ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0001] В основе большинства систем для обработки текстов на естественном языке лежит применение статистических методов, причем минимальные описания языка создаются вручную. Данный подход является недорогим и быстрым, поскольку появление больших объемов корпусов текстов в последние годы и рост вычислительных мощностей позволяют быстро извлекать необходимую статистическую информацию из языка для машинного обучения. Данный подход также распространен, поскольку он оказывается достаточным для решения ряда обычных проблем. Однако данный подход не позволяет создать полную языковую модель, охватывающую все аспекты языка (т.е. морфологию, лексику, синтаксис и лексическую семантику).
[0002] Задача создания такой полной модели, которую можно использовать для решения самых разнообразных задач по обработке языка и созданию стабильных и надежных технологий, все еще требует значительной ручной работы квалифицированных лингвистов.
[0003] Примером семантического словаря тезаурусного типа является WordNet. Словарь WordNet состоит из четырех сетей, соответствующих основным частям речи:
существительные, глаголы, прилагательные и наречия. Базовыми словарными единицами в WordNet являются синонимические ряды («синсеты»), объединяющие слова со схожими концептуально-семантическими и лексическими значениями. Синсеты представляют собой вершины в сетях WordNet, и каждый синеет содержит определения и примеры употребления слов в контексте. Слова, имеющие несколько лексических значений, включаются в несколько синсетов и могут включаться в различные синтаксические и лексические классы.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0004] В настоящем описании представлены способ, система и машиночитаемый носитель для создания семантического описания (словарь тезаурусного типа) целевого языка на основе семантической иерархии для исходного языка и набора параллельных текстов, особенно, в тех случаях, когда исходный язык и целевой язык являются родственными.
[0005] Один вариант осуществления представляет собой способ, содержащий выравнивание параллельных текстов исходного языка и целевого языка таким образом, чтобы текст на исходном языке соответствовал тексту на целевом языке. Способ дополнительно содержит анализ текста на исходном языке с построением синтаксической структуры, содержащей лексический элемент, а также семантической структуры каждого предложения текста на исходном языке. Семантическая структура включает в себя независимое от языка представление предложения на исходном языке. Способ также включает в себя генерирование с помощью переводного словаря гипотезы о соответствии лексических элементов целевого языка лексическим элементам исходного языка. Способ также включает сопоставление, на основе гипотезы, лексического элемента целевого языка соответствующему лексическому элементу исходного языка. Способ дополнительно содержит связывание синтаксической модели лексического элемента целевого языка с синтаксической моделью лексического элемента исходного языка на основе результатов сравнения.
[0006] Другой вариант осуществления относится к системе, содержащей устройство для обработки. Устройство для обработки выполнено с возможностью выравнивания параллельных текстов исходного языка и целевого языка таким образом, чтобы текст на исходном языке соответствовал тексту на целевом языке. Устройство для обработки дополнительно выполнено с возможностью анализа текста на исходном языке с построением синтаксической структуры, включающей лексический элемент на исходном языке, и семантической структуры предложения на исходном языке, причем семантическая структура включает независимое от языка представление предложения на исходном языке. Устройство для обработки дополнительно выполнено с возможностью генерации, на основе переводного словаря, гипотезы о соответствии лексических элементов целевого языка лексическим элементам исходного языка. Далее, устройство для обработки дополнительно выполнено с возможностью осуществлять сопоставление, на основе гипотезы, лексического элемента целевого языка соответствующему лексическому элементу исходного языка. Устройство для обработки дополнительно выполнено с возможностью осуществлять связывание синтаксической модели лексического элемента целевого языка с синтаксической моделью лексического элемента исходного языка на основе результатов сравнения.
[0007] Другой вариант осуществления относится к машиночитаемому носителю информации, содержащему хранящиеся на нем инструкции, причем инструкции содержат инструкции относительно выравнивания параллельных текстов исходного языка и целевого языка таким образом, чтобы текст на исходном языке соответствовал тексту на целевом языке. Инструкции также содержат инструкции для анализа текста на исходном языке с построением синтаксической структуры и семантической структуры предложения на исходном языке, причем синтактическая структура включает лексический элемент на исходном языке, а семантическая структура включает независимое от языка представление предложения на исходном языке. Инструкции также содержат инструкции для генерации, на основе переводного словаря, гипотезы о соответствии лексических элементов целевого языка лексическим элементам исходного языка. Инструкции также содержат иструкции для сопоставления, на основе гипотезы, лексического элемента целевого языка соответствующему лексическому элементу исходного языка. Инструкции также содержат инструкции для связывания синтаксической модели лексического элемента целевого языка с синтаксической моделью лексического элемента исходного языка на основе результатов сравнения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0008] Описанные выше и другие элементы настоящего описания будут в более полной мере понятны из следующего описания и прилагаемой формулы изобретения в сочетании с прилагаемыми рисунками. Описание будет обладать дополнительной специфичностью и подробным изложением при помощи прилагаемых рисунков с учетом того, что на данных рисунках представлено только несколько вариантов осуществления в соответствии с описанием и, следовательно, они не могут считаться ограничивающими объем настоящего изобретения.
[0009] Фиг. 1 является блок-схемой, иллюстрирующей способ настоящего изобретения для автоматического создания семантического описания целевого языка в соответствии с одним вариантом осуществления.
[0010] Фиг. 2 представляет схему, иллюстрирующую описания языка в соответствии с одним вариантом осуществления.
[0011] Фиг. 3 представляет схему, иллюстрирующую морфологические описания в соответствии с одним вариантом осуществления.
[0012] Фиг. 4 представляет схему, иллюстрирующую синтаксические описания в соответствии с одним вариантом осуществления.
[0013] Фиг. 5 представляет схему, иллюстрирующую семантические описания в соответствии с одним вариантом осуществления.
[0014] Фиг. 6 представляет схему, иллюстрирующую лексические описания в соответствии с одним вариантом осуществления.
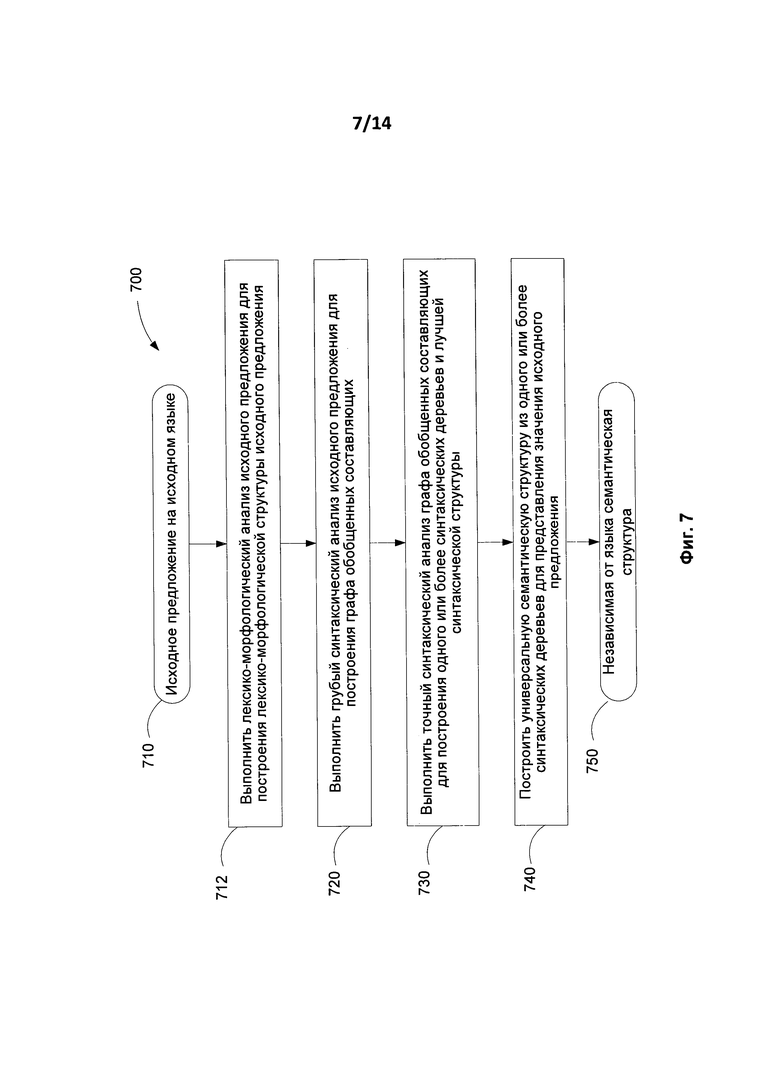
[0015] Фиг. 7 представляет этапы способа анализа в соответствии с одним вариантом осуществления.
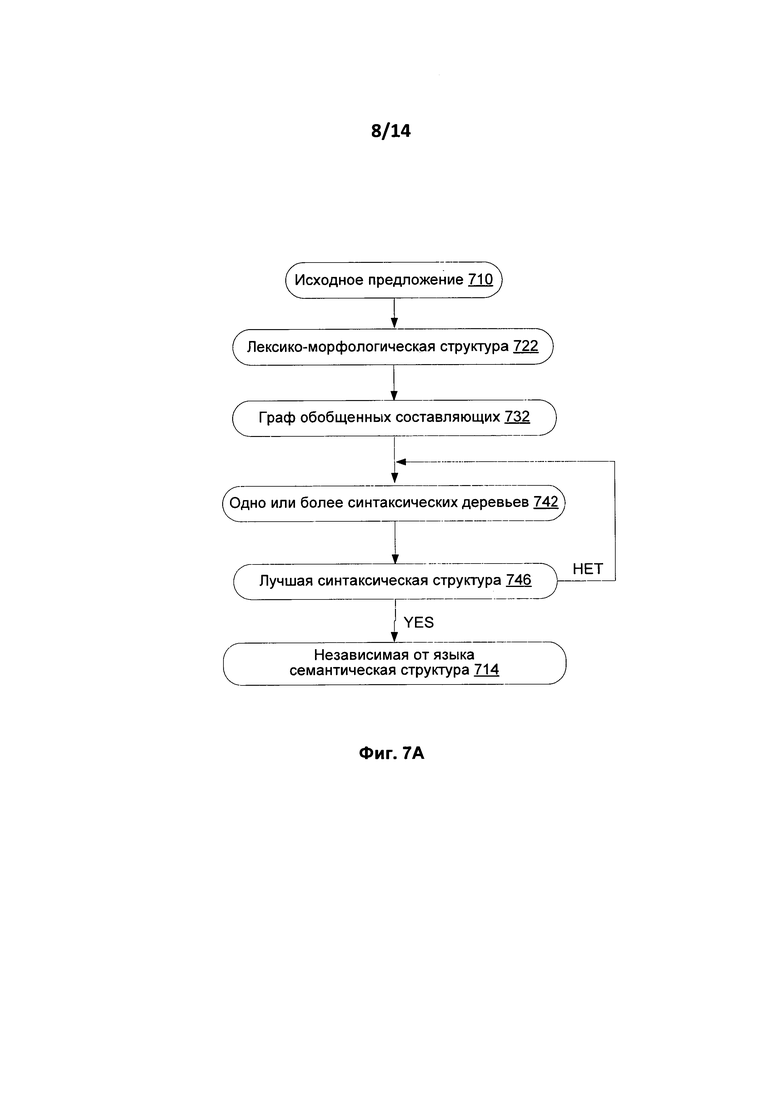
[0016] На Фиг. 7А показана последовательность структур данных, созданных в процессе анализа, в соответствии с одним вариантом осуществления.
