Область техники, к которой относится изобретение
Изобретение относится, в целом, к способу ввода текста в устройство. В частности, изобретение относится к вокализованному текстовому вводу с помощью ввода символов.
Уровень техники
Малые вычислительные устройства, например мобильные телефоны и карманные персональные компьютеры (КПК), используются все чаще. Вычислительная мощность этих устройств позволяет использовать их для доступа в Интернет и просмотра веб-страниц, а также для сохранения контактной информации, просмотра и редактирования текстовых документов и выполнения других задач. Кроме того, отправка и прием текстовых сообщений с помощью мобильных устройств приобрели большую популярность. Например, служба коротких сообщений (SMS) для мобильных телефонов пользуется большим успехом в качестве средства обмена текстовыми сообщениями, но появившаяся недавно усовершенствованная служба обмена сообщениями (EMS), расширение SMS на уровне приложений, как ожидается, обеспечит плавный переход к распространению службы обмена мультимедийными сообщениями (MMS). В результате, эти устройства обеспечивают многочисленные приложения, в которых требуется ввод текста. К сожалению, такой ввод текста на мобильных устройствах может быть затруднен ввиду отсутствия стандартной полномасштабной клавиатуры.
В настоящее время есть два общих способа обеспечения ввода текста с использованием цифровой клавиатуры мобильного телефона, многоотводный подход и одноотводный подход. Согласно многоотводному подходу, пользователь нажимает цифровую клавишу несколько раз, чтобы ввести нужную букву, причем большинство цифровых клавиш отображается в три или четыре буквы алфавита. Например, клавиша двойки обычно отображается в буквы A, B и C. Если пользователь нажмет на клавишу двойки один раз, то будет введена буква А. Если пользователь нажмет на клавишу двойки дважды, то будет введена буква В, а если пользователь нажмет на клавишу двойки трижды, то будет введена буква С.Паузы между вводом последовательных букв слова иногда необходимы, чтобы устройство знало, когда перемещать курсор в следующую позицию ввода буквы. Например, чтобы ввести слово "cab" пользователь нажимает клавишу двойки три раза, чтобы ввести букву С, делает паузу, нажимает клавишу двойки один раз, чтобы ввести букву А, опять делает паузу и нажимает клавишу двойки два раза, чтобы ввести букву В. Другие клавиши, имеющиеся в цифровой клавиатуре, например клавиши фунта ("#") и звездочки ("*"), помимо прочих клавиш, обычно отображаются в символы ввода или осуществляют переключение между верхним регистром и нижним регистром.
Хотя многоотводный подход полезен тем, что пользователи могут ввести любое слово, используя только числовые клавиши, он не позволяет быстро и интуитивно вводить текст.Например, чтобы набрать слово "cab" на стандартной клавиатуре требуется нажать только три клавиши, по одной на каждую букву, многоотводный подход требует шести нажатий клавиш на числовой клавиатуре. По сравнению с использованием стандартной клавиатуры, использование числовых клавиш согласно многоотводному подходу для обеспечения ввода текста предполагает, что пользователю приходится нажимать много клавиш даже для коротких сообщений. Кроме того, велика вероятность ошибки. Например, если пользователь хочет ввести букву В, но делает слишком большую паузу между первым и вторым нажатием клавиши двойки, будут введены две буквы А. В этом случае, устройство интерпретирует паузу как сигнал пользователя о том, что он закончил ввод текущей буквы, А, и переходит в следующую позицию ввода буквы, где он опять вводит А.
Другой подход к вводу текста с использованием числовой клавиатуры это одноотводный словарный подход, например, "T9", распространяемый компанией Tegic. Согласно одноотводному подходу, пользователь однократно нажимает числовую клавишу, связанную с нужной буквой, даже если числовая клавиша отображается в три или четыре разные буквы. Когда пользователь вводит числовую последовательность для слова, устройство пытается распознать слово, которое пользователь намерен ввести, на основании числовой последовательности. Каждая числовая последовательность отображается в общеупотребительное слово, соответствующее последовательности. Например, числовая последовательность 43556 может потенциально соответствовать любому слову из пяти букв, имеющему первую букву G, H или I, поскольку клавиша четверки обычно отображается в эти буквы. Аналогично, последовательность потенциально соответствует любому слову из пяти букв, имеющему вторую букву D, E или F, третью и четвертую букву, выбранную из букв J, K и L, и пятую букву M, N или O, поскольку клавиши тройки, пятерки и шестерки обычно отображаются в эти соответствующие буквы. Однако, поскольку наиболее общеупотребительное слово, соответствующее числовой последовательности 43556, это слово "hello", одноотводный подход предусматривает однозначный ввод этого слова, когда пользователь последовательно нажимает клавиши четыре, три, пять, пять и шесть, чтобы ввести эту числовую последовательность.
Одноотводный подход имеет преимущества над многоотводным подходом, но представляет новые недостатки. Преимуществом одноотводного подхода является то, что пользователю, с высокой вероятностью, придется нажимать столько же кнопок, сколько букв в нужном слове. Например, многоотводный подход требует, чтобы пользователь нажал клавишу двойки шесть раз, чтобы ввести слово "cab".
Напротив, одноотводный подход потенциально требует, чтобы пользователь нажал клавишу двойки три раза, чтобы ввести это слово, предполагая, что числовая последовательность 222 отображается в слово "cab". Поэтому, одноотводный подход экономичнее с точки зрения клавиш по сравнению с многоотводным подходом для ввода текста с использованием числовых клавиш. Он почти так же эффективен с точки зрения клавиш, как и использование стандартной клавиатуры, которая имеет по одной клавише для каждой буквы.
Недостаток одноотводного подхода состоит в том, что слово, отображаемое в данную числовую последовательность, может не быть словом, которое пользователь намеревается ввести, вводя последовательность. Например, последовательность 7333 числовых клавиш соответствует словам "seed" и "reed". Поскольку в каждую последовательность числовых клавиш отображается только одно слово, когда пользователь нажимает клавиши в последовательности 7333 числовых клавиш, может быть введено слово "seed", тогда как пользователь мог хотеть ввести слово "reed". Одноотводный подход полезен главным образом, когда для данной последовательности числовых клавиш существует только одно уникальное слово, или, если для данной последовательности имеется несколько слов, когда пользователь желает ввести наиболее общеупотребительное слово, связанное с последовательностью. Когда слово, отображаемое согласно одноотводному подходу, не является словом, которое имеется в виду, ввод текста снова вернуть к многоотводному подходу или перевести в режим исправления ошибок. Окончательный ввод текста для предполагаемого слова может тогда потребовать больше нажатий клавиш, чем если бы пользователь начал с многоотводного подхода.
Еще один способ ввода текста без использования традиционной клавиатуры предусматривает использование системы распознавания голоса. В таких системах, пользователь вокализует текстовый ввод, который воспринимается вычислительным устройством через микрофон и цифруется. К выборкам оцифрованной воспринятой речи применяется спектральный анализ, и для каждой выборки генерируются векторы признаков или кодовые слова. Затем можно вычислять выходные вероятности по отношению к статистическим моделям, например, скрытым марковским моделям, которые затем используются при выполнении процесса декодирования по Витерби или аналогичного типа обработки. Затем ищут акустическую модель, представляющую речевые блоки, чтобы определить правдоподобные фонемы, представленные векторами особенностей или кодовыми словами, и, следовательно, высказывания, принятые от пользователя системы. Лексикон вокализованных слов-кандидатов ищут, чтобы определить слово, которое с наибольшим правдоподобием представляет вектор особенностей или кодовые слова. Кроме того, для повышения точности слова, созданного системой распознавания речи, можно использовать языковые модели. Языковые модели обычно используются для повышения точности системы распознавания речи за счет ограничения слов-кандидатов теми словами, которые с наибольшим правдоподобием базируются на предыдущих словах. После того как слова воспринятого вокализованного текстового ввода идентифицированы, они поступают в качестве текста в вычислительную систему.
