Изобретение относится к способам и системам, обеспечивающим удобный просмотр изображений на экранах небольшого размера, и может найти применение при создании миниатюрных анимированных изображений (thumbnails), облегчающих поиск нужного изображения в информационных массивах.
Из уровня техники известны решения, касающиеся создания видеоминиатюр для навигации по файлам с видео. Например, выложенная заявка США 2008/0005128 [1] описывает способ и систему для генерации статического или анимированного изображения для предварительного просмотра видеофайлов на экране компактного персонального компьютера. Анимация создается из кадров, которые извлекаются из видео.
Несколько заявок на патенты посвящены созданию анимированных изображений для предварительного просмотра Web-страниц, например выложенная заявка США 2008/0301555 [2]. Согласно этой заявке, действия пользователя по просмотру некоторого сайта записываются в виде снимков экрана, которые являются кадрами анимированного изображения для предварительного просмотра. Такое изображение сохраняется в браузере в виде закладки. Когда пользователь просматривает закладки, он видит, как он просматривал данный сайт ранее.
В выложенной заявке Японии 2008/065656 [3] предлагается создавать анимированные файлы формата GIF для сканированных страниц многостраничного документа. Эти анимированные файлы используются для предварительного просмотра. Кадрами анимации являются уменьшенные изображения страниц документа.
Существует также ряд способов создания "интеллектуальных", то есть более информативных, чем традиционные, миниатюр. Например, статья "Automatic Thumbnail Cropping and its Effectiveness" (Bongwon Suh, Haibin Ling, Benjamin B.Bederson, David W.Jacobs, Proceedings of UIST 2003, ACM) [4] описывает подход к созданию статичного изображения для предварительного просмотра фотографий путем кадрирования одной зоны внимания, которая определяется с помощью детектирования лиц и построения карт важности. В заявляемом изобретении были приняты во внимание идеи, изложенные в [4], в сочетании с идеями, изложенными в статье "Representative Image Thumbnails: Automatic and Manual" (Ramin Samadani, Tim Mauer, David Berfanger, Jim dark, Brett Bausk, Electronic Imaging 2008) [5], которая посвящена способу генерации уменьшенного изображения для предварительного просмотра фотографий, причем такое изображение формируется без изменения композиции исходного изображения при сохранении уровня шумов и степени четкости таких же, как на исходном изображении, что позволяет адекватно оценить качество исходного изображения по миниатюре.
Наиболее близким по своим признакам к заявляемому изобретению является описанный в статье "SmartNails - Display and Image Dependent Thumbnails" (Kathrin Berkner, Edward L.Schwartz, Christophe Marle, Electronic Imaging 2004) [6] способ переформатирования блоков сканированных изображений документов для просмотра на маленьких экранах. Итоговое изображение для предварительного просмотра называется SmartNail. Этот способ предназначен для сохранения распознаваемости документа, изображенного на миниатюре. С этой целью некоторые блоки документа, например, содержащие иллюстрации и заголовки, кадрируются, масштабируются и компактно размещаются на доступном пространстве.
Миниатюры широко используются для предварительного просмотра изображений в интерфейсе пользователя различных устройств, а также в программном обеспечении персональных компьютеров. Традиционно миниатюры генерируют путем уменьшения исходного изображения. Однако часто изображение для предварительного просмотра является слишком маленьким для того, чтобы уверенно распознать изображение или разглядеть его важные детали или оценить его качество, в частности уровень шумов и артефактов сжатия, а также резкость изображения. Например, трудно идентифицировать изображение сканированного документа по его миниатюре. Просмотр миниатюр фотографий также может вызывать проблемы. Зачастую пользователю приходится самостоятельно давать команду устройству об увеличении масштаба фрагмента фото для того, чтобы распознать изображенных людей или предметы. Это достаточно неудобно.
Различные "интеллектуальные" изображения для предварительного просмотра также имеют недостатки. Миниатюры, созданные способом [4], обладают следующими недостатками:
- общий вид исходного изображения становится недоступен для пользователя;
- из нескольких зон внимания, например человеческих лиц на фото, может быть выбрана малоинформативная зона;
- соотношение сторон миниатюры может изменяться;
- невозможно по миниатюре оценить уровень шумов и резкость исходного изображения.
Решение [6] имеет сходные недостатки. Статья [5] предлагает путь для оценки уровня шумов и резкости по миниатюре, но изображение сцены в целом может остаться сложным для распознавания, как и в случае традиционных миниатюр.
Таким образом, задача, на решение которой направлено заявляемое изобретение, состоит в том, чтобы разработать автоматический способ создания миниатюрного анимированного изображения, предназначенного для предварительного просмотра статического изображения нескольких увеличенных зон внимания, таких как человеческие лица, что позволило бы уверенно распознавать изображение. При этом для практической реализации способа требуется также разработать соответствующую систему, объединяющую как известные, так и новые устройства.
Технический результат при решении первой части поставленной задачи достигнут за счет разработки усовершенствованного способа автоматической генерации анимированного изображения для предварительного просмотра статического изображения, при этом такой способ предусматривает выполнение следующих операций:
- на статическом изображении детектируют зоны внимания;
- выбирают зону для оценки качества исходного изображения;
- генерируют анимацию, кадрами которой являются уменьшенные копии целого исходного изображения, кадрированные и масштабированные фрагменты изображения, соответствующие зонам внимания и зоне для оценки качества изображения, и переходы между данными зонами.
Анимация длительностью в несколько секунд демонстрирует уменьшенную копию целого изображения, кадрированные и масштабированные зоны внимания, область для оценки качества изображения. Данный способ комбинирует все полезные качества известных способов, при этом преодолевает их недостатки. Анимированное изображение для предварительного просмотра демонстрирует несколько увеличенных зон внимания, таких как человеческие лица, что позволяет уверенно распознать изображение. Анимированное изображение для предварительного просмотра демонстрирует увеличенный фрагмент исходного изображения, что позволяет оценить уровень шумов, артефактов компрессии, а также резкость исходного изображения. Анимационная видеопоследовательность позволяет пользователю увидеть как изображение в целом, так и его увеличенные фрагменты. Это удобный способ навигации по изображениям на устройствах с небольшим экраном. Кроме того, данный способ создает впечатляющую анимацию из статических изображений, что может быть использовано с целью развлечений.
