Область техники, к которой относится изобретение
Настоящее изобретение относится в общем к системам передачи данных с расширенным спектром, конкретно к процессу поиска сотовой ячейки, осуществляемому мобильной станцией для обеспечения синхронизации с базовой станцией и извлечения длинного кода конкретной сотовой ячейки, а также информации синхронизации кадра, которые используются в системе связи множественного доступа с кодовым разделением каналов (МДКР).
УРОВЕНЬ ТЕХНИКИ
Индустрия сотовых телефонов достигла феноменальных успехов в области коммерческих операций во всем мире. Рост в главных столичных зонах далеко превысил ожидания и опережает пропускную способность системы связи. Если данная тенденция будет сохраняться, то эффект быстрого роста скоро достигнет даже самых маленьких рынков. Доминирующая проблема, связанная с непрерывным ростом, состоит в том, что потребительская база расширяется, в то время как размер электромагнитного спектра, выделенного поставщикам услуг сотовой связи для использования в сетях связи, передающих на радиочастотах, остается ограниченным. Требуются творческие решения для удовлетворения этой увеличивающейся потребности в пропускной способности при ограниченном доступном спектре, а также для поддержания высококачественного обслуживания и чтобы не допустить повышения цен.
В настоящее время, при осуществлении доступа к каналу прежде всего используются способы множественного доступа с частотным разделением каналов (МДЧР) и множественного доступа с временным разделением каналов (МДВР). В системах связи МДЧР физический канал содержит одну радиочастотную полосу, в которой сконцентрирована мощность передачи сигнала. В системах связи МДВР физический канал связи содержит временной интервал в периодическом ряде интервалов времени на одной и той же радиочастоте. Несмотря на то, что при использовании систем связи МДЧР и МДВР достигается приемлемая эффективность, обычно, по причине увеличивающихся запросов клиентов, возникает перегрузка канала связи. Соответственно, в настоящее время предлагаются, рассматриваются и внедряются альтернативные способы доступа к каналу связи.
Расширенный спектр является способом передачи данных, который находит коммерческое применение в качестве нового способа доступа к каналу в беспроводных системах связи. Системы передачи данных с расширенным спектром появились, начиная со Второй Мировой Войны. Ранние применения в большинстве своем были военно-ориентированными (в отношении обеспечения эффективных помех, радара и спутников). Однако сегодня существует увеличивающийся интерес к использованию систем передачи данных с расширенным спектром в других применениях систем связи, включая цифровую сотовую радиосвязь, наземную мобильную радиосвязь и внутренние/внешние персональные сети связи.
Системы передачи данных с расширенным спектром функционируют совершенно иначе, чем стандартные системы связи МДВР и МДЧР. К примеру, в передатчике с расширенным спектром с кодом прямой последовательности в системе МДКР (МДКР-ПП) поток цифровых символов для данного специализированного или общего канала, имеющий основную скорость передачи символов, расширяют на скорости передачи элементарных сигналов. Эта операция расширения включает применение уникального расширяющего кода канала (иногда называемого последовательностью сигнатур) к потоку символов, который при добавлении избыточности увеличивает свою скорость передачи (ширину полосы частот). Обычно поток цифровых символов при расширении умножают на уникальный цифровой код. Промежуточный сигнал, содержащий получающиеся в результате последовательности данных (элементарные сигналы), затем добавляется к другим, обработанным аналогично (то есть, расширенным), промежуточным сигналам, относящимся к другим каналам. Далее для генерирования выходного сигнала для многоканальной передачи данных через среду связи к суммируемым промежуточным сигналам применяется уникальный для базовой станции скремблирующий код (часто называемый "длинным кодом", так как он, в большинстве случаев, длиннее расширяющего кода). После этого промежуточные сигналы, относящиеся к специализированным/общим каналам связи, успешно используют совместно одну частоту средств связи для передачи данных, с многими сигналами, размещенными поверх друг друга, и в частотной области, и во временной области. Поскольку применяемые расширяющие коды являются уникальными для канала, то каждый промежуточный сигнал, передаваемый через общую частоту средств связи, также является уникальным, и путем применения в приемнике соответствующих способов обработки может быть выделен из других сигналов.
В приемнике с расширенным спектром мобильной станции системы МДКР-ПП принимаемые сигналы восстанавливаются с применением, то есть, путем умножения, или согласования соответствующих скремблирующих и расширяющих кодов для сжатия или удаления кодирования из полезного передаваемого сигнала и возвращения к основной скорости передачи символов. Однако, там где расширяющий код используется для других переданных и принятых промежуточных сигналов, в результате получается только шум. Операция сжатия, таким образом, действительно содержит процесс корреляции, который сравнивает принятый сигнал с соответствующим цифровым кодом для восстановления полезной информации из канала связи.
Прежде, чем между базовой станцией и мобильной станцией системы передачи данных с расширенным спектром может возникнуть соединение, или произойти передача информации на радиочастоте, мобильная станция должна найти и синхронизировать себя с опорным сигналом синхронизации данной базовой станции. Этот процесс обычно называется "поиском сотовой ячейки". В системе связи с расширенным спектром МДКР-ПП, например, мобильная станция должна найти границы элементарного сигнала нисходящей линии кадра связи, границы символа и границы кадра тактового генератора опорного сигнала синхронизации.
Наиболее общее решение, внедренное для разрешения проблемы синхронизации, как показано на фигуре 1, подразумевает наличие базовой станции, периодически осуществляющей передачу (с повторяющимся периодом Тр), и мобильной станции, определяющей и обрабатывающей распознаваемый код синхронизации 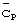 длиной Np элементарных сигналов. Код синхронизации может также определяться, как расширяющий код для символов, маскированных длинным кодом. Этот код синхронизации передается с известной модуляцией и без какого-либо скремблирования длинным кодом. В системе связи МДКР одного вида каждая базовая станция использует отличный, известный код синхронизации, взятый из набора доступных кодов синхронизации. В системе связи МДКР другого вида все базовые станции используют один и тот же код синхронизации, с различиями между базовыми станциями, которые идентифицируются по использованию для передачи различных сдвигов фазы кода синхронизации.
длиной Np элементарных сигналов. Код синхронизации может также определяться, как расширяющий код для символов, маскированных длинным кодом. Этот код синхронизации передается с известной модуляцией и без какого-либо скремблирования длинным кодом. В системе связи МДКР одного вида каждая базовая станция использует отличный, известный код синхронизации, взятый из набора доступных кодов синхронизации. В системе связи МДКР другого вида все базовые станции используют один и тот же код синхронизации, с различиями между базовыми станциями, которые идентифицируются по использованию для передачи различных сдвигов фазы кода синхронизации.
В приемнике с расширенным спектром мобильной станции принятые сигналы демодулируются и используются в фильтре, согласованном с кодом (кодами) синхронизации. Подразумевается, что для обработки кода синхронизации могут использоваться другие схемы детектирования, типа скользящей корреляции. Выходной сигнал согласованного фильтра имеет кратковременный выброс (пик) в моменты времени, соответствующие времени приема периодически передаваемого кода синхронизации. Из-за эффектов многомаршрутной передачи, отдельные пики могут быть обнаружены в связи с одиночной передачей кода синхронизации. При обработке известным образом этих принятых пиков, опорный сигнал синхронизации, относящийся к передающей базовой станции, может быть определен с некоторой погрешностью, равной периоду повторения Тр. Если период повторения равен длине кадра, то опорный сигнал синхронизации может использоваться для синхронизации операций связи мобильной станции и базовой станции в соответствии с синхронизацией кадра.
В то время как для передаваемого кода синхронизации 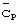 может быть выбрана любая длина Np в элементарных сигналах, практически, длина Np в элементарных сигналах ограничена сложностью согласованного фильтра, предусматриваемого в приемнике мобильной станции. В то же время, предпочтительно ограничить мгновенную пиковую мощность
может быть выбрана любая длина Np в элементарных сигналах, практически, длина Np в элементарных сигналах ограничена сложностью согласованного фильтра, предусматриваемого в приемнике мобильной станции. В то же время, предпочтительно ограничить мгновенную пиковую мощность 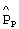 передачи сигнала/канала кода синхронизации, чтобы не вызвать сильную мгновенную интерференцию с другими передаваемыми сигналами/каналами с расширенным спектром.
передачи сигнала/канала кода синхронизации, чтобы не вызвать сильную мгновенную интерференцию с другими передаваемыми сигналами/каналами с расширенным спектром.
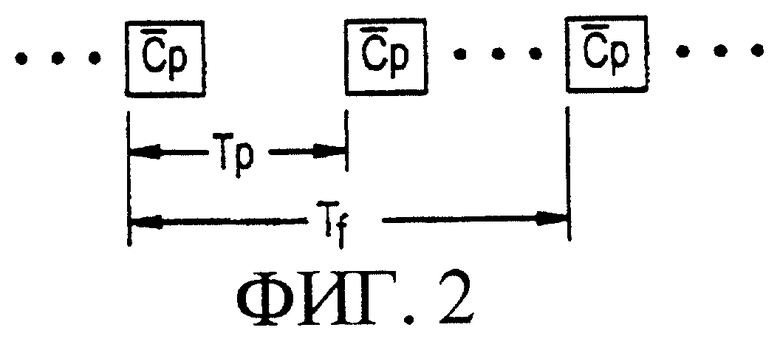
Для обеспечения удовлетворительной средней мощности передачи кода синхронизации с некоторой заданной длиной Np элементарных сигналов, согласно фигуре 2, в системе связи МДКР может стать необходимым использование периода повторения кода синхронизации Тр, меньшего, чем длина кадра Tf.
Другой причиной для передачи многих кодов синхронизации 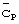 внутри одной длины кадра Тf является, как известно специалистам в данной области техники, поддержка межчастотной синхронизации нисходящей линии связи в режиме уплотнения (сжатия). При обработке в режиме уплотнения, синхронизация нисходящей линии связи на данной несущей частоте осуществляется только на протяжении части кадра, а не на протяжении всего кадра. Тогда, при наличии только одного кода синхронизации
внутри одной длины кадра Тf является, как известно специалистам в данной области техники, поддержка межчастотной синхронизации нисходящей линии связи в режиме уплотнения (сжатия). При обработке в режиме уплотнения, синхронизация нисходящей линии связи на данной несущей частоте осуществляется только на протяжении части кадра, а не на протяжении всего кадра. Тогда, при наличии только одного кода синхронизации 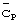 на кадр имеется возможность при отсутствии обработки в режиме уплотнения в течение значительного периода времени обнаружения полностью кода синхронизации. При передаче многих кодов синхронизации
на кадр имеется возможность при отсутствии обработки в режиме уплотнения в течение значительного периода времени обнаружения полностью кода синхронизации. При передаче многих кодов синхронизации 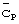 за каждый кадр, для процесса обработки в режиме уплотнения предоставляется много возможностей для осуществления обнаружения за один кадр, и можно будет обнаружить, по меньшей мере, одну передачу кода синхронизации.
за каждый кадр, для процесса обработки в режиме уплотнения предоставляется много возможностей для осуществления обнаружения за один кадр, и можно будет обнаружить, по меньшей мере, одну передачу кода синхронизации.
Однако имеется определенный недостаток в приеме и синхронизации, выполняемых при передаче многочисленных кодов синхронизации 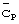 внутри одного кадра длиной Tf. Принятые сигналы снова демодулируются и передаются к фильтру (или коррелятору), согласованному с известным кодом синхронизации. Выходной сигнал согласованного фильтра создает пики в моменты времени, соответствующие моментам приема периодически передаваемого кода синхронизации. При обработке этих пиков может быть найден известным образом опорный сигнал синхронизации для передающей базовой станции, связанный с периодом повторения Тр кода синхронизации. Однако опорный сигнал синхронизации является неоднозначным в отношении синхронизации кадра и, таким образом, не предоставляет информацию, достаточную для обеспечения возможности синхронизации базовой/мобильной станции с опорным сигналом синхронизации. Под неоднозначностью понимается то, что обнаружение пиков кода синхронизации является недостаточным для идентификации границы кадра (то есть, его синхронизации).
