Область техники, к которой относится изобретение
Настоящее изобретение относится в основном к анализу данных, более конкретно к системам и способам для получения информации от работающей в сети системы с использованием распределенного поискового агента по «всемирной паутине» (поискового веб-агента).
Уровень техники
Эволюция компьютерных и сетевых технологий от дорогостоящих низкопроизводительных систем обработки данных до недорогих высокопроизводительных коммуникационных, проблемно-прикладных и развлекательных систем привела к появлению рентабельных и экономящих время средств, предназначенных для снижения бремени выполнения ежедневных задач, таких как переписка, оплата счетов, осуществление покупок, планирование бюджета и сбор информации. Например, компьютерная система, соединенная с Интернет посредством проводной или беспроводной технологии, может обеспечить пользователя непосредственно на его рабочем месте каналом практически мгновенного доступа к информационному богатству репозитория (хранилища объектов баз данных) веб-сайтов и серверов, расположенных по всему миру.
Обычно доступ к информации, предоставляемой через веб-сайты и серверы, обеспечивается посредством веб-браузера (программы просмотра Веб), выполняемой на веб-клиенте (например, компьютере). Например, пользователь Веб может использовать веб-браузер и получить доступ к веб-сайту, вводя Унифицированный Указатель Ресурса (УУР, URL) (например, веб-адрес и/или Интернет-адрес) в адресную строку веб-браузера и нажимая клавишу ввода на клавиатуре или «щелкнув» мышью по кнопке «перейти» («go»). УУР обычно включает в себя четыре фрагмента информации, которая упрощает доступ: протокол (язык компьютеров для взаимодействия друг с другом), который указывает набор правил и стандартов для обмена информацией, местоположение веб-сайта, название организации, которая поддерживает работу веб-сайта, и суффикс (например, com, org, net, gov и edu), который идентифицирует вид организации.
В некоторых ситуациях пользователь априорно знает имя сайта или сервера и/или УУР сайта или сервера, к которому пользователь хочет обратиться. В таких ситуациях пользователь может обратиться к сайту так, как было описано выше, посредством ввода УУР в адресную строку и выполняя соединение с сайтом. Однако в большинстве ситуаций пользователь не знает УУР или имя сайта. Вместо этого пользователь применяет средство поиска (поисковый механизм) для упрощения обнаружения сайта на основании ключевых слов, представленных пользователем. Как правило, поисковый механизм состоит из исполняемых приложений или программ, которые выполняют поиск по ключевым словам в содержимом веб-сайтов и серверов и выдают список ссылок на веб-сайты или серверы, где были найдены ключевые слова. По существу, поисковый механизм включает в себя поисковый веб-агент, или «краулер» (crawler) (называемый также «паук», «червяк» или «робот»), который отыскивает столько документов, сколько возможно, а также связанные с ними УУР. Эта информация затем сохраняется таким образом, чтобы индексатор мог управлять найденными данными. Индексатор считывает документы и создает указатель назначенных приоритетов на основе ключевых слов, содержащихся в каждом документе, и других атрибутов документа. Соответствующий поисковый механизм, как правило, использует свой собственный алгоритм для создания индексов так, чтобы могли быть выданы значащие результаты по запросу.
Таким образом, поисковый веб-агент весьма важен для работы поисковых механизмов. Для того чтобы обеспечивать текущие и актуальные результаты поиска, поисковый агент должен постоянно проводить поиск в Веб для нахождения новых веб-страниц, обновления информации старых веб-страниц и для исключения удаленных, то есть прекративших существование страниц. Количество веб-страниц, отыскиваемых в Интернет, является астрономически большим. Поэтому требуется, чтобы поисковый агент был чрезвычайно быстрым в работе. Поскольку многие поисковые веб-агенты собирают свои данные посредством последовательного опроса, или поллинга, серверов, которые представляют веб-страницы, поисковый агент также должен быть настолько малозаметным, насколько это возможно при доступе к конкретному серверу. Иначе поисковый агент может очень быстро задействовать все ресурсы сервера и привести к отключению сервера. Как правило, поисковый агент идентифицирует себя серверу и запрашивает разрешение перед доступом к веб-страницам. На этом этапе сервер может отказать в доступе некорректно работающему поисковому агенту, который захватывает все ресурсы сервера. Сервер, оказывающий услуги по размещению веб-страниц, как правило, выигрывает от применения поисковых механизмов, поскольку они позволяют пользователям более легко отыскивать их веб-страницы. Поэтому для более полного применения пользователями содержимого серверов большинство серверов приветствуют использование поисковых агентов постольку, поскольку эти агенты не приводят к утечке всех ресурсов серверов.
Одной из оборотных сторон идентификации себя серверу поисковым агентом является возможность сервера в дальнейшем имитировать соединение (выполнять «спуфинг») по отношению к поисковому агенту. Обычно серверы имеют защищенные области, которые они не хотят открывать для обычного Интернета. Когда поисковый агент идентифицирует себя, ему сообщают, к каким областям он не может получить доступ. Если поисковый агент желает поддерживать рабочее взаимодействие с этим конкретным сервером, он должен подчиняться запросам сервера. Однако если сервер желает имитировать соединение или скрыть свое реальное содержимое, он может направить поискового агента в область страниц, которая имитирует правильные УУР, но содержит «альтернативное» содержимое. Таким образом, сервер, который обычно предоставляет информацию только о кошках, может установить свой УУР на информацию о собаках в области, к которой имеет доступ только поисковый агент. Это делается для того, чтобы когда пользователь осуществлял поиск по «собаки», поисковый механизм показывал бы веб-страницы сервера о кошках. Обычно имитацию соединения применяют, когда содержимое сервера предполагается предосудительным со стороны общества, но сервер желает распространять свое содержимое, выходящее за рамки нормальных «ключевых слов». Таким образом, предосудительный материал может быть выдан в списке поискового механизма при использовании общепринятых слов, таких как цветы, собаки, кошки, погода и т.д. Имитация соединения снижает точность, а также и репутацию поисковых механизмов, использующих данные поискового веб-агента, полученные от имитированного соединения.
Раскрытие изобретения
Далее представлено упрощенное раскрытие сущности изобретения для того, чтобы представить базовое понимание некоторых аспектов изобретения. Это раскрытие сущности не является развернутым обзором изобретения. Оно не направлено на определение ключевых/существенных признаков настоящего изобретения или на ограничение объема изобретения. Его единственной целью является представление в упрощенной форме некоторых концепций изобретения в качестве вступительной части более детального описания, которое представлено далее.
Настоящее изобретение относится в основном к анализу данных, более конкретно к системам и способам для получения информации от работающих в сети систем с использованием распределенного поискового веб-агента. Распределенная природа клиентов сервера предполагает обеспечение быстрыми и точными данными поиска веб-агентом. Собранную поисковым веб-агентом сервера информацию сравнивают с данными, полученными клиентами сервера для обновления данных поискового агента. В одном примере настоящего изобретения сравнительные данные получают посредством использования информации, распространенной через страницу результатов поискового механизма. В другом примере настоящего изобретения проверку данных осуществляют посредством клиентских словарей, исходящих от сервера, которые обобщают данные поискового веб-агента. В другом варианте осуществления настоящего изобретения функцию «слабого индикатора» из набора функций слабого индикатора случайным образом посылают клиенту. Этих функций слабого индикатора значительно меньше, чем всех УУР в общем списке, найденных поисковым веб-агентом сервера, чем существенно снижаются объемы обмена данными между сервером и клиентом. Это приводит к упрощению взаимодействия сервер-клиент при сохранении оптимальной точности данных поискового веб-агента.
Настоящее изобретение также упрощает анализ данных посредством обеспечения средств, противостоящих имитации соединения веб-агента, для увеличения точности данных. Сервер, на котором применено настоящее изобретение, может противостоять имитации соединения посредством сравнения данных его поискового веб-агента с данными, представленными клиентом. Это позволяет серверу устранять данные имитации соединения, обеспечивая более высокое качество результатов поискового механизма. Такая возможность облегчает отфильтровывание нежелательного материала, который обычно не выдается в ходе безопасного поиска, обеспечивая тем самым более положительную практику использования поискового механизма клиентами.
Во исполнение вышеупомянутого и соответствующих аспектов приведены некоторые иллюстративные варианты осуществления изобретения, раскрытые в настоящем описании со ссылкой на нижеследующие чертежи. Эти варианты осуществления, однако, отражают лишь немногие из возможных путей применения принципов настоящего изобретения, причем настоящее изобретение следует считать включающим в себя все такие варианты осуществления и их эквиваленты. Другие преимущества и новые признаки настоящего изобретения очевидны из нижеследующего подробного описания, приводимого со ссылкой на соответствующие чертежи.
Краткое описание чертежей
Фиг.1 - структурная схема системы анализа данных в соответствии с вариантом осуществления настоящего изобретения.
Фиг.2 - следующая структурная схема системы анализа данных в соответствии с вариантом осуществления настоящего изобретения.
Фиг.3 - еще одна структурная схема системы анализа данных в соответствии с вариантом осуществления настоящего изобретения.
Фиг.4 - еще одна структурная схема системы анализа данных в соответствии с вариантом осуществления настоящего изобретения.
Фиг.5 - иллюстрация системы анализа данных, использующей страницу результатов поиска, в соответствии с вариантом осуществления настоящего изобретения.
Фиг.6 - структурная схема процесса имитации соединения, который включает в себя систему поискового веб-агента, в соответствии с вариантом осуществления настоящего изобретения.
Фиг.7 - структурная схема процесса контримитации соединения, который включает в себя систему поискового веб-агента, в соответствии с вариантом осуществления настоящего изобретения.
Фиг.8 - блок-схема способа клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения.
Фиг.9 - следующая блок-схема способа клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения.
Фиг.10 - еще одна блок-схема способа клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения.
Фиг.11 - еще одна блок-схема способа клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения.
Фиг.12 - блок-схема способа выработки правильного набора функций слабого индикатора для клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения.
Фиг.13 - иллюстрация примера операционной среды, в которой может быть осуществлено настоящее изобретение.
Фиг.14 - иллюстрация другого примера операционной среды, в которой может быть осуществлено настоящее изобретение.
Осуществление изобретения
Настоящее изобретение раскрыто со ссылкой на чертежи, на которых подобные ссылочные позиции использованы для обозначения подобных элементов. В нижеследующем описании для целей полноты раскрытия приведены многочисленные специальные подробности, чтобы обеспечить полное понимание настоящего изобретения. Очевидным является, однако, что настоящее изобретение может быть осуществлено без этих специальных подробностей. В других примерах на структурных схемах блоками показаны хорошо известные структуры и устройства для того, чтобы не усложнять описание настоящего изобретения.
Используемый в настоящей заявке термин «компонент» предназначен для обозначения элемента, относящегося к компьютеру либо аппаратному обеспечению, совокупности аппаратного и программного обеспечения, программному обеспечению или программному обеспечению в процессе исполнения. Например, компонент может быть, но не ограничиваясь этим, процессом, выполняемым процессором, самим процессором, объектом, исполняемым файлом, потоком операций, программой и/или компьютером. В целях иллюстрации как выполняемое на сервере приложение, так и сервер может быть компьютерным компонентом. Один или более компонентов могут постоянно присутствовать в процессе и/или потоке операций, причем компонент может быть локализован на одном компьютере и/или распределен между двумя или более компьютерами. «Поток» является объектом внутри процесса, который ядро операционной системы планирует для исполнения. Как известно из уровня техники, каждый поток имеет соответствующий «контекст», который представляет собой временные данные, связанные с исполнением потока. Содержание потока включает в себя содержимое системных регистров и виртуальный адрес, принадлежащий процессу потока. Таким образом, фактические данные, включающие в себя контекст потока, изменяются по мере его исполнения.
Настоящее изобретение обеспечивает усовершенствованные системы и способы сохранения индекса веб-документов. Это также может быть использовано для поиска и сохранения данных для других типов информации. Традиционные веб-агенты имеют определенные недостатки, которые устраняются настоящим изобретением. Каждый клиент (т.е. компьютер любого пользователя, имеющего доступ в Веб) хранит локальную информацию, таким образом, он может узнать, изменялась ли веб-страница с момента ее последнего посещения клиентом. Если она изменялась, клиент может передать эту информацию поисковому механизму. Подобным образом сервер может использовать информацию относительно веб-страниц, посещенных клиентами, для обнаружения страниц, неизвестных серверу в настоящее время. Эффективное обнаружение документов и сохранение текущих знаний об этих документах является чрезвычайно важной задачей поиска, как в интранет, так и в Интернет. Настоящее изобретение может также быть использовано применительно к поискам в интранет, где поиск страниц агентом и поддержание информации страниц актуальной являются чрезвычайно востребованными задачами.
Важным компонентом поискового механизма (для Интернет, интранет или других) является поисковый агент по данным или документам. Поисковый агент по документам выполняет две главных задачи: обнаруживает неизвестные документы для индексирования посредством поискового механизма и пытается поддерживать обновленные знания о каждом известном документе. Обе эти задачи сложные и (наряду с качеством ранжирования страниц) являются наиболее важными и явными дифференциаторами качества поисковых механизмов. Поисковый агент по документам обычно основан на серверной модели. Поисковый механизм выполняет топологический поиск агентом в Веб. Начиная с начального набора известных веб-страниц поисковый веб-агент следует по связям от этих страниц и может таким образом обнаружить все веб-страницы, которые соединены посредством пути (набор ссылок УУР) из начального набора. Для поддержания знаний поискового механизма о подборке документов обновленными поиск агентом необходимо часто повторять. Поскольку поисковый агент повторно посещает веб-страницы, каждый раз при своем поиске он может узнать, как часто страница (или подграфа) меняется, и исходя из прошлой частоты изменения выполнять повторный поиск некоторых страниц более часто по сравнению с другими страницами.
Существует ряд недостатков принципа сервер-основанного поиска агентом. Во-первых, поисковый агент может обнаруживать только те страницы, к которым можно перейти по последующим связям, начинающимся от одного из начальных документов. Недавние изучения показали, что огромный процент веб-страниц в настоящее время не индексирован посредством какого-либо поискового механизма. Во-вторых, поисковый механизм может узнать об изменениях в документе (т.е. изменении содержания или о том, что страница больше не существует), только когда поисковому агенту доведется вновь посетить страницу.
