Изобретение относится к вычислительной технике и может быть использовано в системе управления базами данных.
Известно устройство, реализующее иерархический принцип хранения и обработки данных, содержащее блок формирования, блок движения по дереву данных, блок долговременной памяти, блок оперативной памяти, блок переключения на другое дерево данных, блок считывания, блок обновления данных, блок управления, арифметико-логический блок, блок интерпретатора команд управления [1]
Недостатком этого устройства является плохая переносимость данных ввиду абсолютной адресации, существенная зависимость прикладных программ от представления и описания данных, сложность поиска при большой глубине иерархии.
Наиболее близким техническим решением к предлагаемому является устройство, реализующее реляционный принцип хранения и обработки данных, содержащее блок формирования, блок сохранения, блок загрузки, блок добавления записи, блок удаления записи, блок движения по дереву данных, блок долговременной памяти, блок оперативной памяти, блок переключения, блок считывания данных, блок обновления данных, блок индексации, арифметико-логическое устройство, блок управления. Информация представляется в виде нескольких таблиц, хранящихся в отдельных файлах, что обеспечивает хорошую переносимость данных, независимость представления и описания данных от прикладных программ, увеличение скорости поиска и обработки данных [2]
Недостаток этого устройства состоит в необходимости соблюдения ссылочной целостности, на что тратится много времени, а также сложность поиска по нескольким связанным таблицам.
Целью изобретения является сокращение времени поддержки ссылочной целостности и ускорение поиска по сложным запросам, содержащим несколько связанных таблиц.
Поставленная цель достигается тем, что в устройстве для хранения и поиска информации в памяти, содержащем блок оперативной памяти, блок долговременной памяти, блок формирования структуры с блоком формирования первого уровня, блок загрузки данных, блок сохранения данных, блок добавления записи с блоком добавления первого уровня, блок удаления записи с удаления первого уровня, блок движения по дереву данных с блоком движения первого уровня, блок считывания данных, блок обновления данных, блок переключения на другое дерево данных, арифметико-логическое устройство, блок интерпретатора команд, блок индексации и блок управления, выход которого через интерпретатор команд соединен с входом арифметико-логического устройства, первый выход которого соединен с первым входом блока загрузки данных, входом блока сохранения данных, входом блока формирования структуры, входом блока добавления записи и входом блока переключения на другое дерево данных, первый выход блока сохранения данных и выходы блока загрузки данных, блока формирования структуры, блока добавления записи и блока переключения на другое дерево данных объединены и подключены к первому входу оперативной памяти, второй выход блока сохранения данных соединен с входом блока долговременной памяти, выход которого соединен с вторым входом блока загрузки данных, а вход-выход - с выходом-входом блока оперативной памяти, второй выход арифметико-логического устройства соединен с входом блока удаления записи, входом блока движения по дереву данных, входом блока считывания данных, входом блока обновления данных и входом блока индексации, выходы которых соединены с вторым входом блока оперативной памяти, в блок формирования структуры введены блок формирования второго уровня и первый блок анализа параметров, вход которого является входом блока формирования структуры, а выходы подключены соответственно к входу блока формирования первого уровня и входу блока формирования второго уровня, выходы которых объединены и являются выходом блока формирования структуры, в блок добавления записи введены блок добавления второго уровня и второй блок анализа параметров, вход которого является входом блока добавления записи, а выходы подключены соответственно к входу блока добавления первого уровня и входу блока добавления второго уровня, выходы которых объединены и являются выходом блока добавления записи, в блок удаления записи введены блок удаления второго уровня и третий блок анализа параметров, вход которого является входом блока удаления записи, а выходы подключены соответственно к входу блока удаления первого уровня и входу блока удаления второго уровня, выходы которых объединены и являются выходом блока удаления записи, в блок движения по дереву данных введены блок движения второго уровня и четвертый блок анализа параметров, вход которого является входом блока движения по дереву данных, а выходы подключены соответственно к входу блока движения первого уровня и входу блока движения второго уровня, выходы которых объединены и являются выходом блока движения по дереву данных.
Существенными отличительными признаками в указанной выше совокупности являются наличие блока формирования второго уровня, блока добавления второго уровня, блока удаления второго уровня, блока движения второго уровня и первого-четвертого блоков анализа параметров, что обеспечивает появление у заявляемого устройства новых свойств, сформулированных в цели изобретения.
На фиг. 1 показана функциональная схема заявляемого устройства; на фиг. 2 структура записи; на фиг. 3 структура файла базы данных; на фиг. 4 - структура записи в файле на магнитном диске; на фиг. 5 структура подчиненного дерева; на фиг. 6 структура шаблона записи; на фиг. 7 - структура дерева, создаваемого блоком формирования структуры; на фиг. 8 - структура индексных файлов.