внутри одного кадра длиной Tf. Принятые сигналы снова демодулируются и передаются к фильтру (или коррелятору), согласованному с известным кодом синхронизации. Выходной сигнал согласованного фильтра создает пики в моменты времени, соответствующие моментам приема периодически передаваемого кода синхронизации. При обработке этих пиков может быть найден известным образом опорный сигнал синхронизации для передающей базовой станции, связанный с периодом повторения Тр кода синхронизации. Однако опорный сигнал синхронизации является неоднозначным в отношении синхронизации кадра и, таким образом, не предоставляет информацию, достаточную для обеспечения возможности синхронизации базовой/мобильной станции с опорным сигналом синхронизации. Под неоднозначностью понимается то, что обнаружение пиков кода синхронизации является недостаточным для идентификации границы кадра (то есть, его синхронизации).
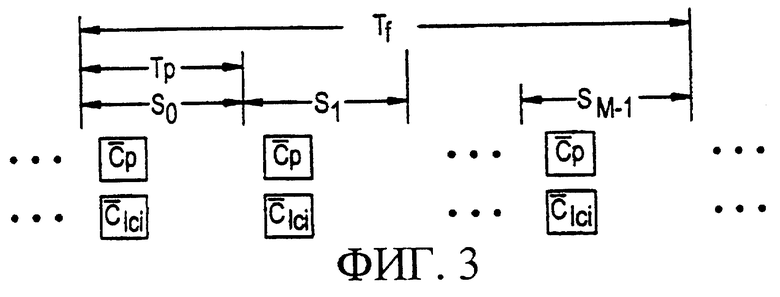
Процесс поиска сотовой ячейки может дополнительно подразумевать получение определенного длинного кода сотовой ячейки, используемого на нисходящей линии связи для скремблирования передачи данных специализированного и общего каналов нисходящей линии связи. Специализированные каналы включают и каналы трафика, и каналы управления, общие каналы также включают каналы трафика и каналы управления (в число которых может включаться канал управления передачей или КУП). Предпочтительно, согласно фигуре 3, код 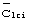 группы длинных кодов передается синхронно с кодами синхронизации
группы длинных кодов передается синхронно с кодами синхронизации 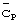 (и еще более предпочтительно, ортогонально к кодам синхронизации
(и еще более предпочтительно, ортогонально к кодам синхронизации 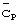 ). Код группы длинных кодов передается с известной модуляцией и без скремблирования длинным кодом. Каждый код
). Код группы длинных кодов передается с известной модуляцией и без скремблирования длинным кодом. Каждый код 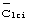 группы длинных кодов определяет конкретное подмножество общего набора длинных кодов, к которому принадлежит используемый для передачи определенный длинный код сотовой ячейки. Например, может иметься сто двадцать восемь общих длинных кодов, сгруппированных в четыре подмножества, каждое из которых состоит из тридцати двух кодов. Идентифицируя передаваемый код
группы длинных кодов определяет конкретное подмножество общего набора длинных кодов, к которому принадлежит используемый для передачи определенный длинный код сотовой ячейки. Например, может иметься сто двадцать восемь общих длинных кодов, сгруппированных в четыре подмножества, каждое из которых состоит из тридцати двух кодов. Идентифицируя передаваемый код 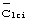 группы длинных кодов, приемник, в данном примере, может сузить поиск извлечения своего длинного кода всего до тридцати двух длинных кодов, содержащихся в подмножестве, идентифицированном принятым кодом
группы длинных кодов, приемник, в данном примере, может сузить поиск извлечения своего длинного кода всего до тридцати двух длинных кодов, содержащихся в подмножестве, идентифицированном принятым кодом 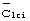 группы длинных кодов.
группы длинных кодов.
Информация синхронизации кадра может быть определена при комбинированной обработке принятых кодов синхронизации 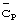 и кодов
и кодов 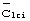 группы длинных кодов. Мобильная станция сначала идентифицирует синхронизацию кода синхронизации, применяя к принятому сигналу
группы длинных кодов. Мобильная станция сначала идентифицирует синхронизацию кода синхронизации, применяя к принятому сигналу 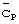 -согласованный фильтр и идентифицируя пики. По этим пикам может быть найден опорный сигнал синхронизации относительно интервалов времени. Определенные, хотя неоднозначно по отношению к синхронизации кадра, расположения интервалов времени идентифицируют синхронизацию для одновременной передачи кода
-согласованный фильтр и идентифицируя пики. По этим пикам может быть найден опорный сигнал синхронизации относительно интервалов времени. Определенные, хотя неоднозначно по отношению к синхронизации кадра, расположения интервалов времени идентифицируют синхронизацию для одновременной передачи кода 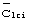 группы длинных кодов. Далее выполняется корреляция с известными расположениями интервалов времени для идентификации кода
группы длинных кодов. Далее выполняется корреляция с известными расположениями интервалов времени для идентификации кода 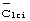 группы длинных кодов. По этой идентификации уменьшается число возможных определенных длинных кодов сотовой ячейки, используемых для осуществления передачи. Наконец, в каждом из известных интервалов времени по каждому из уменьшенного количества длинных кодов (то есть, рассматриваются те длинные коды, которые содержатся в идентифицированном подмножестве
группы длинных кодов. По этой идентификации уменьшается число возможных определенных длинных кодов сотовой ячейки, используемых для осуществления передачи. Наконец, в каждом из известных интервалов времени по каждому из уменьшенного количества длинных кодов (то есть, рассматриваются те длинные коды, которые содержатся в идентифицированном подмножестве 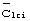 ) выполняется корреляция, чтобы определить, определенный длинный код какой из сотовых ячеек используется для осуществления передачи, и обеспечить опорный сигнал сдвига фазы. Как только найден сдвиг фазы, синхронизация кадра является идентифицированной.
) выполняется корреляция, чтобы определить, определенный длинный код какой из сотовых ячеек используется для осуществления передачи, и обеспечить опорный сигнал сдвига фазы. Как только найден сдвиг фазы, синхронизация кадра является идентифицированной.
В отношении передачи многих кодов синхронизации 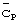 внутри одного кадра длиной Тf в патенте US №5991330 под названием "Синхронизация мобильной станции внутри системы передачи данных с расширенным спектром" рассмотрен альтернативный вариант способа определения синхронизации кадра путем наличия в каждом из интервалов времени не только кода синхронизации
внутри одного кадра длиной Тf в патенте US №5991330 под названием "Синхронизация мобильной станции внутри системы передачи данных с расширенным спектром" рассмотрен альтернативный вариант способа определения синхронизации кадра путем наличия в каждом из интервалов времени не только кода синхронизации 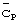 , описанного выше согласно фигуре 2, но также и кода кадровой синхронизации
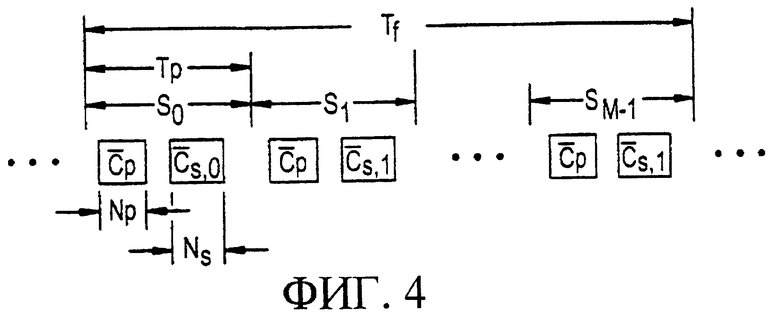
, описанного выше согласно фигуре 2, но также и кода кадровой синхронизации 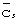 , передаваемого с известной модуляцией и без скремблирования длинным кодом как иллюстрируется фигурой 4. В каждом интервале времени и по всем повторяющимся кадрам используется один и тот же код синхронизации. Коды кадровой синхронизации, однако, являются уникальными для каждого интервала времени в кадре и повторяются в каждом кадре.
, передаваемого с известной модуляцией и без скремблирования длинным кодом как иллюстрируется фигурой 4. В каждом интервале времени и по всем повторяющимся кадрам используется один и тот же код синхронизации. Коды кадровой синхронизации, однако, являются уникальными для каждого интервала времени в кадре и повторяются в каждом кадре.
Чтобы получить информацию синхронизации кадра мобильная станция сначала идентифицирует синхронизацию кода синхронизации, применяя 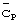 -согласованный фильтр к принятому сигналу и идентифицируя пики. По этим пикам может быть найден опорный сигнал синхронизации относительно интервалов времени. При том, что опорный сигнал синхронизации является неоднозначным относительно синхронизации кадра, информация о расположении интервала времени косвенно указывает на расположение кода кадровой синхронизации
-согласованный фильтр к принятому сигналу и идентифицируя пики. По этим пикам может быть найден опорный сигнал синхронизации относительно интервалов времени. При том, что опорный сигнал синхронизации является неоднозначным относительно синхронизации кадра, информация о расположении интервала времени косвенно указывает на расположение кода кадровой синхронизации 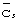 внутри каждого расположенного интервала времени. Далее мобильная станция дополнительно коррелирует набор известных кодов кадровой синхронизации
внутри каждого расположенного интервала времени. Далее мобильная станция дополнительно коррелирует набор известных кодов кадровой синхронизации 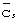 с принятым сигналом в местах расположения кодов кадровой синхронизации. При условии, что позиция каждого кода кадровой синхронизации
с принятым сигналом в местах расположения кодов кадровой синхронизации. При условии, что позиция каждого кода кадровой синхронизации 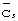 относительно границы кадра известна, как только в определенном расположении найдено соответствие корреляции, граница кадра, относящегося к нему (и следовательно, синхронизация кадра) становится также известной.
относительно границы кадра известна, как только в определенном расположении найдено соответствие корреляции, граница кадра, относящегося к нему (и следовательно, синхронизация кадра) становится также известной.
Хотя предшествующие способы получения информации синхронизации могут обеспечивать удовлетворительные результаты, их рабочие характеристики при ухудшенных условиях радиосвязи оставляют желать лучшего. Неизбежно, во всех описанных выше подходах, соответствующих предшествующему уровню техники, недостаточно хорошие условия линии радиосвязи и повышенный уровень помех могут вызвать принятие мобильной станцией неправильных решений относительно длинного кода или синхронизации кадра, или по обоим упомянутым вопросам. Следовательно, требуется выполнение дополнительных корреляций, отнимающих ценные ресурсы процесса обработки, что является сложным для реализации, при этом замедляется процесс поиска сотовой ячейки. По существу, можно было бы получить большую мощность сигнала, принимая сигнал по большему числу периодов кадра. Однако этот подход может потребовать больше времени, чем считается допустимым для ситуаций переключения (переадресации) связи. Следовательно, требуется эффективный способ получения и индикации синхронизации кадра, и индикации длинного кода во время процесса поиска сотовой ячейки при радиосвязи с ухудшенными условиями. Как подробно описано ниже, настоящее изобретение предлагает такой способ.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
По существу, согласно настоящему изобретению предложен способ более эффективного извлечения длинного кода и синхронизации кадра во время поиска сотовой ячейки путем использования специальной схемы кодирования. Определяется обладающий определенными свойствами набор кода, состоящий из Q-тых кодовых слов длиной М, включающих символы из набора Q коротких кодов. Первым свойством, которое требуется обеспечить, является то, что никакой циклический сдвиг кодового слова не дает в результате правильное кодовое слово. Другими свойствами, которые должны быть обеспечены, являются наличие взаимно-однозначного соответствия между сообщением длинного кода и правильным кодовым словом, и декодер должен при наличии помех и шума обеспечивать с некоторой степенью точности и приемлемой степенью сложности произвольный сдвиг (таким образом неявно определяя синхронизацию кадра) и передаваемое кодовое слово (то есть, относящееся к нему сообщение индикации длинного кода).
