Sp и E энергии речи и эха соответственно можно оценить с использованием любого количества технических решений статистического моделирования. Тогда средние значения в дБ как речи, так и эха для аппроксимации S(a) можно вывести из Sp и E соответственно. Общеизвестные способы ее выполнения находятся в пределах области статистической обработки сигналов, например:
• в предположении гауссова распределения энергии и вычисления нерепрезентативной статистики второго порядка 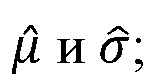
• при построении дискретно-интервальной гистограммы значений энергии для получения потенциально мультимодального распределения, которое после применения этапа оценки параметра максимизации ожидания (ЕМ) для модели смешения (например, гауссовой модели смешения), можно использовать наибольшее среднее значение 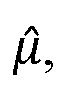 принадлежащее любому из субраспределений в смеси.
принадлежащее любому из субраспределений в смеси.
(РЕШЕНИЕ) Как отмечено в другом месте данного документа, в различных раскрытых реализациях аспект решения определяет, какие устройства получают модификацию аудиообработки, такую как модификация рендеринга, и в некоторых вариантах осуществления индикатор того, насколько значительная модификация необходима для требуемого улучшения SER. Некоторые такие варианты осуществления могут быть выполнены с возможностью увеличения SER на устройстве с помощью наилучшего начального значения SER, например, определенного путем нахождения максимального значения S по всем устройствам во множестве D. Другие варианты осуществления могут быть выполнены с возможностью оппортунистического увеличения SER на устройствах, к которым регулярно обращаются пользователи, что определяется на основе исторических диаграмм использования. Другие варианты осуществления могут быть выполнены с возможностью стремления к увеличению SER в ряде местоположений микрофонов, например, выбора ряда устройств для целей приведенного ниже обсуждения.
После определения одного или более местоположений микрофонов в некоторых таких реализациях требуемое увеличение SER (SERI) можно определить следующим образом:
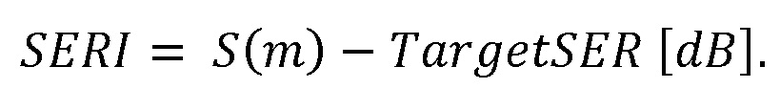
В предыдущем описании m представляет местоположение устройства/микрофона, которое подвергается улучшению, и TargetSER представляет порог, который может быть установлен используемым приложением. Например, алгоритм обнаружения пробуждающего слова может допускать менее высокое рабочее SER, чем распознаватель речи с большим словарным запасом. Обычные значения для TargetSER могут иметь порядок от
-6 дБ до 12 дБ (dB). Как упомянуто, если в некоторых вариантах осуществления S(m) неизвестно или не является простым для оценки, предварительно установленное значение может являться достаточным на основе автономных измерений речи и эха, записанных в обычном звукоотражающем помещении или обстановке. Некоторые варианты осуществления могут определять устройства, для которых требуется модификация аудиообработки (например, рендеринга), путем точного определения f_n в диапазоне от 0 до 1. Другие варианты осуществления могут включать точное определение степени, в которой следует модифицировать аудиообработку (например, рендеринг), в единицах увеличения отношения речь-эхо в децибелах, s_n, что потенциально вычисляют согласно:
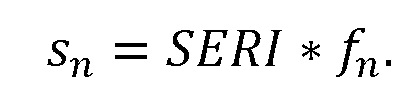
В некоторых вариантах осуществления f_n может вычисляться непосредственно из геометрии устройства, например, следующим образом:
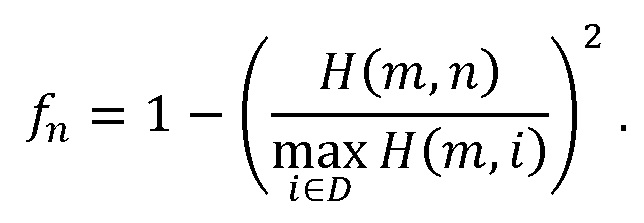
В предыдущем выражении m представляет индекс устройства, которое будет выбрано для наибольшей модификации аудиообработки (например, рендеринга), как отмечено выше. Другие реализации могут включать другие возможности выбора упрощающих или сглаживающих функций в зависимости от геометрии устройства.
Вариант осуществления B (отсылка к пользовательским зонам)
В некоторых вариантах осуществления аспекты контекста и решения согласно настоящему изобретению будут осуществляться в контексте одной или более пользовательских зон. Как подробно описано далее в данном документе, множество акустических признаков 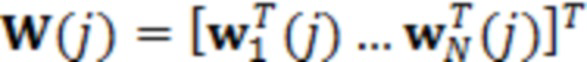 можно использовать для оценки апостериорных вероятностей
можно использовать для оценки апостериорных вероятностей 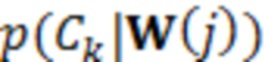 для некоторого множества меток зон
для некоторого множества меток зон 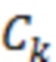 , для
, для  , для K разных пользовательских зон в среде. Привязка каждого аудиоустройства к каждой пользовательской зоне может быть обеспечена самим пользователем как часть процесса обучения, описанного в данном документе, или альтернативно с помощью средств приложения, например, приложения для смартфонов Alexa или приложения для контроллеров смартфонов Sonos S2. Например, некоторые реализации могут обозначать привязку j-го устройства к пользовательской зоне с меткой зоны как
, для K разных пользовательских зон в среде. Привязка каждого аудиоустройства к каждой пользовательской зоне может быть обеспечена самим пользователем как часть процесса обучения, описанного в данном документе, или альтернативно с помощью средств приложения, например, приложения для смартфонов Alexa или приложения для контроллеров смартфонов Sonos S2. Например, некоторые реализации могут обозначать привязку j-го устройства к пользовательской зоне с меткой зоны как 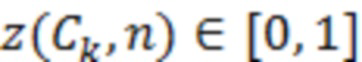 . В некоторых вариантах осуществления как
. В некоторых вариантах осуществления как 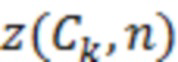 , так и апостериорные вероятности можно считать контекстной информацией. Вместо этого некоторые варианты осуществления могут считать частью контекста сами акустические признаки
, так и апостериорные вероятности можно считать контекстной информацией. Вместо этого некоторые варианты осуществления могут считать частью контекста сами акустические признаки 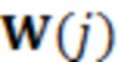 . В других вариантах осуществления частью контекстной информации могут являться более одной из этих величин (, апостериорных вероятностей и самих акустических признаков ) и/или комбинация этих величин.
. В других вариантах осуществления частью контекстной информации могут являться более одной из этих величин (, апостериорных вероятностей и самих акустических признаков ) и/или комбинация этих величин.
В аспекте решения согласно различным вариантам осуществления могут использоваться величины, связанные с одной или более пользовательскими зонами при выборе устройства. Когда доступны z и p, иллюстративное решение можно принять следующим образом:
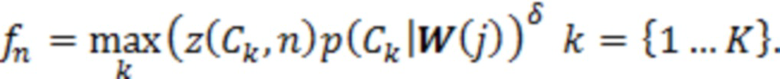
Согласно таким вариантам осуществления устройства с наивысшей привязкой к пользовательским зонам, которые с наибольшей вероятностью содержат пользователя, будут характеризоваться наибольшим применяемым к ним изменением аудиообработки (например, рендеринга). В некоторых примерах δ может представлять собой положительное число в диапазоне [0,5, 4,0]. Согласно некоторым таким примерам δ можно использовать для управления объемом изменения рендеринга в пространстве. В таких реализациях, если δ выбрать равным 0,5, большее изменение рендеринга будет получать большее количество устройств, тогда как значение 4,0 будет ограничивать изменение рендеринга только устройствами, наиболее близкими к наиболее вероятной пользовательской зоне.
Авторы изобретения также предполагают другой класс вариантов осуществления, в которых в аспекте решения непосредственно используются акустические признаки . Например, если степени достоверности пробуждающего слова, связанные с фрагментом речи j, равны 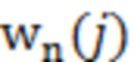 , то выбор устройств можно сделать согласно следующему выражению:
, то выбор устройств можно сделать согласно следующему выражению:
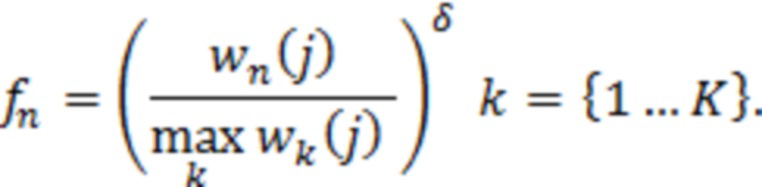
В предыдущем выражении δ интерпретируется так же, как в предыдущем примере, а также применяется для компенсации типичного распределения достоверностей пробуждающего слова, которые могут возникать для конкретной системы пробуждающего слова. Если большинство устройств стремятся сообщить высокие достоверности пробуждающего слова, δ можно выбрать как относительно большее число, такое как, например, 3,0, для повышения пространственной специфичности применения изменения рендеринга. Если достоверность пробуждающего слова стремится к быстрому падению, так как пользователь расположен дальше от устройств, δ можно выбрать как относительно меньшее число, такое как 1,0 или даже 0,5, для включения в применение изменения рендеринга большего количества устройств. Читателю будет понятно, что в некоторых альтернативных реализациях формулы, аналогичные приведенным выше для акустических признаков, таких как оценка уровня речи на микрофоне устройства и/или отношение прямого и отраженного звука для фрагмента речи пользователя, можно заменить достоверностью пробуждающего слова.
На фиг. 2A представлена структурная схема, на которой показаны примеры компонентов оборудования или системы, способной реализовывать различные аспекты настоящего изобретения. Как и на других фигурах, представленных в данном документе, типы и количества элементов, показанных на фиг. 2A, представлены лишь в качестве примера. Другие реализации могут содержать большее количество типов элементов и самих элементов, меньшее количество типов элементов и самих элементов и/или другие типы и количества элементов. Согласно некоторым примерам оборудование 200 может представлять собой или может содержать устройство, выполненное с возможностью выполнения по меньшей мере некоторых способов, раскрытых в данном документе. В некоторых реализациях оборудование 200 может представлять собой или может содержать интеллектуальный динамик, ноутбук, сотовый телефон, планшетное устройство, концентратор умного дома или другое устройство, выполненное с возможностью выполнения по меньшей мере некоторых из способов, раскрытых в данном документе. В некоторых реализациях оборудование 200 может быть выполнено с возможностью реализации администратора аудиосеанса. В некоторых таких реализациях оборудование 200 может представлять собой или может содержать сервер.
В этом примере оборудование 200 содержит систему 205 интерфейсов и систему 210 управления. В некоторых реализациях система 205 интерфейсов может быть выполнена с возможностью осуществления связи с одним или более устройствами, исполняющими или выполненными с возможностью исполнения программных приложений. Такие программные приложения в данном документе иногда могут называться «прикладными программами» или просто «приложениями». В некоторых реализациях система 205 интерфейсов может быть выполнена с возможностью обмена управляющей информацией и связанными данными, относящимися к приложениям. В некоторых реализациях система 205 интерфейсов может быть выполнена с возможностью осуществления связи с одним или более другими устройствами аудиосреды. В некоторых примерах аудиосреда может представлять собой домашнюю аудиосреду. В некоторых реализациях система 205 интерфейсов может быть выполнена с возможностью обмена управляющей информацией и связанными данными с аудиоустройствами аудиосреды. Управляющая информация и связанные данные в некоторых примерах могут относиться к одному или более приложениям, с возможностью осуществления связи с которыми выполнено оборудование 200.
В некоторых реализациях система 205 интерфейсов может быть выполнена с возможностью приема аудиоданных. Аудиоданные могут содержать аудиосигналы, запланированные для воспроизведения по меньшей мере некоторыми динамиками аудиосреды. Аудиоданные могут содержать один или более аудиосигналов и связанные пространственные данные. Пространственные данные могут содержать, например, данные каналов и/или пространственные метаданные. Система 205 интерфейсов может быть выполнена с возможностью доставки подвергнутых рендерингу аудиосигналов в по меньшей мере некоторые громкоговорители набора громкоговорителей среды. В некоторых реализациях система 205 интерфейсов может быть выполнена с возможностью приема входных данных из одного или более микрофонов в среде.
Система 205 интерфейсов может содержать один или более сетевых интерфейсов и/или один или более интерфейсов для внешних устройств (таких как один или более интерфейсов универсальной последовательной шины (USB)). Согласно некоторым реализациям система 205 интерфейсов может содержать один или более беспроводных интерфейсов. Система 205 интерфейсов может содержать одно или более устройств для реализации пользовательского интерфейса, таких как один или более микрофонов, один или более динамиков, систему дисплеев, систему сенсорных датчиков и/или систему датчиков жестов. В некоторых примерах система 205 интерфейсов может содержать один или более интерфейсов между системой 210 управления и системой памяти, такой как необязательная система 215 памяти, представленная на фиг. 2A. Однако в некоторых случаях система 210 управления может содержать систему памяти.
Например, система 210 управления может содержать одно- или многокристальный процессор общего назначения, процессор цифровой обработки сигналов (DSP), интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA) или другое программируемое логическое устройство, схему на дискретных компонентах или транзисторную логическую схему и/или компоненты дискретного аппаратного обеспечения.
В некоторых реализациях система 210 управления может находиться в более чем одном устройстве. Например, одна часть системы 210 управления может находиться в устройстве в одной из сред, изображенных в данном документе, а другая часть системы 210 управления может находиться в устройстве, находящемся за пределами среды, таком как сервер, мобильное устройство (например, смартфон или планшетный компьютер) и т. д. В других примерах одна часть системы 210 управления может находиться в устройстве в одной из сред, изображенных в данном документе, а другая часть системы 210 управления может находиться в одном или более других устройствах среды. Например, функциональные возможности системы управления могут быть распределены по ряду интеллектуальных аудиоустройств среды или могут быть разделены между организующим устройством (таким, которое в данном документе может называться администратором аудиосеанса или концентратором умного дома) и одним или более другими устройствами среды. В некоторых таких примерах система 205 интерфейсов также может находиться в более чем одном устройстве.
В некоторых реализациях система 210 управления может быть выполнена с возможностью по меньшей мере частичного выполнения способов, раскрытых в данном документе. Согласно некоторым примерам система 210 управления может быть выполнена с возможностью реализации способов управления аудиосеансом, которые в некоторых случаях могут включать определение одного или более типов изменений аудиообработки для применения к аудиоданным, которые подвергаются рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств аудиосреды. Согласно некоторым реализациям результатом изменений аудиообработки может являться увеличение отношения речь-эхо на одном или более микрофонах в аудиосреде.
Некоторые или все способы, описанные в данном документе, могут быть выполнены с помощью одного или более устройств в соответствии с инструкциями (например, программным обеспечением), хранящимися на одном или более постоянных носителях данных. Такие постоянные носители данных могут содержать запоминающие устройства, такие как описанные в данном документе, включая, но без ограничения, оперативные запоминающие устройства (RAM), постоянные запоминающие устройства (ROM) и т. д. Один или более постоянных носителей данных могут находиться, например, в необязательной системе 215 памяти, представленной на фиг. 2A, и/или в системе 210 управления. Соответственно, различные изобретательские аспекты объекта изобретения, описанные в данном документе, могут быть реализованы в одном или более постоянных носителях данных, содержащих хранящееся на них программное обеспечение. Программное обеспечение может, например, содержать инструкции для управления по меньшей мере одним устройством для реализации способов управления аудиосеансом. В некоторых примерах программное обеспечение может содержать инструкции для управления одним или более аудиоустройствами аудиосреды с целью получения, обработки и/или предоставления аудиоданных. В некоторых примерах программное обеспечение может содержать инструкции для определения одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств аудиосреды. Согласно некоторым реализациям результатом изменений аудиообработки может являться увеличение отношения речь-эхо на одном или более микрофонах в аудиосреде. Например, программное обеспечение может быть выполнено с возможностью исполнения одним или более компонентами системы управления, такой как система 210 управления согласно фиг. 2A.
В некоторых примерах оборудование 200 может содержать необязательную систему 220 микрофонов, представленную на фиг. 2A. Необязательная система 220 микрофонов может содержать один или более микрофонов. В некоторых реализациях один или более микрофонов могут являться частью или быть связанными с другим устройством, таким как динамик системы динамиков, интеллектуальное аудиоустройство и т. д. В некоторых примерах оборудование 200 может не содержать систему 220 микрофонов. Однако в некоторых таких реализациях оборудование 200 может, тем не менее, быть выполнено с возможностью приема данных микрофонов для одного или более микрофонов в аудиосреде через систему 210 интерфейсов.
Согласно некоторым реализациям оборудование 200 может содержать необязательную систему 225 громкоговорителей, представленную на фиг. 2A. Необязательная система 225 динамиков может содержать один или более громкоговорителей. В данном документе громкоговорители иногда могут называться «динамиками». В некоторых примерах по меньшей мере некоторые громкоговорители необязательной системы 225 громкоговорителей могут быть расположены произвольно. Например, по меньшей мере некоторые динамики необязательной системы 225 громкоговорителей могут быть размещены в местоположениях, не соответствующих какой-либо предписанной стандартом схеме размещения динамиков, такой как Dolby 5.1, Dolby 5.1.2, Dolby 7.1, Dolby 7.1.4, Dolby 9.1, Hamasaki 22.2 и т. д. В некоторых таких примерах по меньшей мере некоторые громкоговорители необязательной системы 225 громкоговорителей могут быть размещены в местоположениях, удобных для данного пространства (например, в тех местоположениях, где имеется пространство для размещения громкоговорителей), а не по какой-либо предписанной стандартом схеме размещения громкоговорителей. В некоторых примерах оборудование 200 может не содержать необязательную систему 225 громкоговорителей.
В некоторых реализациях оборудование 200 может содержать необязательную систему 230 датчиков, представленную на фиг. 2A. Необязательная система 230 датчиков может содержать одну или более камер, сенсорных датчиков, датчиков жестов, датчиков движения и т. д. Согласно некоторым реализациям необязательная система 230 датчиков может содержать одну или более камер. В некоторых реализациях камеры могут представлять собой автономные камеры. В некоторых примерах одна или более камер необязательной системы 230 датчиков могут находиться в интеллектуальном аудиоустройстве, которое может представлять собой аудиоустройство специального назначения или виртуальный помощник. В некоторых таких примерах одна или более камер необязательной системы 230 датчиков могут находиться в TV, мобильном телефоне или интеллектуальном динамике. В некоторых примерах оборудование 200 может не содержать систему 230 датчиков. Однако в некоторых таких реализациях оборудование 200 может, тем не менее, быть выполнено с возможностью приема данных датчика для одного или более датчиков в аудиосреде через систему 210 интерфейсов.
В некоторых реализациях оборудование 200 может содержать необязательную систему 235 дисплеев, представленную на фиг. 2A. Необязательная система 235 дисплеев может содержать один или более дисплеев, таких как один или более светодиодных (LED) дисплеев. В некоторых случаях необязательная система 235 дисплеев может содержать один или более дисплеев на органических светодиодах (OLED). В некоторых примерах, в которых оборудование 200 содержит систему 235 дисплеев, система 230 датчиков может содержать систему сенсорных датчиков и/или систему датчиков жестов поблизости от одного или более дисплеев системы 235 дисплеев. Согласно некоторым таким реализациям система 210 управления может быть выполнена с возможностью управления системой 235 дисплеев с целью представления одного или более графических пользовательских интерфейсов (GUI).
Согласно некоторым примерам оборудование 200 может представлять собой или может содержать интеллектуальное аудиоустройство. В некоторых таких реализациях оборудование 200 может представлять собой или может (по меньшей мере частично) реализовывать детектор пробуждающего слова. Например, оборудование 200 может представлять собой или может (по меньшей мере частично) реализовывать виртуальный помощник.
На фиг. 2B представлена блок-схема, содержащая этапы способа управления аудиосеансом согласно некоторым реализациям. Этапы способа 250, как и других способов, описанных в данном документе, не обязательно выполняются в указанном порядке. В некоторых реализациях один или более этапов способа 250 могут выполняться одновременно. Более того, некоторые реализации способа 250 могут включать больше или меньше этапов, чем представлено и/или описано. Этапы способа 250 могут выполняться одним или более устройствами, которые могут представлять собой (или могут содержать) систему управления, такую как система 210 управления, которая представлена на фиг. 2A и описана выше, или один из других примеров раскрытых систем управления. Согласно некоторым реализациям этапы способа 250 могут по меньшей мере частично выполняться устройством, реализующим то, что в данном документе называется «администратором аудиосеанса».
Согласно данному примеру этап 255 включает прием выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде. В этом примере каждый микрофон из множества микрофонов находится в местоположении микрофона в аудиосреде, и выходные сигналы включают сигналы, соответствующие текущему фрагменту речи человека. В некоторых случаях текущий фрагмент речи может представлять собой фрагмент речи, содержащий пробуждающее слово. Однако выходные сигналы могут также содержать сигналы, которые соответствуют моментам времени, в течение которых человек не разговаривает. Такие сигналы можно использовать, например, для установления исходных уровней эха, шума и т. д.
В этом примере этап 260 включает определение на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку. В этой реализации контекстная информация содержит оценочное текущее местоположение человека и/или оценочную текущую близость человека к одному или более местоположениям микрофонов. Как отмечено выше, выражение «местоположение микрофона» в контексте данного документа указывает местоположение одного или более микрофонов. В некоторых примерах одно местоположение микрофона может соответствовать массиву микрофонов, находящемуся в одном аудиоустройстве. Например, местоположение микрофона может представлять собой одно местоположение, которое соответствует всему аудиоустройству, содержащему один или более микрофонов. В некоторых таких примерах местоположение микрофона может представлять собой одно местоположение, соответствующее средней точке массива микрофонов одного аудиоустройства. Однако в некоторых случаях местоположение микрофона может представлять собой местоположение одного микрофона. В некоторых таких примерах аудиоустройство может содержать только один микрофон.
В некоторых примерах определение контекстной информации может включать осуществление оценки пользовательской зоны, в которой человек расположен в настоящий момент. Некоторые такие примеры могут включать определение ряда текущих акустических признаков из выходных сигналов каждого микрофона и применение классификатора к ряду текущих акустических признаков. Например, применение классификатора может включать применение модели, обученной на ранее определенных акустических признаках, полученных из множества предыдущих фрагментов речи, произнесенных человеком во множестве пользовательских зон в среде. В некоторых таких примерах определение одного или более аспектов контекстной информации, относящейся к человеку, может включать определение, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой человек расположен в настоящий момент. В некоторых таких примерах оценка пользовательской зоны может быть определена без отсылки к геометрическим местоположениям множества микрофонов. Согласно некоторым примерам текущий фрагмент речи и предыдущие фрагменты речи могут представлять собой или могут содержать фрагменты речи, содержащие пробуждающее слово.
Согласно этой реализации этап 265 включает выбор двух или более аудиоустройств аудиосреды по меньшей мере частично на основе одного или более аспектов контекстной информации, при этом каждое из двух или более аудиоустройств содержит по меньшей мере один громкоговоритель. В некоторых примерах выбор двух или более аудиоустройств аудиосреды может включать выбор N оснащенных громкоговорителями аудиоустройств аудиосреды, где N – целое число, превышающее 2. В некоторых случаях выбор двух или более аудиоустройств аудиосреды или выбор N оснащенных громкоговорителями аудиоустройств аудиосреды может включать выбор всех оснащенных громкоговорителями аудиоустройств аудиосреды.
В некоторых примерах выбор двух или более аудиоустройств аудиосреды может по меньшей мере частично основываться на оценочном текущем местоположении человека относительно местоположения микрофона и/или местоположения оснащенного громкоговорителем аудиоустройства. Некоторые такие примеры могут включать определение ближайшего оснащенного громкоговорителем аудиоустройства к оценочному текущему местоположению человека или к местоположению микрофона, ближайшему к оценочному текущему местоположению человека. В некоторых таких примерах два или более аудиоустройств могут включать ближайшее оснащенное громкоговорителем аудиоустройство.
Согласно некоторым реализациям выбор двух или более аудиоустройств может по меньшей мере частично основываться на определении того, является ли оценка отношения сигнал-эхо меньшей, чем порог отношения сигнал-эхо, или равной ему.
Согласно этому примеру этап 270 включает определение одного или более типов изменений аудиообработки для применения к аудиоданным, которые подвергаются рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств. В этой реализации результатом изменений аудиообработки является увеличение отношения речь-эхо на одном или более микрофонах. В некоторых примерах один или более микрофонов могут находиться в ряде аудиоустройств аудиосреды. Однако согласно некоторым реализациям один или более микрофонов могут находиться в одном аудиоустройстве аудиосреды. В некоторых примерах изменение (изменения) аудиообработки может (могут) вызывать снижение уровня воспроизведения громкоговорителя для громкоговорителей двух или более аудиоустройств.
Согласно некоторым примерам по меньшей мере одно из изменений аудиообработки для первого аудиоустройства может отличаться от изменения аудиообработки для второго аудиоустройства. Например, изменение (изменения) аудиообработки может (могут) вызывать первое снижение уровня воспроизведения громкоговорителей для первых громкоговорителей первого аудиоустройства и может (могут) вызывать второе снижение уровня воспроизведения громкоговорителей для вторых громкоговорителей второго аудиоустройства. В некоторых таких примерах снижение уровня воспроизведения громкоговорителя может являться относительно большим для аудиоустройства, характеризующегося большей близостью к оценочному текущему местоположению человека (или к местоположению микрофона, ближайшему к оценочному текущему местоположению человека).
Однако авторы изобретения предполагают множество типов изменений аудиообработки, которые могут осуществляться в некоторых случаях. Согласно некоторым реализациям один или более типов изменений аудиообработки могут включать изменение процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения человека (или от местоположения микрофона, ближайшего к оценочному текущему местоположению человека).
В некоторых реализациях один или более типов изменений аудиообработки могут включать спектральную модификацию. Например, спектральная модификация может включать снижение уровня аудиоданных в полосе частот от 500 Гц до 3 кГц. В других примерах спектральная модификация может включать снижение уровня аудиоданных в полосе частот, характеризующейся более высокой максимальной частотой и/или более низкой минимальной частотой. Согласно некоторым реализациям один или более типов изменений аудиообработки могут включать вставку по меньшей мере одного промежутка в по меньшей мере одну выбранную полосу частот сигнала аудиопроигрывания.
В некоторых реализациях определение одного или более типов изменений аудиообработки может основываться на оптимизации функции стоимости, по меньшей мере частично основанной на оценке отношения сигнал-эхо. В некоторых случаях функция стоимости может по меньшей мере частично основываться на выполнении рендеринга.
Согласно этому примеру этап 275 включает обеспечение применения одного или более типов изменений аудиообработки. В некоторых случаях этап 275 может включать применение одного или более типов изменений аудиообработки с помощью одного или более устройств, управляющих аудиообработкой в аудиосреде. В других случаях этап 275 может включать обеспечение (например, с помощью команд или управляющих сигналов из администратора аудиосеанса) применения одного или более типов изменений аудиообработки с помощью одного или более других устройств аудиосреды.
Некоторые реализации способа 250 могут включать выбор по меньшей мере одного микрофона согласно одному или более аспектам контекстной информации. В некоторых таких реализациях способ 250 может включать выбор по меньшей мере одного микрофона согласно оценочной текущей близости человека к одному или более местоположениям микрофонов. Некоторые реализации способа 250 могут включать выбор по меньшей мере одного микрофона согласно оценке пользовательской зоны. Согласно некоторым таким реализациям способ 250 может включать по меньшей мере частичную реализацию функциональной возможности виртуального помощника в соответствии с сигналами микрофонов, принятыми от выбранного микрофона (выбранных микрофонов). В некоторых таких реализациях способ 250 может включать обеспечение функциональной возможности телеконференции, которая по меньшей мере частично основана на сигналах микрофонов, принятых от выбранного микрофона (выбранных микрофонов).
Некоторые варианты осуществления предоставляют систему (содержащую два или более устройств, например, интеллектуальных аудиоустройств), которая выполнена с возможностью реализации рендеринга и отображения, а также выполнена с возможностью использования программного обеспечения или других проявлений логической схемы (например, с возможностью содержания элемента системы, реализующего логическую схему) для изменения аудиообработки (например, с целью убавления звука одного, двух или более ближайших громкоговорителей). Логическая схема может быть реализована диспетчером, таким как устройство, выполненное с возможностью реализации администратора аудиосеанса, который в некоторых примерах может действовать отдельно от элементов системы, выполненных с возможностью рендеринга.
На фиг. 3A представлена структурная схема системы, выполненной с возможностью реализации отдельной логической схемы управления рендерингом и прослушивания или захвата для ряда устройств. Количества, типы и компоновка элементов, показанных на фиг. 3A–3C, как и на других раскрытых фигурах, являются лишь примерами. Другие реализации могут содержать большее количество типов элементов, меньшее количество типов элементов и/или другие типы элементов. Например, другие реализации могут содержать более трех аудиоустройств, другие типы аудиоустройств и т. д.
Модули, представленные на фиг. 3A–3C, как и на других фигурах, представленных и описанных в настоящем изобретении, могут быть реализованы с помощью аппаратного обеспечения, программного обеспечения, программно-аппаратного обеспечения и т. д. в зависимости от конкретного примера. В некоторых реализациях один или более раскрытых модулей (которые в данном документе в некоторых случаях называются «элементами») могут быть реализованы с помощью системы управления, такой как система 210 управления, описанная выше со ссылкой на фиг. 2A. В некоторых таких примерах один или более из раскрытых модулей могут быть реализованы в соответствии с программным обеспечением, исполняемым одной или более такими системами управления.
