Изобретение относится к вычислительной технике, в частности к системе управления доступом к ресурсам сети Интернет в зависимости от категории запрашиваемых ресурсов и принятой политики безопасности. Система проверяет запросы пользователей на принадлежность к конкретной категории. В случае запрещенной категории запрос к ресурсу блокируется.
В качестве ресурсов сети Интернет выступают так называемые электронные документы, представляющие собой информационные объекты, доступные в сети передачи данных, которые могут быть получены путем информационного сетевого обмена оконечного оборудования пользователя с сервером по протоколу HTTP и далее воспроизведены с помощью оконечного оборудования пользователя в печатном или ином виде.
Каждый электронный документ в World Wide Web имеет URL (Uniform Resourse Locator) - адрес, который включает в себя тип ресурса и местонахождение файла на сервере.
Общий синтаксис таков:
scheme://host.domain[:port]/path/filename.
Множество электронных документов, имеющих одинаковый корневой URL, образуют сайт или ресурс.
Электронный документ в формате HTML принято называть электронным гипертекстовым документом (или просто гипертекстовым документом).
Известна система Microsoft Internet Security and Acceleration (ISA) Server [1], осуществляющая фильтрацию документов, передаваемых по высокоуровневым протоколам (в частности, HTTP). Microsoft Internet Security and Acceleration (ISA) Server проверяет на соответствие заданным условиям не только пакеты сетевого обмена (запрещает или разрешает протоколы целиком), но и содержимое документов.
Чтобы блокировать доступ к нежелательным электронным документам, необходимо задать набор URL, как часть правила брандмауэра внутри существующей конфигурации ISA Server.
Пример использования подобного правила представлен в следующей таблице:
В наборе правил назначаются специальные правила, блокирующие документы, получаемые по протоколу HTTP и HTTPS, содержащие нежелательную строку или ключевое слово. В этом случае, если ISA Server обнаружит такую строку в HTTP-ответе (в границах байтового диапазона) Web-сервера, страница будет блокирована.
Недостатками подобного технического решения по фильтрации ответных строк является низкая полнота (невозможно судить о характере документа, анализируя лишь ограниченный байтовый диапазон) и точность (решение о характере документа принимается лишь по наличию отдельных слов).
Другие технические решения поставленной задачи [2], известные как Cobian Orange Filter компании Deerfield.com и EngagelP Content Filter фирмы LogiSense, предназначены исключительно для работы с информацией, доставляемой по каналам HTTP, и обеспечивают фильтрацию с использованием дополнительных протоколов. Все они используют механизм списков доступа и задание правил доступа.
Известны системы, которые могли бы быть использованы для решения поставленной задачи [3, 4].
Первая из известных систем содержит блоки приема и хранения данных, соединенные с блоками управления и обработки данных, блоки поиска и селекции, подключенные к блокам хранения данных и отображения, синхронизирующие входы которых соединены с выходами блока управления [3].
Существенный недостаток данной системы состоит в невозможности решения задачи обновления списка данных, хранимых в памяти в виде соответствующих документов, одновременно с решением задачи выдачи содержания этих документов пользователям в реальном масштабе времени.
Известна и другая система, содержащая блоки обработки данных, информационные входы которых соединены с блоками приема данных и управления, а выходы подключены к первой группе блоков памяти, центральный процессор, входы которого соединены с выходами блоков памяти первой группы и блоков обработки данных, а выходы соединены с входами блоков памяти второй группы и блоков отображения данных [4].
Последнее из перечисленных выше технических решений наиболее близко к описываемому.
Его недостаток заключается в невысоком быстродействии системы, обусловленном тем, что выполнение процедуры фильтрации данных реализуется через поиск данных по всей базе данных и их последующей обработке центральным процессором, что неизбежно приводит к необоснованным затратам времени.
Цель изобретения - повышение быстродействия системы путем локализации адресов фильтрации записей базы данных допуска по идентификаторам адресов запрашиваемых электронных документов путем актуализации статичных списков доступа и повышения полноты и точности систем контентной фильтрации.
