Изобретение относится к вычислительной технике, в частности к способу формирования структуры агрегированных данных и способу поиска данных посредством структуры агрегированных данных в системе управления базами данных (СУБД), и может быть использовано в СУБД для ускорения поиска различной информации в базе данных (БД), агрегирования найденных данных в группы, для быстрой статистической обработки этих групп и оперативной сортировки искомых данных.
За последние десятилетия в связи с развитием вычислительной техники и использованием компьютерных технологий все более актуальной является задача хранения большого объема различных данных (различной информации), проведения быстрого поиска и анализа востребованных данных, а также управление базами данных, в которых эта информация хранится. Большинство производителей баз данных ориентированы на поддержку продуктов такого класса. Одним из направлений развития является обработка и хранение большого объема различной информации (текстовой, числовой, тип даты и т.д.) в целях поиска и анализа.
Существуют различные подходы к ускорению процесса поиска и анализа данных. Одним из таких подходов является сжатие сохраняемых данных, что позволяет уменьшить ввод/вывод и тем самым ускорить процесс обработки аналитических запросов. Такой подход применим для анализа данных на вычислительной технике с достаточно небольшими требованиями к ресурсам.
Другим подходом является построение индексов, т.е. построение дополнительных структур, которые ускоряют поиск и анализ индексируемых данных.
Самыми распространенными и универсальными индексами, которые формируют и используют для поиска и анализа данных в современных промышленных СУБД, являются B-trees - это сбалансированные В-деревья [1] (R.Bayer, Binary B-Trees for Virtual Memory, ACM-SIGFIDET Workshop, 1971, San Diego, California, Session 5B, pp.219-235).
Структуры В-деревьев как деревьев, отражающих порядок данных [2] (Кнут Д.Э. Искусство программирования, Т.3: Сортировка и поиск, Пер. с англ. Изд.2, М.: Вильямс, 2004, 832 с.), используются, в основном, для интервального поиска данных, т.е. для поиска данных по условиям типа: «равно», «больше», «меньше», «между» и т.п. В некоторых частных случаях структуры В-деревьев используются для ускорения других операций, таких, например, как поиск минимума/максимума, соединение (JOIN), удаление дубликатов (DISTINCT), группирование (GROUP BY) и упорядочение (ORDER BY).
Известно техническое решение [3] (патент US №7,120, 637 ((Positional access using a B-tree», Int. C1. G06F 17/30, опубликован 10 октября 2006 г.), которое заключается в том, что в структуре В-дерева к каждой узловой записи добавляют два целых числа - число ключей, расположенных слева от подчиненного поддерева и число ключей справа от него. Такая структура В-дерева позволяет осуществить позиционный доступ (по номеру ключа в упорядоченном ряду всех ключей дерева) к ключам дерева. Таким образом, кроме поиска при помощи В-деревьев, можно осуществлять навигацию по отсортированной выборке, т.е. двигаться по выборке, используя номера в ответе.
Кроме того, используя эти два числа (число ключей, расположенных слева от подчиненного поддерева и число ключей справа от него) можно достаточно быстро вычислять число ключей, удовлетворяющих некоторому интервальному условию, т.е. достаточно быстро вычислять агрегатную функцию COUNT, определяющую число строк или значений, однако вычисление других агрегатных функций (SUM-суммы, MIN - минимальное значение, МАХ - максимальное значение, AVG - среднее значение) в этих деревьях является не столь эффективным, так как требует сканирования всего интервала ключей, заданного поисковым интервальным условием.
Кроме того, все упомянутые агрегатные функции требуют более сложного и длительного вычисления в том случае, когда задано условие, отличное от интервального.
Наиболее близким техническим решением к заявляемому изобретению является способ-прототип, описанный в патенте [4] (US №6,487,546 «Apparatus and method for aggregate indexes», Int. C17. G06F 17/30, опубликован 26 ноября 2002 г.).
Способ формирования структуры агрегированных индексов, предназначенный для поиска и анализа данных в СУБД, описанный в патенте US №6,487,546, заключается в следующем (фиг.1):
входные данные, состоящие из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, формируют в столбцы значений данных,
выбирают из сформированных столбцов значений данных те столбцы, которые используются в условиях отбора данных при поиске, формируя таким образом ключевую группу столбцов данных,
задают агрегатные функции и определяют столбцы таблицы, которые будут аргументами этих заданных функций при формировании структуры агрегируемых индексов,
формируют строки ключевой группы столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированные строки ключевой группы столбцов данных определяют как ключи,
все ключи упорядочивают по возрастанию,
формируют J уровней страниц, где J - целое неотрицательное число, заполняя их записями, состоящими из ключа, вспомогательных данных и логической ссылки на последовательность номеров строк входных данных,
каждую запись в странице нулевого (далее по тексту 0-го) уровня формируют из ключа и ссылки на последовательность номеров строк входных данных, имеющих одно ключевое значение, вспомогательные данные на этом уровне представляют собой значения заданных агрегатных функций на множестве строк входных данных,
каждую очередную запись в странице первого (далее по тексту 1-го уровня) формируют с использованием последней заполненной страницы 0-го уровня, при этом ключом записи выбирают максимальное значение ключа, сформированное для этой страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех значений соответствующих агрегатных функций страницы 0-го уровня и ссылки на страницу 0-го уровня, по которой построена эта запись,
каждую последующую запись в странице J-го (J>1) уровня формируют с использованием последней заполненной страницы предыдущего (J-1)-го уровня, при этом ключом записи выбирают максимальное значение ключа последней сформированной страницы (J-1)-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех значений соответствующих агрегатных функций страницы (J-1)-го уровня и ссылки на страницу (J-1)-го уровня, по которой строится эта запись,
процесс формирования иерархической структуры записи страниц агрегированных индексов для поиска и анализа данных заканчивают, когда на очередном уровне останется единственная страница, называемая вершинной страницей.
Периодически обновляют входные данные по мере их поступления, для чего находят и удаляют записи структуры агрегированных индексов, относящиеся к удаляемым строкам входных данных, добавляют в структуру агрегированных индексов записи, относящиеся к добавляемым строкам входных данных, выполняют обнаружение и удаляют записи со старым значением ключа, добавляют записи с новым значением ключа. При этом способ-прототип не обеспечивает хранение в индексе значений аргументов агрегатных функций, поэтому при осуществлении поддержки структуры в некоторых случаях требуется определенная дополнительная последовательность действий, включающая доступ к значениям столбцов-аргументов из самой таблицы.
При добавлении в структуру согласно способу-прототипу добавляют следующие данные: значение ключа, значение аргумента и идентификатор добавляемой строки входных данных, для этого сначала определяют все записи структуры, в которых нужно изменить значения заданных агрегатных функций, при этом во всех этих записях каждое значение заданной агрегатной функции изменяется в соответствии с алгоритмом вычисления данной функции: для изменения значения суммы прибавляют к ней значение аргумента, для изменения значения функции числа значений добавляют к нему единицу, для изменения значения функции минимум - MIN или значения функции максимум - MAX заменяют его на новое значение, являющееся минимумом или максимумом из двух значений старого значения агрегатной функции.
При удалении из структуры удаляют значение ключа, значение аргумента и идентификатор удаляемой строки входных данных, для этого сначала определяют все записи структуры, в которых нужно изменить значения заданных агрегатных функций, при этом:
во всех этих записях каждое значение заданной агрегатной функции изменяют в соответствии с алгоритмом вычисления данной функции: для изменения значения суммы отнимают от нее значение аргумента, для изменения значения функции числа значений отнимают от него единицу;
изменение значения функции MIN - минимальное значение или MAX - максимальное значение в записи страницы 0-го уровня может потребовать обращения к записям таблицы, содержащей строки входных данных, для подсчета нового значения; это произойдет только в том случае, когда столбец атрибут удаляемой записи имеет значение, совпадающее с MIN или МАХ, в остальных случаях значение агрегатной функции останется неизменным,
изменение значения функции MIN или значения функции MAX в записи страницы не 0-го уровня может потребовать подсчета нового значения MIN или значения MAX при сканировании всех записей страницы, на которую ссылается данная запись; это произойдет только в том случае, когда столбец-атрибут удаляемой записи имеет значение, совпадающее с MIN или MAX, в остальных случаях значение агрегатной функции останется неизменным,
Кроме того, так же как и в известных структурах, использующих структуру обычных В-деревьев [2], при добавлении или удалении ключа возможно появление или исчезновение записей и даже целых страниц структуры.
Используя сформированные агрегированные индексы, осуществляют поиск данных в системе управления базами данных.
Сформированная структура агрегированных индексов по способу-прототипу [4] (US №6,487,546) существенно ограничивает возможности быстрого поиска и анализа данных в СУБД, поскольку позволяют обеспечить поиск только по следующим видам запросов:
- обычный интервальный поиск, если по условиям поиска требуется найти все строки входных данных, в которых значение ключей находится в интервале, ограниченном двумя заданными значениями ключей, или полуинтервале, ограниченном только с одной из сторон;
- интервальный поиск по предыдущей выборке, если по условиям поиска имеется выборка строк входных данных, отобранных по заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны;
- интервальный поиск с вычислением заданных агрегатных функций, если по условиям поиска имеется выборка строк входных данных, отобранных по заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом множество найденных строк требуется сгруппировать по заданному числу первых столбцов ключевой группы так, чтобы в каждой из групп все значения каждого из заданных первых столбцов совпадали, и для каждой такой группы вычислить указанную агрегатную функцию.
Это ограничение вызвано тем, что в способе-прототипе, основанном на В-деревьях, можно выполнять только интервальный поиск.
Из этого следует, что прототип не сможет эффективно выполнять более сложные типы запросов, в которых, кроме интервального условия, могут встретиться и другие условия поиска, накладываемые на выборку.
В реальных запросах данных редко встречаются только интервальные условия поиска, обычно они соседствуют с другими условиями, например найти общую сумму продаж дешевых товаров (цена которых не превосходит 100 р.), осуществленных в период с 01.06.09 по 31.08.09. В этом запросе есть интервальное условие - «время продаж между 01.06.09 и 31.08.09» и неинтервальное условие - «цена товара меньше или равна 100 р.». Для осуществления поиска записей данных, удовлетворяющих такому запросу, нам нужно логически найти сначала множество строк входных данных, описывающих продажи дешевых товаров, потом найти множество строк входных данных, описывающих все продажи, сделанные за указанный период, а потом пересечь эти два множества. Это не позволит также вычислить сразу агрегатную функцию суммы и нужно будет читать непосредственно строки входных данных для подсчета суммы.
На более сложных типах запросов прототип либо вообще не сможет работать, либо потребует создание дополнительных алгоритмов, увеличивающих объем работы в разы.
Поэтому необходимо создать такую структуру агрегированных данных, которая позволит расширить возможности поиска данных, выполняя более сложные запросы поиска, ускорить поиск данных по различным типам запросов, обеспечивая быструю статистическую обработку и оперативную сортировку искомой информации.
Задача, на решение которой направлено заявляемое изобретение, - это формирование такой структуры агрегированных данных, посредством которой достигается расширение возможностей поиска, выполнение более сложных запросов поиска, ускорение поиска данных по различным типам запросов в системе управления базами данных, агрегирование найденных данных в группы, быстрая статистическая обработка этих групп и оперативная сортировка искомых данных.
Для решения поставленной задачи предлагается группа изобретений, созданных в едином изобретательском замысле, - это способ формирования структуры агрегированных данных и способ поиска данных посредством структуры агрегированных данных в системе управления базами данных.
Заявляемый способ формирования структуры агрегированных данных в системе управления базами данных, в которой
входные данные, состоящие из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, нумеруют по строкам таким образом, что каждая строка получает уникальный номер,
заключается в том, что
выбирают из сформированных столбцов значений данных те столбцы, которые используются в условиях отбора данных при поиске, формируя таким образом ключевую группу столбцов данных,
задают агрегатные функции и определяют столбцы ключевой группы столбцов данных, которые будут аргументами заданных функций при формировании структуры агрегируемых данных,
формируют строки ключевой группы столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированные строки ключевой группы столбцов данных определяют как ключи,
все ключи упорядочивают по возрастанию,
формируют J уровней страниц, где J - целое неотрицательное число, заполняя их записями, состоящими из ключа и вспомогательных данных о местоположении ключа,
каждую запись в странице 0-го уровня формируют из ключа,
каждую очередную запись в странице 1-го уровня формируют с использованием последней заполненной страницы 0-го уровня, при этом ключом записи выбирают максимальное значение ключа, сформированное для этой страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций и ссылки на страницу 0-го уровня, по которой построена эта запись,
каждую последующую запись в странице J-го, J>1, уровня формируют с использованием последней заполненной страницы предыдущего (J-1)-го уровня, при этом ключом записи выбирают максимальное значение ключа последней сформированной страницы (J-1)-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по всем значениям тех же агрегатных функций или значениям аргументов этих функций, вычисленных в странице (J-1)-го уровня, и ссылки на страницу (J-1)-го уровня, по которой строится эта запись,
процесс формирования иерархической структуры записи страниц агрегированных данных для поиска и анализа данных заканчивают, когда на очередном уровне останется единственная страница, называемая вершинной страницей,
периодически обновляют входные данные по мере их поступления, для чего находят и удаляют записи структуры агрегированных данных, относящиеся к удаляемым строкам входных данных, добавляют в структуру агрегированных данных записи, относящиеся к добавляемым строкам входных данных, выполняют обнаружение и удаляют записи со старым значением ключа, добавляют записи с новым значением ключа при замене ключа в строке входных данных,
отличается согласно изобретению тем, что
формируя J уровней страниц записи, заполняют их ссылками на битовый вектор,
при этом каждую запись в странице 0-го уровня формируют из ссылки на битовый вектор, в который установлены в единицу биты с номерами, соответствующими номерам строк входных данных, имеющих тот же ключ,
при формировании каждой очередной записи в странице 1-го уровня в качестве ссылки на битовый вектор выбирают ссылку на объединение всех битовых векторов страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех ключей страницы 0-го уровня, по тем полям, которые соответствуют столбцам, заданным аргументами этих агрегатных функций,
при формировании каждой последующей записи в странице J-го уровня в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы (J-1)-го уровня, такую запись, построенную по странице предыдущего уровня, назначают записью-представителем этой страницы, эта запись содержит ключ, который представляет собой максимальное значение ключа этой страницы, значения заданных агрегатных функций, вычисленные по всем значениям тех же агрегатных функций или значениям аргументов этих функций этой страницы, и битовый вектор, являющийся объединением всех битовых векторов этой страницы, и ссылки на страницу (J-1)-го уровня,
процесс формирования иерархической структуры записи страниц агрегированных данных для поиска и анализа данных заканчивают, когда на очередном уровне останется вершинная страница, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора,
обновляя входные данные, находят и удаляют из сформированной структуры агрегированных данных ключ и номер строки входных данных, содержащей этот ключ, подлежащие удалению или замене на новые данные, для чего находят в структуре агрегированных данных положение удаляемого ключа, для этого
используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы:
считывают из памяти текущую страницу и находят в ней первую запись, значение ключа которой больше либо равно значению удаляемого ключа,
если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы используют в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы,
если считанная страница является страницей 0-го уровня, то обнаруженная запись и есть ключ, подлежащий удалению,
в битовом векторе найденной записи устанавливают в ноль бит с номером строки входных данных, содержащей ключ, подлежащий удалению, если полученный битовый вектор состоит только из одних нулевых бит, то устанавливают признак удаления найденной записи,
если признак удаления текущей записи установлен, то удаляют ее,
если установлен признак замены предшествующей записи, то заменяют запись, находящуюся сразу перед текущей записью, на запись-представителя страницы, являющейся предшествующим братом к странице, которая была текущей на один уровень ниже,
если установлен признак замены следующей записи, то заменяют запись, находящуюся сразу после текущей записи, на запись-представителя страницы, являющейся следующим братом к странице, которая была текущей на один уровень ниже,
при этом две страницы считают братьями, если у них есть общий предок на следующем верхнем уровне - страница следующего наверх уровня, записи которой ссылаются на эти страницы, поскольку ключи в страницах упорядочены, то все значения ключей одной из этих страниц больше всех значений ключей другой страницы, поэтому считают, что одна из этих страниц следует за другой страницей и называется следующим братом или одна из них предшествует другой странице и называется предшествующим братом,
если текущая страница заполнена записями наполовину или более, чем на половину, то вычисляют новую запись-представителя текущей страницы и прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи,
если полученная страница заполнена записями менее чем наполовину и у нее нет страниц, являющихся следующим или предшествующим братом текущей страницы, то вычисляют новую запись-представителя текущей страницы, прекращая обнаружение в текущей странице, и рекурсивно возвращаются в страницу, которая была текущей на уровень выше с признаком замены текущей записи,
если есть страница следующего брата и эта страница заполнена записями таким образом, что все записи текущей страницы можно перенести в эту страницу, то записи текущей страницы переносят в начало страницы ближайшего следующего брата и устанавливают признак удаления текущей записи,
при этом вычисляют новую запись-представителя страницы ближайшего следующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены следующей записи,
если страница ближайшего следующего брата заполнена записями настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего следующего брата переносят в конец текущей страницы столько первых записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей,
при этом вычисляют новую запись-представителя страницы ближайшего следующего брата, выставляют признак замены следующей записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи,
если следующий брат отсутствует, то рассматривают страницу ближайшего предшествующего брата, если эта страница заполнена записями таким образом, что все записи текущей страницы можно перенести в страницу ближайшего предшествующего брата, то записи текущей страницы переносят в конец страницы ближайшего предшествующего брата и устанавливают признак удаления текущей записи,
при этом вычисляют новую запись-представителя страницы предшествующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены предшествующей записи,
если страница ближайшего предшествующего брата заполнена записями настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего предшествующего брата переносят в начало текущей страницы столько последних записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей,
при этом вычисляют запись-представителя страницы измененного ближайшего предшествующего брата, выставляют признак замены предшествующей записи, вычисляют запись-представителя измененной текущей страницы, прекращают обнаружение, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи,
добавляют в структуру агрегированных данных ключ и номер строки входных данных, содержащей этот ключ,
для чего в структуре агрегированных данных находят положение для вставки этого ключа, для этого
используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения на уровне текущей страницы:
считывают из памяти текущую страницу и находят в ней первую запись, значение ключа которой больше либо равно значению добавляемого ключа,
если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы берут в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению поиска на уровне текущей страницы,
если считанная страница является страницей 0-го уровня, то значение ключа найденной записи больше либо равно значению ключа добавляемой записи, при этом, если значения ключей равны, то в битовом векторе найденной записи устанавливают в единицу бит с номером строки входных данных, содержащей вставляемый ключ, и переходят к вычислению записи-представителя текущей страницы, если значение ключа найденной записи больше значения добавляемой записи, то формируют вставляемую запись из ключа добавляемой записи и битвектора, в котором установлен в единицу только один бит с номером строки входных данных, содержащей вставляемый ключ, и устанавливают признак добавления записи,
если считанная страница не является страницей 0-го уровня, то выполняют замену текущей записи на запись-представителя страницы, которая была текущей на один уровень ниже,
если признак добавления не установлен, то вычисляют новую запись-представителя текущей страницы и прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи,
если установлен признак добавления записи и в текущей странице есть место для ее добавления, то новую запись вставляют перед текущей записью, сбрасывают признак добавления записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи,
если установлен признак добавления записи и в текущей странице нет места для размещения новой записи, то создают новую страницу для нового предшествующего брата текущей страницы, первую половину записей текущей страницы переписывают во вновь созданную страницу, вставляют новую запись перед текущей записью и вычисляют запись-представителя страницы предшествующего брата, выставляют признак добавления записи и вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Причем при формировании ключевой группы столбцов данных из сформированных столбцов значений данных выбирают те столбцы, которые содержат аналитические данные.
