Изобретение относится к вычислительной технике, а более конкретно - к способам и устройствам для обеспечения сжатия данных с минимальными потерями.
Из многих известных способов сжатия данных наиболее распространенным является метод Лемпеля-Зива (LZ), основанный на оригинальных алгоритмах сжатия данных без потерь и реализуемый как программно, так и аппаратно. Различные варианты реализации этого метода описаны, например, в патентах США №7650040 [1], 6320986 [2], 5805086 [3], а также в европейском патенте №0666651 [4]. Все решения базируются на использовании словарных моделей, то есть на информационных структурах, именуемых словарем. Во процессе работы словарного метода словарь включает в себя части уже обработанной информации, выступающие в качестве материала, на основе которого осуществляется кодирование. В процессе кодирования уже обработанные повторяющиеся строки заменяются ссылками на словарь. В частности, хорошо известен алгоритм LZ-типа, разработанный Россом Уильямсом (Ross Williams) в 1990-х годах и предлагающий выгодное соотношение пропускной способности и степени сжатия (далее - LZRW3). Как и большинство алгоритмов сжатия, LZRW3 нацелен на программную реализацию, но в то же время имеет потенциал для оптимизации под аппаратное исполнение.
Предыдущие аппаратные реализации алгоритма LZRW3 предоставляют основные улучшения алгоритма в части лучшей аппаратной совместимости, но сохраняют традиционный подход побайтовой обработки данных. Это ограничивает пиковую пропускную способность одним байтом за такт.
Наиболее близким к заявляемому изобретению является европейский патент [4], в котором описаны устройство и способ сжатия данных по методу Лемпеля-Зива, с использованием словаря и блока памяти, для ускорения сжатия и распаковки данных.
Указанный прототип имеет следующие существенные недостатки:
1. Структура упакованных пакетов обязывает упаковщика держать в памяти весь объем сжатых данных для определения итогового размера на выходе.
2. Распаковщик должен держать в памяти весь объем распакованных данных, так как в кэш-таблице могут содержаться ссылки на любой байт из этих данных.
3. Известные аппаратные реализации алгоритма обрабатывают данные с пиковой пропускной способностью 1 байт за такт в случае несжимаемых данных.
Задача, на решение которой направлено заявляемое изобретение, состоит в том, чтобы разработать способ и устройство, обладающие повышенной, по сравнению с известными решениями, производительностью и эффективностью при использовании в системах передачи данных, в сетевых устройствах и устройствах для хранения информации.
Технический результат достигается за счет применения усовершенствованного способа сжатия данных без потерь при записи на целевое устройство, основанного на записи промежуточных сжатых данных в память целевого устройства и их извлечении с целевого устройства для последующей распаковки. При этом основное отличие заявляемого способа состоит в том, что данные принимают и отдают 128-битными блоками, используют 16 независимых блоков памяти для хранения кэшированных кодирующих структур размером 15-байтной длины, что позволяет конфигурировать размер кэш-таблицы посредством задания числа ячеек числами, равными степени 2 в пределах от 16 до 4096, в котором при сжатии осуществляют следующие шаги:
- предсказывают кодирующие структуры с использованием двух связных буферов упреждающей выборки для построения словаря;
- кодируют от двух до пятнадцати байт входного потока в один упакованный символ за один такт;
- используют количество упакованных байт в качестве обратной связи для логики, отвечающей за сдвиг входного потока;
- выбирают кодирующую структуру за один такт путем поиска кэшированной строки с наиболее длинной совпадающей с входной строкой последовательностью символов;
- упаковывают данные в 32-байтные группы, выровненные по два байта;
- упаковывают совпадающие строки в 2-байтный кодирующий символ, состоящий из длины строки, номера блока памяти и значения хэш-функции, определяющего адрес этой строки в блоке памяти.
Таким образом, заявляемое изобретение направлено на преодоление существующих недостатков прототипа и имеет следующий набор улучшенных характеристик по сравнению с известным алгоритмом LZRW3:
1. Способ обработки данных ориентирован на потоковую обработку данных с использованием 128-битных блоков информации.
2. Упаковщику не требуется держать в памяти сжатые данные. Обработанные данные направляются прямо на выход, когда на входе становиться доступным следующий 128-битный блок.
3. Распаковщику не требуется держать в памяти распакованные данные. Только небольшой объем данных используется для поддержания буфера истории обновлений.
4. Используется способ предсказания кодирующих структур для упаковки данных.
5. Способы упаковки и распаковки были оптимизированы для параллельной обработки данных в аппаратной реализации.
6. Нижняя граница пропускной способности для аппаратных реализации упаковщика и распаковщика - два байта за такт.
7. Заявляемый способ ориентирован на использование высокопроизводительной 128-битной шины.
Для осуществления распаковки данных в предлагаемом способе осуществляют следующие шаги:
- извлекают данные из 32-байтных групп, выровненных по два байта;
- декодируют упакованные слова, используя конечный автомат, позволяющий обработать от трех до одного байта за один такт в зависимости от типа упакованного слова и его длины;
- обновляют шестнадцать строк кэш-таблицы одновременно с добавлением только что распакованных байт в конец кэшированной строки по мере их поступления в выходной буфер;
- исключают ячейку кэш-таблицы из схемы автоматического обновления, когда она заполняется пятнадцатью байтами данных до момента запроса на перезапись этой ячейки.
Согласно одному из вариантов осуществления предлагаемого способа при сжатии данных для хранения кэшированных кодирующих структур и доступа к ним используется логическая схема, основанная на принципах организации однопортовой памяти.
Согласно одному из вариантов осуществления предлагаемого способа при распаковке данных для хранения кэшированных кодирующих структур и доступа к ним используется логическая схема, основанная на принципах организации двухпортовой памяти.
Поставленная задача решена также путем создания устройства сжатия данных без потерь, содержащего, по меньшей мере, один блок упаковки данных и, по меньшей мере, один блок распаковки данных, отличающегося тем, что 128-битный вход блока упаковки данных подключен к выходу 128-битной шины целевого устройства для обработки и последующего формирования упакованного пакета, состоящего из 32-байтных упакованных групп, выровненных по два байта, передаваемого посредством 128-битного выхода указанного блока упаковки на шину целевого устройства, и, по меньшей мере, один блок распаковки данных, 128-битный вход которого подключен к выходу 128-битной шины целевого устройства для обработки, последующего восстановления исходных данных из данных, содержащихся в упакованном пакете, и передачи восстановленных данных посредством 128-битного выхода указанного блока распаковки на шину целевого устройства, характеризующегося тем, что:
блок упаковки данных включает в себя
- блок входной логики, вход которого подключен к выходу целевого устройства, а выход которого соединен с входом устройства сравнения,
- устройство сравнения, выполненное с возможностью выполнения подбора соответствующего шаблона упаковки во внутреннем кэше, формирования кэш-таблицы, и соединенное линией обратной связи с блоком входной логики,
- блок логики упаковки, включающий 16-битный вход, подключенный на который из устройства сравнения поступает 16-битный пакет, содержащий упакованное слово или два 8-битных литерала, и внутренний буфер, накапливающий данные для передачи посредством 128-битного выхода блока упаковки на 128-битную шину данных;
а блок распаковки данных включает в себя
- блок входной логики, вход которого подключен к выходу 128-битной шины,
- декодирующий автомат, выполненный с возможностью приема на входе одной 32-байтной упакованной группы с выхода блока входной логики и передачи на вход блока выходной логики двух 8-битных литералов, а на вход блока логики кэш-таблицы - адрес, индекс кэш-таблицы и количество байт, которые требуется извлечь из нее для последующей передачи блоку выходной логики,
- блок логики кэш-таблицы, включающий 16 независимых двухпортовых блоков памяти, буфер смещений, выполненный с возможностью обновления кэш-таблицы в выходном буфере блока выходной логики, и выход, соединенный с блоком выходной логики, выполненным с возможностью обновления выходного буфера, и
- блок выходной логики, содержащий выходной буфер, данные из которого передаются на целевое устройство посредством 128-битного выхода.
Для функционирования устройства обработки данных имеет смысл, чтобы блок входной логики блока упаковки, включающий 128-битный вход, внутренний буфер на пять 128-битных слов, 248-битный выход, был выполнен с возможностью осуществления следующих шагов:
- извлечение данных с 128-битного входа во внутренний буфер,
- осуществление сдвига обработанных данных во внутреннем буфере и дополнение его новыми данными,
- осуществление разблокировки устройства сравнения и блока логики упаковки, как только во внутренний буфер загружается необходимое для их работы количество данных.
