Ссылка на родственную заявку
[1] Данная заявка испрашивает приоритет по заявке на патент Китая №202011408927.0, поданной 3 декабря 2020 года, содержание которой полностью включено в настоящий документ посредством ссылки.
Область техники, к которой относится настоящее изобретение
[2] Варианты осуществления настоящего изобретения относятся к технической области безопасности, в частности, к способу и устройству для обучения изолирующих лесов, а также к способу и устройству для распознавания поискового робота.
Предшествующий уровень настоящего изобретения
[3] В сети публикуется огромное количество страниц на веб-сайтах самого разного толка и т.п. Пользователи свободно заходят на такие страницы на стороне клиента, просматривая соответствующую информацию, такую как новости, трансляции в прямом эфире и короткие видеоролики.
[4] Помимо пользователей на такие страницы заходят и злоумышленники с использованием особого клиента (например, поискового робота или веб-сканера), захватывают конкретную информацию на странице, подделывают приложение для разработки веб-страницы (АРР) веб-сайта или незаконно участвуют в деятельности вебсайта (например, в массовом использовании «красных конвертов» (китайская традиция дарения денег) и купонов) или делают нечто подобное, тем самым создавая угрозы безопасности веб-сайта.
[5] В настоящее время большинство веб-сайтов принимает различные меры для противодействия поисковым роботам, такие как распознавание поискового робота с помощью программного агента (UA), распознавание поискового робота на основании частоты обращений с IP-адреса (адреса Интернет-протокола) и распознавание поискового робота на основании одновременного трафика.
[6] Однако эти способы представляют собой искусственно сформулированные правила, и они легко нарушаются злоумышленниками. Например, получение обычного UA для использования поискового робота позволяет обмануть или обойти способ распознавания поискового робота на основании UA; динамическое изменение IP-адреса поискового робота позволяет обмануть или обойти способ распознавания поискового робота на основании частоты обращений с IP-адреса; поисковый робот может нарушить способ распознавания поискового робота на основании одновременного трафика за счет использования распределенной архитектуры; и т.п. Таким образом, эти способы приводят в итоге к низкой точности распознавания поискового робота и создают большие угрозы безопасности веб-сайта.
Краткое раскрытие настоящего изобретения
[7] Вариантами осуществления настоящего изобретения предложен способ и устройство для обучения изолирующих лесов, а также способ и устройство для распознавания поискового робота с целью предотвращения состояния низкой точности распознавания поискового робота с использованием искусственно сформулированных правил.
[8] Согласно первому аспекту настоящего изобретения вариантами его осуществления предложен способ обучения изолирующих лесов, предусматривающий:
[9] получение множества категорий путем классифицирования унифицированных идентификаторов ресурсов;
[10] получение выборочных данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
[11] кодирование выборочных данных о поведении в вектор в виде выборочного вектора доступа; и
[12] обучение изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента.
[13] Согласно второму аспекту настоящего изобретения вариантами его осуществления дополнительно предложен способ распознавания поискового робота, предусматривающий:
[14] получение целевых данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
[15] кодирование целевых данных о поведении в вектор в виде целевого вектора доступа;
[16] определение изолирующего леса для распознавания поискового робота на стороне клиента, причем получение изолирующего леса обеспечивается способом обучения изолирующих лесов согласно первому аспекту настоящего изобретения;
[17] распознавание аномального IP-адреса путем ввода целевого вектора доступа в изолирующий лес; и
[18] определение того, что клиент с аномального IP-адреса является поисковым роботом.
[19] Согласно третьему аспекту настоящего изобретения вариантами его осуществления дополнительно предложено устройство для обучения изолирующих лесов, включающее в себя:
[20] модуль классификации идентификаторов, выполненный с возможностью получения множества категорий путем классифицирования унифицированных идентификаторов ресурсов;
[21] модуль отслеживания выборочных данных о поведении, выполненный с возможностью получения выборочных данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
[22] модуль кодирования выборочного вектора доступа, выполненный с возможностью кодирования выборочных данных о поведении в вектор в виде выборочного вектора доступа; и
[23] модуль обучения изолирующего леса, выполненный с возможностью обучения изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента.
[24] Согласно четвертому аспекту настоящего изобретения вариантами его осуществления дополнительно предложено устройство для распознавания поискового робота, включающее в себя:
[25] модуль отслеживания целевых данных о поведении, выполненный с возможностью получения целевых данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
[26] модуль кодирования целевого вектора доступа, выполненный с возможностью кодирования целевых данных о поведении в вектор в виде целевого вектора доступа;
[27] модуль определения изолирующего леса, выполненный с возможностью определения изолирующего леса для распознавания поискового робота на стороне клиента, причем получение изолирующего леса обеспечивается способом обучения изолирующих лесов согласно первому аспекту настоящего изобретения;
[28] модуль распознавания аномальных адресов, выполненный с возможностью определения аномального IP-адреса путем ввода целевого вектора доступа в изолирующий лес; и
[29] модуль определения поискового робота, выполненный с возможностью определения того, что клиент по аномальному IP-адресу является поисковым роботом.
[30] Согласно пятому аспекту настоящего изобретения вариантами его осуществления дополнительно предложено компьютерное устройство, включающее в себя:
[31] один или несколько процессоров; и
[32] память, выполненную с возможностью хранения одной или нескольких программ;
[33] причем одна или несколько компьютерных программ при их загрузке и выполнении одним или несколькими процессорами инициирует выполнение одним или несколькими процессорами способа обучения изолирующих лесов согласно первому аспекту или способа распознавания поискового робота согласно второму аспекту настоящего изобретения.
[34] Согласно шестому аспекту настоящего изобретения вариантами его осуществления дополнительно предложен машиночитаемый носитель данных для хранения одной или нескольких компьютерных программ, причем одна или несколько компьютерных программ при их загрузке и выполнении процессором инициирует выполнение процессором способа обучения изолирующих лесов согласно первому аспекту или способа распознавания поискового робота согласно второму аспекту настоящего изобретения.
Краткое описание чертежей
[35] На фиг. 1 представлена блок-схема, иллюстрирующая способ обучения изолирующих лесов согласно одному из вариантов осуществления настоящего изобретения;
[36] На фиг. 2А показана примерная схема, иллюстрирующая принцип действия изолирующего леса согласно одному из вариантов осуществления настоящего изобретения;
[37] На фиг. 2В показана примерная схема, иллюстрирующая другой принцип действия изолирующего леса согласно одному из вариантов осуществления настоящего изобретения;
[38] На фиг. 3 показана примерная схема генерирования изолирующего леса согласно одному из вариантов осуществления настоящего изобретения;
[39] На фиг. 4 представлена блок-схема, иллюстрирующая способ распознавания поискового робота согласно одному из вариантов осуществления настоящего изобретения;
[40] На фиг. 5 представлена схема распределения IP-адресов после сокращения размерности согласно одному из вариантов осуществления настоящего изобретения;
[41] На фиг. 6 показана примерная схема обхода изолирующего леса согласно одному из вариантов осуществления настоящего изобретения;
[42] На фиг. 7 представлена структурная схема устройства для обучения изолирующих лесов согласно одному из вариантов осуществления настоящего изобретения;
[43] На фиг. 8 представлена структурная схема устройства для распознавания поискового робота согласно одному из вариантов осуществления настоящего изобретения; и
[44] На фиг. 9 представлена структурная схема компьютерного устройства согласно одному из вариантов осуществления настоящего изобретения.
Подробное раскрытие настоящего изобретения
[45] Настоящее изобретение будет подробнее описано в привязке к чертежам и на примерах осуществления заявленного изобретения. Следует понимать, что частные варианты осуществления заявленного изобретения, описанные в настоящем документе, представлены исключительно с целью разъяснения, а не ограничения настоящего изобретения. Кроме того, следует также отметить, что для удобства описания на чертежах показаны лишь некоторые, а не все структуры, связанные с настоящим изобретением.
[46] На фиг. 1 представлена блок-схема, иллюстрирующая способ обучения изолирующих лесов согласно некоторым вариантам осуществления настоящего изобретения, где конкретный вариант осуществления применим к ситуации, в которой изолирующий лес обучается на основании поведении поискового робота изолированно от поведения пользователя, причем предложенный способ выполняется устройством для обучения изолирующих лесов с использованием программных и/или аппаратных средств, которое сконфигурировано в компьютерном устройстве, таком как сервер, персональный компьютер или рабочая станция, предусматривая выполнение стадий, описанных ниже.
[47] На стадии 101 классифицируются унифицированные идентификаторы ресурсов для получения множества категорий.
[48] Поисковый робот представляет собой программу-робота, которая автоматически просматривает содержимое сайтов, осуществляя доступ к унифицированному идентификатору ресурсов (URI) в соответствии с заданным правилом.
[49] Идентификатор URI локализует доступные ресурсы сети (Web), такие как документы в формате HTML (гипертекстовый разметочный язык), изображения, видеоклипы и программы.
[50] Идентификатор URI обычно состоит из трех частей:
(1) Механизм именования ресурсов;
(2) Имя хоста хранения ресурсов; и
(3) Имя самого ресурса.
[51] Следует отметить, что указанные три части являются лишь общим способом именования URI, и все, что уникальным образом идентифицирует ресурс, называется URI, а комбинация указанных трех частей является достаточным и необязательным признаком URI.
[52] К примеру, допустим, что на одном из функционирующих сайтов идентификатор URI имеет следующий вид:
https://*.*cdn.cn/front-publish/home-h5-master/css/h5 4545200.ess
[53] Ресурс, представленный этим URI, являет собой каскадную таблицу стилей (CSS), причем доступ к CSS осуществляется по протоколу защищенной передачи гипертекстовых документов (HTTPS), а сама CSS располагается на хост-узле www.*.com (доменное имя) и уникальным образом идентифицируется с помощью «front-publish/home-h5-master/css/h5 4545200.css».
[54] Поисковые роботы делятся на следующие четыре типа:
[55] (1) Поисковый робот общего назначения: он также называется всеохватывающим поисковым роботом, при использовании которого поиск объекта начинается с подборки URI в качестве затравки и постепенно охватывает все сетевое пространство, причем объектом отработки поискового робота общего назначения является, главным образом, поисковая система или крупный интернет-провайдер данных.
[56] (2) Сфокусированный поисковый робот: он также называется тематическим поисковым роботом, т.е. поисковым роботом, который избирательно просматривает контент, точно относящийся к заданным темам. Это может быть, например, поисковый робот для просмотра новостей, поисковый робот для просмотра форумов или поисковый робот для просмотра продуктов, причем сфокусированный поисковый робот часто осуществляет периодический доступ к некоторым данным, крайне чувствительным ко времени, и он широко используется в отношении конкретной цели поиска и удовлетворяет потребностям конкретных групп населения в конкретной информации, получаемой на местах.
[57] (3) Инкрементальный поисковый робот: он представляет собой поисковый робот, который постепенно обновляет загружаемые веб-страницы и просматривает только обновленный контент, фокусируясь на повышении новизны просмотренного контента.
[58] (4) Глубинный поисковый робот: он также называется поисковым роботом глубинной сети (Hidden Web), отвечающим за получение веб-контента, который не может быть индексирован поисковой системой, который недоступен для гиперссылки, или который виден только после передачи определенной формы (например, требуется логин или определенная конфигурация).
[59] Сфокусированный поисковый робот часто используется для поиска данных заданных веб-сайтов, в частности, данных конкретных приложений АРР для захвата конкретной информации в Интернете с тем, чтобы имитировать страницу веб-сайта с целью разработки АРР или для незаконного участия в деятельности этого веб-сайта (например, в массовом использовании «красных конвертов» и купонов), а также в иных целях, что несет угрозу безопасности веб-сайту.
[60] В этом варианте осуществления настоящего изобретения идентификаторы URI собираются и классифицируются особым образом для получения множества категорий.
[61] В общем, идентификаторы URI относятся к одному и тому же веб-сайту или к одному и тому же приложению АРР, но идентификаторы URI также могут относиться к разным веб-сайтам и разным АРР, что не носит ограничительного характера в этом варианте осуществления настоящего изобретения.
[62] Согласно одному из способов классифицирования идентификаторы URI подразделяются на категории в зависимости от выполняемых ими функций.
[63] Поскольку идентификаторы URI с одинаковой функцией обладают идентичной или схожей структурой, для определения функции унифицированного идентификатора ресурса и сведения унифицированных идентификаторов ресурсов, выполняющих одну и ту же функции, в одну категорию необходимо обойти множество частей URI.
[64] Если идентификаторы URI относятся к одному и тому же АРР, а АРР обычно выделяет функцию ресурса за счет использования определенного модуля и способа, то используется косая черта/слэш (т.е. «/») в качестве сегментирующей точки с целью разбивки унифицированного идентификатора ресурса на множество полей. Поле, отображающее доменное имя, модуль и способ, извлекается из соответствующей позиции в качестве целевого поля, после чего определяется целевое поле, отображающее функцию унифицированного идентификатора ресурса. В этом случае предусмотрено, что если это целевое поле присутствует в других идентификаторах URI, то это говорит о том, что данный URI относится к категории, соответствующей целевому полю.
[65] В общем, доменное имя располагается в первом поле после протокола, а модуль располагается во втором поле после протокола. В некоторых случаях поле, отображающее модуль, может быть пустым.
[66] Например, в обозначении «https://*.com/24686574565» конкретного URI «www.*.com» отображает доменное имя; «24686574565» представляет собой способ отображения ряда чатов прямой трансляции; а функция URI состоит в том, чтобы присоединиться к чату прямой трансляции; и поэтому категория определяется как «www.*.com/enter room».
[67] В другом примере в обозначении «https://*.*cdn.cn/front-publish/live-master/css/home/home_9c316ba.css» конкретного URI приложения АРР для прямых трансляций «www.*.com» отображает доменное имя; «home» представляет собой модуль отображения чата прямой трансляции; «css» представляет собой способ отображения CSS; а функция URI состоит в том, чтобы присоединиться к чату прямой трансляции; и поэтому категория определяется как «www.*.com/home/css».
[68] Вышеописанный способ классифицирования идентификаторов URI приведен исключительно для примера, и для классифицирования идентификаторов URI доступны также и другие способы с учетом фактической ситуации при реализации вариантов осуществления настоящего изобретения. Например, для URI веб-сайта форума предусмотрено, что при наличии точки привязки, представляющей отражение страницы (например, предыдущей страницы, следующей страницы, <<или>>), из URI, с которым связана точка привязки, удаляются поля, отображающие цифры, и если оставшиеся поля являются одинаковыми, то устанавливается, что эти оставшиеся поля отображают категорию. К примеру, если из «http://bbs.*.com/foram-99-2.html» и «http://bbs.*.com/foram-99-3.html» удалить блоки «99-2» и «99-3» цифр, то оставшиеся поля будет одинаковыми, а категория будет обозначена как «bbs.*.com/forum», что не носит ограничительного характера в вариантах осуществления настоящего изобретения. Кроме того, помимо способа классифицирования идентификаторов URI, описанного выше, специалисты в данной области техники могут также использовать и другие способы классифицирования идентификаторов URI, исходя из фактических потребностей, что также не носит ограничительного характера в вариантах осуществления настоящего изобретения.
[69] На стадии 102 отслеживается поведение клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов под определенной категорией, с целью получения выборочных данных о поведении.
[70] В процессе работы веб-сайта предусмотрено, что если клиент осуществляет доступ к URI, то используется журнал регистрации для записи информации, связанной с поведением клиента, осуществляющего доступ к URI. Указанная информация включает в себя операционную систему, в которой работает клиент; оконечное устройство/терминал клиента; IP-адрес клиента; время начала осуществления доступа; время окончания осуществления доступа; элемент, на который был произведен клик; и тому подобное.
[71] В представленном варианте осуществления настоящего изобретения IP-адрес используется для идентификации клиента, категория URI используется в качестве подсчета размерности, а информация о поведении клиента под этим IP-адресом, который осуществляет доступ к URI под этой категорией, извлекается из журнала регистрации данных за прошлые периоды в качестве выборочных данных о поведении.
[72] На стадии 103 выборочные данные о поведении кодируются в вектор в виде выборочного вектора доступа.
[73] Выборочные данные о поведении каждого из IP-адресов кодируются в вектор особым образом и используются в качестве выборочного вектора доступа, благодаря чему упрощается последующее обучение изолирующего леса.
[74] Согласно одному из способов кодирования количество унифицированных идентификаторов ресурсов по каждой из категорий, доступ к которым осуществляется клиентом с конкретного IP-адреса, высчитывается из выборочных данных о поведении, категория берется в качестве размерности вектора, а множество количественных параметров, соответствующих множеству категорий, задается в качестве значений множества размерностей, соответствующих множеству категорий в векторе, с целью получения выборочного вектора доступа для каждого из IP-адресов.
[75] К примеру, допустим, что идентификаторы URI разбиты на 400 категорий, категории идентификаторов URI упорядочены, и им присвоены номера от 0 до 399, и если число идентификаторов URI определенной категории с номером доступа IP-адреса, составляющим 0, равно 100, а общее количество идентификаторов URI в категориях с номером доступа от 1 до 399 равно нулю, то выборочный вектор доступа для этого IP-адреса будет иметь следующий вид: [100, 0, 0, 0, …, 0].
[76] В этом варианте осуществления настоящего изобретения количество клиентов, зарегистрированных пользователем, и количество поисковых роботов, осуществляющих доступ к URI, очевидно будет разным, а количество унифицированных идентификаторов ресурсов по множеству категорий, к которым получает доступ клиент с каждого из IP-адресов, рассматривается в качестве значений множества размерностей в выборочном векторе доступа, благодаря чему обеспечивается простота и удобство операции, а также проводится четкое различие между клиентами, зарегистрированными пользователем, и поисковыми роботами, что повышает эффективность изолирующего леса.
[77] Способ кодирования, описанный выше, приведен исключительно для примера, и при реализации вариантов осуществления настоящего изобретения могут использоваться и другие способы кодирования, исходя из конкретной ситуации. К примеру, выборочный вектор доступа для IP-адреса может быть получен путем высчитывания времени, когда клиент с этого IP-адреса осуществляет доступ к унифицированным идентификаторам ресурсов по каждой из категорий, из выборочных данных о поведении; с использованием категории в качестве размерности вектора и заданием множества временных периодов, соответствующих множеству категорий, в качестве значений множества размерностей, соответствующих множеству категорий в векторе; и т.п., что не носит ограничительного характера в вариантах осуществления настоящего изобретения. Кроме того, помимо способа кодирования, описанного выше, специалисты в данной области техники могут также использовать и другие способы кодирования, исходя из фактических потребностей, что также не носит ограничительного характера в вариантах осуществления настоящего изобретения.
[78] Поскольку некоторые идентификаторы URI генерируются на основании метки времени, имени изображения, имени файла и тому подобного, то в случае, если оригинальный веб-сайт обладает множеством функций, количество идентификаторов URI веб-сайта будет составлять миллионы, и даже после классифицирования идентификаторов URI количество категорий идентификаторов URI будет по-прежнему составлять порядка сотен или тысяч. В вариантах осуществления настоящего изобретения предусмотрено, что для сокращения размерности выборочного вектора доступа при сохранении основного компонента функции выборочного вектора доступа - используются такие алгоритмы, как анализ главных компонент (РСА), линейный дискриминантный анализ (LDA) и локально линейное вложение (LLE), с сокращением размерности выборочного вектора доступа до порядка единиц или десятков и снижением вычислительной сложности. Иначе говоря, ресурсы, занятые на обучение изолирующих лесов, сокращаются, но эффективность изолирующего леса остается прежней.
[79] Разумеется, если веб-сайт обладает относительно небольшим числом функций, то после классифицирования идентификаторов URI количество категорий будет составлять порядка единиц или десятков; или же производительность компьютерного устройства будет достаточной для поддержки обучения изолирующего леса с использованием выборочного вектора доступа с широким динамическим диапазоном. При этом изолирующий лес обучается с непосредственным использованием выборочного вектора доступа без сокращения его размерности, что не носит ограничительного характера в этом варианте осуществления настоящего изобретения.
[80] Возьмем в качестве примера метод РСА. Метод РСА представляет собой способ линейного сокращения размерности, цель которого заключается в том, чтобы вложить данные большой размерности в пространство низкой размерности для визуализации с помощью определенной линейной проекции и извлечь максимальную дисперсию данных по спроецированной размерности, благодаря чему используется меньше размерностей данных с сохранением свойств большего количества исходных точек данных.
[81] Допустим, что имеется m n-размерных выборочных векторов доступа, причем выборочные векторы доступа сведены в матрицу в виде первой выборочной матрицы X доступа, состоящей из n строк и m столбцов.
[82] По каждой строке данных в первой выборочной матрице X доступа выполняется усреднение до нуля (вычитание среднего значения строки).
[83] По завершении усреднения до нуля для первой выборочной матрицы X доступа рассчитывается выборочная ковариационная матрица С, 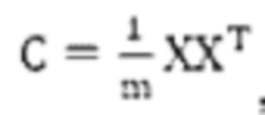 , где величина XT обозначает транспонированную матрицу X.
, где величина XT обозначает транспонированную матрицу X.
[84] Затем рассчитываются выборочные собственные значения и выборочные собственные векторы выборочной ковариационной матрицы С.
[85] Выборочные собственные векторы выстраиваются в строки в направлении сверху вниз в зависимости от абсолютной величины выборочных собственных значений, и первые k строк/строка (k является целым числом) берутся для формирования второй выборочной матрицы Р доступа.
[86] После этого рассчитывается произведение между второй выборочной матрицей Р доступа и первой выборочной матрицей X доступа для получения выборочного вектора Y доступа, причем Y=РХ после сокращения размерности (т.е. приведения к размерности k).
[87] На стадии 104 осуществляется обучение изолирующего леса на основании выборочного вектора доступа с целью распознавания поискового робота со стороны клиента.
[88] Пользователь регистрирует клиента и получает доступ к большому количеству идентификаторов URI при осуществлении доступа к веб-сайту. В качестве примера берется функционирующий сайт, и при открытии его домашней страницы загружается большое количество идентификаторов URI, причем идентификаторы URI имеют следующие формы, такие как данные домашней страницы в виде живого изображения, css-стиль веб-сайта, перечень чатов прямой трансляции и «горячий список»:
[89] https://www.*.com/
[90] https://*.*cdn.cn/front-publish/home-h5-master/css/h5_4545200.es
[91] https://*.*cdn.cn/front-publish/live-master/css/home/home_9c316ba.es
[92] https://*.*cdn.cn/front-publish/live-master/css/home/pre-style-main~31ecd969 5f5e458.css
[93] https://*.* cdn.cn/static/img/ping43.gif?cache=0.41438868879293733
[94] https://global-oss-*.*/*/room-list/get-page-info
[95] ...
[96] Кроме того, по мере осуществления пользователем доступа к большему числу идентификаторов URI с использованием функций веб-сайта разные функции загружают разные URI, доступ ко многим из которых осуществляется без его восприятия пользователем.
[97] Хотя разные пользователи характеризуются разным поведением при осуществлении доступа, например, используемыми функциями, количеством попыток доступа и конкретными используемыми идентификаторами URI, а общее распределение поведенческих паттернов пользователя составляет порядка миллионов и десятков миллионов, то даже если пользователь характеризуется элементом случайности в поведении, общая доля множества идентификаторов URI лежит примерно в рамках нормального распределения.
[98] В случае если клиент представляет собой поисковый робот, этот поисковый робот является более целенаправленным. Например, поисковый робот для поиска информации о привязке на первом этапе просматривает список номеров точек привязки, и после получения этого списка просматривает в пакетном режиме информацию о загрузке URI, отображающую чат прямой трансляции. Если допустить, что URI активной страницы привязки выглядит как https://www.*.com/23214324325 (цифры указывают на идентификатор (ID) чата прямой трансляции), то последовательность URI активности поискового робота будет иметь следующий вид:
[99] https://www.*.com/room-list/get-page-info
[100] https://www.*.com/23214324325
[101] https://www.*.com/23432543654
[102] https://www*.com/24354365462
[103] https://www. *.com/24654654534
[104] https://www.*.com/24686574565
[105] …
[106] Поведение (например, количество попыток доступа) пользователя, осуществляющего доступ к разным идентификаторам URI, и поведение (например, количество попыток доступа) поискового робота, осуществляющего доступ к разным идентификаторам URI, сильно отличаются друг от друга. Поскольку поисковый робот действует более целенаправленно и характеризуется искусственно заданным поведением автомата, то ему сложно имитировать случайное поведение пользователя. Следовательно, учитывая тот факт, что в этом варианте осуществления настоящего изобретения поведение поискового робота по осуществлению доступа является в целом минималистичным, а изолирующий лес (iForest) чувствителен к точкам глобального коэффициента, поисковый робот может быть эффективно идентифицирован на основании разницы в поведении при осуществлении доступа, и, таким образом, происходит обучение изолирующего леса идентификации поискового робота на стороне клиента.
