Область техники, к которой относится изобретение
Настоящее изобретение относится к группированию мультимедийных файлов, в частности видеофайлов, и, особенно, в связи с использованием потоковой передачи.
Предшествующий уровень техники
Термин «потоковая передача» относится к одновременной отправке и воспроизведению данных, обычно мультимедийных данных, таких как аудио- или видеофайлы, при которой получатель может начать воспроизведение данных уже до того, как были приняты все передаваемые данные. Системы потоковой передачи мультимедийных данных содержат сервер потоковой передачи и терминальные устройства, которые получатели используют для установления соединения для передачи данных, обычно через телекоммуникационную сеть, с сервером потоковой передачи. Из сервера потоковой передачи получатели извлекают либо сохраненные данные, либо мультимедийные данные реального масштаба времени, и, наиболее предпочтительно, воспроизведение мультимедийных данных может быть начато почти в режиме реального времени с передачей данных посредством прикладной программы обработки потоковой передачи, включенной в терминал.
С точки зрения сервера потоковой передачи, потоковая передача может осуществляться либо в виде обычной потоковой передачи, либо в виде последовательной загрузки в терминал. При обычной потоковой передаче управление передачей мультимедийных данных и/или содержания данных осуществляется либо таким образом, что скорость передачи в битах по существу соответствует скорости воспроизведения терминального устройства, либо, если телекоммуникационная сеть, используемая в передаче, является узким местом в передаче данных, то таким образом, что скорость передачи в битах по существу соответствует ширине полосы пропускания, доступной в телекоммуникационной сети. При последовательной загрузке передача мультимедийных данных и/или содержания данных вовсе не обязательно должна смешиваться, однако обычно мультимедийные файлы передаются получателю с использованием управления потоком данных посредством протокола передачи данных. Затем терминалы принимают, сохраняют и воспроизводят точную копию данных, переданных из сервера, причем указанная копия может быть позднее вновь воспроизведена на терминале, без необходимости снова начинать потоковую передачу через телекоммуникационную сеть. Однако, мультимедийные файлы, сохраняемые в терминале, обычно бывают очень большими, и их перенос в терминал отнимает много времени, а также для них может потребоваться значительный объем памяти, из-за чего часто предпочтительна обычная потоковая передача.
Видеофайлы в мультимедийных файлах содержат большое число неподвижных кадров, которые, чтобы создать впечатление движущегося изображения, отображаются в быстрой последовательности (обычно от 15 до 30 кадров в секунду). Кадры изображения обычно содержат несколько стационарных фоновых объектов, определяемых информацией изображения, которая по существу остается неизменной, и несколько движущихся объектов, определяемых информацией изображения, которая изменяется в некоторой степени. Информация, состоящая из последовательно отображаемых кадров изображения, обычно во многом подобна, то есть, последовательные кадры изображения содержат большую избыточность. Избыточность, возникающая в видеофайлах, может быть разделена на пространственную, временную и спектральную избыточность. Пространственная избыточность относится к взаимной корреляции смежных пикселей изображения, временная избыточность относится изменениям, имеющим место в конкретных объектах изображения в последовательных кадрах, и спектральная избыточность относится к корреляции различных цветовых составляющих в пределах кадра изображения.
Чтобы уменьшить объем данных в видеофайлах, данные изображения могут быть сжаты в меньшую форму путем снижения объема избыточной информации в кадрах изображения. Кроме того, при кодировании большинство современных видеокодеров понижает качество изображения в некоторых частях кадра изображения, которые являются менее важными в видеоинформации. Далее, многие способы видеокодирования позволяют снижать избыточность битового потока, закодированного из данных изображения, посредством эффективного, свободного от потерь кодирования параметров сжатия, известного как VLC (кодирование с переменной длиной).
Кроме того, многие способы видеокодирования используют вышеописанную временную избыточность последовательных кадров изображения. В указанном случае используется способ, известный как временное прогнозирование с компенсацией движения, то есть содержание некоторых (обычно большинства) кадров изображения в видеопоследовательности прогнозируется на основе других кадров в последовательности путем отслеживания изменений в конкретных объектах или областях в последовательных кадрах изображения. Видеопоследовательность всегда содержит несколько сжатых кадров изображения, информация изображения которых не была определена с использованием временного прогнозирования с компенсацией движения. Такие кадры называются интра-кадрами, или I-кадрами. Соответственно, кадры изображения видеопоследовательности с компенсацией движения, прогнозируемые на основе предыдущих кадров изображения, называются интер-кадрами, или P-кадрами (прогнозированные). Информация изображения P-кадров определяется с использованием одного I-кадра и, возможно, одного или нескольких ранее закодированных P-кадров. Если кадр теряется, то кадры, зависящие от него, далее не могут быть правильно декодированы.
I-кадр обычно инициирует видеопоследовательность, задаваемую как группа изображений (GOP), P-кадры которой могут быть определены только на основе I-кадра и предыдущих P-кадров рассматриваемой GOP. Следующий I-кадр начинает новую группу изображений GOP, причем информация изображения, содержащаяся в нем, не может быть определена на основе кадров предыдущей GOP. Другими словами, группы изображений не перекрываются во времени, и каждая группа изображений может быть декодирована отдельно. Кроме того, многие способы видеосжатия применяют двунаправленно прогнозируемые B-кадры, которые помещаются между двумя опорными кадрами (I- и P-кадрами, или двумя P-кадрами) в группе изображений GOP, причем информация изображения B-кадра прогнозируется на основе обоих кадров - предшествующего опорного кадра и кадра, следующего за B-кадром. Следовательно, B-кадры обеспечивают информацию изображения более высокого качества, чем P-кадры, но обычно они не используются в качестве опорных кадров, и, следовательно, их удаление из видеопоследовательности не ухудшает качество последующих изображений. Однако ничто также не препятствует использованию B-кадров в качестве опорных кадров, только в таком случае они не могут быть удалены из видеопоследовательности без ухудшения качества кадров, зависящих от них.
Каждый видеокадр может быть разделен на так называемые макроблоки, которые содержат цветовые составляющие (как, например, Y (составляющая яркости), U, V (цветоразностные составляющие) всех пикселей прямоугольной области изображения. Более конкретно, макроблоки состоят, по меньшей мере, из одного блока, приходящегося на цветовую составляющую, причем каждый блок содержит цветовые значения (как, например, Y, U или V) одного уровня цвета в соответствующей области изображения. Пространственное разрешение блоков может отличаться от такового для макроблоков, например, U- и V-составляющие могут отображаться с использованием только половины разрешения Y-составляющей. Макроблоки могут быть далее сгруппированы в срезы, причем это те группы макроблоков, которые обычно выбираются в порядке сканирования изображения. В способах видеокодирования временное прогнозирование обычно выполняется в отношении конкретных блоков или макроблоков, а не в отношении конкретных кадров изображения.
Чтобы обеспечить возможность гибкой потоковой передачи видеофайлов, многие системы видеокодирования применяют масштабируемое кодирование, в котором некоторые элементы или группы элементов видеопоследовательности могут быть удалены без воздействия на воссоздание других частей видеопоследовательности. Масштабируемость обычно реализуется посредством группирования кадров изображения в несколько иерархических слоев. Кадры изображения, закодированные в кадры изображения базового слоя, по существу содержат только те, которые являются обязательными для декодирования видеоинформации на приёмном устройстве. Таким образом, базовый слой каждой группы изображений GOP содержит один I-кадр и необходимое число P-кадров. Ниже базового слоя могут быть определены один или несколько слоев улучшения, причем каждый из таких слоев улучшает качество видеокодирования по сравнению с верхним слоем. Таким образом, слои улучшения содержат P- или B-кадры, прогнозированные на основе компенсации движения из одного или нескольких изображений верхнего слоя. Кадры обычно нумеруются в соответствии с рядом членов арифметической прогрессии.
При потоковой передаче скорость передачи в битах должна допускать возможность управления либо на основе используемой полосы пропускания, либо максимального значения скорости декодирования или скорости передачи в битах, соответствующего получателю. Управление скоростью передачи в битах можно осуществлять либо на сервере потоковой передачи, либо в некотором элементе телекоммуникационной сети. Простейшая методика, с помощью которой сервер потоковой передачи может управлять скоростью передачи в битах, заключается в том, чтобы отбрасывать из передачи B-кадры, имеющие большое информационное содержание. Далее, сервер потоковой передачи может определять количество слоев масштабируемости, которые должны передаваться в видеопотоке, и, таким образом, количество слоев масштабируемости может изменяться всегда, когда начинается новая группа изображений GOP. Также можно использовать различные способы кодирования видеопоследовательности. Соответственно, из битового потока в элементе телекоммуникационной сети могут быть удалены B-кадры, а также другие P-кадры слоев улучшения.
Вышеупомянутая схема включает несколько недостатков. Многие способы кодирования, как, например, кодирование по стандарту H.263 ITU/T (Международного союза по телекоммуникациям, Комитет по стандартизации телекоммуникаций) знакомы с процедурой, называемой выбор эталонного изображения. В выборе эталонного изображения, по меньшей мере, часть P-изображения прогнозируется на основе, по меньшей мере, одного изображения, отличающегося от того, которое непосредственно предшествовало P-изображению во временной области. Выбранное эталонное изображение передается в закодированном битовом потоке или в полях заголовка битового потока способом, специфическим для конкретного изображения, сегмента изображения (например, среза или группы макроблоков), макроблока или блока. Выбор эталонного изображения может быть обобщен так, что прогнозирование может быть также выполнено на основе изображений, следующих во времени за изображением, которое должно кодироваться. Далее, выбор эталонного изображения может быть обобщен так, чтобы охватить все типы прогнозируемых во времени кадров, включая B-кадры. Поскольку также можно выбрать, по меньшей мере, одно изображение, предшествующее I-изображению, которое начинает группу изображений GOP в качестве эталонного изображения, то группа изображений, использующая выбор эталонного изображения, не обязательно может декодироваться независимо. Кроме того, регулировка масштабируемости или способа кодирования в сервере потоковой передачи или в элементе сети становится затруднительной, поскольку видеопоследовательность должна быть декодирована, проанализирована и буферизована в течение длительного периода времени, чтобы позволить обнаружить какие-либо зависимости между различными группами изображений.
Еще одна проблема относится к обнаружению кадров изображения, с которых декодер может начать процесс декодирования. Такое обнаружение является полезным для множества целей. Например, конечный пользователь может пожелать начать просмотр видеофайла с середины видеопоследовательности. Другой пример относится к случаю, когда начинают прием передачи видеоданных, соответствующей широковещательной или групповой рассылке, с середины передачи видеоданных. Третий пример относится к потоковой передаче по требованию от сервера и имеет место, когда конечный пользователь желает начать проигрывание с определенного положения в потоке.
Сущность изобретения
Предложены усовершенствованные способ и оборудование, реализующее данный способ, которые обеспечивают возможность обнаружения кадров изображения, с которых декодер может начать процесс декодирования. Различные аспекты настоящего изобретения включают в себя способы, видеокодер, видеодекодер и компьютерные программы, которые характеризуются признаками, изложенными в соответствующих независимых пунктах формулы изобретения. Предпочтительные варианты воплощения настоящего изобретения раскрываются в зависимых пунктах формулы изобретения.
Изобретение основано на идее кодирования видеопоследовательности, содержащей независимую последовательность кадров изображения, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения. В видеопоследовательность кодируется указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения упомянутой независимой последовательности, при этом упомянутый по меньшей мере один опорный кадр изображения включается в данную последовательность. Соответственно, на стадии декодирования из видеопоследовательности декодируется указание по меньшей мере одного кадра изображения, и декодирование видеопоследовательности начинается с упомянутого первого кадра изображения упомянутой независимой последовательности, при этом видеопоследовательность декодируется без прогнозирования на основе какого-либо кадра изображения, декодированного до упомянутого первого кадра изображения.
Как следствие, идея настоящего изобретения заключается в определении начального изображения в независимо декодируемой группе изображений, вследствие чего на стадии декодирования любое изображение, предшествующее упомянутому начальному изображению, определяется как неиспользуемое в качестве эталонного. Соответственно, после декодирования начального изображения все последующие изображения независимо декодируемой последовательности могут быть декодированы без предсказания на основе какого-либо изображения, декодированного до упомянутого начального изображения.
