Изобретение предназначено для улучшения хранения, передачи и обработки импульсно-сигнальной информации и может быть использовано в вычислительной технике, а также в любой технике, использующей микропроцессоры.
Известен способ разделения фрагмента импульсно-сигнальной информации длиной X элементов на заданное число Y подфрагментов, при котором создают Y подфрагментов с одинаковой длиной X/Y элементов (длина последнего может быть меньше X/Y). Недостатком этого способа является недостаточная точность в определении границ логических разных подфрагментов исходного фрагмента. Ошибка dl, равная при фрагментировании таким способом расстоянию от истинной границы L1 до ближайшей полученной, имеет порядок (X/Y)/2: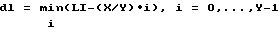
Известны способы сжатия информации с помощью устройств, включающих память для хранения ранее обработанных последовательностей символов, заключающиеся в выделении из исходного потока информации последовательностей символов, уже содержащихся в памяти, и сохранении информации о длине и положении в словаре-памяти последовательностей, уже встречающихся в потоке ранее, а также информации о длине и содержании последовательностей, не найденных в словаре-памяти (1, 2, 3, 4).
Известны также способы сжатия "метод Хаффмана" и "метод Шеннона-Фэно" (1) с помощью устройств, включающих память для хранения информации о структуре "двоичного дерева", создаваемого для преобразования символов в коды, заключающиеся в вычислении для каждого символа фрагмента информации доли таких символов во фрагменте с дальнейшим созданием оптимального "двоичного дерева" (таблицы для преобразования), записью информации о структуре этого "дерева" и последовательном кодировании символов фрагмента так, что длина кода, соответствующего каждому символу, тем короче, чем больше таких символов в исходном фрагменте.
Известны также программы для IBM-совместимых компьютеров, реализующие эти способы:
PKZIP.EXE/PKUNZIP.EXE (1), ARJ.EXE (2) и около 20 других подобных программ (RAR. EXE, HA.EXE, LIMIT.EXE, AIN.EXE и прочие) для сжатия и восстановления исходного вида сжатой информации.
Недостатками этих способов и программ - "архиваторов" является сравнительно малая степень сжатия информации в сравнении с описываемыми способами и реализующей их программой-"архиватором" ARI.EXE для IBM PC XT-совместных компьютеров. Отношение длины информации, сжатой программой API.EXE, к длине той же информации, сжатой какой-либо из вышеупомянутых программ, изменяется в пределах от 0,90 до 0,98, в отдельных исключительных случаях - от 0,8 до 1,01, в большинстве случаев - около 0,95.
Цель изобретения заключается в повышении степени "сжатия" информации без потери ее полезной функции.
Поставленная цель достигается следующим образом.
1) Способ фрагментирования потока импульсно-сигнальной информации, разделенного на исходные фрагменты длиной X элементов, каждый из которых в каждой позиции х может быть разделен на два блока, однозначно зависящие от позиции x, предстоящий A и предыдущий B, на Y подфрагментов, заключающийся в том, что каждой позиции x, причем x изменяется от 2 до X, сопоставляют коэффициент отличия X предстоящего блока A, содержащего элемент в позиции x и все последующие элементы фрагмента вплоть до последнего включительно, от предыдущего блока B, содержащего элементы от 1-го до (x-1)-го включительно: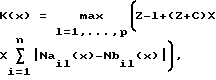
где К(x) - коэффициент отличия, зависящий от позиции x;
n - число возможных "значений" элементов, n равно 2 для битов, 256 - для байтов, 256L - для слоев длиной L байтов;
NaiI(x) - число элементов, имеющих i-тое значение, в части блока A длиной l, содержащей его первый x-ый элемент;
NbiI(x) - число элементов, имеющих i-тое значение, в части блока B длиной l, содержащей его последний (x-я)-ый элемент;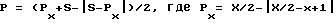 - длина меньшего блока; S - заданный параметр;
- длина меньшего блока; S - заданный параметр;
Z = [X/2] - целая часть числа X/2, максимальное возможное значение Px и P;
C - заданный параметр, 0 или натуральное число (1, 2, 3, 4, ...);
причем, если J = 1, то элементами являются биты, если J = 2 - байты, если J = 3 - слова, где J - заданный параметр, затем из множества этих коэффициентов К(x) выбирают (Y-1) максимальных коэффициентов так, чтобы длины li определяемых ими Y подфрагментов отклонялись от средней длины разделения, равной X/Y, не более чем на R: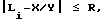
где R - заданный параметр, i = 1, ... , Y-1,
после чего, если Q > 0, из этих Y-1 коэффициентов выбирают те, которые больше Q; К(Хi)>Q.
где Q - заданный параметр, i = 1, ... , Y-1
Специальную последовательность электромагнитных импульсов (конечную или бесконечную), применяемую в технике для передачи информации, здесь и далее называют потоком информации. Конечный, иначе говоря, ограниченный поток информации называют фрагментом информации, или же просто информацией. Фрагмент потока - конечная последовательность бесконечной в общем случае последовательности.
Объемом информации называют число специальных импульсов в конечной последовательности - фрагменте информации: один специальный импульс называют битом; последовательность восьми специальных импульсов называют байтом; любую конечную последовательность байтов, иначе говоря, несколько байтов называют словом; 1024 байта называют килобайтом и так далее.
ВЕЛИЧИНА БИТА принимает два значения: 0 (импульса нет) и 1 (импульс есть).
ВЕЛИЧИНА БАЙТА принимает 256 значений (пронумеруем 256 возможных комбинаций из 8 битов). Например, величина байта "00000000" - 0, "00010100" - 20, "10110110" - 182 "11111111" - 255, и так далее.
"Кодом" называет любую конечную последовательность битов. Последовательность двух битов называют "парой".
Элементами могут быть биты (то есть сами электромагнитные импульсы), байты (последовательности импульсов заданной длины, традиционно в ЭВМ байтом называют последовательность 8-ми битов, намного реже байтами называют последовательности 16-ти или 32-х, 4-х, 1-го или 2-х бит, в общем случае длина байта N - натуральное число) или слова (конечные последовательности байтов, длина слова L - натуральное число, если L = 1, то слово является байтом; если длина байта N = 1, то определение слова совпадает с определением кода).
Часть блока A длиной l, содержащая его первый x-ый элемент, - подфрагмент исходного фрагмента, содержащий элементы от элемента в позиции x до элемента в позиции (x+l-1) включительно.
Часть блока B длиной l, содержащая его последний (x-1)-ый элемент, - подфрагмент исходного фрагмента, содержащий элементы от элемента в позиции (x-1) до элемента в позиции (x-1) включительно.
Стоящая в скобках сумма по i является мерой отличия части блока A длиной l до части блока 8 той же длиной L.
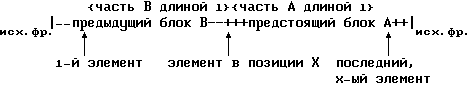
В каждой позиции x длину частей l выбирают такую, при которой эта сумма - мера отличия максимальна.
Эту сумму умножают на (Z+C) и прибавляют к (Z-l), чтобы в случае, когда ее максимальное значение Smax не зависит от l, то есть одинаково при нескольких значениях l, коэффициент K(x) все же зависел от того значения l, при котором она достигает этого значения Smax (см. пример 2).
Почему нельзя в каждой позиции x считать эту сумму - меру отличия один раз, при одном значении l, то есть, не изменяя длину частей B и A, потому что тогда на результат, то есть вычисляемый в этой позиции коэффициент К(x) будет влиять содержание фрагмента в позициях x+l и x-l, а это значение вносит помехи в результат.
С какой целью введен параметр S? Поскольку Px = x-1 пока x-1≤ X/2 и Px = X - (x-1), когда x-1>X/2, то Px - длина меньшего блока. Поскольку P = Px, пока Px≤S, и P = S, когда Px> S, то P = min(S, Px) - длина меньшего блока, не превышающая S. То есть S ограничивает длину частей B и A, причем, если S≥Z, то никакого ограничения нет.
Почему необходим параметр C? Только потому, что в вычислительной технике, основанной на двоичной системе исчисления, умножение на 2n, где n - натуральное число, происходит значительно быстрее, чем умножение на любое другое число Z. Параметр C является той самой разностью между Z и минимальным из чисел 2m≥Z; C = 2m - Z, Z + C = 2m, его применение позволяет увеличить скорость работы устройства, реализующего данный способ.
Почему в пункте 6) необходим параметр R? Если W из полученных Y подфрагментов имеют длину порядка X, то остальные Y-W подфрагментов будут пренебрежимо малы в сравнении с X, что по сути соответствует разделению исходного фрагмента на W подфрагментов. Предполагается, что Y достаточно велико, W порядка 1 по определению. Поэтому чем больше R, тем меньше полученное разбиение соответствует разделению исходного фрагмента именно на Y подфрагментов, так что R можно назвать мерой необходимости получить именно Y подфрагментов, а не меньше.