Для функционирования устройства обработки данных имеет смысл, чтобы устройство сравнения блока упаковки, включающее в себя кэш-таблицу, содержащую 16 независимых однопортовых блоков памяти с селекторами адреса, и каскад сравнения, отвечающий за выбор кодирующей структуры, было выполнено с возможностью осуществления следующих шагов:
- выбор кодирующей структуры за один такт путем поиска кэшированной строки с наиболее длинной совпадающей с входной строкой последовательностью символов,
- формирование кэш-таблицы кодирующих структур,
- предоставление обратной связи для блока входной логики, который содержит информацию о том, сколько байт должно быть пропущено с входа.
Для функционирования устройства обработки данных имеет смысл, чтобы блок логики упаковки блока упаковки, включающий 16-битный вход, 128-битный выходной буфер, накапливающий данные для передачи на 128-битный выход указанного блока, был выполнен с возможностью осуществления следующих шагов:
- упаковка данных в пакет, который состоит из 32-байтных групп упакованных данных, выровненных по два байта,
- упаковка совпадающих строк в 2-байтный кодирующий символ, состоящий из длины строки, номера блока памяти и значения хэш-функции, определяющего адрес этой строки в блоке памяти,
- использование значения линии предела переполнения для перевода блока упаковки в состояние переполнения,
- отправка упакованных данных на 128-битный выход.
Для функционирования устройства обработки данных имеет смысл, чтобы блок входной логики блока распаковки, включающий в себя 128-битный вход, 512-битный внутренний буфер, 256-битный выход, был выполнен с возможностью осуществления следующих шагов:
- извлечение данных с 128-битного входа во внутренний буфер,
- накапливание во внутреннем буфере двух 32-байтных упакованных групп,
- осуществление разблокировки остальных компонентов блока упаковки данных, как только во внутренний буфер загружается необходимое для их работы количество данных.
Для функционирования устройства обработки данных имеет смысл, чтобы декодирующий автомат блока распаковки представлял собой конечный автомат с четырьмя состояниями, имеющий 256-битный выход и передающий на выход данные о распакованном символе, выполненный с возможностью осуществления следующих шагов:
- вырабатывание информации о текущем и следующем упакованных словах и передача ее блоку логики кэш-таблицы и блоку выходной логики,
- декодирование от одного до трех байт упакованных данных за один такт,
- информирование блока входной логики о необходимости загрузки новой упакованной группы.
Для функционирования устройства обработки данных имеет смысл, чтобы блок логики кэш-таблицы блока распаковки, включающий в себя шестнадцать независимых двухпортовых блоков памяти, буфер смещений для обновления кэш-таблицы в выходном буфере блока выходной логики, 24-битный выход, был выполнен с возможностью осуществления следующих шагов:
- обновление кэш-таблицы согласно процессу заполнения выходного буфера и чтение строк из памяти для распаковки упакованных слов;
- обновление каждой из ячеек памяти кэш-таблицы данными, накапливаемыми в выходном буфере.
Для функционирования устройства обработки данных имеет смысл, чтобы блок выходной логики блока распаковки состоял из 16-битного входа для литералов и 24-битного входа для данных из кэш-таблицы, 248-битного выходного буфера, 128-битного выхода и был выполнен с возможностью осуществления следующих шагов:
- пополнение выходного буфера, который используется блоком логики хэш-таблицы в процессе обновления кодирующих структур;
- отправка распакованных данных на 128-битный выход.
Согласно одному из вариантов осуществления предлагаемого устройства обработки данных, по меньшей мере, один блок упаковки данных реализован на базе программируемой пользователем вентильной матрицы (ППВМ).
Согласно другому варианту осуществления предлагаемого устройства обработки данных, по меньшей мере, один блок упаковки данных реализован на базе специализированной для решения конкретной задачи интегральной схемы (ASIC).
Согласно одному из вариантов осуществления предлагаемого устройства обработки данных, по меньшей мере, один блок распаковки данных реализован на базе программируемой пользователем вентильной матрицы (ППВМ).
Согласно другому варианту осуществления предлагаемого устройства обработки данных, по меньшей мере, один блок распаковки данных реализован на базе специализированной для решения конкретной задачи интегральной схемы (ASIC).
Все решения, использованные для выполнения задач по улучшению метода упаковки, являются новыми для данной области, в частности:
- использование двух однобайтных входных символов, выступающих одновременно в качестве двубайтного литерала, начала кодируемой строки и части строки, используемой в предсказании кодирующих структур;
- управление словарем кодирующих структур с использованием механизма кэширования с выборкой на основе хэш-функции;
- механизм предсказания кодирующих структур, использующий два связанных буфера упреждающей выборки для построения словаря;
- механизм автоматического обновления строк кэш-таблицы на основе вставки только что распакованных данных из выходного буфера по мере их поступления.
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими чертежами.
Фиг.1 представляет общую структуру модуля сжатия, выполненную согласно изобретению.
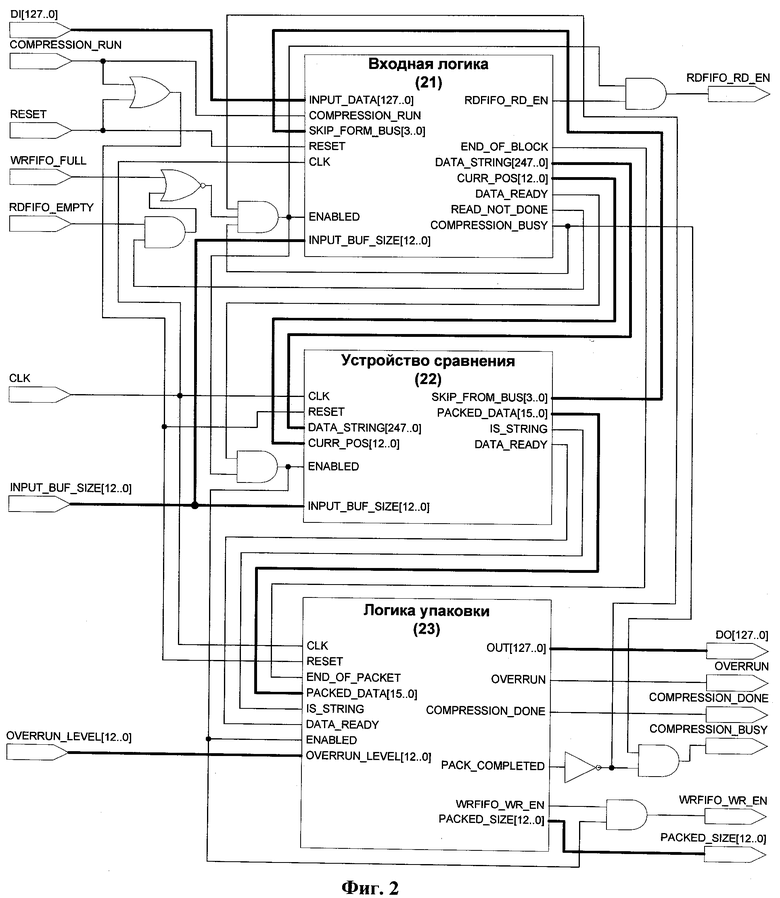
Фиг.2 показывает конфигурацию блока упаковки, согласно изобретению.
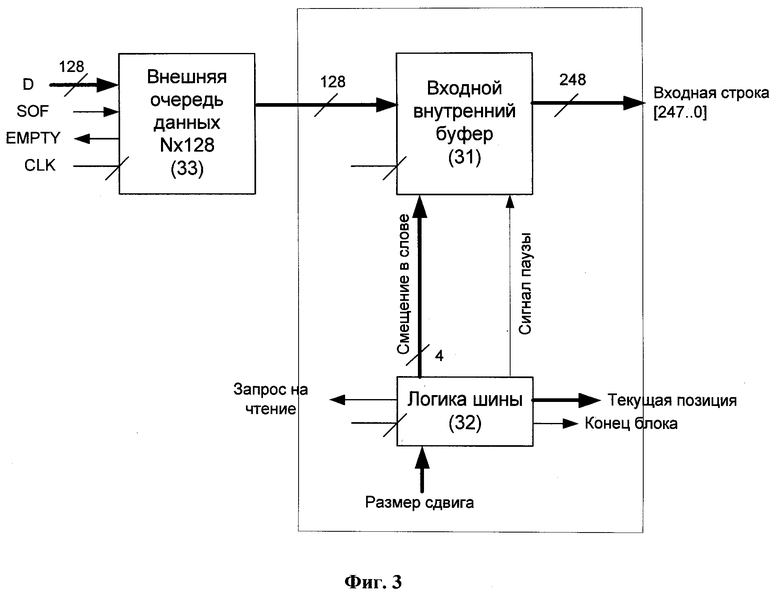
Фиг.3 представляет входную логику упаковщика, согласно изобретению.
