Перекрестная ссылка на родственные заявки
Эта заявка испрашивает приоритет и преимущество предварительной заявки на патент США № 62/580056, озаглавленной «Methods and Apparatus for Efficiently Implementing a Distributed Database within a Network», поданной 1 ноября 2017 г., раскрытие которой включено в настоящий документ посредством ссылки во всей своей полноте.
Предпосылки изобретения
Варианты осуществления, описанные в настоящем документе, относятся в целом к способам и устройствам для реализации системы базы данных повышенной эффективности.
Сущность изобретения
В некоторых вариантах осуществления устройство базы данных, поддерживающей быстрое копирование, содержит процессор и запоминающее устройство, находящееся в электронной связи с процессором. Запоминающее устройство хранит таблицу базы данных со множеством записей, каждая из которых имеет составной ключ, содержащий идентификатор версии. Запоминающее устройство также хранит инструкции, исполняемые для предписания процессору сгенерировать первый виртуальный клон таблицы базы данных и второй виртуальный клон таблицы базы данных, принять запрос в первом виртуальном клоне и модифицировать запрос так, что запрос содержит идентификатор версии первого виртуального клона. Процессор может запрашивать таблицу базы данных с использованием модифицированного запроса для генерирования ответа на основе отчасти каждой записи из набора записей, имеющих идентификатор версии, связанный с предковым путем идентификатора версии первого виртуального клона, и отправлять ответ. Каждый составной ключ содержит идентификатор версии и часть данных.
Краткие описания графических материалов
Фиг. 1 – структурная схема, на которой проиллюстрирована система для реализации базы данных, поддерживающей быстрое копирование, согласно варианту осуществления.
Фиг. 2A – схема, демонстрирующая иерархическое дерево, поддерживающее запросы, и связанную таблицу базы данных согласно варианту осуществления.
Фиг. 2B – схема, демонстрирующая иерархическое дерево, поддерживающее запросы, и связанную таблицу базы данных с примененным принудительно ограничением конфликта согласно варианту осуществления.
Фиг. 3A – блок-схема, на которой проиллюстрирован способ генерирования виртуальных клонов иерархического дерева и взаимодействия с ними согласно варианту осуществления.
Фиг. 3B включает в себя ряд схем, на которых проиллюстрированы временная эволюция таблицы базы данных и взаимодействие с ней с помощью иерархического дерева по фиг. 3A.
Фиг. 4A–4F включают в себя схемы, на которых проиллюстрированы временная эволюция иерархического дерева, включая представления виртуальных клонов, и связанная таблица базы данных согласно варианту осуществления.
Фиг. 4G включает в себя схему, на которой проиллюстрирован процесс запрашивания согласно варианту осуществления.
Фиг. 5 включает в себя ряд схем, на которых проиллюстрирован процесс инкрементальной сборки мусора согласно варианту осуществления.
Фиг. 6 – технологическая блок-схема для реализованного процессором способа сборки мусора (или каскадного удаления) для базы данных с быстрым копированием согласно варианту осуществления.
Фиг. 7 – технологическая блок-схема для реализованного процессором способа сборки мусора (или каскадного удаления) для базы данных с быстрым копированием согласно варианту осуществления.
Фиг. 8A–8D – схемы, на которых проиллюстрирована реализация системы базы данных, поддерживающей быстрое копирование, согласно варианту осуществления.
Фиг. 9 включает в себя ряд схем, на которых проиллюстрированы операции быстрого копирования согласно варианту осуществления.
Подробное описание изобретения
Высокоэффективные системы базы данных согласно настоящему изобретению содержат одну или более физических реляционных баз данных (включающих в себя «таблицу базы данных» и/или используемых в настоящем документе взаимозаменяемо с ними), каждая из которых хранится на энергонезависимом считываемом процессором запоминающем устройстве, и одно или более связанных динамических иерархических деревьев, каждое из которых содержит множество виртуальных клонов, посредством которых может быть осуществлен доступ к данным реляционной базы данных или они могут быть модифицированы при предопределенных условиях и/или в рамках предварительно определенных периодов времени. Способы реализации базы данных и управления ею, изложенные в настоящем документе, значительно быстрее и эффективнее, чем известные способы репликации базы данных и взаимодействия с ней. Реляционные базы данных, описанные в настоящем документе, при реализации согласно настоящему изобретению могут быть названы «поддерживающими быстрое копирование», поскольку много разных «копий» могут быть быстро созданы и/или определены путем создания экземпляра нового виртуального клона, где каждая отличная «копия» относится к «виртуальной» копии – содержимому, воспринимаемому с точки зрения и доступному от отличного связанного виртуального клона. Иначе говоря, можно сказать, что реляционная база данных «обертывается» в класс, который преобразует реляционную базу данных в базу данных, поддерживающую быстрое копирование.
В некоторых реализациях высокоэффективные системы базы данных согласно настоящему изобретению могут быть описаны как «не имеющие лидера» в том смысле, что имеются множество физических реляционных баз данных (т. е. «экземпляров» реляционной базы данных) со связанными динамическими иерархическими деревьями во множестве связанных географически рассредоточенных мест, причем факультативно каждая из них имеет отличного связанного администратора, но не имеется централизованной копии, представляющей собой «ведущего» или «лидера», реляционной базы данных. Другими словами, разные изменения могут быть применены в разных порядках и/или в разные моменты времени в каждой из множества физических реляционных баз данных. Отсутствие лидера в системе распределенной базы данных может повысить безопасность системы распределенной базы данных. Например, при наличии лидера существует единая точка атаки и/или сбоя. Если вредоносное программное обеспечение заражает лидера и/или значение в таблице базы данных лидера изменяют со злым умыслом так, что оно имеет неправильное значение, инфекция и/или неправильное значение могут распространяться по всей сети экземпляров базы данных или могут быть переданы в другой экземпляр распределенной базы данных. В противоположность этому, в системах, не имеющих лидера, согласно настоящему изобретению отсутствует единая точка атаки и/или сбоя. Системы распределенной базы данных, не имеющей лидера, описанные в настоящем документе, могут также повышать скорость конвергенции одного или более алгоритмов консенсуса, уменьшая при этом количество данных, передаваемых между устройствами. Системы распределенной базы данных, описанные в настоящем документе, также являются «поддерживающими быстрое копирование» посредством генерирования виртуальных клонов, которые могут быть использованы для отслеживания разнородных постепенных изменений в отношении содержимого таблицы базы данных. В контексте настоящего документа «быстрая копия» имеет то же значение, что и фраза «виртуальный клон». Поэтому, в отличие от некоторой известной распределенной базы данных, обновления могут быть осуществлены без использования репликации и дублирования, которые могут быть ресурсоемкими и трудоемкими, особенно когда объем данных, которыми управляют, является большим.
В некоторых вариантах осуществления каждый виртуальный клон из набора виртуальных клонов иерархического дерева может выступать в качестве «виртуальной базы данных», в которой доступ к данным реляционной базы данных может быть осуществлен пользователем (например, с помощью запросов), взаимодействующим с тем виртуальным клоном, так, что тому пользователю кажется, что данные хранятся и/или их поиск осуществляется локально в том виртуальном клоне, хотя это не так (т. е. сохранение и запрашивание происходит в реляционной базе данных / таблице). Модификации в отношении таблицы данных реляционной базы данных могут быть применены во множестве виртуальных клонов из набора виртуальных клонов и могут быть связаны с тем виртуальным клоном в рамках реляционной базы данных с использованием «составного ключа» (например, с использованием атрибута, добавляемого в таблицу базы данных, плюс поля существующего ключа таблицы базы данных). Составной ключ может содержать по меньшей мере два значения: идентификатор версии («ID версии»), связанный с по меньшей мере одним виртуальным клоном, и поле, которое относится к свойству таблицы базы данных, на которую ссылаются (например, идентификатору или имени строки (т. е. «записей» или «кортежей»), идентификатору или имени столбца (т. е. «атрибута»), метке данных, значению данных и т. д.), такое как то поле существующего ключа таблицы базы данных (также называемое в настоящем документе «полем виртуального первичного ключа»). Примерные атрибуты включают, но без ограничения, имя виртуального первичного ключа, значение (например, баланс, дебет, кредит, сумму перевода), валюту, описание, дату, количество, счет, версию, продолжительность, порядок и т. д. Части составных ключей могут храниться как часть записей таблицы базы данных, так что правки, осуществляемые одним виртуальным клоном, не влияют на данные таблицы базы данных с точки зрения любого другого виртуального клона. В некоторых вариантах осуществления множеству экземпляров заданного составного ключа не разрешается сосуществовать в рамках таблицы базы данных в любой заданный момент времени (т. е. может иметься только один экземпляр заданного составного ключа в рамках таблицы базы данных). Модификации в отношении таблицы данных реляционной базы данных, осуществляемые конкретным виртуальным клоном, связаны с тем виртуальным клоном с помощью идентификатора версии того виртуального клона, так что последующие запросы или модификации, осуществляемые с помощью того виртуального клона, могут быть применены к более поздней форме реляционной базы данных, как определено совокупными взаимодействиями, осуществляемыми в отношении таблицы базы данных с помощью тех виртуального клона / ID версии. Однако модификации в отношении таблицы базы данных, осуществляемые конкретным виртуальным клоном, незаметны или недоступны с точки зрения других виртуальных клонов. Реализация изменений этим распределенным образом с отнесением изменений к связанным модифицирующим виртуальным клонам изменений на основе связанных ID версии виртуальных клонов устраняет необходимость в репликации, распределении и локальном хранении (например, в каждом из набора узлов сервера, в которых размещаются виртуальные клоны) множества копий данных каждой реляционной базы данных. Способы, изложенные в настоящем документе, могут устранять необходимость в передаче всего содержимого реляционной базы данных множество раз на многие машины в ответ на каждое изменение, выполненное каждой машиной, находящейся в сетевой связи с ней.
Система базы данных, поддерживающей быстрое копирование
Фиг. 1 – схема системы, на которой показаны компоненты системы 100 базы данных, поддерживающей быстрое копирование, согласно некоторым вариантам осуществления. Как показано на фиг. 1, система 100 содержит первое вычислительное устройство 110, находящееся в беспроводной или проводной связи с сетью 105, и одно или более дополнительных вычислительных устройств 120, которые также находятся в беспроводной или проводной связи с сетью 105. Первое вычислительное устройство 110 содержит процессор 111, находящийся в действующей связи со встроенным запоминающим устройством 112, и дисплей 113. Запоминающее устройство 112 хранит одну или более таблиц 114 базы данных (т. е. экземпляр (экземпляры) реляционной базы данных), программу 115 быстрого копирования и инструкции 116 консенсуса (например, которые предписывают процессору реализовать алгоритм консенсуса). Каждая таблица 114 базы данных содержит один или более составных ключей 114A, описанных более подробно ниже. Каждое вычислительное устройство из одного или более дополнительных вычислительных устройств 120 содержит процессор 121, находящийся в действующей связи со встроенным запоминающим устройством 122, и факультативно один или более интерфейсов (например, дисплей, графический пользовательский интерфейс (GUI), беспроводной приемопередатчик и т. д.) (не показаны). Запоминающее устройство 122 содержит одну или более таблиц 124 базы данных (т. е. экземпляр (экземпляры) реляционной базы данных), программу 125 быстрого копирования и инструкции 126 консенсуса (например, которые предписывают процессору реализовать алгоритм консенсуса).
Каждый из процессоров 111 и 121 может содержать одно или более из: процессора общего назначения, центрального процессорного устройства (CPU), микропроцессора, процессора цифровой обработки сигналов (DSP), контроллера, микроконтроллера, конечного автомата и/или т. п. При некоторых обстоятельствах «процессор» в контексте настоящего документа может относиться к интегральной схеме специального назначения (ASIC), программируемому логическому устройству (PLD), программируемой пользователем вентильной матрице (FPGA) и т. д. Термин «процессор» может относиться к комбинации обрабатывающих устройств, например, комбинации DSP и микропроцессора, множеству микропроцессоров, одному или более микропроцессорам в сочетании с ядром DSP или любой другой такой конфигурации.
Каждое из запоминающих устройств 112 и 122 может содержать любой электронный компонент, который может хранить электронную информацию, такую как данные и код (например, инструкции). Термин «запоминающее устройство» может относиться к различным типам энергонезависимых считываемых процессором носителей, таким как оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), неразрушающееся оперативное запоминающее устройство (NVRAM), программируемое постоянное запоминающее устройство (PROM), стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое PROM (EEPROM), флеш-память, магнитное или оптическое хранилище данных, регистры и т. д. Запоминающее устройство находится в так называемой действующей или электронной связи с процессором, если процессор может считывать информацию с запоминающего устройства и/или записывать информацию на него. Запоминающее устройство, которое является неотъемлемой частью процессора, находится в электронной связи с процессором. Примеры энергонезависимых машиночитаемых носителей включают, но без ограничения, магнитные носители данных, такие как жесткие диски, гибкие диски и магнитная лента; оптические носители данных, такие как компакт-диск / цифровые видеодиски (CD/DVD), постоянные запоминающие устройства на компакт-дисках (CD-ROM) и голографические устройства; магнитооптические носители данных, такие как оптические диски; процессоры обработки сигналов несущей частоты; и аппаратные устройства, которые специально приспособлены для хранения и исполнения программного кода, такие как интегральные схемы специального назначения (ASIC), программируемые логические устройства (PLD), постоянные запоминающие устройства (ROM) и оперативные запоминающие устройства (RAM). Другие варианты осуществления, описанные в настоящем документе, относятся к компьютерному программному продукту, который может содержать, например, инструкции и/или компьютерный код, обсуждаемые в настоящем документе.
Системы базы данных, поддерживающей быстрое копирование, согласно настоящему изобретению могут быть реализованы в некоторых вариантах осуществления как аппаратное обеспечение или как программное обеспечение, например, «программа быстрого копирования», как показано и описано ниже со ссылкой на фиг. 1, или другая форма программного обеспечения, хранящегося на энергонезависимом запоминающем устройстве и содержащего инструкции, исполняемые процессором, находящимся в действующей связи с запоминающим устройством. Запоминающее устройство может также хранить реляционную базу данных (и/или процессор может осуществлять доступ к ней). Программа быстрого копирования может представлять собой «класс-обертку» (также называемый «паттерном-оберткой» или «функцией-оберткой»), который «обертывает» реляционную базу данных, с которой он связан. Например, когда программное обеспечение запускается, и запрос на языке структурированных запросов (SQL) принимается на процессоре, процессор может отправлять/пересылать запрос на SQL в реляционную базу данных путем вызова способа в классе-обертке, который может модифицировать запрос перед отправкой запроса в реляционную базу данных. Результаты, возвращенные реляционной базой данных в ответ на запрос на SQL, могут затем быть возвращены/отправлены с применением способа в класс-обертку. Программное обеспечение быстрого копирования может быть приспособлено для выполнения одного или более из следующего в любой комбинации: перехвата вызовов, поступающих в реляционную базу данных, перехвата вызовов, исходящих из реляционной базы данных, добавления поля в реляционную базу данных (например, «версии», как обсуждено ниже), модификации поля реляционной базы данных, удаления поля реляционной базы данных, модификации структуры реляционной базы данных (например, добавления или исключения записи/строки или атрибута/столбца) или любой функции, показанной и описанной ниже со ссылкой на фиг. 2–7.
В некоторых вариантах осуществления система базы данных, поддерживающей быстрое копирование, содержит одну машину (или «узел») или множество машин или «узлов», каждые из которых содержат процессор, действующим образом соединенный с энергонезависимым запоминающим устройством, на котором размещается экземпляр реляционной базы данных и программное обеспечение быстрого копирования. Изначально (т. е. перед применением каких-либо изменений) каждый экземпляр реляционной базы данных является одинаковым. Узлы могут быть географически отделены друг от друга и/или связаны с разными лицами, представляющими собой администраторов, и/или субъектами. Каждый узел может генерировать и/или хранить связанное иерархическое дерево и/или последующие части иерархического дерева (или представление иерархического дерева), включая один или более виртуальных клонов (также называемых в настоящем документе «объектами» или «виртуальными объектами»), посредством которых может быть модифицирована реляционная база данных и/или может быть отправлен в нее запрос. Генерирование иерархического дерева может быть выполнено множество раз по мере расширения и/или модификации основного иерархического дерева. Например, каждый узел может генерировать по меньшей мере два виртуальных клона – первый виртуальный клон и второй виртуальный клон. Первый виртуальный клон может быть использован для применения изменений к полям реляционной базы данных, например, по мере приема в том узле данных об активности (например, с другого узла). Эти изменения могут быть применены автоматически и/или администратором, например, в ответ на прием данных об активности и/или на основе данных об активности. Данные об активности могут содержать данные, относящиеся к одному или более событиям или транзакциям, происходящим или предположительно произошедшим в рамках сети узлов, в отношении которых принимающий узел является участником. Изменения, применяемые первым виртуальным клоном, могут быть просмотрены как совместно представляющие «промежуточный счет» данных об активности при приеме, связанных с одной или более транзакциями или событиями.
В некоторых реализациях данные об активности принимаются в заданном узле вследствие события «синхронизации», инициированного одним или более узлами и/или автоматически реализованного программным обеспечением быстрого копирования (например, запущенного благодаря обнаруженному изменению в рамках сети узлов и/или согласно предварительно определенной временной схеме). Во время синхронизации по меньшей мере два узла из сети узлов обмениваются данными из своих связанных таблиц базы данных. Данные могут представлять собой, например, данные об активности или их часть. Данные, обмен которыми происходит между/среди по меньшей мере двух узлов, могут представлять поднабор или частичный вид общей активности в рамках сети узлов. В некоторых таких случаях изменения, применяемые к таблице базы данных узла с помощью первого виртуального клона, представляют собой «предварительные изменения», последовательность консенсуса и/или достоверность которых не были достигнуты, и/или определение того, отсутствуют ли промежуточные изменения в таблице базы данных, еще не было осуществлено (т. е. консенсус еще не был достигнут/удовлетворен для тех изменений). Записи в рамках таблицы базы данных, которые модифицируются в узле с помощью первого виртуального клона, могут содержать составной ключ, который содержит первый ID версии, связанный с первым виртуальным клоном.
В некоторых реализациях процесс синхронизации включает (1) многократное обновление «текущего состояния» таблицы базы данных (например, зафиксированного переменной состояния базы данных, определенной узлом) на основе одного или более событий (например, включая одну или более транзакций) или транзакций, которые принимаются во время синхронизации, и (2) многократное перестраивание того текущего состояния (например, перестановку порядка событий) каждый раз, когда принимают новую информацию об упорядочении событий или транзакций, например, посредством возвращения к копии более раннего состояния и повторного вычисления текущего состояния путем обработки событий или транзакций в новом порядке. Таким образом, например, каждое вычислительное устройство может поддерживать две версии состояния – одну, обновляемую по мере того, как принимают новые события и транзакции (например, как воплощено первым виртуальным клоном, обсужденным выше), и другую, обновляемую только после того, как будет достигнут консенсус (например, как воплощено вторым виртуальным клоном, обсужденным выше). В некоторый момент времени (например, по истечении предопределенного периода времени, после того как предопределенное количество событий было определено и/или принято, и т. д.) версия состояния, которую обновляют по мере того, как принимают новые события и транзакции, может быть убрана или удалена из иерархического дерева, и новая копия состояния, которую обновляют после того, как будет достигнут консенсус, может быть сгенерирована в качестве новой версии состояния, которую обновляют по мере того, как принимают новые события и транзакции (например, как воплощено третьим виртуальным клоном, обсужденным выше). Вышеизложенный подход может обеспечить синхронизацию обоих состояний. В некоторых случаях состояние (включая разные копии состояния) может храниться в любой подходящей структуре данных, такой как, например, arrayList, «поддерживающий быстрое копирование» (также называемый в настоящем документе arrayList с быстрым клонированием, массивом с быстрым клонированием или массивом, поддерживающим быстрое копирование), хеш-таблица, «поддерживающая быстрое копирование», реляционная база данных, «поддерживающая быстрое копирование», или система файлов, «поддерживающая быстрое копирование» (также называемая в настоящем документе системой файлов с быстрым клонированием и/или файловой системой, поддерживающей быстрое копирование), факультативно с отдельным файлом, создаваемым и/или определяемым в базовой операционной системе для каждой N-байтной (например, 4096-байтной или 1024-байтной) части файла в системе файлов, поддерживающей быстрое копирование.
В контексте настоящего документа «консенсус» относится к определению, достигаемому с использованием алгоритма консенсуса, того, что одно или более изменений, рассматриваемых алгоритмом консенсуса, правильно упорядочены, не являются дубликатами, в них не отсутствуют никакие промежуточные изменения и/или они являются законными (т. е. не являются злонамеренными или мошенническими). Можно сказать, что консенсуса достигают, например, когда все из или по меньшей мере предварительно определенное пороговое количество узлов соглашаются или приходят к заключению с по меньшей мере предварительно определенным пороговым уровнем определенности, что изменения правильно упорядочены, не являются дубликатами, в них не отсутствуют никакие промежуточные изменения и/или они являются подлинными. Например, можно сказать, что последовательность изменений, для которых был достигнут консенсус, отражает «истинное» или верное представление последовательности событий и/или транзакций. В некоторых реализациях консенсус достигается в «раундах», в рамках предопределенного интервала времени, после предопределенного количества итераций алгоритма консенсуса и/или согласно предварительно определенной схеме.
После достижения консенсуса для изменения или набора изменений, применяемых с помощью первого виртуального клона, те изменение или набор изменений могут быть применены к таблице базы данных с помощью второго виртуального клона, и каждая задействованная запись таблицы базы данных может соответственно содержать составной ключ, который содержит второй ID версии, связанный со вторым виртуальным клоном. После того как изменение или набор изменений смогут быть применены к таблице базы данных с помощью второго виртуального клона и факультативно автоматически и/или в ответ на те применяемые изменения, первый виртуальный клон может быть удален, и по меньшей мере два дополнительных виртуальных клона (например, третий виртуальный клон и четвертый виртуальный клон), которые являются потомками второго виртуального клона, могут быть сгенерированы. Процесс быстрого копирования может затем продолжаться с осуществлением предварительных изменений в отношении таблицы базы данных с помощью третьего виртуального клона и с осуществлением изменений после консенсуса в отношении таблицы базы данных с помощью четвертого виртуального клона таким образом, который подобен описанному выше.
В некоторых реализациях алгоритм консенсуса или способ может быть реализован платформой (т. е. программой, реализованной программно, исполняемой на процессоре вычислительного устройства и/или системы, такой как инструкции 116 консенсуса, хранящиеся на запоминающем устройстве 112 и исполняемые процессором 111 вычислительного устройства 110 по фиг. 1). Платформа может собирать, распространять, упорядочивать транзакции и выполнять другие подходящие задачи, связанные с процессами достижения консенсуса.
В некоторых реализациях запросы больше не могут осуществляться с помощью виртуального клона и/или его связанного узла, после того как один или более узлов-потомков, зависящих от него (т. е. проходящих непосредственно от него, двигаясь вниз по иерархическому дереву), были сгенерированы, даже если и после того как один или более узлов-потомков были удалены или исключены из иерархического дерева.
В некоторых реализациях в одну или более таблиц базы данных согласно настоящему изобретению может быть отправлен запрос с помощью одного или более виртуальных клонов. На фиг. 2A и фиг. 2B показаны схемы иерархического дерева, поддерживающего запросы (также называемого в настоящем документе «деревом версий»), согласно варианту осуществления. В некоторых реализациях иерархическое дерево (также называемое в настоящем документе «деревом версий») и/или представление иерархического дерева содержатся и/или хранятся на энергонезависимом запоминающем устройстве. Как показано на фиг. 2A и фиг. 2B, иерархическое дерево, поддерживающее запросы, содержит экземпляр 230 реляционной базы данных и множество его виртуальных клонов V1, V2, V3 и V4. Последовательное представление виртуальных клонов V1, V2 и V3 указывает на то, что виртуальный клон V1 был сгенерирован первым (и факультативно изменения были осуществлены в отношении базы 230 данных с помощью V1), виртуальный клон V2 (виртуальный клон-«потомок» клона V1) был сгенерирован вторым (и факультативно изменения были осуществлены в отношении базы 230 данных с помощью V2) и виртуальный клон V3 (виртуальный клон-«потомок» клона V2) был сгенерирован третьим (и факультативно изменения были осуществлены в отношении базы 230 данных с помощью V3). V3 представляет собой «листовой узел», так как V3 не имеет узлов-детей, проходящих/зависящих от V3. Следует отметить, что в некоторых реализациях после генерирования виртуального клона-потомка изменения в отношении базы 230 данных больше не могут осуществляться с помощью виртуальных клонов-предков, от которых тот непосредственно произошел. Другими словами, после генерирования виртуального клона V3 изменения в отношении базы 230 данных больше не могут применяться с помощью виртуального клона V2 или виртуального клона V1.
В варианте осуществления (показанном на фиг. 2A) запрос, принимаемый в V3, может быть реализован/выполнен последовательным образом, как изложено ниже. Предположим, что база 230 данных содержит запись, имеющую тот же виртуальный первичный ключ, что и версия-предок той записи (также в базе 230 данных). Например, таблица базы данных по фиг. 2A содержит ID записи (RID) атрибутов (виртуальный первичный ключ), имя, ранг и версию, и имеются: (1) запись в базе 230 данных с составным ключом (1001, V3), (2) запись в базе 230 данных с составным ключом (1001, V2) и (3) запись в базе 230 данных с составным ключом (1001, V1). В такой реализации, если дерево версий является таким, как показано на фиг. 2A (где V3 – виртуальный клон-потомок клона V2, и V2 – виртуальный клон-потомок клона V1), и запрос виртуального первичного ключа RID=1001 принимается с помощью виртуального клона V3, процессор будет сначала осуществлять поиск записи с составным ключом, представленным как (1001, V3). Если запись находят с таким составным ключом (что и происходит в примере по фиг. 2A), эту запись возвращают, а запрос завершается. Однако, если запись не была найдена в базе 230 данных с составным ключом (1001, V3) на основе дерева версий, процессор будет далее запрашивать из базы 230 данных составной ключ (1001, V2). Если запись находят в базе 230 данных с таким составным ключом, ту запись возвращают, а запрос завершается. В ином случае процессор запрашивает из базы 230 данных составной ключ (1001, V1). Таким образом, запрос может быть выполнен путем осуществления сначала ссылки на версию с наивысшим номером в дереве версий и постепенного/последовательного прохождения вверх по дереву версий, если результаты не возвращаются. Вышеизложенный процесс запроса может быть описан как процесс запроса, в котором ограничение конфликта не применено принудительно. Другими словами, записи могут сосуществовать в рамках базы 230 данных, имеющей составные ключи с одним и тем же виртуальным первичным ключом и ID версии в рамках одной и той же предковой цепочки/ветви иерархического дерева.
Если вместо этого, учитывая иерархическое дерево, показанное на фиг. 2A, запрос виртуального первичного ключа 1001 принимается с помощью виртуального клона V4 (виртуального клона-потомка клона V1), процессор будет сначала осуществлять поиск записи с составным ключом, представленным как (1001, V4). Если запись находят с таким составным ключом (что и происходит в примере по фиг. 2A), эту запись возвращают, а запрос завершается. Однако, если запись не была найдена в базе 230 данных с составным ключом (1001, V4) на основе дерева версий, процессор будет далее запрашивать из базы 230 данных составной ключ (1001, V1), поскольку V1 является виртуальным клоном-предком клона V4. Если запись находят в базе 230 данных с таким составным ключом, ту запись возвращают, а запрос завершается. В ином случае процессор возвращает такой ответ, как «нуль» или «результаты не найдены».
Хотя вышеизложенное описание относится к запросам виртуального первичного ключа, запросы могут быть структурированы широким множеством других способов. Например, запрос может требовать все записи, имеющие значение для специфицированного атрибута (например, все записи, имеющие значение для атрибута «имя», представленное как «Смит»), все записи, соответствующие значениям для двух или более специфицированных атрибутов (например, все записи, имеющие значение для атрибута «имя», представленное как «Смит», и ранг «4»), все записи, имеющие специфицированный первичный виртуальный ключ и значение для специфицированного атрибута (например, все записи, имеющие первичный виртуальный ключ «1001» и значение для атрибута «имя», представленное как «Смит»), и т. д. В некоторых реализациях запрос не содержит ссылку на виртуальный первичный ключ.
В другом варианте осуществления (показанном на фиг. 2B), запрос, принимаемый в V3, может быть реализован/выполнен с примененным принудительно ограничением конфликта. Ограничение конфликта может содержать правило, специфицирующее, что для заданного составного ключа, содержащего виртуальный первичный ключ и ID версии для виртуального клона «X», не существует другого составного ключа, присутствующего в базе 230 данных, имеющего тот же самый виртуальный первичный ключ и ID версии, который связан с предком клона X, и/или архитектуру базы данных, которая предписывает это. Иначе говоря, когда применяется / применяется принудительно / соблюдается ограничение конфликта для любого заданного виртуального первичного ключа, только один составной ключ, имеющий тот виртуальный первичный ключ и ID версии, связанный с любым виртуальным клоном на заданной «ветви» иерархического дерева, может быть сохранен в рамках таблицы базы данных в заданный момент времени. Таким образом, не может быть множества составных ключей, каждый из которых ссылается на виртуальный первичный ключ и ID версии, связанный с виртуальным клоном по предковому пути иерархического дерева. Запрос может быть реализован/выполнен с примененным принудительно ограничением конфликта в качестве примера, как изложено ниже. Предположим, что дерево версий и база 230 данных являются такими, как показано на фиг. 2B. Если запрос виртуального первичного ключа RID=1001 принимается с помощью виртуального клона V3, процессор осуществляет поиск записей с RID=1001 и (версия=3, или версия=2, или версия=1) и находит их. Следует отметить, что запрос, изначально принятый с помощью V3, может не содержать ссылки на ID версии или может лишь ссылаться на V3 ID версии. Процессор (например, выполняющий программное обеспечение быстрого копирования) может модифицировать запрос так, что включается каждый из V3, V2 и V1 ID версии. Следует отметить, что, если база данных удовлетворяет ограничению конфликта, то полученный в результате набор записей не будет содержать двух отметок с одним и тем же виртуальным первичным ключом, так как результаты имеют записи с версиями, поступающими с одного пути в дереве версий, так что, если две записи имели один и тот же виртуальный первичный ключ, они бы нарушили ограничение конфликта. Таблица результатов может быть сгенерирована, и такой атрибут, как версия (столбец), может быть удален (например, процессором) из таблицы результатов перед возвращением таблицы результатов в результате поиска.
Если вместо этого, учитывая иерархическое дерево, показанное на фиг. 2B, запрос виртуального первичного ключа 1001 принимается с помощью виртуального клона V4, процессор (например, выполняющий программу быстрого копирования) может модифицировать запрос так, что включается каждый из V4 и V1 ID версии. Процессор затем осуществляет поиск записей с RID=1001 и (версия=V4 или версия=V1) и находит их. Если процессор не находит никаких записей, соответствующих модифицированному запросу, процессор возвращает такой ответ, как «нуль» или «результаты не найдены».
Как отмечено выше, хотя вышеизложенное описание по фиг. 2B относится к запросам виртуального первичного ключа, запросы могут быть структурированы широким множеством других способов. Например, запрос может требовать все записи, имеющие значение для специфицированного атрибута (например, все записи, имеющие значение для атрибута «имя», представленное как «Смит»), все записи, соответствующие значениям для двух или более специфицированных атрибутов (например, все записи, имеющие значение для атрибута «имя», представленное как «Смит», и ранг «4»), все записи, имеющие специфицированный первичный виртуальный ключ и значение для специфицированного атрибута (например, все записи, имеющие первичный виртуальный ключ «1001» и значение для атрибута «имя», представленное как «Смит»), и т. д. В некоторых реализациях запрос не содержит ссылку на виртуальный первичный ключ.
Фиг. 3A – блок-схема, на которой проиллюстрирован способ генерирования виртуальных клонов иерархического дерева и взаимодействия с ними. Фиг. 3B включает в себя ряд схем, на которых проиллюстрированы временная эволюция таблицы базы данных и взаимодействие с ней с помощью иерархического дерева согласно способу по фиг. 3A. Чтобы способствовать пониманию, фиг. 3A и фиг. 3B могут быть рассмотрены и изучены вместе. Как показано на фиг. 3B, база 230 данных, содержащая одну или более таблиц базы данных, существует до начала способа 200 по фиг. 3A. Как показано на фиг. 3A, на этапе 202 способ 200 включает генерирование первого виртуального клона. Соответственно и одновременно, на этапе (b) определяют первый виртуальный клон по меньшей мере одной таблицы базы данных, относящейся к базе 230 данных, тем самым инициируя иерархическое дерево, представленный как «V1» со ссылочной позицией 222. Впоследствии, на этапе 204 способ 200 включает генерирование второго виртуального клона, и, соответственно и одновременно, на этапе (c) второй виртуальный клон «V2» (224) добавляют в иерархическое дерево. Хотя на фиг. 3B показано, что он исходит и/или возникает из V1 (таким образом являясь виртуальным клоном-«ребенком» или виртуальным клоном-«потомком» клона V1 и делая V1 виртуальным клоном-«предком» или виртуальным клоном-«предшественником» клона V2), в других случаях V2 может исходить и/или возникать непосредственно из базы 230 данных, так что он не будет иметь виртуального клона-предшественника (в случае чего V1 и V2 называли бы виртуальными клонами, имеющими общего родителя, в рамках иерархического дерева). Продолжая способ 200, на этапе 206 запрос принимают с помощью V2, как изображено на этапе (d) по фиг. 3B. Запрос Q(X) принимают с помощью V2 и осуществляют ссылку на ID записи «X». В ответ на прием запроса процессор, выполняющий программное обеспечение быстрого копирования (например, программу 115 быстрого копирования на фиг. 1), модифицирует запрос на этапе 208 по фиг. 3A для генерирования модифицированного запроса Q(X, V1 или V2), который осуществляет ссылку на ID записи «X», а также версию или множество версий (в этом случае V1 или V2, как показано на этапе (e) по фиг. 3B). Модифицированный запрос вызывает поиск в реляционной базе данных записей таблицы базы данных, соответствующих затребованному ID записи «X» и имеющих идентификатор версии, связанный либо с V1, либо с V2 (поскольку оба виртуальных клона находятся в непосредственной предковой линии, исходящей из базы 230 данных). На этапе 210 модифицированный запрос Q(X, V1 или V2) выполняют так, как представлено на этапе (f) на фиг. 3B, и результат запроса (ответ) R(X, V1) или R(X, V2) возвращают и отправляют на этапе 212 с помощью V2, как показано на этапе (g) по фиг. 3B. Как показано на этапе (g), возвращают либо ответ, связанный с ID записи X и V1, либо ответ, связанный с ID записи X и V2. Если никакие модификации в отношении ID записи X еще не были осуществлены с помощью виртуального клона V2, будет отсутствовать запись, осуществляющая ссылку на ID записи X и V2, и новейшая форма записи, связанной с ID записи X, будет иметь ID версии, связанный с V1.
Фиг. 4A–4F включают в себя представления виртуальных клонов и связанную таблицу базы данных, на которой проиллюстрирована временная эволюция иерархического дерева (этапы (a)–(t)) с примененным ограничением конфликта. В начале (300), как показано на фиг. 4A, таблица 230a базы данных содержит такие атрибуты, как «FID» («ID фрукта», который служит в качестве ID записи и/или ключа для основной таблицы базы данных), «предмет», «фрукт» и «версия», и одну заполненную запись (FID=1001, предмет=пирог, фрукт=яблоко и версия=V1). Также на этапе 300 виртуальные клоны V1 и V2 (непосредственный потомок клона V1) уже существуют (как представлено иерархическим деревом, показанным на этапе (a)). Впоследствии, на этапе 302 создают экземпляр нового виртуального клона V3 (226) и добавляют его в иерархическое дерево без осуществления пока что изменений в отношении таблицы 230a базы данных. Впоследствии, на этапе 304 принимают требование с помощью V3 изменить запись для пирога так, чтобы значение для фрукта было представлено как «груша». В ответ на прием этого требования на этапе 306 новую запись с версией V3 добавляют в таблицу 230a базы данных. Как показано на фиг. 4A, вторая запись, связанная с FID 1001, сохраняет значение «пирог» для такого атрибута, как предмет, включает «грушу» вместо «яблока» для такого атрибута, как фрукт, и имеет связанный идентификатор версии V3 – виртуального клона, с помощью которого изменение было затребовано. В дополнение, поскольку ограничение конфликта соблюдается, значение для такого атрибута, как версия, в первой записи в таблице 230a базы данных изменяют с V1 на V2 (как показано на этапе 306), чтобы гарантировать, что ограничение конфликта удовлетворяется. Следует отметить, что, если ограничение конфликта не было принудительно применено, не потребуется осуществлять такое изменение в отношении первой записи. Следует отметить, что множество записей (как показано на этапе 306 на фиг. 4A) могут иметь одинаковый FID (или «виртуальный первичный ключ»), поскольку составной ключ содержит как FID, так и такой атрибут, как версия. Другими словами, первая запись на этапе 306 имеет составной ключ, представленный как FID = 1001 и версия = V2, и вторая запись на этапе 306 имеет составной ключ, представленный как FID = 1001 и версия = V3, так что составные ключи все еще уникальны и могут быть отличены друг от друга.
Переходя к фиг. 4B и вслед за модификацией таблицы 230a базы данных на этапе 306, принимают запрос Q(пирог) на этапе 308 с помощью V3, осуществляя ссылку на значение «пирог». На этапе 310 запрос модифицируют как Q(пирог, V3 или V1), чтобы осуществить ссылку как на значение «пирог», так и на «V3 или V1», поскольку, подобно обсуждению выше, виртуальные клоны V3 и V1 совместно используют общую предковую линию, исходящую и/или возникающую из базы 230 данных. Модифицированный запрос затем выполняют в отношении таблицы 230a базы данных. Поскольку единственная запись в таблице 230 базы данных, соответствующая как значению «пирог», так и «V3 или V1», – это запись с FID 1001 и версией V3, запрос возвращает ту запись (как показано на этапе 312). Таким образом, так как запрос возник из V3, осуществляют поиск записей, связанных с V1 и V3, но не записей, связанных с V2, который не находится в той же предковой линии, что и V3.
Следует отметить, что в реализациях, которые не соблюдают ограничение конфликта на этапе 310 на фиг. 4B, запрос не будут модифицировать. Вместо этого, процессор будет сначала осуществлять поиск записи, соответствующей значениям «пирог» и «V3». Если такую запись находят (что и происходит в примере этапа 310 по фиг. 4B), ту запись (FID=1001; предмет=пирог; фрукт=груша) возвращают, а запрос завершается. Однако, если в базе 230 данных не была найдена запись, соответствующая значениям «пирог» и «V3», на основе дерева версий процессор будет далее запрашивать из базы 230 данных записи, соответствующие значениям «пирог» и «V1» (т. е. проходя вверх по дереву версий). Если запись находят в базе 230 данных с таким составным ключом, ту запись возвращают, а запрос завершается. В ином случае процессор возвращает такой ответ, как «нуль» или «ответ не найден».
Переходя к фиг. 4C, дополнительный запрос Q(пирог) принимают на этапе 314 с помощью V2 и осуществляют ссылку на значение атрибута «пирог». Снова запрос модифицируют, чтобы осуществить ссылку как на значение «пирог», так и на «V2 или V1», как Q(пирог, V2 или V1), поскольку виртуальные клоны V2 и V1 совместно используют общую предковую линию, исходящую и/или возникающую из базы 230 данных. Модифицированный запрос затем выполняют на этапе 316 в отношении таблицы 230a базы данных. Поскольку единственная запись в таблице 230a базы данных, соответствующая как значению «пирог», так и «V2 или V1», – это запись с FID 1001 и версией V2, запрос возвращает ту запись (как показано на этапе 318). Так как запрос возник из V2, осуществляют поиск записей, связанных с V1 и V2, но не записей, связанных с V3, который не находится в той же предковой линии, что и V2. Соответственно, как V2, так и V3 могут иметь разные версии одной и той же записи 1001 в таблице 230a базы данных.
Переходя к фиг. 4D, дополнительный запрос Q(груша) принимают на этапе 320 снова с помощью V2, но в этот раз осуществляя ссылку на значение атрибута «груша». Снова запрос модифицируют как Q(груша, V2 или V1), чтобы осуществить ссылку как на значение «груша», так и на «V2 или V1», поскольку виртуальные клоны V2 и V1 совместно используют общую предковую линию, исходящую из базы 230 данных. Модифицированный запрос затем выполняют на этапе 322 в отношении таблицы 230a базы данных. Поскольку отсутствует запись в таблице 230a базы данных, соответствующая как значению «груша», так и «V2 или V1», результаты не возвращают на этапе 324 (например, возвращают сигнал и/или уведомление касательно того, что записи, соответствующие запросу, не могут быть найдены). Другими словами, модификация в отношении данных таблицы базы данных, осуществленная с помощью V3, недоступна с помощью V2 и не влияет на его данные, поддерживающие запросы.
Переходя к этапу 326 по фиг. 4E, требование принимают на этапе 326 с помощью V2 для удаления записей с яблоком для такого атрибута, как фрукт, и пирогом для такого атрибута, как предмет, из таблицы 230a базы данных и для добавления записи с бананом для такого атрибута, как фрукт, и хлебом для такого атрибута, как предмет. На этапе 328 и в ответ на требование, принятое с помощью V2 на этапе 326, идентифицируют запись, осуществляющую ссылку на значения атрибута «яблоко» и «пирог», и выполняют одно или более из следующего: запись, осуществляющую ссылку на значения атрибута «яблоко» и «пирог» удаляют из таблицы 230a базы данных, ее ID версии исключают (гарантируя, что он впоследствии не будет доступен с помощью V2) или атрибут, представляющий «удаленный» флаг, добавляют в таблицу 230a базы данных и задают его значение как «истина» для той записи. Также на этапе 328 новую запись, имеющую FID, представленный как 1002, значение такого атрибута, как предмет, представленное как «хлеб», значение такого атрибута, как фрукт, представленное как «банан», и ID версии клона V2, добавляют в таблицу 230a базы данных. Впоследствии на этапе 330 запрос Q(хлеб) принимают с помощью V3, осуществляя поиск записи с таким атрибутом, как предмет, имеющим такое значение, как хлеб. Подобно обсуждению выше, запрос сначала модифицируют так, что он осуществляет ссылку как на значение такого атрибута, как предмет, представленное как хлеб, так и на ID версии «V3 или V1», то есть как Q(хлеб, V3 или V1). Поскольку отсутствует запись в таблице 230a базы данных, соответствующая как значению «хлеб», так и «V3 или V1», результаты не возвращают на этапе 332 (например, возвращают сигнал и/или уведомление касательно того, что записи, соответствующие запросу, не могут быть найдены).
Как продемонстрировано на фиг. 4E, в некоторых реализациях удаление записи из таблицы 230a базы данных осуществляют путем устранения такого атрибута, как версия, из записи (т. е. так, что последующие запросы, осуществляемые с помощью любого виртуального клона, связанного с таблицей 230a базы данных, не будут возвращать запись или любую ее часть). Удаления могут быть осуществлены таким образом, например, когда удаляемая запись имеет ID версии, который существует в предковом пути, к которому принадлежит виртуальный клон, требующий удаление. Однако, если требование удаления осуществляет ссылку на запись, имеющую ID версии, который совместно используется предковым путем требующего виртуального клона и другим путем, который не требует удаление, удаление может быть осуществлено путем удаления записи, на которую осуществляется ссылка, из таблицы 230a базы данных и путем добавления одной или более новых записей в базу 230 данных, причем одна или более новых записей имеют связанные ID версии, осуществляющие ссылку на другой путь (или пути), который не требует (которые не требуют) удаление (т. е. так, что связанные данные остаются доступными для виртуальных клонов по другому пути (другим путям)).
В других реализациях для осуществления удаления записи в таблице 230a базы данных атрибут «удалено» (принимающий такие значения, как истина или ложь) может быть добавлен в каждую запись таблицы 230a базы данных, так что (1) удаление записи для ID версии, который существует только на предковом пути виртуального клона, требующего удаление, осуществляют путем изменения атрибута «удалено» на «истина» для той записи, и (2) удаление записи, имеющей ID версии, который совместно используется предковым путем виртуального клона, требующего удаление, и другим путем, осуществляют путем: (i) определения новой записи в таблице 230a базы данных с ID версии виртуального клона, требующего удаление, и задания значения атрибута «удалено» недавно созданной записи как «истина»; и (ii) определения новой записи в таблице 230a базы данных с ID версии виртуального клона на другом пути и задания значения атрибута «удалено» недавно созданной записи как «ложь».
Переходя к фиг. 4F, требование Q(банан) принимают на этапе 334 и с помощью V2, осуществляя поиск записи с таким атрибутом, как фрукт, имеющим такое значение, как банан. На этапе 336 запрос модифицируют так, что он осуществляет ссылку как на значение такого атрибута, как предмет, представленное как банан, так и на ID версии «V2 или V1», то есть как Q(банан, V2 или V1), и модифицированный запрос выполняют в отношении таблицы 230a базы данных. Поскольку единственная запись в таблице 230a базы данных, соответствующая как значению «банан», так и «V2 или V1», – это запись с FID 1002 и версией V2, запрос возвращает ту запись (как показано на этапе 338).
На фиг. 4G показано дерево версий по фиг. 4F с таблицей 230a базы данных на этапе 340, содержащей записи для каждого из виртуальных клонов V1, V2 и V3 (и показано с не удаленной записью, в которой FID=1001 и версия=V1). Таблица 230a базы данных на этапе 340 может в результате, например, если таблица 230a базы данных не была реализована с ограничением конфликта и начинаясь на этапе 304 на фиг. 4A, иметь следующий вид: (1) требование изменить «пирог» с «яблочного» на «грушевый», что приводит в результате к добавлению новой записи, имеющей FID=1001, значение для атрибута «фрукт», представленное как «груша», и значение для атрибута «версия», представленное как V3 (как показано на этапе 306), и сохранение записи (показанной на этапе 304), имеющей FID=1001, значение для атрибута «фрукт», представленное как «яблоко», и значение для атрибута «версия», представленное как V1, и (2) требование добавить банановый хлеб, осуществленное с помощью V2 (вызывая добавление записи, имеющей FID=1002, значение для атрибута «предмет», представленное как «хлеб», значение для атрибута «фрукт», представленное как «банан», и значение для атрибута «версия», представленное как V2, в таблицу 230a базы данных).
Продолжая с предположением того, что реализация таблицы 230a базы данных на этапе 340 не соблюдает ограничение конфликта, запрос, принятый в V2, осуществляющий ссылку на значение для атрибута «предмет», представленное как «пирог», не будет модифицирован процессором для поиска как в V2, так и в V1 одновременно. Вместо этого, процессор будет сначала осуществлять поиск записи, соответствующей значениям «пирог» и «V2». Поскольку такая запись отсутствует в таблице 230a базы данных на этапе 340, процессор будет далее запрашивать из базы 230 данных записи, соответствующие значениям «пирог» и «V1» (т. е. проходя вверх по дереву версий). Одну запись (FID=1001; предмет=пирог; фрукт=яблоко; версия=V1) находят в таблице 230a базы данных, и ту запись возвращают, а запрос завершается. Подобный запрос, осуществленный в отношении V3, будет возвращать запись (FID=1001; предмет=пирог; фрукт=груша; версия=V3), так как сначала будут осуществлять поиск в V3, и, поскольку запись была идентифицирована, запрос будет завершаться и не будет переходить к поиску в V1 по предковому пути. Вместо этого, если запрос был принят в V3 для «всех пирогов», процессор будет сначала осуществлять в таблице 230a базы данных поиск записи, соответствующей значениям «пирог» и «V3», и будет тем самым идентифицировать первую запись (FID=1001; предмет=пирог; фрукт=груша; версия=V3). Процессор будет затем продолжать осуществлять поиск в V1 (по предковому пути) любых дополнительных записей, содержащих значение «пирог» для атрибута «предмет», и будет идентифицировать вторую запись (FID=1001; предмет=пирог; фрукт=яблоко; версия=V1). Однако, поскольку FID первой записи и второй записи соответствуют (например, как обнаружено процессором на основе сравнения FID записей) запись, имеющая версию V1, будет исключена из результатов запроса, так как поиск в V3 уже идентифицировал запись с FID=1001. Вместо этого, если во время поиска в V1 были идентифицированы дополнительные записи, соответствующие значению «пирог», но имеющие FID, отличный от 1001, те записи будут возвращены как часть ответа на запрос.
Сборка мусора
В некоторых реализациях иерархическое дерево (также называемое в настоящем документе «деревом версий») и/или представление иерархического дерева содержатся и/или хранятся на энергонезависимом запоминающем устройстве в уменьшенной и/или более оптимальной форме за счет формы инкрементальной сборки мусора, выполняемой процессором (например, таким как процессор 111, выполняющий программу 115 быстрого копирования по фиг. 1), действующим образом и с возможностью связи соединенным с запоминающим устройством. В таких реализациях каждый узел иерархического дерева связан с виртуальным клоном и двумя ID последовательности, которые представляют конечные точки строки из множества ID целочисленной последовательности. В качестве примера, ряд ID последовательности 10, 11, 12 и 13 может быть представлен парой ID последовательности (10,13). Узел, связанный только с ID последовательности 42, будет обозначен парой ID последовательности (42, 42). В контексте настоящего документа ID последовательности определяют не так, как ID версии. ID последовательности относится к последовательному порядку, в котором виртуальные клоны иерархического дерева были сгенерированы. Поэтому ID последовательности и ID версии для конкретного виртуального клона могут иметь одно и то же значение, или они могут отличаться. В некоторых таких реализациях, как проиллюстрировано на схемах (a)–(g) по фиг. 5, дерево версий изначально, то есть до расширения до дерева на схеме (a), содержит только один узел (1,1). Каждый раз когда событие быстрого копирования запускает создание и/или определение нового узла в дереве версий, тому новому узлу присваивают ID последовательности следующего целого числа в последовательном порядке. Поэтому второму узлу, добавленному в дерево версий, присваивают ID последовательности (2,2), и N-му узлу присваивают ID последовательности (N, N). В контексте настоящего документа узел X имеет узел-«преемник» Y, если X обозначает пару ID последовательности (A, B), а Y обозначает пару ID последовательности (B+1,C). Другими словами, Y представляет диапазон ID последовательности, который идет сразу после диапазона ID последовательности, представленного как X. Структура данных на запоминающем устройстве (и в базе данных) может хранить для каждого узла дерева версий ссылку на узел (узлы), который является его преемником (которые являются его преемниками). Преемственные взаимоотношения представлены пунктирными линиями на фиг. 5. Следует отметить, что «преемственность» и «происхождение» в контексте настоящего документа являются разными (хотя не взаимоисключающими) концепциями. Например, узел, который является преемником более раннего узла, не обязательно является потомком того более раннего узла (например, на схеме (a) на фиг. 5 узел (6,6) является преемником узла (5,5), но не является потомком на/в предковом пути узла (5,5)), и узел-потомок более раннего узла не обязательно является прямым преемником того более раннего узла (например, на схеме (a) на фиг. 5 узел (6,6) является потомком узла (3,3), но не является прямым преемником узла (3,3)).
В некоторых реализациях «обновление последовательности» для узлов, хранящихся на запоминающем устройстве (например, включая узел X и его узел-преемник Y) (например, для исключения избыточности из дерева версий, повышения производительности и эффективности, уменьшения расхода памяти и/или ресурсов и т. д.), выполняется процессором, выполняющим программное обеспечение быстрого копирования (например, программу 115, 125 быстрого копирования по фиг. 1), причем процессор находится в действующей связи с запоминающим устройством, хранящим дерево версий. Обновление последовательности осуществляется так, как изложено ниже. Сначала предположим, что узел X с диапазоном ID последовательности (A,B) имеет преемника Y с диапазоном ID последовательности (B+1,C), и последовательность узлов, включая узлы X и Y, должна быть обновлена. Новый узел Z может быть определен как имеющий диапазон ID последовательности (A,C) (т. е. имеющий первую конечную точку узла X и вторую конечную точку узла Y). Далее любые взаимоотношения других узлов в дереве версий с узлом X или узлом Y (например, как представлено сплошными и пунктирными линиями на фиг. 5) обновляют так, что они больше не соединяются с узлом X или Y и/или не ссылаются на него, а вместо этого соединяются с узлом Z и/или ссылаются на него. Узлы X и Y могут затем быть исключены/удалены из дерева версий (и соответственно либо удалены из связанной таблицы базы данных, либо аннотированы в ней как удаленные), тем самым завершая событие обновления последовательности. В некоторых реализациях, если обновление последовательности приводит в результате к тому, что узел имеет только один узел-ребенок, который также является преемником того узла, может быть выполнено еще одно обновление последовательности при участии того узла (например, автоматически при обнаружении условия, что узел имеет только один узел-ребенок, который также является преемником того узла) и его одного узла-ребенка способом, подобным вышеизложенному.
В некоторых реализациях удаление узла X из дерева версий осуществляется так, как изложено ниже. Сначала, если узел X имеет узел-родитель, присутствующий в дереве версий, взаимоотношения (например, как представлено сплошной линией в дереве версий, как показано на фиг. 5) между узлом X и его узлом-родителем исключаются. Далее, если узел X имеет узел-преемник, тому узлу-преемнику присваивают новые ID последовательности, и узел X удаляют. Альтернативно, если узел X не имеет узла-преемника, узел X просто удаляют. Если упомянутый выше узел-родитель узла X теперь не имеет узлов-детей, исходящих из него, упомянутый выше узел-родитель удаляют. Если был узел W, который имел узел X в качестве преемника, и узел W теперь имеет только один узел-ребенок, и тот ребенок является его преемником, то узлу-ребенку узла W присваивают новые ID последовательности.
Любое удаление или событие обновления последовательности, описанное выше, может приводить в результате к узлу, вновь не имеющему ребенка, и, следовательно, может запустить другое удаление. Альтернативно или в дополнение любое удаление или событие обновления последовательности, описанное выше, может приводить в результате к новому узлу, имеющему один узел-ребенок, который является его преемником, и, следовательно, может запустить другое событие обновления последовательности. Следовательно, может быть каскад обновлений последовательности и удалений, вызванный одним обновлением последовательности или удалением. В некоторых реализациях система согласно настоящему изобретению приспособлена для выполнения сборки мусора каскадного типа, и другие формы сборки мусора не выполняют в отношении дерева версий. Способы инкрементальной сборки мусора, описанные в настоящем документе (и исполняемые процессором), могут автоматически распознавать и исполнять/реализовать/вызывать возможные/разрешенные упрощения (или предварительно определенный их поднабор) в дереве версий, которые должны быть осуществлены (например, по существу непрерывно и/или по существу в реальном времени). Представление исправленного/упрощенного дерева версий (например, дерева версий по фиг. 5(e), которое заменит дерево версий по фиг. 5(d)) могут затем сохранять на запоминающем устройстве для последующего доступа.
В некоторых реализациях событие удаления может запускать процесс инкрементальной сборки мусора. Например, если дерево версий представлено так, как показано на фиг. 5(a), пунктирные стрелки представляют ссылки на узлы-преемники. В некоторых реализациях базы данных, поддерживающей быстрое копирование, только листовые узлы могут быть удалены. Другими словами, программное обеспечение быстрого копирования может быть приспособлено для удаления «версии» только в том случае, если та версия связана с «листовым» узлом. «Листовой узел» определяют как узел, который не имеет детей (причем узлы-дети представлены сплошными линиями на фиг. 5). Сплошные линии должны игнорироваться во время идентификации листовых узлов.
Предположим, что пользователь требует удаление листового узла (5,5), закрашенного серым на схеме (a) по фиг. 5. Дерево версий после удаления листового узла (5,5) имеет такой вид, как показано на схеме (b) по фиг. 5. Дерево версий схемы (b) является результатом обновления последовательности, при котором узлу (6,6) присваивают пару ID последовательности (5,6), затем обновляют узел (4,4) для осуществления ссылки на узел (5,6) как на его преемника (как представлено пунктирной линией, соединяющей узел (4,4) с узлом (5,6)). Следует отметить, что узел-родитель упомянутого выше узла (5,5), обозначенный как (2,2), все еще имеет узел-ребенок (узел (4,4)) и не имеет своего узла-преемника (узла (3,3)), поскольку он является только ребенком, так что процесс удаления прекращается на дереве версий, показанном на схеме (b) по фиг. 5.
Далее предположим, что пользователь требует удаление узла (4,4) (закрашенного серым на схеме (b) на фиг. 5). Это требование удалить узел (4,4) может запускать несколько действий. Сначала, поскольку узел (4,4) имеет узел-родитель (2,2), исключают взаимоотношения между узлом (2,2) и узлом (4,4), представленные сплошной линией на схеме (b) по фиг. 5. Также обновление последовательности выполняют так, что узлу (5,6) присваивают пару ID последовательности (4,6), как показано на схеме (c) по фиг. 5, теперь с обновленными преемственными взаимоотношениями между узлом (3,3) и узлом (4,6) (узел (4,6) является преемником узла (3,3)). Вследствие вышеизложенных действий узел (2,2) больше не имеет никаких узлов-детей (как показано на схеме (c) по фиг. 5). Поэтому и/или в ответ на это условие и в связи с тем, что запросы больше не могут осуществляться с помощью узла (2,2) (в результате того, что узлы-потомки узла (2,2) были ранее сгенерированы до их удаления), процесс удаления может «каскадироваться» путем автоматического перехода к удалению узла (2,2), что приводит к дереву версий, как показано на схеме (d) по фиг. 5. На этой стадии узел (1,1) имеет только одного ребенка (узел (2,3)), и тот ребенок является его узлом-преемником. Соответственно, как обсуждено выше, обновление последовательности может быть выполнено так, что узлу-ребенку (2,3) присваивают новую пару ID последовательности (1,3), что приводит в результате к дереву версий, как показано на схеме (e) по фиг. 5, причем в этот момент каскадирование заканчивается. Другими словами, дерево версий, как показано на схеме (e) по фиг. 5, представляет собой конечный результат требования пользователя удалить узел (4,4).
Теперь предположим, что пользователь решает удалить листовой узел (4,6) (закрашенный серым на схеме (e) по фиг. 5). Это событие удаления приведет в результате к такой трансформации дерева версий, что оно будет иметь такой вид, как показано на схеме (f) по фиг. 5, что само по себе автоматически запускает конечное обновление последовательности так, что узлу (4,7) (узлу-ребенку узла (1,3)) присваивают новую пару ID последовательности (1,7), что дает конечный результат (единственный узел (1,7)), как показано на схеме (g) по фиг. 5. При продолжении сборки мусора могут быть осуществлены соответствующие изменения в отношении связанной таблицы базы данных, например, такие как на схеме (g) по фиг. 5, причем все записи содержат такой атрибут, как версия, с одинаковым значением (например, «7»). Перед стадией, на которой остается только один узел (например, на схеме (g) по фиг. 5) (т. е. по мере осуществления «сборки мусора» в отношении дерева версий и уменьшения его размера), записи таблицы базы данных (например, такой как таблица 230a базы данных по фиг. 4A–4G) могут быть модифицированы так, что они относятся к сохранившемуся узлу, или могут быть удалены (например, в ответ на удаление узла, который уникально связан с той записью).
Фиг. 6 – технологическая блок-схема для реализованного процессором способа 400 сборки мусора (или каскадного удаления) для базы данных с быстрым копированием согласно варианту осуществления. Как показано на фиг. 6, способ 400 начинается с генерирования на этапе 430 иерархического дерева виртуальных клонов. Впоследствии на этапе 432 принимают инструкцию, направленную на удаление второго виртуального клона из иерархического дерева виртуальных клонов. В ответ на инструкцию, направленную на удаление второго виртуального клона, на этапе 434 модифицируют преемственные взаимоотношения третьего виртуального клона. Также в ответ на инструкцию, направленную на удаление второго виртуального клона, на этапе 436 удаляют второй виртуальный клон. На этапе 438 процессор оценивает, есть ли у первого виртуального клона иерархического дерева виртуальных клонов оставшийся виртуальный клон-ребенок после удаления второго виртуального клона. Если у первого виртуального клона иерархического дерева виртуальных клонов есть оставшийся виртуальный клон-ребенок после удаления второго виртуального клона, но этот ребенок не является его преемником, процесс завершается. Если у первого виртуального клона иерархического дерева виртуальных клонов есть оставшийся виртуальный клон-ребенок после удаления второго виртуального клона, и тот ребенок является его преемником, обновление последовательности может быть выполнено так, как обсуждено выше. Если у первого виртуального клона иерархического дерева виртуальных клонов нет оставшегося виртуального клона-ребенка после удаления второго виртуального клона, первый виртуальный клон удаляют на этапе 440 из иерархического дерева виртуальных клонов.
Фиг. 7 – технологическая блок-схема для дополнительного реализованного процессором способа 500 сборки мусора (или каскадного удаления) для базы данных с быстрым копированием согласно варианту осуществления. Как показано на фиг. 7, способ 500 начинается с генерирования на этапе 530 иерархического дерева виртуальных клонов. Впоследствии на этапе 532 принимают инструкцию, направленную на удаление первого виртуального клона из иерархического дерева виртуальных клонов. В ответ на инструкцию, направленную на удаление первого виртуального клона (например, узла (4,4) по фиг. 5), и на этапе 534 модифицируют преемственные взаимоотношения второго виртуального клона-преемника (например, узла (5,6) по фиг. 5). На этапе 536 удаляют первый виртуальный клон. Преемственные взаимоотношения четвертого виртуального клона (например, узла (3,3) по фиг. 5) затем модифицируют на этапе 538, причем четвертый виртуальный клон является преемником третьего виртуального клона (например, узла (2,2) по фиг. 5), который является предком первого виртуального клона. Третий виртуальный клон затем удаляют на этапе 540.
Фиг. 8A–8D – схемы, на которых проиллюстрирована примерная реализация системы базы данных с быстрым копированием согласно варианту осуществления. Как показано на фиг. 8A, на этапе 800 (и в начальный момент времени, t=0), первый экземпляр базы данных в узле «Джейн» 830A образует часть иерархического дерева, содержащую три виртуальных клона V1, V2 и V3, зависящих от экземпляра 830A базы данных. Экземпляр базы данных в узле Джейн 830A содержит таблицу базы данных с такими атрибутами, как RID, имя, ранг и версия. На этапе 800 существуют две заполненные записи в таблице базы данных – одна имеет имя=Смит, а другая имеет имя=Джонс. Виртуальный клон V1 на этапе 800 может быть связан с предыдущим, «первым» событием консенсуса. Виртуальный клон V2 на этапе 800 может быть использован для осуществления в реальном времени или по существу в реальном времени правок в отношении таблицы базы данных, относящейся к базе 830A данных (например, так, что таблица базы данных отражает текущие счета или состояния по мере приема новых данных, таких как данные транзакции), тогда как виртуальный клон V3 на этапе 800 может быть предназначен для осуществления правок после консенсуса в отношении таблицы базы данных, относящейся к базе 830A данных. Также на фиг. 8A, на этапе 802 (и в начальный момент времени, t=0) показан второй экземпляр базы данных в узле «Боб» 803B, который образует часть другого иерархического дерева, также содержащую два виртуальных клона V1 и V2, каждый из которых непосредственно зависит от экземпляра 830B базы данных. Экземпляр базы данных в узле Боб 830B также содержит таблицу базы данных с такими атрибутами, как RID, имя, ранг и версия. На этапе 802 существуют две заполненные записи в таблице 830B базы данных – одна имеет имя=Смит, а другая имеет имя=Джонс. Другими словами, в первый момент времени t=0 таблицы базы данных экземпляров базы данных в узлах Джейн 830A и Боб 830B содержат одинаковые записи. Следует отметить, что каждая из записей в таблицах базы данных в узле Джейн 830A и в узле Боб 830B содержит значение для такого атрибута, как версия, представленное как V1. Виртуальный клон V1 на этапе 802 может быть связан с предыдущим, «первым» событием консенсуса, которое запустило генерирование новых виртуальных клонов-детей V2 и V3. Виртуальный клон V2 на этапе 802 может быть использован для осуществления в реальном времени или по существу в реальном времени правок в отношении таблицы базы данных, относящейся к базе 830B данных, тогда как виртуальный клон V3 на этапе 802 может быть предназначен для осуществления правок после консенсуса в отношении таблицы базы данных, относящейся к базе 830B данных.
Как показано на фиг. 8B, происходит событие синхронизации, во время которого осуществляют обмен данными (также называемыми в настоящем документе «событием», например, данными транзакции, которые могут быть приняты в реальном времени или по существу в реальном времени, одновременно с транзакциями, к которым они принадлежат) между двумя или более из узла Джейн 830A, узла Боб 830B и факультативно одним или более дополнительными узлами, находящимися в сетевой связи с узлом Джейн 830A и/или узлом Боб 830B. Во время синхронизации узел Джейн 830A принимает в первый момент времени первое событие, специфицирующее, что значение для атрибута «ранг» для записи со значением для атрибута «имя», представленным как «Смит», должно быть увеличено на 1. В ответ на прием первого события процессор в узле Джейн 830A генерирует новую запись для значения «Смит» и при этом включая в ту запись значение для атрибута «версия», представленное как V2, значение для атрибута «RID», представленное как 1001, и значение для атрибута «ранг», представленное как 2+1=3 (не показано). Также в ответ на прием первого события процессор в узле Джейн 830A модифицирует первую запись в таблице базы данных так, что значение для такого атрибута, как версия, представляет собой V3 вместо V1. Также во время синхронизации (либо во время одного и того же, либо во время отдельного события синхронизации) узел Джейн 830A принимает во второй момент времени после первого момента времени второе событие, специфицирующее, что значение для атрибута «ранг» для записи со значением для атрибута «имя», представленным как «Смит», должно быть изменено на 10. В ответ на прием второго события процессор в узле Джейн 830A модифицирует запись, имеющую значение для такого атрибута, как имя, представленное как «Смит», и значение для такого атрибута, как версия, представленное как «V2», так, что запись имеет значение для атрибута «ранг», представленное как 10 (как показано на этапе 804 на фиг. 8B).
Во время синхронизации (одного и того же или отдельного события синхронизации в качестве узла Джейн 830A) узел Боб 830B принимает первое и второе события, но в порядке, противоположном тому, в котором Джейн 830A принимает события. Более конкретно, узел Боб 830B принимает в первый момент времени первое событие, специфицирующее, что значение для атрибута «ранг» для записи со значением для атрибута «имя», представленным как «Смит», должно быть изменено на 10. В ответ на прием первого события процессор в узле Боб 830B генерирует новую запись для значения «Смит» и при этом включая в ту запись значение для атрибута «версия», представленное как V2, значение для атрибута «RID», представленное как 1001, и значение для атрибута «ранг», представленное как 10 (не показано). Также в ответ на прием первого события процессор в узле Джейн 830A модифицирует первую запись в таблице базы данных так, что значение для такого атрибута, как версия, представляет собой V3 вместо V1. Также во время синхронизации (либо во время одного и того же, либо во время отдельного события синхронизации) узел Боб 830B принимает во второй момент времени после первого момента времени второе событие, специфицирующее, что значение для атрибута «ранг» для записи со значением для атрибута «имя», представленным как «Смит», должно быть увеличено на 1. В ответ на прием второго события процессор в узле Боб 830B модифицирует запись, имеющую значение для такого атрибута, как имя, представленное как «Смит», и значение для такого атрибута, как версия, представленное как «V2», так, что запись имеет значение для атрибута «ранг», представленное как 11 (как показано на этапе 806 на фиг. 8B).
События/данные (такие как данные транзакции), принятые с помощью V2 в узле Джейн и в узле Боб, могут быть сохранены в связанных запоминающих устройствах узла Джейн и в узле Боб соответственно, например, в распределенном ациклическом графе (DAG), хешграфе, цепочке данных, блокчейне или любых других подходящих структуре или формате данных. Дополнительные подробности реализации, включающие совместимые структуры данных, изложены в патенте США № 9646029, полное содержание которого включено в настоящий документ посредством ссылки для всех целей.
После события (событий) синхронизации и как показано на этапе 808 на фиг. 8C, процессоры узлов Джейн 830A и Боб 830B достигают консенсуса (например, в результате реализации инструкций консенсуса, таких как инструкции 116 и 126 консенсуса на фиг. 1). Другими словами, алгоритм консенсуса, реализованный процессором узла Джейн 830A (выполняющим программное обеспечение быстрого копирования, хранящееся на запоминающем устройстве того узла), и алгоритм консенсуса, реализованный процессором узла Боб 830B (например, выполняющим программное обеспечение быстрого копирования, хранящееся на запоминающем устройстве того узла), обнаруживают и/или определяют, что консенсус был достигнут. Консенсус может быть достигнут при одном или более из следующих условий в качестве неограничивающего примера: когда завершен «раунд», определенный алгоритмом консенсуса, когда прошло предопределенное количество времени с момента инициирования иерархического дерева, когда прошло предопределенное количество времени с момента предыдущего события консенсуса, когда принято предопределенное количество голосов с других узлов для заданной записи таблицы базы данных того узла, когда произошло предопределенное количество событий синхронизации и т. д. Как показано на фиг. 8C, результатом консенсуса было то, что правильная последовательность принятых событий является такой, что ранг для Смита сначала был увеличен, а затем был изменен на значение, представленное как 10. Поэтому правильным текущим значением для такого атрибута, как ранг, для записи, имеющей значение для такого атрибута, как имя, представленное как Смит, и значение для такого атрибута, как версия, представленное как V2, является «10». Подобным образом, значение ранга для этой записи обновляют с помощью V3, чтобы оно представляло собой «10», как показано на этапе 808. Вследствие достижения консенсуса генерируют новую пару виртуальных клонов V4 и V5, зависящих/происходящих от виртуального клона V3. Недавно сгенерированный виртуальный клон V4 на этапе 808 может затем впоследствии быть использован для осуществления в реальном времени или по существу в реальном времени правок в отношении таблицы базы данных экземпляра базы данных в узле Джейн 830A, тогда как виртуальный клон V5 на этапе 808 может быть предназначен для осуществления правок после консенсуса в отношении таблицы базы данных экземпляра базы данных в узле Джейн 830A. Другими словами, новые виртуальные клоны V4 и V5 могут выполнять функции, ранее выполняемые виртуальными клонами V2 и V3 соответственно. Следует отметить, что в некоторых реализациях после генерирования виртуальных клонов V4 и V5 правки в отношении таблицы базы данных больше не могут осуществляться с помощью виртуального клона V3 (даже если виртуальные клоны V4 и V5 впоследствии удаляют).
Подобно обсуждению по фиг. 8C, как показано на фиг. 8D, узел Боб 830B достигает консенсуса (например, в результате реализации инструкций консенсуса, таких как инструкции 116 и 126 консенсуса на фиг. 1). Другими словами, алгоритм консенсуса, реализованный процессором узла Джейн 830A (например, выполняющим программное обеспечение быстрого копирования, хранящееся на запоминающем устройстве того узла), и алгоритм консенсуса, реализованный процессором узла Боб 830B (выполняющим программное обеспечение быстрого копирования, хранящееся на запоминающем устройстве того узла), обнаруживают и/или определяют, что консенсус был достигнут. Как показано на фиг. 8D, таблица базы данных экземпляра базы данных в узле Боб 830B теперь отражает правильное текущее значение для такого атрибута, как ранг, для записи, имеющей значение для такого атрибута, как имя, представленное как Смит, и значение для такого атрибута, как версия, представленное как V2, как «10». Подобным образом, значение ранга для этой записи обновляют с помощью V3, чтобы оно представляло собой «10», как показано на этапе 810. Подобно обсуждению по фиг. 8C и вследствие достижения второго консенсуса, генерируют новую пару виртуальных клонов V4 и V5, зависящих/происходящих от виртуального клона V3. Недавно сгенерированный виртуальный клон V4 на этапе 808 может затем впоследствии быть использован для осуществления в реальном времени или по существу в реальном времени правок в отношении таблицы базы данных экземпляра базы данных в узле Боб 830B, тогда как виртуальный клон V5 на этапе 808 может быть предназначен для осуществления правок после консенсуса в отношении таблицы базы данных экземпляра базы данных в узле Боб 830B. Другими словами, новые виртуальные клоны V4 и V5 могут выполнять функции, ранее выполняемые виртуальными клонами V2 и V3 соответственно. Следует отметить, что в некоторых реализациях после генерирования виртуальных клонов V4 и V5 правки в отношении таблицы базы данных больше не могут осуществляться с помощью виртуального клона V3 (даже если виртуальные клоны V4 и V5 впоследствии удаляют).
Хотя на фиг. 8A–8D показан и описан консенсус как определяющий правильную последовательность событий (например, транзакций) для гарантирования точности промежуточного «баланса», «счета» или «состояния» записи в таблице базы данных, альтернативно или в дополнение консенсус может быть использован для определения правильной последовательности событий с целью одного или более из: определения текущего владельца актива, определения правильной последовательности записей в рамках таблицы базы данных, определения цепочки обеспечения сохранности или цепочки собственников товара и т. д.
В некоторых вариантах осуществления, изложенных в настоящем документе, устройство (например, вычислительное устройство 110 и/или вычислительное устройство (вычислительные устройства) 120 по фиг. 1) содержит процессор и запоминающее устройство, находящееся в электронной связи с процессором. Запоминающее устройство (например, запоминающее устройство 112 и/или запоминающее устройство 122 по фиг. 1) хранит таблицу базы данных, содержащую множество записей, причем каждая запись из множества записей содержит составной ключ, имеющий идентификатор версии. Запоминающее устройство содержит инструкции, исполняемые для предписания процессору сгенерировать первый виртуальный клон таблицы базы данных и второй виртуальный клон таблицы базы данных. Запоминающее устройство также содержит инструкции, исполняемые для предписания процессору принять запрос в первом виртуальном клоне и модифицировать запрос для определения модифицированного запроса, содержащего идентификатор версии, связанный с первым виртуальным клоном, на основе приема запроса в первом виртуальном клоне. Запоминающее устройство также содержит инструкции, исполняемые для предписания процессору запросить таблицу базы данных с использованием модифицированного запроса для генерирования ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей удовлетворяет запросу; и (2) каждая запись из набора записей имеет идентификатор версии, связанный с предковым путем идентификатора версии, связанного с первым виртуальным клоном. Запоминающее устройство также содержит инструкции, исполняемые для предписания процессору отправить ответ, содержащий набор записей, в качестве ответа на запрос. В некоторых таких вариантах осуществления составной ключ для каждой записи из множества записей содержит идентификатор версии для того составного ключа и часть данных. Множество записей могут быть приспособлены так, что только один из: (1) составного ключа, содержащего значение части данных и идентификатор версии, связанный с первым виртуальным клоном; или (2) составного ключа, содержащего значение части данных и идентификатор версии, связанный со вторым виртуальным клоном, присутствует в таблице базы данных в любой заданный момент времени.
В некоторых вариантах осуществления запоминающее устройство также содержит инструкции, исполняемые для предписания процессору добавить в ответ на инструкцию вставки, принятую с помощью первого виртуального клона, запись в таблицу базы данных. Запись содержит данные и составной ключ, имеющий идентификатор версии, связанный с первым виртуальным клоном, так что: (1) запрос, впоследствии принятый в первом виртуальном клоне и осуществляющий ссылку на данные, возвращает запись; и (2) запрос данных, впоследствии принятый в третьем виртуальном клоне, не возвращает запись.
В некоторых вариантах осуществления запоминающее устройство также содержит инструкции, исполняемые для предписания процессору добавить в ответ на инструкцию, направленную на обновление значения поля первой записи таблицы базы данных с первого значения до второго значения и принятую с помощью третьего виртуального клона, вторую запись в таблицу базы данных. Вторая запись содержит второе значение и составной ключ, имеющий идентификатор версии, связанный с третьим виртуальным клоном. Инструкции могут дополнительно исполняться для модификации в ответ на инструкцию, направленную на обновление значения поля первой записи, составного ключа первой записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что запрос, впоследствии принятый в третьем виртуальном клоне и осуществляющий ссылку на поле, возвращает вторую запись, и запрос, принятый в первом виртуальном клоне и осуществляющий ссылку на поле, возвращает первую запись.
В некоторых вариантах осуществления запоминающее устройство также содержит инструкции, исполняемые для предписания процессору модифицировать в ответ на инструкцию, направленную на удаление записи из множества записей и принятую с помощью третьего виртуального клона, идентификатор версии составного ключа записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что запрос записи, впоследствии принятый в третьем виртуальном клоне, не возвращает запись, и запрос записи, впоследствии принятый в первом виртуальном клоне, возвращает запись.
В некоторых вариантах осуществления ответ представляет собой первый ответ, и модифицированный запрос представляет собой первый модифицированный запрос. Инструкции могут дополнительно исполняться для предписания процессору сгенерировать второй модифицированный запрос, содержащий идентификатор версии второго виртуального клона, если первый ответ соответствует нулю, причем второй виртуальный клон является предком первого виртуального клона. Инструкции могут дополнительно исполняться для предписания процессору запросить таблицу базы данных с использованием второго модифицированного запроса для генерирования второго ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей второго ответа удовлетворяет второму модифицированному запросу; и (2) каждая запись из набора записей второго ответа имеет идентификатор версии, связанный с предковым путем идентификатора версии второго виртуального клона, и отправить второй ответ, содержащий набор записей, в качестве ответа на запрос.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору сохранить на запоминающем устройстве указание того, что первый виртуальный клон является потомком второго виртуального клона.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору сгенерировать третий виртуальный клон таблицы базы данных, причем третий виртуальный клон не является ни предком, ни потомком первого виртуального клона, причем множество записей содержат запись, имеющую составной ключ, содержащий значение части данных и идентификатор версии, связанный с третьим виртуальным клоном.
В некоторых вариантах осуществления устройство содержит процессор и запоминающее устройство, находящееся в электронной связи с процессором. Запоминающее устройство хранит таблицу базы данных и исполняемые процессором инструкции. Исполняемые процессором инструкции содержат инструкции, направленные на предписание процессору сгенерировать иерархическое дерево, содержащее представления множества виртуальных клонов таблицы базы данных, причем множество виртуальных клонов содержат первый виртуальный клон (например, узел (2,2) по фиг. 5), второй виртуальный клон (например, узел (4,4) по фиг. 5), который является виртуальным клоном-ребенком первого виртуального клона, и третий виртуальный клон (например, узел (5,6) по фиг. 5), который является виртуальным клоном-преемником второго виртуального клона. Исполняемые процессором инструкции также содержат инструкции, направленные на предписание процессору модифицировать преемственные взаимоотношения, связанные с третьим виртуальным клоном, в ответ на инструкцию, направленную на удаление второго виртуального клона. Исполняемые процессором инструкции также содержат инструкции, направленные на предписание процессору удалить второй виртуальный клон в ответ на инструкцию, направленную на удаление второго виртуального клона. Исполняемые процессором инструкции также содержат инструкции, направленные на предписание процессору удалить в ответ на инструкцию, направленную на удаление второго виртуального клона, первый виртуальный клон из множества виртуальных клонов, когда первый виртуальный клон не имеет виртуального клона-ребенка после удаления второго виртуального клона.
В некоторых вариантах осуществления множество виртуальных клонов дополнительно содержат четвертый виртуальный клон, который является виртуальным клоном-преемником первого виртуального клона. Инструкции дополнительно исполняются для предписания процессору модифицировать преемственные взаимоотношения, связанные с четвертым виртуальным клоном, в ответ на: инструкцию, направленную на удаление второго виртуального клона; и определение того, что четвертый виртуальный клон является единственным потомком первого виртуального клона после удаления второго виртуального клона.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору автоматически идентифицировать четвертый виртуальный клон из множества виртуальных клонов, который не имеет виртуального клона-ребенка, и удалить четвертый виртуальный клон на основе автоматической идентификации. Альтернативно инструкции могут дополнительно исполняться для предписания процессору автоматически идентифицировать четвертый виртуальный клон из множества виртуальных клонов, который не имеет виртуального клона-ребенка, и в ответ на автоматическую идентификацию (1) модифицировать преемственные взаимоотношения, связанные с пятым виртуальным клоном из множества виртуальных клонов, и (2) удалить четвертый виртуальный клон.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору запустить удаление по меньшей мере одного дополнительного виртуального клона из множества виртуальных клонов в ответ на модификацию преемственных взаимоотношений, связанных с третьим виртуальным клоном.
В некоторых вариантах осуществления преемственные взаимоотношения представляют собой первые преемственные взаимоотношения, и запоминающее устройство дополнительно хранит множество преемственных взаимоотношений, содержащих первые преемственные взаимоотношения.
В некоторых вариантах осуществления таблица базы данных содержит множество записей, и каждая запись из множества записей содержит составной ключ, содержащий идентификатор версии, связанный с виртуальным клоном из множества виртуальных клонов.
В некоторых вариантах осуществления устройство содержит процессор и запоминающее устройство, находящееся в электронной связи с процессором. Запоминающее устройство хранит таблицу базы данных и инструкции, исполняемые для предписания процессору сгенерировать иерархическое дерево, содержащее представления множества виртуальных клонов таблицы базы данных. Инструкции могут также исполняться в ответ на инструкцию, направленную на удаление первого виртуального клона (например, узла (4,4) по фиг. 5) из множества виртуальных клонов, для модификации преемственных взаимоотношений, связанных со вторым виртуальным клоном (например, узлом (5,6) по фиг. 5), причем второй виртуальный клон является виртуальным клоном-преемником первого виртуального клона, удаления первого виртуального клона, модификации преемственных взаимоотношений, связанных с четвертым виртуальным клоном (например, узлом (3,3) по фиг. 5), причем четвертый виртуальный клон является виртуальным клоном-преемником третьего виртуального клона (например, узла (2,2) по фиг. 5), причем третий виртуальный клон является виртуальным клоном-предком первого виртуального клона, и удаления третьего виртуального клона.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору обнаружить то, что второй виртуальный клон является единственным виртуальным клоном-потомком и виртуальным клоном-преемником четвертого виртуального клона, и удалить второй виртуальный клон в ответ на обнаружение того, что второй виртуальный клон является единственным виртуальным клоном-потомком и виртуальным клоном-преемником четвертого виртуального клона.
В некоторых вариантах осуществления таблица базы данных содержит множество записей, и каждая запись из множества записей содержит составной ключ, содержащий идентификатор версии, связанный с виртуальным клоном из множества виртуальных клонов.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору запустить удаление по меньшей мере одного дополнительного виртуального клона из множества виртуальных клонов в ответ на инструкцию, направленную на удаление первого виртуального клона.
В некоторых вариантах осуществления инструкции дополнительно исполняются для предписания процессору автоматически идентифицировать пятый виртуальный клон из множества виртуальных клонов, который не имеет виртуального клона-потомка. Инструкции могут также исполняться в ответ на автоматическую идентификацию для модификации преемственных взаимоотношений, связанных с шестым виртуальным клоном, и для удаления пятого виртуального клона.
В некоторых вариантах осуществления запоминающее устройство дополнительно хранит множество преемственных взаимоотношений, содержащих преемственные взаимоотношения, связанные со вторым виртуальным клоном, и преемственные взаимоотношения, связанные с четвертым виртуальным клоном.
В некоторых реализациях ограничение конфликта гарантирует, что, если запись существует в таблице с заданным составным ключом, таким как (1001, N), то таблица не будет содержать никакой записи с составным ключом, представленным как (1001, M), где M – номер версии, который является предком N в дереве версий. Например, если дерево версий является таким, как показано на фиг. 8C, и если существует запись с ключом (1001, 4), то гарантируется, что не будет никаких записей с ключом (1001, V3) или ключом (1001, V1). Однако может существовать запись с ключом (1001, 2), так как V2 не является предком V4 в дереве.
В некоторых реализациях каждая запись/строка таблицы базы данных изначально содержит ID версии, представленный как 1. Таблица базы данных может затем расти и сокращаться в результате операций, которые выполняют быстрое копирование, добавление, удаление или модификацию, как описано в настоящем документе.
В некоторых реализациях операция удаления может быть выполнена так, как изложено ниже. Запрос на SQL, принимаемый с помощью виртуального клона (или «вида»), может осуществлять ссылку на одну или более записей для удаления. Каждая такая запись может быть удалена так, как изложено ниже. Если запись имеет версию N, то ту запись удаляют. Далее для каждого виртуального клона вдоль непосредственного предкового пути от вида к «корню» иерархического дерева (т. е. экземпляра таблицы базы данных), если существуют дети тех виртуальных клонов, которые не находятся на непосредственном предковом пути, копию удаленной записи с ее версией, измененной на M, добавляют в таблицу базы данных тех детей. Например, с учетом иерархического дерева по фиг. 4B, если запись с ключом (пирог, V2) удаляют посредством V2, то запись удаляют из таблицы. Если запись с ключом (пирог, V1) удаляют посредством V2, то запись удаляют, а копию записи с версией V3 добавляют в таблицу, так как V3 является ребенком клона V1 и не находится на непосредственном предковом пути от базы 230 данных к V2. Следует отметить, что эта операция удаления гарантирует, что последующее чтение посредством V2 не будет возвращать никакую запись с таким виртуальным первичным ключом, как пирог, и что после удаления номера версии из результата последующие чтения посредством V3 будут возвращать тот же результат, что и перед удалением. В дополнение, когда такие операции удаления выполняют в отношении таблицы, удовлетворяющей ограничению конфликта, модифицированная таблица будет продолжать удовлетворять ограничению конфликта.
В некоторых реализациях, если инструкция удаления дает инструкцию удаления одной записи и добавления K новых записей с разными версиями, где K>0, это может быть реализовано путем изменения номера версии записи на один из новых номеров версии, делая затем K-1 копий (каждая из которых имеет разный номер версии). Эта оптимизация исключает одно добавление, что может быть преимущественным (например, может повысить эффективность базы данных), если исполнение модификаций быстрее, чем исполнение добавлений для основной базы данных.
В других реализациях булев атрибут «удалено» может быть добавлен в каждую запись. В качестве примера, с учетом иерархического дерева по фиг. 4B, если запись, которая должна быть удалена с помощью V2, имеет версию V2, то такой атрибут, как удалено, для той записи может быть изменен с такого значения, как ложь, на такое значение, как истина. Однако, если запись, которая должна быть удалена с помощью V2, имеет версию 1, процессор может создать и/или определить новую копию записи с версией V2 и таким атрибутом, как удалено, значение которого задано как истина. Если таблица не обязательно должна удовлетворять ограничению конфликта, запись с версией V1 может оставаться с таким своим атрибутом, как удалено, значение которого задано как ложь. Однако, если таблица должна удовлетворять ограничению конфликта, другая копия записи с версией V3 и таким атрибутом, как удалено, значение которого задано как ложь, может быть создана и/или определена, и запись с версией V1 может быть исключена из таблицы.
В некоторых реализациях операцию вставки (т. е. направленную на вставку записи в таблицу базы данных) выполняют сначала путем выполнения удаления записи, соответствующей виртуальному первичному ключу записи, которая должна быть вставлена, а затем путем вставки новой записи с номером версии, который является родителем виртуального клона, посредством которого инструкция вставки, запускающая операцию вставки, была принята. Например, с учетом иерархического дерева по фиг. 4B, если запрос на SQL, содержащий инструкцию вставки (например, дающую инструкцию, направленную на вставку новой записи со значением виртуального первичного ключа «ежевика»), принимают с помощью V2, запрос может быть модифицирован так, чтобы сначала найти и удалить любую запись, доступную с помощью V2 (т. е. любую запись, имеющую значение для такого атрибута, как версия, которое соответствует виртуальному клону в предковом пути клона V2, т. е. V2 или V1), с таким виртуальным первичным ключом, как ежевика, а затем добавить новую запись с составным ключом (ежевика, V2). Следует отметить, что эта операция добавления сохраняет соблюдение ограничения конфликта.
В некоторых реализациях операцию вставки выполняют (т. е. процесс в ответ на требование вставить запись в таблицу базы данных) сначала путем выполнения чтения (или запрашивания) из таблицы базы данных с использованием того виртуального первичного ключа. Если во время чтения возвращают результат, который соответствует записи, которая должна быть вставлена, сообщение об ошибке может быть возвращено в ответ на требование вставить запись. С другой стороны, если не возвращают результат, который соответствует записи, которая должна быть вставлена, запись вставляют в таблицу базы данных с номером версии, который является родителем виртуального клона, который принял требование. Например, с учетом иерархического дерева по фиг. 4B, если операция вставки на SQL посредством V2 вставит запись с таким виртуальным первичным ключом, как ежевика, эту операцию вставки модифицируют так, что сначала выполняют чтение любой записи с таким виртуальным первичным ключом, как ежевика, и значением для такого атрибута, как версия, представленным как V2 или V1, с использованием операции чтения, описанной выше. Если запрос возвращает какие-либо результаты для чтения, то процессор возвращает сообщение об ошибке в ответ на операцию вставки, так как это является попыткой добавить запись-дубликат, связанную с общим предковым путем. Если запрос не возвращает результат для чтения, то процессор добавляет запись с составным ключом (ежевика, V2). Следует отметить, что эта операция вставки сохраняет соблюдение ограничения конфликта.
В некоторых реализациях операция модификации в отношении записи X может быть реализована сначала путем удаления старой версии записи X, как описано выше, а затем путем добавления/вставки модифицированной версии записи X, как описано выше. Поскольку как удаление, так и вставка сохраняют соблюдение ограничения конфликта, операция модификации также сохраняет соблюдение ограничения конфликта.
В некоторых реализациях дерево версий, такое как иерархическое дерево по фиг. 4B, может быть описано в отдельной таблице, которую добавляют в базу данных или связывают с ней. Система базы данных с быстрым копированием может также кешировать ту информацию о дереве версий на запоминающем устройстве, например, чтобы запросы могли быть быстро транслированы.
Если дерево версий представляет собой длинную цепочку с малым деревом в нижней части, то сравнения версии могут быть упрощены. Например, вместо сравнения версии с длинным списком допустимых версий, поднабор того списка может быть использован для сравнения, например, путем специфицирования того, что «версия < 80», а не длинного списка номеров версии, все из которых меньше 80. Альтернативно могут быть использованы диапазоны, такие как, например, выборка «10 < версия и версия < 15», вместо точного поиска следующего: «версия=11, или версия=12, или версия=13, или версия=14». Вышеизложенное может быть выполнено, например, путем синтаксического разбора строки, которая представляет оригинальный запрос на SQL, модификации полученного в результате дерева синтаксического разбора, а затем преобразования обратно в строку перед передачей строки в фактическую базу данных.
Альтернативно в других случаях основная база данных может поддерживать виды и сохраненные процедуры. Если так, то, когда создают быструю копию базы данных, вид может быть определен для каждой таблицы, что гарантирует, что выборки из той версии таблицы будут выполнены так, как определено выше. Хранимая процедура может быть создана таким образом, что операции записи для вида будут преобразовываться в копирование записей, как описано выше.
В некоторых реализациях система для реляционных баз данных, поддерживающих быстрое копирование (например, доступных с Java), содержит пользовательскую программу (например, написанную на языке Java), которая отправляет запросы на SQL на платформу базы данных, поддерживающей быстрое копирование (например, также написанную на языке Java), которая транслирует их до отправки их в фактическую базу данных. Предположим, например, что реляционная база данных имеет следующую таблицу, именуемую «люди».

Виртуальный первичный ключ представляет собой id_, и присутствуют 3 других атрибута: имя, возраст и штат. Система базы данных, поддерживающей быстрое копирование (например, исполняющая процесс в базе данных, поддерживающей быстрое копирование, с помощью процессора), может преобразовывать их в таблицу, поддерживающую быстрое копирование, путем добавления одного скрытого атрибута, такого как версия_, и добавления символа подчеркивания к другим атрибутам и имени таблицы.

Эта новая таблица имеет составной ключ (id_, версия_), и id_ может называться виртуальным первичным ключом, как отмечено выше. Таким образом, теперь две записи могут иметь одинаковый id_, пока их версия_ отличается. Вышеописанный пример соответствует ограничению конфликта, и операции в этом примере могут сохранить его соблюдение. Если некоторая другая таблица имела внешний ключ id, внешний ключ будет оставаться неизменным, за исключением того, что внешний ключ будет соответствовать атрибуту, именуемому как id_, вместо id. Первоначально внешний ключ привязан к такому виртуальному первичному ключу, как люди.id, что означает, что внешний ключ привязан к не более чем одной записи в таблице, именуемой как люди. Однако сейчас, когда внешний ключ используется в запросе, внешний ключ может соответствовать id_ нескольких записей, и, таким образом, внешний ключ будет интерпретироваться как привязанный к одной записи из того набора записей, которая имеет версию, являющуюся предком вида, использованного для выполнения запроса. В случаях, в которых соблюдается ограничение конфликта, не могут присутствовать две такие записи, поскольку это нарушит ограничение конфликта. Поэтому привязывание внешних ключей может быть совместимо с базой данных, поддерживающей быстрое копирование.
В некоторых реализациях может быть применено принудительно ограничение на имена таблиц и атрибутов, созданных пользователем. Например, может быть реализовано правило, которое специфицирует, что имена и/или атрибуты имеют длину, которая меньше размера обычной таблицы/атрибута основной базы данных как минимум на один символ (например, максимальный размер составляет 79 символов, а не 80 символов, или максимальный размер составляет 63 символа, а не 64 символа). Альтернативно или в дополнение может быть реализовано правило, которое специфицирует, что имена и/или атрибуты не могут оканчиваться символом подчеркивания. Это обеспечивает возможность переименования таблиц и атрибутов. Это также обеспечивает использование оригинального имени таблицы в качестве вида с хранимыми процедурами, если это является целесообразным для конкретной реализации.
Теперь предположим, например, что система (или процессор) выполняет операцию быстрого копирования для версии 1 с целью создания версий 2 и 3 (как показано ниже). Пользовательский код (исполняемый процессором) может предоставить номеру версии каждый запрос на SQL как для операций чтения, так и для операций записи, и тот номер версии будет представлять собой версию листа в дереве версий. В этом случае пользовательский код (исполняемый процессором) больше не может непосредственно читать или писать версию 1, поскольку операции чтения и операции записи выполняются для листа дерева версий. Теперь система выглядит следующим образом, причем операции описаны как выполняемые посредством виртуальных клонов-листьев (кругов).

Операция быстрого копирования совершенно не изменила таблицу. Она изменила только дерево версий, которое показано справа и которое хранится в специальной таблице, которая в некоторых реализациях может быть именована как версии__ (например, с двумя символами подчеркивания на конце), что не показано здесь, но которая может содержать два атрибута: родитель и ребенок.
В некоторых реализациях пользовательская программа создает строку, которая представляет собой запрос на SQL, который необходимо отправить в одну конкретную версию базы данных. Система выполнит синтаксический разбор этой строки, модифицирует полученное в результате дерево синтаксического разбора, затем преобразует его обратно в строку и отправит ту модифицированную строку в фактическую базу данных в качестве запроса на SQL. Таким образом, с точки зрения пользователя кажется, что пользователи читают/пишут в одну из многих копий баз данных, когда на самом деле они читают/пишут в одну объединенную базу данных, в которой представлены быстрые копии.
Предположим, что пользователь (например, с использованием процессора) добавляет новую запись для Дэйва с помощью виртуального клона 3. Это приведет в результате к следующей таблице базы данных.

Теперь запросы посредством версии 2 будут игнорировать (т. е. не обнаруживать) недавно созданную запись для Дэйва, но запросы посредством версии 3 будут видеть Дэйва. Предположим, что пользователь (например, с использованием процессора) теперь выполняет быстрое копирование версии 3 с получением следующей таблицы базы данных.

Запись для Дэйва содержит значение для атрибута «версия», представленное как 3, таким образом, оно будет возвращено за счет запросов, осуществленных с помощью виртуальных клонов 4 и 5, но не за счет запросов к виртуальному клону 2. Предположим, что пользователь (например, с использованием процессора) затем меняет Боб на Бобби посредством виртуального клона 2. Полученная в результате таблица базы данных имеет следующий вид.
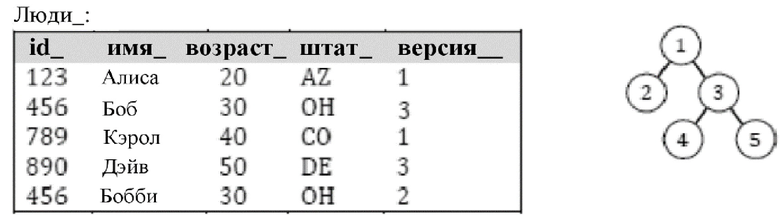
Следует отметить, что это «изменение» реализуется как удаление, после которого следуют два добавления. Оригинальная запись (Боб, 1) удаляется, и копию записи добавляют с версией, представленной как 3, поскольку 3 представляет собой ребенка узла на пути от 2 к 1, однако сама не находится на том пути. Затем новую запись с изменением добавляют с версией, представленной как 2, поскольку запись модифицируют посредством виртуального клона 2.
Теперь существуют две версии с id_=456. Теперь копия старой записи представляет собой версию 3 и, таким образом, все еще видна версиям 4 и 5, как и было до операции. Новая запись представляет собой версию 2 и видна только с помощью виртуального клона 2, поскольку изменение было осуществлено посредством версии 2. Теперь предположим, что пользователь (например, с использованием процессора) удаляет Кэрол посредством виртуального клона 4. Полученная в результате таблица базы данных имеет следующий вид.

Показано, что удалили оригинальную запись (Кэрол, 1), затем добавили две копии записи с версиями 2 и 5, поскольку 2 и 5 представляют собой узлы, которые являются детьми узлов на пути от 4 к 1, однако сами не находятся на том пути.
В итоге, в некоторых случаях операции, выполненные посредством виртуального клона V, выполняются следующим образом:
• удалить запись: удалить оригинальную запись с версией N, но вставить копии оригинальной записи для каждого ребенка узла на пути от виртуального клона V к виртуальному клону N, который сам не находится на том пути;
• добавить запись: чтобы записи-дубликаты не были связаны с одним и тем же предковым путем, предыдущая запись, содержащая по меньшей мере одно значение (например, виртуальный первичный ключ), присущее записи, которую необходимо добавить, и находящаяся в рамках того же предкового пути, сначала может быть удалена, а затем может быть добавлена запись с версией V;
• добавить запись (необязательный вариант): сначала обеспечивается, что при чтении не будет возвращена никакая запись с тем виртуальным первичным ключом, затем возвращается ошибка, если таковая возникнет, в ином случае добавляется запись с версией V;
• модифицировать запись: удаляется старая запись, затем добавляется модифицированная версия записи;
• запросы, соединения и т. д.: такие операции, включающие внешние ключи, как соединения, выполняются в обычном режиме, но только соединяются записи из двух таблиц, в которых те записи имеют номера версии, которые встретятся в рамках одного и того же предкового пути, так что к ним можно получить доступ с помощью виртуального клона V;
• создать/удалить таблицу: убедиться, что пользователь выбрал допустимое имя таблицы (достаточно короткое, последний символ не представляет собой символ подчеркивания), затем добавить символ подчеркивания к имени таблицы. Добавить такой атрибут, как версия__;
• создать/удалить атрибут: убедиться, что имя атрибута достаточно короткое и что оно не оканчивается символом подчеркивания, затем добавить символ подчеркивания.
Запросы таблицы базы данных содержат номер версии. В некоторых случаях представлен способ (например, исполняемый процессором) быстрого копирования виртуального клона. В некоторых случаях также представлен способ (например, исполняемый процессором) удаления виртуального клона. В некоторых реализациях пользователь может удалять виртуальный клон, только если он представляет собой лист. Если удаление виртуального клона оставляет внутренний виртуальный клон без каких-либо детей, то тот виртуальный клон также может быть удален. В таком случае виртуальный клон, не имеющий листьев, не становится листом. Он просто исчезает после удаления его детей. Со временем это может привести к возникновению дерева в виде цепочки виртуальных клонов с одним ребенком, проходящей от корня вниз к глубокому уровню, после чего образуется малое дерево лишь с несколькими ветвями и несколькими узлами. Эти виртуальные клоны с одним ребенком могут занимать место и тратить время, не принося полезных результатов.
В некоторых случаях периодически (или в отдельных случаях) система может исполнять операцию сжатия (например, исполняемую процессором) для устранения таких версий с одним ребенком. Например, если виртуальный клон 42 имеет только одного ребенка, который является виртуальным клоном 99, то операция (например, исполняемая процессором) может быть выполнена в таблицах за счет изменения каждого значения такого атрибута, как версия__, с 42 на 99, и может быть выполнено обновление последовательности, включающее два виртуальных клона в дереве, в результате образуется один виртуальный клон с версией 99.
Несмотря на то что в базу данных могут иметь доступ несколько виртуальных клонов, является приемлемым защита всей базы данных посредством одного правила, например, специфицирующего, что за один раз обрабатывается только один запрос виртуального клона и/или что во время операций сжатия не обрабатывается ни один запрос. Даже до выполнения операции сжатия (например, процессором) запросы могут быть оптимизированы для отражения длинных цепочек в рамках дерева. Например, когда запрос выполняется в отношении версии V=99 и если предки версии V=99 представляют собой версии {1, 10, 12, 20, 23, 32, 42}, то запрос может быть модифицирован (например, процессором) для ограничения его до записей с любой из тех 7 версий. Однако, если на дереве нет других вершин с номерами ниже 23, то запрос может быть упрощен (например, процессором) для запрашивания {<=23, 32, 42}. Другими словами, он запросит записи, которые имеют версию 42, или версию 32, или любой номер версии, который ниже или равен 23. Подобным образом, если применяемые вершины в дереве версий представляют собой {1, 10, 12, 20, 23, 32, 42}, но в дереве не присутствуют другие вершины между 10 и 32, то запрос может быть выполнен для {1, 10…32, 42}. Другими словами, он будет соответствовать версиям, равным 1, равным 42 или любому номеру от 10 до 32 включительно. Эти оптимизации являются особенно полезными, когда было создано и удалено много версий.
Полноценный язык SQL является сложным и имеет много мощных команд, которые злонамеренный пользователь может использовать для получения доступа к информации, выходящей за рамки доступной с помощью виртуального клона, который они запрашивают. В некоторых реализациях эта уязвимость может быть уменьшена за счет обеспечения использования пользователем только небольшого поднабора полноценного SQL и осуществления узлом генерации исключения, когда пользователь принимает любые данные за пределами того поднабора. Например, в некоторых случаях система может быть приспособлена для отклонения запросов в отношении таблицы или атрибута, имена которых образованы посредством операций над строками, поскольку пользователь может использовать их для непосредственного доступа к такой таблице, как люди_, или такому атрибуту, как версия__, или такой таблице, как версии__. Система может отклонять динамические SQL-операторы, такие как Transact-SQL-операторы, которые компилируются во время выполнения. В некоторых случаях эти ограничения могут быть временными. Если запрос требует имена атрибутов в таблице или имена всех таблиц, то запрос может быть модифицирован так, чтобы исключить такой атрибут, как версия_, и такую таблицу, как версии__, и исключить конечный символ подчеркивания из других имен таблиц.
В вышеприведенном описании предполагается, что таблицы и атрибуты были созданы в виртуальном клоне 1 и впоследствии не были модифицированы. Однако пользователь может захотеть изменить схему системы базы данных после создания быстрых копий (также называемых в настоящем документе «виртуальными клонами»), чтобы разные версии имели разные схемы. В некоторых случаях могут быть определены (например, процессором и сохранены на запоминающем устройстве) две новые таблицы, именуемые как таблицы__ и атрибуты__ (обе имеют два символа подчеркивания). В такую таблицу, как таблицы__, могут записываться имена таблиц в версиях. В такую таблицу, как атрибуты__, могут записываться имена атрибутов в каждой таблице в каждой версии.
В некоторых случаях, если любые два виртуальных клона имеют таблицу с одинаковым именем X, то оба могут храниться в одной и той же физической таблице, именуемой как X_. В таблице X_ могут содержаться атрибуты, которые появляются в одной из двух таблиц X. Если каждая из этих двух таблиц X содержит атрибут Y, но они имеет отметки разных типов, то таблица X__ может содержать два разных атрибута с разными именами, которые отображаются в соответствующие атрибуты Y за счет такой таблицы, как атрибуты__.
Если две разные таблицы, именуемой как X, связанные с двумя разными виртуальными клонами, имеют разный атрибут (или набор атрибутов) в качестве своего виртуального первичного ключа, то две таблицы могут храниться отдельно, и в такой таблице, как таблицы__, может храниться информация о том, какие имена были присвоены отдельным таблицам.
В некоторых случаях система может реализовывать способ (например, исполняемый процессором) для сериализации и десериализации одного виртуального клона и для получения хеша одного виртуального клона. За счет сериализации можно преобразовывать таблицы и данные, видимые тому виртуальному клону и/или применяемые к нему, в поток байтов, в котором кодируются схема и данные для того виртуального клона. За счет десериализации можно возвращать тот поток обратно в полноценную базу данных. В некоторых реализациях как сериализация, так и десериализация могут быть выполнены посредством доверенного кода (например, исполняемого процессором), а не посредством пользовательского кода. В некоторых случаях десериализация может быть выполнена только в момент создания виртуального клона 1. Как правило, виртуальный клон 1 представляет собой пустую базу данных без таблиц, видимых для пользовательского кода. За счет десериализации виртуального клона восстанавливают таблицы и данные, которые были видимы до сериализации.
В некоторых случаях хеш базы данных может представлять собой хеш SHA2-384 того сериализованного потока, предполагая, что он был создан в некотором стандартном порядке. Подобным образом, если база данных создана за счет конкретной последовательности запросов на SQL, то та база данных выдает тот же хеш, независимо от того, какой компьютер исполняет те запросы. Таким образом, например, система может сериализовать таблицы в порядке, в котором они были созданы, и сериализовать атрибуты в рамках таблицы в порядке, в котором они были созданы. Альтернативно система может сериализовать таблицы в алфавитном порядке и поля в рамках таблицы в алфавитном порядке. В других реализациях это может быть оптимизировано за счет кеширования хешей каждой таблицы и каждой записи.
Быстрые копии и снапшоты
В некоторых реализациях база данных или структура данных может быть скопирована тремя разными способами: путем определения и/или создания обычной копии, или путем определения и/или создания «быстрой копии» (виртуального клона), или путем определения и/или создания «снапшота». Снапшот отличается от обычной копии и быстрой копии тем, что является неизменяемым. Как обычная копия, так и быстрая копия являются изменяемыми, но отличаются количеством хранимой информации.
Как показано на фиг. 9, сначала (левое дерево, этап (a)) доступ к данным 1 может быть получен посредством «вида» X. Посредством вида X можно как читать, так и писать данные. Далее создают снапшот Y (этап (b)) из X, за счет чего создают копию 2 данных, после чего данные 1 становятся неизменяемыми (серый цвет). После этого данные в копии 2 могут модифицировать или читать посредством X, и причем Y может читать данные в копии 1, но не модифицировать их. Далее на этапе (c) снапшот Z создают из X, за счет чего образуют изменяемую копию 3, и копия 2 становится неизменяемой. Эти снапшоты могут быть реализованы путем создания копии 2 полной копией данных 1. Альтернативно снапшот может быть реализован за счет обеспечения содержания копией 2 только изменений, происходящих после создания снапшота. В любом случае виды Y и Z позволяют только чтение данных, но не запись данных.
Характеристика снапшота отличается от характеристики обычной копии. Характеристика обычной копии может быть описана в отношении фиг. 9. Сначала на этапе (a), как показано на фиг. 9, данные 1 могут читать или модифицировать посредством вида X. Затем, как показано на этапе (b), выполняют обычную копию, которая создает вид Y, а также создает две копии 2 и 3 данных в копии 1. На этом этапе данные 1 могут быть удалены. После этого копию 2 могут читать или модифицировать путем получения доступа к копии 2 посредством X, и копию 3 могут читать или модифицировать путем получения доступа к копии 3 посредством Y.
Эта характеристика обычной копии отличается от характеристики быстрой копии следующим образом, что может быть описано в отношении фиг. 9. Сначала, как показано на этапе (a), данные 1 могут читать или модифицировать посредством вида X. Затем, как показано на этапе (b), выполняют операцию быстрого копирования, за счет которой создают вид (также называемый «быстрой копией») Y. В ходе этой операции быстрого копирования создают копии 2 и 3, каждая из которых изначально является пустой. Данные в копии 1 не удаляют, они становятся неизменяемыми. Если незамедлительно после этого выполняют чтение либо посредством X, либо посредством Y, вид получит прямой доступ и выполнит чтение из данных 1. Если выполняют запись посредством X, изменение заносят в копию 2, а данные 1 не изменяют. Если выполняют запись посредством Y, изменение заносят в копию 3, а данные 1 не изменяют. Если чтение выполняют на X и затребованная информация представляет собой часть изменения, занесенного в копию 2, то ту информацию из копии 2 возвращают. Но если копия 2 не содержит никаких изменений в том фрагменте данных, то чтение проходит за счет данных 1. Подобным образом, при чтении посредством Y сначала проверят копию 3 и чтение продолжат до данных 1, только если в копии 3 не будет найден ответ. Данные на момент быстрого копирования показаны как данные 1 и выделены серым цветом, поскольку они являются неизменяемыми. Затем, снова обращаясь к этапу (c), вид X быстро скопирован с получением Z, что приводит в результате к образованию новых копий 4 и 5, а данные в копии 2 становятся неизменяемыми. Наконец, если вид Y затем удаляют, в результате образуют схему, показанную как этап (d) на фиг. 9. На этапе (d) по фиг. 9 отсутствует копия 3. Она удалена, поскольку больше нет никаких видов, которые могут достичь копии 3. На фиг. 9 каждое из X, Y и Z называют «видом» и также называют «быстрой копией».
В некоторых реализациях форма сборки мусора может в конечном итоге быть выполнена для структуры данных, проиллюстрированной на этапе (d) по фиг. 9. Возможно объединение данных 1 и копии 2 за счет организации данных в копию 1 и применения изменений в копии 2. Тогда возможна замена копии 2 этими объединенными данными и полное удаление данных 1. За счет этой сборки мусора могут увеличить скорость будущих операций чтения с X и Z. Такие операции чтения могут выполнять быстрее, поскольку для чтения с X нужно проверить только копии 4 и 2 в самом неблагоприятном варианте, при этом нет необходимости проверять копии 4, 2 и 1. Подобным образом, операции чтения с Z будут выполнять быстрее, поскольку для них нужно проверить только копии 5 и 2 в самом неблагоприятном варианте и не нужно проверять копии 5, 2 и 1.
Ассоциативные массивы, поддерживающие быстрое копирование
Набор пар ключ-значение может быть реализован несколькими способами, например, в хеш-таблице. Такая система (или процессор) может добавлять, удалять или модифицировать значение, связанное с ключом в течение времени O(1). Она также может выполнять итеративный обход пар ключ-значение в неопределенном порядке в течение времени O(1) на пару. Такая структура данных также может реализовывать наборы, в которых в каждой паре в качестве значения присутствует пустая строка. Это будет обеспечивать время O(1) для проверки элемента на принадлежность множеству, хотя такие операции, как пересечение и объединение, буду выполняться медленнее.
Ассоциативный массив, поддерживающий быстрое копирование, может быть реализован несколькими способами. Один способ (используя фиг. 9 в качестве примера) заключается в создании объекта для каждого круга (или виртуального клона), при этом каждый объект содержит, например, Java HashMap (хеш-таблицу Java), и в создании объекта для каждого квадрата, который представляет вид. Сначала для операций чтения и операций записи посредством X обеспечивают прямой доступ непосредственно к основному ассоциативному массиву в рамках данных 1.
После создания быстрой копии Y создаются пустые ассоциативные массивы копий 2 и 3, и данные 1 отмечаются как неизменяемые. Когда пара ключ-значение записана на X, она также будет записана в копии 2. Чтение X сначала обеспечит чтение копии 2. Если ключ не найден в копии 2, то выполняется чтение данных 1. Подобным образом, после выполнения быстрого копирования Z чтение Z обеспечит чтение копии 5. Если это не удастся, то будет выполнено чтение копии 2. А если и это не удастся, то будет выполнено чтение данных 1. Таким образом, запись в заданный квадрат обеспечивает изменение смежного круга, а чтение вызовет подъем по дереву до тех пор, пока либо не будет найдет ключ, либо не будет запрошен корень. Как показано на фиг. 9(b), если при операции записи относительно X удаляется заданная пара ключ-значение, то процессор может скопировать тот ключ из данных 1 в копию 2 со «значением», которое является специальным значением, представляющим, что пары ключ-значение не существует. Таким образом, будущие операции чтения относительно X для той пары ключ-значение остановятся на копии 2, и вместо продолжения чтения данных 1 и возвращения первоначального значения для того ключа будет сообщено, что для того ключа отсутствует значение.
Итерация пар в Z может быть выполнена за счет итеративного обхода пар в данных 1, затем в копии 2, затем в копии 5. Пара ключ-значение в данных 1, например, используется только в том случае, если в запросе показано, что ее ключ отсутствует как в копии 2, так и в копии 5. Подобным образом, пара ключ-значение в копии 2, например, используется только в том случае, если в запросе показано, что ее ключ отсутствует в копии 5. Пара ключ-значение в копии 5, например, используется без проверки какого-либо другого ассоциативного массива, поскольку копия 5 является листом дерева кругов.
Если для основного ассоциативного массива выполняется итерация в произвольном порядке, то для этого подхода также будет выполняться итерация в произвольном порядке. Если для основного ассоциативного массива выполняется итеративный обход пар ключ-значение в порядке, в котором они были модифицированы в последний раз, то для этого подхода будет использован такой же способ. В обоих этих случаях время на один элемент составляет O(1) для дерева с фиксированной глубиной или O(log d), если дерево имеет глубину, составляющую d уровней.
Если для основного ассоциативного массива выполняется итерация в некотором другом порядке, например, посредством сортировки ключей по алфавиту, то для этого подхода не будет автоматически использован такой же способ. Вместо этого система может сначала скопировать ключи в буфер, затем рассортировать их, а затем выполнить итеративный обход того буфера. Эта операция является дорогой, при этом увеличивается затрачиваемое время на один элемент с O(1) до O(log n) для n-го количества единиц. Это все еще может быть допустимым для некоторых применений.
Дополнительные оптимизации возможны во время выполнения. Например, как показано на фиг. 9(c), ассоциативный массив в копии 2 может быть заменен новым ассоциативным массивом, который объединяет копию 2 и данные 1. Затем новая копия 2 будет представлять собой корень своего собственного дерева, а данные 1 потеряют того ребенка. Если данные 1 больше не имеют никаких детей, данные 1 могут быть удалены. Подобным образом, как показано на фиг. 9(c), копия 5 может быть заменена на объединение копий 1, 2 и 5, а затем стать своим собственным корнем. Объединение двух неизменяемых таблиц, таких как данные 1 и копия 2, может занять некоторое время, однако оно может выполняться в фоновом потоке. Дополнительно по его окончании объединенный ассоциативный массив можно сменить на старый ассоциативный массив и полученные в результате деревья станут менее глубокими, что увеличит скорости операций чтения и итераций.
В дополнение, если виды удалены, некоторые из кругов становятся недоступными и затем могут быть удалены из запоминающего устройства, и любые действия по их объединению могут быть принудительно прекращены. Это позволяет системе отражать то, что показано на фиг. 9(d). Это может быть вызвано процессом сборки мусора в базовом языке. Альтернативно система может реализовывать способ явного удаления вида и сохранять подсчеты ссылок для определения того, когда круг становится сиротой, в момент чего его удаляют.
Операции удаления пар ключ-значение могут быть реализованы в корневом ассоциативном массиве за счет фактического удаления пары ключ-значение. В ассоциативных массивах, которые не являются корневыми, такое удаление может быть осуществлено за счет изменения значения на специальный объект «удалено». Когда объединение ассоциативных массивов обеспечивает преобразование нового ассоциативного массива в корень, итеративный обход их пар ключ-значение может быть выполнен для исключения пар ключ-значение с объектом «удалено».
Другой подход заключается в использовании единой структуры данных, такой как префиксное дерево, вместо дерева хеш-таблиц. В префиксном дереве каждый ключ может представлять собой хеш постоянной длины с предварительно определенным размером, таким как, например, 16, 32 или 64 бита. Ассоциативный массив представлен бинарным деревом, n-й уровень которого представляет n-й бит ключа, и при этом ключ ищут за счет спуска по 16 (или 32, или 64) уровням. Затем значение сохраняют в листе на нижнем уровне. Для разрешений хеш-коллизий ключей лист сохраняет список пар ключ-значение, хотя ожидается, что в целом список будет очень коротким, особенно если хеш-функция неизвестна злоумышленнику, который может попытаться выбрать ключи для создания чрезмерного количества коллизий. Также можно улучшить требования скорости и объема памяти за счет использования n-арного дерева, а не бинарного дерева. Например, 32-арное дерево будет иметь только пять уровней, поскольку 32=25.
Выше описано стандартное префиксное дерево. Для преобразования стандартного префиксного дерева в префиксное дерево, поддерживающее быстрое копирование, на каждом ребре дерева должна быть отмечена информация о том, какие версии данных применяют. Таким образом, как показано на фиг. 9(a), заданная пара ключ-значение может быть добавлена, а ее ребра могут быть помечены ссылочной позицией 1. Затем после быстрого копирования Y и Z пара ключ-значение может быть добавлена к Z. Это может включать добавление еще нескольких ребер к дереву, каждое из которых может быть помечено ссылочной позицией 5. Когда ключ читают с вида Z, система может начать с корня и следовать по ребрам, соответствующим битам ключа, но только по тем ребрам, которые помечены ссылочными позициями 1, 2 или 5. Конечно это означает, что граф, показанный на фиг. 9(c), явно хранят на запоминающем устройстве, или по меньшей мере Z может идентифицировать (например, за счет хранения связи с Z), что его путь к корню графа по фиг. 9(c) проходит через круги, помеченные ссылочными позициями 1, 2 и 5.
По мере создания большего количества быстрых копий проверка ребер на соответствие условиям может стать более сложной. Например, запрос может в конечном итоге спускаться по префиксному дереву только по ребрам, которые помечены одним из номеров {1,2,5,17,32,65,82,97,99}. Однако в некоторых применения может произойти так, что, как ожидается, граф по фиг. 9 в перспективе перерастет в длинную тонкую цепочку от корня практически до низа, которая затем около низа разойдется на множество ветвей. Если номера в кругах присвоены в числовом порядке (как это показано на фигурах), вместо проверки того, помечено ли ребро любым из номеров в длинном списке {1,2,5,17,32,65,82,97,99}, можно проверить, присутствует ли номер в списке {<80,82,97,99}, где отметка «<80» соответствует любому номеру меньше 80. Другими словами, логическое условие не должно становиться сложнее со временем, даже если дерево на фиг. 9 со временем становится выше, пока дерево представляет собой цепочку с малым деревом внизу. Для удаления пары ключ-значение могут использовать специальный объект «удалено», как описано выше. Или такое удаление может быть выполнено за счет пометки ребер как удаленных в конкретных версиях. Затем в версии могут удалять ключ, которым помечают некоторые ребра в префиксном дереве как удаленные для той версии. В том случае, как показано на фиг. 9(c), считают, что ребро присутствует в префиксном дереве для вида Z, если наибольший номер из {1,2,5}, упомянутый для того ребра, указывает, что ребро добавили, а не удалили.
Массивы, поддерживающие быстрое копирование
После создания ассоциативного массива, поддерживающего быстрое копирование, могут быть созданы версии, поддерживающие быстрое копирование, других структур данных. Например, массив, поддерживающий быстрое копирование, может быть образован за счет совмещения фактического массива с ассоциативным массивом, поддерживающим быстрое копирование, таким как ассоциативный массив, поддерживающий быстрое копирование, описанный в предыдущем разделе. Изначально, когда присутствует только один виртуальный клон или вид, операции чтения и операции записи переходят непосредственно на массив. После быстрого копирования операции записи переходят на ассоциативный массив, при этом каждая пара ключ-значение использует индекс массива в качестве ключа и элемент массива в качестве значения. При чтении сначала проверяется ассоциативный массив, и если в нем индекс не найден, то его читают из массива. За счет множества операций быстрого копирования может образовываться дерево ассоциативных массивов. При чтении из одного виртуального клона или вида будет осуществляться подъем по дереву до тех пор, пока не найдется ассоциативный массив с тем ключом, или пока не будет достигнут корень дерева, который представляет собой фактический массив.
Как и ранее, существует возможность сжатия дерева версий по мере необходимости. Например, как показано на фиг. 9(c), можно создать новый массив, отражающий копии 1, 2 и 5. После создания нового массива вид Z может устанавливать соединение с этим новым массивом, связанным с пустым ассоциативным массивом. После такого сжатия как операции чтения, так и операции записи будут выполняться быстрее, пока не создадутся дополнительные быстрые копии, за счет которых дерево снова вырастет. Этот процесс может повторяться/итерироваться. Подобный подход применяется практически к любой коллекции, не только к массивам. Произвольная коллекция обернута в объект, который содержит ассоциативный массив, поддерживающий быстрое копирование, и при операциях чтения и операциях записи ассоциативный массив проверяют до проверки коллекции. Операции чтения и операции записи могут выполняться медленнее, когда за счет множества операций быстрого копирования растет дерево версий, а затем выполняться быстрее, когда дерево сжимается.
Файловая система, поддерживающая быстрое копирование
В файловой системе, поддерживающей быстрое копирование, объект виртуального клона или вида может представлять всю файловую систему. Объект виртуального клона или вида представляется пользователю как отдельный жесткий диск, содержащий дерево каталогов, содержащих файлы. Операция быстрого копирования представляется пользователю для создания нового жесткого диска с точной копией оригинального. Таким образом, оба диска могут быть модифицированы независимо друг от друга, и изменения в одном из них не повлияют на другой. Это может быть реализовано за счет наличия одного фактического каталога, содержащего файлы от всех версий. В базе данных, поддерживающей быстрое копирование, как описано в настоящем документе, хранятся дерево каталогов для каждой версии и указатели на файлы в каждом каталоге. Если в обеих версиях содержится идентичный файл, то системе необходима только одна фактическая копия на реальном жестком диске, и в базе данных могут храниться два указателя на фактическую копию. Когда удаляется последний указатель на файл за счет удаления файла из последнего вида, который может видеть файл, система удаляет физический файл на физическом жестком диске. Этот подход делает копирование операцией O(1). За счет этого также сохраняется пространство на жестком диске вследствие хранения только одной копии файлов-дубликатов.
Система может быть дополнительно оптимизирована за счет разделения файлов на небольшие блоки, такие как, например, блоки размером 2 Кбайта. Теперь база данных хранит список указателей для каждого файла, которые указывают на блоки, составляющие тот файл. Таким образом, если два файла имеют одинаковое содержимое для первого блока размером 2 Кбайта, только одна копия того блока хранится физически, что дополнительно сохраняет пространство. Таким образом, дублирование сокращается не только в случае, когда два виртуальных клона или вида имеют доступ к одному и тому же файлу, но и в случае, когда один виртуальный клон или вид представляет дерево каталогов, содержащее идентичные файлы в двух разных каталогах.
Если существует необходимость быстрого подсчета хешeй файлов или всех поддеревьев каталогов, то та информация также может храниться в базе данных. Хеш каждого блока может храниться и модифицироваться при модификации блока. На самом деле, в некоторых случаях имя файла блока в основной файловой системе может быть определено в качестве хеша файла в шестнадцатеричной системе счисления. Если существует только один указатель для заданного блока X, то модификация блока может включать изменение имени файла. Если присутствует несколько указателей на заданный блок Y, то модификация блока Y может быть реализована за счет выполнения копии блока, модификации блока, а затем изменения имени копии на его хеш.
В таких случаях хеш файла может представлять собой инкрементный хеш, такой как хеш сцепления его блоков. Альтернативно хеш файла может быть определен как сумма хешей пар (положение, данные) для блоков в файле. Хеш каталога может представлять собой сумму хешeй файлов в каталоге. Когда файл изменяют, база данных может обновлять задействованные хеши, например, в фоновом потоке. Альтернативно хеши могут не подсчитываться, пока вызов способа не затребует хеш. В таких случаях хеш может быть подсчитан по требованию. Данная архитектура упрощает реализацию дополнительной особенности, которая обычно не присутствует в традиционных системах файлов. «Транзакции» файловой системы могут быть реализованы в рамках базы данных. Когда система (например, с помощью процессора) вызывает способы файловой системы для проведения операций в файловой системе, система может вызывать способ (например, исполняемый процессором) для инициирования транзакции, затем выполнять несколько вызовов для добавления, исключения или модификации файлов, а затем вызывать способ (например, исполняемый процессор) для осуществления транзакции. В некоторых подобных реализациях, даже если система будет выключена в какое-либо время, файловая система в любом случае отразит либо все эти операции, либо ни одну из них. Эту возможность обычно не добавляют в традиционные файловые системы, поскольку это включает вызовы на традиционную базу данных таким образом, вследствие которого система замедляется. Однако файловая система, поддерживающая быстрое копирование, раскрытая в настоящем документе, уже возмещает эти вычислительные затраты по другим причинам, так что добавление транзакций на самом деле приносит небольшие дополнительные/приростные затраты.
В некоторых реализациях «транзакция» на уровне файловой системы может быть реализована в качестве «транзакции» на уровне базы данных. Если в середине операции произошел сбой, способ восстановления базы данных (например, исполняемый процессором) может включать возвращение базы данных в начало транзакции базы данных. Затем способ восстановления базы данных может обеспечивать прямой доступ через хранимые блоки, чтобы увидеть, что на какие-либо из них база данных больше не осуществляет ссылку, и удалить любые такие идентифицированные блоки. Это способствует быстрому восстановлению правильного состояния, после чего следует более долгий процесс (например, в фоновом потоке) для восстановления потерянного пространства. При этом подходе файлы блока удаляются только после того, как подтверждение отправляется в базу данных, и база данных обновляется.
Далее предоставлено подробное обсуждение системы для файловой системы, поддерживающей быстрое копирование (например, доступной с Java). Пользовательская программа (например, написанная на языке Java и исполняемая процессором) вызывает способы платформы файловой системы, поддерживающей быстрое копирование (например, также написанной на языке Java и исполняемой процессором), которая поддерживает обычные операции файловой системы, плюс несколько не обычных.
Файловая система, поддерживающая быстрое копирование, может обеспечивать доступ пользовательскому коду и/или процессу (исполняемым процессором) к тому, что является томами, каталогами и файлами. В отличие от известных файловых систем файловые системы, поддерживающие быстрое копирование, описанные в настоящем документе, могут способствовать:
- быстрому копированию файла, дерева каталогов или тома;
- быстрому подсчету хешeй файла, дерева каталогов или тома;
- сериализации и десериализации файла, дерева каталогов или тома;
- сериализации и десериализации их поднабора (для дифференциальных копий);
- акцентированию на скорости чтения, а не скорости записи;
- автоматическому удалению дубликатов избыточных каталогов, файлов и частей файлов;
- способности находить файл или каталог при наличии только его хеша (т. е. хеши представляют собой указатели);
- запросам на SQL только для чтения по базе данных, относящихся к метаданным, для файловой системы.
В некоторых реализациях в файловой системе реализуется следующее.
Том – виртуальный жесткий диск, имеющий ее корневой каталог / выполненный в качестве ее корневого каталога.
Каталог – некоторые метаданные плюс отсортированный список из 0 или более (<263) файлов и каталогов.
Файл – некоторые метаданные плюс последовательность из 0 или более (<263) байтов.
ACL (список управления доступом) – файл или каталог, содержащий группу идентификаторов.
Идентификатор – открытый ключ (хранящийся в ACL), представляющий кого-либо, кто может иметь доступ к файловой системе.
Субъект – файл или каталог (также может быть или может не быть ACL).
Блок – последовательность от 0 до количества байтов, равного CHUNK_SIZE (физически хранящихся в качестве Java-файла).
Дерево блоков – набор из 1 или более блоков, упорядоченных в виде дерева, для представления 1 субъекта.
CHUNK_SIZE = 4096 (или другая постоянная).
Метаданные – информация об одном субъекте, включающая его имя, размер (рассчитанный несколькими способами), разрешение на доступ, определяемые пользователем метаданные и т. д.
Разрешения – субъект имеет либо разрешения на чтение для всех, либо имеет специфицированную группу ACL тех, кто имеет разрешения на чтение. Подобное применимо и для записи.
В некоторых реализациях в файловой системе не реализуется следующее.
Ссылки – эта файловая система не имеет ссылок, жестких ссылок, гибких ссылок, символьных ссылок, псевдонимов и т. д. Однако быстрое клонирование обеспечивает нечто подобное: вместо помещения ссылки на библиотеку в каталоге Вы можете просто скопировать всю библиотеку в свой каталог, при этом будет использовано такое же небольшое количество пространства для хранения, будто была использована ссылка.
Каталоги «.» и «..» – структуры данных не отражают существование каталогов «.» или «..». Однако интерфейс может корректно интерпретировать строки пути от пользователя, которые содержат таковые, например, «/тут/../там».
Сжатые/зашифрованные каталоги – отсутствует эквивалент сжатого или зашифрованного каталога, как в Windows или OSX. Однако более слабая форма сжатия (блоки, дубликаты которых удаляются) реализуется повсеместно. Более того, если дерево каталогов имеет флаг readAcl, значение которого задано как истина, для каждого из его файлов и подкаталогов, то данные, имена файлов и имена каталогов будут зашифрованы, хотя топология дерева каталогов и размеры файлов все равно будут видимыми.
Программа Rsync и система Time Machine – в некоторых случаях дифференциальное копирование и/или дифференциальное резервирование могут быть реализованы в файловой системе.
Разрешения по образцу Unix – вследствие сущности файловой системы, поддерживающей быстрое копирование, отсутствует такая присущая концепция, как владелец, группа или пользователи, для файла или каталога. Из операций чтения, записи и исполнения только первые две являются действительными. Следовательно, файловая система, поддерживающая быстрое копирование, может предоставить для каждого файла или папки необязательный список управления доступом (ACL) для чтения и другой ACL для записи. Если приложению пользователя необходимо что-либо помимо этого, пользователь может добавить это в качестве части метаданных пользователя. Кроме того, здесь точные определения чтения и записи несколько отличаются от определений в Unix и других системах.
Для пользователя файловая система отображается со следующим функционированием. Том подобен внешнему жесткому диску, имеющему корневой каталог / выполненный в качестве корневого каталога. Том содержит дерево каталогов. Каждый каталог содержит набор каталогов и файлов. Он не содержит два каталога «.» и «..» или что-либо эквивалентное (хотя в некоторых случаях пользовательский интерфейс может имитировать их наличие). В некоторых случаях пользователь не может создавать или видеть жесткие ссылки, гибкие ссылки, символьные ссылки, псевдонимы и т. д. Видимое дерево каталогов отображается (пользователю) в качестве дерева, а не DAG или циклического графа. Пользователь видит файловую систему, поддерживающую быстрое копирование, как обычную файловую систему, однако операции записи выполняются медленнее, чем обычно, а следующие операции – быстрее, чем обычно:
- быстрое копирование файла, каталога или тома;
- получение хеша файла или всего дерева каталогов;
- получение размера в байтах файла, каталога или всего дерева каталогов;
- сериализация/десериализация файла или дерева каталогов в поток (например, поток Java);
- сериализация/десериализация набора блоков в поток (например, поток Java);
- получение информации, которая облегчает определение дифференциальных копий (как rsync);
- запросы на SQL только для чтения по базе данных, относящихся к метаданным, для файлов в заданном томе.
Система (например, с использованием процессора) может выполнять быстрое клонирование файлов и каталогов, быстрое получение хеша файла или каталога и сериализацию/десериализацию файлов и деревьев каталогов. В некоторых случаях распределенная хеш-таблица (DHT) добавляется на платформу файловой системы, поддерживающей быстрое копирование, и пользователи могут найти и скачать файл или дерево каталогов из интернета при наличии их хеша. В таких случаях то скачивание может быть эффективным с передачей только тех данных, которыми пользователь еще не обладает.
Пользователь видит содержимое тома как конечное дерево каталогов, а не как DAG, циклический граф или бесконечное дерево. В каждом из тех каталогов могут содержаться файлы и другие каталоги. Некоторые из файлов и каталогов могут быть помечены как ACL и, как правило, скрыты, но могут быть видны пользователю по требованию.
В некоторых случаях модель разрешений на доступ включает чтение и запись, но не исполнение, и построена на иерархических группах ACL идентификаторов ID. Пользователь имеет разрешения на чтение для файла или папки, если их функция readAll (читать все) имеет такое значение, как истина, или если их функция readAll имеет такое значение, как ложь, и их функция readAcl (читать Acl) включает того пользователя. Разрешения на запись определены подобным образом (с функцией writeAll (писать все) и функцией writeAcl (писать Acl)).
В следующей таблице, если пользователь имеет разрешения, перечисленные в начале строки, он может выполнять операцию, отмеченную цветом (красный=нет прав, желтый=права только на чтение, зеленый=права на чтение и модификацию), с элементом, перечисленным в соответствующем столбце. Первые 4 столбца предусмотрены для метаданных.

Чтение = пользователь может читать данные.
Отсутствие чтения = пользователь может читать только зашифрованную версию данных, или копировать файл или каталог в другое место, или сериализовать/десериализовать данные.
Модификация = пользователь может изменять любую часть данных. Для каталога это включает изменение собственного имени каталога и добавление/удаление файлов/каталогов в рамках того каталога, но не обязательно обеспечивает возможность чтения или модификации имен тех файлов, что находятся в рамках того каталога.
В некоторых случаях пользователь может копировать, сериализовать или десериализовать файл или дерево каталогов независимо от разрешений. В то время как пользователь это выполняет, он может необязательно задать разрешения на запись для файла или для всего в дереве каталогов (т. е. задать функцию writeAll и функцию writeAcl для каждого из них).
«Субъект» может представлять собой файл или каталог. Каждый субъект имеет свои собственные метаданные и содержимое. «Содержимое» файла определено как последовательность байтов в рамках того файла. Содержимое каталога определено как отсортированная последовательность хешeй файлов и каталогов в рамках того каталога. В некоторых случаях каждый субъект физически хранится в дереве блоков, выполненном из блоков, как определено ниже.
«Блок» представляет собой последовательность байтов, которая физически хранится как один файл в основной файловой системе (например, предоставленной за счет Java). Каталоги, и файлы, и ACL в файловой системе, поддерживающей быстрое копирование, могут быть виртуальными. В таких реализациях только блоки физически существуют на жестком диске пользователя. Тогда как пользователи не видят блоки, основная физическая файловая система выполняет операции и/или использует блоки.
Блок имеет имя файла в физической файловой системе жесткого диска (например, предоставленной за счет Java). В некоторых случаях то имя файла может представлять собой 256-битный хеш его содержимого в шестнадцатеричной системе счисления с нижним регистром. Таким образом, когда блок записан на запоминающее устройство на дисках, блок не модифицируется, хотя он может быть удален. В некоторых случаях блоки могут храниться в одном каталоге в физической файловой системе (например, предоставленной за счет Java) на запоминающем устройстве. В других случаях каталог, содержащий подкаталоги, в которых блоки разделены в соответствии с первыми несколькими символами их имени файла, может быть использован для хранения блоков на запоминающем устройстве.
В некоторых случаях блок не больше, чем количество байтов, равное CHUNK_SIZE. Эта глобальная постоянная может быть определена так, чтобы, например, составлять 4*1024. В других случаях CHUNK_SIZE составляет от 4*1024 до 8*1024*1024 и используется в разреженных комплектах OSX.
Один или более блоков могут быть совмещены с образованием «дерева блоков», которое используется для хранения одного субъекта (файла или каталога). Первый блок начинается с байта «глубина», обозначающего глубину дерева. Таким образом, 0x01 обозначает, что дерево представляет собой только один блок, который является как корнем, так и листом, 0x02 обозначает, что все дети корня представляют собой листья, и т. д. За таким байтом, как глубина, следуют «фиксированные» элементы метаданных для субъекта, как определено в разделе о метаданных ниже.
Для достаточно небольшого субъекта после этого идут все остальные метаданные, а затем содержимое файла или каталога. («Содержимое» каталога представляет собой отсортированный список 32-байтовых хешeй каждого файла и подкаталога в рамках каталога). В качестве примера, если хранимые данные составляют не более количества байтов, равного CHUNK_SIZE, то данные вмещаются в один блок, и тот блок будет иметь глубину одного (0x01), и тот блок содержит все дерево блоков для того субъекта.
Если субъект слишком большой, чтобы вместиться в один блок, то после фиксированных метаданных идет последовательность хешей блоков-детей. Каждый из блоков-детей содержит последовательность хешей блоков их детей и т. д. для внутренних блоков в дереве.
Блоки-листья, если к ним переходят в порядке по вершинам, содержат оставшиеся метаданные, а затем содержимое файла или каталога. В некоторых случаях начало содержимого находится в отдельном блоке-листе с конца метаданных.
В некоторых случаях топология дерева уникально определяется, как представлено ниже. Если дерево может вмещаться в один блок, то оно вмещается в рамках одного блока. В противном случае система может определять дерево таким образом, что, если к узлам переходят в порядке по вершинам, расположенные раньше узлы являются наибольшими и подвергаются ограничению, которое заключается в том, что ни один листовой узел не может содержать байты как из метаданных, так и из содержимого.
В некоторых случаях каждый субъект (файл или каталог) может содержать следующие метаданные в следующем порядке, которые разделены здесь на 3 категории для удобства: (фиксированные, переменные, конфиденциальные).
Фиксированные.
1. Файловая система – 2 байта – версия файловой системы последней модификации.
2. Тип субъекта – 1 байт:
0x00 = ENTITY_FILE = файл;
0x01 = ENTITY_DIR = каталог;
0x80 = ACL_FILE = файл, представляющий группу ACL;
0x81 = ACL_DIR = каталог, представляющий группу ACL.
3. Размер – 8 байтов – количество байтов в этом файле или одном каталоге, если дубликат ни одного блока не был удален.
4. SizeSMetadata (размер конфиденциальных метаданных) – 8 байтов – количество байтов конфиденциальных метаданных.
5. SizeVMetadata (размер переменных метаданных) – 8 байтов – количество байтов переменных метаданных.
6. SizeTree (размер дерева) – 8 байтов – присутствует только для каталогов: общий размер файлов и каталогов в этом дереве каталогов, если ни один дубликат не был удален.
7. Функция readAll – 1 байт – истина (0x01), если все имеют разрешения на чтение этого файла или каталога. В противном случае ложь (0x00) для ограничения их до ACL.
8. Функция writeAll – 1 байт – истина (0x01), если все имеют разрешения на запись этого файла или каталога. В противном случае ложь (0x00) для ограничения их до ACL.
Конфиденциальные.
9. Имя – имя файла или имя каталога представляет собой непустую строку (например, строку Java) с длиной строки String.length()<=255. Подобным образом, не более 255 кодовых единиц UTF-16. В некоторых случаях допустимы все символы Юникода, включая косую черту и двоеточие. В некоторых случаях нет ограничения значений длины путей.
10. UuserMetadata (метаданные пользователя) – список пар ключ-значение, в котором как ключ, так и значение представляют собой строки (например, любая допустимая строка Java подходит), и при этом для одного и того же ключа могут быть предусмотрены несколько пар. Он пустой пока пользователь не вызовет способ для добавления пар.
Переменные.
11. Функция readAcl – 32 байта – присутствует, если функция readAll имеет такое значение, как ложь, – хеш файла ACL или дерева каталогов ACL, представляющий группу ACL идентификаторов ID, которые имеют разрешения на чтение. Система может обеспечивать, что для функции readAcl каталога предусмотрен хеш файла ACL или каталога ACL, хранящийся в рамках каталога. Для функции readAcl файла может быть предусмотрен хеш файла ACL или каталога ACL, хранящийся в том же каталоге, что и файл.
12. WriteAclHash (хеш функции writeAcl) – 32 байта – присутствует, если функция writeAll имеет такое значение, как ложь, – хеш подобен хешу для функции readAcl, однако может указывать на другой субъект.
13. EncryptedKeys (зашифрованные ключи) – присутствуют, если функция readAll имеет такое значение, как ложь. Список из одного зашифрованного ключа на открытый ключ в группе ACL. Список хранится в качестве 8-байтового счетчика, за которым следует каждый из зашифрованных ключей в порядке, соответствующем отсортированному списку ID в группе ACL.
В некоторых случаях в дополнение к 4 типам размера, который хранится, представлен 5-й тип, который не хранится, но повторно подсчитывается (например, процессором) при необходимости. Он представляет собой «размер после удаления дубликатов», который представляет собой общий размер уникальных блоков в этом файле или дереве каталогов. Он будет представлять собой размер на запоминающем устройстве на дисках, если удаление дубликатов будет происходить в рамках этого файла или дерева каталогов, в то же время игнорируя блоки за пределами файла или дерева каталогов.
В некоторых случаях субъект, функция readAll которого имеет такое значение, как ложь, может быть частично зашифрован (например, с использованием процессора). «Конфиденциальные» метаданные зашифрованы, а «фиксированные» и «переменные» метаданные не зашифрованы. Содержимое файла зашифровано, а содержимое каталога не зашифровано.
В некоторых случаях шифрование может представлять собой XTS (NIST SP800-38E) со случайным ключом. «Модуль данных» XTS представляет собой каждый целый блок, за исключением любого блока, который содержит как конфиденциальные, так и переменные метаданные, для которого модуль данных представляет собой только часть конфиденциальных данных. Шифрование конфиденциальных метаданных может представлять собой шифрование XTS с использованием случайного ключа. Шифрование содержимого файла может представлять собой отдельное шифрование XTS с использованием того же ключа, но его биты отражены. Таким образом, если конфиденциальные метаданные модифицируются за счет увеличения их длины, часть метаданных может быть повторно зашифрована, но содержимое повторно не шифруется, поскольку содержимое начинается в начале нового блока.
Затем случайный ключ может быть зашифрован (например, с использованием процессора) с каждым из открытых ключей в отсортированном списке открытых ключей из группы ACL, и результаты хранятся в качестве encryptedKeys. Для файла ACL группа ACL представляет собой отсортированный список ID в файле ACL. Для каталога ACL группа ACL представляет собой отсортированный список ID в файлах ACL в рамках дерева каталогов, корень которого представляет собой тот каталог.
В некоторых случаях, когда группа ID ACL изменяется за счет добавления ID, новый зашифрованный ключ может быть добавлен в список зашифрованных ключей. Когда ID удаляется, выбирается новый случайный ключ, повторно рассчитывается список зашифрованных ключей, и как конфиденциальные метаданные, так и содержимое расшифровываются посредством старого ключа и повторно зашифровываются посредством нового ключа. Кеширование записи может быть использовано для оптимизации этого процесса, например, за счет обеспечения нескольких изменений в отношении ACL в быстрой последовательности, а затем проведения повторного шифрования только этих изменений.
Метаданные пользователя могут представлять собой отсортированный список пар (ключ, значение). Каждый ключ представляет собой строку (например, строку Java), и при этом каждый ключ уникален. Каждое значение может представлять собой список Java<байт[]>, при этом порядок в списке представляет собой порядок, в котором различные значения были добавлены пользователем. Пользователь может добавлять и удалять значения. Когда не остается значений, пара удаляется.
Эти ключи могут представлять собой любую строку, которую пользователь пожелает. В некоторых реализациях пустая строка является допустимой, а ноль не является допустимым. Примеры включают ключи «creatorApp» или «openWith» или ключ «источник», значение которого представляет собой хеш дерева каталогов (при этом в первых двух случаях присутствует один исполняемый файл в каталоге верхнего уровня). Другие примеры включают ключ «миниатюра», связанный с небольшим форматом jpg, или ключи «createdDate» или «modifiedDate», связанные с временем и датой, или ключ «закрепленный», связанный с ID каждого пользователя, который хочет, чтобы этот файл продолжил существовать. Платформа файловой системы, поддерживающей быстрое копирование, может использовать некоторое или все из этого, в зависимости от того, какие ключи предоставляет пользователь.
В некоторых реализациях поле размера может представлять собой 64-битное целое число со знаком с учетом общего размера в байтах каждого блока в дереве блоков для этого субъекта. Если такой же блок появляется на дереве блоков дважды, он учитывается дважды. Соответственно, поле размера представляет собой количество пространства на запоминающем устройстве на физических дисках, которое будет занимать дерево блоков для субъекта, если не будет выполнено удаление дубликатов.
Поле treeSize предусмотрено для каталога, но не для файла или ACL. Поле treeSize может представлять собой сумму размера для этого каталога, плюс размер каждого файла в этом каталоге, плюс размер дерева (treeSize) каждого подкаталога в этом каталоге. Это представляет собой количество пространства, которое это дерево каталогов будет занимать на запоминающем устройстве, если не будет выполнено удаление дубликатов.
В некоторых случаях платформа файловой системы, поддерживающей быстрое копирование, также может отслеживать, за какое количество байтов отвечает каждый пользователь. Для файла с пользователей, которые закрепляют файл, могут взимать байты с «размера». Для каталога с пользователей, которые закрепляют каталог, могут взимать байты с «treeSize». Если никто не закрепил файл, приложение может решить удалить файл, чтобы освободить пространство на запоминающем устройстве. Если дерево каталогов не содержит закрепленных файлов или каталогов, все это дерево каталогов может быть удалено (например, с использованием процессора), чтобы освободить пространство на запоминающем устройстве. Это означает, что с пользователей взимают байты за пространство, которое используется по их требованию, игнорируя удаление дубликатов, которое выполняется, когда два пользователя закрепляют одно и то же. Платформа файловой системы, поддерживающей быстрое копирование, может обеспечивать, что платформа файловой системы, поддерживающей быстрое копирование, не закрепляет ни каталог, ни субъект внутри его дерева каталогов.
В вышеописанной файловой системе предусмотрены операции быстрого чтения и операции медленной записи. В ней также предусмотрен быстрый подсчет хеша. Если пользователь требует хеш файла или каталога, ответ будет представлять собой просто имя физического файла корневого блока его дерева блоков. Он может храниться в реляционной базе данных вместе с метаданными и, таким образом, может быть быстро возвращен. В некоторых случаях хеш SHAZ-256 может быть использован по всей файловой системе. В других случаях хеш SHA3-256 (или любой другой подходящий хеш) может быть использован по всей файловой системе.
Несмотря на то что в некоторых реализациях в файловой системе операции записи выполняются медленно, ее преимущество заключается в том, что каждый раз, когда создаются два файла, имеющие одинаковое количество байтов в одном из их блоков, только одна копия того блока физически сохраняется на запоминающем устройстве, что уменьшает потребление пространства для хранения и обеспечивает пользователю возможность создания копий, которые они в ином случае не смогли бы создать. Например, вместо создания ссылки в каталоге на библиотеку, пользователь (например, с использованием процессора) может просто скопировать всю библиотеку в тот каталог, и та виртуальная копия будет занимать меньше пространства, чем фактическая копия.
В некоторых случаях, если пользователь копирует файл или каталог (даже из одного тома в другой), то система (например, с использованием процессора) физически копирует только указатели на корневой блок субъекта, а не на сами фактические блоки. В настоящем документе термин «указатель» может обозначать хеш субъекта, который хранится в метаданных других субъектов и в базе данных. Если оба каталога /X/ и /Y/ содержат файл A с именем файла N и пользователь модифицирует /X/N, то система сделает B копией A, выполнит затребованную модификацию в отношении B, изменит указатель с /X/N на указание на B и оставит оригинал /Y/N, который все еще будет указывать на A.
Изначально вышепредставленное может быть закодировано, как описано. Это означает, что каждая запись может включать повторный расчет хешей и создание новых блоков, которые хранятся в новых физических файлах. В некоторых случаях систему можно ускорить за счет кеширования записей на RAM и их записывания только на запоминающее устройство на дисках после отсрочки, таким образом множество операций записи в один и тот же файл соединятся в один этап хеширования и создания блоков. Дополнительно в некоторых таких случаях изменение множества файлов в одном каталоге может обеспечить одно изменение для того каталога и каталогов, находящихся над тем каталогом в дереве каталогов. В таком случае перед операциями чтения выполняется запрос базы данных на наличие каких-либо существующих в данный момент кешированных записей, которые повлияют на чтение значений.
В некоторых реализациях блоки, которые составляют файл, выполнены без возможности отображения пользователю, вместо этого пользователь видит только сам файл. Однако в других реализациях система может быть выполнена с возможностью выполнения нескольких способов (например, исполняемых в процессоре), связанных с хешами блоков. Система может позволять пользователю находить хеш корневого блока файла или каталога. Он, по определению, представляет собой хеш того файла или каталога и может быть использован во всей системе в качестве указателя на тот файл или каталог.
В некоторых реализациях пользователь может вызывать способ (например, исполняемый процессором) для сериализации файла, или дерева каталогов, или списка блоков (на которые делают ссылку их хеши) в поток байтов. Альтернативно или в дополнение в некоторых реализациях пользователь может вызывать способ (например, исполняемый процессором) для десериализации такого потока и создания нового файла или каталога в рамках каталога, выбранного пользователем. Десериализованные блоки могут быть добавлены прозрачно / невидимым образом в файловую систему и впоследствии преобразованы в видимые файлы и деревья каталогов, например, когда во всем файле или каталоге присутствуют его блоки. Когда пользователь указывает, что десериализация завершена, система может собрать в мусор любые блоки, которые не были использованы. Такая сборка мусора также может происходить периодически (например, раз в минуту, раз в час, раз в день и т. д.), в отдельных случаях или в любое предопределенное время или временной интервал.
Если пользователь вызывает способ сериализации (например, исполняемый процессором) для файла, то процессор может сериализовать весь файл (т. е. все дерево блоков, в порядке поиска в глубину, обход в прямом порядке) и вывести содержимое каждого блока. В некоторых реализациях ни одно из имен блоков не сериализуют. Если пользователь требует сериализации дерева каталогов, процессор может сериализовать все дерево каталогов (т. е. деревья блоков подкаталогов и файлы в дереве каталогов), выполняя поиск в глубину его каталогов. В обоих случаях сериализация выполняется рекурсивным образом путем сериализации корневого блока, затем каждого из хешей, которые он содержит, и т. д. Система хранит указание на блоки, которые уже были сериализованы, или запоминает такие блоки, таким образом процессор не сериализует один и тот же блок дважды.
При десериализации система может подсчитывать хеш каждого блока из его содержимого (например, для определения имени файла для сохранения того блока), а после завершения процесса может убирать любые блоки, которые в итоге не являются действительной частью полного субъекта.
Если система сериализует набор блоков (за счет передачи набора их хешей), система сериализует только байты в тех блоках в заданном порядке. Способ возвращает набор блоков, на которые осуществляет ссылку набор блоков. Если пользователь десериализует такой набор блоков, то блоки добавляют в систему, и система возвращает набор блоков, на которые осуществляет ссылку набор блоков, которых уже нет на компьютере пользователя.
Система (или процессор) также может исполнять способ для сериализации блоков, не являющихся листьями, файла или дерева каталогов. При десериализации система возвращает пользователю хеши блоков-листьев, которых уже нет в системе пользователя. Таким образом, например, Алиса (с использованием процессора на вычислительном устройстве Алиса) может сериализовать Бобу (на процессор на вычислительном устройстве Боб) листья, а затем элементы, не являющиеся листьями, и Боб как можно раньше узнает точное количество байтов, которое будет передано от Алисы Бобу. Или в альтернативной системе Алиса может сериализовать Бобу блоки, не являющиеся листьями, затем Боб может уведомить Алису о хешах листьев, которые Боб еще не принял, затем Алиса может сериализовать только те листья, которые Боб еще не принял.
Одно преимущество сериализации набора блоков заключается в том, что это позволяет Алисе эффективно отправлять Бобу дерево каталогов, которое, как оказывается, содержит много файлов, которые Боб уже имеет. Алиса сериализует сначала только хеш корневого блока, а затем отправляет его. Боб десериализует хеш корневого блока в каталог на его выбор. Если этот вызов способа (например, исполняемый процессором у Боба) возвращает непустой список хешей, он отправляет тот список Алисе, и она отправляет его обратно для сериализации тех блоков. Затем Боб десериализует блоки и отправляет Алисе список блоков, на который осуществлена ссылка, которых у него еще нет. Это продолжается до тех пор, пока Боб не получит копию всего дерева каталогов. Таким образом, Алиса перемещает все дерево каталогов без отправки блока, который Боб уже имеет.
В некоторых случаях во время десериализации реляционная база данных может отслеживать и/или сохранять метаданные новых блоков, файлов и каталогов. В некоторых случаях в любое заданное время пользователь может видеть файл или каталог как существующий в файловой системе, как только все его блоки (и рекурсивным образом блоки его подкаталогов) были приняты.
В некоторых случаях способ «десериализация завершена» (deserializeDone), исполняемый системой (или процессором), указывает, что пользователь завершил десериализацию. На этом этапе система может убирать любые блоки, которые в итоге не являются частью действительного субъекта. Во время десериализации пользователь может требовать, чтобы новые файл или дерево каталогов были установлены так, что имеют заданное разрешение на запись. Это также может быть выполнено при копировании.
Платформа файловой системы, поддерживающей быстрое копирование, может периодически выполнять операцию, включающую следующие этапы:
- выполнение снапшота базы данных файловой системы и текущего списка событий со времени последнего подписанного состояния;
- сериализация того снапшота на запоминающее устройство на дисках;
- изменение байта на запоминающем устройстве на дисках для указания того, что эти новые файлы в данный момент представляют собой официальные резервные копии.
После сбоя (или даже нормального завершения работы и перезагрузки) платформа файловой системы, поддерживающей быстрое копирование, может выполнять следующее:
- загрузка последнего подписанного состояния;
- десериализация событий из последней официальной резервной копии;
- десериализация базы данных из последней официальной резервной копии;
- начало выполнения нормальной платформы файловой системы, поддерживающей быстрое копирование, с синхронизацией и т. д.
В дополнение, в некоторых реализациях фоновый поток может исполняться для сборки мусора в блоке. Поток сборки мусора может периодически проходить через каталоги блока и сопоставлять эти имена файлов с базой данных. Если поток сборки мусора определяет блок, на который не осуществляет ссылку ни один из текущих томов и на который не осуществляется ссылка в последнем подписанном состоянии, то поток сборки мусора должен удалить тот блок с жесткого диска. В дополнение, в некоторых случаях поток сборки мусора может периодически читать существующие блоки и проверять, чтобы каждый из них имел имя файла, совпадающее с хешем его содержимого. Если они не совпадают, блок может быть удален с жесткого диска. Если блок все еще нужен (согласно базе данных), то этапы могут быть выполнены для повторного скачивания блока из DHT или у другого участника.
Некоторые варианты осуществления и/или способы, описанные в настоящем документе, могут быть выполнены посредством программного обеспечения (исполняемого за счет аппаратного обеспечения), аппаратного обеспечения или их сочетания. Аппаратное обеспечение может включать, например, процессор общего назначения, программируемую пользователем вентильную матрицу (FPGA) и/или интегральную схему специального назначения (ASIC). Программное обеспечение (исполняемое за счет аппаратного обеспечения) может быть выражено различными языками программирования (например, компьютерный код), включая C, C++, Java™, Ruby, Visual Basic™ и/или другой объектно-ориентированный язык, процедурный язык или другой язык программирования и инструменты разработки. Примеры компьютерного кода включают, помимо прочего, микрокод или микроинструкции, машинные инструкции, например, созданные компилятором, код, используемый для создания веб-службы, и файлы, содержащие инструкции более высокого уровня, которые исполняются компьютером с использованием интерпретатора. Например, варианты осуществления могут быть реализованы с использованием императивных языков программирования (например, C, Fortran и т. д.), функциональных языков программирования (Haskell, Erlang и т. д.), логических языков программирования (например, Prolog), объектно-ориентированных языков программирования (например, Java, C++ и т. д.) или других подходящих языков программирования и/или инструментов разработки. Дополнительные примеры компьютерного кода включают, помимо прочего, сигналы управления, зашифрованный код и сжатый код.
Термины «инструкции» и «код» должны интерпретироваться в широком смысле, чтобы включать любой тип машиночитаемого оператора (машиночитаемых операторов). Например, термины «инструкции» и «код» могут относиться к одному или более из программ, стандартных программ, подпрограмм, функций, процедур и т. д. «Инструкции» и «код» могут содержать один машиночитаемый оператор или много машиночитаемых операторов.

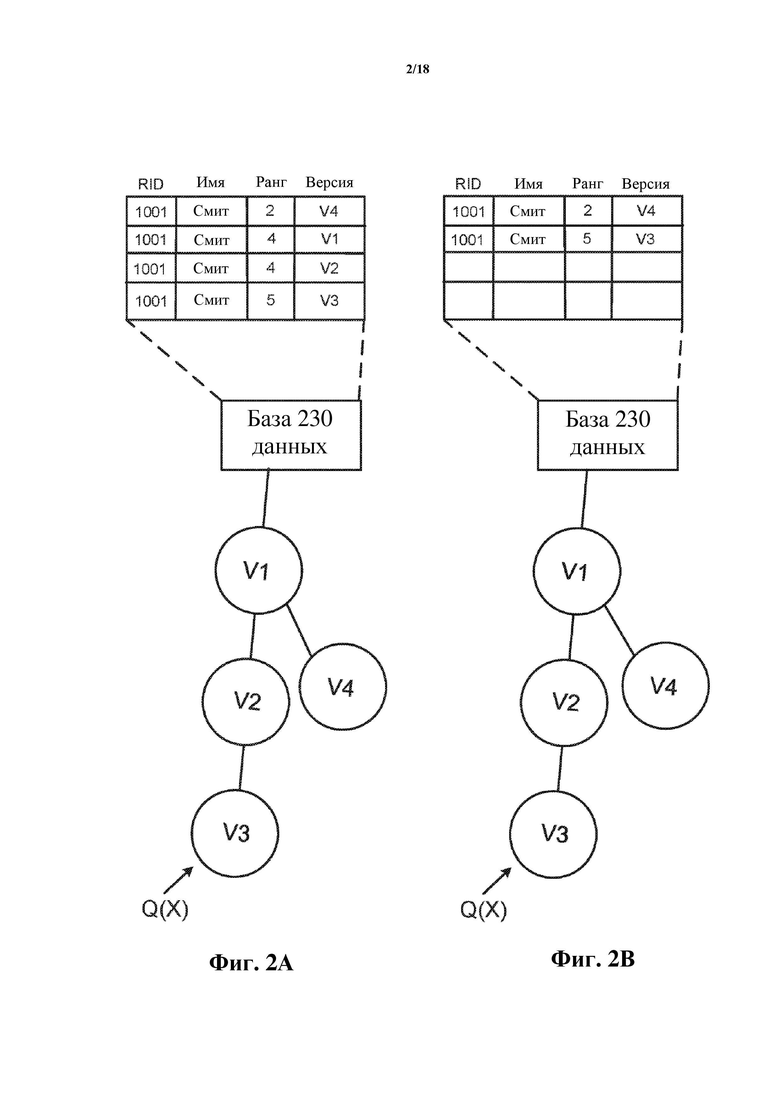
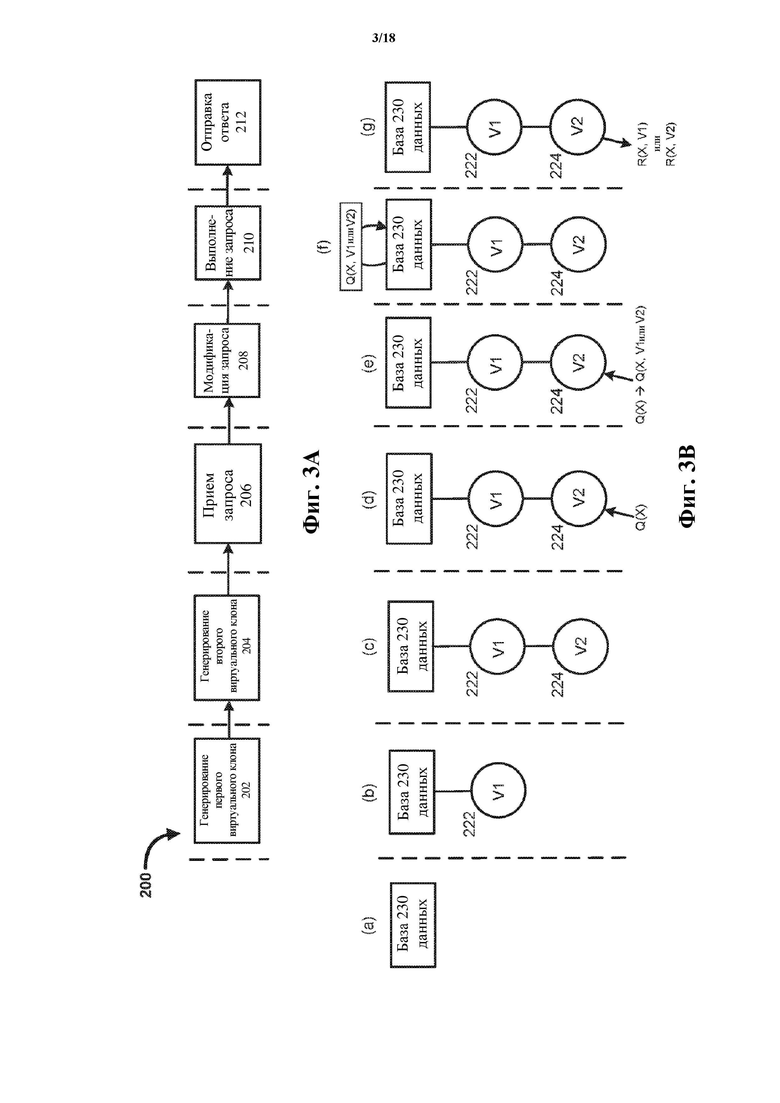


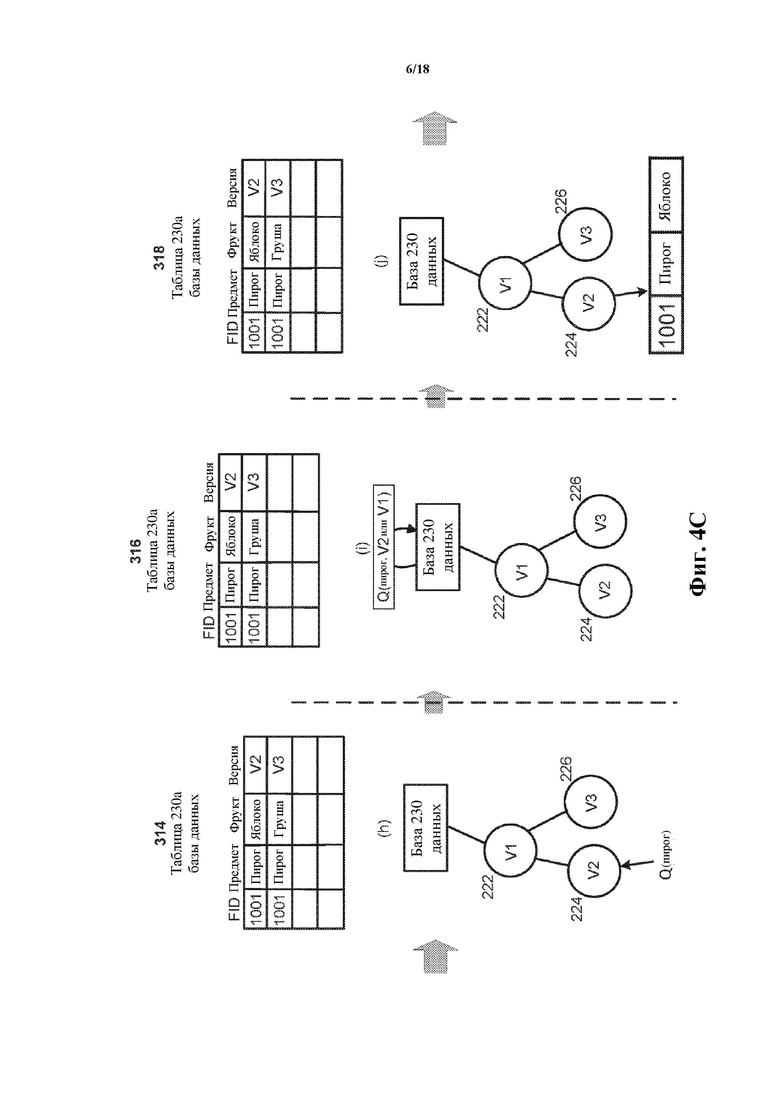
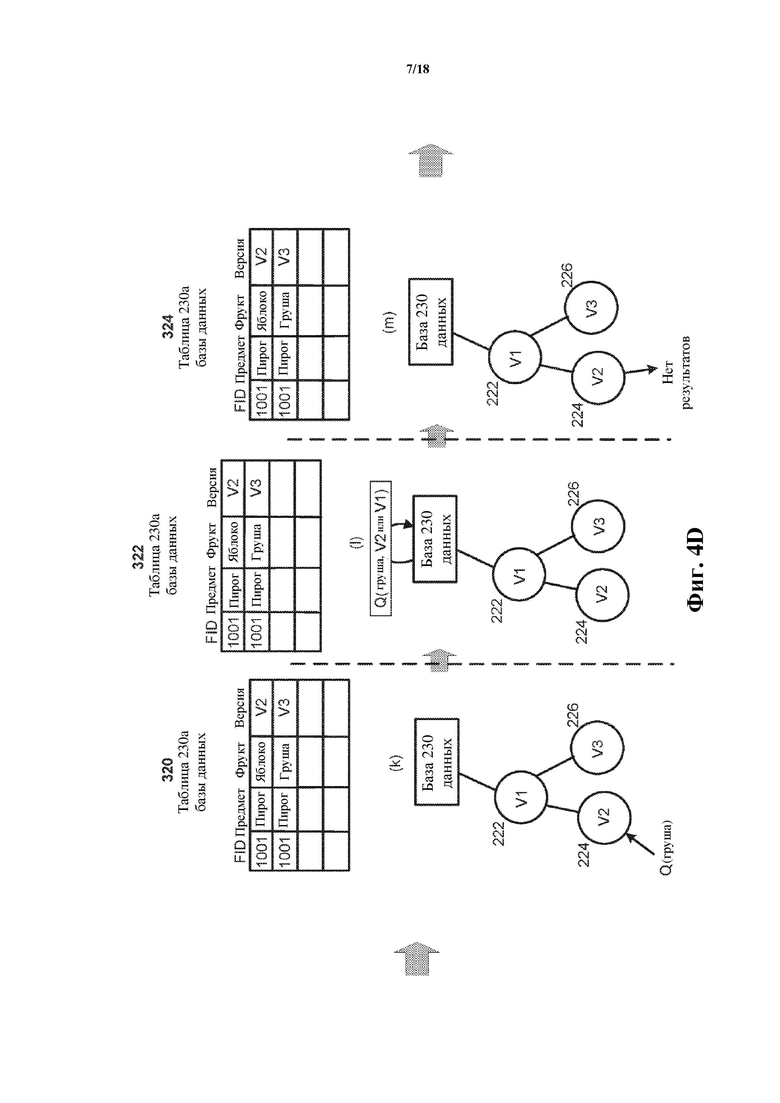





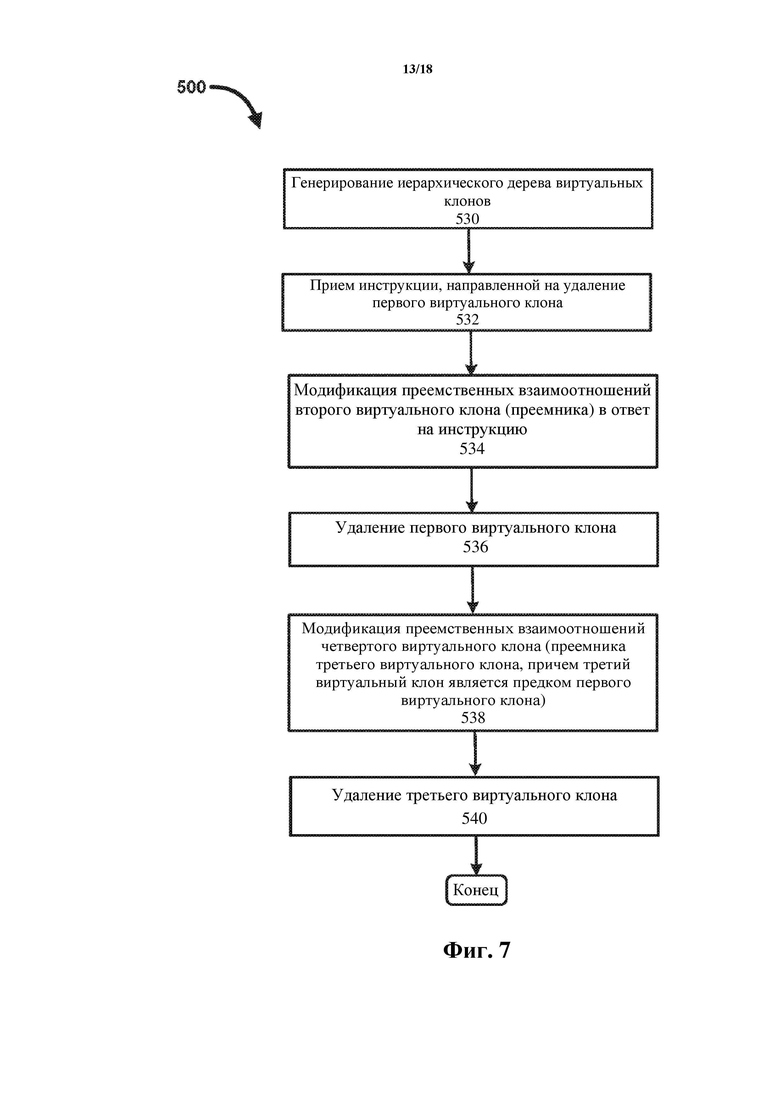
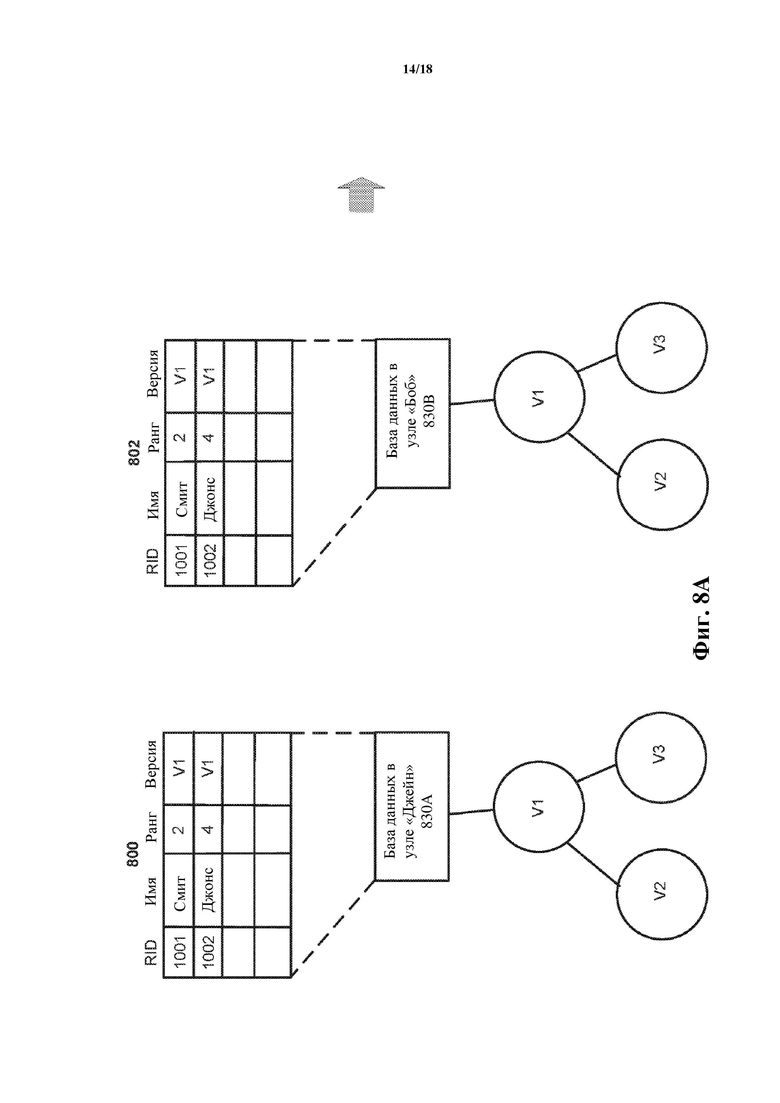


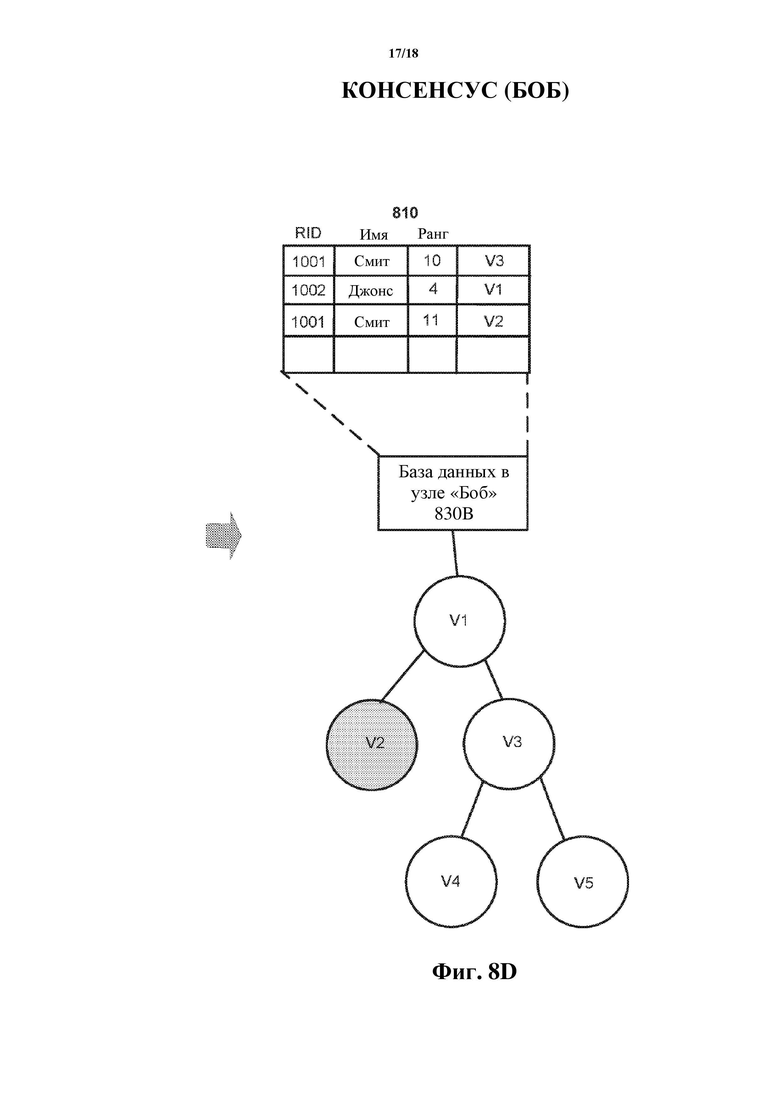
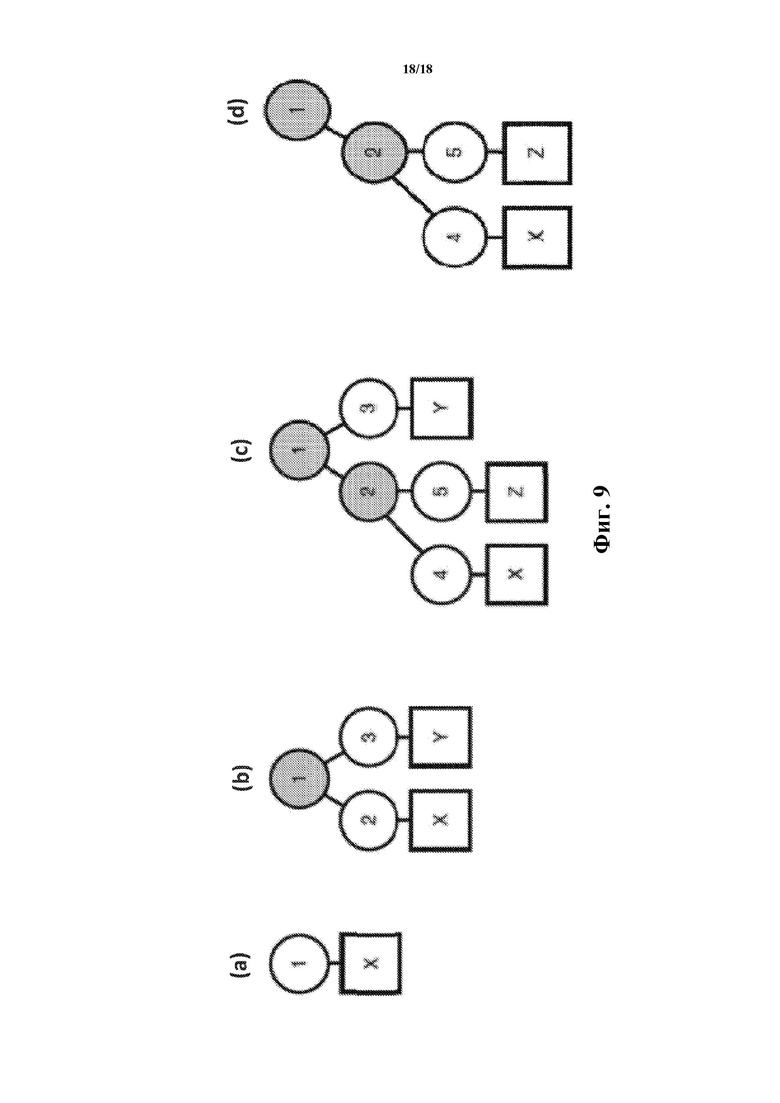
Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности репликации базы данных и взаимодействия с ней. Устройство для реализации базы данных содержит процессор и запоминающее устройство, которое хранит таблицу базы данных со множеством записей, каждая из которых имеет составной ключ, содержащий идентификатор версии; запоминающее устройство также хранит инструкции, исполняемые для предписания процессору сгенерировать первый виртуальный клон таблицы базы данных и второй виртуальный клон таблицы базы данных, принять запрос в первом виртуальном клоне и модифицировать запрос так, что он содержит идентификатор версии первого виртуального клона; процессор может запрашивать таблицу базы данных с использованием модифицированного запроса для генерирования ответа на основе отчасти каждой записи из набора записей, имеющих идентификатор версии, связанный с предковым путем идентификатора версии первого виртуального клона, и отправлять ответ; каждый составной ключ содержит идентификатор версии и часть данных. 3 н. и 18 з.п. ф-лы, 20 ил., 8 табл.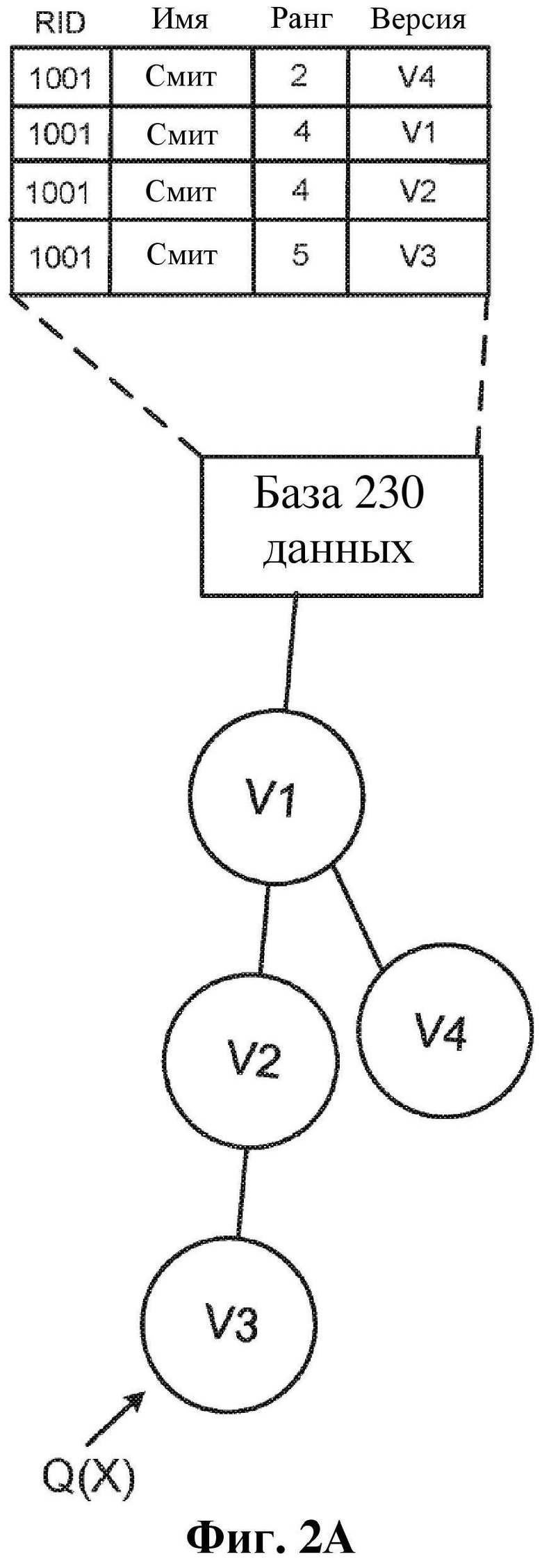
1. Устройство для реализации базы данных, при этом устройство содержит:
процессор; и
запоминающее устройство, находящееся в электронной связи с процессором, причем запоминающее устройство хранит таблицу базы данных, содержащую множество записей, причем каждая запись из множества записей имеет составной ключ, содержащий идентификатор версии,
причем запоминающее устройство содержит инструкции, исполняемые для предписания процессору:
сгенерировать первый виртуальный клон таблицы базы данных и второй виртуальный клон таблицы базы данных;
принять запрос в первом виртуальном клоне, причем запрос не содержит идентификатор версии, связанный с первым виртуальным клоном;
модифицировать запрос на основе приема запроса в первом виртуальном клоне путем добавления идентификатора версии, связанного с первым виртуальным клоном, в запрос для определения модифицированного запроса;
запросить таблицу базы данных с использованием модифицированного запроса для генерирования ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей удовлетворяет запросу; и (2) каждая запись из набора записей имеет идентификатор версии, связанный с предковым путем идентификатора версии, связанного с первым виртуальным клоном;
отправить ответ, содержащий набор записей, в качестве ответа на запрос;
причем составной ключ для каждой записи из множества записей содержит идентификатор версии для того составного ключа и часть данных, причем множество записей приспособлены так, что только один из: (1) составного ключа, содержащего значение части данных и идентификатор версии, связанный с первым виртуальным клоном; или (2) составного ключа, содержащего значение части данных и идентификатор версии, связанный со вторым виртуальным клоном, присутствует в таблице базы данных в любой заданный момент времени.
2. Устройство по п. 1, отличающееся тем, что запоминающее устройство дополнительно содержит инструкции, исполняемые для предписания процессору:
добавить в ответ на инструкцию вставки, принятую с помощью первого виртуального клона, запись в таблицу базы данных, причем запись содержит данные и составной ключ, имеющий идентификатор версии, связанный с первым виртуальным клоном, так что: (1) запрос, впоследствии принятый в первом виртуальном клоне и осуществляющий ссылку на данные, возвращает запись; и (2) запрос данных, впоследствии принятый в третьем виртуальном клоне, не возвращает запись.
3. Устройство по п. 1, отличающееся тем, что инструкции дополнительно исполняются для предписания процессору:
добавить в ответ на инструкцию, направленную на обновление значения поля первой записи таблицы базы данных с первого значения до второго значения и принятую с помощью третьего виртуального клона, вторую запись в таблицу базы данных, причем вторая запись содержит второе значение и составной ключ, имеющий идентификатор версии, связанный с третьим виртуальным клоном; и
модифицировать в ответ на инструкцию, направленную на обновление значения поля первой записи, составной ключ первой записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что:
запрос, впоследствии принятый в третьем виртуальном клоне и осуществляющий ссылку на поле, возвращает вторую запись, и
запрос, принятый в первом виртуальном клоне и осуществляющий ссылку на поле, возвращает первую запись.
4. Устройство по п. 1, отличающееся тем, что инструкции дополнительно исполняются для предписания процессору:
модифицировать в ответ на инструкцию, направленную на удаление записи из множества записей и принятую с помощью третьего виртуального клона, идентификатор версии составного ключа записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что:
запрос записи, впоследствии принятый в третьем виртуальном клоне, не возвращает запись, и
запрос записи, впоследствии принятый в первом виртуальном клоне, возвращает запись.
5. Устройство по п. 1, отличающееся тем, что ответ представляет собой первый ответ и модифицированный запрос представляет собой первый модифицированный запрос, причем инструкции дополнительно исполняются для предписания процессору:
сгенерировать второй модифицированный запрос, содержащий идентификатор версии второго виртуального клона, если первый ответ соответствует нулю, причем второй виртуальный клон является предком первого виртуального клона;
запросить таблицу базы данных с использованием второго модифицированного запроса для генерирования второго ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей второго ответа удовлетворяет второму модифицированному запросу; и (2) каждая запись из набора записей второго ответа имеет идентификатор версии, связанный с предковым путем идентификатора версии второго виртуального клона; и
отправить второй ответ, содержащий набор записей, в качестве ответа на запрос.
6. Устройство по п. 1, отличающееся тем, что инструкции дополнительно исполняются для предписания процессору сохранить на запоминающем устройстве указание того, что первый виртуальный клон является потомком второго виртуального клона.
7. Устройство по п. 1, отличающееся тем, что инструкции дополнительно исполняются для предписания процессору сгенерировать третий виртуальный клон таблицы базы данных, причем третий виртуальный клон не является ни предком, ни потомком первого виртуального клона, причем множество записей содержат запись, имеющую составной ключ, содержащий значение части данных и идентификатор версии, связанный с третьим виртуальным клоном.
8. Способ реализации базы данных, при этом способ включает:
генерирование с помощью процессора первого виртуального клона таблицы базы данных и второго виртуального клона таблицы базы данных, причем таблица базы данных содержит множество записей, причем каждая запись из множества записей имеет составной ключ, содержащий идентификатор версии;
прием с помощью процессора запроса в первом виртуальном клоне, причем запрос не содержит идентификатор версии, связанный с первым виртуальным клоном;
модификацию запроса с помощью процессора и на основе приема запроса в первом виртуальном клоне путем добавления идентификатора версии, связанного с первым виртуальным клоном, в запрос для определения модифицированного запроса;
запрашивание с помощью процессора таблицы базы данных с использованием модифицированного запроса для генерирования ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей удовлетворяет запросу; и (2) каждая запись из набора записей имеет идентификатор версии, связанный с предковым путем идентификатора версии, связанного с первым виртуальным клоном; и
отправку с помощью процессора ответа, содержащего набор записей, в качестве ответа на запрос,
причем составной ключ для каждой записи из множества записей содержит идентификатор версии для того составного ключа и часть данных, причем множество записей приспособлены так, что только один из: (1) составного ключа, содержащего значение части данных и идентификатор версии, связанный с первым виртуальным клоном; или (2) составного ключа, содержащего значение части данных и идентификатор версии, связанный со вторым виртуальным клоном, присутствует в таблице базы данных в любой заданный момент времени.
9. Способ по п. 8, отличающийся тем, что дополнительно включает:
добавление в ответ на инструкцию вставки, принятую с помощью первого виртуального клона, записи в таблицу базы данных, причем запись содержит данные и составной ключ, имеющий идентификатор версии, связанный с первым виртуальным клоном, так что: (1) запрос, впоследствии принятый в первом виртуальном клоне и осуществляющий ссылку на данные, возвращает запись; и (2) запрос данных, впоследствии принятый в третьем виртуальном клоне, не возвращает запись.
10. Способ по п. 8, отличающийся тем, что дополнительно включает:
добавление в ответ на инструкцию, направленную на обновление значения поля первой записи таблицы базы данных с первого значения до второго значения и принятую с помощью третьего виртуального клона, второй записи в таблицу базы данных, причем вторая запись содержит второе значение и составной ключ, имеющий идентификатор версии, связанный с третьим виртуальным клоном; и
модификацию в ответ на инструкцию, направленную на обновление значения поля первой записи, составного ключа первой записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что:
запрос, впоследствии принятый в третьем виртуальном клоне и осуществляющий ссылку на поле, возвращает вторую запись, и
запрос, принятый в первом виртуальном клоне и осуществляющий ссылку на поле, возвращает первую запись.
11. Способ по п. 8, отличающийся тем, что дополнительно включает:
модификацию в ответ на инструкцию, направленную на удаление записи из множества записей и принятую с помощью третьего виртуального клона, идентификатора версии составного ключа записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что:
запрос записи, впоследствии принятый в третьем виртуальном клоне, не возвращает запись, и
запрос записи, впоследствии принятый в первом виртуальном клоне, возвращает запись.
12. Способ по п. 8, отличающийся тем, что ответ представляет собой первый ответ и модифицированный запрос представляет собой первый модифицированный запрос, причем способ дополнительно включает:
генерирование второго модифицированного запроса, содержащего идентификатор версии второго виртуального клона, если первый ответ соответствует нулю, причем второй виртуальный клон является предком первого виртуального клона;
запрашивание таблицы базы данных с использованием второго модифицированного запроса для генерирования второго ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей второго ответа удовлетворяет второму модифицированному запросу; и (2) каждая запись из набора записей второго ответа имеет идентификатор версии, связанный с предковым путем идентификатора версии второго виртуального клона; и
отправку второго ответа, содержащего набор записей, в качестве ответа на запрос.
13. Способ по п. 8, отличающийся тем, что дополнительно включает сохранение указания того, что первый виртуальный клон является потомком второго виртуального клона.
14. Способ по п. 8, отличающийся тем, что дополнительно включает генерирование третьего виртуального клона таблицы базы данных, причем третий виртуальный клон не является ни предком, ни потомком первого виртуального клона, причем множество записей содержат запись, имеющую составной ключ, содержащий значение части данных и идентификатор версии, связанный с третьим виртуальным клоном.
15. Энергонезависимый материальный считываемый процессором носитель, содержащий исполняемые процессором инструкции, предназначенные для:
генерирования с помощью процессора первого виртуального клона таблицы базы данных и второго виртуального клона таблицы базы данных, причем таблица базы данных содержит множество записей, причем каждая запись из множества записей имеет составной ключ, содержащий идентификатор версии;
приема с помощью процессора запроса в первом виртуальном клоне, причем запрос не содержит идентификатор версии, связанный с первым виртуальным клоном;
модификации запроса с помощью процессора и на основе приема запроса в первом виртуальном клоне путем добавления идентификатора версии, связанного с первым виртуальным клоном, в запрос для определения модифицированного запроса;
запрашивания с помощью процессора таблицы базы данных с использованием модифицированного запроса для генерирования ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей удовлетворяет запросу; и (2) каждая запись из набора записей имеет идентификатор версии, связанный с предковым путем идентификатора версии, связанного с первым виртуальным клоном; и
отправки с помощью процессора ответа, содержащего набор записей, в качестве ответа на запрос,
причем составной ключ для каждой записи из множества записей содержит идентификатор версии для того составного ключа и часть данных, причем множество записей приспособлены так, что только один из: (1) составного ключа, содержащего значение части данных и идентификатор версии, связанный с первым виртуальным клоном; или (2) составного ключа, содержащего значение части данных и идентификатор версии, связанный со вторым виртуальным клоном, присутствует в таблице базы данных в любой заданный момент времени.
16. Энергонезависимый материальный считываемый процессором носитель по п. 15, отличающийся тем, что дополнительно содержит исполняемые процессором инструкции, предназначенные для:
добавления в ответ на инструкцию вставки, принятую с помощью первого виртуального клона, записи в таблицу базы данных, причем запись содержит данные и составной ключ, имеющий идентификатор версии, связанный с первым виртуальным клоном, так что: (1) запрос, впоследствии принятый в первом виртуальном клоне и осуществляющий ссылку на данные, возвращает запись; и (2) запрос данных, впоследствии принятый в третьем виртуальном клоне, не возвращает запись.
17. Энергонезависимый материальный считываемый процессором носитель по п. 15, отличающийся тем, что дополнительно содержит исполняемые процессором инструкции, предназначенные для:
добавления в ответ на инструкцию, направленную на обновление значения поля первой записи таблицы базы данных с первого значения до второго значения и принятую с помощью третьего виртуального клона, второй записи в таблицу базы данных, причем вторая запись содержит второе значение и составной ключ, имеющий идентификатор версии, связанный с третьим виртуальным клоном; и
модификации в ответ на инструкцию, направленную на обновление значения поля первой записи, составного ключа первой записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что:
запрос, впоследствии принятый в третьем виртуальном клоне и осуществляющий ссылку на поле, возвращает вторую запись, и
запрос, принятый в первом виртуальном клоне и осуществляющий ссылку на поле, возвращает первую запись.
18. Энергонезависимый материальный считываемый процессором носитель по п. 15, отличающийся тем, что дополнительно содержит исполняемые процессором инструкции, предназначенные для:
модификации в ответ на инструкцию, направленную на удаление записи из множества записей и принятую с помощью третьего виртуального клона, идентификатора версии составного ключа записи так, чтобы он не содержал идентификатор версии, связанный с третьим виртуальным клоном, так что:
запрос записи, впоследствии принятый в третьем виртуальном клоне, не возвращает запись, и
запрос записи, впоследствии принятый в первом виртуальном клоне, возвращает запись.
19. Энергонезависимый материальный считываемый процессором носитель по п. 15, отличающийся тем, что ответ представляет собой первый ответ, и модифицированный запрос представляет собой первый модифицированный запрос, причем считываемый процессором носитель дополнительно содержит исполняемые процессором инструкции, предназначенные для:
генерирования второго модифицированного запроса, содержащего идентификатор версии второго виртуального клона, если первый ответ соответствует нулю, причем второй виртуальный клон является предком первого виртуального клона;
запрашивания таблицы базы данных с использованием второго модифицированного запроса для генерирования второго ответа, содержащего набор записей из множества записей, на основе того, что: (1) каждая запись из набора записей второго ответа удовлетворяет второму модифицированному запросу; и (2) каждая запись из набора записей второго ответа имеет идентификатор версии, связанный с предковым путем идентификатора версии второго виртуального клона; и
отправки второго ответа, содержащего набор записей, в качестве ответа на запрос.
20. Энергонезависимый материальный считываемый процессором носитель по п. 15, отличающийся тем, что дополнительно содержит исполняемые процессором инструкции, предназначенные для сохранения указания того, что первый виртуальный клон является потомком второго виртуального клона.
21. Энергонезависимый материальный считываемый процессором носитель по п. 15, отличающийся тем, что дополнительно содержит исполняемые процессором инструкции, предназначенные для: генерирования третьего виртуального клона таблицы базы данных, причем третий виртуальный клон не является ни предком, ни потомком первого виртуального клона, причем множество записей содержат запись, имеющую составной ключ, содержащий значение части данных и идентификатор версии, связанный с третьим виртуальным клоном.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9251235 B1, 02.02.2016 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| КЛОНИРОВАНИЕ И УПРАВЛЕНИЕ ФРАГМЕНТАМИ БАЗЫ ДАННЫХ | 2006 |
|
RU2417426C2 |

