Область техники
Настоящее изобретение относится к компьютерным системам, более конкретно к системам обнаружения неизвестных вредоносных объектов.
Уровень техники
В настоящее время в антивирусной индустрии широко распространены технологии сигнатурного и эвристического анализа вредоносного программного обеспечения (ПО), что ранее было вполне достаточно для защиты пользователей, так как скорость появления новых вредоносных программ была относительно невысокой: десятки и сотни в день. И даже небольшие антивирусные лаборатории могли проанализировать такое число обнаруживаемых вредоносных файлов.
Рост численности пользователей сети Интернет и приход в сеть электронной коммерции (например, онлайн-магазинов, электронной оплаты услуг в сети) обусловили активное развитие деятельности злоумышленников на сегодняшний день. Число ежедневно обнаруживаемых программ лишь за последние три года возросло более чем в 10 раз. И темпы роста продолжают увеличиваться. Таким образом, антивирусные лаборатории пытаются снизить нагрузку на аналитиков, работающих с поступающими вредоносными файлами, путем внедрения различных автоматических или автоматизированных методов обнаружения неизвестного вредоносного ПО. Сигнатурные способы плохо приспособлены для подобных целей, так как они ориентированы исключительно на нахождение известных объектов. Под объектами будем понимать файлы различного формата, например исполняемые файлы, сценарии, документы и др. Это связано с тем, что в их основе лежит сравнение значений хеш-функции от небольших участков файла. Таким образом, в силу криптографических свойств функций хеширования изменение даже одного бита во входных данных полностью меняет выходной результат. Многие злоумышленники используют этот факт в свою пользу, и, следовательно, во время проверки вредоносный файл с незначительными изменениями может признаться безопасным, так как сигнатуры для него и для выявленных ранее объектов будут отличаться. Для оценки подобных ситуаций в антивирусной индустрии используют два параметра, характеризующих работу антивирусного ПО. Одним из них является уровень обнаружения неизвестного вредоносного программного обеспечения, определяемый как отношение обнаруженных вредоносных объектов ко всему множеству вредоносных объектов, на котором работал антивирус. Другим параметром (уровнем ложных срабатываний) считается отношение количества безопасных объектов, признанных вредоносными, ко всему множеству безопасных объектов, на котором проводилось исследование. Эвристические методы защиты также обладают недостатками при обнаружении неизвестного вредоносного ПО: во-первых, длительное, относительно сигнатурных методов, время работы, а, во-вторых, они уже близки к границе своих возможностей, обеспечивая обнаружение на уровне 60-70%. Дальнейший рост уровня обнаружения может осуществляться лишь в незначительной степени. Это связано прежде всего с тем, что обнаружение вредоносного ПО эвристическими методами является более трудоемким процессом по сравнению с добавлением сигнатуры в базу данных. Поэтому подобный механизм осуществляется только для целых классов вредоносного ПО. Таким образом, эвристические методы не учитывают единичные экземпляры ПО. В том числе, можно также отметить, что они требуют длительной доработки и подвержены риску ложных срабатываний. При этом, используя комплексный подход в области обнаружения вредоносного ПО, предложенный ниже, можно повысить уровень защиты пользователей.
Помимо традиционных методов сигнатурного сравнения и эвристических методов был использован способ построчного сравнения, который заключается в выделении уникальных строк из исполняемого файла и сравнении их с аналогичными элементами, характерными для вредоносного ПО. Примером подобной технологии является заявка US 20050223238 A1, в которой описываются механизмы построчного сравнения. При этом для получения множества уникальных строк на первом этапе из файла удаляются все общеупотребительные строки, например, вызовы различных API-функций, а также строки, которые характерны для безопасного ПО. После указанного удаления по статистике остается около 10-20% от исходного числа строк, именно эта информация и признается уникальной. В дальнейшем происходит сравнение выбранных строк с уже известными аналогами, относящимися к вредоносному ПО. Результатом работы описанного способа является выявление количества одинаковых строк в исследуемом файле и в ранее известном вредоносном ПО. При этом для однозначного выявления вредоносного программного обеспечения в некоторых случаях все же может потребоваться участие человека - антивирусного аналитика.
Впоследствии были предложены варианты определения вредоносного ПО, исходя из сравнения функциональности анализируемой программы с уже известными шаблонами. При этом под функциональностью в большинстве случаев подразумеваются трассы выполнения (см. Фиг.7) и графы вызовов.
Трасса выполнения программы - это последовательность вызываемых процедур и функций с указанием передаваемых им параметров. В качестве примера на Фиг.7 показана часть трассы выполнения для программного «червя». Под вредоносным ПО класса «червь» подразумевается программное обеспечение, которое способно несанкционированно копировать свое тело по сетевым ресурсам с сохранением возможности дальнейшего распространения. С более подробным определением можно ознакомиться по ссылке - http://www.securelist.com/ru/glossary?glossid=152527951. В указанном фрагменте происходит определение сетевого адреса компьютера по его имени, соединение с ним и передача информации. Таким образом, трасса выполнения программы является достаточно удобным инструментом при анализе ПО, так как можно непосредственно отследить сам порядок действий.
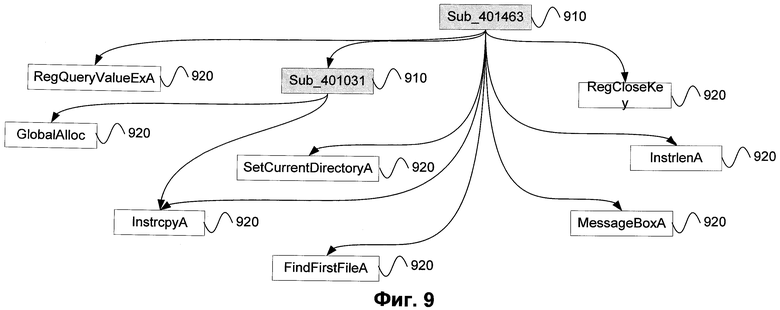
Графы вызовов показывают в статическом режиме структуру ПО, при этом вершинами в них является множество некоторых процедур или функций, а ребра отражают возможность прямого обращения из одной вершины в другую. Графы вызовов обычно делят на два подмножества. В случае невысокой степени детализации речь идет о так называемых call-графах (термин, использующийся в специальной литературе), иначе говорят о flow-графах. В дальнейшем в описании изобретения будем придерживаться аналогичной терминологии. Для сравнения Фиг.8 и Фиг.9 демонстрируют примеры flow- и call-графа соответственно. Фиг.8 представляет собой часть flow-графа для «троянской программы» (подробное определение можно посмотреть по ссылке - http://www.securelist.com/ru/glossary?letter=244#gloss152528302). На Фиг.8 вершинами являются логические блоки (последовательность инструкций на низкоуровневом языке, вызываемых до команды перехода), а ребрами - вызовы одного логического блока из другого. В отличие от flow-графа, в call-графе, как указано на Фиг.9, вершинами являются процедуры или функции, написанные на высокоуровневом языке. При этом условие существования ребра между двумя вершинами не меняется. Также в call-графе выделяют уникальные функции 910 (написанные самим программистом) и стандартные 920 (библиотечные).
Так, например, подобный механизм предложен в заявке US 20070240215 A1, где рассматривается трасса выполнения программы. В патенте US 7093239 B1 шаблон функциональности формируется во время запуска ПО в виртуальной среде. В заявке US 20070094734 A1 описывается порядок построения деревьев, характеризующих процесс выполнения рассматриваемой программы. Недостатком указанных технологий является запуск в виртуальной среде (например, на виртуальной машине или в эмуляторе), что является ресурсоемкой операцией. Также некоторые вредоносные объекты проверяют факт работы в виртуальной среде, в случае которого происходит завершение их деятельности. Если же виртуальная среда не используется, вредоносное ПО может запускаться непосредственно на компьютере, что приведет к его заражению - процессу нежелательному как для пользователя, так и для антивирусной компании. Часто описанный выше механизм называют активным заражением. Обнаружение вредоносного ПО в указанных выше патентах и заявках основано в первую очередь на определении уровня «похожести» на элемент класса вредоносного ПО. При этом термин «похожесть» в области программного обеспечения определяется с точки зрения наличия одинаковых частей и определения их количества. Для этих целей вводится некоторое правило сравнения, например, расстояние Левенштейна между двумя объектами и пороговое значение этого расстояния, при превышении которого объекты признаются принадлежащими разным классам. Так, например, в заявке US 20070136455 A1 описывается механизм классификации ПО на основании задания некоторого правила и порогового значения. В заявке US 20090631001 также предлагается способ классификации (кластеризации), однако он основан на том, какие именно действия выполняются программой. То есть на первом этапе ПО запускается в виртуальной среде (например, на виртуальной машине), а затем на основании заранее известных шаблонов причисляется к тому или иному классу. В том числе на основании указанного способа предлагается классифицировать и вредоносное ПО. Объединение технологий классификации и поведенческого анализа показало хорошие результаты как при обнаружении вредоносных исполняемых файлов, так и при оптимизации размеров антивирусных баз.
