Область техники
Изобретение относится к системам с уменьшенной клавиатурой и, более конкретно, к системам с уменьшенной клавиатурой, использующим устранение неоднозначности на уровне слов для различения неоднозначного нажатия клавиши.
Предшествующий уровень техники
В течение многих лет габариты портативных компьютеров постоянно уменьшаются. Основным компонентом, ограничивающим размеры портативного компьютера, является клавиатура. Если используются стандартные клавиши размера пишущей машинки, то портативный компьютер должен быть, по меньшей мере, такого же размера, как клавиатура. В портативных компьютерах использовались миниатюрные клавиатуры, но оказалось, что клавиши миниатюрной клавиатуры слишком малы и не обеспечивают простоту и легкость обращения с ними пользователя.
Введение в портативный компьютер полноразмерной клавиатуры также препятствует истинному портативному использованию компьютера. Чтобы пользователь мог печатать обеими руками, большинство портативных компьютеров требуют их размещения на плоской рабочей поверхности. Пользователь не может без труда использовать портативный компьютер в положении стоя или при перемещении. В малых портативных компьютерах последнего поколения, называемых персональными цифровыми ассистентами (ПЦА), компании попытались решить эту проблему посредством внедрения в ПЦА программного обеспечения распознавания рукописных текстов. Пользователь может вводить текст непосредственно, записывая его на сенсорной панели или экране. Затем этот рукописный текст преобразуется в цифровые данные с помощью программного обеспечения распознавания. К сожалению, кроме того факта, что печатание или запись авторучкой в основном медленнее, чем набор на клавиатуре, точность и скорость программного обеспечения распознавания рукописных текстов до сих пор являются не очень удовлетворительными. Современные портативные вычислительные устройства, в которых требуется ввод текста, становятся все меньше, что усугубляет положение. Последние достижения в двусторонней передаче сигналов систем поискового вызова, сотовых телефонах и других портативных беспроводных технологиях привели к спросу на малые и портативные системы двусторонней передачи сообщений, в особенности на системы, которые могут как посылать, так и принимать электронную почту.
Следовательно, было бы выгодно разработать клавиатуру для введения текста в компьютер малогабаритной и пригодной для работы одной рукой, в то время как другой рукой пользователь может держать компьютер. В предшествующих разработках рассматривалось использование клавиатуры с уменьшенным числом клавиш. Многие из уменьшенных клавиатур используют массив клавиш 3 на 4, что определяется компоновкой малой клавиатуры телефонного аппарата с тональным кнопочным набором. Каждая клавиша в массиве клавиш содержит множество символов. Следовательно, когда пользователь осуществляет ввод посредством последовательности нажатий клавиш, имеется неоднозначность, так как каждое нажатие клавиши может указывать одну из нескольких букв. Для устранения неоднозначности в последовательности нажатий клавиш было предложено несколько подходов.
Один из предложенных подходов для однозначного определения символов, вводимых на уменьшенной клавиатуре, требует, чтобы для определения каждой буквы пользователь делал ввод путем нажатия двух или более клавиш. Нажатие клавиш может осуществляться либо одновременно (аккорд), либо последовательно (определение множества нажатий). Ни аккорд, ни определение множества нажатий не привели к созданию клавиатуры, достаточно простой и эффективной в использовании. Определение множества нажатий неэффективно, а аккорд является сложным для его освоения и использования.
Другие предложенные подходы для определения правильной последовательности символов, которая соответствует неоднозначной последовательности нажатий клавиш, обобщаются в статье John L. Arnott, Muhammad Y. Javad "Probabilistic Character Disambiguation for Reduced Keyboards Using Small Text Samples", Journal of the International Society for Augmentative and Alternative Communication (в дальнейшем упоминаемую, как "статья Arnott"). В статье Arnott отмечается, что для различения неоднозначности символов в данном контексте большинство подходов устранения неоднозначности использует известную статистику последовательностей символов в соответствующем языке. То есть, для определения соответствующей интерпретации нажатия клавиш существующие системы устранения неоднозначности статистически анализируют неоднозначные группирования нажатий клавиш по мере их ввода пользователем. В статье Arnott также отмечается, что для декодирования текста, вводимого с уменьшенной клавиатуры, ряд систем устранения неоднозначности пытались использовать устранение неоднозначности на уровне слов. Устранение неоднозначности на уровне слов распознает целые слова посредством сравнения последовательности принятых нажатий клавиш с возможными согласованиями в словаре после приема однозначного символа, определяющего конец слова. В статье Arnott обсуждаются многие из недостатков устранения неоднозначности на уровне слов. Например, устранение неоднозначности на уровне слов часто не обеспечивает корректное декодирование слова вследствие ограничений в идентификации необычных слов и неспособности декодировать слова, которые не содержатся в словаре. Из-за ограничений декодирования устранение неоднозначности на уровне слов не обеспечивает безошибочного декодирования неадаптированного английского текста с эффективностью, характеризуемой одним нажатием клавиши на один символ. Следовательно, статья Arnott скорее концентрирует внимание на устранении неоднозначности на уровне символов, чем на устранении неоднозначности на уровне слов, и показывает, что устранение неоднозначности на уровне символов оказывается наиболее многообещающим методом устранения неоднозначности.
Еще один предложенный метод, основанный на устранении неоднозначности на уровне слов, раскрывается в учебнике I.H. Witten, Principles of Computer Speech, Academic Press, 1982 г. (в дальнейшем "метод Witten"). Witten обсуждает систему для уменьшения неоднозначности введенного текста, используя телефонную сенсорную панель. Witten признает, что приблизительно для 92% слов в словаре из 24500 слов неоднозначность не возникнет при сравнении последовательности нажатий клавиш со словарем. Однако Witten отмечает, что при возникновении неоднозначностей они должны быть расшифрованы в интерактивном режиме системой, представляющей неоднозначность пользователю и предлагающей ему сделать выбор между некоторым числом неоднозначных элементов данных. Следовательно, пользователь должен ответить на предсказание, сделанное системой в конце каждого слова. Такой ответ замедляет эффективное использование системы и увеличивает число нажатий клавиш, требуемое для ввода заданного сегмента текста.
Для достижения необходимой эффективности уменьшенной клавиатуры с устранением неоднозначности, приемлемой для использования в портативном компьютере, значительные усилия были посвящены уменьшению числа нажатий клавиш, требуемого для ввода сегмента текста. Одной из существенных проблем, требующих решения, является успешная реализация устранения неоднозначности на уровне слов на тех видах платформ аппаратных средств, на которых это использование является наиболее выгодным. Как упомянуто выше, такие устройства включают пейджеры двустороннего действия, сотовые телефоны и другие портативные беспроводные устройства связи. Эти системы питаются от батареек и, следовательно, конструируются как можно более экономичными с точки зрения конструкции аппаратных средств и использования ресурсов. Прикладные программы, исполняемые в таких системах, должны минимизировать как использование рабочей полосы частот процессора, так и требования к объему памяти. Эти два фактора вообще имеют тенденцию взаимно обратного отношения друг к другу. Поэтому системы устранения неоднозначности на уровне слов для того, чтобы обеспечить удовлетворительный интерфейс пользователя, требуют большую базу данных используемых слов и должны быстро реагировать на ввод посредством нажатия клавиш. Другая проблема представляет собой сжатие требуемой базы данных без значительного влияния на время обработки, требуемое для ее использования.
Еще одна проблема в устранении неоднозначности на уровне слов заключается в предоставлении пользователю достаточной обратной связи при вводе нажатием клавиш. При использовании обычной пишущей машинки или текстового процессора каждое нажатие клавиши представляет уникальный символ, который может быть показан пользователю сразу при вводе. Но при устранении неоднозначности на уровне слов это часто бывает невозможно, так как каждое нажатие клавиши представляет многие символы, и любая последовательность нажатий клавиш может соответствовать многим словам или корням слов. Проблема возникает особенно тогда, когда пользователь делает орфографическую ошибку или ошибку нажатия клавиши, поскольку в этом случае пользователь не может точно знать, что произошла ошибка, пока не будет введена вся последовательность клавиш, а желательное слово не появится.
Система устранения неоднозначности на уровне слов, направленная на решение вышеупомянутых проблем, раскрыта в заявке PCT/US 96/12291, опубликованной 13 февраля 1997 г. в виде международной публикации WO 97/05541.
Система, раскрытая в публикации WO 97/05541, содержит клавиатуру, в которой множество букв и символов присваивается по меньшей мере нескольким клавишам; память для запоминания одного или более словарных модулей; дисплей для представления текстовых выходных данных системы и процессор, оперативно соединенный с клавиатурой, памятью и дисплеем. Слова и корни слов (последовательности букв, которые соответствуют началу слова) запоминаются в словарных модулях с использованием древовидной структуры, которая включает в себя множество взаимосвязанных узлов.
При работе системы устранения неоднозначности на уровне слов, раскрытой в публикации WO 97/05541, когда пользователь осуществляет ввод посредством последовательности нажатий клавиш, системный процессор получает доступ к системной памяти для построения слов и корней слов, которые соответствуют введенной последовательности нажатий клавиш. В частности, каждая введенная последовательность нажатий клавиш соответствует узлу древовидной структуры словарного модуля, который, в свою очередь, соответствует корню слова или слову. При вводе посредством дополнительного нажатия клавиш системный процессор формирует новый набор одного или более корней слов и/или слов, объединяя набор слов и/или корней слов, ассоциированный с предшествующей последовательностью нажатий клавиш (то есть последовательностью нажатий клавиш, которая не содержит последнее нажатие клавиши). В контексте древовидной структуры памяти набор одного или более корней слов и/или предполагаемых слов получается посредством обращения к словам и/или корням слов, ассоциированным с узлами древовидной структуры, которые взаимосвязаны с узлами, представляющими предшествующую последовательность нажатий клавиш и, кроме того, представляющими все возможные корни слов и слова, которые соответствуют полной последовательности нажатий клавиш.
В соответствии с публикацией WO 97/05541 слова и корни слов представляются в устройстве отображения системы в соответствии с частотой использования, ассоциированной с отображаемыми словами и корнями слов. Когда отображается список предполагаемых слов, пользователь системы использует указанную клавишу клавиатуры для выбора желательного предполагаемого слова.
Сущность изобретения
Настоящее изобретение обеспечивает уменьшенную клавиатуру, которая для различения неоднозначности нажатия клавиш использует устранение неоднозначности на уровне слов. В одном из вариантов осуществления система включает в себя индикаторную панель, которая является сенсорной, в которой контакт с поверхностью индикаторной панели генерирует сигналы ввода в систему соответственно местоположению контакта. Альтернативно, клавиатура может быть построена с полноразмерными механическими клавишами.
В одном предпочтительном варианте осуществления девять клавиш с символами и буквами сгруппированы в матрицу размерностью три на три, наряду с дополнительными клавишами специальных функций количеством от трех до шести. Множество букв и символов присваивается некоторым из клавиш, так что нажатие на эти клавиши (в дальнейшем "клавиши данных") является неоднозначным. Пользователь может осуществлять ввод посредством последовательности нажатий клавиш, в которой каждое нажатие клавиши соответствует введению одной буквы из слова. Вследствие того, что отдельное нажатие клавиши неоднозначно, последовательность нажатий клавиш может потенциально соответствовать более чем одному слову с таким же числом букв. Последовательность нажатий клавиш обрабатывается посредством словарных модулей, которые приводят ее в соответствие с соответствующими хранимыми в памяти словами или другими интерпретациями. При приеме каждого нажатия клавиши пользователю представляются на дисплее в списке выбора слова и корни слов, которые соответствуют последовательности нажатий клавиш.
В соответствии с одним из аспектов изобретения одной из клавиш присваивается набор знаков препинания. В предпочтительном варианте воплощения одной из клавиш присваиваются: точка ".", тире "-" и апостроф " ". Пользователь может нажать один из знаков на клавише посредством одной активизации клавиши на том месте, где находится желательный знак препинания. Вследствие того, что этой клавише присваивается набор знаков препинания, нажатие клавиши неоднозначно. Из предшествующего и последующего нажатия клавиши система настоящего изобретения определяет, какой нужен знак препинания, и создает его автоматически. Можно также обеспечить пользователю в списке выбора альтернативные интерпретации последовательности нажатий клавиш.
Предпочтительно интерпретации слов представлены в порядке уменьшения частоты использования, при этом сначала представляются наиболее часто используемые слова. Нужные элементы в списке выбора выбираются посредством нажатия клавиши "Select" (выбор) один или более раз. Нажатие клавиши может быть "отменено" посредством нажатия клавиши "Backspace" (возврат на один шаг).
Чтобы разграничить введенную последовательность нажатий клавиш, пользователь нажимает клавишу "Select" (выбор). После приема клавиши "Select" (выбор) система устранения неоднозначности выбирает наиболее часто используемое слово и добавляет слово к формируемому предложению. Клавиша "Select" (выбор) используется для того, чтобы разграничить введенную последовательность нажатий клавиш. Для создания знака пробела, а также для разграничения введенной последовательности нажатий клавиш используется отдельная однозначная клавиша "Space" (пробел). В одном из предпочтительных вариантов осуществления клавиша "Select" (выбор) "дополнительно нагружается" второй функцией, согласно которой она служит для того, чтобы создавать пробел после выбранного слова, то есть система устранения неоднозначности с уменьшенной клавиатурой автоматически вставляет соответствующий интервал между словами.
Клавиша "Select" (выбор) также используется для того, чтобы выбирать используемые реже обычного слова из списка выбора, представляемого пользователю. Если слово, представленное пользователю в начале списка выбора, не является желательным словом, то пользователь снова нажимает клавишу "Select" (выбор) для того, чтобы перейти от наиболее часто используемого слова ко второму по частоте использования слову и потом снова перейти к третьему по частоте использования слову и так далее. Этот вариант осуществления системы устранения неоднозначности с уменьшенной клавиатурой не имеет специальной клавиши "выполнить" или "принять", действующей на элемент данных сразу после его выбора. Как только желательное слово выбрано пользователем, оно автоматически "принимается" для вывода и добавляется к предложению, составляемому после приема следующего нажатия клавиши символа или знака.
Лингвистическая база данных, которая используется для устранения неоднозначности нажатия клавиш, включает в себя информацию, которая позволяет системе в качестве первого объекта представлять объект слова или корня слова, которое, хотя и не является наиболее частым словом, ассоциированным с узлом, соответствующим текущей последовательности нажатий клавиш, зато образует корень более длинного слова или множества слов, полная частота использования которых больше частоты использования наиболее частого слова, ассоциированного с текущим узлом. Эта особенность "продвижения корня" особенно полезна в системах с ограниченной площадью отображения, в которых список выбора фактически не может быть отображен на экране, и пользователь может видеть только слово, отображаемое в точке вставки, являющееся первым объектом из списка выбора. Результат состоит в том, что объект как целое имеет тенденцию изменяться между нажатиями клавиши намного менее часто, что обеспечивает интерфейс с меньшей степенью "переходов", т.е. такой интерфейс в меньшей степени отвлекает внимание и в меньшей степени вводит в заблуждение.
Такие объекты, как слова и корни слов, запоминаются в одном или более словарных модулях, использующих древовидную структуру. В такой конфигурации слова, соответствующие конкретной последовательности нажатий клавиш, формируются с использованием набора слов и корней слов, ассоциированных с непосредственно предшествующей последовательностью нажатий клавиш (то есть конкретная последовательность нажатий клавиш без последнего нажатия клавиши). Формирование слов таким образом уменьшает объем памяти словарного модуля, поскольку корни слов запоминаются только однажды, наверху древовидной структуры, и совместно используются всеми словами, построенными из них. Древовидная структура также существенно уменьшает требования обработки, поскольку для локализации хранимых объектов не требуется никакого поиска. Слова и корни слов, хранимые в древовидной структуре данных, могут содержать информацию о частоте или о другом критерии приоритета, которые указывают, какой элемент должен быть первым показан пользователю, таким образом, дополнительно снижая требования к обработке. При практическом использовании изобретения древовидная структура данных изменяется с помощью специального алгоритма, который дополнительно сжимает полный объем, требуемый для базы данных, при этом не создавая дополнительных процедур обработки, когда он используется для поиска объектов, ассоциированных с последовательностями нажатий клавиш. Дополнительный аспект модифицированной древовидной структуры представляет собой автоматическую идентификацию обобщенных правил для привязки объектов к последовательностям нажатий клавиш. С помощью таких правил словарный модуль может с высокой вероятностью успеха связывать последовательности нажатий клавиш с такими элементами, как слова и корни слов, которые первоначально не использовались при создании этого словарного модуля.
Внутреннее, логическое представление клавиш в предпочтительном варианте осуществления не должно зеркально отражать физическую конфигурацию, представленную метками на действительных клавишах. Например, в базе данных, сформированной для представления словарного модуля на основе французского словаря, три дополнительных символа (АСА) могут быть ассоциированы с клавишей АВС, которая ассоциирована с безударными версиями символов. Это позволяет пользователю вспоминать и набирать на клавиатуре слова, содержащие специальные ударные символы, выполняя только одну активизацию клавиши, приходящуюся на один символ, просто активизируя логически связанную действительную клавишу для соответствующего ударного символа.
Объединение следующих эффектов: присвоение многих букв клавишам, разграничение слов с помощью клавиши "Select" (выбор), представление наиболее часто встречающегося слова или корня слова в качестве первого слова в списке выбора, включение в список выбора многих интерпретаций, автоматическое добавление к предложению выбранного слова посредством первого нажатия клавиши следующего слова, автоматическое добавление пробелов, возможность сжатия большой базы данных для устранения неоднозначности без существенного ущерба обработке, возможность формирования слов, содержащих специальные ударные знаки, посредством нажатия клавиши, ассоциированной с безударной версией буквы, и возможность автоматического устранения неоднозначности между множеством знаков препинания, присвоенных одной клавише с учетом контекста нажатия клавиши - дает удивительный результат: для многих языков почти 99% слов, найденных в характерной совокупности текстового материала, может быть набрано на клавиатуре системы с чрезвычайно высокой эффективностью. Приблизительно для 95% этих слов для ввода слова в системе устранения неоднозначности с уменьшенной клавиатурой требуется то же самое число нажатий клавиш, что и для введения слова с обычной клавиатурой. Если слова включают ударные знаки, введение слова может обеспечиваться с меньшим количеством нажатий клавиш, чем с обычной клавиатурой. Если слова представляются в порядке частоты использования, желательное слово наиболее часто является первым представляемым словом и зачастую единственным представляемым словом. Затем пользователь может продолжать вводить следующее слово с числом нажатий клавиш не больше обычного. Следовательно, при использовании клавиатуры, имеющей малое число полноразмерных клавиш, достигается высокоскоростное введение текста.
Заявленная система устранения неоднозначности с уменьшенной клавиатурой позволяет уменьшить габариты компьютера или другого устройства, которое включает в себя эту систему. Уменьшенное число клавиш позволяет создать устройство, которое пользователь может держать одной рукой, при этом работая другой рукой. Заявленная система выгодна, в частности, для использования с персональными цифровыми ассистентами (ПЦА), пейджерами с двусторонней связью или другими малогабаритными электронными устройствами, для которых принципиально важным является точный высокоскоростной ввод текста. Система эффективно сжимает большую базу данных для устранения неоднозначности последовательностей нажатий клавиш, не требуя дополнительной ширины полосы обработки при использовании сжатой базы данных. Система может обеспечивать эффективность и простоту при реализации на основе устройства с сенсорным экраном или устройства с ограниченным числом механических клавиш, которые также могут иметь ограниченную площадь экрана дисплея.
Краткое описание чертежей
В дальнейшем изобретение поясняется описанием конкретных вариантов его осуществления со ссылками на чертежи, на которых представлено следующее:
фиг. 1 - схематичное представление предпочтительного варианта осуществления портативного компьютера, включающего систему устранения неоднозначности с уменьшенной клавиатурой согласно настоящему изобретению,
фиг.2 - блок-схема аппаратных средств системы устранения неоднозначности с уменьшенной клавиатурой по фиг.1,
фиг.3А-3В - блок-схема предпочтительного варианта осуществления программного обеспечения устранения неоднозначности для системы устранения неоднозначности с уменьшенной клавиатурой,
фиг.4 - блок-схема предпочтительного варианта осуществления программного обеспечения для определения того, какой текстовой объект должен использоваться как объект по умолчанию в каждом узле древовидной структуры данных для системы устранения неоднозначности с уменьшенной клавиатурой,
фиг. 5А-5Г - блок-схема предпочтительного варианта осуществления процедуры программного обеспечения, выполняемой при каждом нажатии клавиши для устранения неоднозначности нужного знака препинания среди множества знаков препинания, ассоциированных с клавишей, для системы устранения неоднозначности с уменьшенной клавиатурой, фиг. 5А-5В изображают обработку, выполняемую после первоначального приема нажатия клавиши, и фиг.5Г изображает обработку, выполняемую после того, как была закончена вся остальная обработка нажатий клавиш,
фиг.6 сравнивает физическую связь символов с клавишами с примером логической связи, включающей дополнительные ударные версии знаков на действительной клавише,
фиг. 7 - пример таблицы, связывающей логические символы с индексами клавиш,
фиг. 8А - предпочтительная внутренняя конфигурация данных в узле дерева словарного модуля;
фиг.8Б - семантические компоненты предпочтительного варианта осуществления инструкции,
фиг.9 - четыре примера возможных внутренних элементов данных в структуре узлов в предпочтительном варианте осуществления,
фиг. 10 - предпочтительная древовидная структура несжатого словарного модуля,
фиг.11 - пример состояния списков объектов, которые являются предпочтительным вариантом осуществления для промежуточного хранения объектов в процессе извлечения из словарных модулей,
фиг. 12 - блок-схема предпочтительного варианта осуществления процесса программного обеспечения для извлечения текстовых объектов из словарного модуля при наличии списка нажатий клавиш,
фиг. 13 - блок-схема предпочтительного варианта осуществления процесса программного обеспечения для перехода по древовидной структуре словарного модуля при одном нажатии клавиши и изменения состояния списков объектов,
фиг. 14 - блок-схема предпочтительного варианта осуществления процесса программного обеспечения для формирования свернутого, сжатого словарного модуля,
фиг. 15 - блок-схема предпочтительного варианта осуществления процесса программного обеспечения для сворачивания древовидной структуры данных словарного модуля,
фиг. 16 - блок-схема предпочтительного варианта осуществления процесса программного обеспечения для определения местоположения второго узла в дереве словарного модуля, который имеет наибольшую избыточность по сравнению с данным узлом,
фиг. 17 - блок-схема предпочтительного варианта осуществления процесса программного обеспечения для вычисления избыточности между двумя узлами дерева в словарном модуле,
фиг.18А-18К - схематичные представления предпочтительного варианта осуществления системы устранения неоднозначности с уменьшенной клавиатурой при характерном использовании.
