Настоящее изобретение относится к способу обработки естественного языка с использованием системы языковой обработки, в частности электронной системы перевода, в котором письменный или устный текст вводится в систему языковой обработки. Настоящее изобретение также относится к системе перевода и, в частности, к системе онлайнового перевода.
Обработка естественного языка с использованием систем языковой обработки представляет проблему. Естественный язык состоит из последовательности слов, составленной определенным образом для выражения определенного смысла. Проще говоря, системы языковой обработки могут анализировать текст, просматривая последовательность слово за словом. К сожалению, изолированный анализ отдельных слов не дает возможности правильно выявить смысл последовательности. В ряде случаев он приводит к успеху, но очень часто анализ ничего не дает, поскольку текст является чем-то большим, чем просто кластеризация слов. Предложение "colorless green ideas sleep furiously" составлено из слов, упорядоченных синтаксически корректно, т.е. синтаксис (правила и принципы, определяющие структуру предложения на данном языке) применяется верно. Однако легко видеть, что это предложение лишено всякого смысла. Система, которая обращает внимание только на отдельные слова, пытается обрабатывать предложение, тогда как очевидно, что его невозможно разумно обработать.
Например, электронная система перевода может обрабатывать входную текстовую последовательность согласно процессу, показанному на фиг. 1. На блоке 100 пользователь может вводить входную текстовую последовательность для перевода посредством, например, пользовательского интерфейса, электронного документа и т.п. На блоке 102 электронная система перевода может анализировать последовательность на основании правил синтаксиса исходного языка. На блоке 104 электронная система перевода может осуществлять поиск в словаре с использованием входного языка в качестве индекса в словарь выходного языка для каждого слова. На блоке 106 электронная система перевода может выдавать переведенные слова на основании правил синтаксиса выходного языка, и на блоке 108 электронная система перевода может выводить результат пользователю посредством, например, пользовательского интерфейса, электронного документа и т.п.
Некоторые системы, известные в технике, используют семантическую проверку. Эти системы используют лексиконы, которые комбинируют слова с атрибутами. При осуществлении семантической проверки атрибуты должны быть согласованными. Например, слово "животное" соотносится с понятием "живое", камень - с понятием "неживое" и "ест" - с понятием "живое". Используя такого рода семантическую проверку, предложение "камень ест траву" можно указать как неверное, поскольку камни не являются живыми существами, тогда как предложение "живое ест траву" - как верное, поскольку оба слова " животное" и "ест" имеют атрибут «животное».
Предполагается, что эти решения представляют процесс понимания в искусственном интеллекте. К сожалению, этот подход весьма ограничен. При обработке естественного языка предложения, в общем случае, оказываются значительно сложнее и не поддаются обработке такими системами. Для решения этих проблем были предприняты большие усилия. С одной стороны, некоторые утверждают, что программирование семантики невозможно. С другой стороны, существуют компании, которые инвестируют миллионы в исследования, посвященные семантике. Однако до сих пор ни одна система, известная в технике, не способна правильно обрабатывать естественные языки.
В дополнение к вышеизложенному, разработка электронных систем перевода является трудоемким процессом и дает отдельные языковые пары. Например, на фиг. 2 показана концептуальная схема языковых пар для четырех (4) языков: английского, французского, испанского и немецкого. Однако для перевода с любого из четырех языков на любую другую систему перевода фактически используют шесть (6) установок языковых пар, т.е. языковые пары английский-немецкий, английский-французский, английский-испанский, французский-испанский, испанский-немецкий и немецкий-французский.
Сложность такой системы значительно возрастает по мере добавления дополнительных языков. Например, добавление пятого языка - итальянского, добавляет четыре (4) дополнительные языковые пары, в результате чего получается всего десять (10) пар. Примечательно, что для каждой пары - усложненные словари, синтаксис и наборы семантических правил используют большие ресурсы для разработки. Аналогично, в таких системах, каждый перевод осуществляется индивидуально, даже когда требуется перевод на несколько языков.
Таким образом, задачей настоящего изобретения является усовершенствование и дополнительное развитие способа обработки естественного языка, который позволяет правильно обрабатывать семантику текста или другие данные, например входную речь и т.п. Другой задачей изобретения является усовершенствование и дополнительное развитие системы языковой обработки для обработки естественного языка, которая позволяет избежать некоторых или все из вышеозначенных проблем.
Согласно изобретению, для решения вышеупомянутой задачи предложен способ, содержащий признаки п.1. Согласно этому пункту, такой способ характеризуется этапом анализа текста в отношении его синтаксиса и морфологии, этапом извлечения компонентов текста и их взаимосвязи, этапом генерации или использования графа или графического представления текста в качестве представления смысла текста, не зависящего от языка, и этапом осуществления обработки текста с использованием графа или графического представления.
Согласно изобретению, сначала стало понятно, что проблему можно решить с использованием результатов, полученных в области неврологии. Один основной результат связан с тем фактом, что познавательная способность человека отчетливо различает синтаксис и семантику. Если несколько человек, говорящих на разных языках, находятся в одной комнате, где имеется зонт, каждый "знает", что это зонт. Но это "знание" не означает, что слово "зонт" активируется где-то в мозгу присутствующего человека. Однако, в целях общения, объект "зонт" тегируется словом, зависящим от языка. Участники знают объект без использования языка. Например, если они хотят выйти из дома, когда на улице дождь, они активируют "тег" посредством словаря, зависящего от языка, в целях общения. Они, например, спрашивают: "Можно мне взять этот зонт?".
Это четкое разделение синтаксиса и семантики (или информации, зависящей от языка, и информации, не зависящей от языка) лежит в основе способа, отвечающего изобретению. На первом этапе текст, введенный в систему языковой обработки, анализируется в отношении его синтаксиса и морфологии. На этом этапе анализируется грамматическая структура. Это дает первое базовое понимание текста. На следующем этапе извлекаются отдельные компоненты текста. Текст, в общем случае, состоит из предложений, которые содержат подлежащее, дополнение и сказуемое, соответственно. Каждый компонент можно извлекать и выявлять его роль в предложении. Эти отдельные компоненты и их отношения друг с другом используются на следующем этапе генерации графа или графического представления текста. Отдельные компоненты образуют вершины графа и отношения между компонентами представлены ребрами. Граф, в общем случае, выражается матрицами. Однако логическую структуру также можно представлять графически для лучшего понимания людьми. Было обнаружено, что этот граф можно сделать полностью независимым от языка, который используется при вводе текста в систему. Граф включает в себя семантическую информацию, которую легко использовать для дальнейшей обработки.
Вместо графа и/или его графического представления можно использовать другие формы графического представления. Они, например, включают в себя представление с использованием видео, пиктограмм и т.п.
Альтернативно или дополнительно к этапу генерации графа или графического представления, уже существующий граф или графическое представление можно использовать на этапе использования графа или графического представления. Этот граф или графическое представление описывает знание, уже присутствующее в системе языковой обработки. На этом этапе компоненты, извлеченные из текста, сопоставляются с элементами существующего графа или графического представления. Таким образом определяется подмножество существующего графа или графического представления.
Согласно особо предпочтительному варианту осуществления, текстовый ввод в систему языковой обработки моделируется визуально-графическими или пиктографическими средствами. В результате получается визуально-графическая модель, которая представляет текст независимо от языка и которую может понять каждый пользователь системы языковой обработки. Таким образом, пользователи не обязаны иметь знание об используемых языках. Это также справедливо, если пользователь не понимает ни один из языков, используемых в системе языковой обработки.
На этапе анализа текста производится обращение к информации о грамматике языка, используемого во входном тексте. Каждый язык имеет свою особую грамматику, определяющую расстановку слов. Чтобы пользователи могли, не зная программирования, прописывать грамматики, грамматические данные можно вводить посредством редактора грамматики. Предпочтительно, чтобы этот редактор грамматики не зависел от языка. Требуется лишь определенная формализация возможных структур языков. Таким образом можно избежать длительной разработки различных грамматик для каждого отдельно взятого языка и вместо этого получить возможность быстрого и эффективного создания прототипов. Таким образом в систему языковой обработки можно быстро и непосредственно интегрировать новые языки. Грамматики, генерируемые редактором грамматики, можно использовать для языкового анализа, а также для генерации языка.
Предпочтительно, этап анализа текста осуществляется синтаксическим слоем системы языковой обработки. Система языковой обработки может иметь модульную конфигурацию, которая обеспечивает возможность повторного использования и модульность системы. Синтаксический слой может осуществлять сегментацию и токенизацию текста. Сегментация означает разбиение текста на предложения, а токенизация означает выявление конкретных словоформ в предложении. При осуществлении сегментации и токенизации отдельные элементы, а также их взаимосвязь в предложении можно анализировать в отношении синтаксиса и морфологии.
Для улучшения модульности и для обеспечения способа, который можно универсально использовать, синтаксический слой можно привязывать к системе языковой обработки. Это дает возможность легко интегрировать разные языки в систему языковой обработки, добавляя в систему новый синтаксический слой. Поскольку обработка в системе осуществляется с помощью представления текста, не зависящего от языка, способ, отвечающий изобретению, позволяет обрабатывать любой язык. Тексты на новых языках преобразуются в представление, не зависящее от языка, путем привязки нового синтаксического слоя к системе языковой обработки. Таким образом способ можно использовать достаточно универсально.
Каждый язык, привязанный к системе языковой обработки, можно представить в отдельном синтаксическом слое. Таким образом синтаксические вопросы можно конфигурировать полностью независимо друг от друга.
Кроме того, отдельные языки могут иметь общие части синтаксического слоя. Например, верхненемецкий, швейцарский немецкий и австрийский немецкий имеют во многом схожую грамматику. Различаются лишь некоторые правила. В этом случае синтаксический слой может иметь часть, которая является общей для нескольких языков, и может иметь части, специфические для конкретного языка. Это сокращает работу по изменению правил для отдельных языков и облегчает ввод данных, используемых в синтаксическом слое. Таким образом, абстракции языков можно повторно использовать для отдельных синтаксических слоев.
Информация, не зависящая от языка, может извлекаться в реляционном слое. В общем случае информация, не зависящая от языка, содержит объекты, действия и атрибуты, а также их отношения. Объекты обычно представляются существительными в таких языках, как немецкий, английский или китайский. Действия в общем случае описываются глаголами текста. Прилагательные также могут представлять действие. Например, две компании можно тегировать посредством "compete" или "being competitive". Атрибутами могут быть атрибуты ощущений, как то цвет, температура, размер или качество, а также такие атрибуты, как эмоции. Эти объекты, действия и атрибуты извлекаются из текста синтаксическим и реляционным слоем и передаются в семантический слой.
На этапе генерации графа или графического представления объекты, действия и атрибуты предложения или фразы текста связываются друг с другом и представляются в виде графа или графически. Графическое представление (например, в виде матрицы или матриц) облегчает обработку текста в системе языковой обработки. Хотя графы также можно представлять графически, чисто графическое представление (не являющееся графом, например видео или пиктограммы) может быть более мощным, поскольку обеспечивает более высокую гибкость в отношении возможностей представления.
Для достижения языковой независимости системы языковой обработки объекты, действия и атрибуты можно представлять графически или посредством пиктограмм. Например, автомобиль можно представить пиктограммой автомобиля, скамью можно представить пиктограммой скамьи, атрибут "green" может быть зеленой областью, "to give" можно представить пиктограммами человека, передающего объект другому человеку, или посредством видео, и "to bark" можно представить звуком. Таким образом, каждый может понять графическое представление семантики, не тегируя объекты, действия или атрибуты терминами конкретного языка.
Этап обработки текста может содержать этап осмысления извлеченной семантики текста. Это можно делать, сравнивая извлеченную семантику с моделью или определяя расстояние между участвующими сущностями.
Центральной частью способа может быть смысловой мир. Смысловой мир представляет объектный мир. Главной задачей объектного мира является представление объектов, которые обычно представляются существительными в таких языках, как немецкий, английский или китайский. Он состоит из нескольких пространств размерностью от двух до n, содержащих объекты (или их прототипы), и упорядочивает их в осмысленные комбинации.
Объекты объектного мира можно организовывать с использованием структурных деревьев или структурных сетей, которые логически связывают отдельные объекты. Было обнаружено, что люди организуют знание об объектах мира и их отношениях в осмысленную структуру. Эта организация осуществляется неоднородно. Они используют концепции и категории для сохранения и сортировки информации. Такое группирование по категориям может существовать для электронных устройств (например, компьютера, принтеров и цифровых телефонов), бумаги (например, письма, документы и счета-фактуры), зданий (например, домов, музеев и офисов) и т.д. Отдельные объекты категории могут быть связаны с другими категориями. Например, офисное здание имеет несколько комнат, снабженных мебелью, электронными устройствами, бумагами и т.д. Мебель может содержать столы, стулья или книжные полки. С другой стороны, стул может быть офисным стулом, а также креслом-качалкой. И то и другое является стулом, но служит для совершенно разных целей. Таким образом отдельные слова связаны друг с другом в категориях.
Смысловой мир дополнительно содержит пространство действий, которое отвечает за представление действий. Действия могут быть связаны с любой другой единицей в смысловом мире, например, единицу, тегированную английским словом "withdraw", можно связать с объектами "person", "money" и "cashpoint", которые являются участвующими актантами. Такие связи называются молекулами.
Кроме того, смысловой мир может содержать пространство атрибутов, которое содержит атрибуты элементов. Подавляющее большинство атрибутов можно количественно выразить некоторым естественным образом. Атрибуты ощущений, как то цвет, вкус, размер или давление, имеют представление размерностью от одного до трех, используемое в различных контекстах. Цвета, например, можно воспроизводить с использованием цветного шпинделя, который задается оттенком, насыщенностью и яркостью нужного цвета. Эмоции также можно задавать с использованием многомерного представления. Согласно модели, предложенной психологами, для совмещения всех эмоций человека можно использовать шести- или восьмимерный эмоциональный симплекс. Таким образом, эмоции также можно представлять вне зависимости от языка.
Языковое представление текста может быть неоднозначным. Например, в предложении "the chicken is ready to eat" слово «цыпленок» можно интерпретировать либо как едока, либо как блюдо, которое будет съедено. В предложении "we saw the man with the telescope" телескопом пользуется либо человек, либо "мы". Эти неоднозначности разрешаются на основании контекста предложения. Этот контекст можно извлечь из смыслового мира. Если предыдущие предложения относятся к сельскому хозяйству, цыпленок, скорее всего, является едоком. Когда предыдущие предложения связаны с кулинарией, цыпленок, скорее всего, является едой. Эти вопросы, связанные с контекстом, можно решать с помощью смыслового мира.
Неоднозначному тексту будет соответствовать несколько графов или графических представлений, причем количество представлений равно количеству значений, которые можно извлечь из текста. Используя смысловой мир, можно определить представление, которое с наибольшей вероятностью является истинным.
В системе языковой обработки может существовать реляционный слой, который связывает синтаксические слои и семантический слой. Этот реляционный слой может содержать абстракции о возможных отношениях между объектами в слоях. Реляционный слой получает информацию, выводимую синтаксическим слоем, и осуществляет дополнительное обобщение и абстрагирование.
Согласно одному варианту осуществления изобретения, способ можно использовать в системе перевода. В этом случае этап обработки содержит этап генерации перевода текста на язык, отличный от исходного языка текста. Поскольку граф или графическое представление не зависит от языка, он может служить основой для перевода на любой язык. При осуществлении этапов способа сначала исходный текст анализируется в отношении его синтаксиса и морфологии. Затем компоненты текста и их взаимоотношения извлекаются, и эта информация используется для генерации графа или графического представления текста, или для использования существующего графа или графического представления в качестве представления, не зависящего от языка. После необязательной семантической проверки представление, не зависящее от языка, преобразуется в текстовое представление. Этот этап преобразования может осуществляться синтаксическим слоем, поскольку этот слой использует синтаксическую и морфологическую информацию конечного языка. Благодаря модульной конфигурации системы теоретически возможен перевод с каждого языка на любой другой язык. Поскольку между ними существует платформа, не зависящая от языка, каждый язык просто нужно связать с представлением, не зависящим от языка. Таким образом, возможен случай, когда не требуются словари, связывающие отдельные языки друг с другом. Это значительно облегчает разработку автоматической системы перевода.