Поставленная цель достигается тем, что в известную систему, содержащую модуль селекции опорных адресов сайтов в базе данных сервера, информационный и синхронизирующий входы которого являются первыми информационным и синхронизирующим входами системы соответственно, при этом первый информационный вход системы предназначен для приема запросов электронных документов по их сетевым адресам, первый синхронизирующий вход системы предназначен для приема сигналов занесения кодов запросов электронных документов в модуль селекции опорных адресов сайтов в базе данных сервера, а первый информационный выход модуля селекции опорных адресов сайтов в базе данных сервера предназначен для выдачи запросов электронных документов по их сетевым адресам на первый информационный вход сервера базы данных, модуль идентификации адресов электронных документов в списке доступа, один информационный и синхронизирующий входы которого являются вторыми информационным и синхронизирующим входами системы соответственно, при этом второй информационный вход системы предназначен для приема записей базы данных сервера, а второй синхронизирующий вход системы предназначен для приема сигналов занесения записей базы данных сервера в модуль идентификации адресов электронных документов в списке доступа, модуль формирования сигналов управления выборкой записей базы данных сервера, первый информационный вход которого соединен со вторым информационным выходом модуля селекции опорных адресов сайтов в базе данных сервера, синхронизирующий модуль формирования сигналов управления выборкой записей базы данных сервера подключен к синхронизирующему выходу модуля селекции опорных адресов сайтов в базе данных сервера, адресный выход модуля формирования сигналов управления выборкой записей базы данных сервера является адресным выходом системы, предназначенным для выдачи адресов записей базы данных на адресный вход сервера базы данных, а синхронизирующий выход модуля формирования сигналов управления выборкой записей базы данных сервера является первым синхронизирующим выходом системы, предназначенными для выдачи сигналов управления на вход первого канала прерывания сервера базы данных, введены модуль идентификации временных циклов выборки адресов из списка доступа, информационный вход которого соединен с третьим информационным выходом модуля селекции опорных адресов сайтов в базе данных сервера, синхронизирующий вход модуля идентификации временных циклов выборки адресов из списка доступа подключен к синхронизирующему выходу модуля селекции опорных адресов сайтов в базе данных сервера, а счетный вход модуля идентификации временных циклов выборки адресов из списка доступа соединен с тактирующим выходом модуля идентификации адресов электронных документов в списке доступа, при этом один выход модуля идентификации временных циклов выборки адресов из списка доступа подключен к счетному входу модуля формирования сигналов управления выборкой записей базы данных сервера, а другой выход модуля идентификации временных циклов выборки адресов из списка доступа является вторым синхронизирующим выходом системы, предназначенным для выдачи сигналов управления на вход второго канала прерывания сервера базы данных, и модуль селекции доступа к электронным документам, один информационный вход которого соединен с первым выходом модуля селекции опорных адресов сайтов в базе данных сервера, другой информационный вход модуля селекции доступа к электронным документам подключен к информационному выходу модуля идентификации адресов электронных документов в списке доступа, а синхронизирующий вход модуля селекции доступа к электронным документам соединен с синхронизирующим выходом модуля идентификации адресов электронных документов в списке доступа, при этом информационный выход модуля селекции доступа к электронным документам является вторым информационным выходом системы, предназначенным для выдачи кодов электронных адресов документов в сеть Интернет, синхронизирующий выход модуля селекции доступа к электронным документам является третьим синхронизирующим выходом системы, предназначенным для выдачи синхронизирующих сигналов передачи кодов электронных адресов документов в сеть Интернет, а сигнальный выход модуля селекции доступа к электронным документам является сигнальным выходом системы, предназначенным для выдачи сигнала запрета допуска к электронным документам сети.
Сущность изобретения поясняется чертежами, где на фиг.1 представлена структурная схема системы, на фиг.2 - структурная схема модуля селекции опорных адресов сайтов в базе данных сервера, на фиг.3 - структурная схема модуля идентификации адресов электронных документов в списке доступа, на фиг.4 - структурная схема модуля идентификации временных циклов выборки адресов из списка доступа, на фиг.5 - структурная схема модуля формирования сигналов управления выборкой записей базы данных сервера, на фиг.6 - структурная схема модуля селекции доступа к электронным документам, на фиг.7 представлена диаграмма потоков данных в системе, а на фиг.8 представлен алгоритм работы системы
Система (фиг.1) содержит модуль 1 селекции опорных адресов сайтов в базе данных сервера, модуль 2 идентификации адресов электронных документов в списке доступа, модуль 3 идентификации временных циклов выборки адресов из списка доступа, модуль 4 формирования сигналов управления выборкой записей базы данных сервера, модуль 5 селекции доступа к электронным документам.
На фиг.1 также показаны первый 10 и второй 11 информационные входы системы, первый 12 и второй 13 синхронизирующие входы системы, первый 15 и второй 16 информационные выходы системы, адресный 17 выход системы, первый 18, второй 19 и третий 20 синхронизирующие выходы системы, и сигнальный 21 выход системы.
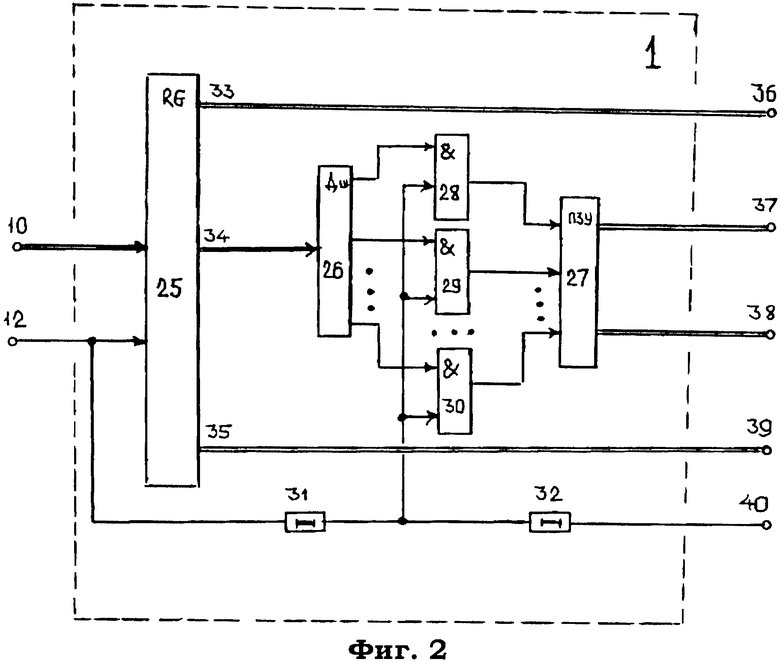
Модуль 1 (фиг.2) селекции опорных адресов сайтов в базе данных сервера содержит регистр 25, дешифратор 26, узел памяти 27, выполненный в виде постоянного запоминающего устройства, элементы 28-30 И и элементы 31, 32 задержки. На чертеже также показаны информационный 10 и синхронизирующий 12 входы, а также первый 36, второй 37, третий 38 и четвертый 39 информационные и синхронизирующий 40 выходы.
