Изобретение относится к подавлению шумов в цифровых системах связи, основанных на передаче кадров, и касается, в частности, способа подавления шумов в таких системах на основе вычитания спектров.
Общей проблемой в обработке сигналов речи является улучшение этих сигналов, исходя из их значений, измеренных в присутствии шума. Одним из подходов к улучшению речевого сигнала на основе измерений в одном канале (от микрофона) является фильтрация в частотной области с применением методов вычитания спектров [1], [2]. При условии, что фоновый шум является долговременно стационарным (по сравнению с речью), модель фонового шума обычно оценивается в течение тех интервалов времени, когда речевой активности нет. Затем в течение кадров с речевой активностью эта оцененная модель шума используется для улучшения речи совместно с оцененной моделью зашумленной речи. Для методов на основе вычитания спектров эти модели традиционно задаются в выражениях спектральной плотности мощности, которая оценивается с помощью классических методов быстрого преобразования Фурье.
При использовании в системах телефонной связи с подвижными объектами ни один из вышеуказанных методов в своей основной форме не обеспечивает выходной сигнал с удовлетворительным качеством звука, то есть
1) неискаженный выходной речевой сигнал,
2) достаточное уменьшение уровня шума,
3) остаточный шум без раздражающих искусственных шумов.
В частности, известно, что методы шумоподавления на основе спектрального вычитания нарушают первое из вышеуказанных требований, когда выполняют второе, или нарушают второе требование, когда выполняют первое. Кроме того, в большинстве случаев в большей или меньшей степени нарушается третье требование, так как эти методы вносят так называемый "музыкальный" шум.
Указанные недостатки, связанные с методами шумоподавления на основе спектрального вычитания, известны и в литературе описано несколько специальных модификаций базовых алгоритмов, предназначенных для определенных ситуаций "речь в шуме". Однако проблема создания способа на основе спектрального вычитания, который для общих ситуаций выполняет требования 1-3, оставалась нерешенной.
Чтобы показать трудности, связанные с улучшением речи на основе зашумленных данных, отметим, что методы вычитания спектров основаны на фильтрации, использующей оцениваемые модели приходящих данных. Если эти оцениваемые модели близки к соответствующим им "истинным" моделям, то они являются хорошим рабочим приближением. Однако вследствие малого времени стационарности речи (10-40 мс), а также из-за физической реальности, соответствующей применению мобильной телефонии (частота дискретизации 8000 Гц, стационарность шума 0,5-2,0 с и т. д.), оцененные модели с большой вероятностью значительно отличаются от действительных и поэтому приводят к получению фильтрованного выходного сигнала с низким качеством звука.
В заявке на европейский патент N 0588526 А1 описывается способ, согласно которому спектральный анализ осуществляется с помощью быстрого преобразования Фурье или линейного кодирования с предсказанием.
Задача настоящего изобретения - предложить такой способ подавления шума, основанный на спектральном вычитании, который обеспечивает лучшее подавление шума без ухудшения при этом качества воспроизводимого звука.
Эта задача решается с помощью способа, отличительные признаки которого изложены в п. 1 формулы изобретения.
Изобретение вместе с его целями и преимуществами будет более понятно из нижеследующего описания с прилагаемыми чертежами.
Фиг. 1 представляет собой блок-схему системы подавления шумов на основе спектрального вычитания, пригодную для осуществления способа согласно настоящему изобретению.
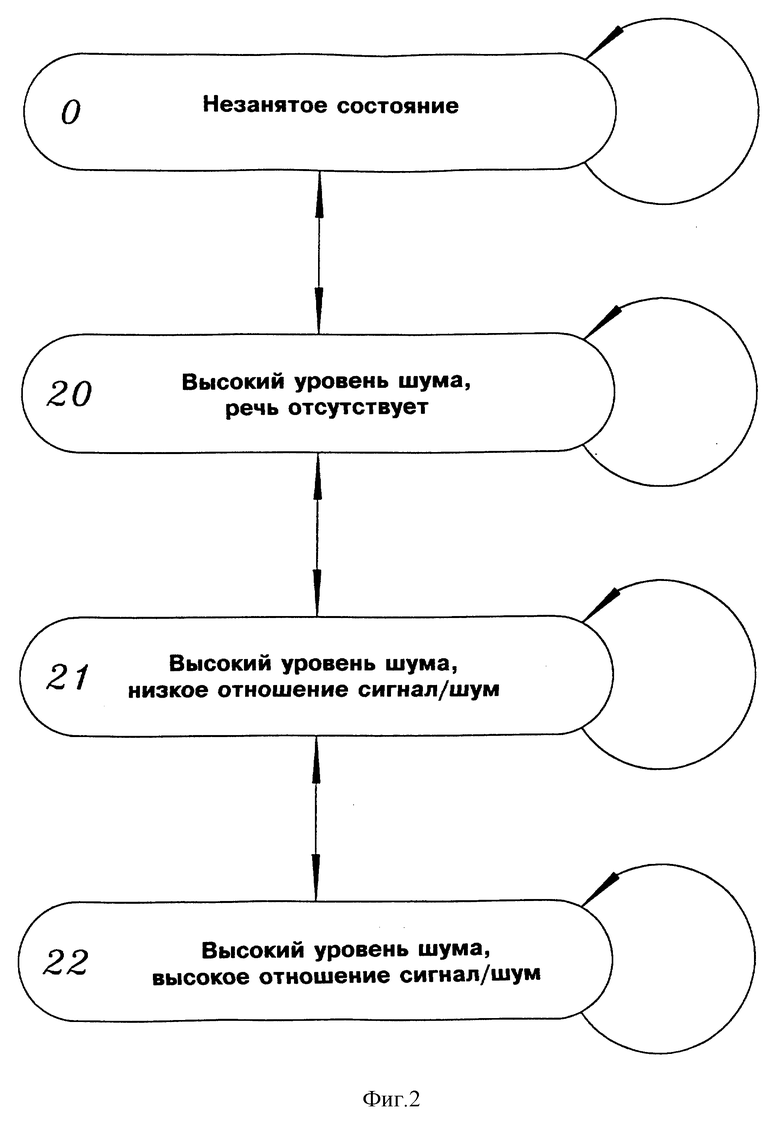
На фиг.2 показана диаграмма состояний детектора речевой активности, который может быть использован в системе, показанной на фиг. 1.
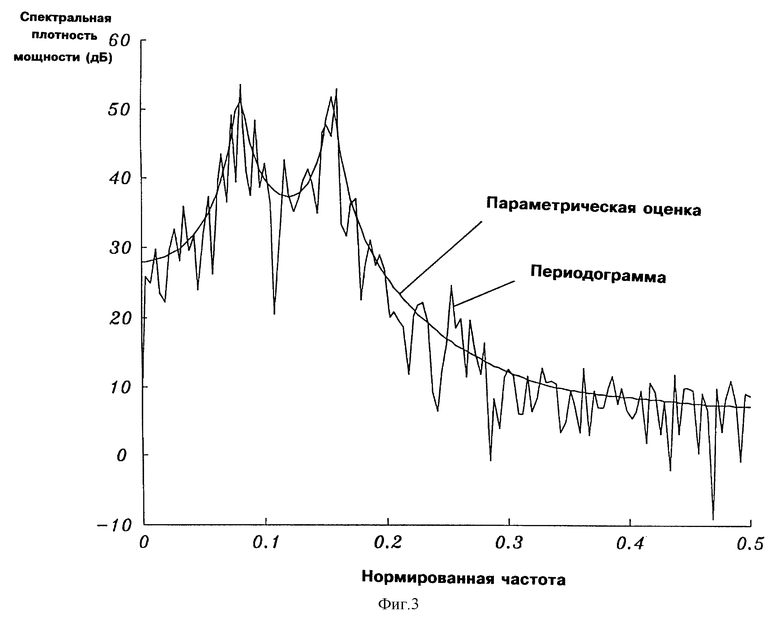
На фиг.3 показана диаграмма двух различных оценок спектральной плотности кадра речи.
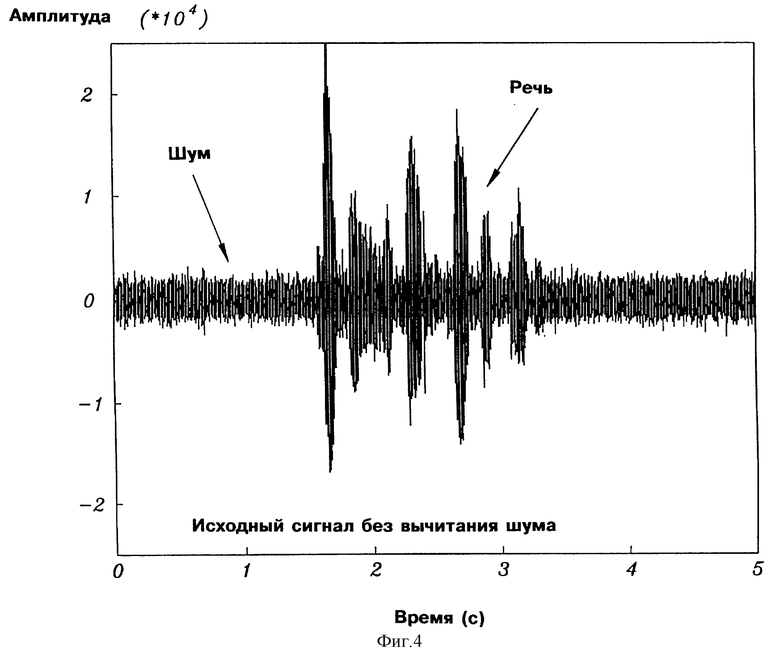
На фиг.4 показана временная диаграмма дискретизированного звукового сигнала, содержащего речь и фоновый шум.
