ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящая заявка на патент испрашивает приоритет по. предварительной заявке на патент США №. 62/905,132, поданной 24 сентября 2019 г. Е-Куи Вангом (Ye-Kui Wang) и озаглавленной «Сигнализация наборов выводимых слоев для многоракурсной масштабируемости» (“Signalling Of Output Layer Sets For Multiview Scalability”), которая настоящим включена посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Настоящее раскрытие в целом относится к видеокодированию и, в частности, относится к конфигурированию наборов выводимых слоев (OLS) в многослойных битовых потоках для поддержки пространственного масштабирования и масштабирования сигнал-шум (SNR) для многоракурсного видео.
УРОВЕНЬ ТЕХНИКИ
[0003] Объем видеоданных, необходимых для представления даже относительно короткого видео, может быть значительным, что может привести к трудностям, когда эти данные должны передаваться в потоковом режиме или иным образом передаваться по сети связи с ограниченной пропускной способностью. Таким образом, видеоданные, как правило, сжимаются перед тем, как передаваться через современные телекоммуникационные сети. Размер видео также может быть проблемой, когда видео хранится на запоминающем устройстве, поскольку ресурсы памяти могут быть ограничены. Устройства сжатия видео часто используют программное и/или аппаратное обеспечение в источнике для кодирования видеоданных перед передачей или хранением, тем самым уменьшая количество данных, необходимых для представления цифровых видеоизображений. Сжатые данные затем принимаются устройством-получателем распаковки видео, которое декодирует видеоданные. С ограниченными сетевыми ресурсами и постоянно растущими требованиями к более высокому качеству видео желательны улучшенные методики сжатия и распаковки, которые улучшают степень сжатия с минимальными потерями в качестве изображения или вообще без них.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0004] В одном варианте осуществления раскрытие включает в себя способ, реализуемый декодером, причем способ содержит: прием приемником декодера битового потока, содержащего набор выводимых слоев (OLS) и набор параметров видео (VPS), при этом OLS включает в себя один или более слоев кодированных снимков, и VPS включает в себя код идентификации режима OLS (ols_mode_idc), задающий то, что для каждого OLS все слои в каждом OLS являются выводимыми слоями; определение процессором декодера выводимых слоев на основе ols_mode_idc в VPS; и декодирование процессором декодера кодированного снимка из выводимых слоев для создания декодированного снимка.
[0005] Некоторые системы видеокодирования выполнены с возможностью декодировать и выводить только самый верхний кодированный слой, обозначенный идентификатором слоя, вместе с одним или более указанными нижними слоями. Это может представлять проблему для масштабируемости, поскольку декодер может не захотеть декодировать самый верхний слой. В частности, декодер обычно запрашивает самый верхний слой, который может поддерживать декодер, но обычно декодер не может декодировать слой, который выше запрошенного слоя. В качестве конкретного примера декодер может захотеть принять и декодировать третий слой из пятнадцати кодированных слоев. Третий слой может быть отправлен в декодер без слоев с четвертого по пятнадцатый, поскольку такие слои не нужны для декодирования третьего слоя. Но декодер может быть не в состоянии должным образом декодировать и отобразить третий слой, потому что самый верхний слой (пятнадцатый слой) отсутствует, а видеосистема направлена на то, чтобы всегда декодировать и отображать самый верхний слой. Это приводит к ошибке при попытке масштабирования видео в таких системах. Это может быть серьезной проблемой, поскольку требование, чтобы декодеры всегда поддерживали самый верхний слой, приводит к тому, что система не может масштабироваться до промежуточных слоев на основе различных требований к оборудованию и сети. Эта проблема усугубляется, когда используется множество ракурсов. При множестве ракурсов для отображения выводится более одного слоя. Например, пользователь может использовать гарнитуру, и для каждого глаза могут отображаться разные слои, чтобы создать впечатление трехмерного (3D) видео. Системы, которые не поддерживают масштабируемость, также не поддерживают масштабируемость с множеством ракурсов.
[0006] Настоящий пример включает в себя механизм поддержки многоракурсной масштабируемости. Слои включены в OLS. Кодер может отправить OLS, содержащий слои для масштабирования в отношении конкретной характеристики, такой как размер или SNR. Кроме того, кодер может передать синтаксический элемент ols_mode_idc, например, в VPS. Синтаксический элемент ols_mode_idc может быть установлен в значение один для указания использования многоракурсной масштабируемости. Например, ols_mode_idc может указывать, что общее количество OLS равно общему количеству слоев, заданных в VPS, что i-й OLS включает в себя слои с 0 по i включительно, и что для каждого OLS все слои рассматриваются как выводимые слои. Это поддерживает масштабируемость, поскольку декодер может принимать и декодировать все слои в конкретном OLS. Поскольку все слои являются выводимыми слоями, декодер может выбирать и визуализировать желаемые выводимые слои. Таким образом, общее количество кодированных слоев может не влиять на процесс декодирования, и ошибки можно избежать, обеспечивая при этом масштабируемое многоракурсное видео. Таким образом, раскрытые механизмы увеличивают функциональные возможности кодера и/или декодера. Кроме того, раскрытые механизмы могут уменьшать размер битового потока и, следовательно, уменьшать использование процессора, памяти и/или сетевых ресурсов как в кодере, так и в декодере. В конкретном варианте осуществления использование ols_mode_idc обеспечивает экономию битов в кодированных битовых потоках, которые содержат множество OLS, между которыми совместно используются многие данные, таким образом обеспечивая экономию серверов потоковой передачи и обеспечивая экономию пропускной способности для передачи таких битовых потоков. Например, преимущество установки ols_mode_idc в один заключается в поддержке вариантов использования, таких как многоракурсные варианты применения, в которых два или более ракурсов, каждый из которых представлен одним слоем, должны выводиться и отображаться одновременно.
[0007] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором ols_mode_idc задает то, что общее количество OLS, заданных в VPS, равно количеству слоев, заданных в VPS.
[0008] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором ols_mode_idc задает то, что i-й OLS включает в себя слои с индексами слоев от нуля до i включительно.
[0009] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором ols_mode_idc равен одному.
[0010] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором VPS включает в себя максимальное количество слоев VPS минус один (vps_max_layers_minus1), которое задает количество слоев, заданных в VPS, которое является максимально допустимым количеством слоев в каждой кодированной видеопоследовательности (CVS), ссылающейся на VPS.
[0011] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором общее количество OLS (TotalNumOlss) равно vps_max_layers_minus1 плюс один, когда ols_mode_idc равен нулю или когда ols_mode_idc равен одному.
[0012] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором количество слоев в i-м OLS (NumLayersInOls[i]) и значение идентификатора слоя заголовка единицы слоя сетевой абстракции (NAL) (nuh_layer_id) j-го слоя в i-м OLS (LayerIdInOLS[i][j]) выводятся следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j]
где vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных в VPS, а each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя.
[0013] В одном варианте осуществления раскрытие включает в себя способ, реализуемый кодером, содержащий: кодирование процессором кодера битового потока, содержащего один или более OLS, включающих в себя один или более слоев кодированных снимков; кодирование в битовый поток процессором VPS, при этом VPS включает в себя ols_mode_idc, задающий то, что для каждого OLS все слои в каждом OLS являются выводимыми слоями; и сохранение в памяти, связанной с процессором, битового потока для передачи в декодер.
[0014] Некоторые системы видеокодирования выполнены с возможностью декодировать и выводить только самый верхний кодированный слой, обозначенный идентификатором слоя, вместе с одним или более указанными нижними слоями. Это может представлять проблему для масштабируемости, поскольку декодер может не захотеть декодировать самый верхний слой. В частности, декодер обычно запрашивает самый верхний слой, который может поддерживать декодер, но обычно декодер не может декодировать слой, который выше запрошенного слоя. В качестве конкретного примера декодер может захотеть принять и декодировать третий слой из пятнадцати кодированных слоев. Третий слой может быть отправлен в декодер без слоев с четвертого по пятнадцатый, поскольку такие слои не нужны для декодирования третьего слоя. Но декодер может быть не в состоянии должным образом декодировать и отобразить третий слой, потому что самый верхний слой (пятнадцатый слой) отсутствует, а видеосистема направлена на то, чтобы всегда декодировать и отображать самый верхний слой. Это приводит к ошибке при попытке масштабирования видео в таких системах. Это может быть серьезной проблемой, поскольку требование, чтобы декодеры всегда поддерживали самый верхний слой, приводит к тому, что система не может масштабироваться до промежуточных слоев на основе различных требований к оборудованию и сети. Эта проблема усугубляется, когда используется множество ракурсов. При множестве ракурсов для отображения выводится более одного слоя. Например, пользователь может использовать гарнитуру, и для каждого глаза могут отображаться разные слои, чтобы создать впечатление трехмерного (3D) видео. Системы, которые не поддерживают масштабируемость, также не поддерживают масштабируемость с множеством ракурсов.
[0015] Настоящий пример включает в себя механизм поддержки многоракурсной масштабируемости. Слои включены в OLS. Кодер может отправить OLS, содержащий слои для масштабирования в отношении конкретной характеристики, такой как размер или SNR. Кроме того, кодер может передать синтаксический элемент ols_mode_idc, например, в VPS. Синтаксический элемент ols_mode_idc может быть установлен в значение один для указания использования многоракурсной масштабируемости. Например, ols_mode_idc может указывать, что общее количество OLS равно общему количеству слоев, заданных в VPS, что i-й OLS включает в себя слои с 0 по i включительно, и что для каждого OLS все слои рассматриваются как выводимые слои. Это поддерживает масштабируемость, поскольку декодер может принимать и декодировать все слои в конкретном OLS. Поскольку все слои являются выводимыми слоями, декодер может выбирать и визуализировать желаемые выводимые слои. Таким образом, общее количество кодированных слоев может не влиять на процесс декодирования, и ошибки можно избежать, обеспечивая при этом масштабируемое многоракурсное видео. Таким образом, раскрытые механизмы увеличивают функциональные возможности кодера и/или декодера. Кроме того, раскрытые механизмы могут уменьшать размер битового потока и, следовательно, уменьшать использование процессора, памяти и/или сетевых ресурсов как в кодере, так и в декодере. В конкретном варианте осуществления использование ols_mode_idc обеспечивает экономию битов в кодированных битовых потоках, которые содержат множество OLS, между которыми совместно используются многие данные, таким образом обеспечивая экономию серверов потоковой передачи и обеспечивая экономию пропускной способности для передачи таких битовых потоков. Например, преимущество установки ols_mode_idc в один заключается в поддержке вариантов использования, таких как многоракурсные варианты применения, в которых два или более ракурсов, каждый из которых представлен одним слоем, должны выводиться и отображаться одновременно.
[0016] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором ols_mode_idc задает то, что общее количество OLS, заданных в VPS, равно количеству слоев, заданных в VPS.
[0017] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором ols_mode_idc задает то, что i-й OLS включает в себя слои с индексами слоев от нуля до i включительно.
[0018] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором ols_mode_idc равен одному.
[0019] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором VPS включает в себя vps_max_layers_minus1, который задает количество слоев, заданных в VPS, которое является максимально допустимым количеством слоев в каждой CVS, ссылающейся на VPS.
[0020] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором TotalNumOlss равен vps_max_layers_minus1 плюс один, когда ols_mode_idc равен нулю или когда ols_mode_idc равен одному.
[0021] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором NumLayersInOls[i] и LayerIdInOLS[i][j] выводятся следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j]
где vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных в VPS, а each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя.
[0022] В одном варианте осуществления раскрытие включает в себя устройство кодирования/декодирования видео, содержащее: процессор, приемник, соединенный с процессором, память, соединенную с процессором, и передатчик, соединенный с процессором, при этом процессор, приемник, память и передатчик выполнены с возможностью осуществлять способ согласно любому из предшествующих аспектов.
[0023] В одном варианте осуществления раскрытие включает в себя долговременный машиночитаемый носитель, содержащий компьютерный программный продукт для использования устройством кодирования/декодирования видео, причем компьютерный программный продукт содержит машиноисполняемые инструкции, хранящиеся на долговременном машиночитаемом носителе, так что при их исполнении процессор предписывает устройству кодирования/декодирования видео выполнять способ согласно любому из предшествующих аспектов.
[0024] В одном варианте осуществления раскрытие включает в себя декодер, содержащий: средство приема для приема битового потока, содержащего OLS и VPS, при этом OLS включает в себя один или более слоев кодированных снимков, и VPS включает в себя ols_mode_idc, задающий то, что для каждого OLS все слои в каждом OLS являются выводимыми слоями; средство определения для определения выводимых слоев на основе ols_mode_idc в VPS; средство декодирования для декодирования кодированного снимка из выводимых слоев для создания декодированного снимка; и средство пересылки для пересылки декодированного снимка для отображения в качестве части декодированной видеопоследовательности.
[0025] Некоторые системы видеокодирования выполнены с возможностью декодировать и выводить только самый верхний кодированный слой, обозначенный идентификатором слоя, вместе с одним или более указанными нижними слоями. Это может представлять проблему для масштабируемости, поскольку декодер может не захотеть декодировать самый верхний слой. В частности, декодер обычно запрашивает самый верхний слой, который может поддерживать декодер, но обычно декодер не может декодировать слой, который выше запрошенного слоя. В качестве конкретного примера декодер может захотеть принять и декодировать третий слой из пятнадцати кодированных слоев. Третий слой может быть отправлен в декодер без слоев с четвертого по пятнадцатый, поскольку такие слои не нужны для декодирования третьего слоя. Но декодер может быть не в состоянии должным образом декодировать и отобразить третий слой, потому что самый верхний слой (пятнадцатый слой) отсутствует, а видеосистема направлена на то, чтобы всегда декодировать и отображать самый верхний слой. Это приводит к ошибке при попытке масштабирования видео в таких системах. Это может быть серьезной проблемой, поскольку требование, чтобы декодеры всегда поддерживали самый верхний слой, приводит к тому, что система не может масштабироваться до промежуточных слоев на основе различных требований к оборудованию и сети. Эта проблема усугубляется, когда используется множество ракурсов. При множестве ракурсов для отображения выводится более одного слоя. Например, пользователь может использовать гарнитуру, и для каждого глаза могут отображаться разные слои, чтобы создать впечатление трехмерного (3D) видео. Системы, которые не поддерживают масштабируемость, также не поддерживают масштабируемость с множеством ракурсов.
[0026] Настоящий пример включает в себя механизм поддержки многоракурсной масштабируемости. Слои включены в OLS. Кодер может отправить OLS, содержащий слои для масштабирования в отношении конкретной характеристики, такой как размер или SNR. Кроме того, кодер может передать синтаксический элемент ols_mode_idc, например, в VPS. Синтаксический элемент ols_mode_idc может быть установлен в значение один для указания использования многоракурсной масштабируемости. Например, ols_mode_idc может указывать, что общее количество OLS равно общему количеству слоев, заданных в VPS, что i-й OLS включает в себя слои с 0 по i включительно, и что для каждого OLS все слои рассматриваются как выводимые слои. Это поддерживает масштабируемость, поскольку декодер может принимать и декодировать все слои в конкретном OLS. Поскольку все слои являются выводимыми слоями, декодер может выбирать и визуализировать желаемые выводимые слои. Таким образом, общее количество кодированных слоев может не влиять на процесс декодирования, и ошибки можно избежать, обеспечивая при этом масштабируемое многоракурсное видео. Таким образом, раскрытые механизмы увеличивают функциональные возможности кодера и/или декодера. Кроме того, раскрытые механизмы могут уменьшать размер битового потока и, следовательно, уменьшать использование процессора, памяти и/или сетевых ресурсов как в кодере, так и в декодере. В конкретном варианте осуществления использование ols_mode_idc обеспечивает экономию битов в кодированных битовых потоках, которые содержат множество OLS, между которыми совместно используются многие данные, таким образом обеспечивая экономию серверов потоковой передачи и обеспечивая экономию пропускной способности для передачи таких битовых потоков. Например, преимущество установки ols_mode_idc в один заключается в поддержке вариантов использования, таких как многоракурсные варианты применения, в которых два или более ракурсов, каждый из которых представлен одним слоем, должны выводиться и отображаться одновременно.
[0027] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором декодер дополнительно выполнен с возможностью осуществления способа согласно любому из предшествующих аспектов.
[0028] В одном варианте осуществления раскрытие включает в себя кодер, содержащий: средство кодирования для: кодирования битового потока, содержащего один или более OLS, включающих в себя один или более слоев кодированных снимков; и кодирования в битовый поток VPS, при этом VPS включает в себя ols_mode_idc, задающий то, что для каждого OLS все слои в каждом OLS являются выводимыми слоями; и средство хранения для хранения битового потока для передачи в декодер.
[0029] Некоторые системы видеокодирования выполнены с возможностью декодировать и выводить только самый верхний кодированный слой, обозначенный идентификатором слоя, вместе с одним или более указанными нижними слоями. Это может представлять проблему для масштабируемости, поскольку декодер может не захотеть декодировать самый верхний слой. В частности, декодер обычно запрашивает самый верхний слой, который может поддерживать декодер, но обычно декодер не может декодировать слой, который выше запрошенного слоя. В качестве конкретного примера декодер может захотеть принять и декодировать третий слой из пятнадцати кодированных слоев. Третий слой может быть отправлен в декодер без слоев с четвертого по пятнадцатый, поскольку такие слои не нужны для декодирования третьего слоя. Но декодер может быть не в состоянии должным образом декодировать и отобразить третий слой, потому что самый верхний слой (пятнадцатый слой) отсутствует, а видеосистема направлена на то, чтобы всегда декодировать и отображать самый верхний слой. Это приводит к ошибке при попытке масштабирования видео в таких системах. Это может быть серьезной проблемой, поскольку требование, чтобы декодеры всегда поддерживали самый верхний слой, приводит к тому, что система не может масштабироваться до промежуточных слоев на основе различных требований к оборудованию и сети. Эта проблема усугубляется, когда используется множество ракурсов. При множестве ракурсов для отображения выводится более одного слоя. Например, пользователь может использовать гарнитуру, и для каждого глаза могут отображаться разные слои, чтобы создать впечатление трехмерного (3D) видео. Системы, которые не поддерживают масштабируемость, также не поддерживают масштабируемость с множеством ракурсов.
[0030] Настоящий пример включает в себя механизм поддержки многоракурсной масштабируемости. Слои включены в OLS. Кодер может отправить OLS, содержащий слои для масштабирования в отношении конкретной характеристики, такой как размер или SNR. Кроме того, кодер может передать синтаксический элемент ols_mode_idc, например, в VPS. Синтаксический элемент ols_mode_idc может быть установлен в значение один для указания использования многоракурсной масштабируемости. Например, ols_mode_idc может указывать, что общее количество OLS равно общему количеству слоев, заданных в VPS, что i-й OLS включает в себя слои с 0 по i включительно, и что для каждого OLS все слои рассматриваются как выводимые слои. Это поддерживает масштабируемость, поскольку декодер может принимать и декодировать все слои в конкретном OLS. Поскольку все слои являются выводимыми слоями, декодер может выбирать и визуализировать желаемые выводимые слои. Таким образом, общее количество кодированных слоев может не влиять на процесс декодирования, и ошибки можно избежать, обеспечивая при этом масштабируемое многоракурсное видео. Таким образом, раскрытые механизмы увеличивают функциональные возможности кодера и/или декодера. Кроме того, раскрытые механизмы могут уменьшать размер битового потока и, следовательно, уменьшать использование процессора, памяти и/или сетевых ресурсов как в кодере, так и в декодере. В конкретном варианте осуществления использование ols_mode_idc обеспечивает экономию битов в кодированных битовых потоках, которые содержат множество OLS, между которыми совместно используются многие данные, таким образом обеспечивая экономию серверов потоковой передачи и обеспечивая экономию пропускной способности для передачи таких битовых потоков. Например, преимущество установки ols_mode_idc в один заключается в поддержке вариантов использования, таких как многоракурсные варианты применения, в которых два или более ракурсов, каждый из которых представлен одним слоем, должны выводиться и отображаться одновременно.
[0031] В необязательном порядке, в любом из предшествующих аспектов предусмотрен другой вариант реализации аспекта, в котором кодер дополнительно выполнен с возможностью осуществления способа согласно любому из предшествующих аспектов.
[0032] Для ясности любой из вышеупомянутых вариантов осуществления может быть объединен с любым одним или более другими вышеупомянутыми вариантами осуществления, чтобы создать новый вариант осуществления в пределах объема настоящего раскрытия.
[0033] Эти и другие особенности будут более понятны из следующего подробного описания, рассматриваемого вместе с сопроводительными чертежами и формулой изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0034] Для более полного понимания этого раскрытия теперь сделана ссылка на следующее краткое описание, рассматриваемое совместно с прилагаемыми чертежами и подробным описанием, в котором одинаковые номера позиций представляют одинаковые части.
[0035] Фиг.1 является блок-схемой последовательности операций примерного способа кодирования видеосигнала.
[0036] Фиг.2 является принципиальной схемой примерной системы кодирования и декодирования (кодека) для кодирования/декодирования видео.
[0037] Фиг.3 является принципиальной схемой, иллюстрирующей примерный видеокодер.
[0038] Фиг.4 является принципиальной схемой, иллюстрирующей примерный видеодекодер.
[0039] Фиг.5 является принципиальной схемой, иллюстрирующей примерную многослойную видеопоследовательность, сконфигурированную для межслойного предсказания.
[0040] Фиг.6 является принципиальной схемой, иллюстрирующей примерную видеопоследовательность с OLS, сконфигурированными для многоракурсной масштабируемости.
[0041] Фиг.7 является принципиальной схемой, иллюстрирующей пример битового потока, включающего в себя OLS, сконфигурированные для многоракурсной масштабируемости.
[0042] Фиг.8 является принципиальной схемой примерного устройства кодирования/декодирования видео.
[0043] Фиг.9 является блок-схемой последовательности операций примерного способа кодирования видеопоследовательности с OLS, сконфигурированными для многоракурсной масштабируемости.
[0044] Фиг.10 является блок-схемой последовательности операций примерного способа декодирования видеопоследовательности, включающей в себя OLS, сконфигурированный для многоракурсной масштабируемости.
[0045] Фиг.11 является принципиальной схемой примерной системы для кодирования видеопоследовательности с OLS, сконфигурированными для многоракурсной масштабируемости.
ПОДРОБНОЕ ОПИСАНИЕ
[0046] Вначале следует понять, что хотя иллюстративная реализация одного или более вариантов осуществления представлена ниже, раскрытые системы и/или способы могут быть реализованы с использованием любого количества способов, известных в настоящее время или существующих. Раскрытие никоим образом не должно ограничиваться иллюстративными реализациями, чертежами и технологиями, проиллюстрированными ниже, включая иллюстративные конструкции и реализации, проиллюстрированные и описанные здесь, но может быть изменено в пределах объема прилагаемой формулы изобретения вместе с полным объемом ее эквивалентов.
[0047] Следующие ниже термины определены следующим образом, если они не используются в данном документе в противоположном контексте. В частности, следующие определения предназначены для дополнительной ясности настоящего раскрытия. Однако в разных контекстах термины могут описываться по-разному. Соответственно, следующие определения следует рассматривать как дополнение и не следует рассматривать как ограничение каких-либо других определений описаний, предоставленных для таких терминов в данном документе.
[0048] Битовый поток - это последовательность битов, включающая в себя видеоданные, которые сжимаются для передачи между кодером и декодером. Кодер - это устройство, которое выполнено с возможностью использования процессов кодирования для сжатия видеоданных в битовый поток. Декодер - это устройство, которое выполнено с возможностью использования процессов декодирования для восстановления видеоданных из битового потока для отображения. Снимок - это массив дискретных отсчетов яркости и/или массив дискретных отсчетов цветности, которые создают кадр или его область. Снимок, который кодируется или декодируется, может называться текущим снимком для ясности обсуждения.
[0049] Единица слоя сетевой абстракции (NAL) представляет собой синтаксическую структуру, содержащую данные в форме полезной нагрузки необработанной байтовой последовательности (RBSP), указание типа данных и перемежающиеся по желанию байтами предотвращения эмуляции. Единица NAL слоя видеокодирования (VCL) представляет собой единицу NAL, кодированную для содержания видеоданных, таких как кодированный фрагмент снимка. Единица NAL не-VCL представляет собой единицу NAL, которая содержит не видеоданные, такие как синтаксис и/или параметры, которые поддерживают декодирование видеоданных, выполнение проверки на согласованность или другие операции. Слой представляет собой набор единиц NAL VCL, которые совместно используют заданную характеристику (например, общее разрешение, частоту кадров, размер снимка и т.д.), и связанных единиц NAL не-VCL. Единицы NAL VCL слоя могут совместно использовать конкретное значение идентификатора слоя заголовка единицы NAL (nuh_layer_id). Кодированный снимок представляет собой кодированное представление снимка, содержащего единицы NAL VCL с конкретным значением идентификатора слоя заголовка единицы NAL (nuh_layer_id) в единице доступа (AU) и содержащего все единицы дерева кодирования (CTU) снимка. Декодированный снимок представляет собой снимок, созданный посредством применения процесса декодирования к кодированному снимку. Кодированная видеопоследовательность (CVS) представляет собой последовательность AU, которые включает в себя в порядке декодирования одну или более AU начала кодированной видеопоследовательности (CVSS) и, в необязательном порядке, еще одну AU, которые не являются AU CVSS. AU CVSS - это AU, включающая в себя единицу предсказания (PU) для каждого слоя, заданного набором параметров видео (VPS), где кодированный снимок в каждой PU является начальным снимком для CVS/кодированной послойно видеопоследовательности (CLVS).
[0050] Набор выводимых слоев (OLS) - это набор слоев, для которых один или более слоев указаны в качестве выводимых слоев. Выводимой слой представляет собой слой, предназначенный для вывода (например, на дисплей). Самый верхний слой - это слой в OLS, который имеет самый большой идентификатор слоя (ID) среди всех слоев в OLS. В некоторых примерных режимах OLS самым верхним слоем всегда может быть выводимый слой. В других режимах указанные слои и/или все слои являются выводимыми слоями. Набор параметров видео (VPS) - это единичный блок (единица) данных, содержащий параметры, относящиеся ко всему видео. Межслойное предсказание - это механизм кодирования текущего снимка в текущем слое посредством ссылки на опорный снимок в опорном слое, где текущий снимок и опорный снимок включены в одну и ту же AU, а опорный слой включает в себя более нижний nuh_layer_id, чем текущий слой.
[0051] Код идентификации режима OLS (ols_mode_idc) представляет собой синтаксический элемент, который указывает информацию, относящуюся к количеству OLS, слоям OLS и выводимым слоям в OLS. Максимальное количество слоев VPS минус один (vps_max_layers_minus1) - это синтаксический элемент, который сигнализирует количество слоев, заданных в VPS, и, следовательно, максимальное количество слоев, допустимых в соответствующем CVS. Каждый слой является флагом OLS (each_layer_is_an_ols_flag) и представляет собой синтаксический элемент, который сигнализирует, содержит ли каждый OLS в битовом потоке единственный слой. Общее количество OLS (TotalNumOLss) - это переменная, задающая общее количество OLS, заданных в VPS. Количество слоев в i-м OLS (NumLayersInOLS[i]) - это переменная, которая задает количество слоев в конкретном OLS, обозначенном значением индекса OLS, равным i. Идентификатор (ID) слоя в OLS (LayerIdInOLS[i][j]) представляет собой переменную, которая задает значение nuh_layer_id j-го слоя в i-м OLS, обозначаемое индексом j слоя и индексом i OLS. vps_layer_id[i] - это синтаксический элемент, который указывает идентификатор слоя i-го слоя.
[0007] В настоящем документе используются следующие аббревиатуры: Блок дерева кодирования (CTB), Единица (единичный блок) дерева кодирования (CTU), Единица кодирования (CU), Кодированная видеопоследовательность (CVS), Объединенная группа экспертов по видео (JVET), Набор клеток с ограничением движения (MCTS), Максимальная единица передачи (MTU), Слой сетевой абстракции (NAL), Набор выводимых слоев (OLS), Порядковый номер снимка (POC), Полезная нагрузка необработанной байтовой последовательности (RBSP), Набор параметров последовательности (SPS), Набор параметров видео (VPS) и Универсальное видеокодирование (VVC).
[0053] Для уменьшения размера видеофайлов с минимальной потерей данных можно использовать многие методики сжатия видео. Например, методики сжатия видео могут включать в себя выполнение пространственного (например, внутрикадрового (интра)) предсказания. Для блочного видеокодирования сегмент (слайс) видео (например, видеоснимок или часть видеоснимка) может быть разделен на видеоблоки, которые также могут называться древовидными блоками, блоками дерева кодирования (CTB), единичными блоками дерева кодирования (CTU), единичными блоками кодирования (CU) и/или узлами кодирования. Видеоблоки в сегменте, закодированном в интра-режиме (I), кодируются с использованием пространственного предсказания относительно опорных дискретных отсчетов в соседних блоках в одном и том же снимке. Видеоблоки в сегменте снимка, закодированном в межкадровом (интер) режиме с однонаправленным предсказанием (P) или двунаправленным предсказанием (B), могут кодироваться, используя пространственное предсказание относительно опорных дискретных отсчетов в соседних блоках в одном и том же снимке или временное предсказание относительно опорных дискретных отсчетов в других опорных снимках. Снимки могут называться кадрами и/или изображениями, а опорные снимки могут называться опорными кадрами и/или опорными изображениями. Пространственное или временное предсказание приводит к блоку предсказания, представляющему блок изображения. Остаточные данные представляют собой пиксельные разности между исходным блоком изображения и блоком предсказания. Соответственно, кодированный в интер-режиме блок кодируется согласно вектору движения, который указывает на блок опорных дискретных отсчетов, формирующих блок предсказания, и остаточные данные, указывающие разность между кодированным блоком и блоком предсказания. Кодированный в интра-режиме блок кодируется в соответствии с режимом внутрикадрового (интра) кодирования и остаточными данными. Для дальнейшего сжатия остаточные данные могут быть преобразованы из области пикселей в область преобразования. В результате получаются остаточные коэффициенты преобразования, которые можно квантовать. Квантованные коэффициенты преобразования могут изначально быть скомпонованы в двумерном массиве. Квантованные коэффициенты преобразования могут сканироваться для создания одномерного вектора коэффициентов преобразования. Для достижения еще большего сжатия может применяться энтропийное кодирование. Такие методики сжатия видео более подробно обсуждаются ниже.
[0054] Чтобы обеспечить точное декодирование закодированного видео, видео кодируется и декодируется согласно соответствующим стандартам видеокодирования. Стандарты видеокодирования включают в себя Сектор стандартизации Международного союза электросвязи (ITU) (ITU-T) H.261, Группа экспертов по кинофильмам (MPEG)-1 Часть 2 Международной организации по стандартизации/Международная электротехническая комиссия (ISO/IEC), ITU-T H.262 или ISO/IEC MPEG-2 Часть 2, ITU-T H.263, ISO/IEC MPEG-4 Часть 2, Усовершенствованное видеокодирование (AVC), также известное как ITU-T H.264 или ISO/IEC MPEG-4 Часть 10, и Высокоэффективное кодирование видео (HEVC), также известное как ITU-T H.265 или MPEG-H Часть 2. AVC включает в себя такие расширения, как Масштабируемое видеокодирование (SVC), Видеокодирование с несколькими ракурсами (MVC) и Видеокодирование с несколькими ракурсами плюс глубина (MVC+D) и трехмерное (3D) AVC (3D-AVC). HEVC включает в себя такие расширения, как Масштабируемое HEVC (SHVC), HEVC с несколькими ракурсами (MV-HEVC) и 3D HEVC (3D-HEVC). Совместная группа экспертов по видео (JVET) ITU-T и ISO/IEC приступила к разработке стандарта видеокодирования, называемого Универсальным видеокодированием (VVC). VVC включен в WD, который включает в себя JVET-N1001-v14.
[0055] Слои снимков могут использоваться для поддержки масштабируемости. Например, видео можно кодировать в множество слоев. Слой может быть кодирован без ссылки на другие слои. Такой слой называется слоем одновременной передачи. Соответственно, слой одновременной передачи может быть декодирован без ссылки на другие слои. В качестве другого примера слой может быть кодирован с использованием межслойного предсказания. Это позволяет кодировать текущий слой, включая только различия между текущим слоем и опорным слоем. Например, текущий слой и опорный слой могут содержать одну и ту же видеопоследовательность, кодированную посредством изменения характеристики, такой как отношение сигнал-шум (SNR), размер снимка, частота кадров и т.д.
[0056] Некоторые системы видеокодирования выполнены с возможностью декодировать и выводить только самый верхний кодированный слой, обозначенный идентификатором слоя (ID), вместе с одним или более указанными нижними слоями. Это может представлять проблему для масштабируемости, поскольку декодер может не захотеть декодировать самый верхний слой. В частности, декодер обычно запрашивает самый верхний слой, который может поддерживать декодер, но обычно декодер не может декодировать слой, который выше запрошенного слоя. В качестве конкретного примера декодер может захотеть принять и декодировать третий слой из пятнадцати кодированных слоев. Третий слой может быть отправлен в декодер без слоев с четвертого по пятнадцатый, поскольку такие слои не нужны для декодирования третьего слоя. Но декодер может быть не в состоянии должным образом декодировать и отобразить третий слой, потому что самый верхний слой (пятнадцатый слой) отсутствует, а видеосистема направлена на то, чтобы всегда декодировать и отображать самый верхний слой. Это приводит к ошибке при попытке масштабирования видео в таких системах. Это может быть серьезной проблемой, поскольку требование, чтобы декодеры всегда поддерживали самый верхний слой, приводит к тому, что система не может масштабироваться до промежуточных слоев на основе различных требований к оборудованию и сети. Эта проблема усугубляется, когда используется множество ракурсов. При множестве ракурсов для отображения выводится более одного слоя. Например, пользователь может использовать гарнитуру, и для каждого глаза могут отображаться разные слои, чтобы создать впечатление трехмерного (3D) видео. Системы, которые не поддерживают масштабируемость, также не поддерживают масштабируемость с множеством ракурсов.
[0057] В данном документе раскрыт механизм для поддержки многоракурсной масштабируемости. Слои включены в наборы выводимых слоев (OLS). Кодер может отправить OLS, содержащий слои для масштабирования в отношении конкретной характеристики, такой как размер или SNR. Пространственная масштабируемость позволяет кодировать видеопоследовательность в слои таким образом, что слои помещаются в наборы выводимых слоев (OLS), так что каждый OLS содержит достаточно данных для декодирования видеопоследовательности в соответствующий размер экрана вывода. Таким образом, пространственная масштабируемость может включать в себя набор слоя(ев) для видеодекодирования для экрана смартфона, набор слоев для видеодекодирования для большого экрана телевизора и наборы слоев для средних размеров экрана. Масштабируемость SNR позволяет кодировать видеопоследовательность в слои таким образом, чтобы слои помещались в OLS, чтобы каждый OLS содержал достаточно данных для декодирования видеопоследовательности с другим SNR. Таким образом, масштабируемость SNR может включать в себя набор слоев, которые могут быть декодированы для видео низкого качества, видео высокого качества и различных промежуточных качеств видео в зависимости от сетевых условий. Кроме того, кодер может передать синтаксический элемент кода идентификации режима OLS (ols_mode_idc), например, в наборе параметров видео (VPS). Синтаксический элемент ols_mode_idc может быть установлен в значение один для указания использования многоракурсной масштабируемости. Например, ols_mode_idc может указывать, что общее количество OLS равно общему количеству слоев, заданных в VPS, что i-й OLS включает в себя слои с 0 по i включительно, и что для каждого OLS все слои рассматриваются как выводимые слои. Это поддерживает масштабируемость, поскольку декодер может принимать и декодировать все слои в конкретном OLS. Поскольку все слои являются выводимыми слоями, декодер может выбирать и визуализировать желаемые выводимые слои. Таким образом, общее количество кодированных слоев может не влиять на процесс декодирования, и ошибки можно избежать, обеспечивая при этом масштабируемое многоракурсное видео. Таким образом, раскрытые механизмы увеличивают функциональные возможности кодера и/или декодера. Кроме того, раскрытые механизмы могут уменьшать размер битового потока и, следовательно, уменьшать использование процессора, памяти и/или сетевых ресурсов как в кодере, так и в декодере.
[0058] Фиг.1 является блок-схемой примерного рабочего способа 100 кодирования видеосигнала. В частности, видеосигнал кодируется в кодере. Процесс кодирования сжимает видеосигнал, используя различные механизмы для уменьшения размера видеофайла. Меньший размер файла позволяет передавать сжатый видеофайл пользователю, уменьшая при этом издержки на полосу пропускания. Затем декодер декодирует сжатый видеофайл, чтобы восстановить исходный видеосигнал для отображения конечному пользователю. Процесс декодирования обычно отражает процесс кодирования, чтобы декодер мог последовательно восстанавливать видеосигнал.
[0059] На этапе 101 видеосигнал вводится в кодер. Например, видеосигнал может быть несжатым видеофайлом, хранящимся в памяти. В качестве другого примера видеофайл может быть захвачен устройством видеозахвата, например видеокамерой, и закодирован для поддержки потоковой передачи видео в реальном времени. Видеофайл может включать в себя как аудио составляющую, так и видео составляющую. Видео составляющая содержит серию кадров изображений, которые при последовательном просмотре создают визуальное впечатление движения. Кадры содержат пиксели, которые выражаются в единицах света, называемых здесь компонентами яркости (или дискретными отсчетами яркости), и цвета, который упоминается как компоненты цветности (или дискретные отсчеты цвета). В некоторых примерах кадры могут также содержать значения глубины для поддержки трехмерного просмотра.
[0060] На этапе 103 видео разбивается на блоки. Разбиение включает в себя разделение пикселей в каждом кадре на квадратные и/или прямоугольные блоки для сжатия. Например, при Высокоэффективном видеокодировании (HEVC) (также известном как H.265 и MPEG-H Часть 2) кадр сначала можно разделить на единицы дерева кодирования (CTU), которые представляют собой блоки заранее заданного размера (например, шестьдесят четыре пикселя на шестьдесят четыре пикселя). Единицы CTU содержат дискретные отсчеты яркости и цветности. Деревья кодирования могут использоваться для разделения CTU на блоки, а затем рекурсивно разделять блоки до тех пор, пока не будут достигнуты конфигурации, поддерживающие дальнейшее кодирование. Например, компоненты яркости кадра могут делиться до тех пор, пока отдельные блоки не будут содержать относительно однородные значения яркости. Кроме того, компоненты цветности кадра могут делиться до тех пор, пока отдельные блоки не будут содержать относительно однородные значения цвета. Соответственно, механизмы разделения меняются в зависимости от содержимого видеокадров.
[0061] На этапе 105 используются различные механизмы сжатия для сжатия блоков изображения, разделенных на этапе 103. Например, может использоваться интер-предсказание и/или интра-предсказание. Интер-предсказание предназначено для использования того факта, что объекты в общей сцене имеют тенденцию появляться в последовательных кадрах. Соответственно, блок, изображающий объект в опорном кадре, не нужно повторно описывать в соседних кадрах. В частности, объект, такой как стол, может оставаться в постоянной позиции на протяжении нескольких кадров. Следовательно, стол описывается один раз, и соседние кадры могут обращаться к опорному кадру. Механизмы сопоставления с образцом могут использоваться для сопоставления объектов в нескольких кадрах. Кроме того, движущиеся объекты могут быть представлены в нескольких кадрах, например, из-за движения объекта или движения камеры. В качестве конкретного примера видео может показывать автомобиль, который движется по экрану в нескольких кадрах. Векторы движения могут использоваться для описания такого движения. Вектор движения - это двумерный вектор, который обеспечивает смещение от координат объекта в кадре до координат объекта в опорном кадре. По существу, интер-предсказание может кодировать блок изображения в текущем кадре как набор векторов движения, указывающих смещение от соответствующего блока в опорном кадре.
[0062] Интра-предсказание кодирует блоки в общем кадре. Интра-предсказание использует тот факт, что компоненты яркости и цветности имеют тенденцию группироваться в кадре. Например, участок зеленого цвета на части дерева имеет тенденцию располагаться рядом с аналогичными участками зеленого цвета. Интра-предсказание использует несколько режимов направленного предсказания (например, тридцать три в HEVC), планарный режим и режим прямого течения (Direct Current (DC)). Направленные режимы указывают, что текущий блок подобен/совпадает с дискретными отсчетами соседнего блока в соответствующем направлении. Планарный режим указывает, что последовательность блоков вдоль строки/столбца (например, плоскости) может быть интерполирована на основе соседних блоков на краях строки. Фактически, планарный режим указывает на плавный переход света/цвета по строке/столбцу за счет использования относительно постоянного наклона при изменении значений. Режим DC используется для сглаживания границ и указывает, что блок подобен/совпадает со средним значением, связанным с дискретными отсчетами всех соседних блоков, связанных с угловыми направлениями режимов направленного предсказания. Соответственно, блоки интра-предсказания могут представлять блоки изображения как различные значения режима реляционного предсказания вместо фактических значений. Кроме того, блоки интер-предсказания могут представлять блоки изображения как значения вектора движения вместо фактических значений. В любом случае в некоторых случаях блоки предсказания могут не точно представлять блоки изображения. Любые отличия хранятся в остаточных блоках. К остаточным блокам могут применяться преобразования для дальнейшего сжатия файла.
[0063] На этапе 107 могут применяться различные методики фильтрации. В HEVC фильтры применяются в соответствии со схемой внутриконтурной фильтрации. Обсуждаемое выше предсказание на основе блоков может привести к созданию изображений с блочностью в декодере. Кроме того, схема предсказания на основе блоков может кодировать блок, а затем восстанавливать кодированный блок для последующего использования в качестве опорного блока. Схема внутриконтурной фильтрации итеративно применяет фильтры подавления шума, фильтры устранения блочности, адаптивные контурные фильтры и фильтры с адаптивным смещением дискретного отсчета (SAO) к блокам/кадрам. Эти фильтры уменьшают такие артефакты блокировки, чтобы можно было точно восстановить закодированный файл. Кроме того, эти фильтры уменьшают артефакты в восстановленных опорных блоках, так что артефакты с меньшей вероятностью создают дополнительные артефакты в последующих блоках, которые кодируются на основе восстановленных опорных блоков.
[0064] После того, как видеосигнал разделен, сжат и отфильтрован, полученные данные кодируются в битовом потоке на этапе 109. Битовый поток включает в себя данные, описанные выше, а также любые данные сигнализации, необходимые для поддержки надлежащего восстановления видеосигнала в декодере. Например, такие данные могут включать в себя данные разбиения, данные предсказания, остаточные блоки и различные флаги, предоставляющие инструкции кодирования для декодера. Битовый поток может храниться в памяти для передачи декодеру по запросу. Битовый поток также может быть передан широковещательным и/или многоадресным образом во множество декодеров. Создание битового потока - это итеративный процесс. Соответственно, этапы 101, 103, 105, 107 и 109 могут происходить непрерывно и/или одновременно во многих кадрах и блоках. Порядок, показанный на Фиг.1 представлен для ясности и простоты обсуждения и не предназначен для ограничения процесса видеокодирования конкретным порядком.
[0065] Декодер принимает битовый поток и начинает процесс декодирования на этапе 111. В частности, декодер использует схему энтропийного декодирования для преобразования битового потока в соответствующий синтаксис и видеоданные. Декодер использует синтаксические данные из битового потока для определения разбиений для кадров на этапе 111. Разбиение должно соответствовать результатам разбиения блока на этапе 103. Теперь описывается энтропийное кодирование/декодирование, используемое на этапе 111. Кодер осуществляет многократный выбор вариантов в процессе сжатия, таких как выбор схем разбиения на блоки из нескольких возможных вариантов на основе пространственного позиционирования значений во входном изображении(ях). Для сигнализации конкретного выбора может использоваться большое количество бинарных элементов (бинов). В данном контексте бинарный элемент - это двоичное значение, которое обрабатывается как переменная (например, битовое значение, которое может варьироваться в зависимости от контекста). Энтропийное кодирование позволяет кодеру отбросить любые варианты, которые явно не подходят для конкретного случая, оставив набор допустимых вариантов. Затем каждому допустимому варианту присваивается кодовое слово. Длина кодовых слов основана на количестве допустимых вариантов (например, один бинарный элемент для двух вариантов, два бинарных элемента для трех-четырех вариантов и т.д.) Затем кодер кодирует кодовое слово для выбранного варианта. Эта схема уменьшает размер кодовых слов, поскольку кодовые слова настолько велики, насколько желательно, чтобы однозначно указать выбор из небольшого поднабора допустимых вариантов, в отличие от однозначного указания выбора из потенциально большого набора всех возможных вариантов. Затем декодер декодирует выбор, определяя набор допустимых вариантов аналогично кодеру. Определив набор допустимых вариантов, декодер может считать кодовое слово и определить выбор, сделанный кодером.
[0066] На этапе 113 декодер выполняет блочное декодирование. В частности, декодер использует обратное преобразование для генерации остаточных блоков. Затем декодер использует остаточные блоки и соответствующие блоки предсказания для восстановления блоков изображения в соответствии с разбиением. Блоки предсказания могут включать в себя как блоки интра-предсказания, так и блоки интер-предсказания, сгенерированные в кодере на этапе 105. Блоки восстановленного изображения затем размещаются в кадрах восстановленного видеосигнала в соответствии с данными разбиения, определенными на этапе 111. Синтаксис для этапа 113 также может передаваться в битовом потоке посредством энтропийного кодирования, как описано выше.
[0067] На этапе 115 выполняется фильтрация кадров восстановленного видеосигнала аналогично этапу 107 в кодере. Например, фильтры подавления шума, фильтры устранения блочности, адаптивные контурные фильтры и фильтры SAO могут применяться к кадрам для удаления артефактов блочности. После фильтрации кадров видеосигнал может выводиться на дисплей на этапе 117 для просмотра конечным пользователем.
[0068] Фиг.2 является принципиальной схемой примерной системы 200 кодирования и декодирования (кодека) для кодирования/декодирования видео. В частности, система 200 кодека обеспечивает функциональные возможности для поддержки реализации рабочего способа 100. Система 200 кодека обобщена для изображения компонентов, используемых как в кодере, так и в декодере. Система 200 кодека принимает и разбивает видеосигнал, как описано в отношении этапов 101 и 103 в рабочем способе 100, что приводит к разделенному видеосигналу 201. Система 200 кодека затем сжимает разделенный видеосигнал 201 в кодированный битовый поток, действуя в качестве кодера, как описано в отношении этапов 105, 107 и 109 в способе 100. Действуя в качестве декодера, система 200 кодека генерирует выходной видеосигнал из битового потока, как описано в отношении этапов 111, 113, 115 и 117 в рабочем способе 100. Система 200 кодека включает в себя компонент 211 общего управления кодером, компонент 213 масштабирования и квантования преобразования, компонент 215 оценки интра-режима, компонент 217 интра-предсказания, компонент 219 компенсации движения, компонент 221 оценки движения, компонент 229 масштабирования и обратного преобразования, компонент 227 анализа управления фильтрами, компонент 225 внутриконтурных фильтров, компонент 223 буфера декодированных снимков и компонент 231 форматирования заголовка и контекстно-адаптивного двоичного арифметического кодирования (CABAC). Такие компоненты соединяются, как показано на Фиг.2, черные линии указывают перемещение данных, которые должны быть закодированы/декодированы, а пунктирные линии указывают перемещение данных управления, которые управляют работой других компонентов. Все компоненты системы 200 кодека могут присутствовать в кодере. Декодер может включать в себя поднабор компонентов системы 200 кодека. Например, декодер может включать в себя компонент 217 интер-предсказания, компонент 219 компенсации движения, компонент 229 масштабирования и обратного преобразования, компонент 225 внутриконтурных фильтров и компонент 223 буфера декодированных снимков. Теперь будут описаны эти компоненты.
[0069] Разделенный видеосигнал 201 представляет собой захваченную видеопоследовательность, которая была разделена на блоки пикселей с помощью дерева кодирования. Дерево кодирования использует различные режимы разделения для разделения блока пикселей на более мелкие блоки пикселей. Затем эти блоки можно разделить на более мелкие блоки. Блоки могут называться узлами в дереве кодирования. Более крупные родительские узлы разделяются на более мелкие дочерние узлы. Количество раз, когда узел делится на подразделения, называется глубиной дерева узлов/кодирования. В некоторых случаях разделенные блоки могут быть включены в единицы кодирования (CU). Например, CU может быть частью CTU, которая содержит блок яркости, блок(-и) цветоразности красного (Cr) и блок(-и) цветоразности синего (Cb) вместе с соответствующими инструкциями синтаксиса для CU. Режимы разделения могут включать в себя двоичное дерево (BT), троичное дерево (TT) и квадратное дерево (QT), используемые для разделения узла на два, три или четыре дочерних узла, соответственно, различной формы в зависимости от применяемых режимов разделения. Разделенный видеосигнал 201 пересылается в компонент 211 общего управления кодером, компонент 213 масштабирования и квантования преобразования, компонент 215 оценки интра-режима, компонент 227 анализа управления фильтрами и компонент 221 оценки движения для сжатия.
[0070] Компонент 211 общего управления кодером выполнен с возможностью принятия решений, связанных с кодированием изображений видеопоследовательности в битовый поток в соответствии с ограничениями применения. Например, компонент 211 общего управления кодером управляет оптимизацией скорости передачи/размера битового потока по сравнению с качеством восстановления. Такие решения могут быть приняты на основе доступности дискового пространства/полосы пропускания и запросов разрешения изображения. Компонент 211 общего управления кодером также управляет использованием буфера с учетом скорости передачи, чтобы уменьшить проблемы опустошения и переполнения буфера. Чтобы управлять этими проблемами, компонент 211 общего управления кодером управляет разбиением, предсказанием и фильтрацией с помощью других компонентов. Например, компонент 211 общего управления кодером может динамически увеличивать сложность сжатия для увеличения разрешения и увеличения использования полосы пропускания или уменьшения сложности сжатия для уменьшения разрешения и использования полосы пропускания. Следовательно, компонент 211 общего управления кодером управляет другими компонентами системы 200 кодека, чтобы сбалансировать качество восстановления видеосигнала с проблемами скорости передачи данных. Компонент 211 общего управления кодером создает данные управления, которые управляют работой других компонентов. Данные управления также направляются в компонент 231 форматирования заголовка и CABAC для кодирования в битовом потоке, чтобы сигнализировать параметры для декодирования в декодере.
[0071] Разделенный видеосигнал 201 также отправляется в компонент 221 оценки движения и компонент 219 компенсации движения для интер-предсказания. Кадр или сегмент разделенного видеосигнала 201 может быть разделен на несколько видеоблоков. Компонент 221 оценки движения и компонент 219 компенсации движения выполняют кодирование с интер-предсказанием принятого видеоблока относительно одного или более блоков в одном или более опорных кадрах для обеспечения временного предсказания. Система 200 кодека может выполнять несколько проходов кодирования, например, чтобы выбрать соответствующий режим кодирования для каждого блока видеоданных.
[0072] Компонент 221 оценки движения и компонент 219 компенсации движения могут быть сильно интегрированы, но проиллюстрированы отдельно для концептуальных целей. Оценка движения, выполняемая компонентом 221 оценки движения, представляет собой процесс генерации векторов движения, которые оценивают движение для видеоблоков. Вектор движения, например, может указывать смещение кодированного объекта относительно блока предсказания. Блок предсказания - это блок, который, как установлено, близко соответствует блоку, который должен быть кодирован, с точки зрения разности пикселей. Блок предсказания также может называться опорным блоком. Такая разность пикселей может определяться суммой абсолютной разности (SAD), суммой квадратов разности (SSD) или другими показателями разности. HEVC использует несколько закодированных объектов, включая CTU, блоки дерева кодирования (CTB) и CU. Например, CTU можно разделить на CTB, которые затем можно разделить на CB для включения в CU. CU может быть закодирован как единица предсказания (PU), содержащая данные предсказания, и/или единицу преобразования (TU), содержащий преобразованные остаточные данные для CU. Компонент 221 оценки движения генерирует векторы движения, PU и TU, используя анализ скорости к искажению в качестве части процесса оптимизации скорости к искажению. Например, компонент 221 оценки движения может определять несколько опорных блоков, множество векторов движения и т.д. для текущего блока/кадра и может выбирать опорные блоки, векторы движения и т.д., имеющие наилучшие характеристики скорости к искажению. Наилучшие характеристики соотношения скорости к искажению уравновешивают как качество восстановления видео (например, количество потерь данных при сжатии), так и эффективность кодирования (например, размер окончательного кодирования).
[0073] В некоторых примерах система 200 кодека может вычислять значения для положений суб-целочисленных пикселей опорных снимков, сохраненных в компоненте 223 буфера декодированных снимков. Например, система 200 видеокодека может интерполировать значения положений четверти пикселя, положений одной восьмой пикселя или других положений дробных пикселей опорного снимка. Следовательно, компонент 221 оценки движения может выполнять поиск движения относительно положений полных пикселей и положений дробных пикселей и выводить вектор движения с точностью до дробных пикселей. Компонент 221 оценки движения вычисляет вектор движения для PU видеоблока в сегменте с интер-кодированием посредством сравнения положения PU с положением блока предсказания опорного снимка. Компонент 221 оценки движения выводит вычисленный вектор движения как данные движения для форматирования заголовка и компонент 231 CABAC для кодирования и движения в компонент 219 компенсации движения.
[0074] Компенсация движения, выполняемая компонентом 219 компенсации движения, может включать в себя выборку или генерацию блока предсказания на основе вектора движения, определенного компонентом 221 оценки движения. Опять же, в некоторых примерах компонент 221 оценки движения и компонент 219 компенсации движения могут быть функционально интегрированы. После приема вектора движения для PU текущего видеоблока компонент 219 компенсации движения может определить местонахождение блока предсказания, на который указывает вектор движения. Затем формируется остаточный видеоблок посредством вычитания значений пикселей блока предсказания из значений пикселей текущего кодируемого видеоблока, формируя значения разности пикселей. В общем, компонент 221 оценки движения выполняет оценку движения относительно компонентов яркости, а компонент 219 компенсации движения использует векторы движения, вычисленные на основе компонентов яркости как для компонентов цветности, так и для компонентов яркости. Блок предсказания и остаточный блок направляются в компонент 213 масштабирования и квантования преобразования.
[0075] Разделенный видеосигнал 201 также отправляется компоненту 215 оценки интра-режима и компоненту 217 интра-предсказания. Как и в случае компонента 221 оценки движения и компонента 219 компенсации движения, компонент 215 оценки интра-режима и компонент 217 интра-предсказания могут быть сильно интегрированы, но проиллюстрированы отдельно для концептуальных целей. Компонент 215 оценки интра-режима и компонент 217 интра-предсказания предсказывают текущий блок относительно блоков в текущем кадре в качестве альтернативы интер-предсказанию, выполняемому компонентом 221 оценки движения и компонентом 219 компенсации движения между кадрами, как описано выше. В частности, компонент 215 оценки интра-режима определяет режим интра-предсказания для использования для кодирования текущего блока. В некоторых примерах компонент 215 оценки интра-режима выбирает соответствующий режим интра-предсказания для кодирования текущего блока из множества проверенных режимов интра-предсказания. Выбранные режимы интра-предсказания затем направляются в компонент 231 форматирования заголовка и CABAC для кодирования.
[0076] Например, компонент 215 оценки интра-режима вычисляет значения скорости к искажению, используя анализ скорости к искажению для различных тестируемых режимов интра-предсказания, и выбирает режим интра-предсказания, имеющий лучшие характеристики скорости к искажению среди тестированных режимов. Анализ соотношения скорости к искажению обычно определяет величину искажения (или ошибки) между закодированным блоком и исходным не кодированным блоком, который был закодирован для создания закодированного блока, а также скорость передачи данных (например, количество битов), используемую для создания закодированного блока. Компонент 215 оценки интра-режима вычисляет отношения скорости к искажению для различных кодированных блоков, чтобы определить, какой режим интра-предсказания показывает наилучшее значение скорости к искажению для блока. Кроме того, компонент 215 оценки интра-режима может быть выполнен с возможностью кодирования блоков глубины карты глубины с использованием режима моделирования глубины (DMM) на основе оптимизации скорости к искажению (RDO).
[0077] Компонент 217 интра-предсказания может генерировать остаточный блок из блока предсказания на основе выбранных режимов интра-предсказания, определенных компонентом 215 оценки интра-режима, когда он реализован в кодере, или считывать остаточный блок из битового потока, когда реализован в декодере. Остаточный блок включает в себя разность в значениях между блоком предсказания и исходным блоком, представленную в виде матрицы. Остаточный блок затем пересылается в компонент 213 масштабирования и квантования преобразования. Компонент 215 оценки интра-режима и компонент 217 интра-предсказания могут работать как с компонентами яркости, так и с компонентами цветности.
[0078] Компонент 213 масштабирования и квантования преобразования выполнен с возможностью дополнительного сжатия остаточного блока. Компонент 213 масштабирования и квантования преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусоидальное преобразование (DST) или концептуально аналогичное преобразование, к остаточному блоку, создавая видеоблок, содержащий значения коэффициентов остаточного преобразования. Также можно использовать вейвлет-преобразования, целочисленные преобразования, преобразования поддиапазонов или другие типы преобразований. Преобразование может преобразовывать остаточную информацию из области значений пикселей в область преобразования, такую как частотная область. Компонент 213 масштабирования и квантования преобразования также выполнен с возможностью масштабирования преобразованной остаточной информации, например, на основе частоты. Такое масштабирование включает в себя применение масштабного коэффициента к остаточной информации, так что разная частотная информация квантуется с разной степенью детализации, что может повлиять на окончательное визуальное качество восстановленного видео. Компонент 213 масштабирования и квантования преобразования также выполнен с возможностью квантования коэффициентов преобразования для дальнейшего снижения битовой скорости (битрейта). Процесс квантования может уменьшить битовую глубину, связанную с некоторыми или всеми коэффициентами. Степень квантования может быть изменена посредством регулировки параметра квантования. В некоторых примерах компонент 213 масштабирования и квантования преобразования может затем выполнить сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. Квантованные коэффициенты преобразования направляются в компонент 231 форматирования заголовка и CABAC для кодирования в битовом потоке.
[0079] Компонент 229 масштабирования и обратного преобразования применяет обратную операцию компонента 213 масштабирования и квантования преобразования для поддержки оценки движения. Компонент 229 масштабирования и обратного преобразования применяет обратное масштабирование, преобразование и/или квантование для восстановления остаточного блока в области пикселей, например, для последующего использования в качестве опорного блока, который может стать блоком предсказания для другого текущего блока. Компонент 221 оценки движения и/или компонент 219 компенсации движения может вычислять опорный блок, добавляя остаточный блок обратно к соответствующему блоку предсказания для использования при оценке движения более позднего блока/кадра. Фильтры применяются к восстановленным опорным блокам для уменьшения артефактов, возникающих во время масштабирования, квантования и преобразования. В противном случае такие артефакты могут вызвать неточное предсказание (и создать дополнительные артефакты) при предсказании последующих блоков.
[0080] Компонент 227 анализа управления фильтрами и компонент 225 внутриконтурных фильтров применяют фильтры к остаточным блокам и/или к восстановленным блокам изображения. Например, преобразованный остаточный блок из компонента 229 масштабирования и обратного преобразования может быть объединен с соответствующим блоком предсказания из компонента 217 интра-предсказания и/или компонента 219 компенсации движения для восстановления исходного блока изображения. Затем фильтры могут быть применены к восстановленному блоку изображения. В некоторых примерах вместо этого фильтры могут применяться к остаточным блокам. Как и в случае с другими компонентами на Фиг.2, компонент 227 анализа управления фильтрами и компонент 225 внутриконтурных фильтров сильно интегрированы и могут быть реализованы вместе, но изображены отдельно для концептуальных целей. Фильтры, применяемые к восстановленным опорным блокам, применяются к конкретным пространственным областям и включают несколько параметров для настройки того, как такие фильтры применяются. Компонент 227 анализа управления фильтрами анализирует восстановленные опорные блоки, чтобы определить, где такие фильтры должны быть применены, и устанавливает соответствующие параметры. Такие данные пересылаются в компонент 231 форматирования заголовка и CABAC в качестве данных управления фильтром для кодирования. Компонент 225 внутриконтурных фильтров применяет такие фильтры на основе данных управления фильтром. Фильтры могут включать в себя фильтр удаления блочности, фильтр подавления шума, фильтр SAO и адаптивный контурный фильтр. Такие фильтры могут применяться в пространственной/пиксельной области (например, в восстановленном блоке пикселей) или в частотной области, в зависимости от примера.
[0081] При работе в качестве кодера отфильтрованный блок восстановленного изображения, остаточный блок и/или блок предсказания сохраняются в компоненте 223 буфера декодированных снимков для последующего использования при оценке движения, как описано выше. При работе в качестве декодера компонент 223 буфера декодированных снимков сохраняет и пересылает восстановленные и отфильтрованные блоки на дисплей в качестве части выходного видеосигнала. Компонент 223 буфера декодированных снимков может быть любым устройством памяти, способным хранить блоки предсказания, остаточные блоки и/или восстановленные блоки изображения.
[0082] Компонент 231 форматирования заголовка и CABAC принимает данные от различных компонентов системы 200 кодека и кодирует такие данные в кодированный битовый поток для передачи в декодер. В частности, компонент 231 форматирования заголовка и CABAC генерирует различные заголовки для кодирования данных управления, таких как общие данные управления и данные управления фильтром. Кроме того, данные предсказания, включая данные интра-предсказания и движения, а также остаточные данные в форме квантованных данных коэффициентов преобразования, все кодируются в битовом потоке. Конечный битовый поток включает в себя всю информацию, требуемую декодером для восстановления исходного разделенного видеосигнала 201. Такая информация может также включать в себя таблицы индексов режима интра-предсказания (также называемые таблицами отображения кодовых слов), определения контекстов кодирования для различных блоков, указания наиболее вероятных режимов интра-предсказания, указание информации о разделах и т.д. Такие данные могут быть закодированы с использованием энтропийного кодирования. Например, информация может быть закодирована с использованием контекстно-адаптивного кодирования с переменной длиной (CAVLC), CABAC, основанного на синтаксисе контекстно-адаптивного двоичного арифметического кодирования (SBAC), энтропийного кодирования с вероятностным интервалом разделения (PIPE) или другого метода энтропийного кодирования. После энтропийного кодирования закодированный битовый поток может быть передан на другое устройство (например, видеодекодер) или заархивирован для последующей передачи или поиска.
[0083] Фиг.3 представляет собой блок-схему, иллюстрирующую примерный видеокодер 300. Видеокодер 300 может использоваться для реализации функций кодирования системы 200 кодека и/или реализации этапов 101, 103, 105, 107 и/или 109 рабочего способа 100. Кодер 300 разделяет входной видеосигнал, в результате чего получается разделенный видеосигнал 301, который по существу аналогичен разделенному видеосигналу 201. Разделенный видеосигнал 301 затем сжимается и кодируется в битовый поток компонентами кодера 300.
[0084] В частности, разделенный видеосигнал 301 пересылается в компонент 317 интра-предсказания для интра-предсказания. Компонент 317 интра-предсказания может быть по существу аналогичным компоненту 215 оценки интра-режима и компоненту 217 интра-предсказания. Разделенный видеосигнал 301 также пересылается в компонент 321 компенсации движения для интер-предсказания на основе опорных блоков в компоненте 323 буфера декодированных снимков. Компонент 321 компенсации движения может быть по существу аналогичным компоненту 221 оценки движения и компоненту 219 компенсации движения. Блоки предсказания и остаточные блоки из компонента 317 интра-предсказания и компонента 321 компенсации движения направляются в компонент 313 преобразования и квантования для преобразования и квантования остаточных блоков. Компонент 313 преобразования и квантования может быть по существу аналогичен компоненту 213 масштабирования и квантования преобразования. Преобразованные и квантованные остаточные блоки и соответствующие блоки предсказания (вместе со связанными данными управления) направляются в компонент 331 энтропийного кодирования для кодирования в битовый поток. Компонент 331 энтропийного кодирования может быть по существу аналогичен компоненту 231 форматирования заголовка и CABAC.
[0085] Преобразованные и квантованные остаточные блоки и/или соответствующие блоки предсказания также направляются из компонента 313 преобразования и квантования в компонент 329 обратного преобразования и квантования для восстановления в опорные блоки для использования компонентом 321 компенсации движения. Компонент 329 обратного преобразования и квантования может быть по существу аналогичен компоненту 229 масштабирования и обратного преобразования. Контурные фильтры в компоненте 325 внутриконтурных фильтров также применяются к остаточным блокам и/или восстановленным опорным блокам, в зависимости от примера. Компонент 325 внутриконтурных фильтров может быть по существу аналогичен компоненту 227 анализа управления фильтрами и компоненту 225 внутриконтурных фильтров. Компонент 325 внутриконтурных фильтров может включать в себя несколько фильтров, как обсуждалось в отношении компонента 225 внутриконтурных фильтров. Отфильтрованные блоки затем сохраняются в компоненте 323 буфера декодированных снимков для использования в качестве опорных блоков компонентом 321 компенсации движения. Компонент 323 буфера декодированных снимков может быть по существу аналогичен компоненту 223 буфера декодированных снимков.
[0086] Фиг.4 - это блок-схема, иллюстрирующая примерный видеодекодер 400. Видеодекодер 400 может использоваться для реализации функций декодирования системы 200 кодека и/или реализации этапов 111, 113, 115 и/или 117 рабочего способа 100. способа 400. Декодер 400 принимает битовый поток, например, от кодера 300, и формирует восстановленный выходной видеосигнал на основе битового потока для отображения конечному пользователю.
[0087] Битовый поток принимается компонентом 433 энтропийного декодирования. Компонент 433 энтропийного декодирования выполнен с возможностью реализации схемы энтропийного декодирования, такой как CAVLC, CABAC, SBAC, PIPE-кодирование или другие методики энтропийного кодирования. Например, компонент 433 энтропийного декодирования может использовать информацию заголовка, чтобы предоставить контекст для интерпретации дополнительных данных, закодированных как кодовые слова в битовом потоке. Декодированная информация включает в себя любую желаемую информацию для декодирования видеосигнала, такую как общие данные управления, данные управления фильтром, информацию о разделах, данные движения, данные предсказания и квантованные коэффициенты преобразования из остаточных блоков. Квантованные коэффициенты преобразования направляются в компонент 429 обратного преобразования и квантования для восстановления в остаточные блоки. Компонент 429 обратного преобразования и квантования может быть аналогичен компоненту 329 обратного преобразования и квантования.
[0088] Восстановленные остаточные блоки и/или блоки предсказания пересылаются в компонент 417 интра-предсказания для восстановления в блоки изображения на основе операций интра-предсказания. Компонент 417 интра-предсказания может быть аналогичен компоненту 215 оценки интра-режима и компоненту 217 интра-предсказания. В частности, компонент 417 интра-предсказания использует режимы предсказания, чтобы найти опорный блок в кадре, и применяет остаточный блок к результату для восстановления блоков изображения с интра-предсказанием. Восстановленные блоки изображения с интра-предсказанием и/или остаточные блоки и соответствующие данные интер-предсказания пересылаются в компонент 423 буфера декодированных снимков через компонент 425 внутриконтурных фильтров, который может быть по существу аналогичен компоненту 223 буфера декодированных снимков и компонент 225 внутриконтурных фильтров соответственно. Компонент 425 внутриконтурных фильтров фильтрует блоки восстановленных изображений, остаточные блоки и/или блоки предсказания, и такая информация сохраняется в компоненте 423 буфера декодированных снимков. Восстановленные блоки изображения из компонента 423 буфера декодированных снимков пересылаются в компонент 421 компенсации движения для интер-предсказания. Компонент 421 компенсации движения может быть по существу аналогичен компоненту 221 оценки движения и/или компоненту 219 компенсации движения. В частности, компонент 421 компенсации движения использует векторы движения из опорного блока для генерации блока предсказания и применяет остаточный блок к результату для восстановления блока изображения. Результирующие восстановленные блоки также могут быть отправлены через компонент 425 внутриконтурных фильтров в компонент 423 буфера декодированных снимков. Компонент 423 буфера декодированных снимков продолжает хранить дополнительные восстановленные блоки изображения, которые могут быть преобразованы в кадры через информацию о разбиении. Такие кадры также можно размещать последовательно. Последовательность выводится на дисплей как восстановленный выходной видеосигнал.
[0089] Фиг.5 является принципиальной схемой, иллюстрирующей примерную многослойную видеопоследовательность 500, сконфигурированную для межслойного предсказания 521. Многослойная видеопоследовательность 500 может кодироваться кодером, таким как система 200 кодека и/или кодер 300, и декодироваться декодером, таким как система 200 кодека и/или декодер 400, например, в соответствии со способом 100. Многослойная видеопоследовательность 500 включена для изображения примерного применения слоев в кодированной видеопоследовательности. Многослойная видеопоследовательность 500 представляет собой любую видеопоследовательность, которая использует множество слоев, таких как слой N 531 и слой N+1 532.
[0090] Например, многослойная видеопоследовательность 500 может использовать межслойное предсказание 521. Межслойное предсказание 521 применяется между снимками 511, 512, 513 и 514 и снимками 515, 516, 517 и 518 в разных слоях. В показанном примере снимки 511, 512, 513 и 514 являются частью слоя N+1 532, а снимки 515, 516, 517 и 518 являются частью слоя N 531. Слой, такой как слой N 531 и/или слой N+1 532, представляет собой группу снимков, которые все связаны со схожим значением характеристики, такой как схожий размер, качество, разрешение, отношение сигнал/шум, функциональные возможности и так далее. Слой может быть формально определен как набор единиц NAL VCL и связанных единиц NAL не-VCL, которые совместно используют один и тот же nuh_layer_id. Единица NAL VCL представляет собой единицу NAL, кодированную для содержания видеоданных, таких как кодированный фрагмент снимка. Единица NAL не-VCL представляет собой единицу NAL, которая содержит не видеоданные, такие как синтаксис и/или параметры, которые поддерживают декодирование видеоданных, выполнение проверки на согласованность или другие операции.
[0091] В показанном примере слой N+1 532 связан с большим размером изображения, чем слой N 531. Соответственно, снимки 511, 512, 513 и 514 в слое N+1 532 имеют больший размер снимка (например, большую высоту и ширину и, следовательно, больше дискретных отсчетов), чем снимки 515, 516, 517 и 518 в слое N 531 в этом примере. Однако такие снимки могут быть разделены между слоем N+1 532 и слоем N 531 по другим характеристикам. Хотя показаны только два слоя, слой N+1 532 и слой N 531, набор снимков может быть разделен на любое количество слоев на основе связанных характеристик. Слой N+1 532 и слой N 531 также могут быть обозначены идентификатором слоя. Идентификатор слоя - это элемент данных, который связан со снимком и указывает, что снимок является частью указанного слоя. Соответственно, каждый снимок 511-518 может быть связан с соответствующим идентификатором (ID) слоя, чтобы указать, какой слой N+1 532 или слой N 531 включает в себя соответствующий снимок. Например, идентификатор слоя может включать в себя идентификатор слоя заголовка единицы NAL (nuh_layer_id), который представляет собой синтаксический элемент, указывающий идентификатор слоя, который включает в себя единицу NAL (например, который включает в себя сегменты и/или параметры снимков в слое). Слою, связанному с более низким качеством/размером битового потока, такому как слой N 531, обычно назначается идентификатор более нижнего слоя, и он упоминается как более нижний слой. Кроме того, слою, связанному с более высоким качеством/размером битового потока, такому как слой N+1 532, обычно назначается идентификатор верхнего слоя и упоминается как верхний слой.
[0092] Снимки 511-518 в разных слоях 531-532 сконфигурированы для отображения альтернативно. В качестве конкретного примера, декодер может декодировать и отобразить снимок 515 в текущее время отображения, если требуется снимок меньшего размера, или декодер может декодировать и отобразить снимок 511 в текущее время отображения, если требуется снимок большего размера. Таким образом, снимки 511-514 на верхнем слое N+1 532 содержат по существу те же данные изображения, что и соответствующие снимки 515-518 на нижнем слое N 531 (несмотря на разницу в размере снимка). В частности, снимок 511 содержит по существу те же данные снимка, что и снимок 515, снимок 512 содержит по существу те же данные снимка, что и снимок 516, и т.д.
[0093] Снимки 511-518 могут быть кодированы посредством ссылки на другие снимки 511-518 в том же слое N 531 или N+1 532. Кодирование снимки со ссылкой на другой снимок в том же слое приводит к интер-предсказанию 523. Интер-предсказание 523 изображено сплошными стрелками. Например, снимок 513 может быть кодирован с использованием интер-предсказания 523 с использованием одного или двух снимков 511, 512 и/или 514 в слое N+1 532 в качестве опорной ссылки, где один снимок используется для однонаправленного интер-предсказания и/или два снимка используются для двунаправленного интер-предсказания. Кроме того, снимок 517 может быть кодирован с использованием интер-предсказания 523 с использованием одного или двух снимков 515, 516 и/или 518 в слое N 531 в качестве опорной ссылки, где один снимок используется для однонаправленного интер-предсказания и/или два снимка используются для двунаправленного интер-предсказания. Когда снимок используется в качестве опорной ссылки для другого снимка в том же слое при выполнении интер-предсказания 523, это снимок может называться опорным снимком. Например, снимок 512 может быть опорным снимком, используемым для кодирования снимка 513 в соответствии с интер-предсказанием 523. Интер-предсказание 523 также может называться внутрислойным предсказанием в многослойном контексте. Таким образом, интер-предсказание 523 представляет собой механизм кодирования дискретных отсчетов текущего снимка посредством ссылки на указанные дискретные отсчеты в опорном снимке, который отличается от текущего снимка, где опорный снимок и текущий снимок находятся в одном слое.
[0094] Снимки 511-518 также могут быть кодированы посредством ссылки на другие снимки 511-518 в других слоях. Этот процесс известен как межслойное предсказание 521 и изображен пунктирными стрелками. Межслойное предсказание 521 представляет собой механизм кодирования дискретных отсчетов текущего снимка посредством ссылки на указанные дискретные отсчеты в опорном снимке, где текущий снимок и опорный снимок находятся в разных слоях и, следовательно, имеют разные идентификаторы слоя. Например, снимок в нижнем слое N 531 может использоваться в качестве опорного снимка для кодирования соответствующего снимка в верхнем слое N+1 532. В качестве конкретного примера снимок 511 может быть кодирован со ссылкой на снимок 515 в соответствии с межслойным предсказанием 521. В таком случае снимок 515 используется как межслойный опорный снимок. Межслойный опорный снимок является опорным снимком, используемым для межслойного предсказания 521. В большинстве случаев межслойное предсказание 521 ограничено таким образом, что текущий снимок, такой как снимок 511, может использовать только межслойный опорный снимок (снимки), которые включены в одну и ту же AU и находятся в нижнем слое, например снимок 515. AU представляет собой набор снимков, связанных с конкретным временем вывода в видеопоследовательности, и, следовательно, AU может включать в себя до одного снимка на слой. Когда доступно множество слоев (например, более двух), межслойное предсказание 521 может кодировать/декодировать текущий снимок на основе множества межслойных опорных снимков на нижних уровнях, чем текущий снимок.
[0095] Видеокодер может использовать многослойную видеопоследовательность 500 для кодирования снимков 511-518 посредством множества различных объединений и/или перестановок интер-предсказания 523 и межслойного предсказания 521. Например, снимок 515 может быть кодирован в соответствии с интра-предсказанием. Затем снимки 516-518 могут быть кодированы в соответствии с интер-предсказанием 523 с использованием снимка 515 в качестве опорного снимка. Кроме того, снимок 511 может быть кодирован в соответствии с межслойным предсказанием 521 с использованием снимка 515 в качестве межслойного опорного снимка. Затем снимки 512-514 могут быть кодированы в соответствии с интер-предсказанием 523 с использованием снимка 511 в качестве опорного снимка. Таким образом, опорный снимок может служить как однослойным опорным снимком, так и межслойным опорным снимком для различных механизмов кодирования. Посредством кодирования снимков верхнего слоя N+1 532 на основе снимков нижнего слоя N 531, верхний слой N+1 532 может избежать использования интра-предсказания, которое имеет гораздо более низкую эффективность кодирования, чем интер-предсказание 523 и межслойное предсказание 521. Как таковая, низкая эффективность кодирования интра-предсказания может быть ограничена снимками самого маленького/самого низкого качества и, следовательно, ограничена кодированием наименьшего количества видеоданных. Снимки, используемые в качестве опорных снимков и/или межслойных опорных снимков, могут быть указаны в записях списка(ов) опорных снимков, содержащихся в структуре списка опорных снимков.
[0096] Для выполнения таких операций такие слои, как слой N 531 и слой N+1 532, могут быть включены в OLS 525. OLS 525 представляет собой набор слоев, для которых один или более слоев указаны в качестве выводимого слоя. Выводимый слой представляет собой слой, предназначенный для вывода (например, на дисплей). Например, слой N 531 может быть включен исключительно для поддержки межслойного предсказания 521 и может никогда не выводиться. В таком случае слой N+1 532 декодируется на основе слоя N 531 и выводится. В таком случае OLS 525 включает в себя слой N+1 532 в качестве выводимого слоя. OLS 525 может содержать множество слоев в различных объединениях. Например, выводимый слой в OLS 525 может быть кодирован в соответствии с межслойным предсказанием 521 на основе одного, двух или многих нижних слоев. Кроме того, OLS 525 может содержать более одного выводимого слоя. Следовательно, OLS 525 может содержать один или более выводимых слоев и любые вспомогательные слои, необходимые для восстановления выводимых слоев. Многослойная видеопоследовательность 500 может быть кодирована с использованием множества различных OLS 525, каждый из которых использует различные объединения слоев.
[0097] В качестве конкретного примера, межслойное предсказание 521 может использоваться для поддержки масштабируемости. Например, видео может быть кодировано в базовом слое, таком как слой N 531, и нескольких слоях улучшения, таких как слой N+1 532, слой N+2, слой N+3 и т.д., которые кодируются согласно межслойному предсказанию 521. Видеопоследовательность может быть кодирована для нескольких масштабируемых характеристик, таких как отношение сигнал-шум (SNR), частота кадров, размер снимка и т.д. Затем можно создать OLS 525 для каждой допустимой характеристики. Например, OLS 525 для первого разрешения может включать в себя только слой N 531, OLS 525 для второго разрешения может включать в себя слой N 531 и слой N+1 532, OLS для третьего разрешения может включать в себя слой N 531, слой N+ 1 532, слой N+2 и т.д. Таким образом, OLS 525 может передаваться, чтобы позволить декодеру декодировать любую версию многослойной видеопоследовательности 500, которая требуется, исходя из сетевых условий, аппаратных ограничений и т.д.
[0098] Фиг.6 является принципиальной схемой, иллюстрирующей примерную видеопоследовательность 600 с OLS, сконфигурированными для многоракурсной масштабируемости. Видеопоследовательность 600 является конкретным примером многослойной видеопоследовательности 500. Таким образом, видеопоследовательность 600 может быть кодирована кодером, таким как система 200 кодека и/или кодер 300, и декодирована декодером, таким как система 200 кодека и/или декодер 400, например, в соответствии со способом 100. Видеопоследовательность 600 пригодна для масштабируемости.
[0099] Примерная видеопоследовательность 600 включает в себя OLS 620, OLS 621 и OLS 622, которые могут быть по существу аналогичны OLS 525. Хотя изображены три OLS, может использоваться любое количество OLS. Ссылка на каждый OLS 620, 621 и 622 осуществляется через индекс OLS, и каждый OLS 620, 621 и 622 включает в себя один или более слоев. В частности, OLS 620, 621 и 622 включает в себя слой 630, слои 630 и 631 и слои 630, 631 и 632, соответственно. Слои 630, 631 и 632 могут быть по существу аналогичны слою N 531 и слою N+1 532. Ссылка на слои 630, 631 и 632 осуществляется через индекс слоя. Видеопоследовательность 600 включает в себя то же количество слоев, что и количество OLS. В частности, OLS 620 с самым нижним индексом OLS содержит слой 630 с самым нижним индексом слоя. Каждый другой OLS включает в себя все слои предшествующего OLS с более нижним индексом OLS плюс один. Например, OLS 621 имеет более высокий индекс OLS, чем OLS 620, и содержит слои 630 и 631, которые являются всеми слоями OLS 620 плюс один. Аналогично, OLS 622 имеет более высокий индекс OLS, чем OLS 621, и содержит слои 630, 631 и 632, которые являются всеми слоями OLS 621 плюс один. Этот шаблон может продолжаться до тех пор, пока не будут достигнуты слой с самым высоким индексом слоя и OLS с самым высоким индексом OLS.
[00100] Кроме того, слой 630 является базовым слоем. Все другие слои 631 и 632 являются слоями улучшения, которые кодируются в соответствии с межслойным предсказанием на основе всех слоев с индексами нижних слоев. В частности, слой 630 является базовым слоем и не кодируется в соответствии с межслойным предсказанием. Слой 631 представляет собой слой улучшения, который кодируется в соответствии с межслойным предсказанием на основе слоя 630. Кроме того, слой 632 представляет собой слой улучшения, который кодируется в соответствии с межслойным предсказанием на основе слоев 630 и 631. В результате OLS 620 содержит слой 630 с SNR самого низкого качества и/или с наименьшим размером изображения. Поскольку OLS 620 не использует никакого межслойного предсказания, OLS 620 может быть полностью декодирован без ссылки на какой-либо слой, кроме слоя 630. OLS 621 содержит слой 631, который имеет более высокое качество SNR и/или размер изображения, чем слой 630, и слой 631 может быть полностью декодирован в соответствии с межслойным предсказанием, поскольку OLS 621 также содержит слой 630. Аналогично, OLS 622 содержит слой 632, который имеет более высокое качество SNR и/или размер изображения, чем слои 630 и 631, и слой 632 может быть полностью декодирован в соответствии с межслойным предсказанием, поскольку OLS 622 также содержит слои 630 и 631. Соответственно, видеопоследовательность 600 кодируется для масштабирования до любого предварительно выбранного SNR и/или размера изображения посредством отправки соответствующего OLS 622, 621 или 620 в декодер. Когда используется больше OLS 622, 621 и 620, видеопоследовательность 600 может масштабироваться до большего качества изображения SNR и/или размеров изображений.
[00101] Соответственно, видеопоследовательность 600 может поддерживать пространственную масштабируемость. Пространственное масштабирование позволяет кодировать видеопоследовательность 600 в слои 630, 631 и 632 таким образом, что слои 630, 631 и 632 помещаются в OLS 620, 621 и 622, так что каждый OLS 620, 621 и 622 содержит достаточно данных для декодирования видеопоследовательности 600 до соответствующего размера экрана вывода. Таким образом, пространственная масштабируемость может включать в себя набор слоев (например, слой 630) для декодирования видео для экрана смартфона, набор слоев для декодирования видео для большого экрана телевизора (например, слои 630, 631 и 632), и наборы слоев (например, слои 630 и 631) для промежуточных размеров экрана. Масштабируемость SNR позволяет кодировать видеопоследовательность 600 в слои 630, 631 и 632 таким образом, что слои 630, 631 и 632 помещаются в OLS 620, 621 и 622, так что каждый OLS 620, 621 и 622 содержит достаточно данных для декодирования видеопоследовательности 600 с другим SNR. Таким образом, масштабируемость SNR может включать в себя набор слоев (например, слой 630), которые могут быть декодированы для видео низкого качества, видео высокого качества (например, слои 630, 631 и 632) и различных промежуточных качеств видео (например, слои 630 и 631) для поддержки различных сетевых условий.
[00102] Настоящее раскрытие обеспечивает эффективную сигнализацию, позволяющую правильно и эффективно использовать видеопоследовательность 600 с многоракурсными слоями. Например, все слои 630, 631 и 632 могут быть обозначены как выводимые слои. Затем декодер может выбрать и визуализировать слои 630, 631 и 632 по желанию для реализации множества ракурсов. Для поддержки этой реализации кодирование видеопоследовательности 600 может быть обозначено в соответствии с синтаксическим элементом ols_mode_idc. Например, синтаксический элемент ols_mode_idc может идентифицировать видеопоследовательность 600 как один режим OLS. Следовательно, синтаксический элемент ols_mode_idc может быть установлен в один и сигнализирован в битовом потоке, чтобы задать, что используется видеопоследовательность 600. Соответственно, декодер может принять любой OLS и может определить на основе ols_mode_idc, что количество OLS 620, 621 и 622 совпадает с количеством слоев 630, 631 и 632, что текущий идентификатор OLS i указывает что текущий OLS содержит набор слоев с идентификаторами от нуля до i и что все слои в текущем OLS являются выводимыми слоями. Затем декодер может декодировать и отобразить слои 630, 631 и/или 632 из OLS 620, 621 и/или 622 по желанию для реализации множества ракурсов.
[00103] Фиг.7 является принципиальной схемой, иллюстрирующей пример битового потока 700, включающего в себя OLS, сконфигурированные для многоракурсной масштабируемости. Например, битовый поток 700 может быть сгенерирован системой 200 кодека и/или кодером 300 для декодирования системой 200 кодека и/или декодером 400 согласно способу 100. Кроме того, битовый поток 700 может включать в себя кодированную многослойную видеопоследовательность 500 и/или видеопоследовательность 600.
[00104] Битовый поток 700 включает в себя VPS 711, один или более наборов 713 параметров последовательности (SPS), множество наборов параметров снимка (PPS) 715, множество заголовков 717 сегментов и данные 720 изображения. VPS 711 содержит данные, относящиеся ко всему битовому потоку 700. Например, VPS 711 может содержать данные, связанные с OLS, слоями и/или подслоями, используемыми в битовом потоке 700. SPS 713 содержит данные последовательности, общие для всех снимков в кодированной видеопоследовательности, содержащейся в битовом потоке 700. Например, каждый слой может содержать одну или более кодированных видеопоследовательностей, и каждая кодированная видеопоследовательность может ссылаться на (обращаться к) SPS 713 для соответствующих параметров. Параметры в SPS 713 могут включать в себя размер снимка, битовую глубину, параметры инструмента кодирования, ограничения битовой скорости и т.д. Следует отметить, что хотя каждая последовательность относится к SPS 713, в некоторых примерах один SPS 713 может содержать данные для множества последовательностей. PPS 715 содержит параметры, которые применяются ко всему снимку. Следовательно, каждый снимок в видеопоследовательности может относиться к PPS 715. Следует отметить, что хотя каждый снимок относится к PPS 715, в некоторых примерах один PPS 715 может содержать данные для множества снимков. Например, множество схожих снимков могут быть кодированы согласно схожим параметрам. В таком случае один PPS 715 может содержать данные для таких схожих снимков. PPS 715 может указывать инструменты кодирования, доступные для сегментов в соответствующих снимках, параметры квантования, смещения и т.д.
[00105] Заголовок сегмента содержит параметры, характерные для каждого сегмента 727 в снимке. Следовательно, может быть один заголовок 717 сегмента на сегмент 727. Заголовок 717 сегмента может содержать информацию о типе сегмента, POC, списки опорных снимков, весовые коэффициенты предсказания, точки входа клетки, параметры устранения блочности и т.д. Следует отметить, что в некоторых примерах битовый поток 700 может также включать в себя заголовок снимка, который представляет собой синтаксическую структуру, содержащую параметры, применимые ко всем сегментам 727 в одном снимке. По этой причине заголовок снимка и заголовок 717 сегмента могут использоваться взаимозаменяемо в некоторых контекстах. Например, некоторые параметры могут быть перемещены между заголовком 717 сегмента и заголовком снимка в зависимости от того, являются ли такие параметры общими для всех сегментов 727 в снимке 725.
[00106] Данные 720 изображения содержат видеоданные, кодированные согласно интер-предсказанию и/или интра-предсказанию и соответствующим данным преобразованных и квантованных остатков. Например, данные 720 изображения могут включать в себя слои 723 снимков 725. Слои 723 могут быть организованы в OLS 721. OLS 721 может быть по существу аналогичен OLS 525, 620, 621 и/или 622. В частности, OLS 721 представляет собой набор слоев для 723, один или более слоев 723 которого заданы как выводимые слои. Когда слои 723 включают в себя многоракурсное видео, все слои 723 могут быть указаны как выводимые слои. Например, битовый поток 700 может быть кодирован так, чтобы включать в себя несколько OLS 721 с видео, кодированным с разными разрешениями, частотами кадров, размерами 725 снимка и т.д. По запросу декодера процесс извлечения битового подпотока может удалить все, кроме запрошенного OLS 721, из битового потока 700. Затем кодер может передать битовый поток 700, содержащий только запрошенный OLS 721 и, следовательно, только видео, которое соответствует запрошенным критериям, в декодер.
[00107] Слой 723 может быть по существу подобен слою N 531, слою N+1 532 и/или слоям 631, 632 и/или 633. Слой 723 обычно представляет собой набор кодированных снимков 725. Слой 723 может быть формально определен как набор единиц NAL VCL, которые при декодировании совместно используют заданную характеристику (например, общее разрешение, частоту кадров, размер изображения и т.д.). Снимок 725 может быть кодирован как набор единиц NAL VCL. Слой 723 также включает в себя связанные единицы NAL не-VCL для поддержки декодирования единиц NAL VCL. Единицы NAL VCL слоя 723 могут совместно использовать конкретное значение nuh_layer_id, которое является примерным идентификатором слоя. Слой 723 может быть слоем одновременной передачи, который кодирован без межслойного предсказания, или слоем 723, который кодирован в соответствии с межслойным предсказанием на основе других слоев.
[00108] Снимок 725 - это массив дискретных отсчетов яркости и/или массив дискретных отсчетов цветности, которые создают кадр или его область. Например, снимок 725 может быть кодированным снимком, который может быть выведен для отображения или использован для поддержки кодирования другого снимка (снимков) 725 для вывода. Снимок 725 может включать в себя набор единиц NAL VCL. Снимок 725 содержит один или более сегментов 727. Сегмент 727 может быть определен как целое число полных клеток или целое число последовательных полных строк единицы дерева кодирования (CTU) (например, в пределах клетки) снимка 725, которые содержатся исключительно в одной единице NAL, в частности, в единице NAL VCL. Сегменты 727 дополнительно делятся на CTU и/или единицы дерева кодирования (CTB). CTU - это группа дискретных отсчетов заранее определенного размера, которая может быть разделена деревом кодирования. CTB является поднабором CTU и содержит компоненты яркости или компоненты цветности CTU. CTU/CTB дополнительно разбиваются на блоки кодирования на основе деревьев кодирования. Затем блоки кодирования можно кодировать/декодировать согласно механизмам предсказания.
[00109] Настоящее раскрытие включает в себя механизмы для поддержки пространственного масштабирования и/или масштабирования SNR для многоракурсного видео, например, посредством использования видеопоследовательности 600. Например, VPS 711 может содержать ols_mode_idc 735. ols_mode_idc 735 представляет собой синтаксический элемент, который указывает информацию, относящуюся к количеству OLS 721, слоям 723 в наборах выводимых слоев (OLS) 721 и выводимым слоям 723 в OLS 721. Выводимый слой 723 представляет собой любой слой, который предназначен для вывода декодером, а не используется исключительно для кодирования на основе ссылок. ols_mode_idc 735 может быть установлен в ноль или два для кодирования других типов видео. ols_mode_idc 735 может быть установлен равным одному для пространственной масштабируемости и/или масштабируемости SNR для многоракурсного видео. Например, ols_mode_idc 735 может быть установлен равным одному, чтобы задать, что общее количество OLS 721 в видеопоследовательности равно общему количеству слоев 723, заданных в VPS 711, что i-й OLS 721 включает в себя слои от нуля до i включительно, и что для каждого OLS 721 все слои, включенные в OLS 721, являются выводимыми слоями. Этот ряд условий может описывать видеопоследовательность 600 с любым количеством OLS 721. Преимущество использования ols_mode_idc 735 заключается в том, что ols_mode_idc 735 обеспечивает экономию битов. Декодер в прикладной системе обычно принимает только один OLS. Однако ols_mode_idc 735 также обеспечивает экономию битов в кодированных битовых потоках, которые содержат множество OLS, между которыми совместно используются многие данные, таким образом обеспечивая экономию на серверах потоковой передачи и обеспечивая экономию пропускной способности для передачи таких битовых потоков. В частности, преимущество установки ols_mode_idc 735 в один заключается в поддержке вариантов использования, таких как многоракурсные варианты применения, в которых два или более ракурсов, каждый из которых представлен одним слоем, должны выводиться и отображаться одновременно.
[00110] В некоторых примерах VPS 711 также включает в себя синтаксический элемент 737 максимального количества слоев VPS минус один (vps_max_layers_minus1). vps_max_layers_minus1 737 представляет собой синтаксический элемент, который сигнализирует количество слоев 723, заданных в VPS 700, и, следовательно, максимальное количество слоев 723, разрешенных в соответствующей кодированной видеопоследовательности в битовом потоке 700. ols_mode_idc 735 может ссылаться на синтаксический элемент vps_max_layers_minus1 737. Например, ols_mode_idc 735 может указывать, что общее количество OLS 721 равно количеству слоев 723, заданному в vps_max_layers_minus1 737.
[00111] Кроме того, VPS 711 может включать в себя each_layer_is_an_ols_flag 733. each_layer_is_an_ols_flag 733 представляет собой синтаксический элемент, который сигнализирует, содержит ли каждый OLS 721 в битовом потоке 700 единственный слой 723. Например, каждый OLS 721 может содержать один слой одновременной передачи, когда не используется масштабируемость. Соответственно, each_layer_is_an_ols_flag 733 может быть установлен (например, равным нулю), чтобы задать, что один или более OLS 721 содержат более одного слоя 723 для поддержки масштабируемости. Таким образом, each_layer_is_an_ols_flag 733 может использоваться для поддержки масштабируемости. Например, декодер может проверить each_layer_is_an_ols_flag 733, чтобы определить, что некоторые из OLS 721 включают в себя более одного слоя 723. Когда each_layer_is_an_ols_flag 733 установлен в ноль и когда ols_mode_idc 735 установлен в один (или ноль, который используется для другого режима), общее количество OLS (TotalNumOlss) может быть установлено равным vps_max_layers_minus1 737. TotalNumOlss - это переменная, используемая как декодером, так и гипотетическим опорным декодером (HRD) в кодере. TotalNumOlss - это переменная, используемая для хранения количества OLS 721 на основе данных в битовом потоке 700. Затем TotalNumOlss можно использовать для декодирования в декодере или проверки ошибок битового потока 700 в HRD в кодере.
[00112] VPS 711 также может включать в себя синтаксический элемент 731 идентификатора слоя VPS (vps_layer_id[i]). vps_layer_id[i] 731 представляет собой массив, в котором хранятся идентификаторы (ID) слоя (например, nuh_layer_id) для каждого слоя. Соответственно, vps_layer_id[i] 731 указывает ID слоя i-го слоя.
[00113] Декодер или HRD могут быть способны использовать данные в VPS 711 для определения конфигурации OLS 721 и слоев 723. В конкретном примере количество слоев в i-м OLS (NumLayersInOls[i]) и идентификатор слоя в OLS (LayerIdInOLS[i][j]), задающем значение nuh_layer_id j-го слоя в i -th OLS, выводятся следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j]
где vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных в VPS, а each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя.
[00114] Данные в VPS 711 могут использоваться для поддержки SNR и/или пространственно масштабируемых слоев 723, включающих в себя многоракурсное видео. Слои 723 могут быть кодированы и включены в OLS 721. Кодер может передать битовый поток 700, включающий в себя запрошенный OLS 721 и VPS 711, в декодер. Затем декодер может использовать информацию в VPS 711 для правильного декодирования слоев 723 в OLS 721. Этот подход поддерживает эффективность кодирования, поддерживая масштабируемость. В частности, декодер может быстро определить количество слоев 723 в OLS 721, определить, что все слои в OLS 721 являются выводимыми слоями, и декодировать выводимые слои в соответствии с межслойным предсказанием. Затем декодер может выбрать выводимые слои, которые должны быть визуализированы для реализации многоракурсности. Соответственно, декодер может принимать слои 723, необходимые для декодирования ракурсов для многоракурсности, и декодер может декодировать и отобразить снимки 725 из слоев 723 по желанию. Таким образом, общее количество кодированных слоев 723 может не влиять на процесс декодирования, и можно избежать одной или нескольких ошибок, как обсуждалось выше. Таким образом, раскрытые механизмы увеличивают функциональные возможности кодера и/или декодера. Кроме того, раскрытые механизмы могут уменьшать размер битового потока и, следовательно, уменьшать использование процессора, памяти и/или сетевых ресурсов как в кодере, так и в декодере.
[00115] Предшествующая информация теперь описывается более подробно ниже. Многослойное видеокодирование также называют масштабируемым видеокодированием или видеокодированием с масштабируемостью. Масштабируемость при видеокодировании может поддерживаться с помощью методик многослойного кодирования. Многослойный битовый поток содержит базовый слой (BL) и один или более слоев расширения (EL). Примеры масштабируемости включают в себя пространственную масштабируемость, масштабируемость качества/отношения сигнал-шум (SNR), многоракурсную масштабируемость, масштабируемость частоты кадров и т.д. Когда используется методика многослойного кодирования, снимок или его часть могут быть кодированы без использования опорного снимка (интра-предсказание), могут быть кодированы посредством ссылки на опорные снимки, которые находятся в том же слое (интер-предсказание), и /или могут быть кодированы посредством ссылки на опорные снимки, которые находятся в другом(их) слое(ах) (межслойное предсказание). Опорный снимок, используемый для межслойного предсказания текущего снимка, называется межслойным опорным снимком (ILRP). Фиг.5 иллюстрирует пример многослойного кодирования для пространственной масштабируемости, в котором снимки на разных слоях имеют разное разрешение.
[00116] Некоторые семейства видеокодирования обеспечивают поддержку масштабируемости в отдельном(ых) профиле(ях) от профиля(ов) для однослойного кодирования. Масштабируемое видеокодирование (SVC) - это масштабируемое расширение усовершенствованного видеокодирования (AVC), обеспечивающее поддержку пространственной, временной масштабируемости и масштабируемости качества. Для SVC в каждом макроблоке (MB) в снимках EL сигнализируется флаг, чтобы указать, предсказывается ли MB EL с использованием совмещенного блока из нижнего слоя. Предсказание из совмещенного блока может включать в себя текстуру, векторы движения и/или режимы кодирования. Реализации SVC не могут напрямую повторно использовать немодифицированные реализации AVC в своей конструкции. Синтаксис макроблока EL SVC и процесс декодирования отличаются от синтаксиса и процесса декодирования AVC.
[00117] Масштабируемое HEVC (SHVC) - это расширение HEVC, обеспечивающее поддержку пространственной масштабируемости и масштабируемости качества. Многоракурсное HEVC (MV-HEVC) - это расширение HEVC, обеспечивающее поддержку многоракурсной масштабируемости. 3D HEVC (3D-HEVC) - это расширение HEVC, обеспечивающее поддержку кодирования 3D-видео, которое является более совершенным и эффективным, чем MV-HEVC. Временная масштабируемость может быть включена как неотъемлемая часть однослойного кодека HEVC. В многослойном расширении HEVC декодированные снимки, используемые для межслойного предсказания, поступают только из одной и той же AU и обрабатываются как долгосрочные опорные снимки (LTRP). Таким снимкам назначаются опорные индексы в списке (списках) опорных снимков вместе с другими временными опорными снимками в текущем слое. Межслойное предсказание (ILP) достигается на уровне единицы предсказания (PU) посредством установки значения опорного индекса для ссылки на межслойное опорный снимок(и) в списке(ах) опорных снимков. Пространственная масштабируемость изменяет опорный снимок или его часть, когда ILRP имеет пространственное разрешение, отличное от текущего кодируемого или декодируемого снимка. Повторная дискретизация опорного снимка может быть реализована либо на уровне снимка, либо на уровне блока кодирования.
[00118] VVC также может поддерживать многослойное видеокодирование. Битовый поток VVC может включать в себя множество слоев. Все слои могут быть независимыми друг от друга. Например, каждый слой может быть кодирован без использования межслойного предсказания. В этом случае слои также называются слоями одновременной передачи. В некоторых случаях некоторые слои кодируются с использованием ILP. Флаг в VPS может указывать, являются ли слои слоями одновременной передачи или используют ли некоторые слои ILP. Когда некоторые слои используют ILP, отношения зависимости слоев между слоями также сигнализируются в VPS. В отличие от SHVC и MV-HEVC, VVC может не задавать OLS. OLS включает в себя заданный набор слоев, где один или более слоев в наборе слоев заданы как выводимые слои. Выводимый слой - это слой OLS, который выводится. В некоторых реализациях VVC для декодирования и вывода может быть выбран только один слой, когда слои являются слоями одновременной передачи. В некоторых реализациях VVC весь битовый поток, включая все слои, задается для декодирования, когда любой слой использует ILP. Кроме того, конкретные слои среди слоев задаются как выводимые слои. Выводимые слои могут быть указаны как только самый верхний слой, все слои или самый верхний слой плюс набор указанных нижних слоев.
[00119] Предшествующие аспекты содержат конкретные проблемы. В некоторых системах видеокодирования, когда используется межслойное предсказание, весь битовый поток и все слои задаются для декодирования, и конкретные слои среди слоев задаются как выводимые слои. Выводимые слои могут быть указаны как только самый верхний слой, все слои или самый верхний слой плюс набор указанных нижних слоев. Для простоты описания проблемы, можно использовать два слоя с верхним слоем, который использует нижний слой для ссылки на межслойное предсказание. Для многоракурсной масштабируемости система должна задавать использование только нижнего слоя (декодирование и вывод только нижнего слоя). Система также должна задать использование обоих слоев (декодирование и вывод обоих слоев). К сожалению, это невозможно в некоторых системах видеокодирования.
[00120] В общем, настоящее раскрытие описывает подходы к простой и эффективной сигнализации наборов выводимых слоев (OLS) для многоракурсной масштабируемости. Описания методик основаны на VVC JVET ITU-T и ISO/IEC. Однако методики также применимы к многослойному видеокодированию, основанному на других спецификациях видеокодека.
[00121] Одна или более из вышеупомянутых проблем могут быть решены следующим образом. В частности, настоящее раскрытие включает в себя простой и эффективный способ сигнализации OLS для пространственной масштабируемости и масштабируемости SNR. Система видеокодирования может использовать VPS для указания того, что некоторые слои используют ILP, что общее количество OLS, заданных в VPS, равно количеству слоев, что i-й OLS включает в себя слои с индексами слоев от 0 до i включительно, и что для каждого OLS выводится только самый верхний слой в OLS.
[00122] Пример реализации предшествующих механизмов выглядит следующим образом. Ниже приведен пример синтаксиса набора параметров видео.
[00123] Пример семантики набора параметров видео выглядит следующим образом. RBSP VPS должна быть доступна для процесса декодирования до того, как на нее будет сделана ссылка, должна быть включена в по меньшей мере одну единицу доступа с TemporalId, равным нулю, или предоставлена через внешние механизмы, а единица NAL VPS, содержащая RBSP VPS, должна иметь nuh_layer_id, равный vps_layer_id[0]. Все единицы NAL VPS с конкретным значением vps_video_parameter_set_id в CVS должны иметь одинаковое содержимое. vps_video_parameter_set_id предоставляет идентификатор VPS для ссылки другими синтаксическими элементами. vps_max_layers_minus1 плюс 1 указывает максимально допустимое количество слоев в каждом CVS, ссылающихся на VPS. vps_max_sub_layers_minus1 плюс 1 задает максимальное количество временных подслоев, которые могут присутствовать в каждой CVS, ссылающейся на VPS. Значение vps_max_sub_layers_minus1 должно быть в диапазоне от нуля до шести включительно.
[00124] vps_all_independent_layers_flag может быть установлен равным одному, чтобы задать, что все слои в CVS кодируются независимо без использования межслойного предсказания. vps_all_independent_layers_flag может быть установлен равным нулю, чтобы задать, что один или более слоев в CVS могут использовать межслойное предсказание. При отсутствии предполагается, что значение vps_all_independent_layers_flag равно единице. Когда vps_all_independent_layers_flag равен одному, предполагается, что значение vps_independent_layer_flag[i] равно единице. Когда vps_all_independent_layers_flag равен нулю, предполагается, что значение vps_independent_layer_flag[0] равно единице. vps_layer_id[i] задает значение nuh_layer_id i-го слоя. Для любых двух неотрицательных целых значений m и n, когда m меньше n, значение vps_layer_id[m] должно быть меньше, чем vps_layer_id[n]. vps_independent_layer_flag[i] может быть установлен равным одному, чтобы задать, что слой с индексом i не использует межслойное предсказание. vps_independent_layer_flag[i] может быть установлен равным нулю, чтобы задать, что слой с индексом i может использовать межслойное предсказание, а vps_layer_dependency_flag[i] присутствует в VPS. Если флаг отсутствует, предполагается, что значение vps_independent_layer_flag[i] равно единице.
[00125] vps_direct_dependency_flag[i][j] может быть установлен равным нулю, чтобы задать, что слой с индексом j не является непосредственным опорным слоем для слоя с индексом i. vps_direct_dependency_flag[i][j] может быть установлен равным одному, чтобы задать, что слой с индексом j является непосредственным опорным слоем для слоя с индексом i. Когда vps_direct_dependency_flag[i][j] отсутствует для i и j в диапазоне от нуля до vps_max_layers_minus1 включительно, считается, что vps_direct_dependency_flag[i][j] равен 0. Переменная DirectDependentLayerIdx[i][j], задающая j-й непосредственно зависимый слой от i-го слоя, выводится следующим образом:
для(i=1; i < vps_max_layers_minus1; i++)
если(!vps_independent_layer_flag[i])
для(j=i, k=0; j >= 0; j--)
если(vps_direct_dependency_flag[i][j])
DirectDependentLayerIdx [i][k++]=j
[00126] Переменная GeneralLayerIdx[i], задающая индекс слоя у слоя с nuh_layer_id, равным vps_layer_id[i], выводится следующим образом:
для(i=0; i <= vps_max_layers_minus1; i++)
GeneralLayerIdx[vps_layer_id[i]]=i
[00127] each_layer_is_an_ols_flag может быть установлен равным одному, чтобы задать, что каждый набор выводимых слоев содержит только один слой, и каждый слой в битовом потоке сам по себе является набором выводимых слоев, причем единственный включенный слой является единственным выводимым слоем. each_layer_is_an_ols_flag может быть установлен равным нулю, чтобы задать, что набор выводимых слоев может содержать более одного слоя. Если vps_max_layers_minus1 равен нулю, предполагается, что значение each_layer_is_an_ols_flag равно единице. В противном случае, когда vps_all_independent_layers_flag равен нулю, предполагается, что значение each_layer_is_an_ols_flag равно нулю.
[00128] ols_mode_idc может быть установлен равным нулю, чтобы задать, что общее количество OLS, заданных в VPS, равно vps_max_layers_minus + 1, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS выводится только самый верхний слой в OLS. ols_mode_idc может быть установлен равным одному, чтобы задать, что общее количество OLS, заданных в VPS, равно vps_max_layers_minus + 1, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS все слои в OLS выводятся. ols_mode_idc может быть установлен равным двум, чтобы задать, что общее количество OLS, заданных в VPS, сигнализируется в явном виде, и для каждого OLS выводятся самый верхний слой и явно сигнализируемый набор нижних слоев в OLS. Значение ols_mode_idc должно быть в диапазоне от нуля до двух включительно. Значение три у ols_mode_idc зарезервировано. Когда vps_all_independent_layers_flag равен одному, а each_layer_is_an_ols_flag равен нулю, предполагается, что значение ols_mode_idc равно двум.
[00129] num_output_layer_sets_minus1 плюс 1 указывает общее количество OLS, заданных в VPS, когда ols_mode_idc равно двум. Переменная TotalNumOlss, указывающая общее количество OLS, заданных в VPS, выводится следующим образом:
если(vps_max_layers_minus1 == 0)
TotalNumOlss=1
иначе если(each_layer_is_an_ols_flag||ols_mode_idc == 0||ols_mode_idc == 1)
TotalNumOlss=vps_max_layers_minus1+1
иначе если(ols_mode_idc == 2)
TotalNumOlssus=_num_output
[00130] Layer_included_flag[i][j] указывает, включен ли j-й слой (например, слой с nuh_layer_id, равным vps_layer_id[j]) в i-м OLS, когда ols_mode_idc равен двум. Layer_included_flag[i][j] может быть установлен равным одному, чтобы задать, что j-й слой включен в i-м OLS. Layer_included_flag[i][j] может быть установлен равным нулю, чтобы задать, что j-й слой не включен в i-м OLS.
[00131] Переменная NumLayersInOls[i], задающая количество слоев в i-м OLS, и переменная LayerIdInOls[i][j], задающая значение nuh_layer_id j-го слоя в i-м OLS, могут быть выведены следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j]}
иначе если(ols_mode_idc == 2) {
для(k=0, j=0; k <= vps_max_layers_minus1; k++)
если(layer_included_flag[i][k])
LayerIdInOls[i][j++]=vps_layer_id [k]
NumLayersInOls [i]=j
}
}
[00132] Переменная OLSLayeIdx[i][j], задающая индекс слоя OLS для слоя с nuh_layer_id, равным LayerIdInOls[i][j], может быть выведена следующим образом:
для(i=0, i < TotalNumOlss; i++)
для j=0; j < NumLayersInOls[i]; j++)
OlsLayeIdx[i][LayerIdInOls[i][j]]=j
[00133] Самый нижний слой в каждом OLS должен быть независимым слоем. Другими словами, для каждого i в диапазоне от нуля до TotalNumOlss - 1 включительно значение vps_independent_layer_flag[GeneralLayerIdx[LayerIdInOls[i][0]]] должно быть равно единице. Каждый слой может быть включен в по меньшей мере один OLS, заданный в VPS. Другими словами, для каждого слоя с конкретным значением nuh_layer_id (например, nuhLayerId равен одному из vps_layer_id[k] для k в диапазоне от 0 до vps_max_layers_minus1 включительно) должна быть по меньшей мере одна пара значений i и j, где i находится в диапазоне от 0 до TotalNumOlss - 1 включительно, а j находится в диапазоне NumLayersInOls[i] - 1 включительно, так что значение LayerIdInOls[i][j] равно nuhLayerId. Любой слой в OLS должен быть выводимым слоем OLS или (непосредственным или косвенным) опорным слоем выводимого слоя в OLS.
[00134] vps_output_layer_flag[i][j] задает, выводится ли j-й слой в i-м OLS, когда ols_mode_idc равен двум. vps_output_layer_flag[i] может быть установлен равным одному, чтобы задать, что выводится j-й слой в i-м OLS. vps_output_layer_flag[i] может быть установлен равным нулю, чтобы задать, что j-й слой в i-м OLS не выводится. Когда vps_all_independent_layers_flag равен одному, а each_layer_is_an_ols_flag равен нулю, можно сделать вывод, что значение vps_output_layer_flag[i] равно единице.
[00135] Переменная OutputLayerFlag[i][j], для которой значение один указывает, что выводится j-й слой в i-м OLS, а значение ноль указывает, что j-й слой в i-м OLS не выводится, может быть выведена следующим образом:
для(i=0, i < TotalNumOlss; i++) {
OutputLayerFlag[i][NumLayersInOls[i] - 1]=1
для(j=0; j < NumLayersInOls[i] - 1; j++)
если(ols_mode_idc[i] == 0)
OutputLayerFlag[i][j]=0
иначе если(ols_mode_idc[i] == 1)
OutputLayerFlag[i][j]=1
иначе если(ols_mode_idc[i] == 2)
OutputLayerFlag[i][j]=vps_output_layer_flag[i][j]
}
[00136] 0-й OLS содержит только самый нижний слой (например, слой с nuh_layer_id, равным vps_layer_id[0]), а для 0-го OLS выводится только включенный слой. vps_constraint_info_present_flag может быть установлен равным одному, чтобы задать, что синтаксическая структура general_constraint_info() присутствует в VPS. vps_constraint_info_present_flag может быть установлен равным нулю, чтобы задать, что синтаксическая структура general_constraint_info() отсутствует в VPS. vps_reserved_zero_7bits должны быть равны нулю в согласующихся битовых потоках. Другие значения для vps_reserved_zero_7bits зарезервированы. Декодеры должны игнорировать значение vps_reserved_zero_7bits.
[00137] general_hrd_params_present_flag может быть установлен равным одному, чтобы задать, что синтаксические элементы num_units_in_tick и time_scale и синтаксическая структура general_hrd_parameters() присутствуют в синтаксической структуре RBSP SPS. general_hrd_params_present_flag может быть установлен равным нулю, чтобы задать, что синтаксические элементы num_units_in_tick и time_scale, и синтаксическая структура general_hrd_parameters() отсутствуют в синтаксической структуре RBSP SPS. num_units_in_tick - это количество единиц времени тактового генератора, работающего на частоте time_scale в герцах (Гц), что соответствует одному приращению (называемому тактом тактового генератора) счетчика тактового генератора. num_units_in_tick должен быть больше нуля. Такт тактового генератора в единицах секунд равен отношению num_units_in_tick к time_scale. Например, когда частота кадров видеосигнала составляет двадцать пять Гц, time_scale может быть равен 27000000, а num_units_in_tick может быть равен 1080000, и, следовательно, такт тактового генератора может быть равен 0,04 секунды.
[00138] Time_scale - это количество единиц времени, проходящих за одну секунду. Например, система координат времени, которая измеряет время с помощью тактового генератора в двадцать семь мегагерц (МГц), имеет time_scale 27000000. Значение time_scale должно быть больше нуля. vps_extension_flag может быть установлен равным нулю, чтобы задать, что в структуре синтаксиса RBSP VPS нет элементов синтаксиса vps_extension_data_flag. vps_extension_flag может быть установлен равным одному, чтобы задать, что в структуре синтаксиса RBSP VPS присутствуют синтаксические элементы vps_extension_data_flag. vps_extension_data_flag может иметь любое значение. Наличие и значение флага vps_extension_data_flag не влияют на согласованность декодера профилям. Соответствующие декодеры должны игнорировать все синтаксические элементы vps_extension_data_flag.
[00139] Фиг.8 является принципиальной схемой примерного устройства 800 кодирования/декодирования видео. Устройство 800 кодирования/декодирования видео подходит для реализации раскрытых примеров/вариантов осуществления, как описано в данном документе. Устройство 800 кодирования/декодирования видео содержит входные порты 820, выходные порты 850 и/или модуль 810 приемопередатчиков (Tx/Rx), включающие в себя передатчики и/или приемники. Устройство 800 кодирования/декодирования видео также включает в себя процессор 830, включающий в себя логический модуль и/или центральный модуль обработки (CPU) для обработки данных и память 832 для хранения данных. Устройство 800 кодирования/декодирования видео может также содержать электрические, оптико-электрические (OE) компоненты, электрическо-оптические (EO) компоненты и/или компоненты беспроводной связи, подключенные к выходным портам 850 и/или входным портам 820 для обмена данными через электрические, оптические или беспроводные сети связи. Устройство 800 кодирования/декодирования видео может также включать в себя устройства 860 ввода и/или вывода (I/O) для передачи данных пользователю и от пользователя. Устройства 860 ввода-вывода могут включать в себя устройства вывода, такие как дисплей для отображения видеоданных, громкоговорители для вывода аудиоданных и т.д. Устройства 860 ввода-вывода могут также включать в себя устройства ввода, такие как клавиатура, мышь, трекбол и т.д., и/или соответствующие интерфейсы для взаимодействия с такими устройствами вывода.
[00140] Процессор 830 реализуется аппаратным обеспечением и программным обеспечением. Процессор 830 может быть реализован в виде одного или более ядер (например, в форме многоядерного процессора), микросхем CPU, программируемых пользователем вентильных матриц (FPGA), специализированных интегральных схем (ASIC) и процессоров цифровых сигналов (DSP). Процессор 830 осуществляет связь с входными портами 820, Tx/Rx 810, выходными портами 850 и памятью 832. Процессор 830 содержит модуль 814 кодирования. Модуль 814 кодирования реализует описанные здесь раскрытые варианты осуществления, такие как способы 100, 900 и 1000, которые могут использовать многослойную видеопоследовательность 500, видеопоследовательность 600 и/или битовый поток 700. Модуль 814 кодирования может также реализовывать любой другой способ/механизм, описанный в данном документе. Кроме того, модуль 814 кодирования может реализовать систему 200 кодека, кодер 300 и/или декодер 400. Например, модуль 814 кодирования может использоваться для кодирования видеопоследовательности в слои и/или OLS для поддержки многоракурсной масштабируемости. Например, модуль 814 кодирования может кодировать и/или декодировать синтаксический элемент ols_mode_idc в/из VPS в битовом потоке. Синтаксический элемент ols_mode_idc может указывать, что общее количество OLS в видеопоследовательности равно общему количеству слоев, заданных в VPS, что i-й OLS включает в себя слои с 0 по i включительно, и что для каждого OLS все слои в OLS выводятся. Следовательно, модуль 814 кодирования может использовать синтаксический элемент ols_mode_idc для указания/определения того, что все слои, принятые из масштабируемого видео, могут быть декодированы и отображены по желанию для реализации многоракурсного видео. Таким образом, модуль 814 кодирования предписывает устройству 800 кодирования/декодирования видео обеспечивать дополнительные функциональные возможности и/или эффективность кодирования при кодировании видеоданных. Таким образом, модуль 814 кодирования улучшает функциональность устройства 800 кодирования/декодирования видео, и решает проблемы, которые характерны для областей техники видеокодирования. Кроме того, модуль 814 кодирования осуществляет перевод устройства 800 кодирования/декодирования видео в другое состояние. В качестве альтернативы, модуль 814 кодирования может быть реализован как инструкции, хранящиеся в памяти 832 и исполняемые процессором 830 (например, как компьютерный программный продукт, хранящийся на долговременном носителе).
[00141] Память 832 содержит один или более типов памяти, таких как диски, ленточные накопители, твердотельные накопители, постоянное запоминающее устройство (ROM), запоминающее устройство произвольного доступа (RAM), флэш-память, троичное запоминающее устройство с адресацией по содержимому (TCAM), статическое запоминающее устройство произвольного доступа (SRAM) и т.д. Память 832 может использоваться как запоминающее устройство при переполнении данных, для хранения программ, когда такие программы выбраны для выполнения, и для хранения инструкций и данных, которые считываются во время выполнения программы.
[00142] Фиг.9 является блок-схемой последовательности операций примерного способа 900 кодирования видеопоследовательности с OLS, сконфигурированными для многоракурсной масштабируемости, такой как многослойная видеопоследовательность 500 и/или видеопоследовательность 600 в битовом потоке 700. Способ 900 может быть использован кодером, таким как система 200 кодека, кодер 300 и/или устройство 800 кодирования/декодирования видео при выполнении способа 100.
[00143] Способ 900 может начинаться, когда кодер принимает видеопоследовательность и решает кодировать эту видеопоследовательность как масштабируемую многоракурсную видеопоследовательность в наборе слоев и OLS, например, на основе пользовательского ввода. Видеопоследовательность может быть сконфигурирована для поддержки множества ракурсов и кодирована для поддержки масштабируемости SNR, пространственной масштабируемости, масштабируемости в соответствии с другими обсуждаемыми здесь характеристиками или их сочетаниями. На этапе 901 кодер может кодировать битовый поток, содержащий один или более OLS, включающих в себя один или более слоев кодированных снимков. Например, слои могут включать в себя базовый слой с наименьшим идентификатором слоя и различные слои улучшения с возрастающими идентификаторами слоя. Каждый слой улучшения с идентификатором слоя j может быть кодирован в соответствии с межслойным предсказанием на основе базового слоя и любых слоев улучшения с идентификатором слоя меньше j. OLS могут включать в себя идентификаторы OLS, которые могут обозначаться буквой i, чтобы различать идентификаторы слоя j. Например, в каждом слое может быть один OLS. Таким образом, OLS с идентификатором OLS ID, равным i, может включать в себя выводимый слой с идентификатором слоя j, где i равен i. OLS с идентификатором OLS, равным i, может также включать в себя все слои с идентификаторами слоев от нуля до j-1 включительно. В данном примере все слои могут быть установлены как выводимые слои. Например, OLS с идентификатором OLS, равным пяти, может включать в себя слои с нуля по пятый, где каждый слой указан как выводимой слой.
[00144] На этапе 903 кодер кодирует VPS в битовый поток. Конфигурация OLS и слоев может указываться в VPS. VPS включает в себя синтаксический элемент ols_mode_idc. ols_mode_idc может быть установлен, чтобы задать, что общее количество OLS, заданных в VPS, равно количеству слоев, заданным в VPS. Кроме того, ols_mode_idc может быть установлен для задания того, что i-й OLS включает в себя слои с индексами слоев от нуля до i и/или j (например, в этом случае i равно j) включительно. ols_mode_idc также может быть установлен, чтобы задать, что для каждого OLS все слои в каждом OLS являются выводимыми слоями. Например, ols_mode_idc может быть установлен в один из нескольких режимов. Описанный выше режим может сигнализироваться, когда ols_mode_idc установлен в один. В некоторых примерах VPS может также включать в себя vps_max_layers_minus1, который задает количество слоев, заданных в VPS. Это также максимально допустимое количество слоев в каждой CVS, ссылающейся на VPS. ols_mode_idc может ссылаться на vps_max_layers_minus1.
[00145] Например, видеопоследовательность может быть декодирована в декодере и/или в гипотетическом опорном декодере (HRD) в кодере для целей проверки стандартов. При декодировании видеопоследовательности переменная общего количества OLS (TotalNumOlss) для видеопоследовательности может быть установлена равной vps_max_layers_minus1 плюс один, когда each_layer_is_an_ols_flag в VPS установлен на ноль, когда ols_mode_idc установлен на ноль или когда ols_mode_idc установлен в один. В качестве конкретного примера, количество слоев в i-м OLS (NumLayersInOls[i]) и идентификатор слоя в OLS (LayerIdInOLS[i][j]), задающий значение nuh_layer_id j-го слоя в i-м OLS, можно вывести следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j]
где vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных в VPS, а each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя. Как только идентификаторы OLS и идентификаторы выводимых слоев известны, HRD в кодере может начать декодирование кодированных снимков в выводимых слоях, используя межслойное предсказание, чтобы выполнить тесты на согласованность, чтобы убедиться, что видео соответствует стандартам.
[00146] На этапе 905 кодер может сохранить битовый поток для передачи в декодер. Например, декодер может знать о доступных OLS (например, через обмен данными и/или другие протоколы, такие как динамическая адаптивная потоковая передача по протоколу передачи гипертекста (DASH)). Декодер может выбрать и запросить OLS с наивысшим идентификатором, который может быть правильно декодирован/отображен декодером. Например, в случае пространственной масштабируемости декодер может запросить OLS с многоракурсным видео и размером снимка, связанным с экраном (экранами), соединенными с декодером. В случае масштабируемости SNR декодер может запросить OLS самым высоким идентификатором с многоракурсным видео, которое может быть декодировано в свете текущих сетевых условий (например, в свете доступной полосы пропускания связи). Кодер и/или промежуточная кэш-память или сервер содержимого могут затем передать OLS и связанный(е) слой(и) в декодер для декодирования. Таким образом, кодер может создать многоракурсную видеопоследовательность, масштабирование которой может увеличиваться или уменьшаться в зависимости от потребностей декодера.
[00147] На Фиг.10 представлена блок-схема последовательности операций примерного способа 1000 декодирования видеопоследовательности, включающей в себя OLS, сконфигурированные для многоракурсной масштабируемости, например, многослойная видеопоследовательность 500 и/или видеопоследовательность 600 в битовом потоке 700. Способ 1000 может быть использован декодером, таким как система 200 кодека, декодер 400 и/или устройство 800 кодирования/декодирования видео при выполнении способа 100.
[00148] Способ 1000 может начинаться, когда декодер начинает прием битового потока, содержащего OLS с набором из слоя(ев) масштабируемой многоракурсной видеопоследовательности, например, в результате применения способа 900. Видеопоследовательность может быть кодирована для поддержки масштабируемости SNR, пространственной масштабируемости, масштабируемости в соответствии с другими обсуждаемыми здесь характеристиками или их сочетанием. На этапе 1001 декодер может принять битовый поток, содержащий OLS и VPS. Например, OLS может включать в себя один или более слоев кодированных снимков. Слои могут включать в себя базовый слой с самым нижним идентификатором слоя и различные слои улучшения с возрастающими идентификаторами слоя. Каждый слой улучшения с идентификатором слоя j может быть кодирован в соответствии с межслойным предсказанием на основе базового слоя и любых слоев улучшения с идентификатором слоя меньше j. OLS может включать в себя идентификатор OLS, который может обозначаться буквой i, чтобы различать идентификаторы слоя j. Например, может быть один OLS в кодированном битовом потоке на слой. Таким образом, OLS с идентификатором OLS ID, равным i, может включать в себя выводимый слой с идентификатором слоя j, где i равен i. OLS, принятый с идентификатором OLS ID i, может также включать в себя все слои с идентификаторами слоев от нуля до j-1 включительно. В данном примере все слои могут быть установлены как выводимые слои. Например, принятый OLS с идентификатором OLS, равным пяти, может включать в себя слои с нуля по пятый, где каждый слой указан как выводимой слой. Конфигурация OLS и слоев может указываться в VPS.
[00149] Например, VPS включает в себя синтаксический элемент ols_mode_idc. ols_mode_idc может быть установлен, чтобы задать, что общее количество OLS, заданных в VPS, равно количеству слоев, заданных в VPS. Кроме того, ols_mode_idc может быть установлен для задания того, что i-й OLS включает в себя слои с индексами слоев от нуля до i и/или j (например, в этом случае i равно j) включительно. ols_mode_idc также может быть установлен, чтобы задать, что для каждого OLS все слои в каждом OLS являются выводимыми слоями. Например, ols_mode_idc может быть установлен в один из нескольких режимов. Описанный выше режим может сигнализироваться, когда ols_mode_idc установлен в один. В некоторых примерах VPS может также включать в себя vps_max_layers_minus1, который определяет количество слоев, указанных VPS. Это также максимально допустимое количество слоев в каждой CVS, ссылающейся на VPS. ols_mode_idc может ссылаться на vps_max_layers_minus1.
[00150] На этапе 1003 декодер может определить выводимые слои на основе ols_mode_idc в VPS. В качестве конкретного примера, при определении конфигурации видеопоследовательности переменная общего количества OLS (TotalNumOlss) для видеопоследовательности может быть установлена равной vps_max_layers_minus1 плюс один, когда each_layer_is_an_ols_flag в VPS установлен на ноль, когда ols_mode_idc установлен в ноль, или когда ols_mode_idc установлен в один. В качестве конкретного примера, количество слоев в i-м OLS (NumLayersInOls[i]) и идентификатор слоя в OLS (LayerIdInOLS[i][j]), указывающий значение nuh_layer_id j-го слоя в i-ом OLS, можно вывести следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j]
где vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных в VPS, а each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя.
[00151] Используя идентификаторы выводимых слоев, декодер может декодировать кодированный(ые) снимок(и) из выводимых слоев, чтобы создать декодированный(ые) снимок(и) на этапе 1005. Например, декодер может декодировать все выводимые слои, используя межслойное предсказание, чтобы декодировать более высокие слои на основе более нижних слоев по желанию. Декодер также может выбирать слои для реализации множества ракурсов. На этапе 1007 декодер может переслать декодированный снимок для отображения в качестве части декодированной видеопоследовательности. Например, декодер может переслать декодированные снимки с первого слоя для отображения на первом экране (или его части) и пересылать снимок со второго слоя, установленного для отображения на втором экране (или его части).
[00152] В качестве конкретного примера декодер может знать о доступных OLS (например, посредством обмена данными и/или других протоколов, таких как динамическая адаптивная потоковая передача по протоколу передачи гипертекста (DASH)). Декодер может выбрать и запросить OLS с наивысшим идентификатором, который может быть правильно декодирован/отображен декодером. Например, в случае пространственной масштабируемости декодер может запросить OLS с размером снимка, связанным с экраном, соединенным с декодером. В случае масштабируемости SNR декодер может запросить OLS с самым высоким идентификатором, который может быть декодирован в свете текущих сетевых условий (например, в свете доступной полосы пропускания связи). Кодер и/или промежуточная кэш-память или сервер содержимого могут затем передать OLS и связанный(е) слой(и) в декодер для декодирования для поддержки множества ракурсов. Таким образом, кодер может создать многоракурсную видеопоследовательность, масштабирование которой может увеличиваться или уменьшаться в зависимости от потребностей декодера. Затем декодер может декодировать запрошенную видеопоследовательность при приеме, используя способ 1000.
[00153] Фиг.11 является принципиальной схемой примерной системы 1100 для кодирования видеопоследовательности с OLS, сконфигурированными для многоракурсной масштабируемости, такой как многослойная видеопоследовательность 500 и/или видеопоследовательность 600 в битовом потоке 700. Система 1100 может быть реализована с помощью кодера и декодера, такого как система 200 кодека, кодер 300, декодер 400 и/или устройство 800 кодирования/декодирования видео. Кроме того, система 1100 может использоваться при реализации способов 100, 900 и/или 1000.
[00154] Система 1100 включает в себя видеокодер 1102. Видеокодер 1102 содержит модуль 1105 кодирования для кодирования битового потока, содержащего один или более OLS, включающих в себя один или более слоев кодированных снимков. Модуль 1105 кодирования дополнительно предназначен для кодирования в битовый поток VPS, при этом VPS включает в себя ols_mode_idc, задающий то, что для каждого OLS все слои в каждом OLS являются выводимыми слоями. Видеокодер 1102 дополнительно содержит модуль 1106 хранения для хранения битового потока для передачи в декодер. Видеокодер 1102 дополнительно содержит модуль 1107 передачи для передачи битового потока в видеодекодер 1110. Видеокодер 1102 может быть дополнительно выполнен с возможностью осуществления любого из этапов способа 900.
[00155] Система 1100 также включает в себя видеодекодер 1110. Видеодекодер 1110 содержит модуль 1111 приема для приема битового потока, содержащего OLS и VPS, при этом OLS включает в себя один или более слоев кодированных снимков, а VPS включает в себя ols_mode_idc, задающий то, что для каждого OLS все слои в каждом OLS являются выводимыми слоями. Видеодекодер 1110 дополнительно содержит модуль 1113 определения для определения выводимых слоев на основе ols_mode_idc в VPS. Видеодекодер 1110 дополнительно содержит модуль 1115 декодирования для декодирования кодированного снимка из выводимых слоев для создания декодированного снимка. Видеодекодер 1110 дополнительно содержит модуль 1115 пересылки для пересылки декодированного снимка для отображения в качестве части декодированной видеопоследовательности. Видеодекодер 1110 может быть дополнительно выполнен с возможностью осуществления любого из этапов способа 1000.
[00156] Первый компонент напрямую связан со вторым компонентом, когда нет промежуточных компонентов, за исключением линии, трассировки или другой среды между первым компонентом и вторым компонентом. Первый компонент косвенно связан со вторым компонентом, когда есть промежуточные компоненты, отличные от линии, следа или другой среды между первым компонентом и вторым компонентом. Термин «связанный» и его варианты включают как напрямую связанные, так и косвенно связанные. Использование термина «примерно» означает диапазон, включающий ± 10% от следующего числа, если не указано иное.
[00157] Также следует понимать, что этапы примерных способов, изложенных в данном документе, не обязательно должны выполняться в описанном порядке, и порядок этапов таких способов следует понимать как просто примерный. Аналогичным образом, в такие способы могут быть включены дополнительные этапы, а некоторые этапы могут быть опущены или объединены в способах, согласующихся с различными вариантами осуществления настоящего раскрытия.
[00158] Хотя в настоящем раскрытии представлено несколько вариантов осуществления, можно понять, что раскрытые системы и способы могут быть воплощены во многих других конкретных формах, не выходя за рамки сущности или объема настоящего раскрытия. Настоящие примеры следует рассматривать как иллюстративные, а не как ограничительные, и цель не ограничиваться приведенными здесь подробностями. Например, различные элементы или компоненты могут быть объединены или интегрированы в другую систему, или определенные функции могут быть опущены или не реализованы.
[00159] Кроме того, методики, системы, подсистемы и способы, описанные и проиллюстрированные в различных вариантах осуществления как дискретные или отдельные, могут быть объединены или интегрированы с другими системами, компонентами, технологиями или способами без отклонения от объема настоящего раскрытия. Другие примеры изменений, замен и преобразований могут быть установлены специалистом в данной области техники и могут быть выполнены без отклонения от сущности и объема, раскрытых в данном документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОТКЛОНЕНИЕ НЕИСПОЛЬЗУЕМЫХ СЛОЕВ В МНОГОСЛОЙНЫХ ВИДЕОПОТОКАХ | 2020 |
|
RU2823559C1 |
| СЛОИ ОДНОВРЕМЕННОЙ ПЕРЕДАЧИ ДЛЯ МНОГОРАКУРСНОГО ПРЕДСТАВЛЕНИЯ ПРИ КОДИРОВАНИИ ВИДЕО | 2020 |
|
RU2828713C1 |
| OLS ДЛЯ ПРОСТРАНСТВЕННОЙ МАСШТАБИРУЕМОСТИ И МАСШТАБИРУЕМОСТИ ПО SNR | 2020 |
|
RU2822990C1 |
| ОТКЛОНЕНИЕ НЕНУЖНЫХ СЛОЕВ В МНОГОСЛОЙНЫХ ВИДЕОПОТОКАХ | 2020 |
|
RU2831434C1 |
| ПРЕДОТВРАЩЕНИЕ ИЗБЫТОЧНОЙ СИГНАЛИЗАЦИИ В МНОГОСЛОЙНЫХ БИТОВЫХ ВИДЕОПОТОКАХ | 2020 |
|
RU2827899C1 |
| Предотвращение избыточной сигнализации в многослойных битовых видеопотоках | 2020 |
|
RU2829492C1 |
| ПРЕДОТВРАЩЕНИЕ ИЗБЫТОЧНОЙ СИГНАЛИЗАЦИИ В МНОГОСЛОЙНЫХ БИТОВЫХ ВИДЕОПОТОКАХ | 2020 |
|
RU2821429C1 |
| ТЕСТЫ НА СООТВЕТСТВИЕ HRD ДЛЯ OLS | 2020 |
|
RU2820076C1 |
| ПАРАМЕТРЫ HRD НА УРОВНЕ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2825440C1 |
| УПРАВЛЕНИЕ МАСШТАБИРУЕМЫМ ВКЛАДЫВАЕМЫМ SEI-СООБЩЕНИЕМ | 2020 |
|
RU2824781C1 |
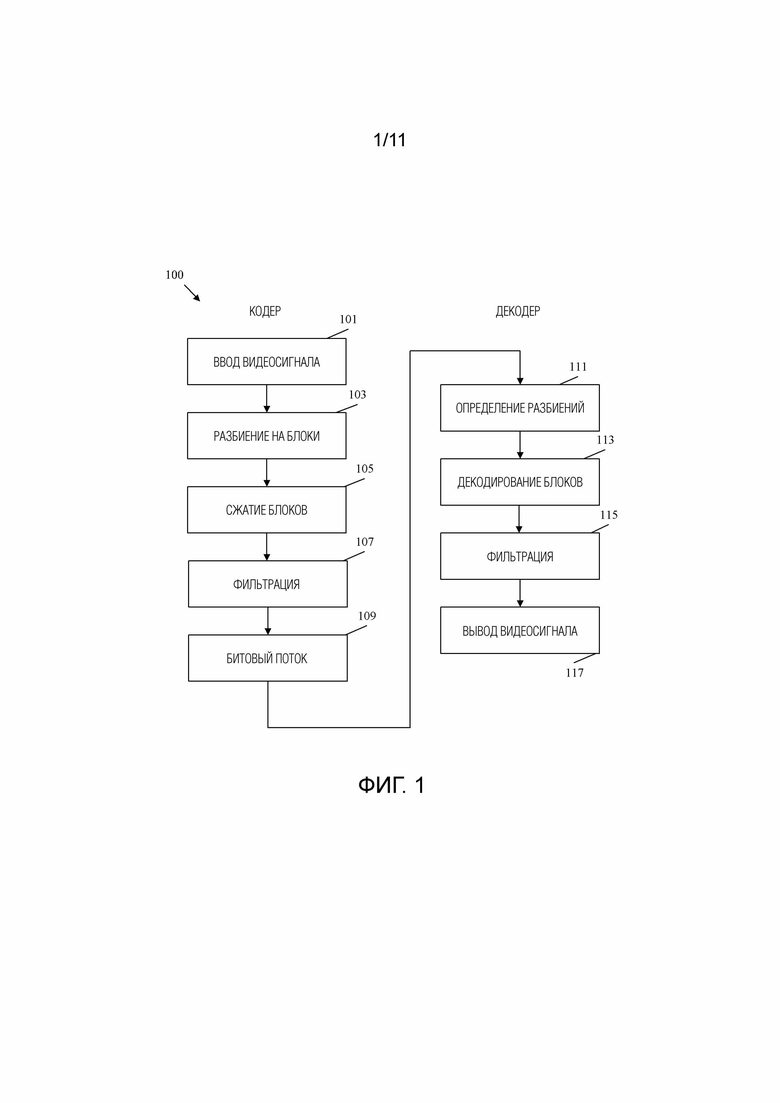
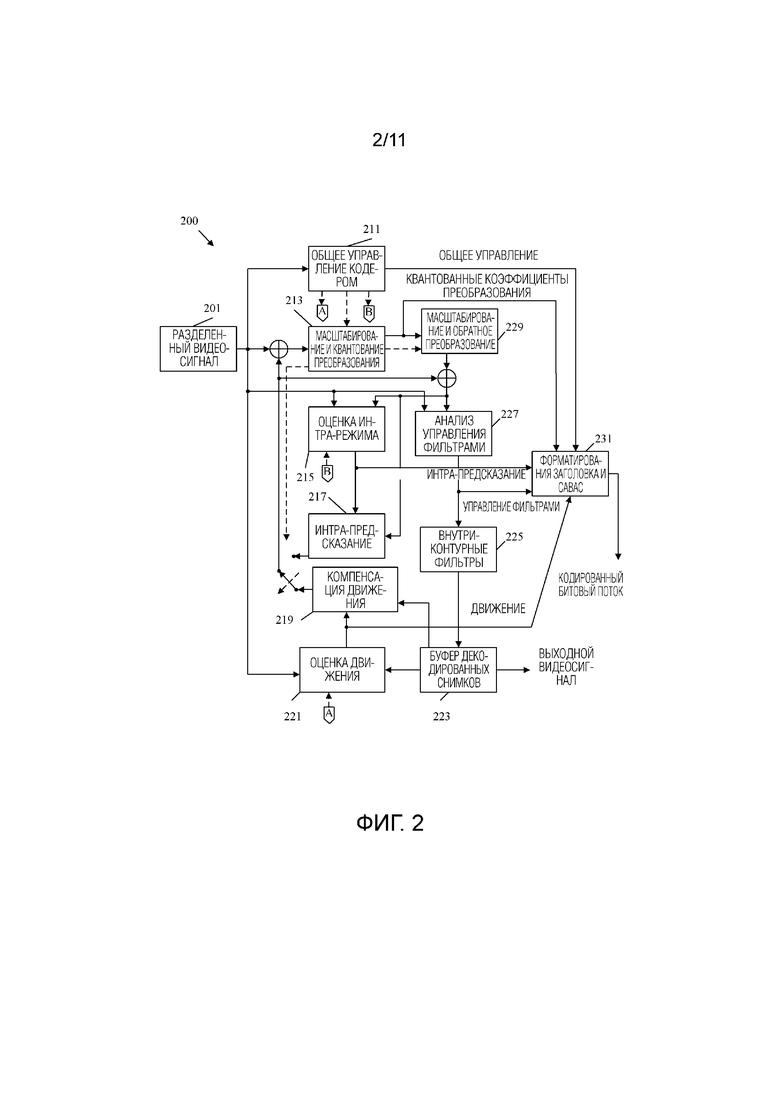
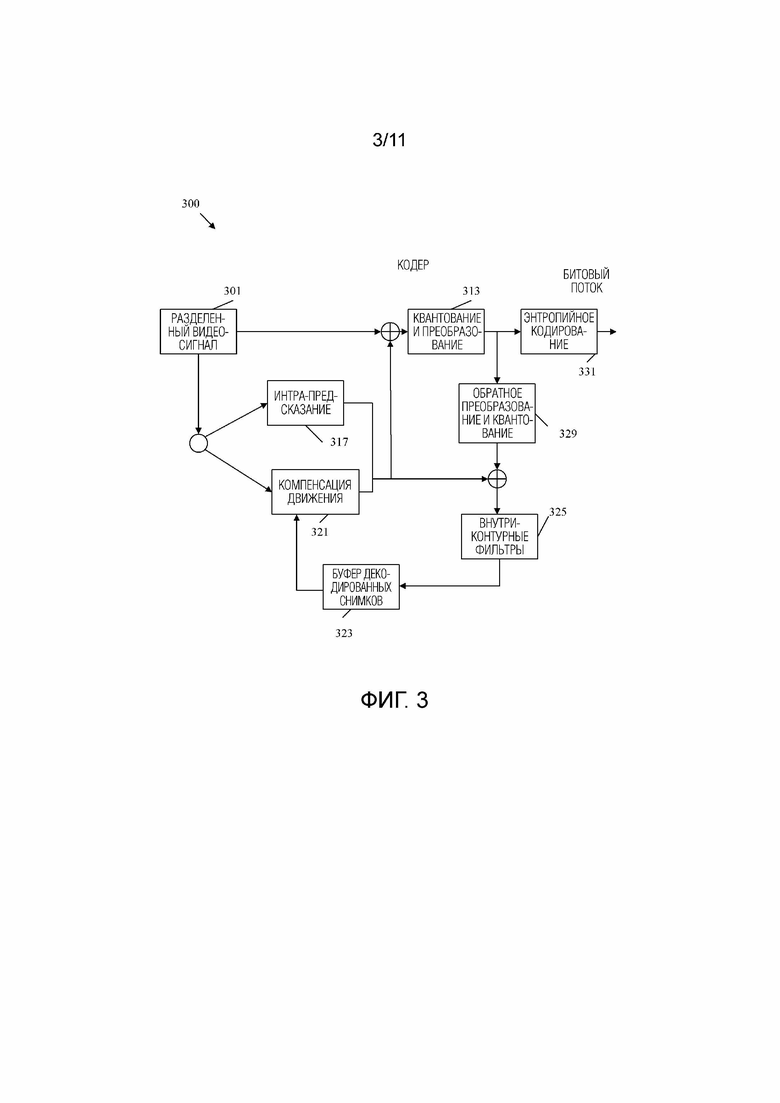
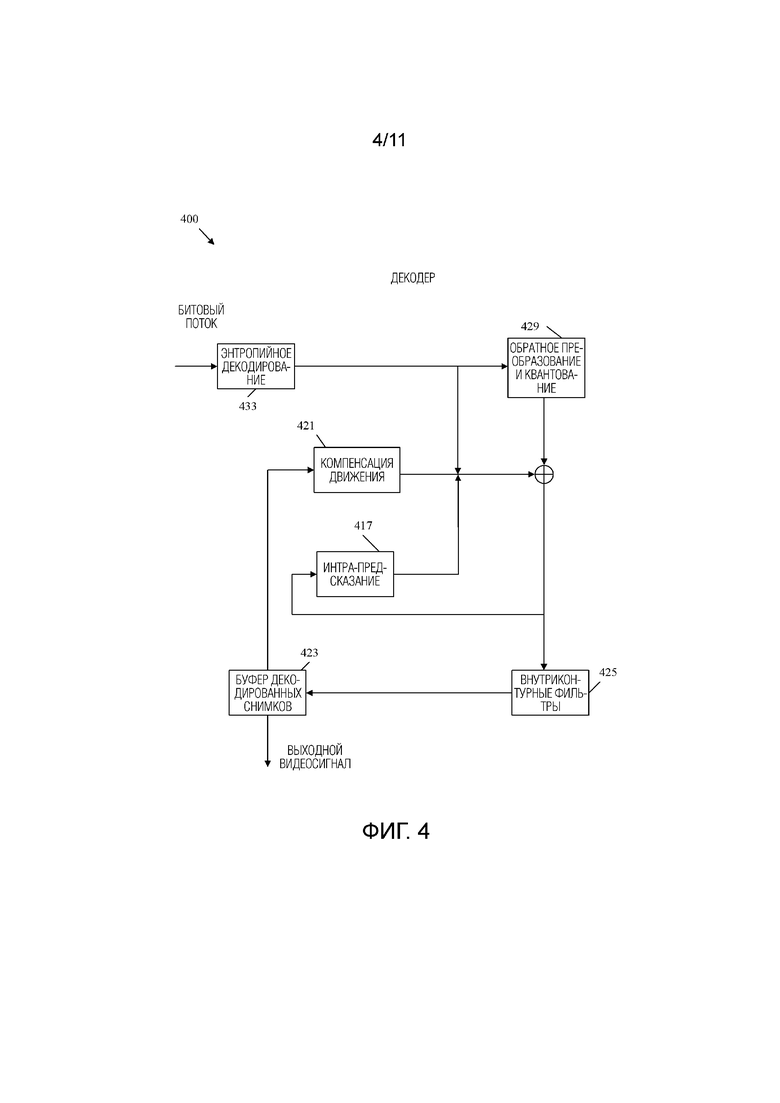
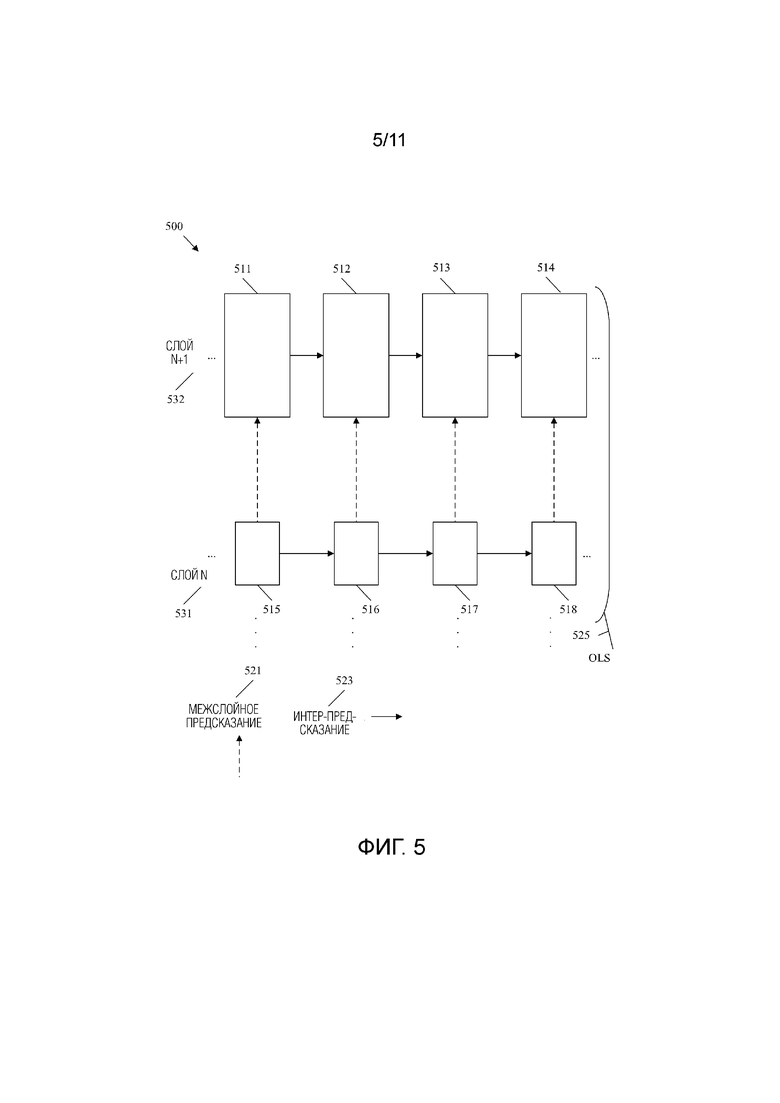
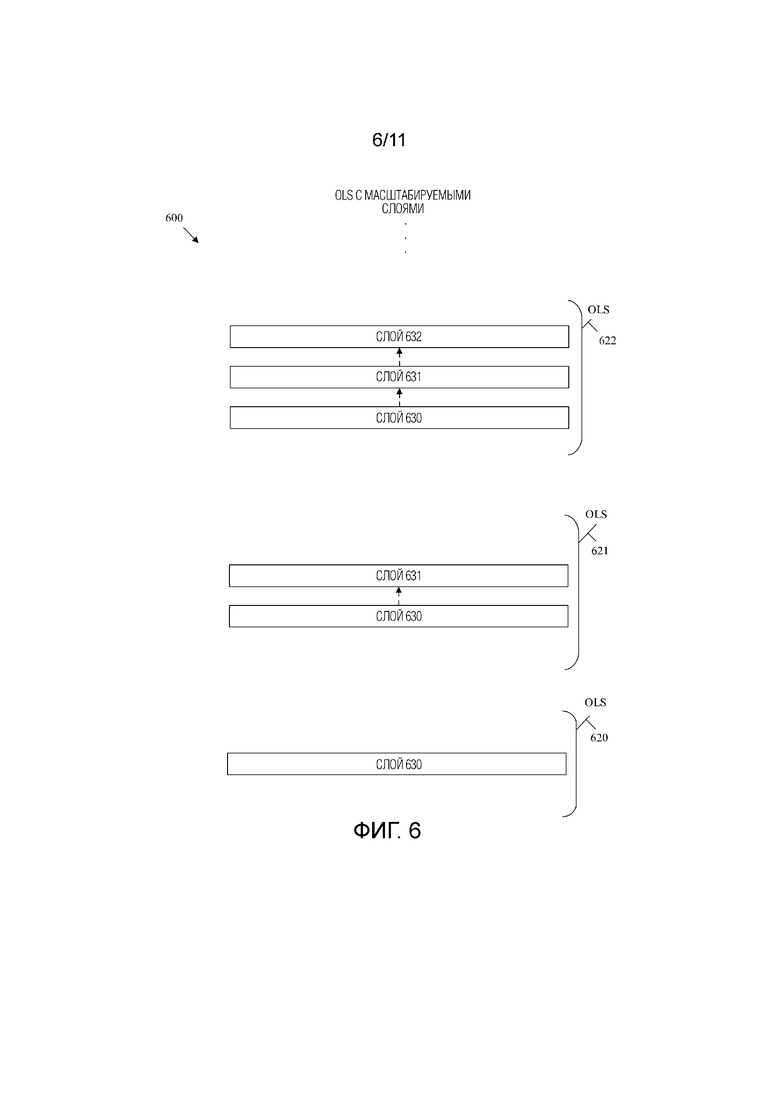
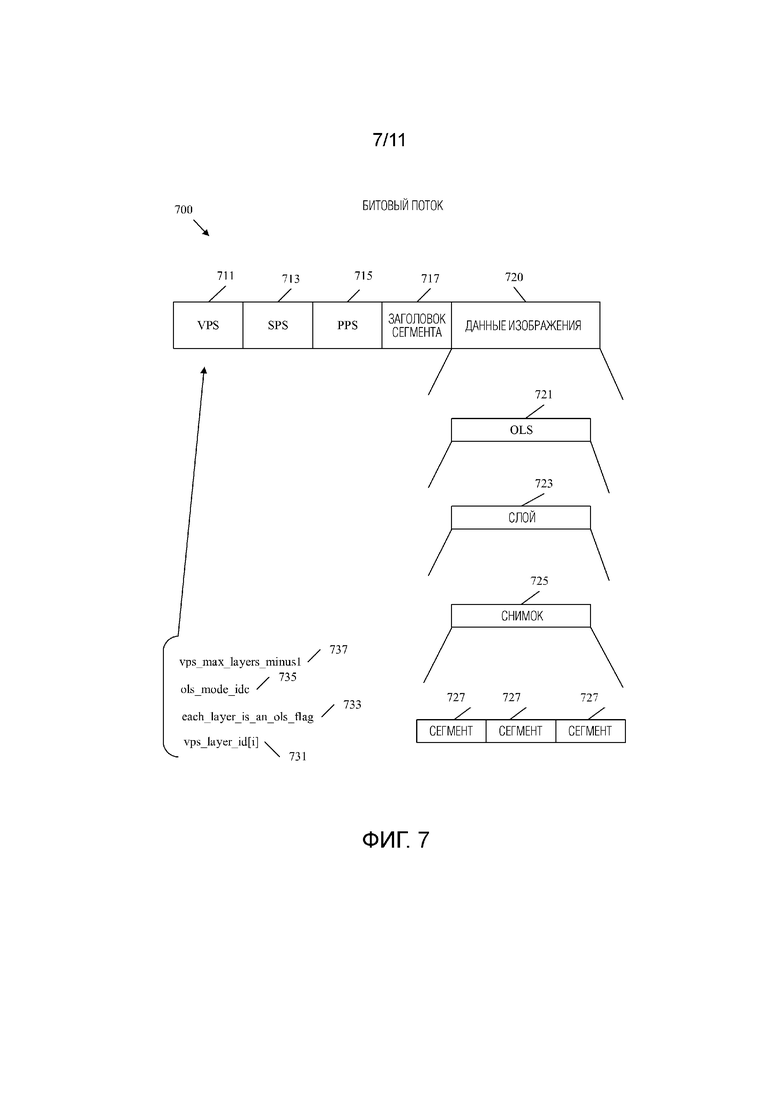
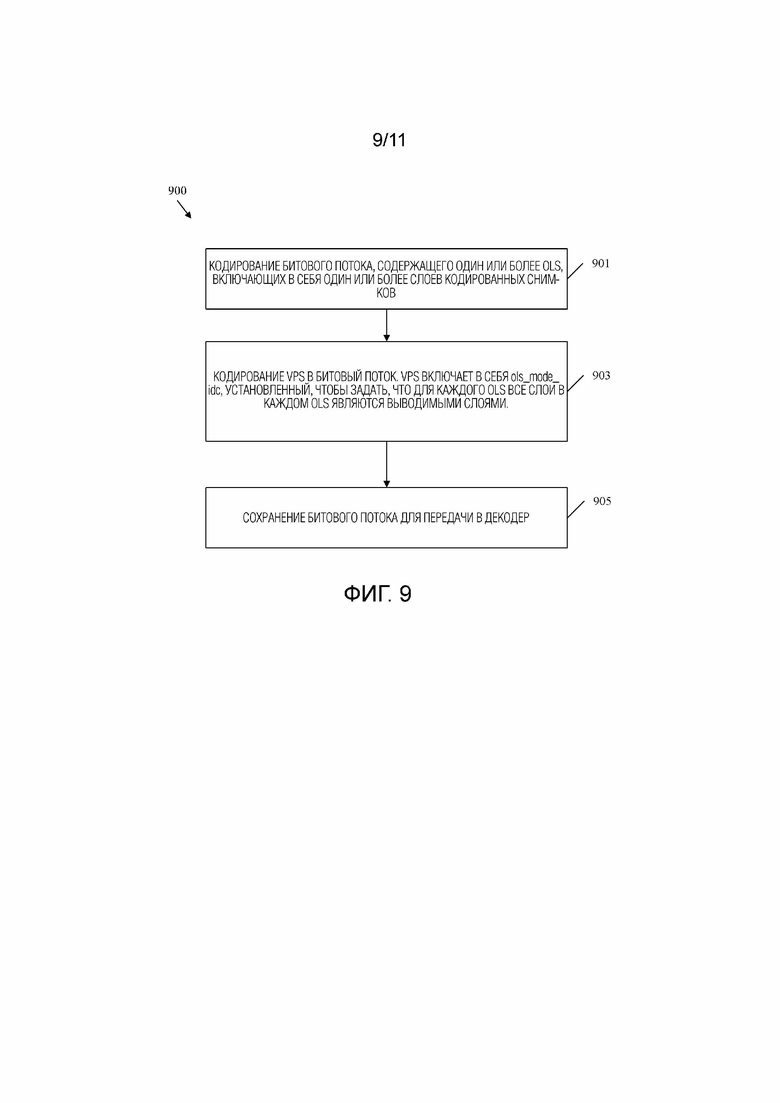
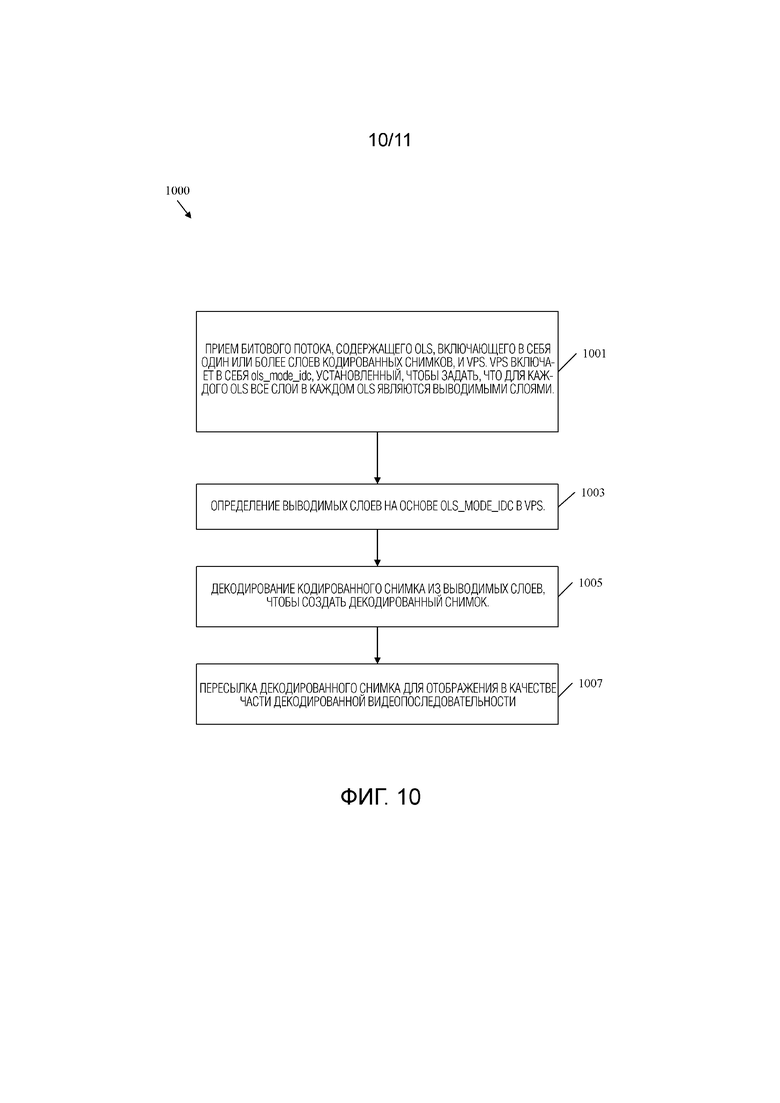
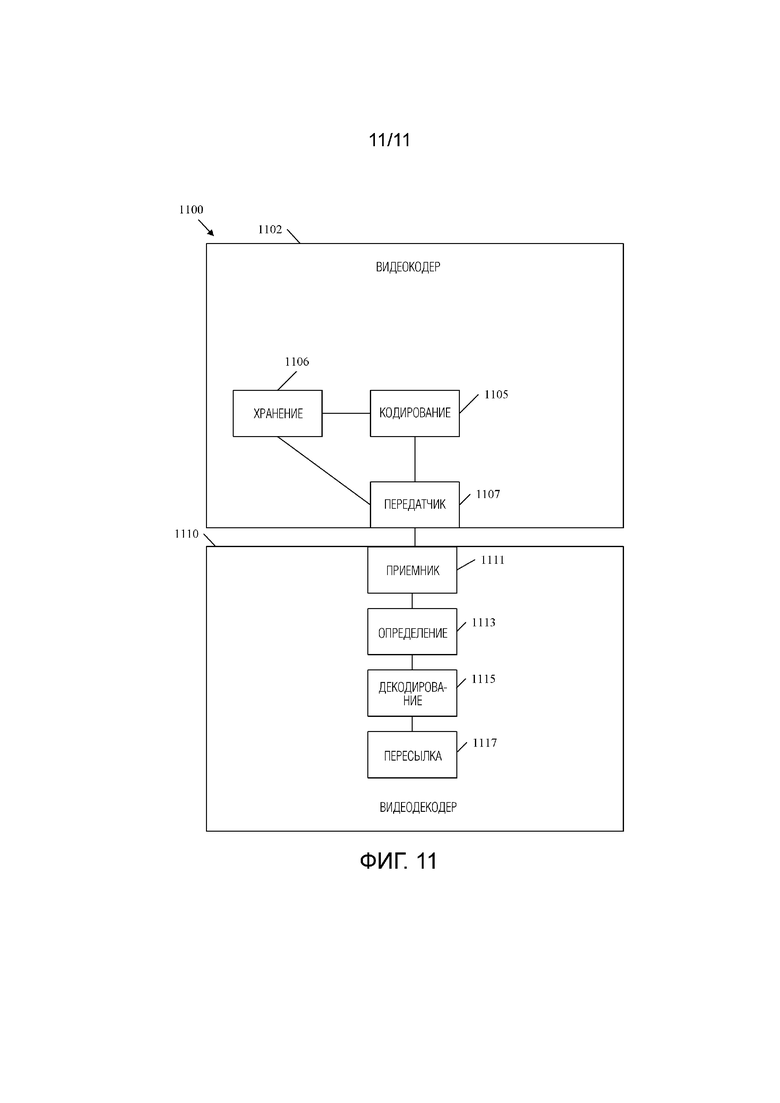
Изобретение относится к средствам для видеокодирования. Технический результат заключается в повышении эффективности видеокодирования. Принимают посредством приемника декодера битовый поток, содержащий набор выводимых слоев (OLS) и набор параметров видео (VPS). Причем OLS включает в себя один или более слоев кодированных снимков, а VPS включает в себя код идентификации режима OLS (ols_mode_idc). При этом ols_mode_idc, равный одному, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS все слои в каждом OLS являются выводимыми слоями. Причем vps_max_layers_minus1 плюс один указывает максимально допустимое количество слоев в каждой кодированной видеопоследовательности (CVS), ссылающейся на VPS. Определяют посредством процессора декодера выводимые слои на основе ols_mode_idc в VPS. Декодируют посредством процессора декодера кодированный снимок из выводимых слоев для создания декодированного снимка. 6 н. и 12 з.п. ф-лы, 11 ил.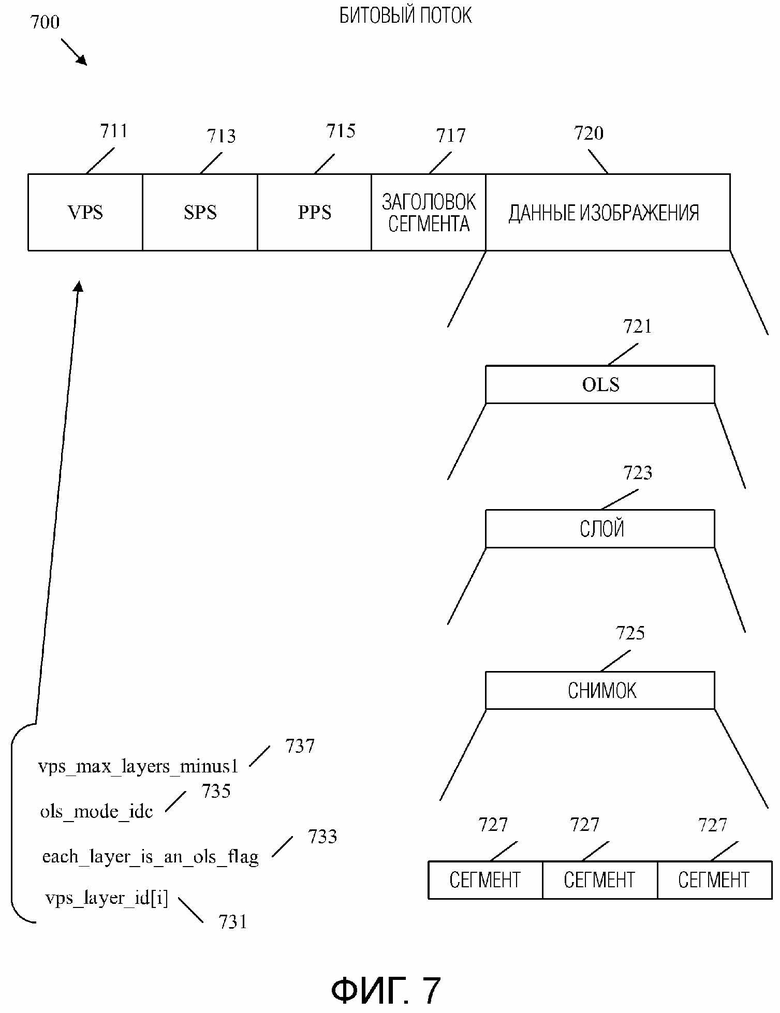
1. Способ декодирования, реализуемый декодером, содержащий этапы, на которых:
принимают посредством приемника декодера битовый поток, содержащий набор выводимых слоев (OLS) и набор параметров видео (VPS), причем OLS включает в себя один или более слоев кодированных снимков, а VPS включает в себя код идентификации режима OLS (ols_mode_idc), при этом ols_mode_idc, равный одному, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS все слои в каждом OLS являются выводимыми слоями, причем vps_max_layers_minus1 плюс один указывает максимально допустимое количество слоев в каждой кодированной видеопоследовательности (CVS), ссылающейся на VPS;
определяют посредством процессора декодера выводимые слои на основе ols_mode_idc в VPS; и
декодируют посредством процессора декодера кодированный снимок из выводимых слоев для создания декодированного снимка.
2. Способ по п.1, в котором ols_mode_idc, равный двум, задает то, что общее количество OLS, заданных посредством VPS, сигнализируется в явном виде.
3. Способ по п.1 или 2, в котором VPS содержит each_layer_is_an_ols_flag, причем each_layer_is_an_ols_flag, равный одному, задает то, что каждый набор выводимых слоев содержит только один слой; each_layer_is_an_ols_flag, равный нулю, задает то, что по меньшей мере один OLS содержит более одного слоя; и когда vps_max_layers_minus1 равно нулю, значение each_layer_is_an_ols_flag предполагается равным единице.
4. Способ по п.3, в котором когда vps_max_layers_minus1 больше нуля, VPS дополнительно содержит vps_all_independent_layers_flag, причем vps_all_independent_layers_flag, равный одному, задает то, что все слои в CVS кодируются независимо без использования межслойного предсказания; vps_all_independent_layers_flag, равный нулю, задает то, что один или более из слоев в CVS используют межслойное предсказание; при этом, когда vps_all_independent_layers_flag равен одному и each_layer_is_an_ols_flag равен нулю, значение ols_mode_idc предполагается равным двум.
5. Способ по любому из пп.1-4, в котором ols_mode_idc, равный нулю, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS выводится только самый верхний слой в OLS.
6. Способ по любому из пп.1-5, в котором количество слоев в i-м OLS и значение идентификатора слоя заголовка единицы слоя сетевой абстракции (NAL) (nuh_layer_id) j-го слоя в i-м OLS получаются следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j],
где NumLayersInOls[i] представляет количество слоев в i-м OLS, LayerIdInOLS[i][j] представляет значение nuh_layer_id j-го слоя в i-м OLS, vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных посредством VPS, и each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя.
7. Способ кодирования, реализуемый кодером, содержащий этапы, на которых:
кодируют посредством процессора кодера битовый поток, содержащий один или более наборов выводимых слоев (OLS), включающих в себя один или более слоев кодированных снимков;
кодируют в битовый поток посредством процессора набор параметров видео (VPS), причем VPS включает в себя код идентификации режима набора выводимых слоев (OLS) (ols_mode_idc), при этом ols_mode_idc, равный одному, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS все слои в каждом OLS являются выводимыми слоями, причем vps_max_layers_minus1 плюс один указывает максимально допустимое количество слоев в каждой кодированной видеопоследовательности (CVS), ссылающейся на VPS; и
сохраняют в память, соединенную с процессором, битовый поток для передачи в декодер.
8. Способ по п.7, в котором ols_mode_idc, равный двум, задает то, что общее количество OLS, заданных посредством VPS, сигнализируется в явном виде.
9. Способ по п.7 или 8, в котором VPS содержит each_layer_is_an_ols_flag, причем each_layer_is_an_ols_flag, равный одному, задает то, что каждый набор выводимых слоев содержит только один слой; each_layer_is_an_ols_flag, равный нулю, задает то, что по меньшей мере один OLS содержит более одного слоя; и когда vps_max_layers_minus1 равно нулю, значение each_layer_is_an_ols_flag предполагается равным единице.
10. Способ по п.9, в котором, когда vps_max_layers_minus1 больше нуля, VPS дополнительно содержит vps_all_independent_layers_flag, причем vps_all_independent_layers_flag, равный одному, задает то, что все слои в CVS кодируются независимо без использования межслойного предсказания; vps_all_independent_layers_flag, равный нулю, задает то, что один или более из слоев в CVS используют межслойное предсказание; при этом, когда vps_all_independent_layers_flag равен одному и each_layer_is_an_ols_flag равен нулю, значение ols_mode_idc предполагается равным двум.
11. Способ по любому из пп.7-10, в котором ols_mode_idc, равный нулю, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS выводится только самый верхний слой в OLS.
12. Способ по любому из пп.7-11, в котором количество слоев в i-м OLS и значение идентификатора слоя заголовка единицы слоя сетевой абстракции (NAL) (nuh_layer_id) j-го слоя в i-м OLS получаются следующим образом:
NumLayersInOls[0]=1
LayerIdInOls[0][0]=vps_layer_id[0]
для(i=1, i < TotalNumOlss; i++) {
если(each_layer_is_an_ols_flag) {
NumLayersInOls[i]=1
LayerIdInOls[i][0]=vps_layer_id[i]
} иначе если(ols_mode_idc == 0 || ols_mode_idc == 1) {
NumLayersInOls[i]=i+1
для(j=0; j < NumLayersInOls[i]; j++)
LayerIdInOls[i][j]=vps_layer_id[j],
где NumLayersInOls[i] представляет количество слоев в i-м OLS, LayerIdInOLS[i][j] представляет значение nuh_layer_id j-го слоя в i-м OLS, vps_layer_id[i] является идентификатором i-го слоя VPS, TotalNumOlss является общим количеством OLS, заданных посредством VPS, и each_layer_is_an_ols_flag является тем, что каждый слой является флагом OLS, что задает, содержит ли по меньшей мере один OLS более одного слоя.
13. Устройство кодирования/декодирования видео, содержащее:
процессор, приемник, соединенный с процессором, память, соединенную с процессором, и передатчик, соединенный с процессором, при этом процессор, приемник, память и передатчик выполнены с возможностью осуществлять способ по любому из пп.1-12.
14. Долговременный машиночитаемый носитель, содержащий компьютерный программный продукт для использования устройством кодирования/декодирования видео, причем компьютерный программный продукт содержит машиноисполняемые инструкции, хранящиеся на долговременном машиночитаемом носителе, так что при их исполнении процессор предписывает устройству кодирования/декодирования видео выполнять способ по любому из пп.1-12.
15. Декодер, содержащий:
средство приема для приема битового потока, содержащего набор выводимых слоев (OLS) и набор параметров видео (VPS), причем OLS включает в себя один или более слоев кодированных снимков, а VPS включает в себя код идентификации режима OLS (ols_mode_idc), при этом ols_mode_idc, равный одному, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS все слои в каждом OLS являются выводимыми слоями, причем vps_max_layers_minus1 плюс один указывает максимально допустимое количество слоев в каждой кодированной видеопоследовательности (CVS), ссылающейся на VPS;
средство определения для определения выводимых слоев на основе ols_mode_idc в VPS;
средство декодирования для декодирования кодированного снимка из выводимых слоев для создания декодированного снимка; и
средство пересылки для пересылки декодированного снимка для отображения в качестве части декодированной видеопоследовательности.
16. Декодер по п.15, при этом декодер дополнительно выполнен с возможностью осуществлять способ по любому из пп.2-6.
17. Кодер, содержащий:
средство кодирования для:
кодирования битового потока, содержащего один или более наборов выводимых слоев (OLS), включающих в себя один или более слоев кодированных снимков, и
кодирования в битовый поток набора параметров видео (VPS), причем VPS включает в себя код идентификации режима набора выводимых слоев (OLS) (ols_mode_idc), при этом ols_mode_idc, равный одному, задает то, что общее количество OLS, заданных посредством VPS, равно vps_max_layers_minus1 плюс один, i-й OLS включает в себя слои с индексами слоев от нуля до i включительно, и для каждого OLS все слои в каждом OLS являются выводимыми слоями, причем vps_max_layers_minus1 плюс один указывает максимально допустимое количество слоев в каждой кодированной видеопоследовательности (CVS), ссылающейся на VPS; и
средство хранения для хранения битового потока для передачи в декодер.
18. Кодер по п.17, при этом кодер дополнительно выполнен с возможностью осуществлять способ по любому из пп.8-12.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9467700 B2, 11.10.2016 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОДАННЫХ | 2015 |
|
RU2653299C2 |

