Изобретение относится к средствам автоматизации обучения и научных исследований и предназначено для использования в интерактивных системах автоматизации научно-исследовательских работ в процессе верификации (проверки, тестирования и т.п.) программного обеспечения (ПО) распределенных вычислительных комплексов (РВК).
Известны интерактивные системы автоматизации основных процессов научных исследований в процессе верификации (проверки, тестирования и т.п.) ПО РВК (см. например, DE 10247914 A1 (BOSCH GMBH ROBERT (DE)) 22.04.2004, G 09 В 9/08; DE 10141737 A1 (DAIMLER CHRYSLER AG (DE)) 03.04.2003, G 09 В 9/08; H 04 L 9/30; H 04 L 12/40; B 60 R 16/02; FR 2559599 A1 (GAUER BERNARD (FR)) 16.08.1985, G 09 В 9/08; GB 2366640 A (IBM) 13.03.2002 G 06 F 1/00; GB 2283341 (SOPHOS PLC (GB)) 03.05.1995 G 06 F 1/00; JP 2004302584 A (NIPPON ELECTRIC CO) 28.10.2004, G 09 В 9/08; JP 2004164617 A (MICROSOFT CORP) 10.06.2004, G 09 В 9/08). В основе работы вышеперечисленных систем использованы способы динамического или статического тестирования ПО. Вышеперечисленные технические решения позволяют для некоторых классов ПО избежать их некорректного исполнения, однако существенным недостатком таких решений является сложность выявления скрытых уязвимостей в исходном коде (ИК) ПО РВК, а также невозможность гарантировать правильность полученных результатов на ранних стадиях проектирования ПО РВК. При этом технические реализации статического способа анализа ПО, как правило, представляют различные модификации лексических сканеров ИК ПО и не позволяют осуществить глубокий анализ ни хода выполнения ПО РВК, ни содержания используемой памяти (например, массивов, переменных и т.п.).
В этой связи главный недостаток известных технических решений предопределен тем, что процессы верификации ПО РВК, как правило, представляют ненаблюдаемые/неуправляемые во времени процессы. При этом сам процесс поиска уязвимости в ИК ПО представляет в большей степени искусство, нежели какую-либо формализованную процедуру. При этом низкая производительность данного класса технических решений обусловлена потерей времени, затрачиваемого на формирование тестовых наборов данных, выбора количественных и качественных характеристик, позволяющих оценить уязвимость ИК ПО, определения входных данных определенных типов, в особенности строкового или процедурного типа, являющиеся наиболее распространенными в практике разработки ПО РВК.
Достижению требуемого технического результата во всех приведенных аналогах, включая соответствующий способ верификации ПО, препятствует то, что ни одно из них не может обеспечить полную наблюдаемость/управляемость за динамикой процесса генерации баз знаний на основных этапах верификации ИК ПО РВК систем автоматизации научно-исследовательских работ.
Задачей изобретения является расширение функциональных возможностей интерактивных процессов выполнения научно-исследовательских работ на основе автоматизации основных процессов генерации баз знаний для верификации ПО РВК, а также повышение точности и достоверности выявления уязвимостей в ИК ПО на основных этапах проектирования и сопровождения (аудита) программного кода сложных вычислительных систем и сетей.
Для решения поставленной задачи предложен способ генерации баз знаний для систем верификации программного обеспечения распределенных вычислительных комплексов и устройство для его реализации.
Способ генерации баз знаний для систем верификации программного обеспечения (ПО) распределенных вычислительных комплексов (РВК), включает совмещение процессов ввода и обработки исходного кода ПО по зависимым или независимым каналам на основе использования сенсорных или механических манипуляторов (клавиатуры, мыши, джойстика и т.п.) рабочего места оператора ЭВМ, сетевых интерфейсов локальной или глобальной сети, при этом участки или точки уязвимости исходного кода ПО определяют на основе преобразования исходного кода ПО во внутреннее представление, которое хранят в виде баз знаний, а точки или участки уязвимости исходного кода ПО определяют на основе автоматического составления и решения соответствующих систем уравнений.
При этом внутреннее представление исходного кода ПО на языке программирования Си представляется в виде динамических массивов и соответствующих баз знаний, которые используются в реальном масштабе времени для верификации ПО распределенных вычислительных комплексов.
Динамические массивы и соответствующие базы знаний трансформации или преобразования дерева исходного кода программного обеспечения в процессе верификации/разбора исходного листинга программы состоят в том, что если дерево с указанной вершиной соответствует определению и содержит внутри себя спецификатор ”extern”, то такое дерево удаляется, кроме этого, если дерево соответствует блочной инструкции, то каждое поддерево блочной инструкции с вершиной в ”ребенке” обрабатываемой вершины заменяется на список поддеревьев, соответствующих инструкциям в этой блочной инструкции.
Точки или участки уязвимости исходного кода ПО определяют на основе автоматического составления и решения линейных систем уравнений.
В качестве зависимых каналов используют интерфейсы жестких, гибких или оптических дисков.
В качестве независимых каналов используют интерфейс последовательного порта или сетевой интерфейс.
В качестве независимых каналов используют интерфейс последовательного порта или сетевой интерфейс, а в качестве зависимых каналов используют интерфейсы жестких, гибких или оптических дисков.
При этом генерацию баз знаний осуществляют на основе использования аннотаций внешних функций ИК ПО РВК.
База знаний представляет набор правил или моделей протоколов верификации ИК ПО, обеспечивающих поддержку интерактивных процессов поиска уязвимости ПО.
Кроме этого, в процессе верификации ИК ПО осуществляют синтаксическую подсветку на экране блока видеоконтроля (БВ), предназначенного для визуализации (БВ) участков уязвимости ИК ПО, при этом используют граф (дерево разбора и т.п.) операторов ИК ПО во внутреннем представлении инструкций языка программирования.
Диагностику процесса верификации ИК ПО осуществляют на основе измерения длительности выполнения основных этапов (циклов и т.п.) поиска уязвимости и сопоставления полученных значений с ранее предписанными или предсказанными оценками показателя (степени, энтропии и т.п.) критичности уязвимости ИК ПО.
Визуальный язык в виде раскрасок графа максимально приближен к профессиональному языку специалистов в прикладной области.
Для реализации предлагаемого способа генерации баз знаний предлагается интерактивное программируемое устройство (ИПУ) для систем верификации программного обеспечения распределенных вычислительных комплексов (СВПО РВК), содержащее аппаратно-программный блок (АПБ) лексического и семантического анализа/разбора, АПБ преобразования кода, АПБ анализа кода; АПБ процессорного управления, видео адаптер, интерфейсы жестких, гибких и оптических дисков, интерфейс последовательного порта, сетевой интерфейс и системную память, которые объединены системной шиной, при этом системная память содержит постоянное запоминающее устройство (ROM) и оперативное запоминающее устройство (RAM/ОЗУ), в ячейках оперативной памяти и жестких дисков размещают/записывают операционные системы, прикладные программы, базы данных и базы знаний, которые содержат листинги исходных программ, грамматику языка программирования (например, грамматику языка программирования Си), правила преобразования дерева разбора листинга программы, дерево разбора листинга программы, таблицу типов языка программирования, аннотации внешних функций, включающие их грамматику и семантику, код программ на языке внутреннего представления, условия корректности языка внутреннего представления исходного кода программы, условия проверки корректности подозрительных точек исходного кода программы, информационную базу, содержащую системы ограничений в виде алгебраических уравнений и неравенств, отчеты об обнаруженных уязвимостях программного кода, включающие:
указание на местоположение возможной уязвимости в исходном коде программы, которое содержит имя файла листинга программы, номер строки и номер позиции в строке программы в котором возможно переполнение буфера запоминающего устройства, контекст исходной программы, содержащий возможное переполнение (некоторую ”окрестность” потенциально опасной точки переполнения буфера запоминающего устройства);
указание причины переполнения буфера запоминающего устройства - значения исходных переменных, приводящих к возникновению уязвимости исходного кода программного обеспечения;
показатель или степень критичности обнаруженной уязвимости исходного кода программного обеспечения;
указание на перечень правил или алгоритмов для устранения уязвимости исходного кода программного обеспечения.
При этом аппаратно-программный блок процессорного управления, обеспечивающий синхронизацию основных режимов интерактивной верификации программного обеспечения распределенных вычислительных комплексов, содержит последовательно соединенные блок нормирующих преобразователей (БНП), модуль коммутатора, модуль аналого-цифрового преобразователя (АЦП), модуль формирования статических координат графоаналитического растра (МФСКГАР), блок видеоконтроля (БВ), импульсный регулятор (ИР) и модуль формирования динамической развертки графоаналитического растра (МФДРГАР), первый и второй информационные входы/выходы которого соединены соответственно с управляющими входами модуля коммутации и аналого-цифрового преобразователя, а третий, четвертый, пятый, шестой, седьмой и восьмой - с вторым, третьим, четвертым, пятым, шестым и седьмым информационными входами/выходами МФСКГАР, при этом второй вход блока видеоконтроля объединен с седьмым информационным входом/выходом МФСКГАР и восьмым информационным входом/выходом МФДРГАР.
Блок видеоконтроля (БВ) содержит модуль регистратора (МР), на выходе которого установлены маска, оптическая система и преобразователь оптического сигнала, выходом подключенный к управляющему входу блока динамической развертки.
При этом оптический коэффициент пропускания маски, через которую проходит оптический сигнал, имеет одно и то же значение для точек одной гипотезы/энтропии о состоянии уязвимости ИК ПО и различное для других значений гипотез.
Маска изготовлена так, что в пространстве ее координат (X, Y, Z) выделены области уязвимости ИК ПО и соответствующие значения могут быть определены на основе оценки степени уязвимости ИК ПО ВРК.
В качестве оценки степени уязвимости ИК ПО ВРК могут быть использованы значения энтропии состояния верифицируемого ИК ПО.
Отличительные признаки предлагаемого способа и устройства для его реализации позволяют расширить функциональные возможности основных процессов верификации ИК ПО распределенных вычислительных комплексов непосредственно при выполнения научно-исследовательских работ на основе использования реальных динамических характеристик распределенных вычислительных систем и сетей, при этом предоставляется возможность повысить достоверность и объективность принимаемых решений на основных этапах исследования, разработки и сопровождения ПО распределенных вычислительных комплексов.
Предлагаемое изобретение поясняется чертежами.
На фиг.1 приведена структура интерактивного программируемого устройства (ИПУ) для систем верификации программного обеспечения распределенных вычислительных комплексов (СВПО РВК), содержащая аппаратно-программный блок (АПБ) лексического и семантического анализа/разбора (АПБ-А), АПБ преобразования кода (АПБ-В), АПБ анализа кода (АПБ-С), АПБ процессорного управления (АПБ-У), видеоадаптер, интерфейсы жестких, гибких и оптических дисков, интерфейс последовательного порта, сетевой интерфейс и системную память, которые объединены системной шиной, при этом системная память содержит постоянное запоминающее устройство (ROM) и оперативное запоминающее устройство (RAM/ОЗУ), в ячейках оперативной памяти и жестких дисков размещают/записывают операционные системы, прикладные программы, базы данных и базы знаний, которые содержат листинги исходных программ (D1), грамматику языка программирования (D2) (например, грамматику языка программирования Си), правила преобразования дерева разбора листинга программы (D3), дерево разбора листинга программы (D4), таблицу типов языка программирования (D5), аннотации внешних функций, включающие их грамматику и семантику (D6), код программ на языке внутреннего представления (D7), условия корректности языка внутреннего представления исходного кода программы (D8), условия проверки корректности подозрительных точек исходного кода программы (D9), информационную базу (D10), содержащую системы ограничений в виде алгебраических уравнений и неравенств, отчеты об обнаруженных уязвимостях программного кода (D11), включающие:
указание на местоположение возможной уязвимости в исходном коде программы, которое содержит имя файла листинга программы, номер строки и номер позиции в строке программы, в котором возможно переполнение буфера запоминающего устройства, контекст исходной программы, содержащий возможное переполнение (некоторую ”окрестность” потенциально опасной точки переполнения буфера запоминающего устройства);
указание причины переполнения буфера запоминающего устройства - значения исходных переменных, приводящих к возникновению уязвимости исходного кода программного обеспечения;
показатель или степень критичности обнаруженной уязвимости исходного кода программного обеспечения;
указание на перечень правил или алгоритмов для устранения уязвимости исходного кода программного обеспечения.
