Предпосылки создания изобретения
1. Область техники, к которой относится изобретение
В общем это изобретение относится к области принятия решения, неопределенности и анализу оптимизации, а более конкретно к системе и способу для оптимизации решений, относящихся к системе объектов, при наличии неопределенности.
2. Описание уровня техники
Имеется большая группа работ, которые обычно выполняются в процессе разведки, разработки и эксплуатации нефтегазовых месторождений (объектов), например, таких работ, как
аренда земли;
регистрация сейсмических данных;
бурение разведочных скважин;
бурение продуктивных скважин;
заканчивание скважин;
монтаж оборудования для технологического процесса и хранение добычи из скважин.
Хотя для проведения этих работ требуются большие капитальные затраты, эти затраты рассматриваются как инвестиции в надежде на получение доходов от реализации (например, от продажи нефти и газа), которые существенно превышают общую сумму затрат. Поэтому в настоящей заявке эти работы могут быть отнесены к инвестиционной деятельности.
При каждой инвестиционной деятельности требуется принимать различные решения, например решения относительно того
сколько земли арендовать и какие участки земли арендовать;
как регистрировать сейсмические данные и какой объем сейсмических данных регистрировать;
сколько бурить разведочных скважин и где бурить разведочные скважины;
как разрабатывать месторождения;
сколько бурить продуктивных и нагнетательных скважин, где бурить скважины и какая конструкция скважины (то есть траектория ствола скважины через пространство) должна быть для каждой из продуктивных скважин;
сколько интервалов перфорации делать в каждой скважине и как распределять местоположения интервалов перфорации вдоль конструкции скважины для каждой скважины;
какой порядок бурения и перфорирования скважин;
какой объем отвести для сооружения технологического оборудования и каким образом соединять скважины с оборудованием и с системами комплексной подготовки нефти и газа;
как обрабатывать флюиды, добываемые из геологического пласта;
какие объекты и в каком порядке разрабатывать и осуществлять добычу на объектах в случае большого количества потенциальных продуктивных объектов.
Кроме того, эти решения должны приниматься с учетом всего большого количества фундаментальных неопределенностей, например неопределенностей таких факторов, как
фьючерсные цены на сдачу в аренду нефтегазоносных участков;
запасы нефти и/или газа на месторождении;
форма и физические свойства коллекторов на каждом месторождении;
количество времени, которое будет затрачено на бурение каждой разведочной скважины и каждой продуктивной скважины;
возможность получения в будущем оборудования, такого как буровое оборудование и передвижная установка для заканчивания скважин;
затраты, связанные с эксплуатацией и техническим обслуживанием продуктивных и нагнетательных скважин и оборудования;
фьючерсные цены на нефть и газ;
устойчивость погодных условий.
В любом случае при принятии решения эти фундаментальные неопределенности влекут за собой неопределенности в выигрыше, а именно в объеме добычи, объеме продаж и прибыли. Поэтому существует необходимость в системах и способах, способных помочь при принятии решений (каждое решение имеет диапазон возможных вариантов), относящихся к разработке нефтегазового месторождения, с учетом фундаментальных неопределенностей.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Согласно одному ряду осуществлений способ анализа влияния неопределенностей, относящихся к набору объектов, может включать в себя этапы, при выполнении которых
(а) принимают информацию, задающую набор переменных неопределенности для большого количества объектов и задающую функциональную зависимость между первой и второй переменными неопределенности, где первая переменная неопределенности является относящейся к первому из объектов, где вторая переменная неопределенности является относящейся ко второму из объектов;
(b) образуют значения для каждой из переменных неопределенности, при этом процесс образования значений включает в себя образование значения для первой переменной неопределенности и вычисление значения для второй переменной неопределенности по значению первой переменной неопределенности на основании функциональной зависимости;
(с) определяют для каждого из объектов соответствующий набор входных данных, используя по меньшей мере соответствующее подмножество значений переменных неопределенности;
(d) для каждого из объектов инициируют выполнение соответствующего набора из одного или нескольких алгоритмов, при этом каждый набор из одного или нескольких алгоритмов оперирует соответствующим набором входных данных, чтобы образовать соответствующий набор выходных данных;
(е) выполняют этапы (b), (c) и (d) много раз для образования большого количества наборов выходных данных для каждого объекта;
(f) вычисляют один или несколько статистических показателей для каждого из объектов на основании соответствующего большого количества наборов выходных данных;
(g) образуют итоговые данные, основанные по меньшей мере частично на статистических показателях объектов;
(h) отображают картину итоговых данных на дисплейном устройстве.
Процесс на этапе (с) определения наборов входных данных для объектов может включать в себя
определение первого набора входных данных, соответствующего первому объекту, с использованием по меньшей мере значения первой переменной неопределенности; и
определение второго набора входных данных, соответствующего второму объекту, с использованием по меньшей мере значения второй переменной неопределенности.
Объекты могут быть объектами, относящимися к разведке и добыче одного или более из нефти и газа. Например, объекты могут включать в себя группу месторождений нефти и газа.
Набор из одного или нескольких алгоритмов для каждого объекта может быть выбран пользователем. Алгоритмы могут быть выбраны из большого разнообразия поддерживаемых алгоритмов.
Согласно одному осуществлению процесс на этапе (d) может включать в себя
распределение наборов входных данных объектов к одному или нескольким удаленным компьютерам для удаленного выполнения соответствующих наборов алгоритмов; и
прием наборов выходных данных от одного или нескольких удаленных компьютеров.
Информация, принимаемая на этапе (а), может также задавать одну или несколько корреляционных связей между переменными неопределенности. В процессе на этапе (b) образования значений для каждой из переменных неопределенности учитывается одна или несколько заданных корреляционных связей. Корреляционные связи могут включать в себя корреляционные связи между переменными неопределенности по различным объектам.
Согласно некоторым осуществлениям процесс на этапе (с) может включать в себя выбор одной из двух или более моделей для включения в один из наборов входных данных на основании значения третьей из переменных неопределенности.
Согласно одному осуществлению процесс на этапе (с) может включать в себя
выбор одной из двух или более моделей на основании значения третьей из переменных неопределенности; и
выбор одной из двух или более подмоделей выбранной модели на основании значения четвертой из переменных неопределенности.
Выбранная подмодель является пригодной к использованию для определения данных, подлежащих включению в один (или несколько) наборов входных данных.
В более общем случае пользователем может быть создано иерархическое дерево моделей, имеющих любое необходимое количество уровней. Структура данных может быть образована путем
прохождения дерева от верха до низа на основании значений одной или нескольких переменных неопределенности; и
присоединения данных, включенных в каждый узел вдоль пройденного пути.
На каждой стадии прохождения соответствующим значением переменной неопределенности определяется, какой узел-потомок должен быть выбран.
Согласно некоторым осуществлениям способ может включать в себя этапы, при выполнении которых
(1) принимают информацию, задающую большое количество переменных решения;
(2) образуют значения для переменных решения, при этом значения переменных решения используют для определения наборов входных данных для объектов;
(3) вычисляют значение глобальной целевой функции по одному или нескольким статистическим показателям каждого из объектов; и
выполняют оптимизатор, чтобы определить одно или несколько множеств значений для переменных решения.
Процесс выполнения оптимизатора может включать в себя выполнение по меньшей мере этапов (2), (e), (f) и (3) несколько раз, при этом оптимизатор конфигурируют для поиска максимума или минимума глобальной целевой функции на протяжении по меньшей мере части пространства, определяемого переменными решения.
Оптимизатор может быть выбираемым пользователем из набора поддерживаемых оптимизаторов.
Процесс (h) отображения картины итоговых данных может включать в себя отображение графического представления по меньшей мере подмножества из одного или нескольких множеств значений для переменных решения.
Информация, принимаемая на этапе (1), может также задавать одно или несколько ограничений на переменные решения. В этом случае при образовании значений для переменных решения соблюдается одно или несколько ограничений.
Информация, принимаемая на этапе (1), может также задавать одну или несколько функциональных зависимостей между переменными решения. В этом случае при образовании значений для переменных решения соблюдается одна или несколько функциональных зависимостей между переменными решения.
Каждая из переменных решения имеет относящееся к ней множество достижимых значений, представляющих возможные результаты соответствующего решения. Кроме того, каждая из переменных неопределенности имеет относящееся к ней множество достижимых значений. Множества достижимых значений могут быть конечными множествами или множествами, имеющими бесконечную мощность.
Согласно одному из осуществлений «оптимизатора» способ может дополнительно включать в себя этап, при выполнении которого
(4) вычисляют значение вспомогательной функции по одному или нескольким статистическим показателям каждого из объектов.
В этом случае процесс выполнения оптимизатора может включать в себя выполнение этапов (2), (e), (f), (3) и (4) несколько раз. Оптимизатор может быть сконфигурирован для поиска максимума или минимума глобальной целевой функции, подчиненной по меньшей мере ограничению на функциональную комбинацию глобальной целевой функции и вспомогательной функции. Функциональная комбинация может быть задана пользователем.
Процесс (h) отображения картины итоговых данных на дисплейном устройстве может включать в себя отображение графика зависимости значения глобальной целевой функции от значения вспомогательной функции.
Согласно другому ряду осуществления способ оптимизации решений, относящихся к разведке, разработке нефтегазовых месторождений и добыче из них, может включать в себя этапы, при выполнении которых
(а) принимают входные данные пользователя, задающие два или более алгоритмов и задающих одну или несколько связей между двумя или более алгоритмами, при этом каждая из связей представляет собой связь между выходными данными одного из алгоритмов и входными данными другого из алгоритмов;
(b) принимают входные данные пользователя, задающие одну или несколько структур данных, согласованных с двумя или более алгоритмами;
(с) производят действия над одной или несколькими структурами данных в ответ на входные данные пользователя, чтобы построить одну или несколько моделей для двух или более алгоритмов, при этом одна или несколько моделей включают в себя одну или несколько переменных неопределенности и одну или несколько переменных решения;
(d) принимают входные данные пользователя, задающие один или несколько статистических показателей, подлежащих вычислению на основании выходных данных двух или более алгоритмов;
(е) принимают входные данные пользователя, задающие функциональную комбинацию статистических показателей, чтобы найти глобальную целевую функцию;
(f) принимают входные данные пользователя, задающие оптимизатор;
(g) осуществляют оптимизацию, используя заданный пользователем оптимизатор, чтобы отыскать оптимум глобальной целевой функции, при этом указанное осуществление оптимизации включает в себя
(g1) образование одного или нескольких значений одной или нескольких переменных решения соответственно;
(g2) инициирование большого количества выполнений двух или более алгоритмов в соответствии с одной или несколькими связями, причем при каждом из выполнений производят действия над соответствующим набором из одной или нескольких конкретизированных моделей, определенных с помощью одной или нескольких моделей, одного или нескольких значений переменных решения и соответствующего множества из одного или нескольких конкретизированных значений одной или нескольких переменных неопределенности;
(g3) вычисление статистических показателей на основании выходных данных, полученных в результате большого количества выполнений;
(g4) вычисление значения целевой функции по статистическим показателям;
(g5) повторение этапов с (g1) по (g4) несколько раз.
Согласно некоторым осуществлениям процессы (а)-(е) могут быть выполнены на клиентском компьютере, а процесс (g) может быть выполнен на серверном компьютере. Поэтому способ может также включать в себя передачу на серверный компьютер информации, задающей два или более алгоритмов, информации, задающей одну или несколько связей, информации, задающей один или несколько статистических показателей, информации, задающей оптимизатор, и информации, задающей глобальную целевую функцию.
Согласно некоторым осуществлениям серверный компьютер может выполнять этап (g2) путем
(g2.1) образования множества из одного или нескольких конкретизированных значений одной или нескольких переменных неопределенности;
(g2.2) определения одной или нескольких конкретизированных моделей по одной или нескольким моделям и множеству из одного или нескольких конкретизированных значений;
(g2.3) передачи одной или нескольких конкретизированных моделей на удаленный компьютер, при этом удаленный компьютер осуществляет одно из большого количества выполнений двух или более алгоритмов на основании одной или нескольких конкретизированных моделей; и
повторения этапов с (g2.1) по (g2.3) для распределения большого количества выполнений по группе из одного или нескольких удаленных компьютеров.
Согласно одному осуществлению способ может дополнительно включать в себя прием входных данных пользователя, задающих диспетчер. Диспетчер представляет собой программу, которая управляет процессом инициирования большого количества выполнений двух или более алгоритмов в группе удаленных компьютеров. Сервер может выполнять диспетчер для реализации указанного повторения этапов с (g2.1) по (g2.3).
Кроме того, способ может включать в себя
прием входных данных пользователя, задающих одну или несколько вспомогательных функций, при этом каждая вспомогательная функция соответствует функциональной комбинации соответствующего поднабора статистических показателей; и
прием входных данных пользователя, задающих одно или несколько ограничений на одну или несколько вспомогательных функций и глобальную целевую функцию.
В процессе выполнения соблюдается одно или несколько ограничений на одну или несколько вспомогательных функций и глобальную целевую функцию.
Способы (или части их) согласно любому или всем осуществлениям, описанным в настоящей заявке, могут быть реализованы на основе программных команд. Программные команды могут храниться на считываемых компьютером запоминающих средах различных видов, таких как магнитный диск, магнитная лента, полупроводниковое запоминающее устройство различных видов, запоминающее устройство на цилиндрических магнитных доменах, компакт-диск, доступный только для чтения и т.д.
Программные команды могут храниться в запоминающем устройстве компьютерной системы (или в запоминающих устройствах группы компьютерных систем). Процессор компьютерной системы может быть сконфигурирован для чтения и выполнения программных команд из запоминающего устройства и, таким образом, для реализации способов согласно осуществлению (осуществлениям) или частей способов.
Кроме того, программные команды (или поднаборы программных команд) могут быть переданы через любую из различных передающих сред, например, по компьютерной сети.
В заявке регистрационный номер 10/653829 на патент США, поданной 9/03/2003 под названием “Method and system for scenario and case decision management”, в качестве изобретателей указаны Cullick, Narayanan и Wilson.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Лучшее понимание настоящего изобретения может быть достигнуто при рассмотрении подробного описания, представленного в настоящей заявке, в сочетании с сопровождающими чертежами, на которых:
Фиг.1 - иллюстрация модулей клиентского приложения и потокового сервера согласно одному ряду осуществлений;
Фиг.2 - иллюстрация потока согласно одному ряду осуществлений, сконфигурированного для выполнения анализа оптимизации решений, относящихся к большому количеству объектов при наличии различных основополагающих неопределенностей (которые моделируются переменными неопределенности);
Фиг.3 - иллюстрация оптимизатора 210 из фиг.2 согласно одному ряду осуществлений;
Фиг.4 - иллюстрация процесса 220 оценивания из фиг.2 согласно одному ряду осуществлений;
Фиг.5 - иллюстрация способа оптимизации решений, относящихся к большому количеству решений, согласно одному ряду осуществлений;
Фиг.6 - иллюстрация операции 520 (то есть операции выполнения процесса оценивания) из фиг.5 согласно одному ряду осуществлений;
Фиг.7 - иллюстрация способа оптимизации решений согласно другому ряду осуществлений;
Фиг.8 - иллюстрация операции 730 (то есть операции выполнения процесса оценивания) из фиг.7 согласно одному ряду осуществлений с акцентированием действия по распределению наборов итерационных данных к другому компьютеру (компьютерам) для выполнения на другом компьютере (компьютерах);
Фиг.9 - иллюстрация способа оптимизации решений согласно еще одному ряду осуществлений;
Фиг.10 - иллюстрация способа анализа большого количества объектов комплексным методом с учетом неопределенностей, связанных с объектами;
Фиг.11 - пример иерархической модели, имеющей два уровня выбора;
Фиг.12А - иллюстрация способа оптимизации решений согласно одному ряду осуществлений, относящихся к разведке, разработке объектов и добыче из них, таких объектов, как месторождения нефти и/или газа;
Фиг.12В - иллюстрация способа выполнения оптимизации согласно одному ряду осуществлений; и
Фиг.13 - структурная схема компьютерной системы согласно одному ряду осуществлений, которая может выполнять функцию серверного компьютера в некоторых осуществлениях и клиентского компьютера в некоторых осуществлениях.
Хотя допускаются различные модификации и альтернативные формы изобретения, конкретные осуществления его показаны для примера на чертежах и описаны подробно в настоящей заявке. Однако должно быть понятно, что чертежи и подробное описание не предполагаются ограничивающими изобретение конкретными раскрытыми формами, а напротив, изобретение охватывает все модификации, эквиваленты и варианты, попадающие в рамки сущности и объема настоящего изобретения, определенные прилагаемой формулой изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ОСУЩЕСТВЛЕНИЙ
Согласно одному ряду осуществлений система управления принятием решений может быть сконфигурирована с предоставлением пользователю средств (например, графических интерфейсов пользователя) для
(а) построения произвольного потока;
(b) построения набора моделей, включающих в себя описания некоторого количества неопределенностей и некоторого количества решений;
(с) задания набора данных для управления выполнением, включающего в себя информацию для квалификации и управления выполнением потока;
(d) инициирования выполнения потока с учетом набора моделей и набора данных для управления выполнением; и
(е) анализа результатов выполнения потока.
Поток представляет собой набор взаимосвязанных алгоритмов, предназначенных для решения задачи. Системой управления принятием решений может предоставляться графический интерфейс пользователя, который позволяет пользователю выбирать, импортировать или создавать алгоритмы и связывать алгоритмы друг с другом для формирования потока.
Поток может быть скомпонован с включением в него одного или нескольких вычислительных циклов. Циклы могут быть вложенными. Циклы потока могут использоваться с любой из разнообразных целей. Например, поток может включать в себя цикл для осуществления оптимизации по пространству, соответствующему некоторому количеству переменных. Переменные, которые подвергаются оптимизации, в настоящей заявке именуются переменными решения. В качестве другого примера, поток может включать в себя цикл для исследования влияния вариации в пространстве, соответствующем некоторому количеству переменных, которые представляют неопределенности. Переменные, которые представляют неопределенности, в настоящей заявке именуются переменными неопределенности.