Подробное описание предпочтительных вариантов осуществления
I. Конструкция системы и основной принцип действия
На фиг.1 изображена система 50 устранения неоднозначности с уменьшенной клавиатурой, сформированная согласно настоящему изобретению, внедренная в миниатюрный портативный компьютер 52. Портативный компьютер 52 содержит уменьшенную клавиатуру 54, выполненную на дисплее 53 с сенсорным экраном. Для целей этого применения термин "клавиатура" определяется в широком смысле, включая любое устройство ввода, включающее сенсорный экран, имеющий определенные области для клавиш, дискретные механические клавиши, мембранные клавиши и т. д. Клавиатура 54 имеет уменьшенное число клавиш ввода данных относительно стандарта клавиатуры QWERTY. В одном из предпочтительных вариантов осуществления клавиатура содержит шестнадцать стандартных полноразмерных клавиш, упорядоченных в четыре столбца и четыре строки. Более конкретно, предпочтительная клавиатура содержит девять клавиш 56 данных, упорядоченных в матрицу, размерностью 3 на 3, включая клавишу 63 знаков препинания, левый столбец из трех клавиш 58 системы, включая клавишу 60 "Select" (выбор), клавишу 62 "Shift" (переключение регистра), клавишу 64 "Space" (пробел) и клавишу 65 "Backspace" (возврат на один шаг) в верхней строке 59, предназначенную для отмены предыдущего нажатия клавиши. Верхняя строка 59 клавиш системы также включает три клавиши режима, помеченные "Accent" (ударение), "Numbers" (числа) и "Symbols" (символы), предназначенные для ввода режимов набора ударных символов, чисел и символов соответственно.
Предпочтительная компоновка букв на каждой клавише в клавиатуре 54 изображена на фиг. 1. Фиг.1 также изображает предпочтительную конфигурацию знаков препинания, ассоциированных с клавишей 63 неоднозначных данных в клавиатуре 54, для английского языка.
Данные вводятся в систему устранения неоднозначности посредством нажатий клавиш на уменьшенной клавиатуре 54. Когда пользователь, используя клавиатуру, вводит последовательность нажатий клавиш, текст отображается на дисплее 53 компьютера. Две области на дисплее отводятся для отображения информации пользователю. Верхняя текстовая область 66 отображает текст, вводимый пользователем, и служит в качестве буфера для ввода и редактирования текста. Область 70 списка выбора, расположенная ниже текстовой области, обеспечивает список слов и других интерпретаций, соответствующих последовательности нажатий клавиш, введенной пользователем. Как будет описано ниже более подробно, область 70 списка выбора помогает пользователю различать неоднозначность во введенных нажатиях клавиш. В другом предпочтительном варианте осуществления система может быть выполнена на устройстве с ограниченным пространством отображения и может отображать только текущий выбранный или наиболее вероятный объект слова в точке 88 вставки в создаваемом тексте.
На фиг. 2 представлена блок-схема аппаратных средств системы устранения неоднозначности с уменьшенной клавиатурой. Клавиатура 54 и дисплей 53 соединены с процессором 100 через соответствующие интерфейсы. С процессором также соединен громкоговоритель 102. Процессор 100 принимает входные данные с клавиатуры и управляет выводом на дисплей и в громкоговоритель. Процессор 100 соединен с памятью 104. Память включает в себя комбинацию временных носителей данных, таких как запоминающее устройство с произвольной выборкой (ЗУПВ), и постоянных носителей данных, таких как постоянное запоминающее устройство (ПЗУ), дискеты, жесткие диски или лазерные компакт-диски. Память 104 содержит все подпрограммы программного обеспечения для управления работой системы. Предпочтительно память содержит операционную систему 106, программное обеспечение 108 устранения неоднозначности и ассоциированные словарные модули 110, которые подробно обсуждаются ниже. Дополнительно память может содержать одну или более прикладных программ 112, 114. Примеры прикладных программ включают текстовые процессоры, словари программного обеспечения и переводчики иностранных языков. Также в виде прикладной программы может быть обеспечено программное обеспечение синтеза речи, позволяющее системе устранения неоднозначности с уменьшенной клавиатурой функционировать в качестве средства коммуникации.
Как показано на фиг.1, система 50 устранения неоднозначности с уменьшенной клавиатурой позволяет пользователю быстро вводить текст или другие данные одной рукой. Данные вводятся с помощью клавиш 56 данных. Каждая из клавиш данных имеет множество значений, представленных сверху на клавише множеством букв, чисел и других символов. (Для целей настоящего описания каждая клавиша данных будет идентифицирована символами в центральной строке клавиш данных, например DEF, для идентификации верхней правой клавиши данных. ) Поскольку отдельные клавиши имеют множество значений, последовательности нажатий клавиш неоднозначны относительно их значения. Следовательно, когда пользователь вводит данные, различные интерпретации нажатий клавиш отображаются на разных областях на дисплее для обеспечения пользователю возможности различения любой неоднозначности. В системах с достаточной доступной площадью отображения список 76 выбора из возможных интерпретаций введенной последовательности нажатий клавиш предоставляется пользователю в области 70 списка выбора. Первый элемент 78 данных в списке выбора выбирается как интерпретация по умолчанию и отображается в текстовой области 66 в точке 88 вставки. В предпочтительном варианте осуществления этот элемент данных отображается с помощью рамки из непрерывной линии, очерченной вокруг него в списке 76 выбора и в точке 88 вставки. Форматирование устанавливает визуальную связь между объектом места вставки и списком выбора и означает, что этот объект выбирается косвенно на основании того, что он является наиболее часто встречающимся объектом в текущем списке выбора. Альтернативно, список выбора вообще не обеспечивается, а в точке 88 вставки отображается только объект по умолчанию (объект, который должен был бы отображаться первым в списке выбора перед любой активизацией клавиши "Select" (выбор)) или текущий выбранный объект, если он был явно выбран.
Список 76 выбора из возможных интерпретаций введенных нажатий клавиш может быть упорядочен разными способами. В нормальном режиме работы нажатия клавиш первоначально интерпретируются как введение букв для записи слова по буквам (в дальнейшем "интерпретация слова"). Следовательно, элементы данных 78, 79 и 80 в списке выбора представляют собой слова, которые соответствуют введенной последовательности нажатий клавиш, с элементами данных, упорядоченными так, чтобы наиболее общее слово, соответствующее последовательности нажатий клавиш, было внесено в список первым. Например, как изображено на фиг. 1, пользователем была введена последовательность нажатий клавиш АВС, GHI и DEF. При вводе клавиш одновременно выполняется просмотр словарного модуля для локализации слов, которые имеют соответствие с последовательностями нажатий клавиши. Слова, идентифицированные в словарном модуле, отображаются пользователю в списке 76 выбора. Слова сортируются согласно частоте использования, с наиболее часто используемыми словами, внесенными в список первыми.
При использовании иллюстративной последовательности нажатий клавиш слова "age" (возраст), "aid" (помощь) и "bid" (предложение) были идентифицированы в словарном модуле как являющиеся наиболее вероятными словами, соответствующими последовательности нажатий клавиш. Из трех идентифицированных слов слово "age" (возраст) используется более часто, чем слова "aid" (помощь) или "bid" (предложение), так что оно в списке выбора перечисляется первым. Первое слово также принимается как интерпретация по умолчанию и предварительно выставляется как текст в точке 88 вставки. Перед нажатием клавиши 60 "Select" (выбор) это первое слово, принятое как интерпретация по умолчанию, выставляется в точке 88 вставки и в списке 76 выбора с использованием идентичного форматирования. Например, как на фиг.1, слово появляется в качестве текста в рамке, очерченной непрерывными линиями, которая является достаточно большой, чтобы вместить слово. В системах без достаточной площади отображения, для отображения на экране фактического списка выбора, список потенциально соответствующих слов сохраняется в памяти, сортируется согласно относительной частоте использования соответствующих текстовых объектов.
В предпочтительном варианте осуществления после введения последовательности нажатий клавиш, соответствующей желательному слову, пользователь просто нажимает клавишу 64 "Space" (пробел). Слово по умолчанию (первое слово в списке выбора) сразу выводится в точке вставки, список выбора очищается и пробел сразу выводится в область текста в точке 88 вставки. Альтернативно, чтобы достичь такого же результата, можно использовать любое другое средство, которое в явном виде формирует однозначно определенный знак (например, такое, как режим ввода символов и нажатие клавиши, которая однозначно ассоциирована с одним конкретным знаком в режиме символов), за исключением того, что конкретный однозначно определенный знак (отличный от пробела) присоединяется к выходному слову в точке 88 вставки. Альтернативно, для получения точки, тире или апострофа может быть нажата клавиша 63 знаков препинания, как объясняется ниже.
Если первый элемент данных в списке выбора не является желательной интерпретацией последовательности нажатий клавиш, то пользователь может продвигаться по элементам в списке выбора посредством неоднократного нажатия клавиши 60 "Select" (выбор). Нажатие клавиши "Select" (выбор) повторно отображает первый элемент данных в списке 76 выбора с рамкой вокруг него, очерченной пунктирными линиями, и также повторно отображает первый элемент данных в точке 88 вставки с аналогичной рамкой вокруг него. Концептуально переход от рамки, очерченной сплошной линией, к рамке, очерченной пунктирной линией, показывает, что текст ближе к принятию в создаваемый текст, выбранный в явном виде на основании нажатия пользователем клавиши "Select" (выбор). Если первый элемент данных в списке выбора является желательной интерпретацией последовательности нажатий клавиш, то пользователь продолжает вводить следующее слово, используя клавиши 56 данных. Если клавиша "Select" (выбор) дополнительно нагружается функцией создания пробела, то пробел создается перед вставкой текста для следующего слова. Другими словами, начало следующего слова будет контактировать (последовательно соединяться) с концом текущего слова без промежуточного пробела.
Для каждого нажатия клавиши "Select" (выбор) следующий элемент данных в списке выбора обводится пунктирной рамкой, и копия элемента данных предварительно выставляется как текст в точке вставки (заменяя предварительно выставленное слово) и обводится пунктирной рамкой. Предварительная вставка следующего элемента данных в текстовую область позволяет пользователю сохранять его внимание на текстовой области, не отвлекаясь к списку выбора. По выбору пользователя система может также быть скомпонована таким образом, что, после приема первого нажатия клавиши "Select" (выбор), слово, предварительно выставленное в точке вставки, может растягиваться (вертикально или горизонтально), чтобы показать копию текущего списка выбора. Пользователь может выбирать максимальное число слов, которые будут отображаться в этой копии списка выбора. Альтернативно, пользователю может потребоваться список выбора, всегда отображаемый в точке вставки, даже до первой активизации клавиши "Select" (выбор). Система устранения неоднозначности интерпретирует начало следующего слова (сообщаемое посредством активизации неоднозначной клавиши 56 данных или посредством создания явного однозначного знака) как подтверждение того, что выбранный в настоящее время элемент данных является желательным элементом данных. Следовательно, выбранное слово остается в точке вставки в качестве выбора пользователя, окружающая рамка полностью исчезает и слово повторно отображается в нормальном тексте без специального форматирования.
Если второй элемент данных в списке выбора является желательным словом, то пользователь переходит к вводу следующего слова после двух нажатий клавиши "Select" (выбор), и система устранения неоднозначности автоматически выставляет второй элемент данных в текстовую область, как нормальный текст. Если второй элемент данных не является желательным словом, то пользователь может проверить список выбора и нажимать клавишу "Select" (выбор) желательное число раз для того, чтобы выбрать желательный элемент данных перед тем, как перейти к вводу следующего слова. Когда достигается конец списка выбора, дополнительные нажатия клавиши "Select" (выбор) приводят к сворачиванию списка выбора и присоединяют к списку выбора новые элементы данных. Эти элементы данных наверху списка выбора удаляются из списка, отображаемого пользователю. Элемент данных, выбранный множеством нажатий клавиши "Select" (выбор), автоматически выставляется в текстовую область, когда пользователь нажимает любую клавишу 56 данных, чтобы продолжить ввод текста. Альтернативно, после введения последовательности нажатий клавиш, соответствующей желательному слову, пользователь может выбирать желательное слово из списка выбора, просто прикасаясь к нему. Выбранное слово сразу выводится в место вставки без добавления пробела, и список выбора очищается. Затем пользователь может нажать клавишу "Space" (пробел) для того, чтобы создать пробел, который сразу выводится в текстовую область в точке 88 вставки.
В большинстве случаев введения текста последовательности нажатий клавиш выбираются пользователем как буквы, образующие слово. Однако должно быть понятно, что множество знаков и символов, ассоциированных с каждой клавишей, допускают несколько интерпретаций отдельного нажатия клавиши и последовательностей нажатий клавиш. В предпочтительном варианте системы устранения неоднозначности с уменьшенной клавиатурой различные интерпретации автоматически определяются и отображаются пользователю в одно время, поскольку последовательность нажатий клавиш интерпретируется и отображается пользователю как список слов.
Например, последовательность нажатий клавиш интерпретируется в терминах корней слов, соответствующих возможным подходящим последовательностям букв, которые может вводить пользователь (в дальнейшем "интерпретация корня"). В отличие от интерпретации слов, корни слов являются неполными словами. Указывая возможные интерпретации последних нажатий клавиш, корень слова позволяет пользователю легко подтверждать, что было введено правильное нажатие клавиши, или возобновлять набор с клавиатуры, когда внимание пользователя было отвлечено в середине слова. Как изображено на фиг.1, последовательность нажатий клавиш АВС GHI DEF интерпретировалась как образующая подходящие корни "che" (приводящий к словам "check" (проверка), "cheer" (приветствие) и т. д. ) и "ahe" (приводящий к словам "ahead" (вперед), "аhеm" и т.д.). Следовательно, интерпретации корней обеспечиваются в списке выбора как элементы данных 81 и 82. Предпочтительно интерпретации корней сортируются согласно составной частоте набора всех возможных слов, которые могут быть созданы из каждого корня дополнительным нажатием клавиш данных. Максимальное число и минимальная составная частота таких отображаемых элементов данных могут быть выбраны пользователем или скомпонованы в системе так, чтобы некоторые интерпретации корней могли не отображаться. В текущем примере корни "bif" (приводящий к слову "bifocals" (бифокальные очки)), "cid" (приводящий к слову "cider" (сидр)) и "bie" (приводящий к слову "biennial" (двухлетний)) не отображаются. При внесении интерпретации корня в список выбора корень опускается, если интерпретация корня дублирует слово, которое отображено в списке выбора. Однако, когда корень опускается, слово, соответствующее опускаемому корню, может быть помечено символом для того, чтобы показать, что также имеются более длинные слова, которые имеют это слово в качестве их корня. Интерпретации корней обеспечивают пользователю обратную связь, подтверждая, что для того, чтобы привести к введению желательного слова, было введено правильное нажатие клавиш.
Действие системы устранения неоднозначности с уменьшенной клавиатурой управляется программным обеспечением 108 устранения неоднозначности. В одном из предпочтительных вариантов осуществления системы клавиша "Select" (выбор) "дополнительно нагружается" так, что она исполняет функцию выбора желательного объекта из списка выбора, а также, в подходящем случае, создает явный знак пробела. В таких системах флаг "OverloadSelect" ("дополнительно_расширенный_ выбор") (упомянутый в блоках 164 и 174А) устанавливается истинным (TRUE). В системах с отдельной клавишей "Space" (пробел), заданной для создания явного знака пробела, флаг "OverloadSelect" (дополнительно_расширенный_выбор) устанавливается ложным (FALSE).
На фиг.3 показана блок-схема главной программы программного обеспечения устранения неоднозначности, которая создает список выбора, чтобы помочь пользователю при устранении неоднозначности неоднозначных последовательностей нажатий клавиш. В блоке 150 система ожидает приема нажатия клавиши с клавиатуры 54. После приема нажатия клавиши в блоке 150А система выполняет предварительную обработку, требуемую для клавиши 63 знаков препинания, показанную на фиг.5А, и обсуждаемую подробно ниже. В блоке 151 принятия решения выполняется проверка, чтобы определить, является ли принятое нажатие клавиши клавишей выбора режима. Если да, то в блоке 172 система устанавливает флаг, чтобы показать текущий режим системы. В блоке 173 принятия решения выполняется проверка, чтобы определить, изменился ли режим системы. Если да, то в блоке 171 надписи на клавишах заново очерчиваются, как это необходимо, чтобы отразить текущий режим системы. Если режим системы не изменился или если он изменился и надписи на клавишах после этого были заново очерчены, то главная программа возвращается к блоку 150 и ожидает другого нажатия клавиши.
С другой стороны, если блок 151 принимает решение, что нажатие клавиши не является клавишей выбора режима, то в блоке 152 принятия решения выполняется проверка, чтобы определить, является ли принятое нажатие клавиши клавишей "Select" (выбор). Если нажатие клавиши не является клавишей "Select" (выбор), то в блоке 153 принятия решения выполняется проверка, чтобы определить, находится ли система в специальном режиме явных знаков, таком как режим явных чисел. Если да, то в блоке 166 принятия решения выполняется проверка, чтобы определить, присутствует ли какая-либо предварительно выбранная статья в списке выбора. Если да, то в блоке 167 статья принимается и выводится как нормальный текст. Если предварительно принятая статья не находится в списке выбора или если она есть и уже была принята, тогда в блоке 168 явный знак, соответствующий нажатию клавиши, выводится в текстовую область. Затем, в блоке 169 принятия решения выполняется проверка, чтобы определить, должен ли режим системы автоматически изменяться, как в случае режима Symbols (символы). Если да, то, выполнение программы переходит к блокам 170 и 171, где режим системы возвращается к предыдущему активному режиму, и надписи на клавишах соответственно заново очерчиваются. Затем выполнение программы возвращается к блоку 150.
Если в блоке 153 нет активного режима явных знаков, то в блоке 154 нажатие клавиши добавляется к сохраненной последовательности нажатий клавиш. В блоке 156 объекты, соответствующие последовательности нажатий клавиш, идентифицируются в словарных модулях системы. Словарные модули представляют собой библиотеки объектов, которые ассоциированы с последовательностями нажатий клавиши. Объектом является любая часть сохраненных данных, которые должны быть найдены на основе принятой последовательности нажатий клавиш. Например, объекты в пределах словарных модулей могут включать числа, буквы, слова, корни слов, фразы или функции системы и макросы. Каждый из этих объектов кратко описан в таблице в конце описания.
Хотя выше описаны предпочтительные словарные объекты, должно быть понятно, что могут рассматриваться и другие объекты. Например, графический объект может быть ассоциирован с сохраненным графическим изображением или объект речи может быть ассоциирован с сохраненной частью речи. Также можно предусмотреть объект орфографии, который мог бы связать последовательность нажатий клавиш слов, которые обычно бывают с орфографической ошибкой и ошибками набора, с правильной орфографией слова. Например, слова, которые включают последовательность букв "iе" или "еi", будут появляться в списке слов, даже если нажатие клавиш для этих букв случайно полностью поменялось на противоположное по сравнению с их правильной последовательностью. Чтобы упростить обработку, каждый словарный модуль предпочтительно содержит похожие объекты. Однако должно быть понятно, что различные объекты могут быть смешаны в пределах словарного модуля.
На фиг. 6 изображена типичная схема одной клавиши 540. Внутреннее, логическое представление клавиш в предпочтительном
варианте осуществления не обязательно является зеркальным отражением физической компоновки. Например, 541 является предпочтительным логическим описанием клавиши, ассоциированной с французским словарным модулем. Во французском алфавите требуются три дополнительных символа 542 (ÂÇÀ). Также, символы предпочтительно индексируются рядом чисел 543 в порядке уменьшения частоты их использования во французском лексиконе. В расширительном смысле фиг. 7 изображает предпочтительную таблицу, соотносящую индексы логических символов с индексами клавиш, которые должны использоваться при устранении неоднозначности нажатия клавиш во французских словах.
На фиг.10 изображена типичная схема словарного модуля 110 объектов слов. Для организации объектов в словарном модуле на основе соответствующей последовательности нажатий клавиш используется древовидная структура данных. Как изображено на фиг.10, каждый узел N1, N2,... N9 в дереве словарных модулей представляет конкретную последовательность нажатий клавиш. Узлы в дереве связаны путями Р1, Р2,... Р9. Поскольку в предпочтительном варианте осуществления системы устранения неоднозначности имеется девять неоднозначных клавиш данных, то каждый родительский узел в дереве словарных модулей может быть ассоциирован с девятью дочерними узлами. Узлы, связанные путями, показывают правильные последовательности нажатий клавиш, в то время как отсутствие пути от узла указывает на неверную последовательность нажатий клавиш, то есть ту, которая не соответствует какому-либо сохраненному слову.
Переход по дереву словарных модулей осуществляется на основе принятой последовательности нажатий клавиш. Например, нажатие первой клавиши данных из корневого узла 111 приводит к выборке данных, ассоциированных с первой клавишей из корневого узла 111, и оценивается после прохода пути Р1 к узлу N1. Нажатие девятой клавиши данных после нажатия первой клавиши данных приводит к выборке данных, ассоциированных с девятой клавишей, из корневого узла N1 и оценивается после прохода пути Р19 к узлу N19. Как будет подробно описано ниже, каждый узел связан с множеством объектов, соответствующих последовательности нажатий клавиш. По мере того, как принимается каждое нажатие клавиши, а также обрабатывается соответствующий узел, создается список объектов из объектов, соответствующих последовательности нажатий клавиш. Список объектов из каждого словарного модуля используется главной программой системы устранения неоднозначности для создания списка 76 выбора.
На фиг. 8А показана диаграмма предпочтительной структуры 400 данных, ассоциированной с каждым узлом. Структура данных содержит информацию, которая связывает каждый родительский узел с дочерними узлами в дереве словарных модулей. Структура данных также содержит информацию (инструкции), предназначенную для того, чтобы идентифицировать объекты, ассоциированные с конкретными последовательностями нажатий клавиш, представленными узлом.
Первое поле в структуре 400 данных узла представляет собой поле 402 битов подходящих клавиш, которое указывает число и идентичность дочерних узлов, которые ассоциированы с родительским узлом, и которые из девяти возможных клавиш ассоциированы с информацией (инструкциями) для идентификации объектов, ассоциированных с конкретными последовательностями нажатий клавиш, представленных узлом. Поскольку в предпочтительном варианте осуществления имеется девять клавиш данных, то с любым родительским узлом может быть связано самое большее девять дочерних узлов, и, следовательно, для того, чтобы показать присутствие или отсутствие дочерних узлов, в поле битов подходящих клавиш обеспечиваются девять битов подходящих клавиш. Каждый бит подходящих клавиш ассоциирован с полем 404а, 404b,... 404n указателя, которое содержит указатель на соответствующую структуру данных дочернего узла в словарном модуле. Так как дочерний узел представляется, если только нажатие клавиши, ассоциированное с дочерним узлом, является подходящим продолжением последовательности нажатий клавиш, ассоциированной с родительским узлом, то число полей указателя изменяется для каждого узла. Например, поле 402 битов подходящих клавиш может указывать, что только шесть из возможных девяти нажатий клавиш приводят к подходящему дочернему узлу. Вследствие того, что имеются только шесть подходящих путей, только шесть полей указателя включается в структуру данных для родительского узла. Поле 402 битов подходящих клавиш используется для того, чтобы установить идентичность полей указателя, содержащихся в пределах структуры данных узла. Если нажатие клавиши не приводит к подходящему дочернему узлу, то ассоциированное поле указателя опускается из структуры данных узла для того, чтобы зафиксировать объем памяти, требуемый для сохранения словарного модуля.
С каждым узлом ассоциировано множество объектов, которые соответствуют последовательности нажатий клавиш, представленной узлом. Каждый из объектов описывается инструкцией в блоке 406 в пакете 408, связанном с конкретной подходящей клавишей, как показано конфигурацией битов в поле 402 битов подходящих клавиш, содержащихся в структуре данных узла.