В результате применения описанного способа границы логически разных подфрагментов исходного фрагмента определяются достаточно точно, намного точнее, чем при использовании других известных способов, что в частности позволяет увеличить степень сжатия информации без потери ее полезной функции.
2) Способ анализа структуры фрагмента потока импульсно-сигнальной информации заключающийся в том, что:
а) фрагментируют исходный фрагмент потока на заданное число подфрагментов по п. 1, причем элементами являются биты, а параметры, задаваемые этому способу фрагментирования, вычисляют как значения заданных функций Q1, R1, S1, C1, Y1 от длины исходного фрагмента X и значений содержащихся в нем битов:
J = 1, Q = Q1(X, Bi), R = R1(X, Bi), S=S1(X, Bi), C = C1(X), Y = Y1(X, Bi),
где Bi - значение i - того бита, i = 1,..., X;
б) вычисляют сумму S1: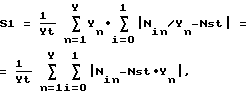
где Nin - число битов в n-ом подфрагменте со значением i;
Yn - число всех битов в n-ом подфрагменте;
Yt - число всех битов во фрагменте;
Nst = 1/2 - средняя теоретическая доля битов;
в) фрагментируют исходный фрагмент потока на заданное число подфрагментов по n. 1, причем элементами являются байты, а параметры, задаваемые этому способу фрагментирования, вычисляют как значения заданных функций Q2, R2, S2, C2, Y2 от длины исходного фрагмента X и значений содержащихся в нем байтов:
J=2, Q=Q2(X,Bi), R=R2(X,Bi), S=S2(X,Bi), C=C2(X), Y=Y2(X,Bi),
где Bi - значение i-того байта, i=1,..., X;
г) вычисляют сумму S2: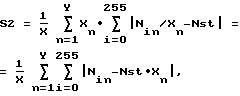 ,
,
где Nin - число байтов в n-ом подфрагменте со значением i;
Xn - число всех байтов в n-ом подфрагменте;
X - число всех байтов во фрагменте;
Nst=1/256 - средняя теоретическая доля байтов:
д) вычисляют сумму S3: если заданный параметр A3>X, то: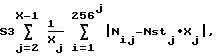
где Nij - число слов длиной j со значением i;
Xj=X-j+1 - число всех слов длиной j во фрагменте;
Nstj=1/256j - средняя теоретическая доля слов длиной j;
если X ≥ A3, то: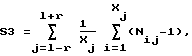
где I - заданная (ожидаемая возможная) длина слов;
r - заданный (ожидаемый возможный) разброс;
Nij - число во всем фрагменте таких слов длиной j, как слово длиной j байт, начинающееся с i-того байта;
Xj=X-j+1 - число всех слов длиной j в фрагменте;
е) вычисляют значения P1, P2, P3 заданных функций FP1, FP2, FP3 от этих трех вычисленных сумм:
P1=FP1(S1), P2=FP2(S2), P3=FP3(S3);
и далее: если P1<KO и P2<KO, Р3<KO, где KO - заданный коэффициент, то делают вывод, что фрагмент соответствует 0-ой модели - бесструктурной информации "хаотичный поток битов",
если P1≥P2 и P1≥P3, то делают вывод, что исходный фрагмент соответствует 1-ой модели - минимальноструктурированной информации "поток битов",
если P2≥P1 и P2≥P3, то делают вывод, что исходный фрагмент соответствует 2-ой модели - слабоструктурированной информации "поток байтов",
если P3≥P1 и P3≥P2, то делают вывод, что исходный фрагмент соответствует 3-ей модели - сильноструктурированной информации "поток слов",
причем, если находят два слова с одинаковой длиной более чем X/K2 байтов, отличающиеся более чем на X/K6 байтов после произвольной перестановки байтов местами и X≥K6, где K5 и K6 - заданные параметры, то делают вывод, что фрагмент соответствует 4-ой модели - сверхструктурированной информации "поток текстов".
Функции Q1, R1, S1, C1, Y1, Q2, R2, S2, C2, Y2 должны принимать существенно меньше значений, чем существует возможных комбинаций их аргументов. Например, C1(X)=65536-[X/2], Y1(X,Bi)=X/256, R1(X,Bi)=X/128, S1(X,Bi)= X/32, Q1(X,Bi)=X/512.
Очевидно, что в первом равенстве вторая сумма, то есть сумма по i, может иметь значения от 0, когда Nin=Yn/2, i=0,1, то есть когда битов "0" и "1" в подфрагменте поровну, до 1, когда N1n=1, N0n=0 или наоборот, то есть, когда все биты в подфрагменте одинаковые.
Поэтому и вся сумма S1 может изменяться от 0 (в случае полного хаоса) до 1 (в случае максимальной структуры).
Таким образом S1 - МЕРА ХАОТИЧНОСТИ ФРАГМЕНТА ПОТОКА БИТОВ.
Аналогично вторая сумма, то есть сумма по i, может принимать значения от 0, когда Nin=Yn/256,i=1,2, то есть когда всех байтов в подфрагменте поровну, до 510/256=2-1/128, когда все байты в подфрагменте одинаковые.
Поэтому и вся сумма S2 может изменяться от 0 (в случае полного хаоса) до 2-1/128 (в случае максимальной структуры). Таким образом S2 - МЕРА ХАОТИЧНОСТИ ФРАГМЕНТА ПОТОКА БАЙТОВ.
Во втором равенстве, применяемом на практике значительно чаще, чем первое, вторая сумма, то есть сумма по i, может принимать значения от 0, в случае отсутствия сильной структуры, до Xj•(Xj-1) в случае, когда все байты подфрагмента одинаковые, а вся сумма S2 - от 0 до (X-1)•(r•2+1)+r2+r-1, где l и r - заданные параметры: ожидаемые длина и разброс. Таким образом S3 - МЕРА ХАОТИЧНОСТИ ПОТОКА СЛОВ.
Далее эти три меры приводят к одной норме. Например, вычисляют отклонения этих мер хаотичности от заданных ожиданий K1, K2, K3 с заданными масштабами M1, M2, M3:
FP1(S1)=(S1-K1)•M1, FP2(S2)=(S2-K2)•M2, FP3(S3)=(S3-K3)•M3,
где K1, K2, K3, M1, M2, M3 - заданные параметры.
Если никакая из трех основных моделей не выделена в том смысле, что на ней акцентируют особое внимание, то ожидания K1, K2, K3 можно взять равными нулю, а масштабы зависят только от других уже заданных параметров: например, если M1= 1, то M2= 256/510, а M3 зависит только от X, если A3>X, или M3= 1/[(X-1)•(r•2+1)+r2+r-1] , если A3≥X. Очевидно, что в случае таких функций FP1, FP2, FP3 не учитывается дисперсия этих трех случайных величин S1, S2, S3, то есть даже, если каждое из значений P1=FP1(S1), P2=FP2(S2), P3=FP3(S3) может изменяться от 0 до 1 включительно, то вероятности событий (P1<W), (P2<W) и (P3<W), где 0≤W≤1, в общем случае неравны. Наконец, выбором максимального из четырех чисел P1, P2, P3, KO производят выбор наиболее адекватной из четырех моделей структуры информации: "хаотичный поток битов", "поток битов", "поток байтов", "поток слов или текст". В каком случае делают вывод, что фрагмент соответствует 4-ой модели - "поток текстов", поскольку "существует два слова с одинаковой длиной более чем X/K5 байтов и отличающиеся более чем на X/K6 байтов после произвольной перестановки байтов местами"? Если была выбрана модель "текст", причем максимальный из "коэффициентов отличия" K, возникших при фрагментировании в пункте в), Kmax таков, что Z-G>X/K5, а H>X/K6≥1, где G - остаток от деления Kmax на (Z+C), H - частное от деления Kmax на (Z+C), K5, K6, C, Z, X - известные числа.
Принятие наиболее адекватной модели структуры информации позволяет улучшить ее обработку, особенно, если об исходной информации не было известно ничего, в частности при сжатии позволяет увеличить степень ее сжатия без потери полезной функции.
з) Способ сжатия потока элементов - слов импульсно-сигнальной информации с помощью удобства, включающего память для организации словаря-памяти, состоит в следующем:
а) Фрагментируют исходный фрагмент на заданное число подфрагментов по п. 1, причем элементами являются байты, если заданная функция разделения F(y) всюду равна нулю и информации о разделении потока на слова нет, или слова, если эта функция F(y) не всюду равна нулю, то есть информация о разделении потока на слова имеется, а параметры, задаваемые этому способу фрагментирования, вычисляют как значения заданных функций Q3, R3, S3, C3, Y3 от длины исходного фрагмента X и значений содержащихся в нем слов: j=1,...,X-1, i=1,. . . , X, J=2 или 3, Q=Q3(X,Bij), R=R3(X,Bij), S=S3(X,Bij), C=C3(X), Y=Y3(X, Bij), где Bij - значение i-того слова длиной j. Например, F(y) задана так, что F(y)= 1 в тех позициях y, в которых байт в предыдущей позиции y-1 имеет значение 32 или 34 или 45, что по стандарту ASCII соответствует пробелу, кавычкам и дефису, а в остальных позициях у F(y)=0.
