ОБЛАСТЬ ТЕХНИКИ
Настоящее раскрытие, в целом, относится к области обработки данных и, в частности, к технологиям кодирования и инициализации служебных метаданных, необходимых для эффективного исполнения приложений, написанных на объектно-ориентированных языках программирования.
УРОВЕНЬ ТЕХНИКИ
Для правильной работы на пользовательском оборудовании (UE), таком, например, как настольный компьютер или мобильный телефон, приложению требуются служебные метаданные, содержащие различные данные времени исполнения. Служебные метаданные обычно генерируются компилятором, который используется вместе с компоновщиком для генерирования исполняемого файла приложения из исходного кода приложения. Существует как минимум два подхода к созданию служебных метаданных, каждый из которых имеет свои преимущества и недостатки.
Первый подход реализован в опережающих (AOT) компиляторах, которые заранее генерируют служебные метаданные, необходимые приложению, и сохраняют служебные метаданные в исполняемом файле приложения. Впоследствии, т.е. во время исполнения, служебные метаданные загружаются из исполняемого файла. Такая AOT-компиляция приводит к ненужному и нежелательному увеличению размера исполняемого файла (т.е. занимаемого места на диске), а также замедляет запуск приложения из-за относительно большого объема загружаемых служебных метаданных.
Второй (противоположный) подход реализован в оперативных (JIT) компиляторах, которые генерируют служебные метаданные, необходимые приложению, по запросу во время исполнения. Следует отметить, что второй подход может использоваться совместно с первым подходом (т.е. некоторые служебные метаданные могут быть сгенерированы заранее, а остальные служебные метаданные могут быть сгенерированы по требованию). Хотя второй подход устраняет накладные расходы на дисковое пространство, присущие первому подходу, он, тем не менее, снижает как время запуска, так и время исполнения приложения. Кроме того, при использовании совместно с первым подходом второй подход также негативно влияет на возможности оптимизации AOT-компиляторов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Это краткое изложение сущности изобретения приведено для представления подборки концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Данное краткое изложение сущности изобретения не предназначено ни для определения ключевых признаков настоящего раскрытия, ни для использования для ограничения объема настоящего раскрытия.
Задачей настоящего раскрытия является предоставление технического решения, которое позволяет получать кодированное представление служебных метаданных приложения во время компиляции и последующую инициализацию служебных метаданных на основе кодированного представления во время запуска.
Указанная выше задача решается посредством признаков из независимых пунктов прилагаемой формулы изобретения. Дополнительные варианты осуществления и примеры очевидны из зависимых пунктов формулы изобретения, подробного описания и прилагаемых чертежей.
Согласно первому аспекту предоставляется устройство для кодирования служебных метаданных приложения. Устройство согласно первому аспекту содержит по меньшей мере один процессор и память, соединенную с по меньшей мере одним процессором. Память приспособлена для хранения исполняемых процессором инструкций, которые предписывают по меньшей мере одному процессору работать следующим образом. Сначала по меньшей мере один процессор принимает исходный код приложения и использует исходный код для определения служебных метаданных приложения. Затем по меньшей мере один процессор получает кодированное представление служебных метаданных. Затем по меньшей мере один процессор компилирует исходный код для генерирования исполняемого файла приложения. Исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных. По меньшей мере один процессор резервирует, по меньшей мере частично, неинициализированный сегмент данных исполняемого файла для служебных метаданных. После этого по меньшей мере один процессор сохраняет кодированное представление служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла и сохраняет сам исполняемый файл в памяти. Посредством сохранения кодированного представления служебных метаданных в памяти (вместо фактических служебных метаданных) устройство согласно первому аспекту способно уменьшить объем исполняемого файла на диске и, в то же время, объем служебных метаданных, загружаемых во время исполнения приложения, по сравнению с обычными AOT-компиляторами.
В одном варианте осуществления первого аспекта неинициализированный сегмент данных исполняемого файла содержит сегмент неинициализированных данных (BSS). Это может обеспечить совместимость устройства согласно первому аспекту с общим стандартным файловым форматом для исполняемых файлов.
В одном варианте осуществления первого аспекта по меньшей мере один процессор сконфигурирован для определения служебных метаданных приложения посредством синтаксического разбора исходного кода приложения. Это может сделать устройство в соответствии с первым аспектом более гибким в использовании.
В одном варианте осуществления первого аспекта память дополнительно приспособлена для хранения базы данных, содержащей множество исходных кодов и служебных метаданных, соответствующих различным приложениям. В этом варианте осуществления по меньшей мере один процессор сконфигурирован для определения служебных метаданных приложения посредством доступа к базе данных, поиска исходного кода приложения в базе данных и считывания служебных метаданных приложения из базы данных. Посредством использования такой базы данных можно ускорить получение служебных метаданных без необходимости каким-либо образом анализировать (например, выполнять синтаксический разбор) исходный код приложения, тем самым также снижая вычислительные затраты.
В одном варианте осуществления первого аспекта по меньшей мере один процессор сконфигурирован для получения кодированного представления служебных метаданных в соответствии с по меньшей мере одним из следующего: тип служебных метаданных, требуемый размер кодированного представления служебных метаданных и требуемое время декодирования кодированного представления служебных метаданных. Посредством реализации этого, становится возможным получить компактное и быстро декодируемое кодированное представление служебных метаданных, тем самым более эффективно уменьшая занимаемый исполняемым файлом объем дискового пространства и время запуска приложения. В свою очередь, сокращение времени запуска приложения может повысить производительность приложения во время исполнения.
В одном варианте осуществления первого аспекта по меньшей мере один процессор дополнительно сконфигурирован для выбора требуемого размера кодированного представления служебных метаданных на основе предварительно выделенного размера памяти, которая должна использоваться для хранения исполняемого файла. Посредством реализации этого, становится возможным обеспечить более рациональное использование памяти в устройстве согласно первому аспекту.
В одном варианте осуществления первого аспекта по меньшей мере один процессор дополнительно сконфигурирован для выбора требуемого времени декодирования на основе предварительно определенного времени запуска приложения. Посредством реализации этого, становится возможным более эффективно декодировать служебные метаданные.
В одном варианте осуществления первого аспекта по меньшей мере один процессор сконфигурирован для получения кодированного представления служебных метаданных с использованием алгоритма сжатия данных общего назначения. Алгоритм сжатия данных общего назначения, такой как, например, кодирование переменной длины, кодирование Little Endian Base 128 (LEB128), кодирование Хаффмана, кодирование на основе цепочного алгоритма Лемпеля-Зива-Маркова (LZMA), кодирование с переменной длиной кодовой последовательности и т.д., может позволить более эффективно сжимать служебные метаданные в качестве кодированного представления.
В одном варианте осуществления первого аспекта по меньшей мере один процессор сконфигурирован для компиляции исходного кода с использованием АОТ-компилятора. Это может сделать устройство в соответствии с первым аспектом более гибким в использовании.
Согласно второму аспекту предоставляется устройство для инициализации служебных метаданных приложения. Устройство согласно второму аспекту содержит по меньшей мере один процессор и память, соединенную с по меньшей мере одним процессором. Память приспособлена для хранения исполняемых процессором инструкций, которые предписывают по меньшей мере одному процессору работать следующим образом. Сначала по меньшей мере один процессор осуществляет доступ к исполняемому файлу приложения. Исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных. Инициализированный сегмент доступных только для чтения данных исполняемого файла содержит кодированное представление служебных метаданных для приложения. Неинициализированный сегмент данных исполняемого файла зарезервирован, по меньшей мере частично, для служебных метаданных. Затем по меньшей мере один процессор получает декодированное представление служебных метаданных путем декодирования кодированного представления служебных метаданных. После этого по меньшей мере один процессор инициализирует служебные метаданные из декодированного представления служебных метаданных в зарезервированном неинициализированном сегменте данных исполняемого файла. Посредством использования исполняемого файла, сконфигурированного таким образом, устройство согласно второму аспекту может надлежащим образом и быстро инициализировать фактические служебные метаданные, необходимые для исполнения и функционирования приложения, тем самым значительно сокращая время запуска приложения.
