Область техники
Настоящее изобретение относится к области информационных технологий, а более конкретно к системам и способам обнаружения фишинговых сайтов и оптимизации обнаружения фишинговых сайтов.
Уровень техники
За последнее десятилетие компьютерные атаки, включающие имитацию сайтов популярных компаний, такие как фишинговые атаки, стали большой проблемой, с которой сталкиваются многие пользователи сети Интернет. Фишинг (англ. phishing от fishing «рыбная ловля, выуживание») — вид интернет-мошенничества, целью которого является получение доступа к конфиденциальным данным пользователей, в частности логинам и паролям. Это достигается путём проведения массовых рассылок электронных писем от имени популярных брендов, а также личных сообщений внутри различных сервисов, например от имени банков или внутри социальных сетей. В письме часто содержится прямая ссылка на сайт, внешне неотличимый от настоящего, либо на сайт с переадресацией. После того как пользователь попадает на поддельную страницу, злоумышленники пытаются различными приёмами побудить пользователя ввести на поддельной странице свои логин и пароль, которые он использует для доступа к определённому сайту, что позволяет злоумышленникам получить доступ к аккаунтам и банковским счетам пользователя.
Существуют и другие способы кражи конфиденциальных данных пользователей. Некоторые фишеры используют JavaScript для изменения адресной строки. Это достигается, например, путем исполнения так называемой атаки «браузер в браузере», в рамках которой злоумышленник создает с помощью HTML фальшивое окно браузера прямо на веб-странице сайта.
Также злоумышленники могут использовать уязвимости в скриптах доверенного сайта. Этот вид мошенничества, известный как «межсайтовый скриптинг» (англ. Cross-Site Scripting), наиболее опасен, так как пользователь взаимодействует с официальным (доверенным) сайтом. Атака с использованием межсайтового скриптинга представляет собой внедрение вредоносного кода в контент доверенного сайта и последующую его работу в динамическом контенте, отображаемом в браузере пользователя (жертвы). Подобный фишинг очень сложно обнаружить без специальных навыков.
Из уровня техники известны решения, направленные на обнаружение кибератак, использующих мошеннические сайты.
Например, из публикации US 20200252428 А1 известно решение для обнаружения фишинговых кибератак. Это решение включает анализ кода, загруженного с веб-страницы по определенному URL-адресу (от англ. uniform resource locator), для выявления ссылок. По ссылкам осуществляется сбор URL-адресов со страниц сайта и анализ кода, соответствующего собранным URL. Если код соответствует коду, относящемуся к известным фишинговым кибератакам (вредоносным URL), то исходный URL-адрес определяется как вредоносный URL. Одним из недостатков представленного решения является увеличение времени анализа при большом объеме данных и невозможности вынесения решения в случае неполного соответствия кода при его сравнении с другим кодом. Одним из вариантов решения, устраняющего указанный недостаток, является применение моделей машинного обучения для ускорения обработки больших объемов информации.
Кроме того, огромный объем информации, представленный в Интернете, тоже является проблемой для быстрого и эффективного мониторинга и анализа веб-сайтов. Так, например, в процессе обработки потока фишинговых URL, а именно когда скачиваются HTML-страницы, которые им соответствуют, вместо реальной фишинговой страницы потенциально получают много типовой информации, например: сообщения о том, что эти страницы уже заблокированы; различные ошибки сервера, если страница заблокирована или удалена администратором; типовой клоакинг (от англ. Cloak), т.е. метод обмана поисковых систем и систем автоматизированного анализа. Количество таких данных может быть достаточно велико. Для решения этой задачи используются контентные обработчики и производные от них технологии, работающие на основании машинного обучения, при этом качество их работы крайне зависит от качества обучающих данных. Практика показала, что именно такая типовая информация мешает добиться высокого качества обнаружения реальной фишинговой атаки. Во-первых, модель машинного обучения обучается обнаруживать то, что обнаружить легко, но уже обнаруживать не нужно, например, по причине того, что эти страницы уже заблокированы, а не действительно сложные фишинговые страницы. Во-вторых, повышается вероятность ложных срабатываний из-за попадания в фишинговые образцы безопасных (легитимных) HTML-страниц.
Соответственно, необходимы решения, способные обнаруживать изменения на сайтах или сходства с фишинговыми сайтами, при этом обеспечивая уменьшение числа ложных срабатываний и увеличение доли истинно-положительных срабатываний. Варианты осуществления настоящего изобретения решают по меньшей мере указанные задачи по отдельности и вместе.
Раскрытие изобретения
Настоящее изобретение относится к решениям для обнаружения фишинговых сайтов и направлено на уменьшение числа ложных срабатываний и увеличение доли истинно-положительных срабатываний при обнаружении фишинговых сайтов с помощью базы хешей деревьев DOM для страниц.
Технический результат настоящего изобретения заключается в уменьшении доли ложных срабатываний и увеличении доли истинно-положительных срабатываний за счет формирования классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов при помощи хешей объектов DOM для страниц.
В одном из вариантов реализации изобретения предлагается способ формирования классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов при помощи хешей объектов DOM страниц, при этом указанный способ содержит этапы, на которых: получают страницы, соответствующие набору ссылок; формируют древовидную структуру в виде DOM-дерева для каждой страницы путем парсинга страницы, во время которого извлекают данные и информацию из страницы; формируют по меньшей мере одну строку, состоящую из элементов DOM-дерева для каждой страницы, на основании шаблона; создают по меньшей мере два хеша для каждой страницы, при этом первый хеш формируют от всей страницы, а второй и последующие хеши – от сформированных строк; формируют два набора данных из сформированных хешей, где первый набор данных содержит информацию о безопасных страницах, а второй набор данных содержит информацию о фишинговых страницах; проводят проверку на наличие разнообразности данных в каждом наборе данных; осуществляют обучение классификатора, включающего модель машинного обучения, на основании сформированных наборов данных.
В другом варианте исполнения способа получают страницы по меньшей мере одним из подходов: скачивают страницы сайта согласно ссылкам в виде текстовых файлов или получают страницы из базы данных.
В еще одном варианте исполнения способа шаблон определяет способ формирования строки из элементов DOM-дерева страницы.
В другом варианте исполнения способа по меньшей мере одним шаблоном является один из следующих шаблонов:
шаблон, согласно которому формируют строку на основании только названий тегов в DOM-дереве страницы (первый шаблон);
шаблон, согласно которому формируют строку на основании названий тегов и названий атрибутов тегов (второй шаблон).
В еще одном варианте исполнения способа формируют по меньшей мере две строки, при этом первую строку формируют на основании первого шаблона, а вторую строку формируют на основании второго шаблона.
В другом варианте исполнения способа проверку осуществляют путем определения, есть ли в наборах данных группы схожих хешей, при этом указанные группы являются достаточно многочисленными.
В еще одном варианте исполнения способа дополнительно проводят очистку данных из наборов данных, где очистка заключается в поиске и удалении из одного из набора данных хешей, которые попали в оба набора данных.
В другом варианте исполнения способа дополнительно проводят проверку на наличие разнообразности данных в каждом из указанных наборе данных.
В еще одном варианте исполнения способа дополнительно после обучения классификатора осуществляют проверку его работы на тестовом подмножестве данных.
В другом варианте исполнения способа проводят переобучение классификатора при выявлении ложного срабатывания во время проверки на тестовом подмножестве данных.
В другом варианте реализации изобретения предлагается система формирования классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов на основании объектов DOM страниц, при этом указанная система включает: средство сбора данных, средство анализа, включающие средство формирования объекта DOM и средство формирование хешей, средство хранения данных, средство обучения, предназначенное для обучения классификатора, включающего модель машинного обучения для поиска фишинговых сайтов, и в которой вычислительное устройство, содержащее по меньшей мере один процессор и по меньшей мере одну память, хранящую машиночитаемые инструкции, исполняемые по меньшей мере одним процессором, осуществляет упомянутый способ.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает пример системы создания классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов.
Фиг. 2 показывает пример системы обнаружения фишинговых сайтов с возможностью последующего переобучения классификатора.
Фиг. 3 показывает пример способа обучения (переобучения) модели машинного обучения для обнаружения фишинговых сайтов.
Фиг. 4 показывает пример способа обнаружения фишинговых сайтов.
Фиг. 5а-5б показывает пример объекта DOM для страницы сайта и формирования строк из объекта DOM.
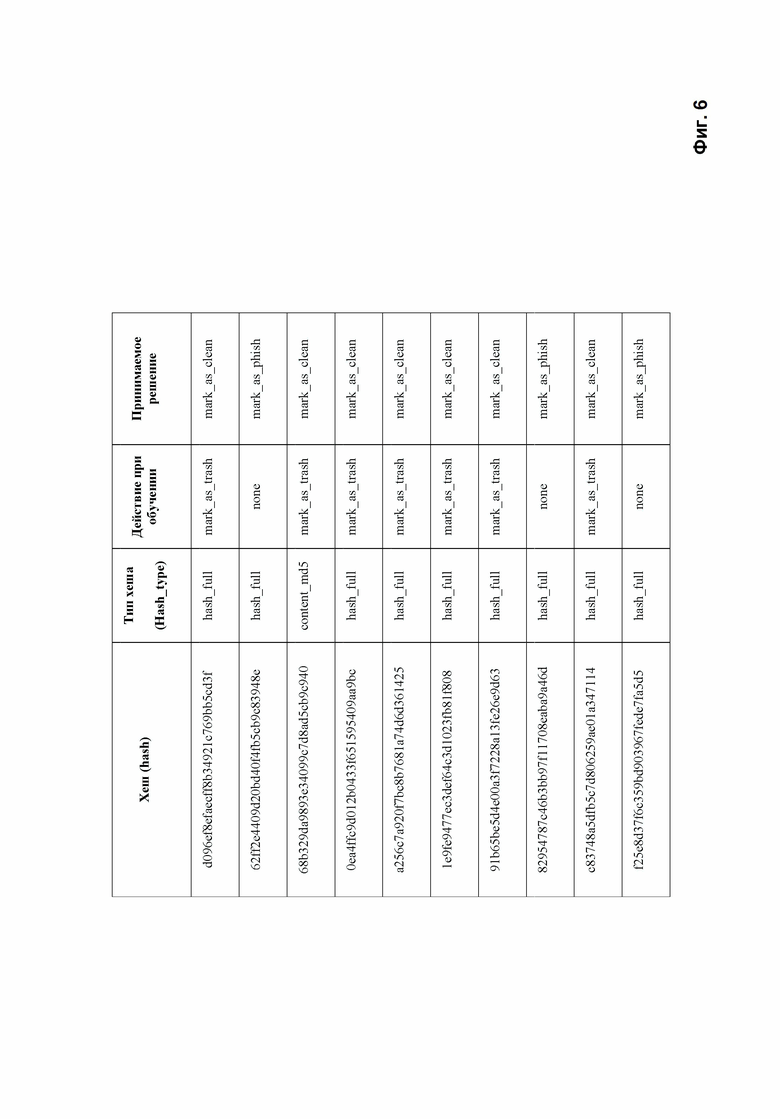
Фиг. 6 показывает пример базы данных, содержащей классифицированные хеш-функции страниц сайтов для обучения модели машинного обучения.