б) Если заданный параметр 0=0, то инициализируют отсутствие внешнего словаря в словаре-памяти, а если 0>0, то выбирают номер внешнего словаря NN и инициализируют NN-ый внешний словарь. Число NN в общем случае получают как значение заданной функции DN от длины обрабатываемого подфрагмента Li и множества чисел Tkj, где Tkj - число слов длиной k со значением j в этом подфрагменте Li: NN=DN(Li,Tkj), где k=1,2,...,Li-1,j=1,2,...,256k.
Например, DN(Li,Tkj)=DN1(Li,Tj), j=0,1,...,255, где Tj - число байтов со значением j в подфрагменте Li. В простейшем случае DN(Li,Tkj)=DN2(Li,T), например, где T - число байтов со значением 32 в подфрагменте Li. Очевидно, что эта заданная функция DN должна принимать столько значений, сколько имеется внешних словарей - 0.
Инициализируют также другой массив - "тень словаря" той же длиной LD элементов, что и словарь, но элементами являются биты, причем в позиции N "тени словаря" здесь и далее записывают бит "1", если байт в позиции N словаря принадлежит слову, уже однажды найденному повторно и использованному для сжатия потока слов, и записывают бит "0", если этот байт в N-ой позиции словаря принадлежит ни разу не использованному слову.
Если заданный параметр H=0, то здесь и далее никакие действия с участием массива "тень словаря" не производят. В первый из создаваемых итоговых потоков записывают значение заданной функции U от длины обрабатываемого подфрагмента Li и значение заданной функции V от этого выбранного номера словаря NN.
в) Выделяют из исходного фрагмента потока слов уже содержащееся или не содержащееся в словаре-памяти слово.
Известен способ выделения (1) из последовательности символов подпоследовательностей, уже содержащихся в словаре-памяти, с помощью "хеширующей функции", то есть функции, последовательно ветвящей процесс поиска этих подпоследовательностей в каждый момент пополам. Совершенно аналогичны способы, в каждой точке ветвящие путь поиска не на 2 пути, а на 4, 8, 16, 32, 64, 128 или 256 путей, требующие больше памяти, но меньше времени. В частности, если в процессе сравнения выделяемого слова с некоторым словом из словаря выясняется, что эти два слова идентичны до самого конца словаря, то дальше сравнение происходит в предложении, что это выделяемое слово уже добавлено к концу словаря.

г) Записывают информацию в пять итоговых потоков: первый - "изменение организации словаря", второй - "длины слов, найденных в словаре", третий - "информация о пути доступа к таким словам", четвертый - "длины слов, не найденных в словаре", пятый - "слова, не найденные в словаре", причем,
- если слово найдено в словаре-памяти, а его длина n больше L или его длина n равна L и "смещение" P меньше M: n>L или (n=L и p<M), где L и M - заданные параметры, то во второй поток записывают значение заданной функции FY от его длины, в третий - его положение в словаре, в четвертый - 0, если и предыдущая запись производилась во второй и третий потоки, либо ничего, если предыдущая запись производилась в четвертый и пятый потоки,
- в обратной случае, то, есть если слово не найдено в словаре-памяти или его длина меньше L, или его длина равна L, а "смещение" p не меньше M: n<L или (n=L и p ≥ M), то в четвертый поток записывают значение заданной функции FN от его длины, а пятый - все это слово целиком, во второй - 0, если и предыдущая запись производилась в четвертый и пятый потоки, либо ничего, если предыдущая запись производилась во второй и третий потоки.
Если это слово - первое выделенное из обрабатываемого подфрагмента слово, то предполагается, что предыдущая запись производилась в четвертый и пятый потоки.
Эта заданная функция FY от длины выделенного слова n может быть равна, например, FY(n)=n-2, а функция FN(n), например, FN(n)=n.
При записи положения найденного слова в словаре в третий поток записывают значение заданной функции FP(p) от "смещения" p-расстояния от позиции, в которой было найдено слово, до конца словаря. Очевидно, что эти функции U, V, FN, FY, и FP должны быть биективными, то есть такими, чтобы по значению функции всегда можно было однозначно определить значение аргумента. Функции F, Q3, R3, S3, C3, Y3, DN должны наоборот принимать существенно меньше значений, чем существует возможных комбинаций их аргументов.
д) Принимают решение о добавлении выделенного слова к концу словаря, причем:
- если слово было найдено, а его длина больше D, где D - заданный параметр, и больше "смещения", то есть расстояния от позиции словаря, в которой оно было найдено, до конца словаря, или эта длина больше E, где E - заданный параметр, то его не добавляют в словарь, а в обратном случае добавляют;
- если слово не было найдено, а его длина больше F или меньше G, где F и G - заданные параметры, то его не добавляют, а в обратном случае добавляют;
е) перед этим добавлением, если было принято решение о добавлении выделенного слова к концу словаря и если сумма добавляемого слова LS и длины словаря LD превышает объем выделенной под словарь памяти LM: LS+LD>LM, где LM-заданный параметр, удаляют необходимое число байтов, а именно LS+LD-LM, из начала словаря-памяти и последовательно переносят биты из тех позиций "тени словаря", где находятся эти удаляемые из словаря байты, в первый поток;
ж) если выделенное слово было найдено, записывают LS битов "1" в те позиции "тени словаря", где оно было найдено;
з) если выделенное слово было добавлено к концу словаря, записывают LS битов "О" в соответствующие позиции "тени словаря";
и) повторяют действия по подпунктам от в) до з) до тех пор, пока не все слова из исходного подфрагмента обработаны;
к) последовательно переносят LD битов из "тени словаря" в первый поток, начиная с позиции, соответствующей началу словаря, и до позиции, соответствующей его концу.
л) если заданный параметр H#O, преобразуют получившийся в пунктах от в) до к) "фрагмент третьего потока", используя полученный "фрагмент первого потока", следующим образом:
в "преобразованный фрагмент третьего потока" записывают значения заданной функции FP(p1) от "новых смещений" p1 - расстояний от позиции PP, в которой было найдено слово, до конца словаря за вычетом числа байтов, принадлежащих неиспользованным словам, находящимся между этой позицией PP и концом словаря, после чего, если сумма длины "фрагмента первого потока" и длины "преобразованного фрагмента третьего потока" меньше длины "фрагмента третьего потока", то в первый поток записывают бит "1" и полученный "фрагмент первого потока", а в третий поток - "преобразованный фрагмент третьего потока", а в обратном случае в первый поток записывают бит "О", а в третий поток - исходный "фрагмент третьего потока";
м) если заданный параметр H=O, то никакие действия с участием массива "тень словаря" в подпунктах б), е), ж), з), к) не производят;
н) повторяют действия по подпунктами от б) до м) до тех пор, пока не все подфрагменты обработаны;
о) повторяют действия по подупнктам от а) до н) до тех пор, пока не все фрагменты длиной X исходного потока обработаны;
п) если в результате действий подпунктов г) или е) L3 (l1, l2, l3, l4, l5, i3)≥0,
где L3- заданная функция, i3 - внешний "общий" параметр, периодически вычисляемый теми из одновременно работающих способов, которые частично или полностью контролируют работу данного описываемого способа, l1, l2, l3, l4, l5 - длины фрагментов итоговых потоков, созданных с момента последней записи в "один итоговый" поток", то сдвигают границу подфрагмента и границу исходного фрагмента к слову, следующему за текущим, затем выполняют действия по подпунктам до н) включительно, после чего записывают в "один итоговый поток" значение F3 заданной функции FE3(l1,l2,l3,l4,l5) от этих длин, затем фрагмент первого потока, созданный с момента последней записи в "один итоговый поток", затем фрагмент второго потока, фрагмент третьего, четвертого и пятого потоков, созданные с момента последней записи в "один итоговый поток".
Например, функция L3(l1,l2,l3,l4,l5,i3)=(l1+l2+l3+l4+l5-131072)•i3 или L3-max(l1, l2, l3, l4, l5)-32768. Функция FE3 должна быть биективной: по ее значению должны быть однозначно восстановимы все пять длин l1,l2,l3,l4,l5. Этот внешний общий параметр i3 периодически вычисляется, если способ реализуется нижеописанным устройством "трехэтапный компрессор" или аналогичным ему элементом "менеджер", либо задается один раз перед началом работы способа, если данный способ реализуют независимо от других, то есть нет одновременно с ним реализуемых частично или полностью контролирующих его работу способов.
Цель - сжатие информации достигается потому, что когда слово найдено в словаре, то его положение в словаре и длину можно записать короче, то есть с использованием меньшего числа битов, чем само это слово из исходного потока.
