Изобретение относится к области вычислительной техники и радиосвязи, обеспечивает транскрибирование по цифровым информационным сигналам низкоскоростных кодеков речи (НКР), используемых в современных телекоммуникационных системах (ТКС) для передачи речевых сообщений, востребовано при создании средств автоматического распознавания речи (АРР) в условиях ведения радиомониторинга (РМ).
Заявленное техническое решение повышает эффективность средств аналогичного назначения за счет исключения процесса декодирования цифровых информационных сигналов, сформированных в НКР и полученных по радиоканалам ТКС, вычисления признаков распознавания фонем путем преобразования параметров речевых сигналов, оцениваемых в процессе функционирования НКР и передаваемых в виде двоичных символов по радиоканалам ТКС, а также за счет классификации входных реализаций по голосовым группам и предварительного определения фонетических классов, к которым относятся анализируемые блоки цифровых информационных сигналов, содержащие данные о параметрах звуков речи, что обеспечивает более полное их описание и сравнение с уточненными эталонными образами фонем, характерных для той или иной голосовой группы.
Известен способ транскрибирования речи в текст для персональных коммуникационных устройств (см. заявка на изобретение №2010109071, МПК Н04В 1/40 (2006.01), опубл. 20.09.2011, Бюл. 26), заключающийся в том, что сформированный диктором речевой сигнал передается в цифровом формате электронной почты в виде файла с помощью персонального коммуникационного устройства на вход системы транскрибирования речи в текст, которая находится вне персонального коммуникационного устройства на удаленном сервере, где осуществляется преобразование принятого речевого сигнала в текстовое сообщение.
Аналог является универсальным для решения широкого круга задач распределенной обработки речевых сигналов, включая транскрибирование, в том числе в условиях использования для передачи речевых сообщений радиоканалов ТКС с применением НКР. Необходимая точность транскрибирования речи в аналоге обеспечивается за счет формирования и использования альтернативных вариантов транскрипций, определения уровня доверия для каждого варианта транскрипций, выбора варианта транскрипции, обладающего наивысшим уровнем доверия, а также за счет использования по меньшей мере одного предпочитаемого словаря транскрипций.
Вместе с тем в аналоге речевой сигнал должен быть представлен для транскрибирования в цифровом формате. К универсальным цифровым форматам речевых сигналов относятся различные виды импульсно-кодовой модуляции (ИКМ), обеспечивающие кодирование формы (огибающей). Применение НКР предполагает сжатие исходного речевого сигнала sp с ИКМ и формирование цифрового сигнала s, который передается по радиоканалу на приемную сторону, где осуществляется синтез речевого сигнала 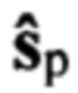 с ИКМ, подобного исходному сигналу . Увеличение степени сжатия исходного речевого сигнала с ИКМ приводит к увеличению отличий (искажений) в синтезированном сигнале sp. Поэтому помимо акустических помех на линии «диктор - микрофон», шумов и помех в радиоканалах, значительное влияние на результаты транскрибирования оказывают искажения, вызванные НКР. Транскрибирование синтезированных речевых сигналов с ИКМ, принятых по каналам радиосвязи с низкоскоростным кодированием, сопровождается снижением доверия до неприемлемого уровня, особенно при использовании НКР с информационной скоростью не более 2,4 кбит/с, применяемых в спутниковых и транкинговых системах радиосвязи, а также в радиосвязи диапазона высоких частот. Меры, обеспечивающие компенсацию влияния НКР на результаты транскрибирования, в аналоге не предусмотрены.
с ИКМ, подобного исходному сигналу . Увеличение степени сжатия исходного речевого сигнала с ИКМ приводит к увеличению отличий (искажений) в синтезированном сигнале sp. Поэтому помимо акустических помех на линии «диктор - микрофон», шумов и помех в радиоканалах, значительное влияние на результаты транскрибирования оказывают искажения, вызванные НКР. Транскрибирование синтезированных речевых сигналов с ИКМ, принятых по каналам радиосвязи с низкоскоростным кодированием, сопровождается снижением доверия до неприемлемого уровня, особенно при использовании НКР с информационной скоростью не более 2,4 кбит/с, применяемых в спутниковых и транкинговых системах радиосвязи, а также в радиосвязи диапазона высоких частот. Меры, обеспечивающие компенсацию влияния НКР на результаты транскрибирования, в аналоге не предусмотрены.
Наиболее близким к заявленному является способ (прототип) и устройство распознавания речи по цифровым сигналам, сформированным с помощью низкоскоростного кодека RPE-LTP-13000 (FR GSM 06.10) сотовой системы связи стандарта GSM, с малым объемом словаря и настройкой на диктора (см. World Intellectual Property Organization. International Publication Number WO 01/31636 A2, РСТЛВ00/01679, G10L 15/02, Publication date 03.05.2001; TanZ.-H., LindbergB. Automatic speech recognition on mobile devices and over communication networks. - London: Springer-Verlag, 2008. - P. 41-56), предусматривающий: поблочный прием цифрового информационного сигнала, сформированного с помощью кодека RPE-LTP-13000 (FR GSM 06.10); выделение двоичных символов из каждого принятого блока в соответствии с протоколом кодирования речи (см. ETSI Recommendation 06.10. GSM full rate speech transcoding. Version 3.2.0. February 1992. - 95 p.), содержащие информацию о квантованных значениях площади отражения в логарифмической шкале Q-LAR (англ. - quantized log area ratio) и характеризующие состояние речевого тракта диктора в дискретные моменты времени передачи звуков речи (фонем); поблочное преобразование двоичных символов, описывающих значения Q-LAR, к десятичному формату и составление из них векторов информативных параметров; вычисление отношения между значениями Q-LAR соседних векторов информативных параметров, по которым определяют наличие и положение интервалов речевой активности диктора (РАД) в принятом цифровом информационном сигнале; выделение векторов информативных параметров, представленных в виде наборов значений Q-LAR и соответствующих положению интервалов РАД; формирование матрицы информативных параметров из векторов информативных параметров, относящихся к одному интервалу РАД, размерность которой определяется длительностью данного интервала РАД; последовательное сравнение методом динамического программирования сформированной матрицы информативных параметров, относящуюся к данному интервалу РАД, с заранее подготовленными эталонными информативными матрицами, количество которых ограничено и определяется объемом эталонного словаря, задающего соответствие эталонных информативных матриц и слов речевых сообщений; определение по результатам сравнения степени сходства между матрицей информативных параметров для каждого интервала РАД и каждой из эталонных информационных матриц, по максимальному значению степени сходства с одной из эталонных информационных матриц устанавливают соответствие между матрицей информативных параметров и одним из слов ограниченного эталонного словаря; составление последовательности символов для каждого интервала РАД.
Достоинство способа-прототипа заключается в том, что декодирование входного цифрового информационного потока не осуществляется, поэтому искажения, возникающие при синтезе речевых сигналов с ИКМ, не оказывают влияние на результаты АРР, а передающая часть низкоскоростного кодека рассматривается как устройство, обеспечивающее извлечение информативных признаков для решения задачи АРР. При этом учитываются особенности преобразования исходных речевых сигналов с ИКМ в низкоскоростном кодеке RPE-LTP-13000 (GSM 06.10) путем выделения наиболее информативных признаков, представленных значениями Q-LAR. Кроме того, на результаты транскрибирования в меньшей степени влияют условия передачи цифровых информационных сигналов НКР по радиоканалам ТКС, так как учитываются битовые ошибки только в двоичных символах, описывающих значения Q-LAR, что приводит к уменьшению вероятности Pwer ошибки распознавания слов по сравнению с результатами обработки синтезированных речевых сигналов с ИКМ. В способе-прототипе важным условием является наличие открытого описания кодека RPE-LTP-13000 (GSM 06.10), в котором содержится информация о составе каждого блока двоичных символов, формируемого кодером, назначении его элементов и порядке их обработки в декодере до получения значений параметров в числовом (десятичном) формате.
В способе-прототипе снижение вероятности Pwer обеспечивается при использовании достаточно малого объема информации (36 бит) о спектре речевого сигнала, извлекаемой из каждого блока sб двоичных символов размерностью 260 бит, сформированного низкоскоростным кодером при передаче речевого сообщения. Остальные компоненты блока sб, содержащие 224 бита дополнительной информации, характеризуют элементы речи (фонемы) и особенности их произнесения диктором, в процессе транскрибирования не используются. В результате искажений, вызванных сжатием речевых сигналов в низкоскоростном кодере, а также при появлении битовых ошибок в принятых цифровых информационных сигналах, вызванных шумами и помехами в радиоканалах ТКС, эффективность распознавания слов уменьшается до уровня ниже, чем задано требуемым значением вероятности Pwer_т ошибки распознавания слов, т.е. Pwer>Pwer_т. Требуемое значение вероятности Pwer_т устанавливается заказчиком, но не должно быть больше уровня Pwer_т=0,3, при котором утрачивается понимание сообщения. Используемый в прототипе метод динамического программирования в большей степени подходит для распознавания отдельных слов, его эффективность зависит от результатов настройки (обучения) на конкретного диктора при заданной скорости произношения слов, что вызывает затруднения в распознавании спонтанной и слитной речи. Кроме того, способ-прототип обеспечивает распознавание речи на эталонном словаре малого объема, что приводит к увеличению значения вероятности Pwer при обработке реальных речевых сигналов, полученных при РМ телефонных каналов ТКС.
Современные средства распознавания слитной речи реализуют ряд процессов, в том числе извлечение информативных признаков, фонетическое и лингвистическое распознавание. Транскрибирование речи объединяет процессы извлечения признаков и фонетического распознавания. Результатом транскрибирования является последовательность элементов речи - фонем, представленных в виде знаков фонетического алфавита. Эффективность транскрибирования речи определяется вероятностью Pcer ошибки распознавания фонем.
Целью заявленного технического решения является разработка способа транскрибирования речи по принятым цифровым информационным сигналам НКР, обеспечивающего уменьшение значения вероятности Pcer ошибки распознавания фонем за счет предварительного определения фонетического класса звуков и классификации исследуемых цифровых сигналов по голосовым группам, а также за счет формирования более точных эталонных описаний фонем и более полного использования принятой информации, содержащейся в цифровых информационных сигналах. Кроме того, достижение требуемого значения вероятности Pcer_тр обеспечивается за счет оценивания качества речи по цифровым информационным сигналам и последующего транскрибирования только тех из них, оценка качества которых превышает пороговый уровень качества.