Согласно другому варианту осуществления изобретения, способ можно использовать для поиска, поскольку он способен значительно улучшать результаты поисковых машин. Пользователь вводит запрос на веб-странице поисковой машины. Этот запрос анализируется синтаксически и морфологически, в результате чего извлекаются компоненты текста и их отношения. Эта информация используется при генерации внутреннего графического представления запроса. Неоднозначности могут определяться и разрешаться. Кроме того, отходя от строчного подхода, отдельные слова запроса можно обобщать, используя абстракции в структурных деревьях. Таким образом можно повысить качество результатов.
Согласно другому варианту осуществления изобретения, способ можно использовать при анализе текста. Он позволяет извлекать темы, представленные в тексте. Это можно использовать для автоматической категоризации текста. Кроме того, это можно использовать для отыскания логических цепочек или информации о семантических структурах в тексте.
Согласно еще одному варианту осуществления изобретения, способ можно использовать для генерации ответов на текстовый ввод в систему языковой обработки. Например, система может автоматически генерировать ответ на запрос, направленный пользователем, запрашивающим поддержку. В отличие от способов, известных в технике, данный способ позволяет анализировать и "понимать" текст, и создавать надлежащий ответ на запрос с использованием знания, представленного в модели смыслового мира.
Возможны и другие варианты осуществления. Поскольку способ предусматривает представление текста, не зависящее от языка, этап обработки можно заменить большим количеством других этапов. Таким образом, изобретение можно использовать очень универсально. Кроме того, при желании, отдельные описанные здесь варианты осуществления можно произвольно комбинировать.
Согласно каждому варианту осуществления, текст, сгенерированный на этапе обработки, можно выводить пользователю в качестве письменного или устного языка или в виде изображения. Если этап обработки содержит этап анализа текста, выход также может содержать статистику или список тем или ввод для поиска.
Для улучшения и облегчения построения баз данных, используемых в системе, знание, необходимое на этапах способа, отвечающего изобретению, можно вводить через веб-интерфейс. Знание может включать в себя теги лексикона, содержимое модели смыслового мира, грамматическую информацию, представление атрибутов и т.п. Эта информация может вводиться открытой группой пользователей, вносящих информацию в режиме, удобном для пользователя.
В отношении системы языковой обработки для обработки естественного языка и, согласно изобретению, для решения вышеупомянутой задачи предложен способ, содержащий признаки п.16. Предпочтительные варианты осуществления изобретения описаны в зависимых п.п.17-27.
Для решения вышеупомянутых задач предложен способ разработки системы языковой обработки по п.28 и его варианты осуществления, описанные в зависимых п.п.29 и 30.
Существуют несколько путей преимущественного построения и дополнительного развития концепции настоящего изобретения. Для этого следует обратиться к пунктам формулы изобретения, подчиненным пунктам 1, 16 или 28, с одной стороны, и к нижеследующему объяснению предпочтительного примера варианта осуществления изобретения, проиллюстрированного на чертежах, с другой стороны. В связи с объяснением предпочтительного примера варианта осуществления изобретения с помощью чертежей будет, в целом, объяснен предпочтительный вариант осуществления и дополнительное развитие концепции. На чертежах:
фиг. 1 - иллюстративная логическая блок-схема традиционного процесса перевода;
фиг. 2 - иллюстративная концептуальная схема варианта осуществления языковых пар, используемых в традиционном процессе перевода, показанном на фиг. 1,
фиг. 3 - структура процесса перевода,
фиг. 4 - графическое представление предложения,
фиг. 5 - возможное представление действий,
фиг. 6 - представления температуры (часть a)) и эмоций (часть b)),
фиг. 7 - иллюстративная логическая блок-схема процесса перевода на основе смыслового мира,
фиг. 8 - иллюстративная концептуальная схема варианта осуществления языковых пар, используемых в процессе перевода на основе смыслового мира, показанном на фиг. 7,
фиг. 9 - иллюстративная блок-схема варианта осуществления системы перевода на основе смыслового мира,
фиг. 10 - иллюстративная блок-схема варианта осуществления системы смыслового мира, показанной на фиг. 9,
фиг. 11 - иллюстративная логическая блок-схема варианта осуществления процесса добавления языка для добавления языка в систему перевода на основе смыслового мира, показанную на фиг. 9,
фиг. 12A - иллюстративная логическая блок-схема варианта осуществления процесса добавления термина для добавления термина в языковой словарь в системе перевода на основе смыслового мира, показанной на фиг. 9,
фиг. 12B - иллюстративная логическая блок-схема другого варианта осуществления процесса добавления термина для добавления термина в языковой словарь в системе перевода на основе смыслового мира, показанной на фиг. 9,
фиг. 13 - иллюстративная блок-схема варианта осуществления системы, включающей в себя один или несколько серверов перевода, способных реализовать систему перевода на основе смыслового мира, показанную на фиг. 9,
фиг. 14 - иллюстративная блок-схема варианта осуществления вычислительной системы, способной реализовать один или несколько компонентов описанной здесь электронной системы.
На фиг. 3 показан пример процесса перевода, согласно вариантам осуществления изобретения. Рассмотрим перевод предложения "die grüne Bank steht im Wald" с использованием изобретения. На фиг. 3 показан семантический слой 2, который является ядром системы 1 языковой обработки. Семантический слой внедрен в реляционный слой 3. К этому реляционному слою 3 привязано несколько синтаксических слоев 4, 5, 6. Каждый синтаксический слой представляет язык: синтаксический слой 4 представляет немецкий, синтаксический слой 5 представляет английский, и синтаксический слой 6 представляет польский.
Текстовый ввод в систему языковой обработки 1 поступает на синтаксический слой 4. Синтаксический слой 4 анализирует текст в отношении его грамматики и синтаксиса. Можно понять, что "Bank" является подлежащим предложения. "Bank" имеет атрибут "grün". "Bank" осуществляет действие "stehen" и это происходит в "Wald". Эти сведения получаются путем синтаксического и морфологического анализа текста.
Компоненты текста и их взаимоотношения можно извлекать. Это можно использовать для генерации универсального представления предложения, не зависящего от языка, которое показано на фиг. 4 в виде графа. Этот граф можно преобразовать в английский или любой другой доступный язык. На первом этапе пиктограмма, представляющая "Bank", переводится английским словом "bench". Атрибут "grün" скамьи переводится словом "green", действие "stehen" переводится словом "is", и представление "Wald" тегируется словом "forest". В результате перевода представления на английский язык получается предложение "the green bench is in the forest".
Как следует из вышеприведенного примера, благодаря тегированию графического представления с помощью другого языка и размещению слова в грамматически верном порядке каждый язык может служить исходным и конечным языком, соответственно.
На фиг. 5 представлено несколько возможных действий, осуществляемых человеком, изображенным в центре. Показаны действия "думать", "сидеть", "идти" и "давать".
На фиг. 6 показаны иллюстративные представления двух атрибутов. На фиг 6a представлена температурная шкала и соответствующие атрибуты. В общем случае, эти представления являются нечеткими и не могут отражать конкретное значение. Теплые блюда будут ощущаться как холодные, если они имеют температуру 10ºC или менее. Они будут обозначаться как тепловатые при температуре 20ºC. Температура 70ºC будет ощущаться как горячая.
На фиг. 6b изображено 4-мерное пространство для представления эмоций. Эмоции, которые можно представлять, являются суперпозицией симплекса: "испуганный", "удивленный", "счастливый" и "сердитый". Представленная здесь эмоция является точкой или областью в этом 4-мерном пространстве.
Во многих вариантах осуществления отношение, модели, синтаксические требования и пр. могут составлять часть одного или многих взаимодействующих компьютерных процессов. Соответственно, согласно вариантам осуществления настоящего раскрытия, компьютерная система применяет объектный мир, не зависящий от языка, тем самым обеспечивая центральный узел для переводов. Согласно варианту осуществления, текст или речь переводится с исходного языка в интерпретацию, не зависящую от языка, до перевода этого представления на один или несколько конечных языков для вывода.
Например, языковые системы настоящего раскрытия обеспечивают отображение синтаксиса и семантики входного языка, например, в граф в смысловом мире, не зависящем от языка. Из этого представления, не зависящего от языка, можно сделать перевод на любой язык или несколько языков. Согласно варианту осуществления, граф, не зависящий от языка, также может быть связан с и/или быть выходом графического или мультимедийного представления. Соответствующий процесс перевода анализирует входной текст (или речь) в отношении его синтаксиса и морфологии, извлекает компоненты текста и их взаимосвязи, генерирует граф текста в качестве представления смысла текста, не зависящего от языка, и осуществляет обработку текста с использованием графа.
Такая система, в общем случае, согласуется с результатами неврологических исследований. Один основной результат включает в себя понимание того факта, что познавательная способность человека различает синтаксис и семантику. Вернемся к рассмотренному выше случаю с зонтом. Это разделение синтаксиса и семантики (или информации, зависящей от языка и информации, не зависящей от языка) составляет часть процесса перевода, предложенного в настоящем раскрытии. Например, при анализе текста в отношении его синтаксиса и морфологии анализируется грамматическая структура. Это дает базовое понимание текста. Содержание этого текста извлекается. Например, текст, в общем случае, включает в себя предложения, которые могут содержать подлежащее, дополнение и сказуемое. Согласно варианту осуществления, можно извлекать каждый компонент и можно выявлять его роль в предложении. Эти компоненты и их взаимоотношения используются при преобразовании текста в граф. Компоненты образуют вершины графа и отношение между компонентами представлены ребрами. Согласно варианту осуществления, этот граф можно сделать частично или полностью независимым от языка, который используется при вводе (или выводе) текста. Граф, в основном, включает в себя семантическую информацию, которую можно непосредственно использовать для дальнейшей обработки.
В ходе анализа текста система обращается к информации о грамматике используемого языка. Каждый язык включает в себя свою особую грамматику, устанавливающую правила расстановки слов. Другой аспект этого раскрытия предусматривает сравнительно прямой, нетехнический способ генерации этих правил грамматики. Чтобы пользователи могли, имея небольшие познания в программировании или вовсе не имея их, прописывать правила грамматики, грамматические данные можно вводить посредством редактора грамматики. Правила грамматики включают в себя определенную формализацию возможных структур данного языка. Таким образом можно избежать длительной разработки различных грамматик для каждого отдельно взятого языка или сократить ее и вместо этого получить возможность быстрого и эффективного создания прототипов. Таким образом в раскрытую здесь систему языковой обработки можно быстрее и легче интегрировать новые языки.
Согласно варианту осуществления, анализ текста осуществляется анализатором, действующим в синтаксическом слое системы языковой обработки. В одном аспекте раскрытия система языковой обработки может иметь модульную конфигурацию, обеспечивающую возможность повторного использования, адаптируемость и расширяемость системы. Анализатор может осуществлять сегментацию и токенизацию текста. Сегментация означает разбиение текста на предложения, а токенизация означает выявление конкретных словоформ в предложении. После осуществления сегментации и токенизации элементы, а также их взаимосвязь в предложении можно анализировать в отношении синтаксиса и морфологии.
Для улучшения модульности и для обеспечения процесса, который можно универсально использовать, объекты синтаксического слоя можно связывать с системой языковой обработки. Это дает возможность легко интегрировать разные языки в систему языковой обработки, добавляя новый анализатор и словарь для каждого языка. Поскольку обработка в системе осуществляется с помощью представления текста, не зависящего от языка, любой язык можно обрабатывать. Тексты на новых языках преобразуются в представление, не зависящее от языка, и затем спаривание с любым другим существующим языком можно использовать для преобразования. Таким образом процесс можно использовать достаточно универсально.
Каждый язык, привязанный к системе языковой обработки, можно представить в виде отдельного множества объектов синтаксического слоя. Таким образом синтаксические вопросы можно конфигурировать независимо друг от друга. Кроме того, существует возможность, что отдельные языки могут иметь общие объекты синтаксического слоя, например анализатор или основные части анализатора. Например, верхненемецкий, швейцарский немецкий и австрийский немецкий языки имеют во многом общие правила грамматики. Различаются лишь некоторые правила. В этом случае единичный анализатор может оперировать с каждым языком, при том, что большинство правил являются общими для нескольких языков и некоторые правила зависят от языка. Это сокращает работу по изменению правил для отдельных языков.
Информация, не зависящая от языка, извлекается в этом синтаксическом и/или необязательном реляционном слое. В общем случае информация, не зависящая от языка, содержит объекты, действия и атрибуты, а также их отношения. Объекты обычно представляются существительными в таких языках, как немецкий, английский или китайский. Действия, в общем случае, описываются глаголами текста. Прилагательные также могут представлять действие. Например, две компании можно тегировать словами "compete" или "competitive". Атрибутами могут быть атрибуты ощущений, как то цвет, температура, размер или качество, а также такие атрибуты, как эмоции. Эти объекты, действия и атрибуты извлекаются из текста объектами синтаксического или реляционного слоя и переводятся в представления в смысловом мире (которые здесь именуются семантическим слоем).
На этапе обработки предложения объекты, действия и атрибуты предложения или фразы текста связываются друг с другом и представляются в виде графа. Граф облегчает обработку текста в системе языковой обработки, поскольку графы можно легко представить в виде матриц.
Для обеспечения языковой независимости системы смыслового мира объекты, действия и атрибуты можно представлять на основании уникального ID. Однако предпочтительно, чтобы каждое представление термина в смысловом мире также имело изображение или иллюстрацию смысла для упрощения работы со смысловым миром (особенно для людей, не владеющих навыками программирования). Например, автомобиль можно представить пиктограммой автомобиля, скамью можно представить пиктограммой скамьи, атрибут "зеленый" может быть зеленой областью, и "давать" можно представить пиктограммами человека, передающего объект другому человеку. Таким образом, графы и объекты смыслового мира можно понимать посредством графических представлений, не тегируя объекты, действия или атрибуты терминами конкретного языка.
Этап обработки текста может содержать этап осмысления извлеченной семантики текста. Это можно делать, сравнивая извлеченную семантику с моделью смыслового мира или определяя расстояние между участвующими объектами смыслового мира. "Расстояние" в этом случае указывает относительное отношение между разными объектами в смысловом мире. Чем ближе друг к другу объекты, тем теснее они связаны или сильнее коррелируют. Чем теснее связано множество объектов в смысловом мире, тем вероятнее, что перевод будет верным.
Смысловой мир содержит объекты терминов, не зависящих от языка ("объекты LIT"). Объекты LIT, в основном, предназначены для представления объектов, которые обычно представляются существительными в таких языках, как немецкий, английский или китайский. Он состоит из нескольких пространств размерностью от 2 до n (2-n), содержащих объекты (или их прототипы), и упорядочивает их в осмысленные комбинации. Другие части речи, например глаголы, также можно представлять объектами.
В одном аспекте раскрытие предусматривает системы и процессы для обеспечения систем перевода. В этом случае граф или другое семантическое представление входного текста не зависит от языка и может служить основой для перевода на любой язык. В общем случае, этапы процесса включают в себя анализ исходного текста в отношении его синтаксиса и морфологии с использованием компонентов текста и их взаимоотношений для генерации графа текста в качестве представления, не зависящего от языка. После необязательной семантической проверки представление, не зависящее от языка, преобразуется в текстовое представление на конечном(ых) языке(ах). Этот этап преобразования может осуществляться синтаксическим слоем, поскольку этот слой уже включает в себя синтаксическую и морфологическую информацию конечного(ых) языка(ов). Теоретически возможен перевод с каждого языка на любой другой язык с минимальным дополнительным усложнением при добавлении в систему каждого нового языка. Поскольку между ними существует платформа, не зависящая от языка, каждый язык просто нужно адаптировать к представлению, не зависящему от языка. Таким образом, не требуются словари, связывающие отдельные языки друг с другом (в отличие от вышеописанной модели, отвечающей уровню техники). Это облегчает разработку автоматической системы перевода.