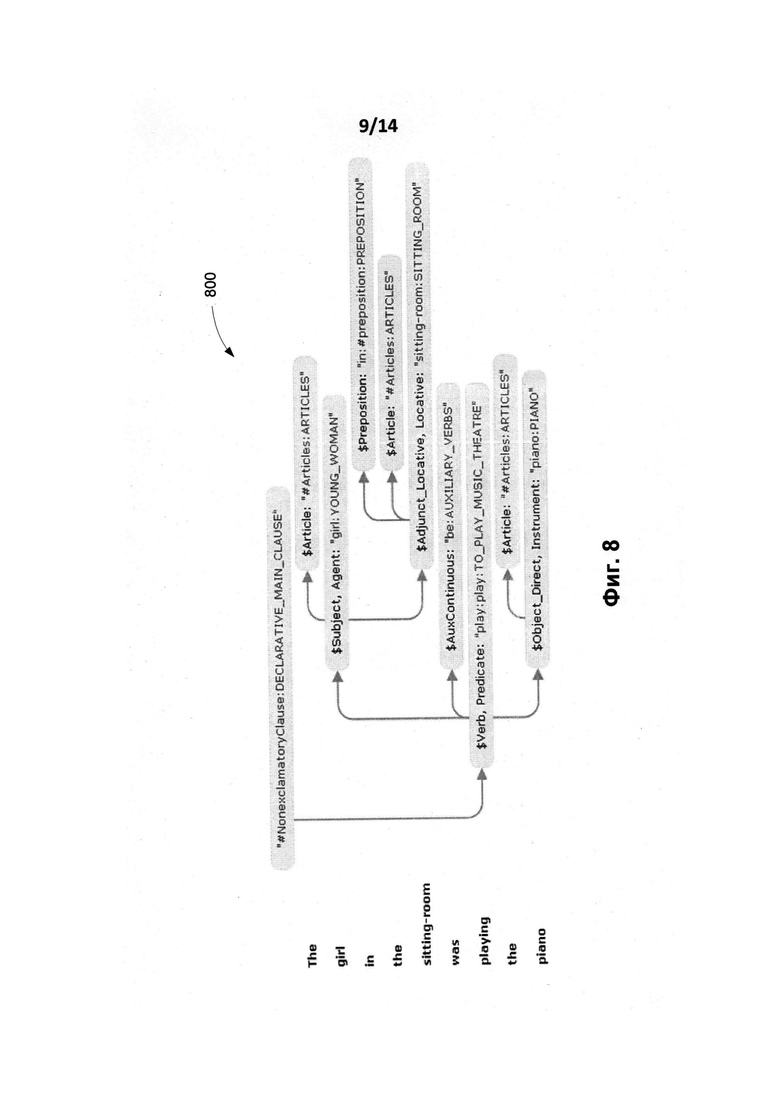
[0017] На Фиг. 8 и 8А представлены два разных синтаксических дерева для английского предложения «The girl in the sitting-room was playing the piano».
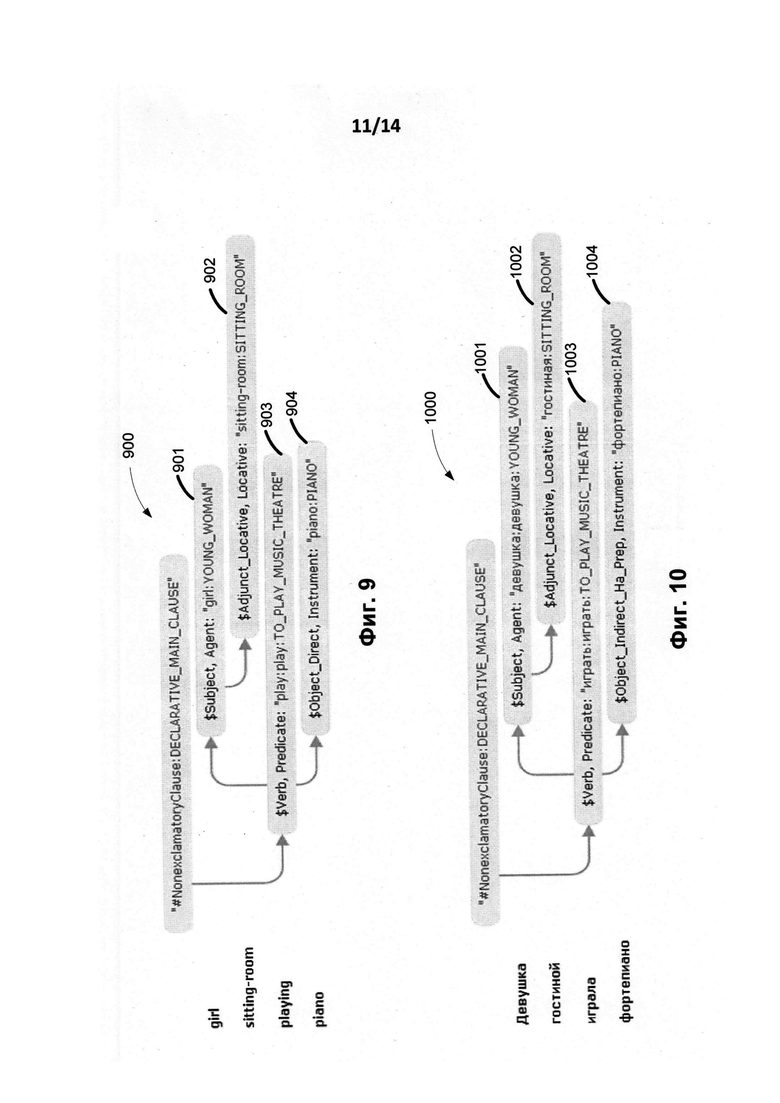
[0018] На Фиг. 9 представлена семантическая структура английского предложения «The girl in the sitting-room was playing the piano».
[0019] На Фиг. 10 представлена семантическая структура русского предложения «Девушка в гостиной играла на фортепиано», которое соответствует английскому предложению «The girl in the sitting-room was playing the piano».
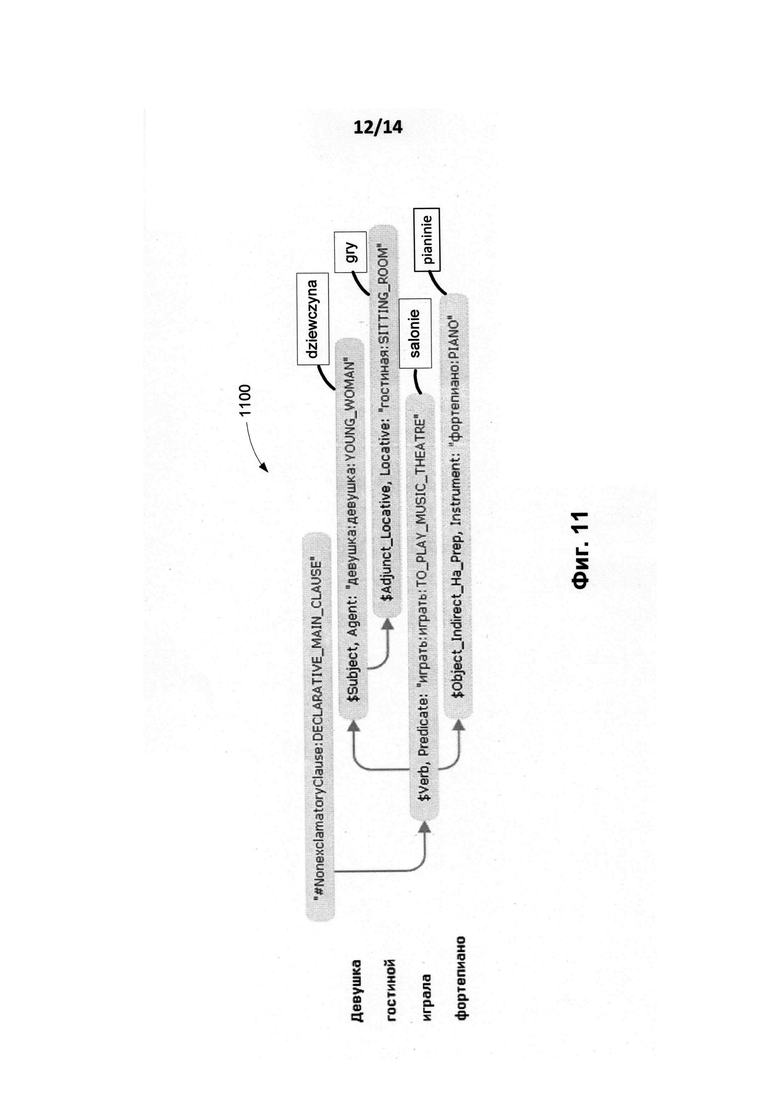
[0020] Фиг. 11 иллюстрирует результат этапа создания семантического описания целевого языка на основе анализа русского предложения «Девушка в гостиной играла на фортепиано» и его польского эквивалента «Dziewczyna w salonie gry na pianinie» в соответствии с одним вариантом осуществления.
[0021] Фиг. 12 иллюстрирует синтаксическую структуру русского предложения «Девушка в гостиной играла на фортепиано».
[0022] На Фиг. 13 приведен возможный пример вычислительного средства которое может быть использовано для реализации данного изобретения.
[0023] Следующее детальное описание содержит ссылки на прилагаемые рисунки. Как правило, на рисунках аналогичные компоненты обозначены аналогичными символами, если только контекст не предполагает иное. Предполагается, что примеры осуществления, описанные в подробном описании, рисунках и формуле изобретения, не являются ограничивающими. Можно использовать другие варианты осуществления и вносить другие изменения без отступления от сущности и объема объекта изобретения, представленного в данном описании. Следует понимать, что аспекты данного изобретения, по существу представленные в данном описании и проиллюстрированные рисунками, можно перераспределять, заменять, комбинировать и моделировать, создавая широкий спектр различных конфигураций, все из которых явным образом предусмотрены настоящим описанием и являются его частью.
ПОДРОБНОЕ ОПИСАНИЕ
[0024] Описанные в настоящем описании способы, машиночитаемые носители и системы предназначены для автоматизации значительных объемов работы лингвистов по созданию семантических и синтаксических описаний языка, добавляемых в систему. В частности, в соответствии с описанными методиками наиболее трудоемкую часть описания лексического синтаксиса можно автоматизировать.