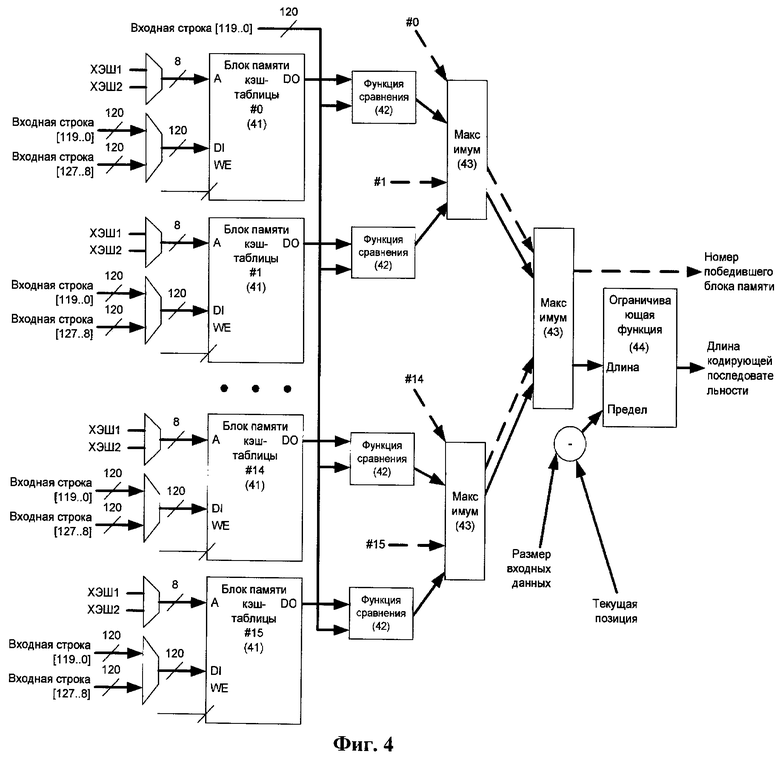
Фиг.4 содержит схему выбора наиболее подходящей кодирующей структуры, согласно изобретению.
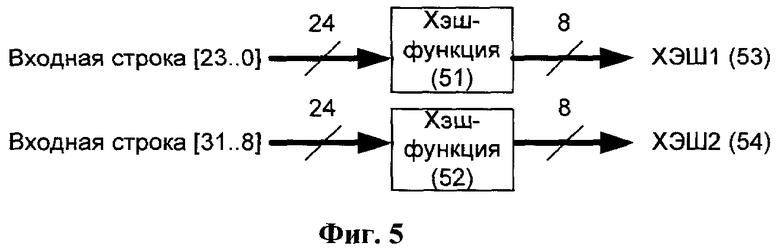
Фиг.5 представляет генерацию хэш-значений, согласно изобретению.
Фиг.6 представляет конфигурацию блока распаковки, согласно изобретению.
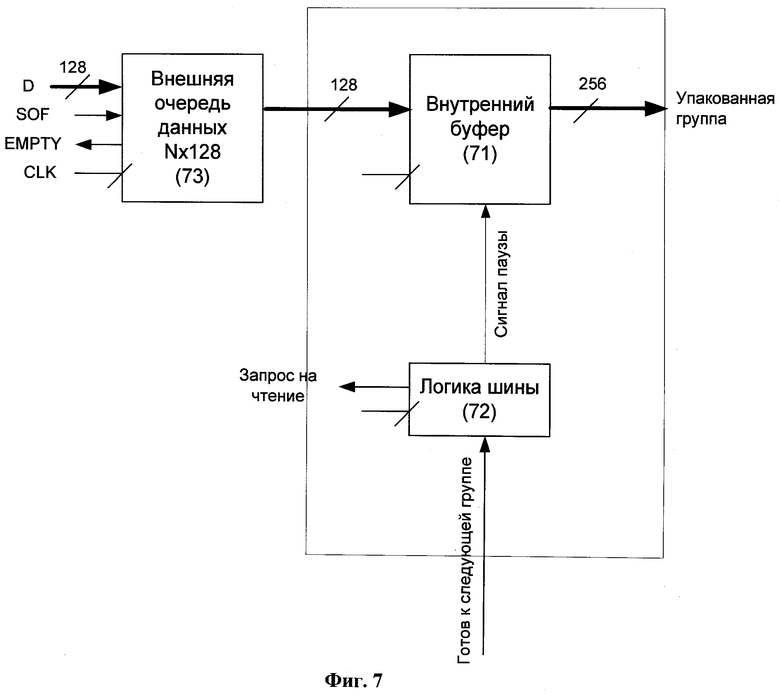
Фиг.7 представляет входную логику распаковщика, согласно изобретению.
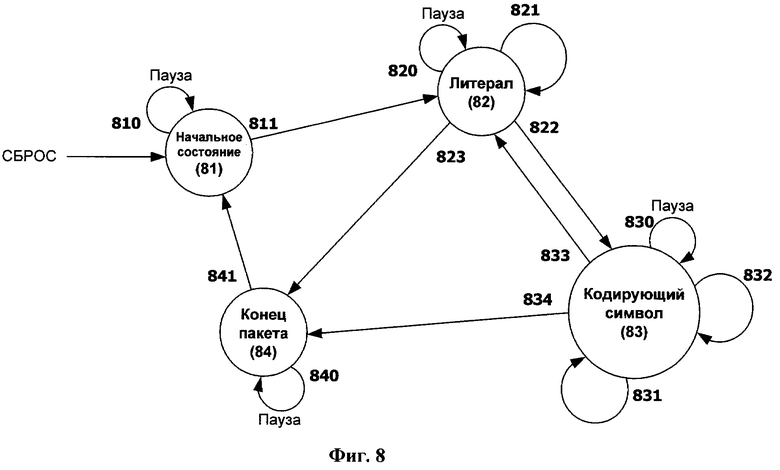
Фиг.8 представляет декодирующий автомат распаковщика, согласно изобретению.
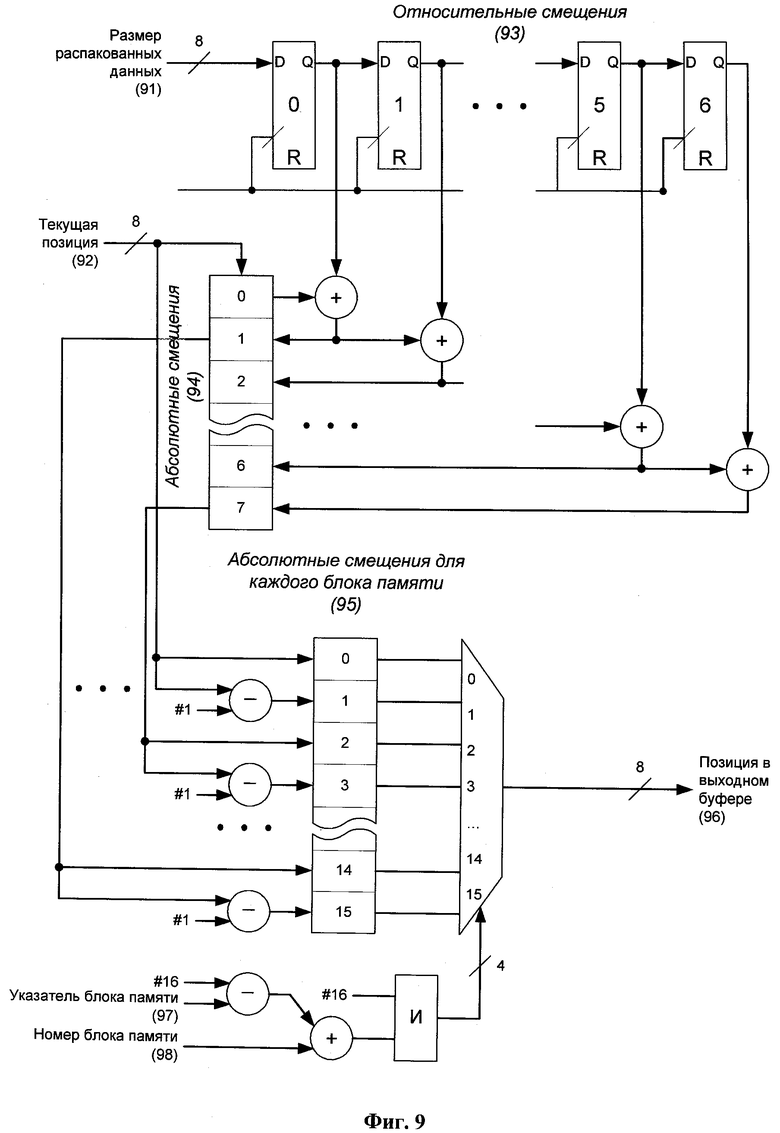
Фиг.9 представляет схему выборки позиции в выходном буфере для обновления кэш-таблицы распаковщика, согласно изобретению.
