Настоящая заявка связана со следующими заявками на патент, переуступленными правопреемнику настоящей заявки и упоминаемыми здесь для сведения:
заявка на патент США № 10/427548, озаглавленная "Кластеризация объектов с использованием межуровневых связей", поданная 01.05.2003 г., и
заявка на патент США (номер еще не присвоен), озаглавленная "Усиленная кластеризация многотипных объектов данных для предложения поисковых терминов", поданная 15.04.2004 г.
Область техники, к которой относится изобретение
Предложенные системы и способы относятся к извлечению информации из массивов данных.
Уровень техники
Ключевое слово или фраза - это слово или набор терминов, предоставляемых человеком, который осуществляет поиск информации в Интернет (так называемым "веб-серфером"), поисковой машине при поиске соответствующей страницы/сайта во Всемирной паутине (WWW). Поисковые машины определяют релевантность веб-сайта на основании ключевых слов и фраз из ключевых слов, которые появляются на странице/сайте. Так как значительный процент трафика веб-сайта обусловлен использованием поисковых машин, промоутеры веб-сайтов осознают, что правильный выбор ключевого слова/фразы имеет важное значение для повышения трафика идостижения желаемой популярности сайта. Методы определения релевантных для веб-сайта ключевых слов в целях оптимизации результатов поисковой машины включают в себя, например, оценку человеком содержания и целей веб-сайта, чтобы идентифицировать релевантное ключевое слово (слова). Эта оценка может включать в себя использование инструмента популярности ключевых слов. Такие инструменты определяют, сколько пользователей ввело конкретное ключевое слово или фразу, содержащую данное ключевое слово, в поисковую машину. Для оптимизации результатов поисковой машины в отношении данного веб-сайта обычно выбираются релевантные для данного веб-сайта ключевые слова, которые признаны наиболее часто используемыми при формировании поисковых запросов.
После определения набора ключевых слов для оптимизации результатов поисковой машины промоутер веб-сайта может пожелать поднять веб-сайт на более высокое положение в результатах поисковой машины (по сравнению с отображаемыми поисковой машиной положениями результатов других веб-сайтов). Для этого промоутер предлагает ключевое слово (слова) с указанием, сколько он платит каждый раз, когда веб-серфер делает выбор (щелкает мышью) из списков промоутера, связанных с данным ключевым словом (словами). Иными словами, предложения ключевых слов являются предложениями с оплатой за каждый выбор (щелчок мышью). Чем выше стоимость предложения ключевого слова по сравнению с другими предложениями для того же самого ключевого слова, тем выше (т.е. с приданием большей важности) поисковая машина будет отображать соответствующий веб-сайт в результатах поиска на основании этого ключевого слова.В свете вышесказанного для промоутеров веб-сайтов было бы желательно иметь системы и способы, которые бы позволили лучше идентифицировать ключевые слова, релевантные для содержания веб-сайтов. Это бы позволило им предлагать предпочтительные для пользователя термины. В идеальном случае эти системы и способы не должны требовать от пользователя оценки содержания веб-сайта для идентификации релевантных ключевых слов для оптимизации поисковой машины и предложения ключевых слов.
Раскрытие изобретения
Предложены системы и способы для предложения родственных терминов. Согласно одному аспекту изобретения, создаются кластеры терминов в зависимости от вычисленного подобия векторов терминов. Каждый вектор термина создается по результатам поиска, связанного с группой предыдущих запросов с высокой частотой появления (ЧП), ранее поданных в поисковую машину. В ответ на получение термина/фразы от какого-либо объекта этот термин/фраза оценивается с учетом терминов/фраз в кластерах терминов, чтобы определить одно или более предложений родственных терминов.
Краткое описание чертежей
В ссылочных номерах, использованных на чертежах, левая цифра указывает конкретную фигуру, на которой впервые появился данный элемент.
Фиг.1 изображает примерную систему для предложения родственных терминов для многосмыслового запроса.
Фиг.2 изображает примерную процедуру для предложения родственных терминов для многосмыслового запроса.
Фиг.3 изображает примерную процедуру для предложенияродственных терминов для многосмыслового запроса. Операции этой процедуры основаны на операциях, изображенных на фиг.2.
Фиг.4 изображает примерную подходящую вычислительную среду, в которой могут быть полностью или частично реализованы описанные ниже системы, устройства и способы для предложения родственных терминов для многосмыслового запроса.
Осуществление изобретения
Общее представление
Может показаться, что простейшим путем предложения родственного термина/фразы является использование принципа сопоставления подстрок, при котором два термина/фразы признаются родственными, если один термин/фраза содержит некоторые или все слова другого термина/фразы. Однако этот метод имеет существенные недостатки. В нем могут не учитываться многие семантически родственные термины, потому что родственные термины не обязательно должны содержать общие слова. Например, рассмотрим случай, когда обувная фирма желает найти термины, родственные с термином "обувь". Если использовать обычный принцип сопоставления, то будут предложены только термины "женская обувь", "уцененная обувь", и т.п. Однако существует еще много других родственных терминов, например "кеды", "кроссовки", "Найк", (т.е. обувь фирмы Найк), и т.п.
Эти проблемы обычных методов сопоставления подстрок решаются в системах и способах для предложения родственных терминов для многосмыслового запроса согласно изобретению. Для этого системы и способы анализируют результаты поисковой машины на наличие терминов/фраз, семантически связанных стерминами/фразами, представленными конечным пользователем (например, промоутером веб-сайта, рекламодателем, и т.д.). Семантическая связь формируется путем анализа контекста (например, текста и/или т.д.) из результатов поисковой машины, контекста, окружающего термин/фразу, который может пролить свет на смысл термина/фразы. Более конкретно, объединяется группа терминов запросов из журнала предыдущих запросов с подсчетом их частоты появления (ЧП). Эти термины запросов подаются по одному в поисковую машину. В одной реализации представленные термины журнала предыдущих запросов имеют относительно высокую частоту появления по сравнению с частотой появления других терминов журнала предыдущих запросов.
В ответ на прием соответствующих из представленных запросов поисковая машина возвращает ранжированный список результатов поиска, включающий в себя их URL, заголовки результатов и краткие описания каждого результата и/или контекст, окружающий представленный запрос. После получения результатов поисковой машины в системах и способах извлекается набор признаков (ключевые слова и соответствующие весовые коэффициенты, вычисленные с помощью известных методов TFIDF) из выбранных возвращенных результатов поиска (например, одного или более результатов высшего ранга). После извлечения признаков соответствующих результатов поисковой машины из представленных поисковых запросов извлеченные признаки нормируются. Нормированные признаки используются для представления каждого поданного запроса и используются в алгоритме кластеризации текста для группирования представленных терминов запроса вкластеры.
В ответ на получение термина/фразы от конечного пользователя этот термин/фразу сравнивают с соответствующими терминами/фразами в кластерах терминов. Так как кластеры терминов включают в себя термины, контекстуально связанные друг с другом, то когда термин/фраза сравнивается с терминами в кластерах, этот термин/фраза оценивается с учетом любого из множества родственных контекстов или "смыслов". В одном варианте, если термин/фраза совпадает с каким-то термином из кластера, этот кластер возвращается конечному пользователю в списке предложенных терминов. Список предложенных терминов содержит термины/фразы, определенные как семантически и/или контекстуально связанные с данным термином/фразой, измерения подобия соответствующего термина/фразы термину/фразе (значения доверия) и соответствующую частоту появления (ЧП) термина/фразы. Возвращенный список упорядочен по комбинации ЧП и значения доверия. Если данный термин/фраза совпадает с терминами более чем в одном кластере терминов, то создается несколько списков предлагаемых терминов. Эти списки упорядочены по размерам кластеров, а термины в каждом списке упорядочены по комбинации ЧП и значения доверия. Если не обнаружено совпадающих кластеров, то термин запроса сопоставляется дальше с расширенными кластерами, созданными из терминов поиска с низкой ЧП.
В одном варианте термины поиска с низкой ЧП кластеризуются путем тренировки классификатора (например, классификатора с алгоритмом k-ближайшего соседа) для кластеров терминов, созданных из терминов журнала предыдущих запросов с высокойчастотой появления. Термины предыдущих запросов, определенные как имеющие низкую частоту появления, подаются по одному в поисковую машину. Затем из выбранных возвращенных результатов поиска (например, первой веб-страницы самого высокого ранга и/или т.п.) извлекаются признаки. Извлеченные признаки нормируются и используются для представления терминов запроса с низкой ЧП. Затем термины запроса классифицируются в существующие кластеры для создания расширенных кластеров на основании тренированного классификатора. После этого представленный конечным пользователем термин/фраза оценивается в свете этих расширенных терминов для идентификации и возврата списка предложенных терминов конечному пользователю.