Поставленная цель достигается тем, что в известном способе принимают поблочно в течение интервала времени Тс цифровой информационный сигнал s размерностью Nэ элементов, сформированный на передающей стороне с помощью заданного низкоскоростного кодека речи, в составе которого любой информационный блок sб имеет заданную размерность Nc двоичных символов, запоминают принятый сигнал, из которого последовательно выделяют Nби информационных блоков, соответствующих интервалам времени речевой активности диктора (РАД), и извлекают из каждого выделенного информационного блока sб двоичные символы, указанные в протоколе низкоскоростного кодирования речи и содержащие информацию о спектре речевого сигнала, составляя из них последовательность sc, преобразуют последовательность sc в вектор признаков dMFCC выбранной размерности, состоящий из значений кепстральных коэффициентов в частотной шкале мел MFCC, составляют совокупность 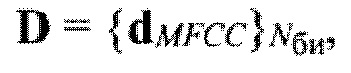 которая является образом входной реализации s, выполняют распознавание протоколов низкоскоростного кодирования, применяемых для формирования цифровых информационных сигналов, по результатам распознавания протоколов выделяют цифровые информационные сигналы, сформированные с помощью известных низкоскоростных кодеров, при выявлении факта применения неизвестного низкоскоростного кодера для формирования цифрового информационного сигнала s выполнение дальнейших операций над данным сигналом прекращают; в противном случае оценивают качество речи по цифровому информационному сигналу s, сформированному с помощью известного низкоскоростного кодера, проверяют соответствие цифрового информационного сигнала требованию по качеству путем сравнения полученной оценки качества речи с его пороговым значением, транскрибирование цифрового информационного сигнала, качество которого не превышает пороговое значение, не осуществляют; присваивают порядковый номер nби=1,2, …, Nби каждому информационному блоку sб(nби), последовательно выделяемому из цифрового сигнала s с помощью идентификаторов принадлежности к интервалам РАД, формируют прямоугольную информативную матрицу Sи размеров Nc × Nби путем последовательного размещения друг под другом информационных блоков sб(nби) в соответствии с их порядковыми номерами nби=1, 2, …, Nби, начиная с первого информационного блока sб(1); определяют, к какому из Nфк фонетических классов относится каждый блок s6(nби) матрицы Sи и используя дополнительную информацию о параметрах речевого сигнала, содержащуюся в анализируемом блоке sб(nби) и указанную в протоколе низкоскоростного кодирования речи, устанавливают для входной реализации s и всех ее элементов идентификатор фонетического класса с номером nфк=1 для вокализованных звуков и nфк=2 для невокализованных звуков речи, обозначая информационный блок sб(nби, nфк); выделяют из информативной матрицы Sи блоки, идентификаторы которых удовлетворяют условию nфк=1, из каждого выделенного блока извлекают двоичные символы, содержащие дополнительную информацию о частоте основного тона речи и указанные в заданном протоколе низкоскоростного кодирования, составляют из них матрицу Sот, каждая строка sот которой характеризует одно значение частоты основного тона речи, преобразуют двоичные символы, содержащиеся в строке sот к десятичному формату по правилам, приведенным в протоколе низкоскоростного кодирования речи, составляют из полученных значений частоты ωот основного тона речи вектор ωот, усредняют его значения, получая величину
которая является образом входной реализации s, выполняют распознавание протоколов низкоскоростного кодирования, применяемых для формирования цифровых информационных сигналов, по результатам распознавания протоколов выделяют цифровые информационные сигналы, сформированные с помощью известных низкоскоростных кодеров, при выявлении факта применения неизвестного низкоскоростного кодера для формирования цифрового информационного сигнала s выполнение дальнейших операций над данным сигналом прекращают; в противном случае оценивают качество речи по цифровому информационному сигналу s, сформированному с помощью известного низкоскоростного кодера, проверяют соответствие цифрового информационного сигнала требованию по качеству путем сравнения полученной оценки качества речи с его пороговым значением, транскрибирование цифрового информационного сигнала, качество которого не превышает пороговое значение, не осуществляют; присваивают порядковый номер nби=1,2, …, Nби каждому информационному блоку sб(nби), последовательно выделяемому из цифрового сигнала s с помощью идентификаторов принадлежности к интервалам РАД, формируют прямоугольную информативную матрицу Sи размеров Nc × Nби путем последовательного размещения друг под другом информационных блоков sб(nби) в соответствии с их порядковыми номерами nби=1, 2, …, Nби, начиная с первого информационного блока sб(1); определяют, к какому из Nфк фонетических классов относится каждый блок s6(nби) матрицы Sи и используя дополнительную информацию о параметрах речевого сигнала, содержащуюся в анализируемом блоке sб(nби) и указанную в протоколе низкоскоростного кодирования речи, устанавливают для входной реализации s и всех ее элементов идентификатор фонетического класса с номером nфк=1 для вокализованных звуков и nфк=2 для невокализованных звуков речи, обозначая информационный блок sб(nби, nфк); выделяют из информативной матрицы Sи блоки, идентификаторы которых удовлетворяют условию nфк=1, из каждого выделенного блока извлекают двоичные символы, содержащие дополнительную информацию о частоте основного тона речи и указанные в заданном протоколе низкоскоростного кодирования, составляют из них матрицу Sот, каждая строка sот которой характеризует одно значение частоты основного тона речи, преобразуют двоичные символы, содержащиеся в строке sот к десятичному формату по правилам, приведенным в протоколе низкоскоростного кодирования речи, составляют из полученных значений частоты ωот основного тона речи вектор ωот, усредняют его значения, получая величину 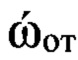 средней частоты основного тона, определяют путем сравнения значения ωот с заранее определенными эталонными значениями частоты
средней частоты основного тона, определяют путем сравнения значения ωот с заранее определенными эталонными значениями частоты 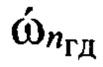 основного тона речи, к какой голосовой группе с номером nгд=1,2, …, Nгд, где Nгд - количество голосовых групп дикторов, относится анализируемый цифровой сигнал, запоминают значение nгд, которое используют далее как идентификатор голосовой группы; формируют на основе информационного блока sб(nби, nфк) вектор признаков, который состоит из значений кепстральных коэффициентов в частотной шкале мел MFCC или других, более информативных признаков, выбираемых заранее в процессе обучения, присваивают вектору признаков выявленный идентификатор группы дикторов nгд, порядковый номер nби и идентификатор фонетического класса nфк, обозначая его d(nф, nфк, nгд), формируют образ
основного тона речи, к какой голосовой группе с номером nгд=1,2, …, Nгд, где Nгд - количество голосовых групп дикторов, относится анализируемый цифровой сигнал, запоминают значение nгд, которое используют далее как идентификатор голосовой группы; формируют на основе информационного блока sб(nби, nфк) вектор признаков, который состоит из значений кепстральных коэффициентов в частотной шкале мел MFCC или других, более информативных признаков, выбираемых заранее в процессе обучения, присваивают вектору признаков выявленный идентификатор группы дикторов nгд, порядковый номер nби и идентификатор фонетического класса nфк, обозначая его d(nф, nфк, nгд), формируют образ 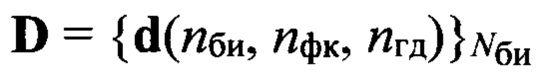 входной реализации; выделяют из заранее составленной эталонной совокупности
входной реализации; выделяют из заранее составленной эталонной совокупности 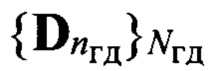 с помощью выявленного идентификатора nгд, общего для всех элементов образа D, множество
с помощью выявленного идентификатора nгд, общего для всех элементов образа D, множество 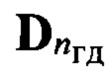 эталонных описаний фонем, характерных для nгд-й группы дикторов, из которого по идентификатору nфк выделяют подмножество
эталонных описаний фонем, характерных для nгд-й группы дикторов, из которого по идентификатору nфк выделяют подмножество 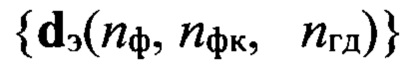 эталонных описаний фонем, где nф - номер фонемы
эталонных описаний фонем, где nф - номер фонемы 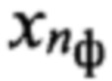 из алфавита Аф фонем объемом Nф символов, относящихся к фонетическому классу nфк и характерных для голосовой группы дикторов с номером nгд, с помощью выбранной меры близости последовательно сравнивают каждый эталонный образ dэ(nф, nфк, nгд), принадлежащий выделенному подмножеству
из алфавита Аф фонем объемом Nф символов, относящихся к фонетическому классу nфк и характерных для голосовой группы дикторов с номером nгд, с помощью выбранной меры близости последовательно сравнивают каждый эталонный образ dэ(nф, nфк, nгд), принадлежащий выделенному подмножеству 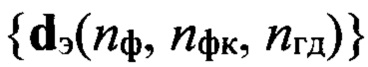 эталонных описаний фонем, с элементами образа
эталонных описаний фонем, с элементами образа 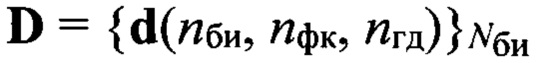 входной реализации и определяют вероятность Рф(nби, nф) соответствия вектора признаков d(nби nфк, nгд) эталонному образу dэ(nф, nфк, nгд), составляя вектор Рф, принимают решение о содержании фонетической информации в анализируемой строке sб(nби), путем установления соответствия фонетического символа
входной реализации и определяют вероятность Рф(nби, nф) соответствия вектора признаков d(nби nфк, nгд) эталонному образу dэ(nф, nфк, nгд), составляя вектор Рф, принимают решение о содержании фонетической информации в анализируемой строке sб(nби), путем установления соответствия фонетического символа 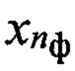 , определяемого по номеру «Ф эталонного образа dэ(nф, nфк, nгд), для которого значение Рф(nби, nф) является максимальным и больше порогового значения Рф_пор(nф), установленного на этапе обучения, анализируют все строки информативной матрицы Sи, и, учитывая номера строк и значения идентификаторов РАД, формируют последовательность фонетических знаков
, определяемого по номеру «Ф эталонного образа dэ(nф, nфк, nгд), для которого значение Рф(nби, nф) является максимальным и больше порогового значения Рф_пор(nф), установленного на этапе обучения, анализируют все строки информативной матрицы Sи, и, учитывая номера строк и значения идентификаторов РАД, формируют последовательность фонетических знаков 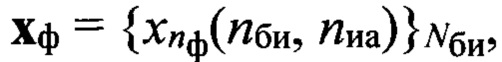 являющуюся результатом транскрибирования.
являющуюся результатом транскрибирования.
Благодаря новой совокупности существенных признаков в заявленном способе обеспечивается транскрибирование речи по цифровым сигналам заданного низкоскоростного кодера с вероятностью ошибки Pcer распознавания фонем, не хуже

за счет отбора входных реализаций, соответствующих требованиям по качеству, определения принадлежности анализируемого цифрового информационного сигнала s к nгд-й голосовой группе, предварительной фонетической классификации информативных блоков, входящих в выделенные интервалы РАД и содержащих информацию о вокализованных либо невокализованных звуках речи, формирования на этапе обучения уточненных эталонных образов и использования их в процессе обработки входных реализаций.