Согласно другому аспекту, раскрытие может обеспечивать процесс, улучшающий поиск в поисковой машине. Например, пользователь вводит запрос на веб-странице поисковой машины. Этот запрос анализируется в отношении его синтаксиса и морфологии, в результате чего извлекаются компоненты текста и их отношения. Эта информация используется для генерации внутреннего графа запроса. Благодаря использованию модели смыслового мира, не зависящей от языка, неоднозначности могут определяться и разрешаться. Кроме того, отходя от строчного подхода к поисковым запросам, отдельные слова запроса можно обобщать, используя абстракции, например, в структурных деревьях, и отношения между словами. Таким образом можно повысить качество результатов.
Согласно еще одному аспекту, раскрытие предусматривает процесс анализа текста и извлечения информации, например, о теме текста. Это можно использовать для автоматической категоризации текста. Кроме того, это можно использовать для отыскания логических цепочек или информации о семантических структурах в тексте.
Согласно каждому варианту осуществления, текст, сгенерированный на этапе обработки, можно выводить пользователю в качестве письменного или устного языка или в виде изображения. Если этап обработки содержит этап анализа текста, выход также может содержать статистику или список тем или ввод для поиска или другой обработки.
Для улучшения и облегчения построения структур данных, баз данных и представлений, используемых в системе, знание, используемое на этапах процесса, отвечающего изобретению, можно вводить через веб-интерфейс. Знание может включать в себя теги лексикона, содержимое смыслового мира, грамматическую информацию, представление атрибутов и т.п. Эта информация может вводиться открытой группой пользователей, вносящих информацию через интерфейс, удобный для пользователя, а не интерфейс, приспособленный для программирования.
Для облегчения полного понимания изобретения в оставшейся части подробного описания изобретение описано со ссылкой на чертежи, снабженные сквозной системой обозначений.
В отличие от недостатков, связанных с фиг. 1 и 2, на фиг. 7 показана иллюстративная логическая блок-схема процесса 300 перевода на основе смыслового мира, согласно вариантам осуществления настоящего раскрытия. Согласно фиг. 7, на блоке 310 текст любой длины, например, предложение или абзац, вводится в электронную систему перевода, согласно раскрытым здесь вариантам осуществления. Например, на блоке 310 можно ввести "The boy is running to the park". На блоке 312 система анализирует предложение для извлечения корневой формы ключевых концепций текста. Обычно это будет, по меньшей мере, подлежащее, сказуемое и, иногда, дополнение предложения. В представленном примере существуют три ключевых термина: (1) boy; (2) run; и (3) park. Эти термины переводятся в не зависящий от языка граф "смысловой мир" (Блок 314). Согласно варианту осуществления, граф включает в себя вершину для каждого из ключевых концептуальных терминов и ребро для иллюстрации их связей с другими терминами. Ключевые концепции переводятся на выбранный язык (Блок 316). В этом примере конечным языком является немецкий: (1) Junge; (2) laufen; и (3) Park. Зависящий от языка модуль анализатора преобразует предложение с использованием надлежащих артиклей, форм глаголов и пр. (Блок 318), и законченное предложение "Der Junge läuft zum Park" выводится пользователю (Блок 320).
Хотя и в упрощенном примере, процесс 300, показанный на фиг. 7, иллюстрирует основные концепции смыслового мира и его графические свойства. На основании данного раскрытия специалист может уяснить себе многие более сложные сценарии ввода на естественном языке, и, как будет рассмотрено ниже, представление в смысловом мире обеспечивает значительную гибкость и силу для решения таких сценариев.
На фиг. 8 показана иллюстративная концептуальная схема языковых пар, согласно настоящему раскрытию. Например, согласно фиг. 8, четыре языка, показанные на фиг. 2, используют четыре (4) языковые пары, а не шесть (6). Кроме того, включение дополнительного языка - итальянского, использует дополнительную языковую пару. Таким образом для пяти языков, согласно настоящему раскрытию, требуется пять (5) языковых пар в отличие от десяти (10), как показано на фиг. 2.
Таким образом, согласно фиг. 8, каждый язык привязан к центральному смысловому миру, а не к какому-либо другому конкретному языку. Это обеспечивает модульный подход к системе перевода, поскольку никакой язык не нужно привязывать ни к какому другому языку по отдельности. Кроме того, системы и процессы, отвечающие этому раскрытию, приводят к значительно менее сложной системе, которую также, в общем случае, значительно дешевле разрабатывать, чем традиционные системы.
Варианты осуществления настоящей системы могут, например, быть особенно полезными в международном интернет-чате или сеансе мгновенного обмена сообщениями. Вариант осуществления раскрытой системы можно использовать в серверной системе мгновенного обмена сообщениями, и каждое сообщение можно переводить на предпочтительный язык отдельных конечных пользователей при передаче сообщений. Существуют многие другие применения раскрытой системы перевода, которые будут более подробно рассмотрены ниже.
Варианты осуществления системы перевода отличаются модульной конструкцией для многоязычной обработки естественных языков и мультимодального взаимодействия. Модули, предназначенные для разных языков, и другие, которые не зависят от языка, могут объединяться в рабочую систему, способную анализировать, рассуждать, искать, переводить и генерировать естественный язык. Варианты осуществления системы осуществляют мультимодальное взаимодействие: ввод и вывод письменного и устного естественного языка, а также вывод в качестве языка, речи, описания или их комбинации. Кроме того, модули, предпочтительно, сконструированы с возможностью повторного использования другими программами. По возможности, модули не зависят от языка, что способствует повторному использованию. Строго определенные интерфейсы и общие программы сопряжения управляют связью между системными компонентами. Благодаря этой конструкции можно осуществлять перевод с каждого языка на любой другой язык. Языки, подлежащие переводу, также могут быть вариациями в пределах единого языка, например может осуществляться перевод со швейцарского немецкого на верхненемецкий или перевод с разговорного стиля в формальный стиль. Признаки различных вариантов осуществления могут преимущественно включать в себя, полностью или частично, следующее:
модульность: простота оперирования, возможность повторного использования, возможность конфигурирования;
web-ориентированность: доступность отовсюду;
программное обеспечение, высокоразвитое с эргономической точки зрения: возможность универсального использования;
общественная основа: возможность универсального расширения;
универсальность: каждый язык можно интегрировать; и
визуально-графическое ядро: не зависит от языка и когнитивно адекватно.
Варианты осуществления этого раскрытия моделируют и имитируют человеческую познавательную обработку для оптимизации понимания естественного языка и генерации, перевода, поисковых машин или других задач связи.
Описанный здесь подход на основе познавательной способности человека разделяет синтаксис и семантику, согласно процессам человеческого мозга, и позволяет различать множественные значения слов. Особые компоненты оперируют правилами синтаксиса или словоформами, зависящими от языка. Семантика обрабатывается в слое, не зависящем от языка, именуемом смысловым миром. Этот подход основан на последних результатах неврологических исследований. Согласно рассмотренному выше примеру зонта, понятие "зонт" при общении является объектом, тегированным словом, зависящим от языка. Участники знают объект без использования языка. Если они хотят выйти из дому, когда на улице дождь, они активируют "тег" посредством словаря, зависящего от языка, для общения с другими людьми: "May I take this umbrella?" или "Könnte ich diesen Schirm nehmen?"
Это помогает объяснить преимущество данного подхода к языковой обработке, состоящее в том, что смысл представляется человеческими средствами и таким образом не зависит от языка. Можно добавлять все естественные языки, поскольку они используют один и тот же смысловой мир. Этот подход может быть полезным не только для перевода, но он также может иметь много других полезных применений. Согласно варианту осуществления смыслового мира, информацию можно добавлять, обрабатывать и сохранять без необходимости в особом синтаксисе языка. Когда информационная единица присутствует в смысловом мире, новые языки можно очень просто добавлять, привязывая синтаксическое представление к единице, не зависящей от языка.
На фиг. 9 показана иллюстративная блок-схема варианта осуществления системы перевода на основе смыслового мира. Например, фиг. 9 включает в себя системные компоненты или модули, которые можно использовать для обеспечения раскрытой языковой обработки и системы перевода. Система 522 смыслового мира включает в себя представления концепций, не зависящие от языка. Система 522 смыслового мира также предоставляет определенным пользователям доступ к мультимедиа для визуализации или озвучивания представлений хранящихся в ней терминов и концепций. Как показано, каждая семантическая система 524 языка привязана к центральному смысловому миру 522. Это обеспечивается с помощью одного или нескольких лингвистических инструментариев 526. Семантические системы 524 языка также содержат один или несколько языковых словарей 528. Каждый язык, представленный в системе перевода, обычно имеет свой собственный словарь 528 для обеспечения конкретных терминов этого языка. Словарные статьи связаны с конкретными объектами в системе 522 смыслового мира. Однако в ряде случаев языки могут быть в достаточной степени родственными, чтобы иметь возможность совместно использовать весь лингвистический инструментарий 526 или его части. Например, различные диалекты можно представить как разные языки, но в общем случае они подчиняются сходным правилам синтаксиса, определяющим, например, структуру предложения и порядок слов. В этом случае единичный лингвистический инструментарий может производить анализ каждого языка на основании всех или почти всех общих правил грамматики. Согласно варианту осуществления, лингвистический инструментарий обеспечивает анализатор (парсер) 530 для извлечения терминов из предложений, подлежащих переводу, а также формулирования грамматических предложений из графов объектного мира. Анализатор 530 опирается на правила 532 грамматики, классы 534 изменения формы слова, шаблоны 536 и пр. для правильного построения и разбора предложения на соответствующем языке. Шаблоны 536 лингвистических инструментов помогают обеспечивать непосредственное расширение терминов в языковом словаре для построения или модификации языка в системе. Например, шаблоны могут обеспечивать фрагменты предложения, которые помогут правильно классифицировать новые термины. В частности, если пользователь желает добавить слово "tiger" в языковой словарь, например, ему могут быть представлены шаблоны, помогающие системе понять части речи или систему координат. Очень простым примером множества шаблонов может быть "A tiger", "I tiger" и "the tiger ball". Пользователь может выбрать один из них для применения, и система может учиться классифицировать новый термин. В этом случае система учится тому, что "tiger" является существительным, которое может принимать неопределенный артикль, а не глагол или прилагательное, соответственно. Аналогично, система может представлять шаблоны для определения, правильно или неправильно спрягается глагол. Благодаря этому процессу любой человек может расширять систему без необходимости знания лингвистики или знания о других языках системы.
Как описано выше, анализатор 530 является компонентом для перевода в или из графов смыслового мира. Однако в другом варианте осуществления реляционный процессор 527 связывает семантическую систему 524 и анализатор 530 с системой 522 смыслового мира. В таком варианте осуществления семантическая система может генерировать граф входного текста, который все еще связан с исходным языком. Этот граф можно дополнительно абстрагировать в его форму, не зависящую от языка, с помощью реляционного процессора 527. Реляционный процессор 527 может извлекать время глагола, информацию предложенной группы и другие детали предложения для помощи в организации или расширении графа, не зависящего от языка. Например, реляционный процессор может указывать "определенный артикль", "длительную форму глагола" или "информацию направления" для примера, показанного на фиг. 7. В различных вариантах осуществления, как очевидно специалисту в данной области техники, анализатор 530 и реляционный процессор 527 могут быть выполнены в виде одного или нескольких модулей, действовать совместно и одновременно или по отдельности и последовательно, и могут делить ответственность любым образом, отличным от описанного здесь. Специалисты в данной области техники также могут понять из данного раскрытия, что могут существовать другие конфигурации, обеспечивающие такие же или почти такие же функции.
На фиг. 10 показан вариант осуществления структур данных, представляющих смысловой мир 522. В общем случае, каждый объект LIT 638 представляет конкретный термин, не зависящий от языка, например термины "building", "room", "city", "house" и "office building", показанные на чертеже. Согласно варианту осуществления, каждый объект является структурой данных, включающей в себя ID 640 объекта, множество из одной или нескольких реляционных связей 644 и необязательное множество из одной или нескольких иерархических связей 646. ID 640 объекта может быть числом или кодом, идентифицирующим компьютерную запись в компьютере, где хранится объект, но, в общем случае, будет нераспознаваем для пользователя. Согласно варианту осуществления, объекты LIT 638 связываются с другими родственными терминами посредством реляционных связей 644. Как показано, "city" и "building" являются родственными, поскольку город включает в себя совокупность зданий; аналогично, "building" имеет совокупность "rooms", так что эти два объекта взаимосвязаны. Согласно варианту осуществления, эти реляционные связи 644 можно взвешивать для указания силы связей. Аналогично, объекты, между которыми существует отношение класс-тип-подтип, могут быть связаны иерархическими связями 646 и могут образовывать древовидную структуру. На фиг. 10 это отношение проиллюстрировано объектами "building", "house" и "office building". "Building" - это общий термин, охватывающий понятия "house" и "office building" как более специфичные типы зданий. Хотя это не показано, сам объект "house" можно связать, например, с подтипами "cottage", "ranch" и "townhouse".
Объекты LIT 638 также могут включать в себя словарные связи 648. Кроме того, словарные объекты 528 включают в себя связи от конкретных терминов 650 языка к надлежащему объекту LIT 638. Например, на фиг. 10 показано, что термин "Bâtiment" - из объекта 526 словаря французского языка, термин "building" - из словаря английского языка и других включенных языков связан с объектом 638 "building". Аналогично, термины "office building" на английском языке, "Bürogebäude" на немецком языке и "immeuble de bureaux" на французском языке связаны с объектом 638 "office building".
Каждый объект также может включать в себя или быть связанным с одним или несколькими медийными представлениями, например визуальным представлением 642. Визуальные представления 642 можно использовать для иллюстрации соответствующего термина в различных ситуациях. Это особенно полезно для помощи пользователям в добавлении в систему нового языка, поскольку они могут отображаться, чтобы пользователь мог понять, с каким термином они должны связываться в новом языковом словаре 528. В некоторых вариантах осуществления в качестве соответствующих медийных представлений можно использовать аудиофайлы, видеофайлы, файлы изображения и пр. Например, "to whistle" (“свистеть”) лучше связать со звуковым файлом или звуковым файлом и изображением, чем просто с визуальным представлением.
Атрибуты объектов также могут быть связаны в системе 522 объектного мира и могут иметь особые реляционные связи. Например, атрибут может представлять собой эмоциональную шкалу, цветовое представление или физические атрибуты, например, температуру, размер или качество. Реляционные связи позволяют располагать конкретные термины вдоль шкалы, что позволяет связывать соответствующую терминологию с конкретными или относительными значениями вдоль шкалы. Например, "tiny", "small", "regular", "large", "huge", "enormous" и "infinite" можно разместить на шкале размера. Само пространство атрибутов может быть многомерным. Атрибуты также можно представлять в виде структурного дерева, например, "scarlet", "carmine" и "crimson" являются подтипами "red". Таким образом, единицы смыслового мира связаны друг с другом разнообразными путями в сети, что позволяет делать сложные умозаключения, необходимые для обработки естественного языка.