[0025] При использовании хорошо описанного исходного языка, включающего в себя все необходимые лингвистические (например, синтаксические и семантические) описания, можно использовать набор выровненных параллельных текстов со словарем перевода для создания аналогичных описаний родственного языка (например, украинского языка на основе русского языка).
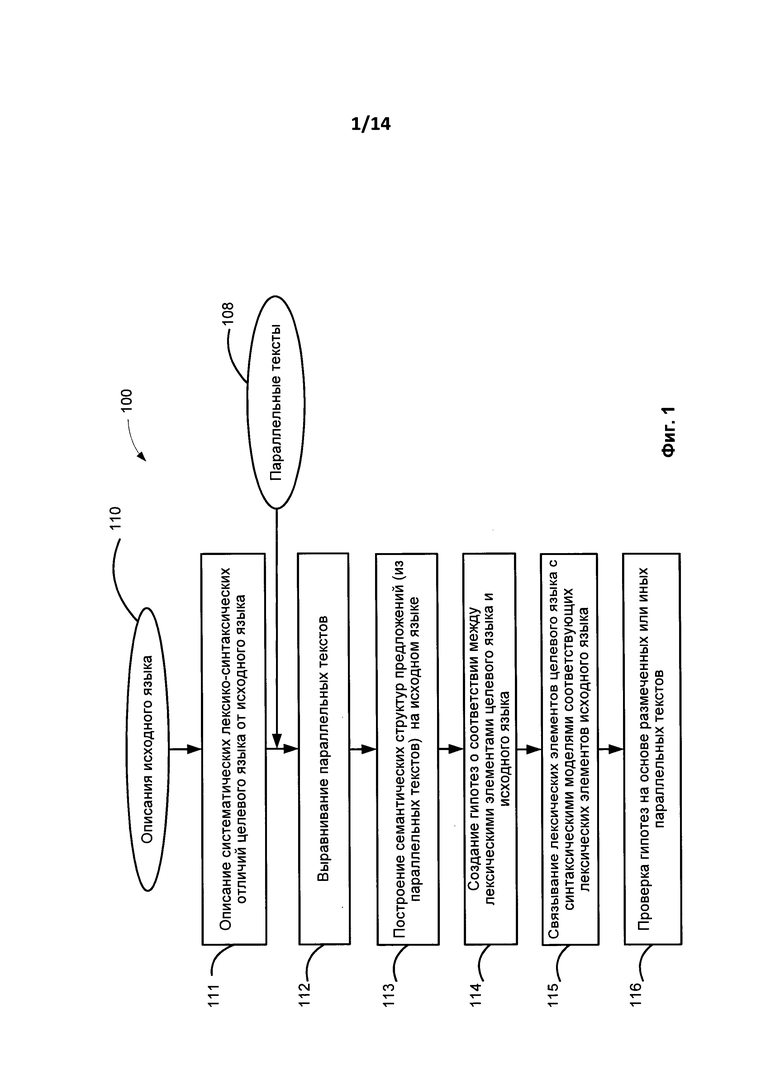
[0026] Необходимые лингвистические описания могут включать в себя лексические описания, морфологические описания, синтаксические описания и семантические описания. На Фиг. 1 представлена блок-схема этапов способа (100) автоматического создания семантического описания целевого языка в соответствии с одним из вариантов осуществления. При использовании альтернативных вариантов осуществления могут выполняться другие действия, их количество также может отличаться. Кроме того, использование блок-схемы не должно выступать в качестве ограничения порядка выполнения действий. Ниже представлен обзор способа (100).
[0027] На этапе (111) лингвистами на основе имеющихся описаний исходного языка (110) формально описываются некоторые систематические лексические и синтаксические отличия целевого языка от исходного языка. На этой основе может строиться базовый синтаксис и морфологическая модель.
[0028] На этапе (112) выравниваются параллельные тексты (108) на исходном языке и целевом языке. Для решения этой задачи может быть использован переводной словарь.
[0029] На этапе (113) предложения из параллельных текстов на исходном языке анализируются с применением технологии глубинного анализа. В этом процессе для построения синтаксических и семантических структур предложений на исходном языке могут быть использованы как независимые от языка описания, так и зависимые от языка описания исходного языка.
[0030] На этапе (114) могут выдвигаться гипотезы о соответствии лексических элементов в предложениях целевого языка и исходного языка с использованием переводного словаря.
[0031] На этапе (115) лексическим элементам целевого языка сопоставляются синтаксические модели соответствующих лексических элементов исходного языка с учетом описанных систематических преобразований и различий. Лексические элементы целевого языка можно заменять синтаксическими моделями соответствующих элементов исходного языка.
[0032] На этапе (116) гипотезы могут проверяться на аннотированных или иных параллельных текстах. Способ (100) и различные его этапы, включая описания языка и структурные элементы, необходимые для поддержки способа (100), будут более подробно описаны ниже.
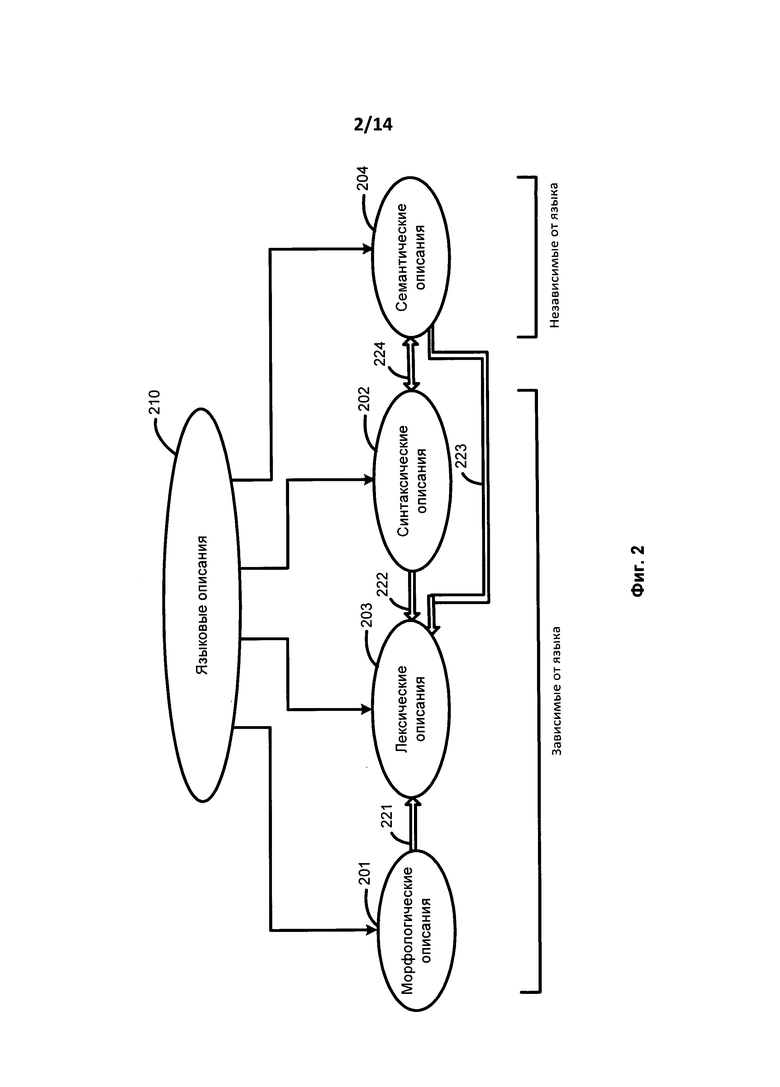
[0033] На Фиг. 2 представлена схема, иллюстрирующая необходимые описания языка (210) и связи между описаниями в соответствии с одним вариантом осуществления изобретения. Описания языка (210) включают в себя морфологические описания (201), синтаксические описания (202), лексические описания (203) и семантические описания (204). Среди описаний языка (210) морфологические описания (201), лексические описания (203) и синтаксические описания (202) создаются для каждого конкретного языка. Каждое из этих описаний языка (210) может быть создано для каждого исходного языка, и, взятые вместе, они представляют собой модель исходного языка. Семантические описания (204) не зависят от языка и используются для описания независимых от языка семантических свойств различных языков, а также для создания независимых от языка семантических структур, представляющих независимые от языка значения предложений.
[0034] Морфологические описания (201), лексические описания (203), синтаксические описания (202), а также семантические описания (204) взаимосвязаны. Лексические описания (204) и морфологические описания (201) объединены связью (221), поскольку любому лексическому значению в лексическом описании (203) может соответствовать морфологическая модель, представленная одним или более грамматическим значением указанного лексического значения. Например, одно или несколько грамматических значений могут быть представлены различными наборами граммем в грамматической системе морфологических описаний (101).
[0035] Кроме того, как показано при помощи связи (222), любое данное лексическое значение в лексических описаниях (203) может также иметь одну или более поверхностных моделей в синтаксических описаниях (202) данного лексического значения. Связь 223 иллюстрирует, что лексические описания (203) также могут быть связаны с семантическими описаниями (204).Поэтому лексические описания (203) и семантические описания (204) могут рассматриваться вместе и в результате образуют «лексико-семантические описания», такие как лексико-семантический словарь.
[0036] Как показано при помощи связи 224, синтаксические описания (202) и семантические описания (204) также связаны. Например, диатезы (такие как 417 на Фиг. 4), которые могут являться частью синтаксических описаний (202), могут рассматриваться как «интерфейс» между поверхностными моделями в конкретном языке и независимыми от языка глубинными моделями (например, 512, как показано на Фиг. 5) семантического описания (204).
[0037] На Фиг. 3 представлена схема, иллюстрирующая морфологические описания в соответствии с одним вариантом осуществления изобретения. Компоненты морфологических описаний (201), среди прочих, включают в себя, описание словоизменения (310), грамматическую систему (320) (например, граммемы и грамматические категории) и описания словообразования (330). Грамматическая система (320) включает в себя набор грамматических категорий, таких как "Part of speech", "Case", "Gender", "Number", "Person", "Reflexivity", "Tense", "Aspect", и т.д., («часть речи», «падеж», «род», «число», «лицо», «возвратность», «время», «залог»)., а также их значения, именуемые «граммемами». Например, такие граммемы могут быть представлены как Adjective, Noun, Verb для обозначения прилагательного, существительного, глагола и т.д. В качестве другого примера, граммемы могут представлять Nominative, Accusative, Genitive (именительный падеж, винительный падеж, родительный падеж и т.д.) В качестве другого примера, такие граммемы могут представлять Feminine, Masculine, Neuter (женский род, мужской род, средний род) и т.д. Существуют также другие граммемы, и объем настоящего изобретения не ограничен определенными граммемами.
[0038] Описание словоизменения (310) показывает, как основная форма слова может меняться в зависимости от падежа, рода, числа, времени и т.п., а также может описывать все возможные формы слова. Словообразование (330) описывает, какие новые слова могут создаваться с применением основного слова (например, в немецком языке существует множество сложных слов - композитов). Граммемы являются единицами грамматической системы (320) и, как показано при помощи стрелки 222 и стрелки 324, граммемы могут использоваться для построения описания словоизменения (310), а также описания словообразования (330).