Заявленный способ поясняется чертежами, на которых показаны:
на фиг. 1 - зависимость вероятности Pwer ошибки распознавания слов от значений вероятности Pcer ошибки распознавания фонем и требования к ним;
на фиг. 2 - алгоритм транскрибирования речи по цифровым сигналам НКР;
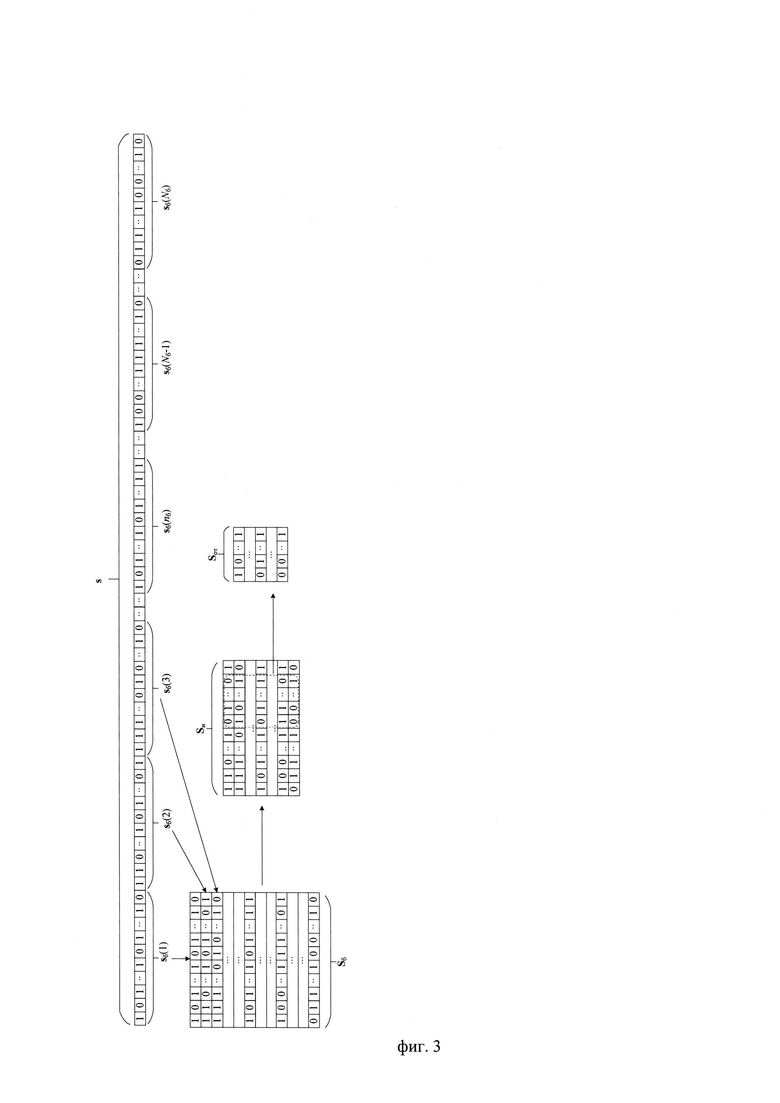
на фиг. 3 - порядок составления информативной матрицы Sи из цифрового информационного сигнала s и выделения из нее матрицы Sот, содержащей данные о частоте ОТ речи;
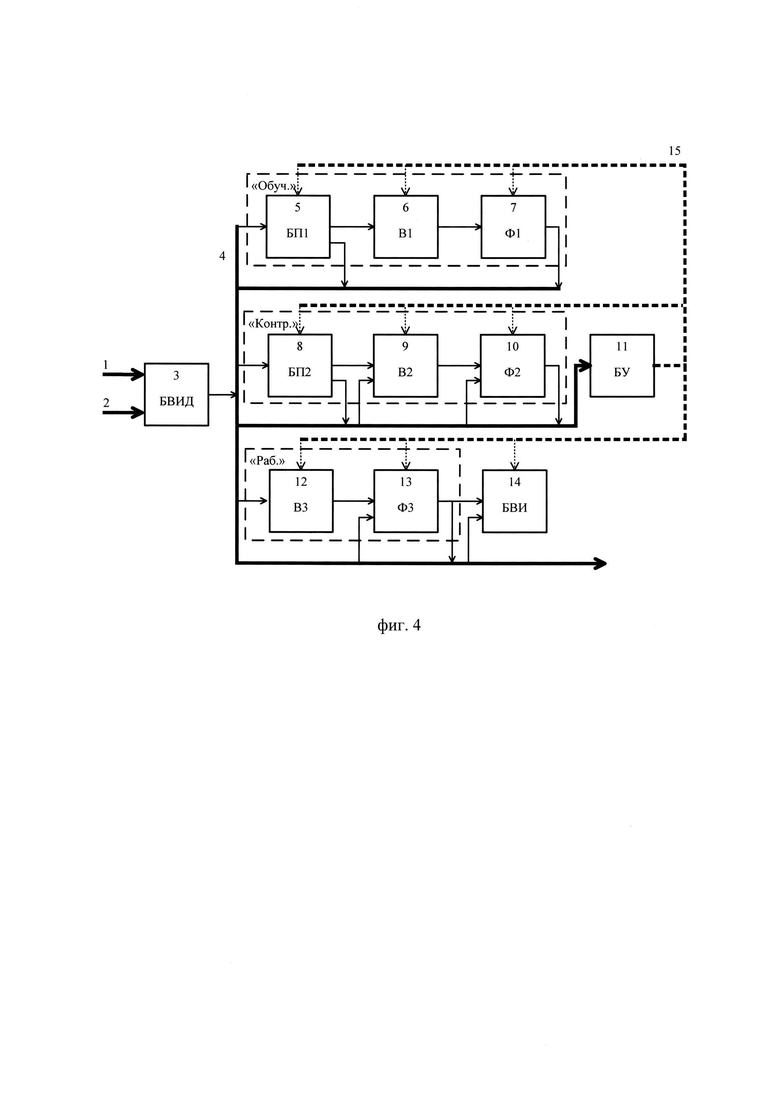
на фиг. 4 - общая структурная схема устройства транскрибирования цифровых сигналов НКР;
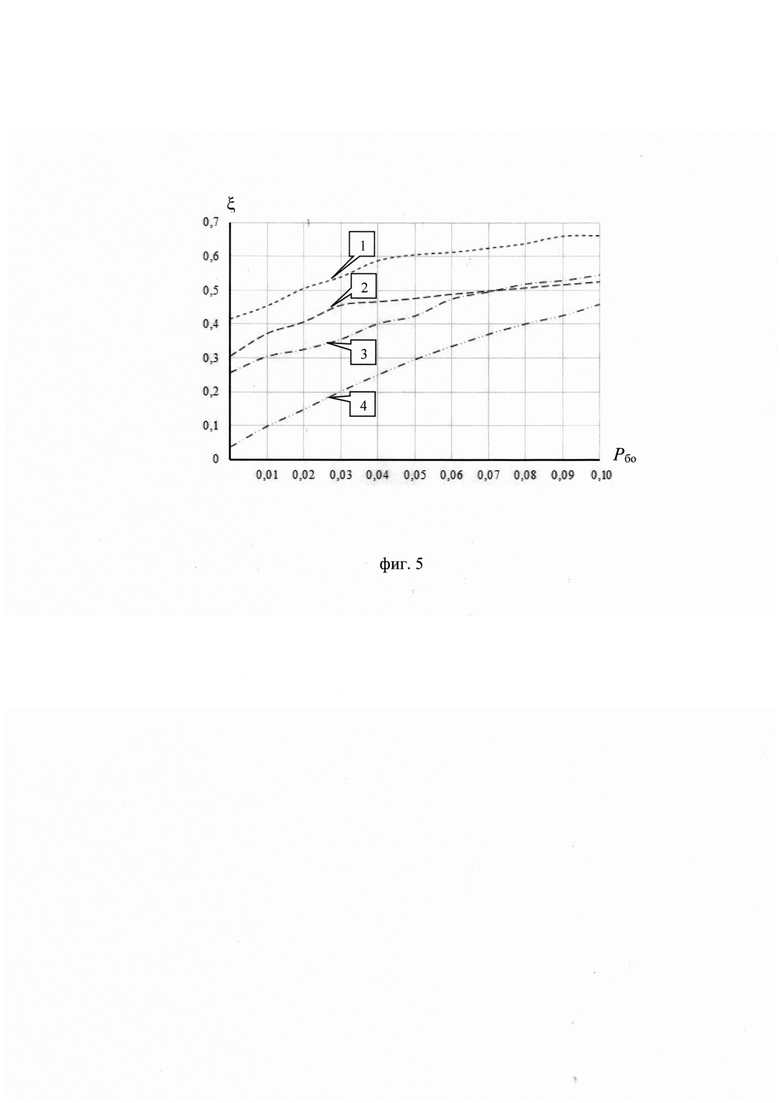
на фиг. 5 - зависимость значений Евклидова расстояния ξ между значениями линейных спектральных частот LSP, полученными из цифрового информационного сигнала s и синтезированного выходного сигнала sp с ИКМ, которые сформированы с помощью низкоскоростного кодека речи MELP-10-2400 (STANAG 4591), от вероятности битовых ошибок Рбо;
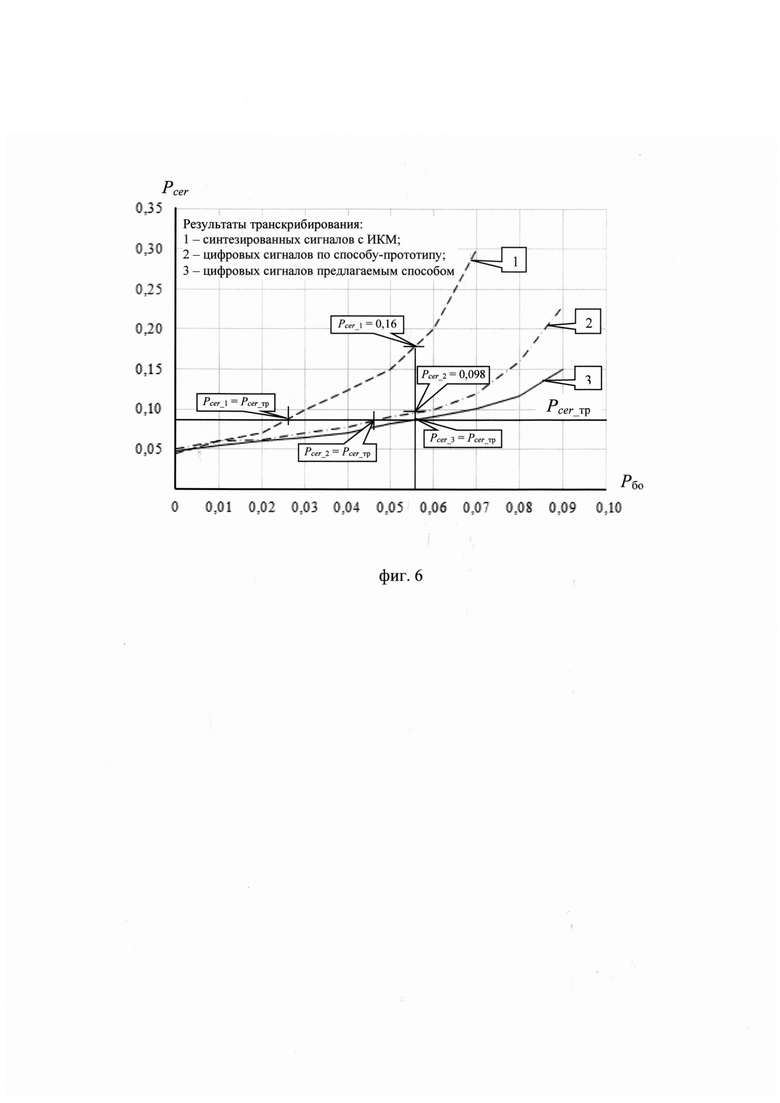
на фиг. 6 - зависимость вероятности Pcer ошибки распознавания фонем от вероятности Рбо появления битовых ошибок в цифровых сигналах, сформированных с помощью низкоскоростного кодека MELP-2400 (STANAG 4591).
При обработке речевых сигналов, поступающих из каналов ТКС, в состав которых входят НКР, наибольшее распространение получили методы транскрибирования синтезированных речевых сигналов с ИКМ и информационной скоростью 64≤Ви≤128 кбит/с, реализуемые на локализованных технических средствах. К другой, менее известной группе, относятся методы транскрибирования цифровых информационных сигналов НКР, имеющих информационную скорость 0,6≤Ви≤16 кбит/с. Эта группа методов отличается распределенной обработкой речевых сигналов, когда оценивание информативных параметров осуществляют в передающей части НКР, а транскрибирование выполняют с использованием этих параметров, выделенных из цифровых информационных сигналов НКР, переданных по каналам ТКС. Возможность уменьшения значения вероятности Pcer ошибки распознавания фонем по результатам анализа цифровых информационных сигналов, сформированных НКР и переданных по радиоканалам ТКС (см. Peinado A., Segura J.C. Speech recognition over digital channels: robustness and standards. - Chichester: John Wiley, 2006. - 257 p.- ISBN 978-0-470-02400-3), обуславливает актуальность разработки способа транскрибирования речи по цифровым информационным сигналам с низкоскоростным кодированием.