Важным техническим преимуществом настоящего изобретения является то, что оно обеспечивает несложное решение для более эффективного распознавания длинного кода и синхронизации кадра во время поиска сотовой ячейки, которое дает кодирующее усиление, которое может использоваться для уменьшения времени поиска и/или для обеспечения требуемого отношения мощности бита информации к шуму (Мб/Ш).
Другим важным техническим преимуществом настоящего изобретения является то, что оно предоставляет возможность найти компромисс между сложностью и эффективностью путем изменения сложности кода, при этом сохраняя фиксированным количество возможных сообщений.
Еще одним важным техническим преимуществом настоящего изобретения является то, что оно предусматривает большее количество кодовых слов, чем стандартные схемы, которые уменьшают и/или ограничивают количество требуемых сообщений базовой станции.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Для более полного понимания предложенных настоящим изобретением способа и устройства, ниже приводится детальное описание вариантов осуществления настоящего изобретения согласно прилагаемым чертежам.
Фигура 1 является диаграммой, иллюстрирующей формат передачи сигнала в канале синхронизации в системе связи множественного доступа с кодовым разделением каналов с кодом прямой последовательности согласно предшествующему уровню техники.
Фигура 2 является диаграммой, иллюстрирующей альтернативный вариант формата передачи сигнала в канале синхронизации в системе связи множественного доступа с кодовым разделением каналов с кодом прямой последовательности согласно предшествующему уровню техники.
Фигура 3 является диаграммой, иллюстрирующей другой альтернативный вариант канала синхронизации и формата передачи группового сигнала длинного кода в системе связи множественного доступа с кодовым разделением каналов с кодом прямой последовательности согласно предшествующему уровню техники.
Фигура 4 является диаграммой, иллюстрирующей еще один альтернативный вариант формата передачи кода синхронизации и кода кадровой синхронизации в системе связи множественного доступа с кодовым разделением каналов с кодом прямой последовательности согласно предшествующему уровню техники.
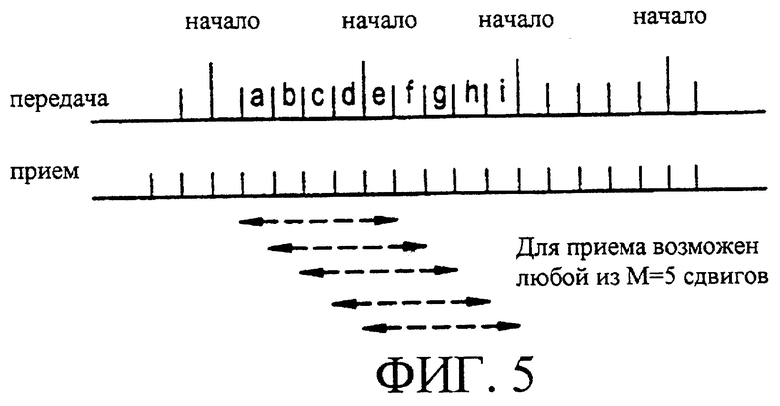
Фигура 5 является диаграммой, иллюстрирующей возможный вариант операций передатчика и приемника, которые могут использоваться для обеспечения настоящего изобретения.
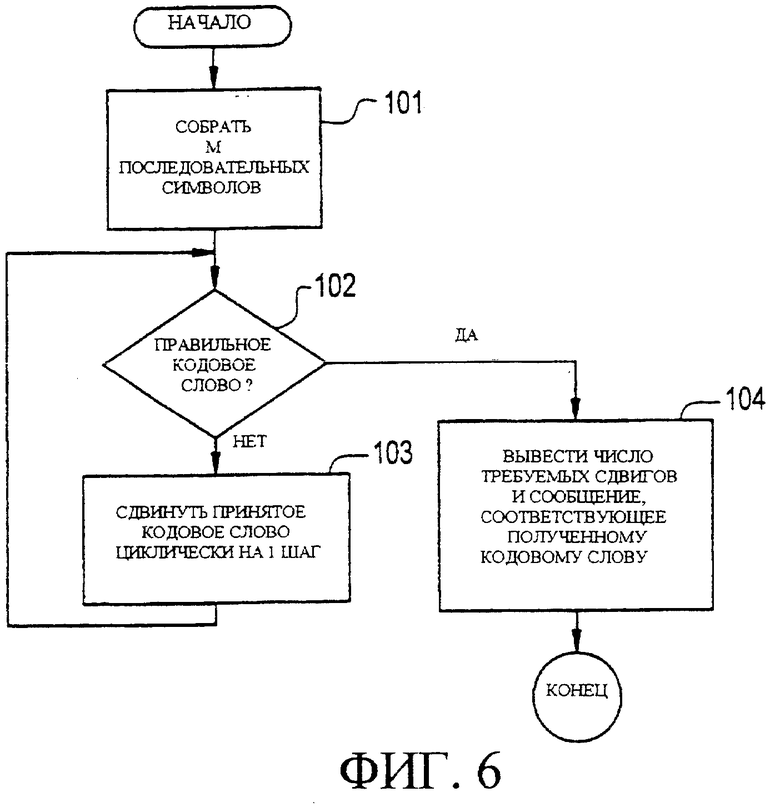
Фигура 6 является блок-схемой, иллюстрирующей обобщенный алгоритм декодирования, который может использоваться в декодере приемника для декодирования кодового слова, описанного выше согласно фигуре 5, в соответствии с предпочтительным вариантом осуществления настоящего изобретения.
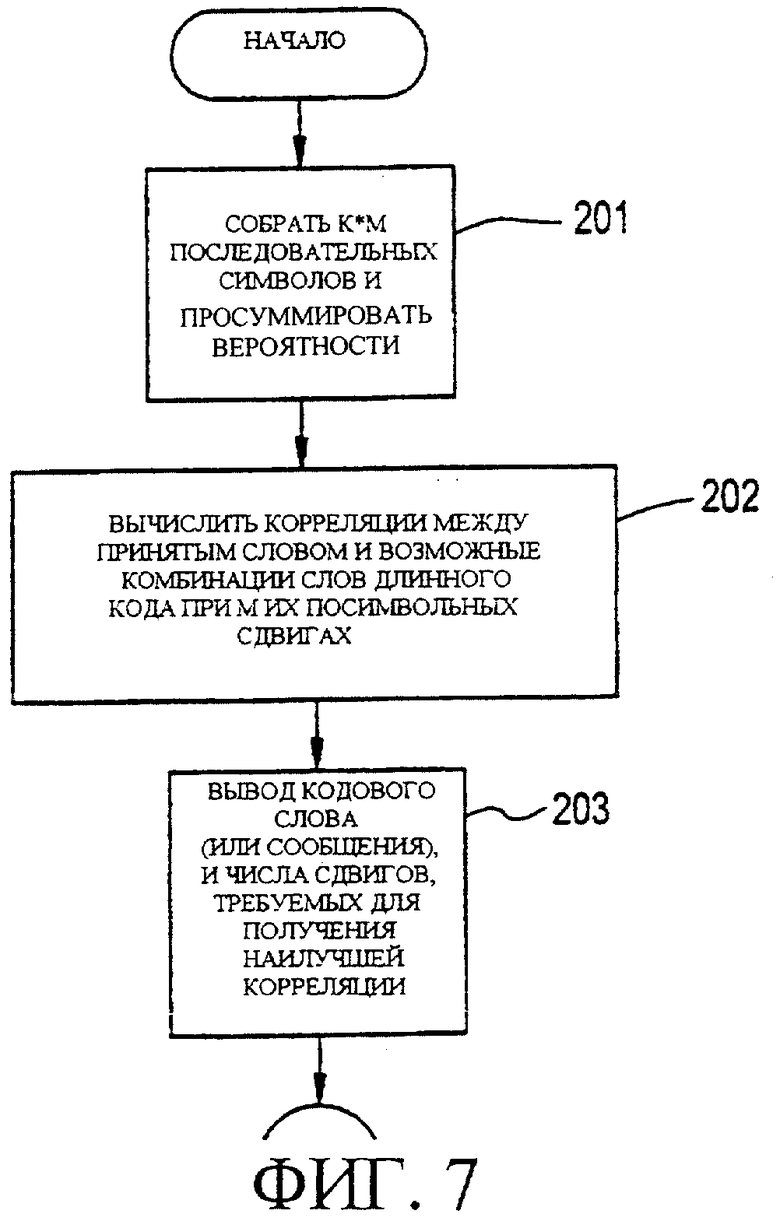
Фигура 7 является блок-схемой, иллюстрирующей согласно второму варианту осуществления настоящего изобретения обобщенный алгоритм декодера максимального правдоподобия, который может использоваться в декодере приемника для декодирования кодового слова, описанного выше согласно фигуре 5 при наличии помех/шума случайного символа/бита.
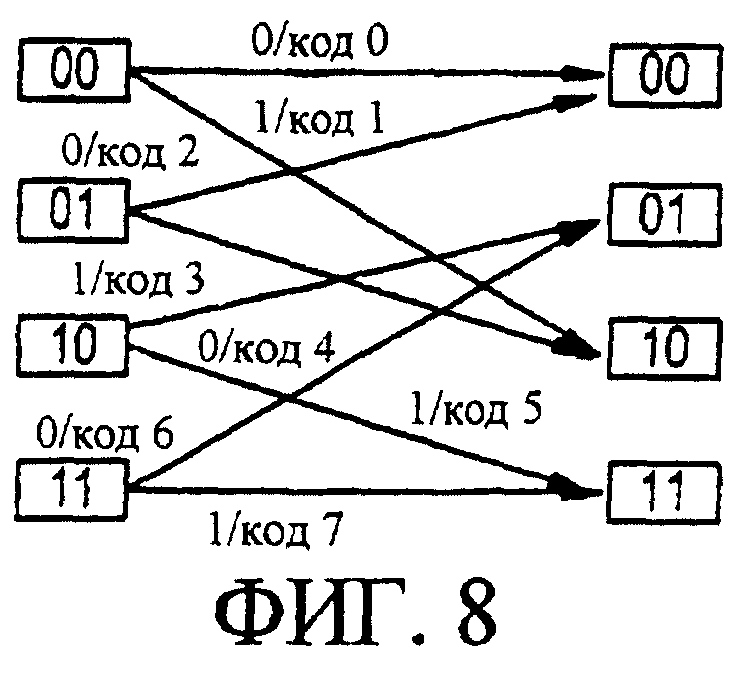
Фигура 8 является диаграммой, на которой иллюстрируется часть возможного варианта решетки для решетчатого кодера, где м=2, при этом данная диаграмма приводится в пояснительных целях для пояснения настоящего изобретения.
