Перекрестная ссылка на родственные заявки
По настоящей заявке испрашивается приоритет предварительной патентной заявки Соединенных штатов, серийный номер 60/615,411, поданной 1 октября 2004 и включенной сюда в ее полноте.
Область техники, к которой относится изобретение
Это изобретение относится, в общем, к компьютерным системам и, более конкретно, к улучшенной системе и способу для определения переключения при неоптимальности целевого объекта назад и приоритета целевого объекта для распределенной файловой системы.
Предшествующий уровень техники
Распределенная файловая система (Dfs) - это сетевой серверный компонент, который определяет местоположение данных в сети и управляет данными в сети. Dfs может использоваться для объединения файлов на различных компьютерах в единое пространство имен, таким образом позволяя пользователю строить единое, иерархическое представление многочисленных файловых серверов и совместно используемых ресурсов файловых серверов в сети. В контексте серверного компьютера или множества серверных компьютеров Dfs можно сравнить с файловой системой для жестких дисков в системе персонального компьютера. Например, аналогично роли файловых систем для предоставления единообразного именованного доступа к коллекциям секторов на дисках, Dfs может предоставлять соглашение единообразного именования и отображения для коллекций серверов, совместно используемых ресурсов и файлов. Таким образом, Dfs может организовывать файловые серверы и их совместно используемые ресурсы в логическую иерархию, которая позволяет большому предприятию администрировать и использовать его информационные ресурсы более эффективно.
Более того, Dfs не ограничена единичным файловым протоколом и может поддерживать задание соответствия серверов, совместно используемых ресурсов и файлов независимо от используемого файлового клиента при условии, что клиент поддерживает исходные сервер и совместно используемый ресурс. Dfs также может обеспечивать прозрачность имен для несравнимых серверных томов и совместно используемых ресурсов. С помощью Dfs администратор может строить единичную иерархическую файловую систему, чье содержимое распределено по всей глобальной сети (WAN) организации.
В прошлом, при соглашении об универсальном именовании (UNC) от пользователя или приложения требовалось определять физический сервер и совместно используемый ресурс, чтобы осуществлять доступ к файловой информации. Например, пользователь или приложение должны были определить \\Server\Share\Path\Filename (\\Сервер\Совместно_используемый_ресурс\Путь\Имя_файла). Даже хотя соглашения UNC могут использоваться напрямую, UNC обычно отображается в букву диска, как например x:, которая в свою очередь может отображаться в \\Server\Share (\\Сервер\Совместно_используемый_ресурс). От этой точки пользователь должен был осуществлять навигацию за отображение перенаправленного диска к данным, к которым он или она желает осуществить доступ. Например, чтобы осуществлять навигацию к конкретному файлу, пользователю требовалась копия x:\Path\More_path\...\Filename (x:\Путь\Еще_путь\...\Имя_файла).
По мере того, как размеры сетей растут, и по мере того, как предприятия начинают использовать существующее хранилище - как внутренне, так и внешне - в целях, таких как внутренние сети (Интернет), отображение единичной буквы диска в индивидуальные, совместно используемые ресурсы масштабируется достаточно плохо. Дополнительно, хотя пользователи могут использовать UNC-имена напрямую, эти пользователи могут быть заявлены количеством мест, где данные могут храниться.
Dfs решает эти проблемы, позволяя связывать серверы и совместно используемые ресурсы в более простое и более легкое для навигации пространство имен. Том Dfs позволяет, чтобы совместно используемые ресурсы иерархически соединялись с другими, совместно используемыми ресурсами. Так как Dfs отображает физическое хранилище в логическое представление, чистая выгода состоит в том, что физическое местоположение любого количества файлов становится прозрачным для пользователей и приложений.
Более того, по мере того, как размер сети растет к уровню глобальной сети, несколько копий одного и того же файла или файлов могут размещаться в нескольких различных местоположениях внутри сети для помощи в уменьшении затрат (в терминах сетевого времени, сетевой нагрузки и т.д.), связанных с извлечением файла из сети. Например, пользователи большой сети, расположенной рядом с местоположением первого сервера, обычно будут использовать копию файла на сервере, ближайшем к ним (т.е. пользователи в Сиэтле могут находиться ближе всего к серверу, названному Redmond, который находится рядом с Сиэтлом). Аналогично, пользователи большой сети, расположенной рядом с местоположением второго сервера, обычно будут использовать копию файла на другом сервере, ближайшем к ним (т.е. пользователи в Таиланде могут находиться ближе всего к серверу, называемому Bangkok, расположенному в Бангкоке). Таким образом, величина связанных с узлом сети затрат (т.е. скалярное число, которое является псевдопроизвольным показателем некоторого количества сетевых параметров, включающих в себя расстояние между клиентом и сервером, степени отделения сервера и другие физические сетевые параметры) извлечения файла может минимизироваться посредством осуществления доступа к ближайшему серверу, имеющему запрашиваемый файл или файлы.
Когда пользователь желает извлечь файл из Dfs, клиентский компьютер, с которого пользователь запрашивает файл, определяет, как приступить к извлечению запрашиваемого файла. Клиентский компьютер может выдать запрос указателей, чтобы получить одно или более местоположений для запрошенного файла или файлов. Указатель может быть относительным путем между запрашивающим клиентским компьютером и серверным компьютером, в котором запрошенный файл или файлы могут быть найдены. Клиентский компьютер может запросить файл или файлы, о которых известно, что они недоступны локально, и может осуществляться определение того, сколько различных местоположений могут предоставить копию запрошенного файла. Обычно, могут иметься сотни или даже тысячи целевых объектов (т.е. относительного пути к файлу), показывающих местоположения, которые могут предоставлять запрошенный файл. Как таковой, ответ на запрос указателей, который возвращается клиентским компьютерам в ответ на запрос указателей, обычно включает в себя список целевых объектов, соответствующих серверам и/или совместно используемым ресурсам, имеющим запрошенный файл.
В прошлом, однако, ответ на запрос указателей, возвращенный клиентскому компьютеру, мог иметь идентифицированные целевые объекты, перечисленные в случайном порядке или, в некоторых случаях, согласно величине связанных с узлом сети затрат. Каждый целевой объект в ответе на запрос указателей не имел в обязательном порядке какое-либо отношение к целевому объекту, который непосредственно предшествовал ему или непосредственно следовал за ним. Как результат, клиентский компьютер мог просто начинать на вершине случайным образом упорядоченного списка целевых объектов и пытаться установить соединение с каждым последующим целевым объектом в списке до тех пор, пока один не среагирует установлением соединения.
Проблема с этой случайностью, однако, состоит в том, что первый доступный целевой объект может, фактически, располагаться буквально на другой стороне мира. Таким образом, величина связанных с узлом сети затрат взаимодействия с этим первым доступным целевым объектом может быть достаточно высокой и нежелательной в долгосрочном плане.
Однако сохранение непрерывности соединения с целевым объектом является до некоторой степени важным. Это известно как "приклеивание" или "липучесть". Таким образом, как только находится первый доступный целевой объект, который способен исполнить файловый запрос клиентского компьютера, обычно все будущие указатели и запросы также направляются к этому целевому объекту, если пользователь клиентского компьютера специально не запросит новый указатель. Поэтому соединение с первым доступным целевым объектом с возможно высокой величиной связанных с узлом сети затрат может оставаться неограниченно долго, вызывая все большие сетевой трафик и общие всеобъемлющие сетевые затраты.
Проблема поддержания неэффективных указателей между клиентским компьютером и серверным компьютером для сохранения непрерывности может иметь результатом сеансы связи с высокими, связанными с узлом сети, затратами. Что необходимо, так это способ для сохранения непрерывности связанных с указателями соединений наряду с уменьшением связанных с узлом сети затрат для связанного с указателем соединения.
Сущность изобретения
Кратко, настоящее изобретение предоставляет систему и способ для организации и сортировки целевых объектов, принятых в ответе на запрос указателей, и для определения переключения при неоптимальности целевого объекта назад и приоритета целевого объекта для переключения при неоптимальности назад в распределенной файловой системе. В одном варианте осуществления способ сортировки может включать в себя запрос от клиентского компьютера, множества местоположений (т.е. целевых объектов) файлов, директорий, совместно используемых ресурсов и т.д., расположенных на одном или более компьютерах в сети компьютеров. Затем, компьютер, такой как Dfs-сервер, может возвращать список целевых объектов клиентскому компьютеру, где список целевых объектов включает в себя множество указателей, в котором каждый указатель соответствует местоположению запрошенного файла или директории в сети компьютеров. Более того, список целевых объектов может сортироваться, базируясь на оценке величины связанных с узлом сети затрат, ассоциированной с каждым соответствующим целевым объектом.
Предпочтительно, менее затратные целевые объекты, идентифицированные серверным компьютером, могут сортироваться на вершину ответа на запрос указателей. Клиентский компьютер может просто логически проанализировать весь ответ с указателями, начиная с менее затратных целевых объектов, чтобы попытаться установить связь, до осуществления попытки установить связь с более высоко затратными целевыми объектами.
Такая система сортировки также может быть реализована при включении использования ранжирования целевых объектов по приоритетам. Более приоритетные целевые объекты также могут сортироваться на вершину ответа на запрос указателей. Более того, ответ на запрос указателей может дополнительно сортироваться, чтобы включать в себя условия как для величины связанных с узлом сети затрат, так и для приоритета целевого объекта. Таким образом, группы целевых объектов, имеющих эквивалентные ассоциированные затраты, связанные с узлом сети, могут дополнительно сортироваться внутри группы согласно соответствующему ассоциированному приоритету целевого объекта для каждого целевого объекта.
В другом варианте осуществления этого изобретения может быть реализована политика переключения при неоптимальности целевого объекта назад и приоритета целевого объекта, которая может использовать список отсортированных целевых объектов, предоставленный в ответе на запрос указателей. Соответственно, компьютерная система может выбирать и назначать целевой объект в качестве установленного целевого объекта из списка целевых объектов, отсортированных согласно величинам связанных с узлом сети затрат, чтобы извлечь, по меньшей мере, один запрошенный файл или директорию на клиентском компьютере. Затем, компьютерная система может определить, ассоциирован ли установленный целевой объект с наименьшей величиной связанных с узлом сети затрат при сравнении со всеми доступными целевыми объектами в отсортированном списке. Если нет, система может переключиться при неоптимальности назад на другой целевой объект, который ассоциирован с величиной связанных с узлом сети затрат, более низкой, чем установленный целевой объект, и назначить этот новый целевой объект в качестве установленного целевого объекта.
Другие преимущества станут видны из последующего подробного описания при рассмотрении его совместно с чертежами, на которых:
Перечень чертежей
Фиг.1 - блок-схема, в общем представляющая компьютерную систему, в которую может быть включено настоящее изобретение;
Фиг.2 - блок-схема, в общем представляющая иллюстративную архитектуру распределенной вычислительной среды для реализации переключения при неоптимальности целевого объекта назад и приоритета целевого объекта в одном варианте осуществления в соответствии с аспектом этого изобретения;
Фиг.3 - блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые для запроса и извлечения файла, используя распределенную файловую систему, в соответствии с аспектом этого изобретения;
Фиг.4 - блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые в одном варианте осуществления для компоновки ответа на запрос указателей, базируясь на величине связанных с узлом сети затрат, в соответствии с аспектом этого изобретения;
Фиг.5 - блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые в одном варианте осуществления для компоновки ответа на запрос указателями, базируясь на приоритете целевого объекта, в соответствии с аспектом этого изобретения;
Фиг.6 - блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые в одном варианте осуществления для переключения при неоптимальности назад на целевой объект с более низкой величиной связанных с узлом сети затрат, которые могут использоваться с отсортированным ответом на запрос указателей, в соответствии с аспектом этого изобретения;
Фиг.7 - блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые в одном варианте осуществления для переключения при неоптимальности назад на целевой объект с более высоким приоритетом, которые могут использоваться с отсортированным ответом на запрос указателей, в соответствии с аспектом этого изобретения; и
Фиг.8 - блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые в одном варианте осуществления для сортировки ответа на запрос указателей, в соответствии с аспектом этого изобретения.
Подробное описание
Иллюстративная операционная среда
Фиг.1 показывает пример подходящей среды 100 вычислительной системы, в которой может быть реализовано это изобретение. Среда 100 вычислительной системы является только одним примером подходящей вычислительной среды и не предназначается для предложения какого-либо ограничения в отношении объема использования или функциональности этого изобретения. Также вычислительная среда 100 не должна интерпретироваться как имеющая какую-либо зависимость или требование, относящиеся к какому-либо компоненту или комбинации компонентов, показанных в иллюстративной операционной среде 100.
Это изобретение является работоспособным с многочисленными другими средами или конфигурациями вычислительных систем общего назначения или специального назначения. Примеры широко известных вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с этим изобретением, включают в себя, но не в ограничительном смысле, персональные компьютеры (ПК, РС), серверные компьютеры, ручные или портативные устройства, планшетные устройства, автономные серверы, многопроцессорные системы, микропроцессорные системы, приставки к телевизору, программируемую бытовую электронику, сетевые PC, мини-компьютеры, универсальные компьютеры (мэйнфреймы), распределенные вычислительные среды, которые включают в себя любое из вышеперечисленных систем или устройств, и подобное.
Это изобретение может описываться в общем контексте машиноисполняемых инструкций, таких как программные модули, исполняемые компьютером. В общем, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и так далее, которые выполняют конкретные задачи или реализуют определенные абстрактные типы данных. Это изобретение также может применяться на практике в распределенных вычислительных средах, где задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть связи. В распределенной вычислительной среде программные модули могут располагаться в локальных и/или удаленных компьютерных носителях данных, включая запоминающие устройства.
Со ссылкой на фиг.1, иллюстративная система для реализации этого изобретения включает в себя вычислительное устройство общего назначения в форме компьютера 110. Компоненты компьютера 110 могут включать в себя, но не в ограничительном смысле, обрабатывающее устройство 120, системную память 130 и системную шину 121, которая соединяет различные системные компоненты, включая системную память, с обрабатывающим устройством 120. Системная шина 121 может относиться к любому из нескольких типов структур шин, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, с использованием любой из многообразия архитектур шин. В качестве примера, но не ограничения, такие архитектуры включают в себя шину промышленной стандартной архитектуры (ISA), шину микроканальной архитектуры (MCA), расширенную ISA (EISA) шину, локальную шину ассоциации по стандартам в области видеоэлектроники (VESA) и шину межсоединения периферийных компонентов (PCI), также известную как шина расширения.
Компьютер 110 обычно включает в себя многообразие машиночитаемых носителей. Машиночитаемые носители могут являться любыми доступными носителями, к которым компьютер 110 может осуществлять доступ, и включают в себя как энергозависимые, так и энергонезависимые носители, и как съемные, так и несъемные носители. В качестве примера, но не ограничения, машиночитаемые носители могут содержать компьютерные носители данных и среды передачи данных. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные носители данных включают в себя, но не в ограничительном смысле, RAM, ROM, EEPROM, флэш-память или память другой технологии, CD-ROM, универсальные цифровые диски (DVD) или другое оптическое дисковое хранилище, магнитные кассеты, магнитную ленту, магнитное дисковое хранилище или другие магнитные запоминающие устройства, или любой другой носитель, который может использоваться для хранения желаемой информации и к которому компьютер 110 может осуществлять доступ. Среды передачи данных обычно реализуют машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущее колебание, или другом транспортном механизме и включают в себя любые среды доставки информации. Термин "модулированный информационный сигнал" означает сигнал, одна или более характеристик которого установлены или изменены таким образом, чтобы кодировать информацию в этом сигнале. В качестве примера, но не ограничения, среды передачи данных включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Комбинации любых из вышеперечисленных сред и носителей должны также охватываться понятием ”машиночитаемый носитель”.
Системная память 130 включает в себя компьютерные носители данных в форме энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ROM) 131 и оперативное запоминающее устройство (RAM) 132. Базовая система 133 ввода/вывода (BIOS), содержащая базовые процедуры, которые помогают переносить информацию между элементами внутри компьютера 110, как, например, в течение запуска, обычно хранится в ROM 131. RAM 132 обычно содержит данные и/или программные модули, которые являются непосредственно доступными для обрабатывающего устройства 120 и/или в настоящем обрабатываются этим устройством. В качестве примера, но не ограничения, фиг.1 показывает операционную систему 134, прикладные программы 135, другие программные модули 136 и данные 137 программ.
Компьютер 110 также может включать в себя другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных. Только в качестве примера, фиг. 1 показывает накопитель 141 на жестких дисках, который считывает с несъемных, энергонезависимых магнитных носителей или записывает на них, магнитный 151 дисковод, который считывает со съемного, энергонезависимого магнитного диска 152 или записывает на него, и оптический 155 дисковод, который считывает со съемного, энергонезависимого оптического диска 156, такого как CD ROM или другой оптический носитель, или записывает на него. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных, которые могут использоваться в иллюстративной операционной среде, включают в себя, но не в ограничительном смысле, кассеты магнитной ленты, платы флэш-памяти, универсальные цифровые диски, цифровую видеоленту, твердотельное RAM, твердотельное ROM, и подобное. Накопитель 141 на жестких дисках обычно подсоединяется к системной шине 121 через интерфейс несъемной памяти, такой как интерфейс 140, и магнитный дисковод 151 и оптический дисковод 155 обычно подсоединяются к системной шине 121 с помощью интерфейса съемной памяти, такого как интерфейс 150.
Накопители и дисководы и их соответствующие компьютерные носители данных, обсужденные выше и показанные на фиг.1, предоставляют хранилище машиночитаемых инструкций, структур данных, программных модулей и других данных для компьютера 110. На фиг.1, например, накопитель 141 на жестких дисках показан как хранящий операционную систему 144, прикладные программы 145, другие программные модули 146 и данные 147 программ. Отметим, что эти компоненты могут быть либо такими же, либо отличающимися от операционной системы 134, прикладных программ 135, других программных модулей 136 и данных 137 программ. Операционной системе 144, прикладным программам 145, другим программным модулям 146 и данным 147 программ здесь даны другие ссылочные позиции, чтобы показать, что, по меньшей мере, они являются другими копиями. Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода, такие как планшет, или электронный цифровой преобразователь 164, микрофон 163, клавиатура 162 и координатно-указательное устройство 161, обычно называемое как мышь, шаровой манипулятор или сенсорная панель. Другие устройства ввода, не показанные на фиг.1, могут включать в себя джойстик, игровую приставку, спутниковую параболическую антенну, сканер или другие устройства, включающие в себя устройство, которое содержит биометрический датчик, датчик состояния окружающей среды, датчик положения или другой тип датчика. Эти и другие устройства ввода часто подсоединяются к обрабатывающему устройству 120 через интерфейс 160 пользовательского ввода, который соединен с системной шиной, но могут подсоединяться с помощью других структур интерфейсов и шин, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или другой тип устройства отображения также подсоединяется к системной шине 121 через некоторый интерфейс, такой как видеоинтерфейс 190. Монитор 191 также может объединяться с панелью сенсорного экрана или подобным. Отметим, что монитор и/или панель сенсорного экрана могут физически подсоединяться к корпусу, в котором заключено вычислительное устройство 110, как, например, в персональном компьютере планшетного типа. В дополнение, компьютеры, такие как вычислительное устройство 110, также могут включать в себя другие периферийные устройства вывода, такие как громкоговорители 195 и принтер 196, которые могут подсоединяться через периферийный интерфейс 194 вывода, или подобное.
Компьютер 110 может работать в сетевой среде, используя логические соединения с одним или более удаленными компьютерами, такими как удаленный компьютер 180. Удаленный компьютер 180 может являться персональным компьютером, сервером, маршрутизатором, сетевым PC, одноранговым устройством или другим общим сетевым узлом, и обычно включает в себя многие или все из элементов, описанных выше в отношении компьютера 110, хотя на фиг.1 было показано только запоминающее устройство 181. Логические соединения, изображенные на фиг.1, включают в себя локальную сеть (LAN) 171 и глобальную сеть (WAN) 173, но также могут включать в себя другие сети. Такие сетевые среды являются обычным явлением в офисах, компьютерных сетях масштаба предприятия, внутренних сетях и сети Интернет. При использовании в сетевой среде LAN, компьютер 110 подсоединяется к LAN 171 через сетевой интерфейс или адаптер 170. При использовании в сетевой среде WAN, компьютер 110 обычно включает в себя модем 172 или другое средство для установления связи через WAN 173, такую как сеть Интернет. Модем 172, который может быть внутренним или внешним, может подсоединяться к системной шине 121 через интерфейс 160 пользовательского ввода или другой подходящий механизм. В сетевой среде программные модули, изображенные по отношению к компьютеру 110, или их части, могут храниться в удаленном запоминающем устройстве. В качестве примера, но не ограничения, фиг.1 показывает удаленные прикладные программы 185 как постоянно находящиеся в запоминающем устройстве 181. Следует принять во внимание, что показанные сетевые соединения являются иллюстративными, и могут использоваться другие средства установления линии связи между компьютерами.
Сортировка ответа на запрос указателей
Настоящее изобретение, в общем, нацелено на систему и способ для определения переключения при неоптимальности целевого объекта назад и приоритета целевого объекта для распределенной файловой системы. Система и способ могут предпочтительно предоставлять способ сортировки для клиентского компьютера, запрашивающего список компьютеров, которые могут иметь желаемый файл или директорию, в сети компьютеров. В ответ на запрос список целевых объектов, которые могут быть предоставлены клиентскому компьютеру, может сортироваться, базируясь на оценке определенных параметров, включая величину связанных с узлом сети затрат, ассоциированную с каждым соответствующим целевым объектом. Как будет видно, менее затратные идентифицированные целевые объекты могут сортироваться на вершину ответа на запрос указателей, так что клиентский компьютер может просто логически проанализировать весь этот ответ на запрос указателей, начиная с менее затратных целевых объектов, чтобы попробовать возможность связи до осуществления попытки установить связь с более высоко затратными целевыми объектами.
Такая система сортировки также может быть реализована при использовании ранжирования целевых объектов по приоритету, в силу чего, в одном варианте осуществления, целевые объекты с более высоким приоритетом также могут сортироваться на вершину ответа на запрос указателей. Более того, ответ на запрос указателей может дополнительно сортироваться таким образом, чтобы включать в себя условия как для величины связанных с узлом сети затрат, так и для приоритета целевого объекта. Таким образом, группы целевых объектов, имеющих эквивалентные ассоциированные величины связанных с узлом сети затрат, могут дополнительно сортироваться внутри группы согласно соответствующему ассоциированному приоритету целевого объекта каждого целевого объекта. Следует понимать, что различные блок-схемы, блок-схемы последовательности операций и сценарии, здесь описываемые, являются только примерами, и имеется много других сценариев, к которым настоящее изобретение будет применяться.
На фиг.2 показана блок-схема, в общем представляющая иллюстративную архитектуру распределенной вычислительной среды для реализации переключения при неоптимальности целевого объекта назад и приоритета целевого объекта в соответствии с аспектом этого изобретения. Обычно, клиентский компьютер 205, который может быть аналогичным персональному компьютеру 110 по фиг.1, может быть в рабочем состоянии подсоединен к первой сети 250, которая может быть частью внутренней сети предприятия или частью сети Интернет. Клиентский компьютер 205 может быть частью Dfs или может включать в себя Dfs клиента 270, который может предоставлять прямой доступ к файлам, расположенным где-либо в Dfs. Сеть также может быть в рабочем состоянии соединена с другими компьютерами, такими как серверный компьютер m1 210, сервер 220 Active Directory(Активного каталога) и сервер 230 корня Dfs. Сервер 220 Active Directory может использоваться, чтобы хранить информацию Dfs, включая информацию ссылочных указателей Dfs. Однако в различных вариантах осуществления эта информация может храниться любым машиночитаемым носителем, доступным для сети 250.
В свою очередь, Dfs-сервер 230 также может быть в рабочем состоянии соединен с другой сетью 280, которая также может являться другой внутренней сетью предприятия или другой частью сети Интернет. Сеть 280 может быть в рабочем состоянии подсоединена к сети 250 через маршрутизатор 260, как это обычно в любой компьютерной сети. Сервер 230 корня Dfs может быть в рабочем состоянии подсоединен к совместно используемому ресурсу корня Dfs 240, который может включать в себя один или более ссылочных указателей. Например, ссылка //r1/s1/l1 может предоставлять указатель на файл или директорию, расположенную в //m1/s1. Подобным образом, ссылка //r1/s1/l2 может предоставлять указатель на файл или директорию, расположенную в //m2/s1. Более того, ссылка может предоставлять указатель на множество компьютеров, серверов, совместно используемых ресурсов и/или директорий. Таким образом, много компьютеров, включая сюда серверный компьютер m2 215, могут быть подключены с возможностью передачи данных к клиентскому компьютеру 205 через огромное число сетей и компьютеров.
Клиентский компьютер 205 может запрашивать и извлекать файлы и/или директории по существу из любого серверного местоположения в сети 250 или сетях 250 и 280. Однако для клиентского компьютера 205 может быть не выполнимо поддерживать информацию обо всех компьютерах, которые могут быть подсоединены к сети 250. В общем, запрос может быть запросом на файл или директорию. Таким образом, хотя любой файл (и/или директории и тому подобное, что подразумевается запросом и извлечением файла всюду в оставшейся части этого раскрытия) может извлекаться из любого компьютера в сети 250, местоположение запрошенного файла клиентскому компьютеру 205 обычно предоставляется из другого источника. Таким образом, серверный компьютер 230 Dfs может быть выполнен с возможностью поддерживать информацию о многих компьютерах, подсоединенных к сетям 250 и 280, так что, когда клиентский компьютер 205 запрашивает файл, который не является локально доступным, серверный компьютер 230 Dfs может предоставить список целевых объектов, причем каждый целевой объект соответствует некоторому пути к запрошенному файлу.
Обычно, серверный компьютер 230 Dfs может возвращать многие сотни или даже тысячи целевых объектов в ответ на запрос указателей и может обеспечивать некоторый порядок для этих целевых объектов согласно некоторому количеству параметров. Согласно двум таким способам сортировки указателей может осуществляться сортировка по величине связанных с узлом сети затрат, ассоциированной с каждым целевым объектом, и сортировка по приоритету целевого объекта, ассоциированному с каждым целевым объектом. Каждый из этих способов сортировки будет описываться более детально ниже.
Как только список целевых объектов может быть отсортирован серверным компьютером 230 Dfs (или другими специализированными компьютерными системами, выполненными с возможностью предоставлять и сортировать целевые объекты в ответ на запрос указателей), он может быть возвращен клиентскому компьютеру 205. Затем клиентский компьютер 205 может итеративно начать пытаться установить связь с каждым целевым объектом (в порядке сортировки) до тех пор, пока с некоторым целевым объектом связь не сможет быть установлена. Файл может располагаться в целевом объекте, соответствующем серверному компьютеру m1 210 в совместно используемом ресурсе s1 212, или просто //m1/s1. Совместно используемый ресурс s1 212 может быть ассоциирован с файловым сервером 211 на серверном компьютере m1 210, и, таким образом, может указываться серверным компьютером 230 Dfs.
Подобным образом, запрошенный файл может располагаться на серверном компьютере m2 215 в совместно используемом ресурсе s2 217. Совместно используемый ресурс s2 212 также может быть ассоциирован с файловым сервером 216 на серверном компьютере m2 215, и, таким образом, также может указываться серверным компьютером 230 Dfs. Однако так как серверный компьютер 215 может быть в рабочем состоянии соединен через сеть 280, путь, который может указываться клиентскому компьютеру, может быть более сложным, так как коммуникационное соединение может устанавливаться через сервер 230 корня Dfs. Посредством использования Dfs в архитектуре по фиг.2, файлы из любого местоположения в сети могут извлекаться через некоторый указатель, предоставленный клиентскому компьютеру 205 серверным компьютером 230 Dfs.
Фиг.3 представляет блок-схему последовательности операций, в общем представляющую этапы, предпринимаемые для запроса и извлечения файла, используя распределенную файловую систему, в соответствии с аспектом настоящего изобретения. Клиентский компьютер 205 может быть частью Dfs или может включать в себя Dfs-клиента 270, который может предоставлять прямой доступ к файлам, расположенным где-либо в Dfs. Клиентский компьютер 205 соответственно может запрашивать и извлекать файлы, как будто все запрашиваемые файлы находятся локально.
Когда клиентскому компьютеру 205 может потребоваться конкретный файл, который не доступен локально в клиентском компьютере 205, на клиентском компьютере 205 может инициироваться запрос файла при использовании Dfs-клиента 270. В различных вариантах осуществления Dfs-клиент также может постоянно находиться на сервере 220 Active Directory и может использоваться, чтобы определять местоположение сервера 230 корня Dfs. На этапе 308 серверный компьютер 230 Dfs может предоставлять клиентскому компьютеру 205 ответ на запрос указателей, который может включать в себя список целевых объектов, соответствующих удаленным серверным компьютерам, доступным через Dfs. Список целевых объектов может сортироваться согласно различным параметрам, таким как величина связанных с узлом сети затрат (способ для этого описывается ниже по отношению к фиг. 4), ассоциированный приоритет (способ для этого описывается ниже по отношению к фиг.5) и/или осведомленность об узле сети (описано в общем ниже).
Более того, ответ на запрос указателей может включать в себя указание ограниченных множеств, каждое из которых включает в себя группу целевых объектов. В одном варианте осуществления указание начала ограниченного множества может делаться посредством предоставления демаркационного значения, ассоциированного с информацией о первом целевом объекте в ограниченном множестве. Это может выполняться посредством предоставления атрибутов границы клиентскому компьютеру в ответе на запрос указателей, таких как величина затрат, связанных с извлечением файла или директории между целевым объектом и клиентским компьютером. Ограниченные множества могут базироваться на любом количестве параметров, включающих в себя величину связанных с узлом сети затрат, осведомленность об узле сети, приоритет целевого объекта и/или степень исправности компьютеров, включенных в указатель. Как здесь используется, степень исправности может означать время ответа для предоставления указателя, нагрузку трафика, загрузку процессора и другие атрибуты компьютера, включенного в указатель, включая метрики производительности.
Как только клиентский компьютер 205 может принять ответ на запрос указателей, клиентский компьютер 205 может начать пытаться установить сеанс связи с каждым целевым объектом в списке в порядке, который является результатом сортировки. Таким образом, клиентский компьютер 205 может попробовать целевой объект 1 на этапе 310, но потерпеть неудачу в соединении. Затем клиентский компьютер 205 может пробовать целевой объект 2 на этапе 312, но также потерпеть неудачу в соединении. Клиентский компьютер 205 может продолжать пробовать соединения с каждым целевым объектом в ответе на запрос указателей до тех пор, пока на этапе 314 не сможет быть установлено соединение с целевым объектом m. Когда связь с целевым объектом сможет быть установлена, этот целевой объект может быть назначен в качестве установленного целевого объекта и может использоваться до тех пор, пока он не станет более не доступным, чтобы сохранять непрерывность связи с целевым объектом. Например, целевой объект m может быть установлен в качестве установленного целевого объекта для последующего извлечения файла до тех пор, пока клиентский компьютер 205 не может запросить новый указатель, например, чтобы обнаружить новый целевой объект, или пока не получит других инструкций.
Специалисты в данной области примут во внимание, что в некоторой реализации может быть выбрано выполнение этих этапов в другом порядке или может быть выбрано выполнение только некоторых из этих этапов в целях эффективности или гибкости при достижении того же эффекта и без отхода от объема настоящего изобретения. Более того, это же понятие может применяться к определению местоположения Dfs-сервера 230 в первую очередь, так как указатели для конкретного Dfs-сервера могут предоставляться сервером 220 Active Directory во многом таким же способом.
Фиг.4 представляет блок-схему последовательности операций, в общем представляющую этапы, предпринимаемые для компоновки ответа на запрос указателей, базируясь на величине связанных с узлом сети затрат, в соответствии с аспектом этого изобретения. В общем, ответ на запрос указателей может сортироваться согласно некоторому количеству параметров, как, например, с помощью величины связанных с узлом сети затрат или осведомленности об узле сети. В одном варианте осуществления целевые объекты, которые находятся внутри того же узла сети, что и клиентский компьютер 205, могут сортироваться согласно осведомленности об узле сети до сортировки согласно величине связанных с узлом сети затрат. Например, целевые объекты в пределах того же узла сети, что и клиентский компьютер 205, могут сортироваться на вершину ответа на запрос указателей, и затем могут использоваться параметры, относящиеся к величине связанных с узлом сети затрат, чтобы сортировать оставшиеся целевые объекты. Фиг.4 может представлять один вариант осуществления способа, который использует величину связанных с узлом сети затрат и осведомленность об узле сети для сортировки целевых объектов в ответе на запрос указателей, генерируемом серверным компьютером 230 Dfs. Специалистами в данной области может быть принято во внимание, однако, что может использоваться любое количество параметров или комбинаций параметров, чтобы сортировать целевые объекты ответа на запрос указателей.
Серверный компьютер 230 Dfs может составлять список целевых объектов, которые могут исполнять запрос указателей от клиентского компьютера 205. Вначале на этапе 402 эти целевые объекты могут компоноваться в случайном порядке. Затем серверный компьютер 230 Dfs может идентифицировать каждый целевой объект, который может находиться внутри того же узла сети (//m1/s1/, например), что и клиентский компьютер 205. На этапе 404 эти идентифицированные целевые объекты могут быть перемещены на вершину списка, чтобы получить в результате ответ на запрос указателей, который теперь сортируется согласно параметру осведомленности об узле сети. В различных вариантах осуществления в этот момент ответ на запрос указателей может быть отправлен назад клиентскому компьютеру 205. Однако в других вариантах осуществления ответ на запрос указателей может быть дополнительно отсортирован согласно другому параметру, величине связанных с узлом сети затрат, как показано на фиг.4.
На этапе 408 оставшиеся целевые объекты могут быть отсортированы согласно ассоциированной величине связанных с узлом сети затрат и разделены в ограниченные множества. Каждый целевой объект, имеющий первую величину связанных с узлом сети затрат, ассоциированную с ним, может быть перемещен в ограниченное множество с другими целевыми объектами, имеющими ту же ассоциированную величину связанных с узлом сети затрат. Подобным образом, второе ограниченное множество может иметь один или более целевых объектов со второй ассоциированной величиной связанных с узлом сети затрат. Таким образом, список целевых объектов затем может становиться отсортированным в ограниченные множества, причем первое ограниченное множество может включать в себя целевые объекты с наименьшей ассоциированной величиной связанных с узлом сети затрат, следующее ограниченное множество может включать в себя целевые объекты со следующей наименьшей ассоциированной величиной связанных с узлом сети затрат, и так далее.
Затем каждое ограниченное множество может включать в себя большое количество целевых объектов, перечисленных в случайном порядке, но имеющих одну и ту же величину связанных с узлом сети затрат, ассоциированных с ними. Таким образом, по мере того, как клиентский компьютер 205 может итеративно выполнять попытки установить сеанс связи, он может сначала делать цикл по целевым объектам, соответствующим наименьшей величине связанных с узлом сети затрат.
Более того, на этапе 410 первый перечисленный целевой объект в каждом ограниченном множестве также может быть ассоциирован с некоторым битом границы, который может быть установлен так, чтобы показывать начало ограниченного множества. Таким способом, клиентский компьютер может легко идентифицировать границу между ограниченными множествами. Бит границы может служить как показатель того, что целевой объект имеет ассоциированную величину связанных с узлом сети затрат более высокую, чем предыдущий целевой объект в списке. Таким образом, может приниматься более информированное решение относительно переключения при неоптимальности назад или переключения при неоптимальности на что-либо с помощью предоставления ограниченных множеств, базирующихся на величинах связанных с узлами сети затрат. Затем серверный компьютер 230 Dfs может скомпоновать конечный ответ на запрос указателей, содержащий отсортированный список целевых объектов, базирующийся на осведомленности об узле сети и величинах связанных с узлами сети затрат, и может передать этот ответ на запрос указателей назад клиентскому компьютеру 205 на этапе 412.
Фиг.5 представляет блок-схему последовательности операций, в общем представляющую этапы, предпринимаемые для компоновки ответа на запрос указателей, базирующегося на приоритете целевого объекта в соответствии с аспектом этого изобретения.
Снова, ответ на запрос указателей может сортироваться согласно некоторому количеству параметров, таких как приоритет целевого объекта и/или осведомленность об узле сети, как кратко упомянуто выше. Фиг.5 может представлять один вариант осуществления способа, который использует приоритет целевого объекта и осведомленность об узле сети, для сортировки целевых объектов в ответе на запрос указателей, сгенерированном серверным компьютером 230 Dfs. Специалистами в данной области может быть принято во внимание, однако, что может использоваться любое количество параметров или комбинаций параметров, чтобы сортировать целевые объекты ответа на запрос указателей. Как обсуждалось выше, серверный компьютер 230 Dfs может составить список целевых объектов, который может исполнять запрос указателей от клиентского компьютера 205. Вначале на этапе 502 эти целевые объекты могут быть скомпонованы в случайном порядке. Затем серверный компьютер 230 Dfs может идентифицировать каждый целевой объект, который находится внутри того же узла сети (например, //m1/s1/), что и клиентский компьютер 205. На этапе 504 эти идентифицированные целевые объекты могут быть перемещены на вершину списка, чтобы предоставить ответ на запрос указателей, который теперь отсортирован согласно параметру осведомленности об узле сети. В некоторых вариантах осуществления в этот момент ответ на запрос указателей может быть отправлен назад клиентскому компьютеру 205. Однако в других вариантах осуществления ответ на запрос указателей может дополнительно сортироваться согласно другому параметру, приоритету целевого объекта, как показано на фиг.5.
Каждый целевой объект, имеющий первый приоритет целевого объекта, такой как глобально высокий, ассоциированный с ним, может быть перемещен в ограниченное множество с другими целевыми объектами, имеющими тот же ассоциированный приоритет целевого объекта. Подобным образом второе ограниченное множество может иметь один или более целевых объектов со вторым ассоциированным приоритетом целевого объекта, таким как глобально низкий. Таким образом, список целевых объектов затем может сортироваться в ограниченные множества, причем первое ограниченное множество может включать в себя целевые объекты с наивысшим ассоциированным приоритетом целевого объекта, т.е. глобально высоким, следующее ограниченное множество включает в себя целевые объекты со следующим наивысшим ассоциированным приоритетом целевого объекта, т.е. нормально высоким, и так далее.
Каждое ограниченное множество может затем включать в себя большое количество целевых объектов, перечисленных в случайном порядке, но имеющих один и тот же приоритет целевого объекта, ассоциированный с каждым. Таким образом, по мере того, как клиентский компьютер 205 может итеративно проходить по целевым объектам и пытаться устанавливать сеанс связи, он может сначала совершать цикл по целевым объектам, соответствующим наивысшему приоритету целевого объекта.
Более того, на этапе 510 первый перечисленный целевой объект в каждом ограниченном множестве также может иметь бит границы, установленный, чтобы показывать начало ограниченного множества. Таким способом, клиентский компьютер 205 может легко идентифицировать границу между ограниченными множествами. Бит границы может служить как показатель того, что целевой объект может иметь более низкий ассоциированный приоритет целевого объекта, чем предыдущий целевой объект в списке. Таким образом, может приниматься более информированное решение о переключении при неоптимальности назад или переключении при неоптимальности на что-либо посредством предоставления ограниченных множеств, базирующихся на приоритете целевого объекта. Серверный компьютер 230 Dfs затем может скомпоновать конечный ответ на запрос указателей, содержащий отсортированный список целевых объектов, базируясь на осведомленности об узле сети и приоритете целевого объекта, и может передать этот ответ на запрос указателей назад клиентскому компьютеру 205 на этапе 512.
Серверный компьютер 230 Dfs также может использовать комбинацию параметров сортировки при установлении отсортированного ответа на запрос указателей. Например, первая сортировка может состоять в том, чтобы перемещать целевые объекты того же узла сети на вершину списка. Затем целевые объекты могут сортироваться, базируясь на глобальных приоритетах, ассоциированных с каждым из них. Например, все целевые объекты, имеющие ассоциированный глобально высокий приоритет, могут сортироваться на вершину ответа на запрос указателей. Подобным образом, все целевые объекты, имеющие ассоциированный глобально низкий приоритет, могут сортироваться в нижнюю часть списка. Затем оставшиеся целевые объекты (которые могут называться как глобальные нормальные) могут дополнительно сортироваться в ограниченные множества, базируясь на связанных с узлом сети затратах.
В другом варианте осуществления вторая сортировка может создавать ограниченные множества, базирующиеся на величинах связанных с узлами сети затрат и обозначаемые посредством установленных битов границы в целевых объектах на вершине каждого множества. Затем каждое ограниченное множество может сортироваться согласно приоритету целевого объекта, так что внутри каждого ограниченного множества (которое внутренне может иметь одну и ту же ассоциированную величину связанных с узлом сети затрат) целевые объекты могут дополнительно упорядочиваться согласно приоритету, ассоциированному с каждым целевым объектом. Таким образом, внутри ограниченных множеств, базирующихся на величинах связанных с узлами сети затрат, целевые объекты на вершине ограниченного множества могут быть ассоциированы с высоким приоритетом, следующая группа целевых объектов может быть ассоциирована со следующим наивысшим приоритетом (нормальным, например), и так далее.
В еще одном варианте осуществления предыдущие два варианта осуществления могут быть реализованы вместе, так что целевые объекты сортируются по приоритету на глобальной основе и внутри каждого ограниченного множества.
В качестве другого примера, первая сортировка может снова состоять в том, чтобы перемещать целевые объекты того же узла сети на вершину списка. Затем вторая сортировка может создавать ограниченные множества, базирующиеся на приоритете целевого объекта и обозначаемые посредством установленных битов границы в целевых объектах на вершине каждого множества. Затем каждое ограниченное множество может сортироваться согласно величине связанных с узлом сети затрат, так что внутри каждого ограниченного множества (которое может внутренне иметь один и тот же ассоциированный приоритет целевого объекта) целевые объекты дополнительно упорядочиваются согласно величине связанных с узлом сети затрат, ассоциированной с каждым целевым объектом. Таким образом, внутри ограниченных множеств, базирующихся на приоритете целевого объекта, целевые объекты на вершине ограниченного множества могут быть ассоциированы с наименьшей величиной связанных с узлом сети затрат, следующая группа целевых объектов может быть ассоциирована со следующей наименьшей величиной связанных с узлом сети затрат, и так далее.
Посредством сортировки целевых объектов в ответе на запрос указателей в установленном порядке и установки определенных битов внутри каждого целевого объекта в ответе на запрос указателей, клиентский компьютер затем может реализовывать эффективную политику переключения при неоптимальности целевого объекта назад и политику переключения при неоптимальности приоритета назад, используя отсортированные целевые объекты из ответа на запрос указателей, как будет описываться ниже.
Переключение при неоптимальности целевого объекта назад и приоритет
В дополнение к способу сортировки для клиентского компьютера, запрашивающего список серверных компьютеров, которые могут иметь желаемый файл в сети серверных компьютеров, система и способ также могут предпочтительно предоставлять политику переключения при неоптимальности целевого объекта назад и приоритета целевого объекта, которая может использовать список отсортированных целевых объектов, предоставленных в ответе на запрос указателей. Как будет видно, компьютерная система может выбрать и назначить некоторый целевой объект в качестве установленного целевого объекта из списка целевых объектов, отсортированного согласно величине связанных с узлом сети затрат. Затем компьютерная система может определить, ассоциирован ли этот установленный целевой объект с наименьшей величиной связанных с узлом сети затрат при сравнении со всеми доступными целевыми объектами в отсортированном списке. Если нет, система может переключиться при неоптимальности назад на другой целевой объект, который ассоциирован с величиной связанных с узлом сети затрат, более низкой, чем установленный целевой объект, и назначить этот новый целевой объект в качестве установленного целевого объекта. Как будет принято во внимание, различные блок-схемы последовательности операций и сценарии, здесь описываемые, являются только примерами, и имеется много других сценариев, к которым будет применяться описанная политика переключения при неоптимальности целевого объекта назад и приоритета целевого объекта.
На фиг.6 показана блок-схема последовательности операций, в общем представляющая этапы, предпринимаемые для переключения при неоптимальности назад на целевой объект с более низкой величиной связанных с узлом сети затрат, которые могут использоваться с отсортированным ответом на запрос указателей в соответствии с аспектом этого изобретения. В различных вариантах осуществления среды политики переключения при неоптимальности целевого объекта назад серверный компьютер 230 Dfs может сортировать информацию о целевых объектах, которая может использоваться системой Dfs при генерировании ответа на запрос указателей. В одном варианте осуществления серверный компьютер 230 Dfs может сортировать информацию о целевых объектах, базируясь на осведомленности об узле сети. В этом режиме ответ на запрос указателей может по существу состоять из двух множеств целевых объектов: одно множество, содержащее целевые объекты в том же узле сети, что и клиентский компьютер 205, и другое множество, содержащее целевые объекты из узлов сети, отличающихся от клиентского компьютера 205. Изначально целевые объекты в каждом множестве могут быть упорядочены случайным образом.
В другом варианте осуществления серверный компьютер 230 Dfs может сортировать указатели, базируясь на величине связанных с узлом сети затрат. В этом режиме работы ответ на запрос указателей может сортироваться в многочисленные ограниченные множества. Каждое ограниченное множество может включать в себя целевые объекты, имеющие одну и ту же величину связанных с узлом сети затрат, как определено Dfs-сервером, (которая может определяться, базируясь на информации о связанных с узлом сети затратах, относящейся к запрашивающему клиентскому компьютеру). Ограниченные множества могут упорядочиваться по возрастанию величины связанных с узлом сети затрат, так что целевые объекты в том же узле сети, что и клиент, могут находиться в первом ограниченном множестве; целевые объекты, имеющие следующую наименьшую величину связанных с узлом сети затрат, могут находиться во втором множестве, и так далее. Сначала целевые объекты внутри каждого множества могут упорядочиваться случайным образом.
Таким образом, когда на этапе 602 клиентский компьютер запрашивает указатель, отсортированный ответ на запрос указателей может предоставляться серверным компьютером 230 Dfs. Клиентский компьютер затем может начать пытаться установить связь с каждым целевым объектом в ответе на запрос указателей, чтобы определить первый доступный целевой объект на этапе 604. Когда целевой объект может не быть доступным по какому-либо числу причин, таких как сетевые ошибки, аварийный отказ целевого объекта и т.д., Dfs-клиент при отказе может переключаться на следующий доступный целевой объект. Например, может делаться попытка установить связь со следующим целевым объектом в списке целевых объектов в ответе на запрос указателей. Когда с некоторым целевым объектом связь может быть установлена, этот конкретный целевой объект может быть назначен в качестве установленного целевого объекта на этапе 606.
Когда один или более предыдущих целевых объектов, которые могут быть более оптимальными, чем установленный целевой объект, становятся доступными снова, DFS-клиент может продолжать использовать установленный целевой объект в целях непрерывности и прозрачности или может получить или снова получить некоторый более оптимальный, доступный целевой объект. Предпочтительно, наличие политики переключения при неоптимальности назад и ограниченных множеств целевых объектов делает возможным получать или снова получать более оптимальный целевой объект, такой как целевой объект с более низкой величиной связанных с узлом сети затрат, когда он доступен.
Таким образом, если политика переключения при неоптимальности целевого объекта назад предписывает (например, имеется установленный бит политики переключения при неоптимальности целевого объекта назад), на этапе 608 клиентский компьютер может определять, что может быть доступным более предпочтительный целевой объект, такой как целевой объект c более низкой величиной связанных с узлом сети затрат. Это определение может осуществляться в любое время и может запускаться клиентским компьютером 205, серверным компьютером 230 Dfs или любым другим удаленным компьютером. Более того, время переключения при неоптимальности назад может соответствовать истекшему количеству времени с момента времени, когда с установленным целевым объектом может быть установлена связь. Например, клиентский компьютер может проверять наличие более оптимального целевого объекта после 30 минут после установления связи для первого установленного целевого объекта. Еще дополнительно, время переключения при неоптимальности назад может соответствовать конкретному времени суток, такому как каждые полчаса или каждые пять минут. Еще дополнительно, время переключения при неоптимальности назад может соответствовать ближайшему следующему запросу от клиентского компьютера 205 на какой-либо файл.
Во время переключения при неоптимальности назад, если может быть доступным более предпочтительный целевой объект, такой как целевой объект с более низкой величиной связанных с узлом сети затрат, то с этим доступным, более предпочтительным целевым объектом может быть установлена связь, и этот доступный, более предпочтительный целевой объект может быть назначен установленным целевым объектом на этапе 612. Однако, если может не быть какого-либо, более предпочтительного доступного целевого объекта, например, с более низкой величиной связанных с узлом сети затрат, то в качестве установленного целевого объекта может продолжать использоваться текущий целевой объект на этапе 610.
Политика переключения при неоптимальности назад может реализовываться для заданного корня/ссылки Dfs в ответе на запрос указателей. Если на некотором отдельном уровне ссылки переключение при неоптимальности целевого объекта назад может не быть активировано, то может использоваться установка для всего пространства имен Dfs. В одном варианте осуществления переключение при неоптимальности целевого объекта назад может блокироваться на уровне ссылки, когда переключение при неоптимальности целевого объекта назад может быть активировано на уровне пространства имен Dfs.
В одном варианте осуществления информация переключения при неоптимальности целевого объекта назад может храниться вместе с другой информацией Dfs, такой как метаданные Dfs. Например, может использоваться поле "Type" ("Тип") в информации каждого корня/ссылки метаданных каждого целевого объекта. Свободное положение бита в этом поле может быть идентифицировано и верифицировано, чтобы работать в унаследованных системах. Это новое положение бита задано как PKT_ENTRY_TYPE_TARGETFAIL.BACK.
Таким образом, обычный формат для метаданных для базирующейся на доменах Dfs (указываемой как "ID BLOB") может быть определен в некотором варианте осуществления с помощью псевдоструктуры, приведенной ниже:
USHORT
WCHAR
USHORT
WCHAR
ULONG
ULONG
USHORT
WCHAR
FILETIME
FILETIME
FILETIME
ULONG
PrefixLength;
Prefix [PrefixLength];
ShortPrefixLength;
ShortPrefix[ShortPrefixLength];
Type;
State;
CommentLength;
Comment[ CommentLength];
PrefixTimeStamp;
StateTimeStamp;
CommentTimeStamp;
Version;
Подобным образом, обычный формат для метаданных для автономной Dfs (указываемой как "ID BLOB") может быть определен с помощью псевдоструктуры, приведенной ниже:
WCHAR
USHORT
WCHAR
GUID
ULONG
ULONG
USHORT
WCHAR
FILETIME
FILETIME
FILETIME
Prefix[PrefixLength];
ShortPrefixLength;
ShortPrefix [ShortPrefixLength];
VolumeId;
State;
Type;
CommentLength;
Comment[CommentLength];
PrefixTimeStamp;
StateTimeStamp;
CommentTimeStamp
Функции интерфейса прикладного программирования (API) NetDfsGetInfo/NetDfsEnum могут извлекать установку из метаданных каждого корня/ссылки. Внешний интерфейс API, который может проверять достоверность параметров, может быть модифицирован соответственно, и процедура, которая может интерпретировать и возвращать специальную информацию "информационного уровня", также может соответственно модифицироваться.
Чтобы поддерживать как приоритет целевого объекта, так и переключение при неоптимальности целевого объекта назад, Dfs-клиент может пытаться переключиться при неоптимальности назад на другой целевой объект с более низкой величиной связанных с узлом сети затрат и/или с более высоким приоритетом. В одном варианте осуществления Dfs-клиент может не переключаться при неоптимальности назад на другой целевой объект с такой же величиной связанных с узлом сети затрат и/или такого же приоритета, как активный в текущее время целевой объект.
В некотором варианте осуществления некоторое множество целевых объектов может определяться как ограниченное множество целевых объектов. Например, ограниченное множество целевых объектов может быть множеством случайно отсортированных целевых объектов, имеющих одну и ту же величину связанных с узлом сети затрат. Указание границы для ограниченного множества целевых объектов в ответе на запрос указателей может делаться, например, посредством включения показателя границы в содержимое указателя.
Соответственно, в некотором варианте осуществления ответ на запрос указателей Dfs-клиенту для корня/ссылки может показывать, активировано ли или нет переключение при неоптимальности назад для этого корня/ссылки, и также может показывать границы ограниченных множеств между возвращенными целевыми объектами. В одном варианте осуществления может использоваться формат ранее существовавшего ответа на запрос указателей для корня/ссылки посредством добавления нового битового поля в существующие определения битового поля как в заголовок указателя, так и в содержимое указателя следующим образом:
typedef struct {
USHORT PathConsumed; // Количество объектов типа WCHAR,
// содержащихся в DfsPathName
USHORT NumberOfReferrals; // Число указателей, здесь
// содержащихся
struct {
ULONG ReferralServers: 1; // Элементы в Referrals[]
// являются серверами указателей
ULONG StorageServers: 1; //Элементы в Referrals[]
// являются серверами хранения
ULONG TargetFailback: 1; // Переключение при
// неоптимальности целевого объекта назад
//активировано для этого корня/ссылки
// пространства имен
};
ULONG ReferralHeaderFlags
};
union { // Вектор указателей
DFS_REFERRAL_V1 v1;
DFS_REFERRAL_V2 v2;
DFS_REFERRAL_V3 v3;
DFS_REFERRAL_V4 v4;
} Referrals[i]; // [ NumberOfReferrals ]
//
// WCHAR String Buffer[];// Используется системой DFS ..
REFERRAL_V2
//
} RESP _GET_DFS_REFERRAL;
typedef RESP _GET_DFS_REFERRAL *PRESP _GET_DFS_REFERRAL;
typedef struct {
USHORT VersionNumber; // == 4
USHORT Size; // Размер этого всего элемента
USHORT ServerType; // Тип сервера: 0 == Не знаю,
1 == SMB, 2 == Netware
union {
struct {
USHORT StripPath: 1; // Удалить PathConsumed символов
// из передней части DfsPathName до передачи
// имени к
// UncShareName
USHORT NameListReferral: 1; // Этот указатель
// содержит
// список расширенных имен
USHORT TargetSetBoundary: 1 // Обозначает, что этот
// целевой объект является первым в некотором
// множестве целевых объектов
// Все целевые объекты внутри имеют одну и ту же
// величину связанных с узлом сети затрат
// или категорию приоритета;
};
USHORT ReferralEntryFlags
};
ULONG TimeToLive; // В количестве секунд
union {
struct {
USHORT DfsPathOffset; // Смещение от начала этого
// элемента до пути для доступа
USHORT DfsAlternatePathOffset; // Смещение от начала
// этого элемента до пути согласно формату 8.3
USHORT NetworkAddressOffset; //Смещение от начала этого
// элемента до сетевого пути
GUID ServiceSiteGuid; // guid для узла сети
};
struct {
USHORT Special NameOffset;// Смещение от этого
// элемента до строки специального имени
USHORT NumberOfExpandedNames;//Количество расширенных
// имен
USHORT ExpandedNameOffset; // Смещение от этого
// элемента до списка расширенных имен
};
} DFS_REFERRAL_V4;
typedef DFS_REFERRAL_V4 *PDFS_REFERRAL_V4;
Специалисты в данной области примут во внимание, что могут использоваться другие структуры данных, такие как отдельная структура данных, для предоставления указания границ ограниченных множеств между целевыми объектами в ответе на запрос указателей или для показа того, может ли или нет быть активировано переключение при неоптимальности назад.
Фиг.7 представляет блок-схему последовательности операций, в общем представляющую этапы, предпринимаемые для переключения при неоптимальности назад на целевой объект с более высоким приоритетом, которые могут использоваться с отсортированным ответом на запрос указателей в соответствии с аспектом этого изобретения. В различных вариантах осуществлениях среды политики переключения при неоптимальности целевого объекта назад серверный компьютер 230 Dfs может сортировать информацию о целевых объектах, базируясь на осведомленности об узле сети. В этом режиме ответ на запрос указателей может, по существу, состоять из двух множеств целевых объектов: одно множество, содержащее целевые объекты из того же узла сети, что и клиентский компьютер 205, и другое множество, содержащее целевые объекты из узлов сети, отличающихся от клиентского компьютера 205. Изначально целевые объекты в каждом множестве могут быть упорядочены случайным образом.
В другом варианте осуществления серверный компьютер 230 Dfs может сортировать указатели, базируясь на приоритете целевого объекта. В этом режиме работы ответ на запрос указателей может сортироваться в многочисленные ограниченные множества. Каждое ограниченное множество может включать в себя целевые объекты, которые могут иметь тот же приоритет целевого объекта, как определяется Dfs сервером, запрашивающим указатель. Ограниченные множества могут упорядочиваться на основе уменьшения приоритета целевого объекта, так что целевые объекты наивысшего приоритета могут находиться в первом ограниченном множестве; целевые объекты, имеющие следующий наивысший приоритет, могут находиться во втором множестве, и так далее. Изначально целевые объекты в каждом множестве могут быть упорядочены случайным образом.
Серверный компьютер 230 Dfs также может использовать комбинацию параметров сортировки при установлении отсортированного ответа на запрос указателей. Например, первая сортировка может состоять в том, чтобы переместить целевые объекты того же узла сети на вершину списка. Затем целевые объекты могут сортироваться, базируясь на глобальных приоритетах, ассоциированных с каждым из них. Например, все целевые объекты, имеющие ассоциированный глобальный высокий приоритет, могут сортироваться на вершину ответа на запрос указателей. Подобным образом, все целевые объекты, имеющие ассоциированный глобальный низкий приоритет, могут сортироваться на нижнюю часть списка. Затем оставшиеся целевые объекты (которые могут называться как глобальные нормальные) могут сортироваться дополнительно в ограниченные множества, базируясь на величине связанных с узлом сети затрат.
В другом варианте осуществления вторая сортировка может создавать ограниченные множества, базирующиеся на величинах связанных с узлами сети затрат и обозначаемые посредством битов границы множества в целевых объектах на вершине каждого множества. Затем каждое ограниченное множество может сортироваться согласно приоритету целевого объекта, так что внутри каждого ограниченного множества (которое может внутренне иметь одну и ту же ассоциированную величину связанных с узлом сети затрат) целевые объекты могут дополнительно упорядочиваться согласно приоритету, ассоциированному с каждым целевым объектом. Таким образом, внутри ограниченных множеств, базирующихся на величине связанных с узлом сети затрат, целевые объекты на вершине ограниченного множества могут ассоциироваться с высоким приоритетом, следующая группа целевых объектов может ассоциироваться со следующим наивысшим приоритетом (например, нормальным), и так далее.
В еще другом варианте осуществления предыдущие два варианта осуществления могут быть реализованы совместно, так что целевые объекты сортируются по приоритету на глобальной основе и внутри каждого ограниченного множества. Таким образом, когда клиентский компьютер 205 запрашивает указатель на этапе 702, серверным компьютером 230 Dfs может предоставляться отсортированный ответ на запрос указателей. Затем клиентский компьютер может начать пытаться установить связь с каждым целевым объектом в ответе на запрос указателей, чтобы определить первый доступный целевой объект на этапе 704. Например, может делаться попытка установить связь со следующим целевым объектом в списке целевых объектов в ответе на запрос указателей. Когда с некоторым целевым объектом связь может быть установлена, этот конкретный целевой объект может быть назначен в качестве установленного целевого объекта на этапе 706.
Когда один или более предыдущих целевых объектов, которые могут быть более оптимальными, чем установленный целевой объект, становятся снова доступными, DFS-клиент может продолжать использовать установленный целевой объект в целях непрерывности и прозрачности или может получить или снова получить некоторый, более оптимальный доступный целевой объект. Предпочтительно, наличие политики переключения при неоптимальности назад и ограниченных множеств целевых объектов делает возможным для более оптимального целевого объекта, такого как целевой объект с более высоким приоритетом целевого объекта, быть полученным или снова полученным, когда он доступен.
Таким образом, если политика переключения при неоптимальности целевого объекта назад предписывает (например, имеется установленный бит политики переключения при неоптимальности целевого объекта назад), на этапе 708 клиентский компьютер может определить, что является доступным более предпочтительный целевой объект, такой как целевой объект внутри более предпочтительного ограниченного множества. Это определение может осуществляться в любое время и может инициироваться клиентским компьютером 205, серверным компьютером 230 Dfs или любым другим удаленным компьютером. Более того, время проверки приоритета может соответствовать истекшему количеству времени после установления установленного целевого объекта. Например, клиентский компьютер 205 может выполнять проверку на наличие более оптимального целевого объекта после 30 минут, после того, как первый установленный целевой объект был установлен. Еще дополнительно, время проверки приоритета может соответствовать конкретному времени дня, как каждые полчаса или каждые пять минут. Еще дополнительно, время проверки приоритета может соответствовать ближайшему следующему запросу на какой-либо файл от клиентского компьютера 205.
Во время проверки приоритета, если некоторый целевой объект, соответствующий более высокому приоритету целевого объекта, может быть доступным, то с этим доступным целевым объектом, соответствующим более высокому приоритету целевого объекта, может устанавливаться связь, и этот целевой объект, соответствующий более высокому приоритету целевого объекта, может быть назначен в качестве установленного целевого объекта на этапе 712. Однако, если может не быть какого-либо доступного целевого объекта с более высоким приоритетом целевого объекта, то в качестве установленного целевого объекта может продолжать использоваться текущий целевой объект на этапе 710.
Таким образом, простой способ ранжирования целевых объектов внутри Dfs сам может предоставлять полезные преимущества сортировки. Серверный приоритет целевого объекта может совпадать с величиной связанных с узлом сети затрат, как описано выше. Серверный приоритет целевого объекта может создавать жесткое ранжирование между целевыми объектами, так что целевой объект более низкого приоритета не может принимать трафик, если доступен целевой объект более высокого приоритета.
Как описано выше, ответ на запрос указателей может сортироваться в ограниченные множества, базирующиеся на ассоциированной величине связанных с узлом сети затрат каждого целевого объекта. Вместе с серверным приоритетом целевого объекта, эти ограниченные множества могут еще базироваться на величине затрат доступа к целевым объектам. Серверный приоритет целевого объекта может просто расширять критерии сортировки по затратам для целевых объектов, таким образом множества могут состоять из тех целевых объектов, которые имеют одни и те же: величину связанных с узлом сети затрат и серверный приоритет целевого объекта.
В одном варианте осуществления серверный приоритет целевого объекта может представляться с помощью двух значений: класса приоритета и ранга приоритета. Классы приоритета могут определяться на двух уровнях: локально, внутри множеств целевых объектов с равной величиной связанных с узлом сети затрат, и глобально. Внутри каждого из них может быть грубое упорядочение целевых объектов высокого, нормального и низкого приоритета. Это может предоставлять пять классов приоритета:
Глобальный высокий приоритет
Величина связанных с узлом сети затрат и высокий приоритет
Величина связанных с узлом сети затрат и нормальный
приоритет
Величина связанных с узлом сети затрат и низкий приоритет
Глобальный низкий приоритет
которые могут быть упорядочены по приоритету, как перечислено. Отметим, что может не быть какого-либо отдельного "глобального нормального" класса, так как он может рассматриваться эквивалентным классам, в которых учитывается величина связанных с узлом сети затрат. Ранг приоритета может быть простым целым числом, равным - 0, 1, 2 и так далее.
При упорядочивании какого-либо указателя, в одном варианте осуществления процесс может быть таким, как изложено ниже:
1. могут быть идентифицированы множества глобальных высоких и глобальных низких целевых объектов, также как оставшиеся "глобальные нормальные" целевые объекты;
2. эти три множества могут располагаться в следующем порядке по приоритету: глобальный высокий, глобальный нормальный и глобальный низкий;
3. если может быть установлена политика исключения, то могут удаляться целевые объекты внутри множества исключения;
4. внутри каждого из этих трех множеств целевые объекты могут упорядочиваться с помощью механизма, использующего величину связанных с узлом сети затрат (либо локального узла сети, либо посредством полной оценки величины связанных с узлом сети затрат), производящего ограниченные множества целевых объектов с равной величиной связанных с узлом сети затрат;
5. внутри множеств "глобальных нормальных" целевых объектов с равными величинами связанных с узлом сети затрат целевые объекты могут упорядочиваться по классу приоритета, т.е. величина связанных с узлом сети затрат и высокий приоритет, нормальный приоритет и низкий приоритет;
6. внутри ограниченных множеств целевых объектов с равными величинами связанных с узлом сети затрат и классами приоритета целевые объекты могут упорядочиваться согласно категории приоритета (0 является наивысшей);
7. внутри ограниченных множеств целевых объектов с равными величинами связанных с узлом сети затрат, классами приоритета и категориями приоритета целевые объекты могут случайно перетасовываться для балансировки загрузки;
Специалисты в данной области примут во внимание, что в некоторой реализации может быть выбрано выполнение этих этапов в другом порядке или может быть выбрано выполнение только некоторых из этих этапов в целях эффективности или гибкости при достижении того же эффекта и без отхода от объема настоящего изобретения.
Графически они могут быть множествами в порядке, в котором клиент будет принимать целевые объекты:
[класс глобального высокого приоритета]
[класс, основанный на величине связанных с узлом сети
затрат, высокого приоритета для целевых объектов
с величиной связанных с узлом сети затрат =0]
[класс, основанный на величине связанных с узлом сети
затрат, нормального приоритета для целевых объектов
с величиной связанных с узлом сети затрат =0]
[класс, основанный на величине связанных с узлом сети
затрат, низкого приоритета для целевых объектов
с величиной связанных с узлом сети затрат =0]
[класс, основанный на величине связанных с узлом сети
затрат, высокого приоритета для целевых объектов
с величиной связанных с узлом сети затрат =1]
[класс, основанный на величине связанных с узлом сети
затрат, нормального приоритета для целевых объектов
с величиной связанных с узлом сети затрат =1]
[класс, основанный на величине связанных с узлом сети
затрат, низкого приоритета для целевых объектов
с величиной связанных с узлом сети затрат =1]
[класс глобального низкого приоритета]
Так как информация приоритета целевого объекта может быть для каждого целевого объекта, естественное место для содержания этой информации может быть в дубликатной информации метаданных Dfs, которая включает в себя список целевых объектов для каждого корня/ссылки. Информация каждого целевого объекта может определяться с помощью псевдоструктуры, приведенной ниже:
ULONG
ULONG
USHORT
WCHAR
USHORT
WCHAR
ReplicaState;
ReplicaType;
ServerNameLength;
ServerName[ServerNameLength];
ShareNameLength;
ShareName[ShareNameLength]
В одном варианте осуществления приоритет целевого объекта может кодироваться в UCHAR для хранения в метаданных:
-Биты 5-7:
класс приоритета
Классы приоритета могут представляться в некотором варианте осуществления посредством следующих значений:
Глобальный высокий
Глобальный низкий
Величина связанных с узлом сети затрат, высокий
Величина связанных с узлом сети затрат, низкий
0x1
0x2
0x3
0x4
В качестве примера, целевой объект ранга приоритета 1 внутри класса глобального низкого приоритета может кодироваться как
Бит 7 6 5 / 4 3 2 1 0
0 1 0 / 0 0 0 0 1
Это кодирование может обеспечивать 32 ранга приоритета и 8 возможных классов приоритета, из которых 5 могут определяться, используя ранг приоритета: глобальный высокий, величина связанных с узлом сети затрат и высокий приоритет, величина связанных с узлом сети затрат и нормальный приоритет, величина связанных с узлом сети затрат и низкий приоритет, и глобальный низкий. Ранг приоритета может быть величиной от 0 до 31, причем 0 рассматривается как наивысший приоритет. Таким образом, целевые объекты с рангом приоритета 0 могут быть возвращены первыми, и целевые объекты с рангом приоритета 31 могут быть возвращены последними внутри каждого множества.
Может использоваться утилита, такая как DfsUTIL, чтобы предоставлять определения класса приоритета непосредственно для операций установки/просмотра. Альтернативно, пользовательский интерфейс может предоставлять классы приоритета с помощью кнопок выбора на странице свойств целевого объекта. Как DfsUTIL, так и пользовательский интерфейс (UI) могут выбирать "класс с величиной связанных с узлом сети затрат и нормальным приоритетом" как устанавливаемый по умолчанию.
Приоритет целевого объекта может рассматриваться как атрибут целевого объекта системы Dfs. Соответственно, вышеописанная величина типа UCHAR может храниться как атрибут для каждого целевого объекта в объекте Dfs, как в активном каталоге, так и реестре в одном варианте осуществления. Новая структура DFS_REPLICA_INFORMATION может предоставляться следующим образом:
typedef struct DFS_REPLICA_INFORMATION
{
ULONG
UCHAR
UCHAR[7]
ULONG
ULONG
UNICODE STRING
UNICODE STRING
DataSize
TargetPriority
Unused
ReplicaState
ReplicaType
ServerName
ShareName
DFS_REPLICA_INFORMATION, *PDFS_REPLICA_INFORMATION;
}
DFS_TARGET_PRIORITY_CLASS может предоставлять новый перечислимый тип, который может определять пять возможных установок класса приоритета целевого объекта в одном варианте осуществления:
typedef enum {
DfsInvalidPriorityClass = -1,
DfsSiteCostNormalPriorityClass 0,
DfsGlobalHighPriorityClass,
DfsSiteCostHighPriorityClass,
DfsSiteCostLowPriorityClass,
DfsGlobaLowPriorityClass
}DFS TARGET PRIORITY CLASS;
Используемая по умолчанию установка приоритета целевого объекта может быть < PriorityClass = SiteCostNormalPriorityClass, PriorityRank = 0>. Это может быть определено проектом, так как используемое по умолчанию значение метаданных низкого уровня будет 0. Значение для DfsSiteCostNormalPriorityClass может быть 0, даже хотя оно может быть ниже по приоритету при сравнении с DfsSiteCostHighPriorityClass. Следующая структура может предоставляться, чтобы инкапсулировать определение приоритета целевого объекта, который может быть кортежем < класс приоритета, ранг приоритета> в одном варианте осуществления:
typedef struct _DFS_TARGET_PRIORITY {
USHORT
USHORT
TargetPriorityRank
Reserved;
} DFS_TARGET_PRIORITY;
Класс DfsReplica, который может представлять целевой объект-корень или объект-ссылку в Dfs-службе, может содержать экземпляр нового класса DfsTargetPriority:
class DfsTargetPriority (
private:
DFS_TARGET_PRIORITY _TargetPriority;
Класс DfsTargetPriority может преобразовывать упакованный UCHAR, содержащий информацию приоритета целевого объекта, взятую из метаданных DFS, в более удобно используемую форму DFS_TARGET_PRIORITY. Он также может создавать упакованную UCHAR величину при заданном DFS_TARGET_PRIORITY. Он также может выполнять задание соответствия между определением класса приоритета для DFS_TARGET_PRIORITY_CLASS и определением класса приоритета, используемым для хранения в метаданных.
Существующая структура REPLICA_COST_INFORMATION может быть преобразована в новый класс, называемый DfsTargetCostInfo:
class DfsTargetCostInfo
private:
ULONG TargetCost; // Величина связанных с узлом сети
// затрат
DfsReplica *pReplica; // Серверный приоритет
является
// атрибутом из DfsReplica BOOLEAN IsBoundary;
public:
BOOLEAN operator<=(DfsTargetCostInfo &rhs);
BOOLEAN operator!={DfsTargetCostInfo &rhs);
DfsTargetCostInfo& operator=(const DfsTargetCostInfo
&rhs);
Существующая структура REFERRAL_INFORMATION может быть преобразована в класс, который будет содержать массив объектов DfsTargetCostInfo. Логика, относящаяся к перетасовыванию, сортировке и генерированию указателей, может быть инкапсулирована в этот новый класс. Этот класс также может преобразовывать сгенерированный массив объектов DfsTargetCostInfo в формат REFERRAL_HEADER, который ожидает протокол DFS.
Сортировка указателей по приоритету целевого объекта может быть реализована следующим образом. При заданных двух целевых объектах, r1 и r2, r1 может рассматриваться < = r2, если r1 должен располагаться в порядке перед r2. Таким образом, если r1 < = r2, отсортированный указатель будет выглядеть как {r1, r2}. Реализация для этого <= сравнения полагается на следующее наблюдение:
Для целевых объектов в классе глобального приоритета, классы приоритета могут сравниваться первыми. А для целевых объектов в классах не глобального приоритета, первыми могут сравниваться величины связанных с узлом сети затрат.
1. Если один или оба целевых объекта могут быть в классе глобального приоритета:
a. Если классы приоритета могут не быть одними и теми же, определить упорядочивание, базируясь на классе приоритета. Например, если r1 может быть в DfsGlobalHighPriorityClass, r1 может располагаться в порядке перед r2 независимо от класса приоритета для r2.
b. Иначе, классы приоритета могут быть одними и теми же, сравнить величины связанных с узлом сети затрат для r1 и r2. r1 < r2, если величина связанных с узлом сети затрат для r1 < величины связанных с узлом сети затрат для r2.
c. Классы приоритета и величины связанных с узлом сети затрат могут быть одними и теми же, идти на этап 3.
2. Ни один целевой объект может не быть в классе глобального приоритета:
a. Если величины связанных с узлом сети затрат для целевых объектов могут не быть одними и теми же, r1 < r2, если величина связанных с узлом сети затрат для r1 < величины связанных с узлом сети затрат для r2.
b. Иначе, величины связанных с узлами сети затрат могут быть одними и теми же, и, таким образом, проверить классы приоритета, r1 < r2, если r1 может быть в классе более высокого приоритета по сравнению с r2.
c. Величины связанных с узлом сети затрат и классы приоритета могут быть одними и теми же, идти на этап 3.
3. Классы приоритета и величины связанных с узлом сети затрат могут быть одними и теми же, r1 < r2, если r1 может иметь ранг более высокого приоритета (численно меньше) по сравнению с r2.
Для классов глобального приоритета, указатели могут сначала упорядочиваться по величинам связанных с узлом сети затрат и затем упорядочиваться по категориям приоритета. Это может происходить, так как это может быть моделью для сравнений в других случаях. Например, для классов приоритета, которые не являются глобальными, может браться в расчет только ранг приоритета, когда величины связанных с узлами сети затрат равны.
Фиг. 8 представляет блок-схему последовательности операций, в общем представляющую этапы, предпринимаемые в одном варианте осуществления для сортировки ответа на запрос указателей, в соответствии с аспектом этого изобретения. Когда запрос указателей может сортироваться, могут быть реализованы различные комбинации вышеописанных способов. В варианте осуществления, показанном на блок-схеме последовательности операций по фиг. 8, каждое из осведомленности об узле сети, величины связанных с узлом сети затрат и приоритета целевого объекта может использоваться в сортировке целевых объектов в ответе на запрос указателей.
На этапе 802 список целевых объектов, которые могут исполнять запрос клиентского компьютера, может быть скомпонован для ответа на запрос указателей для сортировки. Затем на этапе 804 целевые объекты внутри того же узла сети, что и запрашивающий компьютер, могут сортироваться на вершину списка, как было ранее описано, как осведомленность об узле сети. На этапе 806 оставшиеся целевые объекты могут сортироваться согласно глобальному приоритету. Более конкретно, целевые объекты, ассоциированные с глобальным высоким приоритетом, могут сортироваться по направлению к вершине списка целевых объектов, в то время как целевые объекты, ассоциированные с глобальным низким приоритетом, могут сортироваться по направлению к нижней части списка целевых объектов.
Далее целевые объекты, которые могут не быть установлены как либо глобальные высокие, либо глобальные низкие, могут сортироваться согласно ассоциированной величине связанных с узлом сети затрат. В одном варианте осуществления такие целевые объекты, которые могут не быть установлены либо как глобальные высокие, либо как глобальные низкие, могут устанавливаться как глобальные нормальные. Таким образом, эти целевые объекты могут группироваться в ограниченные множества целевых объектов, так что каждый целевой объект в любом заданном ограниченном множестве может быть ассоциирован с величиной связанных с узлом сети затрат, аналогичной или эквивалентной всем другим целевым объектам в том конкретном ограниченном множестве. Более того, в одном варианте осуществления каждый первый целевой объект в каждом ограниченном множестве может включать в себя установленный бит границы, который может показывать начало ограниченного множества.
Каждое ограниченное множество может дополнительно сортироваться на этапе 810, базируясь на приоритете, ассоциированном с каждым целевым объектом в ограниченных множествах. Таким образом, целевые объекты внутри ограниченного множества, ассоциированные с высоким приоритетом, могут сортироваться на вершину ограниченного множества, и целевые объекты внутри ограниченного множества, ассоциированного с низким приоритетом, могут сортироваться к нижней части ограниченного множества. Таким способом, каждое ограниченное множество может сортироваться согласно приоритету и может быть вложенным внутрь сортировки по величине связанных с узлом сети затрат, которая, в свою очередь, может быть вложенной внутрь сортировки по глобальному приоритету.
Опять же, специалисты в данной области примут во внимание, что в некоторой реализации можно выбрать выполнение этих этапов в другом порядке или можно выбрать выполнение только некоторых из этих этапов в целях эффективности или гибкости при достижении такого же эффекта и без отхода от объема настоящего изобретения.
Этим способом система и способ могут поддерживать как приоритет целевого объекта, так и переключение при неоптимальности целевого объекта назад. Система клиентского компьютера может пытаться переключиться при неоптимальности назад к другому целевому объекту с более низкой величиной связанных с узлом сети затрат и/или с более высоким приоритетом. Настоящее изобретение может предпочтительно поддерживать сортировку указателей, базируясь на осведомленности об узле сети и/или приоритете целевого объекта. Сортировка указателей, базирующаяся на осведомленности об узле сети, может предоставить одно множество целевых объектов из того же узла сети, что и Dfs-сервер, предоставляющий указатели системе клиентского компьютера, и другое множество, содержащее все другие целевые объекты. Сортировка указателей, базирующаяся на приоритете целевого объекта, может предоставлять ограниченные множества в порядке приоритета, где каждое ограниченное множество может включать в себя целевые объекты, имеющие один и тот же приоритет целевого объекта, как определенно системой клиентского компьютера, запрашивающей этот указатель. В одном варианте осуществления ответ на запрос указателей может сортироваться в ограниченные множества, имеющие одни и те же величину связанных с узлом сети затрат и серверный приоритет целевого объекта.
Как можно увидеть из предшествующего подробного описания, настоящее изобретение предоставляет улучшенную систему и способ для определения переключения при неоптимальности целевого объекта назад и приоритета целевого объекта для распределенной файловой системы. В ответ на запрос от клиентского компьютера, клиентскому компьютеру может предоставляться список целевых объектов, который может сортироваться, базируясь на оценке величины связанных с узлом сети затрат, ассоциированной с каждым соответствующим целевым объектом. Целевые объекты с более низкими величинами затрат могут сортироваться к вершине ответа на запрос указателей, так что клиентский компьютер может просто логически проанализировать весь ответ на запрос указателей, начиная с целевых объектов с более низкой величиной затрат, чтобы пытаться установить связь до осуществления попытки установить связь с целевыми объектами с более высокой величиной затрат. Дополнительно, сортировка целевых объектов также может быть реализована, используя ранжирование по приоритету для целевых объектов, в силу чего в одном варианте осуществления целевые объекты более высокого приоритета также могут сортироваться на вершину ответа на запрос указателей. Более того, ответ на запрос указателей может дополнительно сортироваться, чтобы включать в себя условия как для величины связанных с узлом сети затрат, так и для приоритета целевого объекта. Таким образом, группы целевых объектов, имеющих эквивалентную ассоциированную величину связанных с узлом сети затрат, могут дополнительно сортироваться внутри группы согласно соответствующему ассоциированному приоритету целевого объекта каждого целевого объекта. Любая компьютерная система дополнительно может использовать отсортированный ответ на запрос указателей настоящего изобретения, чтобы переключаться при неоптимальности назад на целевой объект более высокого приоритета посредством выбора и назначения нового установленного целевого объекта из списка целевых объектов, отсортированных согласно величине связанных с узлом сети затрат и/или приоритету целевого объекта. Как теперь понимается, система и способ, таким образом, предоставляют значительные преимущества и выгоды, необходимые в современной вычислительной технике.
Наряду с тем, что это изобретение допускает различные модификации и альтернативные конструкции, выше были показаны в чертежах и детально описаны его определенные иллюстрированные варианты осуществления. Следует понимать, однако, что нет никакого намерения ограничить это изобретение конкретными раскрытыми формами, но наоборот, намерение состоит в том, чтобы охватить все модификации, альтернативные конструкции и эквиваленты, попадающие в пределы сущности и объема этого изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| АНАЛИЗ МНОГОЧИСЛЕННЫХ ОБЪЕКТОВ С УЧЕТОМ НЕОПРЕДЕЛЕННОСТЕЙ | 2006 |
|
RU2413992C2 |
| РАЗНОСТНЫЕ ВОССТАНОВЛЕНИЯ ФАЙЛА И СИСТЕМЫ ИЗ ОДНОРАНГОВЫХ УЗЛОВ СЕТИ И ОБЛАКА | 2010 |
|
RU2531869C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ТРАНЗАКЦИОННЫХ ФАЙЛОВЫХ ОПЕРАЦИЙ ПО СЕТИ | 2004 |
|
RU2380749C2 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ И ПЕРЕДАЧИ ОБНОВЛЕНИЙ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2004 |
|
RU2357279C2 |
| РАСПРЕДЕЛЕННАЯ СИСТЕМА И СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ВЫБОРКИ ОБЪЕКТОВ | 1998 |
|
RU2210871C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ОБНОВЛЕНИЯ ФАЙЛОВ С ИСПОЛЬЗОВАНИЕМ КОРРЕКТИРОВАНИЯ СЖАТЫМИ ИЗМЕНЕНИЯМИ | 2004 |
|
RU2367005C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ЭФФЕКТИВНОЙ ЗАГРУЗКИ ПАКЕТА ДАННЫХ | 2012 |
|
RU2538911C2 |
| ДИНАМИЧЕСКОЕ РАЗМЕЩЕНИЕ ДАННЫХ ТОЧНЫХ КОПИЙ | 2010 |
|
RU2544777C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ПРОЕЦИРОВАНИЯ СОДЕРЖИМОГО С КОМПЬЮТЕРНЫХ УСТРОЙСТВ | 2004 |
|
RU2389067C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕДЕНИЯ ТРАНЗАКЦИЙ С ОЛИГОПОЛИСТИЧЕСКИМИ ОБЪЕКТАМИ | 2006 |
|
RU2447505C2 |
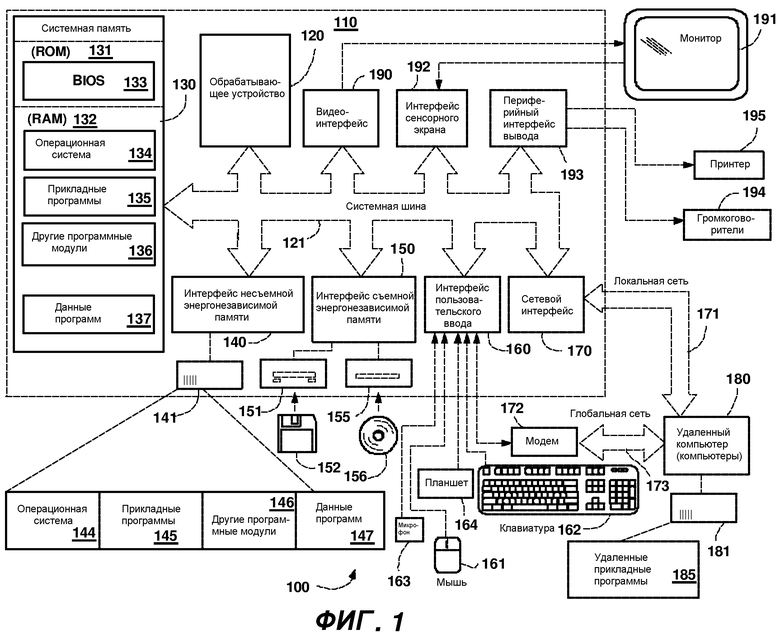
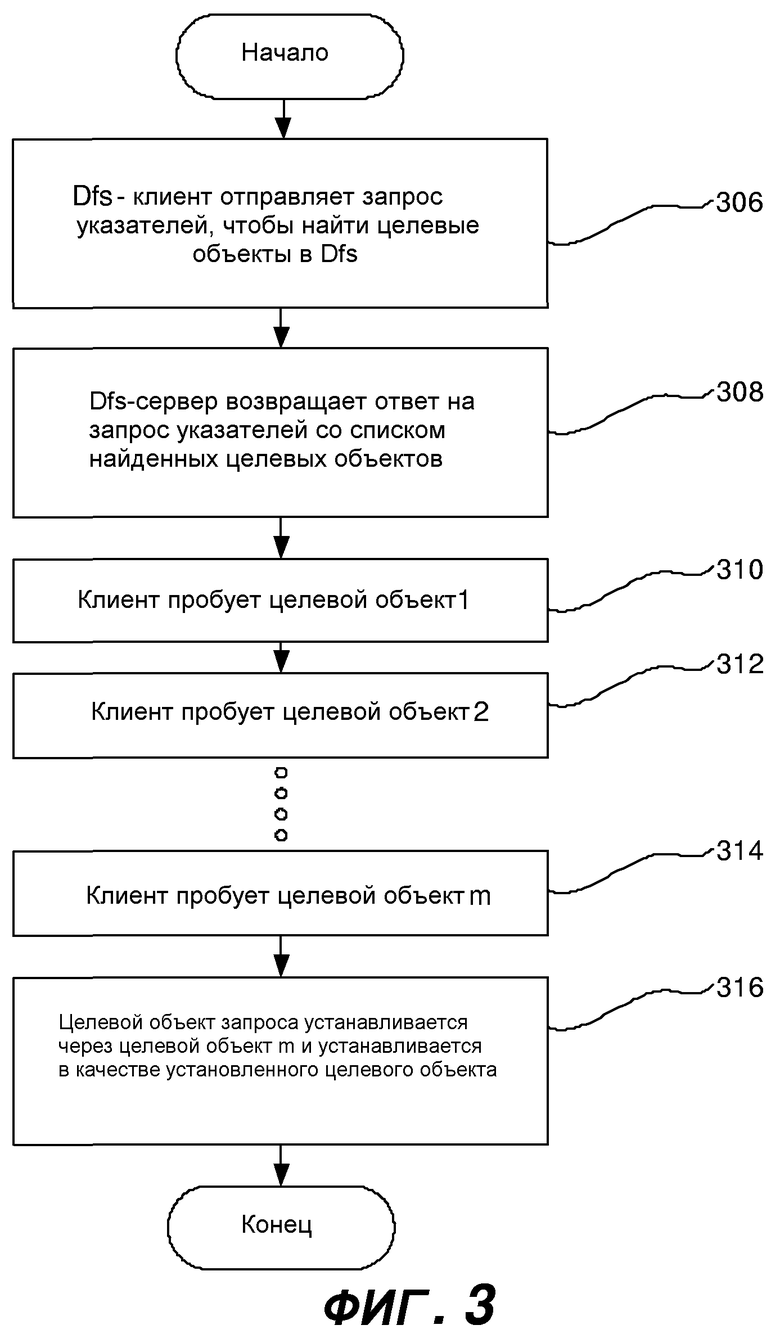
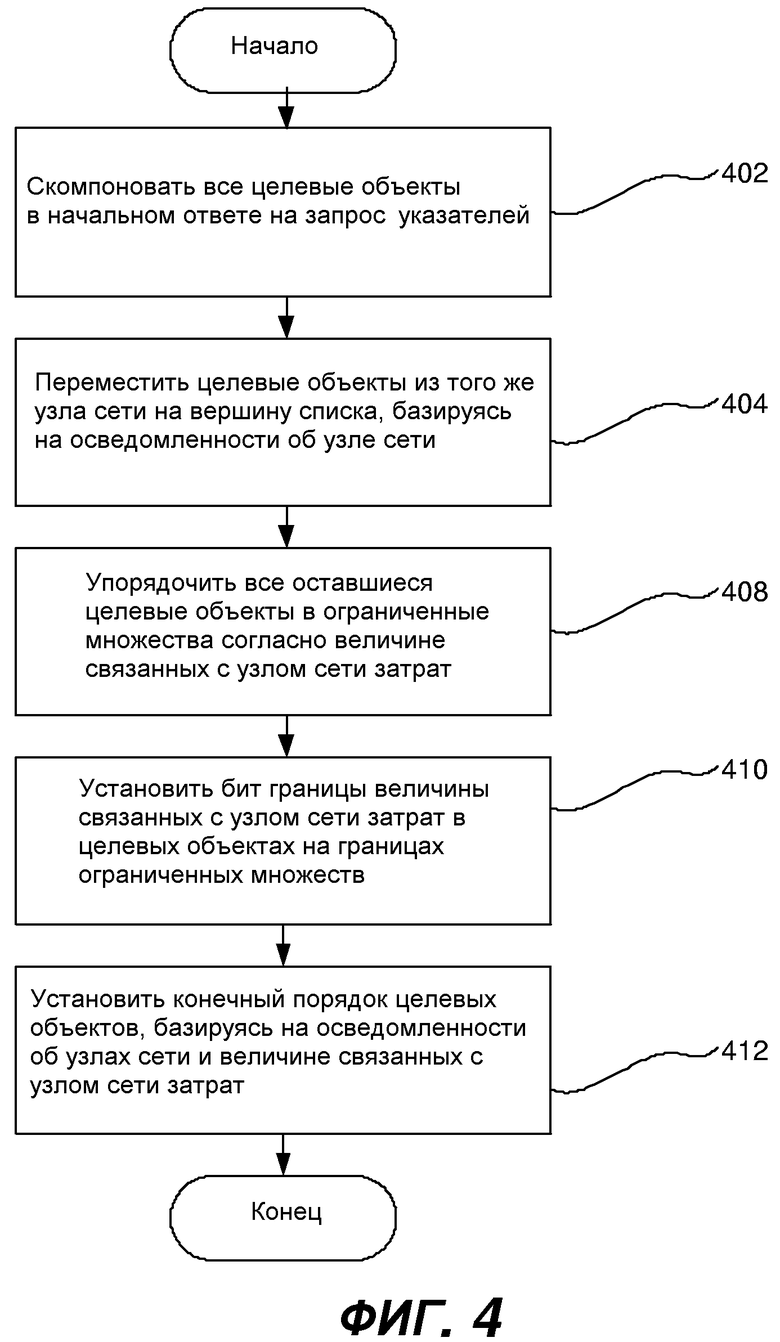
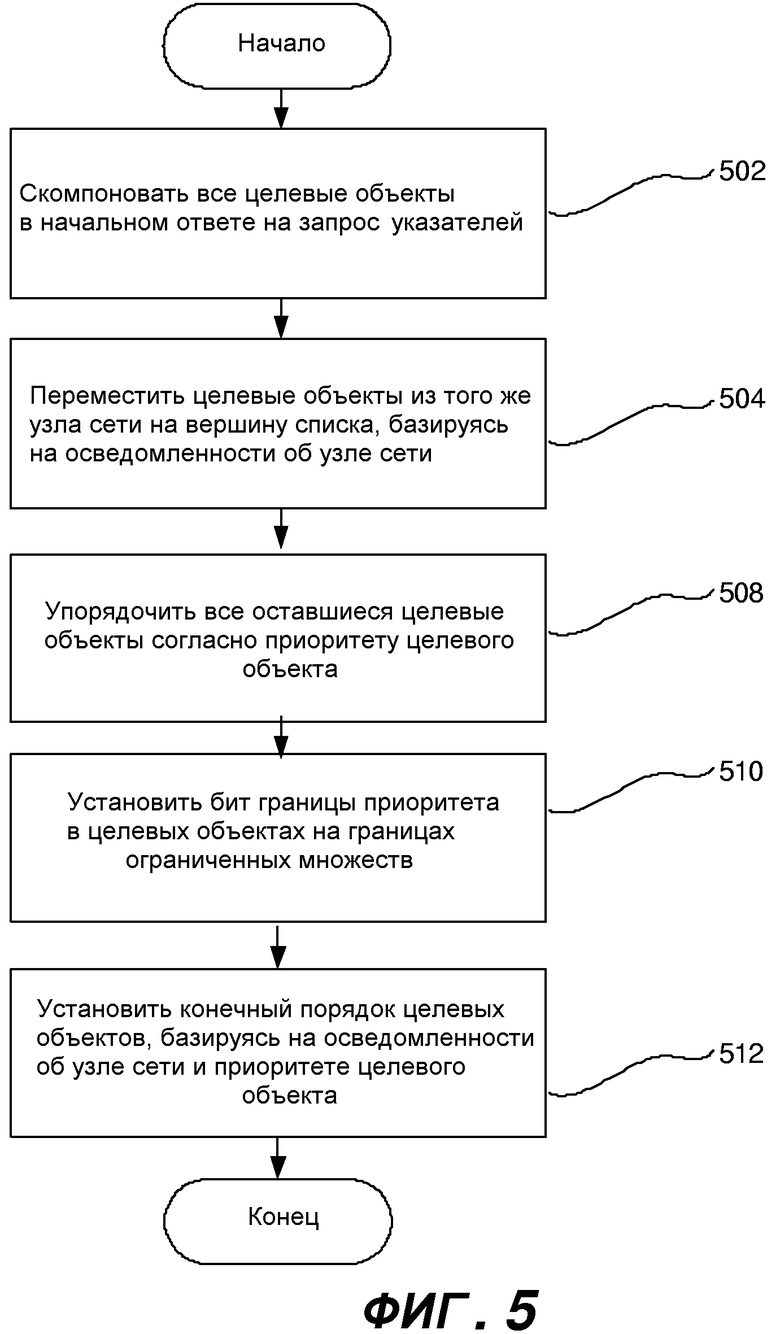
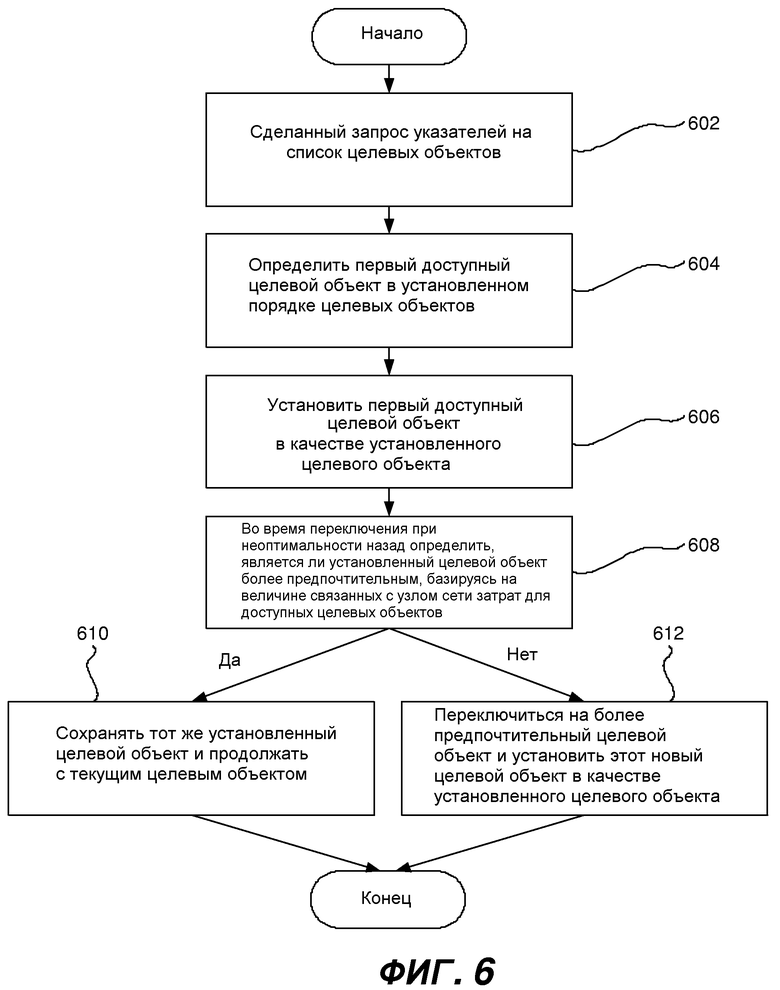
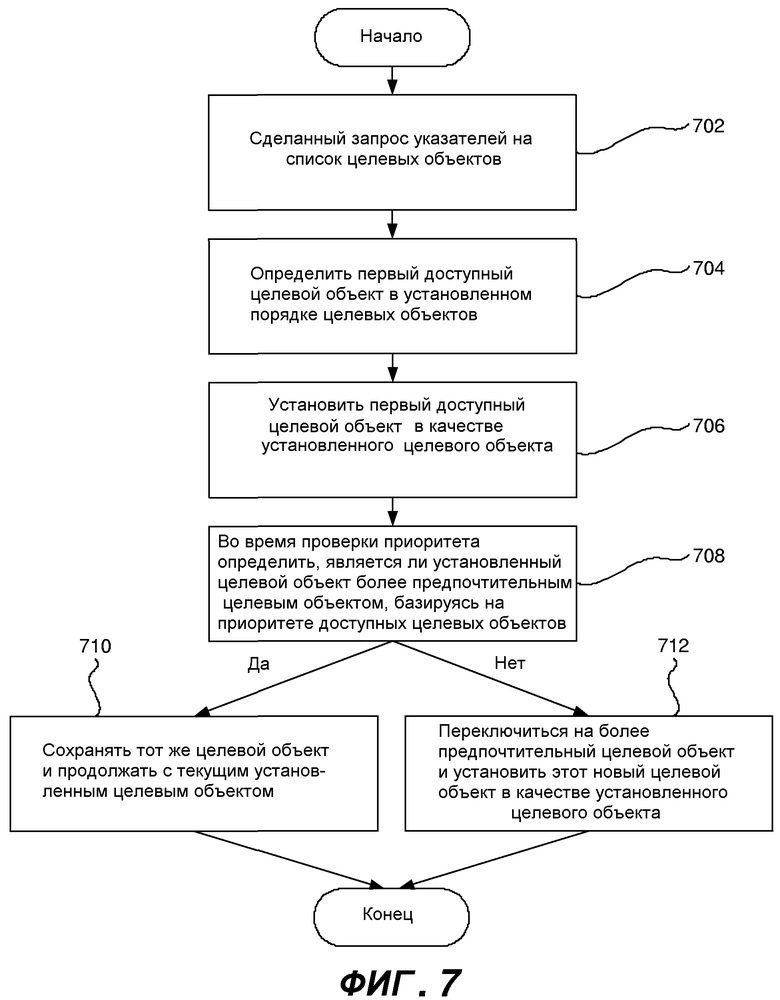
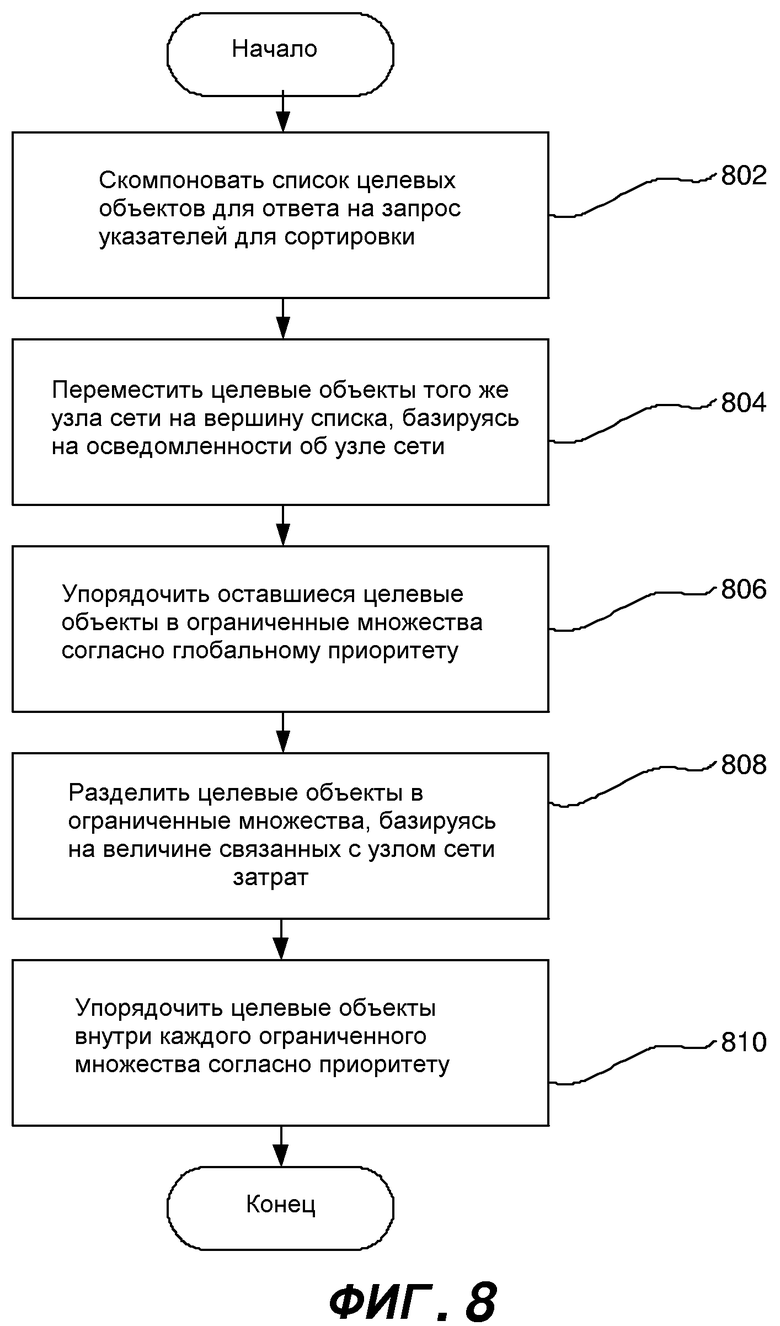
Изобретение относится к области распределенных файловых систем. Техническим результатом является повышение эффективности доступа к файлам. Предоставляются система и способ для организации и сортировки целевых объектов, принятых в ответе на запрос указателей, и для реализации политики переключения при неоптимальности целевого объекта назад и приоритета целевого объекта в распределенной файловой системе. В одном варианте осуществления способ сортировки включает в себя принятие ответа на запрос указателей в форме списка целевых объектов, которые отсортированы в ограниченные множества. Наличие ответа на запрос указателей, отсортированного в ограниченные множества, предоставляет основу для реализации политики переключения при неоптимальности целевого объекта назад и приоритета целевого объекта. Компьютерная система может выбирать некоторый целевой объект из отсортированного списка целевых объектов, отсортированных согласно величине связанных с узлом сети затрат и/или приоритету целевого объекта. Затем компьютерная система может определять, ассоциирован ли установленный целевой объект с более предпочтительным целевым объектом при сравнении со всеми доступными целевыми объектами в отсортированном списке, и если нет, переключаться назад на более предпочтительный целевой объект. 3 н. и 13 з.п. ф-лы, 8 ил.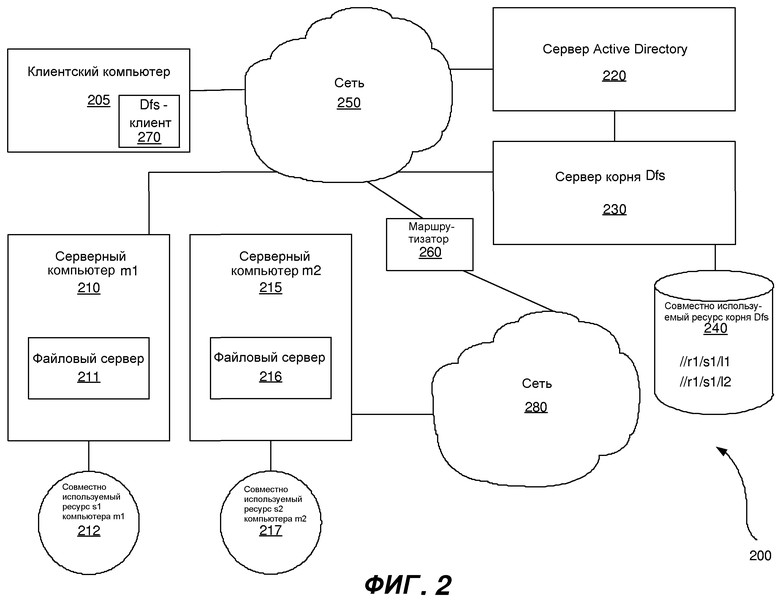
1. Реализуемый в компьютерной системе способ определения местоположения файла в сети компьютеров, содержащий этапы, на которых:
запрашивают посредством клиентского компьютера местоположение файла, расположенного в по меньшей мере одном серверном компьютере в сети серверных компьютеров;
принимают посредством клиентского компьютера список совокупности целевых объектов, причем каждый из этой совокупности целевых объектов соответствует местоположению в сети серверных компьютеров, в котором хранится упомянутый файл, при этом упомянутая совокупность целевых объектов отсортирована в ограниченные множества на основе величины связанных с узлом сети затрат, относящейся к каждому целевому объекту, так что каждое ограниченное множество ассоциировано с одной и той же величиной связанных с узлом сети затрат, причем величина связанных с узлом сети затрат ассоциирована с по меньшей мере одним параметром сети, который используется при извлечении упомянутого файла между одним из упомянутой совокупности целевых объектов и клиентским компьютером, при этом данная совокупность целевых объектов в пределах каждого ограниченного множества дополнительно отсортирована на основе приоритета, назначенного каждому целевому объекту;
выбирают посредством клиентского компьютера первый целевой объект в списке совокупности целевых объектов для осуществления доступа к упомянутому файлу, причем этот первый целевой объект имеет наименьшую величину связанных с узлом сети затрат в отношении любого доступного целевого объекта в списке совокупности целевых объектов;
для последующего доступа к упомянутому файлу определяют посредством клиентского компьютера, доступен ли целевой объект с меньшей величиной связанных с узлом сети затрат из списка совокупности целевых объектов, имеющий меньшую величину связанных с узлом сети затрат, чем первый целевой объект; и
в ответ на доступность целевого объекта с меньшей величиной связанных с узлом сети затрат осуществляют посредством клиентского компьютера доступ к упомянутому файлу, используя этот целевой объект с меньшей величиной связанных с узлом сети затрат.
2. Способ по п.1, в котором список совокупности целевых объектов содержит атрибуты границы, включающие в себя величину связанных с узлом сети затрат между целевым объектом и клиентским компьютером.
3. Способ по п.1, в котором границы каждого ограниченного множества базируются, по меньшей мере частично, на местоположении серверного компьютера, ассоциированного с каждым целевым объектом.
4. Способ по п.1, в котором границы каждого ограниченного множества базируются, по меньшей мере частично, на показателе степени исправности, ассоциированном с серверным компьютером, ассоциированным с каждым целевым объектом.
5. Способ по п.1, в котором определение в отношении целевого объекта с меньшей величиной связанных с узлом сети затрат выполняется всякий раз, когда применяется политика переключения при неоптимальности целевого объекта назад в отношении к целевому объекту с меньшей величиной связанных с узлом сети затрат.
6. Способ по п.5, в котором политика переключения при неоптимальности целевого объекта назад ассоциирована со списком совокупности целевых объектов.
7. Способ по п.5, в котором политика переключения при неоптимальности целевого объекта назад ассоциирована с корнем, который может быть ассоциирован с каждым индивидуальным целевым объектом в списке совокупности целевых объектов.
8. Способ по п.1, дополнительно содержащий этап, на котором удаляют по меньшей мере один целевой объект из списка совокупности целевых объектов на основе политики исключения.
9. Способ по п.1, в котором список совокупности целевых объектов упорядочен таким образом, что целевые объекты, имеющие глобальную высокую установку приоритета целевого объекта, помещены на вершину соответствующего ограниченного множества, а целевые объекты, имеющие глобальную низкую установку приоритета целевого объекта, помещены в нижнюю часть соответствующего ограниченного множества.
10. Распределенная вычислительная система, содержащая:
серверный компьютер, функционально связанный с сетью, причем этот серверный компьютер выполнен с возможностью:
создавать список совокупности целевых объектов,
сортировать этот список совокупности целевых объектов согласно величине связанных с узлом сети затрат, относящейся к каждому из этой совокупности целевых объектов, причем величина связанных с узлом сети затрат ассоциирована с по меньшей мере одним параметром сети, который используется при извлечении файла с серверного компьютера, соответствующего одному из упомянутой совокупности целевых объектов, на клиентский компьютер, запрашивающий этот файл,
дополнительно сортировать список совокупности целевых объектов согласно приоритету, назначенному каждому серверному компьютеру, соответствующему одному из упомянутой совокупности целевых объектов, и
предоставлять упомянутый список клиентскому компьютеру в ответ на запрос файла;
клиентский компьютер, связанный с сетью, причем этот клиентский компьютер выполнен с возможностью:
запрашивать и извлекать файлы с других компьютеров, подключенных к сети,
выбирать первый целевой объект в списке совокупности целевых объектов для осуществления доступа к упомянутому файлу, причем этот первый целевой объект имеет наименьшую величину связанных с узлом сети затрат в отношении любого доступного целевого объекта в списке совокупности целевых объектов;
для последующего доступа к упомянутому файлу определять, доступен ли целевой объект с меньшей величиной связанных с узлом сети затрат из списка совокупности целевых объектов, имеющий меньшую величину связанных с узлом сети затрат, чем первый целевой объект; и
в ответ на доступность целевого объекта с меньшей величиной связанных с узлом сети затрат осуществлять доступ к упомянутому файлу, используя этот целевой объект с меньшей величиной связанных с узлом сети затрат; и
по меньшей один дополнительный серверный компьютер, хранящий запрошенный файл, который соответствует по меньшей мере одному из упомянутых целевых объектов.
11. Распределенная компьютерная система по п.10, в которой серверный компьютер дополнительно выполнен с возможностью сортировать список совокупности целевых объектов в ограниченные множества, так чтобы каждый целевой объект в соответствующем ограниченном множестве был ассоциирован с такой же величиной связанных с узлом сети затрат, что и другие целевые объекты в этом соответствующем ограниченном множестве, и так, чтобы ограниченные множества сортировались согласно величине связанных с узлом сети затрат, ассоциированной с каждым целевым объектом в ограниченном множестве.
12. Распределенная компьютерная система по п.11, в которой серверный компьютер дополнительно выполнен с возможностью сортировать каждый целевой объект в пределах каждого ограниченного множества согласно приоритету, назначенному каждому серверному компьютеру.
13. Распределенная компьютерная система по п.12, в которой клиентский компьютер дополнительно выполнен с возможностью определять, является ли целевой объект с меньшей величиной связанных с узлом сети затрат ассоциированным с некоторым более предпочтительным приоритетом, при сравнении с другими целевыми объектами в списке совокупности целевых объектов и осуществлять доступ к упомянутому файлу, используя целевой объект, имеющий более предпочтительный приоритет.
14. Реализуемый в компьютерной системе способ определения местоположения файла в сети компьютеров, содержащий этапы, на которых:
принимают от клиентского компьютера запрос местоположения запрошенного файла, расположенного в по меньшей мере одном серверном компьютере в сети серверных компьютеров;
определяют множество местоположений в сети серверных компьютеров, в которых находится запрошенный файл;
формируют список совокупности целевых объектов, причем каждый из совокупности целевых объектов соответствует местоположению в сети серверных компьютеров, в котором хранится упомянутый файл;
сортируют список совокупности целевых объектов в ограниченные множества на основе величины связанных с узлом сети затрат, относящейся к каждому целевому объекту, так чтобы каждое ограниченное множество было ассоциировано с одной и той же величиной связанных с узлом сети затрат, причем величина связанных с узлом сети затрат ассоциирована с по меньшей мере одним параметром сети, который используется при извлечении упомянутого файла между одним из упомянутой совокупности целевых объектов и клиентским компьютером;
дополнительно сортируют список совокупности целевых объектов согласно приоритету, назначенному каждому серверному компьютеру, соответствующему одному из упомянутой совокупности целевых объектов;
задают в списке совокупности целевых объектов политику переключения при неоптимальности целевого объекта назад, показывающую, можно ли использовать целевой объект с меньшей величиной связанных с узлом сети затрат, приведенный в списке совокупности целевых объектов, для доступа к упомянутому файлу после того, как для доступа к этому файлу был использован целевой объект с более высокой величиной связанных с узлом сети затрат; и
предоставляют клиентскому компьютеру указание списка совокупности целевых объектов и политики переключения при неоптимальности целевого объекта назад.
15. Способ по п.14, в котором при дополнительной сортировке списка совокупности целевых объектов согласно приоритету сортируют список совокупности целевых объектов так, чтобы каждый целевой объект в пределах каждого ограниченного множества был упорядочен согласно приоритету, назначенному каждому серверному компьютеру, соответствующему одному из упомянутой совокупности целевых объектов.
16. Способ по п.15, в котором при дополнительной сортировке списка совокупности целевых объектов согласно приоритету упорядочивают целевые объекты, имеющие глобальную высокую установку приоритета целевого объекта, на вершину соответствующего ограниченного множества и упорядочивают целевые объекты, имеющие глобальную низкую установку приоритета целевого объекта, на нижнюю часть соответствующего ограниченного множества.
| US 6463454 B1, 08.10.2002 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| РАСПРЕДЕЛЕННАЯ СИСТЕМА И СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ВЫБОРКИ ОБЪЕКТОВ | 1998 |
|
RU2210871C2 |
| Прибор для определения поверхностной прочности стержней для литейного производства | 1948 |
|
SU77637A1 |