Кроме того, согласно варианту осуществления, систему 522 смыслового мира можно представить как виртуальный мир или множество виртуальных миров. Например, можно обеспечить пользовательский интерфейс, позволяющий пользователю перемещаться по виртуальному представлению системы 522 смыслового мира. Пользователь может, например, сначала увидеть "город", состоящий из "зданий", и может сделать увеличение до любого конкретного здания, например "дома" или "офисного здания". После этого пользователь может войти в "комнату" дома, и в каждой комнате могут находиться объекты, представляющие другие термины, например "диван", "стул", "кровать", "стол" и пр. Каждый объект также можно тегировать для отображения языковых представлений терминов, которые привязаны к словарным связям 648 этого объекта LIT 638. Виртуальный мир также может включать в себя представления людей и действий, а также модифицирующие атрибуты. Таким образом, при перемещении к объекту "door" в виртуальном мире может отображаться не только тег "door" английского языка, но и тег цвета "red", тег "wooden" и пр.
В другом варианте осуществления могут существовать множественные "миры" и между ними могут быть связи. Непосредственные объекты могут открывать новые миры. Например, сцена комнаты может изображать окно, через которое видна луна. Кликнув по изображению луны, можно перейти в другой объектный мир, который посвящен космосу. Представление человека может вести в объектный мир, который имитирует клеточную основу или части тела человека. Если пользователь перемещается в офис в офисном здании, там может находиться представление бумаг на столе, перейдя к бумагам (например, кликнув по ним с помощью мыши), можно открыть древовидный интерфейс, демонстрирующий объект 638, соединенный иерархическими связями 646. Например, "бумага" может относиться к словам "реклама", "отчет", "периодический" и пр. В свою очередь, слово "периодический" может быть связано со словами "газета" и "журнал" и т.д.
Перемещение по такому миру может быть полезным инструментом самообразования, поскольку пользователь может, по выбору, просматривать языковые теги на любых языках, подключенных к смысловому миру. Согласно варианту осуществления, пользователь может, по выбору, просматривать теги для языка, который он хочет знать, что помогает ему выучить этот язык. Аналогично, согласно варианту осуществления, термины первичного языка пользователя и другого языка могут отображаться, чтобы пользователь мог сопоставлять их с визуальным представлением.
Различные отношения между объектами 638 в смысловом мире 522 также можно моделировать графически. Пространственные, временные, причинные или метафорические отношения между объектами 638 смыслового мира (а также другие типы отношений) идеально подходят для графического описания. Применительно к переводу эти виды отношений являются основой для определения, какие структуры и формулировки служат для их вербального выражения, поскольку языки различаются способом выражения этих отношений: некоторые языки используют предлоги, другие реализуют их как морфемы, присоединенные к существительному, и т.д. Лучше всего генерировать адекватные структуры и формулировки на основании нейтрального, абстрактного и графического представления. Благодаря этому процессу компоненту генерации не приходится осуществлять комплексное реструктурирование входной структуры (как это делают классические системы машинного перевода), но просто нужно выбирать между доступными структурами конечного языка с использованием отображения отношений в структуры.
Возвращаясь к процессу перевода, показанному на фиг. 7, поясним дополнительные детали, касающиеся системы 522 смыслового мира. При выборе правильных переводов знание о затронутых темах улучшает перевод за счет фильтрации неоднозначных значений, которые не относятся к этим темам. Темы зачастую можно распознать из отношений графического представления текста перевода (см. Блок 314). Для ряда тем существует большое количество кластеров в N-мерном семантическом пространстве. Для отыскания центров кластеров используются эффективные и быстрые алгоритмы кластеризации, например алгоритм кластеризации методом k-средних. Эти центроиды кластеров представляют темы текста.
При наличии неоднозначных переводов тему можно использовать для их разрешения. Например, входной текст может включать в себя "The dog was a Siberian Husky." Термин "dog" фактически имеет множественные значения, включающие в себя "a domesticated canine", "a despicable man" или "an iron bar driven into a stone or timber to provide a means of lifting it". Каждое из этих определений может иметь разные переводы на другие языки и, таким образом, также неоднозначны для системы 522 объектного мира. Однако контекст предложения позволяет выбрать правильный объект объектного мира для использования (тот, который соответствует "a domesticated canine"), поскольку другие объекты предложения, в частности "Siberian Husky", более тесно связаны в смысловом мире объектов с этим объектом, чем с другими. В принципе, "Siberian Husky" и правильный объект "dog" окажутся, например, в подмножестве объектного мира, связанном с животными или домашними питомцами.
Синтаксический анализ текста часто создает много синтаксических графов и некоторые неразрешенные связи между вершинами графа, как в вышеприведенном примере "dog". Статистический подход к выбору наилучшего графа, в общем случае, используется для различения неоднозначностей: теорема Байеса, согласно варианту осуществления. Теорема Байеса утверждает, что вероятность того, что определенный граф дает сведения (семантические сущности), пропорциональна правдоподобию того, что семантические сущности присутствуют в этом графе, умноженной на априорную вероятность присутствия сущности в этом графе. Другие алгоритмы и статистический анализ - известные как или выведенные из стандартных статистических принципов - также можно использовать для устранения неоднозначностей переводов с исходного языка в интерпретацию объекта LIT, и знакомы специалистам в данной области техники.
Один аспект варианта осуществления раскрытой системы языковой обработки предусматривает набор инструментов, помогающий пользователю редактировать языки или добавлять новые. Как объяснено ранее, пользователи могут перемещаться по виртуальному миру, который помогает представлять термины, включенные в смысловой мир, не зависящий от языка. Было бы очень полезно, чтобы множественные заинтересованные стороны помогали добавлять новые термины языка, исправлять неверно употребляемые термины и даже добавлять новые языки в смысловой мир. Хотя все это могут делать опытные программисты, было бы быстрее и проще, если бы большое количество пользователей имели возможность развивать и корректировать смысловой мир. Этот тип групповой деятельности уже проиллюстрировали движение "wiki-" и такие веб-сайты, как "Wikipedia". Согласно варианту осуществления, избранные квалифицированные пользователи, например лингвисты, преподаватели языка и пр., могли бы добавлять языки или редактировать существующие; с другой стороны, можно позволить любому заинтересованному пользователю добавлять и редактировать язык.
Согласно варианту осуществления, система создает определенную формализацию возможных структур языка. Таким образом, можно избежать длительной разработки различных грамматик для каждого отдельно взятого языка и вместо этого получить возможность быстрого и эффективного создания прототипов. Таким образом, можно быстро и легко подключать новые языки. Грамматики используются как для языкового анализа, так и для генерации компонентов.
Дополнительно, графические пользовательские интерфейсы, которые можно называть Lexi-Wikis, позволяют пользователям вносить слова в словари 528, зависящие от языка. Lexi-Wikis предназначены для самого широкого круга пользователей. Из соответствующих слов инструменты генерируют примерные предложения, которые пользователь может легко выбирать или изменять. Какие формы и сколько словоформ нужно представлять пользователю, определяется различными инфлекционными алгоритмами, зависящими от языка. Выбранные пользователем примеры переводятся в комплексное представление, которое может обрабатывать программа. Согласно варианту осуществления, лежащий в основе морфологический процесс использует знание лингвистики и частотную информацию для определения минимальной информации, которую должен предоставлять пользователь. Таким образом он прогнозирует наиболее вероятные словоформы, благодаря чему от пользователя требуется как можно меньше словоформ и как можно меньше действий. Благодаря этому процессу умственная нагрузка или интеллект переносится со стороны пользователя на сторону программного обеспечения.
Очень часто пользователи не способны позиционировать семантические сущности абсолютно, но они вполне способны осознавать отличие от других семантических сущностей. Применяется многомерное масштабирование, алгоритм, предназначенный для размещения многомерных точек на основании матрицы различия, которая является матрицей, содержащей расстояния (или различие) до других семантических сущностей. Эти алгоритмы могут быть нечеткими, что необходимо, поскольку никакие два человека никогда не выберут в точности одинаковое расстояние. Однако они могут прийти к согласию в общем плане (например, "далеко" или "очень близко").
На фиг. 11 описан процесс добавления языка в систему смыслового мира. На блоке 760 пользователь входит в систему. В некоторых вариантах осуществления пользователь может, по желанию, войти в особый режим "модификация пользователя", который позволяет предотвратить незаконные или случайные изменения системы. В меню пользователь может выбрать добавление нового языка (Блок 762). При создании нового языка должен быть создан анализатор синтаксиса для разбора и генерации предложений. Согласно варианту осуществления, система включает в себя правила шаблонов, которые пользователь может выбирать при необходимости (Блок 764). Например, правило может указывать, что прилагательные обычно изменяют существительное, стоящее после них (например, в английском языке), или что они обычно изменяют существительное, стоящее перед ними (например, во французском языке). Правила изменений могут пояснять исключения из этих правил и пр. После создания анализатора термины можно добавлять в словарь нового языка (Блок 766). Каждый термин связывается с объектами смыслового мира (Блок 768).
Привязку новых терминов можно производить любыми способами, включающими в себя процессы, описанные со ссылкой на фиг. 12A и 12B. В одном варианте осуществления пользователь входит в систему (Блок 670) и выбирает добавление термина в конкретный языковой словарь (Блок 872), например, через систему меню. Пользователь может ввести термин (Блок 874). Система может обеспечивать запросы шаблонов, помогающие обеспечить правильное использование контекста (Блок 876). Например, шаблоны могут помогать системе категорировать термины по части речи, правильному или неправильному спряжению глаголов и пр. Ответы также могут помогать обеспечивать конкретный контекст смыслового мира для направления пользователя в надлежащий смысловой мир или область смыслового мира, где находится объект термина, не зависящий от языка. Пользователь может также просматривать виртуальный смысловой мир (Блок 878) и выбирать виртуальное представление, с которым должна быть связана новая словарная статья (Блок 880).
В альтернативном варианте осуществления на фиг. 12B показан другой процесс, посредством которого пользователь может добавлять слова в словари. Согласно фиг. 12B, пользователь входит в систему (Блок 882). Пользователь может просматривать смысловой мир (Блок 884). Выбор объектов в конкретном контексте (Блок 886) может отображать термины, связанные с этим объектом, например, показывая выноску в виртуальном мире. Когда пользователь выбирает объект в отсутствие ассоциированных терминов, пользователь может добавить термин для "тегирования" объекта (Блок 888). Аналогично, пользователь может изменять теги для корректировки или пополнения языковых словарей. Например, представление саксофона в смысловом мире можно тегировать термином "instrument" или "musical instrument" в словаре английского языка. Пользователь может редактировать тег, чтобы показать более точный термин в иерархии путем добавления "saxophone".
Кроме того, к системе можно подключать внешние ресурсы, чтобы представления знания, доступные в Интернете, в общественных или частных базах данных и пр., можно было использовать в компонентах языковой системы. Подключаемые ресурсы могут включать в себя, например, DBpedia, Wiktionary, Open Street Map, научные таксономии, онтологии из Semantic Web®, собственные таксономии пользователей и т.д. Согласно варианту осуществления, компоненты проверки согласованности проверяют согласованность различных представлений и обеспечивают правильное вычисление для потенциально разнородных источников знания. Можно даже интегрировать разные медийные типы, например графику, видео и аудио.
На фиг. 13 показаны вариант осуществления базовой системы перевода и средство доступа к ней. Хотя такая система перевода может принимать различные формы, система перевода на сетевой основе может обеспечивать легкий доступ для большого количества заинтересованных пользователей. Например, в вычислительной системе 994, например, на сервере может храниться, полностью или частично, программный код, который при выполнении обеспечивает некоторые или все функции системы смыслового мира 522, включающей в себя семантические системы 524 языка. Сервер 994 может осуществлять электронную связь с общественной или частной, локальной или глобальной сетью 992, например Интернетом. В свою очередь, различные пользователи могут осуществлять электронную связь с вычислительной системой перевода с помощью других сетевых устройств 990a, 990b. Подходящие пользовательские устройства включают в себя персональные компьютеры, портативные компьютеры, телефоны, подключенные к сети передачи данных, или другие мобильные устройства (например, устройства Blackberry®, устройства Apple iPhone®, другие КПК, мобильные телефоны и пр.). Пользователи могут обращаться к системе перевода через веб-интерфейс с помощью браузера или в некоторых вариантах осуществления специальной программы, установленной на пользовательском устройстве.
Один пользователь может использовать персональный компьютер 990b для доступа к службе перевода, ввода текста для перевода, выбора исходного и конечного языков и приема надлежащего переведенного текста, как описано со ссылкой на фиг. 7. При этом другой пользователь может редактировать и добавлять языки в систему через другой интерфейс на своем компьютере 990a. Предпочтительно, чтобы система перевода была масштабируемой, чтобы несколько пользователей могли обращаться к системе в любой данный момент времени. При таком подходе множественные пользователи могут одновременно пытаться редактировать языки. В предпочтительном варианте осуществления система перевода может обеспечивать механизм блокировки, позволяющий только одному пользователю редактировать, например, конкретную статью словаря 528 или конкретный объект LIT 638 смыслового мира в любой данный момент времени.
Хотя это раскрытие, в основном, посвящено использованию смыслового мира и возможностям анализа языка для создания системы перевода, существуют другие варианты использования такой системы смыслового мира. Например, система смыслового мира позволяет расширять возможности поисковой машины. Описанный здесь вариант осуществления системы позволяет анализировать поисковый запрос на естественном языке, например предложение или вопрос. Система может извлекать ключевые термины и генерировать графы и/или графические эквиваленты, не зависящие от языка. Поскольку эти объекты 638, не зависящие от языка, также связаны с соответствующими объектами LIT, прямой запрос пользователя может быть расширен для включения аналогичных слов, других словоформ, семантически родственных слов и пр.
Например, пользователь вводит запрос на веб-странице поисковой машины: "What recent court decisions define qualifying income tax?" Этот запрос анализируется в отношении его синтаксиса и морфологии, в результате чего извлекаются компоненты текста и их отношения: "court", "decision", "define", "qualifying" и "income tax". Затем эту информацию можно использовать для генерации графа запроса, как при выполнении перевода. Однако эти термины или объекты 638 смыслового мира сами по себе могут не обеспечивать все тематические результаты. Поэтому реляционные и иерархические связи 644, 646 объектного мира можно использовать для расширения терминов поиска. Например, "decision" можно связать с термином "opinion" и "order". Аналогично, "court" можно связать с "judge", и "income tax" можно связать с "IRS". Затем эти дополнительные термины можно использовать для расширения окончательного поиска. Таким образом можно повысить качество результатов, не заставляя пользователя расширять свою терминологию или осуществлять множественные сеансы поиска.
Другой аспект этого раскрытия можно использовать для анализа текста. Для выявления тем, представленных в тексте, можно использовать анализаторы. Это можно использовать для автоматической категоризации текста. Кроме того, это можно использовать для отыскания логических цепочек или информации о семантических структурах в тексте. В рамках предыдущего примера этот анализ текста можно производить с использованием программы поискового агента, который пытается категорировать новые веб-страницы в целях поиска. При анализе текста выход может содержать статистику или список тем, которую/ый можно использовать для тегирования веб-страниц для поискового запроса. Аналогично, аналогичную систему можно использовать в библиотеках для категоризации новых книг, периодических изданий, статей и пр. для генерации каталогов тематических карточек и поисковых баз данных.
Аналогично, выявление тем помогает расширять поисковые запросы в правильном окружении. Например, "decision" из вышеупомянутого поискового запроса можно также связать с "choice", и "court" можно связать с "basketball" или "tennis". Расширение поиска этими терминами, очевидно, будет расширять поиск в неправильное пространство объектного мира. Таким образом, определение, что темой является "taxes" и/или "legal", может помочь поисковой машине расширить термины в надлежащем контексте.
Возможны и другие варианты осуществления. Поскольку раскрытие предусматривает представление текста, не зависящее от языка, обработка этого представления может принимать самые разные формы. Таким образом, раскрытую систему можно использовать в самых разных приложениях. Кроме того, описанные здесь различные варианты осуществления можно комбинировать желаемым образом.