[0039] В соответствии с одним вариантом осуществления изобретения при установлении синтаксических отношений между элементами исходного предложения используется модель составляющей. Составляющая может включать смежную группу из одного или более слов в предложении, которые могут выступать как единое целое. Составляющая имеет некоторое слово, рассматриваемое как ядро этой составляющей, и может включать дочерние составляющие на низших уровнях. Дочерние составляющие также называют зависимыми составляющими, и они могут присоединяться к другим составляющим (т.е. родительскимсоставляющим) при построении синтаксического описания (202) исходного предложения.
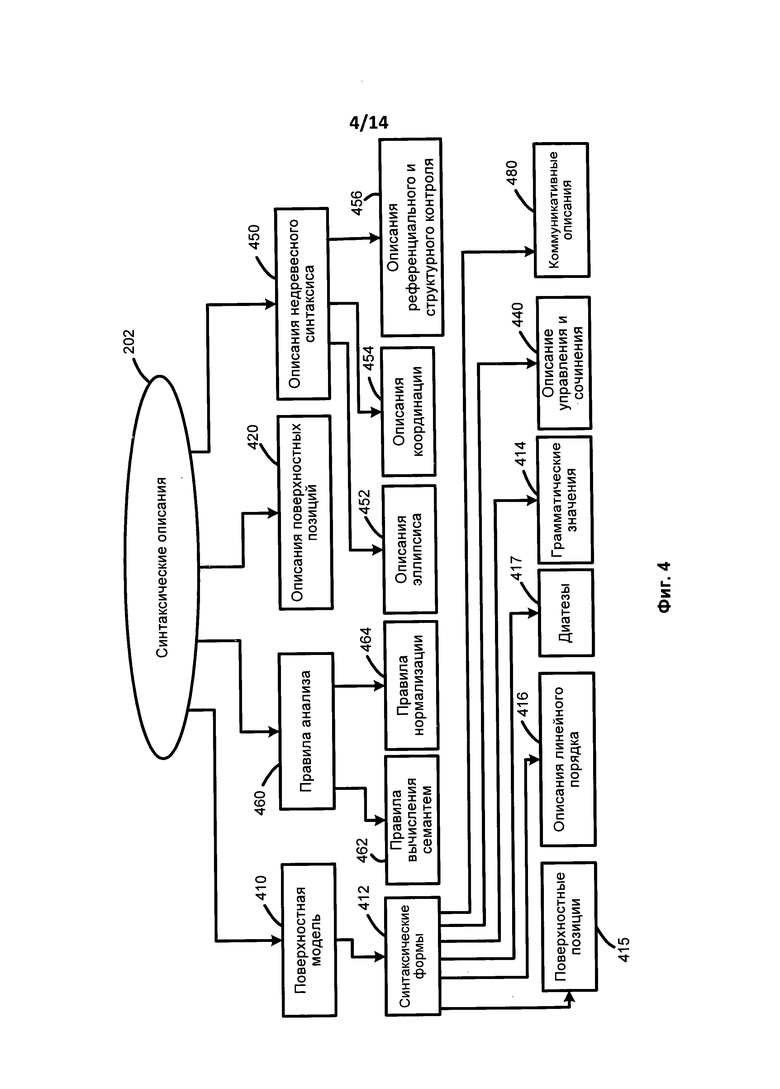
[0040] На Фиг. 4 представлена схема, иллюстрирующая синтаксические описания в соответствии с одним вариантом осуществления изобретения. Компоненты синтаксических описаний (202) могут включать в себя, без ограничений, поверхностные модели (410), описания поверхностных позиций (420), описание недревесного синтаксиса (450) и правила анализа (460). Синтаксические описания (202) используются для создания потенциальных синтаксических структур исходного предложения на исходном языке с учетом свободного линейного порядка слов, недревесных синтаксических явлений (например, согласования, эллипсиса и т.д.), референциальных связей, а также других факторов.
[0041] Поверхностные модели (410) представлены в виде множества одной или более синтаксических форм (т.е. «синтформ» 412) для описания возможных синтаксических структур предложений, которые включены в синтаксические описания (202). В общем случае, всякое лексическое значение в языке связано с его поверхностными (синтаксическими) моделями (410), которые представляют собой составляющие в том случае, когда лексическое значение выступает в качестве «ядра», и включает в себя набор поверхностных позиций дочерних элементов, описание линейного порядка, диатезы и т.д.
[0042] Поверхностные модели (410) могут быть представлены синтформами (412). Каждая синтформа (412) может включать в себя определенное лексическое значение, которое функционирует как «ядро» составляющей, и может, среди прочих, дополнительно включать в себя набор поверхностных позиций (415) своих дочерних составляющих, описание линейного порядка (416), диатезы (417), грамматические значения (414), описания управления и сочинения (440), коммуникативные описания (480) по отношению к ядру составляющей.
[0043] Описания поверхностных позиций (420), как части синтаксических описаний (202), используются для описания общих свойств поверхностных позиций (415), которые используются в поверхностных моделях (410) различных лексических значений в исходном языке. Поверхностные позиции (415) могут использоваться для выражения синтаксических отношений между компонентами предложения. Примеры поверхностных позиций (415) могут, среди прочего, включать в себя, без ограничения: "Subject", "Object_Direcr", "Object_Indirect", "Relative Clause" (т.е. подлежащее, прямое_дополнение, косвенное_дополнение, относительное придаточное предложение).
[0044] При синтаксическом анализе модель составляющей использует множество поверхностных позиций (415) дочерних составляющих и описания их линейного порядка (416), а также описывает грамматические значения (414) возможных заполнителей этих поверхностных позиций (415). Диатезы (417) представляют собой соответствия между поверхностными позициями (415) и глубинными позициями (например, 514 на Фиг. 5). Диатезы (417) представлены связью (например, 224, как показано на Фиг. 2) между синтаксическими описаниями (например, 202, как показано на Фиг. 2) и семантическими описаниями (например, 204, как показано на Фиг. 2). Коммуникативные описания (480) описывают коммуникативный порядок в предложении.
[0045] Синтаксические формы (синтформы) (412) включают набор поверхностных позиций (415) с описанием их линейного порядка (416). Одна или более составляющих для лексического значения словоформы в исходном предложении могут быть представлены поверхностными синтаксическими моделями (410). Каждая составляющая может рассматриваться как одна из реализации модели составляющей путем выбора соответствующей синтформы (412). Выбранные синтаксические формы или синтформы (412) представляют собой наборы поверхностных позиций (415) с указанным линейным порядком. Каждая поверхностная позиция в синтформе может иметь грамматические и семантические ограничения относительно заполнителей этой позиции.
[0046] Описание линейного порядка (416) включает выражения линейного порядка, которые формируются для выражения последовательности, в которой различные поверхностные позиции (415) могут встречаться в предложении. Выражения линейного порядка могут включать названия переменных, названия поверхностных позиций, скобки, граммемы, оценки, а также оператор «или» и т.д. Например, описание линейного порядка простого предложения "Boys play football." может быть представлено в виде "Subject Core Object_Direct", где « Subject» и « Object_Direct» представляют собой названия поверхностных позиций (415), соответствующих порядку слов. Заполнители поверхностных позиций (415), указанные символами элементов предложения, могут присутствовать в том же порядке, как и в выражении линейного порядка.
[0047] Различные поверхностные позиции (415) могут располагаться в в синтформе (412) в строгом «и/или» порядке. Также, скобки могут быть использованы для построения выражений линейного порядка и описывать отношения строгого линейного порядка между различными поверхностными позициями (415). Например, "SurfaceSlot1 SurfaceSlot2" или "(SurfaceSlot1 SurfaceSlot2)" означает, что обе поверхностные позиции расположены в том же выражении линейного порядка, но возможен только определенный порядок следования этих поверхностных позиций относительно друг друга, при котором SurfaceSlot 2 должен следовать за SurfaceSlot 1.
[0048] Далее, квадратные скобки могут использоваться для построения выражений нестрогого линейного порядка различных поверхностных позиций (415) в синтформе (412). Например, [SurfaceSlot1 SurfaceSlot2] указывает, что обе поверхностных позиции принадлежат той же переменной линейного порядка, а их порядок относительно друг друга не имеет значения.
[0049] Выражения линейного порядка в описании линейного порядка (416) могут содержать грамматические значения (414), выраженные граммемами, которым соответствуют дочерние составляющие. Кроме того, два выражения линейного порядка могут быть объединены оператором | («ИЛИ»), Например: (Subject Core Object) | [Subject Core Object].
[0050] Коммуникативные описания (480) описывают порядок слов в синтформе (412) с точки зрения коммуникативных актов, которые необходимо представить в виде выражений коммуникативного порядка, которые аналогичны выражениям линейного порядка. Описание управления и сочинения (440) содержит правила и ограничения на грамматические значения подключаемых составляющих, учитываемые в процессе синтаксического анализа.
[0051] Описания недревесного синтаксиса (450) имеют отношение к обработке различных лингвистических явлений, таких как эллипсис и координация, и используются в преобразовании синтаксической структуры, которая создается на различных этапах анализа в соответствии с вариантами осуществления настоящего изобретения. Описания недревесного синтаксиса (450) могут включать в себя, без ограничений, описания эллипсиса (452), описания согласования (454) и описания референциального и структурного контроля (456).
[0052] Правила анализа (460) как часть синтаксических описаний (202) могут включать в себя правила вычисления семантем (462) и правила нормализации (464). Хотя правила анализа (460) используются во время семантического анализа, правила анализа (460), по существу, описывают свойства конкретного языка и связаны с синтаксическими описаниями (например, 202 на Фиг. 2). Правила нормализации (464) используются в виде правил преобразования для описания преобразований семантических структур, которые могут быть различными в разных языках.
[0053] На Фиг. 5 представлена схема, иллюстрирующая семантические описания в соответствии с одним вариантом осуществления настоящего изобретения. Компоненты семантических описаний (например, 204) не зависят от языка и могут включать в себя семантическую иерархию (510), описание глубинных позиций (520), систему семантем (530) и прагматические описания (540).
[0054] Семантическая иерархия (510) содержит смысловые понятия (семантических объектов) и именованные семантические классы, организованные в соответствии с иерархическими отношениями «родительский объект - дочерний объект», которые аналогичны дереву. В целом, дочерний семантический класс может унаследовать часть или все свойства своего непосредственного родителя, а также всех предшествующих семантических классов более высоких уровней. Например, семантический класс SUBSTANCE (вещество) является дочерним классом семантического класса ENTITY (сущность), и в то же время он является "родителем" для семантических классов GAS (газ), LIQUID (жидкость), METAL (металл), WOOD_MATERIAL (дерево как материал), и т.д.
