Притязание на приоритет по 35 U.S.C. §119
Настоящая Заявка на патент заявляет преимущество Предварительной заявки № 60/538271, озаглавленной «Buffer Size Reduction in a Hierarchical Coding System» (Уменьшение размера буфера в системе иерархического кодирования), зарегистрированной 21 января 2004 года и назначенной правопреемнику этой заявки, и таким образом включенной в явной форме в данный документ посредством ссылки.
I. Область техники, к которой относится изобретение
Настоящее изобретение относится в целом к связи, а конкретнее к методикам для выполнения обнаружения данных для передачи иерархически кодированных данных в системе беспроводной связи.
II. Предшествующий уровень техники
Иерархическое кодирование является методикой передачи данных, посредством которой множества (например, два) потока данных накладываются (например, добавляются) друг на друга и передаются одновременно. «Кодирование» в этом контексте относится скорее к канальному кодированию, чем к кодированию данных в передатчике. Иерархическое кодирование может преимущественно использоваться, например, для доставки услуг широковещательной передачи пользователям внутри обозначенной зоны широковещания. Эти пользователи могут чувствовать различные условия канала и добиваться различных отношений уровня сигнала к совокупному уровню взаимных помех и шумов (SNR). Следовательно, эти пользователи способны принимать данные на различных скоростях передачи данных. С помощью иерархического кодирования широковещательные данные могут разделяться на «основной поток» и «поток расширения». Основной поток обрабатывается и передается способом из условия, чтобы все пользователи в зоне широковещания могли восстановить поток. Поток расширения обрабатывается и передается способом из условия, чтобы все пользователи с лучшими условиями канала могли восстановить поток.
Чтобы восстановить передачу иерархически кодированных данных, приемник сначала обнаруживает и восстанавливает основной поток, трактуя поток расширения как шум. Приемник затем оценивает и подавляет помехи, обусловленные основным потоком. После этого приемник обнаруживает и восстанавливает поток расширения с подавленными помехами от основного потока. Для улучшенной производительности основной поток и поток расширения обычно восстанавливаются последовательно, один поток за раз, в описанном выше порядке. Для восстановления каждого потока обычно требуется большой объем обработки. Более того, может также требоваться большой объем буферизации в зависимости от способа и скорости, с которой каждый поток может быть обнаружен и восстановлен. Большие объемы обработки и буферизации могут влиять на производительность системы и затраты.
Следовательно, существует необходимость в данной области техники в методиках для эффективного выполнения обнаружения данных для передачи иерархически кодированных данных.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В данном документе описываются методики для выполнения обнаружения данных для передачи иерархически кодированных данных. Эти методики могут использоваться для систем беспроводной связи как с одной несущей, так и с несколькими несущими (например, OFDM (мультиплексирование с ортогональным частотным разделением сигналов)).
В одной схеме обнаружения данных принятые символы первоначально получаются для передачи иерархически кодированных данных с помощью множества (например, двух) потоков данных, и логарифмические отношения правдоподобия (LLR) для кодовых битов первого потока данных (основного потока) выводятся на основе принятых символов. LLR для первого потока данных декодируются для получения декодированных данных, которые дополнительно перекодируются и ремодулируются для получения ремодулированных символов для первого потока данных. Помехи, обусловленные первым потоком данных, оцениваются на основе ремодулированных символов. LLR для кодовых битов второго потока данных (потока расширения) затем выводятся на основе LLR для кодовых битов первого потока данных и оцененных помех. LLR для первого потока данных могут быть (1) выведены из принятых символов в реальном масштабе времени без буферизации принятых символов и (2) сохранены в буфере для декодирования. LLR для второго потока данных могут быть (1) выведены после того, как декодирован первый поток данных и (2) сохранены в том же буфере посредством перезаписи LLR для первого потока данных. Принятые символы не используются для выведения LLR для второго потока данных и поэтому их не нужно буферизовать.
В другой схеме обнаружения данных LLR для кодовых битов первого потока данных первоначально выводятся на основе принятых символов. Оценки символов данных (или некодированных символов жесткого решения) для первого потока данных затем выводятся на основе либо принятых символов, либо LLR для первого потока данных. Помехи, обусловленные первым потоком данных, оцениваются на основе оценок символов данных и подавляются в принятых символах для получения символов с подавленными помехами. LLR для кодовых битов второго потока данных затем выводятся на основе символов с подавленными помехами. LLR и для первого, и для второго потоков данных могут вычисляться из принятых символов в реальном масштабе времени без буферизации принятых символов. LLR для второго потока данных могут регулироваться/корректироваться после того, как декодирован первый поток данных посредством (1) обнаружения ошибок в оценках символов данных на основе ремодулированных символов для первого потока данных, и либо (2а) назначения LLR для кодовых битов оценок символов данных, которые ошибочны, для аннулирований, либо (2b) модифицирования LLR для кодовых битов оценок символов данных, которые являются ошибочными, с помощью поправочных коэффициентов, выведенных на основе ремодулированных символов и оценок символов данных.
Различные аспекты и варианты осуществления изобретения описываются более подробно далее.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Признаки и особенность настоящего изобретения станут более очевидными из изложенного ниже подробного описания, рассматриваемого вместе с чертежами, на которых одинаковые ссылочные позиции определяют соответственно одинаковые элементы по всему документу и где:
Фиг. 1 показывает передатчик и приемник в системе беспроводной связи;
Фиг. 2А показывает сигнальное созвездие для QPSK;
Фиг. 2В показывает сигнальное созвездие для иерархического кодирования с помощью QPSK как для основного потока, так и для потока расширения;
Фиг. 3 показывает процессор приема (RX) для первой схемы обнаружения данных;
Фиг. 4 показывает процессор RX для второй схемы обнаружения данных;
Фиг. 5 показывает процессор RX для третьей схемы обнаружения данных; и
Фиг. 6 показывает процессор RX для второй схемы обнаружения данных с помощью схемы модуляции более высокого порядка для основного потока.
ПОДРОБНОЕ ОПИСАНИЕ
Слово «типовой» используется в данном документе, чтобы обозначать «служащий в качестве примера, отдельного случая или иллюстрации». Любой вариант осуществления или проект, описанный в данном документе как «типовой», не обязательно должен быть истолкован как предпочтительный или выгодный по сравнению с другими вариантами осуществления или проектами.
Фиг. 1 показывает блок-схему передатчика 110 и приемника 150 в системе 100 беспроводной связи. В передатчике 110 кодер/модулятор 122а внутри процессора 120 передаваемых (TX) данных принимает, кодирует, перемежает и модулирует (т.е. символьно отображает) основной поток данных (обозначенный как {db}) и предоставляет соответствующий основной поток символов (обозначенный как {sb}). Кодер/модулятор 122b аналогично принимает, кодирует, перемежает и модулирует поток данных расширения (обозначенный как {de}) и предоставляет соответствующий поток символов расширения (обозначенный как {se}). Данные для каждого потока обычно кодируются в пакеты, при этом каждый пакет кодируется отдельно в передатчике и декодируется отдельно в приемнике. Потоки {sb} и {se} символов содержат «символы данных» каждый, которые являются символами модуляции для данных.
Объединитель 130 принимает и объединяет основной поток и поток символов расширения. Внутри объединителя 130 умножитель 132а принимает и умножает основной поток {sb} символов на масштабный коэффициент K b, а умножитель 132b принимает и умножает поток {se} символов расширения на масштабный коэффициент K e. Масштабные коэффициенты K b и K e определяют величину мощности передатчика для использования для основного потока и потока расширения соответственно. Большая часть общей мощности P total передатчика обычно выделяется основному потоку. Сумматор 134 принимает и суммирует масштабированные символы данных от умножителя 132а с масштабированными символами данных от умножителя 132b и предоставляет объединенные или составные символы, которые могут выражаться как:
a.  ,
,  Уравнение (1)
Уравнение (1)
где s b является символом данных для основного потока, s e является символом данных для потока расширения и x является объединенным символом. Масштабирование и объединение выполняются на посимвольной основе.
Блок 138 передатчика (TMTR) принимает поток объединенных символов (обозначенный как {x}) от объединителя 130 и пилот-символы (контрольные символы), обрабатывает объединенные и контрольные символы на основе модели системы и формирует один или более модулированных сигналов. Пилот-символ является символом модуляции для пилот-сигнала, который известен заранее как передатчику, так и приемнику, и может использоваться приемником для оценки канала и других целей. Блок 138 передатчика может выполнять модуляцию с мультиплексированием с ортогональным частотным разделением каналов (OFDM) для передачи объединенных и пилот-символов по множеству поддиапазонов, пространственную обработку для передачи объединенных и пилот-символов из множества антенн и т.д. Модулированный(е) сигнал(ы) передаются через беспроводной канал к приемнику 150.
В приемнике 150 блок 160 приемника (RCVR) принимает один или более сигналов через беспроводной канал, обрабатывает принятый(е) сигнал(ы) способом, дополнительным к обработке, выполняемой блоком 138 передатчика, предоставляет принятые пилот-символы (обозначенные как {yp}) 162 блоку оценки канала, и предоставляет поток принятых символов (обозначенный как {y}) процессору 170 RX. Принятые символы могут выражаться как:
 ,
, Уравнение (2)
Уравнение (2)
где h является комплексным коэффициентом усиления канала для объединенного символа x, n является шумом, наблюдаемым объединенным символом x, и y является принятым символом для объединенного символа x. Шум n включает в себя шум в канале и помехи, шум схемы приемника и т.д.
Блок 162 оценки канала оценивает ответ беспроводного канала на основе принятых пилот-символов и предоставляет оценки  коэффициента усиления канала. Для простоты описание в данном документе предполагает оценку канала без ошибки, т.е.
коэффициента усиления канала. Для простоты описание в данном документе предполагает оценку канала без ошибки, т.е.  .
.
Процессор 170 RX включает в себя детекторы 172 и 176, блок 174 подавления помех, декодеры 182 и 186 и кодер/модулятор 184. Детектор 172 выполняет обнаружение данных на потоке {y} принятых символов для основного потока и предоставляет обнаруженные символы для основного потока (обозначенный как  ). Каждый обнаруженный символ
). Каждый обнаруженный символ  является оценкой символа s
b данных и может быть представлен, например, множеством логарифмических отношений правдоподобия (LLR), как описано далее. Декодер 182 декодирует обнаруженные символы для основного потока и предоставляет декодированный основной поток (обозначенный как
является оценкой символа s
b данных и может быть представлен, например, множеством логарифмических отношений правдоподобия (LLR), как описано далее. Декодер 182 декодирует обнаруженные символы для основного потока и предоставляет декодированный основной поток (обозначенный как  ). Кодер/модулятор 184 затем перекодирует и ремодулирует декодированный основной поток таким же способом, как выполняемый передатчиком 110, и предоставляет ремодулированный основной поток (обозначенный как
). Кодер/модулятор 184 затем перекодирует и ремодулирует декодированный основной поток таким же способом, как выполняемый передатчиком 110, и предоставляет ремодулированный основной поток (обозначенный как  ), который является оценкой основного потока {sb} символов. Блок 174 подавления помех принимает ремодулированный основной поток, оценивает и подавляет помехи, обусловленные основным потоком, в потоке принятых символов и предоставляет поток символов с подавленными помехами (обозначенный как {ye}) детектору 176. Детектор 176 выполняет обнаружение данных в потоке {ye} символов с подавленными помехами для потока расширения и предоставляет обнаруженные символы для потока расширения (обозначенного как
), который является оценкой основного потока {sb} символов. Блок 174 подавления помех принимает ремодулированный основной поток, оценивает и подавляет помехи, обусловленные основным потоком, в потоке принятых символов и предоставляет поток символов с подавленными помехами (обозначенный как {ye}) детектору 176. Детектор 176 выполняет обнаружение данных в потоке {ye} символов с подавленными помехами для потока расширения и предоставляет обнаруженные символы для потока расширения (обозначенного как  ). Декодер 186 декодирует обнаруженные символы для потока расширения и предоставляет декодированный поток расширения (обозначенный как
). Декодер 186 декодирует обнаруженные символы для потока расширения и предоставляет декодированный поток расширения (обозначенный как  ).
).
Контроллеры 140 и 190 управляют функционированием передатчика 110 и приемника 150 соответственно. Модули 142 и 192 памяти предусматривают хранение программных кодов и данных, используемых контроллерами 140 и 190 соответственно.
На обнаружение данных, выполняемое приемником, влияют различные факторы, такие как схема модуляции, используемая для каждого потока данных, конкретная форма, используемая для представления обнаруженных символов, методика, используемая для выполнения обнаружения данных и т.д. Для ясности обнаружение данных в передачах иерархически кодированных данных с квадратурной фазовой модуляцией (QPSK) для обоих потоков и использование LLR для представления обнаруженных символов особо описано ниже.
Фиг. 2А показывает сигнальное созвездие 200 для QPSK, которое включает в себя четыре сигнальных точки с 210а по 210d на двумерной комплексной плоскости. Эти четыре сигнальные точки расположены в координатах 1+j1, 1-j1, -1+j1 и -1-j1 и им даны метки '11', '10', '01' и '00' соответственно. Для модуляции QPSK каждая пара кодовых битов (обозначенная как b
1 и b
2
) отображается в одну из четырех возможных сигнальных точек, и комплексная величина для отображенной сигнальной точки является символом модуляции для пары кодовых битов. Например, бит b
1 может использоваться для синфазной (I) составляющей, а бит b
2 может использоваться для квадратурной (Q) составляющей символа модуляции. В этом случае символ модуляции для каждой пары кодовых битов может выражаться как: s=b
1
+jb
2, где  и
и  .
.
Фиг. 2В показывает сигнальное созвездие 250 для иерархического кодирования с помощью QPSK как для основного потока, так и для потока расширения. Созвездие QPSK для основного потока представляется посредством четырех сигнальных точек с 210а по 210d. Созвездие QPSK для потока расширения накладывается на созвездие QPSK для основного потока и представляется посредством четырех сигнальных точек с 260а по 260d на каждой сигнальной точке 210. Масштабные коэффициенты K b и K e определяют (1) расстояние между сигнальными точками 210 основного потока и центром комплексной плоскости и (2) расстояние между сигнальными точками 260 потока расширения и сигнальными точками 210 основного потока.
Ссылаясь снова на фиг. 2А, с помощью QPSK символ модуляции для одной из только четырех возможных сигнальных точек передается для каждой пары кодовых битов. Однако из-за шума, помех и искажения в беспроводном канале принятый символ (например, символ 212 на фиг. 2А) может не попасть непосредственно в одну из четырех возможных сигнальных точек. Обнаружение данных выполняется для удаления влияния беспроводного канала (например, для удаления комплексного коэффициента h усиления канала) и для выяснения, которая из четырех возможных сигнальных точек является переданным символом s данных. Информация для каждого обнаруженного символа  часто представляется в форме LLR для каждого из двух составляющих кодовых битов b
1 и b
2 для обнаруженного символа. Каждый LLR указывает правдоподобие своего кодового бита b
i
, являясь единицей ('1' или +1) или нулем ('0' или -1). LLR для i-го кодового бита обнаруженного символа
часто представляется в форме LLR для каждого из двух составляющих кодовых битов b
1 и b
2 для обнаруженного символа. Каждый LLR указывает правдоподобие своего кодового бита b
i
, являясь единицей ('1' или +1) или нулем ('0' или -1). LLR для i-го кодового бита обнаруженного символа  может выражаться как:
может выражаться как:
 , для i=1, 2 для QPSK, Уравнение (3)
, для i=1, 2 для QPSK, Уравнение (3)
где b
i есть i-й кодовый бит для обнаруженного символа ;
 есть вероятность, что бит b
i обнаруженного символа равен 1;
есть вероятность, что бит b
i обнаруженного символа равен 1;
a.  есть вероятность, что бит b
i обнаруженного символа равен -1;
есть вероятность, что бит b
i обнаруженного символа равен -1;
b. LLR i является LLR кодового бита b i.
LLR является биполярным значением с большим положительным значением, соответствующим более высокому правдоподобию, что кодовый бит равен +1, и большим отрицательным значением, соответствующим более высокому правдоподобию, что кодовый бит равен -1. LLR нуля указывает, что кодовый бит равновероятно является +1 или -1. LLR для каждого кодового бита обычно квантуется на заранее определенное число битов (или L битов, где L > 1), чтобы облегчить хранение. Число битов для использования для LLR зависит от различных факторов, например, требований декодера, SNR обнаруженных символов и т.д.
Фиг. 1 показывает символическое представление обнаружения данных для передачи иерархически кодированных данных. Обнаружение данных может выполняться различными способами. Далее описываются три схемы обнаружения данных.
Фиг. 3 показывает процессор 170а RX для первой схемы обнаружения данных, в которой основной поток и поток расширения оба обнаруживаются на основе принятых символов {y}. Процессор 170а RX является вариантом осуществления процессора 170 RX по фиг. 1.
В процессоре 170а RX принятые символы {y} первоначально сохраняются в буфере 314. Блок 320 вычисления LLR основного потока извлекает принятые символы из буфера 314 и выполняет обнаружение данных на каждом принятом символе y для получения двух LLR для двух кодовых битов символа s b основного потока, который переносится в этом принятом символе. Два LLR для основного потока могут выражаться как:
 ,
, Уравнение (4)
Уравнение (4)
где  и
и  являются LLR для двух битов символа s
b основного потока в принятом символе y;
являются LLR для двух битов символа s
b основного потока в принятом символе y;
a. h является оценкой коэффициента усиления канала для принятого символа y;
b. «*» означает комплексно сопряженное число;
c. E b является энергией символа s b основного потока; и
d. N 0,b является мощностью шума и помех, наблюдаемых посредством символа s b основного потока.
Предполагается, что символ s
b основного потока имеет комплексное значение  . Энергия символа основного потока равна
. Энергия символа основного потока равна  , а энергия символа потока расширения равна
, а энергия символа потока расширения равна  , где E
total является общей энергией для объединенного символа x. Мощность N
0,b шума и помех включает в себя шум N
0 канала и помехи от потока расширения. Блок 320 вычисления предоставляет LLR основного потока (обозначенные как {LLR
b}) через мультиплексор 322 (Mux) буферу 324 для хранения.
, где E
total является общей энергией для объединенного символа x. Мощность N
0,b шума и помех включает в себя шум N
0 канала и помехи от потока расширения. Блок 320 вычисления предоставляет LLR основного потока (обозначенные как {LLR
b}) через мультиплексор 322 (Mux) буферу 324 для хранения.
Декодер 182 принимает и декодирует LLR основного потока из буфера 324 и предоставляет декодированные данные для основного потока. Декодер 182 может реализовать турбодекодер либо декодер Витерби (Viterbi), если на передатчике выполнялось соответственно турбо- или сверточное кодирование. Турбодекодер выполняет декодирование на LLR в течение множества итераций для получения все более и более лучших оценок переданных битов данных. Процесс декодирования обычно требует некоторого количества времени для завершения и может дополнительно требовать хранения LLR основного потока в течение процесса декодирования (например, для турбодекодера).
После того, как LLR основного потока декодированы, декодированные данные перекодируются и ремодулируются посредством кодера/модулятора 184 для получения ремодулированных символов
. Блок 330 оценки помех принимает и умножает ремодулированные символы на оценки {h} коэффициента усиления канала и предоставляет оценки {i
b
} помех, обусловленные основным потоком. Сумматор 332 принимает и вычитает оценки {i
b} помех из принятых символов {y}, полученных из буфера 314, и предоставляет символы {y
e} с подавленными помехами, которые могут выражаться как:
a. 
 Уравнение (5)
Уравнение (5)
Ремодулированный символ  равен символу s
b основного потока, если основной поток корректно декодирован. Декодирован ли основной поток правильно или с ошибкой, может быть определено на основе CRC (контроля циклически избыточным кодом) или какой-либо другой схемы обнаружения ошибки.
равен символу s
b основного потока, если основной поток корректно декодирован. Декодирован ли основной поток правильно или с ошибкой, может быть определено на основе CRC (контроля циклически избыточным кодом) или какой-либо другой схемы обнаружения ошибки.
Блок 340 вычисления LLR потока расширения выполняет обнаружение данных на символах {y e} с подавленными помехами для получения двух LLR для двух кодовых битов каждого символа s e потока расширения. Два LLR для потока расширения могут выражаться как:
a.  ,
, Уравнение (6)
Уравнение (6)
где LLR e1 и LLR e2 являются LLR для двух битов символа s e потока расширения, выведенных на основе символа y e с подавленными помехами;
a. E e является энергией символа s e потока расширения; и
b. N 0,e является мощностью шума и помех, наблюдаемых посредством символа s e потока расширения.
Блок 340 вычисления предоставляет LLR потока расширения (обозначенные как {LLR
e}) через Mux 322 буферу 324 для хранения. Затем декодер 182 декодирует LLR потока расширения для получения декодированных данных  для потока расширения.
для потока расширения.
Для первой схемы обнаружения данных процессору 170а RX необходимо хранить принятые символы {y} в буфере 314 и LLR основного потока в буфере 324, пока основной поток декодируется декодером 182. Размеры буферов 314 и 324 зависят от размера пакетов данных, задержек декодирования и, возможно, других факторов. Тот же буфер 324 может использоваться для хранения как LLR основного потока, так и LLR потока расширения, так как эти потоки декодируются последовательно.
Фиг. 4 показывает процессор 170b RX для второй схемы обнаружения данных, в которой основной поток обнаруживается на основе принятых символов {y}, и поток расширения обнаруживается на основе LLRs основного потока. Процессор 170b RX является другим вариантом осуществления процессора 170 RX по фиг. 1.
В процессоре 170b RX блок 420 вычисления LLR основного потока выполняет обнаружение данных на принятых символах {y} для получения LLR {LLR
b} основного потока, как показано в уравнении (4). Блок 420 вычисления предоставляет LLR основного потока через мультиплексор 422 буферу 424 для хранения. Декодер 182 принимает и декодирует LLR основного потока из буфера 424 и предоставляет декодированные данные  для основного потока. После того, как LLR основного потока декодированы, кодер/модулятор 184 перекодирует и ремодулирует декодированные данные
для основного потока. После того, как LLR основного потока декодированы, кодер/модулятор 184 перекодирует и ремодулирует декодированные данные  для получения ремодулированных символов
для получения ремодулированных символов  для основного потока.
для основного потока.
LLR основного потока выводятся из и тесно зависимы от принятых символов. LLR потока расширения могут быть, таким образом, вычислены непосредственно из LLR основного потока вместо принятых символов. LLR потока расширения могут выражаться как:
 ,
,
 ,
, Уравнение (7)
Уравнение (7)
 ,
,
 ,
,
где  ,
,
 и
и  обозначает оценку коэффициента усиления по мощности канала для принятого символа y. Первое равенство в уравнении (7) получается посредством подстановки уравнения (5) в уравнение (6). Число в круглых скобках в третьем равенстве предназначается для LLR основного потока. Уравнение (7) указывает, что LLR потока расширения может выводиться из LLR основного потока и ремодулированных символов.
обозначает оценку коэффициента усиления по мощности канала для принятого символа y. Первое равенство в уравнении (7) получается посредством подстановки уравнения (5) в уравнение (6). Число в круглых скобках в третьем равенстве предназначается для LLR основного потока. Уравнение (7) указывает, что LLR потока расширения может выводиться из LLR основного потока и ремодулированных символов.
В процессоре 170b RX умножитель 426 принимает и масштабирует LLR основного потока с коэффициентом G
1 усиления и предоставляет масштабированные LLR основного потока. Блок 430 оценки помех принимает и умножает каждый ремодулированный символ как на каждую ее оценку коэффициента усиления мощности канала, так и на коэффициент G
2 усиления для получения оценки  помех, обусловленных основным потоком. Обработка посредством блока 430 оценки помех отличается от обработки посредством блока 330 оценки помех по фиг. 3. Сумматор 432 принимает и вычитает оценку
помех, обусловленных основным потоком. Обработка посредством блока 430 оценки помех отличается от обработки посредством блока 330 оценки помех по фиг. 3. Сумматор 432 принимает и вычитает оценку  помех из масштабированных LLR основного потока и предоставляет LLR потока расширения, которые отправляются через Mux 422 и к буферу 424 для хранения. Декодер 182 затем декодирует LLR потока расширения для получения декодированных данных
помех из масштабированных LLR основного потока и предоставляет LLR потока расширения, которые отправляются через Mux 422 и к буферу 424 для хранения. Декодер 182 затем декодирует LLR потока расширения для получения декодированных данных  для потока расширения. Как показано в уравнении (7), принятые символы {y} не используются для выведения LLR потока расширения.
для потока расширения. Как показано в уравнении (7), принятые символы {y} не используются для выведения LLR потока расширения.
Для второй схемы обнаружения данных процессору 170b RX не нужно хранить принятые символы, и только один буфер 424 может использоваться для хранения как LLR основного потока, так и LLR потока расширения. Это может значительно снизить требования к буферизации для приемника.
LLR основного потока квантуются и сохраняются с достаточным числом битов из условия, чтобы эти LLR обеспечивали хорошую производительность декодирования для основного потока и дополнительно могли использоваться для выведения LLR потока расширения. Для второй схемы обнаружения данных число битов для использования для LLR основного потока влияет на точность и диапазон LLR для обоих потоков. В одной конкретной реализации турбодекодера LLR квантуются на шесть битов в диапазоне [-8, 8] и с точностью 0,25. Точность означает максимально допустимую ошибку квантования. Диапазон и точность обычно выбираются оба на основе производительности декодирования и косвенно относятся к отношению сигнал-шум квантования (SQNR). Более того, диапазон и точность обычно не изменяются на основе факторов, таких как кодовая скорость или действующее SNR.
На точность LLR потока расширения влияет коэффициент G 1 усиления, используемый для масштабирования LLR основного потока в уравнении (7). Если над мощностью N 0,b шума и помех, наблюдаемых основным потоком, преобладает шум
N 0 канала, а не помехи от потока расширения, то N 0,b приблизительно равна N 0 и поток расширения будет иметь меньшее SNR, чем таковое у основного потока, так как обычно используется меньшая мощность для потока расширения. В этом случае коэффициент G 1 усиления будет меньше единицы и поскольку LLR основного потока масштабируются посредством G 1, на точность LLR потока расширения не воздействует точность LLR основного потока. Однако если коэффициент G 1 усиления больше, чем единица, то один или более дополнительных битов нижнего порядка/меньшей значимости могут использоваться для LLR основного потока.
Диапазон для квантования должен быть достаточно большим для того, чтобы LLR основного потока не насыщались или сокращались до слишком малой величины, которая может ухудшать производительность. Насыщение LLR основного потока обычно не представляет собой серьезную проблему для турбодекодера, но может сильно воздействовать на качество LLR потока расширения, которые выводятся из LLR основного потока. Чтобы определить, сколько дополнительных битов высокого порядка необходимо для того, чтобы предотвратить насыщение LLR, принятый символ y в уравнении (4) может быть заменен на  следующим образом:
следующим образом:
 ,
,
 ,
,  Уравнение (8)
Уравнение (8)
где n b представляет шум и помехи, наблюдаемые основным потоком, который включает в себя помехи от потока расширения.
Если передается символ  основного потока, то каждое из двух LLR для символа s
b будет иметь среднее значение
основного потока, то каждое из двух LLR для символа s
b будет иметь среднее значение  и среднеквадратическое отклонение
и среднеквадратическое отклонение  . SNR для основного потока тогда равно
. SNR для основного потока тогда равно  . Предполагая «разумный» разброс среднего значения плюс трехкратное среднеквадратическое отклонение для принятого символа y, амплитуда LLR должна быть способной принимать значения вплоть до
. Предполагая «разумный» разброс среднего значения плюс трехкратное среднеквадратическое отклонение для принятого символа y, амплитуда LLR должна быть способной принимать значения вплоть до  . Это число увеличивается с увеличением SNR для основного потока. Таким образом, наихудший случай - это когда шум канала равен нулю, и SNR основного потока попадает в минимальный уровень шума, вызываемый помехами от потока расширения. С этой точки зрения SNR основного потока равно SNR
b
=E
b
/E
e, и максимальная амплитуда LLR для приспособления равна
. Это число увеличивается с увеличением SNR для основного потока. Таким образом, наихудший случай - это когда шум канала равен нулю, и SNR основного потока попадает в минимальный уровень шума, вызываемый помехами от потока расширения. С этой точки зрения SNR основного потока равно SNR
b
=E
b
/E
e, и максимальная амплитуда LLR для приспособления равна  . Следует отметить, что это безопасный диапазон, поскольку когда над N
0,b преобладают помехи от потока расширения, шум более не является гауссовым шумом, а шумом QPSK, который не расходится за пределы среднего значения плюс одного среднеквадратичного отклонения.
. Следует отметить, что это безопасный диапазон, поскольку когда над N
0,b преобладают помехи от потока расширения, шум более не является гауссовым шумом, а шумом QPSK, который не расходится за пределы среднего значения плюс одного среднеквадратичного отклонения.
Число битов для использования для LLR основного потока может выбираться на основе отношения энергии символа основного потока к энергии символа потока расширения. Например, если мощность основного потока в четыре раза сильнее, чем мощность потока расширения (или E
b
/E
c=4), то LLR основного потока должны быть квантованы с амплитудой вплоть до  . Для типовой реализации турбодекодера, описанной выше, с диапазоном [-8, 8] LLR основного потока могут быть квантованы и сохранены с двумя дополнительными битами высокого порядка, или 8 битами в итоге. Как другой пример, если мощность основного потока в девять раз сильнее, чем мощность потока расширения (или E
b
/E
c=9), то LLR основного потока должны быть квантованы с амплитудой вплоть до
. Для типовой реализации турбодекодера, описанной выше, с диапазоном [-8, 8] LLR основного потока могут быть квантованы и сохранены с двумя дополнительными битами высокого порядка, или 8 битами в итоге. Как другой пример, если мощность основного потока в девять раз сильнее, чем мощность потока расширения (или E
b
/E
c=9), то LLR основного потока должны быть квантованы с амплитудой вплоть до  , и могут использоваться три дополнительных бита высокого порядка для LLR.
, и могут использоваться три дополнительных бита высокого порядка для LLR.
Хотя LLR основного потока могут храниться с дополнительными битами для второй схемы обнаружения данных, общее требование к памяти будет все еще значительно меньше, чем таковое у первой схемы обнаружения данных, которая хранит как принятые символы, так и LLR основного потока. Это особенно верно, поскольку принятым символам также вероятно требуется большая битовая ширина при наличии потока расширения.
Фиг. 5 показывает процессор 170с RX для третьей схемы обнаружения данных, в которой основной поток обнаруживается на основе принятых символов {y}, а поток расширения обнаруживается с использованием некодированного подавления помех. Процессор 170с RX является еще одним вариантом осуществления процессора 170 RX по фиг. 1.
В процессоре 170с RX блок 520 вычисления LLR основного потока выполняет обнаружение данных на принятых символах {y} для получения LLR основного потока, как показано в уравнении (4). Блок 520 вычисления предоставляет LLR основного потока буферу 524 для хранения. Декодер 182 принимает LLR основного потока из буфера 524 через мультиплексор 526, декодирует эти LLR и предоставляет декодированные данные 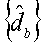 для основного потока.
для основного потока.
Для третьей схемы обнаружения данных LLR потока расширения вычисляются из принятых символов {y} аналогично первой схеме обнаружения данных. Однако помехи, обусловленные основным потоком, оцениваются на основе оценок некодированных символов данных (вместо ремодулированных символов) для основного потока. LLR потока расширения могут таким образом вычисляться одновременно с LLR основного потока вместо необходимости ожидания завершения декодирования основного потока.
Оценка  некодированных символов данных (или просто, оценка символа данных) является оценкой символа s
b основного потока, полученной посредством принятия жесткого решения либо по принятому символу y, либо по LLR основного потока для принятого символа y. Например, ссылаясь на фиг. 2А, оценка символа данных для принятого символа 212 может являться сигнальной точкой на 1+j1, которая является ближайшей сигнальной точкой для принятого символа 212. Оценки символов данных выводятся на основе принятых символов без преимущества возможности исправления ошибок кода, используемой для основного потока. Оценки символов данных являются, таким образом, более подверженными ошибкам, чем ремодулированные символы, которые извлекают выгоду из возможности исправления ошибок кода основного потока. Следовательно, некодированные оценки
некодированных символов данных (или просто, оценка символа данных) является оценкой символа s
b основного потока, полученной посредством принятия жесткого решения либо по принятому символу y, либо по LLR основного потока для принятого символа y. Например, ссылаясь на фиг. 2А, оценка символа данных для принятого символа 212 может являться сигнальной точкой на 1+j1, которая является ближайшей сигнальной точкой для принятого символа 212. Оценки символов данных выводятся на основе принятых символов без преимущества возможности исправления ошибок кода, используемой для основного потока. Оценки символов данных являются, таким образом, более подверженными ошибкам, чем ремодулированные символы, которые извлекают выгоду из возможности исправления ошибок кода основного потока. Следовательно, некодированные оценки  помех, выведенные из оценок символов данных, являются менее надежными, и LLR потока расширения, выведенные из некодированных символов
помех, выведенные из оценок символов данных, являются менее надежными, и LLR потока расширения, выведенные из некодированных символов 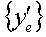 с подавленными помехами, являются также менее надежными, чем те выведенные посредством первой схемы обнаружения данных. Производительность декодирования для потока расширения может ухудшаться, если LLR для оценок символов данных, которые являются ошибочными, задаются значениями высокой надежности (или большего веса) в процессе декодирования.
с подавленными помехами, являются также менее надежными, чем те выведенные посредством первой схемы обнаружения данных. Производительность декодирования для потока расширения может ухудшаться, если LLR для оценок символов данных, которые являются ошибочными, задаются значениями высокой надежности (или большего веса) в процессе декодирования.
Различные схемы могут использоваться для смягчения вредных воздействий ошибок символов данных (или ошибок символов с жестким решением) в декодировании потока расширения. Ошибки символов данных могут обнаруживаться посредством сравнения каждого ремодулированного символа с соответствующей оценкой символа данных и объявления ошибки, если эта пара не равна.
В первой схеме компенсации ошибок LLR потока расширения, соответствующие оценкам символов данных, которые являются ошибочными, задаются отсутствием веса в процессе декодирования. Это может быть достигнуто посредством назначения этих LLR на аннулирования, которыми являются нулевыми значениями LLR, указывающими равное правдоподобие того, что кодовые биты равны +1 или -1. Если частота появления ошибочных символов (SER) является относительно низкой, то эффекты использования аннулирований для LLR, соответствующих ошибкам символов данных, могут быть небольшими. Например, при минимальном уровне шума в 6 дБ (который соответствует основному потоку, имеющему четырехкратную мощность потока расширения), SER равна приблизительно двум процентам. Ухудшение в производительности декодирования от объявления этих ошибок символов с жестким решением как аннулирований не должно быть значительным.
Во второй схеме компенсации ошибок LLR потока расширения, полученные с помощью оценок символов данных, которые являются ошибочными, корректируются на основе ремодулированных символов после того, как декодирован основной поток. LLR потока расширения из уравнения (7) могут выражаться как:
 ,
,
 ,
, Уравнение (9)
Уравнение (9)
 ,
,
где 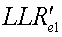 и
и  являются исходными LLR для двух битов символа s
e потока расширения. Уравнение (9) указывает, что исходные и могут быть получены на основе принятого символа y и оценки
являются исходными LLR для двух битов символа s
e потока расширения. Уравнение (9) указывает, что исходные и могут быть получены на основе принятого символа y и оценки  символа данных. После того, как декодирован основной поток и доступны ремодулированные символы, исходные
символа данных. После того, как декодирован основной поток и доступны ремодулированные символы, исходные  и
и 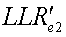 могут быть скорректированы с помощью ремодулированных символов
могут быть скорректированы с помощью ремодулированных символов  для получения итоговых
для получения итоговых  и
и  , которые могут быть декодированы для получения декодированных данных для потока расширения. Если исходные LLR являются насыщенными, то эти LLR могут быть назначены к аннулированиям. Итоговые LLR сохраняются, даже если они являются насыщенными.
, которые могут быть декодированы для получения декодированных данных для потока расширения. Если исходные LLR являются насыщенными, то эти LLR могут быть назначены к аннулированиям. Итоговые LLR сохраняются, даже если они являются насыщенными.
В процессоре 170с RX блок 528 жесткого решения принимает либо LLR основного потока (как показано на фиг. 5), либо принятые символы (не показано на фиг. 5), и выполняет жесткое решение для выведения оценок  символов данных для основного потока. Жесткое решение может быть выполнено, как известно в данной области техники. Например, каждая оценка символа данных может быть назначена сигнальной точке, ближайшей по расстоянию к принятому символу. В отличие от ремодулированных символов оценки символов данных могут выводится с минимальной задержкой.
символов данных для основного потока. Жесткое решение может быть выполнено, как известно в данной области техники. Например, каждая оценка символа данных может быть назначена сигнальной точке, ближайшей по расстоянию к принятому символу. В отличие от ремодулированных символов оценки символов данных могут выводится с минимальной задержкой.
Блок 530 оценки помех принимает и умножает оценки символов данных на оценки {h} коэффициента усиления канала и предоставляет некодированные оценки  помех, обусловленные основным потоком, которые могут выражаться как:
помех, обусловленные основным потоком, которые могут выражаться как:  . Сумматор 532 принимает и вычитает оценки помех из принятых символов {y} и предоставляет некодированные символы
. Сумматор 532 принимает и вычитает оценки помех из принятых символов {y} и предоставляет некодированные символы  с подавленными помехами, которые могут выражаться как:
с подавленными помехами, которые могут выражаться как:  . Блок 540 вычисления LLR потока расширения выполняет обнаружение данных на некодированных символах с подавленными помехами для получения исходных LLR потока расширения
. Блок 540 вычисления LLR потока расширения выполняет обнаружение данных на некодированных символах с подавленными помехами для получения исходных LLR потока расширения  , аналогичных тем, что показаны в уравнении (6). Блок 540 вычисления предоставляет исходные LLR потока расширения буферу 544 для хранения.
, аналогичных тем, что показаны в уравнении (6). Блок 540 вычисления предоставляет исходные LLR потока расширения буферу 544 для хранения.
После того, как декодированы LLR основного потока, кодер/модулятор 184 перекодирует и ремодулирует декодированные данные  для получения ремодулированных символов
для получения ремодулированных символов  для основного потока. Детектор 542 ошибок символов принимает ремодулированные символы
для основного потока. Детектор 542 ошибок символов принимает ремодулированные символы  и оценки
и оценки  символов данных, обнаруживает ошибки в оценках символов данных и предоставляет указание для каждой оценки символов данных, которая обнаружена ошибочной. Детектор 542 ошибок символов может дополнительно вычислять поправочный коэффициент
символов данных, обнаруживает ошибки в оценках символов данных и предоставляет указание для каждой оценки символов данных, которая обнаружена ошибочной. Детектор 542 ошибок символов может дополнительно вычислять поправочный коэффициент  для каждой оценки символа данных, которая является ошибочной, если используется вторая схема компенсации ошибок. Блок 546 регулирования LLR принимает и регулирует исходные LLR
для каждой оценки символа данных, которая является ошибочной, если используется вторая схема компенсации ошибок. Блок 546 регулирования LLR принимает и регулирует исходные LLR  потока расширения из буфера 544 и предоставляет итоговые LLR
потока расширения из буфера 544 и предоставляет итоговые LLR  потока расширения через мультиплексор 526 декодеру 182. Блок 546 регулирования LLR может (1) назначить LLR потока расширения для оценок символов данных, которые ошибочны, для аннулирований, для первой схемы компенсации ошибок или (2) добавить поправочный коэффициент c
b к исходным LLR потока расширения для каждой оценки символа данных, которая является ошибочной, для второй схемы компенсации ошибок.
потока расширения через мультиплексор 526 декодеру 182. Блок 546 регулирования LLR может (1) назначить LLR потока расширения для оценок символов данных, которые ошибочны, для аннулирований, для первой схемы компенсации ошибок или (2) добавить поправочный коэффициент c
b к исходным LLR потока расширения для каждой оценки символа данных, которая является ошибочной, для второй схемы компенсации ошибок.
Для третьей схемы обнаружения данных процессору 170с RX не нужно хранить принятые символы, и два буфера 524 и 544 используются для хранения LLR основного потока и LLR потока расширения соответственно.
Для ясности три схемы обнаружения данных описаны выше для QPSK. Эти схемы обнаружения данных могут также использоваться для схем модуляции более высокого порядка, которые являются схемами модуляции более высокого порядка, чем QPSK. Первая и третья схемы обнаружения данных могут использоваться способом, описанным выше, с любой схемой модуляции для основного потока и любой схемой модуляции для потока расширения. Для третьей схемы обнаружения данных поправочный коэффициент может использоваться для корректирования исходных LLR в соответствии со схемой модуляции, используемой для потока расширения, когда бы ни обнаруживались оценки символов данных, являющиеся ошибочными.
Для второй схемы обнаружения данных LLR основного потока содержат всю информацию в принятых символах и могут, таким образом, использоваться для оценки или восстановления принятых символов. LLR потока расширения могут затем вычисляться из принятых оценок символов. Оценка принятых символов из LLR основного потока может выполняться как описано далее. Для простоты последующее описание предполагает, что для основного потока используется схема модуляции с отображением Грея с более высоким порядком, чем QPSK. С отображением Грея близлежащие сигнальные точки в созвездии (и в горизонтальном, и в вертикальном направлениях для прямоугольного созвездия) имеют метки, которые различаются только в расположении одного бита. Отображение Грея уменьшает количество ошибок кодовых битов для более вероятных ошибочных событий, что соответствует принятому символу, отображенному в сигнальную точку рядом с правильной сигнальной точкой, и в этом случае только один кодовый бит был бы ошибочным. Последующее описание также предполагает, что LLR основного потока вычисляются, используя «приближение с двумя максимумами», которое может выражаться как:
 ,
,
 ,
, Уравнение (10)
Уравнение (10)
где LLR i является LLR для i-го кодового бита для принятого символа y;
a. s i,1 является предполагаемым символом модуляции, который является ближайшим к принятому символу y из условия, что i-й кодовый бит для s i,1 имеет значение +1; и
b. s i,0 является предполагаемым символом модуляции, который является ближайшим к принятому символу y из условия, что i-й кодовый бит для s i,0 имеет значение -1.
Сигнальное созвездие для М-й PSK или M-QAM схемы модуляции содержит M сигнальных точек. Каждая сигнальная точка ассоциативно связывается с меткой B-бита, где B=log2 M. В кодовых битов отображаются в символ модуляции, который является комплексным значением для сигнальной точки, чья метка равна значениям В кодовых битов. В логарифмических отношений правдоподобия вычисляются для каждого принятого символа y с каждым LLR, вычисляемым на основе соответствующей пары предполагаемых символов s i,1 и s i,0 модуляции.
Уравнение (10) предоставляет одно уравнение относительно принятого символа y для каждого кодового бита обнаруженного символа s модуляции. Таким образом, существуют три уравнения для каждого принятого символа для 8-PSK (B=3), четыре уравнения для каждого принятого символа для 16-QAM (B=4) и т.д. Может быть показано, что B уравнений, выведенных из уравнения (10) для В кодовых битов, являются линейными уравнениями. Из этих В уравнений могут быть определены две неизвестных величины, а именно вещественная и мнимая части принятого символа y. Однако трудность заключается в том, что различная пара предполагаемых символов
s i,1 и s i,0 модуляции используется для каждого из B уравнений для принятого символа y, и эти предполагаемые символы модуляции неизвестны. Для 8-PSK и 16-QAM с отображением Грея предполагаемые символы модуляции могут определяться, по меньшей мере, для двух из B кодовых битов для каждого принятого символа y, используя методику, описанную ниже. Два (независимых) линейных уравнения затем имеются в распоряжении для вычисления двух неизвестных величин для вещественной и мнимой частей принятого символа y.
Значения s
i,1 и s
i,0 для двух кодовых битов для принятого символа y могут определяться следующим образом. Прежде всего, уравнение (10) указывает, что знак у LLR каждого кодового бита определяется посредством предполагаемого символа модуляции, который является ближайшим к y/h. Например, если s
i,1 ближе к y/h, чем s
i,0
, то  будет меньше, чем
будет меньше, чем  , и LLR
i будет отрицательной величиной. Наоборот, если s
i,0 ближе к y/h, чем s
i,1, то LLR
i будет положительной величиной. Полностью изменяя это обстоятельство, знаки у LLR из B кодовых битов (жесткие битовые решения) определяют сигнальную точку s
c (жесткое символьное решение), которая является ближайшей к y/h. Например, если LLR
1
=+a, LLR
2
=+b и LLR
3
=-c для символа 8-PSK, где a, b и c все являются положительными величинами, то ближайшая сигнальная точка к этому символу 8-PSK имеет метку '001'.
, и LLR
i будет отрицательной величиной. Наоборот, если s
i,0 ближе к y/h, чем s
i,1, то LLR
i будет положительной величиной. Полностью изменяя это обстоятельство, знаки у LLR из B кодовых битов (жесткие битовые решения) определяют сигнальную точку s
c (жесткое символьное решение), которая является ближайшей к y/h. Например, если LLR
1
=+a, LLR
2
=+b и LLR
3
=-c для символа 8-PSK, где a, b и c все являются положительными величинами, то ближайшая сигнальная точка к этому символу 8-PSK имеет метку '001'.
Чтобы упростить обозначение, ближайшая сигнальная точка s c может быть переобозначена с помощью метки со всеми нулями посредством выполнения операции исключающего ИЛИ (XOR) на метке каждой сигнальной точки в созвездии с меткой ближайшей сигнальной точки. В этом новом обозначении предполагаемый символ s i,0 для каждого из В кодовых битов равен ближайшей сигнальной точке s c или s i,0 =s c для i=1…B. Процедура определения s i,1 зависит от сигнального созвездия и описана, в частности, для 8-PSK и 16-QAM с отображением Грея ниже.
Для 8-PSK восемь сигнальных точек в созвездии являются равномерно расположенными друг от друга на 45° на единичной окружности. Ближняя сигнальная точка к y/h обозначается '000' по процедуре, описанной выше. Для созвездия 8-PSK следующие две ближайшие сигнальные точки к y/h являются двумя соседними сигнальными точками к '000' (т.е. одна сигнальная точка слева и другая сигнальная точка справа от '000' вдоль единичной окружности). Так как созвездие является отображенным по Грею, эти две соседние сигнальные точки отличаются от '000' только в одном расположении бита. Например, если две соседних сигнальных точки помечены как '100' и '010', то s i,1 есть '100' для крайнего левого кодового бита и '010' для среднего кодового бита. Значения s i,1 и s i,0 для двух из трех кодовых битов являются, таким образом, известными и могут использоваться наряду с LLR для этих двух кодовых битов и оценкой h коэффициента усиления канала для вычисления принятого символа y.
Для 16-QAM 16 сигнальных точек размещаются в двумерной сетке, и каждая сигнальная точка имеет по меньшей мере одну соседнюю сигнальную точку вдоль вещественной оси и по меньшей мере одну соседнюю сигнальную точку вдоль мнимой оси. Так как созвездие является отображенным по Грею, эти соседние сигнальные точки отличаются от исходной сигнальной точки не больше, чем на расположение одного бита. Ближайшая сигнальная точка к y/h обозначается '0000' по процедуре, описанной выше. Если две соседних сигнальных точки ближайшей сигнальной точки s c обозначаются как '1000' и '0001', то s i,1 есть '1000' для крайнего левого кодового бита и '0001' для крайнего правого кодового бита. Таким образом, значения s i,1 и s i,0 для двух из четырех кодовых битов известны и могут использоваться для вычисления принятого символа y. Использование одного соседа по горизонтали и одного соседа по вертикали устраняет ситуацию с зависимыми уравнениями.
Фиг. 6 показывает процессор 170d RX для второй схемы обнаружения данных с основным потоком, модулированным с помощью схемы модуляции более высокого порядка. Процессор 170d RX включает в себя большинство блоков процессора 170а RX по фиг. 3 (без буфера 314) и дополнительно включает в себя блок 326 оценки принятых символов.
Блок 320 вычисления LLR основного потока выводит LLR основного потока на основе принятых символов {y} и предоставляет LLR основного потока через мультиплексор 322 буферу 324 для хранения. Блок 326 оценки принятых символов принимает LLR основного потока из буфера 324 и выводит оценки  принятых символов на основе этих LLR, например, как описано выше. Сумматор 332 принимает и вычитает оценки {i
b} помех из оценок
принятых символов на основе этих LLR, например, как описано выше. Сумматор 332 принимает и вычитает оценки {i
b} помех из оценок  принятых символов и предоставляет символы
принятых символов и предоставляет символы  с подавленными помехами. Блок 340 вычисления LLR потока расширения выводит LLR потока расширения на основе символов
с подавленными помехами. Блок 340 вычисления LLR потока расширения выводит LLR потока расширения на основе символов  с подавленными помехами и предоставляет LLR потока расширения через мультиплексор 322 буферу 324 для хранения.
с подавленными помехами и предоставляет LLR потока расширения через мультиплексор 322 буферу 324 для хранения.
Для ясности отдельные блоки вычисления LLR показаны для основного потока и потока расширения на фиг. 3, 5 и 6. Вычисление LLR для обоих потоков может выполняться посредством единого блока вычисления LLR, например, способом мультиплексирования с временным разделением (TDM). Все вычисление для обнаружения данных может также выполняться посредством цифрового процессора сигналов (DSP), имеющего один или более блоков умножения с накоплением и один или более арифметико-логических блоков (ALU). Блок-схемы, показанные на фиг. 3, 4, 5 и 6, могут также использоваться как схемы последовательности операций способа для процессов обнаружения данных.
Методики обнаружения данных, описанные здесь, могут использоваться для систем с одной несущей, а также с несколькими несущими. Несколько несущих могут предоставляться посредством OFDM или каких-либо других конструктивных элементов. OFDM эффективно разделяет общую полосу пропускания системы на множество (N) ортогональных поддиапазонов, которые также называются тонами, поднесущими, элементами дискретизации или частотными каналами. С помощью OFDM каждый поддиапазон ассоциативно связывается с соответствующей поднесущей, которая может модулироваться данными.
Объединенный символ x может передаваться по каждому поддиапазону, используемому для передачи данных. До N объединенных символов может передаваться по N поддиапазонам в каждый период символов OFDM. Передатчик выполняет модуляцию OFDM посредством преобразования во временную область каждой группы из N объединенных и пилот-символов {x(k)}, которые должны быть переданы в один период символов OFDM, используя N-точечное обратное быстрое преобразование Фурье (IFFT) для получения «преобразованного» символа, который содержит N символов шумоподобной последовательности. Чтобы бороться с межсимвольными помехами (ISI), которые вызываются частотно-избирательным замиранием, часть (или Ncp символов шумоподобной последовательности) каждого преобразованного символа обычно повторяется для образования соответствующего символа OFDM. Каждый символ OFDM передается в одном периоде символов OFDM, который равен N+Ncp периодам символов шумоподобной последовательности, где Ncp является длиной циклического префикса.
Приемник получает поток выборок для принятого сигнала и удаляет циклический префикс в каждом принятом символе OFDM для получения соответствующего принятого преобразованного символа. Приемник затем преобразует каждый принятый преобразованный символ в частотную область, используя N-точечное быстрое преобразование Фурье(FFT) для получения N принятых символов {y(k)} для N поддиапазонов. Каждый принятый символ y(k) предназначается для объединенного символа x(k) или пилот-символа, отправленного по поддиапазону k, который искажается коэффициентом h(k) усиления канала и ухудшается шумом n(k), как показано в уравнении (2). Принятые символы могут быть преобразованы в последовательную форму и обработаны, как описано выше для трех схем обнаружения данных.
Методики обнаружения данных, описанные в этом документе, могут также использоваться для более чем двух потоков данных. Обработка (например, вычисление LLR, оценка символов, оценка помех и т.д.), используемая для потока расширения, может повторяться для каждого дополнительного потока данных.
Методики обнаружения данных, описанные в этом документе, могут реализовываться различными средствами. Например, эти методики могут реализовываться в аппаратном обеспечении, программном обеспечении либо их сочетании. Для аппаратной реализации блоки обработки, используемые для выполнения обнаружения данных, могут реализовываться в одной или нескольких специализированных интегральных схемах (ASIC), цифровых процессорах сигналов (DSP), устройствах цифровой обработки сигналов (DSPD), программируемых логических устройствах (PLD), программируемых пользователем вентильных матрицах (FPGA), процессорах, контроллерах, микроконтроллерах, микропроцессорах, других электронных блоках, спроектированных для выполнения описанных здесь функций, или их сочетаниях.
Для программной реализации методики обнаружения данных могут реализовываться с помощью модулей (например, процедур, функций и так далее), которые выполняют описанные здесь функции. Программные коды могут храниться в модуле памяти (например, модуле 192 памяти по фиг. 1) и исполняться процессором (например, контроллером 190). Модуль памяти может реализовываться внутри процессора или внешним по отношению к процессору, в этом случае он может быть коммуникационно соединен с процессором через различные средства, которые известны в данной области техники.
Предшествующее описание раскрытых вариантов осуществления предоставляется, чтобы дать возможность любому специалисту в данной области техники создавать или использовать настоящее изобретение. Различные модификации к этим вариантам осуществления будут полностью очевидны специалистам в данной области техники, а общие принципы, определенные в материалах настоящей заявки, могут быть применены к другим вариантам осуществления без отклонения от сущности или объема изобретения. Таким образом, настоящее изобретение не предназначено, чтобы ограничиваться вариантами осуществления, показанными в материалах настоящей заявки, а должно соответствовать самому широкому объему, согласующемуся с принципами и новейшими признаками, раскрытыми в материалах настоящей заявки.
Изобретение относится к методам выполнения обнаружения для иерархически кодированных данных. Достигаемый технический результат - повышение эффективности обнаружения иерархически кодированных данных. В одной схеме обнаружения выводят логарифмические отношения правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных. Оценивают помехи, обусловленные первым потоком данных. Выводят LLR для кодовых битов второго потока данных на основе LLR для кодовых битов первого потока данных и оцененных помех. Декодируют LLR для кодовых битов первого потока данных для получения декодированных данных из первого потока данных. Декодированные данные перекодируют и ремодулируют для получения ремодулированных символов. Помехи, обусловленные первым потоком данных, оценивают на основе ремодулированных символов. LLR для первого потока данных могут выводиться из принятых символов в реальном масштабе времени без буферизации принятых символов. LLR для второго потока данных могут выводиться после того, как декодирован первый поток данных. 6 н. и 28 з.п. ф-лы, 7 ил.
1. Способ выполнения обнаружения данных в системе беспроводной связи на основе иерархически кодированных данных, содержащий этапы, на которых:
выводят логарифмические отношения правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных;
оценивают помехи, обусловленные первым потоком данных;
выводят LLR для кодовых битов второго потока данных на основе LLR для кодовых битов первого потока данных и оцененных помех, и
декодируют LLR для кодовых битов первого потока данных для получения декодированных данных из первого потока данных.
2. Способ по п.1, дополнительно содержащий этапы, на которых:
перекодируют и ремодулируют декодированные данные для получения ремодулированных символов, где помехи, обусловленные первым потоком данных, оцениваются на основе ремодулированных символов.
3. Способ по п.1, в котором LLR для кодовых битов первого потока данных выводятся из принятых символов в реальном масштабе времени без буферизации принятых символов.
4. Способ по п.1, дополнительно содержащий этапы, на которых:
сохраняют LLR для кодовых битов первого потока данных в буфер; и
сохраняют LLR для кодовых битов второго потока данных в буфер посредством перезаписи LLR для кодовых битов первого потока данных.
5. Способ по п.1, в котором квадратурная фазовая манипуляция (QPSK) используется как для первого, так и для второго потоков данных.
6. Способ по п.1, в котором схема модуляции с более высоким порядком, чем квадратурная фазовая манипуляция (QPSK), используется для кодирования первого потока данных, при этом способ дополнительно содержит этап, на котором:
выводят оценки принятых символов на основе LLR для кодовых битов первого потока данных, и где LLR для кодовых битов второго потока данных выводятся на основе оценок принятых символов и оцененных помех, вместо LLR кодовых битов первого потока данных и оцененных помех.
7. Способ по п.6, в котором этап, на котором выводят оценки принятых символов, включает в себя этап, на котором
формируют два уравнения для каждого принятого символа данных на основе LLR для кодовых битов символа данных, и где оценка принятого символа для принятого символа данных выводится из упомянутых двух уравнений.
8. Способ по п.1, в котором LLR для кодовых битов первого и второго потоков данных выводятся на основе приближения с двумя максимумами, вместо принятых символов данных и LLR кодовых битов в первом потоке данных и оцененных помех соответственно.
9. Способ по п.1, дополнительно содержащий этап, на котором:
выводят оценки коэффициента усиления канала для беспроводного канала, используемого для передачи данных, и где LLR для кодовых битов первого и второго потоков данных и помехи, обусловленные первым потоком данных, выводятся с помощью оценок коэффициента усиления канала, вместо принятых символов данных и LLR для кодовых битов первого потока данных и оцененных помех соответственно.
10. Способ по п.1, в котором первый поток данных является основным потоком, а второй поток данных является потоком расширения для передачи иерархически кодированных данных.
11. Способ по п.1, в котором система беспроводной связи использует мультиплексирование с ортогональным частотным разделением сигналов (OFDM), и в котором принятые символы данных выводятся из множества поддиапазонов.
12. Устройство выполнения обнаружения данных в системе беспроводной связи на основе иерархически кодированных данных, содержащее:
первый блок вычисления, выполненный с возможностью выведения логарифмических отношений правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных;
блок оценки помех, выполненный с возможностью оценки помех, обусловленных первым потоком данных;
второй блок вычисления, выполненный с возможностью выведения LLR для кодовых битов второго потока данных на основе LLR для кодовых битов первого потока данных и оцененных помех, и
декодер, выполненный с возможностью декодирования LLR для кодовых битов первого потока данных для получения декодированных данных первого потока данных.
13. Устройство по п.12, дополнительно содержащее:
кодер и модулятор, выполненные с возможностями перекодирования и ремодулирования декодированных данных для получения ремодулированных символов первого потока данных, и где блок оценки помех выполнен с возможностью оценки помех, обусловленных первым потоком данных, на основе ремодулированных символов.
14. Устройство по п.12, дополнительно содержащее:
буфер, выполненный с возможностью хранения LLR для кодовых битов первого потока данных и хранения LLR для кодовых битов второго потока данных посредством перезаписи LLR для кодовых битов первого потока данных.
15. Устройство по п.12, дополнительно содержащее:
блок оценки канала, выполненный с возможностью выведения оценок коэффициента усиления канала беспроводного канала, используемого для передачи данных, и где LLR для кодовых битов первого и второго потоков данных и помехи, обусловленные первым потоком данных, выводятся с помощью оценок коэффициента усиления канала, вместо принятых символов данных и LLR для кодовых битов первого потока данных и оцененных помех соответственно.
16. Устройство выполнения обнаружения данных в системе беспроводной связи на основе иерархически кодированных данных, содержащее:
средство для выведения логарифмических отношений правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных;
средство для оценки помех, обусловленных первым потоком данных;
средство для выведения LLR для кодовых битов второго потока данных на основе LLR для кодовых битов первого потока данных и оцененных помех; и
средство для декодирования LLR для кодовых битов первого потока данных для получения декодированных данных из первого потока данных.
17. Устройство по п.16, дополнительно содержащее:
средство для перекодирования и ремодулирования декодированных данных для получения ремодулированных символов, соответствующих первому потоку данных, где помехи, обусловленные первым потоком данных, оцениваются на основе ремодулированных символов.
18. Устройство по п.16, где LLR для кодовых битов первого потока данных выводятся из принятых символов данных в реальном масштабе времени без буферизации принятых символов.
19. Устройство по п.16, дополнительно содержащее:
средство для хранения LLR для кодовых битов первого и второго потоков данных, где LLR для кодовых битов второго потока данных сохраняются посредством перезаписи LLR для кодовых битов первого потока данных.
20. Способ выполнения обнаружения данных в системе беспроводной связи на основе иерархически кодированных данных, содержащий этапы, на которых:
выводят логарифмические отношения правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных;
выводят оценки символов данных первого потока данных на основе либо принятых символов данных, либо LLR для кодовых битов первого потока данных;
оценивают помехи, обусловленные первым потоком данных, на основе оценок символов данных;
выводят LLR для кодовых битов второго потока данных на основе принятых символов данных и оцененных помех; и
декодируют LLR для кодовых битов первого потока данных для получения декодированных данных первого потока данных.
21. Способ по п.20, в котором оценки символов данных выводятся посредством принятия жестких решений либо по принятым символам, либо по LLR для кодовых битов первого потока данных.
22. Способ по п.20, дополнительно содержащий этапы, на которых:
перекодируют и ремодулируют декодированные данные для получения
ремодулированных символов, соответствующих первому потоку данных; и
регулируют LLR для кодовых битов второго потока данных на основе
ремодулированных символов и кодовых битов оценок символов данных первого потока данных.
23. Способ по п.22, в котором этап, на котором регулируют LLR, включает в себя этапы, на которых
обнаруживают ошибки в оценках символов данных на основе ремодулированных символов, и
назначают LLR для кодовых битов оценок символов данных, обнаруженных ошибочными, на аннулирования для декодирования.
24. Способ по п.22, в котором этап, на котором регулируют LLR, включает в себя этапы, на которых
обнаруживают ошибки в оценках символов данных на основе ремодулированных символов,
выводят поправочные коэффициенты для оценок символов данных, обнаруженных ошибочными, и
корректируют LLR для кодовых битов оценок символов данных, обнаруженных ошибочными, с помощью поправочных коэффициентов.
25. Способ по п.20, в котором LLR для кодовых битов первого и второго потоков данных выводятся из принятых символов в реальном масштабе времени без буферизации принятых символов.
26. Способ по п.20, дополнительно содержащий этап, на котором:
буферизуют LLR для кодовых битов первого и второго потоков данных для последующего декодирования.
27. Устройство выполнения обнаружения данных в системе беспроводной связи на основе иерархически кодированных данных, содержащее:
первый блок вычисления, выполненный с возможностью выведения логарифмических отношений правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных;
блок принятия решения, выполненный с возможностью выведения оценок символов данных для первого потока данных на основе принятых символов данных;
блок оценки помех, выполненный с возможностью оценки помех, обусловленных первым потоком данных, на основе оценок символов данных;
второй блок вычисления, выполненный с возможностью выведения LLR для кодовых битов второго потока данных на основе принятых символов и оцененных помех; и
декодер, выполненный с возможностью декодирования LLR для кодовых битов первого потока данных для получения декодированных данных первого потока данных.
28. Устройство по п.27, дополнительно содержащее:
кодер и модулятор, выполненный с возможностью перекодирования и ремодулирования декодированных данных для получения ремодулированных символов, соответствующих первому потоку данных; и
блок регулировки, выполненный с возможностью регулирования LLR для кодовых битов второго потока данных на основе ремодулированных символов и кодовых битов оценок символов данных первого потока данных.
29. Устройство по п.28, дополнительно содержащее:
детектор ошибок символов, выполненный с возможностью обнаружения ошибок в оценках символов данных на основе ремодулированных символов, и где блок регулировки, выполненный с возможностью регулирования LLR для кодовых битов оценок символов данных, обнаруженных ошибочными для аннулирования, для декодирования.
30. Устройство по п.28, дополнительно содержащее:
детектор ошибок символов, выполненный с возможностью обнаружения ошибок в оценках символов данных на основе ремодулированных символов, и где блок регулировки выполнен с возможностями выведения поправочных коэффициентов для оценок символов данных, обнаруженных ошибочными, и для корректирования LLR для кодовых битов оценок символов данных, обнаруженных ошибочными, с помощью поправочных коэффициентов.
31. Устройство выполнения обнаружения данных в системе беспроводной связи на основе иерархически кодированных данных, содержащее:
средство для выведения логарифмических отношений правдоподобия (LLR) для кодовых битов первого потока данных на основе принятых символов данных;
средство для выведения оценок символов данных для первого потока данных на основе принятых символов данных;
средство для оценки помех, обусловленных первым потоком данных, на основе оценок символов данных;
средство для выведения LLR для кодовых битов второго потока данных на основе принятых символов данных и оцененных помех; и
средство для декодирования LLR для кодовых битов первого потока данных для получения декодированных данных первого потока данных.
32. Устройство по п.31, дополнительно содержащее:
средство для перекодирования и ремодулирования декодированных данных для получения ремодулированных символов, соответствующих первому потоку данных; и
средство для регулирования LLR для кодовых битов второго потока данных на основе ремодулированных символов и кодовых битов оценок символов данных первого потока данных.
33. Устройство по п.32, в котором средство для регулирования LLR включает в себя
средство для обнаружения ошибок в оценках символов данных на основе ремодулированных символов, и
средство для назначения LLR для кодовых битов оценок символов данных, обнаруженных ошибочными, для аннулирований для декодирования.
34. Устройство по п.32, в котором средство для регулирования LLR включает в себя
средство для обнаружения ошибок в оценках символов данных на основе ремодулированных символов,
средство для выведения поправочных коэффициентов для оценок символов данных, обнаруженных ошибочными, и
средство для корректирования LLR для кодовых битов оценок символов данных, обнаруженных ошибочными, с помощью поправочных коэффициентов.
| US 5966412 А, 12.10.1999 | |||
| СПОСОБ АНАЛОГОВОГО ДЕКОДИРОВАНИЯ ИТЕРАТИВНЫХ БИНАРНЫХ КОДОВ И ДЕКОДЕР ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1995 |
|
RU2113761C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОЦЕНКИ КАЧЕСТВА УСЛУГ НА КАНАЛАХ ПЕРЕДАЧИ В ЦИФРОВОЙ СИСТЕМЕ ПЕРЕДАЧИ | 1998 |
|
RU2202153C2 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Преобразователь постоянного напряжения | 1985 |
|
SU1361686A1 |