На фиг. 13 показана блок-схема одного варианта осуществления вычислительной системы 994, которую можно использовать для реализации некоторых описанных здесь систем и процессов. Например, в одном варианте осуществления вычислительная система 994 может быть приспособлена принимать запросы на перевод от другой компьютерной системы (например, пользовательского ПК 990a, 990b), использовать реализацию смыслового мира для перевода запроса на нужный язык и возвращать перевод. Функции, обеспечиваемые компонентами и модулями вычислительной системы 994, могут объединяться в меньшем количестве компонентов и модулей или, наоборот, распределяться по дополнительным компонентам и модулям.
Вычислительная система 994 включает в себя, например, сервер или персональный компьютер, совместимый с системой IBM, Macintosh, Linux/Unix и т.п. В одном варианте осуществления вычислительное устройство содержит, например, сервер, портативный компьютер, сотовый телефон, карманный персональный компьютер, киоск или аудиоплеер. В одном варианте осуществления иллюстративная вычислительная система 994 включает в себя центральный процессор ("ЦП") 1095, который может включать в себя традиционный микропроцессор. Вычислительная система 994 также включает в себя память 1097, например оперативную память ("ОЗУ") для временного хранения информации и постоянную память ("ПЗУ") для постоянного хранения информации, а также запоминающее устройство 1098 большой емкости, например жесткий диск, дискету или оптическое запоминающее устройство. Обычно модули вычислительной системы 994 подключены к компьютеру с использованием стандартной шинной системы. В разных вариантах осуществления в качестве стандартной шинной системы могут выступать, например, Peripheral Component Interconnect (PCI), MicroChannel, SCSI, Industrial Standard Architecture (ISA) и архитектуры Extended ISA (EISA).
Вычислительная система 994, в общем случае, управляется и координируется операционной системой, например Windows 95, Windows 98, Windows NT, Windows 2000, Windows XP, Windows Vista, Linux, SunOS, Solaris или другими совместимыми операционными системами. В системах Macintosh операционная система может быть любой доступной операционной системой, например MAC OS X. В других вариантах осуществления вычислительная система 994 может действовать под управлением специализированной операционной системы. Традиционные операционные системы управляют и диспетчеризуют компьютерные процессы для выполнения, осуществления операций с памятью, обеспечения файловой системы, сетевых функций и служб ввода/вывода и обеспечивают пользовательский интерфейс, например графический пользовательский интерфейс ("GUI"), помимо прочего.
Иллюстративная вычислительная система 994 включает в себя один или несколько общедоступных устройств и интерфейсов ввода/вывода (I/O) 1096, например клавиатуру, мышь, сенсорную панель, модем, карту Ethernet, микрофон и/или принтер. В одном варианте осуществления устройства и интерфейсы ввода/вывода 1096 включают в себя один или несколько устройств отображения, например монитор, который позволяет визуально представлять данные пользователю. В частности, устройство отображения обеспечивает представление, например, GUI, данных приложений и мультимедийных представлений. Вычислительная система 994 также может включать в себя одно или несколько мультимедийных устройств 1099, например громкоговорители, видеокарты, графические ускорители и микрофоны. Согласно варианту осуществления, пользователь вводит текст, подлежащий переводу или обработке, с помощью клавиатуры или сенсорной панели, представляющей клавиатуру (устройства ввода 1096). С другой стороны, микрофон (другое устройство ввода 1096) воспринимает устный текст. Устный текст может храниться в любом из разнообразных аудиоформатов, например WAV, MP3 или в других форматах. ЦП 1095 может обрабатывать этот аудиотекст и преобразовывать его в письменный текст, например объект строчных данных, файл данных простого текста, документ Microsoft® Word и т.п.
В варианте осуществления, показанном на фиг. 13, устройства и интерфейсы ввода/вывода 1096 обеспечивают интерфейс связи с различными внешними устройствами. Согласно варианту осуществления, вычислительная система 994 подключена к сети 992, например, LAN, WAN или Интернету (см. фиг. 13) проводной, беспроводной или комбинированной линией связи. Сеть 992 сообщается с различными вычислительными устройствами и/или другими электронными устройствами по проводным или беспроводным линиям связи. В иллюстративном варианте осуществления, показанном на фиг. 13, сеть 992 подключена к одному или нескольким пользовательским терминалам или вычислительным устройствам 990a, 990b. Вычислительное устройство 990b может передавать текстовый ввод в форматах аудио или письменного текста на вычислительную систему 994 для обработки. Помимо устройств, проиллюстрированных на фиг. 13, сеть 992 может сообщаться с другими источниками данных или другими вычислительными устройствами. Кроме того, источники данных могут включать в себя один или несколько внутренних и/или внешних источников данных. В некоторых вариантах осуществления одну или несколько баз данных или источников данных можно реализовать с использованием реляционной базы данных, например Sybase, Oracle, CodeBase и Microsoft® SQL Server, а также других типов баз данных, например базы данных с двумерным файлом, базы данных сущностей-отношений и объектно-ориентированной базы данных и/или базы данных на основе записей.
Согласно варианту осуществления, показанному на фиг. 14, вычислительная система 994 также включает в себя модуль приложения, который может выполняться ЦП 1095. Согласно варианту осуществления, показанному на фиг. 13, модуль приложения управляет моделями смыслового мира и данными. Этот модуль может включать в себя, например, компоненты, например программные компоненты, объектно-ориентированные программные компоненты, компоненты классов и компоненты задач, процессы, функции, атрибуты, процедуры, подпроцедуры, сегменты программного кода, драйверы, программно-аппаратное обеспечение (firmware), микрокод, электронные схемы, данные, базы данных, структуры данных, таблицы, массивы и переменные.
В общем случае, используемое здесь слово "модуль" относится к логике, реализованной аппаратными и программно-аппаратными средствами, или к совокупности программных инструкций, возможно, имеющих точки входа и выхода, написанных на языке программирования, например, Java, Lua, C или C++. Программный модуль может компилироваться и линковаться в исполнимую программу, установленную в динамически подгружаемой библиотеке, или может писаться на интерпретируемом языке программирования, например, BASIC, Perl или Python. Очевидно, что программные модули можно вызывать из других модулей или из них самих и/или запускаться в ответ на зарегистрированные события или прерывания. Программные инструкции могут быть зашиты в энергонезависимой памяти, например EPROM. Также очевидно, что аппаратные модули могут состоять из соединенных логических устройств, например вентилей и триггеров, и/или могут состоять из программируемых устройств, например программируемых вентильных матриц или процессоров. Описанные здесь модули предпочтительно реализовать в виде программных модулей, но также можно реализовать аппаратными или программно-аппаратными средствами. В общем случае, описанные здесь модули относятся к логическим модулям, которые можно комбинировать с другими модулями или делить на подмодули вне зависимости от их физической организации или хранения.
Согласно другому иллюстративному варианту осуществления изобретения, ниже приведены некоторые основные признаки изобретения. Их следует рассматривать как пример, иллюстрирующий принципы изобретения.
В дальнейшем мы будем называть систему языковой обработки "Lingupedia", что является торговой маркой Lingupedia Investments Sàri, Люксембург. Lingupedia - это модульная система для автоматизированного перевода текста.
Lingupedia использует полностью модульную конструкцию для многоязычной обработки естественных языков и мультимодального взаимодействия. Модули любого типа могут объединяться в рабочую систему, способную анализировать, рассуждать, искать, переводить и генерировать естественный язык. Система осуществляет мультимодальное взаимодействие: ввод и вывод письменного и устного естественного языка, а также вывод в качестве языка, речи, описания или их комбинации. Модули сконструированы с возможностью повторного использования различными другими программами, либо в системе Lingupedia, например, программами анализа и генерации, либо другими программами. По возможности, модули не зависят от языка, таким образом обеспечивая возможность повторного использования. Строго определенные интерфейсы и общие программы сопряжения управляют связью между системными компонентами. Благодаря этой конструкции можно осуществлять перевод с каждого языка на любой другой язык. Языки, подлежащие переводу, могут быть даже вариациями в пределах единого языка, например может осуществляться перевод со швейцарского немецкого на верхненемецкий или перевод с разговорного стиля в формальный стиль. Lingupedia обладает следующими базовыми признаками:
• модульность: простота оперирования, возможность повторного использования, возможность конфигурирования
• web-ориентированность: доступность отовсюду
• программное обеспечение, высокоразвитое с эргономической точки зрения: возможность универсального использования
• общественная основа: возможность универсального расширения
• универсальность: каждый язык можно интегрировать
• визуально-графическое ядро: не зависит от языка и когнитивно адекватно
Основным принципом системы Lingupedia является подход к моделированию и имитации человеческой когнитивной обработки для оптимизации понимания естественного языка и генерации, перевода, поисковых машин или других задач связи.
Большинство алгоритмов основано на орфографической форме, которая означает просто символизм или байтовую строку без какого-либо смысла. Даже онтологии используют этот подход "дом - это здание", иногда с математическими расстояниями или пространствами, но они всегда используют эти бессмысленные байтовые цепочки. Основной недостаток байтовых цепочек в том, что они зачастую действительно имеют множественные значения, которые могут вовсе не нести никакого смысла: a dog may be a pet, a grab hook, a cramp iron,...
Подход на основе познавательной способности человека наподобие Lingupedia отчетливо разделяет синтаксис и семантику, согласно процессам человеческого мозга, и позволяет различать множественные значения слов. Особые компоненты оперируют правилами синтаксиса или словоформами, зависящими от языка. Семантика обрабатывается в слое, не зависящем от языка, Lingupedia Meaning World (LMW). Этот подход основан на последних результатах неврологических исследований. Пример: если несколько человек, говорящих на разных языках, находятся в одной комнате, где имеется зонт, каждый "знает", что это зонт. Но это "знание" не означает, что слово "зонт" активируется каким-либо образом в мозгу присутствующего человека. Только в целях общения объект "зонт" тегируется словом, зависящим от языка. Участники знают объект без использования языка. Если они хотят выйти из дому, когда на улице дождь, они активируют "тег" посредством словаря, зависящего от языка, но только для общения с другими людьми: "May I take this umbrella?" или "Könnte ich diesen Schirm nehmen?"
Преимущество подхода Lingupedia состоит в том, что смысл представляется человеческими средствами и таким образом не зависит от языка. Таким образом, можно добавлять все естественные языки, поскольку они используют один и тот же смысловой мир. Lingupedia заявляет: наш подход позволяет не только переводить, но и оптимизировать любую работу или программу, использующую естественный язык. В базовом компоненте LMW информацию можно добавлять, обрабатывать и сохранять без необходимости в особом синтаксисе языка. Когда информационная единица присутствует в LMW, новые языки можно очень просто добавлять, привязывая синтаксическое представление к единице, не зависящей от языка.
Кроме того, пользовательские значения могут сохраняться независимо от языка: например, компания, производящая особый принтер, может вывести этот принтер из шаблона данного принтера в LMW, адаптировать выведенный принтер конкретными частями и тегировать его одним или несколькими языками. Изображения с описаниями частей и признаков можно легко вывести из LMW для заданного языка. Таким образом, многоязычная информация об изделии (например, документация, маркетинговая информация или отчеты об ошибках) может автоматически генерироваться из смыслового мира, не зависящего от языка. Связь с потребителем на различных языках и в различных формах (электронную почту, письма, телефонные звонки) можно автоматизировать, т.е. анализировать, интерпретировать, распределять по разным отделам и генерировать для ответа потребителю.
Помимо этого приложения CRM (Customer Relationship Management), LMW полезен в качестве быстрой и эффективной машины информационного поиска, поскольку, применительно к ментальному представлению, он ближе к представлению знания человека, чем другие подходы. Способ Lingupedia превосходит как классический строчный поиск (требующий точных совпадений на уровне орфографической формы), так и недавно предложенный семантический сетевой поиск (требующий особой аннотации текстов, в которых предполагается поиск информации).
В основе работы LMW лежит метод тегирования. Для упрощения навигации по LMW можно активировать так называемое тегирование, зависящее от языка. Если, например, активировано английское тегирование и пользователь переходит к зонту, алгоритм тегирования запрашивает словарь английского языка на предмет статьи, отображающей его для пользователя. Таким образом, пользователи, говорящие на другом языке, получают помощь в отыскании нужной информации.
Знание в LMW представляется различными мирами. В общем случае используются "объектный мир", "структурные деревья/сети", "пространство действий" и "пространство атрибутов".
Главной задачей объектного мира является представление объектов, которые обычно представляются существительными в таких языках, как немецкий, английский или китайский. Он состоит из нескольких пространств размерностью от двух до n, содержащих объекты (или их прототипы) и упорядочивает их в осмысленные комбинации.
Эти объекты организованы в структурные деревья или сети. Люди организуют знание об объектах мира и их отношениях в осмысленную структуру. Эта организация осуществляется неоднородно. Они используют концепции и категории для сохранения и сортировки информации. Такое группирование по категориям может существовать для "электронных устройств" (компьютера, принтера, цифрового телефона) или "бумаг" (писем, документов, счетов-фактур).
Часть пространства действий LMW отвечает за представление действий. Действия могут быть связаны с любой другой единицей в LMW, например единицу, тегированную английским словом "withdraw" или немецким словом "abheben", можно связать с объектами "person", "money" и "cashpoint", которые являются участвующими актантами. Действия необязательно выражаются глаголами: молекулу, посредством действия связанную, например, с двумя компаниями, можно тегировать посредством "compete" или "being competitor". Такие связи называются молекулами.
Пространство атрибутов структурировано напрямую также в отношении полезности. Подавляющее большинство атрибутов можно количественно выразить некоторым естественным образом. Атрибуты ощущений, как то цвет, вкус, размер или давление уже имеют 1-3-мерное представление, используемое в различных контекстах.
В состав Lingupedia также входят следующие дополнительные представления и алгоритмы:
• интеграция внешних ресурсов представления знания
• описания для естественного представления единиц в LMW
• графические отношения между единицами в LMW
• кластеризация по темам в текстах
• статистический анализ для устранения неоднозначностей
• многомерное масштабирование для вычисления сходств
Помимо вышеописанных компонентов, существуют следующие части Lingupedia, предназначенные для моделирования конкретных естественных языков:
• не зависящий от языка редактор грамматики для задания грамматик для каждого языка
• Lexi-Wikis для определения слов каждого языка
• Словарь с многоцелевой конфигурируемостью
Обычно словари не обеспечивают точный смысл: словарь дает следующие англо-немецкие переводы слова «dog»: Anschlag, Bauklammer, Finger, Gerüstklammer, Greifhaken, Hund и немецко-английские переводы слова Hund: canine, dog, hound. Таким образом, предлагается несколько разных значений для одного слова. LMW может интеллектуально проводить различия между этими значениями. Это значит, что прежде всего существуют не зависящие от языка представления смысла, например покрытое шерстью животное, которое тегируется по-английски словом "dog", или особая часть козел, которая также тегируется той же самой орфографической формой "dog" (на немецком языке "Gerüstklammer"). Таким образом, если обычный словарь имеет 30.000 статей на английском, LMW потребуется около 100.000 представлений смысла. Смысл, не зависящий от языка, можно понять из контекста: используется ли этот объект, тегированный словом dog, в области строительства или же он связан с действием, тегированным глаголом bark или walk? После прояснения смысла благодаря нахождению верной единицы в LMW перевод или дальнейшая обработка может осуществляться лучше, чем в любой существующей системе.
Lingupedia может a) использовать и интегрировать существующие внешние ресурсы из сети и b) открывать все компоненты Lingupedia для публичного доступа - синтаксические компоненты, зависящие от языка, а также семантическую область LMW, не зависящую от языка. Кроме того, прямо с начала и даже более с развитием LMW, очень легко интегрировать синтаксическую часть нового языка, поскольку требуется произвести лишь простое тегирование. Lingupedia обеспечивает лингвистический инструментарий для быстрого и легкого тегирования для неопытных пользователей, не требующих особых знаний, и охватывающий каждый человеческий язык.
