Изобретение относится к способам распознавания знаков с применением компьютерных средств и может быть использовано для автоматизированного определения поврежденных номеров отработанных тепловыделяющих сборок.
Известен способ компьютерного распознавания объектов по патенту РФ № 2191431 от 03.12.99, МПК G06K 09/68, в соответствии с которым предварительно приводят изображение объекта, вводимое в компьютер, к нормальному, стандартному для данного способа виду путем изменения масштаба, поворота в требуемое положение, центрирования, вписания в прямоугольник требуемого размера, на экран монитора выводят изображение распознаваемого объекта, преобразованное в изображение, выполненное в градациях - различных степенях яркости одного цвета, например красного, и на него последовательно, поочередно накладывают изображения хранящихся в памяти компьютера шаблонов, выполненных, например, в градациях зеленого, что позволяет увидеть в зоне перекрытия изображений изображение другого, отличного от первых двух цвета, которое и фиксируют как распознанное в случае тождественных, идентичных, а значит имеющих одинаковый контур изображений распознаваемого объекта и шаблона. В принципе распознаваемым объектом может быть цифровой или буквенный символ.
Недостаток в трудности визуального распознавания объекта, особенно в том случае, когда объект претерпел значительные изменения по отношению к своему первоначальному виду, сохраняемому в памяти как один из шаблонов. Кроме того, в рассматриваемом способе геометрические характеристики рассматриваемого объекта стандартизированы, но в реальности данные параметры (например, вид шрифта и его высота) могут варьироваться.
Известен способ автоматического распознавания электронными средствами символов, таких как буквы и/или цифры, отпечатанных на любом материале, включающем структуры с сильной контрастностью (патент РФ № 2249251 от 20.06.2000, МПК G06K 09/80, 09/62). Этот способ включает в себя следующие этапы: отладка, формирование моделей символов, распознавание, регистрация модели фона вместе с фоном считанного изображения, выделение модели зарегистрированного фона из элементарного изображения фона, комбинирование для каждого положения символа модели букв и/или цифр с элементарным изображением соответствующего фона, создание комбинированных моделей, сопоставление неизвестных символов с комбинированными моделями, распознавание каждого неизвестного символа как соответствующего символа, комбинированная модель которого наилучшим образом накладывается на него в соответствии с технологией "сравнение с шаблоном".
Данный способ хорошо зарекомендовал себя в том случае, когда заранее известны исходные параметры комбинации символов, т.е. вид и размеры шрифта, количество символов, и нашел применение в распознавании номеров ценных бумаг, в частности денег. Однако распознавание становится крайне затруднительным, если речь идет об идентификационных номерах с неизвестными параметрами шрифта и фона.
В качестве прототипа выбран способ распознавания номерных знаков транспортных средств, описанный в статье с тем же названием, авторы: Иванов Г.А., Ларионов А.А., Панин Д.В., адрес в Интернете: www.http://zntu.edu.ua/cmis/foto/ivanov/ivan_lar_pan.doc.
Способ заключается в формировании исходного изображения предполагаемой области нахождения идентификационного номера, выделении прямоугольной области размещения идентификационного номера (номерной пластины), выявлении в выделенной области зон нахождения отдельных позиций идентификационного номера и распознавании символов на выявленных позициях номера. При этом распознавание отдельных символов осуществляется с помощью набора нейтронных сетей, организованных в два каскада.
Данный способ разработан для распознавания номерных знаков транспортных средств различных стран Европейского союза, которые, в основном, имеют стандартизированное написание с использованием буквенно-цифровых символов единого вида (шрифта).
Проблема заключается в том, что при распознавании номера, о котором неизвестно ни количество используемых символов, ни используемый шрифт, который к тому же наносился без особых требований к прямолинейности и межсимвольным расстояниям и претерпел значительные повреждения в агрессивных условиях эксплуатации, данный способ не дает требуемого результата.
Задачей данного изобретения является создание способа автоматизированного распознавания идентификационного номера, позволяющего обеспечить максимально возможную достоверность при распознавании поврежденных номеров с неизвестным заранее количеством и шрифтом используемых цифровых символов. Зачастую такие маркировки имеют лишь сохранившиеся фрагменты символов, по которым необходимо восстанавливать исходный символ.
Поставленная задача решается следующим образом.