Элементы согласно фиг. 3A включают следующие элементы:
- аудиоустройства 302, 303 и 304 (которые в некоторых примерах могут представлять собой интеллектуальные аудиоустройства). Согласно этому примеру каждое из аудиоустройств 302, 303 и 304 содержит по меньшей мере один громкоговоритель и по меньшей мере один микрофон;
- элемент 300 представляет форму содержимого, включающего аудиоданные, которые подлежат проигрыванию через одно или более аудиоустройств 302, 303 и 304. В зависимости от конкретной реализации, содержимое 300 может представлять собой линейное или интерактивное содержимое;
- модуль 301 выполнен с возможностью аудиообработки, в том числе, но без ограничения, рендеринга согласно логической схеме рендеринга. Например, в некоторых вариантах осуществления модуль 301 может быть выполнен с возможностью простого копирования аудиоданных содержимого 300 (например, монофонического или стереофонического) поровну во все три аудиоустройства 302, 303 и 304. В некоторых альтернативных реализациях одно или более аудиоустройств 302, 303 и 304 могут быть выполнены с возможностью реализации функциональной возможности аудиообработки, в том числе, но без ограничения, функциональной возможности рендеринга;
- элемент 305 представляет сигналы, распределяемые наружу на аудиоустройства 302, 303 и 304. В некоторых примерах сигналы 305 могут представлять собой или могут включать сигналы, подаваемые на динамики. Как отмечено выше, в некоторых реализациях функциональные возможности модуля 301 могут быть реализованы с помощью одного или более аудиоустройств 302, 303 и 304, и в этом случае сигналы 305 могут являться локальными для одного или более аудиоустройств 302, 303 и 304. Однако они представлены на фиг. 3A как множество сигналов, подаваемых на динамики, поскольку некоторые варианты осуществления (например, описанные ниже со ссылкой на фиг. 4) реализуют простой конечный перехват или постобработку сигналов 305;
- элемент 306 представляет необработанные сигналы микрофонов, захваченные микрофонами аудиоустройств 302, 303 и 304;
- модуль 307 выполнен с возможностью реализации логической схемы обработки сигналов микрофонов и в некоторых примерах логической схемы захвата сигналов микрофонов. Так как в этом примере каждое из аудиоустройств 302, 303 и 304 содержит один или более микрофонов, захваченные необработанные сигналы 306 обрабатываются модулем 307. В некоторых реализациях, как в данном случае, модуль 307 может быть выполнен с возможностью реализации функциональных возможностей эхокомпенсации и/или обнаружения эха;
- элемент 308 представляет локальные и/или глобальные опорные эхосигналы, подаваемые модулем 301 в модуль 307. Согласно этому примеру модуль 307 выполнен с возможностью реализации функциональных возможностей эхокомпенсации и/или обнаружения эха согласно локальным и/или глобальным опорным эхосигналам 308. В некоторых реализациях обработка захвата микрофонов и/или обработка необработанных сигналов микрофонов могут являться распределенными с локальной логической схемой эхокомпенсации и/или обнаружения эха на каждом из аудиоустройств 302, 303 и 304. Конкретная реализация захвата и обработки захвата не является существенной для концепции вычисления и понимания влияния каких-либо изменений рендеринга на общее SER и эффективность обработки захвата и логической схемы;
- модуль 309 представляет собой элемент системы, реализующий общее смешивание или комбинирование захваченных аудиоданных (например, с целью обеспечения восприятия требуемых аудиоданных как излучаемых из конкретного единичного или широкого местоположения). В некоторых реализациях модуль 307 может также обеспечивать функциональную возможность смешивания элемента 309; и
- модуль 310 представляет собой элемент системы, реализующий конечный аспект обработки обнаруженных аудиоданных с целью принятия некоторого решения о том, что было сказано, и имеют ли место в аудиосреде действия, представляющие интерес. Например, модуль 310 может обеспечивать функциональную возможность автоматического распознавания речи (ASR), уровень фонового шума и/или функциональную возможность обнаружения типа, например, для контекста, относящегося к тому, что люди делают в аудиосреде, какие общие уровни шумов присутствуют в аудиосреде, и т. д. В некоторых реализациях некоторые или все из функциональных возможностей модуля 310 могут быть реализованы вне аудиосреды, где находятся аудиоустройства 302, 303 и 304, например, в одном или более устройствах (например, одном или более серверах) поставщика услуг на облачной основе.
На фиг. 3B представлена структурная схема системы согласно другой раскрытой реализации. В этом примере система согласно фиг. 3B содержит элементы системы согласно фиг. 3A и расширяет систему согласно фиг. 3A для включения функциональных возможностей в соответствии с некоторыми раскрытыми вариантами осуществления. Система согласно фиг. 3B содержит элементы для реализации аспектов КОНТЕКСТ, РЕШЕНИЕ и ДЕЙСТВИЕ РЕНДЕРИНГА, применяемых к действующей распределенной аудиосистеме. Согласно некоторым примерам обратная связь с элементами для реализации аспектов КОНТЕКСТ, РЕШЕНИЕ и ДЕЙСТВИЕ РЕНДЕРИНГА может обеспечивать либо увеличение достоверности, если имеют место действия (например, обнаруженная речь), либо возможность достоверного уменьшения опознавания действий (низкой вероятности действий) и, таким образом, возвращения аудиообработки в ее исходное состояние.
Элементы согласно фиг. 3B включают следующие элементы:
- модуль 351 представляет собой элемент системы, который представляет (и реализует) этап КОНТЕКСТ, например, с целью получения индикатора местоположения, из которого может требоваться улучшенное обнаружение аудиоданных (например, с целью увеличения отношения речь-эхо на одном или более микрофонах), и вероятности или опознавания того, что требуется услышать (например, вероятности того, что речь, такая как пробуждающее слово или команда, может быть захвачена одним или более микрофонами). В этом примере модули 351 и 353 реализованы с помощью системы управления, которая в этом случае представляет собой систему 210 управления согласно фиг. 2A. В некоторых реализациях этапы 301 и 307 также могут быть реализованы системой управления, которая в некоторых случаях может представлять собой систему 210 управления. Согласно некоторым реализациям этапы 356, 357 и 358 также могут быть реализованы системой управления, которая в некоторых случаях может представлять собой систему 210 управления;
- элемент 352 представляет канал обратной связи с модулем 351. В этом примере обратная связь 352 обеспечивается модулем 310. В некоторых вариантах осуществления обратная связь 352 может соответствовать результатам аудиообработки (такой как аудиообработка для ASR) из захвата сигналов микрофонов, которые могут являться значимыми для определения контекста; например, опознавание слабого или раннего обнаружения пробуждающего слова или некоторого слабого обнаружения речевой активности можно использовать для запуска повышения достоверности или опознавания контекста, требующего улучшения прослушивания (например, для повышения отношения речь-эхо на одном или более микрофонах);
- модуль 353 представляет собой элемент системы, в котором (или с помощью которого) формируется решение в отношении того, для каких из аудиоустройств необходимо изменить аудиообработку, и на какую величину. В зависимости от конкретной реализации, модуль 353 может применять или не применять информацию о конкретном аудиоустройстве, такую как тип и/или функциональные возможности аудиоустройства (например, функциональные возможности громкоговорителей, функциональные возможности эхоподавления и т. д.), вероятная ориентация аудиоустройства и т. д. Как описано в некоторых примерах ниже, процесс (процессы) принятия решения в модуле 353 могут являться весьма различными для устройства в виде наушников по сравнению с интеллектуальным динамиком или другим громкоговорителем;
- элемент 354 представляет собой выходной сигнал из модуля 353, который в этом примере представляет собой множество управляющих функций, представленных на фиг. 3B в виде значений f_n, в отдельные этапы рендеринга через канал 355 управления, который также может называться сигнальным каналом 355. Множество управляющих функций может являться распределенным (например, с помощью беспроводной передачи) так, что этот сигнальный канал 355 является локальным по отношению к аудиосреде. В этом примере управляющие функции доставляются в модули 356, 357 и 358; и
- модули 356, 357 и 358 представляют собой элементы системы, выполненные с возможностью выполнения изменения в аудиообработке, потенциально включающей, но без ограничения, рендеринг выходных данных (аспект РЕНДЕРИНГ согласно некоторым вариантам осуществления). В этом примере при активации модули 356, 357 и 358 находятся под управлением управляющих функций (в данном примере – значений f_n) выходного сигнала 354. В некоторых реализациях функциональные возможности модулей 356, 357 и 358 могут быть реализованы с помощью этапа 301.
В варианте осуществления согласно фиг. 3B и других реализациях может возникать эффективный цикл обратной связи. Если выходной сигнал 352 элемента 310 (который в некоторых случаях может реализовывать автоматическое распознавание речи или ASR) обнаруживает речь, даже слабую (например, с низкой достоверностью), согласно некоторым примерам, элемент 351 КОНТЕКСТ может оценивать местоположение, на основе которого микрофон (микрофоны) захватил (захватили) звук в аудиосреде (например, какой микрофон (микрофоны) содержит (содержат) больше всего энергии, отличной от эха). Согласно некоторым таким примерам этап 353 РЕШЕНИЕ может выбирать один, два, три или более громкоговорителей аудиосреды и может активировать небольшое значение, относящееся к изменению в рендеринге (например, f_n = 0,25). В случае общего приглушения на 20 дБ, это значение затем будет предписывать уменьшение громкости на выбранном устройстве (выбранных устройствах) на приблизительно 5 дБ, что будет едва заметно для среднего слушателя. Снижение (снижения) уровня может (могут) быть менее заметно (заметны), когда оно скомбинировано (они скомбинированы) с постоянными времени и/или обнаружением событий, и когда другие громкоговорители аудиосреды воспроизводят аналогичное содержимое. В одном примере убавлению звука может быть подвергнуто аудиоустройство 303 (аудиоустройство, ближайшее к говорящему человеку 311). В других примерах убавлению звука могут быть подвергнуты оба аудиоустройства 302 и 303, в некоторых случаях на разную величину (например, в зависимости от оценочной близости к человеку 311). В других примерах убавлению звука, в некоторых случаях на разную величину, могут быть подвергнуты все аудиоустройства 302, 303 и 304. В результате снижения уровня проигрывания одним или более громкоговорителями одного или более аудиоустройств 302, 303 и 304 можно увеличить отношение речь-эхо на одном или более микрофонах вблизи человека 311 (например, одном или более микрофонах аудиоустройства 303). Соответственно, система теперь может лучше «слышать» человека 311, если человек 311 продолжает говорить (например, повторять пробуждающее слово или произносить команду). В некоторых таких реализациях в течение следующего промежутка времени (например, в течение следующих нескольких секунд) и в некоторых случаях непрерывным образом система (например, администратор аудиосеанса, по меньшей мере частично реализованный с помощью этапов 351 и 353) может стремиться быстро отключить громкость звука одного или более громкоговорителей вблизи человека 311, например, путем выбора f_2 = 1.
На фиг. 3C представлена структурная схема варианта осуществления, выполненного с возможностью реализации сети балансировки энергии согласно одному примеру. На фиг. 3C представлена структурная схема системы, которая содержит элементы системы согласно фиг. 3B и расширяет систему согласно фиг. 3B для включения элементов (например, элемента 371) для реализации компенсации энергии (например, для «небольшого прибавления звука на других устройствах»).
В некоторых примерах устройство, выполненное с возможностью управления аудиосеансом (администратор аудиосеанса) системы согласно фиг. 3C (или такой же системы, как система согласно фиг. 3C), может оценивать полосовую энергию в положении слушателя (311), которая теряется в результате аудиообработки (например, снижения уровня одного или более выбранных громкоговорителей (например, громкоговорителей аудиоустройств, принимающих управляющие сигналы, где f_n > 0)), применяемой с целью увеличения отношения речь-эхо на одном или более микрофонах. Тогда администратор аудиосеанса может применять повышение уровня и/или какую-либо иную форму балансировки энергии к другим динамикам аудиосреды с целью компенсации изменений аудиообработки на основе SER.
Весьма часто в ходе рендеринга содержимого, которое каким-либо образом связано, и когда составляющие аудиоданных, которые являются скоррелированными или спектрально подобными, воспроизводятся рядом громкоговорителей аудиосреды (простым примером является монофонический сигнал), значительная балансировка энергии может не являться обязательной. Например, если в аудиосреде имеется 3 громкоговорителя с расстояниями в отношении от 1 до 2, при этом 1 является ближайшим, то убавление звука ближайшего громкоговорителя на 6 дБ, если громкоговорители воспроизводят идентичное содержимое, будет характеризоваться воздействием лишь на 2–3 дБ. А отключение звука ближайшего громкоговорителя может характеризоваться общим воздействием лишь на 3–4 дБ в звуке для слушателя.
В более сложных ситуациях (например, вставки промежутков или пространственного управления) в некоторых примерах форма сохранения энергии и непрерывности восприятия может представлять собой баланс энергии с большим количеством факторов.
На фиг. 3C элемент (элементы) для реализации аспекта КОНТЕКСТ в некоторых примерах может (могут) представлять собой всего лишь уровень аудиоданных (взаимность близости) при слабом обнаружении пробуждающего слова. Иначе говоря, один пример определения аспекта КОНТЕКСТ может основываться на уровне обнаружения какого бы то ни было фрагмента речи, содержащего пробуждающее слово, посредством обнаруженного эха. Такие способы могут включать или не включать фактическое определение отношения речь-эхо в зависимости от конкретной реализации. Однако в некоторых примерах достаточный уровень аспекта КОНТЕКСТ могут обеспечивать простые обнаружение и оценка уровня фрагмента речи, содержащего пробуждающее слово, который обнаруживается в каждом из ряда местоположений микрофонов.
Примеры способов, реализуемых элементами системы для реализации аспекта КОНТЕКСТ (например, в системе согласно фиг. 3C), могут включать, но без ограничения, следующие примеры:
- при обнаружении части пробуждающего слова близость оснащенных микрофонами аудиоустройств можно вывести из достоверности пробуждающего слова. Расчет времени фрагмента речи, содержащего пробуждающее слово, можно также вывести из достоверности пробуждающего слова; и
- некоторую аудиоактивность можно обнаружить в дополнение и сверх эхокомпенсации и эхоподавления, которые применяются к необработанным сигналам микрофонов. В некоторых реализациях может использоваться множество уровней и классификаций энергии для определения того, с какой вероятностью аудиоактивность является голосовой активностью (Обнаружение голосовой активности). Этот процесс может определять достоверность или вероятность голосовой активности. Местоположение голоса может быть основано на вероятности лучшего микрофона для аналогичных ситуаций взаимодействия. Например, устройство, реализующее администратор аудиосеанса, может обладать априорным знанием о том, что ближайшим к пользователю является одно оснащенное микрофонами аудиоустройство, такое как настольное устройство, находящееся в обычном местоположении пользователя или вблизи от него, а не устройство, установленное на стене, которое не находится вблизи обычного местоположения пользователя.
Иллюстративный вариант осуществления элемента системы для реализации аспекта РЕШЕНИЕ (например, в системе согласно фиг. 3C) представляет собой элемент, выполненный с возможностью определения значения достоверности в отношении голосовой активности и с возможностью определения того, какое устройство является ближайшим оснащенным микрофоном аудиоустройством.
В системе согласно фиг. 3C (и другим вариантам осуществления) величина изменения (изменений) аудиообработки, применяемая для увеличения SER в местоположении, может зависеть от расстояния и достоверности в отношении голосовой активности.
Примеры способов реализации аспекта РЕНДЕРИНГ (например, в системе по фиг. 3C) включают:
только убавление звука в дБ; и/или
выравнивание (EQ) речевых полос (например, как описано ниже со ссылкой на фиг. 4); и/или
временную модуляцию изменения в рендеринге (как описано со ссылкой на фиг. 5); и/или
использование временного квантования времени или регулировок для создания (например, вставки в аудиосодержимое) «промежутков» или периодов разреженного по времени и частоте менее интенсивного выходного сигнала, достаточного для получения беглых набросков представляющих интерес аудиоданных. Некоторые примеры описаны ниже со ссылкой на фиг. 9.
На фиг. 4 представлен график, на котором изображены примеры аудиообработки, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды. На графике согласно фиг. 4 представлены примеры спектральной модификации. На фиг. 4 спектральная модификация включает снижение уровня частот, которые, как известно, соответствуют речи, и которые в этих примерах представляют собой частоты в диапазоне от приблизительно 200 Гц до 10 кГц (например, в пределах 5 % или 10 % верхней и/или нижней частоты диапазона). Другие примеры могут включать снижение уровня частот в другой полосе частот, например, от приблизительно 500 Гц до 3 кГц (например, в пределах 5 % или 10 % верхней и/или нижней частоты диапазона). В некоторых реализациях частоты за пределами этого диапазона могут воспроизводиться на более высоком уровне, для того чтобы по меньшей мере частично скомпенсировать снижение громкости, вызванное спектральной модификацией.
Элементы согласно фиг. 4 включают:
601: кривую, представляющую плавное EQ;
602: кривую, представляющую частичное ослабление указанного диапазона частот. Такое частичное ослабление может характеризоваться относительно низкой заметностью, но, тем не менее, оказывать значительное воздействие на обнаружение речи; и
603: кривую, представляющую значительно большее ослабление указанного диапазона частот. Спектральная модификация, подобная представленной с помощью кривой 603, может оказывать значительное воздействие на слышимость речи. В некоторых случаях агрессивная спектральная модификация, подобная той, которая представлена с помощью кривой 603, может обеспечивать альтернативу значительному снижению уровня всех частот.
В некоторых примерах администратор аудиосеанса может вызывать изменения аудиообработки, которые соответствуют переменной во времени спектральной модификации, такой как последовательность, представленная с помощью кривых 601, 602 и 603.
Согласно некоторым примерам одну или более спектральных модификаций можно использовать в контексте других изменений аудиообработки, таких как контекст изменений рендеринга для обеспечения «деформации» воспроизводимых аудиоданных в сторону от местоположения, такого как служебное помещение, спальня, спящий ребенок и т. д. Спектральная модификация (спектральные модификации), используемая (используемые) в связи с такой деформацией, может (могут), например, снижать уровни в низкочастотном диапазоне, например, в диапазоне 20–250 Гц.
На фиг. 5 представлен график, на котором изображена аудиообработка другого типа, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды. В этом примере вертикальная ось представляет значения «f» в диапазоне от 0 до 1, и горизонтальная ось представляет время в секундах. На фиг. 5 представлена схема траектории (указанной кривой 701) относительно времени активации выполнения рендеринга. В некоторых примерах тип аудиообработки, представленный на фиг. 5, может реализовываться с помощью одного или более из модулей 356, 357 или 358. Согласно этому примеру асимметрия постоянной времени (указанной кривой 701) указывает, что система модулируется по управляемому значению (f_n) в течение короткого времени (например, от 100 мс до 1 секунды), но релаксирует от значения f_n (также определенного как значение 703) обратно до нуля намного медленнее (например, 10 секунд или более). В некоторых примерах промежуток времени между 2 секундами и N секундами может составлять несколько секунд, например, в диапазоне от 4 до 10 секунд.
Также на фиг. 5 показана вторая кривая 702 активации, имеющая ступенчатую форму с максимальным значением, в этом примере равным f_n. Согласно этой реализации поднимающиеся ступени соответствуют резким изменениям в уровне самого содержимого, например, появлению голоса или скорости слога.
Как отмечено выше, в некоторых реализациях временное квантование времени или регулировки частоты могут создавать (например, за счет вставки промежутков в аудиосодержимое) «промежутки» или периоды разреженного по времени и частоте выходного сигнала, достаточного для получения беглых набросков представляющих интерес аудиоданных (например, увеличения или уменьшения степени «промежуточности» аудиосодержимого и его восприятия).
На фиг. 6 изображена аудиообработка другого типа, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды. Фиг. 6 представляет пример спектрограммы модифицированного сигнала аудиопроигрывания, в который согласно одному примеру были вставлены принудительные промежутки. Конкретнее, для генерирования спектрограммы по фиг. 6, принудительные промежутки G1, G2 и G3 были вставлены в полосы частот сигнала проигрывания, за счет чего был сгенерирован модифицированный сигнал аудиопроигрывания. На спектрограмме, показанной на фиг. 6, положение по горизонтальной оси указывает время, и положение по вертикальной оси указывает частоту содержимого модифицированного сигнала аудиопроигрывания в момент времени.
Плотность точек в каждом небольшом участке (каждый такой участок центрирован на точке, характеризующейся вертикальной и горизонтальной координатами) указывает энергию содержимого модифицированного сигнала аудиопроигрывания при соответствующей частоте и в момент времени (более плотные участки указывают содержимое, имеющее большую энергию, а менее плотные участки указывают содержимое, имеющее меньшую энергию). Таким образом, промежуток G1 возникает в более раннее время (т. е. в более раннем временном интервале), чем время, в которое (или временной интервал, в который) возникает промежуток G2 или G3, и промежуток G1 был вставлен в полосу более высоких частот, чем полоса частот, в которую был вставлен промежуток G2 или G3.
Введение принудительного промежутка в сигнал проигрывания является отличным от симплексной эксплуатации устройства, при которой устройство устанавливает на паузу проигрываемый поток содержимого (например, для того чтобы лучше слышать пользователя и среду пользователя). Введение принудительных промежутков в сигнал проигрывания согласно некоторым раскрытым вариантам осуществления можно оптимизировать для значительного уменьшения (или исключения) воспринимаемых артефактов, возникающих в результате введения промежутков во время проигрывания, предпочтительно так, что принудительные промежутки не оказывают или оказывают минимальное воспринимаемое воздействие на пользователя, но так, что выходной сигнал микрофона в среде проигрывания указывает на принудительные промежутки (например, для того чтобы промежутки можно было использовать для реализации способа тотального прослушивания). За счет использования принудительных промежутков, которые были введены в соответствии с некоторыми раскрытыми вариантами осуществления, система тотального прослушивания может осуществлять текущий контроль звука, не относящегося к проигрыванию (например, звука, указывающего фоновую активность, и/или шума в среде проигрывания), даже без использования акустического эхокомпенсатора.
Согласно некоторым примерам промежутки можно вставлять в спектрально-временной выходной сигнал из одного канала, что может создавать разреженное ощущение улучшенной способности к прислушиванию, для того чтобы «слышать через промежутки».
На фиг. 7 представлен график, на котором изображена аудиообработка другого типа, которая может увеличивать отношение речь-эхо на одном или более микрофонах аудиосреды. В этом варианте осуществления изменения аудиообработки включают сжатие динамического диапазона.
Этот пример включает переход между двумя крайними значениями ограничения динамического диапазона. В одном случае, представленном кривой 801, администратор аудиосеанса не обеспечивает применение управления динамическим диапазоном, тогда как в другом случае, представленном кривой 802, администратор аудиосеанса обеспечивает применение относительно агрессивного ограничителя. Ограничитель, соответствующий кривой 802, может уменьшать пики выходных аудиоданных на 10 дБ или более. Согласно некоторым примерам коэффициент сжатия может составлять не более 3:1. В некоторых реализациях кривая 802 (или другая кривая сжатия динамического диапазона) может содержать перегиб при -20 дБ или приблизительно -20 дБ (например, в пределах +/-1 дБ, в пределах +/-2 дБ, в пределах +/-3 дБ и т. д.) относительно пикового значения выходного сигнала устройства.
Далее будет описан другой пример варианта осуществления элементов системы для реализации аспекта РЕНДЕРИНГ (изменений аудиообработки, результатом которых является увеличение отношения речь-эхо на одном или более микрофонах, например, в системе согласно фиг. 3B или фиг. 3C). В этом варианте осуществления выполняется балансировка энергии. Как отмечено выше, в одном простом примере администратор аудиосеанса может оценивать полосовую энергию аудиоданных в местоположении или зоне слушателя, которая теряется в результате других изменений аудиообработки для увеличения SER на одном или более микрофонах аудиосреды. Затем администратор аудиосеанса может добавлять в другие динамики повышение, которое компенсирует эту потерянную энергию в местоположении или зоне слушателя.
Весьма часто в ходе рендеринга содержимого, которое каким-либо образом связано, и когда имеются составляющие, которые являются скоррелированными или спектрально подобными в ряде устройств (простым примером является монофонический сигнал), это может вовсе не являться обязательным. Например, если имеется 3 громкоговорителя с расстояниями в отношении от 1 до 2, при этом 1 является ближайшим, то убавление звука ближайшего громкоговорителя на 6 дБ (если громкоговорителями воспроизводится идентичное содержимое), будет характеризоваться воздействием лишь на 2–3 дБ. А отключение звука ближайшего громкоговорителя, вероятно, будет характеризоваться общим воздействием лишь на 3–4 дБ в звуке в местоположении слушателя.
Ниже описаны аспекты дополнительных вариантов осуществления.
1. ФАКТОРЫ ВТОРОГО ПОРЯДКА В ОПРЕДЕЛЕНИИ «БЛИЖАЙШЕГО»
Как будет проиллюстрировано двумя следующими примерами, критерий «близости» или «ближайшего» не обязательно может являться простым критерием расстояния, но вместо этого может представлять собой скалярное ранжирование, которое включает оценочное отношение речь-эхо. Если аудиоустройства аудиосреды не являются одинаковыми, каждое оснащенное громкоговорителем аудиоустройство может характеризоваться разной связью его громкоговорителя (громкоговорителей) с его собственным микрофоном (собственными микрофонами), что оказывает сильное влияние на уровень эха в отношении. Кроме того, аудиоустройства могут иметь разные компоновки микрофонов, которые являются относительно более или относительно менее подходящими для прослушивания, например, с целью обнаружения звука с конкретного направления, а также с целью обнаружения звука в или из конкретного местоположения аудиосреды. Соответственно, в некоторых реализациях вычисление (РЕШЕНИЕ) может учитывать больше, чем близость и взаимность слышимости.
На фиг. 8 представлена схема примера, в котором аудиоустройство, звук которого подлежит убавлению, может не являться аудиоустройством, ближайшим к говорящему человеку. В этом примере аудиоустройство 802 находится относительно ближе к говорящему человеку 100, чем аудиоустройство 805. Согласно некоторым примерам в ситуациях, подобных показанной на фиг. 8, администратор аудиосеанса может учитывать разные исходные уровни SER и характеристики аудиоустройств и убавлять звук устройства (устройств) с наилучшим отношением затраты-выгода при воздействии уменьшения в выходном сигнале на представление аудиоданных в сравнении с выгодой убавления звука выходного сигнала для лучшего захвата речи человека 101.
На фиг. 8 показан пример, в котором в более функциональном критерии «ближайшего» может иметь место сложность и полезность. В этом случае имеется человек 101, издающий звук (речь 102), с возможностью захвата которого выполнен администратор аудиосеанса, и два аудиоустройства 802 и 805, оба с громкоговорителями (806 и 804) и микрофонами (803 и 807). При условии что микрофон 803 находится так близко к громкоговорителю 804 на аудиоустройстве 802, которое находится ближе к человеку 101, может не быть величины убавления звука громкоговорителя этого устройства, которая могла бы привести к конкурентоспособному SER. В этом примере микрофоны 807 на аудиоустройстве 805 выполнены с возможностью образования диаграммы направленности (в среднем приводящей к более благоприятному SER), и поэтому убавление звука громкоговорителей аудиоустройства 805 оказало бы меньшее воздействие, чем убавление звука громкоговорителей аудиоустройства 802. В некоторых таких примерах оптимальным РЕШЕНИЕМ было бы убавление звука громкоговорителей 806.
Другой пример будет описан со ссылкой на фиг. 9. В этом случае, вероятно, наиболее значимой разностью в исходном уровне SER считается то, что она могла бы возникать на двух устройствах: одно – пара наушников, и второе – интеллектуальный динамик.
На фиг. 9 изображена ситуация, в которой устройство с очень высоким SER находится очень близко к пользователю. На фиг. 9 пользователь 101 носит наушники 902 и разговаривает (издавая звук 102 способом, который захватывается как микрофоном 903 на наушниках 902, так и микрофонами устройства 904 в виде интеллектуального динамика). В этом случае устройство 904 в виде интеллектуального динамика может также являться издающим некоторый звук для согласования с наушниками (например, ближний/дальний рендеринг для звука с эффектом присутствия). Ясно, что наушники 902 являются ближайшим устройством вывода для пользователя 101, однако почти отсутствует путь эха от наушников к ближайшему микрофону 903, так как SER для этого устройства будет очень высоким, а воздействие при убавлении звука – очень большим, так как наушники представляют слушателю почти весь результат рендеринга. В этом случае убавление звука интеллектуального динамика 904 было бы более преимущественным, хотя лишь косвенным и противостоящим изменению общего рендеринга (другие слушатели поблизости, слышащие звук), может не быть принято фактическое решение о действии – убавлении звука динамика или ином изменении параметров аудиообработки, которые могли бы увеличить SER приема пользователя способом, который изменил бы к лучшему аудиоданные, доставляемые в аудиосреду, – в некотором смысле оно уже является вполне функциональным вследствие собственного SER устройства в наушниках.