[0055] Каждый семантический класс в семантической иерархии (510) снабжен глубинной моделью (512). Глубинная модель (512) семантического класса включает в себя множество глубинных позиций(514),которые отражают семантические роли дочерних составляющих в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей и возможные семантические классы в качестве заполнителей глубинных позиций. Эти глубинные позиции (514) выражают семантические отношения, например, "agent" (агент), "addressee" (адресат), "instrument" (инструмент), "циап111у"(количество), и т.д. Дочерний класс может наследовать и подстраивать глубинную модель (512) своего прямого родительского семантического класса. Описания глубинных позиций (520) используются для описания общих свойств глубинных позиций (514) и отражают семантические роли дочерних составляющих в глубинных моделях (512).
[0056] Описания глубинных позиций (520) также содержит грамматические и семантические требования к заполнителям глубинных позиций (514). Свойства и ограничения глубинных позиций (514) и их возможных заполнителей, как правило, очень похожи и часто идентичны в различных языках. Таким образом, глубинные позиции (514) не зависят от конкретного языка.
[0057] Система семантем 530 представляет множество семантических категорий и семантем, которые отражают значения семантических категорий. Для примера, семантическая категория "DegreeOfComparison" (степень сравнения) может быть использована для описания степеней сравнения и может включать семантемы, например "Positive", "ComparativeHigherDegree", "SuperlativeHighestDegree", и т.д. В качестве другого примера, семантическая категория "RelationToReferencePoint" может быть использована для описания того, в каком линейном порядке (например, до или после объекта или события) находится в предложении ссылка на него, и ее семантемами являются "Previous" или "Subsequent". Порядок также можно описывать пространственно или с позиции прошедшего времени в широком смысле анализируемых слов. Еще один пример - семантическая категория "EvaluationObjective" может фиксировать наличие объективной оценки, такой как "Bad", "Good" и т.д.
[0058] Системы семантем (530) включают в себя независимые от языка семантические атрибуты, которые выражают не только семантические характеристики, но и стилистические, прагматические и коммуникативные характеристики. Некоторые семантемы можно использовать для выражения единичного значения, которое находит надлежащее грамматическое и/или лексическое выражение в языке. Систему семантем (530) можно разделить на несколько различных категорий в соответствии с их назначением и применением. Например, данные категории могут включать в себя грамматические семантемы (532), лексические семантемы (534) и классифицирующие грамматические (дифференцирующие) семантемы (536).
[0059] Грамматические семантемы (532) используются для описания грамматических свойств компонентов при преобразовании синтаксического дерева в семантическую структуру. Лексические семантемы (534) описывают конкретные свойства объектов (например, «плоский» или «жидкий» и т.п.предмет) и используются при описании углубленных слотов (520) в качестве ограничения для заполнителей углубленных слотов. Классифицирующие грамматические (дифференцирующие) семантемы (536) выражают дифференцирующие свойства объектов в пределах одного семантического класса. Например, "barber" («парикмахер для мужчин» в английском языке) в семантическом классе "HAIRDRESSER" ему будет приписана семантема "RelatedToMen", в то время как в том же семантическом классе есть "hairdresser" и "hairstylist" и др.
[0060] Прагматическое описание (540) позволяет назначить соответствующую тему, стиль или жанр для текстов и объектов семантической иерархии (510). Например, такие прагматические описания могут включать в себя «Экономическую политику», «Международную политику», «Правосудие», «Законодательство», «Торговлю», «Финансы» ("Economic Policy", "Foreign Policy", "Justice", "Legislation", "Trade", "Finance") и т.п. Прагматические описания также могут быть выражены семантемами. Кроме того, прагматический контекст также может быть принят во внимание в процессе семантического анализа.
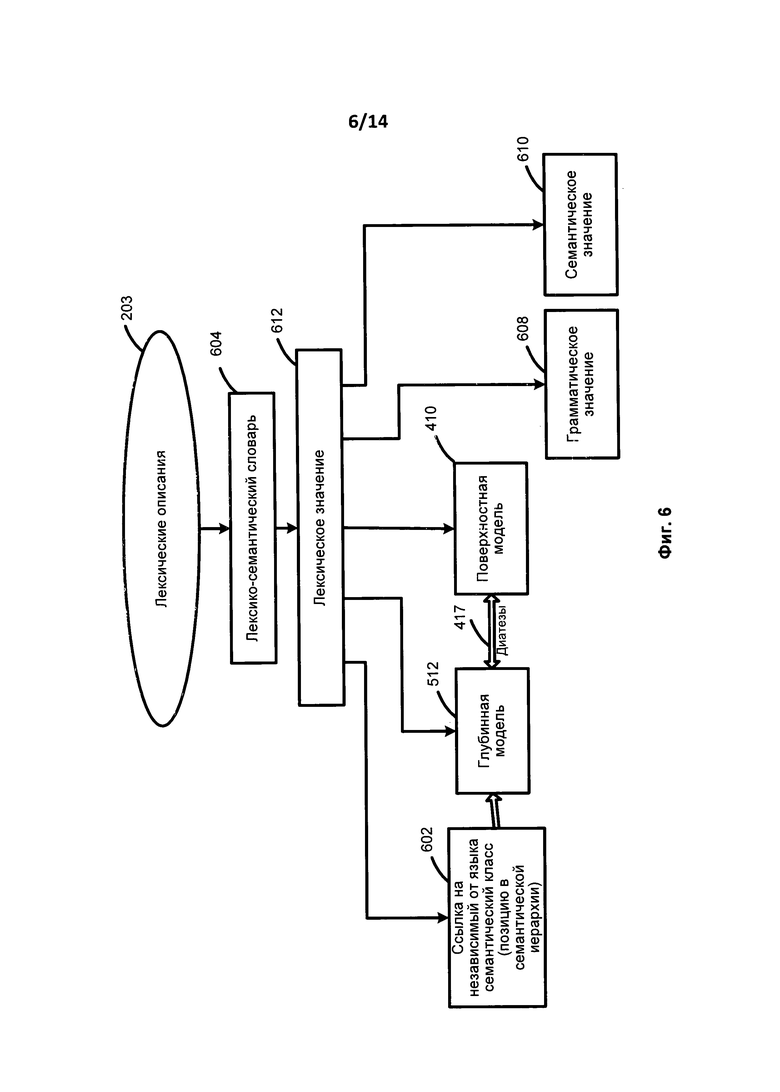
[0061] На Фиг. 6 представлена схема, иллюстрирующая лексические описания в соответствии с одним вариантом осуществления. Лексические описания (203) могут включать в себя лексико-семантический словарь (604), который включает в себя множество лексических значений (612) на определенном языке для каждого компонента предложения. Для каждого лексического значения (612) имеется ссылка (602) на его независимого от языка семантического предка для указания местоположения данного лексического значения в семантической иерархии (510).
[0062] Каждое лексическое значение (612) связано с глубинной моделью (512), описанной независимыми от языка понятиями, а также с поверхностной моделью (410), которая специфична для конкретного языка. Диатезы (417) можно использовать для установления соответствия между поверхностными моделями (410) и глубинными моделями (512) для каждого лексического значения (612). Каждой поверхностной позиции (например, 415) в каждой синтформе (например, 412) поверхностных моделей (410) может быть приписана одна или более диатез (417).
[0063] Если поверхностная модель (410) описывает синтаксические роли заполнителей поверхностных позиций, то глубинная модель (512) по существу описывает семантические роли заполнителей поверхностных позиций. Описание глубинных позиций (520) выражает семантический тип потенциального заполнителя слота и отражает практические аспекты ситуаций, свойств или атрибутов объектов, определяемых словами любого естественного языка. Описания глубинных позиций (520) не зависят от языка, поскольку различные языки могут использовать одни и те же глубинные позиции для описания аналогичных семантических отношений или выражать аналогичные аспекты ситуаций. Заполнители глубинных позиций (514) также по существу обладают одинаковыми семантическими свойствами даже в разных языках. Каждое лексическое значение (612) в конкретном языке наследует семантический класс от своего предка и может подстроить и уточнить глубинную модель, наследуемую от своего предка (512).
[0064] Описание лексических значений и соответствующих им моделей является наиболее трудоемкой частью заполнения семантической иерархии для конкретного языка. Описанный вариант осуществления изобретения позволяет обеспечить частичную или полную автоматизацию данного процесса. В большинстве случаев возможен перенос лексических моделей из исходного языка на соответствующие лексические значения в целевом языке с минимальной коррекцией, если исходный и целевой языки в определенной степени схожи.
[0065] Кроме того, лексические значения (612) могут содержать собственные характеристики и также наследовать другие характеристики от независимого от языка родительского семантического класса. Данные характеристики лексических значений (612) включают в себя грамматические значения (608), которые можно описать как граммемы, а также семантическое значение (610), которое можно описать как семантемы.
[0066] Каждая поверхностная модель (410) лексического значения может включать в себя одну или более синтформ (412). Каждая синтформа поверхностной модели (410) может включать в себя одну или более поверхностных позиций (415) и иметь собственное описание линейного порядка (416) и одно или более грамматических значений (414), выраженных в виде набора грамматических характеристик (граммем), одно или более семантических ограничений для заполнителей поверхностных позиций, а также одну или более диатез (417). Семантические ограничения в отношении заполнителей поверхностных слотов включают в себя набор семантических классов, объекты которых могут заполнять поверхностный слот. Диатезы связывают (224) синтаксические описания (202) и семантические описания (204), и представляют собой соответствия между поверхностными позициями и глубинными позициями в глубинной модели (512).
[0067] С учетом представленного выше, на Фиг.1 подробно описан способ (100) автоматического создания универсального семантического описания целевого языка на основе семантической иерархии исходного языка и набора параллельных текстов.
[0068] На этапе (111) лингвисты формально описывают некоторые систематические лексические и синтаксические отличия целевого языка от исходного языка. Лингвисты также создают модель синтаксиса целевого языка и морфологическую модель целевого языка (например, словарь). Модели синтаксиса целевого языка и модель морфологии целевого языка могут представлять собой отдельные модели или же являться частями единой модели. Например, способ 100 можно применять к паре родственных языков с одинаковым алфавитом или в значительной мере схожими/пересекающимися алфавитами. Лексическое сходство может быть обусловлено похожими механизмами словообразования. Такие пары языков существуют и, как правило, принадлежат к одной языковой группе. Например, пары языков могут включать в себя: русский - украинский, русский - белорусский, латышский - литовский, русский - польский, русский - болгарский, украинский - белорусский, украинский - польский, украинский - словацкий и немецкий - датский и т.п.