Фиг. 7 показывает примеры подозрительных страниц и применение настоящего изобретения.
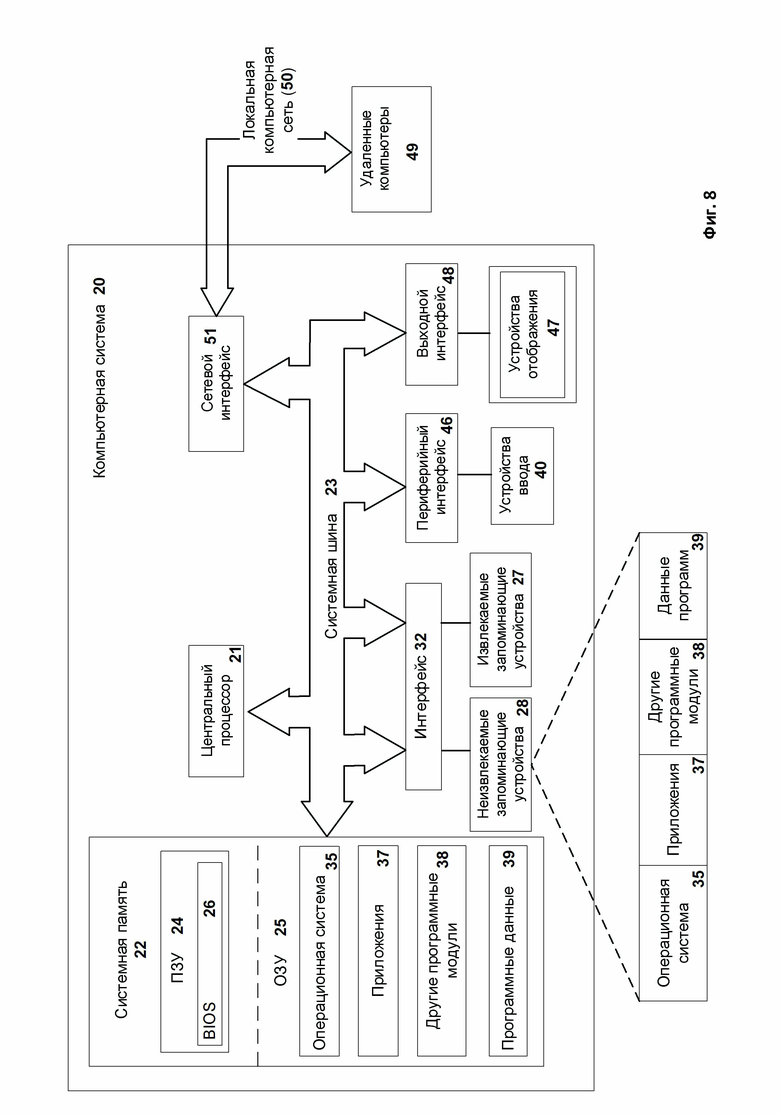
Фиг. 8 иллюстрирует пример компьютерной системы, с помощью которой осуществляется настоящее изобретение.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено в приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Приведенное описание предназначено для помощи специалисту в области техники для исчерпывающего понимания изобретения, которое определяется только в объеме приложенной формулы.
Настоящее изобретение является техническим решением, позволяющим автоматически обнаруживать фишинговые сайты и информировать о найденных изменениях или сходствах с фишинговыми сайтами с помощью компонента, содержащего модель машинного обучения. В рамках настоящего изобретения на основании информации о сайтах, в том числе об их страницах, осуществляется формирование обучающей выборки для обучения или переобучения модели машинного обучения, при этом имея возможность проводить «очистку» данных, получаемых в процессе обнаружения фишинговых сайтов, от «мусорных» данных. Эффективность работы модели машинного обучения зависит от качества данных, на основании которых обучается указанная модель. Поэтому «мусорными» данными считаются данные, которые влияют на появление ошибок первого и второго рода. Другим словами, «мусорные» данные понижают вероятность обнаружения фишинговых сайтов или увеличивают вероятность определения легитимных сайтов как фишинговых, что повышает вероятность ложного срабатывания указанной модели. Таким образом, настоящее изобретение позволяет более эффективно и быстро анализировать большое количество сайтов для выявления фишинговых сайтов, чем существующие технологии.
Стоит отметить, что подходы, представленные при описании настоящего изобретения, в зависимости от реализации позволяют определять сходства между целевым сайтом и большим набором сайтов точнее и быстрее, чем известные из уровня техники решения, предназначенные для сравнения сайтов.
Настоящее изобретение может быть реализовано совместно с такими системами, которые предназначены для сбора информации о сайтах, в том числе контента сайтов, с различных серверов, подключенных к сети Интернет, анализа собранной информации для определения, соответствует ли информация сайта ранее размещенной информации на сайте, классификации сайтов на основании определения сходства в контенте сайтов с ранее классифицированными сайтами, в том числе определения, является ли сайт фишинговым. Настоящее изобретение может являться посредником между сайтами и другими участниками сети, которые обращаются к сайтам, например для определения, является ли сайт фишинговым и вредоносным.
Варианты осуществления настоящего изобретения используют в своей работе анализ страниц сайта через «объектную модель документа» (от англ. Document Object Model) или объект DOM. Объект DOM формируется для каждой страницы, преобразовывается в определенный вид и на его основании формируются несколько типов хешей (англ. hash), позволяющих точнее сравнить страницы сайтов и/или сами сайты. После этого проводится обучение модели машинного обучения, которая в дальнейшем используется для выявления фишинговых сайтов. Такой подход позволяет точнее определить сходства между страницами или сайтами, что влечет уменьшение числа ложных срабатываний при определении фишинговых страниц и/или сайтов и, соответственно, увеличивает долю истинно-положительных срабатываний, т.е. выявлений фишинговых сайтов.
Страница сайта – это самостоятельная часть веб-ресурса, представляющая собой текстовый файл на одном из языков разметки документов (например, в формате HTML или XHTML), при этом страница имеет свой уникальный адрес (URL). Каждая страница создается при помощи языка разметки и содержит по крайней мере главные теги: head, содержащий заголовок (Title) и метаданные (например, Keywords, Description), и основную часть – тело (Body), содержащее контент. У тегов есть значения и атрибуты, у которых также есть значения.
Объект DOM – это независимый от платформы и языка интерфейс, который позволяет динамически получать доступ и обновлять содержимое, структуру и стиль HTML-, XHTML- и XML-текстовых файлов (далее – текстовые файлы). Текстовые файлы могут включать в себя любые данные. Например, текстовый файл может включать полученный от веб-сервера HTML-код для страницы. Объект DOM определяет логическую структуру текстового файла или способ доступа к текстовому файлу и позволяет управлять им через древовидную структуру, называемую деревом DOM. Основой каждого размеченного текстового файла являются теги (англ. tag), в частности HTML-теги. В соответствии с объектом DOM каждый тег текстового файла является объектом. Вложенные теги являются «детьми» родительского элемента. Текст, который находится внутри тега, также является объектом. Объект DOM позволяет клиентским приложениям динамически получать доступ, взаимодействовать и обновлять информацию сайта, полученную от одного или нескольких веб-серверов.
Признак «информация о сайте» может включать любую соответствующую информацию, связанную с сайтом или хостом (например, сервером), на котором размещен сайт. Например, информация о сайте может включать: URL-адрес сайта; HTML-код, полученный после связи с веб-сервером; заголовки (англ. headers) ответа от веб-сервера; метаданные, связанные с HTML-кодом; и любую другую информацию, которая может быть получена от веб-сервера для отображения страницы, связанной с сайтом.
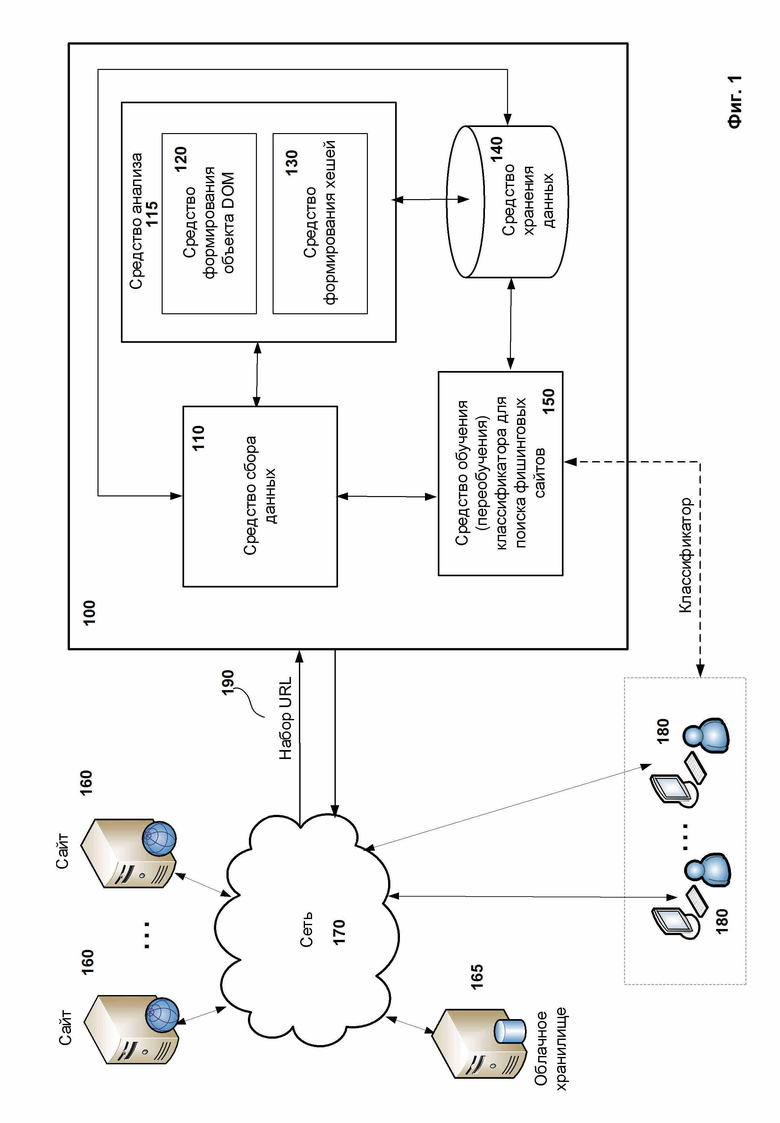
На Фиг. 1 представлен примерный вариант реализации системы создания классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов 100 (далее – система создания классификатора 100). Система создания классификатора 100 предназначена для обучения модели машинного обучения, которая в свою очередь предназначенна для обнаружения фишинговых сайтов.
В одном из вариантов реализации система создания классификатора 100 осуществляется при помощи компьютерной системы, например такой, как представлена на Фиг. 8.
В предпочтительном варианте реализации система создания классификатора 100 включает такие средства, как средство сбора данных 110, средство анализа 115, средство хранения данных 140 и средство обучения классификатора для поиска фишинговых сайтов 150. Средство анализа 115 в свою очередь включает средство формирования объекта DOM 120 и средство формирования хешей 130. В зависимости от реализации все средства могут быть связаны между собой как на аппаратном, так и на программного уровне, при этом возможен вариант реализации совместного применения аппаратного и программного уровней.
Средство сбора данных 110 предназначено для взаимодействия с сайтами 160, которые, как правило, расположены на внешних устройствах, и с устройствами, такими как облачное хранилище 165, для сбора необходимой информации о сайтах. Стоит отметить, что средство сбора данных 110 может быть реализовано в том числе любым подходящим и известным способом, предназначенным для поиска, получения и хранения информации о сайтах.
Взаимодействие с сайтами 160 и устройствами 165 осуществляется как по проводной связи, так и по беспроводной связи, например через сеть 170. В общем случае примером сети 170 является сеть Интернет. Внешними устройствами, на которых расположены сайты 160, являются, например, компьютерные системы типа хостинга, которые размещают данные и хранят их. Такими данными являются не только сами сайты, но и информация, связанная с ними, например URL сайта или страницы сайта. Также средство сбора данных 110 может взаимодействовать с различными DNS-серверами (от англ. Domain name server) и поисковыми системами для сбора информации о сайтах. Внешним устройством 165 является облачное хранилище, которое в свою очередь взаимодействует с поисковыми системами и предназначено для сбора и хранения информации о сайтах. В еще одном варианте реализации устройство 165 является облачной инфраструктурой, например такой, как Kaspersky Security Network (KSN). KSN – это инфраструктура облачных служб, предоставляющая доступ к оперативной базе знаний о репутации файлов, интернет-ресурсов (сайтов) и программного обеспечения. Устройство 165 может содержать как информацию о легитимных файлах, интернет-ресурсах (сайтах) и программном обеспечении, так и о вредоносных, например фишинговых сайтах и страницах.
Средство сбора данных 110 может собирать информацию о сайтах как в автоматическом режиме или взаимодействуя с различными поисковыми системами, так и по запросу других средств системы создания классификатора 100 или запросу, полученному от пользователя системы 100 через одно из средств ввода (не представлены на Фиг. 1). Примером работы средства сбора данных 110 в автоматическом режиме является подход, используемый поисковыми роботами (англ. Web crawler), для регулярного и/или периодического обхода сайтов 160, размещенных на хостингах и доступных через сеть 170.
В одном из вариантов реализации средство 110 получает набор URL 190 от внешнего устройства 165. В этом случае средство 110 собирает информацию о сайтах на основании ссылок URL из набора URL 190. Сбор информации осуществляется путем перехода по полученным ссылкам URL и скачивания необходимой информации, например самого сайта или его страницы в виде текстового файла и других ресурсов сайта.
После сбора информации о сайтах средство сбора данных 110 передает ее средству анализа 115.
Средство анализа 115 предназначено для создания набора хешей для каждого сайта и/или для каждой его страницы. Набор хешей для каждой страницы или сайта содержит по меньшей мере два типа хеша. В предпочтительном варианте реализации набор хешей состоит из трех типов хешей. Три типа хешей позволяют наиболее эффективно проводить поиск похожих сайтов и/или осуществлять обнаружение фишинговых сайтов. В то же время в зависимости от реализации изобретения возможно применение и по крайней мере одного типа хеша, например для задач по определению схожести страниц или сайтов. Стоит отметить, что в варианте реализации, когда применяется только один тип хеша, хеш должен быть создан при помощи объекта DOM.
Средство анализа 115 при помощи средства формирования объекта DOM 120 проводит парсинг каждой страницы, полученной от средства сбора данных 110. Под парсингом страницы подразумевается автоматизированный процесс извлечения данных или информации из страницы, которая имеет вид текстового файла. В процессе парсинга средство анализа 115 при помощи средства формирования объекта DOM 120 создает древовидную структуры страницы, а именно DOM-дерево. Пример DOM-дерева представлен на Фиг. 5а. В одном из вариантов реализации для парсинга страницы средство формирования объекта DOM 120 использует библиотеку lxml для языка Python. В еще одном варианте реализации при помощи библиотеки lxml упомянутое средство 120 в том числе проводит восстановление страниц, например осуществляет корректировку (исправление) DOM-дерева и формирование кода (например, html-кода) страницы на основе древовидной структуры. Например, формирование кода заключается в восстановлении пропущенных закрывающих тегов. После формирования DOM-дерева упомянутое средство 120 передает его средству формирования хешей 130. Средство формирования хешей 130 преобразует полученное DOM-дерево в определенный вид, а именно формирует по меньшей мере одну строку из элементов DOM-дерева страницы согласно определенному шаблону. Каждый шаблон определяет, каким образом формируется строка из элементов DOM-дерева страницы.
Так, для формирования первой строки используется первый шаблон, согласно которому для формирования строки используются только названия тегов. Для этого средство 130 удаляет весь текст и все значения и формирует цепочку тегов, например: html, head, title, body. Можно говорить, что образовавшаяся строка является уникальной. Для формирования второй строки используется второй шаблон, согласно которому принцип остается тот же, что и при формировании первой строки, только используются названия тегов и дополнительно названия атрибутов тегов. На Фиг. 5б представлены примеры обоих строк, которые сформированы на основании DOM-дерева, представленного на Фиг. 5а.
Далее средство 130 формирует хеш для каждой сформированной строки, а также дополнительно формирует хеш и от самой страницы (текстового файла). В одном из вариантов реализации средство 130 формирует хеши на основании алгоритма MD5. Таким образом, средство 130 по меньшей мере формирует три типа хешей для каждой страницы, где первый хеш сформирован от всей страницы (контентный хеш или content_md5), второй хеш (hash_light) сформирован от первой строки, т.е. строки, сформированной согласно первому шаблону, и третий хеш (hash_full) сформирован от второй строки, т.е. строки, сформированной согласно второму шаблону. После формирования всех хешей для каждой страницы средство 130 передает их в средство хранения данных 140. Стоит отметить, что при формировании дополнительных строк на основании дополнительных шаблонов средство 130 также сформирует на их основании и дополнительные хеши.
В одном из вариантов реализации средство 115 в начале работы осуществляет проверку каждой страницы на ее новизну. Другими словами, получало ли ранее средство 115 соответствующую страницу на анализ. В этом случае вначале средство 115 при помощи средства 130 сформирует хеш от самой страницы (первый хеш) и проведет проверку на наличие данного хеша в средстве хранения данных 140. В случае если средство 115 обнаружит хеш в средстве хранения данных 140, то средство 115 исключит данную страницу из дальнейшего анализа. В противном случае, если средство 115 не обнаружит соответствующий хеш в средстве хранения данных 140, то средство 115 проведет дальнейший анализ с учетом того, что хеш от самой страницы уже был сформирован.
Средство хранения данных 140 является машиночитаемым носителем, который предназначен для хранения информации о сайтах и их страницах, при этом хранимая информация включает как сформированные хеши, так и дополнительную информацию о сайтах, например URL HTML-страниц. Дополнительная информация может быть предоставлена как средством анализа 115, так и средством сбора данных 110 или средством обучения 150. Пример хранения данных средством хранения данных 140 представлен на Фиг. 6. В одном из вариантов реализации средство хранения данных 140 представляет собой базу данных, выраженную в виде таблицы, в которой каждая строка содержит информацию для одного хеша. Информация для хеша по меньшей мере включает:
• Hash - значение хеша,
• Hash_type - тип хеша (например, хеш от страницы «content_md5» (первый хеш), хеш «hash_light» (второй хеш), хеш «hash_full» (третий хеш)).
Также средство хранения данных 140 дополнительно содержит информацию для хеша, которая включает назначение хеша и решение, которое выносится по соответствующему хешу. Например, в качестве назначения хеша может быть указано, что хеш используется при обучении (train_action) и каким образом – для тренировки или для проверки. Примером выносимого решения по хешу является указание на то, что хеш относится к хешам, указывающим на фишинговый сайт (mark_as_phish), или хешам, указывающим на «чистую» страницу или сайт (mark_as_clean).
Стоит отметить, что средство 140 содержит информацию как о безопасных страницах, так и о фишинговых страницах. Безопасными страницами являются страницы, которые не представляют угрозы потери данных третьих лиц и на которых не срабатывают механизмы обнаружения фишинговых сайтов. Также такими страницами являются страницы, формируемые и изменяемые только с разрешения владельца сайта, если владелец сайта имеет подтверждённую личность.
В одном из вариантов реализации средство анализа 115 для каждого типа хешей из средства хранения данных 140 определяет их популярность и ранжирует в соответствии с определенной популярностью. В одном из вариантов реализации популярность определяется на основании анализа страниц в интервале 6 (шести) месяцев. Так, средство анализа 115 определяет, какое количество одинаковых хешей от страниц за последние шесть месяцев было сформировано. Соответственно, чем больше количество страниц, имеющих одинаковый хеш, тем более популярным является данный хеш.
Средство обучения 150 предназначено для обучения или переобучения классификатора, включающего модель машинного обучения, для поиска фишинговых сайтов. Средство обучения 150 при обучении классификатора взаимодействует со средством хранения данных 140. Средство обучения 150 формирует два набора данных. Первый набор данных содержит информацию о безопасных страницах, а второй набор данных содержит информацию о фишинговых страницах. В качестве информации о страницах понимается ранее собранная информация о сайтах, в частности информация о хешах. Каждый набор данных формируется на основании информации о хешах, в частности информации о назначении хешей. В частном варианте реализации наборы данных формируются с учетом частоты появления хеша среди всех созданных хешей и длины DOM-дерева, на основании которого хеш создан.
В одном из вариантов реализации информация, содержащаяся в каждом наборе данных, включает информацию о страницах и сайтах, которую можно разделить на три группы. К первой группе относится информация о контенте, содержащемся на страницах, в частности информация об организациях, необходимости ввода пароля, или другие данные пользователей. Ко второй группе относится информация об URL-адресах, в частности информация о форме написания строки и наличии пробелов и специальных знаков. К третьей группе относится информация о страницах, полученная из внешних источников, таких как сервис WHOIS. Также наборы дополнительно могут включать информацию о популярности того или иного домена.
Стоит отметить, что формирование наборов данных при помощи хешей, сформированных на основании DOM-деревьев, позволяет получить указанные наборы данных наиболее сбалансированными, что позволяет в дальнейшем осуществить обучение классификатора с наибольшей эффективностью. Другими словами, такой подход позволяет выдержать баланс между однородной и разнообразной информацией в наборах данных, в частности за счет исключения «мусорных» данных.
В зависимости от варианта реализации при формировании наборов данных могут быть использованы как все хранимые в средстве хранения данных 140 хеши и связанная с ними информация, так и только часть из них. В качестве ограничений при формировании наборов данных выступают количество хешей, хранимых в средстве хранения данных 140, и дата формирования хеша, т.е. актуальность хеша.
Далее средство обучения 150 делит каждый набор данных на две части, где первая часть является обучающим подмножеством (обучающей выборкой), а вторая часть является тестовым подмножеством (тестовой выборкой). На обучающем подмножестве средство обучения 150 проводит обучение классификатора, а именно модели машинного обучения, а при помощи тестового подмножества проводит верификацию (проверку качества работы) обученного классификатора. Например, деление на две части основывается на пропорции от общего объема данных: 70% обучающая выборка и 30% тестовая выборка. Также пропорция может изменяться в зависимости от объема данных в каждом наборе данных.
В частном случае реализации средство обучения 150 осуществляет деление набора данных на три части. В таком случае к указанным двум подмножествам добавляется третье – валидационное подмножество (валидационная выборка). Валидационная выборка предназначена для выбора порога принятия решения для модели машинного обучения, обученной на обучающей выборке. После выбора порога принятия решения проводится окончательная проверка качества работы указанной модели.
В одном из вариантов реализации средство обучения 150 при формировании двух наборов данных дополнительно проводит так называемую очистку данных с целью улучшения выборки данных для обучения. Очистка данных основывается на том, что сформированные хеши, особенно хеши соответствующие типу хеша hash_full (третий хеш), являются достаточно уникальными идентификаторами страниц с точностью до вариативности, связанной с отражением особенностей конкретного пользователя или сессии на сайте. Например, домашняя страница в социальной сети является одной и той же страницей вне зависимости от того, какие имя, фамилия, фотография и подобные данные заполняют соответствующие слоты (например, поля для ввода) страницы. Повторяющиеся уникальные идентификаторы (хеши) страниц при разном контенте также характерны для служебных страниц, таких как сообщения об ошибках. Таким образом, чем чаще тот или иной хеш встречается в обоих наборах данных, тем больше вероятность того, что это служебная страница. При очистке данных используется подход, во время которого средство обучения 150 исключает по крайней мере в одном из наборов данных как повторяющиеся хеши, так и относящиеся к служебным страницам. Такая очистка данных позволяет подготовить наиболее оптимальные наборы данных для обучения классификатора, содержащего модель машинного обучения. Этот подход позволяет устранить один из недостатков машинного обучения, а именно обучение на наборах данных, в которых присутствовали очень похожие объекты. Например, в обоих наборах данных присутствовали одинаковые хеши. При обучении на схожих данных эффективность работы обученной модели машинного обучения падает и возникают ложные срабатывания при вынесении решений такой обученной модель машинного обучения.
В еще одном из вариантов реализации средство обучения 150 осуществляет очистку обоих наборов данных следующим образом. Вначале средство обучения 150 формирует набор самых популярных хешей для чистых хешей и набор самых популярных хешей для фишинговых хешей путем обращения к средству хранения данных 140 и последующего поиска, при условии, что средство 140 еще не содержит информацию о популярности хешей. Далее средство обучения 150 выявляет хеши, которые соответствуют хешам, относящимся к обоим наборам данных. После выявления по крайней мере одного подобного хеша средство обучения 150 определяет, к какой странице относится хеш, и на основании этого удаляет хеш из одного набора данных и оставляет хеш в другом наборе данных. Например, если хеш относится к служебной странице, то данная страница является безопасной, и, соответственно, хеш удаляется из набора данных, относящегося к фишинговых сайтам, и остается в наборе данных, относящемся к безопасным сайтам. Кроме того, средство обучения 150 вносит или изменяет сведения об указанном хеше в средстве хранения данных 140 следующим образом: в столбце «Действие при обучении» указывается «к удалению (none)», и в столбце «Принимаемое решение» указывается «чистый (mark_as_clean)». В еще одном примере если хеш относится к фишинговой странице, то средство обучения 150 оставляет такую страницу только в наборе данных, относящемся к фишинговым сайтам.
Далее средство обучения 150 проводит проверку на наличие разнообразности данных в каждом указанном наборе данных. Так как если в каждом наборе данных есть группа схожих объектов (хешей), при этом такая группа является достаточно многочисленной, то такая выборка данных также может негативно влиять на качество обучения классификатора. Например, набор данных содержит 100 (сто) тысяч групп, при этом объекты одной из группы занимают больше 1% от всего набора. В другом примере набор данных содержит 90 (девяносто) тысяч групп, при этом объекты одной из группы занимают больше 5% от всего набора. В еще одном примере многочисленность определяется эмпирическим путем. Поэтому в каждом наборе данных средство обучения 150 отбирает по меньшей мере одну группу хешей, относящихся к странице, которая встречается в соответствующем наборе данных больше, чем N раз, где N – настраиваемый параметр и определяется практическим путем. В одном из вариантов реализации параметр N определяется на основании соотношения общего количества хешей в наборе данных и хешей, относящихся к одной странице. Если средство обучения 150 не осуществило отбор ни одной группы, значит каждый набор хешей является оптимальным для дальнейшего обучения классификатора, включающего модель машинного обучения. В противном случае средство обучения 150 в каждой отобранной группе отбирает случайным образом по К страниц, где К – настраиваемый параметр и определяется практическим путем. Средство обучения 150 оставляет страницы, хеши которых относятся к отобранным К страницам, в наборе данных и удаляет из набора данных оставшиеся страницы, хеши которых относятся к отобранной группе. Стоит отметить, если набор данных относится к фишинговым сайтам, то средство обучения 150 добавляет соответствующую информацию о странице, а именно о хеше, в средство хранения данных 140. Например, в строку указанного хеша добавится запись, что принимаемое решение – «фишинг». Также средство обучения 150 может осуществить дополнительную проверку, является ли страница, к которой относится хеш, фишинговой. В одном из вариантов реализации дополнительная проверка заключается в запросе к компонентам защиты (не представлены на Фиг. 1), относящимся к решениям анализа и обнаружения фишинговых сайтов, и получении ответа от них. Если набор данных относится к «чистым» сайтам, то средство обучения 150 добавляет в запись о хеше в средстве хранения данных 140, что принимаемое решение – «чистая страница».
Далее средство обучения 150 осуществляет обучение классификатора, включающего модель машинного обучения, на основании сформированных и оптимизированных наборов данных. В зависимости от варианта реализации обучение модели машинного обучения основывается по меньшей мере на одном из принципов: обучение с учителем, такое как логистическая регрессия, линейная регрессия или k-ближайших соседей (англ. k-nearest neighbors algorithm, k-NN); или нейронные сети. После обучения классификатора средство обучения 150 осуществляет верификацию (проверку качества работы) обученного классификатора на тестовом подмножестве. Если обученный классификатор не превысил заданный порог при вынесении неправильных решений, т.е. количество ложных срабатываний ниже предельно допустимого уровня, то средство обучения 150 передает классификатор в работу. В противном случае, если обученный классификатор вынес количество неправильных решений, превышающее заданный порог, т.е. количество ложных срабатываний превысило предельно допустимый уровень, то средство обучения 150 проводит переобучение классификатора. Во время переобучения средство обучения 150 формирует новый или обновляет по меньшей мере один набор данных для обучения. Для обновления набора данных средство обучения 150 формирует запрос средству сбора данных 110 для сбора новой или дополнительной информации о сайтах.
В частном случае реализации при переобучении средство обучения 150 дополнительно может осуществлять изменения в гиперпараметрах модели машинного обучения, например скорости обучения и размере набора данных. Также средство обучения 150 может изменять размеры модели машинного обучения, например количество узлов в нейронной сети.
В одном из вариантов реализации средство обучения 150 передает классификатор для обнаружения фишинговых сайтов компонентам защиты 185, отвечающим за обнаружение фишинговых сайтов на стороне клиентов 180. Компонент защиты 185 представлен при описании Фиг. 2. В зависимости от вариантов реализации компонентами защиты 185 являются такие технические решения, которые направлены как на защиту от кибератак и вредоносного ПО, так и на обеспечение безопасности от кражи данных, при этом указанные решения могут быть реализованы как на клиентах 180, так и на различных серверах корпоративных сетей.
В еще одном из вариантов реализации кроме передачи указанного классификатора компонентам защиты дополнительно передается по меньшей мере один тип сформированных хешей, например третий тип хешей. Указанные хеши также могут использоваться совместно с классификатором при сравнении сайтов на схожесть или обнаружении фишинговых сайтов в качестве предварительного этапа.
В другом варианте реализации если средство обучения 150 при формировании набора данных, относящегося к чистым сайтам, в процессе очистки данных определило, что страница не имеет фишингового контента, то соответствующие ей хеши помечаются как чистые и выносимое решение определяется как чистая страница. Например, страница относится к сообщению сервера об ошибке.