Что касается устройств с рядом динамиков и распределенными микрофонами за пределами некоторого размера, в некоторых обстоятельствах можно рассмотреть одно аудиоустройство с множеством динамиков и множеством микрофонов как группу отдельных устройств, которые лишь случайно являются жестко связанными. В этом случае решение об убавлении звука может применяться к отдельным динамикам. Соответственно, в некоторых реализациях администратор аудиосеанса может считать этот тип аудиоустройства набором отдельных микрофонов и громкоговорителей, тогда как в других примерах администратор аудиосеанса может считать этот тип аудиоустройства одним устройством с составными массивами динамиков и микрофонов. Также видно, что существует двойственность между обработкой динамиков на одном устройстве как отдельных устройств и идеей о том, что в одном аудиоустройстве с множеством громкоговорителей одним из подходов для рендеринга является пространственное управление, что обязательно сообщает характерное изменение выходным сигналам громкоговорителей на одном аудиоустройстве.
Что касается вторичных эффектов ближайшего аудиоустройства (аудиоустройств), исключающих чувствительность пространственной визуализации от аудиоустройств, которые находятся близко к движущемуся слушателю, во многих случаях, даже когда громкоговоритель находится вблизи движущегося слушателя, может не иметь смысла воспроизведение конкретных аудиообъектов или подвергаемого рендерингу материала из ближайшего громкоговорителя (ближайших громкоговорителей). Это просто связано с тем, что громкость прямолинейного пути звука изменяется прямо пропорционально 1/r2, где r – расстояние, на которое распространяется звук, и когда громкоговоритель становится ближе к какому-либо слушателю (r -> 0), устойчивость уровня звуков, воспроизводимых этим громкоговорителем, относительно всего смешанного сигнала становится неудовлетворительной.
В некоторых таких случаях может являться преимущественной реализация варианта осуществления, в котором (например):
- КОНТЕКСТ представляет собой некоторую общую область прослушивания (например, диван вблизи телевизора), в которой предполагается всегда полезным иметь возможность слышать аудиоданные для программы, которую кто-либо смотрит по телевизору;
- РЕШЕНИЕ: для устройства с динамиком на кофейном столике в общей области прослушивания (например, вблизи дивана) устанавливаем f_n = 1; и
- РЕНДЕРИНГ: устройство отключается, и энергия подвергается рендерингу в другом месте.
Воздействием этого изменения аудиообработки является лучшая слышимость для людей на диване. Если кофейный столик находится с одной из сторон дивана, этот способ позволил бы избежать чувствительности близости слушателя к этому аудиоустройству. В то время как в некоторых случаях аудиоустройство может иметь идеальное местоположение, например, для окружающего канала, тот факт, что может иметь место разность уровней в 20 дБ или более через диван до этого динамика, означает, что если точно неизвестно, где находится слушатель/говорящий, то верным решением может являться убавление звука этого ближайшего устройства или его выключение.
На фиг. 10 представлена блок-схема, на которой описан один пример способа, который может выполняться таким оборудованием, как показанное на фиг. 2A. Этапы способа 1000, как и других способов, описанных в данном документе, не обязательно выполняются в указанном порядке. Более того, такие способы могут включать больше или меньше этапов, чем представлено и/или описано. В этой реализации способ 1000 включает оценку местоположения пользователя в среде.
В этом примере этап 1005 включает прием выходных сигналов от каждого микрофона из множества микрофонов в среде. В этом примере каждый из множества микрофонов находится в местоположении микрофона среды. Согласно этому примеру выходные сигналы соответствуют текущему фрагменту речи пользователя. В некоторых примерах текущий фрагмент речи может представлять собой или может содержать фрагмент речи, содержащий пробуждающее слово. Этап 1005 может, например, включать прием системой управления (такой как система 120 управления согласно фиг. 2A) выходных сигналов от каждого микрофона из множества микрофонов в среде через систему интерфейсов (такую как система 205 интерфейсов согласно фиг. 2A).
В некоторых примерах по меньшей мере некоторые из микрофонов в среде могут предоставлять выходные сигналы, являющиеся асинхронными в отношении выходных сигналов, предоставляемых одним или более другими микрофонами. Например, первый микрофон из множества микрофонов может осуществлять выборку аудиоданных согласно первому тактовому сигналу выборки, и второй микрофон из множества микрофонов может осуществлять выборку аудиоданных согласно второму тактовому сигналу выборки. В некоторых случаях по меньшей мере один из микрофонов в среде может быть включен в интеллектуальное аудиоустройство или выполнен с возможностью осуществления связи с ним.
Согласно данному примеру этап 1010 включает определение ряда текущих акустических признаков из выходных сигналов каждого микрофона. В этом примере «текущие акустические признаки» представляют собой акустические признаки, полученные из «текущего фрагмента речи» этапа 1005. В некоторых реализациях этап 1010 может включать прием ряда текущих акустических признаков из одного или более других устройств. Например, этап 1010 может включать прием по меньшей мере некоторых из ряда текущих акустических признаков из одного или более детекторов пробуждающего слова, реализованных с помощью одного или более других устройств. Альтернативно или дополнительно в некоторых реализациях этап 1010 может включать определение ряда текущих акустических признаков из выходных сигналов.
Независимо от того, определены акустические признаки одним устройством или рядом устройств, акустические признаки могут определяться асинхронно. Если акустические признаки определяются рядом устройств, акустические признаки могут определяться в целом асинхронно, если устройства не были выполнены с возможностью координации процесса определения акустических признаков. Если акустические признаки определяются одним устройством, то в некоторых реализациях акустические признаки, тем не менее, могут определяться асинхронно, так как одно устройство может принимать выходные сигналы каждого микрофона в разные моменты времени. В некоторых примерах акустические признаки могут определяться асинхронно, поскольку по меньшей мере некоторые из микрофонов в среде могут предоставлять выходные сигналы, являющиеся асинхронными в отношении выходных сигналов, предоставляемых одним или более другими микрофонами.
В некоторых примерах акустические признаки могут включать метрику достоверности пробуждающего слова, метрику длительности пробуждающего слова и/или по меньшей мере одну метрику принятого уровня. Метрика принятого уровня может указывать принятый уровень звука, обнаруженного микрофоном, и может соответствовать уровню выходного сигнала микрофона.
Альтернативно или дополнительно акустические признаки могут содержать одно или более из следующего:
• среднюю энтропию состояния (чистоту) для каждого состояния пробуждающего слова наряду с одним лучшим (по Витерби) совпадением с акустической моделью;
• CTC-loss (потерю временной классификации коннекционистов) по акустическим моделям детекторов пробуждающего слова;
• детектор пробуждающего слова может быть обучен для предоставления оценки расстояния говорящего от микрофона и/или оценки RT60 в дополнение к достоверности пробуждающего слова. Акустическими признаками могут являться оценка расстояния и/или оценка RT60;
• вместо или в дополнение к широкополосному принятому уровню/мощности на микрофоне, акустическим признаком может являться принятый уровень в ряде расположенных на расстоянии полос частот в логарифмической шкале, шкале «мел» или шкале «барк». Полосы частот могут варьироваться в соответствии с конкретной реализацией (например, 2 полосы частот, 5 полос частот, 20 полос частот, 50 полос частот, 1 октавная полоса частот или 1/3 октавной полосы частот);
• кепстральное представление спектральной информации в предыдущем пункте, вычисленное путем взятия DCT (дискретного косинусного преобразования) логарифма мощностей в полосах;
• мощности в полосах частот, взвешенные для человеческой речи. Например, акустические признаки могут основываться только на конкретной полосе частот (например, 400 Гц – 1,5 кГц). Высшими и низшими частотами в этом примере можно пренебречь;
• достоверность детектора голосовой активности в расчете на полосу или на элемент разрешения;
• акустические признаки могут по меньшей мере частично основываться на долгосрочной оценке шума, для того чтобы пренебречь микрофонами, которые характеризуются неудовлетворительным отношением сигнал-шум;
• эксцесс в качестве критерия «пиковости» речи. Эксцесс может служить индикатором размывания длинным хвостом реверберации;
• оценочные значения времени начала пробуждающего слова. Ожидается, что начало и длительность будут равны в пределах кадра или по всем микрофонам. Выброс может давать ключ к ненадежной оценке. Это предполагает некоторый уровень синхронии – не обязательно для отсчета – но, например, для кадра в несколько десятков миллисекунд.
Согласно этому примеру этап 1015 включает применение классификатора к ряду текущих акустических признаков. В некоторых таких примерах применение классификатора может включать применение модели, обученной на ранее определенных акустических признаках, которые были получены из множества предыдущих фрагментов речи, произнесенных пользователем во множестве пользовательских зон в среде. В данном документе представлены различные примеры.
В некоторых примерах пользовательские зоны могут включать область раковины, область приготовления пищи, область холодильника, область столовой, область дивана, область телевизора, область спальни и/или область дверного проема. Согласно некоторым примерам одна или более из пользовательских зон могут являться предварительно определенными пользовательскими зонами. В некоторых таких примерах одна или более предварительно определенных пользовательских зон могут быть выбраны пользователем в ходе процесса обучения.
В некоторых реализациях применение классификатора может включать применение гауссовой модели смешения, обученной на предыдущих фрагментах речи. Согласно некоторым таким реализациям применение классификатора может включать применение гауссовой модели смешения, обученной на одном или более из нормализованной достоверности пробуждающего слова, нормализованного среднего принятого уровня или максимального принятого уровня предыдущих фрагментов речи. Однако в альтернативных реализациях применение классификатора может основываться на другой модели, такой как одна из других моделей, раскрытых в данном документе. В некоторых случаях модель может быть обучена с применением обучающих данных, помеченных с помощью пользовательских зон. Однако в некоторых примерах применение классификатора включает применение модели, обученной с применением непомеченных обучающих данных, которые не являются помеченными с помощью пользовательских зон.
В некоторых примерах предыдущие фрагменты речи могут представлять собой или могут содержать фрагменты речи, содержащие пробуждающее слово. Согласно некоторым таким примерам предыдущие фрагменты речи и текущий фрагмент речи могли представлять собой фрагменты речи, содержащие одно и то же пробуждающее слово.
В этом примере этап 1020 включает определение, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой пользователь расположен в настоящий момент. В некоторых таких примерах оценка может быть определена без отсылки к геометрическим местоположениям множества микрофонов. Например, оценка может быть определена без отсылки к координатам отдельных микрофонов. В некоторых примерах оценка может быть определена без оценки геометрического местоположения пользователя.
Некоторые реализации способа 1000 могут включать выбор по меньшей мере одного динамика согласно оценочной пользовательской зоне. Некоторые такие реализации могут включать управление по меньшей мере одним выбранным динамиком с целью доставки звука в оценочную пользовательскую зону. Альтернативно или дополнительно некоторые реализации способа 1000 могут включать выбор по меньшей мере одного микрофона согласно оценочной пользовательской зоне. Некоторые такие реализации могут включать доставку сигналов, выводимых по меньшей мере одним выбранным микрофоном, в интеллектуальное аудиоустройство.
На фиг. 11 представлена структурная схема элементов одного примера варианта осуществления, выполненного с возможностью реализации классификатора зон. Согласно этому примеру система 1100 содержит множество громкоговорителей 1104, распределенных в по меньшей мере части среды (например, такой среды, как изображенная на фиг. 1A или фиг. 1B). В этом примере система 1100 содержит средство 1101 многоканального рендеринга громкоговорителей. Согласно этой реализации выходные данные средства 1101 многоканального рендеринга громкоговорителей служат как в качестве ведущих сигналов громкоговорителей (сигналов, подаваемых на динамики, для приведения в действие динамиков 1104), так и в качестве опорных эхосигналов. В этой реализации опорные эхосигналы доставляются в подсистемы 1103 управления эхом через множество опорных каналов 1102 громкоговорителей, которые содержат по меньшей мере некоторые из сигналов, подаваемых на динамики, выведенных из средства 1101 рендеринга.
В этой реализации система 1100 содержит множество подсистем 1103 управления эхом. Согласно этому примеру подсистемы 1103 управления эхом выполнены с возможностью реализации одного или более процессов эхоподавления и/или одного или более процессов эхокомпенсации. В этом примере каждая из подсистем 1103 управления эхом доставляет соответствующий выходной сигнал 1103A управления эхом в один из детекторов 1106 пробуждающего слова. Выходной сигнал 1103A управления эхом содержит эхо, ослабленное относительно ввода в соответствующую одну из подсистем 1103 управления эхом.
Согласно этой реализации система 1100 содержит N микрофонов 1105 (где N – целое число), распределенных в по меньшей мере части среды (например, среды, изображенной на фиг. 1A или фиг. 1B). Микрофоны могут содержать микрофоны массива и/или точечные микрофоны. Например, одно или более интеллектуальных аудиоустройств, расположенных в среде, могут содержать массив микрофонов. В этом примере выходные сигналы микрофонов 1105 доставляются в качестве входных сигналов в подсистемы 1103 управления эхом. Согласно этой реализации каждая из подсистем 1103 управления эхом захватывает выходной сигнал отдельного микрофона 1105 или отдельной группы или подмножества микрофонов 1105.
В этом примере система 1100 содержит множество детекторов 1106 пробуждающего слова. Согласно этому примеру каждый их детекторов 1106 пробуждающего слова принимает выходной аудиосигнал из одной из подсистем 1103 управления эхом и выводит множество акустических признаков 1106A. Акустические признаки 1106A, выводимые из каждой подсистемы 1103 управления эхом, могут содержать (но без ограничения): достоверность пробуждающего слова, длительность пробуждающего слова и критерии принятого уровня. Несмотря на то что три стрелки, изображающие три акустических признака 1106A, показаны как выводимые из каждой подсистемы 1103 управления эхом, в альтернативных реализациях может выводиться больше или меньше акустических признаков 1106A. Кроме того, хотя эти три стрелки падают на классификатор 1107 по более или менее вертикальной линии, это не указывает, что классификатор 1107 обязательно принимает акустические признаки 1106A из всех детекторов 1106 пробуждающего слова одновременно. Как отмечено в другом месте данного документа, акустические признаки 1106A в некоторых случаях могут определяться и/или доставляться в классификатор асинхронно.
Согласно этой реализации система 1100 содержит классификатор 1107 зон, который также можно назвать классификатором 1107. В этом примере классификатор принимает множество признаков 1106A из множества детекторов 1106 пробуждающего слова для множества (например, всех) микрофонов 1105 в среде. Согласно этому примеру выходные данные 1108 классификатора 1107 зон соответствуют оценке пользовательской зоны, в которой пользователь расположен в настоящий момент. Согласно некоторым таким примерам выходной сигнал 1108 может соответствовать одной или более апостериорным вероятностям. Оценка пользовательской зоны, в которой пользователь расположен в настоящий момент, может представлять собой или соответствовать максимальной апостериорной вероятности согласно байесовой статистике.
Ниже описаны иллюстративные реализации классификатора, который в некоторых примерах может соответствовать классификатору 1107 зон согласно фиг. 11. Пусть  – сигнал i-го микрофона,
– сигнал i-го микрофона,  , в дискретное время
, в дискретное время 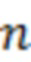 (т. е. сигналы микрофонов, xi(n), являются выходными сигналами N микрофонов 1105). Обработка
(т. е. сигналы микрофонов, xi(n), являются выходными сигналами N микрофонов 1105). Обработка 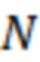 сигналов xi(n) в подсистемах 1103 управления эхом генерирует «чистые» сигналы микрофонов, ei(n), где
сигналов xi(n) в подсистемах 1103 управления эхом генерирует «чистые» сигналы микрофонов, ei(n), где 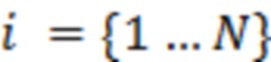 , каждый – в дискретное время . В этом примере чистые сигналы ei(n), называемые 1103A на фиг. 11, подаются в детекторы 1106 пробуждающего слова. В данном случае каждый детектор 1106 пробуждающего слова генерирует вектор признаков
, каждый – в дискретное время . В этом примере чистые сигналы ei(n), называемые 1103A на фиг. 11, подаются в детекторы 1106 пробуждающего слова. В данном случае каждый детектор 1106 пробуждающего слова генерирует вектор признаков 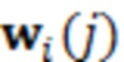 , называемых 1106A на фиг. 11, где
, называемых 1106A на фиг. 11, где 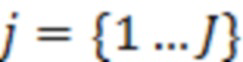 – индекс, соответствующий j-му фрагменту речи, содержащему пробуждающее слово. В этом примере классификатор 1107 принимает в качестве входных данных множество агрегированных признаков, .
– индекс, соответствующий j-му фрагменту речи, содержащему пробуждающее слово. В этом примере классификатор 1107 принимает в качестве входных данных множество агрегированных признаков, .
Согласно некоторым реализациям множество меток зон, , для может соответствовать количеству K разных пользовательских зон в среде. Например, пользовательские зоны могут содержать зону дивана, зону кухни, зону кресла для чтения и т. д. В некоторых примерах в кухне или другом помещении может быть задано более одной зоны. Например, область кухни может включать зону раковины, зону приготовления пищи, зону холодильника и зону столовой. Аналогично область гостиной может содержать зону дивана, зону телевизора, зону кресла для чтения, одну или более зон дверных проемов и т. д. Метки зон для этих зон могут выбираться пользователем, например, в ходе этапа обучения.
В некоторых реализациях классификатор 1107 оценивает апостериорные вероятности множества признаков, 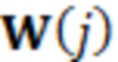 , например, с использованием байесового классификатора. Вероятности указывают вероятность (для j-го фрагмента речи и k-й зоны для каждой из зон Ck и каждого из фрагментов речи) того, что пользователь находится в каждой из зон Ck, и являются примером выходных данных 1108 классификатора 1107.
, например, с использованием байесового классификатора. Вероятности указывают вероятность (для j-го фрагмента речи и k-й зоны для каждой из зон Ck и каждого из фрагментов речи) того, что пользователь находится в каждой из зон Ck, и являются примером выходных данных 1108 классификатора 1107.
Согласно некоторым примерам обучающие данные можно собрать (например, для каждой пользовательской зоны) путем подсказки пользователю выбора или задания зоны, например, зоны дивана. Процесс обучения может включать подсказку пользователю произнесения обучающего фрагмента речи, такого как пробуждающее слово, вблизи выбранной или заданной зоны. На примере зоны дивана процесс обучения может включать подсказку пользователю произнесения обучающего фрагмента речи в центре и на самых краях дивана. Процесс обучения может включать подсказку пользователю повторения обучающего фрагмента речи несколько раз в каждом местоположении в пределах пользовательской зоны. Затем пользователю может быть подсказано перемещение в другую пользовательскую зону и продолжение до тех пор, пока не будут охвачены все обозначенные пользовательские зоны.
На фиг. 12 представлена блок-схема, на которой описан один пример способа, который может выполняться таким оборудованием, как оборудование 200, показанное на фиг. 2A. Этапы способа 1200, как и других способов, описанных в данном документе, не обязательно выполняются в указанном порядке. Более того, такие способы могут включать больше или меньше этапов, чем представлено и/или описано. В этой реализации способ 1200 включает обучение классификатора оценке местоположения пользователя в среде.
В этом примере этап 1205 включает подсказку пользователю произнесения по меньшей мере одного обучающего фрагмента речи в каждом из множества местоположений в пределах первой пользовательской зоны среды. Обучающий фрагмент (обучающие фрагменты) речи в некоторых примерах может (могут) представлять собой один или более примеров фрагмента речи, содержащего пробуждающее слово. Согласно некоторым реализациям первая пользовательская зона может представлять собой любую пользовательскую зону, выбранную и/или заданную пользователем. В некоторых случаях система управления может создавать соответствующую метку зоны (например, соответствующий пример одной из вышеописанных меток зон, ) и может связывать метку зоны с обучающими данными, полученными для первой пользовательской зоны.
Для сбора этих обучающих данных можно использовать автоматизированную систему подсказок. Как отмечено выше, система 205 интерфейсов оборудования 200 может содержать одно или более устройств для реализации пользовательского интерфейса, таких как один или более микрофонов, один или более динамиков, систему дисплеев, систему сенсорных датчиков и/или систему датчиков жестов. Например, оборудование 200 может снабжать пользователя следующими подсказками на экране системы дисплеев, или пользователь может слышать их оглашение через один или более динамиков в ходе процесса обучения:
• «переместитесь к дивану»,
• «произнесите пробуждающее слово десять раз, поворачивая голову»,
• «переместитесь в положение на полпути между диваном и креслом для чтения и произнесите пробуждающее слово десять раз»,
• «встаньте в кухне, как во время приготовления пищи, и произнесите пробуждающее слово десять раз».
В этом примере этап 1210 включает прием первых выходных сигналов от каждого из множества микрофонов в среде. В некоторых примерах этап 1210 может включать прием первых выходных сигналов из всех активных микрофонов в среде, тогда как в других примерах этап 1210 может включать прием первых выходных сигналов из подмножества всех активных микрофонов в среде. В некоторых примерах по меньшей мере некоторые из микрофонов в среде могут предоставлять выходные сигналы, являющиеся асинхронными в отношении выходных сигналов, предоставляемых одним или более другими микрофонами. Например, первый микрофон из множества микрофонов может осуществлять выборку аудиоданных согласно первому тактовому сигналу выборки, и второй микрофон из множества микрофонов может осуществлять выборку аудиоданных согласно второму тактовому сигналу выборки.
В этом примере каждый микрофон из множества микрофонов находится в местоположении микрофона среды. В этом примере первые выходные сигналы соответствуют примерам обнаруженных обучающих фрагментов речи, принятых из первой пользовательской зоны. Так как этап 1205 включает подсказку пользователю произнесения по меньшей мере одного обучающего фрагмента речи в каждом из множества местоположений в пределах первой пользовательской зоны среды, в этом примере термин «первые выходные сигналы» относится к множеству всех выходных сигналов, соответствующих обучающим фрагментам речи для первой пользовательской зоны. В других примерах термин «первые выходные сигналы» может относиться к подмножеству всех выходных сигналов, соответствующих обучающим фрагментам речи для первой пользовательской зоны.
Согласно этому примеру этап 1215 включает определение одного или более первых акустических признаков из каждого из первых выходных сигналов. В некоторых примерах первые акустические признаки могут включать метрику достоверности пробуждающего слова и/или метрику принятого уровня. Например, первые акустические признаки могут включать нормализованную метрику достоверности пробуждающего слова, индикатор нормализованного среднего принятого уровня и/или индикатор максимального принятого уровня.
Как отмечено выше, так как этап 1205 включает подсказку пользователю произнесения по меньшей мере одного обучающего фрагмента речи в каждом из множества местоположений в пределах первой пользовательской зоны среды, в этом примере термин «первые выходные сигналы» относится к множеству всех выходных сигналов, соответствующих обучающим фрагментам речи для первой пользовательской зоны. Соответственно, в этом примере термин «первые акустические признаки» относится к множеству акустических признаков, полученных из множества всех выходных сигналов, соответствующих обучающим фрагментам речи для первой пользовательской зоны. Поэтому в данном примере множество первых акустических признаков имеет по меньшей мере такой же размер, как множество первых выходных сигналов. Если, например, два акустических признака были определены из каждого из выходных сигналов, множество первых акустических признаков будет в два раза больше множества первых выходных сигналов.
В этом примере этап 1220 включает обучение модели классификатора для получения корреляций между первой пользовательской зоной и первыми акустическими признаками. Модель классификатора может представлять собой, например, любую из моделей, описанных в данном документе. Согласно этой реализации модель классификатора обучается без отсылки к геометрическим местоположениям множества микрофонов. Иначе говоря, в этом примере данные в отношении геометрических местоположений множества микрофонов (например, данные координат микрофонов) не предоставляются в модель классификатора в ходе процесса обучения.
На фиг. 13 представлена блок-схема, на которой описан другой пример способа, который может выполняться таким оборудованием, как оборудование 200, показанное на фиг. 2A. Этапы способа 1300, как и других способов, описанных в данном документе, не обязательно выполняются в указанном порядке. Например, в некоторых реализациях по меньшей мере часть процесса определения акустических признаков на этапе 1325 может выполняться перед этапом 1315 или этапом 1320. Более того, такие способы могут включать больше или меньше этапов, чем представлено и/или описано. В этой реализации способ 1300 включает обучение классификатора оценке местоположения пользователя в среде. Способ 1300 предоставляет пример расширенного способа 1200 для ряда пользовательских зон среды.
В этом примере этап 1305 включает подсказку пользователю произнесения по меньшей мере одного обучающего фрагмента речи в местоположении в пределах пользовательской зоны среды. В некоторых случаях этап 1305 может выполняться вышеописанным образом со ссылкой на этап 1205 согласно фиг. 12 за исключением того, что этап 1305 относится к одному местоположению в пределах пользовательской зоны. Обучающий фрагмент (обучающие фрагменты) речи в некоторых примерах может (могут) представлять собой один или более примеров фрагмента речи, содержащего пробуждающее слово. Согласно некоторым реализациям пользовательская зона может представлять собой любую пользовательскую зону, выбранную и/или заданную пользователем. В некоторых случаях система управления может создавать соответствующую метку зоны (например, соответствующий пример одной из вышеописанных меток зон, ) и может связывать метку зоны с обучающими данными, полученными для пользовательской зоны.
Согласно этому примеру этап 1310 выполняется по существу так, как описано выше со ссылкой на этап 1210 согласно фиг. 12. Однако в этом примере процесс этапа 1310 является обобщенным для любой пользовательской зоны, не обязательно первой пользовательской зоны, для которой собраны обучающие данные. Соответственно, выходные сигналы, принятые на этапе 1310, представляют собой «выходные сигналы от каждого из множества микрофонов в среде, причем каждый из множества микрофонов находится в местоположении микрофона в среде, причем выходные сигналы соответствуют примерам обнаруженных обучающих фрагментов речи, принятых из пользовательской зоны». В этом примере термин «выходные сигналы» относится к множеству всех выходных сигналов, соответствующих одному или более обучающим фрагментам речи в местоположении пользовательской зоны. В других примерах термин «выходные сигналы» может относиться к подмножеству всех выходных сигналов, соответствующих одному или более обучающим фрагментам речи в местоположении пользовательской зоны.
Согласно этому примеру этап 1315 включает определение того, достаточное ли количество обучающих данных было собрано для текущей пользовательской зоны. В некоторых таких примерах этап 1315 может включать определение того, были ли для текущей пользовательской зоны получены выходные сигналы, соответствующие пороговому количеству обучающих фрагментов речи. Альтернативно или дополнительно этап 1315 может включать определение того, были ли получены выходные сигналы, соответствующие обучающим фрагментам речи, в пороговом количестве местоположений в пределах текущей пользовательской зоны. Если нет, в этом примере способ 1300 возвращается на этап 1305, и пользователю дается подсказка произнесения по меньшей мере одного дополнительного фрагмента речи в местоположении в пределах той же пользовательской зоны.
Однако если на этапе 1315 определено, что для текущей пользовательской зоны собрано достаточно обучающих данных, в этом примере процесс продолжается на этапе 1320. Согласно этому примеру этап 1320 включает определение того, необходимо ли получить обучающие данные для дополнительных пользовательских зон. Согласно некоторым примерам этап 1320 может включать определение того, были ли обучающие данные получены для каждой пользовательской зоны, которая ранее была идентифицирована пользователем. В других примерах этап 1320 может включать определение того, были ли обучающие данные получены для минимального количества пользовательских зон. Это минимальное количество может быть выбрано пользователем. В других примерах минимальное количество может представлять собой рекомендованное минимальное количество для среды, рекомендованное минимальное количество для помещения среды и т. д.
Если на этапе 1320 определено, что обучающие данные следует получить для дополнительных пользовательских зон, в этом примере процесс продолжается на этапе 1322, который включает подсказку пользователю перемещения в другую пользовательскую зону среды. В некоторых примерах следующая пользовательская зона может быть выбрана пользователем. Согласно этому примеру процесс продолжается на этапе 1305 после подсказки на этапе 1322. В некоторых таких примерах пользователю может быть дана подсказка подтверждения достижения пользователем новой пользовательской зоны после подсказки на этапе 1322. Согласно некоторым таким примерам от пользователя может потребоваться подтверждение пользователем достижения новой пользовательской зоны перед предоставлением подсказки на этапе 1305.
Однако если на этапе 1320 определено, что для дополнительных пользовательских зон не нужно получать обучающие данные, в этом примере процесс продолжается на этапе 1325. В этом примере способ 1300 включает получение обучающих данных для K пользовательских зон. В этой реализации этап 1325 включает определение акустических признаков от первого до G-го из выходных сигналов от первого до H-го, которые соответствуют каждой из пользовательских зон от первой до K-й, для которых получены обучающие данные. В этом примере выражение «первые выходные сигналы» относится к множеству всех выходных сигналов, соответствующих обучающим фрагментам речи для первой пользовательской зоны, и выражение «H-е выходные сигналы» относится к множеству всех выходных сигналов, соответствующих обучающим фрагментам речи для K-й пользовательской зоны. Аналогично выражение «первые акустические признаки» относится к множеству акустических признаков, определенных из первых выходных сигналов, и выражение «G-е акустические признаки» относится к множеству акустических признаков, определенных из H-х выходных сигналов.
Согласно этим примерам этап 1330 включает обучение модели классификатора для получения корреляций между пользовательскими зонами от первой до K-й и акустическими признаками от первого до K-го соответственно. Модель классификатора может представлять собой, например, любую из моделей классификатора, описанных в данном документе.