Первым этапом (шагом) способа является детектирование зон внимания, которые являются важными для узнавания изображения. Такие зоны внимания различаются для изображений разных типов. Все изображения можно разделить, по крайней мере, на два типа: фотографии и изображения документов. Заголовок документа, названия глав, другие надписи относительно большого размера, а также иллюстрации являются важными для узнавания изображения. В большинстве случаев для узнавания фотографии важными являются лица людей с этой фотографии. Если фотография не содержит лиц, то для детектирования зон внимания используется, так называемая, модель мгновенного зрения человека (preattentive human vision model - см., например, http://image.gsfc.nasa.gov/publication/document/2004_galkin.pdf [7]) Эта модель имеет хорошо проработанный математический аппарат и ее результаты достаточно адекватно соответствуют тому, на что человек обращает внимание в первые несколько десятков-сотен мс рассматривания сцены до того, как включается механизм внимательного рассматривания и узнавания (attentive human vision model - см. там же [7]). Строго говоря, при рассматривании миниатюры человек, в основном, находится на стадии внимательного рассматривания, но общей модели зрения в настоящее время не существует, а частные случаи для определенных сцен требуют значительных вычислительных затрат для распознавания сцены. С другой стороны, результаты детектирования зон внимания с помощью модели мгновенного зрения в большинстве случаев выглядят достаточно логичными и совпадают с экспертными оценками.
Для визуальной оценки уровня шумов, артефактов компрессии и резкости изображения пользователь должен просмотреть фрагмент изображения без уменьшения или даже с небольшим увеличением. Используется несколько простых правил для выбора подходящего фрагмента для оценки качества: такой фрагмент должен содержать, по крайней мере, один контрастный перепад и, по крайней мере, одну равномерную область, гистограмма яркостей пикселов фрагмента должна быть достаточно широка, но значения яркости не должны располагаться на границах динамического диапазона. Данные правила применяются для автоматического выбора фрагмента при оценке качества изображения, причем такой фрагмент ищется в центральной части изображения и в зонах внимания, которые были детектированы на предыдущем шаге.
Далее между детектированными зонами реализуются анимированные переходы, которые симулируют наезд камеры, отъезд камеры и панорамирование. Кадры сохраняются в формат, подходящий для хранения анимации или видео, либо демонстрируются в реальном масштабе времени. Все кадры анимации являются фрагментами исходного статического изображения и масштабируются до размеров изображения, предназначенного для предварительного просмотра.
Фиг.1 показывает пример создания анимированного изображения для предварительного просмотра фотографии. На первом этапе детектируются два лица в профиль. Далее в центральной части фотографии на изображении рук ребенка выбирается зона для оценки качества. Анимация симулирует перемещение камеры между сценой в целом и тремя детектированными зонами и состоит из четырех последовательностей кадров и может быть зациклена, то есть после четвертой последовательности кадров снова начинает воспроизводиться первая. Первая последовательность кадров симулирует наезд камеры на первое детектированное лицо, после чего на изображении лица на несколько секунд делается стоп-кадр. Вторая последовательность кадров симулирует панорамирование камеры между лицами, после чего на изображении второго детектированного лица на несколько секунд делается стоп-кадр. Третья последовательность кадров симулирует панорамирование и наезд камеры на руки ребенка, после чего на несколько секунд делается стоп-кадр, что позволяет визуально оценить такие показатели качества изображения, как уровень шумов и резкость изображения. Последняя четвертая последовательность кадров симулирует отъезд камеры до попадания в кадр сцены в целом, после чего на несколько секунд делается стоп-кадр.