Каждая инструкция в каждом пакете 406 описывает один из объектов, соответствующих последовательности нажатий клавиш, представленной каждым узлом. Описание объекта требует поддержания двух списков объектов. Фиг.11 изображает типовые списки объектов, динамически созданные посредством процесса программного обеспечения устранения неоднозначности из родительского и дочернего узлов в дереве словарных модулей. Список 430 объектов представляет собой список объектов, содержащий объекты i-N1, ассоциированные с узлом, представляющим два нажатия клавиш. Список объектов 440 представляет собой список, содержащий объекты i-N2, ассоциированные с узлом, представляющим три нажатия клавиш. Каждый список объектов представляет собой список всех объектов, которые ассоциированы с каждым узлом. Список 430 объектов ассоциирован с родительским узлом, представляющим последовательности нажатий клавиш АВС АВС с клавиатуры фиг.1. Список 440 объектов ассоциирован с дочерним узлом, представляющим последовательность нажатий клавиш АВС АВС TUV. Должно быть понятно, что размер списка объекта изменяется, чтобы учитывать фактическое число объектов, ассоциированных с каждым узлом.
Каждый объект, ассоциированный с дочерним узлом, строится путем добавления последовательности знаков к объекту, который был построен для родительского узла. Следовательно, пакет 406 инструкций на фиг.8А содержит инструкцию 558 с полем 556 OBJECT-LIST-INDEX (индекс списка объектов), показанным на фиг. 8Б, которая из списка объектов родительского узла идентифицирует объект, который используется для построения объекта дочернего узла. Например, на фиг.11 первый объект "bа" в старом списке 430 объектов используется для построения второго объекта "bat" в новом списке 440 объектов. Следовательно, предыдущее поле OBJECT-LIST-INDEX (индекс списка объектов) 556 идентификатора объекта обеспечивает связь с элементами данных в старом списке объектов, чтобы идентифицировать старый объект, используемый для построения нового объекта.
Инструкция 558 также содержит поле 555 LOGICAL-SYMBOL-INDEX (индекс логического символа), предназначенное для того, чтобы показывать, что для построения нового объекта нужно к идентифицированному объекту добавить символ. Следовательно, поля LOGICAL-SYMBOL-INDEX (индекс логического символа) определяют буквы с последней клавиши в последовательности клавиш узла, которые должны присоединяться для построения нового объекта. Буква определяется таблицей типа таблицы, изображенной на фиг.7, в которой полям LOGICAL-SYMBOL-INDEX (индекс логического символа) соответствуют индексы 552 логических символов в первой строке таблицы 550, и строка, в которой появляется указанная клавиша, идентифицируется заданным индексом клавиши в первом столбце таблицы. Например, на фиг. 11 первый объект "CAT" в новом списке 440 объектов строится с использованием второго объекта "СА" в старом списке 430 объектов и добавлением дополнительного нажатия клавиши, чтобы определить Т. В таблице фиг.7 индексов логических символов символ "Т" представляет собой первую логическую букву на клавише TUV, следовательно, поле LOGICAL-SYMBOL-INDEX (индекс логического символа) инструкции, которая создала объект "CAT", устанавливается на 1 и указывает первую букву в таблице. Кодирование объектов этим способом используeт известную последовательность клавиш, ассоциированную с каждым узлом и известной ассоциацией букв к клавишам, чтобы существенно уменьшить объем памяти, требуемый для каждого словарного модуля.
Метод кодирования словаря также позволяет осуществить без поиска доступ к элементам данных словарного модуля. При приеме каждого нового подходящего нажатия клавиши система выполняет инструкции, ассоциированные с клавишей в текущем узле для того, чтобы построить новый список объектов из старого, затем следует единственный указатель на соответствующий дочерний узел. Для того, чтобы добавить новый объект в старую интерпретацию, новый объект определяется, скорее используя поле LOGICAL-SYMBOL-INDEX (индекс логического символа), чем сохраняя каждый объект в словарном модуле. Таким образом, корень слова, который совместно используется множеством объектов в словарном модуле, запоминается только однажды и используется для создания всех объектов, получаемых из него. Для построения списка объектов дочерних узлов используемый способ сохранения требует поддержания списка объектов родительского узла в дереве словарных модулей.
Элементы данных в таблице индексов логических символов, подобной показанной на фиг.7, не обязательно должны быть отдельными символами - один элемент данных может охватывать произвольные последовательности. Например, для того, чтобы сформировать слово "catlike", ко второму объекту "са" из старого списка объектов может быть добавлена цепочка символов "tlike" по стандарту ASCII (американский стандартный код обмена информацией). Таким образом, длина введенной последовательности нажатий клавиш не должна обязательно прямо соответствовать длине ассоциированного объекта. Последовательность по стандарту ASCII, сохраненная в элементе данных в таблице индексов символов, позволила бы идентифицировать словарный объект посредством произвольной последовательности нажатий клавиш, т.е. сохраненным в произвольном местоположении в пределах дерева словарных модулей.
Для ускорения системной обработки аббревиатур и сокращений используется способность сохранения объектов с произвольной последовательностью нажатий клавиш. Аббревиатуры и сокращения могут идентифицироваться посредством последовательности нажатий клавиш, которая соответствует их чисто алфавитному содержанию, игнорируя знаки препинания. Результатом является то, что аббревиатуры и сокращения легко доступны пользователю без ввода знаков препинания, приводя к значительной экономии нажатий клавиш. Например, пользователь может вводить последовательность нажатий клавиш для объекта "didn't", не печатая апостроф между "n" и "t". Инструкция в словарном модуле, которая соответствует последовательности нажатий клавиш "didnt", ссылается на последовательность по стандарту ASCII (американский стандартный код обмена информацией) с апострофом между "n" и "t" как на один символ в таблице. Следовательно, система устранения неоднозначности будет автоматически отображать пользователю правильное слово "didn't", не требуя от пользователя ввода знака препинания. Система устранения неоднозначности использует такую же таблицу для того, чтобы правильно отображать иностранные слова, имеющие уникальные знаки (такие, как "U", который может вводиться как одно нажатие клавиши на клавише TUV). Подобным образом может осуществляться печатание прописными буквами.
Слова, которые должны всегда использоваться со всеми прописными буквами, с первоначальной прописной буквой или с прописной буквой в середине, могут быть ассоциированы с последовательностями нажатий клавиш, которые опускают нажатие клавиши, указывающее прописные буквы, устраняя необходимость для пользователя вводить такую печать прописными буквами. Для определения дополнительной информации относительно создаваемого объекта в каждую инструкцию 558 также может быть включено поле типа объекта. Поле типа объекта может содержать код для определения того, является ли создаваемый объект словом, корнем слова или любым другим объектом. Следовательно, поле типа объекта позволяет смешивать различные типы объектов в пределах данного словарного модуля. Кроме того, поле типа объекта может также включать информацию, касающуюся части речи, информацию относительно того, что объект печатается прописными буквами, или информацию, необходимую для построения различных измененных форм слов и окончаний. Для того, чтобы осуществлять синтаксический анализ, с целью улучшить процесс устранения неоднозначности, система устранения неоднозначности с уменьшенной клавиатурой, использующая словарный модуль, имеющий информацию о частях речи, может использовать дополнительную информацию. Поле типа объекта также может содержать уникальный код для обеспечения возможности передачи текста в сжатом виде. Вместо передачи введенной последовательности нажатий клавиш или ассоциированных знаков с устраненной неоднозначностью в удаленный терминал может передаваться уникальный код.
Одной из ключевых особенностей предпочтительной древовидной структуры данных словарного модуля является то, что объекты, ассоциированные с каждым узлом, запоминаются в структуре 400 данных узла согласно частоте их использования. То есть, объект, построенный посредством первой инструкции в пакете 406, имеет более высокую частоту использования, чем тот, который строится посредством второй инструкции (если она есть) в 406, которая имеет более высокую частоту использования, чем третья инструкция (если она есть). Таким образом, объекты автоматически помещаются в список объектов так, что они сортируются согласно уменьшающейся частоте использования. Для целей настоящего описания частота использования объекта слова связана с вероятностью использования данного слова в пределах типичной совокупности использования, которая пропорциональна числу раз, сколько каждое слово встречается в совокупности. В случае объектов корней слов частота использования определяется посредством суммирования частот всех слов, которые совместно используют тот же самый корень.
Сохранение частоты использования или другой информации о приоритете в каждом узле при работе системы избавляет от потребности определять и сортировать по приоритету каждый объект. Это имеет важное значение в словаре объектов слов, поскольку сохраненные объекты могут включать совместно используемые корни, общие для очень большого числа более длинных слов.
Определение относительного приоритета этих корней динамически потребовало бы прохождения всего дерева дочерних узлов и накопления информации относительно каждого корня, добавляя значительную лишнюю обработку для портативного вычислительного устройства. Таким образом, определение этой информации заранее и сохранение ее в словарных данных уменьшает лишнюю обработку. Кроме того, когда частота использования или приоритет представленa неявно посредством порядка объектов 406 в узле, для этой информации не требуется дополнительного объема памяти.
Хотя предпочтительно объекты запоминаются в пределах структуры 400 данных узла в порядке, соответствующем их частоте использования, должно быть понятно, что частота использования поля также могла бы быть связана с каждой инструкцией. Частота использования поля могла бы содержать характерное число, которое соответствует частоте использования ассоциированного объекта. Частота использования различных объектов могла бы определяться посредством сравнения частоты использования поля каждого объекта. Преимущество использования последней конструкции, которая связывает частоту использования поля с каждым пакетом объектов, состоит в том, что частота использования поля может изменяться системой устранения неоднозначности. Например, система может изменять частоту использования поля для того, чтобы отобразить частоту, с которой пользователь использовал некоторые объекты в пределах словарного модуля во время введения типового текста.
Согласно фиг. 3, в блоке 156 в каждом словарном модуле идентифицируются те объекты, которые соответствуют принятой последовательности нажатий клавиш. Фиг.12 показывает блок-схему подпрограммы 600 процедуры анализа принятой последовательности нажатий клавиш, чтобы идентифицировать соответствующие объекты в конкретном словарном модуле. Подпрограмма 600 строит список объектов для конкретной последовательности нажатий клавиш. Блок 602 очищает новый список объектов. Блок 604 инициирует переход по дереву 110 в корневом узле 111. Блок 604 соответствует получению первого нажатия клавиши. Блоки от 608 до 612 образуют контур для обработки всех доступных нажатий клавиш. Блок 608 вызывает подпрограмму 620 по фиг.13. Блок 610 принятия решения определяет, обработаны ли все доступные нажатия клавиш. Если какие-то нажатия клавиш остаются необработанными, то блок 612 переходит к следующему доступному нажатию клавиши. Если все нажатия клавиш обработаны, то блок 614 возвращает законченный список объектов. Должно быть понятно, что, если главная программа вызывает подпрограмму 600 повторно с новыми последовательностями нажатий клавиш, каждая из которых на одну клавишу больше, чем предыдущие и все клавиши, за исключением последней, такие же, как в предыдущем вызове, то инициализация блоков 602 и 604 может быть обойдена, если подпрограмма 620 вызывается непосредственно, чтобы обработать только самое последнее нажатие клавиши.
На фиг.13 показана блок-схема подпрограммы 620, вызываемой из подпрограммы 600. В главной программе, изображенной на фиг.3, нажатие клавиши обнаруживалось системой в блоке 150. Прием нового нажатия клавиши вызывает переход вниз по дереву словарных модулей, если существует подходящий путь к дочернему узлу, соответствующему нажатию клавиши. Следовательно, в блоке 621 на фиг.13 проверяется поле битов подходящих клавиш узла 400 структуры данных для того, чтобы определить, соответствуют ли подходящая инструкция и указатель принятому нажатию клавиши. В блоке 622 принятия решения выполняется проверка поля битов подходящих клавиш с целью определить, существуют ли подходящий пакет 408, состоящий из инструкций 406 и поле указателя типа 404а, соответствующие введенному нажатию клавиши. Если никакой подходящий пакет не соответствует нажатию клавиши, то в блоке 624 старый список объектов возвращается к главной программе для того, чтобы создать список выбора, потому что принятое нажатие клавиши является частью недействительной последовательности нажатий клавиш, которая не соответствует какому-либо объекту в пределах словарного модуля. Следовательно, ветвь подпрограммы 620, которая содержит блоки 622 и 624, игнорирует любые недействительные последовательности нажатий клавиш и возвращает список объектов, созданный в родительском узле, для возможного включения в список выбора, созданный системой устранения неоднозначности.
Если в блоке 622 принятия решения существует подходящий пакет, соответствующий принятому нажатию клавиши, то подпрограмма переходит к блоку 626, где новый список объектов копируется в старый список объектов. Как отмечено выше, для построения нового списка объектов система устранения неоднозначности начинает с копирования старого списка объектов. Следовательно, в блоке 626 список объектов из предшествующего узла запоминается так, чтобы он мог использоваться для построения нового списка объектов.
Блок 628 извлекает первую подходящую инструкцию, ассоциированную с данной клавишей. Блок 630 инициализирует итератор "NEW-INDEX" (новый индекс) на 1 так, чтобы первая инструкция создавала первый элемент в новом списке объектов. Затем подпрограмма входит в контур, включающий блоки 632-642, для построения списка объектов, ассоциированного с подходящими инструкциями. В блоке 632 проверяется поле 556 OBJECT-LIST-INDEX (индекс списка объектов), и соответствующий объект загружается из старого списка объектов. В блоке 634 проверяется поле 555 LOGICAL-SYMBOL-INDEX (индекс логического символа), и соответствующий символ (ассоциированный с приемом нажатия клавиши посредством таблицы индексов логических символов, такой как 550, изображенной на фиг.7) присоединяется к идентифицированному объекту. Должно быть понятно, что последовательность с длиной больше единицы в блоке 634 может быть присоединена к идентифицированному объекту, если элемент данных в таблице 550 символов на данной клавише 551 и индекс 552 логического символа вмещают последовательность знаков. В блоке 636 объединенные объект и символ запоминаются как новый объект в новом списке объектов. В блоке 638 выполняется проверка, чтобы определить, обработала ли подпрограмма последнюю подходящую инструкцию, ассоциированную с данной клавишей в данном узле. Если последняя подходящая инструкция не была обработана, то в блоке 640 извлекается следующая подходящая инструкция. В блоке 642 осуществляется приращение "NEW-INDEX" (новый индекс).
Если проверка в блоке 638 принятия решения показывает, что для узла построены все объекты, то подпрограмма переходит к блоку 644 и следует за ассоциированным указателем на дочерний узел. В блоке 646 в главную программу возвращается новый список объектов, чтобы создать список выбора. Должно быть понятно, что подпрограмма 600 для создания списка объектов, ассоциированного с каждым узлом, выполняется для каждого нажатия клавиши, принятого от пользователя. Когда пользователь вводит новую последовательность нажатий клавиш, никакого "поиска" словарных модулей не выполняется, поскольку каждое нажатие клавиши просто продвигает подпрограмму на один дополнительный уровень в пределах дерева словарных модулей. Поскольку поиск не выполняется для каждого нажатия клавиши, то словарный модуль возвращает список объектов, ассоциированный с каждым узлом, с минимальными вычислительными затратами.
Должно быть понятно, что отношение между объектами словарного модуля и последовательностями нажатий клавиш характеризует собой детальные особенности реализации словарного модуля. При обработке узла, ассоциированного с текущей последовательностью вводов клавиш, дополнительные дочерние узлы могут пересекаться для того, чтобы идентифицировать вероятные объекты, имеющие последовательность нажатий клавиш, начинающуюся с введенной последовательности нажатий клавиш, и которая появляется с относительной частотой, превышающей некоторый порог. Этот порог может динамически регулироваться на основе характеристик текущего узла типа того, создает ли он достаточно объектов, чтобы заполнить область 70 списка выбора на дисплее. Объекты идентифицируются посредством перехода вниз по дереву словарных модулей по соответствующим путям до тех пор, пока объекты не будут идентифицированы. Такие вероятные объекты могут идентифицироваться при построении базы данных из списка вводимых слов, а узел и инструкция, соответствующие завершению вероятного слова, могут быть маркированы таким образом, чтобы система могла распознавать, когда пересечение данного узла соответствует созданию вероятного слова.
Требуется специальная маркировка, так как тот же самый узел и инструкция могут пересекаться при обработке различных последовательностей вводов клавиш, соответствующих различным словам после того, как древовидная структура была преобразована в процессе сжатия, описанного ниже. Только для того, чтобы отличить вероятную последовательность слов от других последовательностей, должна быть добавлена достаточная информация типа длины последовательности или значений конкретных клавиш в известных положениях в последовательности клавиш. Альтернативно, конечные узлы для вероятного слова могут быть специально помечены таким образом, чтобы они не сливались с узлами, используемыми для других слов, как описано ниже. Затем, программное обеспечение устранения неоднозначности может заранее осуществлять поиск в пределах определенного окружения дочерних узлов текущего узла для этих вероятных объектов, которые, если будут найдены, могут затем помещаться в список выбора прежде, чем вводятся все нажатия клавиш, соответствующие объектам. Эти объекты включаются в дополнение к объектам, которые непосредственно ассоциированы с вводимой последовательностью нажатий клавиш. Отображение объектов, ассоциированных с более длинными последовательностями нажатий клавиши в списке выбора (упоминаемое как особенность "look-ahead" (смотри вперед)), позволяет пользователю произвольно выбирать объекты сразу, не завершая остающиеся нажатия клавиш для определения объекта.
Согласно фиг.3 в блоках 158-165 объекты, найденные посредством просмотра последовательности нажатий клавиш в словарных модулях, располагаются по приоритетам и отображаются пользователю в списке 76 выбора. Чтобы определять последовательность объектов, отображаемых в списке выбора, устанавливаются приоритеты между каждым словарным модулем, а также между возвращенными объектами из каждого словарного модуля.
Для того, чтобы расположить по приоритетам списки объектов, идентифицированные из различных словарных модулей, в блоке 158 проверяется режим работы системы устранения неоднозначности с уменьшенной клавиатурой. Как обсуждалось выше, в нормальном режиме работы интерпретации слов отображаются сначала в списке выбора. Следовательно, списку объектов из словарного модуля слова может быть присвоен более высокий приоритет, чем списку объектов из других словарных модулей. Наоборот, если система устранения неоднозначности находится в числовом режиме работы, то числовым интерпретациям может быть присвоен более высокий приоритет, чем другим словарным модулям. Следовательно, режим системы устранения неоднозначности устанавливает приоритет между списками объектов словарных модулей. Должно быть понятно, что в некоторых режимах списки объектов из словарных модулей могут полностью опускаться из списка выбора.
Списки объектов, созданные из словарных модулей, могут содержать только один элемент данных или множество элементов данных. Следовательно, если список объектов содержит множество элементов данных, то в блоке 160 устанавливается приоритет между объектами из того же самого словарного модуля. Объектам, которые соответствуют конкретной последовательности нажатий клавиш, которые просматриваются в данном словарном модуле, также задают приоритет, который определяет их относительное представление относительно друг друга. Как отмечалось выше, предпочтительно порядок представления по умолчанию устанавливается по уменьшающейся частоте использования в характерной совокупности использования. Следовательно, данные о приоритете, ассоциированные с каждым объектом, используются для упорядочивания объектов в списке выбора. Так как область 70 списка выбора ограничена числом элементов данных, которые могут быть отображены, объекты, которые попадаются с частотой ниже заданной минимальной частоты использования, могут опускаться при начальном отображении списка выбора. Пропущенные объекты могут быть добавлены к списку выбора позже, когда пользователь выполняет прокрутку за пределами отображаемого списка. Список выбора прокручивается автоматически так, чтобы выбранный объект был всегда виден в текущий момент. Пользователь также может использовать специальные кнопки прокрутки, чтобы вручную прокручивать дополнительные объекты для обозрения в случае, когда выбранный в текущий момент объект может прокручиваться вне поля зрения. Альтернативно, при запросе пользователя все объекты списка выбора могут быть отображены одновременно в "ниспадающем" списке.
Многие из свойств, ассоциированных с представлением объектов просмотра в словарном модуле, могут программироваться пользователем посредством обращения к соответствующим меню системы. Например, пользователь может определять порядок отдельных объектов или классов объектов в области списка выбора. Пользователь также может устанавливать уровень приоритетов, который определяет приоритет между словарными модулями и между объектами, идентифицированными из каждого словарного модуля. Таким образом, число элементов данных, представленных пользователю в области списка выбора, может быть сведено к минимуму. Дополнительные элементы данных в области списка выбора могут прокручиваться для попадания в поле зрения посредством повторных нажатий клавиши "Select" (выбор).
После установления приоритетов между объектами в блоке 165 список выбора строится из идентифицированных объектов и представляется пользователю. Первый элемент данных в списке выбора предварительно выставляется и выдвигается на первый план в точке 88 вставки в текстовой области 66 как интерпретация по умолчанию неоднозначной последовательности нажатий клавиш, введенной пользователем. Затем программа программного обеспечения устранения неоднозначности возвращается к блоку 150, чтобы ожидать следующего нажатия клавиши.
Что касается блока 152 принятия решения, если детектированное нажатие клавиши представляет собой клавишу 60 "Select" (выбор), то выбирается ветвь "да" от блока 152 принятия решения к блоку 163 принятия решения, где проверка определяет, является ли текущий список выбора пустым. Если да, то в блоке 164, если флаг "OverloadSelect" (дополнительно_расширенный_выбор) устанавливается истинным (TRUE), генерируется явный пробел и сразу выводится в текстовую область. Флаг "OverloadSelect" (дополнительно_расширенный_выбор) представляет собой системный флаг, который устанавливается истинным (TRUE) в системах, которые не включают явную клавишу 64 "Space" (пробел) и в которых знак пробела генерируется для первой активизации любой непрерывной последовательности активизаций клавиши "Select" (выбор), или если список выбора является пустым в момент активизации клавиши "Select" (выбор). После этой начальной обработки принятого нажатия клавиши, в блоке 164Б система выполняет последующую обработку, требуемую для клавиши 63 знаков препинания, которая изображена на фиг.5Б и обсуждается подробно ниже. Затем выполнение программы возвращается к блоку 150. Если в блоке 163 принятия решения список выбора не является пустым, то используется ветвь "нет" к блоку 174А. В блоке 174А, если флаг "OverloadSelect" (дополнительно_расширенный_выбор) устанавливается истинным (TRUE), то пробел добавляется к концу каждого текстового элемента в списке выбора и в точке вставки. В блоке 174, рамка из сплошной линии вокруг первого элемента данных в списке выбора (и также в точке вставки, где он предварительно помещался) заменяется на пунктирную рамку.
Затем, в блоке 175, показанном на фиг.3, система ожидает обнаружения следующего нажатия клавиши, введенного пользователем. После приема нажатия клавиши в блоке 175А, система выполняет предварительную обработку, требуемую для клавиши 63 знаков препинания, изображенную на фиг.5А и обсуждаемую подробно ниже. В блоке принятия решения 176 выполняется проверка, чтобы определить, является ли следующее нажатие клавиши клавишей "Select" (выбор). Если следующее нажатие клавиши является клавишей "Select" (выбор), то в блоке 178 система переходит к следующему элементу данных в списке выбора и помечает его как выбранный в данный момент элемент. После этой начальной обработки полученного нажатия клавиши в блоке 178Б система выполняет последующую обработку, требуемую для клавиши 63 знаков препинания, которая изображена на фиг. 5Б и обсуждается подробно ниже. В блоке 179 выбранный в данный момент элемент данных предварительно отображается в списке выбора и в точке вставки с пунктирной рамкой вокруг элемента данных. Затем программа возвращается к блоку 175 для обнаружения следующего нажатия клавиши пользователем. Должно быть понятно, что контур, образованный блоками 175-179, позволяет пользователю выбирать различные интерпретации введенной неоднозначной последовательности нажатий клавиш, имеющей меньшую частоту использования, многократным нажатием клавиши "Select" (выбор).