[0069] Этап (111 может быть исключен из способа (100). Однако описания отличий, создаваемые в ходе этапа (111), могут повысить точность результатов применения способа (100). В одном варианте осуществления изобретения лингвист может описать морфологическую модель для целевого языка, включающую в себя парадигмы изменения формы слов, систему грамматических категорий и морфологический словарь. Морфологический словарь также можно составить разными способами. Например, для автоматического построения морфологического словаря на основе корпуса текста можно использовать информацию о способе, описанном в заявке на патент США №11/769,478 «Способ и система составления словаря естественного языка». В другом варианте осуществления изобретения морфологическое описание целевого языка сначала может отсутствовать, однако позднее будет создано в результате использования способа 100 и морфологического словаря исходного языка после установления соответствий между словами исходного языка и целевого языка. В данной ситуации при наличии достаточного объема текста на целевом языке можно воспользоваться возможностью дополнительной проверки гипотез о морфологической модели для каждого слова в корпусе текста в соответствии со способом, описанным в заявке на патент США №11/769,478.
[0070] Например, возможны следующие систематические различия между исходным языком и целевым языком: могут отличаться система падежей, система времен глаголов, а также категории рода или числа существительных или местоимений. Могут существовать и другие различия. Еще один пример: местоимение в одном языке может управляться одним падежом, а соответствующее местоимение в другом языке - другим падежом. Также могут различаться механизмы словообразования, как, например, при образовании сложных слов и т.п. Все данные различия могут быть описаны формально как правила трансформаций. Правила трансформации также можно описать программно (например, в виде программных скриптов или процедур и т.п.).
[0071] Дифференциальные описания целевого языка могут касаться описаний поверхностных позиций (420). Например некоторая поверхностная позиция в целевом языке может использоваться с другим местоимением или требовать другого падежа. Дифференциальные описания могут относиться к диатезам (417); например, возможны разные семантические ограничения в целевом языке. При использовании другого подхода в целевом языке может быть описана линейная последовательность (416). Кроме того, разнообразные различия могут содержаться в описании недревесного синтаксиса (450). По существу любой элемент синтаксических описаний, показанных на Фиг. 4, может отличаться номенклатурой, но данные различия могут быть систематически выявлены и описаны.
[0072] Суть способа настоящего изобретения заключается в том, что, после того как будет установлено соответствие между лексическими элементами исходного языка и целевого языка, скорректировать и отобразить лексические описания (203) и синтаксическое описание (202) (см. Фиг. 4) исходного языка в целевой язык, и получить таким полуавтоматическим путем синтаксическую модель целевого языка, включая поверхностные модели (410) лексических элементов используя описания поверхностных позиций (420), описания референциального и структурного контроля (430), описания управления и согласования (440), описания недревесного синтаксиса (450), а также правил анализа (460) исходного языка и описанных систематических различий.
[0073] Следующий этап способа (112) выполняется с помощью достаточно большого корпуса параллельных текстов. Тексты на двух языках, в которых текст на одном (первом) языке соответствует тексту на другом (втором) языке, называются параллельными текстами; в общем случае, это может быть перевод на второй язык. В данном случае тексты нужны как источник определенного исходного языка и определенного целевого языка. Данные параллельные тексты можно получить любым способом. Лучшие результаты можно обеспечить, если параллельные тексты будут хорошего качества. На этапе (112) параллельные тексты выравниваются (т.е. они форматируются таким образом, чтобы каждое предложение на первом языке соответствовало предложению на втором языке, и наоборот). Для этого можно использовать специальные программы, включая программы, работающие со словарем перевода. Словарь перевода может быть получен из любого электронного словаря или создан из бумажного словаря, используя средства оптического распознавания и программы обработки. Наше требование к программе-выравнивателю состоит в том, что он также должен быть способен явно указывать, какое слово в исходном языке каким словом переведено в целевой язык. Потенциальный способ выравнивания параллельных текстов представлен в заявке на патент США №13/464,447. Этап 112 можно пропустить, если существующие параллельные тексты уже являются выровненными.
[0074] Этап (113) включает в себя анализ каждого предложения на исходном языке в соответствии с технологией глубинного семантико-синтаксического анализа, подробно описанной в патенте США №8,078,450 под названием «Способ и система анализа различных языков и создания независимых от языка семантических структур». Данная технология использует все представленные описания языка (210), включая морфологические описания (201), лексические описания (203), синтаксические описания (202) и семантические описания (204).
[0075] На Фиг. 7 и 7А представлены основные этапы способа семантико-синтаксического анализа 700 и последовательность структур данных, созданных в процессе такого анализа, соответственно.
[0076] На этапе (712) исходное предложение (710) подвергается лексико-морфологическому анализу для построения лексико-морфологической структуры исходного предложения. Лексико-морфологическая структура (722) включает в себя набор всех возможных пар «лексическое значение - грамматическое значение» для каждого лексического элемента (т.е. слова) в предложении.
[0077] Проводится грубый синтаксический анализ исходного предложения (720), в результате чего осуществляется построение графа обобщенных составляющих (732), В ходе грубого синтаксического анализа (720) к каждому лексическому элементу лексико-морфологической структуры (722) применяются все возможные для данного лексического элемента синтаксические модели с проверкой на предмет всех потенциальных синтаксических связей в предложении, что находит свое выражение в создании графа обобщенных составляющих (732).
[0078] Граф обобщенных оставляющих (732) может иметь вид ациклического графа, в котором вершины представляют собой обобщенные лексические значения (в них могут храниться варианты) слов в предложении, а дуги графа представляют собой поверхностные (синтаксические)позиции, выражающие разные типы отношений между соединяемыми лексическими значениями. Применяются все возможные поверхностные синтаксические модели для каждого элемента лексико-морфологической структуры предложения в качестве потенциального ядра составляющих. Затем строятся все возможные составляющие и обобщаются в граф обобщенных составляющих (732). В результате, рассматриваются все возможные синтаксические модели и синтаксические структуры исходного предложения (710), и на основе множества обобщенных составляющих строится граф обобщенных составляющих (732). На уровне поверхностной модели граф обобщенных компонентов (732) отражает все потенциальные связи между словами исходного предложения (713). Поскольку количество вариантов синтаксического анализа может быть очень большим, граф обобщенных составляющих (732) является большим и может иметь большое количество вариантов - как в выборе лексического значения из множества значений, существующего для каждой вершины, так и в выборе поверхностных позиций для дуг графа.
[0079] Для каждой пары «лексическое значение - грамматическое значение» инициализируется ее поверхностная модель, и в поверхностные позиции (415) синтформ (синтаксических форм) (412) поверхностной модели (410) к правым и левым составляющим подключаются другие составляющие. Данные синтаксические описания представлены на Фиг. 4. Если подходящая синтаксическая форма найдена в поверхностной модели (410) соответствующего лексического значения, выбранное лексическое значение может служить ядром новой составляющей (или составляющих).
[0080] Граф (732) обобщенных составляющих сначала строится в виде дерева, начиная от листьев к корням (т.е., снизу вверх). Построение дополнительных составляющих может происходить снизу вверх путем прикрепления дочерних составляющих к родительским составляющим посредством заполнения поверхностных позиций (415) родительских составляющих для того, чтобы охватить все начальные лексические единицы исходного предложения (710). Корнем дерева, являющемся главной вершиной графа (732), обычно становится предикат (сказуемое). В ходе этого процесса дерево обычно становится графом, так как составляющие нижнего уровня (листья) могут быть включены в различные составляющие верхнего уровня (корень).Некоторые составляющие, которые построены для одних и тех же составляющих лексико-морфологической структуры могут быть впоследствии обобщены для того, чтобы получить одну обобщенную составляющую. Составляющие обобщаются на основе лексических значений (612), или грамматических значений (414), например, на основе частей речи, и связей между ними.
[0081] Точный синтаксический анализ (730) выполняется для выделения синтаксического дерева (742) из графа (732) обобщенных составляющих. Может строиться одно или более синтаксических деревьев, для каждого из них вычисляется интегральная оценка, основанная на использовании множества априорных и вычисляемых оценок., Дерево с наилучшей оценкой выбирается для построения лучшей синтаксической структуры (746) для исходного предложения. Фиг. 8 и Фиг. 8А иллюстрируют два разных возможных синтаксических дерева (800) и (800А) соответственно английского предложения "The girl in the sitting-room was playing the piano".
[0082] Синтаксические деревья генерируются как процесс выдвижения и проверки гипотез о возможной синтаксической структуре предложения, причем гипотезы о структуре частей предложения генерируются в рамках гипотезы о структуре всего предложения.
[0083] В процессе перехода от выбранного синтаксического дерева к синтаксической структуре (746) производится установление недревесных связей. Если недревесные связи установить не удалось, то выбирается следующее по значению оценки синтаксическое дерево и делается попытка установить недревесные связи на нем. Результатом точного анализа (730) является лучшая синтаксическая структура (746) анализируемого предложения.
[0084] На этапе (740) создается независимая от языка семантическая структура и, выполняется переход к не зависимой от языка, семантической структуре (750), которая выражает смысл предложения в универсальных не зависимых от языка понятиях. Независимая от языка семантическая структура предложения представляется в виде ациклического графа (дерева, дополненного недревесными связями), где каждое слово определенного языка заменено универсальными (независимыми от языка) семантическими сущностями, называемыми здесь семантическими классами. Переход выполняется с использованием семантических описаний (204) и правил анализа (460), в результате чего имеется структура в виде графа с главной вершиной. В этом графе узлы представляют семантические классы, снабженные множеством атрибутов семантем (т.е., атрибуты выражают лексические, синтаксические и семантические свойства конкретных слов исходного предложения), а дуги представляют глубинные (семантические) отношения между словами (узлами), которые они соединяют. Фиг. 9 иллюстрирует семантическую структуру английского предложения "The girl in the sitting-room was playing the piano" в соответствии с одним из вариантов осущетвления изобретения.
[0085] Важным является тот факт, что если есть два предложения - первое на исходном языке и второе предложение на целевом языке, причем второе предложение является точным переводом первого на целевом языке и обратно, то можно считать, что их семантические структуры, в общем случае, совпадают с точностью до семантических классов. Фиг. 10 иллюстрирует семантическую структуру (1000) в соответствии с одним из вариантов осуществления изобретения. Семантическая структура (1000) соответствует русскому предложению «Девушка в гостиной играла на фортепиано», которое соответствует английскому предложению, приведенному на Фиг. 9 " Семантические структуры (900) и (1000) на Фиг. 9 и Фиг. 10 имеют одинаковые конфигурации и одинаковые семантические классы в узлах структур: YOUNG_WOMAN (901) и (1001), SITTING_ROOM (902) и (1002), TO_PLAY_MUSIC_THEATRE (903) и (1003), и PIANO (904) и (1004).
[0086] Возвращаясь к Фиг. 1, на этапе (114) с использованием переводного словаря делаются гипотезы о соответствии лексических элементов двух предложений. В соответствии с одним из вариантов осущетвления изобретения, Фиг. 11 иллюстрирует действия этого этапа построения семантического описания целевого (польского) языка на основе семантического описания исходного (русского) языка. Фиг. 11 иллюстрирует этот этап на примере разбора русского предложения "Девушка в гостиной играла на фортепиано" и его польского эквивалента "Dziewczyna w salonie gry na pianinie". Использование переводного словаря или информации от выравнивателя, полученной на этапе (112), позволяет установить соответствие лексических элементов: девушка - dziewczyna, гостиная - salonie, играла - gry, фортепиано - pianinie.
[0087] Таким образом, пример, показанный на Фиг. 11, иллюстрирует способ пополнения семантической иерархии в конкретно-языковой части целевого языка. В этом примере после установления соответствия между лексическими элементами двух языков генерируются гипотезы о том, что в соответствующие семантические классы семантической иерархии могут быть добавлены лексические значения польского языка "dziewczyna:YOUNG_WOMAN", " salonie: SITT1NG_ROOM ", "grac: TO_PLAY_MUSIC_THEATRE "(grac является основной формой для глагола gry), "pianinie: PIANO". Окончательное решение о добавлении может быть принято после сопоставления на этапе 115 лексических элементов синтаксических моделей целевого языка и элементов исходного языка и проверки гипотез на этапе 116.
[0088] Предлоги, артикли, частицы и другие вспомогательные части речи могут не отображаться в семантических структурах.; Артикли и частицы могут кодироваться при помощи грамматических семантем, предлоги могут характеризоваться соответствующими поверхностными позициями. Число предлогов в любом языке не слишком велико, и предлог одного языка может переходить в соответствующий ему предлог другого языка, а то, что в разных поверхностных позициях это может происходить по-разному, описывается на этапе (111). Так, в описаниях систематических синтаксических отличий описывается, в каких случаях в поверхностной позиции $Adjunct_Locative русской предлог "в" переходит в польском языке в предлог "w", а в каких, возможно, в другой предлог. Фиг. 12 иллюстрирует синтаксическую структуру (1200) русского предложения "Девушка в гостиной играла на фортепиано", в соответствии с одним из вариантов осущетвления изобретения. В описаниях систематических синтаксических отличий отмечается, в какую поверхностную позицию в польском языке переходит русская поверхностная позиция $Object_Indirect_Ha_Prep (1201). Например, возможно, должна быть введена поверхностная позиция $Object_Indirect_Na_Prep и описано, чем она отличается от $Object_Indirect_Ha_Prep.
[0089] На этапе (115) происходит сопоставление добавляемых лексических элементов синтаксических моделей целевого языка соответствующим элементам исходного языка. Синтаксические модели лексических элементов берутся из соответствующих элементов исходного языка с учетом описанных систематических трансформаций. Например, для лексического значения "grac: TO_PLAY_MUSIC_THEATRE ", может быть принята и адаптирована синтаксическая модель, соответствующая русскому глаголу "играть: TO_PLAY_MUSIC_THEATRE ", т.е. наличие всех (или большинства) возможных для него синтформ должно быть проверено на корпусе размеченных текстов польского языка или на других корпусах параллельных текстов. На этапе (115) также определяется перечень проверяемых синтформ для каждого добавляемого лексического значения. Другими словами, составляется перечень возможных контекстов целевого языка, в которых может встречаться данное лексическое значение.
[0090] На этапе (115) осуществляется проверка гипотез на размеченных или других параллельных текстах целевого языка. Под размеченным текстом может пониматься текст, где каждое слово размечено (снабжено) частью речи. Например, каждый текстможет иметь индекс. Проверка может проводиться по N-граммам, где N=2, 3…
Проверка гипотезы может заключаться в том, что ищутся все возможные контексты из перечня возможных контекстов. Контекст может кодироваться метасредствами с использованием обобщающих понятий, таких как часть речи, семантический класс и др. Те контексты, которые возможно нашли подтверждение в существующих текстовых корпусах, пополняют лексическую модель данного лексического значения. По мере заполнения семантической иерархии возможно дальнейшее обучение с использованием уже занесенных в нее лексических значений целевого языка и проверенных на корпусах текстов моделей. По мере накопления размеченных корпусов лексическая модель пополняется теми синтформами, которые удалось найти в новых текстовых корпусах.
[0091] На ФИГ. 13 представлен возможный пример компьютерной платформы (1300), которую можно использовать для реализации методик данного описания в соответствии с одним вариантом осуществления. Компьютерная платформа (1300) включает в себя по меньшей мере один процессор (1302), подключенный к памяти (1304). Процессор (1302) может представлять собой один и более процессоров и может содержать одно, два или более компьютерных ядер. Процессор (1302) может представлять собой любой доступный в продаже процессор и может применяться в качестве универсального процессора, определенной специальной интегральной схемы (ASIC), одного или более программируемых логических матриц (FPGA), процессора обработки цифровых сигналов (DSP), группы процессорных компонентов или других подходящих электронных процессорных компонентов. Память (1304) может включать в себя оперативные запоминающие устройства (ОЗУ), содержащие главное устройство хранения платформы (1300) и любые дополнительные уровни памяти, например кэшпамять, энергонезависимую память или резервные запоминающие устройства (например, программируемая или флэш-память), ПЗУ и т.п. Кроме того, память (1304) может включать в себя запоминающие устройства, физически расположенные в другом месте в платформе (1300), например любую кэш-память в процессоре (1302), а также любые запоминающие устройства, используемые в качестве виртуальной памяти, например съемные запоминающие устройства (1310). Память (1304) может хранить (самостоятельно или в сочетании с запоминающим устройством (1310)) компоненты базы данных, компоненты объектного кода, компоненты скриптов или любую другую информационную структуру для поддержки различных действий и информационных структур, описанных в данном описании.
Память (1304) или запоминающее устройство (1310) могут содержать компьютерный код или инструкции для процессора (1302) для выполнения процессов, описанных в настоящем описании.
[0092] Компьютерная платформа (1300) также обычно имеет определенное количество входных и выходных портов для передачи и получения информации. Для взаимодействия с пользователем компьютерная платформа (1300) может содержать одно или более устройств ввода (таких как клавиатура, мышь, сканер и т.п.) и дисплей (1308) (такой как жидкокристаллический дисплей). Компьютерная платформа (1300) может также иметь одно или более запоминающих устройств (1310), например, помимо прочего, накопитель на гибких магнитных или иных съемных дисках, накопитель на жестком магнитном диске, запоминающее устройство с прямым доступом (DASD), оптический привод (например, привод компакт-дисков (CD), компакт-дисков в формате DVD и т.д.) и/или ленточный накопитель. Более того, компьютерная платформа (1300) может включать в себя интерфейс для взаимодействия с одной или более сетями (1312) (например, помимо прочего, локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и/или Интернетом) для обеспечения обмена информацией с другими компьютерами, подключенными к сетям. Следует принимать во внимание, что компьютерная платформа (1300), как правило, включает в себя подходящие аналоговые и/или цифровые интерфейсы между процессором 502 и каждым из компонентов (1304), (1306), (1308) и (1312), что хорошо известно специалистам в данной области.
[0093] Компьютерная платформа (1300) может управляться операционной системой (1314) и выполнять различные компьютерные программные приложения (1316), включая компоненты, программы, объекты, модули и т.п. для реализации описанных выше процессов. В частности, компьютерные программные приложения могут включать в себя приложение для сопоставления параллельного текста, приложение для семантико-синтаксического анализа, приложение для оптического распознавания символов, словарное приложение, а также другие установленные приложения для автоматического создания семантического описания целевого языка. Любые из описанных выше приложений могут входить в состав единого приложения или же представлять собой отдельные приложения или плагины и т.п. Приложения (1316) также могут выполняться на одном или более процессорах другого компьютера, соединенного с платформой (1300) через сеть (1312), например, в среде распределенных вычислений, причем вычисления, необходимые для реализации функций компьютерной программы, могут быть распределены по множеству компьютеров в сети.
[0094] Как правило, подпрограммы, выполняемые для реализации вариантов осуществления, могут быть реализованы в виде части операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности инструкций, именуемых «компьютерными программами». Компьютерные программы, как правило, содержат один или более наборов инструкций, которые находятся в разное время в различных устройствах памяти и хранения в компьютере и которые при считывании и исполнении одним или более процессорами компьютера воздействуют на компьютер для выполнения операций, необходимых для исполнения элементов раскрытых вариантов осуществления. Более того, различные варианты осуществления изобретения описаны в контексте полнофункциональных компьютеров и компьютерных систем, и специалистам в данной области будет понятно, что различные варианты осуществления можно распространять в виде программного продукта в различных формах, а также что настоящее изобретение применимо независимо от конкретного типа используемого машиночитаемого носителя. Примеры машиночитаемых носителей включают в себя, без ограничений, носители с возможностью записи, такие как, помимо прочего, устройства оперативной и энергонезависимой памяти, накопители на гибких магнитных и других съемных дисках, накопители на жестких магнитных дисках, оптические диски (например, ПЗУ на компакт-дисках (CD-ROM), компакт-диски в формате DVD, флэш-память и т.п.). Различные варианты осуществления изобретения также могут распространяться через Интернет или в виде скачиваемых из сети программных продуктов.
[0095] В представленном выше описании множество определенных описаний приводятся в разъяснительных целях. Однако специалисту в данной области будет очевидно, что данные определенные описания являются только примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание затруднения понимания описанных вариантов осуществления.
[0096] В данном описании термин «один вариант осуществления» или «вариант осуществления» означает, что конкретный элемент, структура или характеристика, описанные вместе с вариантом осуществления, включены по меньшей мере в один вариант осуществления изобретения. Фраза «в одном варианте осуществления», встречающаяся в различных местах описания, не обязательно обозначает один и тот же вариант осуществления или же отдельные или альтернативные варианты осуществления, взаимоисключающие другие варианты осуществления. Более того, в настоящем описании описаны элементы, которые могут проявляться в некоторых вариантах осуществления, но могут не проявляться в других вариантах осуществления. Аналогичным образом описаны различные требования, которые могут относиться к одним вариантам осуществления и не относиться к другим вариантам осуществления.