4) Способ сжатия потока элементов - байтов импульсно-сигнальной информации с помощью устройства, включающего память для организации "двоичного дерева", заключающийся в том, что:
а) фрагментируют исходный фрагмент "потока байтов" на заданное число подфрагментов по п.1, причем элементами являются байты, а параметры, задаваемые этому способу фрагментирования, вычисляют как значение заданных функций Q4,R4,S4,Y4 от длины исходного фрагмента X и значений содержащихся в нем байтов:
J=2, Q=Q4(X, Bi), R=R4(X, Bi), S=S4(X, Bi), С=С4(X), Y=Y4(X, Bi),
где Bi - значение i-того байта, i=1,...,X;
б) сжимают каждый полученный подфрагмент с построением и использованием "двоичного дерева", причем информацию записывают в четыре итоговых потока: первый - "длины подфрагментов", второй - "о методе сжатия", третий - "структура двоичного дерева", четвертый - "байты, преобразованные в коды", следующим образом:
- в первый поток записывают значение заданной функции F4(l) от длины подфрагмента l;
- если все байты в подфрагменте одинаковые, во второй поток записывают код "110", в четвертый - этот байт;
- если подфрагмент не удалось сжать, во второй поток записывают бит "О", в четвертый - исходный подфрагмент;
- если подфрагмент был сжат с использованием старого "дерева", во второй поток записывают код "10", а в четвертый - коды, преобразованные из байтов с использованием этого старого "двоичного дерева";
- если подфрагмент был сжат с построением и использованием нового "дерева", во второй поток записывают код "111", в третий - информацию о структуре этого нового "дерева", а в четвертый - коды, преобразованные из байтов с использованием этого нового "двоичного дерева";
в) повторяют действия по подпунктам а) и б) до тех пор, пока не все фрагменты длиной X исходного потока обработаны;
г) если в результате действий подпункта б) L4(l1,l2,l3,l4,i4) ≥ 0, где L4 - заданная функция, i4 - внешний общий параметр, периодически вычисляемый теми из одновременно работающих способов, которые частично или полностью контролируют работу данного описываемого способа, l1,l2,l3,l4 - длины фрагментов итоговых потоков, созданных с момента последней записи в "один итоговый поток", то сдвигают границу подфрагмента и границу исходного фрагмента к байту, следующему за последним обработанным, затем выполняют действия по подпункту б), после чего записывают в "один итоговый поток" значение F4 заданной функции FE4(l1,l2,l3,l4) от этих длин, затем фрагмент первого потока, созданный с момента последней записи в "один итоговый поток", затем фрагмент второго потока, фрагменты третьего и четвертого потоков, созданные с момента последней записи в "один итоговый поток".
После записи в первый поток функции от длины подфрагмента, если не все байты в подфрагменте одинаковые, то каждый подфрагмент сжимают 2 раза: сначала с использованием ужу существующего "двоичного дерева", если это возможно, то есть каждому из возможных байтов подфрагмента соответствует код ненулевой длины, затем его же сжимают с использованием "дерева", построенного для него и K из тех следующих за ним подфрагментов, в которых не все байты одинаковые, где K - заданный параметр. Если же таких подфрагментов "следующих за ним, в которых не все байты одинаковые", меньше чем K, то это новое "дерево" строят для них всех.
В обоих случаях итоговую информацию не записывают в итоговые потоки, ее вообще никуда не записывают, но тем не менее вычисляют, сколько битов было бы записано суммарно во второй, третий и четвертый потоки.
Из двух сжатий выбирают то, которое записывает суммарно меньше битов во второй, третий и четвертый потоки. Делают вывод, что подфрагмент "не удалось сжать", если при этом выбранном способе сжатия во второй, третий и четвертый потоки необходимо записать суммарно больше битов, чем содержится в исходном подфрагменте, и если подфрагмент не удалось сжать, во второй поток записывают бит "0", в четвертый - исходный подфрагмент, если подфрагмент выгоднее сжать с использованием старого "дерева", во второй поток записывают код "10", а в четвертый - коды, преобразованные из байтов с использованием этого старого "двоичного дерева", если подфрагмент выгоднее сжать с построением и использованием нового "дерева", во второй поток записывают код "111", в третий - информацию от структуре этого нового "дерева", а в четвертый - коды, преобразованные из байтов с использованием этого нового "двоичного дерева".
Известны способы построения "двоичного дерева" - таблицы для преобразования заданного фрагмента байтов-символов в коды оптимальной формы, то есть такой, с использованием которой достигается минимальное из возможных значений длины преобразованного фрагмента. Это "метод Хаффмана", метод "Шеннона-Фэно" и другие.
Цель - сжатие информации достигается потому, что эту таблицу - "двоичное дерево" строят таким образом, что длина кода, соответствующего каждому байту заданного исходного фрагмента, тем короче, чем больше таких байтов в подфрагменте, причем после применения фрагментирования по п.1 цель достигается лучше, то есть происходит лучшее сжатие, чем без применения фрагментирования.
5) Способ сжатия потока элементов - "битов" импульсно-сигнальной информации заключается в следующем:
а) фрагментируют исходный фрагмент "потока битов" на заданное число подфрагментов по п. 1, причем элементами являются биты, а параметры, задаваемые этому способу фрагментирования, вычисляют как значения заданных функций Q5, R5, S5, C5, Y5 от длины исходного фрагмента X и значений содержащихся в нем битов:
J=1, Q=Q5(X, Bi), R=R5(X, Bi), S=S5(X, Bi), C=C5(X), Y=Y5(X, Bi),
где Bi - значение i-того бита, i=1,...,X;
б) сжимают каждый полученный подфрагмент, причем итоговую информацию записывают в четыре итоговых потока: первый - "длины подфрагментов", второй - "флаг сжатия", третий - "значение X в подфрагменте", четвертый -"хаос" следующим образом:
- в первый поток записывают значение заданной функции F5(l) от длины подфрагмента l,
- если длина подфрагмента меньше T, где T - заданный параметр, его переносят в четвертый поток "хаос",
- если подфрагмент не удалось сжать, во второй поток записывают бит "0", а в четвертый - исходный подфрагмент;
- если подфрагмент был сжат, во второй поток записывают бит "1", в третий - бит, встречающийся в подфрагменте чаще, а в четвертый - бит "пары", если значение длины подфрагмента - нечетное число, затем "пары" преобразуют в коды следующим методом:
подфрагмент "пар" записывают в три итоговых блока - "первый", "второй" и "шум":
пара "XX": "0" в первый блок, где "X" - бит, встречающийся в подфрагменте чаще, "Y" - встречающийся реже,
пара "YY": "1" в первый блок, "0" во второй блок,
пары "XY" и "YX": "1" в первый блок, "1" во второй, первый бит пары, соответственно "X" или "Y" в блок "шум", после чего каждый из этих трех блоков сжимают заново описанным способом по пунктам а) и б),
в) повторяют действия по подпунктам а) и б) до тех пор, пока не все фрагменты длиной X исходного потока обработаны;
г) если в результате действий подпункта б) L5(l1,l2,l3,l4,i5)>0, где L5 - заданная функция, i5 - внешний "общий" параметр, периодическим вычисляемый теми из одновременно работающих способов, которые частично или полностью контролируют работу данного описываемого способа, l1,l2,l3,l4 - длины фрагментов итоговых потоков, созданных с момента последней записи в "один итоговый поток", то сдвигают границу подфрагмента и границу исходного фрагмента к байту, следующему за последним обработанным, затем выполняют действия по подпункту б), после чего записывают в "один итоговый поток", значение F5 заданной функции FE5(l1,l2,l3,l4) от этих длин, затем фрагмент первого потока, созданный с момента последней записи в "один итоговый поток", затем фрагмент второго потока, фрагменты третьего и четвертого потоков, созданные с момента последней записи в "один итоговый поток".
После записи в первый поток функции от длины подфрагмента, если длина подфрагмента не меньше T, то вычисляют, сколько битов будет записано суммарно во второй, третий и четвертый потоки в случае, если подфрагмент будет сжат. Делают вывод, что подфрагмент "не удалось сжать", если при этом туда необходимо записать суммарно больше битов, чем содержится в исходном подфрагменте, после чего этот исходный подфрагмент в зависимости от вывода копируют во второй поток или сжимают описанным методом. При этом сжатии длина первого блока всегда больше нуля, а длина второго блока и "шума" может быть равна нулю.
Перед этими повторными применениями способа, но уже не к подфрагменту исходного фрагмента "потока битов", а к каждому из полученных блоков сохраняют всю информацию, необходимую для дальнейшей работы способа, а именно значения необходимых для этой дальнейшей работы скалярных и векторных переменных, определяют объем памяти, необходимой для повторных запусков способа, выделяют такой объем, затем три раза применяют способ заново, причем после каждого из трех завершений повторных применений способа восстанавливают часть этой необходимой информации и продолжают эту дальнейшую работу - "сжатие заново каждого из трех блоков". Теоретически таких "рекурсивных" повторных применений может быть столько, сколько позволяет объем свободной памяти, но практически, пока X/(2n)>T, где n - номер повторного применения.