Устройство содержит блок 1 формирования структуры (CREATE), блок 2 загрузки данных (USE), блок 3 сохранения данных (CLOSE), блок 4 добавления записи (APPEND), блок 5 удаления записи (DELETE), блок 6 переключения на другое дерево данных (SELECT), блок 7 движения по дереву данных (SKIP), блок 8 считывания данных (GET), блок 9 обновления данных (REPLACE), блок 10 долговременной памяти, блок 11 оперативной памяти (ОЗУ), арифметико-логическое устройство 12 (АЛУ), блок 13 интерпретатора команд, блок управления 14, блок 15 индексации. Выход блока управления соединен с входом блока интерпретатора команд, выход которого соединен с входом АЛУ, первый выход которого соединен с входами блока загрузки данных, блока сохранения данных, блока формирования структуры, блока добавления записи и блока переключения на другое дерево данных, выходы которых соединены с первым входом ОЗУ. Второй выход блока сохранения данных соединен с первым входом блока долговременной памяти, первый выход которого соединен с вторым входом блока загрузки данных, а вход-выход соединен с выходом-входом ОЗУ. Второй выход АЛУ соединен с входами блока удаления записи, блока движения по дереву данных, блока считывания данных, блока обновления данных и блока индексации, выходы которых соединены с третьим входом ОЗУ.
Блок 1 формирования структуры содержит блок 16 формирования первого уровня и блок 17 формирования второго уровня, входами которых являются соответственно первый и второй выходы первого блока анализа параметров 18, а выходы являются выходом блока 1 формирования структуры, входом которого является вход первого блока анализа параметров 18.
Блок 4 добавления записи содержит блок 19 добавления первого уровня и блок 20 добавления второго уровня, входами которых являются соответственно первый и второй выходы второго блока анализа параметров 21, а выходы являются выходом блока 4 добавления записи, входом которого является вход второго блока анализа параметров 21.
Блок 5 удаления записи содержит блок 22 удаления первого уровня и блок 23 удаления второго уровня, входами которых являются соответственно первый и второй выходы третьего блока анализа параметров 24, а выходы являются выходом блока 5 удаления записи, входом которого является вход третьего блока анализа параметров 24.
Блок 7 движения по дереву данных содержит блок 25 движения первого уровня и блок 26 движения второго уровня, входами которых являются соответственно первый и второй выходы четвертого блока анализа параметров 27, а выходы являются выходом блока 7 движения по дереву данных, входом которого является вход четвертого блока анализа параметров 27.
Устройство предназначено для ввода, хранения данных в виде различных древовидных структур, считывания и обновления данных, поиска по запросам. Устройство работает с данными, организованными в бинарные деревья определенной структуры.
Описание структуры данных.
1) Слово минимальная поименованная единица данных.
Слово это последовательность символов кода ASCII, имеющая одну из следующих интерпретаций:
символьная строка;
число (целое или десятичное);
дата;
логическое значение (TRUE или FALSE);
Интерпретация определяется либо по конкретному содержанию, либо задается при создании структуры данных.
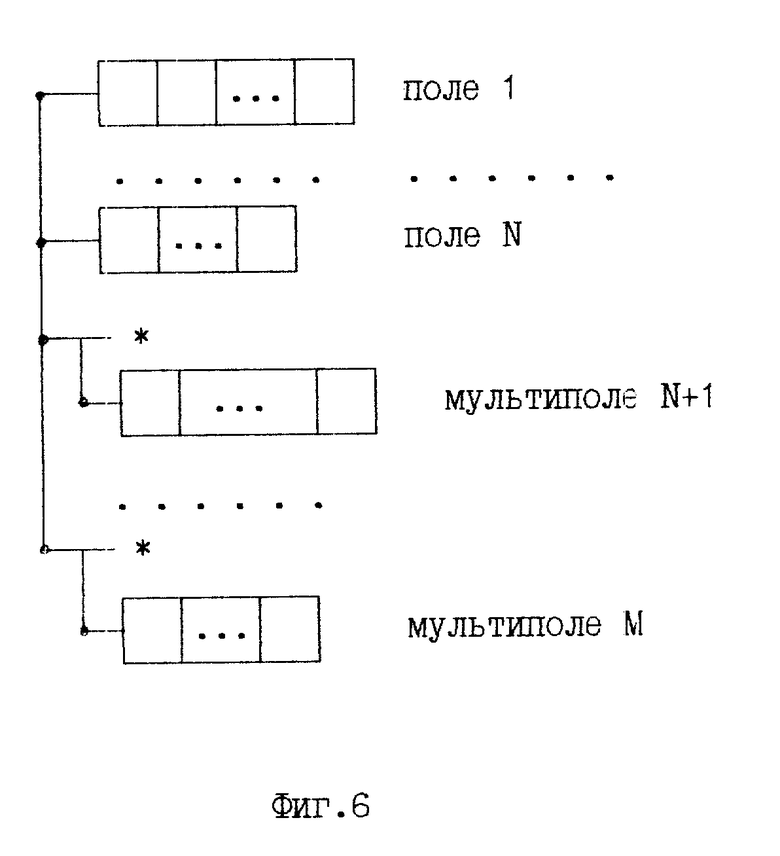
2) Поле поименованная совокупность нескольких слов, (слово 1.слово N). Поле будем называть простым, если оно состоит из одного слова, и сложным или составным, если оно состоит из нескольких слов. Мультиполе поле (простое или составное), которое может принимать несколько значений.