Настоящее изобретение предлагает системы и способы для эффективного обнаружения документов (т.е. данных) и поддержания обновленных знаний об известных документах таким образом, что вышеупомянутые недостатки устраняются. Это достигается посредством распределенного клиент-основанного поиска агентом. Каждый клиент (т.е. машина любого пользователя, который работает в Веб) сохраняет локальную информацию, так что можно узнать, изменилась ли страница со времени последнего посещения ее клиентом. Если она изменилась, клиент может затем сообщить эту информацию поисковому механизму. Таким образом, сервер может использовать информацию о веб-страницах, посещенных клиентами, для обнаружения страниц, неизвестных в настоящий момент серверу.
На фиг.1 представлена структурная схема системы 100 анализа данных в соответствии с вариантом осуществления настоящего изобретения. На примере настоящего изобретения система 100 анализа данных состоит из клиентов 102-106, обозначенных от 1 до «N», где N представляет собой любое число от 1 до бесконечности; системы 108 связи, поискового сервера 110 и серверов 112 веб-страниц. Клиенты 102-106 составляют группу «распределенных ресурсов» для информации веб-страниц для поискового сервера 110. Они в основном функционируют для обеспечения новых УУР, изменений веб-страниц и тому подобного поисковому серверу 110 через систему 108 связи. Система 108 связи включает в себя Интернет, и/или интранет, или тому подобное. Она обеспечивает доступ с целью связи между поисковым сервером 110 и клиентами 102-106. Она также обеспечивает связь между клиентами 102-106 и другими серверами 112 веб-страниц и/или поисковым сервером 110 и другими серверами для сбора информации веб-страниц. По сути, выполняемые функции поискового веб-агента распределены между поисковым сервером 110 и клиентами 102-106 в отличие от функционирования агента только на поисковом сервере. Поисковый сервер 110 использует клиентов 102-106 для получения информации серверов 112 веб-страниц для облегчения отбора собственной информации. Посредством распределения этих выполняемых функций настоящее изобретение обеспечивает более актуальный, достоверный и защищенный от имитации соединения набор данных, данные которого может использовать поисковый механизм.
На фиг.2 представлена другая структурная схема системы 200 анализа данных в соответствии с вариантом осуществления настоящего изобретения. Система 200 анализа данных включает в себя клиент 202 и сервер 204 со средствами связи, обеспечивающими взаимодействие между ними. В ходе обычной работы на сервере 204 размещен поисковый веб-агент, который выполняет поиск в сети связи, такой как Интернет, для других серверов, на которых размещены веб-страницы. Поисковый веб-агент формирует источник информации об этих веб-страницах для использования с механизмом поиска веб-страниц. Сервер 204 затем посылает представление этой информации веб-страниц клиенту 202. Это обеспечивает клиента 202 возможностью независимо проверять информацию веб-страниц при выполнении доступа к серверу, на котором размещена конкретная веб-страница. Клиент 202 может также обнаруживать веб-страницы, которые неизвестны серверу 204. Это позволяет клиенту 202 составлять изменения/статусы и/или новую информацию об известных и неизвестных веб-страницах. Эта информация затем передается серверу 204. Сервер 204 использует информацию для уточнения своих первоначальных данных поиска веб-страниц агентом. Имея распределенные ресурсы, сервер 204 расширяет возможности своего поискового агента без обременения своих собственных прямых ресурсов (т.е. использование процессора, пространства хранения и т.д.). Дополнительно, поскольку веб-агент обычно идентифицирует себя каждому серверу, к которому он обращается за доступом, он рискует быть перенаправленным к ложным данным на таком сервере. Серверы могут также ограничивать количество доступов и время, которое затребует веб-агент у ресурсов сервера. На клиента, осуществляющего доступ к серверу, обычно не накладывается этих ограничений, и его не перенаправляют к ложным данным. Таким образом, данные веб-страницы клиента могут быть использованы для исправления ложных данных, собранных веб-агентом. Этот аспект данного изобретения более подробно раскрыт ниже.
На фиг.3 представлена еще одна структурная схема системы 300 анализа данных в соответствии с вариантом осуществления настоящего изобретения. Система 300 анализа данных включает в себя клиентский компонент 302 системы и серверный компонент 304 системы с системой 306 связи (СС), задействованной между ними. В этом примере настоящего изобретения клиентский компонент 302 системы включает в себя интерфейсный компонент 308 СС, компонент 310 управления клиентом, компонент 312 хранения данных, компонент 308 графического пользовательского интерфейса (ГПИ) СС, обеспечивающий пользователя интерфейсом, который является характерным для конкретного типа применяемой системы связи. Одним из примеров такого интерфейса является веб-браузер, используемый для работы в графическом режиме с информацией, по меньшей мере, «всемирной паутины» (World Wide Web). Веб-браузер может также использоваться для «серфинга» по интранет, такого как веб-страницы, предоставляемые на конкретном предприятии. В других примерах настоящего изобретения с подобной информацией можно работать, используя текстовый интерфейс вместо графического интерфейса пользователя. Обычно именно компонент 308 позволяет пользователю выполнять поисковые запросы поисковым механизмом, находящимся на удаленном сервере, соединенном с системой 306 связи. Таким образом, компонент 308 ГПИ СС передает и/или получает информацию от системы 306 связи. Компонент 310 управления клиентом обеспечивает управление клиентом в части облегчения поиска веб-агентом. Компонент 310 управления клиентом получает и/или передает данные, относящиеся к информации, такой как веб-страницы и тому подобное. Этот компонент 310 выполняет обработку алгоритмов, отслеживает изменения данных и состояния (статуса) и/или управляет локальным хранением данных в системе 300 анализа данных. Этот компонент 310 может также анализировать информацию от компонента 308 ГПИ СС с информацией, получаемой от поискового веб-агента, для определения различий и тому подобного. Компонент 310 управления клиентом позволяет клиенту выступать в качестве «распределенного ресурса» для поискового веб-агента и тому подобного. Этот компонент 310 может также иметь доступ к сохраненным данным и обеспечивать информацию компоненту 308 ГПИ СС. В одном примере настоящего изобретения компонент 308 ГПИ СС передает и/или получает вложенные данные поискового агента. Таким образом, компонент 310 управления клиентом устанавливает взаимодействие компонентом 308 ГПИ СС для получения и/или передачи вложенных данных, относящихся к поисковому агенту. Подобно этот компонент 310 может также направлять и/или получать директивы от сервера таким же образом. В другом примере настоящего изобретения компонент 310 управления клиентом может вести себя подобно серверу и обеспечивать управление другими клиентами как соединенными равноправными узлами локальной вычислительной сети. Для специалиста в данной области техники очевидным является, что выполнение функций компонента 310 управления клиентом и компонента ГПИ СС можно объединить в единый компонент. Возможно также использовать клиент в качестве распределенного ресурса без компонента 308 ГПИ СС. Один пример такого варианта настоящего изобретения может включать в себя, но не ограничиваясь только этим, выполнение одним клиентом приведения в действие и/или управления другим клиентом. Компонент 312 хранения данных используют для хранения, например, данных поискового агента от сервера, данных поискового агента от клиента, изменений веб-страниц, новых данных веб-страниц, параметров управления клиентом и тому подобного. Этот компонент 312 может взаимодействовать с напрямую компонентом 310 управления клиентом и/или компонентом 308 ГПИ СС в зависимости от конкретного примера осуществления настоящего изобретения. Компонент 312 хранения данных может быть также устройством хранения данных, таким как накопитель на жестком диске, постоянное запоминающее устройство, оперативное запоминающее устройство, сменный носитель информации, CD-ROM и тому подобное. В еще одном примере настоящего изобретения к информации, сохраненной в компоненте 312 хранения данных, может быть напрямую выполнен доступ сервером без взаимодействия с компонентом 308 ГПИ СС или компонентом 310 управления клиентом. В ряде случаев это позволяет обеспечить более быстрый поиск данных.
В одном примере настоящего изобретения система 306 связи представляет собой интернет в смысле «Интернет» как глобальной сети компьютерных ресурсов. Эта система 306 может также быть интранет системой в виде глобальной сети (ГЛС) и/или локальной сети (ЛОС) и тому подобной. Система 306 связи может также использовать более традиционные средства связи, такие как, например, телефонные системы, радиосистемы, световые сигнальные (оптические) системы, звуковые системы и тому подобные. Для специалистов в данной области техники очевидным является, что иные глобальные и локальные сетевые структуры могут быть также использованы в настоящем изобретении в качестве системы 306 связи.
Серверный компонент 304 системы включает в себя компонент 314 поискового механизма, компонент 316 управления распределенными ресурсами, компонент 318 поискового агента, компонент 320 хранения данных и, необязательно, компонент 322 размещения данных СС. В другом примере настоящего изобретения компонент 318 поискового агента использует систему 306 связи для доступа к серверам и/или прокси-серверам (брандмауэрам) для получения информации, относящейся к веб-страницам, такой как содержание веб-страницы, возраст, размер, УУР, вложенные связи и тому подобное. Эта информация затем сохраняется в компоненте 320 хранения данных. Компонент 320 хранения данных может быть устройством хранения данных в виде накопителя на жестком диске, постоянного запоминающего устройства, оперативного запоминающего устройства, сменного носителя информации, CD-ROM и тому подобным. Компонент 314 поискового механизма обеспечивает возможность поиска всех веб-страниц, обнаруженных поисковым веб-агентом 318 и сохраненных в компоненте 320 хранения данных. Этот компонент 314 получает поисковый запрос от пользователя и обращается к информации в компоненте 320 хранения данных для составления перечня связей и данных веб-страниц, для направления их пользователю. Таким образом, в обычной системе поисковый компонент 314 может полагаться только на информацию, полученную компонентом 318 поискового агента. Однако в примерах настоящего изобретения контроллер 316 распределенных ресурсов облегчает сбор информации, сохраненной в компоненте 320 хранения данных, позволяя ей быть более ясной, отвечающей современным требованиям и более емкой. Компонент 316 управления распределенными ресурсами обеспечивает управление всеми распределенными ресурсами, такими как, например, клиенты сервера, которые взаимодействуют как один распределенный поисковый агент или «клиент-основанный поисковый веб-агент». Компонент 316 обеспечивает, например, выполнение такой функции, как анализ данных, полученных от распределенных ресурсов, таких как клиентский компонент 302 системы или подобный ему, определение функции, размещение данных и их синхронизацию, обеспечение алгоритмов распределенных ресурсов для определения известных данных поискового агента, получение обновлений данных и/или дополнений, сохранение обновлений данных и/или дополнений в компоненте 320 хранения данных, определение оптимизированного использования распределенных ресурсов, обеспечение постраничных данных для компонента 314 поискового механизма для обеспечения возможности вложения данных в страницы результатов поиска для конкретного поискового запроса, обеспечение постраничных данных для провайдера Интернет-услуг для генерации страниц, которые включают в себя вложенную информацию о связях страниц, и отслеживание характеристик данных, таких как подсчеты, типы, процентное отношение имитаций соединений, источник и тому подобных. В другом примере настоящего изобретения компонент 314 страниц поиска посылает и/или получает информацию для компонента 316 управления распределенными ресурсами вместо непосредственного обращения компонента 316 к системе 306 связи.
В примере настоящего изобретения необязательно присутствующий компонент 322 размещения данных СС взаимодействует как с системой 306 связи, так и с компонентом 316 управления распределенными ресурсами. Компонент 322 размещения данных СС обеспечивает возможность размещения веб-страниц для обеспечения доступа пользователям к веб-странице. Поскольку компонент 322 размещения данных СС взаимодействует с компонентом 316 управления распределенными ресурсами, он может получать и вкладывать информацию связей веб-страниц непосредственно в размещенную на нем веб-страницу. В других примерах настоящего изобретения компонент 322 размещения данных СС взаимодействует напрямую с компонентом 320 хранения данных для доступа к информации для вложения в веб-страницу. В еще одном примере настоящего изобретения компонент 322 размещения данных СС взаимодействует с компонентом 314 поискового механизма для доступа к информации для вложения в его связи веб-страниц. В еще одном примере настоящего изобретения компонент 322 размещения данных СС может резидентно находиться в распределенном ресурсе, таком как клиент. Этот компонент 322 может также находиться на другом сервере, который имеет доступ к серверному компоненту 304 системы. В этом примере клиент (или сервер) станет в действительности сервером для размещенных веб-страниц и будет обеспечивать информацию для вложения в связи веб-страниц из локального средства хранения и/или других локальных средств.
Для специалиста в данной области техники очевидным является, что хотя каждый компонент описан независимо, компонент в других примерах настоящего изобретения может включать в себя выполняемую функцию, связанную с другими компонентами. Подобным образом некоторые компоненты могут быть устранены без изменения объема настоящего изобретения.
На фиг.4 представлена еще одна структурная схема системы 400 анализа данных в соответствии с вариантом осуществления настоящего изобретения. Система 400 анализа данных включает в себя клиентский компонент 402 системы и серверный компонент 404 системы с взаимодействующей с ними системой 406 связи. В этом примере настоящего изобретения серверный компонент 404 системы включает в себя компонент 414 управления распределенными ресурсами и компонент 416 хранения данных. Серверный компонент 404 системы сокращен для того, чтобы сделать акцент на примере настоящего изобретения в отношении получения информации веб-страницы от клиентского компонента 402 системы. Обычно информация поступает потоком к компоненту 414 управления распределенными ресурсами или от него посредством системы 406 связи. Клиентский компонент 402 системы включает в себя компонент 408 управления клиентом, компонент 410 хранения данных и, необязательно, компонент 412 уведомления. В этом примере настоящего изобретения компонент 412 уведомления управляет данными, которые поступают потоком от клиентского компонента 402 системы к серверному компоненту 404 системы. В других примерах настоящего изобретения этот компонент 412 также управляет передачами данных по соединению равноправных узлов между клиентским компонентом 402 системы и другими клиентскими системными компонентами. Более конкретно, компонент 412 уведомления определяет, когда и/или какие данные должны быть переданы от клиентского компонента 402 системы. Определение может быть основано на размере накопленных данных веб-страниц либо на том, обнаружены ли связи, которые неизвестны серверному компоненту 404 системы, важности (значимости) изменений веб-страниц (такой как 50% или более изменение содержания и/или изменение страницы с высоким приоритетом и тому подобное), допуски по истинному времени и/или допуски по обычному времени, установленные компонентом 414 управления распределенными ресурсами, и тому подобное. Компонент 412 уведомления может также использовать алгоритм для определения своих собственных факторов важности и/или собственного планирования времени для передач данных. Для специалиста в данной области техники очевидным является, что выполняемая функция компонента 412 уведомления может быть свойственна компоненту 408 управления клиентом и/или другим клиентским компонентам системы, не представленным на фиг.4.
Для обеспечения полного понимания настоящего изобретения описаны примеры функционирования. В одном примере настоящего изобретения распределенный клиент-основанный поисковый агент работает следующим образом. Предполагается, что существует сервер, получающий входящие сообщения клиента о потенциально новых веб-страницах и изменениях содержания/состояния веб-страниц, а также, что существует набор клиентов, который взаимодействует с сервером. Клиентские машины могут быть либо персональными компьютерами, которые используются для просмотра Веб, либо прокси-сервером, который используется для предоставления страниц персональному компьютеру. Клиенты наделены возможностью собирать информацию о просматриваемых веб-страницах, которая может содержать, но не ограничиваясь только этим, (1) УУР, использованные для перехода к веб-странице, (2) хешированное содержимое веб-страницы, (3) содержимое веб-страницы и (4) время посещения. В некоторых примерах настоящего изобретения (например, прокси-сервер и тому подобное) может быть нецелесообразным придерживаться всей этой информации и некоторой информации можно придерживаться лишь некоторое время.
В другом примере настоящего изобретения клиент записывает УУР веб-страниц, посещенных с помощью конкретного браузера или прокси-сервера в определенный период, и затем посылает этот набор УУР серверу. Сервер затем проверяет, который из УУР был до этого ему неизвестен, и добавляет таковые в перечень известных УУР для будущего поиска агентом/размещения/индексации. Это позволяет механизму поиска, ассоциированному с сервером, знать о веб-страницах, которые могли быть не обнаружены топологическим поиском.
Для того, чтобы уменьшить объем информации, посланной от клиентов серверу, клиент может локально хранить информацию в том случае, если он уже проинформировал сервер о конкретном УУР, и послать информацию серверу, только если это еще не было сделано. Существуют хорошо известные способы эффективного определения, идентичны ли две веб-страницы, выполняемые с помощью целочисленного отображения каждого документа посредством функции хеширования и затем проверки, являются ли два значения хеш-функции идентичными. Если новое значение хеш-функции для содержания, связанного с УУР, отличается от предыдущих значений хеш-функции содержания, связанного с УУР, то содержание изменилось. При каждом посещении клиентом веб-страницы вычисляется значение хеш-функции для той страницы. Если клиент раньше посещал страницу, выполняют проверку, изменилось ли значение хеш-функции. Если оно изменилось, то клиент определяет, что веб-страница изменилась с тех пор, как клиент последний раз имел к ней доступ, и он имеет возможность проинформировать об этом сервер. Клиент локально записывает пару новый <УУР, значение хеш-функции>.
Существует ряд различных путей, при помощи которых клиент может информировать сервер об изменении. Самый простой - послать сообщение о том, что УУР содержание/состояние изменился. Затем сервер может запланировать выполнение как можно быстрее повторного поиска агентом этой страницы. Для изменения намерений сервера снова посетить страницу клиент может послать дополнительную информацию. Если клиент имеет буферизованную копию страницы своего последнего посещения, он может послать старое значение хеш-функции наряду с различиями между старой и новой версией и новое значение хеш-функции. Сначала сервер проверит, соответствует ли старое значение хеш-функции, посланное клиентом, текущему значению хеш-функции у сервера для той страницы. Если это так, то он может обновить содержание страницы соответственно. Следует отметить, что изменения некоторых документов являются более важными, чем других. Например, в одном случае полная страница может быть изменена, в другом только одна запятая добавлена в одно предложение. Клиент может вычислить значимость изменения и либо (а) использовать эту информацию для установления приоритетности обновлений, которые он направляет серверу, либо (б) направить значение важности серверу наряду с другой информацией страницы таким образом, чтобы сервер мог использовать эту информацию при установлении приоритетности повторного поиска агентом/повторной индексации страницы. Примеры изменения функций значимости включают в себя, но не ограничиваются только этим, лингвистическую/семантическую значимость изменения, оценку процентного отношения поисков пользователя, на которые окажет воздействие изменение, и тому подобное. Значимость может быть взвешена посредством оценки популярности страницы.
Одним из недостатков вышеприведенных средств связи является то, что они вызывают существенный трафик служебных данных между клиентами и сервером. Например, если все 100 клиентов посетили страницу «Х» в первый раз, каждый из них посылает сообщение серверу, что им обнаружена страница «Х». Аналогичным образом, когда сервер будет уведомлен, что страница «Y» изменена, ему не требуются дополнительные уведомления об этом от клиентов. Ниже раскрыты дополнительные примеры настоящего изобретения, которые приводят к значительному уменьшению ненужного обмена данными между клиентами и сервером.
На фиг.5 проиллюстрирована система 500 анализа данных, использующая результаты страницы поиска в соответствии с вариантом осуществления настоящего изобретения. Система 500 анализа данных включает в себя клиента 502 со страницей 506 результатов поиска и поисковый сервер 504 со средствами связи для передачи 508 и получения 510 данных от клиента 502 сервером 504. В первом примере варианта осуществления настоящего изобретения клиент 502 уведомляет сервер 504 об измененной веб-странице, но не посылает какой-либо дополнительной информации. Когда пользователь использует поисковый механизм, поисковый сервер 504 предоставляет результаты клиенту, которые содержат значение хеш-функции для серверной версии содержания и флаг свежести, который указывает, известно ли содержание как свежее (актуальное), для каждой веб-страницы в странице 506 результатов поиска. Если клиент 502 посещает одну из страниц в странице 506 результатов поиска, он прежде всего проверяет, знает ли уже сервер 504, что страница не является свежей (например, другой клиент проинформировал сервер 504, но сервер 504 еще не обновил страницу), вычисляет значение хеш-функции содержания страницы и сравнивает с значение хеш-функции, которое представляет поисковый механизм. Если они расходятся, клиент 502 затем посылает серверу 504 уведомление, что содержание, связанное с УУР, изменилось. Когда сервер 504 получает уведомление, он изменяет состояние флаг свежести и УУР добавляется в приоритетную очередь для повторного поиска агентом.
Этот пример может быть распространен на сценарий, где клиенты посылают информацию об отличии страницы на сервер (которая может быть использована сервером, чтобы обновить его информацию о веб-странице без поиска агентом и/или чтобы помочь в определении приоритетности срока, в который сервер должен осуществить повторный поиск веб-страницы агентом). Это может быть выполнено посредством направления поисковым механизмом двух дополнительных полей с каждым результатом поиска, а именно временем последнего уведомления клиентом и значением хеш-функции страницы из последнего уведомления клиентом. Если клиент посещает выданную механизмом поиска страницу и либо (а) флаг известности-несвежего-состояния ложен, либо (б) флаг известности-несвежего-состояния верен и значение хеш-функции по последнему уведомлению клиентом отлично от значения хеш-функции, которое этот клиент вычисляет для страницы, то затем клиент уведомляет сервер. Также возможно обнаружить циклы изменений страницы таким образом, что если страница повторно изменяется с А до В до С до А, в соответствии с настоящим изобретением можно это обнаружить и ограничить клиентские обновления по данной странице.
Дополнительно для уменьшения объема ненужного обмена данными между клиентами и сервером дополнительным преимуществом «Направления Сообщений Посредством Страницы Результатом Поискового Механизма» является то, что оно позволяет избегать некоторых возможных вопросов соблюдения конфиденциальности посредством того, что клиент направляет серверу информацию только о тех веб-страницах, которые сервер уже знает. Таким образом, гарантируется, что клиент не посещает, например, страницу, которую клиент предполагает сохранить в тайне, и не информирует сервер о существовании этой страницы.
Недостатком вышеприведенного примера настоящего изобретения является то, что сервер может узнать информацию только о веб-страницах, которые выданы клиенту по поисковому запросу пользователя. Это требование может быть смягчено посредством информирования сервера о веб-страницах, возвращенных клиенту посредством любого поискового механизма. Клиент оснащен инструментарием для обнаружения, что пользователь использует любой поисковый механизм. Когда клиент посещает результат поиска, он вычисляет значение хеш-функции содержания. Если клиент посещал этот УУР ранее, тогда он будет иметь буферизованное значение хеш-функции содержания. Если эти значения хеш-функций различны, тогда клиент может загрузить УУР и новое значение хеш-функции на сервер (в виде функции времени с момента предыдущего визита и другой информации). Если клиент никогда не посещал УУР, тогда клиент может загрузить УУР и новое значение хеш-функции на сервер (в виде функции времени с момента предыдущего посещения и другой информации).
Однако если клиент имел локальную копию полного перечня УУР, известных серверу, затем, когда он распознает потенциально новый УУР, он может просто проверить и посмотреть, находится ли он в перечне известных УУР, и направить УУР серверу, только если его еще нет в перечне. Аналогичным образом, если клиент имел локальную копию полного перечня пар <УУР, значение хеш-функции> для всех УУР, известных серверу, требуется только послать обновленную информацию, если эта информация является новой для сервера. Сложность с таким вариантом заключается в том, что недопустимо передавать полные перечни каждому клиенту. Например, поисковый механизм может знать о многих миллиардах УУР, что представляет собой многие гигабайты данных. Дополнительно к существенной проблеме с пропускной способностью неразумно будет ожидать, что каждый клиент выделит такой огромный объем памяти своего локального средства хранения информации для таких перечней.
С другой стороны, в другом примере настоящего изобретения обеспечены средства связи, которые устраняют существенную сложность с пропускной способностью. Допустим, задан алфавит S. Тогда S* является набором всех строк, состоящих из букв из S. Определим словарь D как поднабор строк в наборе S*. Функция индикатора I для словаря D, 1:S*→{0,1} имеет свойство I(d)=1 iff d e D. Функция слабого индикатора Iw для словаря D является функцией, которая имеет свойство Iw(d)=0, при d не в D (другими словами, Iw(d)=1 для всех d e D и Iw(d) может быть или 0, или 1 для любого d не в D). Наконец, определим правильный набор функций слабого индикатора I={Iw1, Iw2, …, Iwn} как конечный набор функций слабого индикатора, которые имеют свойство, что для любого d не в D существует, по меньшей мере, один Iwi e I, так что Iwi(d)=0.
Таким образом, каждый клиент получает случайным образом выбранную функцию слабого индикатора из I. Эти функции индикатора значительно меньше, чем полный набор УУР, и, таким образом, их рационально посылать клиентам. Для любого УУР, уже известного серверу, функция указателя правильно определит, что он известен. Для УУР, неизвестного серверу, она может ошибочно пометить его как известный, в этом случае клиент ничего не делает, или правильно пометить его как неизвестный, в этом случае клиент может проинформировать сервер. Посредством определения правильного набора функция слабого индикатора, гарантируется, что в любое время, когда имеется посещенная клиентом веб-страница, которая неизвестна серверу, существует ненулевая вероятность того, что клиентская функция индикатора распознает эту страницу как новую.
Для дальнейшего упрощения примера, приведенного выше, допустим, S={a,b,c,d}, все строки в S* имеют длину меньше чем 4, и словарь D={abc, adc, b, cbd, ddd}. Примером функции слабого индикатора для данного словаря является:
I(string)=1 iff (второй символ является одним из {b,d,null}).
Функция слабого индикатора может быть случайным образом построена для D следующим образом:
(1) Случайное разбиение D на два не перекрывающихся подсловаря D' и D''.
(2) Случайный выбор функции I' слабого индикатора для D', которая состоит из логического произведения одного или более условий формы «i-й символ является элементом набора S (S - поднабор S).
(3) Случайный выбор функции слабого индикатора I'' для D'' таким же образом.
(4) Создание функции I(x)=1 iff I'(x)=1 или I''(x)=1.
Набор всех таких функций слабого индикатора вырабатывает правильный набор функций слабого индикатора. Клиентские словари могут быть распространены также на задачу обнаружения новизны страницы посредством словаря, состоящего из пар <УУР, значение хеш-функции страницы>.
Одним уникальным аспектом настоящего изобретения является обеспечиваемая им возможность сравнивать данные поискового агента с точки зрения специализированного поискового агента и с точки зрения клиента. Это особенно важно ввиду существенного совершенствования серверов. С «более умными» программами серверы становятся более способны контролировать поток и доступ к данным, расположенным на них. Это включает в себя способность блокировать доступ любого или всех пользователей к некоторой или всей информации, найденной на сервере. Даже различные типы пользователей могут иметь различные «уровни дозволений» в отношении доступа к серверу и даже привилегии доступа по времени.
В основном эта повышенная гибкость используется для конструктивных целей, таких как безопасность, взыскание оплаты за доступ и предотвращение злоумышленных проникновений. Однако это многократно использовалось и для маскировки реального содержания веб-страниц, обнаруживаемых на сервере. На фиг.6 показана структурная схема процесса 600 имитации соединения, задействующего в себя систему 602 поискового агента, в соответствии с вариантом осуществления настоящего изобретения. Процесс 600 задействует систему 602 поискового веб-агента и сервер 604 с системой 606 связи, обеспечивающей взаимодействие между ними. Система 602 поискового веб-агента включает в себя компонент 608 поискового агента и компонент 610 хранения данных. Сервер 604 включает в себя управление 612 доступом сервера, данные 614 имитации соединения и реальные данные 616. Когда обычный компонент 608 поискового агента получает доступ к серверу 604, этот компонент 608 идентифицирует себя серверу 604 как поисковый веб-агент. Это предполагается «вежливым». Вежливость является, по сути, самозащитой, поскольку поисковый веб-агент, который злоупотребляет сервером, игнорируя правила сервера, как правило, будет в дальнейшем получать отказ в доступе к серверу. Получение отказа в доступе к серверу особенно критично для поискового механизма, который полагается на доступ к серверу для обеспечения содержимого пользователям поискового механизма. Поэтому поисковые агенты обычно руководствуются правилами вежливости. Другие правила вежливости включают в себя определенное время доступа, использование ресурсов сервера, неразрушающий поиск данных и тому подобное. В этом примере управление 612 доступом сервера идентифицирует компонент 608 поискового агента, и вместо направления доступа к реальным данным 616 это управление 612 направляет компонент 608 поискового агента к данным 614 имитации соединения. Данные имитации соединения обычно содержат ту же информацию УУР, что и реальные данные 616, но с различным содержанием. Это обычно делается, чтобы замаскировать предосудительное содержание. Например, сервер 604 может обмануть поисковый механизм, выдав УУР c содержанием по собакам страстным любителям кошек, ищущим кошачьи игрушки. Сервер 604 собирает данные имитации соединения, используя правильные УУР, но содержание заменено информацией, относящейся к кошкам. Реальные данные 616, однако, содержат информацию, относящуюся к собакам. Таким образом, компонент 608 поискового агента находит данные 614 имитации соединения, полагая, что УУР относятся к кошкам, тогда как на самом деле они относятся к собакам. Компонент 608 поискового агента затем сохраняет данные 614 имитации соединения в компоненте 610 хранения данных, который доступен поисковому механизму.
После этого поиск информации по кошкам посредством поискового механизма выдаст также УУР, которые содержат информацию по собакам. Пример собака/кошка может показаться не столь опасным, но та же самая технология может быть использована для маскировки такой тематики, как реклама, порнография, экстремистская литература, подрывные группировки и другой вызывающий по отношению к обществу материал и тому подобное.
На фиг.7 представлена структурная схема процесса 700 контримитации соединения, задействующая систему 702 поискового веб-агента, в соответствии с вариантом осуществления настоящего изобретения. Процесс 700 задействует систему 702 поискового веб-агента, компонент 704 управления клиентом, веб-сервер 706 и систему 708 связи, обеспечивающую взаимодействие. Система 702 поискового веб-агета включает в себя компонент 710 поискового агента, компонент 712 хранения данных с данными 714 имитации соединения и компонент 716 управления распределенными ресурсами с компонентом 718 сравнения. Компонент 710 поискового агента находит данные 714 имитации соединения на веб-сервере 706, как проиллюстрировано и раскрыто со ссылкой на фиг.6. Данные 714 имитации соединения затем сохраняют в компоненте 712 хранения данных. На этом этапе обычный поисковый механизм (не показан на фиг.7) получает доступ к данным 714 имитации соединения и распределяет их пользователям поискового механизма, не знающим о их реальном содержимом. Однако используя настоящее изобретение, данные 714 имитации соединения могут быть устранены. Это достижимо благодаря тому, что хотя сервер и имитирует соединения с поисковыми агентами, он обычно не имитирует соединения с пользователями, осуществляющими доступ к веб-страницам. Поскольку в настоящем изобретении применены распределенные ресурсы, такие как компонент 704 управления клиентом, этот компонент 704 может получать доступ к серверу 706 как пользователь и находить реальные данные на сервере 706. Компонент 704 управления клиентом может затем направить реальные данные (или «клиентские данные») и/или представление реальных данных компоненту 716 управления распределенными ресурсами. Компонент 718 сравнения в компоненте 716 управления распределенными ресурсами может затем отыскать сохраненные данные 714 имитации соединения и сравнить их с реальными данными, полученными от клиента. Если данные различны, компонент 716 управления распределенными ресурсами может перезаписать данные 714 имитации соединения, находящиеся в компоненте 712 хранения данных, устраняя эту неточность. Это позволяет поисковому механизму получать доступ к точным данным, которые в ином случае были бы ему недоступны.
С учетом показанных и описанных выше примеров систем методологии, которые могут быть применены в соответствии с настоящим изобретением, для лучшего их понимания проиллюстрированы блок-схемами на фиг.8-12. Хотя для целей упрощения описания методологии представлены и описаны в виде последовательностей блоков, очевидным является, что настоящее изобретение не ограничено порядком следования блоков, поскольку некоторые блоки могут в соответствии с настоящим изобретением иметь разный порядок следования и/или следовать одновременно с другими блоками из тех, которые показаны и описаны здесь.
Более того, не все представленные блоки могут потребоваться для выполнения методологий в соответствии с настоящим изобретением.
Изобретение может быть описано в общем контексте выполняемых компьютером инструкций, таких как программные модули, исполняемые одним или более компонентами. Обычно программные модули содержат подпрограммы, программы, объекты, структуры данных и др., которые исполняют конкретные задачи или применяют особые абстрактные типы данных. Выполняемые функции программных модулей могут быть объединены или распределены по желанию в различных вариантах осуществления.
На фиг.8 представлена блок-схема способа 800 клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения. Способ 800 начинается 802 записью клиентом информации веб-страниц, полученной при посещении веб-страниц 804. В простом примере настоящего изобретения информация содержит только УУР посещенных веб-страниц. Более сложные примеры настоящего изобретения могут включать в себя, например, УУР, данные значений хеш-функции содержимого веб-страниц, отметки времени и тому подобное. Клиент затем посылает информацию веб-страниц серверу 806. Возможным также в примере настоящего изобретения является информирование клиентом других клиентов об информации веб-страницы. Вновь в простом примере информация может содержать только УУР, или в сложном примере информация может включать несколько различных типов данных о веб-страницах. В одном примере настоящего изобретения клиент вырабатывает дополнительную информацию, полученную из информации веб-страницы. Эти данные могут включать в себя, например, периоды, в которые веб-страница доступна, легкость доступа (перегрузка, повторные попытки соединения, и т.д.), состояние вложенной связи и подобное. Дополнительно информация веб-страницы может быть внесена в план для управления тем, когда информацию отправляют. Составление плана может быть инициировано клиентом и/или сервером. Критерием отправления информации может быть, но не ограничиваясь только этим, время дня, временная продолжительность, дата, объем собранных данных, тип собранных данных (т.е. неизвестных данных против известных данных, выявленные данные имитации соединения и т.д.) и тому подобное. Для того чтобы уменьшить объем информации, посылаемой клиентами серверу, клиент в одном примере настоящего изобретения может держать информацию локально, если он уже проинформировал сервер о конкретном УУР, и посылать информацию серверу только тогда, когда он это еще не сделал. Когда сервер получает информацию веб-страницы, он просматривает эту информацию на предмет определения, имеются ли в ней какие-либо новые данные по отношению к уже накопленным данным 808. В простом примере настоящего изобретения это включает в себя определение, имеются ли какие-либо новые УУР по сравнению с уже накопленным перечнем УУР на сервере. Когда неизвестная информация обнаружена, сервер добавляет неизвестную информацию к своим накопленным, или «известным», данным 810 и выполнение способа оканчивается 812. Известные данные в одном примере настоящего изобретения являются перечнем УУР, который применяется сервером для последующего поиска веб-агентом, выгрузки и/или индексации и тому подобного.
На фиг.9 представлена другая блок-схема способа 900 клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения. Способ 900 начинается вычислением клиентом значения хеш-функции для содержимого веб-страницы, которую он посетил 904. Когда клиент посещает веб-страницу более чем один раз, предыдущее значение хеш-функции уже вычислено и сохранено для этой веб-страницы. Клиент затем сравнивает только что вычисленное, или «последнее», значение хеш-функции с предыдущим значением хеш-функции для веб-страницы 906. Клиент, выполняя сравнение, может установить значимость обнаруженных расхождений. Например, в одном случае веб-страница может измениться полностью, а в другом случае может быть добавлена только одна запятая в предложение. Клиент может вычислить значимость изменения и либо (а) использовать эту информацию для установления приоритетности, обновлений, которые он посылает серверу, и/или (б) послать значение важности (значимости) серверу наряду с другой информацией веб-страницы с тем, чтобы сервер мог использовать эту информацию для установления приоритетности повторного поиска агентом/повторной индексации страницы. Примеры изменения значимости могут включать в себя, но не ограничиваться только этим, процентное отношение изменений в документе, лингвистическую/семантическую значимость изменения, оценку процентного отношения поисков пользователей, которые вызваны изменением, и тому подобное. Значимость может также быть взвешена посредством оценки популярности страницы. Обычно клиент хранит статус информации веб-страницы локально и обновляет эту сохраненную информацию, когда необходимо 908. Клиент затем информирует сервер об информации 910 состояния веб-страницы. Также возможным в примере настоящего изобретения является информирование клиентом других клиентов об информации состояния веб-страницы. Метод, в соответствии с которым уведомляют сервер и/или клиента, может включать в себя, но не ограничиваясь только этим, только УУР, УУР плюс новое значение хеш-функции и/или УУР плюс новое значение хеш-функции и старое значение хеш-функции и тому подобное. Сервер (или другой клиент) затем сравнивает информацию клиента о состоянии веб-страницы на предмет наличия в ней кроме УУР дополнительной информации со своей серверной информацией о состоянии веб-страницы 912. Если в качестве изменения состояния сервер получает для веб-страницы только УУР, сервер обычно инициирует повторное посещение/поиск агентом такой веб-страницы, чтобы получить новую информацию состояния для сравнения с предыдущей информацией сервера о состоянии веб-страницы. Сервер затем обновляет свою информацию состояния веб-страницы, если это необходимо 914, и выполнение способа оканчивается 916. Для предотвращения намерения сервера осуществить повторное посещение веб-страницы клиент может послать дополнительную информацию. Если клиент имеет буферизованную копию страницы от своего последнего посещения, он может послать старое значение хеш-функции наряду с расхождениями между старой и новой версиями и новое значение хеш-функции. Сначала сервер проверит, соответствует ли старое значение хеш-функции текущему значению хеш-функции у сервера для этой страницы. Если это так, то он может обновить содержание страницы соответственно.
На фиг.10 представлена еще одна блок схема способа 1000 клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения. Способ 1000 начинается 1002 инициированием клиентом поискового запроса поисковому серверу 1004. Поисковый сервер выполняет поисковый запрос и составляет перечень результатов поиска в ответ на запрос 1006. Поисковый сервер затем создает страницу результатов поиска с вложенной информацией о связях веб-страниц 1008. Обычная информация может включать в себя, но не ограничиваясь только этим, значение хеш-функции для серверной версии содержания веб-страницы и/или флаг для индикации того, что содержимое известно как несвежее, для каждой веб-страницы (например, другой клиент сообщил поисковому серверу о новом обновлении для веб-страницы, но поисковый сервер еще не обновил веб-страницу). Таким образом, веб-страница с флагом «известна как несвежая» является веб-страницей, для которой поисковый сервер не желает, чтобы клиент, запрашивающий поиск, направлял информацию об обновлении. Поисковый сервер затем посылает страницу результатов поиска с вложенными связями клиенту, который запросил поиск 1010. По мере посещения клиентом веб-страниц, которые приведены в странице результатов поиска, он проверяет вложенный флаг свежести (или статус свежести), представленный поисковым сервером 1012. Клиент вычисляет значение хеш-функции содержимого веб-страницы, которую он посещает, когда статус свежести указывает «свежая» 1014. Статус свежести указывает, что поисковый сервер считает, что он располагает последней, или наиболее свежей, версией веб-страницы. Таким образом, клиент вычисляет новое значение хеш-функции содержимого веб-страницы и сравнивает его с вложенным значением хеш-функции, представленным поисковым сервером 1016. Клиент затем уведомляет поисковый сервер о том, имеется ли расхождение или дельта между новым значением хеш-функции и значением хеш-функции, представленным сервером, 1018. Поисковый сервер затем получает уведомление и обновляет статус свежести на «известен как несвежий» и также добавляет веб-страницу в перечень на повторный поиск агентом 1020, завершая выполнение способа 1022. Перечень на повторный поиск агентом в этом примере настоящего изобретения является способом, который использует поисковый сервер для обновления своего значения хеш-функции содержимого включенной в перечень страницы со статусом «известен как несвежий». Поисковый сервер «повторно выполняет поиск агентом» или вновь посещает веб-страницу для того, чтобы завершить обновление.
В другом примере вышеизложенный способ распространен на создание способа, в котором клиенты посылают поисковому серверу информацию о различии страниц (которая затем используется для обновления поисковым сервером своей информации о веб-странице без повторного поиска агентом и/или для упрощения установления приоритетности того, когда поисковый сервер должен повторно выполнить поиск веб-страницы агентом) посредством посылки поисковому серверу дополнительных полей с каждым результатом поиска, включая, но не ограничиваясь только этим, время последнего уведомления клиента и значение хеш-функции веб-страницы из последнего уведомления клиента. Если клиент посещает страницу, выданную поисковым сервером и либо (а) флаг «известен как несвежий» является ложным, либо (б) «известен как несвежий» является верным и значение хеш-функции из последнего уведомления клиента отличается от значения хеш-функции, которое этот клиент вычислил для веб-страницы, тогда клиент уведомляет поисковый сервер. Возможным также является распознать циклы изменений страницы так, что если страница периодически меняется от А к В к С к А, это можно распознать и ограничить клиентские обновления об этой странице.
Посредством использования страницы результатов поиска обмен данными между клиентом и сервером существенно снижается в клиент-основанном поиске веб-агентом, как это отмечено в настоящем изобретении. Дополнительно поддерживается конфиденциальность для клиента в силу того факта, что только те веб-страницы, которые сервер представил в странице результатов поиска, обновляются клиентом. Таким образом, если клиент посещает веб-страницу, доступ к которой ограничен, эта информация непреднамеренно не направляется поисковому серверу. Преимущество этого способа является одновременно и недостатком в той части, что поисковый сервер не может использовать клиента для расширения известных ему веб-страниц с целью применения в поисках, даже если новая веб-страница не является частной.
В другом примере настоящего изобретения способ (не проиллюстрирован) использует не только информацию веб-страниц поискового сервера, но и информацию веб-страниц других поисковых серверов. Таким образом, новая веб-страница, выданная другим поисковым сервером клиенту, может быть использована для уведомления поискового сервера о том, что существует новая веб-страница. Это по-прежнему поддерживает конфиденциальность клиента, потому что поисковый сервер уведомляют только об общедоступных веб-страницах, которые сервер не отразил в перечне. Это позволяет поисковому серверу добавлять неизвестные веб-страницы, не подвергая риску доверие клиента. Уведомление может включать в себя, но не ограничиваясь этим, УУР для веб-страницы, значение хеш-функции веб-страницы, отметку времени доступа к веб-странице, дельту нового значения хеш-функции в сравнении с предыдущим значением хеш-функции для веб-страницы и тому подобное.
На фиг.11 представлена еще одна блок-схема способа 1100 клиент-основанного веб-поиска в соответствии с вариантом осуществления настоящего изобретения. Способ 1100 начинается 1102 выработкой поисковым сервером набора функций 1104 слабого индикатора. Способ выработки этих функций раскрыт ниже. Поисковый сервер передает случайным образом выбранные функции слабого индикатора клиентам, включающим в себя клиент-основанный поисковый веб-агент 1106. Клиент затем вырабатывает данные веб-страницы для веб-страниц, которые указаны как неизвестные случайно выбранной функцией слабого индикатора 1108. Обычно только неизвестные веб-страницы точно представлены функцией слабого индикатора. «Известные» веб-страницы могут быть или могут не быть известны на самом деле. Клиент затем передает неизвестные данные веб-страниц серверу 1110. Сервер затем использует эти данные для обновления своей информации, относящейся к веб-страницам 1112, и выполнение способа оканчивается 1114.
На фиг.12 представлена блок-схема способа 1200 выработки правильного набора функций слабого индикатора для клиент-основанного поиска веб-агентом в соответствии с вариантом осуществления настоящего изобретения. Способ 1200 начинается 1202 разбивкой случайным образом словаря, представляющего информацию веб-страниц, находящуюся на поисковом сервере, на не перекрывающиеся подсловари 1204. Обычно подсловари выбирают таким образом, чтобы каждый из них представлял общие черты образуемой группы информации веб-страниц. Функцию слабого (поглощающего) индикатора затем случайным образом выбирают для каждого подсловаря, для представления информации веб-страницы, обнаруженной в конкретном подсловаре 1206. Затем создают функцию так, что I(x)=1 тогда и только тогда, когда, по меньшей мере, одна слабая функция подсловаря равна единице 1208, и выполнение способа оканчивается 1210. Таким образом, вырабатывают «правильный набор» функций слабого индикатора. Так, например, для любого УУР, уже известного серверу, функция индикатора правильно определяет, что он известен. Для УУР, неизвестного серверу, она может ложно пометить его, как известный, и в этом случае клиент ничего не делает, или может правильно пометить его, как неизвестный, в этом случае клиент может проинформировать сервер. По определению правильный набор функций слабого индикатора гарантирует, что в любое время, когда клиентом посещается веб-страница, неизвестная серверу, существует ненулевая вероятность того, что клиентская функция указателя распознает этот сайт как новый.
Для того чтобы представить дополнительный контекст применения различных аспектов настоящего изобретения, фиг.13 и последующее раскрытие информации представлены с намерением обеспечить краткое описание подходящей вычислительной среды 1300, в которой могут быть использованы различные аспекты настоящего изобретения. Несмотря на то что изобретение описано выше в общем контексте исполняемых компьютером инструкций компьютерной программы, которая работает на локальном компьютере и/или удаленном компьютере, для специалистов в данной области техники очевидным является, что настоящее изобретение может быть также использовано в комбинации с другими программными модулями. В основном программные модули включают в себя подпрограммы, программы, компоненты, структуры данных и т.д., которые выполняют особые задачи и/или применяют особые абстрактные типы данных. Более того, для специалистов в данной области техники очевидным является, что изобретенные способы могут быть использованы на практике с другими конфигурациями компьютерной системы, включающими в себя однопроцессорные или многопроцессорные компьютерные системы, миникомпьютеры, универсальные вычислительные машины, а также персональные компьютеры, переносные вычислительные устройства, микропроцессорные и/или программируемые бытовые электронные устройства и тому подобное, каждое из которых может оперативно взаимодействовать с одним или более связанных устройств. Проиллюстрированные варианты осуществления изобретения могут быть также использованы на практике в распределенных вычислительных средах, где определенные задачи выполняются удаленными устройствами обработки, которые связаны посредством сети связи. Однако некоторые, если не все, варианты осуществления изобретения могут быть применены на практике на автономных компьютерах. В распределенной вычислительной среде программные модули могут быть расположены на локальных и/или переносных устройствах хранения данных.
Употребляемый в настоящей заявке термин «компонент» относится к объекту компьютерной техники как аппаратному обеспечению, так и совокупности аппаратного и программного обеспечения, программному обеспечению или программному обеспечению в процессе исполнения. Например, компонент может представлять собой, но не ограничиваясь этим, процесс, выполняемый компьютером, процессор, объект, исполняемый файл, поток выполнения, программу и компьютер. В качестве иллюстрации можно указать, что приложение, выполняемое на сервере, и/или сервер может быть компонентом. Кроме того, компонент может содержать один или более подкомпонентов.
Представленный на фиг.13 пример системной среды 1300 для применения различных аспектов изобретения включает в себя обычный компьютер 1302, включающий в себя блок 1304 обработки, системную память 1306 и системную шину 1308, которая связывает различные компоненты системы, в том числе системную память, с блоком 1304 обработки. Блок 1304 обработки может быть любым предлагаемым к продаже или собственным процессором. Дополнительно блок обработки может быть использован как многопроцессорный элемент, образованный более чем одним процессором, которые могут быть соединены параллельно.
Системная шина 1308 может быть любым из нескольких видов шинной структуры, включающим в себя шину памяти или контроллера памяти, периферийную шину и локальную шину, использующим один из общеизвестных видов шинной архитектуры, такой как PCI, VESA, Microchannel, ISA и EISA, называя только некоторые из них. Системная память 1306 включает в себя постоянное запоминающее устройство (ПЗУ) 1310 и оперативное запоминающее устройство (ОЗУ) 1312. Базовая система 1314 ввода/вывода (BIOS), содержащая основные подпрограммы, которые помогают передавать информацию между элементами внутри компьютера 1302, например, при запуске, сохранена в ПЗУ 1310.
Компьютер 1302 может также включать в себя, например, накопитель 1316 на жестком диске, накопитель 1318 на магнитном диске, например, для чтения или записи на сменный диск 1320, и накопитель 1322 на оптическом диске, например, для чтения и записи на CD-ROM диск 1324 или другой оптический носитель информации. Накопитель 1316 на жестком диске, накопитель 1318 на магнитном диске и накопитель 1322 на оптическом диске связаны с системной шиной 1308 интерфейсом 1326 накопителя на жестком диске, интерфейсом 1328 накопителя на магнитном диске, интерфейсом 1330 накопителя на оптическом диске соответственно. Накопители 1316-1322 и связанные с ними машиночитаемые носители обеспечивают энергонезависимое хранение данных, структур данных, исполняемых компьютером, инструкции и т.д. для компьютера 1302. Несмотря на то что вышеприведенное описание машиночитаемых носителей относится к накопителям на жестком диске, сменном магнитном диске и компакт-диске (CD), для специалиста в данной области техники очевидным является, что другие типы носителей, которые могут быть считаны компьютером, такие как магнитные кассеты, флэш-карты памяти, цифровые видеодиски, картриджи Бернулли и тому подобные, могут быть также использованы в приведенной в качестве примера операционной среде 1300, и, более того, любой из таких носителей может содержать выполняемые компьютером инструкции для осуществления способов по настоящему изобретению.
Ряд программных модулей может быть сохранен в накопителях 1316-1322 и ОЗУ 1312, включая операционную систему 1332, одну или несколько прикладных программ 1334, другие программные модули 1336 и программные данные 1338. Операционная система 1332 может быть любой подходящей операционной системой или комбинацией операционных систем. Например, прикладная программа 1334 и программный модуль 1336 могут выполнять облегченный клиент-основанный поиск веб-агентом в соответствии с вариантом осуществления настоящего изобретения.
Пользователь может вводить в компьютер 1302 команды и информацию посредством одного или нескольких пользовательских устройств ввода, таких как клавиатура 1340 и координатно-указательное устройство (например, мышь 1342). Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую консоль, спутниковую тарелку, беспроводное подключение, сканер и тому подобное. Эти и другие устройства ввода часто подсоединяют к блоку 1304 обработки посредством интерфейса 1344 последовательного порта, который связан с системной шиной 1308, но могут быть подсоединены посредством иных интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 1346 или устройство отображения иного вида также подключают к системной шине 1308 посредством интерфейса, такого как видеоадаптер 1348. Дополнительно к монитору 1346 компьютер 1302 может содержать другие периферийные устройства вывода (не показаны), такие как громкоговорители, принтеры и т.д.
Следует отметить, что компьютер 1302 может работать в сетевой среде, использующей логические соединения с одним или несколькими удаленными компьютерами 1360. Удаленный компьютер 1360 может быть рабочей станцией, компьютером сервера, маршрутизатором, устройством равноправного участника сети или другим узлом общей сети и обычно включает в себя многие или все из описанных элементов, относящихся к компьютеру 1302, однако для целей упрощения изложения на фиг.13 показано только устройство 1362 хранения данных. Логические соединения, представленные на фиг.13, могут включать в себя локальную сеть (ЛОС) 1364 и глобальную сеть (ГЛС) 1366. Такие сетевые среды общеизвестны для применения в офисах, компьютерных сетях предприятий, сетях интранет и Интернет.
При использовании, например, в сетевой среде ЛОС компьютер 1302 соединяют с локальной сетью 1364 посредством сетевого интерфейса или адаптера 1368. При использовании в сетевой среде ГЛС компьютер 1302 обычно включает в себя модем (т.е. телефон, цифровую абонентскую линию, кабель и т.п.) 1370, или подсоединен к серверу передачи данных ЛОС, или имеет другие средства для установления связи по ГЛС 1366, такой как Интернет. Модем 1370, который может быть внутренним или внешним по отношению к компьютеру 1302, подсоединен к системной шине 1308 посредством интерфейса 1344 последовательного порта. В сетевой среде программные модули (включая прикладные программы 1334) и/или программные данные 1338 могут быть сохранены на сменном устройстве 1362 хранения данных. Очевидным является, что показанные сетевые соединения представлены в качестве примеров, и для установления связи между компьютерами 1302 и 1360 могут быть использованы другие средства (например, проводные или беспроводные) при реализации варианта осуществления настоящего изобретения.
В соответствии с практикой, принятой специалистами в области компьютерного программирования, настоящее изобретение описано со ссылками на действия и символические представления операций, которые выполняются компьютером, таким как компьютер 1302 или удаленный компьютер 1360, если не указано иное. Подобные действия и операции иногда упоминают, как компьютерно-исполняемые. Очевидным является, что действия и символически представленные операции включают в себя работу блока 1304 обработки с электрическими сигналами, представляющими биты данных, что приводит к преобразованию или сокращению представления электрических сигналов и поддержанию битов данных в местах сохранения данных в системе памяти (включая системную память 1306, накопитель 1316 на жестком диске, гибкие диски 1320, CD-ROM 1324 и удаленную память 1362) для реконфигурации, таким или иным образом изменения работы компьютерной системы, равно как и другой обработки сигналов. Места сохранения данных, где поддерживают такие биты данных, являются физическими местоположениями, которые имеют особые электрические, магнитные или оптические свойства, соответствующие битам данных.
На фиг.14 представлена другая структурная схема примера компьютерной среды 1400, с которой может взаимодействовать настоящее изобретение. Система 1400 дополнительно иллюстрирует систему, которая включает одного или более клиента(ов) 1402. Клиент(ы) 1402 могут быть аппаратными и/или программными средствами (например, потоками, процессами, вычислительными устройствами). Система 1400 также включает в себя один или несколько серверов 1404. Сервер(ы) 1404 могут быть также аппаратными и/или программными средствами (например, потоками, процессами, вычислительными устройствами). Серверы 1404 могут содержать потоки для выполнения преобразований посредством использования настоящего изобретения, например. Один из возможных обменов данными между клиентом 1402 и сервером 1404 может быть в форме пакета данных, приспособленного для передачи между двумя или более компьютерными процессами. Система 1400 включает в себя структуру 1408 связи, которая может быть использована для облегчения обмена данными между клиентом(клиентами) 1402 и сервером(серверами) 1404. Клиент(ы) 1402 функционально связаны с одним или несколькими средствами 1410 хранения клиентских данных, которые могут быть использованы для хранения информации локально по отношению к клиенту(клиентам) 1402. Подобным образом сервер(ы) 1404 функционально связаны с одним или несколькими средствами 1406 хранения серверных данных, которые могут быть использованы для хранения информации локально по отношению к серверам 1404.
В одном примере настоящего изобретения пакет данных передают между двумя или более компьютерными компонентами, которые облегчают поиск веб-агентом, этот пакет данных состоит из, по меньшей мере, частично информации относящейся к поиску веб-агентом, при котором используют, по меньшей мере, частично распределенную систему для поиска веб-агентом.
В другом примере настоящего изобретения машиночитаемый носитель сохраняет исполняемые компьютером компоненты системы для облегчения поиска веб-агентом, включает в себя, по меньшей мере, частично систему поиска веб-агентом, которая определяет, по меньшей мере, частично информацию, относящуюся к веб-страницам, составленным распределенной системой поиска веб-агентом.
Очевидным является, что системы и/или способы по настоящему изобретению могут быть использованы в системах поиска веб-агентами, упрощая равным образом компьютерные компоненты и компоненты, не относящиеся к компьютерным. Более того, для специалистов в данной области техники очевидным является, что системы и/или способы по настоящему изобретению применимы в широчайшем спектре прикладных технологий электроники, включающих в себя, но не ограничиваясь только этим, компьютеры, серверы и/или переносные электронные устройства и тому подобные, которые могут быть проводными и/или беспроводным и тому подобными.
Для специалиста в данной области техники также очевидным является, что настоящее изобретение может быть использовано не только для сервер-основанных и клиент-основанных систем поисковых агентов, но также для одноранговых (равноправных) систем поисковых агентов. Также возможным является выполнение клиентом задач, обычно связанных с «серверным» поведением, и, таким образом, возможной является передача клиенту некоторых характеристик, связанных с сервером, в некоторых примерах настоящего изобретения. Одним из примеров настоящего изобретения является клиент, который выполняет «подпоиски» агентом в других клиентах для обнаружения и/или выявления информации для направления серверу. Этот пример может быть предпочтительным, например, в сетях, которые имеют критические элементы между определенными клиентами и сервером. Данные могут быть переданы клиенту с наилучшим доступом к серверу. В других примерах настоящего изобретения клиент может проявить поведение сервера посредством инициирования подпоисков агентом в интранет-системе, таким образом передавая информацию серверу от только одного и/или существенно сокращенного числа клиентов, присутствующих в интранете. Таким образом, поисковый сервер может инициировать многочисленные подпоиски агентом в клиентах для расширения своих ресурсов агентского поиска.
Все раскрытое выше включает в себя примеры настоящего изобретения. Безусловно, невозможно описать каждую задуманную совокупность компонентов или методик для целей описания настоящего изобретения, но для обычного специалиста в данной области техники очевидным является, что возможны многие дальнейшие комбинации и перестановки в настоящем изобретении. Соответственно, настоящее изобретение охватывает все такие изменения, модификации и вариации, которые не изменяют сущности изобретения и входят в объем охраны, определяемый нижеследующей формулой изобретения. Более того, при использовании признака «содержит», имеющегося как в описании изобретения, так и в формуле, предполагалось, что он по своей сути является включающим в состав, подобно признаку «включающий в себя», а «включающий в себя» должен толковаться, как переходное слово в формуле изобретения.
