Область техники
Настоящее изобретение относится к способу цифрового кодирования звукового сигнала и, в частности, но не исключительно, речевого сигнала с учетом передачи и/или синтеза этого звукового сигнала. В частности, настоящее изобретение касается устойчивого кодирования и декодирования звуковых сигналов для поддержания удовлетворительных рабочих характеристик в случае появления стертого кадра (кадров), например, из-за канальных ошибок в беспроводных системах или потерянных пакетов в сетевых приложениях с пакетной передачей речи.
Уровень техники
В различных прикладных областях, таких как телеконференции, мультимедиа и беспроводная связь, возрастает потребность в эффективных способах цифрового узкополосного и широкополосного речевого кодирования при условии обеспечении приемлемого компромисса между субъективным качеством и скоростью передачи битов. До недавнего времени в приложениях для речевого кодирования использовалась полоса пропускания телефонной связи, ограниченная диапазоном от 200 до 3400 Гц. Однако широкополосные речевые приложения обеспечивают повышенную разборчивость и натуральность связи по сравнению с полосой пропускания стандартной телефонии. Установлено, что полоса пропускания в диапазоне 50-7000 Гц достаточна для обеспечения годного качества, дающего ощущение диалоговой связи. Для обычных аудиосигналов эта полоса пропускания дает приемлемое субъективное качество, но все же уступающее качеству радиосвязи в FM диапазоне или качеству компакт-дисков (CD), которые работают в диапазонах 20-16000 Гц и 20-20000 Гц соответственно.
Речевой кодер преобразует речевой сигнал в цифровой поток битов, который передается по каналу связи или запоминается в запоминающей среде. Речевой сигнал оцифровывают, то есть дискретизируют и квантуют, обычно по 16 бит на один отсчет. Речевой кодер представляет эти цифровые отсчеты небольшим количеством битов, поддерживая удовлетворительное субъективное качество речи. Речевой декодер или синтезатор работает с переданным или сохраненным потоком битов и преобразует его обратно в звуковой сигнал.
Одним из наилучших имеющихся способов, позволяющих достичь удачного компромисса между субъективным качеством и скоростью передачи битов, является линейное предиктивное кодирование с кодовым возбуждением (CELP). Эта технология кодирования является основой нескольких стандартов речевого кодирования как в беспроводных, так и в проводных приложениях. При кодировании CELP дискретизированный речевой сигнал обрабатывают последовательными блоками из L отсчетов, обычно называемых кадрами, где L - заранее установленное число, соответствующее обычно 10-30 мс. В каждом кадре вычисляется и передается линейный предиктивный (LP) фильтр. Для вычисления LP-фильтра обычно требуется предварительный просмотр, (5-15)-миллисекундный речевой сегмент из следующего кадра. Кадр из L отсчетов делят на меньшие блоки, называемые субкадрами. Обычно количество субкадров равно трем или четырем, что дает (4-10)-миллисекундные субкадры. В каждом субкадре сигнал возбуждения обычно получают из двух компонент: прошлого возбуждения и нововведенного возбуждения фиксированной кодовой книги. Компоненту, образованную из прошлого возбуждения, часто называют возбуждением адаптивной кодовой книги или возбуждением основного тона. Параметры, характеризующие сигнал возбуждения, кодируются и передаются в декодер, где восстановленный сигнал возбуждения используется в качестве входного сигнала LP-фильтра.
Так как основные приложения для речевого кодирования с низкой скоростью передачи битов представляют собой системы беспроводной мобильной связи и сети с пакетной передачей голоса, очень актуальным становится повышение устойчивости речевых кодеков в случае стирания кадров. В беспроводных сотовых системах энергия принятого сигнала может проявлять частые и значительные замирания, что приводит к большим значениям частоты ошибок по битам, причем это особенно сильно проявляется на границах сотовых ячеек. В этом случае канальный декодер не в состоянии исправить ошибки в принятом кадре, вследствие чего детектор ошибок, который обычно используется после канального декодера, объявит такой кадр стертым. В сетевых приложениях с пакетной передачей речи речевой сигнал представляют в виде пакетов, где в каждом пакете обычно содержится 20-миллисекундный кадр. В системах связи с коммутацией пакетов пакеты в маршрутизаторе могут оказаться пропущенными, если количество пакетов оказалось очень большим или пакет смог попасть в приемник после длительной задержки и должен объявляться потерянным, если задержка оказалась больше длины буфера дрожания на стороне приемника. В этих системах в кодеке происходят стирания кадров, частота которых обычно составляет от 3 до 5%. Кроме того, использование широкополосного речевого кодирования является важным ценным качеством этих систем, позволяющим им конкурировать с традиционной коммутируемой телефонной сетью общего пользования (PSTN), где используют традиционные узкополосные речевые сигналы.
Адаптивная кодовая книга или предсказатель основного тона в методе CELP играет важную роль в поддержании высокого качества речи при низких скоростях передачи битов. Однако, поскольку содержание адаптивной кодовой книги основано на сигнале из прошлых кадров, модель кодека оказывается чувствительной к потерям кадров. В случае стирания или потери кадров содержание адаптивной кодовой книги в декодере становится отличным от его содержания в кодере. Таким образом, после маскирования потерянного кадра и приема последующих пригодных кадров синтезированный сигнал в принятых пригодных кадрах отличается от предполагаемого сигнала синтеза, поскольку изменился вклад адаптивной кодовой книги. Воздействие потерянного кадра зависит от характера речевого сегмента, в котором произошло стирание. Если стирание появилось в стационарном сегменте сигнала, то тогда можно выполнить эффективное маскирование стирания кадра, и воздействие на последующие пригодные кадры можно минимизировать. С другой стороны, если стирание появилось в начале речи или в переходной области, то эффект стирания может распространиться на несколько кадров. Например, если потеряно начало вокализованного сегмента, то тогда из содержания адаптивной кодовой книги пропадет первый период основного тона. Это серьезно повлияет на предсказатель основного тона в последующих пригодных кадрах, что приведет к большой временной задержке, прежде чем будет обеспечена сходимость сигнала синтеза к предполагаемому сигналу в кодере.
Сущность изобретения
Настоящее изобретение относится к способу для улучшения маскирования стирания кадров, вызванного кадрами кодированного звукового сигнала, стертыми во время передачи от кодера к декодеру, и для ускорения восстановления в декодере после того, как были приняты нестертые кадры кодированного звукового сигнала, причем способ содержит:
определение в кодере параметров маскирования/восстановления;
передачу в декодер параметров маскирования/восстановления, определенных в кодере; и
в декодере, осуществление маскирования стирания кадров и восстановления в декодере в соответствии с принятыми параметрами маскирования/восстановления.
Настоящее изобретение также относится к способу для маскирования стирания кадров, вызванного кадрами, стертыми во время передачи звукового сигнала, кодированного согласно форме параметров кодирования сигнала, от кодера к декодеру, и для ускорения восстановления в декодере после того, как были приняты нестертые кадры кодированного звукового сигнала, причем способ содержит:
определение в декодере параметров маскирования/восстановления из параметров кодирования сигнала;
в декодере, осуществление маскирования стертых кадров и восстановления в декодере в соответствии с принятыми параметрами маскирования/восстановления.
Согласно настоящему изобретению также предлагается устройство для улучшения маскирования стирания кадров, вызванного кадрами кодированного звукового сигнала, стертыми во время передачи от кодера к декодеру, и для ускорения восстановления в декодере после того, как были приняты нестертые кадры кодированного звукового сигнала, причем устройство содержит:
средство для определения в кодере параметров маскирования/восстановления;
средство для передачи в декодер параметров маскирования/восстановления, определенных в кодере; и
в декодере, средство для осуществления маскирования стирания кадров и восстановления в декодере в соответствии с принятыми параметрами маскирования/восстановления.
Согласно изобретению, кроме того, предлагается устройство для маскирования стирания кадров, вызванного кадрами, стертыми во время передачи звукового сигнала, кодированного на основе формы параметров кодирования сигнала, от кодера к декодеру, и для ускорения восстановления в декодере после того, как были приняты нестертые кадры кодированного звукового сигнала, причем устройство содержит:
средство для определения в декодере параметров маскирования/восстановления из параметров кодирования сигнала;
в декодере, средство для осуществления маскирования стирания кадров и восстановления в декодере в соответствии с принятыми параметрами маскирования/восстановления.
Настоящее изобретение также касается системы для кодирования и декодирования звукового сигнала и декодера звукового сигнала, где используются определенные выше устройства, для улучшения маскирования стирания кадров, вызванного кадрами кодированного звукового сигнала, стертыми во время передачи от кодера к декодеру, и для ускорения восстановления в декодере после того, как были приняты нестертые кадры кодированного звукового сигнала.
Вышеупомянутые и другие цели, преимущества и признаки настоящего изобретения поясняются в последующем, не ограничивающем описании иллюстративных вариантов его осуществления, приведенных только в качестве примеров, со ссылками на сопроводительные чертежи.
Краткое описание чертежей:
фиг.1 - блок-схема системы речевой связи, иллюстрирующая применение устройств речевого кодирования и декодирования согласно настоящему изобретению;
фиг.2 - блок-схема примера устройства широкополосного кодирования (AMR-WB кодер);
фиг.3 - блок-схема примера устройства широкополосного декодирования (AMR-WB декодер);
фиг.4 - упрощенная блок-схема AMR-WB кодера по фиг.2, где модуль субдискретизатора, модуль фильтра верхних частот и модуль предыскажающего фильтра сгруппированы в едином модуле предобработки и где модуль поиска основного тона с обратной связью, модуль вычислителя отклика при нулевом входном сигнале, модуль генератора импульсной характеристики, модуль поиска нововведенного возбуждения и модуль обновления памяти сгруппированы в едином модуле поиска основного тона и нововведенной кодовой книги с обратной связью;
фиг.5 - расширение блок-схемы по фиг.4, в которую добавлены модули, относящиеся к иллюстративному варианту настоящего изобретения;
фиг.6 - блок-схема, проясняющая ситуацию при формировании искусственного приступа; и
фиг.7 - схема, показывающая иллюстративный вариант конечного автомата классификации кадров для маскирования стирания.
Подробное описание иллюстративных вариантов
Хотя в последующем описании иллюстративные варианты настоящего изобретения описаны применительно к речевому сигналу, следует иметь в виду, что концепции настоящего изобретения равным образом применимы к сигналам других типов, в частности, но не исключительно, к звуковым сигналам других типов.
На фиг.1 показана система 100 речевой связи, где используется речевое кодирование и декодирование в контексте настоящего изобретения. Система 100 речевой связи по фиг.1 поддерживает передачу речевого сигнала по каналу 101 связи. Хотя он может содержать, например, провод, оптическую линию или волоконную линию, канал 101 связи обычно содержит, по меньшей мере частично, линию радиочастотной связи. Линия радиочастотной связи часто поддерживает множество одновременно идущих речевых передач, что требует совместного использования ресурсов полосы пропускания, что можно встретить, например, в системах сотовой телефонии. Хотя это не показано, канал 101 связи может быть заменен запоминающим устройством в варианте системы 100 с единым устройством, где кодированный речевой сигнал записывается и сохраняется для последующего воспроизведения.
В системе 100 речевой связи по фиг.1 микрофон 102 создает аналоговый речевой сигнал 103, который подается в аналого-цифровой (A/D) преобразователь 104 для преобразования его в цифровой речевой сигнал 105. Цифровой кодер 106 кодирует цифровой речевой сигнал 105, создавая набор параметров 107 кодирования сигнала, которые кодируются в двоичном виде и доставляются в канальный кодер 108. Необязательный канальный кодер 108 добавляет избыточность в двоичное представление параметров 107 кодирования сигнала перед их передачей по каналу 101 связи.
В приемнике канальный декодер 109 использует указанную избыточную информацию в принимаемом потоке 111 битов для обнаружения и исправления канальных ошибок, появившихся во время передачи. Речевой декодер 110 преобразует поток 112 битов, принимаемый от канального декодера 109, обратно в набор параметров кодирования сигнала и создает из восстановленных параметров кодирования сигнала цифровой синтезированный речевой сигнал 113. Цифровой синтезированный речевой сигнал 113, восстановленный в речевом декодере 110, преобразуется в аналоговую форму 114 цифро-аналоговым (D/A) преобразователем 115 и воспроизводится через блок 116 динамиков.
Раскрытый в настоящем описании иллюстративный вариант эффективного способа маскирования стирания кадров может быть использован узкополосными или широкополосными кодеками с линейным предсказанием. Данный иллюстративный вариант изобретения раскрыт применительно к широкополосному речевому кодеку, стандарты для которого разработаны Международным союзом телекоммуникаций (ITU) в виде Рекомендаций G722.2, известному как кодек AMR-WB (адаптивный многоскоростной широкополосный кодек) [ATU-T Recommendation G. 722.2 "Wideband coding of speech at around 16 kbit/s using Adaptive Multi-Rate Wideband (AMR-WB)", Geneva, 2002]. Этот кодек также был выбран для Проекта партнерства третьего поколения (3GPP), предназначенного для широкополосной телефонии в беспроводных системах третьего поколения [3GPP TS 26.190, "AMR Wideband Speech Codec: Transcoding Functions", 3GPP Technical Specification]. AMR-WB кодек может работать с 9 скоростями передачи битов, лежащими в диапазоне от 6,6 до 23,85 кбит/с. В иллюстративных целях в настоящем изобретении использована скорость передачи битов, равная 12,65 кбит/с.
При этом следует понимать, что данный иллюстративный вариант эффективного маскирования стирания кадров может быть применен для кодеков других типов.
В последующих разделах сначала дается общее представление о AMR-WB кодере и AMR-WB декодере. Затем раскрывается иллюстративный вариант нового подхода к повышению устойчивости работы кодека.
Общее представление о AMR-WB кодере
Дискретизированный речевой сигнал кодируется на поблочной основе устройством 200 кодирования по фиг. 2, которое разбито на одиннадцать модулей под номерами с 201 по 211.
Таким образом, входной речевой сигнал 212 обрабатывают на поблочной основе, то есть в вышеупомянутых блоках из L отсчетов, называемых кадрами.
Согласно фиг.2, входной речевой сигнал 212 подвергается субдискретизации с пониженной частотой в модуле 201 субдискретизатора. Сигнал подвергается субдискретизации с понижением частоты от 16 до 12,8 кГц с использованием способов, хорошо известных специалистам в данной области техники. Субдискретизация повышает эффективность кодирования, поскольку кодируется меньшая полоса пропускания. Это также уменьшает алгоритмическую сложность, поскольку уменьшается количество отсчетов в кадре. После субдискретизации частоты кадр из 320 отсчетов длительностью 20 мс сокращается до кадра из 256 отсчетов (коэффициент субдискретизации составляет 4/5).
Затем входной кадр подается в необязательный модуль 202 предобработки. Модуль 202 предобработки может состоять из фильтра верхних частот с частотой среза 50 Гц. Фильтр 202 верхних частот устраняет нежелательные звуковые компоненты с частотой ниже 50 Гц.
Сигнал, прошедший субдискретизацию и предобработку, обозначается как sp(n), n=0,1,2,...,L-1, где L - длина кадра (256 при частоте дискретизации 12,8 кГц). В иллюстративном варианте предыскажающего фильтра 203 в сигнал sp(n) вводятся предыскажения с использованием фильтра, имеющего следующую передаточную функцию:
P(z)=1-μz-1,
где μ - коэффициент предыскажений со значением, лежащим между 0 и 1 (стандартное значение μ составляет 0,7). Назначение предыскажающего фильтра 203 состоит в увеличении высокочастотного содержимого входного речевого сигнала. Он также уменьшает динамический диапазон входного речевого сигнала, что делает его более подходящим для реализации вычислений с фиксированной точкой. Предыскажения также играют важную роль в достижении правильного итогового перцептивного взвешивания ошибки квантования, что способствует повышению качества звука. Сказанное более подробно объясняется ниже.
Выход предыскажающего фильтра 203 обозначен как sp(n). Этот сигнал используют для выполнения LP-анализа в модуле 204. LP-анализ относится к способам, хорошо известным специалистам в данной области техники. В данном иллюстративном варианте реализации используется автокорреляционный метод. При автокорреляционном методе сигнал sp(n) сначала подвергается обработке обычно с использованием окна Хэмминга, имеющего длину порядка 30-40 мс. На основе этого сигнала, обработанного методом окна, вычисляются значения автокорреляции, а для вычисления коэффициентов аj LP-фильтра используют рекурсию Левинсона-Дурбина, где j=1,...p и где p - порядок LP, который обычно равен 16 при широкополосном кодировании. Параметры aj являются коэффициентами передаточной функции А(z) LP-фильтра, которая задается следующим соотношением:
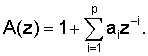
LP-анализ выполняется в модуле 204, который также выполняет квантование и интерполяцию коэффициентов LP-фильтра. Коэффициенты LP-фильтра сначала преобразуют в другой эквивалентную область, более подходящую для квантования и интерполяции. Области линейных спектральных пар (LSP) и спектральных пар иммитанса (ISP) являются двумя областями, в которых можно эффективно выполнить квантование и интерполяцию. 16 коэффициентов LP-фильтра aj могут квантоваться с использованием порядка 30-50 битов посредством расщепленного или многоступенчатого квантования или их комбинации. Целью интерполяции является возможность обновления коэффициентов LP-фильтра в каждом субкадре при их передаче единовременно в каждом кадре, что улучшает рабочие характеристики кодера без увеличения скорости передачи битов. Поскольку нет сомнений, что квантование и интерполяция коэффициентов LP-фильтра хорошо известны специалистам в данной области техники, они далее в настоящем описании не описываются.
Ниже описаны остальные операции кодирования, выполняемые на основе субкадров. В данном иллюстративном варианте реализации входной кадр делится на 4 субкадра по 5 мс (64 отсчета при частоте дискретизации 12,8 кГц). В последующем описании фильтр А(z) обозначает неквантованный интерполированный LP-фильтр субкадра, а фильтр В(z) обозначает квантованный интерполированный LP-фильтр субкадра. Фильтр В(z) подает каждый субкадр в мультиплексор 213 для передачи по каналу связи.
В кодерах "анализа через синтез" поиск параметров оптимального основного тона и нововведенных параметров выполняется путем минимизации среднеквадратической ошибки между входным речевым сигналом 212 и синтезированным речевым сигналом в перцептивно взвешенной области. Взвешенный сигнал sw(n) вычисляется в перцептивно взвешенном фильтре 205 в соответствии с сигналом s(n) из предыскажающего фильтра 203. Используется перцептивно взвешенный фильтр 205 с фиксированным знаменателем, подходящий для широкополосных сигналов. Пример передаточной функции для перцептивно взвешенного фильтра 205 задается следующим соотношением:
W(z)=A(z/y1)/(1-y2z-1), где 0<y2<y1.
Для упрощения анализа основного тона сначала в модуле 206 поиска основного тона без обратной связи исходя из взвешенного речевого сигнала sw(n) оценивается запаздывание TOL основного тона без обратной связи. Затем анализ основного тона с обратной связью, выполняемый в модуле 207 поиска основного тона с обратной связью на субкадровой основе, ограничивается в окрестности запаздывания TOL основного тона без обратной связи, что значительно упрощает поиск LTP параметров: T (запаздывание основного тона) и b (усиление основного тона). Анализ основного тона без обратной связи обычно выполняется в модуле 206 каждые 10 мс (2 субкадра) с использованием способов, хорошо известных специалистам в данной области техники.
Сначала вычисляется искомый вектор x для анализа LTP (долгосрочное предсказание). Обычно это выполняется путем вычитания отклика so при нулевом входном сигнале взвешенного фильтра синтеза W(z)/В(z) из взвешенного речевого сигнала sw(n). Этот отклик so при нулевом входном сигнале вычисляется вычислителем 208 отклика при нулевом входном сигнале в соответствии с квантованным интерполяционным LP-фильтром В(z) из модуля 204 LP-анализа, квантования и интерполяции, и начальными состояниями взвешенного фильтра синтеза W(z)/В(z), хранящимися в модуле 211 обновления памяти в соответствии с LP-фильтрами A(z) и В(z) и вектором u возбуждения. Эта операция хорошо известна специалистам в данной области техники и поэтому далее не описывается.
В генераторе 209 импульсной характеристики вычисляется N-мерный вектор h импульсной характеристики взвешенного фильтра синтеза W(z)/В(z) с использованием коэффициентов LP-фильтра A(z) и В(z) из модуля 204. Эта операция хорошо известна специалистам в данной области техники и поэтому далее подробно не описывается.
Параметры b, T и j основного тона (или кодового словаря основного тона) с обратной связью вычисляют в модуле 207 поиска основного тона с обратной связью, где в качестве входных данных используется искомый вектор x, вектор h импульсной характеристики и запаздывание TOL основного тона без обратной связи.
Поиск основного тона состоит в нахождении наилучших значений запаздывания Т и усиления b основного тона, которые минимизируют взвешенную среднеквадратическую ошибку предсказания основного тона, например,
 ,
,
где j=1,2,...k
между целевым вектором x и масштабированной отфильтрованной версией прошлого возбуждения.
В частности, в данном иллюстративном варианте реализации поиск основного тона (кодового словаря основного тона) содержит три этапа.
На первом этапе в модуле 206 поиска основного тона без обратной связи оценивается запаздывание TOL основного тона без обратной связи в соответствии с взвешенным речевым сигналом sw(n). Как показано выше, анализ основного тона без обратной связи обычно выполняют каждые 10 мс (два субкадра) с использованием способов, хорошо известных специалистам в данной области техники.
На втором этапе в модуле 207 поиска основного тона с обратной связью выполняется поиск критерия С поиска для целых значений запаздывания основного тона в окрестности оцененного запаздывания TOL (обычно ±5) основного тона без обратной связи, что значительно упрощает процедуру поиска. Для обновления отфильтрованного кодового вектора yT (этот вектор определен в последующем описании) используется простая процедура, не требующая вычисления свертки для каждого запаздывания основного тона. Пример критерия С поиска задается выражением
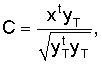
где t обозначает транспонированный вектор.
Как только на втором этапе найдено оптимальное целое значение основного тона, на третьем этапе поиска (модуль 207) с использованием критерия С поиска проверяют дроби в окрестности этого оптимального целого значения основного тона. Например, в стандарте AMR-WB используется разрешение для суботсчетов, равное 1/4 и 1/2.
В широкополосных сигналах гармоническая структура существует только до определенной частоты, зависящей от речевого сегмента. Таким образом, для обеспечения эффективного представления вклада основного тона в голосовых сегментах широкополосного речевого сигнала необходима гибкость для изменения периодичности в широкополосном спектре. Это достигается обработкой кодового вектора основного тона посредством множества фильтров формирования частоты (например, фильтров нижних частот или полосовых фильтров). Затем выбирается фильтр формирования частоты, который минимизирует среднеквадратическую взвешенную ошибку e(j). Выбранный фильтр формирования частоты определяется индексом j.
Индекс T кодового словаря основного тона кодируется и передается в мультиплексор 213 для передачи по каналу связи. Усиление b основного тона квантуется и передается в мультиплексор 213. Для кодирования индекса j используется дополнительный бит, причем этот дополнительный бит также подается в мультиплексор 213.
Как только определены параметры b, T и j основного тона или LTP (долгосрочное предсказание), наступает следующий шаг, на котором модуль 210 поиска нововведенного возбуждения по фиг.2 отыскивает оптимальное нововведенное возбуждение. Сначала обновляется искомый вектор x путем вычитания вклада LTP:
x'=x-byT,
где b - усиление основного тона, а yT - отфильтрованный вектор кодовой книги основного тона (прошлое возбуждение с задержкой T, отфильтрованной выбранным фильтром формирования частоты (индекс j) и подвергнутое свертке с использованием импульсной характеристики h).
Процедура поиска нововведенного возбуждения выполняется в кодовой книге нововведений для нахождения оптимального кодового вектора возбуждения сk и усиления g, которые минимизируют среднеквадратическую ошибку Е между искомым вектором x' и масштабированной отфильтрованной версией кодового вектора сk, например:
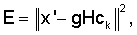
где H - нижняя треугольная матрица свертки, полученная из вектора h импульсной характеристики. Индекс k кодовой книги нововведений, соответствующего найденному оптимальному кодовому вектору сk, и усиление g подаются в мультиплексор 213 для передачи по каналу связи.
Следует отметить, что используемая кодовая книга нововведений является динамической кодовой книгой, состоящей из алгебраической кодовой книги с последующим адаптивным предварительным фильтром F(z), который усиливает конкретные спектральные компоненты, чтобы повысить качество синтезированной речи согласно патенту США № 5444816, выданному Adoul и др. 22 августа 1995 г. В этом иллюстративном варианте реализации поиск в кодовой книге нововведений выполняется в модуле 210 посредством алгебраической кодовой книги, как описано в патентах США №5444816 (Adoul и др.), выданном 22 августа 1995 г.; №5699482, выданном Adoul и др. 17 декабря 1997 г.; №5754976, выданном Adoul и др. 19 мая 1998 г.; и №5701392 (Adoul и др.), датированном 23 декабря 1997 г.
Общее представление о AMR-WB декодере
Речевой декодер 300 по фиг.3, иллюстрирует различные шаги, выполняемые начиная от цифрового входного сигнала 322 (входной поток битов в демультиплексор 317) до выходного дискретизированного речевого сигнала 323 (выход сумматора 321).
Демультиплексор 317 выделяет из двоичной информации (входной поток 322 битов), полученной из цифрового входного канала, параметры модели синтеза. Из каждого полученного двоичного кадра выделяются следующие параметры:
квантованные интерполированные LP-коэффициенты В(z), называемые также параметрами краткосрочного предсказания (STP), которые создаются для каждого кадра;
параметры T, b и j (для каждого субкадра) для долгосрочного предсказания (LTP); и
индекс k кодовой книги нововведений и усиление g (для каждого субкадра).
Текущий речевой сигнал синтезируется на основе этих параметров, как поясняется ниже.
Кодовая книга 318 нововведений в ответ на индекс k формирует кодовый вектор сk нововведений, который масштабируется декодированным коэффициентом усиления g посредством усилителя 324. В иллюстративном варианте реализации кодовая книга нововведений, как описано в вышеупомянутых патентах США №№5444816, 5699482, 5754976 и 5701392, используют для создания кодового вектора сk нововведений.
Сформированный масштабированный кодовый вектор на выходе усилителя 324 обрабатывается частотно-зависимым корректором 305 основного тона.
Коррекция периодичности сигнала возбуждения u повышает качество голосовых сегментов. Коррекция периодичности достигается фильтрацией кодового вектора сk нововведений из кодовой книги нововведений (фиксированного) посредством фильтра F(z) нововведений (корректор 305 основного тона), частотная характеристика которого вводит предыскажения на более высоких частотах в большей степени, чем на более низких частотах. Коэффициенты фильтра F(z) нововведений связаны со значением периодичности в сигнале возбуждения u.
Эффективный иллюстративный способ получения коэффициентов фильтра F(z) нововведений заключается в их привязке к величине вклада основного тона в общем сигнале возбуждения u. Это приводит к зависимости частотной характеристики от периодичности субкадров, причем предыскажения на более высоких частотах оказываются более сильными (сильнее общий спад) для более высоких значений усиления основного тона. Фильтр 305 нововведений обладает эффектом повышения энергии кодового вектора сk нововведений на более низких частотах, когда сигнал возбуждения u более периодичен, что улучшает периодичность сигнала возбуждения u скорее на более низких частотах, чем на более высоких частотах. Предлагаемая форма для фильтра 305 нововведений выглядит следующим образом:
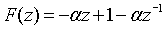
где α - коэффициент периодичности, полученный из уровня периодичности сигнала возбуждения u. Коэффициент периодичности α вычисляется в генераторе 304 коэффициентов вокализации. Сначала в генераторе 304 коэффициентов вокализации вычисляется коэффициент вокализации rV в виде
rv=(Ev-EC)/(EV+EC),
где EV - энергия масштабированного кодового вектора bvT, а EC - энергия масштабированного кодового вектора gck нововведений, то есть

и
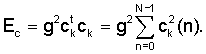
Заметим, что значение rV лежит между -1 и 1 (1 соответствует чисто вокализованным сигналам, а -1 соответствует чисто невокализованным сигналам).
Вышеупомянутый масштабированный кодовый вектор bvT основного тона создается путем применения задержки T основного тона к кодовой книге 301 основного тона для создания кодового вектора основного тона. Затем кодовый вектор основного тона обрабатывается в фильтре 302 нижних частот, частота среза которого выбирается в соответствии с индексом j из демультиплексора 317, для создания отфильтрованного кодового вектора bT основного тона. Затем отфильтрованный кодовый вектор vT основного тона усиливается с коэффициентом усиления b основного тона усилителем 326 для создания масштабированного кодового вектора bvT основного тона.
В данном иллюстративном варианте реализации, затем в генераторе 304 коэффициентов вокализации вычисляется коэффициент α согласно выражению
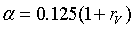
который соответствует значению 0 для чисто невокализованных сигналов и значению 0,25 для чисто вокализованных сигналов.
Таким образом, скорректированный сигнал cf вычисляется путем фильтрации масштабированного кодового вектора gck нововведений в фильтре 305 (F(z) нововведений).
Скорректированный сигнал возбуждения u' вычисляется сумматором 320 в виде
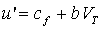
Следует заметить, что эта обработка не выполняется в декодере 200. Таким образом, важно обновить содержимое кодовой книги 301 основного тона с использованием прошлого значения сигнала u возбуждения без коррекции, хранящейся в памяти 303, для поддержания синхронизма между кодером 200 и декодером 300. Соответственно, сигнал возбуждения u используется для обновления памяти 303 кодовой книги 301 основного тона, а скорректированный сигнал возбуждения u' используется на входе фильтра 306 LP синтеза.
Синтезированный сигнал s' вычисляется путем фильтрации скорректированного сигнала возбуждения u' в LP-фильтре 306 синтеза, который имеет вид 1/В(z), где В(z) является квантованным интерполированным LP-фильтром в текущем субкадре. Как можно видеть из фиг.3, квантованные интерполированные LP-коэффициенты В(z) по линии 325 от демультиплексора 317 подаются в LP-фильтр 306 синтеза для соответствующей настройки параметров LP-фильтра 306. Фильтр 307 компенсации предыскажений является инверсным по отношению к предыскажающему фильтру 203 по фиг.2. Передаточная функция фильтра 307 компенсации предыскажений задается в виде
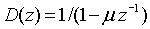
где μ - коэффициент предыскажений, значение которого лежит между 0 и 1 (стандартное значение μ=0,7). Можно также использовать фильтр более высокого порядка.
Вектор s' фильтруется в фильтре D(z) 307 компенсации предыскажений для получения вектора sd, который обрабатывается в фильтре 308 верхних частот для устранения нежелательных частот ниже 50 Гц и затем для получения sh.
Сверхдискретизатор 309 реализует процесс обратной обработки по отношению к субдискретизатору 201 по фиг.2. В данном иллюстративном варианте при сверхдискретизации происходит преобразование частоты дискретизации 12,8 кГц обратно в исходную частоту дискретизации 16 кГц с использованием способов, хорошо известных специалистам в данной области техники. Сигнал синтеза, прошедший сверхдискретизацию, обозначен как S. Сигнал S также называется синтезированным широкополосным промежуточным сигналом.
Сигнал S синтеза, прошедший сверхдискретизацию, не содержит высокочастотные компоненты, которые были потеряны во время процесса субдискретизации (модуль 201 по фиг.2) в кодере 200. Это обеспечивает восприятие низких частот синтезированного речевого сигнала. Для восстановления полной полосы исходного сигнала в модуле 310 выполняется процедура формирования высокочастотных составляющих, для которой требуется входной сигнал от генератора 304 коэффициентов вокализации (фиг.3).
Результирующая шумовая последовательность z, прошедшая полосовую фильтрацию, от модуля 310 формирования высокочастотных составляющих складывается сумматором 321 с синтезированным речевым сигналом S, прошедшим сверхдискретизацию, для получения конечного восстановленного выходного речевого сигнала sout на выходе 323. Пример процесса восстановления высокочастотных составляющих описан в Международной патентной заявке PCT, опубликованной под №WO 00/25305 4 мая 2000 года.
Побитовое распределение для AMR-WB кодека при скорости 12,65 кбит/с показано в Таблице 1.
Побитовое распределение в режиме 12,65 кбит/с
Устойчивое маскирование стирания кадров
Стирание кадров является главным фактором, влияющим на качество синтезированной речи в системах цифровой речевой связи, особенно при работе в беспроводных средах и сетях с коммутацией пакетов. В системах беспроводной сотовой связи энергия принятого сигнала может демонстрировать частые сильные замирания, приводящие к высоким частотам ошибок по битам, что более ярко проявляется на границах сотовых ячеек. В этом случае канальный декодер не в состоянии скорректировать ошибки в принятом кадре, и вследствие этого детектор ошибок, обычно используемый после канального декодера, объявляет такой кадр стертым. В сетевых приложениях с пакетной передачей голоса, таких как протокол передачи речи по Интернету (VoIP), речевой сигнал пакетируется, причем в каждом пакете обычно размещается 20-миллисекундный кадр. При связи с коммутацией пакетов в маршрутизаторе пакет может быть потерян, если количество пакетов становится слишком большим, либо пакет может поступить в приемник после длительной задержки, и он должен будет быть объявлен потерянным, если его задержка оказалась больше длины буфера дрожания на приемной стороне. В этих системах работа кодека обычно сопровождается появлением стертых кадров с частотой от 3 до 5%.
Проблема обработки стирания кадров (FER) по существу является двойственной. Во-первых, когда появляется индикатор стертого кадра, должен быть создан пропавший кадр с использованием информации, посланной в предыдущем кадре, и на основе оценки эволюции сигнала в пропавшем кадре. Успешность оценки зависит не только от стратегии маскирования, но также от места в речевом сигнале, где произошло стирание. Во-вторых, должен быть обеспечен плавный переход, когда восстановилась нормальная работа, то есть когда после блока стертых кадров (одного или нескольких) поступил первый пригодный кадр. Это нетривиальная задача, поскольку истинный синтез и расчетный синтез могут развиваться по-разному. При поступлении первого пригодного кадра нарушается синхронизация декодера с кодером. Основной причиной этого является то, что работа кодеров с низкой скоростью передачи битов основана на предсказании основного тона, а во время стертых кадров содержимое памяти предсказателя основного тона уже не совпадает с содержимым памяти в кодере. Эта проблема усугубляется при наличии множества следующих друг за другом стертых кадров. Что касается маскирования, то трудность восстановления стандартной обработки зависит от типа речевого сигнала, в котором появилась ошибка.
Отрицательный эффект от стираний кадров может быть значительно уменьшен путем адаптивного применения маскирования и восстановления стандартной обработки (далее восстановления) для того типа речевого сигнала, в котором произошло стирание. Для этой цели каждый речевой кадр необходимо классифицировать. Эта классификация может быть выполнена в кодере и передана в декодер. В альтернативном варианте такая оценка может быть выполнена в декодере.
Для наилучшего маскирования и восстановления имеется несколько критических характеристик речевого сигнала, которые необходимо тщательно контролировать. Этими критическими характеристиками являются энергия сигнала или его амплитуда, величина периодичности, спектральная огибающая и период основного тона. В случае восстановления речевого сигнала дополнительного улучшения можно достичь, используя управление фазой. При небольшом увеличении скорости передачи битов для обеспечения более качественного управления можно подвергнуть квантованию и передать ряд дополнительных параметров. Если дополнительная полоса пропускания отсутствует, то параметры могут быть оценены в декодере. При обеспечении управления этими параметрами маскирование и восстановление стирания кадров может быть значительно улучшено, в частности, путем повышения сходимости декодированного сигнала с действительным сигналом в кодере и смягчения эффекта несовпадения между кодером и декодером при восстановлении стандартной обработки.
В данном иллюстративном варианте настоящего изобретения раскрыты способы для эффективного маскирования стирания кадров и способы для выделения и передачи параметров, улучшающих рабочие характеристики и сходимость в декодере для кадров, следующих за стертым кадром. Эти параметры включают в себя два или более из следующих параметров: классификация кадра, энергия, информация о речи и информация о фазе. Кроме того, раскрыты способы для выделения указанных параметров в декодере, если передача дополнительных битов невозможна. Наконец, также раскрыты способы для улучшения сходимости в декодере для пригодных кадров, следующих за стертым кадром.
Способы маскирования стирания кадров согласно настоящему иллюстративному варианту были применены в AMR-WB кодеке, описанном выше. Этот кодек будет служить в качестве примерной основы для реализации способов маскирования FER в последующем описании. Как объяснено выше, входной речевой сигнал 212 кодека имеет частоту дискретизации 16 кГц, но он подвергается субдискретизации с понижением частоты дискретизации до 12,8 кГц перед дальнейшей обработкой. В настоящем иллюстративном варианте выполняется обработка FER субдискретизированного сигнала.
На фиг.4 представлена упрощенная блок-схема AMR-WB кодера 400. В этой упрощенной блок-схеме субдискретизатор 201, фильтр 202 верхних частот и фильтр 203 предыскажений сгруппированы вместе в модуле 401 предобработки. Также модуль 207 поиска с обратной связью, вычислитель 208 отклика при нулевом входном сигнале, вычислитель 209 импульсной характеристики, модуль 210 поиска нововведенного возбуждения и модуль 211 обновления памяти сгруппированы в модуле 402 основного тона и поиска кодовой книги нововведений с обратной связью. Эта группировка сделана для упрощения введения новых модулей, относящихся к иллюстративному варианту настоящего изобретения.
На фиг.5 представлено расширение блок-схемы по фиг.4, где добавлены модули, относящиеся к иллюстративному варианту настоящего изобретения. В этих добавленных модулях от 500 до 507 вычисляются, квантуются и передаются дополнительные параметры с целью улучшения маскирования FER и сходимости и восстановления в декодере после стертых кадров. В данном иллюстративном варианте эти параметры включают в себя информацию о классификации, энергии и фазе сигнала (расчетное положение в кадре первого импульса, относящегося к голосовой щели).
В последующих разделах подробно представлено вычисление и квантование этих дополнительных параметров, причем эти операции поясняются со ссылкой на фиг.5. Среди этих параметров более подробно будет рассмотрена классификация сигнала. В последующих разделах объясняется, как выполняется эффективное маскирование FER с использованием этих дополнительных параметров для улучшения сходимости.
Классификация сигнала для маскирования FER и восстановления
Основополагающая идея, лежащая в основе использования классификации речи для восстановления сигнала при наличии стертых кадров, состоит в том, что стратегия идеального маскирования отличается для квазистационарных речевых сегментов и для речевых сегментов с быстро изменяющимися характеристиками. В то время как наилучшая обработка стертых кадров в нестационарных речевых сегментах может быть в итоге сведена к быстрой сходимости параметров речевого кодирования к характеристикам шума окружающей среды, в случае квазистационарного сигнала параметры речевого кодирования не претерпевают значительных изменений и могут поддерживаться практически постоянными в течение нескольких соседних стертых кадров перед демпфированием. Кроме того, оптимальный способ восстановления сигнала вслед за стертым блоком кадров изменяется с изменением классификации речевого сигнала.
Речевой сигнал можно приблизительно классифицировать на вокализованный, невокализованный и паузы. Вокализованная речь содержит значительный объем периодических компонент и может быть дополнительно разделена на следующие категории: вокализованные приступы, вокализованные сегменты, вокализованные переходы и вокализованные сдвиги. Вокализованный приступ определяется как начало вокализованного речевого сегмента после паузы или невокализованного сегмента. В течение вокализованных сегментов параметры речевого сигнала (спектральная огибающая, период основного тона, отношение периодических и непериодических компонент, энергия) изменяются медленно от кадра к кадру. Вокализованный переход характеризуется быстрыми изменениями вокализованной речи, к примеру, переход между гласными. Вокализованные сдвиги характеризуются постепенным уменьшением энергии и звучания голоса в конце локализованных сегментов.
Невокализованные части сигнала характеризуются отсутствием периодической компоненты и могут быть дополнительно разделены на нестабильные кадры, энергия и спектр которых быстро изменяются, и стабильные кадры, где эти характеристики остаются относительно стабильными. Остальные кадры классифицируются как тишина. Кадры тишины содержат все кадры без активной речи, то есть также и кадры только с шумом, если присутствует фоновый шум.
Не для всех из вышеупомянутых классов требуется отдельная обработка. Поэтому в технологиях маскирования ошибок некоторые классы сигнала сгруппированы вместе.
Классификация в кодере
Если в потоке битов имеется доступная полоса пропускания для включения информации о классификации, то классификацию можно выполнять в кодере. Это дает ряд преимуществ. Наиболее важным из них является то, что часто в речевых кодерах осуществляется упреждающий просмотр. Упреждающий просмотр позволяет оценить эволюцию сигнала в следующем кадре, и следовательно, классификация может быть выполнена с учетом поведения сигнала в будущем. Обычно, чем дольше длится упреждающий просмотр, тем лучше может быть выполнена классификация. Дополнительным преимуществом является упрощение, так как большая часть обработки сигнала, необходимая для маскирования стирания кадров, так или иначе требуется для речевого кодирования. Наконец, преимуществом также является работа с исходным сигналом вместо синтезированного сигнала.
Классификация кадра выполняется с учетом стратегии маскирования и восстановления. Другими словами, любой кадр классифицируется таким образом, чтобы маскирование могло быть оптимальным, если следующий кадр отсутствует, или чтобы восстановление могло быть оптимальным, если предыдущий кадр был потерян. Некоторые из классов, используемых для обработки FER, не требуют передачи, так как они могут быть однозначно получены в декодере. В настоящем иллюстративном варианте используется пять (5) отдельных классов, которые определены ниже:
Класс UNVOICED (невокализованный) содержит все невокализованные речевые кадры и все кадры без активной речи. Кадр вокализованного сдвига также можно классифицировать как UNVOICED, если его конец имеет тенденцию к невокализованному классу, и маскирование, предназначенное для невокализованных кадров, может быть использовано для следующего кадра в случае его потери.
Класс UNVOICED TRANSITION (невокализованный переход) содержит невокализованные кадры с возможным вокализованным приступом на конце. Однако приступ еще слишком короткий или недостаточно хорошо сформирован для использования маскирования, предназначенного для вокализованных кадров. Класс UNVOICED TRANSITION может следовать только за кадром, классифицированным как UNVOICED или UNVOICED TRANSITION.
Класс VOICED TRANSITION (вокализованный переход) содержит вокализованные кадры с относительно слабовокализованными характеристиками. Обычно это вокализованные кадры с быстроизменяющимися характеристиками (переходами между гласными) или вокализованные сдвиги, завершающие весь кадр. Класс VOICED TRANSITION может следовать только за кадром, классифицированным как VOICED TRANSITION, VOICED или ONSET (сдвиг).
Класс VOICED содержит вокализованные кадры со стабильными характеристиками. Этот класс может следовать только за кадром, классифицированным как VOICED TRANSITION, VOICED или ONSET.
Класс ONSET содержит все вокализованные кадры со стабильными характеристиками, следующие после кадра, классифицированного как UNVOICED или UNVOICED TRANSITION. Кадры, классифицированные как ONSET, соответствуют вокализованным кадрам приступов, где приступ достаточно хорошо сформирован для использования маскирования, предназначенного для потерянных вокализованных кадров. Способы маскирования, используемые для стирания кадра, следующего за классом ONSET, такие же, как способы после класса VOICED. Различие состоит в стратегии восстановления. Если потерян кадр класса ONSET (то есть, пригодный кадр VOICED поступает после стирания, но последним пригодным кадром перед стиранием был кадр UNVOICED), для искусственного восстановления потерянного приступа можно использовать специальный способ. Этот сценарий можно увидеть на фиг.6. Способы искусственного восстановления приступов более подробно описываются далее. С другой стороны, если пригодный кадр ONSET поступает после стирания, и последним пригодным кадром перед стиранием был кадр UNVOICED, в указанной специальной обработке нет необходимости, так как приступ не был потерян (не был в потерянном кадре).
На фиг.7 показана схема классификационных состояний. Если имеющаяся полоса пропускания достаточна, то классификация выполняется в кодере, и результаты передаются с использованием 2 битов. Как можно видеть из фиг.7, класс UNVOICED TRANSITION и класс VOICED TRANSITION могут быть сгруппированы вместе, так как они могут быть однозначно различены в декодере (UNVOICED TRANSITION может следовать только за кадрами UNVOICED или UNVOICED TRANSITION, VOICED TRANSITION может следовать только за кадрами ONSET, VOICED или VOICED TRANSITION). Для классификации используют следующие параметры: нормализованную корреляцию rX, показатель наклона спектра et, отношение сигнал-шум snr, показатель стабильности основного тона pc, относительная энергия сигнала в конце текущего кадра ES и счетчик переходов через нуль zc. Как можно видеть из последующего подробного анализа, при вычислении этих параметров используется предварительный просмотр настолько, насколько это возможно, чтобы учесть поведение речевого сигнала также и в следующем кадре.
Нормализованная корреляция rX вычисляется в виде части модуля 206 поиска основного тона без обратной связи по фиг.5. Этот модуль 206 обычно выдает каждые 10 мс (дважды за кадр) оценку основного тона без обратной связи. Здесь это также используется для выдачи нормализованных показателей корреляции. Эти нормализованные значения корреляции вычисляют по текущему взвешенному речевому сигналу sW(n) и прошлому взвешенному речевому сигналу с задержкой основного тона без обратной связи. В целях упрощения вычислений взвешенный речевой сигнал sW(n) подвергают субдискретизации с коэффициентом 2 перед анализом основного тона без обратной связи, снижая частоту дискретизации до 6400 Гц [3GPP TS 26.190, "AMR Wideband Speech Codec: Transcoding Functions", 3GPP Technical Specification]. Средняя корреляция rХ определяется как
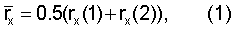
где rX(1), rX(2) - нормализованная корреляция второй половины текущего кадра и упреждающего просмотра соответственно. В данном иллюстративном варианте используют упреждающий просмотр в 13 мс в отличие от стандарта AMR-WB, где используется 5 мс. Нормализованную корреляцию rX(k) вычисляют следующим образом:
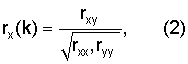
где
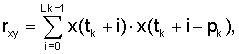
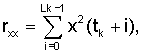
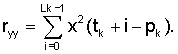
Корреляции rX(k) вычисляют с использованием взвешенного речевого сигнала sW(n). Моменты времени tk относятся к началу текущего кадра и равны 64 и 128 отсчетов соответственно при скорости или частоте дискретизации 6,4 кГц (10 или 20 мс). Значения pk=TOL являются выбранными оценками основного тона без обратной связи. Длина вычисления длительности автокорреляции Lk зависит от периода основного тона. Значения Lk приведены ниже (для частоты дискретизации 6,4 кГц):
Lk=40 отсчетов для pk31 отсчета,
Lk=62 отсчета для pk61 отсчета,
Lk=115 отсчетов для pk> 61 отсчета.
Такие значения Lk гарантируют, что длина коррелированного вектора содержит по меньшей мере один период основного тона, который позволяет надежно обнаружить основной тон без обратной связи. Для длинных периодов основного тона (p1>61 отсчета) rX(1) и rX(2) идентичны, то есть вычисляется только одна корреляция, поскольку длина коррелированных векторов достаточна для того, чтобы отпала необходимость анализа на основе упреждающего просмотра.
Параметр наклона спектра et содержит информацию о распределении энергии по частоте. В настоящем иллюстративном варианте наклон спектра оценивается как отношение энергии, сконцентрированной на низких частотах, к энергии, сконцентрированной на высоких частотах. Однако его можно также оценить другими способами, к примеру отношением двух первых коэффициентов автокорреляции речевого сигнала.
Для выполнения спектрального анализа в модуле 500 по фиг.5 для спектрального анализа и оценки энергии спектра используется дискретное преобразование Фурье. Частотный анализ и вычисление наклона выполняется дважды за кадр. Используются 256 точек быстрого преобразования Фурье (FFT) с 50-процентным перекрытием. Окна для анализа размещают таким образом, чтобы использовать весь упреждающий просмотр. В данном иллюстративном варианте начало первого окна помещено на 24 отсчета после начала текущего кадра. Второе окно находится на 128 отсчетов далее. Для взвешивания входного сигнала с целью частотного анализа можно использовать другие окна. В настоящем иллюстративном варианте использован квадратный корень из окна Хэмминга (который эквивалентен синусному окну). Это окно особенно хорошо подходит для методов с добавочным перекрытием. Таким образом, этот конкретный спектральный анализ можно использовать в возможном алгоритме подавления шума на основе спектрального вычитания и анализа/синтеза с добавочным перекрытием.
В модуле 500 по фиг.5 вычисляют энергию на высоких частотах и низких частотах за перцепционными критическими полосами. В настоящем иллюстративном варианте каждая критическая полоса рассматривается вплоть до следующего числа [J.D.Johnston, "Transform Coding of Audio Signals Using Perceptual Noise Criteria", IEEE Jour. on Selected Areas in Communications, vol.6, no.2, pp.314-323]:
Критические полосы = {100.0, 200.0, 300.0, 400.0, 510.0, 630.0, 770.0, 920.0, 1080.0, 1270.0, 1480.0, 1720.0, 2000.0, 2320.0, 2700.0, 3150.0, 3700.0, 4400.0, 5300.0, 6350.0} Гц.
Энергия на более высоких частотах вычисляется в модуле 500 как среднее значение энергий двух последних критических полос
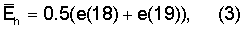
где энергии критических полос e(i) вычисляют как сумму энергий элементов дискретизации в критической полосе, усредненную по количеству элементов дискретизации.
Энергия на более низких частотах вычисляется как среднее значение энергий в 10 первых критических полосах. Средние критические полосы были исключены из вычисления для улучшения различения кадров с высокой концентрацией энергии на низких частотах (обычно вокализированных) и кадров с высокой концентрацией энергии на высоких частотах (обычно невокализованных). В промежутке между низкими и высокими частотами энергетическое содержании не характерно для любого из классов, что приводит к ошибкам при принятии решения.
В модуле 500 энергия на низких частотах вычисляется отдельно для длинных периодов основного тона и коротких периодов основного тона. Для вокализованных сегментов, характерных для речи женщины, для повышения качества различения локализованных и нелокализованных сегментов можно использовать гармоническую структуру спектра. Так, для коротких периодов основного тона 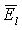 вычисляют по элементам дискретизации и при суммировании учитывают только те частотные элементы дискретизации, которые достаточно близки к речевым гармоникам, то есть,
вычисляют по элементам дискретизации и при суммировании учитывают только те частотные элементы дискретизации, которые достаточно близки к речевым гармоникам, то есть,
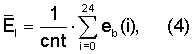
где eb(i) - энергии элементов дискретизации в первых 25 частотных элементах дискретизации (постоянная составляющая не учитывается). Заметим, что эти 25 элементов дискретизации соответствуют первым 10 критическим полосам. В вышеуказанной сумме не равны нулю только члены, относящиеся к элементам дискретизации, находящимся ближе к ближайшим гармоникам, чем определенный частотный порог. Отсчет cnt равен количеству этих ненулевых членов. Порог для элемента дискретизации, включаемого в указанную сумму, был зафиксирован равным 50 Гц, то есть учитывались только те элементы дискретизации, которые ближе чем на 50 Гц к ближайшим гармоникам. Таким образом, если структура является гармонической на низких частотах, в сумму будет включен только член с высокой энергией. С другой стороны, если структура не является гармонической, то выбор членов будет случайным, и сумма окажется меньше. Таким образом, могут быть обнаружены даже невокализованные звуки с высоким энергетическим содержанием на низких частотах. Такая обработка не может быть выполнена для более длинных периодов основного тона, так как разрешение по частоте недостаточно. Пороговое значение основного тона составляет 128 отсчетов, соответствующих 100 Гц. Это означает, что для периодов основного тона длиннее 128 отсчетов, а также для заведомо невокализованных звуков (то есть, когда 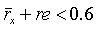 ) оценка энергии на низких частотах выполняется для каждой критической полосы и вычисляется как
) оценка энергии на низких частотах выполняется для каждой критической полосы и вычисляется как
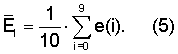
Значение re, вычисленное в модуле 501 оценки шума и коррекции нормализованной корреляции, является коррекцией, которую добавляют к нормализованной корреляции при наличии фонового шума по следующей причине. При наличии фонового шума средняя нормализованная корреляция уменьшается. Однако в целях классификации сигналов это уменьшение не должно влиять на принятие решения об отнесении того или иного сегмента к вокализованному или невокализованному классу. Обнаружено, что зависимость между указанным уменьшением re и общей энергией фонового шума в дБ носит приблизительно экспоненциальный характер и может быть выражена с использованием следующего соотношения:
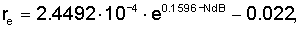
где NdB означает
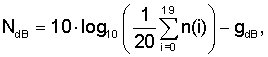
где n(i) оценки энергии шума для каждой критической полосы, нормализованной таким же образом, как e(i), а gdB - максимальный уровень подавления шума в дБ, разрешенный для процедуры ослабления шума. Значение re не должно быть отрицательным. Следует заметить, что при использовании эффективного алгоритма ослабления шума и при достаточно высоком gdB значение re практически равно нулю. Это верно только тогда, когда ослабление шума блокировано или если уровень фонового шума значительно выше, чем максимально допустимое ослабление. Влияние re можно регулировать путем умножения этого члена на константу.
Наконец, результирующие энергии на более низких и более высоких частотах получают путем вычитания оцененной энергии шума из ранее вычисленных значений 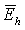 и
и 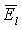 . То есть
. То есть
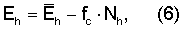
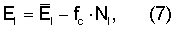
где Nh и Nl - средние энергии шума в двух (2) последних критических полосах и первых десяти (10) критических полосах соответственно, вычисленных с использованием уравнений, подобных уравнениям (3) и (5), а fc - коэффициент коррекции, подбираемый таким образом, чтобы эти показатели оставались близкими к константе при изменении уровня фонового шума. В этом иллюстративном варианте значение fc было зафиксировано равным 3.
Наклон спектра et вычисляется в модуле 503 оценки наклона спектра с использованием соотношения
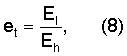
и усредняется в дБ области для двух (2) частотных анализов, выполняемых на каждом кадре
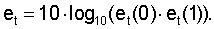
При измерении отношения сигнал-шум (SNR) используется тот факт, что для обычного кодера согласования формы сигнала отношение SNR гораздо выше для вокализованных звуков. Оценка параметра snr должна выполняться в конце цикла субкадра кодера и вычисляться в модуле 504 вычисления SNR с использованием соотношения
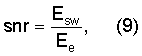
где Esw - энергия взвешенного речевого сигнала Sw(n) текущего кадра из фильтра 205 с перцептивным взвешиванием, а Ee - энергия ошибки между этим взвешенным речевым сигналом и взвешенным сигналом синтеза текущего кадра из фильтра 205' с перцептивным взвешиванием.
Показатель pc стабильности основного тона оценивает изменение периода основного тона. Он вычисляется в модуле 505 классификации сигнала в соответствии с оценками основного тона без обратной связи следующим образом:
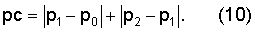
Значения p0, p1, p2 соответствуют оценкам основного тона без обратной связи, вычисленным модулем 206 поиска основного тона без обратной связи из первой половины текущего кадра, второй половины текущего кадра и упреждающего просмотра соответственно.
Относительная энергия Es кадра вычисляется модулем 500 как разность между энергией текущего кадра в дБ и ее долгосрочным средним значением
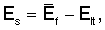
где энергию кадра 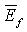 получают в виде суммы энергий критических полос, усредненную по результатам обоих спектральных анализов, выполняемых для каждого кадра
получают в виде суммы энергий критических полос, усредненную по результатам обоих спектральных анализов, выполняемых для каждого кадра
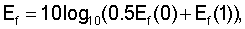
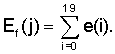
Усредненная за длительный период энергия обновляется на активных речевых кадрах с использованием следующего соотношения:
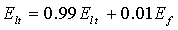 .
.
Последним параметром является параметр zc перехода через нуль, вычисляемый модулем 508 вычисления переходов через нуль по одному кадру речевого сигнала. Этот кадр начинается в середине текущего кадра, при этом используется два (2) субкадра упреждающего просмотра. В данном иллюстративном варианте счетчик zc переходов через нуль подсчитывает количество изменений знака сигнала с положительного на отрицательный в течение этого интервала.
Для более устойчивого выполнения классификации параметры классификации учитываются совместно, формируя функцию полезности fm. Для этой цели параметры классификации сначала масштабируют в диапазоне между 0 и 1, так что значение каждого параметра, типичное для невокализованного сигнала, преобразуется в 0, а значение каждого параметра, типичное для вокализованного сигнала, преобразуется в 1. Между ними используется линейная функция. При рассмотрении параметра px его масштабированная версия получается с использованием выражения
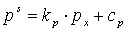
и ограничивается в диапазоне между 0 и 1. Коэффициенты kp и cp функции были найдены экспериментально для каждого из параметров, так чтобы искажение сигнала из-за применения способов маскирования и восстановления, используемых при наличии FER, было минимальным. Значения, использованные в данном иллюстративном варианте реализации, сведены в таблицу 2:
Параметры классификации сигнала и коэффициенты соответствующих функций масштабирования

Функция полезности определена как
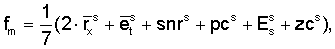
где верхний индекс s указывает масштабированную версию параметров.
Затем выполняется классификация с использованием функции полезности fm и следующих правил, сведенных в таблицу 3:
Правила классификации сигналов в кодере
В случае использования кодера с переменной скоростью передачи битов (VBR) и управляемым источником классификация сигнала неотъемлема от работы кодека. Кодек работает с несколькими скоростями передачи битов, а модуль выбора скорости используется для определения скорости передачи битов, применяемой при кодировании каждого речевого кадра исходя из характера речевого кадра (например вокализованные, невокализованные, переходные кадры, и кадры фонового шума кодируются каждый с использованием специального алгоритма кодирования). Информация о режиме кодирования, а значит, о речевом классе, является неявно выраженной частью потока битов и не нуждается в передаче в явном виде для обработки FER. Затем эту информацию о классе можно использовать для пересмотра решения по классификации, описанного выше.
В применении к AMR-WB-кодеку обнаружение речевой активности (VAD) предоставляется только выбором скорости, управляемой источником. Этот флаг VAD равен 1 для активной речи и равен 0 для паузы. Этот параметр полезен для классификации, так как он непосредственно указывает, что в дальнейшей классификации нет необходимости, если его значение равно 0 (то есть кадр непосредственно классифицирован как UNVOICED). Этот параметр является выходом модуля 402 обнаружения речевой активности (VAD). В литературе существуют другие алгоритмы VAD, причем в целях настоящего изобретения можно использовать любой алгоритм. Например, можно использовать алгоритм VAD, который является частью стандарта G.722.2 [ATU-T Recommendation G. 722.2 "Wideband coding of speech at around 16 kbit/s using Adaptive Multi-Rate Wideband (AMR-WB)", Geneva, 2002]. Здесь алгоритм VAD основан на выходных данных спектрального анализа модуля 500 (на основе отношения сигнал-шум для каждой критической полосы). VAD, используемое в целях классификации, отличается от VAD, используемого в целях кодирования в соответствии с "затягиванием". В речевых кодерах, использующих генерацию комфортного шума (CNG) для сегментов без активной речи (пауза или только шум), затягивание часто добавляется после речевых всплесков (например, CNG в стандарте AMR-WB [3GPP TS 26192, "AMR Wideband Speech Codec: Comfort Noise Aspects", 3GPP Technical Specification]). Во время затягивания речевой кодер продолжает использоваться, и система переключается на CNG только после окончания периода затягивания. В целях классификации для маскирования FER в такой высокой степени защиты нет необходимости. Следовательно, флаг VAD для классификации будет равен 0 также и во время периода затягивания.
В данном иллюстративном варианте классификация выполняется в модуле 505 на основе вышеописанных параметров: нормализованных корреляций (или информации о звучании голоса) rx, наклона спектра et, snr, показателя стабильности основного тона pc, относительной энергии кадра Es, частоты переходов через нуль zc и флага VAD.
Классификация в декодере
Если приложение не допускает передачу информации о классе (нет возможности транспортировки дополнительных битов), классификация может выполняться еще в декодере. Как уже было отмечено, основным недостатком при этом является то, что в речевых декодерах обычно нет утверждающего просмотра. Также часто необходимо ограничивать сложность декодера.
Простая классификация может быть выполнена путем оценки вокализации синтезированного сигнала. В случае кодера типа CELP можно использовать оценку вокализации rV, вычисляемую по уравнению (1). То есть
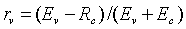 ,
,
где Ev - энергия масштабированного кодового вектора основного тона bvT, а EcT - энергия масштабированного кодового вектора gck нововведений. Теоретически для чисто вокализованного сигнала rV=1, а для чисто невокализованного сигнала rV=-1. Действительная классификация выполняется путем усреднения значений rV по каждым четырем субкадрам. Результирующий коэффициент frV (среднее значение rV каждых четырех субкадров) используют следующим образом.
Правило классификации сигнала в декодере
Так же, как и при классификации в кодере, для облегчения классификации можно использовать другие параметры в декодере, такие как параметры LP фильтра или стабильности основного тона.
В случае использования кодера с переменной скоростью передачи битов и управляемым источником информация о режиме кодирования уже является частью потока битов. Таким образом, если используется, например, чисто невокализованный режим кодирования, кадр может быть автоматически классифицирован как UNVOICED. Аналогично, при использовании чисто вокализованного режима кодирования кадр классифицируется как VOICED.
Речевые параметры для обработки FER
Имеется несколько критических параметров, которые необходимо тщательно регулировать во избежание раздражающих искажений при появлении FER. Если можно передавать небольшое количество дополнительных битов, то тогда эти параметры можно оценивать в кодере, квантовать и передавать. В противном случае некоторые из них можно оценивать в декодере. Эти параметры включают в себя классификацию сигнала, информацию об энергии, информацию о фазе и информацию вокализации. Наиболее важным является точное управление энергией речи. Также можно регулировать фазу и периодичность речи для дальнейшего улучшения маскирования FER и восстановления.
Важность управления энергией выходит на первый план в основном тогда, когда восстанавливается нормальная работа после стертого блока кадров. Так как большинство речевых кодеров используют в своей работе предсказание, в декодере невозможно получить правильную оценку энергии. В вокализованных речевых сегментах неточное значение энергии может поддерживаться в течение нескольких последовательных кадров, что очень раздражает особенно тогда, когда эта неточное значение энергии возрастает.
Даже если управление энергией и является самым важным для вокализованной речи из-за долгосрочного предсказания (предсказание основного тона), оно также важно и для невокализованной речи. Причина этого кроется в том, что в кодерах типа CELP часто используется предсказание квантователя усиления нововведений. Неправильное значение энергии во время невокализованных сегментов может вызвать раздражающую высокочастотную флуктуацию.
Управление фазой можно обеспечить несколькими путями, зависящими в основном от имеющейся полосы пропускания. В данном варианте реализации простое управление фазой обеспечивается во время последних вокализованных приступов путем проведения поиска в приблизительной информации о положении импульса, относящегося к голосовой щели.
Таким образом, кроме информации о классификации сигнала, обсужденной в предыдущем разделе, наиболее важной посылаемой информацией является информация об энергии сигнала и о положении в кадре первого импульса, относящегося к голосовой щели (информация о фазе). Если имеется достаточная полоса пропускания, можно также послать информацию вокализации.
Информация об энергии
Информацию об энергии можно оценивать и пересылать либо в остаточной LP-области, либо в области речевого сигнала. Посылка информации в остаточной области имеет недостаток, связанный с тем, что не учитывается влияние LP-фильтра синтеза. Это может быть особенно ненадежным в случае восстановления речи после нескольких потерянных вокализованных кадров (при появлении FER во время вокализованного речевого сегмента). При поступлении FER после вокализованного кадра обычно используется возбуждение последнего пригодного кадра во время маскирования при некоторой стратегии затухания. При появлении нового LP-фильтра синтеза с первым пригодным кадром после стирания может возникнуть несоответствие между энергией возбуждения и усилением LP-фильтра синтеза. Новый фильтр синтеза может создать сигнал синтеза с энергией, сильно отличающейся от энергии последнего синтезированного стертого кадра, а также от энергии исходного сигнала. По этой причине энергию вычисляют и квантуют в области сигнала.
Энергия Eq вычисляется и квантуется в модуле 506 оценки и квантования энергии. Было установлено, что для передачи энергии достаточно 6 битов. Однако это количество битов можно уменьшить без существенных последствий, если нет в наличии достаточного количества битов. В данном предпочтительном варианте используется 6-битовый равномерный квантователь в диапазоне от -15 дБ до 83 дБ с шагом 1,58 дБ. Индекс квантования задается целой частью:

где E - максимальное значение энергии сигнала для кадров, классифицированных как VOICED или ONSET, или средняя энергия на отсчет для других кадров. Для кадров VOICED или ONSET максимальное значение энергии сигнала вычисляется синхронно с основным тоном в конце кадра следующим образом:
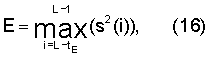
где L - длина кадра, а сигнал s(i) означает речевой сигнал (или речевой сигнал с подавленным шумом, если используется подавление шума). В данном иллюстративном варианте s(i) обозначает входной сигнал после субдискретизации с понижением частоты до 12,8 кГц и предобработки. Если задержка основного тона больше 63 отсчетов, то tE равно запаздыванию основного тона с обратной связью для последнего субкадра. Если задержка основного тона меньше 64 отсчетов, то тогда tE устанавливают равным удвоенному запаздыванию основного тона с обратной связью для последнего субкадра.
Для этих классов E представляет собой среднюю энергию на отсчет для второй половины текущего кадра, то есть tE устанавливается равным L/2, и E вычисляют как
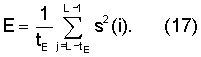
Информация об управлении фазой
Управление фазой особенно важно при восстановлении после потерянного сегмента вокализованной речи по тем же причинам, которые были описаны в предыдущем разделе. После блока стертых кадров теряется синхронизация запоминающих устройств декодера с запоминающими устройствами кодера. Для повторной синхронизации декодера может быть послана некоторая фазовая информации в зависимости от имеющейся полосы пропускания. В описанном иллюстративном варианте реализации посылают информацию о приблизительном положении в кадре первого импульса, относящегося к голосовой щели. Затем эта информация используется для восстановления после потерянных вокализованных приступов, как описано ниже.
Обозначим округленное запаздывание основного тона с обратной связью для первого субкадра как TO. Модуль 507 поиска первого импульса, относящегося к голосовой щели, и квантования отыскивает положение первого импульса τ среди первых отсчетов TO кадра путем поиска отсчета с максимальной амплитудой. Наилучшие результаты получаются тогда, когда положение первого импульса, относящегося к голосовой щели, измеряется в остаточном сигнале, отфильтрованном фильтром нижних частот.
Положение первого импульса, относящегося к голосовой щели, кодируется с использованием 6 битов следующим образом. Точность, используемая для кодирования положения первого импульса, относящегося к голосовой щели, зависит от значения основного тона с обратной связью для первого субкадра TO. Это возможно, поскольку указанное значение известно как кодеру, так и декодеру, и на нем не сказывается распространение ошибки после потери одного или нескольких кадров. Когда TO меньше 64, положение первого импульса, относящегося к голосовой щели, относительно начала кадра кодируется непосредственно с точностью до одного отсчета. Когда 64=TO<128, положение первого импульса, относящегося к голосовой щели, относительно начала кадра кодируется с точностью до 2-х отсчетов с использованием простого целочисленного деления, то есть τ/2. Когда TO=128, положение первого импульса, относящегося к голосовой щели, относительно начала кадра кодируется с точностью до 4-х отсчетов путем дополнительного деления τ на 2. В декодере выполняется обратная процедура. Если TO <64, то принятое квантованное положение используется так, как оно есть. Если 64=TO<128, то принятое квантованное положение умножается на 2 и увеличивается на 1. Если TO=128, то принятое квантованное положение умножается на 4 и увеличивается на 2 (приращение на 2 приводит к равномерно распределенной ошибке квантования).
Согласно другому варианту изобретения, где кодируется форма первого импульса, относящегося к голосовой щели, положение первого импульса, относящегося к голосовой щели, определяется путем корреляционного анализа остаточного сигнала и возможных форм импульса, знаков (положительный или отрицательный) и положений. Форма импульса может быть взята из кодовой книги форм импульса, известной как в кодере, так и в декодере, причем этот способ известен специалистам в данной области техники как векторное квантование. Затем форма, знак и амплитуда первого импульса, относящегося к голосовой щели кодируются и передаются в декодер.
Информация о периодичности
В случае достаточной полосы пропускания информация о периодичности или информация вокализации может быть вычислена, передана и использована в декодере для улучшения маскирования стирания кадров. Информация вокализации оценивается на основе нормализованной корреляции. Она может кодироваться достаточно точно 4 битами, однако возможно будет достаточно 3 или даже 2 бита, если потребуется. Информация вокализации обычно необходима только для кадров с периодическими компонентами, при этом более высокое разрешение вокализации необходимо для сильно вокализованных кадров. Нормализованная корреляция задается уравнением (2), причем эта корреляция используется в качестве индикатора информации вокализации. Она квантуется в модуле 507 поиска первого импульса, относящегося к голосовой щели, и квантования. В данном иллюстративном варианте для кодирования информации вокализации был использован кусочно-линейный квантователь следующим образом:
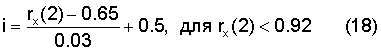 ,
,
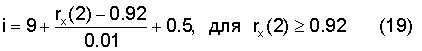 .
.
Вновь кодируется и передается целая часть i. Корреляция rx(2) имеет тот же смысл, что и в уравнении (1). В уравнении (18) вокализация линейно квантуется в диапазоне от 0,65 до 0,89 с шагом 0,03. В уравнении (19) вокализация линейно квантуется в диапазоне 0,92 до 0,98 с шагом 0,01.
Если необходим более широкий диапазон квантования, можно использовать следующее линейное квантование:
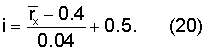 .
.
Это уравнение квантует вокализацию в диапазоне от 0,4 до 1 с шагом 0,04. Корреляция 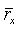 определена в уравнении (2а).
определена в уравнении (2а).
Уравнения (18) и (19) либо уравнение (20) используются затем в декодере для вычисления rx(2) или . Обозначим эту квантованную нормализованную корреляцию как rq. Если вокализация не может быть передана, ее можно оценить, используя коэффициент вокализации из уравнения (2а) путем его отображения в диапазоне от 0 до 1.
Обработка стертых кадров
Способы маскирования FER в данном иллюстративном варианте демонстрируются на примере кодеров типа ACELP. Однако их можно легко применить для любого речевого кодека, где генерируется сигнал синтеза путем фильтрации сигнала возбуждения посредством LP-фильтра синтеза. Стратегия маскирования может быть сведена к сходимости энергии сигнала и огибающей спектра к оцененным параметрам фонового шума. Периодичность сигнала сходится к нулю. Скорость сходимости зависит от параметров класса последнего принятого пригодного кадра и количества последовательных стертых кадров, причем эта скорость регулируется коэффициентом затухания α. Коэффициент α, кроме того, зависит от стабильности LP-фильтра для кадров UNVOICED. Обычно сходимость проявляется медленно, если последний принятый пригодный кадр находится в стабильном сегменте, и быстро, если этот кадр находится в сегменте перехода. Значения α сведены в таблицу 5.
Значения коэффициента затухания α для маскирования FER
Коэффициент стабильности θ вычисляется на основе показателя расстояния между соседними LP-фильтрами. Здесь коэффициент θ относится к показателю расстояния ISF (спектральные частоты иммитанса), который ограничен неравенством 0θ, причем большие значения θ соответствуют более стабильным сигналам. Это приводит к уменьшению флуктуаций энергии и огибающей спектра, когда внутри стабильного невокализованного сегмента появляется изолированный стертый кадр.
Класс сигнала остается неизменным в процессе обработки стертых кадров, то есть класс остается таким же, как в последнем пригодном принятом кадре.
Построение периодической части возбуждения
Для маскирования стертых кадров, следующих за правильно принятым кадром UNVOICED, периодическая часть сигнала возбуждения не создается. Для маскирования стертых кадров, следующих за правильно принятым кадром, иным, чем кадр UNVOICED, формируется периодическая часть сигнала возбуждения путем повторения последнего периода основного тона предыдущего кадра. Если речь идет о первом стертом кадре после пригодного кадра, то этот импульс основного тона сначала фильтруется фильтром нижних частот. В качестве такого фильтра используется трехотводный линейный фазовый фильтр с импульсной характеристикой конечной длительности (FIR) с коэффициентами фильтра, равными 0.18, 0.64, и 0.18. Если имеется информация вокализации, то фильтр можно также выбирать динамически с частотой среза, зависящей от вокализации.
Период основного тона TC, используемый для выбора последнего импульса основного тона, и, следовательно, используемый во время маскирования, определяется таким образом, чтобы можно было избежать или уменьшить гармоники и субгармоники основного тона. При определении периода TC основного тона используется следующая логика:
если ((T3<1.8 Ts) И (T3>0.6 Ts)) или (Tcnt=30), тогда Tc=T3, в противном случае Tc=Ts
Здесь T3 - округленный период основного тона для 4-го субкадра последнего пригодного принятого кадра, а TS - округленный период основного тона для 4-го субкадра последнего пригодного принятого вокализованного кадра с когерентными оценками основного тона. Стабильный вокализованный кадр определен здесь как кадр VOICED, которому предшествует кадр вокализованного типа (VOICED TRANSITION, VOICED, ONSET). Когерентность основного тона в данном варианте реализации проверяется путем анализа того, являются ли оценки основного тона с обратной связью достаточно близкими, то есть находятся ли отношения между основным тоном прошлого субкадра, основным тоном второго субкадра и основным тоном прошлого субкадра предыдущего кадра в интервале (0,7-1,4).
Данное определение периода TC основного тона означает, что, если основной тон в конце прошлого годного кадра и основной тон прошлого стабильного кадра близки друг другу, то используется основной тон последнего пригодного кадра. В противном случае, этот основной тон считается неустойчивым и вместо него используют основной тон последнего стабильного кадра, чтобы избежать воздействия неправильных оценок основного тона на вокализованные приступы. Однако такая логика имеет смысл только в том случае, если последний стабильный сегмент не находится слишком далеко в прошлом. Таким образом, задается показатель Tcnt, который ограничивает сферу влияния последнего стабильного сегмента. Если Tcnt больше или равен 30, то есть, если имеется по меньшей мере 30 кадров с момента последнего обновления TS, то основной тон последнего пригодного кадра используется на систематической основе. Tcnt устанавливается в 0 каждый раз, когда обнаруживается стабильный сегмент, и обновляется TS. Далее период TC поддерживается постоянным во время маскирования для всего стертого блока.
Так как для построения периодической части используется последний импульс возбуждения предыдущего кадра, его усиление является приблизительно конкретным в начале маскированного кадра и может быть установлено равным 1. Затем усиление линейно уменьшается по всему кадру от одного отсчета к другому для достижения значения α в конце кадра.
Значения α соответствуют таблице 5, за исключением того, что эти значения модифицируются для стираний, следующих за кадрами VOICED и ONSET, чтобы учесть эволюцию энергии вокализованных сегментов. Эта эволюция может быть экстраполирована до некоторой степени путем использования значений усиления возбуждения основного тона для каждого субкадра последнего пригодного кадра. В общем случае, если эти значения усиления больше 1, то энергия сигнала возрастает, а если они меньше 1, то энергия убывает. Таким образом, α умножается на корректирующий коэффициент fb, вычисляемый следующим образом:
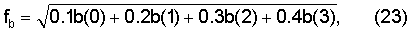
где b(0), b(1), v(2) и b(3) - усиления основного тона для четырех субкадров последнего правильно принятого кадра. Значение fb ограничивают в диапазоне между 0,98 и 0,85, прежде чем их использовать для масштабирования периодической части возбуждения. Таким путем избегают случаев сильного увеличения и уменьшения энергии.
Для стертых кадров, следующих за правильно принятым кадром, отличным от UNVOICED, буфер возбуждения обновляется только этой периодической частью возбуждения. Это обновление используется в дальнейшем для построения возбуждения кодовой книги основного тона в следующем кадре.
Построение случайной части возбуждения
Нововведенная (непериодическая) часть сигнала возбуждения создается случайным образом. Она может быть сформирована в виде случайного шума или путем использования кодовой книги нововведений CELP со случайно генерируемыми векторными индексами. В настоящем иллюстративном варианте был использован простой генератор случайных чисел с приблизительно равномерным распределением. Перед настройкой усиления нововведений случайно сформированное нововведение масштабируется относительно некоторого эталонного значения, привязанного здесь к единичной энергии на отсчет.
В начале стертого блока усиление gs нововведения инициализируется путем использования усилений нововведений возбуждения каждого субкадра последнего пригодного кадра
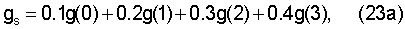
где g(0), g(1), g(2) и g(3) являются усилениями фиксированной кодовой книги, или нововведений, для четырех (4) субкадров последнего правильно принятого кадра. Стратегия ослабления случайной части возбуждения несколько отличается от ослабления возбуждения основного тона. Причина этого состоит в том, что возбуждение основного тона (и следовательно, периодичность возбуждения) стремится к 0, в то время как случайное возбуждение стремится к энергии возбуждения генерации комфортного шума (CNG). Ослабление усиления нововведения задается в виде
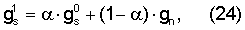
где  - усиление нововведения в начале следующего кадра,
- усиление нововведения в начале следующего кадра,  - усиление нововведения в начале текущего кадра,
- усиление нововведения в начале текущего кадра, 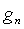 - усиление возбуждения, используемого во время генерации комфортного шума, а α определяется из таблицы 5. По аналогии с ослаблением периодического возбуждения усиление ослабляется линейно по всему кадру от отсчета к отсчету, начиная с и до значения
- усиление возбуждения, используемого во время генерации комфортного шума, а α определяется из таблицы 5. По аналогии с ослаблением периодического возбуждения усиление ослабляется линейно по всему кадру от отсчета к отсчету, начиная с и до значения 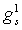 , которое будет достигнуто к началу следующего кадра.
, которое будет достигнуто к началу следующего кадра.
Наконец, если последний пригодный (правильно принятый или нестертый) кадр отличается от UNVOICED, то возбуждение фильтруется через линейный фазовый фильтр FIR верхних частот с коэффициентами -0.0125, -0.109, 0.7813, -0.109, -0.0125. Для уменьшения количества шумовых компонент во время вокализованных сегментов эти коэффициенты фильтра умножаются на поправочный коэффициент, равный (0,75-0,25 rv), причем rv - коэффициент вокализации, определенный в уравнении (1). Затем случайная часть возбуждения добавляется к адаптивному возбуждению для формирования общего сигнала возбуждения.
Если последний пригодный кадр относится к классу UNVOICED, то используют только возбуждение нововведений, которое далее подвергается ослаблению с коэффициентом 0,8. В этом случае обновляется буфер последнего возбуждения возбуждением нововведения, так как периодическая часть возбуждения отсутствует.
Маскирование, синтез и обновления огибающей спектра
Для синтезирования декодированной речи должны быть получены параметры LP-фильтра. Огибающая спектра постепенно перемещается к расчетной огибающей шума окружающей среды. Здесь представление ISF параметров LP используется в виде
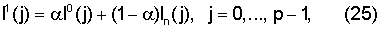
В уравнении 25 I1(j) - это значение j-го ISF текущего кадра, I0(j) - значение j-го ISF предыдущего кадра, In(j) - значение j-го ISF расчетной огибающей комфортного шума, а p - порядок LP-фильтра.
Синтезированную речь получают путем фильтрации сигнала возбуждения посредством LP-фильтра синтеза. Коэффициенты фильтра вычисляются исходя из представления ISF и интерполируются для каждого субкадра (четыре (4) раза за кадр) во время нормальной работы кодера.
Так как и в квантователе усиления нововведений, и квантователе ISF используется предсказание, их память не будет обновляться после возобновления нормальной работы. Для ослабления этого эффекта содержание памяти квантователей оценивается и обновляется в конце каждого стертого кадра.
Восстановление нормальной работы после стирания
Проблема восстановления после стертого блока кадров является основополагающей из-за сильного предсказания, используемого практически во всех современных речевых кодерах. В частности, речевые кодеры типа CELP достигают высокого отношения сигнал-шум для вокализованной речи благодаря тому, что они используют прошлый сигнал возбуждения для кодирования возбуждения настоящего кадра (долгосрочное предсказание или предсказание основного тона). Также предсказание используется в большинстве квантователей (LP-квантователи, квантователи усиления).
Искусственное построение приступа
Самая сложная ситуация, связанная с использованием долгосрочного предсказания в кодерах CELP, имеет место при потере вокализованного приступа. Потерянный приступ означает, что вокализованный речевой приступ появился где-то во время стертого блока. В этом случае последний пригодный принятый кадр был невокализованным, и следовательно, в буфере возбуждения периодическое возбуждение не обнаружено. Однако первый пригодный кадр после стертого блока является вокализованным, буфер возбуждения в кодере имеет высокую периодичность, и адаптивное возбуждение было закодировано с использованием этого периодического прошлого возбуждения. Так как эта периодическая часть возбуждения полностью пропадает в декодере, может потребоваться несколько кадров для восстановления исходя из этой потери.
Если потерян кадр ONSET (то есть пригодный кадр VOICED поступает после стирания, но последним пригодным кадром перед стиранием был кадр UNVOICED, как показано на фиг.6), для искусственного восстановления потерянного приступа и инициирования вокализованного синтеза используется специальный способ. В начале 1-го пригодного кадра после потерянного приступа искусственно формируется периодическая часть возбуждения в виде периодической цепочки импульсов, прошедших фильтрацию нижних частот, которые разделены периодом основного тона. В настоящем иллюстративном варианте фильтр нижних частот представляет собой простой линейный фазовый FIR фильтр с импульсной характеристикой hlow={-0.0125, 0.109, 0.7813, 0.109, -0.0125}. Однако этот фильтр также можно выбирать динамически с частотой среза, соответствующей информации вокализации, если такая информация имеется. Нововведенная часть возбуждения формируется с использованием нормального декодирования CELP. Записи в кодовой книге нововведений также можно выбирать случайным образом (или само нововведение может быть создано случайным образом), так как синхронизация с исходным сигналом была так или иначе потеряна.
На практике длина искусственного приступа ограничена тем, что по меньшей мере один полный период основного тона построен по этому способу, и этот способ реализуется до конца текущего субкадра. После этого возобновляется регулярная обработка ACELP. Рассматриваемый период основного тона является округленным средним значением периодов декодированного основного тона для всех субкадров, где используется восстановление искусственного приступа. Цепочка импульсов, прошедших фильтрацию нижних частот, реализуется путем помещения импульсных характеристик фильтра нижних частот в буфер адаптивного возбуждения (ранее инициализированный в нуль). Первая импульсная характеристика центрируется в квантованном положении 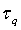 (передаваемом в потоке битов) относительно начала кадра, а остальные импульсы помещаются на расстоянии усредненного основного тона вплоть до конца последнего субкадра, для которого выполняется искусственное восстановление приступа. Если имеющейся полосы частот недостаточно для передачи положения первого импульса, относящегося к голосовой щели, то первая импульсная характеристика может быть помещена произвольно в окрестности половины периода основного тона после начала текущего кадра.
(передаваемом в потоке битов) относительно начала кадра, а остальные импульсы помещаются на расстоянии усредненного основного тона вплоть до конца последнего субкадра, для которого выполняется искусственное восстановление приступа. Если имеющейся полосы частот недостаточно для передачи положения первого импульса, относящегося к голосовой щели, то первая импульсная характеристика может быть помещена произвольно в окрестности половины периода основного тона после начала текущего кадра.
Например, для длины субкадра, составляющей 64 отсчета, будем считать, что периоды основного тона в первом и втором субкадре составят p(0)=70,75 и p(1)=71. Поскольку это превышает размер субкадра, равный 64, искусственный приступ будет сформирован в течение первых двух субкадров, а период основного тона будет равен среднему значению основного тона для двух субкадров, округленному до ближайшего целого, то есть 71. Последние два субкадра будут обрабатываться стандартным декодером CELP.
Затем энергия периодической части возбуждения искусственного приступа масштабируется с усилением, соответствующим квантованной и переданной энергии для маскирования FER (как определено в уравнениях 16 и 17) и делится на коэффициент усиления LP-фильтра синтеза. Усиление LP-фильтра синтеза вычисляется как
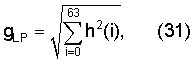
где h(i) - импульсная характеристика LP-фильтра синтеза. Наконец, усиление искусственного приступа уменьшается путем умножения периодической части на 0,96. В альтернативном варианте это значение может соответствовать вокализации, если имелась доступная полоса пропускания для передачи также и информации вокализации. В альтернативном варианте без отклонения от сущности данного изобретения искусственный приступ может также быть сформирован в буфере прошлого возбуждения перед вводом в контур субкадра декодера. Это обеспечило бы преимущество, заключающееся в том, что отпадает необходимость специальной обработки для формирования периодической части искусственного приступа, вместо чего можно будет использовать регулярное декодирование CELP.
LP-фильтр для синтеза речи на выходе в случае построения искусственного приступа не интерполируется. Вместо этого для синтеза всего кадра в целом используют принятые LP-параметры.
Управление энергией
Самой важной задачей при восстановлении после стертого блока кадров является правильное управление энергией синтезированного речевого сигнала. Управлять энергией синтеза необходимо потому, что обычно в современных речевых кодерах используется сильное предсказание. Управление энергией является особенно важным, когда блок стертых кадров появляется во время вокализованного сегмента. При возникновении стирания кадра после вокализованного кадра во время маскирования обычно используют возбуждение последнего пригодного кадра с некоторой стратегией ослабления. При возникновении нового LP-фильтра с первым пригодным кадром после стирания может иметь место несоответствие между энергией возбуждения и усилением нового LP-фильтра синтеза. Новый фильтр синтеза может создать сигнал синтеза с энергией, сильно отличающейся от энергии последнего синтезированного стертого кадра, а также от энергии исходного сигнала.
Управление энергией во время первого пригодного кадра после стертого кадра может быть сведено к следующему. Синтезированный сигнал масштабируется, чтобы его энергия совпадала с энергией синтезированного речевого сигнала в конце последнего стертого кадра в начале первого пригодного кадра и чтобы эта энергия стремилась к значению переданной энергии по направлению к концу кадра с предотвращением слишком значимого увеличения энергии.
Управление энергией выполняется в области синтезированного речевого сигнала. Даже если управление энергией осуществляется в речевой области, сигнал возбуждения должен масштабироваться, так как он служит в качестве памяти долгосрочного предсказания для последующих кадров. Затем производится повторный синтез для сглаживания переходов. Пусть g0 обозначает усиление, используемое для масштабирования 1-го отсчета в текущем кадре, и g1 - усиление, используемое в конце кадра. Тогда сигнал возбуждения масштабируется следующим образом:

где us(i) - масштабированное возбуждение, u(i) - возбуждение перед масштабированием, L - длина кадра, а gAGC(i) - усиление, значение которого начинается с g0 и стремится по экспоненциальному закону к g1
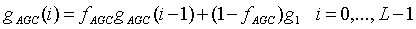
с инициализацией gAGC(-1)=go, где fAGC - коэффициент ослабления, значение которого в данном варианте реализации установлено равным 0,98. Это значение было найдено экспериментально как компромисс, обеспечивающий плавный переход от предыдущего (стертого) кадра, с одной стороны, и масштабирование прошлого периода основного тона для текущего кадра, насколько это возможно, до правильного (переданного) значения, с другой стороны. Это важно, поскольку переданное значение энергии оценивается синхронно с основным тоном в конце кадра. Значения усиления g0 и g1 определяются как
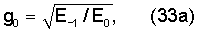
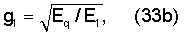
где E-1- энергия, вычисляемая в конце предыдущего (стертого) кадра, E0 - энергия в начале текущего (восстановленного) кадра, E1 - энергия в конце текущего кадра, а Eq - квантованная информация о переданной энергии в конце текущего кадра, вычисляемая в кодере по уравнениям (16, 17). E-1 и E1 вычисляются аналогичным образом, за исключением того, что они рассчитываются по синтезированному речевому сигналу s'. E-1 вычисляется синхронно с основным тоном с использованием периода TC основного тона для маскирования, а E1 использует округленный период T3 основного тона для последнего субкадра. E0 вычисляется аналогичным образом с использованием округленного значения T0 основного тона для первого субкадра, причем уравнения (16, 17) модифицируются к виду

для кадров VOICED и ONSET. tE равно округленному запаздыванию основного тона или двойной длине, если основной тон короче 64 отсчетов. Для других кадров
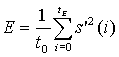
при tE, равном половине длины кадра. Усиления g0 и g1 дополнительно ограничены максимально допустимым значением для предотвращения высокого уровня энергии. Это значение в настоящем иллюстративном варианте реализации было установлено равным 1,2.
При проведении маскирования стирания кадров и восстановления декодера, когда усиление LP-фильтра первого нестертого кадра, принятого после стирания кадра, больше усиления LP-фильтра последнего кадра, стертого во время указанного стирания кадра, выполняется регулировка энергии сигнала возбуждения LP-фильтра, сформированного в декодере во время первого принятого нестертого кадра, до значения усиления LP-фильтра указанного первого принятого нестертого кадра, с использованием следующего соотношения.
Если Eq не может быть передано, то Eq устанавливается равным E1. Однако, если стирание произошло во время вокализованного речевого сегмента (то есть, последний пригодный кадр перед стиранием и первый пригодный кадр после стирания классифицированы как VOICED TRANSITION, VOICED или ONSET), то должны быть приняты дополнительные меры из-за возможного несоответствия между энергией сигнала возбуждения и усилением LP-фильтра, о чем упоминалось ранее. Особенно опасная ситуация возникает тогда, когда усиление LP-фильтра для первого нестертого кадра, принятого вслед за стиранием кадра, больше, чем усиление LP-фильтра последнего кадра, стертого во время упомянутого стирания кадра. В этом частном случае энергия сигнала возбуждения LP-фильтра, сформированного в декодере во время принятого первого нестертого кадра, подстраивается к усилению LP-фильтра принятого первого нестертого кадра, с использованием следующего соотношения:
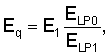
где ELP0 энергия импульсной характеристики LP-фильтра для последнего пригодного кадра перед стиранием, а ELP1 энергия LP-фильтра для первого пригодного кадра после стирания. В этом варианте реализации используются LP-фильтры последних субкадров в одном кадре. Наконец, значение Eq ограничено значением E-1 в этом случае (стирание вокализованного сегмента без передачи информации о Eq).
Следующие исключения, относящиеся к переходам в речевом сигнале, приводят к дополнительной переустановке значения g0. Если искусственный приступ используется в текущем кадре, g0 устанавливается равным 0,5g1 для обеспечения постепенного увеличения энергии приступа.
В случае первого пригодного кадра после стирания, классифицированного как ONSET, предотвращается превышение усиления go над g1. Эта предупредительная мера предпринимается для предотвращения принудительной регулировки усиления в начале кадра (который вероятно еще является по меньшей мере частично невокализованным) от усиления вокализованного приступа (в конце кадра).
Наконец, во время перехода от вокализованного кадра к невокализованному (то есть этот последний пригодный кадр классифицирован как VOICED TRANSITION, VOICED или ONSET, а текущий кадр классифицирован как UNVOICED) или во время перехода от невокализованного активного речевого периода к активному речевому периоду (последний пригодный принятый кадр кодируется как комфортный шум, а текущий кадр кодируется как активная речь), усиление g0 устанавливается равным g1.
В случае стирания вокализованного сегмента может возникнуть проблема с ошибочным значением энергии также и в кадрах, следующих за первым пригодным кадром после стирания. Это может случиться, если даже энергия первого пригодного кадра отрегулирована так, как было описано выше. Для смягчения этой проблемы управление энергией может продолжаться вплоть до конца вокализованного сегмента.
Хотя настоящее изобретение было описано в предшествующем описании применительно к иллюстративному варианту его осуществления, этот иллюстративный вариант можно также модифицировать в объеме прилагаемой формулы изобретения, не выходя за рамки объема и сущности данного изобретения.
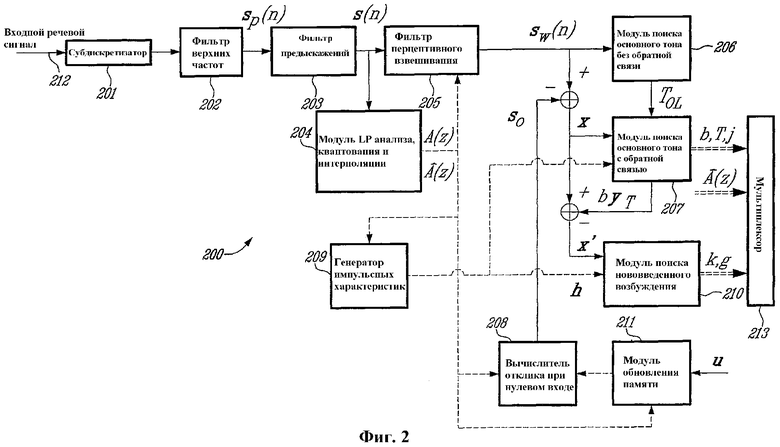
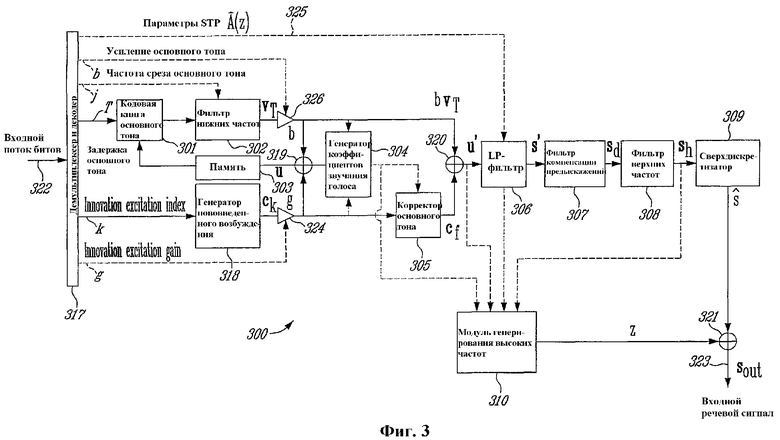
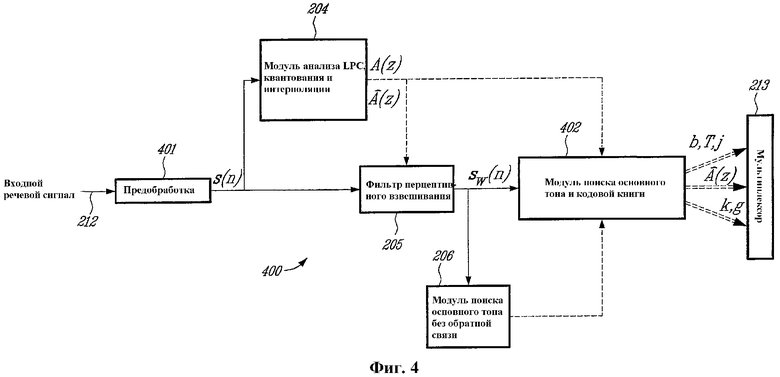
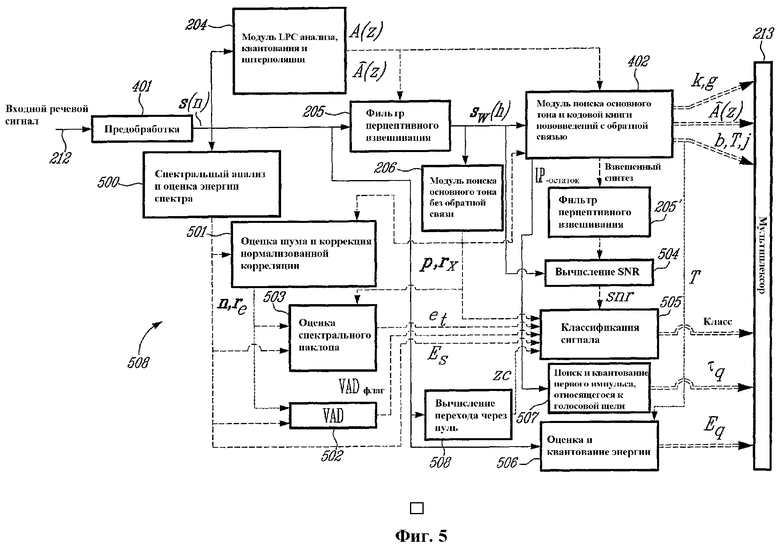

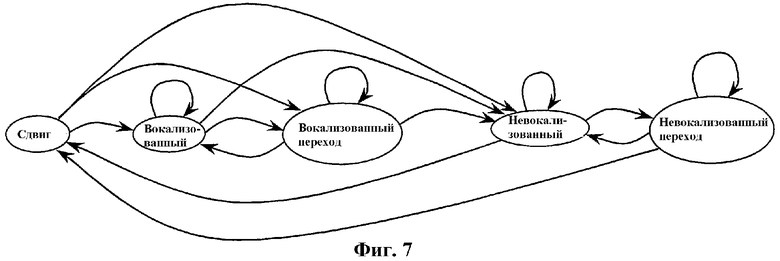
Изобретение относится к способу и устройству для улучшения маскирования кадров кодированного звукового сигнала, стертых во время передачи от кодера к декодеру и для ускорения восстановления в декодере, после того как были приняты нестертые кадры кодированного звукового сигнала. При определении параметров маскирования/восстановления в кодере их передают в декодер, в котором проводится маскирование стертых кадров и восстановление в соответствии с параметрами маскирования/восстановления. Параметры маскирования/восстановления могут выбираться из группы, состоящей из: параметра классификации сигнала, параметра информации об энергии и параметра информации о фазе. Определение параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа, причем эта классификация определяется на основе по меньшей части следующих параметров: параметра нормализованной корреляции, параметра спектрального наклона, параметра отношения сигнал-шум, параметра стабильности основного тона параметра относительной энергии кадра и параметра перехода через нуль. Технический результат, достигаемый при реализации изобретения, состоит в улучшении маскирования стертых кадров кодированного звукового сигнала во время передачи от кодера к декодеру и в ускорении восстановления в декодере после того, как были приняты нестертые кадры кодированного звукового сигнала. 9 н. и 168 з.п. ф-лы, 7 ил., 5 табл.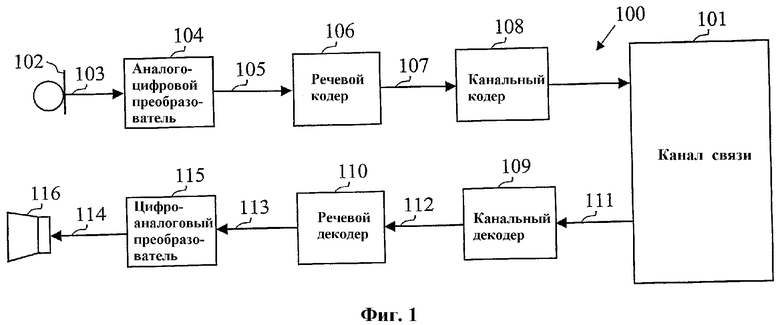
определение в кодере параметров маскирования/восстановления;
передачу в декодер параметров маскирования/восстановления, определенных в кодере; и осуществление маскирования стертых кадров и восстановления в декодере в соответствии с принятыми параметрами маскирования/восстановления.
причем формирование периодической части возбуждения содержит реализацию периодической последовательности импульсов, подвергнутых низкочастотной фильтрации, путем центрирования первой импульсной характеристики фильтра нижних частот на квантованном положении первого импульса, относящегося к голосовой щели, в соответствии с началом кадра; и
помещения каждой из остальных импульсных характеристик фильтра нижних частот на расстоянии, соответствующем среднему значению основного тона, от предыдущей импульсной характеристики вплоть до конца последнего субкадра, затронутого формированием периодической части возбуждения.
измерение первого импульса, относящегося к голосовой щели, в виде отсчета максимальной амплитуды в периоде основного тона; и
квантование положения отсчета максимальной амплитуды в периоде основного тона.
звуковой сигнал является речевым сигналом; и
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, кадра невокализованного перехода, кадра вокализованного перехода, вокализованного кадра или кадра приступа.
вычисление коэффициента качества на основе параметра нормализованной корреляции, параметра спектрального наклона, параметра отношения сигнал-шум, параметра стабильности основного тона, параметра относительной энергии кадра и параметра перехода через нуль; и
сравнение коэффициента качества с пороговыми значениями для определения классификации.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
определение параметров маскирования/восстановления содержит вычисление параметра информации об энергии по отношению к максимальной энергии сигнала для кадров, классифицированных как вокализованные кадры или как кадры приступа, и вычисление параметра информации об энергии по отношению к средней энергии на отсчет для других кадров.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала;
причем способ содержит определение классификации последовательных кадров кодированного звукового сигнала на основе параметра нормализованной корреляции; и
вычисление параметра информации вокализации содержит оценивание указанного параметра информации вокализации на основе нормализованной корреляции.
после приема нестертого невокализованного кадра после стертого кадра, формирование непериодической части сигнала возбуждения LP-фильтра;
вслед за приемом, после стертого кадра, нестертого кадра, отличного от невокализованного, формирование периодической части сигнала возбуждения LP-фильтра путем повторения последнего периода основного тона предыдущего кадра.
определение параметров маскирования/восстановления содержит вычисление параметра информации вокализации;
фильтр нижних частот имеет частоту среза; и
формирование периодической части сигнала возбуждения содержит динамическую регулировку частоты среза по отношению к параметру информации вокализации.
звуковой сигнал является речевым сигналом;
определение параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
генерирование случайным образом непериодической, нововведенной части сигнала возбуждения LP-фильтра дополнительно содержит
фильтрацию нововведенной части сигнала возбуждения посредством фильтра верхних частот, если последний правильно принятый кадр отличается от невокализованного; и
использование только нововведенной части сигнала возбуждения, если последний правильно принятый кадр является невокализованным.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа;
осуществление маскирования стертых кадров и восстановления в декодере содержит, когда кадр приступа потерян, что указывается присутствием вокализованного кадра, следующего за стиранием кадров, и невокализованного кадра перед стиранием кадров, восстановление потерянного кадра приступа путем формирования периодической части сигнала возбуждения в виде подвергнутой низкочастотной фильтрации периодической последовательности импульсов, разделенных периодом основного тона.
управление энергией синтезированного звукового сигнала, сформированного декодером, причем управление энергией синтезированного звукового сигнала содержит масштабирование синтезированного звукового сигнала для воспроизведения энергии синтезированного звукового сигнала в начале первого нестертого кадра, принятого вслед за стиранием кадра, подобной энергии синтезированного сигнала в конце последнего кадра, стертого во время стирания кадров; и
сходимость энергии синтезированного звукового сигнала в принятом первом нестертом кадре к энергии, соответствующей принятому параметру информации об энергии, по направлению к концу принятого первого нестертого кадра при ограничении нарастания энергии.
параметр информации об энергии не передается от кодера к декодеру; и
осуществление маскирования стертых кадров и восстановления в декодере содержит, если усиление LP-фильтра первого нестертого кадра, принятого вслед за стиранием кадров, больше усиления LP-фильтра последнего кадра, стертого во время стирания кадров, регулировку энергии сигнала возбуждения LP-фильтра, сформированного в декодере во время принятого первого нестертого кадра, до усиления LP-фильтра принятого первого нестертого кадра.
регулировка энергии сигнала возбуждения LP-фильтра, сформированного в декодере во время принятого первого нестертого кадра, до усиления LP-фильтра принятого первого нестертого кадра содержит использование следующего соотношения:
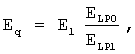
где Е1 - энергия в конце текущего кадра, ЕLP0 - энергия импульсной характеристики LP-фильтра для последнего нестертого кадра, принятого перед стиранием кадров, a ELP1 - энергия импульсной характеристики LP-фильтра для принятого первого нестертого кадра, следующего за стиранием кадра.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
когда первый нестертый кадр, принятый после стирания кадров, классифицирован как кадр приступа, осуществление маскирования стертых кадров и восстановления в декодере содержит ограничение до заданного значения усиления, используемого для масштабирования синтезированного звукового сигнала.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
причем способ содержит обеспечение равенства усиления, используемого для масштабирования синтезированного звукового сигнала в начале первого нестертого кадра, принятого после стирания кадров, усилению, используемому в конце принятого первого нестертого кадра:
во время перехода от вокализованного кадра к невокализованному кадру, если последний нестертый кадр, принятый перед стиранием кадров, классифицирован как вокализованный переход, вокализованный кадр или кадр приступа, а первый нестертый кадр, принятый после стирания кадров, классифицирован как невокализованный кадр; и
во время перехода от периода неактивной речи к периоду активной речи, когда последний нестертый кадр, принятый перед стиранием кадров, кодирован как комфортный шум, а первый нестертый кадр, принятый после стирания кадров, кодирован как активная речь.
определение в кодере параметров маскирования/восстановления; и передачу в декодер параметров маскирования/восстановления, определенных в кодере.
измерение первого импульса, относящегося к голосовой щели, в виде отсчета максимальной амплитуды в периоде основного тона; и
квантование положения отсчета максимальной амплитуды в периоде основного тона.
звуковой сигнал является речевым сигналом; и
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа.
вычисление коэффициента качества на основе параметра нормализованной корреляции, параметра спектрального наклона, параметра отношения сигнал-шум, параметра стабильности основного тона, параметра относительной энергии кадра и параметра перехода через нуль; и
сравнение коэффициента качества с пороговыми значениями для определения классификации.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
определение параметров маскирования/восстановления содержит вычисление параметра информации об энергии по отношению к максимальной энергии сигнала для кадров, классифицированных как вокализованные или как кадр приступа, и вычисление параметра информации об энергии по отношению к средней энергии на отсчет для других кадров.
звуковой сигнал является речевым сигналом;
определение в кодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала;
причем способ содержит определение классификации последовательных кадров кодированного звукового сигнала на основе параметра нормализованной корреляции; и
вычисление параметра информации вокализации содержит оценивание указанного параметра информации на основе нормализованной корреляции.
определение в декодере параметров маскирования/восстановления из параметров кодирования сигнала;
осуществление в декодере маскирования стертых кадров и восстановления в декодере в соответствии с параметрами маскирования/восстановления, определенными в декодере.
звуковой сигнал является речевым сигналом; и
определение в декодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа.
после приема нестертого невокализованного кадра после стирания кадра, генерирование непериодической части сигнала возбуждения LP-фильтра;
вслед за приемом, после стирания кадра, нестертого кадра, отличного от невокализованного, формирование периодической части сигнала возбуждения LP-фильтра путем повторения последнего периода основного тона предыдущего кадра.
определение в декодере параметров маскирования/восстановления содержит вычисление параметра информации вокализации;
фильтр нижних частот имеет частоту среза; и
формирование периодической части сигнала возбуждения LP-фильтра содержит динамическую регулировку частоты среза по отношению к параметру информации вокализации.
звуковой сигнал является речевым сигналом;
определение в декодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или как кадра приступа; и
генерирование случайным образом непериодической, нововведенной части сигнала возбуждения LP-фильтра дополнительно содержит фильтрацию нововведенной части сигнала возбуждения LP-фильтра посредством фильтра верхних частот, если принятый последний нестертый кадр отличается от невокализованного; и
использование только нововведенной части сигнала возбуждения LP-фильтра, если принятый последний нестертый кадр является невокализованным.
звуковой сигнал является речевым сигналом;
определение в декодере параметров маскирования/восстановления содержит классификацию последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа;
осуществление маскирования стертых кадров и восстановления в декодере содержит, если кадр приступа потерян, что указывается присутствием вокализованного кадра, следующего за стиранием кадров, и невокализованного кадра перед стиранием кадров, восстановление потерянного кадра приступа путем формирования периодической части сигнала возбуждения в виде подвергнутой низкочастотной фильтрации периодической последовательности импульсов, разделенных периодом основного тона.
параметр информации об энергии не передается от кодера к декодеру; и
осуществление маскирования стертых кадров и восстановления декодера содержит, если усиление LP-фильтра первого нестертого кадра, принятого вслед за стиранием кадров, больше усиления LP-фильтра последнего кадра, стертого во время стирания кадров, регулировки энергии сигнала возбуждения LP-фильтра, созданного в декодере во время принятого первого нестертого кадра, до усиления LP-фильтра принятого первого нестертого кадра, с использованием следующего соотношения:
где E1 - энергия в конце текущего кадра, ЕLP0 - энергия импульсной характеристики LP-фильтра для последнего нестертого кадра, принятого перед стиранием кадра, a ELP1 - энергия импульсной характеристики LP-фильтра для принятого первого нестертого кадра, следующего за стиранием кадра.
средство для определения в кодере параметров маскирования/восстановления;
средство для передачи в декодер параметров маскирования/восстановления, определенных в кодере; и
средство для осуществления маскирования стертых кадров и восстановления в декодере в соответствии с принятыми параметрами маскирования/восстановления, определенными средством определения.
причем средство для формирования периодической части возбуждения содержит средство для реализации подвергнутой низкочастотной фильтрации периодической последовательности импульсов путем:
центрирования первой импульсной характеристики фильтра нижних частот на квантованном положении первого импульса, относящегося к голосовой щели, в соответствии с началом кадра; и
помещения каждой из остальных импульсных характеристик фильтра нижних частот на расстоянии, соответствующем среднему значению основного тона, от предыдущей импульсной характеристики вплоть до конца последнего субкадра, затронутого формированием периодической части возбуждения.
средство для измерения первого импульса, относящегося к голосовой щели, в виде отсчета максимальной амплитуды в периоде основного тона; и
средство для квантования положения отсчета максимальной амплитуды в периоде основного тона.
звуковой сигнал является речевым сигналом; и
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа.
средство для вычисления коэффициента качества на основе параметра нормализованной корреляции, параметра спектрального наклона, параметра отношения сигнал-шум, параметра стабильности основного тона, параметра относительной энергии кадра и параметра перехода через нуль; и
средство для сравнения коэффициента качества с пороговыми значениями для определения классификации.
звуковой сигнал является речевым сигналом;
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
средство для определения параметров маскирования/восстановления содержит средство для вычисления параметра информации об энергии по отношению к максимальной энергии сигнала для кадров, классифицированных как вокализованный кадр или кадр приступа, и средство для вычисления параметра информации об энергии по отношению к средней энергии на отсчет для других кадров.
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала;
причем устройство содержит средство для определения классификации последовательных кадров кодированного звукового сигнала на основе параметра нормализованной корреляции; и
средство для вычисления параметра информации вокализации содержит средство для оценивания указанного параметра информации вокализации на основе нормализованной корреляции.
средство для генерации, вслед за приемом нестертого невокализованного кадра после стирания кадров, непериодической части сигнала возбуждения LP-фильтра;
средство для формирования, вслед за приемом нестертого, отличного от невокализованного кадра после стирания кадров, периодической части сигнала возбуждения LP-фильтра путем повторения последнего периода основного тона предыдущего кадра.
средство для определения параметров маскирования/восстановления содержит средство для вычисления параметра информации вокализации;
фильтр нижних частот имеет частоту среза; и
средство для формирования периодической части сигнала возбуждения содержит средство для динамической регулировки частоты среза по отношению к параметру информации вокализации.
звуковой сигнал является речевым сигналом;
средство для определения параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
средство для генерирования случайным образом непериодической, нововведенной части сигнала возбуждения LP-фильтра дополнительно содержит:
фильтр верхних частот для фильтрации нововведенной части сигнала возбуждения; и
средство для использования только нововведенной части сигнала возбуждения, если последний правильно принятый кадр является невокализованным.
звуковой сигнал является речевым сигналом;
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа;
средство для осуществления маскирования стертых кадров и восстановления в декодере содержит средство для восстановления потерянного кадра приступа, когда кадр приступа потерян, что указывается присутствием вокализованного кадра, следующего за стиранием кадров, и невокализованного кадра перед стиранием кадров, путем формирования периодической части сигнала возбуждения в виде подвергнутой низкочастотной фильтрации периодической последовательности импульсов, разделенных периодом основного тона.
средство для управления энергией синтезированного звукового сигнала, сформированного декодером, причем средство для управления энергией синтезированного звукового сигнала содержит средство для масштабирования синтезированного звукового сигнала для воспроизведения энергии указанного синтезированного звукового сигнала в начале первого нестертого кадра, принятого вслед за стиранием кадров, подобной энергии синтезированного сигнала в конце последнего кадра, стертого во время стирания кадров; и
средство для сходимости энергии синтезированного звукового сигнала в принятом первом нестертом кадре к энергии, соответствующей принятому параметру информации об энергии, по направлению к концу принятого первого нестертого кадра при ограничении нарастания энергии.
параметр информации об энергии не передается от кодера к декодеру; и
средство для осуществления маскирования стертых кадров и восстановления в декодере содержит средство для регулировки энергии сигнала возбуждения LP-фильтра, сформированного в декодере во время принятого первого нестертого кадра, до усиления LP-фильтра принятого первого нестертого кадра, если усиление LP-фильтра первого нестертого кадра, принятого вслед за стиранием кадров, больше усиления LP-фильтра последнего стертого кадра.
средство для регулировки энергии сигнала возбуждения LP-фильтра, сформированного в декодере во время принятого первого нестертого кадра, до усиления LP-фильтра принятого первого нестертого кадра, содержит средство для использования следующего соотношения:
где E1 - энергия в конце текущего кадра, ELP0 - энергия импульсной характеристики LP-фильтра для последнего нестертого кадра, принятого перед стиранием кадра, a ELP1 - энергия импульсной характеристики LP-фильтра для принятого первого нестертого кадра, следующего за стиранием кадра.
звуковой сигнал является речевым сигналом;
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
если первый нестертый кадр, принятый после стирания кадров, классифицирован как кадр приступа, средство для осуществления маскирования стертых кадров и восстановления в декодере содержит средство для ограничения до заданного значения усиления, используемого для масштабирования синтезированного звукового сигнала.
звуковой сигнал является речевым сигналом;
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
причем устройство содержит средство для обеспечения равенства усиления, используемого для масштабирования синтезированного звукового сигнала в начале первого нестертого кадра, принятого после стирания кадров, усилению, используемому в конце указанного принятого первого нестертого кадра:
во время перехода от вокализованного кадра к невокализованному кадру, если последний нестертый кадр, принятый перед стиранием кадров, классифицирован как вокализованный переход, вокализованный кадр или кадр приступ, а первый нестертый кадр, принятый после стирания кадров, классифицирован как невокализованный кадр; и
во время перехода от периода неактивной речи к периоду активной речи, если последний нестертый кадр, принятый перед стиранием кадров, кодируется как комфортный шум, а первый нестертый кадр, принятый после стирания кадров, кодируется как активная речь.
средство для передачи в декодер параметров маскирования/восстановления, определенных в кодере.
средство для измерения первого импульса, относящегося к голосовой щели, в виде отсчета максимальной амплитуды в периоде основного тона; и
средство для квантования положения отсчета максимальной амплитуды в периоде основного тона.
средство для вычисления коэффициента качества на основе параметра нормализованной корреляции, параметра спектрального наклона, параметра отношения сигнал-шум, параметра стабильности основного тона, параметра относительной энергии кадра и параметра перехода через нуль; и
средство для сравнения коэффициента качества с пороговыми значениями для определения классификации.
звуковой сигнал является речевым сигналом;
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
средство для определения параметров маскирования/восстановления содержит средство для вычисления параметра информации об энергии по отношению к максимальной энергии сигнала для кадров, классифицированных как вокализованные или как кадры приступа, и средство для вычисления параметра информации об энергии по отношению к средней энергии на отсчет для других кадров.
звуковой сигнал является речевым сигналом;
средство для определения в кодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала;
причем устройство содержит средство для определения классификации последовательных кадров кодированного звукового сигнала на основе параметра нормализованной корреляции; и
средство для вычисления параметра информации вокализации содержит средство для оценивания параметра информации вокализации на основе нормализованной корреляции.
средство для определения в декодере параметров маскирования/восстановления из параметров кодирования сигнала;
в декодере, средство для осуществления маскирования стертых кадров и восстановления декодера в соответствии с параметрами маскирования/восстановления, определенными средством определения.
средство для генерирования, вслед за приемом нестертого невокализованного кадра после стирания кадров, непериодической части сигнала возбуждения LP-фильтра;
средство для формирования, вслед за приемом, после стирания кадров нестертого кадра, отличного от невокализованного нестертого кадра периодической части сигнала возбуждения LP-фильтра путем повторения последнего периода основного тона предыдущего кадра.
средство для определения в декодере параметров маскирования/восстановления содержит средство для вычисления параметра информации вокализации;
фильтр нижних частот имеет частоту среза; и
средство для формирования периодической части сигнала возбуждения LP-фильтра содержит средство для динамической регулировки частоты среза по отношению к параметру информации вокализации.
звуковой сигнал является речевым сигналом;
средство для определения в декодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа; и
средство для генерирования случайным образом непериодической, нововведенной части сигнала возбуждения LP-фильтра дополнительно содержит
фильтр верхних частот для фильтрации нововведенной части сигнала возбуждения LP-фильтра, если принятый последний нестертый кадр отличается от невокализованного; и
средство для использования только нововведенной части сигнала возбуждения LP-фильтра, если принятый последний нестертый кадр является невокализованным.
звуковой сигнал является речевым сигналом;
средство для определения в декодере параметров маскирования/восстановления содержит средство для классификации последовательных кадров кодированного звукового сигнала как невокализованного кадра, невокализованного перехода, вокализованного перехода, вокализованного кадра или кадра приступа;
средство для осуществления маскирования стертых кадров и восстановления в декодера содержит средство для восстановления потерянного кадра приступа, если кадр приступа потерян, что указывается присутствием вокализованного кадра, после стирания кадров, и невокализованного кадра перед стиранием кадров путем формирования периодической части сигнала возбуждения в виде подвергнутой низкочастотной фильтрации периодической последовательности импульсов, разделенных периодом основного тона.
параметр информации об энергии не передается от кодера к декодеру; и
средство для осуществления маскирования стертых кадров и восстановления в декодере содержит средство для регулировки энергии сигнала возбуждения LP-фильтра, сформированного в декодере во время принятого первого нестертого кадра, если усиление LP-фильтра первого нестертого кадра, принятого вслед за стиранием кадров, больше усиления LP-фильтра последнего кадра, стертого во время стирания кадров, до усиления LP-фильтра принятого первого нестертого кадра, с использованием следующего соотношения:
где E1 - энергия в конце текущего кадра, ELP0 - энергия импульсной характеристики LP-фильтра для последнего нестертого кадра, принятого перед стиранием кадра, a ELP1 - энергия импульсной характеристики LP-фильтра для принятого первого нестертого кадра, следующего за стиранием кадра.
кодер звукового сигнала, реагирующий на звуковой сигнал, для создания набора параметров кодирования сигнала;
средство для передачи параметров кодирования сигнала в декодер;
декодер для синтеза звукового сигнала в соответствии с параметрами кодирования сигнала; и
устройство по любому из пп.88-132 для маскирования кадров кодированного звукового сигнала, стертых во время передачи от кодера к декодеру.
средство, реагирующее на кодированный звуковой сигнал, для восстановления из кодированного звукового сигнала набора параметров кодирования сигнала;
средство для синтеза звукового сигнала в соответствии с параметрами кодирования сигнала; и
устройство по любому из пп.158-174 для маскирования кадров кодированного звукового сигнала, стертых во время передачи от кодера к декодеру.
средство для передачи набора параметров кодирования сигнала в декодер в соответствии с параметрами кодирования сигнала, для восстановления звукового сигнала; и устройство по любому из пп.133-по 157 для проведения маскирования кадров, стертых во время передачи параметров кодирования сигнала от кодера к декодеру.
| RU 2000102555 А, 10.01.2002 | |||
| Состав для обезвоживания и обессоливания нефти | 1978 |
|
SU747883A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| УСТРОЙСТВО КОДИРОВАНИЯ ВИДЕОСИГНАЛА, ПРЕДСТАВЛЯЮЩЕГО ИЗОБРАЖЕНИЯ, ПРИЕМНИК ТЕЛЕВИЗИОННОГО СИГНАЛА, ВКЛЮЧАЮЩЕГО ДАННЫЕ ЗАГОЛОВКОВ И ПОЛЕЗНЫЕ ДАННЫЕ В ВИДЕ СЖАТЫХ ВИДЕОДАННЫХ | 1992 |
|
RU2128405C1 |
| US 5732389 А, 24.03.1998. | |||