На фиг.2 приведен пример реализации аппаратно-программного блока (АПБ) лексического и семантического анализа/разбора (АПБ - А), в котором приняты следующие обозначения:
На вход АПБ-А поступает набор файлов с исходными текстами анализируемой программы. На выходе АПБ-А получают преобразованное дерево разбора исходного кода программы и таблицу типов, используемых в анализируемой программе, готовые к проведению преобразования во внутреннее представление ”Анализатора” - АПБ-А.
На фиг.3-7 приведены примеры реализации основных модулей АПБ-А.
На фиг.3 приведен пример реализации модуля А1 АПБ-А. Аппаратно программный модуль А1 обеспечивает режим ”лексического и синтаксического разбора исходных текстов программ”, перечень принятых обозначений имеет следующий вид:
В основе работы данного модуля использован алгоритм LR-разбора файла с исходным текстом программы по набору лексических и синтаксических правил разбора. В процессе синтаксического разбора строится дерево разбора и таблица типов.
На фиг.4 приведен пример реализации модуля А2 АПБ-А. Аппаратно программный модуль А2 обеспечивает режим ”преобразования дерева разбора кода программы к виду, пригодному для перевода его во внутреннее представление”, перечень принятых обозначений имеет следующий вид:
Модуль А2 представляет процедуру ”SIMPLIFY SYNTAX TREE”, производящую надлежащее упрощение дерева разбора, результатом которого является дерево разбора и таблица типов, преобразование которых ко внутреннему представлению значительно проще по сравнению с преобразованием ”сырого” дерева разбора.
Схема процедуры ”SIMPLIFY SYNTAX TREE” представлена на фиг.4. В работе процедуры используются две внутренние рекурсивные процедуры ”MARK SCOPES” и ”TRANSFORM SYNTAX TREE”, осуществляющие, соответственно, пометку областей видимости объявлений и определений в дереве разбора и преобразование дерева разбора по заранее заданному набору правил.
На фиг.5 приведен пример реализации рекурсивной процедуры А2.1. ”MARK SCOPES”, при этом приняты следующие обозначения:
На фиг.6 приведен пример реализации рекурсивной процедуры А2.6. ”TRANSFORM SYNTAX TREE”, при этом приняты следующие обозначения:
На вход процедуры TRANSFORM SYNTAX TREE поступает дерево (или поддерево) разбора, на выходе получается результирующее преобразованное дерево разбора. Внутри процедуры происходит рекурсивный вызов этой процедуры и сохранение результатов (дерева разбора) выполнения этого вызова во временном массиве результатов, который размещается в ОЗУ.
При этом оригинальность предлагаемого способа трансформации или преобразования дерева в процессе верификации/разбора исходного листинга программы состоит в том, что если дерево с указанной вершиной соответствует определению и содержит внутри себя спецификатор ”extern”, то такое дерево удаляется, кроме этого, если дерево соответствует блочной инструкции, то каждое поддерево блочной инструкции с вершиной в ”ребенке” обрабатываемой вершины заменяется на список поддеревьев, соответствующих инструкциям в этой блочной инструкции.
На фиг.7 приведен пример реализации аппаратно-программного модуля A3, обеспечивающего режим верификации многофайловых программных проектов на основе реализации процедуры ”MERGE SYNTAX TREES” для компоновки деревьев разбора и таблиц типов, при этом приняты следующие обозначения:
На фиг.8 приведен пример реализации аппаратно-программного блока (АПБ) преобразования кода (АПБ-В), обеспечивающего преобразование дерева разбора исходной программы к внутреннему представлению, при этом приняты следующие обозначения:
На фиг.9 приведен пример реализации модуля В1 АПБ-В. Аппаратно программный модуль В1 (встраивание функций) обеспечивает режим модифицирования дерева разбора, которое находится в базе данных D4. Перечень принятых обозначений имеет следующий вид:
На фиг.10 приведен пример реализации процедуры разворачивания функций (Unwinding Functions - UF). На вход процедуры подается дерево разбора с выделенной вершиной, соответствующей некоторой функции, на выходе получается дерево разбора. На фиг.10 приняты следующие обозначения:
На фиг.11 приведен пример реализации модуля В2 АПБ-В (аппаратно-программный модуль разворачивания структур). На вход модуля В2 подается дерево разбора и таблица типов, на выходе получают модифицированное дерево разбора. Перечень принятых обозначений имеет следующий вид:
На фиг.12 приведен пример реализации модуля В3 АПБ-В. На вход аппаратно-программного модуля В3 (модуль разворачивания выражений) подается преобразованное дерево разбора, а на его выходе получается новое преобразованное дерево разбора. Перечень принятых обозначений имеет следующий вид:
На фиг.13 приведен пример реализации модуля В4 АПБ-В (аппаратно-программный модуль преобразования к внутреннему представлению). На вход модуля В4 подается дерево в виде преобразованного дерева разбора исходного кода и база знаний D6 аннотаций внешних функций, на выходе модуля В4 получают базу данных D7 программ на языке внутреннего представления, базу данных D8 условий корректности языка внутреннего представления исходного кода программы и базу знаний D9 условий проверки корректности подозрительных точек исходного кода программы. Перечень принятых обозначений имеет следующий вид:
На фиг.14 приведен пример реализации процедуры преобразования присваиваний (Assign Transform - AT). На вход процедуры AT подается вершина дерева, соответствующая присваиванию, на выходе процедуры получают инструкции внутреннего представления. На фиг.14 приняты следующие обозначения:
На фиг.15 приведен пример реализации процедуры преобразования переходов (Goto Transform - GT). На вход процедуры подается вершина, соответствующая условному/безусловному переходу, на выходе процедуры получается набор инструкций внутреннего представления. На фиг.15 приняты следующие обозначения:
На фиг.16 приведен пример реализации процедуры преобразования выражений (Simple Arithmetic Expression transform - SAE). На вход процедуры подается вершина, соответствующая арифметическому выражению, на выходе - получают выражение на языке внутреннего представления. На фиг.16 приняты следующие обозначения:
На фиг.17 приведен пример реализации аппаратно-программного блока анализа кода (АПБ-С) программы на языке внутреннего представления и формирование отчета об обнаруженных ”уязвимостях”, при этом приняты следующие обозначения:
На фиг.18-27 приведены примеры реализации основных модулей АПБ-С. На фиг.18 приведен пример реализации модуля С1 АПБ-С. Аппаратно программный модуль С1 обеспечивает поддержку режима ”получения инвариантов в точках внутреннего представления”, перечень принятых обозначений имеет следующий вид:
На фиг.19 приведен пример реализации процедуры определения инвариантов вдоль одного простого пути (Path Invariants - PI). На ее вход поступает некоторый простой путь L=(L[0],…,L[m-1]) управляющего графа программы. На фиг.19 приняты следующие обозначения:
На фиг.20 приведен пример реализации процедуры фильтрации спектров и предикатов (Y-Filter-YF). На фиг.20 приняты следующие обозначения:
На фиг.21 приведен пример реализации процедуры вычисление множества Y (Y-Set-YS). На фиг.21 приняты следующие обозначения:
На фиг.22 приведен пример реализации процедуры определения максимально простых путей в графе (Simple Paths-SP). На фиг.22 приняты следующие обозначения:
На фиг.23 приведен пример реализации процедуры генерации управляющего графа программы (Generate Graph - GG). На фиг.23 приняты следующие обозначения:
На фиг.24 приведен пример реализации модуля С2 АПБ-С. Аппаратно программный модуль С2 обеспечивает режим генерации систем информационной базы знаний D10 и позволяет свести задачу проверки условий корректности в программе на языке внутреннего представления к стандартной задаче линейного программирования. Перечень принятых обозначений имеет следующий вид:
На фиг.25 приведен пример реализации модуля С3 АПБ-С. Аппаратно-программный модуль С3 обеспечивает режим исследования систем ограничений информационной базы знаний D10. Перечень принятых обозначений на фиг.25 имеет следующий вид:
На фиг.26 приведен пример реализации процедуры решения задачи линейного программирования симлекс-методом (Simplex Method - SM). На фиг.26 приняты следующие обозначения:
На фиг.27 приведен пример реализации модуля С4 АПБ-С. Аппаратно программный модуль С4 обеспечивает режим формирования отчета об обнаруженных уязвимостях. Перечень принятых обозначений на фиг.27 имеет следующий вид:
Далее приведены пояснения к обозначениям, использованным для фиг.18-27.
1. На данном шаге происходит считывание инструкций внутреннего представления программы в массив Р. Число инструкций (длина массива) предполагается равным N. Затем осуществляется вызов GG - вызов функции построения управляющего графа программы, которой передаются на вход массив Р и его размер N.
2. Вызов функции поиска максимальных простых путей в управляющем графе, начинающихся из начальной его вершины.
3. Инициализация таблицы инвариантов. Данный шаг заключается в выделении массива размера N, значениями которого являются множества инвариантов, причем i-й элемент массива будет содержать множество инвариантов, полученное в виде вершины графа с индексом i. На данном шаге множества инвариантов во всех элементах массива пусты.
4. Вызов функции PI - поиска инвариантов вдоль простого пути. На вход функции передается управляющий граф и простой путь в виде последовательности принадлежащих ему вершин. На выходе функция возвращает таблицу спектров и таблицу предикатов вдоль данного простого пути.
5. Процедура уточнения таблицы инвариантов.
- Сначала для каждой вершины v простого пути L берется объединенный список Х предикатов таблиц TS(L), TP(L), соответствующих вершине
- затем, если вершина v уже обрабатывалась ранее на другом простом пути L', то из элемента таблицы TI, соответствующего вершине v, выбрасываются все предикаты, которые не встретились в списке X;
- если вершина v обрабатывается впервые, то в элемент таблицы TI, соответствующий вершине v, добавляются все предикаты из списка X.
6. Вычислить Y=Y(L, р+1). В данной функции происходит определение множества вершин v графа, таких что существует пара путей L', L”, не проходящих через вершины L[0],…, L[p], причем путь L' соединяет вершину L[p+1] с вершиной v, путь L” соединяет вершину v с вершиной L[р+1].
7. Рассматривается инструкция L[p], выделяются 4 основных случая.
- Инструкция имеет вид assign х=ехрr, либо assign_a х=…[…], где х - имя переменной, ехрr - некоторое арифметическое выражение.
- Инструкция имеет вид condition х R const, где х - имя переменной, R - один из предикатных символов {<,<=,>,>=,==,!=}, const - некоторое целое число.
- Инструкция имеет вид condition expr1 R expr2, где expr1, expr2 - некоторые арифметические выражения, R - один из предикатных символов {<,<=,>,>=,==,!=}.
- Другой вид инструкции (a_assign, goto, stop).
8. Пересчитать спектр переменной х, подставив в арифметическое выражение ехрr вместо переменных, входящих туда, их спектры из таблицы TS, столбца р. В результате получим новый спектр переменной х. Если инструкция имеет тип assign_a, то считаем, что спектр правой части равен (-inf, +inf).
9. Пересчитать множество предикатов U. Поскольку переменная х изменилась, то условия, содержащие х, которые были выполнены до инструкции L[p], перестанут быть выполнены после инструкции L[p]. В некоторых простейших случаях возможно скорректировать условие таким образом, что после инструкции L[p] оно вновь станет выполнено. Укажем эти условия.
- Пусть ехрr имеет вид х+const. Здесь const - некоторое целое число.
- Пусть предикат u имеет вид а*х+w R с1, где а, с1 - некоторые целые числа, w - предикат, не зависящий от х, R - один из предикатных символов {<,<=,>,>=,==,!=}.
В этом случае можно скорректировать предикат следующим образом:
u'=а*х+w R с2. Здесь с2=с1+const*a. Если инструкция или предикат не удовлетворяют указанным условиям, то предикат необходимо из множества удалить.
10. Пересчитать спектр переменной х. Поскольку предикат, стоящий в инструкции L[p] имеет вид х R const, то ему всегда соответствует некоторый спектр s, выражающий то же самое условие. Например, предикату х<=10 будет соответствовать спектр (-inf, 11), а предикату х!=0 будет соответствовать спектр (-inf, 0)∪[1, +inf). Тогда текущий спектр переменной х нужно пересечь (с помощью операции intersect) со спектром s. При этом крайне важно учесть, какой ветке условного перехода отвечает ребро (L[p], L[p+1]). Если эта ветка соответствует ложности предиката, предикатный символ R нужно заменить на ему противоположный. Пары противоположных предикатных символов: (<,>=); (<=,>); (==, !=).
11. Пополнить множество предикатов U новым предикатом, который записан в теле инструкции условного перехода L[p]. Вне зависимости от вида данного условия, оно всегда будет выполнено. При выполнении данного шага необходимо учесть истинность иди ложность ветки условного перехода, отвечающей ребру (L[p], L[p+1]).
12. Записать спектры всех переменных из р-го столбца таблицы спектров с учетом возможных поправок спектра для отдельной переменной во временную таблицу S.
13. Произвести ”фильтрацию” спектров таблицы S и предикатов множества U. В результате фильтрации будут по-возможности скорректированы, а в худшем случае - отброшены все спектры и предикаты, которые могут оказаться неверны, если учесть инструкции из множества Y, которые могут появиться на трассе выполнения программы раньше точки L[p+1]. Такими инструкциями будут инструкции множества Y (см. шаг 1). Блок-схема работы функции YF будет далее приведена отдельно.
14. Заполнить (р+1)-й столбец таблицы спектров значениями, записанными во временной таблице S и (р+1)-й элемент таблицы предикатов положить равным U.
15. Рассматривается очередная инструкция у, выделяются 4 случая.
А. Инструкция у имеет вид assign х=х+const, где const - некоторое целое число.
В. Инструкция у имеет вид assign х=const, где const - некоторое целое число.
С. Инструкция у имеет вид assign x=…
D. Инструкция у имеет другой вид (тип отличен от assign).
16. Объединить при помощи операции join текущий спектр переменной х (из массива S) со спектром {const}.
17. Удалить из множества U все предикаты, куда входит переменная х.
18. Взять из А очередную необработанную вершину u, пополнить множество В вершинами, смежными с u, но не принадлежащими множеству {L[0],…,L[р-1]}, закончить обработку вершины u.
19. Взять из С очередную необработанную вершину u, пополнить множество D вершинами, не принадлежащими множеству {L[0],…,L[р-1]}, для которых вершина v - смежная, закончить обработку вершины v.
20. Инициализировать очереди Q, R. Очередь R изначально пуста. В очередь Q положить последовательность l={v0}, где v0 - начальная вершина графа (то есть вершина, входящая степень которой равна 0).
21. L'=(L, u). Данное выражение следует понимать следующим образом.
Путь L' получается из пути L добавлением вершины u.
22. Взять из массива СС очередное условие корректности, которое представляет собой пару вида (Р, id), где Р - предикат от переменных внутреннего представления, a id - идентификатор инструкции внутреннего представления, перед которой должен быть истинен предикат Р.
23. Формирование набора t параллельно выполняемых задач происходит путем разделения массива Sys на t примерно равных частей (частей, отличающихся не более чем на 1 систему). Затем каждый процесс будет заниматься исследованием своего подмножества информационной базы.
24. Проверка того, есть ли в системе S тождественно ложные предикаты или пары противоречащих друг другу предикатов.
25. Приведение системы S к виду LP - задачи классического линейного программирования. Ограничения информационной базы являются алгебраическими уравнениями и неравенствами. Для упрощения дальнейших рассуждений выбросим из системы все предикаты, в которых степень многочлена превышает 1. После этого систему S тривиальными арифметическими преобразованиями можно будет привести к следующему виду:
а(1,1)*х(1)+а(1,2)*х(2)+…+а(1,n)*х(n)<=b(1)
…
a(q,1)*x(1)+a(q,2)*x(2)+…+a(q,n)*x(n)<=b(q)
a(q+1,1)*x(1)+a(q+1,2)*x(2)+…+a(q+1,n)*x(n)==b(q+1)
…
a(m,1)*x(1)+a(m,2)*x(2)+…+a(m,n)*x(n)==b(m).
Вводятся дополнительные неотрицательные переменные:
x(n+1),…, x(n+q), x'(1), x”(1),….x'(n),…,x”(n)>=0
так, чтобы выполнялись условия x(i)=x'(i)-x”(i).
Тогда систему S можно переписать в таком виде:
а(1,1)*х'(1)-а(1,1)*х”(1)+…+а(1,n)*х'(n)-а(1,n)*х”(n)+х(n+1)=b(1)
…
a(q,1)*x'(1)-a(q,1)*x”(1)+…+a(q,n)*x'(n)-a(q,n)*x”(n)+x(n+q)==b(q)
a(q+1,1)*x'(1)-a(q+1,1)*x”(1)+…+a(q+1,n)*x'(n)-a(q+1,n)*x”(n)==b(q+1)
…
a(m,1)*x'(1)-a(m,1)*x”(1)+…+a(m,n)*x'(n)-a(m,n)*x”(n)==b(m).
Для простоты записи переименуем все переменные и коэффициенты таким образом, чтобы система S приняла вид:
t(1,1)*y(1)+…+t(1,n')*y(n')=d(1)
…
t(m',1)*y(1)+…+t(m',n')*y(n')=d(m')
y(i)>=0,i=1,…,n',
где m'=m, n'=2*m+q, причем d(i)>=0.
Задача классического линейного программирования:
Рассмотрим задачу максимизации линейной формы 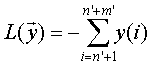 при условиях
при условиях

Пусть L* - решение указанной задачи. Тогда если
- L*<0, то множество решений системы ограничений S пусто;
- L*=0, то система S имеет решения.
26. Вызов функции SIMPLEX-METHOD.
27. Рекуррентные формулы пересчета массивов Е, В для нового базиса.
- B[r]=k;
- E[r][j]=E[r][j]/A[r], где j=1,…,m.
- E[i][j]=E[i][j] - E[r][j]*A[i], где j=1,…, m, i=1,…, m+1, i≠r.
28. Формулы пересчета массива D для нового базиса.
- 
На фиг.28 приведен пример реализации аппаратно-программного блока процессорного управления (АПБ-У), обеспечивающего синхронизацию основных режимов интерактивной верификации программного обеспечения распределенных вычислительных комплексов. На фиг.28 приняты следующие обозначения: У1 - блок нормирующих преобразователей (БНП); У2 - модуль коммутатора; У3 - модуль аналого-цифрового преобразователя (АЦП); У4 - модуль формирования статических координат графоаналитического растра (МФСКГАР); У 5 - модуль формирования динамической развертки графоаналитического растра (МФДРГАР); У6 - блок видеоконтроля (БВ); У7 - импульсный регулятор (ИР).
На фиг.29 приведен пример реализации модуля формирования статических координат графоаналитического растра (МФСКГАР) У4 АПБ-У. На фиг.29 приняты следующие обозначения: У4.1 - первое запоминающее устройство (ЗУ); У4.2 - блок интерполирования; У4.3 - блок выделения экстремума; У4.4 - блок масштабирования; У4.5 - схема формирования дискретных приращений статических координат графоаналитического растра; У 4.6 - блок преобразования статических координат графоаналитического растра; У4.7 - второе ЗУ.
На фиг.30 приведен пример реализации модуля формирования динамических координат графоаналитического растра (МФДРГАР) У5 АПБ-У. На фиг.30 приняты следующие обозначения: У5.1 - схема формирования дискретных приращений динамических координат графоаналитического растра; У5.2 - блок задания постоянных коэффициентов; У5.3 - блок синхронизации; У 5.4 - схема формирования адреса записи.
На фиг.31 приведен пример реализации блока видеоконтроля (БВ) У6 АПБ-У. На фиг.31 приняты следующие обозначения: У6.1 - модуль регистратора (МР) АПБ-У, на выходе которого установлены маска У6.2, оптическая система У6.3 и преобразователь оптического сигнала У6.4, выходом подключенный к входу блока динамической развертки У6.5.
На фиг.32 приведен пример реализации импульсного регулятора У 7 АПБ-У, который содержит блок определения абсолютных значений У 7.1, первый релейный элемент У7.2, первый логический элемент ”И” У7.3, второй релейный элемент У7.4, блок возведения в квадрат У7.5, триггер У7.6, первый, второй и третий блоки выборки-хранения У7.7, У7.8 и У7.9, первый формирователь импульсов У 7.10, источник эталонных напряжений У7.11, первый, второй и третий сумматоры У7.12, У7.13 и У7.14, электронный ключ У7.15, второй формирователь импульсов У7.16, третий релейные элементы У7.17, второй логический элемент ”И” У7.18.
На фиг.33-39 приведены фрагменты результатов работы предлагаемого способа и устройства в процессе верификации ИК ПО распределенных вычислительных комплексов.
В качестве первого примера (пример 1) рассмотрим процесс верификации исходного текста ПО на языке программирования Си. Для ясности изложения будем полагать, что листинг исходного текста программы поступил по независимому интерфейсному каналу последовательного порта (например, введен оператором ЭВМ в ручном режиме на основе использования клавиатуры см. фиг.1, детали сопровождения (ввода, редактирования, распределенного хранения и т.п.) исходного текста ИК ПО опускаются, поскольку они в данном контексте не имеют существенного значения, т.е. в данном примере не будем рассматривать особенности процессов сопровождения ИК ПО распределенных вычислительных комплексов. Основное внимание далее уделим процессу автоматического поиска участков уязвимости в ИК ПО. При этом исходная Си программа представляет собой набор из двух фалов следующего вида:
Файл main.c:
extern int f(int *arr, int ind);
int main()
{
int a[100];
int i;
int j;
for(i=0; i<10; ++i)
for(j=9; j>=i; --j)
a[10*i+j]=0;
return f(a, 55);
}
Файл f.c:
int f(int* arr, int ind)
{
return arr[ind];
}
ИК ПО заносится в базу данных D1. После окончания ввода ИК ПО АПБ-У формирует на системной шине (см. фиг.1) управляющий сигнал в момент времени t1, который подается на вход 1 АПБ-А (см. фиг.2). Таким образом, АПБ-У фиксирует все моменты формирования управляющих сигналов и реакций, соответствующих АПБ и их модулей, на эти воздействия. При этом для краткости изложения далее эти моменты в описании опускаются. После поступления управляющего сигнала запускается АПБ-А, а именно (см. фиг.2)тело цикла, состоящее из аппаратно-программных модулей A.1, A.2, А.3 АПБ-А (далее для краткости изложения будем обозначать первым символом - А.*, принадлежность каждого из используемых аппаратно-программных модулей, т.е. будем идентифицировать соответствующей буквой АПБ, а именно, АПБ-А, просто A.1, A.2 и т.д., АПБ-В - B.1 … и т.п.). При этом этот цикл в рассматриваемом примере будет выполнен ровно 2 раза, так как в наборе анализируемых файлов Си ИК ПО в наличии 2 файла. Соответственно АПБ-У обеспечивает контроль и измерение длительности выполнения не только каждого цикла, но и длительность работы каждого модуля АПБ-А. После выполнения этого цикла будут выполнены действия по соединению результатов разбора листингов ИК ПО в модуле А.8.
Операции, производимые в модуле A.2, раскрыты на фиг.3. Опишем процессы модуля А1 на примере разбора фрагментов листинга из файла main.c.
В процессе выполнения модуля А 1.1 происходит разбиение листинга ИК ПО, получаемого из базы данных D1, на поток лексем согласно правилам из грамматики языка, находящихся в базе данных D2.
Фрагмент начала последовательности лексем с обозначением типа лексем представлен ниже:
'extern' - ключевое слово
'int' - ключевое слово
'f' - идентификатор
'(' - символ'('
'int' - ключевое слово
'*' - символ '*'
'arr' - идентификатор
',' - символ','
'int' - ключевое слово
'ind' - идентификатор
')' - символ')'
';' - символ';'
…
Приведем пример фрагмента грамматики языка программирования Си (см. стандарт ISO:IEC 9899:1999, также называемой ”С99”).
…
statement:
labeled_statement
|compound_statement
|expression_statement
|selection_statement
|iteration_statement
|jump_statement
labeled_statement:
identifier':'statement
|'case' constant_expression':'statement
|'default'':' statement
compound_statement: compound_statement_startblock_item*'}'
compound_statement_start:'{'
block item: declaration|statement
expression_statement: expression?';'
selection_statement:
'if'('expression')' statement
|'if'('expression')' statement
'else' statement
|'switch''('expression')' statement
iteration_statement:
'while''('expression ')'statement
|'do' statement 'while''('expression')'';'
|'for''('expression?';' expression?';'expression?')' statement
|'for''('declaration expression?';'expression?')'statement
jump_statement:
'goto' identifier';'
|'continue'';'
|'break'';'
|'return' expression?';'
translation_unit: |extemal_declaration
translation_unit: translation_unit extemal_declaration
external declaration: declaration|function definition
function_definition: declaration specifiers? declarator declaration*
compound_statement
Для синтаксического разбора рассматриваемого здесь примера ИК ПО, построения дерева разбора и таблицы типов потребуются следующие синтаксические правила, являющиеся подмножеством грамматики языка Си:
1: declaration: declaration_specifiers init_declarator';';
2: declaration_specifiers: (storage_class_specifier|type_specifier|type_qualifier|
function_specifier)+;
3: init_declarator: declarator;
4: declarator: pointer? direct_declarator;
5: direct_declarator: direct_declarator'(' parameter_list')';
6: parameter_list: parameter_declaration*;
7: direct_declarator: identifier;
8: parameter_declaration: declaration_specifiers declarator;
9: storage_class_specifier: 'typedef|'extern'|'static'|'auto'|'register';
10: type_specifier: 'void'|'char'|'short'|'int'|'long'|'float'|'double'|'signed'|'unsigned'| 'Bool'|'_Complex'|'_Imaginary'|struct_or_union_specifier|enum_specifier|typedef_name|typeof_expr|typeof_type;
11: pointer:'*'+;
При выполнении модуля А1.2 происходит очистка временного внутреннего стека, используемого при разборе.
В цикле, состоящем из модулей А1.3, А1.4, А1.5, А1.6, А1.7, А1.8, А1.9, А1.10 и А1.11, производится применение синтаксических правил и построение дерева разбора и таблицы типов. В процессе выполнения последовательности А1.3, А1.4, А1.5, А1.6, А1.7 и А1.8 лексемы помещаются на вершину стека до тех пор, пока не станет возможным применение одного из правил синтаксического разбора. Соответственно длительность выполнения данных циклов и им подобных контролируется АПБ-У на основе измерения соответствующих интервалов времени и сопоставления их с некоторыми наперед заданными значениями, которые соответствуют нормальному режиму работы устройства верификации в целом. Подобные временные параметры устанавливаются на основе опытных данных и при первом обращении могут быть установлены эмпирически, а затем на тестовых примерах уточнены, например, на ИК ПО с известными точками уязвимости. Таким образом, обеспечивается режим обучения (самообучения) устройства верификации в каждом цикле верификации ИК ПО.
В рассматриваем здесь примере на этапе работы модуля А 1.4 на вершину стека помещается лексема 'extern'. При выполнении модулей А1.5, А1.6, А1.7 и А1.8 последовательность из 1 элемента 'extern' приводит к срабатыванию правила 9 и к замене последовательности на поддерево с корневой вершиной sc-spec на этапе выполнения модуля А 1.9. На этапе выполнения модуля А. 10 определяется то, что в ИК ПО, приведенного выше примера, новые типы при обработке не вводятся, поэтому модуль A.11 не выполняется.
На этапе выполнения модуля А 1.4 на вершину стека, а именно в его первую ячейку, помещается лексема 'int'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 последовательность из 1 элемента 'int' приводит к срабатыванию правила 10 и замене последовательности на поддерево с корневой вершиной type-spec. На этапе выполнения модуля А. 10 определяется, что в ИК ПО приведенного выше примера новые типы при обработке не вводятся, поэтому модуль A.11 не выполняется.
На следующем этапе выполнения модуля А1.4 на вершину стека, а именно в его первую ячейку, помещается лексема 'f'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 никакое синтаксическое правило не срабатывает.
На следующем этапе выполнения модуля А1.4 на вершину стека помещается лексема '('. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 никакое синтаксическое правило не срабатывает.
На следующем этапе выполнения модуля А1.4 на вершину стека помещается лексема 'int'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 последовательность из 1 элемента 'int' приводит к срабатыванию правила 10 и замене последовательности на поддерево с корневой вершиной type-spec. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль A.11 не выполняется.
На следующем этапе выполнения модуля А 1.4 на вершину стека помещается лексема '*'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 последовательность из 1 элемента '*' приводит к срабатыванию правила 11 и замене последовательности на поддерево с корневой вершиной pointer. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль А.11 не выполняется.
На следующем этапе выполнения модуля А 1.4 на вершину стека помещается лексема 'аrr'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 срабатывает правило 8 и на шаге А1.9 производится замена последовательности на поддерево с вершиной param-decl. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль А.11 не выполняется.
На следующем этапе выполнения модуля А1.4 на вершину стека помещается лексема ','. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 никакое синтаксическое правило не срабатывает.
На следующем этапе выполнения модуля А 1.4 на вершину стека помещается лексема 'inf. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 последовательность из 1 элемента 'int' приводит к срабатыванию правила 10 и замене последовательности на поддерево с корневой вершиной type-spec. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль A.11 не выполняется.
На следующем этапе выполнения модуля А1.4 на вершину стека помещается лексема 'ind'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 срабатывает правило 8 и на этапе выполнения модуля А1.9 производится замена последовательности на поддерево с вершиной param-decl. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль А.11 не выполняется.
На следующем этапе выполнения модуля А1.4 на вершину стека помещается лексема ')'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 срабатывает правило 5 и на этапе выполнения модуля А1.9 производится замена последовательности на поддерево с вершиной d-d-param. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль A.11 не выполняется.
На следующем этапе выполнения модуля А1.4 на вершину стека помещается лексема';'. В процессе выполнения модулей А1.5, А1.6, А1.7 и А1.8 срабатывает правило 1 и на этапе выполнения модуля А1.9 производится замена последовательности на поддерево с вершиной decl. На этапе выполнения модуля А.10 определяется, что новые типы при обработке не вводятся, модуль А.11 не выполняется.
Дальнейший поток лексем обрабатывается аналогичным образом, пока на этапе выполнения модуля А1.3 не обнаружится, что поток лексем закончен. На этапе выполнения модуля А1.12 определяется, что стек содержит только один элемент - дерево разбора. При этом выполнение всех вышеперечисленных этапов контролируется АПБ-У, т.е. если, например, на этапе выполнения модуля А1.12 произойдет аварийный останов цикла разбора ИК ПО, то АПБ-У обеспечит самодиагностику данного состояния устройства разбора. На этапе выполнения модуля А1.13 производится запись дерева разбора в динамический массив А.4.
Фрагмент дерева разбора, полученного на этапе работы модуля А1, может быть представлен в БВ АПБ-У (см. фиг.28) в виде (см. фиг.33-39), приемлемом для зрительного восприятия и анализа оператором ЭВМ.
После работы модуля А2 дерево разбора для файла main.c примет вид, изображенный на фиг.33.
Фрагмент дерева разбора, полученного на этапе применения модуля лексического и синтаксического разбора к файлу f.c, приведен на фиг.35.
После работы модуля А2 дерево разбора для файла f.c примет вид, изображенный на фиг.36.
После выполнения модуля A3 будет получено преобразованное дерево разбора, вид которого представлен на фиг.37. На фиг.37 темным цветом выделено поддерево, соответствующее описанию функции f., светлым цветом выделен вызов этой функции в исходной программе.
Поскольку пример ИК программ не содержит обращений к внешним функциям, ее внутреннее представление и база данных условий корректности могут быть получены на основе преобразованного дерева разбора программы на этапе применения модулей трансляции дерева разбора во внутреннее представление и генерации условий корректности (см. фиг.8).
В процессе работы модуля В1 осуществляется обращение к процедуре UF для обработки функции main. При обработке вызова функции f будет вызвана процедура UF для функции f. Эта процедура оставит функцию f без изменений, так как она не содержит вызовов функций. После этого, код функции f будет добавлен в код main.
Рассмотрим для простоты преобразованное дерево в виде программы на языке Си.
int a[100];
int i;
int j;
int *arr;
int ind;
int f_ret;
for(i=0; i<10; ++i)
for(j=9; j>=i; --j)
a[10*i+j]=0;
arr=a;
ind=55;
f_ret=arr[ind];
return f_ret;
В приведенном примере присутствуют лишь простые типы, поэтому модуль В2 не выполняет преобразований.
В приведенном примере присутствуют циклы, которые будут на этапе выполнения модуля В3 развернуты. Так например, при преобразовании первого цикла будет получен следующий код на ”псевдо-Си”:
int a[100];
int i;
int j;
int *arr;
int ind;
int f_ret;
i=0;
goto (i<10) ? label1: label2;
label1:
for(j=9; j>=i; --j)
a[10*i+j]=0;
++i;
label2:
arr=a;
ind=55;
f_ret=arr[ind];
return f_ret;
При преобразовании второго цикла будет получен следующий код на ”псевдо-Си”:
int a[100];
int i;
int j;
int *arr;
int ind;
int f_ret;
i=0;
label0:
goto (i<10) ? label1: label2;
label1:
J=9;
label3:
goto (j>=i) ? label4: label5;
label3:
a[10*i+j]=0;
j++;
goto label3;
label4:
++i;
goto label0;
label2:
arr=a;
ind=55;
f_ret=arr[ind];
return f_ret;
На следующем этапе выполнения модуля В4 получается внутреннее представление программы следующего вида:
База данных условий корректности D8 будет представлена в следующем виде:
База знаний D9 соответствия условий корректности подозрительным точкам исходного кода:
1 main.с:3:9:16 1.0 Unable to deduce dereferencing upper bound;
2 main.c:3:9:16 1.0 Unable to deduce dereferencing lower bound;
3 main.с:14:7:15 1.0 Unable to deduce dereferencing upper bound;
4 main.с:14:7:15 1.0 Unable to deduce dereferencing lower bound;
Далее АПБ-У передаст управление АПБ-С. Рассмотрим в рамках данного примера работу каждого из модулей АПБ-С (см. фиг.17-27).
При этом в качестве дополнительного пояснения следует указать на то, что модуль С1 АПБ-С обеспечивает детализированный статический анализ ИК ПО на упрощенном языке внутреннего представления (далее - просто программы). Он позволяет собрать по данному описанию программы сведения, необходимые для доказательства условий корректности, что эквивалентно условию отсутствия в исходной программе уязвимостей, связанных с переполнением буферов ОЗУ. Далее целесообразно изложить описание принципов работы данного модуля.
Функционирование данного модуля тесно связано со следующими объектами:
N - множество целых неотрицательных чисел;
I - множество инструкций внутреннего представления. Размеченный граф представляет собой пару G=(V, Е), где
V - множество вершин, являющееся подмножеством N×M, где М - множество меток вершин графа. Для вершины v=(n, m) число n будем называть индексом вершины, а m - ее меткой,
Е - множество ребер, E⊆V×V.
Путь в графе - последовательность вершин ν1,…νn, где (νi, νi+1)∈E для каждого i=1,…,n-1. Путь называется простым, если в нем нет повторяющихся вершин.
Управляющим графом программы называют размеченный граф, для которого множество меток совпадает с множеством I - инструкцией внутреннего представления программы.
Интервал значений переменной х - это одной из следующих множеств:
- -∞<х<+∞ - undefined_value
- -∞<х<b - left_infinity
- a<x<+∞ - right_infinity
- a≤x<b - interval
- x=a - exact_value
- ⌀ - impossible_value
Здесь также указаны обозначения типов возможных интервалов. Спектром переменной х называют условие на множестве ее возможных значений, заданное в виде объединения непересекающихся интервалов. При этом количество интервалов не должно превышать некоторого наперед заданного значения М.
Над множеством спектров введем бинарные операции intersect(P, Q), join(P, Q).
При этом:
intersect(P, Q) - пересечение спектра Р со спектром Q. Можно показать, что пересечением двух семейств из не более, чем М непересекающихся интервалов является спектром, состоящим из не более, чем 2*М непересекающихся интервалов;
join(P, Q) - объединение спектра Р со спектром Q. Объединение двух семейств из не более, чем М непересекающихся интервалов является спектром, состоящим из не более, чем 2*М непересекающихся интервалов.
Для того чтобы при выполнении операций над спектрами количество интервалов в их описании не возрастало до бесконечности, после выполнения указанных операций в случае, когда число интервалов результирующего спектра превосходит М, необходимо несколько раз провести операцию ”редукции”: случайно выбрать пару соседних интервалов и заменить ее на минимальный интервал, содержащий оба указанных. Пример:

В данном примере изображен спектр, состоящий из трех интервалов. Если М=2, то будут случайным образом выбраны два соседних интервала (например, первый и второй) и объединены в один интервал.
Учитывая возможность выполнения подобной операции ”редукции” спектра будем считать, что введенные ранее операции join и intersect преобразуют пару спектров, состоящих из не более, чем М интервалов в спектр, также состоящий из не более чем М интервалов.
Помимо указанных операций, для спектров также определены обычные арифметические операции - сложение, вычитание, умножение и деление. При этом:
P+Q={y∈Z:y=p+q, p∈P, q∈Q};
P-Q={y∈Z:y=p-q, p∈P, q∈Q};
P*Q=[y∈Z:y=p*q, p∈P, q∈Q};
P/Q={y∈Z:y=p/q, p∈P, q∈Q}.
Здесь также после выполнения арифметической операции со спектрами следует производить ”редукцию” результирующего спектра с тем, чтобы количество интервалов в них не превосходило М.
Спектр переменной х можно понимать, как некий предикат от х, например, спектру
[0,6)∪{10} соответствует предикат (0≤x<6)∨(x==10).
Пусть N - число инструкций во внутреннем представлении программы, К -число переменных.
Таблица инвариантов - это массив TI длины N, элементами которого являются множества предикатов от переменных внутреннего представления программы. Получение таблицы инвариантов является главной задачей данного модуля.
Таблица спектров вдоль простого пути L=(L[1],…, L[n]) - это двумерный массив TS размера К*n, элементами которого являются спектры переменных. TS[k][i] - спектр k-й переменной в точке L[i] программы.
Отметим, что спектр можно тоже понимать как предикат, зависящий от одной переменной. При этом указанный предикат будет обозначать условие, которое выполняется в точке L[i] при условии, что трасса выполнения программы прошла через вершины L[1],…L[i].
Использование спектров предоставляет более гибкий механизм оперирования выведенными предикатами, поскольку над спектрами, как над обычными переменными, можно производить арифметические операции.
Таблица предикатов вдоль простого пути L представляет собой массив ТР длины n, элементами которого являются множества предикатов, причем TP[i] - множество предикатов, которые будут выполнены в точке L[i] программы, но тоже при условии, что трасса выполнения программы прошла через вершины L[1],…,L[i]. Использовать таблицу предикатов необходимо вместе с таблицей спектров, поскольку спектр не позволяет задавать предикаты, зависящие от нескольких переменных, а условия, хранимые в таблице предикатов, невозможно корректировать в случае, когда на простом пути встречается инструкция, изменяющая значение переменной, входящей в предикат.
Таким образом, на этапе выполнения модуля С1 (см. фиг.18) будет осуществлен вызов процедура GG, которая считает 12 инструкцией внутреннего представления и соединит их в управляющий граф. Результат ее работы представлен на фиг.38.
Далее процедура SP модуля С 1 обнаружит следующие максимальные пути в данном графе:
path1=(L1, L2, L3, L4, L5, L6, L7, L8, L9);
path2=(L1, L2, L3, L4, L5, L6, L10, L11);
path3=(L1, L2, L3, L4, L12).
Для каждого из путей path1, path2 и path3 будет вызвана процедура определения инвариантов и с ее помощью определены множество Y, таблицы спектров и таблицы предикатов вдоль каждого из них:
1) Вдоль пути pathl.
Процедура Y-FILTER в точке L4 для спектра переменной i: {0} и множества Y={L4, L5, L6, L7, L8, L9, L10, L11} обнаружит в точке L10 инструкцию ”i=i+1” и пересчитает новый спектр для i по правилу: spec(i)=[min({0}), +inf)=[0, +inf).
Аналогично, в точке L6 для спектра переменной j: {9} и множества Y={L6, L7, L8, L9} процедура обнаружит в точке L8 инструкцию ”j=j-1” и пересчитает новый спектр для j по правилу spec(j)=[-inf, max ({9})+1)=[-inf, 10).
2) Вдоль пути path2.
Множество предикатов будет непусто только в точках L10, L11:
L10:{j-i<0};
L11: {j-i<-1}.
Процедура Y-FILTER на данном пути отработает точно так же как и на пути path1.
3) Вдоль пути path3
Множество предикатов будет пусто во всех точках.
Процедура Y-FILTER на данном пути в точке L4 отработает точно также как и на пути path1 в точке L4. Уточнение таблицы инвариантов для каждого из путей выдаст следующий результат:
После работы модуля C.1 управление передается модулю С.2 (”Генерация систем информационной базы”), который для каждого условия корректности синтезирует свою система ограничений. Предикаты записываются в форме ”expr R const”, где ехрr - некоторое арифметическое выражение, R -предикатный символ, а const - некоторое целое число.
System 1: # correctness condition ″L7 a@offset+10*i+j<a@size;″
a@size==100
a@offset==0
i>=0
i<10
j<10
j-i>=0
a@offset+10*i+j-a@size>=0;
System 2: # correctness condition ″L7 a@offset+10*i+j>=0;″
a@size==100
a@offset==0
i>=0
i<10
j<10
j-i>=0
a@offset+10*i+j<0
System 3: # correctness condition ″L12 a@offset+55<a@size;″
a@size==100
a@offset==0
i>=10
a@offset-a@size>=-55
System 4: # correctness condition ”L12 a@offset+55>=0;”
a@size==100
a@offset==0
i>=10
a@offset<-55
Далее управление передается модулю С.3 (”Исследование систем ограничений информационной базы”). В качестве примера будем полагать, что число параллельных или независимых процессов равно четырем (t=4). На этапе формирования набора параллельно выполняемых задач будет получено задание для каждого из процессов:
для процесса № i - исследовать систему № i на предмет существования решений. Рассмотрим далее работу процесса № 1.
В системе № 1 нет тождественно ложных предикатов или пар противоречащих друг другу предикатов. Поэтому система может быть сведена к задаче линейного программирования, которая может быть представлена в канонической форме (здесь строгие неравенства приведены к нестрогим, а также введены новые неотрицательные переменные, позволяющие перейти от неравенств к равенствам):
-i1+i2+x1+y1==0;
i1-i2+x2+y2==9;
j1-j2+x3+y3==9;
i1-i2-j1+j2+x4+y4==0;
-10*i1+10*i2-j1+j2+a@size1-a@size2-a@offset1+a@offset2+x5+y5==0;
a@size1-a@size2+y6==100;
a@offset1-a@offset2+y7==0.
Здесь для простоты были введены новые неотрицательные переменные:
i1, i2,j1,:)2,a@size1, a@size2,
a@offset1,a@offset2, x1, x2, x3, x4, x5, y1, y2, y3, y4, y5, y6, y7
с условиями i=i1-i2, j=j1-j2 и т.д.
Необходимо максимизировать следующий функционал:
L(Y)=- y1-y2-y3-y4-y5-y6-y7.
Решением данной задачи является значение L*=-1, следовательно? исходная система не имеет решений. Для остальных систем информационной базы также можно показать, что они не имеют решений. Таким образом DNG={}.
Следовательно, модуль С.4 получит на вход пустой список номеров, не выведенных без условий корректности - DNG, и выдаст в базу данных D11 отчет, подтверждающий корректность программы:
No dangerous points found
No buffer overflows are possible
Рассмотрим второй пример ИК ПО следующего вида:
Пример 2.
Исходная С программа
#include<string.h>
#include<stdio.h>
int main(int argc, char** argv)
{
if (argc<2)
return 0;
int len=strlen(argv[1]);
char* p=malloc(len+1);
strcpy (p, argv[1]);
printf(”%s\n”, p);
return 0;
}
На первом этапе работы АПБ-А фрагмент дерева разбора ИК ПО, полученного на этом этапе применения объединенного модуля лексического и синтаксического разбора, представлен на фиг.34.
Темным цветом на иллюстрации выделено поддерево разбора, соответствующее синтаксической конструкции
int len=strlen(argv[1]);
АПБ-А содержит обращения только к внешним библиотечным функциям, поэтому встраивание функций в данном случае не требуется.
Таблица типов пуста, поскольку в данном примере используются только простые типы данных или указатели на них.
Внутреннее представление может быть получено на основе дерева разбора, приведенного выше, а также на основе базы аннотаций для внешних функций.
Рассмотрим два случая:
случай (а): база знаний D6 содержит аннотации для функций strcpy, malloc:
function-annotation (strcpy) {
params {*src}
output {*dest}
pre-conditions {
m_0 src@is_string==1;
m_0 src@size>src@strlen;
m_0 dest@size>dest@offset+src@strlen;
}
instruction {
m_0 dest@is_string=1;
m_1 dest@strlen=src@strlen;
}
}
function-annotation (malloc) {
params {n}
output {*ptr}
pre-conditions {
}
instructions {
m_0 condition _unknown__ ? m_1 : m_5;
m_1 assign ptr@is_null=0;
m_2 assign ptr@size=n;
m_3 assign ptr@offset=0;
m_4 goto m_7;
m_5 assign ptr@is_null=0;
m_6 assign ptr@size=0;
}
}
случай (б): база знаний D6 пополнена аннотацией для функции strlen:
function-annotation (strien) {
params {buf}
output {length}
pre-condition {
m_0 buf@is_string==1;
m_0 buf@size>buf@strlen;
}
instructions {
m_0 length=buf@strlen;
}
}
При этом в случаях (а) и (б) будут получены различные
внутренние представления исходной программы - база данных D7;
базы данных D8 условий корректности;
информационные базы знаний D10;
отчеты об обнаруженных уязвимостях - база данных D111.
В приведенном втором примере присутствуют лишь вызовы библиотечных функций, поэтому модули B.1 и В.2 не выполняют преобразований.
В данном примере присутствует условная конструкция if. Поэтому на этапе работы модуля В.3 она будет преобразована в конструкцию cond-goto (эта конструкция отсутствует в языке Си, однако для простоты мы будем представлять модифицированное дерево разбора в виде программы на языке ”псевдо-Си”).
После выполнения преобразования модулем В.3 из исходных данных получается следующий код:
int len;
char *р;
goto (argc<2) ? label1 : label2;
labell:
return 0;
label2:
len=strlen(argv[1]);
p=malloc(len+1);
strcpy (p, argv[1]);
printf(”%s\n”, p);
return 0;
Как можно видеть, добавлены 2 метки и инструкция условного перехода.
На этапе работы модуля В.4 получают внутреннее представление ИК ПО в виде:
(а)
Инструкции L1, L3 и L4 соответствуют специальным аннотациям, используемым для входных параметров функции main - argc, argv в данном случае. Эти аннотации показывают, что параметр argc равен длине массива argv, а каждый используемый в исходном коде элемент argv[i] является корректной Си-строкой, то есть последовательностью char-символов, оканчивающейся символом '\0'.
Инструкция L2 соответствует проверке условия
if (argc<2)
return 0;
Инструкция L5 соответствует выражению
int len=strlen(argv[1]);
(при этом unknown указывает на неопределенность возвращаемого значения неизвестной функции strlen).
Инструкция L6 получается из выражения
р=malloc(len+1);
и правила вывода в базе аннотаций для функции maiioc (секция instructions):
buf@size=size
buf@offset=offset
применяемого к выражениям р (вместо buf) и len+1 (вместо size).
Инструкции L8, L9 получаются из выражения
strcpy (p, argv[1]);
и правил вывода в базе аннотаций (функция strcpy, секция instructions).
dest@is_string=1
dest@strlen=src@strlen
применяемым к выражениям р (вместо dest) и argv@1 (вместо src).
(б)
Жирным шрифтом выделены инструкции, в которых наблюдается различие внутренних представлений программы в случаях (а) и (б). В случае (а) выделенная жирным инструкция показывает неопределенность возвращаемого значения внешней функции strlen. Добавление аннотации функции strlen в базу знаний D6 в случае (б) позволит на этапе преобразования во внутреннее представление воспользоваться содержащимся в аннотации (в секции instructions) правилом вывода
length=buf@strlen,
примененным к выражениям len (вместо length) и argv@1 (вместо buf), что породит инструкцию L5.
База знаний D9 условий корректности в случаях (а) и (б) будет иметь следующий вид:
L5 1<argv@size;
L5 argv@1@is_string==1;
L5 argv<?1@size>argv@1@strlen:
L8 1<argv@size;
L8 argv@1@is_string==1;
L8 argv@1@size>argv@1@strlen;
L8 p@size>p@offset+argv@1@strlen;
Жирным выделены условия, появляющиеся в D9 при пополнении базы знаний D6 аннотаций. Рассмотрим каждое из условий более подробно.
Условие:
L5 1<argv@size;
позволяет гарантировать отсутствие переполнения при разыменовании argv[1] в выражении
int len=strlen(argv[1]).
Пара условий в точке L5, выделенных жирным шрифтом:
L5 argv@1@is_string==1;
L5 argv@1@size>argv@1@strlen;
получается в случае (б) по правилам вывода в базе аннотаций (функция strlen, секция conditions):
buf@is_string==1
buf@size>buf@strlen
примененным к выражению argv@1 (вместо buf).
Условие
L8 1<argv@size;
позволяет гарантировать отсутствие переполнения при разыменовании argv [1] в выражении
strcpy(p, argv[1]);
Тройка условий в точке L8
L8 argv@1@is_string=1;
L8 argv@1@size>argv@1@strlen;
L8 p@size>p@offset+argv@1@strlen;
получается по правилам вывода в базе аннотаций (функция strcpy, секция conditions):
src@is_string==1
src@size>src@strlen
dest@size>src@strlen
примененным к выражениям argv@1 (вместо src) и р (вместо dest).
База знаний D9 соответствия условий корректности подозрительным точкам исходного кода в случае а):
1 main.с:9:20:26 0.67 Unable to deduce dereferencing upper bound;
2 main.с:11:13:19 0.67 Unable to deduce dereferencing upper bound;
3 main.с:11:3:20 1.0 Buffer is not a valid string;
4 main.с:11:3:20 1.0 Source buffer size is less than string length;
5 main.с:11:3:20 1.0 Target buffer size is less than string length;
База знаний D9 соответствия условий корректности подозрительным точкам исходного кода в случае б):
1 main.с:9:20:26 0.67 Unable to deduce dereferencing upper bound;
2 main.с:11:13:20 1.0 Buffer is not a valid string;
3 main.с:11:13:20 1.0 Target buffer size is less than string length;
4 main.с:11:13:19 0.67 Unable to deduce dereferencing upper bound;
5 main.с:11:3:20 1.0 Buffer is not a valid string;
6 main.с:11:3:20 1.0 Source buffer size is less than string length;
7 main.с:11:3:20 1.0 Target buffer size is less than string length;
На следующем этапе разбора управление передается АПБ-С. При этом работа модуля С1 достаточно полно продемонстрирована в примере 1, поэтому укажем только результат его работы:
в точке L1:
в точке L2:
в точке L3:
в точке L4:
в точке L5:
в точке L6:
в точке L7:
в точке L8:
в точке L9:
в точке L10:
Жирным выделены те условия, которые будут выведены при пополнении базы знаний аннотаций D6, то есть в случае (б).
На следующем этапе работы модуля С.2 осуществляется генерация информационной базы знаний D10. При этом для рассматриваемого случая - случай (а), она будет содержать следующие сведения:
System 1: # correctness condition ″L5 1<argv@size;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
argv@size<=1
System 2: # correctness condition ″L8 1<argv@size;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen=1
p@size - len==1
p@offset=0
argv@size<=1
System 3; # correctness condition ”L8 argv@1@is_string==1;”
argv@size - argc==0
argc>=2
argv@1@is_string=1
argv@1@size - argv@1@strlen==1
p@size - len=1
p@offset==0
argv@1@is_string !=1
System 4: # correctness condition ”L8 argv@1@size>argv@1@strlen;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
p@size - len==1
p@offset=0
argv@1@size - argv@1@strlen<=0
System 5: # correctness condition ″L8 p@size>p@offset+argv@1@strlen;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
p@size - len==1
p@offset=0
p@size - p@offset - argv@1@strlen<=0
для случая (б):
System 1; # correctness condition ”L5 1<argv@size;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen=1
argv@size<=1
System 2: # correctness condition ”L5 argv@1@is_string==1;”
argv@size - argc=0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
argv@1@is_string !=1
System 3: # correctness condition ”L5 argv@1@size>argv@1@strlen;″
argv@size - argc=0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen=1
argv@1@size - argv@1@strlen<=0
System 4: # correctness condition ”L8 1<argv@size;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
len - argv@1@strlen==0
p@size - len==1
p@offset==0
argv@size<=1
System 5: # correctness condition ”L8 argv@1@is_string==1;”
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
len - argv@1@strlen==0
p@size - len==1
p@offset==0
argv@l@is_string !=1
System 6: # correctness condition ”L8 argv@1@size>argv@1@strlen;″
argv@size - argc==0
argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
len - argv@1@strlen==0
p@size - len==1
p@offset==0
argv@1@size - argv@1@strlen<=0
System 7: # correctness condition ”L8 p@size>p@offset+argv@1@strlen;″
argv@size - argc==0 argc>=2
argv@1@is_string==1
argv@1@size - argv@1@strlen==1
len - argv@1@strlen==0
p@size - len==1
p@offset==0
p@size - p@offset - argv@l@strlen<=0
На следующем этапе управление передается модулю С.3. Работа данного модуля достаточно полно раскрыта в примере 1, поэтому укажем только на окончательный результаты.
В случае (а): системы 1-4 не имеют решений, система 5 имеет целочисленное решение:
argc=2
argv@size=2
argv@1@size=1
argv@1@strlen=1
argv@1@is_string=1
len=0
p@size=0
p@is_string=1
p@offset=0
В случае (б): системы 1-7 не имеют решений.
Таким образом, в случае
(a) DNG={5}
(6)DNG={}.
На следующем этапе управление передается модулю С.4 ”Формирование отчета об обнаруженных уязвимостях”.
В случае (а) список DNG={5}. Из базы соответствия условий корректности подозрительным точкам исходного кода будет извлечена запись
”5 main.c:11:3:20 1.0 Target buffer size is less than string length;”
Извлекая из 11-й строки файла main.c выражение, записанное с 3-й по 20-ю позиции, получим фрагмент исходного кода, в котором возможно переполнение буфера: strcpy(p, argv[1]).
Поэтому, будет сгенерирован отчет:
List of dangerous points:
1) Possible buffer overflow vulnerability found at line 11,
positions 3…20, danger level 1.0
Fragment of the source code:
…
strcpy(p, argv [1]);
…
Possible reasons: Target buffer size is possibly less then string length
В случае (б) список DNG пуст, поэтому будет получен отчет, подтверждающий корректность программы:
No dangerous points found
No buffer overflows are possible
Пример 3.
Поскольку в предыдущих примерах таблица типов была пуста, приведем дополнительный пример ИК ПО, демонстрирующий работу модуля С.3 (”разворачивание структур”). Данный пример для простоты будет содержать отдельные участки программного кода.
Исходный код ПО:
typedef int type0;
typedef struct
{
type0 *a;
char *b;
} type1;
typedef struct
{
type1* el;
type1 e2;
type0* e3;
} type2;
…
type1 x;
type2 y;
…
*y.e1=x;
x.a[20]=*y.e3;
Таблица типов для данной части кода:
type0: int
type1: struct {type0* a; char* b;}
type2: struct {type1* el; type1 e2; type0* e3;}
На основании таблицы типов объявление переменной х типа type1 заменяется на объявление двух переменных: х_а и х_b, соответствующих полям структуры type1. Аналогичная замена происходит с объявлением переменной у, в которой сначала разворачивается объявление типа type2, а потом разворачиваются объявления получающихся переменных типа type1, в результате чего образуются 5 переменных: y_e1_a, y_e1_b, y_е2_а, у_е2_b, y_е3.
Присваивание
*у.е1=х;
преобразуется в пару присваиваний, соответствующих полям типа type1:
*У_е1_а=х_а;
*у_е2_b=х_b;
Остальные операции преобразуются аналогичным образом.
Получающийся при этом код эквивалентен коду исходной программы (в смысле операций ячейками памяти), однако содержит только переменные простых типов и указатели:
int* х_а;
char* x_b;
int** y_e1_a;
char** y_e1_b;
int* y_e2_a;
char* y_e2_b;
int* y_e3;
*y_e1_a=x_a;
*y_e2_b=x_b;
x_a[20]=*y_e3.
В общем случае процесс верификации ИК ПО для распределенных вычислительных комплексов представляет динамическую процедуру приема и обработки ИК ПО по зависимым и независимы каналам. При этом АПБ-У осуществляет обработку сигналов, возникающих на системной шине устройства верификации (см. фиг.1) в процессе интерактивной верификации ИК ПО и работы АПБ-А, АПБ-В и АПБ-С. Эти сигналы поступают на входы У1 (блока нормирующих преобразователей (БНП)) (см. фиг.28), при этом согласно предлагаемому способу эти сигналы разбивают на две группы. Для определенности будем полагать, что первая группа сигналов характеризует независимые по времени интерактивные процессы верификации ИК ПО, например, первая группа сигналов представляет набор наблюдаемых интерактивных процессов обработки ИК ПО, поступающих по независимым интерфейсным каналам:
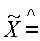 {Х(1), Х(2), Y(1), Y(2), Z(1), Z(2)}, n=3.
{Х(1), Х(2), Y(1), Y(2), Z(1), Z(2)}, n=3.
Вторая группа сигналов поступает по зависимым интерфейсным каналам. Для определенности дальнейшего изложения будем полагать, что эти сигналы представляют работу АПБ-А, АПБ-В, АПБ-С или оператора ЭВМ (в общем случае лица, принимающего решение - ЛПР, агента и т.п.), т.е. это некоторая реакция вида:

Следовательно, в рассматриваемом примере реализации АПБ-У в первой группе будет три независимых канала (n=3) измерений состояния процесса верификации ИК ПО, а во второй - 2n (в данном случае восемь) зависимых каналов измерений состояния процесса верификации ИК ПО распределенных вычислительных комплексов. При этом согласно способу верификации ИК ПО в распределенных вычислительных сетях необходимо хранить в базе данных соответствующие оценки верхних и нижних значений результатов верификации по каждому каналу обработки ИК ПО, т.е. ∀t>0:
X(1)=inf X1(t) или X(1)→min X1(t),
Х(2)=sup X1(t) или Х(2)→max X1 (t),
аналогично
Y(1)=inf Y1(t) или Y(1)→min Y1(t),
Y(2)=sup Y1(t) или Y(2)→max Y1(t),
Z(1)=inf Z1(t) или Z(1)→min Z1(t),
Z(2)=sup Z1(t) или Z(2)→max Z1(t).
Для этого перед началом каждого цикла верификации ИК ПО, например, в момент
t0 формируется сигнал общего сброса на все регистры памяти и обработки сигналов измерений о состоянии основных циклов верификации ИК ПО (этот процесс на фиг. не показан). На первом временном интервале с помощью модуля коммутатора У2 осуществляется опрос следующих каналов БНП У1: первый канал БНП У1 из первой группы независимых интерфейсных каналов устройства верификации ИК ПО, на который поступает в рассматриваемом случае - Х(1); третий канал - Y(1) и пятый - Z(1). Одновременно из второй группы каналов опрашивается первый канал, на который подается для измерения сигнал U(1).
Для рассматриваемого примера этот процесс комбинаторного опроса каналов системной шины устройства верификации ИК ПО из разных групп и запоминание значений сигналов завершается за восемь тактов. Описанная последовательность операций интерактивной верификации ИК ПО реализована на основе фиксации верхних {Х(2), Y(2), Z(2)} и нижних {Х(1), Y(1), Z(1)} границ изменения амплитуд сигналов первой группы каналов измерения состояния основных процессов интерактивной верификации ИК ПО.
Описанную последовательность опроса в предложенной реализации обеспечивает модуль формирования динамической развертки графоаналитического растра (МФДРГАР) У5. Эту процедуру в рассматриваем случае обеспечивает блок У5.3 синхронизации (см. фиг.30) за восемь тактов. Здесь для простоты пояснений полагаем, что значения амплитуд возмущающих воздействий, в качестве которых в данном случае выступает поток ИК ПО, поступающий по независимым интерфейсным каналам, имеет следующий вид:
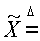 {Х(1), Х(2), Y(1), Y(2), Z(1), Z(2)}, n=3.
{Х(1), Х(2), Y(1), Y(2), Z(1), Z(2)}, n=3.
Соответственно, реакция на эти воздействия:

исследуемого процесса верификации ИК ПО, для всех t={t1,…,t8}.
При этом комбинаторика процедуры (или стратегия) опроса каждого последующего цикла определения точек уязвимости в процессе верификации ИК ПО будет зависеть не только от того, какие претерпели изменения соответствующие измеряемые переменные по каждому из каналов, но и непосредственно зависеть от результатов верификации ИК ПО, которые сопровождаются визуализацией результатов - отображением на БВ У6 (см. фиг.28, 37 и 39).
Так, вышеописанный пример последовательности операций позволяет по каждому из входов второй группы каналов измерения получить значения комбинаторных оценок следующего вида:
U'(1)=fj1(X'(1),Y'(1),Z'(1)),
U'(2)=fj2(X'(2), Y'(2), Z'(2)),
…
U'(8)=fj8(X'(2), Y'(2), Z'(2)).
Одновременно (в данном примере, начиная с такта tg) в блоке выделения экстремума У4.3 МФСКГАР У4 осуществляется процедура определения maxU(.) и minU(.).
Схема У 4.5 формирования дискретных приращений (см. фиг.29) статических координат графоаналитического растра обеспечивает циклическое изменение следующих переменных:
Х (t1)→X1, minU(.)→U1,
YX (I)=(X1 - BX)*MX, I=1,N3, N3=int2[N+1],
YU (I)=(U1 - BU)*MU, I=1,N3, N3=int2[N+1], N={1, 2,…n}.
При этом на каждом i-м такте (в рассматриваемом примере начиная с t18) осуществляется запоминание и накопление приращений, соответственно в XI=XI+НХ и UI=UI+HU, где HХ и HU - постоянные приращения, зависят от физических размеров окна экрана для отображения на БВ У6 результатов верификации ИК ПО. На каждом из i циклов, синхронно с изменением значения i, осуществляется запись полученных YX(.) и YU(.) во второе ЗУ У4.7 МФСКГАР У4 (см. фиг.29) по адресу (i+k), где k - некоторое фиксированное (заданное) смещение адреса в ОЗУ. Начиная с такта tk1=19+10N3, начинает работу вторая схема У5.1 формирования дискретных приращений динамических координат графоаналитического растра МФДРГАР (см. фиг.30), которая обеспечивает приращения как со знаком ”+” так и со знаком ”-”, соответствующие амплитуды сигналов: YI+, ZI+ и YI-, ZI; с постоянным приращением HY и HZ. Причем формирование каждого приращения
YI+(1) на такте tk1=19+10N3,
YI+(2) на такте tk2=24+10N3,
…
YI+(N3) на такте tk3=14+15N3,
совмещено с формированием на выходах блока преобразования статических координат графоаналитического растра У4.6:
FX+(1) на такте ts1, s1=22+10N3,
FX+(2) на такте ts2, s2=27+10N3,
…
FХ+(N3) на такте ts3, s3=17+15N3.
Данные запоминаются во втором У4.7 по соответствующему i-му адресу. Начиная с i=N31=int2[N3+1] такта осуществляется аналогичный циклический процесс формирования приращений ZI+(1),…, ZI+(N3) и FY+(1),…,FY+(N3).
Начиная с такта tk9 (i=N4=int2[2*N+1]), осуществляется формирование на основе циклических приращений следующих переменных:
YI-(1), YI-(2),…. YI-(N3) и FX-(1), FX-(2),…. FX-(N3).
Особенность формирования каждого из данных сигналов (например, амплитуда FX-(.) формируется за девять тактов), которые представляют координаты искомого отображения графоаналитического бинарного поля состояния процесса верификации ИК ПО, состоит в том, что этот процесс осуществляется без промежуточных операций запоминания соответствующих графических объектов в базах данных D4, D5 и D11.
Это позволяет достигнуть предельного быстродействия процесса генерации искомых взаимосвязанных параметрических зависимостей в базах данных и базах знаний в виде обобщенных визуальных отображений динамики процесса верификации ИК ПО распределенных вычислительных комплексов. При этом в блоке У5.3 синхронизации (см. фиг.30) достаточно наличия простого цикла счета (например, последовательного счета импульсов) для формирования адреса записи/считывания. Таким образом, описанное совмещение нескольких функций, связанных с формированием адресов (координат) записи их содержимого по каждому из данных адресов, обеспечивает наиболее высокое быстродействие получения визуальных графо-аналитических образов многомерных данных на плоскости БВ У6.
Режим вывода сформированных графических объектов о состоянии процесса верификации ИК ПО в МР У6.1 (см. фиг.31) может быть осуществлен на основе использования стандартных средств, например, используя ЭЛТ с интерфейсным блоком в виде буферного ЗУ. При этом, если количество строк (разрешение) ЭЛТ равно v, а количество точек в строке n, то объем буферного ЗУ должен составлять n * v. Режим вывода информации о состоянии процесса верификации ИК ПО на экран БВ У6 в этом случае будет осуществляться по аналогии режима ввода, при одном дополнительном условии - согласования его начала с началом кадрового синхроимпульса. При этом строб готовности (начало кадра) устанавливает на адресных входах буферного ЗУ нулевой адрес и по каждому синхросигналу увеличивается текущее значение адреса на единицу. В этом случае максимальный адрес будет равен (n*v - 1). Следовательно, информация в каждой ячейке буферного ЗУ МР У6.1 должна храниться в течение времени развертки одного кадра.
Проекция электронного луча на экране электронно-лучевой трубки МР У6.1 передается на рабочую поверхность преобразователя оптического сигнала У6.4 (в простейшем случае это может быть фотодатчик или ПЗС-матрица) через оптическую систему У6.3 и маску У6.2, выполненную так, что в трехмерном пространстве выделены области, соответствующие гипотезам о различных состояниях уязвимости анализируемого ИК ПО.
При этом оптический коэффициент пропускания маски У6.2, через которую проходит оптический сигнал, имеет одно и то же значение для точек одной гипотезы о состоянии уязвимости ИК ПО и различное для других значений гипотез. Маска У6.2 изготовлена так, что в пространстве ее координат (X, Y, Z) выделены области уязвимости ИК ПО и соответствующие значения могут быть определены из следующего выражения энтропии:

где f(.) - любая интегрируемая по Риману функция или параметрическая зависимость оценки уязвимости ИК ПО (см. пример №2),
Xi, Yj и Zk - текущие значения переменных (или параметрических зависимостей) - входных переменных - (параметров) независимых (или зависимых) координат, о различных состояниях верифицируемого ИК ПО.
Оптический коэффициент пропускания маски У6.2 имеет одно и то же значение для точек, принадлежащих одному и тому же значению Hijk(.), и различное - для других значений гипотез уязвимости Hijk(.) ИК ПО. Данное свойство может быть реализовано, например, с помощью интенсивности почернения, густотой штриховки или частотой точек соответствующих участков маски при учете апертуры электронного луча и разрешающей способности преобразователя оптического сигнала (в простейшем случае - фотоприемника, ПЗС-матрицы и т.п.). Это позволяет при входных величинах Xi, Yj и Zk получать на выходе 2 блока динамической развертки У6.5 сигнал с амплитудой, равной Hijk(.), и с частотой, определяемой параметрами соответствующих генераторов развертки.
В простейшем случае реализации БВ У6 электронный луч перемещается по экрану модуля регистрации У6.1 (см. фиг.31) по заданной траектории на основе управляющих сигналов, поступающих на его вход 2 из блока динамической развертки У6.5.
Рассмотрим процесс формирования периода и длительности следования управляющих воздействий на выходе 1 импульсного регулятора У7, когда на его входе 1 абсолютное значение гипотез уязвимости |Hijk(.)| ИК ПО, получаемое на выходе блока определения абсолютных значений У7.1, меньше Δн/2, где Δн/2 - зона срабатывания первого релейного элемента У7.2 (см. фиг.32, пример реализации импульсного регулятора) и соответствующее ей нормированное значение |e(t)<1. Предполагаем, что нормирование текущих значений Hilk(.) (соответственно значения ошибки определения точек уязвимости ИК ПО - e(t)) осуществляется с коэффициентом Δ=Δн/2.
Пусть в исходном положении триггер У7.6 находится в единичном состоянии, тогда на выходе первого блока выборки-хранения У7.7 будет напряжение

которое подается на первый вход первого сумматора У7.12, на второй вход которого поступает постоянное напряжение (Е) от источника эталонных напряжений У7.11.
В результате на вход первого формирователя импульсов У7.10 подается постоянное напряжение вида:
Uфi=Ui+Е.
Постоянная составляющая Е может быть выбрана, например, из интервала значений с нижней границей, определяемой длительность выполнения самой продолжительной последовательности операций преобразований (обработки) в АПБ устройства верификации ИК ПО, и верхней границей, определяемой, например, как 1/(Kf *Fmax), где Fmax - максимальная частота изменения значений Нijk(.), Kf - постоянный коэффициент, который согласно теореме отсчетов во временном представлении непрерывных сигналов в дискретной форме можно установить ≥2.
В этой связи верхняя граница значений данного интервала может быть априорно выбрана из необходимого условия адекватности представления процесса верификации ИК ПО своими дискретными значениями. Это позволяет обеспечить измерение и обработку значений сигнала Нijk(.) с наименьшей потерей информации о состоянии процесса верификации ИК ПО.
Далее в соответствии с Uфi на выходе формирователя импульсов У7.10 будет сформирован импульс длительностью:
Тi=Кфi *Uфi,
где Кфi - коэффициент передачи формирователя импульсов У 7.10.
Во время действия данного периода Тi в первом блоке выборки-хранения У7.7 формируется напряжение вида:

В конце периода Тi формирователь импульсов У7.10 устанавливает триггер У7.6 в следующее (например, нулевое) устойчивое состояние.
Описанные выше последовательности операций непрерывно повторяются в функциональной зависимости от изменения ошибки определения точек уязвимости ИК ПО - e(t). При этом на каждом из периодов Тi, i=1, 2,…,n, на первый вход первого логического элемента И У7.3 от первого формирователя импульсов У7.10 подается разрешающий сигнал на включение ключа У7.15, коммутирующего входную цепь второго формирователя импульсов У7.16. В момент окончания каждого периода Тi и начала следующего Тi+1, составляющие незначительный по продолжительности промежуток времени, формируется сигнал, достаточный для отключения электронного ключа У7.15. Этим обеспечивается требуемая степень синхронизации между началом момента формирования периода управляющих воздействий в первом формирователе импульсов У7.10 и длительности импульса во втором формирователе импульсов У7.16 для всех Ti, i=1,2,…,n.
При этом формирование напряжений на входе второго формирователя импульсов У7.16 реализовано по схеме, аналогичной вышеописанной на входе первого формирователя импульсов У7.10, с тем лишь отличием, что формирование длительности (ti) выходных импульсов осуществляется в соответствии со значением оценки интегрального изменения квадрата нормированного сигнала Hijk(.) (ошибки определения точки уязвимости ИК ПО) и во все периоды Тi, для которых

где Δтр - зона нечувствительности второго релейного элемента У7.4, устанавливаемая на основе критерия точности воспроизведения (распознавания, прогнозирования и т.п. точек уязвимости ИК ПО распределенных вычислительных комплексов) текущих значений сигнала Hijk(.). Контроль за выполнением этих условий реализован с помощью первого логического элемента И У7.3, управляющего состоянием электронного ключа У7.15 в соответствии с сигналами, поступающими с первого формирователя импульсов У7.10 и релейных элементов У7.2 и У7.4, контролирующих значения Δн/2 и Δтр соответственно. Следовательно, формирование каждого периода Тi осуществляется на основе последовательности операций (Кфi *Е), априорных по отношению к динамике изменения значений сигнала Hijk(.), и корректируется текущими значениями интегральных оценок нормированной ее оценки, полученными на предшествующем периоде дискретизации процесса верификации ИК ПО распределенных вычислительных комплексов.
При этом для всех e(t)∈[-Δн/2, Δн/2] и t>0 всегда выполняется неравенство вида Тi>ti, за исключением только тех моментов времени, для которых вероятность наличия уязвимости в ИК ПО равна нулю (т.е., e(t)=0) или она не выходит за пределы допустимых значений (а именно, не больше |e(t)|=Δн/2).
Таким образом, отличительные признаки предлагаемого способа позволяют расширить функциональные возможности основных процессов верификации ИК ПО распределенных вычислительных комплексов непосредственно при выполнения научно-исследовательских работ на основе использования реальных динамических характеристик распределенных вычислительных систем и сетей, при этом предоставляется возможность повысить достоверность и объективность принимаемых решений на основных этапах исследования, разработки и сопровождения ПО распределенных вычислительных комплексов.
Изобретение относится к средствам автоматизации обучения и научных исследований и может быть использовано в интерактивных системах в процессе верификации программного обеспечения (ПО) распределенных вычислительных комплексов. Технический результат заключается в расширении функциональных возможностей процессов верификации ПО. В способе и устройстве обеспечивают полную управляемость и наблюдаемость основных процессов проверки исходного кода ПО, совмещают процессы ввода и обработки исходного кода ПО по зависимым или независимым интерфейсным каналам. Участки или точки уязвимости исходного кода ПО определяют на основе преобразования исходного кода ПО во внутреннее представление, которое хранят в виде баз знаний, а точки или участки уязвимости исходного кода ПО определяют на основе автоматического составления и решения соответствующих систем уравнений. При этом в процессе верификации осуществляют синтаксическую подсветку на экране участков уязвимости исходного кода ПО, используя граф операторов исходного кода ПО во внутреннем представлении инструкций языка программирования. 2 н. и 7 з.п. ф-лы, 39 ил.
1. Способ генерации баз знаний для систем верификации программного обеспечения (ПО) распределенных вычислительных комплексов (РВК), включает совмещение процессов ввода и обработки исходного кода ПО по зависимым или независимым каналам на основе использования сенсорных или механических манипуляторов рабочего места оператора ЭВМ, сетевых интерфейсов локальной или глобальной сети, при этом участки или точки уязвимости исходного кода ПО определяют на основе преобразования исходного кода ПО во внутреннее представление, которое хранят в виде баз знаний, а точки или участки уязвимости исходного кода ПО определяют на основе автоматического составления и решения соответствующих систем уравнений, в процессе верификации исходного кода ПО на экране блока видеоконтроля (БВ) аппаратно-программного блока процессорного управления осуществляют синтаксическую подсветку для визуализации участков уязвимости исходного кода ПО, при этом используют граф операторов исходного кода ПО во внутреннем представлении инструкций языка программирования.
2. Способ по п.1, отличающийся тем, что диагностику процесса верификации исходного кода ПО осуществляют на основе измерения длительности выполнения основных этапов (циклов) поиска уязвимости и сопоставления полученных значений с ранее предписанными или предсказанными оценками показателя критичности уязвимости исходного кода ПО.
3. Способ по п.1, отличающийся тем, что внутреннее представление исходного кода ПО на языке программирования Си представляется в виде динамических массивов и соответствующих баз знаний, которые используются в реальном масштабе времени для верификации ПО распределенных вычислительных комплексов.
4. Способ по п.1, отличающийся тем, что точки или участки уязвимости исходного кода ПО определяют на основе автоматического составления и решения линейных систем уравнений.
5. Способ по п.1, отличающийся тем, что в качестве зависимых каналов используют интерфейсы жестких, гибких или оптических дисков.
6. Способ по п.1, отличающийся тем, что в качестве независимых каналов используют интерфейс последовательного порта или сетевой интерфейс.
7. Способ по п.1, отличающийся тем, что в качестве независимых каналов используют интерфейс последовательного порта или сетевой интерфейс, а в качестве зависимых каналов используют интерфейсы жестких, гибких или оптических дисков.
8. Способ по любому из пп.1-7, отличающийся тем, что осуществляют генерацию баз знаний на основе использования аннотаций внешних функций ИК ПО РВК, при этом база знаний представляет набор правил или моделей протоколов верификации ИК ПО, обеспечивающих поддержку интерактивных процессов поиска уязвимости ПО.
9. Устройство для реализации способа генерации баз знаний для систем верификации программного обеспечения распределенных вычислительных комплексов (СВПО РВК), содержит аппаратно-программный блок (АПБ) лексического и семантического анализа/разбора, АПБ преобразования кода, АПБ анализа кода, АПБ процессорного управления, видеоадаптер, интерфейсы жестких, гибких и оптических дисков, интерфейс последовательного порта, сетевой интерфейс и системную память, которые объединены системной шиной, при этом системная память содержит постоянное запоминающее устройство (ROM) и оперативное запоминающее устройство (RAM/ОЗУ), в ячейках оперативной памяти и жестких дисков размещают/записывают операционные системы, прикладные программы, базы данных и базы знаний, которые содержат листинги исходных программ, грамматику языка программирования (например грамматику языка программирования Си), правила преобразования дерева разбора листинга программы, дерево разбора листинга программы, таблицу типов языка программирования, аннотации внешних функций, включающие их грамматику и семантику, код программ на языке внутреннего представления, условия корректности языка внутреннего представления исходного кода программы, условия проверки корректности подозрительных точек исходного кода программы, информационная база, содержащая системы ограничений в виде алгебраических уравнений и неравенств, отчеты об обнаруженных уязвимостях программного кода, включает:
указание на местоположение возможной уязвимости в исходном коде программы, которое содержит имя файла листинга программы, номер строки и номер позиции в строке программы в котором возможно переполнение буфера запоминающего устройства, контекст исходной программы, содержащий возможное переполнение или некоторую "окрестность" потенциально опасной точки переполнения буфера запоминающего устройства;
указание причины переполнения буфера запоминающего устройства - значения исходных переменных, приводящих к возникновению уязвимости исходного кода программного обеспечения;
показатель или степень критичности обнаруженной уязвимости исходного кода программного обеспечения;
указание на перечень правил или алгоритмов для устранения уязвимости исходного кода программного обеспечения,
при этом АПБ процессорного управления, обеспечивающий синхронизацию основных режимов интерактивной верификации программного обеспечения распределенных вычислительных комплексов, содержит последовательно соединенные блок нормирующих преобразователей (БНП), модуль коммутатора, модуль аналого-цифрового преобразователя (АЦП), модуль формирования статических координат графоаналитического растра (МФСКГАР), блок видеоконтроля (БВ), импульсный регулятор (ИР) и модуль формирования динамической развертки графоаналитического растра (МФДРГАР), первый и второй информационные входы/выходы которого соединены соответственно с управляющими входами модуля коммутации и аналого-цифрового преобразователя, а третий, четвертый, пятый, шестой, седьмой и восьмой - с вторым, третьим, четвертым, пятым, шестым и седьмым информационными входами/выходами МФСКГАР, при этом второй вход блока видеоконтроля объединен с седьмым информационным входом/выходом МФСКГАР и восьмым информационным входом/выходом МФДРГАР,
блок видеоконтроля (БВ) содержит модуль регистратора (МР), на выходе которого установлены маска, оптическая система и преобразователь оптического сигнала, выходом подключенный к управляющему входу блока динамической развертки, при этом оптический коэффициент пропускания маски имеет одно и то же значение для точек одной гипотезы/энтропии о состоянии уязвимости ИК ПО и различное для других значений гипотез.
| СПОСОБ КОМПЛЕКСНОЙ ЗАЩИТЫ ПРОЦЕССА ОБРАБОТКИ ИНФОРМАЦИИ В ЭВМ ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА, ПРОГРАММНЫХ ЗАКЛАДОК И ВИРУСОВ | 1998 |
|
RU2137185C1 |
| Устройство для формирования заданного закона индукции магнитного поля в ферромагнетике | 1986 |
|
SU1420562A1 |
| JP 2004302584, 28.10.2004 | |||
| МОТОРНО-РЕДУКТОРНОЕ МАСЛО ДЛЯ АВИАЦИОННОЙ ТЕХНИКИ | 2005 |
|
RU2283341C1 |
| DE 10247914 A1, 22.04.2004 | |||
| ПОЧВОГРУНТ ТОРФЯНОЙ "МАЛАХИТ" (ВАРИАНТЫ) | 2007 |
|
RU2366640C2 |
| СПОСОБ ПОВЫШЕНИЯ ИЗВЛЕЧЕНИЯ ЦЕННЫХ КОМПОНЕНТОВ ИЗ СУЛЬФИДНОГО СЫРЬЯ ЭЛЕКТРОИМПУЛЬСНОЙ ОБРАБОТКОЙ | 2014 |
|
RU2559599C1 |