В качестве агрегатных функций вычисляют функции: COUNT, определяющую число строк или значений, или SUM-суммы, или MIN - минимальное значение, или MAX - максимальное значение, или их комбинации, а среднее значение - AVG получают как частное от отношения вычисленной агрегатной функции SUM-суммы к вычисленной агрегатной функции COUNT, определяющей число строк или значений.
При вычислении записи-представителя любой страницы структуры агрегированных данных ключом записи выбирают максимальное значение ключа этой страницы, значения заданных агрегатных функций вычисляют по всем значениям тех же агрегатных функций этой страницы или значениям аргументов этих функций, в качестве битового вектора используют объединение всех битовых векторов этой страницы, а в качестве ссылки на эту страницу, по которой строится эта запись, используют ее номер.
Заявляемый способ поиска данных посредством структуры агрегированных данных в системе управления базами данных, в которой
входные данные состоят из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями,
совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, а каждая строка получила уникальный номер,
столбцы значений данных, которые содержат аналитическую информацию и используются в условиях отбора данных при поиске, сформированы в ключевую группу столбцов данных,
используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированы строки ключевой группы столбцов данных,
сформированные строки ключевой группы столбцов данных определены как ключи, все ключи упорядочены по возрастанию,
агрегированные данные сформированы в иерархическую структуру памяти записи страниц агрегированных данных, представляющую собой J уровней записи страниц, где J - целое неотрицательное число, заполненных записями, состоящими из ключа, ссылки на битовый вектор и вспомогательных данных о местоположении ключа, при этом вершинной страницей иерархической структуры записи страниц агрегированных данных является страница, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора, заключается в том, что
выполняют интервальный поиск, если требуется найти все строки входных данных, в которых значение ключей находится в интервале, ограниченном двумя заданными значениями ключей, или полуинтервале, ограниченном только с одной из сторон,
выполняют интервальный поиск по предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны,
вычисляют агрегатную функцию на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны,
выполняют группирование с вычислением агрегатной функции,
согласно изобретению отличается тем, что,
выполняя интервальный поиск, создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы:
находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска,
находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска,
когда между записями номер один и два находят другие записи, то все битвектора этих записей переписывают в результирующий битовый вектор,
выделяют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня,
если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавшие в указанный интервал поиска,
все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне,
выделяют запись номер два, а в ней ссылку на страницу нижнего уровня записи, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня,
если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы,
если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавшие в указанный интервал поиска, все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне,
поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска;
выполняют интервальный поиск по предыдущей выборке, если имеется выборка строк входных данных, заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, для чего создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, считывают из памяти вершинную страницу структуры агрегируемых данных и рекурсивно переходят к выполнению поиска на уровне вершинной страницы:
находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска,
находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска,
если между записями номер один и номер два есть другие записи, битовые вектора которых имеют непустое пересечение с входным битовым вектором, то все эти пересечения переписывают в результирующий битовый вектор,
если битовый вектор записи номер один имеет непустое пересечение, то используют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня,
если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне,
если битовый вектор записи номер два имеет непустое пересечение, то используют запись номер два, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу нижнего уровня,
если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы,
если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне, при этом результатом поиска является результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию и значение ключа которых находится в заданном интервале поиска,
поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию поиска и значение ключа которых находится в заданном интервале поиска,
выполняют интервальный поиск по предыдущей выборке и сортировку его результатов, если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, и требуется найти среди строк этой выборки и отсортировать по значениям ключей все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, при этом следует упорядочить эти строки по возрастанию ключевых значений, для чего считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы:
находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска,
находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска,
последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что битовый вектор такой очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи,
если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница не является страницей 0-го уровня, то из очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если данная страница является страницей 0-го уровня, то биты этого очередного пересечения указывают на строки входных данных, которые являются очередными по порядку возрастания значений ключей, номера этих битов записывают в выходной поток, который представляет последовательность номеров записей в порядке возрастания значений ключей,
поиск завершают после завершения поиска на уровне вершинной страницы, получая выходной поток номеров искомых строк, удовлетворяющих заданному критерию, причем значение ключа предшествующей строки меньше или равно значению ключа следующей строки,
вычисляют агрегатную функцию на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, при этом на множестве найденных строк требуется вычислить указанную агрегатную функцию, для чего считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы:
находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска,
находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска,
последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что пересечение битового вектора очередной записи и входного битового вектора пусто, то запись пропускают и переходят к следующей записи,
если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница является страницей 0-го уровня, то искомую агрегатную функцию вычисляют, используя текущее значение аргумента этой функции и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором, в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи,
если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу нижнего уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегируемых данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегируемых данных, то искомую агрегатную функцию вычисляют, используя текущее значение искомой функции, значение этой функции, находящейся в текущей записи, и число бит битового вектора очередной записи,
поиск на не нулевом уровне текущей считанной страницы завершают, когда просмотрены все очередные записи между записью номер один и записью номер два, завершают поиск на уровне вершинной страницы, при этом текущее значение искомой агрегатной функции является окончательным значением этой агрегатной функции;
группирование с вычислением агрегатной функции выполняют по каждой из групп, построенных на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих этому заданному критерию, и требуется найти среди строк этой выборки все строки, в которых значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, при этом все множество найденных строк требуется разбить на группы по заданному числу первых столбцов ключевой группы так, чтобы в каждой из групп все значения каждого из заданных первых столбцов совпали, и для каждой такой группы требуется вычислить указанную агрегатную функцию на одном из столбцов ключевой группы, для чего считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы:
находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска,
находят в текущей странице запись номер два, первую запись, ключ которой больше либо равен конечному значению ключа интервала поиска,
последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что битовый вектор очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи,
если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию вычисляют, используя значение аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором,
если данная страница является страницей 0-го уровня, но значение хотя бы одного из заданных первых столбцов ключевой группы не совпадает со значением соответствующего столбца в предыдущей записи, то предыдущую группу данных считают обработанной, значение искомой агрегатной функции на этой группе данных вычисленным, и это значение передают в выходной поток вместе со значением заданных первых столбцов,
при этом новая группа данных начинается текущей записью, а ее текущее значение искомой агрегатной функции вычисляют, используя значение аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора в текущей записи,
если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегированных данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы,
если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значение хотя бы одного из заданных первых столбцов не совпадает со значением соответствующего столбца в предыдущей записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию вычисляют, используя текущее значение этой функции или текущее значение этой функции, находящейся в текущей записи, и число бит битового вектора очередной записи на уровне текущей считанной страницы,
поиск завершают, когда просмотрены все очередные записи между записью номер один и записью номер два,
завершают группирование при завершении поиска на уровне вершинной страницы, при этом завершается выходной поток, в котором очередная группа строк представлена значениями первых столбцов, определяющих группирование, и значением искомой агрегатной функции, вычисленным на строках этой группы,
полученный выходной поток данных в процессе поиска преобразуют в следующий выходной поток данных, в котором, используя полученные значения заданных первых столбцов данных, определяют очередную ключевую группу столбцов данных и значение искомой агрегатной функции.
Причем при выполнении поиска и нахождении в текущей считанной странице записи номер один, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы.
При выполнении поиска и нахождении в текущей считанной странице записи номер два, если не найдено первой записи, значение ключа которой больше либо равно значению конечного ключа интервала поиска, или если конечный ключ отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница является страницей 0-го уровня, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница является страницей 0-го уровня, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления произведения значения аргумента этой функции в текущей записи и числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница является страницей 0-го уровня, то в качестве нового значения искомой агрегатной функции MIN - минимальное значение или искомой агрегатной функции MAX - максимальное значение выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
Если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит битового вектора очередной записи к текущему значению этой функции.
Если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция SUM-суммы является одной из тех агрегатных функций, которую использовали при построении структуры агрегируемых данных, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления значения этой функции, находящейся в текущей записи, к текущему значению этой функции.
Если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция MIN - минимальное значение или MAX - максимальное значение является одной из тех агрегатных функций, которую использовали при построении структуры агрегируемых данных, то в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения искомой функции и значения этой функции, находящейся в текущей записи.
Для вычисления функции AVG - среднее значение вычисляют значения агрегатных функций SUM-суммы и COUNT, определяющую число строк или значений, а значение AVG - среднее значение получают как частное этих двух значений.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления произведения значения аргумента этой функции в текущей записи и числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то в качестве нового значения искомых агрегатных функций MIN - минимальное значение или MAX - максимальное значение выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
Когда новую группу данных начинают с текущей записи, для искомой агрегатной функции COUNT, определяющей число строк или значений, за ее текущее значение принимают число бит пересечения битового вектора очередной записи с входным битовым вектором.
Когда новую группу данных начинают с текущей записи, для искомой агрегатной функции SUM-суммы за ее текущее значение принимают произведение значения аргумента этой функции в текущей записи и числа бит пересечения битового вектора очередной записи с входным битовым вектором.
Когда новую группу данных начинают с текущей записи, для искомых агрегатных функций MIN - минимальное значение или MAX - максимальное значение за ее текущее значение принимают соответственно значение аргумента в текущей записи.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит битового вектора очередной записи к текущему значению этой функции.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция SUM-суммы является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления значения этой функции, находящегося в текущей записи, к текущему значению этой функции.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция MYN - минимальное значение или MAX - максимальное значение является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то в качестве нового значения искомой функции MIN - минимальное значение или MAX - максимальное значение выбирают соответственно минимальное или максимальное из двух значений: текущего значения искомой функции и значения этой функции, находящейся в текущей записи.
Когда завершают выходной поток, в котором очередная группа строк представлена значением искомой агрегатной функции, вычисленным на строках этой группы, при вычислении функции AVG - среднее значение вычисляют значения агрегатных функций SUM-суммы и COUNT, определяющей число строк или значений, а значение функции AVG - среднее значение получают как частное этих двух значений, получая выходной поток данных, содержащий значения заданных первых столбцов данных, которые определяют очередную ключевую группу столбцов данных, значение искомой агрегатной функции SUM-суммы, вычисленное для строк этой ключевой группы столбцов данных, и значение искомой агрегатной функции COUNT, определяющую число строк или значений.
Заявляемый способ формирования структуры агрегированных данных в системе управления базами данных отличается новизной по сравнению с прототипом и известными техническими решениями в данной области техники. Отличия заключаются в том, что, формируя J уровней страниц, заполняют их записями, состоящими из ссылки на битовый вектор, при этом каждую запись в странице 0-го уровня формируют из ссылки на битовый вектор, в который установлены в единицу биты с номерами, соответствующими номерам строк входных данных, имеющих тот же ключ. Формируя каждую очередную запись в странице 1-го уровня, в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех ключей страницы 0-го уровня по тем полям, которые соответствуют столбцам, заданным аргументами этих агрегатных функций. При формировании каждой последующей записи в странице J-го уровня в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы (J-1)-го уровня, такую запись, построенную по странице предыдущего уровня, назначают записью-представителем этой страницы, эта запись содержит ключ, который представляет собой максимальный ключ этой страницы, значения заданных агрегатных функций, вычисленные по всем значениям тех же агрегатных функций или значениям аргументов этих функций этой страницы, и битовый вектор, являющийся объединением всех битовых векторов этой страницы, и ссылки на страницу (J-1)-го уровня. Процесс формирования иерархической структуры записи страниц агрегированных данных для поиска и анализа данных заканчивают, когда на очередном уровне останется вершинная страница, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора.
Поскольку сформированная структура агрегированных данных периодически обновляется (развивается) в динамике по мере обновления входных данных, то соответственно требуется специфическая последовательность физических действий, необходимых для такой поддержки. Предложенная последовательность действий (признаков) подробно описанная в отличительной части формулы, позволяет быстро и безошибочно находить и удалять записи структуры агрегированных данных, относящиеся к удаляемым строкам входных данных, добавлять в структуру агрегированных данных записи, относящиеся к добавляемым строкам входных данных, выполнять обнаружение и удалять записи со старым значением ключа и добавлять записи с новым значением ключа при замене ключа в строке входных данных.
Структуру агрегируемых данных создают таким образом, что она содержит уникальные записи, в каждой такой записи в страницах 0-го уровня, кроме ключа, присутствует битовый вектор, где установлены в единицу биты с номерами, соответствующими тем строкам входных данных, которые имеют это значение ключа. Таким образом, по номеру удаляемой строки всегда можно однозначно найти запись, ключ которой равен значению ключевых столбцов удаляемой строки, а битовый вектор содержит единичку в бите с номером удаляемой строки.
Так как записи в структуре агрегированных данных упорядочены, то поиск записей, которых коснется алгоритм удаления, быстрее вести по паре данных: значению ключа и номеру удаляемой строки.
Все записи структуры агрегируемых, которые требуют изменения в связи с удалением, изменяют так, что в этих записях меняются не только значения агрегатных функций, но еще и битовый вектор этих записей (в нем бит с номером удаляемой записи должен стать нулевым).
Все эти отличительные признаки способа формирования структуры агрегированных данных позволяют получить лучший технический эффект по сравнению с прототипом и известными техническими решениями в данной области техники, а именно расширить возможности поиска, выполнять более сложные запросы поиска и ускорить поиск данных по различным типам запросов в системе управления базами данных.
Заявляемый способ поиска данных посредством структуры агрегированных данных в системе управления базами данных существенно отличается от способа-прототипа и других известных технических решений в данной области техники. Отличия заключаются в следующем.
1. Заявляемый способ предполагает наличие ссылки на битовый вектор в записи страниц агрегированных данных сформированной иерархической структуры, представляющей собой J уровней записи страниц. Прототип не использует ссылки на битовый вектор в записи страниц иерархической структуры.
2. При выполнении интервального поиска создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, рекурсивно выполняя поиск, начиная с вершинной страницы, находят в текущей странице запись номер один и запись номер два, и если между записями номер один и два находят другие записи, то все битвектора этих записей переписывают в результирующий битовый вектор. Это позволяет ускорить поиск, а именно чтение страниц более низкого уровня требуется только для записей номер один и номер два; далее выделяют запись номер один (два), а в ней ссылку на страницу нижнего уровня записи, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня, если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавших в указанный интервал поиска, все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне, поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска.
Способ-прототип не имеет таких признаков, поэтому интервальный поиск выполняет неоптимально, так как приходится делать обход всех поддеревьев интервала между записью номер один и записью номер два.
3. При выполнении интервального поиска по предыдущей выборке создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы, находят в текущей странице запись номер один и запись номер два, и если между записями номер один и номер два есть другие записи, битовые вектора которых имеют непустое пересечение с входным битовым вектором, то все эти пересечения переписывают в результирующий битовый вектор; если битовый вектор записи номер один имеет непустое пересечение, то используют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, и переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне, если битовый вектор записи номер два имеет непустое пересечение, то используют запись номер два, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу нижнего уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы, если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне, при этом результатом поиска является результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию и значение ключа которых находится в заданном интервале поиска, поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию поиска и значение ключа которых находится в заданном интервале поиска; таким образом, чтение страниц более низкого уровня требуется только для крайних записей интервала (записи один и два) и только в том случае, когда битвектора этих записей имеют непустое пересечение с входным битовым вектором.
Способ-прототип не имеет таких признаков, поэтому интервальный поиск с предыдущей выборкой выполняется неоптимально и с ограниченными возможностями, так как приходится делать обход всех поддеревьев интервала между записью номер один и записью номер два.
4. При выполнении интервального поиска по предыдущей выборке и сортировке его результатов создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, рекурсивно выполняют поиск на уровне вершинной страницы, находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, если такой записи не найдено или если конечный ключ отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы, последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два.
Если обнаруживают, что битовый вектор такой очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи. А способ-прототип не имеет такой возможности отказаться от обхода поддеревьев, не содержащих выборки ключей.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница не является страницей 0-го уровня, то из очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись. Таким образом, уже в узлах верхних уровней определяют, есть ли в их потомках нужные ключи, что позволяет ускорить поиск и сделать его оптимальным.
Далее считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если данная страница является страницей 0-го уровня, то биты этого очередного пересечения указывают на строки входных данных, которые являются очередными по порядку возрастания значений ключей, номера этих битов записывают в выходной поток, который представляет последовательность номеров записей в порядке возрастания ключей, поиск завершают после завершения поиска на уровне вершинной страницы, получая выходной поток номеров искомых строк, удовлетворяющих заданному критерию, причем значение ключа предшествующей строки меньше или равно значению ключа следующей строки.