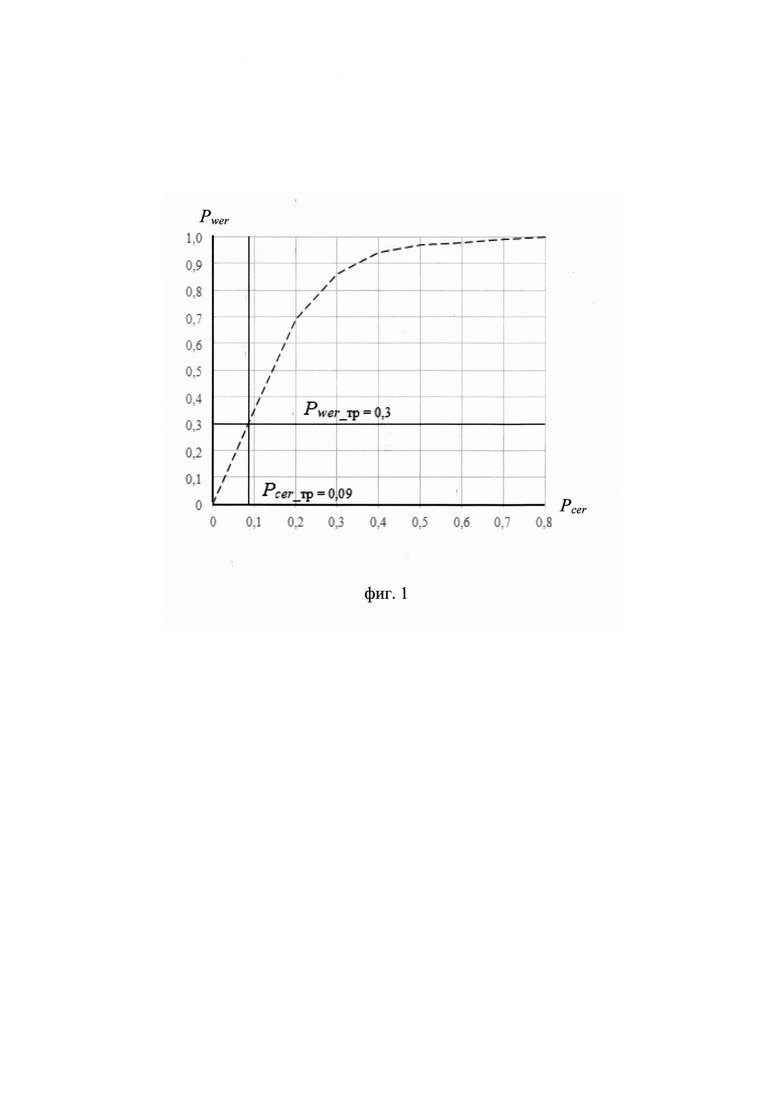
В существующих НКР сжатие исходных речевых сигналов реализуют с потерей информации. Количественно потеря информации отражается как понижение качества синтезируемых речевых сигналов по сравнению с исходными. Требования к качеству синтезированных речевых сигналов при транскрибировании речи человеком определены в ГОСТ Р 51061-97 на основе субъективного метода средних субъективных оценок Qmos качества речи MOS (англ. - mean opinion score) по пятибалльной шкале с дискретностью 0,1 балла согласно рекомендации ITU-TР.830. В соответствии с ГОСТ Р 51061-97 потеря разборчивости речевых сигналов возникает при значениях Qmos<1,7. Значительное ухудшение распознавания речи наступает в пределах 2,9≤Qmo≤1,7. Удовлетворительная разборчивость отмечается при соблюдении условия 2,9≤Qmos≤3,4, а высокая разборчивость - при 3,5≤Qmos≤5,0. Значения качества Qmos синтезированных речевых сигналов с ИКМ, сформированных при вероятности битовой ошибки Рбо≤0,001, могут составлять 2,1≤Qmos≤4,3. Нарушение благоприятных условий передачи радиосигналов (Рбо >> 0,001) приводит к появлению существенной доли битовых ошибок в принимаемых цифровых информационных сигналах и снижению качества Qmos синтезированных речевых сигналов до уровня, меньше порогового значения Qmos_п=2,9. Транскрибирование речевых сигналов, имеющих качество Qmos<Qmos_п, приводит к несоблюдению требования (1) при Pcer_тр = 0,09 (см. О точности и трудоемкости многоэтапного метода коррекции искаженных текстов в зависимости от степени искажения / Вахлаков Д.В., Германович А.В., Мельников С.Ю., Пересыпкин В.А., Цопкало Н.Н. // Известия ЮФУ. Технические науки. - Ростов-на-Дону: ЮФУ. - 2021. - №7(224). - С.130-142), превышению вероятности Pwer ошибки распознавания слов заданного уровня Pwer_т=0,3 (см. фиг. 1), и, как следствие, к утрате понимания полученного речевого сообщения. Поэтому синтезированные речевые сигналы с ИКМ рассматриваются в качестве входных реализаций, пригодных для транскрибирования, при выполнении условия

В некоторых случаях выполнение процессов транскрибирования речи может быть неэффективным из-за большого числа битовых ошибок в цифровых сигналах НКР, возникающих в радиоканалах ТКС, что определяет необходимость предварительной оценки качества цифровых информационных сигналов. Повышение эффективности транскрибирования речи по цифровым сигналам низкоскоростных кодеров, полученными средствами РМ, возможно за счет предварительного отбора входных реализаций s, соответствующих по качеству критерию (1), определяемому. Этот отбор может быть выполнен на основе способа автоматической оценки качества Qmos цифровых сигналов НКР (см. патент РФ на изобретение №RU 2748935 от 01.06.2021. Способ автоматической оценки качества речевых сигналов с низкоскоростным кодированием // В.А. Аладинский, С.В. Кузьминский, П.Л. Смирнов. - РФ: Федеральная служба по интеллектуальной собственности, Бюл. №30, 2021), в котором не требуется декодирование исследуемого цифрового сигнала s к формату sp. Кроме того, данный способ позволяет осуществлять распознавание протоколов НКР, используемых при формировании реализаций S. Описание условий передачи сигналов S в ТКС представляется в виде закономерностей появления битовых ошибок. По результатам анализа выполняют селекцию (отбор) сигналов, сформированных с помощью заданных НКР, и режекция других реализаций.
Уменьшение вероятности Pcer ошибки распознавания фонем при прочих равных условиях достигается за счет использования информативных сегментов исследуемого цифрового сигнала, содержащих информацию о речевом сообщении (см. Recognizing GSM digital speech / A. Gallardo-Antolin, C. Pelaez-Moreno, F. Diaz-de-Maria//Transactions on speech and audio processing. IEEE, November 2005. -Vol.13. - Pp.1186 - 1205), и уточненных эталонных образов, формируемых по цифровым сигналам.
Некоторое уменьшение вероятности Pcer ошибки распознавания фонем возможно при снижении числа эталонных образов, определяемое размерностью совокупности {dэ} эталонных описаний фонем, с которыми осуществляется сравнение образа D входной реализации s. Это обеспечивается за счет предварительной классификации в обучающих выборках вокализованных и невокализованных звуков речи, а также формировании эталонных образов фонем с учетом их классификации по группам дикторов (см. Фомин Я.А., Тарловский Г.Р. Статистическая теория распознавания образов. - М.: Радио и связь, 1986. - 264 с.). Количество Nгд голосовых групп дикторов определяют путем кластеризации признакового пространства, описываемого совокупностью значений 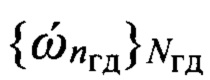 частоты ОТ речи, которые характеризуют эти голосовые группы с номерами nгд=1, 2,…,Nгд. Начальное значение количества Nгд_н=2 групп дикторов также обеспечивает их классификацию по полу (мужчина/женщина). Формирование эталонных описаний по группам звуков происходит при кластеризации признакового пространства на вокализованные (nфк=1) и невокализованные (nфк=2) звуки речи и описывается совокупностью значений
частоты ОТ речи, которые характеризуют эти голосовые группы с номерами nгд=1, 2,…,Nгд. Начальное значение количества Nгд_н=2 групп дикторов также обеспечивает их классификацию по полу (мужчина/женщина). Формирование эталонных описаний по группам звуков происходит при кластеризации признакового пространства на вокализованные (nфк=1) и невокализованные (nфк=2) звуки речи и описывается совокупностью значений 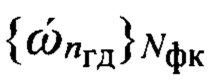 частоты ОТ.
частоты ОТ.
Таким образом, положительный эффект в предлагаемом способе транскрибирования речи по цифровым информационным сигналам НКР проявляется в уменьшении значения вероятности Pcer ошибки распознавания фонем и достигается за счет выполнения следующих действий:
анализа цифровых информационных сигналов, переданных по радиоканалам ТКС, и последующего отбора только тех из них, которые сформированы с помощью заданных (открытых) НКР и соответствуют требованиям по качеству речи;
использования дополнительных данных, содержащихся в цифровом информационном сигнале и позволяющих определить голосовую группу, к которой относится диктор, принимавший участие в формировании речевого сигнала, и выполнить фонетическую классификацию каждой входной реализации;
формирования на этапе обучения уточненных эталонных образов фонем по обучающей выборке, в которой цифровые информационные сигналы сформированы с участием дикторов, относящихся к известным голосовым группам, и разделения полученной совокупности уточненных эталонных образов на фонетические классы;
сравнения каждой входной реализации только с теми уточненными эталонными образами фонем, формируемыми на этапе обучения, которые относятся к установленной голосовой группе и фонетическому классу;
выбора наиболее контрастных признаков распознавания фонем и меры μ для их сравнения.
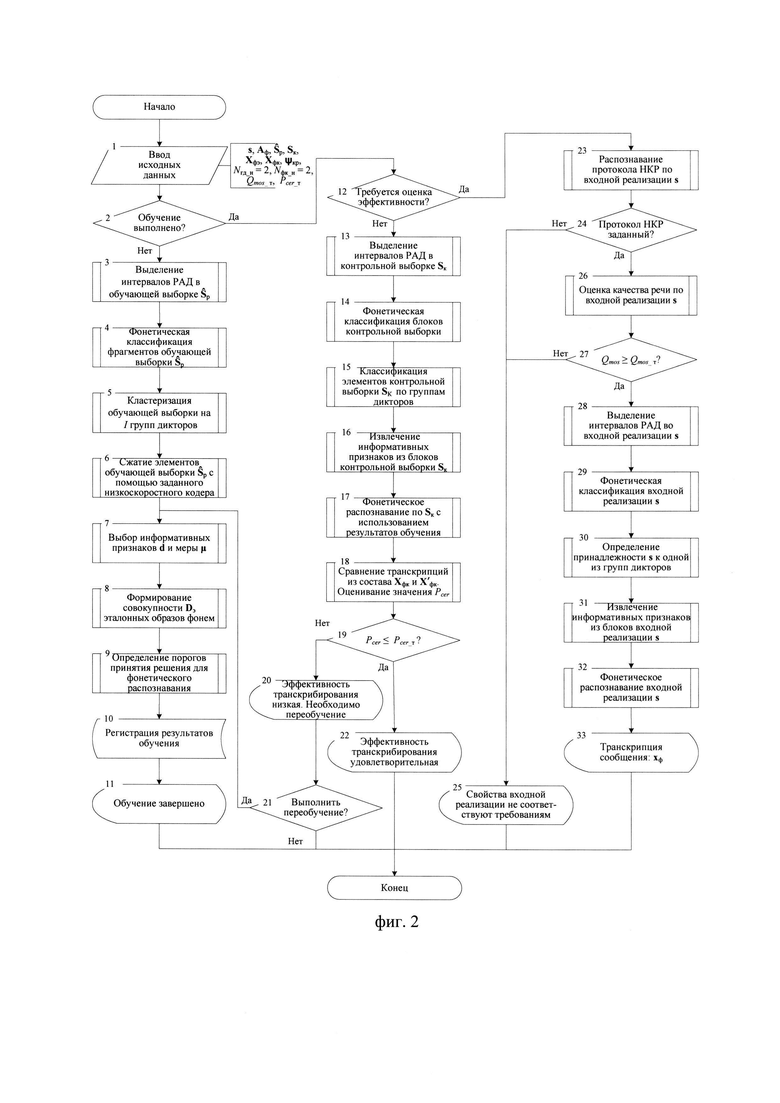
Реализация заявленного способа транскрибирования речи может быть осуществлена следующим образом (см. фиг. 2). До выполнения ввода исходных данных целесообразно установить начальное значение количества голосовых групп дикторов Nгд_н=2 и фонетических классов Nфк_н=2 (вокализованные / невокализованные), установить требуемое значение Pсer_т. В состав исходных данных входит фонетический алфавит Аф объемом Nф символов (фонем), необходимых для транскрибирования речевых сообщений. Также требуются описания процессов преобразования цифровых информационных сигналов на приемной стороне НКР, представленных совокупностью 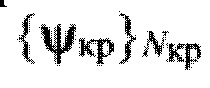 (Nкр - количество описываемых НКР), содержащиеся в опубликованных стандартах (например, см. ETSI/TC SMR. Recommendation GSM 06.10 GSM full rate speech transcoding. 1992, либо STANAG 4591 C3 (Edition 1) The 600 bit/s, 1200 bit/s, 2400 bit/s NATO interoperable narrow band voice coder. - NATO Standardization Agency. 3 October 2008. - 129 p.). Для каждого речевого сигнала
(Nкр - количество описываемых НКР), содержащиеся в опубликованных стандартах (например, см. ETSI/TC SMR. Recommendation GSM 06.10 GSM full rate speech transcoding. 1992, либо STANAG 4591 C3 (Edition 1) The 600 bit/s, 1200 bit/s, 2400 bit/s NATO interoperable narrow band voice coder. - NATO Standardization Agency. 3 October 2008. - 129 p.). Для каждого речевого сигнала 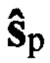 с ИКМ из обучающей выборки
с ИКМ из обучающей выборки 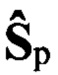 и каждого цифрового сигнала sк из контрольной выборки Sк необходимо заранее сформировать фонетические транскрипции, из которых составляют множество Хфэ эталонных и множество Хфк контрольных транскрипций, присваивают им общие порядковые номера nэ=1,2,…,Nэ, где Nэ - количество элементов в обучающей выборке
и каждого цифрового сигнала sк из контрольной выборки Sк необходимо заранее сформировать фонетические транскрипции, из которых составляют множество Хфэ эталонных и множество Хфк контрольных транскрипций, присваивают им общие порядковые номера nэ=1,2,…,Nэ, где Nэ - количество элементов в обучающей выборке 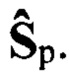
После ввода исходных данных (этап 1) осуществляют выбор режима. В режиме «Обучение» (этап 2, решение: «Да») на этапе 3 в каждом речевом сигнале 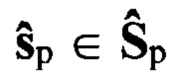 определяют Nиa≥1 интервалов РАД, устанавливая временные метки их начала и окончания, присваивают им порядковые номера nиа=1,2,…, Nиа, где Nиа - количество интервалов РАД. В результате образуется множество упорядоченных пар
определяют Nиa≥1 интервалов РАД, устанавливая временные метки их начала и окончания, присваивают им порядковые номера nиа=1,2,…, Nиа, где Nиа - количество интервалов РАД. В результате образуется множество упорядоченных пар 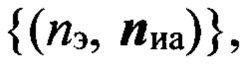 где
где 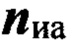 - вектор, описывающий интервалы РАД nэ-го элемента обучающей выборки, включая временные метки. Выполняют в выделенных Nиа интервалах РАД фонетическую классификацию (этап 4) и присваивают идентификаторы фрагментам речевого сигнала, принадлежащих к одному из двух фонетических классов с номерами nфк=1 - вокализованный или nфк=2 - невокализованный классы звуков.
- вектор, описывающий интервалы РАД nэ-го элемента обучающей выборки, включая временные метки. Выполняют в выделенных Nиа интервалах РАД фонетическую классификацию (этап 4) и присваивают идентификаторы фрагментам речевого сигнала, принадлежащих к одному из двух фонетических классов с номерами nфк=1 - вокализованный или nфк=2 - невокализованный классы звуков.
На этапе 5 осуществляют разбиение (кластеризацию) обучающей выборки на Nгд групп дикторов, для чего используют временные метки интервалов РАД и идентификаторы фонетических классов. Выделяют вокализованные фрагменты в каждом речевом сигнале 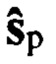 с ИКМ, определяют по выделенным фрагментам средние значения частоты ОТ речи и формируют совокупность
с ИКМ, определяют по выделенным фрагментам средние значения частоты ОТ речи и формируют совокупность 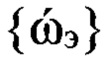 средних значений. Устанавливают методами кластеризации по совокупности
средних значений. Устанавливают методами кластеризации по совокупности 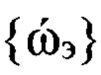 значение Nul≥Nгд_н, определяющее количество групп дикторов (кластеров), участвовавших в формировании обучающей выборки. Вычисляют по совокупности
значение Nul≥Nгд_н, определяющее количество групп дикторов (кластеров), участвовавших в формировании обучающей выборки. Вычисляют по совокупности 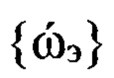 множество средних значений
множество средних значений 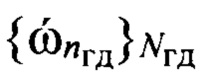 ОТ речи, каждое из которых характеризует nгд-ю группу дикторов, где nгд=1, 2,…,Nгд.
ОТ речи, каждое из которых характеризует nгд-ю группу дикторов, где nгд=1, 2,…,Nгд.
По обучающей выборке с помощью заданного низкоскоростного кодера ϕкр осуществляют сжатие исходных речевых сигналов с ИКМ (этап 6), содержащихся в обучающей выборке , в результате чего формируется эталонная совокупность 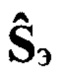 цифровых информационных сигналов. В результате сжатия каждому речевому сигналу
цифровых информационных сигналов. В результате сжатия каждому речевому сигналу 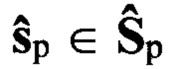 ставят в соответствие эталонный цифровой информационный сигнал
ставят в соответствие эталонный цифровой информационный сигнал 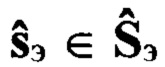 сформированный с помощью заданного низкоскоростного кодера ϕкр и ассоциированный с одной из Nгд групп дикторов. Также на данном этапе по временным меткам, исходя из заданного соответствия речевых сигналов с ИКМ и эталонных цифровых информационных сигналов, осуществляют разметку эталонной совокупности
сформированный с помощью заданного низкоскоростного кодера ϕкр и ассоциированный с одной из Nгд групп дикторов. Также на данном этапе по временным меткам, исходя из заданного соответствия речевых сигналов с ИКМ и эталонных цифровых информационных сигналов, осуществляют разметку эталонной совокупности 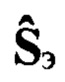 путем присвоения каждому блоку
путем присвоения каждому блоку 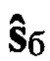 из ее состава следующих идентификаторов: группы дикторов - nгд, интервала РАД - nиа, фонетического класса - nфк.
из ее состава следующих идентификаторов: группы дикторов - nгд, интервала РАД - nиа, фонетического класса - nфк.
На этапе 7 выбирают информативные признаки, представленные в виде вектора признаков размерностью Nп, которые будут использованы для формирования совокупности эталонных образов в режиме «Обучение» и образов входных реализаций в режимах «Контроль» и «Работа». Также выбирают меру μ, которая будет использоваться при сравнении эталонных образов и образов входных реализаций в режимах «Контроль» и «Работа». В состав вектора признаков могут быть включены известные признаки, которые получают из цифрового информационного сигнала s путем его преобразования, например, значения логарифмически масштабированных кепстральных коэффициентов MFCC или линейных кепстральных коэффициентов LPCC, заранее выбираемых в качестве признаков на этапе обучения. Также в состав вектора признаков могут быть введены параметры, непосредственно содержащиеся в каждом блоке цифрового информационного сигнала, в том числе, характеризующие амплитуду речевого сигнала и его спектральные свойства: значения коэффициентов линейного предсказания LPС (англ. - linear predictive coefficient) или линейных спектральных частот LSF (англ. - line spectral frequencies). В качестве меры μ могут выступать гауссовы смеси, скрытые марковские модели (СММ), а также искусственные нейронные сети (ИНС). Осуществляют выбор признаков, включаемых в состав вектора признаков d, и меры μ, обладающих наибольшей информативностью. Вычисляют по каждому выделенному блоку вектор признаков d(nф, nфк, nгд). Используя идентификатор номера фонемы nф, составляют совокупность 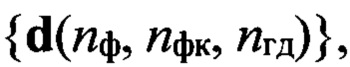 векторов, содержащих признаки фонемы с номером nф.
векторов, содержащих признаки фонемы с номером nф.
На этапе 8 формируют совокупность 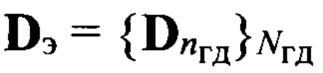 эталонных описаний, включающую в себя Nгд множеств эталонных образов фонем, каждый из которых состоит из подмножеств
эталонных описаний, включающую в себя Nгд множеств эталонных образов фонем, каждый из которых состоит из подмножеств 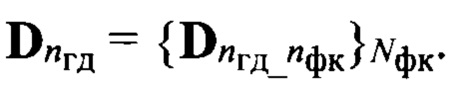 Подмножество
Подмножество 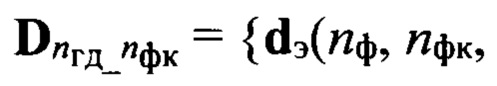
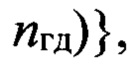 где nф - номер фонемы
где nф - номер фонемы 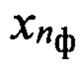 из алфавита Аф фонем объемом Nф символов, содержит эталонные описания фонем, относящихся к одному из двух фонетических классов и характерных для группы дикторов с номером nгд. Эталонное описание фонемы , представленное в виде эталонного образа dэ(nф, nфк, nгд), составляют путем усреднения совокупности векторов сформированной на этапе 7.
из алфавита Аф фонем объемом Nф символов, содержит эталонные описания фонем, относящихся к одному из двух фонетических классов и характерных для группы дикторов с номером nгд. Эталонное описание фонемы , представленное в виде эталонного образа dэ(nф, nфк, nгд), составляют путем усреднения совокупности векторов сформированной на этапе 7.
Экспериментальным путем, с использованием сформированной совокупности Dэ и выбранной меры μ определяют пороги принятия решения 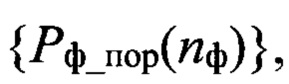 необходимые для фонетического распознавания (этап 9). Осуществляют регистрацию результатов обучения (этап 10) и выводят сообщение - «Обучение завершено» (этап 11).
необходимые для фонетического распознавания (этап 9). Осуществляют регистрацию результатов обучения (этап 10) и выводят сообщение - «Обучение завершено» (этап 11).
При наличии сформированных эталонных описаний (этап 2, решение: «Да») запускают режим «Контроль» (этап 12, решение: «Нет») с целью проверки эффективности разработанного способа транскрибирования цифровых сигналов, сформированных с помощью заданного низкоскоростного кодера ϕкр. В контрольную выборку Sк входят Nк цифровых информационных сигналов, сформированных с помощью заданного низкоскоростного кодера ϕнк с качеством Qmos, удовлетворяющим критерию (1). Выборки 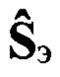 и Sк не пересекаются, т.е.
и Sк не пересекаются, т.е. 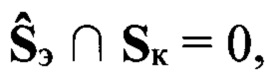 элементам контрольной выборки присвоены порядковые номера nк=1,2,…, Nк.
элементам контрольной выборки присвоены порядковые номера nк=1,2,…, Nк.
Этап 13 предполагает определение интервалов РАД в каждом цифровом сигнале sк контрольной выборки Sк с использованием информации, содержащейся в блоках цифрового сигнала. Результатом является выделение Nиа интервалов РАД и присвоение блокам, входящим в эти интервалы соответствующих идентификаторов nиа=1, 2,…,Nиа, также обозначающих номер интервала РАД. Всем остальным блокам присваивают идентификатор nиа=0, считая, что они не содержат речевой информации. В результате образуется множество упорядоченных пар 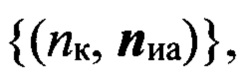 где
где 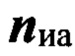 - вектор, характеризующий интервалы РАД nк-го элемента контрольной выборки.
- вектор, характеризующий интервалы РАД nк-го элемента контрольной выборки.
Далее на этапе 14 осуществляют фонетическую классификацию блоков, имеющих идентификаторы интервалов РАД nиа ≠ 0, путем сравнения выделенных значений параметров речевого сигнала, содержащихся в исследуемых блоках с соответствующими эталонными значениями параметров, установленными в режиме «Обучение» (этап 4). Присваивают значение идентификатора nфк = 1 блокам, в которых содержатся данные о вокализованных звуках речи при совпадении выделенных значений с эталонными. Остальным блокам присваивают значение идентификатора nфк=2, считая, что они содержат информацию о невокализованных звуках речи. Результатом является множество {(nк, nби, nфк)} значений классификаторов, по которому определяют фонетические свойства блоков nк-го элемента контрольной выборки.
Осуществляют классификацию элементов (цифровых сигналов) контрольной выборки Sк (этап 15) по группам дикторов путем выделения из цифровых сигналов блоков, имеющих значение идентификатора nфк=1, и используя информацию о значениях ОТ речи, содержащейся в них. Для этого преобразуют соответствующие двоичные символы к десятичному формату по правилам, приведенным в протоколе низкоскоростного кодирования речи. Затем составляют из полученных значений частоты ωот ОТ речи вектор ωот, усредняют его значения, получая величину 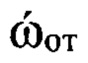 средней частоты ОТ. Выявляют путем сравнения значения
средней частоты ОТ. Выявляют путем сравнения значения 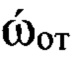 с определенными на этапе обучения эталонными значениями частоты
с определенными на этапе обучения эталонными значениями частоты 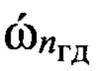 ОТ речи, к какой голосовой группе с номером nгд относится анализируемый цифровой сигнал. По результатам классификации каждому цифровому сигналу sк ∈ Sк присваивают идентификатор с номером nгд группы дикторов. Результатом является множество значений {(nк, nгд)}, по которому определяют принадлежность любого nк-го элемента контрольной выборки к одной из групп дикторов.
ОТ речи, к какой голосовой группе с номером nгд относится анализируемый цифровой сигнал. По результатам классификации каждому цифровому сигналу sк ∈ Sк присваивают идентификатор с номером nгд группы дикторов. Результатом является множество значений {(nк, nгд)}, по которому определяют принадлежность любого nк-го элемента контрольной выборки к одной из групп дикторов.
Извлекают (этап 16) информативные признаки из блоков контрольной выборки Sк, идентификаторы которых удовлетворяют условию nиа ≠ 0. В результате каждому выделенному блоку sбк ставится в соответствие вектор признаков dк(nфк, nгд), которому присваивают идентификаторы nфк и nгд порождающего объекта.
Каждый вектор признаков dк(nби, nфк, nгд), совокупность которых характеризует контрольную выборку Sк, поступает на фонетическое распознавание (этап 17), где его поочередно сравнивают с помощью меры μ с эталонными образами фонем из подмножества {dэ(nби, nфк, nгд)} эталонных описаний фонем, у которых идентификаторы nфк и nгд совпадают по значению с соответствующими идентификаторам вектора признаков dк(nби, nфк, nгд). Определяют вероятность Рф(nби, nфк) соответствия образа dк(nби, nфк, nгд) контрольной реализации и каждому эталонному образу dэ(nби, nфк, nгд), формируя вектор Рф. Принимают решение о содержании фонетической информации в анализируемом блоке sбк путем установления соответствия фонетического символа (знака), обозначаемого с учетом идентификаторов РАД 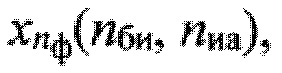 определяемого по номеру nф эталонного образа dэ(nби, nфк, nгд), для которого значение Рф(nби, nфк) является максимальным и больше порогового значения Рф_пор(nф). Последний задают на этапе обучения. Анализируют все выделенные блоки цифрового сигнала sк, составляя транскрипцию
определяемого по номеру nф эталонного образа dэ(nби, nфк, nгд), для которого значение Рф(nби, nфк) является максимальным и больше порогового значения Рф_пор(nф). Последний задают на этапе обучения. Анализируют все выделенные блоки цифрового сигнала sк, составляя транскрипцию 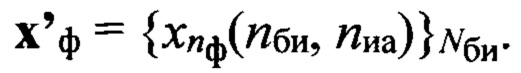 Формируют совокупность Х'фк транскрипций, полученную по результатам обработки контрольной выборки Sк с помощью предлагаемого способа.
Формируют совокупность Х'фк транскрипций, полученную по результатам обработки контрольной выборки Sк с помощью предлагаемого способа.
На этапе 18 сравнивают транскрипции из состава контрольной совокупности Хфк и совокупности Х'фк, полученной по результатам транскрибирования контрольной выборки Sк с помощью предлагаемого способа. При сравнении определяют Nэф - количество операций замены ошибочно распознанных фонем; Nyф - количество операций удаления ошибочно распознанных фонем; Nвф - количество операций вставки нераспознанных фонем; Nфк - общее количество фонем в сформированной совокупности Х'фк. По результатам сравнения вычисляют значение Pcer вероятности ошибки распознавания фонем при обработке предлагаемым способом контрольной выборки Sк по формуле Левенштейна (см. Тампель И.Б., Карпов А.А. Автоматическое распознавание речи. Учебное пособие. - СПб: Университет ИТМО, 2016. - 138 с. )

На этапе 19 принимают решение о соответствии результатов транскрибирования контрольной выборки Sк требованиям к ним по критерию эффективности

При невыполнении условия (4) выводят сообщение: «Эффективность транскрибирования низкая. Необходимо переобучение». Принимают решение о переобучении либо заканчивают выполнение алгоритма (этап 21, решение: «Нет»). В первом случае (этап 21, решение: «Да») возвращаются на этап 7 и составляют более информативный набор d признаков распознавания фонем и/или уточняют меру μ, формируют новую совокупность Dэ эталонных образов, при использовании которых выполняется критерий (4) эффективности транскрибирования по цифровым сигналам с низкоскоростным кодированием. При выполнении условия (4) выводят сообщение: «Эффективность транскрибирования удовлетворяет требованиям» (этап 22).
При выборе режима «Работа» (этап 12, решение: «Да») осуществляется обработка цифровых информационных сигналов, поступающих из каналов ТКС. На этапе 23 известным способом (см. патент РФ на изобретение № 2667462 С1 от 19.09.2018. Способ распознавания протоколов низкоскоростного кодирования, МПК G10L 19/008 (2013.01), Н03М 13/03 (2006.01). Аладинский В.А., Вещунин Е.А., Кузьминский С.В., Смирнов П.Л. - РФ: Федеральная служба по интеллектуальной собственности, Бюл. №26, 2018) проверяют гипотезу о том, что входная реализация s сформирована на основе nп-го заданного (известного) протокола НКР. Если гипотеза не подтверждается (этап 24, решение: «Нет»), то выводят сообщение: «Свойства входной реализации не соответствуют требованиям» и прекращают транскрибирование. В противном случае переходят к этапу 26 и оценивают качество речи по входной реализации s известным способом (см. патент РФ на изобретение № 2748935 от 01.06.2021. Способ автоматической оценки качества речевых сигналов с низкоскоростным кодированием // В.А. Аладинский, С.В. Кузьминский, П.Л. Смирнов. - РФ: Федеральная служба по интеллектуальной собственности, Бюл. №30, 2021), с помощью которого обеспечивается вычисление значения оценки качества Qmos исследуемого цифрового сигнала s, сформированного заданным низкоскоростным кодером, без преобразования к формату ИКМ.
Проверяют на этапе 27 выполнение критерия (2) для входной реализации путем сравнения вычисленного значения Qmos с требуемым значением Qmos_т. При несоответствии цифрового информационного сигнала s заданным требованиям к качеству также выводят сообщение: «Свойства входной реализации не соответствуют требованиям» (этап 25) и прекращают транскрибирование. Если критерий (2) выполняется (этап 27, решение: «Да»), то переходят к этапу 28 и определяют интервалы РАД во входной реализации s с использованием информации, содержащейся в блоках цифрового сигнала. Результатом является выделение Nиа интервалов РАД и присвоение блокам, входящим в эти интервалы соответствующих идентификаторов nиа=1,2,…,Nиа, также обозначающих номер интервала РАД. Всем остальным блокам присваивают идентификатор nиа=0, считая, что они не содержат речевой информации, составляют вектор nиа, характеризующий интервалы РАД на длительности входной реализации s. Выделяют из состава цифрового сигнала s с помощью идентификаторов принадлежности к интервалам РАД блоки, удовлетворяющие условию nиа ≠ 0. Последовательно присваивают выделенным блокам порядковые номера nби=1, 2, …, Nби, формируют (см. Фиг. 3) прямоугольную информативную матрицу Sи размеров Мс × Nби путем последовательного размещения (конкатенации) друг под другом информационных блоков в соответствии с их порядковыми номерами nби=1,2, …, Nби, начиная с первого информационного блока sби(1).
Осуществляют фонетическую классификацию информационных блоков исследуемого сигнала s (этап 29), у которых идентификаторы интервалов РАД удовлетворяют условию nиа ≠ 0, выделяя информативные параметры, содержащихся в строках матрицы Sи и сравнивая их значения с соответствующими эталонными значениями, установленными в режиме «Обучение» (этап 4). При совпадении выделенных значений с эталонными присваивают значение идентификатора nфк=1 строкам, в которых содержатся данные о вокализованных звуках речи. Остальным строкам информативной матрицы Sи присваивают значение идентификатора nфк=2, считая, что они содержат данные о невокализованных звуках речи.
Определяют в ходе выполнения этапа 30 принадлежность цифрового информационного сигнала s, поступившего для анализа, к одной из NГд групп дикторов с использованием информации об ОТ речи, содержащейся в строках матрицы Sи, которые имеют значение идентификатора nфк=1. Составляют из полученных значений частоты ωот ОТ речи вектор ωот, усредняют его значения, получая величину 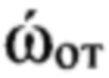 средней частоты ОТ. Сравнивают полученное значение с определенными на этапе обучения эталонными значениями частоты
средней частоты ОТ. Сравнивают полученное значение с определенными на этапе обучения эталонными значениями частоты 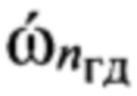 ОТ речи и по наименьшему отклонению от одного из эталонных значений устанавливают, к какой голосовой группе с номером nгд относится анализируемый цифровой сигнал s. Присваивают по результатам классификации анализируемому цифровому сигналу s идентификатор с номером nгд группы дикторов. Данный идентификатор распространяется на все компоненты цифрового сигнала s.
ОТ речи и по наименьшему отклонению от одного из эталонных значений устанавливают, к какой голосовой группе с номером nгд относится анализируемый цифровой сигнал s. Присваивают по результатам классификации анализируемому цифровому сигналу s идентификатор с номером nгд группы дикторов. Данный идентификатор распространяется на все компоненты цифрового сигнала s.
На этапе 31 извлекают данные о спектре речевого сигнала из каждой строки sби(nби) прямоугольной информативной матрицы Sи, у которой идентификатор РАД удовлетворяет условию nиа ≠ 0. Путем преобразования данных о спектре речевого сигнала формируют образ входной реализации, представленный матрицей D размеров Мn × Мби, где Nп - число элементов в векторе признаков d(nби, nфк, nгд), который является строкой матрицы D. Значение Nп задается при обучении.
Выполняют в ходе этапа 32 фонетическое распознавание, для чего по идентификаторам nфк и nгд вектора признаков d(nби, nфк, nгд) выделяют из совокупности Dэ соответствующее подмножество 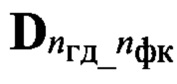 эталонных описаний и последовательно сравнивают с помощью выбранной меры μ каждый эталонный образ dэ(nби, nфк, nгд), принадлежащий к выделенному подмножеству
эталонных описаний и последовательно сравнивают с помощью выбранной меры μ каждый эталонный образ dэ(nби, nфк, nгд), принадлежащий к выделенному подмножеству 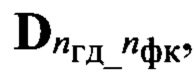 с элементами образа D входной реализации. Определяют значения вероятности Рф(nби, nфк) соответствия вектора признаков d(nби, nфк, nгд) каждому эталонному образу из подмножества {dэ(nби, nфк, nгд)} и составляют вектор Рф. Принимают решение о содержании фонетической информации в анализируемой строке sб(nби), устанавливая в соответствие ему фонетический символ (знак)
с элементами образа D входной реализации. Определяют значения вероятности Рф(nби, nфк) соответствия вектора признаков d(nби, nфк, nгд) каждому эталонному образу из подмножества {dэ(nби, nфк, nгд)} и составляют вектор Рф. Принимают решение о содержании фонетической информации в анализируемой строке sб(nби), устанавливая в соответствие ему фонетический символ (знак) 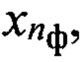 определяемый по номеру nф эталонного образа dэ(nби, nфк, nгд), для которого значение Рф(nби, nф) является максимальным и больше порогового значения Рф_пор(nф), установленного на этапе обучения. Путем анализа всех строк информативной матрицы Sи, учитывая порядковые номера строк и значения идентификаторов РАД, составляют последовательность фонетических знаков
определяемый по номеру nф эталонного образа dэ(nби, nфк, nгд), для которого значение Рф(nби, nф) является максимальным и больше порогового значения Рф_пор(nф), установленного на этапе обучения. Путем анализа всех строк информативной матрицы Sи, учитывая порядковые номера строк и значения идентификаторов РАД, составляют последовательность фонетических знаков 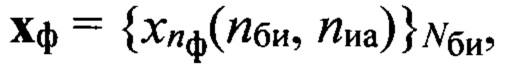 которая является результатом транскрибирования входного цифрового информационного сигнала s.
которая является результатом транскрибирования входного цифрового информационного сигнала s.
Выводят сообщение «Транскрипция сообщения: xф» (этап 33) и завершают работу.
Осуществление технического решения.
Для реализации предлагаемого способа необходимо использовать аппаратные и программные компоненты, объединенные на физическом и логическом уровнях взаимодействия в виде устройства транскрибирования, способные выполнять последовательность действий, задаваемую в разработанном способе (см. фиг. 2). Под аппаратными компонентами устройства транскрибирования подразумеваются электронные вычислительные средства, которые исполняют инструкции (программы) и обеспечивают обработку данных, включая вычисление, формирование, хранение, отображение информации и управление другими электронными вычислительными устройствами. В качестве электронных вычислительных средств могут применяться микро-ЭВМ, микропроцессоры, программируемые логические контроллеры либо программируемые линейные интегральные схемы (ПЛИС), обладающие необходимым быстродействием и имеющие совместимые интерфейсы для взаимодействия с другими компонентами. Также к аппаратным компонентам относятся шины ввода данных, обмена информацией и управления, обеспечивающие взаимодействие аппаратных и программных компонентов, например, на основе протокола TCP/IP. В роли устройств хранения данных могут выступать любые постоянные запоминающее устройство (ПЗУ) с требуемым объемом памяти, в том числе, но не ограничиваясь: жесткий диск HDD (англ. - hard disk drive), флеш-память, твердотельный накопитель SSD (англ. - solid-state drive). Отображение информации возможно с использованием любых графических дисплеев.
Программные компоненты устройства транскрибирования на логическом уровне реализуют последовательность действий, заданную предложенным способом, и формируют машинные инструкции (команды) для аппаратных средств.
Предлагаемая обобщенная структурная схема устройства транскрибирования приведена на фиг. 4. Имеющийся на схеме блок ввода исходных данных (БВИД) предназначен для приема исходных данных, поступающих через установочную шину и шину ввода данных, их первичного анализа, передачи исходных данных и результатов первичного анализа через общую шину 4 обмена данными (ОШОД) в блоки, реализующие режимы функционирования «Обучение», «Контроль» или «Работа», а также в блок управления (БУ). В БУ осуществляется выбор режима функционирования устройства транскрибирования и формирование необходимых управляющих сигналов (инструкций), поступающих через шину управления на остальные блоки. Блок вывода информации (БВИ) является общим и используется для вывода в графической форме служебной информации и результатов транскрибирования.
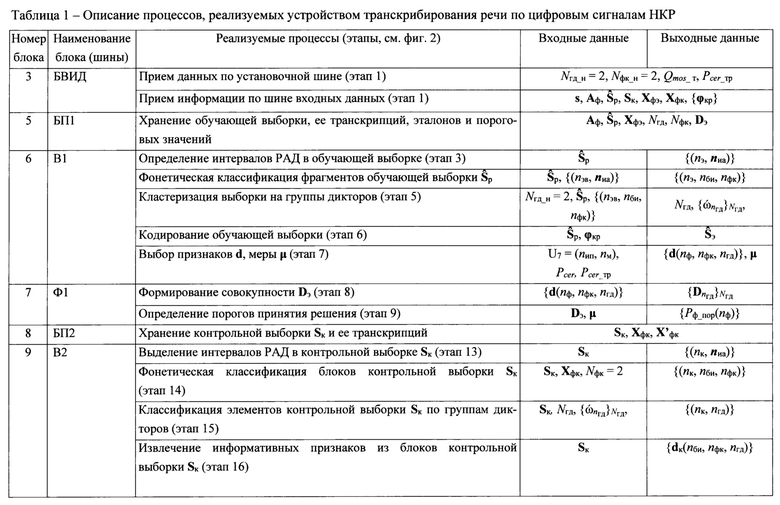
В режиме «Обучение» задействуются первый блок памяти (БП1), первый вычислитель (В1) и первый формирователь (Ф1). Для реализации режима «Контроль» используют второй блок памяти (БП2), второй вычислитель (В2) и второй формирователь (Ф2). В режиме «Работа» используют третий вычислитель (В3) и третий формирователь (Ф3). Кроме того, в режимах «Контроль» и «Работа» используются сформированные эталонные описания фонем, а также пороговые значения, признаки и меры, выбранные в режиме «Обучение» и хранимые в БП1. Описание основных процессов, реализуемых устройством транскрибирования речи по цифровым сигналам НКР, в соответствии с предложенным алгоритмом (см. Фиг. 2) приведено в таблице 1.

Эффективность предлагаемого способа транскрибирования речи оценивалась по речевому корпусу TIMIT (англ. - Texas Instruments & Massachusetts Institute of Technology), в формировании которого принимало участие 630 дикторов из восьми региональных диалектных зон США. Соотношение между тендерными группами дикторов составляло около 70% мужчин и 30% женщин. Разработанный алгоритм (см. фиг. 2) был реализован в среде программирования MATLAB. При формировании исходных данных использованы речевые сигналы с ИКМ из речевого корпуса TIMIT. Этап 7 алгоритма, обеспечивающий сжатие элементов обучающей выборки , был выполнен с помощью низкоскоростного кодера MELP-2400 {STANAG 4591), который применяется на линиях радиосвязи диапазона высоких частот и имеет открытое описание процессов сжатия и синтеза речевых сигналов (см. STANAG 4591 С3 (Edition 1) The 600 bit/s, 1200 bit/s, 2400 bit/s NATO interoperable narrow band voice coder. - NATO Standardization Agency. 3 October 2008. - 129 p.).
Необходимость обработки сигналов низкоскоростного кодера MELP-2400 (STANAG 4591) предложенным способом обусловлена тем, что значение качества синтезированных сигналов с ИКМ Qmos=3,0 удовлетворяет условию (2) только при отсутствии влияния битовых ошибок в канале радиосвязи (см. Kondoz A.M. Digital speech: Coding for low bit rate communication systems. - 2nd ed. -Hoboken: John Wiley & Sons, 2004. - 441 p.- ISBN 0-470-87008-7). В реальных условиях качество речевых сигналов, синтезированных с помощью данного кодера, часто требованиям не соответствует. Поэтому автоматическое транскрибирование синтезированных речевых сигналов с ИКМ известными способами не выполняется.
Информация о спектральных свойствах речевого сигнала, необходимая для формирования признаков распознавания фонем, представлена в каждом блоке цифрового сигнала размерностью 54 бита в виде значений LSF, на которые выделено 25 бит. Для выделения интервалов РАД (этапы 13, 28) использована информация (8 бит) об амплитуде сигнала. Фонетическая классификация блоков цифрового сигнала (этапы 14, 29) осуществлялась с помощью идентификатора апериодичности сигнала (1 бит), по наличию данных о частоте ОТ речи (7 бит) и данных о вокализации речевого сигнала по частотным полосам (4 бита). Определение принадлежности входной реализации к одной из групп дикторов (этапы 15, 30) выполнено на основе данных о частоте ОТ речи (7 бит).
При обучении выполнен выбор признаков распознавания фонем (этап 7) на основе сравнения векторов dMFCC и dLPCC, включающих значения логарифмически масштабированных кепстральных коэффициентов или линейных кепстральных коэффициентов соответственно, с использованием евклидова расстояния ξ при различных значениях вероятности Рбо битовой ошибки (см. фиг. 5). По сравнению с конкурирующим вектором dMFCC более информативным набором признаков распознавания является вектор dLРСС, для которого значения евклидова расстояния ξ, при Рбо=const меньше, что свидетельствует о большей компактности эталонных образов и достигается за счет меньшего количества преобразований. С помощью СММ, которые выбраны на этапе 7 в качестве меры μ, реализовано фонетическое распознавание элементов контрольной выборки Sк (этап 17) и входных реализаций (этап 32).
По завершении обучения в режиме «Контроль» на этапе 18 выполнено сравнение совокупности Хфк контрольных транскрипций и совокупности Х'фк транскрипций, полученных по результатам обработки контрольной выборки Sк с помощью предлагаемого способа. Оценки эффективности разработанного способа транскрибирования речи получены с использованием совокупности Dэ эталонных образов фонем при значениях Nгд = 2, Nфк=2. Результаты оценивания эффективности транскрибирования сигналов, сформированных с помощью низкоскоростного кодека речи MELP-2400 (STANAG 4591) приведены на фиг. 6 в виде зависимости вероятности Pcer ошибки распознавания фонем от вероятности Рбо появления битовых ошибок в цифровых сигналах при их передаче по радиоканалам. График 1 (см. фиг. 6) характеризует возможности транскрибирования синтезированных речевых сигналов, полученных с выхода декодера. Графики 2 и 3 (см. фиг. 6) иллюстрируют возможности транскрибирования цифровых сигналов НКР на основе способа-прототипа, в котором не учитывается дополнительная информация, и предлагаемого способа соответственно.
Эффективность транскрибирования речи при использовании предлагаемого способа подтверждается сравнением значений вероятности Pcer для разных способов при Рбо=0,056. В этих условиях предлагаемый способ обеспечивает выполнение требования (1), т.к. Pcer_b=Pcer_тр. Способ-прототип при данном уровне ошибок уступает разработанному способу в эффективности и требованию (1) не удовлетворяет: Pcer_тр<Pcer_2=0,098. Требование (1) при обработке цифровых сигналов низкоскоростного кодека MELP-2400 (STANAG 4591) выполняется, если Рбо<0,047, что также свидетельствует о большей помехоустойчивости разработанного способа.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ автоматической оценки качества речевых сигналов с низкоскоростным кодированием | 2021 |
|
RU2757860C1 |
| СПОСОБ ВЕРИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМАХ САНКЦИОНИРОВАНИЯ ДОСТУПА | 2007 |
|
RU2351023C2 |
| УСТРОЙСТВО СИНТЕЗА РЕЧИ | 2014 |
|
RU2606312C2 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| Способ пеленгации телефонных радиосигналов с амплитудной модуляцией | 2023 |
|
RU2798775C1 |
| СПОСОБ ОЦЕНКИ ВАРИАТИВНОСТИ ПАРОЛЬНОЙ ФРАЗЫ (ВАРИАНТЫ) | 2013 |
|
RU2598314C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧЕВЫХ КОМАНД УПРАВЛЕНИЯ | 2003 |
|
RU2271578C2 |
| Способ дикторонезависимого распознавания фонемы в речевом сигнале | 2021 |
|
RU2763124C1 |
Изобретение относится к области вычислительной техники и радиосвязи. Технический результат заключается в уменьшении значения вероятности ошибки распознавания фонем Рсer. Технический результат достигается за счет предварительного определения фонетического класса звуков и классификации исследуемых цифровых сигналов по голосовым группам, а также за счет формирования более точных эталонных описаний фонем и более полного использования принятой информации, содержащейся в цифровых информационных сигналах. Кроме того, достижение требуемого значения вероятности Pcer.тр. обеспечивается за счет оценивания качества речи по цифровым информационным сигналам и последующего транскрибирования только тех из них, оценка качества которых превышает пороговый уровень качества. 6 ил., 1 табл.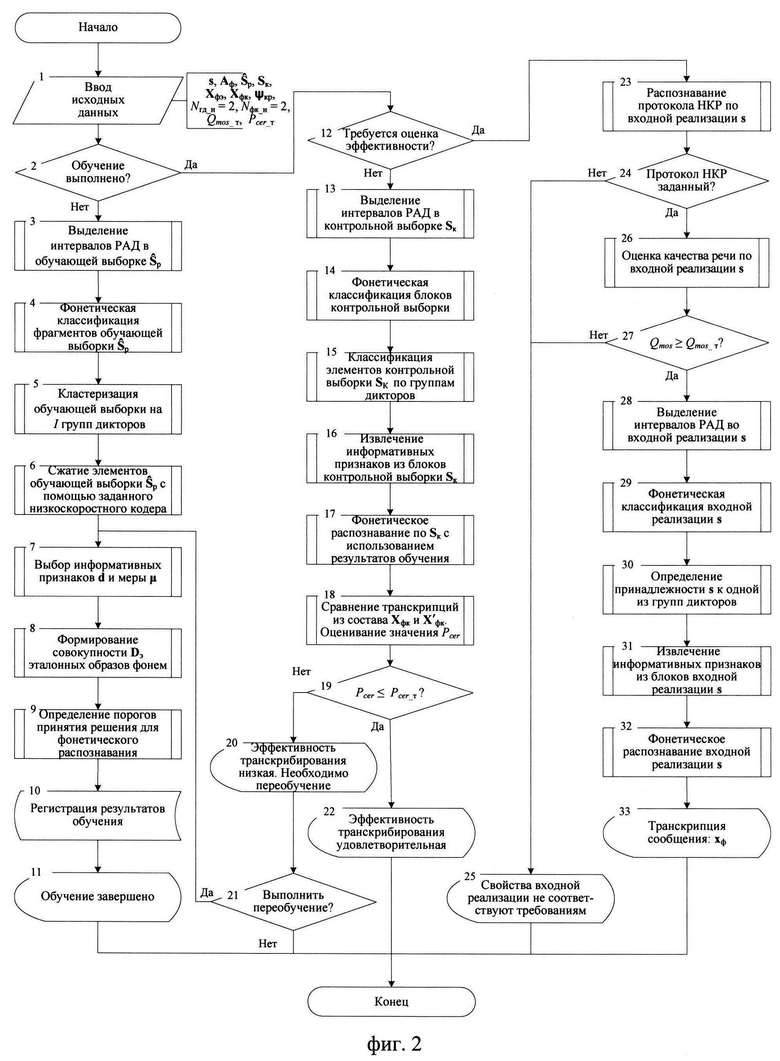
Способ транскрибирования речи по цифровым информационным сигналам с низкоскоростным кодированием, заключающийся в том, что принимают поблочно в течение интервала времени Тс цифровой информационный сигнал s размерностью Nэ элементов, сформированный на передающей стороне с помощью заданного низкоскоростного кодека речи, в составе которого любой информационный блок sб имеет заданную размерность Nc двоичных символов, запоминают принятый сигнал, из которого последовательно выделяют Nби информационных блоков, соответствующих интервалам времени речевой активности диктора (РАД), и извлекают из каждого выделенного информационного блока sб двоичные символы, указанные в протоколе низкоскоростного кодирования речи и содержащие информацию о спектре речевого сигнала, составляя из них последовательность sc, преобразуют последовательность sc в вектор признаков dMFCC выбранной размерности, состоящий из значений кепстральных коэффициентов в частотной шкале мел MFCC, составляют совокупность 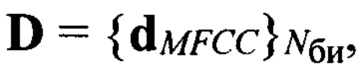 которая является образом входной реализации s, отличающийся тем, что выполняют распознавание протоколов низкоскоростного кодирования, применяемых для формирования цифровых информационных сигналов, по результатам распознавания протоколов выделяют цифровые информационные сигналы, сформированные с помощью известных низкоскоростных кодеров, при выявлении факта применения неизвестного низкоскоростного кодера для формирования цифрового информационного сигнала s выполнение дальнейших операций над данным сигналом прекращают; в противном случае оценивают качество речи по цифровому информационному сигналу s, сформированному с помощью известного низкоскоростного кодера, проверяют соответствие цифрового информационного сигнала требованию по качеству путем сравнения полученной оценки качества речи с его пороговым значением, транскрибирование цифрового информационного сигнала, качество которого не превышает пороговое значение, не осуществляют; присваивают порядковый номер nби=1, 2, …, Nби каждому информационному блоку sб(nби), последовательно выделяемому из цифрового сигнала s с помощью идентификаторов принадлежности к интервалам РАД, формируют прямоугольную информативную матрицу Sи размеров Nc × Nби путем последовательного размещения друг под другом информационных блоков sб(nби) в соответствии с их порядковыми номерами nби=1,2,…, Nби, начиная с первого информационного блока sб(1); определяют, к какому из Nфк фонетических классов относится каждый блок sб(nби) матрицы Sи и, используя дополнительную информацию о параметрах речевого сигнала, содержащуюся в анализируемом блоке sб(nби) и указанную в протоколе низкоскоростного кодирования речи, устанавливают для входной реализации s и всех ее элементов идентификатор фонетического класса с номером nфк=1 для вокализованных звуков и nфк=2 для невокализованных звуков речи, обозначая информационный блок sб(nби, nфк); выделяют из информативной матрицы Sи блоки, идентификаторы которых удовлетворяют условию nфк=1, из каждого выделенного блока извлекают двоичные символы, содержащие дополнительную информацию о частоте основного тона речи и указанные в заданном протоколе низкоскоростного кодирования, составляют из них матрицу Sот, каждая строка sот которой характеризует одно значение частоты основного тона речи, преобразуют двоичные символы, содержащиеся в строке sот к десятичному формату по правилам, приведенным в протоколе низкоскоростного кодирования речи, составляют из полученных значений частоты ωот основного тона речи вектор ωот, усредняют его значения, получая величину
которая является образом входной реализации s, отличающийся тем, что выполняют распознавание протоколов низкоскоростного кодирования, применяемых для формирования цифровых информационных сигналов, по результатам распознавания протоколов выделяют цифровые информационные сигналы, сформированные с помощью известных низкоскоростных кодеров, при выявлении факта применения неизвестного низкоскоростного кодера для формирования цифрового информационного сигнала s выполнение дальнейших операций над данным сигналом прекращают; в противном случае оценивают качество речи по цифровому информационному сигналу s, сформированному с помощью известного низкоскоростного кодера, проверяют соответствие цифрового информационного сигнала требованию по качеству путем сравнения полученной оценки качества речи с его пороговым значением, транскрибирование цифрового информационного сигнала, качество которого не превышает пороговое значение, не осуществляют; присваивают порядковый номер nби=1, 2, …, Nби каждому информационному блоку sб(nби), последовательно выделяемому из цифрового сигнала s с помощью идентификаторов принадлежности к интервалам РАД, формируют прямоугольную информативную матрицу Sи размеров Nc × Nби путем последовательного размещения друг под другом информационных блоков sб(nби) в соответствии с их порядковыми номерами nби=1,2,…, Nби, начиная с первого информационного блока sб(1); определяют, к какому из Nфк фонетических классов относится каждый блок sб(nби) матрицы Sи и, используя дополнительную информацию о параметрах речевого сигнала, содержащуюся в анализируемом блоке sб(nби) и указанную в протоколе низкоскоростного кодирования речи, устанавливают для входной реализации s и всех ее элементов идентификатор фонетического класса с номером nфк=1 для вокализованных звуков и nфк=2 для невокализованных звуков речи, обозначая информационный блок sб(nби, nфк); выделяют из информативной матрицы Sи блоки, идентификаторы которых удовлетворяют условию nфк=1, из каждого выделенного блока извлекают двоичные символы, содержащие дополнительную информацию о частоте основного тона речи и указанные в заданном протоколе низкоскоростного кодирования, составляют из них матрицу Sот, каждая строка sот которой характеризует одно значение частоты основного тона речи, преобразуют двоичные символы, содержащиеся в строке sот к десятичному формату по правилам, приведенным в протоколе низкоскоростного кодирования речи, составляют из полученных значений частоты ωот основного тона речи вектор ωот, усредняют его значения, получая величину 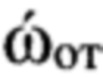 средней частоты основного тона, определяют путем сравнения значения с заранее определенными эталонными значениями частоты
средней частоты основного тона, определяют путем сравнения значения с заранее определенными эталонными значениями частоты 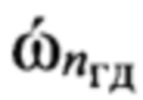 основного тона речи, к какой голосовой группе с номером nгд=1, 2, …, Nгд, где Nгд - количество голосовых групп дикторов, относится анализируемый цифровой сигнал, запоминают значение nгд, которое используют далее как идентификатор голосовой группы; формируют на основе информационного блока sб(nби, nфк) вектор признаков, который состоит из значений кепстральных коэффициентов в частотной шкале мел MFCC или других, более информативных признаков, выбираемых заранее в процессе обучения, присваивают вектору признаков выявленный идентификатор группы дикторов nгд, порядковый номер nби и идентификатор фонетического класса nфк, обозначая его d(nф, nфк nгд), формируют образ
основного тона речи, к какой голосовой группе с номером nгд=1, 2, …, Nгд, где Nгд - количество голосовых групп дикторов, относится анализируемый цифровой сигнал, запоминают значение nгд, которое используют далее как идентификатор голосовой группы; формируют на основе информационного блока sб(nби, nфк) вектор признаков, который состоит из значений кепстральных коэффициентов в частотной шкале мел MFCC или других, более информативных признаков, выбираемых заранее в процессе обучения, присваивают вектору признаков выявленный идентификатор группы дикторов nгд, порядковый номер nби и идентификатор фонетического класса nфк, обозначая его d(nф, nфк nгд), формируют образ 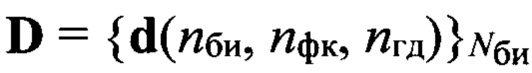 входной реализации; выделяют из заранее составленной эталонной совокупности
входной реализации; выделяют из заранее составленной эталонной совокупности 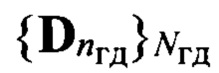 с помощью выявленного идентификатора nгд, общего для всех элементов образа D, множество
с помощью выявленного идентификатора nгд, общего для всех элементов образа D, множество 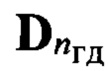 эталонных описаний фонем, характерных для nгд-й группы дикторов, из которого по идентификатору nфк выделяют подмножество {dэ(nф, nфк nгд)} эталонных описаний фонем, где nф - номер фонемы
эталонных описаний фонем, характерных для nгд-й группы дикторов, из которого по идентификатору nфк выделяют подмножество {dэ(nф, nфк nгд)} эталонных описаний фонем, где nф - номер фонемы 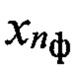 из алфавита Аф фонем объемом Nф символов, относящихся к фонетическому классу nфк и характерных для голосовой группы дикторов с номером nгд, с помощью выбранной меры близости последовательно сравнивают каждый эталонный образ dэ(nф, nфк nгд), принадлежащий выделенному подмножеству {dэ(nф, nфк nгд)} эталонных описаний фонем, с элементами образа
из алфавита Аф фонем объемом Nф символов, относящихся к фонетическому классу nфк и характерных для голосовой группы дикторов с номером nгд, с помощью выбранной меры близости последовательно сравнивают каждый эталонный образ dэ(nф, nфк nгд), принадлежащий выделенному подмножеству {dэ(nф, nфк nгд)} эталонных описаний фонем, с элементами образа 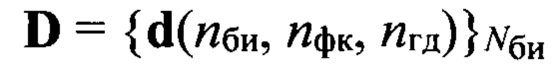 входной реализации и определяют вероятность Рф(nби, nф) соответствия вектора признаков d(nби, nфк nгд) эталонному образу dэ(nф, nфк nгд), составляя вектор Рф, принимают решение о содержании фонетической информации в анализируемой строке sб(nби), путем установления соответствия фонетического символа
входной реализации и определяют вероятность Рф(nби, nф) соответствия вектора признаков d(nби, nфк nгд) эталонному образу dэ(nф, nфк nгд), составляя вектор Рф, принимают решение о содержании фонетической информации в анализируемой строке sб(nби), путем установления соответствия фонетического символа 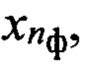 определяемого по номеру nф эталонного образа dэ(nф, nфк nгд), для которого значение Рф (nби, nф) является максимальным и больше порогового значения Рф_пор(nф), установленного на этапе обучения, анализируют все строки информативной матрицы Sи, и, учитывая номера строк и значения идентификаторов РАД, формируют последовательность фонетических знаков
определяемого по номеру nф эталонного образа dэ(nф, nфк nгд), для которого значение Рф (nби, nф) является максимальным и больше порогового значения Рф_пор(nф), установленного на этапе обучения, анализируют все строки информативной матрицы Sи, и, учитывая номера строк и значения идентификаторов РАД, формируют последовательность фонетических знаков 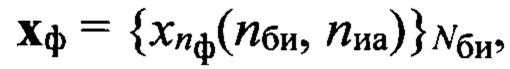 являющуюся результатом транскрибирования.
являющуюся результатом транскрибирования.
| Система помощи водителю наземного транспортного средства при обгоне | 2023 |
|
RU2831762C1 |
| US 20080219466 A1, 11.09.2008 | |||
| US 20100174547 A1, 08.07.2010 | |||
| АУДИОКОДИРОВАНИЕ | 2005 |
|
RU2335809C2 |
| СПОСОБ НИЗКОСКОРОСТНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ РЕЧЕВОГО СИГНАЛА | 2015 |
|
RU2631968C2 |