Однако подобные технологии плохо применимы для других типов вредоносного ПО, например, для сценариев (скриптов, scripts) и документов. В первую очередь, это связано с различиями в технологии работы и с форматом файлов.
Таким образом, требуется создание обобщенной модели обнаружения вредоносных объектов, учитывающей различные типы файлов, такие как, например, исполняемые файлы, скрипты, документы и т.д. В то же время в некоторых случаях существуют ситуации, когда подобные системы не могут однозначно определить вредоносный исполнимый файл. Например, расстояние между объектами превышает заданное пороговое значение, но все же очень близко к нему. Помимо совершенствования технологий обнаружения вредоносных программ, существует также проблема, связанная с временем реагирования на неизвестные компьютерные угрозы. Существуют ситуации, когда на компьютере пользователя невозможно определить, является ли объект вредоносным или нет. В таких случаях на данный момент на сервер антивирусной компании отправляется информация об объекте, например имя, размер, значение хеш-функции. Однако для дальнейшего анализа потребуется получить образец объекта, что может занять длительное время. Передача от пользователя файла целиком могла бы сократить время реакции. Но на данный момент количество поступающих запросов от пользователей, содержащих информацию об имени, размере и хеш-значении файла, на серверы антивирусных компаний достигает десятков тысяч в день, что порождает большой трафик. Таким образом, учитывая степень загруженности сетевых каналов и серверов антивирусных компаний, передача файлов целиком не всегда нецелесообразна, так как возрастет объем трафика, и серверы антивирусных лабораторий будут не в состоянии его обработать. В связи с этим нужно применять механизмы взаимодействия с пользователем, когда о программном обеспечении передается информация, которая, во-первых, существенно меньше в объеме по сравнению с исходным файлом, а во-вторых, обеспечивает высокую надежность при обнаружении вредоносного ПО.
Таким образом, требуется получить способ, который позволял бы минимизировать количество случаев, когда антивирусная система не может в режиме реального времени обработать информацию, приходящую от пользователей, и дать точный ответ по поводу анализируемого объекта.
Наряду с усовершенствованием механизмов определения вредоносного ПО стоит обратить внимание на ретростективу развития отрасли антивирусных технологий. После опубликования (реализации) новых технологий вирусописатели со своей стороны анализируют их. Такой анализ направлен в первую очередь на поиск механизмов, позволяющих избежать обнаружения вредоносного ПО уже известными способами. Таким образом, противодействие «меча» и «щита» будет существовать до тех пор, пока существуют данные, представляющие интерес для кого-либо. Из чего следует, что эффективность даже очень хорошей технологии может снижаться по мере того, как злоумышленники будут находить новые возможности сокрытия вредоносного ПО. Здесь и далее под эффективностью понимается соотношение уровня обнаружения неизвестных вредоносных объектов и уровня ложных срабатываний при таком обнаружении. В частном варианте эффективность антивирусного ПО может определяться как разность между уровнем обнаружения и уровнем ложных срабатываний.
В связи с этим доверие к технологиям, известным и используемым на данный момент, должно быть основано на их текущей эффективности. В качестве примера снижения эффективности обнаружения можно привести ситуацию с построчным сравнением. Злоумышленники, проанализировав суть метода, начинают использовать механизмы, снижающие его эффективность, например шифрование и динамическую генерацию строк. Фиг.13А демонстрирует в качестве примера часть строк для двух троянских программ сходной вредоносной функциональности. Однако при сравнении их строк видно, что практически все из них разные. Таким образом, метод построчного сравнения не даст верного результата в этом случае. Другим примером деградации антивирусной технологии может послужить использование лишних вызовов API-функций в ответ на обнаружение вредоносных программ методом анализа графов вызовов. Фиг.13Б указывает на то, что две вредоносные программы осуществляют одинаковые действия, однако при этом совершают дополнительные (лишние) шаги, которые не влияют на конечный результат. Такие мусорные инструкции затрудняют использование графов вызовов для обнаружения вредоносного ПО.
Анализ предшествующего уровня техники и возможностей позволяет получить новый технический результат, заключающийся в повышении эффективности обнаружения неизвестных вредоносных объектов.
Сущность изобретения
Настоящее изобретение предназначено для компьютерных систем, более конкретно для обнаружения вредоносных объектов.
Технический результат настоящего изобретения заключается в повышении эффективности обнаружения неизвестных вредоносных объектов.
Одним из предметов настоящего изобретения является способ обнаружения неизвестных вредоносных объектов, в котором: а) формируют набор характеристик, каждая из которых описывает файл в общем виде; б) для каждой характеристики выбирают, по крайней мере, один способ ее обработки; в) определяют уровень обнаружения вредоносных объектов, по крайней мере, для одного способа обработки; г) определяют уровень ложных срабатываний, по крайней мере, для одного способа обработки; д) рассчитывают эффективность, по крайней мере, для одного способа обработки путем оценки соотношения уровня обнаружения и уровня ложных срабатываний; е) выбирают тот способ обработки, для которого эффективность обнаружения вредоносных объектов максимальна; ж) используют выбранный способ обработки для обнаружения неизвестных вредоносных объектов.
В частном варианте реализации в указанном выше способе под объектом подразумевается исполняемый файл, файл сценария или документ.
В другом варианте исполнения в качестве характеристик объекта могут выступать, в числе прочего, рабочие области, уникальные строки, последовательности вызовов API-функций, графы вызовов и трассы выполнения.
В еще одном варианте выполнения в описанном выше способе используются полные базы данных вредоносных и безопасных объектов. Также могут быть использованы частичные базы данных, сформированные, например, за сутки или за месяц.
В частном варианте реализации все описанные действия способа совершаются периодически с целью актуализации информации об эффективности способа обработки характеристик.
В другом варианте выполнения представленного способа анализируются объекты заданного типа, тем самым выявляется наиболее эффективный способ обработки при работе с объектами определенного типа.
В еще одном варианте исполнения вышеописанного способа уровень обнаружения вредоносных объектов определяется как отношение количества вредоносных объектов, признанных вредоносными, к общему количеству вредоносных объектов. При этом уровень ложных срабатываний определяется с использованием отношения числа безопасных объектов, признанных вредоносными, к общему количеству безопасных объектов.
В частном варианте реализации эффективность оценивается для комбинации, по крайней мере, двух способов обработки.
Другим предметом настоящего изобретения является система обнаружения неизвестных вредоносных объектов, включающая: средство формирования набора характеристик, каждая из которых описывает объект в общем виде; средство определения уровня обнаружения способа обработки характеристики объекта; средство определения уровня ложных срабатываний способа обработки; средство расчета эффективности способа обработки; средство выбора наиболее эффективного способа обработки; базы данных вредоносных и безопасных объектов.
В частных вариантах выполнения объектом в вышеописанной системе является исполняемый файл, файл сценария или документ.
В еще одном варианте реализации в качестве характеристик объекта выступают рабочие области, уникальные строки, шаблоны поведения, графы и трассы выполнения, порядок вызова API-функций.
В других вариантах исполнения указанной выше системы базы данных вредоносных и безопасных объектов могут использоваться как полностью, так и частично, например, только те данные, которые сформированы за временной интервал, например за сутки, месяц или год.