Способ-прототип не имеет таких признаков, поэтому интервальный поиск по предыдущей выборке выполняется неоптимально и с ограниченными возможностями, т.к. приходится делать обход всех поддеревьев интервала между записью номер один и записью номер два. А выполнить сортировку по значениям ключей строк, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом упорядочить эти строки по возрастанию ключевых значений, вообще не может.
5. При вычислении агрегатной функции на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих этому заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом на множестве найденных строк требуется вычислить указанную агрегатную функцию, то считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы, находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что пересечение битового вектора очередной записи и входного битового вектора пусто, то запись пропускают и переходят к следующей записи. Данные признаки позволяют оптимизировать поиск, так как из рассмотрения выбрасываются целые ветви дерева (страницы уровней записи), в которых не может быть ключей выборки, удовлетворяющих заданному условию. К сожалению, способ-прототип, использующий структуру агрегированных индексов и другие технические решения, использующие структуру В-деревьев, не имеют такой возможности.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница является страницей 0-го уровня, то искомую агрегатную функцию вычисляют, используя текущее значение аргумента этой функции и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором, в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
При этом, например, для искомой функции COUNT, определяющей число строк или значений, к текущему значению этой функции прибавляют число бит непустого пересечения битового вектора очередной записи с входным битовым вектором.
Для искомой функции SUM-суммы к текущему значению этой функции, например, добавляют произведение значения аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором.
Для искомой функции MIN - минимальное значение или MAX - максимальное значение в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу нижнего уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегируемых данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегируемых данных, то искомую агрегатную функцию вычисляют, используя текущее значение искомой функции, значение этой функции, находящейся в текущей записи, и число бит битового вектора очередной записи.
При этом, например, для искомой функции COUNT, определяющей число строк или значений, к текущему значению этой функции прибавляют число бит битового вектора очередной записи.
Для искомой функции SUM-суммы, например, к текущему значению этой функции добавляют значение этой функции, находящейся в текущей записи.
Для искомой функции MIN - минимальное значение или MAX - максимальное значение, например, в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения искомой функции и значения этой функции, находящейся в текущей записи. Эти признаки позволяют реализовать еще одну оптимизацию поиска по сравнению с прототипом и другими техническими решениями, так как в этом случае используется заранее вычисленное частичное значение искомой агрегатной функции, которое будет использовано при вычислении всей агрегатной функции.
Поиск на ненулевом уровне текущей считанной страницы завершают, когда просмотрены все очередные записи между записью номер один и записью номер два, завершают поиск на уровне вершинной страницы, при этом текущее значение искомой агрегатной функции является окончательным значением этой агрегатной функции.
Для вычисления функции AVG - среднее значение, например, вычисляют значения агрегатных функций SUM-суммы и COUNT, определяющей число строк или значений, а значение AVG - среднее значение получают как частное этих двух значений.
6. При выполнении группирования с вычислением агрегатной функции по каждой из групп, построенных на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих этому заданному критерию, и требуется найти среди строк этой выборки все строки, в которых значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом все множество найденных строк требуется разбить на группы по заданному числу первых столбцов ключевой группы так, чтобы в каждой из групп все значения каждого из заданных первых столбцов совпали, и для каждой такой группы требуется вычислить указанную агрегатную функцию на одном из столбцов ключевой группы, то считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы, находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что битовый вектор очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи. Эти признаки по сравнению с прототипом и другими техническими решениями позволяют оптимизировать поиск, так как в данном случае выбрасываются при поиске целые ветви дерева (страницы уровней записи), в которых не может быть ключей выборки, удовлетворяющих заданному условию.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня и если эта очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию вычисляют, используя значение аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором.
При этом, например, для искомой функции COUNT, определяющей число строк или значений, к текущему значению этой функции прибавляют число бит непустого пересечения битового вектора очередной записи с входным битовым вектором.
Для искомой функции SUM-суммы, например, к текущему значению этой функции добавляют произведение значения аргумента этой функции в текущей записи и числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором.
Для искомой функции MIN или MAX в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
Если данная страница является страницей 0-го уровня, но значение хотя бы одного из заданных первых столбцов ключевой группы не совпадает со значением соответствующего столбца в предыдущей записи, то предыдущую группу данных считают обработанной, значение искомой агрегатной функции на этой группе данных вычисленным, и это значение передают в выходной поток вместе со значением заданных первых столбцов, при этом новая группа данных начинается текущей записью, а ее текущее значение искомой агрегатной функции вычисляют, используя значение аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора в текущей записи.
При этом, например, для искомой функции COUNT, определяющей число строк или значений, за ее текущее значение принимают число бит пересечения битового вектора очередной записи с входным битовым вектором.
Для искомой функции SUM-суммы, например, за ее текущее значение принимают произведение значения аргумента этой функции в текущей записи и числа бит пересечения битового вектора очередной записи с входным битовым вектором.
Для искомой функции MIN - минимальное значение или MAX - максимальное значение за ее текущее значение принимают соответственно значение аргумента в текущей записи.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегированных данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегируемых данных, и при этом значение хотя бы одного из заданных первых столбцов не совпадает со значением соответствующего столбца в предыдущей записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию вычисляют, используя текущее значение этой функции или текущее значение этой функции, находящейся в текущей записи и число бит битового вектора очередной записи.
При этом, например, для искомой функции COUNT, определяющей число строк или значений, к текущему значению этой функции прибавляют число бит битового вектора очередной записи.
Для искомой функции SUM-суммы к текущему значению этой функции добавляют значение этой функции, находящееся в текущей записи.
Для искомой функции MIN - минимальное значение или MAX - максимальное значение в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения искомой функции и значения этой функции, находящейся в текущей записи.
Эти признаки обеспечивают еще одну оптимизацию поиска по сравнению с прототипом и другими техническими решениями в данной области техники, так как в этом случае используют заранее вычисленное значение искомой агрегатной функции, которое используют при вычислении всей агрегатной функции.
На уровне текущей считанной страницы поиск завершают, когда просмотрены все очередные записи между записью номер один и записью номер два, завершают группирование при завершении поиска на уровне вершинной страницы, при этом завершается выходной поток, в котором очередная группа строк представлена значениями первых столбцов, определяющих группирование, и значением искомой агрегатной функции, вычисленным на строках этой группы.
При вычислении функции AVG - среднее значение, например, вычисляют значения агрегатных функций SUM-суммы и COUNT, определяющей число строк или значений, а значение функции AVG - среднее значение получают как частное этих двух значений, получая выходной поток данных, содержащий значения заданных первых столбцов данных, которые определяют очередную ключевую группу столбцов данных, значение искомой агрегатной функции SUM-суммы, вычисленное для строк этой ключевой группы столбцов данных, и значение искомой агрегатной функции COUNT, определяющей число строк или значений.
Полученный выходной поток данных в процессе поиска преобразуют в следующий выходной поток данных, в котором, используя полученные значения заданных первых столбцов данных, определяют очередную ключевую группу столбцов данных и значение искомой агрегатной функции.
Таким образом, введение новых признаков согласно заявляемому изобретению позволяет решить поставленную задачу и получить лучший технический эффект, а именно выполнять более сложные запросы поиска данных, ускорить поиск данных по различным типам запросов в системе управления базами данных, агрегировать найденные данные в группы, статистически быстро обработать эти группы и оперативно сортировать искомые данные.
В отличие от прототипа сформированная структура агрегированных данных согласно изобретению позволяет использовать результаты предыдущей работы по поиску строк, удовлетворяющих любым критериям, доступным в современных языках запросов. При этом результаты предыдущего поиска могут ускорить работу заявляемой структуры. Чем больше отсеяно строк в предшествующем поиске, тем быстрее будет проходить обработка запросов.
Далее описание изобретения поясняется примерами выполнения и чертежами.
На фиг.1 выполнена структурная схема алгоритма способа-прототипа.
На фиг.2 показана структура входного потока данных, состоящих из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, пронумерованные по строкам таким образом, что каждая строка получает уникальный номер.
На фиг.3 - структурная схема алгоритма заявляемого способа формирования структуры агрегированных данных в системе управления базами данных (формирование структуры).
На фиг.4 показан пример расположения данных в базе данных в виде таблицы, состоящей из трех столбцов X, Y и Z и двадцати строк.
На фиг.5 показан пример структуры агрегированных данных согласно заявляемому изобретению для таблицы, проиллюстрированной на фиг.4.
На фиг.6 - структурная схема алгоритма заявляемого способа формирования структуры агрегированных данных в системе управления базами данных (показан пример обновления входных данных по мере их поступления, нахождение и удаление из сформированной структуры агрегированных данных ключа и номера строки входных данных, содержащей этот ключ, подлежащие удалению или замене на новые данные).
Фиг.7 иллюстрирует пример страниц записи, которые считают братьями, если у них есть общий предок на странице следующего наверх уровня.
Фиг.8 иллюстрирует путь спуска, например, при поиске записи, которую нужно удалить.
На фиг.9 - структурная схема алгоритма заявляемого способа формирования структуры агрегированных данных в системе управления базами данных (поддержка сформированной структуры агрегированных данных - добавление ключа с номером строки, которая его содержит, в структуру агрегированных данных).
На фиг.10-14 изображена структурная схема алгоритма заявляемого способа поиска данных посредством структуры агрегированных данных в системе управления базами данных, при этом
на фиг.10 - структурная схема алгоритма интервального поиска;
на фиг.11 - структурная схема алгоритма интервального поиска с предыдущей выборкой;
на фиг.12 - структурная схема алгоритма интервального поиска по предыдущей выборке и сортировке его результатов;
на фиг.13 - структурная схема алгоритма вычисления агрегатной функции на результатах интервального поиска в предыдущей выборке (приведена в качестве примера для агрегатной функции SUM-суммы);
на фиг.14 - структурная схема алгоритма группирования с вычислением агрегатной функции по каждой из групп, построенных на результатах интервального поиска в предыдущей выборке (приведена в качестве примера для агрегатной функции SUM-суммы).
На фиг.15 выполнена структурная схема устройства, на котором осуществляют заявляемый способ.
Осуществляют заявляемый способ формирования структуры агрегированных данных следующим образом (фиг.2-9).
В таблице системы управления базами данных входные данные (фиг.2) состоят из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, нумеруют по строкам таким образом, что каждая строка получает уникальный номер. На фиг.4 показан пример расположения данных в базе данных в виде таблицы, состоящей из трех столбцов X, Y и Z и двадцати строк.
Выбирают из сформированных столбцов значений данных те столбцы, которые содержат аналитические данные или используются в условиях отбора данных при поиске, формируя таким образом ключевую группу столбцов данных (фиг.3).
Задают агрегатные функции: функцию SUM-суммы, функцию MIN - минимальное значение или MAX - максимальное значение и определяют столбцы ключевой группы столбцов данных, которые будут аргументами этих заданных функций при формировании структуры агрегируемых данных,
Формируют строки ключевой группы столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированные строки ключевой группы столбцов данных определяют как ключи. Все ключи упорядочивают по возрастанию.
Формируют J уровней страниц, где J - целое неотрицательное число, заполняя их записями, состоящими из ключа, ссылки на битовый вектор и вспомогательных данных о местоположении ключа. Каждую запись в странице 0-го уровня формируют из ключа и из ссылки на битовый вектор, в котором установлены в единицу биты с номерами, соответствующими номерам строк входных данных, имеющим тот же ключ, вспомогательные данные на этом уровне не используют.
Каждую очередную запись в странице 1-го уровня формируют с использованием последней заполненной страницы 0-го уровня, при этом ключом записи выбирают максимальное значение ключа, сформированное для этой страницы 0-го уровня, в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех ключей страницы 0-го уровня по тем полям, которые соответствуют столбцам, заданным аргументами этих агрегатных функций, и ссылки на страницу 0-го уровня, по которой построена эта запись.
Каждую последующую запись в странице J-го (J>1) уровня формируют с использованием последней заполненной страницы предыдущего (J-1)-го уровня, при этом ключом записи выбирают максимальное значение ключа последней сформированной страницы (J-1)-го уровня, в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы (J-1)-го уровня, такую запись, построенную по странице предыдущего уровня, назначают записью-представителем этой страницы, эта запись содержит ключ, который представляет собой максимальный ключ этой страницы, значения заданных агрегатных функций, вычисленные по всем значениям тех же агрегатных функций или значениям аргументов этих функций этой страницы и битовый вектор, являющийся объединением всех битовых векторов этой страницы, и ссылки на страницу (J-1)-го уровня.
Вспомогательные данные записи составляют из значений заданных агрегатных функций по всем значениям тех же агрегатных функций или значениям аргументов этих функций, вычисленных в странице (J-1)-го уровня по соответствующим аргументам этих агрегатных функций, и ссылки на страницу (J-1)-го уровня, по которой строится эта запись.
Процесс формирования иерархической структуры записи страниц агрегированных данных для поиска и анализа данных заканчивают, когда на очередном уровне останется единственная страница, называемая вершинной страницей, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора.
На фиг.5 показан пример структуры агрегированных данных согласно заявляемому изобретению для данных таблицы, проиллюстрированной на фиг.4.
На фиг.5 приведена структура агрегированных данных, где в качестве ключевой группы столбцов выбраны столбцы X и Y таблицы, изображенной на фиг.4. В качестве необходимых для вычисления агрегатных функций в данном примере выбраны две функции: SUM-суммы и MAX - максимальное значение, обе они имеют один и тот же аргумент - столбец Y.
Согласно алгоритму построения структуры агрегированных данных страницы 0-го уровня содержат только значения ключевой группы столбцов, т.е. только значения X и Y, взятые из одной строки таблицы. В таблице некоторые пары {X, Y} встречаются несколько раз (например, {1, 2} встречается в 6-й и в 19-й строке), однако структура агрегированных данных содержит только уникальные пары. Информацию о том, где встречается данная пара, содержит битовый вектор каждой записи (например, битовый вектор упомянутой пары {1, 2} содержит только две единички на 6-ом и на 19-ом месте, указывая тем самым, что пара {1, 2} встречается в 6-й и 19-й строках).
В записях страниц 1-го уровня уже присутствуют значения заданных агрегатных функций, каждая из которых вычислена на значениях Y в соответствующей странице.
В соответствии с описанным алгоритмом построения структуры агрегированных данных первая строка страницы 1-го уровня содержит следующие данные:
2,6 (максимальный ключ первой страницы 0-го уровня),
31,8 (сумма значений 2×2, 2×5, 8, 3, 6 и максимальное из значений 2, 5, 8, 3, 6 первой страницы 0-го уровня).
Битовый вектор этой записи содержит объединение всех битовых векторов, т.е. в нем установлены единички там, где они стояли в битовых векторах первой страницы 0-го уровня.
Первая запись страницы 2-го уровня строится по соответствующей (в данном случае первой, верхней) странице 1-го уровня. В соответствии с описанным алгоритмом построения структуры агрегированных данных первая строка страницы 2-го уровня содержит следующие данные:
4,8 (максимальный ключ первой страницы 1-го уровня),
59,9 (сумма значений 31, 28 и максимальное из значений 8,9 первой страницы 1-го уровня).
Совокупный битовый вектор записи 2-го уровня представляет собой объединение всех битовых векторов в соответствующей странице 1-го уровня, в данном случае
(00000111111111110110)=(00000111111000000010)∪(00000000000111110100)
Аналогичным образом формируют и все другие записи структуры агрегированных данных.
Периодически обновляют входные данные по мере их поступления, для чего находят и удаляют записи структуры агрегированных данных, относящиеся к удаляемым строкам входных данных, добавляют в структуру агрегированных данных записи, относящиеся к добавляемым строкам входных данных, выполняют обнаружение и удаляют записи со старым значением ключа, добавляют записи с новым значением ключа при замене ключа в строке входных данных (фиг.6-9).
При этом (фиг.6) находят и удаляют из сформированной структуры агрегированных данных ключ и номер строки входных данных, содержащей этот ключ, подлежащие удалению или замене на новые данные. Для чего находят в структуре агрегированных данных положение удаляемого ключа, для этого используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы.
Считывают из памяти текущую страницу и находят в ней первую запись, значение ключа которой больше либо равно значению удаляемого ключа.
Если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы используют в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы.
Если считанная страница является страницей 0-го уровня, то обнаруженная запись и есть ключ, подлежащий удалению.
В битовом векторе найденной записи устанавливают в ноль бит с номером строки входных данных, содержащей ключ, подлежащий удалению.
Если полученный битовый вектор состоит только из одних нулевых бит, то устанавливают признак удаления найденной записи.
Если признак удаления текущей записи установлен, то удаляют ее.
Если установлен признак замены предшествующей записи, то заменяют запись, находящуюся сразу перед текущей записью, на запись-представителя страницы, являющейся предшествующим братом к странице, которая была текущей на один уровень ниже.
Если установлен признак замены следующей записи, то заменяют запись, находящуюся сразу после текущей записи, на запись-представителя страницы, являющейся следующим братом к странице, которая была текущей на один уровень ниже.
При этом две страницы считают братьями (фиг.7), если у них есть общий предок на следующем верхнем уровне - страница следующего наверх уровня, записи которой ссылаются на эти страницы; поскольку ключи в страницах упорядочены, то все значения ключей одной из этих страниц больше всех значений ключей другой страницы, поэтому считают, что одна из этих страниц следует за другой страницей и называется следующим братом или одна из них предшествует другой странице и называется предшествующим братом.
Фиг.7 наглядно иллюстрирует страницы записи, которые считают братьями и у них есть общий предок на следующем верхнем уровне. Например, 5 и 6 - братья (5 - предшествующий брат для 6-го), 6 и 7 - братья (7 следующий брат для 6-го), но 8 и 5 - не братья, хотя стоят рядом.
Таким образом, рядом стоящие страницы, которые имеют общего предка на следующем уровне, - это страницы 3 и 4, страницы 6 и 7, 5 и 7.
