Область техники, к которой относится изобретение
[0001] Настоящее раскрытие сущности относится к кодированию видео, и, в частности, к системам, составляющим элементам и способам при кодировании и декодировании видео.
Уровень техники
[0002] В силу совершенствования в технологии кодирования видео, из H.261 и MPEG-1 в H.264/AVC (стандарт усовершенствованного кодирования видео), MPEG-LA, H.265/HEVC (стандарт высокоэффективного кодирования видео) и H.266/VVC (универсальный видеокодек), остается постоянная потребность в том, чтобы предоставлять улучшения и оптимизации для технологии кодирования видео, с тем чтобы обрабатывать постоянно увеличивающийся объем цифровых видеоданных в различных вариантах применения. Настоящее раскрытие сущности относится к дополнительным совершенствованиям, улучшениям и оптимизациям при кодировании видео.
[0003] Следует отметить, что непатентный документ (NPL) 1 относится к одному примеру традиционного стандарта относительно вышеописанной технологии кодирования видео.
Список библиографических ссылок
Непатентные документы
[0004] NPL 1. H.265 (ISO/IEC 23008-2 HEVC)/HEVC (High Efficiency Video Coding)
Сущность изобретения
Техническая задача
[0005] Относительно схемы кодирования, как описано выше, требуются предложения новых схем для того, чтобы (i) повышать эффективность кодирования, повышать качество изображений, уменьшать объемы обработки, уменьшать размеры схем или (ii) надлежащим образом выбирать элемент или операцию. Элемент, например, представляет собой фильтр, блок, размер, вектор движения, опорный кадр или опорный блок.
[0006] Настоящее раскрытие сущности предоставляет, например, конфигурацию или способ, который может способствовать, по меньшей мере, одному из увеличения эффективности кодирования, увеличения качества изображений, уменьшения объема обработки, уменьшения размера схем, надлежащего выбора элемента или операции и т.д. Следует отметить, что настоящее раскрытие сущности может охватывать возможные конфигурации или способы, которые могут способствовать преимуществам, отличным от вышеуказанных преимуществ.
Решение задачи
[0007] Например, кодер согласно аспекту настоящего раскрытия сущности представляет собой кодер, включающий в себя: схему; и запоминающее устройство, соединенное со схемой. Схема, при работе: при формировании прогнозного изображения текущего блока, использует режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок; определяет то, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и кодирует текущий блок с использованием списка возможных вариантов векторов.
[0008] В технологии кодирования видео, должны предлагаться новые способы, чтобы повышать эффективность кодирования, повышать качество изображений и уменьшать размеры схем.
[0009] Каждый из вариантов осуществления либо каждый из части составляющих элементов и способов в настоящем раскрытии сущности обеспечивает возможность, например, по меньшей мере, одного из следующего: повышение эффективности кодирования, повышение качества изображений, уменьшение объема обработки кодирования/декодирования, уменьшение размера схем, повышение скорости обработки кодирования/декодирования и т.д. Альтернативно, каждый из вариантов осуществления либо каждый из части составляющих элементов и способов в настоящем раскрытии сущности обеспечивает возможность, при кодировании и декодировании, соответствующего выбора элемента или операции. Элемент, например, представляет собой фильтр, блок, размер, вектор движения, опорный кадр или опорный блок. Следует отметить, что настоящее раскрытие сущности включает в себя раскрытие сущности относительно конфигураций и способов, которые могут предоставлять преимущества, отличные от вышеописанных преимуществ. Примеры таких конфигураций и способов включают в себя конфигурацию или способ для повышения эффективности кодирования при уменьшении увеличения объема обработки.
[0010] Дополнительные выгоды и преимущества согласно аспекту настоящего раскрытия сущности должны становиться очевидными из подробного описания и чертежей. Выгоды и/или преимущества могут отдельно получаться посредством различных вариантов осуществления и признаков подробного описания и чертежей, и не все из них должны обязательно предоставляться для того, чтобы получать одну или более таких выгод и/или преимуществ.
[0011] Следует отметить, что эти общие или конкретные аспекты могут реализовываться с использованием системы, интегральной схемы, компьютерной программы или машиночитаемого носителя (носителя записи), такого CD-ROM, либо любой комбинации систем, способов, интегральных схем, компьютерных программ и носителей.
Преимущества изобретения
[0012] Конфигурация или способ согласно аспекту настоящего раскрытия сущности обеспечивает возможность, например, по меньшей мере, одного из следующего: повышение эффективности кодирования, повышение качества изображений, уменьшение объема обработки, уменьшение размера схем, повышение скорости обработки, соответствующий выбор элемента или операции и т.д. Следует отметить, что конфигурация или способ согласно аспекту настоящего раскрытия сущности можно предоставлять преимущества, отличные от вышеописанных преимуществ.
Краткое описание чертежей
[0013] Фиг. 1 является принципиальной схемой, иллюстрирующей один пример конфигурации системы передачи согласно варианту осуществления.
Фиг. 2 является схемой, иллюстрирующей один пример иерархической структуры данных в потоке.
Фиг. 3 является схемой, иллюстрирующей один пример конфигурации срезов.
Фиг. 4 является схемой, иллюстрирующей один пример конфигурации плиток.
Фиг. 5 является схемой, иллюстрирующей один пример структуры кодирования в масштабируемом кодировании.
Фиг. 6 является схемой, иллюстрирующей один пример структуры кодирования в масштабируемом кодировании.
Фиг. 7 является блок-схемой, иллюстрирующей один пример функциональной конфигурации кодера согласно варианту осуществления.
Фиг. 8 является блок-схемой, иллюстрирующей пример монтажа кодера.
Фиг. 9 является блок-схемой последовательности операций способа, иллюстрирующей один пример полного процесса кодирования, выполняемого посредством кодера.
Фиг. 10 является схемой, иллюстрирующей один пример разбиения блоков.
Фиг. 11 является схемой, иллюстрирующей один пример функциональной конфигурации модуля разбиения.
Фиг. 12 является схемой, иллюстрирующей примеры шаблонов разбиения.
Фиг. 13A является схемой, иллюстрирующей один пример синтаксического дерева шаблона разбиения.
Фиг. 13B является схемой, иллюстрирующей другой пример синтаксического дерева шаблона разбиения.
Фиг. 14 является диаграммой, иллюстрирующей базисные функции преобразования для каждого типа преобразования.
Фиг. 15 является схемой, иллюстрирующей примеры SVT.
Фиг. 16 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством преобразователя.
Фиг. 17 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством преобразователя.
Фиг. 18 является блок-схемой, иллюстрирующей один пример функциональной конфигурации квантователя.
Фиг. 19 является блок-схемой последовательности операций способа, иллюстрирующей один пример квантования, выполняемого посредством квантователя.
Фиг. 20 является блок-схемой, иллюстрирующей один пример функциональной конфигурации энтропийного кодера.
Фиг. 21 является схемой, иллюстрирующей последовательность операций CABAC в энтропийном кодере.
Фиг. 22 является блок-схемой, иллюстрирующей один пример функциональной конфигурации контурного фильтра.
Фиг. 23A является схемой, иллюстрирующей один пример формы фильтра, используемой в адаптивном контурном фильтре (ALF).
Фиг. 23B является схемой, иллюстрирующей другой пример формы фильтра, используемой в ALF.
Фиг. 23C является схемой, иллюстрирующей другой пример формы фильтра, используемой в ALF.
Фиг. 23D является схемой, иллюстрирующей пример, в котором Y-выборки (первый компонент), используются для кросскомпонентной ALF (CCALF) для Cb и CCALF для Cr (для компонентов, отличающихся от первого компонента).
Фиг. 23E является схемой, иллюстрирующей ромбовидный фильтр.
Фиг. 23F является схемой, иллюстрирующей пример для объединенной CCALF сигналов цветности (JC-CCALF).
Фиг. 23G является схемой, иллюстрирующей пример для возможных вариантов весовых JC-CCALF- индексов.
Фиг. 24 является блок-схемой, иллюстрирующей один пример конкретной конфигурации контурного фильтра, который функционирует в качестве DBF.
Фиг. 25 является схемой, иллюстрирующей пример фильтра удаления блочности, имеющего симметричную характеристику фильтрации относительно границы блока.
Фиг. 26 является схемой для иллюстрации границы блока, для которой выполняется процесс фильтрации для удаления блочности.
Фиг. 27 является схемой, иллюстрирующей примеры Bs-значений.
Фиг. 28 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством модуля прогнозирования кодера.
Фиг. 29 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством модуля прогнозирования кодера.
Фиг. 30 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством модуля прогнозирования кодера.
Фиг. 31 является схемой, иллюстрирующей один пример шестидесяти семи режимов внутреннего прогнозирования, используемых при внутреннем прогнозировании.
Фиг. 32 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством модуля внутреннего прогнозирования.
Фиг. 33 является схемой, иллюстрирующей примеры опорных кадров.
Фиг. 34 является схемой, иллюстрирующей примеры списков опорных кадров.
Фиг. 35 является блок-схемой последовательности операций способа, иллюстрирующей базовую последовательность операций обработки взаимного прогнозирования.
Фиг. 36 является блок-схемой последовательности операций способа, иллюстрирующей один пример MV-извлечения.
Фиг. 37 является блок-схемой последовательности операций способа, иллюстрирующей другой пример MV-извлечения.
Фиг. 38A является схемой, иллюстрирующей один пример категоризации режимов для MV-извлечения.
Фиг. 38B является схемой, иллюстрирующей один пример категоризации режимов для MV-извлечения.
Фиг. 39 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством нормального взаимного режима.
Фиг. 40 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством режима нормального объединения.
Фиг. 41 является схемой для иллюстрации одного примера процесса MV-извлечения посредством режима нормального объединения.
Фиг. 42 является схемой для иллюстрации одного примера процесса MV-извлечения посредством HMVP-режима.
Фиг. 43 является блок-схемой последовательности операций способа, иллюстрирующей один пример преобразования с повышением частоты кинокадров (FRUC).
Фиг. 44 является схемой для иллюстрации одного примера сопоставления с шаблоном (билатерального сопоставления) между двумя блоками, расположенными вдоль траектории движения.
Фиг. 45 является схемой для иллюстрации одного примера сопоставления с шаблоном (сопоставления с эталоном) между эталоном в текущем кадре и блоком в опорном кадре.
Фиг. 46A является схемой для иллюстрации одного примера MV-извлечения в единицах субблоков в аффинном режиме, в котором используются две управляющих точки.
Фиг. 46B является схемой для иллюстрации одного примера MV-извлечения в единицах субблоков в аффинном режиме, в котором используются три управляющих точки.
Фиг. 47A является концептуальной схемой для иллюстрации одного примера MV-извлечения в управляющих точках в аффинном режиме.
Фиг. 47B является концептуальной схемой для иллюстрации одного примера MV-извлечения в управляющих точках в аффинном режиме.
Фиг. 47C является концептуальной схемой для иллюстрации одного примера MV-извлечения в управляющих точках в аффинном режиме.
Фиг. 48A является схемой для иллюстрации аффинного режима, в котором используются две управляющих точки.
Фиг. 48B является схемой для иллюстрации аффинного режима, в котором используются три управляющих точки.
Фиг. 49A является концептуальной схемой для иллюстрации одного примера способа для MV-извлечения в управляющих точках, когда число управляющих точек для кодированного блока и число управляющих точек для текущего блока отличаются друг от друга.
Фиг. 49B является концептуальной схемой для иллюстрации другого примера способа для MV-извлечения в управляющих точках, когда число управляющих точек для кодированного блока и число управляющих точек для текущего блока отличаются друг от друга.
Фиг. 50 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса в аффинном режиме объединения.
Фиг. 51 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса в аффинном взаимном режиме.
Фиг. 52A является схемой для иллюстрации формирования двух треугольных прогнозных изображений.
Фиг. 52B является концептуальной схемой, иллюстрирующей примеры первой части первого сегмента и первого и второго наборов выборок.
Фиг. 52C является концептуальной схемой, иллюстрирующей первую часть первого сегмента.
Фиг. 53 является блок-схемой последовательности операций способа, иллюстрирующей один пример треугольного режима.
Фиг. 54 является схемой, иллюстрирующей один пример ATMVP-режима, в котором MV извлекается в единицах субблоков.
Фиг. 55 является схемой, иллюстрирующей взаимосвязь между режимом объединения и динамическим обновлением векторов движения (DMVR).
Фиг. 56 является концептуальной схемой для иллюстрации одного примера DMVR.
Фиг. 57 является концептуальной схемой для иллюстрации другого примера DMVR для определения MV.
Фиг. 58A является схемой, иллюстрирующей один пример оценки движения в DMVR.
Фиг. 58B является блок-схемой последовательности операций способа, иллюстрирующей один пример оценки движения в DMVR.
Фиг. 59 является блок-схемой последовательности операций способа, иллюстрирующей один пример формирования прогнозного изображения.
Фиг. 60 является блок-схемой последовательности операций способа, иллюстрирующей другой пример формирования прогнозного изображения.
Фиг. 61 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса коррекции прогнозного изображения посредством перекрывающейся блочной компенсации движения (OBMC).
Фиг. 62 является концептуальной схемой для иллюстрации одного примера процесса коррекции прогнозных изображений посредством OBMC.
Фиг. 63 является схемой для иллюстрации модели при условии равномерного прямолинейного движения.
Фиг. 64 является блок-схемой последовательности операций способа, иллюстрирующей один пример взаимного прогнозирования согласно BIO.
Фиг. 65 является схемой, иллюстрирующей один пример функциональной конфигурации модуля взаимного прогнозирования, который выполняет взаимное прогнозирование согласно BIO.
Фиг. 66A является схемой для иллюстрации одного примера способа формирования прогнозных изображений с использованием процесса коррекции яркости посредством компенсации локальной освещенности (LIC).
Фиг. 66B является блок-схемой последовательности операций способа, иллюстрирующей один пример способа формирования прогнозных изображений с использованием процесса коррекции яркости посредством LIC.
Фиг. 67 является блок-схемой, иллюстрирующей функциональную конфигурацию декодера согласно варианту осуществления.
Фиг. 68 является блок-схемой, иллюстрирующей пример монтажа видеодекодера.
Фиг. 69 является блок-схемой последовательности операций способа, иллюстрирующей один пример полного процесса декодирования, выполняемого посредством декодера.
Фиг. 70 является схемой, иллюстрирующей взаимосвязь между модулем определения разбиения и другими составляющими элементами.
Фиг. 71 является блок-схемой, иллюстрирующей один пример функциональной конфигурации энтропийного декодера.
Фиг. 72 является схемой, иллюстрирующей последовательность операций CABAC в энтропийном декодере.
Фиг. 73 является блок-схемой, иллюстрирующей один пример функциональной конфигурации обратного квантователя.
Фиг. 74 является блок-схемой последовательности операций способа, иллюстрирующей один пример обратного квантования, выполняемого посредством обратного квантователя.
Фиг. 75 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством обратного преобразователя.
Фиг. 76 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством обратного преобразователя.
Фиг. 77 является блок-схемой, иллюстрирующей один пример функциональной конфигурации контурного фильтра.
Фиг. 78 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством модуля прогнозирования декодера.
Фиг. 79 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством модуля прогнозирования декодера.
Фиг. 80A является блок-схемой последовательности операций способа, иллюстрирующей часть другого примера процесса, выполняемого посредством модуля прогнозирования декодера.
Фиг. 80B является блок-схемой последовательности операций способа, иллюстрирующей оставшуюся часть другого примера процесса, выполняемого посредством модуля прогнозирования декодера.
Фиг. 81 является схемой, иллюстрирующей один пример процесса, выполняемого посредством модуля внутреннего прогнозирования декодера.
Фиг. 82 является блок-схемой последовательности операций способа, иллюстрирующей один пример MV-извлечения в декодере.
Фиг. 83 является блок-схемой последовательности операций способа, иллюстрирующей другой пример MV-извлечения в декодере.
Фиг. 84 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством нормального взаимного режима в декодере.
Фиг. 85 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством режима нормального объединения в декодере.
Фиг. 86 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством FRUC-режима в декодере.
Фиг. 87 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством аффинного режима объединения в декодере.
Фиг. 88 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством аффинного взаимного режима в декодере.
Фиг. 89 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством треугольного режима в декодере.
Фиг. 90 является блок-схемой последовательности операций способа, иллюстрирующей пример оценки движения посредством DMVR в декодере.
Фиг. 91 является блок-схемой последовательности операций способа, иллюстрирующей один конкретный пример оценки движения посредством DMVR в декодере.
Фиг. 92 является блок-схемой последовательности операций способа, иллюстрирующей один пример формирования прогнозного изображения в декодере.
Фиг. 93 является блок-схемой последовательности операций способа, иллюстрирующей другой пример формирования прогнозного изображения в декодере.
Фиг. 94 является блок-схемой последовательности операций способа, иллюстрирующей другой пример коррекции прогнозного изображения посредством OBMC в декодере.
Фиг. 95 является блок-схемой последовательности операций способа, иллюстрирующей другой пример коррекции прогнозного изображения посредством BIO в декодере.
Фиг. 96 является блок-схемой последовательности операций способа, иллюстрирующей другой пример коррекции прогнозного изображения посредством LIC в декодере.
Фиг. 97 является схемой для описания режима внутриблочного копирования (IBC).
Фиг. 98 является блок-схемой последовательности операций способа, иллюстрирующей один пример операций, выполняемых посредством кодера и декодера согласно первому аспекту.
Фиг. 99 является блок-схемой последовательности операций способа, иллюстрирующей один пример операций, выполняемых посредством кодера и декодера согласно второму аспекту.
Фиг. 100 является блок-схемой последовательности операций способа, иллюстрирующей операции, выполняемые посредством кодера.
Фиг. 101 является блок-схемой последовательности операций способа, иллюстрирующей операции, выполняемые посредством декодера.
Фиг. 102 является схемой, иллюстрирующей общую конфигурацию системы предоставления контента для реализации услуги распространения контента.
Фиг. 103 является схемой, иллюстрирующей пример экрана отображения веб-страницы.
Фиг. 104 является схемой, иллюстрирующей пример экрана отображения веб-страницы.
Фиг. 105 является схемой, иллюстрирующей один пример смартфона.
Фиг. 106 является блок-схемой, иллюстрирующей пример конфигурации смартфона.
Подробное описание вариантов осуществления
[0014] Введение
Кодер согласно аспекту настоящего раскрытия сущности представляет собой кодер, включающий в себя: схему; и запоминающее устройство, соединенное со схемой. Схема, при работе: при формировании прогнозного изображения текущего блока, использует режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок; определяет то, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и кодирует текущий блок с использованием списка возможных вариантов векторов.
[0015] Соответственно, кодер формирует список возможных вариантов векторов без выполнения первого процесса отсечения (далее называется просто "процессом отсечения"), когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера.
[0016] Например, схема может: формировать прогнозное изображение текущего блока с использованием второго вектора; кодировать второй вектор с использованием одного из возможных вариантов векторов, включенных в список возможных вариантов векторов; в первом процессе отсечения, выполняемом при формировании списка возможных вариантов векторов, определять, для каждого из возможных вариантов HMVP-векторов, каждый из которых представляет собой возможный вариант HMVP-вектора, сохраненный в HMVP-таблице, то, является или нет возможный вариант HMVP-вектора идентичным какому-либо из одного или более возможных вариантов векторов, зарегистрированных в списке возможных вариантов векторов; и когда возможный вариант HMVP-вектора не является идентичным какому-либо из одного или более возможных вариантов векторов, формировать список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов.
[0017] Соответственно, кодер формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера.
[0018] Например, схема дополнительно может обновлять HMVP-таблицу с использованием возможного варианта второго вектора, имеющего информацию относительно второго вектора, и при обновлении HMVP-таблицы, схема может: определять то, меньше или равен либо нет размер текущего блока пороговому значению; обновлять HMVP-таблицу без выполнения второго процесса отсечения, когда размер текущего блока меньше или равен пороговому значению; и обновлять HMVP-таблицу посредством выполнения второго процесса отсечения, когда размер текущего блока превышает пороговое значение.
[0019] Соответственно, кодер обновляет HMVP-таблицу без выполнения второго процесса отсечения (далее также называется просто "процессом отсечения"), когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера.
[0020] Например, во втором процессе отсечения, выполняемом при обновлении HMVP-таблицы, схема может: определять то, является или нет возможный вариант второго вектора идентичным какому-либо из возможных вариантов HMVP-векторов; и обновлять HMVP-таблицу посредством сохранения возможного варианта второго вектора в HMVP-таблице, когда возможный вариант второго вектора не является идентичным какому-либо из возможных вариантов HMVP-векторов.
[0021] За счет этого, кодер может регистрировать, в списке возможных вариантов векторов, возможный вариант вектора, который более подходит для текущего блока.
[0022] Например, размер текущего блока может задаваться посредством общего числа пикселов, включенных в текущий блок. Пороговое значение может составлять, например, 16 пикселов.
[0023] Соответственно, кодер формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда общее число пикселов, включенных в текущий блок, меньше или равно пороговому значению (например, меньше или равно 16 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера.
[0024] Например, размер текущего блока может задаваться, по меньшей мере, посредством одного из ширины или высоты текущего блока. Пороговое значение может составлять, например, 4 пиксела x 4 пиксела.
[0025] Соответственно, кодер формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда, по меньшей мере, одно из ширины или высоты текущего блока меньше или равно пороговому значению (например, когда ширина и высота текущего блока меньше или равны 4 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера.
[0026] Например, список возможных вариантов векторов не должен обязательно совместно использоваться текущим блоком и блоком, соседним с текущим блоком.
[0027] Соответственно, кодер использует списки возможных вариантов векторов, каждый из которых формируется для различного текущего блока, и в силу этого точность прогнозирования повышается.
[0028] Например, схема может: при формировании прогнозного изображения текущего блока, использовать IBC-режим при определении необходимости использовать IBC-режим из множества режимов прогнозирования и использовать режим прогнозирования, отличающийся от IBC-режима, при определении необходимости использовать режим прогнозирования, отличающийся от IBC-режима, из множества режимов прогнозирования; при использовании режима прогнозирования, отличающегося от IBC-режима, формировать список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и кодировать текущий блок с использованием списка возможных вариантов векторов.
[0029] Это обеспечивает возможность кодеру надлежащим образом переключать условия, при которых процесс отсечения выполняется, согласно используемому режиму прогнозирования. Это повышает эффективность кодирования кодера.
[0030] Кроме того, декодер согласно аспекту настоящего раскрытия сущности представляет собой декодер, включающий в себя: схему; и запоминающее устройство, соединенное со схемой. Схема, при работе: при формировании прогнозного изображения текущего блока, использует режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок; определяет то, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и декодирует текущий блок с использованием списка возможных вариантов векторов.
[0031] Соответственно, декодер формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера.
[0032] Например, схема может: формировать прогнозное изображение текущего блока с использованием второго вектора; декодировать второй вектор с использованием одного из возможных вариантов векторов, включенных в список возможных вариантов векторов; в первом процессе отсечения, выполняемом при формировании списка возможных вариантов векторов, определять, для каждого из возможных вариантов HMVP-векторов, каждый из которых представляет собой возможный вариант HMVP-вектора, сохраненный в HMVP-таблице, то, является или нет возможный вариант HMVP-вектора идентичным какому-либо из одного или более возможных вариантов векторов, зарегистрированных в списке возможных вариантов векторов; и когда возможный вариант HMVP-вектора не является идентичным какому-либо из одного или более возможных вариантов векторов, формировать список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов.
[0033] Соответственно, декодер формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера.
[0034] Например, схема дополнительно может: обновлять HMVP-таблицу с использованием возможного варианта второго вектора, имеющего информацию относительно второго вектора, и при обновлении HMVP-таблицы, схема может: определять то, меньше или равен либо нет размер текущего блока пороговому значению; обновлять HMVP-таблицу без выполнения второго процесса отсечения, когда размер текущего блока меньше или равен пороговому значению; и обновлять HMVP-таблицу посредством выполнения второго процесса отсечения, когда размер текущего блока превышает пороговое значение.
[0035] Соответственно, декодер обновляет HMVP-таблицу без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера.
[0036] Например, во втором процессе отсечения, выполняемом при обновлении HMVP-таблицы, схема может: определять то, является или нет возможный вариант второго вектора идентичным какому-либо из возможных вариантов HMVP-векторов; и обновлять HMVP-таблицу посредством сохранения возможного варианта второго вектора в HMVP-таблице, когда возможный вариант второго вектора не является идентичным какому-либо из возможных вариантов HMVP-векторов.
[0037] За счет этого, декодер может регистрировать, в списке возможных вариантов векторов, возможный вариант вектора, который более подходит для текущего блока.
[0038] Например, размер текущего блока может задаваться посредством общего числа пикселов, включенных в текущий блок. Пороговое значение может составлять, например, 16 пикселов.
[0039] Соответственно, декодер формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда общее число пикселов, включенных в текущий блок, меньше или равно пороговому значению (например, меньше или равно 16 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера.
[0040] Например, размер текущего блока может задаваться, по меньшей мере, посредством одного из ширины или высоты текущего блока. Пороговое значение может составлять, например, 4 пиксела x 4 пиксела.
[0041] Соответственно, декодер формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда, по меньшей мере, одно из ширины или высоты текущего блока меньше или равно пороговому значению (например, когда ширина и высота текущего блока меньше или равны 4 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера.
[0042] Например, список возможных вариантов векторов не должен обязательно совместно использоваться текущим блоком и блоком, соседним с текущим блоком.
[0043] Соответственно, декодер использует списки возможных вариантов векторов, каждый из которых формируется для различного текущего блока, и в силу этого точность прогнозирования повышается.
[0044] Например, схема может: при формировании прогнозного изображения текущего блока, использовать IBC-режим при определении необходимости использовать IBC-режим из множества режимов прогнозирования и использовать режим прогнозирования, отличающийся от IBC-режима, при определении необходимости использовать режим прогнозирования, отличающийся от IBC-режима, из множества режимов прогнозирования; при использовании режима прогнозирования, отличающегося от IBC-режима, формировать список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и декодировать текущий блок с использованием списка возможных вариантов векторов.
[0045] Это обеспечивает возможность декодеру надлежащим образом переключать условия, при которых процесс отсечения выполняется, согласно используемому режиму прогнозирования. Это повышает эффективность обработки декодера.
[0046] Кроме того, способ кодирования согласно аспекту настоящего раскрытия сущности представляет собой способ кодирования, включающий в себя: при формировании прогнозного изображения текущего блока, использование режима внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок; определение того, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирование списка возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирование списка возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и кодирование текущего блока с использованием списка возможных вариантов векторов.
[0047] Соответственно, устройство, которое осуществляет способ кодирования, формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования устройства, которое осуществляет способ кодирования.
[0048] Кроме того, способ декодирования согласно аспекту настоящего раскрытия сущности представляет собой способ декодирования, включающий в себя: при формировании прогнозного изображения текущего блока, использование режима внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок; определение того, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирование списка возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирование списка возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и декодирование текущего блока с использованием списка возможных вариантов векторов.
[0049] Соответственно, устройство, которое осуществляет способ декодирования, формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки устройства, которое осуществляет способ декодирования.
[0050] Определения терминов
Соответствующие термины могут задаваться так, как указано ниже в качестве примеров.
[0051] (1) изображение
Изображение представляет собой единицу данных, сконфигурированную с набором пикселов, представляет собой кадр или включает в себя блоки, меньшие кадра. Изображения включают в себя неподвижное изображение в дополнение к видео.
[0052] (2) кадр
Кадр представляет собой единицу обработки изображений, сконфигурированную с набором пикселов, и также называется "кадром" или "полем".
[0053] (3) блок
Блок представляет собой единицу обработки, которая представляет собой набор конкретного числа пикселов. Блок также называется так, как указывается в нижеприведенных примерах. Формы блоков не ограничены. Примеры включают в себя прямоугольную форму в MxN пикселов и квадратную форму в MxM пикселов в первую очередь и также включают в себя треугольную форму, круглую форму и другие формы.
[0054] Примеры блоков
- срез/плитка/кирпич
- CTU/суперблок/базовая единица разбиения
- VPDU/единица разбиения для обработки для аппаратных средств
- CU/блочная единица для обработки/блочная единица прогнозирования (PU)/блочная единица ортогонального преобразования (TU)/единица
- субблок
[0055] (4) пиксел/выборка
Пиксел или выборка представляет собой наименьшую точку изображения. Пикселы или выборки включают в себя не только пиксел в целочисленной позиции, но также и пиксел в субпиксельной позиции, сформированной на основе пиксела в целочисленной позиции.
[0056] (5) пиксельное значение/выборочное значение
Пиксельное значение или выборочное значение представляет собой собственное значение пиксела. Пиксельные или выборочные значения естественно включают в себя значение сигнала яркости, значение сигнала цветности, уровень RGB-градации, а также охватывают значение глубины или двоичное значение в 0 или 1.
[0057] (6) флаг
Флаг указывает один или более битов и, например, может представлять собой параметр или индекс, представленный посредством двух или более битов. Альтернативно, флаг может указывать не только двоичное значение, представленное посредством двоичного числа, но также и множественное значение, представленное посредством числа, отличного от двоичного числа.
[0058] (7) сигнал
Сигнал представляет собой сигнал, преобразованный в символьную форму или кодированный с возможностью передавать информацию. Сигналы включают в себя дискретный цифровой сигнал и аналоговый сигнал, который принимает непрерывное значение.
[0059] (8) поток/поток битов
Поток или поток битов представляет собой строку цифровых данных потока цифровых данных. Поток или поток битов может представлять собой один поток либо может быть сконфигурирован с множеством потоков, имеющих множество иерархических слоев. Поток или поток битов может передаваться при последовательной связи с использованием одного тракта передачи либо может передаваться при связи с коммутацией пакетов с использованием множества трактов передачи.
[0060] (9) разность
В случае скалярной величины, необходимо только то, что простая разность (x-y) и вычисление разности должны включаться. Разности включают в себя абсолютное значение разности (|x-y|), квадрат разности (x^2-y^2), квадратный корень разности (√ (x-y)), взвешенную разность (ax-by: a и b являются константами), разность смещения (x-y+a: a является смещением).
[0061] (10) сумма
В случае скалярной величины, необходимо только то, что простая сумма (x+y) и вычисление сумм должны включаться. Суммы включают в себя абсолютное значение суммы (|x+y|), возведенную в квадрат сумму (x^2+y^2), квадратный корень суммы (√ (x+y)), взвешенную разность (ax+by: a и b являются константами), сумму смещения (x+y+a: a является смещением).
[0062] (11) на основе
Фраза "на основе чего-либо" означает то, что вещь, отличная от чего-либо, может рассматриваться. Помимо этого, "на основе" может использоваться в случае, в котором прямой результат получается, либо в случае, в котором результат получается через промежуточный результат.
[0063] (12) используемый, с использованием
Фраза "что-либо, используемое" или "с использованием чего-либо" означает то, что вещь, отличная от чего-либо, может рассматриваться. Помимо этого, "используемый" или "с использованием" может использоваться в случае, в котором прямой результат получается, либо в случае, в котором результат получается через промежуточный результат.
[0064] (13) запрещать, воспрещать
Термин "запрещать" или "воспрещать" может перефразироваться как "не разрешать" или "не позволять". Помимо этого, "незапрещение, невоспрещение" или "разрешение/позволение" не всегда означают "обязательство".
[0065] (14) ограничивать, установление предела/устанавливать предел/с установленным пределом
Термин "ограничивать" или "установление предела/устанавливать предел/с установленным пределом" может перефразироваться как "не разрешать/не позволять" или "неразрешение/непозволение". Помимо этого, "незапрещение, невоспрещение" или "разрешение/позволение" не всегда означают "обязательство". Кроме того, необходимо только то, что часть чего-либо должна запрещаться/воспрещаться количественно или качественно, и что-либо может полностью запрещаться/воспрещаться.
[0066] (15) сигнал цветности
Прилагательное, представленное посредством символов Cb и Cr, указывающее то, что массив выборок или одна выборка представляют один из двух цветоразностных сигналов, связанных с первичными цветами. Термин "сигнал цветности" может использоваться вместо термина "цветность".
[0067] (16) сигнал яркости
Прилагательное, представленное посредством символа или подстрочного индекса Y или L, указывающее то, что массив выборок или одна выборка представляют монохромный сигнал, связанный с первичными цветами. Термин "сигнал яркости" может использоваться вместо термина "яркость".
[0068] Примечания, связанные с описаниями
На чертежах, идентичные ссылки с номерами указывают идентичные или аналогичные компоненты. Размеры и относительные местоположения компонентов не обязательно нарисованы в идентичном масштабе.
[0069] В дальнейшем в этом документе описываются варианты осуществления со ссылкой на чертежи. Следует отметить, что варианты осуществления, описанные ниже, показывают общий или конкретный пример. Числовые значения, формы, материалы, компоненты, компоновка и соединение компонентов, этапов, взаимосвязь и порядок этапов и т.д., указываемых в нижеприведенных вариантах осуществления, представляют собой просто примеры и в силу этого не имеют намерение ограничивать объем формулы изобретения.
[0070] Ниже описываются варианты осуществления кодера и декодера. Варианты осуществления представляют собой примеры кодера и декодера, к которым являются применимыми процессы и/или конфигурации, представленные в описании аспектов настоящего раскрытия сущности. Процессы и/или конфигурации также могут реализовываться в кодере и декодере, отличающихся от кодера и декодера согласно вариантам осуществления. Например, относительно процессов и/или конфигураций, применяемых к вариантам осуществления, может реализовываться любое из следующего:
[0071] (1) Любой из компонентов кодера или декодера согласно вариантам осуществления, представленным в описании аспектов настоящего раскрытия сущности, может заменяться или комбинироваться с другим компонентом, представленным в любом месте в описании аспектов настоящего раскрытия сущности.
[0072] (2) В кодере или декодере согласно вариантам осуществления, дискреционные изменения могут вноситься в функции или процессы, выполняемые посредством одного или более компонентов кодера или декодера, такие как добавление, замена, удаление и т.д. функций или процессов. Например, любая функция или процесс может заменяться или комбинироваться с другой функцией или процессом, представленным в любом месте в описании аспектов настоящего раскрытия сущности.
[0073] (3) В способах, реализованных посредством кодера или декодера согласно вариантам осуществления, могут вноситься дискреционные изменения, такие как добавление, замена и удаление одного или более процессов, включенных в способ. Например, любой процесс в способе может заменяться или комбинироваться с другим процессом, представленным в любом месте в описании аспектов настоящего раскрытия сущности.
[0074] (4) Один или более компонентов, включенных в кодер или декодер согласно вариантам осуществления, могут комбинироваться с компонентом, представленным в любом месте в описании аспектов настоящего раскрытия сущности, могут комбинироваться с компонентом, включающим в себя одну или более функций, представленных в любом месте в описании аспектов настоящего раскрытия сущности, и могут комбинироваться с компонентом, который реализует один или более процессов, реализованных посредством компонента, представленного в описании аспектов настоящего раскрытия сущности.
[0075] (5) Компонент, включающий в себя одну или более функций кодера или декодера согласно вариантам осуществления, либо компонент, который реализует один или более процессов кодера или декодера согласно вариантам осуществления, может комбинироваться или заменяться компонентом, представленным в любом месте в описании аспектов настоящего раскрытия сущности, компонентом, включающим в себя одну или более функций, представленных в любом месте в описании аспектов настоящего раскрытия сущности, либо компонентом, который реализует один или более процессов, представленных в любом месте в описании аспектов настоящего раскрытия сущности.
[0076] (6) В способах, реализованных посредством кодера или декодера согласно вариантам осуществления, любой из процессов, включенных в способ, может заменяться или комбинироваться с процессом, представленным в любом месте в описании аспектов настоящего раскрытия сущности, либо с любым соответствующим или эквивалентным процессом.
[0077] (7) Один или более процессов, включенных в способы, реализованные посредством кодера или декодера согласно вариантам осуществления, могут комбинироваться с процессом, представленным в любом месте в описании аспектов настоящего раскрытия сущности.
[0078] (8) Реализация процессов и/или конфигураций, представленных в описании аспектов настоящего раскрытия сущности, не ограничена кодером или декодером согласно вариантам осуществления. Например, процессы и/или конфигурации могут реализовываться в устройстве, используемом для цели, отличающейся от кодера движущихся кадров или декодера движущихся кадров, раскрытого в вариантах осуществления.
[0079] Конфигурация системы
Фиг. 1 является принципиальной схемой, иллюстрирующей один пример конфигурации системы передачи согласно варианту осуществления.
[0080] Система Trs передачи представляет собой систему, которая передает поток, сформированный посредством кодирования изображения, и декодирует передаваемый поток. Система Trs передачи, такая, как указано, включает в себя, например, кодер 100, сеть Nw и декодер 200, как проиллюстрировано на фиг. 1.
[0081] Изображение вводится в кодер 100. Кодер 100 формирует поток посредством кодирования входного изображения и выводит поток в сеть Nw. Поток включает в себя, например, кодированную информацию изображений и управляющую информацию для декодирования кодированного изображения. Изображение сжимается посредством кодирования.
[0082] Следует отметить, что предыдущее изображение до кодирования и ввода в кодер 100 также называется "исходным изображением", "исходным сигналом" или "исходной выборкой". Изображение может представлять собой видео или неподвижное изображение. Изображение представляет собой общий принцип последовательности, кадра и блока и в силу этого не ограничено пространственной областью, имеющей конкретный размер, и временной областью, имеющей конкретный размер, если не указано иное. Изображение представляет собой массив пикселов или пиксельных значений, и сигнал, представляющий изображение или пиксельные значения, также называется "выборками". Поток может называться "потоком битов", "кодированным потоком битов", "сжатым потоком битов" или "кодированным сигналом". Кроме того, кодер может называться "кодером изображений" или "видеокодером". Способ кодирования, осуществляемый посредством кодера 100, может называться "способом кодирования", "способом кодирования изображений" или "способом кодирования видео".
[0083] Сеть Nw передает поток, сформированный посредством кодера 100, в декодер 200. Сеть Nw может представлять собой Интернет, глобальную вычислительную сеть (WAN), локальную вычислительную сеть (LAN) либо любую комбинацию этих сетей. Сеть Nw не всегда ограничена сетью двунаправленной связи и может представлять собой сеть однонаправленной связи, которая передает широковещательные волны цифровой наземной широковещательной передачи, спутниковой широковещательной передачи и т.п. Альтернативно, сеть Nw может заменяться посредством носителя, такого как универсальный цифровой диск (DVD) и Blu-Ray Disc (BD)(R) и т.д., на который записывается поток.
[0084] Декодер 200 формирует, для примера, декодированное изображение, которое представляет собой несжатое изображение, посредством декодирования потока, передаваемого посредством сети Nw. Например, декодер декодирует поток согласно способу декодирования, соответствующему способу кодирования посредством кодера 100.
[0085] Следует отметить, что декодер также может называться "декодером изображений" или "видеодекодером", и что способ декодирования, осуществляемый посредством декодера 200, также может называться "способом декодирования", "способом декодирования изображений" или "способом декодирования видео".
[0086] Структура данных
Фиг. 2 является схемой, иллюстрирующей один пример иерархической структуры данных в потоке. Поток включает в себя, например, видеопоследовательность. Как проиллюстрировано в (a) по фиг. 2, видеопоследовательность включает в себя набор параметров видео (VPS), набор параметров последовательности (SPS), набор параметров кадра (PPS), дополнительную улучшающую информацию (SEI) и множество кадров.
[0087] В видео, имеющем множество слоев, VPS включает в себя: параметр кодирования, который является общим между частью множества слоев; и параметр кодирования, связанный с некоторыми из множества слоев, включенных в видео, или с отдельным слоем.
[0088] SPS включает в себя параметр, который используется для последовательности, т.е. параметр кодирования, к которому обращается декодер 200 для того, чтобы декодировать последовательность. Например, параметр кодирования может указывать ширину или высоту кадра. Следует отметить, что множество SPS могут присутствовать.
[0089] PPS включает в себя параметр, который используется для кадра, т.е. параметр кодирования, к которому обращается декодер 200 для того, чтобы декодировать каждый из кадров в последовательности. Например, параметр кодирования может включать в себя опорное значение для ширины квантования, которая используется для того, чтобы декодировать кадр, и флаг, указывающий применение прогнозирования со взвешиванием. Следует отметить, что множество PPS могут присутствовать. Каждый из SPS и PPS может называться просто "набором параметров".
[0090] Как проиллюстрировано в (b) по фиг. 2, кадр может включать в себя заголовок кадра и, по меньшей мере, один срез. Заголовок кадра включает в себя параметр кодирования, к которому обращается декодер 200 для того, чтобы декодировать, по меньшей мере, один срез.
[0091] Как проиллюстрировано в (c) по фиг. 2, срез включает в себя заголовок среза и, по меньшей мере, один кирпич. Заголовок среза включает в себя параметр кодирования, к которому обращается декодер 200 для того, чтобы декодировать, по меньшей мере, один кирпич.
[0092] Как проиллюстрировано в (d) по фиг. 2, кирпич включает в себя, по меньшей мере, одну единицу дерева кодирования (CTU).
[0093] Следует отметить, что кадр может не включать в себя срез и может включать в себя группу плиток вместо среза. В этом случае, группа плиток включает в себя, по меньшей мере, одну плитку. Помимо этого, кирпич может включать в себя срез.
[0094] CTU также называется "суперблоком" или "базисной единицей разбиения". Как проиллюстрировано в (e) по фиг. 2, CTU, такая как указано, включает в себя CTU-заголовок и, по меньшей мере, одну единицу кодирования (CU). CTU-заголовок включает в себя параметр кодирования, к которому обращается декодер 200 для того, чтобы декодировать, по меньшей мере, одну CU.
[0095] CU может разбиваться на множество меньших CU. Как проиллюстрировано в (f) по фиг. 2, CU включает в себя заголовок CU, информацию прогнозирования и информацию остаточных коэффициентов. Информация прогнозирования представляет собой информацию для прогнозирования CU, и информация остаточных коэффициентов представляет собой информацию, указывающую остаток прогнозирования, который описывается ниже. Хотя CU является по существу идентичной единице прогнозирования (PU) и единице преобразования (TU), следует отметить, что, например, SBT, которое описывается ниже, может включать в себя множество TU, меньших CU. Помимо этого, CU может обрабатываться для каждой виртуальной конвейерной единицы декодирования (VPDU), включенной в CU. VPDU, например, представляет собой фиксированную единицу, которая может обрабатываться на одной стадии, когда конвейерная обработка выполняется в аппаратных средствах.
[0096] Следует отметить, что поток может не включать в себя часть иерархических слоев, проиллюстрированных на фиг. 2. Порядок иерархических слоев может меняться, или любой из иерархических слоев может заменяться посредством другого иерархического слоя. Здесь, кадр, который представляет собой цель для процесса, который должен выполняться посредством устройства, такого как кодер 100 или декодер 200, называется "текущим кадром". Текущий кадр означает текущий кадр, который должен кодироваться, когда процесс представляет собой процесс кодирования, и текущий кадр означает текущий кадр, который должен декодироваться, когда процесс представляет собой процесс декодирования. Аналогично, например, CU или блок CU, который представляет собой цель для процесса, который должен выполняться посредством устройства, такого как кодер 100 или декодер 200, называется "текущим блоком". Текущий блок означает текущий блок, который должен кодироваться, когда процесс представляет собой процесс кодирования, и текущий блок означает текущий блок, который должен декодироваться, когда процесс представляет собой процесс декодирования.
[0097] Структура кадра: срез/плитка
Кадр может быть сконфигурирован с одной или более единиц срезов или единиц плиток, с тем чтобы декодировать кадр параллельно.
[0098] Срезы представляют собой базовые единицы кодирования, включенные в кадр. Кадр может включать в себя, например, один или более срезов. Помимо этого, срез включает в себя одну или более последовательных единиц дерева кодирования (CTU).
[0099] Фиг. 3 является схемой, иллюстрирующей один пример конфигурации срезов. Например, кадр включает в себя CTU 11×8 и разбивается на четыре среза (срезы 1-4). Срез 1 включает в себя шестнадцать CTU, срез 2 включает в себя двадцать одну CTU, срез 3 включает в себя двадцать девять CTU, и срез 4 включает в себя двадцать две CTU. Здесь, каждая CTU в кадре принадлежит одному из срезов. Форма каждого среза представляет собой форму, полученную посредством разбиения кадра горизонтально. Граница каждого среза не должна обязательно совпадать с концом изображения и может совпадать с любой из границ между CTU в изображении. Порядок обработки CTU в срезе (порядок кодирования или порядок декодирования), например, представляет собой порядок растрового сканирования. Срез включает в себя заголовок среза и кодированные данные. Признаки среза могут записываться в заголовок среза. Признаки включают в себя CTU-адрес верхней CTU в срезе, тип среза и т.д.
[0100] Плитка представляет собой единицу прямоугольной области, включенной в кадр. Каждой из плиток может назначаться номер, называемый "TileId" в порядке растрового сканирования.
[0101] Фиг. 4 является схемой, иллюстрирующей один пример конфигурации плиток. Например, кадр включает в себя CTU 11×8 и разбивается на четыре плитки прямоугольных областей (плитки 1-4). Когда плитки используются, порядок обработки CTU изменяется относительно порядка обработки в случае, если плитки не используются. Когда плитки не используются, множество CTU в кадре обрабатываются в порядке растрового сканирования. Когда множество плиток используются, по меньшей мере, одна CTU в каждой из множества плиток обрабатывается в порядке растрового сканирования. Например, как проиллюстрировано на фиг. 4B, порядок обработки CTU, включенных в плитку 1, представляет собой порядок, который начинается с левого конца первого столбца плитки 1 к правому концу первого столбца плитки 1 и затем начинается с левого конца второго столбца плитки 1 к правому концу второго столбца плитки 1.
[0102] Следует отметить, что одна плитка может включать в себя один или более срезов, и один срез может включать в себя одну или более плиток.
[0103] Следует отметить, что кадр может быть сконфигурирован с одним или более наборов плиток. Набор плиток может включать в себя одну или более групп плиток либо одну или более плиток. Кадр может быть сконфигурирован только с одним из набора плиток, группы плиток и плитки. Например, порядок для сканирования множества плиток для каждого набора плиток в порядке растрового сканирования предположительно представляет собой базовый порядок кодирования плиток. Набор из одной или более плиток, которые являются непрерывными в базовом порядке кодирования в каждом наборе плиток, предположительно представляет собой группу плиток. Такой кадр может быть сконфигурирован посредством модуля 102 разбиения (см. фиг. 7), который описывается ниже.
[0104] Масштабируемое кодирование
Фиг. 5 и 6 являются схемами, иллюстрирующими примеры масштабируемых структур потока.
[0105] Как проиллюстрировано на фиг. 5, кодер 100 может формировать временно/пространственно масштабируемый поток посредством разделения каждого из множества кадров на любые из множества слоев и кодирования кадра в слое. Например, кодер 100 кодирует кадр для каждого слоя, за счет этого достигая масштабируемости, при которой улучшающий слой присутствует выше базового слоя. Такое кодирование каждого кадра также называется "масштабируемым кодированием". Таким образом, декодер 200 допускает переключение качества изображений для изображения, которое отображается посредством декодирования потока. Другими словами, декодер 200 определяет то, вплоть до какого слоя следует декодировать, на основе внутренних факторов, таких как способность к обработке декодера 200, и внешних факторов, таких как состояние полосы пропускания линий связи. Как результат, декодер 200 допускает декодирование контента при свободном переключении между низким разрешением и высоким разрешением. Например, пользователь потока просматривает видео потока наполовину с использованием смартфона по пути домой и продолжает просмотр ролика дома на таком устройстве, как телевизор, соединенный с Интернетом. Следует отметить, что каждое из смартфона и устройства, описанных выше, включает в себя декодер 200, имеющий идентичную или различную производительность. В этом случае, когда устройство декодирует слои вплоть до верхнего слоя в потоке, пользователь может просматривать видео в высоком качестве дома. Таким образом, кодер 100 не должен формировать множество потоков, имеющих различные качества изображений идентичного контента, и в силу этого нагрузка по обработке может уменьшаться.
[0106] Кроме того, улучшающий слой может включать в себя метаинформацию на основе статистической информации относительно изображения. Декодер 200 может формировать видео, качество изображений которого повышено посредством выполнения формирования изображений со сверхразрешением на кадре в базовом слое на основе метаданных. Формирование изображений со сверхразрешением может представлять собой любое из улучшения SN-отношения при идентичном разрешении и увеличения разрешения. Метаданные могут включать в себя информацию для идентификации коэффициента линейной или нелинейной фильтрации, используемой в процессе на основе сверхразрешения, либо информацию, идентифицирующую значение параметра в процессе фильтрации, при машинном обучении или в методе наименьших квадратов, используемом в обработке на основе сверхразрешения.
[0107] Альтернативно, может предоставляться конфигурация, в которой кадр разделяется, например, на плитки, например, в соответствии со смысловым значением объекта в кадре. В этом случае, декодер 200 может декодировать только частичную область в кадре посредством выбора плитки, которая должна декодироваться. Помимо этого, атрибут объекта (человека, автомобиля, шара и т.д.) и позиция объекта в кадре (координаты в идентичных изображениях) могут сохраняться в качестве метаданных. В этом случае, декодер 200 допускает идентификацию позиции требуемого объекта на основе метаданных и определение плитки, включающей в себя объект. Например, как проиллюстрировано на фиг. 6, метаданные могут сохраняться с использованием структуры хранения данных, отличающейся от данных изображения, такой как SEI в HEVC. Эти метаданные указывают, например, позицию, размер или цвет основного объекта.
[0108] Метаданные могут сохраняться в единицах множества кадров, к примеру, как поток, последовательность или единица произвольного доступа. Таким образом, декодер 200 допускает получение, например, времени, в которое конкретный человек появляется в видео, и посредством подгонки информации времени к информации единицы кадров, допускает идентификацию кадра, в котором объект присутствует, и определение позиции объекта в кадре.
[0109] Кодер
Далее описывается кодер 100 согласно этому варианту осуществления. Фиг. 7 является блок-схемой, иллюстрирующей один пример функциональной конфигурации кодера 100 согласно этому варианту осуществления. Кодер 100 кодирует изображение в единицах блоков.
[0110] Как проиллюстрировано на фиг. 7, кодер 100 представляет собой оборудование, которое кодирует изображение в единицах блоков, и включает в себя модуль 102 разбиения, вычитатель 104, преобразователь 106, квантователь 108, энтропийный кодер 110, обратный квантователь 112, обратный преобразователь 114, сумматор 116, запоминающее устройство 118 блоков, контурный фильтр 120, запоминающее устройство 122 кинокадров, модуль 124 внутреннего прогнозирования, модуль 126 взаимного прогнозирования, контроллер 128 прогнозирования и формирователь 130 параметров прогнозирования. Следует отметить, что модуль 124 внутреннего прогнозирования и модуль 126 взаимного прогнозирования сконфигурированы как часть модуль выполнения прогнозирования.
[0111] Пример монтажа кодера
Фиг. 8 является блок-схемой, иллюстрирующей пример монтажа кодера 100. Кодер 100 включает в себя процессор a1 и запоминающее устройство a2. Например, множество составляющих элементов кодера 100, проиллюстрированного на фиг. 7, смонтированы в процессоре a1 и запоминающем устройстве a2, проиллюстрированных на фиг. 8.
[0112] Процессор a1 представляет собой схему, которая выполняет обработку информации, и является доступным для запоминающего устройства a2. Например, процессор a1 представляет собой специализированную или общую электронную схему, которая кодирует изображение. Процессор a1 может представлять собой процессор, такой как CPU. Помимо этого, процессор a1 может представлять собой совокупность множества электронных схем. Помимо этого, например, процессор a1 может выполнять роли двух или более составляющих элементов, отличных от составляющего элемента для сохранения информации, из множества составляющих элементов кодера 100, проиллюстрированного на фиг. 7, и т.д.
[0113] Запоминающее устройство a2 представляет собой специализированное или общее запоминающее устройство для сохранения информации, которая используется посредством процессора a1 для того, чтобы кодировать изображение. Запоминающее устройство a2 может представлять собой электронную схему и может соединяться с процессором a1. Помимо этого, запоминающее устройство a2 может включаться в процессор a1. Помимо этого, запоминающее устройство a2 может представлять собой совокупность множества электронных схем. Помимо этого, запоминающее устройство a2 может представлять собой магнитный диск, оптический диск и т.п. либо может представляться как устройство хранения данных, носитель и т.п. Помимо этого, запоминающее устройство a2 может представлять собой энергонезависимое запоминающее устройство или энергозависимое запоминающее устройство.
[0114] Например, запоминающее устройство a2 может сохранять изображение, которое должно кодироваться, или поток, соответствующий кодированному изображению. Помимо этого, запоминающее устройство a2 может сохранять программу для инструктирования процессору a1 кодировать изображение.
[0115] Помимо этого, например, запоминающее устройство a2 может выполнять роли двух или более составляющих элементов для сохранения информации из множества составляющих элементов кодера 100, проиллюстрированного на фиг. 7. Более конкретно, запоминающее устройство a2 может выполнять роли запоминающего устройства 118 блоков и запоминающего устройства 122 кинокадров, проиллюстрированных на фиг. 7. Более конкретно, запоминающее устройство a2 может сохранять восстановленное изображение (в частности, восстановленный блок, восстановленный кадр и т.п.).
[0116] Следует отметить, что, в кодере 100, не все из множества составляющих элементов, указываемых на фиг. 7 и т.д., могут реализовываться, и не все процессы, описанные выше, могут выполняться. Часть составляющих элементов, указываемых на фиг. 7, может включаться в другое устройство, или часть процессов, описанных выше, может выполняться посредством другого устройства.
[0117] В дальнейшем в этом документе описывается полная последовательность операций процессов, выполняемых посредством кодера 100, и после этого описывается каждый из составляющих элементов, включенных в кодер 100.
[0118] Общая последовательность операций процесса кодирования
Фиг. 9 является блок-схемой последовательности операций способа, иллюстрирующей один пример полного процесса кодирования, выполняемого посредством кодера 100.
[0119] Во-первых, модуль 102 разбиения кодера 100 разбивает каждый из кадров, включенных в исходного изображение, на множество блоков, имеющих фиксированный размер (например, 128×128 пикселов) (этап Sa_1). Модуль 102 разбиения затем выбирает шаблон разбиения для блока фиксированного размера (этап Sa_2). Другими словами, модуль 102 разбиения дополнительно разбивает блок фиксированного размера на множество блоков, которые формируют выбранный шаблон разбиения. Кодер 100 выполняет, для каждого из множества блоков, этапы Sa_3-Sa_9 для блока.
[0120] Контроллер 128 прогнозирования и модуль выполнения прогнозирования, который сконфигурирован с модулем 124 внутреннего прогнозирования и модулем 126 взаимного прогнозирования, формируют прогнозное изображение текущего блока (этап Sa_3). Следует отметить, что прогнозное изображение также называется "прогнозным сигналом", "блоком прогнозирования" или "прогнозными выборками".
[0121] Затем, вычитатель 104 формирует разность между текущим блоком и прогнозным изображением в качестве остатка прогнозирования (этап Sa_4). Следует отметить, что остаток прогнозирования также называется "ошибкой прогнозирования".
[0122] Затем, преобразователь 106 преобразует прогнозное изображение, и квантователь 108 квантует результат для того, чтобы формировать множество квантованных коэффициентов (этап Sa_5).
[0123] Затем, энтропийный кодер 110 кодирует (в частности, энтропийно кодирует) множество квантованных коэффициентов и параметр прогнозирования, связанный с формированием прогнозного изображения, чтобы формировать поток (этап Sa_6).
[0124] Затем, обратный квантователь 112 выполняет обратное квантование множества квантованных коэффициентов, и обратный преобразователь 114 выполняет обратное преобразование результата, чтобы восстанавливать остаток прогнозирования (этап Sa_7).
[0125] Затем, сумматор 116 суммирует прогнозное изображение с восстановленным остатком прогнозирования, чтобы восстанавливать текущий блок (этап Sa_8). Таким образом, восстановленное изображение формируется. Следует отметить, что восстановленное изображение также называется "восстановленным блоком", и в частности, что восстановленное изображение, сформированное посредством кодера 100, также называется "локальным декодированным блоком" или "локальным декодированным изображением".
[0126] Когда восстановленное изображение формируется, контурный фильтр 120 выполняет фильтрацию восстановленного изображения при необходимости (этап Sa_9).
[0127] Кодер 100 затем определяет то, закончено или нет кодирование всего кадра (этап Sa_10). При определении того, что кодирование еще не закончено ("Нет" на этапе Sa_10), процессы с этапа Sa_2 многократно выполняются.
[0128] Хотя кодер 100 выбирает один шаблон разбиения для блока фиксированного размера и кодирует каждый блок согласно шаблону разбиения в вышеописанном примере, следует отметить, что каждый блок может кодироваться согласно соответствующему одному из множества шаблонов разбиения. В этом случае, кодер 100 может оценивать затраты для каждого из множества шаблонов разбиения и, например, может выбирать поток, полученный посредством кодирования согласно шаблону разбиения, который дает в результате наименьшие затраты, в качестве потока, который выводится в конечном счете.
[0129] Альтернативно, процессы на этапах Sa_1-Sa_10 могут выполняться последовательно посредством кодера 100, либо два или более процессов могут выполняться параллельно или могут переупорядочиваться.
[0130] Процесс кодирования посредством кодера 100 представляет собой гибридное кодирование с использованием прогнозного кодирования и кодирования с преобразованием. Помимо этого, прогнозное кодирование выполняется посредством контура кодирования, сконфигурированного с вычитателем 104, преобразователем 106, квантователем 108, обратным квантователем 112, обратным преобразователем 114, сумматором 116, контурным фильтром 120, запоминающим устройством 118 блоков, запоминающим устройством 122 кинокадров, модулем 124 внутреннего прогнозирования, модулем 126 взаимного прогнозирования и контроллером 128 прогнозирования. Другими словами, модуль выполнения прогнозирования, сконфигурированный с модулем 124 внутреннего прогнозирования и модулем 126 взаимного прогнозирования, представляет собой часть контура кодирования.
[0131] Модуль разбиения
Модуль 102 разбиения разбивает каждый из кадров, включенных в исходное изображение, на множество блоков и выводит каждый блок в вычитатель 104. Например, модуль 102 разбиения сначала разбивает кадр на блоки фиксированного размера (например, 128×128 пикселов). Блок фиксированного размера также называется "единицей дерева кодирования (CTU)". Модуль 102 разбиения затем разбивает каждый блок фиксированного размера на блоки переменных размеров (например, 64×64 пикселов или меньше), на основе рекурсивного разбиения на блоки дерева квадрантов и/или двоичного дерева. Другими словами, модуль 102 разбиения выбирает шаблон разбиения. Блок переменного размера также называется "единицей кодирования (CU)", "единицей прогнозирования (PU)" или "единицей преобразования (TU)". Следует отметить, что, в различных видах примеров монтажа, нет необходимости различать между CU, PU и TU; все или некоторые блоки в кадре могут обрабатываться в единицах CU, PU или TU.
[0132] Фиг. 10 является схемой, иллюстрирующей один пример разбиения блоков согласно этому варианту осуществления. На фиг. 10, сплошные линии представляют границы блоков для блоков, разбитых посредством разбиения на блоки дерева квадрантов, и пунктирные линии представляют границы блоков для блоков, разбитых посредством разбиения на блоки двоичного дерева.
[0133] Здесь, блок 10 представляет собой квадратный блок, имеющий 128×128 пикселов. Это блок 10 сначала разбивается на четыре квадратных 64×64-пиксельных блока (разбиение на блоки дерева квадрантов).
[0134] Верхний левый 64×64-пиксельный блок дополнительно вертикально разбивается на два прямоугольных 32×64-пиксельных блока, и левый 32×64-пиксельный блок дополнительно вертикально разбивается на два прямоугольных 16×64-пиксельных блока (разбиение на блоки двоичного дерева). Как результат, верхний левый квадратный 64×64-пиксельный блок разбивается на два 16×64-пиксельных блока 11 и 12 и один 32×64-писелный блок 13.
[0135] Верхний правый квадратный 64×64-пиксельный блок горизонтально разбивается на два прямоугольных 64×32-пиксельных блока 14 и 15 (разбиение на блоки двоичного дерева).
[0136] Левый нижний квадратный 64×64-пиксельный блок сначала разбивается на четыре квадратных 32×32-пиксельных блока (разбиение на блоки дерева квадрантов). Верхний левый блок и нижний правый блок из четырех квадратных 32×32-пиксельных блоков дополнительно разбиваются. Верхний левый квадратный 32×32-пиксельный блок вертикально разбивается на два прямоугольных 16×32-пиксельных блока, и правый 16×32-пиксельный блок дополнительно горизонтально разбивается на два 16×16-пиксельных блока (разбиение на блоки двоичного дерева). Правый нижний 32×32-пиксельный блок горизонтально разбивается на два 32×16-пиксельных блока (разбиение на блоки двоичного дерева). Верхний правый квадратный 32×32-пиксельный блок горизонтально разбивается на два прямоугольных 32×16-пиксельных блока (разбиение на блоки двоичного дерева). Как результат, левый нижний квадратный 64×64-пиксельный блок разбивается на прямоугольный 16×32-пиксельный блок 16, два квадратных 16×16-пиксельных блока 17 и 18, два квадратных 32×32-пиксельных блока 19 и 20 и два прямоугольных 32×16-пиксельных блока 21 и 22.
[0137] Правый нижний 64×64-пиксельный блок 23 не разбивается.
[0138] Как описано выше, на фиг. 10, блок 10 разбивается на тринадцать блоков 11-23 переменного размера на основе рекурсивного разбиения на блоки дерева квадрантов и двоичного дерева. Такое разбиение также называется "разбиением на дерево квадрантов плюс двоичное дерево (QTBT)".
[0139] Следует отметить, что, на фиг. 10, один блок разбивается на четыре или два блока (разбиение на блоки дерева квадрантов или двоичного дерева), но разбиение не ограничено этими примерами. Например, один блок может разбиваться на три блока (разбиение на троичные блоки). Разбиение, включающее в себя такое разбиение на троичные блоки, также называется "разбиением на многотипное дерево (MBT)".
[0140] Фиг. 11 является схемой, иллюстрирующей один пример функциональной конфигурации модуля 102 разбиения. Как проиллюстрировано на фиг. 11, модуль 102 разбиения может включать в себя модуль 102a определения разбиения блоков. Модуль 102a определения разбиения блоков может выполнять следующие процессы в качестве примеров.
[0141] Например, модуль 102a определения разбиения блоков собирает информацию блоков из запоминающего устройства 118 блоков либо из запоминающего устройства 122 кинокадров и определяет вышеописанный шаблон разбиения на основе информации блоков. Модуль 102 разбиения разбивает исходное изображение согласно шаблону разбиения и выводит, по меньшей мере, один блок, полученный посредством разбиения, в вычитатель 104.
[0142] Помимо этого, например, модуль 102a определения разбиения блоков выводит параметр, указывающий вышеописанный шаблон разбиения для преобразователя 106, обратного преобразователя 114, модуля 124 внутреннего прогнозирования, модуля 126 взаимного прогнозирования и энтропийного кодера 110. Преобразователь 106 может преобразовывать остаток прогнозирования на основе параметра. Модуль 124 внутреннего прогнозирования и модуль 126 взаимного прогнозирования могут формировать прогнозное изображение на основе параметра. Помимо этого, энтропийный кодер 110 может энтропийно кодировать параметр.
[0143] Параметр, связанный с шаблоном разбиения, может записываться в поток, как указано ниже в качестве одного примера.
[0144] Фиг. 12 является схемой, иллюстрирующей примеры шаблонов разбиения. Примеры шаблонов разбиения включают в себя: разбиение на четыре области (QT), при котором блок разбивается на две области как горизонтально, так и вертикально; разбиение на три области (HT или VT), при котором блок разбивается в идентичном направлении в соотношении 1:2:1; разбиение на две области (HB или VB), при котором блок разбивается в идентичном направлении в соотношении 1:1; и отсутствие разбиения (NS).
[0145] Следует отметить, что шаблон разбиения не имеет направления разбиения блоков в случае разбиения на четыре области и отсутствия разбиения, и что шаблон разбиения имеет информацию направления разбиения в случае разбиения на две области или три области.
[0146] Фиг. 13A и 13B являются схемой, иллюстрирующей один пример синтаксического дерева шаблона разбиения. В примере по фиг. 13A, во-первых, информация, указывающая то, следует выполнять или нет разбиение (S: флаг разбиения), присутствует, и информация, указывающая то, следует или нет выполнять разбиение на четыре области (QT: QT-флаг), присутствует после нее. Информация, указывающая то, что из разбиения на три области и две области должно выполняться (TT: TT-флаг или BT: BT-флаг), присутствует после нее, и в завершение, информация, указывающая направление разделения (Ver: вертикальный флаг, или Hor: горизонтальный флаг), присутствует. Следует отметить, что каждый, по меньшей мере, один блок, полученный посредством разбиения согласно такому шаблону разбиения, дополнительно может разбиваться многократно в аналогичном процессе. Другими словами, в качестве одного примера, то, выполняется или нет разбиение, то, выполняется или нет разбиение на четыре области, то, какое из горизонтального направления и вертикального направления представляет собой направление, в котором должен выполняться способ разбиения, что из разбиения на три области и разбиения на две области должно выполняться, может рекурсивно определяться, и результаты определения могут кодироваться в потоке согласно порядку кодирования, раскрытому посредством синтаксического дерева, проиллюстрированного на фиг. 13A.
[0147] Помимо этого, хотя информационные элементы, соответственно, указывающие S, QT, TT и Ver, размещаются в перечисленном порядке в синтаксическом дереве, проиллюстрированном на фиг. 13A, информационные элементы, соответственно, указывающие S, QT, Ver и BT, могут размещаться в перечисленном порядке. Другими словами, в примере по фиг. 13B, во-первых, информация, указывающая то, следует или нет выполнять разбиение (S: флаг разбиения), присутствует, и информация, указывающая то, следует или нет выполнять разбиение на четыре области (QT: QT-флаг), присутствует после нее. Информация, указывающая направление разбиения (Ver: вертикальный флаг, или Hor: горизонтальный флаг), присутствует после нее, и в завершение, информация, указывающая то, что из разбиения на две области и разбиения на три области должно выполняться (BT: BT-флаг, или TT: TT-флаг), присутствует.
[0148] Следует отметить, что шаблоны разбиения, описанные выше, представляют собой примеры, и шаблоны разбиения, отличные от описанных шаблонов разбиения, могут использоваться, или часть описанных шаблонов разбиения может использоваться.
[0149] Вычитатель
Вычитатель 104 вычитает прогнозное изображение (прогнозное изображение, которое вводится из контроллера 128 прогнозирования) из исходного изображения в единицах блоков, вводимое из модуля 102 разбиения и разбиваемое посредством модуля 102 разбиения. Другими словами, вычитатель 104 вычисляет остатки прогнозирования текущего блока. Вычитатель 104 затем выводит вычисленные остатки прогнозирования в преобразователь 106.
[0150] Исходный сигнал представляет собой входной сигнал, который введен в кодер 100, и представляет изображение каждого кадра, включенного в видео (например, сигнал яркости и два сигнала цветности).
[0151] Преобразователь
Преобразователь 106 преобразует остатки прогнозирования в пространственной области в коэффициенты преобразования в частотной области и выводит коэффициенты преобразования в квантователь 108. Более конкретно, преобразователь 106 применяет, например, предварительно заданное дискретное косинусное преобразование (DCT) или дискретное синусное преобразование (DST) к остаткам прогнозирования в пространственной области.
[0152] Следует отметить, что преобразователь 106 может адаптивно выбирать тип преобразования из множества типов преобразования и преобразовывать остатки прогнозирования в коэффициенты преобразования посредством использования базисной функции преобразования, соответствующей выбранному типу преобразования. Этот вид преобразования также называется "явным множественным базовым преобразованием (EMT)" или "адаптивным множественным преобразованием (AMT)". Помимо этого, базисная функция преобразования также называется просто "базисом".
[0153] Типы преобразования включают в себя, например, DCT-II, DCT-V, DCT-VIII, DST-I и DST-VII. Следует отметить, что эти типы преобразования могут представляться как DCT2, DCT5, DCT8, DST1 и DST7. Фиг. 14 является диаграммой, иллюстрирующей базисные функции преобразования для каждого типа преобразования. На фиг. 14, N указывает число входных пикселов. Например, выбор типа преобразования из множества типов преобразования может зависеть от типа прогнозирования (одно из внутреннего прогнозирования и взаимного прогнозирования) и может зависеть от режима внутреннего прогнозирования.
[0154] Информация, указывающая то, следует или нет применять такое EMT или AMT (называется, например, "EMT-флагом" или "AMT-флагом"), и информация, указывающая выбранный тип преобразования, нормально передается в служебных сигналах на уровне CU. Следует отметить, что передача в служебных сигналах этой информации не должна обязательно выполняться на уровне CU и может выполняться на другом уровне (например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU).
[0155] Помимо этого, преобразователь 106 может повторно преобразовывать коэффициенты преобразования (которые представляют собой результаты преобразования). Такое повторное преобразование также называется "адаптивным вторичным преобразованием (AST)" или "неразделимым вторичным преобразованием (NSST)". Например, преобразователь 106 выполняет повторное преобразование в единицах субблока (например, 4×4-пиксельного субблока), включенного в блок коэффициентов преобразования, соответствующий остатку внутреннего прогнозирования. Информация, указывающая то, следует или нет применять NSST, и информация, связанная с матрицей преобразования для использования в NSST, нормально передается в служебных сигналах на уровне CU. Следует отметить, что передача в служебных сигналах этой информации не должна обязательно выполняться на уровне CU и может выполняться на другом уровне (например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU).
[0156] Преобразователь 106 может использовать разделимое преобразование и неразделимое преобразование. Здесь, разделимое преобразование представляет собой способ, в котором преобразование выполняется многократно посредством отдельного выполнения преобразования для каждого из направлений согласно числу размерностей вводов. Неразделимое преобразование представляет собой способ выполнения коллективного преобразования, в котором две или более размерностей в многомерных вводах совместно рассматриваются в качестве одной размерности.
[0157] В одном примере неразделимого преобразования, когда ввод представляет собой 4×4-пиксельный блок, 4×4-пиксельный блок рассматривается в качестве единого массива, включающего в себя шестнадцать элементов, и преобразование применяет матрицу преобразования 16×16 к массиву.
[0158] В другом примере неразделимого преобразования, входной блок из 4×4 пикселов рассматривается в качестве единого массива, включающего в себя шестнадцать элементов, и после этого может выполняться преобразование (гиперкубическое преобразование Гивенса), при котором вращение Гивенса выполняется для массива многократно.
[0159] При преобразовании в преобразователе 106, типы преобразования для базисных функций преобразования, которые должны преобразовываться в частотную область согласно областям в CU, могут переключаться. Примеры включают в себя пространственно варьирующееся преобразование (SVT).
[0160] Фиг. 15 является схемой, иллюстрирующей один пример SVT.
[0161] В SVT, как проиллюстрировано на фиг. 5B, CU разбиваются на две равных области горизонтально или вертикально, и только одна из областей преобразуется в частотную область. Тип преобразования может задаваться для каждой области. Например, используются DST7 и DST8. Например, из двух областей, полученных посредством разбиения CU вертикально на две равных области, DST7 и DCT8 могут использоваться для области в позиции 0. Альтернативно, из двух областей, DST7 используется для области в позиции 1. Аналогично, из двух областей, полученных посредством разбиения CU горизонтально на две равных области, DST7 и DCT8 используются для области в позиции 0. Альтернативно, из двух областей, DST7 используется для области в позиции 1. Хотя только одна из двух областей в CU преобразуется, а другая не преобразуется в примере, проиллюстрированном на фиг. 15, каждая из двух областей может преобразовываться. Помимо этого, способ разбиения может включать в себя не только разбиение на две области, но также и разбиение на четыре области. Помимо этого, способ разбиения может быть более гибким. Например, информация, указывающая способ разбиения, может кодироваться и может передаваться в служебных сигналах, идентично CU-разбиению. Следует отметить, что SVT также называется "субблочным преобразованием (SBT)".
[0162] AMT и EMT, описанные выше, могут называться "MTS (множественным выбором преобразования)". Когда MTS применяется, тип преобразования, который представляет собой DST7, DCT8 и т.п., может выбираться, и информация, указывающая выбранный тип преобразования, может кодироваться как информация индекса для каждой CU. Предусмотрен другой процесс, называемый "IMTS (неявным MTS)", в качестве процесса для выбора, на основе формы CU, типа преобразования, который должен использоваться для ортогонального преобразования, выполняемого без кодирования информации индекса. Когда IMTS применяется, например, когда CU имеет прямоугольную форму, ортогональное преобразование прямоугольной формы выполняется с использованием DST7 для короткой стороны и DST2 для длинной стороны. Помимо этого, например, когда CU имеет квадратную форму, ортогональное преобразование прямоугольной формы выполняется с использованием DCT2, когда MTS является эффективным в последовательности, и с использованием DST7, когда MTS является неэффективным в последовательности. DCT2 и DST7 представляют собой просто примеры. Другие типы преобразования могут использоваться, и также можно изменять комбинацию типов преобразования для использования на другую комбинацию типов преобразования. IMTS может использоваться только для блоков внутреннего прогнозирования или может использоваться для блоков внутреннего прогнозирования и блока взаимного прогнозирования.
[0163] Три процесса в виде MTS, SBT и IMTS описываются выше в качестве процессов выбора для избирательного переключения типов преобразования для использования при ортогональном преобразовании. Тем не менее все три процесса выбора могут становиться эффективными, либо только часть процессов выбора может избирательно становиться эффективной. То, становится или нет каждый из процессов выбора эффективным, может идентифицироваться на основе информации флага и т.п. в заголовке, таком как SPS. Например, когда все три процесса выбора являются эффективными, один из трех процессов выбора выбирается для каждой CU, и ортогональное преобразование CU выполняется. Следует отметить, что процессы выбора для избирательного переключения типов преобразования могут представлять собой процессы выбора, отличающиеся от вышеуказанных трех процессов выбора, или каждый из трех процессов выбора может заменяться посредством другого процесса при условии, что, по меньшей мере, одна из следующих четырех функций [1]-[4] может достигаться. Функция [1] представляет собой функцию для выполнения ортогонального преобразования всей CU и кодирования информации, указывающей тип преобразования, используемый при преобразовании. Функция [2] представляет собой функцию для выполнения ортогонального преобразования всей CU и определения типа преобразования на основе предварительно определенного правила без кодирования информации, указывающей тип преобразования. Функция [3] представляет собой функцию для выполнения ортогонального преобразования частичной области CU и кодирования информации, указывающей тип преобразования, используемый при преобразовании. Функция [4] представляет собой функцию для выполнения ортогонального преобразования частичной области CU и определения типа преобразования на основе предварительно определенного правила без кодирования информации, указывающей тип преобразования, используемый при преобразовании.
[0164] Следует отметить, что, то, применяется либо нет каждое из MTS, IMTS и SBT, может определяться для каждой единицы обработки. Например, то, применяется либо нет каждое из MTS, IMTS и SBT, может определяться для каждой последовательности, кадра, кирпича, среза, CTU или CU.
[0165] Следует отметить, что инструментальное средство для избирательного переключения типов преобразования в настоящем раскрытии сущности может перефразироваться посредством способа для избирательного выбора базиса для использования в процессе преобразования, в процессе выбора или в процессе для выбора базиса. Помимо этого, инструментальное средство для избирательного переключения типов преобразования может перефразироваться посредством режима для адаптивного выбора типа преобразования.
[0166] Фиг. 16 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством преобразователя 106.
[0167] Например, преобразователь 106 определяет то, следует или нет выполнять ортогональное преобразование (этап St_1). Здесь, при определении необходимости выполнять ортогональное преобразование ("Да" на этапе St_1), преобразователь 106 выбирает тип преобразования для использования при ортогональном преобразовании из множества типов преобразования (этап St_2). Затем, преобразователь 106 выполняет ортогональное преобразование посредством применения выбранного типа преобразования к остатку прогнозирования текущего блока (этап St_3). Преобразователь 106 затем выводит информацию, указывающую выбранный тип преобразования, в энтропийный кодер 110, с тем чтобы обеспечивать возможность энтропийному кодеру 110 кодировать информацию (этап St_4). С другой стороны, при определении необходимости не выполнять ортогональное преобразование ("Нет" на этапе St_1), преобразователь 106 выводит информацию, указывающую то, что ортогональное преобразование не выполняется, с тем чтобы обеспечивать возможность энтропийному кодеру 110 кодировать информацию (этап St_5). Следует отметить, что то, следует или нет выполнять ортогональное преобразование, на этапе St_1 может определяться, например, на основе размера блока преобразования, режима прогнозирования, применяемого к CU, и т.д. Альтернативно, ортогональное преобразование может выполняться с использованием предварительно заданного типа преобразования без кодирования информации, указывающей тип преобразования для использования при ортогональном преобразовании.
[0168] Фиг. 17 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством преобразователя 106. Следует отметить, что пример, проиллюстрированный на фиг. 17, представляет собой пример ортогонального преобразования в случае, если типы преобразования для использования в ортогональном преобразовании избирательно переключаются, как и в случае примера, проиллюстрированного на фиг. 16.
[0169] В качестве одного примера, первая группа типов преобразования может включать в себя DCT2, DST7 и DCT8. В качестве другого примера, вторая группа типов преобразования может включать в себя DCT2. Типы преобразования, включенные в первую группу типов преобразования, и типы преобразования, включенные во вторую группу типов преобразования, могут частично перекрываться между собой или могут полностью отличаться друг от друга.
[0170] Более конкретно, преобразователь 106 определяет то, меньше или равен либо нет размер преобразования предварительно определенному значению (этап Su_1). Здесь, при определении того, что размер преобразования меньше или равен предварительно определенному значению ("Да" на этапе Su_1), преобразователь 106 выполняет ортогональное преобразование остатка прогнозирования текущего блока с использованием типа преобразования, включенного в первую группу типов преобразования (этап Su_2). Затем, преобразователь 106 выводит информацию, указывающую тип преобразования, который должен использоваться, по меньшей мере, из одного типа преобразования, включенного в первую группу типов преобразования, в энтропийный кодер 110, с тем чтобы обеспечивать возможность энтропийному кодеру 110 кодировать информацию (этап Su_3). С другой стороны, при определении того, что размер преобразования не меньше или равен предварительно определенному значению ("Нет" на этапе Su_1), преобразователь 106 выполняет ортогональное преобразование остатка прогнозирования текущего блока с использованием второй группы типов преобразования (этап Su_4).
[0171] На этапе Su_3, информация, указывающая тип преобразования для использования при ортогональном преобразовании, может представлять собой информацию, указывающую комбинацию типа преобразования, который должен применяться вертикально в текущем блоке, и типа преобразования, который должен применяться горизонтально в текущем блоке. Первая группа типов может включать в себя только один тип преобразования, и информация, указывающая тип преобразования для использования при ортогональном преобразовании, может не кодироваться. Вторая группа типов преобразования может включать в себя множество типов преобразования, и информация, указывающая тип преобразования для использования при ортогональном преобразовании из одного или более типов преобразования, включенных во вторую группу типов преобразования, может кодироваться.
[0172] Альтернативно, тип преобразования может определяться только на основе размера преобразования. Следует отметить, что такие определения не ограничены определением в отношении того, меньше или равен либо нет размер преобразования предварительно определенному значению, и другие процессы также являются возможными при условии, что процессы служат для определения типа преобразования для использования при ортогональном преобразовании на основе размера преобразования.
[0173] Квантователь
Квантователь 108 квантует коэффициенты преобразования, выводимые из преобразователя 106. Более конкретно, квантователь 108 сканирует, в определенном порядке сканирования, коэффициенты преобразования текущего блока и квантует сканированные коэффициенты преобразования на основе параметров квантования (QP), соответствующих коэффициентам преобразования. Квантователь 108 затем выводит квантованные коэффициенты преобразования (в дальнейшем также называются "квантованными коэффициентами") текущего блока в энтропийный кодер 110 и обратный квантователь 112.
[0174] Определенный порядок сканирования представляет собой порядок для квантования/обратного квантования коэффициентов преобразования. Например, определенный порядок сканирования задается как порядок по возрастанию частоты (от низкой к высокой частоте) или порядок по убыванию частоты (от высокой к низкой частоте).
[0175] Параметр квантования (QP) представляет собой параметр, задающий шаг квантования (ширину квантования). Например, когда значение параметра квантования увеличивается, размер шага квантования также увеличивается. Другими словами, когда значение параметра квантования увеличивается, ошибка в квантованных коэффициентах (ошибка квантования) увеличивается.