В еще одном варианте выполнения описанной ранее системы анализируются объекты определенного типа, таким образом, определяется наиболее эффективный способ обработки, например, для исполняемых файлов, для документов и так далее.
В частном варианте реализации предложенной системы дополнительно содержится средство формирования комбинаций способов обработки. При этом эффективность оценивается для комбинации, по крайней мере, двух способов обработки, следовательно, рассматриваются не только единичные способы, но и их различные сочетания.
Третьим предметом настоящего изобретения является машиночитаемый носитель для обнаружения неизвестных вредоносных объектов, на котором сохранена компьютерная программа, при выполнении которой на компьютере выполняются следующие этапы: формирование набора характеристик, каждая из которых описывает объект в общем виде, для всех объектов из баз данных вредоносных и безопасных объектов; выбор способа обработки характеристики объекта; определение уровня обнаружения вредоносных объектов для способа обработки характеристики объекта; оценка уровня ложных срабатываний для способа обработки характеристики объекта; выбор способа обработки, обладающего максимальной эффективностью; выполнение выбранного способа обработки с целью обнаружения неизвестных вредоносных объектов.
Дополнительные преимущества изобретения будут раскрыты далее в ходе описания вариантов реализации изобретения. Также отметим, что все материалы данного описания направлены на детальное понимание того технического предложения, которое изложено в формуле изобретения.
Краткое описание прилагаемых чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут раскрыты дальше в описании со ссылками на прилагаемые чертежи.
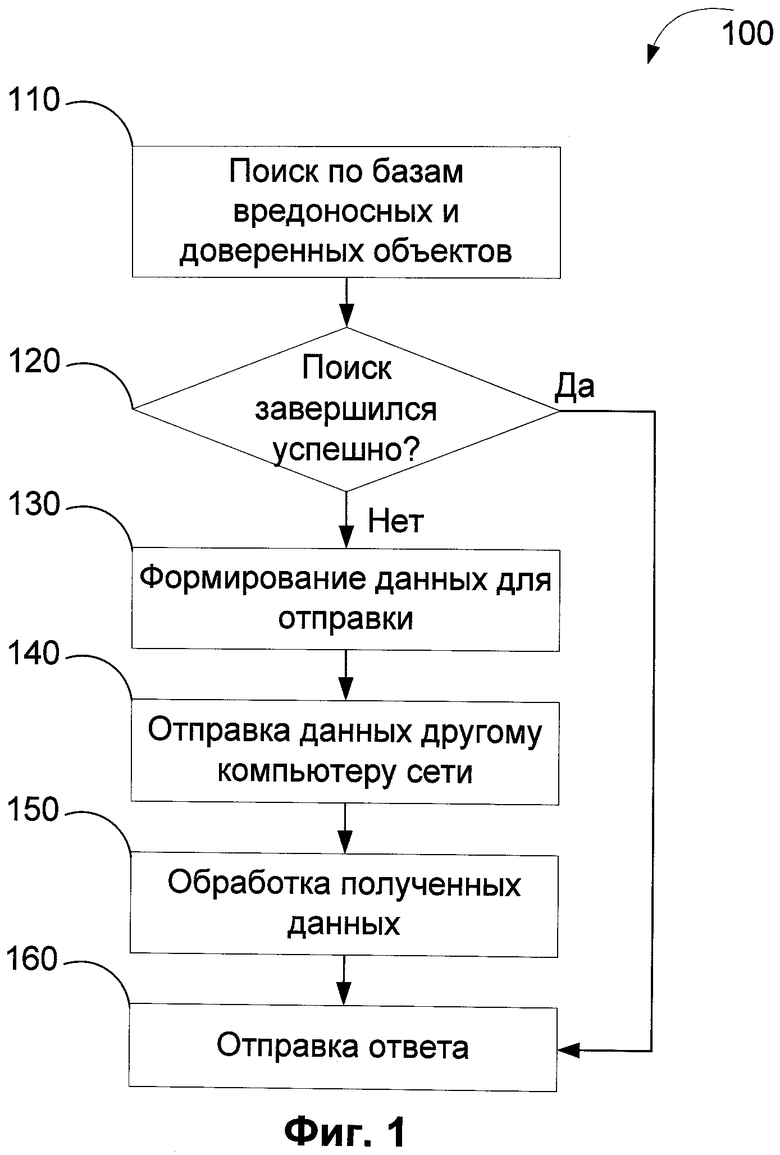
Фиг.1 иллюстрирует механизм обнаружения вредоносных объектов с использованием предлагаемого способа.
Фиг.2 описывает один из вариантов выбора релевантных характеристик исследуемого файла с точки зрения минимизации времени их обработки.
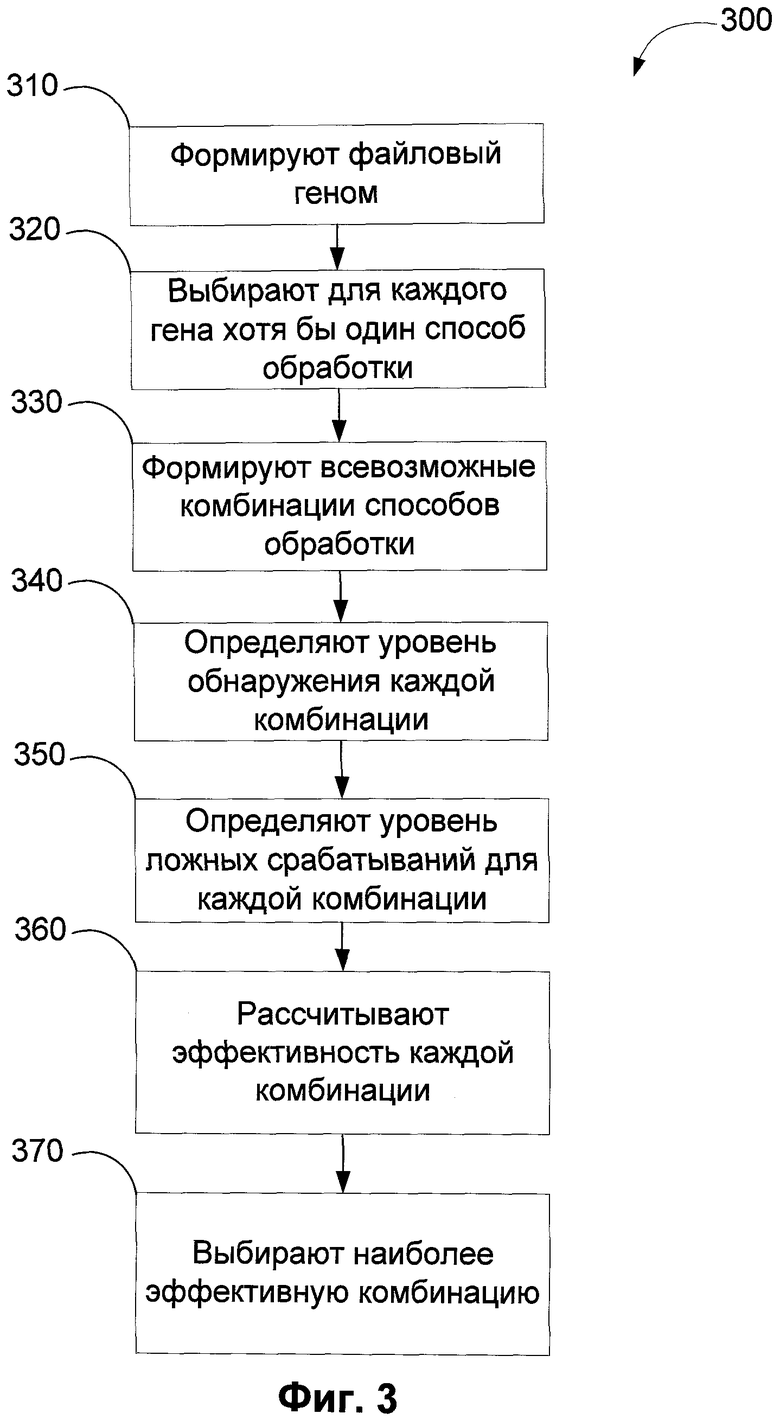
Фиг.3 показывает последовательность действий при нахождении наиболее эффективного способа обработки характеристики объекта для обнаружения неизвестных вредоносных объектов.