Ниже будут описаны некоторые детали компонентов.
В объектном мире все семантические сущности представлены независимо от языка. Представление является графическим, т.е. визуализированным в разных формах. Семантические сущности соответствуют абстрактным или реальным объектам, существующим в своеобразном "модельном" мире. Они организованы в пространства размерностью от двух до n и в осмысленные структуры.
Простые объекты могут открывать новые миры. Например, луна может вести в другое пространство, например орбиту. Альтернативно, представление человека может вести в пространство, которое имитирует клеточную основу или части тела человека. Отношения объектов можно представить, например, в городе, где имеются здания, парки и сады. Здание может быть частным, общественным или офисным зданием. Это здание содержит офисы; офисы содержат объекты, например столы, компьютеры, полки, часы или бумаги. Таким образом, объекты пространственно или функционально связаны с областью знания, представленной офисом или зданием. Объекты могут состоять из частей; часы, например, могут состоять из механического механизма и циферблата с часовой и минутной стрелками. Евклидово расстояние между объектами в этом модельном мире представляет различие между двумя объектами. Евклидово расстояние в семантическом пространстве не эквивалентно евклидову расстоянию в реальном мире. Оно основано на различии или функциональной близости.
LMW использует ассоциативные сети или ориентированные деревья в качестве представления знания. Пользователь может перейти от объекта, например объекта "документ", лежащего на столе в графическом мире, к соответствующему дереву для отыскания, например объекта "уведомление". Каждый объект можно связать с множественными структурными деревьями, например бумажный объект с "бумаги", а также с деревом "материалы", где на одном ярусе находятся вершины «дерево», «металл» и т.д.
В LMW существуют разные типы отношений в сетях: одним типом отношения может быть "является" (“is-a”). При этом объектом является подтип родительской вершины, содержащей надтип. Подтипы наследуют свойства своих надтипов. Возможно множественное наследование. Это дерево "является" используется для перевода подтипов, не имеющих тегирования на конечном языке. Вместо конкретного термина вербализуется более общий надтип ("document" вместо "letter", "take" вместо "withdraw") или выбирается синоним или отрицаемое выражение антонима. Помимо гипонимии, для дедукции и перевода используются также другие отношения: близость, связанность, экземпляризм, членство, рамочная связанность, подобие, синонимия, антонимия, меронимия и т.д. Языки отличаются своим лексическим инвентарем. Эта сеть отношений обеспечивает гибкость генерации естественного языка в системе, которая должна оперировать каждым языком, и где в различных языках не хватает определенных слов либо вследствие особенностей языка, либо вследствие того, что они еще не тегированы в системе Lingupedia. Единицы LMW могут быть искусственными в том смысле, что они являются лишь частью структурных деревьев. Это справедливо для некоторых отношений или построенных вершин.
В особенности, что касается действий, визуализированное представление является когнитивно адекватным, поскольку вербализованное определение представляет трудность для понимания и менее интуитивно для пользователей, чем визуальное. Фильмы, графика, отображающие движения или схематические описания, используются для иллюстрации различных действий. Пространство действий также используется для представления тематических ролей глаголов или других сущностей. Тематические роли соотносят действие с его агентами, темами, целями и т.д. Роли либо задаются пользователем, либо выводятся из свойств графически отображаемого действия. Это элегантный и интуитивный путь присвоения внутренней, тематической структуры действиям и событиям. Это знание о задействованных ролях используется для устранения неоднозначности и для корректной генерации конечного предложения.
Атрибутами объектов могут быть эмоциональная шкала, цветовое представление или физические атрибуты, например температура, размер или качество. Например, слово «биржа» можно связать с двухмерным пространством, которое представляет числовую шкалу, представляющую денежные единицы. С этим пространством можно связать другие единицы, например действия, которые можно тегировать словами "рост" или "спад". Как и пространство действий, пространство атрибутов можно связывать с другими единицами в LMW. Цвет можно связать с объектом, который тегирован словом "автомобиль". Само пространство атрибутов может быть многомерным. Атрибуты могут представлять структурное дерево, например "scarlet", "carmine" и "crimson" являются подтипами "red". Таким образом, единицы смыслового мира связаны друг с другом разнообразными путями в сети, что позволяет делать сложные умозаключения, необходимые для обработки естественного языка.
К системе можно подключать внешние ресурсы, чтобы представления знания, доступные в Интернете, можно было использовать в компонентах системы. Подключаемые ресурсы представляют собой, например, DBpedia, Wiktionary, Open Street Map, научные таксономии, онтологии из Semantic Web®, собственные таксономии пользователей и т.д. Высокоинтеллектуальные компоненты проверки согласованности проверяют согласованность различных представлений и обеспечивают правильное вычисление для широкого круга разнородных источников знания. Можно даже интегрировать разные медийные типы, например графику, видео и аудио. Различные алгоритмы интерпретации или перевода позволяют оперировать с различными типами представлений.
Аватары представляют людей или животных. Аватары, как и все объекты в LMW, выводятся из других аватаров. Таким образом задается внутренняя иерархия объектов, образованных посредством вывода. Человеческое мышление работает - такова гипотеза авторов - и в конечных моделях мира: когда люди представляют себе снятие наличных в банкомате, они не используют слова "I, bank, cashpoint, withdraw". Вместо этого для воображения этого процесса они используют "ментальный образ" или "ментальную сцену", не зависящий/ую от языка. Они могут даже придумывать целые истории, например, в мечтах, без участия своего тела. Они воображают свое тело в искусственном, смоделированном в мозгу окружении. В дальнейшем LMW послужит платформой для такого моделирования с помощью искусственного интеллекта.
Различные отношения также моделируются графически. Пространственные, временные, причинные или метафорические отношения между сущностями (а также другие типы отношений) идеально подходят для графического описания. Применительно к переводу эти виды отношений являются основой для определения, какие структуры и формулировки служат для их вербального выражения, поскольку языки различаются способом выражения этих отношений: некоторые языки используют предлоги, другие реализуют их как морфемы, присоединенные к существительному, и т.д. Лучше всего, и когнитивно адекватно, генерировать адекватные структуры и формулировки на основании нейтрального, абстрактного и графического представления. Согласно этому способу, компоненту генерации не приходится осуществлять комплексное реструктурирование входной структуры (как это делают классические системы машинного перевода), но просто нужно выбирать между доступными структурами конечного языка с использованием отображения отношений в структуры. Эти алгоритмы отображения были разработаны для генерации каждого интегрируемого языка.
Знание о темах улучшает перевод за счет фильтрации неоднозначных значений, которые не относятся к этим темам. Для ряда тем существует большое количество кластеров в N-мерном семантическом пространстве. Для отыскания центров кластеров используются эффективные и быстрые алгоритмы кластеризации, например алгоритм кластеризации методом K-mean. Эти центроиды кластеров представляют темы текста. При наличии неоднозначных переводов тему можно использовать для их разрешения.
Синтаксический анализ текста часто создает много синтаксических графов и некоторые неразрешенные связи между вершинами графа. Статистический подход к выбору наилучшего графа используется: теорема Байеса. Она утверждает, что вероятность того, что определенный граф дает сведения (семантические сущности), пропорциональна правдоподобию того, что семантические сущности присутствуют в этом графе, умноженной на априорную вероятность присутствия сущности в этом графе.
В состав системы Lingupedia входит первый в мире не зависящий от языка редактор грамматики: пользователи могут прописывать грамматики безо всякого знания программирования. Требуется только определенная формализация возможных структур языка. Таким образом можно избежать длительной разработки различных грамматик для каждого отдельно взятого языка и вместо этого получить возможность быстрого и эффективного создания прототипов. Таким образом можно быстро и легко подключать новые языки. Грамматики используются как для языкового анализа, так и для генерации компонентов. Эта концепция модульности и возможности повторного использования компонентов применяется к следующим синтаксическим представлениям и процессам:
• не зависящему от языка, т.е. универсальному, абстрактному представлению грамматической структуры
• грамматикам для анализа и генерации
• синтаксически-морфологическим правилам для анализа и генерации
Графические пользовательские интерфейсы, именуемые Lexi-Wikis, позволяют пользователям вносить слова в лексикон, зависящий от языка. Lexi-Wikis не требуют никакого экспертного знания о языке, но предназначены для самого широкого круга пользователей. Из соответствующих слов инструменты генерируют примерные предложения, которые пользователь может легко выбирать или изменять. Какие формы и сколько словоформ нужно представлять пользователю, определяется различными инфлекционными алгоритмами, зависящими от языка. Выбранные пользователем примеры переводятся в комплексное представление, которое может обрабатывать программа. Лежащий в основе морфологический метод использует знание лингвистики и частотную информацию для определения минимальной информации, которую должен предоставлять пользователь. Таким образом он прогнозирует наиболее вероятные словоформы, благодаря чему от пользователя требуется как можно меньше словоформ и как можно меньше действий. Согласно этому способу, умственная нагрузка или интеллект переносится со стороны пользователя на сторону программного обеспечения.
Словарный метод разработан как универсальный, многоцелевой главный словарь для любых разновидностей приложений естественного языка и для любых типов языков. Словарь предлагает новый уровень представления: уровень фраз, который располагается между отдельными словами и законченными предложениями. Это позволяет очень гибко оперировать единицами языка в континууме слово - фраза - предложение. Многословные выражения, которые до сих пор являются основной проблемой для большинства естественно-языковых систем, можно представить в виде более или менее фиксированной структуры: от совсем неизменяемых и немодифицируемых (имеющих фиксированную форму и не имеющих никакой внутренней структуры) к имеющим внутреннюю структуру с определенными ограничениями (семантическими, синтаксическими, лексическими, прагматическими, стилистическими и т.д.) и до предусматривающих модификации любого типа.
Словарный метод обеспечивает механизм аннотации статей признаками, полезными для различных приложений естественного языка: морфологическими признаками для морфологического анализа и генерации, синтаксическими признаками для синтаксического анализа и генерации, семантическими признаками для семантической обработки, прагматическими признаками для прагматической обработки и диалоговыми признаками для эффективного построения диалогов на естественном языке. Для объяснения метода на основе признаков: обработка естественного языка с использованием его поверхностных форм (строки) не идеальна, поскольку каждый вариант и эквивалент или связанную форму нужно обрабатывать отдельно. Этот подход не эффективен: трудоемкий и подверженный ошибкам для программиста и не дающий пользователю никакой гибкости при взаимодействии с программным обеспечением, например возможности диалога: он должен использовать только те строки, которые подготовила программа; в противном случае он не будет понят. Благодаря использованию признаков применяется более высокий уровень научной абстракции, обеспечивающий более гибкий и естественный характер взаимодействия.
Помимо лингвистической информации, используемой для взаимодействия на письменном языке, в словаре также хранится информация о произношении слов, которая полезна для звукового ввода и вывода при распознавании и синтезе речи. Встроены алгоритмы преобразования. Они переводят представление произношения из внутренней формы в другую форму для дальнейшей обработки программным обеспечением различных типов или для представления пользователю. Таким образом эта информация может гибко использоваться в разных приложениях. Инструмент конфигурации позволяет выбирать именно те части словаря, которые требуются разным приложениям.
Благодаря хранению базовых форм, вместо полных форм (последние обычно используются программным обеспечением, связанным с речью), словарь использует эффективную и гибкую форму представления и обработки и допускает динамическую генерацию всевозможных инфлективных, деривативных и сложных форм. Алгоритм генерации, который создает различные словоформы, в то же время гарантируя правильное произношение, выведенное из и адаптированное к внутренней структуре слов, является частью системы. Словарь также обеспечивает способ представления различных отношений между статьями лексикона. Отношения относятся к разным задачам языковой обработки, например, для сокращения, которое обычно не используется в речи, но только в письменном языке. Если она не используется при синтезе речи, ее полная форма представляется, чтобы сделать ее произносимой. Альтернативно, если статья подлежит поиску с помощью поисковой машины, ее различные орфографические и инфлективные формы безразличны для процесса поиска, хотя до сих пор их приходится представлять в явном виде. Подход Lingupedia позволяет устанавливать связь с ними и легко находить их.