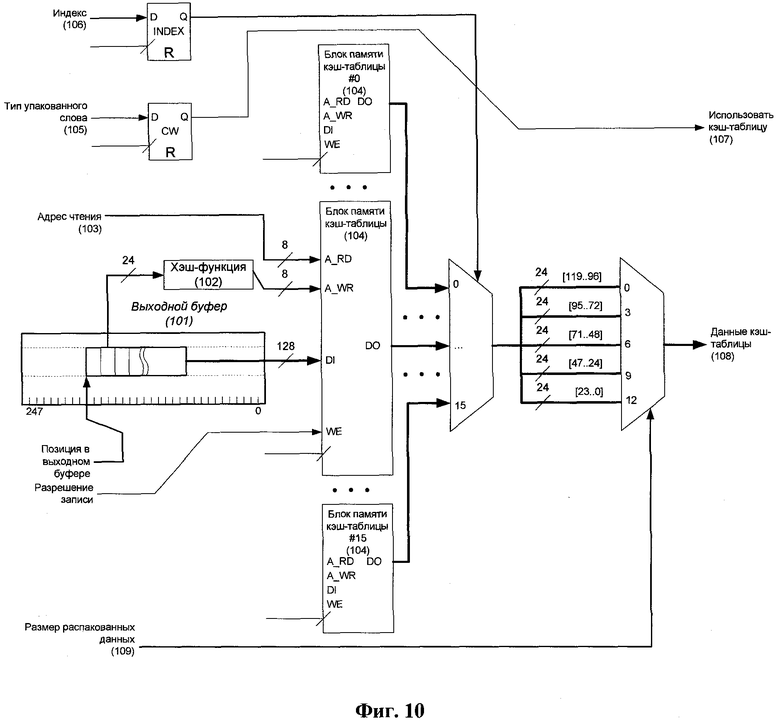
Фиг.10 представляет схему чтения и обновления кэш-таблицы распаковщика, согласно изобретению.
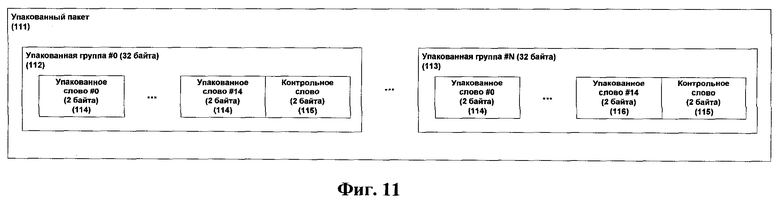
Фиг.11 представляет структуру упакованного пакета, согласно изобретению.
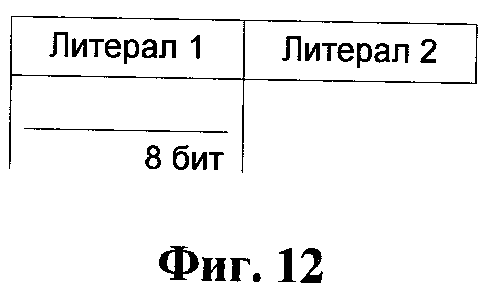
Фиг.12 представляет структуру упакованного слова для литералов, согласно изобретению.
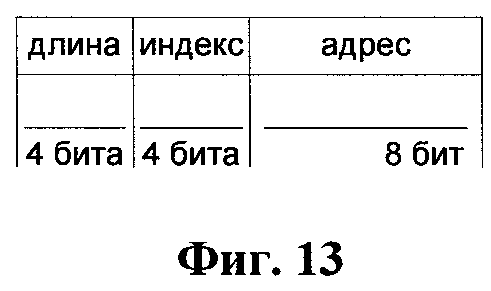
Фиг.13 представляет структуру упакованного слова для кодирующих символов, согласно изобретению.
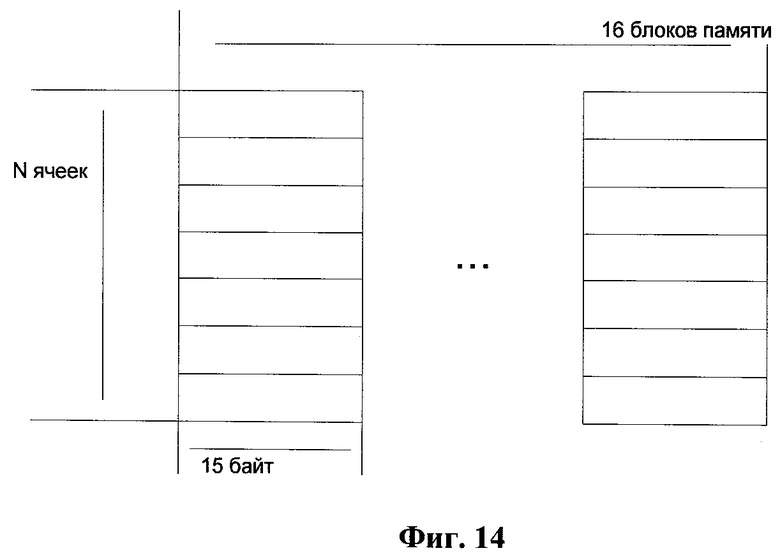
Фиг.14 представляет структуру кэш-таблицы, согласно изобретению.
Фиг.15 представляет блок кэш-таблицы со схемой асинхронного сброса, согласно изобретению.
Фиг.16 представляет схему формирования смещений в выходном буфере для обновления кэш-таблицы, согласно изобретению.
Фиг.1 изображает общую структуру модуля 11 сжатия и его интерфейс для взаимодействия с внешней системой. Модуль сжатия 11 состоит из наборов блоков 12 упаковки данных (далее - упаковщиков 12 данных) и блоков 13 распаковки данных (далее - распаковщиков 13 данных), причем эти блоки логически объединены в единый модуль сжатия, но физически являются независимыми блоками упаковки и распаковки данных, имеющими собственные интерфейсы связи с 128-битной шиной данных на целевом устройстве. Модуль 11 сжатия может содержать любое количество упаковщиков 12 данных и распаковщиков 13 данных. При этом не требуется, чтобы количество упаковщиков и распаковщиков совпадало.
Способ, описанный в заявляемом изобретении, ориентирован на то, что блоки упаковки и распаковки модуля сжатия будут реализованы на базе программируемых пользователем вентильных матриц (ППВМ) или специализированных для решения конкретной задачи интегральных схем (ASIC). Методы упаковки и распаковки данных используют специфические возможности ППВМ и ASIC для выполнения своих функций.
Упаковщик 12 данных базируется на словарном методе сжатия, являющемся производным семейства алгоритмов Лемпеля-Зива. Метод, использующийся в данном изобретении, предусматривает передачу индекса ячейки хэш-таблицы и длины кодирующей структуры для закодированных символов в соответствии с выровненными по 32 байта упакованными группами 112 и 113, которые объединены в упакованный пакет (Фиг.11) единичного входного блока заданного размера.
Упаковщик 12 данных состоит из трех основных компонентов, которые отвечают за различные этапы сжатия. Одна из возможных конфигураций данных компонентов представлена на Фиг.2 и состоит из следующих элементов:
- Входная логика 21,
- Устройство 22 сравнения,
- Логика 23 упаковки.
Входная логика 21 упаковщика 12 данных отвечает за обработку данных со 128-битного входа данных и передачу требуемого объема данных остальным компонентам упаковщика. Устройство 22 сравнения предназначено для подбора подходящего шаблона упаковки во внутреннем кэше, формирования кэш-таблицы и предоставления обратной связи для входной логики, которая содержит информацию о том, сколько байт должно быть пропущено с входа. Логика 23 упаковки отвечает за построение упакованного пакета (Фиг.11) и его передачу в шину данных посредством 128-битного выхода.
После получения сигнала о начале упаковки данных упаковщику 12 данных требуется один такт для сброса всех внутренних сигналов в их начальное состояние и информирование внешней системы о том, что он занят обработкой данных пока входной блок данных не будет полностью обработан.
После инициализации внутренних структур входная логика 21 начинает загрузку 128-битных строк из внешней очереди 33 данных (Фиг.3) и помещает их во внутренний буфер 31 (Фиг.3), который должен обеспечивать хранение, как минимум, пяти входных строк, чтобы обеспечить работу логики, отвечающей за сдвиг по входным данным. Как только достаточное количество строк становится доступно для дальнейшей обработки, входная логика 21 разблокирует устройство 22 сравнения и логику 23 упаковки и начинает процесс упаковки.
Метод упаковки данных использует 16-байтный буфер упреждающей выборки, который разделен на две перекрывающие друг друга части по 15 байт каждая. Первая часть (рабочая) включает в себя первые пятнадцать байт буфера упреждающей выборки, вторая часть использует последние пятнадцать байт. Рабочая часть буфера упреждающей выборки используется в качестве строки для упаковки данных. Все операции упаковки производятся над этой строкой. Вторая часть (упреждающая) буфера упреждающей выборки используется для предсказания будущих структур упаковываемых данных. В процессе обработки обе части буфера помещаются в кэш-таблицу (Фиг.14) для дальнейшего использования.
Входная логика 21 использует первые три байта рабочей и первые три байта упреждающей частей буфера упреждающей выборки для расчета значений хэш-функций 51 и 52 (Фиг.5) для генерации адресов ячеек кэш-таблицы, куда будут помещены обе части буфера. Рабочая часть буфера упреждающей выборки также используется компаратором 22 для выявления наиболее подходящей кодирующей структуры.
Устройство 22 сравнения состоит из кэш-таблицы, которая состоит из шестнадцати независимых однопортовых блоков памяти (Фиг.14) с селекторами адреса, использующимися для расчета адреса, по которому будет размещена входная строка (Фиг.5), и каскада сравнения, отвечающего за выбор наиболее подходящей кодирующей структуры из хранящихся в кэш-таблице (Фиг.4, позиции 42, 43 и 44). Данный каскад обеспечивает определение номера победившего блока памяти, адрес кодирующей структуры и длину кодирующей последовательности.
Значение ХЭШ1 (Фиг.5, позиция 53) используется в качестве адреса для обновления рабочего блока памяти кэш-таблицы. Значение ХЭШ2 (Фиг.5, позиция 54) используется в качестве адреса для обновления блока памяти кэш-таблицы, следующего за рабочим. Как только обе ячейки кэш-таблицы обновлены, указатель рабочего блока памяти сдвигается на две позиции вперед по принципу циклического сдвига. Одновременно с обновлением кэш-таблицы новыми кодирующими структурами происходит выборка наиболее походящей кодирующей структуры для рабочей части буфера упреждающей выборки. Значение ХЭШ1 (53) используется в качестве адреса для выборки кодирующих структур из всех шестнадцати блоков памяти за исключением блока, следующего за рабочим. Для данного блока используется значение ХЭШ2 (54).
Функция 42 сравнения строк сравнивает рабочую часть буфера упреждающей выборки со значениями, хранящимися в ячейках кэш-таблицы, определенных с помощью хэш-функций 53 и 54, и вычисляет количество идентичных байт, начиная от начала сравниваемых строк. Функция 42 сравнения строк состоит из компаратора 152 строк и вентиля И 153 (Фиг.15). Выход компаратора 152 строк для блока памяти кэш-таблицы 41 соединен с соответствующим битом регистра 154 с использованием вентиля 153. Данная схема используется с целью исключить из определения наиболее подходящей кодирующей структуры ячейки кэш-таблицы, которые до этого момента еще не были заполнены данными с входа упаковщика. Для таких ячеек функция сравнения строк 42 возвращает нулевое значение даже в том случае, если по каким-либо причинам компаратор строк 152 вернул значение, отличное от нуля. Длина кодирующей структуры для победившей ячейки проходит через ограничивающую функцию 44, которая уменьшает полученное значение до размера оставшихся входных данных в случае, когда длина победившей кодирующей структуры превышает это значение.
Если длина победившей кодирующей структуры равна или больше трех, то логика 23 упаковки генерирует кодирующий символ (Фиг.13) и устанавливает соответствующий бит в контрольном слове в единицу. В противном случае, если длина победившей кодирующей структуры меньше трех, логика 23 упаковки формирует два 8-битных литерала (Фиг.12), а соответствующий бит контрольного слова устанавливается в ноль. Значение линии обратной связи с входной логикой 21 устанавливается равным длине победившей кодирующей структуры или двум, если были упакованы два литерала. Это информирует входную логику 21 о том, что соответствующее число байт должно быть вытолкнуто из входного буфера.
Логика 23 упаковки использует значение линии предела переполнения, устанавливаемое внешней системой, для перевода блока упаковки в состояние переполнения. Упаковщик 12 данных переходит в состояние переполнения, когда размер упакованного пакета 111 начинает превышать размер, заданный линией переполнения. Логика упаковки информирует внешнюю систему о переходе блока упаковки в состояние переполнения путем установки соответствующего выходного сигнала. После перехода в состояние переполнения упаковщик 12 данных продолжает процесс упаковки данных до тех пор, пока не будет упакован весь блок входных данных или не поступит сигнал от внешней системы о прекращении операции или начале упаковки нового блока данных. Для прекращения упаковки данных при переходе в состояние переполнения выходная линия события переполнения может быть соединена с линией сброса упаковщика 12 данных.
Когда последний байт входного блока упакован, логика 23 упаковки поднимает сигнал завершения упаковки и сбрасывает сигнал занятости упаковщика 12 данных.
Распаковщик 13 данных отвечает за распаковку упакованного пакета 111. Он состоит из четырех основных компонент, ответственных за различные шаги распаковки. Для декодирования индексов кэш-таблицы распаковщик воссоздает кэш-таблицу, идентичную создаваемой в результате работы упаковщика. Одна из возможных конфигураций этих компонент представлена на Фиг.6. Компоненты включают в себя:
- Входная логика 61,
- Декодирующий автомат 63,
- Логика 64 кэш-таблицы,
- Выходная логика 62.
Входная логика 61 распаковщика отвечает за обработку данных со 128-битной входной шины и передачу требуемого объема данных остальным компонентам распаковщика. Декодирующий автомат 63 - это конечный автомат, ответственный за «разворачивание» упакованных групп 112 и 113 и оповещение логики 64 кэш-таблицы о кэшировании декодируемых по шаблону данных. Логика 64 кэш-таблицы отвечает за поддержание кэш-таблицы в виде, идентичном получаемому при работе упаковщика. Выходная логика 62 обеспечивает кэш-таблицу распакованными данными и выводит их на 128-битную выходную шину.
Получая сигнал о старте распаковки, распаковщик тратит один такт для сброса всех внутренних структур в начальное состояние и информирует внешнюю систему о том, что он будет занят, пока не распакует весь пакет 111.
После инициализации внутренних структур входная логика 61 распаковщика начинает загрузку 128-битных строк из внешнего блока 73 (Фиг.7) и помещает их во внутренний буфер 71 (Фиг.7), который продолжает дальнейшее декодирование только при накоплении двух упакованных групп. При накоплении достаточного количества данных для дальнейшей обработки входная логика 61 включает остальные компоненты распаковщика и начинает декодирование данных. Когда декодирующему автомату 63 требуется очередная упакованная группа, он информирует входную логику 72, которая в свою очередь активирует загрузку данных из внешнего буфера 73 во внутренний буфер 71, пока полная группа не будет загружена.
Фиг.8 отображает состояния декодирующего автомата 63 и возможные переходы между ними. Начиная с начального состояния 81, он находится в состояниях 82 и 83 в зависимости от бит контрольного слова текущей обрабатываемой группы. После декодирования последнего слова в последней упакованной группе декодирующий автомат переходит в состояние «Конец пакета» и находится в нем до прихода нового пакета. Каждое состояние поддерживает переход в режим ожидания (Фиг.8, позиции 810, 820, 830 и 840) для обработки пауз в работе внешней системы. Декодирующий автомат вырабатывает информацию о текущем и следующем упакованных словах и передает ее логике 64 кэш-таблицы и выходной логике 62. На каждом шаге осуществляется распаковка от одного до трех байт, поэтому на распаковку одного упакованного слова требуется от одного до нескольких шагов.
