Заявляемое техническое решение относится к области использования больших прикладных базах данных (далее БД) с неструктурированными или слабо структурированными данными, например, библиотеки. Изобретение предназначено для поиска и отбора документов из больших БД документов, в максимальной степени соответствующих запросам пользователя. При этом документами являются печатные издания, такие как книги, журналы, статьи, брошюры, отчеты и т.д.
Быстрый рост объемов накапливаемых данных, в сочетании с возрастающими информационными потребностями людей, требует постоянного совершенствования сопутствующих информационных систем с целью получения документов (информации) максимально удовлетворяющих потребностям потребителя (пертинентной информации). Требование проведения поиска, необходимых пользователям документов, при неопределенных и нечетко формулируемых запросах нуждается в интерактивном участии пользователя системы. При этом, выводимые на экран документы должны:
- не перегружать пользователя объемом излишней информацией (сотни найденных релевантных документов);
- максимально соответствовать потребностям пользователя, что обеспечивается удобным механизмом анализа результатов поиска, наглядностью предоставляемой информации и возможностью интерактивной корректировки запросов.
И при этом информационная система должна работать с полным охватом всей базы данных (БД) и не занимать много времени на обработку запроса (по разным оценкам, не более 20 секунд). Для информационных систем со структурированными данными (таблицами) поиск и обработка данных уже достаточно эффективно работает и встроено в бизнес процессы, это реляционные системы управления базами данных (СУБД), например, Oracle, Microsoft, MySQL. Однако в работе с неструктурированными данными еще очень далеко до получения качественного результата.
К информационно-поисковым системам, ориентированным на работу с неструктурированными данными NoSQL (Shashank Tiwari. Professional NoSQL. — John Wiley & Sons Inc, 2011. — 384 p. — ISBN 9780470942246, [1]), хранимыми в интернете можно отнести, например, Google, Yandex, Rambler, библиотечные поисковые системы. К основным недостаткам способа организации поиска документов этих систем можно отнести:
- низкая степень релевантности документов запросу.
- большое количество документов, выдаваемых по запросу.
- сложный отсев непрофессиональной и недостоверной информации.
В существующих поисковых системах для нахождения необходимой информации отработан механизм поиска информации, основанный на построении инвертированного индекса (Маннинг К.Д., Рагхаван П., Шютце Х. "Введение в информационный поиск". Пер. с англ. – М, ООО «Вильямс», 2011 – 528с., [2]). Создается словарь ключевых слов, основанных на выборке слов из хранимой в базе данных (БД) информации. Словарь может включать любое количество слов, достаточное, с точки зрения разработчика, для отбора необходимой информации. При этом используются прикладные программы проведения лексического, морфологического, синтаксического, семантического анализов. Для выборки слов используется большой спектр отлаженных методов, основанных на алфавитной выборке, В-деревьях, тематическом разделении и других методах.
При построении инвертированного индекса (структура данных) для поиска документов используются два основных подхода:
1) с точностью до документа (US2004030686A1 «Method and system of searching a database of records» (CARDNO ANDREW JOHN; MULGAN NICHOLAS JOHN, 12.02.2004), [3]; US2009030892 «SYSTEM OF EFFECTIVELY SEARCHING TEXT FOR KEYWORD, AND METHOD THEREOF» (IBM, 29.01.2009), [4]). В указанных аналогах [3, 4] каждому слову индекса сопоставляется список документов, где встречается данное слово. Далее осуществляется полнотекстовая обработка документа по всем ключевым словам.
2) с точностью до слова (US5696963 «System, method and computer program product for searching through an individual document and a group of documents» (SMARTPATENTS INC, 09.12.1997), [5]; US2004177064 «Selecting effective keywords for database searches» (IBM, 09.09.2004), [6]). В указанных аналогах [5, 6] Каждому слову индекса сопоставляется список документов, где встречается данное слово, а также указываются позиции слова в документе.
В обоих подходах предлагаемые структуры данных могут дополняться различными параметрами (частотные, семантические и др. характеристики слов, документов). Составляются списки документов, позиций слов и эти списки анализируются на предмет пересечения списков и формирования нового списка в котором все ключевые слова встречаются.
В качестве прототипа к заявляемому способу принят подход с точностью до документа [4].
Достоинством первого варианта является простота и минимальный объем индекса.
Недостатком является большой объем обработки при увеличении анализируемого количества ключевых слов. Высокая чувствительность к порядку обработки слов. Например, после выбора документов по первому сочетанию ключевых слов необходимо задать следующие дополнительные слова, но поиск будет вестись на множестве уже найденных документов. Важен порядок обработки ключевых слов при анализе, корректировке и изменении запроса.
Во втором варианте сразу для каждого слова извлекаются списки документов, где встречается данное слово, как в первом варианте, и дополнительно списки номеров позиций с точностью до позиции слова, начала и окончания слов (или длину), после чего производится операция анализа их пересечения.
Достоинством второго варианта является удобно при обработке небольшого количества ключевых слов. Возможность восстановления текста, с некоторыми потерями качества, при его утрате.
Недостатком является большой объем хранимого индекса, который может превышать объем памяти, занимаемой обрабатываемыми документами. Это зависит от количества ключевых слов, которое надо оптимизировать. Возрастает сложность хранения и обработки списков переменной длины. Большой объем обработки при увеличении анализируемого количества ключевых слов и росте БД.
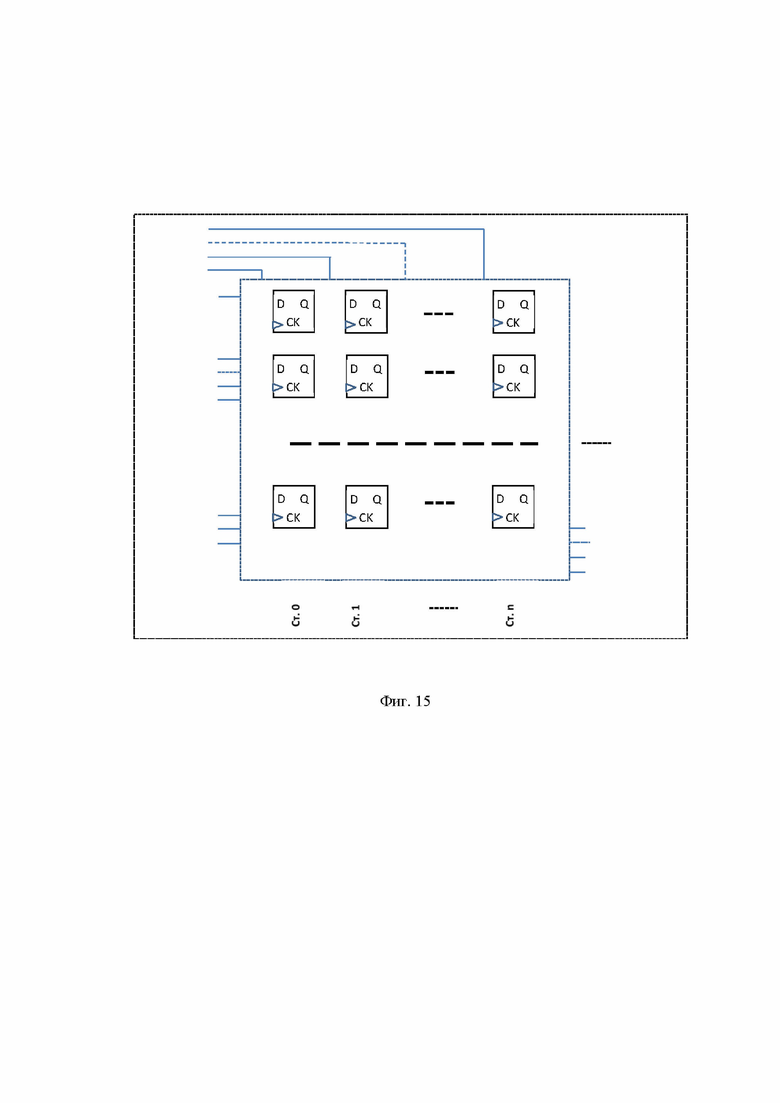
В качестве прототипа к заявляемому устройству принята типовая классическая память для записи и считывания слов (Э. Таненбаум, Т. Остин. Архитектура компьютера, стр. 200, рис. 3.27, [7]). Работа оперативной памяти рассмотрена на примере, состоящем из 4 ячеек памяти (регистров), каждый регистр состоит из 3 бит. В общем случае память не ограничена ни по разрядности регистров, ни по количеству ячеек памяти (регистров). Существуют микросхемы на 8, 16, 32 и 64 бита при 512, 1024 и более ячеек памяти [7] стр. 204, отс.3.30. При увеличении памяти принцип ее работы не изменяется, а показанная на рис. 3.27, [7] схема многократно тиражируется с соответствующим увеличением разрядности регистров, количества входов/выходов и адресов. Здесь каждый триггер хранит один бит информации (на рисунке показаны 4 ряда триггеров по 3 в каждом ряду-регистре). Память содержит четыре 3-разрядных слова. Каждая операция считывает или записывает целое 3-разрядное слово. Логическая схема содержит 8 входных линий, в частности 3 входа для данных – I0, I1, I2; 2 входа для адресов – A0 и A1; 3 входа управления – CS (Chip Select – выбор элемента памяти), RD (ReaD – чтение, этот сигнал позволяет отличать считывание от записи) и OE (Output Enable – разрешение выдачи выходных сигналов), а также 3 выходные линии для данных – O0, O1 и O2. Состояние адресного входа определяет, каким четырем битам памяти разрешается ввод или вывод значения. Логика процесса такова, что бинарная строка <I0, I1, I2> (здесь значение Ii равно 0 или 1, i=0,1,2) записывается в ячейку памяти (регистр) по адресу бинарной строки <A0, A1> в соответствии с командами, поступающими на входы <CS,RD,OE>. А также информация может считываться в соответствии с командами <CS,RD,OE> из регистров, указанных в адресе <A0,A1> в выходную бинарную строку <O0, O1,O2> .
Представим логическую схему рис. 3.27 [7] в обобщенном виде фиг. 13, оставив только важные для понимания элементы: внешние выводы (входы, выходы, адреса, управляющие сигналы) и триггеры памяти.
Прототип рис. 3.27 [7] не позволяет записывать бинарные строки по номерам позиций в ячейках памяти (регистрах) фиг.13 и 14 (по сути, по столбцам Ст.0, Ст.1, Ст2 фиг. 14).
Решаемой технической проблемой является возможность обработки ключевых слов документов и представлении результатов обработки в наглядной и сжатой форме – с точностью до страниц документов. Это позволяет быстро, без чтения документов из БД оценить соответствие документа сформулированному запросу. При этом окончательное решение в рамках анализа найденной страницы, пользователь примет самостоятельно или интерактивно дополнит/изменит ключевые слова и увидит результаты изменений на экране.
Техническим результатом, обеспечиваемым заявляемыми техническими решениями, является аппаратная реализация процесса представления упорядоченного множества списков бинарных строк фиксированной длины <Str1,Str2,…,Strk> в табличную форму, где каждая строка Strj является столбцом таблицы. Обеспечивается возможность построчного чтения и анализа строк таблицы - регистровое отображение <R1,R2,…, Rn> - которое также является множеством бинарных строк, когда каждому номеру j регистра Rj соответствует j-ая позиция бита в списках <Str1,Str2,…,Strk>,. Это позволяет исключить операцию по пересечению списков <Str1,Str2,…,Strk>, относящихся к различным ключевым словам, считая, что каждый i-ый список Stri связан с i-ым ключевым словом, а номер j-го бита в строке Stri отражает номер документа/страницы, что ускоряет процесс отбора документов/страниц документов, т.к. вся строка <R1,R2,…, Rn> относится к одному j-ому документу/странице.
Техническим результатом способа является предложенная структура данных, включающая таблицу ключевых слов (индексный словарь), таблицу документов, таблицу бинарных списков и таблицу бинарных строк документов. Предложенная структура данных позволяет проводить поиск документов по множествам ключевых слов с точностью до страниц документов, без чтения самих документов из БД и представление результата поиска в виде Таблицы ответа, что облегчает процедуру отбора документов в соответствии с заданными критериями.
Также техническими результатами являются:
- При поиске документов не требуется чтение самих документов из БД, при этом выбираются для просмотра только страницы, точно удовлетворяющие требованиям запроса без чтения документов;
- Возможность интерактивного взаимодействия с системой и постоянное циклическое уточнение или изменение запроса путем добавления и исключения ключевых слов в процессе анализа страниц, при этом документы подставляются или исключаются в список или из списка обрабатываемых документов, а слова – в список ключевых слов для поиска документов;
- Процесс поиска документов хорошо масштабируется и распараллеливается;
- Способ позволяет определять приоритет в списке ключевых слов и придавать важность каждому ключевому слову, система может уточнять и предлагать варианты исходя из собираемой статистики, в том числе и персональной для построения индивидуальных моделей пользователя;
- Задание различных множеств на множестве ключевых слов {Si} (например, множество витаминов, кислот, деревьев и т.д.) с целью уточнения смыслов документов и поиска дополнительных вариантов ответов;
- Фиксация длины бинарных строк для номеров страниц документа на уровне 128 байт позволяет отказаться от сортировки списков страниц и реализовать простой механизм наглядного анализа страниц документов;
- Фиксация длины бинарных строк на уровне 128 кБайт и более для больших БД (более десятков миллионов документов) при реализации DM памяти позволяет отказаться от сортировки списков документов. В этом случае длина бинарной строки должна соответствовать максимальному количеству документов в БД. т.к. номер бита в бинарной строке должен соответствовать номеру документа в БД. Например, бинарная строка 128 кБайт соответствует 1 млн. документов;
- Возможность параллельной обработки множеств (десятков и сотен) ключевых слов;
- Свободный просмотр результатов обработки ключевых слов в любой последовательности – последовательность задает индивидуальную важность ключевых слов для пользователя и определяется простой перестановкой столбцов в таблице ответа, что позволяет при отборе страниц учитывать эти приоритеты и при необходимости отбрасывать менее важные слова;
- Итоговые отобранные пользователем таблицы ответов являются удобным средством для построения прикладных формальных алгоритмов анализа документов, построения различных метрик и пространств классификации документов, построения персональных моделей информационного пространства пользователя;
- Точность обработки ограничена страницей документа, при этом страница будет выведена пользователю для его окончательной оценки на предмет ее пертинентности, кроме того при необходимости, можно легко дополнить обработку ключевых слов, в объеме одной страницы.
Сущность заявленного способа состоит в том, что пользователь формирует запрос и указывает ключевые слова и логические операции с ними. Затем происходит выделение ключевых слов в запросе в блоке обработки ключевых слов запроса, использования инвертированного индекса c программами формирования, развития и сопровождения работы инвертированного индекса, при этом упомянутые программы взаимодействуют c блоком индексации, который взаимодействует c базой данных, программами выборки списков по ключевым словам, отличающийся тем, что:
- программы формируют вспомогательные таблицы: ключевых слов, документов, бинарных строк номеров документов и бинарных строк, дополняющие инвертированный индекс, при этом
- таблица ключевых слов содержит список ключевых слов, каждое ключевое слово имеет ссылку на бинарную строку документов и ссылку на строку таблицы документов, а также здесь же указывается дополнительная информация: количество документов, где используется ключевое слово, другие данные о ключевом слове: термин, сокращение, множество или элемент множества;
- таблица документов содержит списки пар, связанных с ключевым словом, пара - это номер документа, в котором используется ключевое слово и ссылка на бинарную строку в таблицы бинарных строк;
- таблица бинарных строк содержит список бинарных строк фиксированной длины, каждая строка связана с номером документа из таблицы документов, при этом каждый бит бинарной строки – соответствует одной странице текста документа, номер бита в строке соответствует номеру страницы этого документа, а 1 или 0, стоящие на определенной позиции, указывают на присутствие или отсутствие заданного ключевого слова на данной странице;
- таблица бинарных строк документов состоит из множества бинарных строк фиксированной длины, при этом каждый номер бита в бинарной строке соответствует номеру документа, а 1 в этом бите означает, что в документе с данным номером встречается заданное ключевое слово;
- после выборки списков по ключевым словам из инвертированного индекса, осуществляют обработку списков документов, представленных в виде бинарных строк в блоке обработки результирующего списка, при этом бинарные строки загружаются для обработки в двойную память, в которой числовое значение строки равна 2n , где n – разрядность регистра памяти, в случае, если все заданные ключевые слова встречаются в документе с номером равным номеру строки в двойной памяти, это позволяет не прибегать к операции пересечения списков, при этом
- в блоке обработки страниц документов по ключевым словам формируется для каждого документа таблица ответа, при этом происходит загрузка бинарных строк из таблицы бинарных строк в двойную память, их сортировка и анализ, при этом в таблице ответа каждому столбцу соответствует свое ключевое слово, столбцы упорядочены в соответствии с их важностью, причем каждый столбец ключевого слова соответствует бинарной строке таблицы бинарных строк, таблица ответа позволяет отразить содержащиеся в документе ключевые слова с точностью до страницы без загрузки самого документа из базы данных.
Сущность заявленного устройства состоит в том, что двойная память для организации поиска документов в прикладных неструктурированных базах данных представляет собой логическую схему памяти, обеспечивающую возможность записи данных по заданному адресу ячейки память, а также возможность чтения из ячеек памяти по заданному адресу ячейки записанных данных и вывод считанных данных в выходные линии в соответствии с сигналами управления CS, RD, OE и СМ, отличающаяся тем, что:
- содержит второй канал ввода данных, обеспечивающий запись битовых строк в заданный бит (номер столбца) ячейки памяти во все ячейки памяти одновременно, при этом длина битовой строки равна количеству ячеек памяти, а количество и разрядность ячеек памяти ограничено технологическими возможностями микроэлектроники;
- вход СМ, выполненный с возможностью переключения работы схемы из режима обычной памяти - записи входных данных в ячейки памяти, в режим двойной памяти – записи входных данных в заданный бит каждой ячейки памяти;
- содержит блок адресации номеров бита в ячейках памяти (номера столбцов), задающих общий номер бита для всех ячеек памяти, в которые осуществляется запись данных;
- после блока адресации ячеек установлен переключатель, который пропускает или блокирует сигнал адреса ячейки памяти в зависимости от управляющего сигнала СМ;
- содержит логические переключатели, установленные на всех входах триггеров памяти, для переключения канала поступления адресов с адресов ячеек памяти на адреса битов в ячейках памяти (столбцов), в зависимости от управляющего сигнала СМ;
- содержит логические переключатели, установленные на всех входах поступления данных триггеров памяти, для переключения каналов получения данных в зависимости от управляющего сигнала СМ;
- выход блока управления записью/чтением CS, RD, OE, соединен с выходом блока выбора номера бита (адреса столбца).
Краткое описание чертежей.
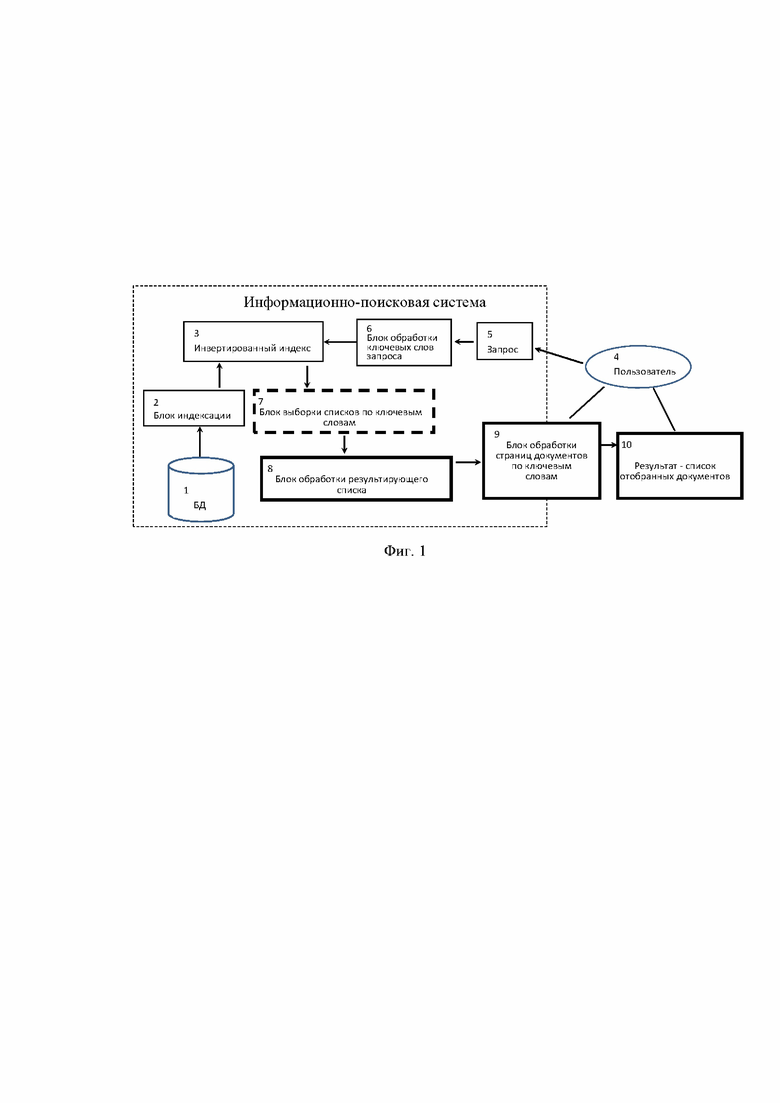
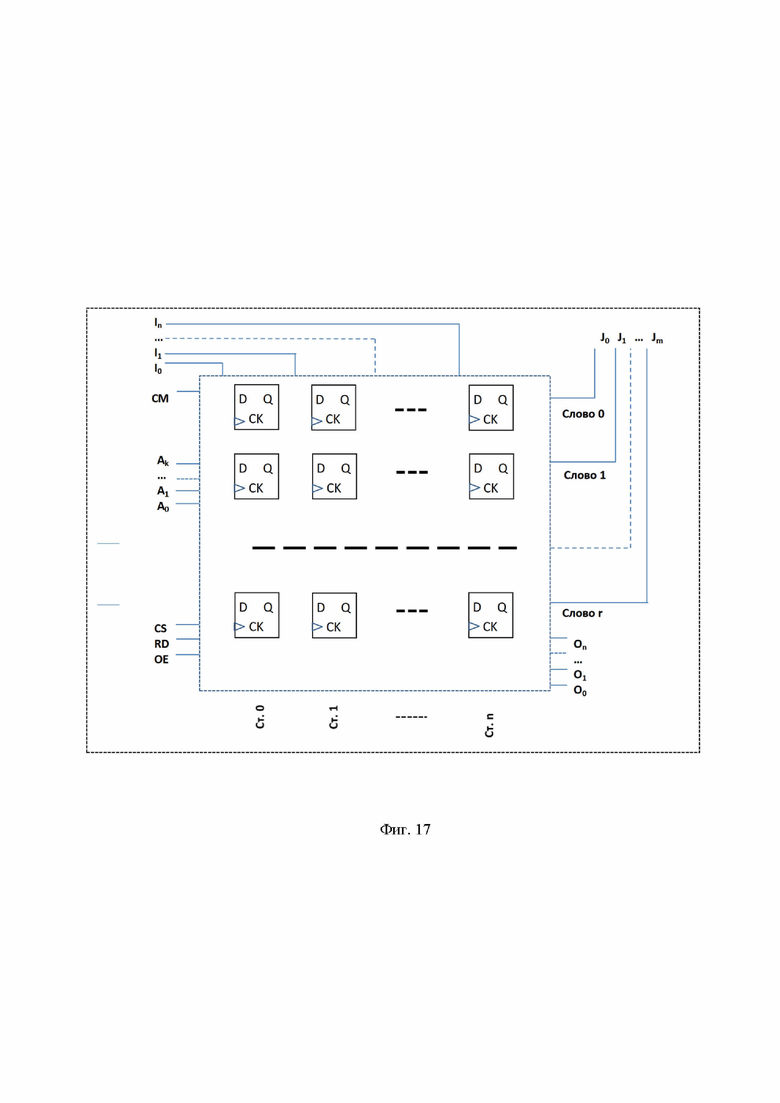
На фиг. 1 показана обобщенная схема способа организации поиска документов в больших БД; на фиг. 2 – структура данных рабочих таблиц; на фиг. 3 – бинарная строка; на фиг. 4 – пример таблицы ответа документов, по столбцам бинарные строки номеров документов ASDi; на фиг. 5 – пример таблицы ответа страниц, по столбцам показаны строки Stri соответствующие ключевым словам; на фиг. 6 – пример уплотненной и упорядоченной таблицы ответа; на фиг. 7 – пример таблицы ответа, £=0,2; на фиг. 8 – пример фрагмента анализируемого текста; на фиг. 9 – блок схема этапов обработки анализируемого текста примера 1; на фиг. 10 – заполнение таблиц примера 1; на фиг. 11 – общий вид условной таблицы ответа; на фиг. 12 – пример таблицы из шести бинарных столбцов длиною в 12 бит каждая; на фиг. 13 – логическая блок-схема для памяти 4 х 3; на фиг. 14 – обобщенная блок-схема схема памяти 4х3, показанной на фиг. 13; на фиг. 15 – обобщенная блок-схема схема памяти на r ячеек памяти разрядностью в n бит; на фиг. 16 – обобщенная блок-схема схема DM памяти 4х4; на фиг. 17 – обобщенная блок-схема схема памяти на r ячеек памяти разрядностью в n бит; на фиг. 18 - пример исполнения логической схемы DM памяти 4х4.
Перечень обозначений фиг. 13 - 17:
I0, I1, I2, I3 – входные данные для записи в регистры;
A0, A1- два входа для адресации ячеек памяти;
CS – выбор элемента памяти;
RD – чтение (позволяет отличать считывание от записи);
OE – разрешение выдачи данных,
J0, J1, J2, J3 – входные данные для записи столбцов;
CL0, CL1- два входа для адресации столбцов;
Ст.0, Ст.1, Ст.2, Ст.3 – столбцы (номера бит в ячейке памяти);
O0, O1, O2, O3 – выходные данные для чтения из ячеек памяти.
Разрешение вывода данных CS·RD·OE.
Осуществление способа.
Способ организации поиска документов в больших БД (фиг. 1) включает следующие типовые этапы:
- Пользователь (4), являющийся заинтересованным потребителем информации, формирует запрос (5) на языке близком к SQL, при этом пользователь указывает ключевые слова и логические операции с ними, причем запрос преимущественно ограничивается простым перечислением слов;
- В блоке обработки ключевых слов запроса (6) происходит выделение ключевых слов в запросе.
- Программы формирования, развития и сопровождения работы инвертированного индекса формируют инвертированный индекс (3), при этом упомянутые программы взаимодействуют с блоком индексации (2), который взаимодействует БД (1), выбирают списки документов по ключевым словам (7), проводят пересечение списков ключевых слов на предмет поиска множества документов, в которых одновременно встречаются заданные ключевые слова и выполняют над ними заданные логические условия, получают результирующий список. Этот список документов уже является промежуточным результатом поиска и может выводиться пользователю. В настоящее время поисковые системы дополняют обработку этого списка полнотестовым поиском всех документов этого списка, что позволяет при выводе информации на экран текста документов подсвечивать цветом все найденные ключевые слова, что облегчает пользователю его просмотр.
Как отмечено на схеме блоки фиг. 1 с первого по седьмой предусматривают типовые функции построения и использования инвертированных индексов в существующих информационно-поисковых системах.
- В блоке обработки результирующего списка документов (8) из результирующего списка по номеру документа из Таблицы документов (12 фиг. 2) считывается адрес бинарной строки, а затем и сама бинарная строка документа из Таблицы бинарных строк (13 фиг. 2) по каждому ключевому слову.
- Блок обработки страниц документов по ключевым словам (9) формирует для каждого документа таблицу ответа (фиг. 4), при этом происходит загрузка бинарных строк в двойную память, далее DM (фиг.17), их сортировка и анализ в соответствии с заданными параметрами по смягчению или ужесточению соответствия ответов запросу. Пользователь может в интерактивном режиме выбирать и просматривать страницы документа, изменять запрос, важность ключевых слов и другие параметры отбора страниц.
- Выводится итоговый список отобранных документов (10) в качестве ответа на поданный запрос.
В существующих поисковых системах осуществляется выборка списков документов, по ключевым словам, (блок 7, фиг.1). Далее программно проводится операция пересечения этих списков на предмет нахождения результирующего списка документов в котором в каждом документе присутствовали все ключевые слова.
В предлагаемом варианте возможно проведение операции пересечения списков документов в DM памяти. Для этого необходимо представлять списки документов в виде бинарных списков фиг. 3 также, как и в случае с бинарными списками страниц Stri, только большего объема (в миллионы бит). При этом потребуется DM память значительно большего размера, что выразится в ее стоимости. Например, для обработки бинарных списков страниц достаточна длина бинарной строки в 128 байт, а для обработки бинарных списков документов потребуется строка порядка 128 Кбайт и более, для единовременной загрузки списка на 1 млн. документов. В этом случае номер бита в бинарной строке будет соответствовать номеру документа, в котором ключевое слово встретилось. Тогда обработка списка, например, в 14 миллионов документов приведет к 14-ти циклическим загрузкам DM памяти. Все, проводимые операции в DM памяти полностью идентичны операциям со списками страниц документов. В этом случае, как осуществляют в системах сейчас, документ выбирают из Таблицы ответов документов (15) и вносят в результирующий список документов блока 7 фиг. 1 в случае полного присутствия всех ключевых слов строке – документе, например, на фиг. 4 это документы 8 и 11 в строках 8 и 11.
БД (1) является хранилищем всех накопленных документов. Формат и структура данных задается выбранной типовой системой управления данными. Сопровождается всем необходимым программным обеспечением: средства записи документов, манипулирования данными, чтения данных, языки работы с данными (описания данных, манипулирования данными, запроса).
Программы формирования, развития и сопровождения работы инвертированного индекса (3) осуществляют запись, чтение, сортировки, внесение изменений, формирование рабочей структуры данных и формирование рабочих векторов ключевых слов (указатели на документы), разделение или объединение индексов, включение или исключение слов, анализ и т.д.
Предлагаемый способ ориентирован, прежде всего, на поиск в печатных изданиях фактографической информации в профессиональных библиотеках (например, биология, генная инженерия, фармакология - информация по лекарствам, механизмам их воздействия на организм, способах лечения болезней и т.д.).
Пусть Ω = {Dj} - множество документов Dj, где j=1,m. Здесь m – количество документов, например, 700’000 документов и более. Документом является книга, журнал, статьи, архивные документы, протоколы и результаты исследований и т.д., т.е. любое печатное издание, удобное для обработки и вывода на экран компьютера.
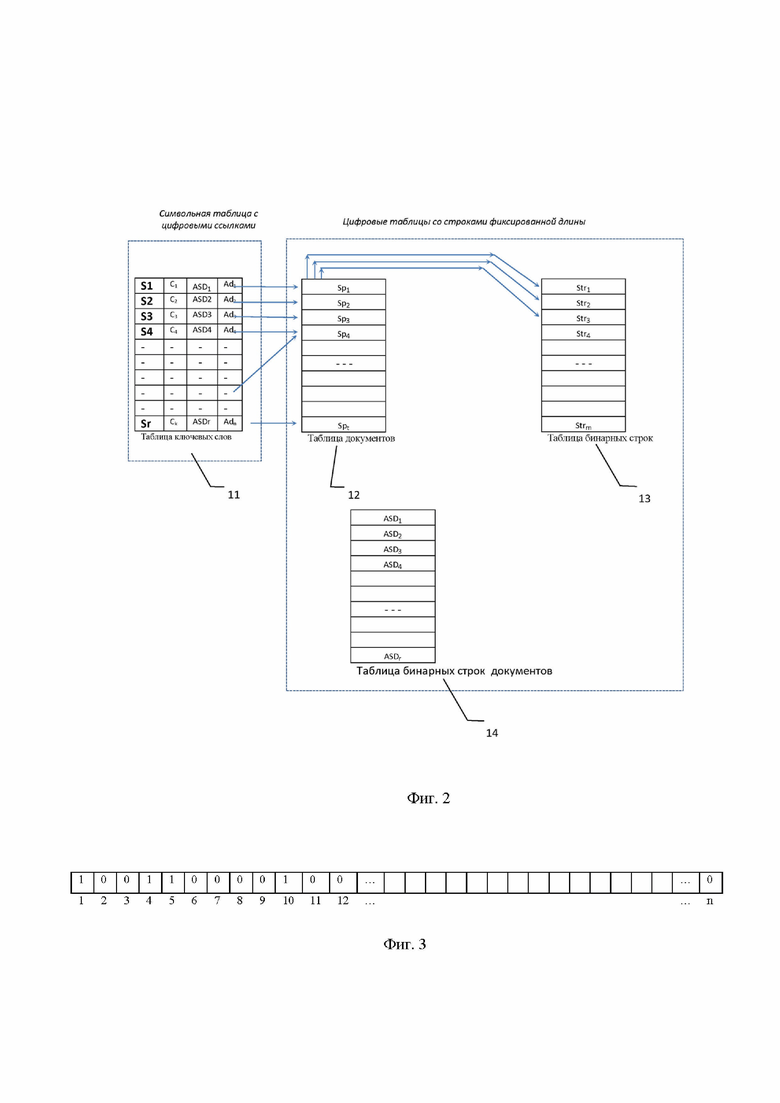
В отличие от прототипа [2] предлагаемый способ включает следующую структуру данных, которая используется в блоках 8, 9 и 10: таблицы ключевых слов (11), таблицы документов (12), таблицы бинарных строк (13) и таблицы бинарных строк документов (14). Структура упомянутых таблиц показана на фиг.2.
Таблица ключевых слов (11) содержит список из r строк. Каждая строка содержит:
- ключевое слово {Si}i=1,r,
- число {Сj}j=1,k, указывающее количество документов, в которых встречается данное ключевое слово,
- адрес ссылки {ASDi}i=1,n на строку из таблицы бинарных строк документов (14),
- адрес ссылки {Adi}i=1,n на строку из таблицы документов (12).
При этом слов больше, чем ссылок. Например, слово “дом” и слова “домик”, “домом” и др. могут иметь одну общую ссылку.
Таблица ключевых слов (11) может быть разбита на произвольное количество разделов - подтаблиц. Эти разделы связаны с семантикой ключевых слов: слова литературные, слова предметной области, сокращения, синонимы, наименования и т.д. Таблица ключевых слов (11) может быть дополнена столбцами, отражающими свойства слов и их различную группировку: синонимы, антонимы, различные классы (множества слов), тематические термины (математика, химия биология и т.д.), семантические классы, искусственные метрики и т.д.
Таблица документов (12) содержит t строк {<Sp>i}i=1,t, где каждая строка Spi состоит из списка пар:
Spi = {<Nd1, Ast1>1, <Nd2, Ast2>2, <Nd3, Ast3>3, . . . <Ndt, Astt> t}i,
где Ndj, j=1,t - номер документа, в котором используется ключевое слово из таблицы ключевых слов (11);
Astri - адрес ссылки на бинарную строку в таблицы бинарных строк (13).
В каждой строке таблицы документов (12) пары упорядочены в соответствии с номерами документов Ndj. Число Сi из таблицы ключевых слов (11) указывает на количество пар в таблице документов (12), связанных с заданным ключевым словом. В таблице документов (12) перечислены все номера документов, в которых встречаются ключевые слова из таблицы ключевых слов (11).
Это позволяет оценить информативность каждого ключевого слова и установить границу отсечения излишних ключевых слов или построить новые. Слово, которое встречается в 95% документов не позволяет эффективно различать документы и выделить среди них требуемое, которое относят к стоп-словам. Новые ключевые слова могут образовывать и сочетания существующих ключевых слов.
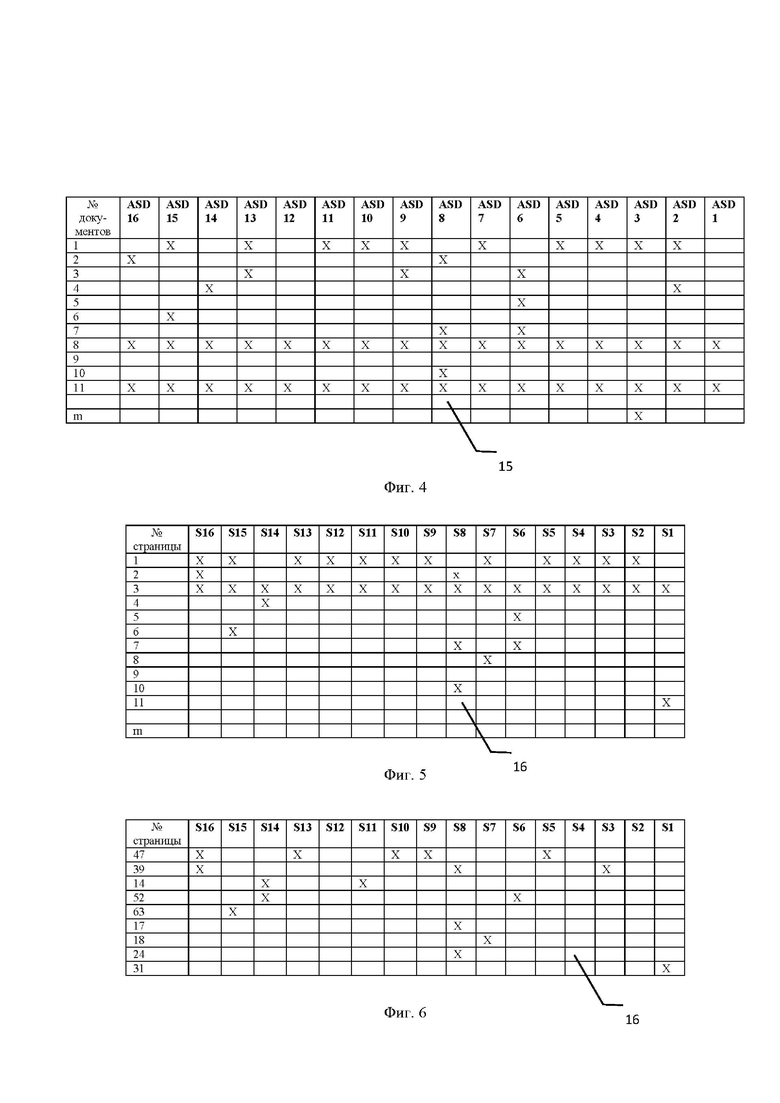
Таблица бинарных строк (13) содержит список из m бинарных строк фиксированной длины {Stri}i=1,m. Структура бинарной строки Stri показана на фиг. 3, где каждая клетка – это один бит, соответствующий одной странице текста документа, номер бита в строке соответствует номеру страницы этого документа, а 1 или 0, стоящие на определенной позиции, указывают на присутствие или отсутствие заданного слова на данной странице.
Пусть документ Dj имеет 2 млн. знаков, что соответствует примерно 1000 страницам текста. Тогда ему будет соответствовать бинарная строка длиной в 1000 Бит или 128 байт. Количество бит в бинарной строке будет больше (кратно степени 2) – появляются резервные биты. Предполагается, что книг с большим количеством страниц крайне мало, а встречающиеся разбиваются на тома (возможно искусственное разбиение).
Предлагаемая структура данных является открытой и всегда может быть дополнена необходимыми для обработки параметрами, отражающие частотные, семантические, логические, морфологические и др. характеристики слов и документов. Это отражается в увеличении размерности таблиц и/или включении дополнительных, отражающие дополнительные характеристики документов и слов. Например, Таблица 11 может пополниться ссылками на дополнительную таблицу двойных/тройных ключевых слов, сокращениями и т.д. Структура может быть дополнена таблицей множеств/подмножеств ключевых слов, например, множество витаминов с перечнем витаминов, множество деревьев с перечнем видов и т.д. Таблицы 12 и 13 могут также включать дополнительные параметры, тем более в каждой бинарной строке есть резерв в 24 байта.
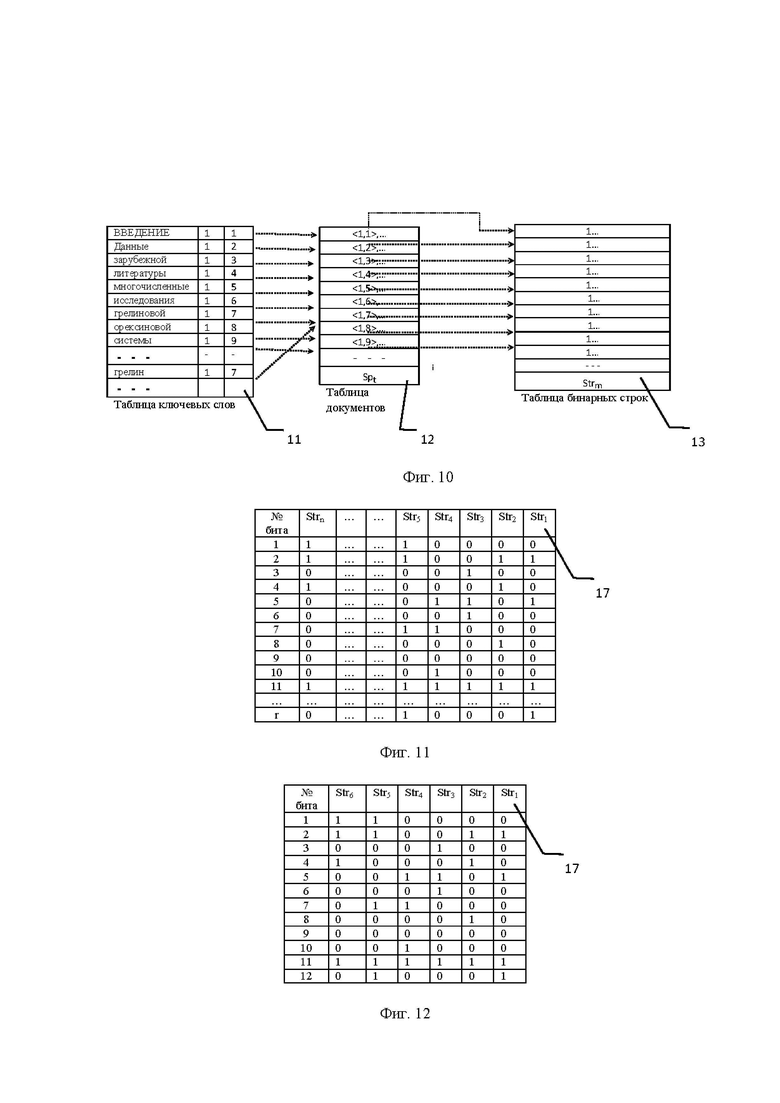
Этапы формирования таблиц (11), (12) и (13) показаны на фиг. 8, 9, 10.
При формировании запроса (5) (фиг. 1) пользователь указывает список ключевых слов <S1,S2,…,Sk>, упорядоченных по их важности для пользователя. Возможно построение классического языка запросов с использованием логических символов И, ИЛИ, НЕ. Ключевые слова задает сам пользователь исходя из личного представления о требуемом содержании искомого документа. Степень важности – индивидуальное восприятие пользователем задаваемых им ключевых слов (числовое значение или просто порядок слов) ключевых слов можно:
- задавать линейной или иной функцией, которую можно рассчитывать строя индивидуальные модели предметной области для каждого пользователя в отдельности;
- самому пользователю при их перечислении (вводе) расстановки слов:
- автоматически исходя из частотных характеристик слов.
Степень важности позволяет отбрасывать наименее важные слова и больше сосредотачиваться на сочетаниях более важных слов. Количество задаваемых ключевых слов ограничено только логикой и уровнем восприятия пользователя условно можно остановиться на 64 словах, хотя для отдельных приложений может потребоваться и значительно больше - при обработке множеств ключевых слов.
На основе запроса по каждому документу строится таблица ответа (16) (фиг. 5), в которой каждому столбцу соответствует свое ключевое слово.
Столбцы упорядочены в соответствии с их важностью. Каждый столбец ключевого слова соответствует бинарной строке таблицы бинарных строк (13). Поэтому при формировании таблицы ответа программа блока (9) считывает и собирает по каждому документу и по каждому ключевому слову в таблицу ответа (16) фиг. 5 готовые бинарные строки фиксированной длины из таблицы бинарных строк (13) и располагает их в соответствии с заданным пользователем порядком важности в столбцах таблицы ответа (16) фиг. 5. При этом порядок записи слов такой, что чем левее (условно, по умолчанию) в таблице ответа расположено слово, тем оно важнее. Слово Si+1 важнее слова Si (фиг. 5).
На фиг. 5 показан пример таблицы ответа (16) на один документ из m страниц по шестнадцать ключевым словам. Каждая i-я строка таблицы ответа (16) фиг. 5 отражает все ключевые слова, которые встретились на данной i-ой странице рассматриваемого документа Dj и представляет собой шестнадцатибитную строку, которая читается как целое число в диапазоне от 0 до 65536 или 216.
Эти числа (битовая строка по каждой странице) хорошо интерпретируются и показывают, какие ключевые слова встретились на данной странице (строке). Максимальное значение числа соответствует строке, полностью заполненной единицами, т.е. все ключевые слова встретились на данной странице. Это позволяет строить простые, понятные и адаптивные алгоритмы:
а) Просмотр таблицы и выделение страниц у которых есть совпадение по все ключевым словам – бинарное число строки равно 2n, где n – количество ключевых слов или 65536 для 216. Документ, в котором больше таких страниц больше соответствует запросу, с учетом заданных логических конструкций. В большинстве запросов пользователей (до 98%) они не прибегают к логическим условиям поиска, а ограничиваются перечислением ключевых слов;
б) Возможно уплотнение таблицы для визуального анализа выбранных документов. Для визуализации исключаются нулевые строки или строки с заданным пользователем низким уровнем отсева. Оставшиеся, не исключенные строки, могут упорядочиваться в зависимости от количества 1 и от заданного порядка по степени важности ключевых слов. Пример преобразованной таблицы ответа (16), приведенной на фиг. 5 показан на фиг. 6 Возможны включения любых алгоритмов обработки текста на странице: выделения слов на расстоянии, фраз, обработки перестановок слов, появления пояснений, синонимов и т.д.
в) Подбор ключевых слов путем исключения минимальных сочетаний наименее важных слов с целью получения полного заполнения остаточного количества слов единицами. Например, для таблицы ответа (16) на фиг. 5 если исключают ключевые слова S1, S6, S8, S14, то получают документ, в котором на странице 1 будет полное совпадение остаточных ключевых слов при минимальных исключениях. Соответствующее число будет равно 212. Возможно использование различных семантических алгоритмов, учитывающих семантические значения слов, особенности предметной области документов и требований пользователя.
г) Индивидуальная настройка просмотра. При большом количестве ключевых слов в запросе (оценка индивидуальна обычно более 20 и зависит от области знаний и квалификации пользователя) пользователь может указать уровень отсечения £ страниц, приведенных в таблице ответа (16) фиг. 5. Здесь
0 < £ ≤ 1,
где число £ отражает уровень требования на соответствие просматриваемых материалов запросу пользователя.
Страницы, на которых доля количества ключевых слов ниже заданного уровня £ х n не будут включаться в результирующую таблицу ответа (16) (результат округляется). Здесь n – количество ключевых слов в запросе. Например, для таблицы ответа (16) фиг. 5 с 16-тью ключевыми словами он может указать уровень отсечения £ = 0,2 (16х0,2=3,2 или 3 ключевых слова), тогда таблица ответа (16) фиг. 5 будет выглядеть так, как показано на фиг. 7.
д) на любом этапе возможен просмотр результатов, добавление новых ключевых слов, исключение существующих, определение различного порядка важности ключевых слов (порядок определяет систему предпочтений, изменяет расчетные метрики, классификацию документов и объем выводимой информации).
Примеры конкретного выполнения.
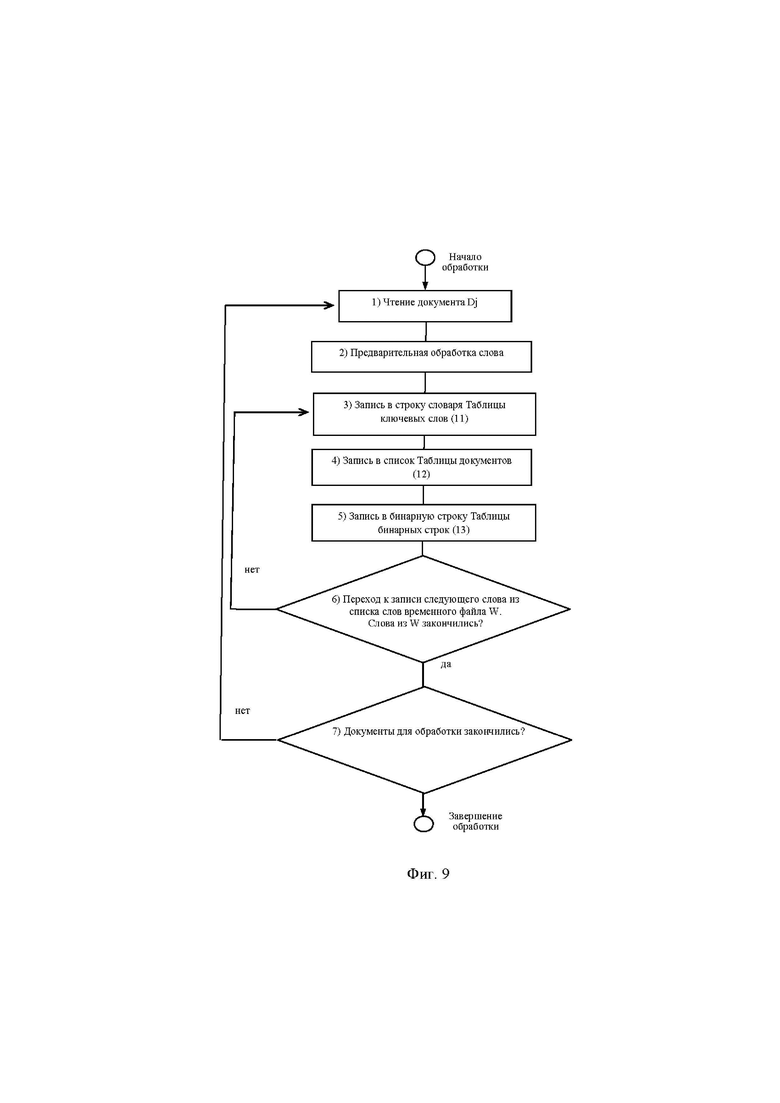
Пример 1. Этапы формирования служебных таблиц 1, 2 и 3 на примере фрагмента текста книги (фиг. 8). Обобщенная типовая схема обработки документа с ее описанием и примерами показана на фиг. 9.
1) на этапе чтения документа выписывают всех ключевые слова этого документа S1, S2, S3, . . . Sn во временный файл W:
Файл W = {S1= “ВВЕДЕНИЕ”, S2=“Данные”, S3=“зарубежной”, S3= “литературы”, S4=“многочисленные”, S5=“исследования”, S6= “грелиновой”,…}. Строчные и прописные буквы одинаковы, не различимы.
2) Обработка слова на предмет требований к формированию словаря.
3) В строку таблицы ключевых слов (11) записывают ключевые слова из временного файла W. Если слово новое, то в таблицу ключевых слов (11) дописывается строка. Далее информация дописывается в таблицу документов (12) и таблицу бинарных строк (13).
Строка в таблице ключевых слов (11) (фиг. 9): {<Введение,1,1>} Первая 1 – количество документов в которых встретилось это слово. Поскольку загружают первый документ, то ставится единица. Вторая 1 – адрес ссылки на первый список в таблице документов (12).
4) В первый список Sp1 таблицы документов (12) записывают номер документа (в таблице документов (12) это первый документ) и адрес ссылки на бинарную строку в таблице бинарных строк (13):
Список Sp1 – {<1,1> }. Здесь первая 1 – номер документа, а вторая 1 – первая бинарная строка.
5) В первую бинарную строку таблицы бинарных строк (13) ставят 1 на первом бите, что означает – данное слово из Таблицы 11 (Введение) встретилось на первой странице. В бинарной строке каждый номер бита соответствует номеру страницы в документе (например, бинарная строка <1,0,0,0,1,1,0,0,0,…> указывает, что заданное слово встретилось на первой, пятой и шестой страницах).
6) Чтение следующего слова из списка временного файла W и переход к выполнению пункта 2. При этом осуществляется контроль за длиной списка слов в файле W. При окончании обработки всех слов из файла W переходим к чтению нового документа, т.е. к выполнению пункта 6.
7) Осуществляют контроль за окончанием списка обрабатываемых документов. Единицы в первой позиции всех показанных бинарных строк фиг. 10 таблицы бинарных строк (13) указывают на то, что все ключевые слова из таблицы ключевых слов (11) находятся на первой странице документа.
Пример 2. Таблица ответа (16) фиг. 5 может быть сформирована (по столбцам) в микрочипе двойной памяти DM. Каждый столбец соответствует одному ключевому слову, а адрес регистра – номеру страницы документа. Таким образом, одна загрузка DM позволяет обработать один документ из БД (1). Множество ключевых слов заданной предметной области можно оптимизировать, задавая границу отсечения ключевых слов в общем словаре таблицы ключевых слов (11). Например, устанавливается граница по частоте, с которой встречается данное ключевое слово в документах (всей БД или раздела БД) не более чем в 20% документах. Ключевые слова, которые встречаются чаще, исключаются из таблицы ключевых слов (11).
Можно устанавливать границы отбора документов и вывода страниц на экран. Например, выводятся только те страницы документа, где количество ключевых слов на странице более установленной границы, например, 80% (в случае определения веса ключевых слов, то граница отсечения может быть и в виде числа). Можно установить требование вывода страниц на которых встречаются все ключевые слова 100%, т.е. отбираются страницы (для примера фиг. 5) с числом равным 65536 для 16 ключевых слов.
Можно задавать произвольные семантические правила: устанавливают обязательные и заменяемые слова, определяют обязательное присутствие не разделяемых сочетаний слов (например, «концентрация кислорода», «увеличение проникновения углекислоты»), задают расстояние (количество символов) между словами.
Реализовывать все классические логические операции над ключевыми словами И, ИЛИ, НЕ-И, НЕ-ИЛИ.
Пример 3. Результат обработки документа выводится в виде таблицы ответа (16) фиг. 6. Здесь страницы, на которых не встретились ключевые слова, не указаны. Все приведенные в таблице страницы упорядочены в соответствии с количеством встретившихся ключевых слов, если встретилось одинаковое количество ключевых слов, то страницы указываются в порядке с важностью ключевых слов, а далее в арифметическом порядке номеров страниц.
Это позволяет наглядно увидеть всю общую картину соответствия документа сформулированному запросу. При наведении курсора на:
- индекс столбца (Si), на экране возникает полное наименование ключевого слова.
- номер страницы, на экране появляется весь текст данной страницы, и пользователь может просмотреть ее на предмет соответствия своим потребностям.
- все ключевые слова, на выводимой на экран странице, выделяются цветом, при этом важность слов отражается в цвете. Оттенок цвета слова отражается в частотном спектре цвета слова (синий соответствует низкой важности, а красный – наиболее важное слово).
Дополнительная индивидуальная настройка доступа. Пользователь может указать уровень отсечения £ страниц, приведенных в Таблице ответа (16) фиг. 5. Здесь
0 < £ ≤ 1
Число £ отражает уровень требования на соответствие просматриваемых материалов запросу пользователя. Страницы, на которых доля количества ключевых слов ниже заданного уровня £ х n не будут включаться в результирующую таблицу ответа (16) фиг. 5 (результат округляется). Здесь n – количество ключевых слов в запросе. Например, для таблицы фиг. 5 с 16-тью ключевыми словами он может указать уровень отсечения £ = 0,2 (16х0,2=3,2 или 3 ключевых слова), тогда таблица ответа (16) фиг. 5 будет выглядеть так, как показано на фиг. 7.
Для дополнительного анализа информации на найденной странице можно использовать все традиционные алгоритмы обработки текстов (элементы семантического анализа).
Найденная выделенная в соответствии с критериями отбора страница документа вводится на экран для ее оценки пользователем и рассмотрения возможных вариантов уточнения – включение дополнительных ключевых слов, исключение заданных, формулировка новых вариантов сочетаний слов.
По сути, таблица ответа (16) является основой для проектирования логической схемы DM памяти.
Осуществление устройства.
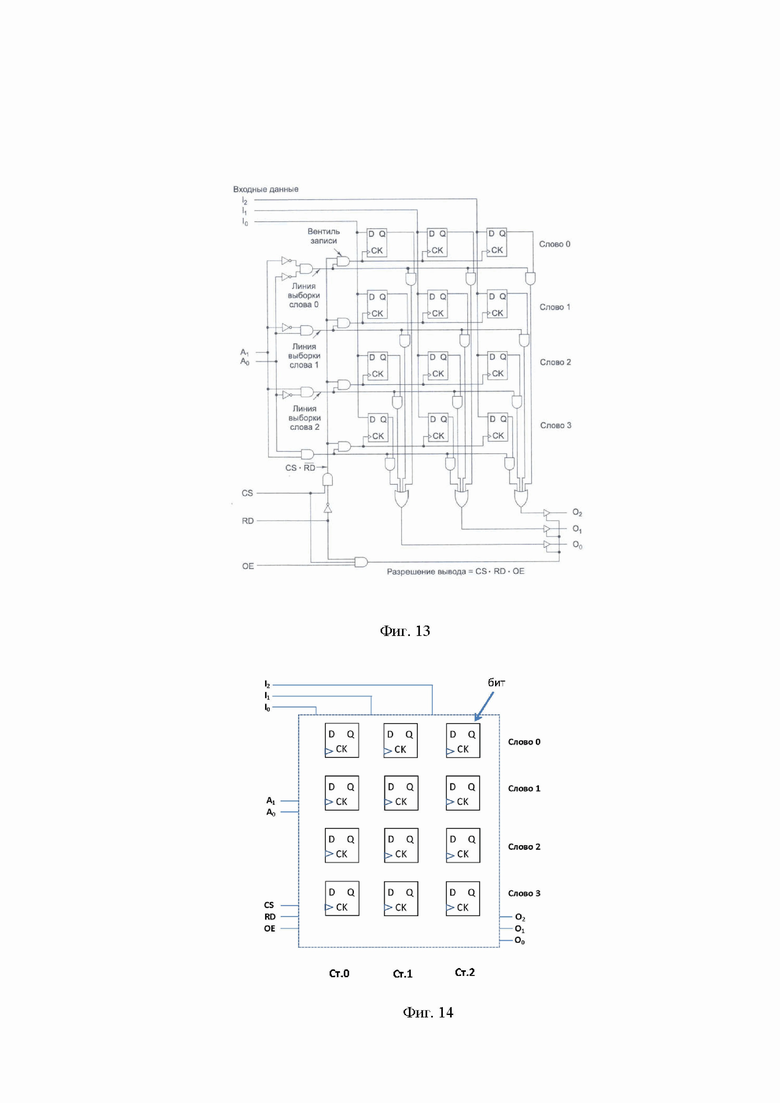
Двойная память Double Memory (далее DM) позволяет обрабатывать независимые списки бинарных строк Str1, Str2, . . . Strn. Для наглядности бинарные строки представлены в виде условной таблицы (17) (фиг. 11), где столбцами являются бинарные строки, а строками – номера битов в бинарных строках. Производится операция распознавания побитного уровня (строки таблицы) пересечения бинарных строк.
Здесь бинарная строка Str1 = <01001000001…1>. Длина строки равна m бит. В представленной таблице количество строк указывается по количеству бит в наиболее длинной строке из обрабатываемого списка строк, короткие строки дополняются нулевыми битами.
Рассмотрим i-ую строку данной таблицы. В ней показано - в каких столбцах на i-ой позиции бита находятся единицы, а в каких строках стоят нули. Например, в строке 11 для всех столбцов в 11-ой позиции стоят единицы (считают, что в строках с 6 по n-1 стоят единицы). Целочисленное (в виде десятичного числа) представление строки позволяет «зашифровать» всю двоичную строку. Так для одиннадцатой строки — это число будет равно 2n.
Пример этой же таблицы (17) сформированной из 6 столбцов длиной в 12 бит представлен на фиг. 12. Та же одиннадцатая строка (при всех единицах в строке) ее целочисленное значение будет равно 26 = 64. Целочисленное значение третьей строки равно 4.
Таким образом, считывая строку таблицы по полученному целому числу, можно точно знать в каких позициях стоят единицы. Причем пользователь, задавая определенный порядок расположения столбцов в таблице задает условную степень важности столбцов, которая обозначена символом ⸖. Тогда столбец с номером (j+1) ⸖ j будем интерпретировать как столбец Strj+1 важнее столбца Strj. Это позволяет использовать семантические алгоритмы предварительной оценки страниц заявленного способа.
Логическая блок-схема для памяти 4 х 3 известна из прототипа [7] стр.200 и представлена на фиг. 13. Обобщенная схема этой же классической памяти, состоящей из 4 регистров (ячеек памяти), каждый регистр которой состоит из 3 бит, показана на фиг. 14. Реальные схемы построены также с той лишь разницей, что разрядность ячеек памяти (регистров) может составлять 8, 16, 32 или 64 бита, а количество ячеек памяти от сотен тысяч и более (схема многократно увеличена), но для понимания логики всех процессов представленных на примерах и обобщениях достаточно.
Далее приводим обобщенную схему памяти - это позволяет не сосредотачиваться на элементном исполнении триггеров и переключающих элементов, т.к. они могут выполняться многовариантно в зависимости от предпочтений разработчика и применяемой технологии, но сохраняет логику всех основных функции памяти – записи/чтения строки в ячейку памяти (регистр) по заданному адресу ячейки памяти.
На обобщенной схеме фиг. 14 зафиксированы только важные элементы - 12 триггеров памяти, каждый триггер хранит 1 бит информации, входы/выходы и управляющие сигналы. Каждый триггер может находиться в одном из двух состояний 1 или 0. Триггеры выстроены в структуру – 4 строки (регистры) по 3 триггера в каждой строке. Предполагается, что входная информация, поступающая в виде бинарных строк, записывается в ячейки памяти (регистры - строки). Регистры пронумерованы и их номера называются адресами ячеек памяти (регистров). Логика процесса такова – бинарная строка <I0, I1, I2> (здесь значение Ii равно 0 или 1, i=0,1,2) записывается в регистр по адресу бинарной строки <A0,A1> в соответствии с командами, поступающими на входы <CS,RD,OE>. А также информация может считываться в соответствии с командами <CS,RD,OE> из регистров, указанных в адресе <A0,A1> в выходную бинарную строку <O0,O1,O2>.
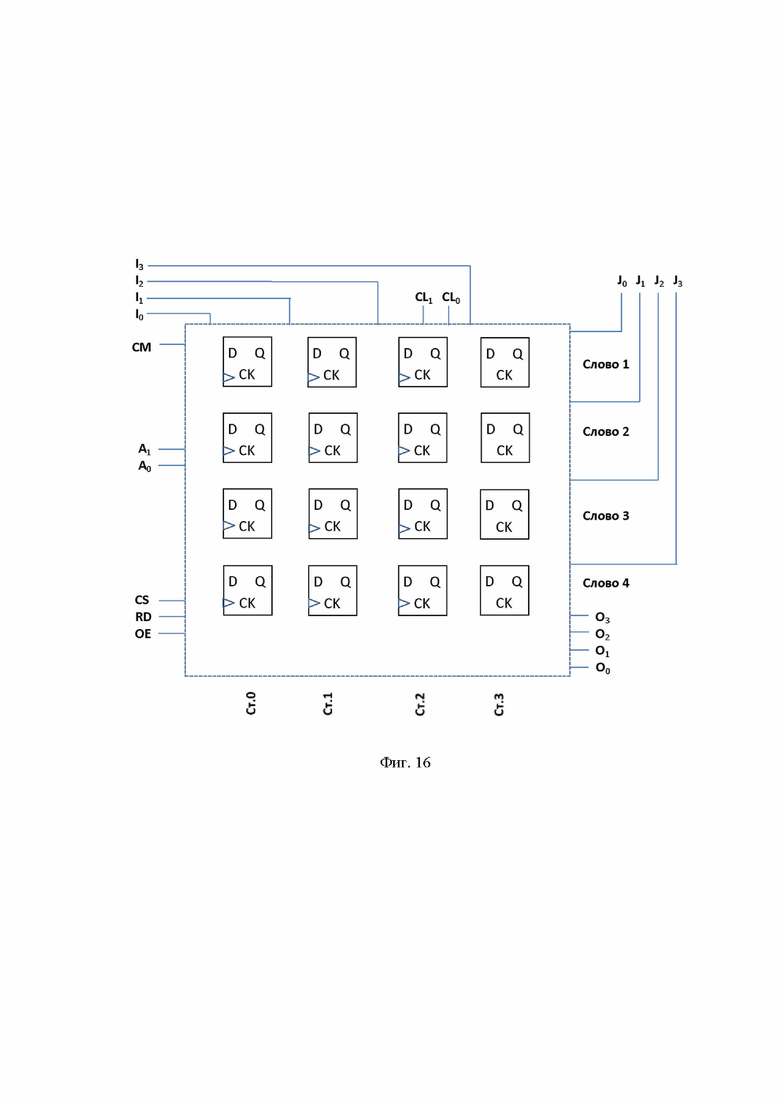
На фиг. 15 показана обобщенная логическая схема классической памяти для r ячеек памяти (регистров), где каждый регистр состоит из n бит, предназначенных для записи входных сигналов I0,I1,…,In и чтения выходных сигналов O0,O1, …,On .
Примеры микросхем оперативной памяти известны из аналога [7] на рис. 3.30 стр. 204.
На фиг. 16 показана предлагаемая обобщенная блок-схема схема примера DM памяти 4х4. Каждый горизонтальный ряд состоит из 4 триггеров, составляющих одно слово. Показаны 4 ячейки памяти (регистра или 4 слова).
В отличие от прототипа [7], DM может работать, как и классическая память – записывать и читать слова по регистрам (их адресам), а также дополнительно позволяет записывать бинарные строки Str1, Str2, . . . Str4 подаваемые последовательно на входы <J0, J1, J2, J3>. Здесь бинарная строка Stri, = <J0, J1, J2, J3>i где i=1,4 записывается в i-ый столбец по адресу из Cт.i из списка адресов Cт.0, Ст.1, Ст.2, Ст.3, указывая адрес столбца на входах <CL0, Cl1>. Информация при этом читается стандартно - по регистрам (словам) на выходы <O0, O1, O2, O3>. Здесь вход СМ (Change Memory) – переключает режим работы памяти с обычной на DM. В режиме обычной памяти она работает в соответствии со схемой классической памяти фиг.13.
Пример обобщенной логической схемы DM памяти на r регистров по n бит каждый показан на фиг. 17. Показан дополнительный вход данных J0,J1,…,Jm , где m ≤ r. Для удобства восприятия логической схемы можно рассматривать таблицу ответа фиг. 11, где строки соответствуют регистрам памяти, а столбцы – бинарным строкам. Разумеется, что DM также, как и обычная память может выполняться с регистрами любых размеров 16, 32, 64 бит и более, а также с любым количеством ячеек памяти (регистров) от 1024 (как в примере со страницами) до сотен миллионов – для обработки больших списков документов.
Описание работы.
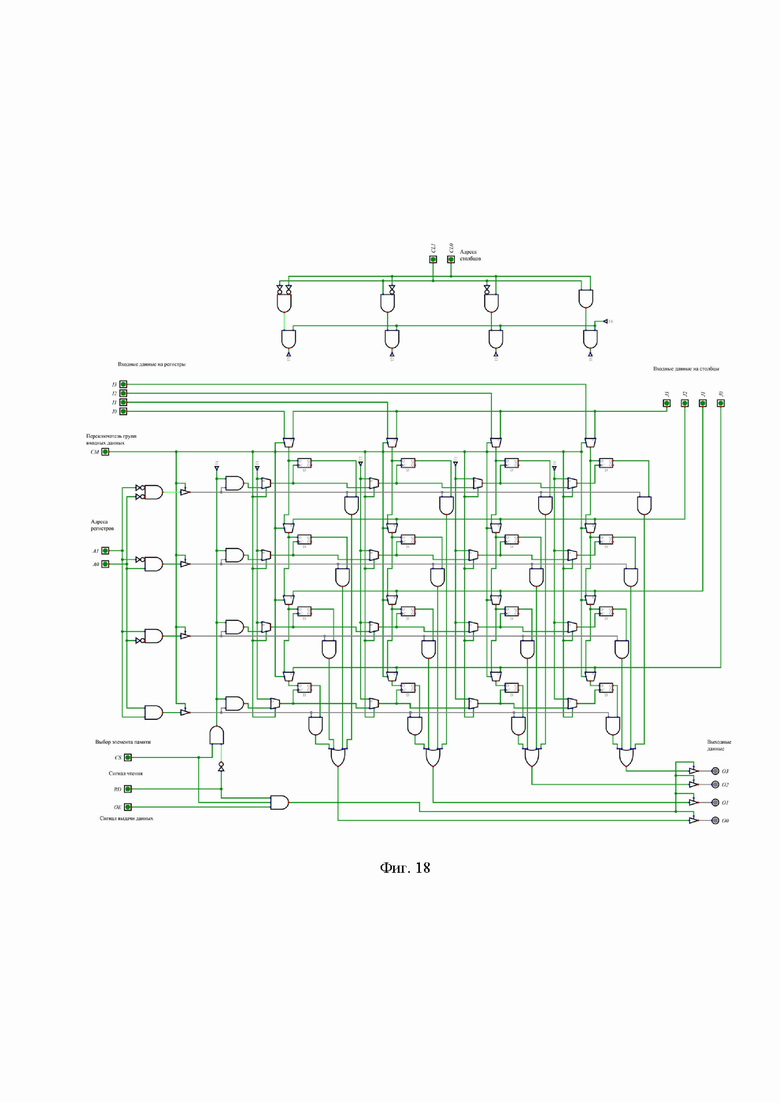
Пример исполнения DM памяти 4 х 4 фиг. 18 и ее обобщенный вид показан фиг. 17. Показано, что вход СМ – переключает работу схемы из режима обычной памят7и в режим DM. В режиме обычной памяти (1 на выходе CM) логическая схема работает также, как и схема, изображенная на фиг. 13. В дополненном DM режиме памяти (0 на выходе CM) логическая схема переключается на ввод данных со входов J0, J1, J2, J3 см. изображенная на фиг. 18 и фиг. 17. Логическая схема рис.13 дополнена см. фиг. 18:
- блоком адресации столбцов CL0 и CL1, задающих текущий адрес столбца, в который будет осуществлена запись данных J0, J1, J2, J3.
- в блоке адресации регистров А0 и А1, на выходе логических элементов И установлены драйверы, которые в зависимости от управляющего сигнала СМ (1- пропускают сигнал адреса регистра, 0 – блокирует сигнал адреса регистра).
- мультиплексорами, установленными на входе C синхронизирующего сигнала триггера (сигнал открывает вход данных триггера) на всех входах триггеров памяти. Мультиплексоры переключают канал поступления адресов с адресов регистра на адреса столбцов (точки Т0, Т1, Т2, Т3) в зависимости от управляющего сигнала СМ.
- мультиплексорами, установленными на всех входах поступления данных D триггеров памяти. Управляющий сигнал СМ переключает каналы получения данных от I0, I1, I2, I3 (при СМ=1) на J0, J1, J2, J3 (при СМ=0) на всех входах D триггеров памяти.
- выход элемента И после блока управления записью/чтением (CS, RD, OE) продлен точкой Т4 до блока выбора адреса столбца.
При переключении входа CM (0 на выходе) в режим DM памяти адресация столбцов осуществляется адресными линиями CL0 и CL1 в верхней части схемы, аналогично адресации регистров, а входные линии I0, I1, I2, I3 запираются сигналом CM на мультиплексорах, установленных перед входом сигнала D на триггер. Для выбора столбца памяти, внешняя логика должна установить сигнал CS в 1, а также установить сигнал RD в 1 для чтения и в 0 для записи. Адресные линии столбцов должны указывать, в какой из четырех 4-разрядных столбцов нужно записывать информацию. При считывании все входные линии для данных не используются. При записи биты, находящиеся на входных линиях J0, J1, J2, J3 для данных, загружаются в выбранный столбец памяти; выходные линии при этом не используются.
Память, изображенная на фиг. 18 работает следующим образом. Четыре вентиля И для выбора столбцов в верхней части схемы формируют декодер. Далее входные инверторы расположены так, что каждый вентиль запускается определенным адресом. Каждый вентиль приводит в действие линию выбора столбцов. Когда микросхема должна производить запись, вертикальная линия CSˑ RD получает значение 1, запуская один из четырех вентилей записи - точки Т0, Т1, Т2, Т3. Выбор вентиля зависит от того, какая именно линия выбора столбца равна 1. Выходной сигнал вентиля записи приводит в действие все сигналы С (вход триггера) для выбранного столбца, загружая входные данные в триггеры этого столбца. Запись производится только в том случае, если сигнал CS равен 1, а RD – 0, при этом записывается только столбец, выбранный адресами CL0 и CL1.
Процесс считывания аналогичен стандартному процессу считывания по схеме фиг. 13 – CM переключается в режим обычной памяти (1 на выходе), указывается адрес регистра (А0, А1), линия CSˑRD принимает значение 0, поэтому все вентили записи блокируются, и ни один из триггеров не меняется. Вместо этого линия выбора слов запускает вентили И, связанные с битами Q (выход триггера) выбранного слова. Таким образом, выбранное слово передает свои данные в 4-входовые вентили ИЛИ, расположенные в нижней части схемы, а остальные три слова выдают 0. Следовательно, выход вентилей ИЛИ идентичен значению, сохраненному в данном слове. Остальные три слова никак не влияют на выходные данные.
Таким образом, после записи столбцов в память DM обеспечивается возможность считывать информацию, хранящуюся в регистрах DM по схеме – по адресам регистров считываем содержание регистров. В результате содержимое i-го регистра показывает всю i-ую позицию в бинарных списках, записанных по столбцам, а целочисленное значение регистра содержит всю эту информацию в сжатом виде, что полностью соответствует таблице ответа (16) фиг. 5 для примера четырех ключевых слов и четырех страницах документа.
DM память может изготавливаться в различных вариантах. Как оптимальный вариант, она может содержать 1024 регистров (слов) на 64 бита (столбцов – количество ключевых слов). Память может устанавливаться автономно или в качестве кэш-памяти с процессором, что ускорит работу алгоритма.
Модификации логической схемы:
- использование одних и тех же каналов для входных данных для записи в регистры (на примере I0, I1, I2, I3) и для входных данных для записи в столбцы (на примере J0, J1, J2, J3). Поскольку эти канала одновременно не используются.
- увеличение разрядности регистров для работы с большим количеством ключевых слов - 1024 регистра по 128 бит;
- для специальных приложений - произвольное количество регистров (десятки миллионов) для работы с большим количеством документов.
- Построение нескольких входных портов (групп регистров) для параллельной работы с несколькими списками.
Таким образом в заявке предлагается подход, основанный на поиске с точностью до страницы. Дополнительно к спискам документов в которых встречается ключевое слово формируются бинарные списки строк документов (фиг. 3), а их обработка заменяет этап полнотекстового анализа документа. Анализ документа заменен страничным просмотром Таблицы ответа Фиг. 4.
Техническая задача решается благодаря тому, что:
- бинарные списки страниц документа являются списками фиксированной длины, что удобно для обработки;
- все страницы документа по заданному ключевому слову представлены в одной бинарной строке;
- аппаратная реализация DM памяти позволяет исключить операции сортировки страниц различных ключевых слов;
- DM память позволяет одновременно обрабатывать множество (десятки) ключевых слов (бинарных списков), на предмет их пересечения. DM обеспечивает быстрое преобразование множества бинарных списков заданных ключевых слов в постраничное отображение документа (каждый регистр памяти в страницу документа) для быстрого просмотра и отбора страниц документа с заданными ключевыми словами без проведения операции по пересечению списков;
- прикладная интерпретация бинарных строк ничем не ограничена. Результат при этом может считываться в виде целых чисел (строка Таблицы ответа фиг. 4), зависящих от: бинарных значений чисел, расположенных в одинаковых позициях бинарных строк, последовательности записи бинарных строк в DM память (порядка ключевых слов в запросе);
- просмотр найденной страницы не затруднит пользователя своим объемом;
- в поисковом алгоритме не понадобится строить различные сложные логические конструкции, такие как, расстояние между ключевыми словами, порядок упоминания ключевых слов, их применение в рамках предложения, абзаца и т.д. Все ключевые слова на странице подсвечиваются фоном и этого достаточно пользователю для ее предметной оценки.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ НАНЕСЕНИЯ ИЗОБРАЖЕНИЯ И ТЕКСТА НА ПОВЕРХНОСТЬ И ПОРТАТИВНОЕ УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2016 |
|
RU2635252C1 |
| СПОРТИВНЫЙ ТРЕНАЖЕР | 2013 |
|
RU2552977C2 |
| Устройство для получения электроэнергии от морских течений подо льдом | 2023 |
|
RU2828695C1 |
| Устройство для накопления электрической энергии в водной среде | 2023 |
|
RU2808329C1 |
| МАТРИЦА ФЛЭШ-ПАМЯТИ С ВНУТРЕННИМ ОБНОВЛЕНИЕМ | 1999 |
|
RU2224303C2 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ПОЛЕЗНОГО КОНТЕНТА ИЗ УСТАНОВОЧНЫХ ФАЙЛОВ МОБИЛЬНЫХ ПРИЛОЖЕНИЙ ДЛЯ ДАЛЬНЕЙШЕЙ МАШИННОЙ ОБРАБОТКИ ДАННЫХ, В ЧАСТНОСТИ ПОИСКА | 2014 |
|
RU2568276C2 |
| СПОСОБ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2019 |
|
RU2709288C1 |
| УПРАВЛЕНИЕ СКОРОСТЬЮ, С КОТОРОЙ ОБРАБАТЫВАЮТСЯ ЗАПРОСЫ НА ПРЕРЫВАНИЕ, ФОРМИРУЕМЫЕ АДАПТЕРАМИ | 2010 |
|
RU2526287C2 |
| СПОСОБ ПРОВЕДЕНИЯ МИГРАЦИИ И РЕПЛИКАЦИИ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2020 |
|
RU2745679C1 |
| СПОСОБ КОМПЛЕКСНОЙ ЗАЩИТЫ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ИНФОРМАЦИИ В КОМПЬЮТЕРНЫХ СИСТЕМАХ И СИСТЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 2001 |
|
RU2259639C2 |

Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в упрощении и ускорении процедуры поиска документов в соответствии с заданными критериями. Технический результат достигается за счёт того, что формируют вспомогательные таблицы: ключевых слов, документов, бинарных строк номеров документов и бинарных строк, дополняющие инвертированный индекс. После выборки списков по ключевым словам, из инвертированного индекса, осуществляют обработку списков документов представленных в виде бинарных строк в блоке обработки результирующего списка. При этом бинарные строки загружаются для обработки в двойную память, в которой числовое значение строки (регистр памяти) равна 2n. В блоке обработки страниц документов по ключевым словам формируется для каждого документа таблица ответа. Двойная память представляет собой логическую схему памяти и содержит каналы ввода данных, вход СМ, переключения работы схемы из режима обычной памяти в режим двойной памяти, блок адресации номеров бита в ячейках памяти, переключатель, логические переключатели. Выход блока управления записью/чтением CS, RD, OE, соединен с выходом блока выбора номера бита (адреса столбца). 2 н.п. ф-лы, 18 ил.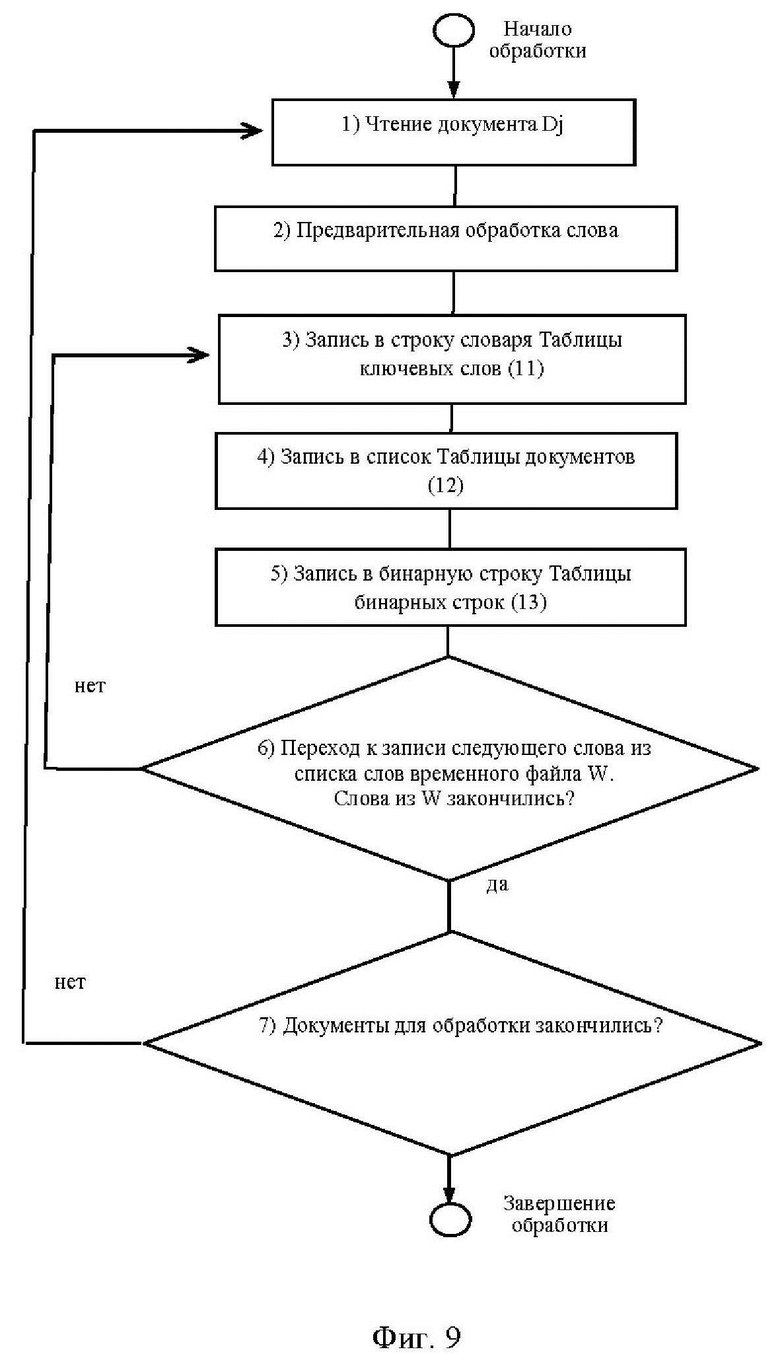
1. Способ для реализации в двойной памяти поиска документов в прикладных базах неструктурированных данных, включающий формирование запроса пользователем в двойную память, при этом пользователь указывает ключевые слова и логические операции с ними, выделение ключевых слов в запросе в блоке обработки ключевых слов запроса, использования инвертированного индекса c программами формирования, развития и сопровождения работы инвертированного индекса, при этом упомянутые программы взаимодействуют c блоком индексации, который взаимодействует c базой данных, программами выборки списков по ключевым словам, отличающийся тем, что:
- программы формируют в двойной памяти вспомогательные таблицы: ключевых слов, документов, бинарных строк номеров документов и бинарных строк, дополняющие инвертированный индекс, при этом
- таблица ключевых слов содержит список ключевых слов, каждое ключевое слово имеет ссылку на бинарную строку документов и ссылку на строку таблицы документов, а также здесь же указывается дополнительная информация: количество документов, где используется ключевое слово, другие данные о ключевом слове: термин, сокращение, множество или элемент множества;
- таблица документов содержит списки пар, связанных с ключевым словом, пара - это номер документа, в котором используется ключевое слово и ссылка на бинарную строку в таблицы бинарных строк;
- таблица бинарных строк содержит список бинарных строк фиксированной длины, каждая строка связана с номером документа из таблицы документов, при этом каждый бит бинарной строки – соответствует одной странице текста документа, номер бита в строке соответствует номеру страницы этого документа, а 1 или 0, стоящие на определенной позиции, указывают на присутствие или отсутствие заданного ключевого слова на данной странице;
- таблица бинарных строк документов состоит из множества бинарных строк фиксированной длины, при этом каждый номер бита в бинарной строке соответствует номеру документа, а 1 в этом бите означает, что в документе с данным номером встречается заданное ключевое слово;
- после выборки списков по ключевым словам из инвертированного индекса, осуществляют обработку списков документов, представленных в виде бинарных строк в блоке обработки результирующего списка, при этом бинарные строки загружаются для обработки в двойную память, в которой числовое значение строки равна 2n , где n – разрядность регистра памяти, в случае, если все заданные ключевые слова встречаются в документе с номером равным номеру строки в двойной памяти, это позволяет не прибегать к операции пересечения списков, при этом
- в блоке обработки страниц документов по ключевым словам формируется для каждого документа таблица ответа, при этом происходит загрузка бинарных строк из таблицы бинарных строк в двойную память, их сортировка и анализ, при этом в таблице ответа каждому столбцу соответствует свое ключевое слово, столбцы упорядочены в соответствии с их важностью, причем каждый столбец ключевого слова соответствует бинарной строке таблицы бинарных строк, таблица ответа позволяет отразить содержащиеся в документе ключевые слова с точностью до страницы без загрузки самого документа из базы данных.
2. Двойная память для организации поиска документов в прикладных неструктурированных базах данных по п. 1, представляющая собой логическую схему памяти, обеспечивающую возможность записи данных по заданному адресу ячейки память, а также возможность чтения из ячеек памяти по заданному адресу ячейки записанных данных и вывод считанных данных в выходные линии в соответствии с сигналами управления CS, RD, OE и СМ, отличающаяся тем, что:
- содержит второй канал ввода данных, обеспечивающий запись битовых строк в заданный бит ячейки памяти во все ячейки памяти одновременно, при этом длина битовой строки равна количеству ячеек памяти, а количество и разрядность ячеек памяти ограничено технологическими возможностями микроэлектроники;
- вход СМ, выполненный с возможностью переключения работы схемы из режима обычной памяти - записи входных данных в ячейки памяти, в режим двойной памяти – записи входных данных в заданный бит каждой ячейки памяти;
- содержит блок адресации номеров бита в ячейках памяти, задающих общий номер бита для всех ячеек памяти, в которые осуществляется запись данных;
- после блока адресации ячеек устанавливается переключатель, который пропускает или блокирует сигнал адреса ячейки памяти в зависимости от управляющего сигнала СМ;
- содержит логические переключатели, установленные на всех входах триггеров памяти, для переключения канала поступления адресов с адресов ячеек памяти на адреса битов в ячейках памяти, в зависимости от управляющего сигнала СМ;
- содержит логические переключатели, установленные на всех входах поступления данных триггеров памяти, для переключения каналов получения данных в зависимости от управляющего сигнала СМ;
- выход блока управления записью/чтением CS, RD, OE, соединен с выходом блока выбора номера бита.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 8046353 B2, 25.10.2011 | |||
| СПОСОБ И СИСТЕМА ДЛЯ ИНДЕКСИРОВАНИЯ И ПОИСКА В БАЗАХ ДАННЫХ | 2005 |
|
RU2398272C2 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПОЛИТЕМАТИЧЕСКИХ МАССИВАХ НЕСТРУКТУРИРОВАННЫХ ТЕКСТОВ | 2008 |
|
RU2409849C2 |
| EP 1483693 B1, 06.08.2008 | |||
| US 7600001 B1, 06.10.2009 | |||
| US 6980976 B2, 27.12.2005 | |||
| US 9355152 B2, 31.05.2016. | |||

