Изобретение относится к уплотнению и разуплотнению данных с использованием каталогов, в частности к методу, которым осуществляют обновление каталогов уплотнения и разуплотнения.
Алгоритм Лемпеля-Зива (ЛЗ) (Lempel-Ziv), известный как Л32, дает теоретическую основу для многочисленных систем уплотнения и разуплотнения данных по каталогам, которые имеют широкое применение. Л32 описан в статье, имеющей название "Уплотнение отдельных последовательностей путем кодирования с переменной скоростью", авторами которой являются Джекоб Зив и Абрахам Лемпель, опубликованной в Трудах ИИЭР по теории информации, том IT-24, 5, сентябрь 1978, страницы 530-536 ("Compression Of Individual Sequences Via Variable-Rate Coding" by Jacob Ziv and Abraham Lempel, IEEE Transactions on Information Theory, Vol. IT-24, No. 5). Повсеместно используемая система уплотнения и разуплотнения данных, известная как ЛЗУ (Лемпеля-Зива-Уэлча), принятая в качестве стандарта уплотнения и разуплотнения для модемов с протоколом V. 42 бис (V.42 bis), описана в патенте США 4,558,302 Уэлча (Welch), выданном 10 декабря 1985г. ЛЗУ (LZW) также был принят в качестве способов уплотнения и разуплотнения, используемых в стандартах передачи изображений в форматах GIF и TIFF, Вариант Л32 описан в патенте США 4,876,541 Сторера (Storer), выданном 24 октября 1989г. Дальнейшие примеры систем уплотнения и разуплотнения на основании каталогов ЛЗ описаны в патенте США 4,464,650 Истмана и др. (Eastman et al. ), выданном 7 августа 1984г.; в патенте США 4,814,746 Миллера и др. ( Miller et al.), выданном 21 марта 1989г.; в патенте США 5,153,591 Кларка (Clark), выданном 6 октября 1992г.; и в заявке на европейский патент с публикационным номером 0 573 208 Al Лемпеля и др. (Lempel et al.) и датой публикации 8 декабря 1993г.
В вышеприведенных системах осуществляют посимвольное сравнение входного потока данных в виде символов со строками символов, хранящимися в каталоге, для того, чтобы определить, совпадают ли они. Как правило, посимвольное сравнение продолжают до тех пор, пока не определено совпадение наибольшей длины. На основании этого совпадения осуществляют вывод уплотненного кода и обновление каталога посредством одной или большего числа дополнительных строк символов. В патенте Сторера ('541) каталог обновляют посредством присоединения всех ненулевых префиксов текущей строки, имеющей совпадение наибольшей длины, к предыдущей строке, имеющей совпадение наибольшей длины. Таким образом, если текущее совпадение наибольшей длины имеет N символов, то после того, как это текущее совпадение наибольшей длины установлено, в каталог добавляют N строк. В патенте Сторера это указано как методика обновления Всех Префиксов (ВП).
Приведен и другой вариант способа уплотнения и разуплотнения данных - групповое кодирование (ГКД). Алгоритм ГКД осуществляет уплотнение повторяющейся последовательности символов или группы символов посредством создания уплотненного кода, указывающего символ или группу символов и длину последовательности. Поэтому ГКД эффективно при кодировании последовательностей одного и того же символа или группы символов, имеющих большую длину. Например, ГКД эффективно при уплотнении большой последовательности пробелов, которые могут содержаться в начале файла данных. ГКД также эффективно при уплотнении изображений, когда изображение содержит большую последовательность идущих один за другим пикселов (элементов изображения), имеющих одинаковое значение, например, в области неба на изображении земли и неба.
Рассмотренные выше алгоритмы уплотнения и разуплотнения по каталогу ЛЗ не особо эффективны при уплотнении повторяющихся последовательностей символов или групп символов, имеющих большую длину. Даже при использовании способа обновления ВП для уплотнения последовательности, имеющей большую длину, требуется большое количество выходных сигналов с уплотненным кодом.
Этот недостаток систем, работа которых основана на каталоге, традиционно преодолевают путем подачи данных на устройство группового кодирования и использования этих данных, имеющих групповое кодирование в системе, основанной на каталоге ЛЗ. При такой архитектуре на входе устройства уплотнения по каталогу используют устройство группового кодирования, а на выходе устройства разуплотнения по каталогу используют устройство группового декодирования. Такая система имеет недостатки, состоящие в увеличении количества оборудования, стоимости, непроизводительных затрат на управление и времени обработки.
Другой подход к обработке повторяющихся последовательностей символов раскрыт в заявке на патент Великобритании GB 2 277 179 А, опубликованной 19 октября 1994г. Для уплотнения входного потока символьных данных и разуплотнения потока уплотненного кода используют традиционный подход ЛЗ. Для того чтобы определить, действительно ли выработанный в текущий момент уплотненный код получен из последовательности, осуществляют текущий контроль результирующих выходных кодов алгоритма уплотнения. Если это так, то вывод устройства уплотнения блокируют до тех пор, пока текущий контроль не покажет, что последовательность завершена. Затем снова разрешают вывод уплотненных кодов. Полученными кодами устройство разуплотнения "заполняет" отсутствующие коды.
Изобретение реализовано в системе уплотнения и разуплотнения данных на основании каталога, в которой преодолены вышеописанные недостатки. Если в каталоге существует строка А, то строку ААА...А кодируют двумя символами с уплотненным кодом вне зависимости от ее длины. Таким образом, кодирование строк повторяющихся символов, например пробелов и нулей, или групп символов, например последовательных пикселов изображения, имеющих одно и то же значение, может быть осуществлено очень эффективно с первого раза.
В алгоритме уплотнения по настоящему изобретению ввод строки в каталог уплотнения осуществляют при считывании и определении наличия совпадения для каждого входного символа. Обычно ввод строки или строк обновления в каталог осуществляют тогда, когда найдено совпадение наибольшей длины и определен выходной символ с уплотненным кодом. Алгоритм работает следующим образом. Каждый раз, когда в каталоге находят неполную строку W и символ С, в каталог вводят новую строку, в которой С является символом расширения на строке PW, где Р является строкой, которая прошла при последней передаче выходного символа с уплотненным кодом. Таким образом, поскольку определено наличие совпадения для строки W, то строку Р расширяют символами из W при установлении их совпадения в процессе поиска строки. Это можно назвать "непрерывным" обновлением каталога, при котором осуществляют непосредственное обновление каталога, посимвольно чередуемое с процессом поиска строки. Таким образом, при осуществлении посимвольного сопоставления входного сигнала с сохраненной строкой W каждый совпадающий символ добавляют в конец растущей строки PW. Процесс обновления заканчивают тогда, когда установлено совпадение входных символов данных с самой длинной строкой W в каталоге.
Когда строка W, для которой определяют наличие совпадения, совпадает со строкой Р, для которой наличие совпадения установлено ранее, то реализуется описанное выше преимущество группового кодирования. Когда это происходит, то устройство уплотнения передает символ с уплотненным кодом, который не распознает устройство разуплотнения. Для поддержания синхронизма с каталогом уплотнения в устройстве разуплотнения используют процесс неопознанного кода, причем этот процесс основан на текущем значении присвоенного кода для устройства разуплотнения, неопознанном коде, декодированной ранее строке и количестве символов в декодированной ранее строке.
Фиг. 1 - блок-схема подсистемы уплотнения данных, используемой в варианте осуществления настоящего изобретения;
Фиг. 2 - блок-схема подсистемы разуплотнения данных для восстановления уплотненного кода на выходе устройства уплотнения по Фиг. 1;
Фиг. 3а - схема, на которой показана репрезентативная структура данных для вершин деревьев поиска каталогов по Фиг. 1 и Фиг. 2;
Фиг. 3б - схема, на которой показана используемая на практике структура данных для вершин деревьев поиска каталогов из Фиг. 1 и Фиг. 2;
Фиг. 4 - схематический чертеж вершины, на котором показана вершина деревьев поиска каталогов по Фиг. 1 и Фиг. 2, соответствующая структуре данных по Фиг. 3а;
Фиг. 4а - схематическое изображение неполного дерева поиска, иллюстрирующего хранение данных с использованием вершины по Фиг. 4;
Фиг. 5 - схематический чертеж вершины, на котором показана вершина деревьев поиска каталогов по Фиг. 1 и Фиг. 2, соответствующая структуре данных по Фиг. 3б;
Фиг. 5а - схематическое изображение неполного дерева поиска с использованием вершины из Фиг. 5 и сохранением тех же самых строк, что и на Фиг. 4а;
Фиг. 6 - схема последовательности операций управления, на которой показаны операции, выполняемые подсистемой уплотнения по Фиг. 1 для осуществления уплотнения данных в соответствии с настоящим изобретением. Схема последовательности операций по Фиг. 6 основана на каталоге уплотнения, инициализацию которого осуществляют посредством всех строк с одиночными символами;
Фиг. 7 - схема последовательности операций управления, на которой показаны операции, выполняемые подсистемой разуплотнения по Фиг. 2 для разуплотнения уплотненного кода, генерация которого осуществлена в соответствии со схемой по Фиг. 6. Схема последовательности операций по Фиг. 7 основана на каталоге разуплотнения, инициализацию которого осуществляют посредством всех строк с одиночными символами;
Фиг. 8 - схема последовательности операций управления, на которой показана обработка неопознанного кода по фиг. 7 и Фиг. 10;
Фиг. 9 - схема последовательности операций управления, подобная схеме по Фиг. 6, но основанная на каталоге уплотнения без инициализации;
Фиг. 10 - схема последовательности операций управления, подобная схеме по Фиг. 7, но основанная на каталоге разуплотнения без инициализации. Схема последовательности операций разуплотнения по Фиг. 10 выполняет разуплотнение уплотненного кода, генерация которого осуществлена в соответствии с Фиг. 9;
Фиг. 11а-11д - схематические изображения неполных деревьев поиска, на которых показаны последовательные состояния каталога уплотнения при уплотнении типичного входного потока символов данных;
Фиг. 12а-12ж - схематические изображения неполных деревьев поиска, на которых показаны последовательные состояния каталога уплотнения, когда входной поток символов данных является группой повторяющихся символов.
На Фиг. 1 показана подсистема 10 уплотнения данных, которая осуществляет уплотнение потока сигналов входных данных в виде символов, подаваемых на вход 11, в поток соответствующих сигналов с уплотненным кодом на выходе 12. Каталог 13 для хранения строк символов обычно реализуют посредством устройства памяти, например ЗУПВ (запоминающего устройства с произвольной выборкой (RAM)) или АП (ассоциативной памяти (САМ)), способом, описанным в вышеуказанных ссылках. Строки символов хранят в базе данных, имеющей структуру дерева поиска, методом, который хорошо известен. Дерево поиска состоит из взаимосвязанных вершин, хранящихся в ячейках памяти каталога 13. Доступ к ячейкам памяти каталога 13 осуществляют посредством адресов 14 известным методом.
Структура данных вершины дерева поиска поясняется при помощи вершины 15, которая включает в себя номер 16 вершины, символьное поле 17 и поля 18 для указателей родственных вершин. Номер 16 вершины идентифицирует вершину дерева, а в качестве номера вершины для удобства используют адрес 14 устройства памяти, в котором сохранена вершина 15. Символьное поле 17 используют для хранения значения символа данных вершины. Поля 18 содержат в себе указатели, которые известным способом связывают вершину 15 с родственными вершинами дерева, например с родительскими и дочерними вершинами, и с вершинами одного уровня.
Подсистема 10 уплотнения включает в себя тракт 20 управления поиском и обновлением, соединенный с каталогом 13 через двунаправленную шину 21 данных и двунаправленную шину 22 управления. Тракт 20 управления поиском и обновлением включает в себя рабочие регистры, обозначенные как регистр 23 текущего символа, регистр 24 текущего совпадения и регистр 25 предыдущего совпадения. Тракт 20 управления поиском и обновлением дополнительно включает в себя генератор 26 кодов для присвоения значений уплотненного кода строкам символов, хранящимся в каталоге 13. Генератор 26 кодов может присваивать номера кодов последовательно или псевдослучайно, например хешированием. Доступ присвоенных кодов к ячейкам каталога 13 осуществляют посредством адресов 14 устройства памяти. Таким образом, адреса 14 (номера 16 вершин) используют в качестве уплотненных кодов для хранящихся в каталоге 13 строк, что является общеизвестным.
Тракт 20 управления поиском и обновлением включает в себя устройство 27 управления для управления операциями подсистемы 10 уплотнения в соответствии со схемами последовательности операций на Фиг. 6 и Фиг. 9 и описанным ниже способом.
Подсистема 10 уплотнения включает в себя регистр 30 символов, который осуществляет буферизацию потока входных символьных данных, полученного на входе 11. Отдельные символы входных данных подают из регистра 30 символов через шину 31 на регистр 23 текущего символа в соответствии с описанными далее операциями. Тракт 20 управления поиском и обновлением осуществляет управление сбором входных символьных данных из регистра 30 символов через шину 32 управления.
В кратком изложении, подсистема 10 уплотнения функционирует следующим образом. Входные символьные данные последовательно вводят в регистр 23 текущего символа и осуществляют поиск по строкам, хранящимся в каталоге 13 до тех пор, пока посредством этого не найдут совпадения наибольшей длины. В этом процессе используют регистр 24 текущего совпадения. Номер 16 вершины для строки, имеющей совпадение наибольшей длины, подают на выход 12 в качестве уплотненного кода. Эти операции поиска такие же, как и описанные в вышеуказанных ссылках. В соответствии с изобретением, поскольку входные символы данных совпадают с символами искомой сохраненной строки каталога, то обновление каталога 13 осуществляют путем расширения строки, соответствующей предыдущему выходному уплотненному коду, текущими входными символами, когда установлено, что они совпадают. В этом процессе используют регистр 25 предыдущего совпадения. При продолжении процесса выборки и определения наличия совпадения входных символов совпадение можно определять по этой расширенной указанным образом строке предыдущего совпадения. Таким образом, строки обновления непосредственно добавляют к каталогу 13, чередуя это с посимвольным поиском строк.
Со ссылкой на Фиг. 2 и продолжая ссылку на Фиг. 1, представлена подсистема 40 разуплотнения, которая осуществляет восстановление символов первоначального входного потока данных из уплотненных сигналов кода, которые поданы на выход 12 из подсистемы 10 уплотнения. Таким образом, подсистема 40 разуплотнения осуществляет на входе 41 прием сигналов с уплотненным кодом и подает соответствующие восстановленные символы строк на выход 42. Подсистема 40 разуплотнения включает в себя каталог 43, который в предпочтительном варианте выполняют в виде ЗУПВ. Каталог 43 структурируют и обновляют так, чтобы он содержал ту же самую базу данных с деревом поиска, что содержится в каталоге 13 подсистемы 10 уплотнения. После приема на входе 41 каждого входного уплотненного кода осуществляют такое обновление каталога 43, чтобы он содержал те же самые строки символов данных, что хранятся в каталоге 13. Структура базы данных с деревом поиска, хранящаяся в каталоге 43, включает в себя взаимосвязанные вершины, хранящиеся в ячейках памяти каталога 43. Доступ к ячейкам памяти каталога 43 осуществляют посредством адреса 44 известным способом.
Структура данных вершины дерева поиска поясняется при помощи вершины 45, которая, как и в приведенном выше описании для вершины 15 каталога 13, включает в себя номер 46 вершины, символьное поле 47 и поля 48 для указателей родственных вершин. Как и в приведенном выше описании для каталога 13, номер 46 вершины идентифицирует вершину дерева, а в качестве номера вершины используют адрес 44 устройства памяти, в котором сохранена вершина 45. Символьное поле 47 используют для хранения значения символа данных вершины. Поля 48 содержат в себе указатели, которые описанным выше способом связывают вершину 45 с родственными вершинами дерева, например с родительскими и дочерними вершинами, и с вершинами одного уровня.
Подсистема 40 разуплотнения включает в себя тракт 50 управления восстановлением и обновлением, соединенный с каталогом 43 через двунаправленную шину 51 данных и двунаправленную шину 52 управления. Тракт 50 управления восстановлением и обновлением включает в себя рабочие регистры, обозначенные как регистр 53 текущего полученного кода и регистр 54 предыдущей строки. В соответствии с изобретением тракт 50 управления восстановлением и обновлением включает в себя тракт 55 обработки неопознанного кода, подробное объяснение которого будет приведено при описании Фиг. 8.
Тракт 50 управления восстановлением и обновлением дополнительно включает в себя генератор 56 кодов для присвоения символьным строкам, хранящимся в каталоге 43, значений уплотненного кода. Генератор 56 кодов может присваивать номера кодов последовательно или псевдослучайно, например, хешированием. Для обеспечения совместимости системы генератор 56 кодов присваивает номера кодов, используя те же самые процесс и алгоритм, которые используют в генераторе 26 кодов подсистемы 10 уплотнения. Доступ присвоенных кодов к ячейкам памяти каталога 43 осуществляют посредством адресов 44 памяти. Таким образом, как и в вышеприведенном описании для подсистемы уплотнения 10, адреса 44 (номера 46 вершин) используют в качестве кодов для строк, хранящихся в каталоге 43.
Тракт 50 управления восстановлением и обновлением включает в себя устройство 57 управления для управления операциями подсистемы 40 разуплотнения в соответствии со схемами последовательности операций по Фиг. 7, Фиг. 8 и Фиг. 10 описанным ниже способом.
Подсистема 40 разуплотнения включает в себя регистр 60 кода, который осуществляет буферизацию сигналов с уплотненным кодом, полученных на входе 41. Отдельные сигналы с уплотненным кодом подают из регистра 60 кода через шину 61 на регистр 53 текущего полученного кода в соответствии с операциями, описанными ниже. Тракт 50 управления восстановлением и обновлением осуществляет управление сбором сигналов с уплотненным кодом из регистра 60 кода через шину 62 управления.
В кратком изложении, подсистема 40 разуплотнения функционирует следующим образом. Посредством адресов 44 осуществляют доступ входного сигнала с уплотненным кодом, введенного в регистр 53 текущего полученного кода, к соответствующей строке, хранящейся в каталоге 43. Когда в процессе восстановления осуществляют обратную трассировку вершин строки по дереву поиска, используя соответствующие указатели 48 вершин, то символы строки восстанавливают по символьному полю 47. Восстановленные символы строки подают в соответствующем порядке на выход 42. Эти операции восстановления строк являются такими же, как и описанные в вышеупомянутых ссылках. Обновление каталога 43 осуществляют путем расширения предыдущей восстановленной строки на каждый символ текущей восстановленной строки. В этом процессе используют регистр 54 предыдущей строки.
Когда подсистема 10 уплотнения осуществляет уплотнение строки с повторяющимися символом или группой символов, то в ответ получают сигнал неопознанного уплотненного кода, который не имеет соответствующей строки, хранящейся в каталоге 43. При получении сигнала неопознанного уплотненного кода для восстановления строки, соответствующей сигналу неопознанного уплотненного кода, используют процесс обработки 55 неопознанного кода. Кроме того, в каталоге 43 подсистемы 40 разуплотнения также сохраняют обновляемые строки, соответствующие тем, которые были сохранены в каталоге 13 подсистемы уплотнения 10 в течение этого процесса уплотнения. Подробное объяснение процесса обработки 55 неопознанного кода будет приведено ниже при описании Фиг. 8.
Со ссылкой на Фиг. 3а, показана типовая структура данных для вершин деревьев поиска каталогов 13 и 43. Поскольку в предпочтительных вариантах осуществления изобретения и в подсистеме 10 уплотнения, и в подсистеме 40 разуплотнения используют для вершин одну и ту же структуру данных, то на Фиг. 3а показаны общие номера ссылок и из Фиг. 1, и из Фиг. 2. Разъяснения для номера 16, 46 вершины и символьного поля 17, 47 были приведены выше. Поля 18, 48 указателей родственных вершин включают в себя поле 66 указателя родительской вершины и поля 67 указателей дочерних вершин. Поле 66 указателя родительской вершины известным способом содержит номер вершины для родительской вершины текущей вершины 15, 45, а поля 67 указателей дочерних вершин содержат номера вершин для дочерних вершин текущей вершины 15, 45.
Подсистема уплотнения 10 хорошо известным в данной области техники способом воздействует на нисходящий поиск по дереву поиска следующим образом. Когда процесс находится в текущей вершине, осуществляют анализ значения символа дочерних вершин, чтобы определить, совпадает ли какая-либо дочерняя вершина с текущим входным символом. Если совпадение обнаружено, то дочерняя вершина становится текущей вершиной, и процесс повторяют для следующего входного символа до тех пор, пока не встретится текущая вершина, которая не имеет дочерней вершины, совпадающей с текущим входным символом. Когда это происходит, то это означает, что в каталоге 13 была найдена строка, имеющая совпадение наибольшей длины, и номер ее вершины используют в качестве сигнала с уплотненным кодом для этой строки, имеющей совпадение наибольшей длины. Поиск в прямом направлении по дереву поиска начинают в корневой вершине, для которой поле 66 указателя родительской вершины содержит нулевое значение.
Как известно, поиск в прямом направлении может быть осуществлен аналогичным способом, путем нахождения следующей вершины для поиска из хеш-функции номера текущей вершины и текущего входного символа. В таком варианте осуществления не использовались бы поля 67 указателей дочерних вершин. В патенте Уэлча ('302) раскрыты варианты осуществления поиска с хешированием в алгоритме ЛЗУ.
Подсистема 40 разуплотнения известным образом использует также структуру данных по Фиг. 3а при обратном поиске по дереву поиска для восстановления строки символов данных, соответствующей сигналу с уплотненным кодом. Сигнал с уплотненным кодом осуществляет адресацию номера 46 вершины, а в символьном поле 47 сохраняют значение символа. Номер вершины в поле 66 указателя родительской вершины затем используют для доступа к родительской вершине и сохраняют в нем значение символа. Процесс продолжают до тех пор, пока не достигнут корневой вершины. Так как посредством этого процесса символы восстанавливают в обратном порядке, для обращения порядка символов используют механизм типа магазинного стека "последним поступил, первым выводится" (ПППВ) или соответствующим образом скомпонованного выходного буфера, восстанавливая таким образом первоначальную строку символов данных.
Расширение строки, хранящейся в каталоге 13 уплотнения или в каталоге 43 разуплотнения, осуществляют следующим образом. Генератор 26 или 56 кодов вырабатывает следующий имеющийся в наличии код пустой ячейки памяти, и номер ее вершины добавляют к указателям 67 дочерних вершин расширяемой вершины. Номер вершины расширяемой вершины вводят в поле 66 указателя родительской вершины пустой ячейки памяти. В символьное поле 17 или 47 пустой ячейки памяти вводят значение символа расширения.
Со ссылкой на Фиг. 3б, показана практически целесообразная структура данных для вершин деревьев поиска каталогов 13 и 43. Эта структура данных и варианты ее реализации в системе уплотнения и разуплотнения описаны в патенте Кларка ('591). Как уже разъяснялось для Фиг. 3а, структура данных по Фиг. 3б может быть использована и в каталоге 13 уплотнения, и каталоге 43 разуплотнения, и поэтому показаны общие номера ссылок и по Фиг. 1, и по Фиг. 2. Разъяснения для номера 16, 46 вершины и символьного поля 17, 47 были приведены выше. В структуре данных по Фиг. 3б поля 18, 48 указателей родственных вершин включают в себя поле 70 указателя родительской вершины, поле 71 указателей дочерней вершины и поле 72 указателей вершин одного уровня. Поле 70 указателя родительской вершины используют таким же самым образом, как и поле 66 указателя родительской вершины, описание которого приведено выше для Фиг. 3а. Поле 67 указателей дочерних вершин по Фиг. 3а заменено полем 71 указателя дочерней вершины и полем 72 указателя вершин одного уровня. В структуре данных по Фиг. 3б родительская вершина использует свое поле 71 указателя дочерних вершин для указания на номер вершины одной из ее дочерних вершин, а та вершина, на которую указано как на дочернюю, использует свое поле 72 указателя вершин одного уровня, для указания на номер вершины одной из тех вершин, для которых она является вершиной того же уровня. Указанная вершина одного уровня в свою очередь использует свое поле 12 указателей вершин одного уровня, для указания на следующую вершину одного уровня. Таким образом, указатели для всех дочерних вершин родительской вершины содержатся в использующем указатели списке вершин одного уровня.
Нисходящий поиск осуществляют способом, который описан выше для Фиг. 3а, за исключением того, что поиск наличия входного символа осуществляют в списке вершин одного уровня. Поиск в обратном направлении с целью восстановления строк осуществляют способом, который описан выше для Фиг. 3а, и выполняют его, устанавливая номер родительской вершины в поле указателя родительской вершины у дочерней вершины и у всех вершин одного уровня. Для облегчения поиска список вершин одного уровня может быть скомпонован в порядке возрастания значений символов.
Расширение строки, которая представлена вершиной, не имеющей дочерних (поле указателя дочерней вершины = 0), осуществляют путем присвоения следующего имеющегося в наличии кода, который, как описано выше, указывает следующую имеющуюся в наличии пустую ячейку памяти, и путем ввода номера вершины этой пустой ячейки памяти в поле 71 указателя дочерней вершины у расширяемой вершины. В поле 70 указателя родительской вершины этой вновь созданной дочерней вершины устанавливают номер родительской вершины, а в символьное поле вновь созданной дочерней вершины вводят значение символа расширения. Если расширяемая вершина уже имеет дочернюю вершину, то создают новую вершину одного уровня и вводят ее в список вершин одного уровня посредством корректировки полей 72 указателей вершин одного уровня соответствующих вершин из списка вершин одного уровня. В поле 70 указателя родительской вершины вновь созданной вершины одного уровня вводят номер родительской вершины.
Со ссылкой на Фиг. 4 и Фиг. 4а, на Фиг. 4 показана схема вершины 80 дерева поиска, соответствующая структуре данных по Фиг. 3а. Адрес (номер вершины), значение символа, родительская вершина и дочерние вершины указаны в подписях к чертежу. На Фиг. 4а представлено неполное дерево поиска, поясняющее хранение данных с использованием структуры вершины 80 по Фиг.4. Неполное дерево поиска на Фиг. 4а включает в себя вершины 81, 82, 83 и 84 и хранит строки ab, ас и ad. Следовательно, поля 67 указателей дочерних вершин (Фиг. 3а) родительской вершины 81 будут содержать номера вершин дочерних вершин 82, 83 и 84, а каждое поле 66 указателя родительской вершины дочерних вершин 82, 83 и 84 будет содержать номер вершины родительской вершины 81.
Со ссылкой на Фиг. 5 и Фиг. 5а, на Фиг. 5 показана схема вершины 90 дерева поиска, соответствующая структуре данных по Фиг. 3б. Адрес (номер вершины), значение символа, родительская вершина, дочерняя вершина и вершина одного уровня указаны в подписях к чертежу. На Фиг. 5а представлено неполное дерево поиска с использованием структуры вершины 90 по Фиг. 5, которое включает в себя вершины 91, 92, 93 и 94. Неполное дерево поиска по Фиг. 5а хранит те же самые строки, что и дерево поиска по Фиг. 4а. Таким образом, в поле 71 указателя дочерней вершины (Фиг. 3б) родительской вершины 91 устанавливают номер вершины дочерней вершины 92. В поле 72 указателя вершины одного уровня в дочерней вершине 92 устанавливают номер вершины для вершины 93 одного уровня, а в поле 72 указателя вершины одного уровня в вершине 93 одного уровня устанавливают номер вершины для вершины 94 одного уровня. В каждом из полей 70 указателя родительской вершины дочерних вершин 92, 93 и 94 устанавливают номер вершины родительской вершины 91.
В приведенных ниже подробных описаниях Фиг. 6-10 объяснение операций будет осуществлено с точки зрения структуры данных по Фиг. 3б, в соответствии со структурой вершины по Фиг. 5 и в соответствии со структурой дерева поиска по Фиг. 5а. Предполагается, что генераторы 26 и 56 кодов осуществляют последовательное присвоение кодов, хотя понятно, что коды могут быть присвоены псевдослучайным образом, например, хешированием. В варианте осуществления с хешированием для определения дальнейшего следующего адреса выполняют хеширование кода номера вершины и символа. В этом варианте осуществления с хешированием не использовались бы указатели дочерней вершины и вершины одного уровня. Однако в схемах последовательности операций на Фиг. 6-10 блоки операций КОД = СЛЕДУЮЩЕМУ ИМЕЮЩЕМУСЯ КОДУ выполняют либо следующий последовательный код, либо следующий хешированный код. В вариантах осуществления с присвоением последовательных кодов эти операционные блоки будут иметь более конкретный вид КОД=КОД+1.
Со ссылкой на Фиг. 6, а также ссылкой на Фиг. 1 и Фиг. 3б представлена схема последовательности операций управления, на которой подробно показаны операции, которые должны быть выполнены трактом 20 управления поиском и обновлением для осуществления уплотнения данных в соответствии с настоящим изобретением. Предполагается, что устройство 27 управления содержит соответствующие схемы для управления выполнением операций, например конечные автоматы.
Схема последовательности операций по Фиг. 6 основана на каталоге 13 уплотнения, инициализированном со всеми строками с одиночными символами. Соответственно, блок 100 обеспечивает очистку и инициализацию каталога 13 посредством всех строк с одиночными символами, которые хранятся в соответствующих кодах (номерах вершин). Эту операцию выполняют с использованием генератора 26 кодов, который осуществляет последовательное присвоение номеров вершин для хранения строк с одиночными символами. В варианте реализации для символов ASCII первые 256 кодов будут назначены генератором объектного кода 26 для хранения 256 строк с одиночными символами. Инициализацию производят посредством установления в символьном поле 17 инициализированных ячеек памяти значения символа для соответствующих символов уплотняемого алфавита. Поле 70 указателя родительской вершины, поле 71 указателя дочерней вершины и поле 72 указателя вершины одного уровня в этих инициализированных ячейках памяти устанавливают равными нулю. Очевидно, что инициализированные ячейки памяти создают корневые вершины для хранения строк в каталоге 13 и, таким образом, поля 70 указателя родительской вершины у этих инициализированных ячеек памяти будут оставаться нулевыми.
Посредством этих операций исходные ячейки памяти каталога 13 устанавливают так, чтобы они содержали соответствующие строки с одиночными символами. В варианте осуществления для символов ASCII первые 256 ячеек памяти каталога 13 содержат 256 соответствующих строк с одиночными символами. При выполнении операций блоком 100 остальные ячейки памяти каталога 13 очищают, устанавливая все их поля равными нулю. В варианте реализации для ASCII осуществляют очистку ячеек памяти каталога с номерами вершин 266 и выше.
В блоке 101 обнуляют регистр 24 текущего совпадения, а в блоке 102 обнуляют регистр 25 предыдущего совпадения. В блоке 103 в регистр 23 текущего символа помещают следующий входной символ.
В блоке 104 выполняют поиск для того, чтобы определить, присутствует ли в каталоге текущая совпадающая строка с присоединенным к ней текущим символом. Может быть использована любая известная подходящая процедура поиска по каталогу, например, те, что раскрыты в вышеописанных ссылках. В частности, при этом для текущего совпадения, не равного нулю, регистр 24 текущего совпадения содержит номер вершины текущей строки, для которой определено наличие совпадения. Осуществляют сравнение значения дочерней вершины, указанной в поле 71 указателя дочерней вершины текущей вершины, которая совпала с входным символом. Если входной символ совпадает с дочерней вершиной текущей вершины, то блок 104 выдает утвердительное решение, и далее идут по ветви "ДА". Если дочерняя вершина не совпадает с текущим символом, то осуществляют просмотр списка вершин одного уровня, на который указала дочерняя вершина, чтобы определить, совпадает ли текущий символ с вершинами одного уровня. Если совпадение установлено, то идут по ветви "ДА". Однако, если текущая вершина не имеет дочерних вершин или текущий символ не совпадает ни с какой из дочерних вершин текущей вершины, то выход из блока 104 осуществляют по ветви "НЕТ".
Если текущее совпадение равно нулю, то блок 104 осуществляет поиск корневой вершины в каталоге 13, имеющей значение символа, равное текущему символу. Так как инициализация каталога 13 может быть произведена посредством всех строк с одиночными символами, то из блока 104 автоматически выходят по ветви "ДА".
Когда из блока 104 выходят по ветви "ДА", то процесс обработки уплотнения по Фиг. 6 находится в той точке, когда в каталоге 13 уже найдено текущее совпадение, к которому присоединен текущий символ, и будет продолжен поиск более длинной строки. Таким образом, в блоке 105 осуществляют обновление текущего совпадения так, чтобы установить новое текущей совпадение равным существующему текущему совпадению, с присоединенным к нему текущим символом. Это выполняют посредством соответствующего обновления номера вершины в регистре 24 текущего совпадения. Когда текущее совпадение не равно нулю, то осуществляют обновление регистра 24 текущего совпадения, вводя в него номер вершины дочерней вершины (или вершины одного уровня), который совпадает с текущим символом, как было рассмотрено выше. Если текущее совпадение равно нулю, то осуществляют обновление регистра 24 текущего совпадения, вводя в него номер вершины строки с одиночным символом, которая совпала с текущим символом. Номер вершины для одиночного символа может быть получен с использованием алгоритмов известным способом или может быть найден посредством поиска инициализированных ячеек памяти для значения текущего символа.
Если из блока 104 выходят по ветви "НЕТ", то текущее совпадение с присоединенным к нему текущим символом не совпадает со строкой, хранящейся в каталоге 13. Текущее совпадение, которое было обнаружено в каталоге, обеспечивает совпадение наибольшей длины с потоком входных данных в виде символов, а текущий символ, который был присоединен к текущему совпадению в блоке 105, "нарушил" совпадение. В этой точке блок 106 выдает сигнал с уплотненным кодом, который отображает совпадение наибольшей длины. Этот код совпадения наибольшей длины находится в регистре 24 текущего совпадения, и он является номером вершины текущего совпадения.
В блоке 107 содержимое регистра 24 текущего совпадения перемещают в регистр 25 предыдущего совпадения. Таким образом, теперь в регистре 25 предыдущего совпадения хранится номер вершины ячейки памяти, которая отображает текущее совпадение наибольшей длины. Регистр 25 предыдущего совпадения затем используют при обновлении каталога 13 способом, который будет раскрыт далее.
После того как текущее совпадение сохранено как предыдущее совпадение, текущий символ сохраняют в блоке 110 в качестве текущего совпадения. Следовательно, блок 110 начинает поиск следующей строки, имеющей совпадение наибольшей длины, используя в качестве первого или корневого символа следующего совпадения тот несовпадающий входной символ, который нарушил последнее совпадение. Следовательно, в блоке 110 в регистре 24 текущего совпадения устанавливают номер вершины инициализированной корневой вершины одиночного символа, которая имеет значение текущего символа. Это может быть выполнено либо алгоритмически, либо посредством поиска описанным выше для блока 105 способом. Для блока 110 необходимо описание логических операций обновления каталога, которое будет приведено ниже.
В альтернативном варианте, в блоке 110 могут быть осуществлены следующие логические операции. Вместо того, чтобы устанавливать текущее совпадение равным текущему символу, как в блоке 110, текущее совпадение может быть установлено равным нулю, а процесс обработки может быть возвращен на вход блока 104. Результат этого альтернативного варианта обработки приводит к тому, что, так как каталог инициализирован, то из блока 104 всегда выходят по ветви "ДА" и таким образом достигают блока 105. Понятно, что тот же самый результат может быть получен посредством изображенного на чертеже блока 110 при меньшем количестве операций обработки. Однако эти логические операции используют при обработке уплотнения без инициализации, показанной на Фиг. 9.
Когда процесс доходит до блока 105, то в каталоге уже найдено расширение текущего символа текущего совпадения и, в соответствии с изобретением, текущий символ используют для расширения предыдущего совпадения, чтобы создать строку обновления, которая будет сохранена в каталоге 13. Однако, когда процесс дошел до блока 105 сразу после получения первого входного символа, то какое-либо предыдущее совпадение отсутствует, и в этой точке процесса не нужно осуществлять обновление каталога 13. Следовательно, блок 111 принятия решений определяет, является ли предыдущее совпадение равным нулю. Это выполняют посредством анализа регистра 25 предыдущего совпадения, который был первоначально установлен в нулевое состояние блоком 102. Если предыдущее совпадение равно нулю, то из блока 111 выходят по ветви "ДА", минуя обновление каталога. Когда после того, как обработан первый входной символ, доходят до блока 105, то предыдущее совпадение не равно нулю, и из блока 111 выходят по ветви "НЕТ" для осуществления обновления каталога в соответствии с настоящим изобретением.
Соответственно, в блоке 112 генератор 26 кодов создает следующий имеющийся в наличии код. Следующий имеющийся в наличии код будет являться номером вершины следующей имеющейся в наличии пустой ячейки памяти каталога для хранения строки обновления. В блоке 113 предыдущее совпадение с присоединенным к нему текущим символом сохраняют в каталоге 13 в этой следующей имеющейся в наличии пустой ячейке памяти, доступ к которой осуществляют по этому следующему имеющемуся коду.
Доступ к памяти блока 113 осуществляют следующим образом. В поле 70 указателя родительской вершины следующей имеющейся в наличии пустой ячейки памяти, доступ к которой осуществляют посредством следующего имеющегося в наличии кода из блока 112, устанавливают номер вершины предыдущего совпадения, находящийся в регистре 25 предыдущего совпадения. В символьном поле 17 этой следующей пустой ячейки памяти устанавливают значение текущего символа из регистра 23 текущего символа. Родительская вершина предыдущего совпадения связана указателем с этой вновь созданной вершиной следующим образом. Номер вершины родительской вершины предыдущего совпадения находится в регистре 25 предыдущего совпадения. Если родительская вершина предыдущего совпадения не имеет дочерних вершин (поле указателя дочерней вершины =0), то из блока 112 в поле 71 указателя дочерней вершины этой родительской вершины предыдущего совпадения вводят следующий имеющийся в наличии код, который является номером вершины вновь созданной дочерней вершины. Если родительская вершина предыдущего совпадения уже имеет дочерние вершины, то этот номер вершины следующего имеющегося в наличии кода вновь созданной вершины вводят в список вершин одного уровня для дочерних вершин родительской вершины предыдущего совпадения. Это выполняют путем корректировки поля 72 указателя вершин одного уровня в вершинах одного уровня из списка так, чтобы разместить в нем вновь созданную вершину одного уровня и таким образом ввести соответствующий номер вершины одного уровня в поле 72 указателя вершин одного уровня во вновь созданной вершине одного уровня.
Блок 114 применяют для обновления регистра 25 предыдущего совпадения таким образом, чтобы указать на номер вершины строки предыдущего совпадения, которая расширена на текущий символ так, как было приведено в описании для блока 113. Это выполняют посредством введения в регистр 25 предыдущего совпадения номера вершины вновь созданной дочерней вершины или вершины одного уровня так, как приведено в описании для блока 113. Этот номер вершины представляет собой следующий имеющийся в наличии код, описание которого приведено относительно блока 112, создаваемый генератором 26 кодов.
После того как обновление каталога согласно блокам 112-114 выполнено, входят в блок 115 принятия решений для того, чтобы определить, является ли текущий входной символ в регистре 23 текущего символа последним входным символом из потока входных данных. Вход в блок 115 также осуществляют по ветви "ДА" из блока 111, минуя обновление каталога, что было рассмотрено выше. Если текущий символ является последним символом, то из блока 115 по ветви "ДА" переходят в блок 116, который осуществляет вывод кода текущего совпадения. Выходной уплотненный код, который создан блоком 116, находится в регистре 24 текущего совпадения. После вывода уплотненного кода блоком 116 входят в блок 117 и обработку заканчивают.
Однако, если текущий символ в регистре 23 текущего символа не является последним входным символом, то выход из блока 115 осуществляют по ветви "НЕТ", которая идет обратно ко входу блока 103 по траектории 118. В соответствии с работой блока 103 в регистр 23 текущего символа вводят следующий входной символ и продолжают обработку по уплотнению данных, показанную на Фиг.6.
Если требуется временно приостановить обработку, то приостановку осуществляют в блоке 119 фиксации на траектории 118.
Из вышеизложенного понятно, что блоки 103-105 осуществляют управление поиском в каталоге 13 совпадающей строки наибольшей длины и что блок 106 создает на выходе уплотненный код, соответствующий совпадению наибольшей длины. Блок 110 начинает поиск следующего совпадения наибольшей длины, начинающегося с символа, который вызвал несовпадение в предыдущем цикле определения совпадения строки.
Блоки 107 и 112-114 осуществляют управление обновлением каталога 13 в соответствии с изобретением. Когда блок 104 определяет, что текущий входной символ успешно осуществил расширение текущего совпадения, блоки 112-114 присоединяют этот символ к строке предыдущего совпадения, которая находится в процессе расширения. Таким образом, обновление каталога является непосредственным и его посимвольно чередуют с поиском строк.
Известно, что, когда текущая строка, для которой определяют наличие совпадения, находится на той же самой траектории дерева поиска, что и предыдущая расширяемая строка, то реализуется способность настоящего алгоритма осуществлять эффективное уплотнение повторяющегося символа или строки группы символов. Результатом уплотнения такой входной строки вне зависимости от ее длины являются два сигнала с уплотненным кодом, что будет пояснено далее для Фиг.8 и Фиг.12.
Со ссылкой на Фиг. 1, а также со ссылкой на Фиг.2 и Фиг.3б представлена схема последовательности операций управления, на которой изображены операции, выполняемые трактом 50 управления восстановлением и обновлением по разуплотнению уплотненного кода, генерация которого осуществлена в соответствии с Фиг. 6. Схема на Фиг. 7 основана на том, что инициализацию каталога 43 разуплотнения осуществляют посредством всех строк с одиночными символами. Считают, что устройство 57 управления содержит соответствующие схемы для управления выполнением операций, например конечные автоматы.
В соответствии с действием блока 130 осуществляют очистку и инициализацию каталога 43 разуплотнения. Операции блока 130 по отношению к каталогу 43 являются такими же, как и описанные выше для блока 100 и каталога 13 уплотнения.
В блоке 131 осуществляют очистку и обнуление регистра 54 предыдущей строки, а в блоке 132 осуществляют ввод уплотненного кода в регистр 53 текущего полученного кода.
Обработку продолжают посредством блока 133 принятия решений, где определяют, имеет ли текущий полученный код, находящийся в регистре 53 текущего полученного кода, соответствующую строку в каталоге 43. Обычно каталог 43 содержит строку, соответствующую текущему полученному коду. Исключение возникает тогда, когда текущий полученный код является следствием того, что в устройстве уплотнения встретился повторяющийся символ или строка группы символов. Выработку решения блока 133 осуществляют посредством обращения к
каталогу 43, используя в качестве адреса текущий полученный код и определяя, действительно ли очищена та ячейка памяти каталога, к которой обращаются. Если ячейка памяти каталога очищена, то строка, соответствующая текущему полученному коду, в каталоге отсутствует. В альтернативном варианте, в варианте осуществления с последовательным присвоением кода, выработка решения блоком 133 может быть осуществлена посредством определения того, является ли текущий полученный код меньшим или равным существующему в настоящий момент коду генератора 56 кодов. Если текущий полученный код меньше или равен существующему в настоящий момент коду генератора 56 кодов, то строка, соответствующая текущему полученному коду, присутствует в каталоге 43. Однако, если текущий полученный код превышает существующий код, то в каталоге 43 пока еще нет строки, соответствующей текущему полученному коду.
Если в каталоге 43 нет строки с текущим полученным кодом, то для выполнения обработки неопознанного кода из блока 133 выходят по ветви "НЕТ". Подробности обработки неопознанного кода будут описаны со ссылкой на Фиг. 8.
Когда текущий полученный код имеет соответствующую строку в каталоге 43, то из блока 133 по ветви "ДА" переходят в блок 134. В блоке 134 осуществляют восстановление символов строки, соответствующей текущему полученному коду, посредством соответствующего известного процесса поиска по каталогу (например, из патента Уэлча ('302) на Фиг. 5 или патента Кларка ('591) на Фиг. 5). Блок 135 выдает параметр n, который устанавливают равным числу символов в восстановленной в блоке 134 строке. Индекс i устанавливают равным 1 в блоке 136. Индекс i используют для последовательного перебора по n символам строки, которая восстановлена в блоке 134 так, чтобы осуществить вывод символов восстановленной строки, начиная с ее первого символа. Соответственно, блок 137 обеспечивает вывод i-того символа строки текущего полученного кода.
Блок 140 принятия решений включен в этот процесс для того, чтобы установить, равна ли нулю предыдущая строка. Эту проверку осуществляют, определяя, равно ли нулю содержимое регистра 54 предыдущей строки. Если регистр 54 предыдущей строки равен нулю, то из блока 140 выходят по ветви "ДА", минуя обновление каталога. Функция блока 140 аналогична описанной выше для блока 111 по Фиг. 6 и, следовательно, выход по ветви "ДА" из блока 140 осуществляют только в ответ на первый полученный входной код.
Когда регистр 54 предыдущей строки не равен нулю, то из блока 140 выходят по ветви "НЕТ", а в блоке 141 генератор 56 кодов выдает следующий имеющийся в наличии код для следующей пустой ячейки памяти каталога 43. В блоке 142 в этой следующей пустой ячейке памяти сохраняют предыдущую строку с присоединенным к ней i-тым символом строки, соответствующей текущему полученному коду. В блоке 143 осуществляют обновление регистра 54 предыдущей строки так, чтобы сохранить в нем номер вершины предыдущей расширенной строки из блока 142. Операции, осуществляемые при выполнении блоков 141-143, являются такими же, как и описанные выше для блоков 112-114 по Фиг. 6. На Фиг. 7 используют регистр 54 предыдущей строки, а Фиг. 6 содержит регистр 25 предыдущего совпадения.
В блоке 144 осуществляют приращение индекса i на единицу. Для входа в блок 144 также используют ветвь "ДА" из блока 140 принятия решений, чтобы, как описано выше, миновать обработку обновления каталога блоками 141-143. Для того чтобы определить, достиг ли индекс i значения n+1, в блоке 145 принятия решений осуществляют проверку. Когда индекс i не равен n+1, из блока 145 выходят по ветви "НЕТ", которая возвращает процесс обработки на вход блока 137. Процесс обработки блоками 137 и 140-145 продолжают до тех пор, пока i не достигнет i=n+1.
Таким образом, в блоке 137 осуществляют вывод n символов строки текущего полученного кода в правильном порядке и осуществляют расширение предыдущей восстановленной строки на все префиксы строки текущего полученного кода. В процессе обработки посредством блоков 141-143 в каталоге 43 разуплотнения сохраняют те же самые строки, что сохранены посредством блоков 112-114 по Фиг. 6 в каталоге 13 уплотнения. Строки, сохраненные в соответствии с действием блоков 141-143 в каталоге 43 разуплотнения, хранят соответственно по тем же самым адресам, что и строки, сохраненные в соответствии с действием блоков 112-114 в каталоге 13 уплотнения.
Когда индекс i достигает значения n+1, то осуществляют переход из блока 145 в блок 146 по ветви "ДА". В блоке 146 для подготовки к обработке следующего входного кода предыдущую строку заменяют на строку текущего полученного кода. Это осуществляют посредством ввода содержимого регистра 53 текущего полученного кода в регистр 54 предыдущей строки. Процесс 55 обработки неопознанного кода завершают при входе в блок 146.
Если только что обработанный текущий полученный код не является последним входным кодом, то блок 147 принятия решений возвращает процесс обработки на вход блока 132 по ветви "НЕТ" из блока 147. Возврат процесса обработки к блоку 132 осуществляют по траектории 148 для того, чтобы инициализировать обработку следующего входного уплотненного кода. Если требуется временно приостановить обработку, то приостановку осуществляют в блоке 149 фиксации на траектории 148. Блок 149 фиксации в устройстве разуплотнения аналогичен блоку 119 фиксации в устройстве уплотнения.
Если в блоке 147 текущий полученный код является последним входным кодом, то выход из блока 147 осуществляют по ветви "ДА" к блоку 150 для завершения обработки.
Из вышеизложенного понятно, что блоки 134 и 137 осуществляют восстановление и вывод символов строки, соответствующей текущему полученному коду, а блоки 141-143 осуществляют обновление каталога 43, сохраняя предыдущую восстановленную строку, которая расширена префиксами текущей восстановленной строки.
Со ссылкой на Фиг. 8 представлен подробный вид процесса обработки 55 неопознанного кода. В блоке 160 индекс i устанавливают равным единице и по описанным далее причинам осуществляют его приращение по модулю n. В блоке 161 восстанавливают n символов предыдущей строки. Предыдущая строка имеет n символов, так как она являлась строкой текущего полученного кода в предыдущем цикле восстановления строки. Блок 161 реализуют посредством доступа к каталогу 43 по содержимому регистра 54 предыдущей строки, используя известный процесс восстановления строки каталога, который был рассмотрен выше для блока 134.
В блоке 162 генератор 56 кодов создает следующий имеющийся в наличии код для следующей пустой ячейки памяти каталога. В блоке 163 в этой следующей пустой ячейке памяти сохраняют предыдущую строку, которая расширена на i-тый символ из предыдущей строки. Чтобы сохранить номер вершины этой расширенной предыдущей строки, в блоке 164 осуществляют замену предыдущей строки на расширенную предыдущую строку из блока 163 посредством обновления регистра 54 предыдущей строки. Операции обновления каталога в блоках 162-164 подобны тем, что были описаны выше для блоков 141-143. Как пояснялось ранее, реализация процедуры обновления каталога в блоках 141-143 была подробно описана для блоков 112-114 из Фиг. 6. При процедуре обработки в блоках 162-164 используют регистр 54 предыдущей строки.
В блоке 165 принятия решений осуществляют проверку для того, чтобы определить, равен ли код, создаваемый в настоящее время генератором 56 кодов, текущему полученному коду из регистра 53 текущего полученного кода. Если существующий в настоящий момент код генератора 56 кодов не достиг значения текущего полученного кода, то из блока 165 выходят по ветви "НЕТ" и переходят к блоку 166, в котором осуществляют приращение индекса i на модуль n плюс единица. Затем процесс обработки замыкают обратно на вход блока 162 для того, чтобы сохранить дополнительные строки обновления, до тех пор, пока существующий в настоящий момент код генератора 56 кодов не станет равным текущему полученному коду.
Когда блок 165 показывает, что существующий в настоящий момент код генератора 56 кодов равен текущему полученному коду в регистре 53 текущего полученного кода, то осуществляют переход из блока 165 в блок 167 по ветви "ДА". Понятно, что, когда блок 165 показывает, что код равен текущему полученному коду, то строку, соответствующую этому неопознанному текущему полученному коду, теперь сохраняют в каталоге 43 разуплотнения.
В блоке 167 восстанавливают символы строки, соответствующей текущему полученному коду, и осуществляют вывод каждого символа, начиная с первого символа. Блок 167 реализуют посредством доступа к каталогу 43 по содержимому регистра 53 текущего полученного кода, используя известные процедуры восстановления строки каталога, которые были рассмотрены выше для блока 134.
Из вышеизложенного очевидно, что посредством обработки в блоках 160-167 создают строку, соответствующую неопознанному уплотненному входному коду, сохраняют в каталоге 43 разуплотнения и осуществляют восстановление ее символов для вывода. Кроме того, очевидно, что, когда устройство уплотнения по Фиг. 6 осуществляет генерацию и сохранение строк, которые относятся к неопознанному коду, то это устройство уплотнения сохраняет также еще n строк помимо строки, соответствующей переданному коду. Разъяснение этого будет приведено далее для Фиг. 12. Обработку в устройстве разуплотнения по созданию и сохранению этих n строк осуществляют следующим образом.
Процесс обработки продолжают в блоке 170, в котором осуществляют приращение индекса i по модулю n на единицу. Блоки 171-173 дублируют процесс обработки блоками соответственно 162-164. Процесс обработки затем продолжают в блоке 174, в котором осуществляют отрицательное приращение параметра n на единицу. Затем осуществляют проверку параметра n в блоке 175 принятия решений, чтобы определить, равно ли n нулю. Если n еще не равно нулю, то выход из блока 175 осуществляют по ветви "НЕТ", ведущей обратно ко входу блока. Когда значение параметра n становится нулевым, то процесс обработки неопознанного кода завершают выходом из блока 175 по ветви "ДА".
Чтобы облегчить создание соответствующих значений символов для строк, сохранение которых осуществлено блоками 163 и 172, в блоках 166 и 170 выполняют приращение индекса i на модуль n. Используют то значение n, которое создано в блоке 135 (Фиг. 7), до того, как осуществлено отрицательное приращение в блоке 174. Значениями символов являются те значения n символов предыдущей строки, которые восстановлены блоком 161 и имеют индекс i. n символов предыдущей строки, восстановленных блоком 161, формируют префикс из n символов для строк, создание и сохранение которых осуществлено блоками 163 и 172.
Обработка в соответствии с Фиг. 8 действует для любой разновидности процесса присвоения кода, который используют в генераторах 26 и 56 кодов, включая последовательное или псевдослучайное присвоение кодов, например хеширование. Для процесса присвоения последовательных кодов логические операции по Фиг. 8 могут быть упрощены следующим образом.
Для варианта присвоения последовательных кодов операция проверки в блоке 165 становится следующей "Код = Текущий Полученный Код + n". Блоки 170-175 исключают и процесс обработки неопознанного кода завершают на выходе из блока 167.
Из вышеупомянутого очевидно, что блок 167 восстанавливает символы строки, соответствующей неопознанному полученному коду, и что блоки 163 и 172 сохраняют в каталоге разуплотнения 43 те же самые строки, которые сохранены в каталоге 13 уплотнения при появлении повторяющегося символа или строки группы символов, что рассмотрено выше для Фиг.6.
Со ссылкой на Фиг. 9, а также со ссылкой на Фиг.1 и Фиг.3б представлена подробная схема последовательности операций управления, которые должны быть выполнены трактом 20 управления поиском и обновлением для осуществления уплотнения данных в соответствии с изобретением. Полагают, что для управления выполнением этих операций устройство 27 управления содержит соответствующие схемы, например конечные автоматы. Схема последовательности операций по Фиг. 9 основана на каталоге уплотнения 13 без инициализации. В варианте осуществления по Фиг. 9 без инициализации, когда символ встретился в первый раз, осуществляют передачу нулевого кода, после чего осуществляют передачу символа в неуплотненном виде. Нулевой код дает указание устройству разуплотнения, что устройством уплотнения осуществлена передача такого символа. Символ, который встретился в первый раз, сохраняют в каталоге 13 устройства уплотнения, чтобы он действовал в качестве сохраненной строки с одиночным символом или корневой вершины по отношению к последующим появлениям этого символа. За исключением процедуры размещения тех символов, которые встретились в первый раз, схема последовательности операций по Фиг. 9 функционирует таким же способом, как и схема по фиг. 6.
В блоке 180 каталог 13 очищают. Очистка каталога может быть осуществлена посредством установления нулевых значений полей 17 и 70-72 по Фиг. 3б.
Схема последовательности операций по Фиг. 9 включает в себя блоки 181-187 и 190-194. Эти блоки являются такими же, как и соответственно блоки 101, 103-107 и 112-117 по Фиг. 6. Приведенные выше пояснения для этих блоков по Фиг. 6 применимы и для соответствующих блоков по Фиг. 9, за исключением следующего.
В блоке 183, когда текущее совпадение равно нулю, осуществляют поиск в каталоге 13 для определения того, была ли эта строка с одиночным символом уже введена в каталог в качестве корневой вершины. Если строка с одиночным символом уже находится в каталоге, то из блока 183 выходят по ветви "ДА", в противном же случае выходят по ветви "НЕТ". Когда текущее совпадение равно нулю, в блоке 184 осуществляют обновление регистра 24 текущего совпадения, вводя номер вершины корневой вершины одиночного символа, совпадение которого было установлено в блоке 182. Кроме того, для блока 187 в варианте осуществления с присвоением последовательного кода присвоение кода начинают с единицы, поскольку в этом варианте осуществления без инициализации все ячейки памяти каталога доступны для сохранения появляющихся на входе строк. Также отмечено, что на Фиг. 9 не требуется наличие блока 111 по Фиг. 6, который обходит обновления каталога. Это следует из того, что в этом варианте осуществления без инициализации первым входным символом является символ, встретившийся в первый раз, который обеспечивает предыдущее совпадение для следующей итерации, что будет описано ниже.
Кроме того, блок 185 аналогичен блоку 106 по Фиг. 6. В блоке 185, как и в блоке 106, выходной уплотненный код находится в регистре 24 текущего совпадения. Однако, когда текущее совпадение равно нулю, то в блоке 185 осуществляют вывод этого нулевого кода, который указывает, что текущий входной символ является символом, который встретился в первый раз.
Схема последовательности операций на Фиг. 9 включает в себя блок 195 принятия решений, который определяет, является ли содержимое регистра 24 текущего совпадения равным нулю. Если текущее совпадение не равно нулю, то осуществляют переход из блока 195 по ветви "НЕТ" в блок 186, в котором содержимое регистра 24 текущего совпадения передают в регистр 25 предыдущего совпадения так, как описано выше для аналогичного блока 107 по Фиг. 6. В блоке 196 осуществляют установку регистра 24 текущего совпадения в нулевое состояние, и процесс обработки переходит на вход блока 183. Блок 186 обеспечивает обновление каталога для операции анализа следующей строки, а блок 196 вызывает то, что поиск следующей строки начинают с символа из регистра 23 текущего символа.
Если из блока 195 выходят по ветви "ДА", то текущее совпадение равно нулю, а в регистре 23 текущего символа находится символ, который встретился в первый раз. Таким образом, блок 197 осуществляет вывод этого символа. Так как блок 185 уже осуществил вывод текущего совпадения с величиной, равной нулю, то, как рассматривалось выше, этому первому текущему символу, который встретился в первый раз и вывод которого осуществлен блоком 197, предшествует нулевой код. В блоке 200 генератор 26 кодов создает следующий имеющийся в наличии код, который указывает на следующую имеющуюся в наличии пустую ячейку памяти в каталоге 13. В блоке 201 в этой следующей пустой ячейке памяти сохраняют текущий символ из регистра 23 текущего символа в качестве корневой вершины строки из одиночного символа. Функцию блока 201 осуществляют посредством сохранения символа из регистра 23 текущего символа в символьном поле 17 этой следующей пустой ячейки памяти. Поле 70 указателя родительской вершины, поле 71 указателя дочерней вершины и поле указателя 72 вершин одного уровня должны были быть все предварительно обнулены в блоке 180.
В блоке 202 в регистре 25 предыдущего совпадения устанавливают значение корневой вершины, созданной в блоке 201 с целью обновления каталога при операции анализа следующей строки. Это осуществляют посредством ввода в регистр 25 предыдущего совпадения номера вершины этой вновь созданной в блоке 201 корневой вершины. Этот номер вершины будет являться кодом, который только что создан в блоке 200.
Блок 203 принятия решений включен сюда для того, чтобы определить, является ли символ в регистре 23 текущего символа последним входным символом. В противном случае, из блока 203 по ветви "НЕТ" переходят на вход блока 182 для получения следующего сигнала символа данных из входного потока. Однако, если текущий символ, проверку которого осуществляют в блоке 203, является последним входным символом, то из блока 203 по ветви "ДА" переходят к блоку 194 для завершения обработки.
Из вышеизложенного очевидно, что блоки 182-184 осуществляют управление поиском в каталоге 13 совпадающей строки наибольшей длины и что блок 185 дает на выходе уплотненный код, соответствующий совпадению наибольшей длины. Блок 185 также обеспечивает вывод нулевого кода, который предшествует передаче символа, появляющегося в первый раз. Блок 196 начинает поиск следующего совпадения наибольшей длины посредством обнуления регистра 24 текущего совпадения. Таким образом, поиск следующего совпадения наибольшей длины начинают с символа, который вызвал несовпадение в цикле определения наличия совпадения для предыдущей строки, причем этот символ находится в регистре 23 текущего символа.
Блоки 186, 187, 190 и 191 осуществляют управление обновлением каталога 13 в соответствии с изобретением. Когда блок 183 определяет, что расширение текущего совпадения успешно осуществлено текущим входным символом, то блоки 187, 190 и 191 присоединяют этот символ к строке предыдущего совпадения, для которой осуществляют процесс ее расширения. Блоки 195, 197 и 200-202 осуществляют управление обслуживанием символов, встречающихся впервые. Блок 202 выдает такой символ в качестве предыдущего совпадения для возможного расширения в цикле определения наличия совпадения для следующей строки. Из схемы логических операций на Фиг. 9 очевидно, что, если последовательно получено несколько таких символов, встречающихся в первый раз, то в цикле определения наличия совпадения для следующей строки будет осуществлено расширение только последнего из этих символов.
Со ссылкой на Фиг. 10, а также со ссылкой на Фиг.2 и Фиг.3б, показана схема последовательности операций управления, на которой представлены операции, выполняемые трактом 50 управления восстановлением и обновлением для разуплотнения уплотненного кода, генерация которого осуществлена в соответствии с Фиг.9. Схема последовательности операций по Фиг. 10 основана на каталоге разуплотнения без инициализации. Считают, что для управления выполнением операций устройство 57 управления содержит соответствующие схемы, например конечные автоматы.
В блоке 210 осуществляют очистку каталога 43 разуплотнения способом, который описан выше для блока 180 по Фиг.9. Таким образом, очистку каталога 43 разуплотнения осуществляют точно таким же способом, что и каталог 13 в варианте осуществления без инициализации, по фиг.9.
Операции, выполняемые схемой последовательности операций разуплотнения по Фиг. 10, являются такими же, как и выполняемые схемой последовательности операций разуплотнения по Фиг. 7, за исключением относящихся к обслуживанию символов, встречающихся в первый раз, которые рассмотрены выше для Фиг. 9. Соответственно, Фиг.10 включает в себя блоки 55, 211-217 и 220-226, которые выполняют те же самые функции, что и блоки соответственно 55, 132-137, 141-147 и 150 по Фиг.7. Приведенные выше описания для блоков 55, 132-137, 141-147 и 150 по Фиг.7 относятся и к соответствующим блокам по Фиг.10.
Блок, соответствующий блоку 140 по Фиг.7, на Фиг.10 не используют. Как описано ранее, когда регистр 54 предыдущей строки равен нулю, то блок 140 осуществляет обход обновления каталога. В варианте осуществления с инициализацией на Фиг. 7 это происходит в ответ на получение первого входного кода. В варианте осуществления без инициализации на Фиг. 10, первый полученный входной код соответствует символу, который встретился в первый раз, создавая таким образом предыдущую строку для обновления в последующих циклах, что будет описано далее.
При обработке в блоках 217, 220 и 221 осуществляют сохранение в каталоге 43 разуплотнения тех же самых строк, что сохранены в каталоге 13 уплотнения блоками 187, 190 и 191 по Фиг. 9. Сохранение строк, которые сохраняют в каталоге 43 разуплотнения в соответствии с действием блоков 217, 220 и 221, осуществляют по тем же соответствующим адресам, что и строк в каталоге 13 уплотнения, сохраняемых в соответствии с действием блоков 187, 190 и 191. Кроме того, когда обработку неопознанного кода блоком 55 (Фиг.8) выполняют применительно к Фиг.10, то блоки 163 и 172 по Фиг.8 осуществляют сохранение в каталоге 43 разуплотнения тех же самых строк, что сохранены в каталоге 13 уплотнения, когда при работе устройства уплотнения по Фиг. 9 появляются повторные символы или строки групп символов.
В частности, блок 212 соответствует блоку 133 по Фиг.7. Приведенное выше описание для блока 133 относится и к блоку 212 за исключением того, что относится к получению нулевого кода, который предшествует приему символа, который встретился в устройстве уплотнения в первый раз. Тем не менее понятно, что, когда процесс обработки доходит до блока 212, то текущий полученный код не будет равным нулю, так как обработку этой ситуации осуществляют в другой ветви Фиг.10, описание которой будет приведено сейчас.
В блоке 211 осуществляют ввод входного сигнала с уплотненным кодом в регистр 53 текущего полученного кода. Блок 230 принятия решений проверяет содержимое регистра 53 текущего полученного кода, чтобы определить, равен ли текущий полученный код нулю. Если текущий полученный код (не равен нулю) обнуляют, то из блока 230 по ветви "НЕТ" переходят ко входу блока 212, в котором продолжают обработку согласно описанному выше.
Однако, если текущий полученный код равен нулю, то предполагают наличие символа, который в устройстве уплотнения по Фиг.9 появляется впервые. Этот символ, соответственно, вводят в блок 231. Для временной фиксации этого символа может быть использован регистр 53 текущего полученного кода. В блоке 232 генератор 56 кодов создает следующий имеющийся в наличии код, соответствующий следующей пустой ячейке памяти каталога 43 разуплотнения. В блоке 233 входной символ сохраняют в этой следующей пустой ячейке памяти в качестве корневой вершины одиночного символа. Это осуществляют в блоке 233 способом, который описан выше для блока 201 по Фиг.9. Таким образом, подсистема 40 разуплотнения осуществляет сохранение в каталоге 43 разуплотнения тех же самых строк с одиночными символами и по тем же самым адресам, которые система 10 уплотнения сохраняет в каталоге 13 уплотнения в варианте осуществления без инициализации по Фиг.9.
В блоке 234 осуществляют вывод символа, полученного в блоке 231, для обеспечения согласования между восстановленными выходными данными из устройства разуплотнения и входными данными, получаемыми устройством уплотнения. Это может быть выполнено посредством вывода этого символа из регистра 53 текущего полученного кода, где осуществлялось временное хранение этого символа.
В блоке 235 параметр n устанавливают равным единице. Если этот появляющийся первый раз и только что обработанный символ опять появляется на входе устройства уплотнения, вызывая таким образом генерацию неопознанного уплотненного кода, то подходящим значением для процесса обработки 55 неопознанного кода, который выполнялся бы в следующем цикле работы устройства разуплотнения, является n=1.
В блоке 236 значение регистра 54 предыдущей строки устанавливают равным значению корневой вершины, созданной в блоке 233 с целью обновления каталога в следующем цикле восстановления строки. Это осуществляют посредством ввода номера вершины этой вновь созданной в блоке 233 корневой вершины в регистр 54 предыдущей строки. Этим номером вершины будет код, только что созданный в блоке 232. Из логических операций на Фиг. 10 понятно, что, если последовательно получено несколько символов, каждый из которых появился впервые, то в следующем цикле восстановления строки будет осуществлено расширение только последнего из этих символов способом, подобным описанному для Фиг. 9.
Выходной сигнал из блока 236 подают на вход блока 225 для продолжения, обработки, согласно описанному выше.
Со ссылкой на Фиг. 11а - Фиг. 11д показаны последовательные состояния каталога 13 уплотнения при уплотнении типичного потока входных данных. Состояния каталога изображены схематично в виде неполных деревьев поиска. Как показано на чертеже, уплотняемый входной поток имеет вид "abcfghx". Изображенные запятые, отображающие анализ строки, являются виртуальными и во входном потоке их нет. Подчеркиванием указан текущий входной символ. Как отмечено на Фиг. 11а, в каталоге 13 первоначально хранятся строки "abc" и "fgh". На Фиг. 11 для строки "abc" только что было установлено, что она является строкой, имеющей совпадение наибольшей длины, и осуществляют вывод кода "abc", что обозначено стрелкой 240. Следовательно, анализ строки "abc" при ее вводе уже осуществлен, что обозначено виртуальной запятой 241.
На Фиг. 11б следующий входной символ "f" совпадает с первым символом строки "fgh", что обозначено стрелкой 242. В соответствии с изобретением строку "abc", которая на Фиг. 11а передана в качестве предыдущего уплотненного кода, расширяют на символ "f", что показано стрелкой 243.
На Фиг. 11в следующий входной символ "g" совпадает со вторым символом сохраненной строки "fgh", и теперь осуществляют расширение предыдущей расширенной строки "abcf на совпадающий входной символ "g". Аналогичным образом, на Фиг. 11г входной символ "h" совпадает с третьим символом строки "fgh", и его присоединяют к растущей предыдущей строке, чтобы теперь сформировать строку "abcfgh".
На Фиг. 11д следующий входной символ "х" нарушает совпадение строки "fgh", и осуществляют вывод кода совпадения "fgh" наибольшей длины, что обозначено стрелкой 244. Анализ строки "fgh" уже был произведен на входе, что обозначено виртуальной запятой 245.
Из Фиг. 11а-Фиг. 11д очевидно, что было осуществлено расширение сохраненной строки "abc" на все префиксы совпавшей строки "fgh" и что обновление каталога является непосредственным и его чередуют с операцией определения наличия совпадения для каждого из символов текущей совпавшей строки. Таким образом, на Фиг.11б для определения наличия совпадений при следующей итерации была доступна строка "abcf. На Фиг.11в для определения наличия совпадений при следующей итерации была доступна строка "abcfg", а на Фиг. 11г для определения наличия совпадений при следующей итерации была доступна строка "abcfgh".
Кроме того, из Фиг. 11а-Фиг.11д понятно, что устройство разуплотнения получает последовательные уплотненные выходные коды для "abc" и "fgh". Когда выходной код для "fgh" получен, устройство разуплотнения использует восстановленную строку "fgh" и строку "ahc", соответствующую предыдущему полученному уплотненному коду, для построения и сохранения строк, которые описаны и показаны на Фиг. 11а-Фиг.11д.
Со ссылкой на Фиг. 12а-Фиг. 12ж представлен способ, в котором отличительная особенность настоящего изобретения, заключающаяся в осуществлении непосредственного обновлении каталога с чередованием, обеспечивает преимущество кодирования с переменной длиной строки. Как рассмотрено выше, в настоящем изобретении осуществляют уплотнение последовательности повторяющихся символа или группы символов в два символа уплотненного кода вне зависимости от длины последовательности. Фиг. 12а-Фиг.12ж представляют собой схематические изображения неполных деревьев поиска, на которых показаны последовательные состояния каталога 13 уплотнения, когда входной поток символов данных является группой повторяющихся символов. Поток входных данных изображен в виде "abababax". В этом примере входных данных следует отметить, что последовательность групп повторяющихся символов заканчивается фрагментом группы символов. Описанные ниже операции также могут применяться, когда последовательность заканчивается полной группой символов. Как и на Фиг. 11а-Фиг. 11д, виртуальные запятые отображают анализ строки, а подчеркивание обозначает текущий входной символ.
На Фиг. 12а в каталоге уплотнения 13 хранится строка "ab", которая совпадает с первыми двумя входными символами. Таким образом, осуществляют вывод кода "ab", что обозначено стрелкой 250. Анализ строки "ab" на входе обозначен виртуальной запятой 251.
На Фиг. 12б текущий входной символ "а" совпадает с первым символом сохраненной строки "ab", что обозначено стрелкой 252. Так как код для "ab" был передан в качестве предыдущего уплотненного кода, к строке "ab" присоединяют совпадающий символ "а", что обозначено стрелкой 253. Теперь в каталоге 13 уплотнения хранится строка "aha", которая может быть использована для определения наличия совпадения.
На Фиг. 12в следующий входной символ "b" совпадает со вторым символом сохраненной строки "aba, и, следовательно, осуществляют расширение строки "aba" на этот символ. Таким образом, в каталоге 13 уплотнения теперь хранится строка "abab", которая может быть использована для определения наличия совпадения.
Очевидно, что при продолжении этой повторяющейся последовательности операция определения совпадения входного символа и расширения сохраненной строки выполнялась бы на той же самой ветви дерева и продолжалась бы до тех пор, пока не получен символ, который нарушает совпадение. При его появлении генератор 26 кодов (Фиг.1) непрерывно создает новые коды для сохранения строк во вновь созданных вершинах. Вплоть до этой точки устройство разуплотнения не знает о тех действиях, которые происходят в устройстве уплотнения, что показано на Фиг. 12б-12е. Последней информацией, полученной устройством разуплотнения, был код вывода строки "ab", что приведено в описании для Фиг.12а.
На Фиг.12ж входной символ "х" нарушает совпадение, так как в каталоге 13 устройства уплотнения строка "ababax" не обнаружена. Следовательно, выводят код совпадения наибольшей длины "ababa", что обозначено стрелкой 254. Соответствующий анализ этой строки был произведен при входе, что обозначено виртуальной запятой 255. Из Фиг.12ж очевидно, что, помимо строки с совпадением наибольшей длины, в каталоге устройства 13 уплотнения были сохранены две дополнительные строки. Этим строкам соответствуют вершины 256 и 257.
Таким образом, из Фиг.12а-Фиг.12ж очевидно, что строка "ababa" группы повторяющихся символов была уплотнена в двух символах кода, обозначенных номерами ссылок 250 и 254. Кроме того, очевидно, что, если последовательность группы повторяющихся символов "ab" продолжена вне Фиг.12е для получения последовательности большей длины, чем изображенная, то для уплотнения по-прежнему будут использованы только два символа кода. Видно, что повторяющаяся последовательность заканчивается фрагментом группы повторяющихся символов, но также ее можно продолжить, чтобы она завершалась полной группой "ab".
Из вышеописанного очевидно, что выходной код, обозначенный на Фиг. 12ж цифрой ссылки 254, не будет опознан в устройстве разуплотнения, так как строка "ababa" еще не сохранена в устройстве разуплотнения. В процессе обработки неопознанного кода по Фиг.8 создают и сохраняют строку "ababa", а также ее префиксы, показанные на Фиг.12б и 12в. Кроме того, в процессе обработки неопознанного кода создают и сохраняют дополнительные расширенные строки, которые обозначены номерами ссылок 256 и 257 по Фиг. 12ж.
Создание, сохранение и вывод строки "ababa", соответствующей неопознанному уплотненному коду, что обозначено стрелкой 254, осуществляют обработкой в блоках 160-167 на Фиг. 8. Создание и сохранение дополнительных строк 256 и 257 осуществляют обработкой в блоках 170-175.
В примере по Фиг.12а-Фиг.12ж предыдущей строкой, используемой при обработке неопознанного кода, является строка "ab", которая уже хранилась в каталоге устройства разуплотнения, когда устройство разуплотнения выполняло цикл восстановления строки в соответствии с Фиг.12а. Чтобы создать строки, изображенные на Фиг.12б-Фиг.12е, на Фиг. 8 параметр n устанавливают равным 2, а приращение индекса i производят по модулю 2, осуществляя таким образом последовательную и многократную подачу символов "ab" на блоки 163 и 172.
Кроме того, из вышеизложенного очевидно, что обработка неопознанного кода приводит к созданию и восстановлению соответствующих строк, когда последовательность повторяющихся символов или повторяющихся групп символов завершается несовпадающим символом, либо поступление входных символов закончилось. Последовательность может завершаться фрагментом группы, состоящей из многих символов, из последовательности групп повторяющихся символов или же полной группой. На Фиг.12а-Фиг.12ж показано завершение символом несоответствия "х" и, кроме того, показано завершение с наличием фрагмента повторяющейся группы. На Фиг.12ж последовательность заканчивается фрагментом "а" повторяющейся группы "ab". Когда последовательность повторяющихся групп завершается полной группой "ab", назначение соответствующих операций можно легко понять из вышеприведенных описаний.
Из вышеизложенного очевидно, что вышеописанная обработка сохраняет префиксные характеристики для строк, сохраненных в каталогах 13 и 43, посредством того, что префиксы сохраненных строк также существуют в каталогах.
Вышеприведенные варианты осуществления уплотняют поток сигналов символов входных данных. Символы входных данных могут относиться к алфавиту любого размера, имеющему любой соответствующий размер разряда символа. Например, символы данных могут быть текстовыми, например символами ASCII-кода, для алфавита, например 256-символьного алфавита, состоящего из восьмибитовых символов ASCII-кода. Входными данными могут также являться двоичные символы из двухсимвольного двоичного алфавита 1 и 0, имеющего символ размером в один бит. Этот тип алфавита имеет место, например, в растровых изображениях. Очевидно, что текстовые данные могут также быть уплотнены через двухсимвольный алфавит основных двоичных данных.
Вышеупомянутые варианты осуществления были описаны с точки зрения поиска совпадения наибольшей длины. Понятно, что процесс непосредственного обновления с чередованием из настоящего изобретения может быть также использован в системах, в которых определяют наличие совпадения строк, которые не обязательно имеют наибольшую длину.
Очевидно, что вышеописанные варианты осуществления изобретения могут быть выполнены аппаратными средствами, программно-аппаратными средствами, программными средствами. или их комбинацией. Может быть легко осуществлена реализация дискретных компонент схемы для выполнения различных описанных функций. В варианте осуществления с программным обеспечением могут быть использованы соответствующие микропроцессоры, запрограммированные при помощи программ, которые могут быть легко получены из вышеописанных схем последовательности операций.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО СЖАТИЯ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ АССОЦИАТИВНОЙ ПАМЯТИ | 1995 |
|
RU2159989C2 |
| ВОСПРОИЗВОДЯЩЕЕ УСТРОЙСТВО И СПОСОБ ВОСПРОИЗВЕДЕНИЯ | 2000 |
|
RU2253146C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ УСКОРЕНИЯ ОПЕРАЦИЙ СЖАТИЯ И РАСПАКОВКИ | 2014 |
|
RU2629440C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| Способ поиска пути по дереву | 2015 |
|
RU2622629C2 |
| УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ | 1996 |
|
RU2182722C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ДИНАМИЧЕСКОГО ГЕНЕРИРОВАНИЯ РАСШИРЕНИЯ ДОПУСКАЮЩЕГО ВЫБОР ПОИСКА | 2004 |
|
RU2367013C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2740865C1 |
| НОСИТЕЛЬ ЗАПИСИ, УСТРОЙСТВО ВОСПРОИЗВЕДЕНИЯ И СПОСОБЫ ЗАПИСИ И ВОСПРОИЗВЕДЕНИЯ | 2006 |
|
RU2393556C2 |
| ПРОГРАММИРУЕМОСТЬ ДЛЯ ХРАНИЛИЩА XML ДАННЫХ ДЛЯ ДОКУМЕНТОВ | 2006 |
|
RU2417420C2 |
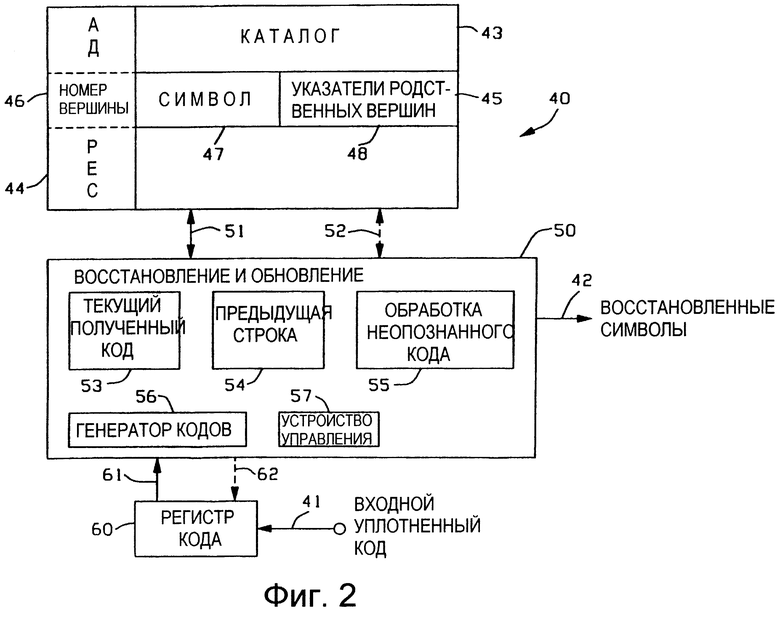
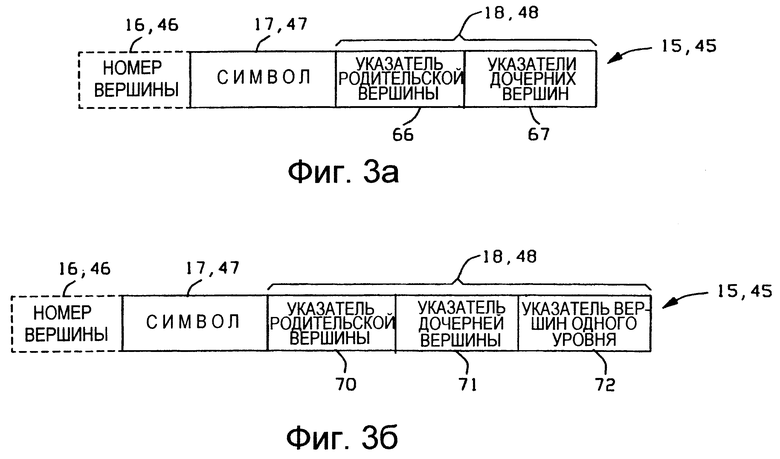
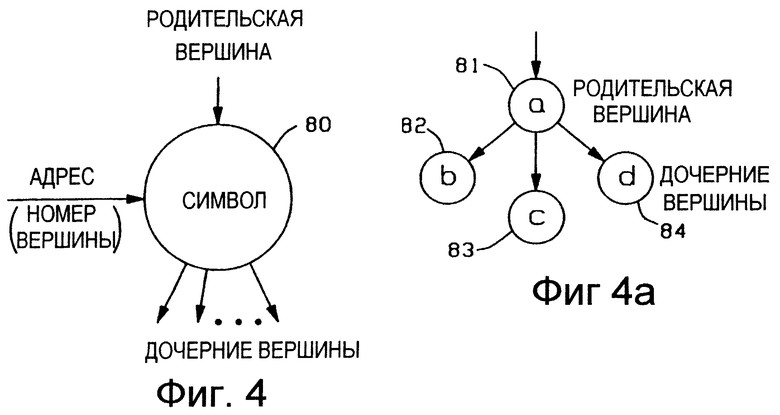
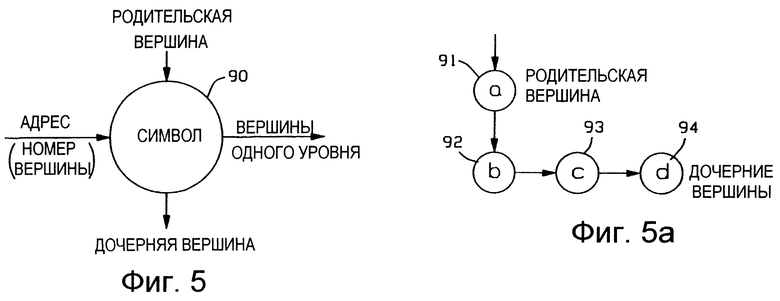
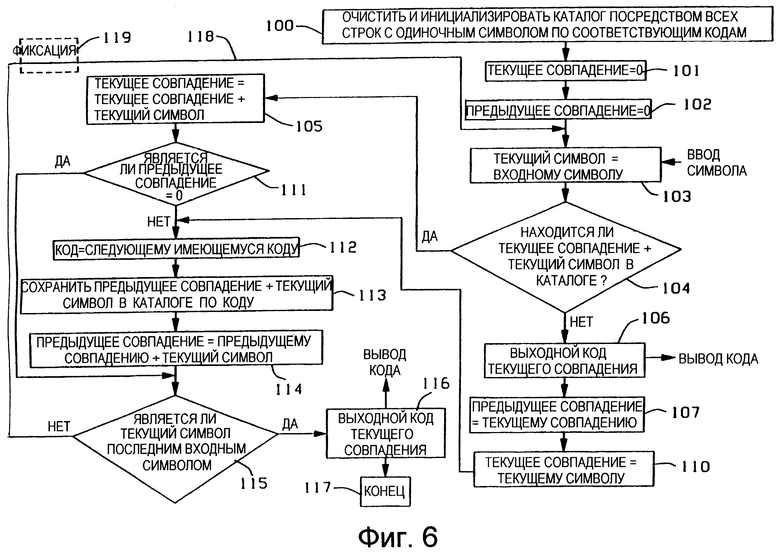
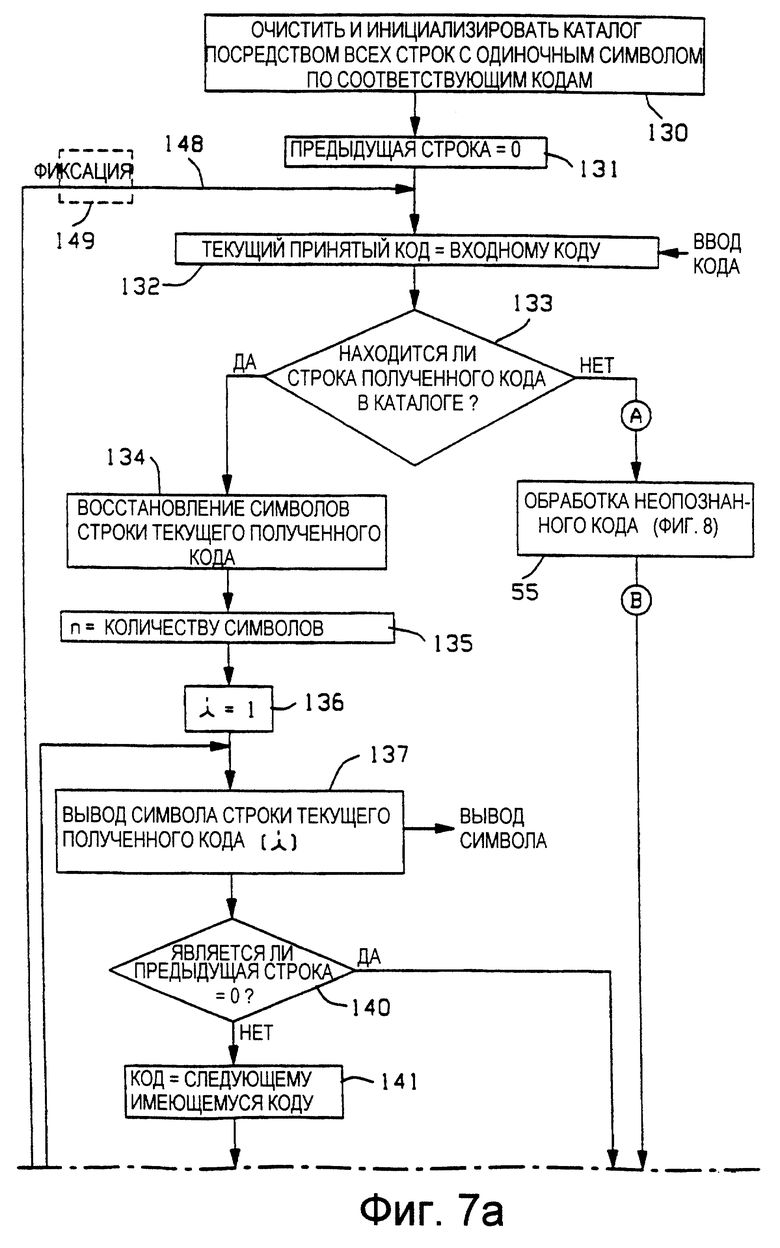
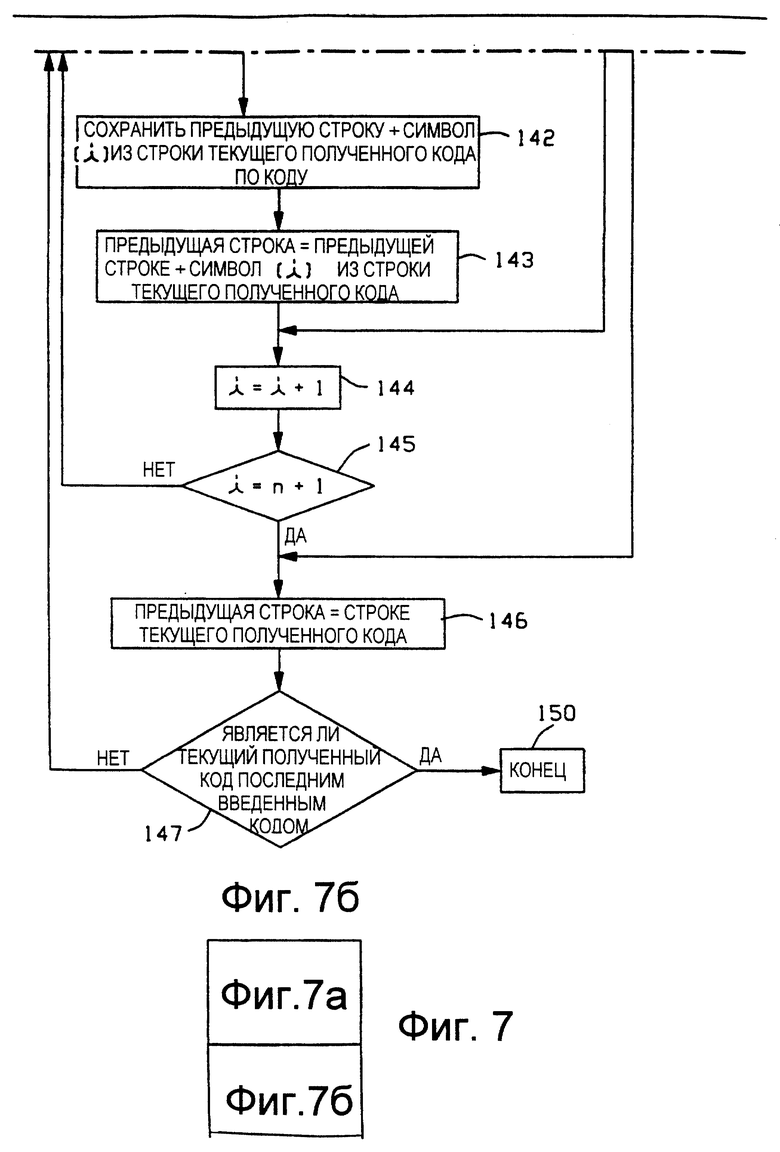
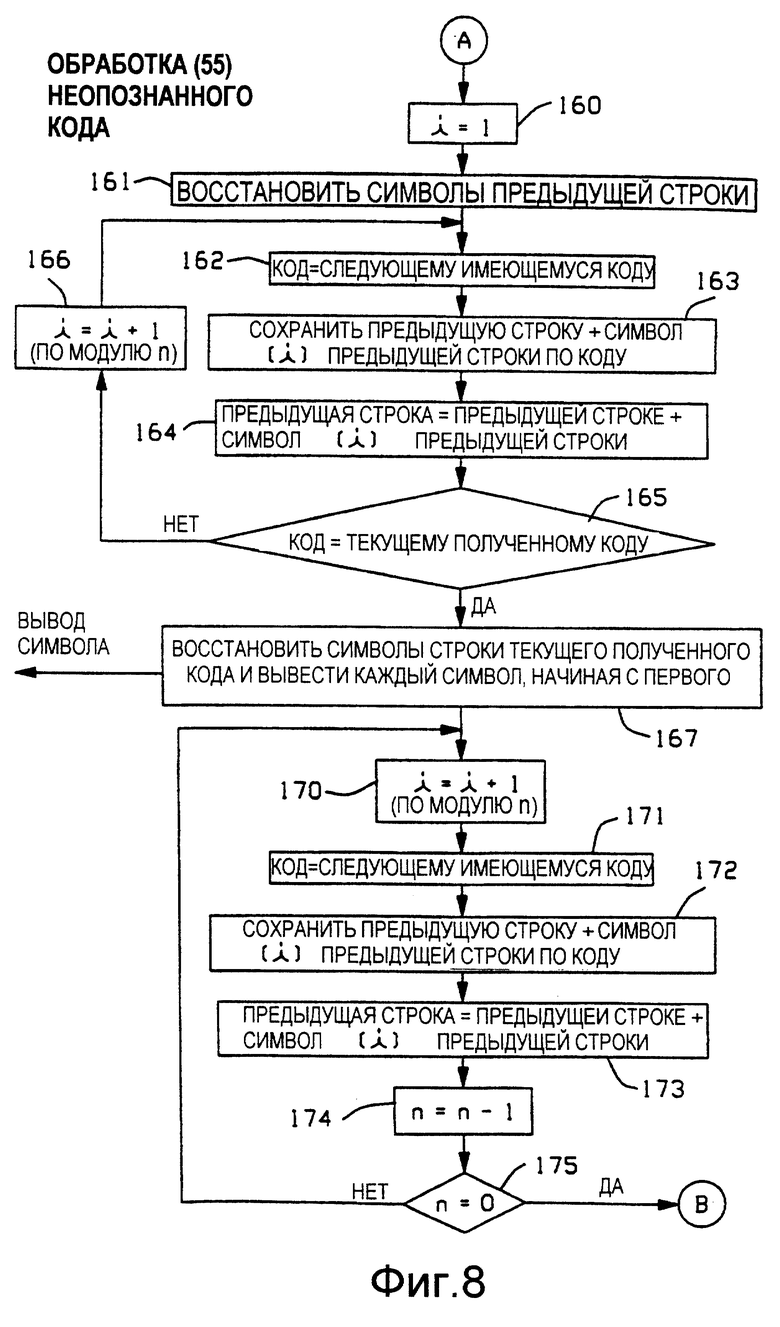
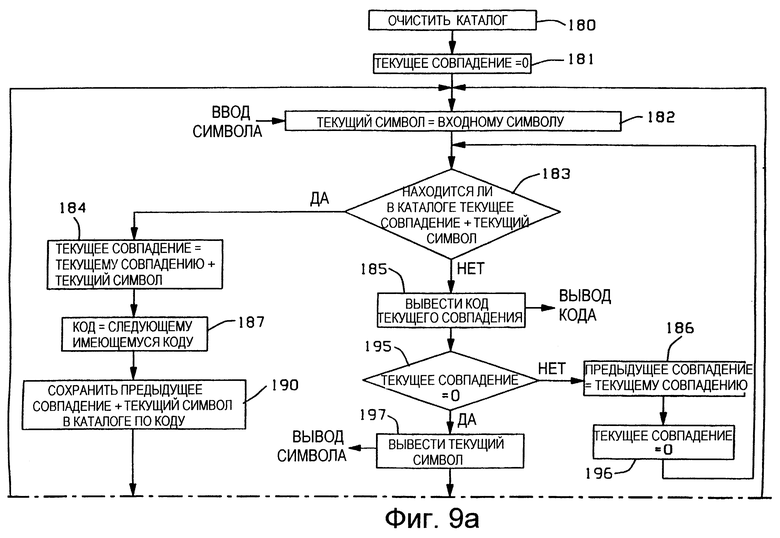
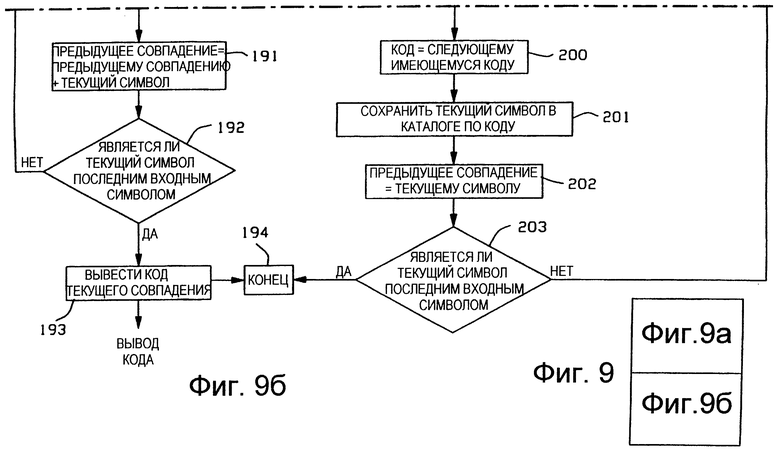
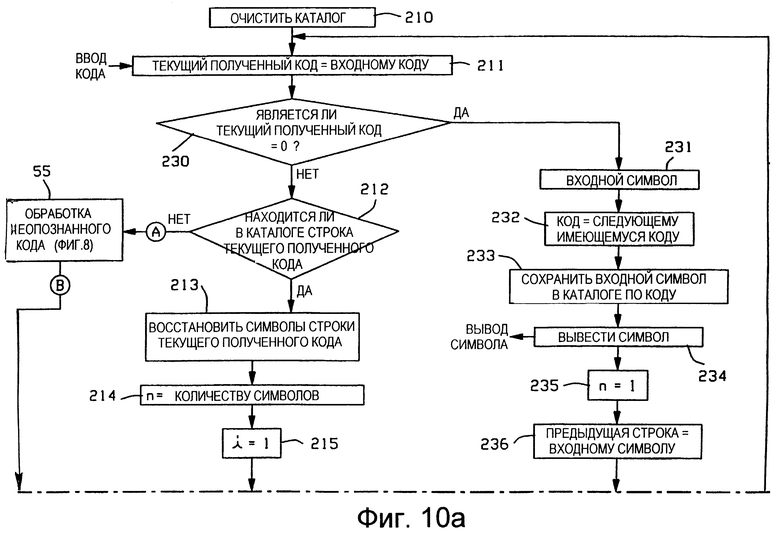
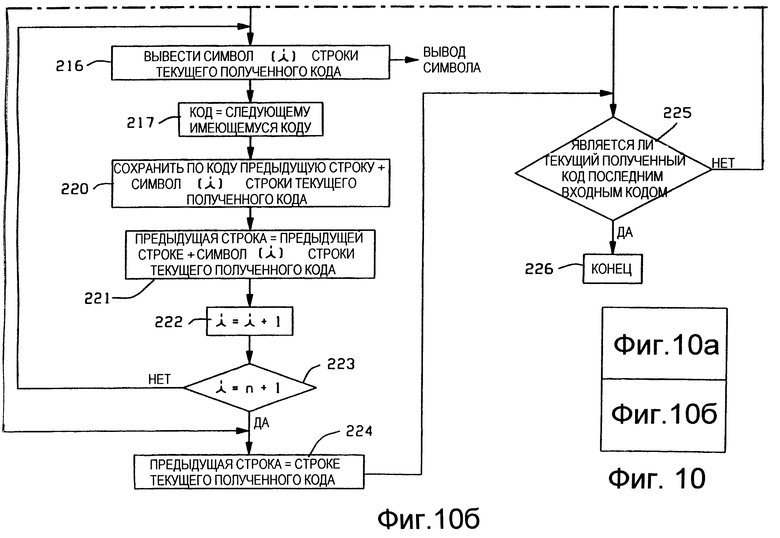
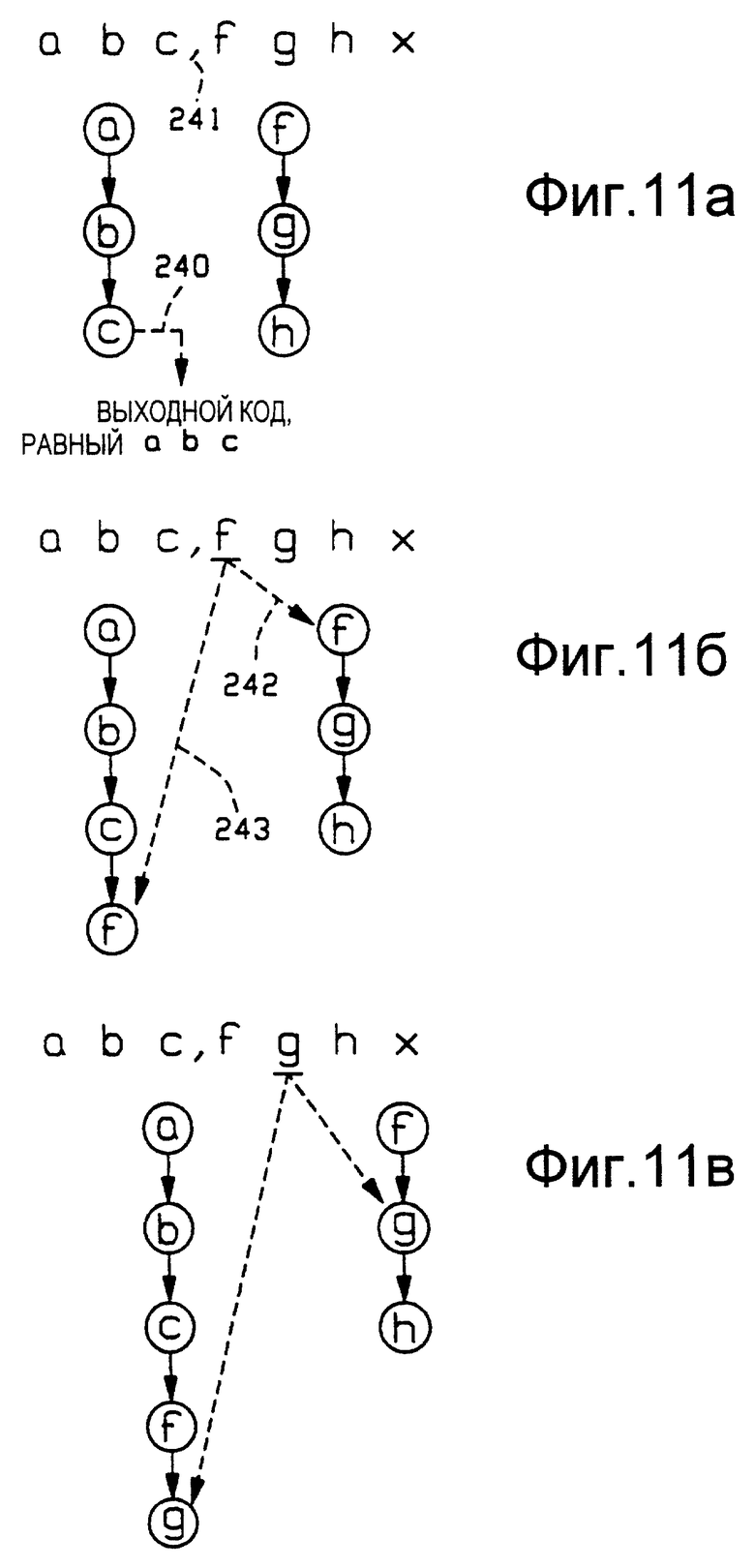
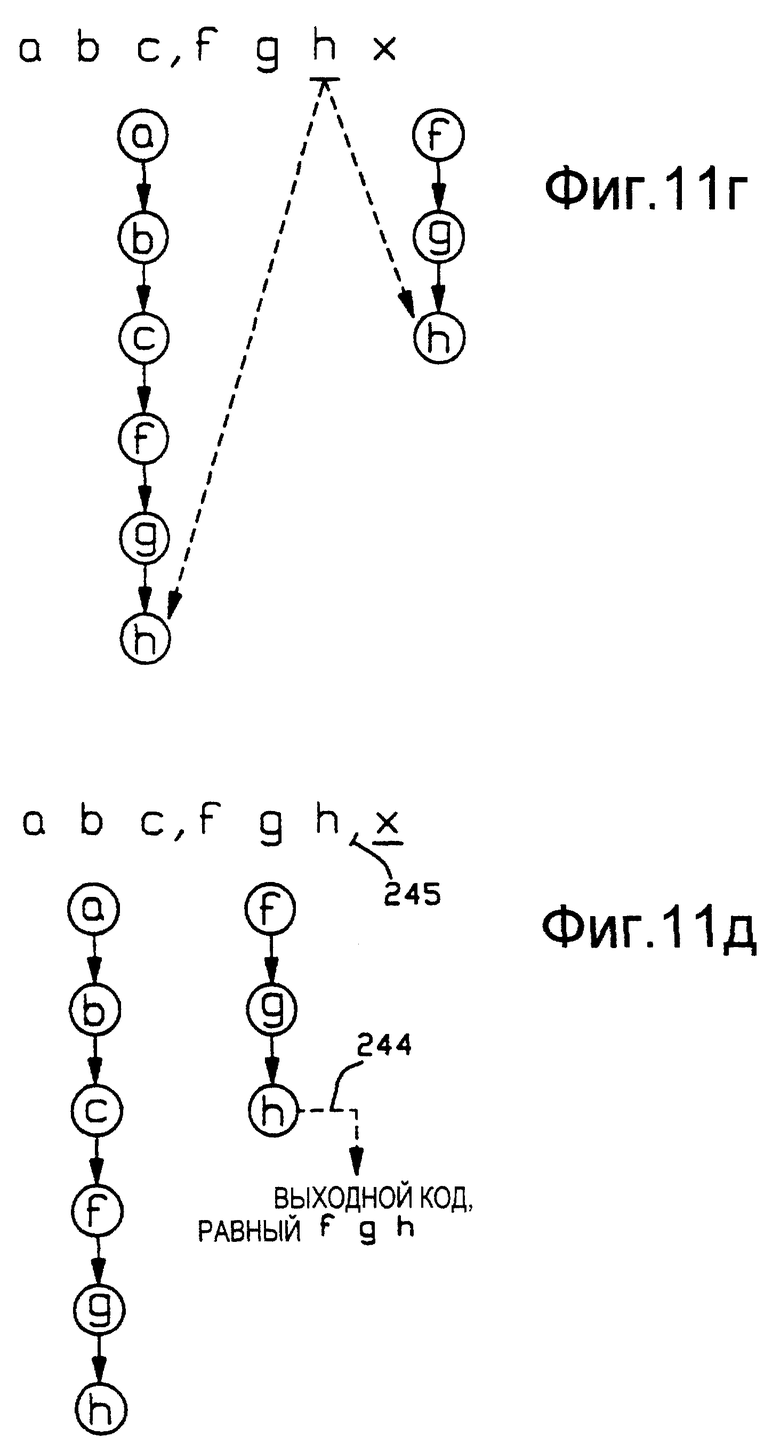
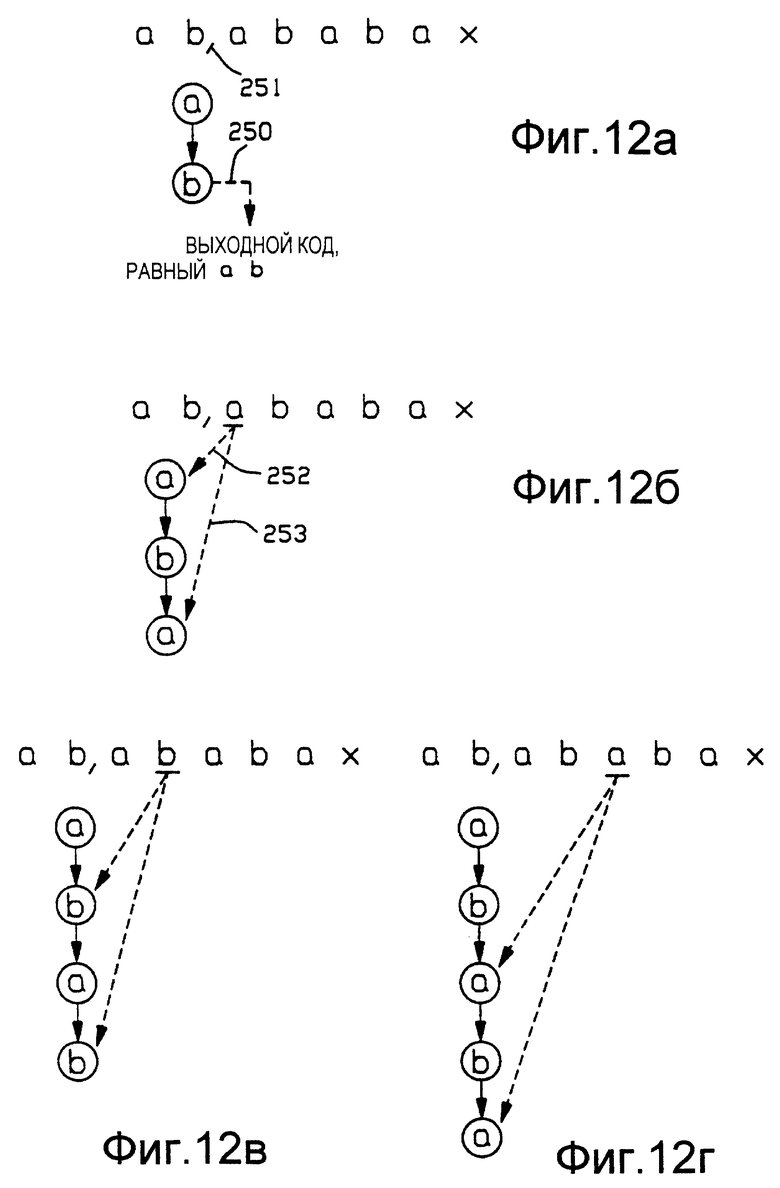
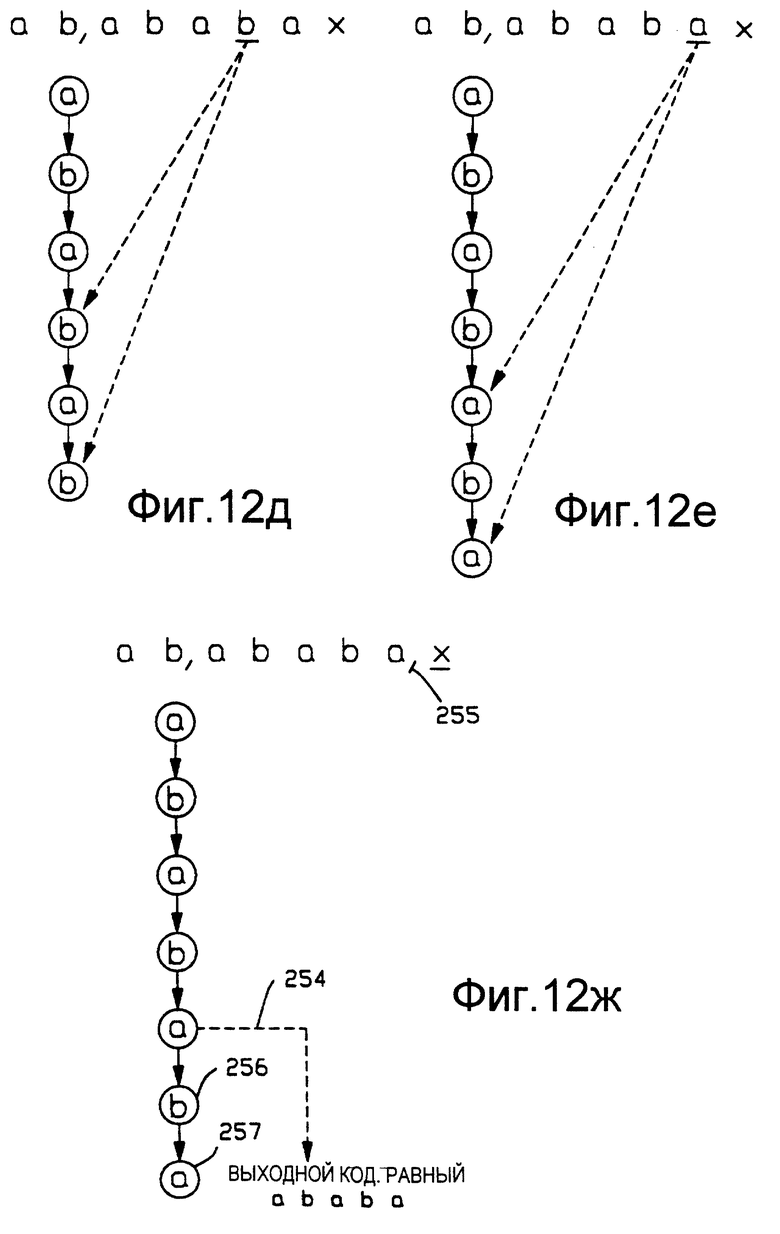
Изобретение относится к уплотнению и разуплотнению данных с использованием каталогов, в частности к методу, которым осуществляют обновление каталогов уплотнения и разуплотнения. Технический результат - повышение точности передачи данных. Для этого в системе уплотнения и разуплотнения данных на основании каталога, в которой, когда в устройстве уплотнения неполная строка W и символ С в каталоге совпадают, в каталог вводят новую строку, имеющую С в качестве символа расширения строки PW, где Р является строкой, соответствующей последнему выведенному сигналу с уплотненным кодом. Строку обновления вводят в каталог уплотнения для каждого считанного и совпавшего входного символа. Обновление является непосредственным, и его чередуют с операцией поиска посимвольного совпадения для текущей строки. Процесс обновления продолжают до тех пор, пока в каталоге не найдено совпадение наибольшей длины. Вывод кода строки, имеющей совпадение наибольшей длины, осуществляют в цикле поиска совпадений строк. Если в каталоге существуют одиночный символ или состоящая из многих символов строка А, то кодирование строки ААА...А осуществляют посредством двух сигналов с уплотненным кодом вне зависимости от длины строки. Это кодирование приводит к появлению в устройстве разуплотнения сигнала неопознанного кода. В ответ на сигнал неопознанного кода устройство разуплотнения осуществляет ввод в каталог устройства разуплотнения строки обновления в соответствии с восстановленной строкой, которая соответствует сигналу предыдущего полученного кода, сигналу неопознанного кода, существующему коду устройства разуплотнения и количеству символов предыдущей восстановленной строки. 4 с. и 34 з.п. ф-лы, 31 ил.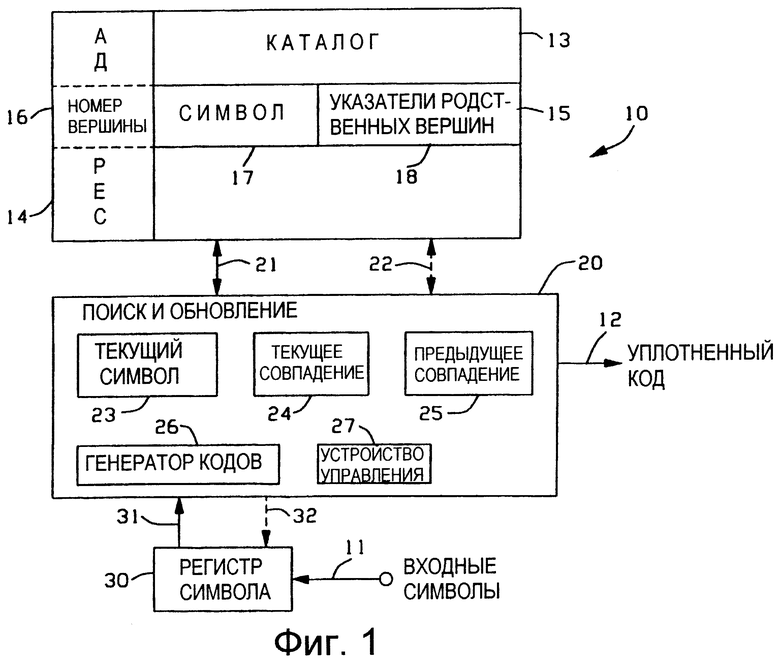
| СПОСОБ ЗАПУСКА ГАЗОТУРБИННЫХ ДВИГАТЕЛЕЙ МНОГОДВИГАТЕЛЬНОГО ЛЕТАТЕЛЬНОГО АППАРАТА | 2004 |
|
RU2277179C2 |
| Устройство для кодирования и декодирования цифрового телевизионного сигнала | 1988 |
|
SU1566485A1 |
| US 5253325 А, 12.10.1993 | |||
| US 4876541 А, 24.10.1989 | |||
| US 4814746 А, 21.03.1989 | |||
| УСТРОЙСТВО для ГРУБОГО ВЫДЕЛЕНИЯ ОСНОВНОГО ТОНА РЕЧЕВОГО СИГНАЛА | 0 |
|
SU280549A1 |
| Соединение труб | 1959 |
|
SU129439A1 |
| Устройство для регистрации нагрузки | 1958 |
|
SU127815A1 |

