Перекрестная ссылка
Изобретение связано по тематике с изобретениями, раскрыми в следующих заявках общего присвоения: патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-1748), поданной одновременно с данной заявкой, под названием "SYSTEMS AND METHODS FOR REPRESENTING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM BUT INDEPENDENT OF PHYSICAL REPRESENTATION"; патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-1749), поданной одновременно с данной заявкой, под названием "SYSTEMS AND METHODS FOR SEPARATING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM FROM THEIR PHYSICAL ORGANIZATION"; патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-1750), поданной одновременно с данной заявкой, под названием "SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A BASE SCHEMA FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-1751), поданной одновременно с данной заявкой, под названием "SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A CORE SCHEMA FOR PROVIDING A TOP-LEVEL STRUCTURE FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-1752), поданной одновременно с данной заявкой, под названием "SYSTEMS AND METHOD FOR REPRESENTING RELATIONSHIPS BETWEEN UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-2734), поданной одновременно с данной заявкой, под названием "STORAGE PLATFORM FOR ORGANIZING, SEARCHING, AND SHARING DATA"; и патентной заявке США № (еще не присвоенной) (Реестр поверенного № MSFT-2735), поданной одновременно с данной заявкой, под названием "SYSTEMS AND METHODS FOR DATA MODELING IN AN ITEM-BASED STORAGE PLATFORM".
Область техники, к которой относится изобретение
Настоящее изобретение относится в целом к области хранения и извлечения информации и, в частности, к активной платформе хранения для организации, поиска и совместного использования различных типов данных в компьютерной системе.
Уровень техники
В течение последнего десятилетия наблюдался рост емкости индивидуального диска примерно на семьдесят процентов (70%) в год. Закон Мура точно предсказал существенный рост вычислительной мощности центральных процессоров (ЦП), произошедший за эти годы. Технологии проводной и беспроводной связи обеспечили большие возможности соединения и пропускную способность. При условии, что современные тенденции сохранятся, через несколько лет средний портативный компьютер будет иметь емкость хранения около одного терабайта (ТБ), и будет содержать миллионы файлов, и жесткие диски емкостью 500 гигабайт (ГБ) получат широкое распространение.
Потребители используют свои компьютеры, в основном, для связи и для организации личной информации, будь то данные в традиционном стиле личной информационной системы (PIM) или мультимедийные данные, например цифровая музыка или фотографии. Объем цифрового контента и возможность хранения необработанных байтов значительно возросли; однако доступные потребителям способы организации и унификации этих данных не получили адекватного развития. Специалисты в области информационных технологий тратят очень много времени на организацию и совместное использование информации и, согласно некоторым исследованиям, специалисты в области информационных технологий тратят 15-25% своего времени на непродуктивную деятельность, связанную с информацией. Согласно другим исследованиям типичный специалист в области информационных технологий тратит ежедневно около 2,5 часов на поиск информации.
Разработчики и департаменты по информационным технологиям (IT) тратят много времени и денег на построение своих собственных хранилищ данных для обычных абстракций хранения для представления личностей, мест, времен и событий. Это приводит не только к дублированию работы, но и к созданию островов общих данных без каких-либо механизмов общего поиска или совместного использования этих данных. Только представьте, сколько адресных книжек может сегодня существовать на компьютере, на котором установлена операционная система Microsoft Windows. Многие приложения, например клиенты электронной почты и персональные финансовые программы, поддерживают отдельные адресные книжки, и приложения в незначительной степени могут совместно пользоваться данными адресных книжек, которые по отдельности поддерживаются каждой такой программой. Следовательно, финансовая программа (наподобие Microsoft Money) не может совместно использовать адреса получателей денег с адресами, поддерживаемыми в папке контактов электронной почты (например, в Microsoft Outlook). Действительно, многие пользователи имеют несколько устройств, и было бы логично, если бы они синхронизировали свои личные данные между ними и по обширной совокупности дополнительных устройств, включая сотовые телефоны, для таких коммерческих услуг как MSN и AOL; тем не менее, для совместной работы с документами общего пользования в основном приходится присоединять документы к сообщениям электронной почты, т.е. действовать вручную и малоэффективно.
Одна из причин такого недостатка сотрудничества, свойственного традиционным подходам к организации информации в компьютерных системах, сводится к использованию систем на основе файлов, папок и директорий ("файловых систем") для организации совокупностей файлов в директорные иерархические структуры папок на основании абстракции физической организации среды хранения, используемой для хранения файлов. Операционная система Multics, разработанная в 60-х годах, впервые использовала файлы, папки и директории для манипулирования сохраняемыми единицами данных на уровне операционной системы. В частности, Multics использовала символические адреса в иерархии файлов (тем самым введя идею пути к файлу), где физические адреса файлов не были прозрачны для пользователя (приложений и конечных пользователей). Эта файловая система никаким образом не была связана с форматом файла для какого-либо отдельного файла, и отношения между файлами не рассматривались на уровне операционной системы (т.е. не относились к положению файла в иерархии). С появлением Multics сохраняемые данные стали организовывать в файлы, папки и директории на уровне операционной системы. Эти файлы, в общем случае, включают в себя саму иерархию файлов («директорию»), воплощенную в особом файле, поддерживаемом файловой системой. Эта директория, в свою очередь, поддерживает список записей, соответствующих всем остальным файлам в директории и положению узла таких файлов в иерархии (именуемых здесь папками). Таким было состояние техники в течение приблизительно сорока лет.
Хотя файловая система обеспечивает разумное представление информации, размещенной в физической системе хранения компьютера, она, тем не менее, является абстракцией этой физической системы хранения, вследствие чего для использования файлов требуется уровень опосредования (интерпретации) между тем, чем манипулирует пользователь (единицы, имеющие контекст, признаки и отношения к другим единицам), и тем, что обеспечивает операционная система (файлами, папками и директориями). Поэтому пользователям (приложениям и/или конечным пользователям) ничего не остается, как вводить единицы информации в структуру файловой системы, даже если это неэффективно, неадекватно или нежелательно по какой-либо причине. Кроме того, существующим файловым системам мало что известно о структуре данных, хранящихся в отдельных файлах и, в результате, большая часть информации остается запертой в файлах, доступных (и понятных) только для приложений, которые их записали. Таким образом, недостаток схематического описания информации и механизмов манипулирования информацией приводит к созданию бункеров данных с очень малой возможностью совместного использования данных между отдельными бункерами. Например, многие пользователи персональных компьютеров (ПК) имеют более пяти различных хранилищ, в которых содержится информация о людях, с которыми они общаются на некотором уровне, например Outlook Contacts, адреса онлайнового эккаунта, Windows Address Book, Quicken Payees, и списки друзей службы мгновенного обмена сообщениями (IM), поскольку организация файлов представляет значительную трудность для этих пользователей ПК. Поскольку в большинстве существующих файловых систем используется модель вложенных папок для организации файлов и папок, по мере возрастания количества файлов, усилия, необходимые для поддержания гибкой и эффективной схемы организации, многократно возрастают. При этом было бы весьма полезно иметь несколько классификаций одного файла; однако использование жестких или мягких связей в существующих файловых системах весьма неудобно и трудно осуществимо.
Ранее было предпринято несколько неудачных попыток исправить недостатки файловых систем. Некоторые из этих предыдущих попыток предполагали использование контентно-адресуемой памяти для обеспечения механизма, позволяющего обращаться к данным по контенту, а не по физическому адресу. Однако эти усилия оказались безуспешными, поскольку, хотя контентно-адресуемая память оказалась полезной для маломасштабного использования такими устройствами, как блоки кэш-памяти и блоки управления памятью, крупномасштабное использование для таких устройств как физические среды хранения, все же было невозможно по ряду причин и, следовательно, такого решения просто не существует. Были предприняты попытки использовать системы объектно-ориентированной базы данных (OODB), но эти попытки, несмотря на сильные стороны базы данных и хорошие нефайловые представления, оказались неэффективными при обработке файловых представлений и не смогли сравниться по скорости, эффективности и простоте с иерархической структурой на основе папок на уровне системы программно-аппаратного интерфейса. Другие попытки, например попытки использовать SmallTalk (и другие производные), оказались весьма эффективными при обработке файловых и нефайловых представлений, но им не хватало признаков баз данных, необходимых, чтобы эффективно организовывать и использовать отношения, существующие между различными файлами данных, вследствие чего общая эффективность таких систем оказалась неприемлемой. Были попытки использовать BeOS (и другие подобные разработки операционных систем), которые оказались неадекватными при обработке нефайловых представлений - страдали теми же недостатками, что и традиционные файловые системы - несмотря на способность адекватно представлять файлы, обеспечивая в то же время некоторые необходимые признаки баз данных.
Технология баз данных - это другая область техники, в которой существуют сходные трудности. Например, хотя модель реляционной базы данных получила большой коммерческий успех, в действительности, независимые поставщики программного обеспечения (ISV) обычно используют незначительную часть функциональных возможностей программных продуктов реляционной базы банных (например, Microsoft SQL Server). Напротив, большинство приложений взаимодействует с таким продуктом посредством таких простых команд, как "gets" и "puts". Хотя для этого существует ряд очевидных причин, например недоверие к платформе или базе данных, одна ключевая причина, которая часто остается незамеченной, состоит в том, что база данных не всегда обеспечивает именно те абстракции, которые нужны большинству поставщиков коммерческих приложений. Например, тогда как реальный мир оперирует понятием «статей», например, «потребителей» или «порядками» (совместно с внедренными «строчными статьями» порядка в качестве статей в или их самих), реляционные базы данных оперируют только терминами таблиц и строк. Поэтому, в то время как приложению могут потребоваться аспекты согласованности, блокировки, безопасности и/или триггеров на уровне статей (и пр.), в общем случае базы данных обеспечивают эти признаки только на уровне таблиц/строк. Хотя это может хорошо работать, если каждая статья отображается в одну строку в некоторой таблице базы данных, в случае порядка с множественными строчными статьями, по той или иной причине статья в действительности отображается на множественные таблицы и, при этом, простая система реляционной базы данных не вполне обеспечивает правильные абстракции. Поэтому приложение должно построить логику над базой данных для обеспечения этих основных абстракций. Другими словами, основная реляционная модель не обеспечивает достаточной платформы для хранения данных, на которой можно легко разрабатывать приложения более высокого уровня, поскольку основная реляционная модель требует уровня опосредования между приложением и системой хранения, где семантическая структура данных может быть видна в приложении в определенных случаях. Хотя некоторые поставщики баз данных встраивают в свои продукты функциональные возможности более высокого уровня, например, обеспечивая реляционные возможности объектов, новые организационные модели и т.п., ни один из них до сих пор не обеспечил необходимого исчерпывающего решения, причем истинно исчерпывающее решение это то, которое обеспечивает как полезные абстракции модели данных (например, «статьи», «расширения», «отношения» и т.д.) для полезных абстракций домена (например, «личности», «места», «события» и т.д.).
Ввиду вышеуказанных недостатков существующих технологий хранения и баз данных необходима новая платформа хранения, обеспечивающая улучшенную способность к организации, поиску и совместному использованию всех типов данных в компьютерной системе - платформа хранения, которая расширяет платформу данных за пределы существующих файловых систем и систем баз данных и которая призвана быть хранилищем для всех типов данных. Настоящее изобретение удовлетворяет эту потребность.
Сущность изобретения
В нижеследующем разделе «сущность изобретения» предусмотрен обзор различных аспектов изобретения. Он не призван обеспечивать исчерпывающего описания всех важных аспектов изобретения, а также определять объем изобретения. Напротив, этот раздел служит введением в нижеследующие подробное описание и чертежи.
Настоящее изобретение относится к платформе хранения для организации, поиска и совместного использования данных. Платформа хранения согласно настоящему изобретению расширяет понятие хранения данных за пределы существующих файловых систем и систем баз данных и призвана быть хранилищем для всех типов данных, включая структурированные, неструктурированные или частично структурированные данные.
Согласно одному аспекту настоящего изобретения платформа хранения настоящего изобретения содержит хранилище данных, реализованное на машине базы данных. Согласно различным вариантам осуществления настоящего изобретения машина базы данных содержит машину реляционной базы данных с реляционными расширениями объекта. Хранилище данных реализует модель данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных. Конкретные типы данных описаны в схемах, и платформа обеспечивает механизм для расширения множества схем для задания новых типов данных (в сущности подтипы основных типов обеспечиваются схемами). Возможность синхронизации способствует совместному использованию данных между пользователями или системами. Обеспечены возможности, аналогичные файловой системе, которые позволяют хранилищу данных взаимодействовать с существующими файловыми системами, но без ограничения такими традиционными файловыми системами. Механизм отслеживания изменений обеспечивает возможность отслеживать изменения в хранилище данных. Платформа хранения дополнительно содержит набор программных интерфейсов приложения, которые позволяют приложениям осуществлять доступ ко всем вышеупомянутым возможностям платформы хранения и доступ к данным, описанным в схемах.
Согласно другому аспекту изобретения модель данных, реализованная посредством хранилища данных, задает единицы хранения данных в терминах статей, элементов и отношений. Статья является единицей данных, сохраняемой в хранилище данных, и может содержать один или более элементов и отношений. Элемент - это экземпляр типа, содержащий одно или более полей (также именуемых здесь свойствами). Отношение - это связь между двумя статьями (используемые здесь эти и другие конкретные термины могут писаться с заглавной буквы, чтобы их можно было отличить от других терминов, используемых в непосредственной близости; однако нет никакого намерения делать различия между термином, написанным с заглавной буквы, например «Статья», и тем же термином, написанным со строчной буквы, например «статья», и никакие такие различия не предполагаются и не подразумеваются).
Согласно другому аспекту изобретения компьютерная система содержит совокупность Статей, причем каждая Статья содержит дискретную сохраняемую единицу информации, которой может манипулировать система программно-аппаратного интерфейса; совокупность Папок статей, которые образуют организационную структуру упомянутых Статей; и систему программно-аппаратного интерфейса для манипулирования совокупностью Статей, причем каждая Статья принадлежит, по меньшей мере, одной Папке статей и может принадлежать более, чем одной Папке статей.
Согласно другому аспекту изобретения компьютерная система содержит совокупность Статей, причем каждая Статья содержит дискретную сохраняемую единицу информации, которой может манипулировать система программно-аппаратного интерфейса, и Статья или некоторые из значений свойства Статьи вычисляются динамически, а не выводятся из постоянного хранилища. Другими словами, система программно-аппаратного интерфейса не требует сохранения Статьи, и поддерживаются определенные операции, например, способность перечислять текущее множество Статей или способность извлекать Статью по ее идентификатору (который более полно описан в разделах, где описан программный интерфейс приложения или API) платформы хранения - например, Статьей может быть текущее местоположение сотового телефона или температура, считанная датчиком температуры.
Согласно другому аспекту изобретения система программно-аппаратного интерфейса для компьютерной системы, причем упомянутая система программно-аппаратного интерфейса манипулирует совокупностью Статей, дополнительно содержит Статьи, связанные между собой совокупностью Отношений, которыми управляет система программно-аппаратного интерфейса. Согласно другому аспекту изобретения предоставляется система программно-аппаратного интерфейса для компьютерной системы, причем упомянутая система программно-аппаратного интерфейса манипулирует совокупностью дискретных единиц информации, имеющих свойства, понимаемые системой программно-аппаратного интерфейса. Согласно другому аспекту изобретения система программно-аппаратного интерфейса для компьютерной системы содержит схему ядра для задания множества Статей ядра, которые упомянутая система программно-аппаратного интерфейса понимает и может непосредственно обрабатывать в заранее определенном и предсказуемом порядке. Согласно другому аспекту изобретения раскрыт способ манипулирования совокупностью дискретных единиц информации («Статей») в системе программно-аппаратного интерфейса для компьютерной системы, причем способ содержит взаимосвязывание упомянутых Статей посредством совокупности Отношений и управление этими Отношениями на уровне системы программно-аппаратного интерфейса.
Согласно другому признаку изобретения API платформы хранения обеспечивает классы данных для каждой статьи, расширения статьи и отношения, заданных в множестве схем платформы хранения. Кроме того, программный интерфейс приложения обеспечивает множество классов структур, которые задают общее множество поведений для классов данных и которые, совместно с классами данных, обеспечивают основную модель программирования для API платформы хранения. Согласно другому признаку изобретения API платформы хранения обеспечивает упрощенную модель запроса, которая позволяет разработчикам прикладных программ формировать запросы на основании различных свойств статей в хранилище данных, при этом разработчик прикладной программы изолирован от подробностей языка запроса нижележащей машины базы данных. Согласно еще одному аспекту API платформы хранения согласно настоящему изобретению API собирает изменения в статье, внесенные прикладной программой, после чего организует их в правильные обновления, необходимые машине базы данных (или машине хранения любого вида), на которой реализовано хранилище данных. Это позволяет разработчикам прикладных программ производить изменения статьи в памяти, оставляя API сложные аспекты обновлений хранилища данных.
Благодаря своей общей основе хранения и схематизированным данным платформа хранения согласно настоящему изобретению позволяет более эффективно разрабатывать приложение для потребителей, специалистов в области информационных технологий и предприятий. Она обеспечивает богатый и расширяемый программный интерфейс приложения, который не только делает доступными возможности, свойственные этой модели данных, но также охватывает и расширяет существующие файловую систему и методы доступа к базе данных.
Другие признаки и преимущества изобретения следуют из нижеследующего подробного описания изобретения и прилагаемых чертежей.
Краткое описание чертежей
Вышеизложенную сущность изобретения, а также нижеследующее подробное описание изобретения можно лучше понять совместно с прилагаемыми чертежами. В целях иллюстрации изобретения на чертежах показаны иллюстративные варианты осуществления различных аспектов изобретения; однако изобретение не ограничивается раскрытыми конкретными способами и инструментариями. На чертежах:
фиг.1 - блок-схема компьютерной системы, в которую можно включить аспекты настоящего изобретения;
фиг.2 - блок-схема компьютерной системы, разделенной на три компонента: аппаратный компонент, компонент системы программно-аппаратного интерфейса и компонент прикладных программ;
фиг.2А - традиционная древовидная иерархическая структура файлов, сгруппированных в папки в директории в операционной системе на основе файлов;
фиг.3 - блок-схема платформы хранения согласно настоящему изобретению;
фиг.4 - структурное соотношение между Статьями, Папками статей и Категориями согласно различным вариантам осуществления настоящего изобретения;
фиг.5А - блок-схема структуры Статьи;
фиг.5В - блок-схема сложных типов свойств Статьи, показанной на фиг.5А;
фиг.5С - блок-схема Статьи «положение», в которой дополнительно описаны ее сложные типы (перечисленные в явном виде);
фиг.6А - иллюстрирует Статью как подтип Статья в Базовой схеме;
фиг.6В - блок-схема подтипа Статья, показанного в фиг.6А, в которой в явном виде перечислены его собственные типы (помимо его прямых свойств);
фиг.7 - блок-схема Базовой схемы, включающей в себя два ее типа классов верхнего уровня, Item и PropertyBase, и выведенные из них дополнительные типы Базовой схемы;
фиг.8А - блок-схема, иллюстрирующая Статьи в Схеме ядра;
фиг.8В - блок-схема, иллюстрирующая типы свойств в Схеме ядра;
фиг.9 - блок-схема, иллюстрирующая Папку статей, входящие в нее статьи и отношения взаимосвязи между Папкой статей и входящими в нее статьями;
фиг.10 - блок-схема, иллюстрирующая Категорию (которая, в свою очередь, сама является статьей), входящие в нее статьи и отношения взаимосвязи между Категорией и входящими в нее статьями;
фиг.11 - диаграмма, иллюстрирующая иерархию типов ссылки модели данных платформы хранения, согласно настоящему изобретению;
фиг.12 - диаграмма, иллюстрирующая, как классифицирующая отношения, согласно варианту осуществления настоящего изобретения;
фиг.13 - диаграмма, иллюстрирующая механизм извещения, согласно варианту осуществления настоящего изобретения;
фиг.14 - диаграмма, иллюстрирующая пример, в котором две транзакции вставляют новую запись в одно и то же бинарное дерево;
фиг.15 - иллюстрирует процесс обнаружения изменения данных согласно варианту осуществления настоящего изобретения;
фиг.16 - пример дерева директории;
фиг.17 - пример, в котором существующая папка файловой системы на основе директории перемещается в хранилище данных платформы хранения согласно аспекту настоящего изобретения;
фиг.18 - иллюстрирует понятие Папок включения согласно варианту осуществления настоящего изобретения;
фиг.19 - иллюстрирует основную архитектуру API платформы хранения;
фиг.20 - схематически представляет различные компоненты стека API платформы хранения;
фиг.21A и 21B - графическое представление иллюстративной Схемы контактов (Статей и Элементов);
фиг.22 - структура среды выполнения API платформы хранения согласно аспекту настоящего изобретения;
фиг.23 - иллюстрирует выполнение операции FindAll согласно варианту осуществления настоящего изобретения;
фиг.24 - иллюстрирует процесс генерации классов API платформы хранения из схемы платформы хранения согласно аспекту настоящего изобретения;
фиг.25 - схема, на которой основана File API, согласно другому аспекту настоящего изобретения;
фиг.26 - диаграмма формата маски доступа, используемой в целях защиты данных, согласно варианту осуществления настоящего изобретения;
фиг.27 (a), (b), и (c) - изображают новые одинаково защищенные области безопасности, вырезанные из существующей области безопасности, согласно варианту осуществления одного аспекта настоящего изобретения;
фиг.28 - диаграмма, иллюстрирующая понятие вида поиска Статьи, согласно варианту осуществления одного аспекта настоящего изобретения;
фиг.29 - диаграмма иллюстративной иерархии статей согласно варианту осуществления настоящего изобретения.Подробное описание изобретения
Содержание
I. Введение
А. Иллюстративная вычислительная среда
В. Традиционное хранение на основе файлов
II. НОВАЯ ПЛАТФОРМА ХРАНЕНИЯ ДЛЯ ОРГАНИЗАЦИИ, ПОИСКА И СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ ДАННЫХ
А. Глоссарий
В. Обзор платформы хранения
С. МОДЕЛЬ ДАННЫХ
1. Статьи
2. Идентификация статьи
а) Ссылки на статью
(1) ItemIDReference
(2) ItemPathReference
b) Иерархия типов ссылки
3. Папки статей и Категории
4. Схемы
a) Базовая схема
b) Схема ядра
5. Отношения
a) Декларация отношения
b) Отношение поддержки
с) Отношения внедрения
е) Правила и ограничения
f) Упорядочение отношений
6. Расширяемость
a) Расширения статьи
b) Расширение типов вложенных элементов
D. МАШИНА БАЗЫ ДАННЫХ
1. Реализация хранилища данных с использованием UDT
2. Отображение статей
3. Отображение расширений
4. Отображение вложенных элементов
5. Идентификация объекта
6. Именование объектов SQL
7. Именование столбцов
8. Виды поиска
а) Статья
(1) Главный вид поиска статьи
(2) Типизированные виды поиска статьи
b) Расширения статьи
(1) Главный вид поиска расширения
(2) Типизированные виды поиска расширения
c) Вложенные элементы
d) Отношения
(1) Главный вид поиска отношения
(2) Виды поиска экземпляра отношения
9. Обновления
10. Отслеживание изменений и надгробия
а) Отслеживание изменений
(1) Отслеживание изменений в «главных» видах поиска
(2) Отслеживание изменений в «типизированных» видах поиска
b) Надгробия
(1) Надгробия статей
(2) Надгробия расширений
(3) Надгробия отношений
(4) Очистка надгробий
11. API и функции помощника
а) Функция [System.Storage].GetItem
b) Функция [System.Storage].GetExtension
с) Функция [System.Storage].GetRelationship
12. Метаданные
а) Метаданные схемы
b) Метаданные экземпляра
Е. Безопасность
1. Обзор
2. Подробное описание модели безопасности
a) Структура описателя безопасности
(1) Формат маски доступа
(2) Общие права доступа
(3) Стандартные права доступа
b) Права, зависящие от статьи
(1) Права, зависящие от объекта «файл» и «директория»
(2) WinFSItemRead
(3) WinFSItemReadAttributes
(4) WinFSItemWriteAttributes
(5) WinFSItemWrite
(6) WinFSItemAddLink
(7) WinFSItemDeleteLink
(8) Права на удаление статьи
(9) Права на копирование статьи
(10) Права на перемещение статьи
(11) Права на просмотр политики безопасности на статье
(12) Права на изменение политики безопасности на статье
(13) Права, не имеющие прямого эквивалента
3. Реализация
а) Создание новой статьи в контейнере
b) Добавление к статье явного ACL
с) Добавление к статье отношения поддержки
d) Удаление отношения поддержки из статьи
е) Удаление явного ACL из статьи
f) Изменение ACL, связанного со статьей
F. Извещения и отслеживание изменений
1. Сохранение событий изменения
а) События
b) Наблюдатели
2. Механизм отслеживания изменений и генерации извещений
а) Отслеживание изменений
b) Управление метками времени
с) Обнаружение изменения данных - обнаружение событий
G. Синхронизация
1. Синхронизация между платформами хранения
а) Приложения управления синхронизацией
b) Аннотация схемы
с) Конфигурация синхронизации
(1) Папка сообщества - отображения
(2) Профили
(3) Расписания
d) Обработка конфликтов
(1) Обнаружение конфликта
(а) Конфликты на основе знания
(b) Конфликты на основе ограничений
(2) Обработка конфликтов
(а) Автоматическое разрешение конфликтов
(b) Регистрация конфликтов
(с) Инспектирование и разрешения конфликтов
(d) Сходимость копий и распространение разрешений конфликтов
2. Синхронизация с хранилищами данных, не связанными с платформой хранения
а) Службы синхронизации
(1) Перечисление изменений
(2) Применение изменений
(3) Разрешение конфликтов
b) Реализация адаптера
3. Безопасность
4. Управляемость
Н. Возможность взаимодействия с традиционными файловыми системами
1. Модель возможности взаимодействия
2. Особенности хранилища данных
а) Не том
b) Структура хранилища
с) Не все файлы мигрируют
d) Доступ из пространства имен NTFS к файлам платформы хранения
е) Ожидаемые буквы пространства имен/привода
I. API ПЛАТФОРМЫ ХРАНЕНИЯ
1. Обзор
2. Именование и области действия
3. Компоненты API платформы хранения
4. Классы данных
5. Структура среды выполнения
а) Классы структуры среды выполнения
(1) ItemContext
(2) ItemSearcher
(a) Целевой тип
(b) Фильтры
(с) Подготовка поисков
(d) Опции Find
b) Структура среды выполнения в процессе работы
(1) Открытие и закрытие объектов ItemContext
(2) Поиск объектов
(а) Опции поиска
(b) FindOne и FindOnly
(с) Короткие вызовы поиска на ItemContext
(d) Нахождение по ИД или пути
(е) Шаблон GetSearcher
6. Безопасность
7. Поддержка отношений
а) Базовые типы отношений
(1) Класс Relationship
(2) Класс ItemReference
(3) Класс ItemIdReference
(4) Класс ItemPathReference
(5) Структура RelationshipId
(6) Класс VirtualRelationshipCollection
b) Сгенерированные типы отношений
(1) Сгенерированные типы отношений
(2) Класс RelationshipPrototype
(3) Класс RelationshipPrototypeCollection
c) Поддержка отношений в классе Item
(1) Класс Item
(2) Класс RelationshipCollection
d) Поддержка отношений в выражениях поиска
(1) Переход от статей к отношениям
(2) Переход от отношений к статьям
(3) Комбинирование обхода отношений
е) Примеры использования поддержки отношений
(1) Поиск отношений
(2) Навигация от отношения к исходной и целевой статьям
(3) Навигация от исходных статей к отношениям
(4) Создание отношений (и статей)
(5) Удаление отношений (и статей)
8. «Расширение» API платформы хранения
a) Поведения домена
b) Поведения добавления значений
с) Поведения добавления значения как поставщики услуг
9. Структура среды разработки
10. Формализм запросов
а) Основы фильтрации
b) Приведения типов
11. Удаленные операции
а) Локальная/удаленная прозрачность в API
b) Реализация удаленных операций в платформе хранения
с) Доступ к хранилищам, не относящимся к платформе хранения
d) Отношение к DFS
е) Отношение к GXA/Indigo
12. Ограничения
13. Совместное использование
а) Представление совместно используемого ресурса
b) Управление совместно используемыми ресурсами
с) Доступ к совместно используемым ресурсам
d) Обнаружимость
14. Семантика Find
15. API Contacts платформы хранения
а) Обзор System.Storage.Contact
b) Поведения домена
16. API File платформы хранения
а) Введение
(1) Отражение тома NTFS в платформе хранения
(2) Создание файлов и директорий в пространстве имен платформы хранения
b) Схема файлов
с) Обзор System.Storage.Files
d) Примеры кода
(1) Открытие файла и запись в него
(2) Использование запросов
e) Поведения домена
J. Заключение
I. Введение
Предмет настоящего изобретения описан конкретно, чтобы удовлетворять установленным требованиям. Однако само по себе описание не призвано ограничивать объем этого патента. Напротив, изобретатели предусматривают, что заявленный предмет можно воплощать и другими способами, включающими в себя другие этапы или сочетания этапов, аналогичных описанным в этом документе, совместно с другими современными или будущими технологиями. Кроме того, хотя термин «этап» можно использовать здесь в значении различных элементов применяемых способов, термин не следует интерпретировать как подразумевающий какой-либо конкретный порядок среди или между различными раскрытыми здесь этапами, если и пока порядок отдельных этапов не описан в явном виде.
А. Иллюстративная вычислительная среда
На компьютере могут выполняться многочисленные варианты осуществления настоящего изобретения. Фиг.1 и нижеследующее описание призваны обеспечивать краткое общее описание подходящей среды вычислительной системы, в которой можно реализовать изобретение. Хотя это не требуется, различные аспекты изобретения можно описать в общем контексте компьютерно-выполняемых команд, например, программных модулей, выполняемых компьютером, например, клиентской рабочей станцией или сервером. В общем случае, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., которые выполняют определенные задачи или реализуют определенные абстрактные типы данных. Кроме того, изобретение можно осуществлять на практике в других конфигурациях компьютерной системы, включая карманные устройства, многопроцессорные системы, микропроцессорную или программируемую бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры, и т.п. Изобретение также можно применять на практике в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, связанными друг с другом посредством сети передачи данных. В распределенной вычислительной среде программные модули размещаются как на локальных, так и на удаленных компьютерных запоминающих устройствах.
Согласно фиг.1 иллюстративная вычислительная система общего назначения включает в себя традиционный персональный компьютер 20 и т.п., включающий в себя процессор 21, системную память 22 и системную шину 23, которая подключает различные компоненты системы, в том числе системную память, к процессору 21. Системная шина 23 может относиться к любому из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину с использованием различных шинных архитектур. Системная память включает постоянную память (ПЗУ) 24 и оперативную память (ОЗУ) 25. Базовая система ввода/вывода (BIOS) 26, содержащая основные процедуры, которые помогают переносить информацию между элементами компьютера, например, при запуске, обычно хранятся в ПЗУ 24. Персональный компьютер 20 также может включать в себя привод 27 жесткого диска, который считывает с или записывает на стационарный жесткий диск, который не показан, привод 28 магнитного диска, который считывает с или записывает на сменный магнитный диск 29, и привод 30 оптического диска, который считывает с или записывает на сменный оптический диск 31, например, CD-ROM или другой оптический носитель. Привод 27 жесткого диска, привод 28 магнитного диска и привод 30 оптического диска подключены к системной шине 23 посредством интерфейса 32 привода жесткого диска, интерфейса 33 привода магнитного диска и интерфейса 34 привода оптического диска, соответственно. Приводы и соответствующие компьютерно-считываемые среды обеспечивают энергонезависимое хранение компьютерно-считываемых команд, структур данных, программных модулей и других данных для персонального компьютера 20. Хотя в описанном здесь иллюстративном варианте осуществления используется жесткий диск, сменный магнитный диск 29 и сменный оптический диск 31, специалистам в данной области очевидно, что в иллюстративной форме также можно использовать другие типы компьютерно-считываемых носителей, на которых могут храниться данные, к которым может осуществлять доступ компьютер, например, магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли, блоки оперативной памяти (ОЗУ), блоки постоянной памяти (ПЗУ) и т.п. Аналогично, иллюстративная среда может также включать в себя многочисленные типы устройств слежения, например тепловые датчики и системы безопасности и пожарной сигнализации, и другие источники информации. На жестком диске, магнитном диске 29, оптическом диске 31, в ПЗУ 24 или ОЗУ 25 могут храниться различные программные модули, в том числе операционная система 35, одна или несколько прикладных программ 36, другие программные модули 37 и программные данные 38. Пользователь может вводить команды и информацию в персональный компьютер 20 через устройства ввода, например клавиатуру 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую антенну, сканер и т.п. Эти и другие устройства ввода часто подключены к процессору 21 через интерфейс 46 последовательного порта, который подключен к системной шине, но могут подключаться посредством других интерфейсов, например параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или устройство отображения другого типа также подключен к системной шине 23 через интерфейс, например видеоадаптер 48. Помимо монитора 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), например громкоговорители и принтеры. Иллюстративная система, показанная на фиг.1, также включает в себя хост-адаптер 55, шину 56 интерфейса малых компьютерных систем (SCSI) и внешнее запоминающее устройство 62, подключенное к шине 56 SCSI.
Персональный компьютер 20 может работать в сетевой среде с использованием логических соединений с одним или несколькими удаленными компьютерами, например удаленным компьютером 49. Удаленный компьютер 49 может представлять собой другой персональный компьютер, сервер, маршрутизатор, сетевой ПК, равноправное устройство или другой общий сетевой узел, и обычно включает в себя многие или все элементы, описанные выше применительно к персональному компьютеру 20, хотя на фиг.1 показано только запоминающее устройство 50. Логические соединения, описанные на фиг.1, включают в себя локальную сеть (ЛС) 51 и глобальную сеть (ГС) 52. Такие сетевые среды обычно применяются в учреждениях, компьютерных сетях в масштабе предприятия, интрасетях и Интернете.
При использовании в сетевой среде ЛС персональный компьютер 20 подключен к ЛС 51 через сетевой интерфейс или адаптер 53. При использовании в сетевой среде ГС, персональный компьютер 20 обычно включает в себя модем 54 или другое средство установления связи в глобальной сети 52, например Интернете. Модем 54, который может быть внутренним или внешним, может быть подключен к системной шине 23 через интерфейс 46 последовательного порта. В сетевой среде программные модули, описанные применительно к персональному компьютеру 20, или часть из них могут храниться в удаленном запоминающем устройстве. Заметим, что показанные сетевые соединения являются иллюстративными, и можно использовать другие средства установления линии связи между компьютерами.
Согласно фиг.2 компьютерную систему 200 можно грубо разделить на три компонента: аппаратный компонент 202, компонент 204 системы программно-аппаратного интерфейса и компонент 206 прикладных программ (также именуемый здесь в некоторых контекстах «пользовательским компонентом» или «программным компонентом»).
В различных вариантах осуществления компьютерной системы 200, согласно фиг.1, аппаратный компонент 202 может содержать центральный процессор (ЦП) 21, память (ПЗУ 24 и ОЗУ 25), базовую систему ввода/вывода (BIOS) 26 и различные устройства ввода/вывода (I/O), например клавиатуру 40, мышь 42, монитор 47 и/или принтер (не показан) и пр. Аппаратный компонент 202 содержит основную физическую инфраструктуру для компьютерной системы 200.
Компонент 206 прикладных программ содержит различные прикладные программы, включая, но без ограничения, компиляторы, системы баз данных, текстовые редакторы, коммерческие программы, видеоигры и т.д. Прикладные программы обеспечивают средства, позволяющие использовать компьютерные ресурсы для решения проблем, обеспечения решений и обработки данных для различных пользователей (машин, других компьютерных систем и/или конечных пользователей).
Компонент системы программно-аппаратного интерфейса 204 содержит (и, в некоторых вариантах осуществления, может содержать исключительно) операционную систему, которая сама по себе содержит, в большинстве случаев, оболочку и ядро. "Операционная система" (ОС) это особая программа, которая выступает в качестве посредника между прикладными программами и компьютерным оборудованием. Компонент 204 системы программно-аппаратного интерфейса также может содержать менеджер виртуальной машины (VMM), общую среду выполнения языка (CLR) или ее функциональный эквивалент, виртуальную машину Java (JVM), или ее функциональный эквивалент, или другие программные компоненты вместо или помимо операционной системы в компьютерной системе. Целью системы программно-аппаратного интерфейса является обеспечение среды, в которой пользователь может выполнять прикладные программы. Цель любой системы программно-аппаратного интерфейса состоит в том, чтобы сделать компьютерную систему удобной для использования, а также эффективно использовать компьютерное оборудование.
Система программно-аппаратного интерфейса обычно загружается в компьютерную систему при запуске, после чего управляет всеми прикладными программами в компьютерной системе. Прикладные программы взаимодействуют с системой программно-аппаратного интерфейса, запрашивая услуги через программный интерфейс приложения (API). Некоторые прикладные программы позволяют конечным пользователям взаимодействовать с системой программно-аппаратного интерфейса через пользовательский интерфейс, например командный язык или графический интерфейс пользователя (ГИП).
Система программно-аппаратного интерфейса традиционно осуществляет различные услуги для приложений. В многозадачной системе программно-аппаратного интерфейса, где могут одновременно выполняться несколько программ, система программно-аппаратного интерфейса определяет, какие приложения должны действовать в каком порядке и сколько времени отпущено на каждое приложение до переключения на другое приложение в порядке очереди. Система программно-аппаратного интерфейса также управляет совместным использованием внутренней памяти среди множественных приложений и оперирует вводом и выводом в и из подключенных аппаратных устройств, например жестких дисков, принтеров и портов коммутируемого доступа. Система программно-аппаратного интерфейса также направляет каждому приложению (и, в определенном случае, конечному пользователю) сообщения относительно статуса операций и о любых ошибках, которые могут произойти. Система программно-аппаратного интерфейса также может брать на себя управление пакетными заданиями (например, печати), благодаря чему инициирующее приложение освобождается от этой работы и может возобновлять другую обработку и/или операции. На компьютерах, которые могут обеспечивать параллельную обработку, система программно-аппаратного интерфейса также управляет делением программы, чтобы она одновременно выполнялась на более чем одном процессоре.
Оболочка системы программно-аппаратного интерфейса (именуемая здесь просто «оболочка») это интерактивный интерфейс конечного пользователя к системе программно-аппаратного интерфейса (оболочку также можно именовать «интерпретатором команд» или, в операционной системе, «оболочкой операционной системы»). Оболочка является внешним слоем системы программно-аппаратного интерфейса, к которому могут непосредственно обращаться прикладные программы и/или конечные пользователи. В отличие от оболочки ядро - это наиболее глубокий слой системы программно-аппаратного интерфейса, который непосредственно взаимодействует с аппаратными компонентами.
Хотя предполагается, что многочисленные варианты осуществления настоящего изобретения особенно пригодны для компьютерных систем, ничто в этом документе не призвано ограничивать изобретение такими вариантами осуществления. Напротив, используемый здесь термин "компьютерная система" призван охватывать любые и все устройства, способные хранить и обрабатывать информацию и/или способные использовать сохраненную информацию для управления поведением или выполнением самого устройства, независимо от того, являются ли такие устройства по своей природе электронными, механическими, логическими или виртуальными.
В. Традиционное хранение на основе файлов
В большинстве современных компьютерных систем «файлы» - это единицы сохраняемой информации, которые могут включать в себя систему программно-аппаратного интерфейса, а также прикладные программы, наборы данных и пр. Во всех современных системах программно-аппаратного интерфейса (Windows, Unix, Linux, Mac OS, системах виртуальных машин и т.п.) файлы являются основными дискретными (сохраняемыми и извлекаемыми) единицами информации (например, данных, программ и т.п.), которыми может манипулировать система программно-аппаратного интерфейса. Группы файлов обычно организуются в «папки». В Microsoft Windows, Macintosh OS и других системах программно-аппаратного интерфейса папка представляет собой коллекцию файлов, которые можно извлекать, перемещать и иначе манипулировать как отдельными единицами информации. Эти папки, в свою очередь, организуются в древовидную иерархическую структуру, именуемую «директорией» (более подробно рассмотренную ниже). В некоторых других системах программно-аппаратного интерфейса, например DOS, z/OS и большинстве операционных систем на базе Unix, термины «директория» и/или «папка» взаимозаменяемы, и в ранних компьютерных системах Apple (например, Apple IIe) вместо термина «директория» используется термин «каталог»; однако здесь все эти термины взаимозаменяемы и рассматриваются как синонимы и призваны дополнительно включать в себя все остальные эквивалентные термины и ссылки на иерархические структуры хранения информации и их компоненты папок и файлов.
Традиционно директория (именуемая также директорией файлов) представляет собой иерархическую структуру, в которой файлы сгруппированы в папки, и папки, в свою очередь, организованы согласно относительным узловым положениям, которые образуют дерево директории. Например, согласно фиг.2А, базовая папка файловой системы на основе DOS (или «корневая директория») 212 может содержать совокупность папок 214, каждая из которых может дополнительно содержать дополнительные папки (в качестве «подпапок» конкретной папки) 216, и каждая из них также может содержать дополнительные папки 218, и так до бесконечности. Каждая из этих папок может иметь один или более файлов 220, хотя, на уровне системы программно-аппаратного интерфейса, отдельные файлы в папке не имеют ничего общего кроме их положения в древовидной иерархии. Неудивительно, что этот подход к организации файлов в иерархии папок косвенно отражает физическую организацию типичных сред хранения, используемых для хранения этих файлов (например, жестких дисков, флоппи-дисков, CD-ROM и т.д.).
Помимо вышеизложенного, каждая папка является контейнером для своих подпапок и своих файлов, т.е. каждая папка имеет свои подпапки и файлы. Например, когда система программно-аппаратного интерфейса удаляет папку, подпапки и файлы этой папки также удаляются (которые, в случае каждой подпапки, дополнительно включает в себя свои собственные подпапки и файлы рекурсивно). Аналогично, каждый файл обычно принадлежит только одной папке, и, хотя файл можно копировать, и копия может находиться в другой папке, копия файла сама по себе является отличной и отдельной единицей, которая не имеет прямой связи с оригиналом (например, изменения исходного файла не отражаются в файле-копии на уровне системы программно-аппаратного интерфейса). В этой связи файлы и папки имеют характерную «физическую» природу, поскольку папки рассматриваются как физические контейнеры, и файлы рассматриваются как дискретные и отдельные физические элементы в этих контейнерах.
II. НОВАЯ ПЛАТФОРМА ХРАНЕНИЯ ДЛЯ ОРГАНИЗАЦИИ, ПОИСКА И СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ ДАННЫХ
Настоящее изобретение относится к платформе хранения для организации, поиска и совместного использования данных. Платформа хранения настоящего изобретения расширяет платформу данных за пределы всех видов рассмотренных выше существующих файловых систем и систем баз данных и предназначена быть хранилищем для всех типов данных, включая новую форму данных, так называемых Статей.
А. Глоссарий
Следующие термины, используемые здесь и в формуле изобретения, имеют следующие значения:
«Статья» - это единица сохраняемой информации, доступная системе программно-аппаратного интерфейса, которая, в отличие от простого файла, является объектом, имеющим основной набор свойств, которые в целом поддерживаются по всем объектам, которые оболочка системы программно-аппаратного интерфейса представляет конечному пользователю. Статьи также имеют свойства и отношения, которые в целом поддерживаются по всем типам статей, включая признаки, которые позволяют вводить новые свойства и отношения (и рассмотренные более подробно ниже).
"Операционная система" (ОС) - это особая программа, которая выступает в качестве посредника между прикладными программами и компьютерным оборудованием. Операционная система содержит, в большинстве случаев, оболочку и ядро.
"Система программно-аппаратного интерфейса" - это программное обеспечение или объединение оборудования и программного обеспечения, которое служит интерфейсом между нижележащими аппаратными компонентами компьютерной системы и приложениями, которые выполняются на компьютерной системе. Система программно-аппаратного интерфейса обычно содержит (и, в некоторых вариантах осуществления, может содержать исключительно) операционную систему. Система программно-аппаратного интерфейса также может содержать менеджер виртуальной машины (VMM), общую среду выполнения языка (CLR) или ее функциональный эквивалент, виртуальную машину Java (JVM), или ее функциональный эквивалент, или другие программные компоненты вместо или помимо операционной системы в компьютерной системе. Целью системы программно-аппаратного интерфейса является обеспечение среды, в которой пользователь может выполнять прикладные программы. Цель любой системы программно-аппаратного интерфейса состоит в том, чтобы сделать компьютерную систему удобной для использования, а также эффективно использовать компьютерное оборудование.
В. Обзор платформы хранения
Согласно фиг.3, платформа хранения 300 согласно настоящему изобретению содержит хранилище данных 302, реализованное на машине базы данных 314. Согласно одному варианту осуществления машина базы данных содержит машину реляционной базы данных с реляционными расширениями объекта. Согласно одному варианту осуществления машина реляционной базы данных 314 содержит машину реляционной базы данных Microsoft SQL Server.
Хранилище данных 302 реализует модель данных 304, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных. Конкретные типы данных описаны в схемах, например схемах 340, и платформа хранения 300 обеспечивает инструменты 346 для развертывания этих схем, а также для расширения этих схем, что более полно описано ниже.
Механизм 306 отслеживания изменений, реализованный в хранилище данных 302, обеспечивает возможность отслеживания изменений в хранилище данных. Хранилище данных 302 также обеспечивает защитные возможности 308 и возможность 310 выдвижения/задвигания, более подробно рассмотренные ниже. Хранилище данных 302 также обеспечивает набор программных интерфейсов приложения 312, которые открывают возможности хранилища данных 302 другим компонентам платформы хранения и прикладным программам (например, прикладным программам 350a, 350b и 350c), которые используют платформу хранения.
Платформа хранения согласно настоящему изобретению дополнительно содержит программные интерфейсы приложений (API) 322, которые позволяют прикладным программам, например прикладным программам 350a, 350b и 350c, осуществлять доступ ко всем вышеупомянутым возможностям платформы хранения и осуществлять доступ к данным, описанным в схемах. API 322 платформы хранения могут использоваться прикладными программами совместно с другими API, например, API 324 DB OLE и API 326 Win32 Microsoft Windows.
Платформа хранения 300 согласно настоящему изобретению может предоставлять разнообразные услуги 328 прикладным программам, включая услугу синхронизации 330, которая облегчает совместное использование данных между пользователями или системами. Например, услуга синхронизации 330 может обеспечивать возможность взаимодействия с другими хранилищами данных 340, имеющими тот же формат, что и хранилище данных 302, а также доступа к хранилищам данных 342, имеющим другие форматы. Платформа хранения 300 также обеспечивает возможности файловой системы, которые допускают возможность взаимодействия хранилища данных 302 с существующими файловыми системами, например, файловой системой 318 NTFS Windows.