[0176] Помимо этого, матрица квантования может использоваться для квантования. Например, несколько видов матриц квантования могут использоваться, соответственно, чтобы выполнять преобразование частоты для размеров, таких как 4×4 и 8×8, режимов прогнозирования, таких как внутреннее прогнозирование и взаимное прогнозирование, и пиксельных компонентов, таких как пиксельные компоненты сигнала яркости и сигнала цветности. Следует отметить, что квантование означает оцифровку значений, дискретизированных с предварительно определенными интервалами, соответственно, в предварительно определенные уровни. В этой области техники, квантование может представляться как другие выражения, к примеру, как округление и масштабирование.
[0177] Способы с использованием матриц квантования включает в себя способ с использованием матрицы квантования, которая задана непосредственно на стороне кодера 100, и способ с использованием матрицы квантования, которая задана в качестве значения по умолчанию (матрицы по умолчанию). На стороне кодера 100, матрица квантования, подходящая для признаков изображения, может задаваться посредством прямого задания матрицы квантования. Тем не менее, этот случай имеет недостаток увеличения объема кодирования для кодирования матрицы квантования. Следует отметить, что матрица квантования, которая должна использоваться для того, чтобы квантовать текущий блок, может формироваться на основе матрицы квантования по умолчанию или кодированной матрицы квантования, вместо непосредственного использования матрицы квантования по умолчанию или кодированной матрицы квантования.
[0178] Предусмотрен способ для квантования высокочастотного коэффициента и низкочастотного коэффициента идентичным образом без использования матрицы квантования. Следует отметить, что этот способ является эквивалентным способу с использованием матрицы квантования (плоской матрицы), все коэффициенты которой имеют идентичное значение.
[0179] Матрица квантования может кодироваться, например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU.
[0180] При использовании матрицы квантования, квантователь 108 масштабирует, для каждого коэффициента преобразования, например, ширину квантования, которая может вычисляться на основе параметра квантования и т.д., с использованием значения матрицы квантования. Процесс квантования, выполняемый вообще без использования матриц квантования, может представлять собой процесс квантования коэффициентов преобразования на основе ширины квантования, вычисленной на основе параметра квантования и т.д. Следует отметить, что, в процессе квантования, выполняемом без использования матриц квантования, ширина квантования может умножаться на предварительно определенное значение, которое является общим для всех коэффициентов преобразования в блоке.
[0181] Фиг. 18 является блок-схемой, иллюстрирующей один пример функциональной конфигурации квантователя 108.
[0182] Например, квантователь 108 включает в себя формирователь 108a параметров разностного квантования, формирователь 108b прогнозированных параметров квантования, формирователь 108c параметров квантования, устройство 108d хранения параметров квантования и модуль 108e выполнения квантования.
[0183] Фиг. 19 является блок-схемой последовательности операций способа, иллюстрирующей один пример квантования, выполняемого посредством квантователя 108.
[0184] В качестве одного примера, квантователь 108 может выполнять квантование для каждой CU на основе блок-схемы последовательности операций способа, проиллюстрированной на фиг. 19. Более конкретно, формирователь 108c параметров квантования определяет то, следует или нет выполнять квантование (этап Sv_1). Здесь, при определении необходимости выполнять квантование ("Да" на этапе Sv_1), формирователь 108c параметров квантования формирует параметр квантования для текущего блока (этап Sv_2) и сохраняет параметр квантования в устройстве 108d хранения параметров квантования (этап Sv_3).
[0185] Затем, модуль 108e выполнения квантования квантует коэффициенты преобразования текущего блока с использованием параметра квантования, сформированного на этапе Sv_2 (этап Sv_4). Формирователь 108b прогнозированных параметров квантования затем получает параметр квантования для единицы обработки, отличающейся от текущего блока, из устройства 108d хранения параметров квантования (этап Sv_5). Формирователь 108b прогнозированных параметров квантования формирует прогнозированный параметр квантования текущего блока на основе полученного параметра квантования (этап Sv_6). Формирователь 108a параметров разностного квантования вычисляет разность между параметром квантования текущего блока, сформированным посредством формирователя 108c параметров квантования, и прогнозированным параметром квантования текущего блока, сформированным посредством формирователя 108b прогнозированных параметров квантования (этап Sv_7). Параметр разностного квантования формируется посредством вычисления разности. Формирователь 108a параметров разностного квантования выводит параметр разностного квантования в энтропийный кодер 110, с тем чтобы обеспечивать возможность энтропийному кодеру 110 кодировать параметр разностного квантования (этап Sv_8).
[0186] Следует отметить, что параметр разностного квантования может кодироваться, например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU. Помимо этого, начальное значение параметра квантования может кодироваться на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU. В это время, параметр квантования может формироваться с использованием начального значения параметра квантования и параметра разностного квантования.
[0187] Следует отметить, что квантователь 108 может включать в себя множество квантователей и может применять зависимое квантование, при котором коэффициенты преобразования квантуются с использованием способа квантования, выбранного из множества способов квантования.
[0188] Энтропийный кодер
Фиг. 20 является блок-схемой, иллюстрирующей один пример функциональной конфигурации энтропийного кодера 110.
[0189] Энтропийный кодер 110 формирует поток посредством энтропийного кодирования квантованных коэффициентов, вводимых из квантователя 108, и параметра прогнозирования, вводимого из формирователя 130 параметров прогнозирования. Например, контекстно-адаптивное двоичное арифметическое кодирование (CABAC) используется в качестве энтропийного кодирования. Более конкретно, энтропийный кодер 110 включает в себя модуль 110a преобразования в двоичную форму, контроллер 110b контекстов и двоичный арифметический кодер 110c. Модуль 110a преобразования в двоичную форму выполняет преобразование в двоичную форму, при котором многоуровневые сигналы, такие как квантованные коэффициенты и параметр прогнозирования, преобразуются в двоичные сигналы. Примеры способов преобразования в двоичную форму включают в себя преобразование в двоичную форму усеченным кодом Райса, экспоненциальные коды Голомба и преобразование в двоичную форму кодом фиксированной длины. Контроллер 110b контекстов извлекает значение контекста согласно признаку или окружающему состоянию синтаксического элемента, т.е. вероятности возникновения двоичного сигнала. Примеры способов для извлечения значения контекста включают в себя обход, обращение к синтаксическому элементу, обращение к верхнему и левому смежным блокам, обращение к иерархической информации и т.д. Двоичный арифметический кодер 110c арифметически кодирует двоичный сигнал с использованием извлеченного значения контекста.
[0190] Фиг. 21 является схемой, иллюстрирующей последовательность операций CABAC в энтропийном кодере 110.
[0191] Во-первых, инициализация выполняется в CABAC в энтропийном кодере 110. При инициализации, выполняется инициализация в двоичном арифметическом кодере 110c и задание начального значения контекста. Например, модуль 110a преобразования в двоичную форму и двоичный арифметический кодер 110c выполняют преобразование в двоичную форму и арифметическое кодирование множества коэффициентов квантования в CTU последовательно. В это время контроллер 110b контекстов обновляет значение контекста каждый раз, когда выполняется арифметическое кодирование. Контроллер 110b контекстов затем сохраняет значение контекста в качестве постобработки. Сохраненное значение контекста используется, например, чтобы инициализировать значение контекста для следующей CTU.
[0192] Обратный квантователь
Обратный квантователь 112 обратно квантует квантованные коэффициенты, которые введены из квантователя 108. Более конкретно, обратный квантователь 112 обратно квантует, в определенном порядке сканирования, квантованные коэффициенты текущего блока. Обратный квантователь 112 затем выводит обратно квантованные коэффициенты преобразования текущего блока в обратный преобразователь 114.
[0193] Обратный преобразователь
Обратный преобразователь 114 восстанавливает ошибки прогнозирования посредством обратного преобразования коэффициентов преобразования, которые введены из обратного квантователя 112. Более конкретно, обратный преобразователь 114 восстанавливает остатки прогнозирования текущего блока посредством выполнения обратного преобразования, соответствующего преобразованию, применяемому к коэффициентам преобразования посредством преобразователя 106. Обратный преобразователь 114 затем выводит восстановленные остатки прогнозирования в сумматор 116.
[0194] Следует отметить, что поскольку информация потеряна в квантовании, восстановленные остатки прогнозирования не совпадают с ошибками прогнозирования, вычисленными посредством вычитателя 104. Другими словами, восстановленные остатки прогнозирования нормально включают в себя ошибки квантования.
[0195] Сумматор
Сумматор 116 восстанавливает текущий блок посредством суммирования остатков прогнозирования, которые введены из обратного преобразователя 114, и прогнозных изображений, которые введены из контроллера 128 прогнозирования. Следовательно, восстановленное изображение формируется. Сумматор 116 затем выводит восстановленное изображение в запоминающее устройство 118 блоков и контурный фильтр 120.
[0196] Запоминающее устройство блоков
Запоминающее устройство 118 блоков представляет собой устройство хранения данных для сохранения блока, который включается в текущий кадр, и упоминается при внутреннем прогнозировании. Более конкретно, запоминающее устройство 118 блоков сохраняет восстановленное изображение, выводимое из сумматора 116.
[0197] Запоминающее устройство кинокадров
Запоминающее устройство 122 кинокадров, например, представляет собой устройство хранения данных для сохранения опорных кадров для использования при взаимном прогнозировании, и также называется "буфером кинокадров". Более конкретно, запоминающее устройство 122 кинокадров сохраняет восстановленное изображение, фильтрованное посредством контурного фильтра 120.
[0198] Контурный фильтр
Контурный фильтр 120 применяет контурный фильтр к восстановленному изображению, выводимому посредством сумматора 116, и выводит фильтрованное восстановленное изображение в запоминающее устройство 122 кинокадров. Контурный фильтр представляет собой фильтр, используемый в контуре кодирования (внутриконтурном фильтре). Примеры контурных фильтров включают в себя, например, адаптивный контурный фильтр (ALF), фильтр удаления блочности (DF или DBF), дискретизированное адаптивное смещение (SAO) и т.д.
[0199] Фиг. 22 является блок-схемой, иллюстрирующей один пример функциональной конфигурации контурного фильтра 120.
[0200] Например, как проиллюстрировано на фиг. 22, контурный фильтр 120 включает в себя модуль 120a выполнения фильтрации для удаления блочности, модуль 120b SAO-выполнения и модуль 120c ALF-выполнения. Модуль 120a выполнения фильтрации для удаления блочности выполняет процесс фильтрации для удаления блочности восстановленного изображения. Модуль 120b SAO-выполнения выполняет SAO-процесс восстановленного изображения после подвергания процессу фильтрации для удаления блочности. Модуль 120c ALF-выполнения выполняет ALF-процесс восстановленного изображения после подвергания SAO-процессу. Ниже подробно описываются процессы ALF и фильтрации для удаления блочности. SAO-процесс представляет собой процесс для повышения качества изображений посредством уменьшения кольцевания (явления, при котором пиксельные значения искажаются как волны вокруг края) и коррекции отклонения в пиксельном значении. Примеры SAO-процессов включают в себя процесс краевого смещения и процесс полосового смещения. Следует отметить, что контурный фильтр 120 не всегда должен включать в себя все составляющие элементы, раскрытые на фиг. 22, и может включать в себя только часть составляющих элементов. Помимо этого, контурный фильтр 120 может быть выполнен с возможностью выполнять вышеуказанные процессы в порядке обработки, отличающемся от порядка обработки, раскрытого на фиг. 22.
[0201] Контурный фильтр > адаптивный контурный фильтр
В ALF, применяется фильтр ошибок по методу наименьших квадратов для удаления артефактов сжатия. Например, один фильтр, выбранный из множества фильтров на основе направления и активности локальных градиентов, применяется для каждого из 2×2-пиксельных субблоков в текущем блоке.
[0202] Более конкретно, сначала каждый субблок (например, каждый 2×2-пиксельный субблок) классифицируется на один из множества классов (например, пятнадцать или двадцать пять классов). Категоризация субблока основана, например, на направленности и активности градиентов. В конкретном примере, индекс C категории (например, C=5D+A) вычисляется на основе направленности D градиентов (например, 0-2 или 0-4) и активности A градиентов (например, 0-4). Затем на основе индекса C категории, каждый субблок классифицируется на один из множества классов.
[0203] Например, направленность D градиентов вычисляется посредством сравнения градиентов множества направлений (например, горизонтального, вертикального и двух диагональных направлений). Кроме того, например, активность A градиентов вычисляется посредством суммирования градиентов множества направлений и квантования результата суммирования.
[0204] Фильтр, который должен использоваться для каждого субблока, определяется из множества фильтров на основе результата такой классификации.
[0205] Форма фильтра, который должен использоваться в ALF, например, представляет собой круглую симметричную форму фильтра. Фиг. 23A-23C иллюстрируют примеры форм фильтра, используемых в ALF. Фиг. 23A иллюстрирует фильтр ромбовидной формы 5×5, фиг. 23B иллюстрирует фильтр ромбовидной формы 7×7, и фиг. 23C иллюстрирует фильтр ромбовидной формы 9×9. Информация, указывающая форму фильтра, нормально передается в служебных сигналах на уровне кадра. Следует отметить, что передача в служебных сигналах этой информации, указывающей форму фильтра, не обязательно должна выполняться на уровне кадра и может выполняться на другом уровне (например, на уровне последовательности, уровне среза, уровне кирпича, уровне CTU или уровне CU).
[0206] Включение или выключение ALF определяется, например, на уровне кадра или на уровне CU. Например, решение касательно того, следует или нет применять ALF к сигналу яркости, может приниматься на уровне CU, и решение касательно того, следует или нет применять ALF к сигналу цветности, может приниматься на уровне кадра. Информация, указывающая включение или выключение ALF, нормально передается в служебных сигналах на уровне кадра или на уровне CU. Следует отметить, что передача в служебных сигналах информации, указывающей включение или выключение ALF, не обязательно должна выполняться на уровне кадра или на уровне CU и может выполняться на другом уровне (например, на уровне последовательности, уровне среза, уровне кирпича или уровне CTU).
[0207] Помимо этого, как описано выше, один фильтр выбирается из множества фильтров, и ALF-процесс субблока выполняется. Набор коэффициентов для коэффициентов, которые должны использоваться для каждого из множества фильтров (например, вплоть до пятнадцатого или двадцать пятого фильтра), нормально передается в служебных сигналах на уровне кадра. Следует отметить, что набор коэффициентов не всегда должен обязательно передаваться в служебных сигналах на уровне кадра и может передаваться в служебных сигналах на другом уровне (например, на уровне последовательности, уровне среза, уровне кирпича, уровне CTU, уровне CU или уровне субблока).
[0208] Контурный фильтр > кросскомпонентный адаптивный контурный фильтр
Фиг. 23D является схемой, иллюстрирующей пример, в котором Y-выборки (первый компонент), используются для кросскомпонентной ALF (CCALF) для Cb и CCALF для Cr (для компонентов, отличающихся от первого компонента). Фиг. 23E является схемой, иллюстрирующей ромбовидный фильтр.
[0209] Один пример CCALF работает посредством применения линейного, ромбовидного фильтра (фиг. 23D, 23E) к каналу сигнала яркости для каждого компонента сигнала цветности. Коэффициенты фильтрации, например, могут передаваться в APS, масштабироваться на коэффициент 2^10 и округляться для представления с фиксированной запятой. Применение фильтров управляется для переменного размера блока и передается в служебных сигналах посредством контекстно-кодированного флага, принимаемого для каждого блока выборок. Размер блока наряду с флагом CCALF-активации принимается на уровне среза для каждого компонента сигнала цветности. Синтаксис и семантика для CCALF предоставляются в приложении. В работе, поддерживаются следующие размеры блоков (в выборках сигналов цветности): 16×16, 32×32, 64×64 и 128×128.
[0210] Контурный фильтр > объединенный кросскомпонентный адаптивный контурный фильтр сигналов цветности
Фиг. 23F является схемой, иллюстрирующей пример для объединенной CCALF сигналов цветности (JC-CCALF).
[0211] Один пример JC-CCALF, в котором только один CCALF-фильтр используется для того, чтобы формировать один CCALF-фильтрованный вывод в качестве сигнала детализации сигнала цветности только для одного цветового компонента, тогда как надлежащим образом взвешенная версия идентичного сигнала детализации сигнала цветности должна применяться к другому цветовому компоненту. Таким образом, сложность существующей CCALF уменьшается примерно наполовину.
[0212] Значение весового коэффициента кодируется как флаг знака и весовой индекс. Весовой индекс (обозначается как weight_index) кодируется в 3 бита и указывает абсолютную величину весового JC-CCALF-коэффициента JcCcWeight. Он не может быть равным 0. Абсолютная величина JcCcWeight определяется следующим образом.
[0213] - Если weight_index меньше или равен 4, JcCcWeight равен weight_index>>2.
[0214] - В противном случае, JcCcWeight равен 4/(weight_index-4).
[0215] Управление включением/выключением на блочном уровне ALF-фильтрации для Cb и Cr является отдельным. Это является идентичным с CCALF, и должны кодироваться два отдельных набора флагов управления включением/выключением на блочном уровне. В отличие от CCALF, в данном документе, размеры блоков управления включением/выключением Cb, Cr являются идентичными, и в силу этого кодируется только одна переменная размера блока.
[0216] Контурный фильтр > фильтр удаления блочности
В процессе фильтрации для удаления блочности, контурный фильтр 120 выполняет процесс фильтрации для границы блока в восстановленном изображении таким образом, чтобы уменьшать искажение, которое возникает на границе блока.
[0217] Фиг. 24 является блок-схемой, иллюстрирующей один пример конкретной конфигурации модуля 120a выполнения фильтрации для удаления блочности.
[0218] Например, модуль 120a выполнения фильтрации для удаления блочности включает в себя: модуль 1201 определения границ; модуль 1203 определения фильтрации; модуль 1205 выполнения фильтрации; модуль 1208 определения обработки; модуль 1207 определения характеристик фильтра; и переключатели 1202, 1204 and 1206.
[0219] Модуль 1201 определения границ определяет то, присутствует или нет пиксел, который должен фильтроваться для удаления блочности (т.е. текущий пиксел), около границы блока. Модуль 1201 определения границ затем выводит результат определения в переключатель 1202 и модуль 1208 определения обработки.
[0220] В случае если модуль 1201 определения границ определяет то, что текущий пиксел присутствует около границы блока, переключатель 1202 выводит нефильтрованное изображение в переключатель 1204. В противоположном случае, в котором модуль 1201 определения границ определяет то, что текущий пиксел не присутствует около границы блока, переключатель 1202 выводит нефильтрованное изображение в переключатель 1206. Следует отметить, что нефильтрованное изображение представляет собой изображение, сконфигурированное с текущим пикселом и, по меньшей мере, одним окружающим пикселом, расположенным около текущего пиксела.
[0221] Модуль 1203 определения фильтрации определяет то, следует или нет выполнять фильтрацию для удаления блочности текущего пиксела, на основе пиксельного значения, по меньшей мере, одного окружающего пиксела, расположенного около текущего пиксела. Модуль 1203 определения фильтрации затем выводит результат определения в переключатель 1204 и модуль 1208 определения обработки.
[0222] В случае если определено то, что модуль 1203 определения фильтрации выполняет фильтрацию для удаления блочности текущего пиксела, переключатель 1204 выводит нефильтрованное изображение, полученное через переключатель 1202, в модуль 1205 выполнения фильтрации. В противоположном случае, в котором определено то, что модуль 1203 определения фильтрации не выполняет фильтрацию для удаления блочности текущего пиксела, переключатель 1204 выводит нефильтрованное изображение, полученное через переключатель 1202, в переключатель 1206.
[0223] При получении нефильтрованного изображения через переключатели 1202 и 1204, модуль 1205 выполнения фильтрации выполняет, для текущего пиксела, фильтрацию для удаления блочности, имеющую характеристику фильтра, определенную посредством модуля 1207 определения характеристик фильтра. Модуль 1205 выполнения фильтрации затем выводит фильтрованный пиксел в переключатель 1206.
[0224] Под управлением модуля 1208 определения обработки, переключатель 1206 избирательно выводит пиксел, который не фильтруется для удаления блочности, и пиксел, который фильтруется для удаления блочности посредством модуля 1205 выполнения фильтрации.
[0225] Модуль 1208 определения обработки управляет переключателем 1206 на основе результатов определений, выполняемых посредством модуля 1201 определения границ и модуля 1203 определения фильтрации. Другими словами, модуль 1208 определения обработки инструктирует переключателю 1206 выводить пиксел, который фильтруется для удаления блочности, когда модуль 1201 определения границ определяет то, что текущий пиксел присутствует около границы блока, и определено то, что модуль 1203 определения фильтрации выполняет фильтрацию для удаления блочности текущего пиксела. Помимо этого, в случае, отличном от вышеописанного случая, модуль 1208 определения обработки инструктирует переключателю 1206 выводить пиксел, который не фильтруется для удаления блочности. Фильтрованное изображение выводится из переключателя 1206 посредством повторения вывода пиксела таким образом. Следует отметить, что конфигурация, проиллюстрированная на фиг. 24, представляет собой один пример конфигурации в модуле 120a выполнения фильтрации для удаления блочности. Модуль 120a выполнения фильтрации для удаления блочности может иметь другую конфигурацию.
[0226] Фиг. 25 является схемой, иллюстрирующей пример фильтра удаления блочности, имеющего симметричную характеристику фильтрации относительно границы блока.
[0227] В процессе фильтрации для удаления блочности, например, один из двух фильтров удаления блочности, имеющих различные характеристики, т.е. сильного фильтра и слабого фильтра, выбирается с использованием пиксельных значений и параметров квантования. В случае сильного фильтра, пикселы p0-p2 и пикселы q0-q2 присутствуют на границе блока, как проиллюстрировано на фиг. 25, пиксельные значения соответствующих пикселов q0-q2 изменяются на пиксельные значения q'0-q'2 посредством выполнения вычислений согласно нижеприведенным выражениям.
[0228] q'0=(p1+2xp0+2xq0+2xq1+q2+4)/8
q'1=(p0+q0+q1+q2+2)/4
q'2=(p0+q0+q1+3xq2+2xq3+4)/8
[0229] Следует отметить, что, в вышеприведенных выражениях, p0-p2 и q0-q2 представляют собой пиксельные значения соответствующих пикселов p0-p2 и пикселов q0-q2. Помимо этого, q3 представляет собой пиксельное значение соседнего пиксела q3, расположенного в противоположной стороне пиксела q2 относительно границы блока. Помимо этого, в правой стороне каждого из выражений, коэффициенты, которые умножаются на соответствующие пиксельные значения пикселов, которые должны использоваться для фильтрации для удаления блочности, представляют собой коэффициенты фильтрации.
[0230] Кроме того, при фильтрации для удаления блочности, отсечение может выполняться таким образом, что вычисленные пиксельные значения не изменяются выше порогового значения. В процессе отсечения, пиксельные значения, вычисленные согласно вышеприведенным выражениям, отсекаются до значения, полученного согласно "предварительно вычисленное пиксельное значение ± 2 x пороговое значение" с использованием порогового значения, определенного на основе параметра квантования. Таким образом, можно предотвращать чрезмерное сглаживание.
[0231] Фиг. 26 является схемой для иллюстрации одного примера границы блока, для которой выполняется процесс фильтрации для удаления блочности. Фиг. 27 является схемой, иллюстрирующей примеры Bs-значений.
[0232] Граница блока, для которой выполняется процесс фильтрации для удаления блочности, например, представляет собой границу между CU, PU или TU, имеющими 8×8-пиксельные блоки, как проиллюстрировано на фиг. 26. Процесс фильтрации для удаления блочности выполняется, например, в единицах четырех строк или четырех столбцов. Во-первых, значения граничной интенсивности (Bs) определяются, как указано на фиг. 27 для блока P и блока Q, проиллюстрированных на фиг. 26.
[0233] Согласно Bs-значениям на фиг. 27, может определяться то, следует или нет выполнять процессы фильтрации для удаления блочности границ блоков, принадлежащих идентичному изображению, с использованием различных интенсивностей. Процесс фильтрации для удаления блочности для сигнала цветности выполняется, когда Bs-значение равно 2. Процесс фильтрации для удаления блочности для сигнала яркости выполняется, когда Bs-значение равно 1 или более, и определенное условие удовлетворяется. Следует отметить, что условия для определения Bs-значений не ограничены условиями, указываемыми на фиг. 27, и Bs-значение может определяться на основе другого параметра.
[0234] Модуль прогнозирования (модуль внутреннего прогнозирования, модуль взаимного прогнозирования, контроллер прогнозирования)
Фиг. 28 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством модуля прогнозирования кодера 100. Следует отметить, что модуль прогнозирования, в качестве одного примера, включает в себя все или часть следующих составляющих элементов: модуль 124 внутреннего прогнозирования; модуль 126 взаимного прогнозирования; и контроллер 128 прогнозирования. Модуль выполнения прогнозирования включает в себя, например, модуль 124 внутреннего прогнозирования и модуль 126 взаимного прогнозирования.
[0235] Модуль прогнозирования формирует прогнозное изображение текущего блока (этап Sb_1). Следует отметить, что прогнозное изображение, например, представляет собой внутреннее прогнозное изображение (внутренний прогнозный сигнал) или взаимное прогнозное изображение (взаимный прогнозный сигнал). Более конкретно, модуль прогнозирования формирует прогнозное изображение текущего блока с использованием восстановленного изображения, которое уже получено для другого блока, через формирование прогнозного изображения, формирование остатка прогнозирования, формирование квантованных коэффициентов, восстановление остатка прогнозирования и суммирование прогнозного изображения.
[0236] Восстановленное изображение, например, может представлять собой изображение в опорном кадре или изображение кодированного блока (т.е. другого блока, описанного выше) в текущем кадре, который представляет собой кадр, включающий в себя текущий блок. Кодированный блок в текущем кадре, например, представляет собой соседний блок относительно текущего блока.
[0237] Фиг. 29 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством модуля прогнозирования кодера 100.
[0238] Модуль прогнозирования формирует прогнозное изображение с использованием первого способа (этап Sc_1a), формирует прогнозное изображение с использованием второго способа (этап Sc_1b) и формирует прогнозное изображение с использованием третьего способа (этап Sc_1c). Первый способ, второй способ и третий способ могут представлять собой взаимно различные способы для формирования прогнозного изображения. Каждый из первого-третьего способов может представлять собой способ взаимного прогнозирования, способ внутреннего прогнозирования или другой способ прогнозирования. Вышеописанное восстановленное изображение может использоваться в этих способах прогнозирования.
[0239] Затем, модуль прогнозирования оценивает прогнозные изображения, сформированные на этапах Sc_1a, Sc_1b и Sc_1c (этап Sc_2). Например, модуль прогнозирования вычисляет затраты C для прогнозных изображений, сформированных на этапе Sc_1a, Sc_1b и Sc_1c, и оценивает прогнозные изображения посредством сравнения затрат C прогнозных изображений. Следует отметить, что затраты C вычисляются согласно выражению модели R-D-оптимизации, например, C=D+λ x R. В этом выражении, D указывает артефакты сжатия прогнозного изображения и представляется, например, как сумма абсолютных разностей между пиксельным значением текущего блока и пиксельным значением прогнозного изображения. Помимо этого, R указывает скорость передачи битов потока. Помимо этого, λ указывает, например, множитель согласно способу множителя Лагранжа.
[0240] Модуль прогнозирования затем выбирает одно из прогнозных изображений, сформированных на этапах Sc_1a, Sc_1b и Sc_1c (этап Sc_3). Другими словами, модуль прогнозирования выбирает способ или режим для получения конечного прогнозного изображения. Например, модуль прогнозирования выбирает прогнозное изображение, имеющее наименьшие затраты C, на основе затрат C, вычисленных для прогнозных изображений. Альтернативно, оценка на этапе Sc_2 и выбор прогнозного изображения на этапе Sc_3 могут выполняться на основе параметра, который используется в процессе кодирования. Кодер 100 может преобразовывать информацию для идентификации выбранного прогнозного изображения, способа или режима в поток. Информация, например, может представлять собой флаг и т.п. Таким образом, декодер 200 допускает формирование прогнозного изображения согласно способу или режиму, выбранному посредством кодера 100, на основе информации. Следует отметить, что, в примере, проиллюстрированном на фиг. 29, модуль прогнозирования выбирает любое из прогнозных изображений после того, как прогнозные изображения формируются с использованием соответствующих способов. Тем не менее, модуль прогнозирования может выбирать способ или режим на основе параметра для использования в вышеописанном процессе кодирования до формирования прогнозных изображений и может формировать прогнозное изображение согласно выбранному способу или режиму.
[0241] Например, первый способ и второй способ могут представлять собой внутренне прогнозирование и взаимное прогнозирование, соответственно, и модуль прогнозирования может выбирать конечное прогнозное изображение для текущего блока из прогнозных изображений, сформированных согласно способам прогнозирования.
[0242] Фиг. 30 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством модуля прогнозирования кодера 100.
[0243] Во-первых, модуль прогнозирования формирует прогнозное изображение с использованием внутреннего прогнозирования (этап Sd_1a) и формирует прогнозное изображение с использованием взаимного прогнозирования (этап Sd_1b). Следует отметить, что прогнозное изображение, сформированное посредством внутреннего прогнозирования, также называется "внутренним прогнозным изображением", и прогнозное изображение, сформированное посредством взаимного прогнозирования, также называется "взаимным прогнозным изображением".
[0244] Затем, модуль прогнозирования оценивает каждое из внутреннего прогнозного изображения и взаимного прогнозного изображения (этап Sd_2). Затраты C, описанные выше, могут использоваться при оценке. Модуль прогнозирования затем может выбирать прогнозное изображение, для которого наименьшие затраты C вычислены, из внутреннего прогнозного изображения и взаимного прогнозного изображения, в качестве конечного прогнозного изображения для текущего блока (этап Sd_3). Другими словами, выбирается способ или режим прогнозирования для формирования прогнозного изображения для текущего блока.
[0245] Модуль внутреннего прогнозирования
Модуль 124 внутреннего прогнозирования формирует прогнозное изображение (т.е. внутреннее прогнозное изображение) текущего блока посредством выполнения внутреннего прогнозирования (также называется "внутрикадровым прогнозированием") текущего блока посредством обращения к блоку или блокам в текущем кадре, которые сохраняются в запоминающем устройстве 118 блоков. Более конкретно, модуль 124 внутреннего прогнозирования формирует внутреннее прогнозное изображение посредством выполнения внутреннего прогнозирования посредством обращения к пиксельным значениям (например, к значениям сигнала яркости и/или сигнала цветности) блока или блоков, соседних с текущим блоком, и затем выводит внутреннее прогнозное изображение в контроллер 128 прогнозирования.
[0246] Например, модуль 124 внутреннего прогнозирования выполняет внутреннее прогнозирование посредством использования одного режима из множества режимов внутреннего прогнозирования, которые предварительно задаются. Режимы внутреннего прогнозирования нормально включают в себя один или более режимов ненаправленного прогнозирования и множество режимов направленного прогнозирования.
[0247] Один или более режимов ненаправленного прогнозирования включают в себя, например, режим планарного прогнозирования и режим DC-прогнозирования, заданные в H.265/HEVC-стандарте.
[0248] Множество режимов направленного прогнозирования включают в себя, например, тридцать три режима направленного прогнозирования, заданные в H.265/HEVC-стандарте. Следует отметить, что множество режимов направленного прогнозирования дополнительно могут включать в себя тридцать два режима направленного прогнозирования в дополнение к тридцати трем режимам направленного прогнозирования (в сумме шестьдесят пять режимов направленного прогнозирования). Фиг. 31 является схемой, иллюстрирующей шестьдесят семь режимов внутреннего прогнозирования в сумме, используемых при внутреннем прогнозировании (два режима ненаправленного прогнозирования и шестьдесят пять режимов направленного прогнозирования). Сплошные стрелки представляют тридцать три направления, заданные в H.265/HEVC-стандарте, и пунктирные стрелки представляют дополнительные тридцать два направления (два режима ненаправленного прогнозирования не проиллюстрированы на фиг. 31).
[0249] В различных видах примеров монтажа, к блоку сигналов яркости можно обращаться при внутреннем прогнозировании блока сигналов цветности. Другими словами, компонент сигнала цветности текущего блока может прогнозироваться на основе компонента сигнала яркости текущего блока. Такое внутреннее прогнозирование также называется "кросскомпонентной линейной моделью (CCLM)". Режим внутреннего прогнозирования для блока сигналов цветности, в котором к такому блоку сигналов яркости обращаются (также называется, например, "CCLM-режимом"), может добавляться в качестве одного из режимов внутреннего прогнозирования для блоков сигналов цветности.
[0250] Модуль 124 внутреннего прогнозирования может корректировать внутренне прогнозированные пиксельные значения на основе горизонтальных/вертикальных опорных пиксельных градиентов. Внутреннее прогнозирование, которое сопровождает этот вид коррекции, также называется "позиционно-зависимым комбинированием с внутренним прогнозированием (PDPC)". Информация, указывающая то, следует или нет применять PDPC (называется, например, "PDPC-флагом"), нормально передается в служебных сигналах на уровне CU. Следует отметить, что передача в служебных сигналах этой информации не должна обязательно выполняться на уровне CU и может выполняться на другом уровне (например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU).
[0251] Фиг. 32 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством модуля 124 внутреннего прогнозирования.
[0252] Модуль 124 внутреннего прогнозирования выбирает один режим внутреннего прогнозирования из множества режимов внутреннего прогнозирования (этап Sw_1). Модуль 124 внутреннего прогнозирования затем формирует прогнозное изображение согласно выбранному режиму внутреннего прогнозирования (этап Sw_2). Затем, модуль 124 внутреннего прогнозирования определяет наиболее вероятные режимы (MPM) (этап Sw_3). MPM включают в себя, например, шесть режимов внутреннего прогнозирования. Два режима из шести режимов внутреннего прогнозирования могут представлять собой планарный режим и режим DC-прогнозирования, и другие четыре режима могут представлять собой режимы направленного прогнозирования. Модуль 124 внутреннего прогнозирования определяет то, включается или нет режим внутреннего прогнозирования, выбранный на этапе Sw_1, в MPM (этап Sw_4).
[0253] Здесь, при определении того, что режим внутреннего прогнозирования, выбранный на этапе Sw_1, включается в MPM ("Да" на этапе Sw_4), модуль 124 внутреннего прогнозирования задает MPM-флаг равным 1 (этап Sw_5) и формирует информацию, указывающую выбранный режим внутреннего прогнозирования, из MPM (этап Sw_6). Следует отметить, что MPM-флаг, заданный равным 1, и информация, указывающая режим внутреннего прогнозирования, кодируются как параметры прогнозирования посредством энтропийного кодера 110.
[0254] При определении того, что выбранный режим внутреннего прогнозирования не включается в MPM ("Нет" на этапе Sw_4), модуль 124 внутреннего прогнозирования задает MPM-флаг равным 0 (этап Sw_7). Альтернативно, модуль 124 внутреннего прогнозирования вообще не задает MPM-флаг. Модуль 124 внутреннего прогнозирования затем формирует информацию, указывающую выбранный режим внутреннего прогнозирования, по меньшей мере, из одного режима внутреннего прогнозирования, который не включается в MPM (этап Sw_8). Следует отметить, что MPM-флаг, заданный равным 0, и информация, указывающая режим внутреннего прогнозирования, кодируются как параметры прогнозирования посредством энтропийного кодера 110. Информация, указывающая режим внутреннего прогнозирования, указывает, например, любое из 0-60.
[0255] Модуль взаимного прогнозирования
Модуль 126 взаимного прогнозирования формирует прогнозное изображение (взаимное прогнозное изображение) посредством выполнения взаимного прогнозирования (также называется "межкадровым прогнозированием") текущего блока посредством обращения к блоку или блокам в опорном кадре, который отличается от текущего кадра и сохраняется в запоминающем устройстве 122 кинокадров. Взаимное прогнозирование выполняется в единицах текущего блока или текущего субблока в текущем блоке. Субблок включается в блок и представляет собой единицу, меньшую блока. Размер субблока может составлять 4×4 пикселов, 8×8 пикселов или другой размер. Размер субблока может переключаться для единицы, такой как срез, кирпич, кадр и т.д.
[0256] Например, модуль 126 взаимного прогнозирования выполняет оценку движения в опорном кадре для текущего блока или текущего субблока и находит опорный блок или опорный субблок, который имеет наилучшее совпадение с текущим блоком или текущим субблоком. Модуль 126 взаимного прогнозирования затем получает информацию движения (например, вектор движения), которая компенсирует движение или изменение с опорного блока или опорного субблока на текущий блок или текущий субблок. Модуль 126 взаимного прогнозирования формирует взаимное прогнозное изображение текущего блока или текущего субблока посредством выполнения компенсации движения (или прогнозирования движения) на основе информации движения. Модуль 126 взаимного прогнозирования выводит сформированное взаимное прогнозное изображение в контроллер 128 прогнозирования.
[0257] Информация движения, используемая при компенсации движения, может передаваться в служебных сигналах в качестве взаимных прогнозных изображений в различных формах. Например, вектор движения может передаваться в служебных сигналах. Другими словами, разность между вектором движения и предиктором вектора движения может передаваться в служебных сигналах.
[0258] Список опорных кадров
Фиг. 33 является схемой, иллюстрирующей примеры опорных кадров. Фиг. 34 является концептуальной схемой, иллюстрирующей примеры списков опорных кадров. Каждый список опорных кадров представляет собой список, указывающий, по меньшей мере, один опорный кадр, сохраненный в запоминающем устройстве 122 кинокадров. Следует отметить, что на фиг. 33, каждый из прямоугольников указывает кадр, каждая из стрелок указывает опорную взаимосвязь кадров, горизонтальная ось указывает время, I, P и B в прямоугольниках указывают внутренний прогнозный кадр, унипрогнозный кадр и бипрогнозный кадр, соответственно, и номера в прямоугольниках указывают порядок декодирования. Как проиллюстрировано на фиг. 33, порядок декодирования кадров представляет собой порядок I0, P1, B2, B3 и B4, и порядок отображения кадров представляет собой порядок I0, B3, B2, B4 и P1. Как проиллюстрировано на фиг. 34, список опорных кадров представляет собой список, представляющий возможные варианты опорных кадров. Например, один кадр (или срез) может включать в себя, по меньшей мере, один список опорных кадров. Например, один список опорных кадров используется, когда текущий кадр представляет собой унипрогнозный кадр, и два списка опорных кадров используются, когда текущий кадр представляет собой бипрогнозный кадр. В примерах по фиг. 33 и 34, кадр B3, который представляет собой текущий кадр currPic, имеет два списка опорных кадров, которые представляют собой L0-список и L1-список. Когда текущий кадр currPic представляет собой кадр B3, возможные варианты опорных кадров для текущего кадра currPic представляют собой I0, P1 и B2, и списки опорных кадров (которые представляют собой L0-список и L1-список) указывают эти кадры. Модуль 126 взаимного прогнозирования или контроллер 128 прогнозирования указывает то, к какому кадру в каждом списке опорных кадров следует фактически обращаться, в форме индекса refIdxLx опорного кадра. На фиг. 34, опорные кадры P1 и B2 указываются посредством индексов refIdxL0 и refIdxL1 опорных кадров.
[0259] Такой список опорных кадров может формироваться для каждой единицы, такой как последовательность, кадр, срез, кирпич, CTU или CU. Помимо этого, из опорных кадров, указываемых в списках опорных кадров, индекс опорного кадра, указывающий опорный кадр, к которому обращаются при взаимном прогнозировании, может передаваться в служебных сигналах на уровне последовательности, уровне кадра, уровне среза, уровне кирпича, уровне CTU или уровне CU. Помимо этого, общий список опорных кадров может использоваться во множестве режимов взаимного прогнозирования.
[0260] Базовая последовательность операций взаимного прогнозирования
Фиг. 35 является блок-схемой последовательности операций способа, иллюстрирующей базовую последовательность операций обработки взаимного прогнозирования.
[0261] Во-первых, модуль 126 взаимного прогнозирования формирует прогнозный сигнал (этапы Se_1-Se_3). Затем, вычитатель 104 формирует разность между текущим блоком и прогнозным изображением в качестве остатка прогнозирования (этап Se_4).
[0262] Здесь, при формировании прогнозного изображения, модуль 126 взаимного прогнозирования формирует прогнозное изображение, например, посредством определения вектора движения (MV) текущего блока (этапы Se_1 и Se_2) и компенсации движения (этап Se_3). Кроме того, при определении MV, модуль 126 взаимного прогнозирования определяет MV, например, посредством выбора возможного варианта вектора движения (возможного MV-варианта) (этап Se_1) и извлечения MV (этап Se_2). Выбор возможного MV-варианта выполняется, например, посредством модуля 126 внутреннего прогнозирования, формирующего список возможных MV-вариантов и выбирающего, по меньшей мере, один возможный MV-вариант из списка возможных MV-вариантов. Следует отметить, что MV, извлекаемые ранее, могут добавляться в список возможных MV-вариантов. Альтернативно, при извлечении MV, модуль 126 взаимного прогнозирования дополнительно может выбирать, по меньшей мере, один возможный MV-вариант, по меньшей мере, из одного возможного MV-варианта и определять выбранный, по меньшей мере, один возможный MV-вариант в качестве MV для текущего блока. Альтернативно, модуль 126 взаимного прогнозирования может определять MV для текущего блока посредством выполнения оценки в области опорного кадра, указываемой посредством каждого из выбранного, по меньшей мере, одного возможного MV-варианта. Следует отметить, что оценка в области опорного кадра может называться "оценкой движения".
[0263] Помимо этого, хотя этапы Se_1-Se_3 выполняются посредством модуля 126 взаимного прогнозирования в вышеописанном примере, процесс, который, например, представляет собой этап Se_1, этап Se_2 и т.п., может выполняться посредством другого составляющего элемента, включенного в кодер 100.
[0264] Следует отметить, что список возможных MV-вариантов может формироваться для каждого процесса в режиме взаимного прогнозирования, или общий список возможных MV-вариантов может использоваться во множестве режимов взаимного прогнозирования. Процессы на этапах Se_3 и Se_4 соответствуют этапам Sa_3 и Sa_4, проиллюстрированным на фиг. 9, соответственно. Процесс на этапе Se_3 соответствует процессу на этапе Sd_1b на фиг. 30.
[0265] Последовательность операций для MV-извлечения
Фиг. 36 является блок-схемой последовательности операций способа, иллюстрирующей один пример MV-извлечения.
[0266] Модуль 126 взаимного прогнозирования может извлекать MV для текущего блока в режиме для кодирования информации движения (например, MV). В этом случае, например, информация движения может кодироваться как параметр прогнозирования и может передаваться в служебных сигналах. Другими словами, кодированная информация движения включается в поток.
[0267] Альтернативно, модуль 126 взаимного прогнозирования может извлекать MV в режиме, в котором информация движения не кодируется. В этом случае, информация движения не включается в поток.
[0268] Здесь, режимы MV-извлечения могут включать в себя нормальный взаимный режим, режим нормального объединения, FRUC-режим, аффинный режим и т.д., которые описываются ниже. Режимы, в которых информация движения кодируется, из числа режимов, включают в себя нормальный взаимный режим, режим нормального объединения, аффинный режим (в частности, аффинный взаимный режим и аффинный режим объединения) и т.д. Следует отметить, что информация движения может включать в себя не только MV, но также и информацию выбора MV-предикторов, которая описывается ниже. Режимы, в которых информация движения не кодируется, включают в себя FRUC-режим и т.д. Модуль 126 взаимного прогнозирования выбирает режим для извлечения MV текущего блока из множества режимов и извлекает MV текущего блока с использованием выбранного режима.
[0269] Фиг. 37 является блок-схемой последовательности операций способа, иллюстрирующей другой пример MV-извлечения.
[0270] Модуль 126 взаимного прогнозирования может извлекать MV текущего блока в режиме, в котором MV-разность кодируется. В этом случае, например, MV-разность кодируется как параметр прогнозирования и передается в служебных сигналах. Другими словами, кодированная MV-разность включается в поток. MV-разность представляет собой разность между MV текущего блока и MV-предиктором. Следует отметить, что MV-предиктор представляет собой предиктор вектора движения.
[0271] Альтернативно, модуль 126 взаимного прогнозирования может извлекать MV в режиме, в котором MV-разность не кодируется. В этом случае, кодированная MV-разность не включается в поток.
[0272] Здесь, как описано выше, режимы MV-извлечения включают в себя нормальный взаимный режим, режим нормального объединения, FRUC-режим, аффинный режим и т.д., которые описываются ниже. Режимы, в которых MV-разность кодируется, из числа режимов включают в себя нормальный взаимный режим, аффинный режим (в частности, аффинный взаимный режим) и т.д. Режимы, в которых MV-разность не кодируется, включают в себя FRUC-режим, режим нормального объединения, аффинный режим (в частности, аффинный режим объединения) и т.д. Модуль 126 взаимного прогнозирования выбирает режим для извлечения MV текущего блока из множества режимов и извлекает MV для текущего блока с использованием выбранного режима.
[0273] Режимы MV-извлечения
Фиг. 38A и 38B являются схемой, иллюстрирующей один пример категоризации режимов для MV-извлечения. Например, как проиллюстрировано на фиг. 38A, режимы MV-извлечения примерно категоризируются на три режима согласно тому, следует или нет кодировать информацию движения, и тому, следует или нет кодировать MV-разности. Три режима представляют собой взаимный режим, режим объединения и режим преобразования с повышением частоты кинокадров (FRUC). Взаимный режим представляет собой режим, в котором оценка движения выполняется, и в котором информация движения и MV-разность кодируются. Например, как проиллюстрировано на фиг. 38B, взаимный режим включает в себя аффинный взаимный режим и нормальный взаимный режим. Режим объединения представляет собой режим, в котором оценка движения не выполняется, и в котором MV выбирается из кодированного окружающего блока, и MV для текущего блока извлекается с использованием MV. Режим объединения представляет собой режим, в котором, по существу, информация движения кодируется, а MV-разность не кодируется. Например, как проиллюстрировано на фиг. 38B, режимы объединения включают в себя режим нормального объединения (также называется "режимом нормального объединения" или "регулярным режимом объединения"), режим объединения с разностью векторов движения (MMVD), режим комбинированного взаимного объединения и внутреннего прогнозирования (CIIP), треугольный режим, ATMVP-режим и аффинный режим объединения. Здесь, MV-разность кодируется исключительно в MMVD-режиме из режимов, включенных в режимы объединения. Следует отметить, что аффинный режим объединения и аффинный взаимный режим представляют собой режимы, включенные в аффинные режимы. Аффинный режим представляет собой режим для извлечения, в качестве MV текущего блока, MV каждого из множества субблоков, включенных в текущий блок, при условии аффинного преобразования. FRUC-режим представляет собой режим, который служит для извлечения MV текущего блока посредством выполнения оценки между кодированными областями, и в котором не кодируются ни информация движения, ни любая MV-разность. Следует отметить, что ниже подробно описываются соответствующие режимы.
[0274] Следует отметить, что категоризация режимов, проиллюстрированных на фиг. 38A и 38B, представляет собой примеры, и категоризация не ограничена этим. Например, когда MV-разность кодируется в CIIP-режиме, CIIP-режим категоризируется на взаимные режимы.
[0275] MV-извлечение > нормальный взаимный режим
Нормальный взаимный режим представляет собой режим взаимного прогнозирования для извлечения MV текущего блока посредством нахождения блока, аналогичного изображению текущего блока, из области опорных кадров, указываемой посредством возможного MV-варианта. В этом нормальном взаимном режиме, MV-разность кодируется.
[0276] Фиг. 39 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством нормального взаимного режима.
[0277] Во-первых, модуль 126 взаимного прогнозирования получает множество возможных MV-вариантов для текущего блока на основе такой информации, как MV множества кодированных блоков, временно или пространственно окружающих текущий блок (этап Sg_1). Другими словами, модуль 126 взаимного прогнозирования формирует список возможных MV-вариантов.
[0278] Затем, модуль 126 взаимного прогнозирования извлекает N (целое число в 2 или более) возможных MV-вариантов из множества возможных MV-вариантов, полученных на этапе Sg_1, в качестве возможных вариантов предикторов векторов движения согласно предварительно определенному порядку приоритетов (этап Sg_2). Следует отметить, что порядок приоритетов определяется заранее для каждого из N возможных MV-вариантов.
[0279] Затем, модуль 126 взаимного прогнозирования выбирает один возможный вариант MV-предиктора из N возможных вариантов MV-предикторов в качестве MV-предиктора для текущего блока (этап Sg_3). В это время, модуль 126 взаимного прогнозирования кодирует, в потоке, информацию выбора MV-предикторов для идентификации выбранного MV-предиктора. Другими словами, модуль 126 взаимного прогнозирования выводит информацию выбора MV-предикторов в качестве параметра прогнозирования в энтропийный кодер 110 через формирователь 130 параметров прогнозирования.
[0280] Затем, модуль 126 взаимного прогнозирования извлекает MV текущего блока посредством обращения к кодированному опорному кадру (этап Sg_4). В это время, модуль 126 взаимного прогнозирования дополнительно кодирует, в потоке, значение разности между извлеченным MV и MV-предиктором в качестве MV-разности. Другими словами, модуль 126 взаимного прогнозирования выводит MV-разность в качестве параметра прогнозирования в энтропийный кодер 110 через формирователь 130 параметров прогнозирования. Следует отметить, что кодированный опорный кадр представляет собой кадр, включающий в себя множество блоков, которые восстановлены после кодирования.
[0281] В завершение, модуль 126 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием извлеченного MV и кодированного опорного кадра (этап Sg_5). Процессы на этапах Sg_1-Sg_5 выполняются для каждого блока. Например, когда процессы на этапах Sg_1-Sg_5 выполняются для каждого из всех блоков в срезе, взаимное прогнозирование среза с использованием нормального взаимного режима заканчивается. Например, когда процессы на этапах Sg_1-Sg_5 выполняются для каждого из всех блоков в кадре, взаимное прогнозирование кадра с использованием нормального взаимного режима заканчивается. Следует отметить, что не все блоки, включенные в срез, могут подвергаться процессам на этапах Sg_1-Sg_5, и взаимное прогнозирование среза с использованием нормального взаимного режима может заканчиваться, когда часть блоков подвергается процессам. Аналогично, взаимное прогнозирование кадра с использованием нормального взаимного режима может заканчиваться, когда процессы на этапах Sg_1-Sg_5 выполняются для части блоков в кадре.
[0282] Следует отметить, что прогнозное изображение представляет собой взаимный прогнозный сигнал, как описано выше. Помимо этого, информация, указывающая режим взаимного прогнозирования (нормальный взаимный режим в вышеприведенном примере), используемый для того, чтобы формировать прогнозное изображение, например, кодируется в качестве параметра прогнозирования в кодированном сигнале.
[0283] Следует отметить, что список возможных MV-вариантов также может использоваться в качестве списка для использования в другом режиме. Помимо этого, процессы, связанные со списком возможных MV-вариантов, могут применяться к процессам, связанным со списком для использования в другом режиме. Процессы, связанные со списком возможных MV-вариантов, включают в себя, например, извлечение или выбор возможного MV-варианта из списка возможных MV-вариантов, переупорядочение возможных MV-вариантов или удаление возможного MV-варианта.
[0284] MV-извлечение > режим нормального объединения
Режим нормального объединения представляет собой режим взаимного прогнозирования для выбора возможного MV-варианта из списка возможных MV-вариантов в качестве MV для текущего блока, за счет этого извлекая MV. Следует отметить, что режим нормального объединения представляет собой режим объединения в узком смысле и также называется просто "режимом объединения". В этом варианте осуществления, режим нормального объединения и режим объединения отличаются, и режим объединения используется в широком смысле.
[0285] Фиг. 40 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством режима нормального объединения.
[0286] Во-первых, модуль 126 взаимного прогнозирования получает множество возможных MV-вариантов для текущего блока на основе такой информации, как MV множества кодированных блоков, временно или пространственно окружающих текущий блок (этап Sh_1). Другими словами, модуль 126 взаимного прогнозирования формирует список возможных MV-вариантов.
[0287] Затем, модуль 126 взаимного прогнозирования выбирает один возможный MV-вариант из множества возможных MV-вариантов, полученных на этапе Sh_1, за счет этого извлекая MV для текущего блока (этап Sh_2). В это время, модуль 126 взаимного прогнозирования кодирует, в потоке, информацию MV-выбора для идентификации выбранного возможного MV-варианта. Другими словами, модуль 126 взаимного прогнозирования выводит информацию MV-выбора в качестве параметра прогнозирования в энтропийный кодер 110 через формирователь 130 параметров прогнозирования.
[0288] В завершение, модуль 126 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием извлеченного MV и кодированного опорного кадра (этап Sh_3). Процессы на этапах Sh_1-Sh_3 выполняются, например, для каждого блока. Например, когда процессы на этапах Sh_1-Sh_3 выполняются для каждого из всех блоков в срезе, взаимное прогнозирование среза с использованием режима нормального объединения заканчивается. Помимо этого, когда процессы на этапах Sh_1-Sh_3 выполняются для каждого из всех блоков в кадре, взаимное прогнозирование кадра с использованием режима нормального объединения заканчивается. Следует отметить, что не все блоки, включенные в срез, могут подвергаться процессам на этапах Sh_1-Sh_3, и взаимное прогнозирование среза с использованием режима нормального объединения может заканчиваться, когда часть блоков подвергается процессам. Аналогично, взаимное прогнозирование кадра с использованием режима нормального объединения может заканчиваться, когда процессы на этапах Sh_1-Sh_3 выполняются для части блоков в кадре.
[0289] Помимо этого, информация, указывающая режим взаимного прогнозирования (режим нормального объединения в вышеприведенном примере), используемый для того, чтобы формировать прогнозное изображение, например, кодируется в качестве параметра прогнозирования в потоке.
[0290] Фиг. 41 является схемой для иллюстрации одного примера процесса MV-извлечения для текущего кадра посредством режима нормального объединения.
[0291] Во-первых, модуль 126 взаимного прогнозирования формирует список возможных MV-вариантов, в котором регистрируются возможные MV-варианты. Примеры возможных MV-вариантов включают в себя: пространственно соседние возможные MV-варианты, которые представляют собой MV множества кодированных блоков, расположенных пространственно окружающими текущий блок; временно соседние возможные MV-варианты, которые представляют собой MV окружающих блоков, на которые проецируется позиция текущего блока в кодированном опорном кадре; комбинированные возможные MV-варианты, которые представляют собой MV, сформированные посредством комбинирования MV-значения пространственно соседнего MV-предиктора и MV-значения временно соседнего MV-предиктора; и нулевой возможный MV-вариант, который представляет собой MV, имеющий нулевое значение.
[0292] Затем, модуль 126 взаимного прогнозирования выбирает один возможный MV-вариант из множества возможных MV-вариантов, зарегистрированных в списке возможных MV-вариантов, и определяет возможный MV-вариант в качестве MV текущего блока.
[0293] Кроме того, энтропийный кодер 110 записывает и кодирует, в потоке, merge_idx, который представляет собой сигнал, указывающий то, какой возможный MV-вариант выбран.
[0294] Следует отметить, что возможные MV-варианты, зарегистрированные в списке возможных MV-вариантов, описанном на фиг. 41, представляют собой примеры. Число возможных MV-вариантов может отличаться от числа возможных MV-вариантов на схеме, список возможных MV-вариантов может быть сконфигурирован таким образом, что некоторые виды возможных MV-вариантов на схеме могут не включаться, либо таким образом, что один или более возможных MV-вариантов, отличных от видов возможных MV-вариантов на схеме, включаются.
[0295] Конечный MV может определяться посредством выполнения динамического обновления векторов движения (DMVR), которое описывается ниже, с использованием MV текущего блока, извлекаемого посредством режима нормального объединения. Следует отметить, что, в режиме нормального объединения, MV-разность не кодируется, но MV-разность кодируется. В MMVD-режиме, один возможный MV-вариант выбирается из списка возможных MV-вариантов, как и в случае режима нормального объединения, MV-разность кодируется. Как проиллюстрировано на фиг. 38B, MMVD может категоризироваться на режимы объединения вместе с режимом нормального объединения. Следует отметить, что MV-разность в MMVD-режиме не всегда должна быть идентичной MV-разности для использования во взаимном режиме. Например, извлечение MV-разностей в MMVD-режиме может представлять собой процесс, который требует меньшего объема обработки, чем объем обработки, требуемый для извлечения MV-разностей во взаимном режиме.
[0296] Помимо этого, режим комбинированного взаимного объединения и внутреннего прогнозирования (CIIP) может выполняться. Режим служит для перекрытия прогнозного изображения, сформированного при взаимном прогнозировании, и прогнозного изображения, сформированного при внутреннем прогнозировании, чтобы формировать прогнозное изображение для текущего блока.
[0297] Следует отметить, что список возможных MV-вариантов может называться "списком возможных вариантов". Помимо этого, merge_idx представляет собой информацию MV-выбора.
[0298] MV-извлечение > HMVP-режим
Фиг. 42 является схемой для иллюстрации одного примера процесса MV-извлечения для текущего кадра посредством HMVP-режима объединения.
[0299] В режиме нормального объединения, MV, например, для CU, которая представляет собой текущий блок, определяется посредством выбора одного возможного MV-варианта из списка возможных MV-вариантов, сформированного посредством обращения к кодированному блоку (например, CU). Здесь, другой возможный MV-вариант может регистрироваться в списке возможных MV-вариантов. Режим, в котором такой другой возможный MV-вариант регистрируется, называется "HMVP-режимом".
[0300] В HMVP-режиме, возможные MV-варианты управляются с использованием буфера на основе принципа "первый на входе - первый на выходе" (FIFO) для HMVP, отдельно от списка возможных MV-вариантов для режима нормального объединения.
[0301] В FIFO-буфере, информация движения, такая как MV блоков, обработанных ранее, сохраняется "самые новые первыми". При управлении FIFO-буфером, каждый раз, когда один блок обрабатывается, MV для самого нового блока (который представляет собой CU, обработанную непосредственно перед этим) сохраняется в FIFO-буфере, и MV самой старой CU (т.е. CU, обработанной раньше всего), удаляется из FIFO-буфера. В примере, проиллюстрированном на фиг. 42, HMVP1 представляет собой MV для самого нового блока, и HMVP5 представляет собой MV для самого старого MV.
[0302] Модуль 126 взаимного прогнозирования затем, например, проверяет то, представляет собой каждый MV, управляемый в FIFO-буфере, или нет MV, отличающийся от всех возможных MV-вариантов, которые уже зарегистрированы в списке возможных MV-вариантов, для режима нормального объединения, начинающегося с HMVP1. При определении того, что MV отличается от всех возможных MV-вариантов, модуль 126 взаимного прогнозирования может добавлять MV, управляемый в FIFO-буфере, в список возможных MV-вариантов для режима нормального объединения, в качестве возможного MV-варианта. В это время, возможный MV-вариант, зарегистрированный из FIFO-буфера, может составлять одни или более.
[0303] Посредством использования HMVP-режима таким образом, можно добавлять не только MV блока, который граничит с текущим блоком пространственно или временно, но также и MV для блока, обработанного ранее. Как результат, варьирование возможных MV-вариантов для режима нормального объединения расширяется, что увеличивает вероятность того, что эффективность кодирования может повышаться.
[0304] Следует отметить, что MV может представлять собой информацию движения. Другими словами, информация, сохраненная в списке возможных MV-вариантов и FIFO-буфере, может включать в себя не только MV-значения, но также и информацию опорных кадров, опорные направления, числа кадров и т.д. Помимо этого, блок, например, представляет собой CU.
[0305] Следует отметить, что список возможных MV-вариантов и FIFO-буфер, проиллюстрированные на фиг. 42, представляют собой примеры. Список возможных MV-вариантов и FIFO-буфер могут отличаться по размеру от списка возможных MV-вариантов и FIFO-буфера на фиг. 42 или могут быть выполнены с возможностью регистрировать возможные MV-варианты в порядке, отличающемся от порядка на фиг. 42. Помимо этого, процесс, описанный здесь, является общим между кодером 100 и декодером 200.
[0306] Следует отметить, что HMVP-режим может применяться для режимов, отличных от режима нормального объединения. Например, также превосходно, если информация движения, такая как MV блоков, обработанных в аффинном режиме в прошлом, может сохраняться "самые новые первыми" и может использоваться в качестве возможных MV-вариантов. Режим, полученный посредством применения HMVP-режима к аффинному режиму, может называться "аффинным режимом на основе предыстории".
[0307] MV-извлечение > FRUC-режим
Информация движения может извлекаться на стороне декодера 200 без передачи в служебных сигналах из стороны кодера 100. Например, информация движения может извлекаться посредством выполнения оценки движения на стороне декодера 200. В это время, на стороне декодера 200, оценка движения выполняется без использования пиксельных значений в текущем блоке. Режимы, в которых оценка движения выполняется на стороне декодера 200 таким образом, включают в себя режим преобразования с повышением частоты кинокадров (FRUC), режим извлечения векторов движения на основе сопоставления с шаблоном (PMMVD) и т.д.
[0308] Один пример FRUC-процесса проиллюстрирован на фиг. 43. Во-первых, список, который указывает, в качестве возможных MV-вариантов, MV для кодированных блоков, каждый из которых граничит с текущим блоком пространственно или временно, формируется посредством обращения к MV (список может представлять собой список возможных MV-вариантов и также использоваться в качестве списка возможных MV-вариантов для режима нормального объединения) (этап Si_1). Затем, наилучший возможный MV-вариант выбирается из множества возможных MV-вариантов, зарегистрированных в списке возможных MV-вариантов (этап Si_2). Например, значения оценки соответствующих возможных MV-вариантов, включенных в список возможных MV-вариантов, вычисляются, и один возможный MV-вариант выбирается в качестве наилучшего возможного MV-варианта на основе значений оценки. На основе выбранного наилучшего возможного MV-варианта, вектор движения для текущего блока затем извлекается (этап Si_4). Более конкретно, например, выбранный наилучший возможный MV-вариант непосредственно извлекается в качестве MV для текущего блока. Помимо этого, например, MV для текущего блока может извлекаться с использованием сопоставления с шаблоном в окружающей области позиции, которая включается в опорный кадр и соответствует выбранному наилучшему возможному MV-варианту. Другими словами, оценка с использованием сопоставления с шаблоном в опорном кадре и значений оценки может выполняться в окружающей области наилучшего возможного MV-варианта, и когда имеется MV, который дает в результате лучшее значение оценки, наилучший возможный MV-вариант может обновляться на MV, который дает в результате лучшее значение оценки, и обновленный MV может определяться в качестве конечного MV для текущего блока. Обновление на MV, который дает в результате лучшее значение оценки, может не выполняться.
[0309] В завершение, модуль 126 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием извлеченного MV и кодированного опорного кадра (этап Si_5). Процессы на этапах Si_1-Si_5 выполняются, например, для каждого блока. Например, когда процессы на этапах Si_1-Si_5 выполняются для каждого из всех блоков в срезе, взаимное прогнозирование среза с использованием FRUC-режима заканчивается. Например, когда процессы на этапах Si_1-Si_5 выполняются для каждого из всех блоков в кадре, взаимное прогнозирование кадра с использованием FRUC-режима заканчивается. Следует отметить, что не все блоки, включенные в срез, могут подвергаться процессам на этапах Si_1-Si_5, и взаимное прогнозирование среза с использованием FRUC-режима может заканчиваться, когда часть блоков подвергается процессам. Аналогично, взаимное прогнозирование кадра с использованием FRUC-режима может заканчиваться, когда процессы на этапах Si_1-Si_5 выполняются для части блоков, включенных в кадр.
[0310] Каждый субблок может обрабатываться аналогично вышеописанному случаю обработки каждого блока.
[0311] Значения оценки могут вычисляться согласно различным видам способов. Например, сравнение проводится между восстановленным изображением в области в опорном кадре, соответствующей MV, и восстановленным изображением в определенной области (область, например, может представлять собой область в другом опорном кадре или область в соседнем блоке текущего кадра, как указано ниже). Разность между пиксельными значениями двух восстановленных изображений может использоваться для значения оценки MV. Следует отметить, что значение оценки может вычисляться с использованием информации, отличной от значения разности.
[0312] Далее подробно описывается сопоставление с шаблоном. Во-первых, один возможный MV-вариант, включенный в список возможных MV-вариантов (также называется "списком для объединения"), выбирается в качестве начальной точки для оценки посредством сопоставления с шаблоном. В качестве сопоставления с шаблоном, может использоваться первое сопоставление с шаблоном или второе сопоставление с шаблоном. Первое сопоставление с шаблоном и второе сопоставление с шаблоном могут называться "билатеральным сопоставлением" и "сопоставлением с эталоном", соответственно.
[0313] MV-извлечение > FRUC > билатеральное сопоставление
При первом сопоставлении с шаблоном, сопоставление с шаблоном выполняется между двумя блоками, которые расположены вдоль траектории движения текущего блока и включаются в два различных опорных кадра. Соответственно, при первом сопоставлении с шаблоном, область в другом опорном кадре, расположенном вдоль траектории движения текущего блока, используется в качестве определенной области для вычисления значения оценки вышеописанного возможного MV-варианта.
[0314] Фиг. 44 является схемой для иллюстрации одного примера первого сопоставления с шаблоном (билатерального сопоставления) между двумя блоками в двух опорных кадрах, расположенных вдоль траектории движения. Как проиллюстрировано на фиг. 44, при первом сопоставлении с шаблоном, два вектора (MV0, MV1) движения извлекаются посредством оценки пары, которая имеет наилучшее совпадение, из числа пар в двух блоках, которые включаются в два различных опорных кадра (Ref0, Ref1) и располагаются вдоль траектории движения текущего блока (Cur block). Более конкретно, разность между восстановленным изображением в указанной позиции в первом кодированном опорном кадре (Ref0), указываемом посредством возможного MV-варианта, и восстановленным изображением в указанной позиции во втором кодированном опорном кадре (Ref1), указываемом посредством симметричного MV, полученная посредством масштабирования возможного MV-варианта во временном интервале отображения, извлекается для текущего блока, и значение оценки вычисляется с использованием значения полученной разности. Превосходно выбирать, в качестве наилучшего MV, возможный MV-вариант, который дает в результате наилучшее значение оценки из множества возможных MV-вариантов.
[0315] При допущении относительно траектории непрерывного движения, векторы (MV0, MV1) движения, указывающие два опорных блока, являются пропорциональными временным расстояниям (TD0, TD1) между текущим кадром (Cur Pic) и двумя опорными кадрами (Ref0, Ref1). Например, когда текущий кадр временно находится между двумя опорными кадрами, и временные расстояния от текущего кадра до соответствующих двух опорных кадров равны друг другу, зеркально-симметричные двунаправленные MV извлекаются при первом сопоставлении с шаблоном.
[0316] MV-извлечение > FRUC > сопоставление с эталоном
При втором сопоставлении с шаблоном (сопоставлении с эталоном), сопоставление с шаблоном выполняется между блоком в опорном кадре и эталоном в текущем кадре (эталон представляет собой блок, соседний с текущим блоком в текущем кадре (соседний блок, например, представляет собой верхний и/или левый соседний блок(и))). Следовательно, при втором сопоставлении с шаблоном, блок, соседний с текущим блоком в текущем кадре, используется в качестве предварительно определенной области для вышеописанного вычисления значения оценки возможного MV-варианта.
[0317] Фиг. 45 является схемой для иллюстрации одного примера сопоставления с шаблоном (сопоставления с эталоном) между эталоном в текущем кадре и блоком в опорном кадре. Как проиллюстрировано на фиг. 45, при втором сопоставлении с шаблоном, MV текущего блока (Cur block) извлекается посредством оценки, в опорном кадре (Ref0), блока, который имеет наилучшее совпадение с блоком, соседним с текущим блоком в текущем кадре (Cur Pic). Более конкретно, разность между восстановленным изображением в кодированной области, которая граничит как слева, так и выше либо или слева, или выше, и восстановленным изображением, которое находится в соответствующей области в кодированном опорном кадре (Ref0) и указывается посредством возможного MV-варианта, извлекается, и значение оценки вычисляется с использованием значения полученной разности. Превосходно выбирать, в качестве наилучшего возможного MV-варианта, возможный MV-вариант, который дает в результате наилучшее значение оценки из множества возможных MV-вариантов.
[0318] Эта информация, указывающая то, следует или нет применять FRUC-режим (называется, например, "FRUC-флагом"), может передаваться в служебных сигналах на уровне CU. Помимо этого, когда FRUC-режим применяется (например, когда FRUC-флаг является истинным), информация, указывающая применимый способ сопоставления с шаблоном (первое сопоставление с шаблоном или второе сопоставление с шаблоном), может передаваться в служебных сигналах на уровне CU. Следует отметить, что передача в служебных сигналах этой информации не должна обязательно выполняться на уровне CU и может выполняться на другом уровне (например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича, уровне CTU или уровне субблока).
[0319] MV-извлечение > аффинный режим
Аффинный режим представляет собой режим для формирования MV с использованием аффинного преобразования. Например, MV может извлекаться в единицах субблоков на основе векторов движения множества соседних блоков. Этот режим также называется "аффинным режимом прогнозирования с компенсацией движения".
[0320] Фиг. 46A является схемой для иллюстрации одного примера MV-извлечения в единицах субблоков на основе MV множества соседних блоков. На фиг. 46A, текущий блок включает в себя шестнадцать 4×4-пиксельных субблоков. Здесь, вектор v0 движения в верхней левой угловой управляющей точке в текущем блоке извлекается на основе MV соседнего блока, и аналогично, вектор v1 движения в верхней правой угловой управляющей точке в текущем блоке извлекается на основе MV соседнего субблока. Два вектора v0 и v1 движения проецируются согласно выражению (1A), указываемому ниже, и векторы (vx, vy) движения для соответствующих субблоков в текущем блоке извлекаются.
[0321] Математическое выражение 1
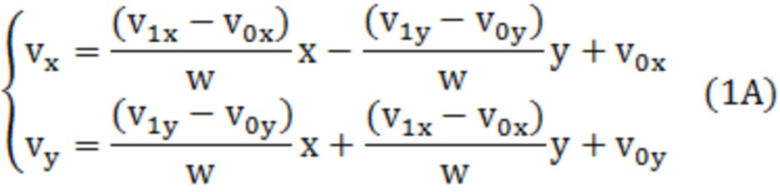
[0322] Здесь, x и y указывают горизонтальную позицию и вертикальную позицию субблока, соответственно, и w указывает предварительно определенный весовой коэффициент.
[0323] Эта информация, указывающая аффинный режим (например, называется "аффинным флагом"), может передаваться в служебных сигналах на уровне CU. Следует отметить, что передача в служебных сигналах этой информации не должна обязательно выполняться на уровне CU и может выполняться на другом уровне (например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича, уровне CTU или уровне субблока).
[0324] Помимо этого, аффинный режим может включать в себя несколько режимов для различных способов для извлечения MV в верхней левой и верхней правой угловых управляющих точках. Например, аффинные режимы включают в себя два режима, которые представляют собой аффинный взаимный режим (также называется "аффинным нормальным взаимным режимом") и аффинный режим объединения.
[0325] Фиг. 46B является схемой для иллюстрации одного примера MV-извлечения в единицах субблоков в аффинном режиме, в котором используются три управляющих точки. На фиг. 46B, текущий блок включает в себя, например, шестнадцать 4×4-пиксельных субблоков. Здесь, вектор v0 движения в верхней левой угловой управляющей точке в текущем блоке извлекается на основе MV соседнего блока. Здесь, вектор v1 движения в верхней правой угловой управляющей точке в текущем блоке извлекается на основе MV соседнего блока, и аналогично, вектор v2 движения в нижней левой угловой управляющей точке для текущего блока извлекается на основе MV соседнего блока. Три вектора v0, v1 и v2 движения могут проецироваться согласно выражению (1B), указываемому ниже, и векторы (vx, vy) движения для соответствующих субблоков в текущем блоке извлекаются.
[0326] Математическое выражение 2
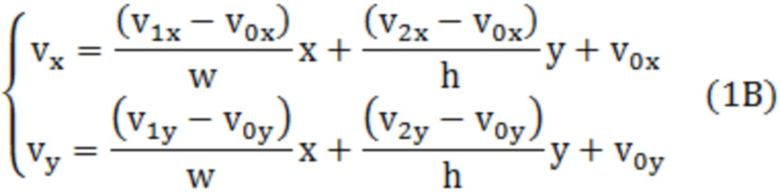
[0327] Здесь, x и y указывают горизонтальную позицию и вертикальную позицию субблока, соответственно, и каждое из w и h указывает предварительно определенный весовой коэффициент. Здесь, w может указывать ширину текущего блока, и h может указывать высоту текущего блока.
[0328] Аффинные режимы, в которых используются различные числа управляющих точек (например, две и три управляющих точки), могут переключаться и передаваться в служебных сигналах на уровне CU. Следует отметить, что информация, указывающая число управляющих точек в аффинном режиме, используемом на уровне CU, может передаваться в служебных сигналах на другом уровне (например, на уровне последовательности, уровне кадра, уровне среза, уровне кирпича, уровне CTU или уровне субблока).
[0329] Помимо этого, такой аффинный режим, в котором используются три управляющих точки, может включать в себя различные способы для извлечения MV в верхней левой, верхней правой и нижней левой угловых управляющих точках. Например, аффинные режимы, в которых используются три управляющих точки, включают в себя два режима, которые представляют собой аффинный взаимный режим и аффинный режим объединения, как и в случае аффинных режимов, в которых используются две управляющих точки.
[0330] Следует отметить, что, в аффинных режимах, размер каждого субблока, включенного в текущий блок, может не быть ограничен 4×4 пикселов и может представлять собой другой размер. Например, размер каждого субблока может составлять 8×8 пикселов.
[0331] MV-извлечение > аффинный режим > управляющая точка
Фиг. 47A, 47B и 47C являются концептуальной схемой для иллюстрации одного примера MV-извлечения в управляющих точках в аффинном режиме.
[0332] Как проиллюстрировано на фиг. 47A, в аффинном режиме, например, MV-предикторы в соответствующих управляющих точках текущего блока вычисляются на основе множества MV, соответствующих блокам, кодированным согласно аффинному режиму, из кодированного блока A (левого), блока B (верхнего), блока C (верхнего правого), блока D (нижнего левого) и блока E (верхнего левого), которые являются соседними с текущим блоком. Более конкретно, кодированный блок A (левый), блок B (верхний), блок C (верхний правый), блок D (нижний левый) и блок E (верхний левый) проверяются в перечисленном порядке, и первый эффективный блок, кодированный согласно аффинному режиму, идентифицируется. MV в каждой управляющей точке для текущего блока вычисляется на основе множества MV, соответствующих идентифицированному блоку.
[0333] Например, как проиллюстрировано на фиг. 47B, когда блок A, который является соседним слева от текущего блока, кодирован согласно аффинному режиму, в котором используются две управляющих точки, векторы v3 и v4 движения, проецируемые в верхней левой угловой позиции и верхней правой угловой позиции кодированного блока, включающего в себя блок A, извлекаются. Вектор v0 движения в верхней левой управляющей точке и вектор v1 движения в верхней правой управляющей точке для текущего блока затем вычисляются из извлеченных векторов v3 и v4 движения.
[0334] Например, как проиллюстрировано на фиг. 47C, когда блок A, который является соседним слева от текущего блока, кодирован согласно аффинному режиму, в котором используются три управляющих точки, векторы v3, v4 и v5 движения, проецируемые в верхней левой угловой позиции, верхней правой угловой позиции и нижней левой угловой позиции кодированного блока, включающего в себя блок A, извлекаются. Вектор v0 движения в верхней левой управляющей точке для текущего блока, вектор v1 движения в верхней правой управляющей точке для текущего блока и вектор v2 движения в нижней левой управляющей точке для текущего блока затем вычисляются из извлеченных векторов v3, v4 и v5 движения.
[0335] Способы MV-извлечения, проиллюстрированные на фиг. 47A-47C, могут использоваться при MV-извлечении в каждой управляющей точке для текущего блока на этапе Sk_1, проиллюстрированном на фиг. 50, или могут использоваться для извлечения MV-предиктора в каждой управляющей точке для текущего блока на этапе Sj_1, проиллюстрированном на фиг. 51, описанном ниже.
[0336] Фиг. 48A и 48B являются концептуальной схемой для иллюстрации другого примера MV-извлечения в управляющих точках в аффинном режиме.
[0337] Фиг. 48A является схемой для иллюстрации аффинного режима, в котором используются две управляющих точки.
[0338] В аффинном режиме, как проиллюстрировано на фиг. 48A, MV, выбранный из MV в кодированном блоке A, блок B и блок C, которые граничат с текущим блоком, используются в качестве вектора v0 движения в верхней левой угловой управляющей точке для текущего блока. Аналогично, MV, выбранный из MV кодированного блока D и блока E, которые граничат с текущим блоком, используется в качестве вектора v1 движения в верхней правой угловой управляющей точке для текущего блока.
[0339] Фиг. 48B является схемой для иллюстрации аффинного режима, в котором используются три управляющих точки.
[0340] В аффинном режиме, как проиллюстрировано на фиг. 48B, MV, выбранный из MV в кодированном блоке A, блок B и блок C, которые граничат с текущим блоком, используются в качестве вектора v0 движения в верхней левой угловой управляющей точке для текущего блока. Аналогично, MV, выбранный из MV кодированного блока D и блока E, которые граничат с текущим блоком, используется в качестве вектора v1 движения в верхней правой угловой управляющей точке для текущего блока. Кроме того, MV, выбранный из MV кодированного блока F и блока G, которые граничат с текущим блоком, используется в качестве вектора v2 движения в нижней левой угловой управляющей точке для текущего блока.
[0341] Следует отметить, что способы MV-извлечения, проиллюстрированные на фиг. 48A и 48B, могут использоваться при MV-извлечении в каждой управляющей точке для текущего блока на этапе Sk_1, проиллюстрированном на фиг. 50, описанном ниже, или может использоваться для извлечения MV-предиктора в каждой управляющей точке для текущего блока на этапе Sj_1, проиллюстрированном на фиг. 51, описанном ниже.
[0342] Здесь, когда аффинные режимы, в которых используются различные числа управляющих точек (например, две и три управляющих точки), могут переключаться и передаваться в служебных сигналах на уровне CU, число управляющих точек для кодированного блока и число управляющих точек для текущего блока могут отличаться друг от друга.
[0343] Фиг. 49A и 49B являются концептуальной схемой для иллюстрации одного примера способа для MV-извлечения в управляющих точках, когда число управляющих точек для кодированного блока и число управляющих точек для текущего блока отличаются друг от друга.
[0344] Например, как проиллюстрировано на фиг. 49A, текущий блок имеет три управляющих точки в верхнем левом углу, верхнем правом углу и левом нижнем углу, и блок A, который граничит слева относительно текущего блока, кодирован согласно аффинному режиму, в котором используются две управляющих точки. В этом случае, векторы v3 и v4 движения, проецируемые в верхней левой угловой позиции и верхней правой угловой позиции в кодированном блоке, включающем в себя блок A, извлекаются. Вектор v0 движения в верхней левой угловой управляющей точке и вектор v1 движения в верхней правой угловой управляющей точке для текущего блока затем вычисляются из извлеченных векторов v3 и v4 движения. Кроме того, вектор v2 движения в нижней левой угловой управляющей точке вычисляется из извлеченных векторов v0 и v1 движения.
[0345] Например, как проиллюстрировано на фиг. 49B, текущий блок имеет две управляющих точки в верхнем левом углу и в верхнем правом углу, и блок A, который граничит слева относительно текущего блока, кодирован согласно аффинному режиму, в котором используются три управляющих точки. В этом случае, векторы v3, v4 и v5 движения, проецируемые в верхней левой угловой позиции в кодированном блоке, включающем в себя блок A, в верхней правой угловой позиции в кодированном блоке и в нижней левой угловой позиции в кодированном блоке, извлекаются. Вектор v0 движения в верхней левой угловой управляющей точке для текущего блока и вектор v1 движения в верхней правой угловой управляющей точке для текущего блока затем вычисляются из извлеченных векторов v3, v4 и v5 движения.
[0346] Следует отметить, что способы MV-извлечения, проиллюстрированные на фиг. 49A и 49B, могут использоваться при MV-извлечении в каждой управляющей точке для текущего блока на этапе Sk_1, проиллюстрированном на фиг. 50, описанном ниже, или может использоваться для извлечения MV-предиктора в каждой управляющей точке для текущего блока на этапе Sj_1, проиллюстрированном на фиг. 51, описанном ниже.
[0347] MV-извлечение > аффинный режим > аффинный режим объединения
Фиг. 50 является блок-схемой последовательности операций способа, иллюстрирующей один пример аффинного режима объединения.
[0348] В аффинном режиме объединения, во-первых, модуль 126 взаимного прогнозирования извлекает MV в соответствующих управляющих точках для текущего блока (этап Sk_1). Управляющие точки представляют собой верхнюю левую угловую точку текущего блока и верхнюю правую угловую точку текущего блока, как проиллюстрировано на фиг. 46A, либо верхнюю левую угловую точку текущего блока, верхнюю правую угловую точку текущего блока и нижнюю левую угловую точку текущего блока, как проиллюстрировано на фиг. 46B. В это время, модуль 126 взаимного прогнозирования может кодировать информацию MV-выбора для идентификации двух или трех извлеченных MV в потоке.
