Настоящее изобретение относится к цифровым системам радиосвязи с подвижными объектами. В частности, изобретение относится к способу улучшения качества приема и воспроизведения речи в цифровом мобильном радиоприемнике в присутствии фонового шума звуковой частоты.
Сотовая система телефонной связи состоит из трех основных компонентов, а именно из коммутационного узла сотовой сети связи, служащего межсетевым интерфейсом для связи с телефонной сетью, имеющей наземные (проводные) линии связи, из нескольких базовых станций, управление которыми осуществляется коммутационным узлом и с помощью аппаратуры которых сигналы, используемые в проводной телефонной сети, преобразуются в радиосигналы, используемые в беспроводной связи, и наоборот, а также из нескольких мобильных радиотелефонных устройств, которые преобразуют радиосигналы, используемые для связи с базовыми станциями, в звуковые акустические сигналы, используемые для связи с абонентами (например, речь, музыку и т.д.), и наоборот.
Связь между базовой станцией и мобильным радиотелефоном возможна лишь в том случае, если и базовая станция, и мобильный телефон используют для радиосвязи идентичные методы модуляции сигналов, а также одинаковые алгоритмы кодирования данных и концепции управления, т.е. оба устройства должны использовать один и тот же интерфейс радиосвязи. В Соединенных Штатах Америки разработано и утверждено несколько стандартов радиосвязи. До недавнего времени вся сотовая телефонная связь в Соединенных Штатах работала в соответствии со стандартом Advanced Mobile Phone Service (AMPS, усовершенствованная система мобильной радиотелефонной связи). Этот стандарт определяет методы кодирования аналогового сигнала с использованием частотной модуляции в диапазоне 800 МГц радиочастотного спектра. Согласно этому стандарту каждому вызову по сотовому телефону на весь сеанс связи выделяется свой канал связи, состоящий из двух полос частот по 30 кГц в этом диапазоне. Во избежание помех между телефонными переговорами под два сеанса связи не может одновременно задействоваться один и тот же канал в пределах одной и той же географической зоны. Поскольку весь диапазон радиочастотного спектра, выделенный для сотовой телефонии, является конечным, этим ограничением определяется и максимальное число пользователей, которые одновременно могут вести телефонные переговоры в сотовой системе телефонной связи.
С целью повысить пропускную способность системы было разработано несколько стандартов, альтернативных AMPS-стандарту. Одним из них является стандарт Interim Standard-54 (IS-54), разработанный Ассоциацией изготовителей электронного оборудования (Electronic Industries Association) и Ассоциацией изготовителей телекоммуникационного оборудования (Telecommunications Industry Association). Этот стандарт предусматривает цифровое кодирование сигналов и модуляцию сигналов с использованием многостанционного доступа с временным разделением каналов (МДВР). Согласно МДВР-методу каждая полоса частот в 30 кГц совместно используется для трех одновременно ведущихся телефонных переговоров, а каждому сеансу связи разрешено занимать весь канал на одну треть от всего выделенного времени. Все время поделено на кадры длительностью 20 мс, а каждый кадр в свою очередь подразделен на три временных интервала. Каждому сеансу связи отводится один временной интервал в каждом кадре.
С целью обеспечить передачу всей информации, занимающей 20 мс телефонного разговора, за один временной интервал речевые и иные звуковые сигналы подвергаются соответствующей обработке с использованием такого метода цифрового сжатия речи, который известен как Vector Sum Excited Linear Prediction (VSELP, возбужденное линейное предсказание с векторной суммой). В каждой совместимой со стандартом IS-54 базовой станции и мобильном радиотелефоне предусмотрен VSELP-кодер и -декодер. Вместо передачи по каналу связи цифрового представления звукового колебательного сигнала VSELP-кодер использует модель речеобразования с целью сжать оцифрованный звуковой сигнал до некоторого набора параметров, которые характеризуют состояние механизма речеобразования во время передачи кадра (например, основной тон речевого сигнала, конфигурация речевого тракта и т.д.). Эти параметры кодируются в виде цифрового потока битов, а затем передаются по каналу на приемник со скоростью 8 килобит в секунду (кбит/с). Эта скорость передачи информации в битах значительно ниже той скорости, которая требуется для кодирования фактического звукового колебательного сигнала. VSELP-декодер в приемнике в этом случае использует указанные параметры для восстановления оценки оцифрованного звукового колебательного сигнала. Передаваемая цифровая речевая информация объединяется в определенном порядке в цифровые информационные кадры длительностью 20 мс, каждый из которых содержит по 160 выборок. При этом каждый речевой кадр содержит 159 битов. VSELP-метод или -алгоритм подробно описан в документе TR45 Full-Rate Speech Coder Compatibility Standard PN- 2972, 1990, опубликованном Ассоциацией изготовителей электронного оборудования и включенном в полном объеме в настоящее описание в качестве ссылки (далее этот документ назван как "VSELP Standard").
VSELP-алгоритм позволяет значительно сократить количество битов, необходимых для передачи звуковой информации по каналу связи. Однако такое сокращение объема информации в существенной степени зависит от выбранной модели речеобразования. Как следствие, этот стандарт не обеспечивает достаточно четкого воспроизведения неречевых звуков. Например, салон автомобиля при его движении неизбежно создает шумовое окружение. Собственный шум от автомобиля в сочетании с внешними шумами создает фоновый шум звуковой частоты, уровень которого значительно превышает уровень обычного фонового шума в неподвижном окружении. В этом случае при использовании VSELP-алгоритма неизбежно приходится много раз кодировать неречевую информацию, равно как и речь с наложенным на нее фоновым шумом.
При использовании VSELP-алгоритма для кодирования речи в присутствии фонового шума возникает две проблемы. Во-первых, звучание фонового шума является неестественным независимо от того, присутствует ли в данный момент в сигнале собственно речь или нет, и, во-вторых, речь подвержена определенным характерным искажениям. Эти проблемы как по отдельности, так и совместно обычно именуются как "завихрение".
Хотя такие искусственные искажения, или артефакты, вносимые процессом кодирования/декодирования, и можно было бы устранить, использовав вместо VSELP-алгоритма иной алгоритм сжатия речи, который не имеет тех же недостатков, тем не менее такой подход потребовал бы изменения технических нормативов интерфейса радиосвязи IS-54. Такое изменение нежелательно, поскольку со стороны поставщиков услуг сотовой телефонной связи, соответствующих производителей и абонентов уже инвестированы в существующее оборудование значительные денежные средства. Так, например, при работе по одному из известных из уровня техники методов кодер речи при детектировании отсутствия речи кодирует специальный кадр для передачи на приемник. В этом специальном кадре содержатся параметры комфортного шума, которые дают команду декодеру речи генерировать комфортный шум, который аналогичен фоновому шуму на передающей стороне. Такие специальные кадры периодически передаются передатчиком в периоды отсутствия речи. Такое решение проблемы "завихрения" требует внесения соответствующих изменений в существующий VSELP-алгоритм сжатия речи, поскольку при этом для указания тех моментов, в которые требуется генерировать комфортный шум, в поток информации необходимо вводить специальные кодированные кадры. Описанная выше процедура реализуется как на передающей, так и на принимающей сторонах канала связи и требует внесения соответствующих изменений в существующий стандарт, определяющий технические нормативы интерфейса радиотелефонной связи. Поэтому такое решение является неудовлетворительным.
Исходя из вышеизложенного, в основу настоящего изобретения была положена задача уменьшить влияние искусственных искажений, вводимых VSELP-алгоритмом (или любым другим алгоритмом кодирования/декодирования речи) при наличии фонового шума звуковой частоты, без необходимости внесения каких-либо изменений в технические нормативы интерфейса радиотелефонной связи.
Было установлено, что описанную выше проблему "завихрения" можно эффективно решить, если в периоды отсутствия речи вносить в сигнал затухание в сочетании с введением в него комфортного шума и применять селективную фильтрацию верхних частот на основе оценки энергии фонового шума.
В соответствии с настоящим изобретением для детектирования речи в принятом речевом сигнале при работе в присутствии шумов детектор активности речи использует оценку энергии. При отсутствии речи система ослабляет сигнал и вводит прошедший низкочастотную фильтрацию белый шум (т.е. комфортный шум) соответствующего уровня. Этот комфортный шум имитирует типичные спектральные характеристики автомобильного или иного фонового шума. Благодаря этому сглаживается "завихрение", а звучание делается более естественным. Когда детектором активности речи установлено наличие в сигнале речи, синтезированный речевой сигнал обрабатывается без ослабления.
Было установлено, что наиболее неприятные на слух искажения, которые вводит кодер речи при одновременном кодировании и речи, и шума, появляются в основном в диапазоне низких частот. Поэтому в зависимости от уровня фонового шума дополнительно к ослаблению, управляемому активностью речи, и введению комфортного шума используют набор фильтров верхних частот. Такой фильтрации речевой сигнал подвергается независимо от того, присутствует ли фактически в сигнале речь или нет. Если обнаруженный уровень шума составляет менее -52 дБ, то фильтрация верхних частот, или, что то же самое, высокочастотная фильтрация, не применяется. Если уровень шума находится между -40 дБ и -52 дБ, то синтезированный речевой сигнал пропускается через фильтр верхних частот с частотой среза 200 Гц. Если же уровень шума превышает -40 дБ, то применяется фильтр верхних частот с частотой среза 350 Гц. В результате применения этих фильтров верхних частот фоновый шум снижается с незначительным влиянием на качество речи.
Настоящее изобретение используется в приемнике (либо в приемнике базовой станции, либо в приемнике подвижной станции (мобильного радиотелефона), либо в обоих приемниках), и, следовательно, для его реализации не требуется внесения каких либо изменений в протокол кодирования/декодирования речи, определяемый существующим стандартом.
Ниже изобретение более подробно поясняется со ссылкой на прилагаемые чертежи, на которых показано: на фиг. 1 - блок-схема цифровой радиоприемной системы по изобретению,
на фиг. 2 - блок-схема предлагаемого имитатора шума, управляемого детектированием активности речи,
на фиг. 3 - характеристика сигнала, описывающая полную акустическую энергию принятого сигнала,
на фиг. 4 - блок-схема драйвера фильтра верхних частот,
на фиг. 5 - последовательность операций, выполняемых детектором активности речи, и
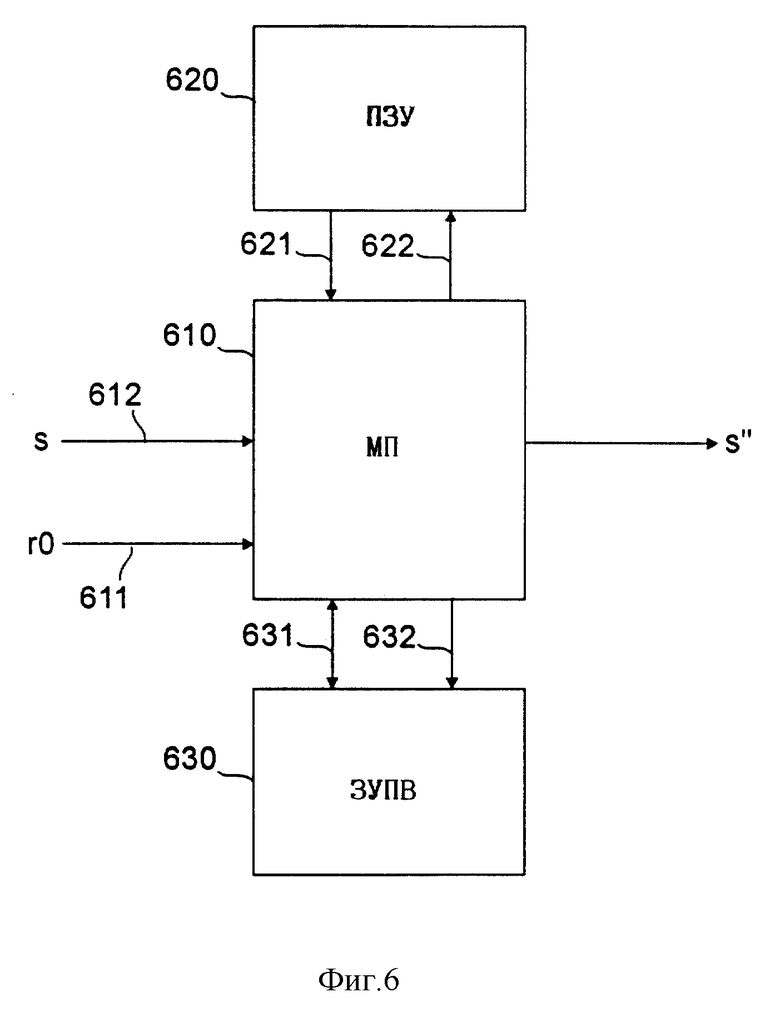
на фиг. 6 - вариант выполнения изобретения на базе микропроцессора.
На фиг. 1 показана цифровая радиоприемная система 10 по изобретению. Переданные по радио колебательные сигналы, соответствующие кодированным речевым сигналам, поступают в демодулятор 20, который обрабатывает эти принятые сигналы, формируя цифровой сигнал d. Этот цифровой сигнал d выдается на декодер 30 канала, который обрабатывает сигнал d для исправления ошибок, возникших при передаче. Результирующий сигнал, сформированный декодером 30 канала, представляет собой сигнал b, состоящий из потока битов кодированной речи, организованного в цифровые информационные кадры в соответствии с VSELP-стандартом, описанном выше. Этот поток битов b подается на декодер 40 речи, в котором он обрабатывается с получением сигнала s, состоящего из потока битов декодированной речи. Указанный декодер 40 выполнен таким образом, чтобы декодировать речь, закодированную в соответствии с VSELP-методом. Затем сигнал s, состоящий из потока битов декодированной речи, подается на имитатор 50 шума, управляемый детектированием активности речи (ИШУДАР) и служащий для устранения любых фоновых "завихрений", присутствующих в сигнале в паузах речевого сигнала, т.е. в периоды отсутствия речи. В одном из вариантов выполнения на ИШУДАР 50 напрямую от декодера 30 канала по сигнальной линии 35 также поступает часть сигнала b, состоящего из потока битов кодированной речи. ИШУДАР 50 использует энергию кодированного по VSELP-алгоритму кадра величиной r0, которая является частью сигнала b, состоящего из потока битов кодированной речи, как более подробно описано ниже. Выходным сигналом ИШУДАР 50 является сигнал s'', состоящий из потока битов декодированной речи. Этот выходной сигнал с ИШУДАР 50 может затем поступать на цифроаналоговый преобразователь 60 (ЦАП), который преобразует цифровой сигнал s'' в аналоговый колебательный сигнал. Этот аналоговый сигнал затем может напрямую передаваться в систему назначения, например, в телефонную сеть. Альтернативно этому выходной сигнал из ИШУДАР 50 может подаваться на другое устройство, преобразующее данные в этом выходном сигнале в некоторый другой цифровой формат, используемый в системе назначения.
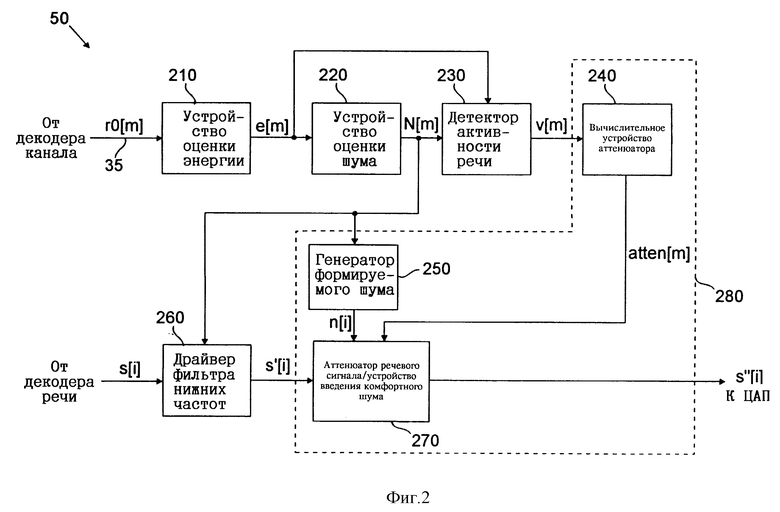
Структура ИШУДАР 50 более подробно показана на фиг. 2. На ИШУДАР по сигнальной линии 35, как показано на фиг. 1, поступает энергия кодированного по VSELP-методу кадра величиной r0, отделенная от состоящего из потока битов кодированной речи сигнала b. Эта величина энергии r0 представляет собой мощность входного речевого сигнала, усредненную по кадру длительностью 20 мс. Величина r0 может принимать 32 возможных значения от 0 до 31. Значение r0 = 0 соответствует энергии кадра, равной 0. Остальные значения величины r0 находятся в диапазоне от минимального значения, равного -64 дБ и соответствующего r0 = 1, до максимального значения, равного -4 дБ и соответствующего r0 = 31. При этом шаг между значениями r0 составляет 2 дБ. Величина r0 энергии кадра более подробно описана в VSELP Standard, стр. 16. Затем энергия кадра величиной r0 подается на устройство 210 оценки энергии, которое определяет усредненную по кадру энергию.
Устройство 210 оценки энергии генерирует сигнал усредненной по кадру энергии e[m] , который характеризует среднюю энергию кадра, вычисленную во время передачи кадра m, где m обозначает номер текущего цифрового информационного кадра. Величина e[m] определяется следующим образом:
Средняя энергия кадра сначала устанавливается на величину первоначальной оценки энергии Eнач. Сама величина Eнач устанавливается на значение больше 31, которое является наибольшим возможным значением для r0. Например, Eнач может быть установлено на значение 32. После инициализации, т.е. после присвоения начальных значений, средняя энергия e[m] кадра будет вычисляться по следующему уравнению: e[m] =α•r0[m]+(1-α)•e[m-1], где α представляет собой константу сглаживания, значение которой лежит в пределах 0≤ α ≤1. Величину α следует выбирать с таким расчетом, чтобы обеспечить приемлемое усреднение энергии по кадру или по кадрам. Было установлено, что оптимальным значением является α = 0,25, при котором обеспечивается наиболее эффективное усреднение энергии по семи цифровым информационным кадрам (140 мс). В принципе для α могут выбираться различные значения, однако предпочтительными являются значения в диапазоне 0,25±0,2.
Как описано выше и показано на фиг. 1, до декодирования состоящего из потока битов кодированной речи сигнала b декодером 40 речи на ИШУДАР 50 сначала поступает энергия кодированного по VSELP-алгоритму кадра величиной r0, отделенная от этого сигнала b. Альтернативно этому указанная энергия кадра величиной r0 может вычисляться самим ИШУДАР 50 на основе состоящего из потока битов декодированной речи сигнала s, принятого от декодера 40 речи. В варианте выполнения, где величина r0 энергии кадра вычисляется самим ИШУДАР 50, не требуется подавать часть энергии сигнала b, состоящего из потока битов кодированной речи, на ИШУДАР 50, и поэтому необходимость в использовании сигнальной линии 35, показанной на фиг. 1, отпадет. Вместо этого ИШУДАР 50 будет обрабатывать только сигнал s, состоящий из потока битов декодированной речи, а величина r0 энергии кадра будет вычисляться в соответствии с VSELP Standard, стр. 16-17. Тем не менее при подаче на ИШУДАР 50 по сигнальной линии 35 энергии величиной r0, отделенной от состоящего из потока битов кодированной речи сигнала b, обеспечивается более быстрая обработка сигнала s в ИШУДАР, поскольку последнему не требуется вычислять r0.
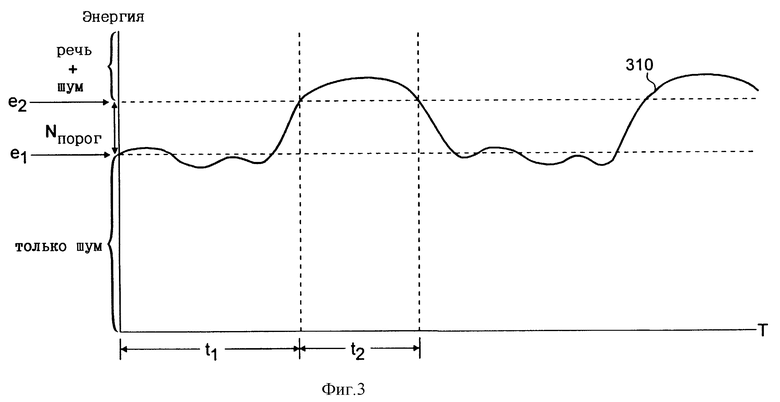
Сигнал средней энергии e[m] кадра, сформированный устройством 210 оценки энергии, характеризует полную среднюю акустическую энергию в принятом речевом сигнале. Эта полная акустическая энергия может включать энергию как речи, так и шума. На фиг. 3 в качестве примера показана характеристика сигнала, описывающая изменение полной акустической энергии типичного принятого сигнала 310 во времени T. При передаче с подвижного объекта на сигнал обычно накладывается окружающий фоновый шум определенного уровня. Уровень энергии этого шума обозначен на фиг. 3 как e1. Когда в сигнале 310 присутствует речь, уровень акустической энергии будет складываться из энергий речи и шума. Согласно фиг. 3 сигнал в этом случае попадает в диапазон, где уровень этой суммарной энергии больше величины e2. В течение временного интервала t1 речь в сигнале 310 отсутствует, и поэтому акустическая энергия в течение этого интервала t1 находится только на уровне окружающего фонового шума. В течение же временного интервала t2, когда в сигнале 310 присутствует речь, акустическая энергия находится на уровне, складывающемся из энергий фонового шума и речи.
Как показано на фиг. 2, сигнал средней энергии e[m] с выхода устройства 210 оценки энергии подается на устройство 220 оценки шума, которое определяет средний уровень фонового шума в сигнале s, состоящем из потока битов декодированной речи. Устройство 220 оценки шума вырабатывает сигнал N[m], который представляет собой оценку этого шума, где
Сначала N[m] устанавливается на начальное значение Nнач, которое является первоначальной оценкой шума. В процессе дальнейшей обработки величина N[m] будет увеличиваться или уменьшаться, исходя из фактического уровня фонового шума, который присутствует в сигнале s, состоящем из потока битов декодированной речи. Nнач устанавливается на уровень, который находится на границе между умеренным и сильным фоновым шумом. Начальная установка N[m] на такой уровень позволяет быстро изменять N[m] в любом направлении в зависимости от фактического уровня фонового шума. Было установлено, что для подвижного объекта Nнач предпочтительно устанавливать на величину r0, равную 13.
Энергия речевой составляющей сигнала не должна включаться в вычисление среднего уровня фонового шума. Например, как показано на фиг. 3, уровень энергии сигнала 310 в течение временного интервала t1 должен включаться, а уровень энергии сигнала 310 в течение временного интервала t2 не должен включаться в вычисление оценки шума N[m], поскольку уровень энергии в течение временного интервала t2 складывается из энергий как фонового шума, так и речи.
Таким образом, средняя энергия e[m] кадра в принятом от устройства 210 оценки энергии сигнале, характеризующем уровень энергии как речи, так и шума, должна быть исключена из вычисления оценки шума N[m] с целью предотвратить смещение этой оценки шума N[m]. Для исключения из расчетов величины средней энергии e[m] кадра, которая характеризует уровень энергии как речи, так и шума, используется верхний порог ограничения шума Nпорог. Таким образом, как указано выше, если e[m] > N[m-1] + Nпорог, то N[m] = N[m-1]. Иными словами, если средняя энергия e[m] текущего кадра превышает оценку шума N[m-1] в предшествующем кадре на величину, равную или большую Nпорог, т.е. речь присутствует, то N[m] не изменяется, оставаясь равным значению, вычисленному для предшествующего кадра. Таким образом, если в течение короткого промежутка времени энергия кадра возрастает на большую величину, то предполагается, что это увеличение обусловлено наличием речи, и энергия не включается в оценку шума. Было установлено, что Nпорог предпочтительно устанавливать на значение, эквивалентное величине r0 энергии кадра, равной 2,5. Такое значение позволяет ограничить рабочий диапазон алгоритма оценки шума и поддерживать отношение звуковой сигнал/шум на уровне выше 5 дБ, поскольку шаг между значениями r0 составляет 2 дБ. С целью обеспечить приемлемую эффективность работы устройства 220 оценки шума значение для Nпорог в целом следует выбирать где - то в пределах от 2 до 4.
В том случае, если за короткий промежуток времени энергия кадра не возрастает на большую величину, то шум оценивается согласно уравнению: N[m] = β•e[m]+(1-β)•N[m-1], где β представляет собой константу сглаживания, значение которой следует выбирать с таким расчетом, чтобы обеспечить приемлемое усреднение энергии по кадру или по кадрам. Было установлено, что предпочтительным значением для β является 0,05, полученное усреднением по 25 кадрам (500 мс). В целом β следует устанавливать на значение в пределах 0,025≤ β ≤0,1.
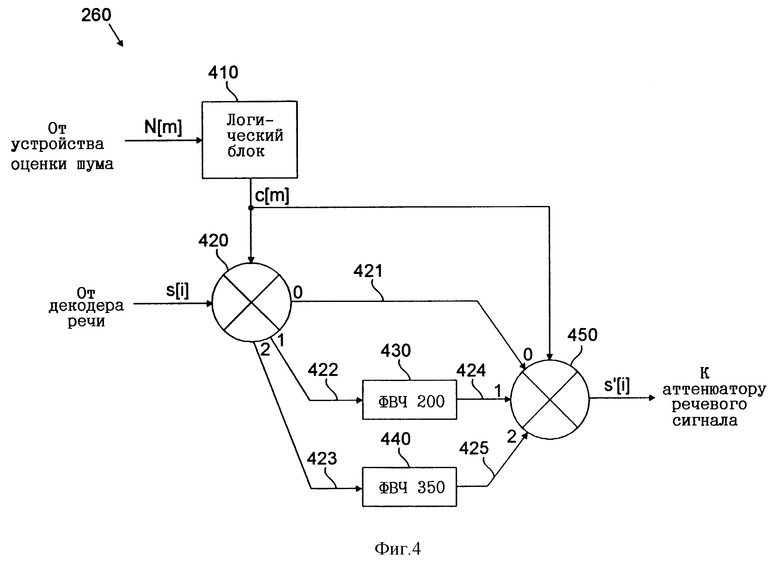
Величина оценки шума N[m] , вычисленная устройством 220 оценки шума, подается на драйвер 260 фильтра верхних частот, который обрабатывает состоящий из потока битов декодированной речи сигнал s, поступающий от декодера 40 речи. Как указано выше, каждый цифровой информационный кадр содержит 160 выборок речевых данных. Драйвер 260 фильтра верхних частот обрабатывает каждую из этих выборок s(i), где i обозначает номер выборки. Структура драйвера 260 фильтра верхних частот более подробно показана на фиг. 4. Величина оценки шума N[m], полученная устройством оценки шума 220, подается на логический блок 410, который содержит логические схемы, служащие для выбора того или иного набора фильтров верхних частот, который будет использоваться для фильтрации каждой выборки s(i) в сигнале s, состоящем из потока битов декодированной речи. В показанной на чертеже схеме предусмотрено два фильтра 430 и 440 верхних частот. Частота среза фильтра 430, который на фиг. 4 обозначен как ФВЧ 200, составляет 200 Гц, а фильтра 440, который на фиг. 4 обозначен как ФВЧ 350, - 350 Гц. Было установлено, что такие значения обеспечивают достижение оптимальных результатов, однако согласно изобретению могут использоваться и иные 1 значения этих частот. Разность между частотами среза фильтров предпочтительно должна составлять по меньшей мере 100 Гц. Для определения, какой из фильтров должен использоваться в текущий момент, логический блок 410 драйвера 260 фильтра верхних частот сравнивает величину оценки шума N[m] с двумя пороговыми значениями. Первое пороговое значение устанавливается на величину, соответствующую величине энергии кадра r0 = 7 (что соответствует -52 дБ), а второе пороговое значение устанавливается на величину энергии кадра r0 = 13 (что соответствует -40 дБ). Если оценка шума N[m] меньше r0 = 7, то фильтрация верхних частот не применяется. Если же величина оценки шума N[m] больше или равна r0 = 7, но меньше r0 = 13, то задействуется фильтр 430 верхних частот с частотой среза 200 Гц. Если величина оценки шума N[m] больше или равна r0 = 13, то используется фильтр 440 верхних частот с частотой среза 350 Гц. Логические операции для определения необходимости в той или иной фильтрации верхних частот можно представить в следующем виде:
Как показано на фиг. 4, эти логические операции выполняются логическим блоком 410. Логический блок 410 будет определять, какой из фильтров должен задействоваться, основываясь на вышеприведенных правилах, и будет выдавать управляющий сигнал c[m] на два матричных переключателя 420, 450. Управляющий сигнал, соответствующий значению 0, указывает, что необходимость в фильтрации верхних частот отсутствует. Управляющий сигнал, соответствующий значению 1, указывает, что должен использоваться фильтр верхних частот с частотой среза 200 Гц. Управляющий сигнал, соответствующий величине 2, указывает, что должен применяться фильтр верхних частот с частотой среза 350 Гц.
Сигнал s[i] подается на матричный переключатель 420 от декодера 40 речи. Этот матричный переключатель 420 направляет сигнал s[i] на одну из соответствующих сигнальных линий 421, 422, 423, выбирая тем самым требуемую в данном случае фильтрацию или пропуская сигнал без фильтрации. Когда значение управляющего сигнала равно 0, сигнал s[i] будет передаваться по сигнальной линии 421. По этой сигнальной линии 421 сигнал s[i] будет поступать на матричный переключатель 450 без фильтрации. Когда значение управляющего сигнала равно 1, сигнал s[i] будет передаваться по сигнальной линии 422, которая соединена с фильтром 430 верхних частот. После прохождения этого фильтра 430 верхних частот сигнал s[i] будет передаваться на матричный переключатель 450 по сигнальной линии 424. Когда значение управляющего сигнала равно 2, сигнал s[i] будет передаваться по сигнальной линии 423, которая соединена с фильтром 440 верхних частот. После прохождения этого фильтра 440 верхних частот сигнал s[i] будет передаваться на матричный переключатель 450 по сигнальной линии 425. Управляющий сигнал c[m] также подается напрямую на матричный переключатель 450. Основываясь на управляющем сигнале c[m], матричный переключатель 450 будет выдавать сигнал, полученный по одной из сигнальных линий 421, 424, 425, на аттенюатор 270 речевого сигнала. Этот выходной сигнал, сформированный драйвером 260 фильтра верхних частот, обозначен как s'[i]. Для специалиста в данной области техники очевидно, что для фильтрации сигнала s, состоящего из потока битов декодированной речи, в драйвере фильтра 260 верхних частот может использоваться любое количество фильтров верхних частот или один фильтр верхних частот с плавно регулируемой частотой среза. Использование большего числа фильтров верхних частот или одного фильтра верхних частот с плавно регулируемой частотой среза позволяет сделать переключение с одного фильтра на другой менее заметным для пользователя.
Как показано на фиг. 2, сигнал s'[i] с выхода драйвера 260 фильтра верхних частот 260 подается на блок 270, в котором объединены аттенюатор речевого сигнала/устройство введения комфортного шума. Этот блок 270, объединяющий аттенюатор речевого сигнала с устройством введения комфортного шума, после обработки сигнала s'[i] формирует обработанный выходной сигнал s''[i], состоящий из потока битов декодированной речи. На вход блока 270 также поступает сигнал n[i] от генератора 250 формируемого шума и сигнал atten[m] от вычислительного устройства 240 аттенюатора. Принцип работы блока 270, состоящего из аттенюатора речевого сигнала/устройства введения комфортного шума, более подробно рассмотрен ниже после описания процесса вычисления его входных сигналов n[i] и atten[m].
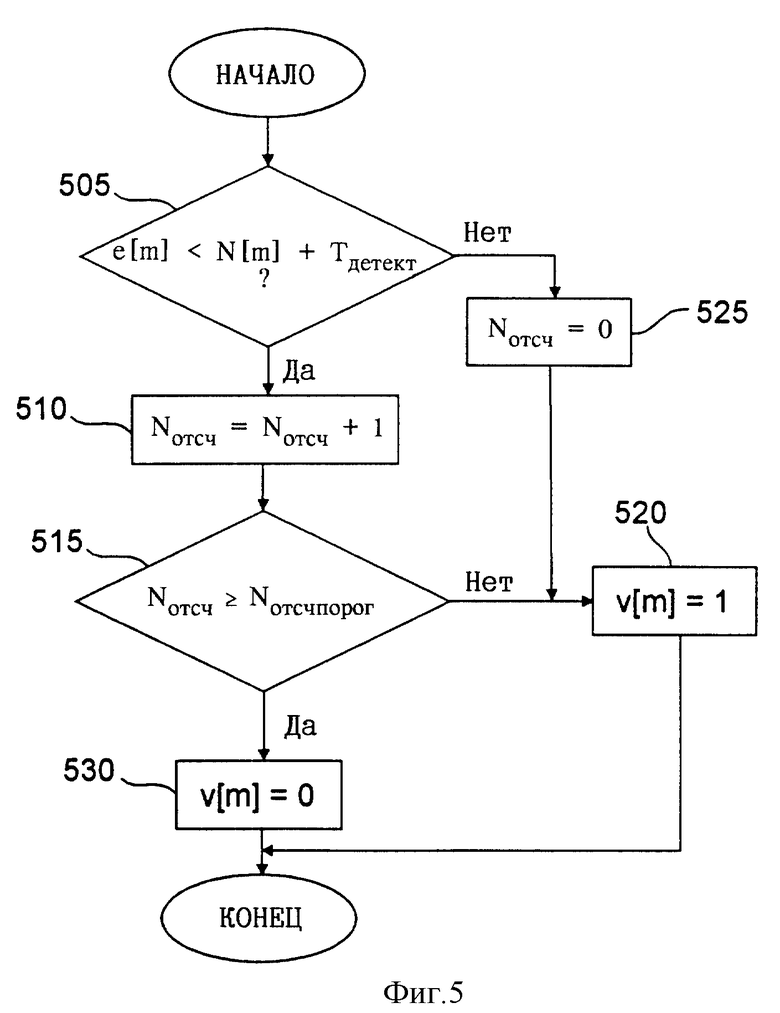
Оценка шума N[m] , рассчитанная устройством 220 оценки шума, и средняя энергия e[m] кадра, рассчитанная устройством 210 оценки энергии, подаются на детектор 230 активности речи. Этот детектор 230 определяет наличие или отсутствие речи в текущем кадре речевого сигнала и генерирует сигнал v[m] детектирования речи, который и указывает на наличие или отсутствие речи. Значение сигнала v[m], равное 0, указывает на отсутствие активности речи в текущем кадре речевого сигнала. Значение же сигнала v[m], равное 1, указывает на наличие такой активности в текущем кадре речевого сигнала. Последовательность выполняемых детектором 230 активности речи операций показана на блок-схеме по фиг. 5. На шаге 505 детектор 230 активности речи определяет, выполняется ли условие e[m] < N(m) +Tдетект, где величина Tдетект обозначает нижний порог детектирования шума и по своей функции аналогична величине Nпорог, рассмотренной выше при описании фиг. 3. Предполагается, что речь может присутствовать только в том случае, когда средняя энергия кадра e[m] превышает величину оценки шума N[m] на некоторую величину Tдетект. Tдетект предпочтительно устанавливать на значение r0, равное 2,5, что подразумевает возможность присутствия речи лишь в том случае, если средняя энергия e[m] кадра превышает величину оценки шума N[m] на 5 дБ. Однако могут использоваться и другие значения. В общем случае значение Tдетект должно лежать в пределах 2,5±0,5.
Во избежание выдачи детектором 230 неправильной информации об отсутствии активности речи, когда последняя фактически присутствует, используется отсчет Nотсч кадров с не детектированной речью. Начальное значение Nотсч устанавливается на ноль и в последующем отсчитывается в прямом направлении до порогового значения Nотсчпорог, которым определяется то максимальное количество кадров с отсутствующей активностью речи, по достижении которого детектор 230 может выдать информацию об отсутствии активности речи. Величину Nотсчпорог можно задать равной шести. Таким образом, детектор 230 выдаст информацию об отсутствии речи только в том случае, если таковая не будет детектирована в шести кадрах (120 мс). Как показано далее на фиг. 5, если на шаге 505 будет установлено, что условие e[m]<N(m)+Tдетект, выполняется, т.е. если средняя энергия e[m] меньше той энергии, для которой была определена возможность присутствия речи, то Nотсч увеличивается на шаге 510 на единицу. Если на последующем шаге 515 будет установлено, что Nотсч≥Nотсчпорог, т.е. что в последовательности из шести кадров речь не была детектирована, то на шаге 530 значение v[m] устанавливается на 0, указывая на отсутствие речи в текущем кадре. Если же на шаге 515 будет установлено, что Nотсч< Nотсчпорог, т. е. еще не достигнуто максимальное, равное шести количество кадров, в которых речь не детектирована, то на шаге 520 значение v[m] устанавливается на 1, указывая на наличие речи в текущем кадре. Если на первом шаге 505 будет установлено, что e[m] ≥N(m)+Tдетект, т.е. если средняя энергия e[m] больше или равна энергии, для которой была определена возможность присутствия речи, то Nотсч на шаге 525 устанавливается на ноль, а значение v[m] устанавливается на шаге 520 на единицу, указывая на наличие речи в текущем кадре.
Сигнал v[m] детектирования речи, сформированный детектором 230 активности речи, подается на вычислительное устройство 240 аттенюатора, которое генерирует сигнал ослабления atten[m] (от англ. "attenuation", ослабление, затухание), характеризующий величину затухания для текущего кадра. Этот сигнал ослабления atten[m] обновляется с каждым кадром, а его значение отчасти зависит от результата, полученного детектором 230 при детектировании активности речи, т.е. от отсутствия или наличия речи. Сигнал atten[m] будет принимать некоторое значение между 0 и 1. Чем ближе значение этого сигнала к 1, тем меньше затухание, вносимое в сигнал, и, соответственно, чем ближе значение этого сигнала к 0, тем выше затухание. Величина максимально возможного ослабления определяется как maxatten, и было установлено, что оптимальным значением для maxatten является 0,65 (т.е. -3,7 дБ). Однако в целом для maxatten можно задавать и другие значения в интервале от 0,3 до 0,8. Коэффициент, на который ослабляется речевой сигнал, обозначен ниже как attenrate (от англ. "rate", коэффициент), а предпочтительным значением для этого коэффициента ослабления attenrate, как было установлено, является 0,98. Однако в общем случае для attenrate можно задавать и другие значения в пределах 0,95±0,04.
Ниже описан процесс вычисления сигнала ослабления atten[m]. Сигнал atten[m] используется блоком 270, объединяющим аттенюатор речевого сигнала/устройство введения комфортного шума, для внесения затухания в сигнал s''[i] , как это более подробно поясняется ниже. Сигнал ослабления atten[m] вычисляется следующим образом. Сначала значение сигнала ослабления atten[m] устанавливается на 1. После задания этого начального значения величина atten(m) будет вычисляться, исходя из наличия или отсутствия речи, что определяется детектором 230 активности речи, а также исходя из условия, достигло ли ослабление максимального уровня, определяемого величиной maxatten. Если v[m] = 1, т.е. речь детектирована, то значение atten[m] устанавливается на 1. Если же v[m] = 0, т.е. речь не детектирована, и если коэффициент ослабления, использовавшийся для внесения затухания в предшествующих кадрах (т.е. attenrate•atten[m-1] ), больше величины максимального ослабления, то затухание для текущего кадра вычисляется с использованием коэффициента ослабления, применявшегося для затухания в предшествующих кадрах. Если v[m] = 0, т. е. речь не детектирована, но коэффициент ослабления, использовавшийся для затухания в предшествующих кадрах, меньше или равен величине максимального ослабления, то затухание для текущего кадра устанавливается на максимальное значение. Величина затухания для текущего кадра в общем случае вычисляется следующим образом:
Таким образом, когда детектором 230 речь не детектирована, значение сигнала ослабления atten[m] снижается с 1 до 0,65 (до maxatten) путем уменьшения на постоянный коэффициент 0,98. Сигнал ослабления atten[m] для текущего кадра, сформированный вычислительным устройством 240 аттенюатора, выдается на блок 270, объединяющий аттенюатор речевого сигнала/устройство введения комфортного шума.
На этот блок 270 от генератора 250 формируемого шума также подается сигнал n[i], который характеризует прошедший низкочастотную фильтрацию белый шум. Такой прошедший низкочастотную фильтрацию белый шум также называется комфортным шумом. На вход генератора 250 формируемого шума от устройства 220 оценки шума подается оценка шума N[m], и этот генератор 250 формирует сигнал n[i] , характеризующий сформированный шум, величина которого рассчитывается следующим образом:
n(i) = ε•wn[i]+(1-ε)•n[i-1],
где wn[i] = δ •dБ2lin (N[m])•ran[i],
где i обозначает номер выборки, описанный выше. Таким образом, n[i] генерируется для каждой выборки в текущем кадре. Функция dБ2lin преобразует оценку шума N[m], выраженную в дБ, в линейную величину. Коэффициент пересчета δ равен 1,7, а коэффициент фильтрации ε равен 0,1. Функция ran[i] служит для формирования случайного числа между -1,0 и 1,0. Таким образом, шум после пропорционального изменения величины с использованием оценки шума N[m] фильтруется фильтром нижних частот. Было установлено, что вышеприведенные значения для коэффициента пересчета δ и коэффициента фильтрации ε являются оптимальными. Однако для этих величин в принципе могут использоваться и другие значения, лежащие для коэффициента δ в пределах от 1,5 до 2,0, а для коэффициента ε - в пределах от 0,05 до 0,15.
Белый шум n[i] , полученный после фильтрации нижних частот, с выхода 5 генератора 220 формируемого шума и сигнал ослабления atten[m] для текущего кадра с выхода вычислительного устройства 240 аттенюатора подаются в блок 270, объединяющий аттенюатор речевого сигнала/устройство введения комфортного шума. Кроме того, на аттенюатор речевого сигнала поступает прошедший фильтрацию верхних частот сигнал s'[i] от драйвера 260 фильтра верхних частот, и этот аттенюатор генерирует обработанный сигнал s'', состоящий из потока битов декодированной речи, согласно следующему уравнению:
s''[i] = atten[m]•s'[i] + (1-atten[m])•n[i],
для i = 0, 1,..., 159.
Таким образом, для каждой выборки s'[i] в речевом сигнале s', прошедшем фильтрацию верхних частот, блок 270 будет вносить затухание в эту выборку s'[i] на величину ослабления atten[m], рассчитанную для текущего кадра. В то же время блок 270 будет также вводить прошедший низкочастотную фильтрацию белый шум n[i], исходя из величины atten[m]. Как следует из вышеприведенного уравнения, если atten[m] = 1, то в сигнал не будет вноситься затухание, и, следовательно, s''[i] = s'[i]. Если же atten[m] = maxatten (0,65), то s''[i] = (0,65•речевой сигнал, прошедший фильтрацию верхних частот) + (0,35•белый шум, прошедший фильтрацию нижних частот). Ослабление сигнала s'[i] в сочетании с введением белого шума (комфортного шума), прошедшего фильтрацию нижних частот, позволяет получить более сглаженный фоновый шум с менее заметным "завихрением". Сигнал s''[i], сформированный блоком 270, состоящим из аттенюатора речевого сигнала/устройства введения комфортного шума, может подаваться на цифроаналоговый преобразователь 60 или на другое устройство, которое преобразует содержащуюся в сигнале информацию в некоторый другой цифровой формат, как это описано выше.
Вычислительное устройство 240 аттенюатора, генератор 250 формируемого шума и блок 270, состоящий из аттенюатора речевого сигнала/устройства введения комфортного шума, работая совместно, как указывалось выше, позволяют снизить уровень фонового "завихрения", когда речь не присутствует в принятом сигнале. Эти три элемента в целом можно рассматривать как единый имитатор шума, который на фиг. 2 выделен пунктирной линий и обозначен позицией 280. Входными сигналами этого имитатора 280 шума являются сигнал v[m] детектирования речи от детектора 230 активности речи, оценка шума N[m] от устройства 220 оценки шума и сигнал s'[i], прошедший с высокочастотную фильтрацию, от драйвера 260 фильтра верхних частот, а его выходным сигналом является обработанный сигнал s''[i], состоящий из потока битов декодированной речи, как описано выше.
В предпочтительном варианте описанный выше ИШУДАР 50 может быть реализован на базе микропроцессора, как показано на фиг. 6. Микропроцессор [МП] 610 соединен информационной шиной 621 и адресной шиной 622 с энергонезависимой памятью 620, такой, как ПЗУ. В этой энергонезависимой памяти 620 хранится программа, по которой ИШУДАР 50 выполняет описанные выше операции. Микропроцессор 610 информационной шиной 631 адресной шиной 632 также соединен с энергозависимой памятью 630, такой, как ЗУПВ. Микропроцессор 610, на вход которого от декодера 40 речи по сигнальной линии 612 поступает сигнал s, состоящий из потока битов декодированной речи, формирует обработанной сигнал s'', состоящий из потока битов декодированной речи. Как описано выше, в одном из вариантов выполнения настоящего изобретения на ИШУДАР 50 подается энергия кодированного по VSELP-алгоритму кадра величиной r0, отделенная от потока битов b кодированной речи. Эта энергия поступает в микропроцессор, как показано на фиг. 6, по сигнальной шине 611. В другом варианте выполнения ИШУДАР сам может рассчитывать величину r0 энергии кадра на основе сигнала s, состоящего из потока битов декодированной речи, и в этом случае сигнальная шина 611 будет отсутствовать.
Описанные выше и показанные на чертежах варианты выполнения являются лишь иллюстративными примерами, поясняющими сущность настоящего изобретения, и поэтому для специалистов в данной области техники должны быть очевидны и другие модификации и изменения, которые можно вносить в настоящее изобретение, не выходя за его объем. В приведенном выше описании для различных величин приведены предпочтительные значения и их интервалы. Однако необходимо отметить, что эти величины относятся к применению настоящего изобретения в условиях, когда связь осуществляется с подвижными объектами. Поэтому для специалистов в данной области должно представляться очевидным, что описанное выше изобретение может применяться при связи в различных окружающих условиях, и в этом случае значения величин и их интервалы могут отличаться от приведенных в данном описании. Следовательно, такое использование в разных окружающих условиях наряду с другими значениями величин, отличными от приведенных в описании, также подпадает под объем настоящего изобретения.
Изобретение используется для улучшения качества звука в приемнике цифровой сотовой радиосистемы. Детектор речевой активности использует оценку энергии, чтобы детектировать наличие речи в принятом речевом сигнале в режиме работы в присутствии шума. Когда речь отсутствует, система ослабляет сигнал и вводит белый шум с фильтрованными нижними частотами. Дополнительно используется набор фильтров верхних частот для фильтрования принятого сигнала на основании уровня фонового шума. Это фильтрование верхних частот применяется к сигналу независимо от того, присутствует ли речевой компонент в сигнале или нет. Таким образом, комбинация аттенюации сигнала с вводом белого шума с фильтрованными нижними частотами в течение периодов отсутствия речи вместе с фильтрованием верхних частот сигнала улучшает качество звука при декодировании речи, которая была закодирована в режиме работы в присутствии шумов. 4 с. и 11 з.п.ф-лы, 6 ил.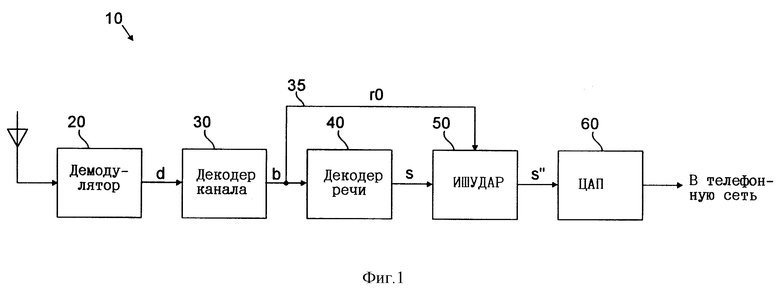
| Способ анализа и синтеза речи и устройство для его осуществления | 1986 |
|
SU1316030A1 |
| Динамический фильтр | 1981 |
|
SU1042158A1 |
| ЭЛЕКТРИЧЕСКАЯ ДИСКОВАЯ МАШИНА | 2003 |
|
RU2256997C1 |
| US 4864561, 05.09.1989 | |||
| СПОСОБ ПОЛУЧЕНИЯ СЛИВОЧНОЙ ПОМАДЫ | 2004 |
|
RU2256351C1 |
| US 5065395 A, 12.11.1991 | |||
| US 5276765 A, 04.01.1994 | |||
| SOUTHCOTT C.B | |||
| и др | |||
| Voice Control of the Pan - Europan Digital Mobile Radio System, GLOBECOMM' 89, т.2, ноябрь 27, 1989, New York. | |||
