Изобретение относится к автоматике и вычислительной технике и может быть использовано для распознавания и селекции заданных видов фрагментов кодированных документальных сообщений при обработке факсимильной информации.
Известен способ распознавания фрагментов изображения [1], основанный на нахождении в памяти пиксельных данных, описывающих вставку размером n*n пикселов в первом изображении, производстве свертки величин интенсивности пикселов вставки с величинами ядра Лапласа с нулевым средним и получении лапласовой вставки, данные которой описывают координаты х, у и величины интенсивности пикселов со знаками, производстве свертки величин интенсивности лапласовой вставки с ядром Гаусса вдоль осей х и у и получении изображения, данные которого описывают положения и величины интенсивностей пикселов со знаками, упорядочивании чисел ядра Гаусса в гауссову последовательность и преобразовании пиксельных данных в бинарные, повторении преобразования над данными вставки размером m*m (m<n) пикселов из второго изображения, получении для каждого из возможных сдвигов величины корреляции пикселов, сравнивании величины корреляций и определении на основе максимальной величины корреляции сдвига.
Недостатком данного изобретения является существенная вычислительная сложность, обусловленная необходимостью обеспечения свертки величин интенсивностей матриц пикселов размера n*n и m*m с соответствующими величинами ядер Лапласа и Гаусса, а также вычисления соответствующих величин корреляций пикселов с последующим их сравнением.
Известен также способ распознавания текстовых изображений [2], основанный на определении прямоугольников, ограничивающих части изображения, потенциально содержащие текст, генерировании последовательности признаков для каждой части изображения, определении набора обученных скрытых марковских моделей (СММ) одиночных знаков с учетом структурных параметров каждого знака, объединении СММ, соответствующих знакам ключевого слова и имеющих один и тот же контекст, конструировании сети СММ, содержащей СММ ключевого слова, и определении с ее помощью наличия ключевого слова во входном изображении.
Как показано в [3], хранение факсимильных изображений в факсимильных банках данных наиболее целесообразно осуществлять в сжатой форме, что обеспечивается использованием специальных видов кодирования, таких как модифицированный код Хаффмана (код МН) или модифицированный код READ (код MR) [4], обеспечивающих меньший объем памяти, необходимой для хранения факсимильного изображения, чем в случае использования других графических форматов.
В этой связи недостатком приведенного выше способа является низкая точность распознавания фрагментов факсимильных изображений, представленных в кодированной форме (МН или MR), так как при этом биты знаков ключевых слов заменяются кодами длин серий двоичных нулей и единиц, что исключает возможность использования признаков, предложенных в указанном выше способе.
Наиболее близким по своей сущности к заявляемому изобретению является способ распознавания кодированных изображений [5], основанный на операции разделения изображения, представленного в форме кодированных электрических сигналов, на несколько участков и оценки размеров Ni этих участков, причем выделяют кодированные строчные участки электрических сигналов, заключенные между двумя соседними кодовыми словами конца строки развертки изображения, удаляют служебные биты заполнения в выделенных строчных участках, различают и выделяют r-е группы, состоящие из М последовательных участков соседних “белых” строк минимальной размерности, сравнивают числа этих групп с соответствующей пороговой величиной N0 и выделяют р-е группы, состоящие из L последовательных “небелых” кодированных строк, сравнивают числа данных групп с соответствующей пороговой величиной N1, оценивают наличие квазипериодичности следования участков, соответствующих кодированным “белым” строкам развертки изображения, определяют среднюю величину квазипериода Qr, оценивают абсолютные величины ip разностей размеров соседних кодированных “небелых” строк, вычисляют отношения dp максимальных и минимальных значений разностей ip, сравнивают полученные величины отношений dp с априорно заданной пороговой величиной D и выносят решение о принадлежности кодированного изображения или его фрагмента графической или текстовой форме.
Недостатком данного способа является низкая точность распознавания кодированных фрагментов факсимильных изображений, представленных в одинаковой форме (графической или текстовой), поскольку используемые в нем признаки предназначены исключительно для различения между собой двух разных форм кодированных фрагментов факсимильных изображений: текстовой и графической. Таким образом, данный способ не позволяет обеспечить достоверное распознавание априорно заданных кодированных текстовых фрагментов среди множества возможных кодированных текстовых фрагментов (так же, как и кодированных графических фрагментов заданного вида среди множества возможных кодированных графических фрагментов факсимильных изображений).
Целью изобретения является повышение точности распознавания фрагментов заданного вида в кодированном факсимильном изображении.