Согласно варианту осуществления, упомянутое указание кодируется в видеопоследовательность в качестве отдельного флага, включаемого в заголовок среза.
Согласно варианту осуществления, значения идентификаторов кодируются для изображений согласно схеме нумерации, и значение идентификатора для указываемого первого изображения независимой последовательности переустанавливается.
Согласно варианту осуществления, в видеопоследовательность кодируется значение идентификатора для упомянутой независимой последовательности.
Преимущество процедуры, соответствующей изобретению, состоит в том, что обеспечивается возможность начинать просмотр видеопоследовательности из произвольной точки, т.е. декодеру предоставляется информация о первом изображении независимо декодируемой последовательности. Таким образом, декодер знает, что посредством декодирования этого первого изображения оказывается возможным продолжать процесс декодирования без какого-либо предсказания на основе какого-либо предшествующего изображения. Соответственно, дополнительное преимущество заключается в том, что декодер может сбросить любое изображение, декодированное до упомянутого начального изображения, из своей буферной памяти, поскольку эти предшествующие изображения более не требуются в процессе декодирования. Дополнительное преимущество состоит в том, что процедура, соответствующая изобретению, позволяет без труда вводить отдельную видеопоследовательность в другую видеопоследовательность.
Еще одним преимуществом является то, что обеспечивается возможность идентификации границы изображений между двумя примыкающими начальными изображениями посредством обращения к номеру подпоследовательности этих начальных изображений. Еще одно преимущество относится к обнаружению потерь кадров изображения, которые начинают независимо декодируемую подпоследовательность. Если такой кадр изображения теряется, например, во время передачи, маловероятно, что результатом применения какого-либо способа скрытия ошибок будет субъективно удовлетворительное качество изображения. Следовательно, преимущество заключается в том, что декодеры обеспечиваются средствами для обнаружения потерь кадров изображения, которые начинают независимо декодируемую подпоследовательность. Декодеры могут реагировать на такую потерю запрашиванием повторной передачи или обновления изображения, например.
Перечень чертежей
Изобретение поясняется ниже описанием конкретных вариантов его воплощения со ссылками на чертежи, на которых представлено следующее:
фиг.1 - общая система потоковой передачи мультимедийных данных, в которой может применяться иерархия масштабируемого кодирования, соответствующая изобретению,
фиг.2 - иерархия масштабируемого кодирования, соответствующая предпочтительному варианту воплощения изобретения,
фиг.3а и 3б - варианты воплощения изобретения для регулировки масштабируемости,
фиг.4а, 4б и 4в - варианты воплощения изобретения для регулировки нумерации изображения,
фиг.5а, 5б и 5в - варианты воплощения изобретения для использования B-кадров в иерархии масштабируемого кодирования,
фиг.6а, 6б и 6в - иерархии масштабируемого кодирования, соответствующие предпочтительным вариантам воплощения изобретения, совместно с выбором эталонного изображения, и
фиг.7 - компоновка согласно предпочтительному варианту воплощения изобретения для кодирования монтажного перехода.
Подробное описание предпочтительных вариантов воплощения
Далее раскрывается система общего назначения, предназначенная для потоковой передачи мультимедийных данных, основополагающие принципы которой могут применяться в отношении любой телекоммуникационной системы. Хотя изобретение описано здесь с конкретной ссылкой на систему потоковой передачи, в которой мультимедийные данные передаются, наиболее предпочтительно, через телекоммуникационную сеть, применяющую протокол передачи данных с коммутацией пакетов, такую как сеть на основе Интернет протокола (IP-сеть), изобретение может быть одинаково хорошо реализовано в сетях с коммутацией каналов, таких как стационарные телефонные сети PSTN/ISDN (коммутируемая телефонная сеть общего пользования/цифровая сеть с комплексными услугами), или в наземных сетях мобильной связи общего пользования (PLMN). Далее, изобретение может применяться при потоковой передаче мультимедийных файлов в форме как обычной потоковой передачи, так и последовательной загрузки, или для реализации, например, видеовызовов.
Также следует отметить, что хотя изобретение описано здесь с конкретной ссылкой на системы потоковой передачи, и изобретение также преимущественно может применяться к ним, оно не ограничено только системами потоковой передачи, но также может применяться к любой системе воспроизведения видео независимо от того, как загружается файл, который должен быть декодирован, и откуда он загружается. Следовательно, изобретение может применяться, например, для проигрывания видеофайла, который должен загружаться с цифрового многофункционального диска (DVD) или с любого другого компьютерного носителя данных, например, в соответствии с изменяющейся производительностью обработки данных, доступной для видеопроигрывания. В частности, изобретение может применяться к различным типам видеокодирования с низкими скоростями передачи в битах, которые обычно используются в телекоммуникационных системах, на которые наложены ограничения полосы пропускания. Одним из примеров является система, определенная в стандарте H.263 ITU-T, а также система, определяемая в стандарте H.26L (возможно позже может стать H.264). В связи с этим, изобретение может применяться к мобильным станциям, например, и в этом случае видеопроигрывание может быть реализовано таким образом, чтобы регулировать как изменение пропускной способности передачи или качества канала, так и доступной в данный момент мощности процессора, когда мобильная станция используется также для выполнения приложений, отличных от видеопроигрывания.
Далее, следует отметить, что, в целях ясности, изобретение будет описано посредством описания кодирования кадра изображения и временного прогнозирования на уровне кадров изображения. Однако, на практике кодирование и временное прогнозирование обычно имеют место на уровне блока или макроблока, как описано выше.
Со ссылкой на фиг.1 будет описана типичная система мультимедийной потоковой передачи, которая является предпочтительной системой для применения процедуры, соответствующей настоящему изобретению.
Система потоковой передачи мультимедийных данных обычно содержит один или несколько мультимедийных источников 100, таких как видеокамера и микрофон, либо файлы видеоизображений или компьютерной графики, хранящиеся на носителе данных. Необработанные данные, полученные из различных мультимедийных источников 100, объединяются в мультимедийный файл в кодере 102, который также может называться модулем редактирования. Необработанные данные, поступающие из одного или нескольких мультимедийных источников 100, сначала захватываются с помощью средства 104 захвата, входящего в кодер 102, причем указанное средство захвата обычно реализуется в виде различных интерфейсных карт, программного драйвера или прикладного программного обеспечения, управляющего функцией карты. Например, видеоданные могут захватываться с помощью платы видеозахвата и соответствующего ей программного обеспечения. Выходные данные средства 104 захвата обычно представляют собой либо несжатый, либо незначительно сжатый поток данных, например несжатые видеокадры формата YUV 4:2:0 или формата JPEG движущегося изображения, когда подразумевается плата видеозахвата.
Редактор 106 связывает различные потоки мультимедийной информации вместе, чтобы синхронизировать видео- и аудиопотоки, которые должны воспроизводиться одновременно по желанию. Редактор 106 может также редактировать каждый поток мультимедийной информации, такой как видеопоток, например, путем деления пополам частоты смены кадров или путем снижения пространственного разрешения. Отдельные, хотя и синхронизированные, потоки мультимедийной информации сжимаются в устройстве 108 сжатия, в котором каждый поток мультимедийной информации сжимается отдельно с помощью устройства 108 сжатия, подходящего для потока мультимедийной информации. Например, видеокадры формата YUV 4:2:0 могут быть сжаты с использованием видеокодирования с низкой скоростью передачи в битах согласно рекомендации стандарта H.263 или H.26L ITU-T. Отдельные синхронизированные и сжатые потоки мультимедийной информации обычно перемежаются в мультиплексоре 110, причем выходные данные, полученные из кодера 102, обычно представляют собой единый однородный битовый поток, который содержит данные множества потоков мультимедийной информации и который может называться мультимедийным файлом. Также следует отметить, что формирование мультимедийного файла не обязательно требует мультиплексирования множества потоков мультимедийной информации в один файл, но сервер потоковой передачи может перемежать потоки мультимедийной информации непосредственно перед их передачей.
Мультимедийные файлы передаются в сервер 112 потоковой передачи, который способен выполнять потоковую передачу либо как потоковую передачу в режиме реального времени, либо в форме последовательной загрузки. При последовательной разгрузке мультимедийные файлы сначала сохраняются в памяти сервера 112, откуда они могут быть извлечены для передачи, когда возникает потребность. При потоковой передаче в режиме реального времени редактор 102 передает непрерывный поток мультимедийной информации мультимедийных файлов в сервер 112 потоковой передачи, а сервер 112 направляет поток непосредственно клиенту 114. В качестве дополнительной опции, потоковая передача в режиме реального времени также может выполняться таким образом, чтобы мультимедийные файлы сохранялись в запоминающем устройстве, которое доступно из сервера 112, откуда может происходить потоковая передача в режиме реального времени, и, когда возникает потребность, начинается передача непрерывного потока мультимедийной информации мультимедийных файлов. В таком случае, редактор 102 не обязательно управляет потоковой передачей каким-либо средством. Сервер 112 потоковой передачи выполняет формирование трафика мультимедийных данных с учетом доступной полосы пропускания, либо максимальной скорости декодирования или проигрывания, соответствующей клиенту 114, причем сервер потоковой передачи способен регулировать скорости передачи в битах потока мультимедийной информации, например, посредством отбрасывания B-кадров из передачи или посредством регулировки количества слоев масштабируемости. Далее, сервер 112 потоковой передачи может модифицировать поля заголовка мультиплексированного потока мультимедийной информации, чтобы уменьшить их размер и инкапсулировать мультимедийные данные в пакеты данных, которые подходят для передачи в применяемой телекоммуникационной сети. Клиент 114 обычно может регулировать, по меньшей мере, до некоторой степени, действие сервера 112, используя подходящий протокол управления. Клиент 114 способен управлять сервером 112, по меньшей мере, таким способом, чтобы для передачи клиенту можно было выбрать требуемый мультимедийный файл, в дополнение к чему клиент обычно способен останавливать или прерывать передачу мультимедийного файла.
Когда клиент 114 принимает мультимедийный файл, этот файл сначала подается в демультиплексор 116, который разделяет потоки мультимедийной информации, содержащиеся в мультимедийном файле. Затем отдельные сжатые потоки мультимедийной информации подаются в устройство 118 распаковки, в котором каждый отдельный поток мультимедийной информации распаковывается устройством распаковки, подходящим для каждого конкретного потока мультимедийной информации. Распакованные и воссозданные потоки мультимедийной информации подаются в модуль 120 проигрывания, где потоки мультимедийной информации воспроизводятся в соответствующем темпе согласно их данным синхронизации и подаются в средство 124 представления. Средство 124 фактического представления может содержать, например, дисплей компьютера или мобильной станции и громкоговорители. Клиент 114 также обычно имеет блок 122 управления, которым обычно конечный пользователь может управлять через интерфейс пользователя, и он обычно управляет как действием сервера через вышеописанный протокол управления, так и действием модуля 120 проигрывания на основе инструкций, подаваемых конечным пользователем.
Следует отметить, что перенос мультимедийных файлов от сервера 112 к клиенту 114 происходит через телекоммуникационную сеть, причем маршрут переноса содержит множество элементов телекоммуникационной сети. Следовательно, возможно, имеется какой-то сетевой элемент, который может выполнять формирование трафика мультимедийных данных в отношении доступной полосы пропускания, либо максимальной скорости декодирования или проигрывания, соответствующей клиенту 114, по меньшей мере частично, тем же самым способом, что был описан выше в связи с сервером потоковой передачи.
Теперь будет описано масштабируемое кодирование в отношении предпочтительного варианта воплощения изобретения со ссылкой на фиг.2. Фиг.2 изображает часть сжатой видеопоследовательности, имеющей первый кадр 200, который является интра-кадром, или I-кадром, и, следовательно, независимо определяемым видеокадром, информация изображения которого определяется без использования временного прогнозирования с компенсацией движения. I-кадр 200 помещается на первом слое масштабируемости, который может быть назван интра-слоем. Каждому слою масштабируемости присваивается уникальный идентификатор, например номер слоя. Следовательно интра-слою может быть присвоен, например, номер 0 или некоторый другой алфавитно-цифровой идентификатор, например буква или комбинация буквы и числа.
Соответственно, подпоследовательности, состоящие из групп из одного или нескольких видеокадров, определяются для каждого слоя масштабируемости, причем, по меньшей мере, одно из изображений в группе (обычно первое или последнее) прогнозируется во времени на основе, по меньшей мере, видеокадра другой подпоследовательности обычно либо более высокого, либо того же самого слоя масштабируемости, причем остальная часть видеокадров прогнозируется во времени либо только на основе видеокадров той же подпоследовательности, либо, возможно, также на основе одного или нескольких видеокадров упомянутой второй подпоследовательности. Подпоследовательность может быть декодирована независимо, безотносительно других подпоследовательностей, за исключением упомянутой второй подпоследовательности. Подпоследовательностям каждого слоя масштабируемости присваивается уникальный идентификатор, используя, например, последовательную нумерацию, начиная с числа 0, заданного для первой подпоследовательности слоя масштабируемости. Поскольку I-кадр 200 определяется независимо и также может быть декодирован независимо при приеме, безотносительно других кадров изображения, он также формирует в некотором смысле отдельную подпоследовательность.
Следовательно, существенный аспект настоящего изобретения заключается в том, чтобы определить каждую подпоследовательность в терминах тех подпоследовательностей, от которых зависит упомянутая подпоследовательность. Другими словами, подпоследовательность содержит информацию обо всех подпоследовательностях, которые непосредственно использовались для прогнозирования кадров изображения рассматриваемой подпоследовательности. Эта информация передается в битовом потоке видеопоследовательности, предпочтительно отдельно от информации фактического изображения, и, следовательно, данные изображения видеопоследовательности, предпочтительно, можно регулировать, поскольку легко определить части видеопоследовательности, которые должны декодироваться независимо и могут быть удалены без воздействия на декодирование остальных данных изображения.
Затем, в пределах каждой подпоследовательности, видеокадрам подпоследовательности даются номера изображений, используя, например, последовательную нумерацию, которая начинается номером 0, заданным первому видеокадру подпоследовательности. Поскольку I-кадр 200 также образует отдельную подпоследовательность, его номером изображения является 0. На фиг.2, I-кадр 200 показывает тип (I), идентификатор подпоследовательности и номер изображения (0.0) кадра.
Фиг.2 далее изображает следующий I-кадр 202 интра-слоя, причем этот кадр, таким образом, также является независимо определенным видеокадром, который был определен без использования временного прогнозирования с компенсацией движения. Частота передачи I-кадров во времени зависит от многих факторов, касающихся видеокодирования, содержания информации изображения и полосы пропускания, которую нужно использовать, и, в зависимости от приложения или от прикладного окружения, I-кадры передаются в видеопоследовательности с интервалами, например, от 0,5 до 10 секунд. Поскольку I-кадр может быть независимо декодирован, он также образует отдельную подпоследовательность. Поскольку это вторая подпоследовательность в интра-слое, последовательная нумерация идентификатора подпоследовательности I-кадра 202 составляет единицу. Далее, поскольку I-кадр 202 также образует отдельную подпоследовательность, в подпоследовательности есть только один видеокадр, и его номер изображения составляет 0. Следовательно, I-кадр 202 может быть обозначен идентификатором (I.1.0). Соответственно, идентификатор следующего кадра на интра-слое составляет (I.2.0) и т.д. В результате, только независимо определенные I-кадры, в которых информация изображения не определяется с использованием временного прогнозирования с компенсацией движения, кодируются в первый слой масштабируемости, т.е. интра-слой. Подпоследовательности также могут быть определены с использованием другого вида нумерации или других идентификаторов при условии, что подпоследовательности можно отличать друг от друга.
Следующий слой масштабируемости, который, например, имеет номер слоя 1 и который может упоминаться как базовый слой, содержит закодированные с компенсацией движения интра- или P-кадры, обычно прогнозируемые только на основе предыдущих кадров изображения, то есть в данном случае на основе I-кадров верхнего интра-слоя. Информация изображения первого P-кадра 204 базового слоя, показанного на фиг.2, определяется с использованием I-кадра 200 интра-слоя. P-кадр 204 начинает первую подпоследовательность базового слоя, и поэтому идентификатор подпоследовательности P-кадра 204 составляет 0. Далее, поскольку P-кадр 204 является первым кадром изображения первой подпоследовательности базового слоя, то номер изображения P-кадра 204 равен 0. Таким образом, P-кадр 204 может быть идентифицирован как (P.0.0).
Последующий во времени P-кадр 206 базового слоя прогнозируется на основе предыдущего P-кадра 204. Таким образом, P-кадры 204 и 206 принадлежат одной и той же подпоследовательности, вследствие чего P-кадр 206 также получает идентификатор подпоследовательности 0. Поскольку P-кадр 206 является вторым кадром изображения в подпоследовательности 0, то номер изображения P-кадра 206 равен 1, и P-кадр 206 может быть идентифицирован как (P.0.1).
Слой масштабируемости, следующий за базовым слоем и имеющий номер слоя 2, называется слоем улучшения 1. Этот слой содержит закодированные с компенсацией движения P-кадры, прогнозируемые только на основе предыдущих кадров изображения, в данном случае, либо на основе I-кадров интра-слоя, либо на основе P-кадров базового слоя. Фиг.2 показывает первый кадр 208 изображения и второй кадр 210 изображения слоя улучшения 1, оба из которых прогнозируются только на основе первого кадра 200 изображения интра-слоя. P-кадр 208 начинает первую подпоследовательность слоя улучшения 1, и, следовательно, идентификатором подпоследовательности P-кадра является 0. Далее, поскольку P-кадр 208 является первым и единственным кадром изображения в упомянутой подпоследовательности, то P-кадр 208 получает номер изображения 0. Таким образом, P-кадр 208 может быть идентифицирован как (P.0.0).
Поскольку второй кадр 210 изображения также прогнозируется только на основе первого кадра 200 изображения интра-слоя, P-кадр 210 начинает вторую подпоследовательность слоя улучшения 1, и, следовательно, идентификатором подпоследовательности P-кадра 210 является 1. Поскольку P-кадр 210 является первым кадром изображения в подпоследовательности, то номер изображения P-кадра 210 равен 0. Таким образом, P-кадр может быть идентифицирован как (P.1.0). Последующий во времени P-кадр 212 слоя улучшения 1 прогнозируется на основе предыдущего P-кадра 210. Таким образом, P-кадры 210 и 212 принадлежат одной и той же подпоследовательности, и, следовательно, P-кадр также получает идентификатор подпоследовательности 1. P-кадр 212 является вторым кадром изображения в подпоследовательности 1, и, следовательно, P-кадр получает номер изображения 1 и может быть идентифицирован как (P.1.1).
Четвертый по времени кадр 214 изображения слоя улучшения 1 прогнозируется на основе первого кадра изображения 204 базового слоя. Таким образом, P-кадр 214 начинает третью подпоследовательность слоя улучшения 1, и, следовательно, P-кадр 214 получает идентификатор подпоследовательности 2. Далее, поскольку P-кадр 214 является первым и единственным кадром изображения в подпоследовательности, то номер изображения P-кадра 214 равен 0. Следовательно, P-кадр 214 может быть идентифицирован как (P.2.0).
Также пятый по времени кадр 216 изображения слоя улучшения 1 прогнозируется только на основе первого кадра изображения 204 базового слоя, таким образом, P-кадр 216 начинает четвертую подпоследовательность слоя улучшения 1, и идентификатор подпоследовательности P-кадра 216 равен 3. Кроме того, поскольку P-кадр 216 является первым кадром в рассматриваемой подпоследовательности, то номер изображения P-кадра 216 равен 0. Следовательно, P-кадр 216 может быть идентифицирован как (P.3.0). Последующий во времени P-кадр 218 слоя улучшения 1 прогнозируется на основе предыдущего P-кадра 216. Таким образом, P-кадры 216 и 218 принадлежат одной и той же подпоследовательности, и, следовательно, идентификатор подпоследовательности P-кадра 218 также равен 3. Поскольку P-кадр 218 является вторым кадром изображения в подпоследовательности 3, номер изображения P-кадра 218 равен 1 и идентификатор P-кадра 218 составляет (P.3.1).
Для простоты и ясности иллюстрации вышеупомянутое раскрытие касается только I- и P-кадров. Однако, специалисту в данной области техники будет очевидно, что масштабируемое видеокодирование изобретения также может быть реализовано с использованием других известных типов кадров изображения, таких как вышеупомянутые B-кадры и, по меньшей мере, SI-кадры, SP-кадры и MH-кадры. SI-кадры соответствуют I-кадрам, но вместе с SP-кадром, они позволяют воссоздавать идентичное изображение. SP-кадр, в свою очередь, является P-кадром, подвергнутым особенному кодированию, которое позволяет воссоздавать идентичное изображение вместе с SI-кадром или другим SP-кадром. SP-кадры обычно помещаются в видеопоследовательность в точки, в которых требуется точка доступа или точка сканирования, или где должно быть возможно изменение параметров кодирования видеопотока. Кадры могут также использоваться для коррекции ошибок и для увеличения допуска на ошибку. В противном случае, SP-кадры подобны обычным P-кадрам, прогнозируемым на основе предыдущих кадров, за исключением того, что они задаются так, что они могут быть заменены другим видеокадром SP- или SI-типа, причем результат декодирования нового кадра является идентичным результату декодирования исходного SP-кадра, который был в видеопотоке. Другими словами, новый SP-кадр, который используется для замены кадра, который был в видеопотоке, прогнозируется на основе другой последовательности или видеопотока, и уже воссозданный кадр имеет идентичное содержание. SP-кадры описаны, например, в более ранней патентной заявке PCT/F102/00004 настоящего заявителя.
Так же как и B-кадры, макроблоки MH-кадров (на основе множества гипотез), основанные на прогнозировании с компенсацией движения, прогнозируются на основе двух других кадров, которые, однако, необязательно расположены рядом с MH-кадром. Более точно, прогнозированные макроблоки вычисляются как среднее из двух макроблоков двух других кадров. Вместо двух кадров макроблоки MH-кадра также могут естественным образом прогнозироваться на основе одного другого кадра. Эталонные изображения могут изменяться согласно макроблоку, другими словами, все макроблоки в одном и том же изображении не обязательно прогнозируются, используя одни и те же кадры.
Таким образом, подпоследовательность охватывает определенный период времени в видеопоследовательности. Подпоследовательности одного и того же слоя или разных слоев могут частично или полностью перекрываться. Если имеются перекрывающиеся во времени кадры изображения в одном и том же слое, то кадры интерпретируются как альтернативные представления одного и того же содержимого изображения и, следовательно, может использоваться любой режим представления изображения. С другой стороны, если имеются перекрывающиеся во времени кадры изображения на разных слоях, то они формируют разные представления того же самого содержимого изображения, и следовательно, представления отличаются по качеству изображения, то есть качество изображения лучше на более низком слое.
Вышеупомянутое раскрытие со ссылкой на фиг.2 иллюстрирует схему масштабируемого кодирования, а также иерархическую структуру и нумерацию изображений согласно предпочтительному варианту воплощения изобретения. В данном варианте воплощения интра-слой содержит только I-кадры, и базовый слой может быть декодирован только с использованием информации, полученной из интра-слоя. Соответственно, декодирование слоя улучшения 1 обычно требует информации как от базового слоя, так и от интра-слоя.
Количество слоев масштабируемости не ограничивается тремя, как описано выше, но можно использовать любое количество слоев улучшения, которое считается необходимым для создания достаточной масштабируемости. Следовательно, номер слоя улучшения 2 равен четырем, а слоя расширения 3 равен пяти и т.д. Поскольку некоторым кадрам изображения в вышеупомянутом примере задан один и тот же идентификатор (например, идентификатором обоих кадров 204 и 208 изображения является (P.0.0)), то включая номер слоя в идентификатор, можно уникальным образом идентифицировать каждый кадр изображения, и в то же самое время, предпочтительно, определяются зависимости каждого кадра изображения от других кадров изображения. Таким образом, каждый кадр изображения идентифицирован уникальным образом, например идентификатором кадра изображения 204 является (P.1.0.0) или просто (1.0.0), и, соответственно, идентификатором изображения 208 является (P.2.0.0) или (2.0.0).
