Изобретение относится к области техники связи, в частности к обработке цифровой информации, и может быть использовано в широком классе систем передачи данных для распознавания протоколов низкоскоростного кодирования речи (НСКР) и контроля корректности применения вокодеров в цифровых системах связи.
Заявленное техническое решение расширяет арсенал средств аналогичного назначения за счет возможности распознавания протоколов НСКР с более высокой точностью в условиях воздействия помех.
Известен способ распознавания радиосигналов (см. Патент РФ 2551903 Способ распознавания радиосигналов авторов: Дворникова А.С., Дворникова С.В., опубликован 10.06.2015 г.), в котором на первом этапе из дискретизированных и квантованных отсчетов эталонных радиосигналов формируют матрицы распределения энергии на основе их фреймовых вейвлет-преобразований. Затем из них, начиная со второй строки, формируют векторы признаков путем построчной конкатенации всех вейвлет-коэффициентов. Далее элементы векторов признаков нормируют и вычисляют их параметры. При этом в качестве параметров определяют усредненную величину нормированных амплитудных значений элементов векторов признаков, а решение принимают по результатам вычисления разностей значений параметров распознаваемого радиосигнала и эталонных радиосигналов. Распознаваемый радиосигнал считают инцидентным эталонному радиосигналу, модуль разницы параметров векторов признаков с которым будет минимальным.
Недостатком способа является недостаточная точность распознавания протоколов НСКР.
Известен способ распознавания низкоскоростного кодирования (см. Патент РФ 2610285 Способ распознавания протоколов низкоскоростного кодирования авторов: Аладинского В.А., Кузьминского С.В., Смирнова П.Л., Чубатого Д.Н., опубликован 08.02.2016 г.), заключающийся в том, что принимают бинарный цифровой информационный поток Y в течение интервала времени ΔT, на основе принятого потока Y формируют нормированную автокорреляционную функцию А, по регулярным с равными интервалами Δτ экстремумам автокорреляционной функции А принимают решение о наличии блочной структуры в цифровом информационном потоке Y, по интервалам между экстремумами автокорреляционной функции А делят цифровой информационный поток Y на информационные блоки объемом Nб бит каждый, последовательно присваивают информационным блокам порядковые номера k=1,2,…, K, начиная с первого информационного блока, формируют прямоугольную информационную матрицу, YK×L, L=Nб, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1,2,…, K, формируют последовательность прямоугольных матриц  , z=1,2,…, Z; Z=Nб-2, содержащих по три соседних столбца прямоугольной информационной матрицы YK×L, где текущий номер z прямоугольной матрицы определяется номером столбца матрицы YK×L, являющимся первым столбцом матрицы , по каждой из матриц вычисляют коэффициент избыточности ϕz, размерности L, на основе полученного набора коэффициентов избыточности формируют измеренный вектор коэффициентов избыточности ϕz путем последовательного их размещения в соответствии с порядковыми номерами z, формируют эталонные вектора коэффициентов избыточности ϕzj эт размерности L известных протоколов НСКР, на основе эталонных векторов коэффициентов избыточности ϕLj эт формируют квадратные эталонные матрицы ФLj эт, j=1,2,…, J, поэлементно сравнивают измеренный вектор коэффициентов избыточности ϕL, со строками
, z=1,2,…, Z; Z=Nб-2, содержащих по три соседних столбца прямоугольной информационной матрицы YK×L, где текущий номер z прямоугольной матрицы определяется номером столбца матрицы YK×L, являющимся первым столбцом матрицы , по каждой из матриц вычисляют коэффициент избыточности ϕz, размерности L, на основе полученного набора коэффициентов избыточности формируют измеренный вектор коэффициентов избыточности ϕz путем последовательного их размещения в соответствии с порядковыми номерами z, формируют эталонные вектора коэффициентов избыточности ϕzj эт размерности L известных протоколов НСКР, на основе эталонных векторов коэффициентов избыточности ϕLj эт формируют квадратные эталонные матрицы ФLj эт, j=1,2,…, J, поэлементно сравнивают измеренный вектор коэффициентов избыточности ϕL, со строками  , всех J квадратных эталонных матриц ФLj эт, определяют отклонения
, всех J квадратных эталонных матриц ФLj эт, определяют отклонения 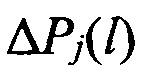 между измеренным вектором коэффициентов избыточности ϕL, и строками всех J квадратных эталонных матриц ФLj эт, принимают решение в пользу j-го протокола НСКР, для которого обеспечивается минимальное и меньше заданного порога R отклонение
между измеренным вектором коэффициентов избыточности ϕL, и строками всех J квадратных эталонных матриц ФLj эт, принимают решение в пользу j-го протокола НСКР, для которого обеспечивается минимальное и меньше заданного порога R отклонение 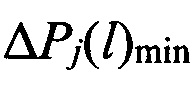 измеренного вектора ϕL от
измеренного вектора ϕL от 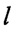 -й строки j-й квадратной эталонной матрицы ФLj эт.
-й строки j-й квадратной эталонной матрицы ФLj эт.
Данный способ при отсутствии помех в цифровом информационном потоке Y обладает высокой вероятностью правильного распознавания протоколов НСКР. Недостатком прототипа является снижение вероятности правильного распознавания протоколов НСКР при появлении одиночных и групповых битовых ошибок в цифровом информационном потоке Y, которые характерны для каналов радиосвязи.
Появление битовых ошибок в цифровом информационном потоке Y носит случайный характер. Поэтому влияние даже одной битовой ошибки в матрице YK×L на эффективность распознавания НСКР в способе-аналоге существенно. Очевидно, что имеющаяся одна битовая ошибка в z-м столбце матрицы YKxL появится в трех прямоугольных матрицах 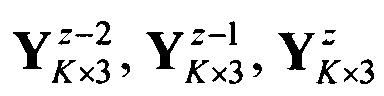 , в которые входит z-й столбец, что приведет к искажениям соответствующих им вычисленных значений коэффициентов избыточности ϕz-2, ϕz-1, ϕz. Последнее приводит к троекратному учету одного и того же ошибочно принятого бита при формировании измеренного вектора ϕL, и, как следствие, к снижению вероятности распознавания протоколов НСКР. Кроме того, аналог требует значительных вычислительных затрат при своей реализации, что определяется троекратным использованием столбцов матрицы YKxL для вычисления признаков распознавания.
, в которые входит z-й столбец, что приведет к искажениям соответствующих им вычисленных значений коэффициентов избыточности ϕz-2, ϕz-1, ϕz. Последнее приводит к троекратному учету одного и того же ошибочно принятого бита при формировании измеренного вектора ϕL, и, как следствие, к снижению вероятности распознавания протоколов НСКР. Кроме того, аналог требует значительных вычислительных затрат при своей реализации, что определяется троекратным использованием столбцов матрицы YKxL для вычисления признаков распознавания.
Наиболее близким по технической сущности к заявленному является способ декодирования циклического помехоустойчивого кода (см. Тимофеев Д.И., Тавалинский Д.А., Чубатый Д.Н. Анализ параметров низкоскоростных кодеров речи в условиях структурной и параметрической неопределенности // Наукоемкие технологии, №8, 2011. С. 4-9), заключающийся в том, что принимают цифровой информационный поток Y в течение интервала времени ΔТ, на основе Y формируют нормированную автокорреляционную функцию А, по регулярным с равными интервалами Δt экстремумам автокорреляционной функции А принимают решение о наличии блочной структуры в информационном потоке Y, по интервалам между экстремумами автокорреляционной функции А делят информационный поток Y на информационные блоки объемом Nб бит каждый, последовательно присваивают информационным блокам порядковые номера k=1,2,…, K, начиная с первого информационного блока, формируют прямоугольную информационную матрицу YK×L, L=Nб; строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1,2,…, K, формируют последовательность прямоугольных матриц , z=1,2,…, Z; Z=Nб-2, содержащих по три соседних столбца прямоугольной информационной матрицы YK×L, где текущий номер z прямоугольной матрицы определяется номером столбца матрицы YK×L, являющийся первым столбцом матрицы , по каждой из матриц вычисляют коэффициент избыточности ϕz, на основе полученного набора коэффициентов избыточности формируют вектор измеренных коэффициентов избыточности ϕz путем последовательного их размещения в соответствии с порядковыми номерами z, формируют эталонные векторы коэффициентов избыточности ϕzj эт известных протоколов НСКР, вектор измеренных коэффициентов избыточности ϕz сравнивают с эталонными векторами коэффициентов избыточности , ϕzj эт j=1,2,…, J, известных протоколов НСКР.
Данный способ позволяет распознавать протоколы НСКР.
Однако, недостатком прототипа является относительно невысокая точность распознавания протоколов НСКР при отсутствии Nп символов в первом блоке цифрового информационного потока Y. Вероятность отсутствия символов в первом блоке цифрового информационного потока Y определяется выражением вида
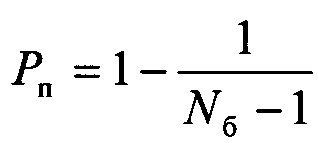 .
.
При выполнении условия 0≤Nп<Nб в информационной матрице YK×L наблюдается сдвиг столбцов влево на величину 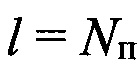 , что вызывает сдвиг значений вектора коэффициентов избыточности ϕz на величину
, что вызывает сдвиг значений вектора коэффициентов избыточности ϕz на величину 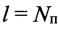 . В этом случае в векторе ϕz будут отсутствовать значения коэффициента избыточности ϕz с номерами z=Nп, Nп+1, а также добавляются значения коэффициента избыточности ϕz с номерами z=Nб-1, Nб. Значения Nб цифровых потоков, формируемых вокодерами, которые разработаны для радиостанций диапазона ВЧ, могут составлять 45, 48, 54, 60, 64, 66, 81 или 96 бит. Таким образом, высока вероятность искажения значений в векторе коэффициентов избыточности ϕz, что приводит к ошибочным решениям в способе-прототипе. Дополнительно точностные характеристики прототипа снижаются из-за некорректного сокращения длины измеренного и эталонного векторов ϕz и ϕzj эт соответственно на два элемента. Последнее приводит к неполному использованию информации о структуре принятого сигнала, и как следствие, к снижению точности распознавания протоколов НСКР.
. В этом случае в векторе ϕz будут отсутствовать значения коэффициента избыточности ϕz с номерами z=Nп, Nп+1, а также добавляются значения коэффициента избыточности ϕz с номерами z=Nб-1, Nб. Значения Nб цифровых потоков, формируемых вокодерами, которые разработаны для радиостанций диапазона ВЧ, могут составлять 45, 48, 54, 60, 64, 66, 81 или 96 бит. Таким образом, высока вероятность искажения значений в векторе коэффициентов избыточности ϕz, что приводит к ошибочным решениям в способе-прототипе. Дополнительно точностные характеристики прототипа снижаются из-за некорректного сокращения длины измеренного и эталонного векторов ϕz и ϕzj эт соответственно на два элемента. Последнее приводит к неполному использованию информации о структуре принятого сигнала, и как следствие, к снижению точности распознавания протоколов НСКР.
Кроме того, реализация прототипа предполагает большой объем вычислений на формирование вектора измеренных коэффициентов избыточности, что снижает его быстродействия.
Целью заявленного технического решения является разработка способа распознавания протоколов НСКР, обеспечивающего повышение точности распознавания в условиях воздействия помех и его быстродействие.
Поставленная цель достигается тем, что в известном способе распознавания протоколов НСКР, включающем прием цифрового информационного потока Y в течение интервала времени ΔT, формирование нормированной автокорреляционной функции А на основе принятого потока Y, принятие решения о наличии блочной структуры в цифровом информационном потоке Y по регулярным с равными интервалами Δτ экстремумам автокорреляционной функции А, по интервалам между экстремумами автокорреляционной функции А деление цифрового информационного потока Y на информационные блоки объемом Nб бит каждый, последовательное присвоение информационным блокам порядкового номера k=1,2,…, K, начиная с первого информационного блока, формирование прямоугольной информационной матрицы YK×L, L=Nб, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1,2,…, K, поочередно выделяют столбцы 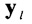 , из матрицы YKxL с номерами
, из матрицы YKxL с номерами 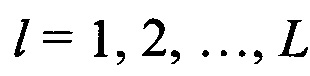 , вычисляют значения математического ожидания
, вычисляют значения математического ожидания 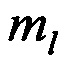 появления определенных импульсов по каждому столбцу
появления определенных импульсов по каждому столбцу 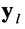 , информационной матрицы YKxL, формируют вектор измеренных значений математического ожидания
, информационной матрицы YKxL, формируют вектор измеренных значений математического ожидания 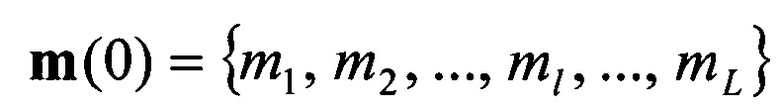 последовательным размещением полученных значений математического ожидания
последовательным размещением полученных значений математического ожидания 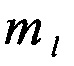 в соответствии с их порядковыми номерами
в соответствии с их порядковыми номерами 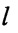 , формируют набор М векторов m
, формируют набор М векторов m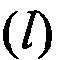 значений математического ожидания
значений математического ожидания 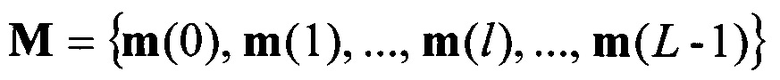 на основе сформированного вектора значений математического ожидания m(0) путем последовательного циркулярного сдвига его значений на величину
на основе сформированного вектора значений математического ожидания m(0) путем последовательного циркулярного сдвига его значений на величину 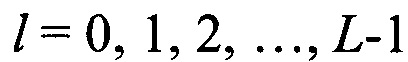 , формируют эталонные векторы значений математического ожидания mjэт, j=1,2,… J, по каждому цифровому информационному потоку Yjэт, соответствующем j-му известному протоколу НСКР, последовательно сравнивают каждый вектор значений математического ожидания
, формируют эталонные векторы значений математического ожидания mjэт, j=1,2,… J, по каждому цифровому информационному потоку Yjэт, соответствующем j-му известному протоколу НСКР, последовательно сравнивают каждый вектор значений математического ожидания 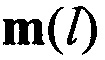 оцениваемого протокола НСКР с эталонными векторами значений математического ожидания mjэт, j=1,2,… J, вычисляют значения вероятности правильного распознавания
оцениваемого протокола НСКР с эталонными векторами значений математического ожидания mjэт, j=1,2,… J, вычисляют значения вероятности правильного распознавания 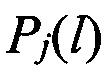 j-го протокола НСКР по каждому -му вектору значений математического ожидания , принимают решение в пользу j-го протокола НСКР, для которого обеспечивается максимальное значение вероятности правильного распознавания
j-го протокола НСКР по каждому -му вектору значений математического ожидания , принимают решение в пользу j-го протокола НСКР, для которого обеспечивается максимальное значение вероятности правильного распознавания 
Благодаря новой совокупности существенных признаков в заявляемом способе повышение вероятности правильного распознавания протоколов НСКР достигается благодаря формированию вектора измеренных значений математического ожидания m(0), что исключило многократное влияние одной и той же битовой ошибки на результаты распознавания.
Уменьшение размерности исходных данных для формирования вектора измеренных значений математического ожидания позволило достигнуть повышение быстродействия предлагаемого способа.
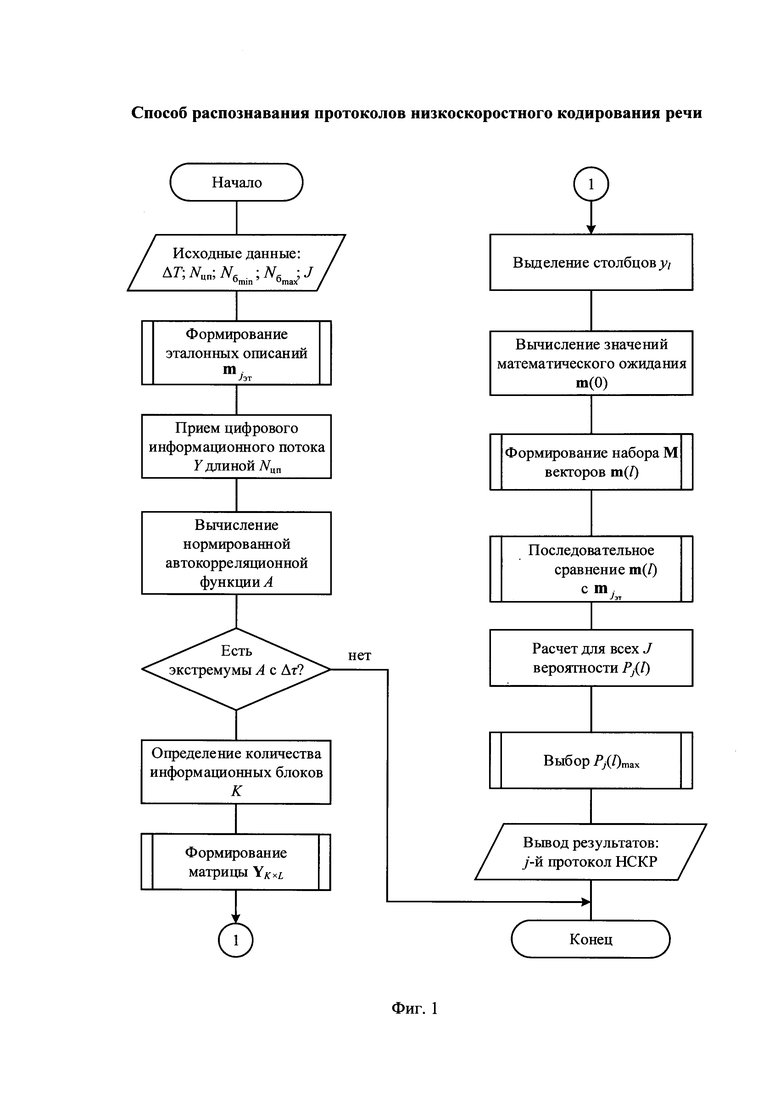
Заявляемый способ поясняется чертежами, на которых:
на фиг. 1 - обобщенный алгоритм распознавания протоколов НСКР;
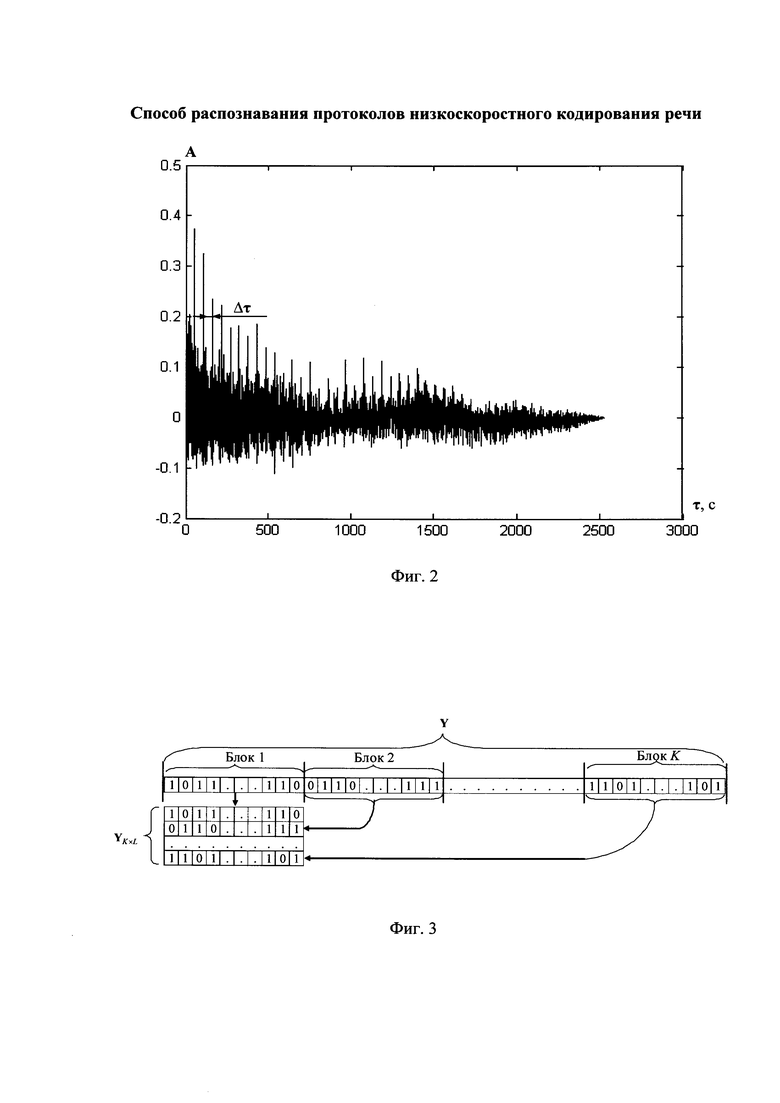
на фиг. 2 - внешний вид автокорреляционной функции информационного потока Y;
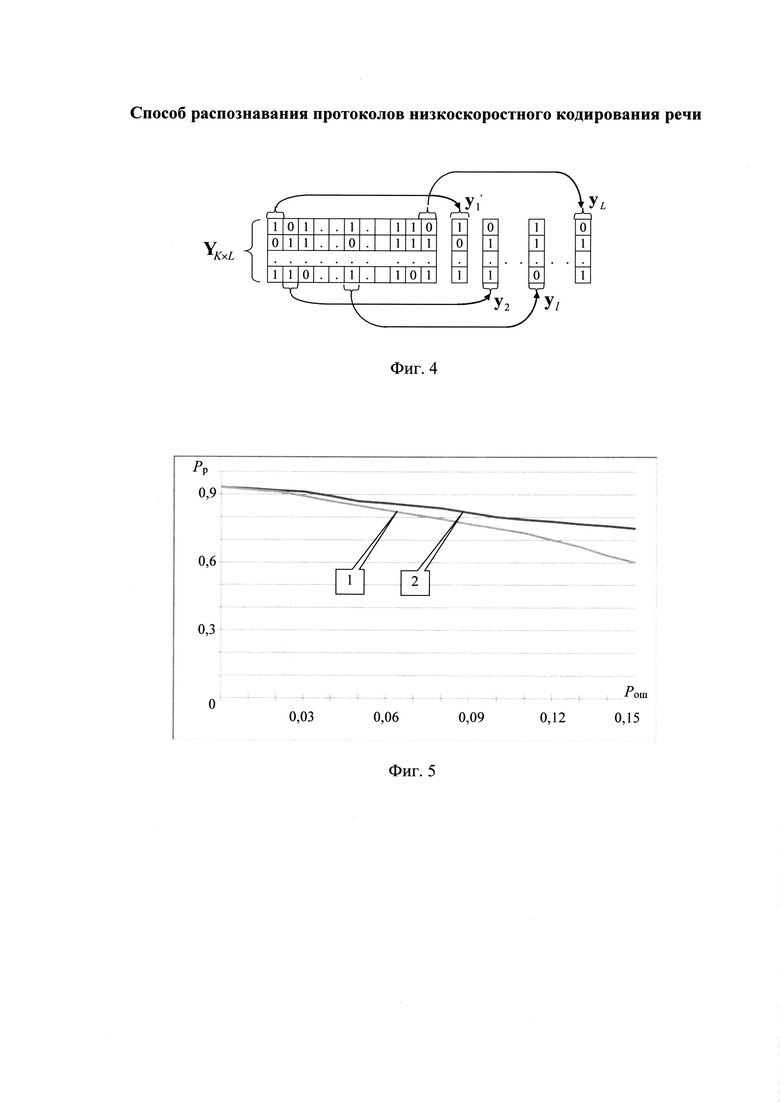
на фиг. 3 - порядок формирования информационной матрицы YKxL;
на фиг. 4 - порядок выделения столбцов 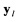 информационной матрицы YKxL;
информационной матрицы YKxL;
на фиг. 5 - результаты имитационного моделирования;
на фиг. 6 - обобщенная структурная схема устройства распознавания протоколов НСКР.
Анализ использования современных низкоскоростных кодеров речи в системах связи свидетельствует о том, что, несмотря на стремление международного союза электросвязи перейти к использованию стандартных кодеров, зачастую разрабатывается новый алгоритм сжатия и соответствующий ему протокол НСКР, что приводит к многообразию низкоскоростных кодеков речи (см. Бондаренко М.Ф., Работягов А.В., Щепковский С.В. Современные методы кодирования речевого сигнала. - Харьков: ХНУРЭ Бионика интеллекта, №2 (69), 2008). В условиях структурной и параметрической неопределенности, в связи с ростом количества протоколов НСКР, усложняется задача их распознавания, решение которой необходимо для последующего декодирования речевых сигналов. Эта задача еще более усугубляется сложной сигнально-помеховой обстановкой в ВЧ-диапазоне.
В силу того, что различные кодеры речевых сигналов формируют различающиеся структуры блоков цифровых потоков (ЦП), анализ последних состоит в определении количества бит в одном из них и выявлении структуры блока ЦП на основе анализа условных вероятностей переходов значений параметра от блока к блоку на всей длине окна линейного предсказания.
В вокодерах, используемых в зарубежных радиостанциях диапазона ВЧ, реализованы - метод кодирования (МК) с десятью коэффициентами линейного предсказания (ЛП) LPC-10 (Linear Predictive Coding), МК с ЛП и смешанным возбуждением MELP (Mixed Excitation Linear Prediction), МК со смешанным многополосным возбуждением ММВБ (Mixed-Multiband Excitation). Основными параметрами ЦП являются: скорость Ввок ЦП (600, 800, 1200 или 2400 бит/с), количество Nб бит в одном информационном блоке (длина информационного блока) и длительность tб его передачи. Последнюю задают на этапе разработки вокодера (см. Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония. Учебное пособие для вузов. - М.: Радио и связь, 2003. - 144 с). Скорость Ввок выходных ЦП связана с параметрами Nб и tб выражением Bвок = Nб/tб, из которого следует Nб = Ввок⋅tб (см. Аладинский В.А., Кузьминский С.В. Анализ цифровых потоков на выходах вокодеров, применяемых на зарубежных линиях радиосвязи диапазона высоких частот.- М.: Успехи современной радиоэлектроники. №7, 2015. С.73-76.). Длительность одного речевого сообщения определяют по формуле ΔT = K⋅tб.
Положительный эффект в предлагаемом способе достигается за счет уменьшения размерности исходных данных, используемых для формирования векторов измеренных и эталонных значений математического ожидания и mjэт соответственно, и представляемых в виде последовательности столбцов 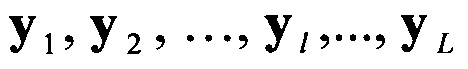 матрицы YKxL. В результате битовые ошибки оказывают влияние на результаты только по одному разу каждая. Влияние сдвига в строках информационной матрицы YKxL (из-за отсутствия Nп символов в первом блоке цифрового информационного потока Y) устраняется путем формирования набора измеренных векторов значений математического ожидания
матрицы YKxL. В результате битовые ошибки оказывают влияние на результаты только по одному разу каждая. Влияние сдвига в строках информационной матрицы YKxL (из-за отсутствия Nп символов в первом блоке цифрового информационного потока Y) устраняется путем формирования набора измеренных векторов значений математического ожидания 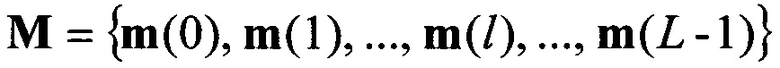 последовательным циркулярным сдвигом значений вектора m(0) на величину
последовательным циркулярным сдвигом значений вектора m(0) на величину 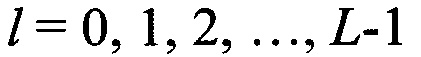 и сравнением всех элементов этого набора.
и сравнением всех элементов этого набора.
Реализация заявленного способа может быть осуществлена следующим образом (см. фиг. 1). На подготовительном этапе рассчитывают эталонные векторы значений математического ожидания mjэт. Для лучшего понимания данная операция рассмотрена после описания действия по формированию измеренного вектора математических ожиданий m(0).
В процессе работы принимают бинарный цифровой информационный поток Y длиной Nцп бит, количество которых определяют на основе выражения

После этого вычисляют нормированную автокорреляционную функцию А, которая характеризует линейную зависимость исходной последовательности Y от последовательности Y(τ), сдвинутой циркулярно на τ=1,2,…, Nцп-1 бит по отношению к Y. Нормированная автокорреляционная функция реального речевого сигнала, вид которой представлен на фиг. 2, имеет явно выраженные локальные максимумы, расположенные с периодичностью Δτ. Следовательно, Δτ соответствует длине информационного блока. Наличие локальных максимумов автокорреляционной функции, расположенных с периодом Δτ, объясняется следующим. Параметры речевого сигнала расположены внутри информационного блока строго в определенном месте. При сдвигах Δτ, кратных длине информационного блока, значение АКФ будет наибольшим. Искомой автокорреляционной функцией (см. фиг. 2) считают совокупность значений вида
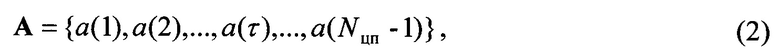 где α(τ)=c(τ)/D(Y) - коэффициент корреляции; с(τ) - коэффициент ковариации; D(Y) - дисперсия цифрового информационного потока Y.
где α(τ)=c(τ)/D(Y) - коэффициент корреляции; с(τ) - коэффициент ковариации; D(Y) - дисперсия цифрового информационного потока Y.
Результатом корреляционного анализа является обнаружение периодической составляющей в цифровом информационном потоке Y. При этом значение периодичности равно длине информационного блока речевого сигнала.
По регулярным с равными интервалами Δτ экстремумам нормированной автокорреляционной функции А принимают решение о наличии блочной структуры в информационном потоке Y. Отсутствие экстремумов нормированной автокорреляционной функции А с равными интервалами Δτ свидетельствует о том, что цифровой информационный поток Y не содержит речевое сообщение, а выполнение его анализа завершается.
При наличии экстремумов нормированной автокорреляционной функции А с равными интервалами Δτ вычисляют количество информационных блоков, содержащихся в цифровом информационном потоке Y следующим образом:

На следующем этапе по интервалам Δτ между экстремумами нормированной автокорреляционной функции А делят информационный поток Y на информационные блоки объемом Nб бит каждый (см. фиг. 3). Последовательно присваивают информационным блокам порядковые номера k=1,2,…, K, начиная с первого информационного блока. Формируют прямоугольную информационную матрицу YKxL, L=Nб, (см. фиг. 3), строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1,2,…, K.
Далее поочередно выделяют столбцы 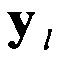 из информационной матрицы YKxL с номерами
из информационной матрицы YKxL с номерами 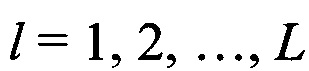 (см. фиг. 4). По совокупности элементов каждого столбца вычисляют математическое ожидание (МО) их появления.
(см. фиг. 4). По совокупности элементов каждого столбца вычисляют математическое ожидание (МО) их появления.
В общем виде МО 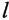 -го столбца
-го столбца 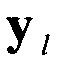 находят по известной формуле (см. Вентцель Е.С., Овчаров Л.А. Теория вероятностей и ее инженерные приложения. - М: Наука, 1988. - 480 с. - ISBN 5-02-013748-0):
находят по известной формуле (см. Вентцель Е.С., Овчаров Л.А. Теория вероятностей и ее инженерные приложения. - М: Наука, 1988. - 480 с. - ISBN 5-02-013748-0):
 где
где  - вероятность появления i-го значения символа в
- вероятность появления i-го значения символа в  столбце
столбце 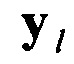 , i=1,2, …, I. В связи с тем, что цифровой поток Y является бинарным (т.е. I=2, а значения символов: 1 или 0), тогда из (4) имеем:
, i=1,2, …, I. В связи с тем, что цифровой поток Y является бинарным (т.е. I=2, а значения символов: 1 или 0), тогда из (4) имеем:

Вероятность появления значения 1 в 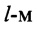 столбце
столбце 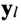 вычисляется по формуле:
вычисляется по формуле:

где  - количество символов со значением 1 в
- количество символов со значением 1 в 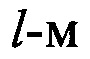 столбце
столбце 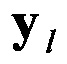 .
.
В свою очередь, при формировании эталонных векторов значений математического ожидания 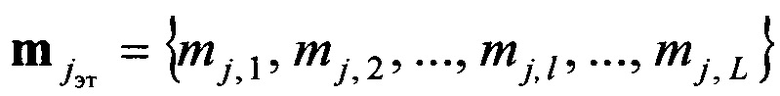
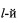 элемент эталонного вектора mjэт j-ого класса определяют из выражения
элемент эталонного вектора mjэт j-ого класса определяют из выражения

где 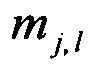 -
- 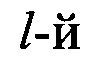 элемент w-й реализации обучающей выборки j-го класса, w=1,2,…, W, w - порядковый номер реализации обучающей выборки; W - объем обучающей выборки.
элемент w-й реализации обучающей выборки j-го класса, w=1,2,…, W, w - порядковый номер реализации обучающей выборки; W - объем обучающей выборки.
На следующем этапе вычисляют значение вероятности правильного распознавания 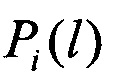 j-го протокола НСКР по каждому
j-го протокола НСКР по каждому 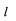 -вектору значений математического ожидания
-вектору значений математического ожидания 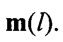 Для рассматриваемого случая J>2 используют следующее выражение вероятности распознавания (см. Ту Дж., Гонсалес Р. Принципы распознавания образов / Пер. с англ. - М.: Мир, 1978, - 411 с.)
Для рассматриваемого случая J>2 используют следующее выражение вероятности распознавания (см. Ту Дж., Гонсалес Р. Принципы распознавания образов / Пер. с англ. - М.: Мир, 1978, - 411 с.)

где рj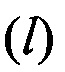 - плотность распределения j-класса. Обычно плотность
- плотность распределения j-класса. Обычно плотность 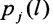 описывают нормальным законом распределения (ЗР). Выбор последнего является приемлемым допущением и единственным вариантом, при котором обеспечивается анализ многомерного ЗР. Нормальная плотность распределения, описываемая многомерным набором признаков
описывают нормальным законом распределения (ЗР). Выбор последнего является приемлемым допущением и единственным вариантом, при котором обеспечивается анализ многомерного ЗР. Нормальная плотность распределения, описываемая многомерным набором признаков  принадлежащая j-му классу, имеет вид (см. Ту Дж., Гонсалес Р. Принципы распознавания образов / Пер. с англ. - М.: Мир, 1978, - 411 с.)
принадлежащая j-му классу, имеет вид (см. Ту Дж., Гонсалес Р. Принципы распознавания образов / Пер. с англ. - М.: Мир, 1978, - 411 с.) 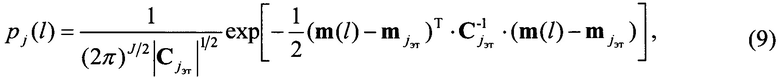
где 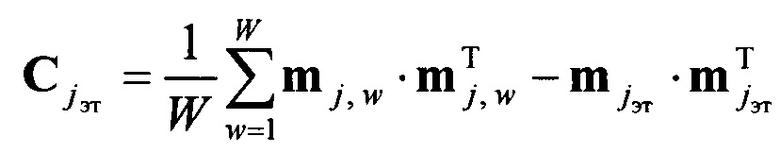 - усредненная ковариационная матрица набора эталонных векторов значений математического ожидания mjэт; w=1,2,…, W, w - порядковый номер реализации обучающей выборки; W - объем обучающей выборки;
- усредненная ковариационная матрица набора эталонных векторов значений математического ожидания mjэт; w=1,2,…, W, w - порядковый номер реализации обучающей выборки; W - объем обучающей выборки; 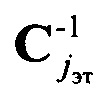 - матрица, обратная
- матрица, обратная 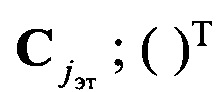 - математическая операция транспонирования.
- математическая операция транспонирования.
По полученной совокупности значений вероятностей распознавания 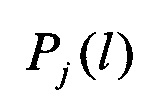 принимают решение в пользу j-го класса, для которого значение вероятности распознавания
принимают решение в пользу j-го класса, для которого значение вероятности распознавания 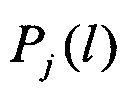 является наибольшим
является наибольшим

Кроме того, выражение (10) позволяет определить вероятность правильного распознавания протокола НСКР: 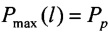 .
.
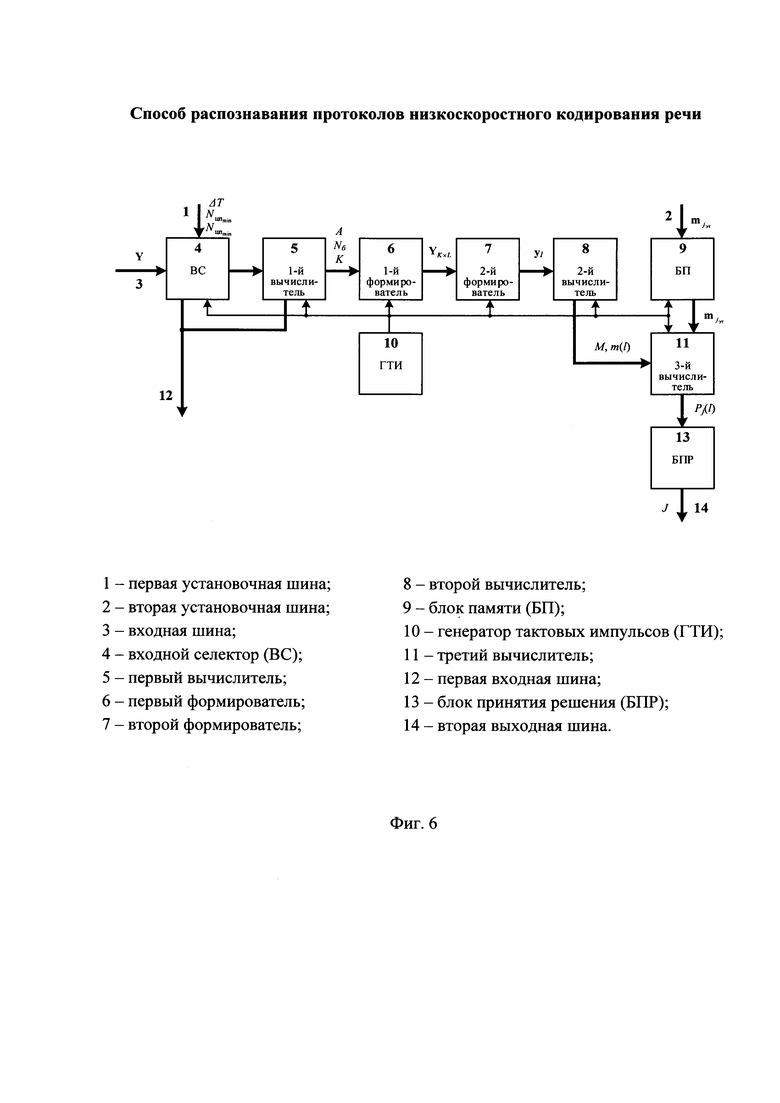
Имитационное моделирование с использованием цифровых информационных потоков, полученных от вокодеров LPC-10-2400 (STANAG 4197) и MELPe-2400 (STANAG 4591) показало следующее (см. фиг. 5). При отсутствии битовых ошибок в цифровом информационном потоке Y вероятности Рр правильного распознавания протоколов НСКР для заявленного способа распознавания и прототипа примерно равны (Рр ≈ 0,93). При увеличении количества ошибок в цифровом информационном потоке Y, определяемое вероятностью появления ошибки Рош, наблюдается сравнительно более высокое значение вероятности Рр правильного распознавания протоколов НСКР для предлагаемого технического решения (см. фиг. 5, кривая 2). Последнее свидетельствует о его более высокой помехоустойчивости по сравнению с прототипом при прочих равных условиях. В предельном случае, когда еще возможно восстановление речевого сообщения (Рош = 0,15), выигрыш по вероятности правильного распознавания протоколов НСКР Рр при использовании предлагаемого способа составляет ~ 0,14.
Кроме того, предлагаемый способ обладает более высоким быстродействием благодаря уменьшению объема вычислений. В прототипе в качестве исходных данных используют коэффициенты избыточности ϕz, вычисляемые из дополнительно сформированных z=Nб-2 прямоугольных матриц. В предлагаемом способе в качестве исходных данных выступают столбцы информационной матрицы YKxL, на основе которых вычисляют МО. В результате достигается уменьшение объема рассчитываемых данных в три раза.
Предлагаемый способ распознавания протоколов НСКР может быть реализован с помощью устройства, обобщенная структурная схема которого приведена на фиг. 6. Устройство содержит последовательно соединенные входной селектор 4, предназначенный для регистрации (запоминания заданного объема входного цифрового информационного потока Y), первый вычислитель 5, предназначенный для вычисления нормированной автокорреляционной функции А в соответствии с (2) и на ее основе определения значений Nб и K (выражения (1) и (3) соответственно), первый формирователь 6, предназначенный для формирования информационной матрицы принятого сигнала YKxL, второй формирователь 7, предназначенный для формирования последовательности столбцов 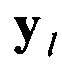 , второй вычислитель 8, предназначенный для вычисления значений математического ожидания
, второй вычислитель 8, предназначенный для вычисления значений математического ожидания 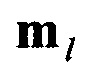 , формирования набора М векторов измеренных значений МО
, формирования набора М векторов измеренных значений МО 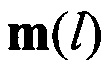 (выражения (4)-(6)), третий вычислитель 11, предназначенный для вычисления значений вероятности правильного распознавания
(выражения (4)-(6)), третий вычислитель 11, предназначенный для вычисления значений вероятности правильного распознавания 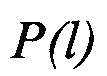 на основе поэлементного сравнения векторов
на основе поэлементного сравнения векторов 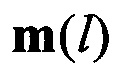 значений математического ожидания из набора М с эталонными значениями векторов математического ожидания mjэт J известных протоколов НСКР в соответствии с (8)-(10), и блок принятия решения 13, предназначенный для определения принадлежности анализируемого цифрового информационного потока Y к наиболее вероятному j-му протоколу НСКР. Кроме того, устройство содержит первый блок памяти 9 и генератор тактовых импульсов 10.
значений математического ожидания из набора М с эталонными значениями векторов математического ожидания mjэт J известных протоколов НСКР в соответствии с (8)-(10), и блок принятия решения 13, предназначенный для определения принадлежности анализируемого цифрового информационного потока Y к наиболее вероятному j-му протоколу НСКР. Кроме того, устройство содержит первый блок памяти 9 и генератор тактовых импульсов 10.
На подготовительном этапе по первой установочной шине 1 задают необходимый минимальный и максимальный объемы выборки сигнала 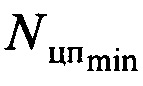 и
и 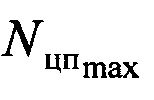 . По второй установочной шине 2 поступают значения эталонных векторов математического ожидания mjэт для всех J известных протоколов НСКР, расчет которых осуществляют в соответствии с (7) на подготовительном этапе и далее хранят в блоке 9.
. По второй установочной шине 2 поступают значения эталонных векторов математического ожидания mjэт для всех J известных протоколов НСКР, расчет которых осуществляют в соответствии с (7) на подготовительном этапе и далее хранят в блоке 9.
В процессе работы устройства (см. фиг. 6) по входной шине 3 на вход блока 4 поступает цифровой информационный поток Y. В функции блока 4 входит его запоминание в объеме 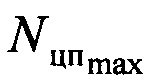 , но не менее чем
, но не менее чем 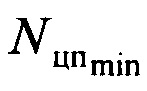 . Эти значения задаются по шине 1. В противном случае на второй группе его выходов (первой выходной шине устройства 12) формируется сигнал об окончании работы устройства и необходимости перейти к анализу другой информационной последовательности.
. Эти значения задаются по шине 1. В противном случае на второй группе его выходов (первой выходной шине устройства 12) формируется сигнал об окончании работы устройства и необходимости перейти к анализу другой информационной последовательности.
Запомненная выборка цифрового информационного потока Y под воздействием тактовых импульсов блока 10 с выхода блока 4 поступает на группу информационных входов первого вычислителя 5. В функции блока 5 входит расчет нормированной автокорреляционной функции А, ее анализ с целью обнаружения регулярных с равными интервалами Δτ экстремумов автокорреляционной функции А, разбиение принятого цифрового информационного потока Y на информационные блоки по Nб бит каждый по их числу в интервалах между экстремумами нормированной автокорреляционной А. С первой группы информационных выходов блока 5 поблочно в Nб бит информационная последовательность Y поступает на группу информационных входов первого формирователя 6. В противном случае, когда в блоке 5 не обнаружены регулярные с равными интервалами Δτ экстремумы функции А, на второй группе его информационных выходов формируется сигнал о завершении анализа принятой информационной последовательности, который поступает на первую выходную шину 12 устройства.
В блоке 6 осуществляют формирование информационной матрицы YKxL путем последовательной поблочной записи цифрового информационного потока Y в соответствии с фиг. 3. Значение информационной матрицы YKxL в параллельном коде далее поступает на группу информационных входов второго формирователя 7. В блоке 7 осуществляют последовательное деление информационной матрицы YKxL на последовательность из L столбцов  (см. фиг. 4).
(см. фиг. 4).
Полученные значения столбцов 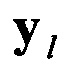 последовательно поступают на группу информационных входов вычислителя 8.
последовательно поступают на группу информационных входов вычислителя 8.
В блоке 8, по мере поступления столбцов , осуществляют расчет значений математического ожидания т, в соответствии с выражениями (4) - (6). Далее из полученных значений m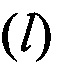 в блоке 8 формируют вектор значений МО m(0). После этого, благодаря последовательному циркулярному сдвигу его значений на величину
в блоке 8 формируют вектор значений МО m(0). После этого, благодаря последовательному циркулярному сдвигу его значений на величину 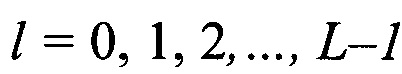 , формируют набор
, формируют набор 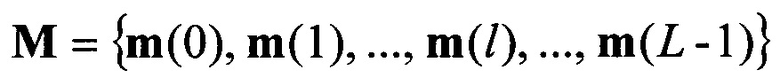 векторов математических ожиданий анализируемого цифрового потока Y.
векторов математических ожиданий анализируемого цифрового потока Y.
Найденные значения совокупности М векторов 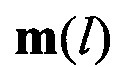 поступают на вторую группу информационных входов третьего вычислителя 11. На вторую группу его информационных входов поступают значения эталонных векторов mjэт МО для всех J известных протоколов НСКР. Поступление
поступают на вторую группу информационных входов третьего вычислителя 11. На вторую группу его информационных входов поступают значения эталонных векторов mjэт МО для всех J известных протоколов НСКР. Поступление 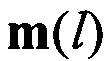 и mjэт на входы блока 11 синхронизируется импульсами блока 10. В функции блока 11 входит расчет значений вероятности правильного распознавания Рj
и mjэт на входы блока 11 синхронизируется импульсами блока 10. В функции блока 11 входит расчет значений вероятности правильного распознавания Рj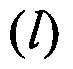 для всех J протоколов НСКР по каждому
для всех J протоколов НСКР по каждому 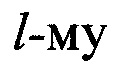 вектору значений МО
вектору значений МО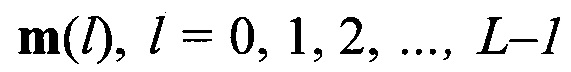 в соответствии с выражениями (8)-(10).
в соответствии с выражениями (8)-(10).
Полученные в блоке 11 значения 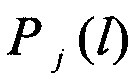 далее поступают на группу информационных входов блока принятия решения 13. В функции последнего входит поиск максимального значения max
далее поступают на группу информационных входов блока принятия решения 13. В функции последнего входит поиск максимального значения max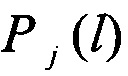 из всей совокупности L×J полученных в блоке 11 значений вероятностей
из всей совокупности L×J полученных в блоке 11 значений вероятностей 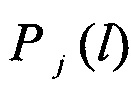 . В качестве идентифицированного протокола НСКР принимают j-й протокол, соответствующий max
. В качестве идентифицированного протокола НСКР принимают j-й протокол, соответствующий max 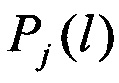 .
.
Реализация элементов устройства распознавания протоколов НСКР известна. Входной селектор 4, первый и второй формирователи 6 и 7 соответственно, блок памяти 9 могут быть реализованы на микросхемах памяти (см. Большие интегральные схемы запоминающих устройств: Справочник / А.Ю. Гордонов и др.: Под ред. А.Ю. Гордонова и Ю.Н. Дьяконова. - М.: Радио и связь. 1990, - 288 с.). Первый, второй и третий вычислители 5, 8 и 11 могут быть реализованы на микропроцессорах с достаточным быстродействием (см. Шевкопляс Б.В. Микропроцессорные структуры. Инженерные решения: Справочник. 2-е изд., перераб. и доп. - М.: Радио и связь. 1990, - 512 с.). Блок принятия решения 15 представляет из себя блок сравнения, который может быть реализован на элементарной логике микросхем ТТЛ.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ распознавания протоколов низкоскоростного кодирования | 2016 |
|
RU2610285C1 |
| Способ автоматической оценки качества речевых сигналов с низкоскоростным кодированием | 2021 |
|
RU2757860C1 |
| Способ распознавания новых протоколов низкоскоростного кодирования | 2020 |
|
RU2748935C1 |
| Способ селекции цифровых потоков | 2018 |
|
RU2701465C1 |
| СПОСОБ ПЕРЕДАЧИ СООБЩЕНИЙ В СИСТЕМАХ С ОБРАТНОЙ СВЯЗЬЮ И ГИБРИДНЫМ АВТОМАТИЧЕСКИМ ЗАПРОСОМ НА ПОВТОРЕНИЕ | 2022 |
|
RU2786023C1 |
| СПОСОБ ГРАВИМЕТРИЧЕСКОЙ СЪЕМКИ АКВАТОРИИ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2014 |
|
RU2575316C1 |
| СПОСОБ ОБНАРУЖЕНИЯ СИГНАЛОВ ИЗВЕСТНОЙ ФОРМЫ НА ОСНОВЕ ВЕКТОРНО-КОСИНУСНОЙ МЕРЫ ПОДОБИЯ | 2021 |
|
RU2783875C1 |
| СПОСОБ АНАЛИЗА НЕСТАЦИОНАРНОГО ПРОЦЕССА | 1998 |
|
RU2159956C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ КАДРОВ ПОТОКА МУЛЬТИМЕДИЙНЫХ ДАННЫХ НА ОСНОВЕ КОРРЕЛЯЦИОННОГО АНАЛИЗА ГИСТОГРАММ ИЗОБРАЖЕНИЙ КАДРОВ | 2015 |
|
RU2607415C2 |
| СИСТЕМА АНАЛИЗА СЕТЕВОГО ТРАФИКА | 2007 |
|
RU2364933C2 |
Изобретение предназначено для распознавания протоколов низкоскоростного кодирования речи (НСКР). Технический результат заключается в повышении точности распознавания протоколов НСКР. Технический результат достигается благодаря увеличению размерности измеренного вектора коэффициентов избыточности ϕZ до ϕL, L=Z+2 и учету эффекта сдвига элементов вектора ϕL путем формирования квадратной эталонной матрицы ΦLj эт для всех J известных протоколов НСКР, j=1, 2 …, J. Для этого принимают цифровой поток Y в течение заданного интервала времени ΔT. Формируют прямоугольную информационную матрицу YK×L, строками которой являются последовательно размещенные друг под другом информационные блоки. Вычисляют вектор коэффициентов избыточности ϕL, поэлементно сравнивают измеренный вектор ϕL со строками  всех J квадратных эталонных матриц ΦLj эт, определяют отклонение
всех J квадратных эталонных матриц ΦLj эт, определяют отклонение 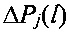 между измеренным вектором ϕL и строками всех J эталонных матриц ΦLj эт, принимают решение в пользу j-го протокола НСКР, для которого обеспечивается минимальное отклонение
между измеренным вектором ϕL и строками всех J эталонных матриц ΦLj эт, принимают решение в пользу j-го протокола НСКР, для которого обеспечивается минимальное отклонение 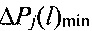 измеренного вектора ϕL от
измеренного вектора ϕL от 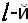 строки j-й квадратной эталонной матрицы ΦLj эт. 6 ил.
строки j-й квадратной эталонной матрицы ΦLj эт. 6 ил.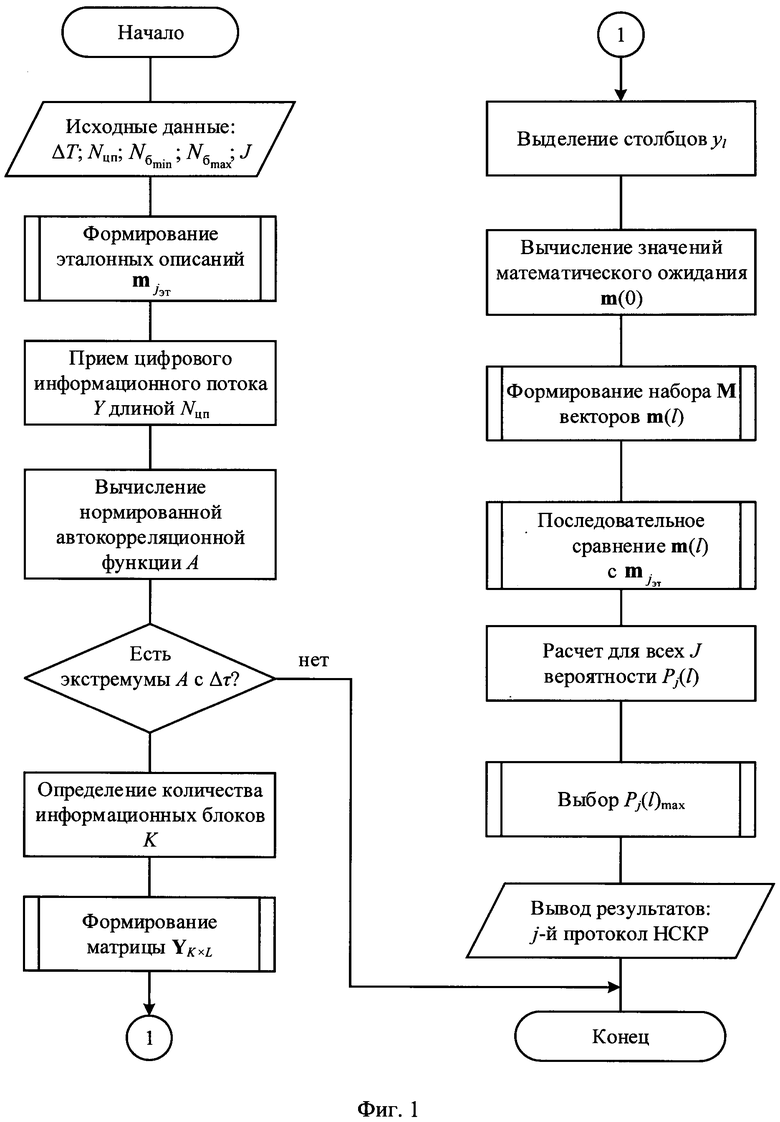
Способ распознавания протоколов низкоскоростного кодирования речи (НСКР), реализуемых в вокодерах, заключающийся в том, что принимают цифровой информационный поток Y в течение интервала времени ΔT, на основе принятого потока Y формируют нормированную автокорреляционную функцию А, по регулярным с равными интервалами Δτ экстремумам автокорреляционной функции А принимают решение о наличии блочной структуры в цифровом информационном потоке Y, по интервалам между экстремумами автокорреляционной функции А делят цифровой информационный поток Y на информационные блоки объемом Nб бит каждый, последовательно присваивают информационным блокам порядковые номера k=1, 2, …, K, начиная с первого информационного блока, формируют прямоугольную информационную матрицу YK×L, L=Nб, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1, 2, …, K, отличающийся тем, что поочередно выделяют столбцы yl из матрицы YK×L с номерами l=1, 2, …, L, по каждому столбцу yl информационной матрицы YK×L вычисляют значение математического ожидания ml появления определенных импульсов, формируют вектор измеренных значений математического ожидания m(0)={m1, m2, …, ml, …, mL} последовательным размещением полученных значений математического ожидания ml в соответствии с их порядковыми номерами l, на основе сформированного вектора значений математического ожидания m(0) путем последовательного циркулярного сдвига его значений на величину l=0, 1, 2, …, L-1 формируют набор М векторов m(l) значений математического ожидания М={m(0), m(1), …, m(l), …, m(L-1)}, формируют эталонные векторы значений математического ожидания 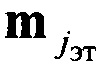 , j=1, 2, …, J, по каждому цифровому информационному потоку
, j=1, 2, …, J, по каждому цифровому информационному потоку 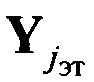 , соответствующему j-му известному протоколу НСКР, каждый вектор значений математического ожидания m(l) оцениваемого протокола НСКР последовательно сравнивают с эталонными векторами значений математического ожидания , j=1, 2, …, J, вычисляют значение вероятности правильного распознавания Pj(l) j-го протокола НСКР по каждому l-му вектору значений математического ожидания m(l), принимают решение в пользу j-го протокола НСКР, для которого обеспечивается максимальное значение вероятности правильного распознавания Pj(l).
, соответствующему j-му известному протоколу НСКР, каждый вектор значений математического ожидания m(l) оцениваемого протокола НСКР последовательно сравнивают с эталонными векторами значений математического ожидания , j=1, 2, …, J, вычисляют значение вероятности правильного распознавания Pj(l) j-го протокола НСКР по каждому l-му вектору значений математического ожидания m(l), принимают решение в пользу j-го протокола НСКР, для которого обеспечивается максимальное значение вероятности правильного распознавания Pj(l).
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2014 |
|
RU2551903C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2010 |
|
RU2423735C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2007 |
|
RU2356064C2 |
| КОДИРУЮЩЕЕ И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО ДЛЯ НИЗКОСКОРОСТНЫХ СИГНАЛОВ | 2011 |
|
RU2565995C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