Если следующее нажатие клавиши не является клавишей "Select" (выбор), то из блока 176 принятия решения программа переходит к блоку 180, где предварительно отображенный элемент данных выбирается как интерпретация последовательности нажатий клавиш и преобразуется в нормальный текст посредством форматирования в текстовой области. В блоке 184 старая последовательность нажатий клавиш очищается из памяти системы, так как прием неоднозначного нажатия клавиши после клавиши "Select" (выбор) указывает системе на начало новой неоднозначной последовательности. Затем используется вновь принятое нажатие клавиши, чтобы начать новую последовательность нажатий клавиш в блоке 154. Из-за того, что интерпретация слов, имеющих самую высокую частоту использования, представляется как выбор по умолчанию, главная программа программного обеспечения устранения неоднозначности позволяет пользователю непрерывно вводить текст с минимальным числом случаев, в которых требуется дополнительная активизация клавиши "Select" (выбор).
Как отмечено выше, в нормальном режиме работы элементы данных в списке 76 выбора, соответствующие словам, представляются в списке первыми. При других обстоятельствах может оказаться желательным представлять первыми в списке другие интерпретации последовательности нажатий клавиш. Например, в системах, где не имеется достаточной площади отображения для того, чтобы обеспечить отображение буквенного "списка" выбора на экране дисплея, набор возможных соответствующих объектов из базы данных запоминается внутри посредством программного обеспечения, и только объект по умолчанию или явно выбранный объект (после одного или более активизаций клавиши "Select" (выбор)) отображается в точке вставки.
В таких системах объект, отображаемый в точке вставки, может значительно изменяться с каждым нажатием клавиши, добавленным к последовательности вводов, так как наиболее частое слово, соответствующее новой последовательности нажатий клавиш, может обладать небольшим сходством или совсем не иметь сходства с наиболее частым словом, соответствующим предыдущей последовательности вводов. В результате объект, отображаемый в точке вставки, может казаться пользователю "скачущим", и постоянное изменение его вида может отвлекать, особенно для новичка или неопытного пользователя. Чтобы уменьшить эту нестационарность в точке вставки, система может быть выполнена так, чтобы объект слова или корня слова мог отображаться, если он соответствует более длинному слову или множеству слов с полной частотой появления, которая превышает порог, вместо отображения всегда наиболее частого объекта слова, соответствующий текущей последовательности клавиш. Результатом этого "продвижения корня" является то, что изменения в слове, отображаемые в точке вставки, часто состоят в простом присоединении дополнительной буквы к предварительно отображенному текстовому объекту. Например, при наборе частого слова "this" пользователь нажимает четыре клавиши TUV, GHI, GHI, PQRS. Без выполнения "продвижения корня" система могла бы в точке вставки отобразить следующую последовательность объектов (по одному): "t", "vi", "ugh", "this". Когда выполняется "продвижение корня", система отображает: "t", "th", "thi", "this". В результате неопытный пользователь будет в большей степени уверен, что система устранения неоднозначности будет правильно интерпретировать его нажатие клавиш. Блок-схема программы на фиг.4 изображает, каким образом система определяет, какой именно объект нужно отобразить в данном узле для данной последовательности нажатий клавиш.
На фиг.4 показана блок-схема программы программного обеспечения, которое создает базу данных слов в древовидной структуре узлов, где каждый узел соответствует неоднозначной последовательности нажатий клавиш. В каждом узле создается множество объектов слов, соответствующих возможным словам или корням слов, которые создаются посредством последовательности нажатий клавиш. В блоке 190 устанавливается порог "MinFactor" (минимальный коэффициент). Этот порог соответствует минимальному коэффициенту, на который полная частота текстового объекта должна превышать полную частоту наиболее частого объекта слова в узле для того, чтобы продвигаться по этому объекту слова (то есть быть объектом по умолчанию, отображаемым первым в списке выбора для этого узла). Полная частота объекта слова представляет собой частоту самого слова плюс сумма частот всех наиболее длинных слов, у которых слово является корнем (то есть соответствует начальным буквам более длинных слов).
В блоке 191 устанавливается второй порог "MaxWordFreq", который соответствует максимальной относительной частоте слова, по которому может продвигаться другой корень. В блоке 192 все узлы дерева пересекаются и маркируются как необработанные. В блоке 193 программа определяет, были ли все узлы дерева обработаны. Если да, то программа останавливается, в противном случае в блоке 194 система извлекает следующий необработанный узел и определяет частоту наиболее частого объекта слова (MostFreqWord), полную частоту этого слова вместе со всеми словами, у которых это слово является корнем (MostFreqWordTot - полная частота наиболее частого слова вместе с однокоренными словами), и объект, для которого полная частота всех слов, у которых этот объект является корнем, является самой высокой среди всех объектов, ассоциированных с узлом (MostFreqStemTot - наибольшая полная частота всех слов с этим корнем).
В блоке 195 система проверяет, превышает ли MostFreqStemTot значение MostFreqWordTot по меньшей мере на коэффициент MinFactor. Если нет, то объект по умолчанию, ассоциированный с узлом, остается неизменным, и система возвращается к блоку 198, где узел маркируется как уже обработанный перед возвращением к блоку 193. Если в блоке 195 частота MostFreqWordTot превышает по меньшей мере на коэффициент MinFactor, то в блоке 196 система проверяет, превышает ли частота текущего объекта по умолчанию, ассоциированного с узлом (MostFreqWord), максимальное значение для слова, по которому может продвигаться другой объект (MaxWordFreq). Если да, то объект по умолчанию, ассоциированный с узлом, остается неизменным, и система возвращается к блоку 198. Если нет, то в блоке 197 узел изменяется так, что объект, ассоциированный с MostFreqStemTot, перед возвращением к блоку 198 обозначается как объект по умолчанию, ассоциированный с узлом.
Проверка в блоке 196 необходима для того, чтобы предотвратить продвижение очень часто встречающихся корней по часто встречающимся словам. Например, корень "fo" слова "for" появляется с очень высокой частотой, так что для разумных значений коэффициента MinFactor (например, 1,5) проверка в блоке 195 будет удовлетворительной даже несмотря на то, что обычное слово "do" также встречается в этом же узле. Слово "do" очевидно встречается с относительно более высокой частотой, и оно могло бы значительно снизить эффективность системы устранения неоднозначности, если "do" не появляется как объект по умолчанию для этого узла.
II. Отличительные признаки системы
1. Устранение неоднозначности знаков препинания
На фиг. 1 представлен один из предпочтительных вариантов осуществления настоящего изобретения, в котором верхняя левая клавиша клавиш 56 данных ("клавиша знаков препинания") ассоциирована со знаками препинания: точка, тире и апостроф. Все эти знаки обычно используются во множестве языков, например и в английском, и во французском языках. Клавише могут быть присвоены другие наборы знаков (например, знаки запятой, тире и двойного тире), и устранение неоднозначности может осуществляться, используя те же самые принципы подхода, как в системе устранения неоднозначности настоящего изобретения. Для того, чтобы определить, какой из знаков препинания необходим, система использует контекст нажатий клавиш относительно нажатия клавиши 63 знаков препинания. Поведение по умолчанию клавиши 63 знаков препинания также может модифицироваться для учета некоторых специальных слоев, представленных в некоторых языках.
Блок-схемы на фиг.5А и 5Б изображают, каким образом система определяет, который из знаков создать для данной активизации клавиши знаков препинания. Различные текстовые объекты, созданные с использованием различных знаков препинания, ассоциированных с клавишей 63 знаков препинания, добавляются к списку выбора. Интерпретация по умолчанию активизации клавиши 63 знаков препинания определяется тем, какой объект добавляется как первый объект в списке выбора. Альтернативные интерпретации также могут быть выбраны посредством активизации клавиши "Select" (выбор) или выявляя желательную интерпретацию в отображаемом списке выбора. Фиг.5А иллюстрирует программу обработки каждого нажатия клавиши, принятого системой перед тем, как нормальная системная обработка согласно фиг.3, в которой система добавляет нажатие клавиши к текущей последовательности вводов нажатия клавиш, определяет, какие слова соответствуют новой последовательности вводов, и создает обновленный список выбора, основанный на новой последовательности. Обработка, изображенная на фиг. 5А, встречается в блоках 150А и 175А на фиг.3. Фиг.5Б изображает программу, которая затем осуществляет последующую обработку вновь созданного списка выбора. Обработка, изображенная на фиг.5Б, реализуется в блоках 164Б и 178Б по фиг.3. В момент инициализации системы все флаги считаются очищенными.
В начале предварительной обработки каждого нажатия клавиши в блоке 200 на фиг. 5А проверяется флаг ClearPunctMode. Флаг ClearPunctMode устанавливается (в блоке 262), чтобы показать, что все флаги и буферы, ассоциированные с клавишами знаков препинания, должны быть очищены в начале обработки следующего нажатия клавиши. Если в блоке 200 флаг оказывается установленным, то в блоке 202 все флаги и буферы, за исключением используемых для обработки клавиши 63 знаков препинания, очищаются. Эти же флаги и буферы также очищаются в момент инициализации системы. Буфер CurPunctWord используется для сохранения текстового объекта, к которому программное обеспечение клавиши знаков препинания будет присоединять знаки препинания для создания объектов, которые добавляются к списку выбора. Флаг pState сохраняет текущее состояние программного обеспечения клавиши знаков препинания и определяет различие между разными возможными случаями для контекста, в котором была активизирована клавиша 63 знаков препинания. Если в блоке 204 текущая клавиша, которая подвергается предварительной обработке, является клавишей 63 знаков препинания, то в блоке 206 текущий объект по умолчанию (или явно выбранный объект) сохраняется в буфере CurPunctWord (буфер хранения слова, к которому должен присоединяться знак препинания), и в блоке 208, флаг pState (текущее состояние программного обеспечения клавиши знаков препинания) устанавливается в положение PUNCT_KEY, показывая, что клавиша 63 знаков препинания была последней принятой клавишей. Блок 212 представляет обычную обработку нажатия клавиши согласно фиг.3, начинающуюся в блоке 151 или 176. Затем, выполнение программы продолжается последующей обработкой согласно фиг.5Б, начинающейся с соединителя Г.
Если в блоке 204 выясняется, что текущая клавиша не является клавишей знаков препинания, то в случае, если в блоке 220 флаг pState (текущее состояние программного обеспечения клавиши знаков препинания) не установлен, в блоке 222 все флаги и буферы, используемые исключительно для обработки клавиши знаков препинания, очищаются, и обычная обработка нажатия клавиши продолжается в блоке 212. Если в блоке 220 флаг pState установлен в состояние, отличное от нуля, то в случае, если в блоке 230 текущая клавиша является одной из клавиш 56 неоднозначных данных, система переходит к блоку 232, проверяющему, установлен ли флаг Apostrophe_S (апостроф с последующей буквой "s") системы. Флаг Apostrophe_S устанавливается истинным (TRUE) только для языков типа английского, в котором принято добавлять к концу слова апостроф с последующей буквой "s" (чтобы образовывать притяжательную или сокращенную форму со словом "is" (является)). Если флаг Apostrophe_S устанавливается истинным (TRUE), то, если в блоке 234 оказывается, что флаг pState установлен в состояние PUNCT_KEY (показывая, что предыдущая активизация клавиши была клавишей знаков препинания), и если в блоке 236 было обнаружено, что текущая клавиша является клавишей данных, ассоциированных с буквой "s" (клавиша PQRS на фиг.1), в блоке 238 флаг pState устанавливается в состояние APOS_S, указывающее, что клавиша 63 знаков препинания была принята и что был распознан специальный случай апострофа с последующей буквой "s". Если какая-либо проверка (в блоке 234 или 236) оказывается неудачной, то в блоке 237 флаг pState устанавливается в состояние PUNCT_RCVD, показывающее, что клавиша 63 знаков препинания была принята и что должна быть выполнена обработка клавиши знаков препинания, но что никакой специальный случай в настоящее время не применяется (типа апострофа, сопровождаемого буквой "s"). В любом случае после того, как флаг pState установлен, в блоке 212 продолжается обычная обработка нажатия клавиши.
Если в блоке 230 определяется, что текущая клавиша не является клавишей неоднозначных данных, то в блоке 250 система определяет, является ли текущая клавиша клавишей "Backspace" (возврат на один шаг). Если да, то в блоке 252 все флаги и буферы, связанные с клавишами знаков препинания, восстанавливаются в состояния, в которых они были до нажатия клавиши возврата, после чего в блоке 212 продолжается нормальная обработка нажатия клавиши "Backspace" (через соединитель В). Если в блоке 250 определено, что текущая клавиша не является клавишей "Backspace", то в блоке 260 выполняется проверка, является ли текущая клавиша клавишей "MODE" (режим), клавишей "Select" (выбор) или клавишей "Shift" (переключения регистра) (то есть клавишей, которая не будет приводить к "принятию" текущего слова и выведению его в текстовой буфер). Если да, то в блоке 212 (через соединитель В) продолжается обычная обработка нажатия клавиши. В противном случае в блоке 260 определяется, что клавиша является одной из тех, которые обеспечивают принятие текущего слова, и в блоке 262 флаг pState очищается, а флаг ClearPunctMode (все флаги и буферы,
ассоциированные с клавишами знаков препинания, очищены) устанавливаются так, чтобы все флаги и буферы, ассоциированные с клавишами знаков препинания, были очищены при приеме следующего нажатия клавиши в блоке 202.
Если в блоке 232 определяется, что флаг Apostrophe_S не был установлен, то в блоке 270 система определяет, установлен ли флаг Apostrophe_Term (слово, заканчивающееся апострофом), и в блоке 272 система определяет, установлен ли флаг pState в состояние PUNCT_APOS (слово, заканчивающееся апострофом, уже добавлено к списку выбора), указывающее, что клавиша 63 знаков препинания была принята и что распознан специальный случай, когда слово, заканчивающееся апострофом, уже добавлено к списку выбора. Флаг Apostrophe_ Term устанавливается истинным (TRUE) для языков типа французского, в котором принято связывать слова, заканчивающиеся апострофом, (например 1 , d и т.д.) со следующим словом, при этом не печатая пробел между двумя словами. В таких языках очень удобно иметь систему, автоматически создающую неявный "Select" (выбор), чтобы позволить пользователю немедленно начать печатать следующее слово, не активизируя явно клавишу "Select". Если проверки в блоках 270 и 272 дали положительный ответ, то текущее взятое по умолчанию или выбранное слово принимается и выводится в текстовый буфер, как если бы клавиша "Select" была активизирована. Тогда в блоке 276 текущий список нажатий клавиш очищается, и выполнение программы переходит к блоку 262, где флаг pState очищается и устанавливается флаг ClearPunctMode. С другой стороны, если в блоке 270 система принимает решение, что флаг Apostrophe_Term не установлен, или в блоке 272 система принимает решение, что флаг pState не установлен в состояние PUNCT_APOS, то в блоке 278 флаг pState устанавливается в состояние PUNCT_RCVD (клавиша знаков препинания была принята и должна обычным образом обрабатываться), и в блоке 212 (через соединитель В) продолжается обычная обработка нажатия клавиши.
После обычной обработки нажатия клавиши, представленной блоком 212 на фиг. 5А (и подробно изображенной на фиг.3), последующая обработка выполняется, как показано на фиг.5Б, начинающейся с соединителя Г. Если в блоке 300 выясняется, что флаг pState не установлен, то никакой следующей обработки не требуется, и подпрограмма просто возвращается к блоку 320. Блоки 302, 304 и 306 проверяют, установлен ли флаг Apostrophe_Term, установлен ли флаг pState в состояние PUNCT_KEY (предыдущая активизация клавиши была клавишей знаков препинания) и заканчивается ли апострофом текущее слово по умолчанию. Если выполняются все три условия, то в блоке 308 флаг pState устанавливается в состояние PUNCT_ APOS, в противном случае система переходит к блоку 310, не устанавливая новое значение для pState. Если в блоке 310 оказалось, что флаг pState установлен в состояние PUNCT_APOS или в состояние PUNCT_KEY, то в блоках 312, 314 и 316 текстовый объект, сохраненный в буфере СurPunctWord (буфер хранения слова, к которому должен присоединяться знак препинания), добавляется к списку выбора после присоединения точки, тире и апострофа соответственно. Если проверка в блоке 310 дала отрицательный ответ и если в блоке 330 выясняется, что флаг pState установлен в состояние APOS_S, то в блоке 332 текстовой объект, сохраненный в буфере CurPunctWord, добавляется к списку выбора после присоединения апострофа и буквы "s". Затем, в блоках 334, 336, 338 и 340 текстовый объект, сохраненный в буфере CurPunctWord, добавляется к списку выбора после присоединения тире, сопровождаемого каждой из букв, ассоциированных с клавишей PQRS. Затем, в блоке 342 флаг pState устанавливается в состояние PUNCT_ RCVD (клавиша знаков препинания была принята и должна обычным образом обрабатываться).
Если в блоке 330 выясняется, что флаг pState не установлен в состояние APOS_ S, то в блоке 352 система проверяет, является ли текущий список выбора пустым. Если нет, то в базе данных находится один или более объектов, которые явно соответствуют текущей последовательности клавиш в буфере нажатия клавиш (который включает по меньшей мере одну активизацию клавиши знаков препинания). В этом случае подпрограмма просто возвращается в блок 364, не изменяя содержимое буфера нажатий клавиш так, чтобы объект базы данных при желании пользователя мог быть записан по буквам. В противном случае, как только выясняется, что в базе данных больше нет соответствующих объектов, в блоке 358 текстовый объект, сохраненный в буфере CurPunctWord, выводится как принятый текст после добавления к нему тире. В блоке 358 нажатия клавиш стираются в начале буфера нажатия клавиши вплоть до нажатия клавиши знаков препинания включительно. Затем в блоке 360 запрашивается база данных, и на основе измененного буфера нажатия клавиш создается обновленный список выбора. Наконец, в блоке 362 все буферы и флаги для клавиши знаков препинания очищаются перед выходом из подпрограммы.
2. Максимизация эффективности при минимизации памяти словарных модулей
В основе комбинации нажатия клавиш в процессе программного обеспечения идентификации объектов подпрограммы 620, изображенной на фиг.13, относящейся к древовидной структуре 110 данных, изображенной на фиг.10, лежит несколько новейших средств для поиска объектов в словаре большего размера, при этом используется меньший объем памяти для словарного модуля и не увеличивается время обработки подпрограммы 620.
Упорядочивая символы в каждой строке таблицы 550 индексов логических символов данного словарного модуля согласно их частоте использования в вводимом лексиконе, большинство инструкций 558 всех узлов 400 в древовидной структуре 110 данных может быть составлено так, чтобы они имели поля LOGICAL-SYMBOL-INDEX (индекс логического символа) 555, равные единице. Аналогично, упорядочивая инструкции 558 всех пакетов подобно 406 во всех узлах 400 таким образом, чтобы объекты корней слов и слов создавались в списке 440 объектов в порядке уменьшения частоты их использования в языке, большинство инструкций 558 из всех узлов 400 в древовидной структуре 110 может быть составлено так, чтобы они имели поля OBJECT-LIST-INDEX (индекс списка объектов) 556, равные единице. Таким образом, большая часть данных в дереве 110 избыточна. Систематическая идентификация избыточности и ее устранения посредством переадресации путей, связывающих родительские узлы с дочерними узлами, и посредством удаления дочерних узлов, уже больше не упоминаемых, приводит к сильно сжатой и свернутой структуре данных, которая содержит намного меньше узлов, инструкций и связей, чем исходное дерево, но при этом обеспечивает нахождение каждого объекта, который может быть найден посредством исходного дерева.
Кроме того, различные случаи переходов в исходном дереве, инструкции которых создают сходные объекты в списке 440 объектов, сливаются в общие пути в свернутом дереве, которые, следовательно, функционируют как обобщенный (в противоположность конкретному) объект, строящий правила, позволяющие уменьшенной структуре создавать гораздо больше объектов, чем первоначально использовалось для задания дерева 110 из данного словарного модуля. Например, не свернутое словарное дерево, созданное из списка 30000 английских слов, могло бы содержать свыше 78000 инструкций в предпочтительном варианте осуществления. После сворачивания по процедуре сворачивания согласно предпочтительному варианту осуществления измененное дерево могло бы содержать менее чем 29000 инструкций, т.е. меньше, чем число объектов слов, которое структура способна находить с применением неоднозначных последовательностей нажатий клавиш и процедуры поиска, реализованной предпочтительным способом в блок-схеме по фиг. 12. Это - замечательный и новый результат, поскольку каждая инструкция изменяет только один объект в списке 430 объектов, присоединяя один символ в ответ на нажатие клавиши. Этот результат является следствием свернутого дерева и процесса поиска программного обеспечения посредством многократного использования общих последовательностей инструкций в качестве общих правил построения объектов.
Фиг. 9 изображает примеры узлов. Узел 560 имеет две подходящие клавиши, которые показаны единицами "1" в поле 562 подходящих клавиш "010100000". В предпочтительном варианте воплощения позиции единиц "1" указывают, что 2-ая и 4-ая клавиши являются подходящими путями и имеют пакеты инструкций и указателей на дочерние узлы 566 и 568, ассоциированные с ними. Пакет 566 содержит три инструкции "(1,1,0)", "(1,2,0)" и "(2,1,1)", за которыми следует указатель "Р", привязывающий узел 560 к дочернему узлу. Если бы подпрограмма 600 обработала список нажатий клавиш, приводящих к узлу 560, то была бы вызвана подпрограмма 620 для обработки "2"-ой клавиши, которая в предпочтительном варианте осуществления является клавишей АВС, что привело бы к следующему. Для построения нового объекта с индексом 1 инструкция 561 присоединила бы к старому объекту с индексом 1 логический символ клавиши АВС ("а"). Третье поле 561, "0", является ложным значением флага остановки "STOP-ELAG" 557, показывающим, что это не последняя инструкция текущего пакета, так что интерпретируется следующая инструкция 563. Для построения нового объекта с индексом 2 инструкция 563 присоединила бы к старому объекту с индексом 2 логический символ клавиши АВС ("а"). Индекс нового объекта будет равен 2, потому что индексы новых строящихся объектов являются неявными в очередности самих инструкций, например 2-ая инструкция всегда строит 2-ой объект. Третье поле инструкции 563, "0", является ложным значением флага остановки "STOP-ELAG" 557, так что интерпретируется следующая инструкция 567. Для построения нового объекта с индексом 3 инструкция 567 присоединила бы к старому объекту с индексом 1 логический символ клавиши АВС ("с"). Третье поле инструкции 567, "1", является истинным значением флага остановки "STOP-ELAG" 557, показывающим, что это - последняя инструкция текущего пакета, так что выполнение подпрограммы 620 перешло бы от блока 638 к блоку 644.
Можно комбинировать два или более узла, заключающих различные пакеты 408 инструкций в один узел, который может служить для той же цели, что и множество узлов отдельно, что означает, что некоторые узлы в дереве 110 словарей являются избыточными в новом смысле. Для целей настоящего изобретения слово "избыточный" используется для двух узлов в том смысле, что одним узлом можно пренебречь при использовании операций процедур программного обеспечения, которые изображены в предпочтительном варианте осуществления на фиг.14-17.
Например, сравним узел 560 с узлом 574 на фиг.9. Пакеты инструкций 566 и 571 на клавише 2 точно согласуются, но инструкция 570 на клавише 4 узла 560 расходится с инструкцией 572 на клавише 4 узла 574, поэтому никакой узел не может выполнять функцию другого, и два узла не могут быть объединены в такой, который бы выполнял функцию их обоих. Сравним узел 560 с узлом 576. Пакеты инструкций 566 и 577, ассоциированные с клавишей 2, в каждом узле точно согласуются. Инструкции 569 и 578 отличаются в компоновке их полей флага остановки "STOP-ELAG" 557, но это различие не приводит к их конфликту. Существенным результатом процесса поиска объекта согласно подпрограмме 620 на фиг. 13 является новый список объектов, созданный посредством выполнения набора инструкций в узле для данной клавиши. Дополнительные объекты могут присоединяться к концу списка объектов без ущерба для правильной обработки любого из этих дочерних узлов. Таким образом, при выполнении дополнительной инструкции после инструкции 578 не возникло бы никаких ошибок в обработке дочерних узлов узла 576. Сущность процесса была бы нарушена только в том случае, если надо было бы выполнить неправильную инструкцию или если надо было бы выполнить слишком много инструкций. Аналогично, присутствие подходящей клавиши на клавише 9 узла 576 не находится в противоречии с отсутствием подходящей клавиши 9 в узле 560. Следовательно, узлы 560 и 576 избыточны и могут быть слиты в новый узел 582, который достигает результирующего эффекта обоих и правильно функционирует в качестве родительского узла обоих дочерних узлов.
Должно быть понятно, что указатели также играют роль в определении избыточности. При последнем нажатии клавиши последовательности в дереве, ассоциированном со словами, которые не продолжаются для образования корней более длинных слов, в предпочтительном варианте осуществления указатели в пакетах 408 подходящих клавиш имеют специальное значение "NULL" (пустой указатель), для того чтобы показать, что больше нет никаких дочерних узлов. Такие узлы называются "конечными узлами". Для двух узлов с дочерними узлами на подходящих клавишах, общих для обоих узлов, соответствующие дочерние узлы должны быть избыточными для их родительских узлов, и так далее до узлов, происходящих от дочерних узлов, до тех пор, пока не будут достигнуты конечные узлы, или до тех пор, пока не окажется, что больше не имеется дочерних узлов на последовательностях подходящих клавиш, общих для сравниваемых узлов.
Фиг.14-17 изображают блок-схемы предпочтительных вариантов осуществления процессов программного обеспечения для сжатия и сворачивания деревьев словарных модулей подобно дереву 110, изображенному на фиг.10. Фиг.14 изображает блок-схему процесса программного обеспечения предпочтительного варианта осуществления для построения сжатого словарного модуля. В блоке 652 словарь просматривается для того, чтобы идентифицировать любые необходимые дополнительные неоднозначные символы, отличные от тех, которые появляются на физических клавишах, таких как на фиг.6 для французского словарного модуля. В блоках 654-656 символам присваиваются их логические индексы на соответствующих им клавишах в порядке уменьшения частоты их использования в вводимом лексиконе, как в примере по фиг.7. При наличии лексикона объектов с частотами использования специалистам должно быть очевидно, каким образом блок 658 строит дерево словаря в виде дерева 110. В блоке 660 избыточные узлы идентифицируются и сливаются вместе, чтобы минимизировать дублирование данных, и, следовательно, превращают изолированные последовательности инструкций, ассоциированные с отдельными объектами, в обобщенные правила для поиска множества объектов. Этот процесс подробно представлен на фиг.15.
Блок 662 распознает все оставшиеся указатели "NULL" (пустой указатель) из конечных узлов и изменяет их, чтобы они указывали на узел с самым большим числом родительских узлов, таким образом, увеличивая число правил в модуле. Должно быть понятно, что для присвоения дочерних узлов указателям "NULL" (пустой указатель) могли бы применяться другие правила и что такие правила могли бы применяться динамически во время поиска объекта на основе коэффициентов, отнесенных к обрабатываемым нажатиям клавиш. В блоке 664 оставшиеся случаи каждой уникальной инструкции 558 и указателя 404а подсчитываются таким образом, чтобы они могли кодироваться как уникальные комбинации битов, причем более короткие комбинации битов присваиваются инструкциям и адресам с более высокой частотой для экономии места. Для того, чтобы инструкциям и адресам присвоить комбинации битов минимальной длины, в предпочтительном варианте осуществления настоящего изобретения используется кодирование Хаффмана. Методы кодирования Хаффмана известны в уровне техники и поэтому здесь не обсуждаются более подробно. Кроме того, узлы, которые являются дочерними узлами многочисленных родительских узлов, могут запоминаться в специальном порядке для того, чтобы облегчить их быстрый поиск и минимизировать число битов, требуемых для их адресации. Наконец, в блоке 666 данные, созданные вышеописанным способом, записываются в файл.
При выборе инструкций 558 для описания объектов, которые должны будут запоминаться при построении дерева в блоке 658, следует иметь в виду, что, когда объектами являются слова или корни слов, их последовательности знаков содержат дополнительные данные, которые могут успешно использоваться для увеличения избыточности узлов в дереве 110. Например, не все пары букв на английском языке являются одинаково широко распространенными, например "s" обычно сочетается с "t". Для того, чтобы с большой вероятностью предсказывать следующую букву в объекте, исходя из предшествующей буквы, можно использовать статистику пар буквы или групп из двух букв. С помощью таких предсказаний логический порядок неоднозначных символов в таблице 550 индексов логических символов может динамически изменяться для того, чтобы дополнительно оптимизировать использование первого положения. Предсказания можно распространить и на триплеты букв, группы из трех букв и вообще на группы из n букв.
На фиг. 15 показана блок-схема предпочтительного варианта осуществления процесса программного обеспечения для сворачивания дерева 110 словарного модуля. Блок 670 берет начало из блока 660 по фиг.14. Блок 672 инициализирует процесс, начинающийся с первого узла дерева 110 по фиг.10 после корневого узла 111. Для того, чтобы расположить узел, который является максимально избыточным по отношению к текущему узлу, если такой вообще имеется, блок 674 вызывает подпрограмму 690, показанную на фиг.16. Если нужный узел найден, то блок 676 принятия решения направляет процедуру обработки в блок 678, где избыточные узлы сливаются вместе, удаляя дублирующие друг друга данные из дерева, подразделяя многочисленные отдельные примеры инструкций на совместно используемые последовательности, которые являются общими правилами для привязки последовательностей нажатий клавиш к объектам. Если блок 676 принятия решения принимает отрицательное решение, то блок 680 принятия решения проверяет, выполнен ли процесс. Если имеются еще узлы для обработки, то процесс переходит к блоку 682, чтобы идентифицировать другой узел.
На фиг. 16 показана блок-схема предпочтительного варианта осуществления процесса программного обеспечения для поиска в дереве 110 узла с наивысшей степенью избыточности относительно данного узла. Блок 690 берет начало из блока 674 по фиг.15. Блок 692 инициализирует метку-заполнитель "MAX-SAVINGS" для измеренной избыточности. Блок 694 инициализирует процесс, начинающийся с корневого узла 111 дерева 110 по фиг.10. Для вычисления избыточности данного узла относительно текущего узла блок 696 вызывает подпрограмму 710 по фиг. 17. Блок 698 принятия решения проверяет, является ли степень избыточности больше, чем сообщено с помощью MAX-SAVINGS. Если да, то блок 700 записывает идентификацию BEST-NODE (лучший узел) для узла, который предварительно был найден, как наиболее избыточный относительно данного узла, и сообщенное измеренное значение избыточности MAX-SAVINGS. Блок 702 принятия решения проверяет, были ли оценены все узлы. Если нет, то процесс переходит к блоку 704, который продвигается от текущего узла к следующему узлу. Из блока 704 процесс возвращается в блок 696. Если результатом проверки в блоке 702 принятия решения является то, что был оценен последний узел, то блок 706 возвращает к блоку 674 подпрограммы 670 по фиг.15 идентификацию наибольшей избыточности узла, если такой вообще имеется, к данному узлу.
На фиг. 17 показана блок-схема предпочтительного варианта осуществления процесса программного обеспечения для вычисления числовой избыточности между двумя указанными узлами. Блок 710 берет начало из блока 696 блок-схемы подпрограммы 690 по фиг.16. Блок 712 инициализирует счет дублирующих инструкций. Блок 714 инициализирует "KEY-INDEX" (индекс клавиши) равным значению 1. Блок 716 считывает пакеты 406 инструкций, ассоциированные с KEY-INDEX, из первого из двух узлов 400, определенных в качестве параметров к подпрограмме, и помещает их во временный список, LIST-A. Если клавиша "KEY-INDEX" не является подходящей клавишей, то никакие инструкции не читаются. Блок 718 считывает пакеты 406 инструкций, ассоциированные с клавишей "KEY-INDEX", из второго из двух узлов 400, определенных в качестве параметров к подпрограмме, и помещает их во временный список, LIST-B. Если клавиша "KEY-INDEX" не является подходящей клавишей, то никакие инструкции не считываются. Блок 720 принятия решения определяет, является ли либо список LIST-A, либо LIST-B пустым. Если нет, то блок 722 извлекает одну инструкцию и из списка LIST-A и списка LIST-B, уменьшая число инструкций, остающихся в каждом из них, на единицу.
Блок 724 принятия решения проверяет, являются ли инструкции одинаковыми в их полях LOGICAL-SYMBOL-INDEX (индекс логического символа) и OBJECT-LIST-INDEX (индекс списка объектов). Если нет, то код неуспеха для состояния без избыточности в блоке 726 возвращается к блоку 696 подпрограммы 690. Если блок принятия решения 724 дает утвердительный ответ, то блок 728 дает приращение счета SAVED-INSTRUCTIONS (сохраненные инструкции). Управление снова переходит к блоку 720. Если блок 720 принятия решения дает утвердительное решение, то управление переходит к блоку 730 принятия решения, который проверяет, сравнивались ли два узла относительно всех возможных клавиш. Если нет, то блок 732 дает приращение для "KEY-INDEX" (индекс клавиши), и управление переходит к блоку 716. Если в блоке 730 принято утвердительное решение, управление переходит к блоку 734, чтобы повторно установить "KEY-INDEX" равным значению 1. Блок 736 проверяет указатели, ассоциированные с клавишей "KEY-INDEX" из двух узлов.
Блок принятия 738 решения проверяет, является ли какой-либо указатель пустым ("NULL" - пустой указатель), что имело бы место для указателя в конечном узле или для любой клавиши, которая не является подходящей. Если нет пустых указателей, управление переходит к блоку 740, который использует подпрограмму 710 рекурсивно, чтобы проверить, являются ли избыточными дочерние узлы, на которые указывают два непустых указателя. Результат блока 740 проверяется в блоке 742 принятия решения. Если оказалось, что два дочерних узла не избыточны, то в блоке 744 код неудачи убирается. В противном случае два дочерних узла оказываются избыточными с некоторой числовой оценкой, которая накапливается блоком 746. Блок 748 принятия решения проверяет, были ли проверены указатели, ассоциированные с последней клавишей (клавиша 9 в предпочтительном варианте осуществления). Если нет, то блок 752 дает приращение "KEY-INDEX" (индекс клавиши) и передает управление к блоку 736. Если проверка в блоке 748 определяет, что все указатели были проверены, то выдается накопленное числовое измерение избыточности двух узлов первоначально идентифицированной при вводе подпрограммы в блок 710.
Должно быть понятно, что вычисление числовых значений избыточности может быть взвешено для учета дополнительных факторов, таких как число ветвей, находящихся в каждом узле, и число родительских узлов, которые указывают на узел, как на дочерний. Должно быть понятно, что если два узла не являются избыточными из-за очередности инструкций, ассоциированных с некоторой клавишей, то очередность инструкций, ассоциированных со словами, имеющими низкую частоту использования в вводимом лексиконе, можно было бы переупорядочить, не затрагивая приоритет инструкций, ассоциированных с объектами, имеющими более высокую частоту использования, таким образом увеличивая избыточность дерева.
III. Пример работы схемы
Фиг. 18А-18К изображают дисплей 53 портативного компьютера 52 во время типичного использования системы устранения неоднозначности с уменьшенной клавиатурой. После включения питания портативного компьютера текстовая область 66 и область 70 списка выбора пусты. На фиг.18А изображено, как пользователь напечатал фразу "This is a test" (Это - проверка). Словарный модуль идентифицировал наиболее вероятную интерпретацию последовательности последних четырех нажатий клавиш TUV, DEF, PQRS, TUV как слово "test" и предварительно выставил эту интерпретацию в месте 900 вставки, и также поместил это слово первым в списке выбора как интерпретацию 901 по умолчанию. Этот первый элемент данных в списке выбора был очерчен вокруг рамкой со сплошной линией (показывая, что это неявно выбранный объект), а также он был предварительно выставлен в текстовой области в месте 900 вставки с рамкой со сплошной линией, очерченной вокруг него. Словарный модуль также идентифицировал интерпретацию слова "vest" и интерпретацию корня "vert" и поместил эти интерпретации в список выбора. Программное обеспечение обработки клавиши знаков препинания, показанное на фиг.5А и 5Б, сохранило текстовый объект "test" в буфере СurPunctWord (буфер хранения слова, к которому должен присоединиться знак препинания).
На фиг. 18Б изображен результат нажатия пользователем клавиши 63 знаков препинания: точку, тире и апостроф .- . В базе данных нет объекта, соответствующего последовательности нажатий клавиш из четырех клавиш TUV, DEF, PQRS, TUV, за которыми следует клавиша 63 знаков препинания. Таким образом, в списке выбора появляются только те текстовые объекты, которые добавляются программным обеспечением обработки клавиши знаков препинания, состоящие из слова "test" из буфера СurPunctWord с присоединенными точкой 911, тире 913 и апострофом 914. Результирующим объектом списка выбора по умолчанию является слово "test" 911, которое также предварительно выставляется в текстовой области в 910 точке вставки.
На фиг. 18В изображен результат нажатия пользователем клавиши "Space" (пробел) 922. Это создало явный знак пробела, который закончил текущую последовательность нажатий клавиш и обусловил принятие системой предварительно выставленного текста "test". Также может быть выведен следующий пробел, после которого появляется системный курсор 920. Сейчас буфер нажатия клавиш пуст, и, таким образом, текущий список 921 выбора также пуст. Это иллюстрирует один из примеров поведения по умолчанию клавиши 63 знаков препинания, когда она активизируется перед активизацией клавиши "Space" (пробел) или "Select" (выбор), при отсутствии совпадения с объектом в базе данных, содержащей соответствующий знак препинания, предыдущий текстовый объект по умолчанию выводится с присоединенной точкой.
В случае системы, разработанной для английского языка (в которой флаг Apostrophe_ S (апостроф с последующей буквой "s" устанавливается истинным (TRUE)), фиг.18Г изображает результат, который следует после фиг.18Б, когда пользователь нажимает клавишу PQRS 932. Это запускает обработку, соответствующую блокам 332-342 на фиг.5Б, и приводит к программному обеспечению обработки клавиши знаков препинания, добавляющему к списку выбора объекты "test's", "test-s", "test-r", "test-p" и "test-q" в этом порядке. Таким образом, результирующим объектом списка выбора по умолчанию является объект "test" 93, который также предварительно выставляется в текстовой области в месте 930 вставки.
Фиг.18Д изображает результат, который следует после фиг.18Г, когда пользователь нажимает клавишу TUV 932 (с целью печатания слова с тире "test-run"). Это запускает обработку, соответствующую блокам 332-340 на фиг.5Б, и приводит к тому, что программное обеспечение обработки клавиши знаков препинания выводит текстовый объект "test-" в качестве принятого текста и изменяет содержимое буфера нажатия клавиш так, чтобы он вместил только два последних нажатия клавиш PQRS и TUV. Опрос базы данных (в блоке 360 на фиг. 5Б), основанный на этих двух нажатиях клавиш, приводит к списку выбора, изображенному на фиг.18Д. Текстовый объект "st" является наиболее частым и поэтому появляется как объект "st" 941 списка выбора по умолчанию, и также предварительно выставляется в текстовой области в месте 940 вставки.
Фиг. 18Е изображает результат, который следует после фиг.18Д, когда пользователь нажимает клавишу MNO 952, чтобы закончить печать слова с тире "test-run". Никакой специальной обработки клавиши знаков препинания не происходит, так как при обработке предыдущего нажатия клавиши в блоке 362 фиг. 5Б были очищены все флаги. Таким образом, система просто обрабатывает текущую последовательность клавиш PQRS, TUV, MNO. Опрос базы данных на основе этих трех нажатий клавиш заканчивается списком выбора, изображенным на фиг. 18Е. Текстовый объект "run" является наиболее частым и, таким образом, появляется как объект "run" 951 списка выбора по умолчанию, и также предварительно выставляется в текстовой области в месте 950 вставки.
Фиг. 18Ë - 18K показывают пример для системы, разработанной для французского языка (в которой флаг Apostrophe_Term (слово, заканчивающееся апострофом) устанавливается истинным (TRUE)). В этом примере пользователь печатает текстовый объект "c est", который фактически состоит из слова "с", ассоциированного со словом "est". Фиг.18Ë изображает результат в случае, когда пользователь нажимает клавишу АВС 962. Список выбора показывает объекты из одного символа, ассоциированные с клавишей АВС для французского языка, включая ударные символы à, â и ç. Никакой специальной обработки клавиши знаков препинания не происходит, так как все флаги, ассоциированные с клавишами знаков препинания, были предварительно очищены. Система просто обрабатывает текущую последовательность клавиш АВС. Опрос базы данных на основе этих нажатий клавиш приводит к списку выбора, показанному на фиг.18Ë. Текстовый объект "а" является наиболее частым и появляется как объект "à" 951 списка выбора по умолчанию, и также предварительно выставляется в текстовой области в месте 960 вставки.
На фиг.18Ж изображен результат нажатия пользователем .- клавиши 63 знаков препинания. Объекты "с" и "а-" запомнены в базе данных и согласно обработке в блоках 156-160 по фиг.3 добавляются к списку выбора после опроса базы данных, так что результирующим объектом списка выбора по умолчанию является объект "с " 971. Следовательно, каждая из проверок в блоках 300-306 на фиг.5Б имеет положительный ответ, и флаг pState (текущее состояние программного обеспечения клавиши знаков препинания) устанавливается в состояние PUNCT_ APOS (слово, заканчивающееся апострофом, уже добавлено к списку выбора) в блоке 308. После объектов "с " 971 и "а-" 973 в списке выбора, программное обеспечение обработки клавиши знаков препинания (в блоках 312, 314 и 316 на фиг.5Б) добавляет объекты 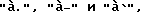 состоящие из объекта буфера СurPunctWord (буфер хранения слова, к которому должен присоединяться знак препинания) "à" с присоединенными точкой 974, тире 975 и апострофом 976. Результирующим объектом списка выбора по умолчанию является объект "с " 971, который также предварительно выставляется в текстовой области в месте 970 вставки.
состоящие из объекта буфера СurPunctWord (буфер хранения слова, к которому должен присоединяться знак препинания) "à" с присоединенными точкой 974, тире 975 и апострофом 976. Результирующим объектом списка выбора по умолчанию является объект "с " 971, который также предварительно выставляется в текстовой области в месте 970 вставки.
На фиг. 18З изображен результат нажатия пользователем клавиши DEF 982. Поскольку в результате обработки предыдущего нажатия клавиши на фиг.18Ж флаг pState (текущее состояние программного обеспечения клавиши знаков препинания) был установлен в состояние PUNCT_APOS (слово, заканчивающееся апострофом, уже добавлено к списку выбора), программное обеспечение обработки клавиши знаков препинания выполняет действия в блоках 274, 276 и 262 на фиг. 5А. Текущий объект "с " списка выбора по умолчанию выводится в качестве принятого текста 983, текущий буфер нажатия клавиш очищается, и система просто обрабатывает результирующую последовательность из одной клавиши DEF как результат добавления текущего нажатия клавиши DEF к очищенному буферу нажатий клавиш. Опрос базы данных, основанный на этих результатах данного нажатия клавиши, приводит к списку выбора, изображенному на фиг.18З. Текстовый объект "d" является наиболее частым и появляется как объект "d" 951 списка выбора по умолчанию, и также предварительно выставляется в текстовой области в месте 980 вставки.
Фигуры 18И и 18К показывают результаты, которые следуют после фиг.18З, когда пользователь нажимает клавишу PQRS 992 (в 18И) и клавишу TUV 997 (в 18К) для того, чтобы закончить печатать слово "est". Никакой специальной обработки клавиши знаков препинания не происходит, так как при обработке предыдущего нажатия клавиши в блоке 262 фиг.5А был установлен флаг ClearPunctMode (все флаги и буферы, ассоциированные с клавишами знаков препинания, очищены), так что все буферы и флаги для клавиши знаков препинания были очищены в блоке 202 (фиг.5А). Таким образом, система просто обрабатывает текущую последовательность клавиш DEF, PQRS, TUV. Опрос базы данных, основанный на этих трех нажатиях клавиш, приводит к списку выбора, изображенному на фиг. 18К. Текстовый объект "est" является наиболее частым и, таким образом, появляется как объект "est" 996 списка выбора по умолчанию, а также предварительно выставляется в текстовой области в месте 995 вставки.
Французский язык содержит множество очень часто используемых суффиксов, предлогов и местоимений, таких как lе, nе, се, de, me, se, je, que, tu и te, которые в случае, когда они предшествуют слову, которое начинается с гласного, изменяют свою последнюю гласную на апостроф и печатаются без пробела перед следующим словом. За исключением режима, поддерживаемого клавишей 63 знаков препинания, иллюстрируемого предшествующим примером, это частое последовательное соединение объектов слов в противном случае потребовало бы дополнительной активизации клавиши "Select" (выбор) пользователем для завершения первого объекта слова (с в показанном примере) перед печатанием второго объекта (est). Таким образом, способность клавиши 63 знаков препинания обеспечивать автоматическое последовательное присоединение к объектам слов, которые заканчиваются апострофом, значительно увеличивает эффективность и естественное ощущение системы для языков типа французского.
Хотя был проиллюстрирован и описан предпочтительный вариант осуществления изобретения, должно быть понятно, что могут быть сделаны различные изменения, не выходящие за рамки объема и сущности изобретения. Например, специалистам должно быть понятно, что клавиатура 54 системы устранения неоднозначности с уменьшенной клавиатурой может иметь самое меньшее три или самое большее двадцать клавиш данных. Раскрытый здесь метод устранения неоднозначности одинаково применим к клавиатуре различных размеров. Могут изменяться конкретные символы, ассоциированные с клавишей 63 знаков препинания. Например, специалистам должно быть понятно, что для некоторых применений точку можно было бы заменить запятой. Кроме того, конкретный выбор того, какой знак препинания создается в различных контекстах окружающих нажатий клавиш, мог бы также быть изменен. Например, две последовательные активизации клавиши 63 знаков препинания, после которых следует "а", могут привести к созданию тире "-", в то время как три последовательных активизации могут создать многоточие "...".