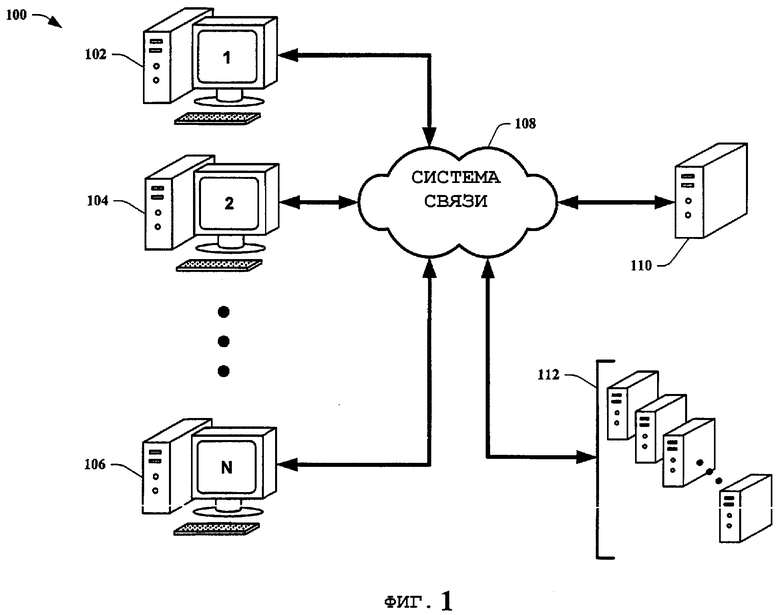
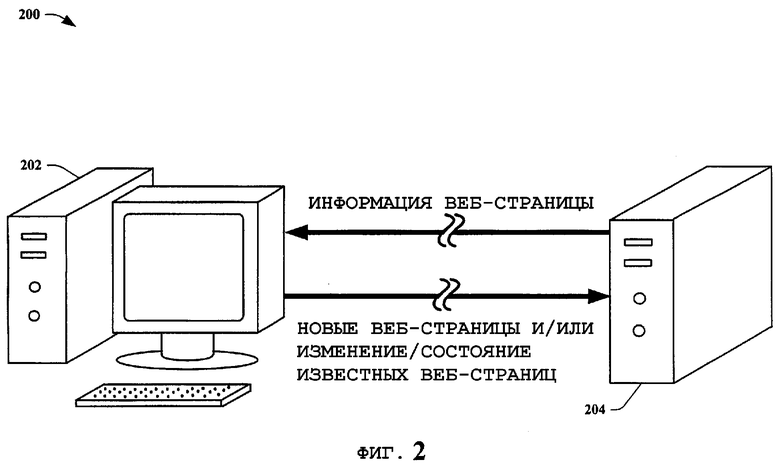
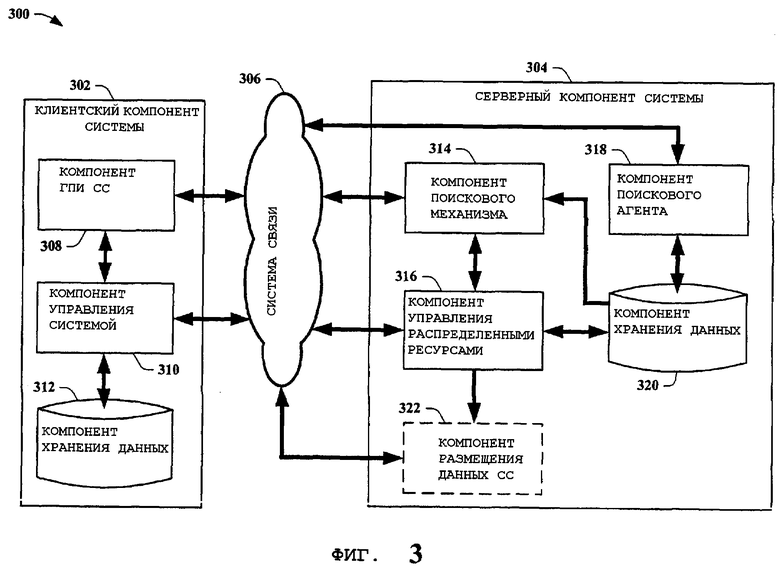
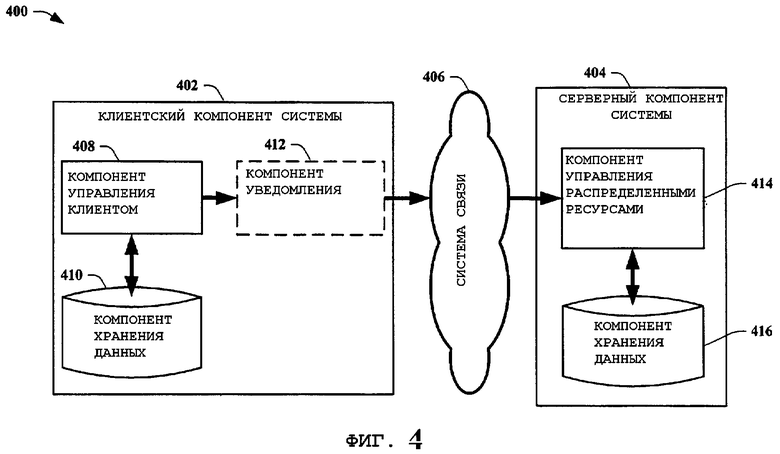
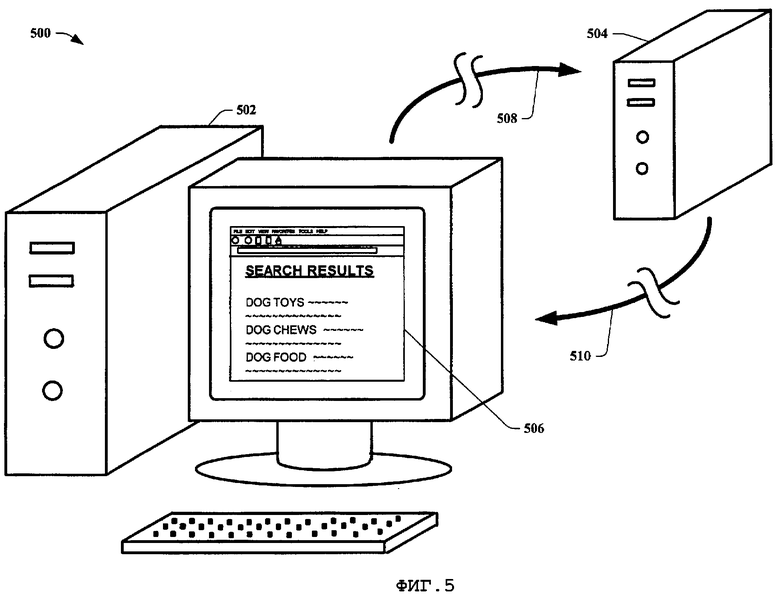
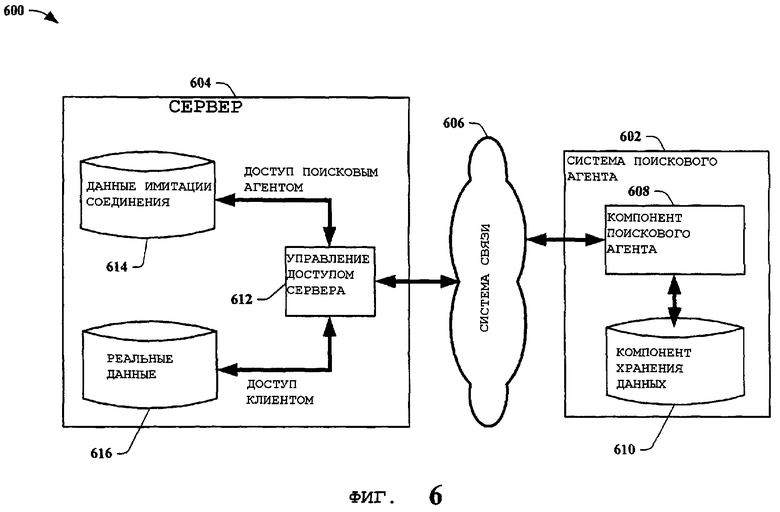
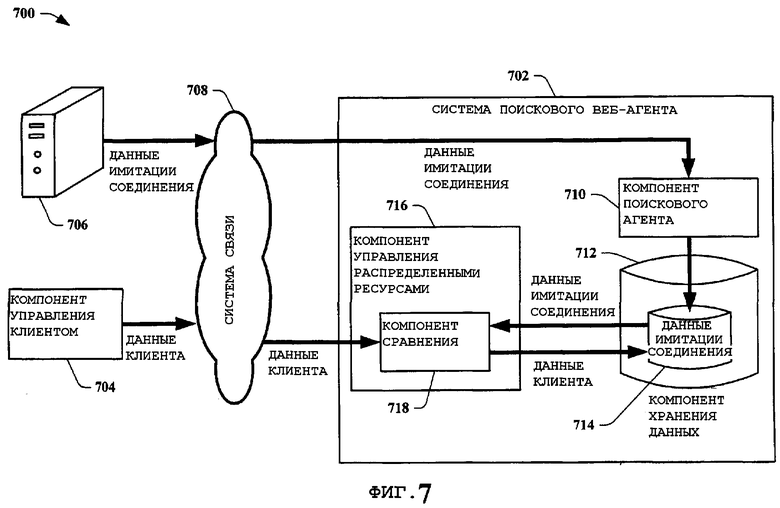
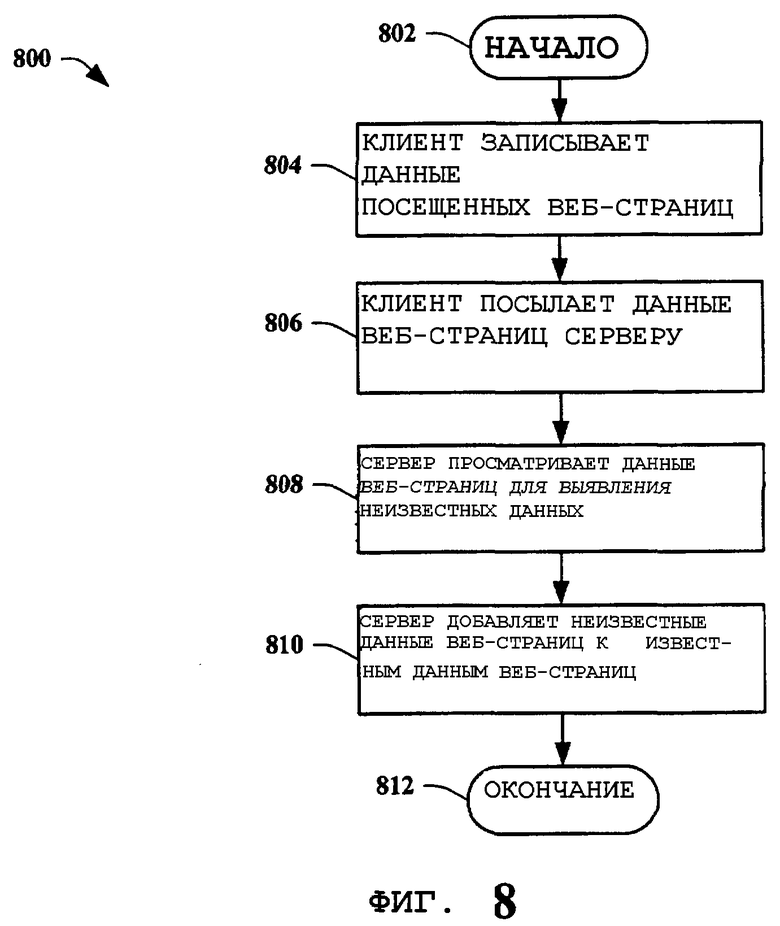
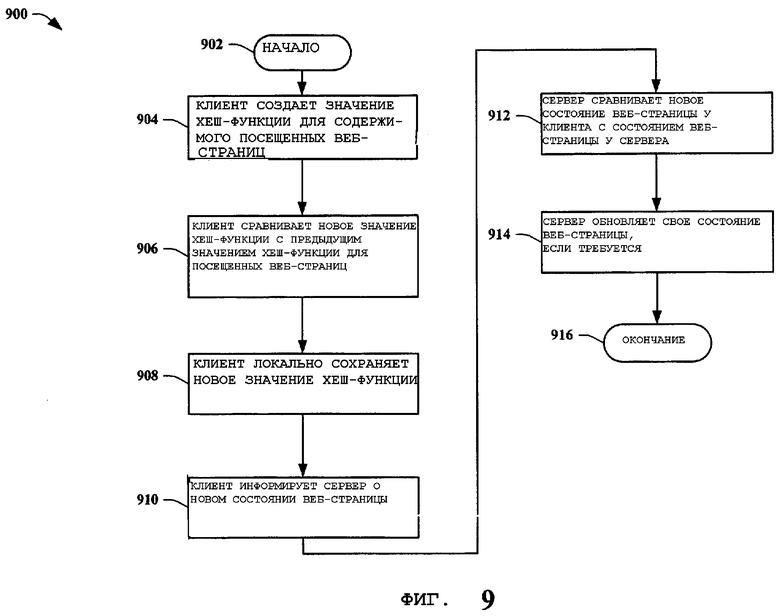
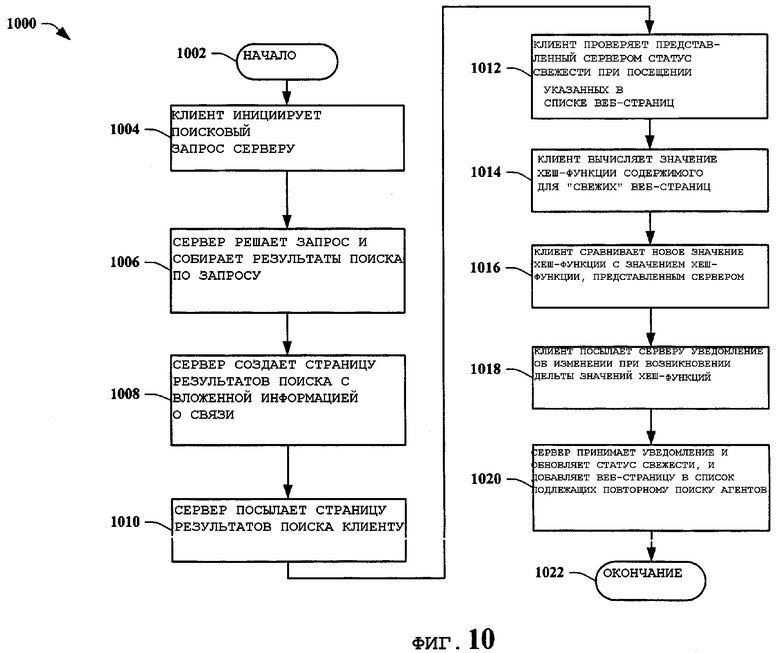
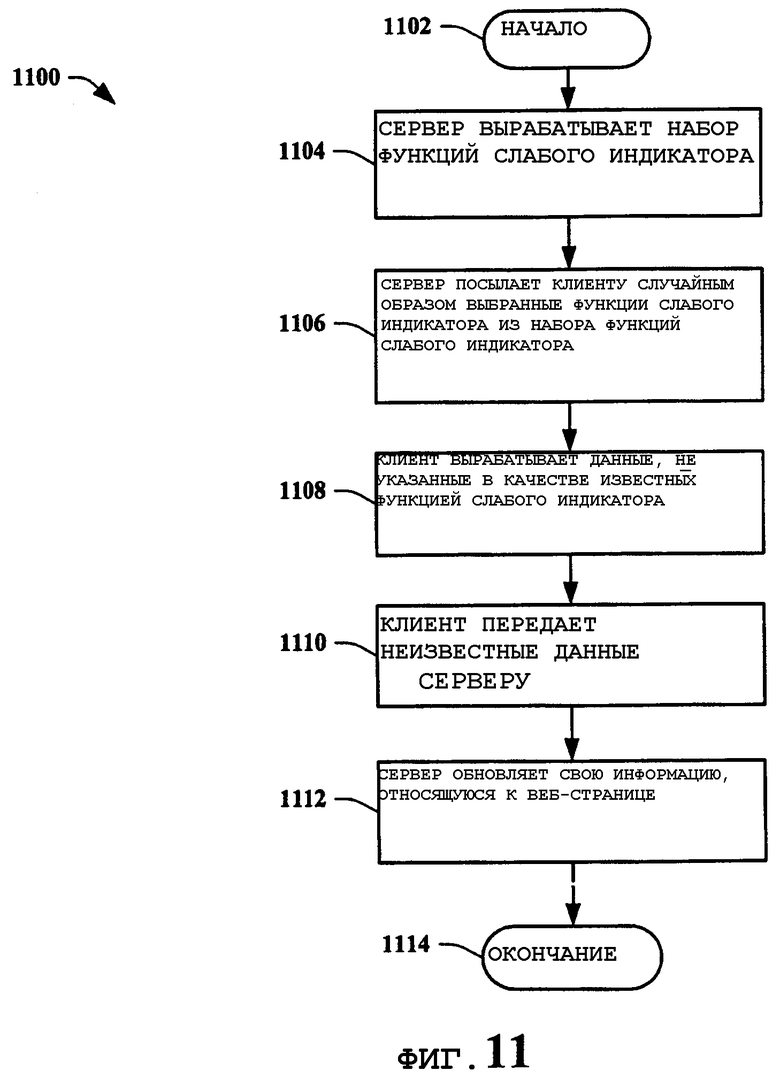
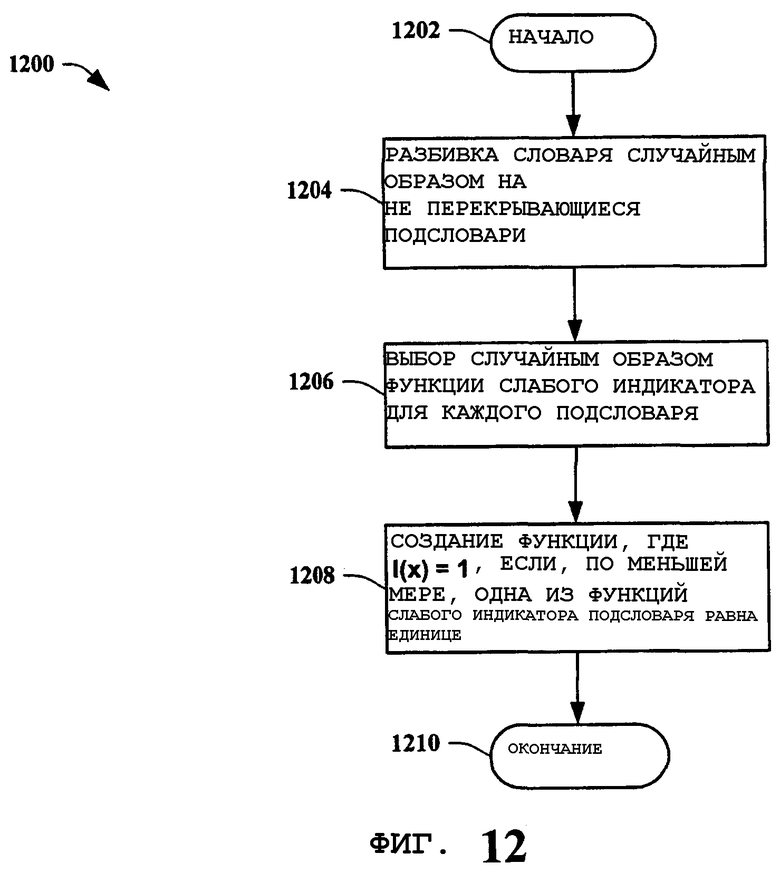
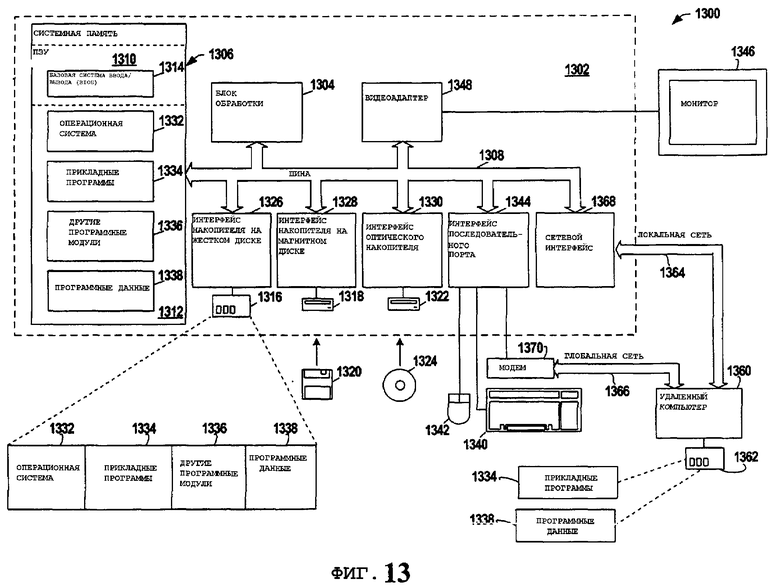
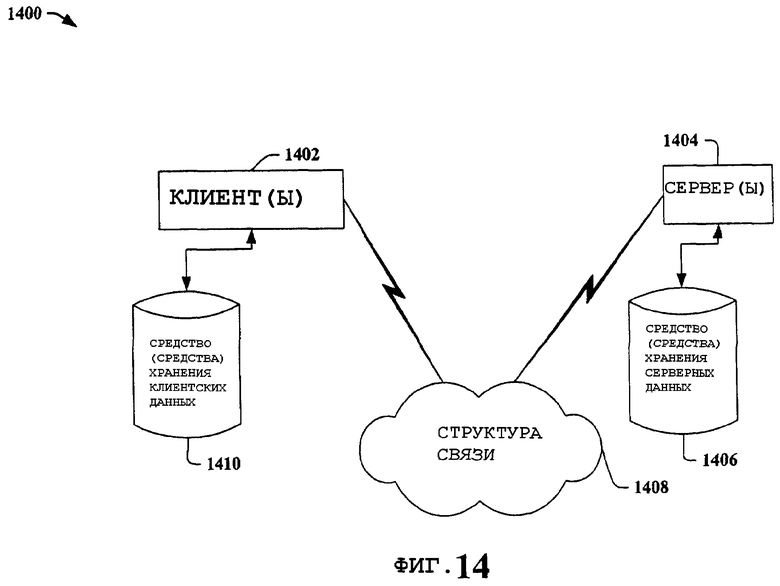
Изобретение относится к анализу данных, более конкретно к системам и способам для получения информации от работающей в сети системы с использованием распределенного поискового агента по «всемирной паутине». Техническим результатом является обеспечение клиентов сервера быстрыми и точными данными поиска веб-агентом. В одном из вариантов изобретения система анализа данных включает в себя первый компонент, связанный с сервером системы анализа данных, который способствует выработке первого набора данных, относящихся к информации веб-страницы, полученной по системе связи, второй компонент, который управляет вторым набором данных, относящихся к информации веб-страницы от, по меньшей мере, одного распределенного ресурса, который взаимодействует с системой связи, причем второй набор данных использован для уточнения первого набора данных, причем уточнение первого набора данных включает в себя добавление неизвестной информации к первому набору данных при получении новой информации от распределенного ресурса посредством второго набора данных или обновление существующей информации в первом наборе данных, если имели место изменения в содержимом информации веб-страницы, как указано вторым набором данных. 8 н. и 97 з.п. ф-лы, 14 ил.
1. Система анализа данных, включающая в себя:
первый компонент, связанный с сервером системы анализа данных, который способствует выработке первого набора данных, относящихся к информации веб-страницы, полученной по системе связи, и
второй компонент, который управляет вторым набором данных, относящихся к информации веб-страницы от, по меньшей мере, одного распределенного ресурса, который взаимодействует с системой связи, причем второй набор данных использован для уточнения первого набора данных, причем уточнение первого набора данных включает в себя добавление неизвестной информации к первому набору данных, при получении новой информации от распределенного ресурса посредством второго набора данных или обновление существующей информации в первом наборе данных, если имели место изменения в содержимом информации веб-страницы как указано вторым набором данных.
2. Система по п.1, в которой первый компонент включает в себя поисковый веб-агент для Интернет.
3. Система по п.1, в которой первый компонент включает в себя поисковый веб-агент для интранет.
4. Система по п.1, в которой второй компонент дополнительно использован для оптимизации приема данных от распределенных ресурсов.
5. Система по п.1, в которой второй компонент обеспечивает функцию планирования для управления приемом второго набора данных от, по меньшей мере, одного распределенного ресурса.
6. Система по п.1, в которой второй компонент использован для способствования снижению трафика через систему связи посредством применения правильного набора функций слабого индикатора, представляющих первый набор данных.
7. Система по п.6, в которой второй компонент дополнительно использован для случайного выбора и передачи функции слабого индикатора, выбранной из правильного набора функций слабого индикатора, по меньшей мере, одному из распределенных ресурсов.
8. Система по п.1, в которой второй компонент дополнительно использован для сравнения первого набора данных и второго набора данных для обнаружения данных имитации соединения, найденных первым компонентом.
9. Система по п.1, в которой второй компонент дополнительно использован для выработки информации состояния о данных, относящихся к первому набору данных, причем информация состояния передается, по меньшей мере, одному распределенному ресурсу.
10. Система по п.9, в которой информация состояния включает в себя, по меньшей мере, частично флаг свежести для указания свежести информации, относящейся к первому набору данных.
11. Система по п.9, в которой информация состояния включает в себя, по меньшей мере, частично хешированное содержимое информации, относящейся к первому набору данных.
12. Система по п.9, в которой информация состояния включает в себя, по меньшей мере, частично копию информации первого набора данных.
13. Система по п.1, в которой система связи включает в себя Интернет.
14. Система по п.1, в которой система связи включает в себя «всемирную паутину» (world wide web).
15. Система по п.1, в которой система связи включает в себя интранет.
16. Система по п.15, в которой интранет включает в себя локальную вычислительную сеть.
17. Система по п.15, в которой интранет включает в себя глобальную вычислительную сеть.
18. Система по п.1, в которой распределенные ресурсы включают в себя доверенные объекты, взаимодействующие с системой связи и вторым компонентом.
19. Система по п.1, в которой первый набор данных включает в себя данные веб-страницы Интернет.
20. Система по п.1, в которой первый набор данных включает в себя данные веб-страницы интранет.
21. Система по п.1, в которой второй набор данных включает в себя, по меньшей мере, частично хешированное содержимое, по меньшей мере, одной веб-страницы.
22. Система по п.1, в которой второй набор данных включает в себя, по меньшей мере, частично Унифицированный Указатель Ресурса (УУР, URL), по меньшей мере, одной веб-страницы.
23. Система по п.1, в которой второй набор данных включает в себя, по меньшей мере, частично отметку времени, относящуюся к времени получения информации о, по меньшей мере, одной веб-странице.
24. Система по п.1, в которой второй набор данных включает в себя, по меньшей мере, частично дельта-указание изменений содержимого, по меньшей мере, одной веб-страницы.
25. Система по п.24, в которой дельта-указание содержит, по меньшей мере частично, хешированное предыдущее содержимое веб-страницы и хешированное новое содержимое веб-страницы.
26. Система по п.1, в которой второй набор данных включает в себя, по меньшей мере частично, указание состояния изменений, по меньшей мере, одной веб-страницы.
27. Система по п.26, в которой указание состояния содержит, по меньшей мере частично, процентное отношение объема изменений содержимого веб-страницы.
28. Система по п.26, в которой указание состояния содержит, по меньшей мере частично, указатель важности изменений для обозначения важности изменений содержимого веб-страницы.
29. Система по п.1, в которой второй набор данных включает в себя данные веб-страницы Интернет.
30. Система по п.1, в которой второй набор данных включает в себя данные веб-страницы интранет.
31. Система по п.1, в которой второй набор данных включает в себя данные, собранные с использованием, по меньшей мере, одной функции слабого индикатора, случайным образом выбранной из набора функций слабого индикатора; причем набор функций слабого индикатора представляет первый набор данных.
32. Система по п.1, дополнительно включающая в себя поисковый компонент для принятия, по меньшей мере, одного поискового запроса и выработки, по меньшей мере, одного поискового ответа при представлении, по меньшей мере, части первого набора данных информацией, вложенной в поисковый ответ.
33. Система по п.1, дополнительно включающая в себя компонент сервера веб-страниц для конструирования веб-страниц, причем, по меньшей мере, часть первого набора данных представлена информацией, вложенной в, по меньшей мере, одну связь, найденную на, по меньшей мере, одной сконструированной веб-странице.
34. Система по п.1, дополнительно включающая в себя компонент хранения для сохранения первого набора данных.
35. Способ облегчения анализа данных, включающий в себя
создание первого набора данных, относящегося ко второму набору данных, полученных из веб-страниц, взаимодействующих с сервером системы связи;
получение третьего набора данных от, по меньшей мере, одного распределенного ресурса, который является взаимодействующим с системой связи; причем третий набор данных включает в себя информацию, относящуюся к веб-странице, выработанную распределенным ресурсом; и
уточнение второго набора данных для отражения информации, полученной из третьего набора данных, посредством:
добавления неизвестной информации к второму набору данных, при получении новой информации от распределенного ресурса посредством третьего набора данных;
обновления существующей информации во втором наборе данных, если имели место изменения в содержимом информации веб-страницы как указано третьим набором данных, и
передачи информации состояния распределенному ресурсу через один или более указателей после анализа информации из третьего набора данных.
36. Способ по п.35, в котором первый набор данных содержит представление второго набора данных.
37. Способ по п.36, в котором представление второго набора данных включает в себя, по меньшей мере частично, хешированное содержимое, по меньшей мере, одной веб-страницы, содержащейся во втором наборе данных.
38. Способ по п.36, в котором представление второго набора данных включает в себя, по меньшей мере частично, указание состояния, по меньшей мере, одной веб-страницы, содержащейся во втором наборе данных.
39. Способ по п.38, в котором указание состояния включает в себя флаг свежести для указания, является ли информация веб-страницы текущей.
40. Способ по п.35, в котором первый набор данных включает в себя копию второго набора данных.
41. Способ по п.39, в котором второй набор данных включает в себя информацию веб-страницы, собранную поисковым веб-агентом.
42. Способ по п.35, в котором третий набор данных включает в себя информацию веб-страницы, основанную на клиентской выборке информации веб-страницы в системе связи.
43. Способ по п.35, в котором система связи включает в себя Интернет.
44. Способ по п.35, в котором система связи включает в себя интранет.
45. Способ по п.35, дополнительно включающий в себя передачу первого набора данных, по меньшей мере, одному распределенному ресурсу, который находится во взаимодействии с системой связи, делая первый набор данных доступным для использования распределенным ресурсом для выработки третьего набора данных.
46. Способ по п.36, дополнительно включающий в себя выработку набора функций слабого указателя для представления второго набора данных, и выбор случайных функций слабого указателя из набора функций слабого указателя для передачи распределенным ресурсам в качестве первого набора данных.
47. Способ по п.46, в котором набор функций слабого указателя включает в себя правильный набор функций слабого указателя, такой, что существует ненулевая вероятность возможности идентификации новой веб-страницы случайно выбранной функцией слабого указателя.
48. Способ по п.46, в котором выработка набора функций слабого указателя включает в себя:
обеспечение словаря, представляющего второй набор данных;
разбиение словаря случайным образом на неперекрывающиеся подсловари; и
создание функции, в которой I(х)=1 тогда и только тогда, когда, по меньшей мере, одна функция слабого указателя подсловаря равна единице.
49. Способ по п.35, дополнительно включающий в себя сравнение третьего набора данных со вторым набором данных для обнаружения данных имитации соединения, содержащихся во втором наборе данных.
50. Способ по п.35, дополнительно включающий в себя оптимизацию получения, по меньшей мере, одного третьего набора данных посредством планирования распределенных ресурсов.
51. Способ по п.35, дополнительно включающий в себя:
получение запроса на поиск веб-страницы от, по меньшей мере, одного распределенного ресурса;
формирование страницы результатов поиска в Веб в ответ на запрос от распределенного ресурса на поиск веб-страницы;
вложение частей первого набора данных в связи, найденные на странице результатов поиска в Веб; и
передачу распределенному ресурсу страницы результатов поиска в Веб, как представления, по меньшей мере, части второго набора данных.
52. Способ по п.35, дополнительно включающий в себя:
конструирование веб-страницы с использованием, по меньшей мере, части первого набора данных для вложения информации о связях, найденных на веб-странице; и
передачу веб-страницы для распространения первого набора данных, по меньшей мере, одному распределенному ресурсу.
53. Система анализа данных, включающая в себя:
средство для выработки, по меньшей мере, одного первого набора данных от сервера системы связи,
средство для управления и получения, по меньшей мере, одного второго набора данных от, по меньшей мере, одного клиента, который взаимодействует с сервером системы связи; и
средство для уточнения первого набора данных с применением, по меньшей мере, одного второго набора данных, причем уточнение первого набора данных включает в себя, по меньшей мере, одного из: добавления неизвестной информации к первому набору данных, при получении новой информации от клиента посредством второго набора данных и обновления существующей информации в первом наборе данных, если имели место изменения в содержимом информации веб-страницы как указано вторым набором данных.
54. Система по п.53, в которой средство для выработки, по меньшей мере, одного первого набора данных содержит поисковый веб-агент.
55. Система по п.54, в которой первый набор данных включает в себя данные, относящиеся к веб-страницам, полученным поисковым веб-агентом.
56. Система по п.53, в которой второй набор данных включает в себя данные сравнения веб-страницы, собранные, по меньшей мере, одним клиентом и основанные, по меньшей мере частично, на представительных данных первого набора данных.
57. Система анализа данных, включающая в себя:
первый компонент, связанный, по меньшей мере, с одним клиентом распределенной системы поиска веб-агентом, который вырабатывает информацию веб-страницы из, по меньшей мере, одного посещенного веб-сайта для применения в распределенной системе поиска веб-агентом, второй компонент, связанный с сервером который получает данные, относящиеся к веб-странице, переданной первым компонентом через систему связи, причем первый компонент получает набор данных от второго компонента для использования в выработке информации веб-страницы, включающей в себя, по меньшей мере, данные сравнения, основанные на информации посещенной веб-страницы и полученном наборе данных.
58. Система по п.57, в которой первый компонент обеспечивает, по меньшей мере, одну отметку времени, имеющую отношение ко времени получения данных, использованных при выработке информации веб-страницы.
59. Система по п.57, в которой первый компонент получает набор вложенных данных поискового веб-агента из, по меньшей мере, одной страницы результатов поиска для использования в выработке информации веб-страницы.
60. Система по п.57, в которой первый компонент получает набор вложенных данных поискового веб-агента из, по меньшей мере, одной веб-страницы для использования в выработке информации веб-страницы.
61. Система по п.57, в которой первый компонент имеет функциональную возможность получать данные веб-страницы косвенно посредством, по меньшей мере, одного другого клиента распределенной системы поискового агента, для обеспечения шлюза со вторым компонентом для существенного снижения потока трафика ко второму компоненту.
62. Система по п.57, в которой выработанная информация веб-страницы включает в себя, по меньшей мере частично, указание состояния изменений содержания, по меньшей мере, одной веб-страницы.
63. Система по п.62, в которой указание состояния содержит, по меньшей мере частично, процентное отношение объема изменений содержимого веб-страницы.
64. Система по п.62, в которой указание состояния содержит, по меньшей мере частично, указатель важности для обозначения важности изменений в содержимом веб-страницы.
65. Система по п.57, в которой, по меньшей мере, часть выработанной информации веб-страницы сделана доступной для передачи клиентом по соединению равноправных узлов посредством системы связи.
66. Система по п.57, в которой выработанная информация веб-страницы собрана с использованием случайно выбранной функции слабого указателя из правильного набора функций слабого указателя, который представляет данные веб-страницы, собранные поисковым веб-агентом.
67. Система по п.57, в которой система связи включает в себя Интернет.
68. Система по п.57, в которой система связи включает в себя интранет.
69. Система по п.57, дополнительно включающая в себя компонент хранения для сохранения информации веб-страницы.
70. Система по п.57, дополнительно включающая в себя компонент уведомления, который определяет, должна ли и когда должна выработанная информация веб-страницы быть сообщена по системе связи.
71. Система по п.70, в которой компонент уведомления получает информацию планирования от второго компонента, причем информация планирования относится к получению и передаче выработанной информации веб-страницы.
72. Система по п.57, в которой первый компонент использует серверы поиска в Веб вне распределенной системы поиска веб-агентом для отыскания данных, неизвестных второму компоненту.
73. Система по п.57, в которой первый компонент делает посредством системы связи данные сравнения доступными по усмотрению для второго компонента.
74. Система по п.57, в которой данные сравнения содержат, по меньшей мере частично, по меньшей мере, один Унифицированный Указатель Ресурса (УУР, URL), по меньшей мере, одной веб-страницы.
75. Система по п.57, в которой данные сравнения содержат, по меньшей мере частично, хешированное содержимое, по меньшей мере, одной веб-страницы, представляющей недавнее посещение, веб-сайта.
76. Система по п.57, в которой данные сравнения содержат, по меньшей мере частично, дельта-указание содержимого, по меньшей мере, одной веб-страницы.
77. Система по п.76, в которой дельта-указание содержит, по меньшей мере частично, хешированное предыдущее содержимое веб-страницы и хешированное новое содержимое веб-страницы.
78. Система по п.57, в которой второй компонент включает в себя сервер распределенной системы поиска агентом.
79. Система по п.57, в которой второй компонент включает в себя клиента распределенной системы поиска агентом.
80. Система по п.57, в которой выработанная информация веб-страницы включает в себя данные, неизвестные второму компоненту.
81. Система по п.57, в которой, по меньшей мере, часть полученного набора данных сделана доступной для передачи клиентом по соединению равноправных узлов посредством системы связи.
82. Система по п.57, в которой полученный набор данных включает в себя словарь для данных, собранных поисковым веб-агентом.
83. Система по п.57, в которой полученный набор данных включает в себя представление данных, собранных поисковым веб-агентом, причем представление данных выработано посредством использования функции слабого индикатора.
84. Система по п.57, в которой полученный набор данных включает в себя копию данных, собранных поисковым Веб-агентом.
85. Система по п.57, дополнительно включающая в себя компонент хранения для сохранения набора данных, полученного от второго компонента.
86. Способ облегчения анализа данных, включающий в себя: составление первого набора данных, полученного от организации доступа к веб-страницам посредством клиента системы связи; и
передачу, избирательно, первого набора данных к объекту, содержащему, по меньшей мере, сервер распределенной системы поиска агентом, которая взаимодействует с системой связи,
получение представления второго набора данных, собранного поисковым веб-агентом, причем второй набор данных относится к, по меньшей мере, одной веб-странице из системы связи, и
использование второго набора данных для управления тем, какие веб-страницы следует посетить для сбора первого набора данных.
87. Способ по п.86, в котором первый набор данных включает в себя, по меньшей мере, частично, Унифицированный Указатель Ресурса (УУР, URL) для, по меньшей мере, одной веб-страницы.
88. Способ по п.86, в котором первый набор данных включает в себя, по меньшей мере, частично, хешированное содержимое, по меньшей мере, одной веб-страницы.
89. Способ по п.86, в котором избирательную передачу выполняют, основываясь на времени дня.
90. Способ по п.86, в котором избирательную передачу выполняют, основываясь на приоритете, по меньшей мере, одной веб-страницы.
91. Способ по п.86, в котором избирательную передачу выполняют, основываясь на процентном отношении изменения содержимого, по меньшей мере, одной веб-страницы.
92. Способ по п.86, в котором избирательную передачу выполняют, основываясь на идентификации, по меньшей мере, одной веб-страницы.
93. Способ по п.86, в котором получение представления второго набора данных выполняют посредством получения веб-страницы с вложенной информацией, извлеченной из второго набора данных и выработанной сервером, предоставляющим услуги по размещению веб-страниц, с доступом ко второму набору данных.
94. Способ по п.86, в котором получение представления второго набора данных выполняют посредством получения страницы результатов поиска с вложенной информацией, извлеченной из второго набора данных и выработанной в ответ на запрос, переданный поисковому серверу, имеющему доступ ко второму набору данных.
95. Способ по п.86, дополнительно включающий в себя: определение того, когда следует передать первый набор данных посредством системы связи, на основании второго набора данных.
96. Способ по п.95, в котором второй набор данных содержит указатель свежести для указания, когда его данные стали устаревшими и требуют обновления посредством первого набора данных.
97. Способ по п.95, в котором второй набор данных содержит план того, когда должен быть передан первый набор данных.
98. Способ по п.86, дополнительно включающий в себя: сравнение, по меньшей мере, части второго набора данных с, по меньшей мере, частью информации, полученной посредством доступа к веб-страницам для создания данных сравнения; и
выработку представления данных сравнения для извлечения первого набора данных.
99. Способ по п.98, в котором первый набор данных включает в себя данные, неизвестные второму набору данных.
100. Способ по п.99, в котором неизвестные данные включают в себя только неизвестные данные, извлеченные из, по меньшей мере, одной страницы результатов поиска из поискового сервера вне распределенной системы поиска.
101. Способ по п.98, в котором первый набор данных включает в себя изменения содержания веб-страниц, представленных вторым набором данных.
102. Способ по п.98, в котором первый набор данных включает в себя информацию состояния, относящуюся к веб-страницам, представленным вторым набором данных.
103. Машиночитаемый носитель, на котором сохранены выполняемые компьютером компоненты, включающие в себя первый компонент, связанный с сервером системы анализа данных который способствует выработке первого набора данных, относящихся к информации веб-страницы, полученной по системе связи, и
второй компонент, который управляет вторым набором данных, относящихся к информации веб-страницы от, по меньшей мере, одного распределенного ресурса, который взаимодействует с системой связи, причем второй набор данных использован для уточнения первого набора данных, причем уточнение первого набора данных включает в себя добавление неизвестной информации к первому набору данных, при получении новой информации от распределенного ресурса посредством второго набора данных или обновление существующей информации в первом наборе данных, если имели место изменения в содержимом информации веб-страницы как указано вторым набором данных.
104. Вычислительное Устройство, применяющее способ облегчения анализа данных по п.35, включающее в себя, по меньшей мере, одно, выбранное из группы, содержащей компьютер, сервер и переносное электронное устройство.
105. Вычислительное устройство, применяющее систему анализа данных по п.1, включающее в себя, по меньшей мере, одно, выбранное из группы, содержащей компьютер, сервер и переносное электронное устройство.
| US 6615258 B1, 02.09.2003 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| СПОСОБ ПЕРЕДАЧИ СООБЩЕНИЙ ЭЛЕКТРОННОЙ ПОЧТЫ В ЛОКАЛЬНОЙ СЕТИ И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 1996 |
|
RU2144270C1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