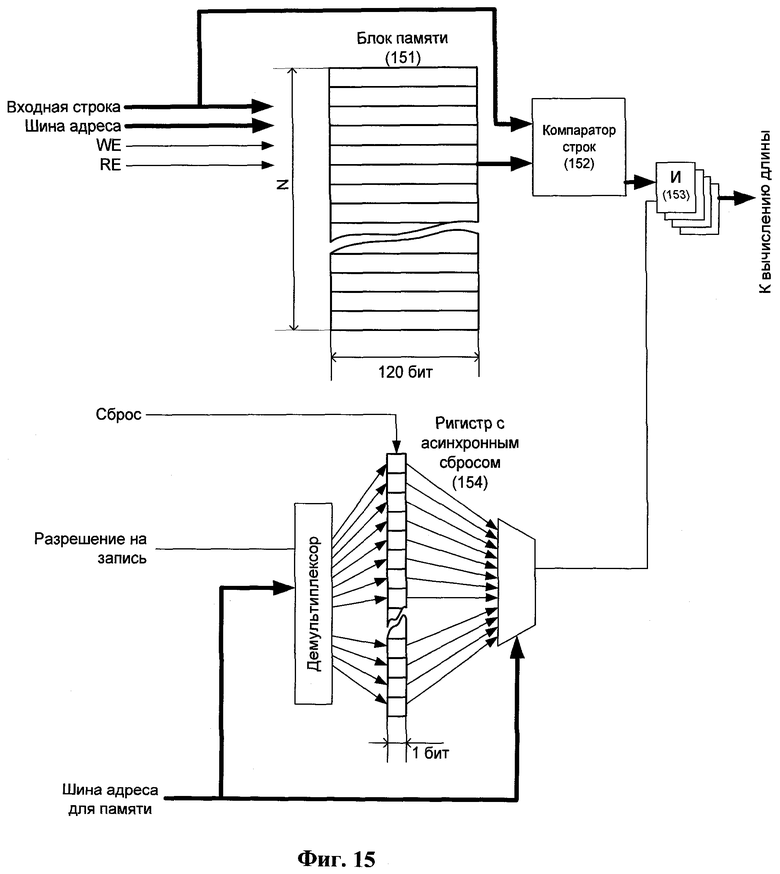
Логика 64 кэш-таблицы включает в себя кэш-таблицу, состоящую из шестнадцати независимых двухпортовых блоков памяти (Фиг.14, Фиг.10 позиция 104). Основная задача данного модуля - обновление кэш-таблицы согласно процессу заполнения выходного буфера (Фиг.10, позиция 101) и чтение строк из памяти для распаковки упакованных слов. На каждом шаге распаковки происходит обновление каждого из блоков памяти данными, накапливаемыми в выходном буфере.
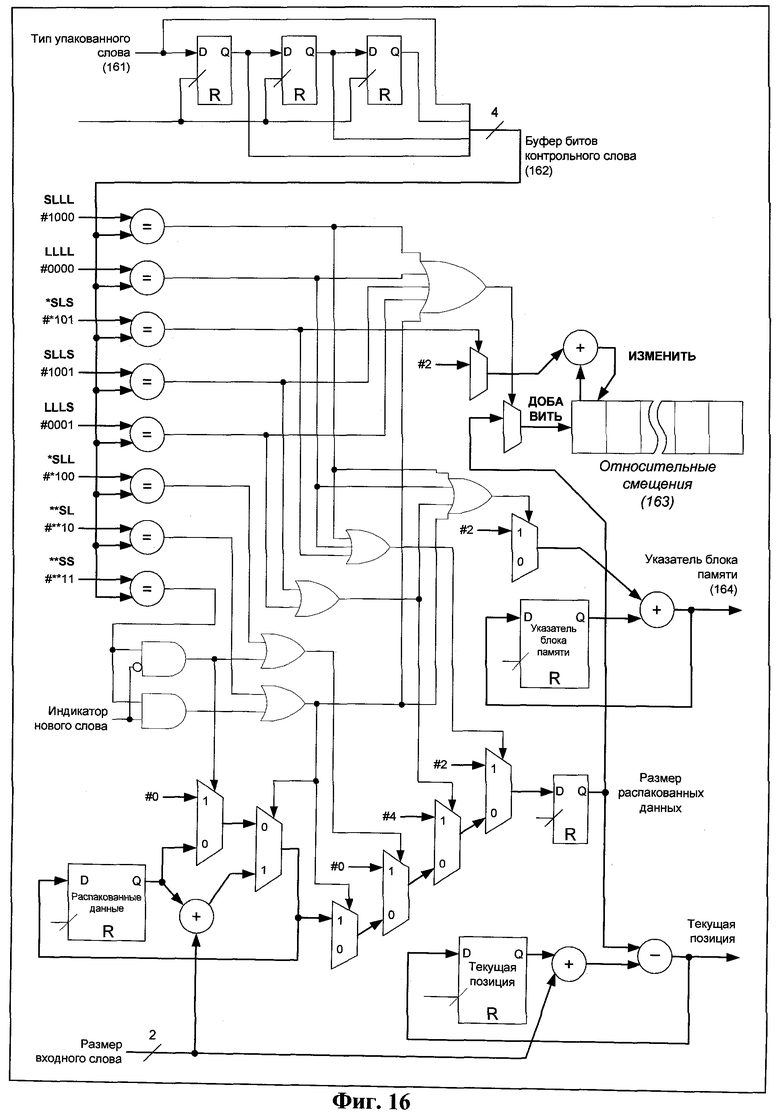
Фиг.9 показывает процедуру определения позиции 96 в выходном буфере для конкретного блока 98 памяти. Буфер 93 смещений содержит последние семь значений (относительные смещения), которые соответствуют размерам данных, распакованных из последних семи упакованных слов. В сочетании с текущей позицией 92 в выходном буфере получаются соответствующие абсолютные смещения 94 и абсолютные смещения для каждого блока 95 памяти, откуда и выбирается позиция 96.
Фиг.10 представляет процесс чтения данных из кэш-таблицы. Адрес 103 чтения передается из декодирующего автомата 63 и является битами адреса кодирующего символа (Фиг.13). Он используется для считывания сохраненных строк из блоков 104 памяти, причем используется только строка из блока, номер которого соответствует битам индекса 106 кодирующего символа (Фиг.13). После обновления кэш-таблицы указатель 163 текущего блока (Фиг.16) может быть сдвинут на два по принципу циклического буфера в зависимости от состояния сигнала 162. Флаг 107 обозначает тип текущего упакованного слова (литерал или кодирующий символ) и сообщает выходной логике, использовать ли данные 108 из кэш-таблицы или данные от декодирующего автомата 63. Так как для распаковки одного кодирующего символа может потребоваться несколько шагов, регистр 109 накапливает количество байт, распакованных на текущем шаге, и определяет смещение для строки из кэш-таблицы для получения данных 108.
Процедура заполнения буфера 163 относительных смещений представлена на Фиг.16. На основе данных о типе упакованных слов 161 в течение четырех шагов получается сигнал 162, имеющий восемь различных состояний и определяющий значение, которое должно быть добавлено или изменено в буфер 163. Он также управляет обновлением указателя 164 блока памяти.
Выходная логика 62 обслуживает выходной буфер и циклический счетчик накопленных байт. Когда накапливается шестнадцать байт, они передаются на внешнюю шину данных и счетчик обнуляется. После вывода всех распакованных данных выходная логика 62 поднимает сигнал о завершении распаковки и сбрасывает сигнал занятости.
Пакет 111 упакованных данных (Фиг.11) состоит из отдельных групп по тридцать два байта каждая. Данные группы представляют собой набор информации об упакованных данных с контрольным словом для их распаковки. Каждая группа 112 в упакованном пакете, за исключением последней группы 113, содержит 16-битное контрольное слово 115 и пятнадцать 16-битных упакованных слов 114, которые содержат закодированный символ или два литерала. Каждая группа начинается с упакованных слов 114 и завершается контрольным словом 115. Последняя группа 113 в упакованном пакете 111 может содержать от одного до пятнадцати упакованных слов 114, которые могут быть распакованы. Оставшиеся упакованные слова 116 заполнены единицами и не используются на стадии распаковки. Данные пустые упакованные слова маркируются в контрольном слове как содержащие кодирующий символ.
Старшие пятнадцать бит контрольного слова (контрольные биты) определяют структуру соответствующей упакованной группы. Наименее значимый бит зарезервирован и установлен в единицу.
Таблица ниже определяет соответствие между позицией упакованного слова в группе и номером контрольного бита:
Если контрольный бит установлен в ноль, то соответствующее упакованное слово содержит два 8-битных литера (Фиг.12).
Если контрольный бит установлен в единицу, то соответствующее упакованное слово содержит кодирующий символ. Кодирующий символ состоит из двух секций: длины упакованной строки и адреса этой строки в кэш-таблице. Длина упакованной строки определяет количество байт, которые должны быть взяты от начала хранящейся в заданной ячейке кэш-таблицы 15-байтной строки. Данное значение лежит в интервале от трех до пятнадцати байт. Адрес кэш-таблицы состоит из двух частей: 8-битный адрес ячейки в блоке памяти кэш-таблицы и 4-битный индекс с номером блока памяти. Фиг.13 описывает возможную конфигурацию упакованного слова для кодирующего символа.
Упаковщик 12 данных и распаковщик 13 данных используют кэш-таблицу фиксированного размера, которая построена на базе хэш-таблицы с открытой адресацией. Данная кэш-таблица разделена на шестнадцать блоков. Структура кэш-таблицы представлена на Фиг.14. Каждый блок таблицы состоит из N ячеек, где N представляет собой число в степени два и находится в пределах от 20 до 28. Чем выше значение N, тем лучше показатель степени сжатия данных, обеспечиваемый разработанным методом. Каждый из блоков кэш-таблицы формируется своим собственным блоком памяти 151 (Фиг.15), является независимым от остальных блоков и может обрабатываться асинхронно.
Каждая ячейка кэш-таблицы может содержать до пятнадцати байт данных. Каждая ячейка кэш-таблицы задается парой чисел (адрес ячейки внутри блока памяти, номер блока памяти). Адрес ячейки выбирается с помощью хэш-функции, которая генерирует значения в интервале от 0 до N-1, используя первые три байта входной строки. Номер блока памяти выбирается по принципу циклического сдвига в интервале от нуля до пятнадцати. Ячейки кэш-таблицы в блоках памяти, имеющие одинаковый адрес, содержат 15-байтные строки, для первых трех байт которых хэш-функция вернула одинаковые значения.
Описываемый метод производит операцию сброса значений кэш-таблицы за один такт. Для этих целей используется маска занятости ячеек кэш-таблицы. Каждый блок кэш-таблицы имеет соответствующий ему битовый регистр 154 с асинхронным сбросом (Фиг.15).
Данный регистр позволяет произвести одновременный сброс каждого отдельного бита и заполняется побитно, когда в соответствующую ячейку кэш-таблицы заносится значение. Биты данного регистра 154 открывают или закрывают вентили И 153 для функции 42 сравнения строк. Если бит установлен в нуль, то использующая его функция вернет нуль, в противном случае будет возвращено количество совпадающих символов, вычисленное компаратором 152 строк.
Описанное устройство сжатия может найти широкое практическое применение в таких областях, как передача данных, сети и устройства хранения информации. В настоящее время широко распространены устройства на основе флэш-памяти из-за повышенной надежности, устойчивости и сниженного потребления энергии. Такие устройства хранения требуют наиболее продуктивное и надежное программное обеспечение (прошивку), использующее преимущества, присущие аппаратным средствам, самым оптимальным способом. Один из вариантов оптимальной реализации - это использование данного устройства в качестве прошивки твердотельных накопителей с высокопроизводительными интерфейсами.
Способ сжатия, используемый упаковщиком и описанный в настоящей заявке, обеспечивает оптимизацию производительности обработки данных и возможность настройки размеров кэш-таблицы и обрабатываемого блока. Производительность устройства и степень сжатия зависят от объема внутренней памяти чипа, доступной для реализации, что делает заявляемый способ более эффективным в среде с объемом памяти, достаточным для хранения полной кэш-таблицы.
Нацеленность на устройства с блоками малых и больших размеров допускает использование описанного способа в современных устройствах на флэш-памяти, обычно имеющих различную физическую структуру.
Устройство сжатия без потерь, описанное в данном документе, имеет характеристики производительности, делающие его эффективным решением для современных устройств на флэш-памяти, в частности для твердотельных накопителей. Используемый в устройстве способ сжатия оптимизирован для высокой скорости обработки и работы с данными с высокими эксплуатационными характеристиками избыточности.
Первичная ориентация на устройства с высокопроизводительными интерфейсами делает данное устройство хорошим выбором для решений уровня предприятий, нацеленных на хранение OLTP баз данных.

Изобретение относится к способам и устройствам для обеспечения сжатия данных с минимальными потерями. Техническим результатом является повышение эффективности сжатия данных без потерь. Способ сжатия данных без потерь заключается том, что в память целевого устройства записывают промежуточные сжатые данные, извлекают данные из памяти целевого устройства для последующей распаковки, при этом данные принимают и отдают 128-битными блоками, используют 16 независимых блоков памяти для хранения кэшированных кодирующих структур размером 15-байтной длины и конфигурируют размер кэш-таблицы посредством задания числа ячеек числами, равными степени 2 в пределах от 16 до 4096, при этом выполняют следующие операции: предсказывают кодирующие структуры с использованием двух связных буферов упреждающей выборки для построения словаря; кодируют от двух до пятнадцати байт входного потока в один упакованный символ за один такт; используют количество упакованных байт в качестве обратной связи для логики, отвечающей за сдвиг входного потока; выбирают кодирующую структуру за один такт путем поиска кэшированной строки с наиболее длинной совпадающей с входной строкой последовательностью символов; упаковывают данные в 32-байтные группы, выровненные по два байта; упаковывают совпадающие строки в 2-байтный кодирующий символ, состоящий из длины строки, номера блока памяти и значения хэш-функции, определяющего адрес этой строки в блоке памяти. 2 н. и 14 з.п. ф-лы, 16 ил.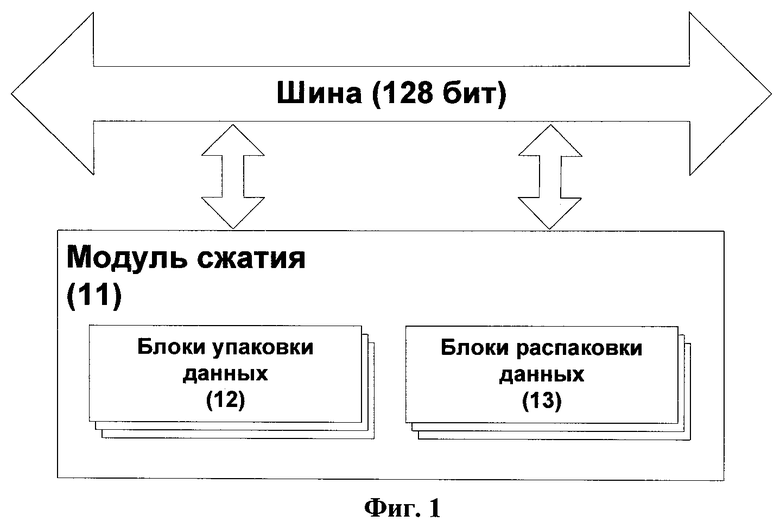
1. Способ сжатия данных без потерь, заключающийся в том, что в память целевого устройства записывают промежуточные сжатые данные, извлекают данные из памяти целевого устройства для последующей распаковки, отличающийся тем, что данные принимают и отдают 128-битными блоками, используют шестнадцать блоков памяти для хранения каптированных кодирующих структур размером 15-байтной длины и конфигурируют размер кэш-таблицы посредством задания числа ячеек числами, равными степени 2 в пределах от 16 до 4096, при этом выполняют следующие операции:
- предсказывают кодирующие структуры с использованием двух связных буферов упреждающей выборки для построения словаря;
- кодируют от двух до пятнадцати байт входного потока в один упакованный символ за один такт;
- используют количество упакованных байт в качестве обратной связи для логики, отвечающей за сдвиг входного потока;
- выбирают кодирующую структуру за один такт путем поиска кэшированной строки с наиболее длинной совпадающей с входной строкой последовательностью символов;
- упаковывают данные в 32-байтные группы, выровненные по два байта;
- упаковывают совпадающие строки в 2-байтный кодирующий символ, состоящий из длины строки, номера блока памяти и значения хэш-функции, определяющего адрес этой строки в блоке памяти.