На фиг. 5 показана временная диаграмма сигнала фиг.3 после вычитания спектра шума в соответствии с известными способами.
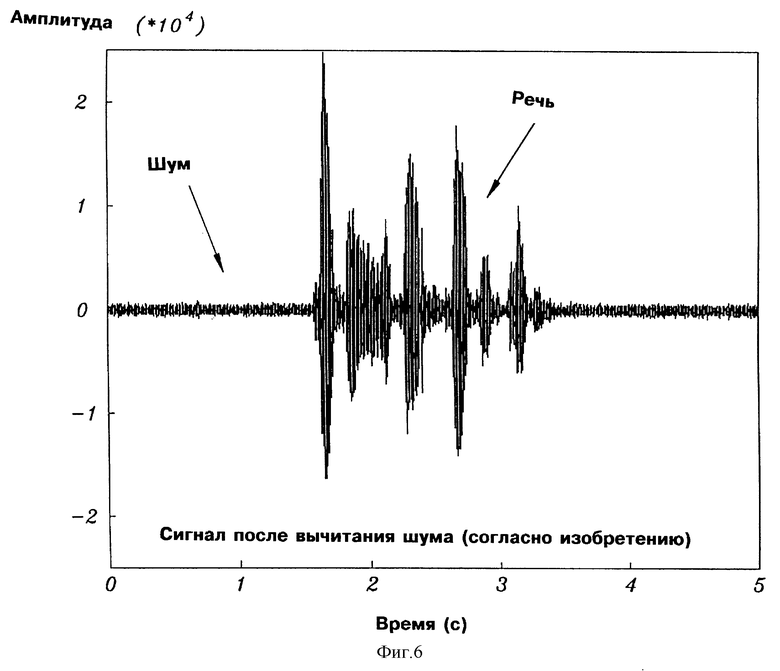
На фиг. 6 показана временная диаграмма сигнала фиг.3 после вычитания спектра шума в соответствии с настоящим изобретением.
На фиг. 7 показана блок- схема алгоритма, поясняющая способ согласно изобретению.
Подробное описание предпочтительных вариантов осуществления изобретения
Методы спектрального вычитания
Рассмотрим кадр речи, искаженной аддитивным шумом
x(k) = s(k)+ν(k) k = 1,...,N, (1)
где x(k), s(k) и ν(k) обозначают соответственно измеренные значения речевого сигнала в присутствии шумов, значения речевого сигнала и значения аддитивного шума, a N - число отсчетов в кадре.
Речь считается стационарной в пределах кадра, тогда как шум считается долговременно стационарным, то есть стационарным на протяжении нескольких кадров. Число кадров, где ν(k) стационарен, обозначается через τ, τ ≫ 1. Кроме того, предполагается, что речевая активность является достаточно низкой, так что модель шума может точно оцениваться во время отсутствия речевой активности.
Обозначим спектральные плотности мощности соответственно измеренного значения, речи и шума как Фx(ω), Фs(ω) и Фν(ω), где
Фx(ω) = Фs(ω)+Фν(ω). (2)
Если известны Фx(ω) и Фν(ω), то величины Фs(ω) и s(k) могут быть оценены с использованием стандартных методов на основе спектрального вычитания (ср. с [2]), кратко описываемых ниже.
Пусть 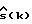 обозначает оценку s(k). Тогда
обозначает оценку s(k). Тогда
где F(•) обозначает некоторое линейное преобразование, например дискретное преобразование Фурье, и где H(ω) - четная вещественная функция в интервале ω ∈ (0,2π) такая, что 0 ≤H(ω)≤1. Функция H(ω) зависит от Фx(ω) и Фν(ω). Так как H(ω) вещественная, фаза, 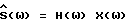 равна фазе искаженного речевого сигнала. Причиной использования вещественной функции H(ω) является нечувствительность человеческого слуха к фазовым искажениям.
равна фазе искаженного речевого сигнала. Причиной использования вещественной функции H(ω) является нечувствительность человеческого слуха к фазовым искажениям.
В общем случае Фx(ω) и Фν(ω) не известны и должны быть заменены в H(ω) оцениваемыми величинами 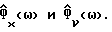 Вследствие нестационарности речи Фx(ω) оценивается на основании одного кадра данных, тогда как Фν(ω) оценивается с использованием данных в кадрах, не содержащих речи, число которых равно τ. Для простоты предполагается, что в распоряжении имеется детектор речевой активности для того, чтобы отличать кадры, содержащие зашумленную речь, от кадров, содержащих только шум. Предполагается, что Фν(ω) оценивается в течение интервалов без речевой активности путем усреднения по нескольким кадрам, например, используя
Вследствие нестационарности речи Фx(ω) оценивается на основании одного кадра данных, тогда как Фν(ω) оценивается с использованием данных в кадрах, не содержащих речи, число которых равно τ. Для простоты предполагается, что в распоряжении имеется детектор речевой активности для того, чтобы отличать кадры, содержащие зашумленную речь, от кадров, содержащих только шум. Предполагается, что Фν(ω) оценивается в течение интервалов без речевой активности путем усреднения по нескольким кадрам, например, используя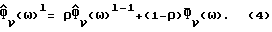
В выражении (4) 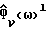 является усредненной (текущей) оценкой спектральной плотности мощности, основанной на данных кадров до l, включая кадр l, а
является усредненной (текущей) оценкой спектральной плотности мощности, основанной на данных кадров до l, включая кадр l, а  является оценкой, основанной на текущем кадре. Скаляр ρ ∈ (0,1) подстраивается с учетом предполагаемой стационарности ν(k). Среднее по τ кадрам грубо соответствует ρ, неявно определяемому как
является оценкой, основанной на текущем кадре. Скаляр ρ ∈ (0,1) подстраивается с учетом предполагаемой стационарности ν(k). Среднее по τ кадрам грубо соответствует ρ, неявно определяемому как
Подходящая оценка спектральной плотности мощности (не предполагающая никаких априорных допущений о форме спектра фонового шума) определяется как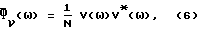
где "*" обозначает комплексно-сопряженную величину и где V(ω) = F(ν(k)). При F(•) = БПФ(•) (БПФ - быстрое преобразование Фурье), 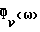 представляет собой периодограмму и
представляет собой периодограмму и 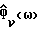 в (4) является усредненной периодограммой, обе они приводят к асимптотически (N >> 1) несмещенным оценкам спектральной плотности мощности с приближенными дисперсиями
в (4) является усредненной периодограммой, обе они приводят к асимптотически (N >> 1) несмещенным оценкам спектральной плотности мощности с приближенными дисперсиями
Аналогичное (7) выражение верно для 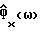 в течение речевой активности (при замене Ф
в течение речевой активности (при замене Ф
Система шумоподавления на основе спектрального вычитания, пригодная для осуществления способа согласно настоящему изобретению, показана в виде блок-схемы на фиг. 1. От микрофона 10 звуковой сигнал x(t) подается на аналого-цифровой преобразователь 12. Аналого-цифровой преобразователь 12 подает цифровые отсчеты звукового сигнала в виде кадров {x(k)} в блок 14 преобразования, например в блок быстрого преобразования Фурье, который преобразует каждый кадр в соответствующий преобразованный в частотную область кадр {X(ω)}. Преобразованный кадр фильтруется с помощью 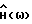 в блоке 16. Эта операция осуществляет фактическое спектральное вычитание. Полученный в результате сигнал
в блоке 16. Эта операция осуществляет фактическое спектральное вычитание. Полученный в результате сигнал 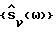 преобразуется обратно во временную область блоком 18 обратного преобразования. Результатом является кадр
преобразуется обратно во временную область блоком 18 обратного преобразования. Результатом является кадр 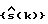 , в котором шум подавлен. Этот кадр может быть подан на эхокомпенсатор 20 и после него - на кодер 22 речи. Сигнал кодированной речи подается затем на канальный кодер и модулятор (эти блоки не показаны) для передачи.
, в котором шум подавлен. Этот кадр может быть подан на эхокомпенсатор 20 и после него - на кодер 22 речи. Сигнал кодированной речи подается затем на канальный кодер и модулятор (эти блоки не показаны) для передачи.
Фактический вид 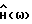 в блоке 16 зависит от оценок
в блоке 16 зависит от оценок  которые формируются в устройстве 24 оценивания спектральной плотности мощности, и от используемого аналитического выражения этих оценок. Примеры различных выражений приведены в табл. 2 в следующем разделе. Приведенное ниже описание будет в основном посвящено рассмотрению различных способов формирования оценок
которые формируются в устройстве 24 оценивания спектральной плотности мощности, и от используемого аналитического выражения этих оценок. Примеры различных выражений приведены в табл. 2 в следующем разделе. Приведенное ниже описание будет в основном посвящено рассмотрению различных способов формирования оценок 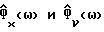 из входного кадра {x(k)}.
из входного кадра {x(k)}.
Устройство 24 оценивания спектральной плотности мощности управляется детектором 26 речевой активности, который использует входной кадр {x(k)} для определения, содержит кадр речь (Р) или фоновый шум (Ф). Подходящий детектор речевой активности описан в [5], [6]. Детектор речевой активности может быть реализован как конечный автомат, имеющий 4 состояния, показанные на фиг. 2. Полученный в результате управляющий сигнал Р/Ф подается в устройство 24 оценивания спектральной плотности мощности. Когда детектор 26 речевой активности обнаруживает речь (Р) (состояния 21 и 22), устройство 24 оценивания будет формировать 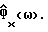 С другой стороны, когда детектор 26 речевой активности обнаруживает неречевую активность (Ф) (состояние 20), устройство 24 оценивания будет формировать
С другой стороны, когда детектор 26 речевой активности обнаруживает неречевую активность (Ф) (состояние 20), устройство 24 оценивания будет формировать 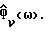 Последняя оценка будет использоваться для формирования
Последняя оценка будет использоваться для формирования 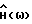 в течение следующей последовательности кадров речи (вместе с
в течение следующей последовательности кадров речи (вместе с 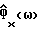 каждого из кадров этой последовательности).
каждого из кадров этой последовательности).
Сигнал Р/Ф подается также в блок 16 спектрального вычитания. Таким образом, блок 16 может применять разные фильтры во время речевых и неречевых кадров. Во время речевых кадров  представляет собой вышеприведенное выражение для
представляет собой вышеприведенное выражение для 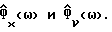 С другой стороны, во время неречевых кадров
С другой стороны, во время неречевых кадров 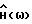 может быть константой Н(0≤ Н≤ 1), что уменьшает уровень фонового звука до того же самого уровня, который остается в речевых кадрах после шумоподавления. Таким образом, воспринимаемый уровень шума будет одинаковым во время речевых и неречевых кадров.
может быть константой Н(0≤ Н≤ 1), что уменьшает уровень фонового звука до того же самого уровня, который остается в речевых кадрах после шумоподавления. Таким образом, воспринимаемый уровень шума будет одинаковым во время речевых и неречевых кадров.
Перед тем как выходной сигнал 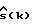 в (3) вычисляется, в предпочтительной форме осуществления изобретения
в (3) вычисляется, в предпочтительной форме осуществления изобретения 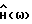 может подвергаться пост-фильтрации в соответствии с
может подвергаться пост-фильтрации в соответствии с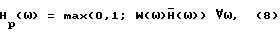
где 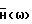 вычисляется в соответствии с табл. 1. Скаляр 0,1 подразумевает, что минимальный уровень шума составляет -20 дБ.
вычисляется в соответствии с табл. 1. Скаляр 0,1 подразумевает, что минимальный уровень шума составляет -20 дБ.
Кроме того, сигнал Р/Ф подается также на кодер 22 речи. Это позволяет выполнять различное кодирование речи и фоновых звуков.
Анализ ошибки спектральной плотности мощности
Является очевидным, что допущения о стационарности s(k) и ν(k) накладывают ограничения на точность оценки 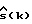 по сравнению с речевым сигналом, не содержащим шума (s(k)). В данном разделе представлен метод анализа для способов спектрального вычитания. Он основан на аппроксимациях первого порядка оценок
по сравнению с речевым сигналом, не содержащим шума (s(k)). В данном разделе представлен метод анализа для способов спектрального вычитания. Он основан на аппроксимациях первого порядка оценок  спектральной плотности мощности (см. (11) ниже) в сочетании с приближенными (аппроксимации нулевого порядка) выражениями для точности вносимых отклонений. Ниже выводится выражение для ошибки оцениваемого сигнала
спектральной плотности мощности (см. (11) ниже) в сочетании с приближенными (аппроксимации нулевого порядка) выражениями для точности вносимых отклонений. Ниже выводится выражение для ошибки оцениваемого сигнала 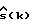 в частотной области вследствие используемого метода (выбора передаточной функции H(ω)) и вследствие неточности используемых формул оценки спектральной плотности мощности. Вследствие того, что слух человека нечувствителен к фазовым искажениям, можно рассматривать ошибку в спектральной плотности мощности, определяемую как
в частотной области вследствие используемого метода (выбора передаточной функции H(ω)) и вследствие неточности используемых формул оценки спектральной плотности мощности. Вследствие того, что слух человека нечувствителен к фазовым искажениям, можно рассматривать ошибку в спектральной плотности мощности, определяемую как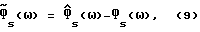
где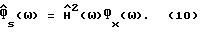
Заметим, что 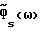 по своей структуре является членом ошибки, описывающим разность (в частотной области) между отфильтрованным измеренным значением речевого сигнала с шумом и значением речевого сигнала. Следовательно,
по своей структуре является членом ошибки, описывающим разность (в частотной области) между отфильтрованным измеренным значением речевого сигнала с шумом и значением речевого сигнала. Следовательно, 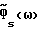 может принимать как положительные, так и отрицательные значения и не является спектральной плотностью мощности какого-либо сигнала во временной области.
может принимать как положительные, так и отрицательные значения и не является спектральной плотностью мощности какого-либо сигнала во временной области. 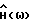 в (10) обозначает оценку H(ω), основанную на
в (10) обозначает оценку H(ω), основанную на  В данном разделе анализ ограничен случаем вычитания спектров мощности (PS) [2] . Другие альтернативы для выбора
В данном разделе анализ ограничен случаем вычитания спектров мощности (PS) [2] . Другие альтернативы для выбора 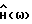 могут быть проанализированы аналогичным образом (см. Приложения А-С). Кроме того, представлены и проанализированы новые альтернативы для
могут быть проанализированы аналогичным образом (см. Приложения А-С). Кроме того, представлены и проанализированы новые альтернативы для 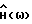 (см. Приложения D-G). Обзор различных подходящих альтернатив для
(см. Приложения D-G). Обзор различных подходящих альтернатив для  дан в табл. 2
дан в табл. 2
По определению H(ω) принадлежит интервалу 0 ≤ H(ω) ≤ 1 что не обязательно для соответствующих оцененных величин в табл. 2, и, следовательно, на практике используется одно- или двухполупериодное выпрямление [1].
Для того, чтобы выполнить анализ, допустим, что длина кадра N достаточно большая (N >> 1), так что  приближенно являются несмещенными. Введем отклонения первого порядка
приближенно являются несмещенными. Введем отклонения первого порядка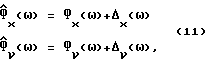
где Δx(ω) и Δν(ω) - стохастические переменные с нулевым средним значением, так что E[Δx(ω)/Фx(ω)]2≪ 1 и E[Δν(ω)/Фν(ω)]2≪ 1. Здесь и далее обозначение E[•] означает математическое ожидание. Кроме того, если время корреляции шума мало по сравнению с длительностью кадра, то 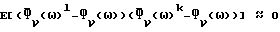 для l ≠ k, где
для l ≠ k, где 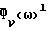 оценка, основанная на данных в l-м кадре. Это подразумевает, что Δx(ω) и Δν(ω) являются приблизительно независимыми. В противном случае, если шум сильно коррелирован, предположим, что Фν(ω) имеет ограниченное число (<< N) пиков (сильных), расположенных на частотах ω1,...,ωn. Тогда
оценка, основанная на данных в l-м кадре. Это подразумевает, что Δx(ω) и Δν(ω) являются приблизительно независимыми. В противном случае, если шум сильно коррелирован, предположим, что Фν(ω) имеет ограниченное число (<< N) пиков (сильных), расположенных на частотах ω1,...,ωn. Тогда  для ω ≠ ωj, j = l,..., п и l≠k и анализ остается действительным для ω ≠ ωj, j = l,..., п.
для ω ≠ ωj, j = l,..., п и l≠k и анализ остается действительным для ω ≠ ωj, j = l,..., п.
Уравнение (11) подразумевает, что используются асимптотически (N >>1) несмещенные оценки спектральной плотности мощности, такие, как периодограмма или усредненная периодограмма. Однако, если использовать асимптотически смещенные оценки спектральной плотности мощности, такие, как оценка спектральной плотности мощности Блэкмана-Тьюки, аналогичный анализ справедлив при замене (11) на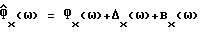
и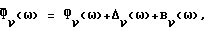
где соответственно Bx(ω) и Bν(ω) - детерминированные члены, описывающие асимптотическое смещение оценок спектральной плотности мощности.
Далее уравнение (11) подразумевает, что 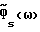 в (9) (в аппроксимации первого порядка) является линейной функцией Δx(ω) и Δν(ω). Ниже рассматриваются характеристики различных способов с точки зрения ошибки смещения
в (9) (в аппроксимации первого порядка) является линейной функцией Δx(ω) и Δν(ω). Ниже рассматриваются характеристики различных способов с точки зрения ошибки смещения 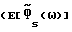 и дисперсии ошибки
и дисперсии ошибки 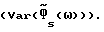 Полный вывод для
Полный вывод для 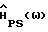 будет дан в следующем разделе. Аналогичный вывод выражений для других перечисленных в табл. 1 способов на основе спектрального вычитания приведен в Приложениях A-G.
будет дан в следующем разделе. Аналогичный вывод выражений для других перечисленных в табл. 1 способов на основе спектрального вычитания приведен в Приложениях A-G.
Анализ 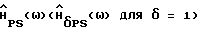
Подставив (10) и 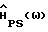 из табл. 2 в (9), используя разложение в ряд Тейлора (1+x)-1≅ 1-x и пренебрегая отклонениями выше первого порядка, после очевидных вычислений получаем
из табл. 2 в (9), используя разложение в ряд Тейлора (1+x)-1≅ 1-x и пренебрегая отклонениями выше первого порядка, после очевидных вычислений получаем
где "≅" использовано для обозначения приблизительного равенства, в котором сохранены только главные члены. Величины Δx(ω) и Δν(ω) являются стохастическими переменными с нулевым математическим ожиданием. Таким образом,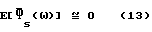
и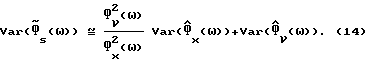
Для того, чтобы продолжить, мы используем общий результат, который для асимптотически несмещенной спектральной оценки 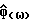 (ср. с (7)) имеет вид
(ср. с (7)) имеет вид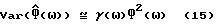
для некоторой (возможно частотно-зависимой) переменной γ(ω). Например, периодограмма соответствует γ(ω) ≈ 1+(sinωN/Nsinω)2 что для N >> 1 сокращается до γ ≈ 1. Объединение (14) и (15) дает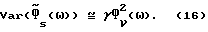
Результаты для 
Аналогичные вычисления для  дают (подробности приведены в Приложении А):
дают (подробности приведены в Приложении А):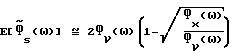
и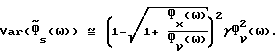
Результаты для 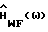
Вычисления для 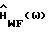 дают (подробности приведены в Приложении В):
дают (подробности приведены в Приложении В):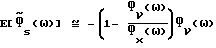
и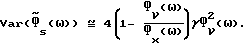
Результаты для 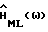
Вычисления для 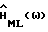 дают (подробности приведены в Приложении С):
дают (подробности приведены в Приложении С):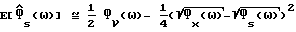
и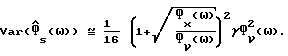
Результаты для 
Вычисления для  дают (
дают ( выводится в Приложении D и анализируется в Приложении Е):
выводится в Приложении D и анализируется в Приложении Е):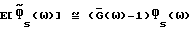
и
Общие характеристики
Для рассматриваемых способов следует заметить, что ошибка смещения зависит только от выбора 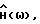 тогда как дисперсия ошибки зависит как от выбора
тогда как дисперсия ошибки зависит как от выбора 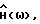 так и от дисперсии используемых оценок спектральной плотности мощности. Например, для оценки Фν(ω) на основе усредненной периодограммы имеем из (7), что γν≈ 1/τ. С другой стороны, если использовать периодограмму одиночного кадра для оценки Фx(ω), то имеем γx≈ 1 Таким образом, для τ ≫ 1 главным членом γν= γx+γν, появляющимся в вышеприведенных уравнениях дисперсии, является γx и поэтому основным источником ошибки является оценка спектральной плотности мощности одиночного кадра, основанная на зашумленной речи.
так и от дисперсии используемых оценок спектральной плотности мощности. Например, для оценки Фν(ω) на основе усредненной периодограммы имеем из (7), что γν≈ 1/τ. С другой стороны, если использовать периодограмму одиночного кадра для оценки Фx(ω), то имеем γx≈ 1 Таким образом, для τ ≫ 1 главным членом γν= γx+γν, появляющимся в вышеприведенных уравнениях дисперсии, является γx и поэтому основным источником ошибки является оценка спектральной плотности мощности одиночного кадра, основанная на зашумленной речи.
Из вышеприведенных замечаний следует, что для улучшения способов спектрального вычитания желательно уменьшить величину γx (выбрать подходящую формулу оценки спектральной плотности мощности, которая дает приблизительно несмещенную оценку с как можно более хорошей характеристикой) и выбрать "хороший" способ спектрального вычитания (выбрать 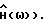 Ключевой идеей настоящего изобретения является то, что величину γx можно уменьшить, используя физическое моделирование голосового тракта (уменьшая число степеней свободы с N (числа отсчетов в кадре) до величины, меньшей, чем N). Хорошо известно, что s(k) могут быть точно описаны авторегрессионной моделью (AR) (обычно порядка p ≈ 10). Это является темой следующих двух разделов.
Ключевой идеей настоящего изобретения является то, что величину γx можно уменьшить, используя физическое моделирование голосового тракта (уменьшая число степеней свободы с N (числа отсчетов в кадре) до величины, меньшей, чем N). Хорошо известно, что s(k) могут быть точно описаны авторегрессионной моделью (AR) (обычно порядка p ≈ 10). Это является темой следующих двух разделов.
Кроме того, точность 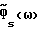 (и, неявно, точность
(и, неявно, точность 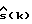 ) зависит от выбора
) зависит от выбора 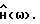 Новые предпочтительные варианты
Новые предпочтительные варианты 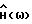 выводятся и анализируются в Приложениях D-G
выводятся и анализируются в Приложениях D-G
Авторегрессионное моделирование речи
В предпочтительной форме осуществления настоящего изобретения s(k) моделируется, как авторегрессионный процесс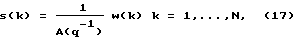
где A(q-1) - нормированный (первый коэффициент равен единице) полином p-го порядка в операторе сдвига в обратном направлении (q-1w(k)= w(k-1) и т. д.),
A(q-1)=1+a1q-1+...+apq-p, (18)
a w(k) - белый шум с нулевым средним значением и с дисперсией σ
При обработке речевого сигнала длина кадра N может не быть достаточно большой для того, чтобы допустить применение способов усреднения внутри кадра с целью уменьшить дисперсию и все же сохранить несмещенность оценки спектральной плотности мощности. Поэтому, чтобы уменьшить влияние первого члена, например, в уравнении (12), следует использовать физическое моделирование голосового тракта. Структура (17) авторегрессии накладывается на s(k). В явном виде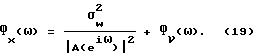
Кроме того, Фν(ω) может быть описано параметрической моделью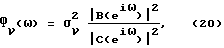
где B(q-1) и 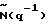 - соответственно полиномы q-го и r-го порядка, определяемые аналогично A(q-1) в (18). Для простоты в приведенном ниже анализе, где оценивается порядок параметрической модели, используется параметрическая модель шума (20). Однако понятно, что возможны также и другие модели фонового шума. Объединяя (19) и (20), можно показать, что
- соответственно полиномы q-го и r-го порядка, определяемые аналогично A(q-1) в (18). Для простоты в приведенном ниже анализе, где оценивается порядок параметрической модели, используется параметрическая модель шума (20). Однако понятно, что возможны также и другие модели фонового шума. Объединяя (19) и (20), можно показать, что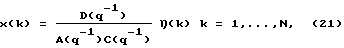
где η(k)- белый шум с нулевым средним значением и дисперсией σ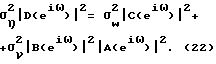
Оценка параметров речи
Оценивание параметров в (17)-(18) является простой процедурой, если не присутствует дополнительный шум. Заметим, что в случае отсутствия шума второй член в правой части (22) исчезает и, таким образом, (21) сокращается до (17) после взаимного уничтожения нулей и полюсов.
Здесь рассматривается оценка спектральной плотности мощности на основе метода автокорреляции. Для этого имеется четыре причины.
Метод автокорреляции хорошо известен. В частности, оцениваемые параметры имеют минимальную фазу, обеспечивающую стабильность получаемого в результате фильтра.
При использовании алгоритма Левинсона способ легко реализуется и имеет низкую вычислительную сложность.
Оптимальная процедура включает в себя нелинейную оптимизацию, явно требующую некоторую процедуру инициализации. Метод автокорреляции ее не требует.
С практической точки зрения удобно, если может быть использована одна и та же процедура оценки для искаженной речи и соответственно чистой речи, если она доступна. Другими словами, способ оценивания должен быть независимым от действительного сценария работы, то есть независимым от отношения сигнал-шум.
Хорошо известно, что модель с авторегрессионным скользящим средним (такая, как (21)) может быть смоделирована процессом авторегресии бесконечного порядка. Когда для оценки параметра доступно конечное число данных, бесконечная авторегрессионная модель усекается. Здесь использована следующая модель: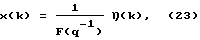
где F(q-1) имеет порядок 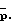 Подходящий порядок модели следует из приведенного ниже анализа. Приближенная модель (23) близка к
Подходящий порядок модели следует из приведенного ниже анализа. Приближенная модель (23) близка к
процессу речи с шумом, если их спектральные плотности мощности приблизительно равны, то есть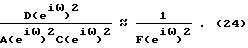
Исходя из физического моделирования голосового тракта, общепринято рассматривать p=degA(q-1)) = 10. Из (24) также следует, что 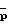 = deg(F(q-1)) >> degA(q-1)) + deg
= deg(F(q-1)) >> degA(q-1)) + deg  (q-1)) = p + r, где p + r грубо равно числу пиков в Фx(ω) С другой стороны, моделирование узкополосных процессов с шумом с использованием авторегрессионных моделей требует
(q-1)) = p + r, где p + r грубо равно числу пиков в Фx(ω) С другой стороны, моделирование узкополосных процессов с шумом с использованием авторегрессионных моделей требует  с целью обеспечить достоверные оценки спектральной плотности мощности. Таким образом,
с целью обеспечить достоверные оценки спектральной плотности мощности. Таким образом,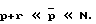
Подходящее практическое правило дается выражением 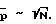 Из вышеприведенного анализа можно ожидать, что параметрический подход выгоден, когда N >> 100. Из (22) можно также заключить, что чем более плоским является спектр шума, тем меньшие значения N допускаются. Даже если
Из вышеприведенного анализа можно ожидать, что параметрический подход выгоден, когда N >> 100. Из (22) можно также заключить, что чем более плоским является спектр шума, тем меньшие значения N допускаются. Даже если 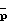 не является достаточно большим, можно ожидать, что параметрический подход даст приемлемые результаты. Причиной этого является то, что параметрический подход дает, с точки зрения дисперсии ошибки, значительно более точные оценки спектральной плотности мощности, чем подход, основанный на периодограмме (в типичном примере отношение между дисперсиями равняется 1:8, см. ниже), что значительно уменьшает на выходе такие паразитные искусственные шумы, как тональный шум.
не является достаточно большим, можно ожидать, что параметрический подход даст приемлемые результаты. Причиной этого является то, что параметрический подход дает, с точки зрения дисперсии ошибки, значительно более точные оценки спектральной плотности мощности, чем подход, основанный на периодограмме (в типичном примере отношение между дисперсиями равняется 1:8, см. ниже), что значительно уменьшает на выходе такие паразитные искусственные шумы, как тональный шум.
Параметрическая оценка спектральной плотности мощности кратко может быть охарактеризована следующим образом. Используют метод автокорреляции и авторегрессионную модель высокого порядка (модель порядка 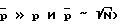 для того, чтобы вычислить параметры авторегрессии
для того, чтобы вычислить параметры авторегрессии 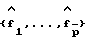 и дисперсию шума
и дисперсию шума  (23). Из оцениваемой авторегрессионной модели вычисляют
(23). Из оцениваемой авторегрессионной модели вычисляют 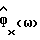 (в N дискретных точках, соответствующих частотным участкам X(ω) в (3)) согласно формуле
(в N дискретных точках, соответствующих частотным участкам X(ω) в (3)) согласно формуле
Затем для выполнения коррекции речи s(k) используется один из рассмотренных и перечисленных в табл. 2 методов спектрального вычитания.
Далее используется аппроксимация низкого порядка для дисперсии параметрической оценки спектральной плотности мощности (аналогично (7) для рассмотренных непараметрических способов) и, таким образом, разложение s(k) в ряд Фурье при допущении, что шум является белым. Тогда асимптотическая (как для числа данных (N >> 1), так и для порядка модели (p >> 1)) дисперсия 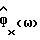 равна
равна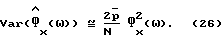
Вышеприведенное выражение действительно также для чистого (высокого порядка) процесса авторегресии. Из (26) непосредственно следует, что 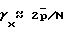 , т. е. согласно упомянутому выше практическому правилу эта переменная приблизительно соответствует
, т. е. согласно упомянутому выше практическому правилу эта переменная приблизительно соответствует 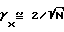 , что можно сравнить с γx≈ 1 для случая оценки спектральной плотности мощности на основе периодограммы.
, что можно сравнить с γx≈ 1 для случая оценки спектральной плотности мощности на основе периодограммы.
Например, для окружающей среды радиотелефона, который не держат при разговоре в руке, можно предположить, что шум стационарен в течение около 0,5 с (при частоте дискретизации 8000 Гц и длине кадра N = 256), что дает τ ≈ 15 и, таким образом, γν≅ 1/15. Кроме того, для 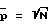 мы имеем γx= 1/8.
мы имеем γx= 1/8.
Фиг. 3 иллюстрирует для типичного речевого кадра различие между оценкой спектральной плотности мощности с помощью периодограммы и параметрической оценкой спектральной плотности мощности в соответствии с настоящим изобретением. В этом примере использованы N=256 (256 отсчетов) и авторегрессионная модель с 10 параметрами. Следует заметить, что параметрическая оценка спектральной плотности мощности 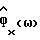 является значительно более сглаженной, чем соответствующая оценка спектральной плотности мощности с помощью периодограммы.
является значительно более сглаженной, чем соответствующая оценка спектральной плотности мощности с помощью периодограммы.
На фиг. 4 показано 5 секунд дискретизированного звукового сигнала, содержащего речь на шумовом фоне. На фиг. 5 показан сигнал фиг. 4 после спектрального вычитания, основанного на оценке спектральной плотности мощности с использованием периодограммы, которая отдает приоритет высокому качеству звука. На фиг. 6 показан сигнал фиг. 4 после спектрального вычитания, основанного на параметрической оценке спектральной плотности мощности в соответствии с настоящим изобретением.
Сравнение фиг. 5 и фиг. 6 показывает, что с помощью способа в соответствии с настоящим изобретением достигается значительное подавление шума (порядка 10 дБ). (Как отмечено выше в связи с описанием фиг. 1, уменьшенные уровни шума одинаковы для речевых и неречевых кадров). Другим отличием, которое не очевидно из фиг. 6, является то, что полученный в результате речевой сигнал искажен меньше, чем речевой сигнал на фиг. 5.
Теоретические результаты в отношении смещения и дисперсии ошибки спектральной плотности мощности для всех рассматриваемых способов суммированы в табл. 3.
Есть возможность классифицировать разные способы. Можно выделить по меньшей мере два критерия выбора подходящего способа.
Во-первых, для низкого мгновенного отношения сигнал/шум желательно, чтобы способ имел низкую дисперсию с целью избежать тональных искусственных шумов в 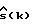 . Это невозможно без увеличенного смещения и для того, чтобы подавить (а не усилить) частотные области с низким мгновенным отношением сигнал/шум, этот член смещения должен иметь отрицательный знак (таким образом заставляя
. Это невозможно без увеличенного смещения и для того, чтобы подавить (а не усилить) частотные области с низким мгновенным отношением сигнал/шум, этот член смещения должен иметь отрицательный знак (таким образом заставляя 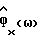 в (9) стремиться к нулю). Способами, которые удовлетворяют этим критериям, являются соответственно вычитание амплитудных спектров (MS), улучшенное вычитание спектра мощности (IPS) и винеровская фильтрация (WF).
в (9) стремиться к нулю). Способами, которые удовлетворяют этим критериям, являются соответственно вычитание амплитудных спектров (MS), улучшенное вычитание спектра мощности (IPS) и винеровская фильтрация (WF).
Во-вторых, для высоких отношений сигнал/шум желательна низкая степень искажений речи. Кроме того, если член смещения является главным, он должен иметь положительный знак. Способы на основе максимального правдоподобия (ML), вычитания спектров мощности (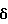 PS, PS), улучшенного вычитания спектров мощности (IPS) и (возможно) винеровской фильтрации (WF), выполняют первое требование. Член смещения доминирует в выражении среднеквадратичной ошибки только для способов на основе принципов максимального правдоподобия (ML) и винеровской фильтрации (WF), причем знак члена смещения положителен для максимального правдоподобия (ML) и соответственно отрицателен для винеровской фильтрации (WF). Таким образом, способы на основе принципа максимального правдоподобия (ML), вычитания спектров мощности (PS,
PS, PS), улучшенного вычитания спектров мощности (IPS) и (возможно) винеровской фильтрации (WF), выполняют первое требование. Член смещения доминирует в выражении среднеквадратичной ошибки только для способов на основе принципов максимального правдоподобия (ML) и винеровской фильтрации (WF), причем знак члена смещения положителен для максимального правдоподобия (ML) и соответственно отрицателен для винеровской фильтрации (WF). Таким образом, способы на основе принципа максимального правдоподобия (ML), вычитания спектров мощности (PS, 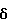 PS) и улучшенного вычитания спектров мощности (IPS) удовлетворяют этому критерию.
PS) и улучшенного вычитания спектров мощности (IPS) удовлетворяют этому критерию.
Алгоритмические аспекты
В данном разделе предпочтительные варианты осуществления способа спектрального вычитания в соответствии с настоящим изобретением описываются со ссылкой на фиг. 7.
1. Входной сигнал:
2. Расчетные переменные: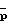 - порядок модели речи в шуме,
- порядок модели речи в шуме,
ρ - коэффициент обновления текущего среднего значения для 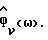
3. Для каждого кадра входных данных выполняют следующие операции:
а) Обнаружение речи (шаг 110)
Переменная Речь устанавливается на "да", если выходной сигнал детектора речевой активности соответствует состоянию st =21 или st =22.
Речь устанавливается на "нет" в случае st = 20. Если выходной сигнал детектора речевой активности соответствует состоянию st = 0, то алгоритм инициализируется заново.
б) Спектральное оценивание
Если Речь, то оценить 
i. Оценить коэффициенты (коэффициенты полинома 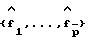 ) и дисперсию
) и дисперсию 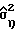 модели (23) со всеми полюсами, используя метод автокорреляции, применяемый к входным данным с подстроенным нулевым средним значением {x(k)} (шаг 120).
модели (23) со всеми полюсами, используя метод автокорреляции, применяемый к входным данным с подстроенным нулевым средним значением {x(k)} (шаг 120).
ii. Вычислить; 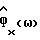 в соответствии с (25) (шаг 130).
в соответствии с (25) (шаг 130).
Если не Речь, то оценить 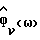 (шаг 140)
(шаг 140)
Обновить спектральную модель фонового шума 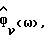 используя (4), где
используя (4), где 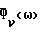 - периодограмма, основанная на входных данных с подстроенным нулевым средним значением, обработанных с помощью метода окна Хэннинга/Хэмминга. Так как здесь используются обработанные методом окна данные, в то время как
- периодограмма, основанная на входных данных с подстроенным нулевым средним значением, обработанных с помощью метода окна Хэннинга/Хэмминга. Так как здесь используются обработанные методом окна данные, в то время как 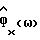 основывается на необработанных этим методом данных, то
основывается на необработанных этим методом данных, то 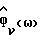 должна быть надлежащим образом нормализована. Подходящее начальное значение для
должна быть надлежащим образом нормализована. Подходящее начальное значение для 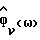 определяется с помощью среднего (по частотным участкам) значения периодограммы первого кадра, масштабированного, например, с коэффициентом 0,25, т. е. первоначально фоновый шум априорно считается белым шумом.
определяется с помощью среднего (по частотным участкам) значения периодограммы первого кадра, масштабированного, например, с коэффициентом 0,25, т. е. первоначально фоновый шум априорно считается белым шумом.
(с) Спектральное вычитание (шаг 150)
i. Вычислить частотную весовую функцию 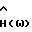 в соответствии с табл. 1.
в соответствии с табл. 1.
ii. Возможная пост-фильтрация, заглушение и подстройка минимального уровня шума.
iii. Вычислить выходной сигнал, используя (3) и данные {x(k)} с подстроенным нулевым средним значением. Данные {x(k)} могут быть обработаны методом окна или нет в зависимости от действительного перекрытия кадров (прямоугольное окно используется для неперекрывающихся кадров, тогда как окно Хэннинга используется при 50% перекрытии).
Из вышеприведенного описания ясно, что настоящее изобретение ведет к значительному подавлению шума без ухудшения при этом качества звука. Это улучшение связано с разными способами оценивания спектра мощности для речевых и неречевых кадров. Эти способы используют преимущество различных характеров речевых и неречевых (фонового шума) сигналов для того, чтобы минимизировать дисперсию соответствующих оценок спектральной плотности мощности.
Для неречевых кадров 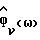 вычисляется способом непараметрического оценивания спектра мощности, например оцениванием с помощью периодограммы, основанной на быстром преобразовании Фурье, которая использует все N отсчеты каждого кадра. При сохранении в неречевых кадрах всех N степеней свободы может быть смоделировано большее многообразие фоновых шумов. Так как фоновый шум предполагается стационарным на протяжении нескольких кадров, уменьшение дисперсии
вычисляется способом непараметрического оценивания спектра мощности, например оцениванием с помощью периодограммы, основанной на быстром преобразовании Фурье, которая использует все N отсчеты каждого кадра. При сохранении в неречевых кадрах всех N степеней свободы может быть смоделировано большее многообразие фоновых шумов. Так как фоновый шум предполагается стационарным на протяжении нескольких кадров, уменьшение дисперсии 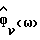 может быть достигнуто усреднением оценки спектра мощности по нескольким неречевым кадрам.
может быть достигнуто усреднением оценки спектра мощности по нескольким неречевым кадрам.
Для речевых кадров  вычисляется способом параметрического оценивания спектра мощности, основанным на параметрической модели речи. В этом случае особый характер речевого сигнала используется для уменьшения числа степеней свободы речевого кадра (до числа параметров в параметрической модели). Модель, основанная на меньшем числе параметров, уменьшает дисперсию оценки спектра мощности. Этот подход предпочтителен для речевых кадров, так как предполагается, что речь стационарна только в течение кадра.
вычисляется способом параметрического оценивания спектра мощности, основанным на параметрической модели речи. В этом случае особый характер речевого сигнала используется для уменьшения числа степеней свободы речевого кадра (до числа параметров в параметрической модели). Модель, основанная на меньшем числе параметров, уменьшает дисперсию оценки спектра мощности. Этот подход предпочтителен для речевых кадров, так как предполагается, что речь стационарна только в течение кадра.
Специалистам в данной области должно быть ясно, что различные модификации и изменения могут быть сделаны в данном изобретении в пределах его сущности и объема, который определен прилагаемой формулой.
Приложение A
Анализ 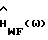
Вычисления для  дают
дают
где во втором равенстве также используется разложение в ряд Тейлора 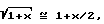 Из (27) следует, что ожидаемая величина
Из (27) следует, что ожидаемая величина 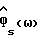 не равна нулю и определяется выражением
не равна нулю и определяется выражением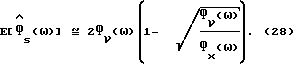
Далее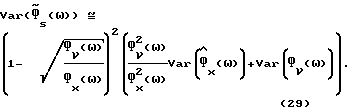
Объединяя (29) и (15), получаем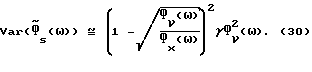
Приложение В
Анализ 
В этом приложении выводится ошибка спектральной плотности мощности для коррекции речи на основе винеровской фильтрации [2]. В этом случаев  определяется с помощью
определяется с помощью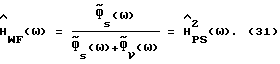
Здесь  является оценкой Фs(ω), а второе равенство вытекает из
является оценкой Фs(ω), а второе равенство вытекает из 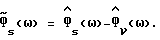
Отметим, что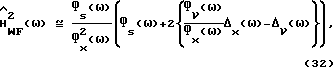
и прямое вычисление дает
Из (33) следует, что
и
Приложение С
Анализ 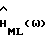
Вычитание в спектральной области на основе метода максимального правдоподобия (ML), с использованием характеристики речи, как колебания детерминированной формы с неизвестной амплитудой и фазой, определяется как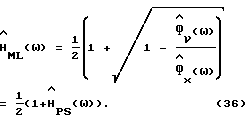
Подставив (11) в (36), в результате очевидных вычислений получим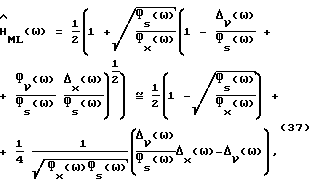
где в первом равенстве используется разложение в ряд Тейлора (1+x)-1≅ 1-x, а во втором -  Теперь можно легко вычислить ошибку спектральной плотности мощности. Подстановка (37) в (9)-(10) дает, если пренебречь отклонениями выше первого порядка в разложении
Теперь можно легко вычислить ошибку спектральной плотности мощности. Подстановка (37) в (9)-(10) дает, если пренебречь отклонениями выше первого порядка в разложении 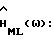
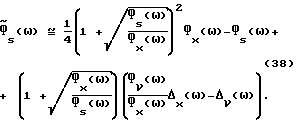
Из (38) следует, что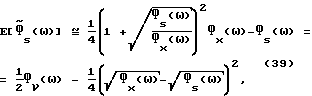
где во втором равенстве используется (2). Далее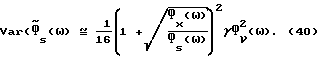
Приложение D
Вывод 
Когда 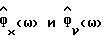 точно известны, квадратичная ошибка спектральной плотности мощности минимизируется с помощью HPS(ω), то есть
точно известны, квадратичная ошибка спектральной плотности мощности минимизируется с помощью HPS(ω), то есть 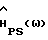 с
с 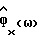 и
и 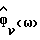 , замененными на
, замененными на 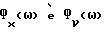 соответственно. Это вытекает непосредственно из (9) и (10), а именно
соответственно. Это вытекает непосредственно из (9) и (10), а именно 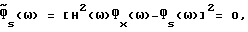 где (2) используется в последнем равенстве. Заметим, что в этом случае H(ω) является детерминированной величиной, тогда как
где (2) используется в последнем равенстве. Заметим, что в этом случае H(ω) является детерминированной величиной, тогда как  - случайной величиной. Если учесть неопределенность оценок спектральной плотности мощности, то это в целом более не соответствует действительности и, чтобы улучшить характеристику
- случайной величиной. Если учесть неопределенность оценок спектральной плотности мощности, то это в целом более не соответствует действительности и, чтобы улучшить характеристику 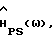 в этом разделе выводится весовая функция, независимая от данных. С этой целью рассматривается выражение для дисперсии в виде
в этом разделе выводится весовая функция, независимая от данных. С этой целью рассматривается выражение для дисперсии в виде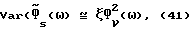
(ξ = 1 для вычитания спектров мощности и 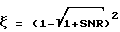 для вычитания амплитудных спектров и γ = γx+γν). Переменная γ зависит только от используемого способа оценки спектральной плотности мощности и не может зависеть от выбора передаточной функции
для вычитания амплитудных спектров и γ = γx+γν). Переменная γ зависит только от используемого способа оценки спектральной плотности мощности и не может зависеть от выбора передаточной функции 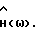 Однако первый коэффициент ξ зависит от выбора
Однако первый коэффициент ξ зависит от выбора 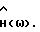 В данном разделе ищется независимая от данных весовая функция
В данном разделе ищется независимая от данных весовая функция 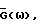 такая, что
такая, что 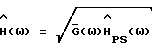 минимизирует математическое ожидание квадратичной ошибки спектральной плотности мощности, то есть
минимизирует математическое ожидание квадратичной ошибки спектральной плотности мощности, то есть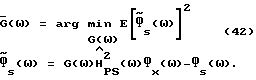
B (42) G(ω) является характеристической весовой функцией. Прежде, чем продолжить, заметим, что если допускается зависимость весовой функции G(ω) от данных, то это дает в результате общий класс способов вычитания в спектральной области, который включает в качестве особых случаев много используемых обычно методов, например вычитание амплитудных спектров с использованием 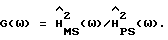 Однако это замечание не представляет особого интереса, так как оптимизация (42) с зависимой от данных G(ω) значительно зависит от вида G(ω). Таким образом, способы, которые используют весовые функции, зависящие от данных, должны быть проанализированы по отдельности, так как в этом случае не может быть получено общих результатов.
Однако это замечание не представляет особого интереса, так как оптимизация (42) с зависимой от данных G(ω) значительно зависит от вида G(ω). Таким образом, способы, которые используют весовые функции, зависящие от данных, должны быть проанализированы по отдельности, так как в этом случае не может быть получено общих результатов.
Для минимизации (42) прямое вычисление дает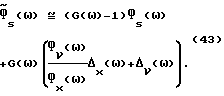
Определяя математическое ожидание квадратичной ошибки спектральной плотности мощности и используя (41), получим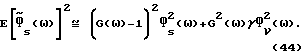
Уравнение (44) является квадратичным для переменной G(ω) и может быть минимизировано аналитически. Результат следующий: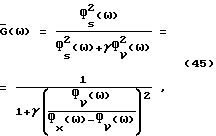
где во втором равенстве используется (2). Не является неожиданным, что 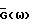 зависит от спектральных плотностей мощности (неизвестных) и переменной γ. Как отмечено выше, нельзя непосредственно заменять неизвестные спектральные плотности мощности в (45) соответствующими оценками и считать, что полученный в результате модифицированный способ является оптимальным, то есть минимизирует (42). Однако можно ожидать, что с принятием во внимание неопределенности
зависит от спектральных плотностей мощности (неизвестных) и переменной γ. Как отмечено выше, нельзя непосредственно заменять неизвестные спектральные плотности мощности в (45) соответствующими оценками и считать, что полученный в результате модифицированный способ является оптимальным, то есть минимизирует (42). Однако можно ожидать, что с принятием во внимание неопределенности 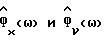 и в процедуре расчета модифицированный способ вычитания спектров мощности будет работать "лучше", чем обычный способ вычитания спектров мощности (PS). На основании вышеприведенных соображений, этот модифицированный способ вычитания спектров мощности назван улучшенным способом вычитания спектров мощности (IPS). Прежде чем анализировать улучшенный способ вычитания спектров мощности (IPS) в Приложении Е, необходимо сделать следующие замечания.
и в процедуре расчета модифицированный способ вычитания спектров мощности будет работать "лучше", чем обычный способ вычитания спектров мощности (PS). На основании вышеприведенных соображений, этот модифицированный способ вычитания спектров мощности назван улучшенным способом вычитания спектров мощности (IPS). Прежде чем анализировать улучшенный способ вычитания спектров мощности (IPS) в Приложении Е, необходимо сделать следующие замечания.
Для высокого мгновенного отношения сигнал/шум (для такой ω, что Фs(ω)/Фν(ω) ≫ 1) из (45) следует, что 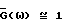 и, так как нормализованная дисперсия ошибки
и, так как нормализованная дисперсия ошибки 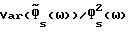 (см. (41)) в данном случае мала, можно сделать вывод, что характеристика улучшенного способа вычитания спектров мощности (IPS) близка (очень близка) к характеристике обычного способа вычитания спектров мощности (PS). С другой стороны, для низкого мгновенного отношения сигнал/шум (то есть для такого значения ω, при котором
(см. (41)) в данном случае мала, можно сделать вывод, что характеристика улучшенного способа вычитания спектров мощности (IPS) близка (очень близка) к характеристике обычного способа вычитания спектров мощности (PS). С другой стороны, для низкого мгновенного отношения сигнал/шум (то есть для такого значения ω, при котором 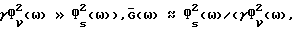 что приводит к формуле (ср. (43)):
что приводит к формуле (ср. (43)):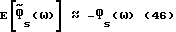
и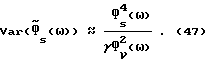
Однако при низком мгновенном отношении сигнал/шум нельзя сделать вывод о том, что (46)-(47) даже приблизительно правильны, если 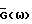 в (45) заменяется на
в (45) заменяется на 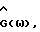 то есть при замене
то есть при замене 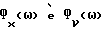 в (45) их оцененными значениями
в (45) их оцененными значениями 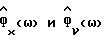 соответственно.
соответственно.
Приложение Е
Анализ 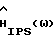
В этом приложении анализируется способ улучшенного вычитания спектров мощности. Принимая во внимание (45), определим 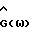 c помощью (45), с
c помощью (45), с 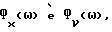 заменяемыми соответствующими оцененными величинами. Можно показать, что
заменяемыми соответствующими оцененными величинами. Можно показать, что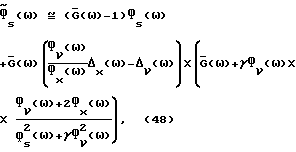
это может быть сопоставлено с (43). В явном виде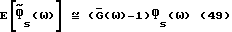
и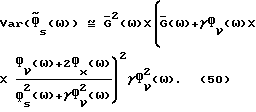
Для высокого отношения сигнал/шум, такого, что Фs(ω)/Фν(ω) ≫ 1, может быть выполнен некоторый анализ (49)-(50). В этом случае можно показать, что
и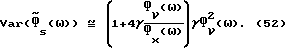
Члены, которыми пренебрегают в (51) и (52), имеют порядок 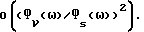 . Таким образом, как уже отмечалось, при высоком отношении сигнал/шум характеристика улучшенного способа вычитания спектров мощности (IPS) сходна с характеристикой обычного способа вычитания спектров мощности (PS). С другой стороны, для низкого отношения сигнал/шум (для таких ω, что
. Таким образом, как уже отмечалось, при высоком отношении сигнал/шум характеристика улучшенного способа вычитания спектров мощности (IPS) сходна с характеристикой обычного способа вычитания спектров мощности (PS). С другой стороны, для низкого отношения сигнал/шум (для таких ω, что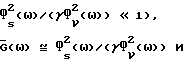
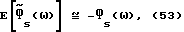
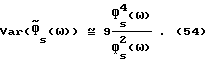
Если сравнить (53)-(54) с соответствующими результатами вычитания спектров мощности (13) и (16), то можно видеть, что для низкого отношения сигнал/шум улучшенный способ вычитания спектров мощности значительно уменьшает дисперсию  по сравнению с обычным способом вычитания спектров мощности, устремляя
по сравнению с обычным способом вычитания спектров мощности, устремляя 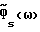 в (9) к нулю. Отношение между дисперсиями при улучшенном способе вычитания спектров мощности (IPS) и обычном вычитании спектров мощности (PS) имеет порядок
в (9) к нулю. Отношение между дисперсиями при улучшенном способе вычитания спектров мощности (IPS) и обычном вычитании спектров мощности (PS) имеет порядок 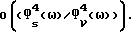 Можно также сравнить (53)-(54) с приближенным выражением (47), отметив, что отношение между ними равняется 9.
Можно также сравнить (53)-(54) с приближенным выражением (47), отметив, что отношение между ними равняется 9.
Приложение F
Вычитание спектров мощности (PS) с оптимальным коэффициентом вычитания δ
Следует рассмотреть часто обсуждаемую модификацию способа вычитания мощности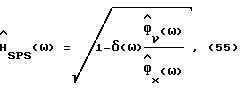
где δ(ω) - функция, возможно зависящая от частоты. В частности, при δ(ω) = δ для некоторой постоянной δ > 1, способ часто называется вычитанием спектров мощности с избыточным вычитанием. Эта модификация значительно уменьшает уровень шума и уменьшает тональные искусственные шумы. При этом она существенно искажает речь, что делает эту модификацию бесполезной для коррекции речи высокого качества. Этот факт легко виден из (55), когда δ ≫ 1. Таким образом, для средних и низких отношений речь/шум (в области ω) выражение под знаком квадратного корня очень часто является отрицательным поэтому выпрямляющее устройство будет приравнивать его к нулю (однополупериодное выпрямление). Это подразумевает, что только те частотные полосы, где отношение сигнал/шум является высоким, будут появляться в выходном сигнале  в (3). Вследствие нелинейности выпрямляющего устройства настоящий метод анализа непосредственно неприменим в этом случае и так как δ>1 приводит к выходному сигналу с низким качеством звука, то далее эта модификация рассматриваться не будет.
в (3). Вследствие нелинейности выпрямляющего устройства настоящий метод анализа непосредственно неприменим в этом случае и так как δ>1 приводит к выходному сигналу с низким качеством звука, то далее эта модификация рассматриваться не будет.
Однако интерес представляет такой случай, когда δ(ω)≤1, что можно видеть из следующего эвристического анализа. Как было установлено ранее, когда 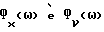 точно известны, (55) c δ(ω) = 1 является оптимальным в отношении минимизации квадратичной ошибки спектральной плотности мощности. С другой стороны, если
точно известны, (55) c δ(ω) = 1 является оптимальным в отношении минимизации квадратичной ошибки спектральной плотности мощности. С другой стороны, если 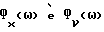 совершенно неизвестны, то есть нет их оценок, то лучшее, что можно сделать - это оценить речь с помощью самих отсчетов речи с шумом, то есть
совершенно неизвестны, то есть нет их оценок, то лучшее, что можно сделать - это оценить речь с помощью самих отсчетов речи с шумом, то есть  , в соответствии с (55) при δ = 0. Ввиду двух вышеуказанных крайних случаев можно ожидать, что если неизвестные
, в соответствии с (55) при δ = 0. Ввиду двух вышеуказанных крайних случаев можно ожидать, что если неизвестные 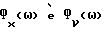 заменяются соответственно на
заменяются соответственно на 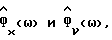 то ошибка
то ошибка 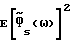 минимизируется для некоторого δ(ω) в интервале 0<δ(ω)<1.
минимизируется для некоторого δ(ω) в интервале 0<δ(ω)<1.
Кроме того, как эмпирическая величина улучшение усредненных спектральных искажений, так и ошибка спектральной плотности мощности, были экспериментально изучены в зависимости от коэффициента вычитания при вычитании амплитудных спектров. На основе нескольких экспериментов был сделан вывод, что оптимальный коэффициент вычитания предпочтительно должен находиться в интервале от 0,5 до 0,9.
Вычисление ошибки спектральной плотности мощности в этом случае дает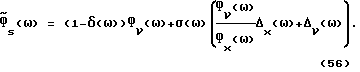
Расчет математического ожидания квадратичной ошибки спектральной плотности мощности дает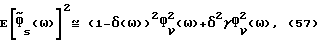
где использовано (41). Уравнение (57) является квадратным по δ(ω) и может быть минимизировано аналитически. Если обозначить оптимальное значение через 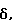 то результат будет следующий
то результат будет следующий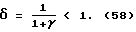
Заметим, что поскольку величина γ в (58) приближенно частотно независима (по меньшей мере для N >> 1), то 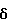 также не зависит от частоты. В частности,
также не зависит от частоты. В частности, 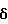 не зависит от
не зависит от 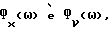 что подразумевает, что дисперсия и смещение
что подразумевает, что дисперсия и смещение 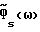 непосредственно следуют из (57).
непосредственно следуют из (57).
В ряде (реальных) случаев значение 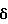 может быть значительно меньше единицы. Например, еще раз рассмотрим
может быть значительно меньше единицы. Например, еще раз рассмотрим 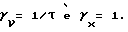 Тогда δ определяется с помощью выражения
Тогда δ определяется с помощью выражения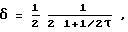
которое для всех τ очевидно является меньшим, чем 0,5. В этом случае тот факт, что δ ≪ 1 показывает, что неопределенность в оценках спектральной плотности мощности (и, в частности, неопределенность в  оказывает большое воздействие на качество выходного сигнала (с точки зрения ошибки спектральной плотности мощности). В особенности, применение δ ≪ 1 подразумевает, что улучшение отношения речь/шум выходного сигнала по сравнению с входным является малым.
оказывает большое воздействие на качество выходного сигнала (с точки зрения ошибки спектральной плотности мощности). В особенности, применение δ ≪ 1 подразумевает, что улучшение отношения речь/шум выходного сигнала по сравнению с входным является малым.
В связи с этим возникает вопрос, существует ли в данном случае, аналогично весовой функции для улучшенного способа вычитания спектров мощности (IPS) в Приложении D, независимая от данных весовая функция 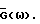 B Приложении G такой способ выводится (и назван δIPS).
B Приложении G такой способ выводится (и назван δIPS).
Приложение G
Вывод 
В этом приложении мы ищем независимый от данных весовой коэффициент 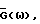 такой, что
такой, что  для некоторой постоянной δ(0≤δ≤1) минимизирует математическое ожидание квадратичной ошибки спектральной плотности (ср. с (42)). Прямое вычисление дает
для некоторой постоянной δ(0≤δ≤1) минимизирует математическое ожидание квадратичной ошибки спектральной плотности (ср. с (42)). Прямое вычисление дает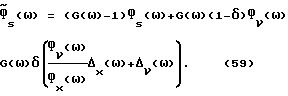
Математическое ожидание квадратичной ошибки спектральной плотности определяется с помощью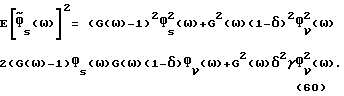
Правая часть (60) является квадратичной по G(ω) и может быть аналитически минимизирована. Результат определяется выражением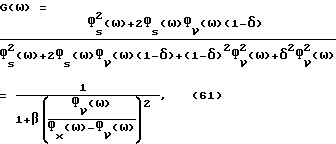
где β в втором равенстве определяется с помощью
Для δ = 1 вышеприведенные (61)-(62) сокращаются до улучшенного способа вычитания спектров мощности (45), а для δ = 0 мы приходим к обычному вычитанию спектров мощности. Замена 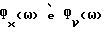 в (61)-(62) соответствующими оцениваемыми величинами
в (61)-(62) соответствующими оцениваемыми величинами 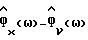 и
и 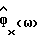 соответственно приводит к способу, который, принимая во внимание улучшенный способ вычитания спектров мощности IPS, назван δIPS. Анализ способа δIPS аналогичен анализу способа вычитания спектров мощности IPS, но требует много громоздких тривиальных вычислений и поэтому опущен.
соответственно приводит к способу, который, принимая во внимание улучшенный способ вычитания спектров мощности IPS, назван δIPS. Анализ способа δIPS аналогичен анализу способа вычитания спектров мощности IPS, но требует много громоздких тривиальных вычислений и поэтому опущен.
Литература
1. S. F. Boll, "Suppression of Acoustic Noise in Speech Using Spectral Subtraction", IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. ASSP-27, April 1979, pp, 113-120.
2. J. S.Lim and A.V. Oppenheim, "Enchancement and Bandwidth Compression of Noisy Speech", Proceedings of the IEEE, Vol. 67, No. 12, December 1979, pp. 1586-1604.
3. J. D. Gibson, B. Koo and S.D. Gray, "Filtering of Colored Noise for Speech Enhancement and Coding", IEEE Transactions on Acoustics, Speech, and Signal Processing, Vol. ASSP-39, No. 8, August 1991, pp. 1732-1742.
4. J.H.L Hansen and M.A. Clements, "Constrained, Iterative Speech Enhancement with Application to Speech Recognition", IEEE Transactions on Signal Processing, Vol. 39, No. 4, April 1991; pp. 795-805.
5. D.K. Freeman, Q. Cosier, C.B. Southcott and I. Boid, "The Voice Activity Detector for the Pan-European Digital Cellular Mobile Telephone Service", 2989 IEEE International Conference Acoustics, Speech and Signal Processing, Glasgow, Scotland, 23-26 March 1989, pp. 369-372.
6. Международная заявка N 89/08910, British Telecommunications PLC.





Подавление шума осуществляется в цифровой системе связи на основе передачи кадров. Каждый кадр содержит заданное число N звуковых ответов и имеет таким образом N степеней свободы. Каждый речевой кадр аппроксимируется параметрической моделью, которая уменьшает число степеней свободы до значения меньшего N и с помощью которой вычисляется оценка спектральной плотности мощности 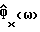 каждого речевого кадра. Функция спектрального вычитания
каждого речевого кадра. Функция спектрального вычитания 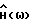 основывается на оценке
основывается на оценке 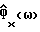 и на оценке спектральной плотности мощности фонового шума в неречевых кадрах
и на оценке спектральной плотности мощности фонового шума в неречевых кадрах 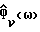 , вычисленной непараметрическим способом оценивания спектра мощности. Технический результат - увеличение подавления шума без ухудшения качества звука. 9 з.п.ф-лы, 7 ил., 3 табл.
, вычисленной непараметрическим способом оценивания спектра мощности. Технический результат - увеличение подавления шума без ухудшения качества звука. 9 з.п.ф-лы, 7 ил., 3 табл.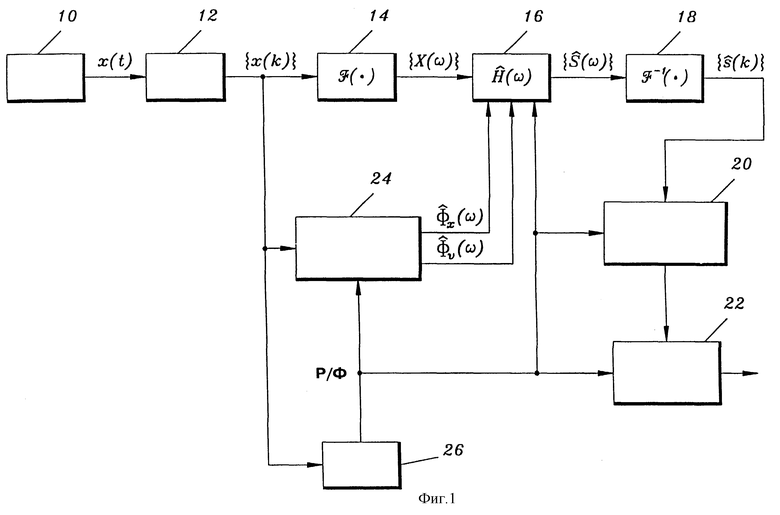
 спектрального вычитания основывается на оценке
спектрального вычитания основывается на оценке 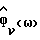 спектральной плотности мощности фонового шума в неречевых кадрах и на оценке
спектральной плотности мощности фонового шума в неречевых кадрах и на оценке  спектральной плотности мощности в речевых кадрах, отличающийся тем, что аппроксимируют каждый речевой кадр приближенной параметрической моделью так, что число степеней свободы уменьшается до значения, меньшего N, вычисляют упомянутую оценку спектральной плотности мощности
спектральной плотности мощности в речевых кадрах, отличающийся тем, что аппроксимируют каждый речевой кадр приближенной параметрической моделью так, что число степеней свободы уменьшается до значения, меньшего N, вычисляют упомянутую оценку спектральной плотности мощности 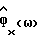 каждого речевого кадра с помощью параметрического способа оценивания спектра мощности, основанного на приближенной параметрической модели, и вычисляют упомянутую оценку
каждого речевого кадра с помощью параметрического способа оценивания спектра мощности, основанного на приближенной параметрической модели, и вычисляют упомянутую оценку 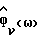 спектральной плотности мощности каждого неречевого кадра непараметрическим способом оценивания спектра мощности.
спектральной плотности мощности каждого неречевого кадра непараметрическим способом оценивания спектра мощности.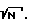
4. Способ по п.3, отличающийся тем, что упомянутая авторегрессионная модель имеет порядок, приблизительно равный 10.
где 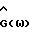 - весовая функция, а δ(ω) - коэффициент вычитания.
- весовая функция, а δ(ω) - коэффициент вычитания.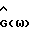 равна 1.
равна 1.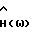 спектрального вычитания соответствует формуле
спектрального вычитания соответствует формуле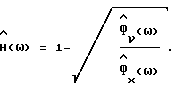
9. Способ по п.3, отличающийся тем, что упомянутая функция 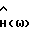 спектрального вычитания соответствует формуле
спектрального вычитания соответствует формуле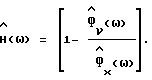
10. Способ по п. 3, отличающийся тем, что упомянутая функция 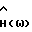 спектрального вычитания соответствует формуле
спектрального вычитания соответствует формуле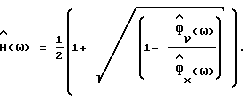
| Экономайзер | 0 |
|
SU94A1 |
| DE 4012349 A1, 25.10.90 | |||
| US 5166981 A, 24.11.92 | |||
| Способ выделения речевого сигнала на фоне помех | 1985 |
|
SU1314373A1 |