[107] Изолирующий лес представляет собой способ быстрого выявления аномалий на основании совокупности, который характеризуется линейной временной сложностью и высокой точностью. Изолирующий лес является алгоритмом, который удовлетворяет требованиям обработки больших массивов данных и применим к выявлению аномалий непрерывных числовых данных. В отличие от алгоритмов выявления аномалий, которые отображают разреженность выборок в виде количественных показателей, таких как расстояние и плотность, изолирующий лес детектирует аномальное значение путем изолирования выборочной точки; т.е. аномалии определяются как выбросы, которые можно без труда изолировать, и которые рассматриваются как точки, разреженные и далекие от совокупностей высокой плотности. Со статистической точки зрения разреженная область в пространстве данных указывает на низкую вероятность возникновения данных в этой области, и поэтому можно считать, что данные, попадающие в такие области, являются аномальными.
[108] Кроме того, в сравнении с традиционно используемыми алгоритмами, такими как LOF (локальный уровень выброса) и кластерный анализ методом K-средних, алгоритм изолирующего леса характеризуется более высокой робастностью в отношении данных широкого диапазона.
[109] На фиг. 2А показана примерная схема, иллюстрирующая принцип действия изолирующего леса согласно некоторым вариантам осуществления настоящего изобретения. Допустим, имеется группа одноразмерных данных, и эта группа данных сегментируется в произвольном порядке таким образом, что точки А и В сегментируются отдельно. Например, задается показатель сегментации; между максимальным значением и минимальным значением случайным образом выбирается величина х; и данные разделяются на левую группу данных и правую группу данных на основании критерия недобора до величины х и превышения или равенства величине х. Эта стадия повторяется отдельно по двум группам данных до тех пор, пока данные больше не могут быть сегментированы. Очевидно, что точка В вычленяется из других данных, и точка В сегментируется немного раз. Точка А группируется с другими точками данных, и точка А сегментируется много раз.
[110] На фиг. 2В показана примерная схема, иллюстрирующая другой принцип действия изолирующего леса согласно некоторым вариантам осуществления настоящего изобретения, где данные расширяются, преобразуясь из одномерных данных в двухмерные данные. Аналогичным образом задается показатель сегментации; по двум осям координат выполняется случайная сегментация; и независимо сегментируются точки А' и В'. Случайным образом выбирается размерность элемента; случайным образом выбирается величина между максимальным значением и минимальным значением элемента; и данные разделяются на левую группу данных и правую группу данных на основании метрического соотношения с собственным значением. Описанная стадия повторяется в левой группе данных и правой группе данных, а данные сегментируются случайным образом на основании значения определенной размерности элемента до тех пор, пока данные больше не могут быть сегментированы; т.е. только одна точка данных является левой, или же ей являются левые данные. Интуитивно точка В' вычленяется из других точек данных, и точка В', по всей видимости, сегментируется всего за несколько операций; точка А' группируется с другими точками данных, и точка А сегментируется много раз.
[111] В общем, как показано на фиг. 2А и 2В, точки В и В' считаются аномальными данными, поскольку они отстоят от других данных на некоторое расстояние, а точки А и А' считаются нормальными данными. Интуитивно, поскольку аномальные данные относительно отделены от остальных точек данных, аномальные данные сегментируются независимо от других точек данных с использованием всего нескольких операций разделения, тогда как нормальные данные - это противоположный случай, что является концепцией изолирующего леса (iForest).
[112] В некоторых вариантах осуществления настоящего изобретения стадия 104 предусматривает следующие подстадии.
[113] На подстадии 1041 определяется показатель для выделения поискового робота.
[114] В выборочном векторе доступа учитываются разные показатели, и в этом варианте осуществления настоящего изобретения из указанных показателей извлекается показатель, способный распознать поисковый робот.
[115] В некоторых вариантах осуществления настоящего изобретения при использовании количество попыток доступа (т.е. значения размерности) в качестве показателя для распознавания поискового робота идентификаторы URI, доступ к которым осуществляется поисковым роботом, и идентификаторы URI, доступ к которым осуществляется большинством пользователей, относительно согласуются друг с другом для некоторых страниц. Однако количество идентификаторов URI, доступ к которым осуществляется поисковым роботом, и количество идентификаторов URI, доступ к которым осуществляется пользователями, сильно отличаются друг от друга. К примеру, количество попыток доступа к активным страницам привязки со стороны пользователя обычно варьируется от 1 до 50 раз, тогда как количество попыток доступа к активным страницам привязки со стороны поискового робота составляет сотни или даже тысячи раз.
[116] В этом примере показателем для распознавания поискового робота определяется количество попыток доступа к унифицированным идентификаторам ресурсов.
[117] В другом примере, при использовании размерности доступа в качестве показателя для распознавания поискового робота, идентификаторы URI, доступ к которым осуществляется поисковым роботом, и идентификаторы URI, доступ к которым осуществляется большинством пользователей, сильно отличаются друг от друга для некоторых страниц. Например, пользователь имеет первичный доступ к идентификаторам URI под категориями 0-50, тогда как поисковый робот имеет первичный доступ к идентификаторам URI под категориями 51-399.
[118] В этом примере показателем для распознавания поискового робота определяется количество всех унифицированных идентификаторов ресурсов, доступ к которым осуществляется по категориям.
[119] Указанный выше показатель приведен исключительно для примера, и при практической реализации вариантов осуществления настоящего изобретения могут быть заданы другие показатели, что зависит от конкретной ситуации. Например, в качестве показателя для распознавания поискового робота может быть определена и использована продолжительность доступа к унифицированным идентификаторам ресурсов или длительность всех унифицированных идентификаторов ресурсов, доступ к которым осуществляется по категориям, и т.п., что не носит ограничительного характера в вариантах осуществления настоящего изобретения. Кроме того, помимо описанного выше способа определения показателя специалисты в данной области техники могут также использовать и другие показатели, исходя из фактических потребностей, что также не носит ограничительного характера в вариантах осуществления настоящего изобретения.
[120] На подстадии 1042, в соответствии с показателем, часть выборочных векторов доступа используется множество раз для генерирования множества изолирующих деревьев с целью получения изолирующего леса.
[121] Изолирующий лес включает в себя t изолирующих деревьев (t является целым числом), причем каждое изолирующее дерево представляет собой бинарную древовидную структуру, изолирующий лес сегментирует данные с использованием бинарного дерева, а глубина точки данных в бинарном дереве отражает степень «сепарации» данных.
[122] Предварительно задается условие обучения. Например, запрещается сегментирование IP-адреса в текущем узле (т.е. IP-адрес в текущем узле является единственным, или же все IP-адреса в текущем узле являются одинаковыми); изолирующее дерево должно достичь заданной высоты; и т.п.
[123] В случае построения изолирующего дерева часть выборочных векторов доступа извлекается случайным образом из общего количества выборочных векторов доступа, причем выборочные векторы доступа используются в качестве корневых узлов изолирующего дерева и обходятся, начиная с корневого узла; т.е. корневой узел представляет собой начальный текущий узел.
[124] Определяется, удовлетворено ли на данный момент времени заданное условие обучения.
[125] Если да (т.е. условие обучения удовлетворено), то устанавливается, что изолирующее дерево обучено.
[126] Если нет (т.е. условие обучения не удовлетворено), то случайным образом генерируется точка отсечения в диапазоне отсечения текущего узла в соответствии с показателем. Диапазон отсечения представляет собой диапазон, образованный значениями выборочных векторов доступа в соответствии с показателем; т.е. минимальное значение и максимальное значение выборочного вектора доступа в соответствии с показателем используются в качестве двух конечных значений диапазона отсечения, вследствие чего точка отсечения располагается между максимальным значением и минимальным значением показателя.
[127] В точке отсечения генерируется гиперплоскость, а пространство текущего узла делится на два подпространства; т.е. текущий узел используется в качестве родительского узла для генерирования первого дочернего узла и второго дочернего узла. Согласно общему правилу первый дочерний узел располагается слева, а второй дочерний узел располагается справа.
[128] Значение выборочного вектора доступа в текущем узле в соответствии с показателем сравнивается с точкой отсечения.
[129] Если значение выборочного вектора доступа в соответствии с показателем меньше точки отсечения, то IP-адрес добавляется в первый дочерний узел.
[130] Если значение выборочного вектора доступа в соответствии с показателем превышает или равно точке отсечения, то IP-адрес добавляется во второй дочерний узел, и осуществляется возврат к стадии определения того, удовлетворено ли на данный момент времени заданное условие обучения или нет. Если условие обучения не удовлетворено, то первый дочерний узел и второй дочерний узел берутся в качестве текущих узлов для непрерывного построения новых узлов до тех пор, пока изолирующее дерево не будет обучено.
[131] Обучение повторяется t раз для генерирования изолирующих деревьев общим числом t с целью обучения изолирующего леса, и после обучения изолирующего леса этот лес тестируется. Если показатели оценки (такие как точность, прецизионность, отклик и значение F1) при тестировании удовлетворяют требованиям, то запускается изолирующий лес для отслеживания IP-адреса и определения того, не является ли клиент под множеством IP-адресов поисковым роботом.
[132] Например, как это показано на фиг. 3, изолирующий лес обучается путем извлечения случайным образом пакета выборочных векторов доступа IP-адресов а, b, с и d из общего набора IP-адресов, после чего IP-адреса а, b, с и d добавляются в узел 300 в качестве корневых узлов, и задается показатель для распознавания поискового робота. Для узла 300 в соответствии с этим показателем случайным образом генерируется точка Ti отсечения из числа значений в выборочных векторах доступа а, b, с и d, причем оба значения а и b меньше значения T1, а значение d превышает значение T1; соответственно, a, b и с добавляются в узел 310 (т.е. в первый дочерний узел), a d добавляется в узел 320 (т.е. во второй дочерний узел). Для узла 320 предусмотрено, что поскольку узел 320 имеет всего один IP-адрес d, построение нового узла прекращается. Для узла 310, в соответствии с показателем, случайным образом генерируется точка Т2 отсечения из числа значений в выборочных векторах доступа a, b и с, причем значение а меньше значения Т2, а значения b и с превышают значение Т2; соответственно, значение а добавляется в узел 311 (т.е. в первый дочерний узел), а значения b и с добавляются в узел 312 (т.е. во второй дочерний узел). Для узла 311 предусмотрено, что поскольку узел 311 имеет всего один IP-адрес а, построение нового узла прекращается. Для узла 312, в соответствии с показателем, случайным образом генерируется точка Т3 отсечения из числа значений в выборочных векторах доступа b и с, причем значение b меньше значения Т3, а значение с превышает значение Т3; соответственно, b добавляется в узел 3121 (т.е. в первый дочерний узел), а значение с добавляется в узел 3122 (т.е. во второй дочерний узел). Для узла 3121 предусмотрено, что поскольку узел 3121 имеет всего один IP-адрес b, построение нового узла прекращается. Для узла 3122 предусмотрено, что поскольку узел 3122 имеет всего один IP-адрес с, построение нового узла прекращается. На этой стадии изолирующее дерево считается обученным, причем высота b и с равна трем, высота а равна двум, а высота d равна единице, и поскольку адрес d изолирован изначально, наиболее вероятно, что d является аномальным адресом.
[133] В этом варианте осуществления настоящего изобретения выполняется классифицирование унифицированных идентификаторов ресурсов для получения множества категорий, и отслеживается поведение клиента с каждого из IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов под определенной категорией, для получения выборочных данных о поведении. Выборочные данные о поведении кодируются в вектор в виде выборочного вектора доступа, и на основании выборочного вектора доступа происходит обучение изолирующего леса для распознавания поискового робота на стороне клиента. С одной стороны, поскольку унифицированные идентификаторы ресурсов с идентичными или схожими функциями обладают идентичной или схожей структурой, классифицирование и подсчет паттернов поведения унифицированных идентификаторов ресурсов при осуществлении доступа не только сохраняют эффективность паттернов поведения при осуществлении доступа, но также и существенно сокращают объем данных паттернов поведения при осуществлении доступа и уменьшают количество ресурсов, занятых обучением изолирующих лесов. С другой стороны, поскольку поисковый робот демонстрирует большую целенаправленность, паттерн поведения поискового робота при осуществлении доступа очевидным образом отличается от аналогичного паттерна пользователя, вследствие чего паттерн поведения поискового робота при осуществлении доступа более разрежен в сравнении с общепринятым поведением при осуществлении доступа, а изолирующая функция чувствительна к этому признаку, в результате чего гарантируется эффективность срабатывания изолирующего леса и обеспечивается эффективное распознавание поискового робота, при этом поведение пользователя при осуществлении доступа не является искусственно сформулированным правилом, изолирующая функция относится к неконтролируемому режиму отслеживания, поисковый робот не может имитировать поведение пользователя при осуществлении доступа, а контролируемое отслеживание невозможно обойти путем подделки стандартного UA, динамической замены IP-адреса, использования распределенной архитектуры и тому подобного, что эффективным образом обеспечивает безопасность веб-сайта.
[134] На фиг. 4 представлена блок-схема, иллюстрирующая способ распознавания поискового робота согласно некоторым вариантам осуществления настоящего изобретения. Этот вариант осуществления настоящего изобретения применим к ситуации, в которой поисковый робот распознается на основании поведения поискового робота изолированно от поведения пользователя, причем предложенный способ выполняется устройством для распознавания поискового робота. Это устройство реализовано с использованием программных и/или аппаратных средств, и оно сконфигурировано в компьютерном устройстве, таком как сервер, персональный компьютер или рабочая станция, предусматривая выполнение стадий, описанных ниже.
[135] На стадии 401 отслеживается поведение клиента с каждого IP-адреса, осуществляющего доступ к унифицированным идентификаторам ресурсов по множеству категорий, для получения целевых данных о поведении.
[136] В процессе работы веб-сайта предусмотрено, что если клиент осуществляет доступ к URI, то используется журнал регистрации для записи информации, связанной с поведением клиента, осуществляющего доступ к URI.
[137] В этом варианте осуществления настоящего изобретения множество категорий задается для URI заранее.
[138] В некоторых вариантах осуществления настоящего изобретения предусмотрено, что если категория URI характеризуется целевым полем (например, полем, отображающим доменное имя, модуль и способ), представляющим определенную функцию, например, «www.*.com/home/css», обходится каждое поле в URI. При наличии целевого поля в URI определяется, что URI относится к определенной категории.
[139] Кроме того, IP-адрес используется для идентификации клиента, категория URI используется в качестве размерности подсчета, а информация о поведении клиента под этим IP-адресом, который осуществляет доступ к URI под этой категорией, извлекается из журнала регистрации в реальном масштабе времени в качестве целевых данных о поведении.
[140] На стадии 402 целевые данные о поведении кодируются в вектор в виде целевого вектора доступа.
[141] Целевые данные о поведении каждого из IP-адресов кодируются в вектор с помощью заданного способа и используются в качестве целевого вектора доступа, благодаря чему облегчается последующая обработка изолирующего леса.
[142] Для отслеживания IP-адреса веб-сайга в масштабе реального времени с целью повышения гибкости отслеживания и обеспечения безопасности веб-сайта запускается поисковый роб от с использованием двух способов, описанных ниже.
[143] В одном из способов запуска предусмотрено, что целевые данные о поведении кодируются в вектор в виде целевого вектора доступа, если время накопления целевых данных о поведении превышает заданное первое пороговое значение; т.е. распознавание поискового робота осуществляется по каждому из IP-адресов с определенными промежутками
[144] В другом способе запуска предусмотрено, что целевые данные о поведении кодируются в вектор в виде целевого вектора доступа, если количество унифицированных идентификаторов ресурсов, доступ к которым осуществляется клиентом с IP-адреса, в целевых данных о поведении превышает заданное второе пороговое значение; т.е. распознавание поискового робота осуществляется по IP-адресу, когда накапливается определенное количество попыток доступа.
[145] В одном из способов кодирования подсчитывается количество унифицированных идентификаторов ресурсов, доступ к которым осуществляется клиентом с IP-адреса по каждой из категорий, в целевых данных о поведении; категория берется в качестве размерности вектора; и множество количественных параметров задается в качестве значений количества размерностей в векторе для получения целевого вектора доступа IP-адрес а.
[146] Кроме того, в случае сохранения основного компонента функции выборочного вектора доступа размерность целевого вектора доступа сокращается с помощью таких алгоритмов, как РСА, LDA и LLE, причем размерность целевого вектора доступа сокращается до порядка единиц или десятков, благодаря чему обеспечивается снижение вычислительной сложности и уменьшение количества ресурсов, занятых обходом изолирующего леса.
[147] Допустим, если взять для примера РСА, что имеется m n-размерных целевых векторов доступа, причем целевые векторы доступа сведены в матрицу в виде первой целевой матрицы X доступа, состоящей из n строк и m столбцов.
[148] По каждой строке данных в первой целевой матрице X доступа выполняется усреднение до нуля (вычитание среднего значения строки).
[149] По завершении усреднения до нуля для первой целевой матрицы X доступа рассчитывается выборочная ковариационная матрица С, 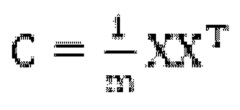 , где величина XT обозначает транспонированную матрицу X.
, где величина XT обозначает транспонированную матрицу X.
[150] Затем рассчитываются целевые собственные значения и целевые собственные векторы выборочной ковариационной матрицы С.
[151] Целевые собственные векторы выстраиваются в строки в направлении сверху вниз в зависимости от абсолютной величины целевых собственных значений, и первые k строк/строка (k является целым числом) берутся для формирования второй целевой матрицы Р доступа.
[152] После этого рассчитывается произведение между второй целевой матрицей Р доступа и первой целевой матрицей X доступа для получения целевого вектора Y доступа, причем Y=РХ после сокращения размерности (т.е. приведения к размерности k).
[153] На стадии 403 определяется изолирующий лес, выполненный с возможностью распознавания поискового робота на стороне клиента.
[154] Способ согласно описанным выше вариантам осуществления настоящего изобретения применим к обучению изолирующего леса для заблаговременного распознавания поискового робота на стороне клиента, и он загружается и запускается при отслеживании IP-адреса в реальном масштабе времени.
[155] На стадии 404 целевой вектор доступа вводится в аномальный IP-адрес, распознанный в изолирующем лесе.
[156] В этом варианте осуществления настоящего изобретения целевой вектор доступа вводится в изолирующий лес. Изолирующий лес осуществляет поиск изолированного целевого вектора доступа, тем самым определяя, является ли IP-адрес нормальным или аномальным.
[157] Поскольку количество аномальных IP-адресов невелико (т.е. аномальные IP-адреса занимают небольшую процентную долю всех IP-адресов), и аномальный IP-адрес отличается от нормального IP-адреса, аномальные IP-адреса изолируются раньше.
[158] Как показано на фиг. 5, в целях визуализации целевой вектор поведения приведен к двухмерному вектору, нормальные IP-адреса сконцентрированы, и большое количество рассеянных точек представляют собой аномальные IP-адреса.
[159] В некоторых вариантах осуществления настоящего изобретения стадия 404 включает в себя подстадии, описанные ниже.
[160] На подстадии 4041 выполняется обход каждого из изолирующих деревьев в изолирующем лесу на основании целевого вектора доступа для расчета аномального значения IP-адреса.
[161] Изолирующий лес включает в себя t изолирующих деревьев, и каждое из изолирующих деревьев обходится целевым вектором доступа каждого из IP-адресов, причем ближе к корневому узлу изолирующего дерева располагается аномальный IP-адрес, тогда как нормальный IP-адрес отстоит дальше от корневого узла, в результате чего аномальное состояние IP-адреса во всем изолирующем лесу всесторонне определяется в привязке к аномальному состоянию IP-адреса в каждом из изолирующих деревьев, и аномальное состояние численно преобразуется в аномальное значение.
[162] В корневой узел изолирующего дерева в каждом из изолирующих деревьев добавляется IP-адрес, который начинает обрабатываться с корневого узла; т.е. корневой узел представляет собой начальный текущий узел.
[163] Определяется показатель для распознавания поискового робота. Например, в качестве показателя для распознавания поискового робота определяется количество унифицированных идентификаторов ресурсов, к которым осуществляется доступ; и/или же в качестве показателя для распознавания поискового робота определяется количество унифицированных идентификаторов ресурсов, к которым осуществляется доступ под определенной категорией.
[164] Запрашивается точка отсечения текущего узла, и с этой точкой отсечения сравнивается значение целевого вектора доступа в текущем узле в соответствии с показателем.
[165] Если значение целевого вектора доступа в соответствии с показателем меньше точки отсечения, то IP-адрес добавляется в первый дочерний узел под текущим узлом.
[166] Если значение целевого вектора доступа в соответствии с показателем превышает или равно точке отсечения, то IP-адрес добавляется во второй дочерний узел под текущим узлом, а точка отсечения возвращается для выполнения запроса по текущему узлу. В случае неудовлетворительной сегментации первый дочерний узел и второй дочерний узел будут использованы в качестве текущих узлов для непрерывного сегментирования множества IP-адресов до тех пор, пока не будет запрещено дальнейшее сегментирование IP-адреса в текущем узле (т.е. пока IP-адрес в текущем узле не будет единственным, или же пока все IP-адреса в текущем узле не будут одинаковыми).
[167] Например, как показано на фиг. 6, изолирующее дерево характеризуется наличием узла 300, узла 310, узла 320, узла 311, узла 312, узла 3121 и узла 3122; для узла 300 задана точка T1 отсечения; для узла 310 задана точка Т2 отсечения; а для узла 312 задана точка Т3 отсечения; и также задан показатель для распознавания поискового робота. Если получение целевого вектора доступа осуществляется путем текущего отслеживания IP-адреса е, и если в соответствии с показателем значение в целевом векторе доступа IP-адреса е меньше величины T1, то е добавляется в узел 310, а если в соответствии с показателем значение в целевом векторе доступа IP-адреса е меньше величины Т2, то е добавляется в узел 311. В этом случае высота е в изолирующем дереве будет составлять 2.
[168] Если целевой вектор доступа обходит каждое из изолирующих деревьев, то аномальное значение IP-адреса рассчитывается на основании высоты (также именуемой длиной и глубиной пути) IP-адреса во всех изолирующих деревьях.
[169] Если допустить, что ГР-адрес концевого узла, где IP-адрес X попадает в изолирующее дерево, записан как Т.size, то длина h(x) пути IP-адреса X на изолирующем дереве будет иметь следующий вид:
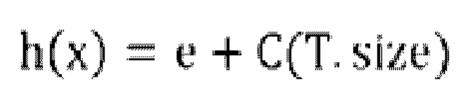
[170], где величина е обозначает количество ребер, которые проходит IP-адрес х на пути от корневого узла до концевого узла изолирующего дерева; а величина C(T.size) рассматривается в качестве корректирующего значения, отображающего среднюю длину пути в построенном бинарном дереве с IP-адресами Т.size.
[171] В общем, величина С(n) отображается следующим образом:
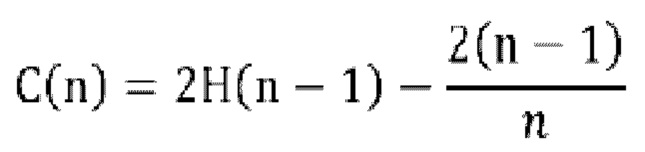
[172], где величина Н(n-1) оценивается с помощью In(n-1)+0,5772156649; а 0,5772156649 является постоянной Эйлера.
[173] IP-адрес х является результатом того, что конечное аномальное значение Score(x) объединяет результаты по множеству изолирующих деревьев:
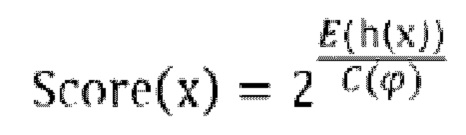
[174], где величина E(h(x)) обозначает среднее значение длины пути IP-адреса х во множестве изолирующих деревьев; величина ϕ обозначает количество IP-адресов в одном изолирующем дереве; а величина С(ϕ) обозначает среднюю длину пути изолирующего дерева, построенного IP-адресами в количестве ϕ, что используется для нормализации.
[175] Для аномального значения Score(x) предусмотрено, что чем короче средняя длина пути IP-адреса х во множестве изолирующих деревьев, тем ближе аномальное значение Score(x) приближается к 1, что указывает на возрастающую вероятность аномальности IP-адреса х; а чем длиннее средняя длина пути IP-адреса х во множестве изолирующих деревьев, тем ближе аномальное значение Score(x) приближается к 0, что указывает на возрастающую вероятность нормальности ГР-адрес а х. Если средняя длина пути IP-адреса х во множестве изолирующих деревьев приближается к общему среднему, то аномальное значение Score(x) составляет около 0,5.
[176] На стадии 4042 определяется, что IP-адрес является аномальным, если аномальное значение превышает заданное пороговое значение.
[177] В общем, чем выше аномальное значение, тем больше степень аномальности IP-адреса, тогда как чем ниже аномальное значение, тем меньше степень аномальности IP-адреса.
[178] Аномальное значение каждого из IP-адресов сравнивается с заданным пороговым значением.
[179] Если аномальное значение определенного IP-адреса превышает пороговое значение, то это указывает на высокую степень аномальности этого IP-адреса, и он определяется как аномальный.
[180] Если аномальное значение определенного IP-адреса меньше или равно пороговому значению, то это указывает на низкую степень аномальности этого IP-адреса, и он определяется как нормальный.
[181] На стадии 405 определяется, что клиент с аномального IP-адреса является поисковым роботом.
[182] В отношении аномального IP-адреса предусмотрено, что клиент под аномальным IP-адресом идентифицируется как поисковый робот, и в отношении клиента под этим IP-адресом выполняется аномальная обработка. Например, блокируется доступ с аномального IP-адреса, клиент под аномальным IP-адресом заносится в черный список, и тому подобное.
[183] В этом варианте осуществления настоящего изобретения предусмотрено, что поскольку кодирование целевого вектора доступа, сокращение размерности целевого вектора доступа, определение показателя для распознавания поискового робота и прочие операции по существу аналогичны кодированию выборочного вектора доступа, сокращению размерности выборочного вектора доступа, определению показателя для распознавания поискового робота и прочим операциям в рамках описанных выше вариантов осуществления настоящего изобретения, то последующее описание будет относительно простым, а соответствующие моменты соотносятся с частичным описанием раскрытых выше вариантов осуществления настоящего изобретения, и поэтому этот вариант осуществления заявленного изобретения подробно не описывается в настоящем документе.
[184] В этом варианте осуществления настоящего изобретения обеспечивается получение данных о поведении клиента с каждого IP-адреса, осуществляющего доступ к унифицированным идентификаторам ресурсов по множеству категорий, с целью получения целевых данных о поведении; целевые данные о поведении кодируются в вектор в виде целевого вектора доступа; определяется изолирующий лес, выполненный с возможностью распознавания поискового робота на стороне клиента; целевой вектор доступа вводится в аномальный IP-адрес, распознанный в изолирующем лесу; и определяется, что клиент с аномального IP-адреса является поисковым роботом. С одной стороны, поскольку унифицированные идентификаторы ресурсов с идентичными или схожими функциями обладают идентичной или схожей структурой, классифицирование и подсчет паттернов поведения унифицированных идентификаторов ресурсов при осуществлении доступа не только сохраняют эффективность паттернов поведения при осуществлении доступа, но также и существенно сокращают объем данных в паттернах поведения при осуществлении доступа и уменьшают количество ресурсов, занятых обучением изолирующих лесов. С другой стороны, поскольку поисковый робот демонстрирует большую целенаправленность, паттерн поведения поискового робота при осуществлении доступа очевидным образом отличается от аналогичного паттерна пользователя, вследствие чего паттерн поведения поискового робота при осуществлении доступа более разрежен в сравнении с общепринятым поведением при осуществлении доступа, а изолирующая функция чувствительна к этому признаку, вследствие чего обеспечивается эффективное распознавание поискового робота изолирующим лесом, а поведение пользователя при осуществлении доступа не является искусственно сформулированным правилом, при этом изолирующая функция относится к неконтролируемому режиму отслеживания, поисковый робот не может имитировать поведение пользователя при осуществлении доступа, а контролируемое отслеживание невозможно обойти путем подделки стандартного UA, динамической замены IP-адреса, использования распределенной архитектуры и тому подобного, что эффективным образом обеспечивает безопасность веб-сайта.
[185] Следует отметить, что в целях удобства описания варианты осуществления способа согласно заявленному изобретению описаны в виде ряда последовательных действий, но специалисты в данной области техники должны понимать, что варианты осуществления настоящего изобретения не ограничены описанными последовательностями действий, поскольку некоторые стадии выполняются в других последовательностях или одновременно согласно вариантам осуществления заявленного изобретения. Кроме того, специалистам в данной области техники должно быть также понятно, что варианты осуществления настоящего изобретения, раскрытые в описании, представляют собой лишь иллюстративные примеры его осуществления, и что предусмотренные действия необязательны для вариантов осуществления заявленного изобретения.
[186] На фиг. 7 представлена структурная схема устройства для обучения изолирующих лесов согласно некоторым вариантам осуществления настоящего изобретения, включающего в себя следующие модули:
[187] модуль 701 классификации идентификаторов, выполненный с возможностью получения множества категорий путем классифицирования унифицированных идентификаторов ресурсов;
[188] модуль 702 отслеживания выборочных данных о поведении, выполненный с возможностью получения выборочных данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов под определенной категорией;
[189] модуль 703 кодирования выборочного вектора доступа, выполненный с возможностью кодирования выборочных данных о поведении в вектор в виде выборочного вектора доступа; и
[190] модуль 704 обучения изолирующего леса, выполненный с возможностью обучения изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента.
[191] В некоторых вариантах осуществления настоящего изобретения модуль 701 классификации идентификаторов включает в себя:
[192] подмодуль определения функций, выполненный с возможностью определения функции унифицированного идентификатора ресурса; и
[193] подмодуль классифицирования функций, выполненный с возможностью сведения унифицированных идентификаторов ресурсов, реализующих одну и ту же функцию, в одну категорию.
[194] В некоторых вариантах осуществления настоящего изобретения подмодуль определения функций включает в себя:
[195] блок сегментирования, выполненный с возможностью разбивки унифицированного идентификатора ресурса на множество полей с косой чертой/слэшем в качестве сегментирующей точки;
[196] блок извлечения целевого поля, выполненный с возможностью извлечения поля, отображающего доменное имя, модуль и способ в виде целевого поля; и
[197] блок представления целевого поля, выполненный с возможностью определения того, что целевое поле отображает функцию унифицированного идентификатора ресурса.
[198] В некоторых вариантах осуществления настоящего изобретения модуль 703 кодирования выборочного вектора доступа включает в себя:
[199] подмодуль подсчета выборочных данных о поведении, выполненный с возможностью подсчета количества унифицированных идентификаторов ресурсов по каждой из категорий, доступ к которым осуществляется клиентом с каждого IP-адреса, в выборочных данных о поведении; и
[200] подмодуль определения размерности выборочного вектора, выполненный с возможностью определения категории в качестве размерности вектора и задания множества количественных параметров в качестве значений для множества размерностей в векторе с целью получения выборочного вектора доступа IP-адреса.
[201] В некоторых вариантах осуществления настоящего изобретения модуль 704 обучения изолирующего леса включает в себя:
[202] подмодуль определения показателя, выполненный с возможностью определения показателя для распознавания поискового робота; и
[203] подмодуль генерирования изолирующих деревьев, выполненный с возможностью получения - в соответствии с показателем - изолирующего леса путем генерирования множества изолирующих деревьев с многократным использованием части выборочных векторов доступа.
[204] В некоторых вариантах осуществления настоящего изобретения подмодуль определения показателя включает в себя:
[205] блок определения количества попыток доступа, выполненный с возможностью определения количества унифицированных идентификаторов ресурсов в качестве показателя для распознавания поискового робота;
[206] и/или
[207] блок определения размерности доступа, выполненный с возможностью определения количества всех унифицированных идентификаторов ресурсов, к которым осуществляется доступ под определенной категорией, в качестве показателя для распознавания поискового робота.
[208] В некоторых вариантах осуществления настоящего изобретения подмодуль генерирования изолирующих деревьев включает в себя:
[209] блок задания корневых узлов, выполненный с возможностью извлечения случайным образом части выборочных векторов доступа в качестве корневых узлов изолирующего дерева;
[210] блок определения условия обучения, выполненный с возможностью определения того, выполнено ли на данный момент времени предварительно заданное условие обучения, вызова блока определения завершения обучения по факту выполнения предварительно заданного условия обучения и вызова блока генерирования точки отсечения по факту невыполнения предварительно заданного условия обучения;
[211] блок определения завершения обучения, выполненный с возможностью определения того, что изолирующее дерево обучено;
[212] блок генерирования точки отсечения, выполненный с возможностью генерирования точки отсечения в диапазоне отсечения текущего узла, причем текущий узел изначально представляет собой корневой узел, а диапазон отсечения представляет собой диапазон, образованный значениями выборочных векторов доступа в соответствии с показателем;
[213] блок генерирования дочерних узлов, выполненный с возможностью генерирования первого дочернего узла и второго дочернего узла, когда текущий узел используется в качестве родительского узла; и
[214] блок выборочного добавления, выполненный с возможностью добавления IP-адреса в первый дочерний узел по факту установления того, что значение выборочного вектора доступа в соответствии с показателем меньше точки отсечения, и добавления IP-адреса во второй дочерний узел по факту установления того, что значение выборочного вектора доступа в соответствии с показателем больше или равно точке отсечения, и возврата к стадии вызова блока определения условия обучения.
[215] В некоторых вариантах осуществления настоящего изобретения дополнительно предусмотрен:
[216] модуль сокращения размерности выборочного вектора доступа, выполненный с возможностью сокращения размерности выборочного вектора доступа.
[217] В некоторых вариантах осуществления настоящего изобретения модуль сокращения размерности выборочного вектора доступа включает в себя:
[218] подмодуль объединения первой выборочной матрицы доступа, выполненный с возможностью сведения выборочных векторов доступа в матрицу в виде первой выборочной матрицы доступа;
[219] подмодуль выборочного усреднения до нуля, выполненный с возможностью усреднения до нуля по каждой строке данных в первой выборочной матрице доступа;
[220] подмодуль расчета выборочной ковариационной матрицы, выполненный с возможностью расчета выборочной ковариационной матрицы для первой выборочной матрицы доступа по факту определения того, что усреднение до нуля завершено;
[221] подмодуль расчета выборочных признаков, выполненный с возможностью расчета выборочных собственных значений и выборочных собственных векторов выборочной ковариационной матрицы;
[222] подмодуль генерирования второй выборочной матрицы доступа, выполненный с возможностью выстраивания выборочных собственных векторов в строки в направлении сверху вниз в зависимости от абсолютных величин выборочных собственных значений и использования первых к строк/строки для формирования второй выборочной матрицы доступа; и
[223] подмодуль сокращения размерности выборочного вектора, выполненный с возможностью получения выборочного вектора доступа после сокращения размерности путем расчета произведения между второй выборочной матрицей доступа и первой выборочной матрицей доступа.
[224] Устройство для обучения изолирующего леса согласно вариантам осуществления настоящего изобретения реализует способ обучения изолирующего леса по любому из вариантов осуществления настоящего изобретения, и оно включает в себя соответствующие функциональные модули и обеспечивает положительный эффект при реализации указанного способа.