В дальнейшем будут описаны более подробно эти и другие аспекты систем и способов для предложения родственных терминов/ключевых слов для многосмыслового запроса.
Примерная система
Со ссылками на чертежи, на которых одинаковые ссылочные номера относятся к одинаковым элементами, будут описаны системы и способы для предложения родственных терминов для многосмыслового запроса, реализованные в подходящей вычислительной среде. Хотя это и не является обязательным, изобретение будет описано в общем контексте исполняемых машиной команд (программных модулей), которые выполняются в персональном компьютере. Программные модули обычно включают в себя подпрограммы, программы, объекты, компоненты, структуры данных, и т.п., которые выполняют конкретные задачи или реализуют конкретные типы абстрактных данных. Несмотря на то, что эти системы и способы описаны в представленном выше контексте, описанные далее действия и операции можно также реализовать и в аппаратных средствах.
На фиг.1 изображена примерная система 100 для предложения родственных терминов для многосмыслового запроса. В этой реализации система 100 содержит сервер 102 редакторского контроля (СРК), связанный через сеть с клиентским вычислительным устройством 106. В ответ на получение термина/фразы 108, например, из клиентского вычислительного устройства 106 или другого приложения (не показано), работающего на СРК 102, СРК 102 формирует и передает список 110 предлагаемых терминов клиентскому вычислительному устройству 106, чтобы позволить конечному пользователю оценить набор терминов, которые семантически/контекстуально связаны с термином/фразой 108, прежде чем действительно предложить термин/фразу. Сеть 104 может содержать любую комбинацию коммуникационных средств локальной вычислительной сети (ЛВС) и глобальной вычислительной сети (ГВС), которые обычно применяются в учрежденческих, промышленных вычислительных сетях, интранет и Интернет. Если система 100 содержит клиентское вычислительное устройство 106, то это вычислительное устройство может быть любым типом вычислительного устройства, таким как персональный компьютер, портативный компьютер, сервер, мобильное вычислительное устройство (например, сотовый телефон, персональный цифровой помощник или ладонный компьютер), и т.п.
Список 110 предложенных терминов содержит, например, термины/фразы, определенные как родственные с термином/фразой 108, измерения относительного подобия термина/фразы термину/фразе 108 (значения доверия) и соответствующую частоту появления термина/фразы (ЧП), т.е. частоту в журнале предыдущих запросов. Методы идентификации родственных терминов/фраз, получения измерений подобия и значений ЧП будут более подробно описаны ниже в разделах, озаглавленных "Анализ ключевых слов", "Извлечение признаков" и "Кластеризация терминов".
В таблице показан примерный список 110 предлагаемых терминов, которые были определены как родственные с термином/фразой 108 "почта". Термины, родственные с термином/фразой 108, показаны в этом примере в столбце 1, озаглавленном "Предложенный термин".
Следует отметить, что в списке предложенных терминов в таблице термины отображены в значениях подобия терминов (см. столбец 2 "Подобие") и частоте их появления (см. столбец 3 "Частота"). Каждое значение подобия термина, вычисленное, как будет описано ниже в разделе "Кластеризация терминов", дает меру подобия между соответствующим предложенным термином (столбец 1) и термином/фразой 108, в данном примере "почта". Каждое значение частоты, или счет, указывает, сколько раз предложенный термин появлялся в журнале предыдущих запросов. Список предложенных терминов сортируется в зависимости от подобия терминов и/или счета частоты появления согласно бизнес-целям.
Любой данный термин/фраза 108 (например, "почта" и т.п.) может иметь более чем один контекст, в котором может использоваться термин поиска. С учетом этого модель ППТ 112 предусматривает индикацию в списке 110 предложенных терминов, какой из предложенных терминов соответствует какому из множества контекстов термина/фразы 108. Например, в таблице термин/фраза 108 "почта" имеет два (2) контекста: (1) традиционная почта и (2) электронная почта. Следует заметить, что для каждого из этих двух контекстов предложенных терминов представлен соответствующий список родственных терминов.
Кроме того, предложенные термины для любого термина/фразы 108 могут быть не только синонимами предложенного термина. Например, в таблице предложенный термин "usp" является акронимом организации, которая обрабатывает почту, а не синонимом предложенного термина "почта". Однако "usp" также является термином, очень родственным предложенному термину "почта", поэтому он показан в списке 110 предложенных терминов. В одном варианте модель ППТ 112 определяет взаимосвязь между родственным термином R (например, "usp") и целевым термином Т (например, "почта") как функцию следующего правила ассоциации: itr(T)→itr(R), где "itr" - заинтересованный. Если пользователь (рекламодатель, промоутер веб-сайта и/или т.п.) заинтересован в R, то он будет также заинтересован в Т.
СРК 102 содержит несколько компьютерных программных модулей для создания списка 110 предложенных терминов. Компьютерные программные модули включают в себя, например, модуль 112 предложения поискового термина (ППТ) и модуль 114 классификации. Модуль ППТ 112 принимает группу предыдущих запросов 116 из журнала 118 запросов. Предыдущие запросы включают в себя термины запроса на поиск, представленные ранее в поисковую машину. Модуль ППТ 112 оценивает предыдущие запросы 116 в зависимости от частоты появления для идентификации поисковых терминов 120 с высокой частотой появления (ЧП) и поисковых терминов 122 с относительно низкой частотой появления. В этой реализации используется конфигурируемое пороговое значение для определения, имеет ли предыдущий запрос относительно более высокую или низкую частоту появления. Например, термины поискового запроса в предыдущих запросах 116, которые появлялись, по меньшей мере, пороговое количество раз, считаются имеющими высокую частотупоявления. Аналогично, термины поискового запроса в предыдущих запросах 116, которые появлялись меньше, чем пороговое количество раз, считаются имеющими низкую частоту появления. Для целей иллюстрации такое пороговое значение показано как соответствующая часть 124 "других данных".
Анализ ключевых слов и извлечение признаков
Модуль ППТ 112 осуществляет поиск терминов 120 запроса с высокой частотой появления с семантическим/контекстуальным значением путем подачи каждого запроса по одному (поисковый запрос 128) в поисковую машину 126. В ответ на прием поискового запроса 128 поисковая машина 126 возвращает ранжированный список (количество которого можно конфигурировать) в поисковом результате 130 в модуль ППТ 112. Ранжированный список содержит URL, заголовки результатов и краткие описания и/или контексты термина запроса, связанного с поданным поисковым запросом 128. Этот ранжированный список сохраняется в результатах 132 поиска. Такое извлечение результатов поиска выполняется для каждого поискового запроса 128.
Модуль ППТ 112 анализирует язык гипертекстовой разметки документов (HTML) для веб-страниц, чтобы извлечь URL, заголовки результатов и краткие описания и/или контексты терминов запроса для каждого термина 120 запроса из каждого найденного результата 132 поиска. URL, заголовки результатов, краткие описания и/или контексты термина запроса, а также запрос 128 на поиск, использованный для получения результата 132 поиска, сохраняются модулем ППТ 112 в соответствующей записи извлеченных признаков 134. После анализа результатов 130 на наличие терминов 120 запроса с высокой частотой появления модуль ППТ 112 выполняет операции предварительной текстовой обработки на извлеченных признаках 134, чтобы создать лингвистические метки из извлеченных признаков в индивидуальных ключевых словах. Для уменьшения размерности меток модуль ППТ 112 удаляет любые слова-остановки (например, артикли и т.п.), а также удаляет обычные суффиксы для нормирования ключевых слов, например, с помощью известного алгоритма Портера выделения основы слов. Модуль ППТ 112 организует полученные извлеченные признаки 134 в один или более векторов 136 терминов.
Каждый вектор 136 термина имеет размеры, основанные на счете частоты термина и обратной частоты документа (TFIDF). Весовой коэффициент для 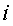 -го вектора
-го вектора 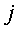 -го ключевого слова вычисляют следующим образом:
-го ключевого слова вычисляют следующим образом:
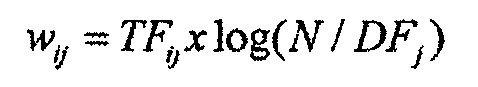
где 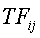 - частота термина (количество появлений ключевого слова в -ой записи),
- частота термина (количество появлений ключевого слова в -ой записи), 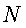 - общее количество терминов запроса, и
- общее количество терминов запроса, и 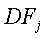 - количество записей, содержащих ключевое слово .