В предыдущем примере пользовательские зоны являлись помеченными (например, согласно соответствующему примеру одной из вышеописанных меток зон, ). Однако в зависимости от конкретной реализации, модель может обучаться либо в соответствии с помеченными, либо в соответствии с непомеченными пользовательскими зонами. В случае помеченных зон каждый обучающий фрагмент речи может сочетаться с меткой, соответствующей пользовательской зоне, например, следующим образом:
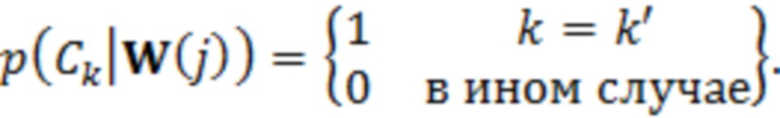
Обучение модели классификатора может включать определение максимального соответствия для помеченных обучающих данных. Без потери общности, соответствующие подходы к классификации для модели классификатора могут включать:
• байесов классификатор, например, с распределениями для каждого класса, которые описываются многомерными нормальными распределениями, гауссовыми моделями смешения с полной ковариацией или гауссовыми моделями смешения с диагональной ковариацией;
• векторное квантование;
• ближайшего соседа (метод k-средних);
• нейронную сеть с многопеременным логистическим выходным уровнем, в котором каждому классу соответствует один выходной сигнал;
● машину опорных векторов (SVM); и/или
● методики бустинга, такие как машины градиентного бустинга (GBM).
В одном примере реализации случая непомеченных зон данные могут автоматически разбиваться на 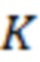 кластеров, где может также являться неизвестным. Непомеченное автоматическое разбиение может выполняться, например, с использованием классической методики кластеризации, например, алгоритма k-средних или моделирования гауссового смешения.
кластеров, где может также являться неизвестным. Непомеченное автоматическое разбиение может выполняться, например, с использованием классической методики кластеризации, например, алгоритма k-средних или моделирования гауссового смешения.
Для повышения робастности, с течением времени по мере произнесения новых фрагментов речи к обучению модели классификатора и параметрам модели можно применять регуляризацию.
Ниже описаны дополнительные аспекты варианта осуществления.
Иллюстративное множество акустических признаков (например, акустических признаков 1106A согласно фиг. 11) может содержать вероятность достоверности пробуждающего слова, средний принятый уровень в течение оценочной длительности наиболее достоверного пробуждающего слова и максимальный принятый уровень в течение длительности наиболее достоверного пробуждающего слова. Признаки могут являться нормализованными относительно их максимальных значений для каждого фрагмента речи, содержащего пробуждающее слово. Обучающие данные могут быть помечены, и для максимизации ожидания обучающих меток может быть обучена гауссова модель смешения (GMM) с полной ковариацией. Оценочная зона может представлять собой класс, максимизирующий апостериорную вероятность.
В приведенном выше описании некоторых вариантов осуществления обсуждается обучение модели акустических зон на основе набора обучающих данных, собранных в ходе подсказанного процесса сбора. В этой модели время обучения (или режим конфигурирования) и время работы (или регулярный режим) можно считать двумя отдельными режимами, в которых может быть размещена система микрофонов. Расширением этой схемы является интерактивное обучение, при котором некоторые или все модели акустических зон обучаются или адаптируются в режиме онлайн (например, во время работы или в регулярном режиме). Иначе говоря, даже после применения классификатора в процессе «во время работы» для осуществления оценки пользовательской зоны, в которой пользователь расположен в настоящий момент (например, в соответствии со способом 1000 согласно фиг. 10), в некоторых реализациях процесс обучения классификатора может продолжаться.
На фиг. 14 представлена блок-схема, на которой описан другой пример способа, который может выполняться таким оборудованием, как оборудование 200, показанное на фиг. 2A. Этапы способа 1400, как и других способов, описанных в данном документе, не обязательно выполняются в указанном порядке. Более того, такие способы могут включать больше или меньше этапов, чем представлено и/или описано. В этой реализации способ 1400 включает продолжающееся обучение классификатора в ходе процесса «во время работы», относящегося к оценке местоположения пользователя в среде. Способ 1400 представляет пример того, что в данном документе называется интерактивным режимом обучения.
В этом примере этап 1405 способа 1400 соответствует этапам 1005–1020 способа 1000. В данном случае этап 1405 включает предоставление, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой пользователь расположен в настоящий момент. Согласно этой реализации этап 1410 включает получение неявной или явной обратной связи в отношении оценки этапа 1405. На этапе 1415 классификатор обновляется в соответствии с обратной связью, принятой на этапе 1405. Этап 1415 может, например, включать один или более способов обучения с подкреплением. Как предполагается штриховой стрелкой от этапа 1415 к этапу 1405, в некоторых реализациях способ 1400 может включать возвращение на этап 1405. Например, способ 1400 может включать предоставление будущих оценок пользовательской зоны, в которой пользователь расположен в этот будущий момент времени, на основе применения обновленной модели.
Явные технические решения для получения обратной связи могут включать:
• запрос пользователя о правильности предсказания с использованием голосового пользовательского интерфейса (UI). Например, пользователю может предоставляться звук, указывающий следующее: «я думаю, Вы находитесь на диване, пожалуйста, скажите «правильно» или «неправильно»;
• информирование пользователя о том, что неверные предсказания можно исправить в любой момент времени с использованием голосового UI. (Например, пользователю может предоставляться звук, указывающий следующее: «я могу предсказать, где Вы находитесь, когда разговариваете со мной. Если я предсказываю неправильно, просто скажите что-то вроде “Аманда, я не на диване. Я на кресле для чтения.”».);
• информирование пользователя о том, что верные предсказания могут поощряться в любой момент времени с использованием голосового UI. (Например, пользователю может предоставляться звук, указывающий следующее: «я могу предсказать, где Вы находитесь, когда разговариваете со мной. Если я предсказываю верно, Вы можете помочь мне дополнительно улучшить мои предсказания, сказав что-нибудь вроде “Аманда, правильно. Я на диване.”»);
• согласно физическим кнопкам или другим элементам UI, которые пользователь может эксплуатировать с целью предоставления обратной связи (например, кнопки «палец вверх» и/или «палец вниз» на физическом устройстве или в приложении для смартфона).
Целью предсказания пользовательской зоны, в которой расположен пользователь, может являться информирование о выборе микрофона или об адаптивной схеме формирования диаграммы направленности, стремящейся более эффективно принимать звук из акустической зоны пользователя, например, с целью лучшего распознавания команды, которая следует за пробуждающим словом. В этих сценариях неявные технические решения для получения обратной связи в отношении качества предсказания зон могут включать:
• штрафование предсказаний, результатом которых является неверное распознавание команды, следующей за пробуждающим словом. Посредник, который может указывать неверное распознавание, может содержать прерывание пользователем отклика голосового помощника до команды, например, путем произнесения отменяющей команды, такой как, например, «Аманда, прекрати!»;
• штрафование предсказаний, результатом которых является низкая достоверность того, что распознаватель речи успешно распознал команду. Многие автоматические системы распознавания речи обладают функциональной возможностью возвращения уровня достоверности с их результатом, который можно использовать для этой цели;
• штрафование предсказаний, результатом которых является отказ детектора пробуждающего слова второго прохода для ретроспективного обнаружения пробуждающего слова с высокой достоверностью; и/или
• подкрепление предсказаний, результатом которых является распознавание пробуждающего слова с высокой достоверностью и/или верное распознавание команды пользователя.
Ниже приведен пример отказа детектора пробуждающего слова второго прохода для ретроспективного обнаружения пробуждающего слова с высокой достоверностью. Предполагается, что после получения выходных сигналов, соответствующих текущему фрагменту речи из микрофонов в среде, и после определения акустических признаков на основе выходных сигналов (например, с помощью множества детекторов пробуждающего слова первого прохода, выполненных с возможностью осуществления связи с микрофонами) акустические признаки доставляются в классификатор. Иначе говоря, акустические признаки, как предполагается, соответствуют обнаруженному фрагменту речи, содержащему пробуждающее слово. Дополнительно предполагается, что классификатор определяет, что человек, произнесший текущий фрагмент речи, с наибольшей вероятностью находится в зоне 3, которая в данном примере соответствует креслу для чтения. Может иметься, например, конкретный микрофон или обученная комбинация микрофонов, для которых известно, что они являются лучшими для прислушивания к голосу человека, когда человек находится в зоне 3, например, для отправки в службу виртуального помощника на облачной основе для распознавания голосовой команды.
Дополнительно предполагается, что после определения того, какой микрофон будет (какие микрофоны будут) использоваться для распознавания речи, но до того, как речь человека будет фактически отправлена в службу виртуального помощника, детектор пробуждающего слова второго прохода действует на сигналы микрофонов, соответствующие речи, обнаруживаемой выбранным микрофоном (выбранными микрофонами) для зоны 3, которую Вы собираетесь передать для распознавания команды. Если этот детектор пробуждающего слова второго прохода не соглашается с вашим множеством детекторов пробуждающего слова первого прохода в том, что пробуждающее слово было фактически произнесено, причиной этого, вероятно, является то, что классификатор неверно предсказал зону. Поэтому такой классификатор следует оштрафовать.
Технические решения для апостериорного обновления модели отображения зон после произнесения одного или более пробуждающих слов могут включать:
• максимальную апостериорную (MAP) адаптацию гауссовой модели смешения (GMM) или модели ближайшего соседа; и/или
• обучение с подкреплением, например, нейронной сети, например, путем связывания соответствующей «прямой унитарной» (в случае верного предсказания) или «обратной унитарной» (в случае неверного предсказания) метки, проверенной экспериментальными данными, с многопеременными логистическими выходными данными и применения обратного распространения онлайн с целью определения новых весовых коэффициентов сети.
Некоторые примеры адаптации МАР в этом контексте могут включать регулировку средних в GMM при каждом произнесении пробуждающего слова. Таким образом, средние могут становиться более подобными акустическим признакам, которые наблюдаются при произнесении следующих пробуждающих слов. Альтернативно или дополнительно такие примеры могут включать регулировку вариации/ковариации или информации о весовых коэффициентах смеси в GMM при каждом произнесении пробуждающего слова.
Например, схема адаптации МАР может являться следующей (new – новый, old – старый):
μi,new = μi,old*α + x*(1-α).
В предыдущем уравнении μi,old представляет среднее i-го гауссиана в смеси, α представляет параметр, который управляет тем, насколько агрессивно должна происходить адаптация MAP (α может находиться в диапазоне [0,9, 0,999]), и x представляет вектор признаков нового фрагмента речи, содержащего пробуждающее слово. Индекс «i» мог бы соответствовать элементу смеси, который возвращает высшую априорную вероятность содержания местоположения говорящего в момент пробуждающего слова.
Альтернативно каждый из элементов смеси может регулироваться в соответствии с их априорной вероятностью содержания пробуждающего слова, например, следующим образом:
Μi,new = μi,old*βi * x(1-βi).
В предыдущем уравнении βi = α * (1-P(i)), где P(i) представляет априорную вероятность того, что наблюдение x связано с элементом i смеси.
В одном примере обучения с подкреплением может иметься три пользовательские зоны. Предполагается, что для конкретного пробуждающего слова модель предсказывает вероятности для трех пользовательских зон как равные [0,2, 0,1, 0,7]. Если второй источник информации (например, детектор пробуждающего слова второго прохода) подтверждает, что третья зона была верна, то метка, проверенная экспериментальными данными, должна быть равна [0, 0, 1] («прямая унитарная»). Апостериорное обновление модели отображения зон может включать обратное распространение ошибки через нейронную сеть, что фактически означает, что нейронная сеть будет более жестко предсказывать зону 3, если снова показан тот же входной сигнал. И наоборот, если второй источник информации показывает, что зона 3 является неверным предсказанием, метка, проверенная экспериментальными данными, в одном примере может быть равна [0,5, 0,5, 0,0]. Обратное распространение ошибки через нейронную сеть будет делать менее вероятным предсказание моделью зоны 3, если в будущем показан такой же входной сигнал.
Гибкий рендеринг обеспечивает возможность рендеринга пространственных аудиоданных для произвольного количества произвольно размещенных динамиков. В виду широкого распространения в доме аудиоустройств, в том числе, но без ограничения, интеллектуальных аудиоустройств (например, интеллектуальных динамиков), существует потребность в реализации технологии гибкого рендеринга, позволяющей потребительским продуктам выполнять гибкий рендеринг аудиоданных и проигрывать подвергнутые этому рендерингу аудиоданные.
Для реализации гибкого рендеринга было разработано несколько технологий. В них задача рендеринга считается задачей минимизации функции стоимости, при этом функция стоимости состоит из двух показателей: первого показателя, который моделирует требуемое пространственное впечатление, которого стремится добиться средство рендеринга, и второго показателя, который присваивает стоимость активации динамиков. К настоящему времени этот второй показатель сосредоточен на создании разреженного решения, в котором активируются только динамики в непосредственной близости к требуемому пространственному положению подвергаемых рендерингу аудиоданных.
Проигрывание пространственных аудиоданных в потребительской среде обычно привязано к предписанному количеству громкоговорителей, размещенных в предписанных положениях, например, окружающий звук 5.1 и 7.1. В этих случаях содержимое разрабатывается специально для связанных громкоговорителей и кодируется в форме обособленных каналов, по одному для каждого громкоговорителя (например, Dolby Digital или Dolby Digital Plus и т. д.). Совсем недавно были предложены форматы пространственных аудиоданных с эффектом присутствия на основе объектов (Dolby Atmos), в которых эта связь между содержимым и конкретными местоположениями громкоговорителей разорвана. Вместо этого содержимое можно описать как множество отдельных аудиообъектов, каждый, возможно, с переменными во времени метаданными, описывающими требуемое воспринимаемое местоположение указанных аудиообъектов в трехмерном пространстве. Во время проигрывания содержимое преобразуется в сигналы, подаваемые на громкоговорители, средством рендеринга, которое адаптируется к количеству и местоположению громкоговорителей в системе проигрывания. Многие такие средства рендеринга, однако, по-прежнему ограничивают местоположения набора громкоговорителей одной из набора предписанных схем размещения (например, 3.1.2, 5.1.2, 7.1.4, 9.1.6 и т. д. в случае Dolby Atmos).
Для перемещения за пределы этого ограниченного рендеринга были разработаны способы, которые обеспечивают возможность гибкого рендеринга аудиоданных на основе объектов через действительно произвольное количество громкоговорителей, размещенных в произвольных положениях. Эти способы требуют того, чтобы средство рендеринга обладало знанием количества и физических местоположений громкоговорителей в пространстве прослушивания. Для того чтобы такая система была применимой на практике для среднего потребителя, может потребоваться автоматизированный способ определения местоположений громкоговорителей. Один такой способ полагается на применение ряда микрофонов, возможно, расположенных совместно с громкоговорителями. Путем проигрывания аудиосигналов через громкоговорители и записи с помощью микрофонов оценивается расстояние между каждым громкоговорителем и микрофоном. Из этих расстояний впоследствии выводятся местоположения как громкоговорителей, так и микрофонов.
Одновременным с введением пространственных аудиоданных на основе объектов в потребительское пространство было быстрое принятие так называемых «интеллектуальных динамиков», таких как линейка продуктов Amazon Echo. Большую популярность этих устройств можно приписать их простоте и удобству, которые обеспечиваются за счет возможности беспроводного подключения и встроенного голосового интерфейса (например, Alexa от Amazon), но звуковые функциональные возможности этих устройств обычно ограничены, в частности, в отношении пространственных аудиоданных. В большинстве случаев эти устройства ограничены монофоническим или стереофоническим проигрыванием. Однако сочетание вышеупомянутого гибкого рендеринга и технологий автоматического определения местоположения с множеством организованных интеллектуальных динамиков может дать систему с весьма изощренными функциональными возможностями пространственного проигрывания, которая по-прежнему будет оставаться чрезвычайно простой для установки потребителем. Потребитель при желании может разместить как можно больше или как можно меньше динамиков где бы это ни было удобно без необходимости в проведении проводов динамиков вследствие возможности беспроводного подключения, а для автоматического определения местоположений динамиков для связанного средства гибкого рендеринга можно использовать встроенные микрофоны.
Удобные алгоритмы гибкого рендеринга рассчитаны на максимально близкое достижение конкретного желательного воспринимаемого пространственного впечатления. В системе организованных интеллектуальных динамиков поддержание время от времени этого пространственного впечатления может не являться наиболее важной или желательной целью. Например, если кто-то одновременно пытается говорить со встроенным голосовым помощником, может потребоваться мгновенно изменить пространственный рендеринг способом, который снижает относительные уровни проигрывания на динамиках вблизи определенных микрофонов, с целью увеличения отношения сигнал-шум и/или отношения сигнал-эхо (SER) сигналов микрофонов, содержащих обнаруженную речь. Некоторые варианты осуществления, описанные в данном документе, могут быть реализованы в виде модификаций существующих способов гибкого рендеринга для обеспечения возможности указанной динамической модификации пространственного рендеринга, например, с целью достижения одной или более дополнительных целей.
Существующие технические решения гибкого рендеринга включают «Амплитудное панорамирование центра масс» (CMAP) и «Гибкую виртуализацию» (FV). С профессиональной точки зрения, оба этих технических решения выполняют рендеринг множества из одного или более аудиосигналов, каждый из которых имеет связанное требуемое воспринимаемое пространственное положение, для проигрывания через набор из двух или более динамиков, при этом относительное значение активации динамиков из набора зависит от модели воспринимаемого пространственного положения указанных аудиосигналов, проигрываемых через динамики, и близости требуемого воспринимаемого пространственного положения аудиосигналов к положениям динамиков. Модель обеспечивает слышимость для слушателя аудиосигнала рядом с его намеченным пространственным положением, а показатель близости управляет тем, какие динамики используются для достижения этого пространственного впечатления. В частности, показатель близости благоприятствует активации динамиков, находящихся рядом с требуемым воспринимаемым пространственным положением аудиосигнала. И для CMAP, и для FV эту функциональную взаимосвязь удобно получить из функции стоимости, записанной в виде суммы двух показателей, одного для пространственного (spatial) аспекта, и одного для близости (proximity):
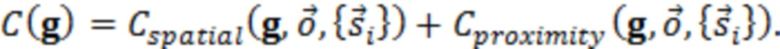 (1)
(1)
В данном случае множество 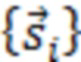 обозначает положения множества M громкоговорителей,
обозначает положения множества M громкоговорителей, 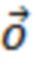 обозначает требуемое воспринимаемое пространственное положение аудиосигнала, и g обозначает M-мерный вектор значений активации динамиков. Для CMAP каждое значение активации в этом векторе представляет коэффициент усиления для динамика, тогда как для FV каждое значение активации представляет фильтр (в этом втором случае g можно эквивалентно рассматривать как вектор комплексных значений на конкретной частоте, и для образования фильтра на множестве частот вычисляется другое g). Оптимальный вектор значений активации находят путем минимизации функции стоимости по значениям активации:
обозначает требуемое воспринимаемое пространственное положение аудиосигнала, и g обозначает M-мерный вектор значений активации динамиков. Для CMAP каждое значение активации в этом векторе представляет коэффициент усиления для динамика, тогда как для FV каждое значение активации представляет фильтр (в этом втором случае g можно эквивалентно рассматривать как вектор комплексных значений на конкретной частоте, и для образования фильтра на множестве частот вычисляется другое g). Оптимальный вектор значений активации находят путем минимизации функции стоимости по значениям активации:
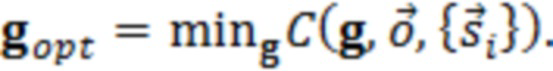 (2a)
(2a)
С помощью известных определений функции стоимости трудно управлять абсолютным уровнем оптимальных (opt) значений активации, являющихся результатом вышеописанной минимизации, хотя относительный уровень между составляющими 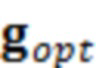 является подходящим. Для решения этой проблемы последующую нормализацию можно выполнить так, чтобы абсолютный уровень значений активации стал управляемым. Например, может требоваться нормализация вектора на единичную длину, что согласовывается с обычно используемыми правилами панорамирования с постоянной энергией:
является подходящим. Для решения этой проблемы последующую нормализацию можно выполнить так, чтобы абсолютный уровень значений активации стал управляемым. Например, может требоваться нормализация вектора на единичную длину, что согласовывается с обычно используемыми правилами панорамирования с постоянной энергией:
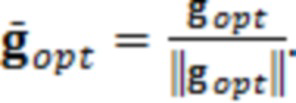 (2b)
(2b)
Точное поведение алгоритма гибкого рендеринга определяется конкретной структурой двух показателей функции стоимости, 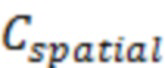 и
и 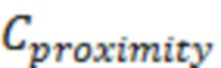 . Для CMAP получают из модели, которая размещает воспринимаемое пространственное положение аудиосигнала, проигрываемого из набора громкоговорителей, в центре массы положений этих громкоговорителей, подвергнутых весовой обработке с помощью связанных с ними активирующих коэффициентов усиления,
. Для CMAP получают из модели, которая размещает воспринимаемое пространственное положение аудиосигнала, проигрываемого из набора громкоговорителей, в центре массы положений этих громкоговорителей, подвергнутых весовой обработке с помощью связанных с ними активирующих коэффициентов усиления, 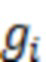 (элементов вектора g):
(элементов вектора g):
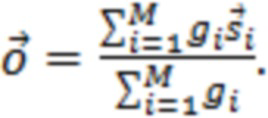 (3)
(3)
Уравнение 3 затем преобразуется в пространственную стоимость, представляющую квадратичную ошибку между требуемым положением аудиоданных и аудиоданными, полученными активированными громкоговорителями:
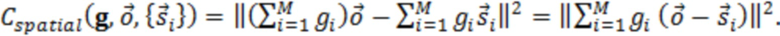 (4)
(4)
Для FV пространственный показатель функции стоимости определяют иначе. Целью является получение бинауральной характеристики b, соответствующей положению аудиообъекта, 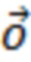 , в левом и правом ушах слушателя. Теоретически b представляет собой вектор фильтров (по одному фильтру для каждого уха) размера 2x1, однако с ним более удобно обращаться как с вектором комплексных значений размера 2x1 на конкретной частоте. Совершая дальнейшие действия с помощью этого представления на конкретной частоте, требуемую бинауральную характеристику можно получить из множества HRTF, индексированных с помощью положения объекта:
, в левом и правом ушах слушателя. Теоретически b представляет собой вектор фильтров (по одному фильтру для каждого уха) размера 2x1, однако с ним более удобно обращаться как с вектором комплексных значений размера 2x1 на конкретной частоте. Совершая дальнейшие действия с помощью этого представления на конкретной частоте, требуемую бинауральную характеристику можно получить из множества HRTF, индексированных с помощью положения объекта:
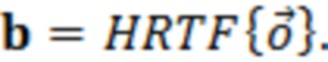 (5)
(5)
В то же время, бинауральная характеристика e размера 2x1, получаемая в ушах слушателя с помощью громкоговорителей, моделируется в виде матрицы звукопередачи, H, размера 2xM, умноженной на вектор комплексных значений активации динамиков, g, размера Mx1:
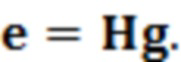 (6)
(6)
Матрица звукопередачи, H, моделируется на основе множества положений громкоговорителей, , относительно положения слушателя. Наконец, пространственная составляющая функции стоимости задана как квадратичная ошибка между требуемой бинауральной характеристикой (уравнение 5) и бинауральной характеристикой, полученной с помощью громкоговорителей (уравнение 6):
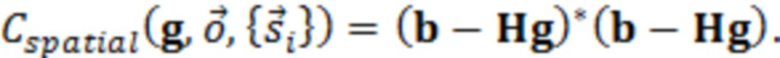 (7)
(7)
Для удобства пространственный показатель функции стоимости для CMAP и FV, заданный в уравнениях 4 и 7, можно в обоих случаях преобразовать в квадратную матрицу, зависящую от значений активации динамиков, g:
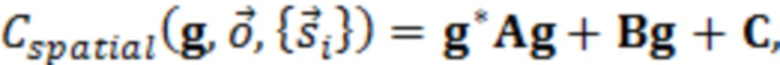 (8)
(8)
где A представляет собой квадратную матрицу размера M x M, B представляет собой вектор размера 1 x M, и C представляет собой скалярную величину. Матрица A имеет ранг 2, поэтому, когда M > 2, существует бесконечное количество значений активации динамиков, g, для которых показатель пространственной ошибки равен нулю. Введение второго показателя функции стоимости, , исключает эту неопределенность и приводит к частному решению со свойствами восприятия, преимущественными по сравнению с другими возможными решениями. Как для CMAP, так и для FV построен так, что значения активации динамиков, положение 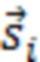 которых отдалено от требуемого положения аудиосигнала, , штрафуются в большей степени, чем значения активации динамиков, положение которых близко к требуемому положению. Такое построение приводит к оптимальному множеству значений активации динамиков, которые являются рассеянными, при этом в значительной степени активируются только динамики в непосредственной близости от требуемого положения аудиосигнала, и на практике это приводит к пространственному воспроизведению аудиосигнала, которое является для восприятия более устойчивым к перемещению слушателя рядом с набором динамиков.
которых отдалено от требуемого положения аудиосигнала, , штрафуются в большей степени, чем значения активации динамиков, положение которых близко к требуемому положению. Такое построение приводит к оптимальному множеству значений активации динамиков, которые являются рассеянными, при этом в значительной степени активируются только динамики в непосредственной близости от требуемого положения аудиосигнала, и на практике это приводит к пространственному воспроизведению аудиосигнала, которое является для восприятия более устойчивым к перемещению слушателя рядом с набором динамиков.
Для этого второй показатель функции стоимости, , можно задать как взвешенную по расстояниям сумму квадратов абсолютных значений активаций динамиков. Компактно это представлено в матричной форме в виде:
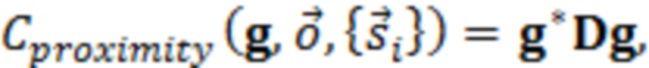 (9a)
(9a)
где D представляет собой диагональную матрицу штрафов за расстояние (distance) между требуемым положением аудиоданных и каждым динамиком:
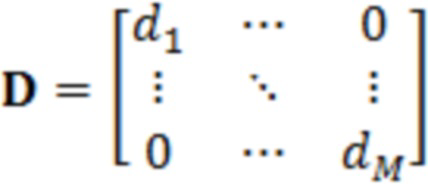 ,
, 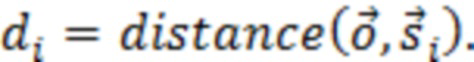 (9b)
(9b)
Функция штрафов за расстояние может принимать множество форм, но полезной параметризацией является следующая:
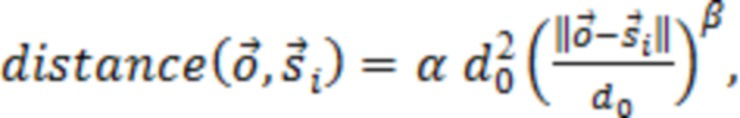 (9c)
(9c)
где 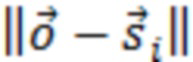 представляет собой евклидово расстояние между требуемым положением аудиоданных и положением динамика, и
представляет собой евклидово расстояние между требуемым положением аудиоданных и положением динамика, и 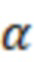 и
и 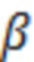 представляют собой перестраиваемые параметры. Параметр указывает глобальную силу штрафа;
представляют собой перестраиваемые параметры. Параметр указывает глобальную силу штрафа; 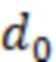 соответствует пространственной протяженности штрафа за расстояние (будут штрафоваться громкоговорители на расстоянии приблизительно или дальше), и учитывает резкость наступления штрафа на расстоянии .
соответствует пространственной протяженности штрафа за расстояние (будут штрафоваться громкоговорители на расстоянии приблизительно или дальше), и учитывает резкость наступления штрафа на расстоянии .
Комбинирование двух показателей функции стоимости, заданных в уравнениях 8 и 9a, приводит к общей функции стоимости:
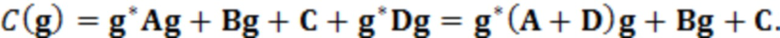 (10)
(10)
Приравнивание нулю производной этой функции стоимости по g и решение для g дает оптимальное решение для значений активации динамиков:
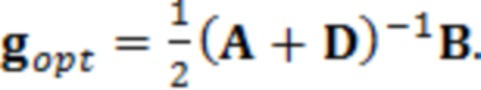 (11)
(11)
В целом оптимальное решение в уравнении 11 может приводить к значениям активации динамиков, отрицательным по величине. Для построения с помощью CMAP гибкого средства рендеринга эти отрицательные значения активации могут являться нежелательными, поэтому уравнение (11) можно минимизировать при условии, что все значения активации остаются положительными.
На фиг. 15 и 16 представлены схемы, на которых изображено иллюстративное множество значений активации динамиков и положений рендеринга объектов. В этих примерах значения активации динамиков и положения рендеринга объектов соответствуют положениям динамиков 4, 64, 165, -87 и -4 градуса. На фиг. 15 представлены значения активации динамиков, 1505a, 1510a, 1515a, 1520a и 1525a, которые содержат оптимальное решение уравнения 11 для этих конкретных положений динамиков. На фиг. 16 положения отдельных динамиков представлены на графике в виде точек 1605, 1610, 1615, 1620 и 1625, которые соответствуют значениям активации динамиков, 1505a, 1510a, 1515a, 1520a и 1525a, соответственно. На фиг. 16 также представлены идеальные положения объектов (иначе говоря, положения, в которых аудиообъекты должны подвергаться рендерингу) для множества возможных углов объектов в виде точек 1630a и соответствующие фактические положения рендеринга для этих объектов в виде точек 1635a, соединенных с идеальными положениями объектов пунктирными линиями 1640a.
Один класс вариантов осуществления включает способы рендеринга аудиоданных для проигрывания по меньшей мере одним (например, всеми или некоторыми) из множества скоординированных (организованных) интеллектуальных аудиоустройств. Например, набор интеллектуальных аудиоустройств, присутствующих (в системе) в доме пользователя, можно организовать для обработки множества вариантов одновременного использования, включая гибкий рендеринг (согласно одному варианту осуществления) аудиоданных для проигрывания всеми или некоторыми (т. е. динамиком (динамиками) всех или некоторых) из интеллектуальных аудиоустройств. Предполагается множество взаимодействий с системой, которые требуют динамических модификаций рендеринга. Такие модификации могут являться, но не обязательно являются, сосредоточенными на пространственной точности воспроизведения.
Некоторые варианты осуществления представляют собой способы рендеринга аудиоданных для проигрывания по меньшей мере одним (например, всеми или некоторыми) из интеллектуальных аудиоустройств набора интеллектуальных аудиоустройств (или для проигрывания по меньшей мере одним (например, всеми или некоторыми) из динамиков другого набора динамиков). Рендеринг может включать минимизацию функции стоимости, при этом функция стоимости содержит по мере один показатель динамической активации динамика. Примеры такого показателя динамической активации динамика включают (но без ограничения):
• близость динамиков к одному или более слушателям;
• близость динамиков к силе притяжения или отталкивания;
• слышимость динамиков относительно некоторого местоположения (например, положения слушателя или детской комнаты);
• функциональные возможности динамиков (например, частотная характеристика и искажение);
• синхронизация динамиков относительно других динамиков;
• выполнение пробуждающего слова; и
• выполнение эхокомпенсации.
Показатель (показатели) динамической активации динамика может (могут) делать возможным по меньшей мере один из множества вариантов поведения, в том числе деформации пространственного представления аудиоданных в сторону от конкретного интеллектуального аудиоустройства, для того чтобы его микрофон мог лучше слышать говорящего или чтобы вторичный аудиопоток можно было лучше слышать из динамика (динамиков) интеллектуального аудиоустройства.
В некоторых вариантах осуществления реализован рендеринг для проигрывания динамиком (динамиками) множества интеллектуальных аудиоустройств, которые являются скоординированными (организованными). В других вариантах осуществления реализован рендеринг для проигрывания динамиком (динамиками) из другого набора динамиков.
Сочетание гибких способов рендеринга (реализованных в соответствии с некоторыми вариантами осуществления) с набором беспроводных интеллектуальных динамиков (или других интеллектуальных аудиоустройств) может приводить к удобной в использовании системе рендеринга пространственного звука с чрезвычайно большими функциональными возможностями. При рассмотрении взаимодействий с такой системой становится очевидно, что с целью оптимизации для других задач, которые могут возникнуть в ходе использования системы, могут потребоваться динамические модификации пространственного рендеринга. Для достижения этой цели один класс вариантов осуществления дополняет существующие гибкие алгоритмы рендеринга (в которых значение активации динамика зависит от ранее раскрытых пространственного показателя и показателя близости) одной или более дополнительными динамически конфигурируемыми функциями, зависящими от одного или более свойств подвергаемых рендерингу аудиосигналов, набора динамиков и/или других внешних входных сигналов. Согласно некоторым вариантам осуществления функция стоимости существующего гибкого рендеринга, приведенная в уравнении 1, дополняется одной или более этими дополнительными зависимостями в соответствии со следующим:
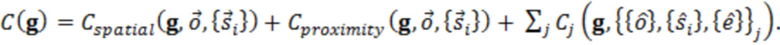 (12)
(12)
В уравнении 12 показатели 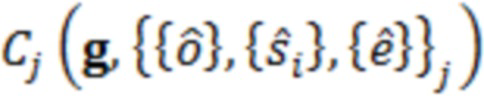 представляют дополнительные показатели стоимости, где
представляют дополнительные показатели стоимости, где 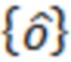 представляет множество из одного или более свойств подвергаемых рендерингу аудиосигналов (например, аудиопрограммы на основе объектов),
представляет множество из одного или более свойств подвергаемых рендерингу аудиосигналов (например, аудиопрограммы на основе объектов), 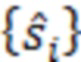 представляет множество из одного или более свойств динамиков, через которые аудиосигналы подвергаются рендерингу, и
представляет множество из одного или более свойств динамиков, через которые аудиосигналы подвергаются рендерингу, и 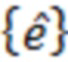 представляет один или более дополнительных внешних входных сигналов. Каждый показатель возвращает стоимость в зависимости от значений активации, g, в отношении комбинации из одного или более свойств аудиосигналов, динамиков и/или внешних входных сигналов, обобщенно представленных множеством
представляет один или более дополнительных внешних входных сигналов. Каждый показатель возвращает стоимость в зависимости от значений активации, g, в отношении комбинации из одного или более свойств аудиосигналов, динамиков и/или внешних входных сигналов, обобщенно представленных множеством 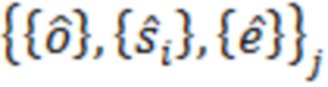 . Следует понимать, что множество содержит минимум только один элемент из любого из , и .
. Следует понимать, что множество содержит минимум только один элемент из любого из , и .
Примеры включают, но без ограничения:
• требуемое воспринимаемое пространственное положение аудиосигнала;
• уровень (возможно, переменный во времени) аудиосигнала; и/или
• спектр (возможно, переменный во времени) аудиосигнала.
Примеры включают, но без ограничения:
• местоположения громкоговорителей в пространстве прослушивания;
• частотную характеристику громкоговорителей;
• ограничения уровня проигрывания громкоговорителей;
• параметры алгоритмов динамической обработки в динамиках, такие как коэффициенты усиления ограничителей;
• результат измерения или оценку звукопередачи из одного динамика в другие;
• критерий выполнения эхокомпенсации в отношении динамиков; и/или
• относительную синхронизацию динамиков относительно друг друга.
Примеры включают, но без ограничения:
• местоположения одного или более слушателей или говорящих в пространстве проигрывания;
• результат измерения или оценку звукопередачи из каждого громкоговорителя в местоположение прослушивания;
• результат измерения или оценку звукопередачи от говорящего в набор громкоговорителей;
• местоположение какого-либо другого ориентира в пространстве проигрывания; и/или
• результат измерения или оценку звукопередачи из каждого динамика к какому-либо другому ориентиру в пространстве проигрывания.
С помощью новой функции стоимости, заданной в уравнении 12, оптимальное множество значений активации можно найти с помощью минимизации по g и, возможно, последующей нормализации, как описано ранее в уравнениях 2a и 2b.
На фиг. 17 представлена блок-схема, на которой описан один пример способа, который может выполняться таким оборудованием или такой системой, как показанные на фиг. 2A. Этапы способа 1700, как и других способов, описанных в данном документе, не обязательно выполняются в указанном порядке. Более того, такие способы могут включать больше или меньше этапов, чем представлено и/или описано. Этапы способа 1700 могут выполняться одним или более устройствами, которые могут представлять собой (или могут содержать) систему управления, такую как система 210 управления, представленная на фиг. 2A.
В этой реализации этап 1705 включает прием аудиоданных системой управления и через систему интерфейсов. В этом примере аудиоданные содержат один или более аудиосигналов и связанные пространственные данные. Согласно этой реализации пространственные данные указывают намеченное воспринимаемое пространственное положение, соответствующее аудиосигналу. В некоторых случаях намеченное воспринимаемое пространственное положение может являться явным, например, указанным метаданными положения, такими как метаданные положения Dolby Atmos. В других случаях намеченное воспринимаемое пространственное положение может являться неявным, например, намеченное воспринимаемое пространственное положение может представлять собой предполагаемое местоположение, связанное с каналом согласно Dolby 5.1, Dolby 7.1 или другому формату аудиоданных на основе каналов. В некоторых примерах этап 1705 включает прием аудиоданных модулем рендеринга системы управления через систему интерфейсов.
Согласно этому примеру этап 1710 включает рендеринг системой управления аудиоданных для воспроизведения через набор громкоговорителей среды с целью получения подвергнутых рендерингу аудиосигналов. В этом примере рендеринг каждого из одного или более аудиосигналов, заключенных в аудиоданных, включает определение относительного значения активации набора громкоговорителей в среде путем оптимизации функции стоимости. Согласно этому примеру стоимость зависит от модели воспринимаемого пространственного положения аудиосигнала при проигрывании обратно через набор громкоговорителей в среде. В этом примере стоимость также зависит от критерия близости намеченного воспринимаемого пространственного положения аудиосигнала к положению каждого громкоговорителя из набора громкоговорителей. В этой реализации стоимость также зависит от одной или более дополнительных динамически конфигурируемых функций. В этом примере динамически конфигурируемые функции основаны на одном или более из следующего: близости громкоговорителей к одному или более слушателям; близости громкоговорителей к положению силы притяжения, при этом сила притяжения представляет собой фактор, благоприятствующий относительно большему значению активации громкоговорителя, расположенного ближе к положению силы притяжения; близости громкоговорителей к положению силы отталкивания, при этом сила отталкивания представляет собой фактор, благоприятствующий относительно меньшему значению активации громкоговорителя, расположенного ближе к положению силы отталкивания; функциональных возможностях каждого громкоговорителя относительно других громкоговорителей в среде; синхронизации громкоговорителей относительно других громкоговорителей; выполнении пробуждающего слова; или выполнении эхокомпенсации.
В этом примере этап 1715 включает доставку через систему интерфейсов подвергнутых рендерингу аудиосигналов в по меньшей мере некоторые громкоговорители из набора громкоговорителей среды.
Согласно некоторым примерам модель воспринимаемого пространственного положения может получать бинауральную характеристику, соответствующую положению аудиообъекта в левом и правом ушах слушателя. Альтернативно или дополнительно модель воспринимаемого пространственного положения может размещать воспринимаемое пространственное положение аудиосигнала, проигрываемого из набора громкоговорителей, в центре массы положений набора громкоговорителей, подвергнутых весовой обработке с помощью связанных с ними активирующих коэффициентов усиления громкоговорителей.
В некоторых примерах одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на уровне одного или более аудиосигналов. В некоторых случаях одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на спектре одного или более аудиосигналов.
Некоторые примеры способа 1700 включают прием информации о схеме размещения громкоговорителей. В некоторых примерах одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на местоположении каждого из громкоговорителей в среде.
Некоторые примеры способа 1700 включают прием информации о технических характеристиках громкоговорителей. В некоторых примерах одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на функциональных возможностях каждого громкоговорителя, которые могут включать одно или более из частотной характеристики, ограничений уровня проигрывания или параметров одного или более алгоритмов динамической обработки громкоговорителей.
Согласно некоторым примерам одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на результате измерения или оценке звукопередачи из каждого громкоговорителя в другие громкоговорители. Альтернативно или дополнительно одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на местоположении слушателя или говорящего для одного или более людей в среде. Альтернативно или дополнительно одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на результате измерения или оценке звукопередачи из каждого громкоговорителя в местоположение слушателя или говорящего. Оценка звукопередачи может, например, по меньшей мере частично основываться на стенах, мебели или других объектах, которые могут находиться между каждым громкоговорителем и местоположением слушателя или говорящего.
Альтернативно или дополнительно одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на местоположении объекта, представляющего собой один или более объектов, не являющихся громкоговорителями, или ориентирах в среде. В некоторых таких реализациях одна или более дополнительных динамически конфигурируемых функций могут по меньшей мере частично основываться на результате измерения или оценке звукопередачи из каждого громкоговорителя в местоположение объекта или местоположение ориентира.
За счет применения одного или более соответствующим образом заданных дополнительных показателей стоимости для реализации гибкого рендеринга можно добиться многочисленных новых и полезных вариантов поведения. Все иллюстративные варианты поведения, перечисленные ниже, рассматриваются в выражении штрафования некоторых громкоговорителей при определенных условиях, считающихся нежелательными. Конечным результатом является то, что эти громкоговорители при пространственном рендеринге множества аудиосигналов активируются в меньшей степени. Во многих таких случаях можно предположить простое убавление звука нежелательных громкоговорителей независимо от какой-либо модификации пространственного рендеринга, но такая стратегия может значительно ухудшать общий баланс аудиосодержимого. Например, некоторые компоненты смешанного сигнала могут стать полностью не слышными. В раскрытых вариантах осуществления, с другой стороны, встраивание этих штрафов в базовую оптимизацию рендеринга обеспечивает возможность адаптации рендеринга и выполнения наилучшего возможного пространственного рендеринга с помощью остальных, менее оштрафованных динамиков. Это решение является намного более изысканным, адаптируемым и эффективным.
Иллюстративные варианты использования включают, но без ограничения:
• обеспечение более сбалансированного пространственного представления по области прослушивания;
○ было обнаружено, что пространственные аудиоданные наилучшим образом представляются через громкоговорители, находящиеся на приблизительно равном расстоянии от намеченной области прослушивания. Стоимость можно построить так, что громкоговорители, находящиеся значительно ближе или дальше, чем среднее расстояние громкоговорителей до области просушивания, штрафуются, за счет чего уменьшается их активация;
• перемещение аудиоданных в сторону от или в направлении к слушателю или говорящему;
○ если пользователь системы пытается говорить с интеллектуальным голосовым помощником системы или связанным с системой, может являться преимущественным создание стоимости, которая штрафует громкоговорители, расположенные ближе к говорящему. Таким образом, эти громкоговорители активируются в меньшей степени, что позволяет связанным с ними микрофонам лучше слышать говорящего;
○ для обеспечения более близкого взаимодействия для одного слушателя, которое минимизирует уровни проигрывания для других в пространстве прослушивания, динамики, удаленные от местоположения слушателя, могут штрафоваться сильнее, для того чтобы в более значительной мере активировать только динамики, ближайшие к слушателю;
• перемещение аудиоданных в сторону от или в направлении к ориентиру, зоне или области;
○ некоторые местоположения вблизи пространства прослушивания, такие как комната ребенка, кровать ребенка, служебное помещение, область чтения, область обучения и т. д., можно считать чувствительными. В этом случае можно построить стоимость, которая штрафует использование динамиков вблизи этого местоположения, зоны или области;
○ альтернативно для такого случая, как описанный выше (или аналогичных случаев), система динамиков может содержать сгенерированные результаты измерений звукопередачи из каждого динамика в комнату ребенка, в частности, если один из динамиков (с присоединенным или связанным микрофоном) находится в самой комнате ребенка. В этом примере вместо использования физической близости динамиков к комнате ребенка можно построить стоимость, которая штрафует применение динамиков, для которых измеренная звукопередача в эту комнату является высокой; и/или
• оптимальное использование функциональных возможностей динамиков;
○ функциональные возможности разных громкоговорителей могут значительно отличаться. Например, один популярный интеллектуальный динамик содержит только одну головку полного диапазона диаметром 1,6 дюйма с ограниченными низкочастотными функциональными возможностями. С другой стороны, другой интеллектуальный динамик содержит низкочастотный громкоговоритель диаметром 3 дюйма с намного большими функциональными возможностями. Эти функциональные возможности обычно отражены в частотной характеристике динамика, поэтому в качестве показателя стоимости можно использовать набор характеристик, связанных с динамиками. На конкретной частоте динамики, обладающие меньшими функциональными возможностями относительно других, согласно измерениям по их частотной характеристике, могут штрафоваться и, таким образом, активироваться в меньшей степени. В некоторых реализациях указанные значения частотных характеристик могут храниться в интеллектуальном динамике, а затем сообщаться в вычислительный блок, ответственный за оптимизацию гибкого рендеринга;
○ многие динамики содержат более одной головки, каждая из которых ответственна за проигрывание отличного диапазона частот. Например, один популярный интеллектуальный динамик представляет собой двухполосную конструкцию, содержащую низкочастотный громкоговоритель для более низких частот и высокочастотный громкоговоритель для более высоких частот. Обычно такой динамик содержит разделительную схему для деления проигрываемого аудиосигнала полного диапазона на соответствующие диапазоны частот и отправки в соответствующие головки. Альтернативно такой динамик может обеспечивать доступ проигрывания с гибким рендерингом к каждой отдельной головке, а также информацию о функциональных возможностях, такую как частотная характеристика, каждой отдельной головки. За счет применения такого показателя стоимости, как описанный выше, в некоторых примерах средство гибкого рендеринга может автоматически строить разделитель между двумя головками на основе их относительных функциональных возможностей на разных частотах;
○ в вышеупомянутом примере используется сосредоточение частотной характеристики на собственных функциональных возможностях динамиков, но это может не точно отражать функциональные возможности динамиков, размещенных в среде прослушивания. В некоторых случаях частотные характеристики динамиков при измерении в намеченном положении прослушивания могут являться доступными с помощью некоторой процедуры калибровки. Такие измерения можно использовать вместо предварительно вычисленных характеристик для лучшей оптимизации применения динамиков. Например, некоторый динамик может по сути характеризоваться весьма высокими функциональными возможностями на конкретной частоте, однако по причине его размещения (например, за стеной или элементом мебели) может генерировать весьма ограниченную характеристику в намеченном положении прослушивания. Измерение, которое захватывает эту характеристику и передает в соответствующий показатель стоимости, может препятствовать значительной активации такого динамика;
○ частотная характеристика представляет собой лишь один аспект функциональных возможностей проигрывания громкоговорителя. Многие громкоговорители меньших размеров начинаются искажаться, а затем сталкиваются с предельным отклонением по мере повышения уровня проигрывания, в частности, для нижних частот. Для уменьшения таких искажений во многих громкоговорителях реализуется динамическая обработка, ограничивающая уровень проигрывания ниже некоторых порогов ограничения, которые могут являться переменными по частоте. В случаях когда динамик находится вблизи или при этих порогах, в то время как другие динамики, принимающие участие в гибком рендеринге, нет, имеет смысл снизить уровень сигнала в ограничивающем динамике и отвести эту энергию в другие, менее нагруженные динамики. Такого поведения можно автоматически добиться в соответствии с некоторыми вариантами осуществления путем надлежащего конфигурирования связанного показателя стоимости. Такой показатель стоимости может включать одно или более из следующего:
■ текущий контроль глобальной громкости проигрывания относительно порогов ограничения громкоговорителей. Например, в большей мере может штрафоваться громкоговоритель, для которого уровень громкости находится ближе к его порогу ограничения;
■ текущий контроль динамических уровней сигналов, возможно, переменных по частоте, во взаимосвязи с порогами ограничения громкоговорителя, возможно, также переменными по частоте. Например, в большей мере может штрафоваться громкоговоритель, для которого подвергаемый текущему контролю уровень сигнала находится ближе к его порогам ограничения;
■ текущий контроль параметров динамической обработки громкоговорителей непосредственно, например, в виде ограничивающих коэффициентов усиления. В некоторых таких примерах в большей мере может штрафоваться громкоговоритель, для которого параметры указывают большее ограничение; и/или
■ текущий контроль фактического мгновенного напряжения, тока и мощности, которые доставляются усилителем в громкоговоритель с целью определения того, действует ли громкоговоритель в линейном диапазоне. Например, в большей мере может штрафоваться громкоговоритель, действующий менее линейно;
○ интеллектуальные динамики со встроенными микрофонами и интерактивный голосовой помощник обычно используют один тип эхокомпенсации для снижения уровня аудиосигнала, проигрываемого из динамика, который принимается записывающим микрофоном. Чем больше это снижение, тем выше вероятность того, что динамик услышит и распознает говорящего в пространстве. Если остаточный сигнал эхокомпенсатора является стабильно высоким, это может являться индикатором того, что динамик приводится в действие в нелинейном участке, где предсказание пути эха становится сложным. В таком случае может иметь смысл отведение энергии сигнала в сторону от этого динамика, поэтому может являться преимущественным показатель стоимости, учитывающий выполнение эхокомпенсации. Такой показатель стоимости может приписывать высокую стоимость динамику, для которого выполнение связанной с ним эхокомпенсации является неудовлетворительным;
○ для достижения предсказуемой визуализации при рендеринге пространственных аудиоданных через ряд громкоговорителей обычно требуется, чтобы проигрывание через набор громкоговорителей было разумным образом синхронизировано во времени. Для проводных громкоговорителей это является данностью, но для множества беспроводных громкоговорителей синхронизация может являться сложной и зависящей от конечного результата. В этом случае для каждого громкоговорителя может являться возможным сообщение его относительной степени синхронизации с целевым значением, и эта степень может затем передаваться в показатель стоимости синхронизации. В некоторых таких примерах громкоговорители с меньшей степенью синхронизации могут штрафоваться в большей мере и, таким образом, исключаться из рендеринга. Дополнительно плотная синхронизация может не требоваться для некоторых типов аудиосигналов, например, составляющих смешанного аудиосигнала, намеченных как диффузные или ненаправленные. В некоторых реализациях составляющие могут быть помечены так, что такие метаданные и показатель стоимости синхронизации можно модифицировать так, что штраф уменьшается.
Ниже описаны дополнительные примеры вариантов осуществления. Аналогично стоимости близости, заданной в уравнениях 9a и 9b, также можно удобно выразить каждый из новых показателей функции стоимости, , в виде взвешенной суммы квадратов абсолютных значений активаций динамиков, например, следующим образом:
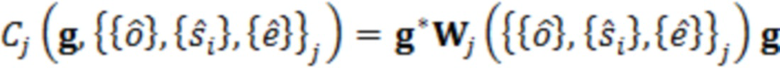 , (13a)
, (13a)
где 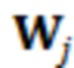 представляет собой диагональную матрицу весовых коэффициентов
представляет собой диагональную матрицу весовых коэффициентов 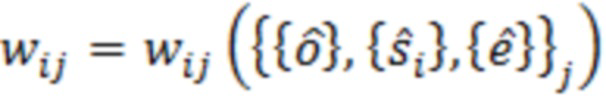 , описывающую стоимость, связанную со значением активации динамика i, для показателя j:
, описывающую стоимость, связанную со значением активации динамика i, для показателя j:
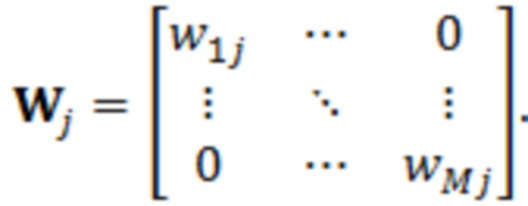 (13b)
(13b)
Комбинирование уравнений 13a и b с квадратной матричной версией функций стоимости CMAP и FV, заданной в уравнении 10, обеспечивает потенциально полезную реализацию общераспространенной функции стоимости (согласно некоторым вариантам осуществления), заданной в уравнении 12:
 (14)
(14)
При таком определении новых показателей функции стоимости общая функция стоимости остается квадратной матрицей, и оптимальное множество значений активации, , можно найти путем дифференцирования уравнения 14 для получения следующего:
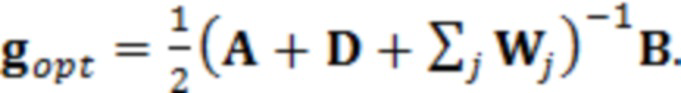 (15)
(15)
Полезно рассматривать каждый из весовых показателей  в зависимости от заданного значения непрерывного штрафа,
в зависимости от заданного значения непрерывного штрафа,  , для каждого из громкоговорителей. В одном иллюстративном варианте осуществления это значение штрафа представляет собой расстояние от объекта (подлежащего рендерингу) до рассматриваемого громкоговорителя. В другом иллюстративном варианте осуществления это значение штрафа представляет неспособность данного громкоговорителя воспроизводить некоторые частоты. На основе этого значения штрафа весовые показатели можно параметризовать в виде:
, для каждого из громкоговорителей. В одном иллюстративном варианте осуществления это значение штрафа представляет собой расстояние от объекта (подлежащего рендерингу) до рассматриваемого громкоговорителя. В другом иллюстративном варианте осуществления это значение штрафа представляет неспособность данного громкоговорителя воспроизводить некоторые частоты. На основе этого значения штрафа весовые показатели можно параметризовать в виде:
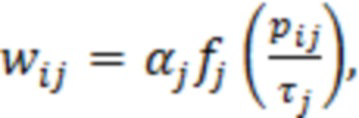 (16)
(16)
где 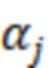 представляет предварительный коэффициент (который учитывает глобальную интенсивность весового показателя), где
представляет предварительный коэффициент (который учитывает глобальную интенсивность весового показателя), где  представляет порог штрафа (рядом или за пределами которого весовой показатель становится значительным), и где
представляет порог штрафа (рядом или за пределами которого весовой показатель становится значительным), и где 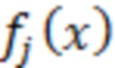 представляет монотонно возрастающую функцию. Например, когда
представляет монотонно возрастающую функцию. Например, когда 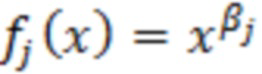 , весовой показатель имеет вид:
, весовой показатель имеет вид:
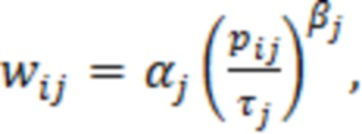 (17)
(17)
где , 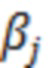 ,
, 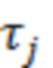 представляют собой перестраиваемые параметры, которые указывают на глобальную силу штрафа, резкость наступления штрафа и протяженность штрафа соответственно. При установке этих перестраиваемых значений следует тщательно следить за тем, чтобы относительное воздействие показателя стоимости,
представляют собой перестраиваемые параметры, которые указывают на глобальную силу штрафа, резкость наступления штрафа и протяженность штрафа соответственно. При установке этих перестраиваемых значений следует тщательно следить за тем, чтобы относительное воздействие показателя стоимости,  , относительно любых других дополнительных показателей стоимости, а также и , соответствовало достижению требуемого результата. Например, в качестве эмпирического правила, если требуется, чтобы конкретный штраф явно доминировал над остальными, то подходящей может являться установка его интенсивности приблизительно в десять раз больше следующей по величине интенсивности штрафа.
, относительно любых других дополнительных показателей стоимости, а также и , соответствовало достижению требуемого результата. Например, в качестве эмпирического правила, если требуется, чтобы конкретный штраф явно доминировал над остальными, то подходящей может являться установка его интенсивности приблизительно в десять раз больше следующей по величине интенсивности штрафа.
В случае штрафования всех громкоговорителей часто удобно вычесть минимальный штраф из всех весовых показателей при последующей обработке так, чтобы не штрафовался по меньшей мере один из динамиков:
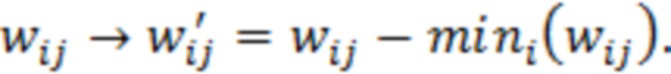 (18)
(18)
Как указано выше, существует множество возможных вариантов использования, которые можно реализовать с использованием новых показателей функции стоимости, описанных в данном документе (и аналогичных новых показателей функции стоимости, используемых в соответствии с другими вариантами осуществления). Далее более конкретные подробности описаны с помощью трех примеров: перемещение аудиоданных в направлении слушателя или говорящего, перемещение аудиоданных в направлении от слушателя или говорящего и перемещение аудиоданных в сторону от ориентира.
В первом примере то, что будет называться в данном документе «силой притяжения», используется для подтягивания аудиоданных к некоторому положению, которое в некоторых примерах может представлять собой положение слушателя или говорящего, положение ориентира, положение мебели и т. д. Это положение в данном документе может называться «положением силы притяжения» или «местоположением аттрактора». В контексте данного документа «сила притяжения» представляет собой фактор, который благоприятствует относительно большему значению активации громкоговорителя, расположенного ближе к положению силы притяжения. Согласно этому примеру весовой коэффициент 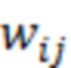 принимает форму уравнения 17 со значением непрерывного штрафа,
принимает форму уравнения 17 со значением непрерывного штрафа, 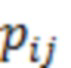 , заданным расстоянием i-го динамика от фиксированного местоположения аттрактора,
, заданным расстоянием i-го динамика от фиксированного местоположения аттрактора, 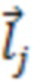 , и пороговым значением , заданным максимальным из этих расстояний по всем динамикам:
, и пороговым значением , заданным максимальным из этих расстояний по всем динамикам:
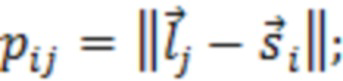 и (19a)
и (19a)
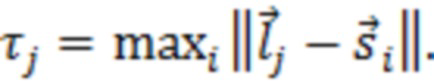 (19b)
(19b)
Для иллюстрации варианта использования с «подтягиванием» аудиоданных к слушателю или говорящему, в частности, устанавливаем = 20, = 3, и приравниваем вектору, соответствующему положению слушателя/говорящего под углом 180 градусов (нижняя центральная часть графика). Эти значения , и являются лишь примерами. В некоторых реализациях может находиться в диапазоне от 1 до 100, и может находиться в диапазоне от 1 до 25. На фиг. 18 представлен график значений активации динамиков в иллюстративном варианте осуществления. В этом примере на фиг. 18 представлены значения активации динамиков, 1505b, 1510b, 1515b, 1520b и 1525b, которые содержат оптимальное решение функции стоимости для таких же положений динамиков, как на фиг. 15 и 16, с добавлением силы притяжения, представленной в виде . На фиг. 19 представлен график положений рендеринга объектов в иллюстративном варианте осуществления. В этом примере на фиг. 19 представлены соответствующие идеальные положения 1630b объектов для множества возможных углов объектов и соответствующие фактические положения 1635b рендеринга для этих объектов, которые соединены с идеальными положениями 1630b объектов пунктирными линиями 1640b. Смещенная ориентация фактических положений 1635b рендеринга к фиксированному положению иллюстрирует влияние весовых коэффициентов аттрактора на оптимальное решение функции стоимости.
Во втором и третьем примерах «сила отталкивания» используется для «отталкивания» аудиоданных в сторону от положения, которое может представлять собой положение человека (например, положение слушателя, положение говорящего и т. д.) или другое положение, такое как положение ориентира, положение мебели и т. д. В некоторых примерах силу отталкивания можно использовать для отталкивания аудиоданных в сторону от некоторой области или зоны среды прослушивания, такой как область рабочего помещения, область чтения, область кровати или спальни (например, кровати или спальни ребенка) и т. д. Согласно некоторым таким примерам в качестве примера зоны или области можно использовать конкретное положение. Например, положение, которое представляет кровать ребенка, может представлять собой оценочное положение головы ребенка, оценочное местоположение источника звука, соответствующее ребенку, и т. д. Это положение в данном документе может называться «положением силы отталкивания» или «местоположением отталкивания». В контексте данного документа «сила отталкивания» представляет собой фактор, который благоприятствует относительно меньшему значению активации громкоговорителя, расположенного ближе к положению силы отталкивания. Согласно этому примеру и заданы относительно фиксированного местоположения отталкивания, , подобно силе притяжения в уравнении 19:
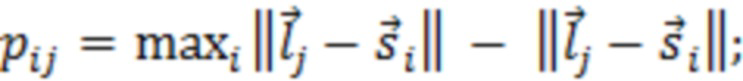 и (19c)
и (19c)
(19d)
Для иллюстрации варианта использования с отталкиванием аудиоданных от слушателя или говорящего в одном примере, в частности, можно установить = 5, = 2, и приравнять вектору, соответствующему положению слушателя/говорящего под углом 180 градусов (в нижней центральной части графика). Эти значения , и являются лишь примерами. Как отмечено выше, в некоторых примерах может находиться в диапазоне от 1 до 100, и может находиться в диапазоне от 1 до 25. На фиг. 20 представлен график значений активации динамиков в иллюстративном варианте осуществления. Согласно этому примеру на фиг. 20 представлены значения активации динамиков, 1505c, 1510c, 1515c, 1520c и 1525c, которые содержат оптимальное решение функции стоимости для таких же положений динамиков, как на предыдущих фигурах, с добавлением силы отталкивания, представленной в виде . На фиг. 21 представлен график положений рендеринга объектов в иллюстративном варианте осуществления. В этом примере на фиг. 21 представлены идеальные положения 1630c объектов для множества возможных углов объектов и соответствующие фактические положения 1635c рендеринга для этих объектов, которые соединены с идеальными положениями 1630c объектов пунктирными линиями 1640c. Смещенная ориентация фактических положений 1635c рендеринга в сторону от фиксированного положения иллюстрирует влияние весовых коэффициентов репеллера на оптимальное решение функции стоимости.
В третьем примере используется случай «отталкивания» аудиоданных в сторону от ориентира, являющегося чувствительным к звуку, такого как дверь в комнату, где спит ребенок. Аналогично последнему примеру приравняем вектору, соответствующему положению двери под углом 180 градусов (нижняя центральная часть графика). Для достижения большей силы отталкивания и полного смещения звукового поля в переднюю часть первичного пространства прослушивания установим = 20, и = 5. На фиг. 22 представлен график значений активации динамиков в иллюстративном варианте осуществления. И снова, в этом примере на фиг. 22 представлены значения активации динамиков, 1505d, 1510d, 1515d, 1520d и 1525d, которые содержат оптимальное решение для такого же набора положений динамиков с добавлением большей силы отталкивания. На фиг. 23 представлен график положений рендеринга объектов в иллюстративном варианте осуществления. И снова, в этом примере на фиг. 23 представлены идеальные положения 1630d объектов для множества возможных углов объектов и соответствующие фактические положения 1635d рендеринга для этих объектов, которые соединены с идеальными положениями 1630d объектов пунктирными линиями 1640d. Смещенная ориентация фактических положений 1635d рендеринга иллюстрирует влияние больших весовых коэффициентов репеллера на оптимальное решение функции стоимости.
В дополнительном примере способа 250 согласно фиг. 2B этот вариант использования отвечает за выбор двух или более аудиоустройств в аудиосреде (этап 265), и в нем применяют силу «отталкивания» к аудиоданным (этап 275). Согласно предыдущему примеру выбор двух или более аудиоустройств может в некоторых вариантах осуществления принимать форму значений f_n, безразмерных параметров, управляющих степенью, с которой происходят изменения аудиообработки. Возможно множество комбинаций. В одном простом примере весовые коэффициенты, соответствующие силе отталкивания, можно выбирать непосредственно как 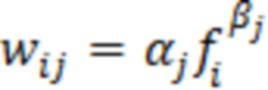 , штрафующий устройства, выбранные с помощью аспекта «решение».
, штрафующий устройства, выбранные с помощью аспекта «решение».
В дополнение к предыдущим примерам определения весовых коэффициентов, в некоторых реализациях весовые коэффициенты можно определить следующим образом:
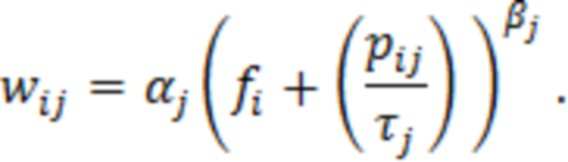
В предыдущем уравнении , , представляют перестраиваемые параметры, которые указывают глобальную силу штрафа, резкость наступления штрафа и протяженность штрафа соответственно, как описано выше со ссылкой на фиг. 17. Соответственно, предыдущее уравнение можно понять как комбинацию ряда показателей штрафов, возникающих в результате ряда одновременных вариантов использования. Например, аудиоданные могут «отталкиваться в сторону» от чувствительного ориентира с использованием показателей 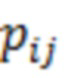 и
и 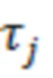 , как описано в более раннем примере, и одновременно «отталкиваться в сторону» от местоположения микрофона, где необходимо улучшить SER, с использованием показателя
, как описано в более раннем примере, и одновременно «отталкиваться в сторону» от местоположения микрофона, где необходимо улучшить SER, с использованием показателя 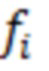 , определенного с помощью аспекта «решение».
, определенного с помощью аспекта «решение».
В предыдущих примерах также введен s_n, выраженный непосредственно в единицах децибел увеличения отношения речь-эхо. Некоторые варианты осуществления могут включать выбор значений 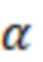 и
и 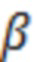 (силы штрафа и резкости наступления штрафа соответственно) в некоторой части на основе значения s_n в дБ, и в ранее указанных формулах для можно использовать
(силы штрафа и резкости наступления штрафа соответственно) в некоторой части на основе значения s_n в дБ, и в ранее указанных формулах для можно использовать  и
и  вместо и соответственно. Например, значение s_i = -20 дБ может соответствовать высокой стоимости активации i-го динамика. В некоторых таких вариантах осуществления можно приравнять числу, которое во много раз больше типичных значений других показателей в функции стоимости, и . Например, новое значение «альфа» можно определить с помощью
вместо и соответственно. Например, значение s_i = -20 дБ может соответствовать высокой стоимости активации i-го динамика. В некоторых таких вариантах осуществления можно приравнять числу, которое во много раз больше типичных значений других показателей в функции стоимости, и . Например, новое значение «альфа» можно определить с помощью 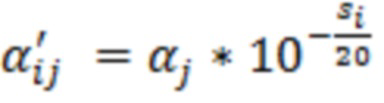 , что для значения s_i = -20 дБ будет приводить к принятию значения, которое в 10 раз больше, чем обычно бывает в функции стоимости. Модификация для установки в диапазоне 0,5 <
, что для значения s_i = -20 дБ будет приводить к принятию значения, которое в 10 раз больше, чем обычно бывает в функции стоимости. Модификация для установки в диапазоне 0,5 < 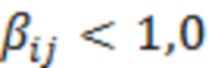 в некоторых случаях может представлять собой подходящую модификацию на основе больших отрицательных значений s_i, «отталкивающих» аудиоданные в сторону от еще большего участка в окрестности i-го динамика. Например, значения s_i можно отобразить в согласно:
в некоторых случаях может представлять собой подходящую модификацию на основе больших отрицательных значений s_i, «отталкивающих» аудиоданные в сторону от еще большего участка в окрестности i-го динамика. Например, значения s_i можно отобразить в согласно:
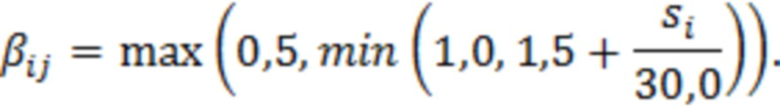
В этом примере для s_i = -20,0 дБ будет равно 0,8333.
Аспекты иллюстративных вариантов осуществления включают следующие пронумерованные иллюстративные варианты осуществления (EEE).
EEE1. Способ (или система) увеличения отношения сигнал-эхо с целью обнаружения голосовых команд от пользователя, в котором (в которой):
a. используют множество устройств для создания выходного материала аудиопрограммы;
b. имеется известный набор расстояний или упорядоченная взаимосвязь для устройств относительно слушателя;
c. система выборочно снижает громкость устройства с наименьшим расстоянием от пользователя.
EEE2. Способ или система согласно EEE1, при этом обнаружение сигнала включает обнаружение из любого издающего шум объекта или из требуемой точки наблюдения за аудиоданными, которая характеризуется известной взаимосвязью расстояния до набора устройств.
EEE3. Способ или система согласно EEE1 или EEE2, при этом упорядочение устройств включает учет расстояния и отношения сигнал-эхо устройства для номинального расстояния от источника.
EEE4. Способ или система согласно любому из EEE1–EEE3, при этом упорядочение учитывает обобщенную близость устройства к пользователю и ее приблизительную взаимность для оценки наиболее эффективного увеличения отношения сигнал-эхо и упорядочения устройств в этом смысле. Аспекты некоторых раскрытых реализаций включают систему или устройство, выполненное (например, запрограммированное) с возможностью выполнения одного или более раскрытых способов, и материальный машиночитаемый носитель данных (например, диск), на котором хранится код для реализации одного или более раскрытых способов или их этапов. Например, система может представлять собой или содержать программируемый процессор общего назначения, процессор цифровой обработки сигналов или микропроцессор, запрограммированный с использованием программного обеспечения или программно-аппаратного обеспечения и/или иным образом выполненный с возможностью выполнения любой из множества операций над данными, включая один или более раскрытых способов или их этапов. Такой процессор общего назначения может представлять собой или содержать компьютерную систему, содержащую устройство ввода, запоминающее устройство и подсистему обработки, запрограммированную (и/или иным образом выполненную) с возможностью выполнения одного или более раскрытых способов (или их этапов) в ответ на передаваемые в нее данные.
Некоторые раскрытые варианты осуществления реализованы в виде конфигурируемого (например, программируемого) процессора цифровой обработки сигналов (DSP), который выполнен (например, запрограммирован и иначе сконфигурирован) с возможностью выполнения требуемой обработки над аудиосигналом (аудиосигналами), включая выполнение одного или более раскрытых способов. Альтернативно некоторые варианты осуществления (или их элементы) могут быть реализованы в виде процессора общего назначения (например, персонального компьютера (РС), или другой компьютерной системы, или микропроцессора, который может содержать устройство ввода и запоминающее устройство), запрограммированного с помощью программного обеспечения или программно-аппаратного обеспечения и/или иначе выполненного с возможностью выполнения любой из множества операций, включая один или более раскрытых способов или их этапов. Альтернативно элементы некоторых раскрытых вариантов осуществления реализованы в виде процессора общего назначения или DSP, выполненного (например, запрограммированного) с возможностью выполнения одного или более раскрытых способов или их этапов, и система также содержит другие элементы (например, один или более громкоговорителей и/или один или более микрофонов). Процессор общего назначения, выполненный с возможностью выполнения одного или более раскрытых способов или их этапов, обычно соединен с устройством ввода (например, мышью и/или клавиатурой), запоминающим устройством и устройством отображения.
Другой аспект некоторых раскрытых реализаций представляет собой машиночитаемый носитель данных (например, диск или другой материальный носитель данных), на котором хранится код для выполнения (например, исполняемый код для выполнения) любого варианта осуществления одного или более раскрытых способов или их этапов.
Несмотря на то что в данном документе описаны конкретные варианты осуществления и применения, средним специалистам в данной области станет ясно, что возможно множество вариаций вариантов осуществления и применений, описанных в данном документе, без отступления от объема материала, раскрытого в описании и формуле данного документа. Следует понимать, что, несмотря на то что были показаны и описаны некоторые реализации, настоящее изобретение не следует ограничивать описанными и показанными конкретными вариантами осуществления или описанными конкретными способами.
| название | год | авторы | номер документа |
|---|---|---|---|
| АВТОМАТИЧЕСКАЯ ЛОКАЛИЗАЦИЯ АУДИОУСТРОЙСТВ | 2021 |
|
RU2825341C1 |
| ДИНАМИЧЕСКАЯ ОБРАБОТКА В УСТРОЙСТВАХ С ОТЛИЧАЮЩИМИСЯ ФУНКЦИОНАЛЬНЫМИ ВОЗМОЖНОСТЯМИ ВОСПРОИЗВЕДЕНИЯ | 2020 |
|
RU2783150C1 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ УПРАВЛЕНИЯ НИЗКИМИ ЗВУКОВЫМИ ЧАСТОТАМИ | 2019 |
|
RU2771954C2 |
| ОПТИМИЗАЦИЯ ГРОМКОСТИ И ДИНАМИЧЕСКОГО ДИАПАЗОНА ЧЕРЕЗ РАЗЛИЧНЫЕ УСТРОЙСТВА ВОСПРОИЗВЕДЕНИЯ | 2018 |
|
RU2777880C2 |
| ОПТИМИЗАЦИЯ ГРОМКОСТИ И ДИНАМИЧЕСКОГО ДИАПАЗОНА ЧЕРЕЗ РАЗЛИЧНЫЕ УСТРОЙСТВА ВОСПРОИЗВЕДЕНИЯ | 2014 |
|
RU2665873C1 |
| ОБРАБОТКА ПРОСТРАНСТВЕННО ДИФФУЗНЫХ ИЛИ БОЛЬШИХ ЗВУКОВЫХ ОБЪЕКТОВ | 2020 |
|
RU2803638C2 |
| ОБРАБОТКА ПРОСТРАНСТВЕННО-ДИФФУЗНЫХ ИЛИ БОЛЬШИХ ЗВУКОВЫХ ОБЪЕКТОВ | 2014 |
|
RU2716037C2 |
| ОПТИМИЗАЦИЯ ГРОМКОСТИ И ДИНАМИЧЕСКОГО ДИАПАЗОНА ЧЕРЕЗ РАЗЛИЧНЫЕ УСТРОЙСТВА ВОСПРОИЗВЕДЕНИЯ | 2014 |
|
RU2631139C2 |
| ОБНАРУЖЕНИЕ ОДНОВРЕМЕННОГО РАЗГОВОРА С ИСПОЛЬЗОВАНИЕМ ПОВЫШАЮЩЕЙ ДИСКРЕТИЗАЦИИ | 2021 |
|
RU2832721C1 |
| ПОДАВЛЕНИЕ ОСТАТОЧНОГО ЭХО | 2021 |
|
RU2834267C1 |
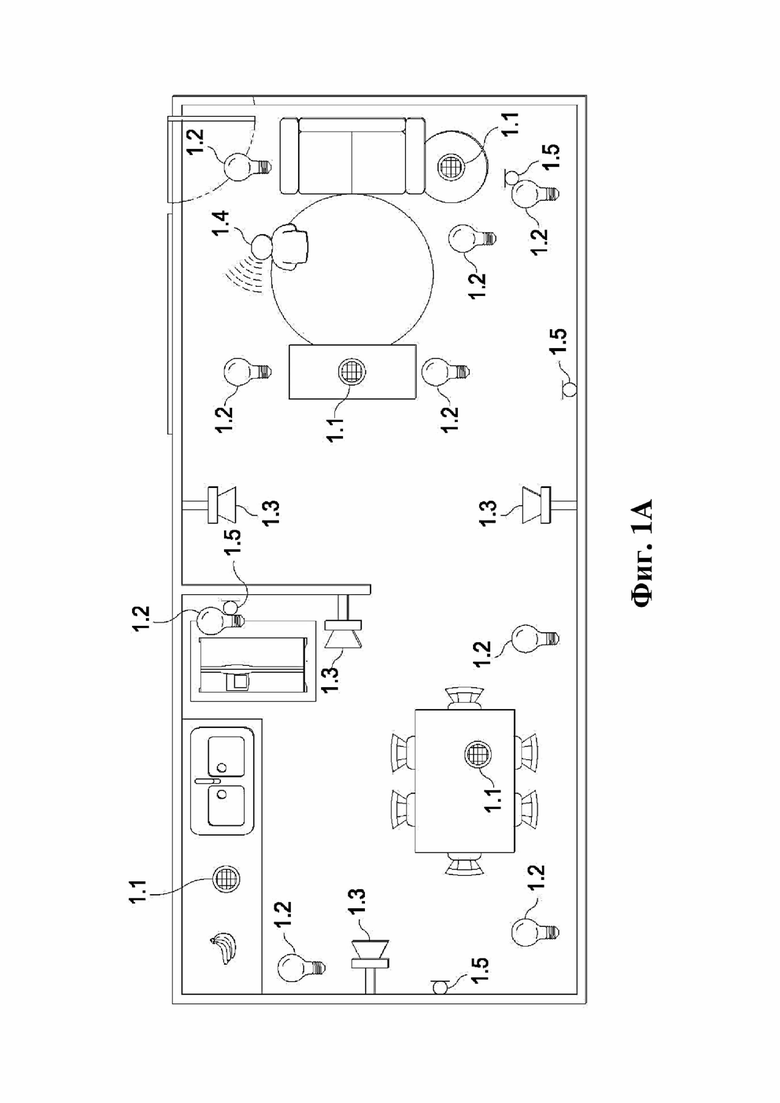
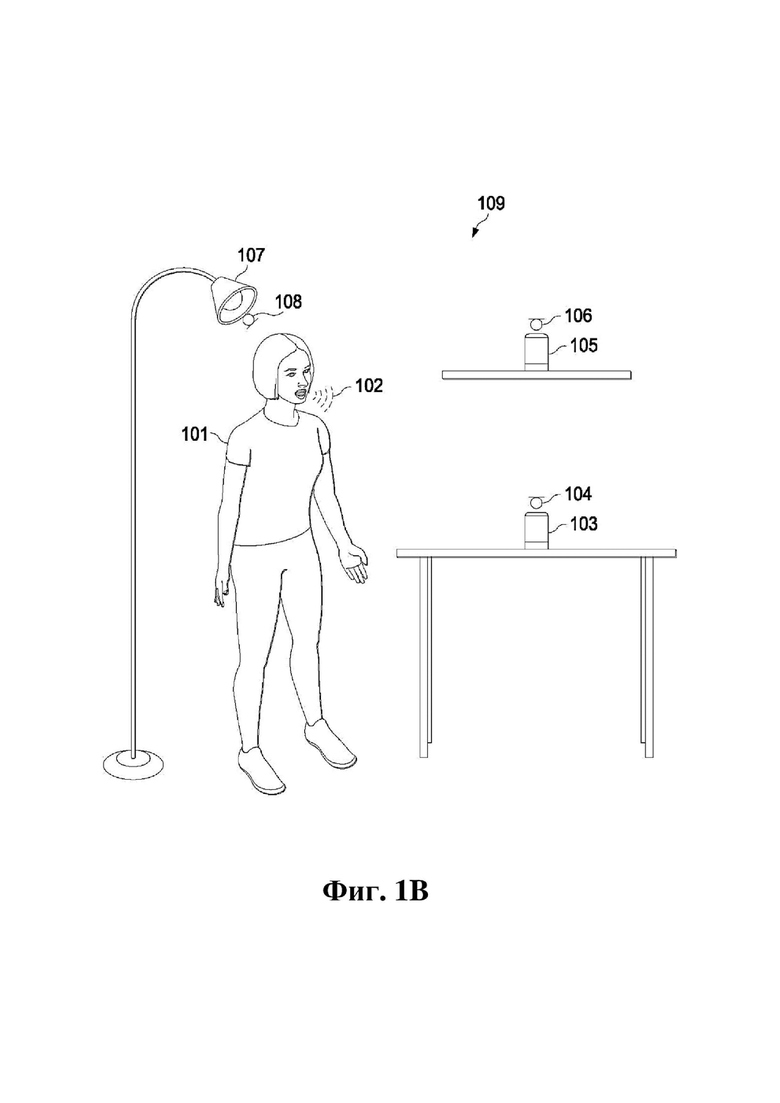
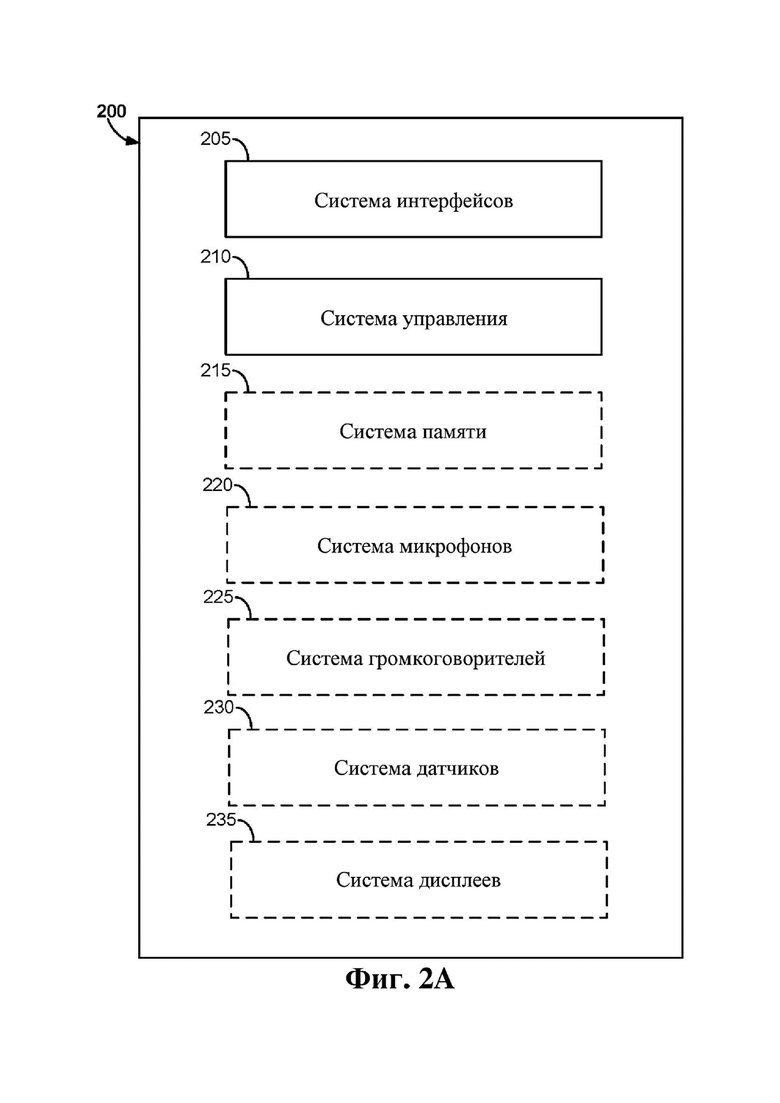
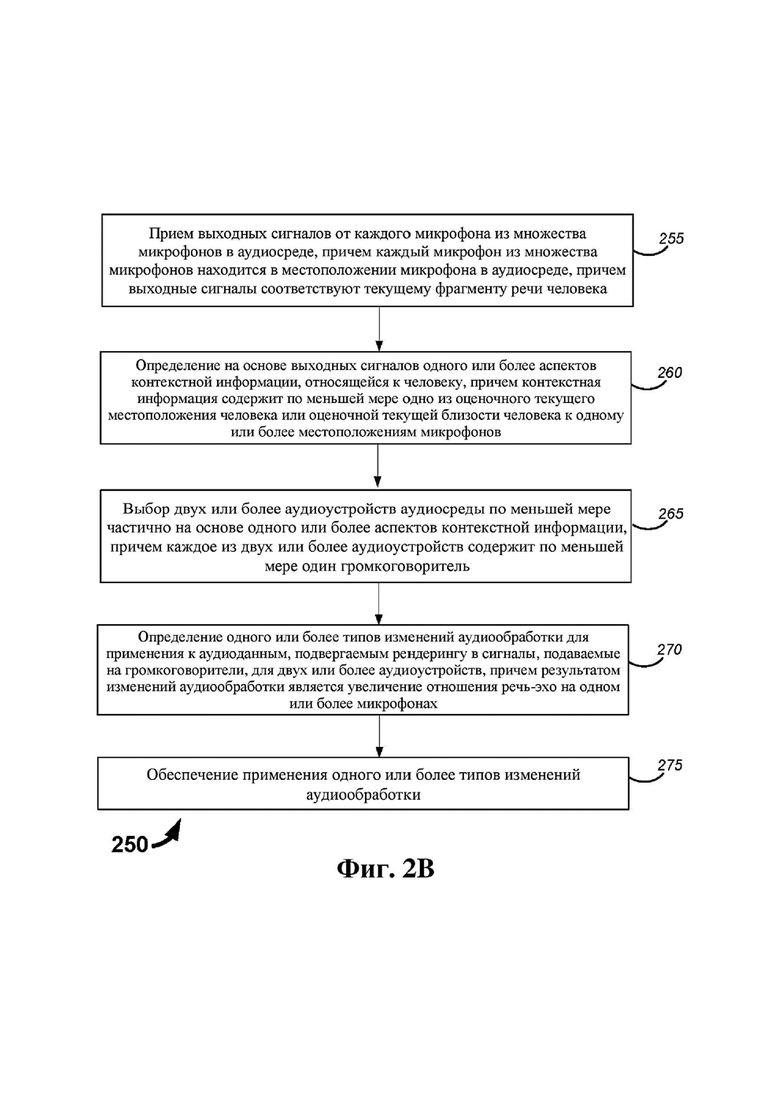
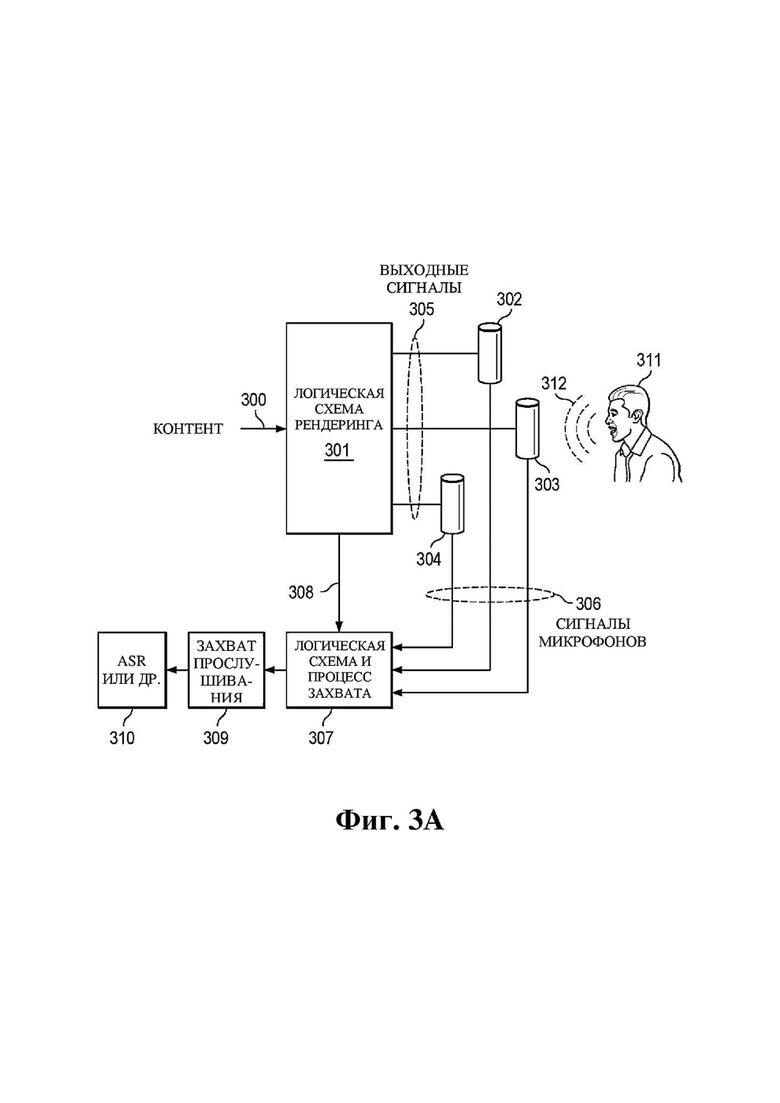
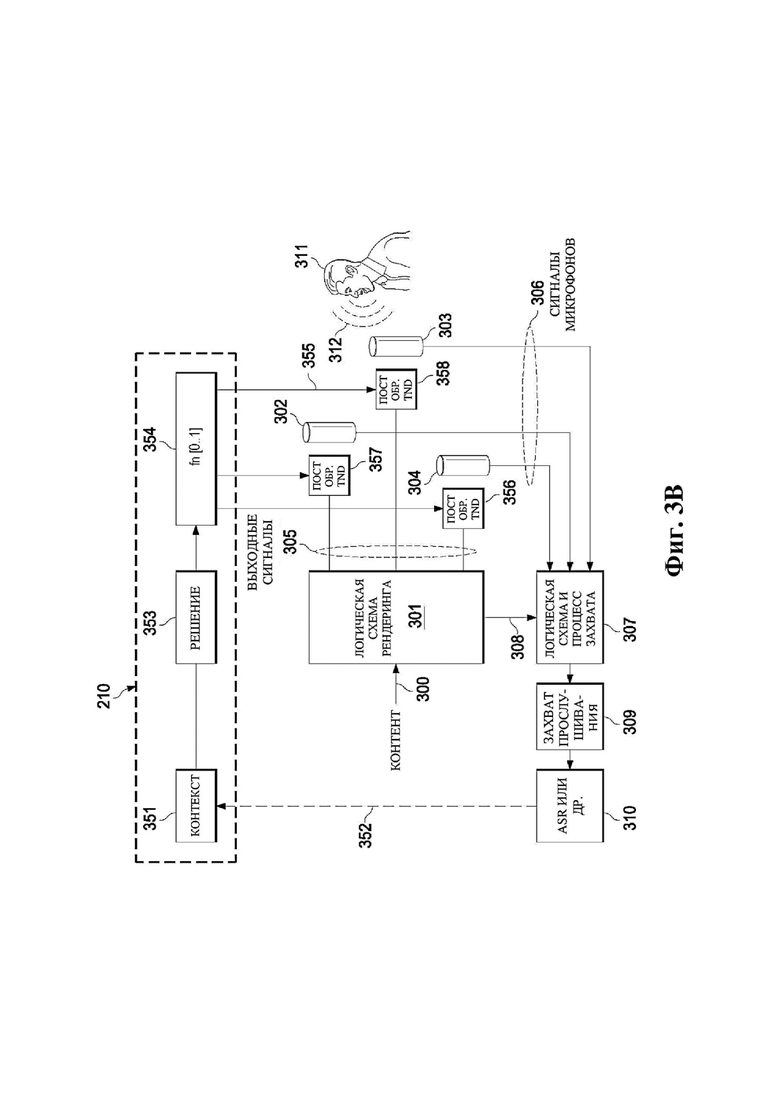
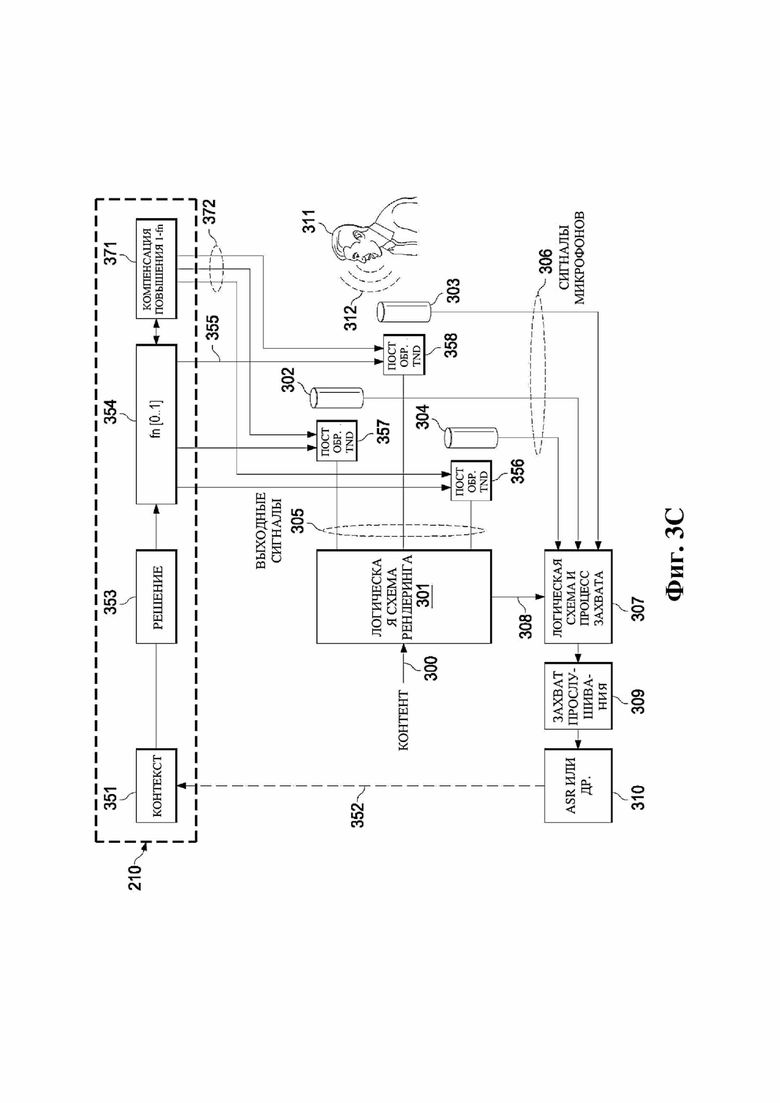
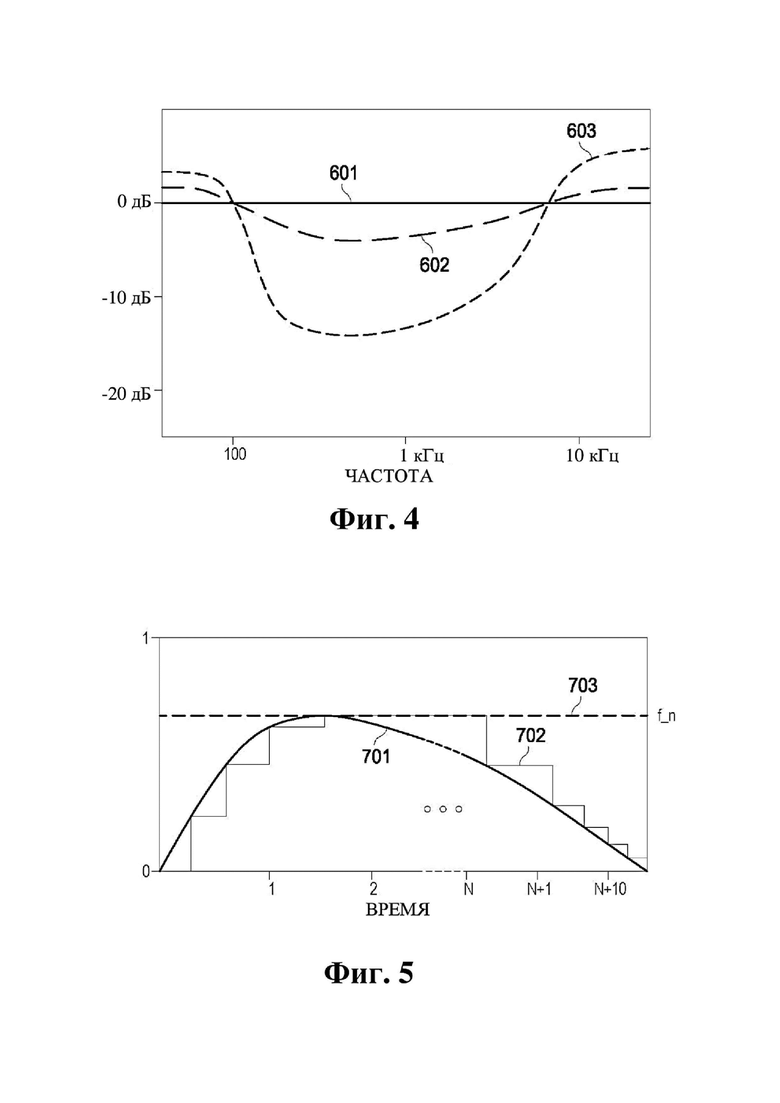
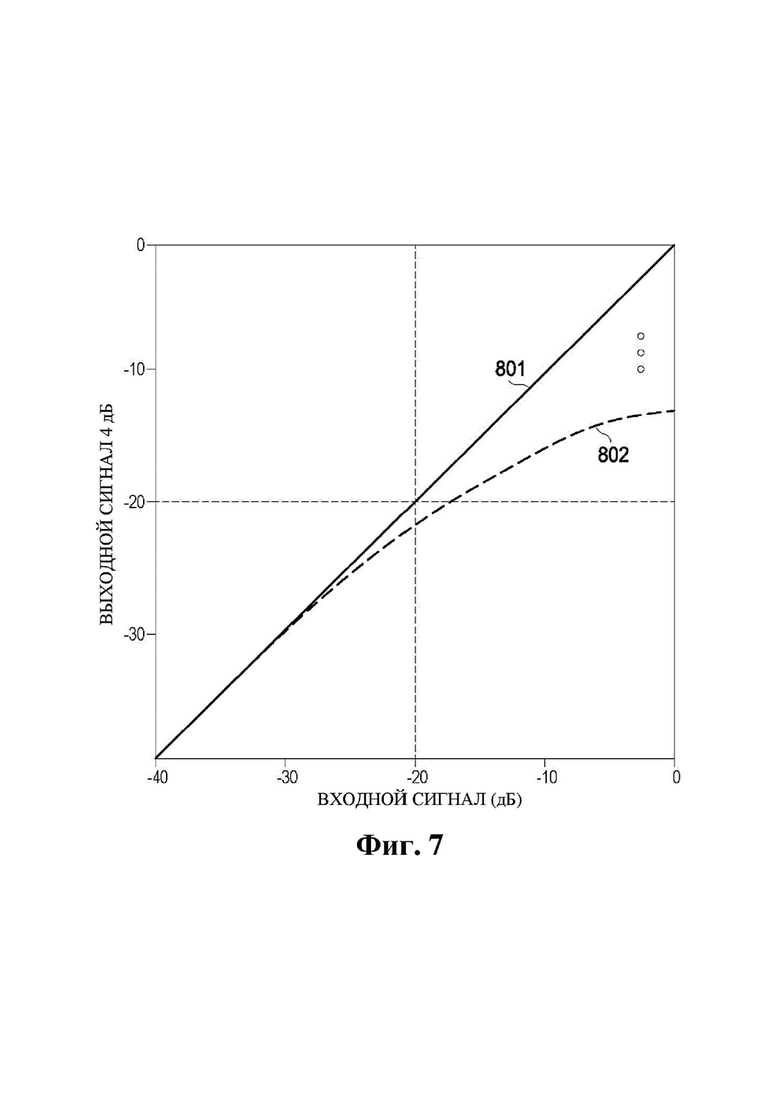
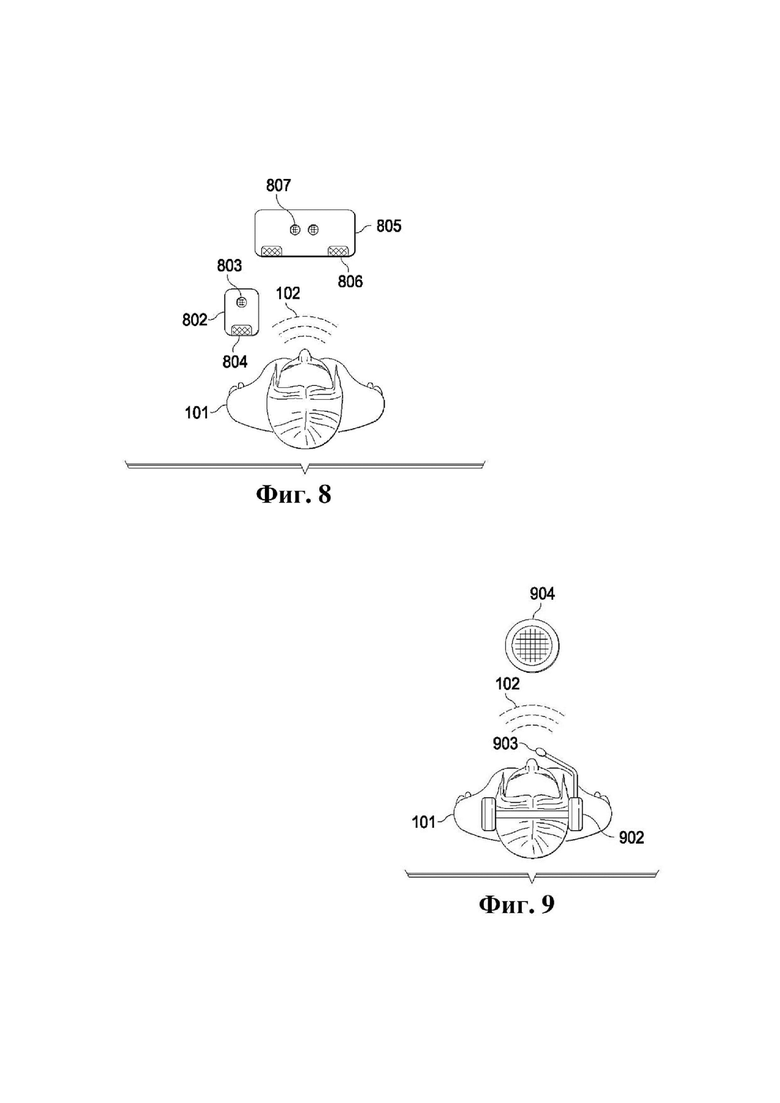
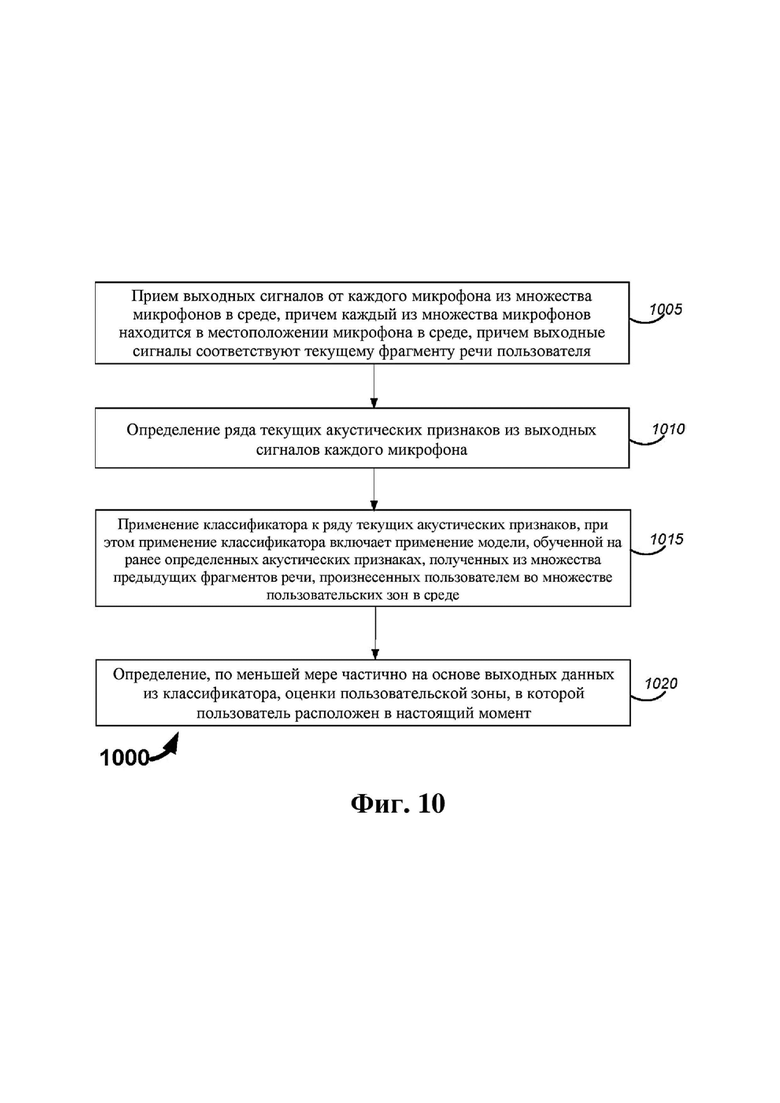
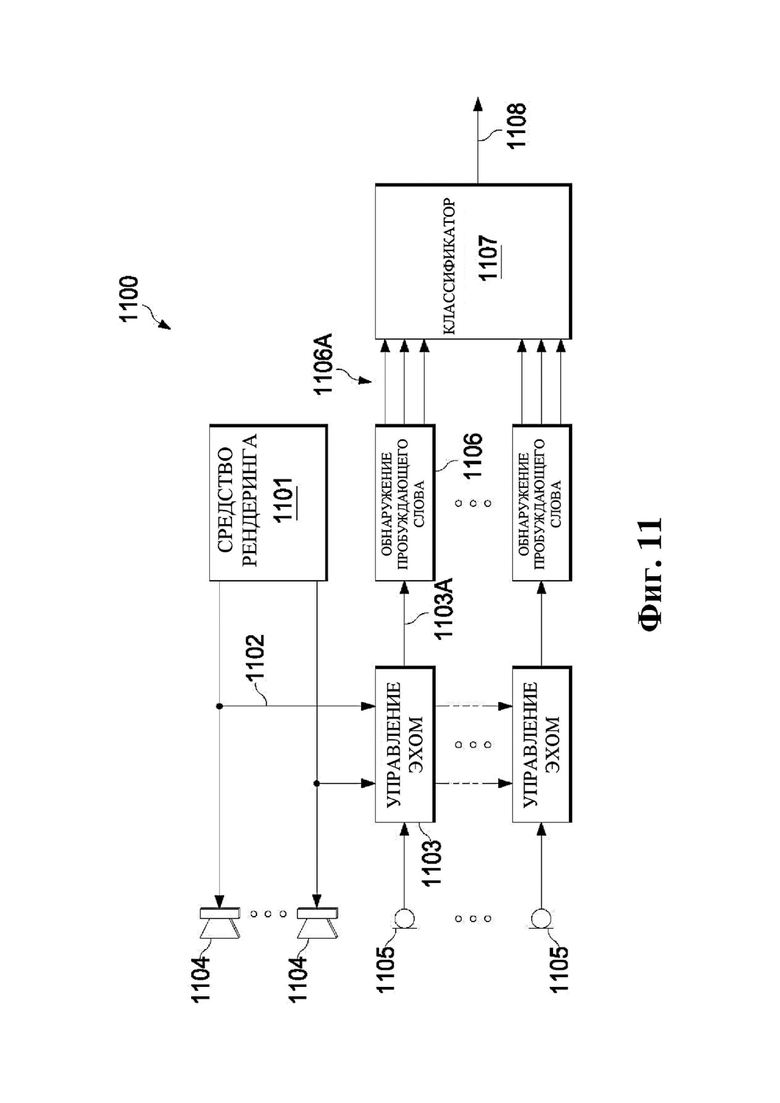
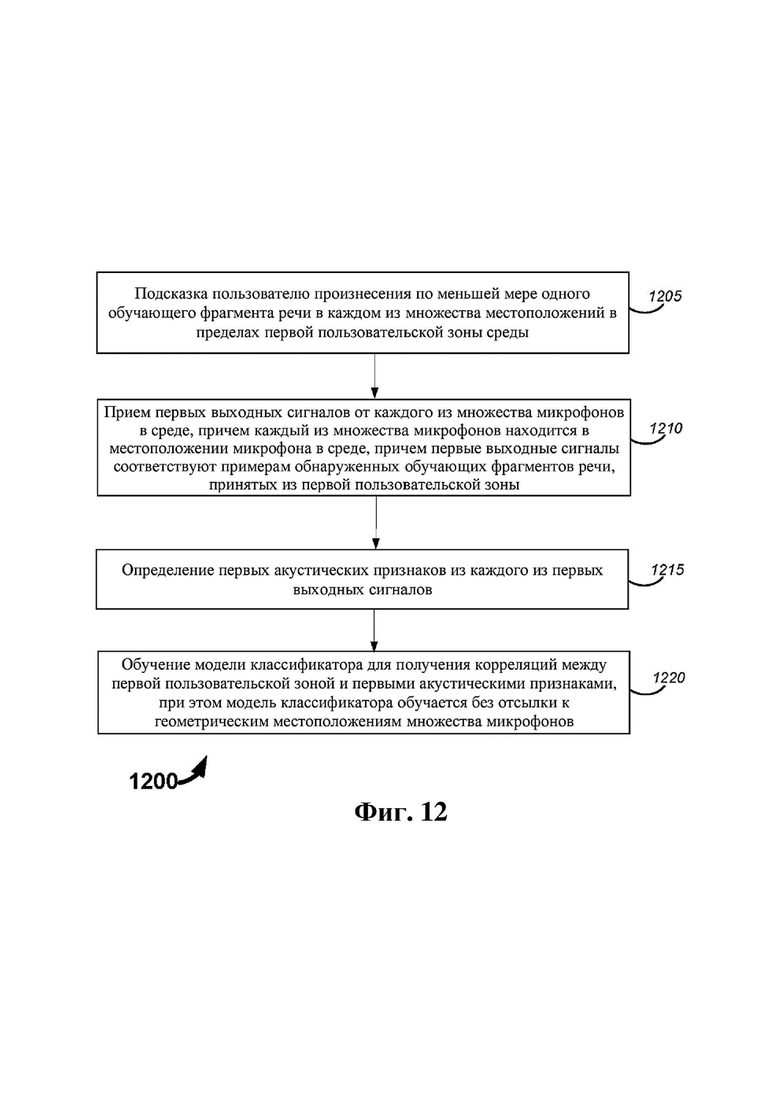
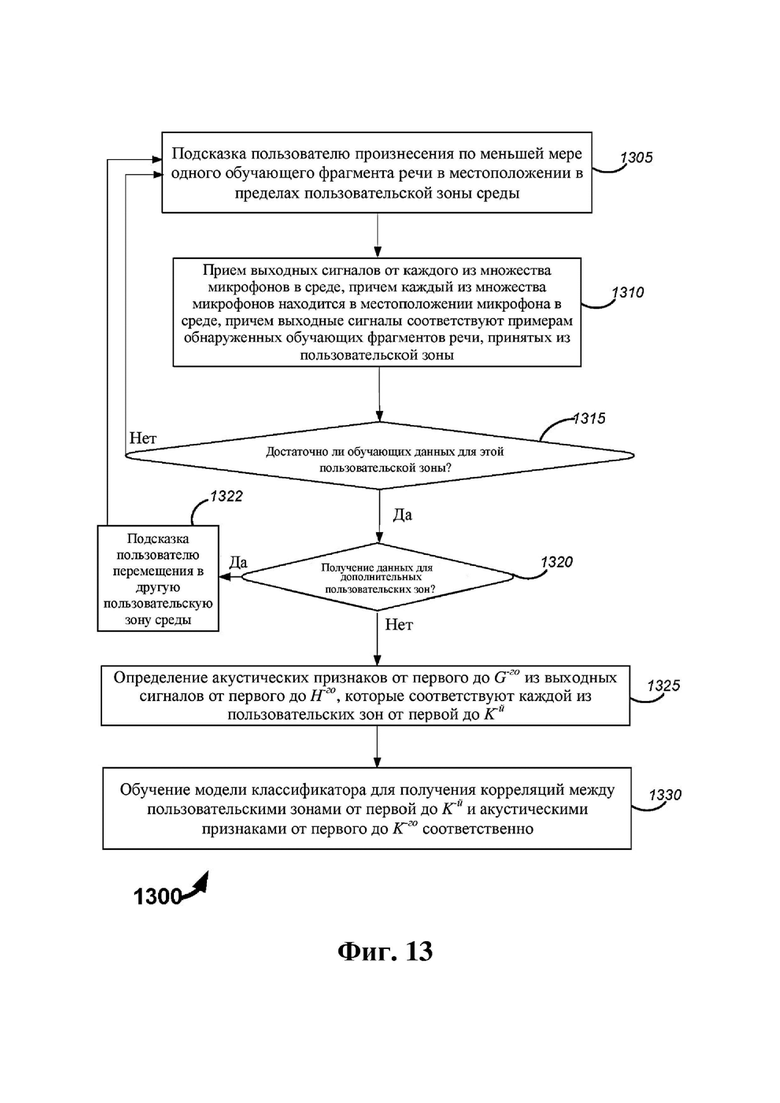
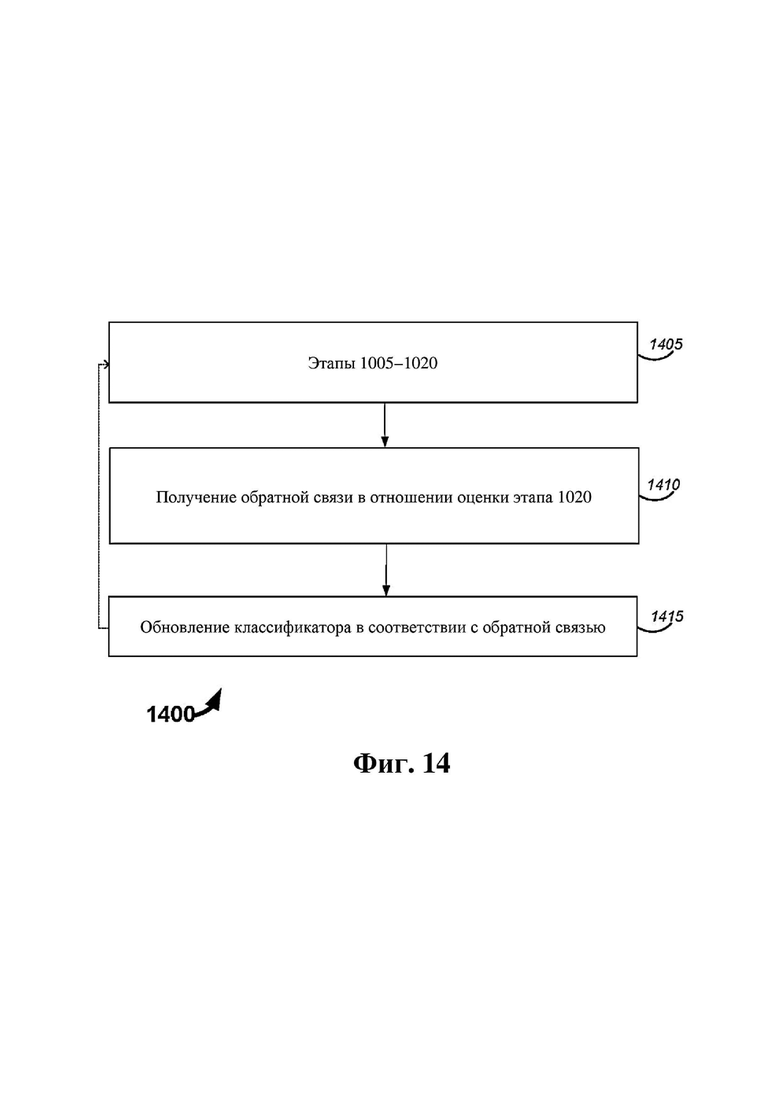
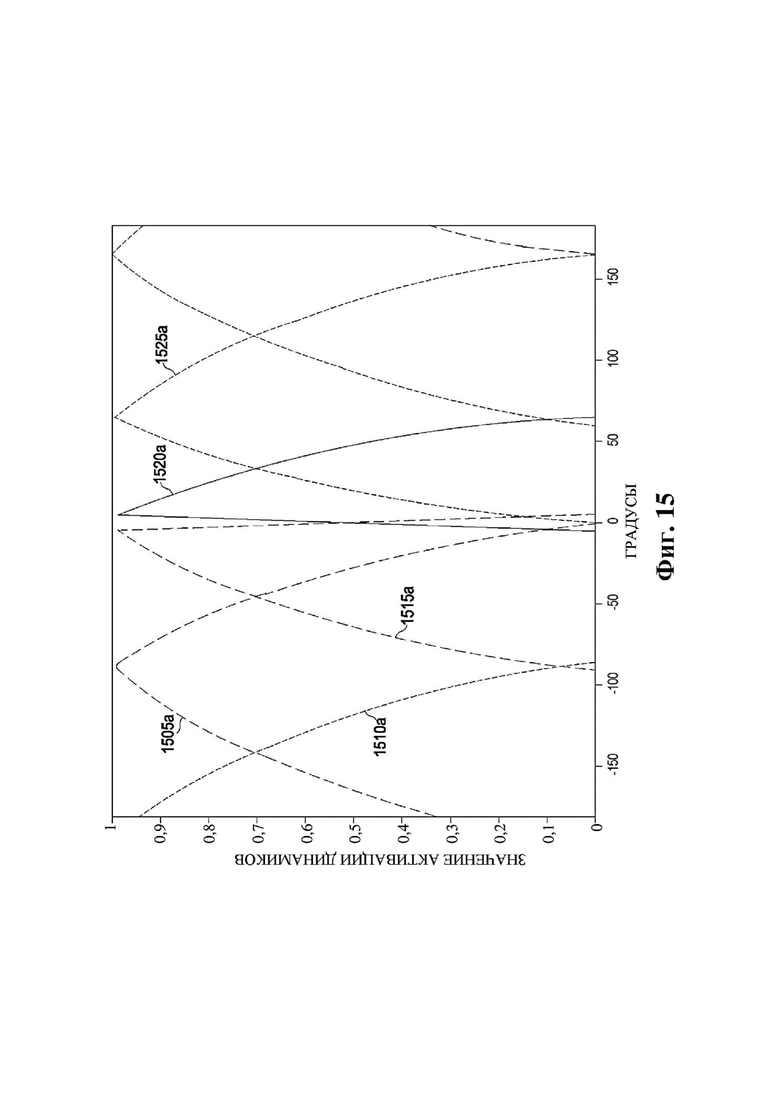
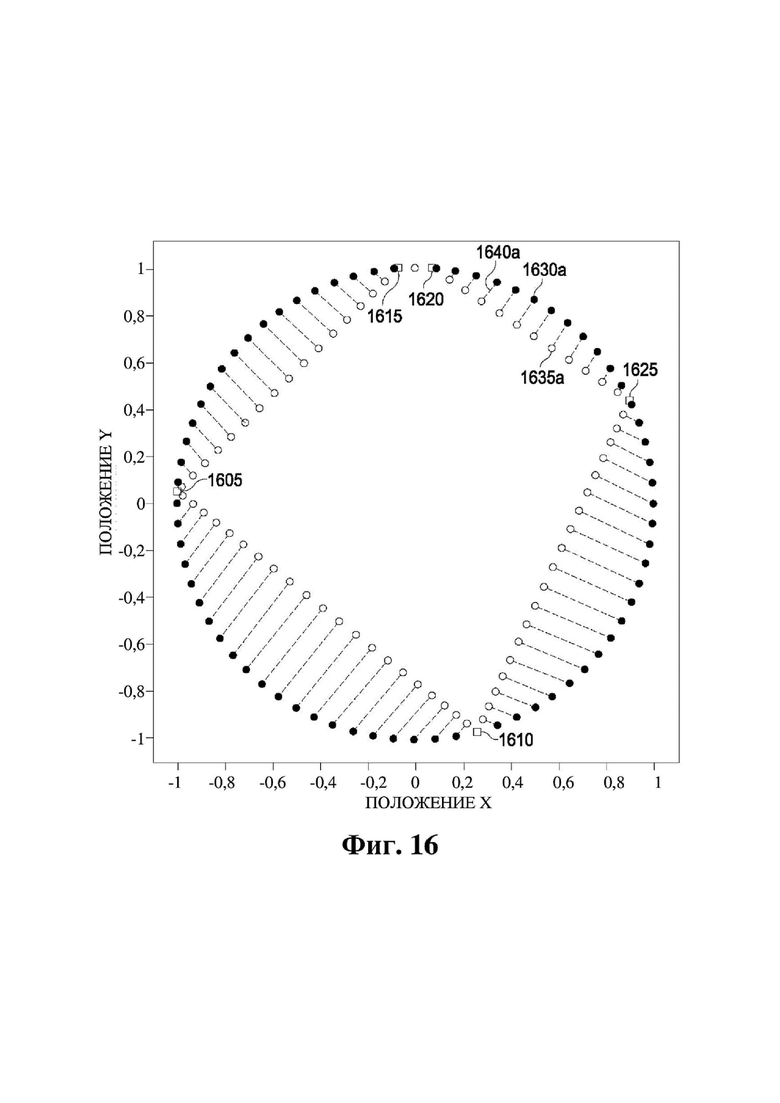

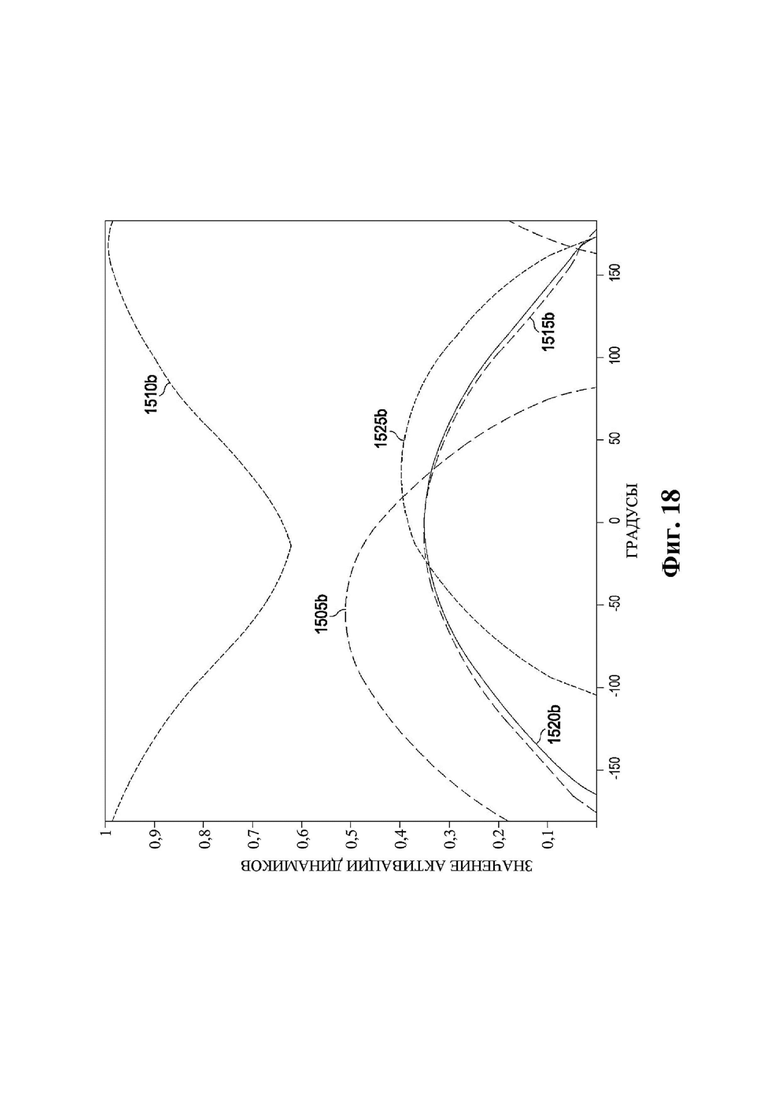
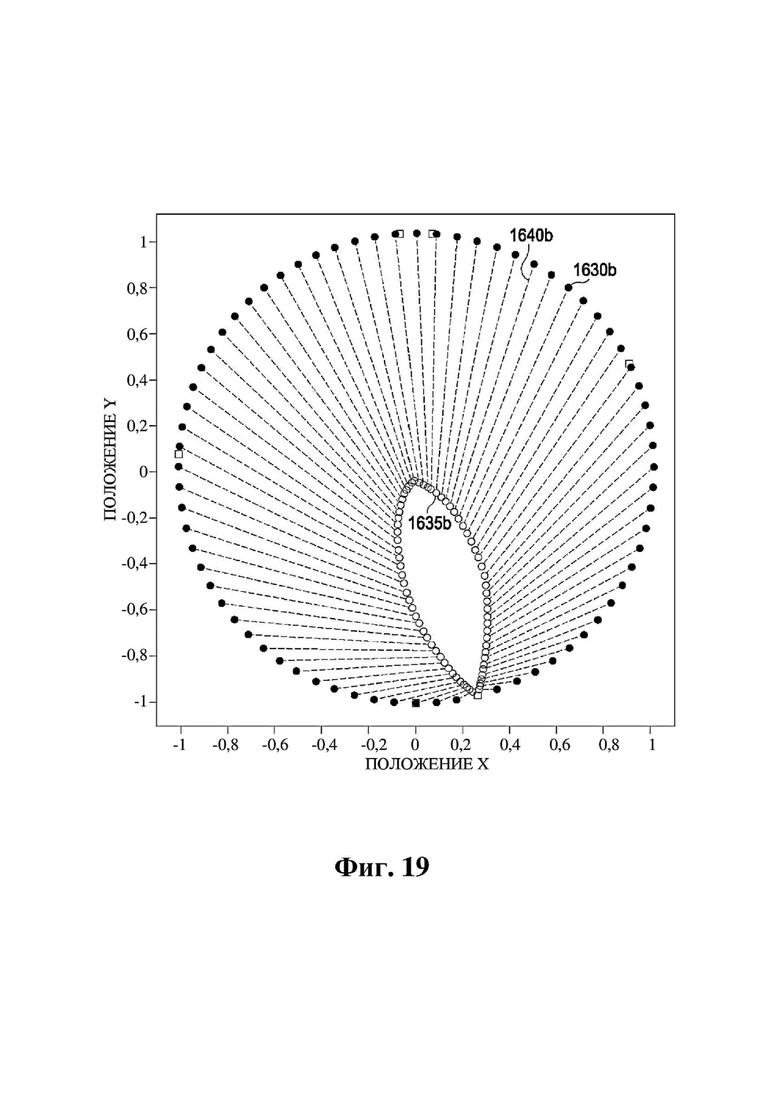
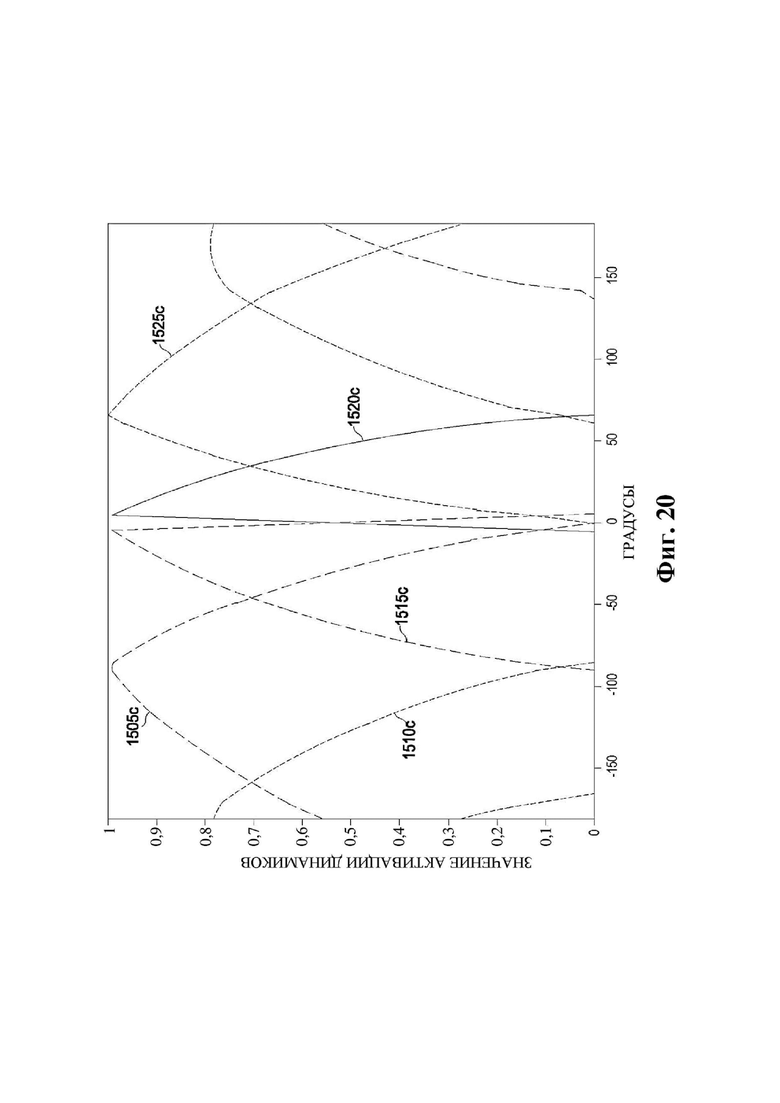
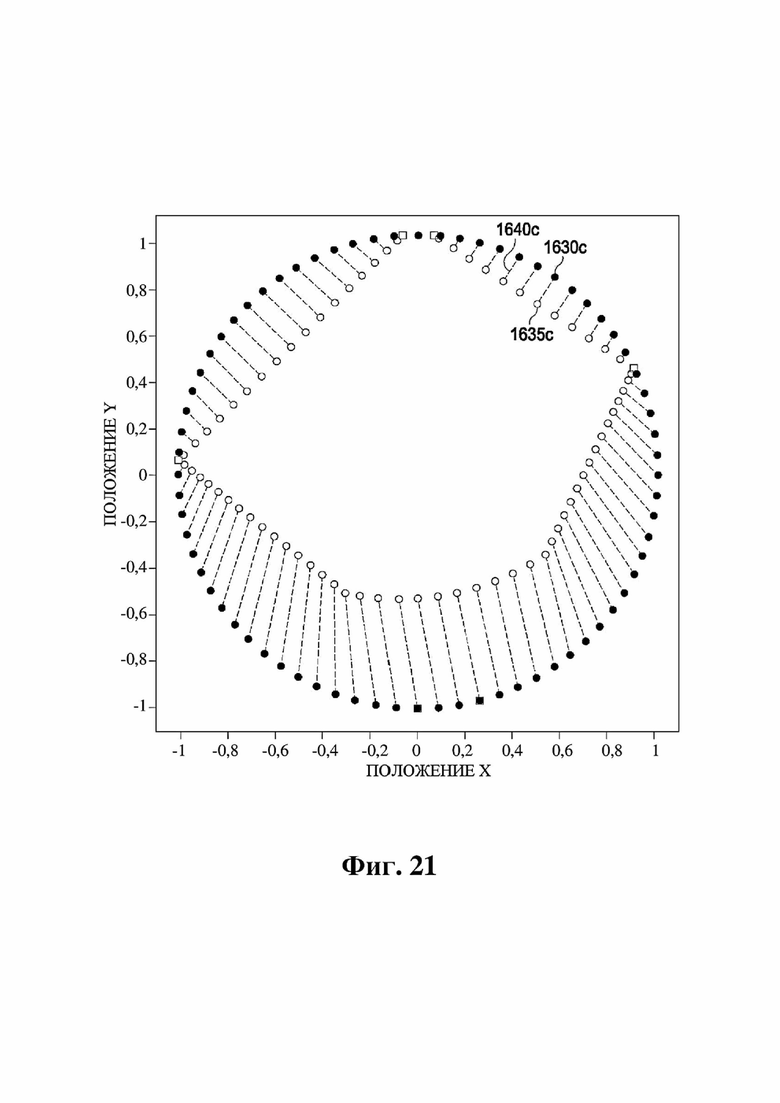
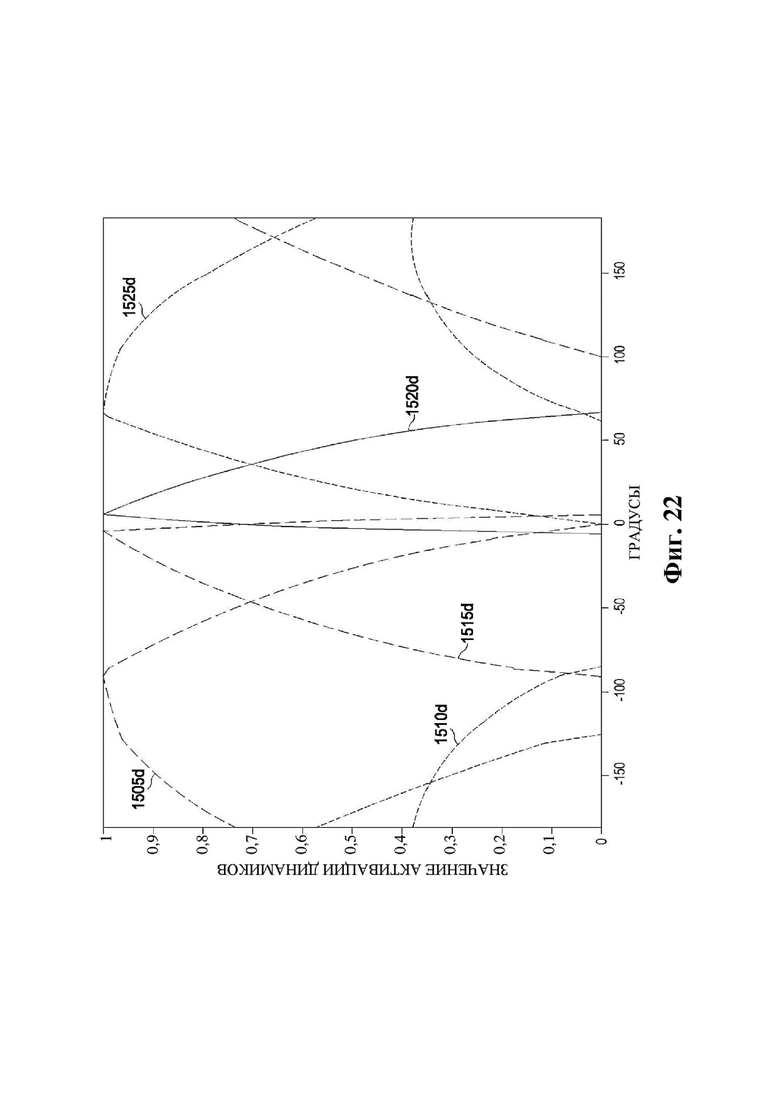
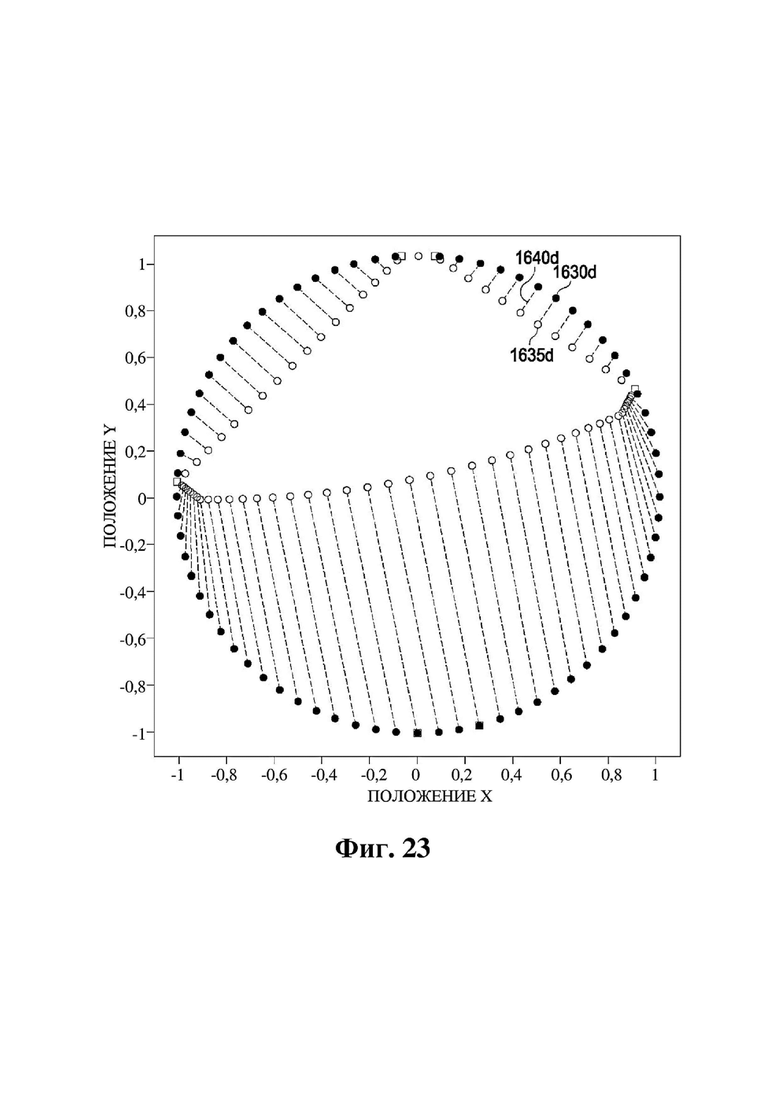
Изобретение относится к акустике. Способ аудиообработки может включать прием выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде, причем выходные сигналы соответствуют текущему фрагменту речи человека, и определение на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку, в том числе оценочной текущей близости человека к одному или более местоположениям микрофонов. Способ может включать выбор двух или более оснащенных громкоговорителями аудиоустройств по меньшей мере частично на основе одного или более аспектов контекстной информации, определение одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для аудиоустройств и обеспечение применения одного или более типов изменений аудиообработки. Технический результат - увеличение отношения речь-эхо на одном или более микрофонах. 5 н. и 21 з.п. ф-лы, 23 ил.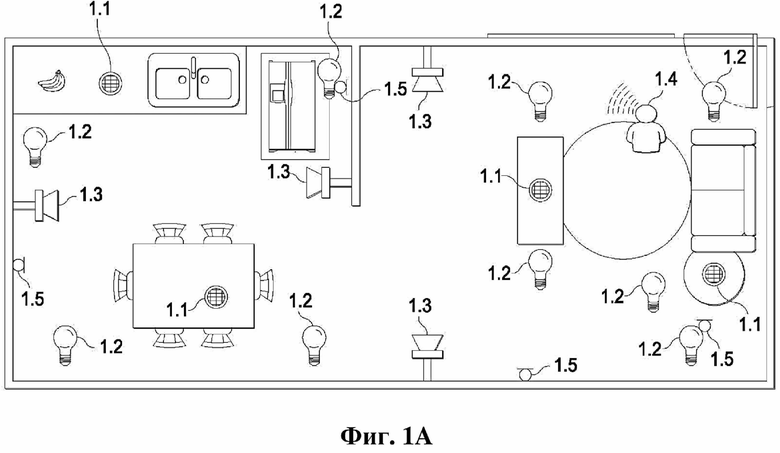
1. Способ управления аудиосеансом, включающий:
прием выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде, причем каждый микрофон из множества микрофонов находится в местоположении микрофона в аудиосреде, причем выходные сигналы включают сигналы, соответствующие текущему фрагменту речи человека;
определение на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку, причем контекстная информация содержит по меньшей мере одно из оценочного текущего местоположения человека или оценочной текущей близости человека к одному или более местоположениям микрофонов;
определение ближайшего оснащенного громкоговорителем аудиоустройства, которое является ближайшим к местоположению микрофона, ближайшему к оценочному текущему местоположению человека;
выбор двух или более аудиоустройств аудиосреды по меньшей мере частично на основе одного или более аспектов контекстной информации, причем каждое из двух или более аудиоустройств содержит по меньшей мере один громкоговоритель, и при этом два или более аудиоустройств включают в себя ближайшее оснащенное громкоговорителем аудиоустройство;
определение одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств, причем результатом изменений аудиообработки является увеличение отношения речь-эхо на микрофоне, ближайшем к оценочному текущему местоположению человека, при этом эхо содержит по меньшей мере некоторую часть аудиоданных, выводимых двумя или более аудиоустройствами, и при этом по меньшей мере одно из изменений аудиообработки для ближайшего аудиоустройства отличается от изменения аудиообработки для второго аудиоустройства из указанных по меньшей мере двух аудиоустройств, при этом один или более типов изменений аудиообработки обеспечивают снижение уровня воспроизведения громкоговорителя для ближайшего аудиоустройства, и при этом один или более типов изменений аудиообработки включают изменение процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения человека; и
обеспечение применения одного или более типов изменений аудиообработки.
2. Способ по п. 1, отличающийся тем, что один или более типов изменений аудиообработки дополнительно включают спектральную модификацию.
3. Способ управления аудиосеансом, включающий:
прием выходных сигналов от каждого микрофона из множества микрофонов в аудиосреде, причем каждый микрофон из множества микрофонов находится в местоположении микрофона в аудиосреде, причем выходные сигналы включают сигналы, соответствующие текущему фрагменту речи человека;
определение на основе выходных сигналов одного или более аспектов контекстной информации, относящейся к человеку, причем контекстная информация содержит по меньшей мере одно из оценочного текущего местоположения человека или оценочной текущей близости человека к одному или более местоположениям микрофонов;
выбор двух или более аудиоустройств аудиосреды по меньшей мере частично на основе одного или более аспектов контекстной информации, причем каждое из двух или более аудиоустройств содержит по меньшей мере один громкоговоритель;
определение одного или более типов изменений аудиообработки для применения к аудиоданным, подвергаемым рендерингу в сигналы, подаваемые на громкоговорители, для двух или более аудиоустройств, причем результатом изменений аудиообработки является увеличение отношения речь-эхо на одном или более микрофонах из множества микрофонов, при этом один или более типов изменений аудиообработки включают спектральную модификацию, и при этом один или более типов изменений аудиообработки дополнительно включают изменение процесса рендеринга с целью деформации рендеринга аудиосигналов в сторону от оценочного текущего местоположения человека; и
обеспечение применения одного или более типов изменений аудиообработки.
4. Способ по п. 3, отличающийся тем, что по меньшей мере одно из изменений аудиообработки для первого аудиоустройства отличается от изменения аудиообработки для второго аудиоустройства.
5. Способ по любому из предыдущих пунктов, отличающийся тем, что один или более типов изменений аудиообработки вызывают снижение уровня воспроизведения громкоговорителя для громкоговорителей двух или более аудиоустройств.
6. Способ по любому из пп. 1–5, отличающийся тем, что выбор двух или более аудиоустройств аудиосреды включает выбор N оснащенных громкоговорителями аудиоустройств аудиосреды, где N – целое число, превышающее 2.
7. Способ по любому из пп. 1–6, отличающийся тем, что выбор двух или более аудиоустройств аудиосреды по меньшей мере частично основан на оценочном текущем местоположении человека относительно по меньшей мере одного из местоположения микрофона или местоположения оснащенного громкоговорителем аудиоустройства.
8. Способ по п. 7 в той части, которая зависима от п. 3, отличающийся тем, что дополнительно включает определение ближайшего оснащенного громкоговорителем аудиоустройства, которое является ближайшим к оценочному текущему местоположению человека или к местоположению микрофона, ближайшему к оценочному текущему местоположению человека, при этом два или более аудиоустройств включают в себя ближайшее оснащенное громкоговорителем аудиоустройство.
9. Способ по любому из пп. 2–8, отличающийся тем, что спектральная модификация включает снижение уровня аудиоданных в полосе частот от 500 Гц до 3 кГц.
10. Способ по любому из пп. 1–9, отличающийся тем, что один или более типов изменений аудиообработки включают вставку по меньшей мере одного промежутка в по меньшей мере одну выбранную полосу частот сигнала аудиопроигрывания.
11. Способ по любому из пп. 1–10, отличающийся тем, что один или более типов изменений аудиообработки включают сжатие динамического диапазона.
12. Способ по любому из пп. 1–11, отличающийся тем, что выбор двух или более аудиоустройств по меньшей мере частично основан на оценке отношения сигнал-эхо для одного или более местоположений микрофонов.
13. Способ по п. 12, отличающийся тем, что выбор двух или более аудиоустройств по меньшей мере частично основан на определении того, является ли оценка отношения сигнал-эхо меньшей, чем порог отношения сигнал-эхо, или равной ему.
14. Способ по п. 12, отличающийся тем, что определение одного или более типов изменений аудиообработки основано на оптимизации функции стоимости, которая по меньшей мере частично основана на оценке отношения сигнал-эхо.
15. Способ по п. 14, отличающийся тем, что функция стоимости по меньшей мере частично основана на выполнении рендеринга.
16. Способ по любому из пп. 1–15, отличающийся тем, что выбор двух или более аудиоустройств по меньшей мере частично основан на оценке близости.
17. Способ по любому из пп. 1–16, отличающийся тем, что дополнительно включает:
определение ряда текущих акустических признаков из выходных сигналов каждого микрофона;
применение классификатора к ряду текущих акустических признаков, при этом применение классификатора включает применение модели, обученной на ранее определенных акустических признаках, полученных из множества предыдущих фрагментов речи, произнесенных человеком во множестве пользовательских зон в среде; и
при этом определение одного или более аспектов контекстной информации, относящейся к человеку, включает определение, по меньшей мере частично на основе выходных данных из классификатора, оценки пользовательской зоны, в которой человек расположен в настоящий момент.
18. Способ по п. 17, отличающийся тем, что оценку пользовательской зоны определяют без отсылки к геометрическим местоположениям множества микрофонов.
19. Способ по п. 17 или 18, отличающийся тем, что текущий фрагмент речи и предыдущие фрагменты речи включают фрагменты речи, содержащие пробуждающее слово.
20. Способ по любому из пп. 1–19, отличающийся тем, что дополнительно включает выбор по меньшей мере одного микрофона согласно одному или более аспектам контекстной информации.
21. Способ по любому из пп. 1–20, отличающийся тем, что один или более микрофонов находятся в ряде аудиоустройств аудиосреды.
22. Способ по любому из пп. 1–20, отличающийся тем, что один или более микрофонов находятся в одном аудиоустройстве аудиосреды.
23. Способ по любому из пп. 1–22, отличающийся тем, что по меньшей мере одно из одного или более местоположений микрофонов соответствует ряду микрофонов одного аудиоустройства.
24. Оборудование для акустической эхокомпенсации, выполненное с возможностью выполнения способа по любому из пп. 1–23.
25. Система для акустической эхокомпенсации, выполненная с возможностью выполнения способа по любому из пп. 1–23.
26. Постоянный носитель данных, содержащий хранящееся на нем программное обеспечение, причем программное обеспечение содержит инструкции для управления одним или более устройствами с целью выполнения способа по любому из пп. 1–23.
| ЕР 2874411 А1, 20.05.2015 | |||
| US 2019115040 A1, 18.04.2019 | |||
| US 2019124462 A1, 25.04.2019 | |||
| US 2010189274 A1, 29.07.2010 | |||
| US 2019096419 A1, 28.03.2019 | |||
| US 2014142927 A1, 22.05.2014 | |||
| JP 2000115351 A, 21.04.2000 | |||
| WO 1995005047 A1 16.02.1995 | |||
| JP 2005151356 A, 09.05.2005 | |||
| EP 3484184 A1, 15.05.2019 | |||
| US 2016140981 A1, 19.05.2016 | |||
| US 2015271616 A1, |