[225] На фиг. 8 представлена структурная схема устройства для распознавания поискового робота согласно некоторым вариантам осуществления настоящего изобретения, включающего в себя следующие модули:
[226] модуль 801 отслеживания целевых данных о поведении, выполненный с возможностью получения целевых данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
[227] модуль 802 кодирования целевого вектора доступа, выполненный с возможностью кодирования целевых данных о поведении в вектор в виде целевого вектора доступа; и
[228] модуль 803 определения изолирующего леса, выполненный с возможностью определения изолирующего леса для распознавания поискового робота на стороне клиента;
[229] модуль 804 распознавания аномального адреса, выполненный с возможностью распознавания аномального IP-адреса путем ввода целевого вектора доступа в изолирующий лес; и
[230] модуль 805 определения поискового робота, выполненный с возможностью определения того, что клиент с аномального IP-адреса является поисковым роботом.
[231] В некоторых вариантах осуществления настоящего изобретения модуль 804 распознавания аномального адреса включает в себя:
[232] подмодуль расчета аномального значения, выполненный с возможностью расчета аномального значения IP-адреса путем обхода каждого из изолирующих деревьев в изолирующем лесу на основании целевого вектора доступа; и
[233] подмодуль определения аномального адреса, выполненный с возможностью определения того, что IP-адрес является аномальным по факту превышения аномальным значением предварительно заданного порогового значения.
[234] В некоторых вариантах осуществления настоящего изобретения подмодуль расчета аномального значения включает в себя:
[235] подмодуль пополнения корневого узла, выполненный с возможностью добавления IP-адреса в корневой узел изолирующего дерева в каждом из изолирующих деревьев;
[236] подмодуль определения показателя, выполненный с возможностью определения показателя для распознавания поискового робота; и
[237] подмодуль запроса точки отсечения, выполненный с возможностью запрашивания точки отсечения текущего узла, причем текущий узел изначально представляет собой корневой узел;
[238] подмодуль пополнения дочерних узлов, выполненный с возможностью добавления IP-адреса в первый дочерний узел под текущим узлом по факту определения того, что значение целевого вектора доступа в соответствии с показателем меньше точки отсечения, и добавления IP-адреса во второй дочерний узел под текущим узлом по факту определения того, что значение целевого вектора доступа в соответствии с показателем больше или равно точке отсечения, и возврата к стадии вызова подмодуля запроса точки отсечения; и
[239] подмодуль расчета аномального значения, выполненный с возможностью расчета аномального значения IP-адреса на основании высоты IP-адреса во всех изолирующих деревьях по факту завершения обхода каждого из изолирующих деревьев целевым вектором доступа.
[240] В некоторых вариантах осуществления настоящего изобретения подмодуль определения показателя включает в себя:
[241] блок определения объема доступа, выполненный с возможностью определения количества унифицированных идентификаторов ресурсов в качестве показателя для распознавания поискового робота;
[242] и/или
[243] блок определения размерности доступа, выполненный с возможностью определения количества всех унифицированных идентификаторов ресурсов, к которым осуществляется доступ под определенной категорией, в качестве показателя для распознавания поискового робота.
[244] В некоторых вариантах осуществления настоящего изобретения модуль 802 кодирования целевого вектора доступа включает в себя:
[245] первый подмодуль запуска, выполненный с возможностью кодирования целевых данных о поведении в вектор в виде целевого вектора доступа по факту превышения заданного первого порогового значения промежутком времени для накопления целевых данных о поведении;
[246] или
[247] второй подмодуль запуска, выполненный с возможностью кодирования целевых данных о поведении в вектор в виде целевого вектора доступа по факту превышения предварительно заданного порогового значения количеством унифицированных идентификаторов ресурсов, доступ к которым осуществляется клиентом с IP-адреса, в целевых данных о поведении.
[248] В некоторых вариантах осуществления настоящего изобретения модуль 802 кодирования целевого вектора доступа включает в себя:
[249] подмодуль подсчета целевых данных о поведении, выполненный с возможностью подсчета количества унифицированных идентификаторов ресурсов по каждой из категорий, доступ к которым осуществляется клиентом с IP-адреса, в целевых данных о поведении; и
[250] подмодуль определения целевой размерности, выполненный с возможностью определения категории в качестве размерности вектора и задания множества количественных параметров в качестве значений множества размерностей в векторе для получения целевого вектора доступа IP-адреса.
[251] В некоторых вариантах осуществления настоящего изобретения дополнительно предусмотрен:
[252] модуль сокращения размерности целевого вектора доступа, выполненный с возможностью сокращения размерности целевого вектора доступа.
[253] В некоторых вариантах осуществления настоящего изобретения модуль сокращения размерности целевого вектора доступа включает в себя:
[254] подмодуль формирования первой целевой матрицы доступа, выполненный с возможностью объединения целевых векторов доступа в матрицу в виде первой целевой матрицы доступа;
[255] подмодуль целевого усреднения до нуля, выполненный с возможностью усреднения до нуля по каждой строке данных в первой целевой матрице доступа;
[256] подмодуль расчета целевой ковариационной матрицы, выполненный с возможностью расчета целевой ковариационной матрицы для первой целевой матрицы доступа по факту завершения усреднения до нуля;
[257] подмодуль расчета целевых признаков, выполненный с возможностью расчета целевых собственных значений и целевых собственных векторов целевой ковариационной матрицы;
[258] подмодуль генерирования второй целевой матрицы доступа, выполненный с возможностью выстраивания целевых собственных векторов в строки в направлении сверху вниз в зависимости от абсолютных величин целевых собственных значений и использования первых к строк/строки для формирования второй целевой матрицы доступа; и
[259] подмодуль сокращения размерности целевого вектора, выполненный с возможностью получения целевого вектора доступа после сокращения размерности путем расчета произведения между второй целевой матрицей доступа и первой целевой матрицей доступа.
[260] Устройство для распознавания поискового робота согласно вариантам осуществления настоящего изобретения реализует способ распознавания поискового робота по любому из вариантов осуществления настоящего изобретения, причем оно содержит соответствующие функциональные модули и обеспечивает положительный эффект при реализации указанного способа.
[261] Фиг. 9 представляет собой структурную схему компьютерного устройства согласно некоторым вариантам осуществления настоящего изобретения. На фиг. 9 показана блок-схема иллюстративного компьютерного устройства 12, пригодного для реализации настоящего изобретения. Компьютерное устройство 12, показанное на фиг. 9, приведено исключительно для примера, и не накладывает какие-либо ограничения на функцию и объем использования вариантов осуществления настоящего изобретения.
[262] Как показано на фиг. 9, компьютерное устройство 12 представляет собой универсальное вычислительное устройство. Компоненты компьютерного устройства 12 включают в себя, помимо прочего: один или несколько процессоров 16 или блоков обработки данных, системную память 28 и шину 18, соединяющую между собой различные компоненты системы, включая системную память 28 и процессор 16.
[263] Шина 18 может быть представлена в виде шинных структур нескольких типов, включая шину памяти или контроллер памяти, периферийную шину, ускоренный графический порт, процессор или локальную шину, использующую любую шинную структуру из множества шинных структур. К примеру, такие структуры включают в себя, помимо прочего, шину со стандартной промышленной архитектурой (ISA), шину с микроканальной архитектурой (MAC), шину с усовершенствованной стандартной промышленной архитектурой, локальную шину VESA (Ассоциации по стандартам в области видеоэлектроники) и локальную шину для подключения периферийных компонентов (шину стандарта PCI).
[264] Компьютерное устройство 12 включает в себя различные носители, считываемые компьютерной системой. Такие носители представляют собой любые подходящие для компьютерного устройства 12 носители и включают в себя как энергозависимые, так и энергонезависимые носители, как съемные, так и несъемные носители.
[265] Системная память 28 включает в себя носитель, считываемый компьютерной системой, выполненный в виде энергозависимого запоминающего устройства, такого как оперативное запоминающее устройство (RAM) 30 и/или кэш-память 32. Компьютерное устройство 12 дополнительно включает в себя другие съемные/несъемные, энергозависимые/энергонезависимые носители данных компьютерной системы. Например, запоминающее устройство 34 выполнено с возможностью считывания данных с несъемного энергонезависимого магнитного носителя (не показан на фиг. 9 и обычно называется «жестким диском») и записи данных на указанный носитель. Хотя это и не показано на фиг. 9, может быть предусмотрен магнитный дисковод для считывания и записи данных на съемный энергонезависимый магнитный диск (например, гибкий магнитный диск) и оптический дисковод для считывания и записи данных на съемный энергонезависимый оптический диск (например, CD-ROM (постоянное запоминающее устройство на компакт-дисках), DVD-ROM (постоянное запоминающее устройство на цифровых универсальных дисках) или иные оптические носители). В этих случаях каждый дисковод соединен с шиной 18 посредством одного или нескольких интерфейсов носителей данных. Память 28 содержит, по меньшей мере, один программный продукт, содержащий группу (например, по меньшей мере, одну) программных модулей, которые выполнены с возможностью выполнения функций вариантов осуществления настоящего изобретения.
[266] Программа/утилита 40, содержащая группу (по меньшей мере, одну) программных модулей 42, хранится в памяти 28. Программные модули 42 включают в себя, помимо прочего, операционную систему, одну или несколько прикладных программ, другие программные модули и данные программ, причем каждый из этих элементов или некоторые их комбинации предусматривают обеспечение сетевой среды. Программный модуль 42, в общем, выполняет функции и/или реализует способы согласно вариантам осуществления заявленного изобретения, описанным в настоящем документе.
[267] Компьютерное устройство 12 также сообщается с одним или несколькими внешними устройствами 14 (например, клавиатурой, указывающим устройством, дисплеем 24); с одним или несколькими устройствами, которые позволяют пользователю взаимодействовать с компьютерным устройством 12; и/или с любыми устройствами (например, сетевой картой, модемом), которые позволяют компьютерному устройству 12 сообщаться с одним или несколькими другими вычислительными устройствами. Такая связь осуществляется через интерфейс ввода/вывода (I/O) 22. Кроме того, компьютерное устройство 12 сообщается с одной или несколькими сетями (например, с локальной сетью (LAN), глобальной сетью (WAN) и/или сетью общего пользования, такой как сеть Интернет) через сетевой адаптер 20. Как показано на фигуре, сетевой адаптер 20 сообщается с другими модулями компьютерного устройства 12 посредством шины 18. Хотя это и не показано на фигуре, но следует понимать, что в сопряжении с компьютерным устройством 12 используются и другие аппаратные и/или программные модули, включающие в себя, помимо прочего: набор микрокоманд, драйвер устройства, блок обработки данных с резервированием, массив внешних дисководов, RAID-систему (массив независимых жестких дисков с избыточностью информации), накопитель на магнитной ленте, систему хранения резервных копий данных и прочие устройства подобного рода.
[268] Процессор 16 приводит в исполнение различные функциональные приложения и осуществляет обработку данных путем выполнения программы, хранящейся в системной памяти 28, например, для реализации способа обучения изолирующих лесов и способа распознавания поискового робота согласно вариантам осуществления настоящего изобретения.
[269] Вариантами осуществления настоящего изобретения дополнительно предложен машиночитаемый носитель данных для хранения одной или нескольких компьютерных программ, причем одна или несколько компьютерных программ при их загрузке и выполнении процессором инициирует выполнение этим процессором стадий описанного выше способа обучения изолирующих лесов и описанного выше способа распознавания поискового робота с достижением такого же технического эффекта. Во избежание повтора он не будет еще раз описан в настоящем документе.
[270] Машиночитаемый носитель данных включает в себя, помимо прочего, например, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, аппарат или устройство или любое сочетание указанных устройств. Частные примеры (неисчерпывающий список) машиночитаемых носителей данных включают в себя: электрическое соединение с одним или несколькими проводами, дискета для портативного компьютера, жесткий диск, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), стираемое программируемое постоянное запоминающее устройство (EPROM или флэш-память), оптоволокно, постоянное запоминающее устройство на компакт-дисках (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или любое подходящее сочетание указанных устройств. В настоящем документе машиночитаемый носитель данных представляет собой любой материальный носитель, который содержит или хранит программу для ее использования системой исполнения команд, аппаратом или устройством или для ее использования во взаимодействия с системой исполнения команд, аппаратом или устройством. Машиночитаемый носитель данных представляет собой энергонезависимый машиночитаемый носитель данных.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2803399C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2772549C1 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2778630C1 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ АКТИВНОСТИ УЧЕТНЫХ ЗАПИСЕЙ В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2023 |
|
RU2824919C1 |
| Способ и система предотвращения вредоносных автоматизированных атак | 2021 |
|
RU2768567C1 |
| Способ и система предотвращения вредоносных автоматизированных атак | 2020 |
|
RU2740027C1 |
| СИСТЕМА, УСТРОЙСТВО И СПОСОБ ДИНАМИЧЕСКОЙ НАСТРОЙКИ И КОНФИГУРИРОВАНИЯ ПРИЛОЖЕНИЙ | 2006 |
|
RU2422882C2 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА УПРАВЛЕНИЯ МОБИЛЬНОСТЬЮ И ЭФФЕКТИВНОГО ПОИСКА ИНФОРМАЦИИ В СЕТИ СВЯЗИ | 2008 |
|
RU2507700C2 |
| Система и способ настройки систем безопасности при DDoS-атаке | 2017 |
|
RU2659735C1 |
| Система и способ определения DDoS-атак | 2017 |
|
RU2676021C1 |
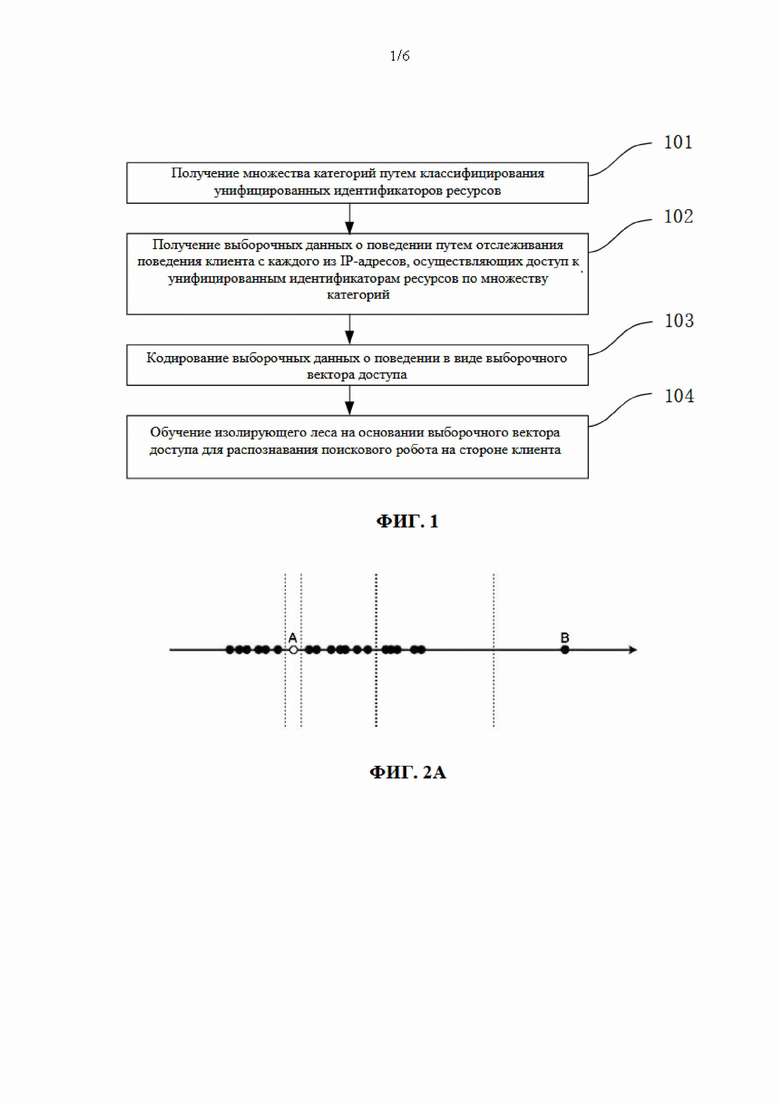
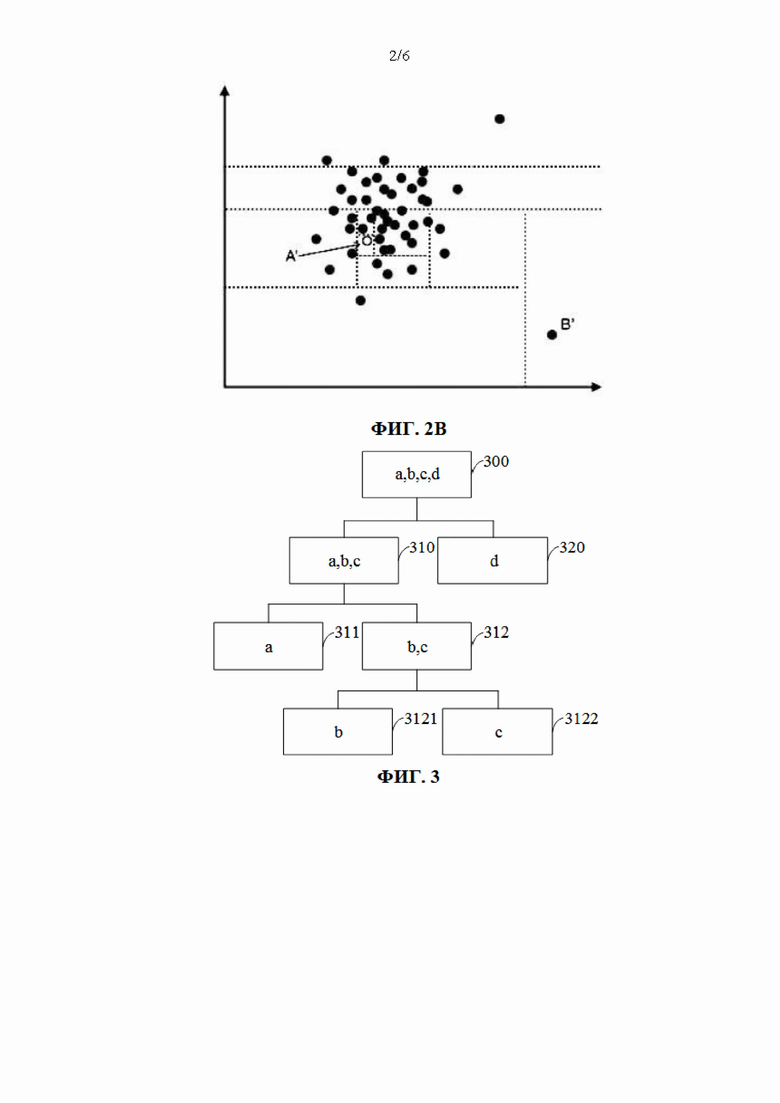
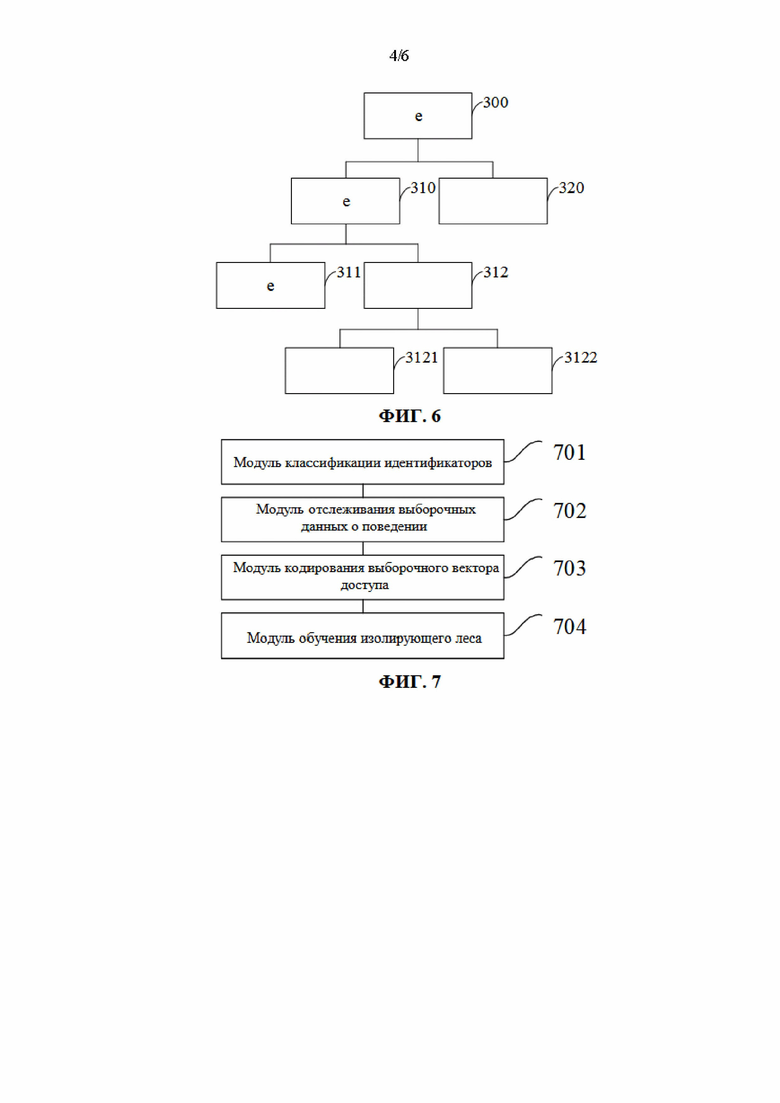

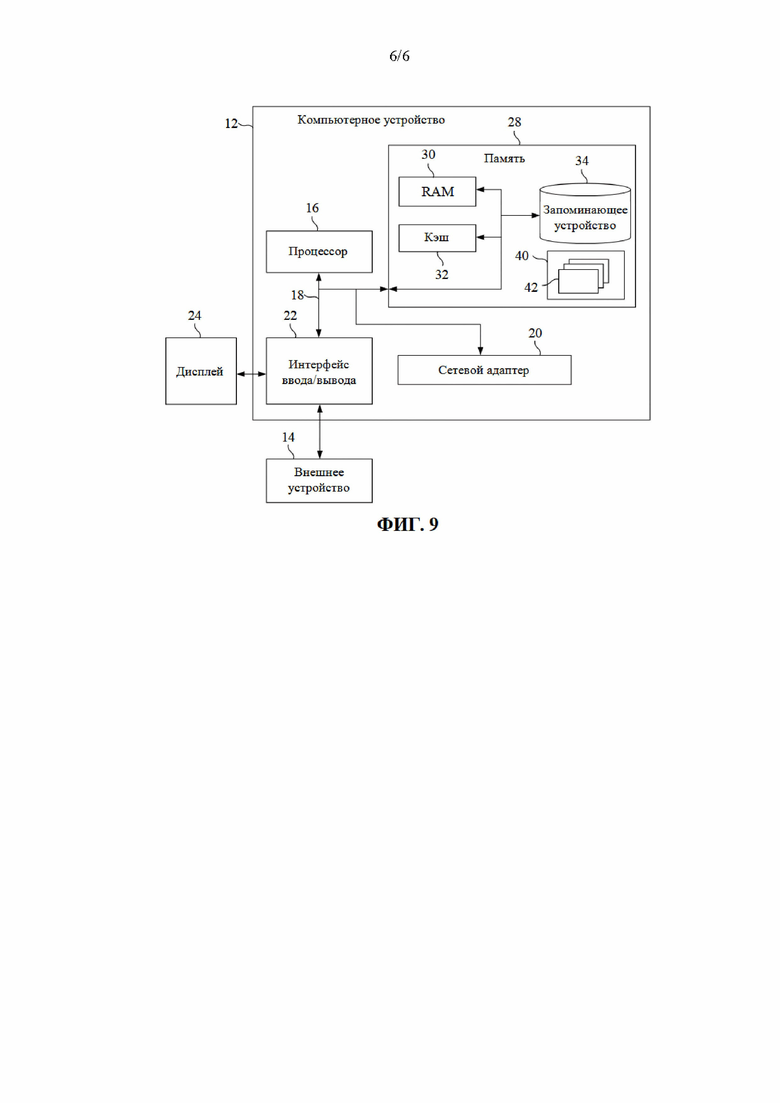
Изобретение относится к области вычислительной техники для распознавания поискового робота. Технический результат заключается в повышении точности распознавания поискового робота, что приводит к повышению безопасности веб-сайта. Технический результат достигается за счет этапов, на которых выполняют: классифицирование унифицированных идентификаторов ресурсов для получения множества категорий (стадия 101); отслеживание поведения клиента с каждого IP-адреса, осуществляющего доступ к унифицированным идентификаторам ресурсов по множеству категорий, и получение выборочных данных о поведении (стадия 102); кодирование выборочных данных о поведении в вектор и использование его в виде выборочного вектора доступа (стадия 103); и обучение изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента (стадия 104). 6 н. и 9 з.п. ф-лы, 10 ил.
1. Способ обучения изолирующего леса, предусматривающий: получение множества категорий путем классифицирования унифицированных идентификаторов ресурсов;
получение выборочных данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
кодирование выборочных данных о поведении в вектор в виде выборочного вектора доступа; и
обучение изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента;
причем обучение изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента предусматривает: определение показателя для распознавания поискового робота; и получение изолирующего леса путем генерирования - в соответствии с показателем - множества изолирующих деревьев с многократным использованием части выборочных векторов доступа;
причем получение изолирующего леса путем генерирования - в соответствии с показателем - множества изолирующих деревьев с многократным использованием части выборочных векторов доступа предусматривает:
извлечение случайным образом части выборочных векторов доступа в качестве корневых узлов изолирующего дерева;
определение того, выполнено ли предварительно заданное условие обучения, определение того, что обучение изолирующего дерева завершено по факту выполнения предварительно заданного условия обучения, и генерирование точки отсечения в диапазоне отсечения по факту невыполнения предварительно заданного условия обучения, при этом текущий узел изначально представляет собой корневой узел, а диапазон отсечения представляет собой диапазон, заданный значениями выборочных векторов доступа в соответствии с показателем;
генерирование первого дочернего узла и второго дочернего узла с родительским узлом в качестве текущего узла; и
добавление IP-адреса в первый дочерний узел по факту установления того, что значение выборочного вектора доступа в соответствии с показателем меньше точки отсечения, и добавление IP-адреса во второй дочерний узел по факту установления того, что значение выборочного вектора доступа в соответствии с показателем больше или равно точке отсечения, и возврат к стадии определения того, удовлетворено ли условие обучения.
2. Способ по п. 1, в котором получение множества категорий путем классифицирования унифицированных идентификаторов ресурсов предусматривает:
определение функций унифицированных идентификаторов ресурсов; и
сведение унифицированных идентификаторов ресурсов, реализующих одну и ту же функцию, в одну категорию.
3. Способ по п. 2, в котором определение функций унифицированных идентификаторов ресурсов предусматривает:
разбивку унифицированного идентификатора ресурса на множество полей с помощью косой черты/слэша в качестве сегментирующей точки;
извлечения поля, отображающего доменное имя, модуль и способ в виде целевого поля; и
определение того, что целевое поле отображает функцию унифицированного идентификатора ресурса.
4. Способ по п. 1, в котором кодирование выборочных данных о поведении в вектор в виде выборочного вектора доступа предусматривает:
подсчет количества унифицированных идентификаторов ресурсов по каждой из категорий, доступ к которым осуществляется клиентом с каждого IP-адреса, в выборочных данных о поведении; и
получение выборочного вектора доступа каждого из IP-адресов, когда каждая из категорий служит размерностью вектора, путем соответствующего задания множества количественных параметров в качестве значений множества размерностей, соответствующих множеству категорий в векторе.
5. Способ по п. 1, в котором определение показателя для распознавания поискового робота предусматривает выполнение по меньшей мере одной из следующих стадий:
определения количества попыток доступа к унифицированным идентификаторам ресурсов в качестве показателя для распознавания поискового робота; и
определения количества попыток доступа ко всем унифицированным идентификаторам ресурсов по множеству категорий в качестве показателя для распознавания поискового робота.
6. Способ по любому из предшествующих пп. 1-5, дополнительно предусматривающий:
сокращение размерности выборочного вектора доступа.
7. Способ по п. 6, в котором сокращение размерности выборочного вектора доступа предусматривает:
объединение выборочных векторов доступа в матрицу в виде первой выборочной матрицы доступа, причем первая выборочная матрица доступа содержит n строк данных;
усреднение до нуля по каждой строке данных в первой выборочной матрице доступа;
расчет выборочной ковариационной матрицы для первой выборочной матрицы доступа по факту определения того, что усреднение до нуля завершено;
расчет выборочных собственных значений и выборочных собственных векторов выборочной ковариационной матрицы;
выстраивание выборочных собственных векторов в строки в направлении сверху вниз в зависимости от абсолютной величины выборочного собственного значения и использование первых k строк/строки для формирования второй выборочной матрицы доступа; и
получение выборочного вектора доступа после сокращения размерности путем расчета произведения между второй выборочной матрицей доступа и первой выборочной матрицей доступа;
при этом величина n является целым положительным числом и n > 1, а величина k является целым положительным числом и 1 < k < n.
8. Способ распознавания поискового робота, предусматривающий:
получение целевых данных о поведении путем отслеживания поведения клиента с
каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
кодирование целевых данных о поведении в вектор в виде целевого вектора доступа;
определение изолирующего леса для распознавания поискового робота на стороне клиента, причем получение изолирующего леса обеспечивается способом обучения изолирующих лесов по любому из предшествующих пп. 1-7;
распознавание аномального IP-адреса путем ввода целевого вектора доступа в изолирующий лес; и
определение того, что клиент с аномального IP-адреса является поисковым роботом.
9. Способ по п. 8, в котором изолирующий лес содержит множество изолирующих деревьев, а распознавание аномального IP-адреса путем ввода целевого вектора доступа в изолирующий лес предусматривает:
расчет аномального значения каждого из IP-адресов путем обхода каждого из изолирующих деревьев в изолирующем лесу на основании целевого вектора доступа; и
определение IP-адреса, соответствующего аномальному значению, в качестве аномального IP-адреса по факту определения того, что аномальное значение превышает предварительно заданное пороговое значение.
10. Способ по п. 9, в котором каждое из изолирующих деревьев содержит множество узлов, а расчет аномального значения каждого из IP-адресов путем обхода каждого из изолирующих деревьев на основании целевого вектора доступа предусматривает:
добавление каждого из IP-адресов в корневой узел изолирующего дерева в каждом из изолирующих деревьев;
определение показателя для распознавания поискового робота; и
запрашивание точки отсечения текущего узла, причем текущий узел изначально представляет собой корневой узел;
добавление IP-адреса в первый дочерний узел под текущим узлом по факту определения того, что значение целевого вектора доступа в соответствии с показателем меньше точки отсечения, или добавление IP-адреса во второй дочерний узел под текущим узлом по факту определения того, что значение целевого вектора доступа в соответствии с показателем больше или равно точке отсечения, и возврат к стадии вызова подмодуля запроса точки отсечения; и
расчет аномального значения каждого из IP-адресов на основании высоты каждого IP-адреса во всех изолирующих деревьях по факту завершения обхода каждого из изолирующих деревьев целевым вектором доступа.
11. Способ по любому из предшествующих пп. 8-10, в котором кодирование целевых данных о поведении предусматривает:
кодирование целевых данных о поведении в вектор в виде целевого вектора доступа по факту превышения заданного первого порогового значения промежутком времени для накопления целевых данных о поведении; или
кодирование целевых данных о поведении в вектор в виде целевого вектора доступа по факту превышения предварительно заданного порогового значения количеством унифицированных идентификаторов ресурсов, доступ к которым осуществляется клиентом с IP-адреса, в целевых данных о поведении.
12. Устройство для обучения изолирующих лесов, содержащее:
модуль классификации идентификаторов, выполненный с возможностью получения множества категорий путем классифицирования унифицированных идентификаторов ресурсов;
модуль отслеживания выборочных данных о поведении, выполненный с возможностью получения выборочных данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий;
модуль кодирования выборочного вектора доступа, выполненный с возможностью кодирования выборочных данных о поведении в вектор в виде выборочного вектора доступа; и
модуль обучения изолирующего леса, выполненный с возможностью обучения изолирующего леса на основании выборочного вектора доступа для распознавания поискового робота на стороне клиента, причем
модуль обучения изолирующего леса содержит:
подмодуль определения показателя, выполненный с возможностью определения показателя для распознавания поискового робота; и
подмодуль генерирования изолирующих деревьев, выполненный с возможностью получения - в соответствии с показателем - изолирующего леса путем генерирования множества изолирующих деревьев с многократным использованием части выборочных векторов доступа;
причем подмодуль генерирования изолирующих деревьев включает в себя:
блок задания корневых узлов, выполненный с возможностью извлечения случайным образом части выборочных векторов доступа в качестве корневых узлов изолирующего дерева;
блок определения условия обучения, выполненный с возможностью определения того, выполнено ли на данный момент времени предварительно заданное условие обучения, вызова блока определения завершения обучения по факту выполнения предварительно заданного условия обучения и вызова блока генерирования точки отсечения по факту невыполнения предварительно заданного условия обучения;
блок определения завершения обучения, выполненный с возможностью определения того, что изолирующее дерево обучено;
блок генерирования точки отсечения, выполненный с возможностью
генерирования точки отсечения в диапазоне отсечения текущего узла, причем текущий узел изначально представляет собой корневой узел, а диапазон отсечения представляет собой диапазон, образованный значениями выборочных векторов доступа в соответствии с показателем;
блок генерирования дочерних узлов, выполненный с возможностью генерирования первого дочернего узла и второго дочернего узла, когда текущий узел используется в качестве родительского узла; и
блок выборочного добавления, выполненный с возможностью добавления IP-адреса в первый дочерний узел по факту установления того, что значение выборочного вектора доступа в соответствии с показателем меньше точки отсечения, и добавления IP-адреса во второй дочерний узел по факту установления того, что значение выборочного вектора доступа в соответствии с показателем больше или равно точке отсечения, и возврата к стадии вызова блока определения условия обучения.
13. Устройство для распознавания поискового робота, содержащее: модуль отслеживания целевых данных о поведении, выполненный с возможностью получения целевых данных о поведении путем отслеживания поведения клиента с каждого из IP-адресов в составе множества IP-адресов, осуществляющих доступ к унифицированным идентификаторам ресурсов по множеству категорий, для получения целевых данных о поведении;
модуль кодирования целевого вектора доступа, выполненный с возможностью кодирования целевых данных о поведении в вектор в виде целевого вектора доступа; и
модуль определения изолирующего леса, выполненный с возможностью определения изолирующего леса для распознавания поискового робота на стороне клиента, причем получение изолирующего леса обеспечивается способом обучения изолирующих лесов по любому из предшествующих пп. 1-7;
модуль распознавания аномальных адресов, выполненный с возможностью определения аномального IP-адреса путем ввода целевого вектора доступа в изолирующий лес; и
модуль определения поискового робота, выполненный с возможностью определения того, что клиент по аномальному IP-адресу является поисковым роботом.
14. Вычислительное устройство для обучения изолирующего леса или распознавания поискового робота, содержащее:
один или несколько процессоров; и
память, выполненную с возможностью хранения одной или нескольких программ;
причем одна или несколько программ при их загрузке и выполнении одним или несколькими процессорами инициирует реализацию одним или несколькими процессорами способа обучения изолирующих лесов по любому из предшествующих пп. 1-7 или способа распознавания поискового робота по любому из предшествующих пп. 8-11.
15. Энергонезависимый машиночитаемый носитель данных для обучения изолирующего леса или распознавания поискового робота, который хранит одну или несколько компьютерных программ, причем одна или несколько компьютерных программ при их загрузке и выполнении процессором инициирует реализацию процессором способа обучения изолирующих лесов по любому из предшествующих пп. 1-7 или способа распознавания поискового робота по любому из предшествующих пп. 8-11.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| ОБНАРУЖЕНИЕ И АНАЛИЗ ЗЛОУМЫШЛЕННОЙ АТАКИ | 2011 |
|
RU2583703C2 |