Очевидно, что функции F4,F5,FE4 и FE5 должны быть биективными, то есть такими, чтобы по значению функции всегда можно было однозначно определить значение аргумента. Функции L4,L5,Q4,R4,S4,C4,Y4,Q5,R5,S5,C5,Y5 должны наоборот принимать существенно меньше значений, чем существует возможных комбинаций их аргументов.
Эти общие параметры i4 и i5 периодически вычисляются, если способ реализуется нижеописанным устройством "трехэтапный компрессор" или аналогичным ему элементом "менеджер", либо задается один раз перед началом работы способа, если данный способ реализуют независимо от других, то есть нет одновременно с ним реализуемых частично или полностью контролирующих его работу способов.
Цель - сжатие информации достигается потому, что если в исходном потоке элементов - "битов" имеется слабая структура, то есть много достаточно длинных фрагментов, состоящих из одинаковых битов или фрагментов, в которых доля одного бита существенно больше доли другого, то такие фрагменты будут выделены при фрагментировании и преобразованы так, что в итоговых потоках соответствующие им коды будут суммарно меньшей длины, чем этот "слабоструктурированный" фрагмент. Очевидно, что после применения фрагментирования по п.1 цель достигается лучше, то есть происходит лучшее сжатие, чем без применения фрагментирования.
6) Способ сжатия информации "в три этапа" по п.3,4 и 5, отличающийся тем, что:
а) на первом этапе к исходному потоку применяют способ, описанный в пункте 3;
б) на втором этапе к полученным фрагментам применяют способ, описанный в пункте 4, причем при создании фрагментов четвертых потоков - "коды, образованные из байтов", эти коды записывают в эти фрагменты не последовательно, как в п. 4, а следующим образом: в начало фрагмента записывают первые биты кодов, образованных из байтов; далее вторые биты: сначала следующие за первым битом "0", если они есть, то есть не существует кода "0", но есть коды "0. . . ", потом следующие за первым битом "1", если есть коды "1..."; далее третьи биты, те, которые есть: сначала следующие за битами "00", затем за "01", "10", "11"; четвертые биты и так далее до N-ых, где N - максимальная длина кода в создаваемом фрагменте;
в) на третьем этапе к получившимся на втором этапе фрагментам применяют способ, описанный в пункте 5.
Очевидно, что эти два возможных способа записи - "последовательный" по п. 4 и "долгий" по п.6 эквивалентны в том смысле, что по фрагменту, образованному одним из них, всегда можно однозначно создавать второй.
Существует два варианта действий с целью создания фрагмента "долгим" способом: или последовательно брать байты из исходного подфрагмента, получать из таблицы преобразований "двоичного дерева" код, затем последовательно записывать биты этого кода в этот создаваемый фрагмент, каждый раз вычисляя позиции, в которые каждый из этих битов должен быть записан, или последовательно заполнять создаваемый фрагмент: сначала первыми битами, затем два раза вторыми, четыре раза третьими, восемь раз четвертыми и так далее, каждый раз последовательно проходя заново исходный подфрагмент с начала до конца.
Первый вариант универсальней, потому что может, как и второй, не использовать дополнительной памяти, работая долго, но может, создавая и используя "таблицу позиций", работать намного быстрее.
7) Устройство для сжатия информации, включающее:
- память для хранения словаря-памяти, структуры двоичного дерева и другой информации, без памяти работа других элементов устройства невозможна;
- "выделитель слов" для выделения слов, содержащихся в словаре-памяти, из потока элементов - слов импульсно-сигнальной информации, без которого невозможна работа компрессора потока слов;
- преобразователь байтов в коды для создания таблицы преобразования байтов в коды, без которого невозможна работа компрессора потока байтов,
отличающееся тем, что снабжено связанными с памятью блоком выделения подфрагментов, предназначенным для разделения фрагментов потока элементов импульсно-сигнальной информации на заданное число подфрагментов, компрессором потока слов, предназначенным для сжатия потока слов и генерирования выходящей сжатой информации, разделенной на пять потоков, компрессором потока байтов, предназначенным для сжатия потока байтов и генерирования выходящей сжатой информации, разделенной на четыре потока, компрессором потока битов, предназначенным для сжатия потока битов и генерирования выходящей сжатой информации, разделенной на четыре потока, блоком управления, предназначенным для вычисления общих параметров, определения порядка работы этих трех компрессоров и порядка записи выходящей сжатой информации в итоговый поток, без которого работа устройства сжатия невозможна.
На фиг.1 изображена схема устройства сжатия информации; на фиг.2 - схема блока выделения подфрагментов; на фиг.3 - схема компрессора потока слов; на фиг.4 - схема компрессора потока байтов; на фиг.5 - схема компрессора потока битов.
Все шесть описанных способов могут быть реализованы в микропроцессорной технике, а также в любых устройствах, содержащих микросхемы памяти и микропроцессор.
Устройство для сжатия потока информации содержит компрессор 1 потока слов, компрессор 2 потока байтов, компрессор 3 потока битов, блок управления 4, выделитель слов 5, преобразователь 6 байтов в коды и блок выделения 7 подфрагментов. Память используется каждым блоком по мере необходимости, выделитель слов используется только компрессором 1, а блок выделения 6 подфрагментов - только компрессором 2.
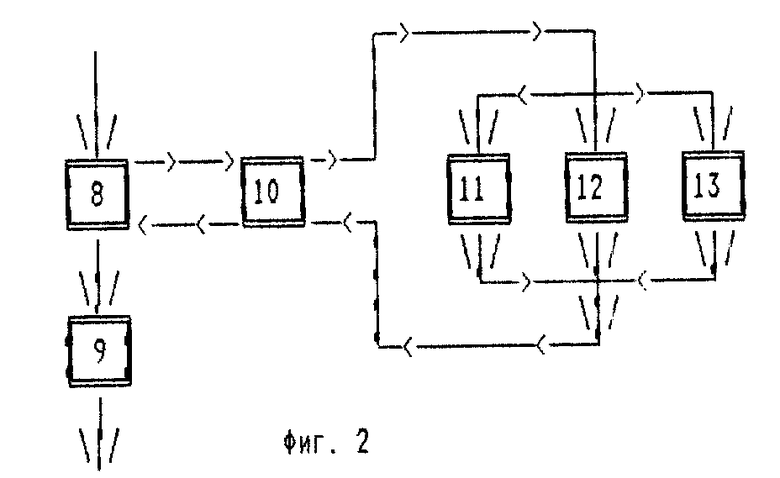
Блок выделения 7 состоит из следующих элементов, соединенных в соответствии со схемой (фиг.2): "Создатель (Y-1) границ" (8), "Создатель необходимого числа границ" (9), "Вычислитель коэффициента K(x)" (10), "Вычислитель суммы для элементов-битов" (11), "Вычислитель суммы для элементов-байтов" (12), "Вычислитель суммы для элементов-слов" (13). Он используется (фиг.1) для "Компрессора" (1), "Компрессора"(2) и "Компрессора"(3).
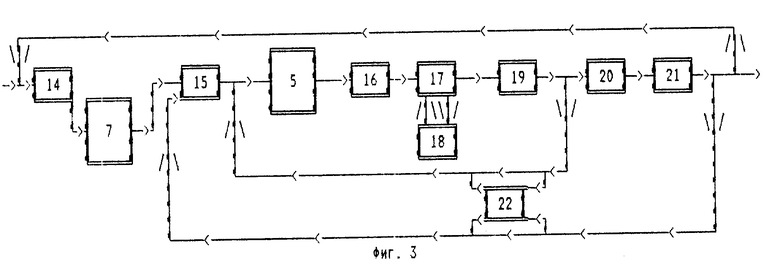
Компрессор 1 состоит из следующих элементов, соединенных в соответствии со схемой (фиг.3): "Вычислитель Q, R, S, C, Y первого этапа" (14), "Инициализатор внешнего словаря и тени словаря " (15), "Создатель 2-го, 3-го, 4-го и 5-го потоков" (16), "Добавитель слов в словарь" (17), "Удалитель слов из словаря" (18), "Записыватель в тень словаря" (19), "Копирователь из тени словаря в первый поток" (20), "Преобразователь третьего и первого потоков"(21), "Создатель одного итогового потока первого этапа" (22).