На основании принципов, представленных в вышеприведенном описании и прилагаемых чертежах, специалист в области техники, к которой относится изобретение, может предложить разнообразные модификации и другие варианты осуществления изложенного здесь изобретения. Таким образом, следует понимать, что изобретение не ограничивается конкретными раскрытыми вариантами осуществления, и что модификации и другие варианты осуществления подлежат включению в объем формулы изобретения. Хотя здесь употребляются конкретные термины, они используются лишь в общем и описательном смысле, но не в целях ограничения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ СЕМАНТИЧЕСКИХ СЛОВАРЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2584457C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ ОНТОЛОГИЧЕСКИХ МОДЕЛЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2596599C2 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| Автоматическое построение семантического описания целевого языка | 2013 |
|
RU2642343C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО ИЗВЛЕЧЕНИЯ СМЫСЛОВЫХ КОМПОНЕНТ ИЗ СЛОЖНОСОЧИНЁННЫХ ПРЕДЛОЖЕНИЙ ЕСТЕСТВЕННО-ЯЗЫЧНЫХ ТЕКСТОВ В СИСТЕМАХ МАШИННОГО ПЕРЕВОДА И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2021 |
|
RU2766060C1 |
| МНОГОЭТАПНОЕ РАСПОЗНАВАНИЕ ИМЕНОВАННЫХ СУЩНОСТЕЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ МОРФОЛОГИЧЕСКИХ И СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2619193C1 |
| РАЗРЕШЕНИЕ КОРЕФЕРЕНЦИИ В ЧУВСТВИТЕЛЬНОЙ К НЕОДНОЗНАЧНОСТИ СИСТЕМЕ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА | 2008 |
|
RU2480822C2 |
| СПОСОБ УПОРЯДОЧЕНИЯ ДАННЫХ, ПРЕДСТАВЛЕННЫХ В ТЕКСТОВЫХ ИНФОРМАЦИОННЫХ БЛОКАХ ДАННЫХ | 2000 |
|
RU2210809C2 |
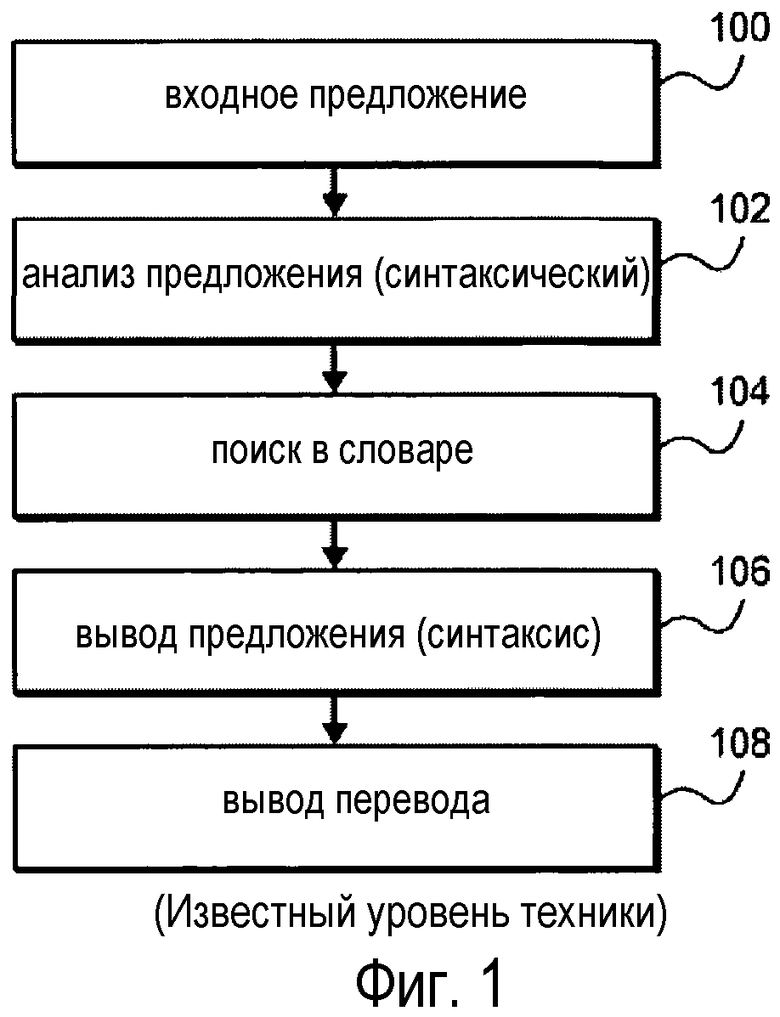
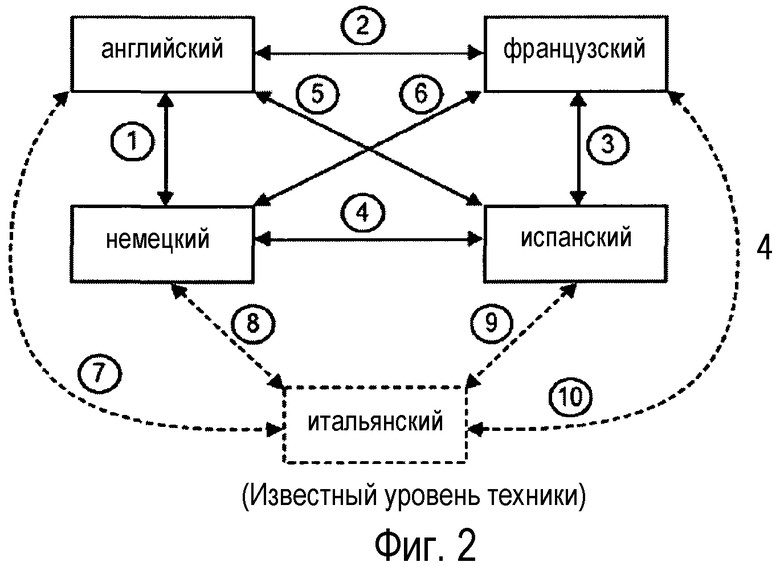
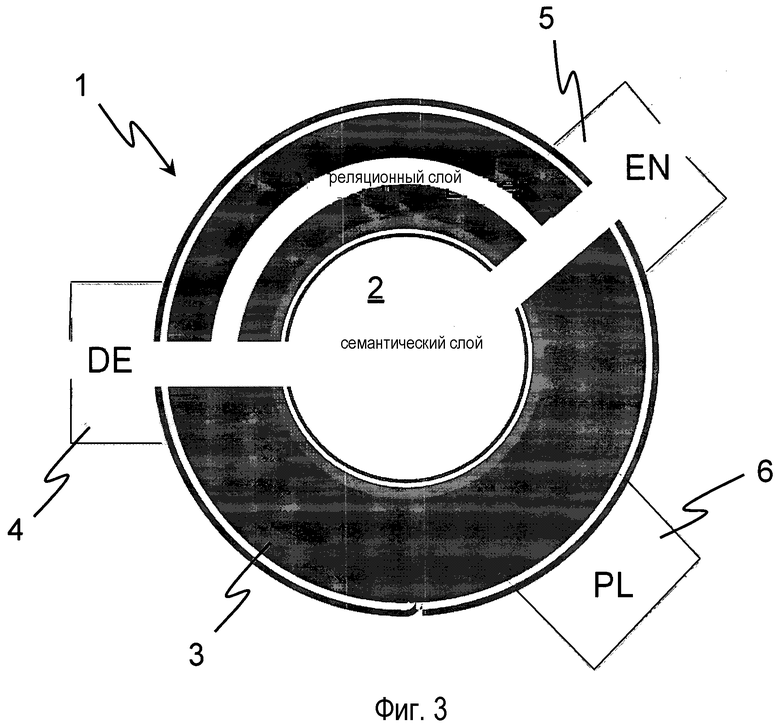
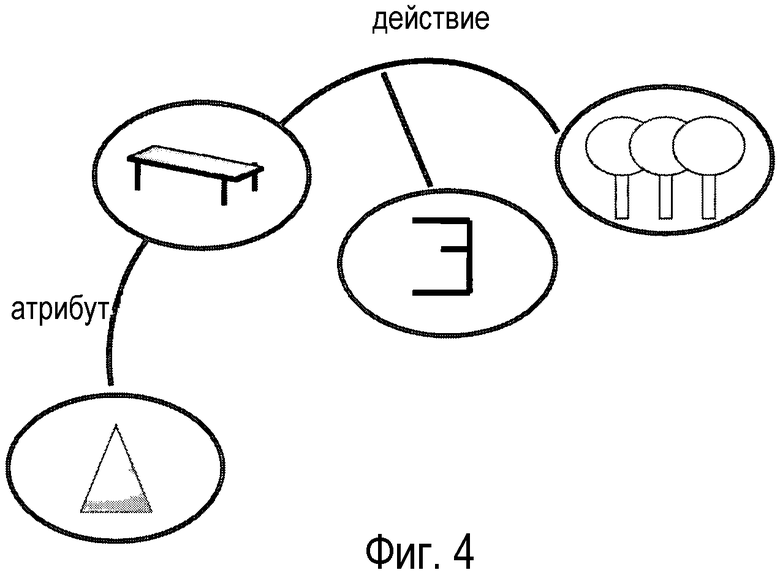
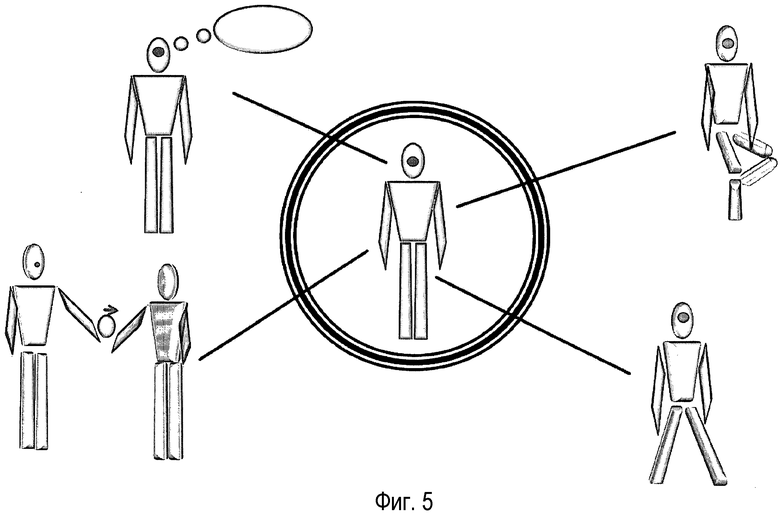
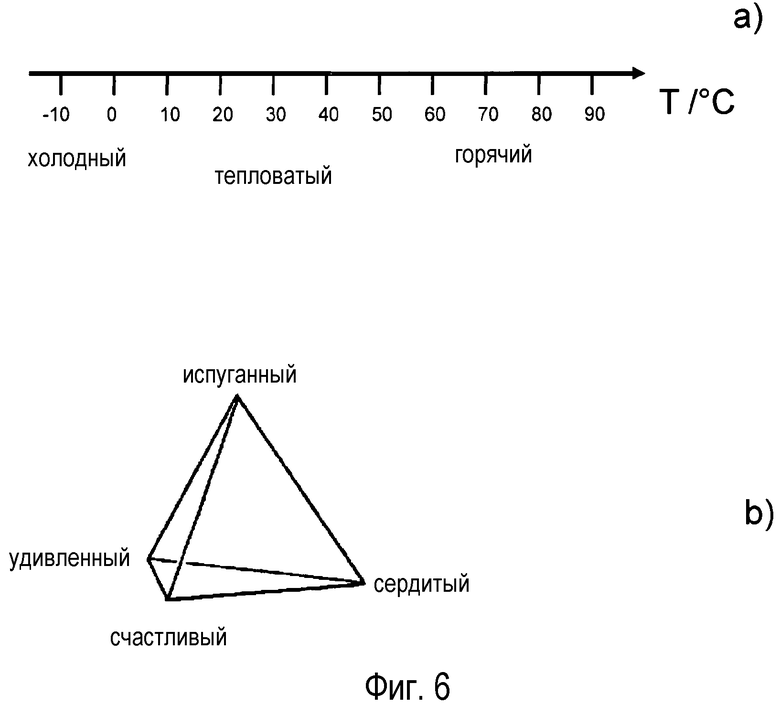
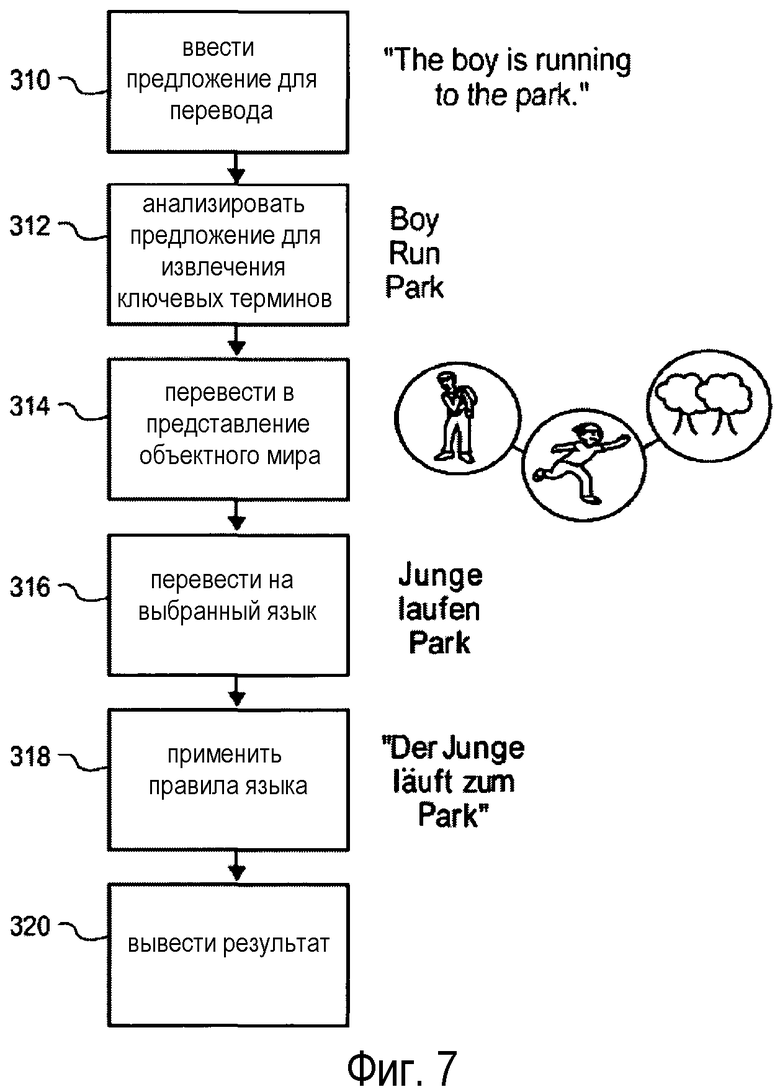
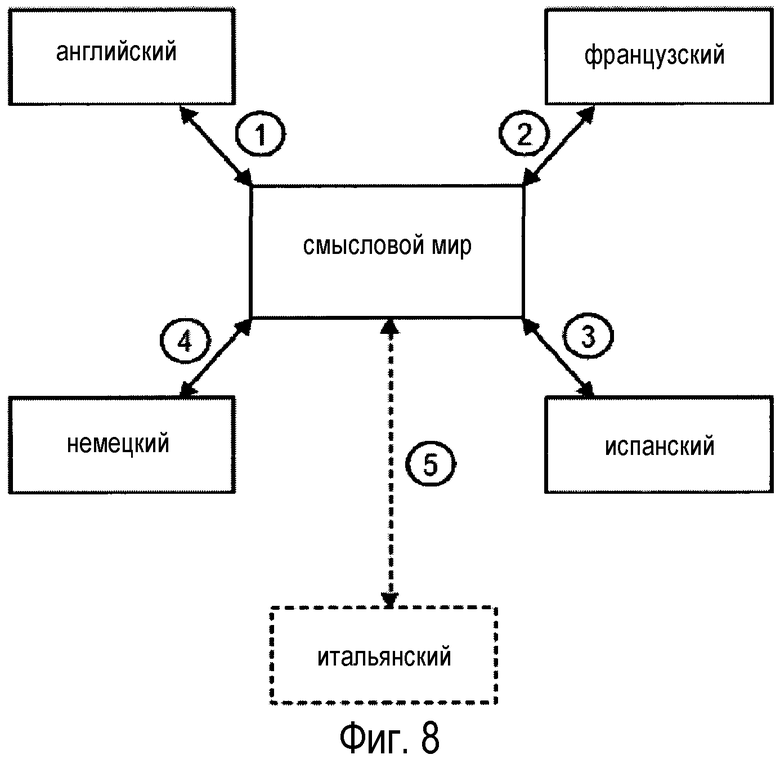
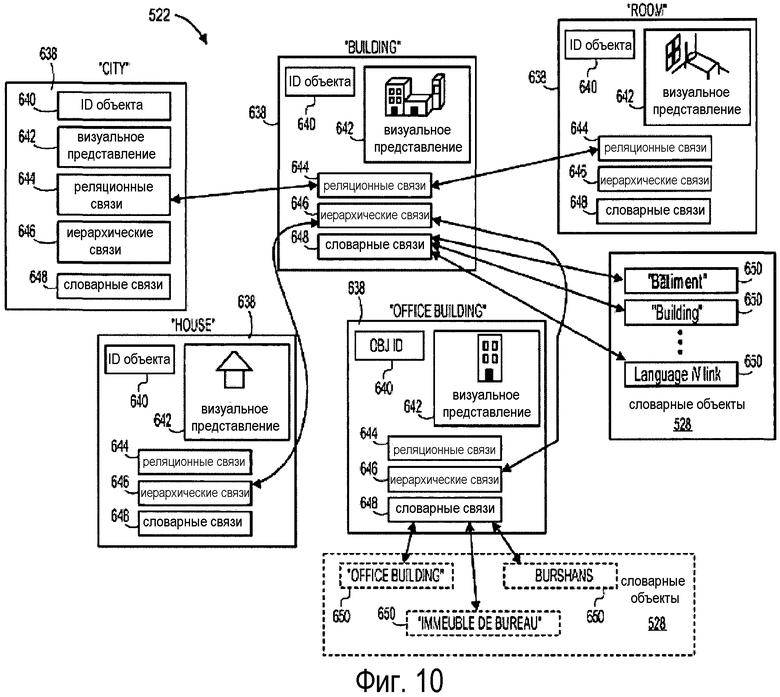
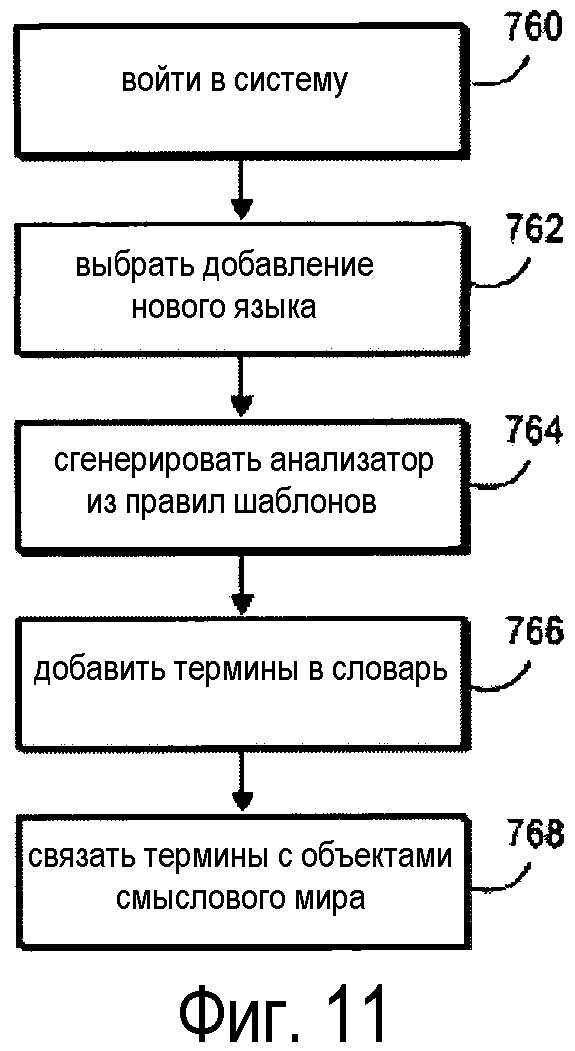
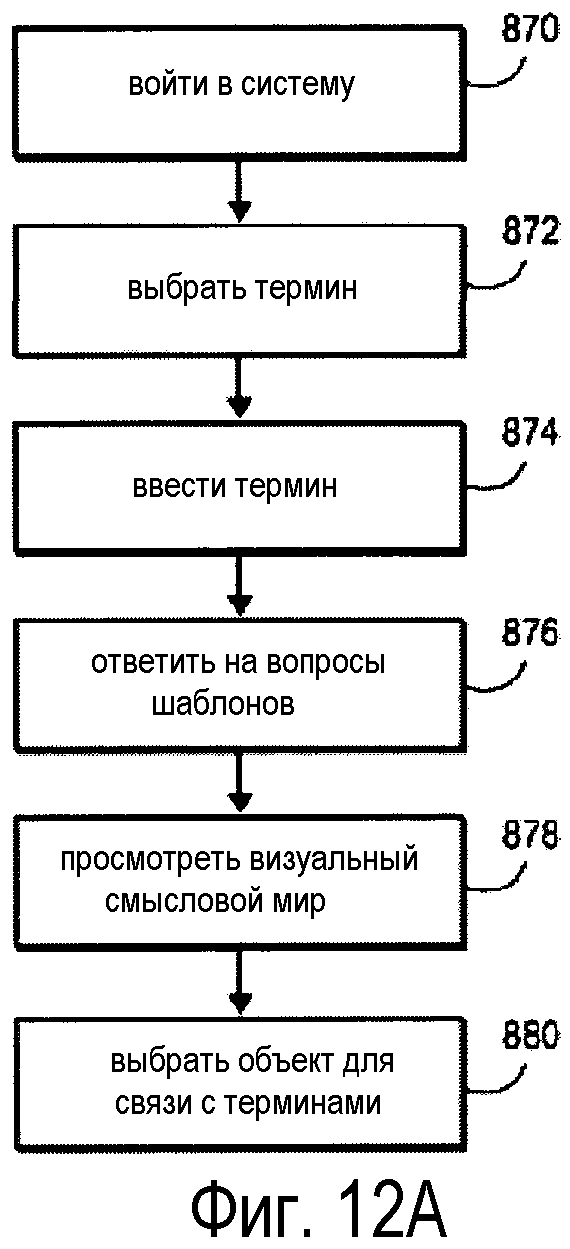
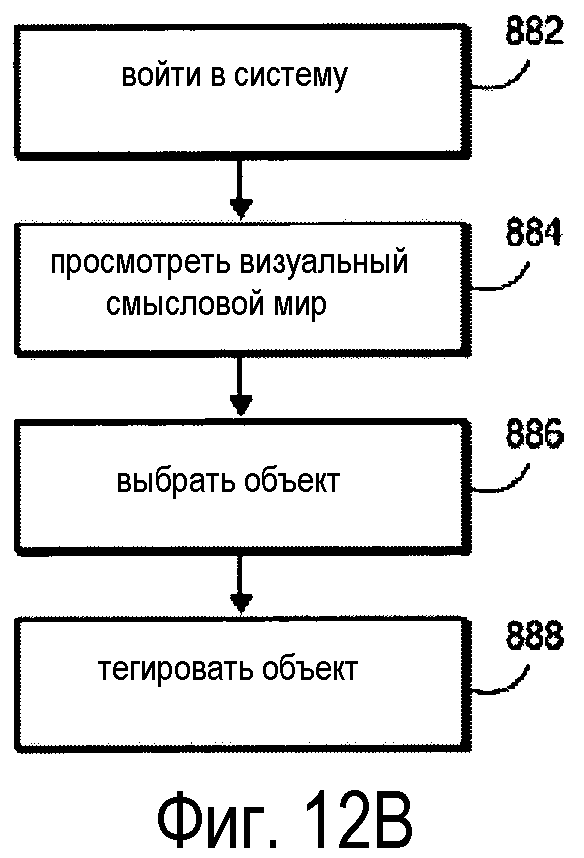
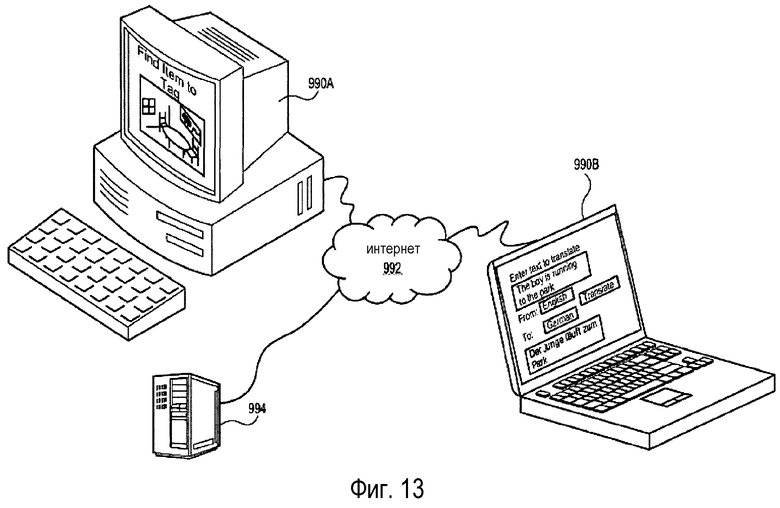
Изобретение относится к способу обработки естественного языка с использованием системы языковой обработки, в частности, электронной системы перевода, в котором письменный или устный текст вводится в систему языковой обработки. Техническим результатом является усовершенствование и дополнительное развитие способа обработки естественного языка, который позволяет правильно обрабатывать семантику текста или прочие данные, например входную речь и т.п. Способ включает в себя этап синтаксического анализа текста. Затем выполняется этап извлечения компонентов текста и их взаимоотношений в тексте. Граф или графическое представление текста генерируется или используется как представление смысла текста, не зависящее от языка. Этот граф или графическое представление используется для осуществления моделирования, представления знания и обработки в системе языковой обработки. Причем на этапе обработки формируют суждение о представлении в модели смыслового мира, таким образом проверяя согласованность извлеченной семантики текста. 3 н. и 26 з.п. ф-лы, 15 ил.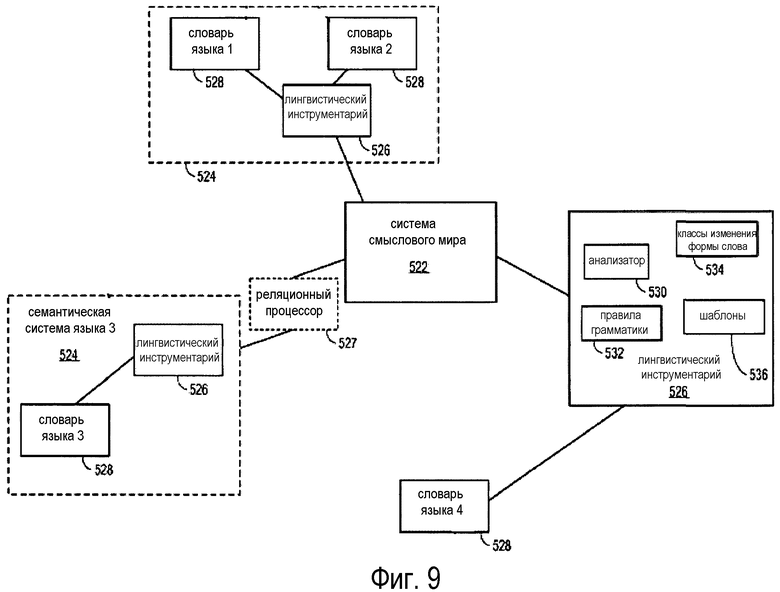
1. Способ обработки естественного языка с использованием системы языковой обработки, в котором письменный или устный текст вводится в систему языковой обработки, содержащий этапы, на которых:
анализируют текст в отношении его синтаксиса и морфологии;
извлекают компоненты текста и их взаимосвязи;
генерируют или используют граф или графическое представление текста в качестве не зависящего от языка представления смысла текста; и
осуществляют обработку текста с использованием графа или графического представления, причем на этапе обработки формируют суждение об упомянутом представлении в модели смыслового мира, таким образом проверяя согласованность извлеченной семантики текста.
2. Способ по п.1, в котором создают визуально-графическую модель текста, причем визуально-графическая модель не зависит от языка, что позволяет пользователям расширять систему языковой обработки, не располагая знанием об используемых языках.
3. Способ по п.1 или 2, в котором грамматические данные, используемые на этапе анализа, вводят в систему языковой обработки посредством редактора грамматики, не зависящего от языка.
4. Способ по п.1, в котором этап анализа осуществляется синтаксическим слоем системы языковой обработки, который осуществляет сегментацию и токенизацию текста, причем синтаксический слой может быть привязан к системе языковой обработки.
5. Способ по п.4, в котором каждый язык, подлежащий обработке системой языковой обработки, представляют в отдельном синтаксическом слое, что позволяет повторно использовать абстракции других языков в отдельных синтаксических слоях.
6. Способ по п.4 или 5, в котором дополнительное абстрагирование и обобщение данных, сгенерированных синтаксическим слоем, осуществляется реляционным слоем, причем данные, предпочтительно, описывают отношения между объектами и их абстракциями.
7. Способ по п.4, в котором информация текста, не зависящая от языка, извлекается в синтаксическом и реляционном слоях, причем информация, не зависящая от языка, передается в семантический слой, и информация, не зависящая от языка, содержит объекты, действия и атрибуты.
8. Способ по п.1, в котором на этапе генерации графа или графического представления объекты, действия и атрибуты предложения или фразы связывают друг с другом.
9. Способ по п. 8, в котором объекты, действия и атрибуты представляют графически.
10. Способ по п.1, в котором на этапе обработки генерируют перевод текста на язык, отличный от исходного языка текста, причем граф или графическое представление является основой перевода.
11. Способ по п.1, в котором на этапе обработки анализируют текст для поиска или другой языковой обработки.
12. Способ по п.10, в котором на этапе обработки генерируют ответ на текст с использованием информации, заданной в модели смыслового мира.
13. Способ по п.1, в котором текст, сгенерированный на этапе обработки, выводят пользователю в качестве письменного или устного языка или в виде изображения.
14. Способ по п.1, в котором знание, используемое на отдельных этапах, вводят с использованием веб-интерфейса для универсального пользования, причем знание может включать в себя теги лексикона, содержимое модели смыслового мира, грамматическую информацию и представление атрибутов.
15. Система для обработки естественного языка, содержащая:
модуль ядра, не зависящий от языка, причем этот модуль манипулирует совокупностью объектов, представляющих термины и отношения между объектами,
совокупность словарных модулей, зависящих от языка, причем каждый словарный модуль имеет совокупность статей, причем каждая статья словарей связана с одним из совокупности объектов, хранящейся в модуле ядра, не зависящем от языка,
анализатор текста, связанный с одним или несколькими из словарных модулей, зависящих от языка, и
генератор предложений, связанный с одним или несколькими из словарей, зависящих от языка,
в которой анализатор текста принимает ввод, извлекает из ввода ключевые термины, использует представление ключевых терминов в виде графа на основе совокупности объектов из модуля ядра, не зависящего от языка, и формирует суждение об упомянутом представлении в модели смыслового мира, таким образом проверяя согласованность извлеченной семантики упомянутого ввода, и генератор предложений формулирует выходной текст на одном из связанных с ним языков на основе представления в виде графа.
16. Система по п.15, в которой ввод содержит письменный текст или устный текст.
17. Система по п.15, содержащая по меньшей мере один лингвистический синтаксический модуль, связанный с одним или несколькими из словарей, зависящих от языка, причем лингвистический синтаксический модуль включает в себя упомянутый анализатор текста, множество правил грамматики и множество шаблонов.
18. Система по п.17, в которой каждый словарь, зависящий от языка, связан с отдельным лингвистическим синтаксическим модулем.
19. Система по п.17, в которой зависящие от языка словари по меньшей мере двух близкородственных языков связаны с одним и тем же лингвистическим синтаксическим модулем.
20. Система по п.15, в которой в модуле ядра, не зависящем от языка, дополнительно хранятся мультимедийные представления соответствующих терминов, хранящихся в этом модуле.
21. Система по п.20, в которой мультимедийные представления содержат изображения, звуки или видеозаписи.
22. Система по п.20, дополнительно содержащая модуль редактирующего компонента, причем модуль редактирующего компонента обеспечивает изменение словарных статей и их связей с одним из совокупности объектов, хранящейся в модуле ядра, не зависящем от языка.
23. Система по п.22, в которой модуль редактирующего компонента дополнительно выполнен с возможностью обеспечивать добавление статей в совокупность словарей, зависящих от языка.
24. Система по п.22, в которой модуль редактирующего компонента приспособлен для доступа к нему через веб-сайт.
25. Система по п.24, в которой мультимедийные представления терминов можно отображать в виртуальном мире.
26. Система по п.22, в которой доступ к модулю редактирующего компонента ограничен квалифицированными пользователями.
27. Способ разработки системы языковой обработки, содержащий этапы, на которых:
разрабатывают ядро, не зависящее от языка, причем данное ядро содержит объекты терминов языка, причем каждый объект терминов языка содержит мультимедийные представления терминов языка и связи между соответствующими терминами языка;
добавляют объект словаря, связанный с конкретным языком;
добавляют слова конкретного языка в объект словаря;
связывают слова с надлежащими объектами терминов языка в ядре; и
обеспечивают веб-интерфейс для универсального пользования, причем веб-интерфейс используется для ввода знания, используемого при функционировании системы языковой обработки, причем знание включает в себя теги лексикона, содержимое модели смыслового мира, грамматическую информацию и представление атрибутов.
28. Способ по п.27, в котором связи между соответствующими терминами языка включают в себя реляционные связи и иерархические связи.
29. Способ по п.27, содержащий этап, на котором создают анализатор языка для конкретного языка на основе правил грамматики и синтаксиса.
| Rada Mihalcea, Ben Leong “Toward Communicating Simple Sentences Using Pictorial Representations”, Proceedings of the 7th Conference of the Association for Machine Translation in the Americas, Cambridge, август 2006, с.119-127 | |||
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| US 7016828 B1, 21.03.2006 | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| ЛИНГВИСТИЧЕСКИ ИНФОРМИРОВАННЫЕ СТАТИСТИЧЕСКИЕ МОДЕЛИ СТРУКТУРЫ СОСТАВЛЯЮЩИХ ДЛЯ УПОРЯДОЧЕНИЯ В РЕАЛИЗАЦИИ ПРЕДЛОЖЕНИЙ ДЛЯ СИСТЕМЫ ГЕНЕРИРОВАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА | 2004 |
|
RU2336552C2 |