В одном варианте осуществления второго аспекта неинициализированный сегмент данных исполняемого файла содержит сегмент неинициализированных данных (BSS-сегмент). Это может обеспечить совместимость устройства согласно второму аспекту с общим стандартным файловым форматом для исполняемых файлов.
В одном варианте осуществления второго аспекта по меньшей мере один процессор сконфигурирован для декодирования кодированного представления служебных метаданных с использованием алгоритма декомпрессии данных общего назначения. Алгоритм декомпрессии данных общего назначения, такой как, например, декодирование переменной длины, декодирование LEB128, декодирование Хаффмана, декодирование LZMA, декодирование с переменной длиной кодовой последовательности и т.д., может повысить эффективность получения декодированного представления служебных метаданных.
Согласно третьему аспекту предоставляется устройство для исполнения приложения. Устройство согласно третьему аспекту содержит устройство согласно первому аспекту и устройство согласно второму аспекту. С этой конфигурацией устройство согласно третьему аспекту может выполнять как функции кодирования, так и инициализации служебных метаданных, обеспечивая при этом те же преимущества, что и рассмотренные выше со ссылкой на устройства согласно первому и второму аспектам.
В соответствии с четвертым аспектом предоставляется способ кодирования служебных метаданных приложения. Способ согласно четвертому аспекту начинается с этапов приема исходного кода приложения и использования исходного кода для определения служебных метаданных приложения. Затем способ согласно четвертому аспекту переходит к этапу получения кодированного представления служебных метаданных. После этого способ по четвертому аспекту переходит к этапу компиляции исходного кода для генерирования исполняемого файла приложения. Исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных. Далее способ согласно четвертому аспекту переходит к этапам резервирования, по меньшей мере частично, неинициализированного сегмента данных исполняемого файла для служебных метаданных и сохранения кодированного представления служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла. Способ согласно четвертому аспекту завершается этапом сохранения самого исполняемого файла. Посредством сохранения в памяти кодированного представления служебных метаданных (вместо фактических служебных метаданных), становится возможным уменьшить занимаемый исполняемым файлом объем дискового пространства и, в то же время, объем служебных метаданных, загружаемых во время исполнения приложения, по сравнению с обычной AOT-компиляцией.
В соответствии с пятым аспектом предоставляется способ инициализации служебных метаданных приложения. Способ согласно пятому аспекту начинается с этапа доступа к исполняемому файлу приложения. Исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных. Инициализированный сегмент доступных только для чтения данных исполняемого файла содержит кодированное представление служебных метаданных для приложения, а неинициализированный сегмент данных исполняемого файла зарезервирован, по меньшей мере частично, для служебных метаданных. Затем способ согласно пятому аспекту переходит к этапу получения декодированного представления служебных метаданных посредством декодирования кодированного представления служебных метаданных. Способ согласно пятому аспекту завершается этапом инициализации служебных метаданных из декодированного представления служебных метаданных в зарезервированном неинициализированном сегменте данных исполняемого файла. Посредством использования сконфигурированного таким образом исполняемого файла становится возможным правильно и быстро инициализировать фактические служебные метаданные, необходимые для исполнения и функционирования приложения, тем самым значительно сокращая время запуска приложения.
В соответствии с шестым аспектом предоставляется компьютерный программный продукт. Компьютерный программный продукт согласно шестому аспекту хранит машиночитаемый носитель данных, содержащий компьютерный код. При исполнении по меньшей мере одним процессором компьютерный код предписывает по меньшей мере одному процессору выполнять способ согласно четвертому аспекту. Посредством использования такого компьютерного программного продукта становится возможным упростить реализацию способа по четвертому аспекту в любом вычислительном устройстве, таком, например, как устройство по первому аспекту.
В соответствии с седьмым аспектом предоставляется компьютерный программный продукт. Компьютерный программный продукт согласно седьмому аспекту хранит машиночитаемый носитель данных, содержащий компьютерный код. При исполнении по меньшей мере одним процессором компьютерный код предписывает по меньшей мере одному процессору выполнять способ согласно пятому аспекту. Посредством использования такого компьютерного программного продукта становится возможным упростить реализацию способа согласно пятому аспекту в любом вычислительном устройстве, таком, например, как устройство согласно второму аспекту.
Другие признаки и преимущества настоящего раскрытия станут очевидны после прочтения нижеследующего подробного описания и рассмотрения прилагаемых чертежей.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Настоящее раскрытие поясняется ниже со ссылкой на прилагаемые чертежи, на которых:
фиг.1 показывает блок-схему устройства для кодирования служебных метаданных приложения в соответствии с одним примерным вариантом осуществления;
фиг.2 показывает блок-схему способа кодирования служебных метаданных приложения в соответствии с одним примерным вариантом осуществления;
фиг.3 показывает блок-схему устройства для инициализации служебных метаданных приложения в соответствии с одним примерным вариантом осуществления;
фиг.4 показывает блок-схему способа инициализации служебных метаданных приложения в соответствии с одним примерным вариантом осуществления;