[0349] Например, когда способы MV-извлечения, проиллюстрированные на фиг. 47A-47C, используются, как проиллюстрировано на фиг. 47A, модуль 126 взаимного прогнозирования проверяет кодированный блок A (левый), блок B (верхний), блок C (верхний правый), блок D (нижний левый) и блок E (верхний левый) в перечисленном порядке и идентифицирует первый эффективный блок, кодированный согласно аффинному режиму.
[0350] Модуль 126 взаимного прогнозирования извлекает MV в управляющей точке с использованием идентифицированного первого эффективного блока, кодированного согласно идентифицированному аффинному режиму. Например, когда блок A идентифицируется, и блок A имеет две управляющих точки, как проиллюстрировано на фиг. 47B, модуль 126 взаимного прогнозирования вычисляет вектор v0 движения в верхней левой угловой управляющей точке текущего блока и вектор v1 движения в верхней правой угловой управляющей точке текущего блока из векторов v3 и v4 движения в верхнем левом углу кодированного блока, включающего в себя блок A, и в верхнем правом углу кодированного блока. Например, модуль 126 взаимного прогнозирования вычисляет вектор v0 движения в верхней левой угловой управляющей точке текущего блока и вектор v1 движения в верхней правой угловой управляющей точке текущего блока посредством проецирования векторов v3 и v4 движения в верхнем левом углу и в верхнем правом углу кодированного блока на текущий блок.
[0351] Альтернативно, когда блок A идентифицируется, и блок A имеет три управляющих точки, как проиллюстрировано на фиг. 47C, модуль 126 взаимного прогнозирования вычисляет вектор v0 движения в верхней левой угловой управляющей точке текущего блока, вектор v1 движения в верхней правой угловой управляющей точке текущего блока и вектор v2 движения в нижней левой угловой управляющей точке текущего блока из векторов v3, v4 и v5 движения в верхнем левом углу кодированного блока, включающего в себя блок A, в верхнем правому углу кодированного блока и в левом нижнем углу кодированного блока. Например, модуль 126 взаимного прогнозирования вычисляет вектор v0 движения в верхней левой угловой управляющей точке текущего блока, вектор v1 движения в верхней правой угловой управляющей точке текущего блока и вектор v2 движения в нижней левой угловой управляющей точке текущего блока посредством проецирования векторов v3, v4 и v5 движения в верхнем левом углу, верхнем правом углу и левом нижнем угле кодированного блока на текущий блок.
[0352] Следует отметить, что, как проиллюстрировано на фиг. 49A, описанном выше, MV в трех управляющих точках могут вычисляться, когда блок A идентифицируется, и блок A имеет две управляющих точки, и что, как проиллюстрировано на фиг. 49B, описанном выше, MV в двух управляющих точках могут вычисляться, когда блок A идентифицируется, и блок A имеет три управляющих точки.
[0353] Затем, модуль 126 взаимного прогнозирования выполняет компенсацию движения каждого из множества субблоков, включенных в текущий блок. Другими словами, модуль 126 взаимного прогнозирования вычисляет MV для каждого из множества субблоков в качестве аффинного MV, с использованием либо двух векторов v0 и v1 движения и вышеуказанного выражения (1A), либо трех векторов v0, v1 и v2 движения и вышеуказанного выражения (1B) (этап Sk_2). Модуль 126 взаимного прогнозирования затем выполняет компенсацию движения субблоков с использованием этих аффинных MV и кодированных опорных кадров (этап Sk_3). Когда процессы на этапах Sk_2 и Sk_3 выполняются для каждого из всех субблоков, включенных в текущий блок, процесс для формирования прогнозного изображения с использованием аффинного режима объединения для текущего блока заканчивается. Другими словами, компенсация движения текущего блока выполняется для того, чтобы формировать прогнозное изображение текущего блока.
[0354] Следует отметить, что вышеописанный список возможных MV-вариантов может формироваться на этапе Sk_1. Список возможных MV-вариантов, например, может представлять собой список, включающий в себя возможные MV-варианты, извлекаемые с использованием множества способов MV-извлечения для каждой управляющей точки. Множество способов MV-извлечения могут представлять собой любую комбинацию способов MV-извлечения, проиллюстрированных на фиг. 47A-47C, способов MV-извлечения, проиллюстрированных на фиг. 48A и 48B, способов MV-извлечения, проиллюстрированных на фиг. 49A и 49B, и других способов MV-извлечения.
[0355] Следует отметить, что списки возможных MV-вариантов могут включать в себя возможные MV-варианты в режиме, в котором прогнозирование выполняется в единицах субблоков, отличном от аффинного режима.
[0356] Следует отметить, что, например, список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном режиме объединения, в котором используются две управляющих точки, и в аффинном режиме объединения, в котором используются три управляющих точки, может формироваться в качестве списка возможных MV-вариантов. Альтернативно, список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном режиме объединения, в котором используются две управляющих точки, и список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном режиме объединения, в котором используются три управляющих точки, могут формироваться отдельно. Альтернативно, список возможных MV-вариантов, включающий в себя возможные MV-варианты в одном из аффинного режима объединения, в котором используются две управляющих точки, и аффинного режима объединения, в котором используются три управляющих точки, может формироваться. Возможный MV-вариант(ы), например, может представлять собой MV для кодированного блока A (левого), блока B (верхнего), блока C (верхнего правого), блока D (нижнего левого) и блока E (верхнего левого) или MV для эффективного блока из блоков.
[0357] Следует отметить, что индекс, указывающий один из MV в списке возможных MV-вариантов, может передаваться как информация MV-выбора.
[0358] MV-извлечение > аффинный режим > аффинный взаимный режим
Фиг. 51 является блок-схемой последовательности операций способа, иллюстрирующей один пример аффинного взаимного режима.
[0359] В аффинном взаимном режиме, как проиллюстрировано, сначала, модуль 126 взаимного прогнозирования извлекает MV-предикторы (v0, v1) или (v0, v1, v2) соответствующих двух или трех управляющих точек текущего блока (этап Sj_1). Управляющие точки представляют собой верхнюю левую угловую точку для текущего блока, верхнюю правую угловую точку для текущего блока и нижнюю левую угловую точку для текущего блока, как проиллюстрировано на фиг. 46A или фиг. 46B.
[0360] Например, когда способы MV-извлечения, проиллюстрированные на фиг. 48A и 48B, используются, модуль 126 взаимного прогнозирования извлекает MV-предикторы (v0, v1) или (v0, v1, v2) в соответствующих двух или трех управляющих точках для текущего блока посредством выбора MV любого из блоков из кодированных блоков около соответствующих управляющих точек для текущего блока, проиллюстрированного на фиг. 48A или на фиг. 48B. В это время, модуль 126 взаимного прогнозирования кодирует, в потоке, информацию выбора MV-предикторов для идентификации выбранных двух или трех MV-предикторов.
[0361] Например, модуль 126 взаимного прогнозирования может определять, с использованием оценки затрат и т.п., блок, из которого выбирается MV в качестве MV-предиктора в управляющей точке, из числа кодированных блоков, граничащих с текущим блоком, и может записывать, в потоке битов, флаг, указывающий то, какой MV-предиктор выбран. Другими словами, модуль 126 взаимного прогнозирования выводит, в качестве параметра прогнозирования, информацию выбора MV-предикторов, такую как флаг, в энтропийный кодер 110 через формирователь 130 параметров прогнозирования.
[0362] Затем, модуль 126 взаимного прогнозирования выполняет оценку движения (этапы Sj_3 и Sj_4) при обновлении MV-предиктора вектора, выбранного или извлеченного на этапе Sj_1 (этап Sj_2). Другими словами, модуль 126 взаимного прогнозирования вычисляет, в качестве аффинного MV, MV каждого из субблоков, который соответствует обновленному MV-предиктору, с использованием либо выражения (1A), либо выражения (1B), описанных выше (этап Sj_3). Модуль 126 взаимного прогнозирования затем выполняет компенсацию движения субблоков с использованием этих аффинных MV и кодированных опорных кадров (этап Sj_4). Процессы на этапах Sj_3 и Sj_4 выполняются для всех блоков в текущем блоке каждый раз, когда MV-предиктор обновляется на этапе Sj_2. Как результат, например, модуль 126 взаимного прогнозирования определяет MV-предиктор, который дает в результате наименьшие затраты, в качестве MV в управляющей точке в контуре оценки движения (этап Sj_5). В это время, модуль 126 взаимного прогнозирования дополнительно кодирует, в потоке, значение разности между определенным MV и MV-предиктором в качестве MV-разности. Другими словами, модуль 126 взаимного прогнозирования выводит MV-разность в качестве параметра прогнозирования в энтропийный кодер 110 через формирователь 130 параметров прогнозирования.
[0363] В завершение, модуль 126 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием определенного MV и кодированного опорного кадра (этап Sj_6).
[0364] Следует отметить, что вышеописанный список возможных MV-вариантов может формироваться на этапе Sj_1. Список возможных MV-вариантов, например, может представлять собой список, включающий в себя возможные MV-варианты, извлекаемые с использованием множества способов MV-извлечения для каждой управляющей точки. Множество способов MV-извлечения могут представлять собой любую комбинацию способов MV-извлечения, проиллюстрированных на фиг. 47A-47C, способов MV-извлечения, проиллюстрированных на фиг. 48A и 48B, способов MV-извлечения, проиллюстрированных на фиг. 49A и 49B, и других способов MV-извлечения.
[0365] Следует отметить, что список возможных MV-вариантов может включать в себя возможные MV-варианты в режиме, в котором прогнозирование выполняется в единицах субблоков, отличном от аффинного режима.
[0366] Следует отметить, что, например, список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном взаимном режиме, в котором используются две управляющих точки, и в аффинном взаимном режиме, в котором используются три управляющих точки, может формироваться в качестве списка возможных MV-вариантов. Альтернативно, список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном взаимном режиме, в котором используются две управляющих точки, и список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном взаимном режиме, в котором используются три управляющих точки, могут формироваться отдельно. Альтернативно, список возможных MV-вариантов, включающий в себя возможные MV-варианты в одном из аффинного взаимного режима, в котором используются две управляющих точки, и аффинного взаимного режима, в котором используются три управляющих точки, может формироваться. Возможный MV-вариант(ы), например, может представлять собой MV для кодированного блока A (левого), блока B (верхнего), блока C (верхнего правого), блока D (нижнего левого) и блока E (верхнего левого) или MV для эффективного блока из блоков.
[0367] Следует отметить, что индекс, указывающий один из возможных MV-вариантов в списке возможных MV-вариантов, может передаваться как информация выбора MV-предикторов.
[0368] MV-извлечение > треугольный режим
Модуль 126 взаимного прогнозирования формирует одно прямоугольное прогнозное изображение для прямоугольного текущего блока в вышеприведенном примере. Тем не менее, модуль 126 взаимного прогнозирования может формировать множество прогнозных изображений, имеющих форму, отличающуюся от прямоугольника, для прямоугольного текущего блока, и может комбинировать множество прогнозных изображений для того, чтобы формировать конечное прямоугольное прогнозное изображение. Форма, отличающаяся от прямоугольника, например, может представлять собой треугольник.
[0369] Фиг. 52A является схемой для иллюстрации формирования двух треугольных прогнозных изображений.
[0370] Модуль 126 взаимного прогнозирования формирует треугольное прогнозное изображение посредством выполнения компенсации движения первого сегмента, имеющего треугольную форму в текущем блоке, посредством использования первого MV первого сегмента для того, чтобы формировать треугольное прогнозное изображение. Аналогично, модуль 126 взаимного прогнозирования формирует треугольное прогнозное изображение посредством выполнения компенсации движения второго сегмента, имеющего треугольную форму в текущем блоке, посредством использования второго MV второго сегмента для того, чтобы формировать треугольное прогнозное изображение. Модуль 126 взаимного прогнозирования затем формирует прогнозное изображение, имеющее прямоугольную форму, идентичную прямоугольной форме текущего блока, посредством комбинирования этих прогнозных изображений.
[0371] Следует отметить, что первое прогнозное изображение, имеющее прямоугольную форму, соответствующую текущему блоку, может формироваться в качестве прогнозного изображения для первого сегмента, с использованием первого MV. Помимо этого, второе прогнозное изображение, имеющее прямоугольную форму, соответствующую текущему блоку, может формироваться в качестве прогнозного изображения для второго сегмента, с использованием второго MV. Прогнозное изображение для текущего блока может формироваться посредством выполнения суммирования со взвешиванием первого прогнозного изображения и второго прогнозного изображения. Следует отметить, что часть, которая подвергается суммированию со взвешиванием, может представлять собой частичную область на границе между первым сегментом и вторым сегментом.
[0372] Фиг. 52B является концептуальной схемой для иллюстрации примеров первой части первого сегмента, которая перекрывается со вторым сегментом, и первого и второго наборов выборок, которые могут взвешиваться в качестве части процесса коррекции. Первая часть, например, может составлять одну четвертую от ширины или высоты первого сегмента. В другом примере, первая часть может иметь ширину, соответствующую N выборок, смежных с краем первого сегмента, где N является целым числом, большим нуля, и N, например, может быть целым числом 2. Как проиллюстрировано, левый пример по фиг. 52B показывает прямоугольный сегмент, имеющий прямоугольную часть с шириной, которая составляет одну четвертую от ширины первого сегмента, с первым набором выборок, включающим в себя выборки за пределами первой части и выборки внутри первой части, и вторым набором выборок, включающим в себя выборки внутри первой части. Центральный пример по фиг. 52B показывает прямоугольный сегмент, имеющий прямоугольную часть с высотой, которая составляет одну четверть от высоты первого сегмента, с первым набором выборок, включающим в себя выборки за пределами первой части и выборки внутри первой части, и вторым набором выборок, включающим в себя выборки внутри первой части. Правый пример по фиг. 52B показывает треугольный сегмент, имеющий многоугольную часть с высотой, которая соответствует двум выборкам, с первым набором выборок, включающим в себя выборки за пределами первой части и выборки внутри первой части, и вторым набором выборок, включающим в себя выборки внутри первой части.
[0373] Первая часть может составлять часть первого сегмента, которая перекрывается со смежным сегментом. Фиг. 52C является концептуальной схемой для иллюстрации первой части первого сегмента, которая составляет часть первого сегмента, которая перекрывается с частью смежного сегмента. Для простоты иллюстрации, показывается прямоугольный сегмент, имеющий перекрывающуюся часть с пространственно смежным прямоугольным сегментом. Сегменты, имеющие другие формы, к примеру, треугольные сегменты, могут использоваться, и перекрывающиеся части могут перекрываться с пространственно смежным или смежным во времени сегментом.
[0374] Помимо этого, хотя приводится пример, в котором прогнозное изображение формируется для каждого из двух сегментов с использованием взаимного прогнозирования, прогнозное изображение может формироваться, по меньшей мере, для одного сегмента с использованием внутреннего прогнозирования.
[0375] Фиг. 53 является блок-схемой последовательности операций способа, иллюстрирующей один пример треугольного режима.
[0376] В треугольном режиме, во-первых, модуль 126 взаимного прогнозирования разбивает текущий блок на первый сегмент и второй сегмент (этап Sx_1). В это время, модуль 126 взаимного прогнозирования может кодировать, в потоке, информацию сегментов, которая представляет собой информацию, связанную с разбиением, на сегменты, в качестве параметра прогнозирования. Другими словами, модуль 126 взаимного прогнозирования может выводить информацию сегментов в качестве параметра прогнозирования в энтропийный кодер 110 через формирователь 130 параметров прогнозирования.
[0377] Во-первых, модуль 126 взаимного прогнозирования получает множество возможных MV-вариантов для текущего блока на основе такой информации, как MV множества кодированных блоков, временно или пространственно окружающих текущий блок (этап Sx_2). Другими словами, модуль 126 взаимного прогнозирования формирует список возможных MV-вариантов.
[0378] Модуль 126 взаимного прогнозирования затем выбирает возможный MV-вариант для первого сегмента и возможный MV-вариант для второго сегмента в качестве первого MV и второго MV, соответственно, из множества возможных MV-вариантов, полученных на этапе Sx_2 (этап Sx_3). В это время, модуль 126 взаимного прогнозирования кодирует, в потоке, информацию MV-выбора для идентификации выбранного возможного MV-варианта, в качестве параметра прогнозирования. Другими словами, модуль 126 взаимного прогнозирования выводит информацию MV-выбора в качестве параметра прогнозирования в энтропийный кодер 110 через формирователь 130 параметров прогнозирования.
[0379] Затем, модуль 126 взаимного прогнозирования формирует первое прогнозное изображение посредством выполнения компенсации движения с использованием выбранного первого MV и кодированного опорного кадра (этап Sx_4). Аналогично, модуль 126 взаимного прогнозирования формирует второе прогнозное изображение посредством выполнения компенсации движения с использованием выбранного второго MV и кодированного опорного кадра (этап Sx_5).
[0380] В завершение, модуль 126 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения суммирования со взвешиванием первого прогнозного изображения и второго прогнозного изображения (этап Sx_6).
[0381] Следует отметить, что хотя первый сегмент и второй сегмент представляют собой треугольники в примере, проиллюстрированном на фиг. 52A, первый сегмент и второй сегмент могут представлять собой трапеции либо другие формы, отличающиеся друг от друга. Кроме того, хотя текущий блок включает в себя два сегмента в примере, проиллюстрированном на фиг. 52A, текущий блок может включать в себя три или более сегментов.
[0382] Помимо этого, первый сегмент и второй сегмент могут перекрываться между собой. Другими словами, первый сегмент и второй сегмент могут включать в себя идентичную пиксельную область. В этом случае, прогнозное изображение для текущего блока может формироваться с использованием прогнозного изображения в первом сегменте и прогнозного изображения во втором сегменте.
[0383] Помимо этого, хотя проиллюстрирован пример, в котором прогнозное изображение формируется для каждого из двух сегментов с использованием взаимного прогнозирования, прогнозное изображение может формироваться, по меньшей мере, для одного сегмента с использованием внутреннего прогнозирования.
[0384] Следует отметить, что список возможных MV-вариантов для выбора первого MV и список возможных MV-вариантов для выбора второго MV могут отличаться друг от друга, либо список возможных MV-вариантов для выбора первого MV также может использоваться в качестве списка возможных MV-вариантов для выбора второго MV.
[0385] Следует отметить, что информация сегментов может включать в себя индекс, указывающий направление разбиения, в котором, по меньшей мере, текущий блок разбивается на множество сегментов. Информация MV-выбора может включать в себя индекс, указывающий выбранный первый MV, и индекс, указывающий выбранный второй MV. Один индекс может указывать множество фрагментов информации. Например, один индекс, совместно указывающий часть или всю информацию сегментов и часть или всю информацию MV-выбора, может кодироваться.
[0386] MV-извлечение > ATMVP-режим
Фиг. 54 является схемой, иллюстрирующей один пример ATMVP-режима, в котором MV извлекается в единицах субблоков.
[0387] ATMVP-режим представляет собой режим, категоризированный на режим объединения. Например, в ATMVP-режиме, возможный MV-вариант для каждого субблока регистрируется в списке возможных MV-вариантов для использования в режиме нормального объединения.
[0388] Более конкретно, в ATMVP-режиме, во-первых, как проиллюстрировано на фиг. 54, временной опорный MV-блок, ассоциированный с текущим блоком, идентифицируется в кодированном опорном кадре, указываемом посредством MV (MV0) соседнего блока, расположенного в левой нижней позиции относительно текущего блока. Затем, в каждом субблоке в текущем блоке, идентифицируется MV, используемый для того, чтобы кодировать область, соответствующую субблоку во временном опорном MV-блоке. MV, идентифицированный таким образом, включается в список возможных MV-вариантов в качестве возможного MV-варианта для субблока в текущем блоке. Когда возможный MV-вариант для каждого субблока выбирается из списка возможных MV-вариантов, субблок подвергается компенсации движения, при которой возможный MV-вариант используется в качестве MV для субблока. Таким образом, прогнозное изображение для каждого субблока формируется.
[0389] Хотя блок, расположенный в левой нижней позиции относительно текущего блока, используется в качестве окружающего опорного MV-блока в примере, проиллюстрированном на фиг. 54, следует отметить, что может использоваться другой блок. Помимо этого, размер субблока может составлять 4×4 пикселов, 8×8 пикселов или другой размер. Размер субблока может переключаться для единицы, такой как срез, кирпич, кадр и т.д.
[0390] Оценка движения > DMVR
Фиг. 55 является схемой, иллюстрирующей взаимосвязь между режимом объединения и DMVR.
[0391] Модуль 126 взаимного прогнозирования извлекает MV для текущего блока согласно режиму объединения (этап Sl_1). Затем, модуль 126 взаимного прогнозирования определяет то, следует или нет выполнять оценку MV, т.е. оценку движения (этап Sl_2). Здесь, при определении необходимости не выполнять оценку движения ("Нет" на этапе Sl_2), модуль 126 взаимного прогнозирования определяет MV, извлекаемый на этапе Sl_1, в качестве конечного MV для текущего блока (этап Sl_4). Другими словами, в этом случае, MV для текущего блока определяется согласно режиму объединения.
[0392] При определении необходимости выполнять оценку движения на этапе Sl_1 ("Да" на этапе Sl_2), модуль 126 взаимного прогнозирования извлекает конечный MV для текущего блока посредством оценки окружающей области опорного кадра, указываемого посредством MV, извлекаемого на этапе Sl_1 (этап Sl_3). Другими словами, в этом случае, MV для текущего блока определяется согласно DMVR.
[0393] Фиг. 56 является концептуальной схемой для иллюстрации другого примера DMVR для определения MV.
[0394] Во-первых, в режиме объединения, например, возможные MV-варианты (L0 и L1) выбираются для текущего блока. Опорный пиксел идентифицируется из первого опорного кадра (L0), который представляет собой кодированный кадр в L0-списке согласно возможному MV-варианту (L0). Аналогично, опорный пиксел идентифицируется из второго опорного кадра (L1), который представляет собой кодированный кадр в L1-списке согласно возможному MV-варианту (L1). Эталон формируется посредством вычисления среднего этих опорных пикселов.
[0395] Затем, каждая из окружающих областей возможных MV-вариантов первого опорного кадра (L0) и второго опорного кадра (L1) оценивается с использованием эталона, и MV, который дает в результате наименьшие затраты, определяется в качестве конечного MV. Следует отметить, что затраты могут вычисляться, например, с использованием значения разности между каждым из пиксельных значений в эталоне и соответствующим одним из пиксельных значений в области оценки, значений возможных MV-вариантов и т.д.
[0396] Совершенно идентичные процессы, описанные здесь, не всегда должны обязательно выполняться. Любой процесс для обеспечения возможности извлечения конечного MV посредством оценки в окружающих областях возможных MV-вариантов может использоваться.
[0397] Фиг. 57 является концептуальной схемой для иллюстрации другого примера DMVR для определения MV. В отличие от примера DMVR, проиллюстрированной на фиг. 56, в примере, проиллюстрированном на фиг. 57, затраты вычисляются вообще без формирования эталона.
[0398] Во-первых, модуль 126 взаимного прогнозирования оценивает окружающую область опорного блока, включенного в каждый из опорных кадров в L0-списке и L1-списке, на основе начального MV, который представляет собой возможный MV-вариант, полученный из каждого списка возможных MV-вариантов. Например, как проиллюстрировано на фиг. 57, начальный MV, соответствующий опорному блоку в L0-списке, представляет собой InitMV_L0, и начальный MV, соответствующий опорному блоку в L1-списке, представляет собой InitMV_L1. При оценке движения, модуль 126 взаимного прогнозирования сначала задает позицию поиска для опорного кадра в L0-списке. На основе позиции, указываемой посредством векторной разности, указывающей позицию поиска, которая должна задаваться, а именно, начального MV (т.е. InitMV_L0), векторная разность для позиции поиска представляет собой MVd_L0. Модуль 126 взаимного прогнозирования затем определяет оцениваемую позицию в опорном кадре в L1-списке. Эта позиция поиска указывается посредством векторной разности для позиции поиска из позиции, указываемой посредством начального MV (т.е. InitMV_L1). Более конкретно, модуль 126 взаимного прогнозирования определяет векторную разность в качестве MVd_L1 посредством зеркалирования MVd_L0. Другими словами, модуль 126 взаимного прогнозирования определяет позицию, которая является симметричной относительно позиции, указываемой посредством начального MV, в качестве позиции поиска в каждом опорном кадре в L0-списке и L1-списке. Модуль 126 взаимного прогнозирования вычисляет, для каждой позиции поиска, общую сумму абсолютных разностей (SAD) между значениями пикселов в позициях поиска в блоках в качестве затрат и узнает позицию поиска, которая дает в результате наименьшие затраты.
[0399] Фиг. 58A является схемой, иллюстрирующей один пример оценки движения в DMVR, и фиг. 58B является блок-схемой последовательности операций способа, иллюстрирующей один пример оценки движения.
[0400] Во-первых, на этапе 1, модуль 126 взаимного прогнозирования вычисляет затраты между позицией поиска (также называется "начальной точкой"), указываемой посредством начального MV, и восемью окружающими позициями поиска. Модуль 126 взаимного прогнозирования затем определяет то, являются или нет затраты в каждой из позиций поиска, отличных от начальной точки, наименьшими. Здесь, при определении того, что затраты в позиции поиска, отличной от начальной точки, являются наименьшими, модуль 126 взаимного прогнозирования изменяет цель на позицию поиска, в которой наименьшие затраты получаются, и выполняет процесс на этапе 2. Когда затраты в начальной точке являются наименьшими, модуль 126 взаимного прогнозирования пропускает процесс на этапе 2 и выполняет процесс на этапе 3.
[0401] На этапе 2, модуль 126 взаимного прогнозирования выполняет поиск, аналогичный процессу на этапе 1, относительно, в качестве новой начальной точки, позиции поиска после того, как цель изменяется, согласно результату процесса на этапе 1. Модуль 126 взаимного прогнозирования затем определяет то, являются или нет затраты в каждой из позиций поиска, отличных от начальной точки, наименьшими. Здесь, при определении того, что затраты в позиции поиска, отличной от начальной точки, являются наименьшими, модуль 126 взаимного прогнозирования выполняет процесс на этапе 4. Когда затраты в начальной точке являются наименьшими, модуль 126 взаимного прогнозирования выполняет процесс на этапе 3.
[0402] На этапе 4, модуль 126 взаимного прогнозирования рассматривает позицию поиска в начальной точке в качестве конечной позиции поиска и определяет разность между позицией, указываемой посредством начального MV, и конечной позицией поиска в качестве векторной разности.
[0403] На этапе 3, модуль 126 взаимного прогнозирования определяет пиксельную позицию с субпиксельной точностью, при которой наименьшие затраты получаются, на основе затрат в четырех точках, расположенных в верхней, нижней, левой и правой позициях относительно начальной точки на этапе 1 или на этапе 2, и рассматривает пиксельную позицию в качестве конечной позиции поиска. Пиксельная позиция с субпиксельной точностью определяется посредством выполнения суммирования со взвешиванием каждого из четырех верхнего, нижнего, левого и правого векторов ((0, 1), (0,-1), (-1, 0) и (1, 0)), с использованием, в качестве весового коэффициента, затрат в соответствующих одной из четырех позиций поиска. Модуль 126 взаимного прогнозирования затем определяет разность между позицией, указываемой посредством начального MV, и конечной позицией поиска в качестве векторной разности.
[0404] Компенсация движения > BIO/OBMC/LIC
Компенсация движения заключает в себе режим для формирования прогнозного изображения и коррекции прогнозного изображения. Режим, например, представляет собой BIO, OBMC и LIC, которые описываются ниже.
[0405] Фиг. 59 является блок-схемой последовательности операций способа, иллюстрирующей один пример формирования прогнозного изображения.
[0406] Модуль 126 взаимного прогнозирования формирует прогнозное изображение (этап Sm_1) и корректирует прогнозное изображение согласно любому из режимов, описанных выше (этап Sm_2).
[0407] Фиг. 60 является блок-схемой последовательности операций способа, иллюстрирующей другой пример формирования прогнозного изображения.
[0408] Модуль 126 взаимного прогнозирования извлекает MV текущего блока (этап Sn_1). Затем, модуль 126 взаимного прогнозирования формирует прогнозное изображение с использованием MV (этап Sn_2) и определяет то, следует или нет выполнять процесс коррекции (этап Sn_3). Здесь, при определении необходимости выполнять процесс коррекции ("Да" на этапе Sn_3), модуль 126 взаимного прогнозирования формирует конечное прогнозное изображение посредством коррекции прогнозного изображения (этап Sn_4). Следует отметить, что в LIC, описанной ниже, яркость и цветность может корректироваться на этапе Sn_4. При определении необходимости не выполнять процесс коррекции ("Нет" на этапе Sn_3), модуль 126 взаимного прогнозирования выводит прогнозное изображение в качестве конечного прогнозного изображения без коррекции прогнозного изображения (этап Sn_5).
[0409] Компенсация движения > OBMC
Следует отметить, что взаимное прогнозное изображение может формироваться с использованием информации движения для соседнего блока в дополнение к информации движения для текущего блока, полученной посредством оценки движения. Более конкретно, взаимное прогнозное изображение может формироваться для каждого субблока в текущем блоке посредством выполнения суммирования со взвешиванием прогнозного изображения на основе информации движения, полученной посредством оценки движения (в опорном кадре), и прогнозного изображения на основе информации движения соседнего блока (в текущем кадре). Такое взаимное прогнозирование (компенсация движения) также называется "перекрывающейся блочной компенсацией движения (OBMC)" или "OBMC-режимом".
[0410] В OBMC-режиме, информация, указывающая размер субблока для OBMC (называется, например, "размером OBMC-блока"), может передаваться в служебных сигналах на уровне последовательности. Кроме того, информация, указывающая то, следует или нет применять OBMC-режим (называется, например, "OBMC-флагом"), передается в служебных сигналах на уровне CU. Следует отметить, что передача в служебных сигналах этой информации не должна обязательно выполняться на уровне последовательности и уровне CU и может выполняться на другом уровне (например, на уровне кадра, уровне среза, уровне кирпича, уровне CTU или уровне субблока).
[0411] В дальнейшем подробнее описывается OBMC-режим. Фиг. 61 и 62 являются блок-схемой последовательности операций способа и концептуальной схемой для иллюстрации краткого представления процесса коррекции прогнозных изображений, выполняемого посредством OBMC.
[0412] Во-первых, как проиллюстрировано на фиг. 62, прогнозное изображение (Pred) посредством нормальной компенсации движения получается с использованием MV, назначенного текущему блоку. На фиг. 62, стрелка "MV" указывает на опорный кадр и указывает то, к чему обращается текущий блок текущего кадра, чтобы получать прогнозное изображение.
[0413] Затем, прогнозное изображение (Pred_L) получается посредством применения вектора (MV_L) движения, который уже извлечен для кодированного блока, соседнего слева от текущего блока, к текущему блоку (многократного использования вектора движения для текущего блока). Вектор (MV_L) движения указывается посредством стрелки "MV_L", указывающей опорный кадр, из текущего блока. Первая коррекция прогнозного изображения выполняется посредством перекрытия двух прогнозных изображений Pred и Pred_L. Это предоставляет преимущество смешивания границы между соседними блоками.
[0414] Аналогично, прогнозное изображение (Pred_U) получается посредством применения MV (MV_U), который уже извлечен для кодированного блока, соседнего выше текущего блока, к текущему блоку (многократного использования MV для текущего блока). MV (MV_U) указывается посредством стрелки "MV_U", указывающей опорный кадр, из текущего блока. Вторая коррекция прогнозного изображения выполняется посредством перекрытия прогнозного изображения Pred_U с прогнозными изображениями (например, Pred и Pred_L), для которых выполнена первая коррекция. Это предоставляет преимущество смешивания границы между соседними блоками. Прогнозное изображение, полученное посредством второй коррекции, представляет собой прогнозное изображение, в котором граница между соседними блоками смешивается (сглаживается), и в силу этого представляет собой конечное прогнозное изображение текущего блока.
[0415] Хотя вышеприведенный пример представляет собой способ коррекции с двумя трактами с использованием левого и верхнего соседних блоков, следует отметить, что способ коррекции может представлять собой способ коррекции с тремя или более трактов с использованием также правого соседнего блока и/или нижнего соседнего блока.
[0416] Следует отметить, что область, в которой выполняется такое перекрытие, может составлять только часть области около границы блока вместо пиксельной области всего блока.
[0417] Следует отметить, что выше описывается процесс коррекции прогнозных изображений согласно OBMC для получения одного прогнозного изображения Pred из одного опорного кадра посредством перекрытия дополнительных прогнозных изображений Pred_L и Pred_U. Тем не менее, когда прогнозное изображение корректируется на основе множества опорных изображений, аналогичный процесс может применяться к каждому из множества опорных кадров. В таком случае, после того, как скорректированные прогнозные изображения получаются из соответствующих опорных кадров посредством выполнения OBMC-коррекции изображений на основе множества опорных кадров, полученные скорректированные прогнозные изображения дополнительно перекрываются, чтобы получать конечное прогнозное изображение.
[0418] Следует отметить, что, в OBMC, текущая блочная единица может представлять собой PU или субблочную единицу, полученную посредством дополнительного разбиения PU.
[0419] Один пример способа для определения того, следует или нет применять OBMC, представляет собой способ для использования obmc_flag, который представляет собой сигнал, указывающий то, следует или нет применять OBMC. В качестве одного конкретного примера, кодер 100 может определять то, принадлежит или нет текущий блок области, имеющей усложненное движение. Кодер задает obmc_flag равным значению "1", когда блок принадлежит области, имеющей усложненное движение, и применяет OBMC при кодировании и задает obmc_flag равным значению "0", когда блок не принадлежит области, имеющей усложненное движение, и кодирует блок без применения OBMC. Декодер 200 переключается между применением и неприменением OBMC посредством декодирования obmc_flag, записываемого в поток.
[0420] Компенсация движения > BIO
Далее описывается способ MV-извлечения. Во-первых, описывается режим для извлечения MV на основе модели при условии равномерного прямолинейного движения. Этот режим также называется "режимом двунаправленного оптического потока (BIO)". Помимо этого, этот двунаправленный оптический поток может записываться в качестве BDOF вместо BIO.
[0421] Фиг. 63 является схемой для иллюстрации модели при условии равномерного прямолинейного движения. На фиг. 63, (vx, vy) указывает вектор скорости, и τ0 и τ1 указывают временные расстояния между текущим кадром (Cur Pic) и двумя опорными кадрами (Ref0, Ref1). (MVx0, MVy0) указывает MV, соответствующие опорному кадру Ref0, и (MVx1, MVy1) указывает MV, соответствующие опорному кадру Ref1.
[0422] Здесь, согласно допущению относительно равномерного прямолинейного движения, демонстрируемого посредством вектора скорости (vx, vy), (MVx0, MVy0) и (MVx1, MVy1) представляются как (vxτ0, vyτ0) и (-vxτ1,- vyτ1), соответственно, и задается следующее уравнение (2) оптического потока:
[0423] Математическое выражение 3
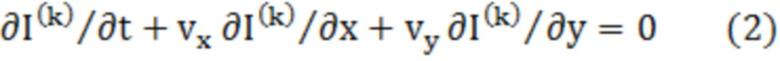
[0424] Здесь, I(k) обозначает значение сигнала яркости из опорного изображения k (k=0, 1) после компенсации движения. Это уравнение оптического потока показывает то, что сумма (i) производной по времени значения сигнала яркости, (ii) произведения горизонтальной скорости и горизонтального компонента пространственного градиента опорного изображения и (iii) произведения вертикальной скорости и вертикального компонента пространственного градиента опорного изображения равна нулю. Вектор движения каждого блока, полученный, например, из списка возможных MV-вариантов, может корректироваться в единицах пикселов, на основе комбинации уравнения оптического потока и эрмитовой интерполяции.
[0425] Следует отметить, что вектор движения может извлекаться на стороне декодера 200 с использованием способа, отличного от извлечения вектора движения, на основе модели при условии равномерного прямолинейного движения. Например, вектор движения может извлекаться в единицах субблока на основе MV множества соседних блоков.
[0426] Фиг. 64 является блок-схемой последовательности операций способа, иллюстрирующей один пример взаимного прогнозирования согласно BIO. Фиг. 65 является схемой, иллюстрирующей один пример функциональной конфигурации модуля 126 взаимного прогнозирования, который выполняет взаимное прогнозирование согласно BIO.
[0427] Как проиллюстрировано на фиг. 65, модуль 126 взаимного прогнозирования включает в себя, например, запоминающее устройство 126a, модуль 126b извлечения интерполированных изображений, модуль 126c извлечения градиентных изображений, модуль 126d извлечения оптических потоков, модуль 126e извлечения значений коррекции и корректор 126f прогнозных изображений. Следует отметить, что запоминающее устройство 126a может представлять собой запоминающее устройство 122 кинокадров.
[0428] Модуль 126 взаимного прогнозирования извлекает два вектора (M0, M1) движения с использованием двух опорных кадров (Ref0, Ref1), отличающихся от кадра (Cur Pic), включающего в себя текущий блок. Модуль 126 взаимного прогнозирования затем извлекает прогнозное изображение для текущего блока с использованием двух векторов (M0, M1) движения (этап Sy_1). Следует отметить, что вектор M0 движения представляет собой вектор (MVx0, MVy0) движения, соответствующий опорному кадру Ref0, и вектор M1 движения представляет собой вектор (MVx1, MVy1) движения, соответствующий опорному кадру Ref1.
[0429] Затем, модуль 126b извлечения интерполированных изображений извлекает интерполированное изображение I0 для текущего блока с использованием вектора M0 движения и опорного кадра L0 посредством обращения к запоминающему устройству 126a. Помимо этого, модуль 126b извлечения интерполированных изображений извлекает интерполированное изображение I1 для текущего блока с использованием вектора M1 движения и опорного кадра L1 посредством обращения к запоминающему устройству 126a (этап Sy_2). Здесь, интерполированное изображение I0 представляет собой изображение, включенное в опорный кадр Ref0, и которое должно извлекаться для текущего блока, и интерполированное изображение I1 представляет собой изображение, включенное в опорный кадр Ref1, и которое должно извлекаться для текущего блока. Каждое из интерполированного изображения I0 и интерполированного изображения I1 может иметь размер, идентичный размеру текущего блока. Альтернативно, каждое из интерполированного изображения I0 и интерполированного изображения I1 может представлять собой изображение, большее текущего блока. Кроме того, интерполированное изображение I0 и интерполированное изображение I1 могут включать в себя прогнозное изображение, полученное посредством использования векторов (M0, M1) движения и опорных кадров (L0, L1) и применения фильтра для компенсации движения.
[0430] Помимо этого, модуль 126c извлечения градиентных изображений извлекает градиентные изображения (Ix0, Ix1, Iy0, Iy1) текущего блока из интерполированного изображения I0 и интерполированного изображения I1. Следует отметить, что градиентные изображения в горизонтальном направлении представляют собой (Ix0, Ix1), и градиентные изображения в вертикальном направлении представляют собой (Iy0, Iy1). Модуль 126c извлечения градиентных изображений может извлекать каждое градиентное изображение, например, посредством применения градиентного фильтра к интерполированным изображениям. Необходимо только то, что градиентное изображение указывает величину пространственного изменения пиксельного значения вдоль горизонтального направления или вертикального направления.
[0431] Затем, модуль 126d извлечения оптических потоков извлекает, для каждого субблока текущего блока, оптический поток (vx, vy), который представляет собой вектор скорости, с использованием интерполированных изображений (I0, I1) и градиентных изображений (Ix0, Ix1, Iy0, Iy1). Оптический поток указывает коэффициенты для коррекции величины пространственного пиксельного перемещения и может называться "локальным значением оценки движения", "скорректированным вектором движения" или "скорректированным весовым вектором". В качестве одного примера, субблок может представлять собой 4×4-пиксельную суб-CU. Следует отметить, что извлечение оптических потоков может выполняться для каждой единицы пикселов и т.п. вместо выполнения для каждого субблока.
[0432] Затем, модуль 126 взаимного прогнозирования корректирует прогнозное изображение для текущего блока с использованием оптического потока (vx, vy). Например, модуль 126e извлечения значений коррекции извлекает значение коррекции для значения пиксела, включенного в текущий блок, с использованием оптического потока (vx, vy) (этап Sy_5). Корректор 126f прогнозных изображений затем может корректировать прогнозное изображение для текущего блока с использованием значения коррекции (этап Sy_6). Следует отметить, что значение коррекции может извлекаться в единицах пиксела либо может извлекаться в единицах множества пикселов или в единицах субблоков.
[0433] Следует отметить, что поток BIO-процесса не ограничен процессом, раскрытым на фиг. 64. Только часть процессов, раскрытая на фиг. 64, может выполняться, либо другой процесс может добавляться или использоваться в качестве замены, либо процессы могут выполняться в другом порядке обработки.
[0434] Компенсация движения > LIC
Далее описывается один пример режима для формирования прогнозного изображения (прогнозирования) с использованием компенсации локальной освещенности (LIC).
[0435] Фиг. 66A является схемой для иллюстрации одного примера способа формирования прогнозных изображений с использованием процесса коррекции яркости, выполняемого посредством LIC. Фиг. 66B является блок-схемой последовательности операций способа, иллюстрирующей один пример способа формирования прогнозных изображений с использованием LIC.
[0436] Во-первых, модуль 126 взаимного прогнозирования извлекает MV из кодированного опорного кадра и получает опорное изображение, соответствующее текущему блоку (этап Sz_1).
[0437] Затем, модуль 126 взаимного прогнозирования извлекает, для текущего блока, информацию, указывающую то, как значение сигнала яркости изменено между текущим блоком и опорным кадром (этап Sz_2). Это извлечение выполняется на основе пиксельных значений сигнала яркости кодированной левой соседней опорной области (окружающей опорной области) и кодированной верхней соседней опорной области (окружающей опорной области) в текущем кадре и пиксельных значений сигнала яркости в соответствующих позициях в опорном кадре, указываемых посредством извлеченных MV. Модуль 126 взаимного прогнозирования вычисляет параметр коррекции яркости, с использованием информации, указывающей то, как значение сигнала яркости изменено (этап Sz_3).
[0438] Модуль 126 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения процесса коррекции яркости, в котором параметр коррекции яркости применяется к опорному изображению в опорном кадре, указываемом посредством MV (этап Sz_4). Другими словами, прогнозное изображение, которое представляет собой опорное изображение в опорном кадре, указываемом посредством MV, подвергается коррекции на основе параметра коррекции яркости. При этой коррекции, яркость может корректироваться, либо цветность может корректироваться. Другими словами, параметр коррекции цветности может вычисляться с использованием информации, указывающей то, как цветность изменена, и процесс коррекции цветности может выполняться.
[0439] Следует отметить, что форма окружающей опорной области, проиллюстрированной на фиг. 66A, представляет собой один пример; может использоваться другая форма.
[0440] Кроме того, хотя здесь описывается процесс, в котором прогнозное изображение формируется из одного опорного кадра, идентично могут описываться случаи, в которых прогнозное изображение формируется из множества опорных кадров. Прогнозное изображение может формироваться после выполнения процесса коррекции яркости опорных изображений, полученных из опорных кадров, идентично вышеописанному.
[0441] Один пример способа для определения того, следует или нет применять LIC, представляет собой способ для использования lic_flag, который представляет собой сигнал, указывающий то, следует или нет применять LIC. В качестве одного конкретного примера, кодер 100 определяет то, принадлежит или нет текущий блок области, имеющей изменение яркости. Кодер 100 задает lic_flag равным значению "1", когда блок принадлежит области, имеющей изменение яркости, и применяет LIC при кодировании и задает lic_flag равным значению "0", когда блок не принадлежит области, имеющей изменение яркости, и выполняет кодирование без применения LIC. Декодер 200 может декодировать lic_flag, записываемый в потоке, и декодировать текущий блок посредством переключения между применением и неприменением LIC в соответствии со значением флага.
[0442] Один пример другого способа определения того, следует или нет применять LIC-процесс, представляет собой способ определения в соответствии с тем, применен или нет LIC-процесс к окружающему блоку. В качестве одного конкретного примера, когда текущий блок обрабатывается в режиме объединения, модуль 126 взаимного прогнозирования определяет то, кодирован или нет кодированный окружающий блок, выбранный при MV-извлечении в режиме объединения, с использованием LIC. Модуль 126 взаимного прогнозирования выполняет кодирование посредством переключения между применением и неприменением LIC согласно результату. Следует отметить, что также в этом примере, идентичные процессы применяются к процессам на стороне декодера 200.
[0443] Процесс коррекции яркости (LIC) описывается со ссылкой на фиг. 66A и 66B и дополнительно описывается ниже.
[0444] Во-первых, модуль 126 взаимного прогнозирования извлекает MV для получения опорного изображения, соответствующего текущему блоку, из опорного кадра, который представляет собой кодированный кадр.
[0445] Затем, модуль 126 взаимного прогнозирования извлекает информацию, указывающую то, как значение сигнала яркости опорного кадра изменено на значение сигнала яркости текущего кадра, с использованием пиксельных значений сигнала яркости кодированных окружающих опорных областей, которые являются соседними слева от или выше текущего блока, и пиксельных значений сигнала яркости в соответствующих позициях в опорных кадрах, указываемых посредством MV, и вычисляет параметр коррекции яркости. Например, предполагается, что пиксельное значение сигнала яркости данного пиксела в окружающей опорной области в текущем кадре составляет p0, и что пиксельное значение сигнала яркости пиксела, соответствующего данному пикселу в окружающей опорной области в опорном кадре, составляет p1. Модуль 126 взаимного прогнозирования вычисляет коэффициенты A и B для оптимизации A*p1+B=p0 в качестве параметра коррекции яркости для множества пикселов в окружающей опорной области.
[0446] Затем, модуль 126 взаимного прогнозирования выполняет процесс коррекции яркости с использованием параметра коррекции яркости для опорного изображения в опорном кадре, указываемом посредством MV, чтобы формировать прогнозное изображение для текущего блока. Например, предполагается, что пиксельное значение сигнала яркости в опорном изображении составляет p2, и что скорректированное по яркости пиксельное значение сигнала яркости прогнозного изображения составляет p3. Модуль 126 взаимного прогнозирования формирует прогнозное изображение после подвергания процессу коррекции яркости посредством вычисления A*p2+B=p3 для каждого из пикселов в опорном изображении.
[0447] Например, область, имеющая определенное число пикселов, извлеченных из каждого из верхнего соседнего пиксела и левого соседнего пиксела, может использоваться в качестве окружающей опорной области. Помимо этого, окружающая опорная область не ограничена областью, которая является соседней с текущим блоком, и может представлять собой область, которая не является соседней с текущим блоком. В примере, проиллюстрированном на фиг. 66A, окружающая опорная область в опорном кадре может представлять собой область, указываемую посредством другого MV в текущем кадре, из окружающей опорной области в текущем кадре. Например, другой MV может представлять собой MV в окружающей опорной области в текущем кадре.
[0448] Хотя здесь описываются операции, выполняемые посредством кодера 100, следует отметить, что декодер 200 выполняет аналогичные операции.
[0449] Следует отметить, что LIC может применяться не только к сигналу яркости, но также и к сигналу цветности. В это время, параметр коррекции может извлекаться отдельно для каждого из Y, Cb и Cr, или общий параметр коррекции может использоваться для любого из Y, Cb и Cr.
[0450] Помимо этого, LIC-процесс может применяться в единицах субблоков. Например, параметр коррекции может извлекаться с использованием окружающей опорной области в текущем субблоке и окружающей опорной области в опорном субблоке в опорном кадре, указываемом посредством MV текущего субблока.
[0451] Контроллер прогнозирования
Контроллер 128 прогнозирования выбирает одно из внутреннего прогнозного изображения (изображения или сигнала, выводимого из модуля 124 внутреннего прогнозирования) и взаимного прогнозного изображения (изображения или сигнала, выводимого из модуля 126 взаимного прогнозирования) и выводит выбранное прогнозное изображение в вычитатель 104 и сумматор 116.
[0452] Формирователь параметров прогнозирования
Формирователь 130 параметров прогнозирования может выводить информацию, связанную с внутренним прогнозированием, взаимным прогнозированием, выбором прогнозного изображения в контроллере 128 прогнозирования и т.д. в качестве параметра прогнозирования в энтропийный кодер 110. Энтропийный кодер 110 может формировать поток, на основе параметра прогнозирования, который вводится из формирователя 130 параметров прогнозирования, и квантованных коэффициентов, которые вводятся из квантователя 108. Параметр прогнозирования может использоваться в декодере 200. Декодер 200 может принимать и декодировать поток и выполнять процессы, идентичные процессам прогнозирования, выполняемым посредством модуля 124 внутреннего прогнозирования, модуля 126 взаимного прогнозирования и контроллера 128 прогнозирования. Параметр прогнозирования может включать в себя (i) выбираемый прогнозный сигнал (например, MV, тип прогнозирования или режим прогнозирования, используемый посредством модуля 124 внутреннего прогнозирования или модуля 126 взаимного прогнозирования), или (ii) необязательный индекс, флаг или значение, которое основано на процессе прогнозирования, выполняемом в каждом из модуля 124 внутреннего прогнозирования, модуля 126 взаимного прогнозирования и контроллера 128 прогнозирования, либо которое указывает процесс прогнозирования.
[0453] Декодер
Далее описывается декодер 200, допускающий декодирование потока, выводимого из кодера 100, описанного выше. Фиг. 67 является блок-схемой, иллюстрирующей функциональную конфигурацию декодера 200 согласно этому варианту осуществления. Декодер 200 представляет собой оборудование, которое декодирует поток, который представляет собой кодированное изображение в единицах блоков.
[0454] Как проиллюстрировано на фиг. 67, декодер 200 включает в себя энтропийный декодер 202, обратный квантователь 204, обратный преобразователь 206, сумматор 208, запоминающее устройство 210 блоков, контурный фильтр 212, запоминающее устройство 214 кинокадров, модуль 216 внутреннего прогнозирования, модуль 218 взаимного прогнозирования, контроллер 220 прогнозирования, формирователь 222 параметров прогнозирования и модуль 224 определения разбиения. Следует отметить, что модуль 216 внутреннего прогнозирования и модуль 218 взаимного прогнозирования сконфигурированы как часть модуля выполнения прогнозирования.
[0455] Пример монтажа декодера
Фиг. 68 является блок-схемой, иллюстрирующей пример монтажа декодера 200. Декодер 200 включает в себя процессор b1 и запоминающее устройство b2. Например, множество составляющих элементов декодера 200, проиллюстрированного на фиг. 67, смонтированы в процессоре b1 и запоминающем устройстве b2, проиллюстрированных на фиг. 68.
[0456] Процессор b1 представляет собой схему, которая выполняет обработку информации, и является доступным для запоминающего устройства b2. Например, процессор b1 представляет собой специализированную или общую электронную схему, которая декодирует поток. Процессор b1 может представлять собой процессор, такой как CPU. Помимо этого, процессор b1 может представлять собой совокупность множества электронных схем. Помимо этого, например, процессор b1 может выполнять роли двух или более составляющих элементов, отличных от составляющего элемента для сохранения информации, из множества составляющих элементов декодера 200, проиллюстрированного на фиг. 67, и т.д.
[0457] Запоминающее устройство b2 представляет собой специализированное или общее запоминающее устройство для сохранения информации, которая используется посредством процессора b1 для того, чтобы декодировать поток. Запоминающее устройство b2 может представлять собой электронную схему и может соединяться с процессором b1. Помимо этого, запоминающее устройство b2 может включаться в процессор b1. Помимо этого, запоминающее устройство b2 может представлять собой совокупность множества электронных схем. Помимо этого, запоминающее устройство b2 может представлять собой магнитный диск, оптический диск и т.п. либо может представляться как устройство хранения данных, носитель и т.п. Помимо этого, запоминающее устройство b2 может представлять собой энергонезависимое запоминающее устройство или энергозависимое запоминающее устройство.
[0458] Например, запоминающее устройство b2 может сохранять изображение или поток. Помимо этого, запоминающее устройство b2 может сохранять программу для инструктирования процессору b1 декодировать поток.
[0459] Помимо этого, например, запоминающее устройство b2 может выполнять роли двух или более составляющих элементов для сохранения информации из множества составляющих элементов декодера 200, проиллюстрированного на фиг. 67, и т.д. Более конкретно, запоминающее устройство b2 может выполнять роли запоминающего устройства 210 блоков и запоминающего устройства 214 кинокадров, проиллюстрированных на фиг. 67. Более конкретно, запоминающее устройство b2 может сохранять восстановленное изображение (в частности, восстановленный блок, восстановленный кадр и т.п.).
[0460] Следует отметить, что, в декодере 200, не все из множества составляющих элементов, проиллюстрированных на фиг. 67 и т.д., могут реализовываться, и не все процессы, описанные выше, могут выполняться. Часть составляющих элементов, указываемых на фиг. 67 и т.д., может включаться в другое устройство, или часть процессов, описанных выше, может выполняться посредством другого устройства.
[0461] В дальнейшем в этом документе, описывается полная последовательность операций процессов, выполняемых посредством декодера 200, и после этого описывается каждый из составляющих элементов, включенных в декодер 200. Следует отметить, что некоторые составляющие элементы, включенные в декодер 200, выполняют процессы, идентичные процессам, выполняемым посредством некоторых составляющих элементов, включенных в кодер 100, и в силу этого идентичные процессы подробно не описываются повторно. Например, обратный квантователь 204, обратный преобразователь 206, сумматор 208, запоминающее устройство 210 блоков, запоминающее устройство 214 кинокадров, модуль 216 внутреннего прогнозирования, модуль 218 взаимного прогнозирования, контроллер 220 прогнозирования и контурный фильтр 212, включенные в декодер 200, выполняют процессы, аналогичные процессам, выполняемым посредством обратного квантователя 112, обратного преобразователя 114, сумматора 116, запоминающего устройства 118 блоков, запоминающего устройства 122 кинокадров, модуля 124 внутреннего прогнозирования, модуля 126 взаимного прогнозирования, контроллера 128 прогнозирования и контурного фильтра 120, включенных в кодер 100, соответственно.
[0462] Общая последовательность операций процесса декодирования
Фиг. 69 является блок-схемой последовательности операций способа, иллюстрирующей один пример полного процесса декодирования, выполняемого посредством декодера 200.
[0463] Во-первых, модуль 224 определения разбиения в декодере 200 определяет шаблон разбиения каждого из множества блоков фиксированного размера (128×128 пикселов), включенных в кадр, на основе параметра, который вводится из энтропийного декодера 202 (этап Sp_1). Этот шаблон разбиения представляет собой шаблон разбиения, выбранный посредством кодера 100. Декодер 200 затем выполняет процессы этапов Sp_2-Sp_6 для каждого из множества блоков шаблона разбиения.
[0464] Энтропийный декодер 202 декодирует (в частности, энтропийно декодирует) кодированные квантованные коэффициенты и параметр прогнозирования текущего блока (этап Sp_2).
[0465] Затем, обратный квантователь 204 выполняет обратное квантование множества квантованных коэффициентов, и обратный преобразователь 206 выполняет обратное преобразование результата для того, чтобы восстанавливать остатки прогнозирования текущего блока (этап Sp_3).
[0466] Затем, модуль выполнения прогнозирования, включающий в себя все или часть из модуля 216 внутреннего прогнозирования, модуля 218 взаимного прогнозирования и контроллера 220 прогнозирования, формирует прогнозное изображение текущего блока (этап Sp_4).
[0467] Затем, сумматор 208 суммирует прогнозное изображение с остатком прогнозирования для того, чтобы формировать восстановленное изображение (также называется "декодированным блоком изображений") текущего блока (этап Sp_5).
[0468] Когда восстановленное изображение формируется, контурный фильтр 212 выполняет фильтрацию восстановленного изображения (этап Sp_6).
[0469] Декодер 200 затем определяет то, закончено или нет декодирование всего кадра (этап Sp_7). При определении того, что декодирование еще не закончено ("Нет" на этапе Sp_7), декодер 200 многократно выполняет процессы, начиная с этапа Sp_1.
[0470] Следует отметить, что процессы этих этапов Sp_1-Sp_7 могут выполняться последовательно посредством декодера 200, либо два или более процессов могут выполняться параллельно. Порядок обработки двух или более процессов может модифицироваться.
[0471] Модуль определения разбиения
Фиг. 70 является схемой, иллюстрирующей взаимосвязь между модулем 224 определения разбиения и другими составляющими элементами. Модуль 224 определения разбиения может выполнять следующие процессы в качестве примеров.
[0472] Например, модуль 224 определения разбиения собирает информацию блоков из запоминающего устройства 210 блоков или запоминающего устройства 214 кинокадров и, кроме того, получает параметр из энтропийного декодера 202. Модуль 224 определения разбиения затем может определять шаблон разбиения блока фиксированного размера, на основе информации блоков и параметра. Модуль 224 определения разбиения затем может выводить информацию, указывающую определенный шаблон разбиения, в обратный преобразователь 206, модуль 216 внутреннего прогнозирования и модуль 218 взаимного прогнозирования. Обратный преобразователь 206 может выполнять обратное преобразование коэффициентов преобразования, на основе шаблона разбиения, указываемого посредством информации из модуля 224 определения разбиения. Модуль 216 внутреннего прогнозирования и модуль 218 взаимного прогнозирования могут формировать прогнозное изображение, на основе шаблона разбиения, указываемого посредством информации из модуля 224 определения разбиения.
[0473] Энтропийный декодер
Фиг. 71 является блок-схемой, иллюстрирующей один пример функциональной конфигурации энтропийного декодера 202.
[0474] Энтропийный декодер 202 формирует квантованные коэффициенты, параметр прогнозирования и параметр, связанный с шаблоном разбиения, посредством энтропийного декодирования потока. Например, CABAC используется при энтропийном декодировании. Более конкретно, энтропийный декодер 202 включает в себя, например, двоичный арифметический декодер 202a, контроллер 202b контекстов и модуль 202c отмены преобразования в двоичную форму. Двоичный арифметический декодер 202a арифметически декодирует поток с использованием значения контекста, извлекаемого посредством контроллера 202b контекстов, в двоичный сигнал. Контроллер 202b контекстов извлекает значение контекста согласно признаку или окружающему состоянию синтаксического элемента, т.е. вероятности возникновения двоичного сигнала, идентично тому, что выполняется посредством контроллера 110b контекстов кодера 100. Модуль 202c отмены преобразования в двоичную форму выполняет отмену преобразования в двоичную форму для преобразования двоичного сигнала, выводимого из двоичного арифметического декодера 202a, в многоуровневый сигнал, указывающий квантованные коэффициенты, как описано выше. Это преобразование в двоичную форму выполняется согласно способу преобразования в двоичную форму, описанному выше.
[0475] Вследствие этого, энтропийный декодер 202 выводит квантованные коэффициенты каждого блока в обратный квантователь 204. Энтропийный декодер 202 может выводить параметр прогнозирования, включенный в поток (см. фиг. 1), в модуль 216 внутреннего прогнозирования, модуль 218 взаимного прогнозирования и контроллер 220 прогнозирования. Модуль 216 внутреннего прогнозирования, модуль 218 взаимного прогнозирования и контроллер 220 прогнозирования допускают выполнение процессов прогнозирования, идентичных процессам прогнозирования, выполняемым посредством модуля 124 внутреннего прогнозирования, модуля 126 взаимного прогнозирования и контроллера 128 прогнозирования на стороне кодера 100.
[0476] Энтропийный декодер
Фиг. 72 является схемой, иллюстрирующей последовательность операций CABAC в энтропийном декодере 202.
[0477] Во-первых, инициализация выполняется в CABAC в энтропийном декодере 202. При инициализации, инициализация в двоичном арифметическом декодере 202a и задание начального значения контекста выполняется. Двоичный арифметический декодер 202a и модуль 202c отмены преобразования в двоичную форму затем выполняют арифметическое декодирование и отмену преобразования в двоичную форму, например, кодированных данных CTU. В это время, контроллер 202b контекстов обновляет значение контекста каждый раз, когда выполняется арифметическое декодирование. Контроллер 202b контекстов затем сохраняет значение контекста в качестве постобработки. Сохраненное значение контекста используется, например, чтобы инициализировать значение контекста для следующей CTU.
[0478] Обратный квантователь
Обратный квантователь 204 обратно квантует квантованные коэффициенты текущего блока, которые представляют собой вводы из энтропийного декодера 202. Более конкретно, обратный квантователь 204 обратно квантует квантованные коэффициенты текущего блока, на основе параметров квантования, соответствующих квантованным коэффициентам. Обратный квантователь 204 затем выводит обратно квантованные коэффициенты преобразования (которые представляют собой коэффициенты преобразования) текущего блока в обратный преобразователь 206.
[0479] Фиг. 73 является блок-схемой, иллюстрирующей один пример функциональной конфигурации обратного квантователя 204.
[0480] Обратный квантователь 204 включает в себя, например, формирователь 204a параметров квантования, формирователь 204b прогнозированных параметров квантования, устройство 204d хранения параметров квантования и модуль 204e выполнения обратного квантования.
[0481] Фиг. 74 является блок-схемой последовательности операций способа, иллюстрирующей один пример обратного квантования, выполняемого посредством обратного квантователя 204.
[0482] Обратный квантователь 204 может выполнять процесс обратного квантования в качестве одного примера для каждой CU на основе последовательности операций, проиллюстрированной на фиг. 74. Более конкретно, формирователь 204a параметров квантования определяет то, следует или нет выполнять обратное квантование (этап Sv_11). Здесь, при определении необходимости выполнять обратное квантование ("Да" на этапе Sv_11), формирователь 204a параметров квантования получает параметр разностного квантования для текущего блока из энтропийного декодера 202 (этап Sv_12).
[0483] Затем, формирователь 204b прогнозированных параметров квантования затем получает параметр квантования для единицы обработки, отличающейся от текущего блока, из устройства 204d хранения параметров квантования (этап Sv_13). Формирователь 204b прогнозированных параметров квантования формирует прогнозированный параметр квантования текущего блока на основе полученного параметра квантования (этап Sv_14).
[0484] Формирователь 204a параметров квантования затем суммирует параметр разностного квантования для текущего блока, полученный из энтропийного декодера 202, и прогнозированный параметр квантования для текущего блока, сформированный посредством формирователя 204b прогнозированных параметров квантования (этап Sv_15). Это суммирование формирует параметр квантования для текущего блока. Помимо этого, формирователь 204a параметров квантования сохраняет параметр квантования для текущего блока в устройстве 204d хранения параметров квантования (этап Sv_16).
[0485] Затем, модуль 204e выполнения обратного квантования обратно квантует квантованные коэффициенты текущего блока в коэффициенты преобразования, с использованием параметра квантования, сформированного на этапе Sv_15 (этап Sv_17).
[0486] Следует отметить, что параметр разностного квантования может декодироваться на уровне битовой последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU. Помимо этого, начальное значение параметра квантования может декодироваться на уровне последовательности, уровне кадра, уровне среза, уровне кирпича или уровне CTU. В это время, параметр квантования может формироваться с использованием начального значения параметра квантования и параметра разностного квантования.
[0487] Следует отметить, что обратный квантователь 204 может включать в себя множество обратных квантователей и может обратно квантовать квантованные коэффициенты с использованием способа обратного квантования, выбранного из множества способов обратного квантования.
[0488] Обратный преобразователь
Обратный преобразователь 206 восстанавливает остатки прогнозирования посредством обратного преобразования коэффициентов преобразования, которые представляют собой вводы из обратного квантователя 204.
[0489] Например, когда информация, синтаксически проанализированная из потока, указывает то, что EMT или AMT должно применяться (например, когда AMT-флаг является истинным), обратный преобразователь 206 обратно преобразует коэффициенты преобразования текущего блока на основе информации, указывающей синтаксически проанализированный тип преобразования.
[0490] Кроме того, например, когда информация, синтаксически проанализированная из потока, указывает то, что NSST должно применяться, обратный преобразователь 206 применяет вторичное обратное преобразование к коэффициентам преобразования.
[0491] Фиг. 75 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством обратного преобразователя 206.
[0492] Например, обратный преобразователь 206 определяет то, присутствует или нет информация, указывающая то, что ортогональное преобразование не выполняется, в потоке (этап St_11). Здесь, при определении того, что эта информация не присутствует ("Нет" на этапе St_11), обратный преобразователь 206 получает информацию, указывающую тип преобразования, декодированный посредством энтропийного декодера 202 (этап St_12). Затем, на основе информации, обратный преобразователь 206 определяет тип преобразования, используемый для ортогонального преобразования в кодере 100 (этап St_13). Обратный преобразователь 206 затем выполняет обратное ортогональное преобразование с использованием определенного типа преобразования (этап St_14).
[0493] Фиг. 76 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством обратного преобразователя 206.
[0494] Например, обратный преобразователь 206 определяет то, меньше или равен либо нет размер преобразования предварительно определенному значению (этап Su_11). Здесь, при определении того, что размер преобразования меньше или равен предварительно определенному значению ("Да" на этапе Su_11), обратный преобразователь 206 получает, из энтропийного декодера 202, информацию, указывающую то, какой тип преобразования использован посредством кодера 100, по меньшей мере, из одного типа преобразования, включенного в первую группу типов преобразования (этап Su_12). Следует отметить, что эта информация декодируется посредством энтропийного декодера 202 и выводится в обратный преобразователь 206.
[0495] На основе информации, обратный преобразователь 206 определяет тип преобразования, используемый для ортогонального преобразования в кодере 100 (этап Su_13). Обратный преобразователь 206 затем выполняет обратное ортогональное преобразование для коэффициентов преобразования текущего блока с использованием определенного типа преобразования (этап Su_14). При определении того, что размер преобразования не меньше или равен предварительно определенному значению ("Нет" на этапе Su_11), обратный преобразователь 206 обратно преобразует коэффициенты преобразования текущего блока с использованием второй группы типов преобразования (этап Su_15).
[0496] Следует отметить, что обратное ортогональное преобразование посредством обратного преобразователя 206 может выполняться согласно последовательности операций, проиллюстрированной на фиг. 75 или фиг. 76 для каждой TU, в качестве одного примера. Помимо этого, обратное ортогональное преобразование может выполняться посредством использования предварительно заданного типа преобразования без декодирования информации, указывающей тип преобразования, используемый для ортогонального преобразования. Помимо этого, тип преобразования конкретно представляет собой DST7, DCT8 и т.п. При обратном ортогональном преобразовании, используется базисная функция обратного преобразования, соответствующая типу преобразования.
[0497] Сумматор
Сумматор 208 восстанавливает текущий блок посредством суммирования остатка прогнозирования, который представляет собой ввод из обратного преобразователя 206, и прогнозного изображения, которое представляет собой ввод из контроллера 220 прогнозирования. Другими словами, восстановленное изображение текущего блока формируется. Сумматор 208 затем выводит восстановленное изображение текущего блока в запоминающее устройство 210 блоков и контурный фильтр 212.
[0498] Запоминающее устройство блоков
Запоминающее устройство 210 блоков представляет собой устройство хранения данных для сохранения блока, который включается в текущий кадр, и упоминается при внутреннем прогнозировании. Более конкретно, запоминающее устройство 210 блоков сохраняет восстановленное изображение, выводимое из сумматора 208.
[0499] Контурный фильтр
Контурный фильтр 212 применяет контурный фильтр к восстановленному изображению, сформированному посредством сумматора 208, и выводит фильтрованное восстановленное изображение в запоминающее устройство 214 кинокадров и устройство отображения и т.д.
[0500] Когда информация, указывающая включение или выключение ALF, синтаксически проанализированная из потока, указывает то, что ALF включен, один фильтр из множества фильтров выбирается на основе направления и активности локальных градиентов, и выбранный фильтр применяется к восстановленному изображению.
[0501] Фиг. 77 является блок-схемой, иллюстрирующей один пример функциональной конфигурации контурного фильтра 212. Следует отметить, что контурный фильтр 212 имеет конфигурацию, аналогичную конфигурации контурного фильтра 120 кодера 100.
[0502] Например, как проиллюстрировано на фиг. 77, контурный фильтр 212 включает в себя модуль 212a выполнения фильтрации для удаления блочности, модуль 212b SAO-выполнения и модуль 212c ALF-выполнения. Модуль 212a выполнения фильтрации для удаления блочности выполняет процесс фильтрации для удаления блочности восстановленного изображения. Модуль 212b SAO-выполнения выполняет SAO-процесс восстановленного изображения после подвергания процессу фильтрации для удаления блочности. Модуль 212c ALF-выполнения выполняет ALF-процесс восстановленного изображения после подвергания SAO-процессу. Следует отметить, что контурный фильтр 212 не всегда должен включать в себя все составляющие элементы, раскрытые на фиг. 77, и может включать в себя только часть составляющих элементов. Помимо этого, контурный фильтр 212 может быть выполнен с возможностью выполнять вышеуказанные процессы в порядке обработки, отличающемся от порядка обработки, раскрытого на фиг. 77.
[0503] Запоминающее устройство кинокадров
Запоминающее устройство 214 кинокадров, например, представляет собой устройство хранения данных для сохранения опорных кадров для использования при взаимном прогнозировании, и также называется "буфером кинокадров". Более конкретно, запоминающее устройство 214 кинокадров сохраняет восстановленное изображение, фильтрованное посредством контурного фильтра 212.
[0504] Модуль прогнозирования (модуль внутреннего прогнозирования, модуль взаимного прогнозирования, контроллер прогнозирования)
Фиг. 78 является блок-схемой последовательности операций способа, иллюстрирующей один пример процесса, выполняемого посредством модуля прогнозирования декодера 200. Следует отметить, что модуль выполнения прогнозирования включает в себя все или часть следующих составляющих элементов: модуль 216 внутреннего прогнозирования; модуль 218 взаимного прогнозирования; и контроллер 220 прогнозирования. Модуль выполнения прогнозирования включает в себя, например, модуль 216 внутреннего прогнозирования и модуль 218 взаимного прогнозирования.
[0505] Модуль прогнозирования формирует прогнозное изображение текущего блока (этап Sq_1). Это прогнозное изображение также называется "прогнозным сигналом" или "блоком прогнозирования". Следует отметить, что прогнозный сигнал, например, представляет собой внутренний прогнозный сигнал или взаимный прогнозный сигнал. Более конкретно, модуль прогнозирования формирует прогнозное изображение текущего блока с использованием восстановленного изображения, которое уже получено для другого блока через формирование прогнозного изображения, восстановление остатка прогнозирования и суммирование прогнозного изображения. Модуль прогнозирования декодера 200 формирует прогнозное изображение, идентичное прогнозному изображению, сформированному посредством модуля прогнозирования кодера 100. Другими словами, прогнозные изображения формируются согласно способу, общему между модулями прогнозирования, или взаимно соответствующими способами.
[0506] Восстановленное изображение, например, может представлять собой изображение в опорном кадре или изображение декодированного блока (т.е. другого блока, описанного выше) в текущем кадре, который представляет собой кадр, включающий в себя текущий блок. Декодированный блок в текущем кадре, например, представляет собой соседний блок относительно текущего блока.
[0507] Фиг. 79 является блок-схемой последовательности операций способа, иллюстрирующей другой пример процесса, выполняемого посредством модуля прогнозирования декодера 200.
[0508] Модуль прогнозирования определяет способ или режим для формирования прогнозного изображения (этап Sr_1). Например, способ или режим может определяться, например, на основе параметра прогнозирования и т.д.
[0509] При определении первого способа в качестве режима для формирования прогнозного изображения, модуль прогнозирования формирует прогнозное изображение согласно первому способу (этап Sr_2a). При определении второго способа в качестве режима для формирования прогнозного изображения, модуль прогнозирования формирует прогнозное изображение согласно второму способу (этап Sr_2b). При определении третьего способа в качестве режима для формирования прогнозного изображения, модуль прогнозирования формирует прогнозное изображение согласно третьему способу (этап Sr_2c).
[0510] Первый способ, второй способ и третий способ могут представлять собой взаимно различные способы для формирования прогнозного изображения. Каждый из первого-третьего способов может представлять собой способ взаимного прогнозирования, способ внутреннего прогнозирования или другой способ прогнозирования. Вышеописанное восстановленное изображение может использоваться в этих способах прогнозирования.
[0511] Фиг. 80A и фиг. 80B иллюстрируют блок-схему последовательности операций способа, иллюстрирующую другой пример процесса, выполняемого посредством модуля прогнозирования декодера 200.
[0512] Модуль прогнозирования может выполнять процесс прогнозирования согласно потоку, проиллюстрированному на фиг. 80A и фиг. 80B в качестве одного примера. Следует отметить, что внутриблочное копирование, проиллюстрированное на фиг. 80A и 80B, представляет собой один режим, который принадлежит взаимному прогнозированию, и в котором блок, включенный в текущий кадр, называется "опорным изображением" или "опорным блоком". Другими словами, к кадру, отличающемуся от текущего кадра, не обращаются при внутриблочном копировании. Помимо этого, PCM-режим, проиллюстрированный на фиг. 80A, представляет собой один режим, который принадлежит внутреннему прогнозированию, и в котором преобразование и квантование не выполняются.
[0513] Модуль внутреннего прогнозирования
Модуль 216 внутреннего прогнозирования выполняет внутреннее прогнозирование посредством обращения к блоку в текущем кадре, сохраненном в запоминающем устройстве 210 блоков, на основе режима внутреннего прогнозирования, синтаксически проанализированного из потока, чтобы формировать прогнозное изображение текущего блока (т.е. внутреннего прогнозного изображения). Более конкретно, модуль 216 внутреннего прогнозирования выполняет внутреннее прогнозирование посредством обращения к пиксельным значениям (например, значениям сигнала яркости и/или сигнала цветности) блока или блоков, соседних с текущим блоком, чтобы формировать внутреннее прогнозное изображение, и затем выводит внутреннее прогнозное изображение в контроллер 220 прогнозирования.
[0514] Следует отметить, что, когда выбирается режим внутреннего прогнозирования, в котором обращаются к блоку сигналов яркости при внутреннем прогнозировании блока сигналов цветности, модуль 216 внутреннего прогнозирования может прогнозировать компонент сигнала цветности текущего блока на основе компонента сигнала яркости текущего блока.
[0515] Кроме того, когда информация, синтаксически проанализированная из потока, указывает то, что PDPC должна применяться, модуль 216 внутреннего прогнозирования корректирует внутренне прогнозированные пиксельные значения на основе горизонтальных/вертикальных опорных пиксельных градиентов.
[0516] Фиг. 81 является схемой, иллюстрирующей один пример процесса, выполняемого посредством модуля 216 внутреннего прогнозирования декодера 200.
[0517] Модуль 216 внутреннего прогнозирования сначала определяет то, присутствует или нет MPM-флаг, указывающий 1, в потоке (этап Sw_11). Здесь, при определении того, что MPM-флаг, указывающий 1, присутствует ("Да" на этапе Sw_11), модуль 216 внутреннего прогнозирования получает, из энтропийного декодера 202, информацию, указывающую режим внутреннего прогнозирования, выбранный в кодере 100, из MPM (этап Sw_12). Следует отметить, что эта информация декодируется посредством энтропийного декодера 202 и выводится в модуль 216 внутреннего прогнозирования. Затем, модуль 216 внутреннего прогнозирования определяет MPM (этап Sw_13). MPM включают в себя, например, шесть режимов внутреннего прогнозирования. Модуль 216 внутреннего прогнозирования затем определяет режим внутреннего прогнозирования, который включается во множество режимов внутреннего прогнозирования, включенных в MPM, и указывается посредством информации, полученной на этапе Sw_12 (этап Sw_14).
[0518] При определении того, что MPM-флаг, указывающий 1, не присутствует ("Нет" на этапе Sw_11), модуль 216 внутреннего прогнозирования получает информацию, указывающую режим внутреннего прогнозирования, выбранный в кодере 100 (этап Sw_15). Другими словами, модуль 216 внутреннего прогнозирования получает, из энтропийного декодера 202, информацию, указывающую режим внутреннего прогнозирования, выбранный в кодере 100 из числа, по меньшей мере, одного режима внутреннего прогнозирования, который не включается в MPM. Следует отметить, что эта информация декодируется посредством энтропийного декодера 202 и выводится в модуль 216 внутреннего прогнозирования. Модуль 216 внутреннего прогнозирования затем определяет режим внутреннего прогнозирования, который не включается во множество режимов внутреннего прогнозирования, включенных в MPM, и указывается посредством информации, полученной на этапе Sw_15 (этап Sw_17).
[0519] Модуль 216 внутреннего прогнозирования формирует прогнозное изображение согласно режиму внутреннего прогнозирования, определенному на этапе Sw_14 или на этапе Sw_17 (этап Sw_18).
[0520] Модуль взаимного прогнозирования
Модуль 218 взаимного прогнозирования прогнозирует текущий блок посредством обращения к опорному кадру, сохраненному в запоминающем устройстве 214 кинокадров. Прогнозирование выполняется в единицах текущего блока или текущего субблока в текущем блоке. Следует отметить, что субблок включается в блок и представляет собой единицу, меньшую блока. Размер субблока может составлять 4×4 пикселов, 8×8 пикселов или другой размер. Размер субблока может переключаться для единицы, такой как срез, кирпич, кадр и т.д.
[0521] Например, модуль 218 взаимного прогнозирования формирует взаимный прогнозный сигнал текущего блока или субблока посредством выполнения компенсации движения посредством использования информации движения (например, вектора движения), синтаксически проанализированной из кодированного потока битов (например, параметра прогнозирования, выводимого из энтропийного декодера 202), и выводит взаимный прогнозный сигнал в контроллер 220 прогнозирования.
[0522] Когда информация, синтаксически проанализированная из потока, указывает то, что OBMC-режим должен применяться, модуль 218 взаимного прогнозирования формирует взаимное прогнозное изображение с использованием информации движения соседнего блока в дополнение к информации движения текущего блока, полученной через оценку движения.
[0523] Кроме того, когда информация, синтаксически проанализированная из потока, указывает то, что FRUC-режим должен применяться, модуль 218 взаимного прогнозирования извлекает информацию движения посредством выполнения оценки движения в соответствии со способом сопоставления с шаблоном (билатеральным сопоставлением или сопоставлением с эталоном), синтаксически проанализированным из потока. Модуль 218 взаимного прогнозирования затем выполняет компенсацию движения (прогнозирование) с использованием извлеченной информации движения.
[0524] Кроме того, когда BIO-режим должен применяться, модуль 218 взаимного прогнозирования извлекает MV на основе модели при условии равномерного прямолинейного движения. Помимо этого, когда информация, синтаксически проанализированная из потока, указывает то, что аффинный режим должен применяться, модуль 218 взаимного прогнозирования извлекает MV для каждого субблока, на основе MV множества соседних блоков.
[0525] Последовательность операций для MV-извлечения
Фиг. 82 является блок-схемой последовательности операций способа, иллюстрирующей один пример MV-извлечения в декодере 200.
[0526] Модуль 218 взаимного прогнозирования определяет, например, то, следует или нет декодировать информацию движения (например, MV). Например, модуль 218 взаимного прогнозирования может выполнять определение согласно режиму прогнозирования, включенному в поток, или может выполнять определение на основе другой информации, включенной в поток. Здесь, при определении необходимости декодировать информацию движения, модуль 218 взаимного прогнозирования извлекает MV для текущего блока в режиме, в котором информация движения декодируется. При определении необходимости не декодировать информацию движения, модуль 218 взаимного прогнозирования извлекает MV в режиме, в котором информация движения не декодируется.
[0527] Здесь, режимы MV-извлечения могут включать в себя нормальный взаимный режим, режим нормального объединения, FRUC-режим, аффинный режим и т.д., которые описываются ниже. Режимы, в которых информация движения декодируется, из числа режимов, включают в себя нормальный взаимный режим, режим нормального объединения, аффинный режим (в частности, аффинный взаимный режим и аффинный режим объединения) и т.д. Следует отметить, что информация движения может включать в себя не только MV, но также и информацию выбора MV-предикторов, которая описывается ниже. Режимы, в которых информация движения не декодируется, включают в себя FRUC-режим и т.д. Модуль 218 взаимного прогнозирования выбирает режим для извлечения MV для текущего блока из множества режимов и извлекает MV для текущего блока с использованием выбранного режима.
[0528] Фиг. 83 является блок-схемой последовательности операций способа, иллюстрирующей другой пример MV-извлечения в декодере 200.
[0529] Например, модуль 218 взаимного прогнозирования может определять то, следует или нет декодировать MV-разность, т.е., например, может выполнять определение согласно режиму прогнозирования, включенному в поток, или может выполнять определение на основе другой информации, включенной в поток. Здесь, при определении необходимости декодировать MV-разность, модуль 218 взаимного прогнозирования может извлекать MV для текущего блока в режиме, в котором MV-разность декодируется. В этом случае, например, MV-разность, включенная в поток, декодируется в качестве параметра прогнозирования.