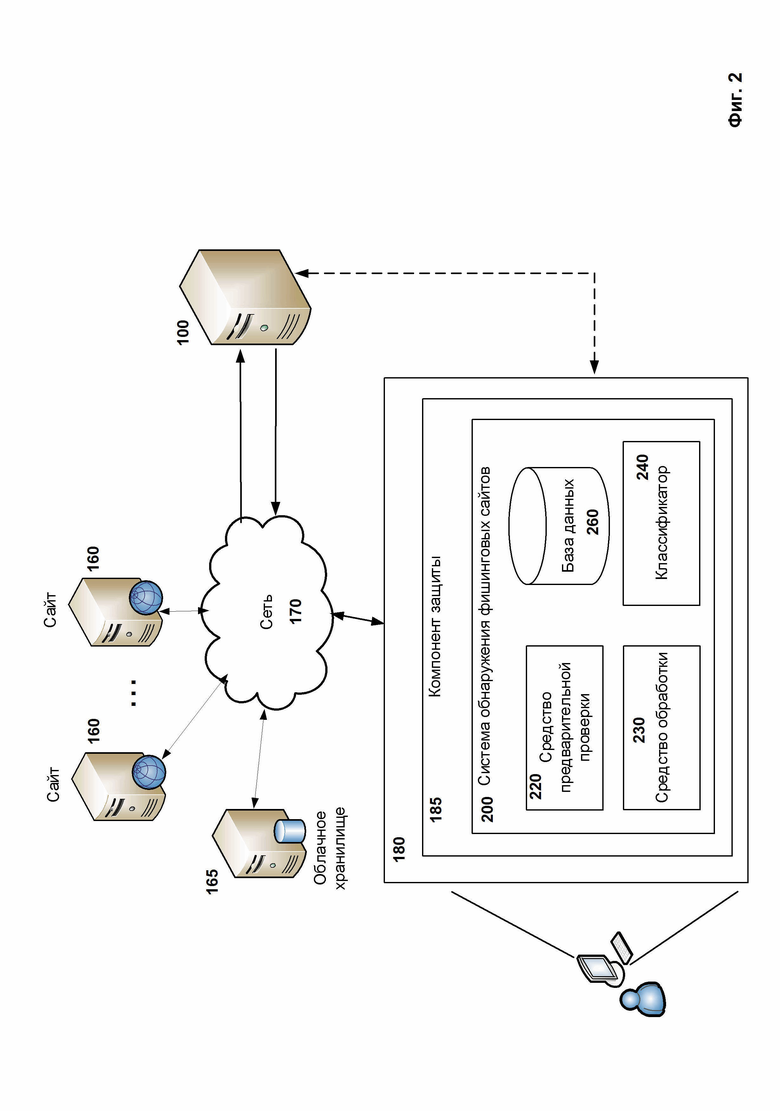
Фиг. 2 показывает пример системы обнаружения фишинговых сайтов. Система обнаружения фишинговых сайтов (далее – система обнаружения) 200 осуществляется при помощи по меньшей мере одной компьютерной системы, например такой, как представлена на Фиг. 8.
В зависимости от варианта реализации система обнаружения 200 может осуществляться как в составе компонента защиты 185 или отдельно от компонента защиты 185 (не показано на Фиг. 2) на устройстве клиента 180, так и совместно с системой создания классификатора 100 на одном устройстве, при этом система обнаружения 200 осуществляет взаимодействие с системой создания классификатора 100 вне зависимости от варианта реализации. Кроме того, система обнаружения 200 и система создания классификатора 100 могут быть реализованы единой системой.
В одном из вариантов реализации система обнаружения 200 включает такие средства, как средство предварительной проверки 220, средство обработки 230, классификатор 240, включающий модель машинного обучения, и базу данных 260. В зависимости от вариантов реализации все средства могут быть связаны между собой как на аппаратном, так и на программном уровне, при этом возможен вариант реализации и совместного применения аппаратного и программного уровней.
Компонент защиты 185 при получении задачи на проверку сайта или его страницы передает соответствующие данные в систему обнаружения 200. Задача может быть получена в виде URL (ссылки), в этом случае компонент защиты 185 предварительно скачает контент (текст HTML-кода страницы) соответствующего ресурса по полученной ссылке. Кроме того, компонент защиты 185 при необходимости преобразует каждую страницу HTML в текстовый файл.
Средство предварительной проверки 220 предназначено для проверки полученной системой обнаружения 200 страницы с помощью хешей из базы данных 260. Указанное средство 220 формирует хеш от самой страницы (текстового файла). В одном из вариантов реализации хеш формируется на основании алгоритма MD5. В другом варианте реализации хеш может быть сформирован и на основании любого другого известного алгоритма хеширования, например CRC32, SHA256, SHA512. После средство 220 сравнивает сформированный хеш с хешами из базы данных 260. База данных 260 содержит по меньшей мере два набора хешей, где один набор включает хеши от безопасных страниц, а второй набор включает хеши от фишинговых страниц. В случае, если средство 220 найдет сформированный хеш в базе данных 260, то система обнаружения 200 определит проверяемый файл как фишинговый или безопасный, в зависимости от набора хешей, в котором был обнаружен проверяемый хеш. В противном случае, если хеш не обнаружен в базе данных 260, средство 220 передает страницу средству обработки 230.
В одном из вариантов реализации система обнаружения 200 не включает средство предварительной проверки 220. В этом случае полученная страница сразу попадает в средство обработки 230, которое и осуществляет предварительный анализ страницы.
Средство обработки 230 предназначено для преобразования страницы по меньшей мере в одну строку из элементов DOM-дерева страницы согласно определенному шаблону, формирования по меньшей мере одного хеша для каждой сформированной строки и проверки сформированных хешей в базе данных 260. Стоит отметить, что обработка страницы для формирования определенного типа хешей аналогична работе средства анализа 115. Можно говорить, что функциональные возможности средства обработки 230 соответствует функциональным возможностям средства анализа 115. Так, сначала средство обработки 230 проводит парсинг (синтаксический анализ) страницы, в результате которого создает древовидную структуру страницы, т.е. DOM-дерево. Далее средство обработки 230 преобразует DOM-дерево по меньшей мере в одну строку согласно определенному шаблону из элементов DOM-дерева страницы. После средство обработки 230 формирует хеш от каждой сформированной строки. В одном из вариантов реализации средство 230 по меньшей мере формирует два типа хешей для каждой страницы, где один хеш (hash_light) сформирован от строки, сформированной согласно первому шаблону, и другой хеш (hash_full) сформирован от строки, сформированной согласно второму шаблону. После формирования всех хешей для страницы средство 230 осуществляет проверку полученной страницы путем сравнения сформированных хешей с подобными хешами из базы данных 260. В том случае, если хеши были найдены в базе данных 260, система обнаружения 200 выносит решение, является ли сайт фишинговым. В противном случае, если хеши не были найдены, средство 230 передает полученную страницу классификатору 240. В частности, под передачей полученной страницы в том числе понимается и передача информации о контенте и метаданных страницы.
В еще одном варианте реализации средство предварительной проверки 220 и средство обработки 230 реализуются совместно. В этом случае предварительная проверка полученной страницы осуществляется как при помощи хеша, сформированного от всей страницы, так и при помощи по крайней мере одного хеша, сформированного от строки из элементов DOM-дерева страницы. Например, сначала осуществляется проверка при помощи хеша от всей страницы, и если хеш не был найден в базе данных 260, то осуществляется проверка при помощи хешей, сформированных от строк из элементов DOM-дерева страницы, т.е. хеши применяются последовательно. Также использование упомянутых хешей может осуществляться параллельно.
Классификатор 240 включает модель машинного обучения и предназначен для определения, является ли страница фишинговой, на основании полученной информации от средства обработки 230. Классификатор 240 предоставляет на вход обученной модели машинного обучения полученную информацию. Модель машинного обучения на выходе предоставляет классификатору 240 решение о соответствии страницы известным фишинговым страницам или сайтам. Классификатор 240 предоставляет компоненту защиты 185 решение, является ли сайт фишинговым.
База данных 260 является машиночитаемым носителем, который предназначен для хранения и предоставления хранимых данных средствам системы обнаружения 200 по запросу. Как упоминалось ранее, хранимыми данными по меньшей мере являются два набора хешей, где один соответствует безопасным страницам, а другой соответствует фишинговым страницам. Стоит отметить, что в указанные наборы попадают страницы, которые однозначно можно определить как безопасные страницы или фишинговые.
В одном из вариантов реализации система обнаружения 200 имеет возможность осуществить переобучение классификатора 240. В этом случае система обнаружения 200 направляет каждое вынесенное решение в систему создания классификатора 100. В свою очередь система создания классификатора 100 проводит оценку каждого вынесенного решения. В случае, если система создания классификатора 100 определит решение как ложное, то проведет переобучение классификатора, а именно модели машинного обучения. Переобучение проводится с учетом определенного по меньшей мере одного ложного решения. После этого система создания классификатора 100 предоставит переобученный классификатор системе обнаружения 200.
Стоит отметить, что классификатор 240 предназначен для определения того, является ли сайт фишинговым или нет, в тех случаях, когда другие механизмы защиты не смогли вынести решение. Такие ситуации характерны, когда злоумышленники маскируют свои сайты путем их изменения. Как правило, изменения относятся к контенту сайта.
Рассмотрим особенности применения представленных в настоящем изобретении хешей, сформированных на основании DOM-деревьев страниц HTML, представленных на Фиг. 7.
Предположим, что первая страница содержит некоторый HTML и контент, при этом страница является подозрительной страницей. Например, предполагается, что первая страница является фишинговой страницей, которая предназначена для кражи банковских данных.
Вторая страница является также подозрительной страницей и другой версией первой страницы. Отличие заключается в том, что вторая страница обладает той же функциональностью, но при этом противодействует обнаружению путем подмены части символов и добавления ложных (англ. fake) значений для атрибутов классов. Стоит отметить, что на Фиг. 7 для демонстрации подмены очевидны, в настоящих образцах гомографические атаки выполняются более искусно.
Для каждой страницы формируют хеши согласно указанному ранее принципу, а именно:
• Формируют md5-хеш от каждой страницы;
• Получают DOM-дерево с помощью парсинга HTML-страницы с помощью библиотеки lxml;
• Преобразуют сформированное DOM-дерево для каждой страницы в две строки:
• Для первой строки используют первый шаблон, согласно которому сохраняют только названия тегов,
• Для второй строки используют второй шаблон, согласно которому сохраняют названия тегов и названия атрибутов тегов.
• Формируют хеши для полученных строк.
Так, хеши, основанные на MD5, для каждой страницы от целой страницы будут иметь вид:
Для первой страницы – 397ac9d66c21ec19ae55a3c758d6443d,
Для второй страницы – 39c7706b85321872a6e4bae79eff3064.
Видно, что внесенные изменения в контент второй страницы изменили и хеш второй страницы. Поэтому сгруппировать страницы на основании хешей таких страниц (файлов) не получится и потребуется каждый раз формировать новые образцы (хеши) для блокировки фишинговых сайтов (например, при блокировке по сигнатуре). Другими словами, если хеш создается от всей страницы, то небольшое изменение в контенте страницы изменит и такой хеш.
В то же время структура страниц осталось одной и той же:
Первая строка (структура тегов):
Для первой страницы:
doc | html | head | title | /title | /head | body | h1 | /h1 | /body | /html | /doc
Для второй страницы (с маскировкой):
doc | html | head | title | /title | /head | body | h1 | /h1 | /body | /html | /doc
Вторая строка (структура тегов и атрибутов):
Для первой страницы:
doc | html | head |title | /title | /head | body | h1:class | /h1 | /body | /html | /doc
Для второй страницы (с маскировкой):
doc | html | head |title | /title | /head | body | h1:class | /h1 | /body | /html | /doc
Видно, что строки для обеих страниц получились идентичные. Поэтому сформировав хеши на основании полученных строк, хеши для обеих страниц будут одинаковые. Например, строки второго типа в виде хешей (структура тегов и атрибутов) будут иметь вид:
для первой страницы – fbec7f8965c8f1c9c5986c076b7de5cd,
для второй страницы – fbec7f8965c8f1c9c5986c076b7de5cd.
Таким образом, при использовании заявленного решения дополнительно имеется возможность на основании преобразования объектов DOM страниц в строки формировать хеши и группировать в кластеры похожие страницы.
В одном из вариантов реализации представленный принцип предназначен не только для поиска фишинговых сайтов, но и для обнаружения схожих страниц.
В качестве примера рассмотрим две страницы:
https://www.google.com/error
https://www.google.com/another_error.
Сформированные хеши на основании целых страниц будут отличаться, в то время как сформированные хеши на основании представленного решения (с помощью объектов DOM и строк) - нет:
Хеши на основании целых страниц:
1) cfa900f6311e2e675c95de0788684d2b,
2) 696531ac087387b995e3376a36b333d1.
Хеши на основании строки первого типа для указанных страниц:
1) 4841ea35c8deb90b749f2f1b2aed8a11,
2) 4841ea35c8deb90b749f2f1b2aed8a11.
Хеши на основании строки второго типа для указанных страниц:
1) d8085a405ad249ece59f79744c94158f,
2) d8085a405ad249ece59f79744c94158f.
Так можно легко находить большие группы схожих с точностью до структуры страниц и удалять их из обучающей выборки (или балансировать выборку, оставляя из каждой группы только несколько примеров).
Фиг. 3 показывает пример способа обучения (переобучения) модели машинного обучения для обнаружения фишинговых сайтов.
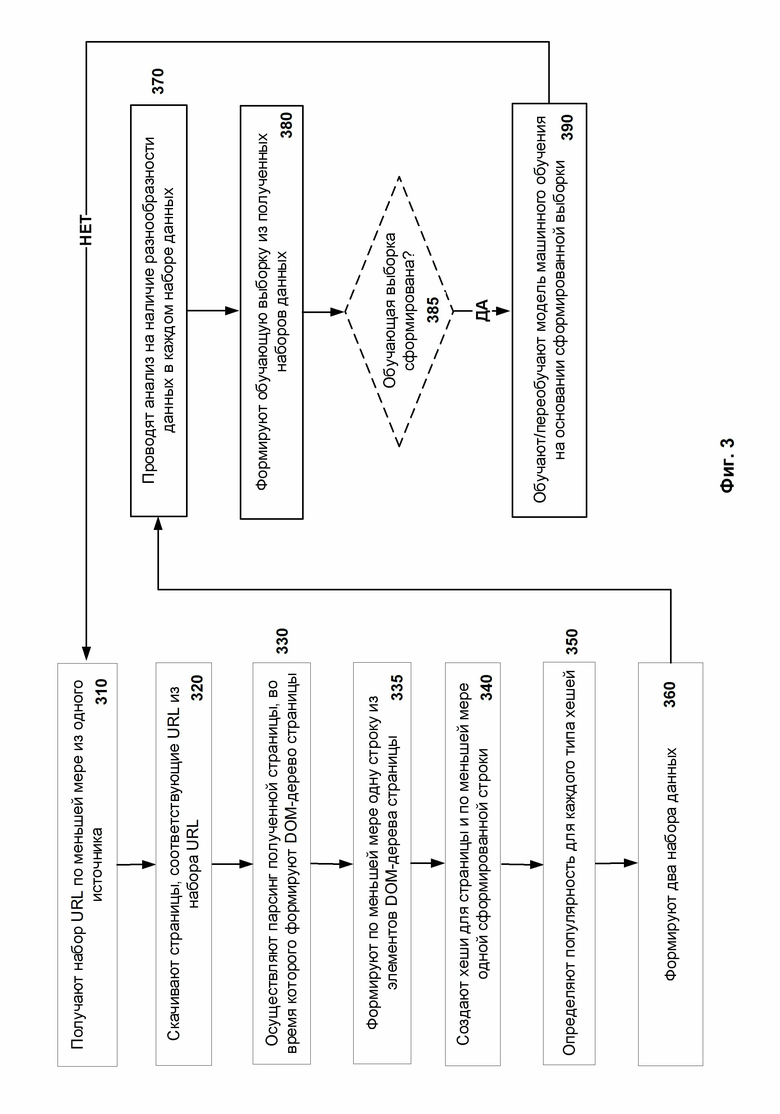
На шаге 310 получают набор URL при помощи средства сбора данных 110 из различных источников.
На шаге 320 при помощи средства сбора данных 110 осуществляют скачивание страниц и/или сайтов в виде текстовых файлов формата HTML согласно URL из полученного набора.
В одном из вариантов реализации шаги 310 и 320 могут не выполняться. В этом случае получают страницы для обучения из средства хранения данных 140 либо из аналогичной базы данных, которая хранит информацию о сайтах.
В предпочтительном варианте реализации шаги 330, 335 и 340 выполняют при помощи средства анализа 115.
На шаге 330 осуществляют парсинг каждой полученной страницы, во время которого формируют DOM-дерево соответствующей страницы. В процессе парсинга создают древовидную структуру страницы, а именно DOM-дерево.
На шаге 335 формируют по меньшей мере одну строку из элементов DOM-дерева для каждой полученной страницы согласно определенному шаблону. Каждый шаблон определяет, каким образом формируется строка из элементов DOM-дерева страницы. Стоит отметить, что для формирования первой строки используется первый шаблон, согласно которому для формирования строки используются только названия тегов. Для формирования второй строки используется второй шаблон, согласно которому для формирования строки используются названия тегов и дополнительно названия атрибутов тегов.
На шаге 340 создают хеш для каждой сформированной строки и хеш для всей полученной страницы. В частном случае реализации хеш от всей полученной страницы не создают. В предпочтительном варианте реализации создают три типа хешей для каждой страницы, где первый хеш сформирован от всей страницы (контентный хеш), второй хеш (hash_light) сформирован от первой строки и третий хеш (hash_full) сформирован от второй строки, при этом на шаге 335 формируют две строки для каждой страницы. После формирования всех хешей для каждой страницы переходят к шагу 350.
На шаге 350 определяют популярность для каждого типа хешей, сформированных для страниц, соответствующих полученному набору URL. Популярность определяют на основании анализа страниц в течение 6 (шести) месяцев. Так, определяют какое количество одинаковых хешей от страниц за последние шесть месяцев было сформировано. Соответственно, чем больше количество страниц, имеющих одинаковый хеш, тем более популярным становится хеш. В одном из вариантов реализации данный шаг может быть исключен и в этом случае после шага 340 переходят к шагу 360.
На шаге 360 формируют два набора данных, где первый набор данных содержит информацию о безопасных страницах, а второй набор данных содержит информацию о фишинговых страницах. В качестве информации о страницах по меньшей мере понимается ранее собранная информация о сайтах. Каждый набор данных формируется на основании информации о хешах. В частности, наборы данных формируются с учетом частоты появления хеша среди всех созданных хешей и длины DOM-дерева, на основании которого хеш создан.
В одном из частных вариантов реализации на шаге 360 информация, содержащаяся в каждом наборе данных, дополнительно включает информацию о страницах и сайтах, которую можно разделить на три группы. К первой группе относится информация о контенте, содержащемся на страницах. Ко второй группе относится информация об URL-адресах. К третьей группе относится информация о страницах, полученная из внешних источников, таких как сервис WHOIS.
В еще одном частном варианте реализации на шаге 360 дополнительно каждый набор данных делят на две части, где первая часть является обучающим подмножеством (обучающей выборкой), а вторая часть является тестовым подмножеством (тестовой выборкой).
В другом частном варианте реализации на шаге 360 дополнительно осуществляют очистку данных с целью улучшения выборки данных для обучения. Во время очистки данных в наборах данных выявляют хеши, которые соответствуют хешам, относящимся к обоим наборам данных, при этом хеши сформированы на основании DOM-деревьев. После выявления по крайней мере одного подобного хеша определяют, к какой странице относится хеш, и на основании этого удаляют соответствующую хешу страницу из одного набора данных и оставляют в другом наборе данных соответствующую хешу страницу. Пример реализации представлен при описании Фиг. 1.
На шаге 370 проводят анализ на наличие разнообразности данных в каждом наборе данных. Во время анализа определяют, есть ли в наборах данных группы схожих объектов (хешей), при этом указанные группы являются достаточно многочисленными. Если есть, то в соответствующем наборе данных отбирают по меньшей мере одну группу хешей, относящихся к страницам, которые встречаются в соответствующем наборе данных больше, чем N раз. В одном из вариантов реализации параметр N определяется на основании соотношения общего количества хешей в наборе данных и хешей, относящихся к одной странице. Далее в каждой отобранной группе отбирают случайным образом по К страниц. После этого оставляют страницы, хеши которых относятся к отобранным К страницам, в наборе данных и удаляют из набора данных оставшиеся страницы, хеши которых относятся к отобранной группе. Если ни одной группы не выявлено, то каждый набор данных уже является оптимальным.
На шаге 380 формируют обучающую выборку путем добавления полученных наборов данных. Каждый набор данных содержит информацию о страницах, соответствующих оставшимся хешам.
Дополнительно на шаге 385 проверяют, сформирована ли обучающая выборка. Если сформирована, то обучающую выборку передают на обучение модели машинного обучения. Если не сформирована, то возвращаются к шагу 310, где получают новый набор URL.
На шаге 390 осуществляют обучение модели машинного обучения, являющейся частью классификатора, на основании сформированной выборки.
Дополнительно на шаге 390 проводят верификацию (проверку) обученной модели машинного обучения. Если обученная модель машинного обучения не превысила заданный порог при вынесении неправильных решений на тестовом подмножестве, т.е. количество ложных срабатываний ниже предельно допустимого уровня, то способ заканчивает работу. В противном случае, если обученная модель машинного обучения вынесла количество неправильных решений, превышающее заданный порог, т.е. количество ложных срабатываний превысило предельно допустимый уровень, то проводят переобучение модели машинного обучения представленным способом.
Фиг. 4 показывает пример способа обнаружения фишинговых сайтов.
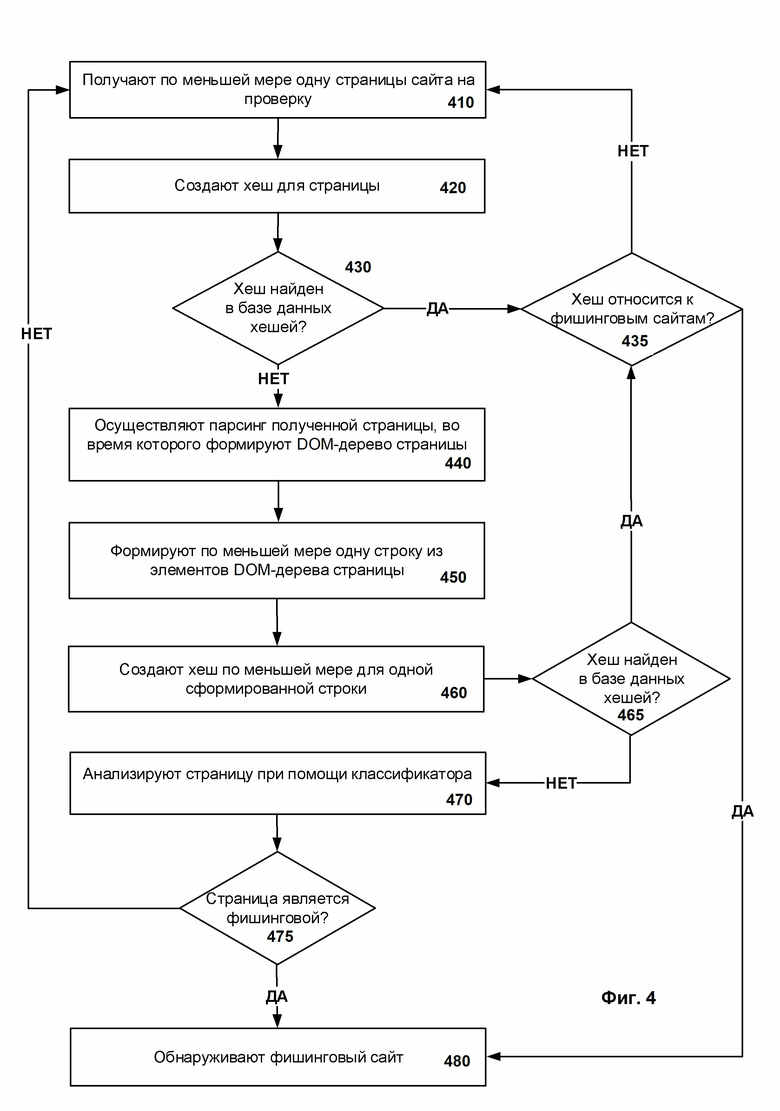
На шаге 410 получают по меньшей мере одну страницу сайта на проверку. Страница сайта предоставляется в виде текстового документа формата HTML.
На шаге 420 создают хеш от целой страницы и на шаге 430 осуществляют поиск хеша в базе данных 260. В случае если хеш найден в базе данных 260, то переходят к шагу 435. В противном случае, если хеш не найден в базе данных 260, то переходят к шагу 440.
На шаге 435 определяют, к какому набору хешей относится хеш, найденный на шаге 430 в базе данных 260. В случае, если хеш относится к набору «чистых» хешей, то переходят к шагу 410 для проверки следующей страницы. В противном случае, если хеш относится к набору фишинговых хешей, то переходят к шагу 480, где выносят решение об обнаруженном фишинговом сайте.
На шаге 440 осуществляют парсинг каждой полученной страницы, во время которого формируют DOM-дерево соответствующей страницы. В процессе парсинга создают древовидное представление структуры страницы, а именно DOM-дерево.
На шаге 450 формируют по меньшей мере одну строку из элементов DOM-дерева страницы согласно определенному шаблону. Стоит отметить, что для формирования первой строки используется первый шаблон, согласно которому для формирования строки используются только названия тегов. Для формирования второй строки используется второй шаблон, согласно которому для формирования строки используются названия тегов и дополнительно названия атрибутов тегов.
На шаге 460 создают хеши для страницы из по меньшей мере одной сформированной строки. В предпочтительном варианте реализации формируют три типа хешей для каждой страницы, где первый хеш сформирован от всей страницы (контентный хеш), второй хеш (hash_light) сформирован от первой строки и третий хеш (hash_full) сформирован от второй строки.
На шаге 465 осуществляют поиск по меньшей мере одного хеша в базе данных 260. В случае если по меньшей мере один хеш найден в базе данных 260, то переходят к шагу 490. В противном случае, если ни один хеш не найден в базе данных 260, то переходят к шагу 470.
На шаге 470 анализируют страницу при помощи классификатора на основании по меньшей мере одного созданного хеша. Для этого передают информацию о странице, соответствующей указанному хешу, на вход модели машинного обучения. В частности, под передачей информации о странице в том числе понимается и передача информации о контенте и метаданных страницы.
На шаге 475 принимают решение, является ли страница фишинговой, на основании полученного на выходе результата анализа моделью машинного обучения. В случае, если модель машинного обучения вынесла решение о том, что страница не относится к фишинговым, то переходят к шагу 410 для проверки следующей страницы, либо заканчивают работу, если проверены все страницы сайта. В противном случае, если модель машинного обучения вынесла решение о том, что страница относится к фишинговым, то переходят к шагу 480.
На шаге 480 принимают решение об обнаруженном фишинговом сайте на основании информации, полученной после шага 475 или шага 435.
В частном случае реализации шаги 420 и 430 могут быть исключены. В этом случае после получения страницы на проверку на шаге 410 переходят к шагу 440.
В еще одном частном случае реализации создание хеша для страницы, предусмотренное на шаге 420, выполняется совместно с созданием хешей на шаге 460. В этом случае шаг 430 выполняется на шаге 465.
На Фиг. 8 представлена компьютерная система, на которой могут быть реализованы различные варианты систем и способов, раскрытых в настоящем документе. Компьютерная система 20 может представлять собой систему, сконфигурированную для реализации настоящего изобретения и может быть в виде одного вычислительного устройства или в виде нескольких вычислительных устройств, например, настольного компьютера, портативного компьютера, ноутбука, мобильного вычислительного устройства, смартфона, планшетного компьютера, сервера, мейнфрейма, встраиваемого устройства и других форм вычислительных устройств.
Как показано на Фиг. 8, компьютерная система 20 включает в себя: центральный процессор 21, системную память 22 и системную шину 23, которая связывает разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, способную взаимодействовать с любой другой шинной архитектурой. Примерами шин являются: PCI, ISA, PCI-Express, HyperTransport™, InfiniBand™, Serial ATA, I2C и другие подходящие соединения между компонентами компьютерной системы 20. Центральный процессор 21 содержит один или несколько процессоров, имеющих одно или несколько ядер. Центральный процессор 21 исполняет один или несколько наборов машиночитаемых инструкций, реализующих способы, представленные в настоящем документе. Системная память 22 может быть любой памятью для хранения данных и/или компьютерных программ, исполняемых центральным процессором 21. Системная память может содержать как постоянное запоминающее устройство (ПЗУ) 24, так и память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами компьютерной системы 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Компьютерная система 20 включает в себя одно или несколько устройств хранения данных, таких как одно или несколько извлекаемых запоминающих устройств 27, одно или несколько неизвлекаемых запоминающих устройств 28, или комбинации извлекаемых и неизвлекаемых устройств. Одно или несколько извлекаемых запоминающих устройств 27 и/или неизвлекаемых запоминающих устройств 28 подключены к системной шине 23 через интерфейс 32. В одном из вариантов реализации извлекаемые запоминающие устройства 27 и соответствующие машиночитаемые носители информации представляют собой энергонезависимые модули для хранения компьютерных инструкций, структур данных, программных модулей и других данных компьютерной системы 20. Системная память 22, извлекаемые запоминающие устройства 27 и неизвлекаемые запоминающие устройства 28 могут использовать различные машиночитаемые носители информации. Примеры машиночитаемых носителей информации включают в себя машинную память, такую как кэш-память, SRAM, DRAM, ОЗУ не требующую конденсатора (Z-RAM), тиристорную память (T-RAM), eDRAM, EDO RAM, DDR RAM, EEPROM, NRAM, RRAM, SONOS, PRAM; флэш-память или другие технологии памяти, такие как твердотельные накопители (SSD) или флэш-накопители; магнитные кассеты, магнитные ленты и магнитные диски, такие как жесткие диски или дискеты; оптические носители, такие как компакт-диски (CD-ROM) или цифровые универсальные диски (DVD); и любые другие носители, которые могут быть использованы для хранения нужных данных и к которым может получить доступ компьютерная система 20.
Системная память 22, извлекаемые запоминающие устройства 27 и неизвлекаемые запоминающие устройства 28, содержащиеся в компьютерной системе 20 используются для хранения операционной системы 35, приложений 37, других программных модулей 38 и программных данных 39. Компьютерная система 20 включает в себя периферийный интерфейс 46 для передачи данных от устройств ввода 40, таких как клавиатура, мышь, стилус, игровой контроллер, устройство голосового ввода, устройство сенсорного ввода, или других периферийных устройств, таких как принтер или сканер через один или несколько портов ввода/вывода, таких как последовательный порт, параллельный порт, универсальная последовательная шина (USB) или другой периферийный интерфейс. Устройство отображения 47, такое как один или несколько мониторов, проекторов или встроенных дисплеев, также подключено к системной шине 23 через выходной интерфейс 48, такой как видеоадаптер. Помимо устройств отображения 47, компьютерная система 20 оснащена другими периферийными устройствами вывода (на Фиг. 8 не показаны), такими как динамики и другие аудиовизуальные устройства.