Такие системы распознавания требуют значительной мощности обработки для обработки вокализованного текстового ввода и получения достаточно точных результатов. Хотя мобильные устройства будущего могут иметь возможность реализовать такие системы распознавания речи, современным мобильным вычислительным устройствам недостает вычислительной мощности, необходимой, чтобы делать это полезным образом. Кроме того, мобильным вычислительным устройствам обычно не хватает емкости памяти, которая требуется для непрерывного распознавания речи с большим словарем. Соответственно, мобильные вычислительные устройства опираются на рассмотренные выше способы ввода текста с использованием ограниченных клавиатур.
Имеется непреходящая потребность в усовершенствованных способах ввода текста в устройства, в том числе мобильные вычислительные устройства.
Раскрытие изобретения
Изобретение, в целом, относится к способу ввода текста в устройство. Согласно способу обеспечивается первый ввод символа, который указывает первый символ текстового ввода. Затем воспринимается вокализация текстового ввода. Затем идентифицируют вероятное слово-кандидат для первого слова вокализации на основании первого ввода символа и анализа вокализации. Наконец, вероятное слово-кандидат отображается для пользователя.
Краткое описание чертежей
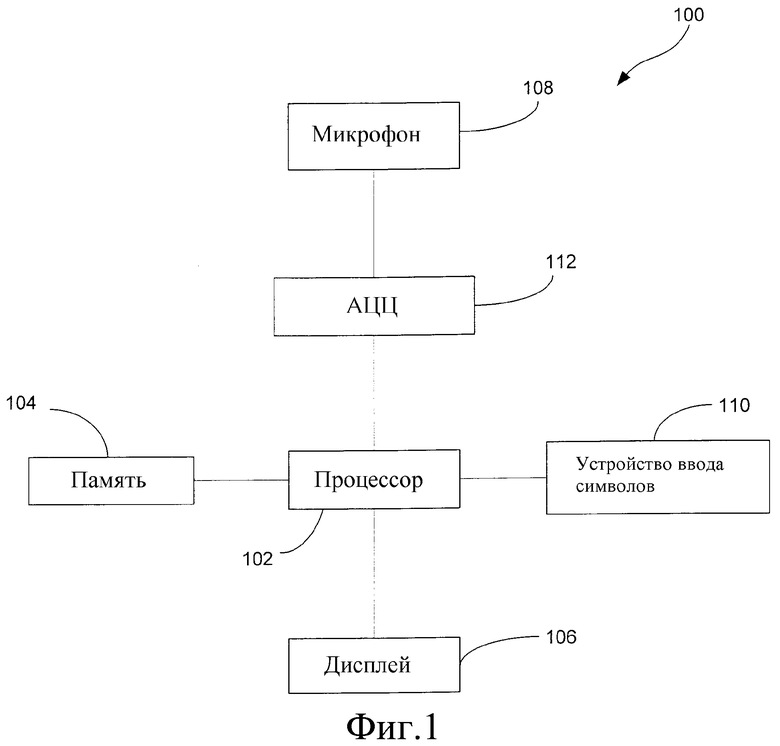
Фиг.1 - упрощенная блок-схема иллюстративного вычислительного устройства, в котором можно использовать изобретение.
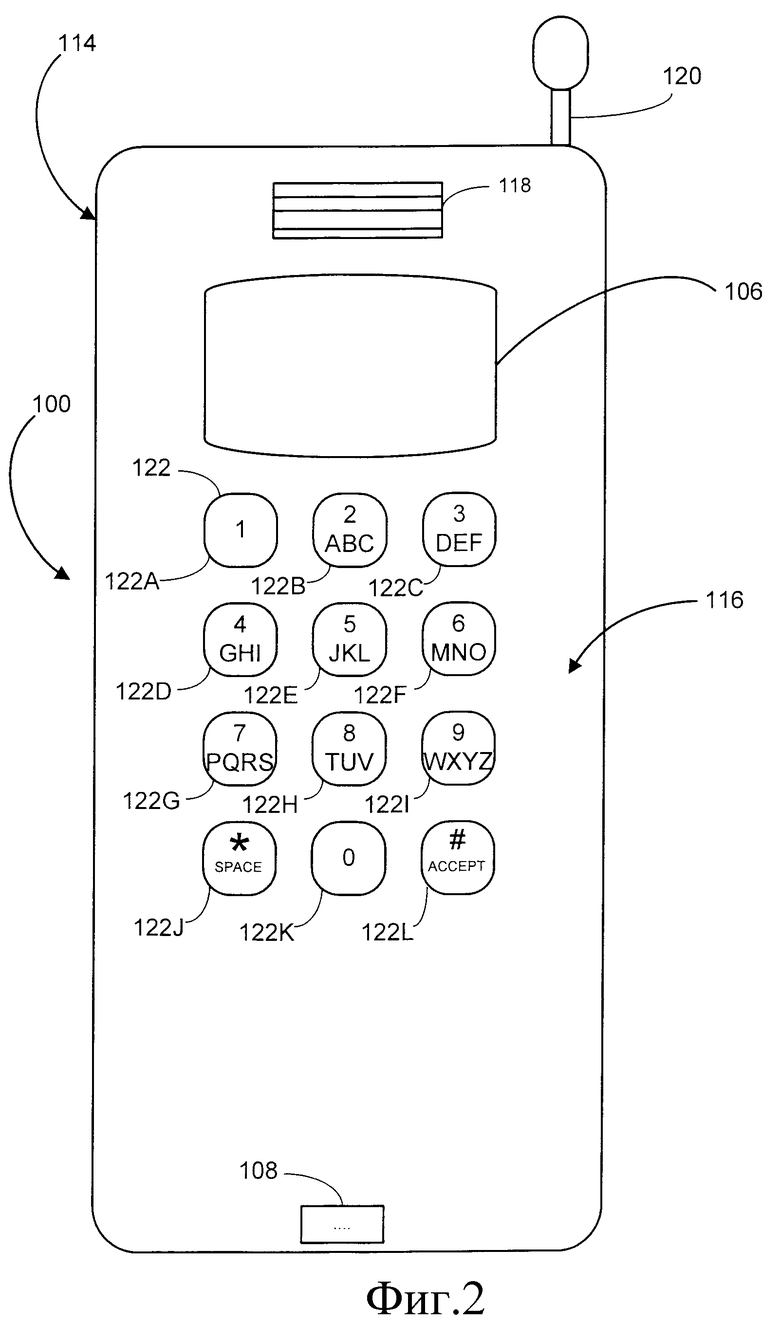
Фиг.2 - схематическое изображение мобильного телефона, в котором можно использовать изобретение.