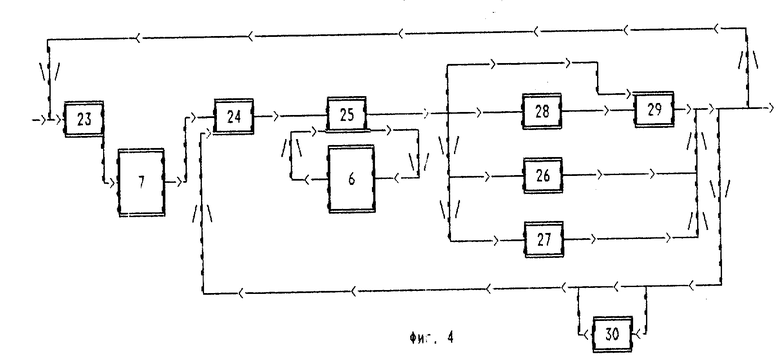
Компрессор 2 (фиг.4) состоит из следующих элементов, соединенных в соответствии со схемой (фиг.4): "Вычислитель Q, R, S, C, Y второго этапа" (23), "Создатель первого потока второго этапа" (24), "Создатель второго потока второго этапа" (25), "Записыватель байта в четвертый поток" (26), "Копирователь подфрагмента в четвертый поток" (27), "Создатель третьего потока" (28), "Преобразователь байтов в коды способом п.6" (29), "Создатель одного итогового потока второго этапа" (30).
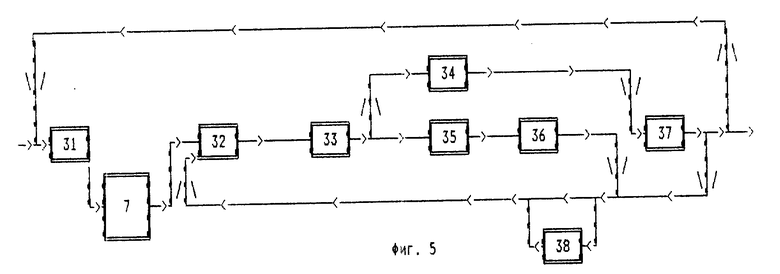
Компрессор 3 (фиг.5) состоит из следующих элементов, соединенных в соответствии со схемой (фиг.5): "Вычислитель Q, R, S, C, Y третьего этапа"(32), "Создатель второго потока третьего этапа" (33), "Копирователь подфрагмента в поток-хаос" (34), "Создатель третьего потока и блоков" (35), "Сохранитель состояния"(36), "Определитель-востановитель состояния" (37), "Создатель одного итогового потока третьего этапа" (38).
В функции (4) (фиг.1) входит следующее:
а) определение выполненности заданного критерия A (если в данном состоянии критерий A выполнен, то в данный момент времени "первый этап компрессора" (1) работает);
б) определение выполненности заданного критерия Б (если он выполнен, то второй этап компрессора"(2) работает);
в) определение выполненности заданного критерия В (если он выполнен, то третий этап компрессора" (3) работает);
г) вычисление общих параметров i3, i4, i5;
д) передача информации о длинах фрагментов, составляющих фрагменты "одного итогового потока" "первого этапа компрессора"(1), "второму этапу компрессора"(2);
е) передача информации о длинах фрагментов, составляющих фрагменты "одного итогового потока" "второго этапа компрессора".
Например, устройство таково, что одновременная работа трех или любых двух из этих трех "этапов компрессора" невозможна, в любой момент времени работает только один из них. В этом случае, например,
критерий А: "заполнен фрагментами пяти потоков не весь буфер заданной длиной LL",
критерий Б: "буфер заданной длиной LL создан "первым этапом компрессора" (1), но обработан "вторым этапом компрессора" (2) не весь",
критерий В: "фрагмент, соответствующий одному из двадцати создаваемых "вторым этапом компрессора" (2) потоков, создан, но не обработан "третьим этапом компрессора" (3) до конца".
Тогда "Менеджер" (4) должен в момент, когда стал выполненным критерий Б, приостановить работу "первого этапа компрессора" (1) и начать или продолжить работу "второго этапа компрессора" (2), передав ему информацию о длинах, составляющих фрагменты "одного итогового потока" фрагмента пяти итоговых потоков "первого этапа компрессора" (1), в момент, когда стал выполненным критерий В, приостановить работу "второго этапа компрессора" (2) и начать или продолжить работу "третьего этапа компрессора" (3), передав ему информацию о длинах составляющих фрагменты "одного итогового потока" фрагментов четырех итоговых потоков "второго этапа компрессора" (2), а в момент, когда стал выполненным критерий А, приостановить работу "третьего этапа компрессора" (3) и продолжить работу "первого этапа компрессора"(1).
Работа блока выделения подфрагментов (фиг.2).
"Создатель (Y-1) границ" (8) инициирует необходимые векторные и скалярные переменные, в частности вычисляет значение средней длины разделения, равной X/Y, и присваивает величине позиции X значение 2, затем (X-1) раз вызывает "вычислителя коэффициента K(x)" (10), после каждого раза увеличивая значения переменной X на 1, то есть вызывает до тех пор, пока значение x не достигнет величины (X+1), причем получаемые коэффициенты K(x) записывает в "массив коэффициентов". После того как этот цикл по x завершен, "создатель (Y-1) границ" (8) выбирает их этого массива (Y-1) максимальных коэффициентов K(x) так, чтобы длины определенных ими Y подфрагментов отклонялись от средней длины разделения, равной X/Y, не более чем на заданное значение R, причем те позиции, в которых эти максимальные коэффициенты находятся, сохраняет в "массиве границ". После этого создает "массив максимальных коэффициентов", сокращая" массив коэффициентов" до (Y-1) элементов, оставляя в нем только те коэффициенты, адреса которых занесены в "массив границ".
"Создатель необходимого числа границ" (9) из двух имеющихся массивов одинаковой длины (Y-1) - "массива границ" и "массива максимальных коэффициентов" удаляет элементы в тех позициях, в которых в "массиве коэффициентов" находятся числа, меньшие заданного параметра (Q+1), после каждого удаления уменьшая значение переменной Y на 1, причем, если Q=0, то "создатель необходимого числа границ" (9) не делает ничего.
"Вычислитель коэффициента K(x)" (10) присваивает переменной IK значение 0, затем вычисляет значение переменной P, затем последовательно P раз вызывает, в зависимости от значения параметра J, если J=1, "вычислителя суммы для элементов-битов" (11), если J=2, "вычислителя суммы для элементов-байтов" (12), если J=3, "вычислителя суммы для элементов-слов"(13); вычисляет, используя полученную сумму, значение коэффициента K(x) при данной "длине частей" 1; сравнивает полученное значение K(x) со значением переменной IK; если K(x) > IK, то присваивает переменной IK значение K(x). После завершения цикла "вычислитель коэффициента K(x)" (10) прекращает работу, передавая "создателю (Y-1) границ" (8) значение переменной IK.
"Вычислитель суммы для элементов-битов" (11) вычисляет значение суммы, рассматривая исходный фрагмент длиной X элементов как фрагмент, состоящий из битов.
"Вычислитель суммы для элементов-байтов" (12) вычисляет значение суммы, рассматривая исходный фрагмент длиной X элементов как фрагмент, состоящий из байтов.
"Вычислитель суммы для элементов-слов" (13) вычисляет значение суммы, рассматривая исходный фрагмент длиной X элементов как фрагмент, состоящий из слов.
Работа компрессора потока слов (фиг.3).
"Вычислитель Q, R, S, C, Y первого этапа" (14) вычисляет значения заданных функций Q3, R3, S3, C3, Y3, и присваивает необходимые значения переменным J, Q, R, S, C, Y, после чего запускает блок выделения подфрагментов, а затем передает управление "инициатору внешнего словаря и тени словаря" (15).
"Инициализатор внешнего словаря и тени словаря" (15) инициализирует массивы "словарь" и "тень словаря", а также другие переменные "первого этапа компрессора" (1).
"Создатель 2-го, 3-го, 4-го и 5-го потоков" (16), используя результаты работы "выделителя слов" (5), записывает необходимую информацию во второй, третий, четвертый и пятый потоки.
"Добавитель слов в словарь" (17) принимает решение о добавлении выделенного слова к концу словаря, причем, если было принято решение о добавлении выделенного слова к концу словаря, то, используя "удалитель слов из словаря" (18), удаляет необходимое число слов из начала словаря и добавляет слово к концу словаря.
"Удалитель слов из словаря" (18) удаляет заданное число слов из начала словаря, причем, если заданный параметр H#0, последовательно переносит биты из тех позиций "тени словаря", где находятся эти удаляемые из словаря слова, в первый поток.
"Записыватель в тень словаря" (19), если H#0 и если выделенное слово было найдено, сохраняет в той позиции "тени словаря", где было найдено выделенное слово, информацию о том, что слово в этой позиции словаря было встречено повторно и использовано в процессе сжатия; затем, если H#О и если выделенное слово было добавлено к концу словаря, сохраняет в той же позиции "тени словаря", где было добавлено выделенное слово, информацию о том, что слово в этой позиции не было встречено повторно, после чего передает управление в зависимости от значений переменных либо создателю одного итогового потока первого этапа"(22), если не все слова подфрагмента обработаны, либо "копирователю из тени словаря в первый поток" (20), если все слова подфрагмента обработаны.
"Копирователь из тени словаря в первый поток" (20), если H#О, копирует необходимое число битов, а именно столько, сколько байтов в словаре, из "тени словаря" в первый поток, начиная с позиции, соответствующей началу словаря, и до позиции, соответствующей его концу.
"Преобразователь третьего и первого потоков" (21), если H#О 0, вышеописанным образом преобразует фрагменты третьего и первого потоков, а после завершения работы передает управление, в зависимости от значений переменных, либо "создателю одного итогового потока первого этапа" (22), если не все подфрагменты обработаны, либо "вычислителю Q, R, S, C, Y первого этапа" (14), если не все фрагменты исходного потока обработаны, либо завершает работу "первого этапа компрессора" (1), если все фрагменты исходного потока обработаны.
"Создатель одного итогового потока первого этапа" (22) в случае необходимости, а именно, если L3≥0, записывает в "один итоговый поток" первого этапа значения F3 заданной функции FE3(11, 12, 13, 14, 15) от длин 11, 12, 13, 14, 15 фрагментов итоговых потоков, созданных с момента последней записи в "один итоговый поток" первого этапа, затем фрагмент первого потока, созданный с момента последней записи в "один итоговый поток" первого этапа, затем фрагмент второго потока, фрагменты третьего, четвертого и пятого потоков, созданные с момента последней записи, в "один итоговый поток" первого этапа, и передает управление процессом, в зависимости от значений переменных, "выделителю слов" (5), если не все слова подфрагмента обработаны, или "инициализатору внешнего словаря и тени словаря" (15), если все слова подфрагмента обработаны.
Работа компрессора потока байтов (фиг.4).
"Вычислитель Q, R, S, C, Y второго этапа" (23) вычисляет значения заданных функций Q3, R3, S3, Y3 и присваивает необходимые значения переменных J, Q, R, S, C, Y, после чего запускает блок выделения подфрагментов. а затем передает управление "создателю первого потока второго этапа" (24).
"Создатель первого потока второго этапа" (24) записывает значения заданной функции F4 от длины подфрагмента l в первый поток.
"Создатель второго потока второго этапа" (25), используя "создателя дерева с вычислением итоговой длины преобразованного фрагмента" (6), делает вывод, каким образом необходимо сжать подфрагмент, после чего, в зависимости от этого вывода, либо записывает во второй поток код "0" и передает управление процессом "копирователю подфрагмента в четвертый поток" (27), либо записывает во второй поток код "110" и передает управление процессом "записывателю байта в четвертый поток" (26), либо записывает во второй поток код "111" и передает управление процессом "создателю третьего потока" (28), либо записывает во второй поток код "10" и передает управление процессом "преобразователю байтов в коды способом п.6" (29).
"Создатель третьего потока" (28) записывает всю необходимую информацию о "двоичном дереве" - таблице преобразования байтов в коды в третий поток и передает управление "преобразователю байтов в коды способом п.6" (29). "Записыватель байта в четвертый поток" (26) записывает заданный байт в четвертый поток. "Копирователь подфрагмента в четвертый поток" (27) копирует заданный подфрагмент потока байтов в четвертый поток.
"Преобразователь байтов в коды способом п.6" (29) преобразует байты в коды, используя таблицу преобразования - "двоичное дерево".
Каждый из последних трех элементов после завершения работы передает управление, в зависимости от значений переменных, либо "создателю итогового потока второго этапа" (30), если не все подфрагменты обработаны, либо "вычислителю Q, R, S, C, Y второго этапа" (23), если не все фрагменты исходного потока обработаны, либо завершает работу "второго этапа компрессора" (2), если все фрагменты исходного потока обработаны, причем эти последние два элемента, если в процессе их работы значение заданной функции L4(11, 12, 13, 14, i4)≥0, то сдвигают границу подфрагмента и границу исходного фрагмента к байту подфрагмента, следующему за последним обработанным, необходимым образом преобразуют последние элементы фрагментов второго, третьего и четвертого потоков и завершают работу.
"Создатель одного итогового потока второго этапа" (30), в случае необходимости, а именно, если L4≥0, записывает в "один итоговый поток" второго этапа значение F4 заданной функции FE4 (11, 12, 13, 14) от длин 11, 12, 13, 14 фрагментов итоговых потоков, созданных с момента последней записи в "один итоговый поток" второго этапа, затем фрагмент первого потока, созданный с момента последней записи в "один итоговый поток" второго этапа, затем фрагмент второго потока, фрагмент третьего и четвертого потоков, созданные с момента последней записи в "один итоговый поток" второго этапа, и передает управление "создателю первого потока второго этапа" (24).
Работа компрессора потока битов (фиг.5)
"Вычислитель Q, R, S, C, Y третьего этапа" (31) вычисляет значения заданных функций Q3, R3, S3, C3, Y3 и присваивает необходимые значения переменным J, Q, R, S, C, Y, после чего запускает блок выделения подфрагментов, а затем передает управление "создателю первого потока третьего этапа" (32).
"Создатель первого потока третьего этапа" (32) записывает значение заданной функции F5 от длины подфрагмента 1 в первый поток.
"Создатель второго потока третьего этапа" (33) делает вывод, каким образом необходимо сжать подфрагмент, после чего, в зависимости от этого вывода, либо передает управление процессом "копирователю подфрагмента в поток-хаос" (34), либо записывает во второй поток код "0" и передает управление процессом "копирователю подфрагмента в поток-хаос" (34), либо записывает во второй поток код "1" и передает управление процессом "создателю третьего потока и блоков" (35).
"Копирователь подфрагмента в поток-хаос" (34) копирует заданный подфрагмент потока битов в четвертый поток и передает управление "определителю-восстановителю состояния" (37).
"Создатель третьего потока и блоков" (35) записывает в третий поток бит, встречающийся в подфрагменте чаще, и преобразует "пары" в коды, создавая три блока, и передает управление "сохранителю состояния" (36).
"Сохранитель состояния" (36) сохраняет всю информацию, необходимую для дальнейшей работы способа, а именно значения необходимых для этой дальнейшей работы скалярных и векторных переменных, определяет объем памяти, необходимой для повторных применений способа, и выделяет такой объем, затем передает управление процессом "создателю одного итогового потока третьего этапа" (38).
"Определитель-восстановитель состояния" (37) определяет и в случае необходимости изменяет состояние "третьего этапа компрессора" (3), то есть совокупность всех скалярных, векторных и матричных переменных, после чего, в зависимости от этого определенного им состояния, передает управление либо "создателю одного итогового потока третьего этапа" (38), либо "вычислителю Q, R, S, C, Y третьего этапа" (31), либо завершает работу "третьего этапа компрессора" (3).
"Создатель одного итогового потока третьего этапа" (38) в случае необходимости, а именно, если L5≥0, записывает в "один итоговый поток" третьего этапа значения F5 заданной функции FE5 (11, 12, 13, 14) от длин 11, 12, 13, 14 фрагментов итоговых потоков, созданных с момента последней записи в "один итоговый поток" третьего этапа, затем фрагмент первого потока, созданный с момента последней записи в "один итоговый поток" третьего этапа, затем фрагмент второго потока, фрагменты третьего и четвертого потоков, созданные с момента последней записи в "один итоговый поток" третьего этапа, и передает управление "создателю первого потока третьего этапа" (32).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВСТРАИВАНИЯ СЖАТОГО СООБЩЕНИЯ В ЦИФРОВОЕ ИЗОБРАЖЕНИЕ | 2011 |
|
RU2467486C1 |
| Устройство для реализации подстановок | 1989 |
|
SU1683025A1 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ В ВИДЕ УЛЬТРАСЖАТОГО НАНОБАР-КОДА (ВАРИАНТЫ) | 2013 |
|
RU2656734C2 |
| СПОСОБ И УСТРОЙСТВО СЖАТИЯ ДАННЫХ | 2011 |
|
RU2450441C1 |
| Компрессионный накопитель данных и устройство для его осуществления | 2019 |
|
RU2739705C1 |
| СПОСОБ И СИСТЕМА ЗАЩИТЫ ПОДЛИННОСТИ ВИДЕО, ГЕНЕРИРУЕМЫХ МОДЕЛЬЮ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2839835C1 |
| СПОСОБ И СИСТЕМА ЗАЩИТЫ ПОДЛИННОСТИ ИЗОБРАЖЕНИЙ, ГЕНЕРИРУЕМЫХ МОДЕЛЬЮ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2829566C1 |
| Способ организации поиска документов в прикладных базах неструктурированных данных и аппаратная версия двойной памяти для его осуществления | 2022 |
|
RU2792584C1 |
| СПОСОБ СЖАТИЯ ПОСЛЕДОВАТЕЛЬНОСТИ ИНФОРМАЦИОННЫХ СИГНАЛОВ | 1993 |
|
RU2080738C1 |
| РЕЖИМЫ БЫСТРОГО ДОСТУПА К ПРОИЗВОЛЬНОЙ ТОЧКЕ ДЛЯ СЕТЕВОЙ ПОТОКОВОЙ ПЕРЕДАЧИ КОДИРОВАННЫХ ВИДЕОДАННЫХ | 2011 |
|
RU2571375C2 |
Изобретение предназначено для улучшения хранения, передачи и обработки импульсно-сигнальной информации и может быть использовано в вычислительной технике, а также в любой технике, использующей микропроцессоры. Сущность способа фрагментирования потока импульсно-сигнальной информации заключается в том, что исходный фрагмент разделяют на заданное число подфрагментов, затем в каждой позиции исходного фрагмента вычисляют коэффициенты отличия последующего блока от предыдущего блока и из множества полученных коэффициентов отличия выбирают число максимальных коэффициентов так, чтобы длина каждого подфрагмента отклонялась от средней длины подфрагментов не более чем на Р. При анализе структуры фрагмента после выбора числа максимальных коэффициентов отличия вычисляют значения величин, являющихся мерами хаотичности фрагментов потока битов, байтов и слов соответственно, по которым вычисляют в соответствии с заданными функциями значения нормированных мер хаотичности, по которым выносят решение о структуре исходного фрагмента. Сжатие каждого из полученных подфрагментов потока элементов-слов достигают путем записи в итоговые фрагменты для содержащихся в словаре-памяти слов - их длин и позиций в словаре-памяти, для отсутствующих в словаре-памяти слов - самих этих слов целиком, при сжатии потока элементов-байтов сжатие каждого из полученных подфрагментов осуществляют путем противопоставления каждому из возможных значений элементов-байтов числа байтов с таким значением в подфрагменте и в соответствии с результатом сопоставления выбирают код, соответствующий каждому значению байта, а сжатие каждого из полученных фрагментов потока элементов - байтов осуществляют путем многократного преобразования исходного подфрагмента в четыре итоговых фрагмента и основного из этих четырех в те же четыре итоговых фрагмента, пока в результате этого преобразования суммарное количество битов во всех четырех итоговых фрагментах уменьшается. 6 с.п. ф-ы, 5 ил.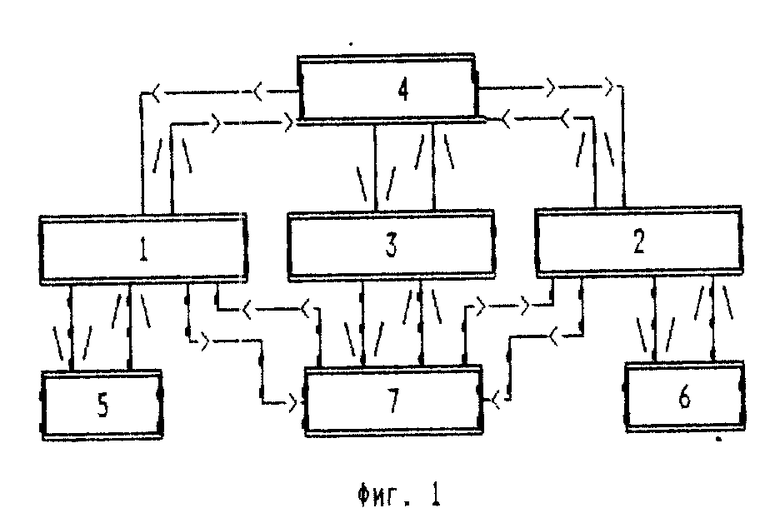
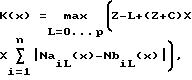
где n - число возможно значений элементов;
Nai L - число элементов, имеющих i-е значение, в интервале последующего блока от х-го до (х + L)-го элемента;
Nbi L - число элементов, имеющих i-е значение, в интервале предыдущего блока от (х-1-L)-го до (х-1)-го элемента;
Р - меньшая из длин блоков, не превышающая заданного параметра S;
Z = [x/2] - целая часть число Х/2;
С - заданный параметр, 0 или натуральное число;
затем из множества полученных коэффициентов К(х) выбирают (Y-1) максимальных коэффициентов так, чтобы длина L каждого из Y подфрагментов отклонялась от средней длины подфрагментов, равной X/Y, не более чем на R.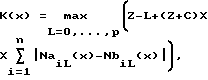
где n - число возможных значений элементов;
Nai L - число элементов, имеющих i-е значение, в интервале последующего блока от х-го до (х + L)-го элемента включительно;
Nbi L - число элементов, имеющих i-е значение, в интервале предыдущего блока от (х-1-L)-го до (х-1)-го элемента включительно;
Р - меньшая из длин блоков, не превышающая заданного параметра S;
Z = [x/2] - целая часть X/2;
С - заданный параметр, 0 или натуральное число,
затем из множества полученных коэффициентов К(х) выбирают (Y-1) максимальных коэффициентов так, чтобы длина L каждого из Y подфрагментов отклонялась от средней длины подфрагментов, равной X/Y, не более чем на R, после чего вычисляют значения величин S1, S2, S3, являющихся мерами хаотичности фрагмента потока битов, байтов и слов соответственно по формулам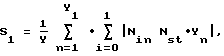
где Ni n - число битов в n-м подфрагменте со значением i;
Yn - число всех битов в n-м подфрагменте;
Y - число всех битов в фрагменте;
Ns t = 1/2 - средняя теоретическая доля битов,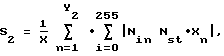
где Ni n - число байтов в n-м подфрагменте со значением i;
Xn - число всех байтов в n-м подфрагменте;
X - число всех байтов в форагменте;
Ns t = 1/256 - средняя теоретическая доля байтов,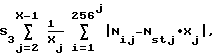
где Ni j - число слов длиной j байтов со значением i;
Xi = X - j + 1 - число всех слов длиной j байтов в фрагменте;
Ns t j = 1/256 - средняя теоретическая доля слов длиной j,
далее по этим трем значениям вычисленных сумм S1, S2, S3 вычисляют в соответствии с заданными функциями значения нормированных мер хаотичности Р1, Р2, Р3, по которым выносят решение о структуре исходного фрагмента потока импульсно-сигнальной информации.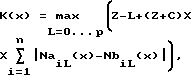
где n - число возможных значений элементов;
Nai L - число элементов, имеющих i-е значение в интервале последующего блока от х-го до (х + L)-го элемента включительно;
Nbi L - число элементов, имеющих i-е значение в интервале предыдущего блока от (х - 1 - L)-го до (х - 1)-го элемента включительно;
Р - меньшая из длин блоков, не превышающая заданного параметра S;
Z = [X/2] - целя часть числа Х/2;
С - заданный параметр, 0 или натуральное число,
затем из множества полученных коэффициентов К(х) выбирают (Y - 1) максимальных коэффициентов так, чтобы длина L каждого из Y подфрагментов отклонялась от средней длины подфрагментов, равной X/Y, не более чем на R, а сжатия каждого из полученных подфрагментов достигают путем записи в итоговые фрагменты для содержащихся в словаре-памяти слов - их длин и позиций в словаре-памяти, для отсутствующих в словаре-памяти слов - самих этих слов целиком.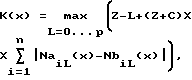
где n - число возможных значений элемента-байта;
Nai L - число элементов-байтов, имеющих i-е значение в интервале последующего блока от х-го до (х + L)-го элементов;
Nbi L - число элементов-байтов, имеющих i-е значение в интервале от (х - 1 - L)-го до (х - 1)-го элементов;
Р - меньшая из длин блоков, не превышающая заданного параметра S,
Z = [X/2] - целая часть X/2,
С - заданный параметр, 0 или натуральное число (1,2,3,...),
затем из множества полученных коэффициентов К(х) выбирают (Y - 1) максимальных коэффициентов так, чтобы длина L каждого из Y подфрагментов отклонялась от средней длины подфрагментов, равной X/Y, не более чем на R, а сжатие каждого из полученных подфрагментов осуществляют путем сопоставления каждому из возможных значений элементов-байтов числа байтов с таким значением в подфрагменте и в соответствии с результатом сопоставления выбирают код, соответствующий каждому значению байта.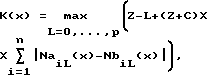
где n - число возможных значений элементов-битов;
Nai L - число элементов-битов, имеющих i-е значение в интервале последующего блока от х-го до (х + L)-го элемента включительно;
Nbi L - число элементов-битов, имеющих i-е значение в интервале предыдущего блока от (х - 1 - L)-го до (х - 1)-го элемента включительно;
Р - меньшая из длин блоков, не превышающая заданного параметра S,
Z = [X/2] - целя часть числа X/2;
С - заданный параметр, 0 или натуральное число,
затем из множества полученных коэффициентов К(х) выбирают (Y - 1) максимальных коэффициентов так, чтобы длина L каждого из Y подфрагментов отклонялась от средней длины подфрагментов, равной X/Y, не более чем на R, а сжатие каждого из полученных подфрагментов осуществляют путем многократного преобразования исходного подфрагмента в четыре итоговых фрагмента и основного из этих четырех в те же четыре итоговых фрагмента пока в результате этого преобразования суммарное количество битов во всех четырех итоговых фрагментах уменьшается.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| US, патент, 5049881, кл | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| US, патент, 5051745, кл | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| US, патент, 5140321, кл | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