Если текущая страница заполнена записями наполовину или более чем наполовину, то вычисляют новую запись-представителя текущей страницы и прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если полученная страница заполнена записями менее чем наполовину и у нее нет страниц, являющихся следующим или предшествующим братом текущей страницы, то вычисляют новую запись-представителя текущей страницы, прекращая обнаружение в текущей странице, и рекурсивно возвращаются в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если есть страница следующего брата и эта страница заполнена таким образом, что все записи текущей страницы можно перенести в эту страницу, то записи текущей страницы переносят в начало страницы ближайшего следующего брата и устанавливают признак удаления текущей записи.
При этом вычисляют новую запись-представителя страницы ближайшего следующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены следующей записи.
Если страница ближайшего следующего брата заполнена настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего следующего брата переносят в конец текущей страницы столько первых записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей.
При этом вычисляют новую запись-представителя страницы ближайшего следующего брата, выставляют признак замены следующей записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если следующий брат отсутствует, то рассматривают страницу ближайшего предшествующего брата, если эта страница заполнена таким образом, что все записи текущей страницы можно перенести в страницу ближайшего предшествующего брата, то записи текущей страницы переносят в конец страницы ближайшего предшествующего брата и устанавливают признак удаления текущей записи.
При этом вычисляют новую запись-представителя страницы предшествующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены предшествующей записи.
Если страница ближайшего предшествующего брата заполнена записями настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего предшествующего брата переносят в начало текущей страницы столько последних записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей.
При этом вычисляют запись-представителя страницы измененного ближайшего предшествующего брата, выставляют признак замены предшествующей записи, вычисляют запись-представителя измененной текущей страницы, прекращают обнаружение, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Для лучшего понимания описанной части алгоритма способа приведена фиг.8, которая наглядно иллюстрирует путь спуска при поиске записи, которую необходимо удалить (для простоты изложения описания и понимания именно процедуры спуска при поиске записи, которую следует удалить, опущены другие понятия признаков формулы).
Рассмотрим подробнее фиг.8, на которой иллюстративно представлены страницы (номера указаны арабскими цифрами в кружочках), которые заполнены записями, причем на одном уровне все эти записи упорядочены по возрастанию значений ключей. Все записи страницы 8 имеют ключи, меньшие, чем ключи записей страницы 5, 6, 7 и так далее. То есть по-другому, последняя запись страницы 8 имеет максимальный ключ (в этой странице). Причем этот ключ меньше, чем первый (а, значит, минимальный) ключ в странице 5.
Из этого следует, что и страницы на одном уровне имеют определенный порядок - 8, потом следует 5, 6, 7 и так далее.
На примере страниц 1, 4 и 6 показан путь спуска при поиске записи, которую следует удалить. По алгоритму удаления ищем в вершине (страница 1) первую запись с ключом, большим или равным искомому, пусть это будет Запись №3. Берем ее ссылку вниз - это страница 4. Читаем ее и снова ищем первую запись с ключом, большим или равным искомому, пусть это будет Запись №3/2 (ссылка вниз на страницу 6).
Читаем 6-ю страницу, ищем в ней. Пусть находим вторую запись (Запись №3/2/2) и обнуляем бит с номером удаляемой записи. Если после этого получаем битвектор, составленный из одних нулевых бит, то удаляется вся запись (Запись №3/2/2).
В том случае, если удалено столько, что 6-я страница стала заполненной менее чем наполовину, то записи 6-й страницы пытаются перенести в начало страницы ближайшего следующего брата, то есть в начало страницы 7. Если все записи с 6-й страницы переносят в 7-ю страницу, тогда получается, что 6-я страница не нужна (она не содержит записи и ее можно удалить).
Из изложенного выше следует, что в 4-й странице Запись №3/2 также не нужна и ее также нужно удалить, потому что она ни на что не ссылается.
Но ее правая запись (Запись №3/3 - представитель 7-й страницы на верхнем уровне), которая ссылается на 7-ю страницу, должна измениться, т.к. она отвечает за большую часть, состоящую из записей, которые были в этой странице, плюс записи, что перенесли из 6-й страницы.
Это значит, что у Записи №3/3 будет другой битвектор (больший того, который был ранее), другие значения агрегатных функций (например, сумму посчитали по большему числу записей).
Поэтому после переноса записи текущей страницы с ближайшего следующего брата - в 7-ю страницу заново вычисляют представителя ближайшего следующего брата, то есть ту запись, которая будет представлять 7-ю страницу на верхнем уровне - в 4-й странице, таким образом вычисляют новую Запись №3/3.
После этого, рекурсивно, поднимаются выше - на 4-ю страницу, где необходимо удалить Запись №3/2 и заменить Запись №3/3 на новую запись, которая была передана снизу с признаком замены следующей записи.
Если есть ближайший следующий брат, тогда работают с ним. Но если его нет, например 7-й страницы нет, тогда можно работать с ближайшим предшествующим братом, в нашем случае страница 5.
Опять же, если 6-я страница записей оказалась заполнена меньше, чем положено, то все записи 6-й страницы без изменения их порядка переносят в конец 5-й страницы (в конец для того, чтобы не нарушить порядок ключей, - все, что в 6-й странице, должно быть больше и располагаться «правее», чем то, что в 5-й странице). Тогда вычисляют новую запись-представителя предшествующего брата 5-й страницы и выставляют признак замены предшествующей Записи №3/1.
Далее обратимся к фиг.9, которая иллюстрирует алгоритм заявляемого способа, когда добавляют в структуру агрегированных данных ключ и номер строки входных данных, содержащей этот ключ.
Для чего в структуре агрегированных данных находят положение для вставки этого ключа. Для этого используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения на уровне текущей страницы.
Считывают из памяти текущую страницу и находят в ней первую запись, значение ключа которой больше либо равно значению удаляемого ключа. Если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы берут в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению поиска на уровне текущей страницы.
Если считанная страница является страницей 0-го уровня, то значение ключа найденной записи больше либо равно значению ключа добавляемой записи, при этом, если значения ключей равны, то в битовом векторе найденной записи устанавливают в единицу бит с номером строки входных данных, содержащей вставляемый ключ, и переходят к вычислению записи-представителя текущей страницы.
Если значение ключа найденной записи больше значения добавляемой записи, то формируют вставляемую запись из ключа добавляемой записи и битвектора, в котором установлен в единицу только один бит с номером строки входных данных, содержащей вставляемый ключ, и устанавливают признак добавления записи.
Если считанная страница не является страницей 0-го уровня, то выполняют замену текущей записи на запись-представителя страницы, которая была текущей на один уровень ниже.
Если признак добавления не установлен, то вычисляют новую запись-представителя текущей страницы и прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если установлен признак добавления записи и в текущей странице есть место для ее добавления, то новую запись вставляют перед текущей, сбрасывают признак добавления записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если установлен признак добавления записи и в текущей странице нет места для размещения новой записи, то создают новую страницу для нового предшествующего брата текущей страницы, первую половину записей текущей страницы переписывают во вновь созданную страницу, вставляют новую запись перед текущей записью и вычисляют запись-представителя страницы предшествующего брата, выставляют признак добавления записи и вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Причем при вычислении записи-представителя любой страницы структуры агрегированных данных ключом записи выбирают максимальное значение ключа этой страницы, значения заданных агрегатных функций вычисляют по всем значениям тех же агрегатных функций этой страницы или значениям аргументов этих функций, в качестве битового вектора используют объединение всех битовых векторов этой страницы, а в качестве ссылки на эту страницу, по которой строится эта запись, используют ее номер.
Заявляемый способ поиска данных посредством структуры агрегированных данных в системе управления базами данных осуществляют следующим образом (фиг.10-14).
Поиск данных в системе управления базами данных выполняют при условии, что входные данные состоят из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, нумеруют по строкам таким образом, что каждая строка получает уникальный номер, столбцы значений данных, которые содержат аналитическую информацию и используются в условиях отбора данных при поиске, сформированы в ключевую группу столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированы строки ключевой группы столбцов данных, сформированные строки ключевой группы столбцов данных определены как ключи, все ключи упорядочены по возрастанию, агрегированные данные сформированы в иерархическую структуру памяти записи страниц агрегированных данных, представляющую собой J уровней записи страниц, где J - целое неотрицательное число, заполненных записями, состоящими из ключа, ссылки на битовый вектор и вспомогательных данных о местоположении ключа, при этом вершинной страницей иерархической структуры записи страниц агрегированных данных является страница, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора.
Выполняют интервальный поиск (фиг.10), если требуется найти все строки входных данных, в которых значение ключей находится в интервале, ограниченном двумя заданными значениями ключей, или полуинтервале, ограниченном только с одной из сторон, создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы: находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, если такой записи не найдено или если конечный ключ отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы, когда между записями номер один и два находят другие записи, то все битвектора этих записей переписывают в результирующий битовый вектор, выделяют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавших в указанный интервал поиска, все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне, выделяют запись номер два, а в ней ссылку на страницу нижнего уровня записи, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы, если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавших в указанный интервал поиска, все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне, поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска.
Интервальный поиск выполняют известные способы, использующие для поиска многочисленные структуры организации данных, основанных на структурах В-деревьев, упомянутых, например, выше [1].
Во всех известных реализациях, использующих структуры В-деревьев, интервальный поиск связан с обходом всех страниц В-дерева, содержащих ключи, находящиеся в искомом интервале. Чем шире интервал, тем больше требуется работы для поиска всех ключей, входящих в интервал. В предельном случае (отсутствие условий, ограничивающих интервал) придется обойти все дерево.
Заявляемый способ формирования структуры агрегированных данных в отличие от прототипа и других известных способов, использующих структуру В-деревьев, во всех узлах страниц записи содержит битовые векторы, которые однозначно описывают строки входных данных, ключи которых находятся между ключом данной записи и ключом записи предыдущей. Таким образом, если в узле между записями, которые отвечают за концы (границы) поискового интервала (номер один и номер два), есть другие записи, то битовые вектора этих записей указывают на записи входных данных, ключи которых удовлетворяют интервальному условию.
Таким образом, для большинства записей страницы верхнего уровня не потребуется спуск в страницы нижних уровней. Спуск в страницы нижних уровней потребуется только для крайних записей (номер один, если существует левая граница, и номер два, если существует правая). При этом придется прочесть не более чем 2×Высота_дерева страниц (в сбалансированном дереве высота - это число страниц в любой его ветви). Из этого следует, что работа интервального поиска практически не зависит от размера интервала.
Выполняют интервальный поиск по предыдущей выборке (фиг.11), если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны. Для чего создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска.
Считывают из памяти вершинную страницу структуры агрегируемых данных и рекурсивно переходят к выполнению следующего поиска на уровне вершинной страницы.
Находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска. Если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы.
Находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, если такой записи не найдено или если конечный ключ отсутствует в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы.
Если между записями номер один и номер два есть другие записи, битовые вектора которых имеют непустое пересечение с входным битовым вектором, то все эти пересечения переписывают в результирующий битовый вектор.
Если битовый вектор записи номер один имеет непустое пересечение, то используют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись.
Считывают по этой ссылке страницу следующего вниз уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне.
Если битовый вектор записи номер два имеет непустое пересечение, то используют запись номер два, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу нижнего уровня.
Если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы.
Если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне, при этом результатом поиска является результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию и значение ключа которых находится в заданном интервале поиска.
Поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию поиска и значение ключа которых находится в заданном интервале поиска.
Предполагается, что заявляемый способ формирования структуры агрегированных данных используется в СУБД, основанной на последовательном вычислении предикатов, например СУБД ЛИНТЕР [5] (В.Е.Максимов, Л.А.Козленко, С.П.Маркин, И.А.Бойченко. Защищенная реляционная СУБД ЛИНТЕР, Открытые системы #11-12/1999). Речь идет о системах, которые полностью решают очередной предикат, прежде чем перейти к обработке следующего. В противоположность этому многие системы не пытаются получить полный ответ на поставленное условие. Такие системы работают по принципу «необходимой работы», заключающейся в том, что первый ответ обрабатываемого предиката поступает на вход второму предикату и т.д. При этом некоторый N-й ответ первого предиката может вообще не потребоваться пользователю, и следовательно, получать все ответы первого предиката вовсе не необходимо.
Однако в аналитических системах, где получаются общие оценки по полным выборкам или такие выборки группируются/сортируются, полные выборки чаще всего необходимы.
Очень часто различные условия поиска соседствуют с интервальным поиском. При этом к моменту интервального поиска может быть уже найдена выборка, удовлетворяющая некоторым другим условиям.
В некоторых СУБД такая выборка представляет собой битовый вектор, в котором установлены в единицу биты с номерами строк, удовлетворяющих некоторым условиям. Заявляемое изобретение будет наиболее эффективно именно в таких СУБД.
Рассматриваемый интервальный поиск по предыдущей выборке предполагает, что, кроме интервального условия, мы имеем еще входной битовый вектор, определяющий некоторое множество записей, удовлетворяющих каким-то другим условиям. При этом стоит задача найти среди этих записей те, ключи которых удовлетворяют интервальному условию. Этот поиск очень похож на интервальный поиск, только в результирующий битовый вектор записывают не битовые вектора записей, а их пересечения с входным битовым вектором.
Выполняют интервальный поиск по предыдущей выборке и сортировку его результатов (фиг.12), если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, при этом следует упорядочить эти строки по возрастанию ключевых значений. Для чего считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы. Находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы. Находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, если такой записи не найдено или если конечный ключ отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы.
Последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что битовый вектор такой очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница не является страницей 0-го уровня, то из очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись. Считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если данная страница является страницей 0-го уровня, то биты этого очередного пересечения указывают на строки входных данных, которые являются очередными по порядку возрастания значений ключей. Номера этих битов записывают в выходной поток, который представляет последовательность номеров записей в порядке возрастания ключей.
Поиск завершают после завершения поиска на уровне вершинной страницы, получая выходной поток номеров искомых строк, удовлетворяющих заданному критерию, причем значение ключа предшествующей строки меньше или равно значению ключа следующей строки.
Отметим, что часто используемые структуры агрегированных индексов (В-деревья) в известных технических решениях, например [1], представляют собой достаточно универсальную структуру, которая позволяет не только выполнять поиск, но также и получать упорядоченную по ключу последовательность ответов. Однако упомянутое упорядочение возможно только для интервального поиска.
Если выборка не представляет собой интервальный поиск (в данном случае выборка представляет собой интервальный поиск по предыдущей выборке, в вырожденном случае, когда концы интервала не определены, имеем просто некую произвольную выборку, которую необходимо упорядочить), то структура В-деревьев часто работает очень неоптимально потому, что для очень разреженных выборок придется все равно сканировать все дерево (в направлении возрастания/убывания ключей) и для каждого ключа проверять его принадлежность к имеющейся выборке.
Заявляемый способ формирования структуры агрегированных данных содержит в структуре битовые векторы во всех узлах дерева, ее записи имеют битовые векторы, которые однозначно описывают строки входного потока, ключи которых находятся в поддереве с вершиной, на которую ссылается данная запись.
Таким образом, для большинства записей страницы верхнего уровня не потребуется спуск в страницы нижних уровней. Спуск в страницы нижних уровней потребуется только для тех записей, битовый вектор которых имеет непустое пересечение с входным битовым вектором, описывающим предыдущую выборку.
Вычисляют агрегатную функцию на результатах интервального поиска в предыдущей выборке (на фиг.13 приведен пример - алгоритм для агрегатной функции SUM-суммы), если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих этому заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом на множестве найденных строк требуется вычислить указанную агрегатную функцию SUM-суммы.
Считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы. Находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы.
Находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, если такой записи не найдено или если конечный ключ отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы.
Последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если пересечение битового вектора очередной записи и входного битового вектора пусто, то запись пропускают и переходят к следующей записи.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и если данная страница является страницей 0-го уровня, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
Если страница не является страницей 0-го уровня, и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу нижнего уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция SUM-суммы не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегируемых данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция SUM-суммы является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления значения этой функции, находящейся в текущей записи, к текущему значению этой функции.
Поиск на ненулевом уровне текущей считанной страницы завершают, когда просмотрены все очередные записи между записью номер один и записью номер два.
Завершают поиск на уровне вершинной страницы, при этом текущее значение искомой агрегатной функции суммы является окончательным значением этой агрегатной функции.
Заявляемый способ формирования структуры агрегированных данных работает таким образом, что в каждый текущий момент времени содержит множество значений определенной агрегатной функции, которые вычислены на множестве ключей, находящихся в листе дерева (страница с 0-ым уровнем) или в целом поддереве.
Кроме того, сформированная структура согласно заявляемому способу в каждой записи имеет битовый вектор, описывающий строки входного потока, ключи которых находятся в поддереве с вершиной, на которую ссылается данная запись.
Таким образом, в этой структуре в некоторых случаях можно определить, что битовый вектор записи целиком входит в битовый вектор предыдущей выборки, поэтому без лишних вычислений можно воспользоваться тем значением определенной агрегатной функции, которое вычислено для поддерева данной записи.
С другой стороны, в этой структуре можно вообще не принимать в расчет те записи, битовые векторы которых имеют пустое пересечение с битовым вектором предыдущей выборки.
И в первом, и во втором случаях мы будем иметь существенную оптимизацию при вычислении агрегатной функции.
Выполняют группирование с вычислением агрегатной функции суммы по каждой из групп, построенных на результатах интервального поиска в предыдущей выборке (фиг.14), если имеется некая выборка строк входных данных, отобранных по заданному критерию, и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих этому заданному критерию, и требуется найти среди строк этой выборки все строки, в которых значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом все множество найденных строк требуется разбить на группы по заданному числу первых столбцов ключевой группы так, чтобы в каждой из групп все значения каждого из заданных первых столбцов совпали, и для каждой такой группы требуется вычислить указанную агрегатную функцию на одном из столбцов ключевой группы. Для чего считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы.
Находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, то в качестве записи номер один используют первую запись страницы.
Находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно конечному значению ключа интервала поиска, если такой записи не найдено или если конечное значение ключа отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы.
Последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и если обнаруживают, что битовый вектор очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи.
Если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления произведения значения аргумента этой функции в текущей записи и числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
Если данная страница является страницей 0-го уровня, но значение хотя бы одного из заданных первых столбцов ключевой группы не совпадает со значением соответствующего столбца в предыдущей записи, то предыдущую группу данных считают обработанной, значение искомой агрегатной функции суммы на этой группе данных вычисленным, и это значение передают в выходной поток вместе со значением заданных первых столбцов.
При этом новая группа данных начинается текущей записью, за ее текущее значение принимают произведение значения аргумента этой функции в текущей записи и числа бит пересечения битового вектора очередной записи с входным битовым вектором.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция, например, SUM-суммы не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегированных данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция, например, SUM-суммы является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных и при этом значение хотя бы одного из заданных первых столбцов не совпадает со значением соответствующего столбца в предыдущей записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы.
Если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция, например, SUM-суммы является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию SUM-суммы вычисляют путем добавления значения этой функции, находящегося в текущей записи, к текущему значению этой функции.
На уровне текущей считанной страницы поиск завершают, когда просмотрены все очередные записи между записью номер один и записью номер два.
Завершают группирование при завершении поиска на уровне вершинной страницы, при этом завершается выходной поток, в котором очередная группа строк представлена значениями первых столбцов, определяющих группирование, и значением искомой агрегатной функции SUM-суммы, вычисленным на строках этой группы.
Из изложенного выше следует, что заявляемый способ может выполнить такую сложную операцию, как группирование с вычислением агрегатных функций для каждой из групп.
Известные способы, использующие структуру В-деревьев, также допускают операцию группирования, но только в исключительном случае - интервального поиска (в вырожденном случае - это группирование по ключу упорядочения по всей таблице). Возможности способа-прототипа также ограничены группированием результатов интервального поиска, но при этом в некоторых случаях прототип вычислит агрегатные функции более оптимально по сравнению со способами, использующими структуру обычных В-деревьев. Это следует из того, что способ-прототип хранит в дереве значения определенных заранее агрегатных функций, вычисленных на множестве ключей, находящихся в листьях поддерева.
Однако способ-прототип сможет воспользоваться этими значениями только при группировании результатов интервального поиска.
Поэтому в ситуации, когда требуется группирование с вычислением агрегатных функций на произвольной выборке, будет бессилен как способ-прототип, так и все другие известные способы, использующие структуру разновидностей В-деревьев.
Осуществляют заявляемое изобретение на устройстве, структурная схема которого выполнена на фиг.15.
Устройство (фиг.15) для осуществления заявляемых способов содержит известные в вычислительной (цифровой компьютерной) технике устройства и блоки, например, аналогичные тем, которые описаны в патенте US №6,487,546 «Apparatus and method for aggregate indexes», Int. C1.7 G06F 17/30, опубликован 26 ноября 2002 г. Однако алгоритм работы этих известных блоков в части реализации признаков изобретения существенно отличается от прототипа.
Устройство (фиг.15) содержит блок управления курсором дисплея 9, блок ввода данных 10, дисплей 11, канал передачи информации 12, оперативное запоминающее устройство (ОЗУ) 13, постоянное запоминающее устройство (ПЗУ) 14, запоминающее устройство (ЗУ) 15, процессор 16, интерфейс связи 17, локальную сеть 18, ЭВМ 19, интернет 20 и сервер 21, при этом входы блока управления курсором дисплея 9, блока ввода данных 10 и дисплея 11 объединены и соединены по шине с первым выходом канала передачи информации 12, выходы блока управления курсором дисплея 9, блока ввода данных 10 и дисплея 11 соединены по шине с первым входом канала передачи информации 12, вторые вход и выход канала передачи информации 12 соединены по шине соответственно с выходом и входом ОЗУ 13, третьи вход и выход канала передачи информации 12 соединены по шине соответственно с выходом и входом ПЗУ 14, четвертые вход и выход канала передачи информации 12 соединены по шине соответственно с выходом и входом ЗУ 15, пятые вход и выход канала передачи информации 12 соединены по шине соответственно с выходом и входом процессора 16, шестые вход и выход канала передачи информации 12 соединены по шине соответственно с первыми выходом и входом интерфейса связи 17, вторые вход и выход которого соединены соответственно с первыми выходом и входом локальной сети 18, вторые вход и выход которой соединены соответственно с выходом и входом ЭВМ 19, третьи выход и вход локальной сети 18 соединены соответственно с первыми входом и выходом интернета 20, вторые выход и вход интернета 20 соединены соответственно с входом и выходом сервера 21.
Способ формирования структуры агрегируемых данных в системе управления базами данных осуществляют на устройстве (фиг.15).
Входные данные поступают из блока ввода данных 10 или дисплея 11, могут также поступать по сети через локальную сеть 18 и интерфейс связи 17. Входные данные, состоящие из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, нумерован по строкам таким образом, что каждая строка получила уникальный номер, хранятся также в ПЗУ 14 и/или ЗУ 15.
Выбирают через блок управления курсором дисплея 9, блок ввода данных 10 или дисплей 11 или по сети через локальную сеть 18 и/или интерфейс связи 17 из сформированных столбцов значений данных те столбцы, которые содержат аналитические данные или используются в условиях отбора данных при поиске и анализе, формируя таким образом ключевую группу столбцов данных.
Информацию о сформированной ключевой группе столбцов данных хранят в ЗУ 15 и, возможно, в ПЗУ 14. Для оперативного использования эту информацию записывают в ОЗУ 13.
Задают через блок управления курсором дисплея 9, блок ввода данных 10 или дисплей 11 или по сети через локальную сеть 18 и интерфейс связи 17 агрегатные функции: функцию SUM-суммы, функцию MIN - минимальное значение или MAX - максимальное значение и определяют столбцы ключевой группы столбцов данных, которые будут аргументами этих заданных функций при формировании структуры агрегируемых данных, записывают в ЗУ 15 и, возможно, в ПЗУ 14.
По управляющему сигналу процессора 16 через канал передачи информации 12 посредством ОЗУ 13 и ЗУ 14 формируют строки ключевой группы столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированные строки ключевой группы столбцов данных определяют как ключи. Все ключи упорядочивают по возрастанию.
Посредством блоков 12, 13, 15 и 16 формируют J уровней страниц, где J - целое неотрицательное число, заполняя их записями, состоящими из ключа, ссылки на битовый вектор и вспомогательных данных о местоположении ключа. Упомянутые страницы структуры агрегируемых данных размещают в ЗУ 15.
Каждую запись в странице 0-го уровня формируют из ключа и из ссылки на битовый вектор, в который установлены в единицу биты с номерами, соответствующими номерам строк входных данных, имеющих тот же ключ. Вспомогательные данные на этом уровне не используют. Упомянутые битовые вектора структуры агрегируемых данных в общем случае также размещают на ЗУ 15.
Каждую очередную запись в странице 1-го уровня формируют с использованием последней заполненной страницы 0-го уровня, при этом ключом записи выбирают максимальное значение ключа, сформированное для этой страницы 0-го уровня, в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех ключей страницы 0-го уровня по тем полям, которые соответствуют столбцам, заданным аргументами этих агрегатных функций, и ссылки на страницу 0-го уровня, по которой построена эта запись.
Каждую последующую запись в странице J-го (J>1) уровня формируют с использованием последней заполненной страницы предыдущего (J-1)-го уровня, при этом ключом записи выбирают максимальное значение ключа последней сформированной страницы (J-1)-го уровня, в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы (J-1)-го уровня, такую запись, построенную по странице предыдущего уровня, назначают записью-представителем этой страницы, эта запись содержит ключ, который представляет собой максимальный ключ этой страницы, значения заданных агрегатных функций, вычисленные по всем значениям тех же агрегатных функций или значениям аргументов этих функций этой страницы, и битовый вектор, являющийся объединением всех битовых векторов этой страницы, и ссылки на страницу (J-1)-го уровня. Вспомогательные данные записи составляют из значений заданных агрегатных функций по всем значениям тех же агрегатных функций или значениям аргументов этих функций, вычисленных в странице (J-1)-го уровня по соответствующим аргументам этих агрегатных функций, и ссылки на страницу (J-1)-го уровня, по которой строится эта запись.
Процесс формирования иерархической структуры записи страниц агрегированных данных заканчивают, когда на очередном уровне останется единственная страница, называемая вершинной страницей, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора. Сформированную иерархическую структуру записи страниц агрегированных данных записывают в ЗУ 15.
Периодически обновляют входные данные по мере их поступления, для чего находят и удаляют записи структуры агрегированных данных, добавляют в структуру агрегированных данных записи, относящиеся к добавляемым строкам входных данных, выполняют обнаружение и удаляют записи со старым значением ключа, добавляют записи с новым значением ключа при замене ключа в строке входных данных.
Через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13 и ЗУ 15 по алгоритму для осуществления поддержки сформированной структуры агрегированных данных находят и удаляют из сформированной структуры агрегированных данных ключ и номер строки входных данных, содержащей этот ключ, подлежащие удалению или замене на новые данные, для чего находят в структуре агрегированных данных положение удаляемого ключа, для этого
используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы:
Используя канал передачи 12, в блоках считывают из памяти текущую страницу и находят в ней первую запись, ключ которой больше либо равен удаляемому ключу.
Если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы используют в найденной записи ссылку (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13) на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы. Если считанная страница является страницей 0-го уровня, то обнаруженная запись и есть ключ, подлежащий удалению.
В битовом векторе найденной записи устанавливают в ноль бит (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13 и ЗУ 15) с номером строки входных данных, содержащей ключ, подлежащий удалению, если полученный битовый вектор состоит только из одних нулевых бит, то устанавливают признак удаления найденной записи. Если признак удаления текущей записи установлен, то удаляют ее.
Если установлен признак замены предшествующей записи, то заменяют запись (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13), находящуюся сразу перед текущей записью, на запись-представителя страницы, являющейся предшествующим братом к странице, которая была текущей на один уровень ниже.
Если установлен признак замены следующей записи, то заменяют запись (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13), находящуюся сразу после текущей записи, на запись-представителя страницы, являющейся следующим братом к странице, которая была текущей на один уровень ниже.
Если текущая страница заполнена наполовину или более чем наполовину, то вычисляют новую запись-представителя текущей страницы и выходят из поиска в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если полученная страница заполнена менее чем наполовину и у нее нет страниц, являющихся следующим или предшествующим братом текущей страницы, то вычисляют новую запись-представителя текущей страницы, прекращая обнаружение в текущей странице, и рекурсивно возвращаются в страницу, которая была текущей на уровень выше с признаком замены текущей записи (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13).
Если есть страница следующего брата и эта страница заполнена таким образом, что все записи текущей страницы можно перенести в эту страницу, то записи текущей страницы переносят в начало страницы ближайшего следующего брата и устанавливают признак удаления текущей записи (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13 и ЗУ 15). При этом вычисляют новую запись-представителя страницы ближайшего следующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены следующей записи.
Если страница ближайшего следующего брата заполнена настолько, что в нее невозможно полностью перелить записи текущей страницы, то из страницы ближайшего следующего брата переливают в конец текущей страницы столько первых записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13 и ЗУ 15). При этом вычисляют новую запись-представителя страницы ближайшего следующего брата, выставляют признак замены следующей записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Если следующий брат отсутствует, то рассматривают страницу ближайшего предшествующего брата, если эта страница заполнена таким образом, что все записи текущей страницы можно перенести в страницу ближайшего предшествующего брата, то записи текущей страницы переносят в конец страницы ближайшего предшествующего брата и устанавливают признак удаления текущей записи. При этом вычисляют новую запись-представителя страницы предшествующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены предшествующей записи.
Если страница ближайшего предшествующего брата заполнена настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего предшествующего брата переносят в начало текущей страницы столько последних записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей. При этом вычисляют запись-представителя страницы измененного ближайшего предшествующего брата, выставляют признак замены предшествующей записи, вычисляют запись-представителя измененной текущей страницы, прекращают обнаружение, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13 и ЗУ 15 добавляют в структуру агрегированных данных ключ и номер строки входных данных, содержащей этот ключ, для чего в структуре агрегированных данных находят положение для вставки этого ключа. Для этого
используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения на уровне текущей страницы:
считывают из памяти текущую страницу и находят в ней (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13) первую запись, ключ которой больше либо равен удаляемому ключу;
если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы берут в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению поиска на уровне текущей страницы;
если считанная страница является страницей 0-го уровня, то ключ найденной записи больше либо равен ключу добавляемой записи, при этом, если ключи равны, то в битовом векторе найденной записи устанавливают в единицу бит с номером строки входных данных, содержащей вставляемый ключ, и переходят к вычислению записи-представителя текущей страницы, если ключ найденной записи больше добавляемой записи, то формируют вставляемую запись из ключа добавляемой записи и битвектора, в котором установлен в единицу только один бит с номером строки входных данных, содержащей вставляемый ключ, и устанавливают признак добавления записи;
если считанная страница не является страницей 0-го уровня, то выполняют замену текущей записи на запись-представителя страницы, которая была текущей на один уровень ниже;
если признак добавления не установлен, то вычисляют новую запись-представителя текущей страницы и выходят из поиска в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи;
если установлен признак добавления записи и в текущей странице есть место для ее добавления, то новую запись вставляют перед текущей, сбрасывают признак добавления записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи;
если установлен признак добавления записи и в текущей странице нет места для размещения новой записи, то создают новую страницу (через канал передачи информации 12 по управляющему сигналу с процессора 16 в ОЗУ 13 и ЗУ 15) для нового предшествующего брата текущей страницы, первую половину записей текущей страницы переписывают во вновь созданную страницу, вставляют новую запись перед текущей записью и вычисляют запись-представителя страницы предшествующего брата, выставляют признак добавления записи и вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
Способ поиска данных посредством структуры агрегируемых данных в системе управления базами данных осуществляют на устройстве (фиг.15) по описанному выше алгоритму.
Запросы на вид поиска через блок управления курсором дисплея 9, блок ввода данных 10, дисплей 11 поступают по шине на первые входы канала передачи 12, по управляющему сигналу процессора 16 через пятые входы и вторые и четвертые выходы канала передачи информации 12 поступает на входы ОЗУ 13 и ЗУ 15.
Однако запросы, использующие предыдущую выборку (входной битовый вектор), чаще всего являются очередным этапом обработки более сложного запроса, поэтому они создаются частично в ОЗУ 13, частично в ЗУ 15 и выполняются по управляющему сигналу с процессора 16.
Сам запрос на поиск хранится в ОЗУ 13, при этом некоторые виды поисковых запросов имеют входной битовый вектор, который может храниться частично в ОЗУ 13, частично в ЗУ 15.
Для запросов с интервальным поиском и интервальным поиском с предыдущей выборкой результатом работы является битовый вектор, который может храниться частично в ОЗУ 13 (небольшая оперативная часть битового вектора), частично в ЗУ 15, это - так называемый результирующий битовый вектор. Если результирующий битовый вектор невелик, для его хранения может быть достаточно только его оперативной части в ОЗУ 13.
Результирующий битовый вектор потом может быть использован процессором 16 в качестве входного битового вектора для реализации других запросов, а может служить основой для построения в ОЗУ 13 ответов для передачи их пользователю по каналу передачи информации 12 на блоки 9, 10, 11 или через интерфейс связи 17, локальную сеть 18.
Для запросов интервального поиска по предыдущей выборке и сортировке его результатов результатом работы является выходной поток битовых векторов (располагающихся частично в ОЗУ 13, частично в ЗУ 15). Очередной такой битовый вектор описывает очередной набор строк входных данных, удовлетворяющих условию запроса, в этом наборе все строки имеют один и тот же ключ, причем ключ этого набора больше, чем ключ предыдущего набора.
Каждый такой очередной битовый вектор выходного потока может быть использован процессором 16 в качестве входного битового вектора для реализации других запросов, а может служить основой для построения в ОЗУ 13 ответов для передачи их пользователю по каналу передачи информации 12 на блоки 9, 10, 11 или через интерфейс связи 17, локальную сеть 18.
Для запросов на вычисление агрегатной функции на результатах интервального поиска в предыдущей выборке результатом работы является значение агрегатной функции, хранящееся в ОЗУ 13.
Это значение потом может быть использовано процессором 16 для формирования нового запроса или передано пользователю по каналу передачи информации 12 на блоки 9, 10, 11 или через интерфейс связи 17, локальную сеть 18.
Для запросов на группирование с вычислением агрегатной функции по каждой из групп, построенных на результатах интервального поиска в предыдущей выборке, результатом работы является выходной поток значений (хранящихся в ОЗУ 13), в который для каждой группы записывают значение искомой агрегатной функции на этой очередной группе и значения заданных первых столбцов (которые имеют все ключи в группе).
Каждая такая запись выходного потока может быть использована процессором 16 как для формирования нового запроса, так и для передачи пользователю по каналу передачи информации 12 на блоки 9, 10, 11 или через интерфейс связи 17, локальную сеть 18.
Таким образом, заявляемая группа изобретений, созданных в едином изобретательском замысле, позволяет получить лучший технический эффект по сравнению с известным уровнем в данной области техники, а именно может быть сформирована такая структура агрегированных данных, которая периодически обновляется и поддерживается в динамике и позволяет выполнять более сложные запросы поиска данных, ускорять поиск данных по различным типам запросов в системе управления базами данных, агрегировать найденные данные в группы, быстро находить статистику по этим группам и оперативно сортировать искомые данные. Особенно актуальным является быстрое агрегирование и сбор статистики произвольного запроса.
Список литературы
1. R.Bayer, Binary B-Trees for Virtual Memory, ACM-SIGFIDET Workshop, 1971, San Diego, California, Session 5B, pp.219-235.
2. Кнут Д.Э. Искусство программирования, Т. 3: Сортировка и поиск, Пер. с англ. Изд. 2, М.: Вильямс, 2004, 832 с.
3. Патент US №7,120,637 «Positional access using a B-tree», Int. C1. G06F 17/30, опубликован 10 октября 2006 г.
4. Патент US №6,487,546 «Apparatus and method for aggregate indexes», Int. C1.7 G06F 17/30, опубликован 26 ноября 2002 г.
5. В.Е.Максимов, Л.А.Козленко, С.П.Маркин, И.А.Бойченко, Защищенная реляционная СУБД ЛИНТЕР, Открытые системы #11-12/1999.
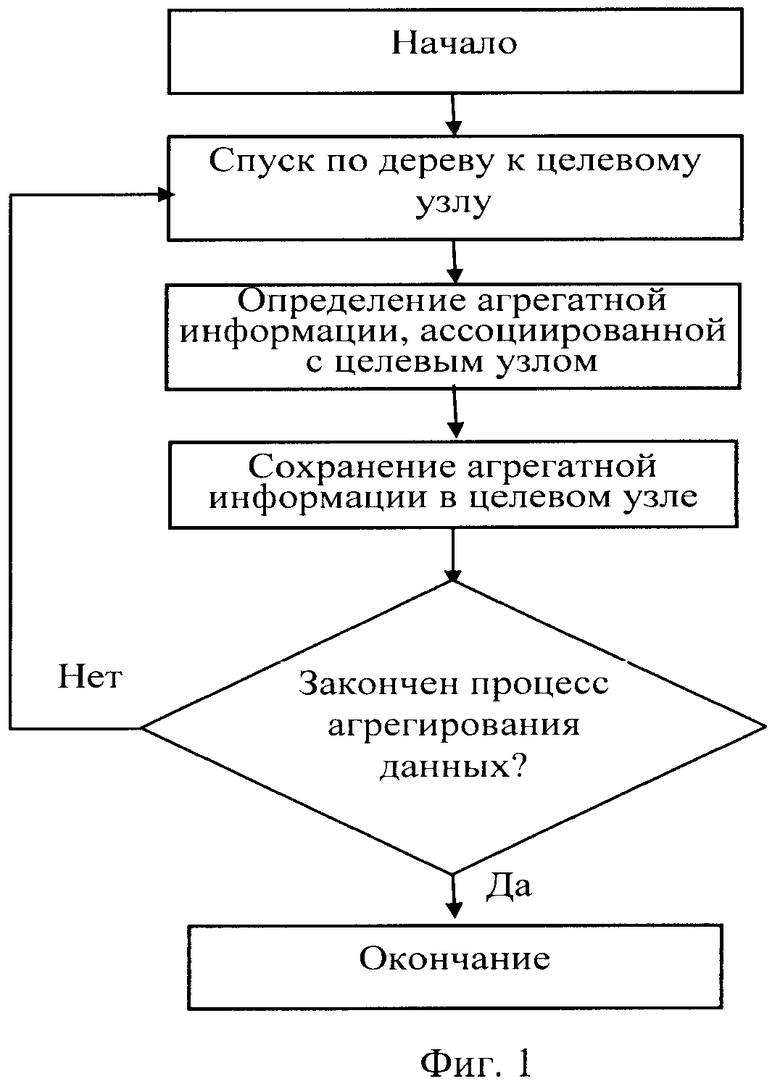
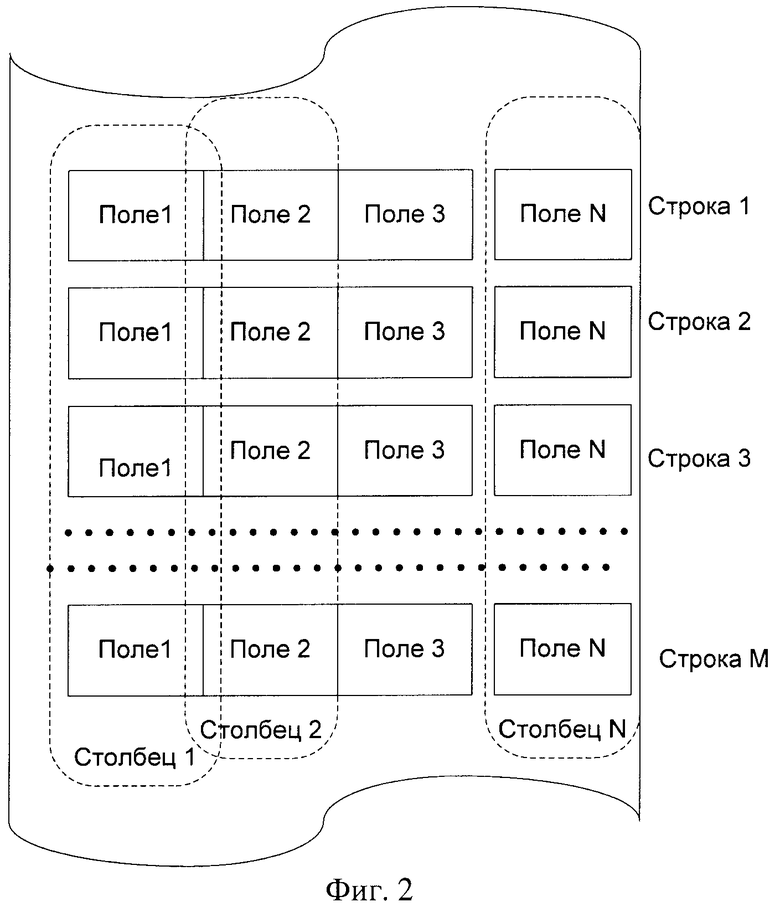
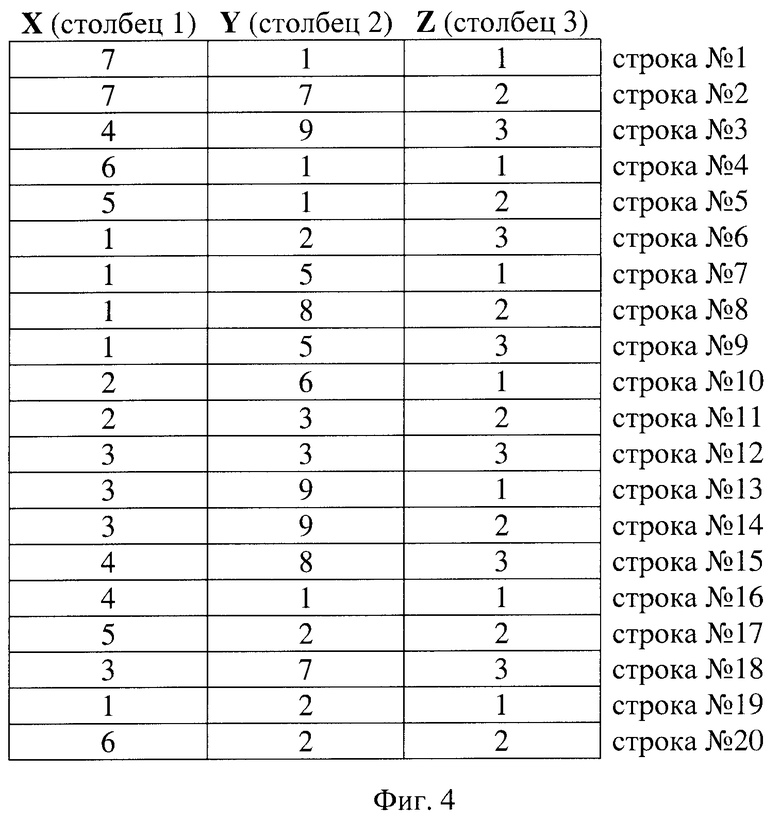
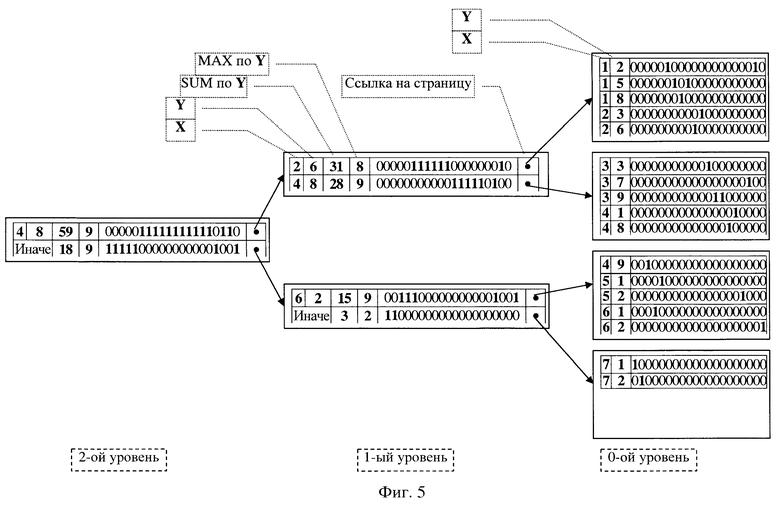
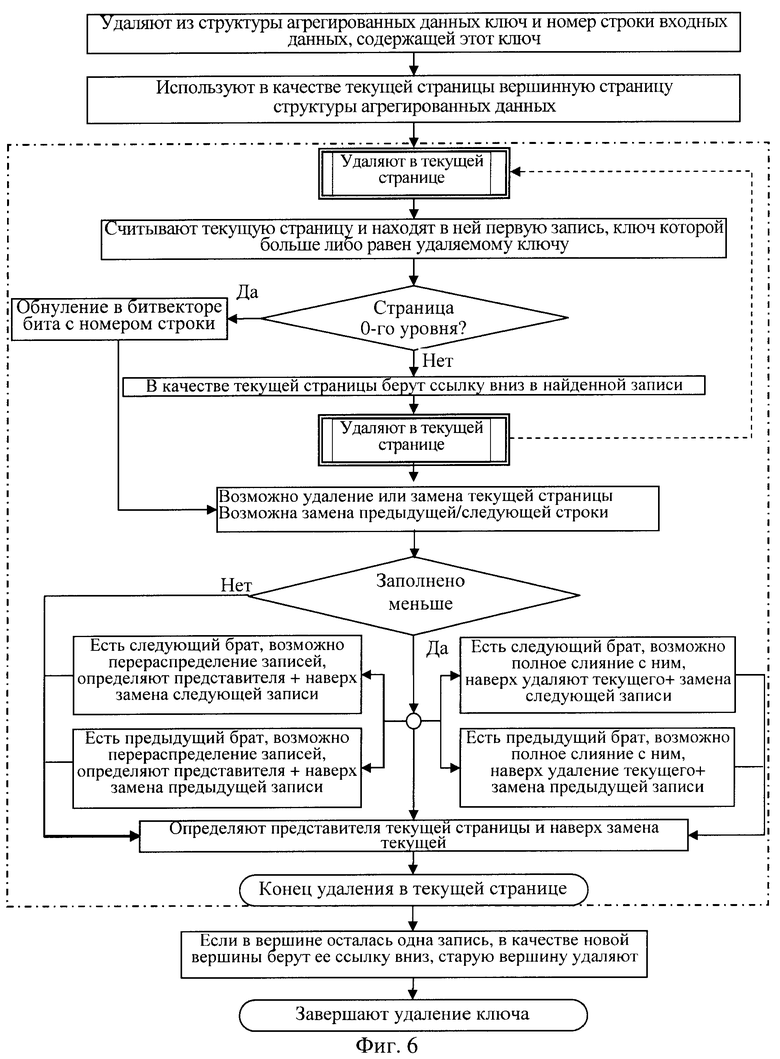
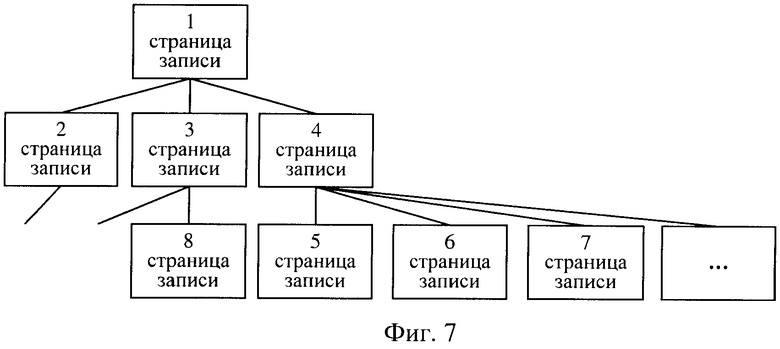
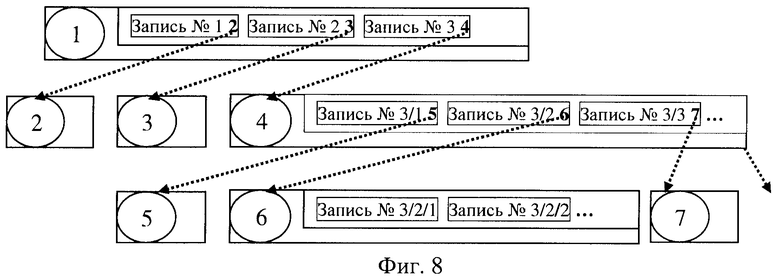
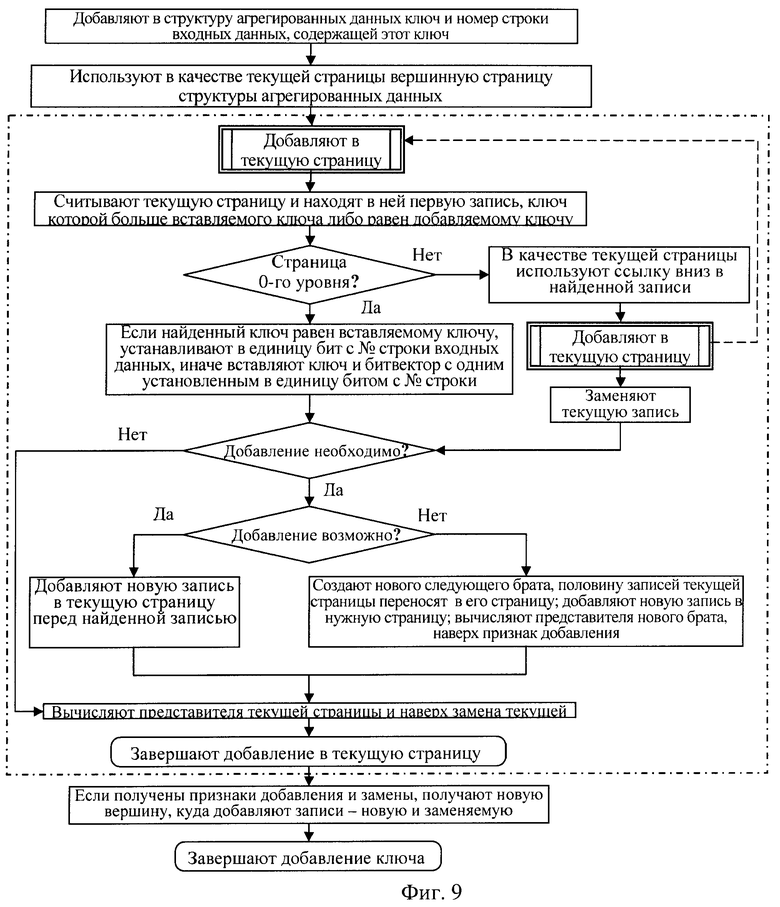
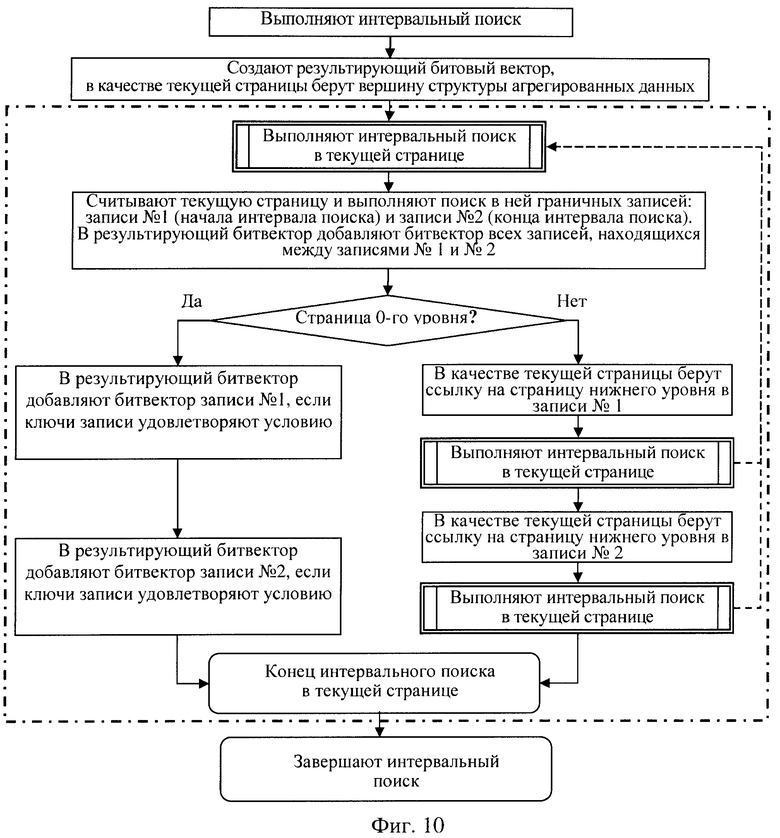
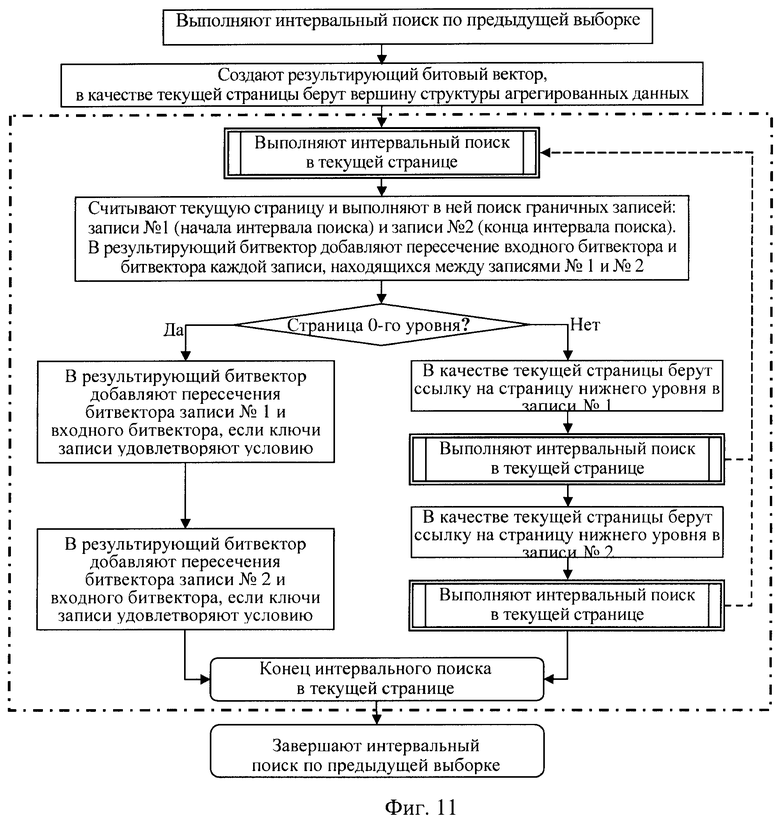
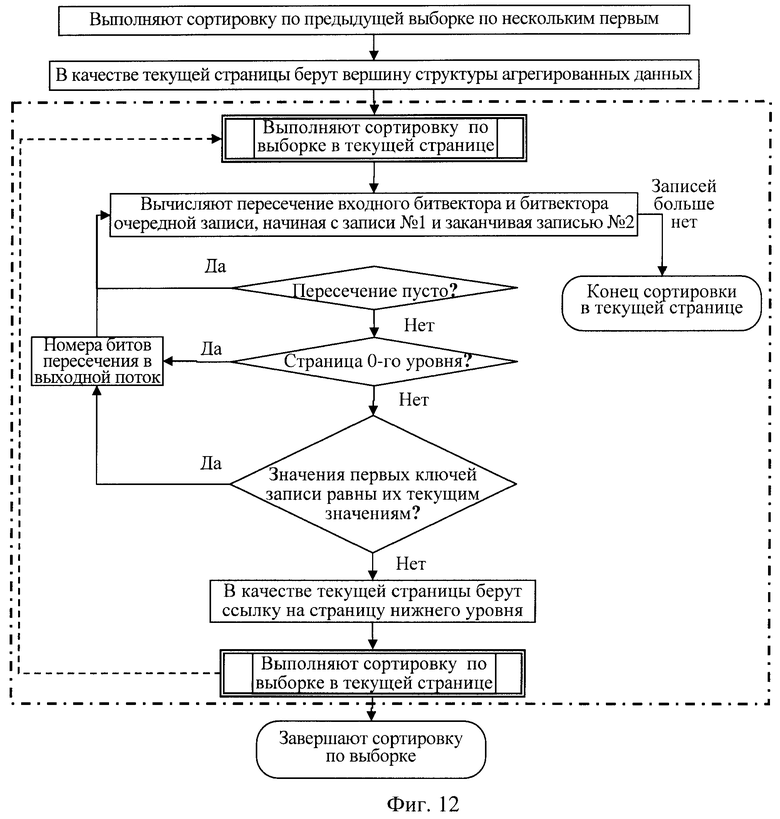
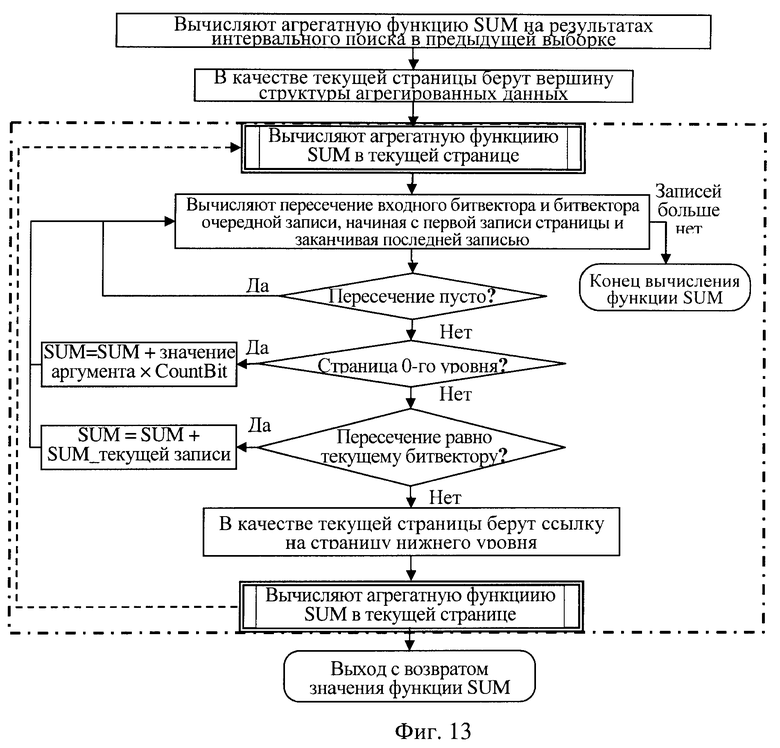
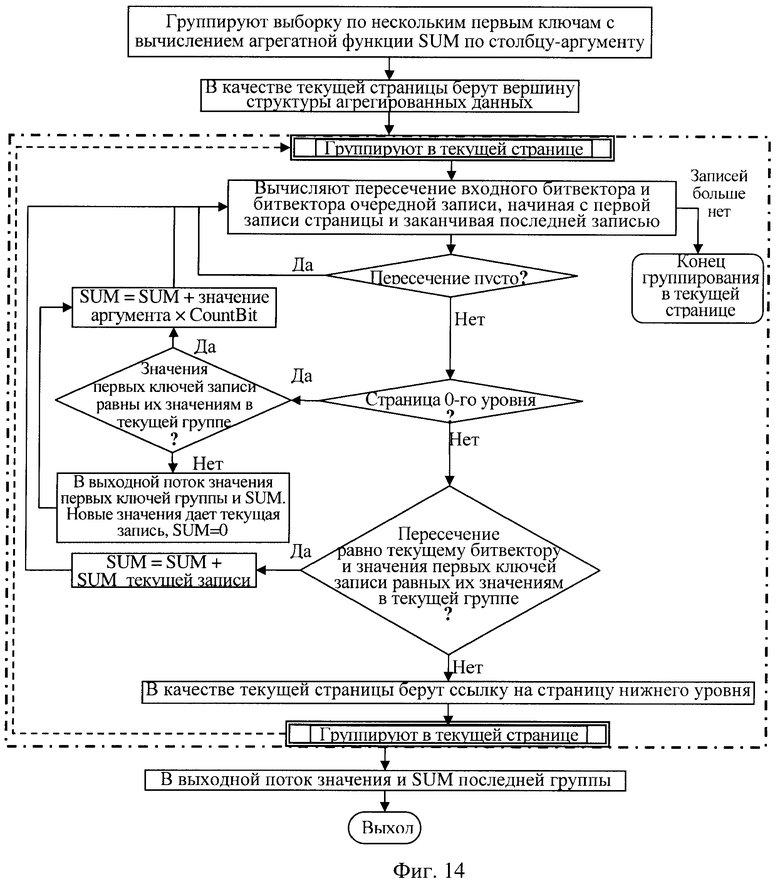
Изобретение относится к вычислительной технике, в частности к способу формирования структуры агрегированных данных и способу поиска данных посредством структуры агрегированных данных в системе управления базами данных (СУБД), и может быть использовано в СУБД. Техническим результатом является расширение возможностей поиска за счет ускорения поиска данных по различным типам запросов в системе управления базами данных, быстрой статистической обработке этих групп и оперативной сортировке искомой информации, которые достигаются благодаря сформированной структуре агрегированных данных и ее динамического обновления. Новизна и технический результат изобретения заключаются в том, что, формируя иерархическую структуру записи страниц агрегированных данных в СУБД, каждый блок совокупностей записей этой структуры с вершиной в странице N, кроме максимального ключа страницы N и ссылки на страницу N, представлен в записи более верхнего уровня битовым вектором, описывающим все ключи этого блока, и значениями агрегатных функций (указанных заранее), посчитанных на ключах этого блока. При этом каждую запись в странице 0-го уровня формируют, используя ссылку на битовый вектор, в котором установлены в единицу биты с номерами строк входных данных, имеющих тот же ключ. 2 н. и 22 з.п. ф-л., 15 ил.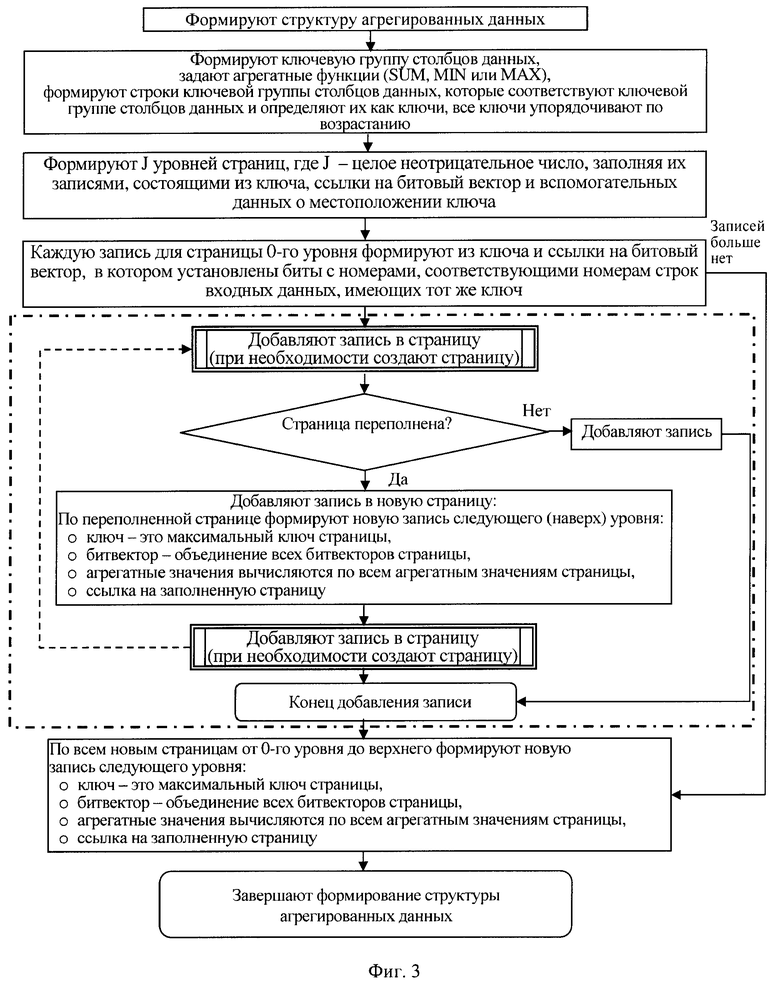
1. Способ формирования структуры агрегированных данных в системе управления базами данных, в которой входные данные, состоящие из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, а совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, нумеруют по строкам таким образом, что каждая строка получает уникальный номер, заключающийся в том, что выбирают из сформированных столбцов значений данных те столбцы, которые используются в условиях отбора данных при поиске, формируя, таким образом, ключевую группу столбцов данных, задают агрегатные функции и определяют столбцы ключевой группы столбцов данных, которые будут аргументами заданных функций при формировании структуры агрегируемых данных, формируют строки ключевой группы столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированные строки ключевой группы столбцов данных определяют как ключи, все ключи упорядочивают по возрастанию, формируют J уровней страниц, где J - целое неотрицательное число, заполняя их записями, состоящими из ключа и вспомогательных данных о местоположении ключа, каждую запись в странице 0-го уровня формируют из ключа, каждую очередную запись в странице 1-го уровня формируют с использованием последней заполненной страницы 0-го уровня, при этом ключом записи выбирают максимальное значение ключа, сформированное для этой страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций и ссылки на страницу 0-го уровня, по которой построена эта запись, каждую последующую запись в странице J-го (J>1) уровня формируют с использованием последней заполненной страницы предыдущего (J-l)-го уровня, при этом ключом записи выбирают максимальное значение ключа последней сформированной страницы (J-1)-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по всем значениям тех же агрегатных функций или значениям аргументов этих функций, вычисленных в странице (J-1)-го уровня, и ссылки на страницу (J-1)-го уровня, по которой строится эта запись, процесс формирования иерархической структуры записи страниц агрегированных данных для поиска и анализа данных заканчивают, когда на очередном уровне останется единственная страница, называемая вершинной страницей, периодически обновляют входные данные по мере их поступления, для чего находят и удаляют записи структуры агрегированных данных, относящиеся к удаляемым строкам входных данных, добавляют в структуру агрегированных данных записи, относящиеся к добавляемым строкам входных данных, выполняют обнаружение и удаляют записи со старым значением ключа, добавляют записи с новым значением ключа при замене ключа в строке входных данных, отличающийся тем, что, формируя J уровней страниц записи, заполняют их ссылками на битовый вектор, при этом каждую запись в странице 0-го уровня формируют из ссылки на битовый вектор, в который установлены в единицу биты с номерами, соответствующими номерам строк входных данных, имеющих тот же ключ, при формировании каждой очередной записи в странице 1-го уровня в качестве ссылки на битовый вектор выбирают ссылку на объединение всех битовых векторов страницы 0-го уровня, вспомогательные данные записи составляют из значений заданных агрегатных функций по множеству всех ключей страницы 0-го уровня по тем полям, которые соответствуют столбцам, заданным аргументами этих агрегатных функций, при формировании каждой последующей записи в странице J-го уровня в качестве ссылки на битовый вектор записи выбирают ссылку на объединение всех битовых векторов страницы (J-1)-го уровня, такую запись, построенную по странице предыдущего уровня, назначают записью-представителем этой страницы, эта запись содержит ключ, который представляет собой максимальное значение ключа этой страницы, значения заданных агрегатных функций, вычисленные по всем значениям тех же агрегатных функций или значениям аргументов этих функций этой страницы, и битовый вектор, являющийся объединением всех битовых векторов этой страницы, и ссылки на страницу (J-1)-го уровня, процесс формирования иерархической структуры записи страниц агрегированных данных для поиска и анализа данных заканчивают, когда на очередном уровне останется вершинная страница, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора; обновляя входные данные, находят и удаляют из сформированной структуры агрегированных данных ключ и номер строки входных данных, содержащей этот ключ, подлежащие удалению или замене на новые данные, для чего находят в структуре агрегированных данных положение удаляемого ключа, для этого в качестве текущей страницы используют вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы: считывают из памяти текущую страницу и находят в ней первую запись, значение ключа которой больше либо равно значению удаляемого ключа, если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы используют в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению обнаружения положения удаляемого ключа на уровне текущей страницы, если считанная страница является страницей 0-го уровня, то обнаруженная запись и есть ключ, подлежащий удалению, в битовом векторе найденной записи устанавливают в ноль бит с номером строки входных данных, содержащей ключ, подлежащий удалению, если полученный битовый вектор состоит только из одних нулевых бит, то устанавливают признак удаления найденной записи, если признак удаления текущей записи установлен, то удаляют ее, если установлен признак замены предшествующей записи, то заменяют запись, находящуюся сразу перед текущей записью, на запись-представителя страницы, являющейся предшествующим братом к странице, которая была текущей на один уровень ниже, если установлен признак замены следующей записи, то заменяют запись, находящуюся сразу после текущей записи, на запись-представителя страницы, являющейся следующим братом к странице, которая была текущей на один уровень ниже, при этом две страницы считают братьями, если у них есть общий предок на следующем верхнем уровне - страница следующего наверх уровня, записи которой ссылаются на эти страницы; поскольку ключи в страницах упорядочены, то все значения ключей одной из этих страниц больше всех значений ключей другой страницы, поэтому считают, что одна из этих страниц следует за другой страницей и называется следующим братом, или одна из них предшествует другой странице и называется предшествующим братом, если текущая страница заполнена записями на половину или более, чем на половину, то вычисляют новую запись-представителя текущей страницы и прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи, если полученная страница заполнена записями менее чем на половину и у нее нет страниц, являющихся следующим или предшествующим братом текущей страницы, то вычисляют новую запись-представителя текущей страницы, прекращая обнаружение в текущей странице, и рекурсивно возвращаются в страницу, которая была текущей на уровень выше с признаком замены текущей записи, если есть страница следующего брата и эта страница заполнена записями таким образом, что все записи текущей страницы можно перенести в эту страницу, то записи текущей страницы переносят в начало страницы ближайшего следующего брата и устанавливают признак удаления текущей записи, при этом вычисляют новую запись-представителя страницы ближайшего следующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены следующей записи, если страница ближайшего следующего брата заполнена записями настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего следующего брата переносят в конец текущей страницы столько первых записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей, при этом вычисляют новую запись-представителя страницы ближайшего следующего брата, выставляют признак замены следующей записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи, если следующий брат отсутствует, то рассматривают страницу ближайшего предшествующего брата, если эта страница заполнена записями таким образом, что все записи текущей страницы можно перенести в страницу ближайшего предшествующего брата, то записи текущей страницы переносят в конец страницы ближайшего предшествующего брата и устанавливают признак удаления текущей записи, при этом вычисляют новую запись-представителя страницы предшествующего брата, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены предшествующей записи, если страница ближайшего предшествующего брата заполнена записями настолько, что в нее невозможно полностью перенести записи текущей страницы, то из страницы ближайшего предшествующего брата переносят в начало текущей страницы столько последних записей, сколько необходимо для того, чтобы в обеих страницах получилось примерно равное число записей, при этом вычисляют запись-представителя страницы измененного ближайшего предшествующего брата, выставляют признак замены предшествующей записи, вычисляют запись-представителя измененной текущей страницы, прекращают обнаружение, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи, добавляют в структуру агрегированных данных ключ и номер строки входных данных, содержащей этот ключ, для чего в структуре агрегированных данных находят положение для вставки этого ключа, для этого используют в качестве текущей страницы вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению обнаружения на уровне текущей страницы: считывают из памяти текущую страницу и находят в ней первую запись, значение ключа которой больше либо равно значению добавляемого ключа, если считанная страница не является страницей 0-го уровня, то в качестве текущей страницы берут в найденной записи ссылку на страницу следующего вниз уровня, которая породила эту запись, и рекурсивно переходят к выполнению поиска на уровне текущей страницы, если считанная страница является страницей 0-го уровня, то значение ключа найденной записи больше либо равно значению ключа добавляемой записи, при этом, если значения ключей равны, то в битовом векторе найденной записи устанавливают в единицу бит с номером строки входных данных, содержащей вставляемый ключ, и переходят к вычислению записи-представителя текущей страницы, если значение ключа найденной записи больше значения добавляемой записи, то формируют вставляемую запись из ключа добавляемой записи и битвектора, в котором установлен в единицу только один бит с номером строки входных данных, содержащей вставляемый ключ, и устанавливают признак добавления записи, если считанная страница не является страницей 0-го уровня, то выполняют замену текущей записи на запись-представителя страницы, которая была текущей на один уровень ниже, если признак добавления не установлен, то вычисляют новую запись-представителя текущей страницы и прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи, если установлен признак добавления записи, и в текущей странице есть место для ее добавления, то новую запись вставляют перед текущей записью, сбрасывают признак добавления записи, вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи, если установлен признак добавления записи, и в текущей странице нет места для размещения новой записи, то создают новую страницу для нового предшествующего брата текущей страницы, первую половину записей текущей страницы переписывают во вновь созданную страницу, вставляют новую запись перед текущей записью и вычисляют запись-представителя страницы предшествующего брата, выставляют признак добавления записи и вычисляют новую запись-представителя текущей страницы, прекращают обнаружение в текущей странице, рекурсивно возвращаясь в страницу, которая была текущей на уровень выше с признаком замены текущей записи.
2. Способ по п.1, отличающийся тем, что при формировании ключевой группы столбцов данных из сформированных столбцов значений данных выбирают те столбцы, которые содержат аналитические данные.
3. Способ по п.1, отличающийся тем, что в качестве агрегатных функций вычисляют, функции: COUNT, определяющей число строк или значений, или SUM - суммы, или MIN - минимальное значение, или МАХ - максимальное значение или их комбинации, a AVG - среднее значение получают как частное от отношения вычисленной агрегатной функции SUM - суммы к вычисленной агрегатной функции COUNT, определяющей число строк или значений.
4. Способ по п.1, отличающийся тем, что при вычислении записи-представителя любой страницы структуры агрегированных данных ключом записи выбирают максимальное значение ключа этой страницы, значения заданных агрегатных функций вычисляют по всем значениям тех же агрегатных функций этой страницы или значениям аргументов этих функций, в качестве битового вектора используют объединение всех битовых векторов этой страницы, а в качестве ссылки на эту страницу, по которой строится запись, используют ее номер.
5. Способ поиска данных посредством структуры агрегированных данных в системе управления базами данных, в которой входные данные состоят из строк одинаковой структуры, где каждая строка представлена набором полей с заданными значениями, совокупность значений одного и того же поля в разных строках образует столбец значений данных, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, а каждая строка получила уникальный номер, столбцы значений данных, которые содержат аналитическую информацию и используются в условиях отбора данных при поиске, сформированы в ключевую группу столбцов данных, используя поля строк входных данных, которые соответствуют ключевой группе столбцов данных, сформированы строки ключевой группы столбцов данных, сформированные строки ключевой группы столбцов данных определены как ключи, все ключи упорядочены по возрастанию, агрегированные данные сформированы в иерархическую структуру памяти записи страниц агрегированных данных, представляющую собой J уровней записи страниц, где J - целое неотрицательное число, заполненных записями, состоящими из ключа, ссылки на битовый вектор и вспомогательных данных о местоположении ключа, при этом вершинной страницей иерархической структуры записи страниц агрегированных данных является страница, содержащая записи, в которых записаны значения заранее определенных агрегатных функций с наибольшей степенью агрегирования, а также наиболее полные битовые вектора, заключающийся в том, что выполняют интервальный поиск, если требуется найти все строки входных данных, в которых значение ключей находится в интервале, ограниченном двумя заданными значениями ключей, или полуинтервале, ограниченном только с одной из сторон, выполняют интервальный поиск по предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, вычисляют агрегатную функцию на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию, и требуется найти среди строк этой выборки все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, выполняют группирование с вычислением агрегатной функции, отличающийся тем, что, выполняя интервальный поиск, создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы: находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, когда между записями номер один и два находят другие записи, то все битвектора этих записей переписывают в результирующий битовый вектор, выделяют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавшие в указанный интервал поиска, все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне, выделяют запись номер два, а в ней ссылку на страницу нижнего уровня записи, которая породила эту запись, считывают по этой ссылке страницу следующего вниз нижнего уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы, если эта страница является страницей 0-го уровня, то в ней находят все значения ключей, попавшие в указанный интервал поиска, все битовые вектора найденных ключей переписывают в результирующий битовый вектор и завершают поиск на нулевом уровне, поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска; выполняют интервальный поиск по предыдущей выборке, если имеется выборка строк входных данных, заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, для чего создают результирующий битовый вектор для установки в нем битов, соответствующих номерам искомых строк входных данных, значение ключа которых находится в заданном интервале поиска, считывают из памяти вершинную страницу структуры агрегируемых данных и рекурсивно переходят к выполнению поиска на уровне вершинной страницы: находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, если между записями номер один и номер два есть другие записи, битовые вектора которых имеют непустое пересечение с входным битовым вектором, то все эти пересечения переписывают в результирующий битовый вектор, если битовый вектор записи номер один имеет непустое пересечение, то используют запись номер один, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне, если битовый вектор записи номер два имеет непустое пересечение, то используют запись номер два, а в ней ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу нижнего уровня, если эта страница не является страницей 0-го уровня, то рекурсивно переходят к выполнению поиска на уровне считанной страницы, после завершения которой завершают поиск на уровне текущей страницы, если эта страница является страницей 0-го уровня, то в ней находят все ключи, битовые вектора которых имеют непустое пересечение с входным битовым вектором и которые попали в указанный интервал, переписывают эти пересечения в результирующий битовый вектор и завершают поиск на нулевом уровне, при этом результатом поиска является результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию и значение ключа которых находится в заданном интервале поиска, поиск завершают после завершения поиска на уровне вершинной страницы, получая результирующий битовый вектор, биты которого соответствуют номерам искомых строк входных данных, которые удовлетворяют заданному критерию поиска и значение ключа которых находится в заданном интервале поиска; выполняют интервальный поиск по предыдущей выборке и сортировку его результатов, если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, и требуется найти среди строк этой выборки и отсортировать по значениям ключей все те строки, где значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, при этом следует упорядочить эти строки по возрастанию ключевых значений, для чего считывают из памяти вершинную страницу структуры агрегируемых данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы: находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и, если обнаруживают, что битовый вектор такой очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, и, если данная страница не является страницей 0-го уровня, то из очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если данная страница является страницей 0-го уровня, то биты этого очередного пересечения указывают на строки входных данных, которые являются очередными по порядку возрастания значений ключей, номера этих битов записывают в выходной поток, который представляет последовательность номеров записей в порядке возрастания значений ключей, поиск завершают после завершения поиска на уровне вершинной страницы, получая выходной поток номеров искомых строк, удовлетворяющих заданному критерию, причем значение ключа предшествующей строки меньше или равно значению ключа следующей строки; вычисляют агрегатную функцию на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих заданному критерию, при этом на множестве найденных строк требуется вычислить указанную агрегатную функцию, для чего считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы: находят в текущей считанной странице запись номер один, первую запись, значение ключа которой больше либо равно начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, значение ключа которой больше либо равно значению конечного ключа интервала поиска, последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и, если обнаруживают, что пересечение битового вектора очередной записи и входного битового вектора пусто, то запись пропускают и переходят к следующей записи, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, и, если данная страница является страницей 0-го уровня, то искомую агрегатную функцию вычисляют, используя текущее значение аргумента этой функции и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором, в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу нижнего уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, и искомая агрегатная функция не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегируемых данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если страница не является страницей 0-го уровня, и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, и искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегируемых данных, то искомую агрегатную функцию вычисляют, используя текущее значение искомой функции, значение этой функции, находящейся в текущей записи, и число бит битового вектора очередной записи, поиск на ненулевом уровне текущей считанной страницы завершают, когда просмотрены все очередные записи между записью номер один и записью номер два, завершают поиск на уровне вершинной страницы, при этом текущее значение искомой агрегатной функции является окончательным значением этой агрегатной функции; группирование с вычислением агрегатной функции выполняют по каждой из групп, построенных на результатах интервального поиска в предыдущей выборке, если имеется выборка строк входных данных, отобранных по заданному критерию и заданных в виде входного битового вектора с битами, номера которых соответствуют номерам строк входных данных, удовлетворяющих этому заданному критерию, и требуется найти среди строк этой выборки все строки, в которых значение ключей находится в интервале, ограниченном двумя заданными ключами, или полуинтервале, ограниченном только с какой-либо одной стороны, и при этом все множество найденных строк требуется разбить на группы по заданному числу первых столбцов ключевой группы так, чтобы в каждой из групп все значения каждого из заданных первых столбцов совпали, и для каждой такой группы требуется вычислить указанную агрегатную функцию на одном из столбцов ключевой группы, для чего считывают из памяти вершинную страницу структуры агрегированных данных и переходят рекурсивно к выполнению поиска на уровне вершинной страницы: находят в текущей считанной странице запись номер один, первую запись, ключ которой больше либо равен начальному значению ключа интервала поиска, находят в текущей странице запись номер два, первую запись, ключ которой больше либо равен конечному значению ключа интервала поиска, последовательно считывают каждую очередную запись, начиная с записи номер один и заканчивая записью номер два, и, если обнаруживают, что битовый вектор очередной записи не пересекается с входным битовым вектором, то запись пропускают и переходят к следующей записи, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня, и, если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию вычисляют, используя значение аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора очередной записи с входным битовым вектором, если данная страница является страницей 0-го уровня, но значение хотя бы одного из заданных первых столбцов ключевой группы не совпадает со значением соответствующего столбца в предыдущей записи, то предыдущую группу данных считают обработанной, значение искомой агрегатной функции на этой группе данных вычисленным, и это значение передают в выходной поток вместе со значением заданных первых столбцов, при этом новая группа данных начинается текущей записью, а ее текущее значение искомой агрегатной функции вычисляют, используя значение аргумента этой функции в текущей записи и число бит непустого пересечения битового вектора в текущей записи, если страница не является страницей 0-го уровня, и пересечение битового вектора очередной записи с входным битовым вектором не совпадает с битовым вектором очередной записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня, и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция не совпадает ни с одной агрегатной функцией, использованной при построении структуры агрегированных данных, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня, и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значение, хотя бы одного из заданных первых столбцов не совпадает со значением соответствующего столбца в предыдущей записи, то в очередной записи используют ссылку на страницу следующего вниз уровня, которая породила эту запись, считывают по этой ссылке страницу следующего вниз уровня, и рекурсивно переходят к выполнению поиска на уровне считанной страницы, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию вычисляют, используя текущее значение этой функции или текущее значение этой функции, находящейся в текущей записи и число бит битового вектора очередной записи, на уровне текущей считанной страницы, поиск завершают, когда просмотрены все очередные записи между записью номер один и записью номер два, завершают группирование при завершении поиска на уровне вершинной страницы, при этом завершается выходной поток, в котором очередная группа строк представлена значениями первых столбцов, определяющих группирование, и значением искомой агрегатной функции, вычисленным на строках этой группы, полученный выходной поток данных в процессе поиска преобразуют в следующий выходной поток данных, в котором, используя полученные значения заданных первых столбцов данных, определяют очередную ключевую группу столбцов данных и значение искомой агрегатной функции.
6. Способ по п.5, отличающийся тем, что при выполнении поиска и нахождении в текущей считанной странице записи номер один, если начальное значение ключа отсутствует, в случае, когда значение ключа находится в полуинтервале, ограниченном только сверху, в качестве записи номер один используют первую запись страницы.
7. Способ по п.5, отличающийся тем, что при выполнении поиска и нахождении в текущей считанной странице записи номер два, если не найдено первой записи, значение ключа которой больше либо равно значению конечного ключа интервала поиска, или, если конечный ключ отсутствует, в случае полуинтервала поиска, то в качестве записи номер два используют последнюю запись страницы.
8. Способ по п.5, отличающийся тем, что, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, и если данная страница является страницей 0-го уровня, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
9. Способ по п.5, отличающийся тем, что, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором и, если данная страница является страницей 0-го уровня, то искомую агрегатную функцию SUM - суммы вычисляют путем добавления произведения значения аргумента этой функции в текущей записи и числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
10. Способ по п.5, отличающийся тем, что, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, и если данная страница является страницей 0-го уровня, то в качестве нового значения искомой агрегатной функции MIN - минимальное значение или искомой агрегатной функции МАХ - максимальное значение выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
11. Способ по п.5, отличающийся тем, что, если страница не является страницей 0-го уровня и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит битового вектора очередной записи к текущему значению этой функции.
12. Способ по п.5, отличающийся тем, что, если страница не является страницей 0-го уровня, и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, и искомая агрегатная функция SUM - суммы является одной из тех агрегатных функций, которую использовали при построении структуры агрегированных данных, то искомую агрегатную функцию SUM - суммы вычисляют путем добавления значения этой функции, находящейся в текущей записи, к текущему значению этой функции.
13. Способ по п.5, отличающийся тем, что, если страница не является страницей 0-го уровня, и непустое пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, и искомая агрегатная функция MIN - минимальное значение или МАХ - максимальное значение является одной из тех агрегатных функций, которую использовали при построении структуры агрегируемых данных, то в качестве нового значения искомой функции выбирают соответственно минимальное или максимальное из двух значений: текущего значения искомой функции и значения этой функции, находящейся в текущей записи.
14. Способ по п.5, отличающийся тем, что для вычисления функции AVG - среднее значение, вычисляют значения агрегатных функций SUM - суммы и COUNT, определяющей число строк или значений, a AVG - среднее значение получают как частное этих двух значений.
15. Способ по п.5, отличающийся тем, что, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня, и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
16. Способ по п.5, отличающийся тем, что, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня, и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то искомую агрегатную функцию SUM - суммы вычисляют путем добавления произведения значения аргумента этой функции в текущей записи и числа бит непустого пересечения битового вектора очередной записи с входным битовым вектором к текущему значению этой функции.
17. Способ по п.5, отличающийся тем, что, если битовый вектор очередной записи имеет непустое пересечение с входным битовым вектором, а данная страница является страницей 0-го уровня, и если очередная запись принадлежит очередной группе строк, где значения заданных первых ключевых столбцов совпадают со значениями соответствующих ключевых столбцов в предыдущей записи, то в качестве нового значения искомых агрегатных функций MIN - минимальное значение или МАХ - максимальное значение выбирают соответственно минимальное или максимальное из двух значений: текущего значения функции и значения аргумента в текущей записи.
18. Способ по п.5, отличающийся тем, что, когда новую группу данных начинают с текущей записи, для искомой агрегатной функции COUNT, определяющей число строк или значений, за ее текущее значение принимают число бит пересечения битового вектора очередной записи с входным битовым вектором.
19. Способ по п.5, отличающийся тем, что, когда новую группу данных начинают с текущей записи, для искомой агрегатной функции SUM - суммы за ее текущее значение принимают произведение значения аргумента этой функции в текущей записи и числа бит пересечения битового вектора очередной записи с входным битовым вектором.
20. Способ по п.5, отличающийся тем, что, когда новую группу данных начинают с текущей записи, для искомых агрегатных функций MIN - минимальное значение или МАХ - максимальное значение за ее текущее значение принимают соответственно значение аргумента в текущей записи.
21. Способ по п.5, отличающийся тем, что, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию COUNT, определяющую число строк или значений, вычисляют путем прибавления числа бит битового вектора очередной записи к текущему значению этой функции.
22. Способ по п.5, отличающийся тем, что, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция SUM - суммы является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то искомую агрегатную функцию SUM - суммы вычисляют путем добавления значения этой функции, находящегося в текущей записи, к текущему значению этой функции.
23. Способ по п.5, отличающийся тем, что, если страница не является страницей 0-го уровня и пересечение битового вектора очередной записи с входным битовым вектором совпадает с битовым вектором очередной записи, а искомая агрегатная функция MIN - минимальное значение или МАХ - максимальное значение является одной из тех агрегатных функций, которые использованы при построении структуры агрегированных данных, и при этом значения заданных первых столбцов записи совпадают со значениями соответствующих столбцов в предыдущей записи, то в качестве нового значения искомой функции MIN - минимальное значение или МАХ - максимальное значение выбирают соответственно минимальное или максимальное из двух значений: текущего значения искомой функции и значения этой функции, находящейся в текущей записи.
24. Способ по п.5, отличающийся тем, что, когда завершают выходной поток, в котором очередная группа строк представлена значением искомой агрегатной функции, вычисленным на строках этой группы, при вычислении функции AVG - среднее значение, вычисляют значения агрегатных функций SUM - суммы и COUNT, определяющей число строк или значений, а значение функции AVG - среднее значение получают как частное этих двух значений, получая выходной поток данных, содержащий значения заданных первых столбцов данных, которые определяют очередную ключевую группу столбцов данных, значение искомой агрегатной функции SUM - суммы, вычисленное для строк этой ключевой группы столбцов данных, и значение искомой агрегатной функции COUNT, определяющей число строк или значений.
| US 6487546 В1, 26.11.2002 | |||
| МНОГОМЕРНАЯ БАЗА ДАННЫХ И СПОСОБ УПРАВЛЕНИЯ МНОГОМЕРНОЙ БАЗОЙ ДАННЫХ | 2008 |
|
RU2389066C2 |
| Прибор для регистрации порывов ветра | 1939 |
|
SU63036A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