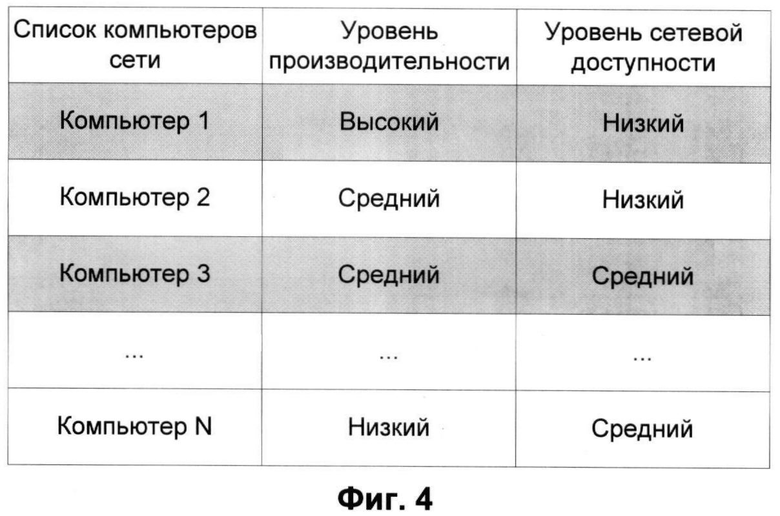
Фиг.4 иллюстрирует процесс выбора компьютера, способного провести анализ набора характеристик исследуемого объекта.
Фиг.5 демонстрирует примерную архитектуру системы, реализующей способ на Фиг.3.
Фиг.6 показывает примерную схему компьютера общего назначения, на котором развертывается настоящее техническое решение.
Фиг.7 демонстрирует пример части трассы выполнения программного червя.
Фиг.8 иллюстрирует часть flow-графа для троянской программы.
Фиг.9 показывает часть call-графа для программного червя.
Фиг.10 описывает сущность рабочих областей исполняемого файла.
Фиг.11 схематично изображает структуру файла в формате PDF.
Фиг.12 демонстрирует пример оценки эффективности обнаружения неизвестных вредоносных объектов.
Фиг.13А иллюстрирует пример модификации строк в программе таким образом, чтобы построчное сравнение было невозможным.
Фиг.13Б показывает способ противодействия анализу графа вызовов ПО путем добавления инструкций, не несущих полезной нагрузки.
Фиг.14 иллюстрирует пример соотношения эффективности работы каждого способа по отдельности и их комбинации.
Подробное описание предпочтительных вариантов осуществления
Объекты и признаки настоящего изобретения, способы для достижения этих признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
В область решаемых задач входит повышение эффективности обнаружения неизвестных вредоносных объектов.
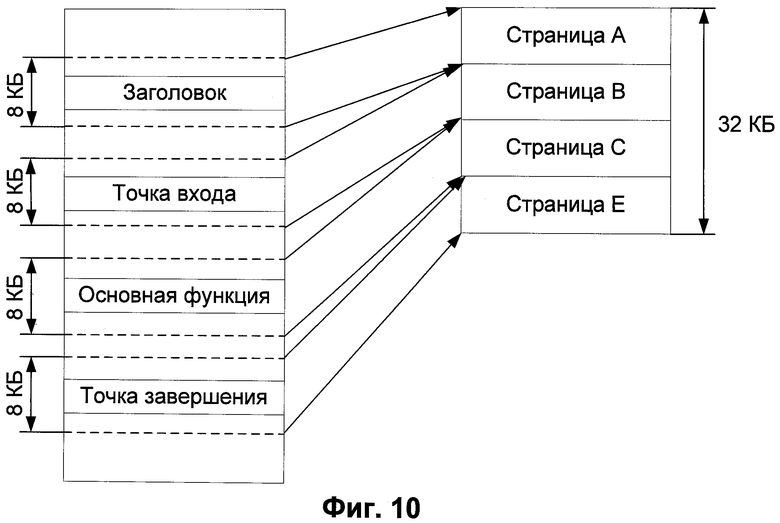
Основные преимущества настоящего изобретения вытекают из использования «файлового генома» (далее будем использовать этот термин без кавычек) для обнаружения вредоносного ПО и адаптивного выбора способа проверки объекта. Под файловым геномом подразумевается набор характеристик, каждая из которых в общем виде описывает файл таким образом, чтобы можно было определить его принадлежность к одному из классов. В одном из вариантов реализации файловый геном состоит из набора так называемых «генов» (по аналогии с биологией), при этом ген является аналогом характеристики объекта. В дальнейшем для простоты изложения будем использовать термин «ген». В частности, файловый геном может включать уникальные строки исследуемого объекта, его рабочие области, трассу выполнения, заранее предопределенные шаблоны вредоносного поведения, flow-граф, call-граф и т.д. Стоит отметить, что может существовать несколько способов обработки каждого гена. Способом обработки гена считается применение заранее определенных действий при работе с геном, которые направлены на принятие решения о том, является объект вредоносным или нет. Например, одним из способов обработки call-графа является сравнение его с аналогичными известными элементами из баз данных. Здесь и далее под рабочими областями понимаются некоторые части файла, в частности, загруженные в оперативную память, которые наиболее полно его описывают. В качестве примера на Фиг.10 изображен один из вариантов получения рабочих областей исполняемого файла, используемого в среде операционных систем семейства Windows. Такие файлы называют РЕ-файлами (см. http://www.microsoft.com/whdc/system/platform/firmware/PECOFF.mspx). Они имеют свою определенную структуру, а именно: заголовки, набор секций, таблицы импорта, перемещений и т.д. При этом информативными элементами для анализа в данном случае являются заголовок, точка входа, указание на основную функцию и иные служебные области. Фиг.10 представляет собой частный вариант реализации получения рабочей области. В качестве наиболее важных частей файла выбираются заголовок, адрес в оперативной памяти, с которого начинается выполнение программы (точка входа), указатель на основную функцию и указатель на завершение выполнения. В дальнейшем до и после указанных частей берется по 4 КБ данных. Таким образом, формируется 32 КБ информации, которая помещается в оперативную память, и с ней происходит дальнейшая работа. Такой подход минимизирует время обработки файла, так как непосредственный доступ к объекту на жестком диске является самой медленной операцией на компьютере, а работа с оперативной памятью существенно быстрее.