Также, специалистам должно быть понятно, что в компьютер могут быть включены дополнительные словарные модули, например словарные модули, содержащие юридические термины, медицинские термины и термины иностранных языков. Посредством системного меню пользователь может компоновать систему таким образом, чтобы дополнительные слова словаря могли быть вызваны так, чтобы появляться в списке возможных слов первыми или последними, со специальной окраской или освещением. Следовательно, должно быть понятно, что в пределах прилагаемой формулы изобретения изобретение может быть на практике реализовано иначе, чем конкретно описано выше.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА УСТРАНЕНИЯ НЕОДНОЗНАЧНОСТИ С УМЕНЬШЕННОЙ КЛАВИАТУРОЙ | 1998 |
|
RU2206118C2 |
| СИСТЕМА УСТРАНЕНИЯ НЕОДНОЗНАЧНОСТИ РЕДУЦИРОВАННОЙ КЛАВИАТУРЫ | 1996 |
|
RU2221268C2 |
| ВВОД ТЕКСТА В ЭЛЕКТРОННОЕ УСТРОЙСТВО СВЯЗИ | 2003 |
|
RU2316040C2 |
| АППАРАТНЫЙ ВЕДУЩИЙ ТЕРМИНАЛ ДЛЯ СИСТЕМЫ ДОСТАВКИ ТЕЛЕВИЗИОННЫХ ПРОГРАММ И СПОСОБА ЕГО ИСПОЛЬЗОВАНИЯ | 1993 |
|
RU2112325C1 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ОНТОЛОГИЙ ПРЕДМЕТНЫХ ОБЛАСТЕЙ | 2011 |
|
RU2541221C2 |
| СПОСОБ, СИСТЕМА И КЛАВИАТУРА ДЛЯ ВВОДА ИЕРОГЛИФОВ | 2017 |
|
RU2671043C1 |
| ВЫВЕДЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ПРЕДЫДУЩИХ ВЗАИМОДЕЙСТВИЙ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2011 |
|
RU2544787C2 |
| УСТРАНЕНИЕ НЕОДНОЗНАЧНОСТИ КЛАВИАТУРНОГО ВВОДА | 2015 |
|
RU2707148C2 |
| СПОСОБ ВВОДА ТЕКСТА | 2004 |
|
RU2377664C2 |
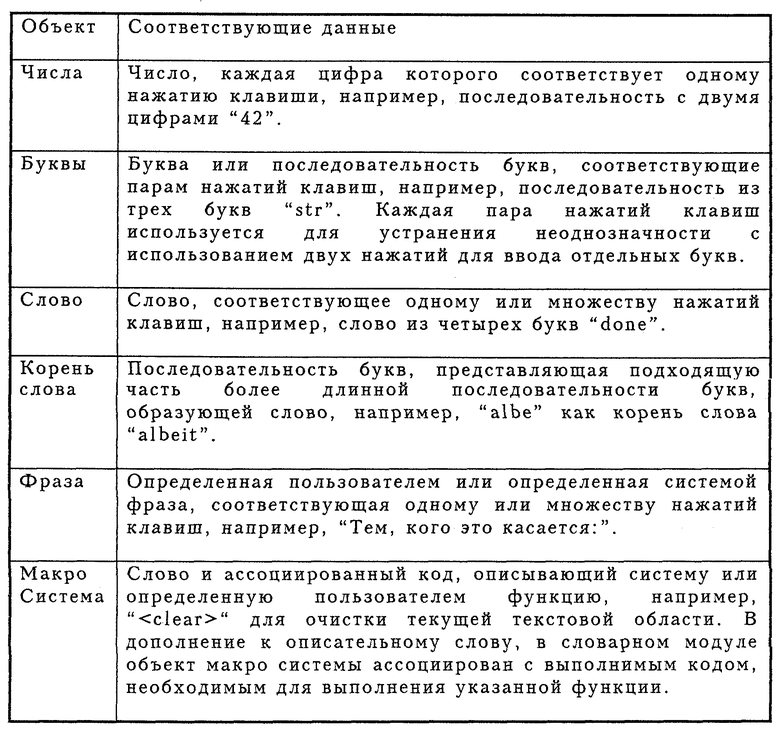
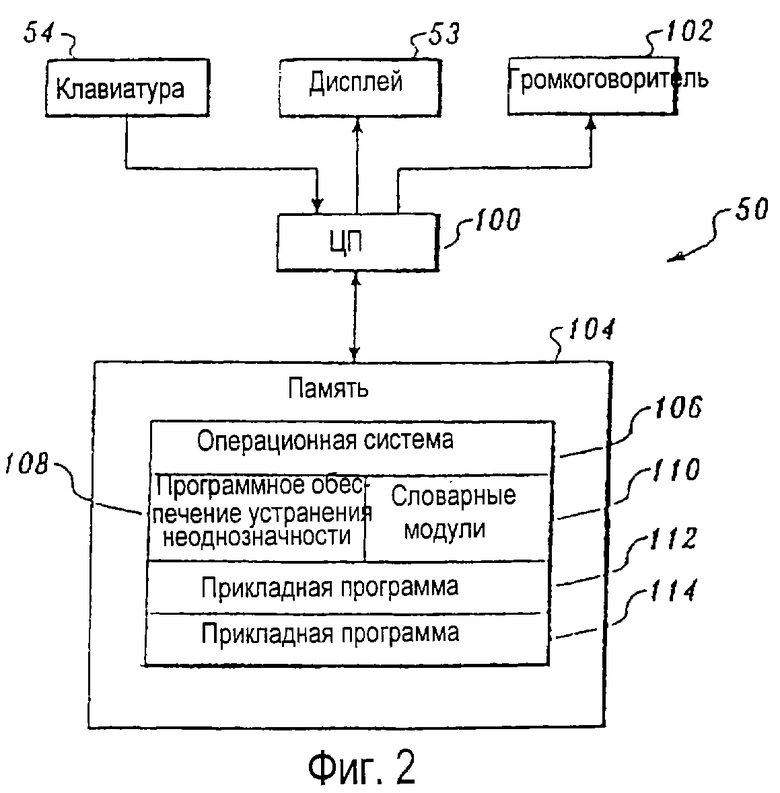
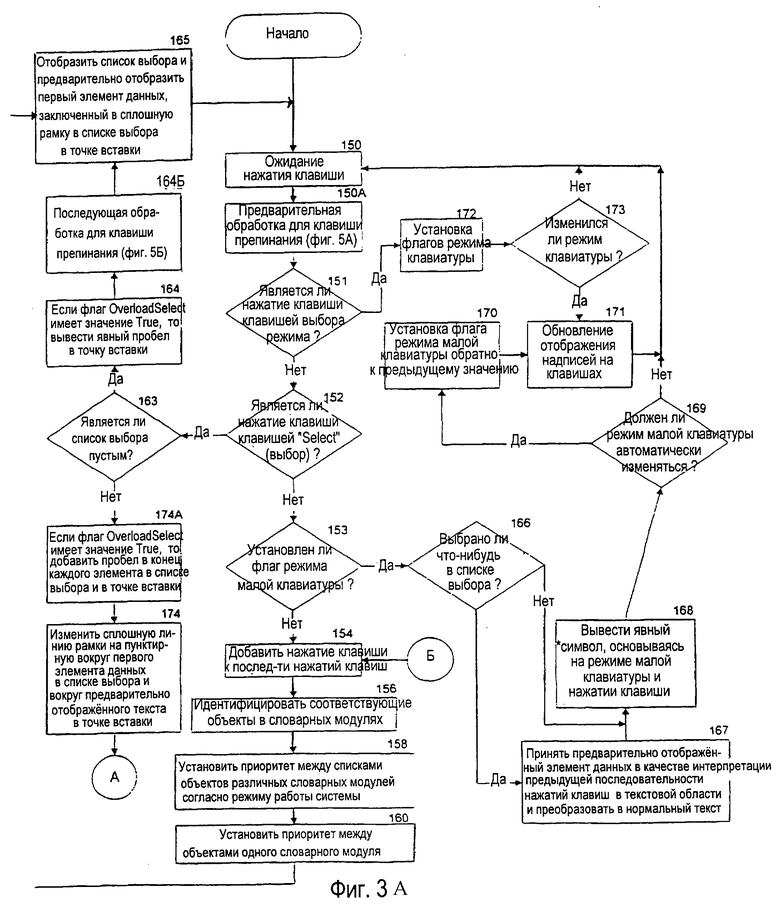
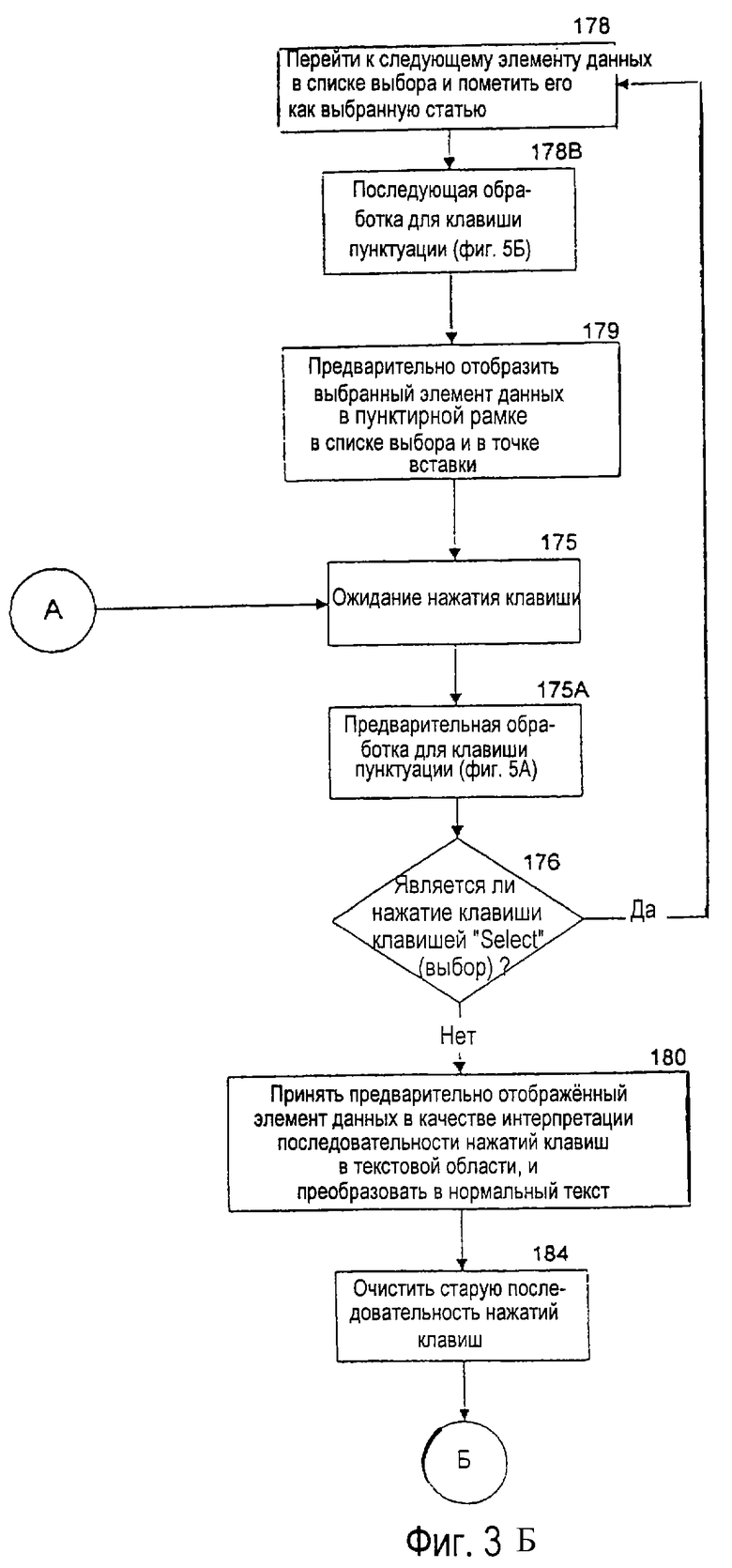
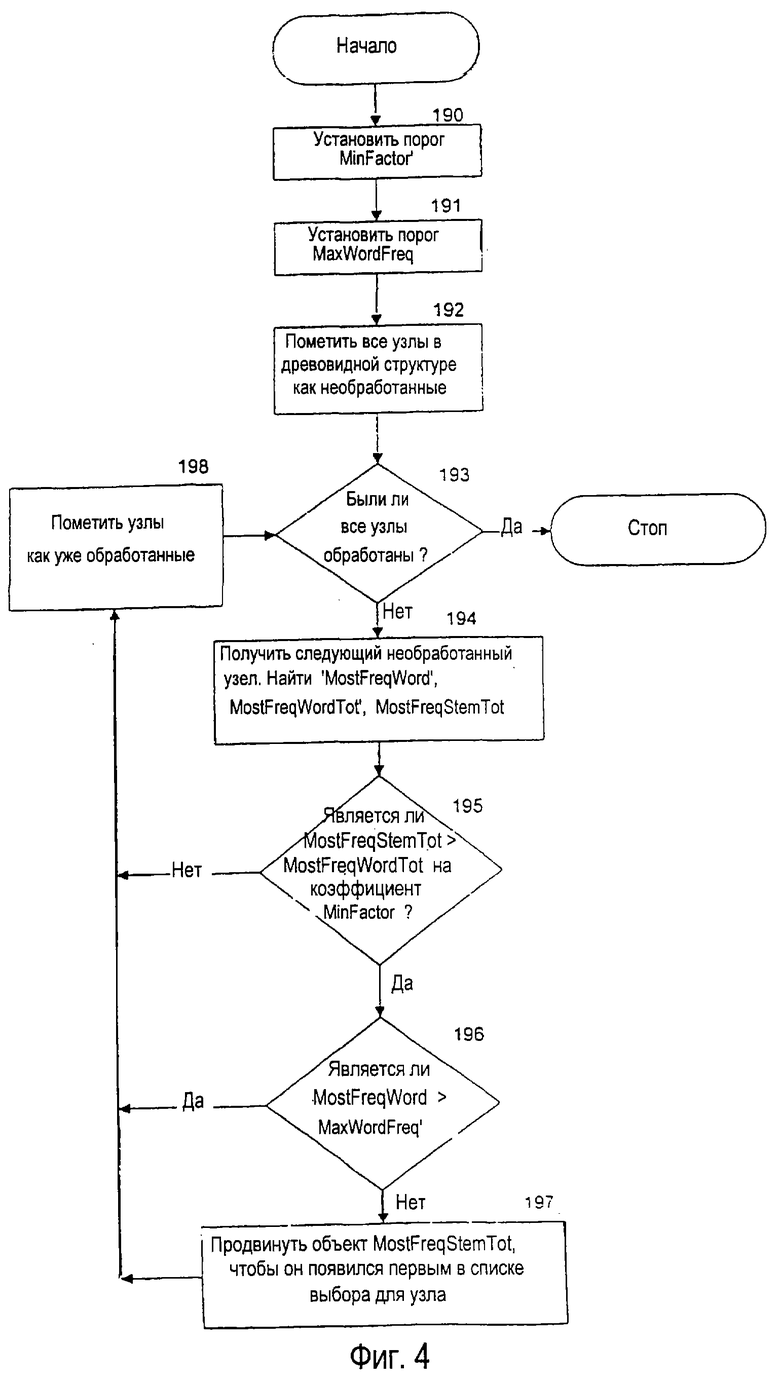
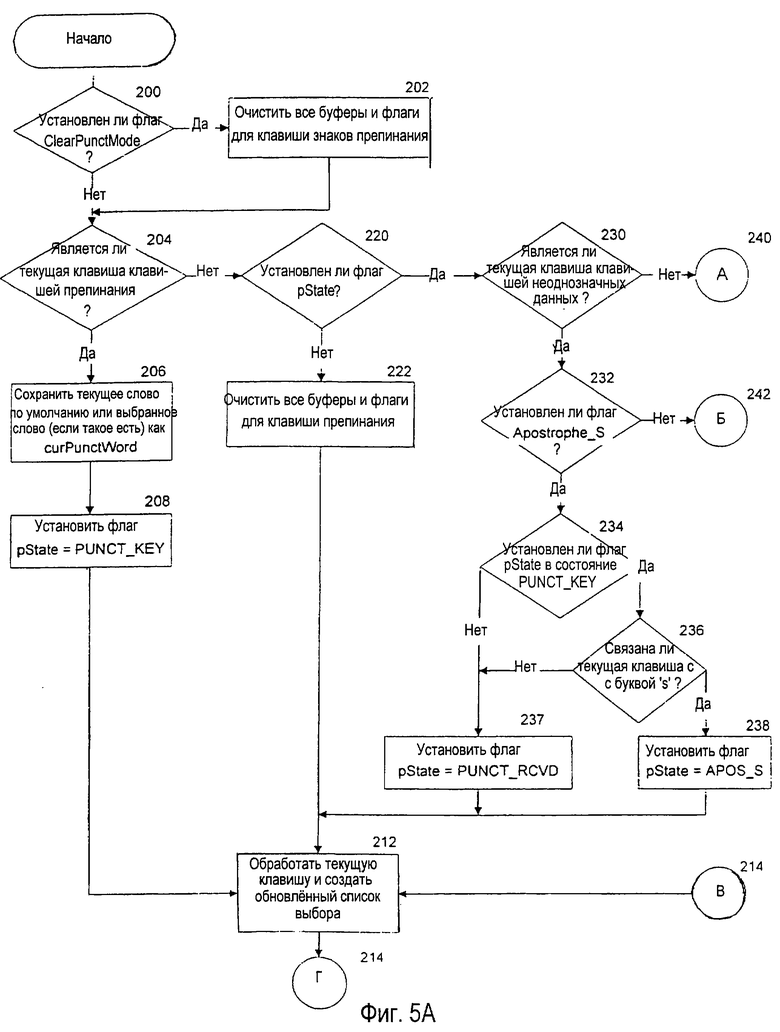
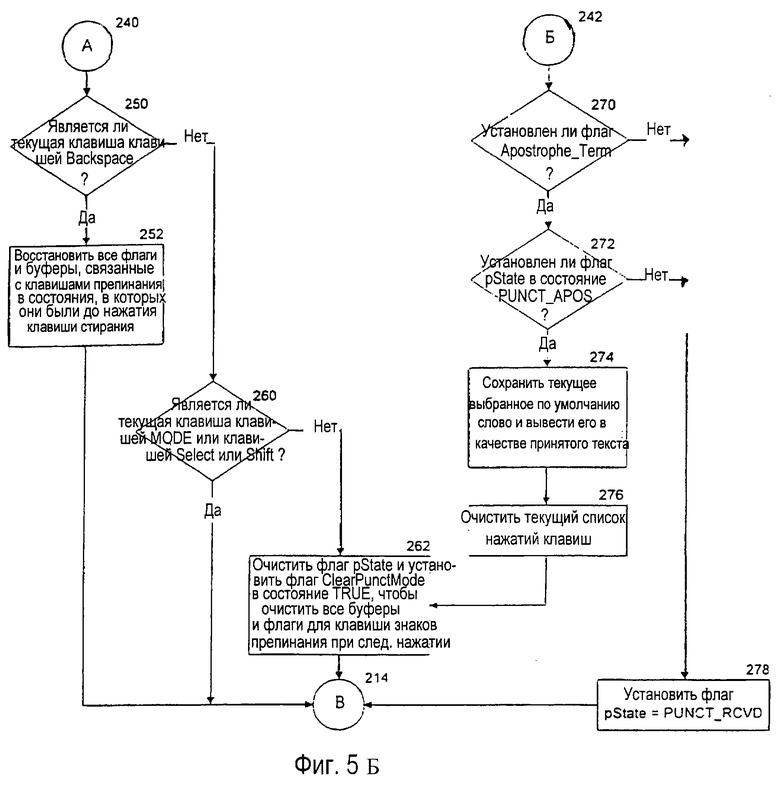
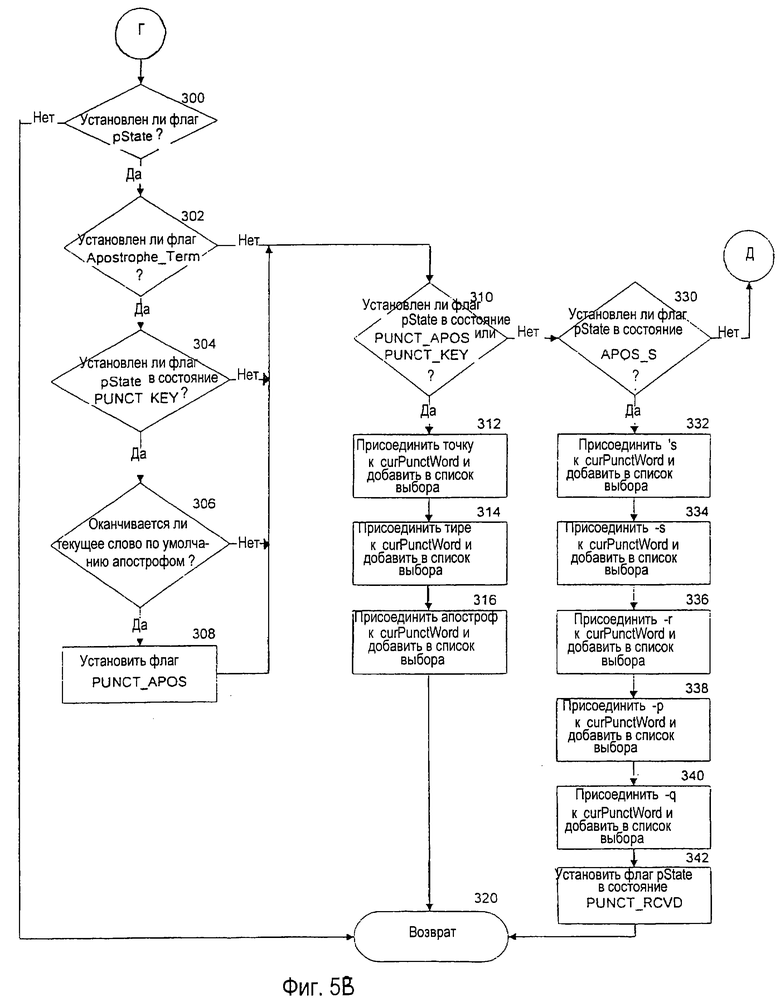
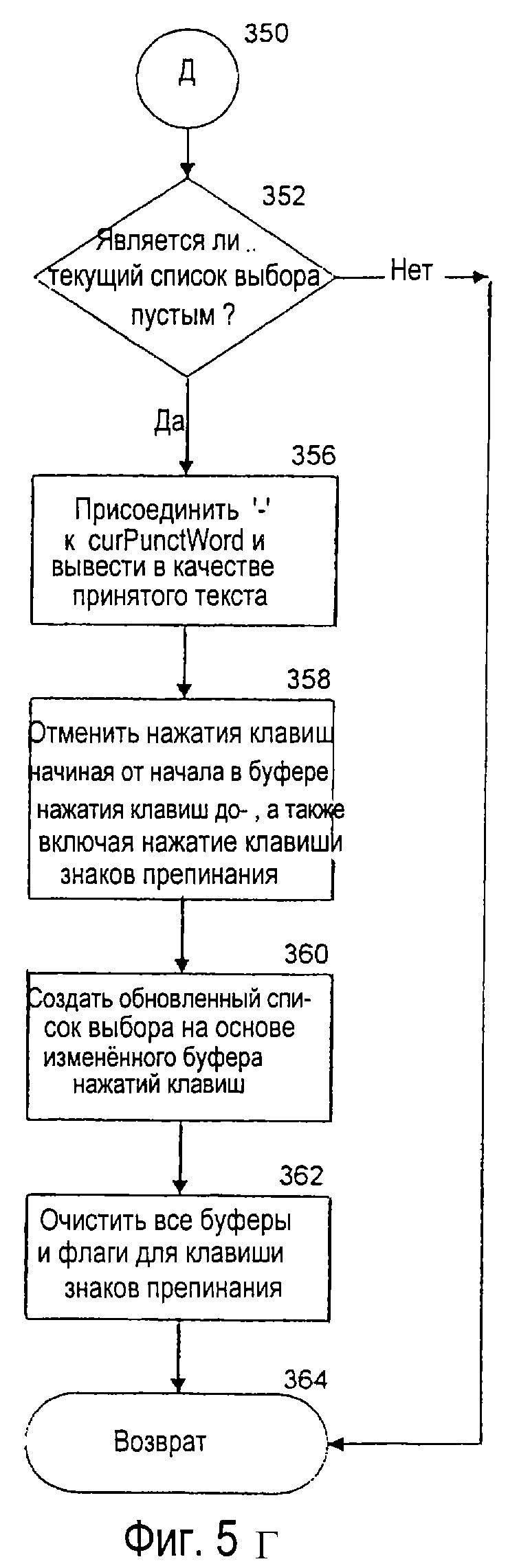
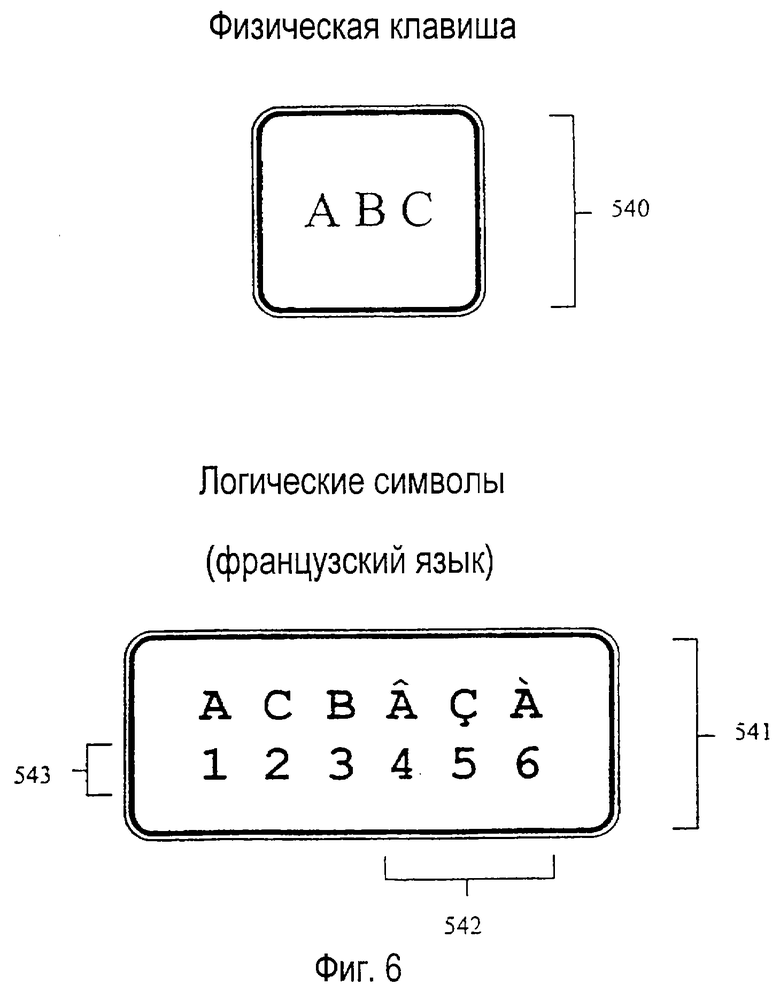
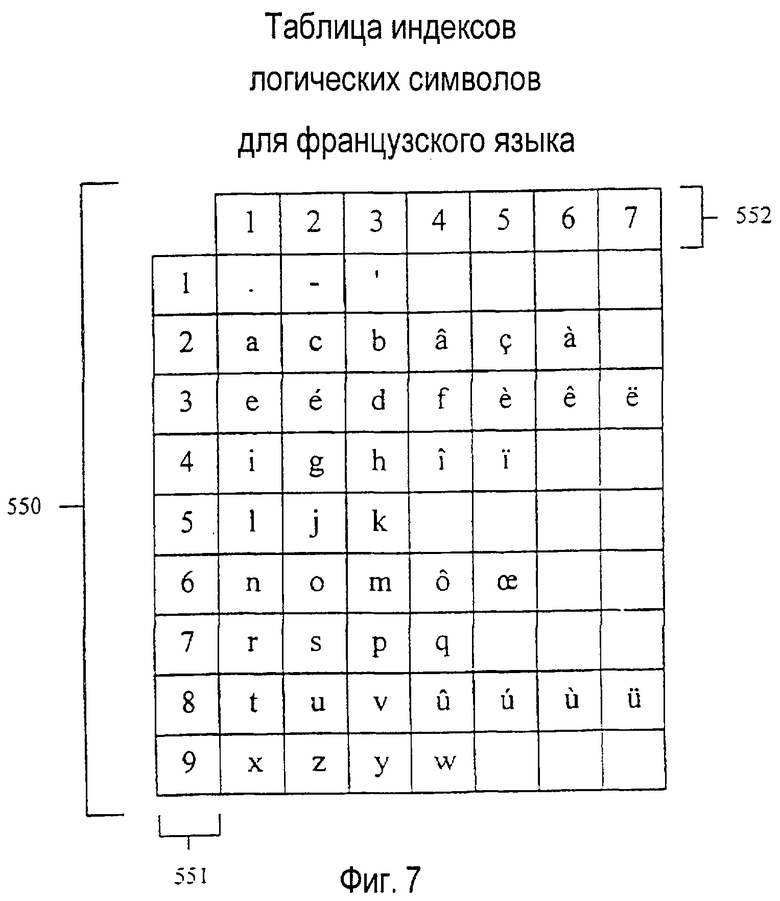
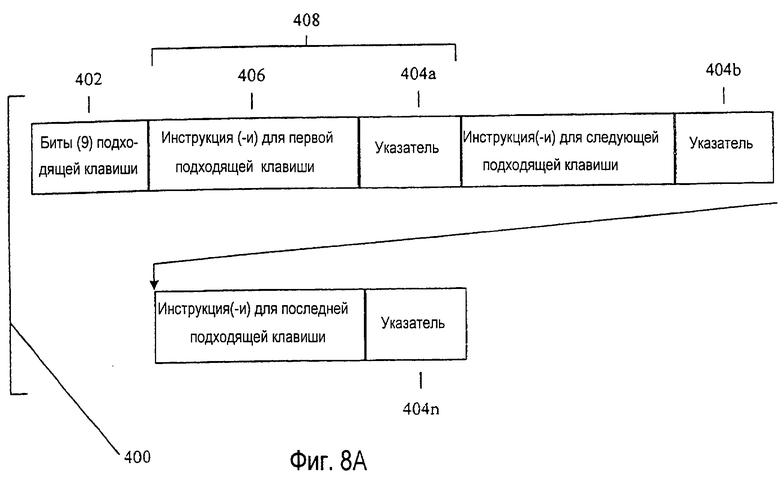

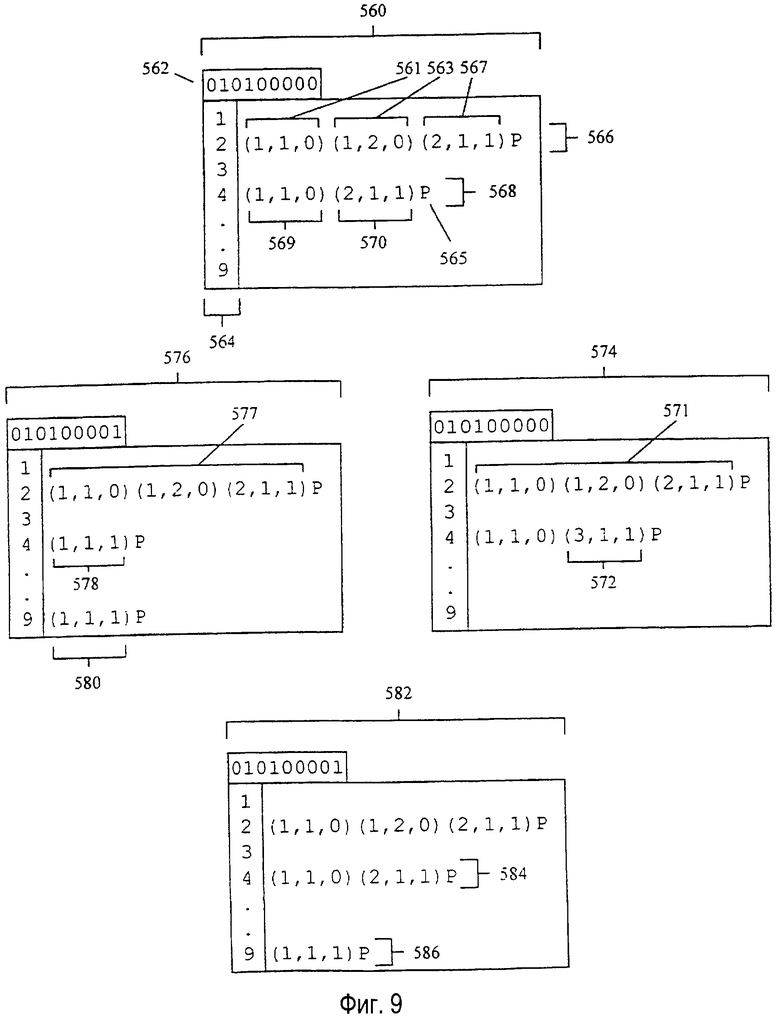
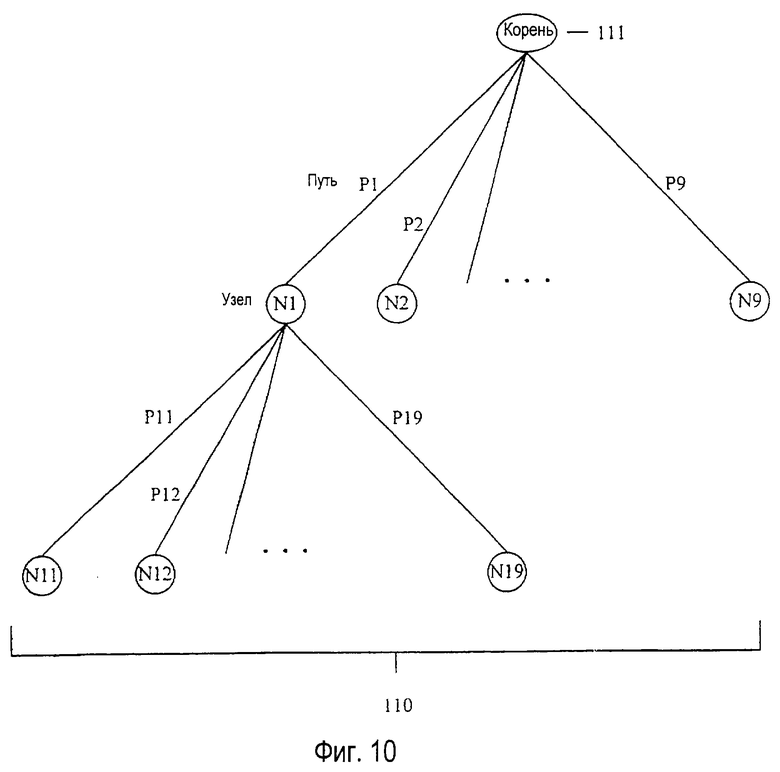
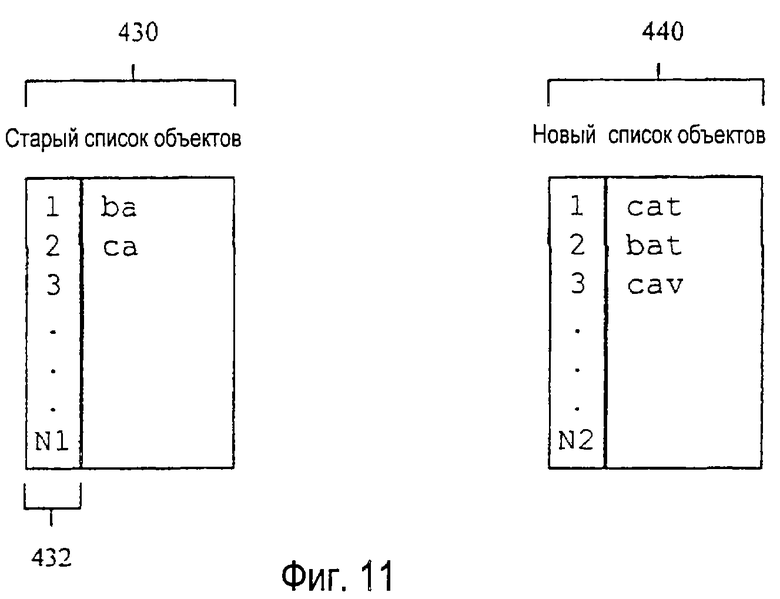
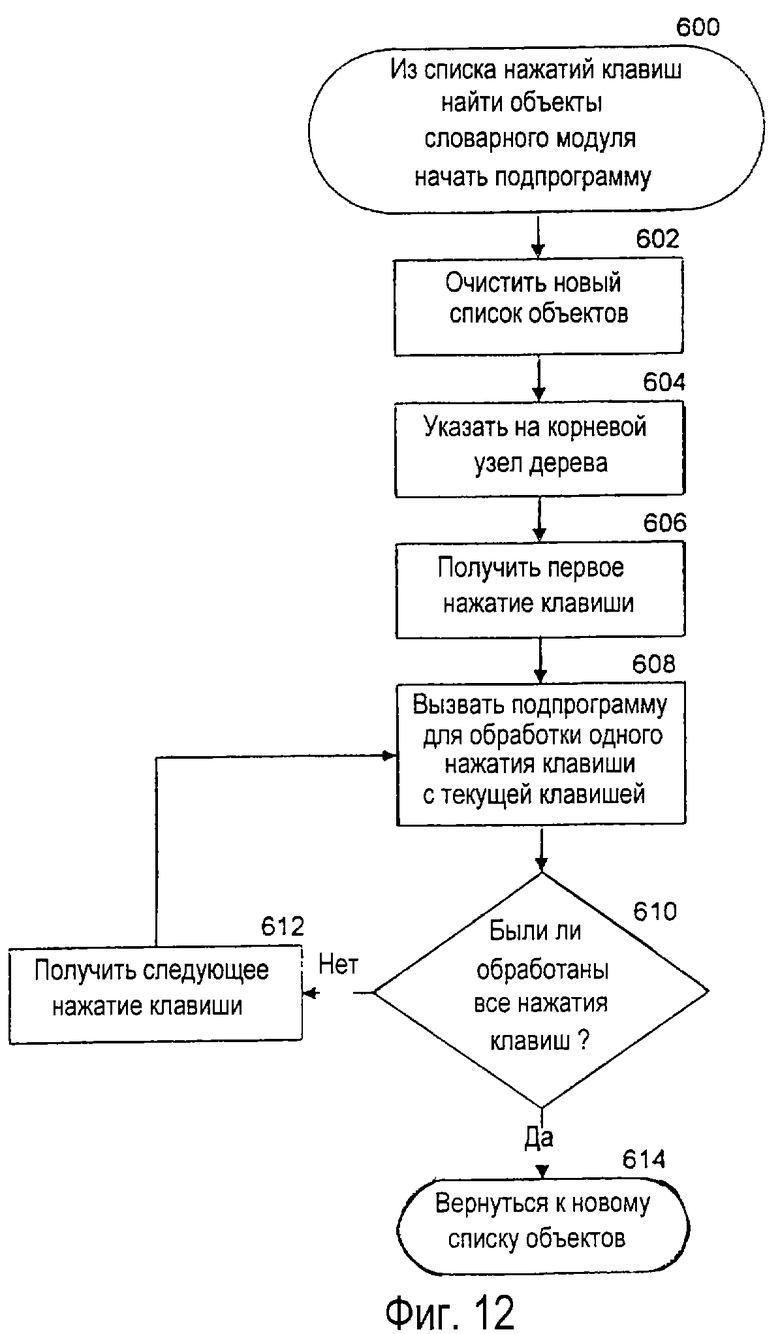
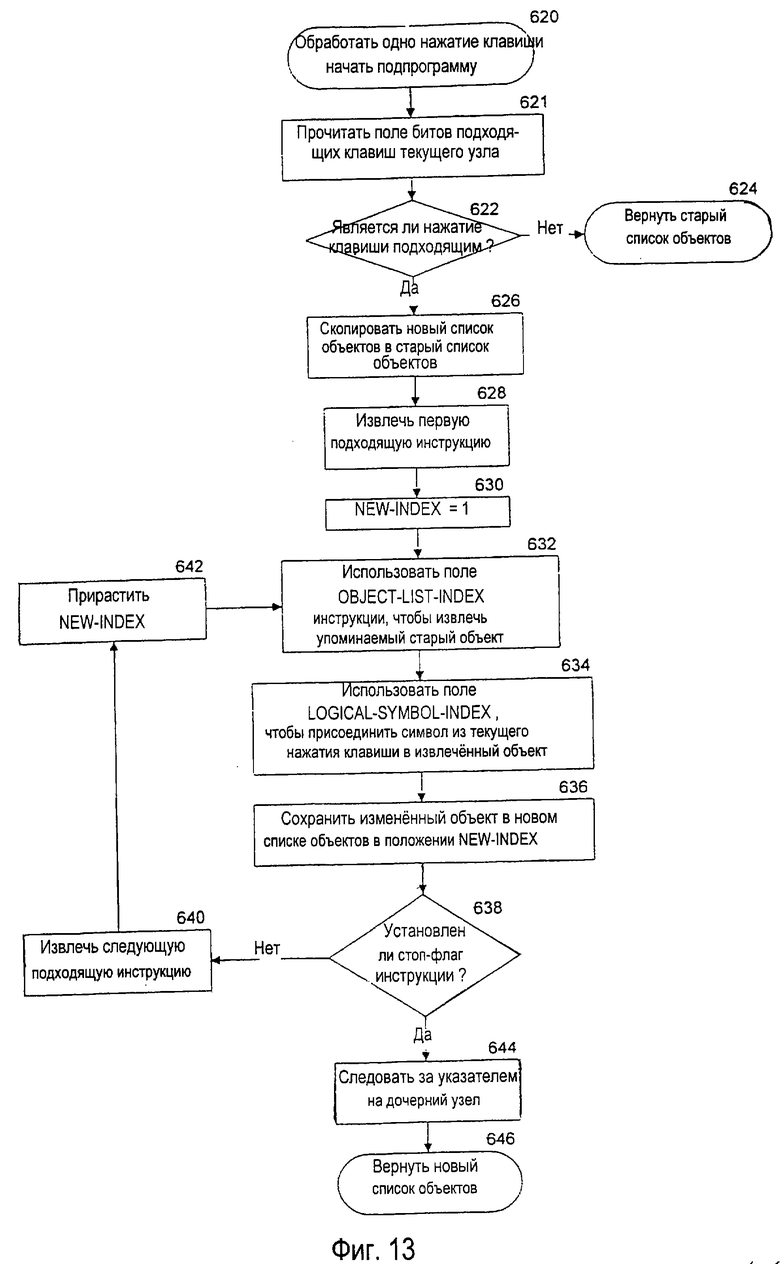
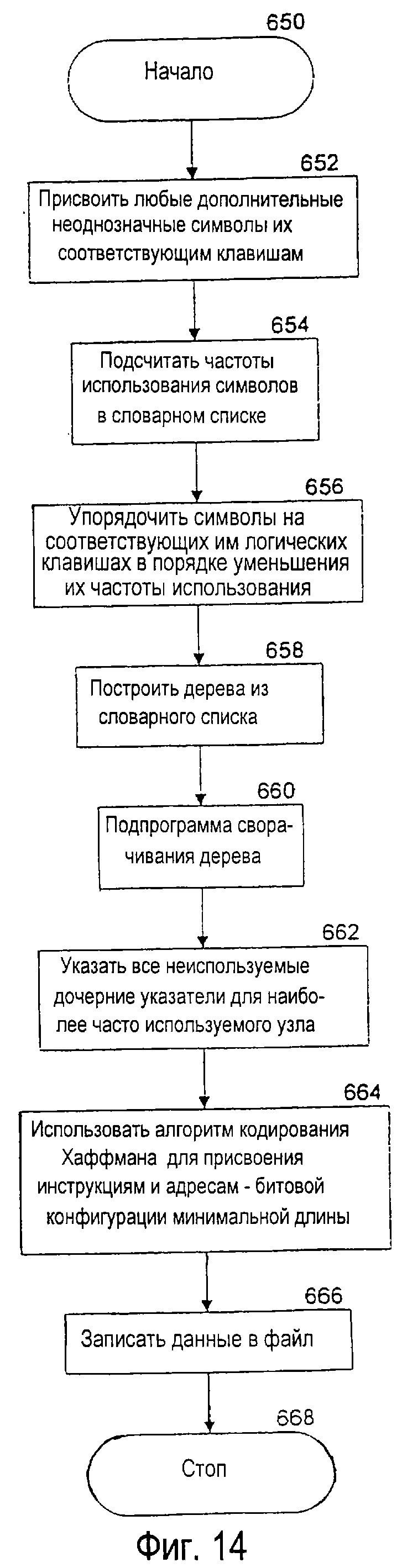
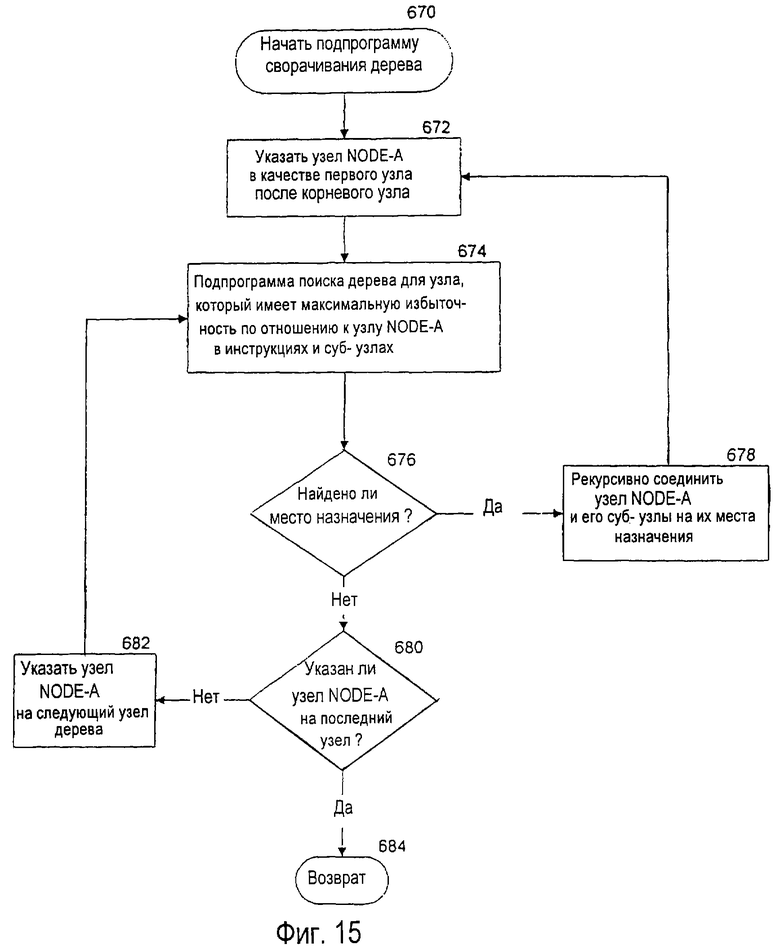
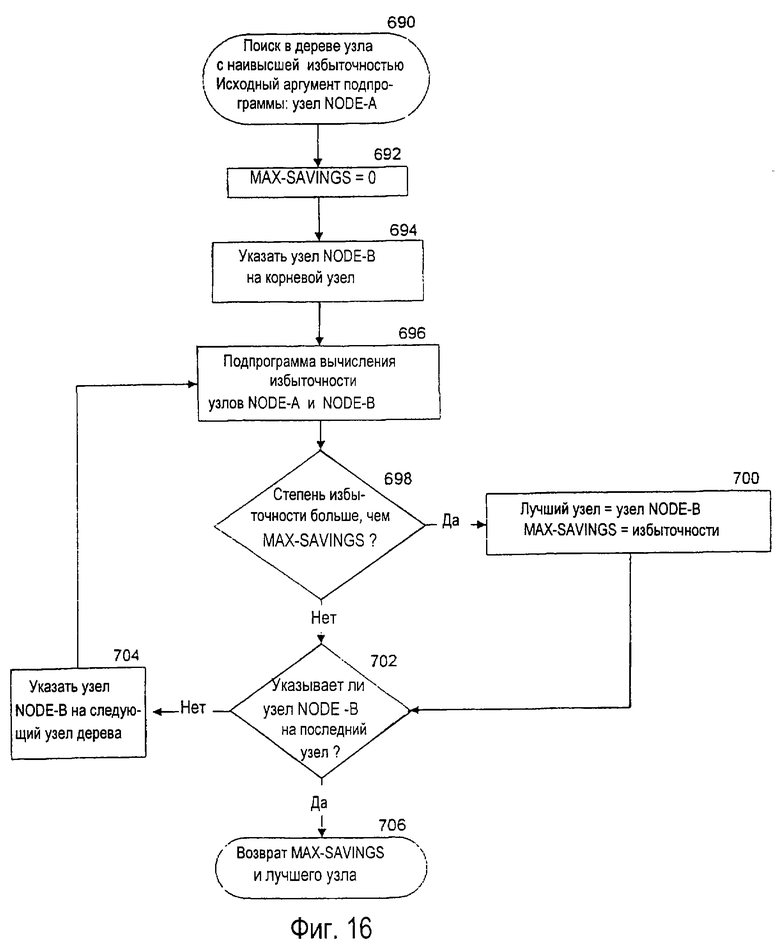
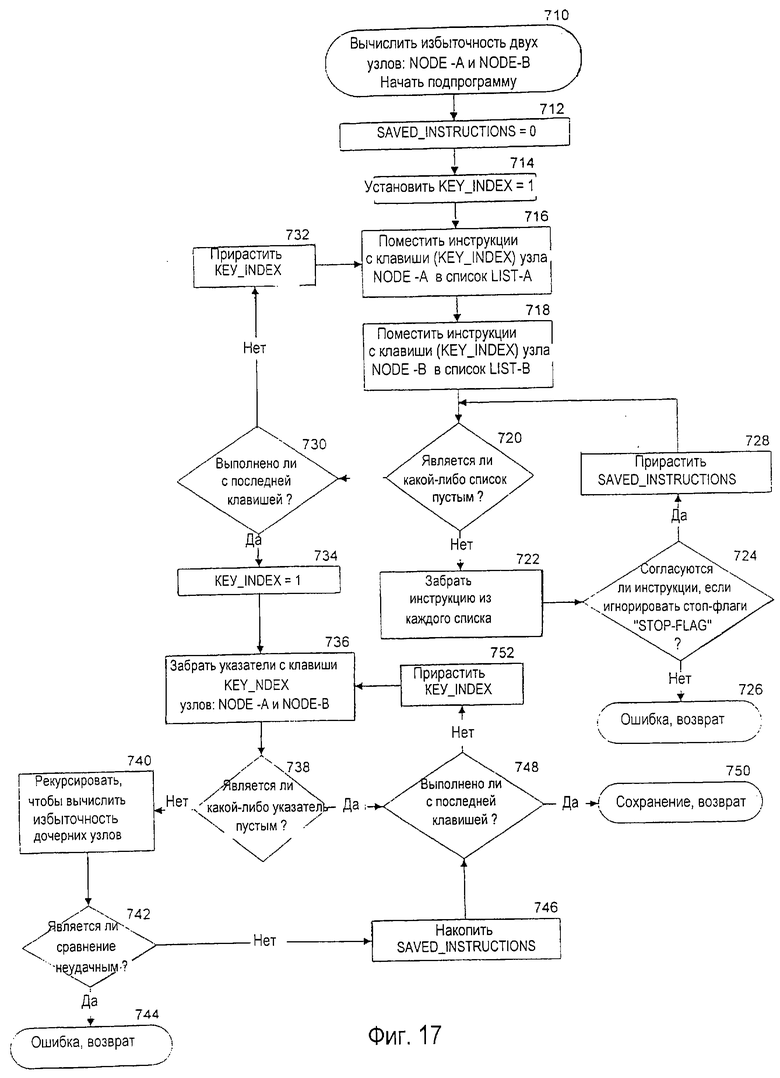
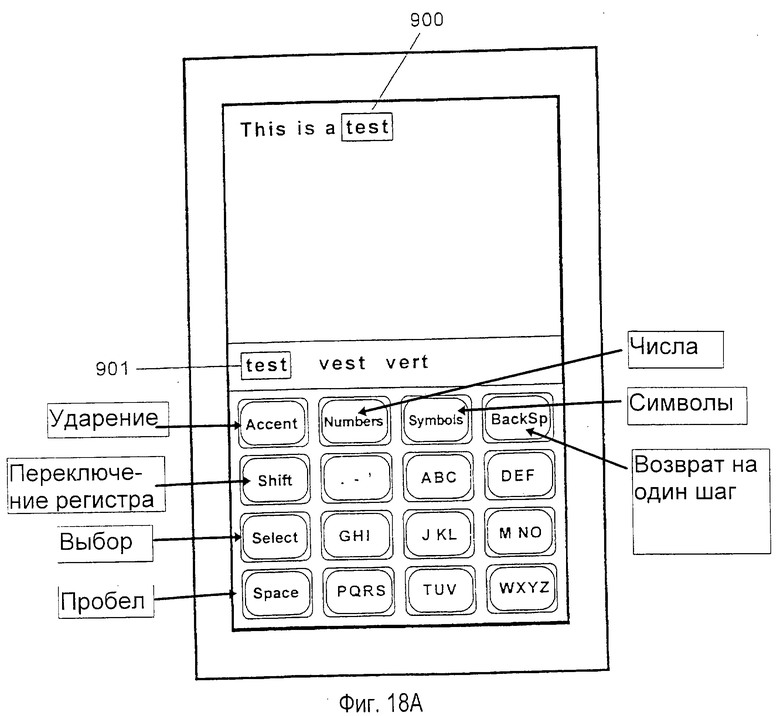
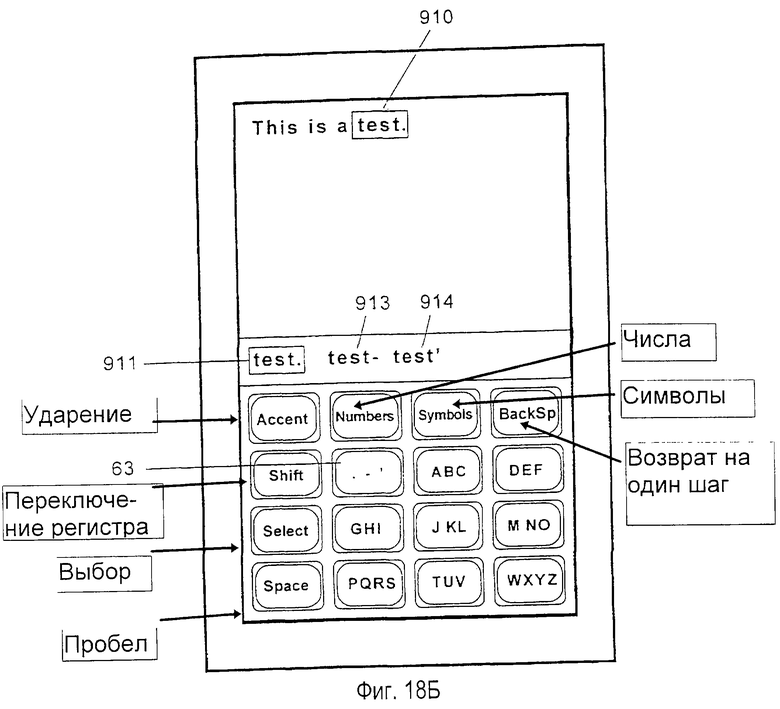
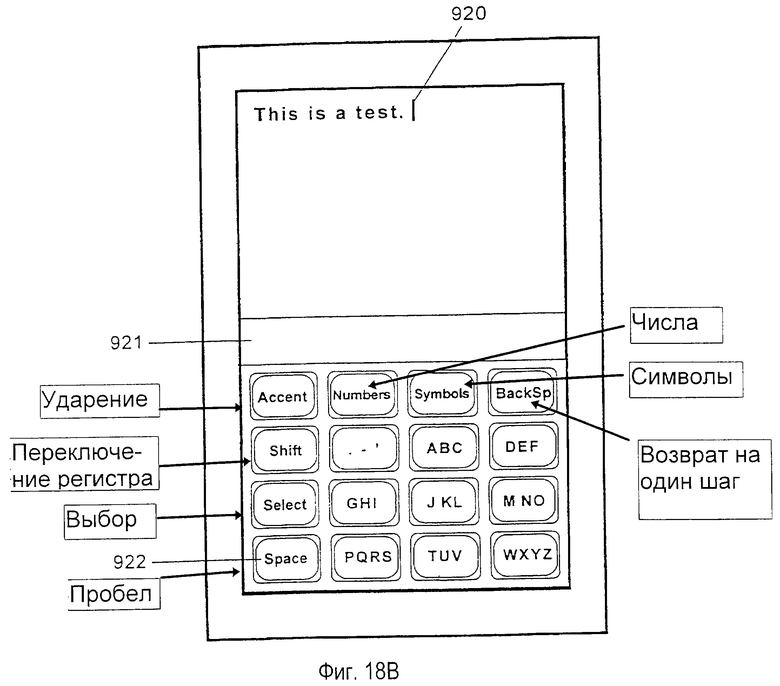

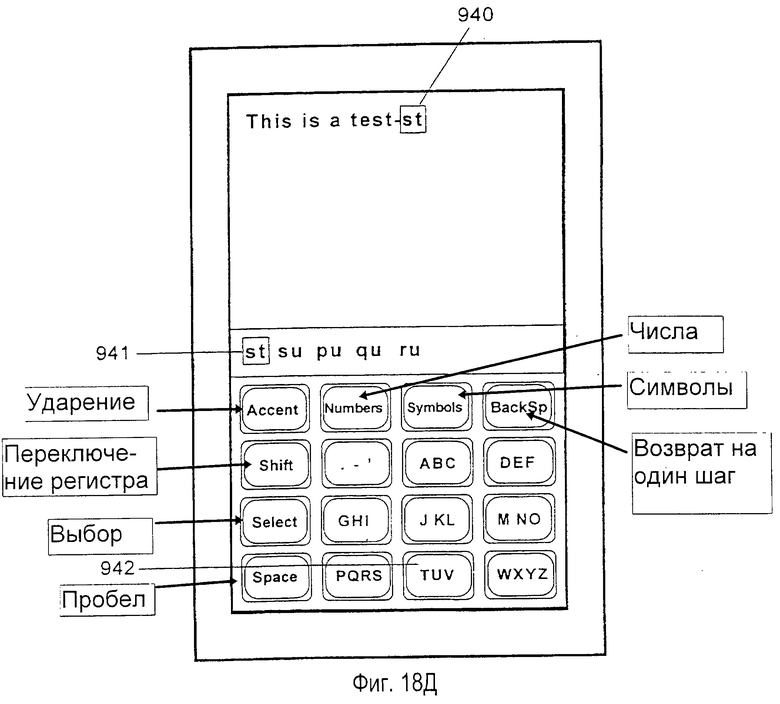
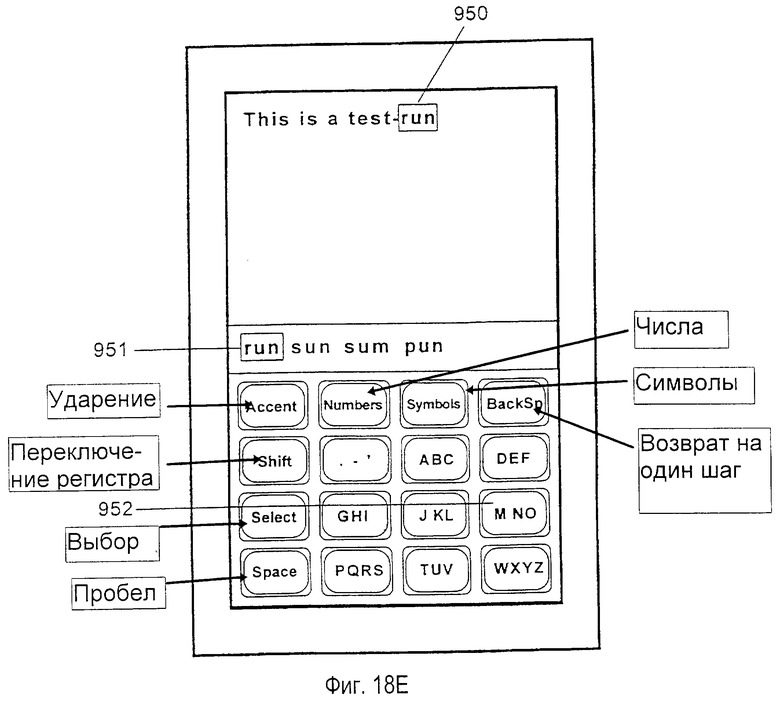
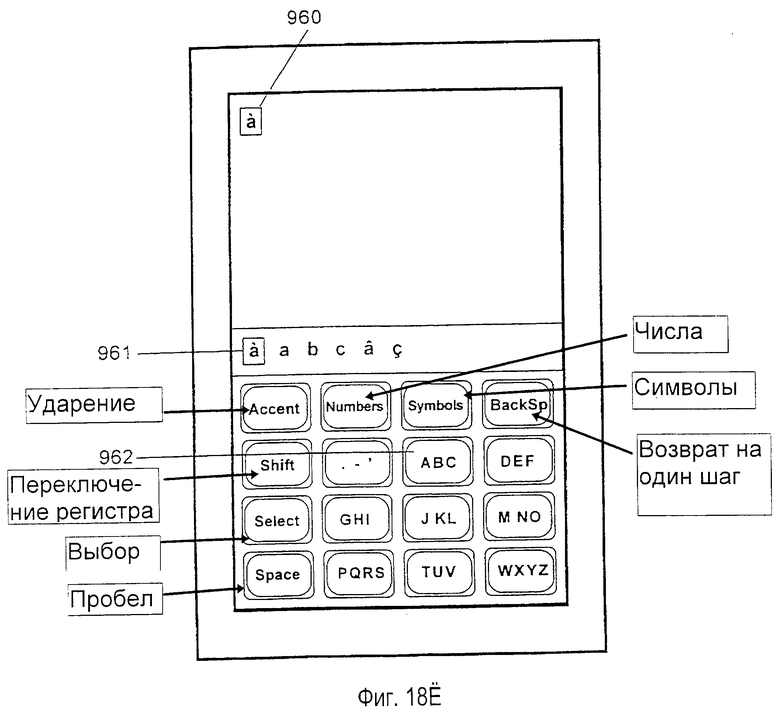
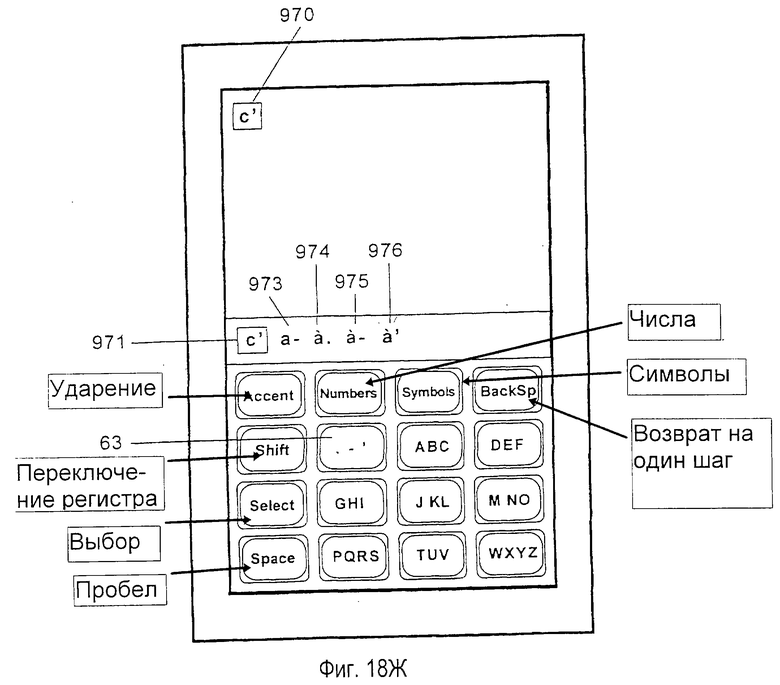
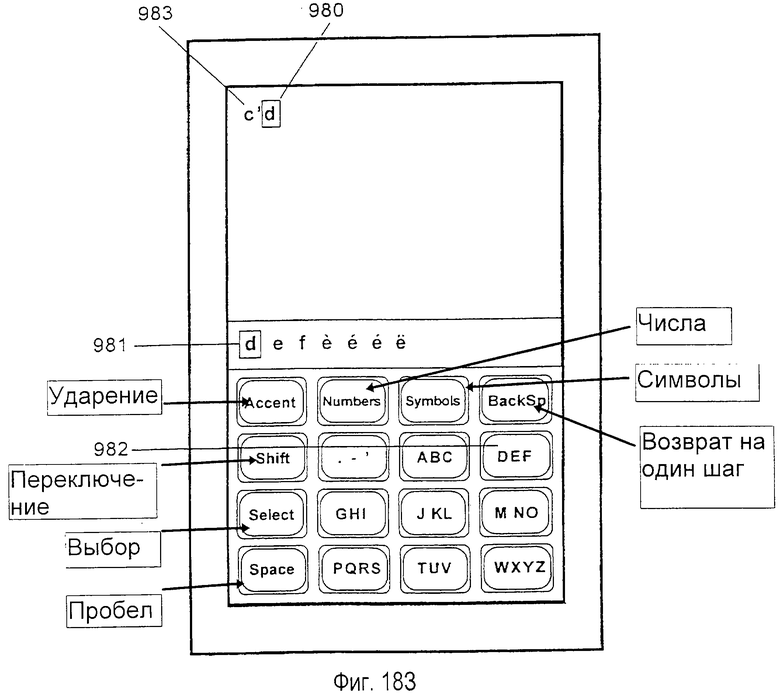
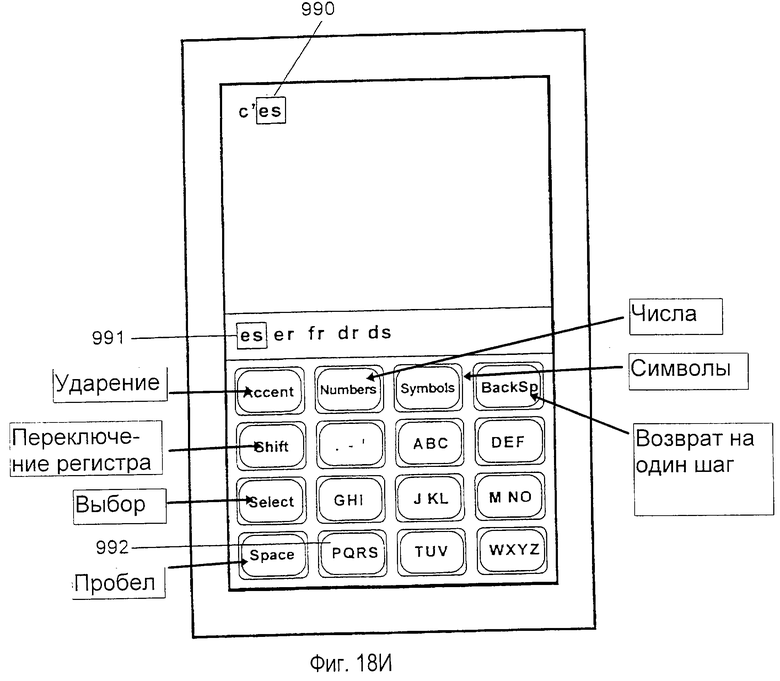