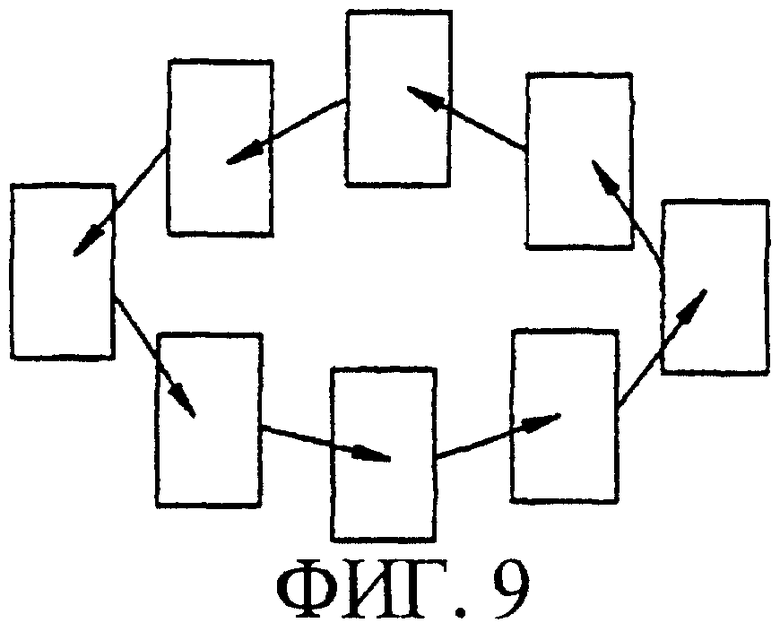
Фигура 9 является схематической диаграммой, на которой иллюстрируется возможный вариант кольцевой решетки с М, равным 8, при этом данная схематическая диаграмма приводится в пояснительных целях для пояснения настоящего изобретения.
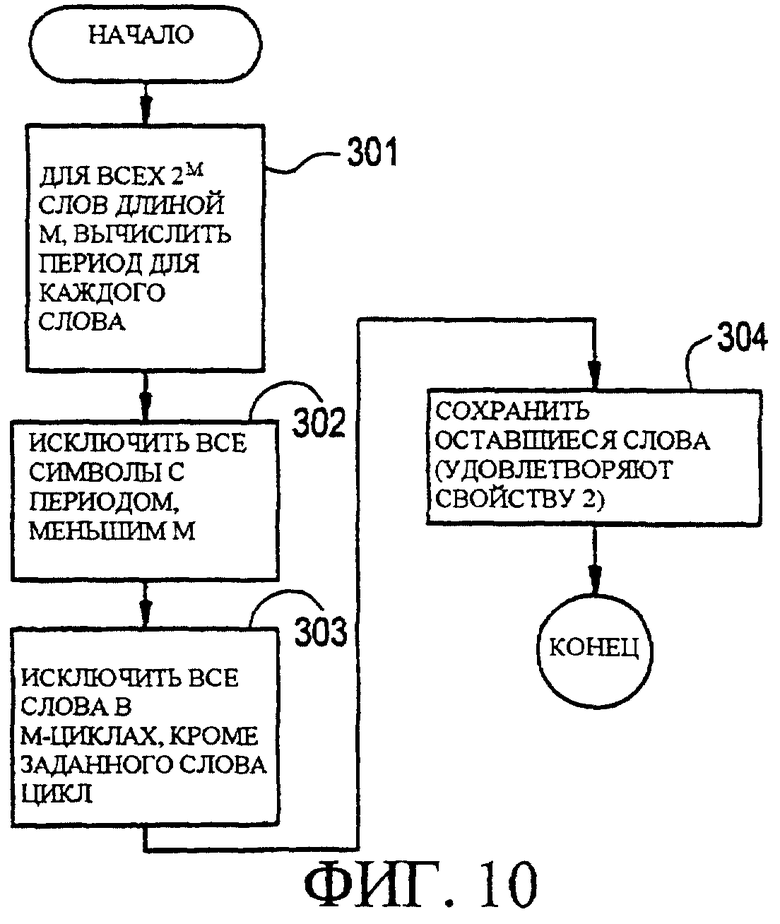
Фигура 10 является блок-схемой возможного варианта алгоритма, который может использоваться кодером для генерирования всех слов, удовлетворяющих свойству 2 настоящего изобретения.
Фигура 11 иллюстрирует код синхронизации, который может быть получен при реализации алгоритма кодирования, описанного согласно фигуре 10.
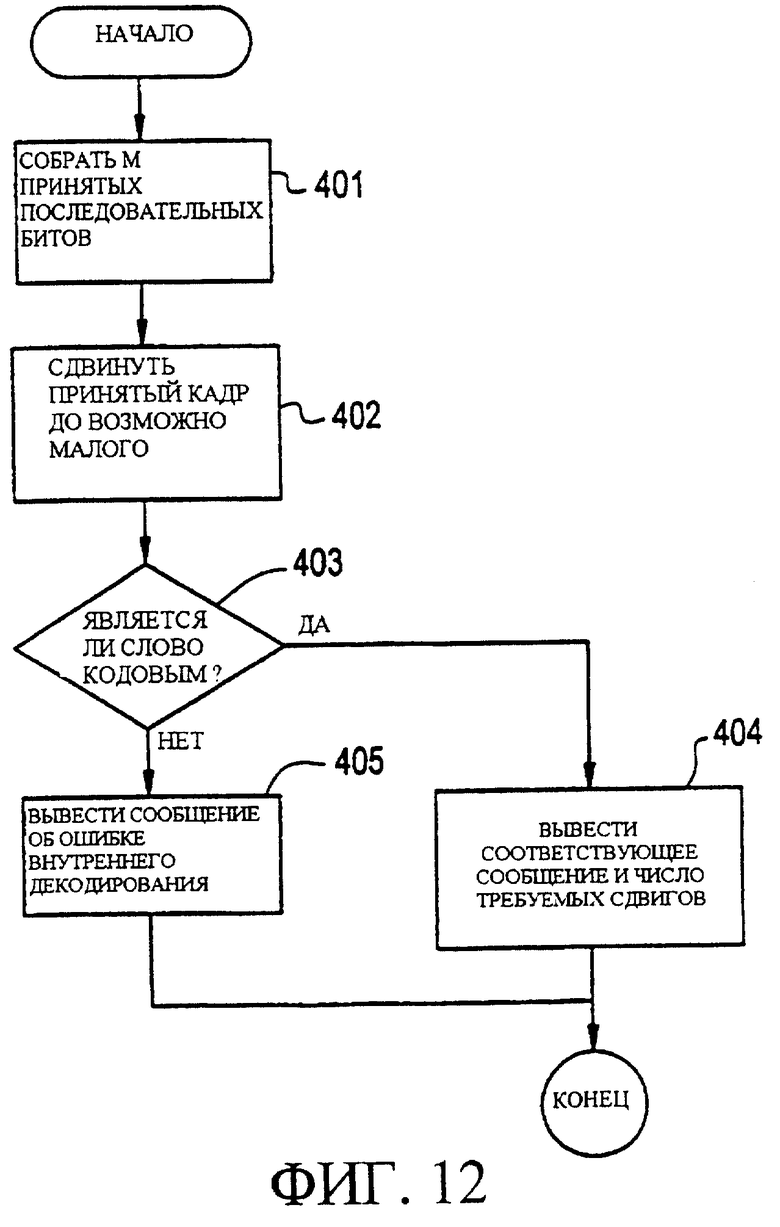
Фигура 12 является блок-схемой, иллюстрирующей способ, предложенный настоящим изобретением, для декодирования возможного варианта кода синхронизации, описанного выше согласно фигуре 11.
Фигура 13 показывает исходный текст программы Matlab для алгоритма поиска кода синхронизации, описанного согласно фигуре 12.
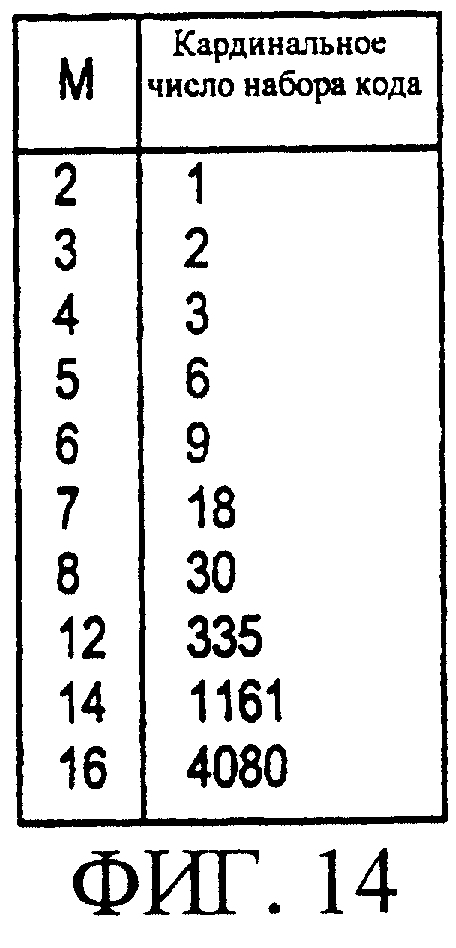
Фигура 14 показывает кардинальное число некоторых кодов синхронизации для малых значений М.
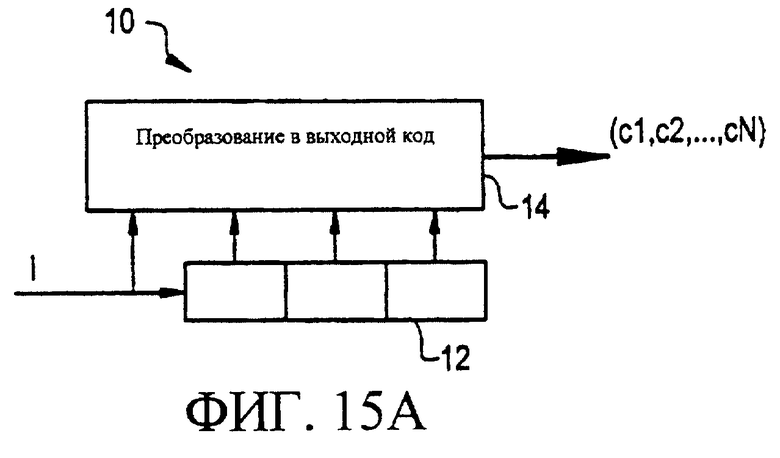
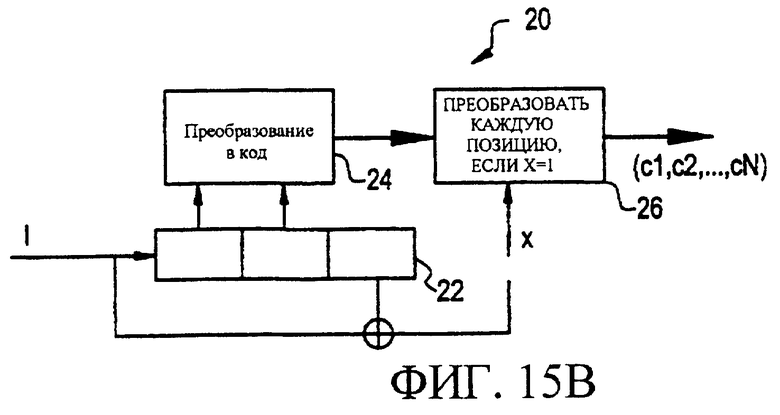
Фигуры 15А и 15В являются функциональными схемами возможных вариантов решетчатых кодеров, которые могут использоваться для реализации настоящего изобретения.