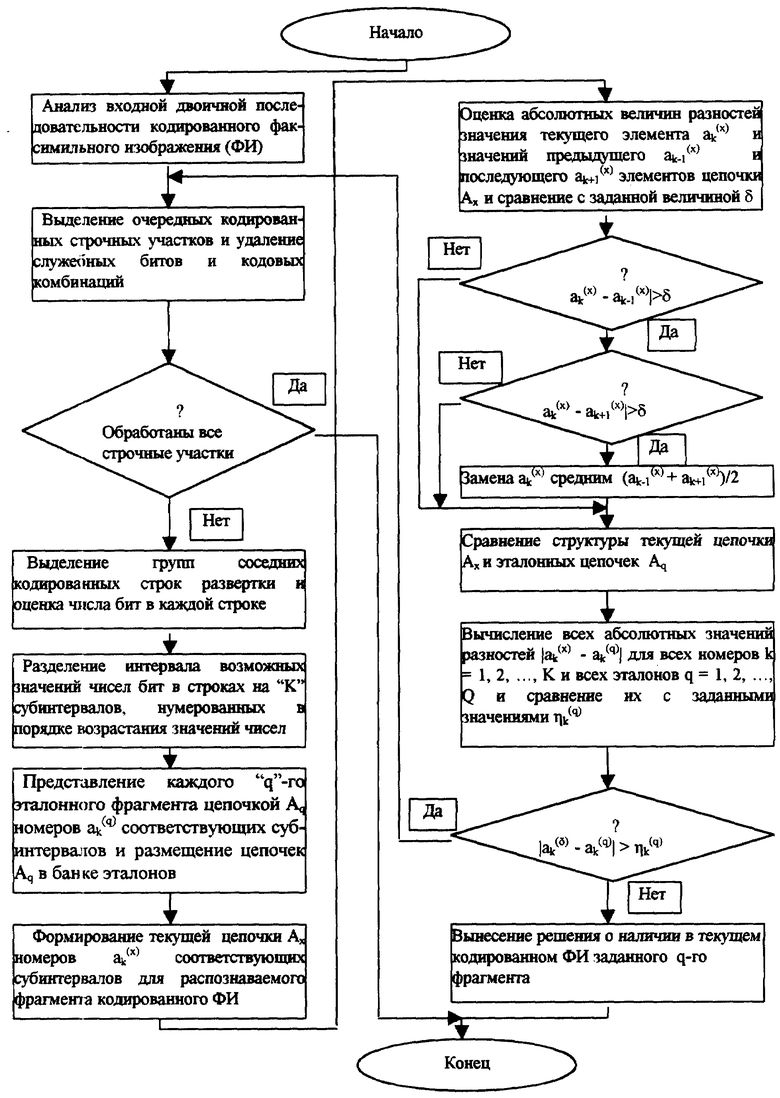
Цель достигается тем, что в известный способ, включающий выделение кодированных строчных участков электрических сигналов, удаление из них служебных битов и кодовых комбинаций, выделение групп соседних кодированных строк развертки, оценку числа бит в каждой кодированной строке, входящей в данную группу, согласно изобретению введены операции, при которых интервал возможных значений числа бит в каждой кодированной строке развертки разделяют на "К" субинтервалов ak (k=1, 2,... , К), нумерованных в порядке возрастания возможных значений длин этих строк, представляют на этапе обучения каждого "q"-ro (q=1, 2,... , Q, Q - число заданных эталонных фрагментов факсимильного изображения) эталонного фрагмента цепочкой Aq номеров а
Оценивают абсолютные величины разностей | a
Выносят решение о принадлежности текущего фрагмента, заданного цепочкой Ax, "q"-мy эталонному фрагменту, заданному цепочкой Aq, если абсолютные величины разностей значений элементов а
Сопоставительный анализ со способом, выбранным в качестве прототипа, показывает, что заявляемый способ отличается новыми операциями разделения интервала возможных значений числа бит в каждой кодированной строке развертки на "К" субинтервалов ak (k=1, 2,... , К), нумерованных в порядке возрастания значений длин этих строк, представления на этапе обучения каждого "q"-го (q=1, 2,... , Q, Q - число заданных эталонных фрагментов факсимильного изображения) эталонного фрагмента цепочкой Aq номеров а
Таким образом, заявляемый способ соответствует критерию изобретения "новизна".
Изобретение имеет "изобретательский уровень", т.к. оно для специалиста явным образом не следует из уровня техники.
Изобретение может быть использовано в различных областях промышленности, а именно связанных с техникой передачи и обработки изображений, с информационно-вычислительной техникой, а также в других областях народного хозяйства, и соответствует критерию "промышленная применимость".
На чертеже представлена блок-схема алгоритма распознавания кодированных изображений.
Предлагаемый способ реализуется следующим образом.
В последовательности двоичных кодированных электрических сигналов факсимильного изображения после удаления служебных битов и кодовых слов выделяются текущие группы соседних кодированных строк развертки и затем производится оценка числа бит в каждой кодированной строке, входящей в данную группу. Далее на этапе обучения интервал возможных значений числа бит в каждой кодированной строке развертки разделяется на "К" субинтервалов ak (k=1, 2,... , К), нумерованных в порядке возрастания значений длин этих строк, а каждый "q"-й (q=1, 2,... , Q, Q - число заданных эталонных фрагментов факсимильного изображения) эталонный фрагмент представляется цепочкой Aq номеров а
Способ реализуется на базе использования однокристальной микроЭВМ или ПЭВМ с процессором PENTIUM, обеспечивающих ввод данных кодированного факсимильного изображения объема 50-150 кбайт в память ОЭВМ/ПЭВМ и последующую арифметико-логическую обработку этих данных.
Способ позволяет на базе введенных операций использовать связь между структурой строчного фрагмента факсимильного изображения и структурой сформированных цепочек номеров интервалов величин размеров кодированных строк этого фрагмента и тем самым повысить точность распознавания заданных фрагментов в кодированном факсимильном изображении.
Источники информации
1. Патент США №5604819, МКИ G 06 K 9/00 от 15.03.93.
2. Патент США №5592568, МКИ G 06 K 9/68 от 13.02.93.
3. Введение к реализации системы поиска факсимильных изображений. Экспресс-информация, сер. Информатика, - 1993, №3, с.6.
4. Рекомендации МККТТ. Серия Т.4. Синяя книга. Т. VII, вып. VII.3, 1988, с.17.
5. Патент РФ №2126552, МКИ G 06 K 9/00.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ СИГНАЛОВ ЦВЕТНЫХ ФАКСИМИЛЬНЫХ СООБЩЕНИЙ | 2006 |
|
RU2312467C1 |
| СПОСОБ РАСПОЗНАВАНИЯ КОДИРОВАННЫХ ИЗОБРАЖЕНИЙ | 1995 |
|
RU2126552C1 |
| Способ распознавания протоколов низкоскоростного кодирования | 2016 |
|
RU2610285C1 |
| СПОСОБ ЛОКАЛИЗАЦИИ ДОРОЖНЫХ ЗНАКОВ И РАСПОЗНАВАНИЯ ИХ ГРУПП И ПОДГРУПП | 2012 |
|
RU2488164C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ СИГНАЛОВ | 2012 |
|
RU2485586C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ГРАФИЧЕСКОГО ФАЙЛА С ИСПОЛЬЗОВАНИЕМ СЛОВАРЕЙ И ДОПОЛНИТЕЛЬНЫХ ДАННЫХ | 2005 |
|
RU2295154C1 |
| Способ распознавания протоколов низкоскоростного кодирования речи | 2017 |
|
RU2667462C1 |
| Способ транскрибирования речи по цифровым сигналам с низкоскоростным кодированием | 2023 |
|
RU2801621C1 |
| Устройство для коррекции ошибок приемника факсимильных сигналов | 1980 |
|
SU976506A2 |
| Способ передачи факсимильных изображений с распознаванием символов | 1989 |
|
SU1695510A1 |
Изобретение относится к автоматике и вычислительной технике. Его применение при распознавании и селекции заданных видов фрагментов кодированных документальных сообщений при обработке факсимильной информации позволяет получить технический результат в виде повышения точности распознавания заданных фрагментов в кодированном факсимильном изображении. Этот результат достигается благодаря тому, что в способ введены операции разделения интервала возможных значений числа бит в каждой кодированной строке развертки на "К" субинтервалов ak (k=1,2,...,К), представления на этапе обучения каждого "q"-го эталонного фрагмента цепочкой Aq номеров а
| СПОСОБ РАСПОЗНАВАНИЯ КОДИРОВАННЫХ ИЗОБРАЖЕНИЙ | 1995 |
|
RU2126552C1 |
| US 5787202 A, 28.07.1998 | |||
| ЩИТОВОЙ ДЛЯ ВОДОЕМОВ ЗАТВОР | 1922 |
|
SU2000A1 |
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| US 5745600 A, 28.04.1998. | |||