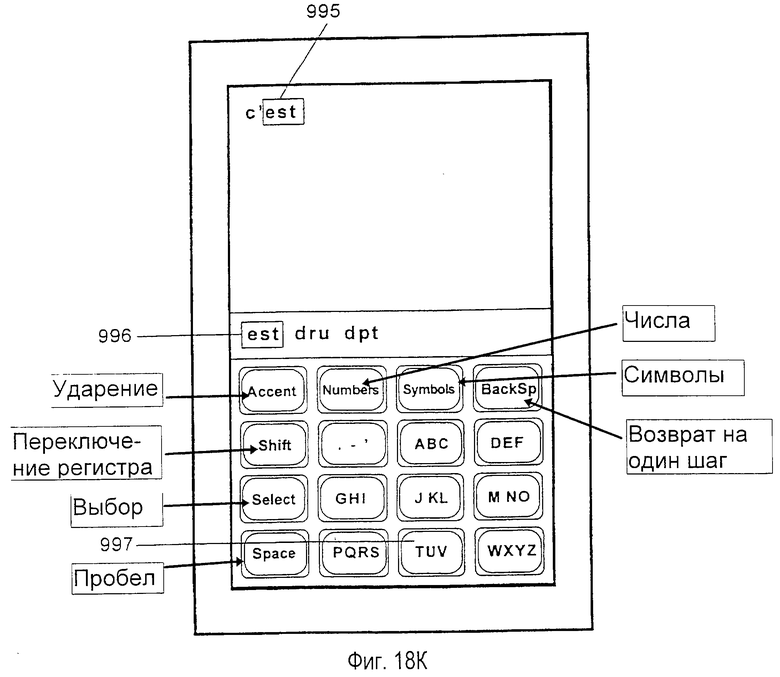
Изобретение относится к вычислительной технике. Техническим результатом является уменьшение габаритов устройства, повышение скорости ввода текста, а также уменьшение объема базы данных. Для этого система содержит устройство ввода, память, дисплей, процессор, при этом в памяти содержится множество объектов, которые имеют числовые индексы и ассоциированы с последовательностью нажатий клавиш и относительной частотой использования, все объекты в памяти организованы в древовидной структуре, процессор идентифицирует объекты с самыми высокими частотами использования и отображает эти объекты на дисплее, каждая вводимая последовательность нажатий клавиш устройства ввода обрабатывается с помощью полного словаря, состоящего из объектов, хранящихся в памяти, при этом слова, которые соответствуют последовательности нажатий клавиш, представляются пользователю в порядке уменьшения частоты использования. 6 с. и 84 з.п. ф-лы, 18 ил., 1 табл.
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| Фотоэлектрический формирователь импульсов | 1977 |
|
SU660212A1 |
| СПОСОБ ВВОДА ИНФОРМАЦИИ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1993 |
|
RU2088965C1 |
| КЛАВИАТУРА ДЛЯ ПЕРСОНАЛЬНЫХ И ДРУГИХ ЭЛЕКТРОННЫХ ВЫЧИСЛИТЕЛЬНЫХ МАШИН И СРЕДСТВ | 1994 |
|
RU2088964C1 |
| US 5664896 А, 09.09.1997 | |||
| US 4891786 А, 02.01.1990. | |||