[0097] Хотя некоторые примеры осуществления описаны и представлены на прилагаемых рисунках, следует понимать, что такие варианты осуществления являются лишь иллюстрирующими, но не ограничивающими, и что данные варианты осуществления не ограничены конкретными показанными и описанными схемами и комбинациями, поскольку обычному специалисту в данной области после изучения настоящего описания будут очевидны и различные другие модификации. В подобной технологической области, где рост происходит быстро и дальнейшие улучшения предвидеть непросто, описанные варианты осуществления можно легко подвергать модификациям в комбинации и особенностях, чему будут способствовать технологические достижения, и это не будет считаться отклонением от принципов настоящего описания.
| название | год | авторы | номер документа |
|---|---|---|---|
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| РАЗРЕШЕНИЕ СЕМАНТИЧЕСКОЙ НЕОДНОЗНАЧНОСТИ ПРИ ПОМОЩИ НЕ ЗАВИСЯЩЕЙ ОТ ЯЗЫКА СЕМАНТИЧЕСКОЙ СТРУКТУРЫ | 2013 |
|
RU2579699C2 |
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
| РАЗРЕШЕНИЕ СЕМАНТИЧЕСКОЙ НЕОДНОЗНАЧНОСТИ ПРИ ПОМОЩИ СТАТИСТИЧЕСКОГО АНАЛИЗА | 2013 |
|
RU2592395C2 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| РАЗРЕШЕНИЕ СЕМАНТИЧЕСКОЙ НЕОДНОЗНАЧНОСТИ ПРИ ПОМОЩИ СЕМАНТИЧЕСКОГО КЛАССИФИКАТОРА | 2013 |
|
RU2579873C2 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2657173C2 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| ВЫЯВЛЕНИЕ СЛОВОСОЧЕТАНИЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2618374C1 |




Изобретение относится к способу, системе и машиночитаемому носителю данных для создания модели целевого языка на основании лингвистического описания исходного языка. Технический результат заключается в повышении полноты автоматически создаваемой модели целевого языка. В способе выполняют получение лингвистического описания, включающего семантическое и синтаксическое описания для исходного языка, первого текста на исходном языке и второго текста на целевом языке, сопоставление первого текста и второго текста так, чтобы текст на исходном языке соответствовал тексту на целевом языке, анализ первого текста для построения синтаксической и семантической структуры предложения текста на исходном языке, причем синтаксическая структура содержит лексический элемент исходного языка и семантическая структура содержит независимое от языка представление предложения текста на исходном языке, применение словаря перевода для создания гипотезы о лексическом элементе целевого языка, соответствующем лексическому элементу исходного языка, сопоставление на основе этой гипотезы лексического элемента целевого языка с соответствующим лексическим элементом исходного языка и создание семантико-синтаксической модели на основе результатов указанного сопоставления и различий между целевым языком и исходным языком. 3 н. и 17 з.п. ф-лы, 15 ил.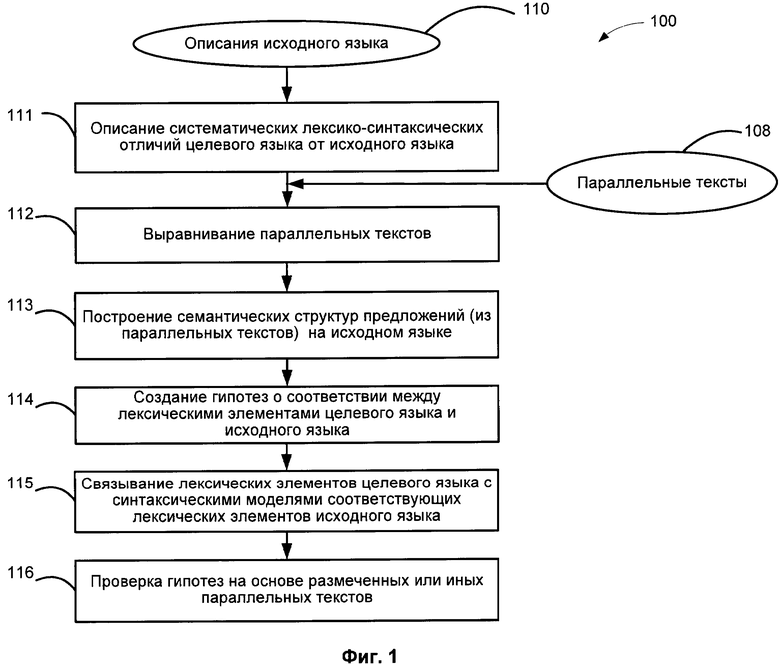
1. Способ создания модели целевого языка на основании лингвистического описания исходного языка, содержащий:
получение компьютерной платформой лингвистического описания, включающего по меньшей мере одно из семантического описания и синтаксического описания, для по меньшей мере одного из исходного языка, первого текста на исходном языке и второго текста на целевом языке;
сопоставление первого текста на исходном языке и второго текста на целевом языке при помощи устройства для обработки данных таким образом, чтобы текст на исходном языке соответствовал тексту на целевом языке;
анализ первого текста на исходном языке для построения синтаксической структуры и семантической структуры по меньшей мере одного предложения текста на исходном языке, причем синтаксическая структура содержит по меньшей мере один лексический элемент исходного языка и семантическая структура содержит независимое от языка представление по меньшей мере одного предложения текста на исходном языке;
применение словаря перевода для создания по меньшей мере одной гипотезы о лексическом элементе целевого языка, соответствующем лексическому элементу исходного языка;
сопоставление, на основе указанной гипотезы о лексическом элементе целевого языка, лексического элемента целевого языка с соответствующим лексическим элементом исходного языка; и
создание семантико-синтаксической модели целевого языка посредством принятия семантико-синтаксической модели лексического элемента исходного языка в качестве семантико-синтаксической модели соответствующего лексического элемента целевого языка на основе результатов указанного сопоставления и различий между целевым языком и исходным языком.
2. Способ по п. 1, дополнительно включающий создание формального описания лексико-синтаксических различий между целевым языком и исходным языком и синтаксической модели лексического элемента исходного языка.
3. Способ по п. 1, в котором второй текст на целевом языке является переводом первого текста исходного языка во второй текст целевого языка или наоборот.
4. Способ по п. 1, в котором анализ первого текста на исходном языке включает грубый и/или точный синтаксический анализ; и
создание семантической структуры каждого предложения текста на исходном языке с помощью семантико-синтаксической модели исходного языка.
5. Способ по п. 4, в котором семантико-синтаксическая модель исходного языка включает зависимые от языка по меньшей мере одно из морфологических описаний, лексических описаний, синтаксических описаний, независимых от языка семантических описаний.
6. Способ по п. 1, дополнительно включающий проверку гипотезы о лексическом элементе целевого языка на основе аннотированного текста или иного параллельного текста.
7. Способ по п. 1, дополнительно включающий выбор лучшего синтаксического дерева из множества синтаксических деревьев, соответствующих предложению на исходном языке, причем синтаксическая и семантическая структура предложения на исходном языке основана на выбранном лучшем синтаксическом дереве.
8. Система создания модели целевого языка на основании лингвистического описания исходного языка, содержащая:
компьютерную платформу, выполненную с возможностью получения лингвистического описания, включающего по меньшей мере одно из семантического описания и синтаксического описания, для по меньшей мере одного из исходного языка, первого текста на исходном языке и второго текста на исходном языке;
устройство для обработки данных, выполненное с возможностью:
сопоставления первого текста на исходном языке и второго текста на целевом языке таким образом, чтобы текст на исходном языке соответствовал тексту на целевом языке;
анализа первого текста на исходном языке для построения синтаксической структуры и семантической структуры по меньшей мере одного предложения текста на исходном языке, причем синтаксическая структура содержит по меньшей мере один лексический элемент исходного языка и семантическая структура содержит независимое от языка представление по меньшей мере одного предложения текста на исходном языке;
применения словаря перевода для создания по меньшей мере одной гипотезы о лексическом элементе целевого языка, соответствующем лексическому элементу исходного языка;
сопоставления, на основе указанной гипотезы о лексическом элементе целевого языка, лексического элемента целевого языка с соответствующим лексическим элементом исходного языка; и
создания семантико-синтаксической модели целевого языка посредством принятия семантико-синтаксической модели лексического элемента исходного языка в качестве семантико-синтаксической модели соответствующего лексического элемента целевого языка на основе результатов указанного сопоставления и различий между целевым языком и исходным языком.
9. Система по п. 8, в которой синтаксическая модель лексического элемента исходного языка основана на формально описанных лексико-синтаксических различиях между целевым языком и исходным языком.
10. Система по п. 8, в которой второй текст на целевом языке является переводом первого текста исходного языка во второй текст целевого языка или наоборот.
11. Система по п. 8, в которой для анализа первого текста на исходном языке устройство для обработки данных дополнительно выполнено с возможностью:
выполнения грубого и/или точного синтаксического анализа; и
создания семантической структуры каждого предложения текста на исходном языке с помощью семантико-синтаксической модели исходного языка.
12. Система по п. 11, в которой семантико-синтаксическая модель исходного языка включает зависимые от языка по меньшей мере одно из морфологических описаний, лексических описаний, синтаксических описаний, независимых от языка семантических описаний.
13. Система по п. 8, в которой устройство для обработки данных дополнительно выполнено с возможностью проверки гипотезы о лексическом элементе целевого языка на основе аннотированного текста или иного параллельного текста.
14. Система по п. 8, в которой устройство для обработки данных дополнительно выполнено с возможностью выбора лучшего синтаксического дерева из множества синтаксических деревьев, соответствующих предложению на исходном языке, а синтаксическая и семантическая структура предложения на исходном языке основана на выбранном лучшем синтаксическом дереве.
15. Постоянный машиночитаемый носитель данных, имеющий хранящиеся на нем инструкции для создания модели целевого языка на основании лингвистического описания исходного языка, которые при их исполнении побуждают компьютерную платформу:
получать лингвистическое описание, включающее по меньшей мере одно из семантического описания и синтаксического описания, для по меньшей мере одного из исходного языка, первого текста на исходном языке и второго текста на целевом языке;
и при их исполнении устройством обработки данных побуждают его:
сопоставлять первый текст на исходном языке и второй текст на целевом языке таким образом, чтобы текст на исходном языке соответствовал тексту на целевом языке;
анализировать первый текст на исходном языке для построения синтаксической структуры и семантической структуры по меньшей мере одного предложения текста на исходном языке, причем синтаксическая структура содержит по меньшей мере один лексический элемент исходного языка и семантическая структура содержит независимое от языка представление по меньшей мере одного предложения текста на исходном языке;
применять словарь перевода для создания по меньшей мере одной гипотезы о лексическом элементе целевого языка, соответствующем лексическому элементу исходного языка;
сопоставлять, на основе указанной гипотезы о лексическом элементе целевого языка, лексический элемента целевого языка с соответствующим лексическим элементом исходного языка; и
создавать семантико-синтаксическую модель целевого языка посредством принятия семантико-синтаксической модели лексического элемента исходного языка в качестве семантико-синтаксической модели соответствующего лексического элемента целевого языка на основе результатов указанного сопоставления и различий между целевым языком и исходным языком.
16. Носитель данных по п. 15, в котором синтаксическая модель лексического элемента исходного языка основана на формально описанных лексико-синтаксических различиях между целевым языком и исходным языком.
17. Носитель данных по п. 15, в котором второй текст на целевом языке является переводом первого текста исходного языка во второй текст целевого языка или наоборот.
18. Носитель данных по п. 15, в котором анализ первого текста на исходном языке дополнительно включает:
выполнение грубого и/или точного синтаксического анализа; и
создание семантической структуры каждого предложения текста на исходном языке с помощью семантико-синтаксической модели исходного языка.
19. Носитель данных по п. 18, в котором семантико-синтаксическая модель исходного языка включает зависимые от языка по меньшей мере одно из морфологических описаний, лексических описаний, синтаксических описаний, независимых от языка семантических описаний.
20. Носитель данных по п. 15, дополнительно содержащий инструкции по проверке гипотезы о лексическом элементе целевого языка на основе аннотированного текста или иного параллельного текста.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |