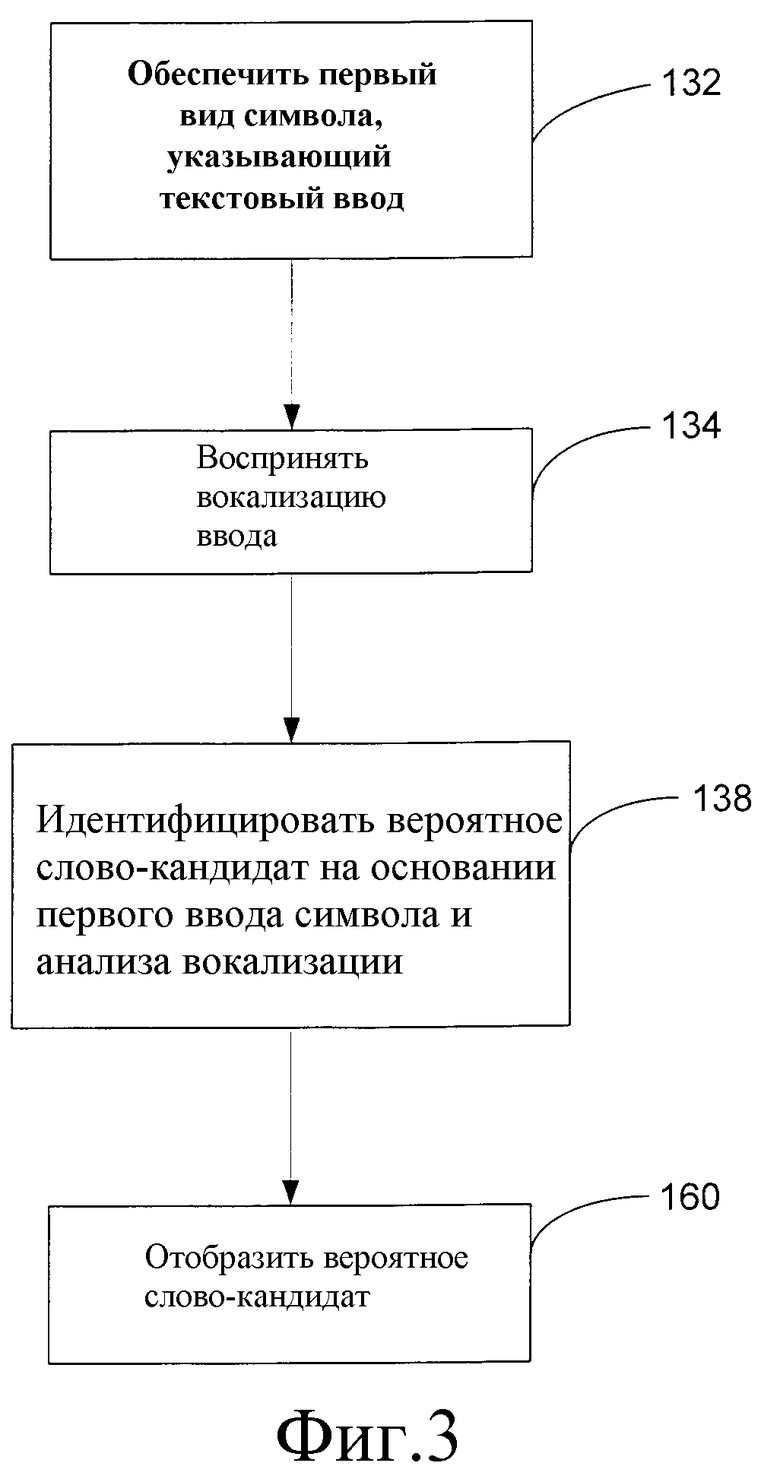
Фиг.3 - логическая блок-схема способа ввода текста в устройство согласно вариантам осуществления изобретения.
Фиг.4 - блок-схема иллюстративной системы, которую можно использовать для реализации способа, отвечающего изобретению.
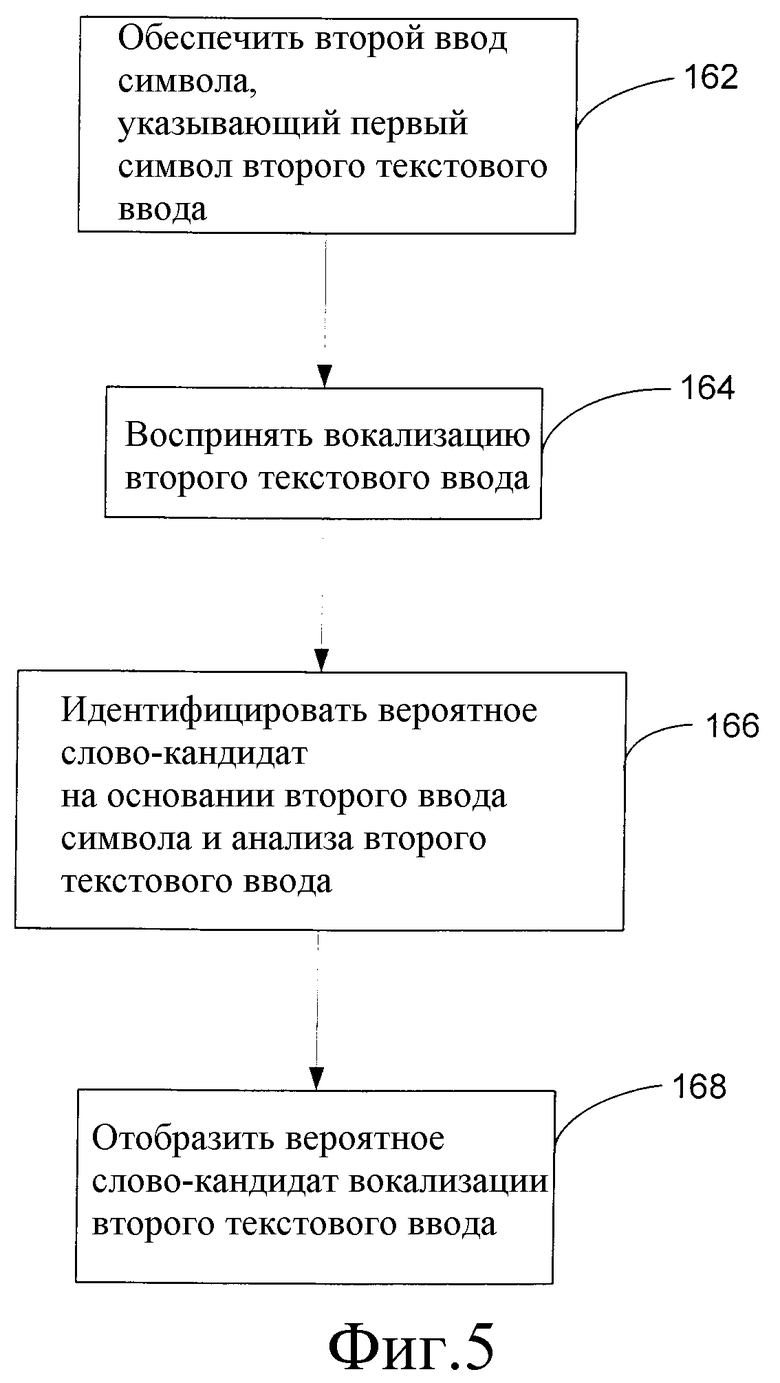
Фиг.5 - логическая блок-схема способа ввода текста в устройство согласно вариантам осуществления изобретения.
Фиг.6 - логическая блок-схема способа ввода текста в устройство согласно вариантам осуществления изобретения.
Осуществление изобретения
Настоящее изобретение, в целом, относится к способу ввода текста в вычислительные устройства. Хотя способ, отвечающий настоящему изобретению, можно реализовать в вычислительных устройствах, содержащих традиционную полномасштабную клавиатуру, он наиболее полезен, когда используется в сочетании с мобильными вычислительными устройствами, где такая клавиатура отсутствует.
На фиг.1 показана логическая блок-схема иллюстративного вычислительного устройства 100, в котором можно реализовать изобретение. Устройство 100 может быть мобильным вычислительным устройством, например мобильным телефоном, карманным персональным компьютером (КПК), мобильной системой хранения (например, МР3-проигрывателем), пультом дистанционного управления или другими мобильными вычислительными устройствами, в которых отсутствует традиционная полномасштабная клавиатура. Устройство 100 представляет собой только один пример подходящей вычислительной среды для настоящего изобретения не предусматривает никакого ограничения объема использования или функциональных возможностей изобретения. Кроме того, устройство 100 не следует рассматривать как имеющую какую-либо зависимость или требование, относящееся к одному или нескольким компонентам, показанным на фиг.1.
Устройство 100 может содержать контроллер или процессор 102, компьютерно- или машинно-считываемую память 104, дисплей 106, микрофон 108 и устройство 110 ввода символов. Память 104 - это машинно-считываемая память, к которой может обращаться процессор 102. Память 104 может содержать технологии энергозависимой или энергонезависимой памяти и может быть удаляемым из устройства 100 или фиксированным в нем. Например, память 104 может включать в себя, но без ограничения, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или другое запоминающее устройство.
Память 104 предназначена для хранения команд, например программных модулей, которые могут выполняться процессором 102 для реализации способа, отвечающего настоящему изобретению. В общем случае, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и пр., которые выполняют отдельные задачи или реализуют те или иные абстрактные типы данных. Изобретение также можно осуществить на практике в распределенных вычислительных средах, где задачи вычисляются удаленными устройствами обработки, связанными посредством сети связи. В распределенной вычислительной среде, программные модули могут размещаться как в локальных, так и в удаленных запоминающих устройствах.
Процессор 102 предназначен для отображения текста и изображений на дисплее 106 в соответствии с традиционными операциями вычислительного устройства. Дисплей 106 может представлять собой любой подходящий дисплей. Для мобильных вычислительных устройств дисплей 106 обычно является небольшим плоским дисплеем, например жидкокристаллическим дисплеем (ЖКД), который также может быть сенсорным. Альтернативно, дисплей 106 может быть дисплеем большего размера, например дисплеем на основе электронно-лучевой трубки (ЭЛТ) или большим дисплеем другого типа, например большим плоскопанельным дисплеем.
Пользователь может использовать микрофон 108 устройства 100 для ввода вокализации. Вокализация, предпочтительно, преобразуется к цифровому виду с помощью аналого-цифрового преобразователя (АЦП) 112. Согласно более подробно описанному ниже, устройство 100 может обрабатывать оцифрованную вокализацию для извлечения вероятных слов-кандидатов, содержащихся в вокализации. Это обычно осуществляется путем выполнения модуля распознавания речи или языковой обработки, содержащегося в памяти 104, с использованием процессора 102 для обработки оцифрованной вокализации.
Пользователь использует устройство 110 ввода символов для ввода буквенно-цифровых символов, специальных символов, пробелов и т.д. в качестве текстового ввода в устройство 100. Кроме того, устройство 110 ввода символов можно использовать для выделения, перемещения курсора, прокрутки страницы, навигации по опциям и меню и для осуществления других функций. Хотя устройство 110 ввода символов может представлять собой традиционную клавиатуру, настоящее изобретение наиболее полезно применительно к вычислительным устройствам 100, имеющим ограниченное устройство 110 ввода символов, которое обычно меньше, имеет меньше клавиш и ограничено по своим функциональным возможностям относительно полномасштабных клавиатур. Ввод символов с использованием таких ограниченных устройств 110 ввода символов может быть медленным и сложным.
Ограниченные устройства 110 ввода символов могут принимать много разных форм. Некоторые ограниченные устройства 110 ввода, обычно используемые в КПК, образованы сенсорным дисплеем, например дисплеем 106. Одно такое устройство 110 ввода символов образовано отображением миниатюрной клавиатуры на сенсорном дисплее 106. Пользователь может выбирать нужные символы для ввода текста, касаясь отображаемого символа пером, по аналогии с традиционной клавиатурой. Другое такое устройство 110 ввода символов позволяет пользователям писать символы на дисплее 106 или путем обозначения вводимых символов, каждый из которых отображается на конкретную последовательность нажатий клавиш, которые можно применять к сенсорному дисплею с использованием пера. Когда пользователь обеспечивает ввод текста с использованием устройства 110 ввода символов любого типа, текстовый ввод обеспечивается на дисплее 106.
В мобильных вычислительных устройствах, например мобильных телефонах, используется ограниченное устройство 110 ввода символов в виде числовой клавиатуры. На фиг.2 показана упрощенная схема устройства 100 в виде мобильного телефона 114, которое содержит такую числовую клавиатуру 116, дисплей 106 и микрофон 108. Мобильный телефон 114 может также содержать громкоговоритель 118, антенну 120, а также схему связи в виде приемопередатчика (не показан) и другие компоненты, которые не имеют отношения к настоящему изобретению.
Числовая клавиатура 116 содержит ряд числовых клавиш 122 и другие клавиши. В целом, числовая клавиатура 116 отличается от стандартной клавиатуры тем, что она не имеет уникальной клавиши для каждого символа. Поэтому числовая клавиатура 116 является ограниченным устройством 110 ввода символов. Клавиатура 116 имеет следующие числовые клавиши: клавишу 122A единицы, клавишу 122B двойки, клавишу 122C тройки, клавишу 122D четверки, клавишу 122E пятерки, клавишу 122F шестерки, клавишу 122G семерки, клавишу 122H восьмерки, клавишу 122I девятки и клавишу 122J нуля. Числовая клавиатура 116 также имеет клавишу 122K звездочки (*) и клавишу 122L знака фунта (#). Числовая клавиатура 116 также может иметь другие специализированные клавиши, помимо показанных на фиг.2, или меньше клавиш, чем показано на фиг.2. Клавиши 122 числовой клавиатуры 116 могут быть реальными, физическими клавишами или виртуальными, программируемыми клавишами, отображаемыми на дисплее 106, если дисплей 106 является сенсорным экраном.
Все числовые клавиши 122 числовой клавиатуры 116, за исключением клавиши 122A единицы и клавиши 122J нуля, соответствуют трем или четырем буквам алфавита. Клавиша 122B двойки соответствует буквам A, B и C. Клавиша 122C тройки соответствует буквам D, E и F. Клавиша 122D четверки соответствует буквам G, H и I. Клавиша 122E пятерки соответствует буквам J, K и L. Клавиша 122F шестерки соответствует буквам M, N и O. Клавиша 122G семерки соответствует буквам P, Q, R и S. Клавиша 122H восьмерки соответствует буквам T, U и V. Наконец, клавиша 122I девятки соответствует буквам W, X, Y и Z. Знаки препинания и специальные символы могут быть включены либо в неиспользуемые клавиши, например клавишу 122A единицы, либо также могут быть включены в другие числовые клавиши 122 совместно с буквами. Кроме того, каждую числовую клавишу 122 можно использовать для ввода обозначенного на ней числа или символа.
В мобильных вычислительных устройствах, отвечающих уровню техники, например, мобильных телефонах, используются многоотводные и одноотводные методы для ввода текста в устройство 100. Такие методы могут быть сложными и неэффективными не только потому, что нуждаются в обеспечении, по меньшей мере, одного ввода с использованием клавиш 122 для каждого символа текста. Кроме того, одноотводный метод, которому часто не удается распознать слово, которое пользователь пытается ввести. Например, чтобы ввести слово "hello", один пользователь последовательно нажимает клавишу 122D четверки, клавишу 122C тройки, клавишу 122E пятерки два раза и клавишу 122F шестерки. Поскольку введенная числовая последовательность 43556 может соответствовать другим словам, помимо слова "hello", задуманное слово является неоднозначным. Кроме того, лексикон, используемый устройством, который содержит слова, соответствующие конкретным числовым последовательностям, может не содержать слово, которое пользователю нужно ввести. Это, в общем случае, приводит к ошибке «вне словаря» (OOV), в каковом случае обычно требуется, чтобы пользователь сменил на устройстве режим ввода текста с одноотводного режима на многоотводный режим и повторно ввел нужный текстовый ввод с начала. В результате, пользователь может быть вынужден выполнить значительно больше нажатий числовых клавиш, чем количество букв, содержащихся в слове.
Настоящее изобретение позволяет значительно уменьшить количество нажатий клавиш, которое необходимо для ввода нужного текста в устройство 100, по сравнению со способами, отвечающими уровню техники. Это осуществляется посредством комбинации распознавания речи с пользовательским вводом. Результатом является система ввода текста, которая отличается простотой, эффективностью и точностью. На фиг.3 показана логическая блок-схема, представляющая этапы способа, отвечающего различным вариантам осуществления изобретения. На фиг.4 показана блок-схема иллюстративной системы 128, которую можно использовать для реализации вариантов осуществления способа на устройстве 100. Компоненты системы 128, в целом, соответствуют программным модулям и командам, которые содержатся, например, в памяти 104 и выполняются процессором 102, показанным на фиг.1, для осуществления различных этапов способа.
Когда устройство 100 установлено в режим ввода текста, пользователь обеспечивает первый ввод 130 символа на этапе 132. Первый ввод 130 символа указывает первый символ текстового ввода, который пользователь желает ввести. Например, когда желаемым текстовым вводом является "BERRY", пользователь обеспечивает первый ввод 130 символа, который указывает букву «В».
Первый ввод 130 символа может быть фактическим первым символом текстового ввода, который непосредственно введен пользователем с использованием, например, многоотводного метода на числовой клавиатуре 116 (фиг.2), сенсорном дисплее, традиционной клавиатуре, устройстве 110 ввода другого типа (фиг.1) или другом средстве. Одним недостатком этого варианта осуществления изобретения является то, что ограниченные устройства 110 ввода символов, например, числовая клавиатура 116 может вынуждать пользователя нажимать клавишу 122 несколько раз, чтобы ввести нужный символ, что описано выше.
Первый ввод 130 символа пользователь также может ввести в соответствии с одноотводным методом. Таким образом, для числовой клавиатуры 116, пользователь должен нажать клавишу 122, соответствующую нужному символу, только один раз. Согласно этому варианту осуществления изобретения первый ввод 130 символа представляет «В», а также «А» и «С».
На этапе 134 способа воспринимается вокализация 136 текстового ввода. Для этого пользователь наговаривает в микрофон 108 текстовый ввод, который цифруется АЦП 112 и сохраняется в памяти 104 или иначе обрабатывается процессором 102, в соответствии с традиционными методами распознавания речи. Предпочтительно, вокализация 136 воспринимается после того, как пользователь обеспечивает первый ввод 130 символа.
Восприятие вокализации 136 можно запускать многими разными способами. Предпочтительно, устройство 100 обеспечивает указатель, например, на дисплее 106, информирующий пользователя о начале вокализации текстового ввода. Согласно одному варианту осуществления изобретения этап 134 восприятия начинается, когда пользователь обеспечивает первый ввод 130 символа на этапе 132 способа. Соответственно, для одноотводного метода ввода, нажатие числовой клавиши, соответствующей первому символу текстового ввода, когда устройство 100 находится в режиме ввода текста, начинает этап 134 восприятия. Согласно другому варианту осуществления изобретения, этап 134 восприятия начинается с нажатия и удержания клавиши устройства 110 ввода символов. Это особенно полезно для одноотводного метода, согласно которому для обозначения первого ввода 130 символа нажимают только одну клавишу, но можно реализовать и для многоотводного и других методов ввода текстового ввода. Устройство 100 также может содержать специальную аппаратную или программируемую клавишу, используемую для запуска этапа 134 восприятия.
Согласно другому варианту осуществления изобретения этап 134 восприятия может быть предназначен для исправления ситуаций, когда пользователь начинает говорить прежде, чем нажата клавиша, или прежде, чем обнаружено другое событие, запускающее восприятие вокализации. Один способ решения этого вопроса состоит в непрерывной буферизации нескольких сотен миллисекунд любой вокализации пользователя в памяти 104, когда устройство 100 работает в режиме ввода текста. Буферизованную вокализацию можно использовать для восприятия «фальстарта» вокализации текстового ввода, которая начинается до запускающего события, которую можно включить в состав ввода вокализации 136, который поступает на распознаватель 142 речи (фиг.4) на этапе 134 восприятия.
Этап 134 восприятия может оканчиваться либо по истечении определенного периода времени, либо при отпускании кнопки или клавиши, которую удерживают, чтобы начать восприятие вокализованного текстового ввода. Альтернативно, этап 134 восприятия может оканчиваться после того, как система обнаружит окончание вокализации текстового ввода. По окончании этапа 134 восприятия, устройство 100, предпочтительно, извещает об этом пользователя, например, путем удаления указателя, который был обеспечен в начале этапа 134 восприятия.
Согласно одному варианту осуществления изобретения, текстовый ввод, обеспеченный пользователем, должен быть разбит на отдельные или единичные слова. Соответственно, вокализация 136 текстового ввода соответствует единичному или отдельному слову текстового ввода. Процесс ввода текста путем выбора первого ввода символа и проговаривания или вокализации единичного слова текстового ввода является достаточно естественным при использовании одноотводного метода для ввода первого ввода 130 символа. Кроме того, текстовый ввод из одного слова имеет свои преимущества применительно к мобильному вычислительному устройству. В частности, требуется меньше памяти для анализа вокализации 136 и возможны более точные результаты распознавания речи, что будет рассмотрено ниже.
Согласно другому варианту осуществления изобретения пользователь обеспечивает текстовый ввод в виде нескольких слов. Ввиду, в общем случае, ограниченной емкости памяти и мощности обработки мобильных вычислительных устройств, длина текстового ввода, предпочтительно, ограничена. Соответственно, пользователю разрешается вводить лишь короткое выражение или предложение. Согласно одному варианту осуществления изобретения, указатель, извещающий пользователя о начале и окончании этапа восприятия, может иметь вид таймера (т.е. таймера обратного отсчета) или отображения линейки, длина которой указывает истекшее время и окончание этапа 134 восприятия. Варианты осуществления настоящего изобретения, предусматривающие ввод одного слова и нескольких слов, первоначально действуют практически одинаково в отношении первого слова текстового ввода и соответствующего первого слова вокализации.
На этапе 138 способа, вероятное слово-кандидат 140 идентифицируется для первого слова вокализации 136 текстового ввода на основании первого ввода 130 символа и анализа вокализации 136. В общем случае, способ предусматривает сужение списка потенциальных слов-кандидатов для первого слова текстового ввода (режим многословного текстового ввода) или слова текстового ввода (режим единичного или изолированного текстового ввода) посредством исключения слов, которые не удовлетворяют набору критериев, установленных первым вводом 130 символа. Например, когда одноотводный первый ввод 130 символа соответствует нескольким символам, например "ABC", список возможных слов-кандидатов может быть ограничен только теми словами, которые начинаются с "A", "B" или "C". В результате, система 128 устройства 100 может не только обеспечивать более точные результаты, но может обеспечивать результаты значительно быстрее, чем если бы анализировались все потенциальные слова-кандидаты для вокализации 136. Это особенно выгодно для мобильных вычислительных устройств 100, которым недостает мощности обработки, используемой другими вычислительными системами, которые реализуют системы распознавания речи.
Анализ вокализации 136 обычно осуществляется распознавателем 142 речи (фиг.4). Распознаватель 142 речи, в общем случае, осуществляет спектральный анализ цифровых выборок вокализации 136, чтобы идентифицировать список вероятных слов-кандидатов 144 из лексикона или списка вероятных слов-кандидатов 146, которые с наибольшим правдоподобием соответствуют вокализации 136 текстового ввода.
Распознаватель 142 речи может также включать в себя языковую модель 148, которая может повысить точность распознавателя 142 речи. Языковая модель 148 указывает, какие последовательности слов в словаре возможны, или, в целом, предоставляет информацию о правдоподобии различных последовательностей слов. Примерами языковых моделей являются языковые модели 1-граммы, 2-граммы и N-граммы. Языковая модель 1-граммы рассматривает только вероятность отдельного слова, а языковая модель 2-граммы рассматривает предыдущее слово текстового ввода как оказывающее влияние на то, каковым является текущее вокализованное слово текстового ввода. Аналогично, языковые модели 3-граммы, 4-граммы и N-граммы рассматривают два, три или N-1 слов, непосредственно предшествующие нужному текстовому вводу, при определении совпадения с вокализацией 136. Ввиду общего недостатка мощности обработки в мобильных компьютеризированных устройствах 100, может потребоваться ограничение языковой модели 148 языковыми моделями 1- или 2-граммы.
Этап 138 идентификации обычно осуществляется модулем 150 прогнозирования. Согласно одному варианту осуществления изобретения, модуль 150 прогнозирования получает список 144 вероятных слов-кандидатов и ввод 130 символа. Модуль 148 прогнозирования идентифицирует вероятное слово-кандидат 140 из списка 144 вероятных слов-кандидатов на основании первого ввода 130 символа. Модуль 150 прогнозирования, предпочтительно, выбирает в качестве вероятного слова-кандидата 140 слово с наивысшим рангом в списке 144 вероятных слов-кандидатов, имеющих ввод 130 символа в качестве первой буквы.
Согласно другому варианту осуществления изобретения, на этапе 138 идентификации сначала сужают лексикон или список 146 вокализованных слов-кандидатов распознавателя 142 речи с использованием первого ввода 130 символа, что указано пунктирной линией 152 на фиг.4. В результате, список 146 вокализованных слов-кандидатов сокращается до усеченного списка 154 вокализованных слов-кандидатов путем исключения всех вокализованных слов-кандидатов, которые не начинаются с символа или символов, указанных первым вводом 130 символа. Усеченный список 154 вокализованных слов-кандидатов дополнительно сокращается для формирования списка 144 вероятных слов-кандидатов для первого слова вокализации 136 на основании анализа, производимого распознавателем 142 речи. В результате, каждое слово из списка 144 вероятных слов-кандидатов, предоставляемого модулю 150 прогнозирования, начинается с символа или символов, указанных вводом 130 символа. Затем модуль 150 прогнозирования идентифицирует вероятное слово-кандидат 140, которое, предпочтительно, является кандидатом наивысшего ранга в списке 144 вероятных слов-кандидатов.
Другой вариант осуществления этапа 138 идентификации включает в себя осуществление одноотводного анализа первого ввода 130 символа. В общем случае, модуль 150 прогнозирования использует первый ввод 130 символа для сужения лексикона или списка 156 входных слов-кандидатов только до тех слов, первые символы которых соответствуют первому вводу 130 символа. Таким образом, список 156 входных слов-кандидатов сокращается до усеченного списка 158 входных слов-кандидатов для первого слова вокализации 136. Затем модуль 150 прогнозирования сравнивает список 144 вероятных слов-кандидатов, полученный в результате анализа вокализации 136, произведенного распознавателем 142 речи, с усеченным списком 158 входных слов-кандидатов. Затем модуль 150 прогнозирования идентифицирует вероятное слово-кандидат 140 как слово-кандидат, находящееся в списке вокализованных слов-кандидатов и в усеченном списке входных слов-кандидатов. Предпочтительно, модуль 150 прогнозирования выбирает вероятное слово-кандидат 140 как слово, имеющее наивысший ранг в списке 144 вероятных слов-кандидатов, которое имеет совпадение в усеченном списке 158 входных слов-кандидатов.
На окончательном этапе 160 способа вероятное слово-кандидат 140 отображается для пользователя, например, на дисплее 106 устройства 100. Альтернативно, пользователю могут отображаться несколько вероятных слов-кандидатов, удовлетворяющих этапу 138 идентификации. Отображение вероятного слова можно рассматривать как ввод вероятного слова-кандидата в устройство 100 даже, если оно еще не одобрено пользователем.
Отображенное вероятное слово-кандидат 140 затем может быть одобрено для завершения текстового ввода слова или отклонено пользователем. В общем случае, вероятное слово-кандидат 140 одобряется и вводится в качестве текстового ввода в устройство 100 по выбору пользователя. Согласно одному варианту осуществления изобретения, пользователь вводит отображаемое вероятное слово-кандидат 140, нажимая аппаратную или программируемую клавишу на устройстве 100. Согласно одному варианту осуществления изобретения, пользовательский выбор, предпочтительно, осуществляется нажатием одной из клавиш 122 числовой клавиатуры, которые не соответствуют буквенно-числовым символам, например, клавиши 122K звездочки или клавиши 122L знака фунта. Однако, следует понимать, что для ввода отображаемого вероятного слова-кандидата можно использовать многие традиционные способы выбора.
Когда пользователь вводит текст по одному слову и отображенное слово одобрено пользователем и ведено, способ может быть продолжен согласно логической блок-схеме, изображенной на фиг.5. На этапе 162 пользователь обеспечивает второй ввод символа, который указывает первый символ второго текстового ввода. Второй ввод символа может обеспечиваться в соответствии с вышеописанными процедурами обеспечения первого ввода 130 символа. Затем, на этапе 164, вокализация второго текстового ввода воспринимается наподобие описанного выше в отношении этапа 134 (фиг.3). Затем, на этапе 166, идентифицируется вероятное слово-кандидат для вокализации второго текстового ввода на основании второго ввода символа и анализа вокализации второго текстового ввода. Этот этап осуществляется, по существу, таким же образом, как описано выше в отношении этапа 138 способа, представленного на фиг.3. Наконец, вероятное слово-кандидат для вокализации второго текстового ввода отображается на этапе 168. Затем пользователь получает возможность выбрать или отклонить отображаемое вероятное слово-кандидат, согласно описанному выше.
Языковая модель 146 распознавателя 150 речи может учитывать предыдущие слова текстового ввода, чтобы идентифицировать текущее слово, которое пользователь пытается ввести. Соответственно, этап 166 идентификации вероятного слова-кандидата для вокализации второго текстового ввода может также базироваться на ранее введенном вероятном слове-кандидате 140.
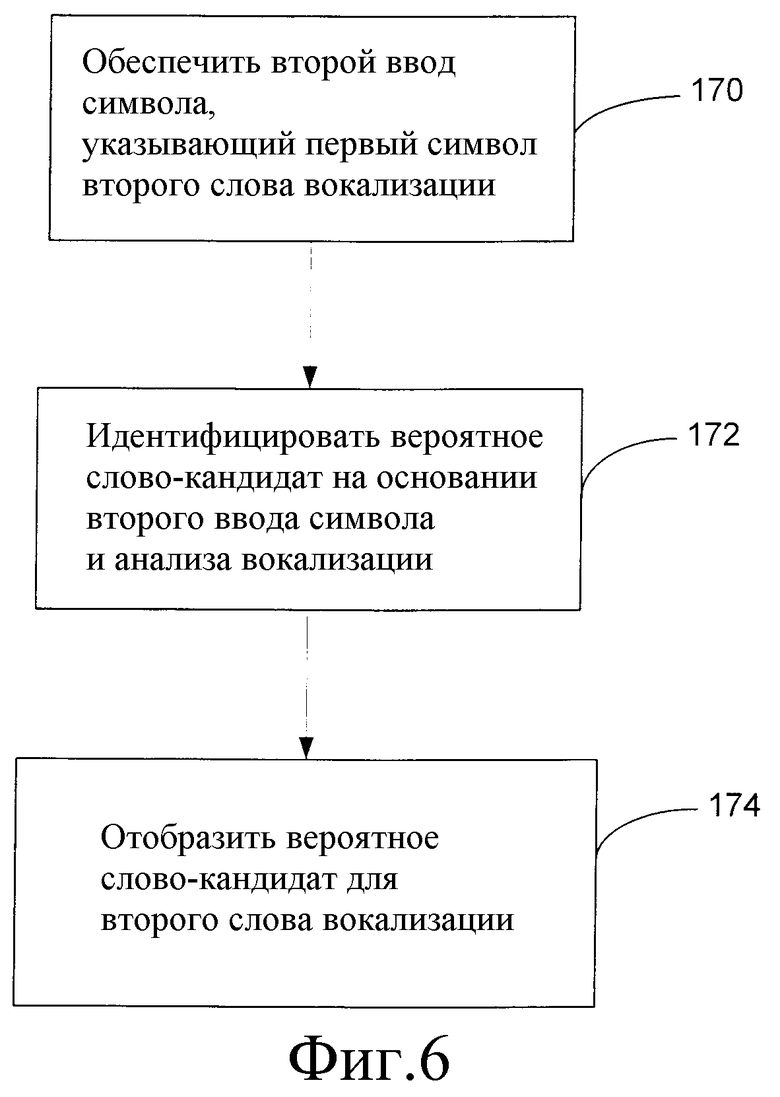
Когда пользователь водит текст в многословном формате, отображаемое вероятное слово одобрено пользователем, и не все слова вокализации 136 идентифицированы, способ может быть продолжен согласно логической блок-схеме, изображенной на фиг.6. На этапе 170 способа обеспечивается второй ввод символа, указывающий первую букву второго слова вокализации 136, воспринятой на этапе 134 способа, представленного на фиг.3. Согласно отмеченному выше, второй ввод символа может быть обеспечен в соответствии с вышеописанными процедурами обеспечения первого ввода 130 символа. Затем, на этапе 172, идентифицируется вероятное слово-кандидат для второго слова вокализации 136 на основании анализа вокализации 136 и второго ввода символа. Затем, на этапе 174, вероятное слово-кандидат отображается пользователю для одобрения или отклонения. Если пользователь одобряет это вероятное слово-кандидат, то способ возвращается к этапу 170 и повторяется, пока не будут идентифицированы слова вокализации 136. Как и выше, этап 172 идентификации вероятного слова-кандидата для второго слова вокализации может дополнительно опираться на ранее введенное вероятное слово-кандидат 140 с использованием соответствующей языковой модели 146 распознавателя 150 речи.
Согласно вышеупомянутому, пользователь также имеет возможность отклонять отображаемое вероятное слово-кандидат 140, обеспечивая соответствующий ввод. Согласно одному варианту осуществления, в устройстве 100 предусмотрена клавиша, нажатие которой приводит к отклонению отображаемого вероятного слова-кандидата 140. Эта клавиша может быть программируемой клавишей или аппаратной клавишей устройства 100. Например, если клавиша 122K звездочки используется для одобрения отображаемого вероятного слова-кандидата 140, то клавишу 122L символа фунта можно использовать для отклонения отображаемого вероятного слова-кандидата. Для отображаемого вероятного слова-кандидата можно также использовать многие другие способы.
Согласно одному варианту осуществления изобретения когда пользователь отклоняет вероятное слово-кандидат, пользователю отображаются одно или несколько альтернативных вероятных слов-кандидатов, которые отвечают критериям этапа 138 идентификации (фиг.3), в соответствии с их рангом. Например, когда нужно ввести слово "BURY", вероятное слово-кандидат 140, отображаемое системой 128, может быть "BERRY". После того как пользователь отклоняет отображаемое вероятное слово, система 128 может отобразить наиболее правдоподобные альтернативы, например, нужное слово "BURY", а также, например, "BARRY". Затем пользователю предоставляется возможность выбрать между отображаемыми альтернативными вероятными словами-кандидатами.
Согласно другому варианту осуществления изобретения отклонение отображаемого вероятного слова-кандидата 140 происходит, когда пользователь обеспечивает второй ввод символа, который указывает второй символ первого слова вокализации 136 нужного текстового ввода. Ввод второго ввода символа можно производить наподобие описанного выше для первого ввода 130 символа. Система 128 устройства 100 размещает одно или несколько альтернативных вероятных слов-кандидатов, удовлетворяющих способу, реализованному на этапе 138 (фиг.3) и имеет первый и второй вводы символов. Затем альтернативные вероятные слова-кандидаты могут отображаться пользователю для выбора или отклонения. Этот процесс может повторяться для ввода третьего и последующих символов текстового ввода.
В случае, если отображаемые альтернативные вероятные слова все же не совпадают со словом текстового ввода, нужного пользователю, режим ввода текста для устройства 100 можно переключить на многоотводный режим, чтобы пользователь мог ввести нужное слово непосредственно в устройство 100.
Хотя настоящее изобретение описано со ссылками на конкретные варианты осуществления, специалисты могут внести изменения, касающиеся формы и деталей, не выходя за рамки сущности и объема изобретения. Кроме того, хотя вышеприведенное описание в основном относится к алфавитным языкам, например английскому, специалистам в данной области очевидно, что принципы данного изобретения также применимы к другим языкам, например, восточно-азиатским, методы ввода которых не основаны на алфавитах.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВВОД ТЕКСТА В ЭЛЕКТРОННОЕ УСТРОЙСТВО СВЯЗИ | 2003 |
|
RU2316040C2 |
| СИСТЕМА УСТРАНЕНИЯ НЕОДНОЗНАЧНОСТИ С УМЕНЬШЕННОЙ КЛАВИАТУРОЙ | 1998 |
|
RU2206118C2 |
| УДОБНЫЙ ДЛЯ ПОЛЬЗОВАТЕЛЯ ВВОД ТЕКСТОВЫХ ЭЛЕМЕНТОВ | 2010 |
|
RU2562364C2 |
| СПОСОБ ВВОДА ДАННЫХ | 2004 |
|
RU2359312C2 |
| ВВОД ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ДВУХ АЛФАВИТОВ И ФУНКЦИЯ ВЫДЕЛЕНИЯ КЛАВИШ | 2010 |
|
RU2525748C2 |
| СИСТЕМА УСТРАНЕНИЯ НЕОДНОЗНАЧНОСТИ С УМЕНЬШЕННОЙ КЛАВИАТУРОЙ | 1998 |
|
RU2214620C2 |
| ПРЕДСКАЗАНИЕ СЛОВА | 2007 |
|
RU2424547C2 |
| БЫСТРЫЕ ЗАДАЧИ ДЛЯ ЭКРАННЫХ КЛАВИАТУР | 2014 |
|
RU2675152C2 |
| АВТОМОБИЛЬНАЯ КОММУНИКАЦИОННО-РАЗВЛЕКАТЕЛЬНАЯ СИСТЕМА | 2015 |
|
RU2690208C2 |
| СПОСОБ АДАПТИВНОГО ВВОДА ТЕКСТОВОЙ ИНФОРМАЦИИ С ИСПОЛЬЗОВАНИЕМ СЕНСОРНЫХ ЭКРАНОВ | 2011 |
|
RU2477878C1 |
Изобретение относится к способу ввода текста в устройство. Изобретение позволяет повысить точность распознавания речи при вокализованном вводе текста в устройство без увеличения вычислительных мощностей устройства. При вводе текста в устройство обеспечивается первый ввод символа путем нажатия и удержания клавиши, указывающий первый символ текстового ввода. Затем воспринимается вокализация текстового ввода. После этого идентифицируется вероятное слово-кандидат для первого слова вокализации на основании первого ввода символа и анализа вокализации. Наконец, вероятное слово-кандидат отображается для пользователя. 2 н. и 37 з.п. ф-лы, 6 ил.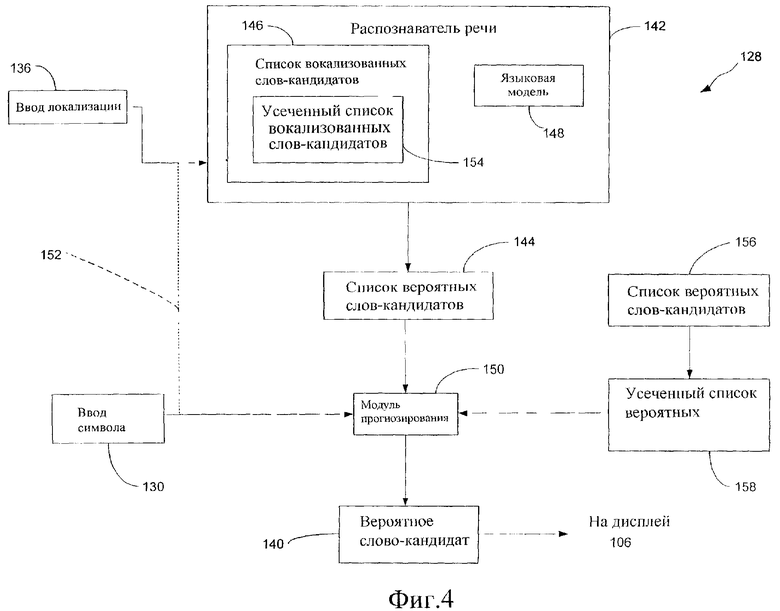
1. Способ ввода текста в устройство, содержащий этапы, на которых
a) обеспечивают путем нажатия и удерживания клавиши первый ввод символа, указывающий первый символ слова текстового ввода,
b) воспринимают вокализацию слова текстового ввода,
c) идентифицируют вероятное слово-кандидат для вокализации на основании первого ввода символа и анализа вокализации и
d) отображают вероятное слово-кандидат.
2. Способ по п.1, по которому этап b) восприятия начинается в результате этапа а) обеспечения.
3. Способ по п.1, по которому этап b) восприятия начинается до этапа а) обеспечения.
4. Способ по п.1, по которому этап b) восприятия заканчивается по истечении определенного периода времени.
5. Способ по п.1, по которому этап b) восприятия заканчивается после обнаружения окончания вокализации.
6. Способ по п.1, по которому на этапе а) обеспечения нажимают клавишу, соответствующую нескольким символам.
7. Способ по п.2, по которому этап b) восприятия заканчивается по истечении определенного периода времени.
8. Способ по п.1, по которому этап b) восприятия заканчивается, когда отпускают клавишу.
9. Способ по п.1, по которому на этапе с) идентификации обеспечивают список вероятных слов-кандидатов на основании анализа вокализации, и
идентифицируют вероятное слово-кандидат из списка вероятных слов-кандидатов для вокализации на основании первого ввода символа.
10. Способ по п.9, который содержит следующие этапы:
отклоняют вероятное слово-кандидат в соответствии со вводом пользователя, и
отображают альтернативное вероятное слово-кандидат из списка вероятных слов-кандидатов.
11. Способ по п.1, по которому на этапе с) идентификации
сужают список вокализованных слов-кандидатов с использованием первого ввода символа для формирования усеченного списка вокализованных слов-кандидатов,
сужают усеченный список вокализованных слов-кандидатов до списка вероятных слов-кандидатов для вокализации на основании анализа вокализации, и
идентифицируют вероятное слово-кандидат из списка вероятных слов-кандидатов.
12. Способ по п.11, который также содержит этапы
отклоняют вероятное слово-кандидат в соответствии со вводом пользователя, и
отображают альтернативное вероятное слово-кандидат из списка вероятных слов-кандидатов.
13. Способ по п.1, по которому на этапе с) идентификации
анализируют вокализацию для создания списка вокализованных слов-кандидатов,
сужают список входных слов-кандидатов с использованием первого ввода символа для формирования усеченного списка входных слов-кандидатов для вокализации, сравнивают список вокализованных слов-кандидатов с усеченным списком входных слов-кандидатов, и
идентифицируют вероятное слово-кандидат как слово-кандидат, находящееся в списке вокализованных слов-кандидатов и усеченном списке входных слов-кандидатов.
14. Способ по п.13, который также содержит этапы:
отклоняют вероятное слово-кандидат в соответствии со вводом пользователя, и
отображают альтернативное вероятное слово-кандидат, которое находится в списке вокализованных слов-кандидатов и усеченном списке входных слов-кандидатов.
15. Способ по п.1, содержащий этап, на котором обеспечивают второй ввод символа, указывающий второй символ слова текстового ввода, причем вероятное слово-кандидат, идентифицированное на этапе с), основано на первом и втором вводах символа и анализе вокализации.
16. Способ по п.1, содержащий этап, на котором вводят вероятное слово-кандидат в соответствии с выбором пользователя.
17. Способ по п.16, который содержит следующие этапы:
обеспечивают второй ввод символа, указывающий первый символ второго слова текстового ввода,
воспринимают вокализацию второго слова текстового ввода,
идентифицируют вероятное слово-кандидат для вокализации второго слова текстового ввода на основании второго ввода символа и анализа вокализации второго слова текстового ввода, и
отображают вероятное слово-кандидат для вокализации второго слова текстового ввода.
18. Способ по п.17, по которому этап идентификации вероятного слова-кандидата для вокализации второго слова текстового ввода дополнительно основывается на введенном вероятном слове-кандидате.
19. Способ ввода текста в устройство, содержащий этапы, на которых
a) обеспечивают первый ввод символа, указывающий первый символ текстового ввода, причем непрерывно буферизируют любую вокализацию пользователя в памяти, пока упомянутое устройство находится в режиме ввода текста,
b) воспринимают вокализацию текстового ввода,
c) идентифицируют вероятное слово-кандидат для первого слова вокализации на основании первого ввода символа и анализа вокализации, и
d) отображают вероятное слово-кандидат.
20. Способ по п.19, по которому текстовый ввод состоит из одного слова.
21. Способ по п.19, по которому текстовый ввод состоит из нескольких слов.
22. Способ по п.19, по которому этап b) восприятия начинается в результате этапа а) обеспечения.
23. Способ по п.22, по которому этап b) восприятия заканчивается по истечении определенного периода времени.
24. Способ по п.19, по которому на этапе а) обеспечения нажимают клавишу, соответствующую нескольким символам.
25. Способ по п.19, по которому на этапе а) обеспечения нажимают и удерживают клавишу, и этап b) восприятия начинается в результате этапа а) обеспечения.
26. Способ по п.25, по которому этап b) восприятия заканчивается по истечении определенного периода времени.
27. Способ по п.25, по которому этап b) восприятия заканчивается, когда отпускают клавишу.
28. Способ по п.19, по которому на этапе с) идентификации обеспечивают список вероятных слов-кандидатов на основании анализа вокализации, и
идентифицируют вероятное слово-кандидат из списка вероятных слов-кандидатов для первого слова вокализации на основании первого ввода символа.
29. Способ по п.28, который содержит следующие этапы:
отклоняют вероятное слово-кандидат в соответствии со вводом пользователя, и
отображают альтернативное вероятное слово-кандидат из списка вероятных слов-кандидатов.
30. Способ по п.19, по которому на этапе с) идентификации сужают список вокализованных слов-кандидатов с использованием первого ввода символа для формирования усеченного списка вокализованных слов-кандидатов,
сужают усеченный список вокализованных слов-кандидатов для формирования списка вероятных слов-кандидатов для первого слова вокализации на основании анализа вокализации, и идентифицируют вероятное слово-кандидат из списка вероятных слов-кандидатов.
31. Способ по п.30, который содержит следующие этапы:
отклоняют вероятное слово-кандидат в соответствии со вводом пользователя, и
отображают альтернативное вероятное слово-кандидат из списка вероятных слов-кандидатов.
32. Способ по п.19, по которому на этапе с) идентификации анализируют вокализацию для создания списка вокализованных слов-кандидатов,
сужают список входных слов-кандидатов с использованием первого ввода символа для формирования усеченного списка входных слов-кандидатов для первого слова вокализации,
сравнивают список вокализованных слов-кандидатов с усеченным списком входных слов-кандидатов, и
идентифицируют вероятное слово-кандидат как слово-кандидат, находящееся в списке вокализованных слов-кандидатов и усеченном списке входных слов-кандидатов.
33. Способ по п.32, который содержит следующие этапы:
отклоняют вероятное слово-кандидат в соответствии со вводом пользователя, и
отображают альтернативное вероятное слово-кандидат, которое находится в списке вокализованных слов-кандидатов и усеченном списке входных слов-кандидатов.
34. Способ по п.19, содержащий этап, на котором обеспечивают второй ввод символа, указывающий второй символ текстового ввода, причем вероятное слово-кандидат, идентифицированное на этапе с), основано на первом и втором вводах символа и анализе вокализации.
35. Способ по п.19, содержащий этап, на котором вводят вероятное слово-кандидат в соответствии с выбором пользователя.
36. Способ по п.35, который содержит следующие этапы:
обеспечивают второй ввод символа, указывающий первый символ второго текстового ввода,
воспринимают вокализацию второго текстового ввода,
идентифицируют вероятное слово-кандидат для вокализации второго текстового ввода на основании второго ввода символа и анализа вокализации второго текстового ввода, и
отображают вероятное слово-кандидат для вокализации второго текстового ввода.
37. Способ по п.36, по которому этап идентификации вероятного слова-кандидата для вокализации второго текстового ввода дополнительно основывается на введенном вероятном слове-кандидате.
38. Способ по п.35, который содержит следующие этапы:
обеспечивают второй ввод символа, указывающий первый символ второго слова вокализации,
идентифицируют вероятное слово-кандидат для второго слова вокализации на основании второго ввода символа и анализа вокализации, и
отображают вероятное слово-кандидат для второго слова вокализации.
39. Способ по п.38, по которому этап идентификации вероятного слова-кандидата для второго слова вокализации дополнительно основывается на введенном вероятном слове-кандидате.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| RU 99144600 A, 10.06.2001 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |