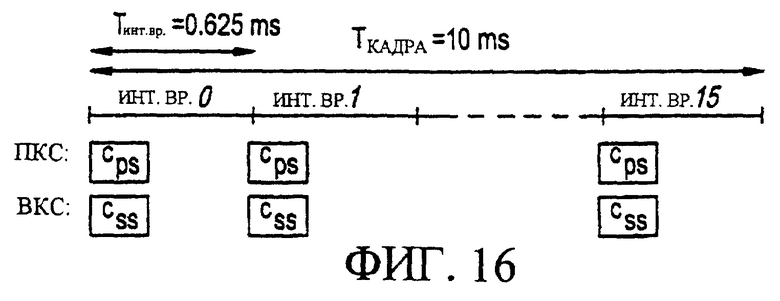
Фигура 16 является диаграммой, иллюстрирующей способ поиска сотовой ячейки, который должен использоваться мобильной станцией, как описано в ранее разработанных предложениях ARIB по широкополосным системам связи МДКР.
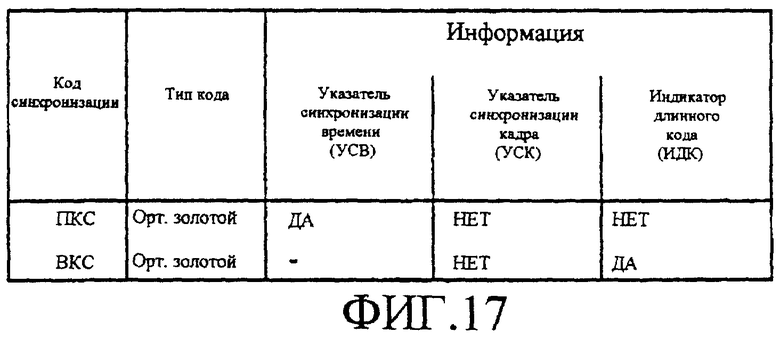
Фигура 17 является таблицей, иллюстрирующей некоторые характеристики первичного кода синхронизации и вторичного кода синхронизации.
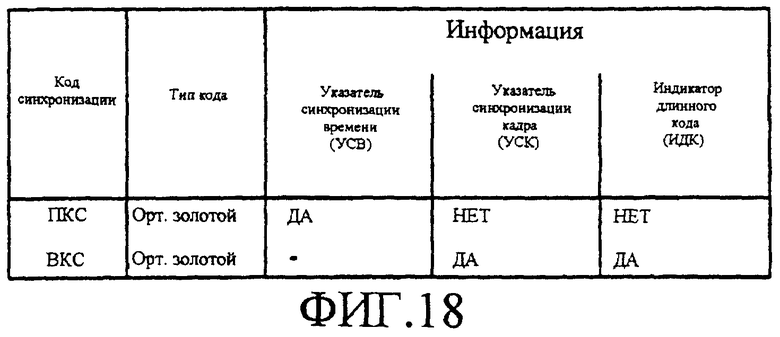
Фигура 18 является таблицей, в которой приводится информация, которая, согласно настоящему изобретению, может быть предоставлена первичным кодом синхронизации или вторичным кодом синхронизации для поиска сотовой ячейки.
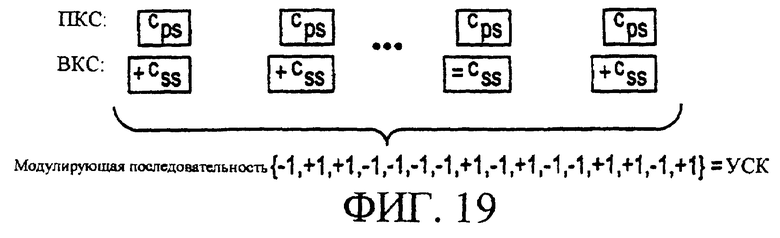
Фигура 19 является возможным вариантом способа обеспечения показанных на фигуре 18 первичного кода синхронизации и вторичного кода синхронизации для поиска сотовой ячейки согласно настоящему изобретению.
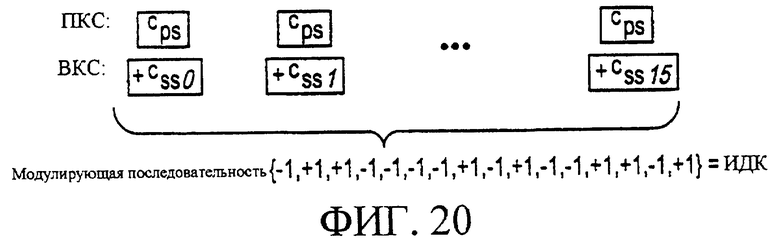
Фигура 20 является вторым возможным вариантом способа обеспечения показанных на фигуре 18 первичного кода синхронизации и вторичного кода синхронизации для поиска сотовой ячейки согласно настоящему изобретению.
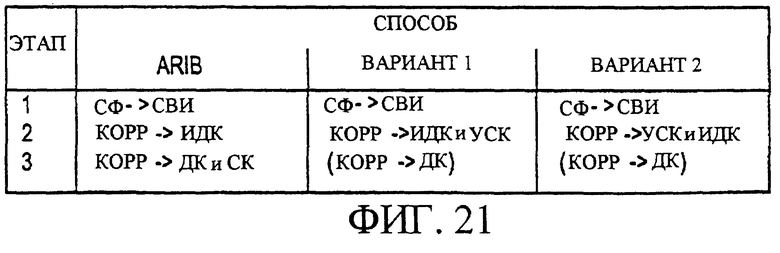
Фигура 21 является таблицей, описывающей два алгоритма (способа) поиска сотовой ячейки, которые могут быть использованы для реализации настоящего изобретения, при этом данная таблица также обеспечивает сравнение двух возможных вариантов способа поиска сотовой ячейки, предложенных настоящим изобретением, со способом поиска сотовой ячейки согласно предложениям ARIB по широкополосным системам связи МДКР.
ПОДРОБНОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Ниже описываются предпочтительный вариант осуществления настоящего изобретения и его преимущества, поясняемые чертежами 1-21, в которых используется сквозная нумерация.
По существу, согласно настоящему изобретению, предложен способ более эффективного извлечения длинного кода и синхронизации кадра во время поиска сотовой ячейки, использующий специальную схему кодирования. Определяется обладающий определенными свойствами набор кода, состоящий из Q-тых кодовых слов длиной М, включающий символы из набора Q коротких кодов. Первым свойством, которое требуется обеспечить, является то, что никакой циклический сдвиг кодового слова не дает в результате правильное кодовое слово. Другими свойствами, которые следует обеспечить, являются наличие взаимно однозначного соответствия между сообщением длинного кода и правильным кодовым словом, и декодер должен при наличии помех и шума обеспечивать с некоторой степенью точности и приемлемой степенью сложности произвольный сдвиг (таким образом неявно определяя синхронизацию кадра), и передаваемое кодовое слово (то есть, относящееся к нему сообщение индикации длинного кода).
Более конкретно, для пояснения рассматриваемого варианта осуществления, предположим, что передатчик передает М символов, выбранных из Q-того алфавита (например, алфавит, содержащий Q ортогональных коротких кодов длиной N). Эти передаваемые символы составляют передаваемое кодовое слово, и набор длиной М Q-тых последовательностей (кодовых слов) может быть определен, как код. Кроме того, одно и то же кодовое слово передается несколько раз.
Приемник (передаваемых кодовых слов) имеет информацию о времени начала и конца символа, но не обладает информацией о времени начала и конца кодового слова. Также, передаваемый сигнал постепенно затухает, подвергается воздействию помех, и/или шума. Задачей приемника, также, является (1) извлечение передаваемого кодового слова (и соответствующего сообщения) возможно при отсутствии информации относительно времени начала/конца этого кодового слова, и (2) извлечение времени начала/конца кодовых слов. Фигура 5 является диаграммой, иллюстрирующей описанные выше операции передатчика и приемника.
Согласно фигуре 5 передаваемые символы обозначаются а, b, с, ... , и т.д. Следует отметить, что в этом примере символы а, b, с, d из-за периодичности передаваемого сигнала соответственно равны символам f, g, h, i. Также, следует отметить, что любой набор из М последовательных символов содержит всю информацию, необходимую для декодирования приемником принимаемого сигнала, при предположении, что приемник имеет информацию о синхронизации кадра кода. В рассматриваемом примере М равняется 5. Если нет информации о синхронизации кадра кода, то процесс декодирования является нетривиальным. Однако, в этом примере, для простоты, предполагается наличие информации о синхронизации кадра кода, наряду с использованием кода, обладающего определенными известными свойствами. В приемнике (RX) любой из набора последовательных символов в М=5 сдвигах может содержать информацию, необходимую для декодирования принятого сигнала.
В последующем описании, для простоты можно предположить, что интервал времени между символами является нулевым. Также, чтобы убедиться, что поврежденные символы, соответствующие кодовому слову, извлекаются с допустимой степенью надежности, можно предположить, что используется стандартный способ декодирования.
Канал (с точки зрения приемника) может быть описан, как введение произвольных ошибок символов, возникающих из-за помех и шума, которые могут сдвинуть кодовые слова на случайное число (полных) Q-тых символов. Передатчик повторно передает одно и то же сообщение несколько раз. Следовательно, любые М принятых последовательных символов (независимо от их позиции) могут представлять собой кодовое слово, соответствующее неизвестному циклическому сдвигу. Также, набор кода, состоящий из Q-тых кодовых слов длиной М (с символами из набора Q коротких кодов) определяется следующими свойствами.
Свойство 1: имеется взаимно-однозначное соответствие между сообщением длинного кода и правильным кодовым словом (имеется L кодовых слов или сообщений).
Свойство 2: никакой циклический сдвиг (из Q-тых символов) кодового слова не дает в результате правильное кодовое слово (если число сдвигов не является нулевым или кратным М, что является тривиальным решением).
Свойство 3: декодер должен с некоторой степенью точности и, предпочтительно, при приемлемой степени сложности обеспечивать случайный сдвиг (таким образом неявно определяя синхронизацию кадра), и передаваемое кодовое слово (то есть, соответствующую ему информацию длинного кода или ИДК сообщение) при наличии помех и шума. Особенно, как подробно описано ниже, предпочтительный вариант осуществления настоящего изобретения использует коды, которые прежде всего обеспечивают свойство 2. Также, как описано ниже, следует, что эти коды удовлетворяют и Свойствам 1, 3.
Сначала, чтобы дополнительно облегчить понимание настоящего изобретения, рассмотрим (упрощенный) канал, в котором не происходят ошибки бита/символа, и только происходит неизвестное число циклических сдвигов символа неизвестного, неоднократно передаваемого кодового слова. Приемник должен определить и фактический сдвиг, и передаваемое кодовое слово.
Фигура 6 является блок-схемой, иллюстрирующей, согласно предпочтительному варианту осуществления настоящего изобретения, обобщенный алгоритм декодирования, который может использоваться в декодере приемника для декодирования кодового слова, описанного выше (хотя данный алгоритм не является наиболее эффективным способом декодирования). При операции 101 декодер собирает М последовательных символов (принятое слово). Далее, при операции 102 декодер определяет, является ли принятое слово правильным кодовым словом. Если нет, то декодер выполняет операцию 103. Иначе, декодер выполняет операцию 104.
Также, если принятое слово не является правильным кодовым словом, то при операции 103, декодер циклически сдвигает принятое слово на один шаг (символ), и после этого возвращается к выполнению операции 102. Или же при операции 104, декодер выводит число осуществленных сдвигов при операции 103, выполненных для получения правильного кодового слова, и, таким образом, получает сообщение, соответствующее этому кодовому слову. Число вывода сдвигов при операции 104 дает синхронизацию кадра кодового слова.
Фигура 7 является блок-схемой, иллюстрирующей, согласно второму варианту осуществления настоящего изобретения, обобщенный алгоритм декодера максимального правдоподобия, который может использоваться в декодере приемника для декодирования кодового слова, описанного выше, при наличии помех/шума символа/бита (однако данный подход также не является наиболее эффективным). Обобщенный алгоритм декодера максимального правдоподобия обеспечивает оценку или вероятность относительно того, насколько вероятно принятые биты составляют и являются фактически кодовым словом. Оценку или вероятность представляют в виде значения вероятности (правдоподобия). В данном возможном варианте осуществления настоящее изобретение предусматривает сборку k· M символов перед фактическим декодированием принятого слова, которая обеспечивает более правильную оценку декодируемого слова, чем описанный выше первый способ, так как при этом получается множество (k) экземпляров всех кодовых символов.
При использовании в декодере возможного варианта алгоритма максимального правдоподобия, предусматриваемого данным вариантом осуществления, при операции 201 декодер собирает k· M последовательных символов (принятое слово) и комбинирует значения вероятностей символов. При операции 202 для каждого из L кодовых слов и каждого из М циклических сдвигов символа декодер вычисляет корреляции между принятым словом и соответствующими комбинациями L кодовых слов по их М посимвольным сдвигам. Декодер сохраняет и кодовое слово и число необходимых сдвигов, которые приводят к наилучшей корреляции. При операции 203 декодер выводит сохраненное кодовое слово (или соответствующее сообщение) и число сдвигов, которые привели к наилучшей корреляции.
Согласно третьему варианту осуществления настоящего изобретения будет описан более эффективный алгоритм декодирования вместе с примером, иллюстрирующим существование кодов, которые могут удовлетворять свойствам 1-3. По существу, согласно данному возможному варианту осуществления, представленный алгоритм декодирования объединяет так называемый решетчатый код хвостовых битов и код синхронизации, такой, что удовлетворяются все свойства 1-3. Также, код конструируется путем последовательного соединения (конкатенации) внутреннего решетчатого кода с внешним кодом, обладающим свойствами синхронизации, так, чтобы сконструированный общий код удовлетворял свойству 2. Из этого следует, что свойства 1 и 3 будут также удовлетворены.
Специально, согласно данному возможному варианту осуществления настоящего изобретения, сначала рассматривают (только посредством примера) входной двоичный внутренний решетчатый кодер хвостовых битов, который производит Q-тые символы. Эти символы могут представлять собой сложный скалярный или сложный векторный сигнал. Предполагается, что обеспечивается входной двоичный кадр длиной М битов. Предполагается, что входное, начальное состояние, в котором должен находиться кодер для того, чтобы завершить действия в том же самом состоянии, может быть вычислено следующим образом. Для полиномиальных кодеров порядка М начальное состояние может быть установлено равным последним М битам во входном кадре. Следовательно, кодер и декодер стартуют и заканчивают действия в одинаковом состоянии. Однако данное состояние неизвестно декодеру. Также, правильные кодовые слова являются словами, которые могут быть получены путем перемещения по решетке, начиная с определенного состояния и заканчивая в том же самом состоянии, соответствующем начальному состоянию.
Фигура 8 является диаграммой, на которой показан возможный вариант секции решетки для м=2 решетчатого кодера, который приводится в пояснительных целях. Четыре прямоугольника, размещаемые вертикально в правой стороне фигуры 8, представляют собой четыре возможных состояния регистра сдвига для решетчатого кодера при м=2, содержимое которых указано внутри данных прямоугольников. Полная решетка содержит М последовательно соединенных (конкатенированных) секций, идентичных секции решетки, показанной на фигуре 8.
Для решетчатого кодера хвостовых битов решетка обходит вокруг и последний столбец состояний становится таким же, как и первый. Стрелки с метками (например, I/код 1) указывают, что при условии данного текущего состояния кодера (состояние, из которого выходит стрелка) и входного сигнала (I), текущим выходным символом является код (1), и следующим, состоянием будет то, на которое указывает стрелка. Следует отметить, что стрелки, показанные на фигуре 8, имеют особые метки, но этим не ограничивается настоящее изобретение. Приведенные на фигуре метки кода предусмотрены только для пояснительных целей и не предназначаются для определения используемых конкретных функций согласования.
Как поясняется секцией решетки, показанной на фигуре 8, все фазы решетки в коде решетки идентичны, и один и тот же код повторяется много раз. Следовательно, путь кодового слова может рассматриваться, как путь в кольцевой решетке, показанной на фигуре 9. Также, фигура 9 является схематической диаграммой возможного варианта кольцевой решетки с М, равным 8. Каждый показанный прямоугольник представляет собой столбец состояний (например, типа одного из правого/левого столбцов, показанных на фигуре 8), и каждая показанная стрелка указывает набор возможных изменений (переходов) состояний и соответствующее отношение входа-выхода. Как упомянуто ранее, согласно настоящему изобретению, все показанные фазы решетки являются идентичными. Следовательно, любой циклический сдвиг выходной последовательности символов является также правильной выходной последовательностью. Также, состояние начала и состояние конца в пути кольцевой решетки являются одинаковыми, но фактическая позиция в решетке, где находится состояние начала/конца является неизвестной.
Используемый декодер собирает М последовательно принятых символов и делает предположение о позиции состояния начала/конца в решетке. Все циклические сдвиги допустимых траекторий также являются допустимыми траекториями. Следовательно, может быть декодирована (при предположении, что уровень шума является не слишком высоким) правильная траектория (но не позиция начала/конца). Следует отметить, что хотя этот алгоритм кодера хвостовых битов не удовлетворяет свойству 2 (выше), все посимвольные циклические сдвиги кодового слова являются правильными кодовыми словами. Однако использование такой структуры решетки легко позволяет использовать программно решаемые способы декодирования и структурированные диаграммы решетки для более эффективного декодирования. Краткий обзор известных способов, которые могут использоваться для декодирования решетчатых кодов хвостовых битов, приводится в работе Р.Коха и С.-Е.Сандберга "Эффективный адаптивный кольцевой алгоритм Витерби для декодирования обобщенных сверточных кодов хвостовых битов", труды ИИЭЭ по транспортным технологиям, том 43, номер 1, 1994, и в патенте US №5355376. Таким образом, предполагая, что была декодирована правильная траектория (наиболее вероятный случай), может быть получен вариант кольцевых сдвигов входного М битового кадра.
С целью ограничения описанных выше слов внутреннего кода так, чтобы выполнялось свойство 2, вводится внешний код синхронизации длиной М бит, который составляет упомянутый М битовый кадр. Как описано ниже, внешний код синхронизации удовлетворяет свойству 2. Следовательно, если рассматривать и внутренний, и внешний коды как единый код, то данный результирующий единый код удовлетворяет свойству 2.
После того, как был декодирован внутренний код, может быть получен сдвинутый вариант внешнего кода. Однако только один точный сдвиг этого декодируемого слова производит правильное внешнее кодовое слово. Следовательно, слово, полученное после декодирования внутреннего кода, является сдвинутым, пока не будет получено правильное кодовое слово. Число требуемых сдвигов определяет синхронизацию кадра и сообщение, соответствующее ИДК. Если после выполнения М сдвигов правильное кодовое слово так и не появляется, то может быть сделан вывод о том, что произошла ошибка внутреннего декодирования, таким образом настоящее изобретение предусматривает форму обнаружения ошибок.
Далее иллюстрируется тот факт, что такие коды синхронизации (которые удовлетворяют свойству 2) действительно существуют, и для малых значений М перечисляют кодовые слова во внешнем коде. Также, далее определяется решетчатый код для ряда различных вариантов осуществления.
Здесь описывается серия возможных кодов синхронизации (и их кардинальное число) таких, что каждый код может обеспечить свойство 2 согласно настоящему изобретению. В рассматриваемом примере, в пояснительных целях, М устанавливается равным 5, но дальнейшие рассуждения также справедливы для любого значения М. Согласно свойству 2, ограничение, накладываемое на кодовые слова заключается в том, что любой (нетривиальный) циклический сдвиг должен дать в результате отличное не-кодовое слово. Также, определяется "период" слова, как число циклических сдвигов, необходимых, для возвращения к этому слову. В данном варианте осуществления период предполагается меньшим или равным М. "Р-цикл" определяется, как набор "р"-слов с периодом "р", который получается при сдвиге "р" слов периода. Ограничение, накладываемое на каждое кодовое слово заключается в том, что оно имеет период М, и что М-1 сдвигов не дают в результате кодовые слова. При определенных выше условиях, кодером может быть использован следующий алгоритм, иллюстрируемый фигурой 10, для генерирования всех слов, которые удовлетворяют свойству 2.
Согласно фигуре 10 при операции 301, для всех 2M слов длиной М, кодер вычисляет период этих слов. Затем при операции 302 кодер исключает из рассмотрения все слова с периодами меньше М. При операции 303 кодер исключает все слова в М-циклах за исключением одного, которое может представлять цикл (например, наименьшее, если слово рассматривается, как двоичное число). При операции 304, кодер делает допущение, что оставшиеся слова удовлетворяют свойству 2 и составляют код, представляющий интерес. Иллюстрация описанного выше алгоритма приводится на фигуре 11. Как показано, М равняется 5. Стрелки, направленные направо (->), указывают, что имел место циклический сдвиг (например, правый). Учитываются все 25=32 слова, и шесть слов остаются в возникающем в результате коде синхронизации (крайний правый столбец). Следовательно, в рассмотренном примере, код синхронизации, представляющий интерес, содержит шесть кодовых слов 1, 3, 5, 7, 11, 15 (десятичное число), и, следовательно, L=6.
Фигура 12 является блок-схемой, иллюстрирующей способ декодирования возможного варианта кода синхронизации, описанного выше согласно фигуре 11 в соответствии с настоящим изобретением. При операции 401, декодер собирает М последовательных битов (полученных после внутреннего декодирования). При операции 402 декодер сдвигает полученный кадр, пока этот кадр не становится настолько маленьким, насколько возможно (например, приобретает вид двоичного числа), максимум М раз. При операции 403 декодер определяет, является ли возникшее в результате слово кодовым словом. Если это так, то при операции 404 декодер выводит сообщение, соответствующее кодовому слову вместе с числом сдвигов, которые были необходимы для получения кодового слова. Иначе, если возникшее в результате слово не является кодовым, то может быть сделано предположение о том, что произошла ошибка при внутреннем декодировании. В этом случае, при операции 405 декодер может вывести сообщение об ошибке внутреннего декодирования. На фигуре 13 приведена распечатка описанного выше алгоритма поиска кода синхронизации, а на фигуре 14 приведено кардинальное число (то есть, определяющее количество, но не порядок) некоторых кодов синхронизации для малых значений М.
В системе МДКР-ПП М кодовых символов могут содержать число Q так называемых коротких кодов длиной N. Эти короткие коды часто ортогональны друг другу, или иначе имеют хорошие характеристики взаимной корреляции. Рассмотрим низкоскоростной, независимый от времени решетчатый код, в котором символы на ветвях решетки являются векторами, которые выбираются из набора Q векторов, определенных выше (или просто символами, как называется здесь). Например, подобный набор векторов описывается в патенте US №5193094.
Фигуры 15А и 15В являются функциональными схемами возможных вариантов решетчатых кодеров 10 и 20, соответственно, которые могут быть использованы для реализации настоящего изобретения. По существу, такой решетчатый кодер строится в виде регистра сдвига (12, 22) длиной м, с входным сигналом, I, и преобразователя (14, 24), который выполняет преобразование состояния соответствующего регистра сдвига (12, 22) и текущего входного сигнала, I, в выходной вектор (например, с1, с2, ... , cN). В решетчатых кодерах 10, 20, как показано на фигуре, длина регистра сдвига (m) равна 3. Следовательно, каждый из регистров сдвига 12, 22 может принимать 8 различных состояний. Набор необходимых векторов/символов (например, с1, с2, ... , cN) составляет набор ортогональных векторов для ортогонального решетчатого кодера 10 (фигура 15А), и набор ортогональных или диаметрально противоположных векторов для суперортогонального решетчатого кодера 20 (фигура 15В).
По существу, ортогональный код решетки получается, если преобразование состояния регистра и входного сигнала, I, дает в результате вектор, и, если набор таким образом полученных векторов формирует набор ортогональных векторов. Суперортогональный код формируется, если первые m-1 состояний регистра определяют ортогональный вектор, и могут быть взяты в качестве выходного вектора, если сумма по модулю 2 входного бита и содержания состояния m-го регистра не равна 1. В этом случае выходной вектор поразрядно инвертируется инвертором 26. При стандартном преобразовании, типа 0/1->+1/-1, можно заметить, что выходные данные для некоторого состояния являются диаметрально противоположными векторами в зависимости от входных данных 0 и 1, соответственно. По существу, такие коды являются подходящими для применения в МДКР-ПП, такие коды могут быть использованы, как символы, из-за свойственного им эффекта расширения (очень низкая скорость кода), хороших характеристик корреляции, и свойственных им возможностей по исправлению ошибок благодаря решетчатой структуре.
Дополнительно к описанному выше согласно настоящему изобретению новому способу кодирования (декодирования) предложен также новый способ использования для поиска сотовой ячейки указателя синхронизации кадра (УСК), использующего схему кодирования, предлагаемую настоящим изобретением, например, схему поиска сотовой ячейки согласно предложениям ARIB для широкополосной системы связи МДКР. По существу, относящиеся к извлечению информации каналы, передаваемые по нисходящей линии связи, описанные в текущих предложениях ARIB по широкополосной системе связи МДКР, облегчают используемую мобильной станцией трехэтапную процедуру извлечения информации. Однако так как упомянутые, относящиеся к извлечению информации, каналы не содержат информации о синхронизации кадра, заключительный этап предложенной ARIB процедуры является довольно сложным и/или требующим больших временных затрат. Как описано ниже, настоящее изобретение предлагает, по крайней мере, два способа, которые могут использоваться для обеспечения УСК, например, внутри структуры схемы, предлагаемой ARIB по широкополосной системе связи МДКР.
Конкретно, фигура 16 является диаграммой, иллюстрирующей способ поиска сотовой ячейки, который следует использовать мобильной станции согласно предложениям ARIB по широкополосным системам связи МДКР. В каждом интервале времени первичный код синхронизации (ПКС) и вторичный код синхронизации (ВКС) передаются параллельно, оба с известной модуляцией, но без скремблирования длинным кодом. Протяженность ПКС/ВКС составляет один символ физического канала, передающего 16 килосимвол/сек, или 256 элементарных сигналов. В системе имеется NВКС допустимых ВКС, которые дают log2(NВКС) битов информации, которую нужно использовать для ИДК. Характеристики ПКС и ВКС суммируются в таблице, приведенной на фигуре 17. Как поясняется фигурой 17, для мобильной станции не предусматривается никакой УСК, что может привести к гораздо более длительному поиску сотовой ячейки, чем это необходимо.
Фигура 18 является таблицей, в которой приводится информация, которая может быть предоставлена ПКС/ВКС для поиска сотовой ячейки согласно настоящему изобретению. Хотя данная информация может быть предоставлена несколькими способами, ниже описаны два возможных варианта осуществления, которые могут быть использованы для предлагаемых здесь схем поиска сотовой ячейки.
Конкретно, согласно одному варианту осуществления настоящего изобретения (как поясняется фигурой 19), как в предлагаемой ARIB схеме, ВКС является одинаковым в каждом интервале времени в кадре, и в системе имеются NВКС допустимых ВКС, которые дают log2(NВКС) битов информации, которая должна быть использована для ИДК. ВКС на всем протяжении кадра дополнительно модулируются одним из NМОД возможных вариантов допустимой (например, двоичной) последовательности длиной 16. Данный способ предлагает ИДК и другие log2(NМОД) битов информации для использования ИДК. Результирующие модулирующие последовательности длиной 16 имеют хорошие характеристики автокорреляции.
Если значение NМОД больше 1, то также должны быть обеспечены следующие свойства: (1) хорошая взаимная корреляция и (2) циклический сдвиг любой правильной модулирующей последовательности не может привести к другой правильной модулирующей последовательности (и любой циклический сдвиг ее). Если модулирующие последовательности, полученные таким образом, удовлетворяют упомянутым свойствам, то УСК становится известным при обнаружении любой правильной модулирующей последовательности в приемнике мобильной станции. Когерентное обнаружение принимаемого сигнала облегчается за счет использования ПКС в качестве эталонных символов для получения опорного сигнала фазы канала. Также, свойственно УСК. Следовательно, все log2(NВКС)+log2(NМОД) битов информации могут быть использованы для ИДК.
Согласно второму варианту осуществления настоящего изобретения (как поясняется фигурой 20), имеется последовательность 16-ти ВКС, которая повторяется в каждом кадре. Вообще, имеется NВКС_ посл подобных ВКС последовательностей, которые могут быть использованы в системе, производящей log2 (NВКС_ посл) битов информации, которая может использоваться для ИДК. В этом случае, предпочтительно, чтобы каждая последовательность ВКС являлась уникальной, и индивидуальные ВКС имели хорошие характеристики автокорреляции и взаимной корреляции. Однако можно предположить, что на практике будет выполняться равенство NВКС_ посл=1.
При нахождении правильной последовательности ВКС, по существу получается УСК, и последовательность ВКС может также модулироваться, согласно способу, описанному непосредственно выше для первого варианта осуществления, который производит log2(NМОД) битов информации для использования ИДК. В данном случае, ИДК может использовать 65,536 различных значений (более чем достаточно), которые обеспечивают большую эффективность обнаружения ИДК.
Фигура 21 является таблицей, которая поясняет два алгоритма (способа) поиска сотовой ячейки, которые могут использоваться для реализации настоящего изобретения. Также, таблица, показанная на фигуре 21, обеспечивает сравнение двух возможных вариантов способа поиска сотовой ячейки согласно настоящему изобретению с действующим способом поиска сотовой ячейки согласно предложениям ARIB по широкополосной системе связи МДКР. Строки таблицы (этапы) на фигуре 21 иллюстрируют включаемые стадии поиска сотовой ячейки. Например, на первой стадии (этап 1), используется согласованный фильтр (СФ) для обеспечения синхронизации временных интервалов (СВИ). На второй стадии, при коррелировании (КОРР) с ВКС, поскольку ПКС обеспечивает указатель фазы, корреляции могут когерентно накапливаться. С другой стороны, корреляции могут быть выполнены только один раз на интервале времени, потому что на интервал времени имеется только один ВКС. При коррелировании с длинным кодом (ДК) на третьей стадии, корреляции должны накапливаться некогерентно. Однако данная корреляция может быть выполнена над последовательными символами, так как длинный код применяется к каждому символу в кадре. В данном случае, корреляция выполняется путем последовательного соединения длинного кода и известного короткого кода КУП, который всегда передается по нисходящей линии связи. Если длинный код может быть точно указан с помощью ИДК, то необходим только один этап корреляции согласно двум возможным вариантам осуществления, описанным выше. Однако с предлагаемой в настоящее время ARIB схемой поиска сотовой ячейки, для получения синхронизации кадра (СК) в дополнение к этапам, описанным выше, требуется дополнительный поиск.
Для иллюстрации путем примера операций приемника, необходимых для осуществления способов, поясняемых фигурой 21, могут быть сделаны следующие выборки: NВКС=256 длинных кодов, сгруппированных как 16× 16, NМОД=1, NВКС_ посл=1, при этом предполагается (для простоты), что когерентное накопление 16 корреляций (по 256 элементарных сигналов каждая) является достаточным для адекватного обнаружения. При обеспечении предлагаемой в настоящее время ARIB схемы поиска сотовой ячейки формируется следующая матрица корреляции:
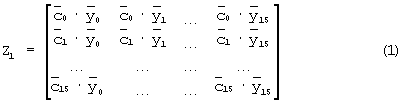
где 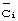 обозначают 16 различных ВКС,
обозначают 16 различных ВКС, 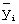 обозначают 16 последовательно принятых ВКС, и скалярное произведение обозначает, что корреляция осуществлена. При наличии 16 корреляторов в приемнике мобильной станции, 16 корреляторов должны использоваться для 16 интервалов времени, чтобы сформировать 256 корреляций Z1. Элементы Z1 могут также быть умножены на соединения соответствующих ПКС корреляций для устранения сдвига фазы, получившегося в результате ошибок синхронизации частоты и канала радиосвязи. Можно допустить, как то, что это умножение уже выполнено в матрице (1) выше, так и выполнение умножения во время описываемых ниже этапов. Затем строки Z1 суммируются. Одна из этих сумм будет иметь большее значение, чем остальные, которое и определяет ВКС.
обозначают 16 последовательно принятых ВКС, и скалярное произведение обозначает, что корреляция осуществлена. При наличии 16 корреляторов в приемнике мобильной станции, 16 корреляторов должны использоваться для 16 интервалов времени, чтобы сформировать 256 корреляций Z1. Элементы Z1 могут также быть умножены на соединения соответствующих ПКС корреляций для устранения сдвига фазы, получившегося в результате ошибок синхронизации частоты и канала радиосвязи. Можно допустить, как то, что это умножение уже выполнено в матрице (1) выше, так и выполнение умножения во время описываемых ниже этапов. Затем строки Z1 суммируются. Одна из этих сумм будет иметь большее значение, чем остальные, которое и определяет ВКС.
Согласно первому варианту осуществления (способ 1, описанный выше), также формируется матрица (1). Однако, чтобы осуществить способ 1, матрица (1) дополнительно умножается на следующую матрицу:
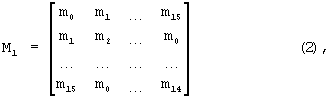
где столбцы содержат все циклические сдвиги модулирующей последовательности (здесь для простоты принимается, что это реальные значения). Умножение Z1M1 дает в результате матрицу 16× 16, где один из элементов будет иметь большее значение, чем остальные. Индекс строки этого элемента определяет ИДК, а индекс столбца определяет синхронизацию кадра (УСК).
Согласно второму варианту осуществления настоящего изобретения (способ 2, описанный выше), вместо матрицы (1) формируется следующая матрица:
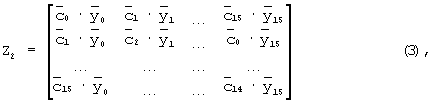
где 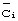 являются ВКС из последовательности ВКС. Матрица (3) затем умножается на следующую матрицу:
являются ВКС из последовательности ВКС. Матрица (3) затем умножается на следующую матрицу:
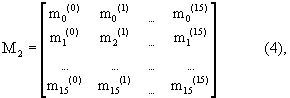
где столбцы представляют все 16 возможных модулирующих последовательностей (снова для простоты предполагаются реальные значения). Перемножение матриц Z2M2 снова дает в результате матрицу 16х16, где один из элементов должен был бы иметь большее значение, чем остальные. Индекс строки этого элемента определяет УСК, а индекс столбца определяет ИДК.
Операции для описанных выше способов настоящего изобретения могут быть расширены для включения более общих случаев. Например, если требуется большее количество модулирующих последовательностей, то матрица M1 (M2) может быть расширена новыми столбцами, содержащими все сдвиги всех возможных м-последовательностей. Если требуется большее количество последовательностей ВКС при выполнении второго способа, описанного выше, то матрица Z2 может быть расширена добавлением строк сдвинутых корреляций со всеми возможными последовательностями ВКС. Если имеется больше длинных кодов на группу, то матрица, Z1, описанная выше для первого способа, может быть расширена добавлением большего количества строк корреляций. По существу, с ограниченным набором корреляторов для использования, корреляции могут выполняться в последовательных кадрах, и при этом продолжается их когерентное накопление. Данное наблюдение в соответствии с настоящим изобретением допустимо для обоих описанных выше способов поиска сотовой ячейки.
Далее дается сравнение двух способов поиска сотовой ячейки, предлагаемых настоящим изобретением, со схемой поиска сотовой ячейки согласно предложениям ARIB по широкополосной системе связи МДКР. Для осуществления такого сравнения, предполагается, что параметры системы, показанные ниже в таблице 1, применимы для каждого из следующих случаев.
16× 16, 32× 4
Следующие таблицы 2-5 иллюстрируют преимущества двух способов поиска сотовой ячейки, предложенных настоящим изобретением, перед способом поиска сотовой ячейки согласно предложениям ARIB по широкополосным системам связи МДКР. Например, таблица 2, приведенная ниже, показывает число требуемых корреляций 256 элементарных сигналов, и время, требуемое для получения синхронизации нисходящей линии связи для трех схем поиска сотовой ячейки для случая, где не содержится группировки длинного кода.
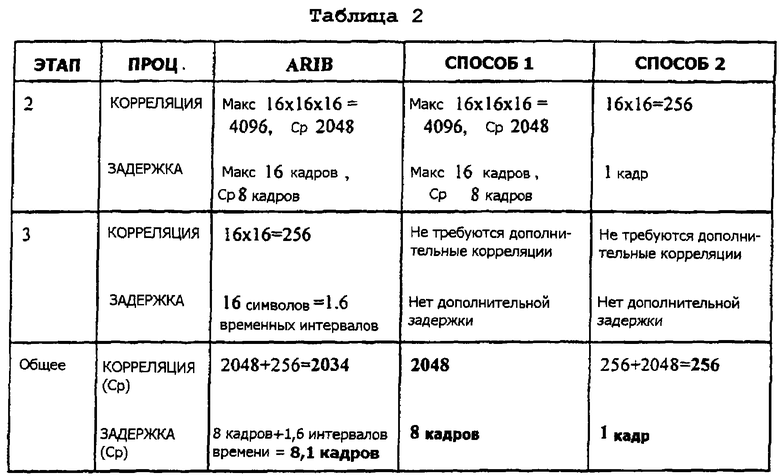
Таблица 3, приведенная ниже, показывает ту же самую информацию для случая, где имеются четыре группы длинного кода, каждая из которых содержит 32 кода.
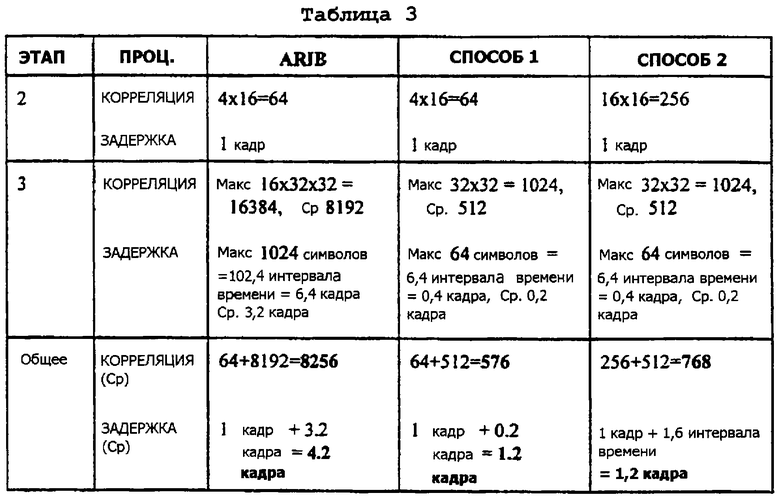
Таблица 4, приведенная ниже, показывает ту же самую информацию для случая, где имеются 16 групп длинных кодов, в каждой из которых содержится 16 кодов.
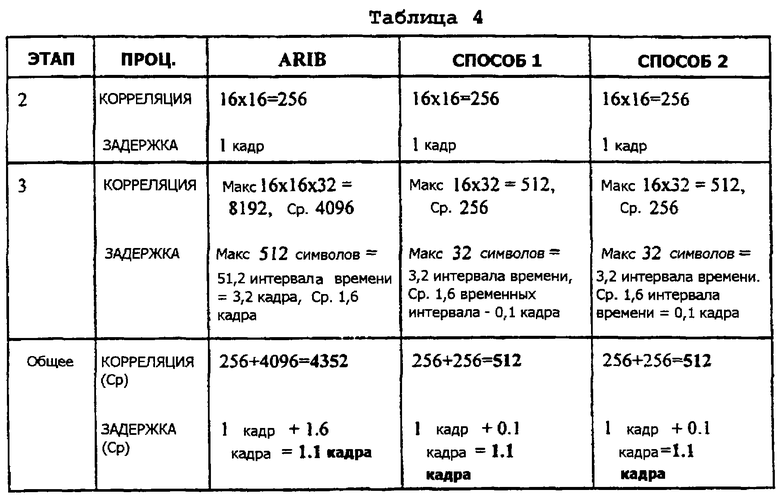
Таблица 5, приведенная ниже, показывает ту же самую информацию для случая, где имеются 32 группы длинных кодов, в каждой из которых содержится 4 кода.
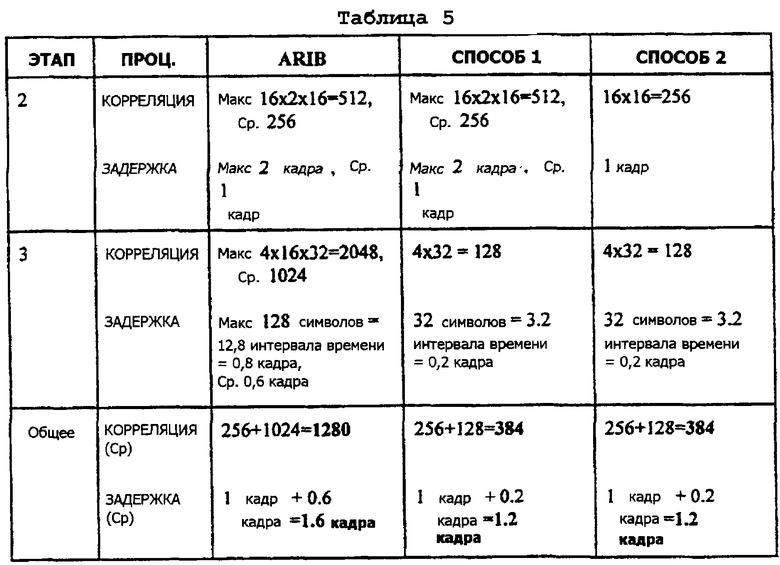
Первый этап (согласованной фильтрации или СФ) является одинаковым для всех трех способов. Следовательно, этот этап опускается из таблиц 2-5, приведенных выше, в целях простоты изложения. Для некоторых корреляций даны максимальное и среднее значения. Причиной такого подхода является то, что когда выполняется поиск при недостаточной информации (слепой поиск) для ДК и СК, процесс корреляции может быть завершен прежде, чем найдены все возможные комбинации, если было получено достаточно хорошее соответствие. При выполнении слепых поисков (например, среди N различных кодов), в среднем должны быть проведены N/2 кода. Однако для наихудшего случая, придется проверить все N кодов. Также, может быть принято решение выполнить умножение матриц, Z1M1, немедленно, и их сложность, таким образом, не учитывается в таблицах, приведенных выше. В заключение, как поясняется таблицами 2-5, два возможных варианта способа поиска сотовой ячейки, описанных выше и выполняемых согласно настоящему изобретению, облегчают, делают быстрее и менее сложным, процесс поиска сотовой ячейки в мобильной станции, включая и начальную синхронизацию, и во время ситуаций сообщения характеристик передачи. Также, как показывают таблицы 2-5, представленные выше, и задержка, и сложность способов поиска сотовой ячейки, предлагаемых настоящим изобретением, ниже, чем для способа поиска сотовой ячейки согласно предложениям ARIB. В частности, третья стадия (этап 3) процедуры поиска сотовой ячейки в мобильной станции, выполняемая согласно двум способам, предусматриваемым настоящим изобретением, является в 16 раз быстрее и менее сложной, чем в способе, предлагаемом ARIB.
Хотя иллюстрировался сопровождающими чертежами и был описан в предшествующем детальном описании предпочтительный вариант осуществления способа и устройства, предложенных настоящим изобретением, понятно, что настоящее изобретение не исчерпывается рассмотренными вариантами осуществления, а может быть различным образом модифицировано путем перестановок, изменений и замен, без отступления от сущности изобретения, которая изложена и определена формулой изобретения.
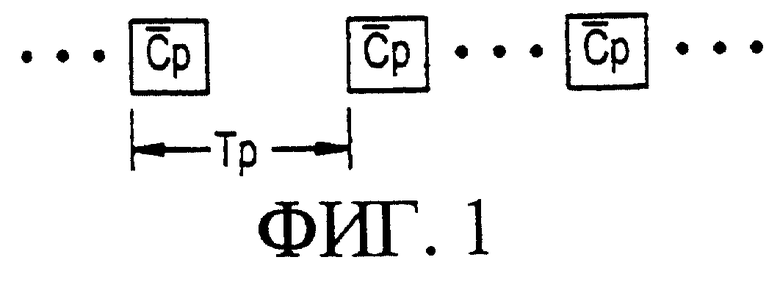


Изобретение относится к системам передачи данных с расширенным спектром, а конкретно к процессу поиска сотовой ячейки, осуществляемому мобильной станцией для обеспечения синхронизации с базовой станцией. Сущность изобретения состоит в кодировании для более эффективного извлечения длинного кода и синхронизации кадра при поиске сотовой ячейки в системе связи МДКР. Определяется обладающий определенными свойствами набор кодов, состоящий из Q-тых кодовых слов длиной М, включающий символы из набора Q коротких кодов. Первым свойством является то, что никакой циклический сдвиг кодового слова не дает в результате правильное кодовое слово. Другими свойствами являются наличие взаимно однозначного соответствия между сообщением длинного кода и правильным кодовым словом. При этом декодер при наличии помех и шума обеспечивает с приемлемой степенью сложности поиск как случайного сдвига (таким образом неявно определяя синхронизации кадра), так и передаваемого кодового слова (то есть, относящееся к нему сообщение индикации длинного кода). Технический результат, достигаемый при осуществлении изобретения, состоит в обеспечении несложного решения для более эффективного распознавания длинного кода и синхронизации кадра во время поиска сотовой ячейки, которое дает кодирующее усиление для уменьшения времени поиска и/или для обеспечения требуемого отношения мощности бита информации к шуму. 5 н. и 14 з.п. ф-лы, 21 ил., 5 табл.
| US 5559829 А, 24.09.1996 | |||
| СПОСОБ ПЕРЕДАЧИ И ПРИЕМА ИНФОРМАЦИИ С КОДОВЫМ УПЛОТНЕНИЕМ СИГНАЛОВ | 1991 |
|
RU2014738C1 |
| RU 2002374 C1, 30.10.1993 | |||
| Домовый номерной фонарь, служащий одновременно для указания названия улицы и номера дома и для освещения прилежащего участка улицы | 1917 |
|
SU93A1 |
| ЕР 0563020 А3, 29.09.1993. | |||