фиг.5 показывает блок-схему устройства для исполнения приложения в соответствии с одним примерным вариантом осуществления;
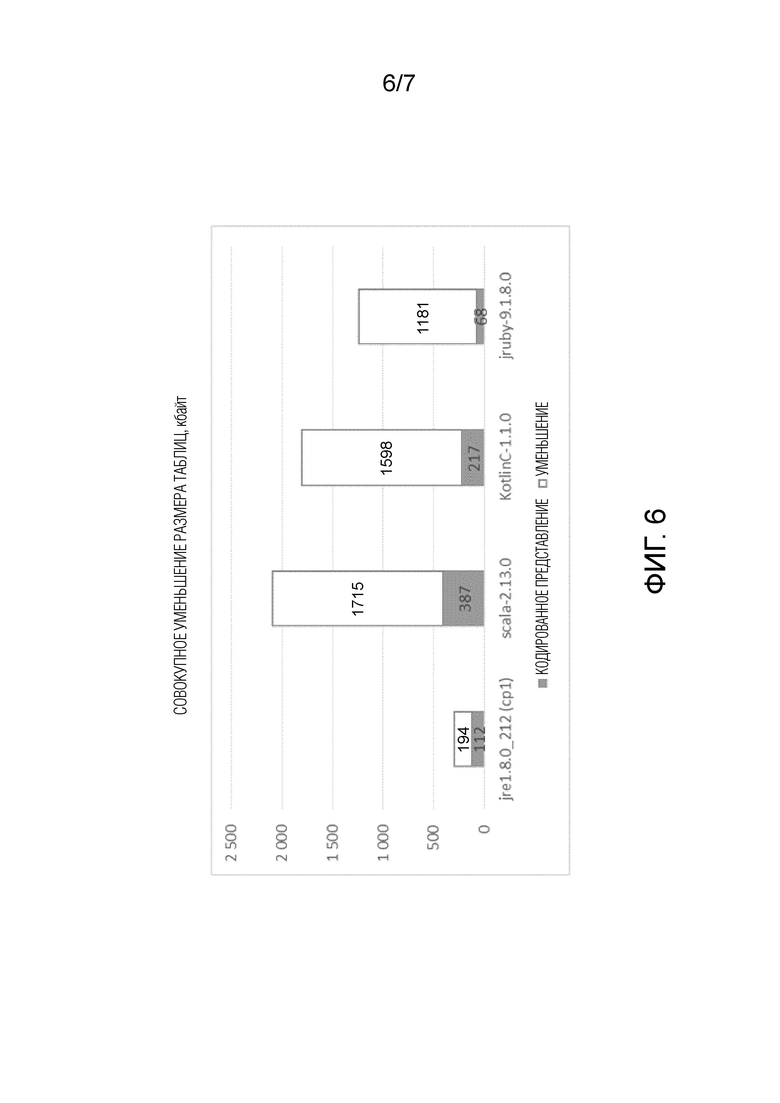
фиг.6 представляет гистограмму, показывающую совокупное уменьшение размера кодированного представления макета VMT в килобайтах для различных сред исполнения Java; и
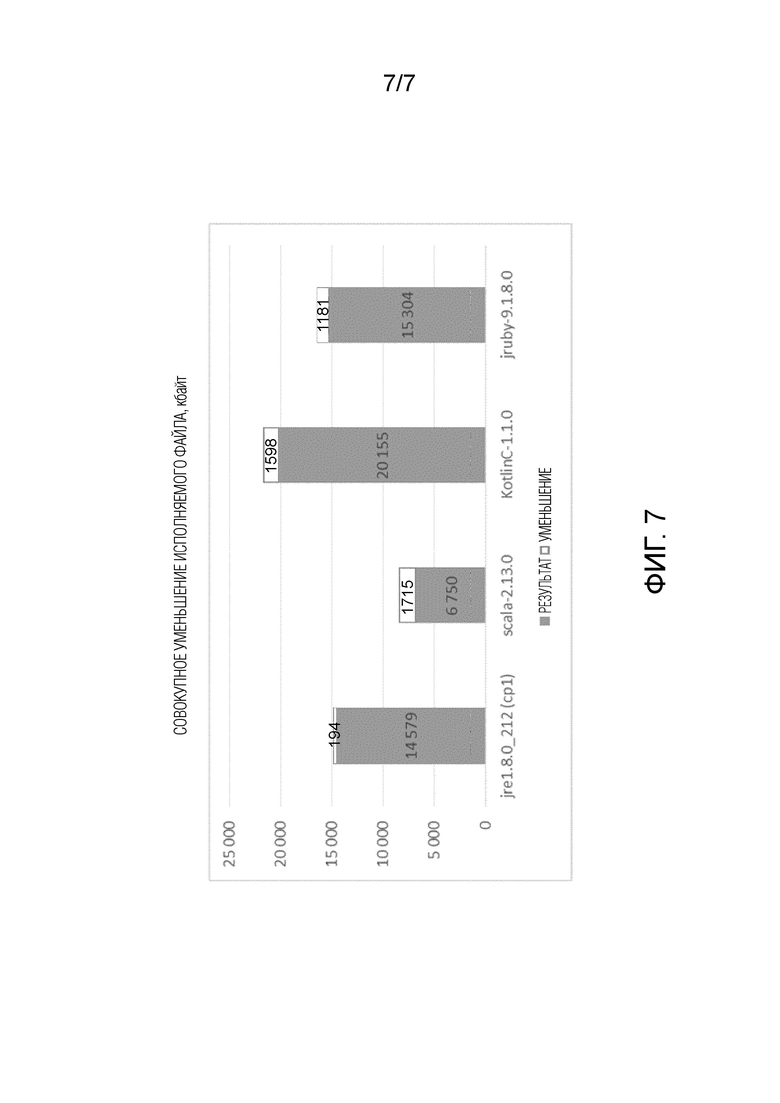
фиг.7 представляет гистограмму, показывающую совокупное уменьшение размера всего исполняемого файла в килобайтах для тех же сред исполнения Java.
ПОДРОБНОЕ ОПИСАНИЕ
Различные варианты осуществления настоящего раскрытия дополнительно описываются более подробно со ссылкой на прилагаемые чертежи. Однако настоящее раскрытие может быть реализовано во многих других формах, и его не следует рассматривать как ограниченное какой-либо определенной структурой или функцией, обсуждаемой в последующем описании. Напротив, эти варианты осуществления приведены для того, чтобы сделать описание настоящего изобретения подробным и полным.
В соответствии с подробным описанием специалистам в данной области техники будет очевидно, что объем настоящего раскрытия охватывает любой его вариант осуществления, который раскрыт в данном документе, независимо от того, реализуется ли этот вариант осуществления независимо или совместно с любым другим вариантом осуществления настоящего раскрытия. Например, устройства и способы, раскрытые в настоящем документе, могут быть реализованы на практике с использованием любого количества вариантов осуществления, представленных в настоящем документе. Кроме того, следует понимать, что любой вариант осуществления настоящего изобретения может быть реализован с использованием одного или нескольких из элементов, представленных в прилагаемой формуле изобретения.
Слово «примерный» используется здесь в значении «используемый в качестве иллюстрации». Если не указано иное, любой вариант осуществления, описанный здесь как «примерный», не следует рассматривать как предпочтительный или имеющий преимущество перед другими вариантами осуществления.
В соответствии с вариантами осуществления, раскрытыми в данном документе, пользовательское оборудование или сокращенно UE может относиться к мобильному устройству, мобильной станции, мобильному терминалу, абонентскому устройству, мобильному телефону, сотовому телефону, смартфону, беспроводному телефону, персональному цифровому ассистенту (PDA), устройству беспроводной связи, настольному компьютеру, портативному компьютеру, планшетному компьютеру, игровому устройству (например, игровой консоли, игровому контроллеру и т.д.), нетбуку, смартбуку, ультрабуку, медицинскому устройству или медицинскому оборудованию, биометрическому датчику, носимому устройству (например, смарт-часам, смарт-очкам, смарт-браслету и т.д.), развлекательному устройству (например, аудиоплееру, видеоплееру и т.д.), автомобильному компоненту или датчику, интеллектуальному измерителю/датчику, беспилотному транспортному средству (например, промышленному роботу, квадрокоптеру и т.д.), промышленному производственному оборудованию, устройству глобальной системы навигации и определения местоположения (GPS), устройству Интернета вещей (IoT), устройству связи межмашинного типа (MTC), группе устройств/датчиков массивного IoT (MIoT) или массивного MTC (mMTC) или любому другому подходящему устройству, сконфигурированному для поддержки беспроводной или проводной связи. В некоторых примерных вариантах осуществления UE может относиться к по меньшей мере двум совместно расположенным и взаимосвязанным UE, определенным таким образом.
Как используется в раскрытых здесь вариантах осуществления, прикладная программа, или приложение для краткости, может относиться к программе программного обеспечения, которая исполняется в UE. Некоторые примеры приложений включают в себя web-браузеры, программы электронной почты, текстовые процессоры, электронные таблицы, игры, утилиты и т.д. В общем, термин «приложение» может охватывать любую программу, которая выполняет определенную функцию на UE. Здесь также подразумевается, что приложение хранится в одном или нескольких исполняемых файлах и реализуется ими. Такой исполняемый файл может содержать инициализированный сегмент данных и неинициализированный сегмент данных. Неинициализированный сегмент данных включает в себя все глобальные переменные и статические переменные, которые инициализируются нулем или не имеют явной инициализации в исходном коде приложения. В свою очередь, инициализированный сегмент данных содержит неинициализированные статические и глобальные переменные в исходном коде приложения. Инициализированный сегмент данных далее делится на сегмент данных и сегмент данных, доступных только для чтения (RO-данных). Сегмент RO-данных обычно хранит все глобальные и статические переменные, которые доступны только для чтения, в то время как сегмент данных предназначен для чтения и записи, что означает, что хранящиеся в нем переменные могут быть изменены во время исполнения приложения.
В соответствии с раскрытыми здесь вариантами осуществления служебные метаданные могут относиться к данным и структурам времени исполнения (например, таблице виртуальных методов (VMT), таблице интерфейсных методов (IMT), информации о макете (layout) экземпляра класса для сборщика мусора (GC) и т.д.), которые необходимы для эффективного исполнения приложения. Служебные метаданные обычно генерируются компиляторами на основе исходного кода приложения и используются позже во время исполнения приложения. Служебные метаданные часто содержат прямые ссылки на другие структуры данных (которые должны вводиться в действие во время исполнения), которые могут обновляться во время загрузки (т.е. когда приложение впервые загружается операционной системой UE для исполнения) и, таким образом, не может быть легко сжат.