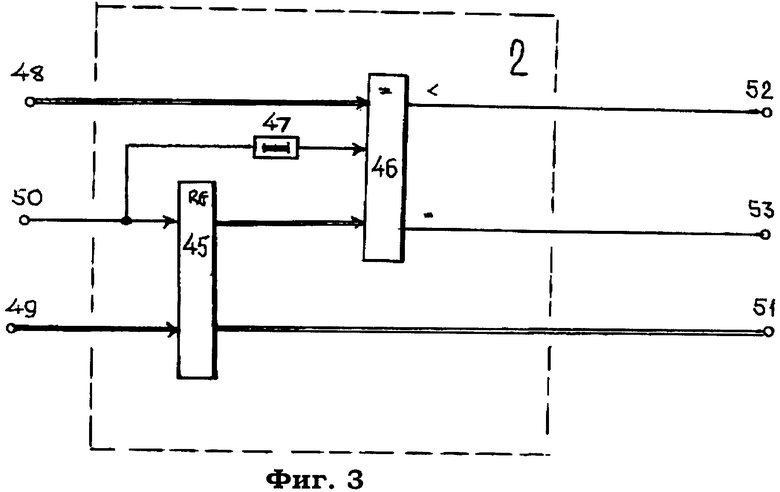
Модуль 2 (фиг.3) идентификации адресов электронных документов в списке доступа содержит регистр 45, компаратор 46, элемент 47 задержки. На чертеже показаны первый 48 и второй 49 информационные и синхронизирующий 50 входы, а также информационный 51, тактирующий 52 и синхронизирующий 53 выходы.
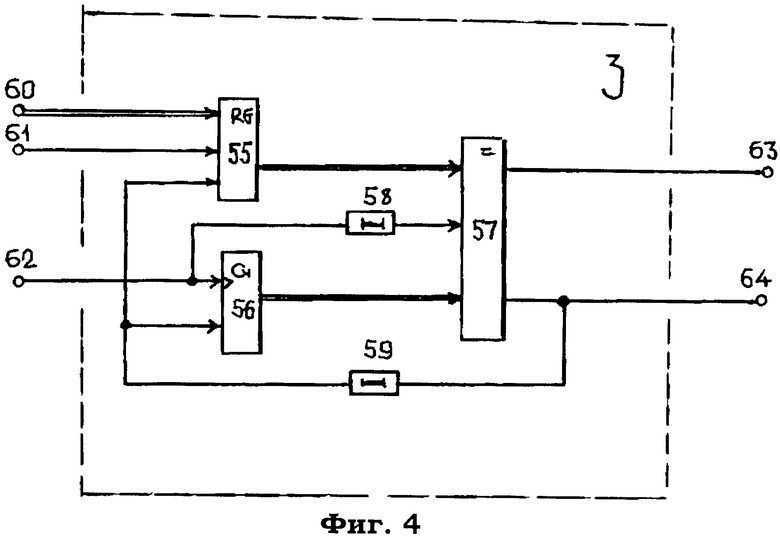
Модуль 3 (фиг.4) идентификации временных циклов выборки адресов из списка доступа содержит регистр 55, счетчик 56, компаратор 57, элементы 58, 59 задержки.
На чертеже показаны информационный 60, синхронизирующий 61 и счетный 62 входы, а также первый 63 и второй 64 выходы.
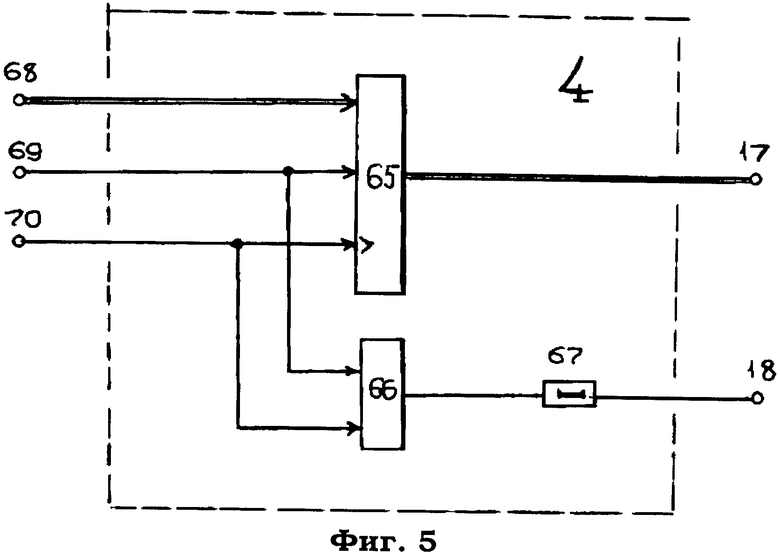
Модуль 4 (фиг.5) формирования сигналов управления выборкой записей базы данных сервера содержит счетчик 65, элемент 66 ИЛИ, элемент 67 задержки. На чертеже показаны информационный 68, синхронизирующий 69 и счетный 70 входы, а также адресный 17 и синхронизирующий 18 выходы.