Согласно предпочтительному варианту воплощения изобретения, номер кадра эталонного изображения определяется согласно конкретному заданному алфавитно-цифровому ряду, как, например, целое число между 0 и 255. Когда значение параметра достигает максимального значения N (например, 255) в рассматриваемом ряде определение значения параметра начинается с начала, то есть от минимального значения ряда (например, 0). Таким образом, кадр изображения идентифицирован уникальным образом в пределах конкретной подпоследовательности до точки, где такой же номер изображения используется снова. Идентификатор подпоследовательности также может быть определен согласно конкретной, заранее заданной арифметической прогрессии. Когда значение идентификатора подпоследовательности достигает максимального значения N прогрессии, определение идентификатора начинается снова с начала прогрессии. Однако, подпоследовательности не может быть присвоен идентификатор, который еще находится в использовании (в пределах того же самого слоя). Используемый ряд может быть также определен способом, отличным от арифметической прогрессии. Один альтернативный вариант состоит в том, чтобы присваивать случайные идентификаторы подпоследовательности, учитывая то, что присвоенный идентификатор не должен использоваться снова.
Проблема нумерации кадров изображения возникает, когда пользователь желает начать просмотр видеофайла в середине видеопоследовательности. Такие ситуации встречаются, например, когда пользователь желает прокрутить локально сохраненный видеофайл назад или вперед или просмотреть файл потоковой передачи в определенной точке; когда пользователь инициирует проигрывание файла потоковой передачи из случайной точки или когда обнаруживается, что видеофайл, который должен быть воспроизведен, содержит ошибку, которая прерывает проигрывание или требует, чтобы проигрывание было возобновлено с точки, следующей за ошибкой. Когда просмотр видеофайла возобновляется со случайной точки после предыдущего просмотра, в нумерации изображения обычно возникает неоднородность. Декодер обычно интерпретирует это как неумышленную потерю кадров изображения и неоправданно пытается воссоздать кадры изображения, которые считаются потерянными.
Согласно предпочтительному варианту воплощения настоящего изобретения, этого можно избежать в декодере, задавая начальное изображение в независимо декодируемой группе изображений GOP, которое активируется в случайной точке видеофайла, и номер начального изображения устанавливается равным нулю. Таким образом, эта независимо декодируемая группа изображений может быть, например, подпоследовательностью интра-слоя, в каковом случае в качестве начального изображения используется I-кадр, или если применяется масштабирование, исходящее из базового слоя, то независимо декодируемая группа изображений является подпоследовательностью базового слоя, в каковом случае первый кадр изображения подпоследовательности, обычно I-кадр, обычно используется в качестве начального изображения. Следовательно, при активации в случайной точке декодер предпочтительно устанавливает идентификатор первого кадра изображения, предпочтительно I-кадра, независимо декодируемой подпоследовательности на ноль. Поскольку декодируемая подпоследовательность также может содержать другие кадры изображения, идентификатор которых равен нулю (например, когда вышеупомянутые алфавитно-цифровые ряды начинаются с начала), начало подпоследовательности, то есть ее первый кадр изображения, может быть показано декодеру, например, посредством отдельного флага, добавленного к полю заголовка среза кадра изображения. Это позволяет декодеру правильно интерпретировать номера изображений и находить правильный кадр изображения, который инициирует подпоследовательность из кадров изображения видеопоследовательности.
Вышеупомянутая система нумерации обеспечивает только один пример того, как уникальная идентификация кадров изображения согласно изобретению может быть выполнена так, чтобы взаимозависимости между кадрами изображения показывались в одно и тоже время. Однако, способы видеокодирования, в которых может применяться способ настоящего изобретения, такие как способы видеокодирования согласно стандартам H.263 и H.26L ITU-T, применяют кодовые таблицы, которые в свою очередь используют коды с переменной длиной слова. Когда коды с переменной длиной слова используются, например, для кодирования номеров слоев, более низкий индекс кодового слова, то есть меньший номер слоя, означает более короткое кодовое слово. На практике, масштабируемое кодирование, соответствующее настоящему изобретению, будет использоваться в большинстве случаев таким способом, при котором базовый слой будет содержать значительно больше кадров изображения, чем интра-слой. Это оправдывает использование более низкого индекса, то есть меньшего номера слоя, на базовом слое, чем на интра-слое, поскольку объем закодированных видеоданных тем самым преимущественно уменьшается. Следовательно, интра-слою предпочтительно присваивается номер 1, а базовому слою дается номер 0. Альтернативно, код может быть сформирован использованием несколько меньшего числа битов для кодирования номера базового слоя, чем номера интра-слоя, в каковом случае, действительное значение номера слоя несущественно ввиду длины созданного кода.
Далее, согласно второму предпочтительному варианту воплощения изобретения, когда количество слоев масштабируемости должно оставаться малым, первый слой масштабируемости, в частности, может кодироваться так, чтобы содержать как интра-слой, так и базовый слой. С точки зрения иерархии кодирования, самый простой способ представить это состоит в том, чтобы совсем отбросить интра-слой и обеспечить базовый слой закодированными кадрами, состоящими из независимо определяемых I-кадров, информация изображения которых была определена без использования временного прогнозирования с компенсацией движения, и из кадров изображения, прогнозированных на основе предыдущих кадров, причем кадры изображения в данном случае являются P-кадрами с компенсацией движения, прогнозируемыми на основе I-кадров того же слоя. Таким образом, номер слоя 0 может по прежнему использоваться для базового слоя и, если слои улучшения кодируются в видеопоследовательность, то слою улучшения 1 присваивается номер слоя 1. Последнее иллюстрируется далее со ссылками на фиг.3а и 3б.
Фиг.3a изображает немасштабируемую структуру видеопоследовательности, в которой все кадры изображения помещаются в один и тот же слой масштабируемости, то есть в базовый слой. Видеопоследовательность содержит первый кадр изображения 300, который является I-кадром (I.O.O) и который, таким образом, инициирует первую подпоследовательность. Кадр 300 изображения используется для прогнозирования второго кадра 302 изображения подпоследовательности, то есть P-кадра (P.0.1), который затем используется для прогнозирования третьего кадра 304 изображения подпоследовательности, то есть P-кадра (P.0.2), который в свою очередь используется для прогнозирования следующего кадра изображения 306, то есть P-кадра (P.O.3). Затем видеопоследовательность обеспечивается I-кадром (1.1.0), закодированным в ней, то есть I-кадром 308, который, таким образом, инициирует вторую подпоследовательность в видеопоследовательности. Этот вид немасштабируемого кодирования может использоваться, например, когда применяемая прикладная задача не позволяет использовать масштабируемое кодирование или в этом нет необходимости. Например, в применении видеофона с коммутацией каналов, ширина полосы канала остается постоянной, и видеопоследовательность кодируется в режиме реального времени, и следовательно, обычно нет необходимости масштабируемого кодирования.
Фиг.3б в свою очередь, иллюстрирует пример того, каким образом масштабируемость может быть при необходимости добавлена к объединенному интра- и базовому слою. Здесь тоже базовый слой видеопоследовательности содержит первый кадр изображения 310, который является I-кадром (1.0.0) и который инициирует первую подпоследовательность базового слоя. Кадр изображения 310 используется для прогнозирования второго кадра изображения 312 подпоследовательности, то есть P-кадра (P.0.1), который затем используется для прогнозирования третьего кадра изображения 314 подпоследовательности, то есть P-кадра (P.0.2). Однако слой улучшения 1 также кодируется в эту видеопоследовательность, и она содержит первую подпоследовательность, первый и единственный кадр изображения 316 которой является P-кадром (P.0.0), который прогнозируется на основе первого кадра изображения 310 базового слоя. Первый кадр изображения 318 второй подпоследовательности слоя улучшения в свою очередь прогнозируется на основе второго кадра изображения 312 базового слоя, и, следовательно, идентификатор этого P-кадра является (P.1.0). Следующий кадр изображения 320 слоя улучшения снова прогнозируется на основе предыдущего кадра изображения 318 того же самого слоя, и следовательно, он принадлежит к той же подпоследовательности и его идентификатором, таким образом является (P.1.1).
В этом варианте воплощения настоящего изобретения подпоследовательности базового слоя могут быть декодированы независимо, хотя подпоследовательность базового слоя может зависеть от другой подпоследовательности базового слоя. Декодирование подпоследовательностей базового слоя требует информации от базового слоя и/или от второй подпоследовательности слоя улучшения 1, декодирование подпоследовательностей слоя улучшения 2 требует информации от слоя улучшения 1 и/или от второй подпоследовательности слоя улучшения 2 и т.д. Согласно этому варианту воплощения, I-кадры не ограничиваются только базовым слоем, но более низкие слои улучшения также могут содержать I-кадры.
Основная идея, лежащая в основе упомянутых вариантов воплощения, состоит в том, что подпоследовательность содержит информацию обо всех подпоследовательностях, от которых она зависит, то есть обо всех подпоследовательностях, которые использовались для прогнозирования, по меньшей мере, одного из кадров изображения рассматриваемой подпоследовательности. Однако, согласно варианту воплощения, также возможно то, что подпоследовательность содержит информацию обо всех подпоследовательностях, которые зависят от рассматриваемой подпоследовательности, другими словами, обо всех подпоследовательностях, в которых, по меньшей мере, один кадр изображения был спрогнозирован с использованием, по меньшей мере, одного кадра изображения рассматриваемой подпоследовательности. Поскольку в последнем случае зависимости обычно определяются в прямом направлении во времени, буферы кадров изображения могут успешно использоваться в кодировании способом, который будет описан позже.
Во всех вышеупомянутых вариантах воплощения нумерация кадров изображения зависит от конкретной подпоследовательности, то есть новая подпоследовательность всегда начинает нумерацию с начала. Таким образом, идентификация отдельного кадра изображения требует, чтобы были определены номер слоя, идентификатор подпоследовательности и номер кадра изображения. Согласно предпочтительному варианту воплощения изобретения, кадры изображения могут независимо нумероваться с использованием последовательной нумерации, в которой последовательные кадры эталонного изображения в порядке кодирования обозначаются номерами, получающими приращение, равное единице. Что касается номеров слоев и идентификаторов подпоследовательностей, можно использовать вышеописанную процедуру нумерации. Это позволяет при необходимости уникальным образом идентифицировать каждый кадр изображения без использования номера слоя и идентификатора подпоследовательности.
Это иллюстрируется примером, показанным на фиг.4a, в котором базовый слой содержит первый во времени I-кадр 400 (1.0.0). Данный кадр используется для прогнозирования первого кадра 402 изображения слоя улучшения 1, то есть (P.0.1), который затем используется для прогнозирования второго кадра 404 изображения, принадлежащего к той же самой подпоследовательности (с идентификатором подпоследовательности 0), то есть (P.0.2), который используется для прогнозирования третьего кадра 406 изображения той же самой подпоследовательности, то есть (P.0.3) который используется для прогнозирования четвертого кадра 408 изображения (P.0.4), и, наконец, четвертый кадр - для прогнозирования пятого кадра изображения 410 (P.O.5). Следующий во времени кадр 412 изображения видеопоследовательности расположен на базовом слое, где он находится в той же самой подпоследовательности, что и I-кадр 400, хотя во времени он является только седьмым закодированным кадром изображения, и поэтому его идентификатором является (P.0.6). Затем, для прогнозирования первого кадра 414 изображения второй подпоследовательности слоя улучшения 1 используется седьмой кадр, то есть (P.1.7) который затем используется для прогнозирования второго кадра 416 изображения, принадлежащего к той же самой подпоследовательности (с идентификатором подпоследовательности 1), то есть (P.1.8) который в свою очередь используется для прогнозирования третьего кадра 418 изображения (P.1.9), третий - для прогнозирования четвертого кадра 420 изображения (P.1.10) и, наконец, четвертый - для прогнозирования пятого кадра изображения 422 (P.1.11) той же самой подпоследовательности. Опять же, следующий во времени кадр 424 изображения видеопоследовательности расположен на базовом слое, где он находится в той же самой подпоследовательности, что и I-кадр 400 и P-кадр 412, хотя во времени он является только тринадцатым закодированным кадром изображения, и поэтому его идентификатором является (P.0.12). Для ясности иллюстрации, вышеупомянутое описание варианта воплощения не содержит идентификаторы слоев, но очевидно, что для осуществления масштабируемости идентификатор слоя также должен передаваться вместе с видеопоследовательностью, обычно как часть идентификаторов кадров изображения.
Фиг.4б и 4в изображают альтернативные варианты воплощения для группирования кадров изображения видеопоследовательности, изображенной на фиг.4а. Кадры изображения на фиг.4б нумеруются согласно подпоследовательности, то есть новая подпоследовательность всегда начинает нумерацию с начала (с нуля). Фиг.4в в свою очередь, применяет нумерацию кадров изображения, которая соответствует таковой по фиг.4а, за исключением того, что P-кадры базового слоя заменены парами SP-кадров, чтобы обеспечить возможность идентичного воссоздания информации изображения.
Как утверждалось выше, процедура, соответствующая изобретению, также может осуществляться с использованием B-кадров. Пример этого иллюстрируется на фиг.5а, 5б и 5в. Фиг.5a изображает видеопоследовательность во временной области, причем эта последовательность содержит P-кадры P1, P4 и P7 с B-кадрами, помещенными между ними, при этом взаимозависимости B-кадров в отношении временного прогнозирования показаны стрелками. Фиг.5б изображает предпочтительное группирование кадров изображения видеопоследовательности, в которой указаны взаимозависимости, изображенные на фиг.5а. Фиг.5б иллюстрирует нумерацию кадров изображения в отношении конкретных подпоследовательностей, при которой новая подпоследовательность всегда начинает нумерацию кадров изображения с нуля. Фиг.5в, в свою очередь, иллюстрирует нумерацию кадров изображения, которая является последовательной в порядке временного прогнозирования, в котором следующий эталонный кадр всегда получает следующий номер изображения по отношению к ранее закодированному эталонному кадру. Кадр изображения (B1.8) (и (B2.10)) не служит в качестве эталонного кадра прогнозирования для любого другого кадра, следовательно, он не затрагивает нумерации кадров изображения.
Вышеупомянутые примеры иллюстрируют различные альтернативные варианты того, каким образом можно регулировать масштабируемость кодирования видеопоследовательности с использованием способа настоящего изобретения. С точки зрения терминального устройства, воспроизводящего видеопоследовательность, чем больше слоев масштабируемости доступно или чем больше слоев масштабируемости оно способно декодировать, тем выше качество изображения. Другими словами, увеличение объема информации изображения и скорости передачи в битах, используемой для передачи информации, улучшает временное или пространственное разрешение или пространственное качество данных изображения. Соответственно, более высокий номер слоев масштабируемости также устанавливает значительно более высокие требования к пропускной способности обработки данных терминального устройства, выполняющего декодирование.
Кроме того, вышеупомянутые примеры иллюстрируют преимущество, полученное при использовании подпоследовательностей. Взаимозависимости каждого кадра изображения от других кадров изображения в подпоследовательности обозначаются с помощью идентификаторов кадров изображения однозначным способом. Таким образом, подпоследовательность образует независимое целое, которое, при необходимости, может не входить в рассматриваемую видеопоследовательность, без воздействия на декодирование последующих кадров изображения этой видеопоследовательности. В этом случае не декодируются только кадры изображения рассматриваемой подпоследовательности и тех подпоследовательностей на том же и/или на более низких слоях масштабируемости, которые зависят от нее.
Данные идентификатора кадра изображения, передаваемые вместе с видеопоследовательностью, предпочтительно включены в полях заголовка видеопоследовательности или в полях заголовка протокола передачи, который должен использоваться для передачи видеопоследовательности. Другими словами, данные идентификатора прогнозированных кадров изображения не входят в данные изображения закодированной видеопоследовательности, но всегда входят в поля заголовка, вследствие чего зависимости кадров изображения могут детектироваться без декодирования изображений фактической видеопоследовательности. Данные идентификаторов кадров изображения могут быть сохранены, например, в буферной памяти сервера потоковой передачи, когда видеопоследовательность кодируется для передачи. Кроме того, подпоследовательности могут независимо декодироваться на каждом слое масштабируемости, поскольку кадры изображения подпоследовательности не зависят от других подпоследовательностей того же самого слоя масштабируемости.
Согласно варианту воплощения изобретения, кадры изображения, содержащиеся в подпоследовательности, могут зависеть также от других подпоследовательностей того же самого слоя масштабируемости. Затем эта зависимость должна быть передана, например, в сервер потоковой передачи, выполняющий формирование трафика, поскольку взаимозависимые подпоследовательности, расположенные на одном и том же слое, не могут быть раздельно удалены из видеопоследовательности, которая должна передаваться. Предпочтительный способ выполнения такой передачи состоит в том, чтобы включить данную зависимость в идентификаторы кадров изображения, которые должны передаваться, например, посредством составления списка пар «слой - подпоследовательность», от которых зависит рассматриваемая подпоследовательность. Это также обеспечивает предпочтительный способ обозначения зависимости от другой подпоследовательности того же самого слоя масштабируемости.
Вышеупомянутые примеры иллюстрируют ситуацию, в которой кадры изображения прогнозируются во времени на основе предыдущих кадров изображения. Однако, в некоторых способах кодирования, выбор эталонного изображения дополнительно расширен, чтобы также включить прогнозирование информации изображения кадров изображения на основе последующих во времени кадров изображения. Выбор эталонного изображения предлагает самые разнообразные средства для создания различных структур масштабируемых во времени кадров изображения и позволяет уменьшить чувствительность к ошибкам видеопоследовательности. Один из методов кодирования, основанный на выборе эталонного изображения, представляет собой задержку интра-кадра. Интра-кадр помещается в свое "правильное" во времени положение в видеопоследовательности, но его положение задерживается во времени. Кадры изображения видеопоследовательности, которые находятся между "правильным" положением интра-кадра и его действительным положением, прогнозируются в обратном направлении во времени от рассматриваемого интра-кадра. Это естественно требует, чтобы незакодированные кадры изображения были буферизированы на достаточно длительный период времени так, чтобы все кадры изображения, которые должны отображаться, могли быть закодированы и расположены в порядке их представления. Перенос интра-кадра и связанное с этим определение подпоследовательностей согласно изобретению иллюстрируются далее со ссылкой на фиг.6.
Фиг.6a изображает часть видеопоследовательности, в которой интра-кадр содержит единственный I-кадр 600, который во времени переносится в положение, показанное на фиг.6, хотя "правильное" положение I-кадра в видеопоследовательности было бы на месте первого кадра изображения. Кадры изображения видеопоследовательности между "правильным" положением и реальным положением 600, таким образом, прогнозируются в обратном направлении во времени от I-кадра 600. Это иллюстрируется подпоследовательностью, закодированной в слой улучшения 1 и имеющей первый прогнозированный в обратном направлении во времени кадр изображения 602, который является P-кадром (P.0.0). Данный кадр используется для прогнозирования во времени предыдущего кадра изображения 604, то есть P-кадра (P.0.1), который в свою очередь используется для прогнозирования кадра 606 изображения, то есть P-кадра (P.0.2), и, наконец, кадр 606 - для прогнозирования кадра 608 изображения, то есть P-кадра (P.0.3), который находится в положении, которое могло бы быть "правильным" положением I-кадра 600 в видеопоследовательности. Соответственно, I-кадр 600 на базовом слое используется для прогнозирования в прямом направлении во времени подпоследовательности, содержащей четыре P-кадра 610, 612, 614 и 616, то есть P-кадра (P.0.0), (P.O.1), (P.0.2) и (P.0.3).
Тот факт, что в данном примере прогнозированные в обратном направлении во времени кадры изображения помещаются на более низкий слой, чем прогнозированные в прямом направлении во времени кадры изображения, указывает, что для иллюстрации, прогнозированные в обратном направлении кадры изображения в этом примере кодирования считаются субъективно менее значимыми, чем прогнозированные в прямом направлении кадры изображения. Естественно, обе подпоследовательности могли бы быть обе помещены в один и тот же слой, в каковом случае они считались бы равными, или прогнозированная в обратном направлении подпоследовательность могла бы быть на верхнем слое, в каковом случае она считались бы субъективно более значимой.
Фиг.6б и 6в показывают альтернативу кодированию видеопоследовательности по фиг.6а. На фиг.6б обе прогнозированные в прямом и обратном направлениях подпоследовательности помещаются на базовый слой, причем I-кадр расположен только на интра-слое. Таким образом, прогнозированная в прямом направлении подпоследовательность на этом слое является второй подпоследовательностью, и ее идентификатором подпоследовательности является 1. На фиг.6в, в свою очередь, I-кадр и прогнозированная в прямом направлении подпоследовательность, основанная на нем, расположены на базовом слое, в то время как прогнозированная в обратном направлении подпоследовательность расположена на слое улучшения 1.
Кроме того, согласно предпочтительному варианту воплощения изобретения, вышеописанная масштабируемость может использоваться для кодирования того, что известно как монтажный переход в видеопоследовательность. Видеоматериал, такой как последние известия, музыкальные видеоклипы и отрывки кинофильмов, часто содержат быстрые переходы между отдельными сценами материала изображения. Иногда переходы бывают скачкообразными, но часто используется процедура, известная как монтажный переход, в которой переход от одной сцены к другой производится путем затемнения, стирания, наплывающей мозаики или прокрутки кадров изображения предыдущей сцены, и соответственно, путем представления кадров изображения более поздней сцены. С точки зрения эффективности кодирования, видеокодирование монтажного перехода часто наиболее проблематично, поскольку кадры изображения, появляющиеся в течение монтажного перехода, содержат информацию о кадрах изображения как конечной, так и начальной сцены.
Типичный монтажный переход, постепенное исчезновение изображения выполняется путем постепенного снижения интенсивности или освещенности кадров первой сцены до нуля при постепенном увеличении интенсивности кадров изображения второй сцены до ее максимального значения. Такой монтажный переход называется переходом между сценами с перекрестным затенением.
Вообще говоря, компьютерное изображение можно рассматривать как состоящее из слоев или объектов изображения. Каждый объект может быть задан в отношении, по меньшей мере, трех типов информации: структуры объекта изображения, его формы и прозрачности, и порядка разбиения на слои (глубины) в отношении к фону изображения и к другим объектам изображения. Форма и прозрачность часто определяются, используя так называемую альфа-плоскость, которая измеряет непрозрачность и значение которой обычно определяется отдельно для каждого объекта изображения, возможно, исключая фон, который обычно считается непрозрачным. Таким образом, значение альфа-плоскости непрозрачного объекта изображения, такого как фон, может быть установлено равным 1,0, тогда как значение альфа-плоскости полностью прозрачного объекта изображения равно 0,0. Значения между ними задают интенсивность видимости конкретного объекта изображения на картинке пропорционально к фону или к другим, по меньшей мере, частично перекрывающимся объектам изображения, которые имеют более высокое значение глубины, чем рассматриваемый объект изображения.
Совмещение объектов изображения в слоях согласно их форме, прозрачности и положению глубины называется составлением сцены. Практически процедура основана на использовании средневзвешенных значений. Сначала объект изображения, который является самым близким к фону, то есть самый глубокий согласно его положению по глубине, помещается на фон, и объединенное изображение формируется из них обоих. Значения пикселей объединенного изображения вычисляются как средневзвешенные значения посредством значений альфа-плоскости фонового изображения и рассматриваемого объекта изображения. Затем значение альфа-плоскости объединенного изображения устанавливается равным 1,0, после чего оно служит как фоновое изображение для следующего объекта изображения. Процесс продолжается до тех пор, пока все объекты изображения не будут привязаны к изображению.
Далее будет описана процедура согласно предпочтительному варианту воплощения изобретения, в которой слои масштабируемости видеопоследовательности объединяются с вышеописанными объектами изображения кадров изображения и их типами информации для обеспечения монтажного перехода с масштабируемым видеокодированием, которое также имеет хорошую эффективность сжатия.
Далее иллюстрируется упомянутый вариант воплощения на примере и в упрощенном виде путем использования в качестве примеров перехода между сценами с перекрестным затенением, с одной стороны, и скачкообразного монтажного перехода с другой стороны. Кадры изображения, которые должны отображаться во время монтажного перехода, обычно формируются из двух совмещенных кадров изображения, причем первый кадр изображения содержит первую сцену изображения, а второй кадр изображения - вторую сцену. Один из кадров изображения служит в качестве фонового изображения, а другой, который упоминается как основное изображение, помещается поверх фонового изображения. Непрозрачность фонового изображения, то есть его значение непрозрачности, является постоянной. Другими словами, значения его альфа-плоскости на конкретных пикселях не регулируются.
В данном варианте воплощения изобретения как фоновое, так и основное изображения задаются согласно слою масштабируемости. Это иллюстрируется на фиг.7, которая изображает пример того, как кадры изображения двух различных сцен могут быть помещены на слои масштабируемости во время монтажного перехода согласно изобретению. Фиг.7 показывает первый кадр изображения 700 первой (конечной) сцены, расположенной на базовом слое. Кадр изображения 700 может быть либо I-кадром, содержащим информацию изображения, которая не была определена с использованием временного прогнозирования с компенсацией движения, или он может быть P-кадром, который является кадром изображения с компенсацией движения, прогнозируемым на основе предыдущих кадров изображения. Кодирование второй (начальной) сцены начинается в течение следующего во времени кадра изображения, и согласно изобретению, кадры изображения сцены также помещаются на базовом слое. Затем остальные кадры изображения 702, 704 второй (конечной) сцены помещаются на слой улучшения 1. Эти кадры изображения обычно являются P-кадрами.
В рассматриваемом варианте воплощения кадры изображения второй (начальной) сцены помещаются на базовом слое, по меньшей мере, на протяжении монтажного перехода. Первый кадр изображения 706 сцены обычно является I-кадром и используется для временного прогнозирования последующих кадров изображения сцены. Следовательно, последующие кадры изображения второй сцены являются прогнозируемыми во времени кадрами, обычно P-кадрами, такими как кадры 708 и 710, показанные на фиг.7.
Согласно предпочтительному варианту воплощения изобретения, такое размещение кадров изображения на слоях масштабируемости может использоваться для осуществления реализации перехода между сценами с перекрестным затенением посредством определения слоя изображения, который находится на базовом слое всегда в виде фонового изображения максимальной непрозрачности (100%) или значения непрозрачности. Во время монтажного перехода кадры изображения, расположенные на слоях улучшения, помещаются на фоновое изображение, и их непрозрачность регулируется, например, посредством подходящих фильтров, так что кадры постепенно изменяются от непрозрачного до прозрачного.
В видеопоследовательности по фиг.7 не имеется никаких кадров изображения на более низких слоя масштабируемости на протяжении первого кадра 700 изображения базового слоя. В течение этого времени, первый кадр 700 изображения только кодируется в видеопоследовательность.
Следующий кадр 706 изображения базового слоя начинает новую (вторую) сцену, в течение которой кадр 706 изображения обеспечивается позиционированием по глубине, посредством чего он размещается как фоновое изображение и его значение непрозрачности устанавливается на максимум. Одновременно с кадром 706 изображения базового слоя имеется кадр 702 изображения конечной (первой) сцены на слое улучшения 1. Чтобы обеспечить возможность проведения перехода между сценами с перекрестным затенением, прозрачность кадра 702 должна быть увеличена. Пример по фиг.7 предполагает, что непрозрачность кадра 702 изображения устанавливается на 67%, и, кроме того, кадр 702 изображения обеспечивается позиционированием по глубины, которое определяет его как основное изображение. В этот момент времени изображение, объединяющее кадры изображения 706 и 702, кодируется в видеопоследовательность, причем изображение 706 визуально воспринимается как слабое изображением на фоне, а изображение 702 - как более сильное изображение на переднем плане, поскольку его значение непрозрачности весьма высокое (67%).
В течение следующего во времени кадра изображения имеется второй кадр 708 изображения второй сцены на базовом слое, причем кадр 708 соответственно обеспечен позиционированием по глубине, определяющим его как фоновое изображение, и его значение непрозрачности устанавливается на максимум. Слой улучшения 1 дополнительно содержит последний кадр 704 изображения одновременной во временном отношении конечной (первой) сцены, причем значение непрозрачности кадра устанавливается на 33%, и кроме того, кадр 704 изображения обеспечивается позиционированием по глубине, которое также определяет его как основное изображение. Следовательно, в этот момент времени изображение, объединенное из кадров изображения 708 и 704, кодируется в видеопоследовательность, причем изображение 708 отображается как более сильное изображение на фоне, а изображение 704 - как более слабое изображение на переднем плане, поскольку его значение непрозрачности больше не превышает 33%.
В течение следующего во времени кадра изображения базовый слой содержит третий кадр 710 изображения второй сцены. Поскольку первая сцена завершена, только кадр 710 изображения кодируется в видеопоследовательность, и отображение второй сцены продолжается с кадра 710.
Вышеупомянутое раскрытие описывает, посредством примера, позиционирование кадров изображения согласно изобретению на слоях масштабируемости для реализации перехода между сценами с перекрестным затенением, что является выгодным с точки зрения эффективности кодирования. Однако, возможно, что когда видеопоследовательность передается или декодируется, возникает ситуация, в которой скорость передачи в битах видеопоследовательности должна регулироваться согласно максимальному значению ширины полосы пропускания и/или скорость декодирования терминального устройства, доступных для передачи данных. Этот вид управления скоростью передачи в битах вызывает проблемы, когда монтажный переход должен выполняться с использованием способов видеокодирования предшествующего уровня техники.
Теперь предпочтительный вариант воплощения позволяет удалить один или несколько слоев масштабируемости или независимо декодируемых подпоследовательностей, заключенных в них, из видеопоследовательности, в результате чего можно снизить скорость передачи в битах видеопоследовательности, и при этом видеопоследовательность может быть декодирована без снижения частоты изображений. В позиционировании кадров изображения согласно фиг.7, данную операцию можно осуществить удалением слоя улучшения 1 из видеопоследовательности. Таким образом, видеопоследовательность используется только для отображения кадров 700, 706, 708 и 710 изображения базового слоя. Другими словами, прямой переход от первой (конечной) сцены ко второй (начальной) сцене происходит в форме скачкообразного монтажного перехода, то есть непосредственно от кадра 700 изображения первой сцены к I-кадру 706 изображения, который начинает вторую сцену. Таким образом, переход не является переходом между сценами с перекрестным затенением, а является скачкообразным монтажным переходом. Однако, монтажный переход может быть выполнен выгодным способом без воздействия на качество изображения, и зритель обычно не ощущает скачкообразный монтажный переход, выполняемый вместо перехода между сценами с перекрестным затенением каким-либо способом, типа размывания или искажения. Напротив, так как реализация в соответствии с предшествующим уровнем техники не позволяет удалять слои масштабируемости, монтажный переход часто может требовать снижения частоты изображений, что зритель может принять за рывок или нарушение.
Таким образом, изобретение обеспечивает предпочтительное средство выполнения формирования трафика мультимедийных данных в сервере потоковой передачи, содержащем информацию о различных подпоследовательностях видеопоследовательности: их среднюю скорость передачи в битах, местоположение относительно полной видеопоследовательности, длительность и их взаимозависимости относительно слоев. Сервер потоковой передачи также определяет максимальное значение ширины полосы пропускания, доступное для передачи данных, и/или скорости декодирования терминального устройства. На основе этой информации сервер потоковой передачи решает сколько слоев масштабируемости и какие подпоследовательности передаются в видеопоследовательности. Таким образом, при необходимости может выполняться управление скоростью передачи в битах путем выполнения сначала грубой регулировки количества слоев масштабируемости, после которой легко можно выполнить более тонкую регулировку в отношении конкретных подпоследовательностей. В простейшем случае, средство управления скоростью передачи в битах, принимающее решение в отношении конкретных подпоследовательностей на счет того, будет ли конкретная подпоследовательность добавлена к видеопоследовательности или удалена из нее. В случае удаления желательно удалить полные подпоследовательности из видеопоследовательности, поскольку удаление отдельных изображений может привести к ошибкам в других изображениях той же самой подпоследовательности. По той же причине, все подпоследовательности более низкого слоя улучшения должны быть отброшены, если они зависят от удаленной подпоследовательности более высокого слоя. Если на одном и том же слое масштабируемости имеются взаимозависимые подпоследовательности, то подпоследовательности, зависящие от более ранней подпоследовательности, должны быть удалены, если более ранняя подпоследовательность удалена.
Если данные идентификатора кадра изображения добавляются к видеопоследовательности, которая должна передаваться, то формирование трафика также может выполняться в элементе телекоммуникационной сети, который должен использоваться для переноса видеопоследовательности, например, в маршрутизаторе Интернет, в различных шлюзах либо на базовой станции или контроллере базовых станций сети мобильной связи. Для того чтобы сетевой элемент был способен поддерживать и обрабатывать информацию подпоследовательности, он должен иметь дополнительную память и дополнительные ресурсы обработки данных. По этой причине, формирование трафика, которое должно выполняться в сети, наиболее вероятно может выполняется с использованием простых способов обработки, таких как DiffServ, то есть дифференцированные услуги, процедура, которая поддерживается некоторыми сетями, основанными на IP (Интернет протоколе). В способе DiffServ каждому IP-пакету данных присваивается приоритет, в результате чего пакеты данных с более высоким приоритетом передаются получателю быстрее и надежнее, чем пакеты данных с более низким приоритетом. Это преимущественно применимо к масштабируемости изобретения посредством определения не только масштабируемости на конкретных слоях, но также приоритетов в отношении конкретных подпоследовательностей, что обеспечивает возможность усовершенствованного назначения приоритетов.
Имеется много альтернатив для добавления данных идентификатора кадра изображения к видеопоследовательности, которая должна передаваться. Кроме того, также можно не включать какие-либо данные идентификатора в видеопоследовательность, когда формирование трафика выполняется только в сервере потоковой передачи. Данные идентификатора могут быть включены в поля заголовка видеопоследовательности или в поля заголовка используемого протокола передачи, такого как RTP (протокол реального времени). Согласно предпочтительному варианту воплощения изобретения, данные идентификатора могут передаваться с использованием механизма дополнительной информации повышения качества (SEI). SEI обеспечивает механизм доставки данных, который передается синхронно с содержимым видеоданных, таким образом, помогая в декодировании и отображении видеопоследовательности. В частности, механизм SEI при использовании для переноса информации слоя и подпоследовательности, раскрывается более подробно в документе Rec.H.264 (ISO/IEC 14496-10:2002), Приложение D стандарта ITU-T. В тех случаях, в которых для передачи данных идентификатора используется отдельный протокол передачи, формирование трафика также может выполняться на одном из сетевых элементов по маршруту переноса. Кроме того, принимающее терминальное устройство может управлять декодированием.
Если кодер или декодер поддерживает выбор эталонного изображения, то кодирование видеопоследовательности требует, чтобы декодированные кадры изображения были буферизированы перед кодированием, так чтобы позволить прогнозировать во времени зависимости между различными кадрами изображения, которые должны прогнозироваться во времени на основе одного или нескольких других кадров изображения. Буферизация кадров изображения может быть организована, по меньшей мере, двумя различными способами, а именно либо как механизм скользящего окна, либо как адаптивное управление буферной памятью. При механизме скользящего окна в качестве буфера используются кадров М изображения, которые были закодированы последними. Кадры в буферной памяти находятся в декодированной и воссозданной форме, что позволяет использовать их как эталонные изображения при кодировании. В процессе кодирования буферизация кадров изображения функционирует на основе принципа FIFO (первым прибыл, первым обслужен). Изображения, которые не используются в качестве эталонного изображения, как, например, известные B-изображения, не должны сохраняться в буфере. Альтернативно, буферизация также может быть реализована как адаптивное управление буферной памятью, в каковом случае, буферизация изображения не ограничена принципом FIFO, но кадры изображения, в которых нет необходимости, можно удалять из буфера в середине процесса, или, соответственно, некоторые кадры изображения могут сохраняться в буфере в течение более длительного времени, если они нужны как эталонные изображения для более поздних кадров изображения. Известный выбор эталонного изображения реализуется путем индексирования кадров изображения, которые находятся в буферной памяти в определенном порядке, причем индексы изображения затем используются для ссылки на изображение в сочетании, например, с компенсацией движения. Этот способ индексирования в основном обеспечивает лучшую эффективность сжатия по сравнению, например, с использованием номеров изображения для ссылки на конкретное изображение, когда должны передаваться эталонные изображения с компенсацией движения.
Вышеупомянутый способ индексирования эталонного изображения является чувствительным к погрешностям передачи, поскольку буферы кодера отправителя и декодера получателя должны содержать соответствующие воссозданные изображения в идентичном порядке для гарантии того, что кодер и декодер формируют одинаковый порядок индексирования. Если в буферах кодера и декодера кадры изображения индексируются в разном порядке, то в декодере может использоваться неправильное эталонное изображение. Для предотвращения этого существенно, чтобы управление декодером могло осуществляться так, чтобы учитывать кадры изображения и подпоследовательности, которые кодер преднамеренно удалил из видеопоследовательности. В этом случае, нумерация кадров изображения может содержать пропуски, которые декодер обычно интерпретирует как ошибки и пробует воссоздать кадры изображения, интерпретируемые как потерянные. По этой причине существенно, чтобы кодер был способен сообщать декодеру, что пропуски в нумерации передаваемых кадров изображения являются намеренными.
В ответ на это и при условии, что для буферизации кадров изображения используется механизм скользящего окна, декодер вводит в буферную память количество кадров изображения, содержание которых может быть абсолютно произвольным, соответствующее номерам пропущенных изображений. Затем упомянутые произвольные кадры изображения обозначаются идентификатором "недействительный", чтобы указать, что рассматриваемые кадры не принадлежат к действительной видеопоследовательности, но являются заполняющими кадрами, вводимыми в целях управления буферной памятью. Заполняющий кадр может быть естественным образом реализован с использованием только индикаторов памяти, то есть предпочтительно данные не вводятся в буферную память, а управление памятью используется просто для сохранения ссылки на обобщенный "недействительный" кадр. Ввод кадров изображения действительной видеопоследовательности продолжается с правильного номера кадра изображения после того, как упомянутое количество заполняющих кадров, обозначенных номерами пропущенных изображений, было введено в буфер, что позволяет буферной памяти кодера и декодера предпочтительно сохранять синхронность. Если во время декодирования обнаружена ссылка на номер изображения, который, как затем оказалось, указывает заполняющий кадр, расположенный в буфере, то в декодере инициируются действия по исправлению ошибок, чтобы воссоздать действительное эталонное изображение, например, запрашивая кодер повторно передать рассматриваемое эталонное изображение.
Далее, процедура, соответствующая изобретению, позволяет использовать отдельную буферную память на различных слоях масштабируемости или, соответственно, в отношении конкретных подпоследовательностей. Таким образом, каждый слой масштабируемости может иметь отдельную буферную память, которая является концептуально отдельной и функционирует на основе принципа скользящего окна. Аналогично, каждую подпоследовательность также можно обеспечить концептуально отдельной буферной памятью, которая также функционирует на основе принципа скользящего окна. Это означает, что буферная память всегда освобождается, когда заканчивается подпоследовательность. Отдельная буферная память может использоваться предпочтительным способом для уменьшения потребности в передаче сигналов в некоторых ситуациях, в которых обычная буферизация по принципу скользящего окна была бы неадекватной, и вместо нее должно было использоваться активное адаптивное управление буферной памятью.
Стандарт H.26L задает отсчет порядка изображений как положение изображения в порядке вывода. Процесс декодирования, определенный в стандарте H.26L, использует отсчет порядка изображений для определения упорядочения индексов по умолчанию для эталонных изображений в B-срезах, для представления различий порядка изображений между кадрами и полями для масштабирования векторов при прогнозировании вектора движения и для взвешенного прогнозирования неявного режима в B-срезах и для определения того, когда последовательные срезы в порядке декодирования принадлежат различным изображениям. Отсчет порядка картинок кодируется и передается для каждого изображения.
В одном из вариантов воплощения изобретения декодер использует отсчет порядка изображений, чтобы сделать заключение относительно того, являются ли изображения перекрывающимися во времени. Предпочтительно декодер выводит изображения на самом высоком принятом слое. В отсутствие информации слоя, декодер делает заключение, что самое последнее перекрывающееся во времени изображение в порядке декодирования находится на самом высоком принятом слое.
Вышеупомянутое раскрытие описывает процедуру для кодирования видеокадров с целью создания масштабируемой, сжатой видеопоследовательности. Действительная процедура выполняется в видеокодере, таком как устройство сжатия 108 по фиг.1, которое может быть любым известным видеокодером. Например, может использоваться видеокодер согласно рекомендациям H.263 или H.26L стандарта ITU-T, причем кодер сконфигурирован так, чтобы формировать, согласно изобретению, первую подпоследовательность в видеопоследовательности, при этом, по меньшей мере, часть этой подпоследовательности формируется путем кодирования I-кадров, чтобы формировать, по меньшей мере, вторую подпоследовательность в видеопоследовательности, при этом, по меньшей мере, часть этой подпоследовательности формируется путем кодирования, по меньшей мере, P- или B-кадров, и, по меньшей мере, один видеокадр второй подпоследовательности прогнозируется на основе, по меньшей мере, одного видеокадра первой подпоследовательности; а также для того, чтобы определить в видеопоследовательности данные идентификации, по меньшей мере, видеокадров второй подпоследовательности.
Согласно процедуре, соответствующей изобретению, каждая подпоследовательность конкретного слоя масштабируемости предпочтительно является независимо декодируемой, естественным образом учитывая зависимости от более высоких слоев масштабируемости и возможно от других подпоследовательностей того же самого слоя масштабируемости. Таким образом, масштабируемо сжатая видеопоследовательность, такая как описанная выше, может быть декодирована посредством декодирования первой подпоследовательности видеопоследовательности, причем, по меньшей мере, часть подпоследовательности сформирована путем кодирования, по меньшей мере, I-кадров, посредством декодирования, по меньшей мере, второй подпоследовательности видеопоследовательности, причем, по меньшей мере, часть второй подпоследовательности сформирована путем кодирования, по меньшей мере, P- или B-кадров, и по меньшей мере, один видеокадр второй подпоследовательности прогнозируется на основе, по меньшей мере, одного видеокадра первой подпоследовательности, и посредством определения данных идентификации и зависимостей, по меньшей мере, видеокадров, содержащихся во второй подпоследовательности видеопоследовательности, а также посредством воссоздания, по меньшей мере, части видеопоследовательности на основе зависимостей подпоследовательностей.
Фактическое декодирование происходит в видеодекодере, таком как средством 118 распаковки по фиг.1, который может быть любым известным видеодекодером. Например, может использоваться видеодекодер с низкой скоростью передачи в битах согласно рекомендации H.263 или H.26L стандарта ITU-T, который в настоящем изобретении сконфигурирован так, чтобы декодировать первую подпоследовательность видеопоследовательности, причем, по меньшей мере, часть этой подпоследовательности сформирована путем кодирования I-кадров; чтобы декодировать, по меньшей мере, вторую подпоследовательность видеопоследовательности, причем, по меньшей мере, часть второй подпоследовательности сформирована путем кодирования, по меньшей мере, P- или B-кадров, и по меньшей мере, один видеокадр второй подпоследовательности прогнозируется на основе, по меньшей мере, одного видеокадра первой подпоследовательности. Видеодекодер сконфигурирован для определения данных идентификации и зависимостей, по меньшей мере, видеокадров, содержащихся во второй подпоследовательности видеопоследовательности, и для воссоздания, по меньшей мере, части видеопоследовательности на основе зависимостей подпоследовательностей.
Существенным аспектом в работе системы потоковой передачи, соответствующей настоящему изобретению, является то, что кодер и декодер размещаются, по меньшей мере, таким образом, что кодер в рабочем состоянии подключен к серверу потоковой передачи, а декодер в рабочем состоянии подключен к приемному терминальному устройству. Однако, различные элементы системы потоковой передачи, в частности терминальные устройства, могут включать в себя функциональные возможности, которые обеспечивают возможность двухстороннего переноса мультимедийных данных, то есть передачу и прием. Таким образом, кодер и декодер могут быть реализованы в форме так называемого видеокодека, объединяющего функциональные возможности декодера и кодера.
Следует отметить, что согласно настоящему изобретению, функциональные элементы вышеописанной системы потоковой передачи и ее элементы, такие как сервер потоковой передачи, видеокодер, видеодекодер и терминал, предпочтительно реализуются посредством программного обеспечения, посредством решений на основе аппаратных средств или как комбинация их обоих. Способы кодирования и декодирования изобретения особенно подходят для реализации в виде компьютерного программного обеспечения, содержащего машиночитаемые команды для выполнения шагов процесса, соответствующего изобретению. Предпочтительный способ осуществления кодера и декодера состоит в том, чтобы хранить их в средстве хранения данных в виде программного кода, который может быть исполнен устройством, подобным компьютеру, такому как персональный компьютер (ПК) или мобильная станция, для обеспечения функциональных возможностей кодирования/декодирования на рассматриваемом устройстве.
Другая альтернатива состоит в том, чтобы реализовать изобретение как видеосигнал, содержащий масштабируемо сжатую видеопоследовательность, которая в свою очередь содержит видеокадры, закодированные согласно, по меньшей мере, первому и второму форматам кадров, причем видеокадры согласно первому формату кадров независимы от других видеокадров, а видеокадры второго формата кадров прогнозируются на основе, по меньшей мере, одного из множества других видеокадров. Согласно изобретению, рассматриваемый видеосигнал содержит, по меньшей мере, первую подпоследовательность, по меньшей мере, часть которой сформирована путем кодирования, по меньшей мере, видеокадров первого формата кадров; по меньшей мере, вторую подпоследовательность, по меньшей мере, часть которой сформирована путем кодирования, по меньшей мере, видеокадров второго формата кадров; и при этом, по меньшей мере, один видеокадр второй подпоследовательности прогнозируется на основе, по меньшей мере, одного видеокадра первой подпоследовательности; и, по меньшей мере, одно поле данных, которое определяет видеокадры, принадлежащие второй подпоследовательности.
Специалисту в данной области техники очевидно, что по мере развития технологии базовая идея изобретения может быть реализована различными способами. Поэтому изобретение и варианты его воплощения не ограничиваются вышеупомянутыми примерами, но они могут варьироваться в рамках объема, определяемого формулой изобретения.