Есть как минимум два существующих подхода к генерации служебных метаданных: так называемые АОТ-компиляция и JIT-компиляция. АОТ-компиляция задействует заблаговременное создание всех служебных метаданных, необходимых для определенного приложения, а затем их сохранение в исполняемом файле приложения. Таким образом, АОТ-компиляция приводит к увеличению занимаемого исполняемым файлом объема на диске, а также замедляет запуск приложения из-за относительно большого объема загружаемых служебных метаданных. Вместо этого, JIT-компиляция задействует генерацию всех служебных метаданных точно в срок (т.е. при запуске приложения). JIT-компиляцию можно использовать вместе с AOT-компиляцией. Хотя JIT-компиляция устраняет накладные расходы на дисковое пространство, характерные для AOT-компиляции, тем не менее она снижает как время запуска, так и время исполнения приложения. Кроме того, JIT-компиляция, используемая совместно с АОТ-компиляцией, также негативно влияет на возможности оптимизации обычных AOT-компиляторов. В общем, каждый из этих подходов выполняет генерацию служебных метаданных как единый непрерывный процесс, создавая все необходимые служебные метаданные либо во время компиляции (AOT), либо во время исполнения (JIT).
Примерные варианты осуществления, раскрытые в данном документе, обеспечивают техническое решение, которое позволяет смягчить или даже устранить упомянутые выше недостатки, характерные для предшествующего уровня техники. В частности, раскрытое здесь техническое решение включает получение и сохранение кодированного представления служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла приложения и резервирование, по меньшей мере частично, неинициализированного сегмента данных исполняемого файла для самих служебных метаданных. Кодированное представление затем декодируется во время исполнения приложения для инициализации служебных метаданных в зарезервированном неинициализированном сегменте данных. Посредством реализации этого, становится возможным уменьшить объем дискового пространства (размер исполняемого файла) приложения, поскольку кодированное представление служебных метаданных хранится только в исполняемом файле, а не в фактических служебных метаданных. Кроме того, кодированное представление служебных метаданных быстро декодируется, что сокращает время запуска приложения.
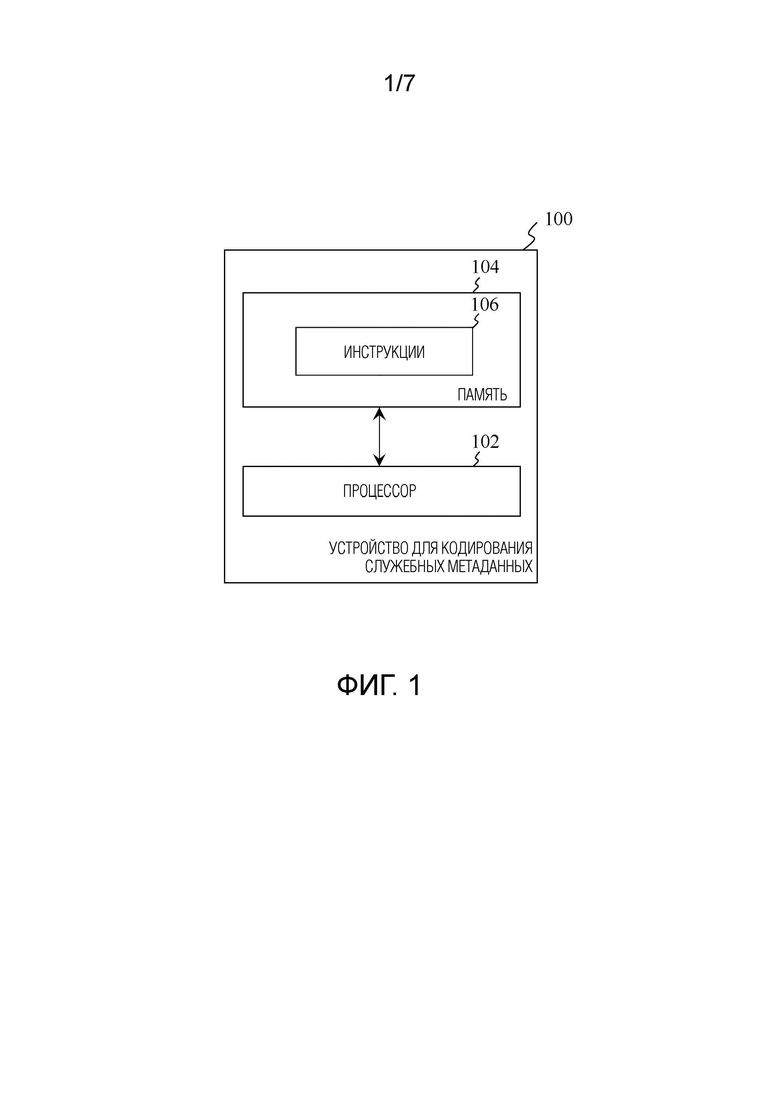
На фиг. 1 показана блок-схема устройства 100 для кодирования служебных метаданных приложения в соответствии с одним примерным вариантом осуществления. Устройство 100 может быть частью UE или реализовано как отдельное устройство (например, удаленный сервер), доступ к которому может осуществляться UE через беспроводное или проводное соединение. Как показано на фиг. 1, устройство 100 содержит процессор 102 и память 104. Память 104 хранит исполняемые процессором инструкции 106, которые при их исполнении процессором 102 предписывают процессору 102 сжимать служебные метаданные приложения в их кодированное представление, как будет более подробно описано ниже. Следует отметить, что количество, расположение и взаимосвязь конструктивных элементов, составляющих устройство 100, которые показаны на Фиг.1, не подразумеваются ограничивающими настоящее раскрытие, а просто используются для обеспечения общего представления о том, как конструктивные элементы могут быть реализованы в устройстве 100. Например, процессор 102 может быть заменен несколькими процессорами, а память 104 может быть заменена несколькими съемными и/или стационарными запоминающими устройствами, в зависимости от конкретных вариантов применения. Кроме того, при индивидуальной реализации устройство 100 может дополнительно содержать приемопередатчик, сконфигурированный для выполнения приема и передачи данных для различных целей. В некоторых вариантах осуществления такой приемопередатчик может быть реализован как два отдельных устройства, одно для операции приема, а другое для операции передачи. Независимо от реализации, приемопередатчик предназначен для выполнения различных операций, необходимых для осуществления приема и передачи данных, таких, например, как модуляция/демодуляция, кодирование/декодирование сигнала и т.д.
Процессор 102 может быть реализован в виде центрального процессора (CPU), процессора общего назначения, одноцелевого процессора, микроконтроллера, микропроцессора, специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA), процессора цифровых сигналов (DSP), устройства на основе сложной программируемой логики и т.д. Следует также отметить, что процессор 102 может быть реализован в виде любой комбинации одного или нескольких вышеперечисленных элементов. Например, процессор 102 может представлять собой комбинацию двух или более микропроцессоров.
Память 104 может быть реализована как классическая энергонезависимая или энергозависимая память, используемая в современных электронно-вычислительных машинах. Например, энергонезависимая память может включать в себя постоянное запоминающее устройство (ПЗУ, ROM), ферроэлектрическое оперативное запоминающее устройство (ОЗУ, RAM), программируемое ПЗУ (PROM), электрически стираемое PROM (EEPROM), твердотельный накопитель (SSD), флэш-память, магнитное дисковое хранилище (например, жесткие диски и магнитные ленты), оптическое дисковое хранилище (например, диски CD, DVD и Blu-ray) и т.д. Что касается энергозависимой памяти, ее примеры включают в себя динамическое ОЗУ (DRAM), синхронное DRAM (SDRAM), SDRAM с удвоенной скоростью передачи данных (DDR SDRAM), статическое ОЗУ (SRAM) и т.д.
Исполняемые процессором инструкции 106, хранящиеся в памяти 104, могут быть сконфигурированы как исполняемый компьютером код, который предписывает процессору 102 выполнять аспекты настоящего раскрытия. Машиноисполняемый код для выполнения операций или этапов для аспектов настоящего раскрытия может быть написан в любой комбинации одного или нескольких языков программирования, таких как Java, C++ и т.п. В некоторых примерах машиноисполняемый код может быть в форме языка высокого уровня или в предварительно скомпилированной форме и генерироваться интерпретатором (также предварительно сохраненным в памяти 104) на лету.