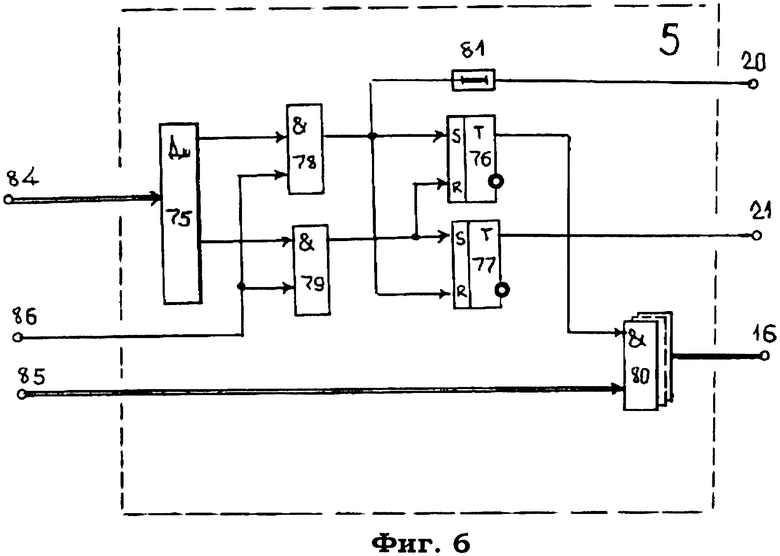
Модуль 5 (фиг.6) селекции доступа к электронным документам содержит дешифратор 75, триггеры 76, 77, элементы 78, 79 И, группа 80 элементов И, элемент 91 задержки. На чертеже показаны первый 84 и второй 85 информационные и синхронизирующий 86 входы, а также информационный 16, синхронизирующий 20 и сигнальный 21 выходы системы.
Работа системы основана на использовании автоматического классификатора электронных документов для определения тематики документов.
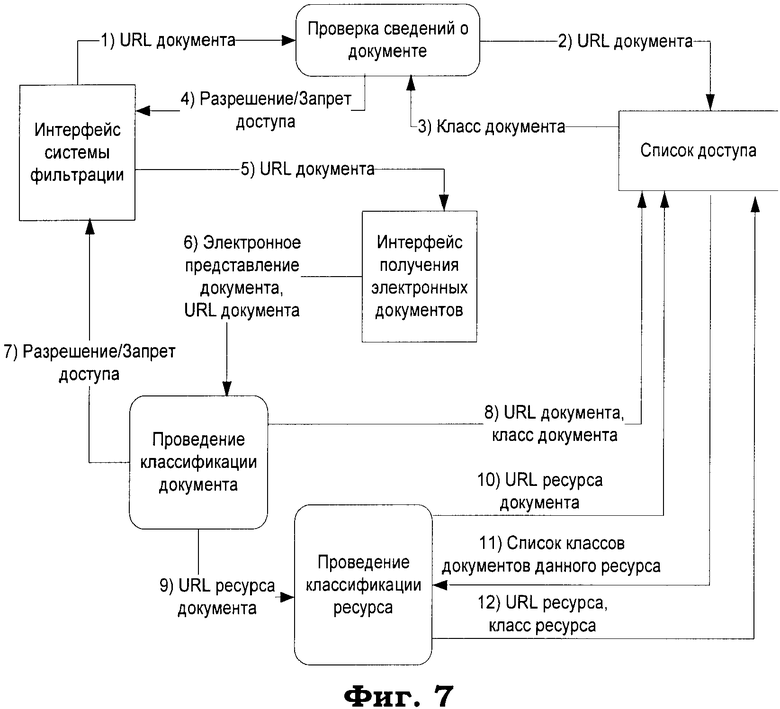
В данном случае под классификацией электронного документа понимается следующая последовательность действий (фиг.7):
- преобразование гипертекстового представления к специальному формату данных: отделение текста естественного языка от служебной HTML-разметки;
- анализ выделенного текста естественного языка с целью выделения значимых фрагментов; учет веса их вхождений в тексте для построения модели представления текста документа;
- сравнение построенной модели представления текста с моделями заранее предопределенных классов документов, содержащими отличительные признаки и их значения, характеризующие тематику этих классов;
- принятие решения на основе проведенного сравнения об отнесении документа к одному или нескольким классам, при этом принятие решения о блокировании передачи HTTP-запроса пользователя к серверу в случае, когда тематика запрошенного электронного документа определена как нежелательная.
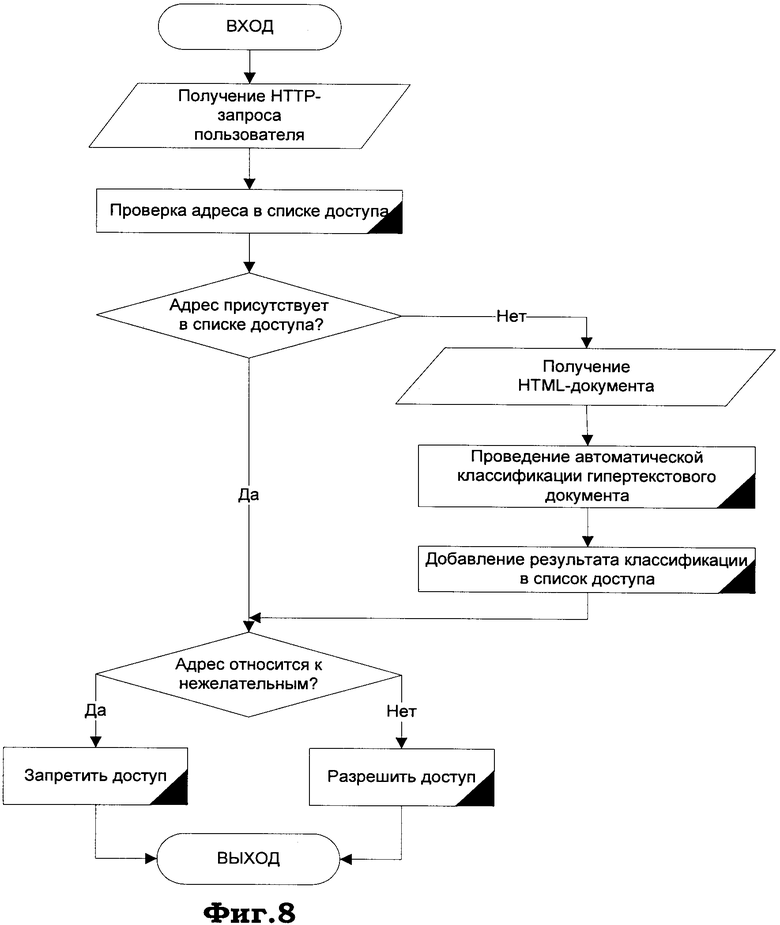
Общий алгоритм работы системы приведен на фиг.8 и заключается в выполнении следующей последовательности операций:
- на вход 10 системы поступает запрос на доступ к электронному документу по его URL (шаги 1 и 2 диаграммы потоков данных).
- проводится проверка сведений о документе в списке доступа (шаг 3). Если в списке доступа присутствует запись о классе непосредственно запрашиваемого URL, то результатом будет разрешение или запрет доступа, если класс документа допустимый или нежелательный соответственно (шаг 4). Если в списке доступа отсутствуют сведения непосредственно о запрашиваемом URL, но при этом ресурс, к которому относится документ, помечен как нежелательный, то в результате производится запрет доступа к документу.
Следующие шаги выполняются только в случае, когда в списке доступа отсутствуют сведения о документе и о ресурсе, к которому принадлежит документ:
- запускается механизм автоматической классификации: для этого в интерфейс получения электронных документов передается URL классифицируемого документа (шаг 5). Интерфейс получения электронных документов предоставляется внешней вызывающей программой или реализуется непосредственно как функция подсистемы автоматической классификации;
- гипертекстовое представление и URL документа передаются далее для проведения непосредственно классификации документа (шаг 6);
- после определения класса документа через интерфейс фильтрации возвращается разрешение/запрет на доступ в соответствии с определенным классом (шаг 7), а также производится помещение информации в список доступа (шаг 8);
- дополнительно запускается механизм классификации ресурса, к которому относится документ (шаг 9). Для проведения процедуры классификации ресурса производится запрос сведений обо всех известных документах, относящихся к ресурсу (шаги 10, 11). Результат классификации ресурса также помещается в список доступа (шаг 12).
Классификация ресурса производится по следующему правилу: ресурс является нежелательным тогда и только тогда, когда доля документов, относящихся к этому ресурсу и классифицированных как нежелательные, превышает пороговую величину А, которая определяется на этапе настройки системы. В остальных случаях ресурс считается допустимым.
Таким образом, система реализует следующие процедуры:
- в список доступа помещаются именно те документы и ресурсы, доступ к которым осуществляет пользователь на практике;
- однажды классифицированные документы не подвергаются повторной классификации при последующих обращениях пользователя.
Идентификатор электронного документа представляет собой следующую структуру:
Идентификатор ресурса аналогичен идентификатору электронного документа, но второе поле pathID имеет всегда нулевое значение.
Проиллюстрируем этот факт на следующем примере: пусть URL-адрес документа - http://www.site.com/foo/bar/doc.html.
Тогда siteID=CRC32(http://www.site.com),
pathID=CRC32(foo/bar/doc.html),
и идентификатор электронного документа - есть пара (siteID, pathID), а идентификатор соответственного ресурса, к которому принадлежит документ - (siteID, 0).
Структура данных, характеризующая тематическую принадлежность документа, выглядит следующим образом:
Для доступа к соответствующим электронным документам на вход 10 системы поступает идентификатор электронного документа в виде кодограммы, имеющий следующую структуру данных:
Данная кодограмма с входа 10 системы поступает на информационный вход модуля 1 и далее на информационный вход регистра 25, в который указанные коды заносятся синхронизирующим импульсом с входа 12.
С выхода 33 регистра 25 вся кодовая комбинация через выход 36 модуля 1 выдается как на выход 15 системы и далее на информационный вход сервера базы данных допуска, так и на вход 85 модуля 5.
С выхода 34 регистра 25 модуля 1 код siteID поступает на информационный вход дешифратора 26, который расшифровывает поступивший код и подготавливает цепь прохождения сигнала с входа 12, открывая один из элементов 28-30 И. Для определенности положим, что высокий потенциал поступил на один вход элемента 30 И.
Параллельно с этим синхронизирующий импульс с входа 12 системы задерживается элементом 31 модуля 1 на время срабатывания регистра 25 и дешифратора 26 и далее опрашивает состояние элементов 28-30 И.
Учитывая то обстоятельство, что открытым по одному входу будет только элемент 30 И, то пройдя этот элемент И, синхроимпульс поступает, во-первых, на вход считывания соответствующей фиксированной ячейки памяти постоянного запоминающего устройства 27, где хранятся коды опорных адресов разделов памяти сервера базы данных, содержащих данные сайтов siteID.
Структура кода данных сайтов siteID имеет следующий вид:
Код опорного адреса первой записи данного siteID считывается из памяти блока 27 и через выход 37 модуля 1 поступает на вход 68 модуля 4 и далее на информационный вход счетчика 65, а код общего количества записей данных адресов в разделе базы данных siteID с выхода 38 модуля 1 поступает на информационный вход 60 модуля 3 и далее на информационный вход регистра 55.
Одновременно с этим тот же импульс считывания с выхода элемента 31 задерживается элементом 32 задержки на время считывания содержимого фиксированной ячейки ПЗУ 27 и затем с выхода 40 модуля 1 поступает как на синхронизирующий вход 61 модуля 3, так и на синхронизирующий вход 69 модуля 4.
Код с входа 68 модуля 4 синхронизирующим импульсом с входа 69 заносится в счетчик 65, с выхода которого этот код поступает на адресный выход 17 системы.
Одновременно этот же синхронизирующий импульс проходит через элемент 66 ИЛИ и задерживается на время занесения кода опорного адреса в счетчик 65 элементом 67. Затем данный импульс выдается на выход 18 системы в качестве сигнала управления считыванием содержимого ячейки памяти базы данных сервера по адресу, указанному на выходе 17 системы.
Код же общего количества записей данных адресов в разделе базы данных siteID с выхода 38 модуля 1 заносится через вход 60 модуля 3 в регистр 55 тем же синхронизирующим импульсом с выхода 40 модуля 1 через вход 61 модуля 3. С выхода регистра 55 этот код подается на один вход компаратора 57.
По сигналу с выхода 18 системы сервер базы данных (на чертеже не показан) переходит на подпрограмму считывания содержимого ячейки базы данных по указанному на выходе 17 адресу, выдачи считанной записи базы данных на информационный 11 вход системы и занесения ее атрибутов в модуль 2 синхронизирующим импульсом, поступающим с сервера на вход 13 системы.
В результате этого с входа 49 в регистр 45 синхронизирующим импульсом с входа 50 будут занесены атрибуты первой считанной из базы данных записи, имеющие следующую структуру:
- либо запрещения доступа к электронному документу с данным адресом
Код pathID из первой считанной записи из базы данных с первого выхода регистра 45 поступает на один вход компаратора 46, на другой информационный вход которого с выхода 39 модуля 1 поступает код pathID запрашиваемого электронного документа.
Синхронизирующий импульс с входа 13 системы задерживается элементом 47 задержки на время занесения записи базы данных в регистр 45 модуля 2 и поступает на синхронизирующий вход компаратора 46.
По синхронизирующему сигналу компаратор 46 сравнивает входные коды, и, если сравниваемые атрибуты pathID не совпадают между собой, то на выходе 52 модуля 2 формируется сигнал, поступающий на вход 62 модуля 3 и далее на счетный вход счетчика 56, фиксирующего число записей, считанных из базы данных сервера.
К данному моменту времени счетчик 56 зафиксирует факт осуществления считывания первой записи из базы данных сервера. Выход счетчика 56 подключен к одному входу компаратора 57, сравнивающего общее число записей данного сайта в базе данных сервера, хранящегося в регистре 55, с числом записей в счетчике 56.
Компаратор 57 модуля 3 сравнивает показания регистра 55 и счетчика 56 по синхронизирующему импульсу, поступающему на синхронизирующий вход компаратора 67 с выхода элемента 58 задержки.
Поскольку в счетчике 56 зафиксирована первая единица, то его показания будут меньше показаний регистра 55 и на выходе 63 модуля 3 появляется импульс, который через вход 70 модуля 4 будет поступать на счетный вход счетчика 65, увеличивая базовый адрес ячейки считывания на единицу.
Кроме того, этот же импульс проходит через элемент 66 ИЛИ на вход элемента 67 задержки, где задерживается на время окончания срабатывания счетчика 65, и далее вновь выдается через выход 18 системы в качестве сигнала управления считыванием очередной записи базы данных по адресу, сформированному на выходе 17 системы.
По сигналу с выхода 18 системы сервер базы данных вновь переходит на подпрограмму считывания содержимого ячейки базы данных по указанному на выходе 17 адресу, выдачи считанной записи базы данных на информационный вход 11 системы и занесения ее атрибутов в регистр 45 модуля 2 синхронизирующим импульсом, поступающим с сервера на вход 13.
Этот процесс считывания записей базы данных сервера будет продолжаться до тех пор, пока показания счетчика 56 и регистра 55 не сравняются между собой, что будет свидетельствовать о том, что запрашиваемого адреса электронного документа в базе данных сервера нет. В этом случае импульс формируется на выходе 64 модуля 3 и через выход 19 системы поступает на вход второго канала прерывания сервера базы данных.
С приходом этого сигнала сервер переходит на подпрограмму автоматической классификации запрашиваемого идентификатора электронного документа, в соответствии с которой данные идентификатора электронного документа с выхода 15 системы поступают в сервер базы данных, где осуществляется следующая последовательность операций:
- преобразование гипертекстового представления к специальному формату данных: отделение текста естественного языка от служебной HTML-разметки;
- анализ выделенного текста естественного языка с целью выделения значимых фрагментов; учет веса их вхождений в тексте для построения модели представления текста документа;
- сравнение построенной модели представления текста с моделями заранее предопределенных классов документов, содержащими отличительные признаки и их значения, характеризующие тематику этих классов;
- принятие решения на основе проведенного сравнения об отнесении документа к одному или нескольким классам, при этом принятие решения о блокировании передачи HTTP-запроса пользователя к серверу в случае, когда тематика запрошенного электронного документа определена как нежелательная, как это показано на фиг.8.
Если же сравниваемые атрибуты pathID на входах компаратора 46 модуля 2 совпадают между собой, то на выходе 53 модуля 2 формируется сигнал, поступающий на вход 86 модуля 5 и далее на одни входы элементов 78, 79 И, управляемые дешифратором 75, на вход 84 которого с выхода 51 модуля 2 поступает код признака доступа к данному электронному документу.
Дешифратор 75 расшифровывает код признака доступа, и если доступ к данному электронному документу разрешен, то дешифратор 75 открывает по второму входу элемент 78 И, через который проходит импульс с входа 86 и поступает как на прямой вход триггера 76, устанавливая его в единичное состояние, так и на обратный вход триггера 77, подтверждая его исходное состояние.
Переходя в единичное состояние, триггер 76 с прямого выхода высоким потенциалом открывает по одному входу элементы 80 И группы, на другой вход 85 которых с выхода 36 модуля 1 поступает идентификатор электронного документа, который через элементы 80 И группы выдаются на выход 16 системы.
Кроме того, синхронизирующий импульс с выхода элемента 78 И задерживается элементом 81 на время срабатывания триггера 76 и подключения элементов 80 И группы и с выхода 20 системы выдается в качестве синхронизирующего сигнала выдачи электронного идентификатора электронного документа.
Если же на входе дешифратора 75 будет зафиксирован код признака запрета доступа к адресу данного электронного документа, то открыт по второму входу будет элемент 79 И, через который синхронизирующий импульс с входа 86 установит триггер 77 в единичное состояние, а триггер 76 будет установлен в исходное состояние, при котором низким потенциалом с прямого выхода триггера 76 элементы 80 И группы будут закрыты, блокируя тем самым доступ к электронному документу.
Высокий потенциал с прямого выхода триггера 77 выдается на выход 21 системы в качестве сигнала запрета доступа к данному электронному документу.
Таким образом, система осуществляет блокировку электронных документов, которые либо принадлежат к нежелательным ресурсам, либо сами классифицированы как нежелательные.
Применение метода автоматической классификации электронных документов, с помощью которого осуществляется анализ гипертекстового представления документа, выделение отличительных признаков, производится сравнение их значений и принимается решение о принадлежности документа к категории нежелательных либо допустимых, является отличительной чертой предложенной системы динамической контентной фильтрации.
Таким образом, введение новых модулей и новых конструктивных связей позволило существенно повысить быстродействие системы путем локализации адресов записей базы данных по идентификаторам электронных документов.
Источники информации
1. Тумбс Д. Фильтрация Web-контента с использованием ISA Server /Открытые системы: [Электронный документ] / (http://www.osp.ru/win2000/2006/08/3829260/).
2. Хилл Б. Решения для фильтрации Web-контента /Открытые системы: [Электронный документ] / (http://www.osp.ru/win2000/2004/05/177073/).
3. Патент США №5136708, М. кл. G06F 15/16, 1992.
4. Патент США №5129083, М. кл. G06F 12/00, 15/40, 1992 (прототип).
| название | год | авторы | номер документа |
|---|---|---|---|
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА МОНИТОРИНГА ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА ПАСПОРТНО-ВИЗОВОГО ДЕЛОПРОИЗВОДСТВА | 2008 |
|
RU2369904C1 |
| ТЕХНОЛОГИЧЕСКАЯ ПЛАТФОРМА ИНТЕГРАЦИИ РЕСУРСОВ СЕТИ ИНТЕРНЕТ ДЛЯ ПРОВЕДЕНИЯ ФЕДЕРАЛЬНЫХ ВЫБОРОВ И РЕФЕРЕНДУМОВ | 2012 |
|
RU2513721C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА ПРИ ПРОВЕДЕНИИ ДИСТАНЦИОННОГО ЭЛЕКТРОННОГО ГОЛОСОВАНИЯ | 2010 |
|
RU2421788C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ДИСТАНЦИОННОГО ЭЛЕКТРОННОГО ГОЛОСОВАНИЯ ПРИ ПРОВЕДЕНИИ ВЫБОРОВ И РЕФЕРЕНДУМОВ | 2011 |
|
RU2452029C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА УЧЕТА И КОНТРОЛЯ ВЫДАЧИ ВОЕННОСЛУЖАЩИМ СТРЕЛКОВОГО ОРУЖИЯ | 2011 |
|
RU2450345C1 |
| АВТОМАТИЗИРОВАННОЕ РАБОЧЕЕ МЕСТО УЧАСТНИКА ЗАКОНОТВОРЧЕСКОЙ ДЕЯТЕЛЬНОСТИ ГОСУДАРСТВЕННОЙ АВТОМАТИЗИРОВАННОЙ СИСТЕМЫ "ЗАКОНОТВОРЧЕСТВО" | 2012 |
|
RU2485589C1 |
| СИСТЕМА ВЕДЕНИЯ РЕЕСТРА ПОЛЬЗОВАТЕЛЕЙ ПОРТАЛА ОБЕСПЕЧЕНИЯ ЗАКОНОТВОРЧЕСКОЙ ДЕЯТЕЛЬНОСТИ | 2012 |
|
RU2486587C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЕРИФИКАЦИИ ДАННЫХ ГРАЖДАН ПРИ ОФОРМЛЕНИИ И ВЫДАЧЕ БИОПАСПОРТОВ | 2008 |
|
RU2378687C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА РЕГИСТРАЦИИ ПЕРСОНАЛЬНЫХ БИОМЕТРИЧЕСКИХ ДАННЫХ ЗАЯВИТЕЛЕЙ НА ПОЛУЧЕНИЕ ПАСПОРТНО-ВИЗОВЫХ ДОКУМЕНТОВ | 2008 |
|
RU2395838C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ГРАЖДАН ПО ДАННЫМ ПАСПОРТНО-ВИЗОВЫХ ДОКУМЕНТОВ | 2008 |
|
RU2392662C1 |
Изобретение относится к вычислительной технике, в частности к системе управления доступом к ресурсам сети Интернет в зависимости от категории запрашиваемых ресурсов и принятой политики безопасности. Техническим результатом является повышение быстродействия системы путем локализации адресов поиска записей списков доступа базы данных сервера по идентификаторам электронных документов. Система содержит модуль селекции опорных адресов сайтов в базе данных сервера, модуль идентификации адресов электронных документов в списке доступа, модуль идентификации временных циклов выборки адресов из списка доступа, модуль формирования сигналов управления выборкой записей базы данных сервера, модуль селекции доступа к электронным документам. 8 ил., 6 табл.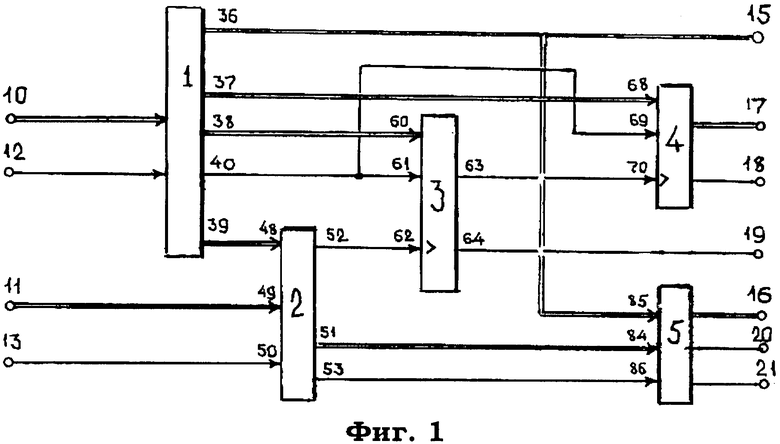
Система управления доступом к ресурсам сети Интернет, содержащая модуль селекции опорных адресов сайтов в базе данных сервера, информационный и синхронизирующий входы которого являются первыми информационным и синхронизирующим входами системы соответственно, при этом первый информационный вход системы предназначен для приема запросов электронных документов по их сетевым адресам, первый синхронизирующий вход системы предназначен для приема сигналов занесения кодов запросов электронных документов в модуль селекции опорных адресов сайтов в базе данных сервера, а первый информационный выход модуля селекции опорных адресов сайтов в базе данных сервера предназначен для выдачи запросов электронных документов по их сетевым адресам на первый информационный вход сервера базы данных, модуль идентификации адресов электронных документов в списке доступа, один информационный и синхронизирующий входы которого являются вторыми информационным и синхронизирующим входами системы соответственно, при этом второй информационный вход системы предназначен для приема записей базы данных сервера, а второй синхронизирующий вход системы предназначен для приема сигналов занесения записей базы данных сервера в модуль идентификации адресов электронных документов в списке доступа, модуль формирования сигналов управления выборкой записей базы данных сервера, первый информационный вход которого соединен со вторым информационным выходом модуля селекции опорных адресов сайтов в базе данных сервера, синхронизирующий модуль формирования сигналов управления выборкой записей базы данных сервера подключен к синхронизирующему выходу модуля селекции опорных адресов сайтов в базе данных сервера, адресный выход модуля формирования сигналов управления выборкой записей базы данных сервера является адресным выходом системы, предназначенным для выдачи адресов записей базы данных на адресный вход сервера базы данных, а синхронизирующий выход модуля формирования сигналов управления выборкой записей базы данных сервера является первым синхронизирующим выходом системы, предназначенными для выдачи сигналов управления на вход первого канала прерывания сервера базы данных, отличающаяся тем, что система содержит модуль идентификации временных циклов выборки адресов из списка доступа, информационный вход которого соединен с третьим информационным выходом модуля селекции опорных адресов сайтов в базе данных сервера, синхронизирующий вход модуля идентификации временных циклов выборки адресов из списка доступа подключен к синхронизирующему выходу модуля селекции опорных адресов сайтов в базе данных сервера, а счетный вход модуля идентификации временных циклов выборки адресов из списка доступа соединен с тактирующим выходом модуля идентификации адресов электронных документов в списке доступа, при этом один выход модуля идентификации временных циклов выборки адресов из списка доступа подключен к счетному входу модуля формирования сигналов управления выборкой записей базы данных сервера, а другой выход модуля идентификации временных циклов выборки адресов из списка доступа является вторым синхронизирующим выходом системы, предназначенным для выдачи сигналов управления на вход второго канала прерывания сервера базы данных, и модуль селекции доступа к электронным документам, один информационный вход которого соединен с первым выходом модуля селекции опорных адресов сайтов в базе данных сервера, другой информационный вход модуля селекции доступа к электронным документам подключен к информационному выходу модуля идентификации адресов электронных документов в списке доступа, а синхронизирующий вход модуля селекции доступа к электронным документам соединен с синхронизирующим выходом модуля идентификации адресов электронных документов в списке доступа, при этом информационный выход модуля селекции доступа к электронным документам является вторым информационным выходом системы, предназначенным для выдачи кодов электронных адресов документов в сеть Интернет, синхронизирующий выход модуля селекции доступа к электронным документам является третьим синхронизирующим выходом системы, предназначенным для выдачи синхронизирующих сигналов передачи кодов электронных адресов документов в сеть Интернет, а сигнальный выход модуля селекции доступа к электронным документам является сигнальным выходом системы, предназначенным для выдачи сигнала запрета допуска к электронным документам сети.
| US 5129083 А, 07.07.1992 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ УПРАВЛЕНИЯ ДОСТУПОМ К ИНТЕРНЕТУ В КОМПЬЮТЕРНОЙ СИСТЕМЕ И СЧИТЫВАЕМЫЙ КОМПЬЮТЕРОМ НОСИТЕЛЬ ИНФОРМАЦИИ ДЛЯ ХРАНЕНИЯ КОМПЬЮТЕРНОЙ ПРОГРАММЫ | 2001 |
|
RU2231115C2 |
| СПОСОБ ДОСТУПА К РЕСУРСАМ ИНТЕРНЕТ | 2001 |
|
RU2209464C2 |
| US 5136708 A, 04.08.1992 | |||
| US 7272639 В1, 18.09.2007 | |||
| СПОСОБ СОЕДИНЕНИЯ ДЕТАЛЕЙ | 2009 |
|
RU2418999C1 |