В способе автоматизированного распознавания идентификационного номера, заключающемся в формировании исходного изображения предполагаемой области нахождения идентификационного номера, в выделении прямоугольной области размещения идентификационного номера, выявлении в выделенной прямоугольной области зон нахождения отдельных позиций идентификационного номера и распознавании символов на выявленных позициях номера, согласно изобретению предварительно сформированное исходное изображение очищают с помощью морфологического фильтра, а после выявления зон нахождения отдельных позиций идентификационного номера определяют по сохранившимся фрагментам символов координаты приблизительных центров каждой позиции и приблизительный параметр шрифта, использованного в процессе нанесения идентификационного номера, исходя из которого формируют первоначальный набор шаблонов символов с приблизительным шрифтом распознаваемого номера. Процесс распознавания символов на выявленных позициях номера производят путем последовательного наложения шаблонов с изменяющимися параметрами шрифта символов на зоны нахождения позиций номера с циклическим смещением шаблонов относительно найденных приблизительных центров позиций и сравнительного анализа, в ходе которого для каждой позиции идентификационного номера выявляют шаблон, имеющий максимальное значение коэффициента совпадения с фрагментами символа, находящегося на данной позиции.
Технический результат заключается в оптимизации процесса подгонки шаблонов к фрагментам символов идентификационного номера с неизвестными заранее параметрами. Подгонка осуществляется за счет изменения геометрических параметров шрифта шаблонов и прецизионного поиска оптимального места их расположения в зонах нахождения символов. При этом сам процесс подгонки существенно облегчается за счет предварительной очистки изображения идентификационного номера от фона, благодаря чему фрагменты символов становятся более выделенными. В результате обеспечивается достоверность распознавания посредством выбора тех шаблонов, с которыми происходит максимально возможное совпадение фрагментов символов по каждой позиции идентификационного номера.
Кроме того, в случае сомнительно распознанных позиций сравнительный анализ может включать эвристическую оценку, проводимую по характерным фрагментам символов, находящихся на данных позициях, что обеспечивает точность распознавания символов, незначительно отличающихся друг от друга.
Кроме того, в качестве приблизительного параметра шрифта идентификационного номера можно использовать характерную ширину символов, соответствующую ширине выявленных позиций. Параметр ширины символов является достаточно универсальным и подходит для всех видов шрифтов.
Кроме того, в процессе распознавания символов на выявленных позициях номера шрифт символов унифицированных шаблонов изменяют посредством уменьшения ширины шрифта, а также уменьшения отношения высоты шрифта к ширине, что увеличивает точность распознавания идентификационного номера, за счет точного совпадения шаблонов с фрагментами символов позиций номера.
Кроме того, при распознавании позиций номера поочередно используют позитивные и негативные шаблоны для каждого символа. Первый тип шаблонов содержит зоны, совпадающие с фрагментами символов, а второй тип шаблона содержит участки фона, не совпадающие с фрагментами символов. Благодаря этому увеличивается вероятность точного распознавания идентификационного номера, так как появляется возможность оценить соотношение между уровнем сигнала (яркости зон, где должны находиться сохранившиеся фрагменты символов) и фона (яркости зон, где не должны находиться фрагменты символов).
На фиг.1 показано исходное изображение предполагаемой области нахождения идентификационного номера.
На фиг.2 изображена прямоугольная область размещения идентификационного номера, выделенная на исходном очищенном изображении.
На фиг.3 представлен первоначальный набор шаблонов символов с приблизительным шрифтом распознаваемого номера.
Способ автоматизированного распознавания идентификационного номера включает в себя следующие этапы.
Вначале формируется исходное изображение предполагаемой области нахождения идентификационного номера (фиг.1). Затем данное изображение очищается морфологическим ориентирно-направленным фильтром, в результате чего частично устраняется искажающее влияние фона.
Из очищенного исходного изображения выделяется прямоугольная область размещения идентификационного номера (фиг.2). Границы области размещения номера могут определяться оператором или находиться либо по характерным реперам (например, краям лыски, на которую нанесен номер), либо по различию в освещенности символов и фона (символы светлее фона и наоборот).
После выявления области размещения номера производится поиск зон нахождения отдельных позиций идентификационного номера и определение по сохранившимся фрагментам символов координат приблизительных центров каждой позиции (фиг.2). С этой целью формируется вектор - строка AMrow, каждый j-й элемент которой содержит среднее арифметическое значение элементов j-ого вектор-столбца матрицы 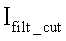 изображения области размещения идентификационного номера на отфильтрованном изображении:
изображения области размещения идентификационного номера на отфильтрованном изображении:
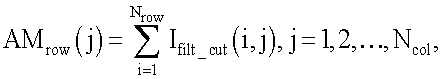
где Nrow - количество строк в матрице 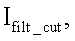 a Ncol - количество столбцов в
a Ncol - количество столбцов в 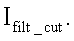
Из полученной вектор-строки AMrow формируется "сглаженная" вектор-строка 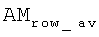 , каждый j-й элемент которой содержит среднее арифметическое диапазона значений [AMrow(j-Δ),AMrow(j+Δ)], при этом параметр Δ определяется заранее, исходя из средней степени поврежденности идентификационного номера. Далее, анализируя вектор
, каждый j-й элемент которой содержит среднее арифметическое диапазона значений [AMrow(j-Δ),AMrow(j+Δ)], при этом параметр Δ определяется заранее, исходя из средней степени поврежденности идентификационного номера. Далее, анализируя вектор 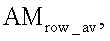 определяют координаты (X(k)) приблизительных центров каждой позиции номера, например, в результате поиска максимумов функции
определяют координаты (X(k)) приблизительных центров каждой позиции номера, например, в результате поиска максимумов функции 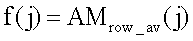 (фиг.2). Координата Y может определяться как середина изображения
(фиг.2). Координата Y может определяться как середина изображения 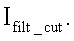
По сохранившимся фрагментам символов номера определяется приблизительный параметр шрифта, использованного в процессе нанесения идентификационного номера. В качестве приблизительного параметра шрифта может использоваться характерная ширина символов Wx, соответствующая ширине выявленных позиций (фиг.2). Ширина выявленных позиций определяется в результате анализа положительной части функции 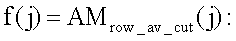
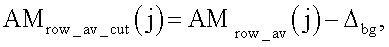
где значение Δbg определяется заранее, исходя из средней степени поврежденности идентификационного номера.
Формируется первоначальный набор бинарных шаблонов символов с приблизительным шрифтом распознаваемого номера. Приблизительный шрифт соответствует найденной характерной ширине Wx символов, а его высота Wy пропорциональна ширине Wx. Кроме того, при распознавании позиций номера могут использоваться позитивные (первый ряд) и негативные (второй ряд) шаблоны для каждого символа, фиг.3. Темным цветом на шаблонах отмечены области, которым присвоены значения 1, а светлым - 0. Первый тип шаблонов содержит ненулевые области, совпадающие с фрагментами символов; а второй тип шаблона содержит ненулевые области, являющиеся участками фона, не совпадающего с фрагментами символов.
Проводится сравнительное распознавание символов на выявленных позициях номера. С этой целью последовательно на каждую позицию номера накладывают поочередно все шаблоны. Наложение происходит посредством поэлементного перемножения матрицы текущего t-ого шаблона 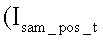 - позитивного,
- позитивного, 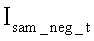 - негативного) на матрицу
- негативного) на матрицу  такого же размера, содержащую прямоугольный фрагмент изображения
такого же размера, содержащую прямоугольный фрагмент изображения 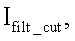 причем центр данного фрагмента совпадает с координатами (X(k), Y) приблизительного центра текущей распознаваемой k-й позиции номера:
причем центр данного фрагмента совпадает с координатами (X(k), Y) приблизительного центра текущей распознаваемой k-й позиции номера:
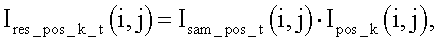 при
при 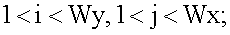
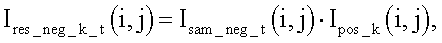 при
при 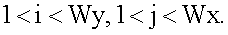
Для обеспечения большей точности совпадения шаблонов с фрагментами символов позиций номера матрицы 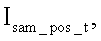
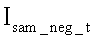 (т.е. шрифт символов шаблонов) могут пропорционально изменяться посредством уменьшения ширины Wx, а также отношения высоты Wy к ширине Wx; кроме того, при наложении шаблонов на позиции номера может осуществляться их незначительная циклическая, практически, прецизионная подвижка относительно друг друга, за счет соответствующего смещения центра матрицы
(т.е. шрифт символов шаблонов) могут пропорционально изменяться посредством уменьшения ширины Wx, а также отношения высоты Wy к ширине Wx; кроме того, при наложении шаблонов на позиции номера может осуществляться их незначительная циклическая, практически, прецизионная подвижка относительно друг друга, за счет соответствующего смещения центра матрицы 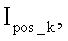 относительно текущих координат X(k), Y.
относительно текущих координат X(k), Y.
Далее для каждой полученной матрицы 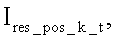
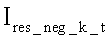 вычисляется среднее арифметическое значение ее элементов: для позитивных шаблонов -
вычисляется среднее арифметическое значение ее элементов: для позитивных шаблонов - 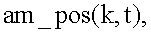 для негативных шаблонов -
для негативных шаблонов - 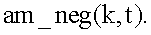 После чего, для каждого сопоставления t-ого шаблона с k-й позицией идентификационного номера вычисляется значение коэффициента (k_ver(k,t)) совпадения шаблона с фрагментами символа позиции номера. Значение коэффициента k_ver(k,t) может быть вычислено, как соответствующая разность am_pos(k,t)-am_neg(k,t).
После чего, для каждого сопоставления t-ого шаблона с k-й позицией идентификационного номера вычисляется значение коэффициента (k_ver(k,t)) совпадения шаблона с фрагментами символа позиции номера. Значение коэффициента k_ver(k,t) может быть вычислено, как соответствующая разность am_pos(k,t)-am_neg(k,t).
В итоге для каждой k-й позиции номера находится t-й шаблон символа, имеющий из соответствующего множества максимальное значение коэффициента k_ver.
Кроме того, для сомнительно распознанных позиций дополнительно проводят эвристическую оценку. Например, для позиций номера, распознанных как 3, по характерным фрагментам производят их сравнение с цифрой 5. Если позиция распознается как цифра 3, то ее сравнивают с цифрой 8. Если позиция распознается как цифра 5, то ее сравнивают с цифрой 6. В другой ситуации для позиций номера, распознанных как 8, по характерным фрагментам производят их сравнение с цифрой 6. Если позиция распознается как цифра 8, то ее сравнивают с цифрой 2 и т.д.
Для описанного алгоритма разработана компьютерная программа. Способ обеспечивает высокую точность дистанционного автоматического распознавания маркировочных номеров отработанных тепловыделяющих сборок и предназначен для использования в системах учета и контроля отработавших ядерных материалов в ядерной энергетике.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПОЗНАВАНИЯ ИДЕНТИФИКАЦИОННОЙ МАРКИРОВКИ НА ЦИЛИНДРИЧЕСКОЙ ПОВЕРХНОСТИ | 2008 |
|
RU2400812C2 |
| СПОСОБ СЧИТЫВАНИЯ НОМЕРОВ ТЕПЛОВЫДЕЛЯЮЩИХ СБОРОК | 2004 |
|
RU2309470C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЦИЛИНДРИЧЕСКИХ ОБЪЕКТОВ | 2007 |
|
RU2347293C2 |
| УСТРОЙСТВО ДЛЯ СЧИТЫВАНИЯ ЗАВОДСКИХ НОМЕРОВ ТЕПЛОВЫДЕЛЯЮЩИХ СБОРОК | 2009 |
|
RU2400840C1 |
| СПОСОБ МАРКИРОВКИ ОБЪЕКТА И РАСПОЗНАВАНИЯ ЕЕ ПОСЛЕ ВНЕШНИХ ВОЗДЕЙСТВИЙ | 2011 |
|
RU2454716C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ИДЕНТИФИКАЦИОННЫХ ДАННЫХ НА БАНКОВСКОЙ КАРТЕ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2014 |
|
RU2565007C1 |
| СПОСОБ СЕЛЕКЦИИ ПО ДАЛЬНОСТИ МНОЖЕСТВЕННЫХ ОБЪЕКТОВ | 2012 |
|
RU2498336C1 |
| СПОСОБ РЕГИСТРАЦИИ ИДЕНТИФИКАЦИОННОЙ МЕТКИ ЦИЛИНДРИЧЕСКОГО ОБЪЕКТА И УСТРОЙСТВО РЕГИСТРАЦИИ ИДЕНТИФИКАЦИОННОЙ МЕТКИ | 2003 |
|
RU2261434C2 |
| СПОСОБ ИЗМЕРЕНИЯ ПОЛОЖЕНИЯ ОБЪЕКТА | 2005 |
|
RU2308676C2 |
| СПОСОБ СЕЛЕКЦИИ ОБЪЕКТОВ НА УДАЛЁННОМ ФОНЕ | 2013 |
|
RU2552123C2 |



Изобретение относится к способам распознавания знаков с применением компьютерных средств и может быть использовано для автоматизированного определения поврежденных номеров отработанных тепловыделяющих сборок. Техническим результатом является повышение достоверности при распознавании поврежденных номеров с неизвестным заранее количеством и шрифтом используемых цифровых символов по их сохранившимся фрагментам. Для этого формируют исходное изображение предполагаемой области нахождения идентификационного номера, выделяют прямоугольную область его размещения, выявляют в ней зоны нахождения отдельных позиций номера, распознают символы на выявленных позициях. При этом предварительно сформированное исходное изображение очищают с помощью морфологического фильтра, определяют координаты приблизительных центров каждой позиции идентификационного номера в выявленных зонах их нахождения, определяют по сохранившимся фрагментам символов номера координаты каждой позиции и приблизительный параметр шрифта, использованного в процессе нанесения идентификационного номера, формируют первоначальный набор шаблонов символов с приблизительным шрифтом распознаваемого номера. В процессе распознавания символов осуществляют последовательное наложение шаблонов с изменяющимися параметрами шрифта символов на зоны нахождения позиций номера с циклическим смещением шаблонов относительно найденных приблизительных центров позиций и производят сравнительный анализ, в ходе которого для каждой позиции выявляют шаблон, имеющий максимальное значение коэффициента совпадения с фрагментами символа, находящегося на данной позиции. 4 з.п. ф-лы, 3 ил.
1. Способ автоматизированного распознавания идентификационного номера, заключающийся в формировании исходного изображения предполагаемой области нахождения идентификационного номера, в выделении прямоугольной области размещения идентификационного номера, в выявлении в выделенной прямоугольной области зон нахождения отдельных позиций идентификационного номера и в распознавании символов на выявленных позициях номера, отличающийся тем, что предварительно сформированное исходное изображение очищают с помощью морфологического фильтра, а после выявления зон нахождения отдельных позиций идентификационного номера определяют по сохранившимся фрагментам символов номера координаты приблизительных центров каждой позиции и приблизительный параметр шрифта, использованного в процессе нанесения идентификационного номера, исходя из которого формируют первоначальный набор шаблонов символов с приблизительным шрифтом распознаваемого номера, при этом процесс распознавания символов на выявленных позициях номера производят путем последовательного наложения шаблонов с изменяющимися параметрами шрифта символов на зоны нахождения позиций номера с циклическим смещением шаблонов относительно найденных приблизительных центров позиций, и сравнительного анализа, в ходе которого для каждой позиции выявляют шаблон, имеющий максимальное значение коэффициента совпадения с фрагментами символа, находящегося на данной позиции.
2. Способ автоматизированного распознавания идентификационного номера по п.1, отличающийся тем, что в сравнительный анализ вводят эвристическую оценку сомнительно распознанных позиций, проводимую по характерным фрагментам символов, находящихся на данных позициях.
3. Способ автоматизированного распознавания идентификационного номера по п.1, отличающийся тем, что в качестве приблизительного параметра шрифта идентификационного номера используют характерную ширину символов, соответствующую ширине выявленных позиций.
4. Способ автоматизированного распознавания идентификационного номера по п.3, отличающийся тем, что в процессе распознавания символов на выявленных позициях номера шрифт символов шаблонов изменяют посредством уменьшения ширины шрифта и отношения высоты шрифта к ширине.
5. Способ автоматизированного распознавания идентификационного номера по п.1, отличающийся тем, что в процессе распознавания символов на выявленных позициях номера поочередно используют позитивные и негативные шаблоны символов.
| СПОСОБ ФАКСИМИЛЬНОГО РАСПОЗНАВАНИЯ И ВОСПРОИЗВЕДЕНИЯ ТЕКСТА ПЕЧАТНОЙ ПРОДУКЦИИ | 2003 |
|
RU2260208C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ГРАФИЧЕСКИХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ ПРИНЦИПА ЦЕЛОСТНОСТИ | 2003 |
|
RU2259592C2 |
| JP 8137990 A, 31.05.1996 | |||
| GB 1345686 A, 30.01.1974 | |||
| JP 11353413 A, 24.12.1999 | |||
| УСТРОЙСТВО ДЛЯ РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЙ СИМВОЛОВ | 2000 |
|
RU2178916C2 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