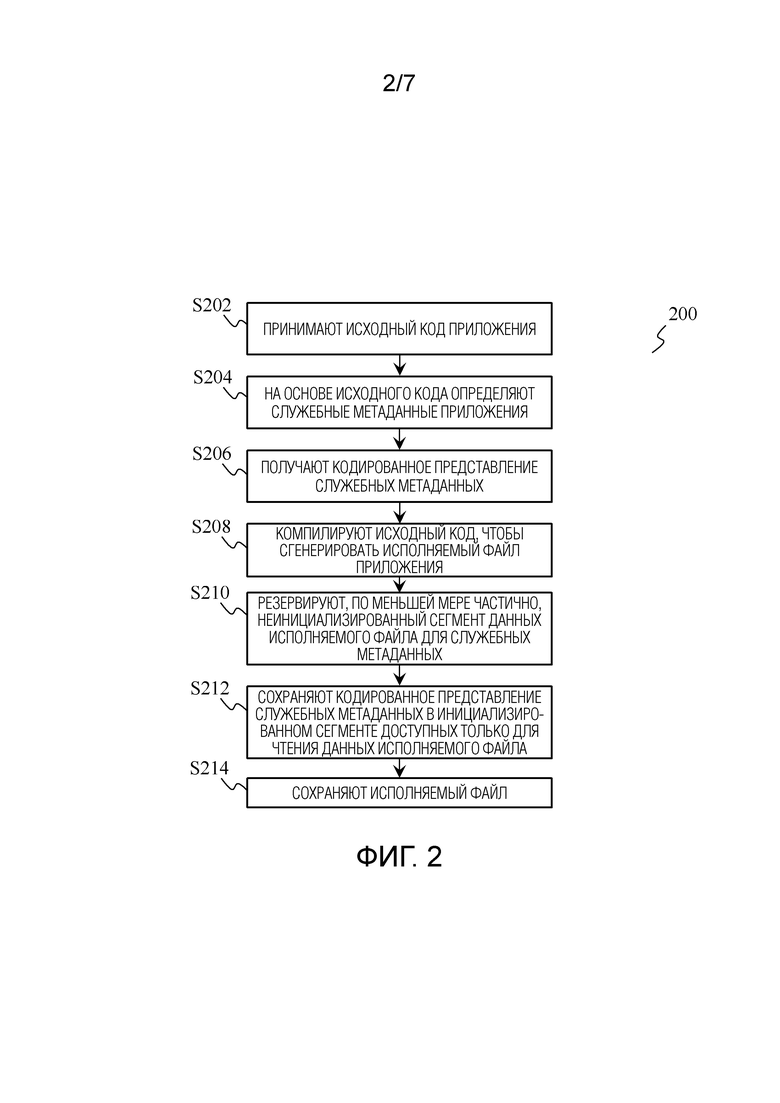
На фиг. 2 показана блок-схема способа 200 кодирования служебных метаданных приложения в соответствии с одним примерным вариантом осуществления. В целом, способ 200 описывает работу устройства 100. Способ 200 начинается с этапа S202, на котором процессор 102 принимает исходный код приложения. Исходный код может быть написан на любом объектно-ориентированном языке программирования, таком, например, как Java, C++, C#, Python, R, PHP, JavaScript, Ruby, Perl, Object Pascal и т.п. Исходный код может быть предоставлен процессору 102 извне (например, поставщиком приложений) или он может быть написан пользователем устройства 100 с использованием любого подходящего программного обеспечения для программирования. Затем способ 200 переходит к этапу S204, на котором процессор 102 использует исходный код для определения служебных метаданных приложения. После этого инициируется следующий этап S206, на котором процессор 102 получает кодированное представление служебных метаданных. Далее способ 200 переходит к этапу S208, на котором процессор 102 компилирует исходный код, чтобы сгенерировать исполняемый файл приложения. Этап S208 может быть выполнен с использованием обычного АОТ-компилятора; однако, это не следует рассматривать как какое-либо ограничение настоящего раскрытия, которое позволяет использовать любые другие подходящие компиляторы для той же цели. Исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения (RO-данных), и неинициализированный сегмент данных. Далее способ 200 переходит к этапу S210, на котором процессор 102 резервирует, по меньшей мере частично, неинициализированный сегмент данных исполняемого файла для служебных метаданных, и этапу S212, на котором процессор 102 сохраняет кодированное представление служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла. Способ 200 завершается этапом S214, на котором процессор 102 сохраняет сам исполняемый файл в памяти 104 устройства 100.
В одном примерном варианте осуществления неинициализированный сегмент данных исполняемого файла содержит сегмент неинициализированных данных (BSS). Это может обеспечить совместимость устройства согласно первому аспекту с общим стандартным файловым форматом для исполняемых файлов (например, форматом исполняемого и компонуемого файла, или ELF для краткости, который является общим файловым форматом для исполняемых файлов в системах Linux). В другом примерном варианте осуществления неинициализированный сегмент данных исполняемого файла может быть сконфигурирован как часть инициализированного сегмента данных; однако этот возможный вариант менее эффективен, чем предыдущий (т.е. с BSS-сегментом), потому что он приведет к пустой трате места в исполняемом файле и потенциальному замедлению запуска приложения.
В одном примерном варианте осуществления процессор 102 сконфигурирован для определения служебных метаданных приложения на этапе S204 способа 200 посредством синтаксического разбора исходного кода приложения. Помимо синтаксического разбора, процессор 102 также может определять служебные метаданные используя любые другие подходящие средства анализа исходного кода.
В еще одном примерном варианте осуществления память 104 дополнительно приспособлена для хранения базы данных, содержащей множество исходных кодов и служебных метаданных, соответствующих различным приложениям. В этом варианте осуществления процессор 102 сконфигурирован для определения служебных метаданных приложения на этапе S204 способа 200 посредством доступа к базе данных, нахождения исходного кода приложения в базе данных и считывания служебных метаданных приложения из базы данных. Сама база данных может быть структурирована в табличной форме. База данных может быть сконфигурирована таким образом, что каждая строка соответствует определенному исходному коду, а каждый столбец содержит компонент служебных метаданных, соответствующий этому исходному коду. В качестве альтернативы, база данных может быть сконфигурирована как набор таблиц, каждая из которых связана с определенным исходным кодом и содержит служебные метаданные для этого исходного кода. Процессор 102 может быть сконфигурирован опрашивать и вести базы данных с использованием любого подходящего языка программирования, например, языка структурированных запросов (SQL). Посредством использования такой базы данных можно ускорить получение служебных метаданных без необходимости каким-либо образом анализировать (например, выполнять синтаксический разбор) исходный код приложения, тем самым также снижая вычислительные затраты.
В одном примерном варианте осуществления процессор 102 конфигурируется на этапе S206 способа 200 получать кодированное представление служебных метаданных в соответствии с по меньшей мере одним из следующего: тип служебных метаданных, требуемый размер кодированного представления служебных метаданных и требуемое время декодирования кодированного представления служебных метаданных. Требуемый размер кодированного представления служебных метаданных может быть выбран на основе предварительно выделенного размера памяти, которая должна использоваться для хранения исполняемого файла. Требуемое время декодирования может быть выбрано на основе предварительно определенного времени запуска приложения. Посредством реализации этого, становится возможным получить компактное и быстро декодируемое кодированное представление служебных метаданных, тем самым более эффективно уменьшая объем дискового пространства, занимаемого исполняемым файлом, и время запуска приложения.
Кодированное представление служебных метаданных может быть получено процессором 102 с использованием алгоритма сжатия данных общего назначения. Примеры алгоритма сжатия данных общего назначения включают в себя, но не в ограничительном смысле, кодирование переменной длины, кодирование Little Endian Base 128 (LEB128), кодирование Хаффмана, кодирование на основе цепочного алгоритма Лемпеля-Зива-Маркова (LZMA), кодирование с переменной длиной кодовой последовательности и т.д. Алгоритм сжатия данных общего назначения позволяет более эффективно сжимать служебные метаданные в виде кодированного представления.
Фиг. 3 показана блок-схема устройства 300 для инициализации служебных метаданных приложения в соответствии с одним примерным вариантом осуществления. Устройство 300 может быть частью того же UE, что и устройство 100, или оно может быть реализовано как отдельное устройство, сконфигурированное для связи с устройством 100 посредством беспроводного или проводного соединения. Как показано на фиг. 3, устройство 300 содержит процессор 302 и память 304. Память 304 хранит исполняемые процессором инструкции 306, которые при их исполнении процессором 302 вызывают инициализацию процессором 302 служебных метаданных приложения, как будет более подробно описано ниже. Следует отметить, что количество, расположение и взаимосвязь конструктивных элементов, составляющих устройство 300, которые показаны на фиг. 3, не подразумеваются ограничивающими настоящее раскрытие, а просто используются для обеспечения общего представления о том, как конструктивные элементы могут быть реализованы в устройстве 300. Например, процессор 302 может быть заменен несколькими процессорами, а память 304 может быть заменена несколькими съемными и/или стационарными запоминающими устройствами, в зависимости от конкретных вариантов применения. Кроме того, при индивидуальной реализации устройство 300 может дополнительно содержать приемопередатчик, сконфигурированный для выполнения приема и передачи данных для различных целей. В некоторых вариантах осуществления такой приемопередатчик может быть реализован как два отдельных устройства, одно для операции приема, а другое для операции передачи. Независимо от реализации, приемопередатчик предназначен для выполнения различных операций, необходимых для выполнения приема и передачи данных, таких, например, как модуляция/демодуляция, кодирование/декодирование сигнала и т.д.
В общем, процессор 302, память 304 и исполняемые инструкции 306 могут быть реализованы таким же или подобным образом, как процессор 102, память 104 и исполняемые инструкции 106, соответственно, в устройстве 100.
На фиг. 4 показана блок-схема способа 400 инициализации служебных метаданных приложения в соответствии с одним примерным вариантом осуществления. В целом, способ 400 описывает работу устройства 300. Способ 400 начинается с этапа S402, на котором процессор 302 осуществляет доступ к исполняемому файлу приложения, который был сохранен на этапе S214 способа 200 в памяти 104 устройства 100. Если устройство 100 и устройство 300 реализованы в одном и том же UE, указанный доступ к исполняемому файлу на этапе S402 способа 400 включает в себя загрузку или считывание исполняемого файла из памяти 104 устройства 100. В то же время, если устройство 300 реализовано удаленно от устройства 100, процессор 302 может осуществлять доступ к исполняемому файлу путем связи (через проводное или беспроводное соединение) с устройством 100 для скачивания исполняемого файла из памяти 104. Как отмечалось выше, исполняемый файл содержит кодированное представление служебных метаданных в своем инициализированном сегменте данных, доступных только для чтения, а его неинициализированный сегмент данных (например, BSS-сегмент) зарезервирован, по меньшей мере частично, для служебных метаданных. Затем способ 400 переходит к этапу S404, на котором процессор 302 получает декодированное представление служебных метаданных путем декодирования кодированного представления служебных метаданных. Этап S404 может выполняться процессором 302 с использованием алгоритма декомпрессии данных общего назначения. Примеры алгоритма декомпрессии данных общего назначения включают в себя, но не в ограничительном смысле, декодирование переменной длины, декодирование LEB128, декодирование Хаффмана, декодирование LZMA, декодирование с переменной длиной кодовой последовательности и т.д. Способ 400 завершается этапом S406, на котором процессор 302 инициализирует служебные метаданные из декодированного представления служебных метаданных в зарезервированном неинициализированном сегменте данных исполняемого файла.
На фиг. 5 показана блок-схема устройства 500 для исполнения приложения в соответствии с одним примерным вариантом осуществления. Устройство 500 может быть реализовано как любое UE, описанное выше. Как показано на Фиг.5, устройство 500 состоит из устройства 100 и устройства 300. В этой конфигурации устройство 500 может выполнять как функции кодирования, так и инициализации служебных метаданных, обеспечивая при этом те же преимущества, что и рассмотренные выше со ссылкой на устройства 100 и 300.
Ниже приведен один пример того, как вышеописанные устройства 100 и 300 могут работать совместно или как может работать устройство 500. В частности, предполагается, что служебные метаданные приложения представлены самой большой структурой служебных метаданных в объектно-ориентированном программировании - таблицей виртуальных методов (VMT). VMT как таковая представляет собой массив ссылок на код методов, связанных с каждым классом и непосредственно доступных из каждого объекта данного класса. VMT имеет иерархическую структуру: подкласс наследует макет VMT суперкласса, добавляя новые записи и/или перезаписывая записи переопределяемых методов новым адресом реализации. Во время компиляции процессор 102 присваивает, используя подходящий компилятор (например, AOT-компилятор), каждому методу уникальный индекс в объявлении VMT классов, называемый виртуальным номером или vnum. Затем компилятор использует этот номер для эффективного создания виртуального вызова в качестве опосредованного вызова с помощью записи VMT с заданным виртуальным номером. Следует также отметить, что настоящее раскрытие не ограничивается только VMT, и способы 200 и 300 могут в равной степени использоваться в отношении других структур служебных метаданных, таких, например, как таблицы интерфейсных методов (IMT) и т.д.
Теперь давайте применим способ 200 для генерации VMT для примера иерархии классов на произвольном объектно-ориентированном языке (например, Java, C# и т.д.), который выглядит следующим образом:

Приведенная выше иерархия состоит из двух классов B и C, где класс C расширяет класс B, переопределяет метод «a», определенный в B, своей собственной реализацией и определяет метод «e» в дополнение к методам «b», «c» и «d», уже определенным в B. Результирующая структура VMT для этой иерархии во время исполнения приложения должна выглядеть следующим образом:

В этом случае способ 200 может быть реализован следующим образом. Сначала на этапах S202-S204 процессор 102 принимает исходный код классов, определенных в приложении, и использует АОТ-компилятор для синтаксического разбора исходного кода, чтобы определить служебные метаданные для классов. Служебные метаданные представлены в виде макета VMT для классов. Этот макет может быть таким же простым, как массив внутренних представлений методов, отражающих адреса в результирующей структуре VMT, лишь бы сохранялось иерархическое свойство VMT. Затем макет VMT кодируется процессором 102 как компактное кодированное представление на этапе S206. Чтобы полностью реконструировать вышеописанную VMT во время исполнения приложения, достаточно иметь только различие в макете VMT между классом C и его суперклассом B. Это различие может быть закодировано как последовательность инструкций с одним аргументом, что схематично показано в Таблице 1 ниже, где «methodID» - уникальный идентификатор реализации метода (он может быть глобальным, индивидуальным для класса, индивидуальным для пакета и т.д.).
Таблица 1. Инструкции кодирования VMT
Каждая инструкция в Таблице 1 представлена как целое число, где младший значащий бит используется, чтобы различать эти заданные два вида инструкций (т.е. 'Put' ('Поместить') и 'Skip' ('Пропустить')), а остальные биты представляют аргумент инструкции. Эти целые числа дополнительно кодируются с использованием кодирования переменной длины (например, LEB128). Забегая вперед, следует отметить, что результирующий закодированный большой двоичный объект (blob) (то есть, кодированное представление служебных метаданных) сохраняется в инициализированном сегменте доступных только для чтения данных исполняемого файла на этапе S212.
Описанный выше возможный процесс кодирования макета VMT для класса C может быть представлен в виде следующего псевдокода (аналогичный псевдокод может быть написан и для суперкласса B):
1. Инициализируют переменную 'skipAmount' значением 0;
2. Для каждой записи в макете VMT на языке C:
a. Если запись унаследована от макета суперкласса (имеет ту же реализацию метода), то переменную 'skipAmount' увеличивают на 1;
b. В противном случае, если переменная 'skipAmount' больше 0, то выдают инструкцию 'Skip(skipAmount)' и выдают инструкцию 'Put(id(m))', где 'id(m)' - это 'methodID' метода в записи;
3. Записывают упомянутый ряд выданных инструкций в метаданные.
Таким образом, результирующее кодированное представление макета VMT для суперкласса B из приведенного выше примера иерархии классов содержит четыре инструкции 'Put' с 'methodID' каждой записи в макете VMT для суперкласса B. В свою очередь, результирующее кодированное представление макета VMT для класса C содержит следующие инструкции:

После того, как получены кодированные представления макетов VMT для всех классов, процессор 102 компилирует исходный код, чтобы сгенерировать исполняемый файл на этапе S208 и резервирует, по меньшей мере частично, неинициализированный сегмент данных исполняемого файла для служебных метаданных, т.е. самой VMT, на этапе S210. Другими словами, процессор 102 выделяет неинициализированное пространство для VMT в исполняемом файле, и его адрес используется непосредственно в исходном коде для инициализации вновь созданного объекта класса этого VMT. Это пространство может быть выделено в сегменте BSS, который представлен в исполняемом файле как одно целое число - общий размер сегмента в байтах. Таким образом, данное выделение представляет собой просто инкрементное приращение размера сегмента BSS на размер VMT. В приведенном выше примере иерархии классов размеры VMT для классов B и C составляют 4 и 5 адресов, соответственно (при 32-разрядной архитектуре размер адреса составляет 4 байта, поэтому размеры VMT будут равны 16 и 20 байтам).
Когда кодированное представление макетов VMT для всех классов получено и сохранено в инициализированном сегменте доступных только для чтения данных исполняемого файла, а неинициализированный сегмент данных исполняемого файла зарезервирован, по меньшей мере частично, для самих VMT, процессор 102 сохраняет исполняемый файл в памяти 104 на последнем этапе S214 способа 200.
При запуске приложения способ 400 может выполняться следующим образом. На этапе S402 процессор 302 осуществляет доступ к исполняемому файлу, хранящемуся в памяти 104, и считывает или скачивает кодированное представление макетов VMT для каждого класса. Затем это кодированное представление декодируется процессором 302 на этапе S404 и одновременно используется для инициализации структур VMT на этапе S406. Всю инициализацию структур VMT можно представить в виде следующего псевдокода:
1. Выполняют этап инициализации времени запуска для VMT суперкласса B;
2. Копируют уже инициализированную VMT суперкласса B в VMT этого класса, расположенную в BSS-сегменте;
3. Инициализируют переменную 'slot' значением 0;
4. Для каждой декодированной инструкции:
a. Если инструкцией является 'Put(id)', помещают адрес метода с 'id' в запись 'slot' VMT;
b. В противном случае используют инструкцию 'Skip(skipAmount)', поэтому выполняют приращение 'slot' на 'skipAmount'.
Для демонстрации эффективности способов 200 и 400, выполняемых устройствами 100 и 300 соответственно, т.е. значительного сокращения как дискового пространства, занимаемого исполняемым файлом, так и времени запуска приложения, они были протестированы на различных приложениях и библиотеках, которые написаны на нескольких языках на основе виртуальной машины Java (JVM) и в конечном итоге исполняются на JVM (или среде исполнения Java (JRE)) с поддержкой AOT-компиляции. В частности, во время тестов использовались следующие приложения и библиотеки:
jre1.8.0_212(cp1) - стандартная библиотека и среда исполнения для Java SE 8 с компактным профилем 1 (написана на Java);
scala-2.13.0 - стандартная библиотека для языка программирования Scala (написана на Scala);
KotlinC-1.1.0 - компилятор языка программирования Kotlin (написан на Kotlin); и
jruby-9.1.8.0 - реализация языка программирования Ruby с использованием JVM (написана на Ruby и Java).
Все эти приложения и библиотеки были заблаговременно скомпилированы и оценены с точки зрения совокупных размеров кодированного представления макетов VMT и IMT и исполняемого файла в килобайтах.
В частности, фиг. 6 представляет гистограмму, показывающую общее уменьшение размера кодированного представления макетов VMT и IMT. Окончательный размер кодированного представления макетов VMT и IMT (т.е. служебных метаданных) показан как сплошная часть каждой полосы, а уменьшение размера, обеспечиваемое способом 200, показано как пустая часть полосы. Как видно, совокупное уменьшение размера кодированного представления для всех случаев очень существенное (более 50% по всем тестам и до 97% по некоторым).
Фиг.7 представляет гистограмму, показывающую совокупное уменьшение размера исполняемого файла. Точно так же, окончательный размер исполняемого файла показан как сплошная часть каждой полосы, а уменьшение размера, обеспечиваемое способом 200, показано как пустая часть полосы. Уменьшение размера исполняемого файла существенно в трех случаях (т.е. для scala-2.13.0, KotlinC-1.1.0 и jruby-9.1.8.0), но этого достаточно, чтобы считать его чрезвычайно жизнеспособным, особенно для встроенных устройств или устройств с ограниченными ресурсами.
Следует отметить, что каждый этап или операция способов 200 и 300 либо любые комбинации этапов или операций могут быть реализованы с помощью различных средств, таких как аппаратные средства, программно-аппаратные средства и/или программное обеспечение. Например, один или более этапов или операций, описанных выше, могут быть воплощены исполняемыми процессором инструкциями, структурами данных, программными модулями и другими подходящими представлениями данных. Кроме того, исполняемые инструкции, которые воплощают этапы или операции, описанные выше, могут храниться на соответствующем носителе данных и исполняться процессорами 102 и 302. Этот носитель данных может быть реализован как любой машиночитаемый носитель данных, сконфигурированный для чтения упомянутым по меньшей мере одним процессором для исполнения исполняемых процессором команд. Такие машиночитаемые носители информации могут включать в себя как энергозависимые, так и энергонезависимые носители, как съемные, так и несъемные носители. В качестве примера, а не ограничения, машиночитаемые носители содержат носители, реализованные любым способом или технологией, подходящей для хранения информации. Более подробно, практические примеры машиночитаемых носителей включают в себя, но не в ограничительном смысле, носители для доставки информации, ОЗУ, ПЗУ, EEPROM, флэш-память или другие технологии памяти, CD-ROM, цифровые универсальные диски (DVD), голографические носители или другие накопители на оптических дисках, магнитную ленту, магнитные кассеты, накопители на магнитных дисках и другие магнитные запоминающие устройства.
Хотя здесь описаны иллюстративные варианты осуществления настоящего раскрытия, следует отметить, что в варианты осуществления настоящего раскрытия могут быть внесены любые различные изменения и модификации без отклонения от объема правовой охраны, который определяется прилагаемой формулой изобретения. В прилагаемой формуле изобретения слово «содержащий» не исключает других элементов или операций, а упоминание в единственном числе не исключает множественного числа. Тот факт, что определенные меры указаны во взаимно различных зависимых пунктах формулы изобретения, не означает, что комбинация этих мер не может быть использована с пользой.



Изобретение относится к способам обработки данных и в частности к методикам кодирования и инициализации служебных метаданных, необходимых для эффективного исполнения приложений, написанных на объектно-ориентированных языках программирования. Технический результат заключается в уменьшении объема дискового пространства приложения за счет хранения кодированного представления служебных метаданных только в исполняемом файле. Технический результат достигается за счет выполнения этапов способа: получения и сохранения кодированного представления служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла приложения и резервирования, по меньшей мере частично, неинициализированного сегмента данных исполняемого файла для самих служебных метаданных. 7 н. и 12 з.п. ф-лы, 7 ил., 1 табл.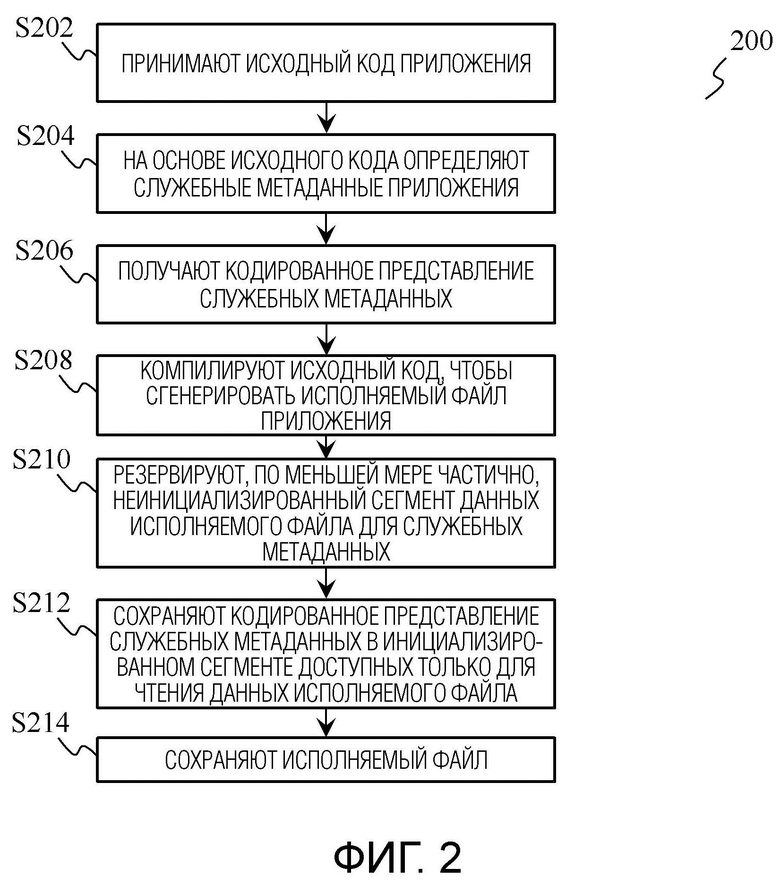
1. Устройство для кодирования служебных метаданных приложения, содержащее:
по меньшей мере один процессор; и
память, соединенную по меньшей мере с одним процессором и приспособленную для хранения исполняемых процессором инструкций,
при этом по меньшей мере один процессор выполнен с возможностью, при исполнении исполняемых процессором инструкций:
- принимать исходный код приложения;
- на основе исходного кода определять служебные метаданные приложения;
- получать кодированное представление служебных метаданных посредством использования алгоритма сжатия данных общего назначения;
- компилировать исходный код для генерирования исполняемого файла приложения, причем исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных;
- резервировать, по меньшей мере частично, неинициализированный сегмент данных исполняемого файла для служебных метаданных;
- сохранять кодированное представление служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла; и
- сохранять исполняемый файл в памяти.
2. Устройство по п.1, при этом неинициализированный сегмент данных исполняемого файла содержит сегмент неинициализированных данных (BSS).
3. Устройство по п.1 или 2, в котором по меньшей мере один процессор выполнен с возможностью определять служебные метаданные приложения посредством синтаксического разбора исходного кода приложения.
4. Устройство по п.1 или 2, в котором память дополнительно приспособлена для хранения базы данных, содержащей множество исходных кодов и служебных метаданных, соответствующих различным приложениям, при этом по меньшей мере один процессор выполнен с возможностью определять служебные метаданные приложения посредством доступа к базе данных, нахождения исходного кода приложения в базе данных и считывания служебных метаданных приложения из базы данных.
5. Устройство по любому одному из пп.1-4, в котором по меньшей мере один процессор выполнен с возможностью получать кодированное представление служебных метаданных в соответствии по меньшей мере с одним из:
типа служебных метаданных;
требуемого размера кодированного представления служебных метаданных; и
требуемого времени декодирования кодированного представления служебных метаданных.
6. Устройство по п.5, в котором по меньшей мере один процессор дополнительно выполнен с возможностью выбирать требуемый размер кодированного представления служебных метаданных на основе предварительно выделенного размера памяти, которая должна использоваться для хранения исполняемого файла.
7. Устройство по п.5 или 6, в котором по меньшей мере один процессор дополнительно выполнен с возможностью выбирать требуемое время декодирования на основе предварительно определенного времени запуска приложения.
8. Устройство по любому одному из пп.1-7, при этом алгоритм сжатия данных общего назначения содержит по меньшей мере одно из кодирования переменной длины, кодирования Little Endian Base 128 (LEB128), кодирования Хаффмана, кодирования на основе цепочного алгоритма Лемпеля-Зива-Маркова (LZMA) и кодирования с переменной длиной кодовой последовательности.
9. Устройство по любому одному из пп.1-8, в котором по меньшей мере один процессор выполнен с возможностью компиляции исходного кода с использованием опережающего компилятора.
10. Устройство по любому одному из пп.1-9, при этом служебные метаданные содержат по меньшей мере одно из таблицы виртуальных методов, таблицы интерфейсных методов и информации о макете экземпляра класса для сборщика мусора.
11. Устройство для инициализации служебных метаданных приложения, содержащее:
по меньшей мере один процессор; и
память, соединенную по меньшей мере с одним процессором и приспособленную для хранения исполняемых процессором инструкций,
при этом по меньшей мере один процессор выполнен с возможностью, при исполнении исполняемых процессором инструкций:
- осуществлять доступ к исполняемому файлу приложения, при этом исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных, причем инициализированный сегмент доступных только для чтения данных исполняемого файла содержит кодированное представление служебных метаданных для приложения, и неинициализированный сегмент данных исполняемого файла зарезервирован, по меньшей мере частично, для служебных метаданных;
- получать декодированное представление служебных метаданных посредством декодирования кодированного представления служебных метаданных с использованием алгоритма декомпрессии данных общего назначения;
- инициализировать служебные метаданные из декодированного представления служебных метаданных в зарезервированном неинициализированном сегменте данных исполняемого файла.
12. Устройство по п.11, при этом неинициализированный сегмент данных исполняемого файла содержит сегмент неинициализированных данных (BSS).
13. Устройство по п.11 или 12, при этом алгоритм декомпрессии данных общего назначения содержит по меньшей мере одно из кодирования переменной длины, кодирования Little Endian Base 128 (LEB128), кодирования Хаффмана, кодирования на основе цепочного алгоритма Лемпеля-Зива-Маркова (LZMA) и кодирования с переменной длиной кодовой последовательности.
14. Устройство по любому одному из пп.11-13, при этом служебные метаданные содержат по меньшей мере одно из таблицы виртуальных методов, таблицы интерфейсных методов и информации о макете экземпляра класса для сборщика мусора.
15. Устройство для исполнения приложения, содержащее:
устройство по любому одному из пп.1-10; и
устройство по любому одному из пп.11-13.
16. Способ кодирования служебных метаданных приложения,
содержащий этапы, на которых:
принимают исходный код приложения;
на основе исходного кода определяют служебные метаданные приложения;
получают кодированное представление служебных метаданных посредством использования алгоритма сжатия данных общего назначения;
компилируют исходный код для генерирования исполняемого файла приложения, причем исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных;
резервируют, по меньшей мере частично, неинициализированный сегмент данных исполняемого файла для служебных метаданных;
сохраняют кодированное представление служебных метаданных в инициализированном сегменте доступных только для чтения данных исполняемого файла; и
сохраняют исполняемый файл.
17. Способ инициализации служебных метаданных приложения, содержащий этапы, на которых:
осуществляют доступ к исполняемому файлу приложения, причем исполняемый файл содержит инициализированный сегмент данных, доступных только для чтения, и неинициализированный сегмент данных, причем инициализированный сегмент доступных только для чтения данных исполняемого файла содержит кодированное представление служебных метаданных для приложения, и неинициализированный сегмент данных исполняемого файла зарезервирован, по меньшей мере частично, для служебных метаданных;
получают декодированное представление служебных метаданных посредством декодирования кодированного представления служебных метаданных с использованием алгоритма декомпрессии данных общего назначения;
инициализируют служебные метаданные из декодированного представления служебных метаданных в зарезервированном неинициализированном сегменте данных исполняемого файла.
18. Машиночитаемый носитель данных, содержащий компьютерный код, который при его исполнении по меньшей мере одним процессором предписывает по меньшей мере одному процессору выполнять способ по п.16.
19. Машиночитаемый носитель данных, содержащий компьютерный код, который при его исполнении по меньшей мере одним процессором предписывает по меньшей мере одному процессору выполнять способ по п.17.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| CN 109885290 A, 14.06.2019 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |