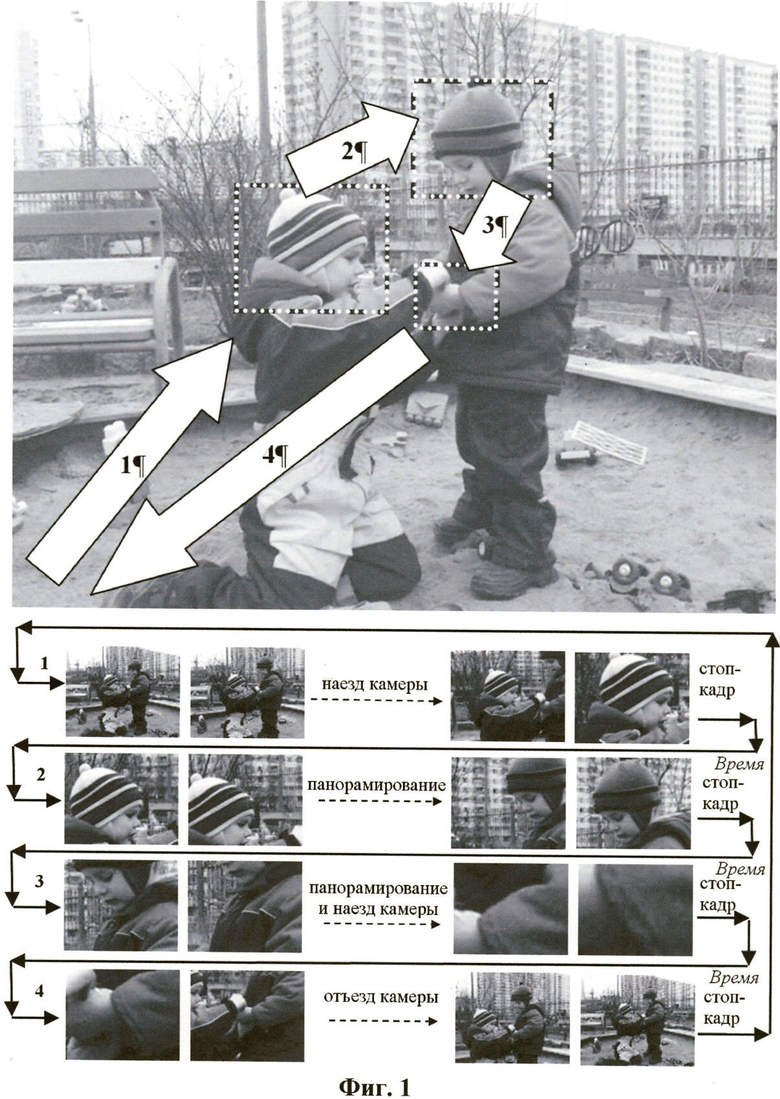
Фиг.2 показывает пример создания анимированного изображения для предварительного просмотра сканированного изображения. Заголовок и фотографическая иллюстрация детектируются на первом этапе. Фрагмент изображения, содержащий заголовок статьи, подходит для оценки качества изображения. Анимация симулирует перемещение камеры между сценой в целом и двумя детектированными зонами, причем поскольку область заголовка достаточно велика и вытянута горизонтально, то вдоль этой области выполняется панорамирование. Анимация состоит из четырех последовательностей кадров и может быть зациклена, также может попеременно воспроизводиться в прямом и обратном порядке. Первая последовательность кадров симулирует наезд камеры на левую часть детектированной зоны заголовка. Вторая последовательность кадров симулирует медленное панорамирование слева направо вдоль зоны заголовка, после чего на несколько секунд делается стоп-кадр, что позволяет визуально оценить качество изображения. Третья последовательность кадров симулирует панорамирование камеры от правой части зоны заголовка до детектированной зоны фотографической иллюстрации, после чего на несколько секунд делается стоп-кадр. Последняя четвертая последовательность кадров симулирует отъезд камеры до попадания в кадр всей сцены, то есть всего изображения документа, после чего на несколько секунд делается стоп-кадр.
Длительность анимации одного цикла анимации не должна быть большой. Оптимальное время находится в диапазоне от 10 до 14 секунд, что, с одной стороны, позволяет пользователю надежно распознать изображение и оценить его качество, с другой стороны, не утомительно для просмотра. Таким образом, количество детектируемых зон внимания должно быть ограничено тремя-пятью.
Фиг.1 - пример создания анимированного изображения для предварительного просмотра фотографии.
Фиг.2 - пример создания анимированного изображения для предварительного просмотра изображения документа.
Фиг.3 - блок-схема основных шагов способа.
Фиг.4 - блок-схема детектирования зон внимания.
Фиг.5 - таблица, демонстрирующая значение средней по цветовым каналам R, G, В энергии нормализованных матриц совместной встречаемости для различных типов изображений.
Фиг.6 - блок-схема сегментации изображений документов.
Фиг.7 - пример, демонстрирующий детектированные зоны внимания для изображения документа.
Фиг.8 - пример, демонстрирующий детектированные зоны внимания и карту важности для фотографии.
Фиг.9 - схема системы для генерации анимированного изображения для предварительного просмотра из статичного изображения.
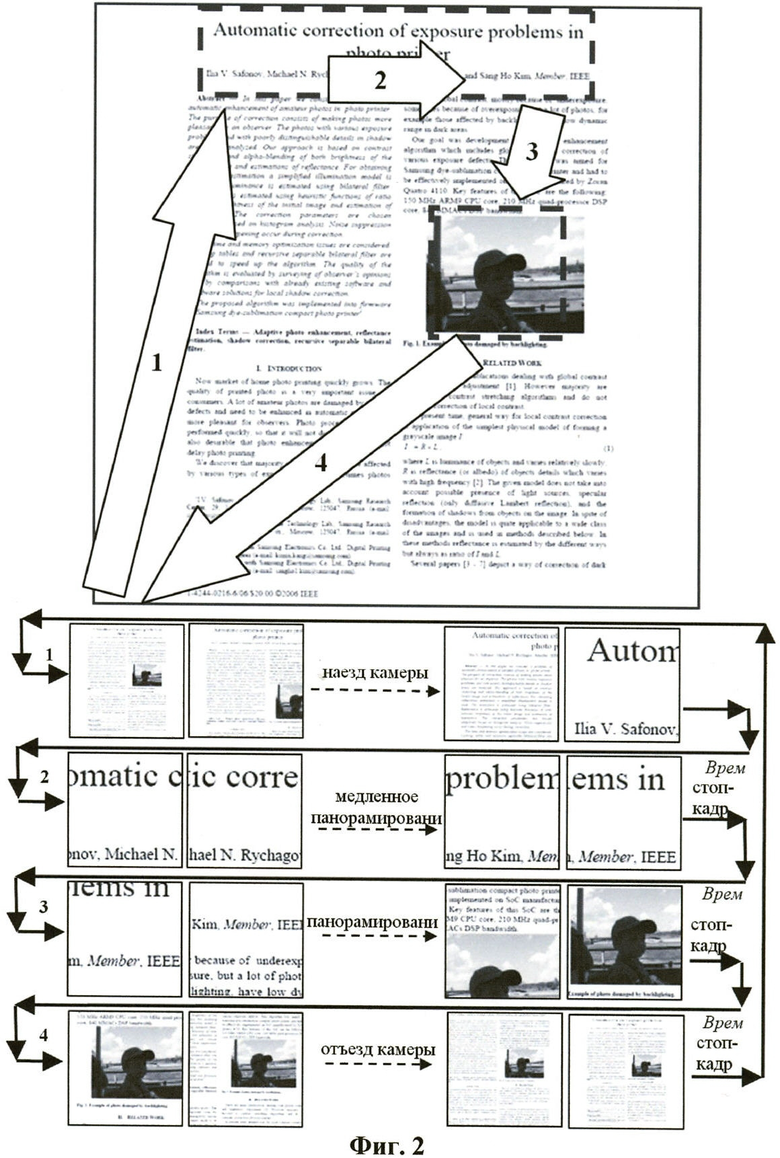
Основные шаги способа генерации анимированного изображения для предварительного просмотра показаны на Фиг.3. На шаге 301 детектируют зоны внимания на исходном изображении. На шаге 302 выбирают зону для оценки качества изображения. На шаге 303 генерируют анимацию, кадрами которой являются уменьшенные копии целого исходного изображения, кадрированные и масштабированные фрагменты изображения, соответствующие зонам внимания и зоне для оценки качества изображения, и кадры-переходы между данными зонами.