Компьютерная система 20 может работать в сетевом окружении, используя сетевое соединение с одним или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 является рабочим персональным компьютером или сервером, который содержит большинство или все упомянутые компоненты, отмеченные ранее при описании сущности компьютерной системы 20, представленной на Фиг. 8. В сетевом окружении также могут присутствовать и другие устройства, например, маршрутизаторы, сетевые станции или другие сетевые узлы. Компьютерная система 20 может включать один или несколько сетевых интерфейсов 51 или сетевых адаптеров для связи с удаленными компьютерами 49 через одну или несколько сетей, таких как локальная компьютерная сеть (LAN) 50, глобальная компьютерная сеть (WAN), интранет и Интернет. Примерами сетевого интерфейса 51 являются интерфейс Ethernet, интерфейс Frame Relay, интерфейс SONET и беспроводные интерфейсы.
Варианты раскрытия настоящего изобретения могут представлять собой систему, способ, или машиночитаемый носитель (или носитель) информации.
Машиночитаемый носитель информации является осязаемым устройством, которое сохраняет и хранит программный код в форме машиночитаемых инструкций или структур данных, к которым имеет доступ центральный процессор 21 компьютерной системы 20. Машиночитаемый носитель может быть электронным, магнитным, оптическим, электромагнитным, полупроводниковым запоминающим устройством или любой подходящей их комбинацией. В качестве примера, такой машиночитаемый носитель информации может включать в себя память с произвольным доступом (RAM), память только для чтения (ROM), EEPROM, портативный компакт-диск с памятью только для чтения (CD-ROM), цифровой универсальный диск (DVD), флэш-память, жесткий диск, портативную компьютерную дискету, карту памяти, дискету или даже механически закодированное устройство, такое как перфокарты или рельефные структуры с записанными на них инструкциями.
Система и способ, настоящего изобретения, могут быть рассмотрены в терминах средств. Термин "средство", используемый в настоящем документе, относится к реальному устройству, компоненту или группе компонентов, реализованных с помощью аппаратного обеспечения, например, с помощью интегральной схемы, специфичной для конкретного приложения (ASIC) или FPGA, или в виде комбинации аппаратного и программного обеспечения, например, с помощью микропроцессорной системы и набора машиночитаемых инструкций для реализации функциональности средства, которые (в процессе выполнения) превращают микропроцессорную систему в устройство специального назначения. Средство также может быть реализовано в виде комбинации этих двух компонентов, при этом некоторые функции могут быть реализованы только аппаратным обеспечением, а другие функции - комбинацией аппаратного и программного обеспечения. В некоторых вариантах реализации, по крайней мере, часть, а в некоторых случаях и все средство может быть выполнено на центральном процессоре 21 компьютерной системы 20. Соответственно, каждое средство может быть реализовано в различных подходящих конфигурациях и не должно ограничиваться каким-либо конкретным вариантом реализации, приведенным в настоящем документе.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что при разработке любого реального варианта осуществления настоящего изобретения необходимо принять множество решений, специфических для конкретного варианта осуществления, для достижения конкретных целей, и эти конкретные цели будут разными для разных вариантов осуществления. Понятно, что такие усилия по разработке могут быть сложными и трудоемкими, но, тем не менее, они будут обычной инженерной задачей для тех, кто обладает обычными навыками в данной области, пользуясь настоящим раскрытием изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обнаружения фишинговых сайтов и система его реализующая | 2023 |
|
RU2813242C1 |
| Система и способ обнаружения фишинговых веб-страниц | 2024 |
|
RU2836604C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ФИШИНГОВЫХ ВЕБ-СТРАНИЦ | 2016 |
|
RU2637477C1 |
| Способ определения фишингового электронного сообщения | 2020 |
|
RU2790330C2 |
| Система и способ обнаружения модификации веб-ресурса | 2018 |
|
RU2702081C2 |
| Способ и система для идентификации кластеров аффилированных веб-сайтов | 2020 |
|
RU2740856C1 |
| СИСТЕМА И СПОСОБ СБОРА ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ФИШИНГА | 2016 |
|
RU2671991C2 |
| СПОСОБ УПРАВЛЕНИЯ ДИАЛОГОМ И СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА В ПЛАТФОРМЕ ВИРТУАЛЬНЫХ АССИСТЕНТОВ | 2020 |
|
RU2759090C1 |
| МЕТОД ПОСТРОЕНИЯ КОРПУСА ТЕКСТОВ НА ОСНОВЕ ИНТЕРНЕТ-ФОРУМОВ | 2013 |
|
RU2565473C2 |
| СИСТЕМА, СПОСОБ И ПОСТОЯННЫЙ МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ПРОВЕРКИ ВЕБ-СТРАНИЦ | 2015 |
|
RU2632149C2 |


Изобретение относится к вычислительной технике. Технический результат заключается в уменьшении доли ложных срабатываний и увеличении доли истинно-положительных срабатываний при обнаружении фишинговых сайтов. Способ формирования классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов при помощи хешей объектов DOM страниц содержит этапы, на которых получают страницы, соответствующие набору ссылок; формируют древовидную структуру в виде DOM-дерева для каждой страницы; формируют по меньшей мере одну строку, состоящую из элементов DOM-дерева для каждой страницы; создают по меньшей мере два хеша для каждой страницы; формируют два набора данных из сформированных хешей; проводят проверку на наличие разнообразности данных в каждом наборе данных; осуществляют обучение классификатора на основании сформированных наборов данных. 2 н. и 9 з.п. ф-лы, 9 ил.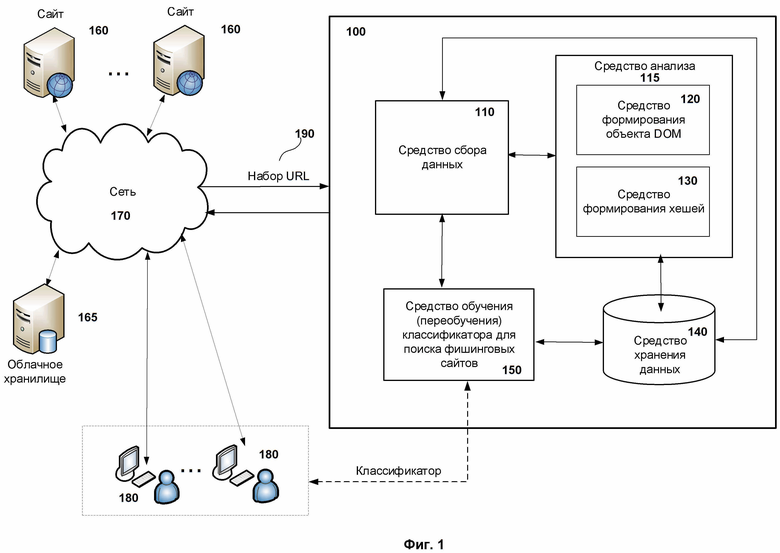
1. Способ формирования классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов при помощи хешей объектов DOM страниц, при этом указанный способ содержит этапы, на которых:
а) получают страницы, соответствующие набору ссылок (URL);
б) формируют древовидную структуру в виде DOM-дерева для каждой страницы путем парсинга страницы, во время которого извлекают данные и информацию из страницы;
в) формируют по меньшей мере одну строку, состоящую из элементов DOM-дерева для каждой страницы, на основании шаблона;
г) создают по меньшей мере два хеша для каждой страницы, при этом первый хеш формируют от всей страницы, а второй и последующие хеши – от сформированных строк;
д) формируют два набора данных из сформированных хешей, где первый набор данных содержит информацию о безопасных страницах, а второй набор данных содержит информацию о фишинговых страницах;
е) проводят проверку на наличие разнообразности данных в каждом наборе данных;
ж) осуществляют обучение классификатора, включающего модель машинного обучения, на основании сформированных наборов данных.
2. Способ по п. 1, в котором получают страницы по меньшей мере одним из подходов: скачивают страницы сайта согласно ссылкам в виде текстовых файлов или получают страницы из базы данных.
3. Способ по п. 1, в котором шаблон определяет способ формирования строки из элементов DOM-дерева страницы.
4. Способ по п. 3, в котором по меньшей мере одним шаблоном является один из следующих шаблонов:
а) шаблон, согласно которому формируют строку на основании только названий тегов в DOM-дереве страницы (первый шаблон);
б) шаблон, согласно которому формируют строку на основании названий тегов и названий атрибутов тегов (второй шаблон).
5. Способ по п. 1, в котором формируют по меньшей мере две строки, при этом первую строку формируют на основании первого шаблона, а вторую строку формируют на основании второго шаблона.
6. Способ по п. 1, в котором на этапе е) проверку осуществляют путем определения, есть ли в наборах данных группы схожих хешей, при этом указанные группы являются достаточно многочисленными.
7. Способ по п. 1, в котором дополнительно проводят очистку данных из наборов данных, где очистка заключается в поиске и удалении из одного из набора данных хешей, которые попали в оба набора данных.
8. Способ по п. 1, в котором дополнительно проводят проверку на наличие разнообразности данных в каждом из указанных наборе данных.
9. Способ по п. 1, в котором дополнительно после обучения классификатора осуществляют проверку его работы на тестовом подмножестве данных.
10. Способ по п. 9, в котором проводят переобучение классификатора при выявлении ложного срабатывания во время проверки на тестовом подмножестве данных.
11. Система формирования классификатора, включающего модель машинного обучения, для обнаружения фишинговых сайтов на основании объектов DOM страниц, при этом указанная система включает:
а) средство сбора данных,
б) средство анализа, включающие средство формирования объекта DOM и средство формирование хешей,
в) средство хранения данных,
г) средство обучения, предназначенное для обучения классификатора, включающего модель машинного обучения для поиска фишинговых сайтов,
д) и в которой вычислительное устройство, содержащее по меньшей мере один процессор и по меньшей мере одну память, хранящую машиночитаемые инструкции, исполняемые по меньшей мере одним процессором, осуществляет способ по любому из пп. 1-10.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Способ устранения уязвимостей устройств, имеющих выход в Интернет | 2016 |
|
RU2636700C1 |