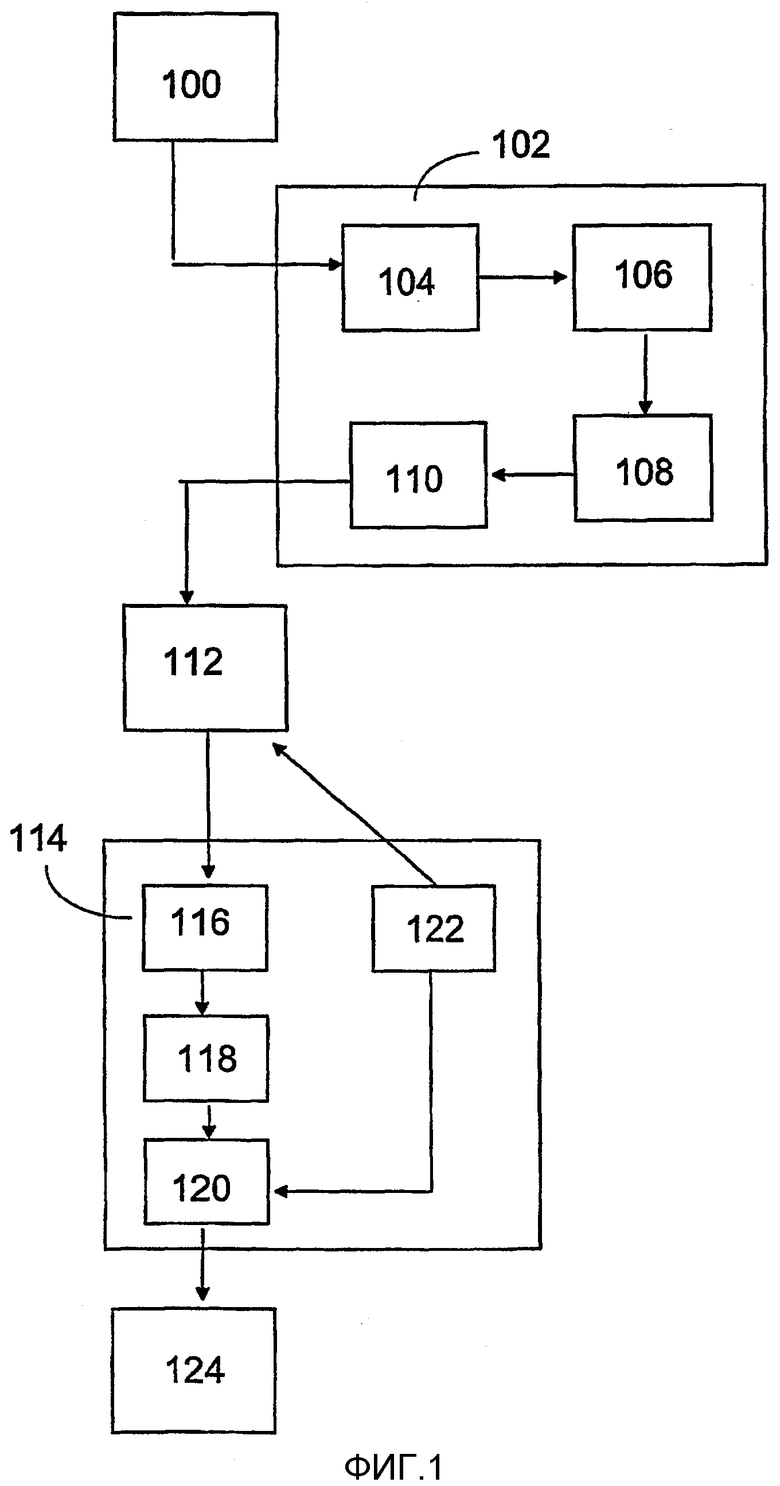

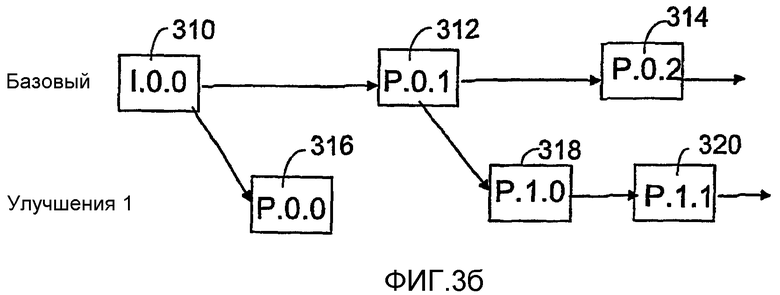






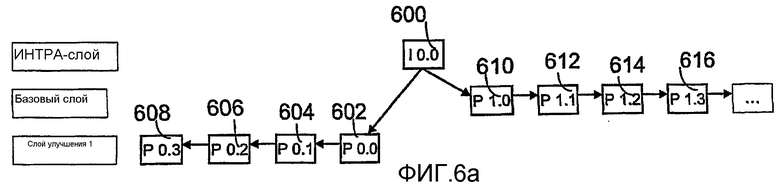


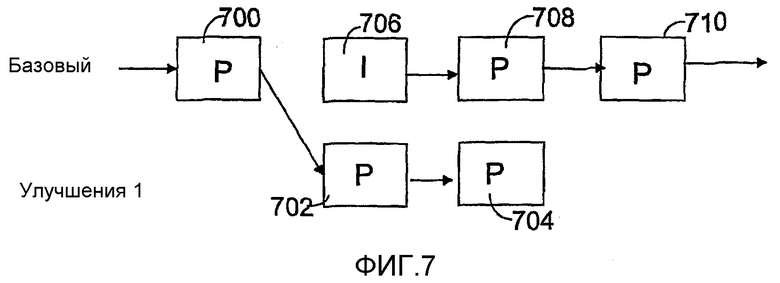
Изобретение относится к области видеокодирования, и в частности к группированию видеофайлов с использованием потоковой передачи. Техническим результатом является обеспечение высокого качества восстановленного изображения. Технический результат достигается тем, что способ кодирования видеопоследовательности содержит независимую последовательность кадров изображения, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения. В видеопоследовательность кодируется указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения упомянутой независимой последовательности, при этом упомянутый по меньшей мере один опорный кадр изображения включается в данную последовательность. На стадии декодирования из видеопоследовательности декодируется указание по меньшей мере одного кадра изображения, и декодирование видеопоследовательности начинается с упомянутого первого кадра изображения упомянутой независимой последовательности, при этом видеопоследовательность декодируется без прогнозирования на основе какого-либо кадра изображения, декодированного до упомянутого первого кадра изображения. 7 н. и 9 з.п. ф-лы, 14 ил.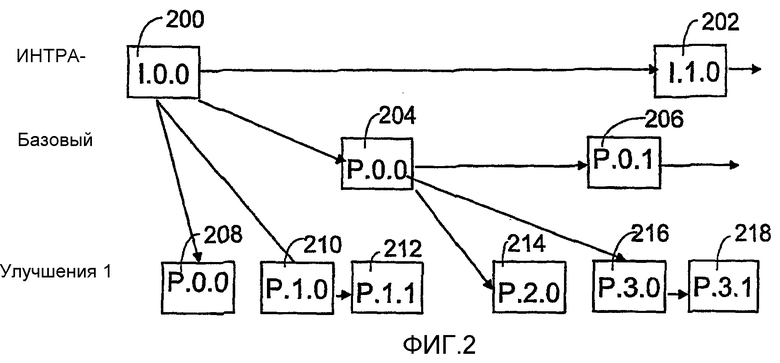
1. Способ кодирования видеопоследовательности, содержащей независимую последовательность кадров изображения, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что содержит этап, на котором кодируют в видеопоследовательность указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения упомянутой независимой последовательности, при этом упомянутый по меньшей мере один опорный кадр изображения включают в данную последовательность.
2. Способ по п.1, отличающийся тем, что кодируют упомянутое указание в видеопоследовательность в качестве отдельного флага, включаемого в заголовок среза.
3. Способ по п.1, отличающийся тем, что кодируют значения идентификаторов для кадров изображения согласно схеме нумерации, переустанавливают значение идентификатора для указанного первого кадра изображения независимой последовательности.
4. Способ по п.1, отличающийся тем, что кодируют в видеопоследовательность значение идентификатора для независимой последовательности.
5. Видеокодер для кодирования видеопоследовательности, содержащей независимую последовательность кадров изображения, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что выполнен с возможностью кодирования в видеопоследовательность указания по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения упомянутой независимой последовательности, при этом упомянутый по меньшей мере один опорный кадр изображения включается в данную последовательность.
6. Видеокодер по п.5, отличающийся тем, что выполнен с возможностью кодирования упомянутого указания в видеопоследовательность в качестве отдельного флага, включаемого в заголовок среза.
7. Видеокодер по п.5, отличающийся тем, что выполнен с возможностью кодирования значений идентификаторов для кадров изображения согласно схеме нумерации, переустановки значения идентификатора для указанного первого кадра изображения независимой последовательности.
8. Видеокодер по п.5, отличающийся тем, что выполнен с возможностью кодирования в видеопоследовательность значения идентификатора для независимой последовательности.
9. Машиночитаемый носитель, на котором хранится исполняемый в устройстве обработки данных компьютерный программный код, предназначенный для кодирования видеопоследовательности, содержащей независимую последовательность кадров изображения, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что компьютерный программный код содержит компьютерный программный код для кодирования в видеопоследовательность указания по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения упомянутой независимой последовательности, при этом упомянутый по меньшей мере один опорный кадр изображения включается в данную последовательность.
10. Способ декодирования сжатой видеопоследовательности, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что содержит этапы, на которых декодируют из видеопоследовательности указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения независимой последовательности, причем данная последовательность включает в себя упомянутый по меньшей мере один опорный кадр изображения, начинают декодирование видеопоследовательности с упомянутого первого кадра изображения упомянутой независимой последовательности, при этом видеопоследовательность декодируется без прогнозирования на основе какого-либо кадра изображения, декодированного до упомянутого первого кадра изображения.
11. Способ по п.10, отличающийся тем, что упомянутое указание является отдельным флагом, включенным в заголовок среза.
12. Способ по п.10 или 11, отличающийся тем, что декодируют значения идентификаторов для кадров изображения согласно схеме нумерации, переустанавливают значение идентификатора для указанного первого кадра изображения независимой последовательности.
13. Видеодекодер для декодирования сжатой видеопоследовательности, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что выполнен с возможностью декодировать из видеопоследовательности указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения независимой последовательности, причем данная последовательность включает в себя упомянутый по меньшей мере один опорный кадр изображения, начинать декодирование видеопоследовательности с упомянутого первого кадра изображения упомянутой независимой последовательности, при этом видеопоследовательность декодируется без прогнозирования на основе какого-либо кадра изображения, декодированного до упомянутого первого кадра изображения.
14. Машиночитаемый носитель, на котором хранится исполняемый в устройстве обработки данных компьютерный программный код, предназначенный для декодирования сжатой видеопоследовательности, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что компьютерный программный код содержит компьютерный программный код для того, чтобы декодировать из видеопоследовательности указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения независимой последовательности, причем данная последовательность включает в себя упомянутый по меньшей мере один опорный кадр изображения, компьютерный программный код для того, чтобы начинать декодирование видеопоследовательности с упомянутого первого кадра изображения упомянутой независимой последовательности, при этом видеопоследовательность декодируется без прогнозирования на основе какого-либо кадра изображения, декодированного до упомянутого первого кадра изображения.
15. Видеосигнал, содержащий сжатую видеопоследовательность, включающую в себя независимую последовательность кадров изображения, при этом по меньшей мере один опорный кадр изображения является прогнозируемым на основе по меньшей мере одного предыдущего кадра изображения, который предшествует в порядке декодирования предыдущему опорному кадру изображения, отличающийся тем, что содержит указание по меньшей мере одного кадра изображения, который является первым, в порядке декодирования, кадром изображения упомянутой независимой последовательности, при этом упомянутый по меньшей мере один опорный кадр изображения включен в данную последовательность.
16. Видеосигнал по п.15, отличающийся тем, что содержит значение идентификатора для упомянутой независимой последовательности.
| STEPHAN WENGER, Temporal Scalability using P-Pictures for Low-Latency Applications, IEEE Signal Processing Society 1998 Workshop on Multimedia Signal Processing, Los Angeles, December 7-9, 1998 | |||
| УСТРОЙСТВО КОДИРОВАНИЯ ВИДЕОСИГНАЛА, ПРЕДСТАВЛЯЮЩЕГО ИЗОБРАЖЕНИЯ, ПРИЕМНИК ТЕЛЕВИЗИОННОГО СИГНАЛА, ВКЛЮЧАЮЩЕГО ДАННЫЕ ЗАГОЛОВКОВ И ПОЛЕЗНЫЕ ДАННЫЕ В ВИДЕ СЖАТЫХ ВИДЕОДАННЫХ | 1992 |
|
RU2128405C1 |
| Горючая смесь на основе ацетилена и пропан-бутановой фракции | 1961 |
|
SU147283A1 |
| US 6072831 A, 06.06.2000 | |||
| US 6337881 B1, 08.01.2002 | |||
| RU 2137194 C1, 10.09.1999 | |||
| Information | |||