Блок-схема на Фиг.4 поясняет процедуру детектирования зон внимания. На шаге 401 классифицируют исходное изображение на фотографию или изображение документа. Классификация осуществляется путем сравнения с порогом средней по цветовым каналам R, G, В энергии нормализованных матриц совместной встречаемости En для уменьшенной копии изображения:
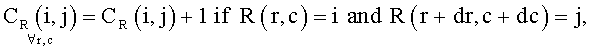
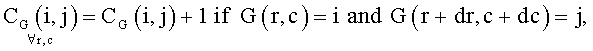
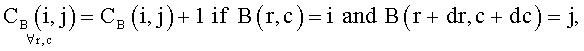
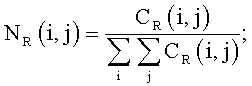
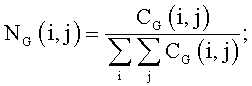
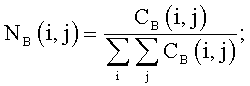
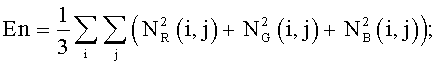
где r, с - координаты пиксела изображения, dr, dc - смещения по строке и столбцу от текущего пиксела. Применение трех матриц совместной встречаемости для цветных каналов R, G, В позволяет детектировать изображения документов с цветным фоном.
Фиг.5 демонстрирует таблицу значений En для нескольких уменьшенных копий изображений для dr=0 и dc=1. Средняя по цветовым каналам энергия нормализованных матриц совместной встречаемости En различается для фотографий и изображений документов на несколько порядков. Как правило, для фотографий En меньше 0,01, тогда как для типичных изображений документов En имеет значение около 0,1. Данный подход работает и для растрированных цветных и для черно-белых изображений.
Если изображение классифицировано как фотография (условие 402), то детектируют лица (шаг 403). В настоящее время детектирование лиц используется во множестве устройств. Существует достаточно большое количество способов детектирования лиц. Например, широко известная библиотека функций OpenCV содержит реализацию способа детектирования лиц человека в фас и профиль. Этот способ описан в статье "Rapid object detection using a boosted cascade of simple features", (P.Viola, M.Jones, Proc. Conference Computer Vision and Pattern Recognition, 2001) [8]. В целом, детекторы лиц, основанные на способе Viola-Jones, обеспечивают неплохие результаты, но не могут уверенно детектировать повернутые относительно сторон изображения лица. В последние годы было предложено несколько методов для многоракусного детектирования лиц, например, один из них описан в статье "Robust head pose estimation using LGBP" (B.Ma, W.Zhang, S.Shan, X.Chen, W.Gao, Proc. of International Conference Pattern Recognition, pp.512-515, 2006) [9].
Затем детектируют зоны внимания по карте важности (шаг 404), основываясь на модели мгновенного зрения человека. Эта модель хорошо обоснована, и существует более сотни публикаций, обсуждающих способ реализации данной модели и построения карты важности или "выпуклости" (saliency map). В частности, эффективный с вычислительной точки зрения способ построения карты важности описан в статье "Efficient Construction of Saliency Map" (Wen-Fu Lee, Tai-Hsiang Huang, Yi-Hsin Huang, Mei-Lan Chu, Homer H. Chen SPIE-IS&T / Vol.7240, 2009) [10]. Фиг.8 демонстрирует пример фотографии и соответствующей ему карты важности. Зонами внимания являются две области с наибольшими значениями в карте важности. Эти детектированные зоны обозначены на фотографии.
Если изображение классифицировано как изображение документа, то выполняется переход на шаг 405, на котором сегментируют изображение, то есть детектируют на нем заголовки и иллюстрации. Блок-схема сегментации документа показана на Фиг.6. На шаге 601 изображение конвертируется из цветного в полутоновое I:
I(r,c)=(R(r,c)+G(r,c)+B(r,c))/3,
где r, c - координаты пиксела изображения.
Уменьшение размера изображения до размера, который обеспечивает читаемость текста размера 18 типографских пунктов и более, выполняется на шаге 602. На шаге 603 детектируют контрастные перепады. Для этого сначала используют свертку с фильтром Лапласиан-Гауссиана
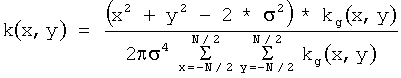 ,
,
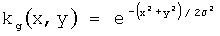 ,
,
где N - размер ядра свертки, σ - среднеквадратичное отклонение, (х,у) - координаты в декартовой системе с началом координат в центре ядра. В предпочтительном варианте изобретения N=13 и σ=2.
Затем определяют пересечения нулевого уровня и обозначают их на изображении с детектированными контрастными перепадами BW, используя следующие правила для каждого пиксела изображения:
BW(r,c)=1, если (|Ie(r,c)-Ie(r,c+1)|>=Т и Ie(r,c)<0 и Ie(r,c+1)>0)
или (|Ie(r,c)-Ie(r,c-1)|>=Т и Ie(r,c)<0 и Ie(r,c-1)>0)
или (|Ie(r,c)-Ie(r-1,c)|>=Т и Ie(r,c)<0 и Ie(r-1,c-1)>0)
или (|Ie(r,c)-Ie(r+l,c)|>=Т и Ie(r,с)<0 и Ie(r+1,с-1)>0);
иначе BW(r,c)=0,
где Ie - результат фильтрации полутонового изображения I Лапласианом-Гауссиана, r, с - координаты пиксела изображения, порог Т задается из диапазона [0,015-0,02].
На шаге 604 сегментируют области текста. Сегментированное изображение L создается по формуле
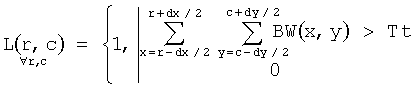 ,
,
где dx, dy - размеры блока изображения, Tt - предопределенный порог. В предпочтительном варианте изобретения dx=dy=16, Tt=20. Заметим, что кроме текста, таким образом, сегментируются диаграммы и графики. Далее на изображении L ищутся связные области, для каждой такой области определяются размеры описывающего прямоугольника. Области с маленькой шириной или высотой исключаются из рассмотрения. Каждая связная область в L является областью текста.
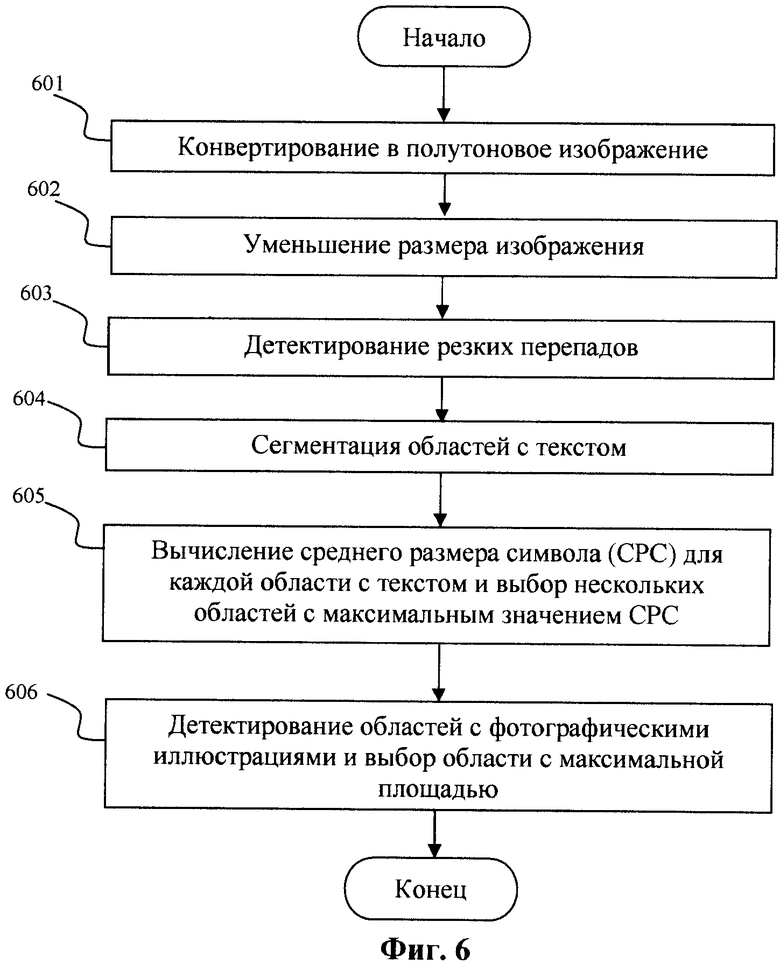
На шаге 605 вычисляют для каждой области текста средний размер символа и выбирают нескольких областей с максимальным значением среднего размера символа. Для этого сначала из изображения I×L (поэлементное перемножение) получают бинарное изображение Ω путем бинаризации по порогу Tz, где порог определяется хорошо известным способом Отсу (Otsu). Далее на Ω ищут связные области и для них вычисляют высоту описывающего прямоугольника. Средняя высота для связных областей с Ω для каждой области текста считается средним размером символа. Координаты описывающих прямоугольников для областей текста с максимальным значением среднего размера символов являются координатами зон внимания.
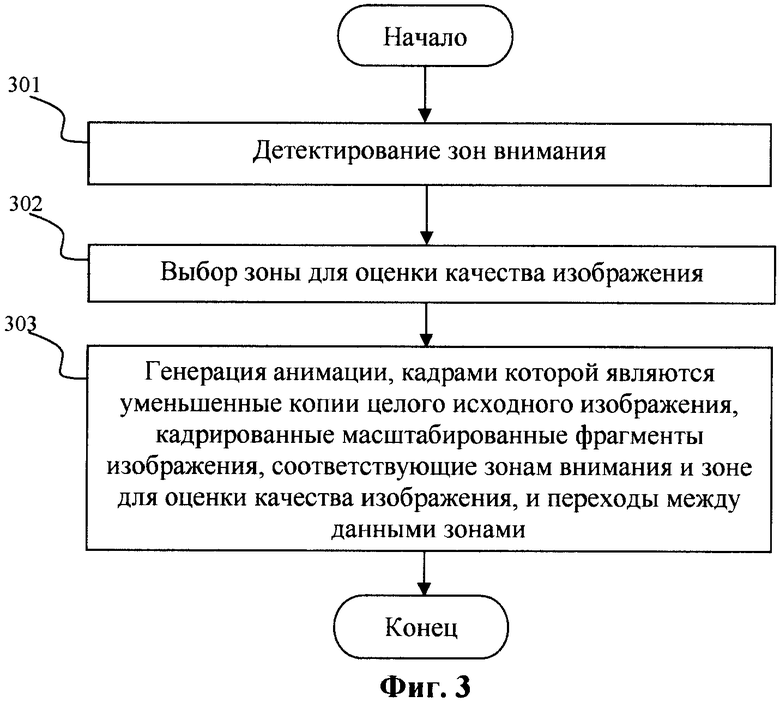
На шаге 606 детектируют области с иллюстрациями и выбирают область с максимальной площадью. Для детектирования иллюстраций изображение I разбивают на неперекрывающиеся блоки размера N×M. Для каждого блока вычисляют нормализованную энергию матрицы совместной встречаемости Ei
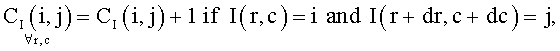
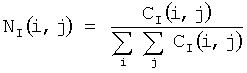 ;
;
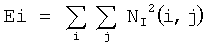 ,
,
где r, с - координаты пикселов блока, dr, dc - смещения от текущей точки. В предпочтительном варианте реализации изобретения: dr=0, dc=1, М=N=32. Если Ei<0.01, то все пикселы блока отмечаются как относящиеся к фотографической иллюстрации. Далее все отмеченные пикселы объединяют в связные области. Области маленькой площади исключают из рассмотрения. Область с площадью более трети площади изображения также исключают из рассмотрения, так как она, вероятно, относится к фону. Описывающий прямоугольник области максимальной площади из оставшихся областей рассматривают в качестве зоны иллюстрации. Фиг.7 демонстрирует детектированные зоны внимания для изображения документа.
Порядок обхода зон выбирают следующим образом. Первым кадром всегда является уменьшенная копия целого изображения. Длительность одного цикла анимации задают в качестве параметра. Она не должна быть слишком большой. Оптимальным с точки зрения удержания внимания человека можно считать длительность от 10 до 14 сек. Таким образом, число просматриваемых зон, на которых акцентируется внимание, ограничено 3-5. После выбора необходимого числа зон устанавливают порядок их обхода таким образом, чтобы обеспечивать кратчайший путь в геометрическом смысле. Размеры выбранных зон корректируют, чтобы обеспечить соотношение сторон как у изображения для предварительного просмотра. Анимация может быть зациклена, также может попеременно воспроизводиться в прямом и обратном порядке.
Далее между зонами реализуются анимированные переходы, которые симулируют наезд камеры, отъезд камеры, панорамирование и стоп-кадр. Наезд камеры, отъезд камеры и панорамирование между двумя зонами симулируют посредством создания N промежуточных кадров с помощью следующей последовательности действий:
- координаты вершин прямоугольника, по которому осуществляется кадрирование, вычисляют с помощью уравнения прямой в параметрическом виде
x(t)=x1+t×(x2-x1),
y(t)=y1+t×(y2-y1),
где (x1, y1) - координаты соответствующей вершины начальной зоны, (х2 у2) - координаты вершины конечной зоны, параметр t увеличивается от 0 до 1 с шагом dt=1/(N-1);
- кадр вырезают (кадрируют) из исходного изображения по вычисленным координатам;
- кадр масштабируют до размеров изображения для предварительного просмотра.
При такой последовательности действий эффект наезда камеры получается, если для двух последующих кадров коэффициент уменьшения изображения при масштабировании увеличивается. Эффект отъезда камеры получается, если для двух последующих кадров коэффициент уменьшения изображения при масштабировании уменьшается. Эффект панорамирования получается, если для двух последующих кадров коэффициент уменьшения изображения при масштабировании не изменяется или изменяется незначительно. Для создания эффекта стоп-кадра соответствующий кадр включается в видеопоследовательность несколько раз подряд.
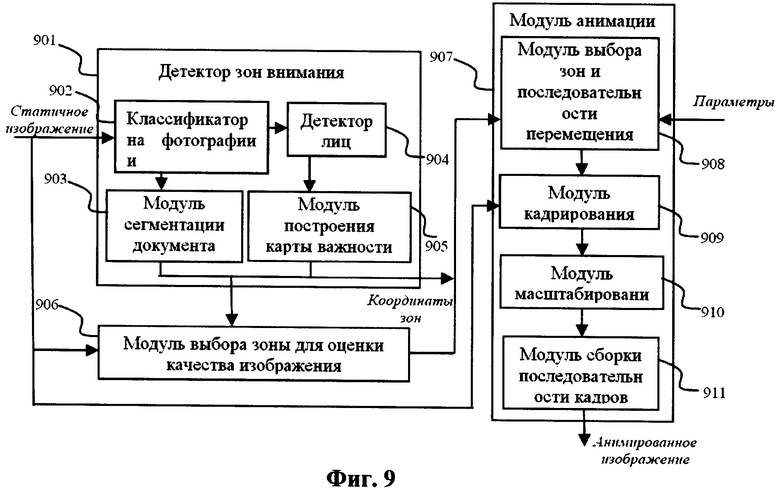
Схема системы генерации анимированного изображения для предварительного просмотра статического изображения показана на Фиг.9. Система содержит детектор 901 зон внимания, модуль 906 выбора зоны для оценки качества изображения, модуль 907 анимации. Детектор 901 зон внимания выполнен с возможностью определения координат зон внимания на исходном статическом изображении. На вход детектора 901 подают статическое изображение, а на выходе получают координаты детектированных зон внимания. Выход детектора 901 связан с входами модуля 906 выбора зоны для оценки качества изображения и модуля 907 анимации. Модуль 906 выбора зоны для оценки качества изображения выполнен с возможностью определения координат области изображения, позволяющей оценить уровень шумов, артефактов компрессии и резкость изображения. На вход модуля 906 подают исходное статическое изображение и координаты зон внимания из детектора 901 зон внимания. Модуль 906 выдает на выход координаты зоны для оценки качества изображения, которые поступают на вход модуля 907 анимации. Модуль 907 анимации выполнен с возможностью создания анимированного изображения небольшого размера для предварительного просмотра из относительно большого исходного статического изображения. На вход модуля 907 подают исходное статическое изображение, параметры анимации, например длительность анимации, координаты зон внимания из детектора зон внимания, координаты зоны для оценки качества изображения из модуля 906 выбора зоны для оценки качества изображения. Модуль 907 выдает на выход анимированное изображение для предварительного просмотра.
Детектор 901 зон внимания содержит классификатор 902 на изображения документов и фотографии, модуль 903 сегментации документа, детектор 904 лиц, модуль 905 построения карты важности. Классификатор 902 выполнен с возможностью осуществления классификации исходного статического изображения как изображения документа и передачи его в модуль 903 сегментации документа, или классификации его как фотографию и передачи его в детектор 904 лиц. Детектор 904 лиц выполнен с возможностью выявления координат расположения человеческих лиц на изображении, передачи координат и исходного изображения в модуль 905 построения карты важности. Модуль 905 построения карты важности выполнен с возможностью построения на основе модели мгновенного зрения человека карты важности, определения по ней зоны внимания и передачи координат зон внимания на выход детектора 901 зон внимания. Модуль 903 сегментации документа выполнен с возможностью выделения на изображении документа областей текста максимального размера и иллюстрации, передачи координат выделенных зон на выход детектора 901 зон внимания.
Модуль 907 анимации содержит модуль 908 выбора зон и последовательности перемещения между ними, модуль 909 кадрирования, модуль 910 масштабирования, модуль 911 сборки последовательности кадров. Модуль 908 выбора зон и последовательности перемещения между ними выполнен с возможностью получения на вход координат зон внимания и параметров анимации, в частности, длительность цикла анимации, и выбора из всего множества зон нескольких зон в зависимости от длительности анимации, выбора порядка обхода зон, чтобы обеспечить кратчайший суммарный путь, вычисления координат всех кадров анимации и передачи их в модуль кадрирования. Модуль 909 кадрирования выполнен с возможностью получения на вход исходного изображения и выделения (вырезки) из него кадров по заданным координатам, передачи кадров в модуль масштабирования. Модуль 910 масштабирования выполнен с возможностью осуществления масштабирования каждого кадра до размера изображения для предварительного просмотра, передачи масштабированных кадров в модуль сборки последовательности кадров. Модуль 911 сборки последовательности кадров выполнен с возможностью сбора всех кадров в файл формата, который позволяет воспроизводить видео или анимацию, или трансляции кадров на выход модуля анимации.
Все перечисленные блоки и модули могут быть выполнены в виде системы на кристалле (SoC), или в виде программируемой логической матрицы (FPGA), или в виде специализированной интегральной схемы (ASIC). Работа модулей ясна из их описания или описания способа генерации анимированного изображения для предварительного просмотра.
Хотя указанный выше вариант выполнения изобретения был изложен с целью иллюстрации, специалистам ясно, что возможны разные модификации, добавления и замены, не выходящие из объема и смысла настоящего изобретения, раскрытого в прилагаемой формуле изобретения. В частности, зоны внимания могут задаваться пользователем интерактивно, например, может быть записана последовательность действий пользователя, такие как масштабирование и прокручивание, при просмотре изображения на маленьком экране.
Способ и система предназначены для устройств с относительно маленьким экраном для удобного для пользователя просмотра статических изображений. Изобретение может быть использовано в мобильных телефонах, компактных персональных компьютерах (PDA), цифровых фотокамерах, цифровых фотоальбомах и фоторамках, фотопринтерах. Анимированное изображение для предварительного просмотра сканированных изображений документов может применяться в многофункциональных периферийных устройствах, оборудованных экраном для предварительного просмотра. Кроме того, изобретение предоставляет выразительный способ для навигации по коллекциям изображений на персональном компьютере или в Интернет-приложениях.



Изобретение относится к способам обработки изображений. Способ генерации анимированного изображения для предварительного просмотра статического изображения состоит из следующих этапов: детектируют на исходном изображении зоны внимания; выбирают зону для оценки качества изображения; генерируют анимацию, кадрами которой являются уменьшенные копии целого исходного изображения, кадрированные масштабированные фрагменты изображения, соответствующие зонам внимания и зоне для оценки качества изображения, и кадры-переходы между данными зонами. Указанный способ реализуется при помощи соответствующего устройства Технический результат заключается в автоматическом создании миниатюрного анимированного изображения. 2 н. и 9 з.п. ф-лы, 9 ил.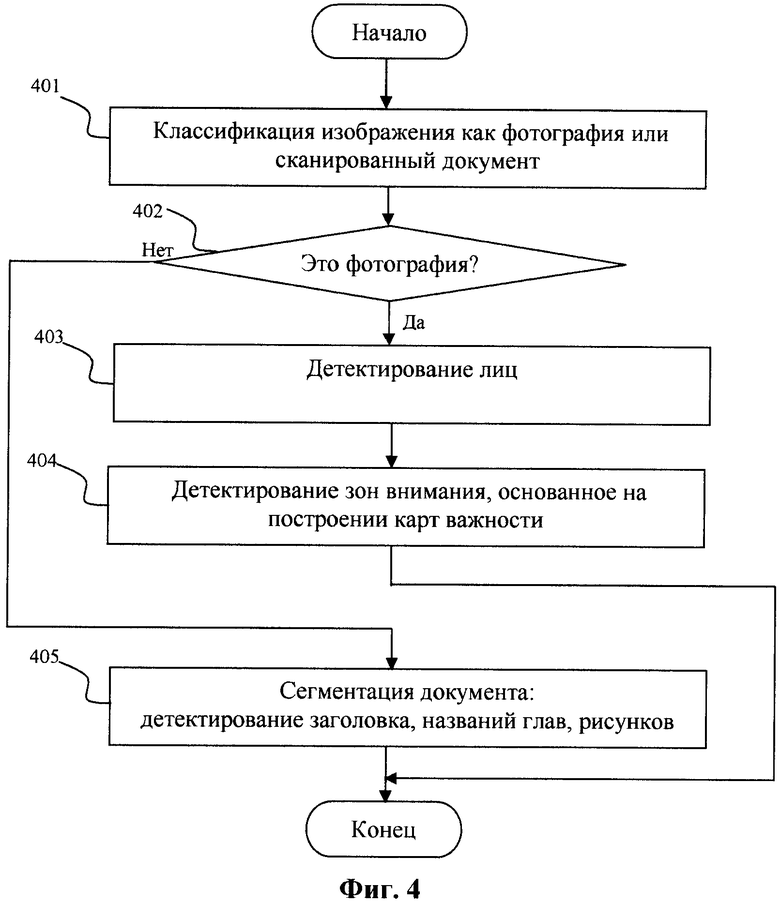
1. Способ генерации анимированного изображения, предназначенного для предварительного просмотра статического изображения, при этом способ предусматривает выполнение следующих операций:
детектируют на исходном изображении зоны внимания;
выбирают зону для оценки качества изображения;
генерируют анимацию, кадрами которой являются уменьшенные копии целого исходного изображения, кадрированные масштабированные фрагменты изображения, соответствующие зонам внимания и зоне для оценки качества изображения, и кадры-переходы между данными зонами.
2. Способ по п.1, отличающийся тем, что процедура детектирования зон внимания состоит из следующих этапов:
классифицируют исходное изображение на фотографию или изображение документа;
детектируют лица и детектируют зоны внимания, основываясь на построении карт важности, если изображение классифицировано как фотография;
детектируют на изображении заголовки и иллюстрации, если изображение классифицировано как изображение документа.
3. Способ по п.1, отличающийся тем, что зону для оценки качества изображения выбирают в центральной части изображения или в зонах внимания, которые были детектированы ранее, причем зона для оценки качества изображения выбирают в соответствии со следующими правилами: зона для оценки качества должна содержать, по крайней мере, один контрастный перепад и, по крайней мере, одну равномерную область, гистограмма яркостей пикселов зоны должна быть достаточно широка, но значения яркости не должны располагаться на границах динамического диапазона.
4. Способ по п.1, отличающийся тем, что с помощью анимации симулируют такие эффекты видеосъемки, как наезд камеры, отъезд камеры и панорамирование между детектированными зонами и вдоль зон большого размера, а также стоп-кадр.
5. Способ по п.1, отличающийся тем, что анимацию зацикливают с возможностью попеременного воспроизведения в прямом и обратном порядке.
6. Способ по любому из пп.1 и 2, отличающийся тем, что классификацию изображений на фотографии и изображения документов осуществляют на основе анализа средней по цветовым каналам R, G и В энергии нормализованной матрицы совместной встречаемости для уменьшенной копии изображения.
7. Способ по любому из пп.1 и 2, отличающийся тем, что процедура детектирования на изображении документа заголовков и иллюстраций включает в себя выполнение следующих операций:
конвертируют изображение в полутоновое;
уменьшают размер изображения;
детектируют контрастные перепады;
сегментируют области текста;
вычисляют для областей текста средний размер символа и выбирают нескольких областей с максимальным значением среднего размера символа;
детектируют области с иллюстрациями и выбирают область с максимальной площадью.
8. Способ по п.7, отличающийся тем, что процедура детектирования контрастных перепадов включает в себя выполнение следующих операций:
фильтруют изображения фильтром Гауссиан-Лапласиана;
определяют пересечения нулевого уровня.
9. Система генерации анимированного изображения для предварительного просмотра статического изображения, содержащая:
детектор зон внимания, выполненный с возможностью определения координат зон внимания на исходном статическом изображении, при этом на вход детектора зон внимания поступает статическое изображение; на выходе детектора формируются данные о координатах детектированных зон внимания; выход детектора связан с входами модуля выбора зоны для оценки качества изображения и модуля анимации;
модуль выбора зоны для оценки качества изображения, выполненный с возможностью определения координат области изображения, позволяющей оценить уровень шумов, артефакты компрессии и резкость изображения; на вход модуля поступает исходное статическое изображение и координаты зон внимания из детектора зон внимания; на выходе модуля формируются координаты зоны для оценки качества изображения, которые поступают на вход модуля анимации;
модуль анимации, выполненный с возможностью генерации анимированного изображения небольшого размера, предназначенного для предварительного просмотра, из относительно большого исходного статического изображения; на вход модуля поступает исходное статическое изображение, параметры анимации, включая длительность анимации, координаты зон внимания из детектора зон внимания, координаты зоны для оценки качества изображения из модуля выбора зоны для оценки качества изображения; на выходе модуля формируется анимированное изображение, предназначенное для предварительного просмотра.
10. Система по п.9, отличающаяся тем, что детектор зон внимания содержит:
классификатор на изображения документов и фотографии, выполненный с возможностью классификации исходного статического изображения как изображения документа и передачи его в модуль сегментации документа, или классификации исходного статического изображения как фотографии и передачи его в детектор лиц;
детектор лиц, выполненный с возможностью детектирования координат расположения человеческих лиц на изображении, передачи координат и исходного изображения в модуль построения карты важности;
модуль построения карты важности, выполненный с возможностью построения на основе модели мгновенного зрения человека карты важности, определения по ней зоны внимания и передачи координаты зон внимания на выход детектора зон внимания;
модуль сегментации документа, выполненный с возможностью выделения на изображении документа областей текста максимального размера и иллюстрации, передачи координат выделенных зон на выход детектора зон внимания.
11. Система по п.9, отличающаяся тем, что модуль анимации содержит:
модуль выбора зон и последовательности перемещения между ними, выполненный с возможностью получения на вход координат зон внимания и параметров анимации, включая длительность цикла анимации, выбора из всего множества зон нескольких зон в зависимости от длительности анимации, выбора порядка обхода зон, обеспечивающего кратчайший суммарный путь, вычисления координат всех кадров анимации и передачи их в модуль кадрирования;
модуль кадрирования, выполненный с возможностью получения на вход исходного изображения и выделения из него кадров по заданным координатам, передачи кадров в модуль масштабирования;
модуль масштабирования, выполненный с возможностью масштабирования каждого кадра до размера изображения, предназначенного для предварительного просмотра, передачи масштабированных кадров в модуль сборки последовательности кадров;
модуль сборки последовательности кадров, выполненный с возможностью сбора всех кадров в файл формата, позволяющего воспроизводить видео или анимацию, или трансляции кадров на выход модуля анимации.
| ПЕРВАЯ СТУПЕНЬ КАТАЛИТИЧЕСКОЙ СИСТЕМЫ ОКИСЛЕНИЯ АММИАКА | 2008 |
|
RU2383490C1 |
| WO 2008112759, 18.09.2008 | |||
| US 2007188774 A1, 16.08.2007 | |||
| WO 2007111790 A2, 04.10.2007. | |||