Цикл может включать в себя итератор, алгоритм (или, в более общем случае, библиотеку алгоритмов) и, при желании, диспетчер. При выполнении потока итератор является ответственным за образование наборов итерационных данных для соответствующих выполнений алгоритмов. Каждое выполнение алгоритма осуществляется на основании соответствующего одного из наборов итерационных данных. Каждый набор итерационных данных содержит данные, используемые для алгоритма в качестве входных данных. В настоящей заявке каждое выполнение алгоритма именуется «итерацией». Однако термин «итерация» не означает требования последовательной обработки одной итерации после другой. На самом деле итератор и диспетчер могут быть сконфигурированы для осуществления параллельных итераций. Например, в предвидении соответствующего числа итераций итератор может быть сконфигурирован для образования некоторого количества наборов итерационных данных. Диспетчер может обнаруживать другие компьютеры (или процессоры), которые имеют незанятый диапазон вычислительных возможностей, и распределять наборы итерационных данных к другим компьютерам с тем, чтобы итерации могли быть осуществлены параллельно или, в зависимости от числа свободных компьютеров, по меньшей мере частично параллельно.
Согласно одному осуществлению диспетчер может сжимать один или несколько наборов итерационных данных для формирования исполняемого файла и передавать исполняемый файл на один из удаленных компьютеров (имеющий незанятый диапазон вычислительных возможностей). В удаленном компьютере исполняемый файл может быть распакован для восстановления наборов итерационных данных и осуществлено выполнение алгоритма, один раз для каждого из наборов итерационных данных. Алгоритм может включать в себя код, который передает результаты каждого выполнения обратно на первый компьютер (то есть на компьютер, на котором выполняется программа-диспетчер) для сохранения.
Как отмечалось выше, исполняемый файл может включать в себя сжатые наборы итерационных данных. Если в удаленном компьютере еще нет копии выполняемого кода для алгоритма, диспетчер может сжать копию выполняемого кода и включить сжатый код в исполняемый файл.
Как указывалось выше, поток представляет собой набор взаимосвязанных алгоритмов, предназначенных для решения задачи. Алгоритмы работают на основании структур данных. Алгоритмы различных видов работают на основании структур данных различных видов. Например, имитатор движения флюидов в коллекторе, разработанный для прогнозирования объемов добычи нефти, газа и воды, функционирует при ином наборе структур данных, чем экономический алгоритм, разработанный для прогнозирования экономической отдачи. Системой управления принятием решений может предоставляться интерфейс, через который пользователь может задавать местоположения источников файлов (например, местоположения файловой системы в сети) и/или баз данных, содержащих структуры данных. Кроме того, системой управления принятием решений могут инициироваться инструментальные средства, которые позволяют пользователю создавать и модифицировать структуры данных.
Каждая структура данных включает в себя множество из одного или нескольких значений данных. Однако некоторые значения данных из структуры данных могут представлять собой параметры или величины, которые являются неопределенными. Поэтому системой управления принятием решений пользователю может предоставляться механизм для выбора значения данных в структуре данных и для продвижения значения данных в переменную неопределенности путем привнесения множества достижимых значений для переменной неопределенности и распределения вероятностей для переменной неопределенности. (По умолчанию исходное значение данных может быть включено в качестве одного из значений во множество достижимых значений переменной неопределенности.) Любое количество значений данных из любого количества структур данных может быть продвинуто таким образом в переменные неопределенности.
Кроме того, значение данных в структуре данных может представлять один возможный результат решения. Пользователь может захотеть рассмотреть другие возможные результаты решения. Поэтому системой управления принятием решений может предоставляться пользователю механизм для выбора значения данных из структуры данных и для продвижения значения данных в переменную решения путем привнесения множества достижимых значений, представляющих возможные результаты решения. (Например, количество скважин, подлежащих бурению на определенном месторождении, может быть равно любому целому числу от А до В включительно. В качестве другого примера, производительность определенного насоса может быть равна любому значению в диапазоне от X до Y, выраженному в кубических футах в секунду.) По умолчанию исходное значение данных может быть включено в качестве одного из элементов множества достижимых значений. Любое количество значений данных из любого количества структур данных может быть продвинуто таким образом в переменные решения.
Множество достижимых значений для переменной решения или переменной неопределенности может быть конечным множеством (например, конечным множеством численных значений, задаваемых пользователем) или бесконечным множеством (например, интервалом вещественной линии или области в n-мерном пространстве Евклида, где n - целое положительное число).
Пользователь может различными способами задавать распределение вероятностей для переменной неопределенности. Если переменная неопределенности имеет множество достижимых значений, которое является непрерывным, системой управления принятием решений может предоставляться пользователю возможность задавать плотность распределения вероятностей (ПРВ) путем выбора вида плотности распределения вероятностей (например, нормального, равномерного, треугольного и т.д.) и задавать параметры, определяющие конкретную плотность распределения вероятностей в рамках выбранного вида. Если переменная неопределенности имеет множество достижимых значений, которое является конечным, системой управления принятием решений может предоставляться пользователю возможность ввода значений вероятности (или численных значений, которые в дальнейшем могут быть нормированы относительно значений вероятности) для достижимых значений переменной неопределенности. Системой управления принятием решений может предоставляться пользователю возможность приводить плотность распределения вероятностей в качественное и количественное согласие с существующим множеством значений для переменной неопределенности (возможно, по аналогии).
Возможен случай, когда структур данных две или более, при этом каждая может быть привнесена в качестве входных данных в определенный алгоритм (или в определенный набор алгоритмов). Пользователю может быть точно не известно, какую из двух или более структур данных использовать. Например, для одного и того же коллектора могут быть две геоклеточные модели, и может быть неясно, какая модель является лучшим представлением физического коллектора. Следовательно, пользователь может захотеть создать поток, в котором алгоритм выполняется несколько раз, при этом каждый раз с использованием случайно выбранной одной из двух или более структур данных. Поэтому системой управления принятием решений пользователю может быть предоставлен механизм для образования переменной неопределенности, достижимые значения которой согласованы соответственно с двумя или более структурами данных. Пользователь может присвоить значения вероятности двум или более достижимым значениям. Каждое значение вероятности представляет вероятность того, что соответствующая структура данных будет выбрана из любой определенной реализации переменной неопределенности. Пользователь может делать выбор, чтобы образовывать любое количество переменных неопределенности этого вида. Набор структур данных, которые таким образом преобразуются в достижимые значения переменной неопределенности, называется «подчиненным переменной неопределенности».
Кроме того, возможен случай, когда структур данных две или более, при этом они представляют альтернативные результаты решения. Например, структур данных может быть две или более, при этом каждая представляет возможную реализацию для местоположений скважин и соединений трубопроводов оборудования. Поэтому системой управления принятием решений пользователю может предоставляться механизм для образования переменной решения, достижимые значения которой согласованы соответственно с двумя или более структурами данных. Набор структур данных, которые таким образом преобразуются в достижимые значения переменной решения, называется «подчиненным переменной решения».
Поэтому системой управления принятием решений пользователю предоставляется возможность
(1) задавать местоположения источников для структур данных, создавать структуры данных и модифицировать структуры данных;
(2) продвигать значения данных из структур данных в переменные неопределенности и переменные решения;
(3) подчинять структуры данных переменным неопределенности;
(4) подчинять структуры данных переменным решения.
Некоторые структуры данных могут быть отнесены к моделям, поскольку они описывают (характеризуют) представляющие интерес системы. Например, структуры данных могут включать в себя геоклеточные модели коллекторов, модели конструкций скважин и т.д. Объекты, вытекающие из операций (2), (3) и (4), в настоящей заявке также именуются моделями.
Система управления принятием решений может быть сконфигурирована для поддержки использования очень точных моделей физического коллектора, моделей скважин, моделей продуктивного потока и экономических моделей.
Некоторые из переменных неопределенности могут быть коррелированными. Поэтому системой управления принятием решений пользователю предоставляется возможность задавать корреляционные связи между парами переменных неопределенности. Например, пользователь может выбирать пару переменных неопределенности и вводить коэффициент корреляции, чтобы задавать корреляционную связь между парой переменных неопределенности. Согласно некоторым осуществлениям пользователь может выбирать группу из двух или более переменных неопределенности и вводить корреляционную матрицу для группы. При выполнении потока переменные неопределенности конкретизируются способом, в котором принимаются во внимание корреляционные связи, заданные пользователем.
Некоторые переменные неопределенности могут иметь между собой функциональные зависимости, например функциональные зависимости вида Y=f(X), Y=f(X1,X2), Y=f(X1,X2,X3) и т.д., где X, X1 X2, X3 и Y суть переменные неопределенности. Поэтому системой управления принятием решений может предоставляться интерфейс пользователя, который позволяет пользователю задавать такие функциональные зависимости. Могут поддерживаться любые из большого разнообразия функций (включая линейные и нелинейные функции). Согласно некоторым осуществлениям интерфейс пользователя позволяет пользователю конструировать произвольную алгебраическую функцию переменных неопределенности. При выполнении потока переменные неопределенности конкретизируются способом, в котором принимаются во внимание эти функциональные зависимости. Например, если Y=f(X), конкретизация для Y может быть получена, прежде всего, конкретизацией X и затем оцениванием функции f на основании конкретизации X. Аналогичным образом, переменные решения могут иметь функциональные зависимости между собой, например функциональные зависимости вида Y=f(X), Y=f(X1,X2), Y=f(X1,X2,X3) и т.д., где X, X1, X2, X3 и Y суть переменные решения. Поэтому один и тот же интерфейс пользователя (или другой интерфейс пользователя) может быть использован для задания таких функциональных зависимостей между переменными решения.
Некоторые из переменных решения или функциональных комбинаций переменных решения могут быть подчинены ограничениям. Поэтому системой управления принятием решений может предоставляться интерфейс пользователя, который позволяет пользователю задавать ограничивающие условия, такие как
Y ″неравенство″ Х,
Y ″неравенство″ f(X),
Y ″неравенство″ f(X1,X2),
Y ″неравенство″ f(X1,X2,X3),
и т.д.,
на переменные решения, такие как X, X1, X2, X3 и Y, где ″неравенство″ может быть любым из операторов неравенства, <, ≤, > или ≥. Может поддерживаться любая из большого разнообразия функций f (в том числе линейные и нелинейные функции). Согласно некоторым осуществлениям интерфейс пользователя предоставляет пользователю возможность конструировать произвольную алгебраическую функцию переменных решения. При выполнении потока осуществляется оптимизация, при которой принимаются во внимание ограничивающие условия, заданные пользователем на переменные решения.
Кроме того, системой управления принятием решений может предоставляться интерфейс пользователя, через который пользователь может задавать набор данных для управления выполнением. Набор данных для управления выполнением содержит информацию для регулирования и квалификации выполнения потока. Например, набор данных для управления выполнением может включать в себя такую информацию, как
способ конкретизации переменных неопределенности в потоке;
и
количество итераций для соответствующих циклов в потоке.
В способе конкретизации методом Монте-Карло переменные неопределенности (или некоторый поднабор переменных неопределенности) могут быть конкретизированы случайным образом путем использования генераторов случайных чисел. В способе конкретизации на основе латинского гиперкуба переменные неопределенности (или некоторый поднабор переменных неопределенности) могут быть конкретизированы путем использования хорошо известного метода латинского гиперкуба. В способе конкретизации на основе планирования эксперимента переменные неопределенности (или некоторый поднабор переменных неопределенности) могут быть конкретизированы путем использования любого из различных, хорошо известных методов планирования эксперимента.
С течением времени пользователь может сконструировать некоторое количество потоков, некоторое количество наборов моделей и некоторое количество наборов данных для управления выполнением. Системой управления принятием решений пользователю может предоставляться возможность выбора потока, набора моделей и набора данных для управления выполнением и инициирования выполнения потока с учетом набора данных для управления выполнением и набора моделей. Кроме того, системой управления принятием решений пользователю может предоставляться больший контроль над тем, каким образом поток может быть выполнен. Например, согласно некоторым осуществлениям поток может выполняться для осуществления конкретных итераций, которые по различным причинам могут отрицательно сказываться на предшествующих выполнениях потока. Согласно другим осуществлениям дополнительные итерации могут быть произведены относительно потоков, которые были выполнены ранее.
Системой управления принятием решений пользователю могут предоставляться различные средства для создания потоков различных видов. Например, согласно некоторым осуществлениям программа для управления принятием решений может включать в себя построитель потока решений, который сконфигурирован для автоматизации процесса построения потока с целью оптимизации решений, относящихся к разработке набора объектов (например, набора нефтегазовых месторождений) способом, в котором учитываются различные неопределенности, относящиеся к набору объектов.
Архитектура клиент-сервер
Система управления принятием решений может быть реализована путем выполнения программы управления принятием решений в одной группе из одного или нескольких компьютеров.
Программа управления принятием решений может быть разделена на клиентское приложение и серверное приложение с протоколом связи между клиентским приложением и серверным приложением. Например, протокол связи может быть реализован путем использования удаленного вызова метода (RMI) или Web-служб.
Клиентское приложение может выполняться на клиентском компьютере, а серверное приложение может выполняться на серверном компьютере. Однако условие, что клиентское приложение и серверное приложение должны выполняться на отдельных компьютерах, не является необходимым. Если компьютер имеет достаточную вычислительную мощность, клиентское приложение и серверное приложение могут выполняться на этом компьютере.
Серверное приложение может быть сконфигурировано для использования диспетчеров. Диспетчер представляет собой программу (или систему программ), сконфигурированную для распределения независимых групп вычислений (например, итераций большого задания) по другим процессорам (или компьютерам) для выполнения на этих других процессорах. Другие процессоры могут быть распределены по сети, такой как локальная вычислительная сеть, глобальная сеть или Интернет. Кроме того, другие процессоры могут быть частью аппаратного устройства с разделяемой памятью, такого как кластер, и могут быть использованы как единый блок (например, в ситуации параллельного выполнения вычислений).
Согласно некоторым осуществлениям основные модули клиентского приложения и серверного приложения (то есть потоковый сервер) могут быть такими, какие показаны на фиг.1.
Клиентское и серверное приложения
Клиентское приложение 100 может включать в себя построитель 107 потоков, менеджер 102 моделей, исполнитель 109 потоков и выходной анализатор 112.
Построителем 107 потоков предоставляется интерфейс пользователя, через который пользователь осуществляет постановку задачи и создает поток для решения ее.
Менеджером 102 моделей предоставляется интерфейс, через который пользователь может осуществлять создание, построение и модификацию моделей, включающих в себя переменные решения и переменные неопределенности.
Исполнитель 109 потоков используется для инициирования выполнения потоков. В ответ на требование пользователя о выполнении потока исполнитель потоков отправляет поток вместе с совместимым набором моделей и совместимым набором данных управления выполнением в потоковый сервер с тем, чтобы поток мог быть выполнен. Кроме того, исполнитель потоков может принимать информацию о состоянии из потокового сервера, относящуюся к выполняемым в настоящее время потокам и очередным потокам, и отображать для пользователя информацию о состоянии. Потоковый сервер может отправлять результаты выполнения потока обратно в исполнитель потоков и/или сохранять результаты в базе данных.
Потоковый сервер может включать в себя удаленный интерфейс 160 прикладного программирования (API-интерфейс), предназначенный для связи с клиентскими приложениями, такими как клиентское приложение 100.
Выходным анализатором 112 пользователю предоставляется возможность осуществления анализа данных по результатам выполнения потока.
Потоковый сервер 155 может выполнять потоки (или управлять выполнением потоков), которые передаются в качестве заданий от клиентского приложения. Потоковым сервером 155 может предоставляться информация о состоянии выполняемых заданий в исполнитель потоков. Кроме того, потоковый сервер обеспечивает возможность снятия заданий.
Модули клиентского приложения
Как отмечалось выше, клиентское приложение может быть разделено, как показано на фиг.1, на ряд модулей. Каждый модуль может иметь относящийся к нему интерфейс прикладного программирования (API-интерфейс), и через эти интерфейсы осуществляется связь различных модулей. Таким образом, клиентское приложение может включать в себя API-интерфейс 103 менеджера моделей, API-интерфейс 106 построителя потока решений, API-интерфейс 108 построителя потоков, API-интерфейс 110 исполнителя потоков и API-интерфейс 113 выходного анализатора.
Согласно некоторым осуществлениям эти API-интерфейсы являются только обеспечивающими сопряжение между модулями, поэтому модули могут быть разработаны независимо.
Кроме того, каждый из модулей, для которого требуется связь с внешними приложениями, может иметь удаленный интерфейс прикладного программирования. Поэтому согласно некоторым осуществлениям клиентское приложение может включать в себя удаленный API-интерфейс 104 менеджера моделей и удаленный API-интерфейс 111 исполнителя потоков.
Менеджер моделей
Менеджером 102 моделей может предоставляться интерфейс, который позволяет пользователю импортировать, создавать, редактировать и сопровождать модели, например модели, включающие в себя переменные неопределенности и переменные решения, описанные выше. Менеджер моделей также может сопровождать модели в проектах или других структурах, задаваемых пользователем.
Виды структур данных, подлежащих включению в модели, предназначенные для определенного потока, зависят от алгоритмов, включаемых в поток. Поэтому менеджер моделей может осуществлять связь с построителем потоков для уверенности в том, что пользователь поставляет структуры данных, которые являются согласованными с алгоритмами определенного потока. Например, менеджером моделей может приниматься от построителя потоков перечень алгоритмов в потоке. В таком случае менеджер модели может сосредотачиваться на запросе от пользователя видов структур данных, подходящих для перечисленных алгоритмов. И наоборот, модели, выбранные пользователем, могут определять вид потока, который может быть выполнен. Поэтому, если пользователь создает и вводит структуру данных, то в таком случае пользователю может быть рекомендовано выбирать только те потоки, которые способны выполнять эту модель. Согласно некоторым осуществлениям менеджер моделей может быть сконфигурирован для запуска хорошо известных инструментальных программных средств с целью создания и редактирования моделей определенных видов. Например, каждая модель может быть специфического вида, а каждый вид может иметь специфическое инструментальное средство, зарегистрированное для обеспечения возможности создания модели, редактирования ее, просмотра и т.д. Такое решение может быть аналогичным редакторам свойств по технологии JavaBean, которыми предоставляется специализированный графический интерфейс пользователя, регистрируемый по технология JavaBean. Кроме того, в таком решении могут использоваться некоторые из представлений в рамках каркаса активации по технологии JavaBeans.
Поскольку нет необходимости в том, чтобы структуры данных, поставляемые пользователем, включали в себя переменные решения или переменные неопределенности, менеджером моделей могут предоставляться обобщенные механизмы для продвижения значений данных из структур данных в переменные решения и переменные неопределенности совместно со структурами данных и для подчинения структур данных переменным решения и переменным неопределенности.
Менеджер моделей может функционировать как менеджер ситуаций, позволяя клонировать существующую модель и изменять субкомпоненты.
Построитель потоков
Алгоритмы являются компоновочными блоками потоков. Алгоритм может рассматриваться как процесс, который имеет входные данные и образует выходные данные. Поток представляет собой набор алгоритмов, которые взаимосвязаны друг с другом для решения определенной задачи. Следует отметить, что при желании сам поток может быть преобразован в алгоритм.
Построителем 107 потоков предоставляется интерфейс пользователя, с помощью которого пользователь может создавать произвольные потоки. Например, построителем потоков пользователю может предоставляться возможность выбора алгоритмов из набора имеющихся алгоритмов и связи алгоритмов друг с другом (то есть связи выходных данных алгоритмов с входными данными других алгоритмов) для формирования потока. Набор имеющихся алгоритмов может включать в себя ряд алгоритмов, полезных для планирования разведки, разработки и/или эксплуатации ряда месторождений, например, таких алгоритмов, как геологические или геостатистические имитаторы, имитаторы материального баланса, имитаторы движения флюидов в коллекторе, имитаторы насосно-компрессорных труб, имитаторы процессов в оборудовании, имитаторы сети трубопроводов и экономические алгоритмы. Согласно некоторым осуществлениям имитаторы могут быть выполнены путем использования одного или нескольких инструментальных средств, коммерческих или с открытым исходным кодом (например, имитатора Landmark повышения экономической эффективности коллектора или другого имитатора на основе конечно-разностного метода или метода конечных элементов, или имитатора линий тока, имитатора Petex GAP наземного трубопровода, Microsoft's Excel, имитатора Petex MBAL материального баланса, геостатистического генератора GSLIB).
Кроме того, построителем потоков пользователю может предоставляться возможность построения алгоритмов из рабочей памяти или импортирования программ, которые могут быть использованы как алгоритмы. Согласно некоторым осуществлениям построителем потоков пользователю может предоставляться возможность задания произвольной алгебраической функции в качестве алгоритма или импортирования нейронной сети для использования в качестве алгоритма.
Согласно одному ряду осуществлений при формировании направленных связей между алгоритмами построителем потоков могут накладываться ограничения на вид данных. Например, построителем потоков может разрешаться присоединение выходных целочисленных данных от одного алгоритма к входным данным с плавающей запятой второго алгоритма, но запрещаться присоединение выходных данных с плавающей запятой к входным целочисленным данным.
В построителе потоков может использоваться механизм поиска для нахождения алгоритмов. Механизм поиска может поддерживать поиск по категории алгоритма (такой как «алгоритм динамики добычи»), типу входных данных, типу выходных данных и т.д.
Согласно некоторым осуществлениям построитель потоков может быть сконфигурирован путем использования одного или нескольких коммерческих инструментальных средств (например, системы Landmark управления принятием решений в пространстве решений).
После создания алгоритмы и потоки могут быть зарегистрированы менеджером моделей как
пригодные к использованию пользователем;
пригодные к использованию членами коллектива, совместно работающими над проектом;
пригодные к использованию в компании;
готовые для внешнего распределения по заказчикам.
Исполнитель потоков
Исполнителем 109 потоков может предоставляться интерфейс пользователя, который позволяет пользователю инициировать выполнение потоков. Когда пользователь выдает команду на инициирование выполнения потока с учетом набора моделей и набора данных для управления выполнением, исполнитель потоков составляет задание, включающее в себя поток, набор моделей и набор данных для управления выполнением, и представляет задание в потоковый сервер. Потоковый сервер может сгенерировать уникальный идентификатор для задания и переслать идентификатор задания в исполнитель потоков. В исполнителе потоков идентификатор задания может быть записан.
В дополнение к получению потоков с построителя потоков и моделей от менеджера моделей исполнитель потоков может также загружать описание потока и относящихся к нему моделей из набора входных файлов (например, XML-файлов), задаваемых пользователем. Исполнитель потоков может отображать перечень заданий, включающий в себя задания, которые выполняются в настоящее время (в том числе текущее состояние их), и задания, которые находятся на стадии ожидания. Интерфейс исполнителя потоков позволяет пользователю снимать задания. Кроме того, интерфейс исполнителя потоков может позволять пользователю получать доступ к любым, уже имеющимся результатам задания. Результаты могут быть отображены через пользовательский интерфейс выходного анализатора.
Исполнитель потоков может быть сконфигурирован для направления заданий на любой из большого количества потоковых серверов. Потоковые серверы можно создавать из группы компьютеров, связанных через сеть. Исполнителем потока клиенту может предоставляться возможность решать, на какой потоковый сервер должно быть направлено задание. Для выполнения заданий различных видов различные потоковые серверы могут быть изготовлены по индивидуальным заказам.
Выходной анализатор
Основной задачей выходного анализатора 112 может быть предоставление пользователю средства для осмысливания выходных данных, получаемых в результате выполнения задания (то есть потока с учетом заданного набора моделей и набора данных для управления выполнением). Выходные данные могут быть сложными, поскольку поток может иметь сложную структуру, например структуру с внешним циклом и многочисленными внутренними циклами.
Выходной анализатор может быть сконфигурирован для обеспечения пользователю возможности исследования выходных данных от выполненного потока и наблюдения результатов от потока, все еще выполняемого на потоковом сервере.
Выходной анализатор может иметь доступ ко всему набору инструментальных средств анализа данных, а также способен форматировать выходные данные с тем, чтобы они могли быть проанализированы в стороннем инструментальном средстве (таком как Microsoft Excel).
Интерфейс вычислителя результатов
Клиентское приложение может также включать в себя интерфейс вычислителя результатов (не показан). Интерфейс вычислителя результатов позволяет пользователю задавать специальные вычисления, которые должны быть встроены в поток. Специальные вычисления могут быть полезными в случае, когда выходные данные первого алгоритма (или первого набора алгоритмов) не являются точно входными данными, необходимыми для второго алгоритма (или второго набора алгоритмов), но могут быть использованы для вычисления входных данных, необходимых для второго алгоритма. Интерфейс вычислителя результатов позволяет пользователю
выбирать один или несколько выходных аргументов из первого набора из одного или нескольких алгоритмов потока и
задавать функцию (например, произвольную алгебраическую функцию) одного или нескольких выходных аргументов;
задавать входной аргумент второго алгоритма (отличного от одного или нескольких алгоритмов из первого набора), то есть получать результат оценивания функции по выбранным выходным аргументам.
В построителе потоков или построителе потока решений эта информация может использоваться для образования алгоритма вычислителя результатов, который реализует заданную функцию, с тем, чтобы алгоритм вычислителя результатов был встроен в поток между первым набором алгоритмов и вторым алгоритмом. Пользователь может задавать любое желаемое количество специальных вычислений, чтобы они производились (во время выполнения потока) между алгоритмами или наборами алгоритмов в потоке.
Потоковый сервер
Потоковый сервер 155 может быть разделен, как показано на фиг.1, на некоторое количество отдельных модулей. Потоковый сервер может быть сконфигурирован для выполнения заданий. Задание включает в себя поток и набор входных данных.
В зависимости от количества заданий потоковый сервер может выполнять их параллельно, при этом потоковый сервер может устанавливать очередь ожидания выполнений. Потоковый сервер может обладать способностью снимать задания или изменять приоритет заданий.
Потоковый сервер может быть снабжен простым интерфейсом пользователя (например, по HTML-форме).
В отличие от клиентского приложения потоковый сервер обычно может выполняться на другом компьютере. Однако потоковый сервер можно также выполнять на том же самом компьютере, что и клиентское приложение.
Потоковый сервер поддерживает диалог с исполнителем потока, информируя исполнителя потока о состоянии заданий и т.д.
Связь между исполнителем потока и потоковым сервером может быть основана на любом из большого разнообразия известных протоколов, таких как дистанционный вызов метода (RMI) или Web-службы.
Алгоритмы, модели, итераторы и диспетчеры
Система управления принятием решений сконфигурирована для выполнения потоков, которые включают в себя набор взаимосвязанных алгоритмов. Поток может выполняться на основании моделей с относящимися к ним переменными неопределенности и переменными решения в качестве входных данных. Например, модели могут включать в себя значения данных, которые продвинуты в переменные решения, значения данных, которые продвинуты в переменные неопределенности, структуры данных, которые подчинены переменным решения, структуры данных, которые подчинены переменным неопределенности, или любое сочетание их.
Поток может включать в себя циклы, сконфигурированные для итерационного выполнения наборов алгоритмов. Диспетчеры могут быть использованы для распределения итераций по многочисленным компьютерам для параллельного выполнения.
По умолчанию может быть предусмотрен диспетчер, который выполняет все итерации относящегося к нему цикла на локальном хост-компьютере.
Кроме того, может быть предусмотрен сетевой диспетчер, который осуществляет поиск свободных компьютеров в сети и распределение итераций по этим свободным компьютерам.
Кроме того, может быть предусмотрен диспетчер метакомпьютерной сети, который распределяет итерации по сети компьютеров.
Весьма вероятно, что количество моделей, особенно моделей, постоянно находящихся в памяти, и количество алгоритмов, которые работают в согласовании с моделями, будет возрастать с течением времени. Поэтому система управления принятием решений может быть сконфигурирована для перекрытия по своему усмотрению притока новых моделей и алгоритмов.
Согласно некоторым осуществлениям система управления принятием решений может иметь интерфейс командного типа. Входные данные пользователя, направляемые через интерфейс командного типа, могут быть собраны и сохранены. При желании этим обеспечивается способ повторения набора интеракций.
Построитель потока решений
Клиентское приложение программы управления принятием решений может также включать в себя построитель потока решений. Построителем потока решений может предоставляться интерфейс пользователя, который ускоряет процесс построения потока с целью оптимизации решений, относящихся к разведке, разработке и эксплуатации объектов, таких как нефтегазовые месторождения.
Согласно некоторым осуществлениям построитель потока решений может быть специально сконфигурирован для ускорения конструирования потока, включающего в себя внешний цикл оптимизации и набор внутренних циклов «исследования неопределенности», например, по одному внутреннему циклу на объект.
Построителем потока решений может предоставляться графический интерфейс пользователя, через который пользователь может
а) задавать наименования объектов, подлежащих анализу;
b) задавать вид для каждого из объектов, например, из таких видов, как разведочное месторождение, вскрытое месторождение и эксплуатируемое месторождение;
с) задавать один или несколько алгоритмов (например, алгоритмов имитации процесса), подлежащих включению во внутренний цикл для каждого объекта;
d) задавать источники структур данных, согласованных с алгоритмами, задаваемыми на этапе (с);
е) производить операции над структурами данных с целью построения моделей для каждого из объектов, при этом модели могут включать в себя переменные неопределенности и/или переменные решения, описанные выше;
f) задавать глобальные переменные решения и глобальные переменные неопределенности;
g) задавать функциональные зависимости между переменными неопределенности и функциональные зависимости между переменными решения, в том числе функциональные зависимости в пределах объектов и по объектам;
h) задавать корреляционные связи между переменными неопределенности, в том числе корреляционные связи между переменными неопределенности в пределах объектов и по объектам;
i) задавать ограничения на переменные решения или функциональные комбинации переменных решения;
j1) задавать одну или несколько представляющих интерес величин для каждого объекта A(k), k=1, 2, …,NA, где каждая из величин представляет функциональную комбинацию из одного или нескольких выходных аргументов алгоритмов, относящихся к объекту A(k);
j2) задавать статистические показатели, подлежащие вычислению, для каждого объекта A(k), k=1, 2, …,NA, на основании одной или нескольких заданных величин для объекта A(k);
k1) задавать глобальную целевую функцию S в виде функциональной комбинации из первого поднабора статистических показателей;
k2) задавать одну или несколько вспомогательных функций, при этом каждая вспомогательная функция является функциональной комбинацией, соответствующей поднабору статистических показателей;
k3) задавать одно или несколько ограничений, в том числе на одну или несколько вспомогательных функций и/или глобальную целевую функцию;
l) выбирать оптимизатор (то есть из набора поддерживаемых оптимизаторов) для внешнего цикла оптимизации;
m) выбирать диспетчер из набора поддерживаемых диспетчеров;
n) задавать, должна ли оптимизация быть максимизацией или минимизацией.
В соответствии с информацией, задаваемой пользователем, построитель потока решений может образовывать поток, имеющий внешний цикл оптимизации и набор внутренних циклов.
Как указано в (b) выше, виды объектов могут включать в себя разведочные месторождения, вскрытое месторождение и эксплуатируемое месторождение. Также предполагаются другие виды объектов.
Как указано в (с) выше, пользователь может задавать один или несколько алгоритмов (например, алгоритмов имитации процесса), подлежащих включению во внутренний цикл для каждого объекта. Построитель потока решений может принимать входные данные пользователя, задающие конкретный объект, на который в настоящее время должно быть обращено внимание, и отображать перечень (или некоторое графическое представление) набора алгоритмов, соответствующих виду рассматриваемого объекта, из которого пользователь может осуществлять выбор. Различные виды алгоритмов соответствуют различным объектам.
Как указано в (d) выше, пользователь может задавать источники структур данных, согласованных с алгоритмами, задаваемыми в (с). Например, интерфейс построителя потока решений может быть сконфигурирован так, чтобы пользователь мог задавать для каждого объекта местоположения файловых систем (например, местоположения файловых систем в компьютерной сети) для файлов данных или баз данных, содержащих структуры данных. Кроме того, пользователь может задавать информационные входы (или наборы информационных входов) в базы данных, содержащие структуры данных.
Примеры структур данных для объекта включают в себя
(1) приповерхностную (подземную) структурную архитектуру, геометрию и объем объекта;
(2) подземное трехмерное распределение свойств объекта, включая, но без ограничения ими, объем порового пространства, нефтенасыщенность и газонасыщенность, водонасыщенность, геологическую литологию, разрывы и трещины;
(3) физическое местоположение объекта относительно поверхности моря или земной поверхности и географическое местоположение объекта;
(4) количество скважин и местоположения скважин на объекте, которые могут быть пробурены в дальнейшем;
(5) количество скважин, которые уже пробурены на объекте;
(6) объем углеводородов, соотнесенный с объектом;
(7) потенциальные запасы, соотнесенные с объектом;
(8) картину изменения во времени добычи нефти, газа и воды, соотнесенную с объектом;
(9) картину изменения во времени закачивания газа и воды, соотнесенную с объектом;
(10) виды оборудования, которое относится к объекту; и
(11) виды оборудования, которое может быть изготовлено в дальнейшем для объекта.
Другие примеры структур данных включают в себя модели коллектора, экономические модели, модели сети трубопроводов, модели технологического оборудования и модели насосно-компрессорных труб скважины.
Виды структур данных, которые задаются для объекта, могут зависеть от видов алгоритмов, которые должны быть использованы для объектов. Например, имитатор материального баланса, состоящий из аналитических или алгебраических выражений, может основываться на «резервуарной» модели для объекта, при этом резервуарная модель имеет единственный набор свойств для представления всего объекта. Для прогнозирования потоков нефти, газа и воды в динамике во времени имитатор движения флюидов в коллекторе с представлением дифференциальными уравнениями в частных производных движения флюидов в пористых средах и с конечно-разностной формулировкой может быть основан на трехмерной пространственной модели коллектора. Экономический алгоритм для прогнозирования прибыли в динамике во времени может быть основан на экономической модели, включающей в себя цены, ставки налогообложения и фискальные сложности. Построитель потока решений может подсказывать пользователю, чтобы он вводил структуры данных того вида, который согласован с алгоритмами, уже заданными для объекта в (с).
Как указано в (е) выше, заявитель может производить операции над структурами данных с целью построения моделей для каждого из объектов, особенно для моделей, включающих в себя переменные неопределенности и переменные решения. Например, пользователь может
продвигать значения данных из структур данных в переменные неопределенности;
продвигать значения данных из структур данных в переменные решения;
подчинять структуры данных переменным неопределенности; и
подчинять структуры данных переменным решения.
Примеры переменных решения для объектов включают в себя
количество скважин;
местоположения скважин на поверхности;
диаметр трубопроводов; и
объем компрессоров;
вид скважины (имеющей достижимые значения, такой как горизонтальная, вертикальная или многоствольная);
геометрию скважины;
траекторию бурения скважины (в коллекторе, относящемся к объекту);
вид платформы (имеющей достижимые значения, такой как подводная и на оттяжках);
переменную решения, подчиняющуюся набору графиков бурения скважин;
переменную решения, подчиняющуюся набору графиков заканчивания скважин;
переменную решения, подчиняющуюся набору графиков ввода в действие оборудования.
Примеры переменных неопределенности для объектов включают в себя
объем углеводородов;
продуктивность углеводородов;
стоимость скважин и/или оборудования; и
цены на нефть и газ.
Глобальные переменные решения представляют собой переменные решения, которые неоднозначно связаны с единственным объектом. Например, размер капитала, имеющегося в наличии для группы объектов, является примером глобальной переменной решения. Глобальные переменные неопределенности представляют собой переменные неопределенности, которые неоднозначно связаны с единственным объектом. Например, цена на нефть является примером глобальной переменной неопределенности.
Как указано выше в (g), пользователь может задавать функциональные зависимости между переменными неопределенности и функциональные зависимости между переменными решения. Согласно некоторым осуществлениям интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности
выбора переменной неопределенности (из набора VUN переменных неопределенности, относящихся к текущей задаче) в качестве зависимой переменной и выбора одной или нескольких других переменных неопределенности (из набора VUN) в качестве независимых переменных; и
задания функции (например, произвольной алгебраической функции) независимых переменных для нахождения функциональной зависимости между независимыми переменными и зависимой переменной.
Набор VUN переменных неопределенности, относящихся к текущей задаче, включает в себя переменные неопределенности, заданные в (е), и глобальные переменные неопределенности.
Кроме того, интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности
выбора переменной решения (из набора VD переменных решения, относящихся к текущей задаче) в качестве зависимой переменной и выбора одной или нескольких других переменных решения (из набора VD) в качестве независимых переменных; и
задания функции (например, произвольной алгебраической функции) независимых переменных для определения функциональной зависимости между независимыми переменными и зависимой переменной.
Набор VD переменных неопределенности, относящихся к текущей задаче, может включать в себя глобальные переменные решения и переменные решения, заданные в (е).
Построителем потока решений может предоставляться пользователю возможность задания любого количества функциональных зависимостей путем многократного использования интерфейса построителя потока решений, описанного выше. Например, пользователь может задавать функциональные зависимости следующих видов:
функциональную зависимость между переменными неопределенности (или переменными решения) в пределах объекта, то есть когда зависимая переменная и одна или несколько независимых переменных относятся к одному и тому же объекту;
функциональную зависимость между переменными неопределенности (или переменными решения) по объектам, то есть когда зависимая переменная и одна или несколько независимых переменных относятся к двум или более объектам; и
функциональную зависимость между переменными неопределенности (или переменными решения), где зависимая переменная и/или одна или несколько независимых переменных являются глобальными переменными.
«Алгебраическая функция» представляет собой функцию, которая определяется выражением, включающим в себя только алгебраические действия над аргументами функции, такие как сложение, вычитание, умножение, деление, извлечение целочисленного (или рационального) корня и возведение в целую (или рациональную) степень.
Как указано в (h) выше, пользователь может задавать корреляционные связи между переменными неопределенности. Согласно одному ряду осуществлений интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности
выбора пары переменных неопределенности из набора VUN переменных неопределенности; и
ввода коэффициента корреляции для задания корреляционной связи между парой переменных неопределенности.
Пользователь может задавать любое количество таких корреляционных связей путем многократного использования интерфейса построителя потока решений, описанного выше. Например, пользователь может задавать корреляционные связи между парами переменных неопределенности, к которым относятся следующие формы:
пара переменных неопределенности в пределах объекта (то есть относящаяся к одному и тому объекту);
пара переменных неопределенности по объектам (то есть когда одна переменная из пары относится к одному объекту, а другая переменная из пары относится к другому объекту);
пара переменных неопределенности, где одна или обе переменные являются глобальными переменными неопределенности.
Согласно некоторым осуществлениям пользователь может выбирать группу из двух или более переменных неопределенности и вводить корреляционную матрицу для группы.
При выполнении потока переменные неопределенности конкретизируются способом, в котором учитываются заданные пользователем корреляционные связи.
Как указано в (i) выше, пользователь может задавать ограничения на переменные решения или функциональные комбинации переменных решения. Согласно одному ряду осуществлений интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности
выбора первой переменной Y решения из набора VD переменных решения;
выбора набора из одной или нескольких переменных X1, X2, …,XN решения (отличных от Y) из набора VD переменных решения, где N - целое положительное число;
задания при желании функции f (например, произвольной алгебраической функции) одной или нескольких переменных X1, X2, …,XN решения; и
выбора оператора неравенства, обозначаемого как «неравенство», из набора {<, ≤, > или ≥}, чтобы задавать ограничение вида
Y «неравенство» f(X1,X2,…,XN).
Кроме того, интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности задания ограничений вида Y «неравенство» С, где С - заданная пользователем постоянная.
Набор VD переменных решения может включать в себя глобальные переменные решения и переменные решения, заданные в (е). Любая из большого разнообразия функций f (включая линейные и нелинейные функции) может быть поддержана. Согласно некоторым осуществлениям интерфейс построителя потока решений позволяет пользователю конструировать произвольную алгебраическую функцию выбранных переменных X1, X2, …,XN решения.
Интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности задания любого количества ограничений на переменные решения путем многократного использования интерфейса построителя потока решений, описанного выше. Например, пользователь может задавать ограничения, к которым относятся следующие формы:
ограничение на переменные решения в пределах объекта, то есть когда все переменные решения, охваченные ограничением, относятся к одному и тому же объекту;
ограничение на переменные решения по объектам, то есть когда переменные решения, охваченные ограничением, относятся к двум или более объектам;
ограничение на переменные решения, в том числе на одну или несколько глобальных переменных решения.
При выполнении потока осуществляется оптимизация, в процессе которой учитываются заданные пользователем ограничения.
Как указано в (j1) выше, пользователь может задавать одну или несколько представляющих интерес величин для каждого объекта A(k), k=1, 2, …,NA.
Согласно одному ряду осуществлений пользователь может задавать величину для объекта A(k) путем
выбора одного или нескольких выходных аргументов из алгоритмов, относящихся к объекту A(k), и/или выбора одной или нескольких величин, которые ранее были заданы для объекта A(k); и
задания функции (например, произвольной алгебраической функции) выбранных выходных аргументов и/или ранее заданных величин.
Путем использования этой процедуры для каждого объекта может быть задано любое количество величин.
Кроме того, интерфейс построителя потока решений может отображать перечень обычно используемых величин, согласованных с видами алгоритмов, которые относятся к текущему рассматриваемому объекту A(k). Пользователь может задавать представляющие интерес величины путем выбора величин из перечня.
Примеры представляющих интерес величин, относящихся к объекту, включают в себя такие величины, как чистая приведенная стоимость, общие балансовые запасы, общее количество добытой нефти и т.д.
Как указано в (j2) выше, пользователь может задавать статистические показатели, подлежащие вычислению, для каждого объекта A(k), k=1, 2, …, NA, то есть статистические показатели на основании одной или нескольких величин, которые были заданы для объекта A(k). Согласно одному ряду осуществлений интерфейс построителя потока решений может предоставлять пользователю возможность задания статистического показателя для каждой из одной или нескольких величин, которые были заданы для каждого объекта путем
ввода математического выражения, определяющего статистический показатель;
выбора статистического показателя из перечня обычно используемых статистических показателей.
Примеры обычно используемых статистических показателей включают в себя
среднее значение;
среднеквадратическое отклонение;
квантиль порядка p, где p - задаваемое пользователем значение между нулем и единицей.
Кроме того, интерфейс построителя потока решений может предоставлять пользователю возможность задания более чем одного статистического показателя на основании одной и той же величины. Например, пользователь может захотеть вычислить среднее значение и среднеквадратическое отклонение от чистой приведенной стоимости для объекта.
Как часть выполнения потока одна или несколько величин, заданных для каждого объекта, могут быть оценены несколько раз с получением совокупности значений для каждой величины. Каждый статистический показатель, заданный для величины, вычисляется по соответствующей совокупности.
Как указано в (k1) выше, пользователь может задавать глобальную целевую функцию S в виде функциональной комбинации первого поднабора статистических показателей. С этой целью согласно одному ряду осуществлений интерфейс построителя потока решений может быть сконфигурирован для обеспечения пользователю возможности
нахождения первого поднабора путем выбора одного или нескольких статистических показателей, которые были заданы для каждого объекта; и
задания функции (например, линейной комбинации или произвольной алгебраической функции) статистических показателей из первого поднабора.
В соответствии с одним типичным сценарием пользователь может выбирать один статистический показатель S k, соответствующий каждому объекту A(k), k=1, 2, …, NA, и задавать глобальную целевую функцию S как линейную комбинацию вида
 .
.
Пользователь может вводить значения коэффициентов c k, чтобы они умножались на соответствующие статистические показатели S k. Например, пользователь может придавать глобальной целевой функции S такую форму, чтобы она представляла собой линейную комбинацию среднего значения чистой приведенной стоимости для каждого объекта A(k).
Как указано в (k2) выше, пользователь может задавать одну или несколько вспомогательных функций, при этом каждая вспомогательная функция является функциональной комбинацией соответствующего поднабора статистических показателей. Согласно одному ряду осуществлений для задания вспомогательной функции интерфейс построителя потока решений может предоставлять пользователю возможность
выбора одного или нескольких статистических показателей, которые были заданы для каждого объекта; и
задания функции (например, произвольной алгебраической функции) статистик выбранных статистических показателей.
Используя эту процедуру, пользователь задает любое количество вспомогательных функций.
В соответствии с одним типичным сценарием пользователь может находить вспомогательную функцию Н путем выбора одного статистического показателя T k, соответствующего каждому объекту A(k), k=1, 2,…, NA, и задания линейной комбинации вида
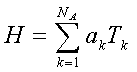
или вида
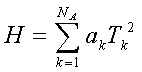 .
.
Пользователь может вводить значения коэффициентов 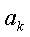 , чтобы они были умножены на соответствующие статистические показатели. Например, пользователь может придать вспомогательной функции Н такую форму, чтобы она представляла собой линейную комбинацию квадрата среднеквадратического отклонения от чистой приведенной стоимости для каждого объекта A(k).
, чтобы они были умножены на соответствующие статистические показатели. Например, пользователь может придать вспомогательной функции Н такую форму, чтобы она представляла собой линейную комбинацию квадрата среднеквадратического отклонения от чистой приведенной стоимости для каждого объекта A(k).
Как указано в (k3) выше, пользователь может задавать одно или несколько ограничений, в том числе на одну или несколько вспомогательных функций и/или глобальную целевую функцию S. Согласно одному ряду осуществлений пользователь может задавать одно или несколько ограничений, каждое из которых имеет вид
J «взаимосвязь» С,
где J - задаваемая пользователем функция, аргументы которой выбираются из набора FC, включающего в себя одну или несколько вспомогательных функций и глобальную целевую функцию S, при этом «взаимосвязь» представляет собой зависимость, выбираемую из набора {<, ≤, >, ≥, =}, где С - задаваемая пользователем постоянная. Пользователь может задавать такое ограничение путем
выбора одного или нескольких аргументов для функции J из набора FC;
задания функциональной комбинации (например, произвольной алгебраической функциональной комбинации) из одного или нескольких выбранных аргументов;
выбора зависимости «взаимосвязь» из набора {<, ≤, >, ≥, =}; и
задания постоянной С.
Путем использования этой процедуры может быть задано любое количество ограничений.
В соответствии с одним типичным сценарием пользователь может основываться на этой процедуре для задания ограничения вида J=H/S<C, где H - вспомогательная функция и S - глобальная целевая функция. Например, Н может быть линейной комбинацией квадратов среднеквадратических отклонений от чистой приведенной стоимости, при одном отклонении на объект, а S может быть линейной комбинацией средних значений чистых приведенных стоимостей, при одном среднем значении на объект.
Как указано в (l) выше, пользователь может выбирать оптимизатор. Согласно одному ряду осуществлений построителем потока решений пользователю может предоставляться возможность выбора из набора поддерживаемых оптимизаторов. Предполагается, что глобальная целевая функция S является сугубо нелинейной и имеющей много локальных минимумов (или максимумов) на протяжении глобального пространства, определяемого переменными решения. Кроме того, это глобальное пространство, на протяжении которого должна осуществляться оптимизация, может иметь изолированные островки допустимых векторов среди огромного количества недопустимых векторов. Следовательно, желательно использовать оптимизаторы, которые не ограничиваются нахождением единственного локального минимума (или максимума) и не останавливаются внутри единственного островка. Поэтому набор поддерживаемых оптимизаторов может включать в себя стохастические оптимизаторы, например, оптимизаторы, которые в методике поиска используют случайность.
Согласно некоторым осуществлениям построителем потока решений пользователю может предоставляться возможность выбора из оптимизаторов такого оптимизатора, как
(1) оптимизатор поиска с разбросом;
(2) оптимизатор поиска с запретом;
(3) оптимизатор, основанный на метаэвристическом сочетании поиска с разбросом, поиска с запретом, нейронных сетей и линейного программирования;
(4) оптимизатор, основанный на генетическом алгоритме.
Набором VD переменных решения из потока представлены решения, которые поддаются управлению. Каждая переменная решения имеет заданное пользователем множество достижимых значений. Декартово произведение множеств достижимых значений переменных решения в VD является глобальным пространством решений, на протяжении которого должна осуществляться оптимизация и при этом подчиняться любым ограничениям, которые пользователь может задавать на переменные решения или функциональные комбинации переменных решения, и подчиняться одному или нескольким ограничениям, определенным в (k3), в том числе на одну или несколько вспомогательных функций и/или глобальную целевую функцию.
Вектор в глобальном пространстве решений именуется вектором решения. Иначе говоря, вектор решения представляет собой вектор значений, то есть одного значения, выбираемого из каждого множества достижимых значений переменных решения в VD.
Согласно некоторым осуществлениям построителем потока решений может предоставляться пользователю возможность привнесения набора начальных оценочных векторов, которые оптимизатор может использовать в процессе поиска.
Набор VUN переменных неопределенности из потока отражает неопределенности. Каждая переменная неопределенности имеет заданное пользователем множество достижимых значений. Декартово произведение множеств достижимых значений переменных неопределенности в VUN является глобальным пространством неопределенностей, которое должно быть итерационно исследовано. Вектор в глобальном пространстве неопределенностей именуется вектором неопределенности. Иначе говоря, вектор неопределенности является вектором значений, то есть одного значения, выбираемого из каждого множества достижимых значений переменных неопределенности в VUN.
Согласно некоторым осуществлениям построитель потока решений может формировать поток 200 в ответ на информацию (a)-(n), заданную пользователем. Как показано на фиг.2, поток 200 может включать в себя оптимизатор 210, выбранный пользователем в (l), и процесс 220 оценивания. Оптимизатор 210 может формировать векторы x решения в глобальном пространстве решений, подчинять переменные решения заданным пользователем ограничениям. Процесс 220 оценивания осуществляется относительно векторов x решения для образования соответствующих значений S(x) глобальной целевой функции S и соответствующих значений H(x) вспомогательной функции Н, описанной ниже. Значения S(x) глобальной целевой функции и значения H(x) вспомогательной функции поступают на оптимизатор. Оптимизатором эти значения используются для образования скорректированных векторов решения при попытке минимизации (или максимизации) глобальной целевой функции с использованием заданного пользователем ограничения на вспомогательную функцию H(x) (или на сочетание вспомогательной функции и глобальной целевой функции). Оптимизатор может работать в соответствии с любым из ряда алгоритмов оптимизации. Структура цикла, включающая в себя оптимизатор и процесс оценивания, именуется в настоящей заявке «внешним» циклом.
Согласно одному ряду осуществлений оптимизатор 210 может быть сконфигурирован для выполнения операций в соответствии с нижеследующей методикой, показанной на фиг.3. Оптимизатор может выполняться на серверном компьютере.
При выполнении операции 310 оптимизатор 210 может создавать эталонный набор допустимых векторов решения. (Вектор решения считается допустимым, если он удовлетворяет заданным пользователем ограничениям на переменные решения.) При первой итерации в соответствии с операцией 310 эталонный набор может быть образован путем формирования начального набора векторов решения, которые являются пространственно различными (то есть получены путем использования методов случайного формирования), и затем преобразования начального набора векторов решения в допустимые векторы решения. Однако при любой итерации после операции 310 эталонный набор может быть образован путем
выбора «наилучших» векторов решения в количестве n1 из предыдущей версии эталонного набора (то есть «наилучших» в соответствии с оценкой с помощью глобальной целевой функции);
образования набора пространственно различных векторов (например, полученных путем использования методов случайного формирования);
преобразования различных векторов для получения различных допустимых векторов;
добавления разнообразных допустимых векторов в количестве n2 к векторам в количестве n1 для повышения пространственного разнообразия эталонного набора.
Оптимизатор может рассортировывать n1 наилучших векторов решения по порядку значений S(x) их глобальной целевой функции. Оптимизатор может также рассортировывать n2 дополнительных векторов в соответствии с мерой расстояния.
При выполнении операции 320 оптимизатор 210 может образовывать новые векторы xновые путем формирования комбинаций (например, линейных комбинаций) поднаборов векторов эталонного набора. Новые векторы необязательно должны быть допустимыми векторами. Поднаборы могут включать в себя два или более векторов эталонного набора.
При выполнении операции 330 оптимизатор 210 может преобразовывать новые векторы решения в допустимые векторы xf решения с использованием линейной программы и/или частично-целочисленной программы.
При выполнении операции 340 оптимизатор 210 может представлять допустимые векторы xf решения для выполнения процесса 220 оценивания с целью вычисления значений S(xf) глобальной целевой функции и значений H(xf) вспомогательной функции, соответствующих допустимым векторам xf решения.
При выполнении операции 350 оптимизатор может корректировать эталонный набор путем использования значений S(xf) глобальной целевой функции и значений H(xf) вспомогательной функции, вычисленных на этапе операции 340. Согласно одному осуществлению оптимизатор может исследовать каждый из допустимых векторов xf, чтобы установить
(1) условие, заключающееся в том, что допустимый вектор имеет лучшее значение H(xf) глобальной целевой функции, чем текущие наихудшие n1 векторов решения в функции значения глобальной целевой функции, и в этом случае допустимый вектор xf может заменить наихудший вектор;
(2) условие, заключающееся в том, что допустимый вектор имеет большую меру расстояния, чем текущие наихудшие n2 дополнительных векторов.
В любом случае оптимизатор может заменять наихудший вектор допустимым вектором. Если никакой из допустимых векторов xf не удовлетворяет условию (1) или (2), эталонный набор остается тем же самым, то есть корректировка является нулевой корректировкой.
При выполнении операции 360 оптимизатор может определять, не изменился ли эталонный набор в результате выполнения операции 350. Если это произошло, оптимизатор может осуществить еще одну итерацию согласно операциям 320-360. Если опорный набор не изменился, оптимизатор может переходить к операции 365.
При выполнении операции 365 оптимизатор может определять, удовлетворяется ли условие окончания. Если условие окончания не удовлетворяется, оптимизатор может осуществить продолжение с операции 310, чтобы регенерировать эталонный набор с другим набором из n2 различных допустимых векторов. Если условие окончания удовлетворяется, оптимизатор может осуществлять продолжение с операции 370.
Согласно различным осуществлениям предполагаются разные условия окончания. Например, условие окончания может быть условием, при котором
(1) по меньшей мере один вектор решения из эталонного набора имеет лучшее достижимое значение глобальной целевой функции, чем определенный пользователем порог, в то время как удовлетворяется одно или несколько ограничений, касающихся одной или нескольких вспомогательных функций и/или глобальной целевой функции; или
(2) выполняется заданное количество nмакс итераций внешнего цикла (являющихся результатом осуществления операций с 310 по 365); или
(3) проходит заданное время Tмакс вычислений; или
(4) выполняется любое сочетание из (1), (2) и (3).
Максимальное количество nмакс итераций и максимальное время Tмакс вычислений могут быть заданы пользователем.
При выполнении операции 370 оптимизатор может сохранять в базе данных векторы эталонного набора вместе с соответствующими им значениями глобальной целевой функции и значениями вспомогательной функции. Выходным анализатором может осуществляется считывание из базы данных и отображение графического представления значения глобальной целевой функции и значения (значений) вспомогательной функции для каждого из векторов эталонного набора (или в качестве альтернативы для n1 наилучших векторов эталонного набора).
Согласно одному ряду осуществлений процесс 220 оценивания может быть организован для выполнения действий в соответствии с приведенной ниже методикой, показанной на фиг.4. Процесс оценивания может выполняться на серверном компьютере.
При выполнении операции 410 для процесса оценивания из оптимизатора может приниматься вектор x решения.
При выполнении операции 420 модулем конкретизация процесса оценивания могут создаваться NI векторов неопределенности способом, в котором учитываются заданные пользователем функциональные зависимости и корреляционные связи между переменными неопределенности, при этом NI является заданным пользователем целым положительным числом. С помощью NI векторов неопределенности исследуется глобальное пространство неопределенностей. Векторы неопределенности могут быть образованы в соответствии с заданным пользователем способом конкретизации, описанным выше. Каждый вектор Uj неопределенности, j=1, 2,…, NI, имеет конкретизированное значение для каждой из переменных неопределенности в наборе VUN (то есть в наборе всех переменных неопределенности, относящихся к текущей задаче). Каждое конкретизированное значение выбирается из набора достижимых значений соответствующей одной из переменных неопределенности.
При выполнении операции 425 процесса оценивания могут создаваться NI наборов итерационных данных на основании моделей в предвидении NI итераций «внутреннего цикла» для каждого объекта A(k), k=1, 2, …, NA, где NI - количество итераций и NA - количество объектов. Например, в процессе оценивания могут создаваться наборы итерационных данных в соответствии со следующим псевдокодом:
для k от 1 до NA:
для j от 1 до NI:
создается набор IDS(k,j) итерационных данных для алгоритмов объекта A(k) с использованием подвектора x(k) вектора x решения, который соответствует объекту A(k), и подвектора Uj(k) вектора Uj неопределенности, который соответствует объекту A(k);
сохраняется набор IDS(k,j) итерационных данных в буфере IBUFF(k) итераций для объекта A(k);
End For
End For.
Нет необходимости в выполнении команды For Loop (прерывание цикла после выполнения фиксированное число раз) относительно показателя k строго последовательным образом. Например, эта команда For Loop может быть сконфигурирована для выполнения операций многопоточным образом, например, с использованием одного потока на каждое значение k.
Следует напомнить, что системой управления принятием решений пользователю предоставляется возможность построения моделей путем
(1) подчинения наборов структур данных переменным решения;
(2) подчинения наборов структур данных переменным неопределенности;
(3) продвижения значений данных из структур данных в переменные решения; и
(4) продвижения значений данных из структур данных в переменные неопределенности.
Значения подвектора x(k) решения и значения подвектора Uj(k) неопределенности могут быть использованы для определения одной или нескольких структур данных на основании моделей. В частности, одно или несколько значений подвектора x(k) решения и/или одно или несколько значений подвектора Uj(k) неопределенности могут быть использованы для выбора структур данных на основании моделей, в том числе наборов альтернативных структур данных. Кроме того, одно или несколько значений подвектора x(k) решения и/или одно или несколько значений подвектора Uj(k) неопределенности могут быть подставлены в модели, включающие в себя переменные решения и/или переменные неопределенности. Структуры данных, определяемые значениями подвектора x(k) решения и значениями подвектора Uj(k) неопределенности, могут быть включены в набор IDS(k,j) итерационных данных. Набор итерационных данных может включать в себя достаточно данных для выполнения набора алгоритмов, которые определены для объекта A(k). Подвекторы x(k) необязательно должны быть непересекающимися. Например, значения, соответствующие глобальным переменным решения, могут обнаруживаться в более чем одном из подвекторов x(k). Аналогичным образом, подвекторы Uj(k) необязательно должны быть непересекающимися.
При выполнении операции 430 диспетчер процесса оценивания может распределять (то есть посылать) NI наборов итерационных данных для каждого объекта A(k), k=1, 2,…,NA, на один или несколько других компьютеров, где NI - количество итераций, подлежащих выполнению относительно каждого объекта. Например, диспетчер может работать в соответствии со следующим псевдокодом:
для k от 1 до NA:
While (пока выполняется условие), что буфер IBUFF(k) итераций не является пустым:
обнаружение свободного компьютера CP;
считывание одного или нескольких наборов IDS(k,j) итерационных данных из буфера IBUFF(k) итераций;
сжатие одного или нескольких наборов итерационных данных и упаковка сжатых данных в исполняемый файл данных;
передача исполняемого файла в компьютер CP для создания каждого из одного или нескольких наборов итерационных данных на компьютере CP;
EndWhile (окончание при выполнении условия)
EndFor.
Диспетчер может включать копию выполняемого кода для алгоритмов, относящихся к объекту A(k), в исполняемый файл данных в том случае, когда компьютер CP еще не имеет копии этого кода. Кроме того, диспетчер может включать адресацию буфера INB(k) данных, относящихся к объекту A(k), в исполняемый файл данных. Буфер INB(k) данных может быть размещен в запоминающем устройстве серверного компьютера. Компьютер CP выполняет набор алгоритмов, относящихся к объекту A(k), на основании каждого набора IDS(k,j) итерационных данных, включенного в исполняемый файл данных, собирает выходные данные (алгоритмов), полученные в результате выполнения, в соответствующий набор ODS(k,j) выходных данных и передает набор ODS(k,j) выходных данных в буфер INB(k) данных.
Нет необходимости в выполнении команды For Loop относительно показателя k строго последовательным образом. Например, эта команда For Loop может быть сконфигурирована для выполнения операций многопоточным образом, например, с использованием одного потока на каждое значение k.
Кроме того, нет необходимости в выполнении операций 425 и 430 строго последовательным образом. Например, многочисленные цепочки задач по команде For Loop могут быть выполнены многопоточным образом на этапе операции 430 вместе с многочисленными цепочками задач по команде For Loop (относительно показателя k) на этапе операции 425. Согласно одному осуществлению k-й поток диспетчера может быть запущен сразу же после начала образования k-го потока набора итерационных данных. Например, при образовании k-го потока набора итерационных данных k-й поток диспетчера может запускаться после сохранения одного или нескольких наборов итерационных данных в буфере IBUFF(k) итераций.
Серверный компьютер может включать в себя один или несколько процессоров.
При выполнении операции 440 накапливающий сумматор результатов процесса оценивания может сохранять наборы ODS(k,j) выходных данных, образованные другими компьютерами (на которые наборы данных были распределены для выполнения). Набор ODS(k,j) выходных данных представляет собой выходные данные алгоритмов, относящихся к объекту A(k), выполненных на основании набора IDS(k,j) итерационных данных. Согласно одному ряду осуществлений накапливающий сумматор результатов может выполнять операции в соответствии со следующим псевдокодом:
для k от 1 до NA:
j←0;
While (пока выполняется условие) j≤NI
осуществляется прием набора ODS(k,j) выходных данных из буфера INB(k) входных данных;
осуществляется распаковка данных информационного наполнения из набора ODS(k,j) выходных данных;
осуществляется сохранение распакованных данных из набора ODS(k,j) выходных данных в базе данных (то есть в базе данных, снабженной индексами k и j);
j←j+1;
EndWhile (окончание при выполнении условия)
EndFor (команда).
Нет необходимости в выполнении команды For Loop относительно показателя k строго последовательным образом. Например, эта команда For Loop может быть сконфигурирована для выполнения операций многопоточным образом, например, с использованием одного потока на каждое значение k.
Кроме того, нет необходимости в выполнении операций 430 и 440 строго последовательным образом. Например, многочисленные цепочки задач по команде For Loop могут быть выполнены многопоточным образом на этапе операции 440 вместе с многочисленными цепочками задач по команде For Loop на этапе операции 430. Согласно одному осуществлению k-й поток накапливающего сумматора может быть запущен сразу же после начала k-го потока диспетчера. Например, k-й поток диспетчера может запускать k-й поток накапливающего сумматора после получения распределенного первого исполняемого файла данных для объекта A(k).
При выполнении операции 445 вычислителем результатов процесса оценивания для каждого объекта A(k), k=1, 2, …,NA, и для каждой итерации j=1, 2, …,NI может вычисляться значение каждой заданной пользователем величины для объекта с использованием значений выходного аргумента из набора ODS(k,j) выходных данных. Поэтому вычислитель результатов образует совокупность NI значений для каждой заданной пользователем величины.
При выполнении операции 445В вычислителем результатов для каждого объекта A(k), k=1, 2, …,NA, может вычисляться значение каждого заданного пользователем статистического показателя для объекта на основании соответствующей одной из совокупностей.
Операции 445А и 445В совместно именуются операцией 445.
Согласно одному ряду осуществлений вычислитель результатов может быть сконфигурирован для выполнения операции 445 в соответствии со следующим псевдокодом:
для k от 1 до NA:
j←0;
While (пока выполняется условие) j≤NI,
для каждой заданной пользователем величины, относящейся к объекту A(k),
осуществляется считывание значения (значений) из набора ODS(k,j) выходных данных для вычисления значения заданной пользователем величины;
осуществляются вычисление и сохранение значения величины;
EndFor
j←j+1;
EndWhile (окончание при выполнении условия)
для каждого заданного пользователем статистического показателя, относящегося к объекту A(k):
вычисления значения заданного пользователем статистического показателя по NI значениям соответствующей, заданной пользователем величины.
EndFor
EndFor.
Команду For Loop относительно индекса k нет необходимости выполнять поточным образом. Например, эта команда For Loop может быть сконфигурирована для выполнения операций многопоточным образом, например, с использованием одного потока на каждое значение k.
Кроме того, нет необходимости в выполнении операций 440 и 445 строго последовательным образом. Например, многочисленные цепочки задач по команде For Loop могут быть выполнены многопоточным образом на этапе операции 445 вместе с многочисленными цепочками задач по команде For Loop на этапе операции 440. Согласно одному осуществлению k-й поток вычисления результатов может быть запущен сразу же после начала k-го потока суммирования результатов. Например, k-й поток суммирования результатов может запускать k-й поток вычисления результатов после помещения первого из наборов ODS(k,j) выходных данных в базу данных.
При выполнении операции 450 вычислитель глобальных результатов может вычислять
значение S(x) глобальной целевой функции S на основании заданного пользователем первого поднабора из набора GT статистических показателей (то есть объединения статистических показателей из каждого объекта);
значение каждой вспомогательной функции на основании соответствующего, заданного пользователем поднабора из полного набора GT статистических показателей.
Согласно одному ряду осуществлений способ оптимизации решений, касающихся большого количества объектов, может включать в себя следующие операции, показанные на фиг.5.
На этапе операции 510 компьютер (например, серверный компьютер, включающий в себя один или несколько процессоров) может принимать информацию, задающую:
переменные решения и переменные неопределенности для большого количества объектов; и
для каждого объекта соответствующий набор из одного или нескольких алгоритмов.
На этапе операции 515 компьютер может образовывать вектор решения. Вектор решения включает в себя значение для каждой из переменных решения. Каждая из переменных решения имеет относящийся к ней набор достижимых значений.
На этапе операции 520 компьютер может выполнять процесс оценивания относительно вектора решения для определения по меньшей мере значения глобальной целевой функции для вектора решения. См. ниже описание процесса оценивания.
На этапе операции 530 компьютер может выполнять оптимизатор. Выполнение оптимизатора включает в себя многократное осуществление операций 515 и 520, в результате чего образуются большое количество векторов решения и соответствующих значений глобальной целевой функции. Оптимизатор использует большое количество векторов решения и соответствующих значений глобальной целевой функции для образования и многократной корректировки эталонного набора векторов решения, чтобы оптимизировать глобальную целевую функцию.
На этапе операции 540 компьютер может сохранять в запоминающем устройстве (например, в системной памяти компьютера) данные, включающие в себя большое количество векторов решения и соответствующие им значения глобальной целевой функции.
На этапе операции 545 компьютер может отображать графическое представление по меньшей мере поднабора векторов решения из эталонного набора.
Оптимизатор может быть реализован как любой из ряда оптимизаторов, в частности, как стохастический оптимизатор. Например, оптимизатором может быть
(1) оптимизатор поиска с разбросом;
(2) оптимизатор поиска с запретом;
(3) оптимизатор, основанный на метаэвристическом сочетании поиска с разбросом, поиска с запретом, нейронных сетей и линейного программирования; или
(4) оптимизатор, основанный на генетическом алгоритме.
Операция 520 выполнения процесса оценивания может включать в себя следующие операции, показанные на фиг.6.
На этапе операции 520А компьютер может образовывать вектор неопределенности. Вектор неопределенности включает в себя значение для каждой из переменных неопределенности.
На этапе операции 520В компьютер может образовывать для каждого объекта набор данных для соответствующего набора алгоритмов с использованием соответствующего поднабора из одного или нескольких значений в векторе решения и соответствующего поднабора из одного или нескольких значений в векторе неопределенности.
На этапе операции 520С компьютер может инициировать выполнение набора алгоритмов для каждого объекта на основании соответствующего набора данных, чтобы получать выходные аргументы, соответствующие объекту. Компьютер может инициировать выполнение на других компьютерах, например, путем пересылки наборов данных на другие компьютеры (и, при необходимости, выполняемого кода для соответствующих алгоритмов).
На этапе операции 520D компьютер может вычислять для каждого объекта одно или несколько значений одной или нескольких соответствующих величин по выходным аргументам, соответствующим объекту.
На этапе операции 520Е компьютер может выполнять операции, включающие в себя операции с 520А по 520D, несколько раз, в результате чего образуется совокупность значений каждой величины для каждого объекта.
На этапе операции 520F компьютер может вычислять один или несколько статистических показателей для каждого объекта на основании одной из совокупностей.
На этапе операции 520G компьютер может комбинировать первый поднабор статистических показателей для определения значения глобальной целевой функции, соответствующего вектору решения. Комбинирование первого поднабора статистических показателей может быть осуществлено в соответствии с заданной пользователем функциональной комбинацией (например, в соответствии с линейной комбинацией).
Информацией (относящейся к 510 выше) может задаваться одна или несколько функциональных зависимостей между переменными неопределенности. Операция 520А образования вектора неопределенности может быть выполнена способом, в котором учитывается одна или несколько функциональных зависимостей между переменными неопределенности. Пользователь может задавать функциональные зависимости, например, через клиентский графический интерфейс пользователя, который реализуется на другом компьютере (например, на клиентском компьютере).
Информацией также может задаваться одна или несколько корреляционных связей между переменными неопределенности. В этом случае операция 520А образования вектора неопределенности может быть выполнена способом, в котором учитываются указанные корреляционные связи. Переменные неопределенности могут составлять два или более поднаборов, относящихся соответственно к двум или более объектам. Корреляционные связи могут включать в себя корреляционные связи между переменными неопределенности по различным объектам.
Информацией также может задаваться одно или несколько ограничений на переменные решения. В этом случае операция 515 образования вектора решения может выполняться с учетом одного или нескольких ограничений на переменные решения.
Операция 520 выполнения процесса оценивания относительно вектора решения может обеспечить получение соответствующего значение вспомогательной функции в дополнение к указанному значению глобальной целевой функции. Поэтому операция 520 может дополнительно включать в себя
операцию (520Н) комбинирования второго поднабора статистических показателей для определения значения вспомогательной функции, соответствующего вектору решения.
Оптимизатор может использовать значения глобальной целевой функции и значения вспомогательной функции, соответствующие большому количеству векторов решения, при указанной многократной корректировке эталонного набора, чтобы оптимизировать целевую функцию, подчиненную одному или нескольким ограничениям.
Пользователь может задавать структуру одного или нескольких ограничений. Например, пользователь может задавать ограничение на функциональную комбинацию вспомогательной функции и глобальной целевой функции. (Сама функциональная комбинация может быть задана пользователем.) В качестве другого примера, пользователь может задавать ограничение только на вспомогательную функцию. Операция 520Н может включать в себя комбинирование второго поднабора статистических показателей в соответствии с линейной комбинацией, коэффициенты которой заданы с помощью указанной информации.
Каждая из переменных решения имеет относящееся к ней множество достижимых значений, представляющих возможные результаты соответствующего решения. Кроме того, каждая из переменных неопределенности имеет относящееся к ней множество достижимых значений. Множества достижимых значений могут быть конечными множествами числовых значений, структурами данных, программами и т.д. Множества достижимых значений также могут быть интервалами числовой линии или, в более общем случае, заданными пользователем областями в n-мерном пространстве, где n - целое положительное число.
Согласно одному осуществлению график зависимости значения глобальной целевой функции от значения вспомогательной функции для каждого из указанного большого количества векторов решения может быть отображен с использованием дисплейного устройства (такого как монитор, проектор, головной дисплей и т.д.).
Операция 540 сохранения данных может включать в себя сохранение большого количества векторов решения вместе с соответствующими им значениями глобальной целевой функции и соответствующими значениями вспомогательной функции в базе данных в запоминающем устройстве.
Согласно некоторым осуществлениям компьютер может
производить операции над базой данных для идентификации поднабора из большого количества векторов решения, которые имеют оптимальные значения глобальной целевой функции для определенного значения вспомогательной функции;
повторять указанные операции для большого количества значений вспомогательной функции; и
сохранять поднаборы, идентифицированные при указанном повторении.
Кроме того, компьютер также может
производить операции над базой данных для определения геометрического места оптимальных значений глобальной целевой функции с учетом значения вспомогательной функции; и
отображать геометрическое место оптимальных значений.
Графическое представление поднабора из большого количества векторов решения, которое соответствует точке на геометрическом месте оптимальных значений, может быть отображено в ответ на выбор точки пользователем.
Пользователь может задавать большое количество объектов, переменные решения и переменные неопределенности для каждого объекта и набор из одного или нескольких алгоритмов для каждого объекта. Переменными решения являются переменные, которые подвергаются оптимизации.
Переменные неопределенности могут быть исследованы случайным образом (или по псевдослучайным образом) для создания вариации во входных данных, поступающих в алгоритмы для каждого объекта.
Набор из одного или нескольких алгоритмов для по меньшей мере одного из объектов может включать в себя алгоритм для оценивания добычи нефти и газа в динамике во времени и экономических показателей для объекта. Алгоритмом для оценивания добычи нефти и газа в динамике во времени может быть
имитатор материального баланса, который оперирует со структурой данных резервуарной модели;
вычисление материального баланса, выполняемое в электронно-табличных моделях;
имитатор движения флюидов в коллекторе, который оперирует с трехмерной структурой данных;
алгоритм, задаваемый набором из одного или нескольких заданных пользователем алгебраических выражений.
Кроме того, набор из одного или нескольких алгоритмов для по меньшей мере одного из объектов может включать в себя один или несколько из
алгоритма для оценивания транспортировки нефти и газа на поверхности, например имитатора процесса в сети наземных трубопроводов,
алгоритма для оценивания транспортировки нефти, газа и воды на поверхности, например, аналитической модели сети наземных трубопроводов или набора из одного или нескольких заданных пользователем алгебраических выражений, и
алгоритма для оценивания объема нефти и газа и трехмерных свойств коллектора.
Алгоритм для оценивания объема нефти и газа и трехмерных свойств коллектора может быть реализован в виде
геостатистического алгоритма формирования свойств геологической среды, определяемого с помощью набора из одного или нескольких заданных пользователем алгебраических выражений; или
имитатора материального баланса.
Алгоритм для вычисления экономических показателей объекта может быть реализован в виде
алгоритмов, основанных на электронных таблицах, которые могут включать в себя полные фискальные модели и модели долевого распределения добычи;
алгоритмов, основанных на аналитических экономических моделях и наборе из одного или нескольких заданных пользователем алгебраических выражений.
Согласно другому ряду осуществлений способ оптимизации решений, относящихся к большому количеству объектов, осуществляемый путем выполнения программного кода на первом компьютере (например, на серверном компьютере), может включать в себя следующие операции, показанные на фиг.7.
На этапе операции 710 первый компьютер (например, серверный компьютер, включающий в себя один или несколько процессоров) может принимать информацию, задающую переменные решения и переменные неопределенности для большого количества объектов и задающую для каждого объекта соответствующий набор из одного или нескольких алгоритмов.
На этапе операции 720 первый компьютер может создавать вектор решения, при этом вектор решения включает в себя значение для каждой из переменных решения.
На этапе операции 730 первый компьютер может выполнять процесс относительно вектора решения, чтобы определять по меньшей мере значения глобальной целевой функции для вектора решения.
На этапе операции 740 первый компьютер может выполнять оптимизатор, при этом указанное выполнение оптимизатора включает в себя многократное выполнение действий 720 и 730, в результате чего образуется большое количество векторов решения и соответствующих значений глобальной целевой функции, а оптимизатор использует большое количество векторов решения и соответствующих значений глобальной целевой функции для образования и многократной корректировки эталонного набора векторов решений, чтобы оптимизировать глобальную целевую функцию.
На этапе операции 750 первый компьютер может сохранять в запоминающем устройстве данные, включающие в себя большое количество векторов решения и соответствующих им значений глобальной целевой функции.
Операция 730 по выполнению процесса оценивания может включать в себя следующие операции, показанные на фиг.8.
На этапе операции 730А первый компьютер может образовывать NI векторов неопределенности, при этом каждый вектор неопределенности содержит конкретизированные значения для каждой из переменных неопределенности, где NI - целое положительное число.
На этапе операции 730В первый компьютер может образовывать NI наборов итерационных данных для каждого объекта, при этом каждый из наборов итерационных данных образуется с использованием части вектора решения и части соответствующего одного из векторов неопределенности.
На этапе операции 730С первый компьютер может распределять NI наборов итерационных данных для каждого объекта на один или несколько вторичных компьютеров для инициирования выполнения набора алгоритмов для объекта на основании каждого из соответствующих NI наборов итерационных данных, где при каждом выполнении набора алгоритмов для объекта на основании набора итерационных данных образуется соответствующий набор выходных данных.
На этапе операции 730D первый компьютер может принимать NI наборов выходных данных для каждого из объектов от одного или нескольких вторичных компьютеров и сохранять в запоминающем устройстве NI наборов выходных данных.
На этапе операции 730Е первый компьютер может вычислять для каждого объекта и каждого из NI наборов выходных данных, соответствующих объекту, одно или несколько значений для одной или нескольких соответствующих величин по данным в наборе выходных данных, в результате чего образуется совокупность NI значений каждой величины для каждого объекта.
На этапе операции 730F первый компьютер может вычислять один или несколько статистических показателей для каждого объекта на основании соответствующей одной из совокупностей.
На этапе операции 730G первый компьютер может осуществлять комбинирование первого поднабора статистических показателей для определения значения глобальной целевой функции, соответствующего вектору решения.
Первый компьютер и один или несколько вторичных компьютеров могут быть связаны с помощью компьютерной сети, например локальной вычислительной сети, интрасети, глобальной сети, Интернета и т.д.
При осуществлении операции распределения наборов итерационных данных инициируется распределенное выполнение на большом количестве вторичных компьютеров наборов алгоритмов на основании наборов итерационных данных. Вторичные компьютеры могут быть объединены в мегакомпьютерную сетевую структуру.
Согласно одному осуществлению в зависимости от имеющейся производительности системы обработки на первом компьютере поднабор из наборов итерационных данных может быть выполнен локально первым компьютером.
Информация может быть получена от пользователя при выполнении процесса на клиентском компьютере и передана на первый компьютер в соответствии с этим процессом.
Согласно еще одному ряду осуществлений способ оптимизации решений, касающихся большого количества объектов, может включать в себя следующие операции, показанные на фиг.9.
На этапе операции 910 компьютер (например, серверный компьютер, включающий в себя один или несколько процессоров) может принимать информацию, задающую большое количество объектов, объектную целевую функцию для каждого из объектов и набор алгоритмов для каждого объекта.
На этапе операции 920 компьютер может создавать вектор решения, включающий в себя значения для набора переменных решения.
На этапе операции 930 компьютер может создавать NI векторов неопределенности, при этом каждый из NI векторов неопределенности является следствием отдельной конкретизации набора переменных неопределенности, где NI - положительное целое число.
На этапе операции 940 компьютер может вычислять первую совокупность NI значений для каждой целевой функции объекта путем осуществления NI итераций выполнения соответствующего набора алгоритмов и оперирования с выходными данными, создаваемыми на каждой из NI итераций указанного выполнения, и при каждом выполнении соответствующего набора алгоритмов производятся действия над набором входным данных, определенным с помощью значений переменных решения и соответствующего одного из векторов неопределенности.
На этапе операции 950 компьютер может вычислять первый статистический показатель объекта по каждой целевой функции объекта на основании соответствующей совокупности значений.
На этапе операции 960 компьютер может вычислять значение глобальной целевой функции на основании первого статистического показателя объекта.
На этапе операции 970 компьютер может выполнять оптимизатор, при этом выполнение оптимизатора включает в себя многократное осуществление операций с 920 по 960, в результате чего образуется большое количество векторов решения и соответствующих значений глобальной целевой функции, и при этом оптимизатор использует большое количество векторов решения и соответствующих значений глобальной целевой функции для образования и многократной корректировки эталонного набора векторов решения, чтобы оптимизировать глобальную целевую функцию.
Согласно некоторым осуществлениям компьютер может
вычислять второй статистический показатель для каждого объекта по соответствующей одной из совокупностей; и
вычислять значение вспомогательной функции на основании второго статистического показателя объекта.
При выполнении оптимизатора может осуществляться попытка оптимизации (то есть максимизации или минимизации) глобальной целевой функции, подчиненной ограничению, наложенному на одну или несколько функций из вспомогательных функций и глобальной целевой функции.
Согласно ряду осуществлений способ анализа влияния неопределенностей, относящихся к группе объектов, может включать в себя следующие действия, показанные на фиг.10. Способ может быть реализован компьютером (например, компьютером, включающим в себя один или несколько процессоров) или группой компьютеров.
На этапе 1010 компьютер может принимать информацию, задающую набор переменных неопределенности для множества объектов и задающую функциональную зависимость между первой и второй переменными неопределенности. Первая переменная неопределенности может быть связана с первым из объектов. Вторая переменная неопределенности может быть связана со вторым из объектов. Информация может быть введена пользователем через графический интерфейс пользователя, например, интерфейс системы управления принятием решений или построителя потока решений, описанный выше.
На этапе 1012 компьютер может образовывать значения для каждой из переменных неопределенности. Конкретизация переменных любым из многочисленных методов, описанных различным образом в настоящей заявке, может быть использована для образования значений переменных неопределенности. Метод конкретизации может быть выбран пользователем.
Процесс образования значений для переменных неопределенности может включать в себя образование значения для первой переменной неопределенности и вычисление значения для второй переменной неопределенности по значению первой переменной неопределенности на основании функциональной зависимости. Поэтому первая переменная неопределенности считается зависимой от второй переменной неопределенности. Как описано выше, согласно различным осуществлениям, может быть установлено любое количество таких зависимостей между переменными неопределенности. Зависимости могут быть установлены в пределах объектов, а также по объекту.
На этапе 1014 компьютер может определять для каждого из объектов соответствующий набор входных данных путем использования по меньшей мере соответствующего подмножества значений переменных неопределенности. Процесс определения наборов входных данных может включать в себя
определение первого набора входных данных, соответствующего первому объекту, с использованием по меньшей мере значения первой переменной неопределенности; и
определение второго набора входных данных, соответствующего второму объекту, с использованием по меньшей мере значения второй переменной неопределенности.
Различные примеры определения наборов входных данных с использованием значений переменных неопределенности приведены выше в различных осуществлениях. Например, значение переменной неопределенности может быть подставлено в набор входных данных или может быть использовано для управления выбором структуры данных, которая должна быть подставлена в набор входных данных.
На этапе 1016 для каждого из объектов компьютер может инициировать выполнение соответствующего набора из одного или нескольких алгоритмов. Каждый набор из одного или нескольких алгоритмов может работать на основании соответствующего набора входных данных для образования соответствующего набора выходных данных.
На этапе 1018 компьютер может выполнять 1012, 1014 и 1016 много раз для образования большого количества наборов выходных данных для каждого объекта. Наборы выходных данных могут быть сохранены в запоминающей среде для, например, последующего просмотра и/или анализа. Согласно одному осуществлению запоминающей средой может быть жесткий диск.
На этапе 1020 компьютер может вычислять один или несколько статистических показателей для каждого из объектов на основании соответствующего большого количества наборов выходных данных. Статистические показатели могут быть заданы пользователем. См. различные примеры статистических показателей, заданных в различных осуществлениях, описанных выше, например, в осуществлениях, описанных в сочетании с фиг.4, 6, 8 и 9. Статистические показатели также могут быть сохранены в запоминающей среде.
На этапе 1022 компьютер может образовывать итоговые данные, основанные по меньшей мере частично на статистических показателях объектов. Например, итоговые данные могут включать в себя функциональную комбинацию статистических показателей большого количества объектов, например заданную пользователем функциональную комбинацию.
На этапе 1024 компьютер может отображать картину итоговых данных на дисплейном устройстве.
Согласно некоторым осуществлениям объекты могут быть объектами, относящиеся к разведке или добыче одного или более из нефти и газа. Например, объекты могут включать в себя группы нефтегазовых месторождений.
Набор из одного или нескольких алгоритмов для каждого объекта может быть выбран пользователем. Алгоритмы могут быть выбраны из большого разнообразия поддерживаемых алгоритмов. См. различные примеры алгоритмов, описанные выше.
Согласно одному осуществлению процесс 1016 инициирования выполнения может включать в себя
распределение наборов входных данных объектов к одному или нескольким удаленным компьютерам для удаленного выполнения соответствующих наборов алгоритмов; и
прием наборов выходных данных от одного или нескольких удаленных компьютеров.
См. примеры, описанные выше, в особенности примеры диспетчера, описанные выше.
Информацией, принятой на этапе 1010, может также задаваться одна или несколько корреляционных связей между переменными неопределенности. В этом случае в процессе 1012 образования значений для каждой из переменных неопределенности учитывается одна или несколько заданных корреляционных связей. Корреляционные связи могут включать в себя корреляционные связи между переменными неопределенности в пределах объектов или по различным объектам. Как описано выше, также предполагаются корреляционные связи между тремя или более переменными неопределенности.
Согласно некоторым осуществлениям процесс 1014 определения наборов входных данных для объектов может включать в себя выбор одной из двух или более моделей для встраивания в один из наборов входных данных на основании значения третьей из переменных неопределенности. Вспомним из рассмотрения, приведенного выше, что модели могут быть подчинены переменным неопределенности. Переменными неопределенности осуществляется управление выбором одной из подчиненных моделей.
Согласно одному осуществлению процесс 1014 может включать в себя
выбор одной из двух или более моделей на основании значения третьей из переменных неопределенности; и
выбор одной из двух или более подмоделей выбранной модели на основании значения четвертой из переменных неопределенности.
Выбранная подмодель является пригодной для определения данных, подлежащих включению в один (или несколько) набор входных данных.
В более общем случае, модель может представлять собой иерархическое дерево моделей, имеющее соответствующие переменные неопределенности. Пользователь может создавать такие иерархические модели с любым желаемым количеством уровней. Структура данных может быть образована путем
прохождения дерева от верха до низа на основании значений одной или нескольких переменных неопределенности; и
присоединения данных, включенных в каждый узел вдоль пройденного пути.
На каждой стадии прохождения соответствующим значением переменной неопределенности задается, какой узел-потомок должен быть выбран. Для примера, на фиг.11 показана иерархическая модель, имеющая два уровня выбора. Переменная X неопределенности управляет первым выбором файла 1 или {файла 2, параметра 3} с вероятностями 0,6 и 0,4 соответственно. Вторая переменная Y неопределенности управляет вторым выбором параметра 1 или параметра 2 с вероятностями 0,2 и 0,8 соответственно. Файл 1 и файл 2 представляют собой файлы данных, а параметр 1, параметр 2 и параметр 3 представляют собой значения параметров.
Согласно некоторым осуществлениям способ может дополнительно включать в себя
(1) прием информации, задающей множество переменных решения;
(2) образование значений для переменных решения, при этом значения переменных решения используются для определения наборов входных данных для объектов;
(3) вычисление значения глобальной целевой функции по одному или нескольким статистическим показателям каждого из объектов; и
выполнение оптимизатора для определения одного или нескольких множеств значений для переменных решения.
Процесс выполнения оптимизатора может включать в себя выполнение по меньшей мере операций (2), 1018, 1020 и (3) несколько раз, при этом оптимизатор конфигурируют для поиска максимума или минимума глобальной целевой функции на протяжении по меньшей мере части пространства, заданного переменными решения. Для детализации примеров (1), (2), (3) и указанного выполнения оптимизатора можно обратиться к осуществлениям способа, описанным выше в сочетании с фиг.2-9.
Оптимизатор может быть выбираемым пользователем из набора поддерживаемых оптимизаторов.
Процесс 1024 отображения картины итоговых данных может включать в себя отображение графического представления по меньшей мере подмножества из одного или нескольких множеств значений для переменных решения. Графическое представление может включать в себя график, карту, таблицу, перечень, изображение, снабженное символьными маркерами и т.д.
Информацией, принятой в (1), может также задаваться одно или несколько ограничений на переменные решения. В этом случае при образовании значений для переменных решения учитывается одно или несколько ограничений. Ограничения, например, описанные выше, могут быть заданы пользователем. Ограничения могут включать в себя линейные и/или нелинейные ограничения.
Информацией, принятой в (1), может также задаваться одна или несколько функциональных зависимостей между переменными решения. В этом случае при образовании значений для переменных решения учитывается одна или несколько функциональных зависимостей между переменными решения. Функциональные зависимости, например, описанные выше, могут быть заданы пользователем.
Каждая из переменных решения имеет соответствующее множество достижимых значений, представляющее возможные результаты соответствующего решения. Кроме того, каждая из переменных неопределенности имеет относящееся к ней множество достижимых значений. Множества достижимых значений могут быть конечными множествами или множествами, имеющими бесконечную мощность.
Согласно одному осуществлению способ может также включать в себя
(4) вычисление значения вспомогательной функции по одному или нескольким статистическим показателям каждого из объектов.
В этом случае процесс выполнения оптимизатора может включать в себя выполнение (2), 1018, 1020, (3) и (4) несколько раз. Оптимизатор может быть сконфигурирован для поиска максимума или минимума глобальной целевой функции, подчиняющейся по меньшей мере ограничению на функциональную комбинацию глобальной целевой функции и вспомогательной функции. Функциональная комбинация может быть задана пользователем. См. примеры вспомогательной функции и функциональной комбинации, приведенные в различных осуществлениях выше.
Процесс 1024 отображения картины итоговых данных на дисплейном устройстве может включать в себя отображение графика зависимости значения глобальной целевой функции от значения вспомогательной функции.
Согласно еще одному ряду осуществлений способ оптимизации решений, касающихся разведки, разработки нефтегазовых месторождений и добычи из них, может включать в себя следующие действия, показанные на фиг.12А.
На этапе 1210 могут быть приняты входные данные пользователя, задающие два или более алгоритмов и задающие одну или несколько связей между двумя или более алгоритмами. Каждая из связей представляет собой связь между выходными данными одного из алгоритмов и входными данными другого из алгоритмов. Пользователь может использовать графический интерфейс пользователя (например, графический интерфейс пользователя построителя потоков или построителя потока решений, описанный различным образом выше).
На этапе 1212 могут быть приняты входные данные пользователя, задающие одну или несколько структур данных, согласованных с двумя или более алгоритмами. См. различные примеры, приведенные выше.
Чтобы осуществить построение одной или нескольких моделей для двух или более алгоритмов, на этапе 1214 могут быть произведены действия над одной или несколькими структурами данных в ответ на входные данные пользователя. Одна или несколько моделей могут включать в себя одну или несколько переменных неопределенности и одну или несколько переменных решения. Процесс построения моделей на основании структур данных может включать в себя, как описано выше, продвижение значений данных из структур данных в переменные неопределенности и подчинение двух или более структур данных переменной неопределенности.
На этапе 1216 могут быть приняты входные данные пользователя, задающие один или несколько статистических показателей, подлежащих вычислению на основании выходных данных одного или нескольких алгоритмов. См. различные примеры статистических показателей, приведенные выше.
Чтобы найти глобальную целевую функцию, на этапе 1218 могут быть приняты входные данные пользователя, задающие функциональную комбинацию статистических показателей. Предполагается любая из различных функциональных комбинаций, включая линейные и нелинейные комбинации.
На этапе 1220 могут быть приняты входные данные пользователя, задающие оптимизатор. Оптимизатор может быть выбран из поддерживаемого набора оптимизаторов. Согласно одному осуществлению программный код для оптимизатора может быть без труда добавлен пользователем к поддерживаемому набору.
Чтобы отыскать оптимум глобальной целевой функции, на этапе 1222 может быть выполнена оптимизация с использованием заданного пользователем оптимизатора. Например, оптимизация может быть выполнена так, как описано выше, в сочетании с фиг.2-9.
Согласно некоторым осуществлениям процессы 1216 и 1218 могут быть пропущены.
Согласно некоторым осуществлениям способ может также включать в себя отображение графического представления хода оптимизации, описанной различным образом выше. Например, способ может включать в себя одно или несколько из
отображения графика зависимости целевой функции от индекса внешней итерации (то есть индекса цикла оптимизации);
отображения графика зависимости значения целевой функции от значения вспомогательной функции, включающего в себя точки, представляющие итерации внешнего цикла (то есть цикла оптимизации);
отображения графика зависимости целевой функции от функциональной комбинации целевой функции и вспомогательной функции, при этом график включает в себя точки, представляющие итерации внешнего цикла;
отображения графика геометрического места оптимальных значений, описанного выше; и
отображения графического представления значений переменных решения, образуемых при оптимизации.
Процесс выполнения оптимизации может включать в себя следующие действия, показанные на фиг.12В.
На этапе 1230 может быть образовано одно или несколько значений одной или нескольких переменных решения соответственно. Например, см. рассмотрение, приведенное выше, относительно образования векторов решения по набору переменных решения.
На этапе 1232 может быть инициировано большое количество выполнений двух или более алгоритмов в соответствии с одной или несколькими связями. Каждое из выполнений может производится на основании соответствующего набора из одной или нескольких конкретизированных моделей, определенных с помощью одной или нескольких моделей, одного или нескольких значений переменной решения и соответствующего набора из одного или нескольких конкретизированных значений одной или нескольких переменных неопределенности. За детализацией примеров инициирования множества выполнений можно обратиться к сделанному выше описанию, относящемуся к действиям с 410 по 445А из фиг.4, сделанному выше описанию, относящемуся к действиям с 520А по 520Е из фиг.6, сделанному выше описанию, относящемуся к действиям с 730А по 730Е из фиг.8, и сделанному выше описанию, относящемуся к действиям 930 и 940 из фиг.9.
На этапе 1234 статистические показатели могут быть вычислены на основании выходных данных, полученных в результате множества выполнений.
На этапе 1236 значение глобальной целевой функции может быть вычислено по статистическим показателям в соответствии с заданной пользователем функциональной комбинацией.
На этапе 1230 процессы этапов с 1230 по 1238 могут быть повторены несколько раз, например, до тех пор, пока не будет удовлетворяться условие окончания. См. различные примеры условия окончания, приведенные выше.
Согласно некоторым осуществлениям процессы с 1210 по 1220 могут быть выполнены на клиентском компьютере, а процесс 1222 может быть выполнен на серверном компьютере. Поэтому способ может также включать передачу на серверный компьютер информации, задающей два или более алгоритмов, информации, задающей одну или несколько связей, информации, задающей один или несколько статистических показателей, информации, задающей оптимизатор, и информации, задающей глобальную целевую функцию.
Согласно некоторым осуществлениям серверный компьютер может выполнять процесс 1222 путем
(1) образования множества из одного или нескольких конкретизированных значений одной или нескольких переменных неопределенности;
(2) определения одной или нескольких конкретизированных моделей на основании одной или нескольких моделей и множества из одного или нескольких конкретизированных значений;
(3) передачи одной или нескольких конкретизированных моделей на удаленный компьютер, при этом удаленный компьютер осуществляет одно из большого количества выполнений двух или более алгоритмов на основании одной или нескольких конкретизированных моделей; и
повторения с (1) по (3) для распределения большого количества выполнений по группе из одного или нескольких удаленных компьютеров.
Согласно одному осуществлению способ может также включать в себя прием входных данных пользователя, задающих метод конкретизации, описанный выше. Методом конкретизации определяется, каким образом конкретизированные переменные образуются на основании переменных неопределенности.
Согласно одному осуществлению способ может также включать прием данных пользователя, задающих диспетчер. Диспетчер представляет собой программу, которая управляет процессом инициализации большого количества выполнений двух или более алгоритмов в группе удаленных компьютеров. Для реализации указанного повторения с (1) по (3) диспетчер может выполняться на сервере. Согласно одному осуществлению программный код для новых диспетчеров может быть включен пользователем в систему управления принятием решений.
Кроме того, способ может включать в себя
прием входных данных пользователя, задающих одну или несколько вспомогательных функций, при этом каждая вспомогательная функция соответствует функциональной комбинации соответствующего поднабора статистических показателей; и
прием входных данных пользователя, задающих одно или несколько ограничений на одну или несколько вспомогательных функций и глобальную целевую функцию.
В процессе выполнения оптимизации осуществляется учет одного или нескольких ограничений на одну или несколько вспомогательных функций и глобальную целевую функцию.
Один или несколько алгоритмов могут включать в себя алгоритмы, которыми моделируются процессы, относящиеся к разведке, разработке или добыче нефти или газа. Например, один или несколько алгоритмов могут включать в себя алгоритмы, которыми моделируются процессы, относящиеся к одному или нескольким месторождениям, таким как разведочные месторождения, вскрытые месторождения и эксплуатируемые месторождения.
Согласно одному осуществлению способ может также включать в себя прием входных данных пользователя, задающих функциональные зависимости между переменными неопределенности, например, описанные выше. В процессе образования конкретизированных значений для переменных неопределенности учитываются функциональные зависимости между переменными неопределенности.
Согласно одному осуществлению способ может также включать в себя прием входных данных пользователя, задающих функциональные зависимости между переменными решения, например, описанные выше. В процессе образования значений переменных решения учитываются функциональные зависимости между переменными решения.
Согласно одному осуществлению пользователь может задавать корреляционные связи между переменными неопределенности, например, описанные выше. В процессе образования конкретизированных значений переменных неопределенности учитываются заданные пользователем корреляционные связи.
Согласно одному осуществлению могут быть приняты входные данные пользователя, задающие вычисления, подлежащие выполнению на промежуточной стадии между выводом данных из одного или нескольких алгоритмов и вводом данных в другой алгоритм. (Эти входные данные пользователя могут быть частью входных данных пользователя, принимаемых на этапе 1210.) Программный код, описывающий вычисления, может быть встроен в алгоритм вычислителя. См. рассмотрение, приведенное выше, касающееся вычислителя результатов и интерфейса вычислителя результатов. Два или более алгоритмов из этапа 1210 могут включать в себя один или несколько таких алгоритмов вычислителя.
Фиг.13 - структурная схема компьютерной системы
На фиг.13 представлена структурная схема, отображающая компьютерную систему 1300 согласно одному ряду осуществлений, которая может выполнять функции серверного компьютера или клиентского компьютера, как это было ранее описано различным образом в настоящей заявке, или компьютера, рассмотренного выше в сочетании с фиг.10.
Компьютерная система 1300 может включать в себя по меньшей мере один блок 1360 центрального процессора (то есть процессор), который соединен с главной шиной 1362. Блок 1360 центрального процессора может быть любого из различных типов, включая, но без ограничения ими, процессор x86, процессор PowerPC, блок центрального процессора из семейства SPARC (с масштабируемой архитектурой процессора) процессоров RISC (с упрощенным набором команд), а также и другие. Запоминающая среда, обычно включающая в себя полупроводниковое оперативное запоминающее устройство и называемая в настоящей заявке основной памятью 1366, может быть связана с главной шиной 1362 через посредство контроллера 1364 памяти. В основной памяти 1366 могут храниться программы, выполняемые для реализации любого или всех или любой подгруппы различных способов согласно осуществлениям, описанным в настоящей заявке. В основной памяти также может храниться программное обеспечение операционной системы, а также другое программное обеспечение для работы компьютерной системы.
Главная шина 1362 может быть связана с шиной 1370 расширения или ввода/вывода через шинный контроллер 1368 или шинную мостовую логику. Шина 1370 расширения может включать в себя слоты для различных устройств, таких как видеокарта 1380, жесткий диск 1382, устройства 1390 хранения информации (такие как дисковод для компакт-дисков, ленточный накопитель, накопитель на гибких дисках и т.д.) и сетевой интерфейс 1322. Видеокарту 1380 можно соединять с дисплейным устройством, таким как монитор, проекционный аппарат или головной дисплей. Сетевой интерфейс 1322 (например, устройство сети Ethernet) может быть использован для связи с другими компьютерами через сеть.
Компьютерная система 1300 может также включать в себя устройства 1392 ввода-вывода, такие как мышь, клавиатура, громкоговорители.
Компьютерная система 1300 согласно вариантам осуществления, нацеленная на использование в качестве серверного компьютера, может быть усилена за счет более высокой производительности процессора (например, могут иметься несколько процессоров) большей емкости запоминающего устройства и большей пропускной способности доступа к сети, чем компьютерная система согласно вариантам осуществления, нацеленная на использование в качестве клиентского компьютера. Клиентский компьютер может включать в себя мышь, клавиатуру, громкоговорители и видеокарту (или графический ускоритель), тогда как нет необходимости в том, чтобы серверный компьютер включал в себя эти предметы.
Любой способ (или часть его) согласно осуществлениям, описанным в настоящей заявке, может быть реализован на основе программных команд. Программные команды могут храниться на считываемой компьютером запоминающей среде. Программные команды могут считываться и выполняться (компьютером или группой компьютеров) для реализации способа (или части его) согласно осуществлениям.
Терминология
В настоящей заявке использованы следующие термины.
Алгоритм:
Алгоритм представляет собой вычислительный метод.
Аргумент:
Входные данные и выходные данные алгоритма именуются аргументами. Аргумент может быть входными данными для алгоритма, или выходными данными от алгоритма, или как входными, так и выходными данными. Каждый аргумент может иметь уникальное имя (относящееся к алгоритму, для которого он определен) и также конкретный тип объекта, который он может нести (например, функцию, преобразующую целое число в эквивалентное число с плавающей запятой, целое число, строку и т.д.).
Карта аргументов:
Библиотека аргументов, принадлежащих к алгоритму, именуется картой аргументов.
Цикл:
Цикл используется для выполнения алгоритма несколько раз (однако, как отмечалось выше, необязательно последовательно). Цикл может быть может быть образован из итератора алгоритма, алгоритма и необязательного диспетчера (то есть механизма для распределения итераций алгоритма). Построителем потоков пользователю предоставляется возможность выбора различных итераторов алгоритма для использования в цикле и выбора различных диспетчеров для использования в цикле. Цикл сам представляет собой алгоритм. Карта аргументов цикла может быть определена как комбинация карты аргументов итератора алгоритма и карты аргументов алгоритма.
Запоминающая среда:
Запоминающая среда представляет собой среду, сконфигурированную для хранения информации. Примеры запоминающих сред включают в себя магнитные среды различных видов (например, магнитную ленту или магнитный диск); оптические среды различных видов (например, компакт-диск, доступный только для чтения); полупроводниковые оперативные запоминающие устройства и постоянные запоминающие устройства различных видов; различные среды, основанные на сохранении электрического заряда или других физических величин; и т.д.
Итератор алгоритма:
Итератор алгоритма используется для получения наборов итерационных данных, предназначенных для соответствующего алгоритма в пределах цикла. Итератор алгоритма может иметь пару карт аргументов. Действие одной карты аргументов проявляется в пределах и вне цикла, и она используется в качестве входных данных и выходных данных итератора алгоритма. Вторая карта аргументов используется для связи с соответствующим алгоритмом в пределах цикла.
Диспетчер:
Диспетчер используется для распределения итераций соответствующего алгоритма.
Алгоритм сценария:
Алгоритмом сценария представляется сценарий (такой как сценарий Jython или сценарий Perl), встроенный в алгоритм. Входные аргументы алгоритма могут быть привнесены в сценарий, а выходные аргументы сценария могут быть выходными аргументами алгоритма.
Алгоритм процесса:
Алгоритмом процесса представляется внешний процесс, который встраивается в алгоритм. Алгоритмы процесса могут включать в себя алгоритмы имитации процесса и алгоритмы оптимизации. Алгоритм имитации процесса осуществляет моделирование физической системы, обычно на основе одной или нескольких моделей, задаваемых в виде входных данных. Одним примером алгоритма моделирования процесса является имитатор движения флюидов через пористые среды, именуемый имитатором коллектора.
Поток:
Поток представляет собой набор взаимосвязанных алгоритмов. Для связи выходного аргумента одного алгоритма с входным аргументом второго алгоритма построитель потоков может потребовать приведения в соответствие имени и типа аргумента. Например, выходные данные INT (точные числовые данные) могут быть переданы во входные данные FLOAT (приближенные числовые данные). Однако передача выходных данных STRING (строка) во входные данные INT может быть запрещена. Графический интерфейс пользователя может быть предусмотрен для обеспечения возможности связи различных алгоритмов вручную. После того как поток создан, при желании он может быть преобразован в алгоритм.
Хотя выше осуществления были описаны очень подробно, многочисленные изменения и модификации станут очевидными для специалистов в данной области техники после полного понимания приведенного выше раскрытия. Предполагается, что нижеследующая формула изобретения будет интерпретироваться с охватом всех таких изменений и модификаций.


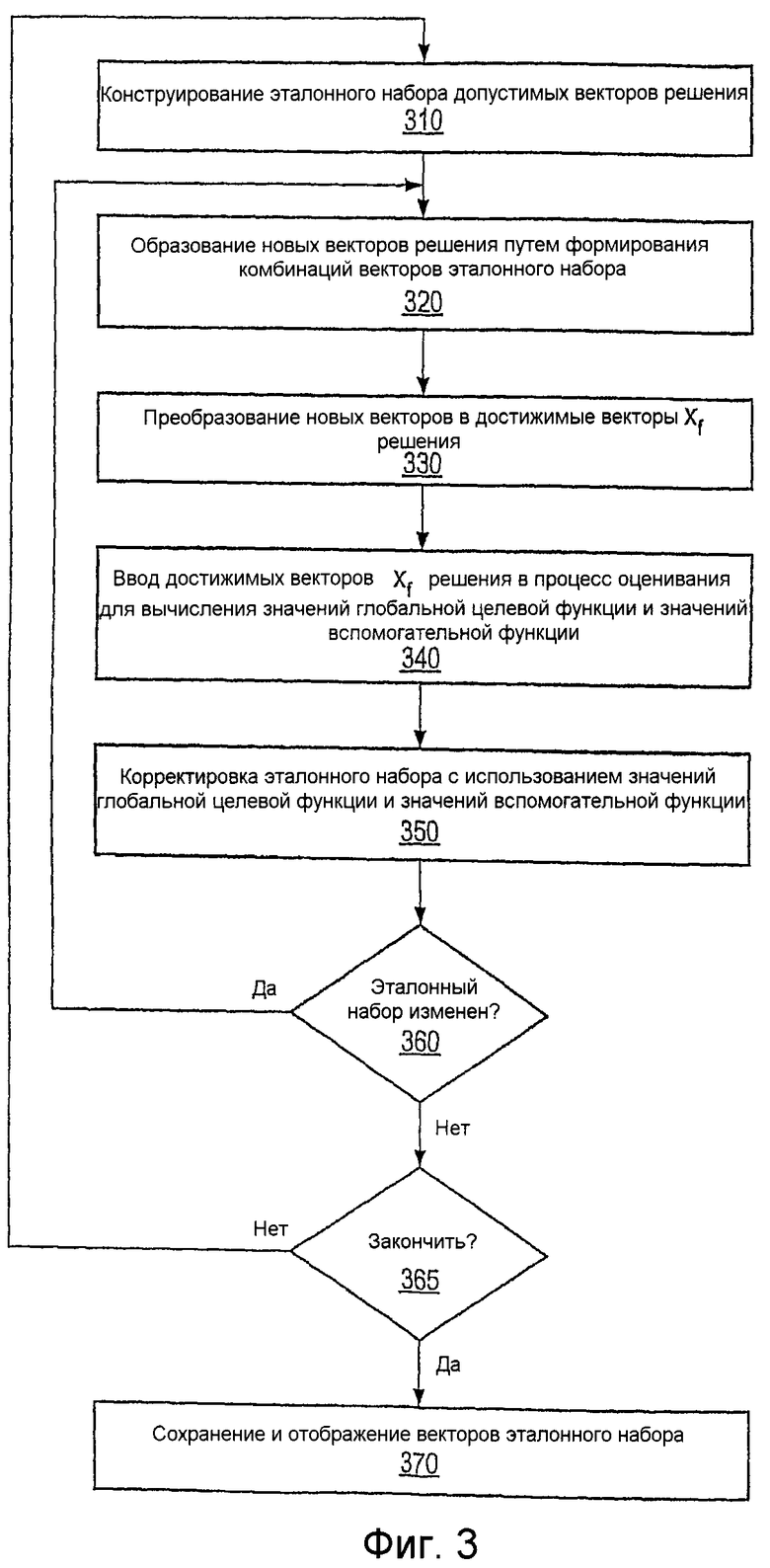


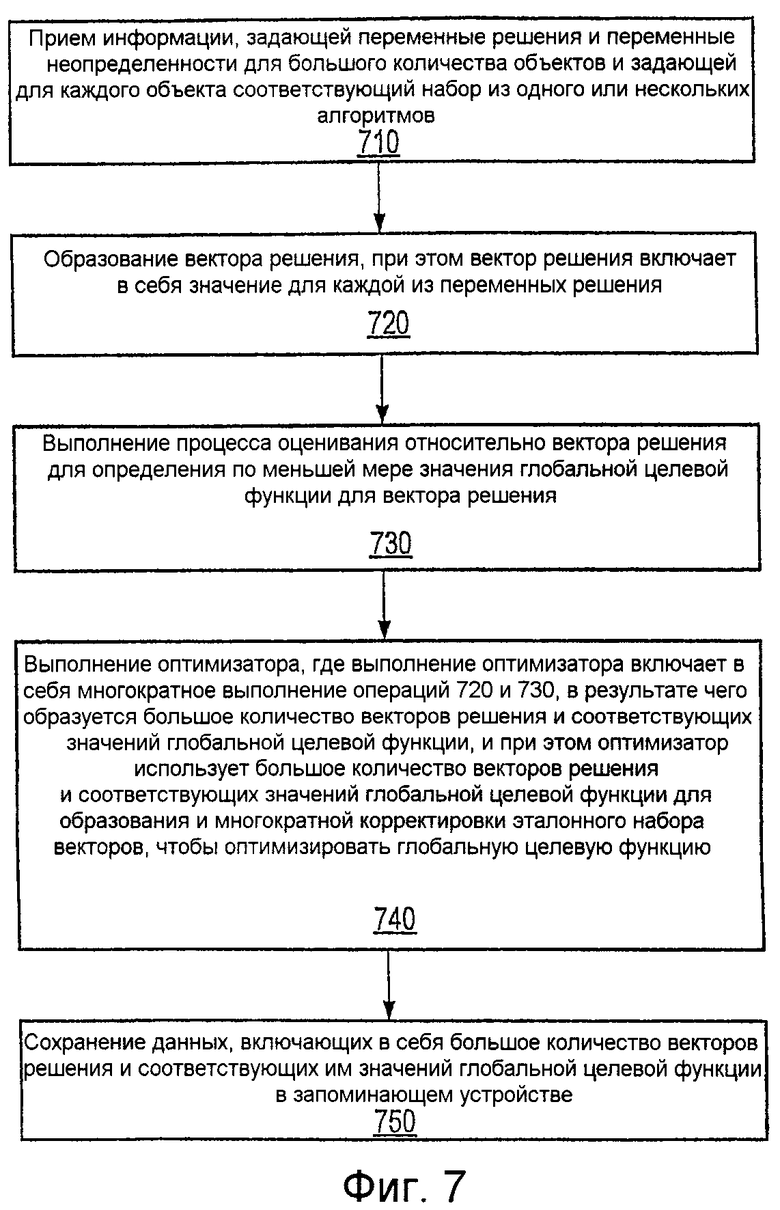

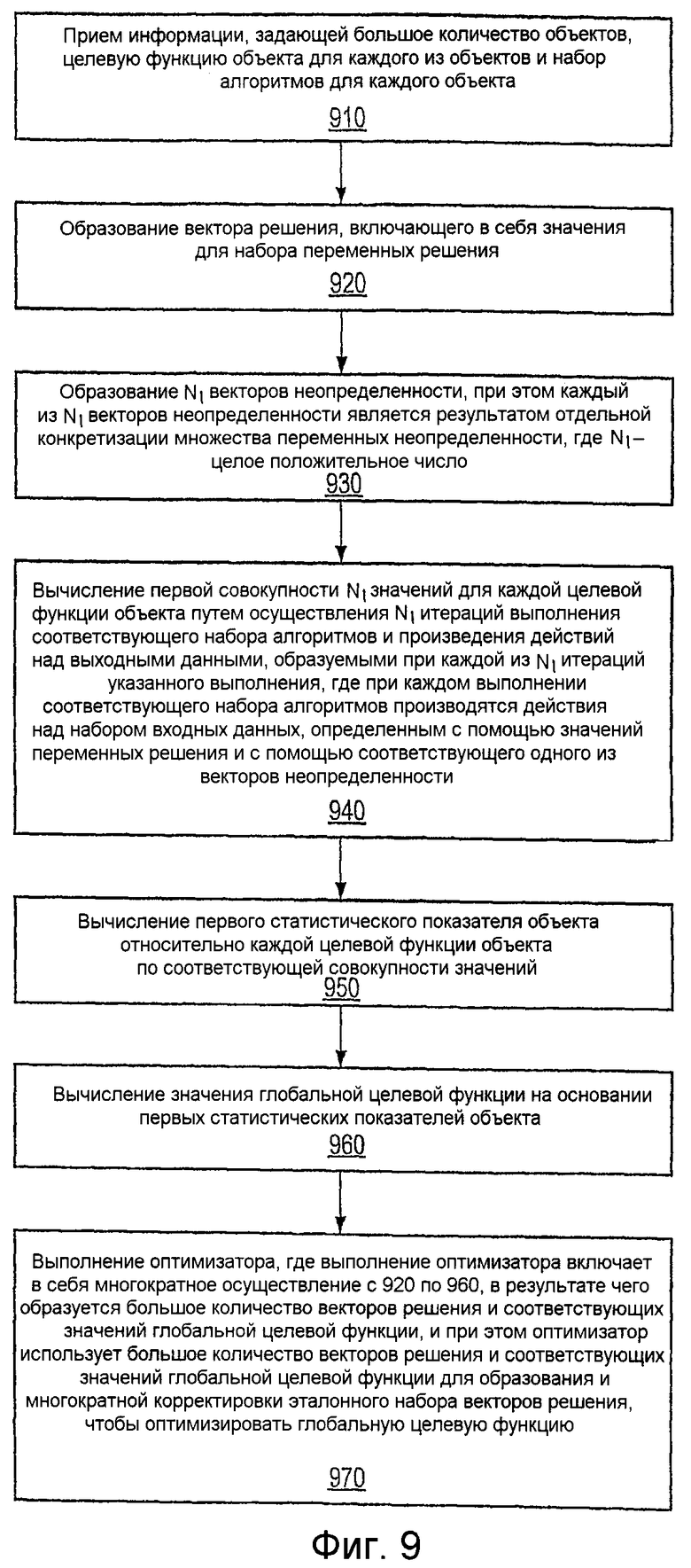

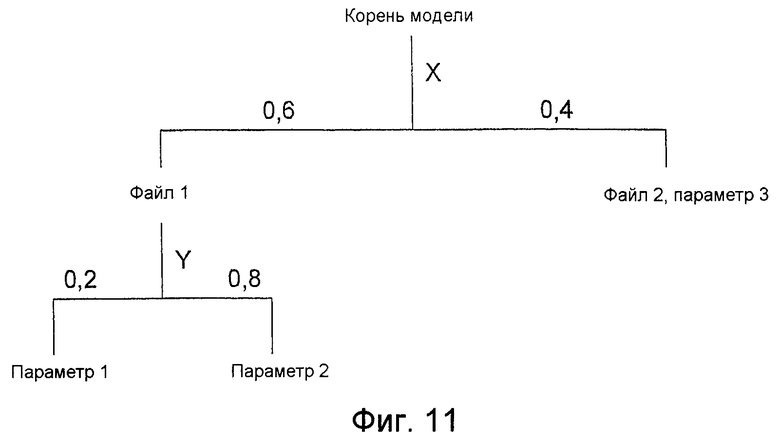

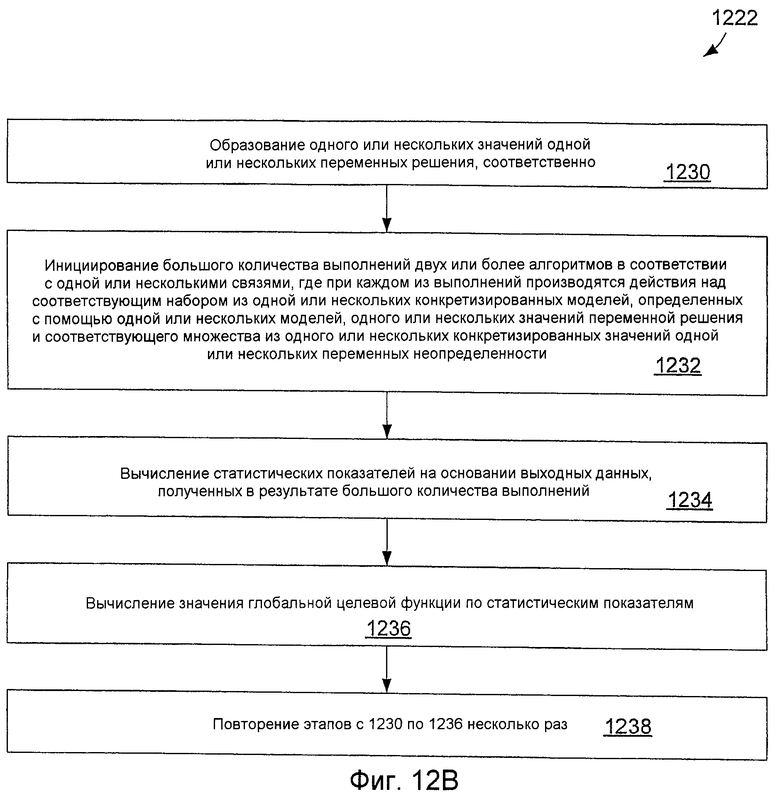

Изобретение относится к вычислительной технике. Технический результат заключается в расширении арсенала технических средств. Способ определения количества скважин для бурения во множестве объектов, причем объектами являются месторождения нефти и/или газа, в котором принимают первую информацию, задающую набор переменных неопределенности для упомянутого множества объектов и задающую функциональную зависимость между первой и второй переменными неопределенности; принимают вторую информацию, задающую множество переменных решения; выполняют оптимизацию, при этом выполнение оптимизации включает в себя выполнение множества оценок глобальной целевой функции, причем каждая оценка глобальной целевой функции включает в себя этапы формирования значения для переменных решения, и выполнения множества итераций из набора операций. А также считываемый компьютером запоминающий носитель и компьютерная система, реализующие способ. 3 н. и 15 з.п. ф-лы, 14 ил.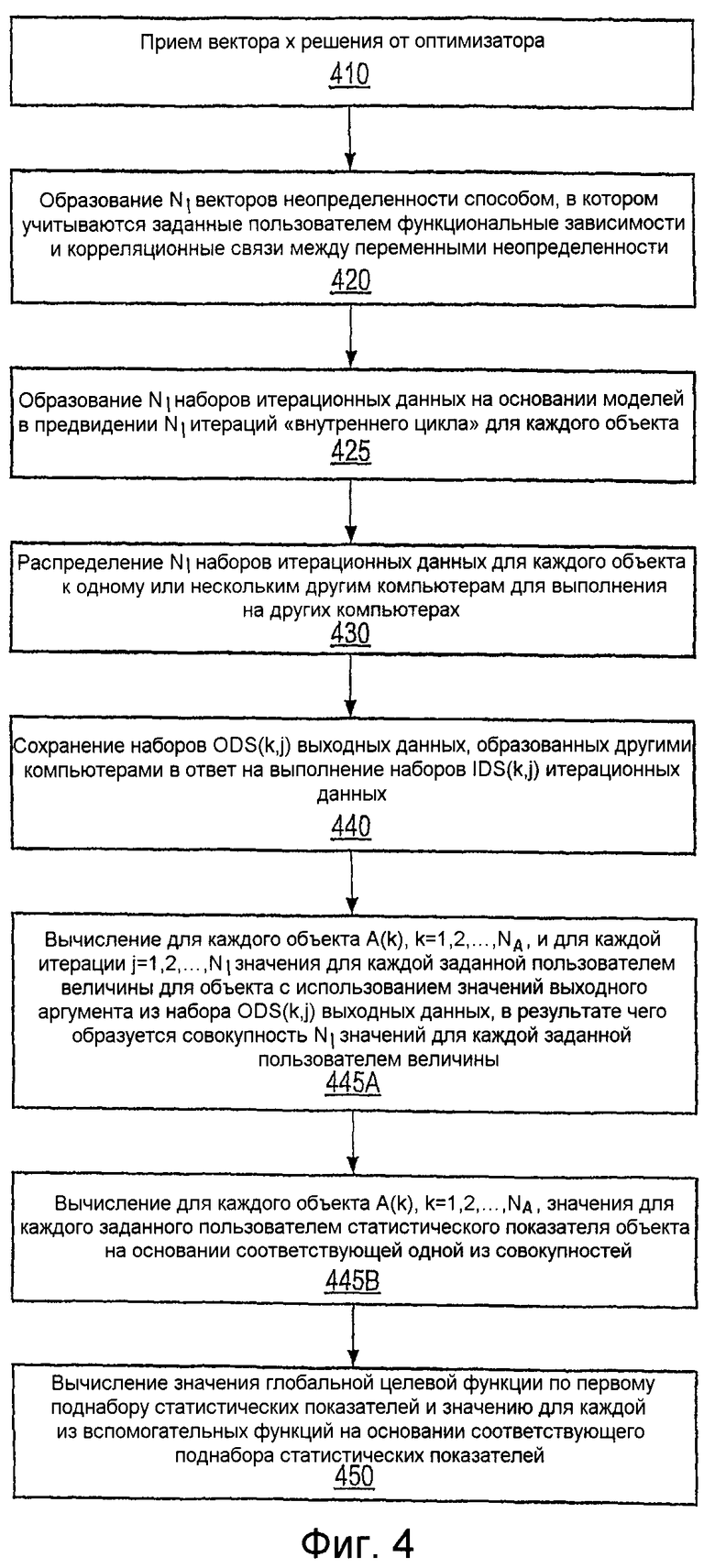
1. Способ определения количества скважин для бурения во множестве объектов, причем объектами являются месторождения нефти и/или газа, содержащий этапы, на которых
принимают первую информацию, задающую набор переменных неопределенности для упомянутого множества объектов и задающую функциональную зависимость между первой и второй переменными неопределенности, причем первая переменная неопределенности ассоциирована с первым из объектов, при этом вторая переменная неопределенности ассоциирована со вторым из объектов;
принимают вторую информацию, задающую множество переменных решения;
выполняют оптимизацию, при этом выполнение оптимизации включает в себя выполнение множества оценок глобальной целевой функции, причем каждая оценка глобальной целевой функции включает в себя этапы формирования значения для переменных решения и выполнения множества итераций из набора операций, при этом набор операций включает в себя:
(а) генерирование значений для переменных неопределенности, при этом указанное генерирование включает в себя генерирование значения для первой переменной неопределенности и вычисление значения для второй переменной неопределенности по значению первой переменной неопределенности на основании функциональной зависимости;
(b) определение набора входных данных для объектов, используя значения переменных неопределенности и значения переменных решения, при этом упомянутое определение включает в себя определение для каждого из объектов соответствующего одного из наборов входных данных, используя по меньшей мере соответствующий поднабор значений переменных неопределенности, при этом указанное определение включает в себя
(b1) определение первого набора входных данных, соответствующего первому объекту, с использованием по меньшей мере значения первой переменной неопределенности; и
(b2) определение второго набора входных данных, соответствующего второму объекту, с использованием по меньшей мере значения второй переменной неопределенности;
(c) для каждого из объектов инициируют выполнение соответствующего набора из одного или более алгоритмов, при этом каждый набор из одного или более алгоритмов оперирует соответствующим набором входных данных, чтобы генерировать соответствующий набор выходных данных;
для каждого из объектов вычисляют один или более статистических показателей на основании множества наборов выходных данных, сгенерированных для упомянутого объекта в упомянутом множестве итераций;
вычисляют значение глобальной целевой функции из упомянутых одного или более статистических показателей для каждого из объектов, при этом оптимизация выполняется для поиска максимума или минимума упомянутой глобальной целевой функции в по меньшей мере части пространства, заданной переменными решения, при этом упомянутое выполнение оптимизации определяет оптимизирующий набор значений переменных решения;
отображают графическое представление по меньшей мере поднабора значений на дисплейном устройстве, и
выполняют бурение скважин в упомянутом множестве объектов, причем количество скважин определено посредством оптимизирующего набора значений переменных решения.
2. Способ по п.1, в котором бурение упомянутого количества скважин включает в себя бурение количества скважин в местоположениях, которые определены посредством оптимизирующего набора значений переменных решения.
3. Способ по п.1, дополнительно содержащий получение данных добычи нефти, газа и воды из одной или более существующих нефтяных и/или газовых скважин в одном или более объектов для формирования картины изменения во времени добычи, при этом упомянутое определение наборов входных данных для объектов включает в себя определение наборов входных данных для одного или более объектов, используя упомянутую картину изменения во времени добычи.
4. Способ по п.1, в котором набор из одного или более алгоритмов для каждого объекта выбирается пользователем.
5. Способ по п.1, в котором на этапе инициирования выполнения
распределяют наборы входных данных для объектов к одному или нескольким удаленным компьютерам для удаленного выполнения соответствующих наборов алгоритмов; и
принимают наборы выходных данных от одного или более удаленных компьютеров.
6. Способ по п.1, в котором упомянутая первая информация также задает одну или более корреляционных связей между переменными неопределенности, при этом упомянутое генерирование значений для переменных неопределенности производят с учетом одной или более заданных корреляционных связей.
7. Способ по п.6, в котором переменные неопределенности включают в себя третью переменную неопределенности и четвертую переменную неопределенности, относящиеся к различным объектам из числа упомянутых объектов, при этом одна или более корреляционных связей включают в себя корреляционную связь между третьей и четвертой переменными неопределенности.
8. Способ по п.1, в котором этап определения набора входных данных включает в себя выбор одной из двух или более моделей для включения в один из наборов входных данных на основании значения третьей из переменных неопределенности.
9. Способ по п.1, в котором этап определения набора входных данных включает в себя
выбор одной из двух или более моделей на основании значения третьей из переменных неопределенности;
выбор одной из двух или более подмоделей выбранной модели на основании значения четвертой из переменных неопределенности;
при этом выбранная подмодель является пригодной к использованию для определения данных, подлежащих включению в один из наборов входных данных.
10. Способ по п.1, в котором оптимизация выполняется оптимизатором, выбираемым пользователем из набора поддерживаемых оптимизаторов.
11. Способ по п.1, в котором упомянутая вторая информация также задает одно или более ограничений на переменные решения, причем при упомянутом генерировании значений для переменных решения соблюдают одно или более ограничений.
12. Способ по п.1, в котором упомянутая вторая информация также задает одну или более функциональных зависимостей между переменными решения, причем при упомянутом генерировании значений для переменных решения соблюдают упомянутую одну или более функциональных зависимостей между переменными решения.
13. Способ по п.1, в котором каждая из переменных решения имеет относящийся к ней задаваемый пользователем набор достижимых значений, представляющих возможные результаты соответствующего решения, при этом каждая из переменных неопределенности имеет относящийся к ней задаваемый пользователем набор достижимых значений.
14. Способ по п.1, в котором каждая оценка глобальной целевой функции также включает в себя
вычисление значения вспомогательной функции по одному или более статистическим показателям каждого из объектов.
15. Способ по п.14, в котором оптимизация выполняется для поиска упомянутого максимума или минимума глобальной целевой функции, подчиненной по меньшей мере ограничению на функциональную комбинацию глобальной целевой функции и вспомогательной функции.
16. Способ по п.14, в котором упомянутое отображение графического представления включает в себя
отображение графика зависимости значения глобальной целевой функции от значения вспомогательной функции.
17. Считываемый компьютером запоминающий носитель, который хранит программные команды, при этом программные команды при исполнении реализуют любой один из способов по пп.1-16.
18. Компьютерная система, содержащая
запоминающее устройство, хранящее программные команды; и
по меньшей мере один процессор, сконфигурированный для считывания и выполнения программных команд, при этом упомянутые программные команды при исполнении реализуют любой один из способов по пп.1-16.
| US 2003225606 A1, 04.12.2003 | |||
| US 2004220790 A1, 04.11.2004 | |||
| US 6308162 B1, 23.10.2001 | |||
| СПОСОБ ГЕОФИЗИЧЕСКОЙ РАЗВЕДКИ ДЛЯ ОПРЕДЕЛЕНИЯ НЕФТЕГАЗОПРОДУКТИВНЫХ ТИПОВ ГЕОЛОГИЧЕСКОГО РАЗРЕЗА ПЕРЕМЕННОЙ ТОЛЩИНЫ | 2002 |
|
RU2205434C1 |