В, по меньшей мере, некоторых вариантах осуществления платформа хранения 320 может также обеспечивать прикладные программы с дополнительными возможностями, позволяющими оперировать данными и обеспечивающими взаимодействие с другими системами. Эти возможности могут быть воплощены в виде дополнительных услуг 328, например, услуги 334 Info Agent и услуги 332 извещения, а также в виде других утилит 336.
В, по меньшей мере, некоторых вариантах осуществления платформа хранения воплощена в системе программно-аппаратного интерфейса компьютерной системы или составляет ее неотъемлемую часть. Например, и без ограничения, платформа хранения согласно настоящему изобретению может быть воплощена в операционной системе, менеджере виртуальной машины (VMM), общей среды выполнения языка (CLR), или ее функционального эквивалента, или виртуальной машины Java (JVM), или ее функционального эквивалента, или составлять их неотъемлемую часть.
Благодаря своей общей основе хранения и схематизированным данным платформа хранения согласно настоящему изобретению позволяет более эффективно разрабатывать приложение для потребителей, специалистов в области информационных технологий и предприятий. Она обеспечивает богатую и расширяемую область программирования, которая не только делает доступными возможности, свойственные этой модели данных, но также охватывает и расширяет существующие файловую систему и методы доступа к базе данных.
В нижеследующем описании и согласно различным фигурам платформа хранения 300 настоящего изобретения может именоваться "WinFS." Однако это название платформы хранения используется только для удобства описания и не предполагает никакого ограничения.
С. МОДЕЛЬ ДАННЫХ
Хранилище данных 302 платформы хранения 300 настоящего изобретения реализует модель данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных, находящихся в хранилище. В модели данных согласно настоящему изобретению, «статья» является основной единицей хранения информации. Модель данных обеспечивает механизм декларирования Статей и Расширений статьи и для задания отношений между Статьями и для организации Статей в Папках статей и в Категориях, что более подробно описано ниже.
Модель данных опирается на два примитивных механизма, Типы и Отношения. Типы - это структуры, которые обеспечивают формат, определяющий форму экземпляра Типа. Формат выражается в виде упорядоченного множества Свойств. Свойство - это имя для значения или множества значений данного Типа. Например, тип USPostalAddress (почтовый адрес США) может иметь свойства Street (улица), City (город), Zip (индекс), State (штат), причем значения Street, City и State имеют тип String (строка), а значение Zip имеет тип Int32. Street может быть многозначным (т.е. иметь множество значений), благодаря чему свойство Street может иметь больше одного значения. Система задает определенные примитивные типы, которые можно использовать совместно с другими типами, которые включают в себя String, Binary, Boolean, Int16, Int32, Int64, Single, Double, Byte, DateTime, Decimal and GUID. Свойства Типа можно задавать с использованием любого из примитивных типов или (с некоторыми ограничениями, указанными ниже) любого из построенных типов. Например, можно задать Тип Location (положение), который имеет Свойства Coordinate (координаты) и Address (адрес), где Свойство Address имеет вышеописанный тип USPostalAddress. Свойства также могут быть обязательными или необязательными.
Можно задавать отношения, представляющие отображение между множествами экземпляров двух типов. Например, можно задать Отношение между Типом Person (личность) и Типом Location (место), именуемое LivesAt (живет в), которое указывает, кто где живет. Отношение имеет имя, две концевые точки, а именно: исходная концевая точка и целевая концевая точка. Отношения могут также иметь упорядоченное множество свойств. Исходная и целевая концевые точки имеют Имя и Тип. Например, Отношение LivesAt имеет Источник, именуемый Жилец (Occupant) типа Person и Цель, именуемый Местожительством (Dwelling) типа Location и, кроме того, имеет свойства StartDate (начальная дата) и EndDate (конечная дата), указывающие период времени, в течение которого жилец проживает по данному месту жительства. Заметим, что человек может проживать по нескольким местам жительства в течение времени, и местожительство может иметь нескольких жильцов, поэтому, наиболее вероятно, место для помещения информации StartDate и EndDate находится на самом отношении.
Отношения задают отношение между экземплярами, которое ограничивается типами, заданными как типы концевых точек. Например, отношение LivesAt не может быть отношением, в котором Жильцом является Автомобиль, поскольку Автомобиль не является Личностью.
Модель данных позволяет задавать отношение подтип-супертип между типами. Отношение подтип-супертип, также известное как отношение BaseType (базовый тип), задается таким образом, что, если Тип А является базовым типом для Типа В, справедливо утверждение, что каждый экземпляр В также является экземпляром А. Это можно выразить и так, что каждый экземпляр, который соответствует В, также должен соответствовать А. Если, например, A имеет свойство Name (имя) типа String, а В имеет свойство Age (возраст) типа Int16, то экземпляр В должен иметь как Name, так и Age. Иерархию типов можно предусмотреть как дерево, в качестве корня которого выступает один супертип. Ветви от корня обеспечивают подтипы первого уровня, ветви на этом уровне обеспечивают подтипы второго уровня и т.д. до краевых подтипов, которые сами не имеют подтипов. Дерево не обязано быть однородным по глубине, но не может содержать циклов. Данный Тип может иметь нуль или много подтипов и нуль или один супертип. Данный экземпляр может соответствовать, самое большее, одному типу совместно с супертипами данного типа. Другими словами, для данного экземпляра на любом уровне в дереве экземпляр может соответствовать, самое большее, одному подтипу на этом уровне.
Тип называется абстрактным, если экземпляры типа также должны быть экземпляром подтипа типа.
1. Статьи
Статья это единица сохраняемой информации, доступная системе программно-аппаратного интерфейса, которая, в отличие от простого файла, является объектом, имеющим основной набор свойств, которые в целом поддерживаются по всем объектам, которые платформа хранения представляет конечному пользователю или прикладной программе. Статьи также имеют свойства и отношения, которые в целом поддерживаются по всем типам статей, включая признаки, которые позволяют вводить новые свойства и отношения, что рассмотрено ниже.
Статьи являются объектами общих операций, таких как копирование, удаление, перемещение, открытие, печать, резервное сохранение, дублирование и т.д. Статьи являются единицами, которые можно сохранять и извлекать, и все формы сохраняемой информации, которой манипулирует платформа хранения, существуют в виде Статей, свойств Статей или Отношений между Статьями, каждое из которых более подробно рассмотрено ниже.
Статьи призваны представлять относящиеся к реальному миру и легко понимаемые единицы данных, как то: Контакты, Личности, Услуги, Места, Документы (всевозможных сортов) и т.д. На фиг.5А показана блок-схема структуры Статьи. Неспецифицированное имя Статьи это "Location". Специфицированное имя Статьи это "Core.Location", которое указывает, что структура этой Статьи задана как конкретный тип Статьи в Схеме ядра (схема ядра более подробно рассмотрена ниже.)
Статья положения имеет свойство или свойства, включающие в себя EAddress, MetropolitanRegion, Neighborhood и PostalAddress. Конкретный тип свойства для каждого из них указан непосредственно после имени свойства и отделен от имени свойства двоеточием (":"). Справа от имени типа количество значений, разрешенных для этого типа свойства, указано в квадратных скобках ("[ ]"), причем звездочка ("*") справа от двоеточия (":") указывает неопределенное и/или неограниченное количество («много»). «1» справа от двоеточия указывает, что может быть, самое большее, одно значение. Нуль («0») слева от двоеточия указывает, что свойство является необязательным (может вовсе не иметь значения); «1» слева от двоеточия указывает, что должно быть, по меньшей мере, одно значение (свойство обязательное). Neighborhood и MetropolitanRegion имеют тип "nvarchar" (или эквивалентные), который является предпочтительным типом данных или «простым типом» (что указано здесь отсутствием заглавной буквы). Однако EAddresses и PostalAddresses являются свойствами заданных типов или "сложных типов" (что обозначено здесь заглавной буквой) типов EAddress и PostalAddress соответственно. Сложный тип - это тип, который выведен из одного или более простых типов данных и/или из других сложных типов. Сложные типы для свойств Статьи также образуют "вложенные элементы", поскольку детали сложного типа вложены в прямую статью для задания ее свойств, и информация, относящаяся к этим сложным типам, поддерживается посредством статьи, которая имеет эти свойства (в границах Статьи, которые описаны ниже). Эти понятия определения типов общеизвестны и очевидны специалистам в данной области.
На фиг.5В показана блок-схема, иллюстрирующая сложные типы свойств PostalAddress и EAddress. Тип свойства PostalAddress определяет, что Статья со свойством типа PostalAddress ожидаемо имеет нуль или одно значение City, нуль или одно значение CountryCode, нуль или одно значение MailStop и любое количество (от нуля до многих) PostalAddressType и т.д. и т.п. Таким образом, задается форма данных для конкретного свойства в Статье. Хотя в данной заявке это используется в необязательном порядке, другой способ представления сложных типов в Статье «положение» состоит в том, чтобы извлекать Статью с индивидуальными свойствами каждого сложного типа из перечисленных здесь. На фиг.5С показана блок-схема, иллюстрирующая Статью «положение», в которой ее сложные типы дополнительно описаны. Однако следует понимать, что это альтернативное представление Статьи «положение» на этой фиг.5С относится к именно той Статье, которая проиллюстрирована на фиг.5А. Платформа хранения согласно настоящему изобретению также позволяет определение подтипов, благодаря чему один тип свойства может быть подтипом другого (где один тип свойства наследует свойства другого, родительского типа свойства).
Аналогичные, но отличные от свойств и их типов свойств, Статьи внутренне представляют свои собственные Типы статьи, которые также могут подлежать определению подтипов. Другими словами, платформа хранения согласно нескольким вариантам осуществления настоящего изобретения позволяет Статье быть подтипом другой Статьи (благодаря чему одна статья наследует свойства другой, родительской статьи). Кроме того, для различных вариантов осуществления настоящего изобретения каждая статья является подтипом "Item" («статья») типа статьи, который является первым и основным типом статьи, найденным в Базовой схеме (базовая схема также будет подробно рассмотрена ниже), на фиг.6А показана Статья, в данном примере Статья «положение», как подтип типа статьи «Статья», найденного в Базовой схеме. На этом чертеже стрелка указывает, что Статья «положение» (как и все остальные Статьи) является подтипом типа статьи «Статья». Тип статьи «Статья», как основная Статья, из которой выводятся все остальные статьи, имеет ряд важных свойств, например, ItemId, и различные метки времени, благодаря чему задает стандартные свойства всех Статей в операционной системе. На фиг.6А, эти свойства типа статьи «Статья» наследуются статьей «положение» и, таким образом, становятся свойствами статьи «положение».
Хотя способ представления свойств в Статье «положение», унаследованных из типа статьи «Статья», состоит в извлечении статьи «Положение» с индивидуальными свойствами каждого типа свойства из указанной здесь родительской Статьи. На фиг.6В показана блок-схема, иллюстрирующая Статью «положение», в которой, помимо его прямых свойств, описаны унаследованные ей типы. Следует заметить и понимать, что эта Статья является той же Статьей, которая проиллюстрирована на фиг.5А, хотя в данной фигуре статья «положение» показана со всеми своими свойствами, как прямыми, показанными на этой фигуре и фиг.5А, так и унаследованными, показанными на этой фигуре, но не на фиг.5А (тогда как на фиг.5А эти свойства представлены посредством стрелки, указывающей, что Статья «положение» это подтип типа статьи «статья»).
Статьи являются автономными объектами; таким образом, если Вы удаляете Статью, все прямые и унаследованные свойства также удаляются. Аналогично, при извлечении Статьи, получают Статью и все ее прямые и унаследованные свойства (включая информацию, относящуюся к ее сложным типам свойств). Определенные варианты осуществления настоящего изобретения позволяют запрашивать подмножество свойств при извлечении конкретной статьи; однако, по умолчанию, согласно многим таким вариантам осуществления при извлечении обеспечивают Статью со всеми ее прямыми и унаследованными свойствами. Кроме того, свойства Статей также можно расширить путем добавления новых свойств к существующим свойствам типа этой Статьи. Эти «расширения» после этого являются подлинными свойствами Статьи, и подтипы этого типа статьи могут включать в себя свойства расширения.
«Граница» Статьи представлена ее свойствами (включая сложные типы свойств, расширения и т.д.). Граница Статьи также представляет предел операции, осуществляемой на Статье, например, копирования, удаления, перемещения, создания и т.д. Например, в некоторых вариантах осуществления настоящего изобретения, при копировании статьи, все, что находится в границах статьи, также копируется. Для каждой статьи, граница охватывает следующее:
- Тип статьи для Статьи и, если Статья является подтипом другой Статьи (что имеет место в нескольких вариантах осуществления настоящего изобретения, где все Статьи выводятся из одной Статьи и Типа статьи в Базовой схеме), любую применимую информацию подтипов (т.е. информацию, относящуюся к родительскому типу статьи). Если копируемая исходная Статья является подтипом другой Статьи, то копия также может быть подтипом той же Статьи.
- Свойства и расширения сложного типа статьи, если таковые имеются. Если исходная Статья имеет свойства сложных типов (природных или расширенных), то копия также может иметь те же сложные типы.
- Записи статьи на «отношениях принадлежности», т.е. собственный список Статьи, где указано, какие другие Статьи ("Целевые статьи") принадлежат данной Статье («Статье-владельцу»). Это, в частности, относится к Папке статей, подробнее рассмотренной ниже, и к правилу, установленному ниже, согласно которому все Статьи должны принадлежать, по меньшей мере, одной Папке статей. Кроме того, в связи с внедренными статьями, более подробно описанными ниже, внедренная статья считается частью статьи, в которую она внедрена, для таких операций, как копирование, удаление и т.д.
2. Идентификация статьи
Статьи уникально идентифицируются в глобальном пространстве статей посредством ItemID. Тип Base.Item задает поле ItemID типа GUID, в котором хранится идентификация Статьи. Статья должна иметь в точности одну идентификацию в хранилище данных 302.
а) Ссылки на статью
Ссылка на статью это структура данных, которая содержит информацию для нахождения и идентификации Статьи. В модели данных абстрактный тип задан под названием ItemReference, из которой выводятся все типы ссылки на статью. Тип ItemReference задает виртуальный метод под названием Resolve. Метод Resolve разрешает ItemReference и возвращает Статью. Этот метод подменяется конкретными подтипами ItemReference, которые реализуют функцию, которая извлекает Статью по ссылке. Метод Resolve вызывается как часть API платформы хранения 322.
(1) ItemIDReference
ItemIDReference - это подтип ItemReference. Он задает поля Locator (указатель) и ItemID. Поле Locator дает имя (т.е. идентифицирует) домен статьи. Оно обрабатывается методом разрешения указателей, который может разрешать значение поля Locator по отношению к домену статьи. Поле ItemID имеет тип ItemID.
(2) ItemPathReference
ItemPathReference - это частный случай ItemReference, который задает поля Locator и Path (путь). Поле Locator идентифицирует домен статьи. Оно обрабатывается методом разрешения указателей, который может разрешать значение поля Locator по отношению к домену статьи. Поле Path содержит (относительный) путь в пространстве имен платформы хранения, имеющий корень в домене статьи, обеспеченном полем Locator.
Этот тип ссылки нельзя использовать в операции set. Ссылка должна, в общем случае, разрешаться посредством процесса разрешения пути. Метод Resolve API 322 платформы хранения обеспечивает эту функциональную возможность.
b) Иерархия типов ссылки
Рассмотренные выше формы ссылки представлены посредством иерархии типов ссылки, проиллюстрированной на фиг.11. Дополнительные типы ссылки, которые наследуют от этих типов, можно задать в схемах. Их можно использовать в декларации отношения как тип целевого поля.
3. Папки статей и Категории
Согласно рассмотренному более подробно ниже, группы Статей можно организовать в особые Статьи, именуемые Папками статей (которые не следует путать с папками файлов). Однако в отличие от большинства файловых систем, статья может принадлежать более чем одной Папке статей, поэтому, при осуществлении доступа к Статье в одной Папке статей и ее ревизии, к этой ревизованной Статье можно осуществлять доступ непосредственно из другой Папки статей. В сущности, хотя доступ к Статье может осуществляться из разных Папок статей, то, к чему осуществляется доступ, является фактически той же самой Статьей. Однако Папка статей не обязательно владеет всеми входящими в нее статьями, или может просто совладеть статьями совместно с другими папками, так что удаление Папки статей не обязательно приводит к удалению Статьи. Тем не менее, согласно нескольким вариантам осуществления настоящего изобретения, Статья должна принадлежать, по меньшей мере, одной Папке статей, поэтому, при удалении единичной Папки статей для конкретной Статьи, то, для некоторых вариантов осуществления, статья автоматически удаляется или, в альтернативных вариантах осуществления, Статья автоматически становится элементом Папки статей, принятой по умолчанию (например, Папки статей "Trash Can" (корзина), концептуально аналогичной папкам, используемым в различных системах на основе файлов и папок).
Согласно подробнее рассмотренному ниже, Папки также могут принадлежать Категориям, основанным на общей описанной характеристике, например, (а) типу (или типам) статей, b) конкретному прямому или унаследованному свойству (или свойствам) или с) конкретному значению (или значениям), соответствующему свойству статьи. Например, Статья, содержащая конкретные свойства для информации личных контактов, может автоматически принадлежать Категории Contact, и любая статья, имеющая свойства информации контактов, будет автоматически принадлежать этой категории. Аналогично, любая статья, имеющая свойство положения со значением "New York City", может автоматически принадлежать Категории NewYorkCity.
Категории концептуально отличаются от Папок статей тем, что, в то время как Папки статей могут содержать Статьи, которые не связаны друг с другом (т.е. без общей описанной характеристики), каждая Статья в Категории имеет общий(ее) тип, свойство или значение («общность»), который(ое) описано для этой Категории, и это та общность, которая образует базис для ее отношения к другим Статьям в Категории. Кроме того, тогда как принадлежность Статьи к конкретной Папке не обязательно базируется на каком-либо конкретном аспекте этой Статьи, для определенных вариантов осуществления, все статьи, имеющие общность, категорически связанную с Категорией, могут автоматически становиться элементами Категории на уровне системы программно-аппаратного интерфейса. В принципе, Категории также можно рассматривать как виртуальные Папки статей, принадлежность к которым базируется на результатах конкретного запроса (например, в контексте базы данных), и, таким образом, Статьи, которые отвечают условиям этого запроса (заданным общностями Категории), будут содержать принадлежность к Категории.
На фиг.4 показано структурное соотношение между Статьями, Папками статей и Категориями согласно различным вариантам осуществления настоящего изобретения. Статьи 402, 404, 406, 408, 410, 412, 414, 416, 418, и 420 принадлежат различным Папкам статей 422, 424, 426, 428, и 430. Некоторые Статьи могут принадлежать более чем одной Папке статей, например, Статья 402 принадлежит Папкам статей 422 и 424. Некоторые Статьи, например статья 402, 404, 406, 408, 410, и 412, также принадлежат одной или более Категориям 432, 434, и 436, тогда как другие статьи, например Статьи 414, 416, 418, и 420, могут не принадлежать ни одной Категории (хотя это весьма маловероятно в некоторых вариантах осуществления, где обладание каким-либо свойством автоматически влечет за собой принадлежность к Категории, и, таким образом, чтобы не принадлежать никакой категории в таком варианте осуществления, Статья не должна иметь никаких признаков). В отличие от иерархической структуры папок структуры Категорий и Папок статей больше походят на ориентированные графы. В любом случае Статьи, Папки статей и Категории являются Статьями (хотя и разных Типов статей).
В отличие от файлов, папок и директорий, Статьи, Папки статей и Категории согласно настоящему изобретению не имеют характерной «физической» природы, поскольку они не имеют концептуально эквивалентных физических контейнеров, благодаря чему Статьи могут существовать в более чем одном таком месте. Возможность для статей существовать в более чем одной Папке статей, а также возможность объединения в Категории, обеспечивает расширенные и обогащенные возможности манипуляции данными и возможности структуры хранения на уровне программно-аппаратного интерфейса, превышающие возможности, доступные в современной технике.
4. Схемы
a) Базовая схема
Для обеспечения универсальной основы для создания и использования Статей, различные варианты осуществления платформы хранения согласно настоящему изобретению содержат Базовую схему, которая устанавливает принципиальную структуру для создания и организации Статей и свойств. Базовая схема задает определенные специальные типы Статей и свойств и признаки этих специальных основных типов, из которых можно дополнительно выводить подтипы. Использование этой Базовой схемы позволяет программисту принципиально отличать Статьи (и их соответствующие типы) от свойств (и их соответствующих типов). Кроме того, Базовая схема задает основное множество свойств, которыми могут обладать все Статьи, поскольку все Статьи (и их соответствующие Типы статей) выводятся из этой основной Статьи в Базовой схеме (и ее соответствующего Типа статьи).
Согласно фиг.7 и в связи с несколькими вариантами осуществления настоящего изобретения базовая схема задает три типа верхнего уровня: Item, Extension и PropertyBase. Показано, что тип Item задан свойствами этого основного типа статьи "Item". Напротив, тип свойства верхнего уровня "PropertyBase" не имеет заранее заданных свойств и является лишь анкером, из которого выводятся все остальные типы свойств и посредством которого все производные типы свойств связаны между собой (будучи сообща выведены из единого типа свойства). Свойства типа Extension задают, какую Статью расширяет расширение, а также идентификацию, позволяющую отличить одно расширение от другого, поскольку Статья может иметь несколько расширений.
ItemFolder это подтип типа статьи «статья», который, помимо свойств, унаследованных от Статьи, определяет Отношение для установления связей с ее элементами (если таковые имеются), тогда как IdentityKey и Property являются подтипами PropertyBase. В свою очередь, CategoryRef является подтипом IdentityKey.
b) Схема ядра
Различные варианты осуществления платформы хранения согласно настоящему изобретению содержат Схему ядра, которая обеспечивает принципиальную структуру для структур типов Статей верхнего уровня. На фиг.8А показана блок-схема, иллюстрирующая Статьи в Схеме ядра, и на фиг.8В показана блок-схема, иллюстрирующая типы свойств в Схеме ядра. Различия между файлами с разными расширениями (*.com, *.exe, *.bat, *.sys, и т.д.) и другие подобные критерии в системах на основе файлов и папок аналогичны по функции Схема ядра. В системе программно-аппаратного интерфейса на основе Статей Схема ядра задает множество типов статей ядра, которые прямо (по типу статьи) или косвенно (по подтипу статьи) характеризуют все Статьи в один или более тип статьи Схемы ядра, которые система программно-аппаратного интерфейса на основе статей понимает и может непосредственно обрабатывать заранее определенным и предсказуемым способом. Заранее заданные типы статей отражают наиболее общеупотребительные Статьи в системе программно-аппаратного интерфейса на основе статей и, таким образом, повышается уровень эффективности системы программно-аппаратного интерфейса на основе статей, понимающей эти заранее заданные типы статей, которые содержат Схему ядра.
В некоторых вариантах осуществления Схема ядра является нерасширяемой, т.е. никакие дополнительные типы статей нельзя непосредственно вывести в качестве подтипов из типа статьи в Базовой схеме за исключением конкретных заранее заданных производных типов статей, которые являются частью Схемы ядра. Препятствуя образованию расширений к Схеме ядра (т.е. препятствуя добавлению новых Статей к Схеме ядра), платформа хранения разрешает использовать типы статей Схемы ядра, поскольку каждый последующий тип статьи с необходимостью является подтипом типа статьи Схемы ядра. Эта структура допускает разумную степень гибкости при задании дополнительных типов статей, в то же время сохраняя преимущества наличия заранее заданного множества типов статей ядра.
Для различных вариантов осуществления настоящего изобретения и согласно фиг.8А конкретные типы статей, поддерживаемые Схемой ядра, могут включать в себя одно или несколько из следующего:
- Категории: Статьи данного типа статьи (выведенных из него подтипов) представляют пригодные Категории в системе программно-аппаратного интерфейса на основе статей.
- Предметы потребления: Статьи, которые являются идентифицируемыми ценными вещами.
- Устройства: Статьи, имеющие логическую структуру, которая поддерживает возможности обработки информации.
- Документы: Статьи, содержимое которых не интерпретируется системой программно-аппаратного интерфейса на основе статей, но интерпретируется прикладной программой, соответствующей типу документа.
- События: Статьи, в которых записаны определенные события в среде.
- Места: Статьи, представляющие физические положения (например, географические положения).
- Сообщения: Статьи связи между двумя или более принципалами (определены ниже).
- Принципалы: Статьи, имеющие, по меньшей мере, одну однозначно доказуемую идентификацию помимо ItemId (например, идентификацию личности, организации, группы, домовладения, органа власти, службы и т.д.).
- Утверждения: Статьи, имеющие особую информацию, касающуюся среды, включая, без ограничения, политики, подписки, мандаты и т.д.
Аналогично и согласно фиг.8В конкретные типы свойств, поддерживаемые Схемой ядра, могут включать в себя одно или несколько из следующего:
- Сертификаты (выводимые из основного типа PropertyBase в Базовой схеме)
- Ключи идентификации принципалов (выводимые из типа IdentityKey в Базовой схеме)
- Почтовый адрес (выводимый из типа Property в Базовой схеме)
- Богатый текст (выводимый из типа Property в Базовой схеме)
- Электронный адрес (Eaddress) (выводимый из типа Property в Базовой схеме)
- IdentitySecurityPackage (выводимый из типа Relationship в Базовой схеме)
- RoleOccupancy (выводимый из типа Relationship в Базовой схеме)
Эти Статьи и Свойства описаны ниже согласно их соответствующим свойствам, показанным на фиг.8А и 8В.
5. Отношения
Отношения являются бинарными отношениями, в которых одна Статья считается исходной (источником), а другая - целевой (целью). Исходная статья и целевая статья связаны отношением. Исходная статья, в общем случае, управляет временем жизни отношения. Таким образом, при удалении исходной статьи, удаляется также отношение между Статьями.
Отношения подразделяются на отношения включения и отношения ссылки. Отношения включения управляют временем жизни целевых статей, а отношения ссылки не обеспечивают никакой семантики управления временем жизни. На фиг.12 показано, каким образом классифицируются отношения.
Типы отношений включения далее подразделяются на отношения поддержки и внедрения. При удалении всех отношений поддержки Статьи статья удаляется. Отношение поддержки управляет временем жизни цели посредством ссылки на механизм отсчета. Отношения внедрения позволяют моделировать составные Статьи, и их можно рассматривать как исключающие отношения поддержки. Статья может быть целью одного или нескольких отношений поддержки; но Статья может быть целью только одного отношения внедрения. Статья, которая является целью отношения внедрения, не может быть целью никакого другого отношения поддержки или внедрения.
Отношения ссылки не управляют временем жизни целевой статьи. Они могут быть висящими, т.е. могут не иметь целевой статьи. Отношения ссылки можно использовать для моделирования ссылок на Статьи в любом месте глобального пространства имен статей (т.е., включая удаленные хранилища данных).
Выборка Статьи не предполагает автоматической выборки ее отношений. Приложения должны в явном виде запрашивать отношения Статьи. Кроме того, изменение отношения не приводит к изменению исходной или целевой статьи; аналогично, добавление отношения не влияет на исходную/целевую статью.
a) Декларация отношения
Явные типы отношений задаются следующими элементами:
- Имя отношения задается в атрибуте Name.
- Тип отношения, один из следующих: Holding, Embedding, Reference. Он задается в атрибуте Type.
- Исходная и целевая концевые точки. Каждая концевая точка задает имя и тип Статьи, на которую идет ссылка.
- Поле исходной концевой точки, в общем случае, имеет тип ItemID (не декларируется) и должно ссылаться на Статью, находящуюся в том же хранилище данных, что и экземпляр отношения.
- Для отношений поддержки и внедрения, поле целевой концевой точки должно иметь тип ItemIDReference и должно ссылаться на Статью, находящуюся в том же хранилище, что и экземпляр отношения. Для отношения ссылки, целевая концевая точка может быть любой концевой точкой типа ItemReference и может ссылаться на Статьи в других хранилищах данных платформы хранения.
- В необязательном порядке, можно декларировать одно или несколько полей скалярного типа или типа PropertyBase. Эти поля могут содержать данные, связанные с отношением.
- Экземпляры отношений хранятся в глобальной таблице отношений.
- Каждый экземпляр отношения уникально идентифицируется комбинацией (ИД исходной статьи, ИД отношения). ИД отношения уникален в данном ИД исходной статьи для всех отношений, источником которых является данная статья, независимо от их типов.
Исходная статья является владельцем отношения. Хотя Статья, указанная как владелец, управляет временем жизни отношения, само по себе отношение отделено от статей, к которым оно относится. API 322 платформы хранения обеспечивает механизмы представления отношений, связанных со статьей.
Приведем пример декларации отношения:
<Relationship Name="Employment" BaseType="Reference">
<Source Name="Employee" ItemType="Contact.Person"/>
<Target Name='Employer" ItemType="Contact.Organization"
ReferenceType="ItemIDReference"/>
<Property Name="StartDate" Type="the storage
platformTypes.DateTime"/>
<Property Name="EndDate" Type="the storage
platformTypes.DateTime"/>
<Property Name="Office" Type="the storage
platformTypes.DateTime"/>
</Relationship>
Это пример отношения ссылки. Отношение нельзя создать, если статьи «лицо», на которую идет ссылка посредством исходной ссылки, не существует. Кроме того, при удалении статьи «лицо», экземпляры отношения между лицом и организацией удаляются. Однако при удалении статьи «организация», отношение не удаляется и зависает.
b) Отношение поддержки
Отношения поддержки используются для моделирования счетчика ссылок на основании управления временем жизни целевых статей.
Статья может быть исходной концевой точкой для нуля или более отношений со статьями. Статья, которая не внедрена в Статью, может быть целью для одного или более отношений поддержки.
Тип ссылки целевой концевой точки должен быть ItemIDReference и он должен ссылаться на статью, находящуюся в том же хранилище, что и экземпляр отношения.
Отношения поддержки применяют управление временем жизни целевой концевой точки. Создание экземпляра отношения поддержки и статьи, которая является его целью, является элементарной операцией. Можно создавать дополнительные экземпляры отношения поддержки, нацеленные на ту же статью. При удалении последнего экземпляра отношения поддержки, имеющего целевой концевой точкой данную статью, целевая статья также удаляется.
Типы статей, являющихся концевыми точками, указанные в декларации отношения, обычно применяются при создании экземпляра отношения. Типы статей, являющихся концевыми точками, не могут изменяться после задания отношения.
Отношения поддержки играют ключевую роль при формировании пространства имен статей. Они содержат свойство "Name", которое задает имя целевой статьи относительно исходной статьи. Относительное имя уникально для всех отношений поддержки, имеющих источником данную статью. Упорядоченный список этих относительных имен, начинающийся с корневой статьи и оканчивающийся данной статьей, образует полное имя статьи.
Отношения поддержки образуют ориентированный ациклический граф (DAG). При создании отношения поддержки система гарантирует, что цикл не создается, и, таким образом, гарантирует, что пространство имен статей образует DAG.
Хотя отношение поддержки управляет временем жизни целевой статьи, оно не управляет операционной согласованностью статьи, являющейся целевой концевой точкой. Целевая статья операционно независима от статьи, которая владеет ею через отношение поддержки. Операции Copy, Move, Backup и пр. на статье, которая является источником отношения поддержки, не влияют на статью, которая является целью того же отношения, например, резервное копирование статьи «папка» не предполагает автоматического резервного копирования всех статей в этой папке (целей отношения FolderMember).
Приведем пример отношения поддержки:
<Relationship Name="FolderMembers" BaseType="Holding">
<Source Name="Folder" ItemType="Base.Folder"/>
<Target Name="Item" ItemType="Base.Item"
ReferenceType="ItemIDReference"/>
</Relationship>
Отношение FolderMembers задает понятие Папки как общего вида коллекции Статей.
с) Отношения внедрения
Отношения внедрения моделируют концепцию исключительного управления временем жизни целевой статьи. Они задают понятие составных статей.
Создание экземпляра отношения внедрения и статьи, которая является его целью, является элементарной операцией. Статья может быть источником для нуля или более отношений внедрения. Однако статья может быть целью одного и только одного отношения внедрения. Статья, которая является целью отношения внедрения, не может быть целью отношения поддержки.
Тип ссылки целевой концевой точки должен быть ItemIDReference и должен ссылаться на статью, находящуюся в том же хранилище данных, что и экземпляр отношения.
Типы статей, являющихся концевыми точками, указанные в декларации отношения, обычно применяются при создании экземпляра отношения. Типы статей, являющихся концевыми точками, не могут изменяться после задания отношения.
Отношения внедрения управляют операционной согласованностью целевой концевой точки. Например, операция преобразования статьи к последовательному виду может включать в себя преобразование к последовательному виду всех отношений внедрения, исходящих от данной статьи, а также всех их целей; копирование статьи также приводит к копированию всех внедренных в нее статей.
Приведем пример декларации:
<Relationship Name="ArchiveMembers" BaseType="Embedding">
<Source Name="Archive" ItemType="Zip.Archive"/>
<Target Name="Member" ItemType="Base.Item "
ReferenceType="ItemIDReference"/>
<Property Name="ZipSize" Type="the storage
platformTypes.bigint"/>
<Property Name="SizeReduction" Type="the storage
platformTypes.float"/>
</Relationship>
d) Отношения ссылки
Отношение ссылки не управляет временем жизни статьи, на которую оно ссылается. Более того, отношения ссылки не гарантируют существование цели, а также не гарантируют тип цели, указанной в декларации отношения. Это значит, что отношения ссылки могут зависать. Кроме того, отношение ссылки может ссылаться на статьи в других хранилищах данных. Отношения ссылки можно рассматривать как понятие, аналогичное ссылкам на веб-страницах.
Приведем пример декларации отношения ссылки:
<Relationship Name="DocumentAuthor" BaseType='Reference">
<Sourc ItemType="Document" ItemType="Base.Document"/>
<Target ItemType="Author" ItemType="Base.Author"
ReferenceType="ItemIDReference"/>
<Property Type="Role" Type="Core.CategoryRef"/>
<Property Type="DisplayName" Type="the storage
platformTypes.nvarchar(256)"/>
</Relationship>
В целевой концевой точке разрешен любой тип ссылки. Статьи, которые участвуют в отношении ссылки, могут иметь любой тип статьи.
Отношения ссылки используют для моделирования отношений между статьями, наименее связанных с управлением временем жизни. Поскольку существование цели не требуется, отношение ссылки удобно для моделирования слабосвязанных отношений. Целевые статьи отношения ссылки могут находиться в других хранилищах данных, включая хранилища на других компьютерах.
е) Правила и ограничения
К отношениям применяются следующие дополнительные правила и ограничения:
1. Статья должна быть целью (в точности одного отношения внедрения) или (одного или более отношений поддержки). Исключение составляет корневая статья. Статья может быть целью нуля или более отношений ссылки.
2. Статья, которая является целью отношения внедрения, не может быть источником отношений поддержки. Она может быть источником отношений ссылки.
3. Статья не может быть источником отношения поддержки, если она выдвинута из файла. Она может быть источником отношений внедрения и отношений ссылки.
4. Статья, которая может быть выдвинута из файла, не может быть целью отношения внедрения.
f) Упорядочение отношений
Согласно, по меньшей мере, одному варианту осуществления, платформа хранения согласно настоящему изобретению поддерживает упорядочение отношений. Упорядочение достигается посредством свойства под названием "Order" (порядок) в базовом определении отношения. На поле Order не накладывается никаких ограничений, связанных с уникальностью. Порядок отношений с одним и тем же значением свойства «порядок» не гарантируется, однако гарантируется, что они будут стоять после отношений с более низким значением «порядка» и перед отношениями с более высоким значением «порядка».
Приложения могут получать отношения в порядке, принятом по умолчанию, благодаря упорядочению по комбинации (SourceItemID, RelationshipID, Order). Все экземпляры отношения, имеющие источником данную статью, упорядочены как единая коллекция независимо от типа отношений в коллекции. Однако это гарантирует, что все отношения данного типа (например, FolderMembers) являются упорядоченным подмножеством коллекции отношений для данной статьи.
API 312 хранилища данных для манипулирования отношениями реализует множество операций, которые поддерживают упорядочение отношений. Для облегчения объяснения этих операций, введем следующие термины:
RelFirst это первое отношение в упорядоченной коллекции со значением порядка OrdFirst;
RelLast это последнее отношение в упорядоченной коллекции со значением порядка OrdLast;
RelX это данное отношение в упорядоченной коллекции со значением порядка OrdX;
RelPrev это ближайшее к RelX отношение в коллекции со значением порядка OrdPrev, меньшим чем OrdX;
RelNext это ближайшее к RelX отношение в коллекции со значением порядка OrdNext, большим, чем OrdX.
InsertBeforeFirst(SourceItemID, Relationship)
Вставляет отношение как первое отношение в коллекции. Значение свойства «порядок» нового отношения может быть меньше, чем OrdFirst.
InsertAfterLast(SourceItemID, Relationship)
Вставляет отношение как последнее отношение в коллекции. Значение свойства «порядок» нового отношения может быть больше, чем OrdLast.
InsertAt(SourceItemID, ord, Relationship)
Вставляет отношение с указанным значением свойства «порядок».
InsertBefore(SourceItemID, ord, Relationship)
Вставляет отношение перед отношением с данным значением порядка. Новому отношению можно присвоить значение «порядок», находящееся между OrdPrev и ord, неисключительно.
InsertAfter(SourceItemID, ord, Relationship)
Вставляет отношение после отношения с данным значением порядка. Новому отношению можно присвоить значение «порядок», находящееся между ord и OrdNext, неисключительно.
MoveBefore(SourceItemID, ord, RelationshipID)
Перемещает отношение с данным ИД отношения перед отношением с указанным значением «порядок». Отношению можно присвоить новое значение «порядок», находящееся между OrdPrev и ord, неисключительно.
MoveAfter(SourceItemID, ord, RelationshipID)
Перемещает отношение с данным ИД отношения после отношения с указанным значением «порядок». Отношению можно присвоить новое значение «порядок», находящееся между ord и OrdNext, неисключительно.
Как было отмечено выше, каждая статья должна быть элементом Папки статей. В терминах отношений каждая статья должна иметь отношение с Папкой статей. В некоторых вариантах осуществления настоящего изобретения, определенные отношения представляются Отношениями, существующими между Статьями.
Согласно реализации для различных вариантов осуществления настоящего изобретения Отношение обеспечивает направленное бинарное отношение, которое «расширяется» одной Статьей (исходной) до другой Статьи (целевой). Отношение принадлежит исходной статье (статье, которая расширяет его) и, таким образом, Отношение удаляется при удалении источника (например, Отношение удаляется при удалении исходной статьи). Кроме того, в некоторых случаях, Отношение может одновременно принадлежать (находиться в совместном владении) целевой статье, и такая принадлежность может отражаться в свойстве IsOwned (или эквивалентном ему) Отношения (согласно фиг.7 для типа свойства Отношения). В этих вариантах осуществления создание нового отношения IsOwned автоматически ведет к приращению счетчика ссылок на целевую статью, и удаление отношения IsOwned автоматически ведет к отрицательному приращению счетчика ссылок на целевую статью. Для этих конкретных вариантов осуществления статьи продолжают существовать, если они имеют счетчик ссылок больше нуля, и автоматически удаляются, если и когда счетчик достигает нуля. Опять же, Папка статей является Статьей, которая имеет (или способна иметь) множество отношений с другими Статьями, причем эти другие Статьи содержат принадлежность к Папке статей. Другие фактические реализации отношений возможны и предусмотрены настоящим изобретением для обеспечения описанных здесь функциональных возможностей.
Независимо от фактической реализации отношение является выбираемым соединением от одного объекта к другому. Способность статьи принадлежать более чем одной Папке статей, а также одной или нескольким Категориям, и являются ли эти статьи, папки и категории публичными или частными, определяется значениями, приписываемыми наличию (или отсутствию) в структуре на основе статей. Эти логические отношения являются значениями, присвоенными множеству отношений, независимо от физической реализации, которые конкретно используются для обеспечения описанных здесь функциональных возможностей. Логические отношения устанавливаются между Статьей и ее Папкой(ами) статей или Категориями (и наоборот), поскольку, в сущности, Папки статей и Категории являются особыми типами статей. Следовательно, с Папками статей и Категориями можно обращаться таким же образом, как с любыми другими Статьями - копировать, добавлять в сообщение электронной почты, внедрять в документ и т.д. без ограничения - и Папки статей и Категории можно преобразовывать к последовательному виду и из последовательного вида (импортировать и экспортировать) с использованием тех же механизмов, что и для других статей (например, в XML все статьи могут иметь последовательный формат, и этот формат в равной мере применяется к Папкам статей, Категориям и Статьям.)
Вышеупомянутые отношения, которые представляют отношение между Статьей и ее Папкой(ами) статей, можно логически расширить от Статьи на Папку статей, от Папки статей на Статью или на обе. Отношение, которое логически расширяется от Статьи на Папку статей, указывает, что Папка статей является публичной по отношению к этой Статье и совместно использует свою информацию принадлежности с этой Статьей; напротив, отсутствие логического отношения от Статьи к Папке статей указывает, что Папка статей является частной по отношению к этой Статье и не использует совместно свою информацию принадлежности с этой Статьей. Аналогично, отношение, которое логически расширяется от Папки статей на Статью, указывает, что Статья является публичной и совместно используемой по отношению к этой Папке статей, тогда как отсутствие логического отношения от Папки статей к Статье указывает, что статья является частной и не совместно используемой. Следовательно, когда Папка статей экспортируется в другую систему, именно «публичные» Статьи совместно используются в новом контексте, и, когда статья ищет свои папки статей для других, совместно используемых статей, именно «публичные» Папки статей снабжают статью информацией относительно совместно используемых статей, принадлежащих им.
На фиг.9 показана блок-схема, иллюстрирующая Папку статей (которая, сама по себе, также является Статьей), входящие в нее статьи и отношения взаимосвязи между Папка статей и входящими в нее статьями. Папка 900 статей содержит совокупность Статей 902, 904 и 906. Папка 900 статей имеет Отношение 912 от себя к Статье 902, которое указывает, что Статья 902 является публичной и совместно используемой по отношению к Папке 900 статей, ее элементам 904 и 906 или любым другим Папкам статей, Категориям или Статьям (не показаны), которые могут осуществлять доступ к Папке 900 статей. Однако не существует Отношения от Статьи 902 к Папке 900 статей, которое указывает, что Папка 900 статей является частной по отношению к Статье 902 и не использует совместно свою информацию принадлежности со Статьей 902. С другой стороны, Статья 904 имеет Отношение 924 от себя к Папке 900 статей, которое указывает, что Папка 900 статей является публичной и совместно использует свою информацию принадлежности со Статьей 904. Однако не существует Отношения от Папки 900 статей к Статье 904, которое указывает, что Статья 904 является частной и не совместно используемой по отношению к Папке 900 статей, ее элементам 902 и 906 и любым другим Папкам статей, Категориям или Статьям (не показаны), которые могут осуществлять доступ к Папке 900 статей. В отличие от этих Отношений (или в их отсутствие) к Статьям 902 и 904, Папка 900 статей имеет Отношение 916 от себя к Статье 906, и Статья 906 имеет Отношение 926 обратно к Папке 900 статей, которые совместно указывают, что статья 906 является публичной и совместно используемой по отношению к Папке 900 статей, ее элементам 902 и 904 и любым другим Папкам статей, Категориям или Статьям (не показаны), которые могут осуществлять доступ к Папке 900 статей, и что Папка 900 статей является публичной и совместно использует свою информацию принадлежности со Статьей 906.
Согласно рассмотренному ранее, Статьи в Папке статей не нуждаются в совместном использовании общности, поскольку Папки статей не «описаны». С другой стороны, категории описаны общностью, которая является общей для всех входящих в нее статей. Поэтому принадлежность к Категории внутренне ограничена Статьями, имеющими описанную общность и, в определенных вариантах осуществления, все Статьи, отвечающие описанию Категории, автоматически становятся элементами Категории. Таким образом, в то время как Папки статей позволяют представлять структуры тривиальных типов на основании их принадлежности, Категории допускают принадлежность на основании заданной общности.
Конечно, описания Категории логичны по природе и поэтому Категорию можно описывать посредством любого логического представления типов, свойств и/или значений. Например, логическим представлением Категории может быть условие принадлежности к ней, согласно которому Статья должна иметь одно из двух свойств или оба. Если эти описанные свойства для Категории обозначить как "A" и "B", то принадлежность к Категории может предусматривать, что Статьи имеют свойство А, но не В, Статьи имеют свойство В, но не А, и Статьи имеют оба свойства А и В. Это логическое представление свойств описывается логическим оператором "OR", при этом множество элементов, описанных Категорией, представляет собой Статьи, имеющие свойство A OR B. Аналогичные логические операторы (включая без ограничения "AND", "XOR" и "NOT" по отдельности или в совокупности) также можно использовать для описания категории, что очевидно специалистам в данной области.
Несмотря на разницу между Папками статей (не описаны) и Категориями (описаны), отношение категорий к статьям и отношение статей к категориям, по существу, такие же, как описанные выше для папок статей и статей во многих вариантах осуществления настоящего изобретения.
На фиг.10 показана блок-схема, иллюстрирующая категорию (которая сама по себе является статьей), входящие в нее статьи и отношения взаимосвязи между категорией и входящими в нее статьями. Категории 1000 принадлежат статьи 1002, 1004, и 1006, которые все совместно используют комбинацию общих свойств, значений или типов 1008, описанных (описание общности 1008') категорией 1000. Категория 1000 имеет отношение 1012 от себя к статье 1002, которое указывает, что статья 1002 является публичной и совместно используемой по отношению к категории 1000, ее элементам 1004 и 1006 и любым другим категориям, папкам статей или статьям (не показаны), которые могут осуществлять доступ к категории 1000. Однако не существует отношения от статьи 1002 к категории 1000, которое указывает, что категория 1000 является частной по отношению к статье 1002 и не использует совместно свою информацию принадлежности со статьей 1002. С другой стороны, статья 1004 имеет отношение 1024 от себя к категории 1000, которое указывает, что категория 1000 является публичной и совместно использует свою информацию принадлежности со статьей 1004. Однако не существует отношения, расширенного от категории 1000 к статье 1004, которое указывает, что статья 1004 является частной и не совместно используемой по отношению к категории 1000, другим ее элементам 1002 и 1006 и любым другим категориям, папкам статей или статьям (не показаны), которые могут осуществлять доступ к категории 1000. В отличие от этого отношения (или в его отсутствие) со статьями 1002 и 1004, категория 1000 имеет отношение 1016 от себя к статье 1006, и статья 1006 имеет отношение 1026 обратно к категории 1000, которые совместно указывают, что статья 1006 является публичной и совместно используемой по отношению к категории 1000, входящим в нее статьям 1002 и 1004 и любым другим категориям, папкам статей или статьям (не показаны), которые могут осуществлять доступ к категории 1000, и что категория 1000 является публичной и совместно использует свою информацию принадлежности со статьей 1006.
Наконец, поскольку Категории и Папки статей сами являются Статьями, и Статьи могут иметь Отношение друг к другу, Категории могут иметь Отношение к Папкам статей и наоборот, и Категории, Папки статей и Статьи могут иметь Отношение к другим Категориям, Папкам статей и Статьям, соответственно, согласно некоторым альтернативным вариантам осуществления. Однако в различных вариантах осуществления структурам Папки статей и/или структурам Категории запрещено, на уровне системы программно-аппаратного интерфейса, содержать циклы. Когда структуры Папки статей и Категории похожи на ориентированные графы, варианты осуществления, запрещающие циклы, напоминают ориентированные ациклические графы (DAG), которые, согласно математическому определению из теории графов, являются ориентированными графами, в которых ни один путь не может начинаться и заканчиваться в одной и той же вершине.
6. Расширяемость
Платформа хранения предназначена быть снабженной начальным множеством схем 340 согласно описанному выше. Кроме того, согласно, по меньшей мере, некоторым вариантам осуществления, платформа хранения позволяет потребителям, в том числе независимым поставщикам программного обеспечения (ISV), создавать новые схемы 344 (т.е. новые типы «статья» (Item) и «вложенный элемент» (Nested Element)). Этот раздел посвящен механизму создания таких схем путем расширения типов «статья» и типов «вложенный элемент» (или просто типов «элемент»), заданных в начальном множестве схем 340.
Предпочтительно, расширение начального множества типов статей и вложенных элементов ограничивается следующим образом:
ISV разрешено вводить новые типы Item, т.е. подтип Base.Item;
ISV разрешено вводить новые типы Nested Element, т.е. подтип Base.NestedElement;
ISV разрешено вводить новые расширения, т.е. подтип Base.NestedElement; но,
ISV не может определять подтипы любых типов (типов Item, Nested Element или Extension), заданных начальным множеством схем 340 платформы хранения.
Поскольку тип статьи или тип вложенного элемента, заданные начальным множеством схем платформы хранения, могут не вполне отвечать потребностям ISV, необходимо позволить ISV видоизменять тип. Это возможно с помощью формализации расширений. Расширения - это сильно типизированные экземпляры, но (а) они не могут существовать независимо и (b) они должны быть присоединены к статье или вложенному элементу.
Помимо удовлетворения необходимости в расширяемости схемы, расширения также призваны решать вопрос «множественного определения типов». Поскольку, в некоторых вариантах осуществления, платформа хранения может не поддерживать множественное наследование или перекрытие подтипов, приложения могут использовать расширения для моделирования перекрывающихся экземпляров типа (например, Документ является одновременно юридическим документом и защищенным документом).
a) Расширения статьи
Для обеспечения расширяемости статей модель данных дополнительно задает абстрактный тип под названием Base.Extension. Это корневой тип в иерархии типов расширений. Приложения могут определять подтипы Base.Extension для создания конкретных типов расширений.
Тип Base.Extension задан в Базовой схеме следующим образом:
<Type Name="Base.Extension" IsAbstract="True">
<Propety Name="ItemID"
Type="the storage platformTypes.uniqueidentified"
Nullable="false" MultiValued="false"/>
<Property Name="ExtensionID"
Type="the storage platformTypes.uniqueidentified"
Nullable="false" MultiValued="false"/>
</Type>
Поле ItemID содержит ItemID статьи, с которой связано расширение. Статья с этим ItemID должна существовать. Расширение нельзя создать, если статьи с данным ItemID не существует. При удалении статьи все расширения с тем же ItemID удаляются. Кортеж (ItemID,ExtensionID) уникально идентифицирует экземпляр расширения.
Структура тип расширения аналогична структуре типа статьи.
Типы расширений имеют поля.
Поля могут быть примитивных типов или типов вложенного элемента.
Типы расширений допускают определение подтипов.
К типам расширений применяются следующие ограничения:
расширения не могут быть источниками и целями отношений;
экземпляры типов расширений не могут существовать независимо от статьи; и
Типы расширений нельзя использовать как типы полей в определениях типов платформы хранения.
На типы расширений, которые могут быть связаны с данным типом статьи, не накладываются никакие ограничения. Любой тип расширения может расширять любой тип статьи. Когда к статье присоединено несколько экземпляров расширения, они независимы друг от друга как по структуре, так и по поведению.
Экземплярам расширения обеспечивается хранение и доступ отдельно от статьи. Все экземпляры типа расширения доступны для глобального вида расширений. Можно составить эффективный запрос, который возвратит все экземпляры данного типа расширения независимо от того, со статьей какого типа они связаны. API платформы хранения обеспечивают модель программирования, которая позволяет сохранять, извлекать и изменять расширения на статьях.
Типы расширения могут представлять собой типы, полученные путем определения подтипов с использованием единичной модели наследования платформы хранения. Вывод из типа расширения создает новый тип расширения. Структура или поведение расширения не может подменять или заменять структуру или поведения иерархии типов статей.
По аналогии с типами статей экземпляры типа расширения могут быть непосредственно доступны за счет вида, связанного с типом расширения. ItemID расширения указывает, какой статье оно принадлежит, и его можно использовать для извлечения соответствующего объекта «статья» из глобального вида статьи.
В целях операционной согласованности, расширения рассматриваются как часть статьи. Операции Copy/Move, Backup/Restore и другие общеизвестные операции, заданные на платформе хранения, могут выполняться на расширениях как на части статьи.
Рассмотрим следующий пример. В наборе типов Windows задается тип Contact (контакт).
<Type Name="Contact" BaseType="Base.Item">
<Property Name="Name"
Type="String"
Nullable="false"
MultiValued="false"/>
<Property Name="Address"
Type="Address"
Nullable="true"
MultiValued="false"/>
</Tуре>
Разработчик приложения CRM желает присоединить расширение приложения CRM к контактам, хранящимся в платформе хранения. Разработчик приложения задает расширение CRM, содержащее дополнительную структуру данных, которой может манипулировать приложение.
<Type Name="CRMExtension" BaseType="Base.Extension">
<Property Name="CustomerID"
Type="String"
Nullable="false"
MultiValued="false"/>
…
</Type>
Разработчик приложения HR также желает присоединить к контактам дополнительные данные. Эти данные независимы от данных приложения CRM. Опять же, разработчик приложения может создать расширение
<Type Name="HRExtension" EBaseType="Base.Extension">
<Property Name="EmployeeID"
Type="String"
Nullable="false"
MultiValued="false"/>
…
</Type>
CRMExtension и HRExtension это два независимых расширения, которые можно присоединить к статьям «контакт». Их создание и доступ к ним осуществляются независимо друг от друга.
В вышеприведенном примере поля и методы типа CRMExtension не могут подменять поля и методы иерархии контактов. Следует заметить, что экземпляры типа CRMExtension могут быть присоединены к другим типам статей, помимо «контактов».
При извлечении статьи «контакт», ее расширения статьи не извлекаются автоматически. Для данной статьи «контакт», к связанным с ней расширениям статьи, можно осуществить доступ, запросив глобальный вид расширений для расширений с тем же ItemId.
Ко всем расширениям CRMExtension в системе можно осуществлять доступ через вид типа CRMExtension, независимо от того, какой статье оно принадлежит. Все расширения статьи для статьи совместно используют один и тот же идентификатор статьи. В вышеприведенном примере экземпляр статьи «контакт» и экземпляры присоединенных CRMExtension и HRExtension имеют одинаковый ItemID.
В следующей таблице сведены сходства и различия типов статьи, расширения и вложенного элемента:
b) Расширение типов вложенных элементов
Типы вложенных элементов не расширяются с помощью того же механизма, что и типы статей. Расширениям вложенных элементов обеспечены хранение и доступ с помощью тех же механизмов, что и для полей типов вложенных элементов.
Модель данных задает корень для типов вложенных элементов под названием Element:
<Type Name="Element" IsAbstract="True">
<Property Name="ElementID"
Type="the storage platformTypes.uniqueidentifier"
Nullable="false"
MultiValued="false"/>
</Type>
Тип NestedElement наследует от этого типа. Тип элемента NestedElement дополнительно задает поле, которое является множеством нескольких элементов.
<Type Name="NestedElement" BaseType="Base.Element"
IsAbstract="True">
<Property Name="Extensions"
Type="Base.Element"
Nullable="false"
MultiValued="true"/>
</Type>
Расширения вложенного элемента отличаются от расширений статьи следующим.
Расширения вложенного элемента не являются типами расширения. Они не принадлежат иерархии типов расширения, корнем которой является тип Base.Extension.
Расширения вложенного элемента хранятся совместно с другими полями статьи и не являются глобально доступным - нельзя составить запрос, который извлекает все экземпляры данного типа расширения.
Эти расширения хранятся таким же образом, что и другие вложенные элементы (статьи). Аналогично другим вложенным множествам расширения вложенного элемента хранятся в UDT. Они доступны через поле Extensions типа вложенного элемента.
Интерфейсы коллекции, используемые для доступа к многозначным свойствам, также используются для доступа и итерации по множеству расширений типа.
Следующая таблица сводит и сравнивает расширения статьи и расширения вложенного элемента.
D. МАШИНА БАЗЫ ДАННЫХ
Как отмечено выше, хранилище данных реализовано на машине базы данных. Согласно данному варианту осуществления машина базы данных содержит машину реляционной базы данных, которая реализует язык запросов SQL, например машину Microsoft SQL Server, с реляционными расширениями объекта. В этом разделе описано отображение модели данных, которую реализует хранилище данных, на реляционное хранилище и обеспечивает информацию на логическом API, потребляемом клиентами платформы хранения, согласно данному варианту осуществления. Однако понятно, что при использовании другой машины базы данных можно использовать другое отображение. Действительно, помимо реализации принципиальной модели данных на машине реляционной базы данных, ее также можно реализовать на других типах баз данных, например, объектно-ориентированных базах данных и базах данных XML.
Объектно-ориентированная (ОО) система базы данных обеспечивает устойчивость и транзакции для объектов языка программирования (например, C++, Java). Понятие «статья» платформы хранения отображается в «объект» в объектно-ориентированных системах, хотя встроенные коллекции нужно добавлять к объектам. Другие понятия типов платформы хранения, например наследование и типы вложенного элемента, также отображаются в объектно-ориентированную систему типов. Объектно-ориентированные системы обычно уже поддерживают идентификацию объекта; поэтому идентификацию статьи можно отображать в идентификацию объекта. Поведения статьи (операции) отображаются в объектные методы. Однако объектно-ориентированным системам обычно недостает организационных возможностей и средств поиска. Кроме того, объектно-ориентированные системы не обеспечивают поддержку для неструктурированных и частично структурированных данных. Для поддержки описанной здесь полной модели данных платформы хранения такие понятия как отношения, папки и расширения нужно добавлять в объектную модель данных. Кроме того, нужно реализовывать такие механизмы, как продвижения, синхронизация, извещения и безопасность.
Подобно объектно-ориентированным системам базы данных XML, основанные на XSD (определение схемы XML), поддерживают систему типов, основанную на единичном наследовании. Система типов статьи согласно настоящему изобретению может отображаться в модель типов XSD. XSD также не обеспечивают поддержку поведений. XSD для статей нужно дополнять поведениями статей. Базы данных XML имеют дело с отдельными документами XSD и не имеют возможностей организации и широкомасштабного поиска. Как и с объектно-ориентированными базами данных, для поддержки описанной здесь модели данных, в такие базы данных XML нужно включать другие понятия, например отношения и папки; кроме того, нужно реализовать такие механизмы, как синхронизация, извещения и безопасность.
1. Реализация хранилища данных с использованием UDT
Согласно данному варианту осуществления машина 314 реляционной базы данных, которая, согласно одному варианту осуществления, содержит машину Microsoft SQL Server, поддерживает встроенные скалярные типы. Встроенные скалярные типы являются «родными» и «простыми». Они являются родными в том смысле, что пользователь не может задавать свои собственные типы, и они являются простыми в том смысле, что они не могут инкапсулировать сложную структуру. Типы, заданные пользователем (далее UDT), обеспечивают механизм для расширяемости типов за пределы система родных скалярных типов, позволяя пользователям расширять систему типов путем задания сложных, структурированных типов. Будучи задан пользователем, UDT не может использоваться где-либо в системе типов, в которой можно использовать встроенный скалярный тип.
Согласно аспекту настоящего изобретения схемы платформы хранения отображаются в классы UDT в хранилище машины базы данных. Статьи хранилища данных отображаются в классы UDT, выводимые из типа Base.Item. Как и статьи, расширения также отображаются в классы UDT и используют наследование. Корневым типом расширения является Base.Extension, из которого выводятся все типы расширения.
UDT - это класс CLR, он имеет состояние (т.е. поля данных) и поведение (т.е. процедуры). UDT задаются с использованием любого управляемого языка - C#, VB.NET и т.д. Методы и операторы UDT можно вызывать в T-SQL для экземпляра этого типа. UDT может быть: типом столбца в строке, типом параметра процедуры в T-SQL или типом переменной в T-SQL.
Следующий пример иллюстрирует основы UDT. Пусть MapLib.dll имеет ассемблер, именуемый MapLib. В этом ассемблере имеется класс, именуемый Point, под пространством имен BaseTypes:
namespace BaseTypes
{
public class Point
{
//возвращает расстояние от заданной точки.
public double Distance(Point p)
{
// возвращает расстояние между точкой p и этой точкой
}
// другое содержимое в классе
}
}
Следующий код T-SQL связывает класс Point с UDT SQL Server, именуемым Point. Первый этап вызывает "CreateAssembly", который загружает ассемблер MapLib в базу данных. Второй этап вызывает "Create Type" для создания типа, заданного пользователем, "Point" и связывания его с управляемым типом BaseTypes.Point:
CREATE ASSEMBLY MapLib FROM '\\mysrv\share\MapLib.dll'
go
CREATE TYPE Point
EXTERNAL NAME 'BaseTypes.Point'
go
После создания UDT "Point" можно использовать как столбец в таблице, и в T-SQL можно вызывать методы, как показано ниже:
Create table Cities(
Name varchar(20),
State varchar(20),
Location Point)
-- Извлекают расстояние между городами
-- из координат (32,23)
Declare @p point(32, 23), @distance float
Select Location::Distance(@p)
From Cities
Отображения схемы платформы хранения в классы UDT довольно прямые на высоком уровне. В общем случае схема платформы хранения отображается в пространство имен CLR. Тип платформы хранения отображается в класс CLR. Наследование класса CLR отражает наследование типа платформы хранения, и свойство платформы хранения отображается в свойство класса CLR.
Иерархия статьи, показанная на фиг.29, используется в качестве примера в этом документе. Показан тип Base.Item, из которого выводятся все типы статьи, совместно с множеством производных типов статьи (например, Contact.Person и Contact.Employee), с наследованием, указанным стрелками.
2. Отображение статей
Если нужно, чтобы можно было глобально искать статью, и для поддержки в реляционной базе данных, согласно данному варианту осуществления наследования и подставимости типов, одна возможная реализация хранения статей в хранилище базы данных предусматривает хранение всех статей в одной таблице со столбцом типа Base.Item. Используя подставимость типов, можно сохранять статьи всех типов и можно фильтровать поиски по типу и подтипу статьи с использованием оператора Юкона "is of (Тип)".
Однако благодаря вопросам, связанным со служебной нагрузкой, связанной с таким подходом, согласно данному варианту осуществления статьи делятся по типу верхнего уровня, например, статьи каждого «семейства» типов хранятся в отдельной таблице. Согласно этой схеме разделения таблица создается для каждого типа статьи, наследующего непосредственно от Base.Item. Типы, наследующие ниже их, хранятся в соответствующей таблице семейства типов с использованием подставимости типов, как описано выше. Только первый уровень наследования от Base.Item рассматривается особо. Для примера иерархии статьи, показанного на фиг.29, это дает следующие таблицы семейств типов:
create table Contact.[Table!Person] (
_Item Contact.Person not null,
{информация отслеживания изменений}
)
create table Doc.[Table!Document] (
_Item Doc.Document not null,
{Информация отслеживания изменений}
)
«Теневая» таблица используется для хранения копий свойств, подлежащих глобальному поиску, для всех статей. Эта таблица может поддерживаться методом Update() API платформы хранения, посредством которого производятся все изменения данных. В отличие от таблиц семейств типов, эта глобальная таблица статей содержит только скалярные свойства верхнего уровня статьи, а не весь объект статьи UDT. Структура глобальной таблицы статей такова:
create table Base.[Table!Item] (
ItemID uniqueidentifier not null constraint
[PK_Clu_Item!ItemID] primary key clustered,
TypeID uniqueidentifier not null,
{Дополнительные свойства Base.Item},
{Информация отслеживания изменений}
)
Глобальная таблица статей допускает навигацию к объекту статьи, хранящемуся в таблице семейств типов, благодаря открытию ItemID и TypeID. ItemID, в общем случае, уникально идентифицирует статью в хранилище данных. TypeID можно отображать с использованием метаданных, которые здесь не описаны, в имя типа и вид, содержащий статью.
Поскольку отыскание статьи по ее ItemID может быть обычной операцией, как в контексте глобальной таблицы статей, так и в другом месте, обеспечивается функция GetItem() для извлечения объекта статьи по данному ItemID статьи. Эта функция имеет следующую декларацию:
Base.Item Base.GetItem (uniqueidentifier ItemID)
Для удобства доступа и для сокрытия деталей реализации, насколько это возможно, все запросы статей должны быть относительно видов, построенных на вышеописанных таблицах статей. В частности, виды можно создавать для каждого типа статьи относительно соответствующей таблицы семейств типов. Эти виды типов могут выбирать все статьи соответствующего типа, включая подтипы. Для удобства, помимо объекта UDT, виды могут представлять столбцы для всех полей верхнего уровня этого типа, включая унаследованные поля. Виды для примера иерархии статьи, показанного на фиг.29, таковы:
create view Contact.Person as
select _Item.ItemID, {Свойства Base.Item},
{Свойства Contact.Person},
{Информация отслеживания изменений}, _Item
from Contact.[Table!Person]
--Заметим, что вид Contact.Employee использует предикат
-- "where" для ограничения множества найденных статей
-- экземплярами Contact.Employee
create view Contact.Employee as
select _Item.ItemID, {Свойства Base.Item},
{Свойства Contact.Person},
{Свойства Contact.Employee},
{Информация отслеживания изменений},
cast (_Item as Contact.Employee)
from Contact.[Table!Person]
where _Item is of (Contact.Employee)
create view Doc.Document as
select _Item.ItemID, {Свойства Base.Item},
{Свойства Doc.Document},
{Информация отслеживания изменений}, _Item
from Doc.[Table!Document]
--Заметим, что вид Doc.WordDocument uses предикат "where"
-- для ограничения множества найденных статей экземплярами
-- Doc.WordDocument
create view Doc.WordDocument as
select _Item.ItemID, {Свойства Base.Item},
{Свойства Doc.Document},
{Свойства Doc.WordDocument},
{Информация отслеживания изменений},
cast (_Item as Doc.WordDocument)
from Doc.[Table!Document]
where _Item is of (Doc.WordDocument)
Для полноты, вид также можно создавать по глобальной таблице статей. Этот вид первоначально открывает те же столбцы, что и таблица:
create view Base.Item as
select ItemID, TypeID, {Свойства Base.Item},
{Информация отслеживания изменений}
from Base.[Table!Item]
3. Отображение расширений
Расширения весьма сходны со статьями и подчиняются некоторым из тех же требований. В качестве другого корневого типа, поддерживающего наследование, расширения подлежат многим из тех же соображений и компромиссов в хранении. Вследствие этого к расширениям применяется аналогичное отображение семейств типов, вместо подхода единой таблицы. Конечно, в других вариантах осуществления, можно использовать подход единой таблицы.
Согласно данному варианту осуществления расширение связано с точно одной статьей посредством ItemID и содержит ExtensionID, который является уникальным в контексте статьи. Таблица расширений имеет следующее определение:
create table Base.[Table!Extension] (
ItemID uniqueidentifier not null,
ExtensionID uniqueidentifier not null,
TypeID uniqueidentifier not null,
{Свойства Base.Extension},
{Информация отслеживания изменений},
constraint [PK_Clu_Extension!ItemID!ExtensionID]
primary key clustered (ItemID asc, ExtensionID asc)
)
Как и для статей, может быть обеспечена функция для извлечения расширения по его идентификации, которая образована парой ItemID и ExtensionID. Эта функция имеет следующую декларацию:
Base.Extension Base.GetExtension(uniqueidentifier ItemID, uniqueidentifier ExtensionID)
Для каждого типа расширения создается Вид, по аналогии с видами типов статьи. Пусть иерархия расширения параллельна примеру иерархии статьи, со следующими типами: Base.Extension, Contact.PersonExtension, Contact.EmployeeExtension. Можно создать следующие виды:
create view Base.Extension as
select ItemID, ExtensionID, TypeID,
{Свойства Base.Extension},
{Информация отслеживания изменений}
from Base.[Table!Extension]
create view Contact.[Extension!PersonExtension] as
select _Extension.ItemID,
_Extension.ExtensionID,
{Свойства Base.Extension},
{Свойства Contact.Person Extension},
{Информация отслеживания изменений}, _Extension
from Base.[Table!PersonExtension]
create view Contact.[Extension!EmployeeExtension] as
select _Extension.ItemID,
_Extension.ExtensionID,
{Свойства Base.Extension},
{Свойства Contact.PersonExtension},
{Свойства Contact.EmployeeExtension},
{Информация отслеживания изменений},
cast (_Extension as Contact.EmployeeExtension)
from Base.[Table!PersonExtension]
where _Extension is of (Contact.EmployeeExtension)
4. Отображение вложенных элементов
Вложенные элементы являются типами, которые могут быть внедрены в статьи, расширения, отношения или другие вложенные элементы для формирования глубоко вложенных структур. Наподобие статей и расширений, вложенные элементы реализуются как UDT, но они хранятся в статьях и расширениях. Поэтому вложенные элементы не имеют хранилища, отображающегося за пределы их контейнеров статей и расширений. Другими словами, в системе не существует таблиц, в которых непосредственно хранятся экземпляры типов вложенного элемента, не существует видов, относящихся конкретно к вложенным элементам.
5. Идентификация объекта
Каждая сущность в модели данных, т.е. каждая(ое) статья, расширение и отношение, имеет уникальное ключевое значение. Статья уникально идентифицируется своим ItemId. Расширение уникально идентифицируется составным ключом (ItemId, ExtensionId). ItemId, ExtensionId и RelationshipId являются значениями типа GUID.
6. Именование объектов SQL
Все объекты, созданные в хранилище данных, могут сохраняться в имени схемы SQL, выведенной из имени схемы платформы хранения. Например, Базовая схема платформы хранения (часто именуемая "Base"), может порождать типы в схеме SQL "[System.Storage]", например, "[System.Storage].Item". Сгенерированные имена снабжены спецификатором в качестве префикса во избежание конфликтов именования. При необходимости восклицательный знак (!) используется в качестве разделителя для логической части имени. В нижеприведенной таблице описано соглашение именования, используемое для объектов в хранилище данных. Каждый элемент схемы (статья, расширение, отношение и вид) перечислен совместно с соглашением декорации именования, используемым для доступа к экземплярам в хранилище данных.
[Master!Item]
[OfficeDoc]
[Master!Extension]
[Extension!StickyNote]
[Master!Relationship]
[Relationship!AuthorsFrom Document]
[View!DocumentTitles]
7. Именование столбцов
При отображении любой объектной модели в хранилище возникает возможность конфликтов именования вследствие дополнительной информации, хранящейся совместно с объектом приложения. Во избежание конфликтов именования все столбцы, не связанные с типом (столбцы, которые не отображаются непосредственно в именованное свойство при декларировании типов), снабжаются префиксом в виде знака подчеркивания (_). Согласно данному варианту осуществления знаки подчеркивания (_) не разрешены в качестве начального символа любого свойства идентификатора. Кроме того, для унификации именования между CLR и хранилищем данных, все свойства типов платформы хранения или элемента схемы (отношения и т.д.) должны иметь первый символ в виде заглавной буквы.
8. Виды поиска
Виды обеспечиваются платформой хранения для поиска сохраненного контента. Вид SQL обеспечивается для каждого типа статьи и расширения. Кроме того, виды обеспечиваются для поддержки отношений и видов (заданных в Модели данных). Все виды SQL и нижележащие таблицы в платформе хранения предназначены только для чтения. Данные можно сохранять или изменять с использованием метода Update() API платформы хранения, что более подробно описано ниже.
Каждый вид, заданный в явном виде в схеме платформы хранения (задается разработчиком схемы, а не автоматически генерируется платформой хранения) доступен по имени вида SQL [<имя схемы>].[View!<имя вида>]. Например, вид под названием "BookSales" в схеме "AcmePublisher.Books" будет доступен с использованием имени "[AcmePublisher.Books].[View!BookSales]". Поскольку выходной формат вида является регулируемым для каждого вида (задан произвольным запросом, обеспеченным стороной, задающей вид), столбцы непосредственно отображаются на основании определения вида схемы.
Все виды поиска SQL в хранилище данных платформы хранения используют следующее соглашение по упорядочению для столбцов:
1. Логические «ключевые» столбцы результата вида, например, ItemId, ElementId, RelationshipId, …
2. Типизированная информация метаданных результата, например, TypeId.
3. Столбцы отслеживания изменений, например, CreateVersion, UpdateVersion,...
4. Столбцы, зависящие от типа (Свойства объявленного типа).
5. Виды, зависящие от типа (виды семейства) также содержат объектный столбец, который возвращает объект.
Члены каждого семейства типов можно искать с использованием ряда видов статьи, причем имеется один вид на тип статьи в хранилище данных.
а) Статья
Каждый вид поиска статьи содержит строку для каждого экземпляра статьи конкретного типа или его подтипов. Например, вид для типа Document может возвращать экземпляры Document, LegalDocument и ReviewDocument. Приведенные в этом примере виды Статьи можно осмыслить, как показано на фиг.28.
(1) Главный вид поиска статьи
Каждый экземпляр хранилища данных платформы хранения задает особый вид статьи, именуемый главным видом статьи. Этот вид обеспечивает сводную информацию по каждой статье в хранилище данных. Вид обеспечивает один столбец на свойство типа статьи, столбец, который описывает тип статьи и несколько столбцов, которые используются для обеспечения информации отслеживания изменений и синхронизации. Главный вид статьи идентифицируется в хранилище данных с использованием имени "[System.Storage].[Master!Item]".
(2) Типизированные виды поиска статьи
Каждый тип статьи также имеет вид поиска. Хотя этот вид аналогичен виду корневой статьи, он также обеспечивает доступ к объекту статьи посредством столбца "_Item". Каждый типизированный вид поиска статьи идентифицируется в хранилище данных с использованием имени [имя схемы].[имя типа статьи]. Например [AcmeCorp.Doc].[OfficeDoc].
b) Расширения статьи
Все расширения статьи в хранилище WinFS также доступны с использованием видов поиска.
(1) Главный вид поиска расширения
Каждый экземпляр хранилища данных задает особый вид расширения, именуемый главным видом расширения. Этот вид обеспечивает сводную информацию по каждому расширению в хранилище данных. Вид имеет столбец на свойство расширения, столбец, который описывает тип расширения и несколько столбцов, которые используются для обеспечения информации отслеживания изменений и синхронизации. Главный вид расширения идентифицируется в хранилище данных с использованием имени "[System.Storage].[Master!Extension]".
(2) Типизированные виды поиска расширения
Каждый тип расширения также имеет вид поиска. Хотя этот вид аналогичен главному виду расширения, он также обеспечивает доступ к объекту статьи посредством столбца _Extension. Каждый типизированный вид поиска расширения [имя схемы].[расширение!имя типа расширения]. Например [AcmeCorp.Doc].[Extension!OfficeDocExt].
c) Вложенные элементы
Все вложенные элементы хранятся в экземплярах статей, расширений или отношений. Поэтому доступ к ним осуществляется путем запроса соответствующего вида поиска статьи, расширения или отношения.
d) Отношения
Согласно рассмотренному выше, отношения образуют основную единицу связи между статьями в хранилище данных платформы хранения.
(1) Главный вид поиска отношения
Каждое хранилище данных обеспечивает главный вид отношения. Этот вид обеспечивает информацию обо всех экземплярах отношения в хранилище данных. Главный вид отношения идентифицируется в хранилище данных с использованием имени "[System.Storage].[Master!Relationship]".
(2) Виды поиска экземпляра отношения
Каждое объявленное отношение также имеет вид поиска, который возвращает все экземпляры конкретного отношения. Хотя этот вид аналогичен главному виду отношения, он также обеспечивает именованные столбцы для каждого свойства данных отношения. Каждый экземпляр отношения вида поиска идентифицируется в хранилище данных с использованием имени [имя схемы].[Relationship!имя отношения]. Например, [AcmeCoip.Doc].[Relationship!DocumentAuthor].
9. Обновления
Все виды в хранилище данных платформы хранения предназначены только для чтения. Для создания нового экземпляра элемента модели данных (статьи, расширения или отношения) или для обновления существующего экземпляра нужно использовать методы ProcessOperation или ProcessUpdategram API платформы хранения. Метод ProcessOperation является единственной сохраненной процедурой, заданной хранилищем данных, которая потребляет «операцию», которая детализирует действие, подлежащее выполнению. Метод ProcessUpdategram является сохраненной процедурой, которая принимает упорядоченное множество операций, именуемое «апдейтграммой», которое коллективно детализирует множество действий, подлежащих выполнению.
Формат операции является расширяемым и обеспечивает различные операции над элементами схемы. Некоторые общие операции включают в себя
1. Операции над статьями:
а. CreateItem (создает новую статью в контексте внедрения или отношения поддержки),
b. UpdateItem (обновляет существующую статью),
2. Операции над отношениями:
а. CreateRelationship (создает экземпляр отношения ссылки или поддержки),
b. UpdateRelationship (обновляет экземпляр отношения),
с. DeleteRelationship (удаляет экземпляры отношения),
3. Операции над расширениями,
а. CreateExtension (добавляет расширение к существующей статье),
b. UpdateExtension (обновляет существующее расширение),
с. DeleteExtension (удаляет расширение),
10. Отслеживание изменений и надгробия
Услуги отслеживания изменений и надгробий обеспечены хранилищем данных, что более подробно рассмотрено ниже. Этот раздел обеспечивает обзор информации отслеживания изменений, открытой в хранилище данных.
а) Отслеживание изменений
Каждый вид поиска, обеспеченный хранилищем данных, содержит столбцы, используемые для обеспечения информации отслеживания изменений; столбцы являются общими по всем видам статьи, расширения и отношения. Виды схемы платформы хранения, заданные в явном виде разработчиками схем, не обеспечивают автоматически информацию отслеживания изменений - такая информация обеспечивается косвенно через виды поиска, на которых построен сам вид.
Для каждого элемента в хранилище данных информация отслеживания изменений доступна из двух мест - «главного» вида элемента и «типизированного» вида элемента. Например, информация отслеживания изменений на типе статьи AcmeCorp.Document.Document доступна из главного вида статьи "[System.Storage].[Master!Item]" и типизированного вида поиска статьи [AcmeCorp.Document].[Document].
(1) Отслеживание изменений в «главных» видах поиска
Информация отслеживания изменений в главных видах поиска обеспечивает информацию по созданию и обновлению версий элемента, информацию о том, какой партнер синхронизации создал элемент, какой партнер синхронизации последним обновил элемент и номера версий от каждого партнера для создания и обновления. Партнеры в отношениях синхронизации (описаны ниже) идентифицируются ключом партнера. Единичный объект UDT под названием _ChangeTrackingInfo типа [System.Storage.Store].ChangeTrackingInfo содержит всю эту информацию. Тип задан в схеме System.Storage. _ChangeTrackingInfo доступен во всех глобальных видах поиска для статьи, расширения и отношения. Определение типа для ChangeTrackingInfo таково:
<Type Name="ChangeTrackingInfo" BaseType="Base.NestedElement">
<FieldProperty Name="CreationLocalTS"
Type="SqlTypes.SqlInt64"
Nullable="False"/>
<FieldProperty Name="CreatingPartnerKey"
Type="SqlTypes.SqlInt32" Nullable="False"/>
<FieldProperty Name="CreatingPartnerTS"
Type="SqlTypes.SqlInt64" Nullable="False"/>
<FieldProperty Name="LastUpdateLocalTS"
Type="SqlTypes.SqlInt64" Nullable="False"/>
<FieldProperty Name="LastUpdatingPartnerKey"
Type="SqlTypes.SqlInt32" Nullable="False"/>
<FieldProperty Name="LastUpdatingPartnerTS"
Type="SqlTypes.Sqllnt64"
Nullable="False"/>
</Type>
Эти свойства содержат следующую информацию:
(2) Отслеживание изменений в «типизированных» видах поиска
Помимо обеспечения той же информации, что и глобальный вид поиска, каждый типизированный вид поиска обеспечивает дополнительную информацию, записывающую состояние синхронизации каждого элемента в топологии синхронизации.
b) Надгробия
Хранилище данных обеспечивает информацию надгробий для статей, расширений и отношений. Виды надгробий обеспечивают информацию как о живых, так и о захороненных сущностях (статьях, расширениях и отношениях) в одном месте. Виды надгробий статьи и расширения не обеспечивают доступ к соответствующему объекту, тогда как вид надгробия отношения обеспечивает доступ к объекту отношения (объект отношения равен NULL в случае захороненного отношения).
(1) Надгробия статей
Надгробия статей извлекаются из системы посредством вида [System.Storage].[Tombstone!Item].
(2) Надгробия расширений
Надгробия расширений извлекаются из системы с использованием вида [System.Storage].[Tombstone!Extension]. Информация отслеживания изменений расширений аналогична обеспечиваемой для статей с дополнением свойства ExtensionId.
(3) Надгробия отношений
Надгробия отношений извлекаются из системы посредством вида [System.Storage].[Tombstone!Relationship]. Информация надгробий отношений аналогична обеспечиваемой для расширений. Однако обеспечивается дополнительная информация о ItemRef цели экземпляра отношения. Кроме того, выбирается объект отношения.
(4) Очистка надгробий
Во избежание неограниченного роста информации надгробий хранилище данных обеспечивает задание очистки надгробий. Это задание определяет, когда можно отбросить информацию надгробий. Задание вычисляет границу на локальном создании/обновлении версии, после урезает информацию надгробий, отбрасывая все более ранние версии надгробия.
11. API и функции помощника
Базовое отображение также обеспечивает ряд функций помощника. Эти функции обеспечены в помощь обычным операциям на модели данных.
а) Функция [System.Storage].GetItem
//Возвращает объект статьи, заданный ItemId
//
Item GetItem (ItemId ItemId)
b) Функция [System.Storage].GetExtension
//Возвращает объект расширения, заданный ItemId и
//ExtensionId
//
Extension GetExtension (ItemId ItemId, ExtensionId ExtensionId)
с) Функция [System.Storage].GetRelationship
// Возвращает объект отношения, заданный ItemId и
// RelationshipId
//
Relationship GetRelationship (ItemId ItemId, RelationshipId RelationshipId)
12. Метаданные
Существует два типа метаданных, представленных в хранилище: метаданные экземпляра (тип статьи и т.д.) и метаданные типа.
а) Метаданные схемы
Метаданные схемы хранятся в хранилище данных как экземпляры типов статьи из метасхемы.
b) Метаданные экземпляра
Метаданные экземпляра используются приложением для запроса типа статьи и находят расширения, связанные со статьей. На основании ItemId для статьи, приложение может запрашивать глобальный вид статьи для возвращения типа статьи и использовать это значение для запроса вида Meta.Type для возвращения информации об объявленном типе статьи. Например,
// Возвращает метаданные объекта статьи для данного
// экземпляра статьи
SELECT m._Item AS metadataInfoObj
FROM [System.Storage].[Item] i INNER JOIN [Meta].[Type] m
ON i._TypeId = m.ItemId
WHERE i.ItemId = @ItemId
Е. Безопасность
В этом разделе описана модель безопасности для платформы хранения настоящего изобретения согласно одному варианту осуществления.
1. Обзор
Согласно данному варианту осуществления степень фрагментарности, с которой задается и применяется политика безопасности платформы хранения, соответствует уровню различных операций на статье в данном хранилище данных; невозможно обеспечить безопасность частей статьи отдельно от целого. Модель безопасности задет множество принципалов, которым может быть разрешен или запрещен доступ для осуществления этих операций на статье посредством Списков управления доступом (ACL). Каждый ACL является упорядоченной коллекцией записей управления доступом (ACE).
Политику безопасности для статьи можно полностью описать посредством дискреционной политики управления доступом и системной политики управления доступом. Каждая из них является множеством ACL. Первое множество (DACL) описывает дискреционный доступ, предоставленный различным принципалам владельцем статьи, тогда как второе множество ACL называют SACL (системными списками управления доступом), которые задают, как осуществляется системный аудит, когда объектом манипулируют определенными способами. Кроме того, каждая статья в хранилище данных связана с SID, который соответствует владельцу статьи (SID владельца).
Основной механизм для организации статей в хранилище данных платформы хранения - это механизм иерархии включения. Иерархия включения реализуется с использованием отношений поддержки между статьями. Отношение поддержки между двумя статьями А и В, выраженное как «А содержит В», позволяет статье А влиять на время жизни статьи В. В общем случае, статья в хранилище данных не может существовать, пока существует отношение поддержки от другой статьи к ней. Отношение поддержки, помимо того, что управляет временем жизни статьи, обеспечивает необходимый механизм для распространения политики безопасности для статьи.
Политика безопасности, заданная для каждой статьи, состоит из двух частей - части, которая в явном виде задана для этой статьи, и части, которая унаследована от родителя статьи в хранилище данных. Явно заданная политика безопасности для любой статьи состоит из двух частей - части, которая управляет доступом к рассматриваемой статье, и части, которая влияет на политику безопасности, унаследованную всеми ее потомками в иерархии включения. Политика безопасности, унаследованная потомком, является функцией явно заданной политики и унаследованной политики.
Поскольку политика безопасности распространяется через отношения поддержки и также может подменяться на любой статье, необходимо указывать, как определена эффективная политика безопасности для статьи. Согласно данному варианту осуществления статья в иерархии включения хранилища данных наследует ACL вдоль каждого пути от корня хранилища до статьи.
В унаследованном ACL для любого данного пути упорядочение различных ACE в ACL определяет окончательную политику безопасности, которая применяется. Для описания упорядочения ACE в ACL используется следующая система обозначений. Упорядочение ACE в ACL, который унаследован статьей, определяется следующими двумя правилами.
Первое правило наслаивает ACE, унаследованные от различных статей на пути к статье I от корня иерархии включения. ACE, унаследованные от более близкого контейнера, получают преимущество над записями, унаследованными от удаленного контейнера. С интуитивной точки зрения это позволяет администратору подменять ACE, унаследованные от более удаленных в иерархии включения. Правило таково:
Для всех унаследованных ACL L на статье I
Для всех статей I1, I2
Для всех ACE A1 и A2 в L,
I1 является предком I2, и
I2 является предком I3, и
A1 является ACE, унаследованной от I1, и
A2 является ACE, унаследованной от I2
Влечет
А2 предшествует А1 в L.
Второе правило устанавливает положение ACE, которые отказывают в доступе к статье, впереди ACE, которые предоставляют доступ к статье.
Для всех унаследованных ACL L на статье I
Для всех статей I1
Для всех ACE A1 и A2 в L,
I1 является предком I2, и
A1 является ACCESS_DENIED_ACE, унаследованной от I1, и
A2 является ACCESS_GRANTED_ACE унаследованной от I1
Влечет
А1 предшествует А2 в L.
В случае, когда иерархия включения является деревом, имеется в точности один путь от корня дерева к статье, и статья имеет в точности один унаследованный ACL. В этих обстоятельствах ACL, унаследованный статьей, совпадает с ACL, унаследованный файлом (статьей) в существующей модели безопасности Windows в терминах относительного упорядочения ACE в них.
Однако иерархия включения в хранилище данных является ориентированным ациклическим графом (DAG), поскольку множественные отношения поддержки разрешены для статей. В этих условиях существует несколько путей к статье от корня иерархии включения. Поскольку статья наследует ACL вдоль каждого пути, она связана с коллекцией ACL, а не с одним из них. Заметим, что в этом состоит отличие от традиционной модели файловой системы, где с файлом или папкой связан в точности один ACL.
Существуют два аспекта, которые нужно рассмотреть, когда иерархия включения является DAG, а не деревом. Необходимо описание, как вычисляется эффективная политика безопасности для статьи, когда она наследует более одного ACL от своих родителей, и их организация и представление имеет прямое отношение к администрированию модели безопасности для хранилища данных платформы хранения.
Следующий алгоритм оценивает права доступа данного принципала к данной статье. На протяжении этого документа для описания ACL, связанных со статьей, используется следующая система обозначений.
Inherited_ACLs(ItemId) - множество ACL, унаследованных статьей, идентифицированных посредством ItemId, от своих родителей в хранилище.
Explicit_ACL(ItemId) - ACL, явно заданный для статьи, идентифицированной посредством ItemId.
NTSTATUS
ACLAccessCheck(
Вышеописанная процедура возвращает STATUS_SUCCESS, если запрошенный доступ не был явно отклонен, и pGrantedAccess определяет, какие из прав, запрошенных пользователем, были предоставлены указанным ACL. Если какой-либо из запросов доступа был явно отклонен, процедура возвращает STATUS_ACCESS_DENIED.
NTSTATUS
WinFSItemAccessCheck(
{
pExplicitACL = GetExplicitACLForItem(ItemId);
GetInheritedACLsForItem(ItemId,&pInheritedACLs,&NurnberOfInheritedAC Ls)
Status = ACLAccessCheck(
pOwnerSid,
pExplicitACL,
DesiredAccess,
ClientToken,
pPrivilegeSet,
&GrantedAccess);
if (Status != STATUS_SUCCESS)
return Status;
if (DesiredAccess == GrantedAccess)
return STATUS_SUCCESS;
for(
i = 0;
(i < NumberOfInheritedACLs && Status == STATUS_SUCCESS);
i++){
GrantedAccessForACL = 0;
Status = ACLAccessCheck(
pOwnerSid,
pExplicitACL,
DesiredAccess,
ClientToken,
pPrivilegeSet,
&GrantedAccessForACL);
if (Status == STATUS_SUCCESS) {
GrantedAccess != GrantedAccessForACL;
}
}
if ((Status == STATUS-SUCCESS) &&
(GrantedAccess != DesiredAccess)) {
Status = STATUS_ACCESS_DENIED;
}
return Status;
}
Сфера влияния политики безопасности, заданной на любой статье, покрывает все потомки статьи в иерархии включения, заданной на хранилище данных. Для всех статей, где задана явная политика, мы в результате задаем политику, которая наследуется всеми ее потомками в иерархии включения. Эффективные ACL, унаследованные всеми потомками, получают, беря каждый из ACL, унаследованных статьей, и добавляя наследуемые ACE в явном ACL в начало ACL. Это называется множеством наследуемых ACL, связанных со статьей.
В отсутствие какой-либо явной спецификации безопасности в иерархии включения, имеющей корнем статью папки, спецификация безопасности статьи применяется ко всем потомкам этой статьи в иерархии включения. Таким образом, каждая статья, для которой обеспечена явная спецификация политики безопасности, задает область одинаково защищенных статей, и эффективные ACL для всех статей в области образуют множество наследуемых ACL для этой статьи. Это полностью задает области в случае, когда иерархия включения представляет собой дерево. Если с каждой областью связать число, то будет достаточно просто включить область, которой принадлежит статья, совместно со статьей.
Однако для иерархий включения, которые являются DAG, точки в иерархии включения, в которых эффективная политика безопасности изменяется, определяется двумя разновидностями статей. К первой относятся статьи, для которых были заданы явные ACL. Обычно в иерархии включения существуют точки, где администратор в явном виде задал ACL. Ко второй относятся статьи, которые имеют более одного родителя, и с разными родителями связаны разные политики безопасности. Обычно это статьи, которые являются точками слияния политик безопасности, заданных для тома, и указывают начало новой политики безопасности.
Благодаря этому определению все статьи в хранилище данных попадают в одну из двух категорий - те, которые являются корнем одинаково защищенной области безопасности, и те, которые таковыми не являются. Статьи, которые не задают области безопасности, принадлежат в точности одной области безопасности. Как и в случае деревьев, эффективную безопасность для статьи можно задавать, указывая область, к которой принадлежит статья, совместно со статьей. Это обеспечивает прямую модель администрирования безопасности хранилища данных платформы хранения на основании различных одинаково защищенных областей в хранилище.
2. Подробное описание модели безопасности
В этом разделе подробно описано обеспечение безопасности статей путем описания того, как индивидуальные права в описателе безопасности и содержащихся в них ACL влияют на различные операции.
a) Структура описателя безопасности
Прежде чем подробно описать модель безопасности полезно рассмотреть описатели безопасности в более общем аспекте. Описатель безопасности содержит информацию безопасности, связанную с защищаемым объектом. Описатель безопасности состоит из структуры SECURITY_DESCRIPTOR и связанной с ней информацией безопасности. Описатель безопасности может включать в себя следующую информацию безопасности:
1. SID'ы для владельца и первичной группы объекта.
2. DACL, которая задает права доступа, разрешенные или запрещенные конкретным пользователям или группам.
3. SACL, который задает типы попыток доступа, которые генерируют записи аудита для объекта.
4. Множество битов управления, которые уточняют значение описателя безопасности или отдельных его элементов.
Предпочтительно, приложения не способны непосредственно манипулировать содержимым описателя безопасности. Существуют функции для задания и извлечения информации безопасности в описателе безопасности объекта. Кроме того, имеются функции для создания и инициализации описателя безопасности для нового объекта.
Дискреционный список управления доступом (DACL) идентифицирует доверенных лиц, которым разрешен или запрещен доступ к защищаемому объекту. Когда процесс пытается осуществить доступ к защищаемому объекту, система проверяет ACE в DACL объекта, чтобы определить, предоставить ли доступ к нему. Если объект не имеет DACL, система предоставляет полный доступ любому. Если DACL объекта не имеет ACE, система отклоняет все попытки доступа к объекту, поскольку DACL не дает никаких прав доступа. Система последовательно проверяет ACE, пока не найдет одну или более ACE, которые разрешают все запрошенные права доступа или пока не будут запрещены какие-либо из запрошенных прав доступа.
Системный список управления доступом (SACL) позволяет администратору регистрировать попытки доступа к защищенному объекту. Каждая ACE указывает типы попыток доступа со стороны указанного доверенного лица, что заставляет систему генерировать запись в журнале событий безопасности. ACE в SACL может генерировать записи аудита при неудачной попытке доступа, при удачной попытке доступа или в обоих случаях. SACL также может выдавать сигнал тревоги, когда неуполномоченный пользователь пытается осуществить доступ к объекту.
Все типы ACE содержат следующую информацию управления доступом:
1. Идентификатор безопасности (SID), которая идентифицирует доверенное лицо, к которому применяется ACE.
2. Маска доступа, которая задает права доступа под управлением ACE.
3. Флаг, указывающий тип ACE.
4. Множество битовых флагов, которые определяют, могут ли дочерние контейнеры или объекты наследовать ACE от первичного объекта, к которому присоединен ACL.
В нижеследующей таблице приведены три типа ACE, поддерживаемые всеми защищаемыми объектами.
(1) Формат маски доступа
Все защищаемые объекты организуют свои права доступа с использованием формата маски доступа, показанной на фиг.26. В этом формате, 16 младших битов предназначены для прав доступа, зависящих от объекта, следующие 7 битов предназначены для стандартных прав доступа, которые применяются к большинству типов объектов, и 4 старших бита используются для указания общих прав доступа, которые каждый тип объекта может отображать в множество стандартных и зависящих от объекта прав. Бит ACCESS_SYSTEM_SECURITY соответствует праву доступа SACL объекта.
(2) Общие права доступа
Общие права задаются в 4 старших битах маски. Каждый тип защищаемого объекта отображает эти биты в множество своих стандартных и зависящих от объекта прав доступа. Например, объект файла отображает бит GENERIC_READ в стандартные права доступа READ_CONTROL и SYNCHRONIZE и в права доступа, зависящие от объекта, FILE_READ_DATA, FILE_READ_EA, и FILE_READ_ATTRIBUTES. Объекты других типов отображают бит GENERIC_READ в какое-либо множество прав доступа, пригодных для этого типа объекта.
Общие права доступа можно использовать для указания типа доступа, необходимых при открытии описателя объекту. Это обычно проще, чем задавать все соответствующие стандартные и особые права. В нижеследующей таблице приведены константы, заданные для общих прав доступа.
(3) Стандартные права доступа
Каждый тип защищаемого объекта имеет множество прав доступа, которые соответствуют операциям, характерных для этого типа объекта. Помимо этих прав доступа, зависящих от объекта, имеется множество стандартных прав доступа, которые соответствуют операциям, общим для большинства типов защищаемых объектов. В нижеследующей таблице показаны константы, заданные для стандартных прав доступа.
b) Права, зависящие от статьи
В структуре маски доступа, показанной на фиг.26, права, зависящие от статьи, размещаются в разделе «права, зависящие от объекта» (младшие 16 битов). Поскольку, согласно данному варианту осуществления, платформа хранения открывает два набора API для администрирования безопасности - Win32 и API платформы хранения, права, зависящие от объекта, файловой системы нужно рассматривать для мотивирования построения прав, зависящих от объекта, платформы хранения.
(1) Права, зависящие от объекта «файл» и «директория»
Рассмотрим следующую таблицу:
Согласно вышеприведенной таблице заметим, что файловые системы делают принципиальные различия между файлами и директориями, по причине права, относящиеся к файлам и директориям, перекрываются на одних и тех же битах. Файловые системы задают весьма фрагментарные права, позволяющие приложениям управлять поведением на этих объектах. Например, они позволяют приложениям делать различия между атрибутами (FILE_READ/WRITE_ATTRIBUTES), расширенными атрибутами и потоком данных, связанным с файлом.
Целью модели безопасности платформы хранения согласно настоящему изобретению является упрощение модели присвоения прав, чтобы приложениям, оперирующим статьями хранилища данных (контактами, адресами электронной почты и т.д.), в общем случае, не приходилось делать различия, например, между атрибутами, расширенными атрибутами и потоками данных. Однако для файлов и папок сохраняются фрагментарные права Win32 и задается семантика доступа посредством платформы хранения, что позволяет сохранять совместимость с приложениями Win32. Это отображение рассматривается для каждого из прав на статью, указанного ниже.
Следующие права на статью указаны совместно с соответствующими допустимыми операциями. Также предусмотрены эквивалентные права Win32, резервирующие каждое из этих прав на статью.
(2) WinFSItemRead
Это право позволяет осуществлять доступ для чтения ко всем эквивалентам статьи, включая статьи, связанные со статьей через отношения внедрения. Оно также допускает перечисление статей, привязанных к этой статье через отношения поддержки (наподобие отображения директории). При этом включаются имена статей, связанных отношениями ссылки. Это право отображается в
Файл:
(FILE_READ_DATA | SYNCHRONIZE)
Папку:
(FILE_LIST_DIRECTORY | SYNCHRONIZE)
Семантика такова, что приложение безопасности не может задавать WinFSItemReadData и указывать маску прав как комбинацию указанных выше прав на файл.
(3) WinFSItemReadAttributes
Это право позволяет осуществлять доступ для чтения к основным атрибутам статьи, хотя файловые системы делают различия между основными атрибутами файла и потоками данных. Предпочтительно, эти основные атрибуты это те, которые размещены в базовой статье, из которой выводятся все статьи. Это право отображается на:
Файл:
(FILE_READ_ATTRIBUTES)
Папку:
(FILE_READ_ATTRIBUTES)
(4) WinFSItemWriteAttributes
Это право позволяет осуществлять доступ для записи к основным атрибутам статьи, хотя файловые системы делают различия между основными атрибутами файла и потоками данных. Предпочтительно, эти основные атрибуты это те, которые размещены в базовой статье, из которой выводятся все статьи. Это право отображается на:
Файл:
(FILE_WRITE_ATTRIBUTES)
Папку:
(FILE_WRITE_ATTRIBUTES)
(5) WinFSItemWrite
Это право позволяет записывать все элементы статьи, включая статьи, связанные отношениями внедрения. Это право также дает возможность добавлять отношения внедрения в другие статьи или удалять их оттуда. Это право отображается на:
Файл:
(FILE_WRITE_DATA)
Папку:
(FILE_ADD_FILE)
В хранилище данных платформы хранения не делается различий между статьями и папками, поскольку статьи также могут иметь отношения поддержки к другим статьям в хранилище данных. Поэтому, если вы имеете права FILE_ADD_SUBDIRECTORY (или FILE_APPEND_DATA), ваша статья может быть источником отношений к другим статьям.
(6) WinFSItemAddLink
Это право дает возможность добавлять отношения поддержки к статьям в хранилище. Следует заметить, что, поскольку модель безопасности для множественных отношений поддержки изменяет безопасность на статье и изменения могут обходить WRITE_DAC, если приходят из более высокой точки в иерархии, WRITE_DAC требуется на статье назначения, чтобы можно было создать отношение к ней. Это право отображается на:
Файл:
(FILE_APPEND_DATA)
Папку:
(FILE_ADD_SUBDIRECTORY)
(7) WinFSItemDeleteLink
Это право дает возможность удалять поддержку статьи, даже если право удалять эту статью не дано принципалу. Это согласуется с моделью файловой системы и помогает осуществлять очистку. Это право отображается на:
Файл:
(FILE_DELETE_CHILD) - заметим, что файловые системы не имеют файловый эквивалент этому праву, но мы имеем понятие о статьях, имеющих отношения поддержки к другим, и, следовательно, переносят это право также на непапки.
Папку:
(FILE_DELETE_CHILD)
(8) Права на удаление статьи
Статья уничтожается при устранении последнего отношения поддержки к статье. Не существует явного обозначения удаления статьи. Существует операция очистки, которая удаляет все отношения поддержки к статье, но это средство более высокого уровня, а не системный примитив.
Любую статью, указанную с использованием пути, можно отвязать при удовлетворении любого из двух условий: (1) родительская статья по этому пути дает субъекту доступ для записи или (2) стандартные права на самой статье дают DELETE. При удалении последнего отношения статья исчезает из системы. Любую статью, указанную с использованием ItemID, можно отвязать, если стандартные права на самой статье дают DELETE.
(9) Права на копирование статьи
Статью можно копировать из исходной папки в папку назначения, если субъекту дано WinFSItemRead на статье и WinFSItemWrite на папке назначения.
(10) Права на перемещение статьи
Для перемещения файла в файловой системе требуется просто право DELETE на исходном файле и FILE_ADD_FILE на директории назначения, поскольку это сохраняет ACL на пункте назначения. Однако при вызове MoveFileEx можно задать флаг (MOVEFILE_COPY_ALLOWED), который позволяет приложению указывать, что это случай перемещения между томами, он может допускать семантику CopyFile. Есть 4 потенциальных варианта в отношении того, что происходит с описателем безопасности при перемещении:
1. Весь ACL переносится с файлом - семантика перемещения внутри тома, принятая по умолчанию.
2. Весь ACL переносится с файлом и маркируется как защищенный.
3. Переносятся только явные ACE и они повторно наследуются на пункте назначения.
4. Ничто не переносится и ничто не наследуется повторно на пункте назначения - семантика перемещения между томами, принятая по умолчанию - то же самое, что копирование файла.
В данной модели безопасности, если приложение задает флаг MOVEFILE_COPY_ALLOWED, четвертый вариант осуществляется для меж- и внутритомных случаев. Если этот флаг не задан, осуществляется второй вариант, если пункт назначения находится в той же области безопасности (т.е. одинаковые семантики наследования). Перемещение на уровне платформы хранения реализует четвертый вариант, а также требует READ_DATA на источнике, почти как копирование.
(11) Права на просмотр политики безопасности на статье
Безопасность статьи можно просматривать, если статья дает субъекту стандартное право READ_CONTROL.
(12) Права на изменение политики безопасности на статье
Безопасность статьи можно изменять, если статья дает субъекту стандартное право WRITE_DAC. Однако, поскольку хранилище данных обеспечивает неявное наследование, от этого зависит, как можно изменять безопасности на иерархиях. Правило состоит в том, что, если корень иерархии дает WRITE_DAC, то политику безопасности можно изменять на всей иерархии независимо от того, дают ли конкретные статьи в иерархии (или DAG) право WRITE_DAC субъекту.
(13) Права, не имеющие прямого эквивалента
Согласно данному варианту осуществления FILE_EXECUTE (FILE_TRAVERSE для директорий) не имеют прямого эквивалента в платформе хранения. Модель сохраняет их для совместимости с Win32, но на основании этих прав не принимаются решения на предоставление доступа. Что касается FILE_READ/WRITE_EA, поскольку статьи хранилища данных не имеют обозначений расширенных атрибутов, семантика для этого бита не предусмотрена. Однако бит остается для совместимости с Win32.
3. Реализация
Все статьи, задающие одинаково защищенные области, имеют связанные с ними ячейки в таблице безопасности. Таблица безопасности задана следующим образом:
Ячейка «Идентификация статьи» это идентификация статьи для корня одинаково защищенной области безопасности. Ячейка «Упорядоченный путь к статье» - это упорядоченный путь, связанный с корнем одинаково защищенной области безопасности. Ячейка «Явный ACL статьи» - это явный ACL, заданный для корня одинаково защищенной области безопасности. В некоторых случаях он может быть равен NULL, например, при задании новой области безопасности, поскольку статья имеет нескольких родителей, принадлежащих разным областям. Ячейка «ACL путей» - это множество ACL, унаследованных статьей, и ячейка «ACL областей» это множество ACL, заданных для одинаково защищенной области безопасности, связанной со статьей.
Вычисление эффективной безопасности для любой статьи в данном хранилище усиливает эту таблицу. Для определения политики безопасности, связанной со статьей, получают область безопасности, связанную со статьей, и извлекают ACL, связанные с этой областью.
При изменении политики безопасности, связанной со статьей, либо прямого, путем добавления явных ACL, либо косвенного, путем добавления отношений поддержки, что приводит к формированию новых областей безопасности, таблица безопасности обновляется, тем самым гарантируя пригодность вышеописанного алгоритма для определения эффективной безопасности статьи.
Опишем различные изменения, вносимые в хранилище и соответствующие алгоритмы для поддержания таблицы безопасности.
а) Создание новой статьи в контейнере
При создании новой статьи в контейнере, она наследует все ACL, связанные с контейнером. Поскольку вновь созданная статья имеет в точности одного родителя, она принадлежит той же области, что и родитель. Таким образом, нет необходимости создавать новую ячейку в таблице безопасности.
b) Добавление к статье явного ACL
При добавлении ACL к статье, он задает новую область безопасности для всех ее потомков в иерархии включения, которые принадлежат той же области безопасности, что и сама эта статья. Для всех статей, принадлежащих другим областям безопасности, но являющихся потомками данной статьи в иерархии включения, область безопасности остается неизменной, но эффективный ACL, связанный с областью, изменяется, отражая добавление нового ACL.
Введение этой новой области безопасности может обуславливать задание дополнительных областей для всех статей, которые имеют множественные отношения поддержки с предками, которые охватывают старую область безопасности и вновь заданную область безопасности. Для всех таких статей нужно задавать новую область безопасности, и процедура повторяется.
На фиг.27(a), (b), и (c) показано, что новые одинаково защищенные области безопасности выделяются из существующей области безопасности благодаря введению нового явного ACL. Это указано узлом, обозначенным 2. Однако введение этой новой области приводит к созданию дополнительной области 3, поскольку статья имеет множественные отношения поддержки.
Следующая последовательность обновлений таблиц безопасности отражает разбиение одинаково защищенных областей безопасности.
с) Добавление к статье отношения поддержки
Добавление к статье отношения поддержки обуславливает одну из трех возможностей. Если цель отношения поддержки, т.е. рассматриваемая статья, является корнем области безопасности, то эффективный ACL, связанный с областью, изменяется, и никаких дополнительных изменений таблицы безопасности не требуется. Если область безопасности источника нового отношения поддержки идентична области безопасности существующих родителей статьи, то никаких изменений не требуется. Если же статья в данный момент имеет родителей, которые принадлежат другим областям безопасности, то формируется новая область безопасности, имеющая данную статью в качестве корня области безопасности. Это изменение распространяется на все статьи в иерархии включения путем изменения области безопасности, связанной со статьей. Все статьи, принадлежащие той же области безопасности, что и рассматриваемая статья и ее потомки в иерархии включения, нуждаются в изменении. После проведения изменения, все статьи, имеющие множественные отношения поддержки, должны быть проверены на предмет необходимости дальнейших изменений. Дополнительные изменения могут потребоваться, если какая-либо из этих статей имеет родителей в других областях безопасности.
d) Удаление отношения поддержки из статьи
При удалении отношения поддержки из статьи возможно слияние области безопасности с ее родительской областью при выполнении определенных условий. В частности, это может происходить при следующих условиях: (1) если удаление отношения поддержки приводит к тому, что статья имеет одного родителя, и для этой статьи не задано ни одного явного ACL; (2) если удаление отношения поддержки приводит к тому, что все родители статьи принадлежат одной и той же области безопасности, и для этой статьи не задано ни одного явного ACL. В этих обстоятельствах область безопасности можно маркировать как идентичную родительской. Эту маркировку нужно применять ко всем статьям, чьи области безопасности соответствуют области, подвергающейся слиянию.
е) Удаление явного ACL из статьи
При удалении явного ACL из статьи возможно слияние области безопасности, конем которой является данная статья, с областями безопасности ее родителей. В частности, это происходит, если удаление явного ACL приводит к тому, что родители статьи в иерархии включения принадлежат одной и той же области безопасности. В этих обстоятельствах область безопасности можно маркировать как идентичную родительской, и изменения применяются ко всем статьям, чьи области безопасности соответствуют области, подвергающейся слиянию.
f) Изменение ACL, связанного со статьей
В этом сценарии не требуется никаких добавлений к таблице безопасности. Эффективный ACL, связанный с областью, обновляется, и новое изменение ACL распространяется на области безопасности, подверженные его влиянию.
F. Извещения и отслеживание изменений
Согласно другому аспекту настоящего изобретения платформа хранения обеспечивает возможность извещения, которая позволяет приложениям отслеживать изменения данных. Эта особенность предназначена, в основном, для приложений, которые поддерживают подвижное состояние или выполняют коммерческую логику на событиях изменения данных. Приложения регистрируют извещения на статьях, расширениях статей и отношениях статей. Извещения доставляются асинхронно после осуществления изменений данных. Приложения могут фильтровать извещения по статье, расширению и типу отношения, а также по типу операции.
Согласно одному варианту осуществления API 322 платформы хранения обеспечивает две разновидности интерфейсов для извещений. В первой приложения регистрируют простые события изменения данных, обусловленные изменениями статей, расширений статей и отношений статей. Во второй приложения создают объекты «наблюдатель» для мониторинга множеств статей, расширений статей и отношений статей. Состояние объекта наблюдателя можно сохранять и повторно создавать после сбоя системы или после того, как система проработает в автономном режиме в течение продолжительного периода времени. Единичное извещение может отражать множественные обновления.
1. Сохранение событий изменения
В данном разделе приведено несколько примеров использования интерфейсов извещения, обеспеченных API 322 платформы хранения.
а) События
Статьи, расширения статей и отношения статей открывают события изменения данных, которые используются приложениями для регистрации извещений изменения данных. Следующий иллюстративный код демонстрирует определение обработчиков событий ItemModified и ItemRemoved на базовом классе Item.
// События
public event ItemModifiedEventHandler Item ItemModified;
public event ItemRemovedEventHandler Item ItemRemoved;
Все извещения несут достаточно данных для извлечения измененной статьи из хранилища данных. Следующий иллюстративный код демонстрирует регистрацию событий на статье, расширении статьи или отношении статей:
myItem.ItemModified += new
ItemModifiedEventHandler(this.onItemUpdate);
myItem.ItemRemoved += new
ItemRemovedEventHandler(this.onItemDelete);
Согласно данному варианту осуществления платформа хранения гарантирует извещение приложений об изменении или удалении соответствующей статьи после последней доставки извещения или в случае новой регистрации после последней выборки из хранилища данных.
b) Наблюдатели
Согласно данному варианту осуществления платформа хранения задает классы наблюдателей для мониторинга объектов, связанных с (1) папкой или иерархией папок, (2) контекстом статьи или (3) конкретной статьей. Для каждой из этих трех категорий платформа хранения обеспечивает определенные классы наблюдателей, которые отслеживают соответствующие статьи, расширения статей или отношения статей, например, платформа хранения обеспечивает соответствующие классы FolderItemWatcher, FolderRelationshipWatcher и FolderExtensionWatcher.
Для создания наблюдателя приложение может запросить извещения для ранее существующих статей, т.е. статей, расширений или отношений. Эта возможность характерна для приложений, которые поддерживают частный кэш статей. В отсутствие запроса приложения принимают извещения для всех обновлений, которые происходят после создания объекта наблюдателя.
Совместно с доставкой извещений платформа хранения выдает объект "WatcherState" (состояние наблюдателя). WatcherState может быть преобразован к последовательному виду и сохранен на диске. После этого состояние наблюдателя можно использовать для воссоздания соответствующего наблюдателя после сбоя или после повторного соединения после периода автономной работы. Вновь воссозданный наблюдатель будет повторно генерировать неквитированные извещения. Приложения обозначают доставку извещения, вызывая метод "Exclude" на соответствующем состоянии наблюдателя, выдающий ссылку на извещение.
Платформа хранения доставляет отдельные копии состояния наблюдателя на каждый обработчик событий. Состояния наблюдателя, принятые при последующих вызовах одного и того же обработчика событий, предполагают доставку всех ранее принятых извещений.
В порядке примера следующий иллюстративный код демонстрирует определение FolderItemWatcher.
public class FolderItemWatcher: Watcher
{
// Конструкторы
public FolderItemWatcher_Constructor(Folder folder);
public FolderItemWatcher_Constructor1(Folder folder,
Type itemType);
public FolderItemWatcher_Constructor2(ItemContext context,
ItemId folderId);
public FolderItemWatcher_Constructor3(Folder folder,
Type itemType, FolderItemWatcherOptions options);
public FolderItemWatcher_Constructor4(ItemContext context,
ItemId folderId, Type itemType);
public FolderItemWatcher_Constructor5(ItemContext context,
ItemId folderId, Type
itemType, FolderItemWatcherOptions options);
// Свойства
public ItemId FolderItemWatcher_FolderId {get;}
public Type FolderItemWatcher_ItemType {get;}
public FolderItemWatcherOptions
FolderItemWatcher_Options (get;}
// События
public event ItemChangedEventHandler
FolderItemWatcher_ItemChanged;
}
Следующий иллюстративный код демонстрирует, как создавать объект наблюдатель папки для мониторинга содержимого папки. Наблюдатель генерирует извещения, т.е. события, когда добавляются новые статьи музыки или существующие статьи музыки обновляются или удаляются. Наблюдатели папок отслеживают либо конкретную папку, либо все папки в иерархии папок.
myFolderItemWatcher = new FolderItemWatcher(myFolder,
typeof(Music));
myFolderItemWatcher.ItemChanged += new
ItemChangedEventHandler(this.onItemChanged);
2. Механизм отслеживания изменений и генерации извещений
Платформа хранения обеспечивает простой, но эффективный механизм отслеживания изменений данных и генерации извещений. Клиент извлекает извещения на том же самом соединении, которое используется для извлечения данных. Это, в общем случае, упрощает проверки безопасности, устраняет задержки и ограничения на возможных сетевых конфигурациях. Извещения извлекаются путем выдачи операторов выбора. Во избежание опроса клиенты могут использовать признак "waitfor", обеспеченный машиной 314 базы данных. На фиг.13 показана основная концепция извещения платформы хранения. Этот запрос waitfor может выполняться синхронно, и в этом случае вызывающий поток блокируется до получения результатов, или асинхронно, в этом случае поток не блокируется, и результаты возвращаются на отдельном потоке, когда они доступны.
Комбинация "waitfor" и "select" привлекательна для мониторинга изменений данных, которые входят в конкретный диапазон данных, поскольку изменения можно отслеживать, задавая блокировку извещений на соответствующем диапазоне данных. Это поддерживается для многих общих сценариев платформы хранения. Изменения отдельных статей можно эффективно отслеживать, задавая блокировки извещений на соответствующем диапазоне данных. Изменения папок и деревьев папок можно отслеживать, задавая блокировки извещений на диапазонах путей. Изменения типов и их подтипов можно отслеживать, задавая блокировки извещений на диапазонах типов.
В общем случае существует три разные фазы, связанные с обработкой извещений: (1) изменение или даже обнаружение данных, (2) согласование подписок и (3) доставка извещений. Исключая синхронную доставку извещений, т.е. доставку извещений как часть транзакции, осуществляющей изменение данных, платформа хранения может реализовать две формы доставки извещений:
1) немедленное обнаружение событий: обнаружение событий и согласование подписки осуществляется как часть транзакции обновления; извещения вставляются в таблицу, отслеживаемую абонентом;
2) отсроченное обнаружение событий: обнаружение событий и согласование подписки осуществляется после выполнения транзакции обновления; после этого фактический абонент или посредник обнаруживает события и генерирует извещения.
Немедленное обнаружение событий требует дополнительного кода для выполнения как части операций обновления. Это позволяет захватывать все интересующие события, включающие события, указывающие относительное изменение состояния.
Отсроченное обнаружение событий устраняет необходимость в добавлении дополнительного кода для операций обновления. Отсроченное обнаружение событий, естественно, группирует обнаружение событий и доставку событий и хорошо согласуется с инфраструктурой выполнения запросов машины 314 базы данных (например, SQL Server).
Отсроченное обнаружение событий опирается на журнал или след, оставленный операциями обновления. Платформа хранения поддерживает множество логических меток времени совместно с надгробиями для удаленных статей данных. При сканировании хранилища данных на предмет изменений клиенты выдают метку времени, которая задает низкий водяной знак для обнаружения изменений, и множество меток времени во избежание дублирования извещений. Приложения могут принимать извещения для всех изменений, произошедших после времени, указанного низким водяным знаком.
Более сложные приложения с доступом к видам ядра могут дополнительно оптимизировать и сокращать количество операторов SQL, необходимых для мониторинга потенциально большого множества статей за счет создания частного параметра и дублирования таблиц фильтров. Приложения с особыми потребностями, например, которые должны поддерживать богатые виды, могут использовать доступную структуру отслеживания изменений для мониторинга изменений данных и обновления их частных снимков.
Поэтому предпочтительно, согласно одному варианту осуществления, платформа хранения реализует подход отсроченного обнаружения событий, который более подробно описан ниже.
а) Отслеживание изменений
Все определения статей, расширений и отношений статей несут уникальный идентификатор. Отслеживание изменений поддерживает множество логических меток времени для регистрации моментов создания, обновления и удаления для всех статей данных. Записи надгробий используются для представления удаленных статей данных.
Приложения используют эту информацию, чтобы эффективно отслеживать, была(о) ли конкретная(ое) статья, расширение статьи или отношение статей вновь создана(о), обновлена(о) или удалена(о) после последнего обращения приложения к хранилищу данных. Следующий пример иллюстрирует этот механизм.
create table [item-extension-relationship-table-template] (
identifier uniqueidentifier not null default newid()
created bigint, not null, -- @ @ dbts when created
updated bigint, not null, -- @ @ dbts when last updated
…
)
Все удаленные статьи, расширения статей и отношения записываются в соответствующую таблицу надгробий. Ниже показан шаблон.
create table [item-extension-relationship-tombstone
table-template] (
identifier uniqueidentifier not null,
deleted bigint not null, -- @@ dbts when deleted,
created bigint not null, -- @@ dbts when created
upated bigint not null, -- @@ dbts when last updated
…
)
По соображениям эффективности, платформа хранения поддерживает набор глобальных таблиц для статей, расширений статей, отношений и имен путей. Эти глобальные таблицы поиска могут использоваться приложениями для эффективного мониторинга диапазона данных и извлечения соответствующей метки времени и информации типа.
b) Управление метками времени
Логические метки времени являются «локальными» по отношению к хранилищу базы данных, т.е. тому платформы хранения. Метки времени являются монотонно возрастающими 64-битовыми значениями. Для обнаружения, произошло ли изменение данных после последнего соединения с томом платформы хранения, часто бывает достаточно оставлять одну метку времени. Однако, в большинстве реалистических сценариев, приходится оставлять несколько больше меток времени, чтобы проверять дубликаты. Причины этого объяснены ниже.
Таблицы реляционной базы данных представляют собой логические абстракции, надстроенные на множестве физических структур данных, т.е. бинарных деревьев, «куч» и т.д. Присвоение метки времени вновь созданной или обновленной записи не является элементарным действием. Вставка этой записи в нижележащие структуры данных может происходить в разные моменты времени, что позволяет приложениям видеть записи в произвольном порядке.
На фиг.14 показаны две транзакции, обе из которых вставляют новую запись в одно и то же бинарное дерево. Поскольку транзакция Т3 вставляет свою запись до запланированной вставки транзакции Т2, приложение, сканирующее бинарное дерево, может видеть записи, вставленные транзакцией Т3, до вставленных Т2. Таким образом, читатель может неправильно предположить, что увидел все записи, созданные до времени «10». Чтобы решить этот вопрос, машина 314 базы данных обеспечивает функцию, которая возвращает низкий водяной знак, до которого все изменения были произведены и вставлены в соответствующие нижележащие структуры данных. В вышеприведенном примере, возвращенный низкий водяной знак имеет значение «5», исходя из предположения, что читатель начал до того, как была проведена транзакция Т2. Низкий водяной знак, обеспеченный машиной 314 базы данных, позволяет приложениям эффективно определять, какие статьи игнорировать при сканировании базы данных или диапазона данных на предмет изменений данных. В общем случае, предполагается, что транзакции ACID длятся очень короткое время, поэтому ожидается, что низкие водяные знаки очень близки к наиболее недавно установленной метке времени. При наличии долговременных транзакций, приложения должны оставлять индивидуальные метки времени для обнаружения и отбрасывания дубликатов.
с) Обнаружение изменения данных - обнаружение событий
Запрашивая хранилище данных, приложения получают низкий водяной знак. Затем приложения используют этот водяной знак для сканирования хранилища данных на предмет записей, метки времени создания, обновления или удаления которых больше, чем возвращенный низкий водяной знак. Этот процесс показан на фиг.15.
Во избежание дублирования извещений приложения запоминают метки времени, которые больше возвращенного низкого водяного знака, и используют их для отфильтровывания дубликатов. Приложения создают локальные временные таблицы сеансов для эффективной обработки большого множества дублирующих друг друга меток времени. Перед выдачей оператора выбора приложение вставляет все дублирующие друг друга метки времени, возращенные ранее, и удаляет те из них, которые старше последнего возвращенного низкого водяного знака, что проиллюстрировано ниже.
delete from $duplicates where ts < @oldLowWaterMark;
insert into $duplicates(ts) values(…),…,(…);
waitfor(select *, getLowWaterMark() as newLowWaterMark
from [global!items]
where updated >= @oldLowWaterMark
and updated not in (select * from $duplicates))
G. Синхронизация
Согласно другому аспекту настоящего изобретения платформа хранения обеспечивает услугу синхронизации 330, которая (i) позволяет множественным экземплярам платформы хранения (каждая из которых имеет собственное хранилище данных 302) синхронизировать части своего контента согласно гибкому множеству правил, и (ii) обеспечивает инфраструктуру для третьих сторон для синхронизации хранилища данных платформы хранения настоящего изобретения с другими источниками данных, которые реализуют собственнические протоколы.
Синхронизация между платформами хранения происходит в группе участвующих копий. Например, согласно фиг.3, может быть желательно обеспечить синхронизацию между хранилищем данных 302 платформы хранения 300 с другим удаленным хранилищем данных 338 под управлением другого экземпляра платформы хранения, возможно, действующего на другой компьютерной системе. Все члены этой группы не обязательно должны быть известны любой данной копии в любое данное время.
Разные копии могут производить изменения независимо (т.е. одновременно). Процесс синхронизации определяется как информирование каждой копии об изменениях, произведенных другими копиями. Этой возможности синхронизации внутренне присуща множественная мастеризация.
Возможность синхронизации настоящего изобретения позволяет копиям:
- определять, о каких изменениях знает другая копия;
- запрашивать информацию об изменениях, о которых этой копии не известно;
- переносить информацию об изменениях, о которых другой копии не известно;
- определять, когда два изменения конфликтуют друг с другом;
- локально применять изменения;
- переносить разрешения конфликтов на другие копии для обеспечения сходимости;
- разрешать конфликты на основании заданных политик для разрешения конфликтов.
1. Синхронизация между платформами хранения
Основное применение услуги синхронизации 330 платформы хранения настоящего изобретения состоит в синхронизации множественных экземпляров платформы хранения (каждый из которых имеет собственное хранилище данных). Услуга синхронизации действует на уровне схем платформы хранения (а не нижележащих таблиц машины 314 базы данных). Так, например, «области действия» используются для задания множеств синхронизации, которые рассмотрены ниже.
Услуга синхронизации действует по принципу «чистых изменений». Вместо записи и передачи отдельных операций (как при транзакционном дублировании) услуга синхронизации передает конечный результат этих операций, таким образом часто консолидируя результаты множественных операций в единое результирующее изменение.
Услуга синхронизации, в общем случае, не признает границы транзакции. Другими словами, если два изменения произведены в хранилище данных платформы хранения в одной транзакции, нет никакой гарантии, что эти изменения автоматически применяются ко всем остальным копиям - одно может произойти без другого. Исключение из этого принципа состоит в том, что, если два изменения произведены в одной и той же статье в одной и той же транзакции, то эти изменения гарантированно передаются и автоматически применяются к другим копиям. Таким образом, статьи являются единицами согласованности для услуги синхронизации.
а) Приложения управления синхронизацией
Любое приложение может подключаться к услуге синхронизации и инициировать операцию синхронизации. Такое приложение обеспечивает все параметры, необходимые для осуществления синхронизации (см. профиль синхронизации ниже). Такие приложения называются здесь приложениями управления синхронизацией (SCA).
При синхронизации двух экземпляров платформы хранения синхронизация инициируется на одной стороне посредством SCA. Это SCA информирует локальную услугу синхронизации для синхронизации с удаленным партнером. С другой стороны, услуга синхронизации пробуждается сообщениями, передаваемыми услугой синхронизации от машины-источника. Оно отвечает на основании информации устойчивой конфигурации (см. отображения ниже), присутствующей на машине назначения. Услуга синхронизации может действовать по расписанию или в ответ на события. В этих случаях услуга синхронизации, реализующая расписание, становится SCA.
Для обеспечения синхронизации нужно выполнить два этапа. Во-первых, разработчик схем должен аннотировать схему платформы хранения надлежащей семантикой синхронизации (указывающей блоки изменения, описанные ниже). Во-вторых, синхронизация должна быть правильно сконфигурирована на всех машинах, имеющих экземпляр платформы хранения, который должен участвовать в синхронизации (как описано ниже).
b) Аннотация схемы
Основным понятием услуги синхронизации является понятие блока изменения. Блок изменения - это мельчайший кусок схемы, индивидуально отслеживаемый платформой хранения. Для каждого блока изменения услуга синхронизации может определять, изменился ли он после последней синхронизации.
Указание блоков изменения в схеме служит нескольким целям. Во-первых, это позволяет определить, насколько информативна услуга синхронизации на проводе. Когда в блоке изменения производятся изменения, весь блок изменения передается другим копиям, поскольку услуга синхронизации не знает, какая часть блока изменения подверглась изменению. Во-вторых, это позволяет определить степень фрагментарности обнаружения конфликта. Когда один и тот же блок изменения подвергается двум одновременным изменениям (эти термины подробно определены в последующих разделах), услуга синхронизации возбуждает конфликт; если же одновременные изменения производятся в разных блоках изменения, конфликт не возбуждается, и изменения автоматически сливаются. В-третьих, это сильно влияет на объем метаданных, поддерживаемых системой. Большой объем метаданных услуг синхронизации сохраняется в расчете на блок изменения; таким образом, чем меньше блок изменения, тем больше служебная нагрузка синхронизации.
Для задания блоков изменения требуется найти правильные компромиссы. По этой причине услуга синхронизации позволяет разработчикам схем участвовать в процессе.
Согласно одному варианту осуществления услуга синхронизации не поддерживает блоки изменения, которые больше элемента. Однако она поддерживает способность разработчиков схем задавать блоки изменения, которые меньше элемента, а именно, группировать множественные атрибуты элемента в отдельный блок изменения. Согласно этому варианту осуществления для этого используется следующий синтаксис:
<Type Name="Appointment" MajorVersion="1" MinorVersion="0"
ExtendsType="Base.Item" Extends Version="1">
<Field Name="MeetingStatus" Type="the storage
platformTypes.uniqueidentifier Nullable="False"/>
<Field Name="OrganizerName" Type="the storage
platformTypes.nvarchar(512)" Nullable="False"/>
<Field Name="OrganizerEmail" Type="the storage
platformTypes.nvarchar(512)"
TypeMajorVersion="1" MultiValued="True"/>
…
<ChangeUnit Name="CU_Status">
<Field Name="MeetingStatus"/>
</ChangeUnit>
<ChangeUnit Name="CU_Organizer"/>
<Field Name="OrganizerName"/>
<Field Name="OrganizerEmail"/>
</ChangeUnit>
…
</Type>
с) Конфигурация синхронизации
Группа партнеров платформы хранения, которые желают поддерживать определенные части своих данных в синхронизме, называется сообществом синхронизации. Хотя члены сообщества хотят оставаться в синхронизме, им не обязательно представлять данные в точности одинаковым способом; другими словами, партнеры синхронизации могут преобразовывать данные, которые они синхронизируют.
В сценарии взаимодействия равноправных устройств для равноправных устройств непрактично поддерживать отображения преобразования для всех своих партнеров. Вместо этого, услуга синхронизации пользуется подходом задания "папок сообщества". Папка сообщества - это абстракция, представляющая гипотетическую «совместно используемую папку», с которой синхронизируются все члены сообщества.
Это понятие лучше всего проиллюстрировать на примере. Если Джо хочет поддерживать папки My Documents на нескольких своих компьютерах в синхронизме Джо задает папку сообщества, именуемую, скажем, JoesDocuments. Затем, на каждом компьютере, Джо конфигурирует отображение между гипотетической папкой JoesDocuments и логической папкой My Documents. С этого момента, когда компьютеры Джо синхронизируются друг с другом, они говорят в терминах документов в JoesDocuments, а не их локальных статей. Таким образом, все компьютеры Джо понимают друг друга без необходимости знать, кто такие другие - Папка сообщества становится лингва-франка сообщества синхронизации.
Конфигурирование услуги синхронизации состоит из трех этапов: (1) задание папок между локальными папками и папками сообщества; (2) задание профилей синхронизации, которые определяют, что синхронизируется (например, с кем синхронизироваться и какие подмножества нужно передавать и какие принимать); и (3) задание расписаний, согласно которым должны запускаться профили, или запуск их вручную.
(1) Папка сообщества - отображения
Отображения папки сообщества сохраняются на отдельных машинах как файлы конфигурации XML. Каждое отображение имеет следующую схему:
/отображения/папка сообщества
Этот элемент дает имя папке сообщества, для которой предназначено это отображение. Имя подчиняется следующему синтаксису папок.
/отображения/локальная папка
Этот элемент дает имя локальной папке, в которую отображение преобразует. Имя подчиняется правилам синтаксиса для папок. Папка должна уже существовать, чтобы отображение было действительным. Статьи в этой папке рассматриваются для синхронизации посредством этого отображения.
/отображения/преобразования
Этот элемент задает, как преобразовывать статьи из папки сообщества в локальную папку и наоборот. В частности, это значит, что никакие ИД не отображаются. Эта конфигурация, в основном, используется для создания кэша папки.
/отображения/преобразования/ИД отображений
Этот элемент требует, чтобы вновь сгенерированные локальные ИД присваивались всем статьям, отображаемым из папки сообщества, вместо повторного использования ИД сообщества. Среда выполнения синхронизации будет поддерживать отображения ИД для преобразования статей в двух направлениях.
/отображения/преобразования/локальный корень
Этот элемент требует, чтобы корневые статьи в папке сообщества были сделаны дочерними статьями указанного корня.
/отображения/действовать за
Этот элемент управляет, от чьего имени обрабатываются запросы относительно этого отображения. Если отсутствует, предполагается отправитель.
/отображения/ действовать за/отправитель
Наличие этого элемента указывает, что нужно действовать за отправителя сообщений на это отображение, и запросы, обработанные под его мандатом.
(2) Профили
Профиль синхронизации это полный набор параметров, необходимых для начала синхронизации. Он передается SCA среде выполнения синхронизации для инициирования синхронизации. Профили синхронизации для синхронизации между платформами хранения содержат следующую информацию:
- локальная папка, служащая источником и пунктом назначения для изменений;
- имя удаленной папки, с которой нужно синхронизироваться - эта папка должна быть опубликована от удаленного партнера посредством отображения, как описано выше;
- направление - услуга синхронизации поддерживает синхронизацию только передачи, только приема и передачи-приема;
- локальный фильтр - выбирает, какую локальную информацию передавать удаленному партнеру. Выражается как запрос платформы хранения по локальной папке;
- удаленный фильтр - выбирает, какую удаленную информацию извлекать из удаленного партнера - выражается как запрос платформы хранения по папке сообщества;
- преобразования - задает, как преобразовывать статьи в локальный формат и из него;
- локальная безопасность - указывает, подлежат ли изменения, извлеченные из удаленной концевой точки, применению по разрешению удаленной концевой точки (подмененной) или пользователя, локально инициирующего синхронизацию;
- политика разрешения конфликтов - указывает, следует ли конфликты отбрасывать, регистрировать или автоматически разрешать - в последнем случае, указывает, какой алгоритм разрешения конфликтов использовать, а также параметры конфигурации для него.
Услуга синхронизации обеспечивает класс CLR среды выполнения, который позволяет простое построение профилей синхронизации. Профили могут также преобразовывать к последовательному виду в файлы XML или из них для простоты хранения (часто рядом со схемами). Однако не существует стандартного места в платформе хранения, где хранятся все свойства; SCA могут строить профиль на пятне, даже не сохраняя его. Заметим, что для инициирования синхронизации не требуется иметь локальное отображение. Вся информация синхронизации может быть задана в профиле. Однако отображение требуется для ответа на запросы синхронизации, инициированные удаленной стороной.
(3) Расписания
Согласно одному варианту осуществления услуга синхронизации не обеспечивает собственную инфраструктуру планирования. Напротив, она опирается на другой компонент для выполнения этой задачи - Windows Scheduler, имеющийся в операционной системе Microsoft Windows. Услуга синхронизации включает в себя утилиту командной строки, которая действует как SCA и запускает синхронизацию на основании профиля синхронизации, хранящегося в файле XML. Эта утилита позволяет очень легко конфигурировать Windows Scheduler для запуска синхронизации либо по расписанию, либо в ответ на события, например вход или выход пользователя.
d) Обработка конфликтов
Обработка конфликтов в услуге синхронизации делится на три стадии: (1) обнаружение конфликта, которое происходит в момент применения изменения - этот этап определяет, можно ли безопасно применить изменение; (2) автоматическое разрешение и регистрация конфликтов - на этом этапе (который имеет место сразу после обнаружения конфликта) осуществляется консультация с алгоритмами автоматического разрешения конфликтов, чтобы посмотреть, можно ли разрешить конфликт - если нет, конфликт можно в необязательном порядке зарегистрировать; и (3) инспекция и разрешение конфликта - этот этап имеет место, если некоторые конфликты были зарегистрированы, и осуществляется вне контекста сеанса синхронизации - в это время зарегистрированные конфликты можно разрешить и удалить из журнала.
(1) Обнаружение конфликта
Согласно данному варианту осуществления услуга синхронизации обнаруживает два типа конфликтов: на основе знания и на основе ограничения.
(а) Конфликты на основе знания
Конфликт на основе знания происходит, когда две копии производят независимые изменения в одном и том же блоке изменения. Два изменения называются независимыми, если они производятся без знания друг о друге - другими словами, версия первого не покрывается знанием второго и наоборот. Услуга синхронизации автоматически обнаруживает все такие конфликты на основании вышеописанного знания копий.
Иногда полезно рассматривать конфликты как разветвления в истории версий блока изменения. Если конфликты происходят во время жизни блока изменения, его история версий является простой цепью - каждое изменение происходит после предыдущего. В случае конфликта на основе знания два изменения происходят параллельно, вызывая расщепление цепи и ее превращение в дерево версий.
(b) Конфликты на основе ограничений
Бывают случаи, когда независимые изменения нарушают ограничения целостности при совместном применении. Например, такой конфликт может возникнуть, когда две копии создают файл с одним и тем же именем в одной и той же директории.
Конфликт на основе ограничения предусматривает два независимых изменения (как и конфликт на основе знания), но они не относятся к одному и тому же блоку изменения. Напротив, они относятся к разным блокам изменения, но с ограничением, существующим между ними.
Услуга синхронизации обнаруживает нарушения ограничений в момент применения изменения и автоматически возбуждает конфликты на основе ограничения. Для разрешения конфликтов на основе ограничения обычно требуется специальный код, который изменяет изменения таким образом, чтобы они не нарушали ограничение. Услуга синхронизации не обеспечивает универсальный механизм для этого.
(2) Обработка конфликтов
Когда конфликт обнаружен, услуга синхронизации может совершить одно из трех действий (по выбору инициатора синхронизации в профиле синхронизации): (1) отклонить изменение, возвратив его отправителю; (2) зарегистрировать конфликт в журнале конфликтов; или (3) автоматически разрешить конфликт.
При отклонении изменения, услуга синхронизации действует как если бы изменение не поступало на копию. Отправителю направляется отрицательное квитирование. Эта политика разрешения особенно полезна на безголовых копиях (например, файловых серверах), где регистрация конфликтов невыполнима. Напротив, такие копии заставляют других иметь дело с конфликтами, отклоняя их.
Инициаторы синхронизации конфигурируют разрешение конфликтов в своих профилях синхронизации. Услуга синхронизации поддерживает объединение множественных алгоритмов разрешения конфликтов в одном профиле следующими способами - во-первых, задавая список алгоритмов разрешения конфликтов, подлежащих испытанию по очереди, пока один из них не приведет к успеху; и, во-вторых, связывая алгоритмы разрешения конфликтов с типами конфликтов, например, направляя конфликты на основе знания между обновлениями на один алгоритм разрешения конфликтов, а все остальные конфликты - в журнал.
(а) Автоматическое разрешение конфликтов
Услуга синхронизации обеспечивает ряд алгоритмов разрешения конфликтов, принятых по умолчанию. Этот список включает в себя:
- локальный приоритет: игнорировать входящие изменения, если они конфликтуют с локально сохраненными данными;
- удаленный приоритет: игнорировать локальные данные, если они конфликтуют с входящими изменениями;
- приоритет последней записи: выбор локального приоритета или удаленного приоритета для каждого блока изменения на основании метки времени изменения (заметим, что услуга синхронизации, в общем случае, не опирается на значения часов; этот алгоритм разрешения конфликтов является единственным исключением из этого правила);
- детерминистический: выбор приоритета таким образом, чтобы гарантировать, что он будет одинаковым на всех копиях, но не будет иметь смысла в других случаях - один вариант осуществления услуг синхронизации использует лексикографические сравнения ИД партнеров для реализации этого признака.
Кроме того, ISV могут реализовать и установить свои собственные алгоритмы разрешения конфликтов. Специализированные алгоритмы разрешения конфликтов могут принимать параметры конфигурации; такие параметры должны быть указаны SCA в разделе «Разрешение конфликтов» профиля синхронизации.
Когда алгоритм разрешения конфликтов обрабатывает конфликт, он возвращает список операций, которые необходимо осуществить (вместо конфликтующих изменений) обратно в среду выполнения. Затем услуга синхронизации применяет эти операции, надлежащим образом отрегулировав удаленное знание, чтобы оно включало в себя решение обработчика конфликтов.
Возможно, что при применении разрешения обнаруживается еще один конфликт. В этом случае новый конфликт должен быть разрешен до возобновления первоначальной обработки.
Рассматривая конфликты как ответвления в истории версий статьи, разрешения конфликтов можно рассматривать как соединения - объединение двух ветвей с образованием одной точки. Таким образом, разрешения конфликтов преобразуют истории версий в DAG.
(b) Регистрация конфликтов
Алгоритм регистрации конфликтов является весьма специфической разновидностью алгоритма разрешения конфликтов. Услуга синхронизации регистрирует конфликты как статьи типа ConflictRecord. Эти записи связываются с конфликтующими статьями (если сами статьи не были удалены). Каждая запись конфликта содержит: входящее изменение, вызвавшее конфликт; тип конфликта: между обновлениями, между обновлением и удалением, между удалением и обновлением, между вставками или на основе ограничения; и версию входящего изменения и знание копии, передавшего его. Зарегистрированные конфликты доступны для инспектирования и разрешения, согласно описанному ниже.
(с) Инспектирование и разрешения конфликтов
Услуга синхронизации обеспечивает API для приложений для проверки журнала конфликтов и для предложения разрешений конфликтов в нем. API позволяет приложению перечислять все конфликты или конфликты, связанные с данной Статьей. Он также позволяет таким приложениям разрешать зарегистрированные конфликты одним из трех способов: (1) удаленный приоритет - принятие зарегистрированного изменения и перезапись конфликтующего локального изменения; (2) локальный приоритет - игнорирование конфликтующих частей зарегистрированного изменения; и (3) предложение нового изменения - когда приложение предлагает поглощать то, что, по его мнению, разрешает конфликт. После разрешения конфликтов приложением услуга синхронизации удаляет их из журнала.
(d) Сходимость копий и распространение разрешений конфликтов
В сложных сценариях синхронизации один и тот же конфликт может быть обнаружен на множественных копиях. Если это происходит, может происходить следующее: (1) конфликт может быть разрешен на одной копии, и разрешение может быть направлено на другую копию; (2) конфликт автоматически разрешается на обеих копиях; или (3) конфликт разрешается на обеих копиях вручную (посредством API инспектирования конфликтов).
Для обеспечения сходимости услуга синхронизации передает разрешения конфликтов на другие копии. Когда изменение, разрешающее конфликт, поступает на копию, услуга синхронизации автоматически находит в журнале любые записи конфликтов, которые были разрешены этим обновлением, и исключает их. В этом смысле разрешение конфликтов на одной копии связывается на всех остальных копиях.
Если разные копии выбирают для разрешения одного и того же конфликта разные приоритеты, то услуга синхронизации применяет принцип связывания разрешения конфликтов и автоматически выбирает, какое из двух разрешений будет иметь приоритет над другим. Приоритетное решение выбирается детерминистическим способом, который гарантированно дает всегда одни и те же результаты (один вариант осуществления использует лексикографические сравнения ИД копий).
Если разные копии предлагают разные «новые изменения» для одного и того же конфликта, услуга синхронизации рассматривает этот новый конфликт как особый конфликт и использует блок регистрации конфликтов для предотвращения его распространения на другие копии. Такая ситуация обычно возникает при разрешении конфликтов вручную.
2. Синхронизация с хранилищами данных, не связанными с платформой хранения
Согласно другому аспекту платформы хранения настоящего изобретения платформа хранения обеспечивает архитектуру для ISV, позволяющую реализовать адаптеры синхронизации, допускающие синхронизацию платформы хранения с такими известными системами, как Microsoft Exchange, AD, Hotmail и т.д. Адаптеры синхронизации имеют преимущества над многими службами синхронизации, обеспечиваемыми услугой синхронизации, что описано ниже.
Несмотря на название, адаптеры синхронизации не предусматривают реализацию в виде модулей, встраиваемых в некоторую архитектуру платформы хранения. При желании «адаптер синхронизации» может представлять собой любое приложение, которое использует интерфейсы среды выполнения услуги синхронизации для получения таких услуг, как перечисление и применение изменений.
Чтобы другим было проще конфигурировать и запускать синхронизацию с данной машиной базы данных, писателям адаптеров синхронизации разрешается открывать стандартный интерфейс адаптера синхронизации, который запускает синхронизацию, заданную профилем синхронизации, который описан выше. Профиль предоставляет адаптеру информацию конфигурации, часть которой адаптеры передают среде выполнения синхронизации для управления услугами среды выполнения (например, папку, подлежащую синхронизации).
а) Службы синхронизации
Услуга синхронизации предоставляет писателям адаптеров ряд служб синхронизации. До конца этого раздела удобно называть машину, на которой платформа хранения производит синхронизацию, «клиентом», а машину базы данных, не связанную с платформой хранения, с которой говорит адаптер, - «сервером».
(1) Перечисление изменений
На основании данных отслеживания изменений, поддерживаемых услугой синхронизации, перечисление изменений позволяет адаптерам синхронизации легко перечислять изменения, произошедшие в папке хранилища данных после последней попытки синхронизации с этим партнером.
Изменения перечисляются на основании понятия «анкера» - непрозрачной структуры, которая представляет информацию о последней синхронизации. Анкер принимает Знание от платформы хранения, что описано в последующих разделах. Адаптеры синхронизации, использующие услуги перечисления изменений, делятся на две широкие категории: использующие «сохраненные анкеры» и использующие «выданные анкеры».
Различие между ними состоит в том, где хранится информация о последней синхронизации - на клиенте или на сервере. Адаптерам часто бывает проще хранить эту информацию на клиенте - машина базы данных часто не способна удобно хранить эту информацию. С другой стороны, если несколько клиентов синхронизируются с одной и той же машиной базы данных, сохранение этой информации на клиенте неэффективно и в некоторых случаях неправильно - клиент оказывается неосведомленным об изменениях, которые другой клиент уже протолкнул на сервер. Если адаптер хочет использовать анкер, хранящийся на сервере, то адаптеру нужно подать его обратно на платформу хранения во время перечисления изменений.
Чтобы платформа хранения поддерживала анкер (для локального или удаленного хранения), платформу хранения нужно уведомить об изменениях, которые были успешно применены на сервере. Эти и только эти изменения могут быть включены в анкер. В ходе перечисления изменений адаптеры синхронизации используют интерфейс квитирования, чтобы сообщать, какие изменения были успешно применены. В конце синхронизации адаптеры, использующие выданные анкеры, должны считать новый анкер (который включает в себя все успешно примененные изменения) и передать его на свою машину базы данных.
Часто адаптеры нуждаются в сохранении данных, зависящих от адаптера, совместно со статьями, которые они вставляют в хранилище данных платформы хранения. Общими примерами таких данных являются удаленные ИД и удаленные версии (метки времени). Услуга синхронизации обеспечивает механизм хранения этих данных, и перечисление изменений обеспечивает механизм приема этих дополнительных данных совместно с возвращаемыми изменениями. Это, в большинстве случаев, исключает необходимость для адаптеров повторно запрашивать базу данных.
(2) Применение изменений
Применение изменений позволяет адаптерам синхронизации применять изменения, принятые от их машины базы данных, к локальной платформе хранения. Ожидается, что адаптеры преобразуют изменения в схему платформы хранения.
Основной функцией применения изменений является автоматическое обнаружение конфликтов. Как в случае синхронизации между платформами хранения, конфликт определяется как перекрывающиеся изменения, произведенные без знания друг о друге. Когда адаптеры используют применение изменений, они должны задавать анкер, относительно которого осуществляется обнаружение конфликта. Применение изменений возбуждает конфликт при обнаружении перекрывающегося локального изменения, которое не покрывается знанием адаптера. По аналогии с перечислением изменений адаптеры могут использовать либо сохраненные, либо выданные анкеры. Применение изменений поддерживает эффективное хранение метаданных, зависящих от адаптера. Такие данные могут присоединяться адаптером к применяемым изменениям и могут сохраняться услугой синхронизации. Данные могут возвращаться на следующем перечислении изменений.
(3) Разрешение конфликтов
Вышеописанные механизмы разрешения конфликтов (возможности регистрации и автоматического разрешения) также доступны адаптерам синхронизации. Адаптеры синхронизации могут задавать политику для разрешения конфликтов при применении изменений. Если указано, конфликты можно передавать на указанный обработчик конфликтов и разрешать (если возможно). Конфликты также можно регистрировать. Возможно, что адаптер может обнаружить конфликт при попытке применить локальное изменение к машине базы данных. В этом случае адаптер может все равно передать конфликт в среду выполнения синхронизации для разрешения согласно политике. Кроме того, адаптеры синхронизации могут требовать, чтобы любые конфликты, обнаруженные услугой синхронизации, обратно передавались им для обработки. Это особенно удобно в случае, когда машина базы данных способна сохранять или разрешать конфликты.
b) Реализация адаптера
Хотя некоторые «адаптеры» являются просто приложениями, использующими интерфейсы среды выполнения, адаптерам разрешается реализовывать стандартные интерфейсы адаптера. Эти интерфейсы позволяют приложениям управления синхронизацией: требовать, чтобы адаптер осуществлял синхронизацию согласно данному профилю синхронизации; отменял выполняющуюся синхронизацию; принимал отчет о ходе выполнения (процент готовности) выполняющейся синхронизации.
3. Безопасность
Услуга синхронизации стремится вносить как можно меньше в модель безопасности, реализованную платформой хранения. Вместо того, чтобы задавать новые права на синхронизацию, используются существующие права. В частности:
- любой, кто может читать статью хранилища данных, может перечислять изменения к этой статье;
- любой, кто может писать в статью хранилища данных, может применять изменения к этой статье; и
- любой, кто может расширять статью хранилища данных, может связывать с этой статьей метаданные синхронизации.
Услуга синхронизации не поддерживает защищенную информацию авторства. Когда изменение производится на копии А пользователем U и переносится на копию В, тот факт, что изменение первоначально произведено на А (или пользователем U), утрачивается. Если В переносит это изменение на копию С, это делается от имени В, а не А. Это приводит к следующему ограничению: если копии не доверено вносить в статью собственные изменения, она не может переносить изменения, сделанные другими.
При инициировании услуги синхронизации это делает приложение управления синхронизацией. Услуга синхронизации подменяет идентификацию SCA и осуществляет все операции (как локально, так и удаленно) от его имени. Для примера, предположим, что пользователь U не может предписать локальной услуге синхронизации извлечь из удаленной платформы хранения изменения для статей, к которым пользователь U не имеет доступа для чтения.
4. Управляемость
Мониторинг распределенной общности копий является сложной задачей. Услуга синхронизации может использовать алгоритм «заметания» для сбора и распространения информации о состоянии копий. Свойства алгоритма заметания гарантируют, что информация обо всех сконфигурированных копиях, в итоге, будет собрана и что будут обнаружены сбойные (не отвечающие) копии.
Эта информация мониторинга в масштабе общности становится доступной каждой копии. Инструменты мониторинга можно запускать на произвольно выбранной копии, чтобы проверять эту информацию мониторинга и принимать административные решения. Любые изменения конфигурации должны производиться непосредственно на копиях, подлежащих изменению.
Н. Возможность взаимодействия с традиционными файловыми системами
Как отмечено выше, платформа хранения настоящего изобретения, по меньшей мере, в некоторых вариантах осуществления предусматривает реализацию в виде неотъемлемой части системы программно-аппаратного интерфейса компьютерной системы. Например, платформа хранения настоящего изобретения может быть реализована как неотъемлемая часть операционной системы, например, принадлежащей семейству операционных систем Microsoft Windows. В этой связи API платформы хранения становится частью API операционной системы, посредством которых прикладные программы взаимодействуют с операционной системой. Таким образом, платформа хранения становится средством, с помощью которого прикладные программы сохраняют информацию на операционной системе, благодаря чему модель данных на основе статей платформы хранения заменяет традиционную файловую систему такой операционной системы. Например, будучи реализована в семействе операционных систем Microsoft Windows, платформа хранения может заменить файловую систему NTFS, реализованную в этой операционной системе. В настоящее время прикладные программы осуществляют доступ к услугам файловой системы NTFS через API Win32, открытые семейством операционных систем Windows.
Понимая, однако, что полная замена файловой системы NTFS платформой хранения настоящего изобретения потребовала бы перекодирования существующих прикладных программ на основе Win32 и что такое перекодирование может быть нежелательно, было бы полезно, если бы платформа хранения настоящего изобретения обеспечивала некоторую возможность взаимодействия с существующими файловыми системами, например NTFS. Согласно одному варианту осуществления настоящего изобретения платформа хранения позволяет прикладным программам, которые опираются на модель программирования Win32, осуществлять доступ к содержимому как хранилища данных платформы хранения, так и традиционной файловой системы NTFS. Для этого платформа хранения использует соглашение именования, которое является супермножеством соглашений именования Win32, для облегчения возможности взаимодействия. Кроме того, платформа хранения поддерживает доступ к файлам и директориям, хранящимся в томе платформы хранения, через API Win32.
1. Модель возможности взаимодействия
Согласно этому аспекту настоящего изобретения и согласно рассмотренному выше иллюстративному варианту осуществления платформа хранения реализует одно пространство имен, в котором могут быть организованы нефайловые и файловые статьи. В этой модели достигаются следующие преимущества:
1. Папки в хранилище данных могут содержать как файловые, так и нефайловые статьи, тем самым представляя единое пространство имен для файловых и схематизированных данных. Кроме того, она также обеспечивает универсальную модель безопасности, совместного использования и администрирования для всех пользовательских данных.
2. Поскольку файловые и нефайловые статьи доступны с использованием API платформы хранения и этот подход не предусматривает применение каких-либо особых правил для файлов, он представляет разработчикам приложений более ясную модель программирования для работы.
3. Все операции пространства имен проходят через платформу хранения и потому обрабатываются синхронно. Важно отметить, что глубокое продвижение свойств (выводимых из содержимого файлов) по-прежнему происходит асинхронно, но синхронные операции обеспечивают гораздо более предсказуемую среду для пользователей и приложений.
Вследствие этой модели, согласно данному варианту осуществления, могут не предоставляться возможности поиска по источникам данных, которые не мигрируют в хранилище данных платформы хранения. Они включают в себя сменные носители, удаленные серверы и файлы на локальном диске. Обеспечен адаптер синхронизации, который объявляет статьи-посредники (сокращенные клавиатурные команды + продвинутые метаданные) в платформе хранения для статей, находящихся в сторонних файловых системах. Статьи-посредники не пытаются выдавать себя за файлы либо в терминах иерархии пространства имен источника данных, либо в терминах безопасности.
Симметрия, достигнутая в пространстве имен и модели программирования между файловым и нефайловым контентом, обеспечивает приложениям лучший путь для перемещения контента из файловых систем в более структурированные статьи в хранилище данных платформы хранения с течением времени. Благодаря обеспечению родного типа статьи «файл» в хранилище данных платформы хранения прикладные программы могут переносить данные файлов в платформу хранения, в то же время сохраняя возможность манипулировать этими данными посредством Win32. В конце концов, прикладные программы смогут полностью перейти к API платформы хранения и структурировать свои данные в терминах статей платформы хранения, а не файлов.
2. Особенности хранилища данных
Для обеспечения нужного уровня взаимодействия, согласно одному варианту осуществления, реализованы следующие особенности хранилища данных платформы хранения.
а) Не том
Хранилище данных платформы хранения не открывается как отдельный том файловой системы. Платформа хранения усиливает «потоки файлов», непосредственно базирующиеся на NTFS. Таким образом, формат «на диске» не подвергается изменениям, что избавляет от необходимости открывать платформу хранения как новую файловую систему на уровне томов.
Вместо этого строится хранилище данных (пространство имен), соответствующее тому NTFS. База данных и «потоки файлов», резервирующие эту часть пространство имен, находятся в томе NTFS, с которым связано хранилище данных платформы хранения. Также обеспечено хранилище данных, соответствующее системному тому.
b) Структура хранилища
Структуру хранилища лучше всего проиллюстрировать на примере. Рассмотрим, например, дерево директории на системном томе машины под названием HomeMachine, как показано на фиг.16. Согласно с признаком возможности взаимодействия с файловой системой, согласно настоящему изобретению, соответствующим c:\привод, существует хранилище данных платформы хранения, открытое API Win32 через совместно используемое UNC, например, "WinFSOnC". Это делает соответствующее хранилище данных доступным через следующее имя UNC: \\HomeMachine\WinFSOnC.
В данном варианте осуществления файлы и/или папки должны в явном виде переходить из NTFS в платформу хранения. Поэтому, если пользователь желает переместить папку My Documents в хранилище данных платформы хранения, чтобы воспользоваться всеми дополнительными особенностями поиска/категоризации, обеспечиваемыми платформой хранения, иерархия будет выглядеть, как показано на фиг.17. Важно заметить, что эти папки действительно перемещаются в данном примере. Надо также отметить, что пространство имен перемещается в платформу хранения, фактические потоки переименовываются как «потоки файлов» с соответствующими указателями, подключенными в платформе хранения.
с) Не все файлы мигрируют
Файлы, которые соответствуют пользовательским данным или которые нуждаются в поиске/категоризации, обеспечиваемым платформой хранения, являются кандидатами на миграцию в хранилище данных платформы хранения. Предпочтительно, для ограничения вопросов совместимости прикладной программы с платформой хранения, набор файлов, которые мигрируют в платформу хранения настоящего изобретения, в контексте операционной системы Microsft Windows, ограничивается файлами в папке MyDocuments, Internet Explorer (IE) Favorites, IE History и файлами Desktop.ini в директории Documents and Settings. Предпочтительно, миграция системных файлов Windows не разрешена.
d) Доступ из пространства имен NTFS к файлам платформы хранения
Согласно описанному здесь варианту осуществления желательно, чтобы файлы, мигрировавшие в платформу хранения, не были доступны через пространство имен NTFS даже, если фактические потоки файлов хранятся в NTFS. Это позволяет избежать сложных вопросов блокировки и безопасности, возникающих из многоголовой реализации.
е) Ожидаемые буквы пространства имен/привода
Доступ к файлам и папкам в платформе хранения обеспечивается через имя UNC в виде \\<имя машины>\<совместно используемое имя Winfs>. Для класса приложений, которым для работы требуются буквы приводов, буква привода может отображаться в это имя UNC.
I. API ПЛАТФОРМЫ ХРАНЕНИЯ
Согласно отмеченному выше, платформа хранения содержит API, который позволяет прикладным программам осуществлять доступ к особенностям и возможностям платформы хранения, рассмотренной выше, и осуществлять доступ к статьям, хранящимся в хранилище данных. В этом разделе описан один вариант осуществления API платформы хранения для платформы хранения настоящего изобретения.
На фиг.19 показана основная архитектура API платформы хранения, согласно данному варианту осуществления. API платформы хранения использует SQLClient 1900 для разговора с локальным хранилищем данных 302, и также может использовать SQLClient 1900 для разговора с удаленным хранилищем данных (например, хранилищем данных 340). Локальное хранилище 302 также может разговаривать с удаленным хранилищем данных 340 с использованием либо DQP (процессора распределенного запроса) или посредством вышеописанной услуга синхронизации ("Sync") платформы хранения. API 322 платформы хранения также действует как API моста для извещений хранилища данных, передавая подписки приложения машине 332 извещения и маршрутизируя извещения на приложение (например, приложение 350a, 350b или 350c), что также описано выше. В одном варианте осуществления, API 322 платформы хранения может также задавать ограниченную архитектуру «провайдер», так чтобы она могла осуществлять доступ к данным в Microsoft Exchange и AD.
1. Обзор
Механизм доступа к данным согласно данному варианту осуществления API платформы хранения настоящего изобретения относится к четырем областям: запрос, навигация, действия, события.
Запрос
Согласно одному варианту осуществления, хранилище данных платформы хранения реализовано на машине 314 реляционной базы данных; в результате, полная выразительная сила языка SQL присуща платформе хранения. Объекты запроса высокого уровня обеспечивают упрощенную модель для запрашивания хранилища, но могут не инкапсулировать полную выразительную силу хранения.
Навигация
Модель данных платформы хранения строит богатую, расширяемую систему типов на абстракциях нижележащей базы данных. Для разработчика, данные платформы хранения являются сетью статей. API платформы хранения обеспечивает навигацию от статьи к статье посредством фильтрации, отношений, папок и т.д. Это более высокий уровень абстракции, чем базовые запросы SQL; в то же время, это допускает богатые возможности фильтрации и навигации для использования с привычными шаблонами кодирования CLR.
Действия
API платформы хранения открывает общие действия на всех статьях - Create, Delete, Update; они открываются как методы на объектах. Кроме того, действия, зависящие от домена, например, SendMail, CheckFreeBusy, и т.д. также доступны как методы. Структура API использует строго определенные шаблоны, которые ISV могут использовать для добавления значения путем задания дополнительных действий.
События
Данные в платформе хранения являются динамическими. Чтобы приложения могли реагировать на изменение данных в хранилище, API открывает богатые возможности формирования событий, подписки и извещения.
2. Именование и области действия
Полезно различать пространство имен и именование. Термин «пространство имен», в обычном использовании, означает множество всех имен, доступных в некоторой системе. Система может быть схемой XML, программой, сетью, множеством всех сайтов ftp (и их содержимого) и т.д. «Именование» - это процесс или алгоритм, используемый для присвоения уникальных имен всем сущностям, представляющим интерес в пространстве имен. Таким образом, именование представляет интерес, поскольку желательно однозначно ссылаться на данный элемент в пространстве имен. Таким образом, используемый термин "пространство имен" означает множество всех имен, доступных во всех экземплярах платформы хранения в универсуме. Статьи называются сущностями в пространстве имен платформы хранения. Соглашение именования UNC используется для обеспечения уникальности имен статей. Каждая статья в каждом хранилище платформы хранения в универсуме адресуема по имени UNC.
Наивысшим уровнем организации в пространстве имен платформы хранения является «услуга» - которая является просто экземпляром платформы хранения. Следующим уровнем организации является «том». Том - это наибольший автономный контейнер статей. Каждый экземпляр платформы хранения содержит один или более томов. В томе существуют «статьи». Статьи являются единицами данных в платформе хранения.
Данные в реальном мире почти всегда организованы согласно некоторой системе, которая имеет смысл в данном домене. На более низком уровне все такие схемы организации данных представляют идею деления универсального множества наших данных в поименованные группы. Согласно рассмотренному выше, это понятие моделируется в платформе хранения посредством понятия «папки». Папка является особым типом папки; существует 2 типа папок: Папки включения и Виртуальные папки.
Согласно фиг.18 Папка включения - это статья, которая содержит отношения поддержки к другим статьям и является эквивалентным общего понятия папки файловой системы. Каждая статья «содержится» в, по меньшей мере, одну папку включения.
Виртуальная папка - это более динамический способ организации коллекции статей; это просто имя, данное множеству статей - множество либо перечисляется в явном виде, либо задается посредством запроса. Виртуальная папка сама является статьей и может рассматриваться как представляющая множество отношений (не поддержки) к множеству статей.
Иногда существует необходимость моделировать идею более тесного включения; например, документ Word, внедренный в сообщение электронной почты, в этом смысле, более тесно связан со своим контейнером, чем, например, файл, содержащийся в папке. Эта идея выражается понятием внедренных статей. Внедренная статья имеет отношение особого рода, которое ссылается на другую статью; ссылочную статью можно привязывать или иначе манипулировать только в контексте содержащей статьи.
Наконец, платформа хранения обеспечивает понятие категорий как способ классификации статей и элементов. С каждой(ым) статьей или элементом в платформе хранения может быть связана одна или несколько категорий. Категория, в сущности, является просто именем, присвоенным статье/категории. Это имя можно использовать в поисках. Модель данных платформы хранения позволяет задавать иерархию категорий, и, таким образом, обеспечивать древовидную классификацию данных.
Однозначное имя статьи представляет собой триплет: (<имя услуги>, <ИД тома>, <ИД статьи>). Некоторые статьи (в частности, папки и виртуальные папки) являются коллекциями других статей. Это дает возможность идентифицировать статьи альтернативным способом: (<имя услуги>, <ИД тома>, <путь к статье>).
Имена платформы хранения включают в себя обозначение контекста услуги: контекст услуги это имя, которое отображается в пару (<имя тома>, <путь>). Он идентифицирует статью или множество статей - например, папку, виртуальную папку, и т.д. Благодаря понятию контекстов услуги, имя UNC для любой статьи в пространстве имен платформы хранения становится:
\\<имя услуги>\<контекст услуги>\<путь к статье>.
Пользователи могут создавать и удалять контексты услуги. Кроме того, корневая директория в каждом томе имеет заранее заданный контекст: volume-name$.
ItemContext определяет область действия запроса (например, операции Find) путем ограничения результатов, возвращаемых этими статьями, которые существуют на указанном пути.
3. Компоненты API платформы хранения
На фиг.20 схематически представлены различные компоненты API платформы хранения согласно данному варианту осуществления изобретения. API платформы хранения состоит из следующих компонентов: (1) классов данных 2002, которые представляют типы элементов и статей платформы хранения, (2) структуры среды выполнения 2004, которая регулирует живучесть объекта и обеспечивает классы поддержки 2006; и (3) инструменты 2008, которые используются для генерации классов CLR из схем платформы хранения.
Согласно одному аспекту настоящего изобретения в среде разработки автор схемы передает документ 2010 схемы и код для методов 2012 домена набору инструментов 2008 среды разработки API платформы хранения. Эти инструменты генерируют классы данных 2002 клиентской стороны и сохраняют схему 2014 и сохраняют определения 2016 классов для этой схемы. «Доменом» называется конкретная схема; например, мы говорим о методах домена, но не о классах в Схеме контактов, и т.д. Эти классы данных 2002 используются разработчиком приложения в среде выполнения совместно с классами 2006 структуры среды выполнения API платформы хранения для манипулирования данными платформы хранения.
В целях иллюстрации различных аспектов API платформы хранения настоящего изобретения представлены примеры, основанные на иллюстративной Схеме контактов. Графическое представление этой иллюстративной схемы показано на фиг.21A и 21B.
4. Классы данных
Согласно аспекту настоящего изобретения каждый тип статьи, расширения статьи и элемента, а также каждое отношение в хранилище данных платформы хранения имеет соответствующий класс в API платформы хранения. Грубо говоря, поля типа отображаются в поля класса. Каждая статья, расширение статьи и элемент в платформе хранения доступна(о) как объект соответствующего класса в API платформы хранения. Разработчик может делать запрос на создание, изменение или удаление этих объектов.
Платформа хранения содержит начальное множество схем. Каждая схема задает множество типов статьи и элемента и множество отношений. Ниже приведен один вариант осуществления алгоритма для генерации классов данных из этих схемных сущностей:
Для схемы S:
Для каждой статьи I в S генерируется класс названием System.Storage.S.I. Этот класс имеет следующие члены:
- Перегруженные конструкторы, включая конструкторы, позволяющие задавать начальную папку и имя новой статьи.
- Свойство каждого поля в I. Если поле является многозначным, свойство будет коллекцией соответствующего типа элемента.
- Перегруженный статический метод для нахождения множественных статей, отвечающих фильтру (например, метод под названием "FindAll").
- Перегруженный статический метод для нахождения единичной статьи, отвечающей фильтру (например, метод под названием "FindOne").
- Статический метод для нахождения статьи по ее идентификатору (например, метод под названием "FindByID").
- Статический метод для нахождения статьи по ее имени относительно ItemContext (например, метод под названием "FindByName").
- Метод для сохранения изменений статьи (например, метод под названием "Update").
- Перегруженные статические методы Create для создания новых экземпляров статьи. Эти методы позволяют различными способами задавать начальную папку статьи.
Для каждого элемента Е в S генерируется класс под названием System.Storage.S.E. Этот класс имеет следующие члены:
- Свойство каждого поля в Е. Если поле является многозначным, свойство будет коллекцией соответствующего типа элемента.
Для каждого элемента Е в S генерируется класс под названием System.Storage.S.Ecollection. Этот класс следует общим руководящим принципам структуры. NET для сильно типизированной коллекции классов. Для типов элементов на основе отношений этот класс также будет включать в себя следующие члены:
- Перегруженный метод для нахождения множественных объектов статьи, которые отвечают фильтру, который неявно включает в себя статью, в которой коллекция играет роль источника. Перегрузки включают в себя некоторые допускающие фильтрацию на основании подтипа статьи (например, метод под названием "FindAllTargetItems").
- Перегруженный метод для нахождения объектов типа вложенного элемента, которые отвечают фильтру, который неявно включает в себя статью, в которой коллекция играет роль источника (например, метод под названием "FindAllRelationships").
- Перегруженный метод для нахождения объектов типа вложенного элемента, которые отвечают фильтру, который неявно включает в себя статью, в которой коллекция играет роль источника (например, метод под названием "FindAllRelationshipsForTarget").
- Перегруженный метод для нахождения единичного объекта типа вложенного элемента, который отвечает фильтру, который неявно включает в себя статью, в которой коллекция играет роль источника (например, метод под названием "FindOneRelationship").
- Перегруженный метод для нахождения единичного объекта типа вложенного элемента, которые отвечают фильтру, который неявно включает в себя статью, в которой коллекция играет роль источника (например, метод под названием "FindOneRelationshipForTarget").
Для отношения R в S генерируется класс под названием System.Storage.S.R. Этот класс имеет один или два подкласса в зависимости от того, если роли одного или более отношений указывают поле концевой точки.
Классы также генерируются таким образом для каждого Расширения статьи, которое было создано.
Классы данных существуют в пространстве имен System.Storage.<имя схемы>, где <имя схемы> - это имя соответствующей схемы, например, Contacts, Files и т.д. Например, все классы, соответствующие Схеме контактов, находятся в пространстве имен System.Storage.Contacts.
Например, согласно фиг.21A и 21B, схема контактов дает следующие классы, содержащиеся в пространстве имен System.Storage.Contact:
- Статьи: Item, Folder, WellKnownFolder, LocalMachineDataFolder, UserDataFolder, Principal, Service, GroupService, PersonService, PresenceService, ContactService, ADService, Person, User, Group, Organization, HouseHold
- Элементы: NestedElementBase, NestedElement, IdentityKey, SecurityID, EAddress, ContactEAddress, TelehoneNumber, SMTPEAddress, InstantMessagingAddress, Template, Profile, FullName, FamilyEvent, BasicPresence, WindowsPresence, Relationship, TemplateRelationship, LocationRelationship, FamilyEventLocationRelationship, HouseHoldLocationRelationship, RoleOccupancy, EmployeeData, GroupMemberShip, OrganizationLocationRelationship, HouseHoldMemberData, FamilyData, SpouseData, ChildData
В качестве следующего примера подробная структура типа Person, заданного в Схеме контактов, показана ниже в виде XML:
<Type Name="Person" MajorVersion="1" MinorVersion="0"
ExtendsType="Core.Principal" ExtendsVersion=”1"/>
<Field Name="Birthdate" Type="the storage
platformTypes.datetime" Nullable="true"
TypeMajorVersion="1"/>
<Field Name="Gender" Type="Base.CategoryRef"
Nullable="true"MultiValued="false"
TypeMajorVersion="1"/>
<Field Name="PersonalNames" Type="Contact.FullName"
Nullable="true" MultiValued="true"
TypeMajorVersion="1”/>
<Field Name="PersonalEAddresses" Type="Core.EAddress"
Nullable="true" MultiValued="true"
TypeMajorVersion="1”/>
<Field Name="PersonalPostalAddresses"
Type="Core.PostalAddress" Nullable="true"
MultiValued="true" TypeMajorVersion="1"/>
<Field Name="PersonalPicture" Type="the storage
platformTypes.image" Nullable="true"
TypeMajorVersion="1"/>
<Field Name="Notes" Type="Core.RichText" Nullable="true"
MultiValued="true" TypeMajorVersion="1”/>
<Field Name="Profession" Type="Base.CategoryRef"
Nullable="true" MultiValued="true"
TypeMajorVersion="1”/>
<Field Name="DataSource" Type="Base.IdentityKey"
Nullable="true"MultiValued="true"
TypeMajorVersion="1"/>
<Field Name="ExpirationDate" Type="the storage
platformTypes.datetime" Nullable="true"
TypeMajorVersion="1”/>
<Field Name="HasAllAddressBookData" Type="the storage
platformTypes.bit" Nullable="true"
TypeMajorVersion="1”/>
<Field Name="EmployeeOf" Type="Contact.EmployeeData"
Nullable="true" MultiValued="true"
TypeMajorVersion="1"/>
</Type>
Этот тип порождает следующий класс (показаны только публичные члены):
partial public class Person:
System.Storage.Core.Principal,
System.Windows.Data.IDataUnit
{
public System.Data.SqlTypes.SqlDateTime
Birthdate {get; set;}
public System.Storage.Base.CategoryRef
Gender {get; set;}
public System.Storage.Contact.FullNameCollection
PersonalNames {get;}
public System.Storage.Core.EAddressCollection
PersonalEAddresses {get;}
public System.Storage.Core.PostalAddressCollection
PersonalPostalAddresses {get;}
public System.Data.SqlTypes.SqlBinary
PersonalPicture {get; set;}
public System.Storage.Core.RichTextCollection
Notes {get;)
public System.Storage.Base.CategoryRefCollection
Profession {get;}
public System.Storage.Base.IdentityKeyCollection
DataSource {get;}
public System.Data.SqlTypes.SqlDateTime
Expiration Date {get; set;}
public System.Data.SqlTypes.SqlBoolean
HasAllAddressBookData {get; set;}
public System.Storage.Contact.EmployeeDataCollection
EmployeeOf {get;}
public Person();
public Person(System.Storage.Base.Folder folder, string name);
public static new System.Storage.FindResult
FindAll(System.Storage.ItemStore store);
public static new System.Storage.FindResult
FindAll(
System.Storage.ItemStore store, string filter);
public static new Person
FindOne(
System.Storage.ItemStore store,
string filter);
public new event
System.Windows.Data.PropertyChangedEventHandler
PropertyChangedHandler;
public static new Person
FindByID(
System.Storage.ItemStore store, long item_key);
}
В порядке еще одного примера, подробная структура типа TelephoneNumber, заданного в Схеме контактов, показана ниже в виде XML:
<Type Name="TelephoneNumber" ExtendsType="Core.EAddress"
MajorVersion="1" MinorVersion="0"
ExtendsVersion="1"/>
<Field Name="CountryCode" Type="the storage
platformTypes.nvarchar(50)" Nullable="true"
MultiValued="TypeMajorVersion="1”/>
<Field Name="AreaCode" Type="the storage
platformTypes.nvarchar(256)" Nullable="true"
TypeMajorVersion="1”/>
<Field Name="Number" Type="the storage
platformTypes.nvarchar(256)" Nullable="true"
TypeMajorVersion="1”/>
<Field Name="Extension" Type="the storage
platformTypes.nvarchar(256)" Nullable="true"
TypeMajorVersion=1”/>
<Field Name="PIN" Type="the storage
platformTypes.nvarchar(50)" Nullable="true"
TypeMajorVersion="1”/>
</Type>
Этот тип порождает следующий класс (показаны только публичные члены):
partial public class TelephoneNumber:
System.Storage.Core.EAddress,
System.Windows.Data.IDataUnit
{
public System.Data.SglTypes.SqlString CountryCode
{get; set;}
public System.Data.SqlTypes.SqlString AreaCode
{get; set;}
public System.Data.SqlTypes.SqlString Number
{get; set;}
public System.Data.SqlTypes.SqlString Extension
{get; set;}
public System.Data.SqlTypes.SqlString PIN
{get; set;}
public TelephoneNumber();
public new event
System.Windows.Data.PropertyChangedEventHandler
PropertyChangedHandler;
}
Иерархия классов, полученных из данной схемы, непосредственно отражает иерархию типов в этой схеме. Например, рассмотрим типы статьи, заданные в Схеме контактов (см. фиг.21A и 21B). Иерархия классов, соответствующая этому в API платформы хранения будет выглядеть следующим образом:
Object
DataClass
ElementBase
RootItemBase
Item
Principal
Group
Household
Organization
Person
User
Service
PresenceService
ContactService
ADService
RootNestedBase
… (классы элементов)
Еще одна схема, схема, которая позволяет представлять все аудио/видео-среды в системе (разрезанные на аудио-файлы, аудио- CD, DVD, домашнее видео и т.д.), позволяет пользователям/приложениям сохранять, организовывать, осуществлять поиск и манипулировать разными видами аудио/видео-средами. Базовая схема мультимедийного документа достаточно общая для представления любых сред, и расширения этой базовой схемы предназначены для обработки свойств, связанных с доменом, отдельно для аудио- и видео-сред. Представляется, что эта и многие, многие другие схемы действуют прямо или косвенно под Схемой ядра.
5. Структура среды выполнения
Основной моделью программирования API платформы хранения является живучесть объекта. Прикладные программы (или «приложения») выполняют поиск в хранилище и возвращают объекты, представляющие данные в хранилище. Приложения изменяют возвращаемые объекты или создают новые объекты, в результате чего эти изменения распространяются в хранилище. Этим процессом управляет объект ItemContext. Механизмы поиска выполняются с использованием объекта ItemSearcher, и результаты поиска становятся доступными через объект FindResult.
а) Классы структуры среды выполнения
Согласно другому аспекту изобретения API платформы хранения структура среды выполнения реализует ряд классов для поддержки операции классов данных. Эти классы структуры задают общее множество поведений для классов данных и, совместно с классами данных обеспечивают основную модель программирования для API платформы хранения. Классы в структуре среды выполнения принадлежат пространству имен System.Storage. Согласно данному варианту осуществления классы структуры содержат следующие главные классы: ItemContext, ItemSearcher, и FindResult. Также могут быть предусмотрены другие младшие классы, значения перечисления и делегаты.
(1) ItemContext
Объект ItemContext (i) представляет множество доменов статьи, в котором прикладная программа хочет осуществить поиск, (ii) поддерживает информацию состояния для каждого объекта, который представляет состояние данных, извлекаемых из платформы хранения, и (iii) управляет транзакциями, используемыми при взаимодействии с платформой хранения и любой файловой системой, с которой может взаимодействовать платформа хранения.
В качестве машины живучести объекта ItemContext обеспечивает следующие услуги:
1. Преобразование из последовательного вида данных, считанных из хранилища в объекты.
2. Поддержание идентификации объекта (один и тот же объект используется для представления данной статьи независимо от того, сколько раз эта статья включена в результат запросов).
3. Отслеживание состояния объектов.
ItemContext также осуществляет ряд услуг, уникальных для платформы хранения:
1. Генерирует и выполняет операции апдейтграммы платформы хранения, необходимые для продления жизни изменений.
2. Создает соединения с множественными хранилищами данных при необходимости обеспечения гладкой навигации отношений ссылки и разрешения изменения и сохранения объектов, извлеченных из многодоменного поиска.
3. Гарантирует, что статьи, зарезервированные в файле, надлежащим образом обновляются при сохранении изменений объекта(ов), представляющих эту статью.
4. Управляет транзакциями по множественным соединениям платформы хранения и, при обновлении данных, хранящихся в статьях, зарезервированных в файле, и свойств потоков файлов, по файловой системе, подвергнутой транзакции.
5. Осуществляет операции создания, копирования, перемещения и удаления статей, которые учитывают семантику отношений платформы хранения, статьи, зарезервированные в файле, и типизированные свойства потока.
В Приложении А представлен исходный код класса ItemContext согласно одному варианту его осуществления.
(2) ItemSearcher
Класс ItemSearcher поддерживает простые поиски, которые возвращают объекты статьи целиком, потоки объектов статьи или потоки значений, проецируемых из статьи. ItemSearcher инкапсулирует функциональные возможности ядра, общие для: понятия целевого типа и параметризованных фильтров, которые применяются к этому целевому типу. ItemSearcher также позволяет предварительно компилировать или подготавливать механизмы поиска в порядке оптимизации, когда один и тот же поиск будет выполняться для множественных типов. В Приложении В представлен исходный код класса ItemSearcher и несколько тесно связанных классов согласно одному варианту их осуществления.
(a) Целевой тип
Целевой тип поиска задается при конструировании ItemSearcher. Целевой тип является типом CLR, который отображается в запрашиваемое расширение хранилищем данных. В частности, это тип CLR, который отображается в типы статьи, отношения и расширения статьи, а также схематизированные виды.
При извлечении механизма поиска с использованием метода ItemContext.GetSearcher, целевой тип механизма поиска задается как параметр. При вызове метода GetSearcher на типе статьи, отношения или расширения статьи (например, Person.GetSearcher), целевым типом является тип статьи, отношения или расширения статьи.
Выражения поиска, обеспеченные в ItemSearcher (например, фильтр поиска и опции сквозного нахождения или определения проекции) всегда относятся к целевому типу поиска. Эти выражения могут задавать свойства целевого типа (включая свойства вложенных элементов) и могут задавать соединения с отношением и расширениями статьи, как описано в другом месте.
Целевой тип поиска делается доступным через свойство только для чтения (например, свойство ItemSearcher.Type)
(b) Фильтры
ItemSearcher содержит свойство для задания фильтров (например, свойство под названием "Filters" как коллекция объектов SearchExpression), которое задает фильтр, используемый при поиске. Все фильтры в коллекции объединяются с использованием логического оператора AND при выполнении поиска. Фильтр может содержать ссылки на параметры. Значения параметров указаны посредством свойства Parameters.
(с) Подготовка поисков
В ситуациях, когда один и тот же поиск подлежит неоднократному выполнению, возможно, только с изменением параметров, некоторого улучшения выполнения можно добиться путем предварительной компиляции или подготовки поиска. Это осуществляется с помощью множества методов подготовки на ItemSearcher (например, метод для подготовки Find, который возвращает одну или несколько статей, возможно, под названием "PrepareFind", и метод для подготовки Find, который возвращает проекцию, возможно, под названием "PrepareProject"). Например:
ItemSearcher searcher =...;
PreparedFind pf = searcher.PrepareFind();
…
result = pf.FindAll();
…
result = pf.FindAll();
(d) Опции Find
Существует ряд опций, которые можно применять к простому поиску. Они могут быть заданы, например, в объекте FindOptions и переданы методам Find. Например:
ItemSearcher searcher = Person.GetSearcher(context);
FindOptions options = new FindOptions();
options.MaxResults = 10;
options.SortOptions.Add("PersonalNames.Surname",
SortOrder.Ascending);
FindResult result = searcher.FindAll(options);
Для удобства опции сортировки также могут передаваться непосредственно методам Find:
ItemSearcher searcher = Person.GetSearcher(context);
FindResult result = searcher.FindAll(
new SortOption("PersonalNames.Surname",
SortOrder.Ascending));
Опция DelayLoad определяет, загружаются ли значения больших бинарных свойств при извлечении результатов поиска или задерживается ли загрузка до получения ссылки на них. Опция MaxResults определяет максимальное количество возвращаемых результатов. Это эквивалентно заданию TOP в запросе SQL. Она чаще всего используется совместно с сортировкой.
Можно задать последовательность объектов SortOption (например, с использованием свойства FindOptions.SortOptions). Результаты поиска сортируются, как указано первым объектом SortOption, затем, как указано вторым объектом SortOption, и т.д. SortOption задает выражение поиска, которое указывает свойство, используемое для сортировки. Выражение задает одно из следующих:
1) скалярное свойство в целевом типе поиска;
2) скалярное свойство во вложенном элементе, достижимое от целевого типа поиска путем обхода однозначных свойств; или
3) результат функции агрегирования с пригодным аргументом (например, Max, применяемое к скалярному свойству во вложенном элементе, которое достижимо от целевого типа поиска путем обхода многозначного свойства или отношения).
Пусть, например, целевой тип поиска это System.Storage.Contact.Person:
1. "Birthdate" - пригодно, дата рождения это скалярное свойство типа Person.
2. "PersonalNames.Surname" - непригодно, PersonalNames это многозначное свойство и никакая функция агрегирования не используется.
3. "Count(PersonalNames)" - пригодно, счетчик для PersonalNames.
4. "Case(Contact.MemberOfHousehold).Household.HouseholdEAddresses.StartDate" - непригодно, использует отношение и многозначные свойства без функции агрегирования.
5. "Max(Cast(Contact.MemberOfHousehold).Household.HouseholdEAddresses.StartDate)" - пригодное, наиболее последняя начальная дата домашнего электронного адреса.
(3) Поток результатов статьи ("FindResult")
ItemSearcher (например, посредством метода FindAll) возвращает объект, который можно использовать для доступа к объектам, возращенных поиском (например, объекту "FindResult"). В Приложении С представлен исходный код класса FindResult и нескольких тесно связанных классов согласно одному варианту их осуществления.
Имеются два разных метода получения результатов из объекта FindResult: использование шаблона читателя, заданного посредством IObjectReader (и IAsyncObjectReader) и использование шаблона перечислителя, заданного посредством IEnumerable и IEnumerator. Шаблон перечислителя является стандартным в CLR и поддерживает языковые конструкции наподобие foreach в C#. Например:
ItemSearcher searcher = Person.GetSearcher(context);
searcher.Filters.Add("PersonalNames.Surname = 'Smith'");
FindResult result = searcher.FindAll();
foreach(Person person in result)...;
Шаблон читателя поддерживается, потому что это во многих случаях позволяет более эффективно обрабатывать результат за счет исключения копирования данных. Например:
ItemSearcher searcher = Person.GetSearcher(context);
searcher.Filters.Add("PersonalNames.SurName = 'Smith'”);
FindResult result = searcher.FindAll();
while(result.Read())
{
Person person = (Person)result.Current;
…
}
Кроме того, шаблон читателя поддерживает асинхронную операцию:
ItemSearcher searcher = Person.GetSearcher(context);
searcher.Filters.Add("PersonalNames.SurName = 'Smith'”);
FindResult result = searcher.FindAll();
IAysncResult asyncResult = result.BeginRead(new
AsyncCallback(MyCallback));
void MyCallback(IAsyncResult asyncResult)
{
if( result.EndRead( asyncResult))
{
Person person = (Person)resuIt.Current;
…
}
}
Согласно данному варианту осуществления FindResult должен быть закрыт, когда он больше не нужен. Это можно делать, вызывая метод Close или используя языковые конструкции, например, оператор использования C#. Например:
ItemSearcher searcher = Person.GetSearcher(context);
searcher.Filters.Add( "PersonalNames.SurName = 'Smith'”);
using(FindResult result = searcher.FindAll())
{
while(result.Read())
{
Person person = (Person)result.Current;
…
}
}
b) Структура среды выполнения в процессе работы
На фиг.22 показана структура среды выполнения в процессе работы. Структура среды выполнения действует следующим образом:
1. Приложение 350a, 350b, или 350c связывается со статьей в платформе хранения.
2. Структура 2004 создает объект ItemContext 2202, соответствующий связанной статье и возвращает его приложению.
3. Приложение передает Find в этом ItemContext для получения коллекции статей; возвращенная коллекция в принципе является объектным графом 2204 (вследствие отношений).
4. Приложение изменяет, удаляет и вставляет данные.
5. Приложение сохраняет изменения, вызывая метод Update().
с) Общие шаблоны программирования
В этом разделе представлены различные примеры того, как можно использовать классы структуры API платформы хранения для манипуляции статьями в хранилище данных.
(1) Открытие и закрытие объектов ItemContext
Приложение получает объект ItemContext, который оно будет использовать для взаимодействия с хранилищем данных, например, вызывая статический метод ItemContext.Open и обеспечивая путь или пути, которые идентифицируют домены статей, которые будут связаны с ItemContext. Домены статей рассматривают механизмы поиска, выполняемые с использованием ItemContext, так что только одна статья домена и статьи, содержащиеся в этой статье, будут подлежать поиску. Рассмотрим примеры:
Открыть ItemContext с помощью совместно используемого ресурса платформы хранения DefaultStore на локальном компьютере
ItemContext ic = ItemContext.Open();
Открыть ItemContext с помощью данного совместно используемого ресурса платформы хранения
ItemContext ic = ItemContext.Open(@"\\myserver1\DefaultStore");
Открыть ItemContext с помощью статьи используемого ресурса платформы хранения
ItemContext ic = ItemContext.Open(@"\\myserver1\WinFSSpecs\api\m6");
Открыть ItemContext с помощью множественных доменов статей
ItemContext ic = ItemContext.Open(@"\\myserver1\My Documents",
@”\\jane1\My Documents",
@"\\jane2\My Documents");
Когда ItemContext больше не нужен, его нужно закрыть.
В явном виде закрыть ItemContext
ItemContext ic = ItemContext.Open();
…
ic.Close();
Закрыть с использованием утверждения с ItemContext
using( ItemContext ic = ItemContext.Open())
{
…;
}
(2) Поиск объектов
Согласно другому аспекту настоящего изобретения API платформы хранения обеспечивает упрощенную модель запроса, которая позволяет разработчикам прикладных программ формировать запросы на основании различных свойств статей в хранилище данных, при этом разработчик прикладной программы изолирован от подробностей языка запроса нижележащей машины базы данных.
Приложения могут выполнять поиск по доменам, указанным при открытии ItemContext с использованием объекта ItemSearcher, возвращенного методом ItemContext.GetSearcher. Доступ к результатам поиска осуществляется с использованием объекта FindResult. Предположим следующие декларации для примеров, приведенных ниже:
ItemContext ic =...;
ItemSearcher searcher = null;
FindResult result = null;
Item item = null;
Relationship relationship = null;
ItemExtension itemExtension = null;
Основной шаблон поиска предполагает использование объекта ItemSearcher, извлеченного из ItemContext путем вызова метода GetSearcher.
Поиск всех статей данного типа
searcher = ic.GetSearcher(typeof(Person));
result = searcher.FindAll();
foreach(Person p in result)...;
Поиск статей данного типа, которые удовлетворяют фильтру
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("PersonalNames.Surname = 'Smith'”);
result = searcher.FindAll();
foreach(Person p in result)...;
Использовать параметр в строке фильтра
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("Birthdate < @Date");
searcher. Parameters["Date"] = someDate;
result = searcher.FindAll();
foreach(Person p in result)…;
Поиск отношений данного типа и удовлетворяющих фильтру
searcher = ic.GetSearcher(typeof(EmployeeEmployer));
searcher.Filters.Add( "StartDate <= @Date AND (EndDate >=
@Date OR isnull(EndDate))");
searcher.Parameters["Date"] = someDate;
result = searcher.FindAll();
Foreach(EmployeeEmployer ee in result)...;
Поиск статей с отношениями данного типа и удовлетворяющих фильтру
searcher = ic.GetSearcher(typeof(Folder));
searcher.Filters.Add("MemberRelationships.Name like 'A%'");
// См. [ApiRel]
result = searcher.FindAll();
Foreach(Folder f in result)...;
Поиск расширений статьи данного типа и удовлетворяющих фильтру
searcher = ic.GetSearcher(typeof(ShellExtension));
searcher.Filters.Add( "Keywords.Value = 'Foo'”);
result = searcher.FindAll();
foreach(ShellExtension se in result)…;
Поиск статей с расширениями данного типа и удовлетворяющих фильтру
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("Extensions.Cast(@Type).Keywords.Value
= 'Foo"'); // См. [ApiExt]
searcher.Parameters["Type"] = typeof(ShellExtension);
result = searcher.FindAll();
foreach(Person p in result)…;
(а) Опции поиска
При выполнении поиска можно задавать различные опции, включая сортировку, загрузку с задержкой и ограничение количества результатов.
Сортировка результатов поиска
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("PersonalNames.Surname = 'Smith'");
SearchOptions options = new SearchOptions();
options.SortOptions.Add(new SortOption("Birthdate",
SortOrder.Ascending));
result = searcher.FindAll(options);
foreach(Person p in result)...;
// Доступен короткий вызов:
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("PersonalNames.Surname = 'Smith'”);
result = searcher.FindAll(new SortOption("Birthdate",
SortOrder.Ascending));
foreach(Person p in result)...;
Ограничение количества результатов
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("PersonalNames.Surname = 'Smith'”);
SearchOptions options = new SearchOptions();
options.MaxResults = 10;
result = searcher.FindAll(options);
foreach(Person p in result)...;
(b) FindOne и FindOnly
В случае, когда полезным является извлечение только одного результата, особенно при задании мягких критериев. Кроме того, ожидается, что некоторые поиски возвращают только один объект, и не ожидается, что они не возвратят ни одного объекта.
Поиск одного объекта
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("PersonalNames.Surname = 'Smith'");
Person p = searcher.FindOne(new SortOption("Birthdate"
SortOrder.Ascending)) as Person;
if(p != null)...;
Поиск одного объекта, который, как ожидается, всегда существует
searcher = ic.GetSearcher(typeof(Person));
searcher.Filters.Add("PersonalNames[Surname = 'Smith' AND
Givenname 'John']");
try
{
Person p = searcher.FindOnly();
…;
}
catch(Exception e)
{
…;
}
(с) Короткие вызовы поиска на ItemContext
Существует также ряд методов короткого вызова на ItemContext, которые, насколько возможно, упрощают выполнение поисков.
Поиск с использованием короткого вызова ItemContext.FindAll
result = ic.FindAll(typeof(Person),
"PersonalNames.Surname = 'Smith'");
foreach(Person p in result)...;
Поиск с использованием короткого вызова ItemContext.FindOne
Person p = ic.FindOne(typeof(Person),
"PersonalNames.Surname = 'Smith'") as Person;
(d) Нахождение по ИД или пути
Кроме того, статьи, отношения и расширения статей можно извлекать, обеспечивая их идентификаторы. Статьи также можно извлекать с помощью пути.
Получение статей, отношений и расширений статей по их идентификаторам
item = ic.FindItemById(iid);
relationship = ic.FindRelationshipById(iid, rid);
itemExtension = ic.FindItemExtensionById(iid, eid);
Получение статей по пути
// Только один домен
item = ic.FindItemByPath(@"temp\foo.txt");
// Один или несколько доменов
result = ic.FindAllItemsByPath(@"temp\foo.txt”);
foreach(Item I in result)...;
(е) Шаблон GetSearcher
В API платформы хранения есть много мест, где желательно обеспечить метод помощника, который выполняет поиск в контексте другого объекта или с конкретными параметрами. Шаблон GetSearcher обеспечивает эти сценарии. В API существует много методов GetSearcher. Каждый из них возвращает ItemSearcher, заранее сконфигурированный, на осуществление данного поиска. Например:
searcher = itemContext.GetSearcher();
searcher = Person.GetSearcher();
searcher =
EmployeeEmployer.GetSearcherGivenEmployer(organization);
searcher = person.GetSearcherForReports();
Перед выполнением поиска можно задать дополнительные фильтры:
searcher = person.GetSearcherForReports();
searcher.Filters.Add("PersonalNames.Surname='Smith'");
Вы можете выбрать вид представления результата:
FindResult findResult = searcher.FindAll();
Person person = searcher.FindOne();
(3) Обновление хранилища
После извлечения объекта путем поиска, приложение, при необходимости, может его изменить. Можно также создавать новые объекты и связывать их с существующими объектами. После того как приложение произведет все изменения, образующие логическую группу, приложение вызывает ItemContext.Update для сохранения этих изменений в хранилище. Согласно еще одному аспекту API платформы хранения настоящего изобретения, API собирает изменения статьи, сделанные прикладной программой, после чего организует их в правильные обновления, необходимые машине базы данных (или машине хранения любого рода), на которой реализовано хранилище данных. Это позволяет разработчикам прикладных программ совершать изменения статьи в памяти, оставляя API сложные аспекты обновления хранилища данных.
Сохранение изменений в одной статье
Person p = ic.FindltemById(pid) as Person;
p.DisplayName = "foo";
p.TelephoneNumbers.Add(new TelephoneNumber("425-555-1234"));
ic.Update();
Сохранение изменений в нескольких статьях
Household h1 = ic.FindItemById(hid1) as Household;
Household h2 = ic.FindItemById(hid2) as Household;
Person p = ic.FindItemById(pid) as Person;
h1.MemberRelationships.Remove(p);
h2.MemberRelationships.Add(p);
ic.Update();
Создание новой статьи
Folder f = ic.FindItemById(fid) as Folder;
Person p = new Person();
p.DisplayName = "foo";
f.Relationships.Add(new FolderMember(p, "foo"));
ic.Update();
// Или с использованием короткого вызова...
Folder f = ic.FindItemById(fid) as Folder;
Person p = new Person();
p.DisplayName = “foo”;
f.MemberRelationships.Add(p, "foo");
ic.Update();
Удаление отношений (и, возможно, целевой статьи)
searcher = ic.GetSearcher(typeof(FolderMember));
searcher.Filters.Add("SourceItemId=@fid");
searcher.Filters.Add("TargetItemId=@pid");
searcher.Parameters.Add("fid", fid);
searcher.Parameters.Add("pid", pid);
foreach(FolderMember fm in searcher.FindAll())
fm.MarkForDelete();
ic.Update();
// Или с использованием короткого вызова…
Folder f = ic.FindItemById(fid) as Folder;
f.MemberRelationships.Remove(pid);
ic.Update();
Добавление расширения статьи
Item item = ic.FindItemById(iid);
MyExtension me = new MyExtension();
me.Foo = "bar";
item.Extensions.Add(me);
ic.Update();
Удаление расширений статей
searcher = ic.GetSearcher(typeof( MyExtension));
searcher.Filters.Add("ItemId=@iid");
searcher.Parameters.Add( "iid", iid);
foreach(MyExtension me in searcher.FindAll())
me.MarkForDelete();
ic.Update();
// Или с использованием короткого вызова...
Item i = ic.FindltemById(iid);
i.Extensions.Remove(typeof(MyExtension));
ic.Update();
6. Безопасность
Согласно предыдущему разделу II.E (Безопасность), согласно данному варианту осуществления API платформы хранения, существует пять методов, доступных на контексте статьи для извлечения и изменения политики безопасности, связанной со статьей в хранилище. Перечислим их:
1. GetItemSecurity;
2. SetItemSecurity;
3. GetPathSecurity;
4. SetPathSecurity;
5. GetEffectiveItemSecurity.
GetItemSecurity и SetItemSecurity обеспечивают механизм для извлечения и изменения явного ACL, связанного со статьей. Этот ACL не зависит от существующих путей к статье и будет в игре независимым от отношений поддержки, для которых эта статья является целевой. Это позволяет администраторам, при желании, делать безопасность независимой от существующих путей к статье.
GetPathSecunty и SetPathSecurity обеспечивают механизм для извлечения и изменения ACL, существующего на статье вследствие отношения поддержки от другой папки. Этот ACL состоит из ACL различных предков статьи совместно с рассматриваемым путем совместно с явным ACL, если какие-либо обеспечены для этого пути. Разница между этим ACL и ACL в предыдущем случае состоит в том, что этот ACL остается в игре только пока существует отношение поддержки, в то время как явный ACL статьи не зависит от любого отношения поддержки к статье.
ACL, который може быть задан на статье с помощью SetItemSecurity и SetPathSecurity, ограничивается наследуемыми и зависящими от объекта ACE. Они не могут содержать никаких ACE, помеченных как унаследованные.
GetEffectiveItemSecurity извлекает различные ACL, основанные на пути, а также явный ACL на статье. Это отражает политику авторизации в сущности на данной статье.
7. Поддержка отношений
Согласно рассмотренному выше модель данных платформы хранения задает «отношения», которые позволяет связывать статьи друг с другом. При генерации классов данных для схемы для каждого типа отношения формируются следующие классы:
1. Класс, который представляет отношение само по себе. Этот класс выводится из Класса отношений и содержит члены, зависящие от типа отношения.
2. Сильно типизированный «виртуальный» класс коллекций. Этот класс извлекается из VirtualRelationshipCollection и позволяет создавать и удалять экземпляры отношения.
В этом разделе описана поддержка отношений в API платформы хранения.
а) Базовые типы отношений
API платформы хранения обеспечивает ряд типов в пространстве имен System.Storage, которые образуют основу API отношений. Вот они:
1. Relationship - базовый тип всех классов отношений
2. VirtualRelationshipCollection - базовый тип для всех коллекций отношений
3. ItemReference, ItemIdReference, ItemPathReference - представляют типы ссылок на статью; отношение между этими типами показано на фиг.11.
(1) Класс Relationship
Ниже приведен базовый класс для классов отношений.
public abstract class Relationship: StoreObject
{
// Создать с помощью значений по умолчанию.
protected Relationship(ItemIDReference
targetItemReference);
// Сообщает отношению, что оно добавлено в коллекцию
//отношений. Объект будет опрашивать коллекцию, чтобы
// определить исходную статью, контекст статьи и т.д.
internal AddedToCollection(VirtualRelationshipCollection
collection);
// ИД отношения.
public Relationshipld RelationshipId {get;}
// ИД исходной статьи.
public Itemld SourceItemId {get;}
// Получить исходную статью.
public Item SourceItem {get;}
// Ссылка на целевую статью.
public ItemIdReference TargetItemReference {get;}
// Получить целевую статью
//(calls TargetItemReference.GetItem()).
public Item TargetItem {get;}
// Определяет, имеет ли уже ItemContext соединение с
// доменом целевой статьи (вызывает
//TargetItemReference.IsDomainConnected).
public bool IsTargetDomainConnected {get;}
// Имя целевой статьи в пространстве имен. Имя должно
// быть уникальным по всем отношениям поддержки
// исходной статьи.
public OptionalValue<строка> Name {get; set;}
// Определяет, является ли оно отношением поддержки
// или ссылки.
public OptionalValue<булево> IsOwned {get; set;}
}
(2) Класс ItemReference
Ниже приведен базовый класс для типов ссылок на статью.
public abstract class ItemReference: NestedElement
{
// Создать с помощью значений по умолчанию.
protected ItemReference();
// Возвращает ссылочную статью.
public virtual Item GetItem();
// Определить, установлено ли соединение с доменом
//ссылочной статьи.
public virtual bool IsDomainConnected();
}
Объекты ItemReference могут идентифицировать статьи, которые существуют в хранилище, отличном от того, где размещена сама ссылка на статью. Каждый производный тип указывает, как строится и используется ссылка на удаленное хранилище. Реализации GetItem и IsDomainConnected в производных классах используют многодоменную поддержку контекста статьи для загрузки статей из нужного домена и для определения, установлено соединение с доменом.
(3) Класс ItemIdReference
Ниже представлен класс ItemIdRefrence - ссылка на статью, которая использует ИД статьи для идентификации целевой статьи.
public class ItemIdReference: ItemReference
{
// Построить новую ItemIdReference с помощью
// значений по умолчанию.
public ItemIdReference();
// Построить новую ItemIdReference для указанной статьи.
// Домен, связанный со статьей, используется как указатель.
public ItemIdReference(Item item);
// Построить новую ItemIdReference с пустым указателем и
// и ИД данной целевой статьи.
public ItemIdReference(ItemId itemid);
// Построить новую ItemIdReference с данными значениями
// указателя и ИД статьи.
public ItemIdReference(string locator, ItemId itemid);
// ИД целевой статьи.
public ItemId ItemId {get; set;)
// Путь, указывающий статью WinFS, которая содержит
// целевую статью в своем домене. Если пустой, то
// домен, содержащий статью, неизвестен.
public OptionalValue<строка> Locator {get; set;}
// Определить, установлено ли соединение с доменом
// ссылочной статьи.
public override bool IsDomainConnected();
// Извлекает ссылочную статью.
public override Item GetItem();
}
GetItem и IsDomainConnected используют многодоменную поддержку контекста статьи для загрузки статей из нужного домена и для определения, установлено соединение с доменом. Этот признак еще не реализован.
(4) Класс ItemPathReference
Класс ItemPathReference является ссылкой на статью, которая использует путь для идентификации целевой статьи. Ниже приведен код для этого класса:
public class ItemPathReference: ItemReference
{
// Построить ссылку на статью по пути с помощью значений
// по умолчанию.
public ItemPathReference();
// Построить ссылку на статью по пути без помощи указателя
// и данного пути.
public ItemPathReference(string path);
// Построить ссылку на статью по пути с помощью данных
// указателя и пути.
public ItemPathReference(string locator, string path);
// Путь, указывающий статью WinFS, которая содержит
// целевую статью в своем домене.
public OptionalValue<строка> Locator {get; set;}
// Путь к целевой статье относительно домена статьи
// заданного указателем.
public string Path {get; set;}
// Определить, установлено ли соединение с доменом
// ссылочной статьи.
public override bool IsDomainConnected();
// Извлекает ссылочную статью.
public override Item GetItem();
}
GetItem и IsDomainConnected используют многодоменную поддержку контекста статьи для загрузки статей из нужного домена и для определения, установлено соединение с доменом.
(5) Структура RelationshipId
Структура RelationshipId инкапсулирует GUID ИД отношения.
public class RelationshipId
{
// Генерирует новый GUID ИД отношения.
public static RelationshipId NewRelationshipId();
// Инициализировать с новым GUID ИД отношения.
public RelationshipId();
// Инициализировать с указанным GUID.
public RelationshipId(Guid id);
// Инициализировать со строковым представлением GUID.
public RelationshipId(string id);
// Возвращает строковое представление GUID ИД отношения.
public override string ToString();
// Преобразует экземпляр System.Guid в экземпляр
// RelationshipId.
public static implicit operator RelationshipId(Guid guid);
// Преобразует экземпляр RelationshipId в
// экземпляр System.Guid
public static implicit operator Guid(RelationshipId
relationshipId);
}
Этот тип значения инкапсулирует GUID так, чтобы параметры и свойства могли быть сильно типизированы как ИД отношения. OptionalValue<RelationshipId> следует использовать, когда ИД отношения обнуляемо. Значение Empty (пусто), например, обеспечиваемое System.Guid.Empty, не открывается. RelationshipId нельзя построить с помощью пустого значения. При использовании конструктора, принятого по умолчанию, для создания RelationshipId, создается новый GUID.
(6) Класс VirtualRelationshipCollection
Класс VirtualRelationshipCollection реализует коллекцию объектов отношения, которая включает в себя объекты из хранилища данных, плюс новые объекты, добавленные к коллекции, но не включает в себя объекты, удаленные из хранилища. Объекты указанного типа отношения с данным ИД исходной статьи включаются в коллекцию.
Это исходная статья для класса коллекций отношений, которая генерируется для каждого типа отношения. Этот класс можно использовать как тип свойства в типе исходной статьи для обеспечения доступа и простоты манипуляций отношениями данной статьи.
Перечисление содержимого VirtualRelationshipCollection требует загрузки из хранилища потенциально большого количества объектов отношений. Приложения должны использовать свойство Count для определения, сколько отношений можно загрузить прежде, чем они будут перечислять содержимое коллекции. Добавление и удаление объектов в/из коллекции не требует загрузки отношений из хранилища.
Для эффективности предпочтительно, чтобы эти приложения искали отношения, удовлетворяющие конкретным критериям, а не перечисляли все отношения статьи с использованием объекта VirtualRelationshipCollection. Добавление объектов отношений в коллекцию приводит к созданию представленных отношений в хранилище при вызове ItemContext.Update. Удаление объектов отношений из коллекции приводит к удалению представленного отношения из хранилища при вызове ItemContext.Update. Виртуальная коллекция содержит правильное множество объектов независимо от того, добавляется/удаляется ли объект отношения посредством коллекции Item.Relationships или любой другой коллекции отношений на этой статье.
Класс VirtualRelationshipCollection задан следующим кодом:
public abstract class VirtualRelationshipCollection:
ICollection
{
// Коллекция будет содержать отношения указанного типа,
// которыми владеет статья, указанная itemId.
protected VirtualRelationshipCollection(ItemContext
itemContext,
ItemId itemId,
Type relationshipType);
// Перечислитель возвратит все объекты, извлеченные
// из хранилища за минусом объекта, который
// с состоянием Deleted помимо объектов, имеющих
// состояние Inserted.
public IEnumerator GetEnumerator();
// Возвращает счетчик количества объектов отношения,
// которые будут возвращены перечислителем. Этот счетчик
// вычисляется без необходимости извлекать все
// объекты из хранилища.
public int Count {get;}
// Всегда возвращает ложь.
public bool ICollection.IsSynchronized() {get;}
// Всегда возвращает этот объект.
public object ICollection.SyncRoot {get;}
// Ищет в хранилище нужные объекты.
public void Refresh();
// Добавляет указанное отношение в коллекцию. Объект
// должен иметь состояние Constructed или Removed.
// Если состояние - Constructed, оно меняется на Added.
// Если состояние - Removed, оно меняется на Retrieved или
// изменяется как нужно. ИД исходной статьи отношения
// должен совпадать с ИД исходной статьи,
// обеспеченным при построении коллекции.
protected void Add(Relationship relationship);
// Удаляет указанное отношение из коллекции. Состояние
// объекта должно быть Added, Retrieved или Modified. Если
// состояние объекта - Added, его нужно изменить на
// Constructed. Если состояние объекта - Retrieved или
// Modified, его нужно изменить на Removed.
// ИД исходной статьи отношения должно совпадать с ИД
// исходной статьи, обеспеченным
// при построении коллекции.
protected void Remove(Relationship relationship);
// Объекты, которые были удалены из коллекции.
public ICollection RemovedRelationships {get;}
// Объекты, которые были добавлены в коллекцию.
public ICollection AddedRelationships {get;}
// Объекты, которые извлечены из хранилища.
// Эта коллекция будет пустой до перечисления
// VirtualRelationshipCollection или вызова Refresh
// (если значение этого свойства не
// приводит к заполнению коллекции).
public ICollection StoredRelationships {get;}
// Асинхронные методы.
public IAsyncResult BeginGetCount(IAsyncCallback callback,
object state );
public int EndGetCount(IAsyncResult asyncResult);
public IAsyncResult BeginRefresh(IAsyncCallback callback,
object state);
public void EndRefresh( IAsyncResult asyncResult);
}
b) Сгенерированные типы отношений
При генерации классов для схемы платформы хранения, для каждой декларации отношения генерируется класс. Помимо класса, который представляет само отношение, для каждого отношения также генерируется класс коллекции отношений. Эти классы используются как тип свойств в классах исходной и целевой статьи отношения.
В этом разделе описаны классы, которые генерируются с использованием ряда классов «прототипов». Таким образом, когда задана декларация отношения, описывается класс, который генерируется. Важно заметить, что имена классов, типов и концевых точек в классах прототипов являются заполнителями для имен, указанных в схеме для отношения, их не следует понимать буквально.
(1) Сгенерированные типы отношений
В этом разделе описаны классы, которые генерируются для каждого типа отношения. Например:
<Relationship Name="RelationshipPrototype" BaseType="Holding">
<Source Name="Head” ItemType="Foo"/>
<Target Name="Tail” ItemType="Bar"
ReferenceType="ItemIDReference"/>
<Property Name="SomeProperty" Type="WinFSTypes.String"/>
</Relationship>
Для данного определения отношения будут сгенерированы классы RelationshipPrototype и RelationshipPrototypeCollection. Класс RelationshipPrototype представляет само отношение. Класс RelationshipPrototypeCollection обеспечивает доступ к экземплярам RelationshipPrototype, для которых указанная статья является исходной концевой точкой.
(2) Класс RelationshipPrototype
Это прототипический класс отношений для отношения поддержки под названием "HoldingRelationshipPrototype", где исходная концевая точка называется "Head" (голова) и задает тип статьи "Foo", и целевая концевая точка называется "Tail" (хвост) и задает тип статьи "Bar". Это задается следующим образом:
public class RelationshipPrototype: Relationship
{
public RelationshipPrototype(Bar tailItem);
public RelationshipPrototype(Bar tailItem, string name);
public RelationshipPrototype(Bar tailItem, string name,
bool IsOwned);
public RelationshipPrototype(Bar tailItem, bool IsOwned);
public RelationshipPrototype(ItemidReference
tailItemReference);
// Получить головную статью (вызывает base.SourceItem).
ublic Foo HeadItem {get;}
// Получить хвостовую статью (вызывает base.TargetItem).
public Bar TailItem {get;}
// Представляет дополнительные свойства, объявленные
// в схеме для отношения. Они генерируются просто как
// свойства в статье или типе вложенного элемента.
public string SomeProperty {get; set;}
public static ItemSearcher GetSearcher(ItemContext
itemContext);
public static ItemSearcher GetSearcher(Foo headItem);
public static FindResult FindAll(string filter);
public static RelationshipPrototype FindOne(string filter);
public static RelationshipPrototype FindOnly(string
filter);
}
(3) Класс RelationshipPrototypeCollection
Это прототипический класс, генерируемый с классом RelationshipPrototype, который поддерживает коллекцию экземпляров отношения RelationshipPrototype, которыми владеет указанная статья. Он задан следующим образом:
public class RelationshipPrototypeCollection:
VirtualRelationshipCollection
{
public RelationshipPrototypeCollection(ItemContext
itemContext, ItemId headItemId);
public void Add(RelationshipPrototype relationship);
public RelationshipPrototype Add(Bar bar);
public RelationshipPrototype Add(Bar bar, string name);
public RelationshipPrototype Add(Bar bar, string name,
bool IsOwned);
public RelationshipPrototype Add(Bar bar, bool IsOwned);
public void Remove(RelationshipPrototype relationship);
public void Remove(Bar bar);
public void Remove(Itemld barItemId);
public void Remove(Relationshipld relationshipId);
public void Remove(string name);
}
c) Поддержка отношений в классе Item
Класс Item содержит свойство Relationships, которое обеспечивает доступ к отношениям, в которых статья является источником отношения. Свойство Relationships имеет тип RelationshipCollection.
(1) Класс Item
Ниже показан код, представляющий свойства контекста отношения для класса Item:
public abstract class Item: StoreObject
{
…
// Коллекция отношений, в которой эта статья является
// источником.
public RelationshipCollection Relationships {get;}
…
}
(2) Класс RelationshipCollection
Этот класс обеспечивает доступ к экземплярам отношения, в которых данная статья является источником отношения. Он задан следующим образом:
public class RelationshipCollection:
VirtualRelationshipCollection
{
public RelationshipCollection(ItemContext itemContext,
ItemId headItemId);
public void Add(Relationship relationship);
public Relationship Add(Bar bar);
public Relationship Add(Bar bar, string name);
public Relationship Add(Bar bar, string name,
bool IsOwned);
public Relationship Add(Bar bar, bool IsOwned);
public void Remove(Relationship relationship);
public void Remove(Bar bar);
public void Remove(Itemld barItemId);
public void Remove(RelationshipId relationshipId);
public void Remove(string name);
}
d) Поддержка отношений в выражениях поиска
Можно задать прохождение связи между отношениями и статьями, связанными отношениями, в выражении поиска.
(1) Переход от статей к отношениям
Когда текущий контекст выражения поиска является множеством статей, связь между статьями и экземплярами отношения, в которых статья является источником, можно сделать с использованием свойства Item.Relationships. Связь с отношениями конкретного типа можно задать с использованием оператора Cast выражения поиска.
В выражении поиска также можно использовать сильно типизированные коллекции отношений (например, Folder.MemberRelationships). Приведение к типу отношения может быть неявным.
После задания множества отношений свойства этого отношения доступны для использования в предикатах или в качестве цели проекции. При использовании для задания цели проекции будет возвращено множество отношений. Например, следующее утверждение будет находить все персоны, относящиеся к организации, где свойство StartDate отношений имело значение, большее или равное '1/1/2000'.
FindResult result = Person.FindAll(context,
"Relationships.Cast(Contact.EmployeeOfOrganization).StartDate
> '1/1/2000'”);
Если тип Person имело свойство EmployerContext типа EmployeeSideEmployerEmployeeRelationships (сгенерированного для типа отношения EmployeeEmployer), это можно записать в виде:
FindResult result = Person.FindAll(context,
"EmployerRelationships.StartDate > '1/1/2000'”);
(2) Переход от отношений к статьям
Когда текущий контекст выражения поиска является множеством отношений, связь от отношения к любой концевой точке отношения можно пройти, указав имя концевой точки. После задания множества статей, связанных отношением, свойства этих статей доступны для использования в предикатах или как цель проекции. При использовании для задания цели проекции будет возвращено множество статей. Например, следующее утверждение будет найдено для всех отношений EmployeeOfOrganization (независимо от организации), где фамилия работника - "Smith":
FindResult result = EmployeeOfOrganization.FindAll(context,
"Employee.PersonalNames[SurName='Smith']");
Для фильтрации типа статьи концевой точки можно использовать оператор Cast выражения поиска. Например, чтобы найти все экземпляры отношения MemberOfFolder, где членом является статья Person с фамилией "Smith":
FindResult result = MemberOfFolder.FindAll(context,
"Member.Cast(Contact.Person).PersonalNames[Surname='Smith']");
(3) Комбинирование обхода отношений
Два предыдущих шаблона, перехода от статей к отношениям и от отношений к статьям, можно комбинировать для достижения произвольных сложных переходов. Например, чтобы найти все организации с работником по фамилии "Smith":
FindResult result = Organization.FindAll(context,
"EmployeeRelationships." +
"Employee." +
"PersonalNames[SurName = 'Smith']");
В нижеследующем примере будут найдены все статьи Person, представляющие людей, живущих в доме, находящемся в области "New York" (TODO: это больше не поддерживается … что является альтернативой).
FindResult result = Person.FindAll(context,
"Relationships.Cast(Contact.MemberOfHousehold)." +
"Household." +
"Relationships.Cast(Contact.LocationOfHousehold)." +
"MetropolitonRegion = 'New York'”);
е) Примеры использования поддержки отношений
Ниже приведены примеры того, как можно использовать поддержку отношений в API платформы хранения для манипулирования отношениями. Для нижеприведенных примеров предположим следующие декларации:
ItemContext ic =...;
ItemId fid =...; // ИД статьи папки
Folder folder = Folder.FindById(ic, fid);
ItemId sid =...;// ИД статьи источника.
Item source = Item.FindById(ic, sid);
ItemId tid =...; // ИД целевой статьи.
Item target = Item.FindById(ic, tid);
ItemSearcher searcher = null;
(1) Поиск отношений
Можно искать отношения по источнику или цели. Для выбора отношений указанного типа и тех, кому даны значения свойств, можно использовать фильтры. Фильтры также можно использовать для выбора отношений, основанных на связанном типе статьи или значениях свойства. Например, можно осуществлять следующие поиски:
Все отношения, где данная статья является источником
searcher = Relationship. GetSearcher(folder);
foreach(Relationship relationship in searcher.FindAll())...;
Все отношения, где данная статья является источником, имя которой совпадает с "A%"
searcher = Relationship.GetSearcher(folder);
searcher.Filters.Add("Name like 'A%'");
foreach(Relationship reiationship in searcher.FindAll())...;
Все отношения FolderMember, где данная статья является источником
searcher = FolderMember.GetSearcher(folder);
foreach(FolderMember folderMember in searcher.FindAll())...;
Все отношения FolderMember, где данная статья является источником и имеет имя наподобие 'A%'
searcher = FolderMember.GetSearcher(folder);
searcher.Filters.Add("Name like 'A%'");
foreach(FolderMember folderMember in searcher.FindAll())...;
Все отношения FolderMember, где целевая статья является Person
searcher = FolderMember.GetSearcher(folder);
searcher.Filters.Add("MemberItem.Cast(Person)");
foreach(FolderMember folderMember in searcher.FindAll())...;
Все отношения FolderMember, где целевая статья является Person с Surname "Smith"
searcher = FolderMember.GetSearcher(folder);
searcher.Filters.Add("MemberItem.Cast(Person).PersonalNames
Surname='Smith'");
foreach(FolderMember folderMember in
searcher.FindAll())...;
Помимо API GetSearcher, показанного выше, каждый класс отношений поддерживает статические API FindAll, FindOne и FindOnly. Кроме того, тип отношения можно задавать, вызывая ItemContext.GetSearcher, ItemContext.FindAll, ItemContext.FindOne или ItemContext.FindOnly.
(2) Навигация от отношения к исходной и целевой статьям
После извлечения объекта отношения посредством поиска, можно осуществлять «навигацию» к целевой или исходной статье. Базовый класс отношений обеспечивает свойства SourceItem и TargetItem, которые возвращают объект Item. Сгенерированный класс отношений обеспечивает эквивалентные сильно типизированные и именованные свойства (например, FolderMember.FolderItem и FolderMember.MemberItem). Например:
Навигация к исходной и целевой статье для отношения с именем "Foo"
searcher = Relationship.GetSearcher();
searcher.Filters.Add("Name='Foo'");
foreach(Relationship relationship in searcher.FindAll())
{
Item source = relationship.SourceItem;
Item target = relationship.TargetItem;
}
Навигация к целевой статье
searcher = FolderMember.GetSearcher(folder);
searcher.Filters.Add("Name like 'A%'");
foreach(FolderMember folderMember in searcher.FindAll())
{
Item member = folderMember.TargetItem;
…
}
Навигация к целевой статье работает даже, если целевая статья не находится в домене, где было найдено отношение. В таких случаях API платформы хранения, при необходимости, открывает соединение с целевым доменом. Приложения могут определять, потребуется ли соединение, до извлечения целевой статьи.
Проверка целевой статьи в несоединенном домене
searcher = Relationship.GetSearcher(source);
foreach(Relationship relationship in searcher.FindAll())
{
if(reltionship.IsTargetDomainConnected)
{
Item member = relationship.TargetItem;
…
}
}
(3) Навигация от исходных статей к отношениям
При данном объекте статьи можно осуществлять навигацию к отношениям, для которых статья является источником, без выполнения явного поиска. Это делается с использованием свойства коллекции Item.Relationships или сильно типизированного свойства коллекции, например, Folder.MemberRelationships. От отношения можно осуществлять навигацию к целевой статье. Такая навигация работает даже, если целевая статья не находится в домене статьи, связанном с ItemContext исходной статьи, в том числе, когда исходная статья не находится в том же хранилище, что и целевая статья. Например:
Навигация от исходной статьи к отношению и далее к целевым статьям
Console.WriteLine("Item {0} is the source of the following
relationships:", source.ItemId);
foreach(Relationship relationship in source.Relationships)
{
Item target = relationship.TargetItem;
Console.WriteLine("{0} ==> {1}",
relationship.RelationshipId, target.ItemId);
}
Навигация от статьи папки к отношениям Foldermember и далее к целевым статьям
Console.WriteLine("Item {0} is the source of the following
relationships:", folder.ItemId);
foreach(FolderMember folderMember in
folder.MemberRelationships)
{
Item target = folderMember.GetMemberItem();
Console.WriteLine("{0} ==> {1}",
folderMember.RelationshipId, target.ItemId);
}
Статья может иметь много отношений, поэтому приложения должны использовать предостережение при перечислении коллекции отношений. В общем случае поиск нужно использовать для идентификации конкретных отношений, представляющих интерес, вместо перечисления всей коллекции. Все же, если модель программирования для отношений на основе коллекции достаточно ценна и статьи со многими отношениями достаточно редки, риск совершения неправильного действия со стороны разработчика оправдан. Приложения могут проверять ряд отношений в коллекции и, при необходимости, использовать другую модель программирования. Например:
Проверка размера коллекции отношений
if(folder.MemberRelationships.Count > 1000 )
{
Console.WriteLine("Too many relationships!");
}
else
{
…
}
Вышеописанные коллекции отношений являются «виртуальными» в том смысле, что они в действительности не заполняются объектами, которые представляют каждое отношение, пока приложение не предпринимает попытку перечислить коллекцию. Если коллекция перечисляется, результаты отражают то, что находится в хранилище, плюс то, что добавлено приложением, но пока не сохранено, но не любые отношения, которые были удалены приложением, но не сохранены.
(4) Создание отношений (и статей)
Новые отношения создаются путем создания объекта отношения, добавления его в коллекцию отношений в исходной статье и обновления ItemContext. Для создания новой статьи нужно создать отношение поддержки или внедрения. Например:
Добавление новой статьи к существующей старой
Bar bar = new Bar();
folder.Relationships.Add(new FolderMember(bar, "name"));
ic.Update();
// или
Bar bar = new Bar();
folder.MemberRelationships.Add(new FolderMember(bar, "name"));
ic.Update();
// или
Bar bar = new Bar();
folder.MemberRelationships.Add(bar, name);
ic.Update();
Добавление существующей статьи к существующей папке
folder.MemberRelationships.Add(target, "name");
ic.Update();
Добавление существующей статьи к новой папке
Folder existingFolder = ic.FindItemById(fid) as Folder;
Folder newFolder = new Folder();
existingFolder.MemberRelationships.Add( newFolder, "a name");
newFolder.MemberRelationships.Add(target, "a name");
ic.Update();
Добавление новой статьи к новой папке
Folder existingFolder = ic.FindItemById(fid) as Folder;
Folder newFolder = new Folder();
existingFolder.MemberRelationships.Add(newFolder, "a name");
Bar bar = new Bar();
newFolder.MemberRelationships.Add(bar, "a name");
ic.Update();
(5) Удаление отношений (и статей)
Удаление отношения поддержки
// Если ИД исходной статьи и отношения известны…
RelationshipId rid =...;
Relationship r = ic.FindRelationshipById(fid, rid);
r.MarkForDelete;
ic.Update();
// Иначе…
folder.MemberRelationships.Remove(target);
ic.Update();
8. «Расширение» API платформы хранения
Согласно отмеченному выше каждая схема платформы хранения порождает множество классов. Эти классы имеют стандартные методы, например Find*, а также имеют свойства для получения и задания значений полей. Эти классы и соответствующие методы образуют основу API платформы хранения.
a) Поведения домена
Помимо этих стандартных методов, каждая схема имеет множество методов, зависящих от домена. Перечислим эти поведения домена. Например, некоторые из поведений домена в Схеме контактов таковы:
- Пригоден ли адрес электронной почты?
- Для данной папки, получить коллекцию всех элементов папки.
- Для данного ИД статьи, получить объект, представляющий эту статью.
- Для данного лица, получить его онлайновый статус.
- Помощник функционирует для создания нового контакта или временного контакта.
- И т.д.
Важно отметить, что, хотя мы делаем различия между «стандартными» поведениями (Find* и т.д.) и поведениями домена, для программиста они выглядят просто методами. Различие между этими методами заключается в том, что стандартные поведения генерируются автоматически из файлов схемы инструментами среды разработки API платформы хранения, тогда как поведения домена закодированы аппаратно.
По своей природе эти поведения домена должны задаваться вручную. Это создает практическую проблему: начальная версия C# требует, чтобы вся реализация класса была в едином файле. Для этого приходится редактировать самогенерирующиеся файлы классов для добавления поведений домена. Это само по себе может составлять проблему.
Для решения подобных проблем в C# был введен признак, именуемый частичными классами. В основном, частичный класс допускает реализацию классов для охвата множественных файлов. Частичный класс - это то же самое, что регулярный класс за исключением того, что его декларации предшествует ключевое слово partial:
partial public class Person: DerivedItemBase
{
// реализация
}
Теперь поведения домена для Person можно поместить в другой файл, например, так:
partial public class Person
{
public EmailAddress PrimaryEmailAddress
{
get {/*реализация*/}
}
}
b) Поведения добавления значений
Классы данных с поведениями домена образуют основу, на которой разработчик строит приложения. Однако невозможно, а также нежелательно, чтобы классы данных открывали каждое мыслимое поведение, относящееся к этим данным. Платформа хранения позволяет разработчику строить на базовых функциональных возможностях, обеспечиваемых API платформы хранения. Основным шаблоном здесь является написание класса, методы которого принимают один или более классов данных платформы хранения в качестве параметров. Например, классы добавления значения для отправки электронной почты с использованием Microsoft Outlook или с использованием службы сообщений Microsoft Windows могут иметь следующий вид:
MailMessage m = MailMessage.FindOne(...);
OutlookEMailServices.SendMessage(m);
Person p = Person.FindOne(...);
WindowsMessagerServices m = new WindowsMessagerServices(p);
m.MessageReceived += new MessageReceivedHandler(f);
m.SendMessage("Hello");
Эти классы добавления значения можно регистрировать с помощью платформы хранения. Данные регистрации связаны с метаданными схемы, которые платформа хранения поддерживает для каждого установленного типа платформы хранения. Эти метаданные хранятся как статьи платформы хранения и могут запрашиваться.
Регистрация классов добавления значения является мощным признаком; например, она допускает следующий сценарий: кликнув правой кнопкой мыши по объекту Person в обозревателе оболочки, можно вывести набор допустимых действий из классов добавления значения, зарегистрированных для Person.
с) Поведения добавления значения как поставщики услуг
Согласно данному варианту осуществления API платформы хранения обеспечивает механизм, посредством которого классы добавления значения можно регистрировать как «услуги» для данного типа. Это позволяет приложению задавать и получать поставщиков услуг (= классы добавления значения) данного типа. Классы добавления значения, желающие использовать этот механизм, должны реализовать общеизвестный интерфейс; например:
interface IChatServices
{
void SendMessage(string msg);
event MessageReceivedHandler MessageReceived;
}
class WindowsMessengerServices: IChatServices
{
…
}
class YahooMessengerServices: IChatServices
{
…
}
Все классы данных API платформы хранения реализуют интерфейс ICachedServiceProvider. Этот интерфейс расширяет интерфейс System.IServiceProvider следующим образом:
interface ICachedServiceProvider: System.IServiceProvider
{
void SetService(System.Type type, Object provider);
void RemoteService(System.Type type);
}
С помощью этого интерфейса приложения могут задавать экземпляр поставщика услуг, а также запрашивать поставщика услуг конкретного типа.
Для поддержки этого интерфейса класс данных платформы хранения поддерживает хэш-таблицу поставщиков услуг, где они распределены по типам. При запросе поставщика услуг реализация сначала смотрит в хэш-таблицу, чтобы проверить, задан ли поставщик услуг указанного типа. Если нет, инфраструктура запрашиваемого поставщика услуг используется для идентификации поставщика услуг указанного типа. Затем создается экземпляр этого поставщика услуг, он добавляется в хэш-таблицу и возвращается. Заметим, что возможен также совместно используемый метод на классе данных для запрашивания поставщика услуг и передачи операции этому поставщику услуг. Например, это можно использовать для обеспечения метода Send на классе почтовых сообщений, который использует систему электронной почты, указанную пользователем.
9. Структура среды разработки
В этом разделе описано, как схема платформы хранения получает превращенные в API платформы хранения классы на клиенте и классы UDT на сервере согласно данному варианту осуществления изобретения. Диаграмма на фиг.24 демонстрирует используемые компоненты.
Согласно фиг.24 типы в схеме содержатся в файле XML (блок 1). Этот файл также содержит ограничения уровня полей и уровня статей, связанные со схемой. Генератор классов платформы хранения (xfs2cs.exe - блок 2) берет этот файл и генерирует частичные классы для UDT хранилища (блок 5) и частичные классы для классов клиента (блок 3). Для каждого домена схемы существуют дополнительные методы, которые мы называем поведениями домена. Существуют поведения домена, имеющие смысл на хранилище (блок 7), на клиенте (блок 6) и в обоих местах (блок 4). Код в блоках 4, 6 и 7 пишется вручную (не генерируется автоматически). Частичные классы в блоках 3, 4 и 6 совместно образуют полную реализацию классов для классов доменов API платформы хранения. Блоки 3, 4 и 6 компилируются (блок 8) для формирования классов API платформы хранения - блок 11 (фактически, API платформы хранения это результат компиляции блоков 3, 4 и 6, полученных из всех доменов начальной схемы). Помимо классов доменов существуют также дополнительные классы, реализующие поведение добавления значения. Эти классы используют один или более классов в одном или более доменов схемы. Это представлено блоком 10. Частичные классы в блоках 4, 5 и 7 совместно образуют полную реализацию классов для классов UDT сервера. Блоки 4, 5 и 7 компилируются (блок 9) для формирования ассемблера UDT стороны сервера - блок 12 (фактически, ассемблер UDT стороны сервера является результатом компиляции и плюсования блоков 4, 5 и 7, полученных из всех доменов начальной схемы). Модуль генератора команд DDL [ЯОД?] (блок 13) берет ассемблер UDT (блок 12) и файл схемы (блок 1) и устанавливает их на хранилище данных. Этот процесс предполагает, помимо прочего, генерацию таблиц и видов для типов в каждой схеме.
10. Формализм запросов
Будучи приведен к основам, шаблон приложения при использовании API платформы хранения представляет собой: открытие ItemContext; использование Find с критерием фильтрации для извлечения нужных объектов; манипулирование объектами; отправку изменений обратно в хранилище. Этот раздел посвящен синтаксису строки фильтра.
Строка фильтра, обеспечиваемая при отыскании объектов данных платформы хранения, описывает, каким условиям должны удовлетворять свойства объектов, чтобы их можно было возвратить. Синтаксис, используемый API платформы хранения, поддерживает приведения типов и обход отношений.
а) Основы фильтрации
Строка фильтра либо пуста, что указывает на необходимость возвращения всех объектов данного типа, либо является логическим выражением, которому должен удовлетворять каждый возвращаемый объект. Среда выполнения API платформы хранения знает, как эти имена свойств отображаются в имена полей типа платформы хранения и, в конце концов, в виды SQL, поддерживаемые хранилищем платформы хранения.
Рассмотрим следующие примеры:
// Найти всех людей
FindResult res1 = Person.FindAll(ctx)
// Найти всех людей, имеющих значение свойства Gender (пол)
// равное "Male" (мужской)
FindResult res2 = Person.FindAll(ctx, "Gender='Male'")
// Найти всех людей, имеющих значение свойства Gender,
// равное "Male", и родившихся в прошлом тысячелетии.
FindResult res3 = Person.FindAll(
ctx,
"Gender='Male' And Birthdate < '1/1/2001'”)
В фильтре также можно использовать вложенные объекты свойства. Например:
// Найти всех людей, измененных за последние 24 часа
FindResult res1 = Person.FindAll(
ctx,
String.Format("Item.Modified > '{0}'",
DateTime.Now.Subtract(new TimeSpan(24,0,0))));
Для коллекций, можно фильтровать члены, используя условия в квадратных скобках. Например:
// Найти всех людей по имени "John" и по фамилии "Smith"
FindResult res1 = Person.FindAll(
ctx,
"PersonalNames[GivenName='John' And Surname='Smith']")
// Найти всех людей с адресом в реальном времени от провайдера
// 'x' и с категорией онлайнового статуса 'y'
FindResult res2 = Person.FindAll(
ctx,
"PersonalRealtimeAddress[ProviderURI='x'].BasicPresence." +
"OnlineStatus.Category='y'")
В нижеследующем примере перечисляются все люди, рожденные с 12/31/1999:
ItemContext ctx = ItemContext.Open("Work Contacts");
FindResult results =
Person.FindAll(ctx, "Birthdate > '12/31/1999'”
foreach(Person person in results)
Console.WriteLine(person.DisplayName);
ctx.Close();
Строка 1 создает новый объект ItemContext для доступа к "Work Contacts" на совместно используемом ресурсе платформы хранения на локальном компьютере. Строки 3 и 4 получают коллекцию объектов Person, где свойство Birthdate указывает время после 12/31/1999, что задано выражением "Birthdate > '12/31/1999'". Выполнение операции FindAll проиллюстрировано на фиг.23.
b) Приведения типов
Часто случается так, что тип значения, хранящегося в свойстве, выводится из объявленного типа свойств. Например, свойство PersonalEAddresses в Person содержит коллекцию типов, выведенных из EAddress, например, EMailAddress и TelephoneNumber. Для фильтрации на основании регионального телефонного кода необходимо перейти от типа EAddress к типу TelephoneNumber:
// Найти всех людей с телефонным номером, имеющим
// региональный код 425
FindResult res1 = Person.FindAll(
ctx,
"PersonalEAddresses." +
"Cast(System.Storage.Contact.TelephoneNumber))." +
"AreaCode='425"');
// Альтернативно, можно передать имя типа следующим образом:
FindResult res1 = Person.FindAll(
ctx,
String.Format("PersonalEAddresses.Cast({0})).AreaCode='425',
typeof(TelephoneNumber).FullName))
с) Синтаксис фильтра
Ниже описан синтаксис фильтра, поддерживаемый API платформы хранения, согласно одному варианту осуществления.
Filter::= EmptyFilter | Condition
EmptyFilter::=
Condition::= SimpleCondition | CompoundCondition |
ParenthesizedCondition
SimpleCondition::= ExistanceCheck | Comparison
ExistanceCheck::= PropertyReference
Comparison::= PropertyReference ComparisonOp Constant
CompoundCondition::= SimpleCondition BooleanOp Condition
ParenthesizedCondition::= '('Condition')'
ComparisonOp::='!=' | '==' | '=' | '<' | '>' | '>=' | '<='
BooleanOp::= 'And' | '&&' | 'Or' | '||'
Constant::= StringConstant | NumericConstatant
StringConstant:: ''' (любой символ Unicode)* '''
Примечание: внедренные символы ' устраняются дублированием
NumericConstant::= 0-9*
PropertyReference::= SimplePropertyName |
CompoundPropertyName
SimplePropertyName::= (все символы Unicode за исключением
'.' и пробела)* Filter?
Filter::= '[' Condition ']'
CompoundPropertyName::=
(TypeCast | RelationshipTraversal |
SimplePropertyName) '. ' PropertyReference
TypeCast::= 'Cast(' TypeName ')'
RelationshipTraversal::= TraversalToSource |
TraversalToTarget
TraversalToSource::= 'Source('FullRelationshipName')'
TraversalToTarget::= 'Target('FullRelationshipName')'
TypeName::= полностью уточненное имя типа CLR
FullRelationshipName::= SchemaName '.' RelationshipName
SchemaName::= the storage platformName
RelationshipName::= the storage platformName
the storage platformName::= заданное в [SchemaDef]
11. Удаленные операции
а) Локальная/удаленная прозрачность в API
Доступ к данным в платформе хранения нацелен на экземпляр локальной платформы хранения. Локальный экземпляр служит маршрутизатором, если запрос (или его часть) ссылается на удаленные данные. Таким образом, уровень API обеспечивает локальную/удаленную прозрачность: не существует структурной разницы в API между локальным и удаленным доступом к данным. Это исключительно функция запрашиваемой области действия.
Хранилище данных платформы хранения также реализует распределенные запросы; таким образом, можно соединяться с экземпляром локальной платформы хранения и осуществлять запрос, который включает в себя статьи из разных томов, некоторые из которых находятся на локальном хранилище, а некоторые - на удаленном хранилище. Хранилище объединяет результаты и представляет их приложению. С точки зрения API платформы хранения (а, стало быть, и разработчика приложения) любой удаленный доступ полностью гладкий и прозрачный.
API платформы хранения позволяет приложению определять, представляет ли данный объект ItemContext (возвращаемый методом ItemContext.Open) локальное или удаленное соединение с использованием свойства IsRemote - это свойство на объекте ItemContext. Помимо прочего, приложение может пожелать обеспечить визуальную обратную связь, в помощь ожиданиям пользователя относительно производительности, надежности и т.д.
b) Реализация удаленных операций в платформе хранения
Хранилища данных платформы хранения разговаривают друг с другом с использованием особого провайдера OLEDB, который действует над HTTP (провайдер OLEDB по умолчанию использует TDS). В одном варианте осуществления распределенный запрос проходит через функциональную возможность OPENROWSET машины реляционной базы данных. Для осуществления фактических удаленных операций обеспечена специальная функция, заданная пользователем (UDF): DoRemoteQuery(server, queryText).
с) Доступ к хранилищам, не относящимся к платформе хранения
Согласно одному варианту осуществления платформы хранения настоящего изобретения не существует общей архитектуры провайдера, которая позволяет любому хранилищу участвовать в доступе к данным платформы хранения. Однако обеспечена ограниченная архитектура провайдера для конкретного случая Microsoft Exchange и Microsoft Active Directory (AD). При этом предполагается, что разработчики могут использовать API платформы хранения и осуществлять доступ к данным в AD и Exchange, как если бы они были в платформе хранения, но что данные, к которым они осуществляют доступ, ограничиваются схематизированными типами платформы хранения. Таким образом, адресная книжка (= коллекция типов Person платформы хранения) поддерживается в AD, и почта, календарь и контакты поддерживаются для Exchange.
d) Отношение к DFS
Промоутер свойств платформы хранения не продвигает прошлые точки установки. Несмотря на то, что пространство имен достаточно богато для осуществления доступа через установочные точки, запросы через них не проходят. Тома платформы хранения могут выглядеть как концевые узлы в дереве DFS.
е) Отношение к GXA/Indigo
Разработчик может использовать API платформы хранения для открытия «головы GXA» поверх хранилища данных. В принципе, здесь нет никакого отличия от создания любой другой веб-услуги. API платформы хранения не разговаривает с хранилищем данных платформы хранения с использованием GXA. Согласно отмеченному выше, API разговаривает с локальным хранилищем с использованием TDS; локальное хранилище манипулирует любыми удаленными операциями с использованием услуги синхронизации.
12. Ограничения
Модель данных платформы хранения допускает ограничения значений на типах. Эти ограничения оцениваются на хранилище автоматически, и процесс является прозрачным для пользователя. Заметим, что ограничения проверяются на сервере. Иногда, как отмечено здесь, желательно давать разработчику гибкость в проверке того, что входные данные удовлетворяют ограничениям, не создавая служебной нагрузки обратной передачи на сервер. Это особенно полезно в интерактивных приложениях, где конечный пользователь вводит данные, которые используются для наполнения объекта. API платформы хранения обеспечивает этот механизм.
Напомним, что схема платформы хранения задана в файле XML, который используется платформой хранения для генерации соответствующих объектов базы данных, представляющих схему. Она также используется структурой среды разработки API платформы хранения для автоматической генерации классов.
Ниже частично приведен текст файла XML, используемого для генерации Схемы контактов:
<Schema Name="Contacts" MajorVersion="1" MinorVersion="8”>
<ReferencedSchema Name="Base" MajorVersion="1"/>
<Type Name="Person" MajorVersion=”1" MinorVersion="0"
ExtendsType="Principal" ExtendsVersion="1">
<Field Name="Birthdate" Type="the storage
platformTypes.datetime"
Nullable="true" MultiValued="false"/>
<Field Name="Gender" Type="the storage
platformTypes.nvarchar(16)"
Nullable="true" MultiValued="false"/>
<Field Name="PersonalNames" Type="FullName"
TypeMajorVersion="1"
Nullable="true" MultiValued="true"/>
<Field Name="PersonalEAddresses" Type="EAddress"
TypeMajorVersion="1" Nullable="true"
MultiValued="true"/>
<Field Name="PersonalPostalAddresses"
Type="PostalAddress"
TypeMajorVersion="1" Nullable="true"
MultiValued="true"/>
<Check>expression</Check>
</Type>
…
…
</Schema>
Тэги Check в вышеприведенном XML задают ограничения на типе Person. Может существовать более одного тэга проверки. Вышеописанное ограничение обычно проверяется в хранилище. Чтобы задать, что ограничение также может проверяться в явном виде приложением, вышеописанный XML изменяется следующим образом:
<Schema Name="Contacts" MajorVersion="1" MinorVersion="8”>
<ReferencedSchema Name="Base" MajorVersion="1"/>
<Type Name="Person"...>
<Field Name="Birthdate" Type="the storage
platformTypes.datetime" Nullable="true"
MultiValued="false"/>
…
<Check InApplication="true">expression</Check>
</Type>
…
…
</Schema>
Обратите внимание на новый атрибут "InApplication" на элементе <Check>, который задан равным истине. Это заставляет API платформы хранения выявлять ограничение в API посредством частного метода на классе Person, именуемого Validated. Приложение может вызывать этот метод на объекте, чтобы гарантировать пригодность данных, предотвращая потенциально бесполезный возврат данных на сервер. Это возвращает логическое значение, указывающее результаты проверки. Заметим, что ограничения значения все же применяются на сервере независимо от того, вызывает ли клиент метод <объект>.Validate(). Приведем пример того, как можно использовать Validate:
ItemContext ctx = ItemContext.Open();
// Создать контакт в папке My Contacts пользователя.
Folder f = UserDataFolder.FindMyPersonalContactsFolder(ctx);
Person p = new Person(f);
// Задать дату рождения лица.
p.Birthdate = new DateTime(1959, 6, 9);
// Добавить имя, категоризированное как персональное имя
FullName name = new FullName(FullName.Category.PrimaryName);
name.GivenName = "Joe";
name.Surname = "Smith";
p.PersonalNames.Add(name);
// проверить объект Person
if (p.Validate() == false)
{
// данные не представляют действительное лицо
}
// сохранить изменения
p.Update();
ctx.Close();
Существует несколько путей доступа к хранилищу платформы хранения - API платформы хранения, ADO.NET, ODBC, OLEDB и ADO. Возникает вопрос официальной проверки ограничений, т.е. как мы можем гарантировать, что данные, записанные, скажем, из ODBC, проходят через те же ограничения целостности данных, как если бы данные были записаны из API платформы хранения. Поскольку все ограничения проверяются на хранилище, ограничения теперь являются официальными. Независимо от того, какой путь API используется для доступа к хранилищу, все записи в хранилище фильтруются посредством проверок ограничения на хранилище.
13. Совместное использование
Совместно используемый ресурс в платформе хранения имеет вид \\<имя DNS>\<услуга контекста>,
где <имя DNS> это имя DNS машины, и <услуга контекста> это папка включения, виртуальная папка или статья в томе на этой машине. Пусть, например, машина "Johns_Desktop" имеет том, именуемый Johns_Information, и в этом томе существует папка, именуемая Contacts_Categories; эта папка содержит папку, именуемую Work, в которой находятся рабочие контакты Джона:
\\Johns_Desktop\Johns_Information$\Contacts_Categories\Work
Это можно совместно использовать как "WorkContacts". Благодаря определению этого совместно используемого ресурса, \\Johns_Desktop\WorkContacts\JaneSmith является пригодным именем платформы хранения и идентифицирует статью Person под названием JaneSmith.
а) Представление совместно используемого ресурса
Тип статьи совместно используемого ресурса имеет следующие свойства: имя совместно используемого ресурса и цель совместно используемого ресурса (это может быть неподдерживающая связь). Например, имя вышеупомянутого совместно используемого ресурса - WorkContacts, и цель - Contacts_Categories\Work на томе Johns_Information. Ниже приведен фрагмент схемы для типа Share:
<Schema
xmlns=http://schemas.microsoft.com/winfs/2002/11/18/schema
Name="Share" MajorVersion="1" MinorVersion="0">
<ReferencedSchema Name="Base" MajorVersion="1"/>
<ReferencedSchema Name="the storage platformTypes"
MajorVersion="1”/>
<Type Name="Share" MajorVersion="1" MinorVersion="0"
ExtendsType="Base.Item" ExtendsVersion="1">
<Field Name="Name" Type="the storage
platformTypes.nvarchar(512)"
TypeMajorVersion="1”/>
<Field Name="Target" Type="Base.RelationshipData"
TypeMajorVersion="1”/>
</Type>
</Schema>
b) Управление совместно используемыми ресурсами
Поскольку совместно используемый ресурс является статьей, совместно используемыми ресурсами можно управлять в точности, как другими статьями. Совместно используемый ресурс можно создавать, удалять или изменять. Совместно используемый ресурс также защищается таким же образом, как другие статьи платформы хранения.
с) Доступ к совместно используемым ресурсам
Приложение осуществляет доступ к совместно используемому ресурсу удаленной платформы хранения, передавая имя совместно используемого ресурса (например, \\Johns_Desktop\WorkContacts) API платформы хранения при вызове метода ItemContext.Open(). ItemContext.Open возвращает экземпляр объекта ItemContext. Затем API платформы хранения разговаривает с услугой локальной платформы хранения (напомним, что доступ к совместно используемым ресурсам удаленной платформы хранения производится посредством локальной платформы хранения). В свою очередь, услуга локальной платформы хранения разговаривает с услугой удаленной платформы хранения (например, WorkContacts). Затем услуга удаленной платформы хранения транслирует WorkContacts в Contacts_Categories\Work и открывают ее. После этого запрос и другие операции осуществляются наподобие других областей действия.
d) Обнаружимость
Согласно одному варианту осуществления прикладная программа может обнаружить совместно используемые ресурсы, доступные под данным <именем DNS> следующими способами. Согласно первому способу API платформы хранения принимает имя DNS (например, Johns_Desktop) как параметр области применения в методе ItemContext.Open(). Затем API платформы хранения связывается с хранилищем платформы хранения с этим именем DNS как части строки соединения. Благодаря этому соединению, единственно, что может сделать приложение, это вызвать ItemContext.FindAll(typeof(Share)). Затем услуга платформы хранения объединяет все совместно используемые ресурсы на всех присоединенных томах и возвращает коллекцию совместно используемых ресурсов. Согласно второму способу, на локальной машине, администратор может легко обнаружить совместно используемые ресурсы на конкретном томе посредством FindAll(typeof(Share)), или конкретной папке посредством FindAll(typeof(Share), "Target(ShareDestination).Id = folderId").
14. Семантика Find
Методы Find* (независимо от того, вызваны ли они на объекте ItemContext или на отдельной статье), в общем случае, применяются к статьям (включая внедренные статьи) в данном контексте. Вложенные элементы не имеют Find - в них нельзя производить поиск независимо от содержащих их статей. Это согласуется с семантикой, нужной модели данных платформы хранения, где вложенные элементы выводят свою «идентификацию» из содержащей статьи. Чтобы прояснить эту идею, приведем примеры пригодных и непригодных операций нахождения:
а) Показать мне все телефонные номера в системе, имеющие региональный код 206.
Непригоден, поскольку нахождение осуществляется на телефонных номерах - элементе - без ссылки на статью.
b) Показать мне все телефонные номера во всех статьях Person, имеющие региональный код 206.
Непригоден, несмотря на ссылку на Person (=статья), такой критерий не задействует эту статью.
с) Показать мне все телефонные номера Murali (=одно единственное лицо), имеющие региональный код 206.
Пригоден, поскольку существует критерий поиска на статье (лицо по имени "Murali").
Исключениями для этого правила являются типы вложенного элемента, прямо или косвенно выведенные из типа Base.Relationship. Эти типы можно запрашивать по отдельности через классы отношений. Такие запросы могут поддерживаться, поскольку реализация платформы хранения использует «главную таблицу связей» для сохранения элементов отношения вместо внедрения их в UDT статей.
15. API Contacts платформы хранения
В этом разделе приведен обзор API Contacts платформы хранения. Схема, лежащая в основе API Contacts, показана на фиг.21A и 21B.
а) Обзор System.Storage.Contact
API платформы хранения включает в себя пространство имен для того, чтобы иметь дело со статьями и элементами в Схеме контактов. Это пространство имен называется System.Storage.Contact. Эта схема имеет, например, следующие классы:
- Статьи: UserDataFolder, User, Person, ADService, Service, Group, Organization, Principal, Location
- Элементы: Profile, PostalAddress, EmailAddress, TelephoneNumber, RealTimeAddress, EAddress, FullName, BasicPresence, GroupMembership, RoleOccupancy
b) Поведения домена
Ниже приведен список поведений домена для Схемы контактов. Рассматривая поведения домена с достаточно высокого уровня, их можно разделить на интуитивно понятные категории:
- статические помощники, например, Person.CreatePersonalContact() для создания нового личного контакта;
- помощники экземпляра, например user.AutoLoginToAllProfiles(), который осуществляет вход пользователя (экземпляр класса User) во все профили, помеченные как предназначенные для автоматического входа;
- CategoryGUID, например, Category.Home, Category.Work и т.д.;
- производные свойства, например, emailAddress.Address() - возвращает строку, которая объединяет поля имени пользователя и домена данного emailAddress (= экземпляр класса EmailAddress); и
- производные коллекции, например, person.PersonalEmailAddresses - для данного экземпляра класса Person, получают его личный адрес электронной почты.
В нижеследующей таблице приведены, для каждого класса в Контактах, который имеет поведения домена, список этих методов и категория, которой они принадлежат.
16. API File платформы хранения
В этом разделе приведен обзор API File платформы хранения согласно одному варианту осуществления настоящего изобретения.
а) Введение
(1) Отражение тома NTFS в платформе хранения
Платформа хранения обеспечивает способ индексации по контексту в существующих томах NTFS. Для этого извлекаются («продвигающие») свойства из каждого потока файла или директории в NTFS и эти свойства сохраняются как статьи в платформе хранения.
Схема файлов платформы хранения задает два типа статьи - File и Directory - для сохранения продвинутых сущностей файловой системы. Тип Directory - это подтип типа Folder; это папка включения, которая содержит другие статьи Directory или статьи File.
Статья Directory может содержать статьи Directory и File; она не может содержать статьи никакого другого типа. Что касается платформы хранения, статьи Directory и File предназначены только для чтения из любых API доступа к данным. Услуга менеджера продвижения файловой системы (FSPM) асинхронно продвигает измененные свойства в платформу хранения. Свойства статей File и Directory могут изменяться посредством API Win32. API платформы хранения можно использовать для чтения любых свойств этих статей, включая поток, связанный со статьей File.
(2) Создание файлов и директорий в пространстве имен платформы хранения
После продвижения тома NTFS в том платформы хранения все файлы и директории в нем находятся в особой части этого тома. Эта область предназначена только для чтения с точки зрения платформы хранения; FSPM может создавать новые директории и файлы и/или изменять свойства существующих статей.
Остаток пространства имен этого тома может содержать обычный диапазон типов статей платформы хранения - Principal, Organization, Document, Folder и т.д. Платформа хранения также позволяет создавать файлы и директории в любой части пространства имен платформы хранения. Эти «родные» файлы и директории не имеют эквивалентов в файловой системе NTFS; они целиком хранятся в платформе хранения. Кроме того, изменения свойств видны немедленно.
Однако модель программирования остается такой же: они по прежнему предназначены только для чтения в отношении API доступ к данным платформы хранения. «Родные» файлы и директории должны обновляться с использованием API Win32. Это упрощает ментальную модель разработчика, которая представляет собой:
1. Любой тип статьи платформы хранения можно создать где угодно в пространстве имен (если, конечно, этому не препятствуют права).
2. Любой тип статьи платформы хранения можно читать с использованием API платформы хранения.
3. Все типы статьи платформы хранения записываются с использованием API платформы хранения за исключением File и Directory.
4. Для записи статей File и Directory независимо от того, где они находятся в пространстве имен, используется API Win32.
5. Изменения статей File/Directory в «продвинутом» пространстве имен могут немедленно проявляться в платформе хранения; в «непродвинутом» пространстве имен, изменения немедленно отражаются в платформе хранения.
b) Схема файлов
На фиг.25 показана схема, на которой основан API File.
с) Обзор System.Storage.Files
API платформы хранения включает в себя пространство имен для работы с объектами файлов. Это пространство имен называется System.Storage.Files. Информационные элементы классов в System.Storage.Files непосредственно отражают информацию, хранящуюся в хранилище платформы хранения; эта информация «продвигается» из объектов файловой системы или может быть создана внутренне с использованием API Win32. Пространство имен System.Storage.Files имеет два класса: FileItem и DirectoryItem. Элементы этих классов и их методы легко предсказать, посмотрев на диаграмму схемы на фиг.25. FileItem и DirectoryItem предназначены только для чтения из API платформы хранения. Для их изменения нужно использовать API Win32 или классы в System.IO.
d) Примеры кода
В этом разделе приведены три примера кода, иллюстрирующие использование классов System.Storage.Files.
(1) Открытие файла и запись в него
Этот пример показывает, как производить «традиционные» манипуляции с файлом.
ItemContext ctx = ItemContext.Open();
FileItem f = FileItem.FindByPath(ctx,
@”\My Documents\billg.ppt");
// пример обработки свойств файла - гарантировать, что
// файл не предназначен только для чтения
if (!f.IsReadOnly)
{
FileStream fs = f.OpenWrite();
// Чтение, запись, закрытие потока файла fs
}
ctx.Close();
В строке 3 используется метод FindByPath для открытия файла. В строке 7 показано использование продвинутого свойства, IsReadOnly, для проверки, является ли файл записываемым. Если да, то в строке 9 мы используем метод OpenWrite() на объекте FileItem для получения потока файла.
(2) Использование запросов
Поскольку хранилище платформы хранения поддерживает свойства, продвинутые из файловой системы, на файлах можно легко делать богатые запросы. В этом примере перечислены все файлы, измененные за последние три дня:
// Перечислить все файлы, измененные за последние 3 дня
FindResult result = FileItem. FindAll(
ctx
"Modified >= '{0}'",
DateTime.Now.AddDays(-3));
foreach(FileItem file in result)
{
…
}
Вот другой пример использования запросов - отыскание всех записываемых файлов определенного типа (=расширение):
// Найти все записываемые файлы.cs
// в конкретной директории.
// Эквивалентно: dir c:\win\src\api\*.cs /a-r-d
DirectoryItem dir =
DirectoryItem.FindByPath(ctx, @"c:\win\src\api");
FindResult result = dir.GetFiles(
"Extension='cs' and IsReadOnly=false");
foreach(File file in result)
{
…
}
e) Поведения домена
Согласно одному варианту осуществления, помимо стандартных свойств и методов, класс файлов также имеет поведения домена (прописанные вручную свойства и методы). Эти поведения, в общем случае, базируются на методах в соответствующих классах System.IO.
J. Заключение
Согласно проиллюстрированному выше настоящее изобретение относится к платформе хранения для организации, поиска и совместного использования данных. Платформа хранения настоящего изобретения расширяет понятие хранения данных за пределы существующих файловых систем и систем базы данных и предназначена быть хранилищем для всех типов данных, включая структурированные, неструктурированные или частично структурированные данные, например реляционные (табличные) данные, XML и новую форму данных, так называемые Статьи. Благодаря своей общей основе хранения и схематизированным данным платформа хранения согласно настоящему изобретению позволяет более эффективно разрабатывать приложение для потребителей, специалистов в области информационных технологий и предприятий. Она обеспечивает богатый и расширяемый программный интерфейс приложения, который не только делает доступными возможности, свойственные этой модели данных, но также охватывает и расширяет существующие файловую систему и методы доступа к базе данных. Понятно, что изменения можно производить согласно вышеописанным вариантам осуществления, не выходя за рамки сущности изобретения. Соответственно, настоящее изобретение не ограничивается конкретными раскрытыми вариантами осуществления, но призвано охватывать все модификации, отвечающие сущности и объему изобретения, заданным в прилагаемой формуле изобретения.
Из вышеизложенного следует, что различные системы, способы и аспекты настоящего изобретения могут быть, полностью или частично, реализованы в виде программного кода (например, команд). Этот программный код может храниться на компьютерно-считываемом носителе, например, магнитном, электрическом или оптическом носителе данных, в том числе, без ограничения, флоппи-диске, CD-ROM, CD-RW, DVD-ROM, DVD-RAM, магнитной ленте, флэш-памяти, жестком диске или любом другом машинно-считываемом носителе информации, причем, когда программный код загружается в машину, например, компьютер или сервер, и выполняется на ней, машина становится устройством для практического применения изобретения. Настоящее изобретение также может быть реализовано в виде программного кода, который передается по некоторой среде передачи, например по электрическим проводам или кабелям, по оптическим волокнам, по сети, включая Интернет или интрасеть или посредством любого другого вида передачи, причем, когда программный код поступает и загружается в машину, например компьютер или сервер, и выполняется на ней, машина становится устройством для практического применения изобретения. При реализации на процессоре общего назначения программный код объединяется с процессором для обеспечения уникального устройства, которое действует аналогично специальным логическим схемам.
Приложение А
namespace System.Storage
{
abstract class ItemContext: IDisposable, IServiceProvider
{
Создание ItemContext и управление элементами
// Приложения не могут напрямую создавать объекты
// ItemContext и выводить классы из ItemContext
interal ItemContext();
// Создать ItemContext, который можно использовать
// для поиска по указанным путям или, если ни один
// путь не указан, в хранилище по умолчанию
// на локальном компьютере
public static ItemContext Open();
public static ItemContext Open(string path);
public static ItemContext Open(params string[] paths);
// Возвратить указанные пути, когда ItemContext создан
public string[] GetOpenPaths();
// Создать копию этого ItemContext. Копия будет
// иметь независимую транзакцию, кэширование
// и состояние обновления. Кэш первоначально
// будет пустым. Ожидается, что использование
// клонированного ItemContext будет более
// эффективно, чем открытие нового ItemContext
// с использованием тех же доменов статей.
public ItemContext Clone();
// Закрыть ItemContext. Любая попытка использовать
// ItemContext после закрытия приведет
// к ObjectDisposedException.
public void Close();
void IDisposable.Dispose();
// Истина, если любой домен, указанный, когда
// ItemContext был открыт, разрешался на удаленном
// компьютере.
public bool IsRemote { get; }
// Возвращает объект, который может обеспечивать
// запрашиваемый тип услуги. Возвращает null,
// если запрашиваемая услуга не может быть
// предоставлена. Использование шаблона
// IServiceProvider позволяет выделить API, который
// обычно не используется и может смутить
// разработчиков, из класса ItemContext. ItemContext
// может обеспечивать следующие виды услуг:
// IItemSerialization, IStoreObjectCache
public object GetService(Type serviceType);
Обновление связанных элементов
// Сохраняет изменение, представленные измененными
// объектами и все объекты, переданные MarkForCreate
// или MarkForDelete. Может выбрасывать
// UpdateCollisionException при обнаружении конфликта
// обновлений.
public void Update();
// Сохраняет изменения, представленные указанными
// объектами. Объекты должны либо изменяться, либо
// передаваться MarkForCreate или MarkForDelete, иначе
// выбрасывается ArgumentException. Может выбрасывать
// UpdateCollisionException при обнаружении конфликта
// обновлений.
public void Update(object objectToUpdate);
public void Update(IEnumerable objectsToUpdate);
// Обновляет контент указанных объектов из хранилища.
// Если объект изменен, изменения переписываются, и
// объект больше не считается измененным. Выбрасывает
// ArgumentException, если задано что-либо другое, чем
// объект статьи, расширении статьи или отношения.
public void Refresh(object objectToRefresh);
public void Refresh(IEnumerable objectsToRefresh);
// Возбуждается, если обновление обнаруживает, что
// данные изменились в хранилище между моментами
// извлечения измененного объекта и попытки сохранить
// его. Если ни один описатель события не
// зарегистрирован, обновление выбрасывает исключение.
// Если описатель события зарегистрирован, он может
// выбросить исключение, чтобы прервать обновление,
// заставить измененный объект переписать данные в
// хранилище или соединить изменения, сделанные в
// хранилище и в объекте.
public event ChangeCollisionEventHandler
UpdateCollision;
// Возбуждается в различные моменты в ходе обработки
// обновлений для обеспечения информации о ходе
// обновления
public event UpdateProgressEventhandler UpdateProgress;
// Асинхронные версии Update
public IAsyncResult BeginUpdate(IAsyncCallback
callback, object state);
public IAsyncResult BeginUpdate(object objectToUpdate,
IAsyncCallback callback, object state);
public IAsyncResult BeginUpdate(IEnumerable
objectsToUpdate, IAsyncCallback callback,
object state);
public void EndUpdate(IAsyncResult result);
// Асинхронные версии Refresh
public IAsyncResult BeginRefresh(object
objectToRefresh, IAsyncCallback callback,
object state);
public IAsyncResult BeginRefresh(IEnumerable
objectsToRefresh, IAsyncCallback callback,
object state);
public void EndRefresh(IAsyncResult result);
Элементы, связанные с транзакцией
// Начинает транзакцию с указанного уровня изоляции.
// Уровень изоляции по умолчанию это ReadCommited. Во
// всех случаях, начинается распределенная транзакция,
// поскольку ей может понадобиться охватить свойства
// статьи потокового типа.
public Transaction BeginTransaction();
public Transaction BeginTransaction(
System.Data.IsolationLevel isolationLevel);
Элементы, связанные с поиском
// Создать ItemSearcher, который будет осуществлять
// поиск в этом контексте статьи объектов указанного
//типа. Выбрасывает ArgumentException, если указан тип,
// отличный от статьи, отношения или расширения статьи.
public ItemSearcher GetSearcher(Type type);
// Найти статью по ее ИД.
public Item FindItemById(ItemId itemId);
// Найти статью по данному пути к ней. Путь может быть
// абсолютным или относительным. Если он относительный,
// будет выброшено NotSupportedException, если, когда
// ItemContext был открыт, были заданы множественные
// домены статьи. Возвратит null, если такой статьи не
// существует. Создает соединение с частью
// \\machine\share домена для извлечения статьи. Статья
// будет связана с этим доменом.
public Item FindItemByPath( string path );
// Найти статью по данному пути к ней. Путь относится к
// указанному домену статьи. Создает соединение с
//указанным доменом для извлечения статьи. Статья будет
// связана с этим доменом. Возвратит null, если такой
// статьи не существует.
public Item FindItemByPath(string domain, string path);
// Найти отношение по ее ИД
public Relatioinship FindRelationshipById(ItemId
itemID, RelationshipId relationshipId);
// Найти расширение статьи по ее ИД
public ItemExtension FindItemExtensionById(ItemId
itemId, ItemExtensionId itemExtensionId);
// Найти все статьи, отношения или расширения статьи
// указанного типа, в необязательном порядке
// удовлетворяющие данному фильтру. Выбрасывает
//ArgumentException, если указан тип, отличный от этих.
public FindResult FindAll( Type type );
public FindResult FindAll( Type type, string filter);
// Найти любую статью, отношения или расширения статьи
// указанного типа, которая удовлетворяет данному
// фильтру. Выбрасывает ArgumentException, если указан
// тип, отличный от этих. Возвращает null, если такой
// объект не найден.
public object FindOne(Type type, string filter);
// Найти статью, отношение или расширения статьи
// указанного типа, которая удовлетворяет данному
// фильтру. Выбрасывает ArgumentException, если указан
// тип, отличный от одного из них. Выбрасывает
// MultipleObjectsFoundException, если найдено более
// одного объекта.
public object FindOnly(Type type, string filter);
// Возвращает истину, если статья, отношение или
// расширения статьи указанного типа, которая
// удовлетворяет данному фильтру, существует.
// Выбрасывает ArgumentException, если указан тип,
// отличный от одного из них.
public bool Exists( Type type, string filter );
// Указывает, как объекты, возвращенные в результате
// поиска, относятся к отображению идентификации
// объекта, поддерживаемому ItemContext.
public SearchColllisionMode SearchCollisionMode {
get; set;}
// Возбуждается, когда PreserveModifiedObjects задан
// для ResultMapping. Это событие позволяет приложению
// избирательно обновлять модифицированный объект
// данными, извлеченными посредством поиска.
public event ChangeCollisionEventHandler
SearchCollision;
// Включает объект из другого ItemContext в этот
// контекст статьи. Если объект, представляющий ту же
//самую статью, отношение или расширение статьи, уже не
// существует, это отображение идентификации
// ItemContext, клон объекта создается и добавляется к
// отображению. Если объект существует, он обновляется
// состоянием и контентом указанного объекта в
// соответствии с SearchCollisionMode.
public Item IncorporateItem( Item item );
public Relationship IncorporateRelationship(
Relationship relationship);
public ItemExtension IncorporateItemExtension(
ItemExtension itemExtension);
}
// Описатель для событий ItemContext.UpdateCollision и itemSearcher.SearchColIision
public delegate void ChangeCollisionEventHandler(
object source, ChangeCollisionEventArgs args);
// Аргументы для делегата ChangeCollisionEventHandler
public class ChangeCollisionEventArgs: EventArgs
{
// Измененный объект статьи, расширении статьи или
// отношения
public object ModifiedObject {get;}
// Свойства из хранилища
public IDictionary StoredProperties {get;}
}
// Описатель для ItemContext.UpdateProgress.
public delegate void UpdateProgressEventHandler(
ItemContext itemContext,
UpdateProgressEventArgs args);
// Аргументы для делегата UpdateProgressEventHandler
public class ChangeCollisionEventArgs: EventArgs
{
// Текущая операция обновления
public UpdateOperation CurrentOperation { get; }
// Объект, обновляемый в данный момент
public object CurrentObject { get;}
}
//Указывает, как объекты, возвращенные в результате поиска,
// относятся к отображению идентификации объектов,
// поддерживаемому ItemContext.
public enum SearchCollisionMode
{
// Указывает, как следует создавать и возвращать новые
//объекты. Объекты, представляющие одну и ту же статью,
// расширение статьи или отношение в отображении
// идентификации игнорируются. Если эта опция задана,
// событие SearchCollision не будет возбуждаться.
DoNotMapSearchResults,
// Указывает, что объекты из отображения идентификации
// должны быть возвращены. Если контент объекта был
// изменен приложением, измененный контент объекта
//сохраняется. Если объект не был изменен, этот контент
//обновляется данными, возвращенными в результате
// поиска. Приложение может обеспечивать описатель для
// события SearchCollision и избирательно обновлять
// нужный объект.
PreserveModifiedObjects,
// Указывает, что объекты из отображения идентификации
// должны быть возвращены. Контент объекта обновляется
//данными, возвращенными в результате поиска, даже если
// объект был изменен приложением. Если эта опция
// задана, событие SearchCollision не будет
// возбуждаться.
OverwriteModifiedObjects
}
// Текущая операция обновления
public enum UpdateOperation
{
//Обеспечивается при первом вызове Update.
// CurrentObject будет null.
OverallUpdateStarting,
// Обеспечивается непосредственно перед тем, как Update
// возвращает после успешного обновления. CurrentObject
// будет null.
OverallUpdateCompletedSucessfully,
// Обеспечивается непосредственно перед тем, как Update
// выбрасывает исключение. CurrentObject будет объектом исключения.
OverallUpdateCompletedUnsuccessfully,
// Обеспечивается, когда начинается обновление объекта.
// CurrentObject будет ссылаться на объект, который
// будет использоваться для обновления.
ObjectUpdateStaring,
// Обеспечивается, когда необходимо новое соединение.
// CurrentObject будет строкой, которая содержит путь,
// идентифицирующий домен статьи, передаваемую
// ItemContext.Open или извлекаемую из поля Location
// отношения.
OpeningConnection
}
}Приложение В
namespace System.Storage
{
// Выполняет поиск по конкретному типу в контексте статьи.
public class ItemSearcher
{
Конструкторы:
public ItemSearcher();
public ItemSearcher(Type targetType,
ItemContext context);
public ItemSearcher(Type targetType,
ItemContext context,
params SearchExpression[] filters);
Свойства:
//Фильтры, используемые для идентификации совпадающих
// объектов.
public SearchExpressionCollection Filters {get;}
// ItemContext, который указывает домены, в которых
// будет производиться поиск.
public ItemContext ItemContext {get; set;}
// Коллекция параметров поиска.
public ParameterCollection Parameters {get;}
// Тип, с которым будет работать механизм поиска.
// Для простых механизмов поиска это тип объекта,
// который будет возвращен.
public Type TargetType {get; set;}
Методы поиска
// Найти объекты TargetType, которые удовлетворяют
// условиям, указанным фильтрами. Возвращает пустой
// FindResult, если таких объектов не существует.
public FindResult FindAll();
public FindResult FindAll(FindOptions findOptions);
public FindResult FindAll(params SortOption[]
sortOptions);
// Найти любой один объект TargetType, который
// удовлетворяет условиям, указанным фильтрами.
// Возвращает null, если такого объекта не существует.
public object FindOne();
public object FindOne(FindOptions findOptions);
public object FindOne(params SortOption[]
sortOptions);
// Найти объект TargetType, который удовлетворяет
// условиям, указанным фильтрами. Выбрасывает
// ObjectNotFoundException, если такой объект
// не найден.
public object FindOnly();
public object FindOnly(FindOptions findOptions);
// Определить, существует ли объект TargetType, который
// удовлетворяет условиям, указанным фильтрами.
public bool Exists();
//Создает объект, который можно использовать для более
// эффективного выполнения того же поиска повторно.
public PreparedFind PrepareFind();
public PreparedFind PrepareFind(FindOptions
findOptions);
public PreparedFind PrepareFind(params SortOption[]
sortOptions);
// Извлекает количество записей, которые будут
// возвращены FindAll().
public int GetCount();
// Асинхронные версии различных методов
public IAsyncResult BeginFindAll(AsyncCallback
callback, object state);
public IAsyncResult BeginFindAll(FindOptions
findOptions, AsyncCallback callback,
object state);
public IAsyncResult BeginFindAll(SortOption[]
sortOptions, AsyncCallback callback,
object state);
public FindResult EndFindAll(IAsyncResult ar);
public IAsyncResult BeginFindOne(AsyncCallback
callback, object state);
public IAsyncResult BeginFindOne(FindOptions
findOptions, AsyncCallback callback,
object state);
public IAsyncResult BeginFindOne(SortOption[]
sortOptions, AsyncCallback callback,
object state);
public object EndFindOne(IAsyncResult asyncResult);
public IAsyncResult BeginFindOnly(AsyncCallback
callback, object state);
public IAsyncResult BeginFindOnly(FindOptions
findOptions, AsyncCallback callback,
object state);
public IAsyncResult BeginFindOnly(SortOption[]
sortOptions, AsyncCallback callback,
object state);
public object EndFindOnly( IAsyncResult asyncResult);
public IAsyncResult BeginGetCount(AsyncCallback
callback, object state);
public int EndGetCount( IAsyncResult asyncResult);
public IAsyncResult BeginExists(AsyncCallback callback,
object state);
public bool EndExists(IAsyncResult asyncResult);
}
//Опции, используемые при выполнении поиска.
public class FindOptions
{
public FindOptions();
public FindOptions(params SortOption[] sortOptions);
// Указывает, должны ли загружаться с задержкой поля,
// загружаемые с задержкой.
public bool DelayLoad {get; set;}
// Количество возвращаемых совпадений
public int MaxResults {get; set;}
// Коллекция опций сортировки
public SortOptionCollection SortOptions {get;}
}
// Представляет имя и значение параметра.
public class Parameter
{
// Инициализирует объект Parameter именем и значением.
public Parameter(string name, object value);
// Имя параметра
public string Name {get;}
// Значение параметра
public object Value {get; set;}
}
//Коллекция пар имя/значение параметра
public class ParameterCollection: (Collection
{
public ParameterCollection();
public int Count {get;}
public object this[string name] {get; set;}
public object SyncRoot {get;}
public void Add(Parameter parameter);
public Parameter Add(string name, object value);
public bool Contains(Parameter parameter);
public bool Contains(string name);
public void CopyTo(Parameter[] array, int index);
void ICollection.CopyTo(Array array, int index);
IEnumerator IEnumerable.GetEnumerator();
public void Remove(Parameter parameter);
public void Remove(string name);
}
// Представляет поиск, оптимизированный для повторного
// выполнения
public class PreparedFind
{
public ItemContext ItemContext {get;}
public ParameterCollection Parameters {get;}
public FindResult FindAll();
public object FindOne();
public object FindOnly();
public bool Exists();
}
// Указывает опции сортировки, используемые в поиске.
public class SortOption
{
// Инициализирует объект значениями по умолчанию.
public SortOption();
// Инициализирует объект SortOptions посредством
// SearchExpression, order.
public SortOption(SearchExpression searchExpression,
SortOrder order);
// SearchExpression поиска, который идентифицирует
// свойство, по которому будет производиться
// сортировка.
public SearchExpression Expression {get; set;}
// Указывает возрастающий или убывающий порядок
// сортировки
public SortOrder Order {get; set;}
}
// Коллекция объектов опций сортировки
public class SortOptionCollection: IList
{
public SortOptionCollection();
public SortOption this[int index] {get; set;}
public int Add(SortOption value);
public int Add(SearchExpression expression,
SortOrder order);
int IList.Add(object value);
public void Clear();
public bool Contains(SortOption value);
bool IList.Contains(object value);
public void CopyTo(SortOption[] array, int index);
void ICollection.CopyTo(Array array, int index);
public int Count {get;}
IEnumerator IEnumerable.GetEnumerator();
public void Insert(int index, SortOption value);
void IList.Insert(int index, object value);
public int IndexOf(SortOption value);
int IList.IndexOf(object value);
public void Remove(SortOption value);
void IList.Remove(object value);
public void RemoveAt(int index);
public object SyncRoot {get;}
}
// Указывает порядок сортировки с использованием объекта
// SortOption
public enum SortOrder
{
Ascending,
Descending
}
}Приложение С
namespace System.Storage
{
public abstract class FindResult: IAsyncObjectReader
{
public FindResult();
// Перемещает FindResult в следующую позицию
// в результате.
public bool Read();
public IAsyncResult BeginRead(AsyncCallback callback,
object state);
public bool EndRead(IAsyncResult asyncResult);
// Текущий объект.
public object Current {get;}
// Возвращает, содержит ли FindResult какие-либо
// объекты.
public bool HasResults {get;}
// Возвращает, закрыт ли FindResult
public bool IsClosed {get;}
// Возвращает тип статей этого FindResult
public Type ObjectType {get;}
// Закрывает FindResult
public void Closed;
void IDisposable.Dispose();
//Возвращает перечислитель над FindResult, начинающийся
// с текущей позиции. Продвигает любой перечислитель,
// когда FindResult продвигает все перечислители,
// а также сам FindResult.
IEnumerator IEnumerable.GetEnumerator();
public FindResultEnumerator GetEnumerator();
}
public abstract class FindResultEnumerator: (Enumerator,
IDisposable
{
public abstract object Current {get;}
public abstract bool MoveNext();
public abstract void Reset();
public abstract void Close();
void IDisposable.Dispose();
}
}
namespace System
{
//Общий интерфейс для итерации по объектам.
public interface IObjectReader: IEnumerable, IDisposable
{
object Current {get;}
bool IsClosed {get;}
bool HasResults {get;}
Type ObjectType {get;}
bool Read();
void Close();
}
// Добавляет асинхронные методы в IObjectReader.
public interface IAsyncObjectReader: IObjectReader
{
IAsyncResult BeginRead(AsyncCallback callback,
object state);
bool EndRead(IAsyncResult result);
}
}
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ УСЛУГ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ АППАРАТНОЙ/ПРОГРАММНОЙ ИНТЕРФЕЙСНОЙ СИСТЕМОЙ | 2004 |
|
RU2377646C2 |
| СИСТЕМЫ И СПОСОБЫ РАСШИРЕНИЙ И НАСЛЕДОВАНИЯ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО-ПРОГРАММНОГО ИНТЕРФЕЙСА | 2004 |
|
RU2412475C2 |
| БЕЗОПАСНОСТЬ В ПРИЛОЖЕНИЯХ СИНХРОНИЗАЦИИ РАВНОПРАВНЫХ УЗЛОВ | 2006 |
|
RU2421799C2 |
| СПОСОБЫ РАЗВЕРТЫВАНИЯ И СВЕРТЫВАНИЯ ДЛЯ ОБЕСПЕЧЕНИЯ УПРАВЛЕНИЯ СВОЙСТВАМИ ФАЙЛОВ МЕЖДУ СИСТЕМАМИ ОБЪЕКТОВ | 2004 |
|
RU2348973C2 |
| СИСТЕМА И СПОСОБ ПРЕДСТАВЛЕНИЯ ДЛЯ ПОЛЬЗОВАТЕЛЯ ВЗАИМОСВЯЗАННЫХ ЭЛЕМЕНТОВ | 2004 |
|
RU2358312C2 |
| ИНТЕРФЕЙС ПРИКЛАДНОГО ПРОГРАММИРОВАНИЯ ХРАНИЛИЩА ДЛЯ ОБЩЕЙ ПЛАТФОРМЫ ДАННЫХ | 2006 |
|
RU2408061C2 |
| ОТОБРАЖЕНИЕ МОДЕЛИ ФАЙЛОВОЙ СИСТЕМЫ В ОБЪЕКТ БАЗЫ ДАННЫХ | 2006 |
|
RU2409847C2 |
| СИСТЕМА И СПОСОБЫ ОБЕСПЕЧЕНИЯ УЛУЧШЕННОЙ МОДЕЛИ БЕЗОПАСНОСТИ | 2004 |
|
RU2564850C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |

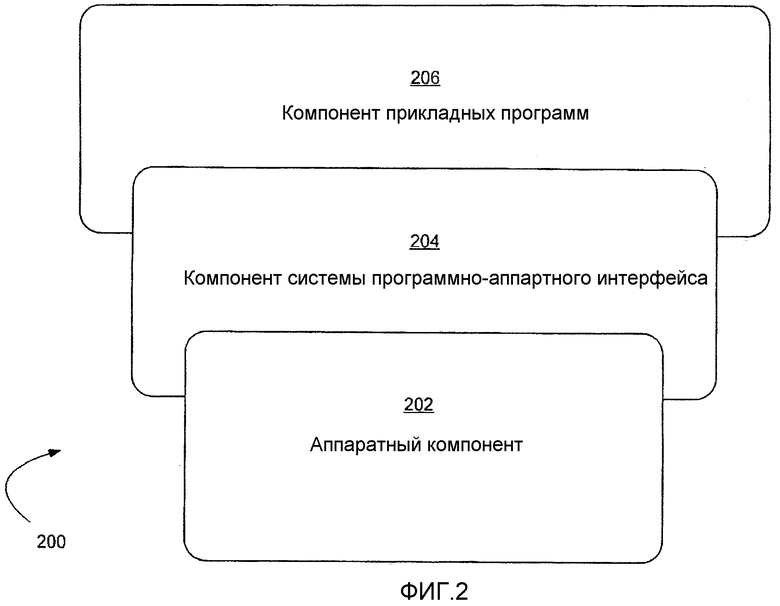

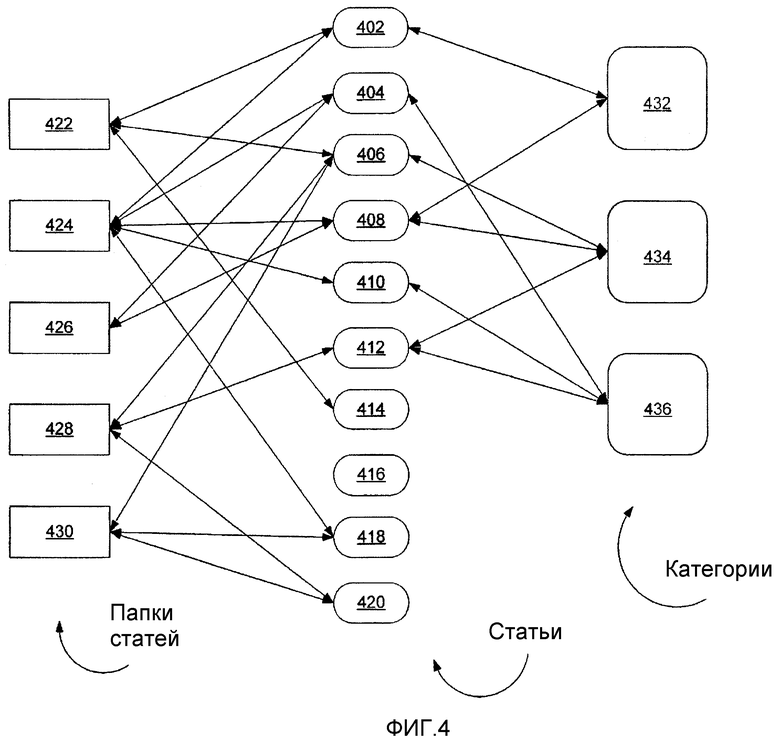
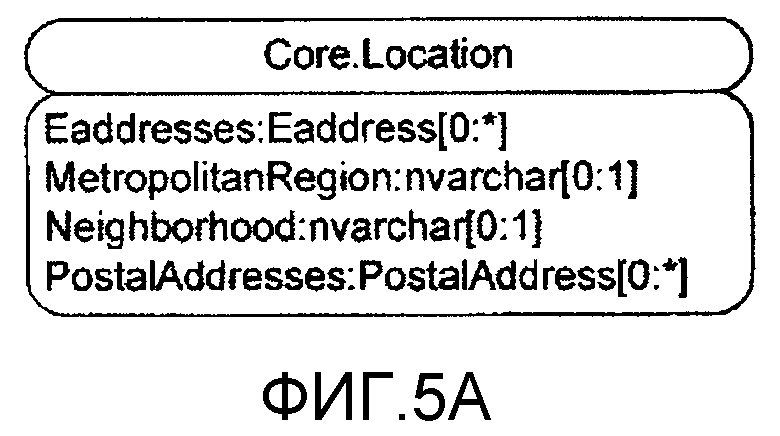


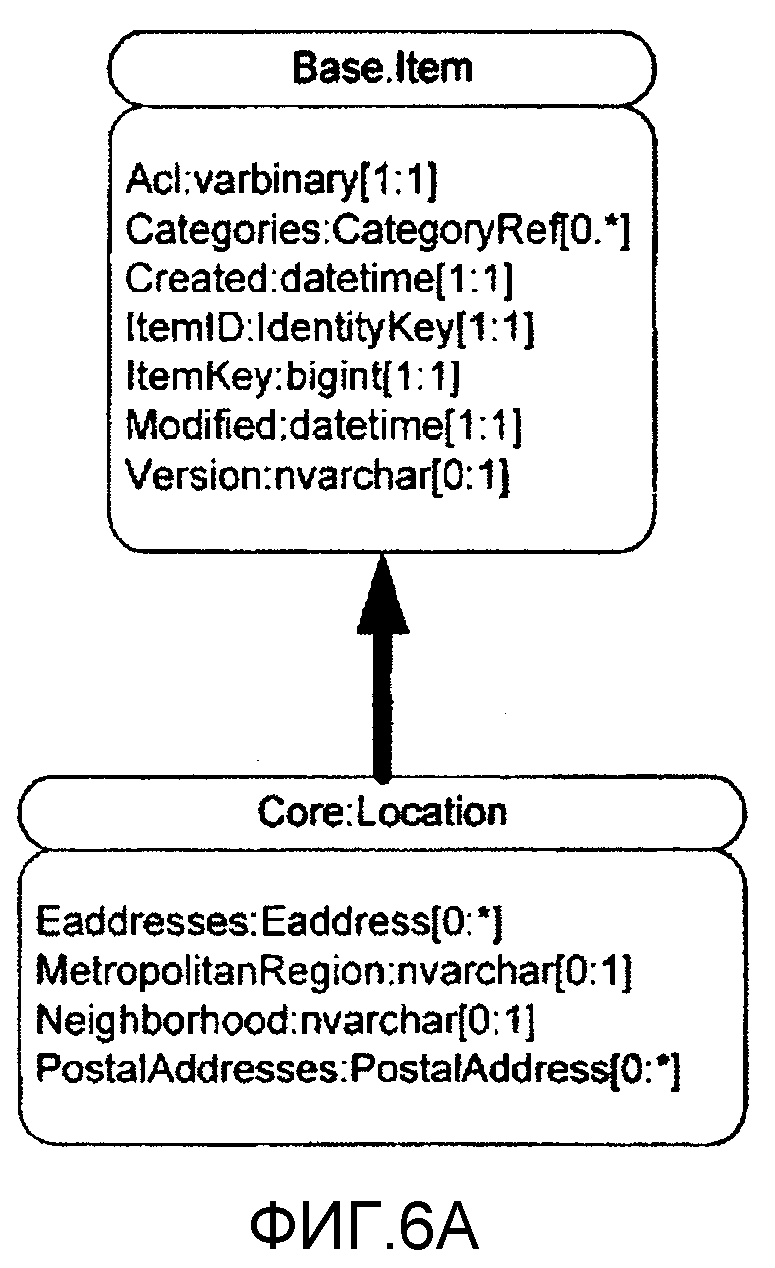
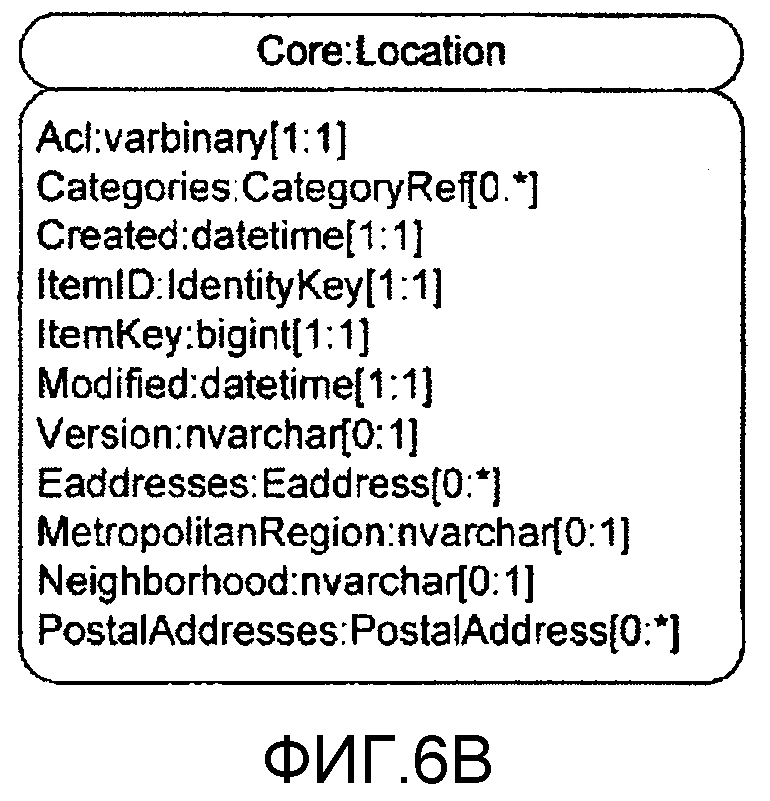
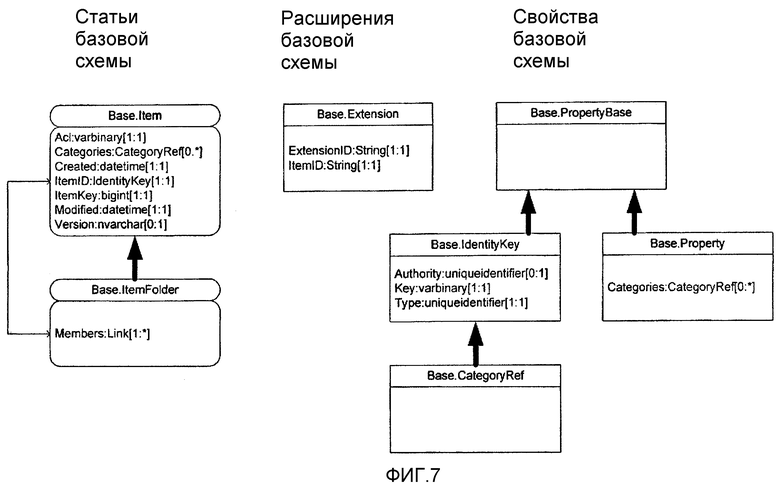
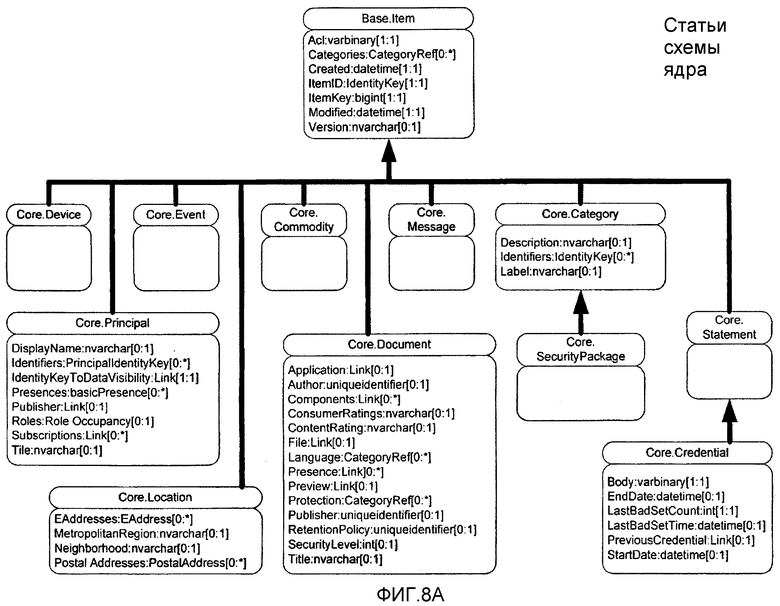
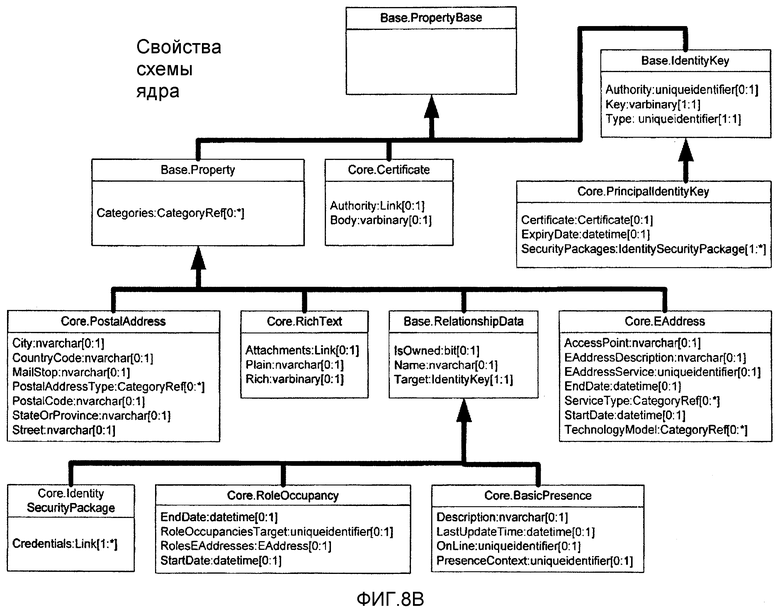
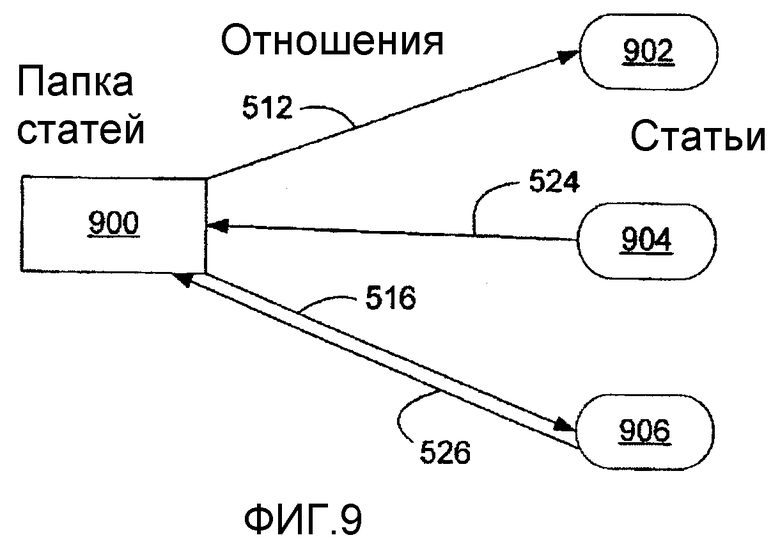
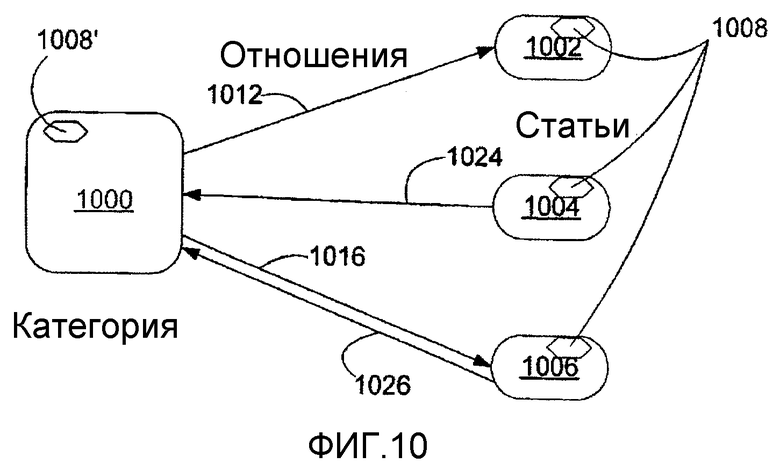

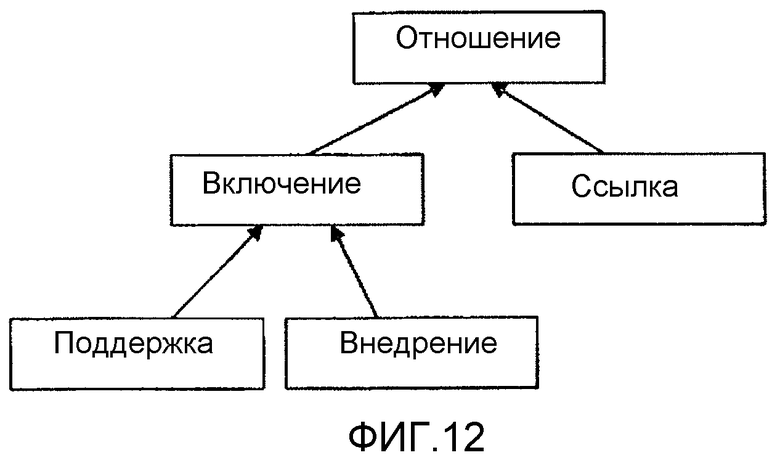
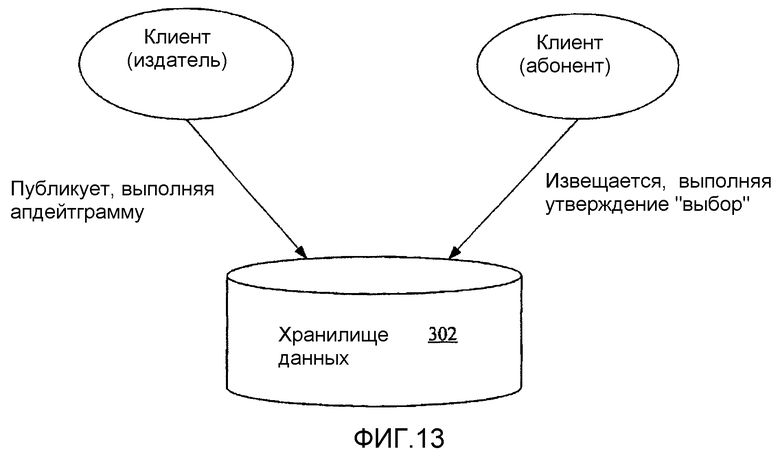
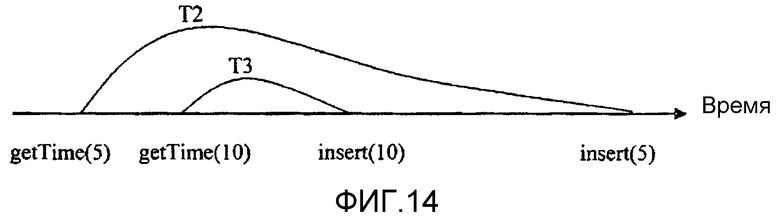
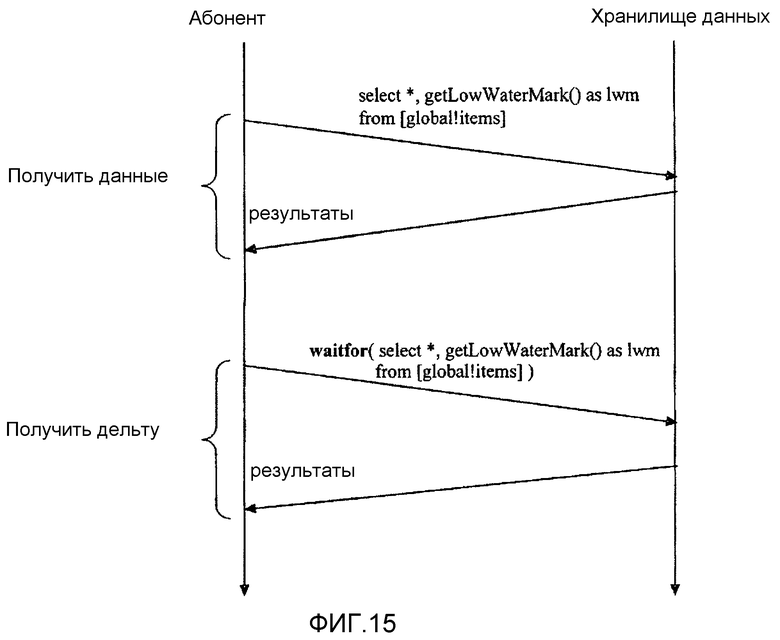
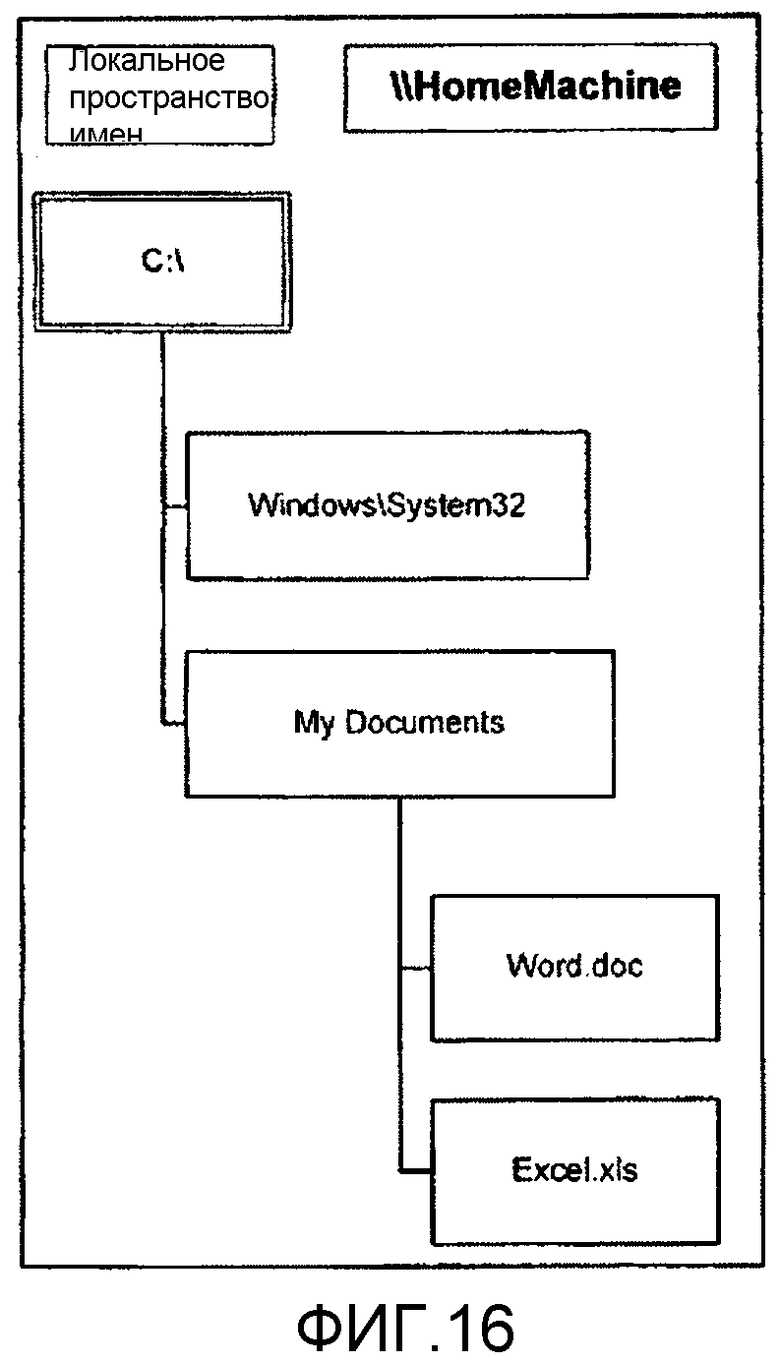
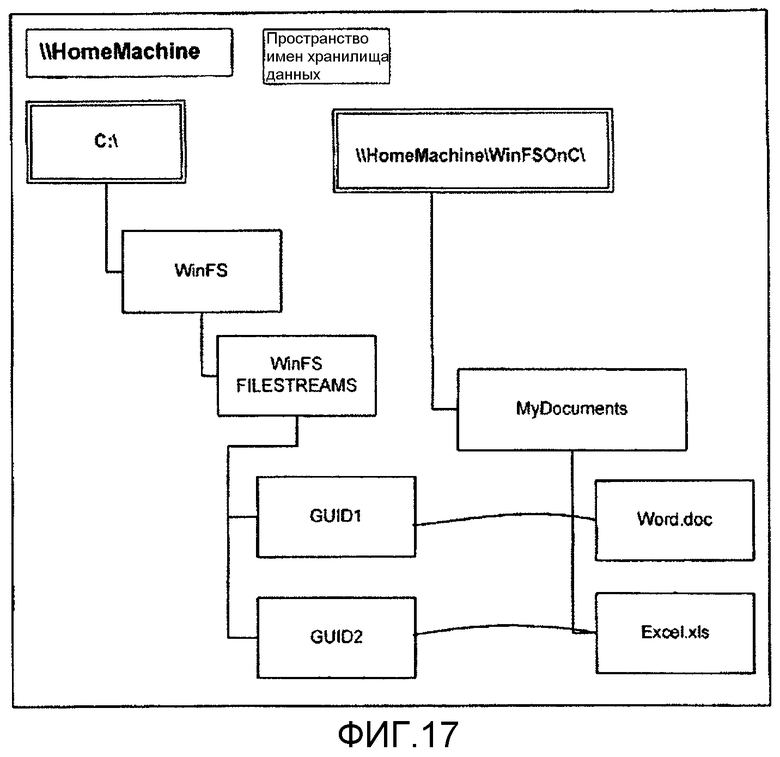
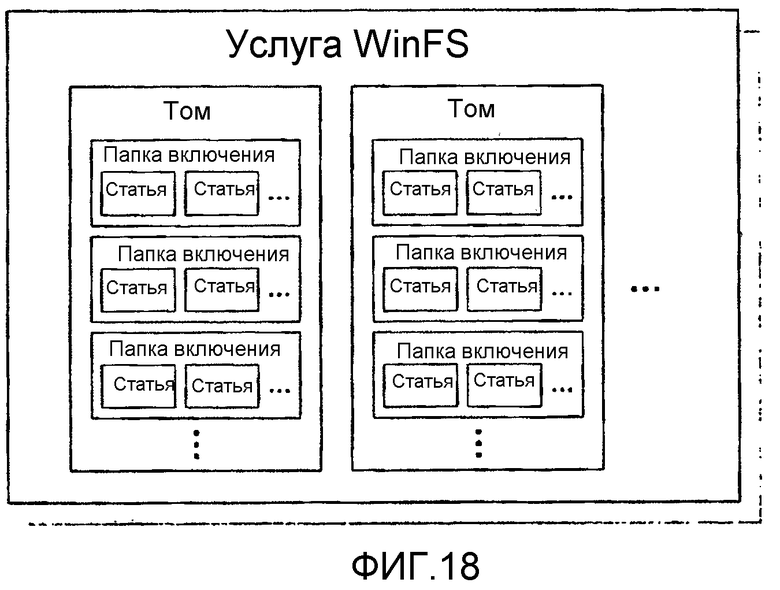

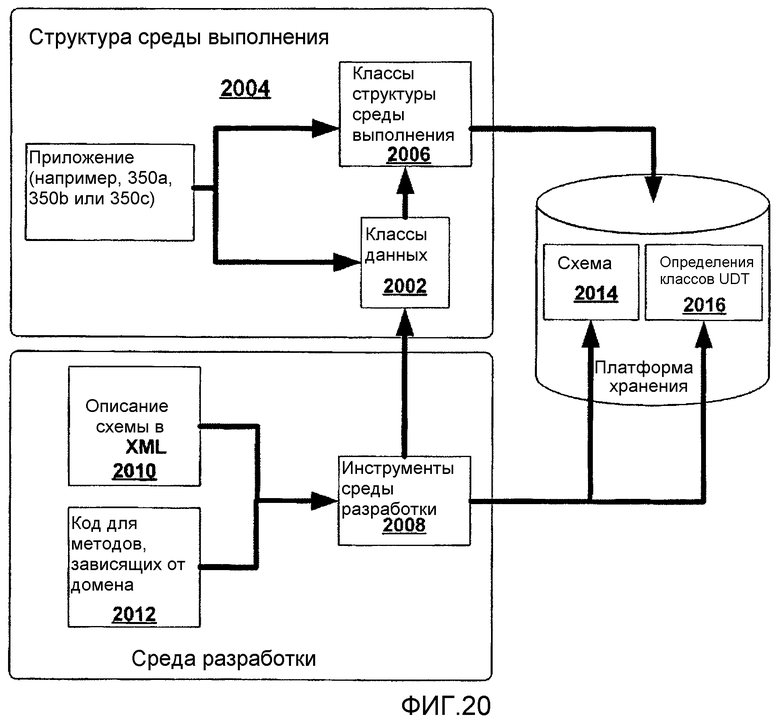

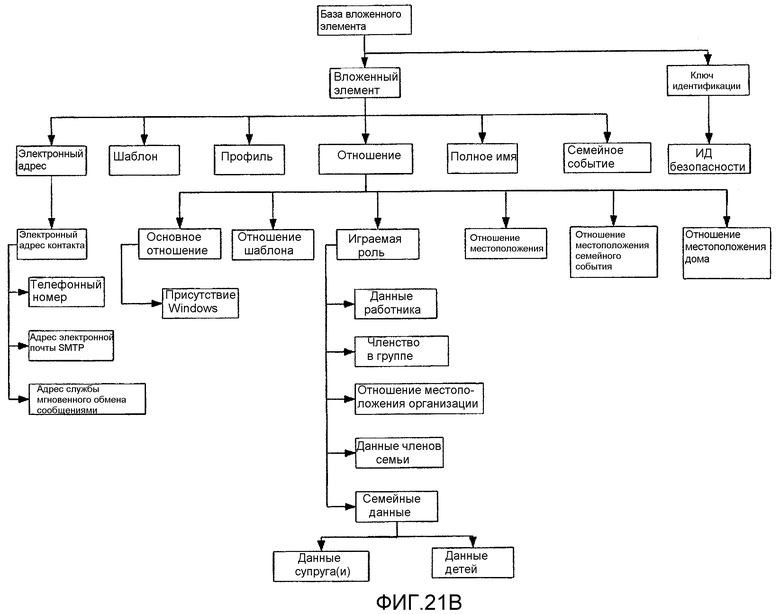

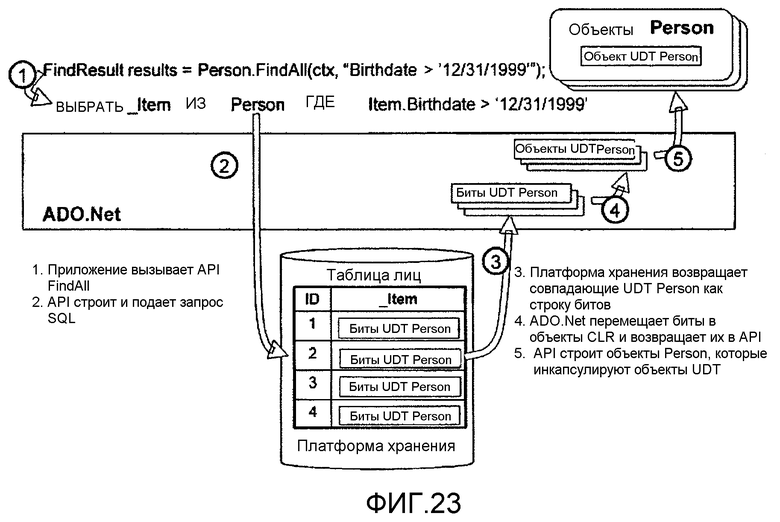
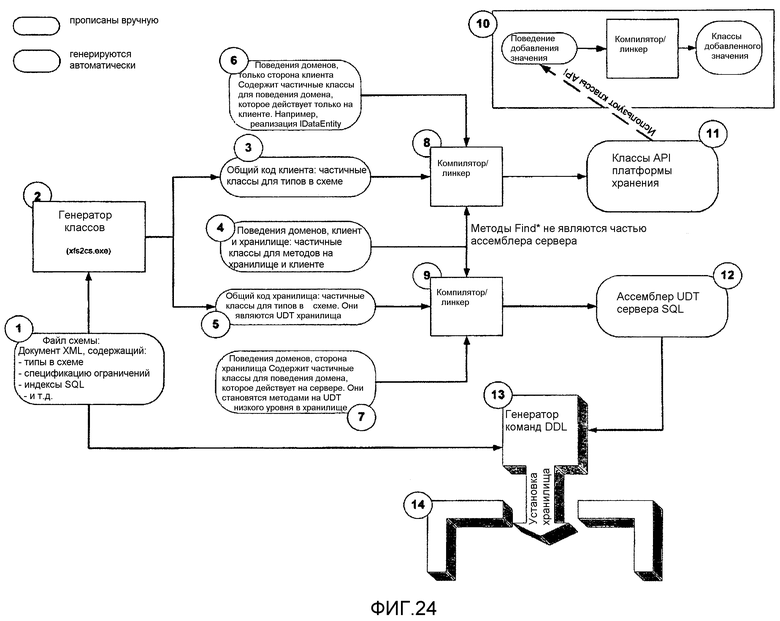

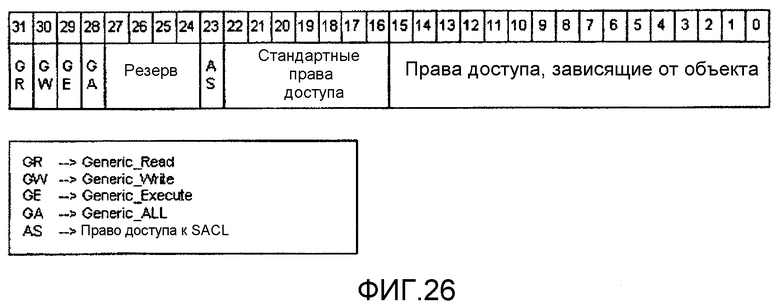
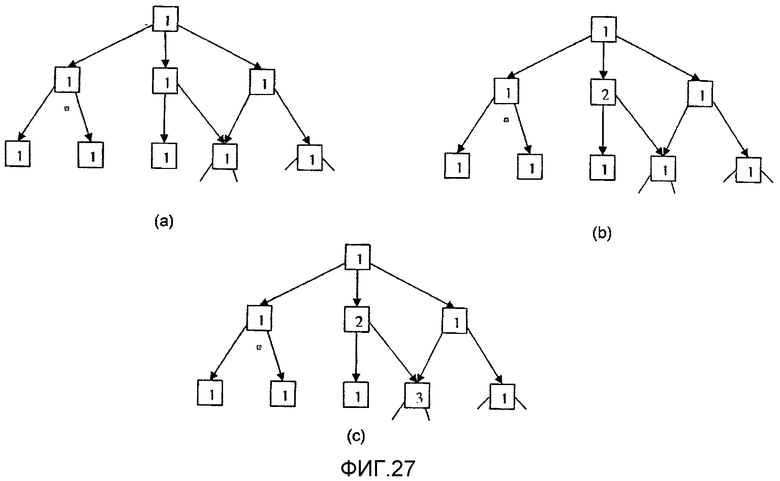
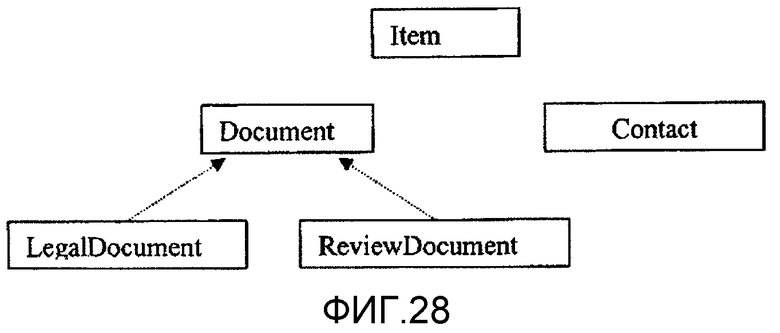
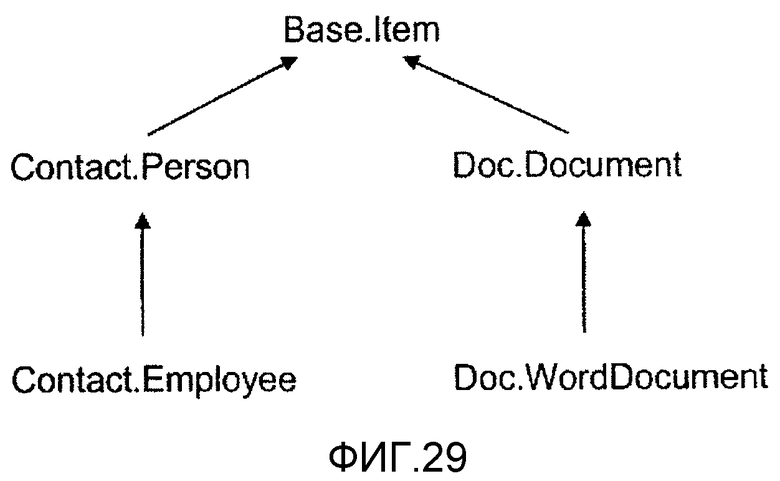
Изобретение относится к области информационных технологий, в частности к платформе хранения информации. Технический результат заключается в увеличении быстродействия доступа к хранилищу данных. Платформа хранения включает: процессор и считываемый компьютером носитель данных, содержащий записанные на нем инструкции, реализующие компьютером функции операционной системы, содержащей ядро, включающее средства управления базами данных, генерации элементов, включающих в себя метаданные и сохранения элементов, при этом средства управления базами данных содержат базовую схему и механизм, выполненный с возможностью расширения упомянутой базовой схемы для определения схемы для данных и разделения данных на программно определенные элементы изменения, основываясь на схеме для данных, причем элемент изменения представляет собой наименьшую часть схемы, которая может быть индивидуально отслежена средствами управления базами данных. 3 н. и 13 з.п. ф-лы, 35 ил.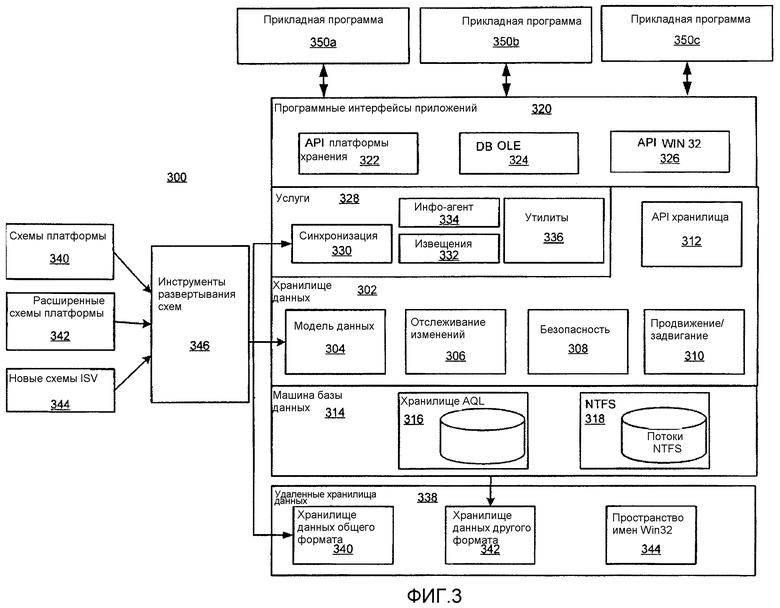
1. Платформа хранения, включающая в себя процессор и считываемый компьютером носитель данных, содержащий записанные на нем инструкции, которые, при выполнении их компьютером, приводят к реализации упомянутым компьютером функций операционной системы, при этом упомянутая операционная система содержит ядро, включающее в себя программные средства управления базами данных, выполненные с возможностью сохранения данных в упомянутой файловой системе в виде потоков файлов, генерации элементов, включающих в себя метаданные для упомянутых потоков файлов, и сохранения упомянутых элементов с помощью упомянутых программных средств управления базами данных, при этом упомянутые программные средства управления базами данных содержат базовую схему и механизм, выполненный с возможностью расширения упомянутой базовой схемы для определения схемы для упомянутых данных и разделения упомянутых данных на программно определенные элементы изменения, основываясь на упомянутой схеме для упомянутых данных, причем упомянутый элемент изменения представляет собой наименьшую часть схемы, которая может быть индивидуально отслежена упомянутыми программными средствами управления базами данных, при этом размер элемента изменения является регулируемым;
упомянутая операционная система дополнительно включает в себя подсистему синхронизации, выполненную с возможностью синхронизации упомянутых данных, сохраненных с помощью упомянутых программных средств управления базами данных, с удаленным компьютером, основываясь на изменениях, которые являются последовательно пронумерованными и отслеживаются в отношении каждого элемента изменения;
при этом
упомянутые данные заданы в терминах статей, элементов и отношений, при этом статья является единицей данных, сохраняемой в хранилище данных, и содержит один или более элементов, причем элемент представляет собой экземпляр типа, содержащий одно или более полей, и отношение представляет собой связь между, по меньшей мере, двумя статьями,
множество схем, которые задают разные типы статей, элементов и отношений, и
программный интерфейс приложения, содержащий класс для каждой из различных статей, элементов и отношений, заданных в множестве схем.
2. Платформа хранения по п.1, в которой данные также могут храниться в хранилище данных в виде расширения к существующему типу статьи, и в которой программный интерфейс приложения содержит класс для каждого отдельного расширения статьи.
3. Платформа хранения по п.1, в которой класс для каждого типа статьи, элемента и отношения генерируется автоматически на основании множества схем, которые задают каждый тип статьи, элемента и отношения.
4. Платформа хранения по п.1, в которой классы для каждого типа статьи, элемента и отношения задают множество классов данных, и в которой программный интерфейс приложения дополнительно содержит второе множество классов, которые задают общее множество поведений для классов данных.
5. Платформа хранения по п.4, в которой второе множество классов содержит первый класс, который представляет область действия платформы хранения и который обеспечивает контекст для запросов на хранилище данных, и второй класс, который представляет результаты запроса на хранилище данных.
6. Платформа хранения по п.1, дополнительно содержащая машину базы данных, на которой реализовано хранилище данных, и в которой разные типы статей, элементов и отношений в хранилище данных реализованы в машине базы данных как типы, заданные пользователем (UDT).
7. Платформа хранения по п.6, в которой программный интерфейс приложения обеспечивает модель запроса, которая позволяет разработчикам прикладных программ формировать запросы на основании различных свойств статей в хранилище данных, таким образом, чтобы разработчик прикладной программы был изолирован от деталей языка запросов машины базы данных.
8. Способ обеспечения программного интерфейса приложения между прикладной программой и платформой хранения для хранения, организации, совместного использования и поиска данных, причем платформа хранения содержит хранилище данных, в котором данные, хранящиеся в нем, заданы в терминах статей, элементов и отношений, при этом статья является единицей данных, сохраняемой в хранилище данных, и содержит один или более элементов, причем элемент представляет собой экземпляр типа, содержащий одно или более полей, и отношение представляет собой связь между, по меньшей мере, двумя статьями, способ содержит этапы, на которых
обеспечивают множество схем, которые задают разные типы статей, элементов и отношений, и
генерируют, как часть программного интерфейса приложения, класс для каждой из различных статей, элементов и отношений, заданных во множестве схем;
при этом платформа хранения включает в себя процессор и считываемый компьютером носитель данных, содержащий записанные на нем инструкции, которые при выполнении их компьютером приводят к реализации упомянутым компьютером функций операционной системы, при этом упомянутая операционная система содержит ядро, включающее в себя программные средства управления базами данных, причем упомянутые программные средства управления базами данных выполнены с возможностью сохранения данных в упомянутой файловой системе в виде потоков файлов, генерации элементов, включающих в себя метаданные для упомянутых потоков файлов, и сохранения упомянутых элементов с помощью упомянутых программных средств управления базами данных, при этом упомянутые программные средства управления базами данных содержат базовую схему и механизм, выполненный с возможностью расширения упомянутой базовой схемы для определения схемы для упомянутых данных и разделения упомянутых данных на программно определенные элементы изменения, основываясь на упомянутой схеме для упомянутых данных, причем упомянутый элемент изменения представляет собой наименьшую часть схемы, которая может быть индивидуально отслежена упомянутыми программными средствами управления базами данных, при этом размер элемента изменения является регулируемым;
упомянутая операционная система дополнительно включает в себя подсистему синхронизации, выполненную с возможностью синхронизации упомянутых данных, сохраненных с помощью упомянутых программных средств управления базами данных, с удаленным компьютером, основываясь на изменениях, которые являются последовательно пронумерованными и отслеживаются в отношении каждого элемента изменения.
9. Способ по п.8, в котором данные также могут храниться в хранилище данных в виде расширения к существующему типу статьи и в котором способ дополнительно содержит генерацию класса для каждого отдельного расширения статьи.
10. Способ по п.9, в котором сгенерированные классы для каждого типа статьи, элемента и отношения задают множество классов данных, и в котором способ дополнительно содержит этап, на котором обеспечивают, как дополнительную часть программного интерфейса приложения, второе множество классов, которые задают общее множество поведений для классов данных.
11. Способ по п.10, в котором второе множество классов содержит первый класс, который представляет область действия платформы хранения и который обеспечивает контекст для запросов на хранилище данных, и второй класс, который представляет результаты запроса на хранилище данных.
12. Способ по п.8, в котором хранилище данных платформы хранения реализовано на машине базы данных и в котором способ дополнительно содержит этап, на котором реализуют разные типы статей, элементов и отношений в хранилище данных как типы, заданные пользователем, (UDT) в машине базы данных.
13. Компьютерная система, содержащая процессор и компьютерочитаемый носитель информации, содержащий инструкции, хранимые на нем, которые при исполнении процессором побуждают процессор реализовать программный интерфейс приложения, операционную систему и хранилище данных, при этом хранилище данных сконфигурировано для хранения данных, заданных в терминах статей, элементов и отношений, в которой статья является единицей данных, сохраняемой в хранилище данных, и содержит один или более элементов, причем элемент представляет собой экземпляр типа, содержащий одно или более полей, и отношение представляет собой связь между, по меньшей мере, двумя статьями, причем программный интерфейс приложения, включает в себя классы данных, представляющие элемент платформы хранения и типы статей, структуру среды выполнения, сконфигурированную для регулирования живучести объекта и обеспечения классов поддержки и инструменты, сконфигурированные
для генерации классов CLR из схем платформы хранения,
при этом упомянутая операционная система включает в себя ядро, включающее в себя программные средства управления базами данных, для сохранения данных в упомянутой файловой системе в виде потоков файлов, генерации элементов, включающих в себя метаданные для упомянутых потоков файлов, и сохранения упомянутых элементов с помощью упомянутых программных средств управления базами данных, при этом упомянутые программные средства управления базами данных содержат базовую схему и механизм, выполненный с возможностью расширения упомянутой базовой схемы для определения схемы для упомянутых данных и разделения упомянутых данных на программно определенные элементы изменения, основываясь на упомянутой схеме для упомянутых данных, причем упомянутый элемент изменения представляет собой наименьшую часть схемы, которая может быть индивидуально отслежена упомянутыми программными средствами управления базами данных, и размер элемента изменения является регулируемым;
упомянутая операционная система дополнительно включает в себя подсистему синхронизации, выполненную с возможностью синхронизации упомянутых данных, сохраненных с помощью упомянутых программных средств управления базами данных, с удаленным компьютером, основываясь на изменениях, которые являются последовательно пронумерованными и отслеживаются в отношении каждого элемента изменения.
14. Компьютерная система по п.13, в котором данные также могут храниться в хранилище данных в виде расширения к существующему типу статьи, и в котором программный интерфейс приложения дополнительно содержит класс для каждого отдельного расширения статьи.
15. Компьютерная система по п.13, в которой классы для каждого типа статьи, элемента и отношения задают множество классов данных, и в которой программный интерфейс приложения дополнительно содержит второе множество классов, которые задают общее множество поведений для классов данных.
16. Компьютерная система по п.15, в которой второе множество классов содержит первый класс, который представляет область действия платформы хранения и который обеспечивает контекст для запросов на хранилище данных, и второй класс, который представляет результаты запроса на хранилище данных.
| СИСТЕМА ТЕСТИРОВАНИЯ "ТЕЛЕТЕСТИНГ" | 1998 |
|
RU2186423C2 |
| US 5630069, 13.05.1997 | |||
| US 6112024 А, 29.08.2000 | |||
| US 6370541 В1, 09.04.2002 | |||
| US 6047291 A, 04.04.2000. | |||