[0530] При определении необходимости вообще не декодировать MV-разность, модуль 218 взаимного прогнозирования извлекает MV в режиме, в котором MV-разность не декодируется. В этом случае, кодированная MV-разность не включается в поток.
[0531] Здесь, как описано выше, режимы MV-извлечения включают в себя нормальный взаимный режим, режим нормального объединения, FRUC-режим, аффинный режим и т.д., которые описываются ниже. Режимы, в которых MV-разность кодируется, из числа режимов включают в себя нормальный взаимный режим и аффинный режим (в частности, аффинный взаимный режим) и т.д. Режимы, в которых MV-разность не кодируется, включают в себя FRUC-режим, режим нормального объединения, аффинный режим (в частности, аффинный режим объединения) и т.д. Модуль 218 взаимного прогнозирования выбирает режим для извлечения MV для текущего блока из множества режимов и извлекает MV для текущего блока с использованием выбранного режима.
[0532] MV-извлечение > нормальный взаимный режим
Например, когда информация, синтаксически проанализированная из потока, указывает то, что нормальный взаимный режим должен применяться, модуль 218 взаимного прогнозирования извлекает MV на основе информации, синтаксически проанализированной из потока, и выполняет компенсацию (прогнозирование) движения с использованием MV.
[0533] Фиг. 84 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством нормального взаимного режима в декодере 200.
[0534] Модуль 218 взаимного прогнозирования декодера 200 выполняет компенсацию движения для каждого блока. В это время, сначала, модуль 218 взаимного прогнозирования получает множество возможных MV-вариантов для текущего блока на основе такой информации, как MV множества декодированных блоков, временно или пространственно окружающих текущий блок (этап Sg_11). Другими словами, модуль 218 взаимного прогнозирования формирует список возможных MV-вариантов.
[0535] Затем, модуль 218 взаимного прогнозирования извлекает N (целое число в 2 или более) возможных MV-вариантов из множества возможных MV-вариантов, полученных на этапе Sg_11, в качестве возможных вариантов предикторов векторов движения (также называются "возможными вариантами MV-предикторов") согласно предварительно определенным рангам в порядке приоритетов (этап Sg_12). Следует отметить, что ранги в порядке приоритетов определяются заранее для соответствующих N возможных вариантов MV-предикторов.
[0536] Затем, модуль 218 взаимного прогнозирования декодирует информацию выбора MV-предикторов из входного потока и выбирает один возможный вариант MV-предиктора из N возможных вариантов MV-предикторов в качестве MV-предиктора для текущего блока с использованием декодированной информации выбора MV-предикторов (этап Sg_13).
[0537] Затем, модуль 218 взаимного прогнозирования декодирует MV-разность из входного потока и извлекает MV для текущего блока посредством суммирования значения разности, которое представляет собой декодированную MV-разность, и выбранного MV-предиктора (этап Sg_14).
[0538] В завершение, модуль 218 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием извлеченного MV и декодированного опорного кадра (этап Sg_15). Процессы на этапах Sg_11-Sg_15 выполняются для каждого блока. Например, когда процессы на этапах Sg_11-Sg_15 выполняются для каждого из всех блоков в срезе, взаимное прогнозирование среза с использованием нормального взаимного режима заканчивается. Например, когда процессы на этапах Sg_11-Sg_15 выполняются для каждого из всех блоков в кадре, взаимное прогнозирование кадра с использованием нормального взаимного режима заканчивается. Следует отметить, что не все блоки, включенные в срез, могут подвергаться процессам на этапах Sg_11-Sg_15, и взаимное прогнозирование среза с использованием нормального взаимного режима может заканчиваться, когда часть блоков подвергается процессам. Аналогично, взаимное прогнозирование кадра с использованием нормального взаимного режима может заканчиваться, когда процессы на этапах Sg_11-Sg_15 выполняются для части блоков в кадре.
[0539] MV-извлечение > режим нормального объединения
Например, когда информация, синтаксически проанализированная из потока, указывает то, что режим нормального объединения должен применяться, модуль 218 взаимного прогнозирования извлекает MV и выполняет компенсацию (прогнозирование) движения с использованием MV.
[0540] Фиг. 85 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством режима нормального объединения в декодере 200.
[0541] В это время, сначала, модуль 218 взаимного прогнозирования получает множество возможных MV-вариантов для текущего блока на основе такой информации, как MV множества декодированных блоков, временно или пространственно окружающих текущий блок (этап Sh_11). Другими словами, модуль 218 взаимного прогнозирования формирует список возможных MV-вариантов.
[0542] Затем, модуль 218 взаимного прогнозирования выбирает один возможный MV-вариант из множества возможных MV-вариантов, полученных на этапе Sh_11, за счет этого извлекая MV текущего блока (этап Sh_12). Более конкретно, модуль 218 взаимного прогнозирования получает информацию MV-выбора, включенную в качестве параметра прогнозирования в поток, и выбирает возможный MV-вариант, идентифицированный посредством информации MV-выбора в качестве MV для текущего блока.
[0543] В завершение, модуль 218 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием извлеченного MV и декодированного опорного кадра (этап Sh_13). Процессы на этапах Sh_11-Sh_13 выполняются, например, для каждого блока. Например, когда процессы на этапах Sh_11-Sh_13 выполняются для каждого из всех блоков в срезе, взаимное прогнозирование среза с использованием режима нормального объединения заканчивается. Помимо этого, когда процессы на этапах Sh_11-Sh_13 выполняются для каждого из всех блоков в кадре, взаимное прогнозирование кадра с использованием режима нормального объединения заканчивается. Следует отметить, что не все блоки, включенные в срез, подвергаются процессам на этапах Sh_11-Sh_13, и взаимное прогнозирование среза с использованием режима нормального объединения может заканчиваться, когда часть блоков подвергается процессам. Аналогично, взаимное прогнозирование кадра с использованием режима нормального объединения может заканчиваться, когда процессы на этапах Sh_11-Sh_13 выполняются для части блоков в кадре.
[0544] MV-извлечение > FRUC-режим
Например, когда информация, синтаксически проанализированная из потока, указывает то, что FRUC-режим должен применяться, модуль 218 взаимного прогнозирования извлекает MV в FRUC-режиме и выполняет компенсацию (прогнозирование) движения с использованием MV. В этом случае, информация движения извлекается на стороне декодера 200 без передачи в служебных сигналах из стороны кодера 100. Например, декодер 200 может извлекать информацию движения посредством выполнения оценки движения. В этом случае, декодер 200 выполняет оценку движения вообще без использования пиксельных значений в текущем блоке.
[0545] Фиг. 86 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством FRUC-режима в декодере 200.
[0546] Во-первых, модуль 218 взаимного прогнозирования формирует список, указывающий MV декодированных блоков, пространственно или временно соседних с текущим блоком, посредством обращения к MV в качестве возможных MV-вариантов (список представляет собой список возможных MV-вариантов и может использоваться также в качестве списка возможных MV-вариантов для режима нормального объединения (этап Si_11). Затем, наилучший возможный MV-вариант выбирается из множества возможных MV-вариантов, зарегистрированных в списке возможных MV-вариантов (этап Si_12). Например, модуль 218 взаимного прогнозирования вычисляет значение оценки каждого возможного MV-варианта, включенного в список возможных MV-вариантов, и выбирает один из возможных MV-вариантов в качестве наилучшего возможного MV-варианта на основе значений оценки. На основе выбранного наилучшего возможного MV-варианта, модуль 218 взаимного прогнозирования затем извлекает MV для текущего блока (этап Si_14). Более конкретно, например, выбранный наилучший возможный MV-вариант непосредственно извлекается в качестве MV для текущего блока. Помимо этого, например, MV для текущего блока может извлекаться с использованием сопоставления с шаблоном в окружающей области позиции, которая включается в опорный кадр и соответствует выбранному наилучшему возможному MV-варианту. Другими словами, оценка с использованием сопоставления с шаблоном в опорном кадре и значений оценки может выполняться в окружающей области наилучшего возможного MV-варианта, и когда имеется MV, который дает в результате лучшее значение оценки, наилучший возможный MV-вариант может обновляться на MV, который дает в результате лучшее значение оценки, и обновленный MV может определяться в качестве конечного MV для текущего блока. Обновление на MV, который дает в результате лучшее значение оценки, может не выполняться.
[0547] В завершение, модуль 218 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения компенсации движения текущего блока с использованием извлеченного MV и декодированного опорного кадра (этап Si_15). Процессы на этапах Si_11-Si_15 выполняются, например, для каждого блока. Например, когда процессы на этапах Si_11-Si_15 выполняются для каждого из всех блоков в срезе, взаимное прогнозирование среза с использованием FRUC-режима заканчивается. Например, когда процессы на этапах Si_11-Si_15 выполняются для каждого из всех блоков в кадре, взаимное прогнозирование кадра с использованием FRUC-режима заканчивается. Каждый субблок может обрабатываться аналогично вышеописанному случаю обработки каждого блока.
[0548] MV-извлечение > аффинный режим объединения
Например, когда информация, синтаксически проанализированная из потока, указывает то, что аффинный режим объединения должен применяться, модуль 218 взаимного прогнозирования извлекает MV в аффинном режиме объединения и выполняет компенсацию (прогнозирование) движения с использованием MV.
[0549] Фиг. 87 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством аффинного режима объединения в декодере 200.
[0550] В аффинном режиме объединения, во-первых, модуль 218 взаимного прогнозирования извлекает MV в соответствующих управляющих точках для текущего блока (этап Sk_11). Управляющие точки представляют собой верхнюю левую угловую точку текущего блока и верхнюю правую угловую точку текущего блока, как проиллюстрировано на фиг. 46A, либо верхнюю левую угловую точку текущего блока, верхнюю правую угловую точку текущего блока и нижнюю левую угловую точку текущего блока, как проиллюстрировано на фиг. 46B.
[0551] Например, когда способы MV-извлечения, проиллюстрированные на фиг. 47A-47C, используются, как проиллюстрировано на фиг. 47A, модуль 218 взаимного прогнозирования проверяет декодированный блок A (левый), блок B (верхний), блок C (верхний правый), блок D (нижний левый) и блок E (верхний левый) в этом порядке и идентифицирует первый эффективный блок, декодированный согласно аффинному режиму.
[0552] Модуль 218 взаимного прогнозирования извлекает MV в управляющей точке с использованием идентифицированного первого эффективного блока, декодированного согласно аффинному режиму. Например, когда блок A идентифицируется, и блок A имеет две управляющих точки, как проиллюстрировано на фиг. 47B, модуль 218 взаимного прогнозирования вычисляет вектор v0 движения в верхней левой угловой управляющей точке текущего блока и вектор v1 движения в верхней правой угловой управляющей точке текущего блока посредством проецирования векторов v3 и v4 движения в верхнем левом углу и правом верхнем углу декодированного блока, включающего в себя блок A, на текущий блок. Таким образом, MV в каждой управляющей точке извлекается.
[0553] Следует отметить, что, как проиллюстрировано на фиг. 49A, MV в трех управляющих точках могут вычисляться, когда блок A идентифицируется, и блок A имеет две управляющих точки, и что, как проиллюстрировано на фиг. 49B, MV в двух управляющих точках могут вычисляться, когда блок A идентифицируется, и когда блок A имеет три управляющих точки.
[0554] Помимо этого, когда информация MV-выбора включается в качестве параметра прогнозирования в потоке, модуль 218 взаимного прогнозирования может извлекать MV в каждой управляющей точке для текущего блока с использованием информации MV-выбора.
[0555] Затем, модуль 218 взаимного прогнозирования выполняет компенсацию движения каждого из множества субблоков, включенных в текущий блок. Другими словами, модуль 218 взаимного прогнозирования вычисляет MV для каждого из множества субблоков в качестве аффинного MV, с использованием либо двух векторов v0 и v1 движения и вышеуказанного выражения (1A), либо трех векторов v0, v1 и v2 движения и вышеуказанного выражения (1B) (этап Sk_12). Модуль 218 взаимного прогнозирования затем выполняет компенсацию движения субблоков с использованием этих аффинных MV и декодированных опорных кадров (этап Sk_13). Когда процессы на этапах Sk_12 и Sk_13 выполняются для каждого из всех субблоков, включенных в текущий блок, взаимное прогнозирование с использованием аффинного режима объединения для текущего блока завершается. Другими словами, компенсация движения текущего блока выполняется для того, чтобы формировать прогнозное изображение текущего блока.
[0556] Следует отметить, что вышеописанный список возможных MV-вариантов может формироваться на этапе Sk_11. Список возможных MV-вариантов, например, может представлять собой список, включающий в себя возможные MV-варианты, извлекаемые с использованием множества способов MV-извлечения для каждой управляющей точки. Множество способов MV-извлечения могут представлять собой любую комбинацию способов MV-извлечения, проиллюстрированных на фиг. 47A-47C, способов MV-извлечения, проиллюстрированных на фиг. 48A и 48B, способов MV-извлечения, проиллюстрированных на фиг. 49A и 49B, и других способов MV-извлечения.
[0557] Следует отметить, что список возможных MV-вариантов может включать в себя возможные MV-варианты в режиме, в котором прогнозирование выполняется в единицах субблоков, отличном от аффинного режима.
[0558] Следует отметить, что, например, список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном режиме объединения, в котором используются две управляющих точки, и в аффинном режиме объединения, в котором используются три управляющих точки, может формироваться в качестве списка возможных MV-вариантов. Альтернативно, список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном режиме объединения, в котором используются две управляющих точки, и список возможных MV-вариантов, включающий в себя возможные MV-варианты в аффинном режиме объединения, в котором используются три управляющих точки, могут формироваться отдельно. Альтернативно, список возможных MV-вариантов, включающий в себя возможные MV-варианты в одном из аффинного режима объединения, в котором используются две управляющих точки, и аффинного режима объединения, в котором используются три управляющих точки, может формироваться.
[0559] MV-извлечение > аффинный взаимный режим
Например, когда информация, синтаксически проанализированная из потока, указывает то, что аффинный взаимный режим должен применяться, модуль 218 взаимного прогнозирования извлекает MV в аффинном взаимном режиме и выполняет компенсацию (прогнозирование) движения с использованием MV.
[0560] Фиг. 88 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством аффинного взаимного режима в декодере 200.
[0561] В аффинном взаимном режиме, сначала, модуль 218 взаимного прогнозирования извлекает MV-предикторы (v0, v1) или (v0, v1, v2) соответствующих двух или трех управляющих точек текущего блока (этап Sj_11). Управляющие точки представляют собой верхнюю левую угловую точку текущего блока, верхнюю правую угловую точку текущего блока и нижнюю левую угловую точку текущего блока, как проиллюстрировано на фиг. 46A или фиг. 46B.
[0562] Модуль 218 взаимного прогнозирования получает информацию выбора MV-предикторов, включенную в качестве параметра прогнозирования в поток, и извлекает MV-предиктор в каждой управляющей точке для текущего блока с использованием MV, идентифицированного посредством информации выбора MV-предикторов. Например, когда способы MV-извлечения, проиллюстрированные на фиг. 48A и 48B, используются, модуль 218 взаимного прогнозирования извлекает предикторы (v0, v1) или (v0, v1, v2) векторов движения в управляющих точках для текущего блока посредством выбора MV блока, идентифицированного посредством информации выбора MV-предикторов, из декодированных блоков около соответствующих управляющих точек для текущего блока, проиллюстрированного на фиг. 48A либо на фиг. 48B.
[0563] Затем, модуль 218 взаимного прогнозирования получает каждую MV-разность, включенную в качестве параметра прогнозирования в поток, и суммирует MV-предиктор в каждой управляющей точке для текущего блока и MV-разность, соответствующую MV-предиктору (этап Sj_12). Таким образом, MV в каждой управляющей точке для текущего блока извлекается.
[0564] Затем, модуль 218 взаимного прогнозирования выполняет компенсацию движения каждого из множества субблоков, включенных в текущий блок. Другими словами, модуль 218 взаимного прогнозирования вычисляет MV для каждого из множества субблоков в качестве аффинного MV с использованием либо двух векторов v0 и v1 движения и вышеуказанного выражения (1A), либо трех векторов v0, v1 и v2 движения и вышеуказанного выражения (1B) (этап Sj_13). Модуль 218 взаимного прогнозирования затем выполняет компенсацию движения субблоков с использованием этих аффинных MV и декодированных опорных кадров (этап Sj_14). Когда процессы на этапах Sj_13 и Sj_14 выполняются для каждого из всех субблоков, включенных в текущий блок, взаимное прогнозирование с использованием аффинного режима объединения для текущего блока завершается. Другими словами, компенсация движения текущего блока выполняется для того, чтобы формировать прогнозное изображение текущего блока.
[0565] Следует отметить, что вышеописанный список возможных MV-вариантов может формироваться на этапе Sj_11, аналогично этапу Sk_11.
[0566] MV-извлечение > треугольный режим
Например, когда информация, синтаксически проанализированная из потока, указывает то, что треугольный режим должен применяться, модуль 218 взаимного прогнозирования извлекает MV в треугольном режиме и выполняет компенсацию (прогнозирование) движения с использованием MV.
[0567] Фиг. 89 является блок-схемой последовательности операций способа, иллюстрирующей пример взаимного прогнозирования посредством треугольного режима в декодере 200.
[0568] В треугольном режиме, во-первых, модуль 218 взаимного прогнозирования разбивает текущий блок на первый сегмент и второй сегмент (этап Sx_11). В это время, модуль 218 взаимного прогнозирования может получать, из потока, информацию сегментов, которая представляет собой информацию, связанную с разбиением, в качестве параметра прогнозирования. Модуль 218 взаимного прогнозирования затем может разбивать текущий блок на первый сегмент и второй сегмент согласно информации сегментов.
[0569] Затем, сначала, модуль 218 взаимного прогнозирования получает множество возможных MV-вариантов для текущего блока на основе такой информации, как MV множества декодированных блоков, временно или пространственно окружающих текущий блок (этап Sx_12). Другими словами, модуль 218 взаимного прогнозирования формирует список возможных MV-вариантов.
[0570] Модуль 218 взаимного прогнозирования затем выбирает возможный MV-вариант для первого сегмента и возможный MV-вариант для второго сегмента в качестве первого MV и второго MV, соответственно, из множества возможных MV-вариантов, полученных на этапе Sx_11 (этап Sx_13). В это время, модуль 218 взаимного прогнозирования может получать, из потока, информацию MV-выбора для идентификации выбранного возможного MV-варианта, в качестве параметра прогнозирования. Модуль 218 взаимного прогнозирования затем может выбирать первый MV и второй MV согласно информации MV-выбора.
[0571] Затем, модуль 218 взаимного прогнозирования формирует первое прогнозное изображение посредством выполнения компенсации движения с использованием выбранного первого MV и декодированного опорного кадра (этап Sx_14). Аналогично, модуль 218 взаимного прогнозирования формирует второе прогнозное изображение посредством выполнения компенсации движения с использованием выбранного второго MV и декодированного опорного кадра (этап Sx_15).
[0572] В завершение, модуль 218 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения суммирования со взвешиванием первого прогнозного изображения и второго прогнозного изображения (этап Sx_16).
[0573] Оценка движения > DMVR
Например, информация, синтаксически проанализированная из потока, указывает то, что DMVR должна применяться, модуль 218 взаимного прогнозирования выполняет оценку движения с использованием DMVR.
[0574] Фиг. 90 является блок-схемой последовательности операций способа, иллюстрирующей пример оценки движения посредством DMVR в декодере 200.
[0575] Модуль 218 взаимного прогнозирования извлекает MV для текущего блока согласно режиму объединения (этап Sl_11). Затем, модуль 218 взаимного прогнозирования извлекает конечный MV для текущего блока посредством выполнения поиска в области, окружающей опорный кадр, указываемый посредством MV, извлекаемого на Sl_11 (этап Sl_12). Другими словами, MV текущего блока определяется согласно DMVR.
[0576] Фиг. 91 является блок-схемой последовательности операций способа, иллюстрирующей конкретный пример оценки движения посредством DMVR в декодере 200.
[0577] Во-первых, на этапе 1, проиллюстрированном на фиг. 58A, модуль 218 взаимного прогнозирования вычисляет затраты между позицией поиска (также называется "начальной точкой"), указываемой посредством начального MV, и восемью окружающими позициями поиска. Модуль 218 взаимного прогнозирования затем определяет то, являются или нет затраты в каждой из позиций поиска, отличных от начальной точки, наименьшими. Здесь, при определении того, что затраты в одной из позиций поиска, отличных от начальной точки, являются наименьшими, модуль 218 взаимного прогнозирования изменяет цель на позицию поиска, в которой получаются наименьшие затраты, и выполняет процесс на этапе 2, проиллюстрированном на фиг. 58A. Когда затраты в начальной точке являются наименьшими, модуль 218 взаимного прогнозирования пропускает процесс на этапе 2, проиллюстрированном на фиг. 58A, и выполняет процесс на этапе 3.
[0578] На этапе 2, проиллюстрированном на фиг. 58A, модуль 218 взаимного прогнозирования выполняет поиск, аналогичный процессу на этапе 1, относительно позиции поиска после того, как цель изменяется, в качестве новой начальной точки согласно результату процесса на этапе 1. Модуль 218 взаимного прогнозирования затем определяет то, являются или нет затраты в каждой из позиций поиска, отличных от начальной точки, наименьшими. Здесь, при определении того, что затраты в одной из позиций поиска, отличных от начальной точки, являются наименьшими, модуль 218 взаимного прогнозирования выполняет процесс на этапе 4. Когда затраты в начальной точке являются наименьшими, модуль 218 взаимного прогнозирования выполняет процесс на этапе 3.
[0579] На этапе 4, модуль 218 взаимного прогнозирования рассматривает позицию поиска в начальной точке в качестве конечной позиции поиска и определяет разность между позицией, указываемой посредством начального MV, и конечной позицией поиска в качестве векторной разности.
[0580] На этапе 3, проиллюстрированном на фиг. 58A, модуль 218 взаимного прогнозирования определяет пиксельную позицию с субпиксельной точностью, при которой наименьшие затраты получаются, на основе затрат в четырех точках, расположенных в верхней, нижней, левой и правой позициях относительно начальной точки на этапе 1 или на этапе 2, и рассматривает пиксельную позицию в качестве конечной позиции поиска. Пиксельная позиция с субпиксельной точностью определяется посредством выполнения суммирования со взвешиванием каждого из четырех верхнего, нижнего, левого и правого векторов ((0, 1), (0,-1), (-1, 0) и (1, 0)), с использованием, в качестве весового коэффициента, затрат в соответствующих одной из четырех позиций поиска. Модуль 218 взаимного прогнозирования затем определяет разность между позицией, указываемой посредством начального MV, и конечной позицией поиска в качестве векторной разности.
[0581] Компенсация движения > BIO/OBMC/LIC
Например, когда информация, синтаксически проанализированная из потока, указывает то, что коррекция прогнозного изображения должна выполняться при формировании прогнозного изображения, модуль 218 взаимного прогнозирования корректирует прогнозное изображение на основе режима для коррекции. Режим, например, представляет собой одно из BIO, OBMC и LIC, описанных выше.
[0582] Фиг. 92 является блок-схемой последовательности операций способа, иллюстрирующей один пример формирования прогнозного изображения в декодере 200.
[0583] Модуль 218 взаимного прогнозирования формирует прогнозное изображение (этап Sm_11) и корректирует прогнозное изображение согласно любому из режимов, описанных выше (этап Sm_12).
[0584] Фиг. 93 является блок-схемой последовательности операций способа, иллюстрирующей другой пример формирования прогнозного изображения в декодере 200.
[0585] Модуль 218 взаимного прогнозирования извлекает MV для текущего блока (этап Sn_11). Затем, модуль 218 взаимного прогнозирования формирует прогнозное изображение с использованием MV (этап Sn_12) и определяет то, следует или нет выполнять процесс коррекции (этап Sn_13). Например, модуль 218 взаимного прогнозирования получает параметр прогнозирования, включенный в поток, и определяет то, следует или нет выполнять процесс коррекции, на основе параметра прогнозирования. Этот параметр прогнозирования, например, представляет собой флаг, указывающий то, должен либо нет применяться каждый из вышеописанных режимов. Здесь, при определении необходимости выполнять процесс коррекции ("Да" на этапе Sn_13), модуль 218 взаимного прогнозирования формирует конечное прогнозное изображение посредством коррекции прогнозного изображения (этап Sn_14). Следует отметить, что, в LIC, яркость и цветность прогнозного изображения может корректироваться на этапе Sn_14. При определении необходимости не выполнять процесс коррекции ("Нет" на этапе Sn_13), модуль 218 взаимного прогнозирования выводит конечное прогнозное изображение без коррекции прогнозного изображения (этап Sn_15).
[0586] Компенсация движения > OBMC
Например, когда информация, синтаксически проанализированная из потока, указывает то, что OBMC должна выполняться при формировании прогнозного изображения, модуль 218 взаимного прогнозирования корректирует прогнозное изображение согласно OBMC.
[0587] Фиг. 94 является блок-схемой последовательности операций способа, иллюстрирующей пример коррекции прогнозного изображения посредством OBMC в декодере 200. Следует отметить, что блок-схема последовательности операций способа на фиг. 94 указывает поток коррекции прогнозного изображения с использованием текущего кадра и опорного кадра, проиллюстрированного на фиг. 62.
[0588] Во-первых, как проиллюстрировано на фиг. 62, модуль 218 взаимного прогнозирования получает прогнозное изображение (Pred) посредством нормальной компенсации движения с использованием MV, назначенного текущему блоку.
[0589] Затем, прогнозное изображение (Pred_L) получается посредством применения вектора (MV_L) движения, который уже извлечен для кодированного блока, соседнего слева от текущего блока, к текущему блоку (многократного использования вектора движения для текущего блока). Модуль 218 взаимного прогнозирования затем выполняет первую коррекцию прогнозного изображения посредством перекрытия двух прогнозных изображений Pred и Pred_L. Это предоставляет преимущество смешивания границы между соседними блоками.
[0590] Аналогично, модуль 218 взаимного прогнозирования получает прогнозное изображение (Pred_U) посредством применения MV (MV_U), который уже извлечен для декодированного блока, граничащего выше текущего блока с текущим блоком (многократного использования вектора движения для текущего блока). Модуль 218 взаимного прогнозирования затем выполняет вторую коррекцию прогнозного изображения посредством перекрытия прогнозного изображения Pred_U с прогнозными изображениями (например, Pred и Pred_L), для которых выполнена первая коррекция. Это предоставляет преимущество смешивания границы между соседними блоками. Прогнозное изображение, полученное посредством второй коррекции, представляет собой прогнозное изображение, в котором граница между соседними блоками смешивается (сглаживается), и в силу этого представляет собой конечное прогнозное изображение текущего блока.
[0591] Компенсация движения > BIO
Например, когда информация, синтаксически проанализированная из потока, указывает то, что BIO должен выполняться при формировании прогнозного изображения, модуль 218 взаимного прогнозирования корректирует прогнозное изображение согласно BIO.
[0592] Фиг. 95 является блок-схемой последовательности операций способа, иллюстрирующей пример коррекции прогнозного изображения посредством BIO в декодере 200.
[0593] Как проиллюстрировано на фиг. 63, модуль 218 взаимного прогнозирования извлекает два вектора (M0, M1) движения, с использованием двух опорных кадров (Ref0, Ref1), отличающихся от кадра (Cur Pic), включающего в себя текущий блок. Модуль 218 взаимного прогнозирования затем извлекает прогнозное изображение для текущего блока с использованием двух векторов (M0, M1) движения (этап Sy_11). Следует отметить, что вектор M0 движения представляет собой вектор (MVx0, MVy0) движения, соответствующий опорному кадру Ref0, и вектор M1 движения представляет собой вектор (MVx1, MVy1) движения, соответствующий опорному кадру Ref1.
[0594] Затем, модуль 218 взаимного прогнозирования извлекает интерполированное изображение I0 для текущего блока с использованием вектора M0 движения и опорного кадра L0. Помимо этого, модуль 218 взаимного прогнозирования извлекает интерполированное изображение I1 для текущего блока с использованием вектора M1 движения и опорного кадра L1 (этап Sy_12). Здесь, интерполированное изображение I0 представляет собой изображение, включенное в опорный кадр Ref0, и которое должно извлекаться для текущего блока, и интерполированное изображение I1 представляет собой изображение, включенное в опорный кадр Ref1, и которое должно извлекаться для текущего блока. Каждое из интерполированного изображения I0 и интерполированного изображения I1 может иметь размер, идентичный размеру текущего блока. Альтернативно, каждое из интерполированного изображения I0 и интерполированного изображения I1 может представлять собой изображение, большее текущего блока. Кроме того, интерполированное изображение I0 и интерполированное изображение I1 могут включать в себя прогнозное изображение, полученное посредством использования векторов (M0, M1) движения и опорных кадров (L0, L1) и применения фильтра для компенсации движения.
[0595] Помимо этого, модуль 218 взаимного прогнозирования извлекает градиентные изображения (Ix0, Ix1, Iy0, Iy1) текущего блока, из интерполированного изображения I0 и интерполированного изображения I1 (этап Sy_13). Следует отметить, что градиентные изображения в горизонтальном направлении представляют собой (Ix0, Ix1), и градиентные изображения в вертикальном направлении представляют собой (Iy0, Iy1). Модуль 218 взаимного прогнозирования может извлекать градиентные изображения, например, посредством применяя градиентный фильтр к интерполированным изображениям. Градиентные изображения могут представлять собой градиентные изображения, каждое из которых указывает величину пространственного изменения пиксельного значения вдоль горизонтального направления или величину пространственного изменения пиксельного значения вдоль вертикального направления.
[0596] Затем, модуль 218 взаимного прогнозирования извлекает, для каждого субблока текущего блока, оптический поток (vx, vy), который представляет собой вектор скорости, с использованием интерполированных изображений (I0, I1) и градиентных изображений (Ix0, Ix1, Iy0, Iy1). В качестве одного примера, субблок может представлять собой 4×4-пиксельную суб-CU.
[0597] Затем, модуль 218 взаимного прогнозирования корректирует прогнозное изображение для текущего блока с использованием оптического потока (vx, vy). Например, модуль 218 взаимного прогнозирования извлекает значение коррекции для значения пиксела, включенного в текущий блок, с использованием оптического потока (vx, vy) (этап Sy_15). Модуль 218 взаимного прогнозирования затем может корректировать прогнозное изображение для текущего блока с использованием значения коррекции (этап Sy_16). Следует отметить, что значение коррекции может извлекаться в единицах пиксела либо может извлекаться в единицах множества пикселов или в единицах субблоков.
[0598] Следует отметить, что поток BIO-процесса не ограничен процессом, раскрытым на фиг. 95. Только часть процессов, раскрытая на фиг. 95, может выполняться, либо другой процесс может добавляться или использоваться в качестве замены, либо процессы могут выполняться в другом порядке обработки.
[0599] Компенсация движения > LIC
Например, когда информация, синтаксически проанализированная из потока, указывает то, что LIC должна выполняться при формировании прогнозного изображения, модуль 218 взаимного прогнозирования корректирует прогнозное изображение согласно LIC.
[0600] Фиг. 96 является блок-схемой последовательности операций способа, иллюстрирующей пример коррекции прогнозного изображения посредством LIC в декодере 200.
[0601] Во-первых, модуль 218 взаимного прогнозирования получает опорное изображение, соответствующее текущему блоку из декодированного опорного кадра с использованием MV (этап Sz_11).
[0602] Затем, модуль 218 взаимного прогнозирования извлекает, для текущего блока, информацию, указывающую то, как значение сигнала яркости изменено между текущим кадром и опорным кадром (этап Sz_12). Это извлечение выполняется на основе пиксельных значений сигнала яркости для декодированной левой соседней опорной области (окружающей опорной области) и декодированной верхней соседней опорной области (окружающей опорной области) и пиксельных значений сигнала яркости в соответствующих позициях в опорном кадре, указываемых посредством извлеченных MV. Модуль 218 взаимного прогнозирования вычисляет параметр коррекции яркости, с использованием информации, указывающей то, как значение сигнала яркости изменено (этап Sz_13).
[0603] Модуль 218 взаимного прогнозирования формирует прогнозное изображение для текущего блока посредством выполнения процесса коррекции яркости, в котором параметр коррекции яркости применяется к опорному изображению в опорном кадре, указываемом посредством MV (этап Sz_14). Другими словами, прогнозное изображение, которое представляет собой опорное изображение в опорном кадре, указываемом посредством MV, подвергается коррекции на основе параметра коррекции яркости. При этой коррекции, яркость может корректироваться, либо цветность может корректироваться.
[0604] Контроллер прогнозирования
Контроллер 220 прогнозирования выбирает либо внутреннее прогнозное изображение, либо взаимное прогнозное изображение и выводит выбранное изображение в сумматор 208. В целом, конфигурации, функции и процессы контроллера 220 прогнозирования, модуля 216 внутреннего прогнозирования и модуля 218 взаимного прогнозирования на стороне декодера 200 могут соответствовать конфигурациям, функциям и процессам контроллера 128 прогнозирования, модуля 124 внутреннего прогнозирования и модуля 126 взаимного прогнозирования на стороне кодера 100.
[0605] Описание режима внутриблочного копирования (IBC)
Модуль 126 взаимного прогнозирования (см. фиг. 7) кодера 100 согласно первому аспекту может обращаться к декодированному пикселу (т.е. к пикселу, который кодирован и декодирован) в кадре, который включает в себя текущий блок (т.е. в текущем кадре), в дополнение к предыдущему и будущему кадрам. Например, модуль 126 взаимного прогнозирования может обращаться только к пикселу, включенному в кадр. Такой режим прогнозирования называется "внутриблочным копированием (IBC)". IBC-режим может использоваться в качестве одного режима нормального взаимного прогнозирования и может использоваться, например, с режимом объединения, нормальным взаимным режимом, режимом пропуска и т.п. В дальнейшем в этом документе, подробнее описывается IBC-режим со ссылкой на чертежи.
[0606] Фиг. 97 является схемой для описания IBC-режима. Часть (a) по фиг. 97 является схемой, иллюстрирующей один пример области, к которой можно обращаться в IBC-режиме. Часть (b) по фиг. 97 является схемой, иллюстрирующей один пример блочного вектора (BV).
[0607] В процессе взаимного прогнозирования для текущего блока, модуль 126 взаимного прогнозирования обращается к блоку, который кодирован и декодирован и находится в кадре, отличающемся от кадра, включающего в себя текущий блок (т.е. текущего кадра). Тем не менее, в процессе прогнозирования с использованием IBC-режима, модуль 126 взаимного прогнозирования обращается только к пикселам, которые кодированы и декодированы и находятся в кадре, включающем в себя текущий блок, аналогично процессу внутреннего прогнозирования. Например, как проиллюстрировано в части (a) по фиг. 97, пикселы, к которым можно обращаться в кадре, представляют собой пикселы, расположенные в верхней или левой стороне текущего блока. Область, включающая в себя такие пикселы, называется "допускающей ссылку областью".
[0608] Кроме того, чтобы идентифицировать опорный блок в кинокадре или кадре, который включает в себя текущий блок, кодер 100 может определять вектор, который указывает смещение опорного блока относительно текущего блока. Этот вектор называется "блочным вектором (BV)". Далее описывается то, как BV выражается.
[0609] Как проиллюстрировано в части (b) по фиг. 97, блочный вектор включает в себя, например, компонент по оси X и компонент по оси Y. Компонент (BVx) по оси X указывает горизонтальный сдвиг опорного блока относительно текущего блока в кадре. Компонент (BVy) по оси Y указывает вертикальный сдвиг опорного блока относительно текущего блока в кадре. Например, когда точка начала координат (т.е. начальная точка) BV представляет собой пиксельную позицию в верхнем левом углу текущего блока, конечная точка BV представляет собой пиксельную позицию в верхнем левом углу опорного блока. В этом случае, BV представляет собой вектор, который соединяет верхний левый угол текущего блока и верхний левый угол опорного блока. Кодер 100 передает в служебных сигналах BV в кодированном потоке битов, чтобы обеспечивать возможность декодеру 200, при декодировании кодированного потока битов, идентифицировать опорный блок, выбранный посредством кодера 100.
[0610] HMVP-режим
Далее подробнее описывается HMVP-режим снова со ссылкой на фиг. 42. Список возможных MV-вариантов (в дальнейшем в этом документе также называется "списком возможных вариантов векторов движения"), проиллюстрированный на чертеже, может представлять собой список возможных MV-вариантов для режима объединения или может представлять собой список возможных MV-вариантов для нормального взаимного режима.
[0611] В режиме объединения и нормальном взаимном режиме, вектор движения (MV) текущего блока определяется посредством выбора одного возможного MV-варианта (в дальнейшем в этом документе также называется "возможным вариантом прогнозирования" или "возможным вариантом вектора движения") из списка возможных MV-вариантов, сформированного посредством обращения к обработанным блокам. Например, при формировании прогнозного изображения текущего блока в нормальном взаимном режиме, кодер 100 выбирает один возможный MV-вариант из списка возможных MV-вариантов, принимает разность между MV текущего блока и возможным MV-вариантом и кодирует разность и индекс возможного MV-варианта. Кроме того, например, при формировании прогнозного изображения текущего блока в режиме объединения, кодер 100 выбирает один индекс объединения из списка возможных MV-вариантов объединения, чтобы выбирать возможный MV-вариант и индекс опорного кадра, которые ассоциированы с индексом объединения. Кодер 100 кодирует выбранный индекс объединения. В списке возможных MV-вариантов регистрируются: например, пространственно соседние предикторы векторов движения (также называются "пространственно соседними возможными MV-вариантами"), которые представляют собой векторы движения кодированных блоков, которые пространственно окружают текущий блок; и временно соседние предикторы векторов движения (также называются "временно соседними возможными MV-вариантами"), которые представляют собой векторы движения соседних блоков, которые находятся в кодированном опорном кадре и на которые проецируется позиция текущего блока. Возможные MV-варианты в HMVP-режиме (в дальнейшем в этом документе также называются "возможными вариантами HMVP-векторов движения") представляют собой один пример возможных MV-вариантов, зарегистрированных в списке возможных MV-вариантов.
[0612] В HMVP-режиме, возможные MV-варианты управляются с использованием FIFO-буфера для HMVP-режима (в дальнейшем в этом документе также называется "HMVP-таблицей"), отдельно от списков возможных MV-вариантов для режима объединения и нормального взаимного режима. В FIFO-буфере, предварительно определенное число (например, 5 на фиг. 42) возможных вариантов прогнозирования (также называются "возможными MV-вариантами"), имеющих информацию, связанную с MV (в дальнейшем называется "MV-информацией") блоков, обработанных в прошлом (т.е. блоков, обработанных перед текущим блоком), сохраняются в порядке блочной обработки, начиная с самого нового. Например, как проиллюстрировано на фиг. 42, каждый раз, когда кодер 100 обрабатывает один блок, кодер 100 сохраняет, в FIFO-буфере, возможный вариант прогнозирования, имеющий MV-информацию самого нового блока (другими словами, блока, обработанного непосредственно перед одним блоком). Следует отметить, что каждый раз, когда кодер 100 заканчивает обработку одного блока, кодер 100 может сохранять, в FIFO-буфере, возможный вариант прогнозирования, имеющий MV-информацию одного блока.
[0613] Следует отметить, что список возможных вариантов блочных векторов для IBC-режима формируется с использованием BV вместо MV, и HMVP-таблица сохраняет возможные варианты блочных векторов (возможные BV-варианты) вместо возможных MV-вариантов. В дальнейшем в этом документе, MV и BV называются "векторами", возможные MV-варианты и возможные BV-варианты называются "возможными вариантами векторов", и список возможных вариантов векторов движения и список возможных вариантов блочных векторов называются "списками возможных вариантов векторов". При необходимости, MV и возможные MV-варианты могут читаться как BV и возможные BV-варианты, и BV и возможные BV-варианты могут читаться как MV и возможных MV-варианты. Следует отметить, что сочетание возможных BV-вариантов и возможных MV-вариантов может регистрироваться в списке возможных вариантов векторов движения и списке возможных вариантов блочных векторов.
[0614] При сохранении в FIFO-буфере возможного варианта прогнозирования, имеющего новую MV-информацию, кодер 100 удаляет из FIFO-буфера возможный вариант прогнозирования, имеющий MV-информацию самого старого блока (т.е. блока, обработанного раньше всего) в FIFO-буфере. За счет этого, кодер 100 может управлять возможными вариантами прогнозирования в FIFO-буфере в актуальном состоянии. Следует отметить, что в примере, проиллюстрированном на фиг. 42, HMVP1 в FIFO-буфере представляет собой возможный вариант прогнозирования, имеющий MV-информацию самого нового блока, и HMVP5 в FIFO-буфере представляет собой возможный вариант прогнозирования, имеющий MV-информацию самого старого блока.
[0615] Далее, со ссылкой на фиг. 42, описывается процесс отсечения в процессе регистрации возможных MV-вариантов HMVP-режима в списках возможных MV-вариантов для режима объединения и нормального взаимного режима и в процессе обновления FIFO-буфера.
[0616] Процесс отсечения
Процесс отсечения представляет собой процесс сравнения MV, который должен регистрироваться, например, в списке, и MV, зарегистрированном, например, в списке, и определения того, являются или нет идентичными MV-значения (либо MV-информация) этих MV. В HMVP-режиме, предусмотрено два типа процесса отсечения: (1) процесс отсечения для регистрации в списке возможных MV-вариантов из HMVP-таблицы (он называется "первым процессом отсечения"), и (2) процесс отсечения для регистрации MV непосредственно предыдущего обработанного блока (т.е. самого нового MV) в HMVP-таблице (т.е. обновления HMVP-таблицы) (он называется "вторым процессом отсечения").
[0617] Ссылаясь на фиг. 42, например, в первом процессе отсечения, описанном в (1) выше, кодер 100 определяет, для каждого из возможных MV-вариантов (например, HMVP1-HMVP5) в FIFO-буфере, то, имеет или нет возможный MV-вариант MV-информацию, отличающуюся от MV-информации всех возможных MV-вариантов, зарегистрированных в списке возможных MV-вариантов. Более конкретно, кодер 100 определяет, для каждого из возможных MV-вариантов (HMVP1-HMVP5 в этом примере) в FIFO-буфере, то, отличается или нет MV-информация возможного MV-варианта от MV-информации всех возможных вариантов прогнозирования (т.е. возможных MV-вариантов), зарегистрированных в списке возможных MV-вариантов, в порядке, начиная с возможного MV-варианта, имеющего MV-информацию самого нового блока (здесь, HMVP1). При определении того, что MV-информация HMVP1 отличается от MV-информации всех возможных MV-вариантов в списке возможных MV-вариантов, кодер 100 регистрирует HMVP1 в списке возможных MV-вариантов. Затем, кодер 100 выполняет идентичный процесс для каждого из оставшихся возможных MV-вариантов (здесь, HMVP2-HMVP5) в FIFO-буфере. Следует отметить, что общее число возможных вариантов векторов движения HMVP, зарегистрированных в списке возможных MV-вариантов из FIFO-буфера, может быть равным 1 либо может быть равным 2 или более.
[0618] Использование HMVP-режима, как описано выше, позволяет регистрировать, в списке возможных MV-вариантов, не только возможные MV-варианты, имеющие MV-информацию блока, пространственно или временно соседнего с текущим блоком, но также и возможный MV-вариант, имеющий MV-информацию блока, обработанного в прошлом. Это приводит к большему числу варьирований возможных MV-вариантов для режима объединения и нормального взаимного режима. Соответственно, кодер 100 может выбирать более надлежащий возможный MV-вариант для текущего блока, и в силу этого эффективность кодирования повышается.
[0619] Кроме того, например, во втором процессе отсечения, описанном в (2) выше, кодер 100 сравнивает MV блока, непосредственно до этого обработанного (HMVP0), со всеми возможными MV-вариантами, зарегистрированными в FIFO-буфере (HMVP1-HMVP5 на чертеже), чтобы определять то, отличается или нет MV-информация HMVP0 от MV-информации всех возможных MV-вариантов. При определении того, что MV-информация HMVP0 отличается от MV-информации всех возможных MV-вариантов в FIFO-буфере, кодер 100 удаляет MV самого старого блока в FIFO-буфере (HMVP5 в этом примере) и регистрирует HMVP0 в FIFO-буфере в качестве MV самого нового блока. С другой стороны, при определении того, что MV-информация HMVP0 является идентичной MV-информации любого из возможных MV-вариантов, кодер 100 не регистрирует HMVP0 в FIFO-буфере, но поддерживает текущий FIFO-буфер (т.е. FIFO-буфер, в котором HMVP1-HMVP5 регистрируются) как есть.
[0620] Следует отметить, что MV-информация может включать в себя не только значение MV, но также и информацию относительно опорного кадра, такую информацию, как опорное направление и число опорных кадров, и т.п.
[0621] Хотя списки возможных MV-вариантов для режима объединения и нормального взаимного режима описаны здесь, настоящее раскрытие сущности не ограничено этим примером. Например, в процессе прогнозирования IBC-режима, кодер 100 формирует, для каждого текущего блока, список возможных BV-вариантов, в котором регистрируются возможные BV-варианты.
[0622] Следует отметить, что список возможных MV-вариантов и FIFO-буфер, проиллюстрированные на фиг. 42, представляют собой просто пример; список возможных MV-вариантов и FIFO-буфер могут иметь размер, отличающийся от проиллюстрированного размера, и могут иметь такую конфигурацию, в которой возможные MV-варианты регистрируются в порядке, отличающемся от проиллюстрированного порядка.
[0623] Хотя кодер 100 описывается здесь в качестве примера, вышеуказанные процессы являются общими как для кодера 100, так и для декодера 200.
[0624] Первый аспект
Ниже описываются кодер 100 и декодер 200 согласно первому аспекту.
[0625] Кодер 100: при формировании прогнозного изображения текущего блока, использует IBC-режим, в котором обращаются к кодированной области кадра, который включает в себя текущий блок; определяет то, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и кодирует текущий блок с использованием списка возможных вариантов векторов.
[0626] Кроме того, декодер 200: при формировании прогнозного изображения текущего блока, использует IBC-режим, в котором обращаются к кодированной области кадра, который включает в себя текущий блок; определяет то, меньше или равен либо нет размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов; когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем возможные варианты первых векторов имеют информацию относительно первого вектора, используемого для обработанного блока; когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и декодирует текущий блок с использованием списка возможных вариантов векторов.
[0627] Фиг. 98 является блок-схемой 1000 последовательности операций способа, иллюстрирующей один пример операций, выполняемых посредством кодера 100 и декодера 200 согласно первому аспекту.
[0628] В процессе прогнозирования для текущего кадра, кодер 100 начинает циклический процесс, который выполняется на поблочной основе (не проиллюстрировано). Во-первых, кодер 100 определяет размер текущего блока в IBC-режиме (S1001). IBC-режим представляет собой режим прогнозирования, в котором к обработанной области кадра, включающего в себя текущий блок, обращаются при формировании прогнозного изображения текущего блока.
[0629] Затем, кодер 100 определяет то, меньше или равен либо нет размер текущего блока пороговому значению (S1002). Например, размер текущего блока может задаваться посредством общего числа пикселов, включенных в текущий блок. В таком случае, пороговое значение составляет, например, 16 пикселов. Кроме того, например, размер текущего блока может задаваться, по меньшей мере, посредством одного из ширины или высоты текущего блока. В таком случае, пороговое значение составляет, например, 4 пиксела x 4 пиксела.
[0630] Затем, при определении того, что размер текущего блока не меньше или равен пороговому значению; другими словами, при определении того, что размер текущего блока превышает пороговое значение ("Нет" в S1003), кодер 100 формирует список возможных вариантов блочных векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта блочного HMVP-вектора в списке возможных вариантов блочных векторов (S1004). Например, когда кодер 100 формирует список возможных вариантов блочных векторов для IBC-режима, кодер 100 выполняет на этапе S1004 первый процесс отсечения для каждого из возможных вариантов блочных HMVP-векторов в порядке, начиная с самого нового возможного варианта блочного HMVP-вектора, т.е. начиная с возможного варианта блочного HMVP-вектора, который последним введен в HMVP-таблицу, до возможного варианта блочного HMVP-вектора, который первым введен в HMVP-таблицу. Более конкретно, кодер 100 сравнивает каждый возможный вариант блочного HMVP-вектора со всеми возможными вариантами блочных векторов, зарегистрированными в таблице списка возможных вариантов векторов текущего блока в порядке, начиная с возможного варианта блочного HMVP-вектора, который последним введен в HMVP-таблицу, и определяет то, отличается или нет возможный вариант блочного HMVP-вектора от всех возможных вариантов блочных векторов. Например, вектор (MV или BV), используемый для соседнего блока, может регистрироваться в списке возможных вариантов блочных векторов. Например, когда список возможных вариантов блочных векторов включает в себя возможный вариант блочного вектора, который является идентичным возможному варианту блочного HMVP-вектора, который последним введен в HMVP-таблицу, кодер 100 не добавляет возможный вариант блочного HMVP-вектора в список возможных вариантов блочных векторов. С другой стороны, когда список возможных вариантов блочных векторов не включает в себя возможный вариант блочного вектора, идентичный возможному варианту блочного вектора HMVP-режима, который последним введен в HMVP-таблицу, кодер 100 добавляет возможный вариант блочного вектора HMVP-режима в список возможных вариантов блочных векторов. Идентичный процесс выполняется для других возможных вариантов блочных HMVP-векторов, сохраненных в HMVP-таблице. Общее число возможных вариантов блочных HMVP-векторов, добавляемых в список возможных вариантов блочных векторов, может быть равным 1 либо может быть равным 2 или более в зависимости от общего числа вакансий в списке.
[0631] С другой стороны, при определении того, что размер текущего блока меньше или равен пороговому значению ("Да" на S1003), кодер 100 формирует список возможных вариантов блочных векторов посредством регистрации возможного варианта блочного HMVP-вектора в списке возможных вариантов блочных векторов без выполнения первого процесса отсечения (S1005). Другими словами, кодер 100 на этапе S1005 добавляет возможные варианты блочных HMVP-векторов, сохраненные в HMVP-таблице, в список возможных вариантов блочных векторов в порядке, начиная с самого нового. Общее число возможных вариантов блочных HMVP-векторов, добавляемых в список возможных вариантов блочных векторов, может быть равным 1 либо может быть равным 2 или более в зависимости от числа вакансий в списке. Таким образом, когда размер текущего блока меньше или равен пороговому значению, кодер 100 пропускает процесс отсечения, за счет этого уменьшая общее число циклов обработки, необходимых для формирования списка возможных вариантов блочных векторов. Это повышает эффективность кодирования кодера 100. Соответственно, чтобы уменьшать общее число циклов обработки, необходимых для формирования списка возможных вариантов блочных векторов, кодер 100 не должен обязательно иметь один список возможных вариантов блочных векторов, совместно используемый текущим блоком и блоком, соседним с текущим блоком. Например, в режиме объединения, кодеру 100 не должен обязательно иметь список для объединения, совместно используемый текущим блоком и блоком, соседним с текущим блоком.
[0632] Ссылаясь на фиг. 98 снова, кодер 100 кодирует текущий блок с использованием списка возможных вариантов блочных векторов, сформированного на этапе S1004 или на этапе S1005 (S1006).
[0633] После повторения процессов этапов S1001-S1006 для всех блоков, включенных в текущий кадр, кодер 100 заканчивает циклический процесс, выполняемый на поблочной основе (не проиллюстрировано).
[0634] Хотя кодер 100 описывается здесь в качестве примера, вышеуказанные процессы являются общими как для кодера 100, так и для декодера 200.
[0635] Здесь, кодер 100 определяет то, следует или нет пропускать процесс отсечения, на основе того, меньше или равен либо нет размер текущего блока пороговому значению при формировании списка возможных вариантов векторов в IBC-режиме; тем не менее, кодер 100 также может выполнять идентичный процесс при формировании списка возможных вариантов векторов в режиме объединения и нормальном взаимном режиме. Например, при формировании списка возможных вариантов векторов в режиме объединения (списка возможных MV-вариантов объединения), кодер 100 определяет то, следует или нет пропускать процесс отсечения, на основе того, меньше или равен либо нет размер текущего блока пороговому значению. В списке возможных MV-вариантов объединения регистрируются возможные MV-варианты и информация опорных кадров (индексы опорных кадров) в ассоциации друг с другом. Таким образом, даже когда возможные варианты векторов имеют идентичное MV-значение, в процессе отсечения определяется то, что возможные варианты векторов не являются идентичными, если возможные варианты векторов имеют различную информацию опорных кадров.
[0636] Хотя здесь описывается пример, в котором кодер 100 выполняет процесс прогнозирования с использованием IBC-режима, кодер 100 может выполнять процесс прогнозирования с использованием IBC-режима при определении необходимости использовать IBC-режим из множества режимов прогнозирования и выполнять процесс прогнозирования с использованием режима прогнозирования, отличающегося от IBC-режима при определении необходимости использовать режим прогнозирования, отличающийся от IBC-режима, из множества режимов прогнозирования. Например, при использовании режима прогнозирования, отличающегося от IBC-режима, кодер 100 может формировать список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы и кодировать текущий блок с использованием списка возможных вариантов векторов.
[0637] Технические преимущества первого аспекта
Первый аспект настоящего раскрытия сущности вводит ограничение согласно размеру текущего блока, в процесс отсечения, выполняемый для возможных вариантов HMVP-векторов при формировании списка возможных вариантов векторов. Это обеспечивает возможность кодеру 100 и декодер 200, при формировании списка возможных вариантов векторов, пропускать процесс отсечения для сравнения возможных вариантов HMVP-векторов, сохраненных в HMVP-таблице, с возможными вариантами векторов, зарегистрированными в списке возможных вариантов векторов, когда размер текущего блока меньше или равен пороговому значению. Как результат, общее число циклов, необходимых для выполнения процесса отсечения при формировании списка возможных вариантов векторов, уменьшается, когда размер текущего блока меньше или равен пороговому значению. Соответственно, кодер 100 и декодер 200 согласно первому аспекту обеспечивают уменьшение объема обработки, и в силу этого эффективность кодирования кодера 100 и эффективность обработки декодера 200 повышается.
[0638] Хотя первый аспект описывает пример, в котором вышеописанное ограничение по размерам вводится в процесс отсечения, выполняемый при регистрации возможного варианта блочного HMVP-вектора в списке возможных вариантов блочных векторов из HMVP-таблицы при формировании списка возможных вариантов блочных векторов для IBC-режима; тем не менее, вышеописанное ограничение по размерам также может вводиться в формирование списка возможных MV-вариантов для режима объединения и нормального взаимного режима.
[0639] Второй аспект
В дальнейшем в этом документе описываются кодер 100, декодер 200, способ кодирования и способ декодирования согласно второму аспекту. Тогда как первый аспект описывает процесс формирования списка возможных вариантов векторов, второй аспект описывает процесс обновления HMVP-таблицы.
[0640] Кодер 100 согласно второму аспекту дополнительно выполняет обновление HMVP-таблицы с использованием возможного варианта второго вектора, имеющего информацию относительно второго вектора. При обновлении HMVP-таблицы, кодер 100 определяет то, меньше или равен либо нет размер текущего блока пороговому значению, обновляет HMVP-таблицу без выполнения второго процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и обновляет HMVP-таблицу посредством выполнения второго процесса отсечения, когда размер текущего блока превышает пороговое значение.
[0641] Декодер 200 согласно второму аспекту дополнительно выполняет обновление HMVP-таблицы с использованием возможного варианта второго вектора, имеющего информацию относительно второго вектора. При обновлении HMVP-таблицы, декодер 200 определяет то, меньше или равен либо нет размер текущего блока пороговому значению, обновляет HMVP-таблицу без выполнения второго процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и обновляет HMVP-таблицу посредством выполнения второго процесса отсечения, когда размер текущего блока превышает пороговое значение.
[0642] Фиг. 99 является блок-схемой последовательности операций способа 2000, иллюстрирующей один пример операций, выполняемых посредством кодера 100 и декодера 200 согласно второму аспекту.
[0643] В процессе прогнозирования для текущего кадра, кодер 100 начинает циклический процесс, который выполняется на поблочной основе (не проиллюстрировано). Во-первых, кодер 100 определяет размер текущего блока в IBC-режиме (S2001).
[0644] Затем, кодер 100 определяет блочный вектор (вышеуказанный второй вектор) текущего блока (не проиллюстрировано). В IBC-режиме, второй вектор представляет собой вектор, который указывает позицию, в кадре, опорного блока, соответствующего текущему блоку.
[0645] Затем, кодер 100 определяет то, меньше или равен либо нет размер текущего блока пороговому значению (S2002). Например, размер текущего блока может задаваться посредством общего числа пикселов, включенных в текущий блок. В таком случае, пороговое значение составляет, например, 16 пикселов. Кроме того, например, размер текущего блока может задаваться, по меньшей мере, посредством одного из ширины или высоты текущего блока. В таком случае, пороговое значение составляет, например, 4 пиксела x 4 пиксела.
[0646] При определении того, что размер текущего блока не меньше или равен пороговому значению; другими словами, при определении того, что размер текущего блока превышает пороговое значение ("Нет" на S2003), кодер 100 обновляет HMVP-таблицу посредством выполнения второго процесса отсечения (S2004). В это время, кодер 100 обновляет HMVP-таблицу с использованием возможного варианта второго блочного вектора, имеющего информацию относительно второго блочного вектора. Второй блочный вектор представляет собой блочный вектор, используемый для формирования прогнозного изображения текущего блока. Например, во втором процессе отсечения, кодер 100 определяет то, является или нет возможный вариант второго блочного вектора идентичным какому-либо из возможных вариантов первых блочных векторов (т.е. возможных вариантов блочных HMVP-векторов) в HMVP-таблице, и когда возможный вариант второго блочного вектора не является идентичным какому-либо из возможных вариантов блочных HMVP-векторов, обновляет HMVP-таблицу посредством сохранения возможного варианта второго блочного вектора в HMVP-таблице. С другой стороны, когда возможный вариант второго блочного вектора является идентичным какому-либо из возможных вариантов блочных HMVP-векторов в HMVP-таблице, кодер 100 отбрасывает возможный вариант второго блочного вектора. Процесс обновления HMVP-таблицы посредством выполнения второго процесса отсечения включает в себя процесс отбрасывания возможного варианта второго блочного вектора. Следует отметить, что пороговое значение является идентичным пороговому значению, описанному в первом аспекте, и в силу этого его описание опускается.
[0647] Следует отметить, что, как описано в первом аспекте, в режиме объединения и нормальном взаимном режиме, возможный вариант вектора движения включает в себя MV-информацию, имеющую информацию возможных MV-вариантов и опорных кадров. Таким образом, когда процесс прогнозирования выполняется для текущего блока в режиме объединения или в нормальном взаимном режиме, то, что возможный вариант второго вектора движения и возможный вариант HMVP-вектора движения являются идентичными друг другу во втором процессе отсечения, означает то, что MV-информация этих возможных вариантов векторов движения является идентичной. Напротив, когда процесс прогнозирования выполняется для текущего блока в IBC-режиме, то, что возможный вариант второго блочного вектора и возможный вариант блочного HMVP-вектора являются идентичными друг другу, означает то, что векторные значения этих возможных вариантов блочных векторов являются идентичными. Более конкретно, на этапе S2004, кодер 100 сравнивает возможный вариант блочного вектора, имеющий информацию относительно блочного вектора, которая указывает позицию опорного блока, соответствующего текущему блоку в кадре (т.е. возможного варианта второго блочного вектора), со всеми возможными вариантами блочных векторов, сохраненными в HMVP-таблице (т.е. с возможными вариантами первых блочных векторов или с возможными вариантами блочных HMVP-векторов), и определяет то, является или нет возможный вариант второго блочного вектора идентичным какому-либо из возможных вариантов блочных HMVP-векторов. Кодер 100 отбрасывает возможный вариант второго блочного вектора, когда HMVP-таблица включает в себя возможный вариант блочного HMVP-вектора, имеющий векторное значение, идентичное векторному значению возможного варианта второго блочного вектора текущего блока. Другими словами, возможный вариант второго блочного вектора не добавляется в HMVP-таблицу. С другой стороны, кодер 100 добавляет возможный вариант второго блочного вектора в HMVP-таблицу, когда HMVP-таблица не включает в себя возможный вариант блочного HMVP-вектора, имеющий векторное значение, идентичное векторному значению возможного варианта второго блочного вектора. В это время, самый старый возможный вариант блочного HMVP-вектора в HMVP-таблице удаляется.
[0648] Ссылаясь на фиг. 99 снова, при определении того, что размер текущего блока меньше или равен пороговому значению ("Да" на S2003), кодер 100 обновляет HMVP-таблицу без выполнения второго процесса отсечения (S2005). Например, кодер 100 обновляет HMVP-таблицу посредством сохранения в HMVP-таблице возможного варианта второго блочного вектора, имеющего информацию относительно второго блочного вектора, и удаления самого старого возможного варианта блочного HMVP-вектора в HMVP-таблице. Более конкретно, при выполнении процесса прогнозирования для текущего блока в IBC-режиме, кодер 100 на этапе S2005 добавляет возможный вариант блочного вектора, имеющий информацию относительно блочного вектора текущего блока (т.е. возможного варианта второго блочного вектора), в HMVP-таблицу без выполнения процесса отсечения.
[0649] Затем, кодер 100 кодирует текущий блок после выполнения процесса обновления HMVP-таблицы, проиллюстрированной на этапе S2004 и на этапе S2005 (этап S2006). Следует отметить, что процесс обновления HMVP-таблицы может выполняться после кодирования текущего блока.
[0650] После повторения процессов этапов S2001-S2006 для всех блоков, включенных в текущий кадр, кодер 100 заканчивает циклический процесс, выполняемый на поблочной основе (не проиллюстрировано).
[0651] Хотя кодер 100 описывается здесь в качестве примера, вышеуказанные процессы являются общими как для кодера 100, так и для декодера 200.
[0652] Хотя IBC-режим описывается здесь в качестве примера, даже в режиме объединения и нормальном взаимном режиме (например, в AMVP-режиме), HMVP-таблица используется для формирования списка возможных MV-вариантов согласно тому, меньше или равен либо нет размер текущего блока пороговому размеру, как описано в первом аспекте. Следовательно, даже в режиме объединения и AMVP-режиме, вышеописанный процесс обновления HMVP-таблицы может выполняться идентично IBC-режиму.
[0653] Технические преимущества второго аспекта
Второй аспект настоящего раскрытия сущности вводит ограничение согласно размеру текущего блока, в процесс отсечения, выполняемый при обновлении HMVP-таблицы. Это обеспечивать возможность кодеру 100 и декодеру 200, при обновлении HMVP-таблицы, пропускать процесс отсечения сравнения второго вектора, используемого для прогнозирования текущего блока со всеми возможными вариантами HMVP-векторов, сохраненными в HMVP-таблице, когда размер текущего блока меньше или равен пороговому значению. Как результат, общее число циклов, необходимых для выполнения процесса отсечения при обновлении HMVP-таблицы, уменьшается, когда размер текущего блока меньше или равен пороговому значению. Соответственно, кодер 100 и декодер 200 согласно второму аспекту обеспечивают уменьшение объема обработки, и в силу этого эффективность кодирования кодера 100 и эффективность обработки декодера 200 повышается.
[0654] Хотя второй аспект описывает пример введения вышеописанного ограничения по размерам в процесс отсечения, выполняемый при обновлении HMVP-таблицы с использованием блочного вектора текущего блока, прогнозированного в IBC-режиме, вышеописанное ограничение по размерам также может вводиться в режиме объединения и нормальном взаимном режиме.
[0655] Комбинация с другими аспектами
Один или более аспектов, раскрытых здесь, могут комбинироваться, по меньшей мере, с частью других аспектов настоящего раскрытия сущности. Кроме того, часть процессов, проиллюстрированных на блок-схемах последовательности операций способа, часть конфигураций устройств, часть синтаксиса и/или других функций согласно одному или более аспектов, раскрытых здесь, могут комбинироваться с другими аспектами.
[0656] Все процессы/элементы, описанные выше, не обязательно требуются. Устройство/способ может включать в себя часть процессов/элементов. Процессы, описанные выше, могут выполняться посредством декодера, аналогично кодеру.
[0657] Дополнительные замечания
При обычном взаимном прогнозировании, кодер 100 обращается к блоку, включенному в кадр, отличающийся от текущего кадра; тогда как в IBC-режиме кодер 100 обращается к обработанному блоку, включенному в обработанную область в кадре, включающем в себя текущий блок, т.е. в текущем кадре. В это время, область, к которой обращаются (также называется "допускающей ссылку областью"), представляет собой область, которая расположена около текущего блока и обрабатывается относительно недавно, и в силу этого сохранение допускающей ссылку области в запоминающем устройстве быстро доступной области в аппаратном механизме, а не в запоминающем устройстве за пределами аппаратного механизма представляет собой признак IBC-режима. Как результат, в процессе прогнозирования IBC-режима, кодер 100 не должен обязательно осуществлять доступ к запоминающему устройству за пределами аппаратного механизма; другими словами, пропускная способность запоминающего устройства становится необязательной. Следовательно, кодер 100 осуществляет доступ к запоминающему устройству только в аппаратном механизме и в силу этого может выполнять процесс прогнозирования на относительно высокой скорости. Соответственно, в IBC-режиме, размер текущего блока может принимать меньшее значение, чем в других режимах взаимного прогнозирования. Тем не менее, когда размер текущего блока является небольшим, число раз, когда процесс формирования списка возможных вариантов векторов выполняется, может увеличиваться, и объем обработки для формирования списка возможных вариантов векторов может становиться больше, чем в других режимах взаимного прогнозирования. Помимо этого, число раз, когда процесс обновления HMVP-таблицы выполняется, также может увеличиваться, и объем обработки может становиться больше, чем в других режимах взаимного прогнозирования. С учетом вышеизложенного, в случае выполнения процесса прогнозирования в IBC-режиме, можно сокращать объем обработки посредством пропуска процесса отсечения при формировании списка возможных вариантов векторов и обновлении HMVP-таблицы аналогично настоящему варианту осуществления. Это может разрешать узкое место модуля 126 взаимного прогнозирования.
[0658] Следует отметить, что технология согласно настоящему варианту осуществления не ограничена IBC-режимом и также может использоваться в других режимах взаимного прогнозирования идентичным способом. Процессы, идентичные процессам, описанным в вышеуказанных аспектах, могут выполняться во всех используемых режимах взаимного прогнозирования либо могут выполняться в одном или более режимов прогнозирования из всех используемых режимов взаимного прогнозирования. Например, идентичные процессы могут выполняться, из всех режимов взаимного прогнозирования, в режиме, в котором размер текущего блока может быть равным пороговому значению (например, 16 пикселов, т.е.=4 пиксела x 4 пиксела).
[0659] Характерный пример процессов
Далее описывается характерный пример процессов, выполняемых посредством вышеописанных кодера 100 и декодера 200.
[0660] Фиг. 100 является блок-схемой последовательности операций способа, иллюстрирующей операции, выполняемые посредством кодера 100. Например, кодер 100 включает в себя схему и запоминающее устройство, соединенное со схемой. Схема и запоминающее устройство, включенные в кодер 100, могут соответствовать процессору a1 и запоминающему устройству a2, проиллюстрированным на фиг. 8. Схема кодера 100, при работе, выполняет следующее. При формировании прогнозного изображения текущего блока, схема кодера 100 использует IBC-режим, в котором обращаются к обработанной области кадра, включающего в себя текущий блок.
[0661] Например, схема кодера 100 определяет то, меньше или равен либо нет размер текущего блока пороговому значению (S3001). Когда размер текущего блока меньше или равен пороговому значению ("Да" на S3001), схема формирует список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения (S3002), и когда размер текущего блока превышает пороговое значение ("Нет" в S3001), схема формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы (S3003) и кодирует текущий блок с использованием списка возможных вариантов векторов (S3004).
[0662] В HMVP-таблице, возможные варианты первых векторов, имеющие информацию относительно первого вектора, используемого для обработанного блока, сохраняются в качестве возможных вариантов HMVP-векторов посредством FIFO-способа, и список возможных вариантов векторов формируется для каждого текущего блока.
[0663] Соответственно, кодер 100 формирует список возможных вариантов векторов без выполнения первого процесса отсечения (далее называется "процессом отсечения"), когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера 100. Кроме того, поскольку кодер 100 использует IBC-режим при формировании прогнозного изображения текущего блока, можно идентифицировать опорный блок, который кодирован и декодирован и находится в кадре, который включает в себя текущий блок, на основе вектора движения, указывающего опорный блок, и считывает идентифицированный опорный блок. Вследствие этого, кодер 100 может идентифицировать, из кодированных блоков в кадре, который включает в себя текущий блок, блок, к которому следует обращаться для текущего блока, на основе вектора, указывающего позицию, соответствующую текущему блоку, и считывать идентифицированный блок.
[0664] Например, схема кодера 100 может формировать прогнозное изображение текущего блока с использованием второго вектора и кодировать второй вектор с использованием одного из возможных вариантов векторов, включенных в список возможных вариантов векторов. В первом процессе отсечения, выполняемом при формировании списка возможных вариантов векторов, схема кодера 100 может определять, для каждого из возможных вариантов HMVP-векторов, сохраненных в HMVP-таблице, то, является или нет возможный вариант HMVP-вектора идентичным какому-либо из одного или более возможных вариантов векторов, зарегистрированных в списке возможных вариантов векторов. Когда возможный вариант HMVP-вектора не является идентичным какому-либо из одного или более возможных вариантов векторов, схема кодера 100 может формировать список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов.
[0665] Соответственно, кодер 100 формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера 100.
[0666] Например, схема кодера 100 дополнительно может выполнять обновление HMVP-таблицы с использованием возможного варианта второго вектора, имеющего информацию относительно второго вектора. При обновлении HMVP-таблицы, схема кодера 100 может определять то, меньше или равен либо нет размер текущего блока пороговому значению. Когда размер текущего блока меньше или равен пороговому значению, схема кодера 100 может обновлять HMVP-таблицу без выполнения второго процесса отсечения. С другой стороны, когда размер текущего блока превышает пороговое значение, схема кодера 100 может обновлять HMVP-таблицу посредством выполнения второго процесса отсечения.
[0667] Соответственно, кодер 100 обновляет HMVP-таблицу без выполнения второго процесса отсечения (в дальнейшем также называется "процессом отсечения"), когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера 100.
[0668] Например, схема кодера 100 может определять, во втором процессе отсечения, выполняемом при обновлении HMVP-таблицы, то, является или нет возможный вариант второго вектора идентичным какому-либо из возможных вариантов HMVP-векторов. Когда возможный вариант второго вектора не является идентичным какому-либо из возможных вариантов HMVP-векторов, схема кодера 100 может обновлять HMVP-таблицу посредством сохранения возможного варианта второго вектора в HMVP-таблице.
[0669] За счет этого, кодер 100 может регистрировать, в списке возможных вариантов векторов, возможный вариант вектора, который более подходит для текущего блока.
[0670] Например, размер текущего блока может задаваться посредством общего числа пикселов, включенных в текущий блок. Например, пороговое значение может составлять 16 пикселов.
[0671] Соответственно, кодер 100 формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда общее число пикселов, включенных в текущий блок, меньше или равно пороговому значению (например, меньше или равно 16 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера 100.
[0672] Например, размер текущего блока может задаваться, по меньшей мере, посредством одного из ширины или высоты текущего блока. Например, пороговое значение может составлять 4 пиксела x 4 пиксела.
[0673] Соответственно, кодер 100 формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда, по меньшей мере, одно из ширины или высоты текущего блока меньше или равно пороговому значению (например, когда ширина и высота текущего блока меньше или равны 4 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность кодирования кодера 100.
[0674] Например, список возможных вариантов векторов не должен обязательно совместно использоваться текущим блоком и блоком, соседним с текущим блоком.
[0675] Соответственно, кодер 100 использует списки возможных вариантов векторов, каждый из которых формируется для различного текущего блока, и в силу этого точность прогнозирования повышается.
[0676] Например, при формировании прогнозного изображения текущего блока, схема кодера 100 может использовать IBC-режим при определении необходимости использовать IBC-режим из множества режимов прогнозирования и использовать режим прогнозирования, отличающийся от IBC-режима, при определении необходимости использовать режим прогнозирования, отличающийся от IBC-режима, из множества режимов прогнозирования. При использовании режима прогнозирования, отличающегося от IBC-режима, схема кодера 100 может формировать список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы и кодировать текущий блок с использованием списка возможных вариантов векторов.
[0677] Это обеспечивает возможность кодеру 100 надлежащим образом переключать условия, при которых процесс отсечения выполняется, согласно используемому режиму прогнозирования. Это повышает эффективность кодирования кодера 100.
[0678] Фиг. 101 является блок-схемой последовательности операций способа, иллюстрирующей операции, выполняемые посредством декодера 200. Например, декодер 200 включает в себя схему и запоминающее устройство, соединенное со схемой. Схема и запоминающее устройство, включенные в декодер 200, могут соответствовать процессору b1 и запоминающему устройству b2, проиллюстрированным на фиг. 68. Схема декодера 200, при работе, выполняет следующее. При формировании прогнозного изображения текущего блока, схема декодера 200 использует IBC-режим, в котором обращаются к обработанной области кадра, включающего в себя текущий блок.
[0679] Например, схема декодера 200 определяет то, меньше или равен либо нет размер текущего блока пороговому значению (S4001). Когда размер текущего блока меньше или равен пороговому значению ("Да" на S4001), схема декодера 200 формирует список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения (S4002). С другой стороны, когда размер текущего блока превышает пороговое значение ("Нет" в S4001), схема декодера 200 формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы (S4003). Затем, схема декодера 200 декодирует текущий блок с использованием списка возможных вариантов векторов, сформированного на этапе S4002 или S4003 (S4004).
[0680] Соответственно, декодер 200 формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера 200. Кроме того, поскольку декодер 200 использует IBC-режим при формировании прогнозного изображения текущего блока, можно идентифицировать, из декодированных блоков в кадре, который включает в себя текущий блок, блок, к которому следует обращаться для текущего блока на основе вектора, указывающего позицию, соответствующую текущему блоку, и считывать идентифицированный блок. Вследствие этого, декодер 200 может идентифицировать, из декодированных блоков в кадре, который включает в себя текущий блок, блок, к которому следует обращаться для текущего блока, на основе вектора, указывающего позицию, соответствующую текущему блоку, и считывать идентифицированный блок.
[0681] Например, схема декодера 200 может формировать прогнозное изображение текущего блока с использованием второго вектора и декодировать второй вектор с использованием одного из возможных вариантов векторов, включенных в список возможных вариантов векторов. В первом процессе отсечения, выполняемом при формировании списка возможных вариантов векторов, схема декодера 200 может определять, для каждого из возможных вариантов HMVP-векторов, сохраненных в HMVP-таблице, то, является или нет возможный вариант HMVP-вектора идентичным какому-либо из одного или более возможных вариантов векторов, зарегистрированных в списке возможных вариантов векторов. Когда возможный вариант HMVP-вектора не является идентичным какому-либо из одного или более возможных вариантов векторов, схема декодера 200 может формировать список возможных вариантов векторов посредством регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов.
[0682] Соответственно, декодер 200 формирует список возможных вариантов векторов без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера 200.
[0683] Например, схема декодера 200 дополнительно может выполнять обновление HMVP-таблицы с использованием возможного варианта второго вектора, имеющего информацию относительно второго вектора. При обновлении HMVP-таблицы, схема декодера 200 может определять то, меньше или равен либо нет размер текущего блока пороговому значению. Когда размер текущего блока меньше или равен пороговому значению, схема декодера 200 может обновлять HMVP-таблицу без выполнения второго процесса отсечения. С другой стороны, когда размер текущего блока превышает пороговое значение, схема декодера 200 может обновлять HMVP-таблицу посредством выполнения второго процесса отсечения.
[0684] Соответственно, декодер 200 обновляет HMVP-таблицу без выполнения процесса отсечения, когда размер текущего блока меньше или равен пороговому значению, и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера 200.
[0685] Например, схема декодера 200 может определять, во втором процессе отсечения, выполняемом при обновлении HMVP-таблицы, то, является или нет возможный вариант второго вектора идентичным какому-либо из возможных вариантов HMVP-векторов. Когда возможный вариант второго вектора не является идентичным какому-либо из возможных вариантов HMVP-векторов, схема декодера 200 может обновлять HMVP-таблицу посредством сохранения возможного варианта второго вектора в HMVP-таблице.
[0686] За счет этого, декодер 200 может регистрировать, в списке возможных вариантов векторов, возможный вариант вектора, который более подходит для текущего блока.
[0687] Например, размер текущего блока может задаваться посредством общего числа пикселов, включенных в текущий блок. Например, пороговое значение может составлять 16 пикселов.
[0688] Соответственно, декодер 200 формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда общее число пикселов, включенных в текущий блок, меньше или равно пороговому значению (например, меньше или равно 16 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера 200.
[0689] Например, размер текущего блока может задаваться, по меньшей мере, посредством одного из ширины или высоты текущего блока. Например, пороговое значение может составлять 4 пиксела x 4 пиксела.
[0690] Соответственно, декодер 200 формирует список возможных вариантов векторов и обновляет HMVP-таблицу без выполнения процесса отсечения, когда, по меньшей мере, одно из ширины или высоты текущего блока меньше или равно пороговому значению (например, когда ширина и высота текущего блока меньше или равны 4 пикселам), и в силу этого объем обработки уменьшается. Это повышает эффективность обработки декодера 200.
[0691] Например, список возможных вариантов векторов не должен обязательно совместно использоваться текущим блоком и блоком, соседним с текущим блоком.
[0692] Соответственно, декодер 200 использует списки возможных вариантов векторов, каждый из которых формируется для различного текущего блока, и в силу этого точность прогнозирования повышается.
[0693] Например, при формировании прогнозного изображения текущего блока, схема декодера 200 может использовать IBC-режим при определении необходимости использовать IBC-режим из множества режимов прогнозирования и использовать режим прогнозирования, отличающийся от IBC-режима, при определении необходимости использовать режим прогнозирования, отличающийся от IBC-режима, из множества режимов прогнозирования. При использовании режима прогнозирования, отличающегося от IBC-режима, схема декодера 200 может формировать список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы и декодировать текущий блок с использованием списка возможных вариантов векторов.
[0694] Это обеспечивает возможность декодеру 200 надлежащим образом переключать условия, при которых процесс отсечения выполняется, согласно используемому режиму прогнозирования. Это повышает эффективность обработки декодера 200.
[0695] Каждый элемент может представлять собой схему, как описано выше. Эти схемы могут совместно формировать одну схему либо могут представлять собой отдельные схемы. Каждый элемент может реализовываться с использованием процессора общего назначения либо может реализовываться с использованием специализированного процессора.
[0696] Процесс, выполняемый посредством конкретного элемента, может выполняться посредством другого элемента. Кроме того, порядок, в котором выполняются процессы, может изменяться, или множество процессов могут выполняться параллельно. Кодирующее устройство декодирования может включать в себя кодер 100 и декодер 200.
[0697] Хотя аспекты кодера 100 и декодера 200 описываются выше на основе более чем одного примера, аспекты кодера 100 и декодера 200 не ограничены такими примерами. Аспекты кодера 100 и декодера 200 также могут охватывать различные модификации каждого примера, которые являются возможными для специалистов в данной области техники, и варианты осуществления, реализованные посредством комбинирования элементов в различных примерах, до тех пор, пока такие модификации и варианты осуществления не отступают от сущности настоящего раскрытия сущности.
[0698] Настоящий аспект может выполняться посредством комбинирования одного или более аспектов, раскрытых в данном документе, по меньшей мере, с частью других аспектов согласно настоящему раскрытию сущности. Помимо этого, настоящий аспект может выполняться посредством комбинирования, с другими аспектами, части процессов, указываемых на любой из блок-схем последовательности операций способа согласно аспектам, части конфигурации любого из устройств, части синтаксисов и т.д.
[0699] Реализации и варианты применения
Как описано в каждом из вышеописанных вариантов осуществления, каждый функциональный или рабочий блок типично может реализовываться, например, в качестве MPU (микропроцессора) и запоминающего устройства. Кроме того, процессы, выполняемые посредством каждого из функциональных блоков, могут реализовываться в качестве модуля выполнения программ, такого как процессор, который считывает и выполняет программное обеспечение (программу), записанное на носителе, таком как ROM. Программное обеспечение может быть распределенным. Программное обеспечение может записываться на множестве носителей, таких как полупроводниковое запоминающее устройство. Следует отметить, что каждый функциональный блок также может реализовываться в качестве аппаратных средств (специализированной схемы).