- количество записей, содержащих ключевое слово .
Кластеризация терминов
Модуль ППТ 112 группирует подобные термины для создания кластеров 138 терминов из векторов 136 терминов. Для этого в данном варианте реализации, если каждый термин имеет векторное представление, используется косинусная функция для измерения подобия между парой терминов (напомним, что векторы были нормированы):
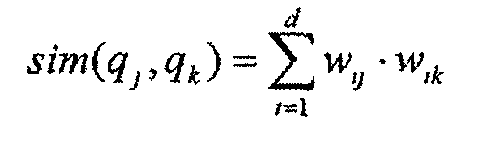 Следовательно, расстояние между двумя терминами (мера подобия) определяют как:
Следовательно, расстояние между двумя терминами (мера подобия) определяют как:
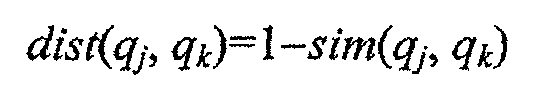
Такие измерения подобия показаны как соответствующая часть 124 "другие данные". Примеры значений подобия показаны в списке 110 предложенных терминов в таблице.
Модуль ППТ 112 использует вычисленную меру (меры) подобия для кластеризации/группировки терминов, представленных векторами 134 ключевых слов, в кластер(ы) 138 терминов. Более конкретно, в данном варианте реализации модуль ППТ 112 использует известный алгоритм кластеризации на основании плотности (DBSCAN) для создания кластера(ов) 138 терминов. В DBSCAN используется два параметра: 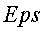 и
и 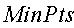 . - это максимальное расстояние между точками в кластере 138. В данном контексте точки являются эквивалентами векторов, потому что каждый вектор можно представить точкой стрелки вектора, когда его начало обращено к источнику. - это минимальное количество точек в кластере 138. Для создания кластера 138 DBSCAN начинает обработку с произвольной точки
. - это максимальное расстояние между точками в кластере 138. В данном контексте точки являются эквивалентами векторов, потому что каждый вектор можно представить точкой стрелки вектора, когда его начало обращено к источнику. - это минимальное количество точек в кластере 138. Для создания кластера 138 DBSCAN начинает обработку с произвольной точки 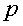 и извлекает все досягаемые по плотности точки из относительно и . Если - окруженная точка, то эта процедура дает кластер 138 относительно и . Если - пограничная точка, то невозможно достичь по плотности никаких точек из , и DBSCAN обращается к следующей точке.
и извлекает все досягаемые по плотности точки из относительно и . Если - окруженная точка, то эта процедура дает кластер 138 относительно и . Если - пограничная точка, то невозможно достичь по плотности никаких точек из , и DBSCAN обращается к следующей точке.
Сопоставление терминов
В ответ на получение термина/фразы 108 от конечного пользователя (например, рекламодателя, промоутера веб-сайта, ит.п.) модуль ППТ 112 сравнивает термин/фразу 108 с соответствующими терминами/фразами в кластере 130 терминов. Так как кластеры 138 терминов содержат термины, контекстуально связанные друг с другом, термин/фраза 08 оценивается с учетом множества родственных и предыдущих контекстов, или "смыслов". В одном варианте изобретения, если модуль ППТ 112 определяет, что термин/фраза 108 совпадает с термином/фразой из кластера 138, модуль 112 предложения терминов поиска формирует список 110 предлагаемых терминов из кластера 138. В этом варианте совпадение должно быть точным совпадением или совпадением с небольшим количеством отклонений, таких как формы единственного/множественного числа, ошибки в написании, знаки пунктуации, и т.п. Возвращенный список организован по комбинации ЧП и значения доверия.
Если модуль ППТ 112 определяет, что термин/фраза 108 совпадает с терминами во множестве кластеров 138 терминов, он формирует множество списков 110 предлагаемых терминов из терминов во множестве кластеров 138 терминов. Эти списки упорядочиваются по размерам кластеров, а термины в каждом списке упорядочиваются по комбинации ЧП и значения доверия.
Классификация терминов с низкой ЧП
Модуль 114 классификации формирует список 110 предлагаемых терминов, когда кластеры 138 терминов, созданные из терминов 120 запроса с высокой частотой появления (ЧП), не содержат терминов, одинаковых с введенным конечным пользователем термином/фразой. При этом модуль 114 классификации создает тренированный классификатор 140 из кластеров 138 терминов, сформированных изтерминов 120 журнала запросов с высокой частотой появления (ЧП). Термины в кластерах 138 терминов уже имеют соответствующие векторы ключевых слов в модели векторного пространства, пригодной для операций классификации. Кроме того, удаление слов-остановок и выделение основы слов (удаление суффиксов) уменьшили размер векторов 136 терминов (на которых основаны кластеры 138). В одном варианте изобретения можно использовать дополнительные методы уменьшения размера, например, выбор признаков или репараметризацию.
В этом варианте для классификации терминов 120 запроса неизвестного класса модуль 114 классификации использует алгоритм классификатора по 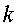 -ближайшему соседу для нахождения наиболее подобных соседей во всех терминах 120 запроса известного класса на основании соответствующих им векторов признаков и использует взвешенное множество классовых меток соседей, чтобы предсказать класс нового термина запроса. В данном случае каждому термину запроса, уже находящему в кластерах 138 терминов, назначается такая же метка, как метка соответствующих им кластеров, а каждый кластер 138 помечается простыми последовательными номерами. Эти соседи взвешиваются с использованием подобия каждого соседа с
-ближайшему соседу для нахождения наиболее подобных соседей во всех терминах 120 запроса известного класса на основании соответствующих им векторов признаков и использует взвешенное множество классовых меток соседей, чтобы предсказать класс нового термина запроса. В данном случае каждому термину запроса, уже находящему в кластерах 138 терминов, назначается такая же метка, как метка соответствующих им кластеров, а каждый кластер 138 помечается простыми последовательными номерами. Эти соседи взвешиваются с использованием подобия каждого соседа с 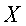 , где подобие измеряется евклидовым расстоянием или значением косинуса между двумя векторами. Подобие косинусов определяется следующим образом:
, где подобие измеряется евклидовым расстоянием или значением косинуса между двумя векторами. Подобие косинусов определяется следующим образом:
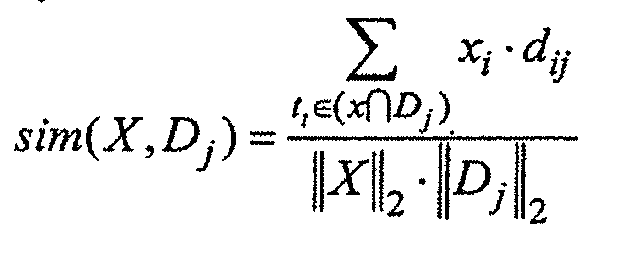
где - проверяемый термин, т.е. термин запроса, подлежащийклассифицированию, представленный как вектор;  -
-  -ый тренировочный термин;
-ый тренировочный термин; 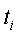 - слово, совместно используемое и ;
- слово, совместно используемое и ; 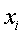 - весовой коэффициент ключевого слова в ;
- весовой коэффициент ключевого слова в ;  - весовой коэффициент ключевого слова в ;
- весовой коэффициент ключевого слова в ; 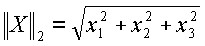 - норма , и
- норма , и  - норма . Следовательно, классовая метка проверяемого термина является взвешенным большинством всех меток класса соседей:
- норма . Следовательно, классовая метка проверяемого термина является взвешенным большинством всех меток класса соседей:
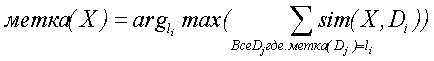
В другом варианте изобретения используются другая статистическая классификация и метод обучения машины (например, регрессионные модели, байсовы классификаторы, деревья решений, нейронные сети и машины с векторами поддержки), отличные от метода классификации по ближайшему соседу, для создания тренированного классификатора 140.
Модуль 114 классификации подает термины запроса 122 с низкой частотой появления (ЧП) по одному (через соответствующий поисковый запрос 128) в поисковую машину 126. В ответ на получение результата 130 поиска, связанного с конкретным поисковым запросом 128, с помощью уже описанных методов, модуль 114 классификации извлекает признаки (извлеченные признаки 134) из одного или более извлеченных результатов 132 поиска, идентифицированные результатом 130 поиска. В этом варианте признаки извлекаются из первого результата 132 поиска высшего ранга. Для каждого извлеченного и проанализированного результата 132 поиска модуль 114 классификации сохраняет в соответствующейзаписи извлеченных признаков 134 следующую информацию: URL, заголовки результатов, краткие описания и/или контексты терминов запроса и поисковый запрос 128, использованный для получения найденного результата 132 поиска. Затем модуль 114 классификации устанавливает метки, уменьшает размерность и нормирует извлеченные признаки 134, полученные из терминов 122 запроса с низкой ЧП, для создания векторов 136 терминов. После этого классификатор 114 формирует кластеры терминов запроса, создавая соответствующую группу кластеров 138. Эта операция кластеризации выполняется с использованием тренированного классификатора 140 (сформированного из терминов 120 запроса с высокой ЧП).
Классификатор 114 оценивает термин/фразу 108, представленную конечным пользователем, относительно расширенных кластеров терминов (сформированных на основании терминов запроса с низкой ЧП) для идентификации и возврата одного или более списков 110 предлагаемых терминов конечному пользователю. Пример такой процедуры был описан выше и будет описан в следующем разделе.
Примерная процедура
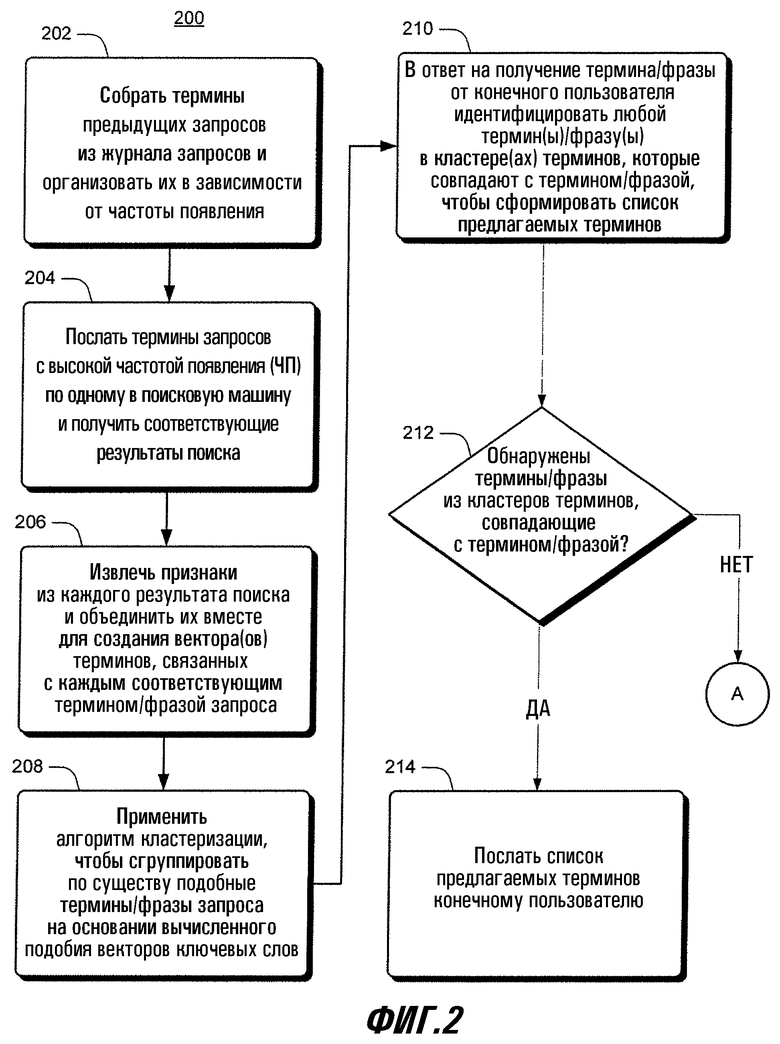
На фиг.2 проиллюстрирована примерная процедура 200 для предложения родственных терминов для многосмыслового запроса. В целях обсуждения операции будут описаны в связи с элементами на фиг.1 (Все ссылочные номера начинаются с номера чертежа, на котором впервые появился этот элемент). В блоке 202 модуль 212 предложения поискового термина (ППТ) (фиг.1) собирает термины 116 предыдущих запроса из журнала 120 запросов. Модуль ППТ 112 организует предыдущие запросы 116 в зависимости от частоты появления. В блоке 204 модуль ППТ 112 посылает термины 120 запроса с высокой частотой появления в поисковую машину 132 и получает соответствующие результаты 130 поиска. В блоке 206 модуль ППТ 112 извлекает фрагменты описания из каждого результата 130 поиска и объединяет фрагменты описания (извлеченные признаки 134) вместе, чтобы создать векторы 136 терминов. Соответствующий вектор 136 термина создается для каждого соответствующего термина 120 запроса с высокой частотой появления.
В блоке 208 модуль ППТ 112 применяет алгоритм кластеризации, чтобы сгруппировать по существу подобные термины на основании векторов 136 терминов в кластеры 138 терминов. В блоке 210 в ответ на получение фразы/термина от конечного пользователя модуль ППТ 112 формирует список 110 предлагаемых терминов из любых ключевых слов/ключевых фраз из кластеров 138 терминов, определенных как по существу подобные фразе/термину 108. В блоке 212 модуль ППТ 112 определяет, было ли определено, что какие-либо ключевые слова/фразы из кластеров 138 ключевых слов по существу подобны термину/фразе 108. Если это так, то процедура продолжается в блоке 214, в котором модуль ППТ 112 посылает список 110 предлагаемых терминов конечному пользователю. В противном случае процедура продолжается в блоке 302 на фиг.3, как показано отсылкой "А".
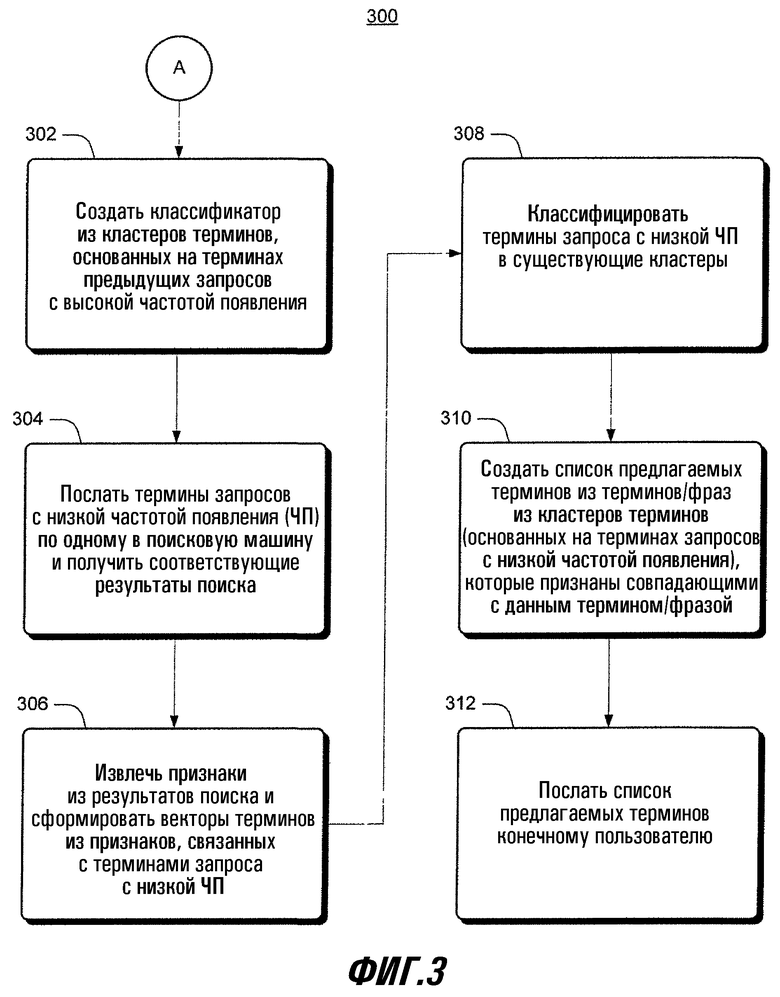
На фиг.3 показана примерная процедура 300 предложения родственных терминов для многосмыслового запроса. Операции процедуры 300 основаны на операциях процедуры 200 на фиг.2. В целях дискуссии операции процедуры будут описаны в связи с элементами на фиг.1. (Все ссылочные номера начинаются с номера чертежа, на котором впервые появился этот элемент.) В блоке 302 модуль ППТ 112 формирует классификатор 140 из кластеров 138 терминов, которые в данный момент основаны на терминах 120 с высокой частотой появления. В блоке 304 модуль ППТ 112 посылает термины 122 запроса с низкой частотой появления по одному в поисковую машину 132 и получает соответствующие результаты 130 поиска. В блоке 306 модуль ППТ 112 извлекает фрагменты описания (извлеченные признаки 134) из результатов 130 поиска и формирует из них векторы терминов 136. В блоке 308 модуль ППТ 112 классифицирует векторы 136 терминов, сформированные из терминов 122 запроса с низкой частотой появления, с учетом тренированного классификатора 140, чтобы создать соответствующие кластеры 138 терминов на основании терминов запроса с низкой частотой появления.
В блоке 310 модуль ППТ 112 создает список 110 предлагаемых терминов из ключевых слов/ключевых фраз из кластеров терминов 138 на основании терминов 122 с низкой частотой появления, которые определены как по существу подобные термину/фразе 108. В блоке 312 модуль ППТ 112 посылает список 110 предлагаемых терминов конечному пользователю.
Примерная рабочая среда
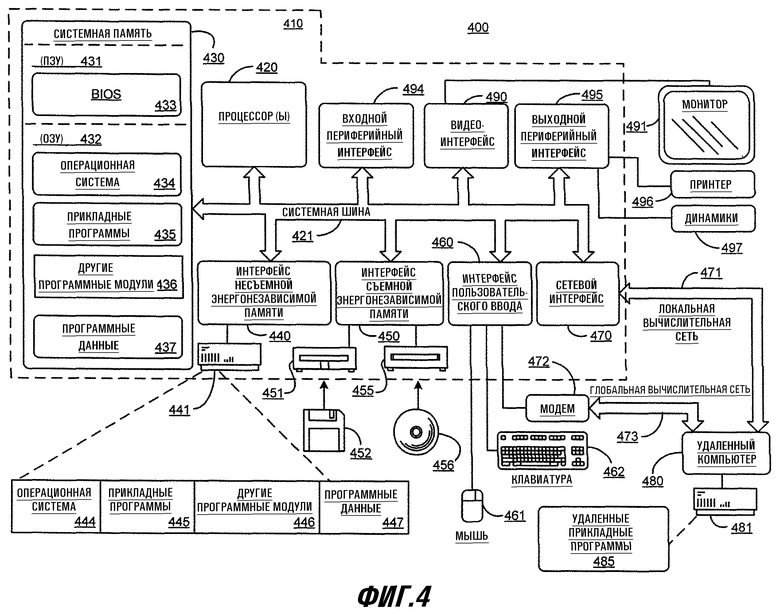
На фиг.4 показан пример подходящей вычислительной среды 400, в которой можно полностью или частично реализовать систему 100, изображенную на фиг.1, и способы, проиллюстрированные на фиг.2 и 3. Примерная вычислительная среда 400 является всего лишь одним примером подходящей вычислительной среды, и ее не следует понимать как ограничительную для объема использования или функций предложенных систем и способов. Также не следует понимать вычислительную среду 400 как имеющую какую-то зависимость или требования в отношении любой комбинации элементов, проиллюстрированных в вычислительной среде 400.
Предложенные системы и способы могут работать с множеством других универсальных или специализированных сред или конфигураций вычислительных систем. Примеры известных вычислительных систем, сред и/или конфигураций, которые могут быть пригодными для использования, включают в себя, без ограничения перечисленным, персональные компьютеры, серверы, мультипроцессорные системы, микропроцессорные системы, сетевые ПК, миникомпьютеры, универсальные вычислительные машины, распределенные вычислительные среды, содержащие любые из перечисленных систем или устройств, и т.д. Компактные или разделенные варианты этой структуры могут быть также реализованы в клиентах с ограниченными ресурсами, например, в ладонных компьютерах или других вычислительных устройствах. Изобретение может быть реализовано в распределенной вычислительной среде, в которой задачи выполняются удаленными процессорами, связанными между собой через коммуникационную сеть. В распределенной вычислительной среде программные модули могут находиться как в локальных, так и удаленных запоминающих устройствах.
На фиг.4 изображена примерная система для предложения родственных терминов для многосмыслового запроса, которая содержит универсальное вычислительное устройство в форме компьютера 410. Описанные далее аспекты компьютера 420 являются примерным воплощением клиентского вычислительного устройства сервера PSS 102 (фиг.1) и/или клиентского вычислительного устройства 106. Компоненты компьютера 410 могут включать в себя, без ограничения перечисленным, процессор (процессоры) 420, системную память 430 и системную шину 421, которая объединяет различные элементы системы, включая системную память и процессор 420. Системная шина 421 может быть любого из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, с использованием ряда шинных архитектур. Например, такие архитектуры могут включать в себя, без ограничения перечисленным, шину промышленной стандартной архитектуры (ISA), шину микроканальной архитектуры (VCA), расширенную ISA (EISA), локальную шину Ассоциации по стандартам видеооборудования (VESA) и шину межсоединения периферийных компонентов (PCI), также известную как шина расширения.
Компьютер 410 обычно содержит ряд машиночитаемых носителей. Машиночитаемые носители могут быть любыми имеющимися носителями, к которым может обращаться компьютер 410, и включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители. Например, машиночитаемый носитель может быть, без ограничения перечисленным, компьютерным и коммуникационным носителем. Компьютерный носитель включает в себя энергонезависимые и энергозависимые, съемные и несъемные носители, реализованные по любой методике или технологии, для хранения такой информации, как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители включают в себя, без ограничения перечисленным, ОЗУ,ПЗУ, ЭППЗУ, флэш-память и память по другой технологии, CD-ROM, цифровые универсальные диски (DVD) или другие оптические дисковые носители, магнитные кассеты, магнитную ленту, магнитные диски или другие устройства магнитной памяти, или любые другие носители, которые можно использовать для хранения требуемой информации и к которым может обращаться компьютер 410.
Коммуникационный носитель обычно представляет собой машиночитаемые команды, структуры данных, программные модули или другие данные на модулированном сигнале данных, например несущей волне или другом механизме транспорта, и включает в себя любые носители для передачи информации. Термин "модулированный сигнал данных" подразумевает сигнал, имеющий одну или несколько характеристик, установленных или изменяемых таким образом, чтобы закодировать информацию в сигнале. Например, коммуникационный носитель включает в себя проводную среду, например проводную сеть или прямое проводное соединение, и беспроводную среду, например акустическую, РЧ, инфракрасную или другую беспроводную среду. Комбинации любых перечисленных выше сред также подпадают под объем понятия машиночитаемого носителя.
Системная память 430 содержит компьютерный носитель в форме энергозависимой и/или независимой памяти, такой как постоянное запоминающее устройство (ПЗУ) 431 и оперативное запоминающее устройство (ОЗУ) 432. Базовая система 433 ввода/вывода (BIOS), содержащая основные программы, обеспечивающие передачу информации между элементами в компьютере 410, например, во время запуска, обычно хранится в ПЗУ 431. ОЗУ 432 обычно содержит данные и/или программные модули, которые доступны в данныймомент и/или с которыми в данный момент оперирует процессор 420. Например, без ограничения перечисленным, фиг.4 иллюстрирует операционную систему 434, прикладные программы 435, другие программные модули 436 и программные данные 437. В одном варианте компьютер 410 является сервером PSS 102. В этом сценарии прикладные программы 435 содержат модуль 112 предложения поисковых терминов и модуль 114 классификации. В этом же сценарии программные данные 437 содержат термин/фразу 108, список 110 предложенных терминов, предыдущие запросы 116, поисковый запрос 128, результат 130 поиска, результаты 132 поиска, извлеченные признаки 134, векторы 136 терминов, кластеры 138 ключевых слов, тренированный классификатор 140 и другие данные 124.
Компьютер 410 может также содержать другие съемные/несъемные, энергозависимые/независимые запоминающие устройства. Например, на фиг.4 показан накопитель 441 на жестких дисках, который считывает или осуществляет запись на несъемный, энергонезависимый магнитный носитель; накопитель 451 на магнитных дисках, который считывает или осуществляет запись на съемный, энергонезависимый магнитный диск 452, и накопитель 455 на оптических дисках, который считывает или осуществляет запись на съемный энергонезависимый оптический диск 456, такой как CD-ROM или другой оптический носитель. Другие съемные/несъемные энергонезависимые/зависимые запоминающие устройства, которые можно использовать в примерной рабочей среде, включают, без ограничения перечисленным, кассеты магнитной ленты, карты флэш-памяти, цифровые универсальные диски, цифровую видеопленку, полупроводниковые ОЗУ, полупроводниковые ПЗУ, и т.п. Накопитель 441 на жестких дисках обычно подсоединен к системной шине 421 через интерфейс несъемной памяти, такой как интерфейс 440; накопитель 451 на магнитных дисках и накопитель 455 на оптических дисках обычно подсоединены к системной шине 421 через интерфейс съемной памяти, такой как интерфейс 450.
Эти накопители и связанные с ними носители, обсуждавшиеся выше и проиллюстрированные на фиг.4, обеспечивают хранение машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 410. Например, на фиг.4 накопитель 441 на жестких дисках показан как хранящий операционную систему 444, прикладные программы 445, другие программные модули 446 и программные данные 447. Следует отметить, что эти компоненты могут быть такими же или отличными от операционной системы 434, прикладных программ 435, других программных модулей 436 и программных данных 437. Операционная система 444, прикладные программы 445, другие программные модули 446 и программные данные 446 обозначены другими номерами, чтобы показать, что они являются, по меньшей мере, другими копиями.
Пользователь может вводить команды и информацию в компьютер через устройства ввода, такие как клавиатура 462 и указательное устройство 461, обычно называемое мышь, трекбол или сенсорная панель. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую приставку, спутниковую тарелку, сканер или т.п. Эти и другие устройства ввода часто бывают подсоединены к процессору 420 через интерфейс 460 пользовательского ввода, который подсоединен к системной шине421, но может быть подсоединен также через другой интерфейс и шинные структуры, такие как параллельный порт, игровой порт или универсальная последовательная шина (USB).
Через интерфейс, такой как видеоинтерфейс 490, к системной шине 421 также подсоединен монитор 491 или другой тип устройства отображения. Кроме монитора компьютеры также могут содержать другие периферийные устройства вывода, такие как динамики 497 и принтер 496, которые могут быть подсоединены через выходной периферийный интерфейс 495.
Компьютер 410 работает в сетевой среде с использованием логических соединений с одним или более удаленными компьютерами, такими как удаленный компьютер 480. Удаленный компьютер 480 может быть персональным компьютером, сервером, маршрутизатором, сетевым ПК, одноранговым устройством или другим обычным сетевым узлом и в зависимости от конкретного применения может содержать многие или все элементы, описанные выше в связи с компьютером 410, несмотря на то, что на фиг.4 проиллюстрировано только запоминающее устройство 481. Логические соединения, показанные на фиг.4, включают в себя локальную вычислительную сеть (ЛВС) 471 и глобальную вычислительную сеть (ГВС) 473, но могут также содержать и другие сети. Такие сетевые среды обычно распространены в учрежденческих, промышленных компьютерных сетях, интранет и Интернет.
При использовании в сетевой среде ЛВС компьютер 410 подсоединяют к ЛВС 471 через сетевой интерфейс или адаптер 470. При использовании в сетевой среде ГВС компьютер 410 обычно содержит модем 472 или другие средства для установления связи через ГВС 473, например, Интернет. Модем 472, который может быть внутренним или внешним, может быть подсоединен к системной шине 421 через интерфейс 460 пользовательского ввода или другой подходящий механизм. В сетевой среде программные модули, показанные в связи с компьютером 410, или их части могут храниться в удаленном запоминающем устройстве. Например, без ограничения перечисленным, на фиг.4 показаны удаленные прикладные программы 485, как постоянно находящиеся в запоминающем устройстве 481. Показанные сетевые соединения являются всего лишь примером, и можно использовать другие средства установления каналов связи между компьютерами.
Заключение
Несмотря на то, что системы и способы для предложения родственных терминов были описаны с конкретным указанием конструктивных признаков и/или технологических операций или действий, понятно, что варианты воплощения изобретения, охарактеризованные в прилагаемой формуле изобретения, не обязательно ограничены этими описанными признаками или действиями. Следовательно, конкретные признаки и действия были раскрыты только как примерные формы реализации заявленного объекта.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОВЕРКА РЕЛЕВАНТНОСТИ МЕЖДУ КЛЮЧЕВЫМИ СЛОВАМИ И СОДЕРЖАНИЕМ ВЕБ-САЙТА | 2005 |
|
RU2375747C2 |
| АННОТАЦИЯ ПОСРЕДСТВОМ ПОИСКА | 2007 |
|
RU2439686C2 |
| СПОСОБ ОБРАБОТКИ ЦЕЛЕВОГО СООБЩЕНИЯ, СПОСОБ ОБРАБОТКИ НОВОГО ЦЕЛЕВОГО СООБЩЕНИЯ И СЕРВЕР (ВАРИАНТЫ) | 2014 |
|
RU2589856C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СПОСОБ И СИСТЕМА СОГЛАСОВАНИЯ СХЕМ БАЗ ДАННЫХ WEB | 2005 |
|
RU2386997C2 |
| ОБЕСПЕЧЕНИЕ РУКОВОДСТВА ТЕМАТИЧЕСКИМ ПОИСКОМ | 2012 |
|
RU2628200C2 |
| СЕРВЕР ДЛЯ ОПРЕДЕЛЕНИЯ ПОИСКОВОЙ ВЫДАЧИ НА ПОИСКОВЫЙ ЗАПРОС И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2013 |
|
RU2583739C2 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СИСТЕМА ДЛЯ ИДЕНТИФИКАЦИИ ПЕРЕФРАЗИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ МАШИННОГО ПЕРЕВОДА | 2004 |
|
RU2368946C2 |
| СИСТЕМА, СПОСОБ И ИНТЕРФЕЙС ДЛЯ ОБЕСПЕЧЕНИЯ ПЕРСОНАЛИЗИРОВАННОГО ПОИСКА И ДОСТУПА К ИНФОРМАЦИИ | 2005 |
|
RU2419858C2 |
Изобретение относится к системе и способу для предложения родственных терминов. Техническим результатом является расширение функциональных возможностей за счет улучшения идентификации ключевых слов, релевантных для содержания веб-сайта. В способе формируются кластеры терминов в зависимости от вычисленного подобия векторов терминов. Вектор каждого термина создается из результатов поиска, связанных с группой предыдущих запросов с высокой частотой появления (ЧП), поданных ранее в поисковую машину. В ответ на получение термина/фразы от объекта этот термин/фраза оценивается, принимая во внимание термины/фразы в кластерах терминов, чтобы идентифицировать одно или более предложений родственных терминов. Система реализует указанный способ. 4 н. и 42 з.п. ф-лы, 4 ил., 1 табл.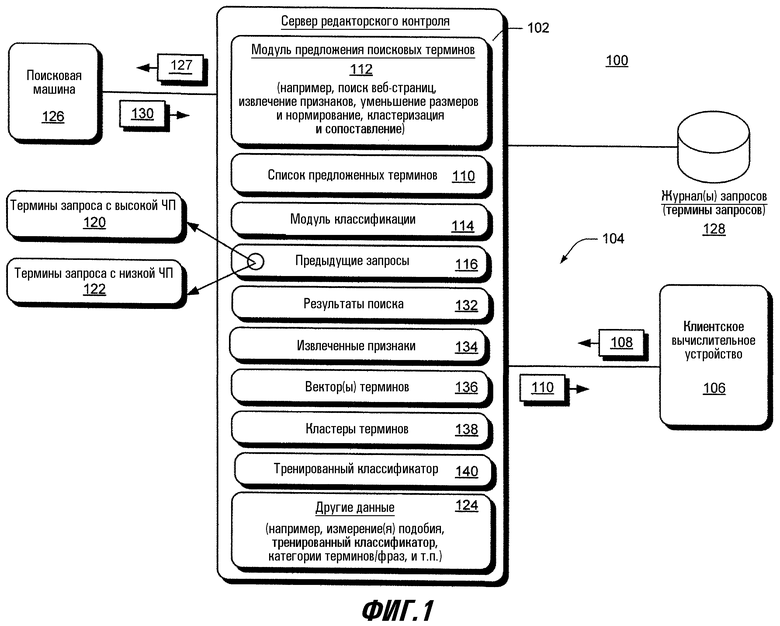
1. Компьютерно-реализуемый способ предложения родственных терминов, содержащий этапы, на которых
собирают результаты поиска посредством осуществления многосмыслового запроса, причем осуществление многосмыслового запроса содержит этапы, на которых
определяют термины/фразы, семантически связанные с поданными в запросе терминами/фразами, причем семантические связи обнаруживают посредством сбора контекста терминов/фраз для определения значения,
формируют пороговое значение частоты появления (ЧП),
назначают предыдущим запросам высокую ЧП или низкую ЧП на основании сформированного порогового значения,
создают векторы терминов из результатов поиска, связанных с набором предыдущих запросов с высокой ЧП, поданных ранее в поисковую машину,
создают кластеры терминов в зависимости от вычисленного подобия векторов терминов,
в ответ на получение термина/фразы от объекта, оценивают этот термин/фразу посредством осуществления многосмыслового запроса, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов, при этом идентификация основывается на комбинации ЧП и значения доверия и
возвращают по меньшей мере один список предложенных терминов, упорядоченный согласно комбинации ЧП и значения доверия, при этом несколько списков предложенных терминов создаются, когда термин/фраза совпадает с терминами в более чем одном кластере терминов.
2. Способ по п.1, по которому объектом является компьютерное программное приложение или конечный пользователь.
3. Способ по п.1, в котором также определяют вычисленное подобие как
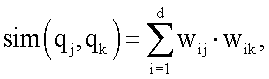
где d - представляет размерность вектора; q - представляет запрос; k - индекс размерности, а весовой коэффициент w для i-го вектора j-го термина вычисляют как
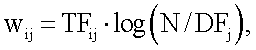
где TFij - частота термина; N - общее количество терминов запроса, и DFj - количество записей извлеченных признаков, которые содержат j-й термин i-го вектора.
4. Способ по п.1, в котором также собирают термины предыдущих запросов из журнала запросов и определяют термины предыдущих запросов, имеющие высокую ЧП.
5. Способ по п.1, в котором перед созданием кластеров терминов также уменьшают размерность векторов терминов и нормируют векторы терминов.
6. Способ по п.1, в котором при оценивании также
определяют совпадение между термином/фразой и термином (терминами/фразой (фразами) из одного или более кластеров терминов, и,
в ответ на определение, создают предложение (предложения) родственных терминов, содержащее данный термин (термины)/фразу (фразы).
7. Способ по п.6, в котором предложение (предложения) родственных терминов также содержит для каждого термина/фразы из термина (терминов)/фразы (фраз) значение частоты появления, указывающее, сколько раз данный термин/фраза появлялся в группе собранных предыдущих запросов.
8. Способ по п.1, в котором при создании кластеров терминов также посылают соответствующие из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска, и
извлекают признаки из, по меньшей мере, подгруппы результатов поиска, соответствующих соответствующим запросам, и
создают векторы терминов из признаков как функции частоты термина и обратной частоты документа.
9. Способ по п.8, в котором признаки содержат заголовок, описание и/или контекст для соответствующих предыдущих терминов запроса с высокой ЧП.
10. Способ по п.8, в котором соответствующие результаты содержат результаты поиска высшего ранга.
11. Способ по п.1, в котором кластеры терминов являются первой группой кластеров терминов, при этом также
определяют, что отсутствует совпадение между термином/фразой и терминами/фразами, и,
в ответ на это определение, создают вторую группу кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор термина создают из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и
оценивают термин/фразу, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
12. Способ по п.11, в котором при создании также
идентифицируют предыдущие запросы с низкой ЧП из предыдущих запросов, собранных из журнала запросов,
посылают соответствующие запросы из, по меньшей мере, подгруппы предыдущих запросов с низкой ЧП в поисковую машину для получения результатов поиска,
извлекают признаки из, по меньшей мере, подгруппы результатов поиска и,
создают векторы терминов из признаков как функции частоты термина и обратной частоты документа.
13. Способ по п.12, в котором после кластеризации также
определяют, что отсутствует совпадение между термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и,
в ответ на определение, идентифицируют совпадение между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, причем вторая группа основана на предыдущих запросах с низкой ЧП, и
в ответ на идентификацию, формируют предложение (предложения) родственных терминов, содержащее данный термин (термины)/фразу (фразы).
14. Машиночитаемый носитель, содержащий исполняемые машиной команды, которые при исполнении процессором побуждают его выполнять способ предложения родственных терминов, содержащий этапы, на которых
собирают результаты поиска посредством осуществления многосмыслового запроса, причем осуществление многосмыслового запроса содержит этапы, на которых
определяют термины/фразы, семантически связанные с поданными в запросе терминами/фразами, причем семантические связи обнаруживают посредством сбора контекста терминов/фраз для определения значения,
формируют пороговое значение частоты появления (ЧП),
назначают предыдущим запросам высокую ЧП или низкую ЧП на основании сформированного порогового значения,
создают векторы терминов из результатов поиска, связанных с набором предыдущих запросов с высокой ЧП, поданных ранее в поисковую машину,
создают кластеры терминов в зависимости от вычисленного подобия векторов терминов,
в ответ на получение термина/фразы от объекта, оценивают этот термин/фразу посредством осуществления многосмыслового запроса, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов, при этом идентификация основывается на комбинации ЧП и значения доверия,
возвращают по меньшей мере один список предложенных терминов, упорядоченный согласно комбинации ЧП и значения доверия, при этом несколько списков предложенных терминов создаются, когда термин/фраза совпадает с терминами в более чем одном кластере терминов.
15. Машиночитаемый носитель по п.14, в котором объектом является компьютерное программное приложение или конечный пользователь.
16. Машиночитаемый носитель по п.14, который также содержит исполняемые машиной команды для определения вычисленного подобия как
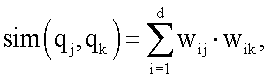
где d - представляет размерность вектора; q - представляет запрос; k - индекс размерности, а весовой коэффициент w для i-го вектора j-го термина вычисляют как
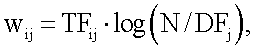
где TFij - частота термина, N - общее количество терминов запроса, и DFj - количество записей извлеченных признаков, которые содержат j-й термин i-го вектора.
17. Машиночитаемый носитель по п.14, в котором способ также содержит сбор терминов предыдущих запросов из журнала запросов и определение предыдущих терминов запроса, имеющих высокую ЧП.
18. Машиночитаемый носитель по п.14, в котором способ также содержит уменьшение размерности векторов термина и нормирование векторов терминов, причем уменьшение и нормирование выполняются перед созданием кластеров терминов.
19. Машиночитаемый носитель по п.14, в котором оценивание термина/фразы посредством осуществления многосмыслового запроса также содержит
идентификацию совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и,
в ответ на идентификацию, создание предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
20. Машиночитаемый носитель по п.19, в котором предложение (предложения) родственных терминов также содержит для каждого термина/фразы из терминов/фраз значение частоты появления, показывающее, сколько раз данный термин/фраза появлялся в группе собранных предыдущих запросов.
21. Машиночитаемый носитель по п.14, в котором создание кластеров терминов также содержит
посылку соответствующих запросов из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска,
извлечение признаков, по меньшей мере, из подгруппы результатов поиска, соответствующих упомянутым соответствующим запросам, и
создание векторов терминов из признаков как функции частоты терминов и обратной частоты документа.
22. Машиночитаемый носитель по п.21, в котором признаки включают в себя заголовок, описание и/или контекст для терминов соответствующих запросов из предыдущих запросов с высокой ЧП.
23. Машиночитаемый носитель по п.21, в котором соответствующие запросы содержат результаты поиска высшего ранга.
24. Машиночитаемый носитель по п.14, в котором кластеры терминов являются первой группой кластеров терминов, и в котором способ также содержит
определение, что отсутствует совпадение между термином/фразой и терминами/фразами, и, в ответ на определение, что отсутствует совпадение между термином/фразой и терминами/фразами
создание второй группы кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и
оценивание термина/фразы, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
25. Машиночитаемый носитель по п.24, в котором создание второй группы кластеров терминов также содержит
идентификацию предыдущих запросов с низкой ЧП из предыдущих запросов, извлеченных из журнала запросов,
посылку соответствующих запросов, по меньшей мере, из подгруппы предыдущих запросов с низкой ЧП в поисковую машину для получения результатов поиска,
извлечение признаков, по меньшей мере, из подгруппы результатов поиска и
создание векторов терминов из признаков как функции частоты термина и обратной частоты документа.
26. Машиночитаемый носитель по п.25, в котором способ также содержит после кластеризации
определение, что отсутствует совпадение между термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и,
в ответ на данное определение, идентификацию совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, основанной на предыдущих запросах с низкой ЧП, и,
в ответ на идентификацию, формирование предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
27. Система предложения родственных терминов для многосмыслового запроса, содержащая
процессор и
память, подсоединенную к процессору, содержащую исполняемые машиной команды, которые при исполнении процессором побуждают его выполнять способ предложения родственных терминов, содержащий этапы, на которых
собирают результаты поиска посредством осуществления многосмыслового запроса, причем осуществление многосмыслового запроса содержит этапы, на которых
определяют термины/фразы, семантически связанные с поданными в запросе терминами/фразами, причем семантические связи обнаруживают посредством сбора контекста терминов/фраз для определения значения,
формируют пороговое значение частоты появления (ЧП),
назначают предыдущим запросам высокую ЧП или низкую ЧП на основании сформированного порогового значения,
создают векторы терминов из результатов поиска, связанных с набором предыдущих запросов с высокой ЧП, поданных ранее в поисковую машину,
создают кластеры терминов в зависимости от вычисленного подобия векторов терминов,
в ответ на получение термина/фразы от объекта, оценивают термин/фразу посредством осуществления многосмыслового запроса, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов, при этом идентификация основывается на комбинации ЧП и значения доверия, и,
возвращают по меньшей мере один список предложенных терминов, упорядоченный согласно комбинации ЧП и значения доверия, при этом несколько списков предложенных терминов создаются, когда термин/фраза совпадает с терминами в более чем одном кластере терминов.
28. Система по п.27, в которой объектом является компьютерное программное приложение и/или конечный пользователь.
29. Система по п.27, которая также содержит исполняемые машиной команды для определения вычисленного подобия как

где d - представляет размерность вектора; q - представляет запрос; k - индекс размерности, а весовой коэффициент w для i-го вектора j-го термина вычисляют как
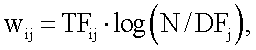
где TFij - частота термина; N - общее количество терминов запроса; DFj - количество записей извлеченных признаков, которые содержат j-й термин i-го вектора.
30. Система по п.27, которая также содержит исполняемые машиной команды для сбора терминов предыдущих запросов из журнала запросов, и определения терминов предыдущих запросов, имеющих высокую ЧП.
31. Система по п.27, которая также содержит исполняемые машиной команды, выполняемые процессором перед созданием кластеров терминов для уменьшения размерности векторов терминов и нормирования векторов терминов.
32. Система по п.27, в которой оценивание также содержит
идентификацию совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и,
в ответ на идентификацию, создание предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
33. Система по п.32, в которой предложение (предложения) родственных терминов также содержит для каждого термина/фразы из термина(терминов)/фразы (фраз) значение частоты появления, показывающее, сколько раз данный термин/фраза появлялся в группе собранных предыдущих запросов.
34. Система по п.27, в которой создание кластеров терминов также содержит
посылку соответствующих из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска,
извлечение признаков, по меньшей мере, из подгруппы результатов поиска, соответствующих упомянутым соответствующим запросам, и
создание векторов терминов из признаков как функции частоты термина и обратной частоты документа.
35. Система по п.34, в которой признаки включают в себя заголовок, описание и/или контекст для соответствующих терминов из предыдущих запросов с высокой ЧП.
36. Система по п.34, в которой соответствующие запросы содержат результаты поиска высшего ранга.
37. Система по п.27, в которой кластеры терминов являются первой группой кластеров терминов, при этом исполняемые машиной команды также содержат команды для определения, что отсутствует совпадение между термином/фразой и терминами/фразами, и,
в ответ на это определение, создания второй группы кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и
оценки термина/фразы, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
38. Система по п.37, в которой создание второй группы кластеров терминов также содержит
идентификацию предыдущих запросов с низкой ЧП из предыдущих запросов, собранных из журнала запросов,
посылку соответствующих запросов, по меньшей мере, из подгруппы предыдущих запросов с низкой ЧП в поисковую машину для получения результатов поиска,
извлечение признаков, по меньшей мере, из подгруппы результатов поиска и
создание векторов терминов из признаков как функции частоты термина и обратной частоты документа.
39. Система по п.38, которая также содержит исполняемые машиной команды, исполняемые процессором после кластеризации для
определения, что отсутствует совпадение между термином/фразой и термином (терминами)/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и,
в ответ на упомянутое определение, идентификации совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, основанной на предыдущих запросах с низкой ЧП, и,
в ответ на идентификацию, создания предложения (предложений) родственных терминов, содержащего данный термин (термины)/фразу (фразы).
40. Система предложения родственных терминов для многосмыслового запроса, содержащая
средство для сбора результатов поиска посредством осуществления многосмыслового запроса,
средство для определения терминов/фраз, семантически связанных с поданными в запросе терминами/фразами, причем семантические связи обнаруживают посредством сбора контекста терминов/фраз для определения значения,
средство для формирования порогового значения частоты появления (ЧП),
средство для назначения предыдущим запросам высокой ЧП или низкой ЧП на основании сформированного порогового значения,
средство для создания векторов терминов из результатов поиска, связанных с набором предыдущих запросов с высокой ЧП, поданных ранее в поисковую машину,
средство для создания кластеров терминов как функции вычисленного подобия векторов терминов,
средство для оценивания, в ответ на получение термина/фразы от объекта, термина/фразы, принимая во внимание термины/фразы в кластерах терминов, для идентификации одного или более предложений родственных терминов, при этом идентификация основывается на комбинации ЧП и значения доверия, и
средство для возвращения по меньшей мере один список предложенных терминов, упорядоченный согласно комбинации ЧП и значения доверия, при этом несколько списков предложенных терминов создаются, когда термин/фраза совпадает с терминами в более чем одном кластере терминов.
41. Система по п.40, в которой объектом является компьютерное программное приложение и/или конечный пользователь.
42. Система по п.40, которая также содержит средство для сбора терминов предыдущих запросов из журнала запросов и средство для определения терминов предыдущих запросов с высокой ЧП.
43. Система по п.40, в которой средство для оценивания также содержит
средство для идентификации совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров терминов, и средство для создания, в ответ на идентификацию, предложения (предложений) родственных терминов, содержащего термин (термины)/фразу (фразы).
44. Система по п.40, в которой средство для создания кластеров терминов также содержит
средство для посылки соответствующих запросов из предыдущих запросов с высокой ЧП в поисковую машину для получения результатов поиска,
средство для извлечения признаков, по меньшей мере, из подгруппы результатов поиска, соответствующих упомянутым соответствующим запросам, и
средство для создания векторов терминов из признаков.
45. Система по п.40, в которой кластеры терминов являются первой группой кластеров терминов, при этом система также содержит
средство для определения, что отсутствует совпадение между термином/фразой и терминами/фразами, и,
средство для создания, в ответ на определение, второй группы кластеров терминов из вычисленного подобия векторов терминов, причем каждый вектор терминов создан из результатов поиска, связанных с группой предыдущих запросов с низкой ЧП, поданных ранее в поисковую машину, и
средство для оценки термина/фразы, принимая во внимание термины/фразы второй группы кластеров терминов, для идентификации одного или более предложений родственных терминов.
46. Система по п.45, которая также содержит
средство для определения, что отсутствует совпадение между данным термином/фразой и термином (терминами/фразой (фразами) из первой группы кластеров терминов, основанной на предыдущих запросах с высокой ЧП, и
средство для идентификации, в ответ на определение, совпадения между термином/фразой и термином (терминами)/фразой (фразами) из одного или более кластеров из второй группы кластеров терминов, основанной на предыдущих запросах с низкой ЧП, исредство для создания, в ответ на упомянутую идентификацию, предложения (предложений) родственных терминов, содержащего термин (термины)/фразу (фразы).
| ПАРАЛЛЕЛЬНАЯ СИСТЕМА ИНФОРМАЦИОННОГО ПОИСКА | 2001 |
|
RU2195015C1 |
| СПОСОБ ПОИСКА В БАЗАХ ДАННЫХ С РАЗМЕТКОЙ ДАННЫХ | 2000 |
|
RU2177174C1 |
| US 5931907 A, 03.08.1999 | |||
| US 6006225 A, 21.12.1999. | |||