2. Способ по п.1, отличающийся тем, что при распаковке данных осуществляют следующие шаги:
- извлекают данные из 32-байтных групп, выровненных по два байта;
- декодируют упакованные слова, используя конечный автомат, позволяющий обработать от трех до одного байта за один такт в зависимости от типа упакованного слова и его длины;
- обновляют шестнадцать строк кэш-таблицы одновременно с добавлением только что распакованных байт в конец кэшированной строки по мере их поступления в выходной буфер;
- исключают ячейку кэш-таблицы из схемы автоматического обновления, когда она заполняется пятнадцатью байтами данных до момента запроса на перезапись этой ячейки.
3. Способ по п.1, отличающийся тем, что при сжатии данных для хранения кэшированных кодирующих структур и доступа к ним используют логическую схему, основанную на принципах организации однопортовой памяти.
4. Способ по п.1, отличающийся тем, что при распаковке данных для хранения кэшированных кодирующих структур и доступа к ним используют логическую схему, основанную на принципах организации двухпортовой памяти.
5. Устройство сжатия данных без потерь, содержащее, по меньшей мере, один блок упаковки данных и, по меньшей мере, один блок распаковки данных, отличающееся тем, что 128-битный вход блока упаковки данных подключен к выходу 128-битной шины целевого устройства для обработки и последующего формирования упакованного пакета, состоящего из 32-байтных упакованных групп, выровненных по два байта, передаваемого посредством 128-битного выхода указанного блока упаковки на шину целевого устройства, и, по меньшей мере, один блок распаковки данных, 128-битный вход которого подключен к выходу 128-битной шины целевого устройства для обработки, последующего восстановления исходных данных из данных, содержащихся в упакованном пакете, и передачи восстановленных данных посредством 128-битного выхода указанного блока распаковки на шину целевого устройства, отличающееся тем, что
блок упаковки данных включает в себя
- блок входной логики, вход которого подключен к выходу целевого устройства, а выход которого соединен с входом устройства сравнения,
- устройство сравнения, выполненное с возможностью выполнения подбора соответствующего шаблона упаковки во внутреннем кэше, формирования кэш-таблицы, и соединенное линией обратной связи с блоком входной логики,
- блок логики упаковки, включающий 16-битный вход, подключенный на который из устройства сравнения поступает 16-битный пакет, содержащий упакованное слово или два 8-битных литерала, и внутренний буфер, накапливающий данные для передачи посредством 128-битного выхода блока упаковки на 128-битную шину данных;
а блок распаковки данных включает в себя
- блок входной логики, вход которого подключен к выходу 128-битной шины,
- декодирующий автомат, выполненный с возможностью приема на входе одной 32-байтной упакованной группы с выхода блока входной логики и передачи на вход блока выходной логики двух 8-битных литералов, а на вход блока логики кэш-таблицы - адрес, индекс кэш-таблицы и количество байт, которые требуется извлечь из нее для последующей передачи блоку выходной логики,
- блок логики кэш-таблицы, включающий шестнадцать независимых двухпортовых блоков памяти, буфер смещений, выполненный с возможностью обновления кэш-таблицы в выходном буфере блока выходной логики, и выход, соединенный с блоком выходной логики, выполненным с возможностью обновления выходного буфера, и
- блок выходной логики, содержащий выходной буфер, данные из которого передаются на целевое устройство посредством 128-битного выхода.
6. Устройство по п.5, отличающееся тем, что блок входной логики блока упаковки, включающий 128-битный вход, внутренний буфер на пять 128-битных слов, 248-битный выход, выполнен с возможностью осуществления следующих шагов:
- извлечение данных с 128-битного входа во внутренний буфер,
- осуществление сдвига обработанных данных во внутреннем буфере и дополнение его новыми данными,
- осуществление разблокировки устройства сравнения и блока логики упаковки, как только во внутренний буфер загружается необходимое для их работы количество данных.
7. Устройство по п.5, отличающееся тем, что устройство сравнения блока упаковки, включающее в себя кэш-таблицу, содержащую шестнадцать независимых однопортовых блоков памяти с селекторами адреса, и каскад сравнения, отвечающий за выбор кодирующей структуры, выполнено с возможностью осуществления следующих шагов:
- выбор кодирующей структуры за один такт путем поиска кэшированной строки с наиболее длинной совпадающей с входной строкой последовательностью символов,
- формирование кэш-таблицы кодирующих структур,
- предоставление обратной связи для блока входной логики, который содержит информацию о том, сколько байт должно быть пропущено с входа.
8. Устройство по п.5, отличающееся тем, что блок логики упаковки блока упаковки, включающий 16-битный вход, 128-битный выходной буфер, накапливающий данные для передачи на 128-битный выход указанного блока, выполнен с возможностью осуществления следующих шагов:
- упаковка данных в пакет, который состоит из 32-байтных групп упакованных данных выровненных по два байта,
- упаковка совпадающих строк в 2-байтный кодирующий символ, состоящий из длины строки, номера блока памяти и значения хэш-функции, определяющего адрес этой строки в блоке памяти,
- использование значения линии предела переполнения для перевода блока упаковки в состояние переполнения,
- отправка упакованных данных на 128-битный выход.
9. Устройство по п.5, отличающееся тем, что блок входной логики блока распаковки, включает в себя 128-битный вход, 512-битный внутренний буфер, 256-битный выход и выполнен с возможностью осуществления следующих шагов:
- извлечение данных с 128-битного входа во внутренний буфер,
- накапливание во внутреннем буфере двух 32-байтных упакованных групп,
- осуществление разблокировки остальных компонентов блока упаковки данных, как только во внутренний буфер загружается необходимое для их работы количество данных.
10. Устройство по п.5, отличающееся тем, что декодирующий автомат блока распаковки выполнен в виде конечного автомата с четырьмя состояниями, имеющий 256-битный выход и передающий на выход данные о распакованном символе, выполненный с возможностью осуществления следующих шагов:
- вырабатывание информации о текущем и следующем упакованных словах и передача ее блоку логики кэш-таблицы и блоку выходной логики,
- декодирование от одного до трех байт упакованных данных за один такт,
- информирование блока входной логики о необходимости загрузки новой упакованной группы.
11. Устройство по п.5, отличающееся тем, что блок логики кэш таблицы блока распаковки, включающий в себя шестнадцать двухпортовых блоков памяти, буфер смещений для обновления кэш-таблицы в выходном буфере блока выходной логики, 24-битный выход, выполнен с возможностью осуществления следующих шагов:
- обновление кэш-таблицы согласно процессу заполнения выходного буфера и чтение строк из памяти для распаковки упакованных слов,
- обновление каждой из ячеек памяти кэш-таблицы данными, накапливаемыми в выходном буфере.
12. Устройство по п.5, отличающееся тем, что блок выходной логики блока распаковки состоит из 16-битного входа для литералов и 24-битного входа для данных из кэш-таблицы, 248-битного выходного буфера, 128-битного выхода и выполнен с возможностью осуществления следующих шагов:
- пополнение выходного буфера, который используется блоком логики хэш-таблицы в процессе обновления кодирующих структур,
- отправка распакованных данных на 128-битный выход.
13. Устройство по п.5, отличающееся тем, что, по меньшей мере, один блок упаковки данных реализован на базе программируемой пользователем вентильной матрицы (ППВМ).
14. Устройство по п.5, отличающееся тем, что, по меньшей мере, один блок упаковки данных реализован на базе специализированной для решения конкретной задачи интегральной схемы (ASIC).
15. Устройство по п.5, отличающееся тем, что, по меньшей мере, один блок распаковки данных реализован на базе программируемой пользователем вентильной матрицы (ППВМ).
16. Устройство по п.5, отличающееся тем, что, по меньшей мере, один блок распаковки данных реализован на базе специализированной для решения конкретной задачи интегральной схемы (ASIC).
| Нелинейный фильтр | 1974 |
|
SU666651A1 |
| СПОСОБ СЖАТИЯ ДАННЫХ | 2006 |
|
RU2386210C2 |
| СПОСОБ СЖАТИЯ И ВОССТАНОВЛЕНИЯ ДАННЫХ БЕЗ ПОТЕРЬ | 2009 |
|
RU2403677C1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