[0700] Кроме того, обработка, описанная в каждом из вариантов осуществления, может реализовываться через интегрированную обработку с использованием одного оборудования (системы) и, альтернативно, может реализовываться через децентрализованную обработку с использованием множества элементов оборудования. Кроме того, процессор, который выполняет вышеописанную программу, может представлять собой один процессор или множество процессоров. Другими словами, может выполняться интегрированная обработка, и, альтернативно, может выполняться децентрализованная обработка.
[0701] Варианты осуществления настоящего раскрытия сущности не ограничены вышеуказанными примерными вариантами осуществления; различные модификации могут вноситься в примерные варианты осуществления, результаты которых также включаются в пределы объема вариантов осуществления настоящего раскрытия сущности.
[0702] Далее описываются примеры вариантов применения способа кодирования движущихся кадров (способа кодирования изображений) и способа декодирования движущихся кадров (способа декодирования изображений), описанных в каждом из вышеуказанных вариантов осуществления, а также различных систем, которые реализуют примеры вариантов применения. Такая система может характеризоваться как включающая в себя кодер изображений, который использует способ кодирования изображений, декодер изображений, который использует способ декодирования изображений, и кодер-декодер изображений, который включает в себя как кодер изображений, так и декодер изображений. Другие конфигурации такой системы могут модифицироваться для каждого отдельного случая.
[0703] Примеры использования
Фиг. 102 иллюстрирует общую конфигурацию системы ex100 предоставления контента, подходящей для реализации услуги распространения контента. Зона, в которой предоставляется услуга связи, разделяется на соты требуемых размеров, и базовые станции ex106, ex107, ex108, ex109 и ex110, которые представляют собой стационарные беспроводные станции в проиллюстрированном примере, расположены в соответствующих сотах.
[0704] В системе ex100 предоставления контента, устройства, включающие в себя компьютер ex111, игровое устройство ex112, камеру ex113, бытовой прибор ex114 и смартфон ex115, соединяются с Интернетом ex101 через поставщика ex102 Интернет-услуг или сеть ex104 связи и базовые станции ex106-ex110. Система ex100 предоставления контента может комбинировать и соединять любые из вышеуказанных устройств. В различных реализациях, устройства могут прямо или косвенно соединяться между собой через телефонную сеть или связь ближнего радиуса действия, а не через базовые станции ex106-ex110. Дополнительно, потоковый сервер ex103 может соединяться с устройствами, включающими в себя компьютер ex111, игровое устройство ex112, камеру ex113, бытовой прибор ex114 и смартфон ex115, например, через Интернет ex101. Потоковый сервер ex103 также может соединяться, например, с терминалом в публичной точке доступа в самолете ex117 через спутник ex116.
[0705] Следует отметить, что вместо базовых станций ex106-ex110, могут использоваться точки беспроводного доступа или публичные точки доступа. Потоковый сервер ex103 может соединяться с сетью ex104 связи непосредственно, а не через Интернет ex101 или поставщика ex102 Интернет-услуг, и может соединяться с самолетом ex117 непосредственно, а не через спутник ex116.
[0706] Камера ex113 представляет собой устройство, допускающее захват неподвижных изображений и видео, к примеру, цифровую камеру. Смартфон ex115 представляет собой смартфон, сотовый телефон или телефон по стандарту системы персональных мобильных телефонов (PHS), который может работать согласно стандартам системы мобильной связи для 2G-, 3G-, 3,9G- и 4G-систем, а также 5G-системы следующего поколения.
[0707] Бытовой прибор ex114, например, представляет собой холодильник или устройство, включенное в домашнюю систему совместной выработки тепла и электроэнергии на топливных элементах.
[0708] В системе ex100 предоставления контента, терминал, включающий в себя функцию захвата изображений и/или видео, допускает, например, потоковую передачу вживую посредством соединения с потоковым сервером ex103, например, через базовую станцию ex106. При потоковой передаче вживую, терминал (например, компьютер ex111, игровое устройство ex112, камера ex113, бытовой прибор ex114, смартфон ex115 или терминал в самолете ex117) может выполнять обработку кодирования, описанную в вышеприведенных вариантах осуществления, для контента неподвижных изображений или видеоконтента, захваченного пользователем через терминал, может мультиплексировать видеоданные, полученные через кодирование, и аудиоданные, полученные посредством кодирования аудио, соответствующего видео, и может передавать полученные данные на потоковый сервер ex103. Другими словами, терминал функционирует в качестве кодера изображений согласно одному аспекту настоящего раскрытия сущности.
[0709] Потоковый сервер ex103 передает в потоковом режиме передаваемые данные контента в клиенты, которые запрашивают поток. Примеры клиента включают в себя компьютер ex111, игровое устройство ex112, камеру ex113, бытовой прибор ex114, смартфон ex115 и терминалы в самолете ex117, которые допускают декодирование вышеописанных кодированных данных. Устройства, которые принимают передаваемые в потоковом режиме данные, декодируют и воспроизводят принимаемые данные. Другими словами, устройства могут функционировать в качестве декодера изображений согласно одному аспекту настоящего раскрытия сущности.
[0710] Децентрализованная обработка
Потоковый сервер ex103 может реализовываться в качестве множества серверов или компьютеров, между которыми разделяются такие задачи, как обработка, запись и потоковая передача данных. Например, потоковый сервер ex103 может реализовываться в качестве сети доставки контента (CDN), которая передает в потоковом режиме контент через сеть, соединяющую несколько краевых серверов, расположенных по всему миру. В CDN, краевой сервер физически около клиента динамически назначается клиенту. Контент кэшируется и передается в потоковом режиме на краевой сервер, чтобы уменьшать время загрузки. В случае, например, определенного типа ошибки или изменения подключения, например, вследствие пика в трафике, можно передавать в потоковом режиме данные стабильно на высоких скоростях, поскольку можно избегать затрагиваемых частей сети, например, посредством разделения обработки между множеством краевых серверов или переключения нагрузок потоковой передачи на другой краевой сервер и продолжения потоковой передачи.
[0711] Децентрализация не ограничена просто разделением обработки для потоковой передачи; кодирование захваченных данных может разделяться между и выполняться посредством терминалов, на серверной стороне либо обоими способами. В одном примере, при типичном кодировании, обработка выполняется в двух контурах. Первый контур служит для обнаружения того, насколько усложненным является изображение, на покадровой или посценовой основе либо для обнаружения нагрузки при кодировании. Второй контур служит для обработки, которая сохраняет качество изображений и повышает эффективность кодирования. Например, можно снижать нагрузку по обработке терминалов и повышать качество и эффективность кодирования контента за счет инструктирования терминалам выполнять первый контур кодирования и инструктирования серверной стороне, которая принимает контент, выполнять второй контур кодирования. В таком случае, при приеме запроса на декодирование, кодированные данные, получающиеся в результате первого контура, выполняемого посредством одного терминала, могут приниматься и воспроизводиться на другом терминале приблизительно в реальном времени. Это позволяет реализовывать плавную потоковую передачу в режиме реального времени.
[0712] В другом примере, камера ex113 и т.п. извлекает количество признаков из изображения, сжимает данные, связанные с количеством признаков, в качестве метаданных, и передает сжатые метаданные на сервер. Например, сервер определяет значимость объекта на основе количества признаков и изменяет точность квантования, соответственно, чтобы выполнять сжатие, подходящее для смыслового значения (или значимости контента) изображения. Данные количества признаков являются, в частности, эффективными при повышении точности и эффективности прогнозирования векторов движения во время второго прохода сжатия, выполняемого посредством сервера. Кроме того, кодирование, которое имеет относительно низкую нагрузку по обработке, такое как кодирование переменной длины (VLC), может обрабатываться посредством терминала, и кодирование, которое имеет относительно высокую нагрузку по обработке, такое как контекстно-адаптивное двоичное арифметическое кодирование (CABAC), может обрабатываться посредством сервера.
[0713] В еще одном другом примере, возникают случаи, в которых множество видео приблизительно идентичной сцены захватываются посредством множества терминалов, например, на стадионе, в торговом центре или на фабрике. В таком случае, например, кодирование может быть децентрализовано посредством разделения задач обработки между множеством терминалов, которые захватывают видео, и, при необходимости, другими терминалами, которые не захватывают видео, и сервером в расчете на единицу. Единицы, например, могут представлять собой группы кадров (GOP), кадры или плитки, получающиеся в результате разделения кадра. Это позволяет уменьшать время загрузки и достигать потоковой передачи, которая находится ближе к реальному времени.
[0714] Поскольку видео имеют приблизительно идентичную сцену, управление и/или инструкции могут выполняться посредством сервера таким образом, что на видео, захваченные посредством терминалов, можно перекрестно ссылаться. Кроме того, сервер может принимать кодированные данные из терминалов, изменять опорную взаимосвязь между элементами данных либо корректировать или заменять непосредственно кадры и затем выполнять кодирование. Это позволяет формировать поток с увеличенным качеством и эффективностью для отдельных элементов данных.
[0715] Кроме того, сервер может передавать в потоковом режиме видеоданные после выполнения транскодирования, чтобы преобразовывать формат кодирования видеоданных. Например, сервер может преобразовывать формат кодирования из MPEG в VP (например, VP9) и может преобразовывать H.264 в H.265.
[0716] Таким образом, кодирование может выполняться посредством терминала или одного или более серверов. Соответственно, хотя устройство, которое выполняет кодирование, называется "сервером" или "терминалом" в нижеприведенном описании, некоторые или все процессы, выполняемые посредством сервера, могут выполняться посредством терминала, и аналогично некоторые или все процессы, выполняемые посредством терминала, могут выполняться посредством сервера. Это также применяется к процессам декодирования.
[0717] Трехмерный многоракурсный режим
Происходит увеличение использования изображений или видео, комбинированных из изображений или видео различных сцен, параллельно захваченных, либо идентичной сцены, захваченной из различных углов посредством множества терминалов, таких как камера ex113 и/или смартфон ex115. Видео, захваченное посредством терминалов, комбинируется, например, на основе отдельно полученной относительной позиционной взаимосвязи между терминалами или областями в видео, имеющими совпадающие точки-признаки.
[0718] В дополнение к кодированию двумерных движущихся кадров, сервер может кодировать неподвижное изображение на основе анализа сцен движущегося кадра, автоматически либо в момент времени, указываемый пользователем, и передавать кодированное неподвижное изображение в приемный терминал. Кроме того, когда сервер может получать относительную позиционную взаимосвязь между терминалами захвата видео, в дополнение к двумерным движущимся кадрам, сервер может формировать трехмерную геометрию сцены на основе видео идентичной сцены, захваченной из различных углов. Сервер может отдельно кодировать трехмерные данные, сформированные, например, из облака точек, и, на основе результата распознавания или отслеживания человека или объекта с использованием трехмерных данных, может выбирать или восстанавливать и формировать видео, которые должно передаваться в приемный терминал, из видео, захваченных посредством множества терминалов.
[0719] Это обеспечивает возможность пользователю пользоваться сценой посредством свободного выбора видео, соответствующих терминалам захвата видео, и обеспечивает возможность пользователю пользоваться контентом, полученным посредством извлечения видео в выбранной точке обзора из трехмерных данных, восстановленных из множества изображений или видео, видео. Кроме того, аналогично видео, звук может записываться из относительно различных углов, и сервер может мультиплексировать аудио из конкретного угла или пространства с соответствующим видео и передавать мультиплексированное видео и аудио.
[0720] В последние годы, также становится популярным контент, который представляет собой составной объект из реального мира и виртуального мира, к примеру, контент в стиле виртуальной реальности (VR) и дополненной реальности (AR). В случае VR-изображений, сервер может создавать изображения из точек обзора левого и правого глаза и выполнять кодирование, которое допускает ссылку между двумя изображениями точек обзора, такое как многовидовое кодирование (MVC), и альтернативно, может кодировать изображения в качестве отдельных потоков без ссылки. Когда изображения декодируются в качестве отдельных потоков, потоки могут синхронизироваться при воспроизведении таким образом, чтобы воссоздавать виртуальное трехмерное пространство в соответствии с точкой обзора пользователя.
[0721] В случае AR-изображений, сервер накладывает информацию виртуальных объектов, существующую в виртуальном пространстве, на информацию камеры, представляющую пространство реального мира, на основе трехмерной позиции или перемещения с точки зрения пользователя. Декодер может получать или сохранять информацию виртуальных объектов и трехмерные данные, формировать двумерные изображения на основе перемещения с точки зрения пользователя и затем формировать наложенные данные посредством прозрачного соединения изображений. Альтернативно, декодер может передавать, в сервер, движение с точки зрения пользователя в дополнение к запросу на информацию виртуальных объектов. Сервер может формировать наложенные данные на основе трехмерных данных, сохраненных на сервере, в соответствии с принимаемым движением, и кодировать и передавать в потоковом режиме сформированные наложенные данные в декодер. Следует отметить, что наложенные данные включают в себя, в дополнение к RGB-значениям, значение α, указывающее прозрачность, и сервер задает значение α для секций, отличных от объекта, сформированного из трехмерных данных, например, равным 0, и может выполнять кодирование в то время, когда эти секции являются прозрачными. Альтернативно, сервер может задавать фон как определенное RGB-значение, такое как цветовая рирпроекция, и формировать данные, в которых зоны, отличные от объекта, задаются в качестве фона.
[0722] Декодирование аналогично передаваемых в потоковом режиме данных может выполняться посредством клиента (т.е. терминалов), на серверной стороне либо разделяться между ними. В одном примере, один терминал может передавать запрос на прием на сервер, запрошенный контент может приниматься и декодироваться посредством другого терминала, и декодированный сигнал может передаваться в устройство, имеющее дисплей. Можно воспроизводить данные с высоким качеством изображений посредством децентрализации обработки и надлежащего выбора контента независимо от способности к обработке непосредственно терминала связи. В еще одном другом примере, в то время как телевизор, например, принимает данные изображений, которые имеют большой размер, область кадра, такая как плитка, полученная посредством разделения кадра, может декодироваться и отображаться на персональном терминале или терминалах зрителя или зрителей телевизора. Это позволяет зрителям совместно использовать вид с большими кадрами, а также каждому зрителю проверять свою назначенную зону или обследовать область более подробно крупным планом.
[0723] В ситуациях, в которых множество беспроводных соединений являются возможными на небольшие, средние и большие расстояния, в помещениях или вне помещений, может быть возможным прозрачно принимать контент с использованием стандарта системы потоковой передачи, такого как MPEG DASH. Пользователь может переключаться между данными в реальном времени при свободном выборе декодера или оборудования отображения, включающего в себя терминал пользователя, дисплеи, размещаемые в помещениях или вне помещений, и т.д. Кроме того, например, с использованием информации относительно позиции пользователя, декодирование может выполняться при переключении того, какой терминал обрабатывает декодирование, а какой терминал обрабатывает отображение контента. Это позволяет преобразовывать и отображать информацию в то время, когда пользователь находится в движении на маршруте в пункт назначения, на стене близлежащего здания, в которое встраивается устройство, допускающее отображение контента, или на части земли. Кроме того, также можно переключать скорость передачи битов принимаемых данных на основе достижимости для кодированных данных по сети, к примеру, когда кодированные данные кэшируются на сервере, быстро доступном из приемного терминала, либо когда кодированные данные копируются на краевой сервер в службе доставки контента.
[0724] Оптимизация веб-страниц
Фиг. 103, например, иллюстрирует пример экрана отображения веб-страницы на компьютере ex111. Фиг. 104, например, иллюстрирует пример экрана отображения веб-страницы на смартфоне ex115. Как проиллюстрировано на фиг. 103 и фиг. 104, веб-страница может включать в себя множество ссылок на изображения, которые представляют собой ссылки на контент изображений, и внешний вид веб-страницы отличается в зависимости от устройства, используемого для того, чтобы просматривать веб-страницу. Когда множество ссылок на изображения являются просматриваемыми на экране до тех пор, пока пользователь явно не выбирает ссылку на изображение, либо до тех пор, пока ссылка на изображение не находится в аппроксимированном центре экрана, или полная ссылка на изображение не вписывается в экран, оборудование отображения (декодер) может отображать, в качестве ссылок на изображения, неподвижные изображения, включенные в контент, или I-кадры, может отображать видео, такое как анимированный GIF-файл с использованием множества неподвижных изображений или I-кадров, например, либо может принимать только базовый слой и декодировать и отображать видео.
[0725] Когда ссылка на изображение выбирается пользователем, оборудование отображения выполняет декодирование при предоставлении наивысшего приоритета для базового слоя. Следует отметить, что если имеется информация в HTML-коде веб-страницы, указывающая то, что контент является масштабируемым, оборудование отображения может декодировать вплоть до улучшающего слоя. Дополнительно, чтобы гарантировать воспроизведение в реальном времени, до того, как осуществляется выбор, либо когда полоса пропускания сильно ограничивается, оборудование отображения может уменьшать задержку между моментом времени, в который декодируется опережающий кадр, и моментом времени, в который отображается декодированный кадр (т.е. задержку от начала декодирования контента до отображения контента) посредством декодирования и отображения только прямых опорных кадров (I-кадра, P-кадра, прямого опорного B-кадра). Еще дополнительно, оборудование отображения может намеренно игнорировать опорную взаимосвязь между кадрами и приблизительно декодировать все B- и P- кадры в качестве прямых опорных кадров и затем выполнять нормальное декодирование по мере того, как число кадров, принимаемых во времени, увеличивается.
[0726] Автономное вождение
При передаче и приеме в данных неподвижных изображений или видеоданных, таких как двух- или трехмерная картографическая информация для автономного вождения или вождения с использованием помощи автомобиля, приемный терминал может принимать, в дополнение к данным изображений, принадлежащим одному или более слоев, информацию, например, относительно погоды или дорожных работ в качестве метаданных, и ассоциировать метаданные с данными изображений при декодировании. Следует отметить, что метаданные могут назначаться в расчете на слой и, альтернативно, могут просто мультиплексироваться с данными изображений.
[0727] В таком случае, поскольку автомобиль, беспилотный аппарат, самолет и т.д., содержащий приемный терминал, является мобильным, приемный терминал может прозрачно принимать и выполнять декодирование при переключении между базовыми станциями из числа базовых станций ex106-ex110 посредством передачи информации, указывающей позицию приемного терминала. Кроме того, в соответствии с выбором, осуществленным пользователем, ситуацией пользователя и/или полосой пропускания соединения, приемный терминал может динамически выбирать то, до какой степени принимаются метаданные, либо то, до какой степени, например, обновляется картографическая информация.
[0728] В системе ex100 предоставления контента, клиент может принимать, декодировать и воспроизводить, в реальном времени, кодированную информацию, передаваемую пользователем.
[0729] Потоковая передача контента от людей
В системе ex100 предоставления контента, в дополнение к длительному контенту с высоким качеством изображений, распространяемому посредством объекта распространения видео, одноадресная или многоадресная потоковая передача короткого контента с низким качеством изображений от человека также является возможной. Популярность такого контента от людей с большой вероятностью должна еще более возрастать. Сервер может сначала выполнять обработку редактирования для контента перед обработкой кодирования, чтобы уточнять контент от людей. Это может достигаться, например, с использованием следующей конфигурации.
[0730] В реальном времени, при захвате видеоконтента или контента изображений либо после того, как контент захвачен и накоплен, сервер выполняет обработку распознавания на основе необработанных данных или кодированных данных, такую как обработка ошибок при захвате, обработка поиска сцен, анализ смысловых значений и/или обработка обнаружения объектов. После этого, на основе результата обработки распознавания сервер (при указании или автоматически) редактирует контент, примеры чего включают в себя: коррекцию, такую как коррекция фокуса и/или размытости при движении; удаление сцен с низким приоритетом, таких как сцены, которые имеют низкую яркость по сравнению с другими кадрами или находятся не в фокусе; регулирование краев объектов; и регулирование цветовых тонов. Сервер кодирует отредактированные данные на основе результата редактирования. Известно, что чрезмерно длительные видео имеют тенденцию принимать меньшее число видов. Соответственно, чтобы сохранять контент в пределах конкретной продолжительности, которая масштабируется с продолжительностью исходного видео, сервер может, в дополнение к сценам с низким приоритетом, описанным выше, автоматически вырезать сцены с незначительным перемещением на основе результата обработки изображений. Альтернативно, сервер может формировать и кодировать видеодайджест на основе результата анализа смыслового значения сцены.
[0731] Могут возникать случаи, в которых контент от людей может включать в себя контент, который нарушает авторское право, моральное право, книжные права и т.д. Такой случай может приводить к непредпочтительной ситуации для создателя, к примеру, когда контент совместно используется за пределами объема, намеченного создателем. Соответственно, перед кодированием, сервер, например, может редактировать изображения таким образом, чтобы, например, размывать лица людей на периферии экрана или размывать внутреннюю часть дома. Дополнительно, сервер может быть выполнен с возможностью распознавать лица людей, отличных от зарегистрированного человека, в изображениях, которые должны кодироваться, и когда такие лица появляются в изображении, может применять мозаичный фильтр, например, к лицу человека. Альтернативно, в качестве предварительной обработки или постобработки для кодирования, пользователь может указывать, по причинам авторского права, область изображения, включающую в себя человека, или область фона, которая должна обрабатываться. Сервер может обрабатывать указанную область, например, посредством замены области другим изображением или размытия области. Если область включает в себя человека, человек может отслеживаться в движущемся кадре, и область головы пользователя может заменяться другим изображением по мере того, как человек перемещается.
[0732] Поскольку имеется спрос на просмотр в реальном времени контента, сформированного людьми, который зачастую имеет небольшой размер данных, декодер сначала принимает базовый слой в качестве наивысшего приоритета и выполняет декодирование и воспроизведение, хотя это может отличаться в зависимости от полосы пропускания. Когда контент воспроизводится два или более раз, к примеру, когда декодер принимает улучшающий слой во время декодирования и воспроизведения базового слоя и циклично выполняет воспроизведение, декодер может воспроизводить видео с высоким качеством изображений, включающее в себя улучшающий слой. Если поток кодируется с использованием такого масштабируемого кодирования, видео может быть низкокачественным в невыбранном состоянии или в начале видео, но оно может предлагать восприятие, в котором качество изображений потока постепенно увеличивается интеллектуальным способом. Это не ограничено просто масштабируемым кодированием; идентичное восприятие может предлагаться посредством конфигурирования одного потока из низкокачественного потока, воспроизведенного в первый раз, и второго потока, кодированного с использованием первого потока в качестве опорного.
[0733] Другие примеры реализации и вариантов применения
Кодирование и декодирование может выполняться посредством LSI ex500 (большой интегральной схемы) (см. фиг. 102), которая типично включается в каждый терминал. LSI ex500 может быть сконфигурирована из одной микросхемы или множества микросхем. Программное обеспечение для кодирования и декодирования движущихся кадров может интегрироваться в некоторый тип носителя (такой как CD-ROM, гибкий диск или жесткий диск), который является считываемым, например, посредством компьютера ex111, и кодирование и декодирование могут выполняться с использованием программного обеспечения. Кроме того, когда смартфон ex114 оснащен камерой, могут передаваться видеоданные, полученные посредством камеры. В этом случае, видеоданные кодируются посредством LSI ex500, включенной в смартфон ex115.
[0734] Следует отметить, что LSI ex500 может быть выполнена с возможностью загружать и активировать приложение. В таком случае, терминал сначала определяет то, является он или нет совместимым со схемой, используемой для того, чтобы кодировать контент, либо то, допускает он или нет выполнение конкретной услуги. Когда терминал не является совместимым со схемой кодирования контента, либо когда терминал не допускает выполнение конкретной услуги, терминал сначала загружает кодек или прикладное программное обеспечение, а затем получает и воспроизводит контент.
[0735] Помимо примера системы ex100 предоставления контента, которая использует Интернет ex101, по меньшей мере, кодер движущихся кадров (кодер изображений) или декодер движущихся кадров (декодер изображений), описанные в вышеприведенных вариантах осуществления, могут реализовываться в цифровой широковещательной системе. Идентичная обработка кодирования и обработка декодирования могут применяться для того, чтобы передавать и принимать широковещательные радиоволны, накладываемые с мультиплексированными аудио- и видеоданными, с использованием, например, спутника, даже если она приспосабливается к многоадресной передаче, тогда как одноадресная передача осуществляется проще с системой ex100 предоставления контента.
[0736] Аппаратная конфигурация
Фиг. 105 иллюстрирует дополнительные сведения относительно смартфона ex115, показанного на фиг. 102. Фиг. 106 иллюстрирует пример конфигурации смартфона ex115. Смартфон ex115 включает в себя антенну ex450 для передачи и приема радиоволн в/из базовой станции ex110, камеру ex465, допускающую захват видео и неподвижных изображений, и дисплей ex458, который отображает декодированные данные, такие как видео, захваченное посредством камеры ex465, и видео, принимаемое посредством антенны ex450. Смартфон ex115 дополнительно включает в себя пользовательский интерфейс ex466, такой как сенсорная панель, модуль ex457 аудиовывода, такой как динамик для вывода речи или другого аудио, модуль ex456 аудиоввода, такой как микрофон для аудиоввода, запоминающее устройство ex467, допускающее сохранение декодированных данных, таких как захваченные видео или неподвижные изображения, записанное аудио, принимаемые видео или неподвижные изображения и почтовые сообщения, а также декодированные данные, и гнездо ex464, которое представляет собой интерфейс для SIM-карты ex468 для авторизации доступа к сети и различным данным. Следует отметить, что внешнее запоминающее устройство может использоваться вместо запоминающего устройства ex467.
[0737] Главный контроллер ex460, который всесторонне управляет дисплеем ex458 и пользовательским интерфейсом ex466, схема ex461 подачи мощности, контроллер ex462 ввода из пользовательского интерфейса, процессор ex455 видеосигналов, интерфейс ex463 камеры, контроллер ex459 отображения, модулятор/демодулятор ex452, мультиплексор/демультиплексор ex453, процессор ex454 аудиосигналов, гнездо ex464 и запоминающее устройство ex467, соединяются через шину ex470.
[0738] Когда пользователь включает кнопку питания схемы ex461 подачи мощности, смартфон ex115 включается в работоспособное состояние, и каждый компонент снабжается мощностью из аккумуляторного блока.
[0739] Смартфон ex115 выполняет обработку, например, для вызовов и передачи данных, на основе управления, выполняемого посредством главного контроллера ex460, который включает в себя CPU, ROM и RAM. При выполнении вызовов, аудиосигнал, записанный посредством модуля ex456 аудиоввода, преобразуется в цифровой аудиосигнал посредством процессора ex454 аудиосигналов, к которому применяется обработка с расширенным спектром посредством модулятора/демодулятора ex452 и применяется обработка цифро-аналогового преобразования и преобразования частоты посредством приемо-передающего устройства ex451, и результирующий сигнал передается через антенну ex450. Принимаемые данные усиливаются, преобразуются по частоте и подвергаются аналого-цифровому преобразованию, подвергаются обратной обработке с расширенным спектром посредством модулятора/демодулятора ex452, преобразуются в аналоговый аудиосигнал посредством процессора ex454 аудиосигналов и затем выводятся из модуля ex457 аудиовывода. В режиме передачи данных, текст, данные неподвижных изображений или видеоданные передаются посредством главного контроллера ex460 через контроллер ex462 ввода из пользовательского интерфейса на основе операции пользовательского интерфейса ex466 основного корпуса. Аналогичная обработка передачи и приема выполняется. В режиме передачи данных, при отправке видео, неподвижного изображения или видео и аудио, процессор ex455 видеосигналов кодирует со сжатием, посредством способа кодирования движущихся кадров, описанного в вышеприведенных вариантах осуществления, видеосигнал, сохраненный в запоминающем устройстве ex467, или видеосигнал, вводимый из камеры ex465, и передает кодированные видеоданные в мультиплексор/демультиплексор ex453. Процессор ex454 аудиосигналов кодирует аудиосигнал, записанный посредством модуля ex456 аудиоввода, в то время как камера ex465 захватывает видео или неподвижное изображение, и передает кодированные аудиоданные в мультиплексор/демультиплексор ex453. Мультиплексор/демультиплексор ex453 мультиплексирует кодированные видеоданные и кодированные аудиоданные с использованием определенной схемы, модулирует и преобразует данные с использованием модулятора/демодулятора ex452 (схемы модулятора/демодулятора) и приемо-передающего устройства ex451 и передает результат через антенну ex450.
[0740] Когда видео, вложенное в почтовом сообщении или в чате, или видео, содержащее ссылку из веб-страницы, принимается, например, для того чтобы декодировать мультиплексированные данные, принимаемые через антенну ex450, мультиплексор/демультиплексор ex453 демультиплексирует мультиплексированные данные, чтобы разделять мультиплексированные данные на поток битов видеоданных и поток битов аудиоданных, предоставляет кодированные видеоданные в процессор ex455 видеосигналов через синхронную шину ex470 и предоставляет кодированные аудиоданные в процессор ex454 аудиосигналов через синхронную шину ex470. Процессор ex455 видеосигналов декодирует видеосигнал с использованием способа декодирования движущихся кадров, соответствующего способу кодирования движущихся кадров, описанному в вышеприведенных вариантах осуществления, и видео или неподвижное изображение, включенное в связанный файл движущихся кадров, отображается на дисплее ex458 через контроллер ex459 отображения. Процессор ex454 аудиосигналов декодирует аудиосигнал и выводит аудио из модуля ex457 аудиовывода. Поскольку потоковая передача в режиме реального времени становится все более популярной, могут возникать случаи, в которых воспроизведение аудио может быть социально нецелесообразным, в зависимости от окружения пользователя. Соответственно, в качестве начального значения, например, может быть предпочтительной конфигурация, в которой только видеоданные воспроизводятся, т.е. аудиосигнал не воспроизводится; и аудио может синхронизироваться и воспроизводиться только тогда, когда ввод принимается от пользователя, щелкающего видеоданные.
[0741] Хотя смартфон ex115 использован в вышеприведенном примере, возможны три другие реализации: приемо-передающий терминал, включающий в себя как кодер, так и декодер; передающий терминал, включающий в себя только кодер; и приемный терминал, включающий в себя только декодер. В описании цифровой широковещательной системы, приводится пример, в котором мультиплексированные данные, полученные в результате мультиплексирования видеоданных с аудиоданными, принимаются или передаются. Тем не менее, мультиплексированные данные могут представлять собой видеоданные, мультиплексированные с данными, отличными от аудиоданных, такими как текстовые данные, связанные с видео. Дополнительно, непосредственно видеоданные, а не мультиплексированные данные могут приниматься или передаваться.
[0742] Хотя главный контроллер ex460, включающий в себя CPU, описывается как управляющий процессами кодирования или декодирования, различные терминалы зачастую включают в себя GPU. Соответственно, является приемлемой конфигурация, в которой большая зона обрабатывается сразу посредством использования характеристик с точки зрения производительности GPU через запоминающее устройство, совместно используемое посредством CPU и GPU, либо через запоминающее устройство, включающее в себя адрес, которое управляется таким образом, чтобы обеспечивать возможность широкого использования посредством CPU и GPU. Это позволяет сокращать время кодирования, поддерживать характер реального времени потоковой передачи и уменьшать задержку. В частности, обработка, связанная с оценкой движения, фильтрацией для удаления блочности, дискретизированным адаптивным смещением (SAO) и преобразованием/квантованием, может эффективно выполняться посредством GPU, вместо CPU, например, в единицах кадров, одновременно.
Промышленная применимость
[0743] Настоящее раскрытие сущности является применимым, например, к телевизионным приемникам, цифровым записывающим видеоустройствам, автомобильным навигационным системам, мобильным телефонам, цифровым камерам, цифровым видеокамерам, системам телеконференц-связи, электронным зеркалам и т.д.
Список номеров ссылок
[0744] 100 - кодер
102 - модуль разбиения
102a - модуль определения разбиения блоков
104 - вычитатель
106 - преобразователь
108 - квантователь
108a - формирователь параметров разностного квантования
108b, 204b - формирователь прогнозированных параметров квантования
108c, 204a - формирователь параметров квантования
108d, 204d - устройство хранения параметров квантования
108e - модуль выполнения квантования
110 - энтропийный кодер
110a - модуль преобразования в двоичную форму
110b, 202b - контроллер контекстов
110c - двоичный арифметический кодер
112, 204 - обратный квантователь
114, 206 - обратный преобразователь
116, 208 - сумматор
118, 210 - запоминающее устройство блоков
120, 212 - контурный фильтр
120a, 212a - модуль выполнения фильтрации для удаления блочности
120b, 212b - модуль SAO-выполнения
120c, 212c - модуль ALF-выполнения
122, 214 - запоминающее устройство кинокадров
124, 216 - модуль внутреннего прогнозирования
126, 218 - модуль взаимного прогнозирования
126a, a2, b2 - запоминающее устройство
126b - модуль извлечения интерполированных изображений
126c - модуль извлечения градиентных изображений
126d - модуль извлечения оптических потоков
126e - модуль извлечения значений коррекции
126f - корректор прогнозных изображений
128, 220 - контроллер прогнозирования
130, 222 - формирователь параметров прогнозирования
200 - декодер
202 - энтропийный декодер
202a - двоичный арифметический декодер
202c - модуль отмены преобразования в двоичную форму
204e - модуль выполнения обратного квантования
224 - модуль определения разбиения
1201 - модуль определения границ
1202, 1204, 1206 - переключатель
1203 - модуль определения фильтрации
1205 - модуль выполнения фильтрации
1207 - модуль определения характеристик фильтра
1208 - модуль определения обработки
a1, b1 – процессор.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДЕР, ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ | 2024 |
|
RU2839119C1 |
| КОДЕР, ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ | 2020 |
|
RU2808454C1 |
| СИСТЕМА И СПОСОБ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2020 |
|
RU2817290C2 |
| СИСТЕМА И СПОСОБ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2020 |
|
RU2827369C2 |
| СИСТЕМА И СПОСОБ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2020 |
|
RU2819086C2 |
| СИСТЕМА И СПОСОБ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2024 |
|
RU2831745C1 |
| СИСТЕМА И СПОСОБ ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2024 |
|
RU2840722C1 |
| ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ | 2019 |
|
RU2795260C2 |
| СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ | 2023 |
|
RU2840336C2 |
| Устройство и способ для передачи потока битов | 2020 |
|
RU2830599C2 |
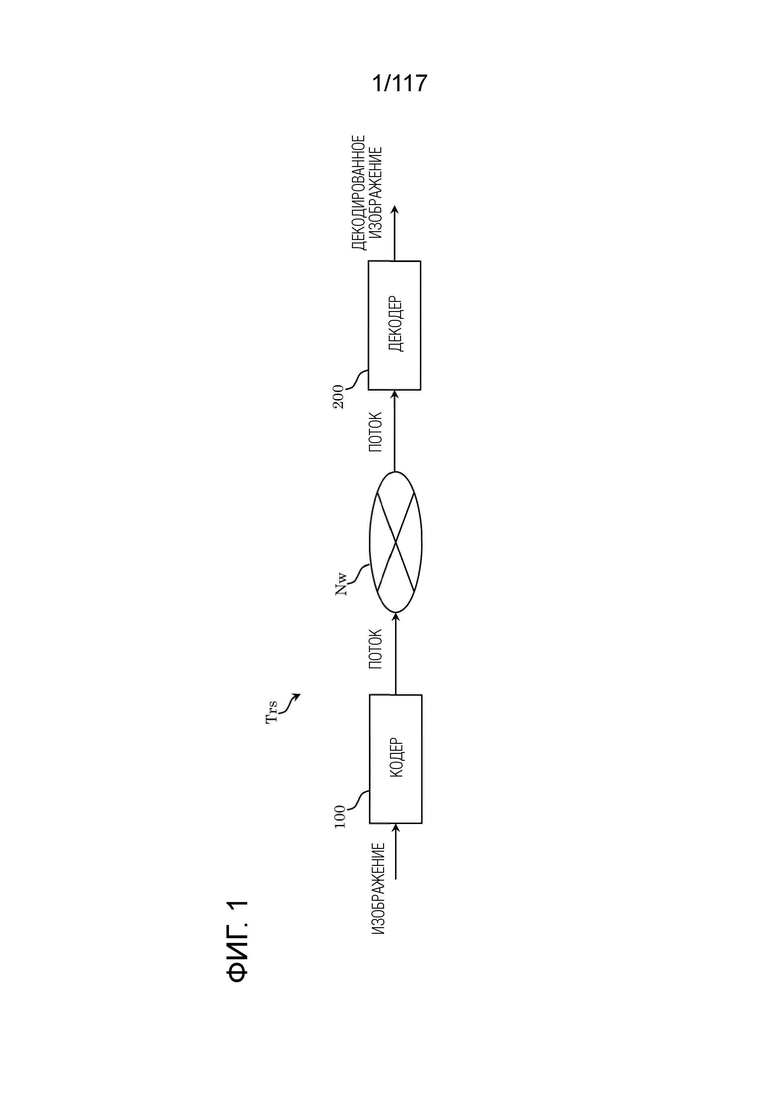
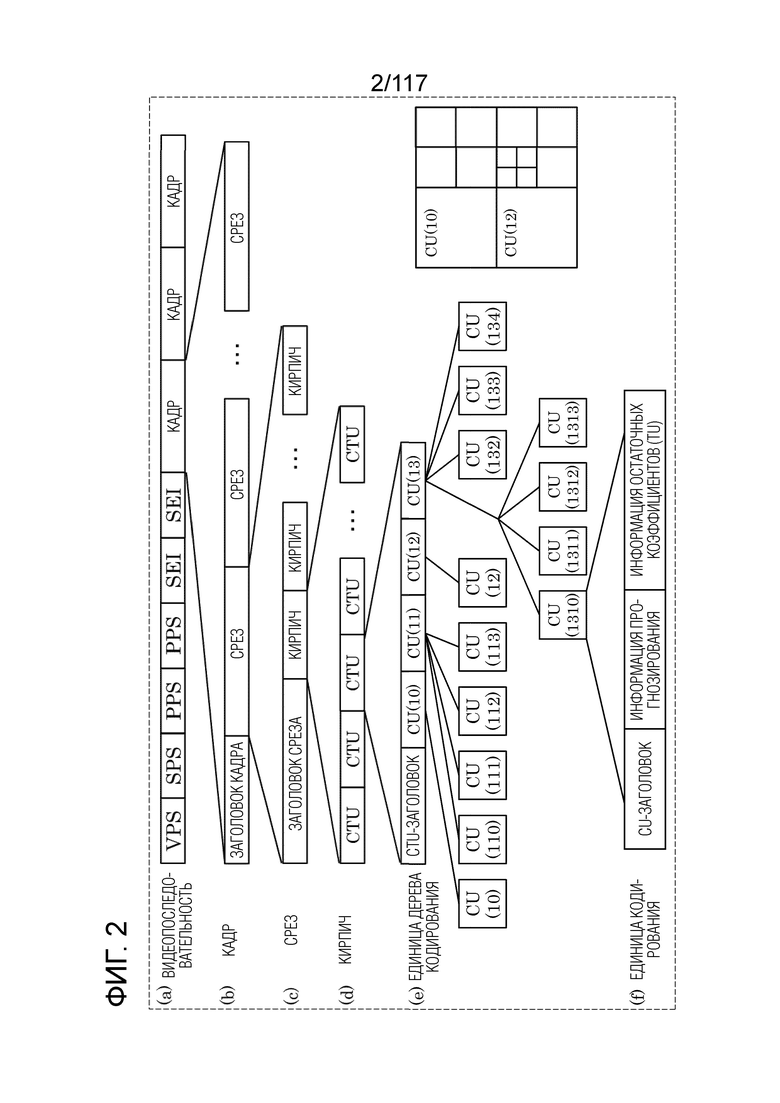
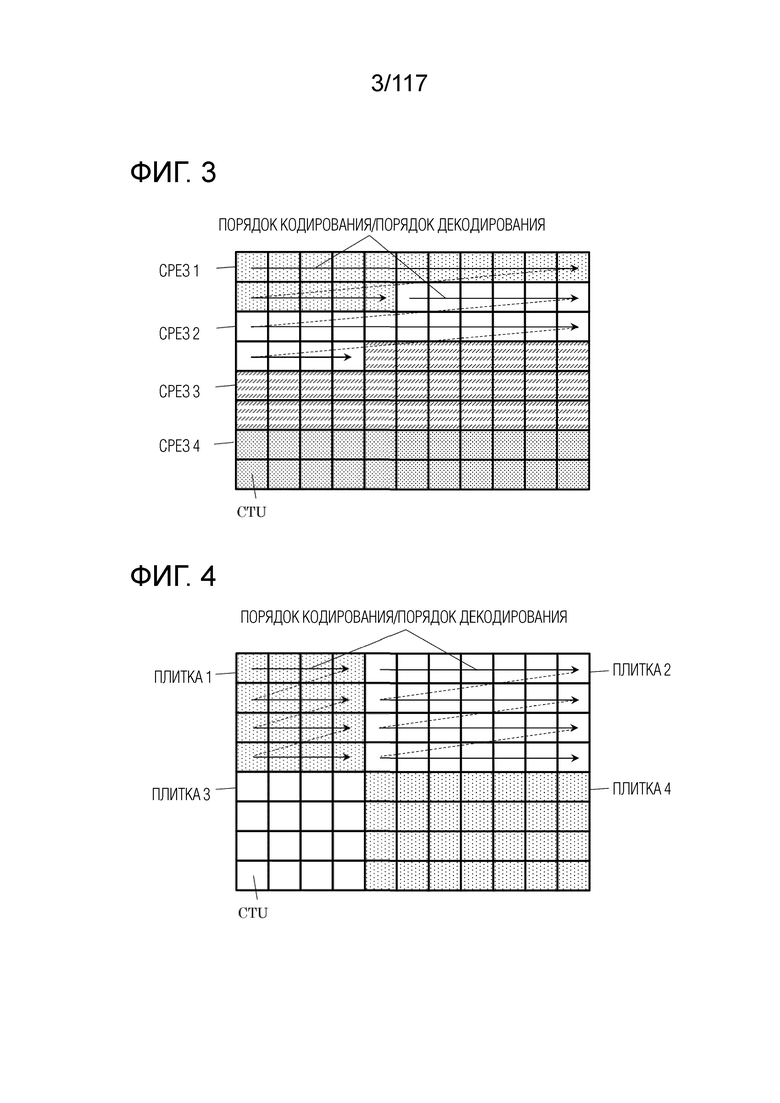
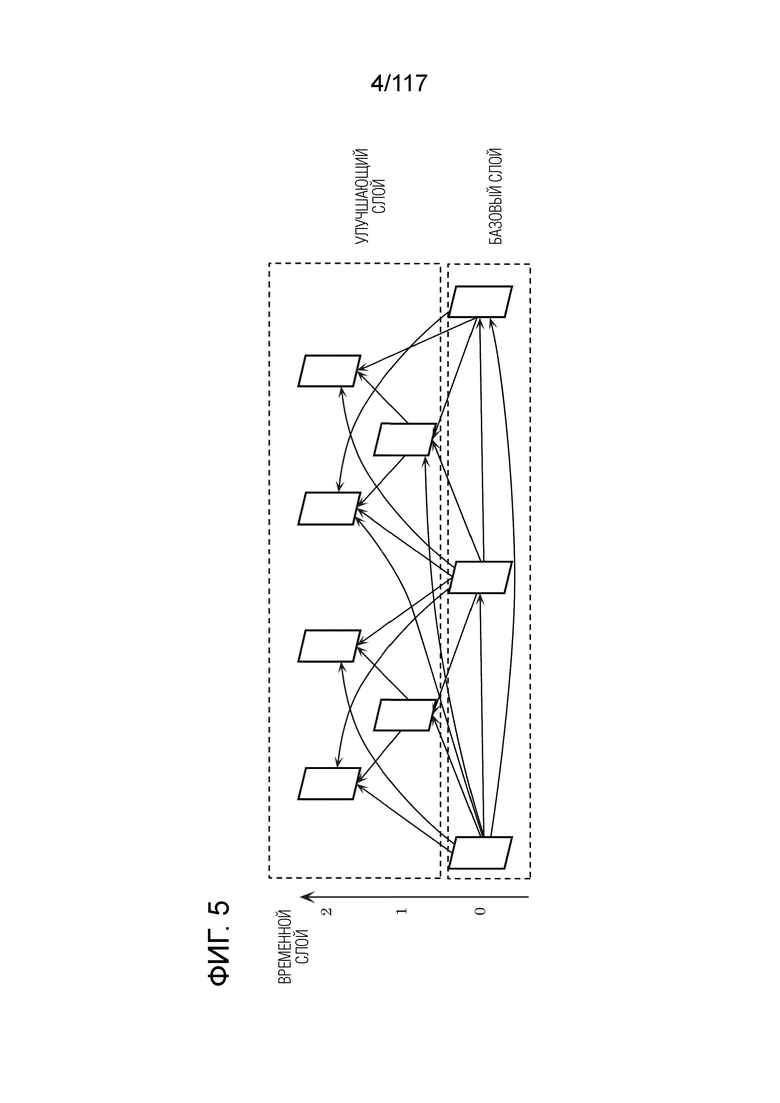
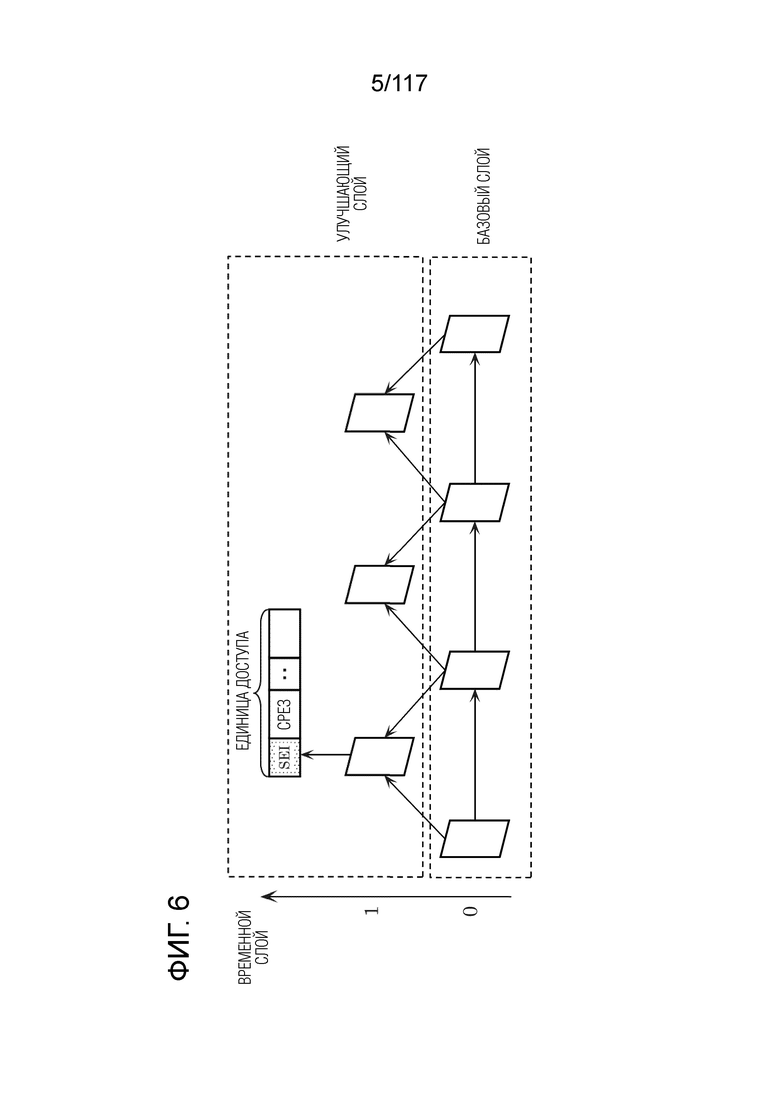
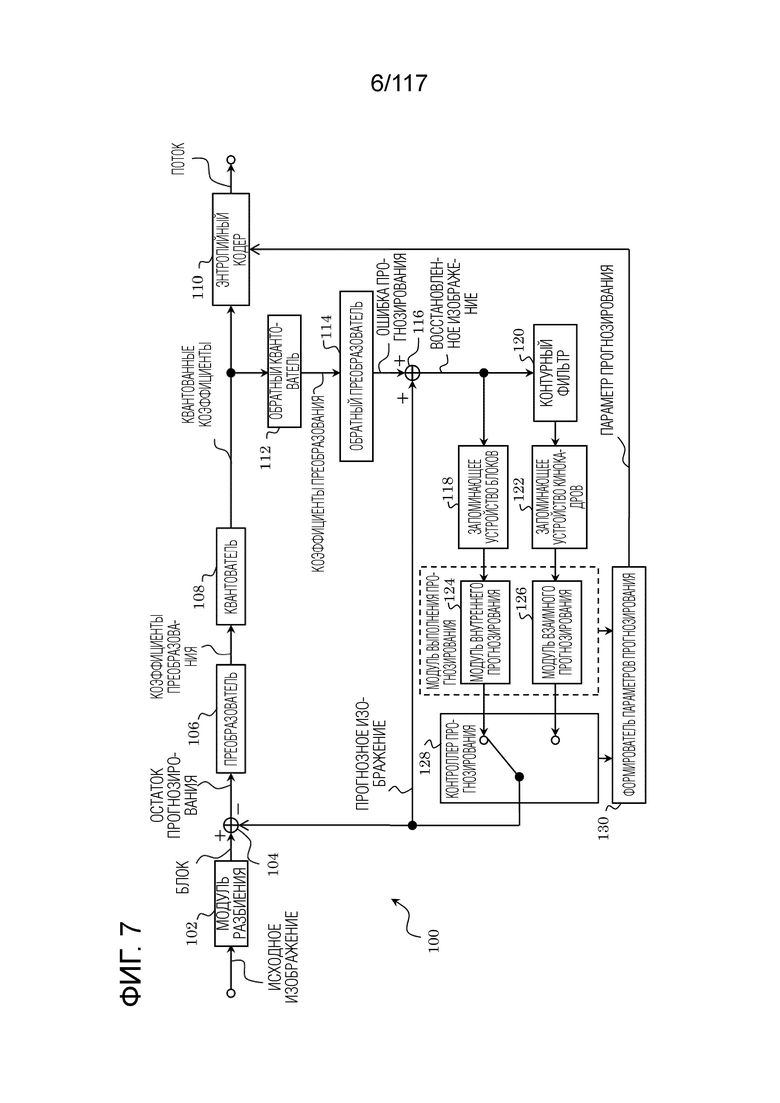
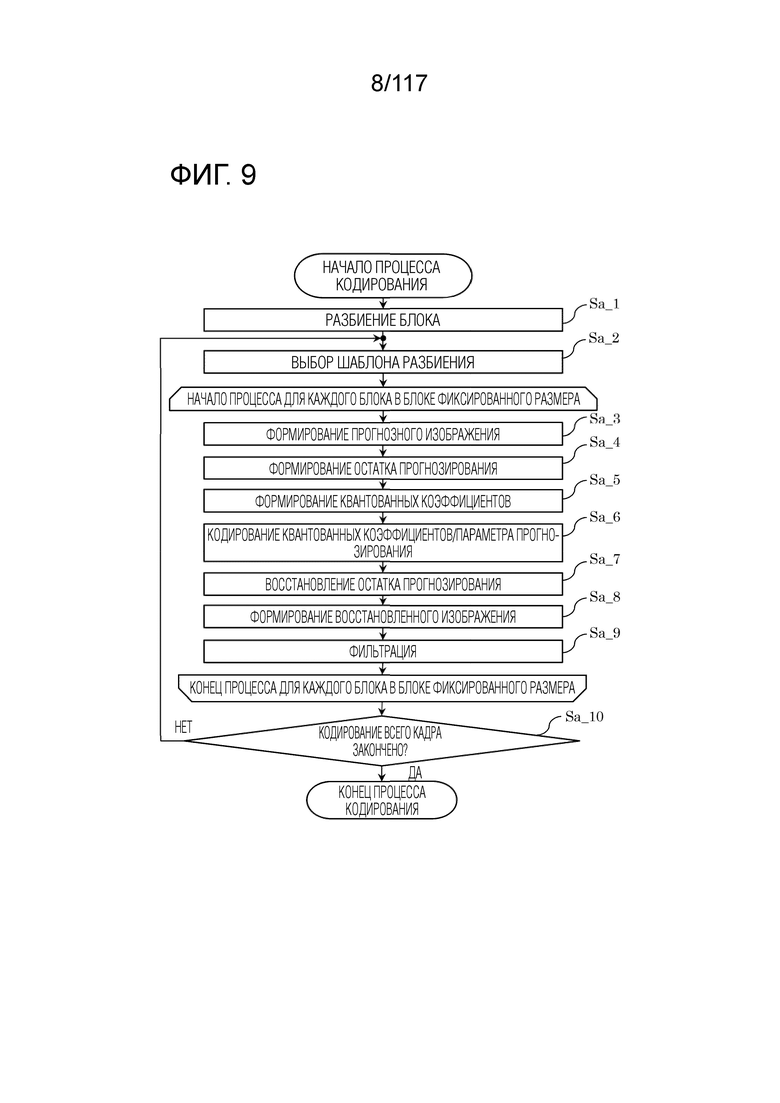
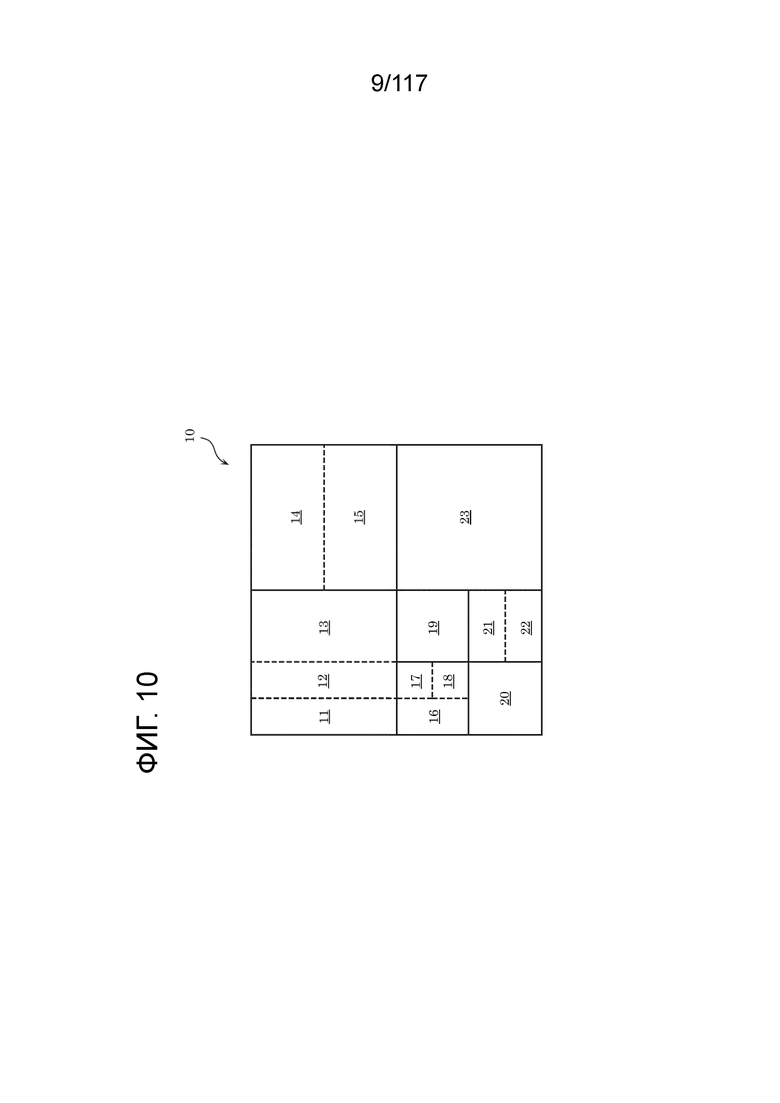
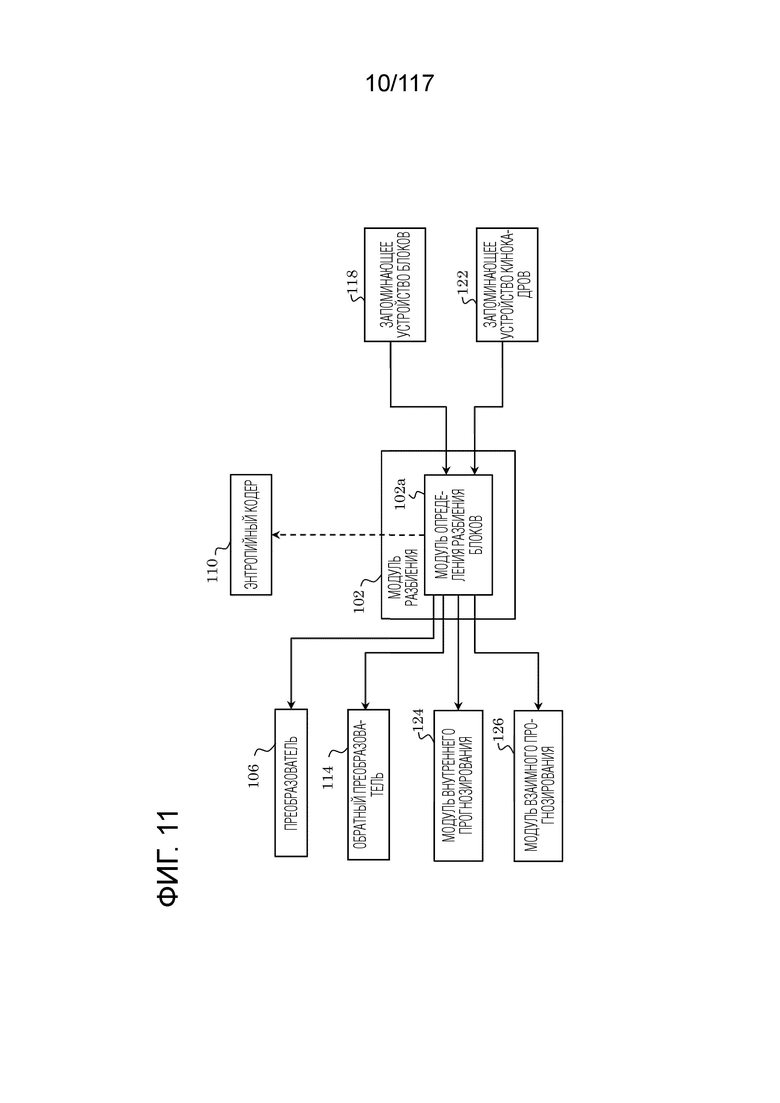
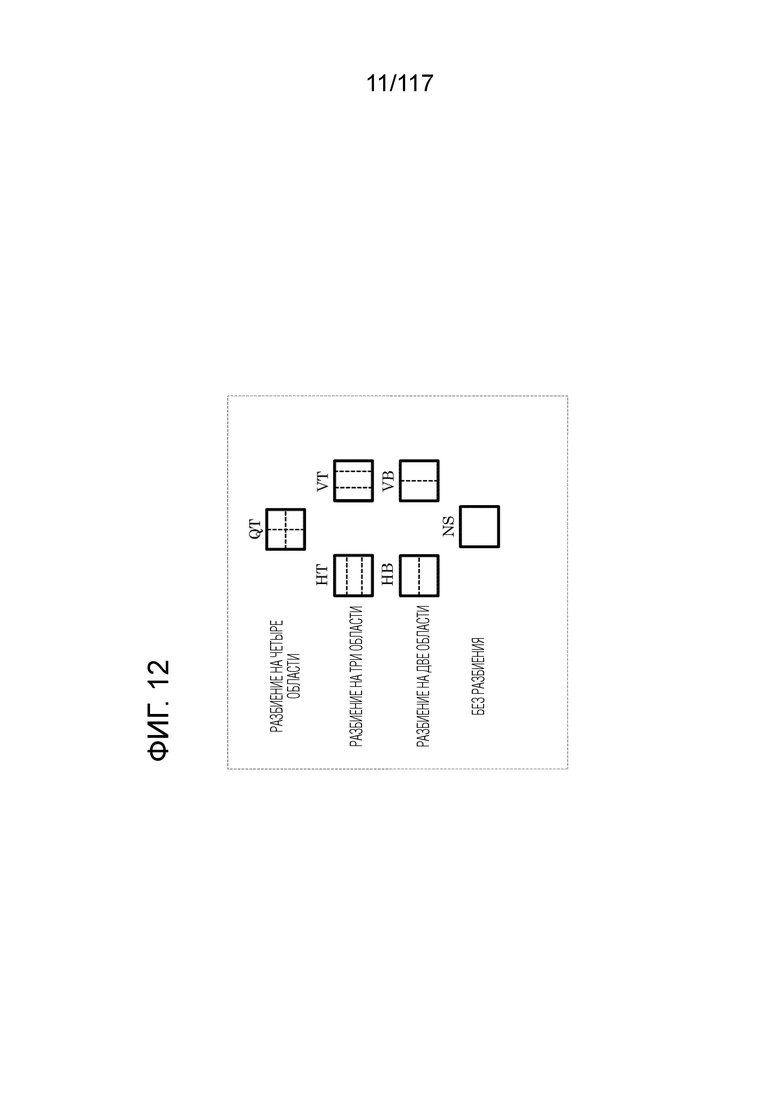
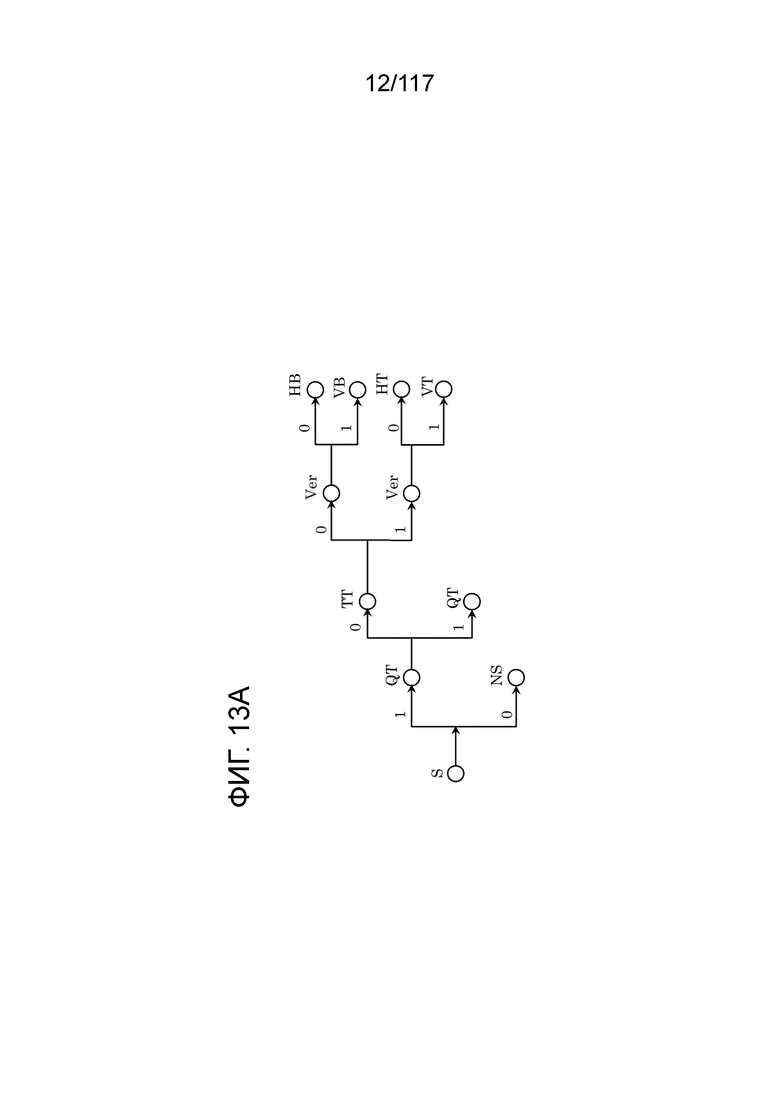
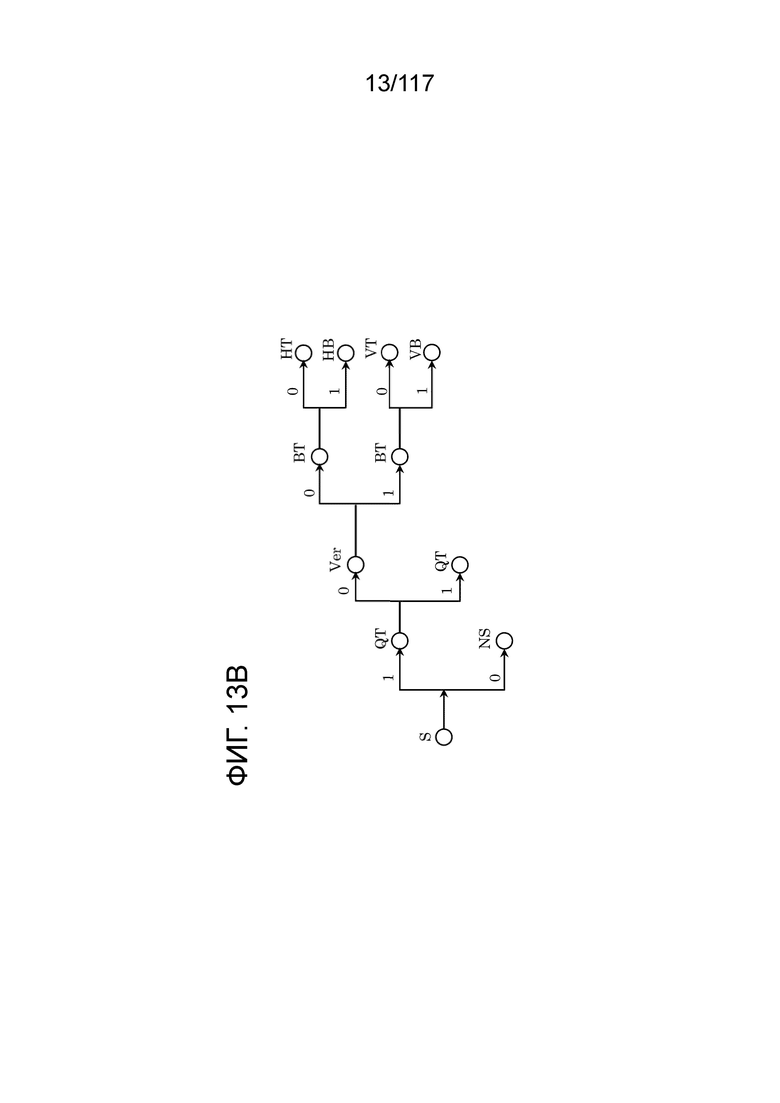
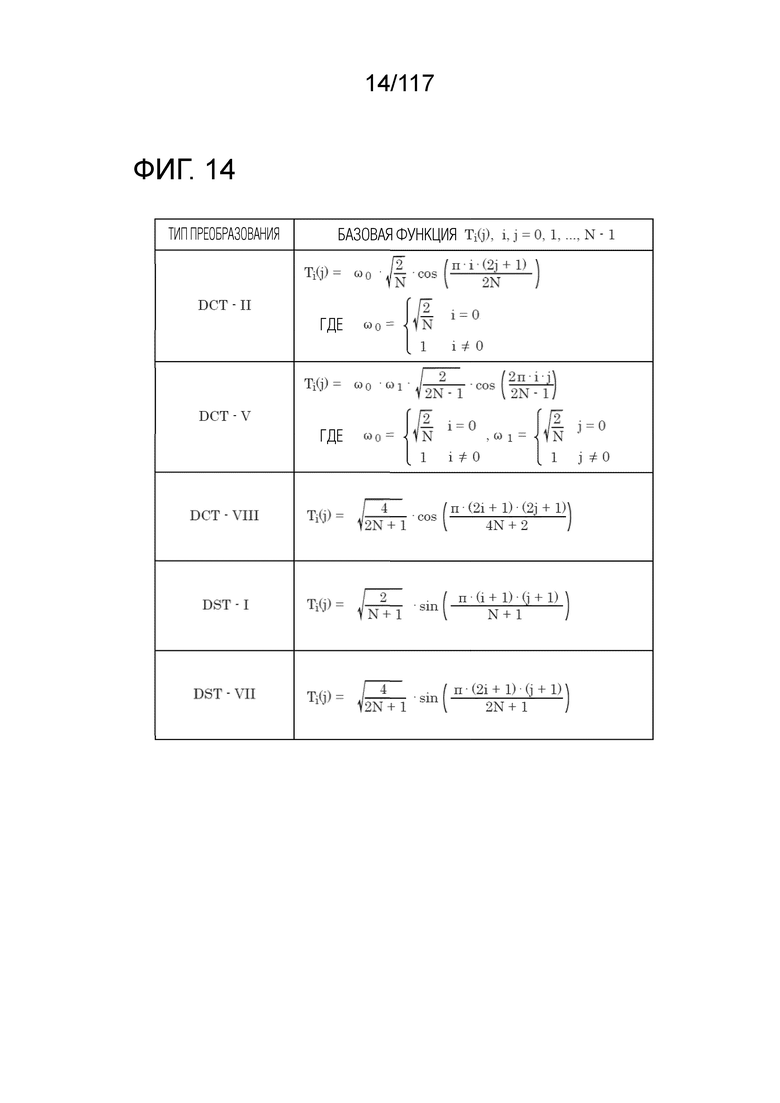
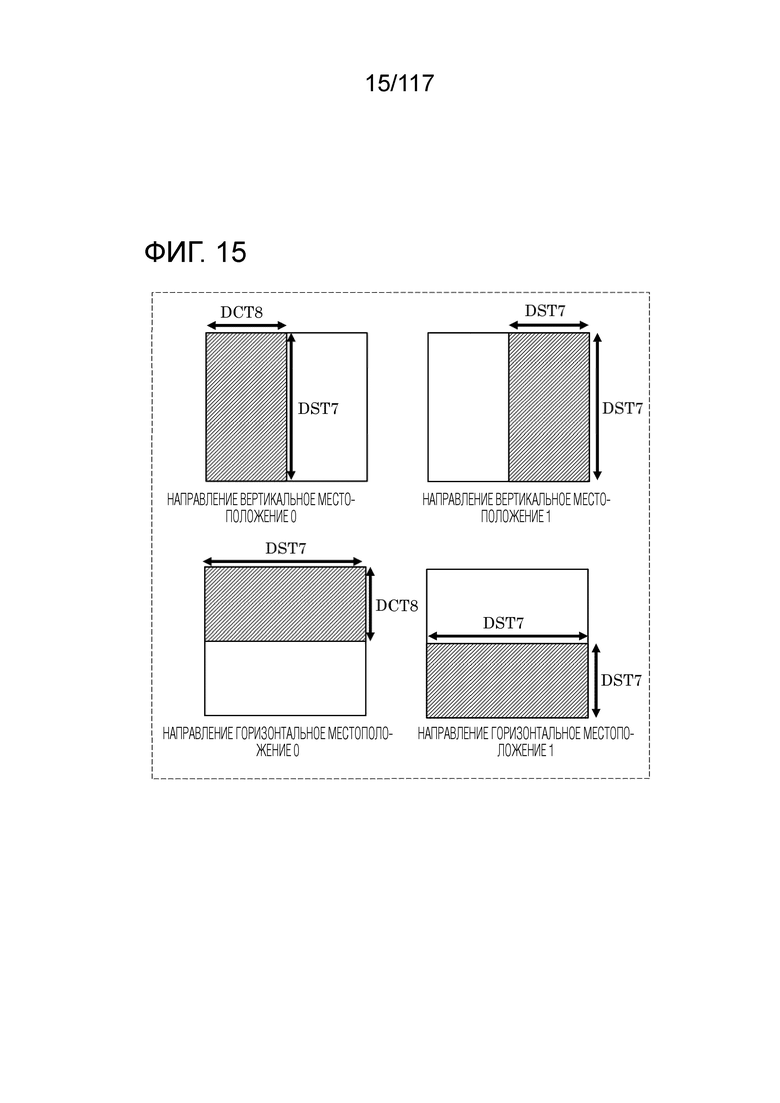
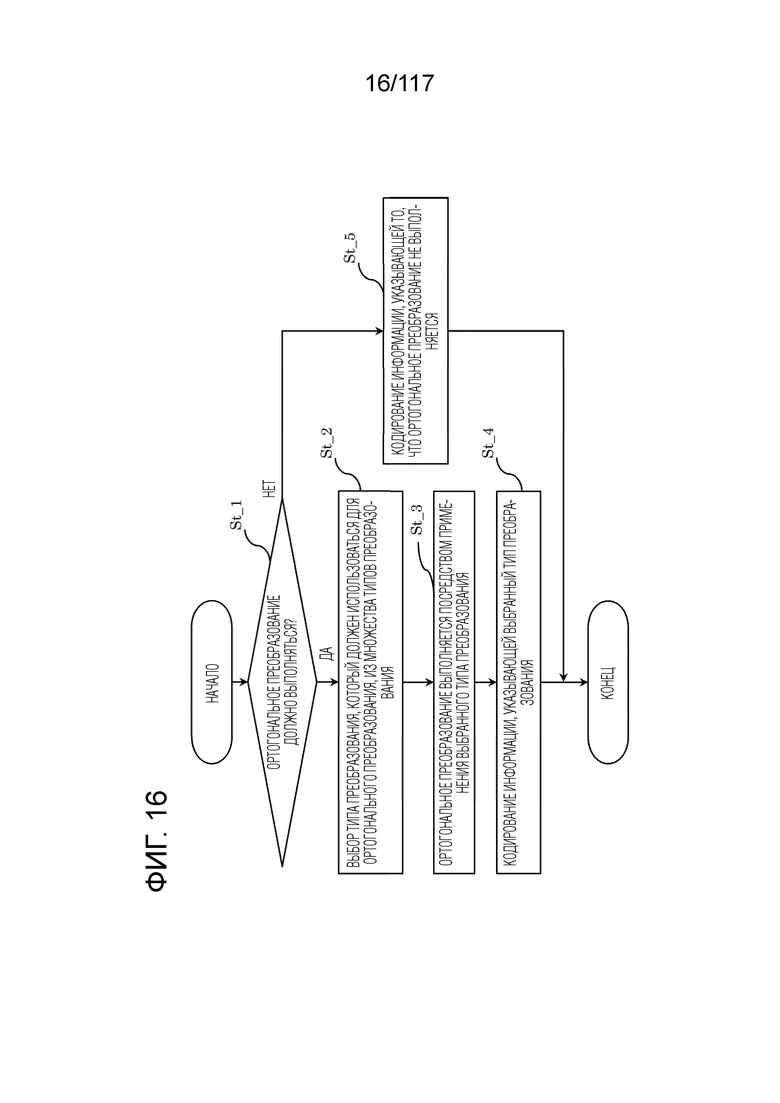
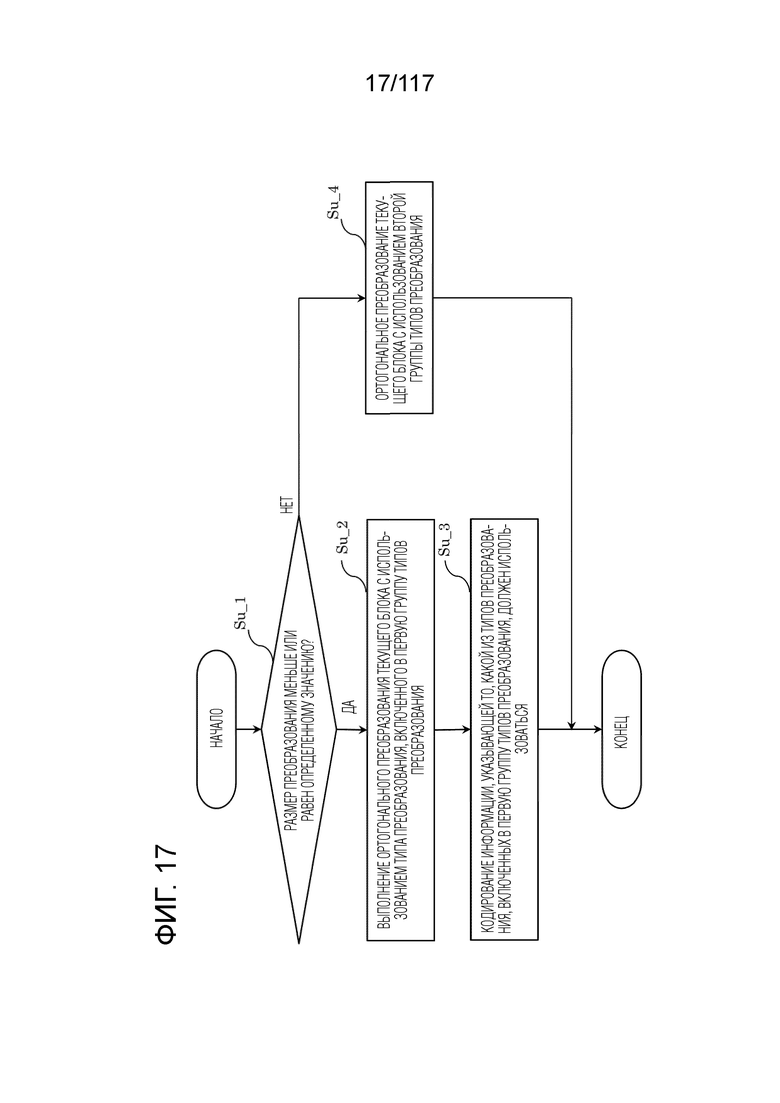
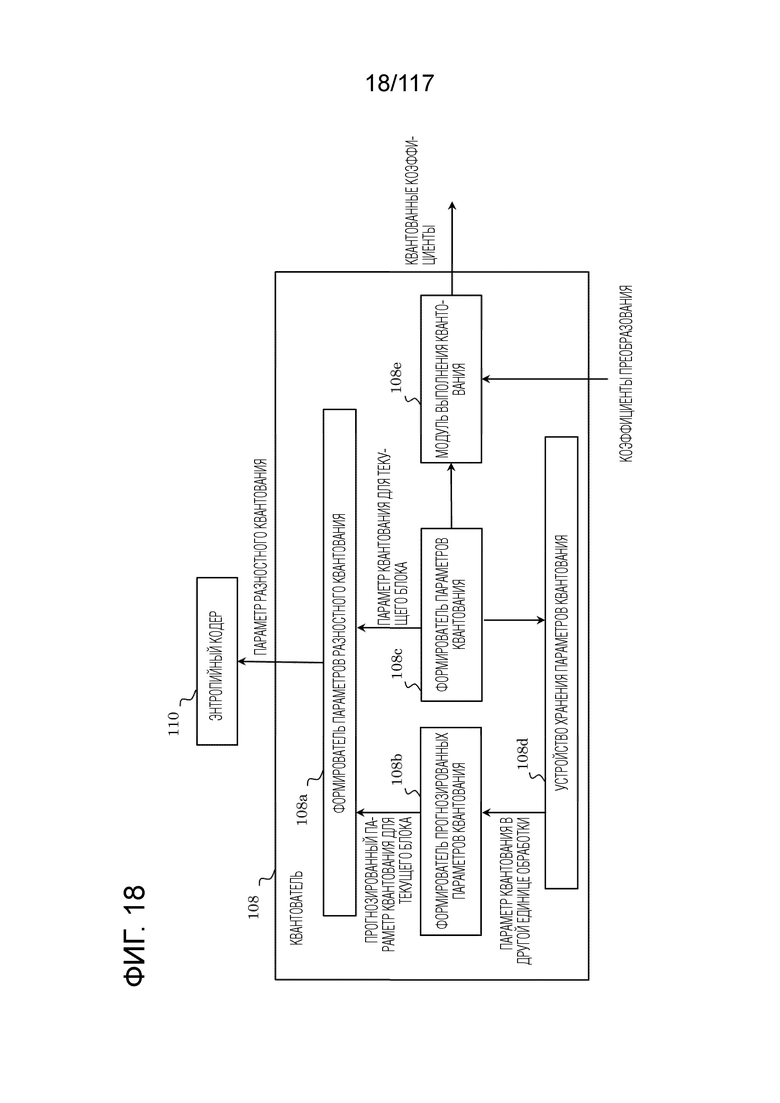
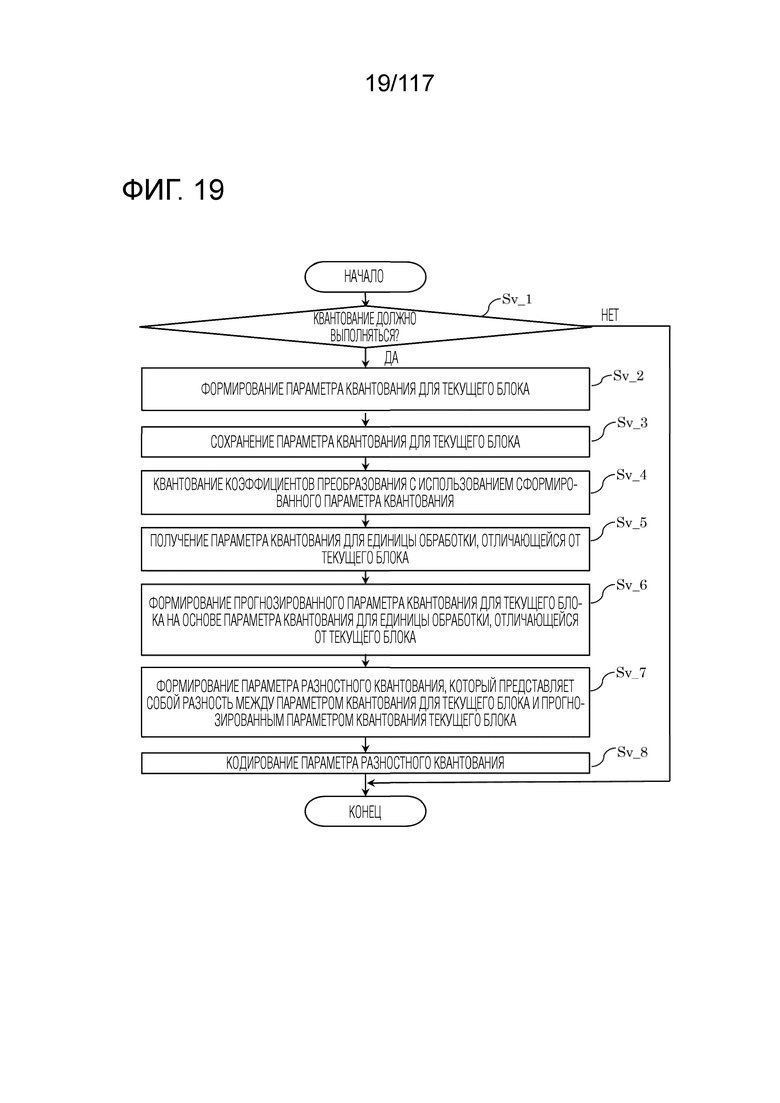
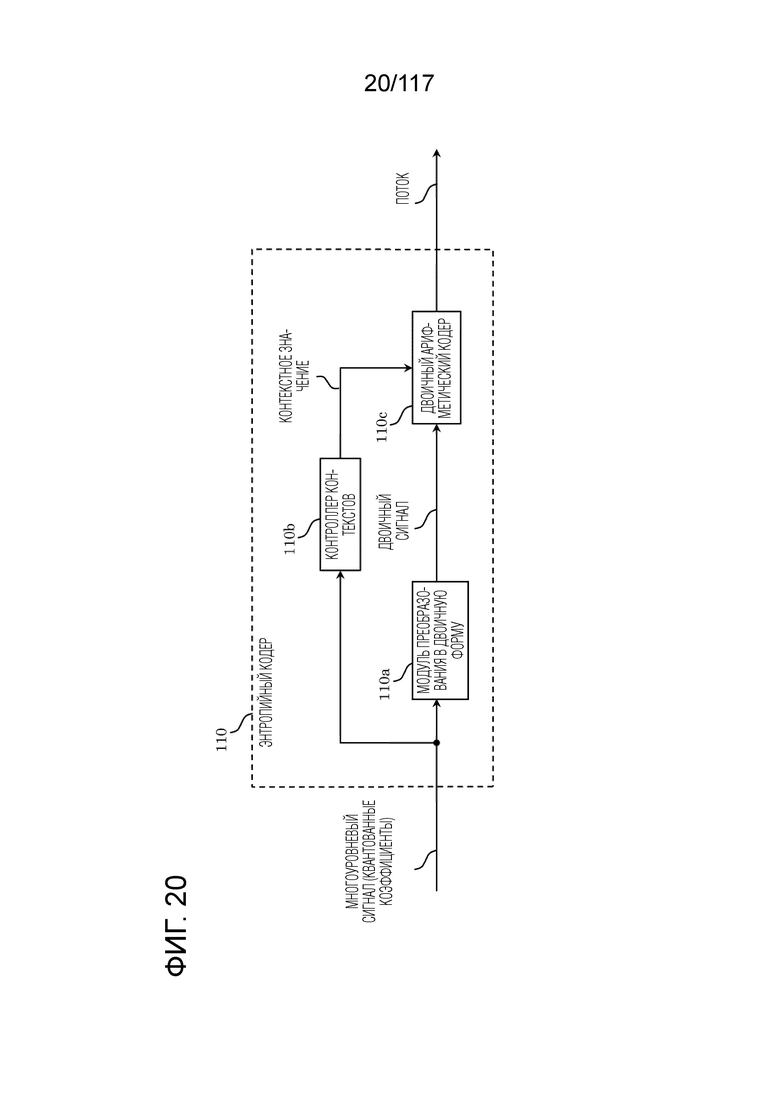
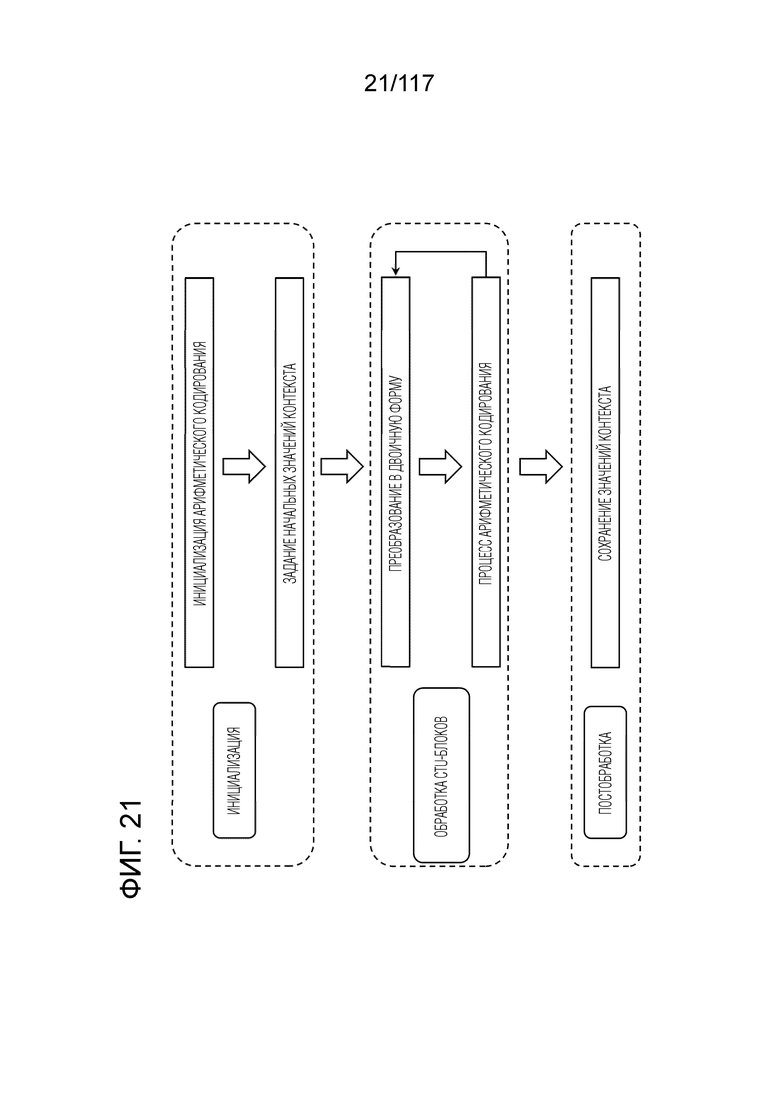
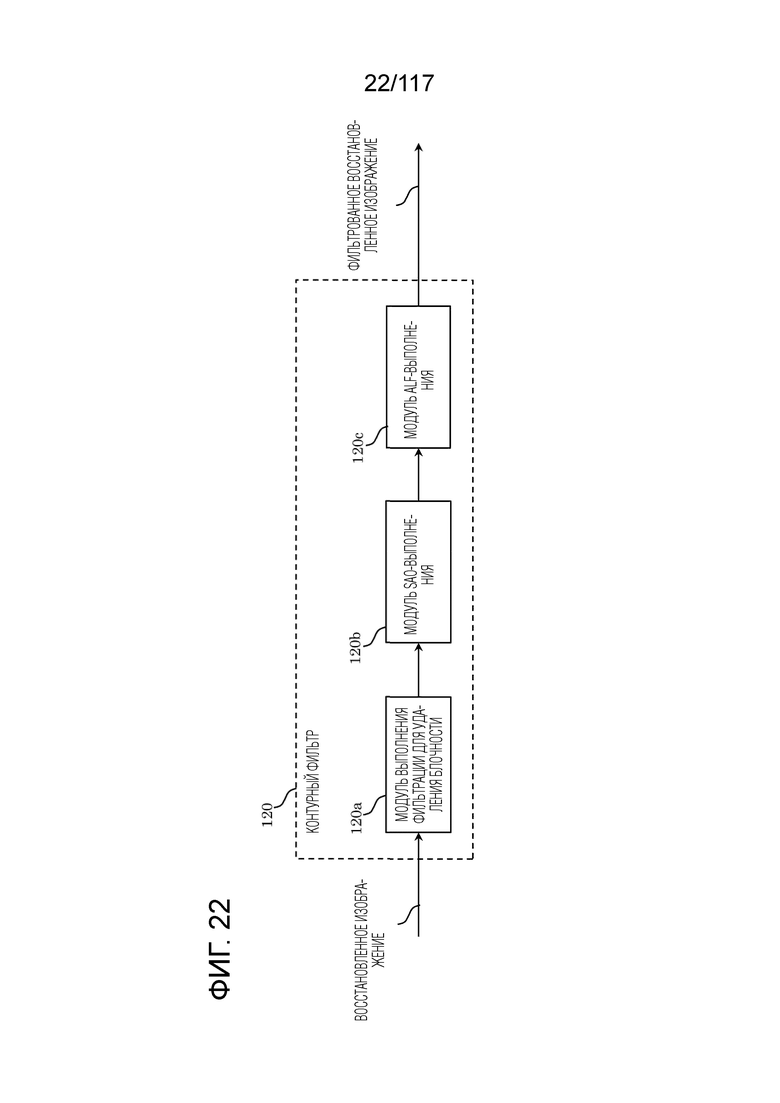
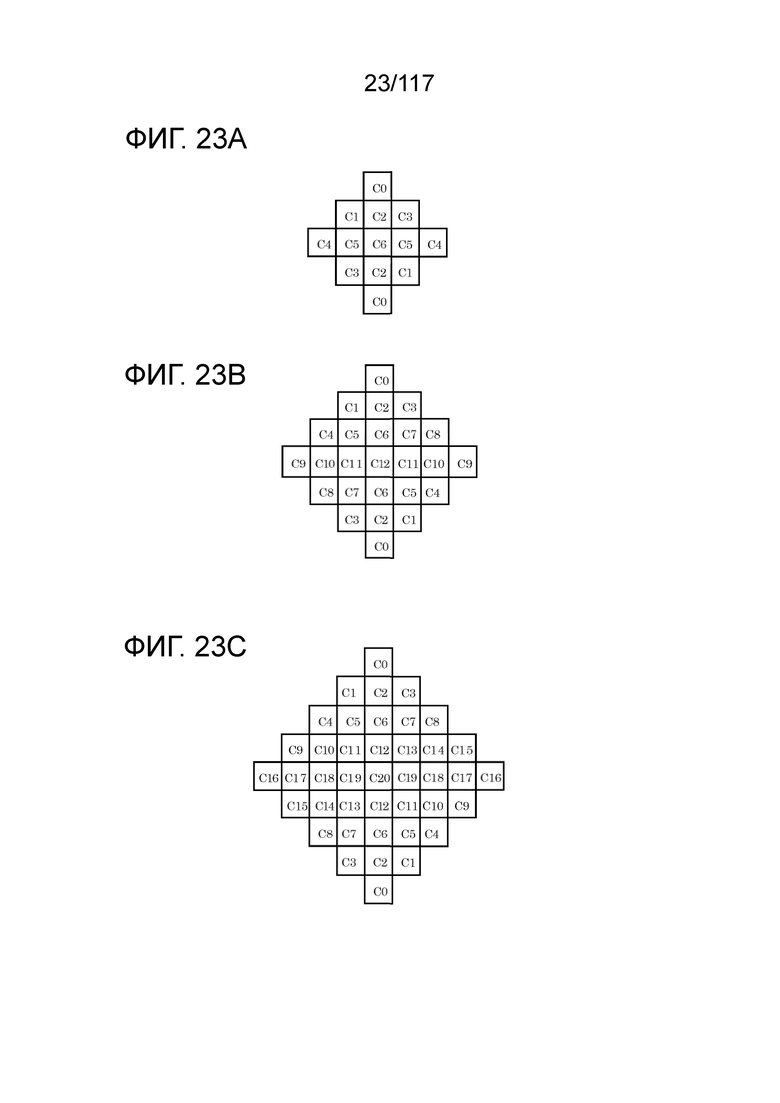
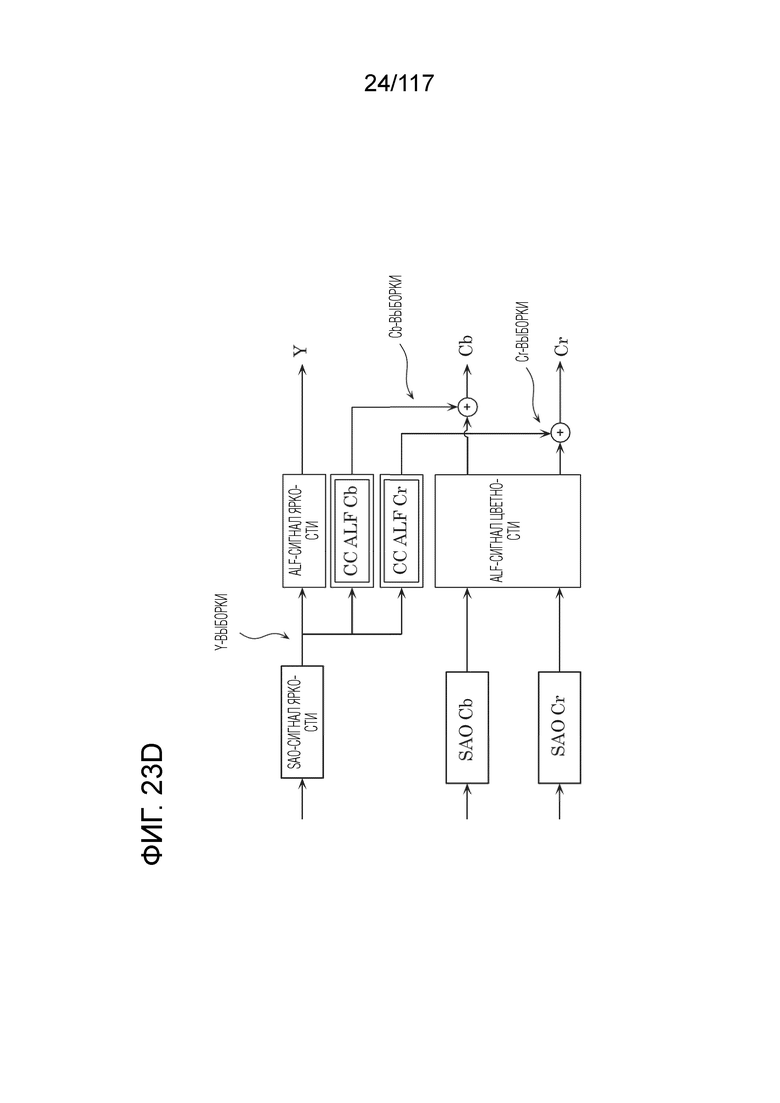
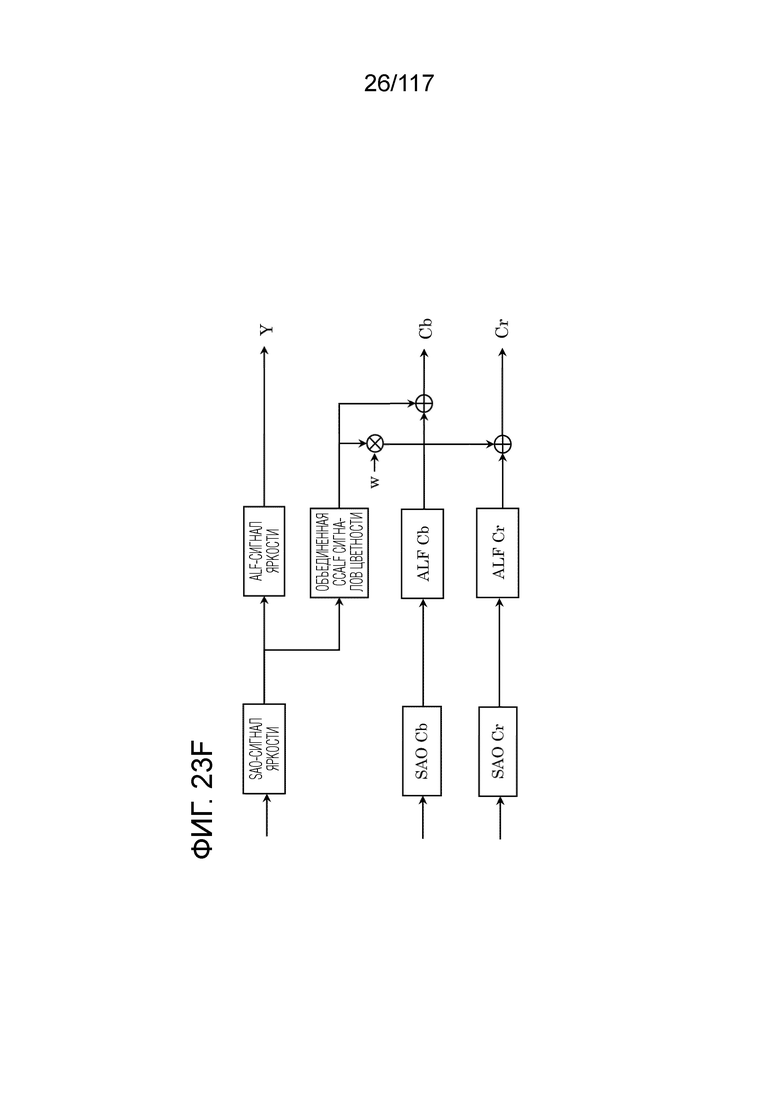
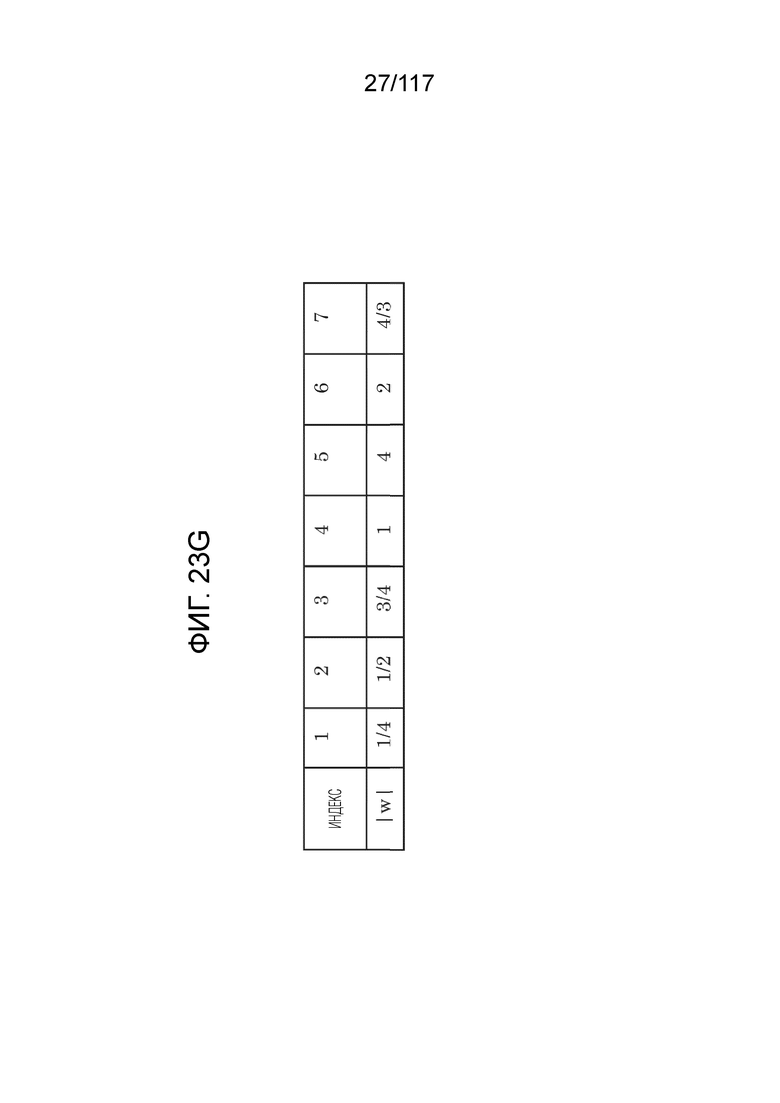
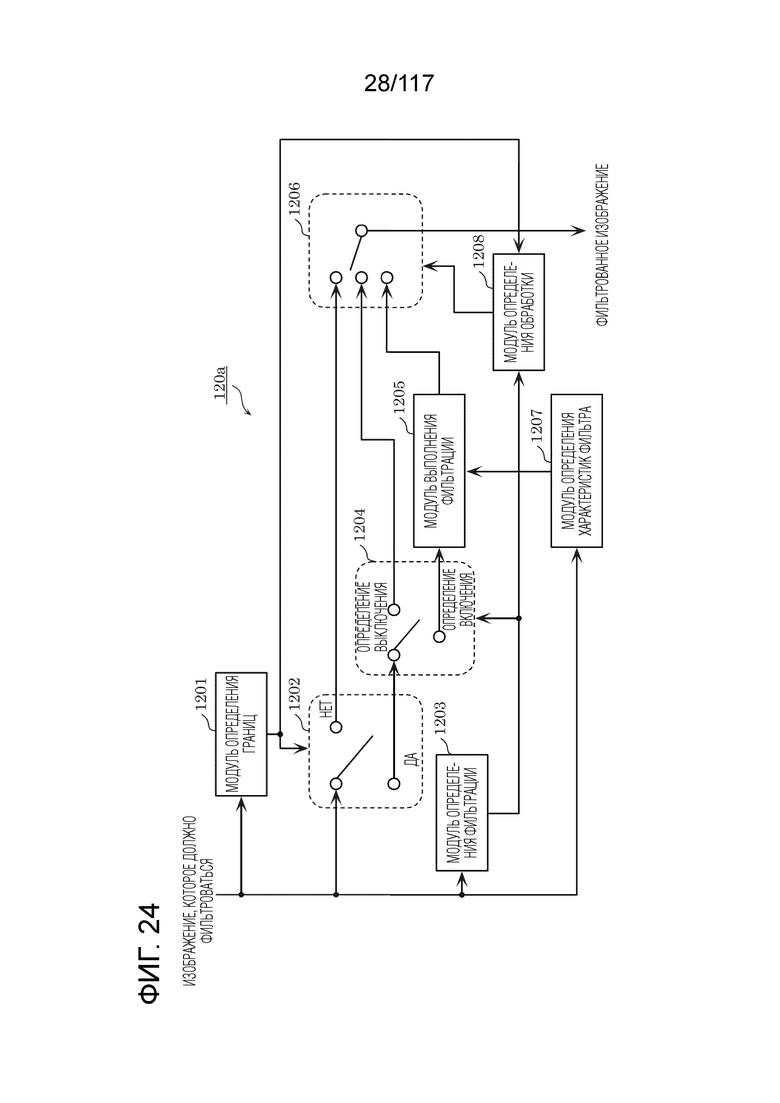
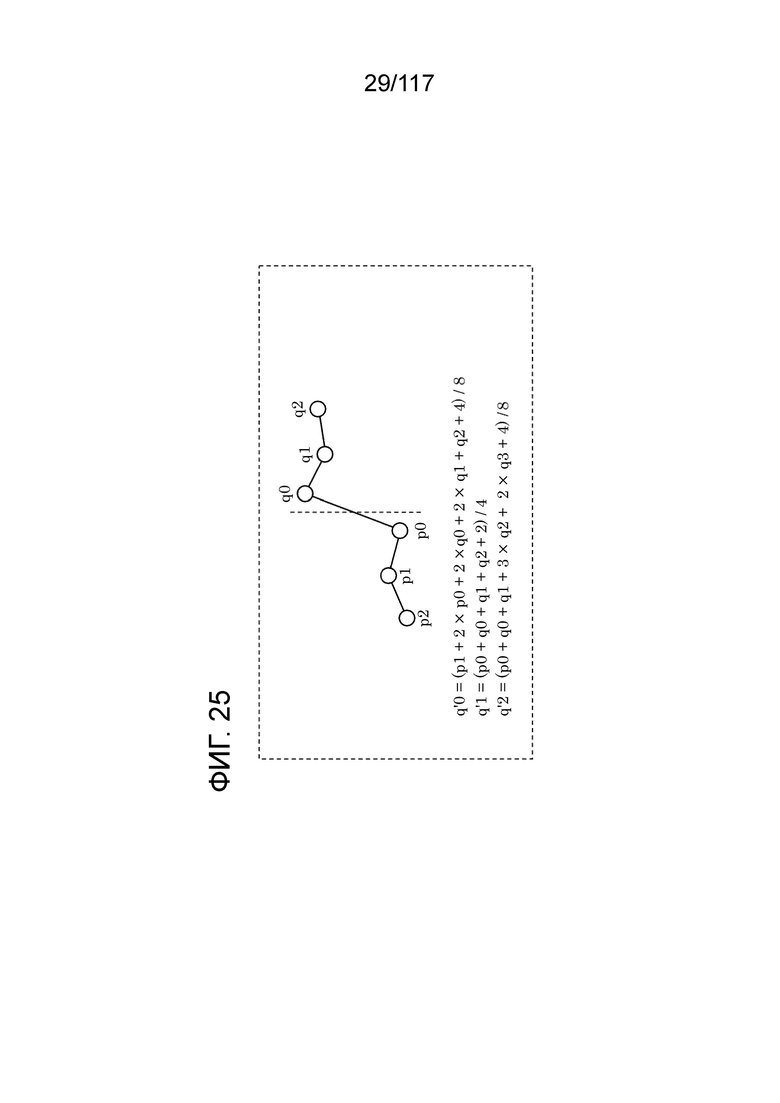
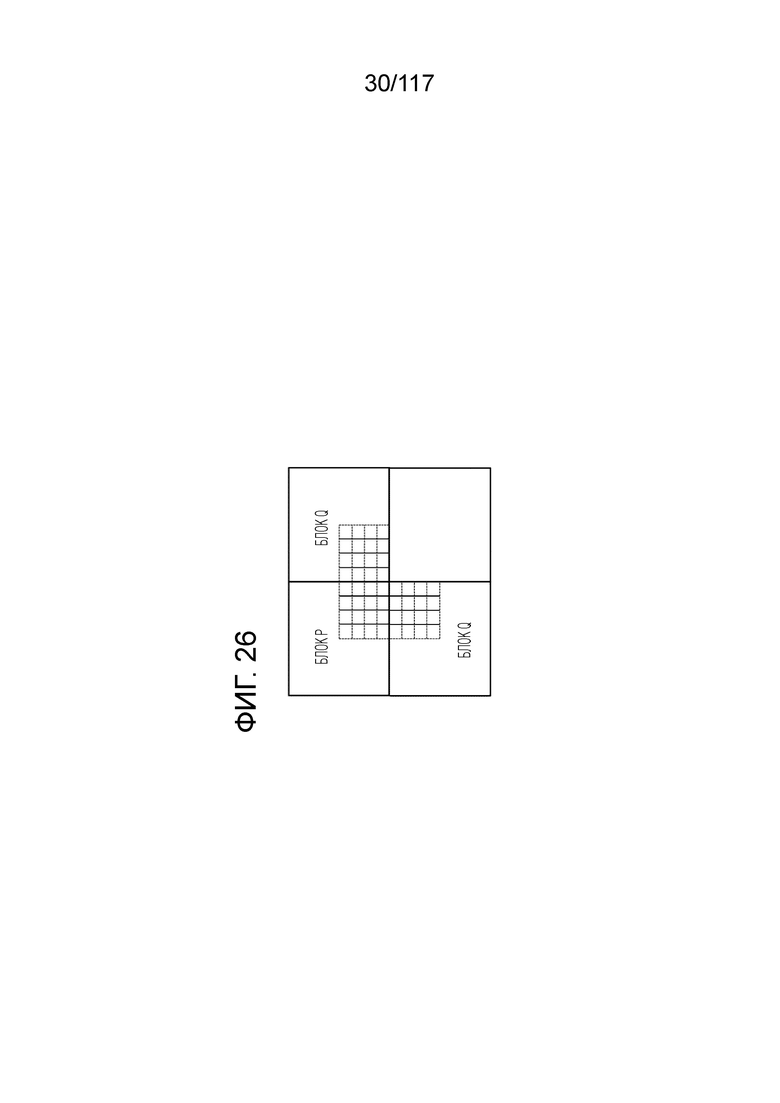
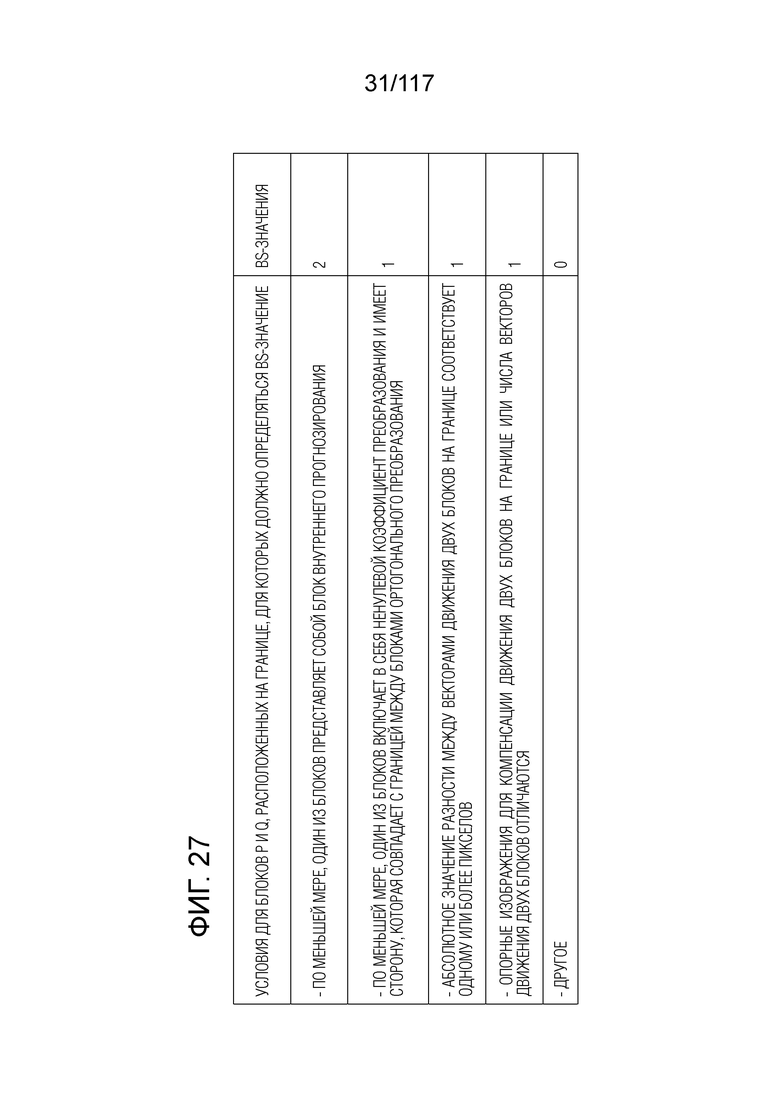
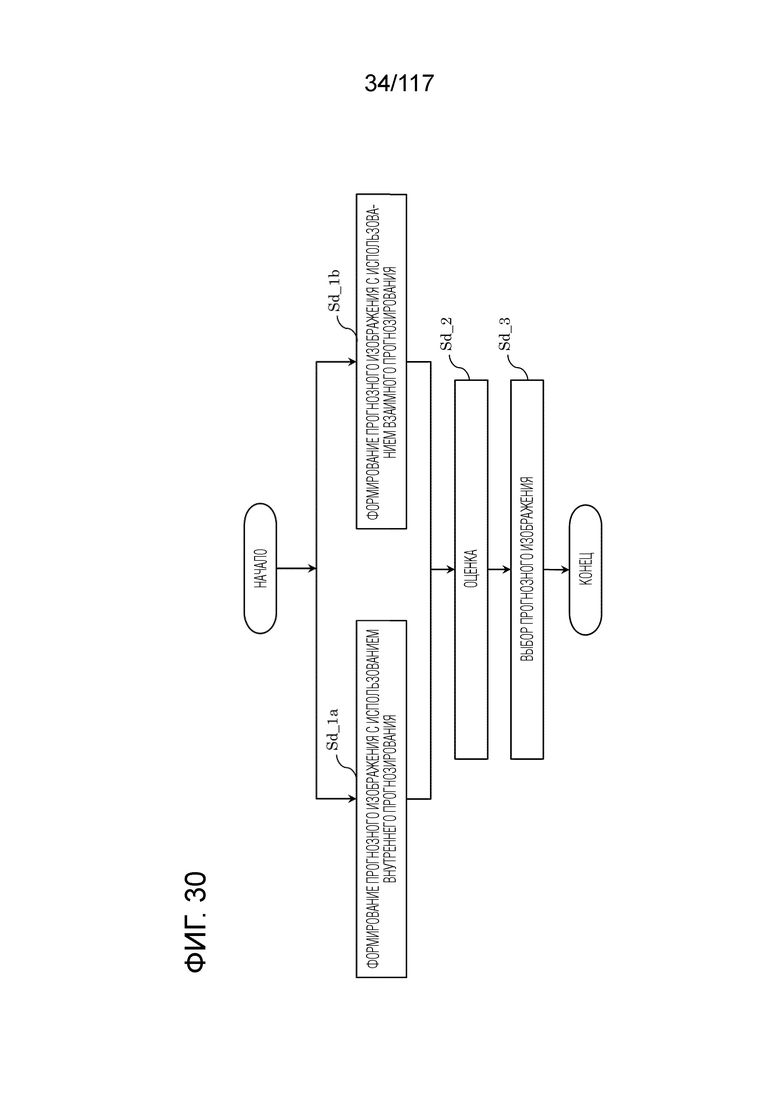
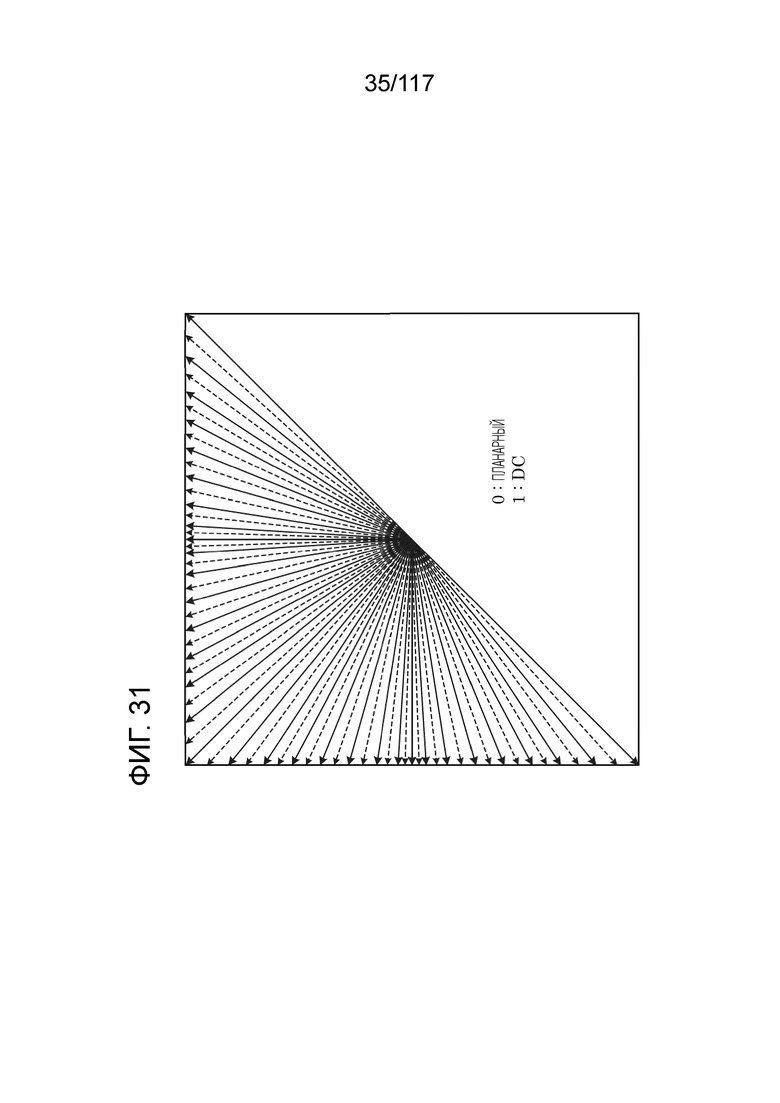
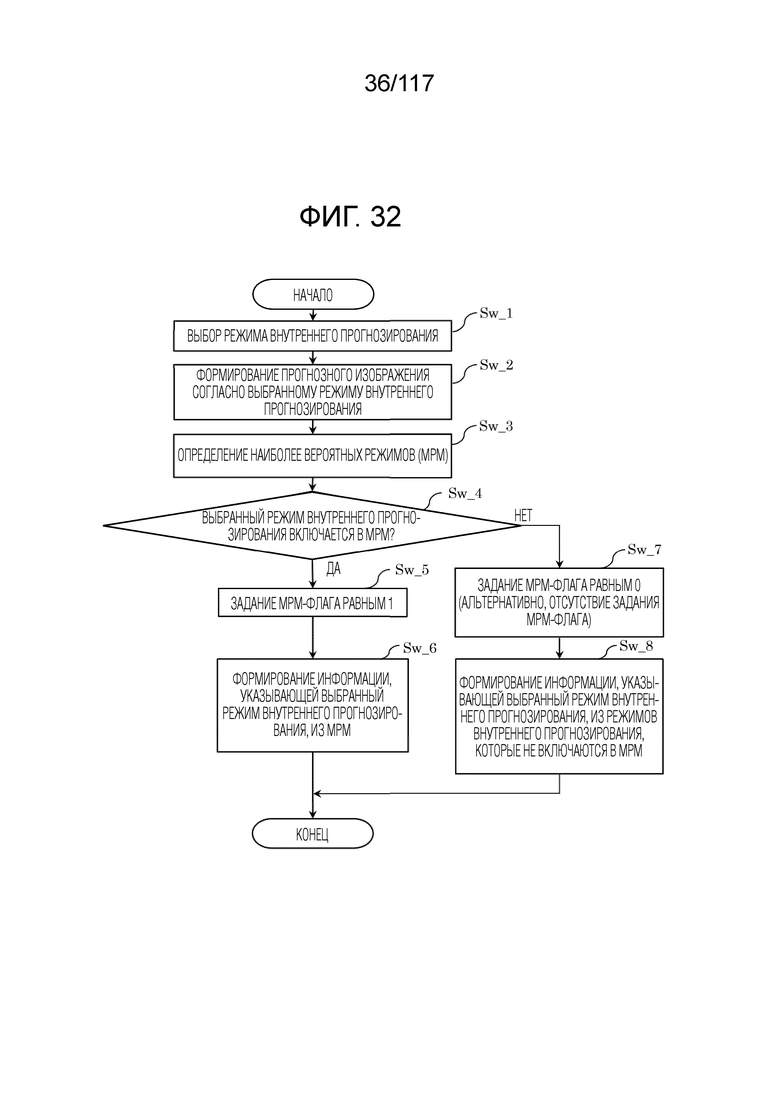
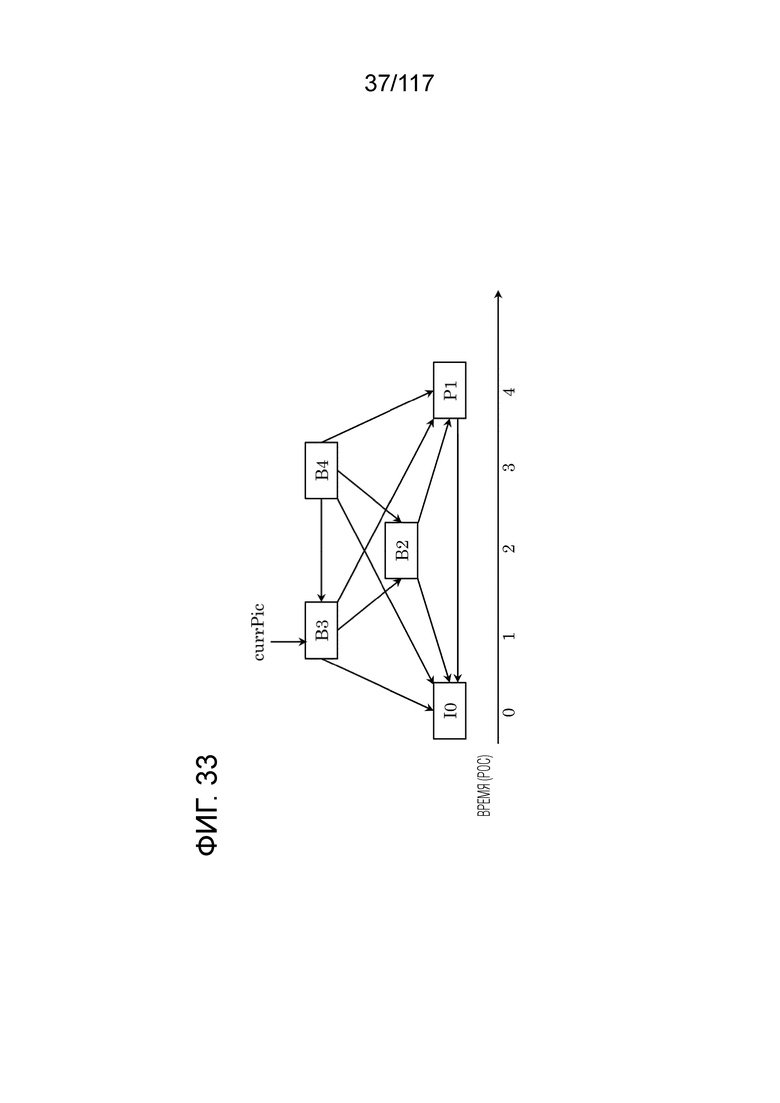
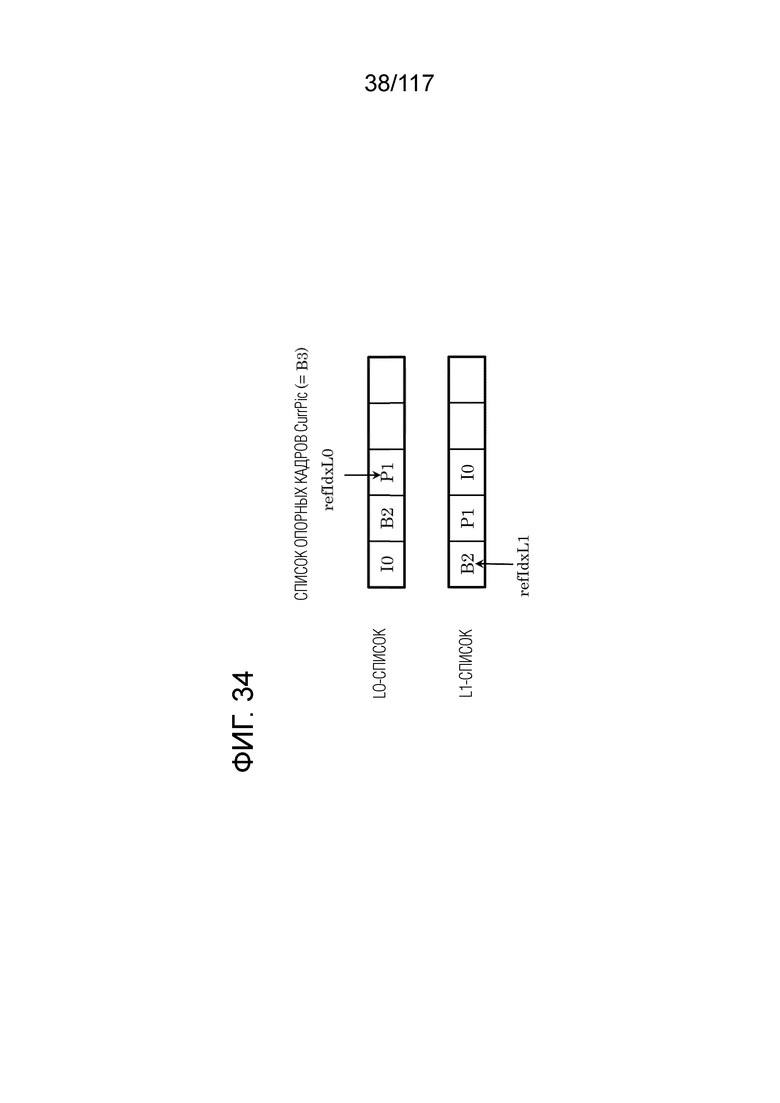
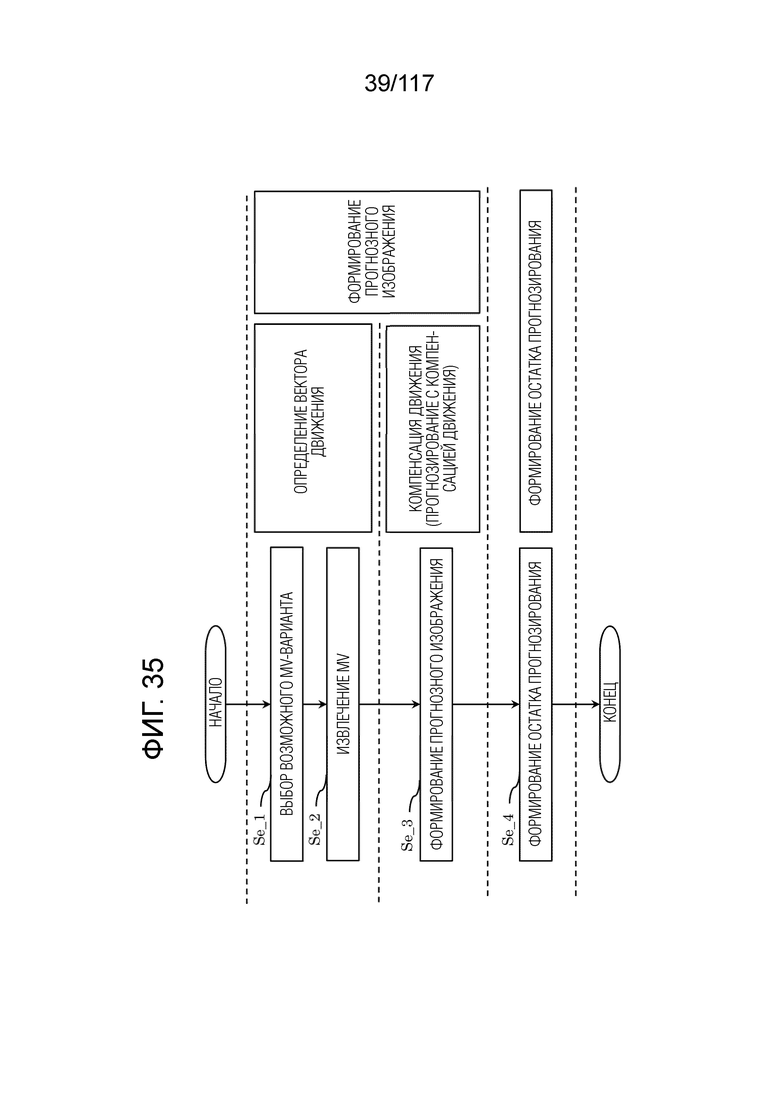
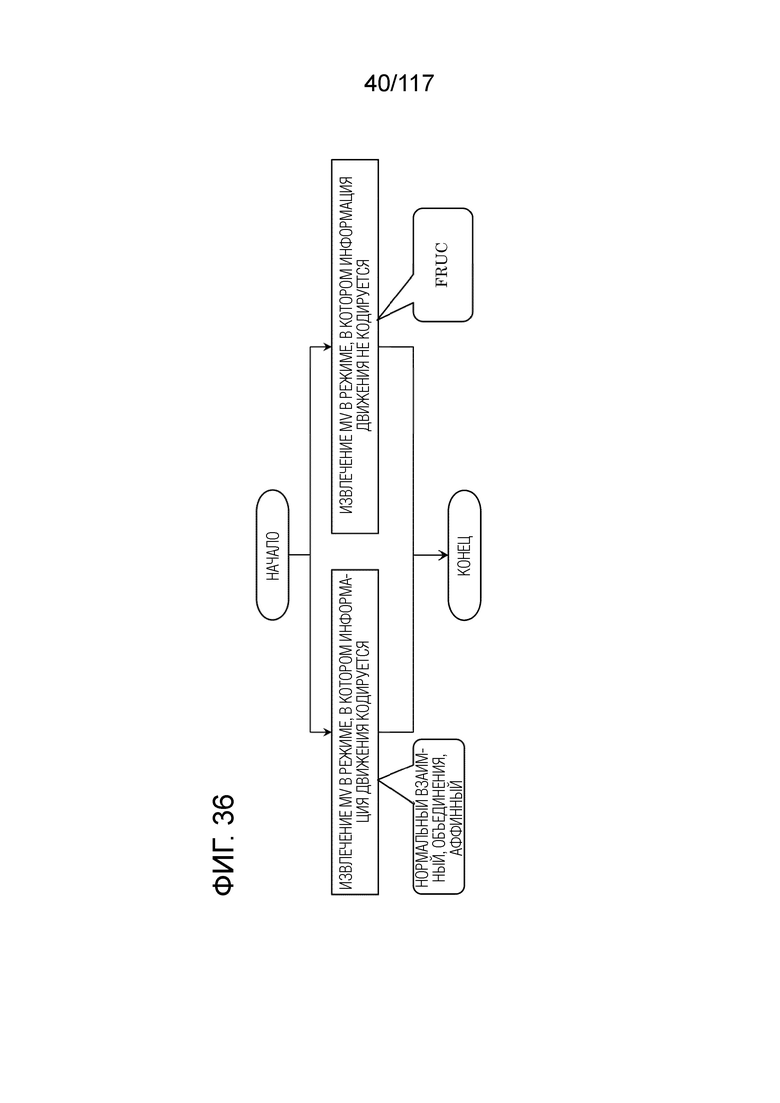
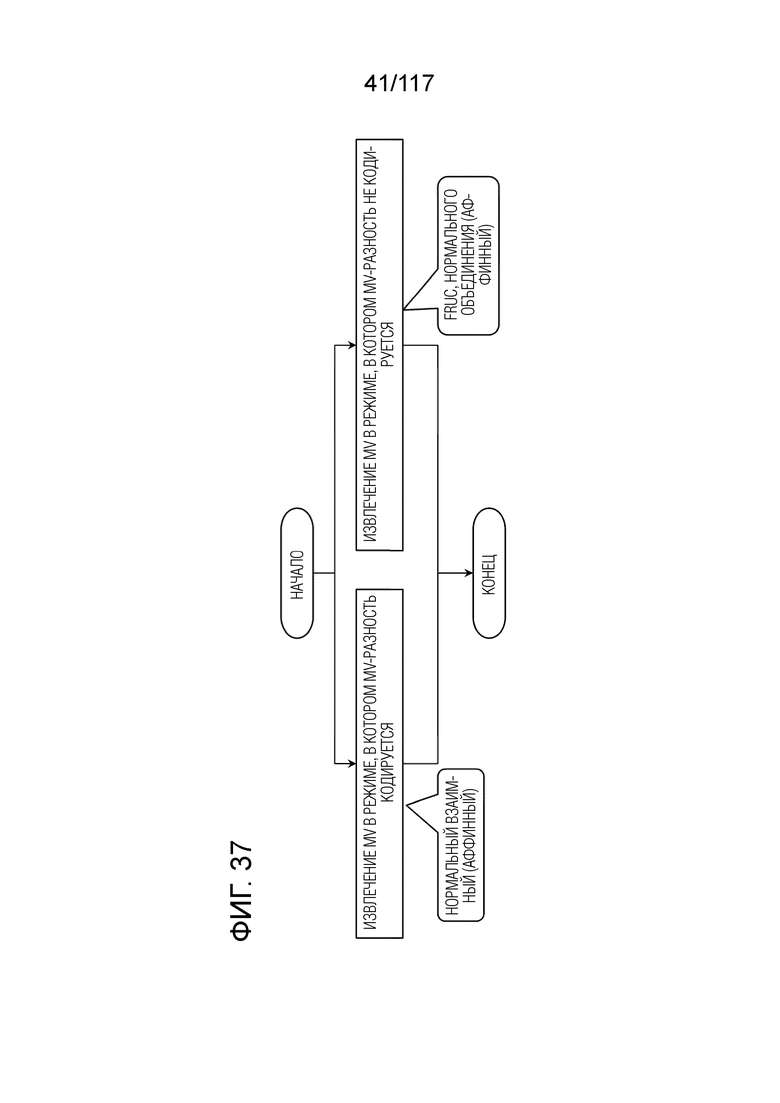
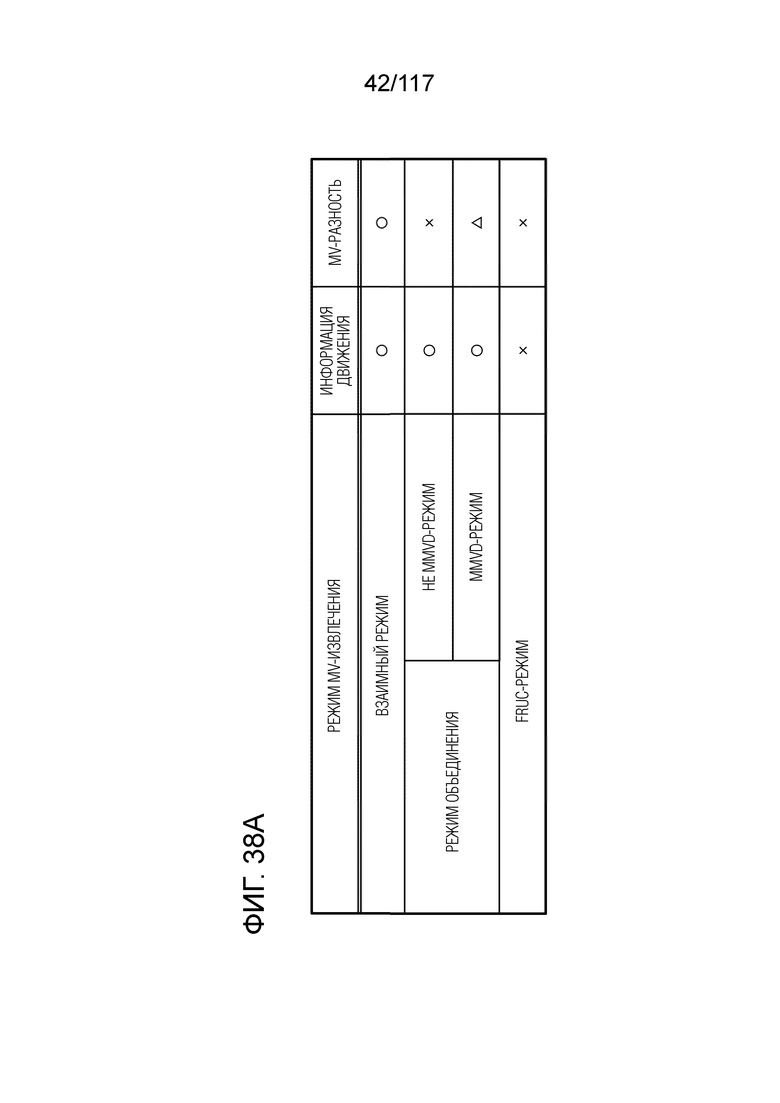
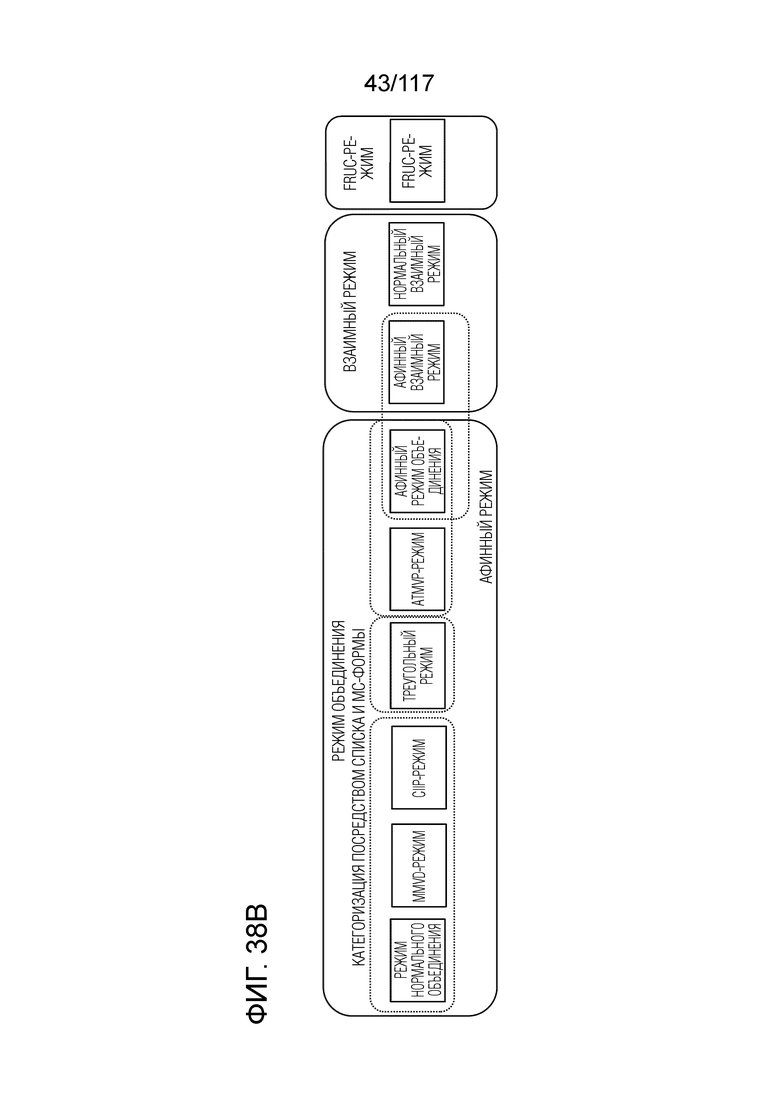
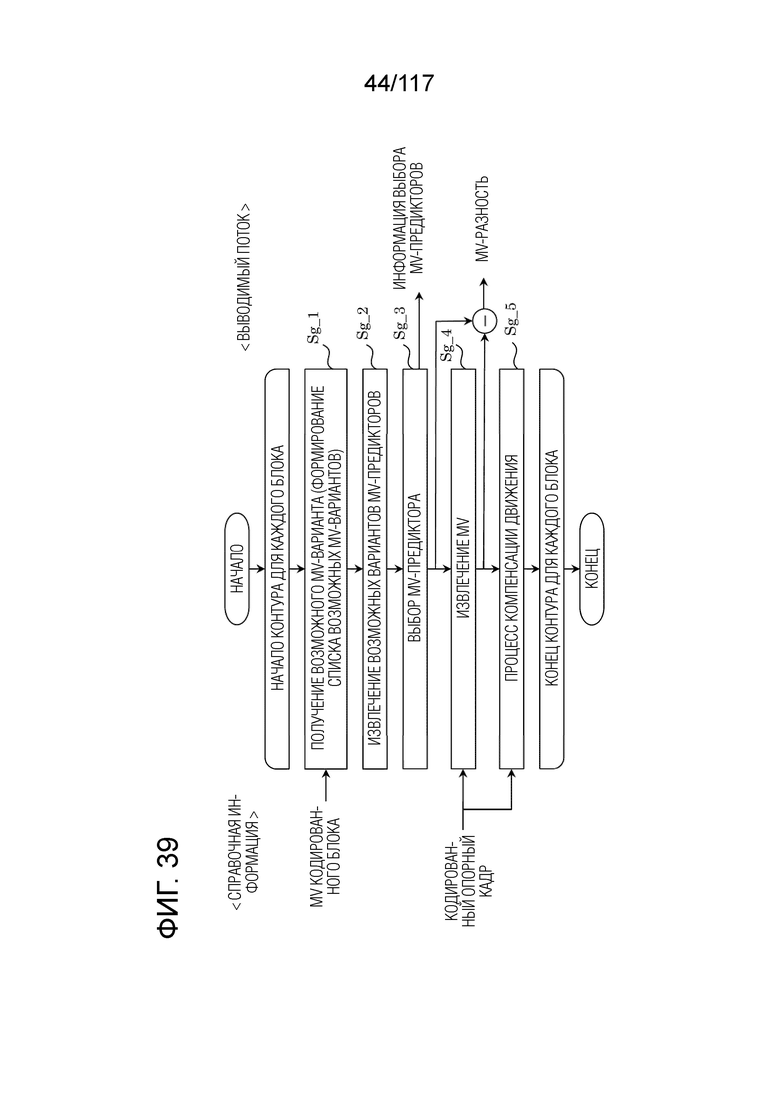
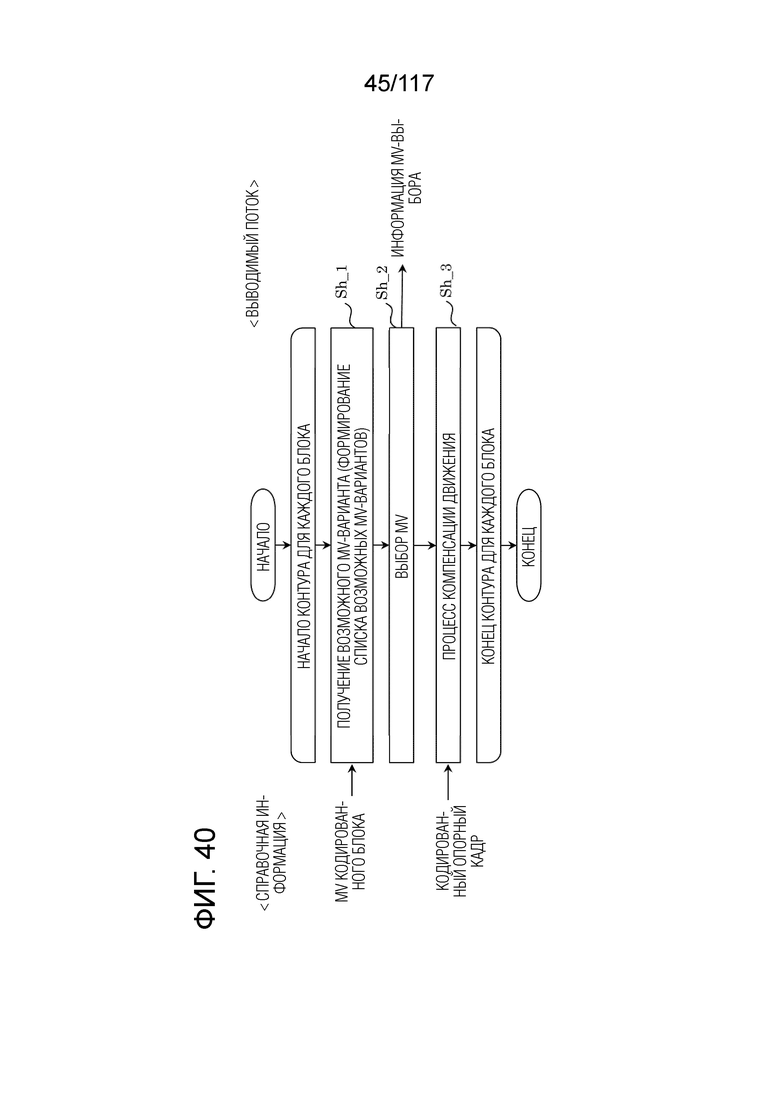
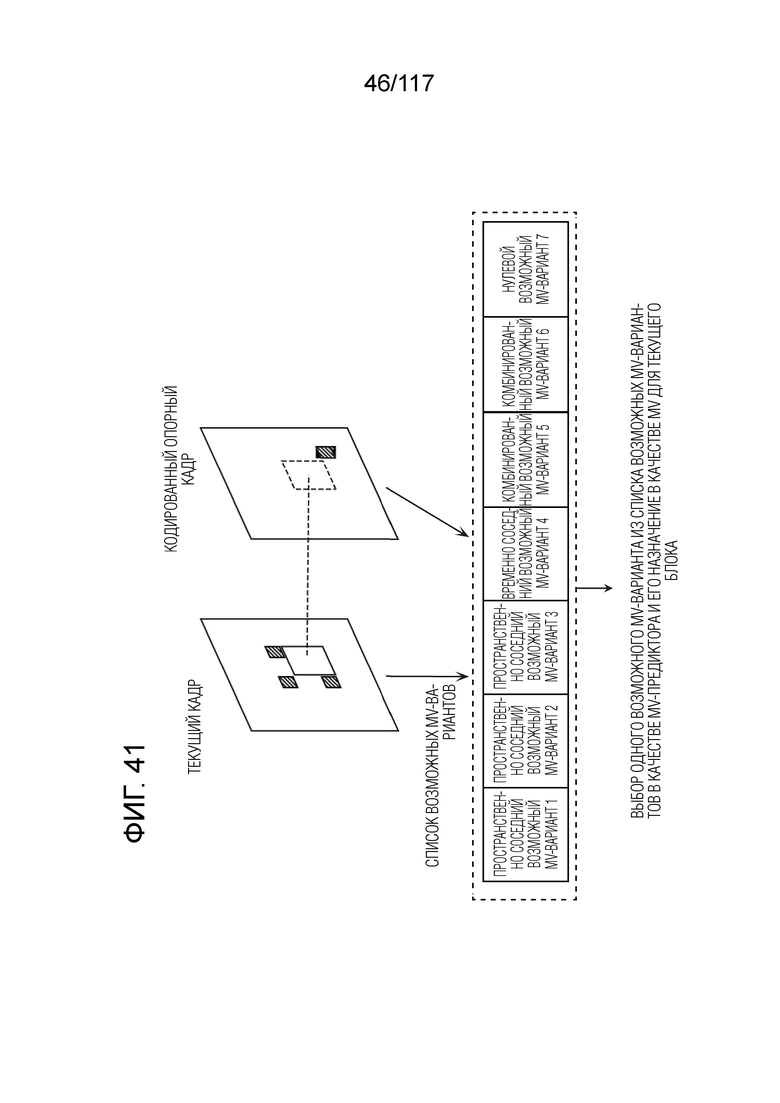
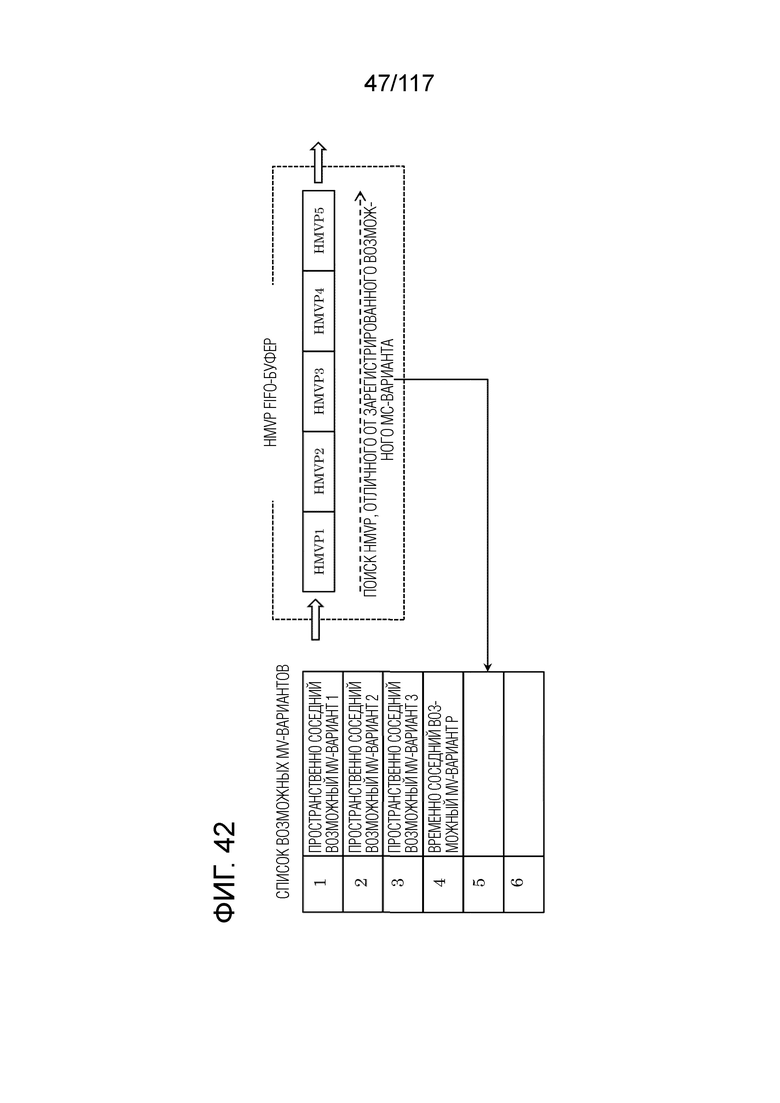
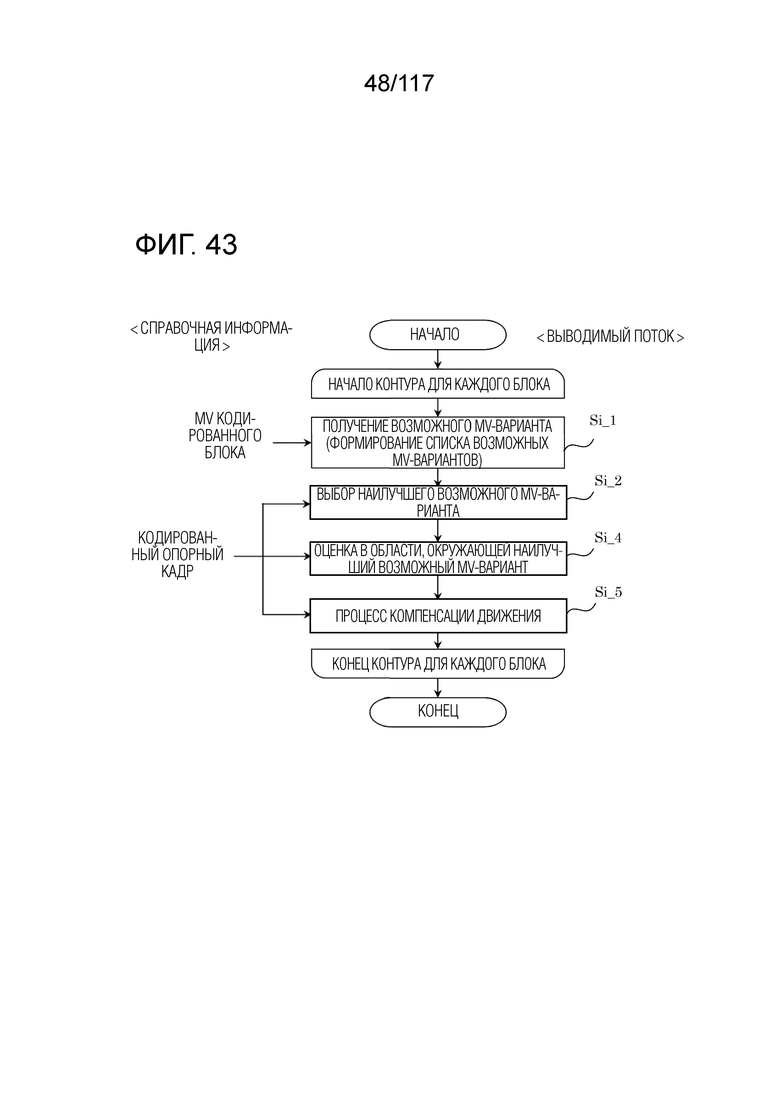
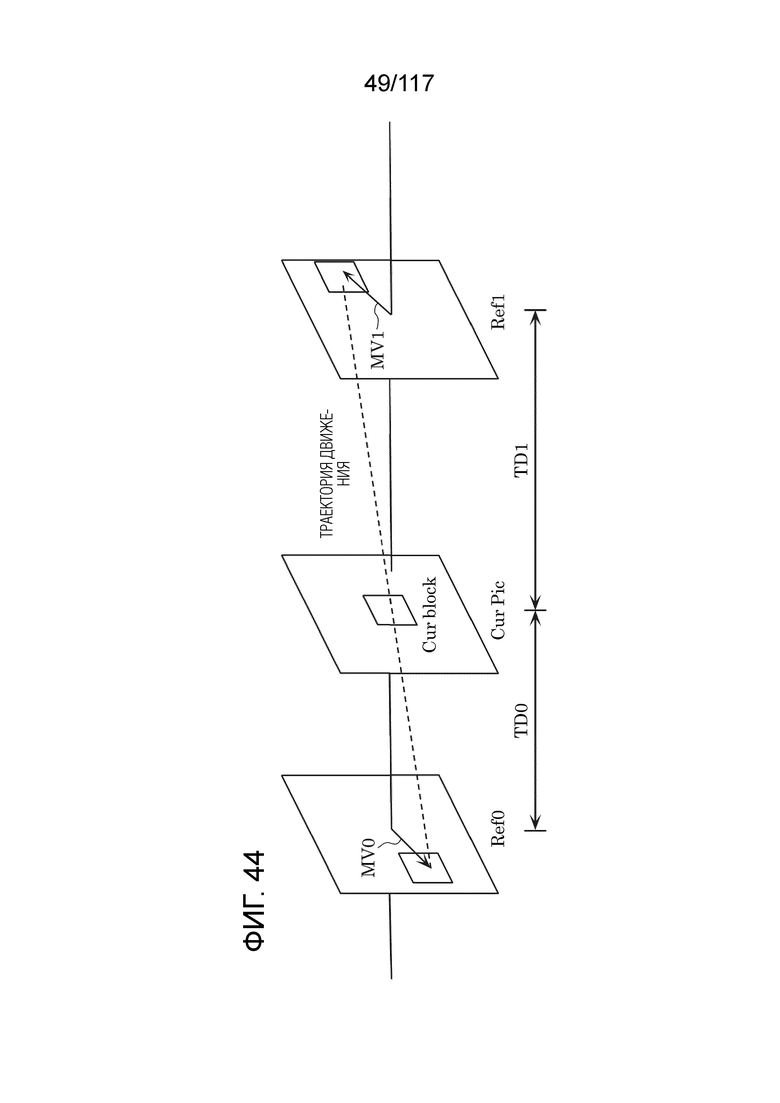
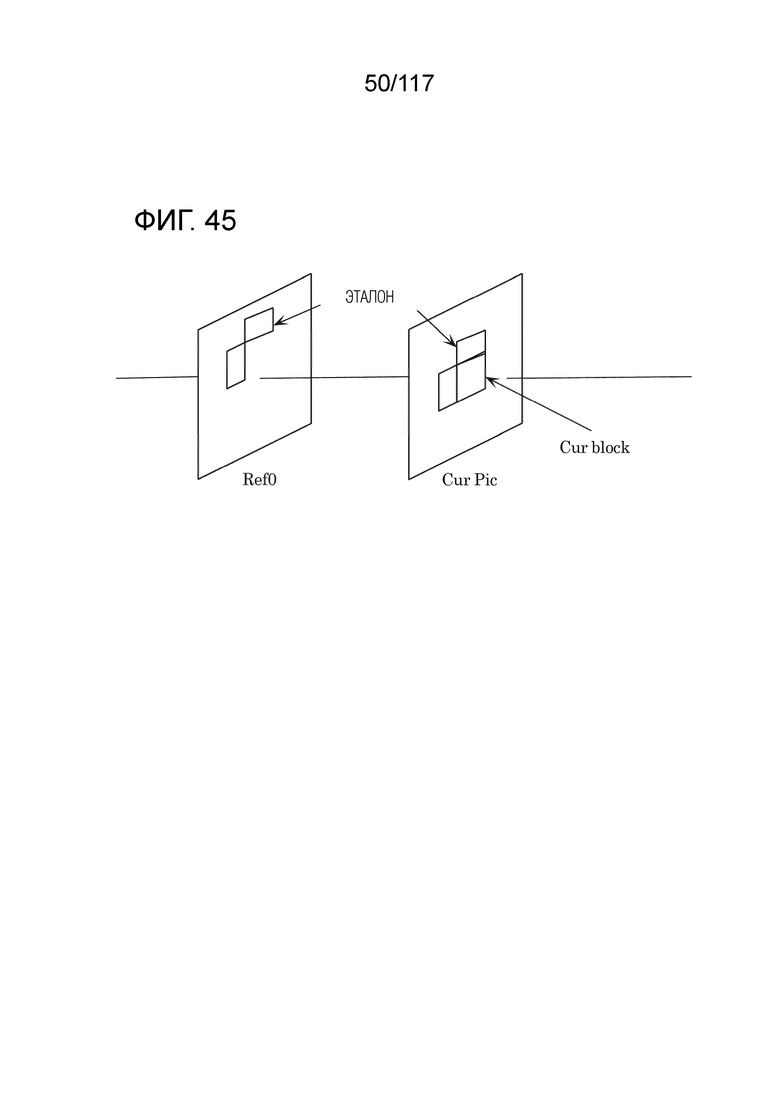
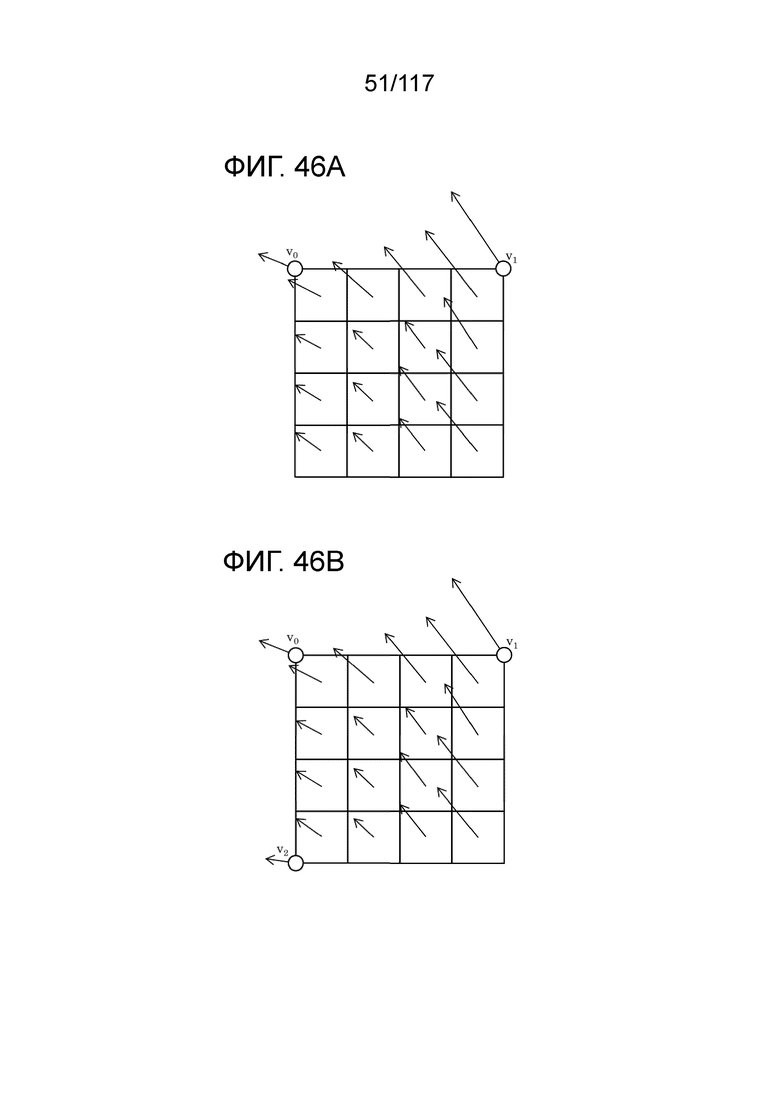
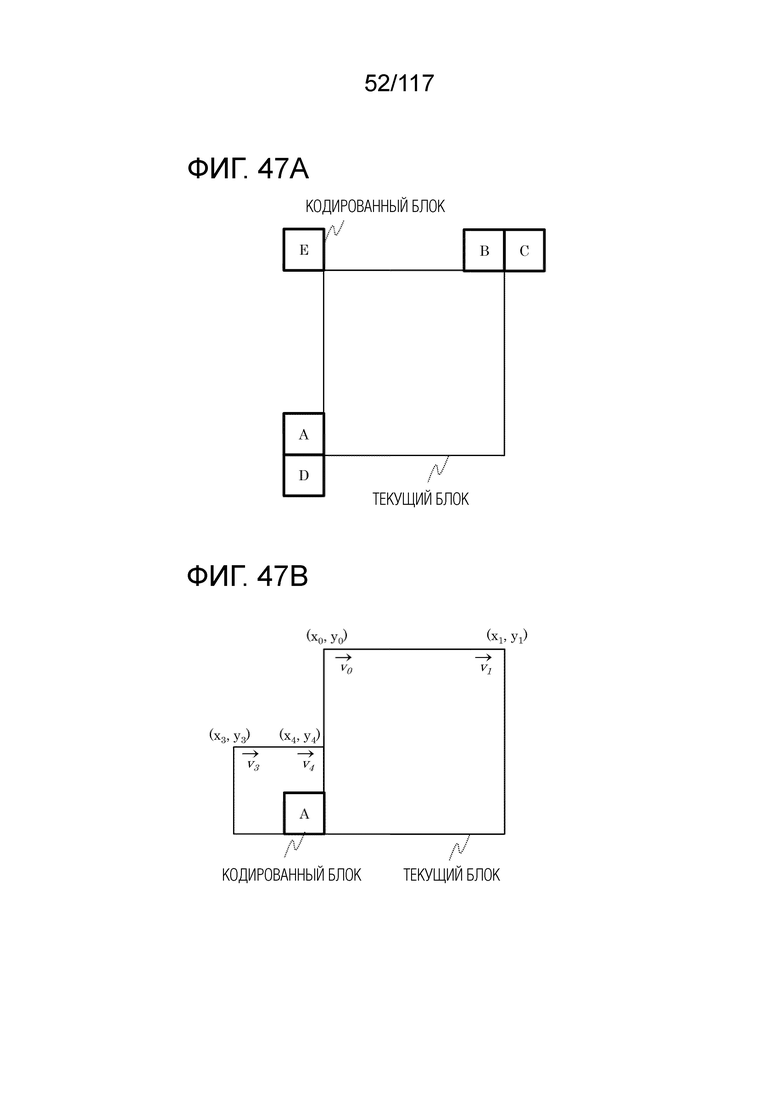
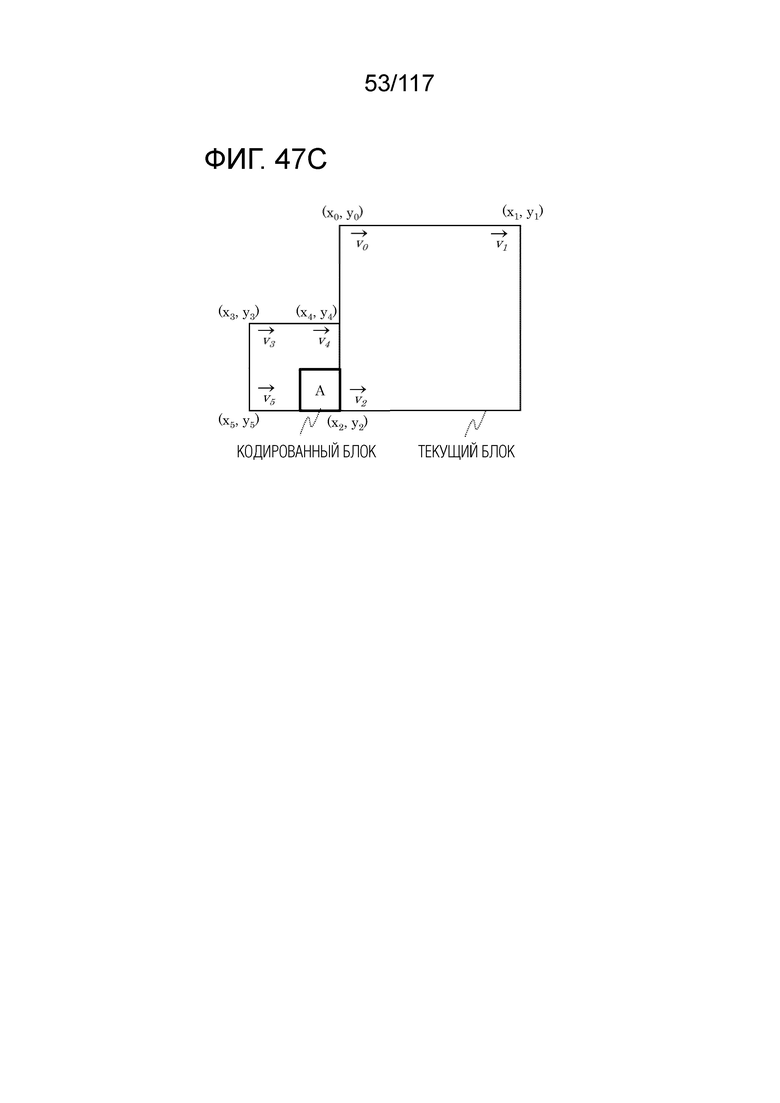
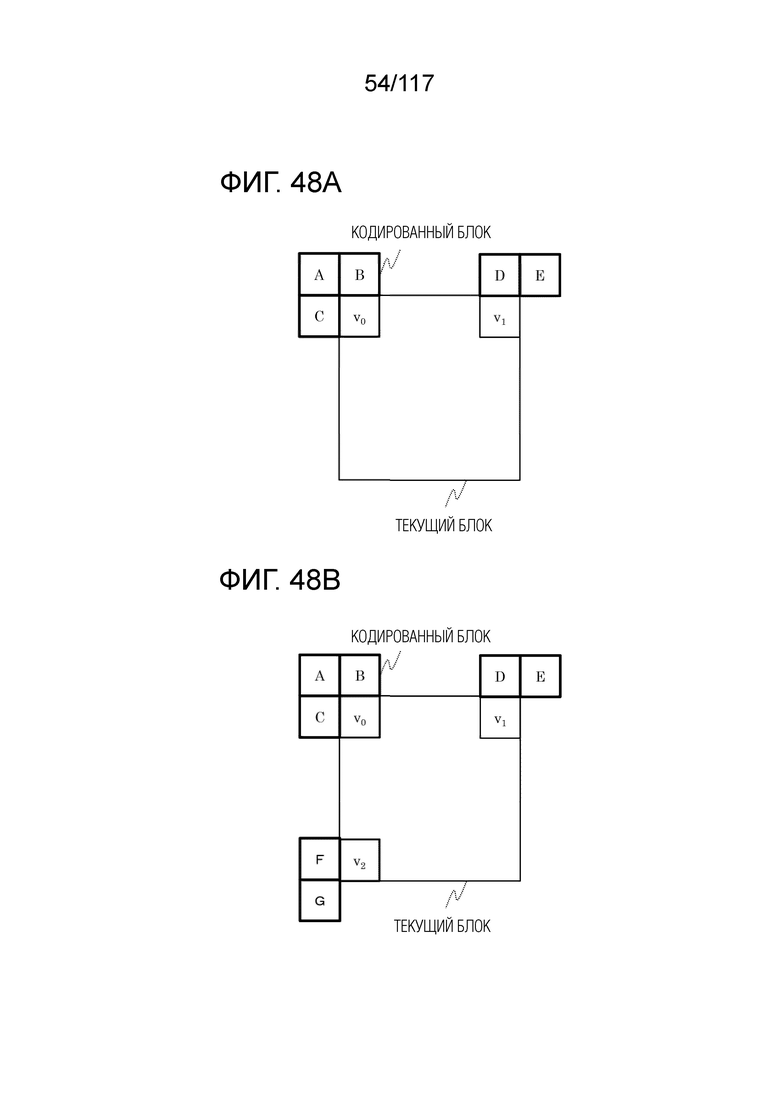
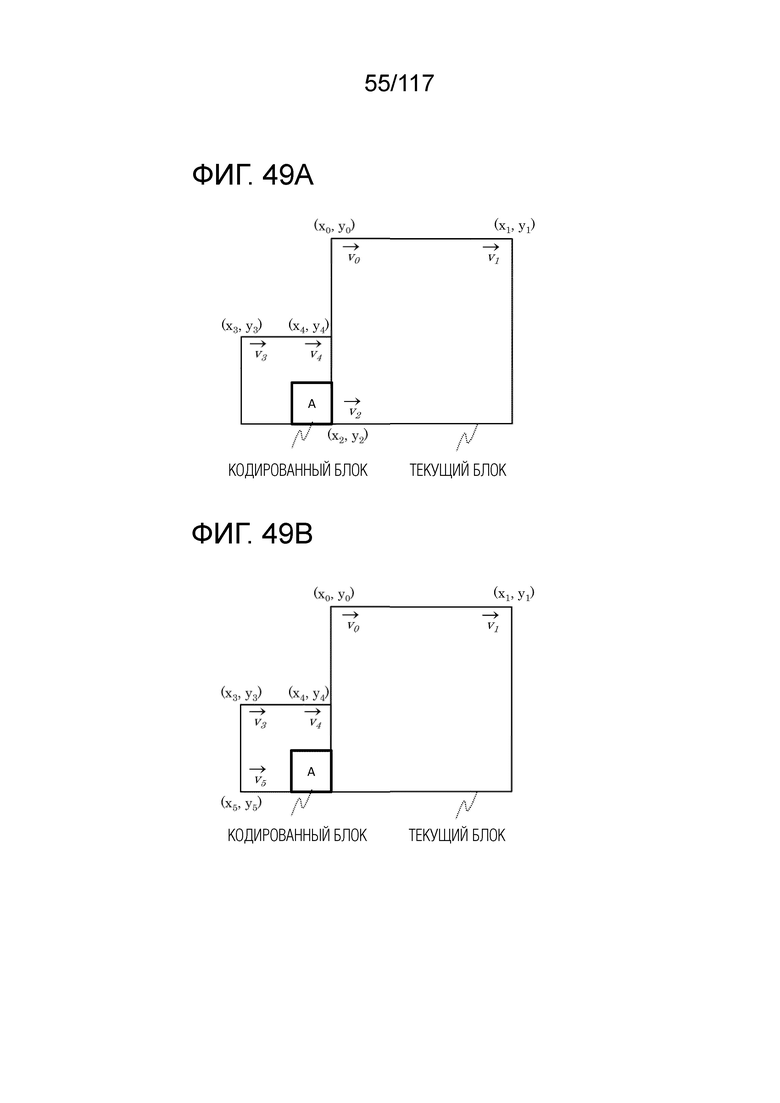
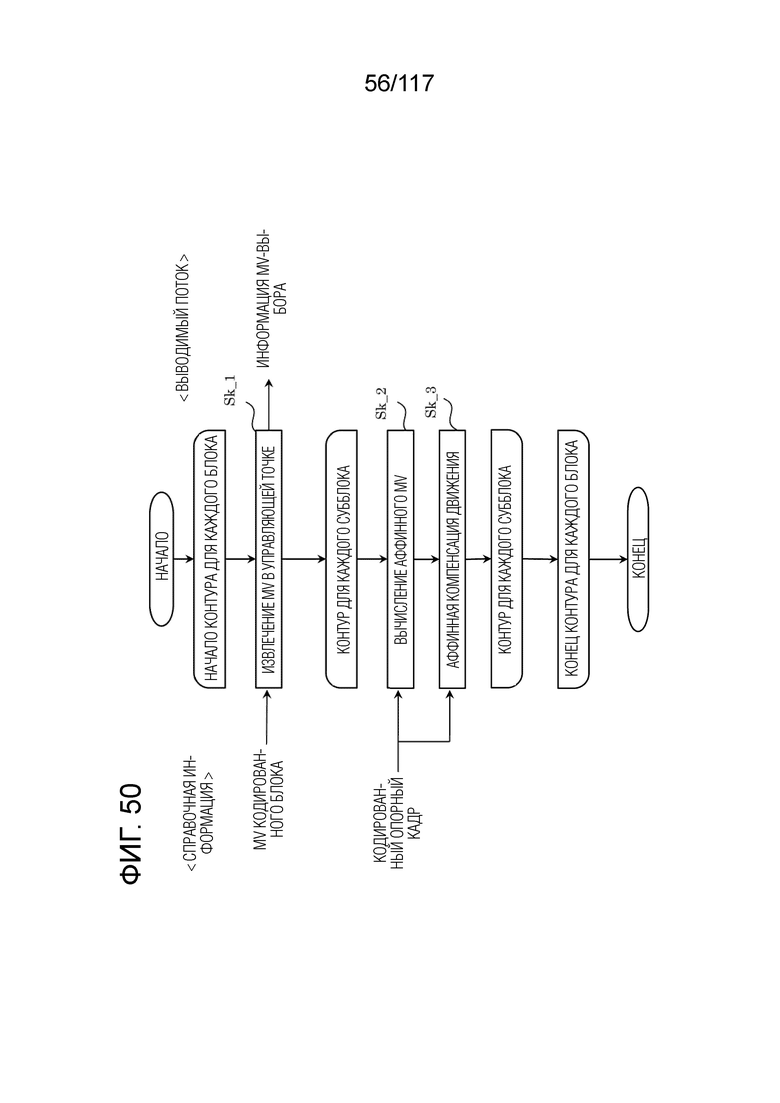
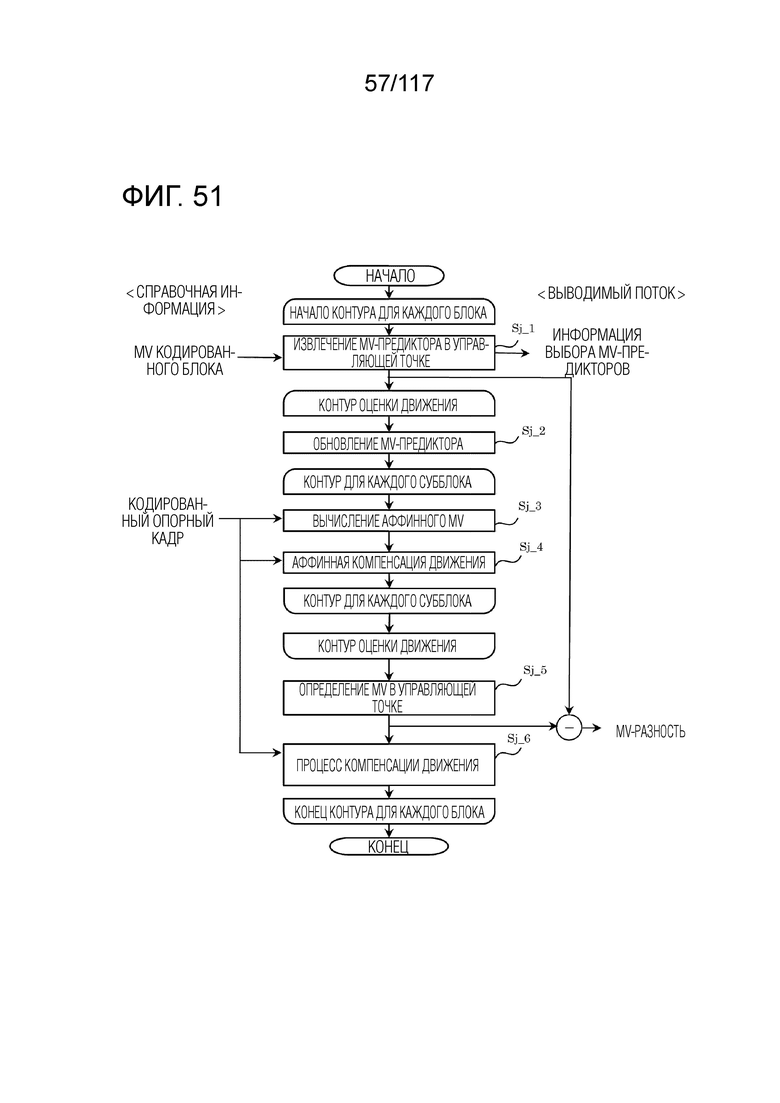
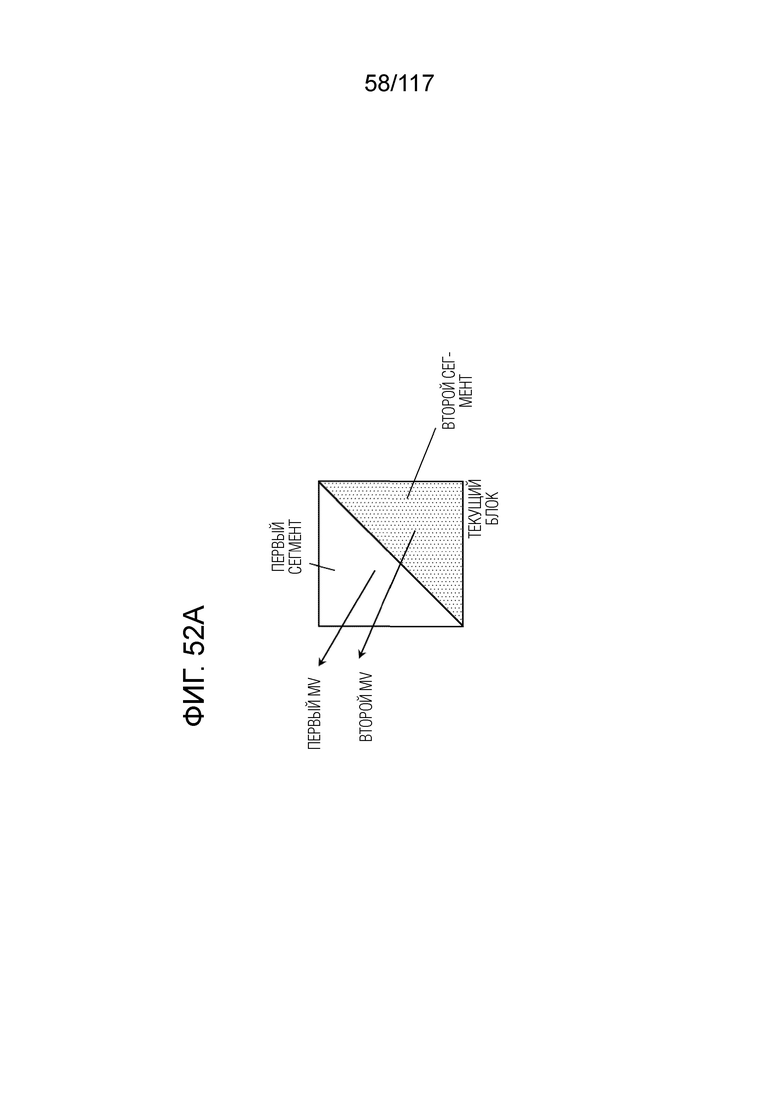
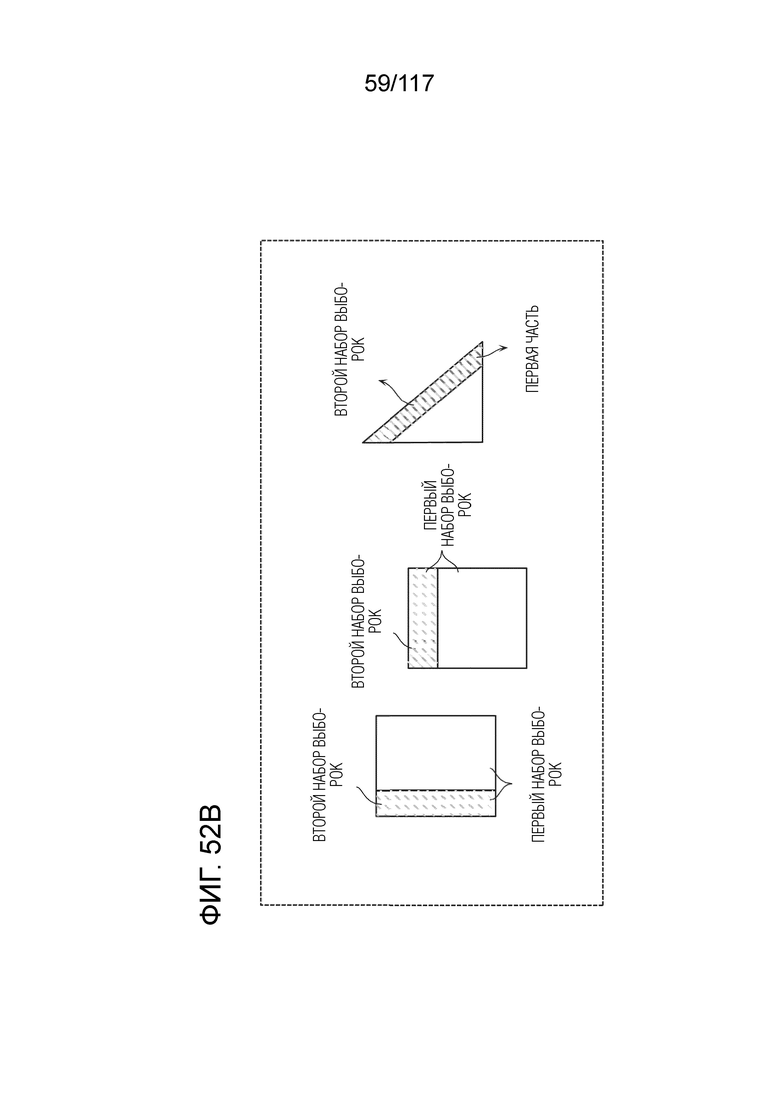
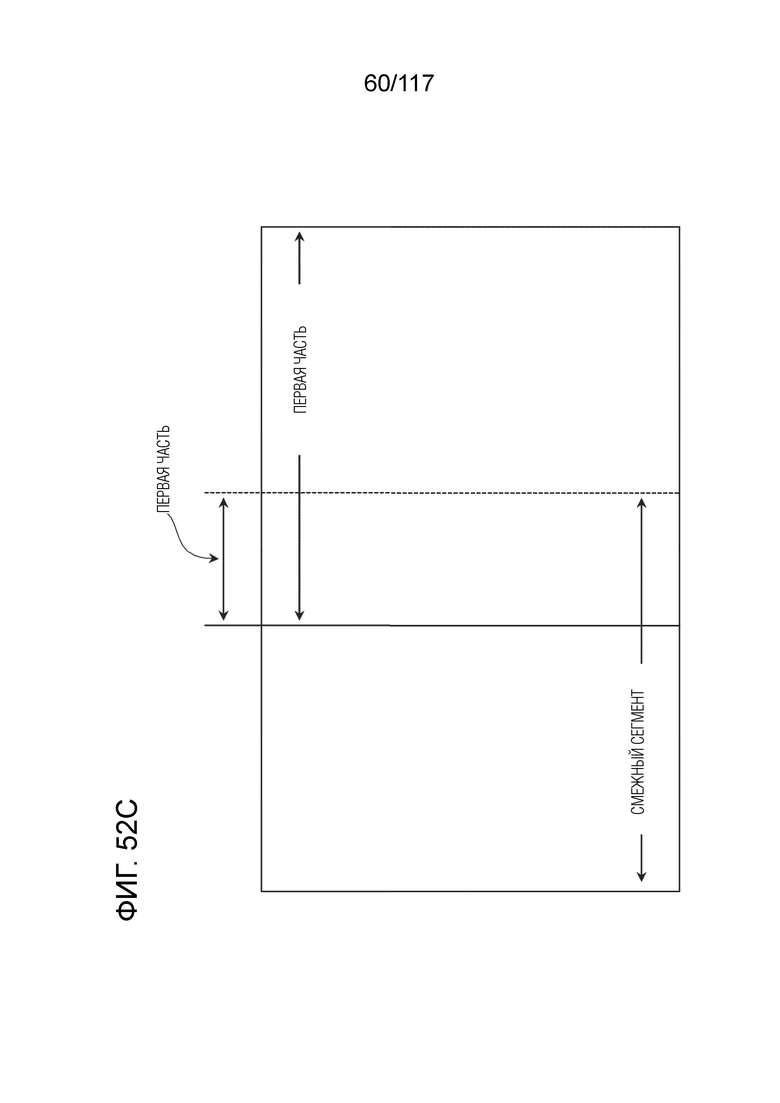
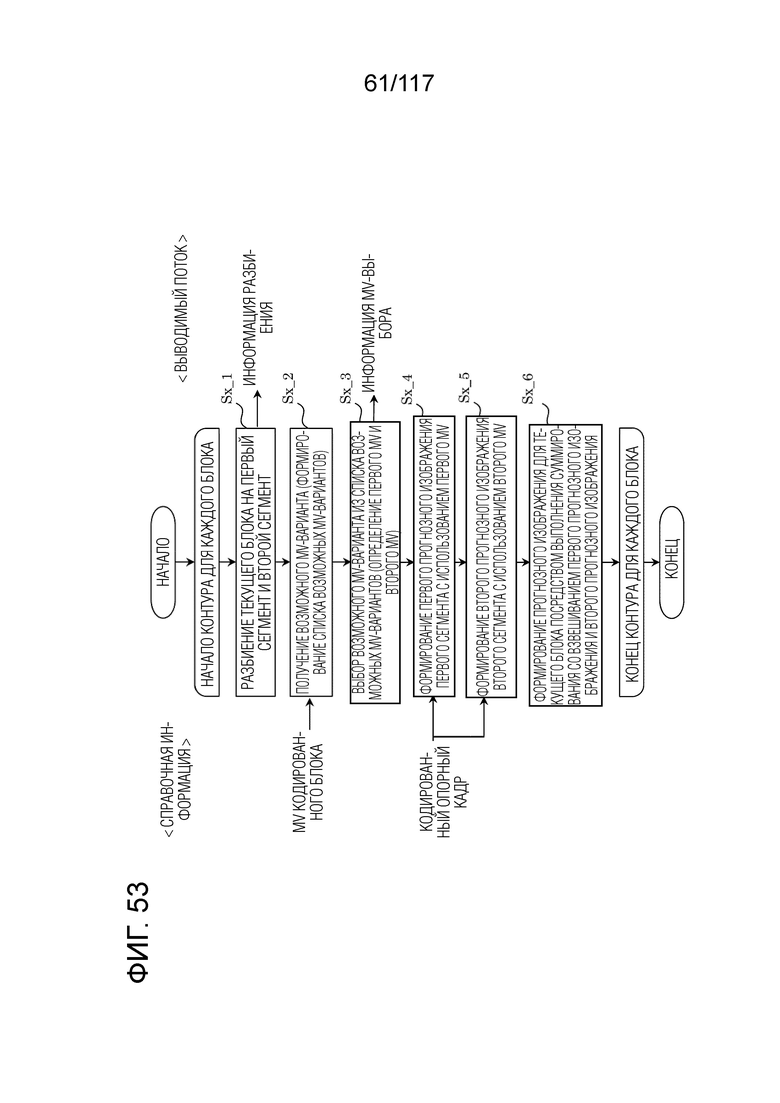
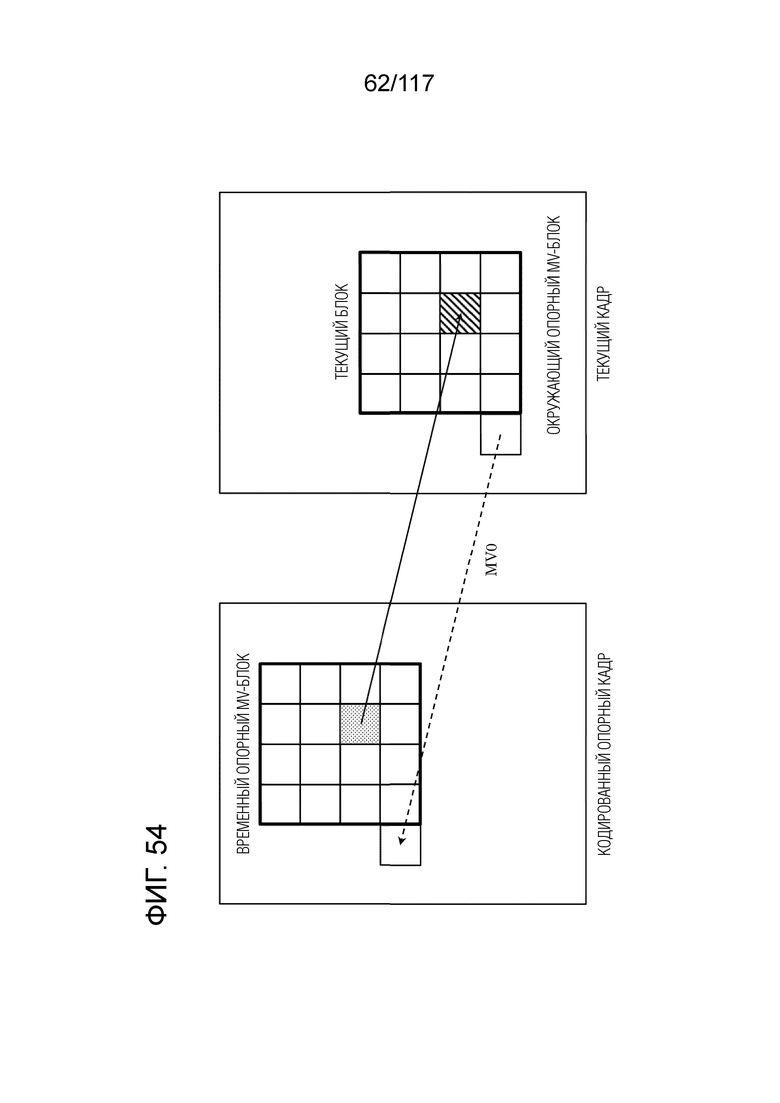
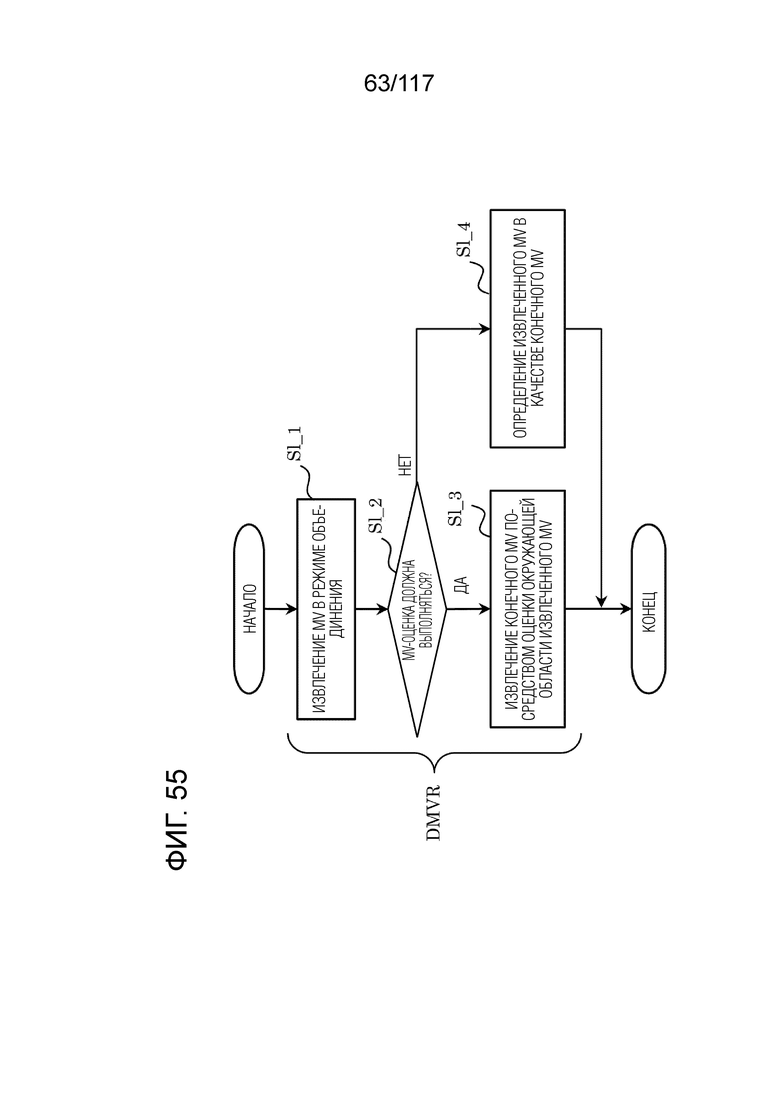
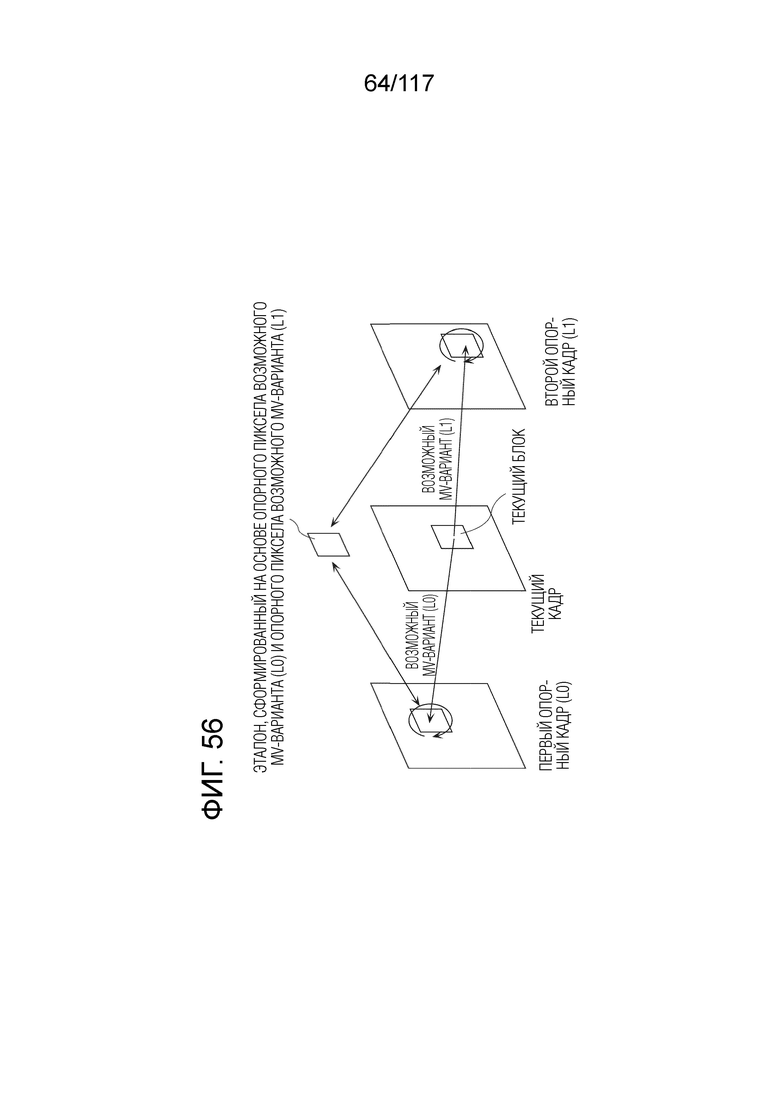
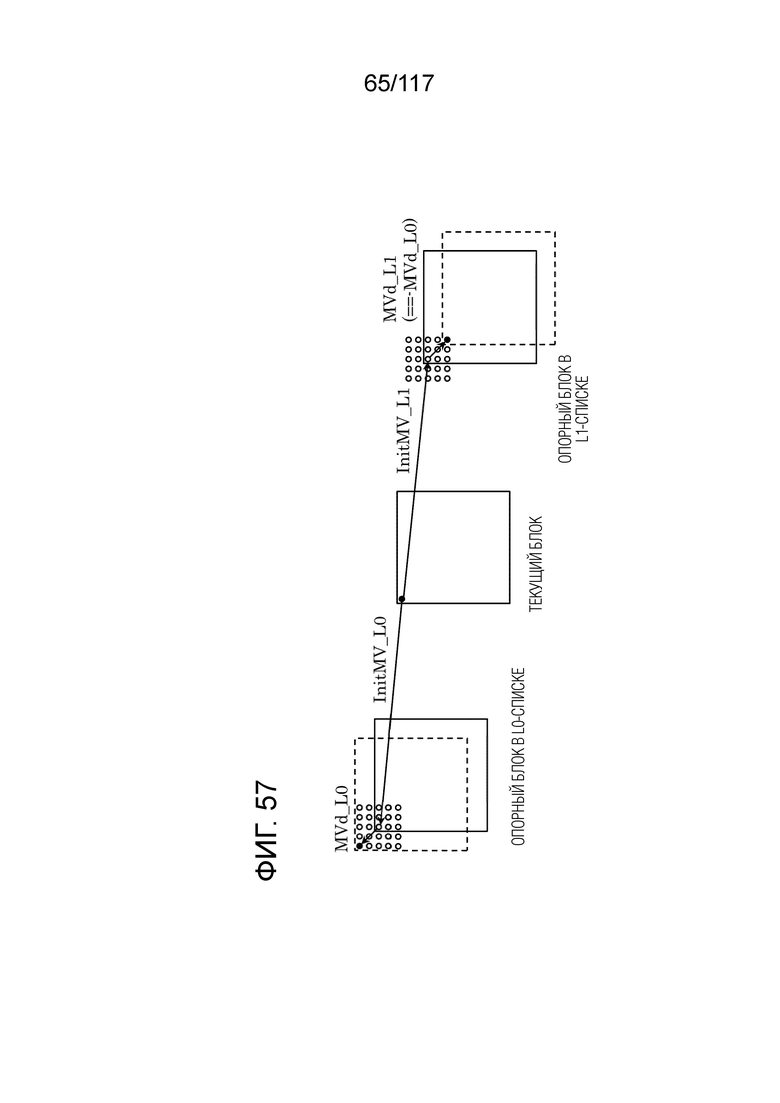
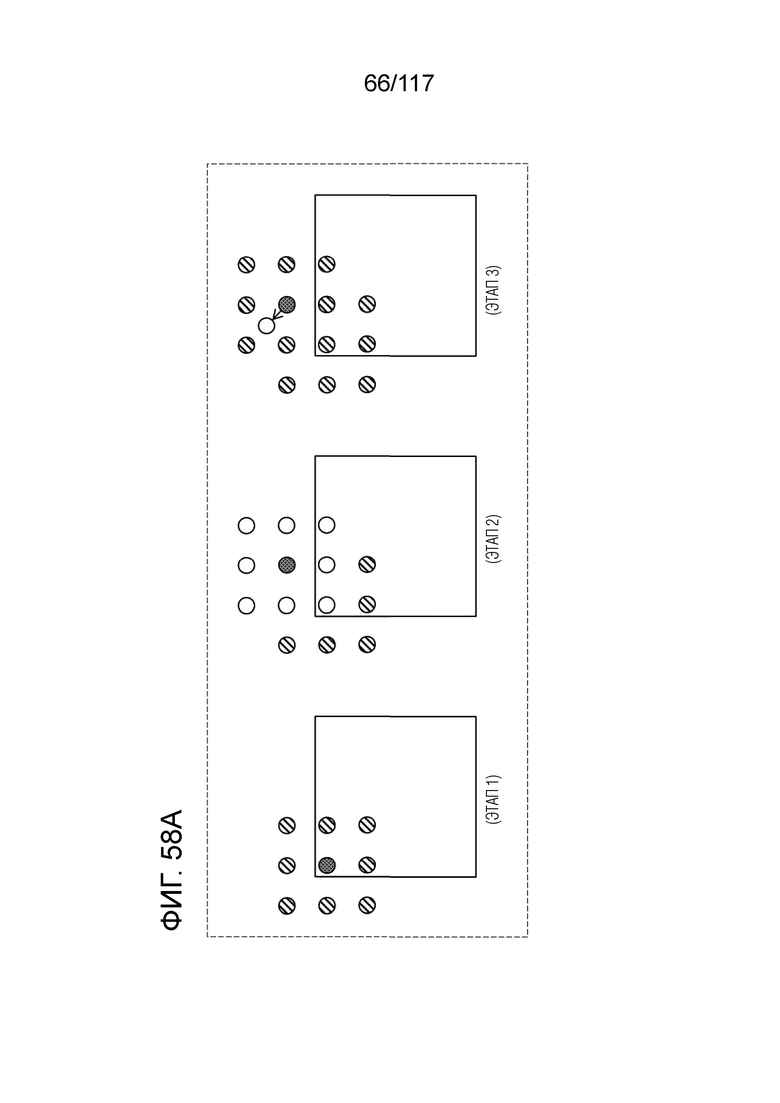
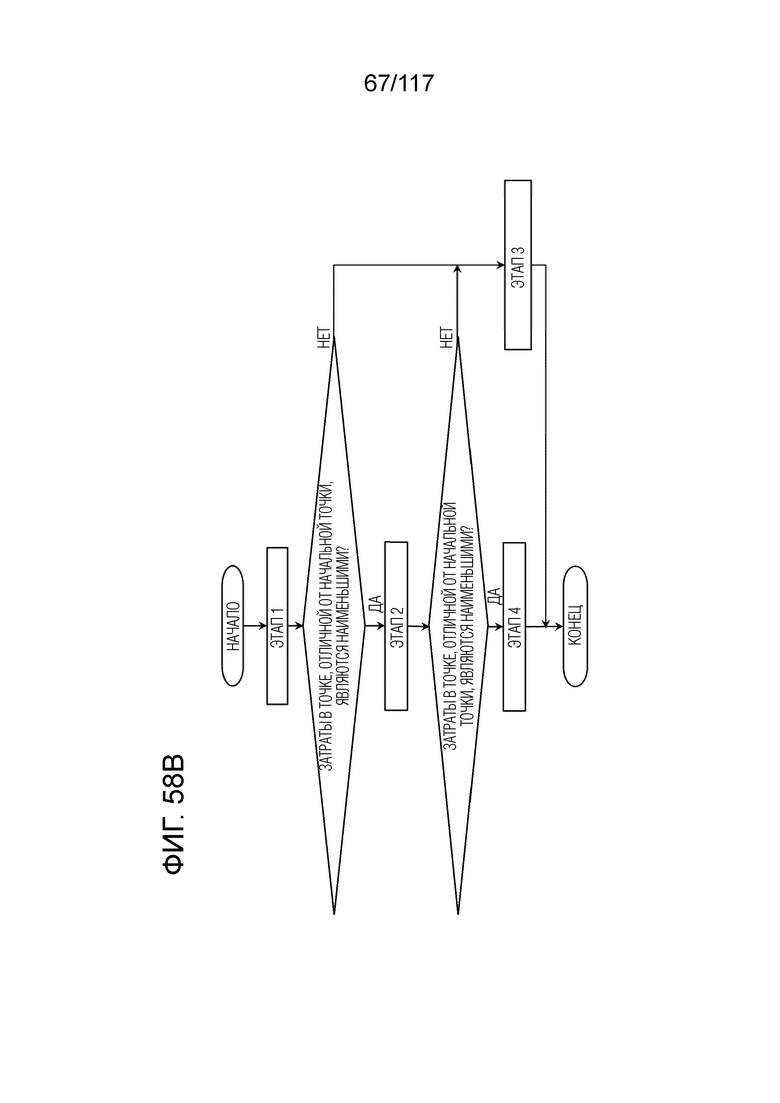
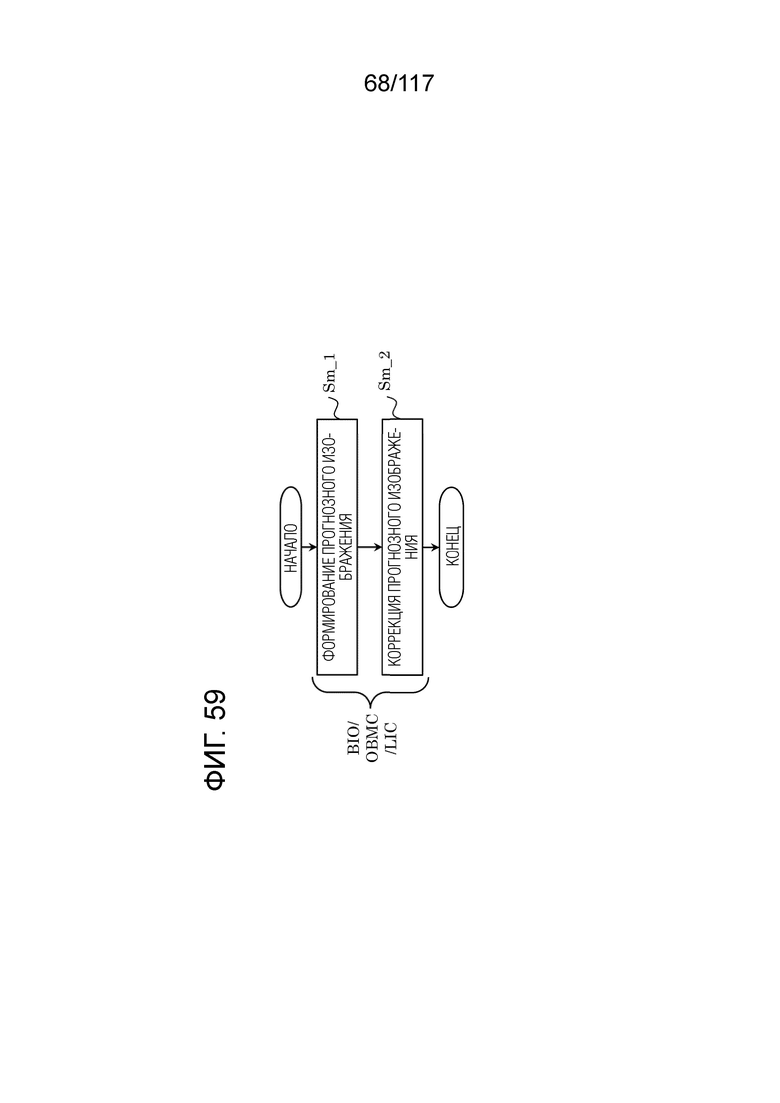
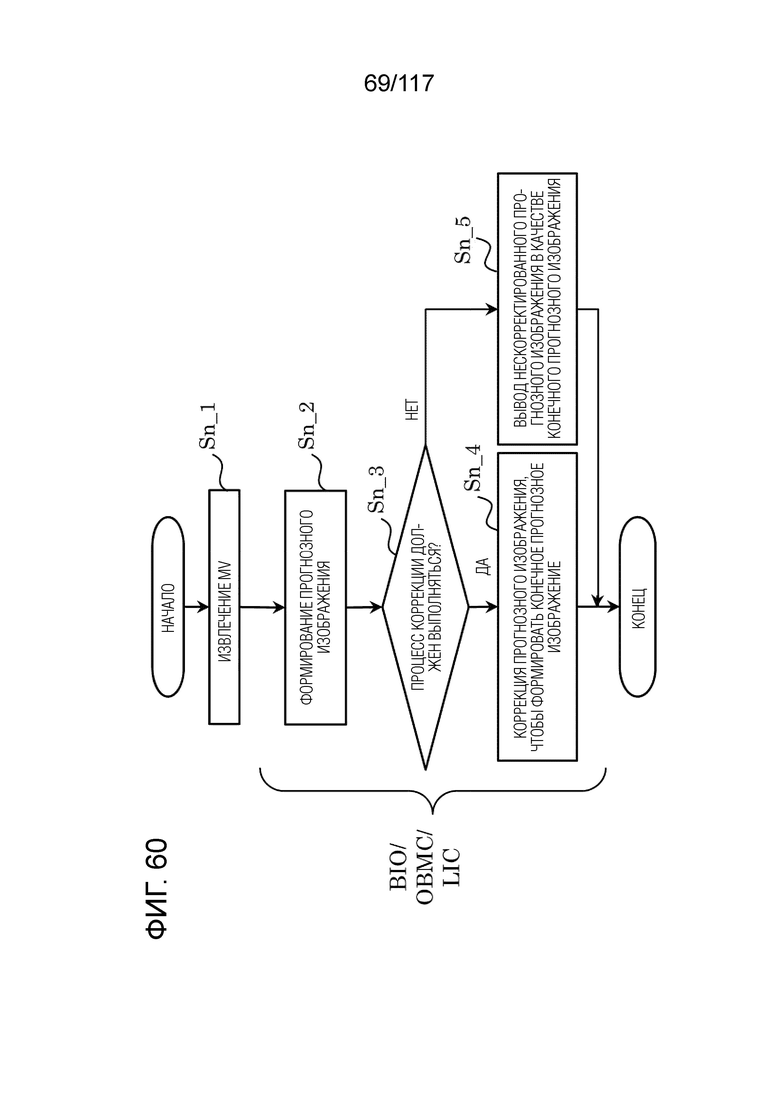
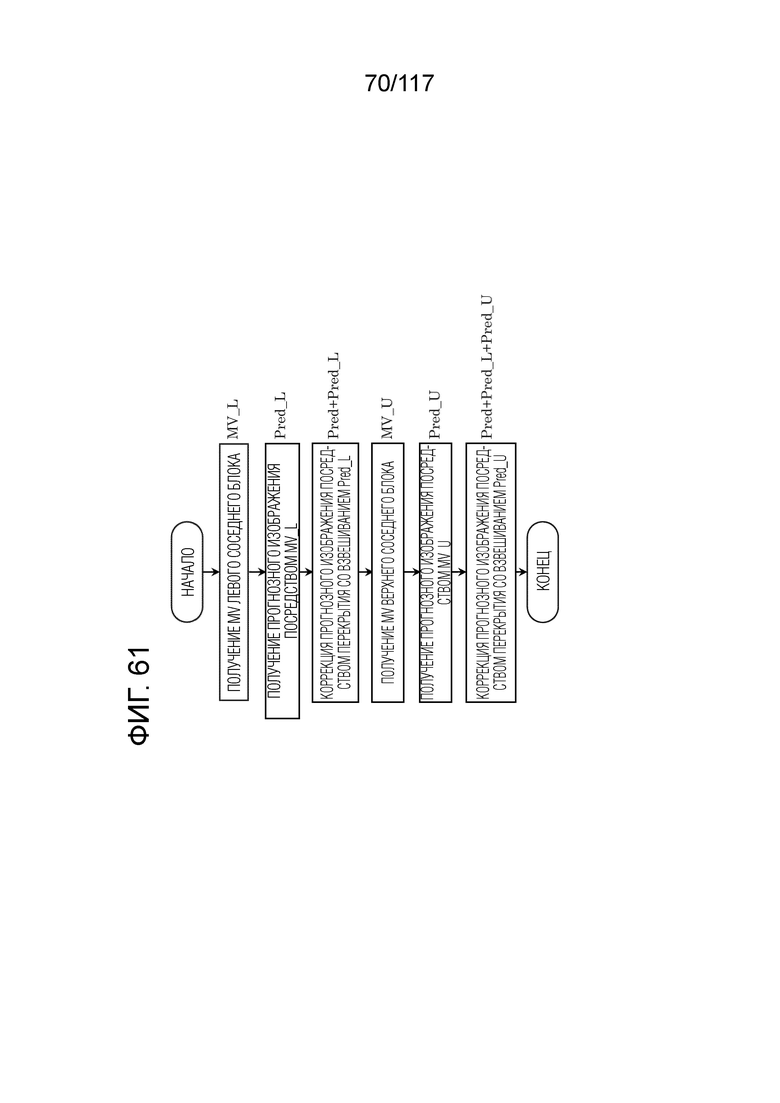
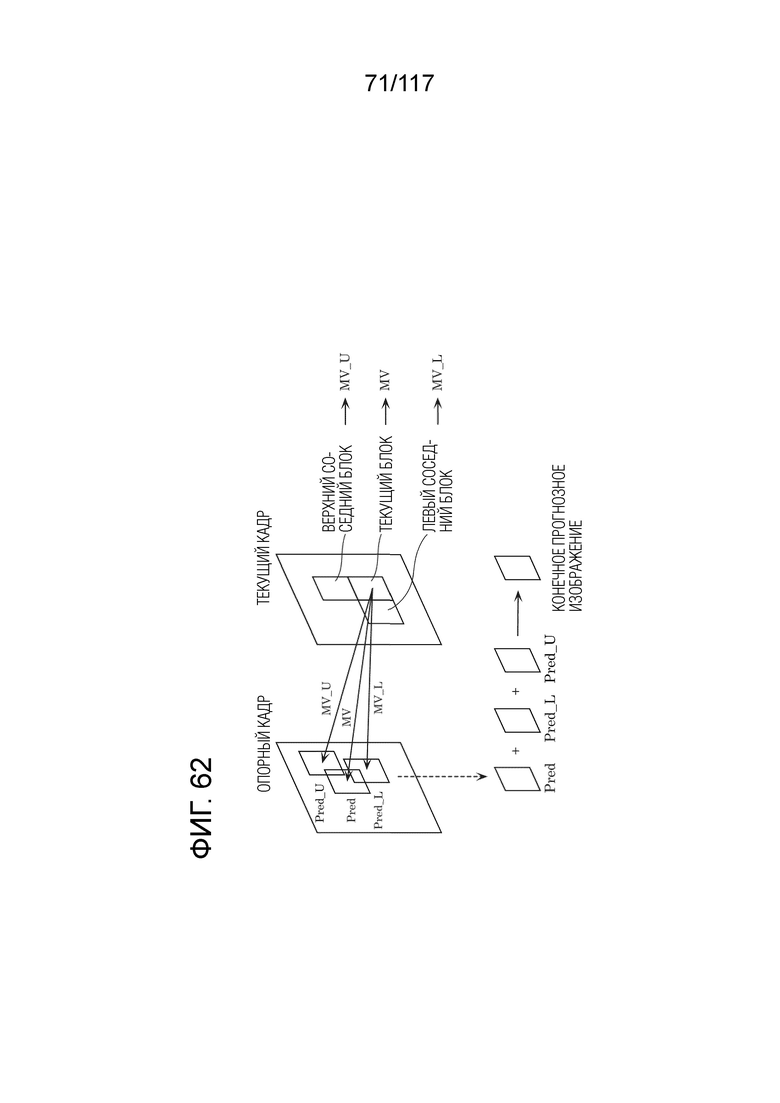
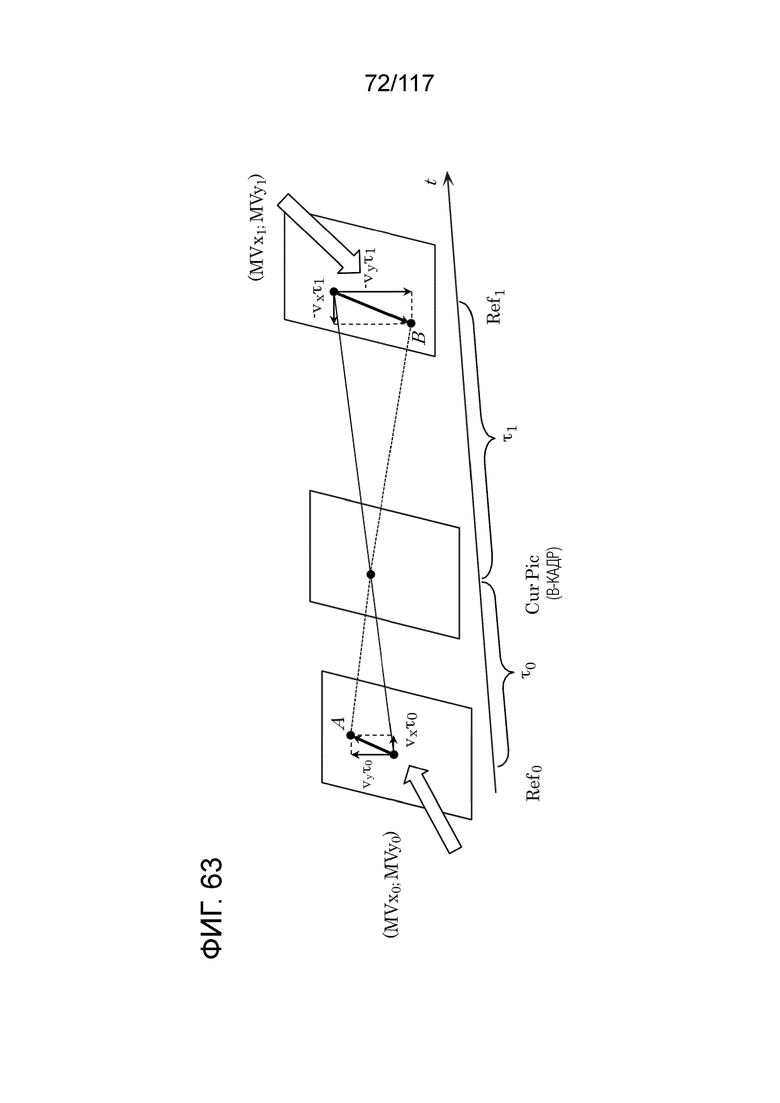
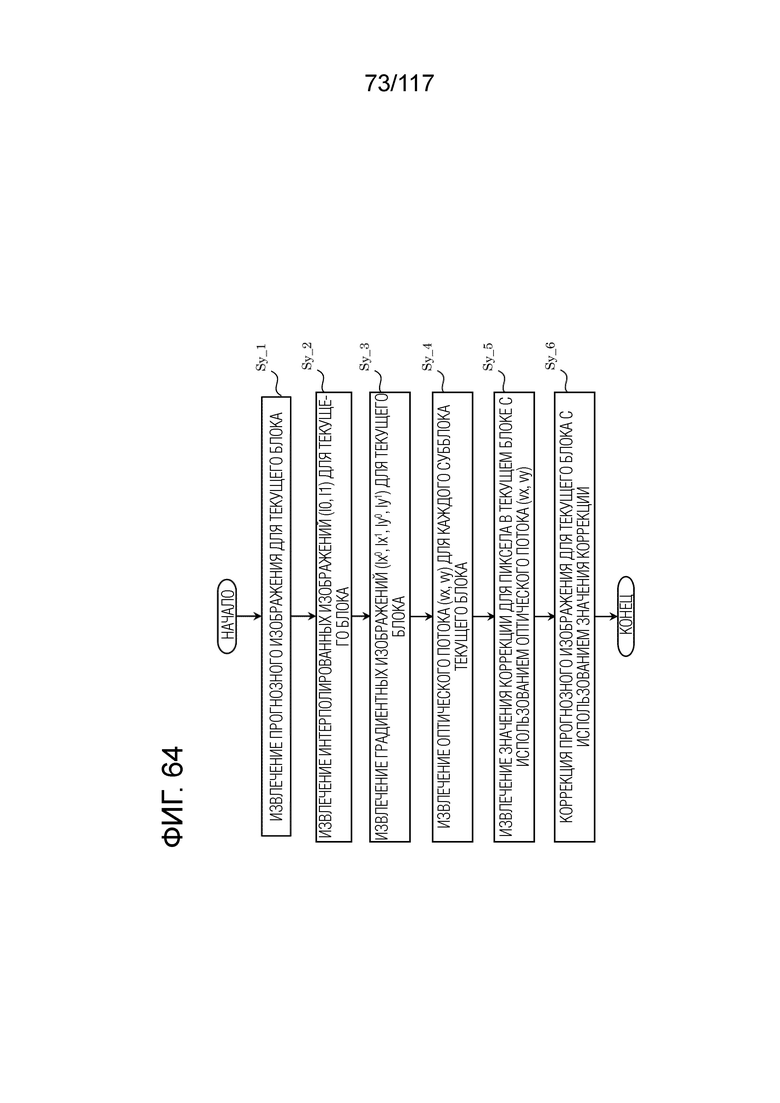

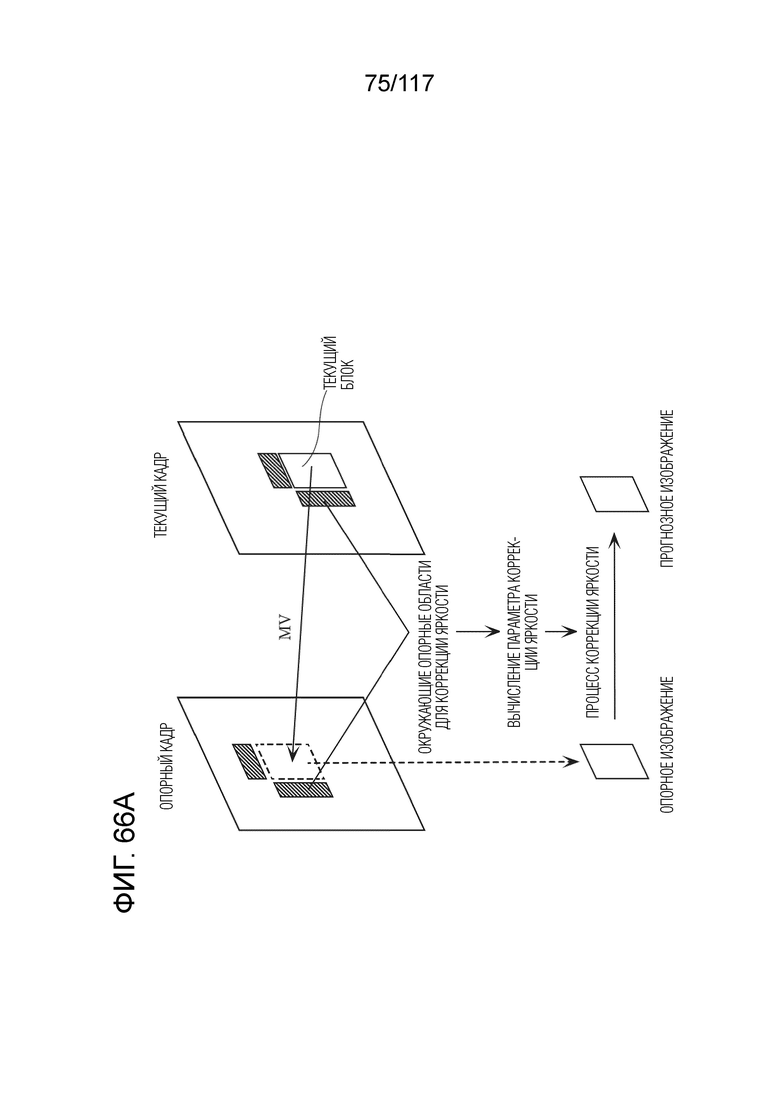
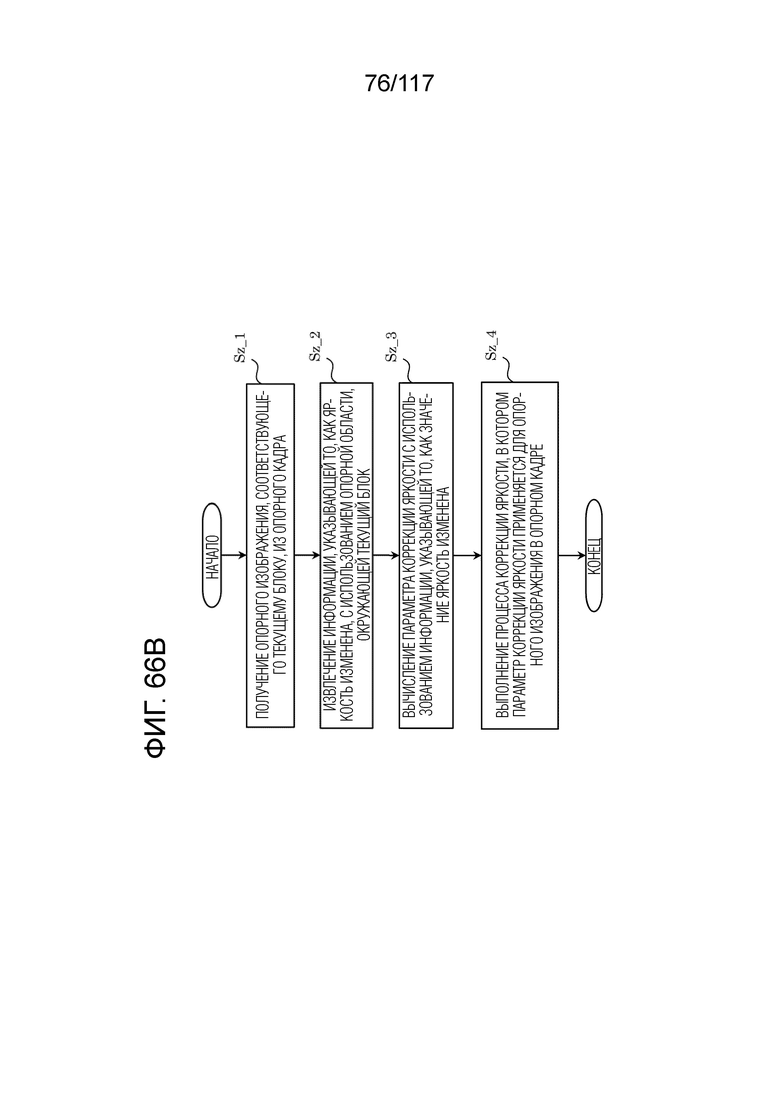
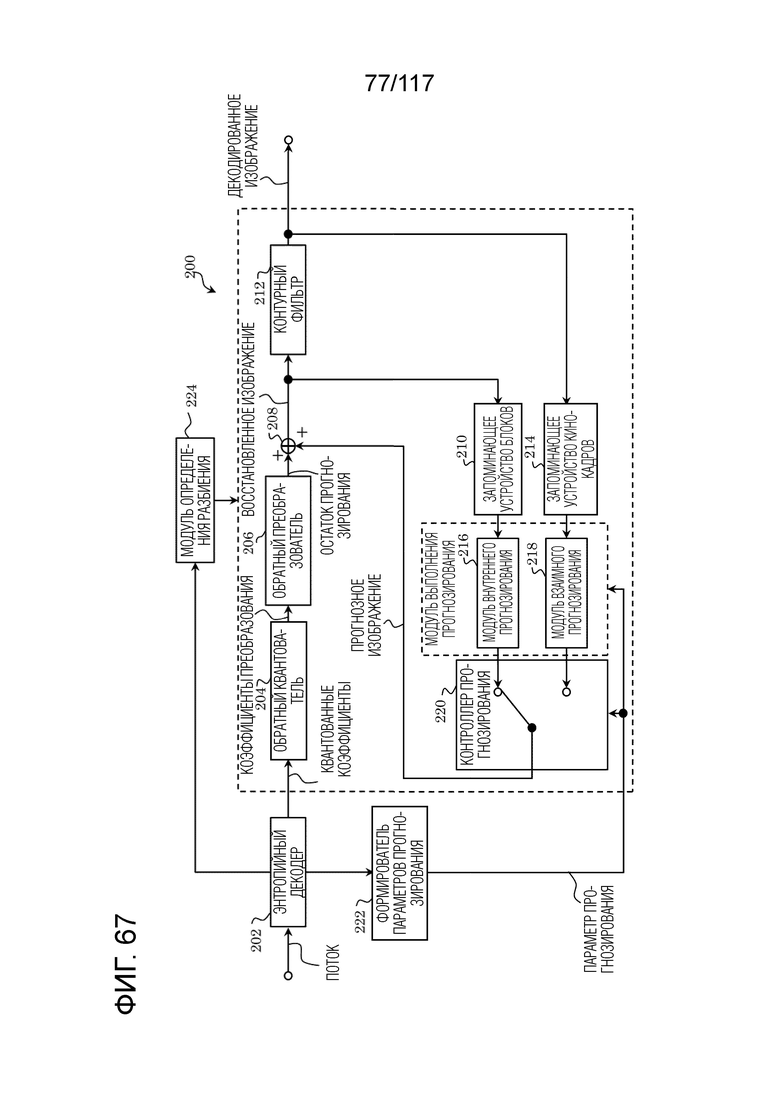
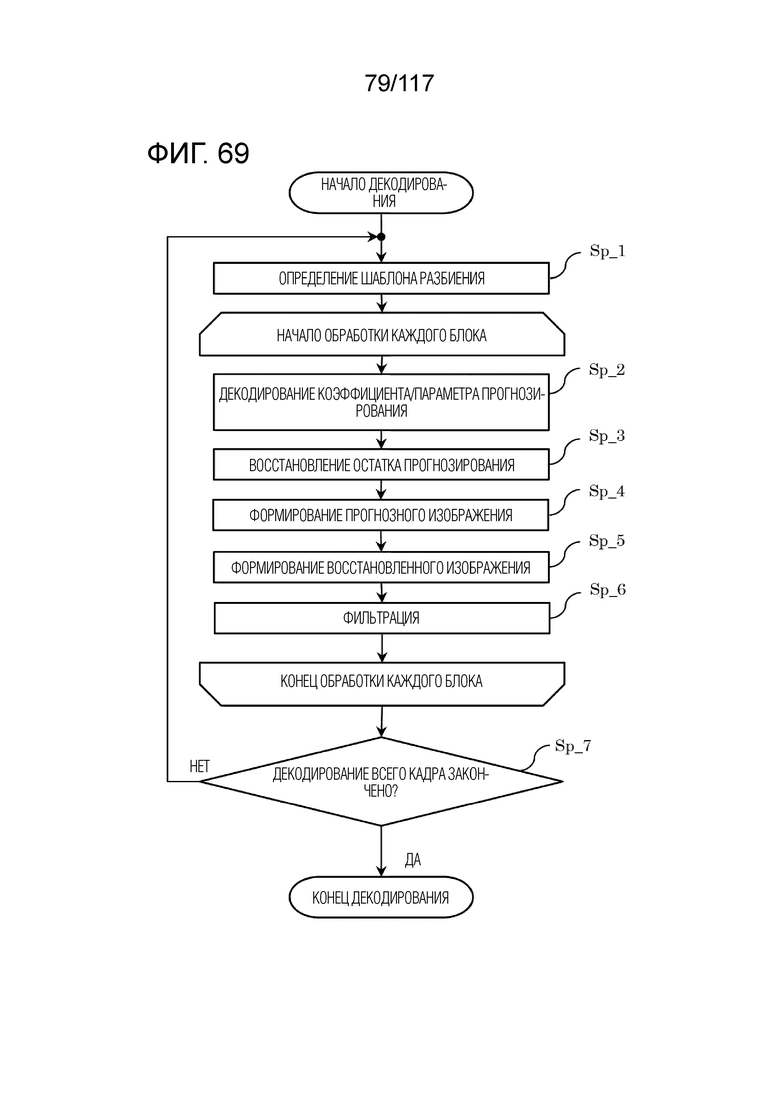
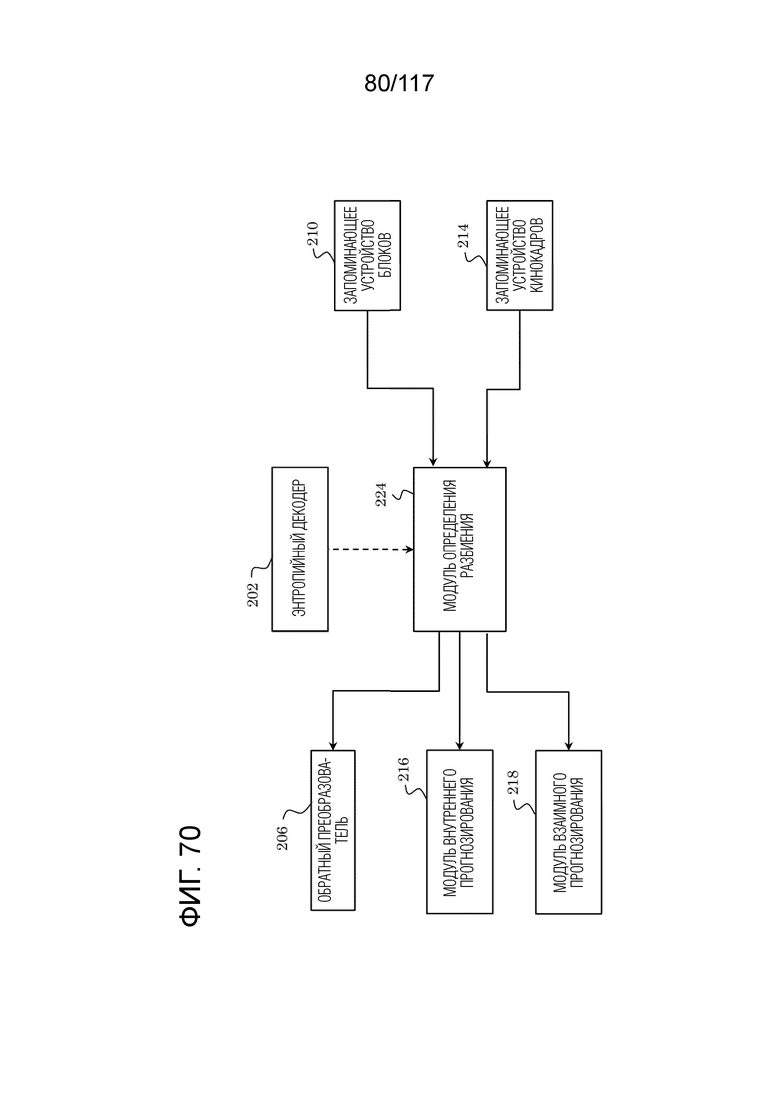
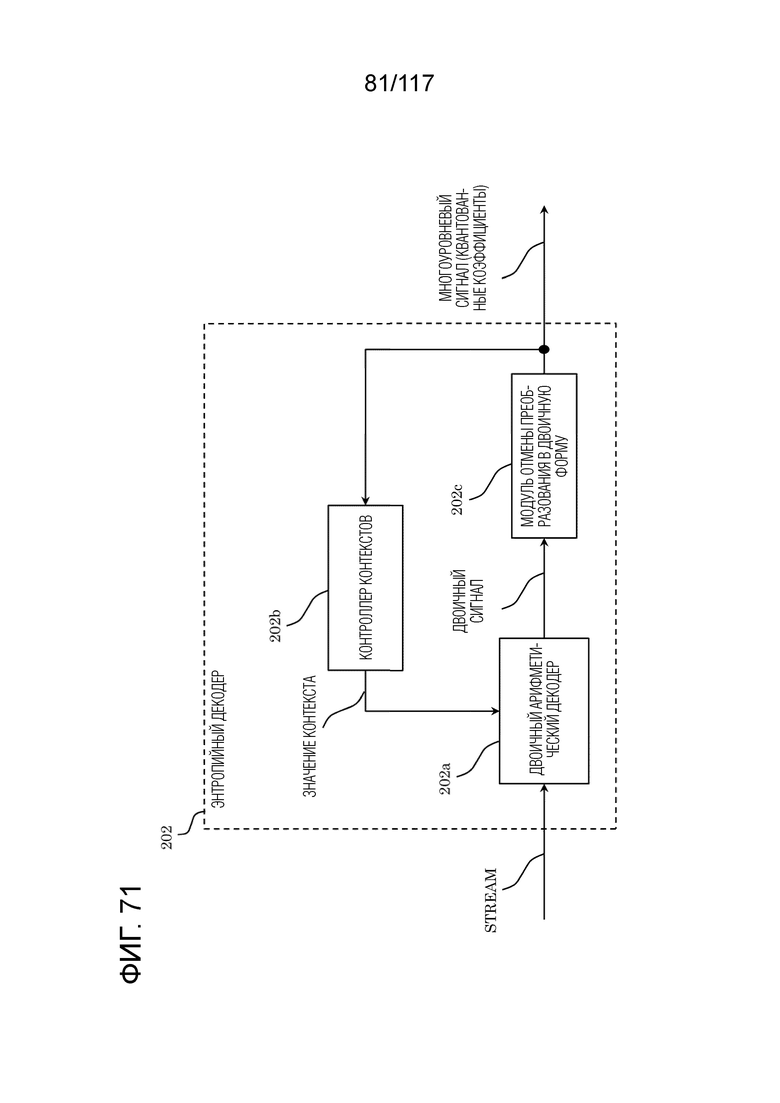
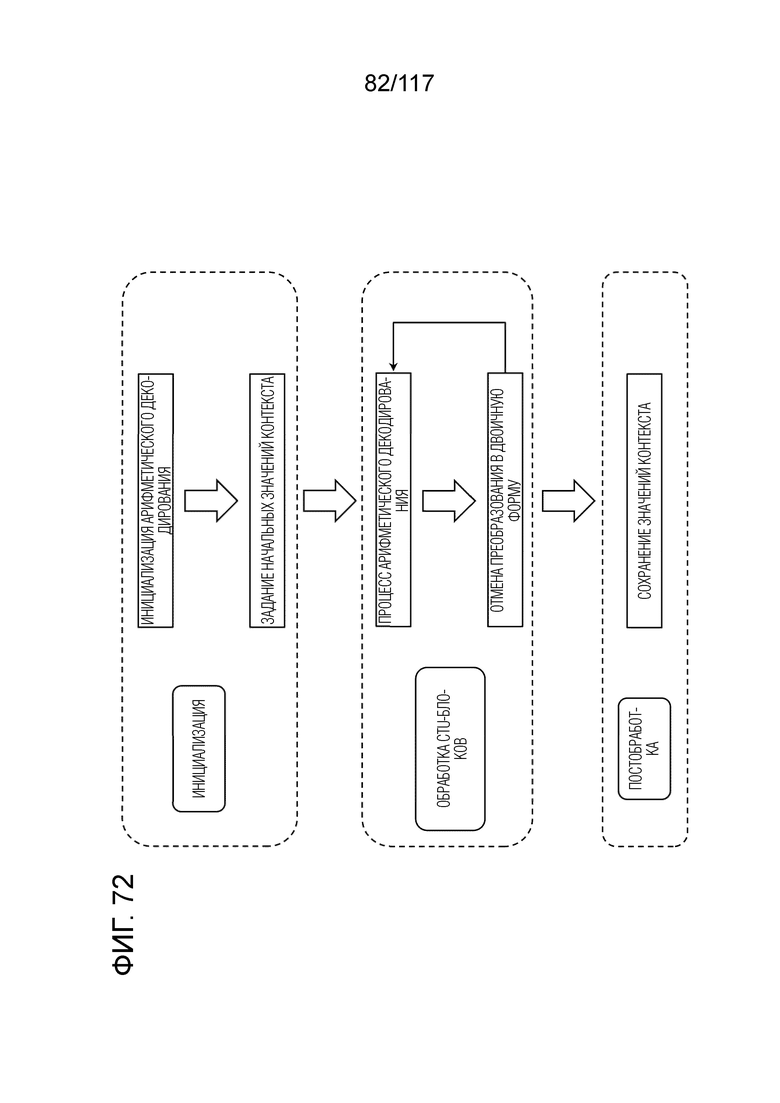
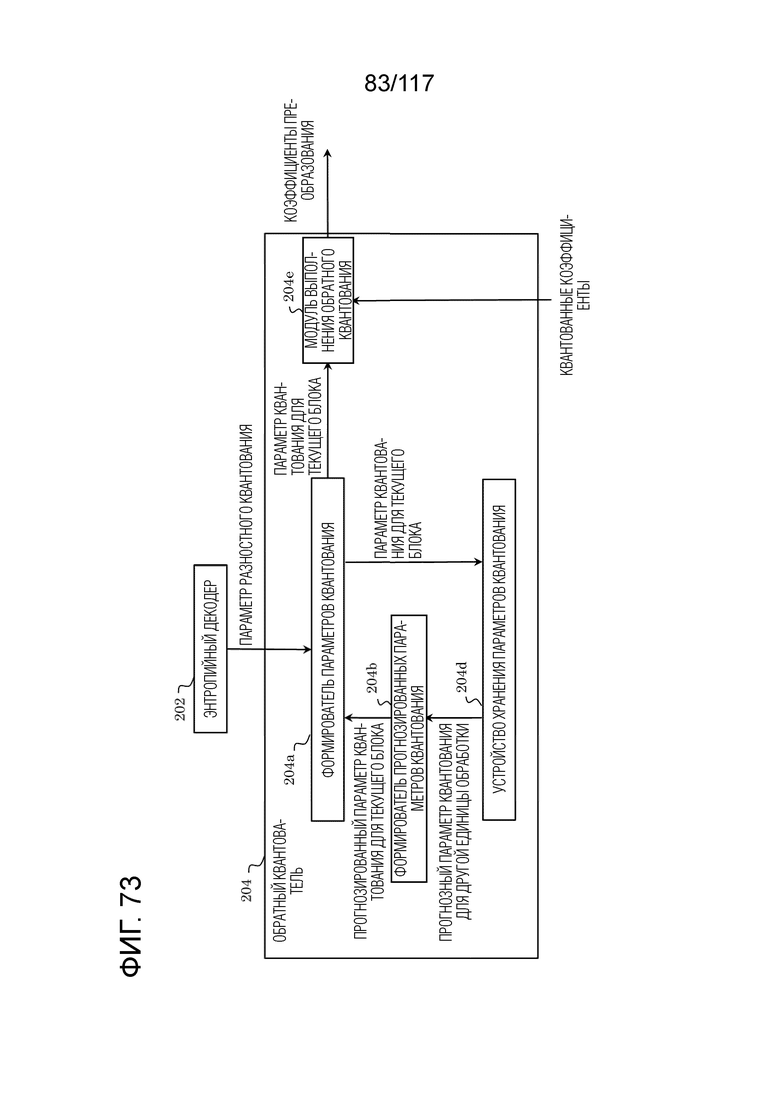
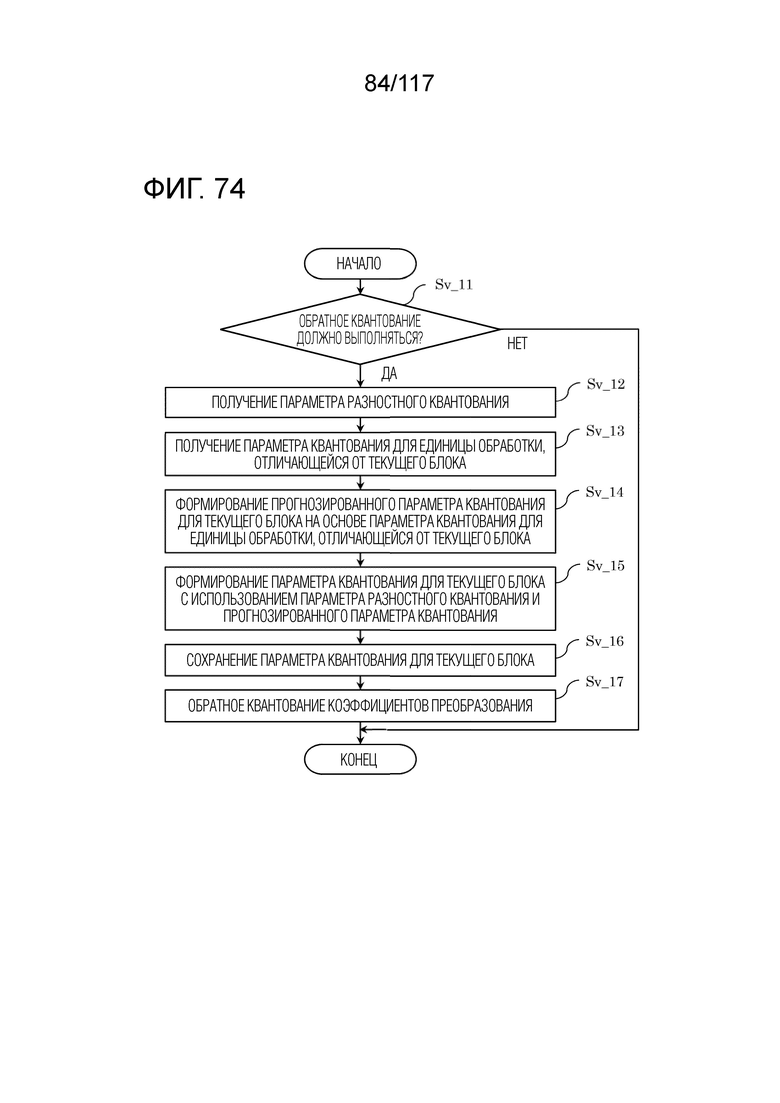
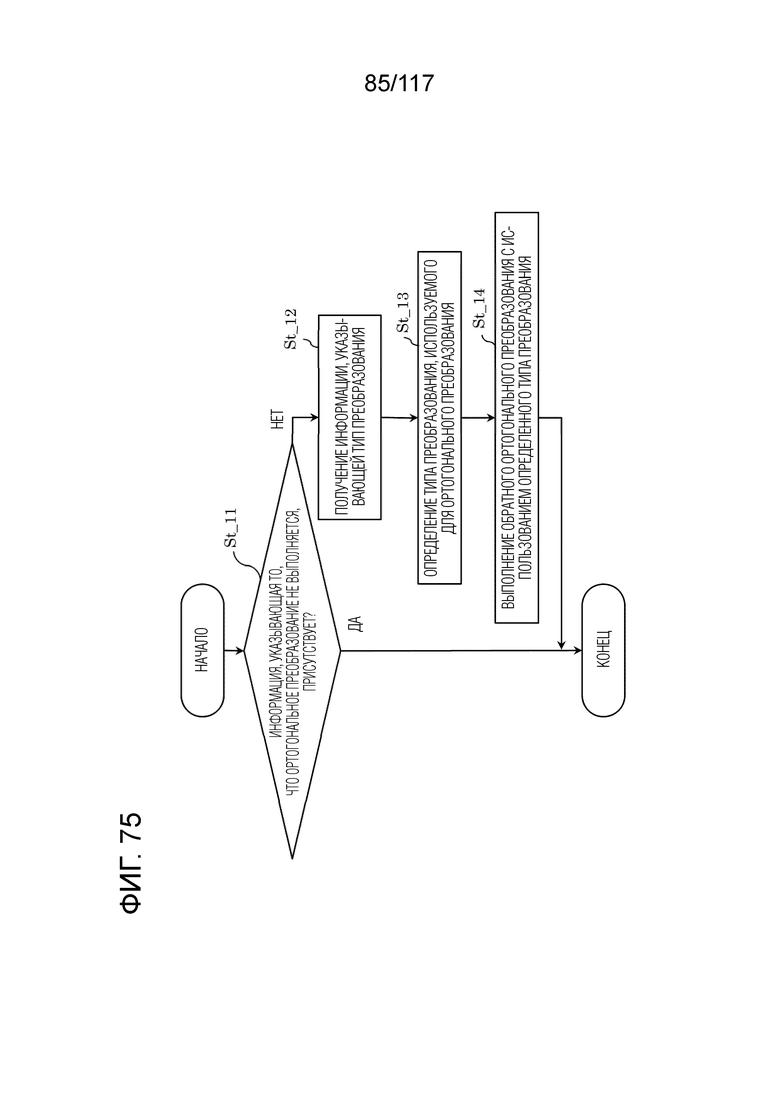
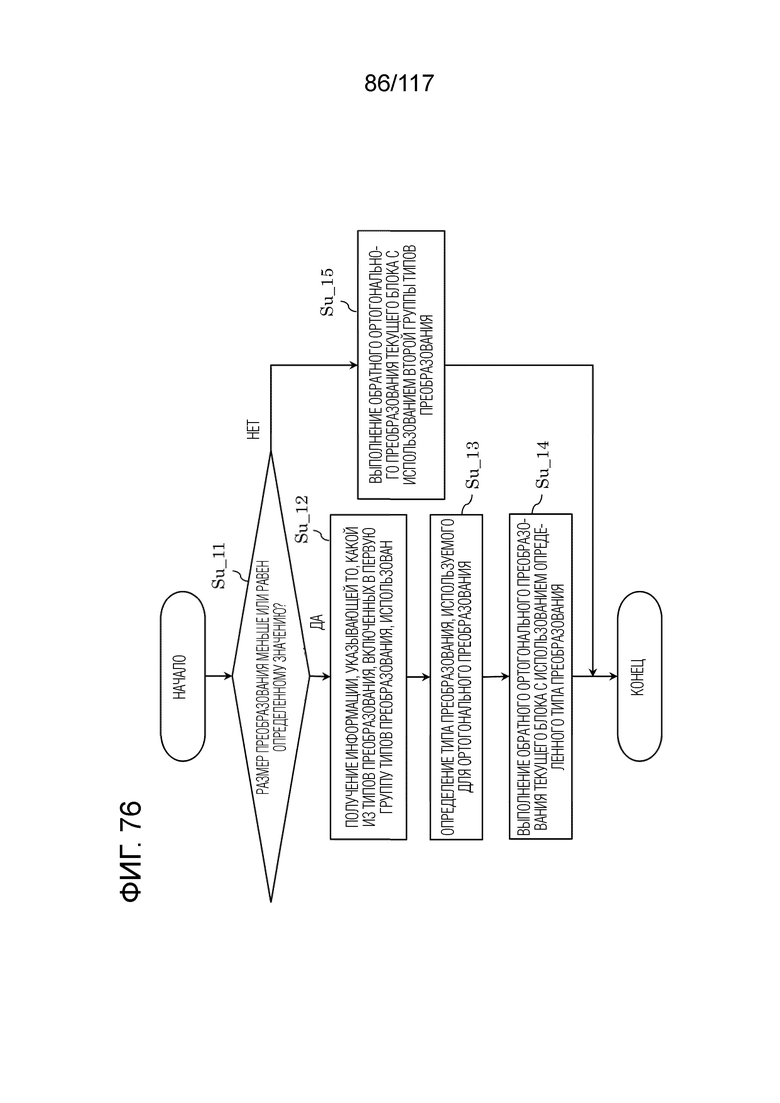
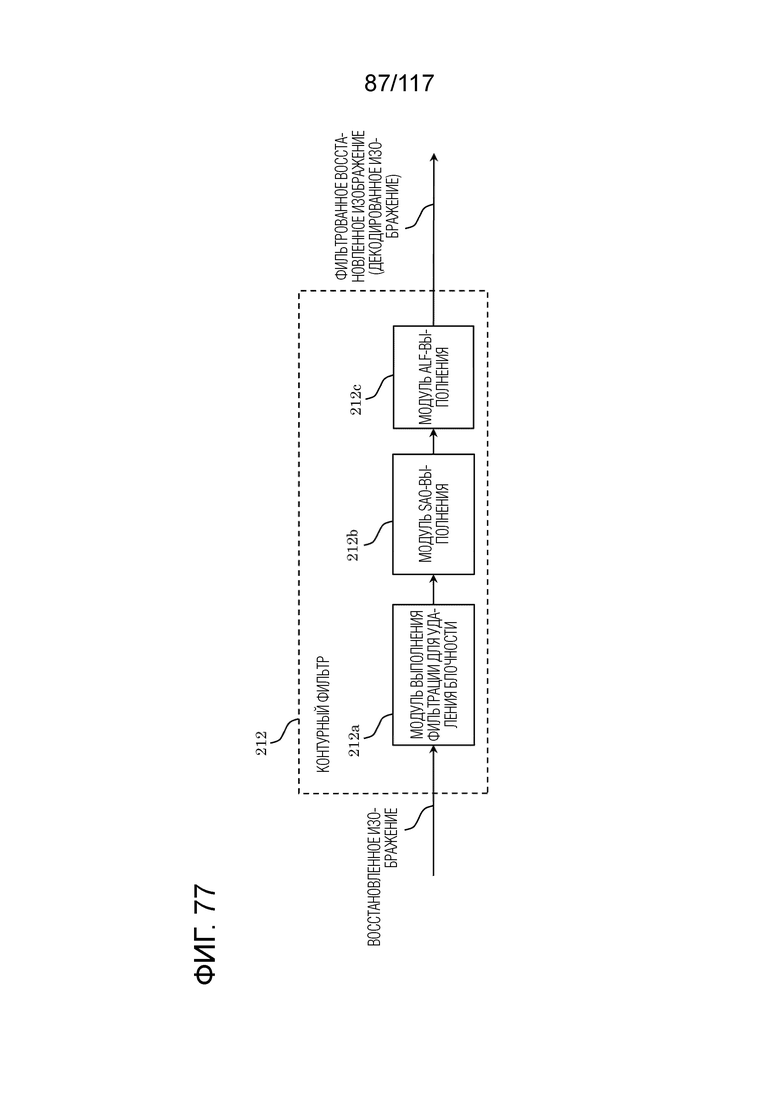
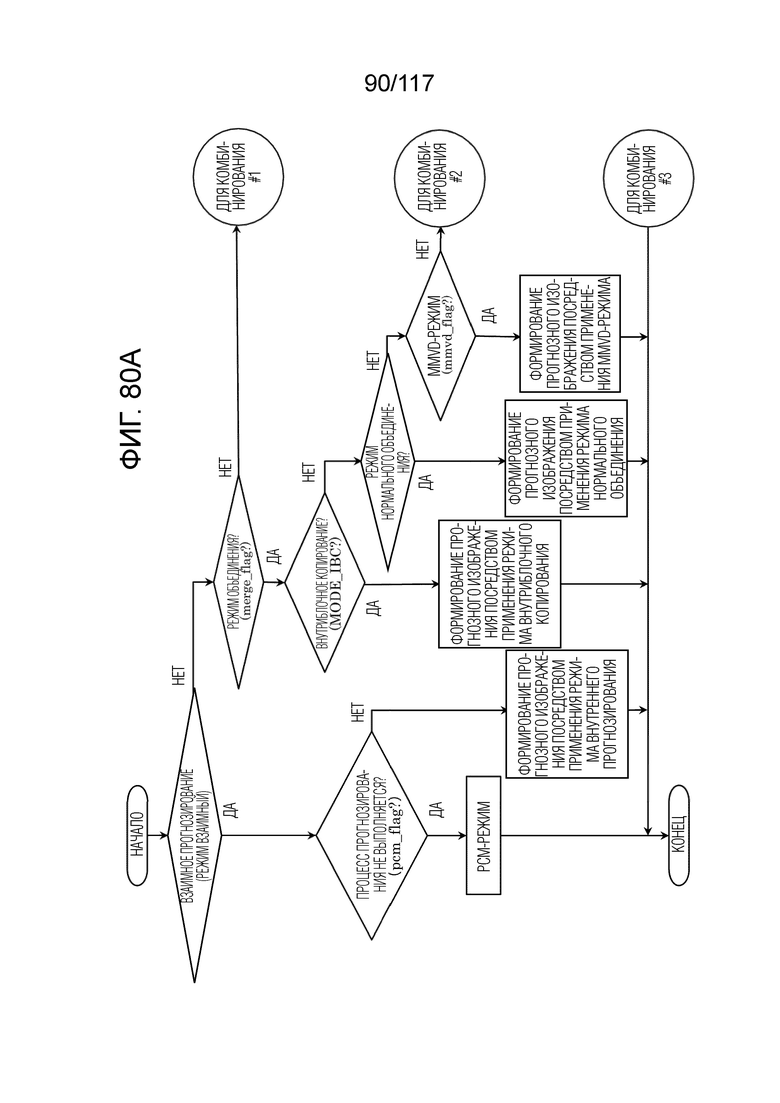
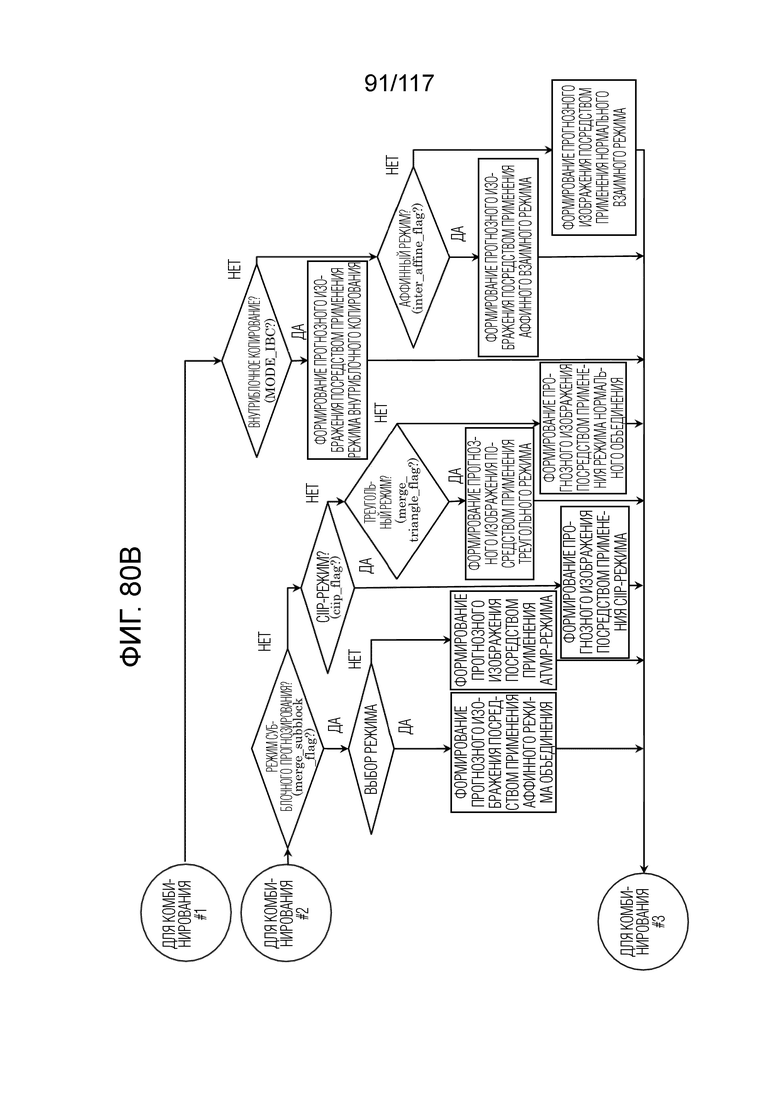
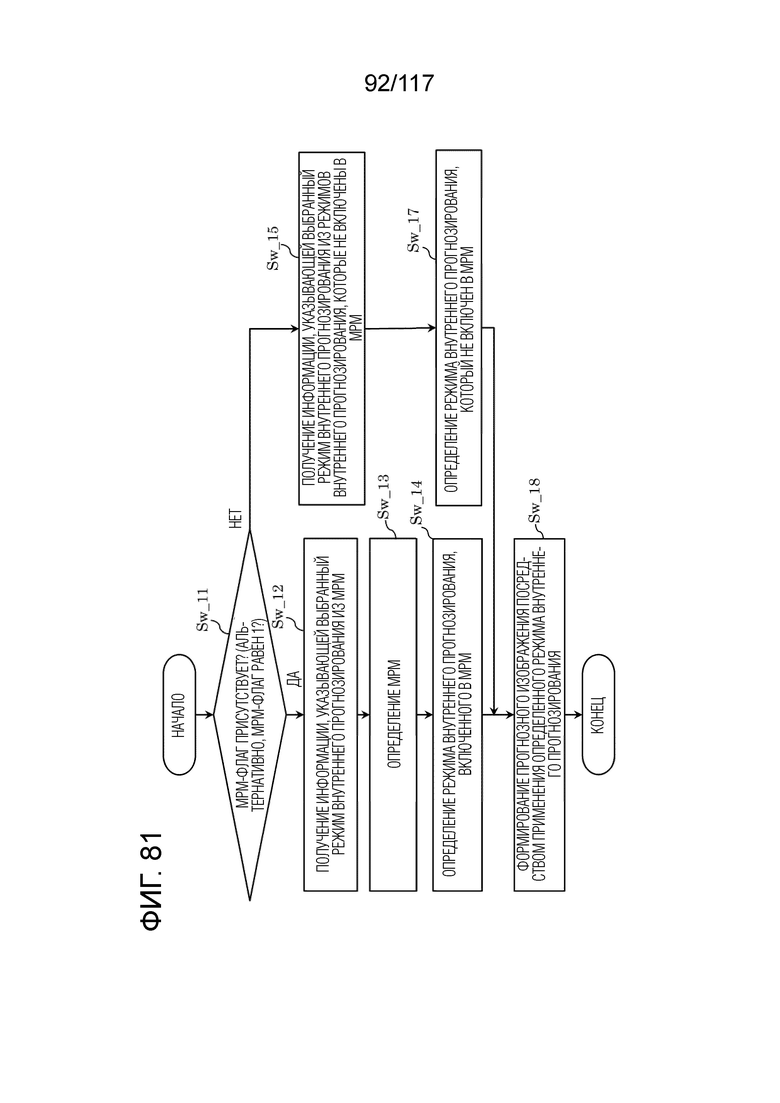
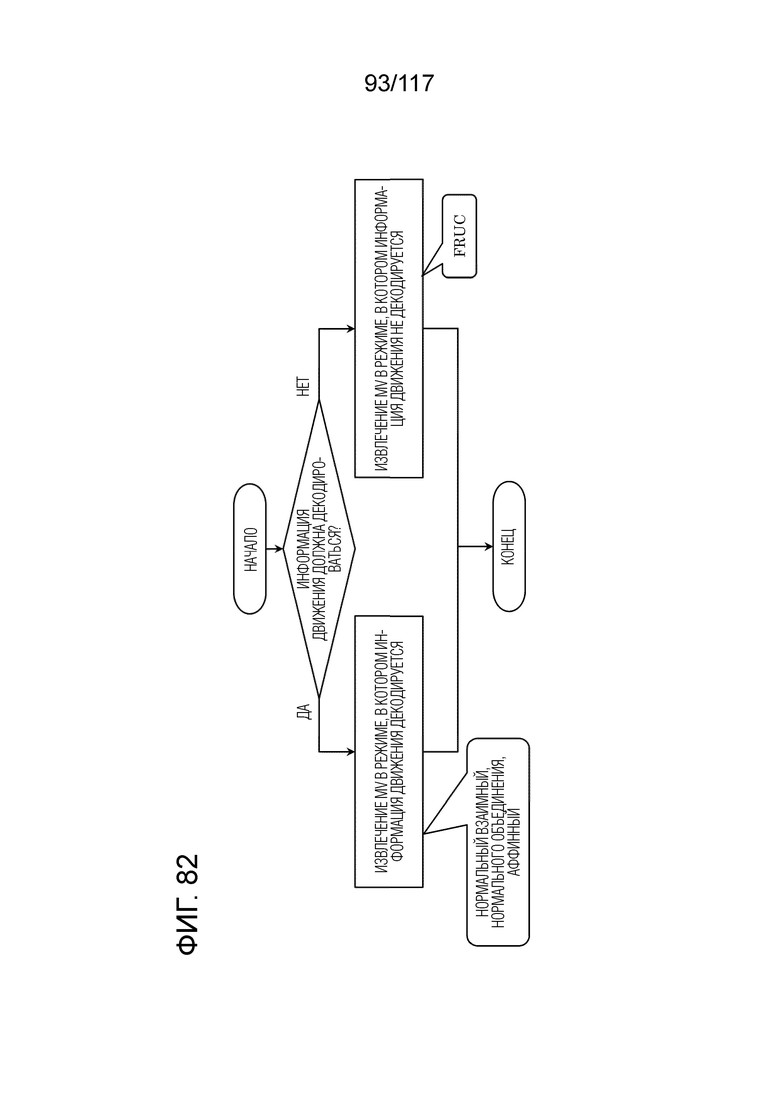
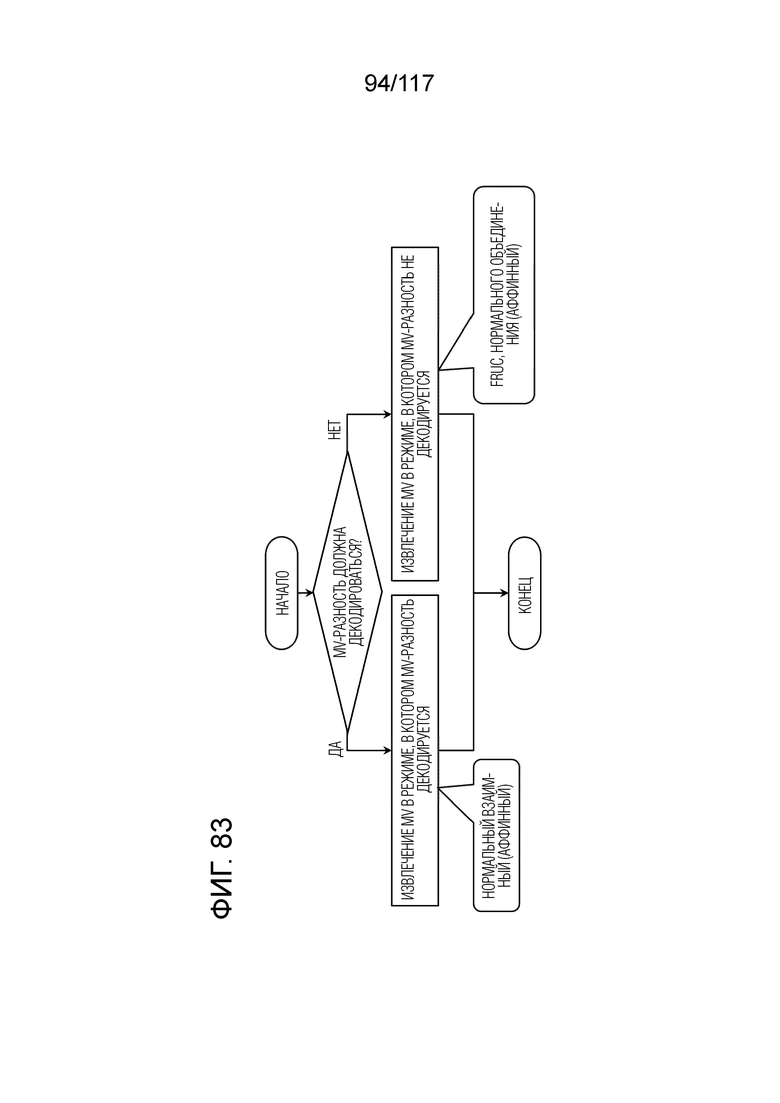
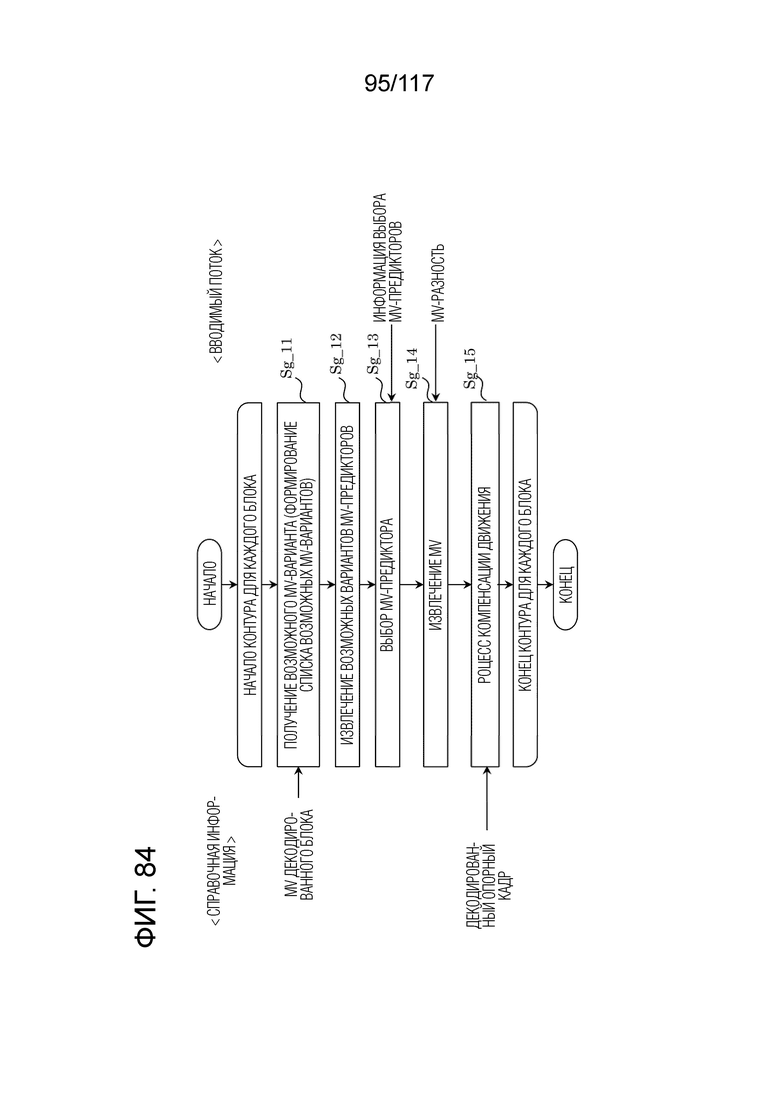
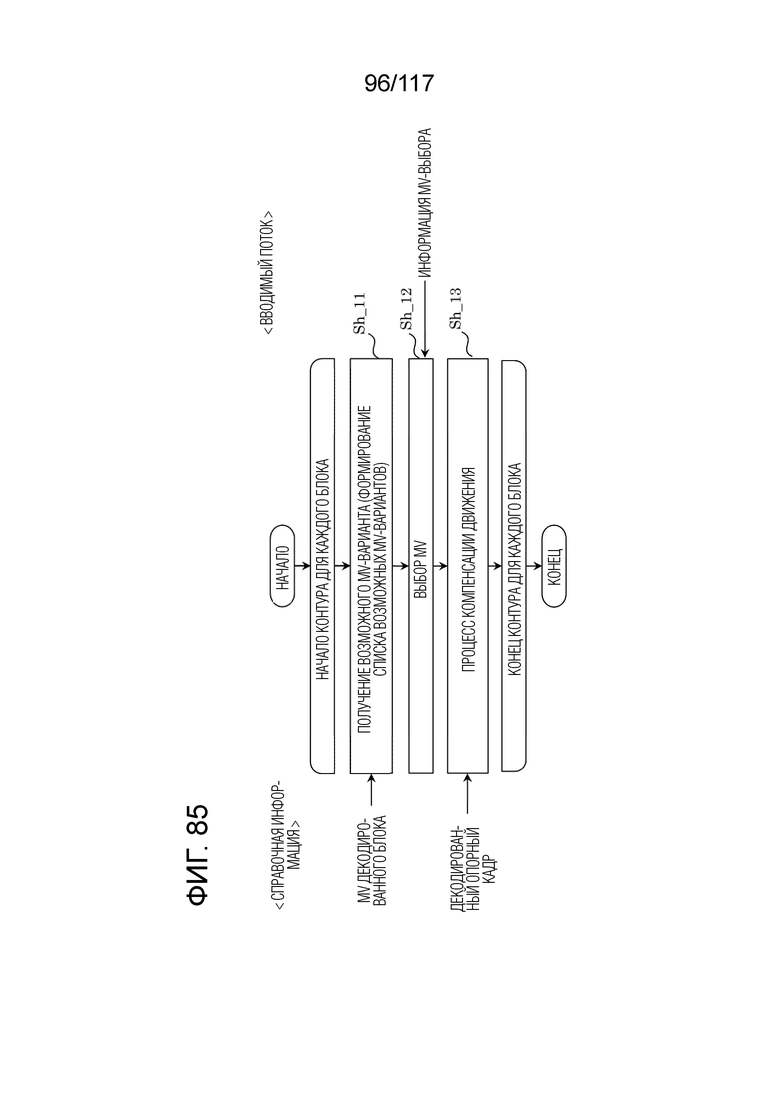
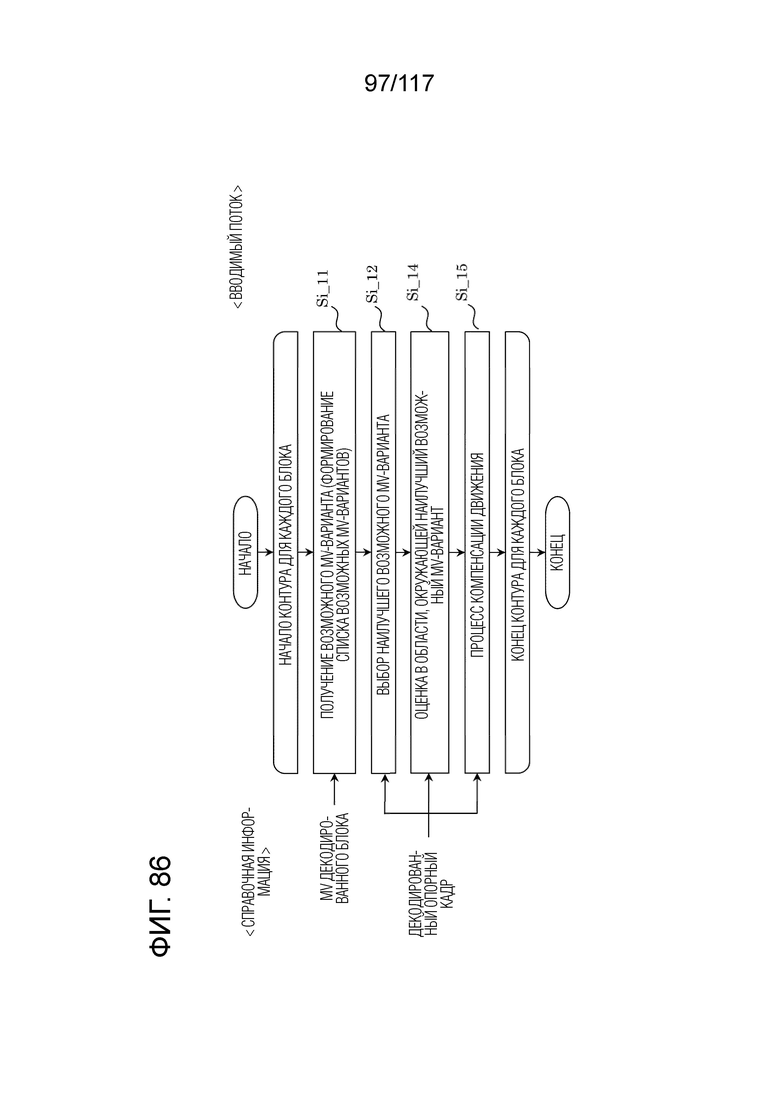
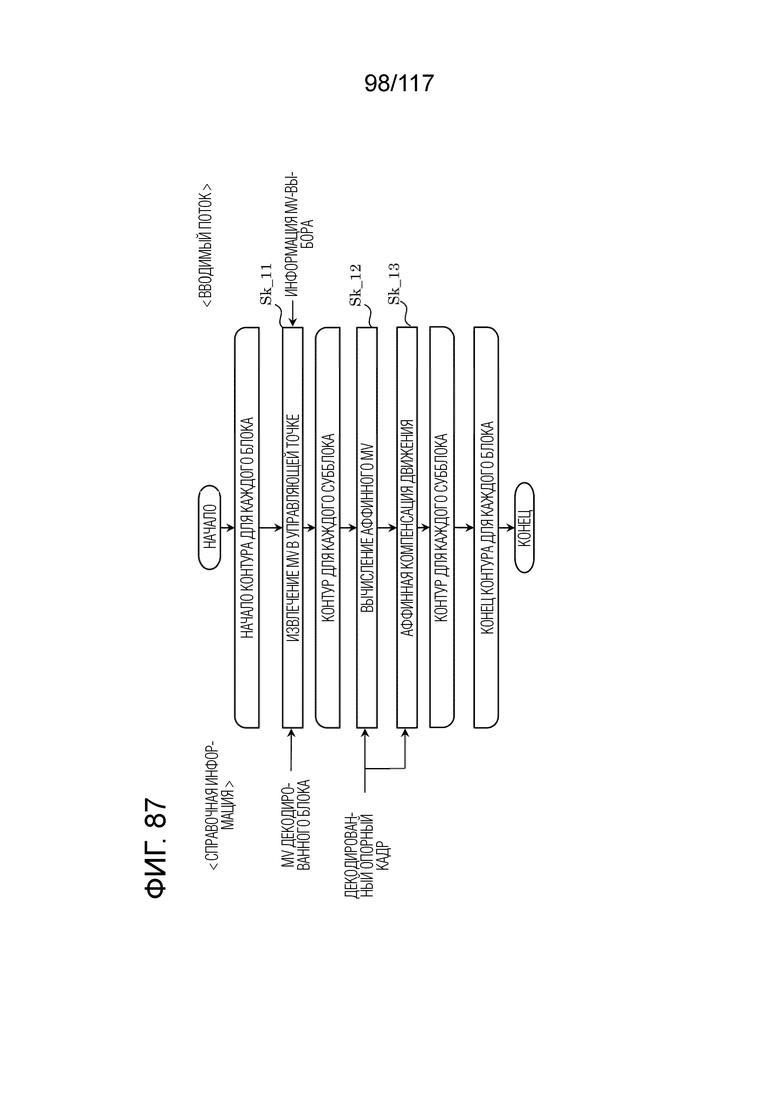
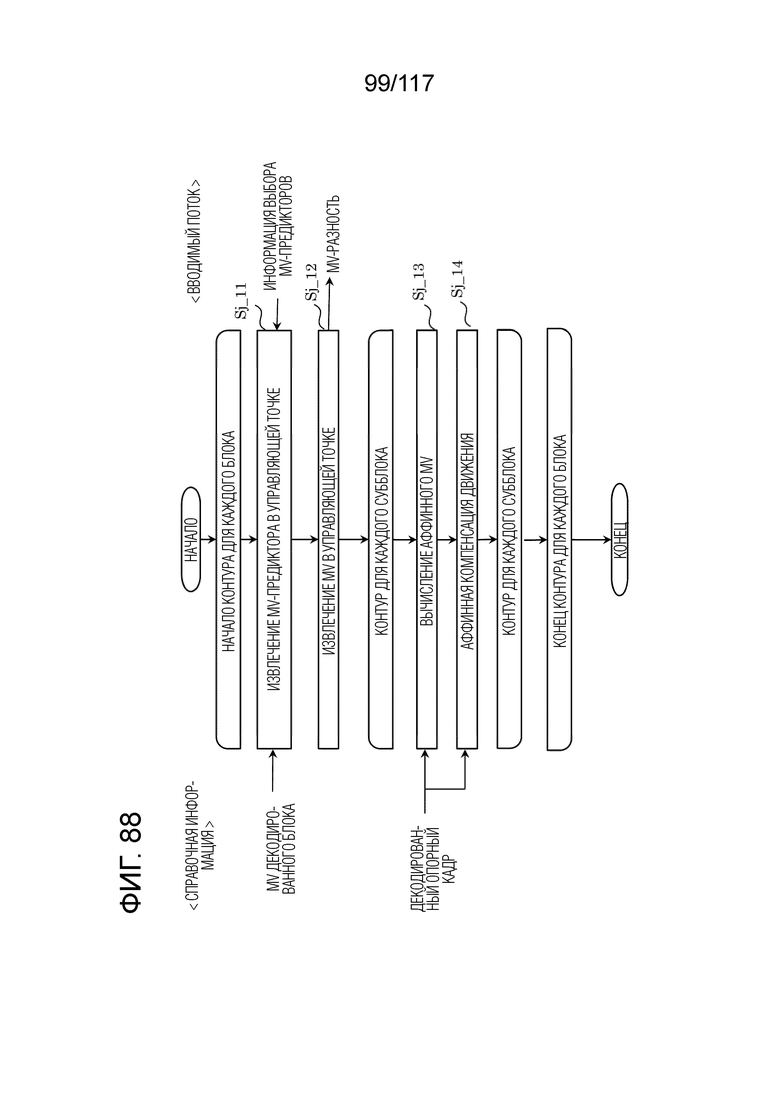
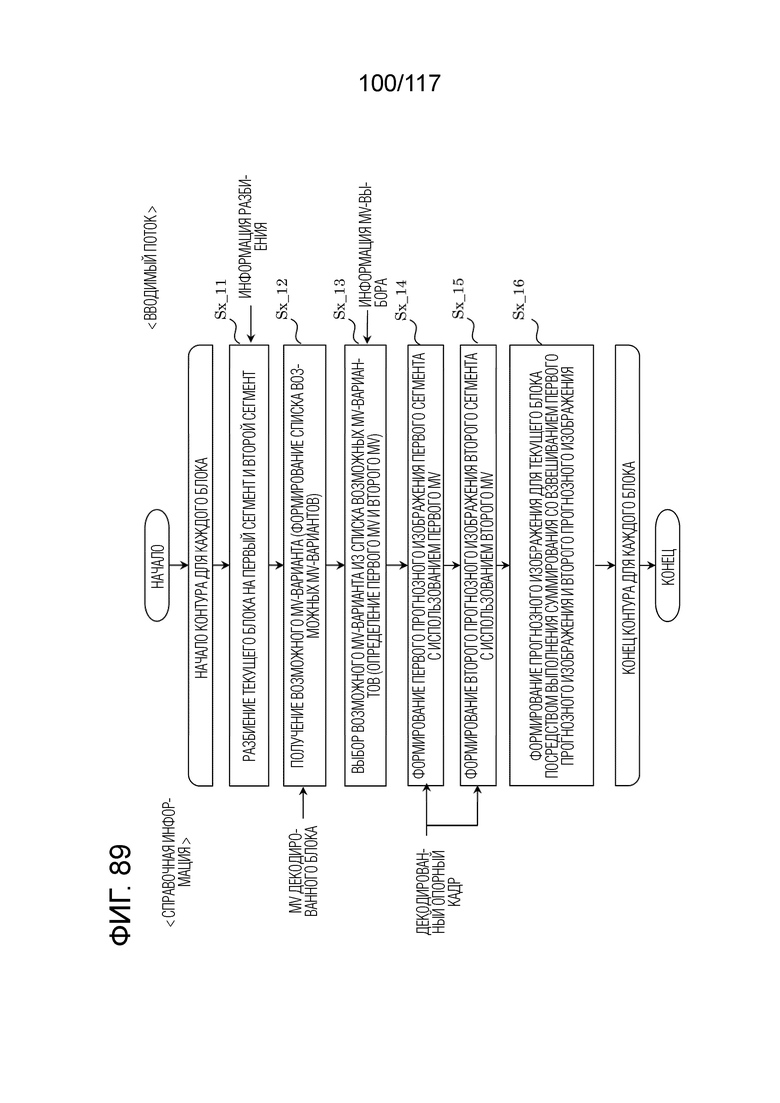
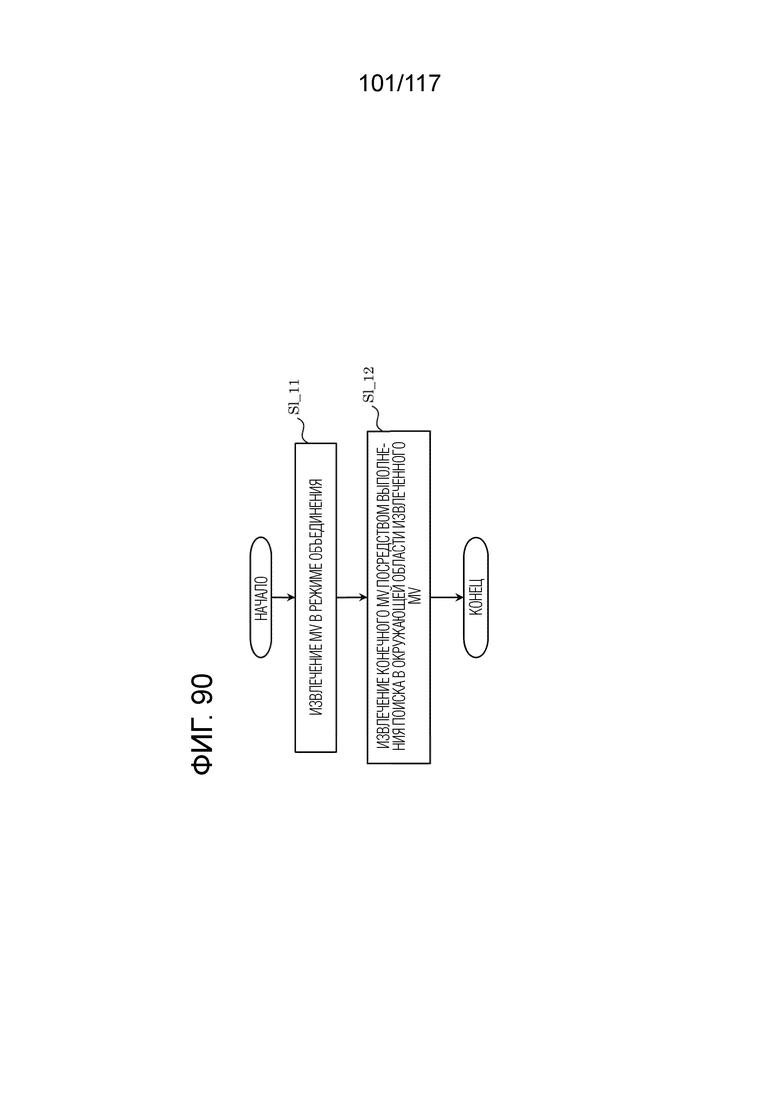
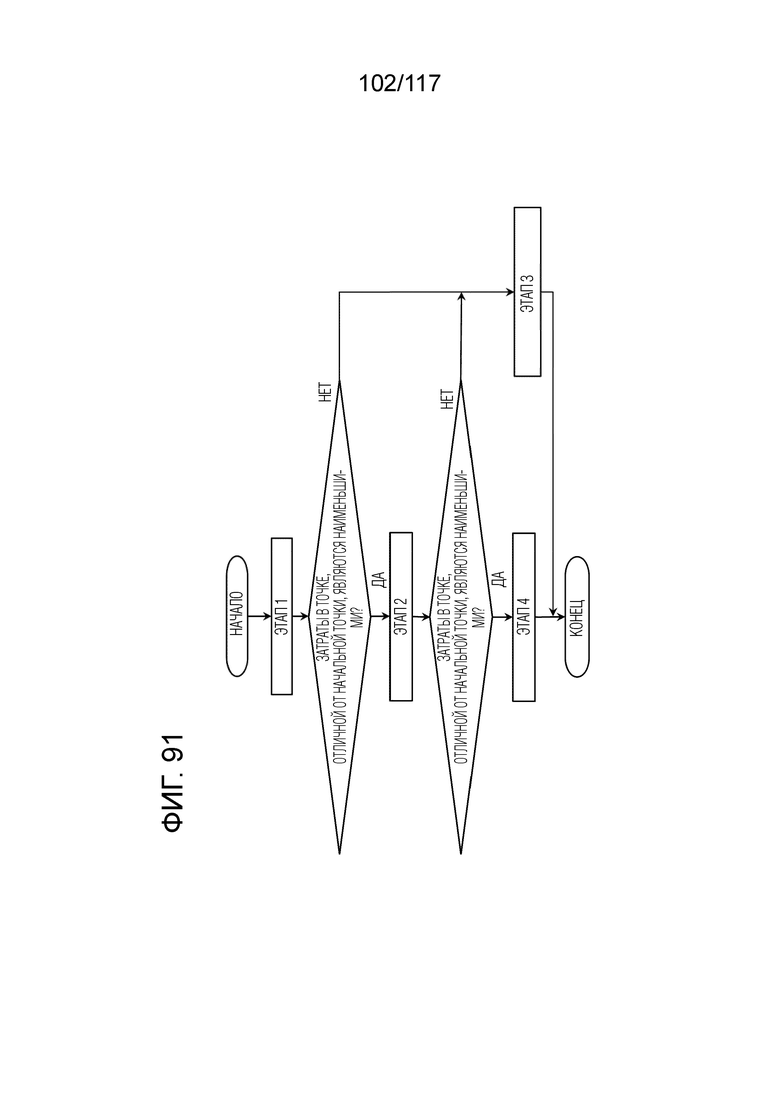
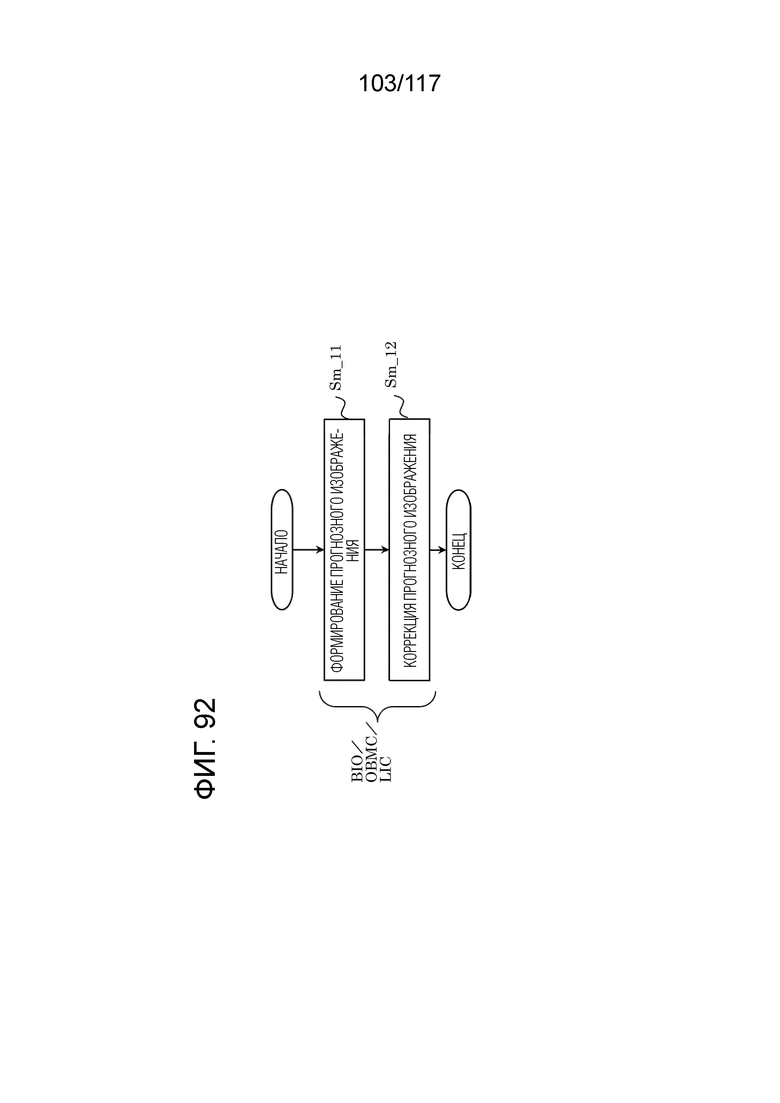
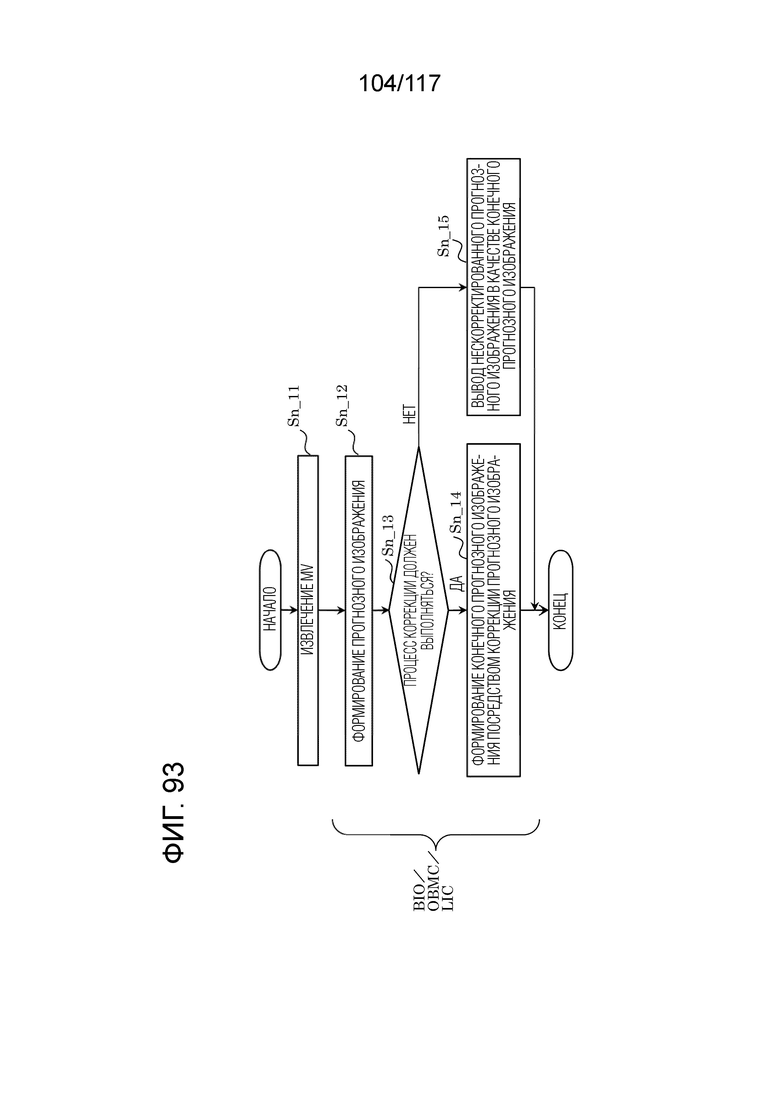
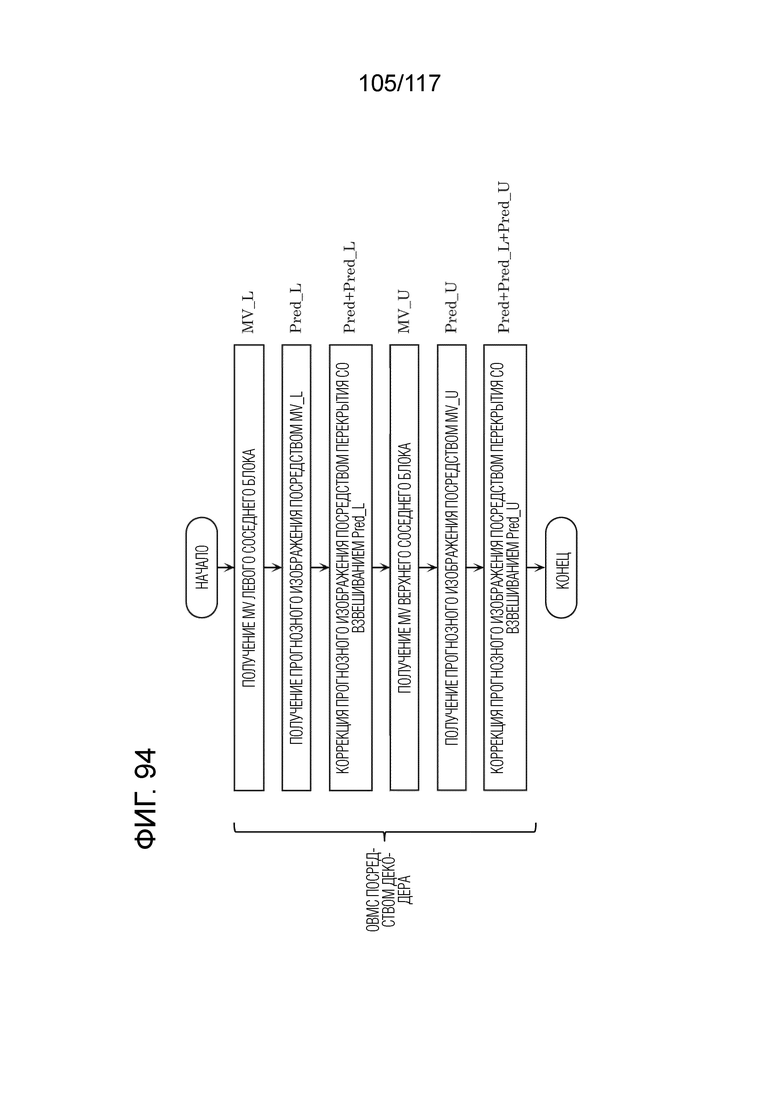
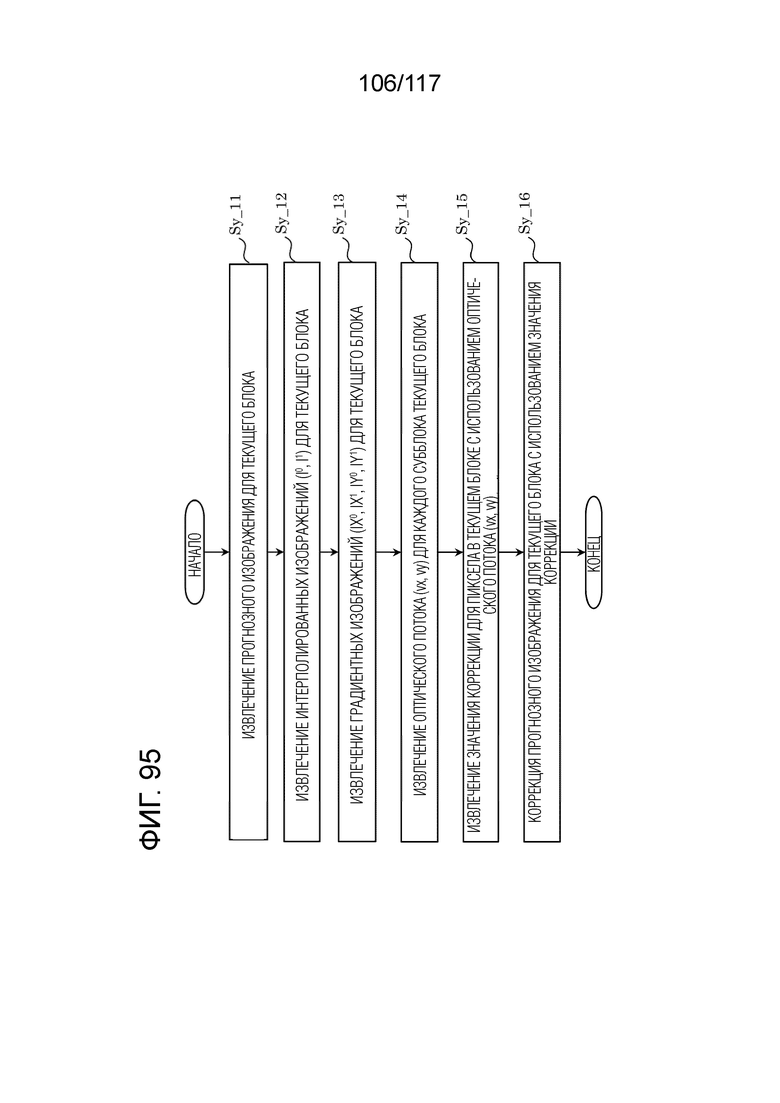
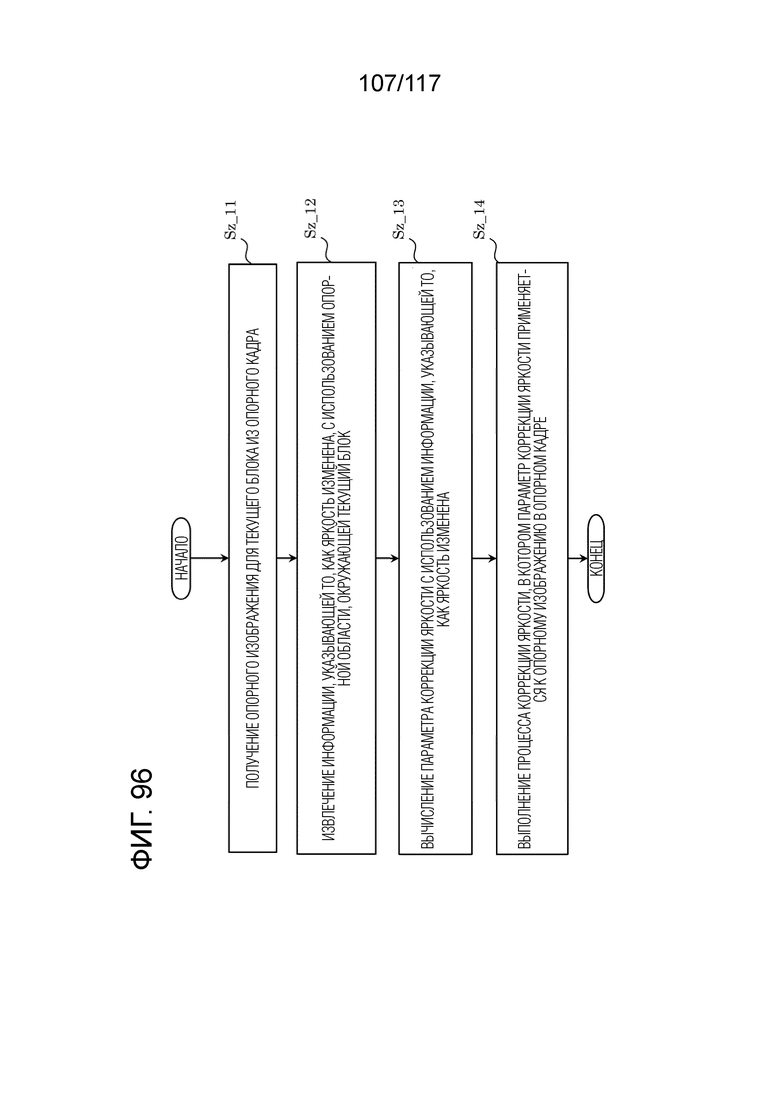
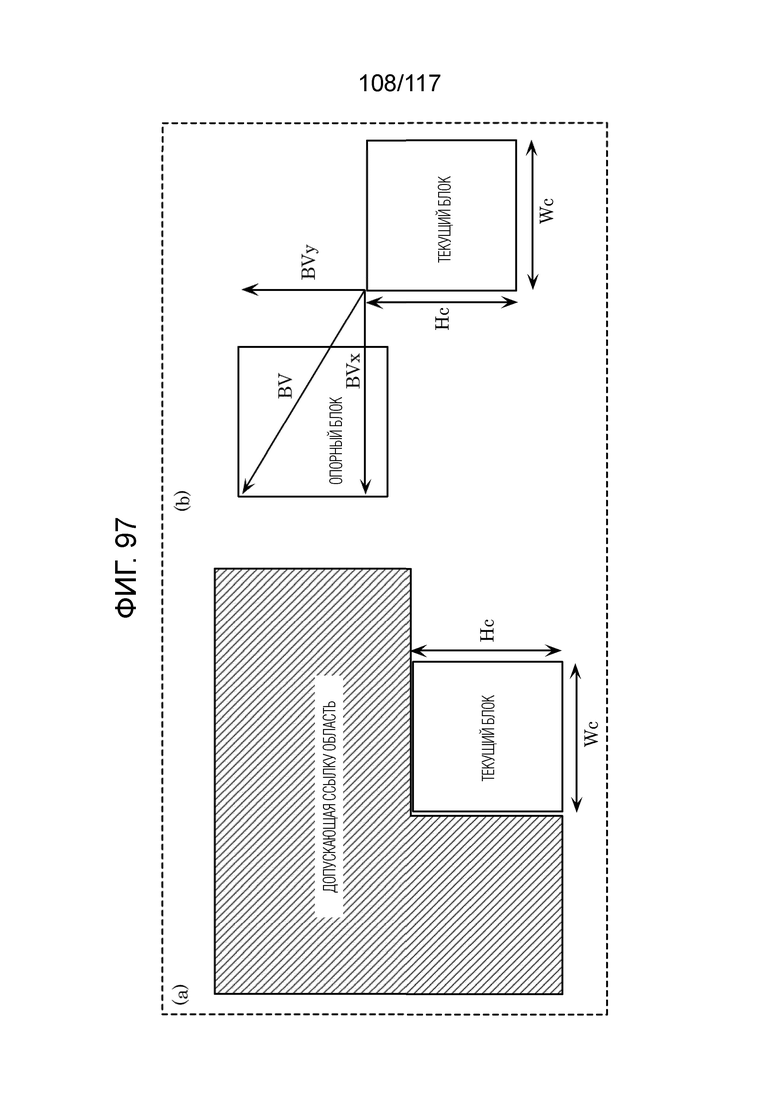
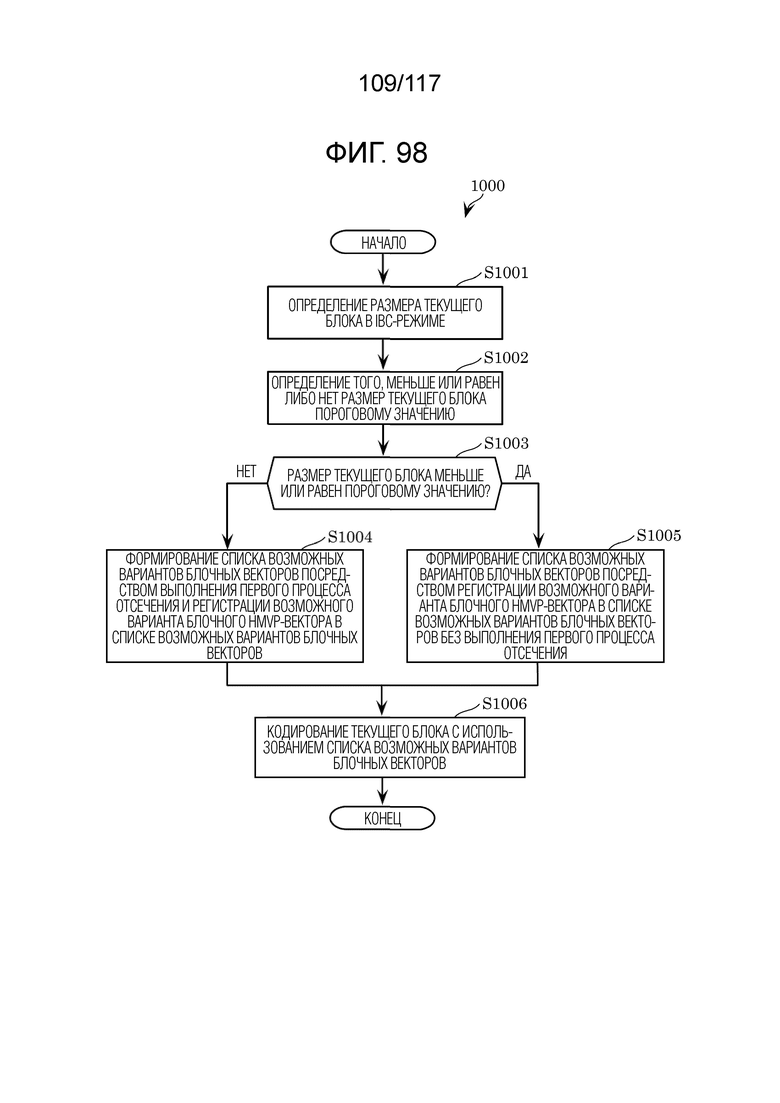
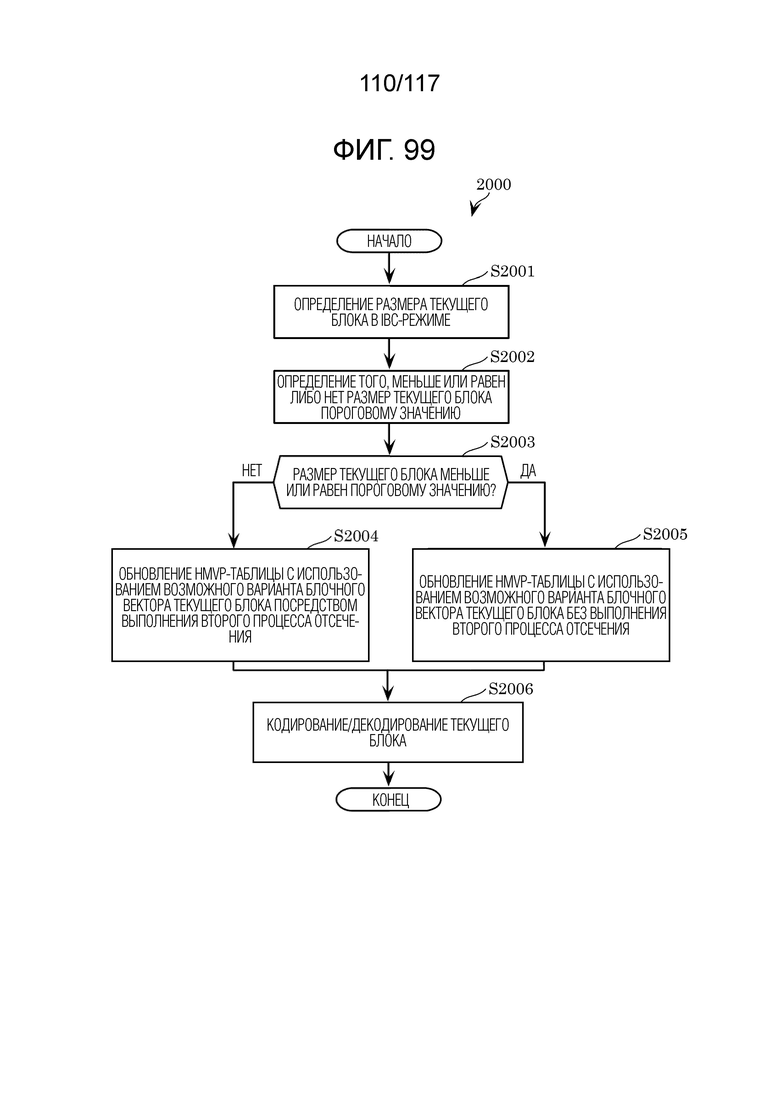
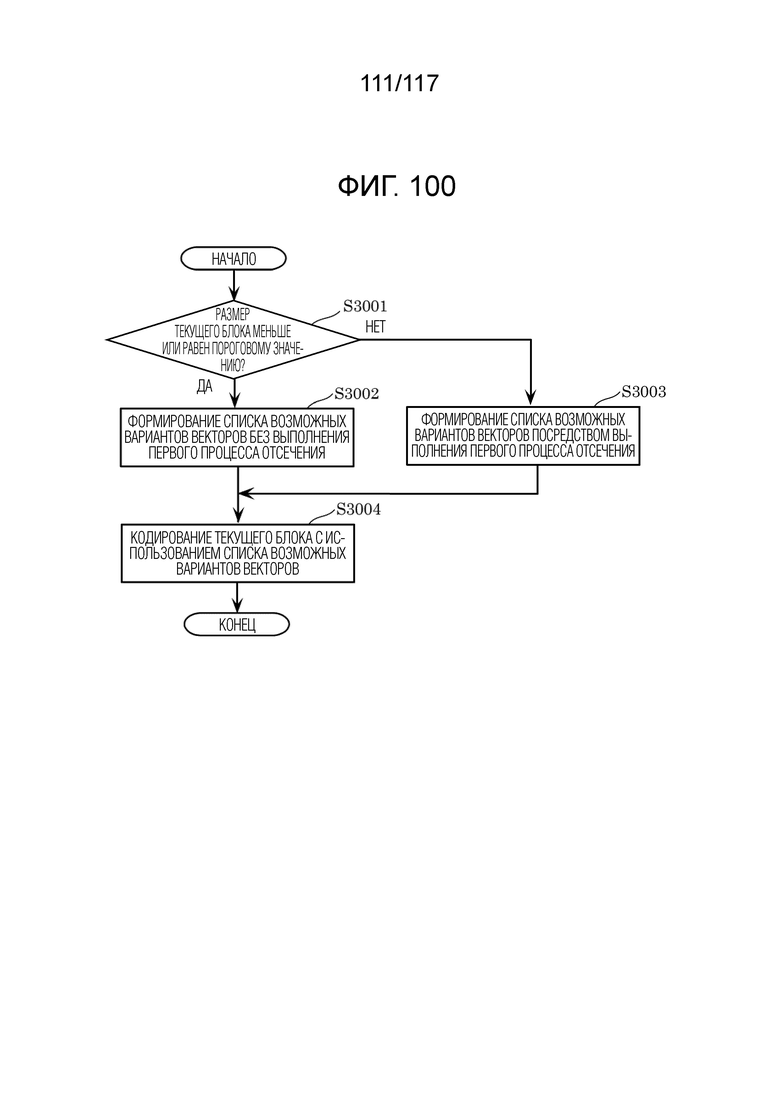
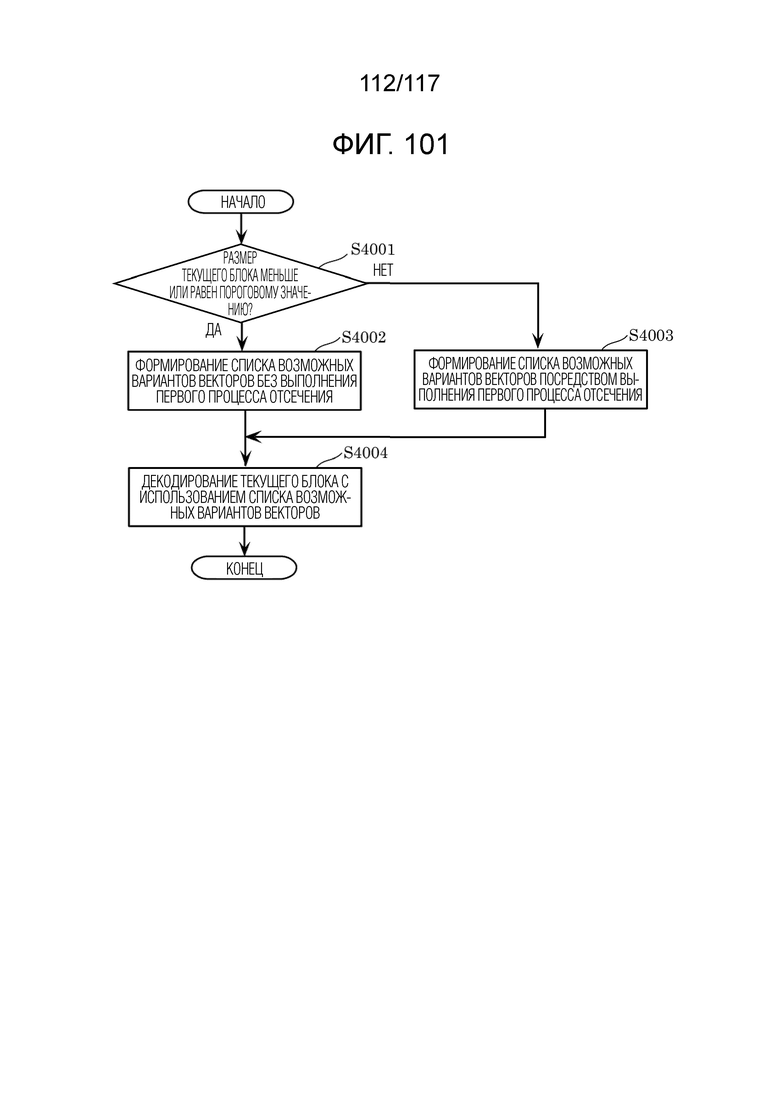
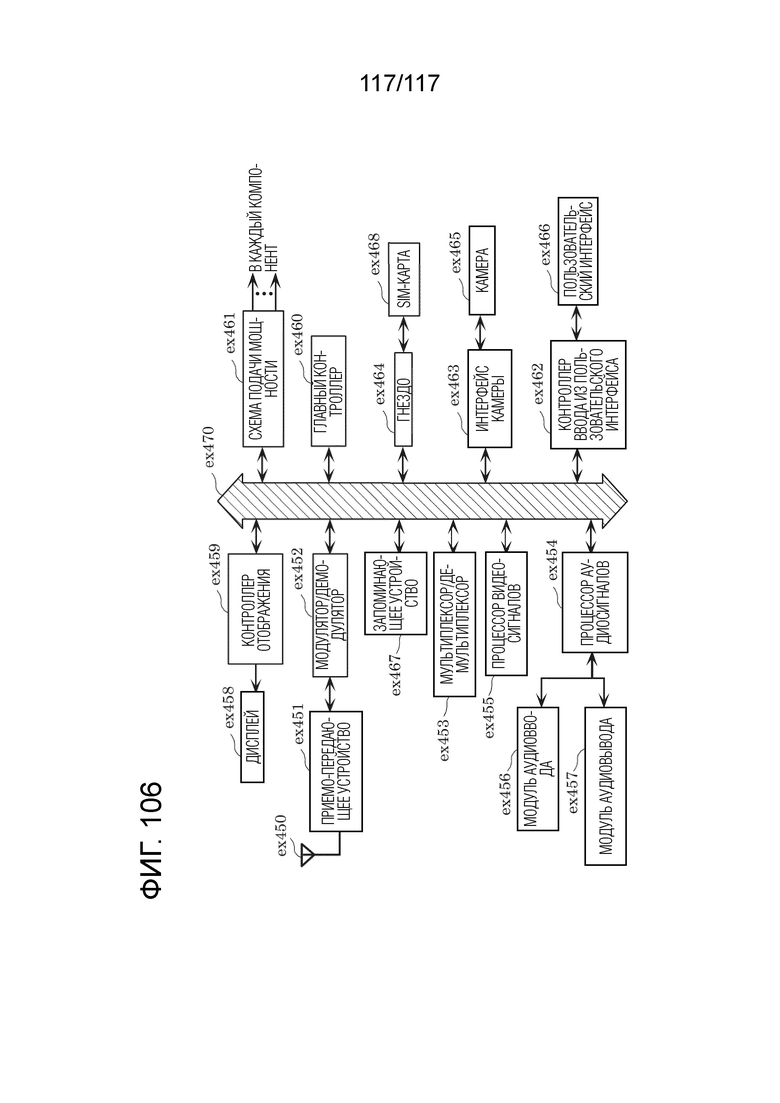
Изобретение относится к кодированию и декодированию изображений. Технический результат заключается в повышении эффективности кодирования и декодирования изображений. Такой результат обеспечивается за счет того, что определяют то, меньше или равен либо нет размер текущего блока, который представляет собой единицу, для которой формируется список возможных вариантов векторов, пороговому значению; когда размер текущего блока меньше или равен пороговому значению, формируют список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения; когда размер текущего блока превышает пороговое значение, формируют список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы, и кодируют текущий блок с использованием списка возможных вариантов векторов 4 н.п. ф-лы, 124 ил., 3 табл.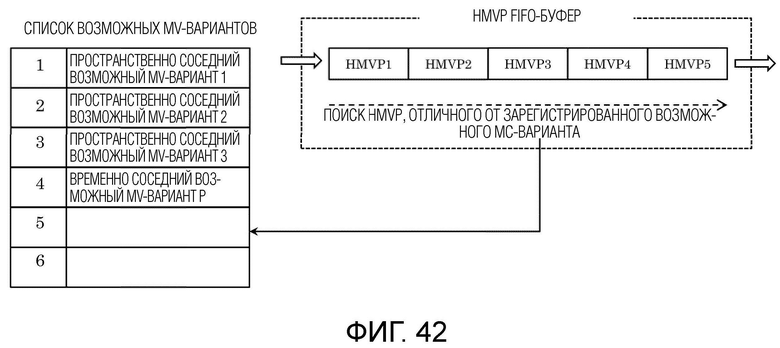
1. Кодер, содержащий:
схему; и
запоминающее устройство, соединенное со схемой,
при этом схема, при работе:
при формировании прогнозного изображения текущего блока, использует режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок;
определяет то, меньше или равен размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов;
когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем каждый из возможных вариантов первых векторов имеет информацию относительно первого вектора, используемого для обработанного блока;
когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и
кодирует текущий блок с использованием списка возможных вариантов векторов, и
при этом первый процесс отсечения представляет собой процесс сравнения возможного варианта HMVP-вектора, сохраненного в HMVP-таблице, и возможного варианта вектора, зарегистрированного в списке возможных вариантов векторов, и определения, являются ли возможный вариант HMVP-вектора и вектор-кандидат идентичными.
2. Декодер, содержащий:
схему; и
запоминающее устройство, соединенное со схемой,
при этом схема, при работе:
при формировании прогнозного изображения текущего блока, использует режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок;
определяет то, меньше или равен размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов;
когда размер текущего блока меньше или равен пороговому значению, формирует список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем каждый из возможных вариантов первых векторов имеет информацию относительно первого вектора, используемого для обработанного блока;
когда размер текущего блока превышает пороговое значение, формирует список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и
декодирует текущий блок с использованием списка возможных вариантов векторов, и
при этом первый процесс отсечения представляет собой процесс сравнения возможного варианта HMVP-вектора, сохраненного в HMVP-таблице, и возможного варианта вектора, зарегистрированного в списке возможных вариантов векторов, и определения, являются ли возможный вариант HMVP-вектора и вектор-кандидат идентичными.
3. Способ кодирования, содержащий этапы, на которых:
при формировании прогнозного изображения текущего блока, используют режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок;
определяют то, меньше или равен размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов;
когда размер текущего блока меньше или равен пороговому значению, формируют список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем каждый из возможных вариантов первых векторов имеет информацию относительно первого вектора, используемого для обработанного блока;
когда размер текущего блока превышает пороговое значение, формируют список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и
кодируют текущий блок с использованием списка возможных вариантов векторов,
при этом первый процесс отсечения представляет собой процесс сравнения возможного варианта HMVP-вектора, сохраненного в HMVP-таблице, и возможного варианта вектора, зарегистрированного в списке возможных вариантов векторов, и определения, являются ли возможный вариант HMVP-вектора и вектор-кандидат идентичными.
4. Способ декодирования, содержащий этапы, на которых:
при формировании прогнозного изображения текущего блока, используют режим внутриблочного копирования (IBC), в котором обращаются к обработанной области кадра, который включает в себя текущий блок;
определяют то, меньше или равен размер текущего блока пороговому значению, причем текущий блок представляет собой единицу, для которой формируется список возможных вариантов векторов, включающий в себя возможные варианты векторов;
когда размер текущего блока меньше или равен пороговому значению, формируют список возможных вариантов векторов посредством регистрации возможного варианта вектора с использованием предиктора вектора движения на основе предыстории (HMVP) в списке возможных вариантов векторов из HMVP-таблицы без выполнения первого процесса отсечения, причем HMVP-таблица сохраняет, посредством способа "первый на входе - первый на выходе" (FIFO), каждый из возможных вариантов первых векторов в качестве возможного варианта HMVP-вектора, причем каждый из возможных вариантов первых векторов имеет информацию относительно первого вектора, используемого для обработанного блока;
когда размер текущего блока превышает пороговое значение, формируют список возможных вариантов векторов посредством выполнения первого процесса отсечения и регистрации возможного варианта HMVP-вектора в списке возможных вариантов векторов из HMVP-таблицы; и
декодируют текущий блок с использованием списка возможных вариантов векторов,
при этом первый процесс отсечения представляет собой процесс сравнения возможного варианта HMVP-вектора, сохраненного в HMVP-таблице, и возможного варианта вектора, зарегистрированного в списке возможных вариантов векторов, и определения, являются ли возможный вариант HMVP-вектора и вектор-кандидат идентичными.
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |