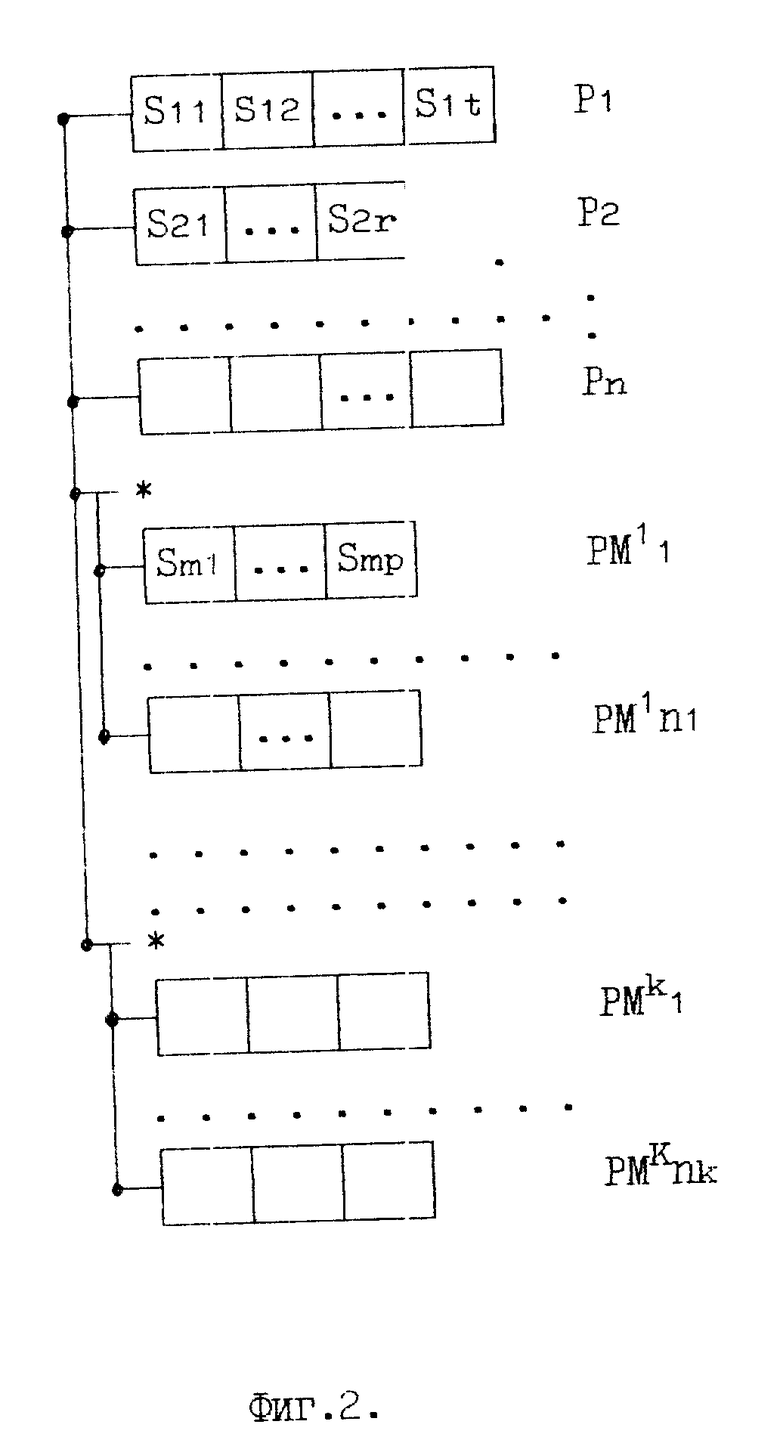
3) Запись непоименованная совокупность определенным образом упорядоченных полей и мультиполей. Общий вид записи в виде бинарного дерева представлен на фиг. 2.
Здесь P1, P2,Pn поля (простые или составные); PM
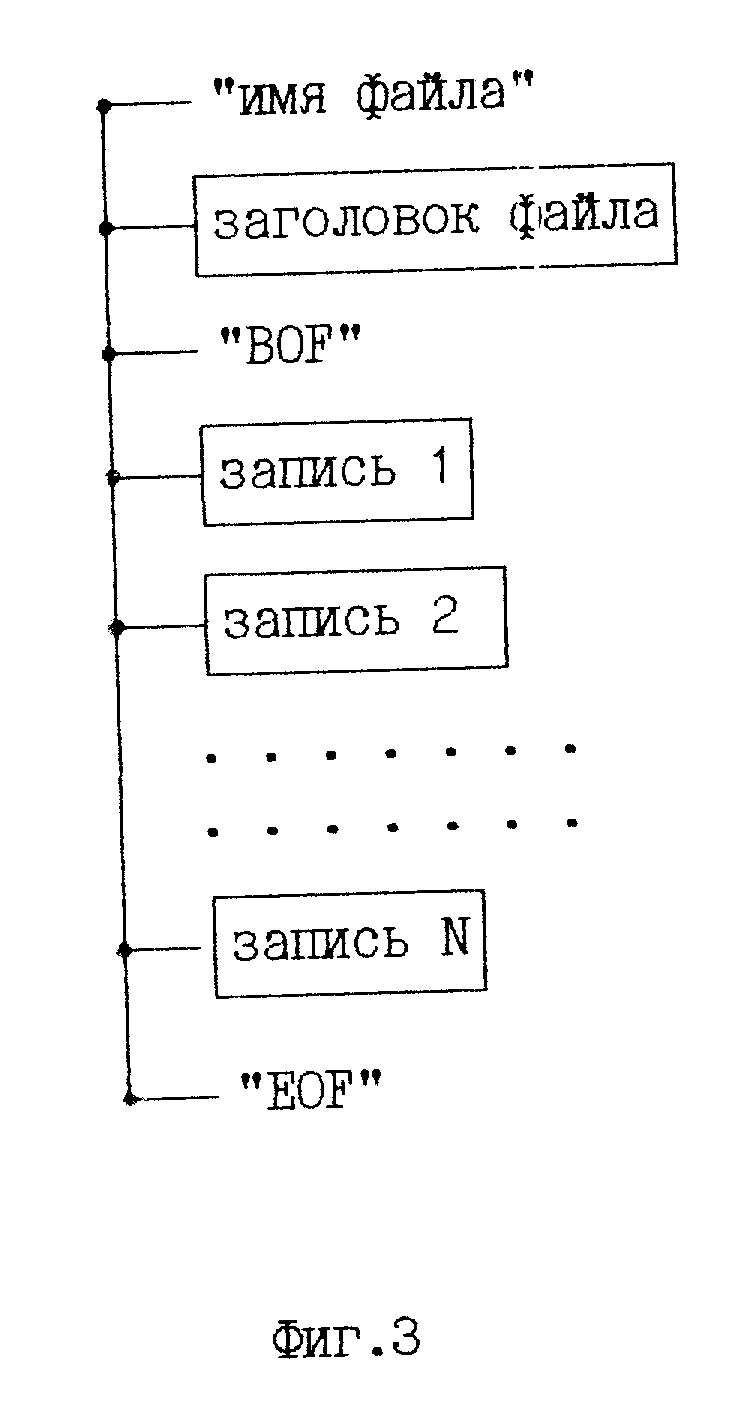
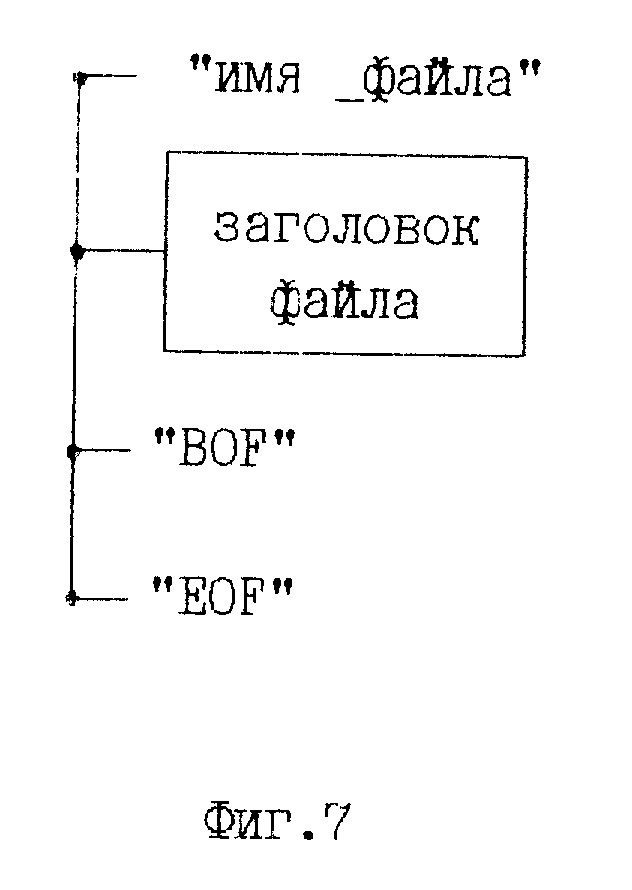
4) Файл базы данных (БД) упорядоченная совокупность записей одной структуры. Общий вид файла БД в виде бинарного дерева представлен на фиг. 3. Здесь "Заголовок файла" бинарное дерево, содержащее вспомогательную информацию (таблицу имен полей и слов, шаблон записи и т.д.), "BOF" признак начала файла, "EOF" признак конца файла, "запись 1", "запись N" - записи одинаковой структуры.
5) База данных совокупность одного или нескольких файлов БД.
Организация бинарных деревьев в ОЗУ стандартная: каждая ячейка памяти (узел дерева) содержит четыре поля: левого указателя, правого указателя, указателя на родительскую вершину и данных (или указателя на данные).
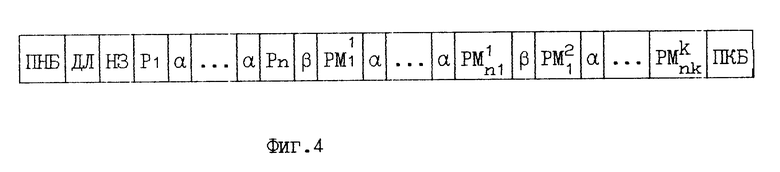
На ВЗУ (магнитный диск) файл БД хранится в последовательном файле, состоящем из блоков переменной длины. Каждый блок это одна запись файла БД (см. фиг. 4).
Обозначения:
ПНБ признак начала блока;
ДЛ длина блока в байтах;
НЗ порядковый номер записи файла БД;
α спецсимвол, разделитель между полями записи;
b спецсимвол, разделитель между группами мультиполей;
P1.Pn поля записи БД;
PM
ПКБ признак конца блока.
Для быстрого доступа к блоку по номеру записи создается каталог, указывающий номер кластера магнитного диска, где находится блок с нужной записью.
Устройство работает следующим образом.
С выхода блока управления 14 поступает очередная команда управления, которая представляет собой ключевое слово и параметры. Команда поступает в блок 13 интерпретатора команд, который распознает команду и посылает код команды и параметры в виде строки символов в блок 12 АЛУ. АЛУ активизирует соответствующий блок, выполняющий данную команду (блоки 1-9, 15) и пересылает в этот блок параметры. Активизированный блок выполняет соответствующие действия с данными, после чего в интерпретатор поступает очередная управляющая команда. Рассмотрим отдельно работу каждого исполнительного блока.
Блок формирования структуры 1, выполняющий команду CREATE, формирует структуру записи файла БД, описывает имена и характеристики слов и полей записи, а также устанавливает отношение к родительскому и подчиненному файлам БД.
Синтаксис команды CREATE:
CREATE имя_файла 1
Relation имя_файла 2,имя файла S
имя_поля 1 имя_слова 11 тип K11
имя_слова 12 тип K12
имя_слова 1n1 тип K1n1}
имя_поля N имя_слова N1 тип KN1
имя_слова NnN тип KN1nN}
имя_поля N+1 multy имя_слова N+1,1 тип KN+1,1
имя_слова N+1nN+1 тип KN+1,nN+1}
имя_поля M multy имя_слова M1 тип KM1
имя_слова MnM тип KMnM}
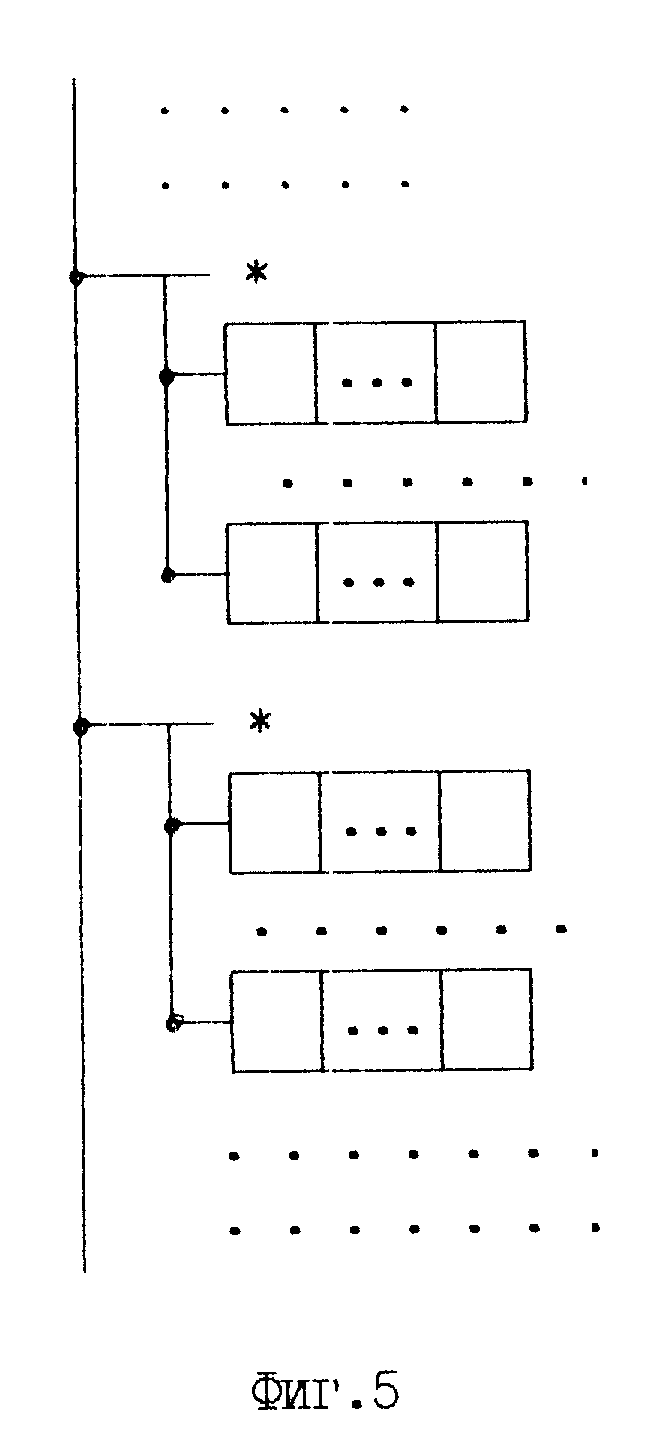
Здесь имя_ файла 1 имя создаваемого файла БД, имя_файла 2, имя_файла S имена подчиненных файлов, имя_поля i имя поля записи, имя_слова j имя слова, входящего в состав поля, тип один из типов данных (строка символов, число или дата), Kij количество позиций, отводимых для данного слова, multy означает, что данное поле является мультиполем. Файл БД называется подчиненным, если он содержит одинаковое с родительским количеством записей, и каждая запись состоит только из одного мультиполя. Структура подчиненного файла показана на фиг. 5. Для создания подчиненного файла команда CREATE имеет следующий формат:
CREATE имя_файла Subord
имя_поля multy имя_слова 1 тип K1
имя_слова N тип KN}
Блок 16 формирует первый уровень записи, т.е. создает в ОЗУ узел U1 первого уровня область памяти из четырех ячеек U1=ad1, ad2, ad3, ad4} Для шаблона записи ad1= 0, ad2=0, ad3=0, в ad4 записывается адрес поля данных. Если параметры содержат ключевое слово "multy", то срабатывает блок 17, который формирует 2-й уровень записи, т.е. создает в ОЗУ узел U2 второго уровня. Это также область памяти из 4-х ячеек, U2=ad5, ad6, ad7, ad8} где ad6= 0, ad7= 0, в ad5 записывается адрес узла U1 (области памяти U1), в ad8 адрес поля данных 2-го уровня (мультиполя). В узле U1 в ad3 записывается адрес U2.
Блок 18 анализа параметров содержит несколько ячеек ОЗУ, в которых записаны эталонные значения параметров, и одной ячейки ОЗУ, куда записывается поступившее значение параметра. Поступившее значение сравнивается с эталонным, и на выход блока поступает сигнал, соответствующий значению параметра. Аналогичным образом устроены и работают также блоки 21, 24, 27 анализа параметров.
Результатом работы блока 1 формирования структуры CREATE является создание в ОЗУ дерева, представленного на фиг. 7. Заголовок файла бинарное дерево, содержащее шаблон записи (фиг. 6) и таблицу имен полей и слов записи.
Блок загрузки данных 2, выполняющий команду USE, загружает файл БД из долговременной памяти (магнитный диск) в ОЗУ в виде бинарного дерева (см. фиг. 3). Параметром команды USE является имя файла БД.
Блок сохранения данных 3, выполняющий команду CLOSE, записывает файл БД из ОЗУ на магнитный диск, освобождает память ОЗУ. Параметром команду CLOSE является имя файла БД.
Блок добавления записи 4, выполняющий команду APPEND, в зависимости от параметров либо добавляет пустую запись (шаблон) в конце файла БД, находящегося в ОЗУ, после последней записи, перед "EOF" (блок 19), либо добавляет шаблон мультиполя в конец соответствующей группы мультиполя (блок 20). В первом случае команда записывается так: APPEND(&), во втором APPEND (имя_мультиполя). Блок 20 добавления 2-го уровня формирует узел U2(k+1)=ad1(k+1), ad2(k+1), ad3(k+1), ad4(k+1)} и запрашивает область памяти для нового поля данных. Новый узел связан с последним узлом U2(k) группы мультиполя следующими соотношениями: ad1(k+1)= адрес узла U2(k), ad2(k+1)=0, ad3(k+1)=0, ad4(k+1)= адрес нового поля данных, ad2(k)=адрес узла U2(k+1). Для файла БД, имеющего подчиненные файлы, команды APPEND(&) вызывает автоматическое добавление пустой записи во все подчиненные файлы. Если они не загружены в память, выдается сообщение об ошибке. В подчиненном файле команда APPEND(&) игнорируется.
Блок 5 удаления записи, выполняющий команду DELETE, в зависимости от параметров либо удаляет текущую запись файла БД (блок 22), либо удаляет текущее поле из группы мультиполя (блок 23). В первом случае команда записывается так: DELETE(&), во втором DELETE (имя_мультиполя). Блок 23 удаления 2-го уровня изменяет содержимое предыдущего и последующего узлов группы мультиполя. Если удается текущее k-е поле, то ad2(k-1) присваивается значение адреса узла U2(k+1), а ad1(k+1) присваивается значение адреса узла U2(k-1). Для файла БД, имеющего подчиненные файлы, команда DELETE(&) вызывается автоматическое удаление соответствующей записи во всех подчиненных файлах. Если они не загружены в ОЗУ, выдается сообщение об ошибке. В подчиненном файле команда DELETE(&) игнорируется.
Блок 6 переключения на другое дерево данных, выполняющий команду SELECT, осуществляет переключение на другой файл БД, находящийся в ОЗУ. Параметром команды SELECT является имя файла БД или номер его рабочей области.
Блок 7 движения по дереву данных, выполняющий команду SKIP, в зависимости от параметров осуществляет движение либо по дереву файла БД от одной записи к другой (блок 25), либо внутри текущей записи по полям группы мультиполя (блок 26). В первом случае команда записывается так: SKIP(&n), во втором SKIP (имя_ мультиполя, n), где n число шагов (впереди, если n>0 и назад, если n<0). Блок 26 движения 2-го уровня изменяет адрес узла текущего поля. Если текущим полем было k-е поле из группы мультиполя, то при движении на 1 шаг вперед адресом узла нового текущего поля будет ad2(k), при движении на 1 шаг назад адресом узла нового текущего поля будет ad1(k),
где U2(k)=ad1(k), ad2(k), ad3(k), ad4(k)} узел k-го поля.
Блок 8 считывания данных, выполняющий команду GET, считывает данные из поля текущей записи файла БД. Формат команды GET(имя_поля (имя_слова)). Если имя_поля имя мультиполя, то считываются данные из текущего поля группы.
Блок 9 обновления данных, выполняющий команду REPLACE, записывает данные в поле текущей записи файла БД. Формат команды REPLACE(имя_поля (имя_слова), Const), где Const записываемое в БД данное (символьная строка, число или дата). Если имя_поля имя мультиполя, то данные записываются в текущее поле группы.
Блок 15 индексации, выполняющий команду INDEX, осуществляет индексацию по любому слову как поля, так и мультиполя. В первом случае индексный файл будет иметь вид, представленный на фиг. 8а, во втором на фиг. 8б,
где Ki номера записей файла БД;
mi порядковый номер мультиполя внутри группы;
Si значение индексируемого слова.

Изобретение относится к вычислительной технике и может быть использовано в системе управления базами данных. Целью изобретения является сокращение времени поддержки ссылочной целостности и ускорение поиска по сложным запросам, содержащим несколько связанных таблиц. Поставленная цель достигается тем, что в устройстве для хранения и поиска информации в памяти, содержащем блок оперативной памяти 11, блок долговременной памяти 10, блок формирования структуры 1 с блоком формирования первого уровня 16, блок загрузки данных 2, блок сохранения данных 3, блок добавления записи 4 с блоком добавления первого уровня 19, блок удаления записи 5 с блоком удаления первого уровня 22, блок движения по дереву данных 7 с блоком движения первого уровня 25, блок считывания данных 8, блок обновления данных 9, блок переключения на другое дерево данных 6, арифметико-логическое устройство 12, блок интерпретатора команд 13, блок индексации 15 и блок управления 14, в блок формирования структуры введены блок формирования второго уровня 17 и первый блок анализа параметров 18, в блок добавления записи введены блок добавления второго уровня 20 и второй блок анализа параметров 21, в блок удаления записи введены блок удаления второго уровня 23 и третий блок анализа параметров 24, в блок движения по дереву данных 7 введены блок движения второго уровня 26 и четвертый блок анализа параметров 27. 8 ил.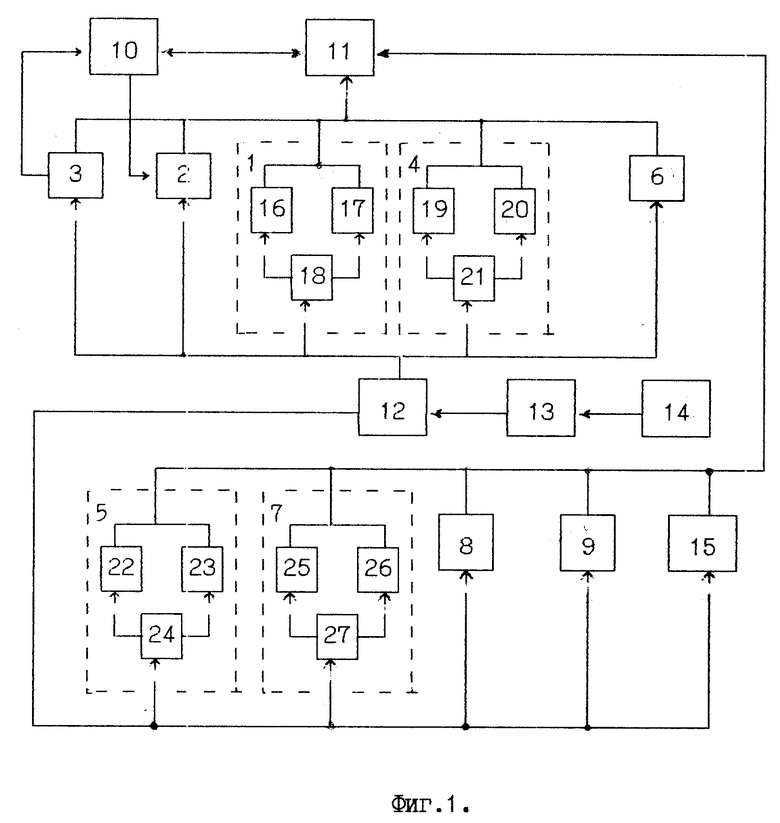
Устройство для хранения и поиска информации в памяти, содержащее блок оперативной памяти, блок долговременной памяти, блок формирования структуры с блоком формирования первого уровня, блок загрузки данных, блок сохранения данных, блок добавления записи с блоком добавления первого уровня, блок удаления записи с блоком удаления первого уровня, блок движения по дереву данных с блоком движения первого уровня, блок считывания данных, блок обновления данных, блок переключения на другое дерево данных, арифметико-логическое устройство, блок интерпретатора команд, блок индексации и блок управления, выход которого через интерпретатор команд соединен с входом арифметико-логического устройства, первый выход которого соединен с первым входом блока загрузки данных, входом блока сохранения данных, входом блока формирования структуры, входом блока добавления записи и входом блока переключения на другое дерево данных, первый выход блока сохранения данных и выходы блока загрузки данных, блока формирования структуры, блока добавления записи и блока переключения на другое дерево данных объединены и подключены к первому входу блока оперативной памяти, второй выход блока сохранения данных соединен с входом блока долговременной памяти, выход которого соединен с вторым входом блока загрузки данных, в вход-выход с выходом-входом блока оперативной памяти, второй выход арифметико-логического устройства соединен с входом блока удаления записи, входом блока движения по дереву данных, входом блока считывания данных, входом блока обновления данных и входом блока индексации, выходы которых соединены с вторым входом блока оперативной памяти, отличающееся тем, что в блок формирования структуры введены блок формирования второго уровня и первый блок анализа параметров, вход которого является входом блока формирования структуры, а выходы подключены соответственно к входу блока формирования первого уровня и входу блока формирования второго уровня, выходы которых объединены и являются выходом блока формирования структуры, в блок добавления записи введены блок добавления второго уровня и второй блок анализа параметров, вход которого является входом блока добавления записи, а выходы подключены соответственно к входу блока добавления первого уровня и входу блока добавления второго уровня, выходы которых объединены и являются выходом блока добавления записи, в блок удаления записи введены блок удаления второго уровня и третий блок анализа параметров, вход которого является входом блока удаления записи, а выходы подключены соответственно к входу блока удаления первого уровня и входу блока удаления второго уровня, выходы которых объединены и являются выходом блока удаления записи, в блок движения по дереву данных введены блок движения второго уровня и четвертый блок анализа параметров, вход которого является входом блока движения по дереву данных, а выходы подключены соответственно к входу блока движения первого уровня и входу блока движения второго уровня, выходы которых объединены и являются выходом блока движения по дереву данных.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| IBM, Corporation, Information Managment System | |||
| IBM Fovm, N GH 20 - 1260 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Codde, Normalized Data Base Structure Proc, 1971, ACM SIGFIDET Workshop oeData Deseription Assess and Control. | |||