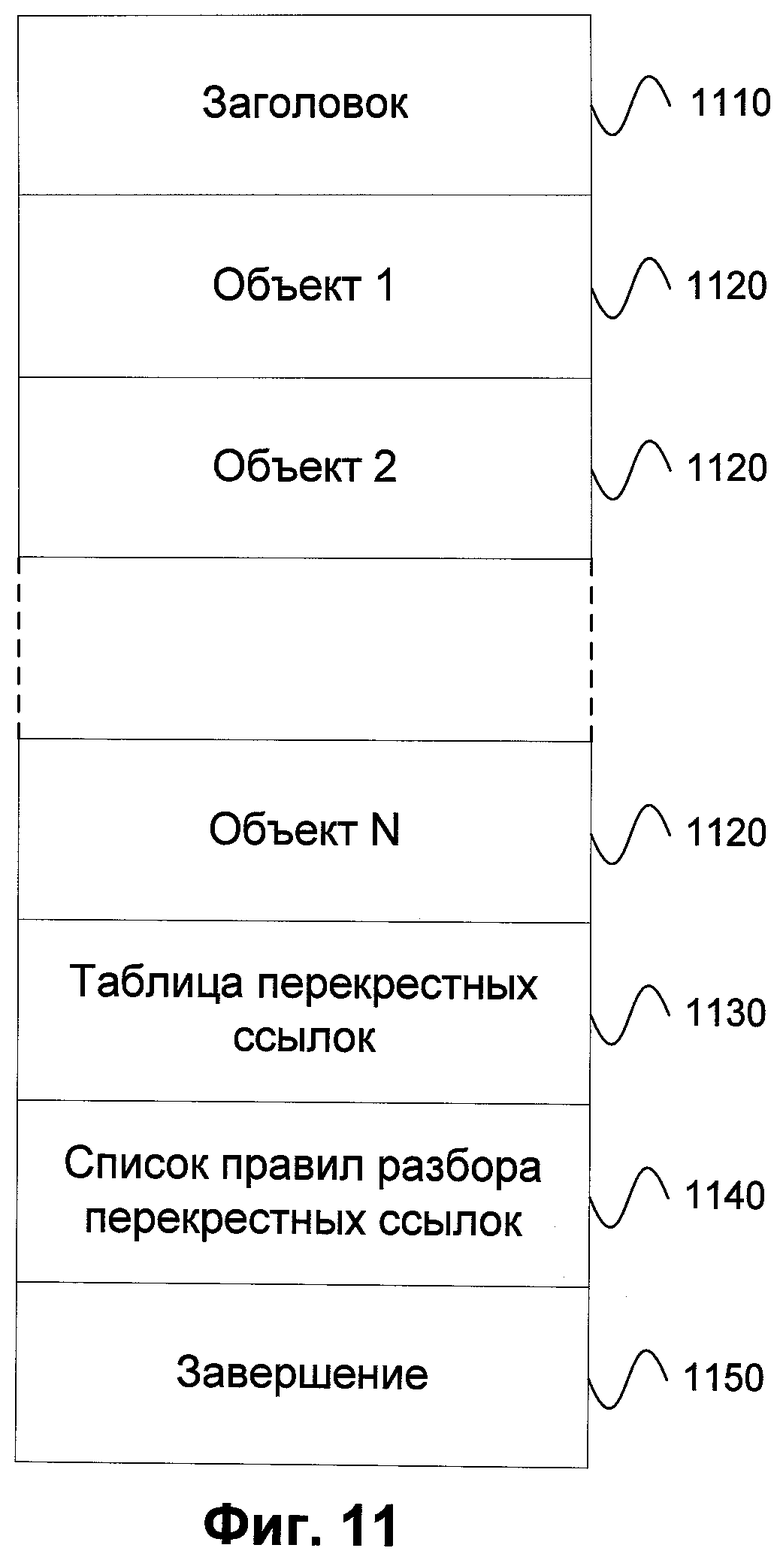
Однако при анализе файлов другого формата, например PDF, в качестве рабочих областей выступают другие части файла. В данном случае в первую очередь может рассматриваться его активное содержимое, такое как java-скрипты (сценарии, написанные на языке javascript). Это связано с тем, что выполнение java-скрипта в теле документа является небезопасной операцией, так как java-скрипт внутри себя может вызвать, в том числе, и исполняемый файл. Структура формата PDF изображена на Фиг.11, из которой видно, что существует четкое разделение между объектами внутри файла и существует таблица перекрестных ссылок между ними.
Каждый из генов может обрабатываться различными способами. Например, если для анализа выбран call-граф, тогда полученная последовательность, в том числе, сравнивается с аналогичными последовательностями, хранящимися в базе данных. В то же время гены, базы данных для которых не занимают много места, могут быть обработаны без запросов к центральной базе данных. Для этого указанные базы данных передаются пользователям, и с их помощью может происходить проверка непосредственно на компьютере пользователя.
Фиг.1 демонстрирует способ обнаружения неизвестных объектов. На этапе 110 сравнивается значение хеш-функции от анализируемого объекта с теми значениями, которые хранятся в базах данных вредоносных и безопасных объектов. Причем указанные базы данных могут работать под управлением любых из существующих, а также будущих СУБД, например, Oracle, MySQL, Microsoft SQL Server и т.д. В качестве функции хеширования может быть использована как любая известная на данный момент, например MD5, SHA-1, SHA-2, Skein, так и разработанная позднее. Предварительный этап 110 обусловлен в первую очередь трудоемкостью процесса формирования и обработки файлового генома. Таким образом, вначале мы минимизируем то множество, для которого должны происходить проверки, путем выявления неизвестного ПО. Затем для отобранных объектов осуществляем проверки в соответствии с алгоритмами, описанными ниже. Следовательно, благодаря описанному подходу указанный недостаток себя не проявляет.
На шаге 120, в случае если поиск прошел успешно, анализ завершается. В противном случае переходят к шагу 130, где для исследуемого объекта формируется файловый геном для дальнейшего анализа. При этом характер и объем данных может определяться в зависимости от возможностей и ресурсов компьютера и типа анализируемого файла. Более подробно процесс получения указанной информации изображен на Фиг.2 и Фиг.3. В тот момент, когда данные подготовлены, на этапе 140 они отправляются тому компьютеру, который по своим характеристикам способен их обработать. Выбор компьютера может осуществляться несколькими способами. Один из вариантов реализации представлен на Фиг.4. Далее на шаге 150 происходит обработка полученных данных в соответствии ранее определенными способами. Предположим, что на предыдущем этапе для отправки на другой компьютер был выбран шаблон функциональности. Таким образом, на шаге 150 указанная информация сначала подвергается точному сравнению с аналогичными объектами, хранящимися в базе вредоносных объектов. Такая итерация включена в связи с тем, что, с одной стороны, операция нечеткого поиска является ресурсоемкой, а с другой - могут существовать ситуации, когда сравнение по значениям хеш-функции прошло безуспешно, но шаблоны функциональности полностью совпадают. При положительном результате сравнения объект признается вредоносным, иначе происходит нечеткий поиск. Нечеткий поиск в данном контексте означает применение алгоритмов нечеткого сравнения строк, например, Левенштейна, Ландау-Вишкина и т.д. То есть рассматриваемый шаблон функциональности представляется в виде последовательности (строки), которая сравнивается с другими шаблонами функциональности, которые уже существуют в базе данных. В этом случае определяется степень похожести между объектами, а решение принимается на основе превышения некоторого заданного порога.
В частном варианте реализации степень похожести может определяться так, как описано в патенте US 5440742.
В другом частном варианте реализации шаблону функциональности может присваиваться определенный рейтинг опасности, по которому будет приниматься решение, считать объект вредоносным или нет. В частности, рейтинг опасности может определяться так, как указано в патенте US 7530106, или следующим образом:
- из неизвестного шаблона функциональности выделяются все логические блоки;
- определяется статус каждого из выделенных блоков;
- в зависимости от статуса и количества появлений блоку выставляется рейтинг опасности;
- рейтинг опасности для всего шаблона функциональности формируется путем объединения рейтингов по всем логическим блокам.
В частном варианте реализации рейтинг опасности для всего шаблона функциональности может быть подсчитан путем простого суммирования всех полученных ранее рейтингов с последующим нормированием. В описанной последовательности действий под логическим блоком может пониматься, в частности, список ассемблерных инструкций, выполняемых до команды передачи управления (см. описание Фиг.8). Также можно выделить несколько возможных статусов логического блока: вредоносный (встречается только во вредоносных шаблонах), безопасный (встречается только в безопасных шаблонах), смешанный (встречается как во вредоносных, так и в безопасных шаблонах) и неизвестный (такой блок, который встречается впервые).
На основании полученного рейтинга опасности шаблона функциональности принимается решение о признании объекта вредоносным.
В дальнейшем после окончания обработки полученных данных переходят к пункту 160, где пользователю отправляется ответ о том, является ли объект вредоносным.
Фиг.2 иллюстрирует один из частных вариантов процесса выбора релевантных генов. Способ их определения основан на минимизации времени получения ответа о наличии вредоносной составляющей. Таким образом, в первую очередь выбирается способ, посредством которого будет производиться обнаружение неизвестного вредоносного ПО. На основании выбранного способа формируется необходимая информация. В частном варианте реализации описанный процесс осуществляется с использованием нечеткой логики. Определяются две лингвистические переменные: «эффективность способа» и «ресурсоемкость получения входных данных для способа», - для каждой из которых определяется терм-множество, например, {«низкая», «средняя», «высокая»}. При этом эффективность способов периодически пересматривается. Затем сформированный упорядоченный список можно разделить на категории в зависимости от типовой конфигурации компьютера, например «маломощный», «средний», «высокопроизводительный». В качестве примера для подобного анализа может быть приведен патент RU 98611 «Система улучшения производительности персонального компьютера за счет адаптивной настройки конфликтных приложений». Таким образом, на основании указанного способа может быть сформирован оптимальный набор генов, который компьютер пользователя в состоянии выделить из исследуемого файла и которые дадут наилучшие результаты при обнаружении вредоносного программного обеспечения.
Фиг.3 представляет способ определения наиболее эффективной комбинации способов обработки генов для обнаружения неизвестных вредоносных объектов. Здесь и далее под комбинацией способов обработки генов подразумевается множество способов нахождения неизвестных вредоносных объектов и соответствующих им генов, состоящее, по крайней мере, из одного элемента. Эффективность в данном случае будет определяться как соотношение уровня обнаружения и уровня ложных срабатываний. При этом под уровнем обнаружения неизвестного вредоносного программного обеспечения понимается отношение обнаруженных вредоносных объектов ко всему множеству вредоносных объектов, на котором работал антивирус, а уровнем ложных срабатываний - отношение количества безопасных объектов, признанных вредоносными, ко всему множеству безопасных объектов, на котором проводилось исследование.
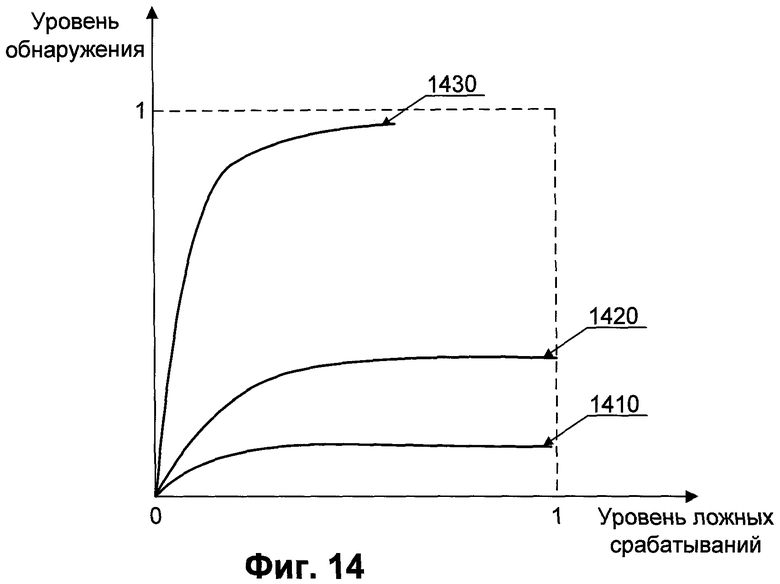
Использование различных комбинаций способов обработки генов обусловлено тем, что в некоторых случаях не самые эффективные способы обработки по отдельности дают наилучший результат при совместной работе. Так, Фиг.14 представляет собой пример, когда применение способов обработки 1410 и 1420 вместе нелинейно повышает эффективность обнаружения вредоносных объектов. Результат их совместной работы изображен кривой 1430.
В предлагаемом способе на шаге 310 для всех объектов из баз данных вредоносных и безопасных объектов формируют файловый геном. В дальнейшем на этапе 320 выбирают для каждого гена, по крайней мере, один способ обработки. Затем на стадии 330 формируют, по крайней мере, одну комбинацию способов обработки генов, для которых впоследствии оценивается эффективность их работы. Стоит отметить, что сформированная комбинация может состоять лишь из одного способа обработки гена. Для расчета эффективности на этапах 340 и 350 определяется уровень обнаружения и уровень ложных срабатываний для каждой комбинации. Затем на основании данных, полученных на предыдущих стадиях, на шаге 360 рассчитывают эффективность каждой рассмотренной комбинации. Фиг.12 показывает частный вариант определения эффективности при обнаружении вредоносных объектов. Затем полученные ранее результаты оценки сравниваются на шаге 370, и из всех комбинаций выбирается наиболее эффективная. В соответствии с выбранной комбинацией в дальнейшем формируются только те гены, которые требуются для ее осуществления.
Стоит отметить, что эффективность комбинаций способов обработки может пересматриваться время от времени, что обеспечит более актуальную информацию о степени доверия им, и, следовательно, повысит качество обнаружения неизвестного вредоносного ПО.
При появлении генов, неизвестных ранее, предварительные значения эффективности для них по каждому типу объектов заносятся в базу данных. При этом по мере набора статистики указанные значения пересматриваются.
Также могут возникнуть ситуации, когда появляется новый тип файлов, при этом анализ существующих генов не дает удовлетворительных результатов. То есть существует большое количество случаев, когда обработка и анализ известных генов дают ошибочный результат. Таким образом, при появлении новых типов файлов может возникнуть потребность выделения новых генов. При этом процесс определения информации о файле, которая может считаться геном, носит итеративный характер.
Также подвергаются временному анализу и сами базы данных с генами, а именно рассматривается мощность покрытия множества вредоносных программ отдельным геном. Под мощностью покрытия подразумевается процент вредоносных объектов, которые выявляются при помощи одного гена. Как было указано выше, эффективность комбинаций способов обработки может меняться со временем, это относится и к мощности покрытия. Для оценки таких изменений полезна средняя мощность покрытия множества вредоносных объектов генами, которая вычисляется как среднее арифметическое от всех мощностей покрытия указанного множества генами. При этом снижение указанной величины может свидетельствовать как о снижении эффективности комбинации, в соответствии с которой формируются гены, а также о необходимости изменения правил добавления новых генов.
Фиг.4 иллюстрирует процесс выбора компьютера, который по своим характеристикам может обработать файловый геном. В частном варианте реализации на центральном сервере может храниться информация о параметрах компьютеров сети и статистики времени их работы. Например, все множество компьютеров сети может быть разделено по уровню производительности, аналогично патенту RU 98611 «Система улучшения производительности персонального компьютера за счет адаптивной настройки конфликтных приложений». В дальнейшем в зависимости от ресурсоемкости выбранного на этапе 130 способа определяется подмножество компьютеров с требуемыми характеристиками. Затем подмножество еще раз сужается вследствие определения уровня сетевой доступности. Здесь под сетевой доступностью понимается период нахождения компьютера в сети, степень его загруженности, пропускная способность каналов связи и т.п. При этом, если среди компьютеров пользователей не нашлось требуемого объекта, в роли анализирующего компьютера может выступить сервер антивирусной компании. Если же количество компьютеров, удовлетворяющих заданным критериям велико, из них может быть выбрано лишь некоторое подмножество. Пусть, например, требуется найти компьютер со средними характеристиками для анализа некоторого программного обеспечения. На Фиг.4 изображено множество компьютеров с указанными параметрами, в том числе компьютер 2 и компьютер 3. При этом только один из них - компьютер 3 - обладает средним уровнем сетевой доступности, т.е. вероятность получения ответа от него выше, чем от компьютера 2. Следовательно, для обработки данных в рассматриваемом случае может быть выбран лишь компьютер 3.
Фиг.5 демонстрирует примерную архитектуру системы, реализующей способ 300. Система 500 включает средство формирования файлового генома 510, предназначенное для выделения различных генов из объектов, принадлежащих базам данных вредоносных 520 и безопасных 530 объектов. Также система 500 содержит средство 540 формирования всевозможных комбинаций способов обработки генов, которые представляют собой некоторое множество, например, {Ген 1:Способ 1, Ген 2:Способ 5, Ген 7:Способ 11, …}. Далее описываемая система включает средство оценки уровня обнаружения 550 и средство оценки уровня ложных срабатываний 560, связанные с базами данных вредоносных 520 и безопасных 530 объектов соответственно, а также со средством расчета эффективности 570. Средство 570 анализирует данные, полученные от средств 550 и 560, а затем определяет эффективность каждой комбинации. В дальнейшем средство выбора 580 сравнивает рассчитанные значения эффективности и выбирает наибольшее.
На первом этапе средство 510 формирует файловый геном для объектов из баз данных вредоносных 520 и безопасных 530 объектов, затем обращается к средству формирования всевозможных комбинаций 540, которое из имеющихся генов и соответствующих им способов генерирует различные их сочетания. Так как комбинация способов обработки может состоять из одного элемента, то в частных вариантах исполнения системы 500 средство 540 может отсутствовать. Далее для сформированных комбинаций оценивается уровень обнаружения неизвестных вредоносных объектов и уровень ложных срабатываний средствами 550 и 560 соответственно. Указанные оценки в дальнейшем учитывается средством расчета эффективности 570, предназначенным для определения эффективности работы каждой комбинации. При этом эффективность может рассчитываться с использованием различных механизмов. Фиг.12 представляет собой один из частных вариантов определения указанной величины. Значения, полученные средством 570, сравниваются между собой средством выбора 580. Таким образом, средство выбора 580 отмечает наиболее эффективную комбинацию способов обработки генов при обнаружении неизвестных вредоносных объектов. Следовательно, при использовании найденной комбинации будет повышаться эффективность обнаружения неизвестных вредоносных программ.
В частном варианте реализации могут рассматриваться объекты определенного типа, то есть определяться комбинации способов обработки, которые лучше всего подходят для их обработки. Также могут быть использованы части баз данных вредоносных и безопасных объектов, например, за заданный промежуток времени.
В одном из вариантов реализации системы 500 файловый геном состоит из одного гена - шаблона функциональности. В таком случае в системе 500 существует лишь один ген, а средство формирования файлового генома 510 аналогично соответствующим элементам из системы, описанной в патенте US 5440742. Таким образом, на первом этапе средство 510 строит шаблон функциональности для объектов из баз данных 520 и 530 аналогично патенту US 5440742. Далее средство формирования комбинаций способов обработки 540 генерирует различные сочетания одного гена (шаблон функциональности) и способов его обработки. При этом одним из них может являться способ, описанный в патенте US 5440742. В дальнейшем сформированные комбинации оцениваются средствами 550 и 560 с точки зрения уровня обнаружения и уровня ложных срабатываний. На основании проведенной оценки средство расчета эффективности 570 определяет эффективность работы каждой комбинации. После чего средство выбора 580 выявляет наиболее эффективную комбинацию. Так как в предложенном варианте реализации фигурирует лишь один ген, то все комбинации отличаются лишь сочетаниями способов обработки. Также с течение времени эффективность способов может пересматриваться.
При появлении новых генов ранее собранные коллекции вредоносных объектов могут быть заново проанализированы, в том числе, могут быть обнаружены гены, соответствующие безопасным объектам. После такой перепроверки существует возможность обновления и внесения правок в базу данных.
Фиг.6 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая, в свою очередь, память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20, в свою очередь, содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс привода магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.).
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35 и дополнительные программные приложения 37, другие программные модули 38 и программные данные 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который, в свою очередь, подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47 персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например колонки, принтер и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг.6. В вычислительной сети могут присутствовать также и другие устройства, например маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 51 и глобальную вычислительную сеть (WAN) 52. Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 51 через сетевой адаптер или сетевой интерфейс 53. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью 52, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными, и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
Фиг.7 иллюстрирует пример части трассы выполнения программного червя. В представленном фрагменте трассы выполнения осуществляются порядок действий, описанный ниже. На шаге 710 определяется сетевой адрес компьютера по его имени, в качестве параметра передается строка «mxl.mail.yahoo.com». Далее на этапе 720 происходит попытка установки соединения с ним, которая завершается успешно. После этого осуществляется получение данных 730, а затем на стадии 740 вычисляется длина интересующей строки, которая впоследствии отправляется на шаге 750. Таким образом, из трассы выполнения программы становится понятно, какие функции и с какими параметрами вызываются, что оказывается полезным для анализа ПО при сравнении шаблонов функциональности.
Фиг.8 демонстрирует часть flow-графа для троянской программы. На Фиг.8 вершинами является совокупность ассемблерных инструкций, выполняемых до перехода. Две вершины связаны ребром тогда и только тогда, когда из одной из них существует вызов другой. При этом можно отметить как безусловные переходы 810, так и условные - 820. Для условного перехода 820 всегда существует некоторое предположение, которое либо выполняется, либо нет. Например, запись «jnz short loc_40686 В» означает переход в область lос_40686 В в случае, если значение флага ZF отлично от нуля.
Фиг.9 представляет собой часть call-графа, построенного для программного червя. Вершинами в данном случае являются некоторые процедуры или функции языка высокого уровня, например, «открыть файл». При этом из них можно выделить стандартные или встроенные функции 920, а также уникальные 910, которые были написаны конкретным программистом для себя. Ребро соединяет две вершины в том случае, если из одной функции существует вызов другой. Например, внутри функции Sub_401463 вызываются функции RegQueryValueExA, Sub_401031, RegCloseKey и т.д., то есть из вершины Sub_401463 существуют ребра в RegQueryValueExA, Sub_401031 и в RegCloseKey.
Фиг.10 показывает пример формирования рабочих областей. В частном варианте реализации в качестве наиболее информативных частей файла выбираются заголовок, адрес в оперативной памяти, с которого начинается выполнение программы (точка входа), указатель на основную функцию и указатель на завершение выполнения. В дальнейшем до и после указанных частей берется по 4 КБ данных. Таким образом, формируется 32 КБ информации, которая помещается в оперативную память и с ней происходит дальнейшая работа. Такой подход минимизирует время обработки файла, так как непосредственный доступ к объекту на жестком диске является самой медленной операцией на компьютере, а работа с оперативной памятью существенно быстрее.
Фиг.11 демонстрирует структуру файла в формате PDF. Описываемый формат подразумевает наличие заголовка 1110, который начинается с '%PDF'. Далее идет список объектов файла 1120, для которых указывается, в числе прочего, номер и тип, а также способ, с помощью которого он закодирован. Окончание каждого объекта отмечается специальной меткой. В таблице перекрестных ссылок 1130 указываются ссылки на другие объекты внутри документа, а в следующей секции 1140 прописываются правила разбора этой таблицы. Область 1150 показывает завершение документа, которое помечается последовательностью символов '%EOF'.
Фиг.12 представляет собой пример определения эффективности обработки неизвестного объекта. Значение эффективности принадлежит отрезку от 0 до 1. В частном варианте реализации, такое значение может определяться эмпирически. Например, берем множество вредоносных и безопасных объектов определенного типа. Для каждого элемента множества выделяем требуемые гены. Далее обрабатываем полученные гены заранее определенными способами. По результатам обработки принимаем решение о том, является ли объект вредоносным. Таким образом, на последнем шаге получаем множество Х объектов, признанных вредоносными. Тогда эффективность обработки неизвестного объекта может быть рассчитана по формуле:
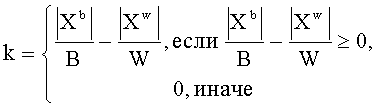
где k - эффективность способа обработки неизвестного объекта,
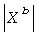 - количество вредоносных объектов, признанных вредоносными,
- количество вредоносных объектов, признанных вредоносными,
 - количество безопасных объектов, признанных вредоносными,
- количество безопасных объектов, признанных вредоносными,
В, W - заданное количество вредоносных и безопасных объектов соответственно.
Как отмечалось ранее, описанный способ определения эффективности может осуществляться периодически для формирования наиболее актуальных оценок.
Фиг.13А демонстрирует пример обмана механизма построчного сравнения файлов. Фиг.13А показывает часть строк для двух троянских программ, которые имеют одинаковый функционал, но различаются в наименовании используемых файлов. Таким образом, оба объекта совершают вредоносные действия, однако при сравнении их строк видно, что практически все из них разные. Из этого следует, что метод построчного сравнения не даст положительного результата в этом случае.
Фиг.13Б представляет один из вариантов противодействия обнаружению вредоносных программ методом сравнения графов вызовов. В указанных списках вызываемых функций злоумышленниками включены дополнительные шаги, которые не влияют на конечный результат. При этом сравнение указанных графов вызовов не признает их похожими. Следовательно, такие мусорные инструкции затрудняют использование графов вызовов для обнаружения вредоносного ПО.
Фиг.14 иллюстрирует пример работы комбинации 1430 двух способов обработки генов 1410 и 1420. Здесь по оси ординат отложен уровень обнаружения неизвестных вредоносных объектов, а по оси абсцисс - уровень ложных срабатываний. Таким образом, способ обработки 1410 гена А и способ обработки 1420 гена Б по отдельности имеют не высокую эффективность, однако существуют ситуации, когда эффективность их совместного применения 1430 значительно превышает как эффективность каждого из способов по отдельности, так и их суммарную эффективность.
В заключение следует отметить, что приведенные в описании сведения являются только примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ адаптирования шаблонов опасного поведения программ к компьютерным системам пользователей | 2017 |
|
RU2652448C1 |
| СИСТЕМА И СПОСОБ УВЕЛИЧЕНИЯ КАЧЕСТВА ОБНАРУЖЕНИЙ ВРЕДОНОСНЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ ПРАВИЛ И ПРИОРИТЕТОВ | 2012 |
|
RU2514140C1 |
| СПОСОБ И СИСТЕМА АНАЛИЗА РАБОТЫ ПРАВИЛ ОБНАРУЖЕНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2013 |
|
RU2568285C2 |
| Способ избирательного использования шаблонов опасного поведения программ | 2017 |
|
RU2665909C1 |
| Способ выявления вредоносных файлов с использованием графа связей | 2023 |
|
RU2823749C1 |
| СПОСОБ АВТОМАТИЧЕСКОГО ФОРМИРОВАНИЯ ЭВРИСТИЧЕСКИХ АЛГОРИТМОВ ПОИСКА ВРЕДОНОСНЫХ ОБЪЕКТОВ | 2012 |
|
RU2510530C1 |
| Система и способ классификации объектов | 2017 |
|
RU2679785C1 |
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОЙ МОДИФИКАЦИИ АНТИВИРУСНОЙ БАЗЫ ДАННЫХ | 2012 |
|
RU2536664C2 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ФАЙЛОВ ОПРЕДЕЛЕННОГО ТИПА | 2014 |
|
RU2583712C2 |
| Система и способ машинного обучения модели обнаружения вредоносных файлов | 2017 |
|
RU2673708C1 |






Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности обнаружения неизвестных вредоносных объектов. Способ обнаружения неизвестных вредоносных объектов, в котором: формируют набор характеристик, каждая из которых описывает объект, для всех объектов из баз данных вредоносных и безопасных объектов; для каждой характеристики выбирают, по крайней мере, один способ обработки характеристики объекта; определяют уровень обнаружения вредоносных объектов, по крайней мере, для одного способа обработки характеристики объекта; определяют уровень ложных срабатываний, по крайней мере, для одного способа обработки характеристики объекта; рассчитывают эффективность, по крайней мере, для одного способа обработки характеристики объекта путем оценки соотношения уровня обнаружения и уровня ложных срабатываний; выбирают способ обработки, для которого эффективность обнаружения вредоносных объектов максимальна; используют выбранный способ обработки для обнаружения неизвестных вредоносных объектов. 3 н. и 15 з.п. ф-лы, 15 ил.
1. Способ обнаружения неизвестных вредоносных объектов, в котором:
а) формируют набор характеристик, каждая из которых описывает объект, для всех объектов из баз данных вредоносных и безопасных объектов;
б) для каждой характеристики выбирают, по крайней мере, один способ обработки характеристики объекта;
в) определяют уровень обнаружения вредоносных объектов, по крайней мере, для одного способа обработки характеристики объекта;
г) определяют уровень ложных срабатываний, по крайней мере, для одного способа обработки характеристики объекта;
д) рассчитывают эффективность, по крайней мере, для одного способа обработки характеристики объекта путем оценки соотношения уровня обнаружения и уровня ложных срабатываний;
е) выбирают способ обработки, для которого эффективность обнаружения вредоносных объектов максимальна;
ж) используют выбранный способ обработки для обнаружения неизвестных вредоносных объектов.
2. Способ по п.1, где объектом является исполняемый файл, файл сценария или документ.
3. Способ по п.1, где в качестве характеристики выступает, по крайней мере, одна из следующих:
- рабочие области,
- уникальные строки,
- последовательности вызовов API-функций,
- графы вызовов,
- трасса выполнения.
4. Способ по п.1, в котором используются полные базы данных вредоносных и безопасных объектов.
5. Способ по п.1, в котором используются базы данных вредоносных и безопасных объектов, сформированные за временной интервал.
6. Способ по п.1, в котором все действия выполняются периодически.
7. Способ по п.1, в котором анализируются объекты определенного типа.
8. Способ по п.1, в котором определение уровня обнаружения вредоносных объектов определяется как отношение числа вредоносных объектов, признанных вредоносными, к общему числу вредоносных объектов.
9. Способ по п.1, в котором определение уровня ложных срабатываний осуществляется с использованием отношения количества безопасных объектов, признанных вредоносными, к общему количеству безопасных объектов.
10. Способ по п.1, в котором эффективность оценивается для комбинации, по крайней мере, двух способов обработки характеристик объекта.
11. Система обнаружения неизвестных вредоносных объектов, которая включает:
- средство формирования набора характеристик, каждая из которых описывает объект, связанное со средством определения уровня обнаружения, средством определения уровня ложных срабатываний и с базами данных вредоносных и безопасных объектов,
- средство определения уровня обнаружения, по крайней мере, для одного способа обработки характеристики объекта, которое также связано с базой данных вредоносных объектов и со средством расчета эффективности,
- база данных вредоносных объектов, предназначенная для хранения коллекций вредоносных объектов,
- средство определения уровня ложных срабатываний, по крайней мере, для одного способа обработки характеристики объекта, связанное с базой данных безопасных объектов и со средством расчета эффективности,
- база данных безопасных объектов, предназначенная для хранения коллекций безопасных объектов,
- средство расчета эффективности, предназначенное для оценки соотношения уровня обнаружения и уровня ложных срабатываний, по крайней мере, для одного способа обработки характеристики объекта, которое также связано со средством выбора,
- средство выбора, предназначенное для выбора наиболее эффективного способа обработки характеристики объекта для обнаружения неизвестных вредоносных объектов,
- средство обнаружения, предназначенное для обнаружения неизвестных вредоносных объектов выбранным способом.
12. Система по п.11, в которой объектом является исполняемый файл, файл сценария или документ.
13. Система по п.11, в которой характеристика объекта включает, по крайней мере, один из следующих элементов:
- рабочие области программного обеспечения,
- уникальные строки,
- шаблоны поведения,
- графы выполнения,
- трассы выполнения,
- порядок вызова API-функций.
14. Система по п.11, в которой используются полные базы данных вредоносных и безопасных объектов.
15. Система по п.11, в которой используются базы данных вредоносных и безопасных объектов, сформированные за временной интервал.
16. Система по п.11, в которой анализируются объекты определенного типа.
17. Система по п.11, в которой эффективность оценивается для комбинации, по крайней мере, двух способов обработки характеристик объекта.
18. Машиночитаемый носитель для обнаружения неизвестных вредоносных объектов, на котором сохранена компьютерная программа, при выполнении которой на компьютере выполняются следующие этапы:
- формирование набора характеристик, каждая из которых описывает объект, для всех объектов из баз данных вредоносных и безопасных объектов,
- выбор, по крайней мере, одного способа обработки характеристики объекта,
- определение уровня обнаружения вредоносных объектов, по крайней мере, для одного способа обработки характеристики объекта,
- оценка уровня ложных срабатываний, по крайней мере, для одного способа обработки характеристики объекта,
- расчет эффективности, по крайней мере, для одного способа обработки характеристики объекта,
- выбор способа обработки характеристики объекта, у которого эффективность максимальна,
- выполнение выбранного способа обработки с целью обнаружения неизвестных вредоносных объектов.
| АНТИБАКТЕРИАЛЬНАЯ КОМПОЗИЦИЯ ДЛЯ ЛЕЧЕНИЯ ЖИВОТНЫХ | 2002 |
|
RU2228743C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| ПРИСПОСОБЛЕНИЕ К ЗЕРНОВЫМ КОМБАЙНАМ ДЛЯ ВЫТИРАНИЯ И ОЧИСТКИ СЕМЯН ТРАВ | 1950 |
|
SU91202A1 |
| СПОСОБ ЗАЩИТЫ ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ ОТ НЕСАНКЦИОНИРОВАННЫХ ВОЗДЕЙСТВИЙ | 2004 |
|
RU2271613C1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

