Перекрестные ссылки на родственные заявки
Данная заявка испрашивает приоритет патентной заявки США № 10/693,574 (реестр поверенного № MSFT-2847), поданной 24 октября 2003 г., на «СИСТЕМЫ И СПОСОБЫ РАСШИРЕНИЙ И НАСЛЕДОВАНИЯ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО-ПРОГРАММНОГО ИНТЕРФЕЙСА»; патентной заявки США № 10/646,580 (реестр поверенного № MSFT-2735), поданной 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ МОДЕЛИРОВАНИЯ ДАННЫХ В ПЛАТФОРМЕ ХРАНЕНИЯ НА ОСНОВЕ ЭЛЕМЕНТОВ ДАННЫХ»; и Международной патентной заявки № PCT/US 03/26144 (реестр поверенного № MSFT-2779), поданной 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ МОДЕЛИРОВАНИЯ ДАННЫХ В ПЛАТФОРМЕ ХРАНЕНИЯ НА ОСНОВЕ ЭЛЕМЕНТОВ ДАННЫХ»; содержание которых включено в данное описание изобретения посредством ссылки.
Заявка относится к сущности изобретений, раскрытых в следующих совместно переуступленных заявках, содержание которых включено посредством ссылки в настоящую заявку во всей полноте (и частично суммировано здесь для удобства): патентная заявка США № 10/647,058 (реестр поверенного № MSFT-1748), поданная 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ ПРЕДСТАВЛЕНИЯ БЛОКОВ ИНФОРМАЦИИ ПОД УПРАВЛЕНИЕМ СИСТЕМЫ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА, НО НЕЗАВИСИМО ОТ ФИЗИЧЕСКОГО ПРЕДСТАВЛЕНИЯ»; патентная заявка США № 10/646,941 (реестр поверенного № MSFT-1749), поданная 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ ОТДЕЛЕНИЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА, ОТ ИХ ФИЗИЧЕСКОЙ ОРГАНИЗАЦИИ»; патентная заявка США № 10/646,940 (реестр поверенного № MSFT-1750), поданная 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ РЕАЛИЗАЦИИ БАЗОВОЙ СХЕМЫ ДЛЯ ОРГАНИЗАЦИИ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА»; патентная заявка США № 10/646,632 (реестр поверенного № MSFT-1751), поданная 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ РЕАЛИЗАЦИИ СХЕМЫ ЯДРА ДЛЯ ОБЕСПЕЧЕНИЯ СТРУКТУРЫ ВЕРХНЕГО УРОВНЯ ДЛЯ ОРГАНИЗАЦИИ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА»; патентная заявка США № 10/646,645 (реестр поверенного № MSFT-1752), поданная 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ ОТНОШЕНИЙ МЕЖДУ БЛОКАМИ ИНФОРМАЦИИ, УПРАВЛЯЕМЫМИ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА»; патентная заявка США № 10/646,575 (реестр поверенного № MSFT-2733), поданная 21 августа 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ ВЗАИМОДЕЙСТВИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ ЭЛЕМЕНТОВ ДАННЫХ»; патентная заявка США № 10/646,646 (реестр поверенного № MSFT-2734), поданная 21 августа 2003 г., на «ПЛАТФОРМУ ХРАНЕНИЯ ДЛЯ ОРГАНИЗАЦИИ, ПОИСКА И СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ ДАННЫХ»; патентная заявка США № 10/692,779 (реестр поверенного № MSFT-2829), поданная 24 октября 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ РЕАЛИЗАЦИИ СХЕМЫ ЦИФРОВЫХ ИЗОБРАЖЕНИЙ ДЛЯ ОРГАНИЗАЦИИ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА»; патентная заявка США № 10/692,515 (реестр поверенного № MSFT-2844), поданная 24 октября 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ УСЛУГ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА»); патентная заявка США № 10/692,508 (реестр поверенного № MSFT-2845), поданная одновременно с данной на «СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ РЕЛЯЦИОННЫХ И ИЕРАРХИЧЕСКИХ УСЛУГ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА»; и патентная заявка США № 10/693,362 (реестр поверенного № MSFT-2846), поданная 24 октября 2003 г., на «СИСТЕМЫ И СПОСОБЫ ДЛЯ РЕАЛИЗАЦИИ СХЕМ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО/ПРОГРАММНОГО ИНТЕРФЕЙСА».
Область техники
Настоящее изобретение относится к области хранения и извлечения информации и, в частности, к активной платформе хранения для организации, поиска и совместного использования различных типов данных в компьютеризованной системе. Различные варианты осуществления настоящего изобретения направлены на использование способов расширения и наследования, используемых системой аппаратно-программного интерфейса для управления данными.
Предшествующий уровень техники
В течение последнего десятилетия емкость отдельного диска росла примерно на семьдесят процентов (70%) в год. Закон Мура точно предсказал значительный рост мощности центральных процессоров (ЦП), произошедший в последние годы. Проводные и беспроводные технологии обеспечили значительные возможности связности и расширения полосы. Если предположить, что современные тенденции сохранятся, то через несколько лет средний портативный компьютер будет обладать емкостью хранения около одного терабайта и содержать миллионы файлов, и жесткие диски емкостью 500 гигабайт будут в порядке вещей.
Потребители используют свои компьютеры главным образом для передачи и организации личной информации, будь то данные в формате электронной записной книжки (ЭЗК) или мультимедийные данные, например цифровая музыка или фотографии. Объем цифрового содержимого и возможность хранения необработанных байтов существенно возросли; однако доступные потребителям способы организации и унификации этих данных не получили должного развития. Специалисты в сфере информационных технологий тратят очень много времени на управление и совместное использование информации и по оценкам ряда исследований специалисты в сфере информационных технологий тратят 15-25% своего времени на непродуктивную деятельность, связанную с информацией. Согласно оценкам других исследований, специалист в сфере информационных технологий тратит около 2,5 часов в день на поиск информации.
Разработчики и подразделения информационных технологий (ИТ) затрачивают много времени и денег на построение собственных хранилищ данных для обычных абстракций хранения для представления людей, мест, времен и событий. Это не только приводит к двойной работе, но и создает островки общих данных без каких-либо механизмов общего поиска или совместного использования этих данных. Посмотрите, сколько адресных книжек может сегодня существовать на компьютере, где установлена операционная система Microsoft Windows. Многие приложения, например клиенты электронной почты и персональные финансовые программы, поддерживают индивидуальные адресные книжки, и немногие из приложений совместно используют данные адресной книжки, которые индивидуально поддерживает каждая такая программа, вследствие чего финансовая программа (например, Microsoft Money) не пользуется адресами получателей платежей совместно с адресами, поддерживаемыми в папке контактов электронной почты (например, в Microsoft Outlook). Действительно, многие пользователи имеют множество устройств и по логике должны синхронизировать свои личные данные между ними и по большому количеству дополнительных источников, включая сотовые телефоны с коммерческими службами, например MSN и AOL; тем не менее, взаимодействие совместно используемых документов в основном достигается за счет присоединения документов к сообщениям электронной почты, т.е. вручную и неэффективно.
Одна из причин этого недостатка взаимодействия состоит в том, что традиционные подходы к организации информации в компьютерных системах сосредоточены на использовании систем на основе файлов/папок и директорий (“файловых систем”) для организации множества файлов в иерархии директорий папок на основе абстрагирования от физической организации среды хранения, используемой для хранения файлов. Операционная система Multics, разработанная в 1960-х годах, может по праву считаться пионером в использовании файлов, папок и директорий для управления сохраняемыми блоками данных на уровне операционной системы. В частности, Multics использовала символические адреса в иерархии файлов (тем самым представляя идею пути к файлу), где физические адреса файлов были непрозрачны для пользователя (приложений и конечных пользователей). Эта файловая система полностью не учитывала формат файла для любого отдельного файла, и отношения между файлами не рассматривались на уровне операционной системы (т.е. иные, чем место файла в иерархии). С появлением Multics сохраняемые данные были организованы в файлы, папки и директории на уровне операционной системы. Эти файлы, в общем случае, включают в себя саму иерархию файлов («директорию»), воплощенную в особом файле, поддерживаемом файловой системой. Эта директория, в свою очередь, поддерживает список элементов, соответствующих всем остальным файлам в директории, и узловой точке таких файлов в директории (ниже именуемых папками). Данный уровень техники имеет место уже примерно сорок лет.
Однако обеспечивая рациональное представление информации, размещенной в физической системе хранения файловая система тем не менее является абстракцией этой физической системы хранения, и потому использование файлов требует уровня преобразования логических адресов в физические (интерпретации) между тем, чем манипулирует пользователь (блоками, имеющими контекст, признаки и отношения с другими блоками), и тем, что обеспечивает операционная система (файлами, папками и директориями). Поэтому пользователям (приложениям и/или конечным пользователям) ничего не остается как размещать блоки информации в структуре файловой системы, даже если это неэффективно, неудобно или по какой-либо другой причине нежелательно. Кроме того, существующие файловые системы мало знают о структуре данных, хранящихся в отдельных файлах, и поэтому большая часть информации остается запертой в файлах, которые могут быть доступны (и понятны) только для приложений, которые их записали. Следовательно, этот недостаток схематического описания информации и механизмов управления информацией приводит к созданию «силосных ям» данных с малым совместным использованием данных между отдельными «силосными ямами». Например, многие пользователи персональных компьютеров (ПК) имеют более пяти различных хранилищ, в которых содержится информация о людях, с которыми они взаимодействуют, на некотором уровне, например список контактов программы Outlook (Outlook Contacts), адреса онлайновых учетных записей, адресная книжка Windows (Windows Address Book), Quicken Payees и списки друзей в службе мгновенного обмена сообщениями (IM), поскольку организация файлов представляет существенную проблему этим пользователям ПК. Поскольку большинство существующих файловых систем используют модельное представление вложенных папок для организации файлов и папок, по мере возрастания количества файлов усилия, необходимые для поддержания гибкой и эффективной организационной схемы, становятся просто устрашающими. В таких ситуациях было бы очень полезно иметь несколько классификаций одного файла; однако, использование аппаратных или программных связей в существующих файловых системах является громоздким и трудно поддерживаемым.
Ранее было предпринято несколько безуспешных попыток преодолеть недостатки файловых систем. В некоторых из этих предыдущих попыток предусматривалось использование памяти с адресацией по содержимому для обеспечения механизма, который позволяет обращаться к данным по содержимому, а не по физическому адресу. Однако эти попытки оказались безуспешными, потому что хотя память с адресацией по содержимому продемонстрировала свою полезность для маломасштабного использования такими устройствами, как блоками кэш-памяти и блоками управления памятью, крупномасштабное использование для таких устройств, как физические носители данных, по разным причинам пока невозможно и поэтому такого решения просто не существует. Были предприняты другие попытки с использованием систем объектно-ориентированной базы данных (ООБД), но эти попытки хотя и проявляли сильные стороны базы данных и хорошие нефайловые представления, не были эффективными в обработке файловых представлений и не могли соперничать в скорости, эффективности и простоте с иерархической структурой на основе файлов и папок на уровне системы аппаратно-программного интерфейса. Другие попытки, например с использованием SmallTalk (и других производных), оказались весьма эффективными в обработке файловых и нефайловых представлений, однако не имели характеристик базы данных, необходимых для эффективной организации и использования отношений, существующих между различными файлами данных, и потому общая эффективность таких систем была неприемлема. Другие попытки, связанные с использованием BeOS, и другие подобные исследования операционных систем оказались неадекватными в обработке нефайловых представлений, что является ключевым недостатком традиционных файловых систем, несмотря на способность адекватно представлять файлы, одновременно обеспечивая некоторые необходимые особенности базы данных.
Технология баз данных - это еще одна область техники, в которой существуют аналогичные проблемы. Например, хотя модель реляционной базы данных получила большой коммерческий успех, истинные независимые продавцы программных продуктов (НПП) обычно используют малую толику функциональных возможностей программных продуктов реляционной базы данных (например, Microsoft SQL Server). Вместо этого взаимодействие приложения с таким продуктом происходит в виде простых операций «взять» и «положить». Несмотря на ряд очевидных причин для этого, например скептическое отношение к платформе или базе данных, важнейшая причина, которая часто остается без внимания, состоит в том, что база данных не всегда обеспечивает именно те абстракции, в которых действительно нуждается большинство продавцов бизнес-приложений. Например, реальный мир обозначается такими «элементами данных», как «клиенты» или «заказы» (совместно с внедренными в заказ «линейными элементами данных» в качестве элементов данных в них или их самих), реляционные базы данных говорят только на языке таблиц и строк. Следовательно, хотя приложению могут быть желательны аспекты, подобные согласованности, блокировке, безопасности и/или запускам на уровне элементов данных, в общем случае базы данных обеспечивают эти особенности только на уровне таблиц/строк. Хотя это может хорошо работать, если каждый элемент данных отображается в единичную строку в некоторой таблице в базе данных, в случае заказа с множеством линейных элементов данных могут быть причины, по которым элемент данных фактически отображается на множество таблиц, и в этом случае простая система реляционной базы данных просто не обеспечивает правильных абстракций. Следовательно, приложение должно строить логику поверх базы данных для обеспечения своих базовых абстракций. Другими словами, базовая реляционная модель не обеспечивает достаточной платформы для хранения данных, на которой можно легко разрабатывать приложения более высокого уровня, поскольку базовая реляционная модель требует уровень преобразования логических адресов в физические между приложением и системой хранения, где семантическая структура данных может быть видимой в приложении только в определенных случаях. Хотя некоторые продавцы баз данных встраивают в свои продукты функциональные возможности более высокого уровня, например обеспечивают объектные реляционные возможности, новые организационные модели и т.п., ни один еще не обеспечил некоторого необходимого универсального решения, где истинно универсальное решение это то, которое обеспечивает как полезные абстракции модели данных (например, «элементы данных», «расширения», «отношения» и пр.) для полезных абстракций области (например, «лица», «местоположения», «события» и т.д.).
Ввиду вышеизложенных недостатков существующих технологий хранения данных и баз данных необходима новая платформа хранения, которая обеспечивает повышенную возможность организации, поиска и совместного использования всех типов данных в компьютерной системе - платформа хранения, которая продлевает и расширяет платформу данных за пределы существующих файловых систем и систем баз данных, и которая предназначена для хранения всех типов данных. Настоящее изобретение совместно с родственными изобретениями, ранее включенными сюда посредством ссылки, удовлетворяет эту потребность. В частности, настоящее изобретение обеспечивает способы расширения и наследования объектов, манипулируемых системой аппаратно-программного интерфейса.
Сущность изобретения
Нижеследующая сущность обеспечивает обзор различных аспектов изобретения, описанных в связи с родственными изобретениями, ранее включенными сюда посредством ссылки. Эта сущность не призвана ни обеспечивать исчерпывающее описание всех важных аспектов изобретения, ни задавать объем изобретения. Напротив, эта сущность призвана служить введением к нижеследующему подробному описанию и чертежам.
Настоящее изобретение, равно как и родственные изобретения, относятся к платформе хранения для организации, поиска и совместного использования данных. Платформа хранения, отвечающая настоящему изобретению, распространяет и расширяет концепцию хранения данных за пределы существующих файловых систем и систем баз данных и предназначена для хранения всех типов данных, включая структурированные, неструктурированные или частично структурированные данные.
Платформа хранения, отвечающая настоящему изобретению, содержит хранилище данных, реализованное в виде машины базы данных. Машина базы данных содержит машину реляционной базы данных с объектными реляционными расширениями. Хранилище данных реализует модель данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и безопасность данных. Конкретные типы данных описаны в схемах, и платформа обеспечивает механизм расширения множества схем для определения новых типов данных (в особенности подтипов базовых типов, обеспечиваемых схемами). Функция синхронизации облегчает совместное использование данных среди пользователей или систем. Предусмотрены функции наподобие файловой системы, которые обеспечивают возможность взаимодействия хранилища данных с существующими файловыми системами, но не ограничиваются такими традиционными файловыми системами. Механизм отслеживания изменений обеспечивает возможность отслеживать изменения хранилища данных. Платформа хранения дополнительно содержит множество программных интерфейсов приложения, которые позволяют приложениям обращаться ко всем вышеперечисленным возможностям платформы хранения и обращаться к данным, описанным в схемах.
Модель данных, реализованная хранилищем данных, задает блоки хранения данных в терминах элементов данных (статей), элементов и отношений. Статья - это блок данных, сохраняемый в хранилище данных, который может содержать один или несколько элементов и отношений. Элемент является экземпляром типа, содержащим одно или несколько полей (также именуемое здесь свойством). Отношение - это связь между двумя статьями. (Используемые здесь эти и другие конкретные термины могут быть написаны с заглавной буквы для выделения их среди других терминов, используемых рядом; однако это не значит, что существует какое-либо различие между термином, написанным с заглавной буквы, например «Статья», и тем же термином, написанным строчными буквами, например «статья», и не следует предполагать или подразумевать никакого различия между ними.)
Компьютерная система дополнительно содержит совокупность Статей, где каждая Статья образует дискретный сохраняемый блок информации, которым может манипулировать система аппаратно-программного интерфейса; совокупность Папок статей, которые образуют организационную структуру упомянутых Статей; и систему аппаратно-программного интерфейса для манипулирования совокупностью Статей, причем каждая Статья принадлежит, по меньшей мере, одной Папке статей и может принадлежать более одной Папке статей.
Статью или некоторые значения свойств Статьи можно вычислять динамически вместо того, чтобы извлекать из постоянного хранилища. Другими словами, система аппаратно-программного интерфейса не требует хранения Статьи, и поддерживаются определенные операции, например возможность перечисления текущего множества Статей или возможность извлечения Статьи по ее идентификатору (которая более подробно описана в разделах, описывающих программный интерфейс приложения или API) платформы хранения, например Статья может представлять собой текущее местоположение сотового телефона или показание температуры на датчике температуры. Система аппаратно-программного интерфейса может манипулировать множеством Статей и может дополнительно содержать Статьи, взаимосвязанные посредством множества Отношений, находящихся под управлением системы аппаратно-программного интерфейса.
Система аппаратно-программного интерфейса для компьютерной системы дополнительно содержит схему ядра для определения множества Статей ядра, которые система аппаратно-программного интерфейса понимает и может непосредственно обрабатывать заранее определенным и прогнозируемым способом. Чтобы манипулировать множеством Статей, компьютерная система связывает Статьи посредством множество Отношений и управляет Отношениями на уровне системы аппаратно-программного интерфейса.
API платформы хранения обеспечивает классы данных для каждой статьи, расширение статьи и отношение, заданное в наборе схем платформы хранения. Кроме того, программный интерфейс приложения обеспечивает набор классов конструкции, которые задают общий набор поведений для классов данных и которые совместно с классами данных обеспечивают базовую модель программирования для API платформы хранения. API платформы хранения обеспечивает упрощенную модель запросов, которая позволяет разработчикам прикладных программ формировать запросы на основании различных свойств статей в хранилище данных таким образом, что разработчику прикладных программ не требуется вникать в детали языка запросов соответствующей машины базы данных. API платформы хранения также собирает изменения в статье, произведенные прикладной программой, и затем организует их в правильные обновления, необходимые машине базы данных (или машине хранения любого рода), на которой реализовано хранилище данных. Это позволяет разработчикам прикладных программ производить изменения статьи в памяти, оставляя при этом сложную работу по изменениям хранилища данных на долю API.
Посредством своей общей основы хранения и схематизированных данных платформа хранения, отвечающая настоящему изобретению, обеспечивает более эффективную разработку приложений для потребителей, специалистов в сфере информационных технологий и предприятий. Она обеспечивает обогащенный и расширяемый программный интерфейс приложения, который не только делает доступными возможности, присущие ее модели данных, но также охватывает и расширяет существующую файловую систему и способы доступа к базе данных.
В соответствии с этой объединяющей структурой взаимосвязанных изобретений (подробно описанной в Разделе II Подробного описания), настоящее изобретение, в частности, ориентировано на использование Расширений для расширения функциональных возможностей типов Статей и Свойств, а также для использования Наследования для облегчения эффективного поиска и организации среди родственных Статей (подробно описанного в Разделе III Подробного описания). Другие признаки и преимущества изобретения явствуют из нижеследующего подробного описания изобретения и прилагаемых чертежей.
Краткое описание чертежей
Вышеизложенную сущность, а также нижеследующее подробное описание изобретения легче понять, рассматривая их в сочетании с прилагаемыми чертежами. В целях иллюстрации изобретения на чертежах показаны иллюстративные варианты осуществления различных аспектов изобретения; однако, изобретение не ограничивается конкретными раскрытыми способами и средствами.
На чертежах
фиг.1 - блок-схема, представляющая компьютерную систему, в которой могут быть реализованы аспекты настоящего изобретения;
фиг.2 - блок-схема, иллюстрирующая компьютерную систему, разделенную на три группы компонентов: компонент аппаратных средств, компонент системы аппаратно-программного интерфейса и компонент прикладных программ;
фиг.2А - иллюстрирует традиционную древовидную иерархическую структуру файлов, сгруппированных в папки в директории в файловой операционной системе;
фиг.3 - блок-схема, иллюстрирующая платформу хранения;
фиг.4 - иллюстрирует структурное отношение между Статьями, Папками статей и Категориями;
фиг.5А - блок-схема, иллюстрирующая структуру Статьи;
фиг.5В - блок-схема, иллюстрирующая сложные типы свойств Статьи, показанной на фиг.5А;
фиг.5С - блок-схема, иллюстрирующая Статью «Местоположение», в которой дополнительно описаны ее сложные типы (перечислены в явном виде);
фиг.6А - иллюстрирует Статью как подтип Статьи, найденной в Базовой схеме;
фиг.6В - блок-схема, иллюстрирующая подтип Статья, показанный на фиг.6А, в котором его унаследованные типы перечислены в явном виде (помимо его непосредственных свойств);
фиг.7 - блок-схема, иллюстрирующая Базовую схему, включающую в себя два ее типа классов верхнего уровня, Item и PropertyBase, и дополнительные типы Базовой схемы, выводимые из них;
фиг.8А - блок-схема, иллюстрирующая Статьи в Схеме ядра;
фиг.8В - блок-схема, иллюстрирующая типы свойств в Схеме ядра;
фиг.9 - блок-схема, иллюстрирующая Папку статей, входящие в нее Статьи и Отношения взаимосвязи между Папкой статей и входящими в нее Статьями;
фиг.10 - блок-схема, иллюстрирующая Категорию (которая опять же сама является Статьей), входящие в нее Статьи и Отношения взаимосвязи между Категорией и входящими в нее Статьями;
фиг.11 - схема, иллюстрирующая иерархию типов ссылки в модели данных платформы хранения;
фиг.12 - схема, иллюстрирующая классификацию отношений;
фиг.13 - схема, иллюстрирующая механизм уведомления;
фиг.14 - схема, иллюстрирующая пример, в котором две транзакции вставляют новую запись в одно и то же Б-дерево;
фиг.15 - иллюстрирует процесс обнаружения изменения данных;
фиг.16 - иллюстрирует иллюстративное дерево директории;
фиг.17 - показывает пример, в котором существующая папка файловой системы на основе директорий перемещается в хранилище данных платформы хранения;
фиг.18 - иллюстрирует концепцию папок Включения;
фиг.19 - иллюстрирует базовую архитектуру API платформы хранения;
фиг.20 - схематически представляет различные компоненты стека API платформы хранения;
фиг.21А - графическое представление иллюстративной схемы Статьи «Контакты»;
фиг.21В - графическое представление Элементов для иллюстративной схемы Статьи «Контакты», показанной на фиг.21А;
фиг.22 - иллюстрирует конструкцию среды выполнения API платформы хранения;
фиг.23 - иллюстрирует выполнение операции «найти все»;
фиг.24 - иллюстрирует процесс, посредством которого классы API платформы хранения генерируются из схемы платформы хранения;
фиг.25 - иллюстрирует схему, на которой основан API «Файл»;
фиг.26 - схема, иллюстрирующая формат маски доступа, используемый в целях защиты данных;
фиг.27 - (части a, b, и c) обозначают новую идентично защищенную область безопасности, вырезанную из существующей области безопасности;
фиг.28 - схема, иллюстрирующая концепцию поискового вида Статьи;
фиг.29 - схема, иллюстрирующая иллюстративную иерархию Статьи;
фиг.30А - иллюстрирует интерфейс Интерфейс1 как канал связи между первым и вторым сегментами кода;
фиг.30В - иллюстрирует интерфейс как содержащий объекты интерфейса I1 и I2, которые обеспечивают связь между первым и вторым сегментами кода системы через среду М;
фиг.31А - иллюстрирует, как функцию, обеспеченную интерфейсом Интерфейс1, можно разделить для преобразования связей интерфейса на множество интерфейсов Интерфейс1A, Интерфейс 1B, Интерфейс 1C;
фиг.31В - иллюстрирует, как функцию, обеспеченную интерфейсом I1, можно разделить на множество интерфейсов I1a, I1b, I1c;
фиг.32А - иллюстрирует сценарий, где точность несущественного параметра можно игнорировать или заменить произвольным параметром;
фиг.32В - иллюстрирует сценарий, где интерфейс заменяется подстановочным интерфейсом, который задан для игнорирования или добавления параметров к интерфейсу;
фиг.33А - иллюстрирует сценарий, где 1-й и 2-й Сегменты кода объединяются в модуль, содержащий их обоих;
фиг.33В - иллюстрирует сценарий, где интерфейс полностью или частично может быть записан в одну строку в другой интерфейс для формирования объединенного интерфейса;
фиг.34А - иллюстрирует как один или несколько фрагментов промежуточного программного обеспечения могут преобразовывать связи на первом интерфейсе для согласования их с одним или несколькими другими интерфейсами;
фиг.34В - иллюстрирует как можно ввести сегмент кода с помощью интерфейса, чтобы принимать передачи от одного интерфейса, но передавать функциональные возможности второму и третьему интерфейсам;
фиг.35А - иллюстрирует как компилятор своевременной активизации (JIT) может преобразовывать передачи от одного сегмента кода к другому сегменту кода;
фиг.35В - иллюстрирует как JIT-метод динамического переписывания одного или нескольких интерфейсов можно применять для динамической факторизации или иного изменения интерфейса;
фиг.36 - иллюстрирует ряд взаимосвязанных Статей и подмножества их Отношений;
фиг.37А - иллюстрирует недостатки стандартного выделения подтипов Статей в целях конкретного приложения;
фиг.37В - иллюстрирует частичное решение проблем стандартного выделения подтипов; и
фиг.37С - иллюстрирует один вариант осуществления настоящего изобретения для расширения Статьи с помощью Расширения, которое отличается и отделено от самого Контакта, и таким образом обеспечивает функцию выделения множества типов.
Подробное описание
и совместного использования данных
поисковых видах
поисковых видах
разрешений конфликтов
без хранения
Системой)
I. Введение
Предмет настоящего изобретения описан с той степенью конкретизации, которая отвечает установленным требованиям. Однако описание само по себе не призвано ограничивать объем этого патента. Напротив, изобретателями предполагалось, что сущность заявленного изобретения может быть воплощена и другими способами, включающими различные этапы или комбинации этапов, аналогичные описанным в этом документе, в сочетании с другими современными или будущими технологиями. Кроме того, хотя термин «этап» можно использовать здесь для обозначения различных элементов применяемого способа, термин не следует интерпретировать как предусматривающий какой-либо конкретный порядок среди различных раскрытых здесь этапов, за исключением тех случаев, когда порядок отдельных этапов описан в явном виде.
А. Иллюстративная вычислительная среда
Многочисленные варианты осуществления настоящего изобретения могут выполняться на компьютере. Фиг.1 и нижеследующее рассмотрение призвано обеспечивать общее описание подходящей вычислительной среды, в которой может быть реализовано изобретение. Хотя это и не требуется, различные аспекты изобретения можно описать в общем контексте компьютерно-выполняемых команд, например программных модулей, выполняемых компьютером, например, клиентской рабочей станцией или сервером. В общем случае, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.п., которые выполняют определенные задачи или реализуют определенные абстрактные типы данных. Кроме того, изобретение можно осуществлять на практике с применением других конфигураций компьютерной системы, включая карманные устройства, многопроцессорные системы, программируемую бытовую электронику на основе микропроцессора, сетевые ПК, мини-компьютеры, универсальные компьютеры и т.д. Изобретение также можно осуществлять на практике в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, связанными друг с другом посредством вычислительной сети. В распределенной вычислительной среде программные модули могут размещаться как в локальных, так и в удаленных запоминающих устройствах.
Согласно фиг.1, иллюстративная вычислительная система общего назначения включает в себя традиционный персональный компьютер 20 и т.п., включающий в себя блок 21 обработки, системную память 22 и системную шину 23, которая соединяет различные компоненты системы, включая системную память, с блоком 21 обработки. Системная шина 23 может представлять собой любой из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующих любую из разнообразных шинных архитектур. Системная память включает в себя постоянную память (ПЗУ) 24 и оперативную память (ОЗУ) 25. Базовая система ввода/вывода 26 (BIOS), содержащая базовые процедуры, которые помогают переносить информацию между элементами персонального компьютера 20, например при запуске, хранится в ПЗУ 24. Персональный компьютер 20 может дополнительно включать дисковод 27 жестких дисков для считывания с жесткого диска и записи на жесткий диск, который не показан, дисковод 28 магнитных дисков для считывания со сменного магнитного диска или записи на сменный магнитный диск 29 и дисковод 30 оптических дисков для считывания со сменного оптического диска или записи на сменный оптический диск, например CD-ROM или другие оптические носители. Дисковод 27 жестких дисков, дисковод 28 магнитных дисков и дисковод 30 оптических дисков связаны с системной шиной 23 посредством интерфейса 32 дисковода жестких дисков, интерфейса 33 дисковода магнитных дисков и интерфейса 34 дисковода оптических дисков соответственно. Дисководы и связанные с ними компьютерно-считываемые носители обеспечивают энергонезависимое хранение компьютерно-считываемых команд, структур данных, программных модулей и других данных для персонального компьютера 20. Хотя в описанной здесь иллюстративной среде используется жесткий диск, сменный магнитный диск 29 и сменный оптический диск 31, специалистам в данной области очевидно, что в иллюстративной операционной среде можно использовать и другие типы компьютерно-считываемых носителей, в которых могут храниться данные, доступные компьютеру, например, магнитные кассеты, карты флэш-памяти, цифровые видео-диски, картриджи Бернулли, блоки оперативной памяти (ОЗУ), блоки постоянной памяти (ПЗУ) и т.п. Аналогично иллюстративная среда может также включать в себя многие типы устройств слежения, например тепловые датчики и охранные и противопожарные системы и другие источники информации.
На жестком диске, магнитном диске 29, оптическом диске 31, в ПЗУ 24 или ОЗУ 25 может храниться ряд программных модулей, включая операционную систему 35, одну или несколько прикладных программ 36, другие программные модули 37 и программные данные 38. Пользователь может вводить команды и информацию в персональный компьютер 20 через устройства ввода, например клавиатуру 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, спутниковую антенну, сканер и т.п. Эти и другие устройства ввода часто соединяются с блоком обработки 21 через интерфейс 46 последовательного порта, который подключен к системной шине, но может соединяться посредством других интерфейсов, например параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или устройство отображения другого типа также подключено к системной шине 23 через интерфейс, например видеоадаптер 48. Помимо монитора 47 персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), например громкоговорители и принтеры. Иллюстративная система, показанная на фиг.1, также включает в себя хост-адаптер 55, шину «интерфейса малых компьютерных систем» (SCSI) и внешнее запоминающее устройство 62, подключенное к шине 56 SCSI.
Персональный компьютер 20 может работать в сетевой среде, используя локальные соединения с одним или несколькими удаленными компьютерами, например удаленным компьютером 49. Удаленный компьютер 49 может представлять собой другой персональный компьютер, сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой общий сетевой узел и обычно включает в себя многие или все элементы, описанные выше применительно к персональному компьютеру 20, хотя на фиг.1 проиллюстрировано только запоминающее устройство 50. Логические соединения, обозначенные на фиг.1, включают в себя локальную сеть (ЛС) 51 и глобальную сеть (ГС) 52. Такие сетевые среды обычно имеют место в офисных сетях, компьютерных сетях в масштабе предприятия, интранетах и в Интернете.
При использовании в сетевой среде ЛС персональный компьютер 20 подключен к ЛС 51 через сетевой интерфейс или адаптер 53. При использовании в сетевой среде ГС персональный компьютер 20 обычно включает в себя модем 54 или другое средство установления каналов связи по глобальной сети 52, например Интернету. Модем 54, который может быть внутренним или внешним, подключен к системной шине 23 через интерфейс 46 последовательного порта. В сетевой среде программные модули, описанные применительно к персональному компьютеру 20, или часть из них могут храниться в удаленном запоминающем устройстве. Очевидно, что показанные сетевые соединения являются иллюстративными, и можно использовать другие средства установления каналов связи между компьютерами.
Согласно блок-схеме, изображенной на фиг.2, компьютерную систему 200 можно грубо разделить на три группы компонентов: компонент 202 оборудования, компонент 204 системы аппаратно-программного интерфейса и компонент 206 прикладных программ (также именуемый в некоторых контекстах «пользовательским компонентом» или «компонентом программного обеспечения»).
В различных вариантах осуществления компьютерной системы 200, согласно фиг.1, компонент 202 оборудования может содержать центральный процессор (ЦП) 21, память (ПЗУ 24 и ОЗУ 25), базовую систему ввода/вывода (BIOS) 26 и различные устройства ввода/вывода, например клавиатуру 40, мышь 42, монитор 47 и/или принтер (не показан) и пр. Компонент 202 оборудования содержит базовую физическую инфраструктуру компьютерной системы 200.
Компонент 206 прикладных программ содержит различные программы, в том числе, но без ограничения, системы баз данных, текстовые редакторы, бизнес-программы, видеоигры и т.п. Прикладные программы обеспечивают средства для использования компьютерных ресурсов для решения задач, обеспечения решений и обработки данных для различных пользователей (машин, других компьютерных систем и/или конечных пользователей).
Компонент 204 системы аппаратно-программного интерфейса содержит и в некоторых вариантах осуществления может состоять исключительно из операционной системы, которая сама содержит в большинстве случаев оболочку и ядро. «Операционная система» (ОС) это особая программа, которая действует как посредник между прикладными программами и оборудованием компьютера. Компонент системы 204 аппаратно-программного интерфейса также может содержать администратор виртуальных машин (АВМ), среду выполнения общего языка (CLR) или ее функциональный эквивалент, виртуальную машину Java (JVM) или ее функциональный эквивалент или другие подобные компоненты программного обеспечения вместо или дополнительно к операционной системе в компьютерной системе. Целью системы аппаратно-программного интерфейса является обеспечение среды, в которой пользователь может выполнять прикладные программы. Цель любой системы аппаратно-программного интерфейса состоит в том, чтобы сделать компьютерную систему удобной в использовании, а также эффективно использовать оборудование компьютера.
Система аппаратно-программного интерфейса, в общем случае, загружается в компьютерную систему при запуске, после чего управляет всеми прикладными программами в компьютерной системе. Прикладные программы взаимодействуют с системой аппаратно-программного интерфейса, запрашивая службы через программный интерфейс приложения (API). Некоторые прикладные программы позволяют конечным пользователям взаимодействовать с системой аппаратно-программного интерфейса через пользовательский интерфейс, например командный язык или графический интерфейс пользователя (ГИП).
Система аппаратно-программного интерфейса традиционно осуществляет различные сервисы для приложений. В многозадачной системе аппаратно-программного интерфейса, где одновременно может выполняться множество программ, система аппаратно-программного интерфейса определяет, в каком порядке должны действовать приложения, и сколько времени нужно выделить каждому приложению, прежде чем переключиться на другое приложение. Система аппаратно-программного интерфейса также управляет совместным использованием внутренней памяти среди множества приложений и обрабатывает ввод и вывод в присоединенные аппаратные устройства, например жесткие диски, принтеры и коммутируемые порты, и из них. Система аппаратно-программного интерфейса также посылает сообщения каждому приложению (и в определенном случае конечному пользователю), касающиеся состояния операций и любых ошибок, которые могут возникнуть. Система аппаратно-программного интерфейса также может брать на себя управление пакетными заданиями (например, печати), в результате чего инициирующее приложение освобождается от этой работы и может возобновить другую обработку и/или операции. На компьютерах, которые могут обеспечивать параллельную обработку, система аппаратно-программного интерфейса также управляет разделением программы, чтобы она одновременно выполнялась на более чем одном процессоре.
Оболочка системы аппаратно-программного интерфейса (далее именуемая просто «оболочкой») - это интерактивный интерфейс конечного пользователя к системе аппаратно-программного интерфейса. (Оболочку также можно называть «интерпретатором команд» или в операционной системе «оболочкой операционной системы»). Оболочка является внешним слоем системы аппаратно-программного интерфейса, к которому прикладные программы и/или конечные пользователи могут непосредственно осуществлять доступ.
Хотя предполагается, что многочисленные варианты осуществления настоящего изобретения особенно хорошо подходят для компьютеризованных систем, ничто в этом документе не предусматривает ограничения изобретения такими вариантами осуществления. Напротив, используемый здесь термин «компьютерная система» призван охватывать любые и все устройства, способные хранить и обрабатывать информацию и/или способные использовать сохраненную информацию для управления поведением самого устройства, независимо от того, является ли это устройство по своей природе электронным, механическим, логическим или виртуальным.
В. Традиционное хранение на основе файлов
В большинстве современных компьютерных систем «файлы» представляют собой блоки сохраняемой информации, которые могут включать в себя систему аппаратно-программного интерфейса, а также прикладные программы, наборы данных и т.д. Во всех современных системах аппаратно-программного интерфейса (Windows, Unix, Linux, Mac OS, системах виртуальной машины и т.д.) файлы являются базовыми дискретными (сохраняемыми и извлекаемыми) блоками информации (например, данных, программ и т.п.), которыми может манипулировать система аппаратно-программного интерфейса. Группы файлов обычно организуются в «папки». В Microsoft Windows, Macintosh OS и других системах аппаратно-программного интерфейса, папка является собранием файлов, которые можно извлекать, перемещать и иначе манипулировать как единичными блоками информации. Эти папки, в свою очередь, организуются в древовидную иерархическую структуру, именуемую «директорией» (более подробно рассмотрена ниже). В некоторых других системах аппаратно-программного интерфейса, например DOS, z/OS и в большинстве операционных систем на основе Unix, термины «директория» и/или «папка» являются взаимозаменяемыми, и ранние компьютерные системы Apple (например, Apple IIe) использовали термин «каталог» вместо директории; однако при использовании здесь все эти термины считаются синонимами и взаимозаменяемыми и призваны дополнительно включать в себя все остальные эквивалентные термины, обозначающие и ссылающиеся на иерархические структуры хранения информации и их компоненты папок и файлов.
Традиционно директория (также именуемая директорией папок) представляет собой древовидную иерархическую структуру, в которой файлы сгруппированы в папки, и папки, в свою очередь, организованы в соответствии с относительными узловыми точками, которые образуют дерево директории. Например, согласно фиг.2А, базовая папка файловой системы на основе DOS (или «корневая директория») 212 может содержать совокупность папок 214, каждая из которых может дополнительно содержать дополнительные папки (как «подпапки» этой конкретной папки) 216, и каждая из них также может содержать дополнительные папки 218 до бесконечности. Каждая из этих папок может иметь один или несколько файлов 220, хотя на уровне системы аппаратно-программного интерфейса отдельные файлы в папке не имеют между собой ничего общего, кроме их положения в древовидной иерархии. Неудивительно, что этот подход к организации файлов в иерархии папок опосредованно отражает физическую организацию типичных сред хранения, используемых для хранения этих файлов (например, жестких дисков, флоппи-дисков, CD-ROM и т.д.).
В дополнение к вышеизложенному каждая папка является контейнером для своих подпапок и их файлов, т.е. каждая папка владеет своими подпапками и файлами. Например, когда система аппаратно-программного интерфейса удаляет папку, подпапки и файлы этой папки также удаляются (что рекурсивно в случае каждой подпапки дополнительно относится к ее собственным подпапкам и файлам). Аналогично каждый файл, в общем случае, принадлежит только одной папке, и хотя можно скопировать файл и поместить копию в другую папку, копия файла сама по себе является отличным и отдельным блоком, который не имеет прямой связи с оригиналом (например, изменения файла-оригинала не отражаются на файле-копии на уровне системы аппаратно-программного интерфейса). Отсюда следует, что файлы и папки являются типично «физическими» по своей природе, поскольку папки рассматриваются как физические контейнеры, и файлы рассматриваются как дискретные и отдельные физические элементы в этих контейнерах.
II. Платформа хранения WINFS для организации,
поиска и совместного использования данных
Настоящее изобретение совместно с родственными изобретениями, включенными посредством ссылки, согласно описанному выше, посвящено платформе хранения для организации, поиска и совместного использования данных. Платформа хранения, отвечающая настоящему изобретению, распространяет и расширяет платформу данных за пределы видов существующих файловых систем и систем баз данных, рассмотренных выше, и предназначена для хранения всех типов данных, включая новую форму данных, именуемую Статьями.
С. Глоссарий
Нижеследующие термины, используемые здесь и в формуле изобретения, имеют следующее значение:
- «Статья» - это блок сохраняемой информации, доступный системе аппаратно-программного интерфейса, который в отличие от простого файла является объектом, имеющим базовое множество свойств, которые в общем порядке поддерживаются по всем объектам, представляемых конечному пользователю оболочкой системы аппаратно-программного интерфейса. Статьи также имеют свойства и отношения, которые в общем порядке поддерживаются по всем типам Статьи, включая признаки, которые позволяют вводить новые свойства и отношения (что более подробно описано ниже).
- «Операционная система» (ОС) - это особая программа, которая действует как посредник между прикладными программами и аппаратными средствами компьютера. Операционная система содержит в большинстве случаев оболочку и ядро.
- «Система аппаратно-программного интерфейса» - это программное обеспечение или сочетание аппаратных средств и программного обеспечения, которое служит в качестве интерфейса между соответствующими компонентами аппаратных средств компьютерной системы и приложениями, выполняющимися в компьютерной системе. Система аппаратно-программного интерфейса обычно содержит (и в некоторых вариантах осуществления может исключительно содержать) операционную систему. Система аппаратно-программного интерфейса может также содержать администратор виртуальных машин (АВМ), среду выполнения общего языка (CLR) или ее функциональный эквивалент, виртуальную машину Java (JVM) или ее функциональный эквивалент, или любые подобные компоненты программного обеспечения вместо или в дополнение к операционной системе в компьютерной системе. Целью системы аппаратно-программного интерфейса является обеспечение среды, в которой пользователь может выполнять прикладные программы. Цель любой системы аппаратно-программного интерфейса состоит в том, чтобы сделать компьютерную систему удобной в использовании, а также эффективно использовать аппаратные средства компьютера.
D. Обзор платформы хранения
Согласно фиг.3, платформа 300 хранения содержит хранилище 302 данных, реализованное в машине 314 базы данных. Согласно одному варианту осуществления, машина базы данных содержит машину реляционной базы данных с объектными реляционными расширениями. Согласно одному варианту осуществления, машина 314 реляционной базы данных содержит машину реляционной базы данных Microsoft SQL Server. Хранилище 302 данных реализует модель 304 данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных. Конкретные типы данных описаны в схемах, например схемах 340, и платформа 300 хранения обеспечивает инструменты 346 для развертывания этих схем, а также для расширения этих схем, что более подробно описано ниже.
Механизм 306 отслеживания изменений, реализованный в хранилище 302 данных, обеспечивает возможность отслеживать изменения в хранилище данных. Хранилище 302 данных также обеспечивает функции 308 защиты и функцию 310 продвижения/отмены продвижения, которые более подробно рассмотрены ниже. Хранилище 302 данных также обеспечивает множество программных интерфейсов 312 приложения для представления возможностей хранилища 302 данных другим компонентам платформы хранения и прикладным программам (например, прикладным программам 350a, 350b и 350c), которые используют платформу хранения. Платформа хранения, отвечающая настоящему изобретению, содержит также программные интерфейсы приложения (API) 322, которые позволяют прикладным программам, например прикладным программам 350a, 350b и 350c, осуществлять доступ ко всем вышеперечисленным возможностям платформы хранения и осуществлять доступ к данным, описанным в схемах. API 322 платформы хранения могут использоваться прикладными программами совместно с другими API, например API 324 БД OLE и API 326 Win32 Microsoft Windows.
Платформа хранения 300, отвечающая настоящему изобретению, может обеспечивать различные сервисы 328 для прикладных программ, включая сервис 330 синхронизации, который облегчает совместное использование данных среди пользователей или систем. Например, сервис 330 синхронизации может обеспечивать возможность взаимодействия с другими хранилищами 340 данных, имеющими такой же формат, что и хранилище 302 данных, а также доступ к хранилищам 342 данных, имеющим другие форматы. Платформа 300 хранения также обеспечивает функции файловой системы, которые допускают возможность взаимодействия хранилища 302 данных с существующими файловыми системами, например файловой системой 318 NTFS Windows. Согласно, по меньшей мере, некоторым вариантам осуществления, платформа 320 хранения может также обеспечивать прикладные программы дополнительными возможностями, позволяющими воздействовать на данные и обеспечивающими взаимодействие с другими системами. Эти возможности могут быть воплощены в виде дополнительных сервисов 328, например сервиса 334 Info Agent и сервиса 332 уведомления, а также в виде других утилит 336.
Согласно, по меньшей мере, некоторым вариантам осуществления, платформа хранения воплощена в системе аппаратно-программного интерфейса компьютерной системы или образует его неотъемлемую часть. Например, и без ограничения, платформа хранения, отвечающая настоящему изобретению, может быть воплощена в операционной системе, администраторе виртуальных машин (АВМ), среде выполнения общего языка (CLR) или ее функционального эквивалента, или виртуальной машине Java (JVM), или ее функционального эквивалента или может образовывать их неотъемлемую часть. Посредством своего общего фундамента хранения и схематизированных данных платформа хранения, отвечающая настоящему изобретению, позволяет более эффективно разрабатывать приложения для потребителей, специалистов в сфере информационных технологий и предприятий. Она обеспечивает обширную и расширяемую область программирования, которая не только делает доступными возможности, присущие ее модели данных, но также охватывает и расширяет существующую файловую систему и методы доступа к базе данных.
В нижеследующем описании и на различных чертежах платформа хранения 300, отвечающая настоящему изобретению, может именоваться “WinFS”. Однако это название используется для обозначения платформы хранения исключительно для удобства описания и не предполагает никаких ограничений.
Е. Модель данных
Хранилище 302 данных платформы 300 хранения, отвечающей настоящему изобретению, реализует модель данных, которая поддерживает организацию, поиск, совместное использование и защиту данных, находящихся в хранилище. В модели данных, отвечающей настоящему изобретению, «Статья» - это основной блок сохраняемой информации. Модель данных обеспечивает механизм объявления Статей и Расширений статей и установления отношений между Статьями и организации Статей в Папках статей и в Категориях, что описано более подробно ниже.
Модель данных опирается на два примитивных механизма - Типы и Отношения. Типы - это структуры, обеспечивающие формат, который управляет формой экземпляра Типа. Формат выражается в виде упорядоченного множества Свойств. Свойство - это имя значения или множества значений данного Типа. Например, тип «почтовый адрес США» может иметь свойства «улица», «город», «индекс», «штат», в которых «улица», «город» «штат» имеют тип String (строка), а индекс имеет тип Int32 (32-разрядное целое). «Улица» может быть многозначным свойством (т.е. иметь множество значений), что позволяет адресу иметь более одного значения для свойства «улица». Система задает определенные примитивные типы, которые можно использовать при построении других типов: они включают в себя String, Binary, Boolean, Int16, Int32, Int64, Single, Double, Byte, DateTime, Decimal and GUID. Свойства Типа можно задавать с использованием любых примитивных типов или (с некоторыми ограничениями, указанными ниже) любых построенных типов. Например, можно задать Тип «местоположение», имеющий Свойства «координата» и «адрес», где Свойство «адрес» имеет вышеописанный тип «почтовый адрес США». Свойства также могут быть обязательными или необязательными.
Отношения могут быть декларированы и представляют отображение между множествами экземпляров двух типов. Например, можно декларировать Отношение между Типом «лицо» и Типом «местонахождение», именуемое «проживает в», которое определяет, кто где проживает. Отношение имеет имя, две конечных точки, а именно исходную конечную точку и целевую конечную точку. Отношения также имеют упорядоченное множество свойств. Исходная и целевая конечные точки имеют Имя и Тип. Например, Отношение «проживает в» имеет исходную конечную точку, именуемую «жилец» типа «лицо» и целевую конечную точку, именуемую «местожительство» типа «местонахождение» и, кроме того, имеет свойства «начальная дата» и «конечная дата», указывающие период времени, в течение которого жилец проживал по данному местожительству. Заметим, что «лицо» может проживать по нескольким местожительствам в течение некоторого времени, и местожительство может иметь несколько жильцов, поэтому наиболее вероятно, что информация «начальная дата» и «конечная дата» будет помещена в само отношение.
Отношения задают отображение между экземплярами, которое ограничено типами, заданными как типы конечной точки. Например, отношение «проживает в» не может быть отношением, в котором «жильцом» является «автомобиль», поскольку «автомобиль» не является «лицом».
Модель данных позволяет задавать отношение подтип-супертип между типами. Отношение подтип-супертип, также именуемое отношением «базовый тип», задано таким образом, что если Тип А является Базовым типом для Типа В, должно быть справедливо утверждение, что каждый экземпляр В всегда является экземпляром А. Это отношение можно выразить иначе, а именно: каждый экземпляр, соответствующий В, должен также соответствовать А. Если, например, А имеет свойство «имя» Типа «строка», а В имеет свойство «возраст» Типа Int16, то В должен иметь как «имя», так и «возраст». Иерархию типов можно представить в виде дерева с единичным супертипом в качестве корня. Ветви от корня обеспечивают подтипы первого уровня, ветви на этом уровне обеспечивают подтипы второго уровня и т.д. до концевых подтипов, которые сами не имеют подтипов. Дерево не ограничивается однородной глубиной, но не может содержать циклов. Данный Тип может иметь нуль или много подтипов и нуль один супертип(ов). Данный экземпляр может соответствовать максимум одному типу совместно с супертипами этого типа. Иными словами, для данного экземпляра на любом уровне дерева экземпляр может соответствовать максимум одному подтипу на этом уровне. Тип называется абстрактным, если экземпляры типа должны также быть экземплярами подтипа этого типа.
1. Статьи
Статья - это блок сохраняемой информации, который в отличие от простого файла является объектом, имеющим базовое множество свойств, которые в общем порядке поддерживаются по всем объектам, представляемых конечному пользователю оболочкой системы аппаратно-программного интерфейса. Статьи также имеют свойства и отношения, которые в общем порядке поддерживаются по всем типам Статьи, включая признаки, которые позволяют вводить новые свойства и отношения, что рассмотрено ниже.
Статьи являются объектами общих операций, таких как копирование, удаление, перемещение, открытие, печать, резервирование, восстановление, дублирование и т.д. Статьи являются блоками, которые можно сохранять и извлекать, и все формы сохраняемой информации, которой манипулирует платформа хранения, существуют в виде Статей, свойств статей или отношений между статьями, каждое из которых более подробно рассмотрено ниже.
Статьи призваны представлять относящиеся к реальному миру и интуитивно понятные блоки данных, например Контакты, Люди, Услуги, Места, Документы (разнообразных видов) и т.д. На фиг.5А показана блок-схема, иллюстрирующая структуру Статьи. Неквалифицированное имя Статьи - «местожительство». Квалифицированное имя Статьи - “Core.Location”, которое указывает, что эта структура Статьи задана как конкретный тип Статьи в Схеме ядра. (Схема ядра более подробно рассмотрена ниже.)
Статья «местожительство» имеет совокупность свойств, включая EAddresses, MetropolitanRegion, Neighborhood и PostalAddresses. Конкретный тип каждого свойства указан непосредственно после имени свойства и отделен от имени свойства двоеточием (:). Справа от имени типа, количество значений, допустимое для этого типа свойства, указано в квадратных скобках ([ ]), где звездочка (*) справа от двоеточия (:) указывает неуказанное и/или неограниченное количество («много»). Цифра «1» справа от двоеточия указывает, что может быть максимум одно значение. Нуль (0) слева от двоеточия указывает, что свойство является необязательным (может вовсе не быть значений). «1» слева от двоеточия указывает, что должно быть, по меньшей мере, одно значение (свойство является обязательным). Оба свойства Neighborhood и MetropolitanRegion имеют тип “nvarchar” (или эквивалентный), который является заранее заданным типом данных или «простым типом» (и обозначен без заглавной буквы). Однако EAddresses и PostalAddresses являются свойствами заданных типов или «сложных типов» (что обозначено заглавной буквой) EAddress и PostalAddress соответственно. Сложный тип - это тип, который выводится из одного или нескольких простых типов данных и/или из других сложных типов. Сложные типы для свойств Статьи также образуют “вложенные элементы”, поскольку детали сложного типа вложены в непосредственную Статью для задания ее свойств, и информация, касающаяся этих сложных типов, поддерживается в Статье, которая имеет эти свойства (в границе Статьи, которая рассмотрена ниже). Эти концепции типизации общеизвестны и очевидны специалистам в данной области.
На фиг.5В показана блок-схема, иллюстрирующая сложные типы свойств PostalAddress и EAddress. Тип свойства PostalAddress определяет, что, предположительно Статья, имеющая свойство типа PostalAddress, имеет нуль или одно значение City, нуль или одно значение CountryCode, нуль или одно значение MailStop и любое количество (от нуля до много) значений PostalAddressType и т.д. и т.п. Таким образом, задается форма данных для конкретного свойства в Статье. Тип свойства EAddress задан аналогично, как показано. Хотя в данной заявке это используется в необязательном порядке, другой способ представления сложных типов в Статье «местожительство» состоит в том, чтобы изобразить статью с отдельными свойствами каждого из перечисленных здесь сложных типов. На фиг.5С показан блок-схема, иллюстрирующая Статью «местожительство», где дополнительно описаны ее сложные типы. Следует, однако, понимать, что это альтернативное представление Статьи «местожительство» на этой фиг.5С в точности соответствует Статье, проиллюстрированной на фиг.5А. Платформа хранения, отвечающая настоящему изобретению, также допускает выделение подтипов, благодаря чему один тип свойства может быть подтипом другого (где один тип свойства наследует свойства другого, родительского типа свойства).
Аналогично, но не идентично свойствам и их типам свойств, Статьи по природе своей представляют свои собственные Типы статьи, которые также могут подлежать выделению подтипов. Другими словами, платформа хранения в нескольких вариантах осуществления настоящего изобретения допускает, чтобы Статья была подтипом другой Статьи (благодаря чему одна Статья наследует свойства другой, родительской Статьи). Кроме того, для различных вариантов осуществления настоящего изобретения каждая Статья является подтипом типа Статьи «Статья», который является первым и основным типом Статьи, найденным в Базовой схеме. (Базовая схема также будет рассмотрена ниже более подробно.) На фиг.6А проиллюстрирована Статья, в данном примере Статья «местожительство», как подтип типа Статьи «Статья», найденный в Базовой схеме. На этом чертеже стрелка указывает, что Статья «местожительство» (наподобие всех остальных Статей) является подтипом типа Статьи «Статья». Тип Статьи «Статья», как основная Статья, из которой выводятся все остальные Статьи, имеет ряд важных свойств, например ItemId и различные метки времени, и таким образом задает стандартные свойства всех Статей в операционной системе. На этом чертеже данные свойства типа Статьи «Статья» наследуются «местожительством» и таким образом становятся свойствами «местожительства».
Другой способ представления свойств в Статье «местожительство», унаследованных от типа Статьи «Статья», состоит в том, чтобы изобразить «местожительство» с отдельными свойствами каждого типа свойства из перечисленной здесь родительской Статьи. На фиг.6В показана блок-схема, иллюстрирующая Статью «местожительство», в которой помимо ее непосредственных свойств описаны ее унаследованные типы. Следует заметить и понять, что эта Статья идентична Статье, показанной на фиг.5А, хотя на этом чертеже «местожительство» проиллюстрировано со всеми его свойствами, как непосредственными, показанными на этом чертеже и на фиг.5А, так и унаследованными, показанными на этом чертеже, но не на фиг.5А (тогда как на фиг.5А эти свойства указаны посредством ссылки с помощью стрелки, показывающей, что Статья «местожительство» является подтипом типа Статьи «Статья»).
Статьи являются самостоятельными объектами, таким образом, если удаляется Статья, то все непосредственные и унаследованные свойства Статьи также удаляются. Аналогично при извлечении Статьи получают Статью и все ее непосредственные и унаследованные свойства (включая информацию, касающуюся ее сложных типов свойств). Определенные варианты осуществления настоящего изобретения могут предусматривать запрашивание подмножества свойств при извлечении конкретной Статьи; однако по умолчанию во многих таких вариантах осуществления, при извлечении Статья обеспечивается со всеми ее непосредственными и унаследованными свойствами. Кроме того, свойства Статьи можно также расширять путем добавления новых свойств к существующим свойствам типа этой Статьи. Поэтому эти «расширения» являются истинными свойствами Статьи, и подтипы этого типа Статьи могут автоматически включать в себя свойства расширения.
«Граница» Статьи представлена ее свойствами (включая сложные типы свойств, расширения и т.п.). Граница Статьи также представляет предел операций, осуществляемых в отношении Статьи, таких как копирование, удаление, перемещение, создание и пр. Например, в нескольких вариантах осуществления настоящего изобретения, при копировании Статьи копируется также все, что находится внутри этой границы Статьи. Для каждой Статьи граница охватывает следующее:
- Тип Статьи для Статьи и, если Статья является подтипом другой Статьи (что имеет место в нескольких вариантах осуществления настоящего изобретения, когда все Статьи выводятся из одной Статьи и Типа Статьи в Базовой схеме), любую применимую информацию подтипов (т.е. информацию, касающуюся родительского Типа Статьи). Если копируемая исходная Статья является подтипом другой Статьи, копия также может быть подтипом той же Статьи;
- Свойства и расширения сложного типа Статьи, если таковые существуют. Если исходная Статья имеет свойства сложных типов (собственные или расширенные), копия также может иметь те же сложные типы;
- Записи Статьи на «отношениях принадлежности», т.е. собственный список Статьи, в котором перечислено, какие другие Статьи («целевые статьи») принадлежат данной Статье («владеющей Статье»). Это особенно важно в связи с Папками статей, более подробно рассмотренными ниже, и установленным ниже правилом, согласно которому все статьи должны принадлежать, по меньшей мере, одной Папке статей. Кроме того, что касается внедренных статей, рассмотренных более подробно ниже, внедренная статья считается частью Статьи, в которую она внедрена, для таких операций, как копирование, удаление и т.п.
2. Идентификация статьи
Статьи уникальным образом идентифицируются в пространстве глобальных статей посредством ItemID. Тип Base.Item определяет поле ItemID типа GUID, в котором хранится идентификация Статьи. Статья должна иметь одну и только одну идентификацию в хранилище 302 данных.
Ссылка на статью - это структура данных, содержащая информацию для определения местоположения и идентификации Статьи. В модели данных определен абстрактный тип, именуемый ItemReference, из которого выводятся все типы ссылки на статью. Тип ItemReference определяет виртуальный метод, именуемый Resolve. Метод Resolve разрешает ItemReference и возвращает Статью. Этот метод подменяется конкретными подтипами ItemReference, которые реализуют функцию, извлекающую Статью по ссылке. Метод Resolve используется как часть API 322 платформы хранения.
ItemIDReference является подтипом ItemReference. Он задает поля Locator и ItemID. Поле Locator присваивает имя (т.е. идентифицирует) область статей. Оно обрабатывается методом разрешения локаторов, который может разрешать значение Локатора в область статей. Поле ItemID имеет тип ItemID.
ItemPathReference - это частный случай ItemReference, который определяет поля Locator и Path (Путь). Поле Locator идентифицирует область статей. Оно обрабатывается методом разрешения локаторов, который может разрешать значение Локатора на область статей. Поле Path содержит (относительный) путь в пространстве имен платформы хранения с корнем в области статей, обеспеченной Локатором.
Этот тип ссылки может быть использован в множественной операции. В общем случае, ссылка должна разрешаться посредством процесса разрешения пути. Метод Resolve API 322 платформы хранения обеспечивает эту функцию.
Рассмотренные выше формы ссылок представлены посредством иерархии типов ссылки, проиллюстрированной на фиг.11. Дополнительные типы ссылки, которые наследуют от этих типов, можно определить в схемах. Их можно использовать в декларации отношения как тип целевого поля.
3. Папки статей и категории
Как рассмотрено более подробно ниже, группы Статей можно организовать в особые Статьи, именуемые Папками статей (которые не надо путать с папками файлов). Однако в отличие от большинства файловых систем Статья может принадлежать более одной Папке статей, так что при обращении к Статье и ее пересмотре в одной Папке статей, к этой пересмотренной Статье затем можно обращаться непосредственно из другой Папки статей. В сущности, хотя доступ к статье может осуществляться из разных Папок статей, доступ фактически осуществляется к одной и той же Статье. Однако Папка статей не обязана владеть всеми входящими в нее Статьями или может просто совладеть Статьями наряду с другими папками, так что удаление Папки статей не обязательно приводит к удалению Статьи. Тем не менее, в нескольких вариантах осуществления настоящего изобретения Статья должна принадлежать, по меньшей мере, одной Папке статей, так что при удалении единичной Папки статей для конкретной Статьи в некоторых вариантах осуществления Статья автоматически удаляется или в альтернативных вариантах осуществления Статья автоматически становится членом Папки статей, принятой по умолчанию (например, Папки статей «корзина», концептуально аналогична папкам с аналогичными именами, используемым в различных системах на основе файлов и папок).
Как рассмотрено более подробно ниже, Статьи могут также принадлежать Категориям на основании общих описанных характеристик, например (а) типа (или типов) статьи, (b) конкретного непосредственного или унаследованного свойства (или свойств), или (с) конкретного значения (или значений), соответствующего свойству Статьи. Например, Статья, содержащая конкретные свойства для личной контактной информации, может автоматически принадлежать Категории «контакт», и любая статья, имеющая свойства контактной информации, будет аналогично автоматически принадлежать этой Категории. Аналогично любая Статья, имеющая свойство местожительства со значением «город Нью-Йорк», может автоматически принадлежать Категории «город Нью-Йорк».
Категории принципиально отличаются от Папок статей тем, что Папки статей могут содержать Статьи, не связанные между собой (т.е. без общей описанной характеристики), а каждая Статья в Категории имеет общий тип, общее свойство или значение («общность»), описанный/ое для этой Категории, и это та общность, которая образует основание для его отношения к и между другими Статьями в Категории. Кроме того, членство Статьи в конкретной Папке не обязательно основано на каком-либо конкретном аспекте этой Статьи, для определенных вариантов осуществления все Статьи, имеющие общность, категорически связанную с категорией, могут автоматически становиться членами Категории на уровне системы аппаратно-программного интерфейса. В принципе, Категории можно также рассматривать как виртуальные Папки статей, членство которых основано на результатах особого запроса (например, в контексте базы данных), и Статьи, отвечающие условиям этого запроса (заданным общностями Категории) будут содержать членство в Категории.
Фиг.4 иллюстрирует структурное отношение между Статьями, Папками статей и Категориями. Совокупность Статей 402, 404, 406, 408, 410, 412, 414, 416, 418 и 420 являются членами различных Папок статей 422, 424, 426, 428 и 430. Некоторые Статьи могут принадлежать более одной Папке статей, например Статья 402 принадлежит Папкам статей 422 и 424. Некоторые Статьи, например Статьи 402, 404, 406, 408, 410 и 412 также являются членами одной или более Категорий 432, 434 и 436, тогда как другие статьи, например Статьи 414, 416, 418 и 420, могут не принадлежать ни одной из Категорий (хотя это весьма маловероятно в определенных вариантах осуществления, где обладание любым свойством автоматически влечет членство в Категории, и, таким образом, в таком варианте осуществления Статья не должна иметь никаких признаков, чтобы не быть членом ни одной из категорий). В отличие от иерархической структуры папок Категории и Папки статей имеют структуры более похожие на ориентированные графы, как показано. В любом случае Статьи, Папки статей и Категории являются Статьями (хотя и относятся к разным типам статей).
В отличие от файлов, папок и директорий Статьи, Папки статей и Категории, отвечающие настоящему изобретению, не являются по природе своей типично «физическими», поскольку они не имеют концептуальных эквивалентов физических контейнеров, и потому Статьи могут существовать в более чем одном таком месте. Возможность существования Статей в более чем одной Папке статей, а также возможность их организации в Категории обеспечивает расширенную и обогащенную степень манипуляции данными и возможности структуры хранения на уровне аппаратно-программного интерфейса, сверх того, что доступно в уровне техники.
4. Схемы
а) Базовая схема
Для обеспечения универсального основания для построения и использования Статей различные варианты осуществления платформы хранения, отвечающей настоящему изобретению, содержат базовую схему, которая устанавливает концептуальную конструкцию для создания и организации Статей и свойств. Базовая схема задает определенные особые типы Статей и свойств и признаки этих особых основных типов, из которых можно дополнительно выводить подтипы. Использование этой базовой схемы позволяет программисту концептуально отличать статьи (и их соответствующие типы) от свойств (и их соответствующих типов). Кроме того, базовая схема задает основное множество свойств, которыми могут обладать все Статьи, поскольку все Статьи (и их соответствующие Типы статьи) выводятся из этой основной статьи в базовой схеме (и ее соответствующего Типа статьи).
Согласно фиг.7 и в связи с несколькими вариантами осуществления настоящего изобретения базовая схема задает три типа верхнего уровня: Item (статья), Extension (расширение) и PropertyBase (базовое свойство). Показано, что тип Статьи задается свойствами этого основного типа Статьи “Item”. Напротив, тип свойства “PropertyBase” верхнего уровня не имеет заранее определенных свойств и является всего лишь указателем, из которого выводятся все остальные типы свойств и посредством которого все производные типы свойств связаны между собой (будучи, в общем порядке, выводимы из единичного типа свойства). Свойства типа расширения задают, какую Статью расширяет расширение, а также идентификацию для отличения одного расширения от другого, поскольку Статья может иметь множественные расширения.
ItemFolder - это подтип типа Статьи Item, который помимо свойств, унаследованных от «статьи», характеризует «отношение» для установления связей со своими членами (если имеются), тогда как IdentityKey и Property являются подтипами PropertyBase. В свою очередь, CategoryRef является подтипом IdentityKey.
b) Схема ядра
Различные варианты осуществления платформы хранения, отвечающей настоящему изобретению, также содержат схему ядра, которая обеспечивает концептуальную конструкцию для структур типов Статьи верхнего уровня. На фиг.8А показана блок-схема, иллюстрирующая статьи в схеме ядра, а на фиг.8В показана блок-схема, иллюстрирующая типы свойства в схеме ядра. Различия, проводимые между файлами на основании разных расширений (*.com, *.exe, *.bat, *.sys, и т.д.) и других критериев в системах на основе файлов и папок аналогичны функции схемы ядра. В системе аппаратно-программного интерфейса на основе статей схема ядра задает множество типов статей ядра, которые непосредственно (по типу Статьи) или опосредованно (по подтипу Статьи) характеризуют все статьи в одном или нескольких типах Статьи схемы ядра, которые система аппаратно-программного интерфейса на основе статей понимает и может непосредственно обрабатывать заранее определенным и прогнозируемым способом. Заранее определенные типы Статьи отражают наиболее общие Статьи в системе аппаратно-программного интерфейса на основе статей и таким образом система аппаратно-программного интерфейса на основе статей, понимающая эти заранее определенные типы Статьи, которые образуют схему ядра, повышает уровень эффективности.
В определенных вариантах осуществления схема ядра не является расширяемой, т.е. никакие дополнительные типы Статьи нельзя выделить как подтипы из типа Статьи в базовой схеме, за исключением особых заранее определенных производных типов Статьи, которые являются частью схемы ядра. Препятствуя расширениям схемы ядра (т.е. препятствуя добавлению новых статей к схеме ядра), платформа хранения дает исключительное право использовать типы статьи схемы ядра, поскольку каждый последующий тип Статьи с необходимостью является подтипом типа статьи схемы ядра. Эта структура обеспечивает разумную степень гибкости при определении дополнительных типов Статьи, в то же время пользуясь преимуществами наличия заранее определенного множества типов статей ядра.
Для различных вариантов осуществления настоящего изобретения и согласно фиг.8А, особые типы Статьи, поддерживаемые схемой ядра, могут включать в себя одно или более из следующего:
- Категории: Статьи этого типа Статьи (и выводимых из него подтипов) представляют действительные Категории в системе аппаратно-программного интерфейса на основе статей;
- Предметы потребления: Статьи, которые являются идентифицируемыми ценностями;
- Устройства: Статьи, имеющие логическую структуру, которая поддерживает возможности обработки информации;
- Документы: Статьи, содержимое которых не интерпретируется системой аппаратно-программного интерфейса на основе статей, но интерпретируется прикладной программой, соответствующей типу документа;
- События: Статьи, в которых записаны определенные происшествия в среде;
- Положения: Статьи, представляющие физические положения (например, географические положения);
- Сообщения: Статьи обмена информацией между двумя принципалами (описаны ниже);
- Принципалы: Статьи, имеющие, по меньшей мере, одну окончательно доказанную идентификацию помимо ItemId (например, идентификацию личности, организации, группы, семьи, учреждения, службы и пр.);
- Утверждения: Статьи, имеющие особую информацию, касающуюся среды, в том числе без ограничения полисы, подписки, мандаты и т.п.
Аналогично и согласно фиг.8В особые типы свойства, поддерживаемые схемой ядра, могут включать в себя одно или более из следующего:
- Сертификаты (производные от основного типа PropertyBase в базовой схеме);
- Идентификационные ключи принципалов (производные от типа IdentityKey в базовой схеме);
- Почтовый адрес (производный от Типа свойства в базовой схеме);
- Обогащенный текст (производный от Типа свойства в базовой схеме);
- EAddress (производный от Типа свойства в базовой схеме);
- IdentitySecurityPackage (производный от Типа отношения в базовой схеме);
- RoleOccupancy (производный от Типа отношения в базовой схеме);
- BasicPresence (производный от Типа отношения в базовой схеме).
Эти Статьи и Свойства дополнительно описаны в отношении их соответствующих свойств, указанных на фиг.8А и фиг.8В.
5. Отношения
Отношения являются бинарными отношениями, где одна Статья выступает в качестве источника, а другая Статья в качестве цели. Исходная статья и целевая статья связаны отношением. Исходная статья, в общем случае, управляет временем жизни отношения. Т.е. при удалении исходной статьи отношение между статьями также удаляется.
Отношения делятся на отношения включения и отношения ссылки. Отношения включения управляют временем жизни целевых статей, а отношения ссылки не обеспечивают никакой семантики управления временем жизни. Фиг.12 иллюстрирует классификацию отношений.
Типы отношений включения дополнительно подразделяются на отношения поддержания и внедрения. При удалении всех отношений поддержания для статьи статья удаляется. Отношение поддержания управляет временем жизни цели посредством механизма отсчета ссылок. Отношения внедрения позволяют моделировать составные статьи и могут рассматриваться как исключительные отношения поддержания. Статья, являющаяся целью отношения внедрения, может не быть целью никакого другого отношения поддержания или внедрения.
Отношения ссылки не управляют временем жизни целевой статьи. Они могут быть висящими - целевой статьи может не существовать. Отношения ссылки можно использовать для моделирования ссылок на Статьи в другом месте пространства глобальных имен статьи (т.е. включая удаленные хранилища данных).
Извлечение статьи не приводит к автоматическому извлечению ее отношений. Приложения должны в явном виде запрашивать отношения Статьи. Кроме того, изменение отношения не приводит к изменению исходной или целевой статьи; аналогично добавление отношения не влияет на исходную/целевую статью.
а) Объявление отношения
Явные типы отношений определены следующими элементами:
- Имя отношения определено в атрибуте Имя;
- Тип отношения, один из следующих: поддержание, внедрение, ссылка. Это определено в атрибуте Тип;
- Исходная и целевая конечные точки. Каждая конечная точка определяет имя и тип упоминаемой статьи;
- Поле «исходная конечная точка» в общем случае имеет тип ItemID (не декларируется) и оно должно ссылаться на Статью в том же хранилище данных, что и экземпляр отношения;
- Для отношений поддержания и внедрения поле «целевая конечная точка» должно иметь тип ItemIDReference и оно должно ссылаться на Статью в том же хранилище, что и экземпляр отношения. Для отношений ссылки целевая конечная точка может иметь любой тип ItemReference и может ссылаться на Статьи в других хранилищах данных платформы хранения;
- В необязательном порядке можно объявить одно или несколько полей скалярного типа или типа PropertyBase. Эти поля могут содержать данные, связанные с отношением;
- Экземпляры отношения хранятся в таблице глобальных отношений;
- Каждый экземпляр отношения уникальным образом идентифицируется комбинацией (ИД исходной статьи, ИД отношения). ИД отношения уникален в данном ИД исходной статьи для всех отношений, источником которых является данная Статья, независимо от их типов.
Исходная статья является владельцем отношения. Хотя статья, обозначенная как владелец, управляет временем жизни отношения, само отношение существует отдельно от Статей, которые оно связывает. API 322 платформы хранения обеспечивает механизм представления отношений, связанных со статьей.
Ниже приведен пример декларирования отношения:
<Relationship Name="Employment" BaseType="Reference">
<Source Name="Employee" ItemType="Contact.Person"/>
<Target Name="Employer" ItemType="Contact.Organization"
ReferenceType="ItemIDReference"/>
<Property Name="StartDate" Type="the storage
platformTypes.DateTime"/>
<Property Name="EndDate" Type="the storage
platformTypes.DateTime"/>
<Property Name="Office" Type="the storage
platformTypes.DateTime"/>
</Relationship>
Это пример отношения ссылки. Отношение не может быть создано, если Статья «лицо» (person), на которое ссылается исходная ссылка, не существует. Кроме того, при удалении Статьи «лицо» экземпляры отношения между лицом и организацией удаляются. Однако при удалении Статьи «организация» (Organization) отношение не удаляется, а подвисает.
b) Отношение поддержания
Отношения поддержания используются для моделирования счетчика ссылок на основании управления временем жизни целевых статей.
Статья может быть исходной конечной точкой для нуля или более отношений для Статей. Статья, которая не является внедренной статьей, может быть целью одного или более отношений поддержания.
Ссылка на целевую конечную точку должна иметь тип ItemIDReference и должна указывать Статью в том же хранилище, что и экземпляр отношения.
Отношения поддержания реализуют управление временем жизни целевой конечной точки. Создание экземпляра отношения поддержания и статьи, для которого она является целью, является атомарной операцией. Можно создавать дополнительные экземпляры отношения поддержания, нацеленные на ту же статью. При удалении последнего экземпляра отношения поддержания, для которого данная Статья является целевой конечной точкой, целевая статья также удаляется.
Типы статей-конечных точек, определенные в декларации отношения, в общем случае реализуются при создании экземпляра отношения. Типы статей-конечных точек нельзя изменять после установления отношения.
Отношения поддержания играют ключевую роль в формировании пространства имен статей. Они содержат свойство «имя», которое определяет имя целевой статьи по отношению к исходной статье. Это относительное имя является уникальным для всех отношений поддержания, для которых данная Статья является источником. Упорядоченный список этих относительных имен, начиная с корневой Статьи и до данной Статьи, образует полное имя Статьи.
Отношения поддержания образуют ориентированный ациклический граф (ОАГ). При создании отношения поддержания система гарантирует, что цикл не создается, тем самым гарантируя, что пространство имен статей образует ОАГ.
Хотя отношение поддержания управляет временем жизни целевой статьи, оно не управляет операционной согласованностью Статьи-целевой конечной точки. Целевая статья операционно независима от Статьи, которая ей владеет, посредством отношения поддержания. Копирование, перемещение, резервирование и другие операции над Статьей, которая является источником отношения поддержания, не влияет на Статью, которая является целью того же отношения, например резервирование Статьи «папка» не приводит к автоматическому резервированию всех Статей в папке (целей отношения FolderMember (член папки)).
Ниже приведен пример отношения поддержания:
<Relationship Name="FolderMembers" BaseType="Holding”>
<Source Name="Folder" ItemType="Base.Folder"/>
<Target Name="Item" ItemType="Base.Item"
ReferenceType="ItemIDReference" />
</Relationship>
Отношение FolderMembers (члены папки) обеспечивает концепцию Папки как общего собрания Статей.
с) Отношения внедрения
Отношения внедрения моделируют концепцию исключительного управления временем жизни целевой статьи. Они обеспечивают концепцию составных статей.
Создание экземпляра отношения внедрения и Статьи, которая является ее целью, является атомарной операцией. Статья может быть источником нуля или более отношений внедрения. Однако Статья может быть целью одного и только одного отношения внедрения. Статья, которая является целью отношения внедрения, не может быть целью отношения поддержания.
Ссылка на целевую конечную точку должна иметь тип ItemIDReference и должна указывать Статью в том же хранилище данных, что и экземпляр отношения.
Типы Статей-конечных точек, определенные в декларировании отношения, в общем случае реализуются при создании экземпляра отношения. Типы Статей-конечных точек нельзя изменять после установления отношения.
Отношения внедрения управляют операционной согласованностью целевой конечной точки. Например, операция сериализации Статьи может включать в себя сериализацию всех отношений внедрения, для которых Статья является источником, а также всех их целей; копирование Статей также приведет к копированию всех ее внедренных статей.
Ниже приведен пример декларирования:
<Relationship Name="ArchiveMembers" BaseType="Embedding”>
<Source Name="Archive" ItemType="Zip.Archive"/>
<Target Name="Member" ItemType="Base.Item "
ReferenceType="ItemIDReference"/>
<Property Name="ZipSize" Type="the storage
platformTypes.bigint"/>
<Property Name="SizeReduction" Type="the storage
platformTypes.float"/>
</Relationship>
d) Отношения ссылки
Отношение ссылки не управляют временем жизни Статьи, на которую оно ссылается. Кроме того, отношения ссылки не гарантируют существование цели, а также не гарантируют тип цели, как определено в декларации отношения. Это значит, что отношения ссылки могут подвисать. Кроме того, отношение ссылки может указывать Статьи в других хранилищах данных. Отношения ссылки можно рассматривать как концепцию, аналогичную ссылкам на веб-страницах.
Ниже приведен пример декларирования отношения ссылки:
<Relationship Name="DocumentAuthor" BaseType="Reference">
<Source ItemType="Document" ItemType="Base.Document"/>
<Target ItemType="Author" ItemType="Base.Author"
ReferenceType="ItemIDReference"/>
<Тип свойства="Role" Type="Core.CategoryRef"/>
<Тип свойства="DisplayName" Type="the storage
platformTypes.nvarchar(256)"/>
</Relationship>
В целевой конечной точке допустимы любые типы ссылки. Статьи, участвующие в отношении ссылки, могут относиться к любому типу Статьи.
Отношения ссылки используются для моделирования большинства отношений между Статьями без управления временем жизни. Поскольку существование цели не обязательно, отношение ссылки удобно для моделирования слабосвязанных отношений. Отношение ссылки можно использовать для указания Статей в других хранилищах данных, включая хранилища на других компьютерах.
е) Правила и ограничения
К отношениям применяются следующие дополнительные правила и ограничения:
- Статья должна быть целью (строго одного отношения внедрения) или (одного или более отношений поддержания). Одним исключением является корневая Статья. Статья может быть целью нуля или более отношений ссылки;
- Статья, которая является целью отношения внедрения, не может быть источником отношений поддержания. Она может быть источником отношений ссылки;
- Статья не может быть источником отношений поддержания, если она продвинута из файла. Она может быть источником отношений внедрения и отношений ссылки;
- Статья, которая продвинута из файла, не может быть целью отношения внедрения.
f) Упорядочение отношений
Согласно, по меньшей мере, одному варианту осуществления, платформа хранения, отвечающая настоящему изобретению, поддерживает упорядочение отношений. Упорядочение достигается с помощью свойства под именем «порядок» (“Order”) в определении базового отношения. Не существует ограничения уникальности по полю Order. Порядок отношений с одним и тем же значением свойства «порядок» не гарантируется, однако гарантируется, что они могут быть упорядочены после отношений с более низким значением «порядка» и перед отношениями с более высоким значением поля «порядок».
Приложения могут получать отношения в порядке, принятом по умолчанию, путем упорядочения по комбинации (SourceItemID, RelationshipID, Order). Все экземпляры отношения, для которых данная Статья является источником, упорядочены как единичная коллекция независимо от типа отношений в коллекции. Это, однако, гарантирует, что все отношения данного типа (например, «члены папки») являются упорядоченным подмножеством коллекции отношений для данной Статьи.
API 312 хранилища данных для манипулирования отношениями реализуют множество операций, которые поддерживают упорядочение отношений. Чтобы лучше объяснить операции, введем следующие термины:
- RelFirst - первое отношение в упорядоченной коллекции с порядковым значением OrdFirst;
- RelLast - последнее отношение в упорядоченной коллекции с порядковым значением OrdLast;
- RelX - данное отношение в коллекции с порядковым значением OrdX;
- RelPrev - ближайшее к RelX отношение в коллекции с порядковым значением OrdPrev, меньшим чем OrdX;
- RelNext - ближайшее к RelX отношение в коллекции с порядковым значением OrdPrev, большим чем OrdX.
Операции включают в себя, но без ограничения:
- InsertBeforeFirst(SourceItemID, Relationship) - вставляет отношение как первое отношение в коллекции. Значение свойства «порядок» нового отношения может быть меньше, чем OrdFirst;
- InsertAfterLast(SourceItemID, Relationship) - вставляет отношение как последнее отношение в коллекции. Значение свойства «порядок» нового отношения может быть больше, чем OrdLast;
- InsertAt(SourceItemID, ord, Relationship) - вставляет отношение с определенным значением для свойства «порядок»;
- InsertBefore(SourceItemID, ord, Relationship) - вставляет отношение перед отношением с данным порядковым значением. Новому отношению может быть присвоено значение «порядок», находящееся между OrdPrev и ord, неисключительно;
- InsertAfter(SourceItemID, ord, Relationship) - вставляет отношение после отношения с данным порядковым значением. Новому отношению может быть присвоено значение «порядок», находящееся между ord и OrdNext, неисключительно;
- MoveBefore(SourceItemID, ord, RelationshipID) - перемещает отношение с данным ИД отношения перед отношением с указанным значением «порядок». Отношению может быть присвоено новое значение «порядок», находящееся между OrdPrev и ord, неисключительно;
- MoveAfter(SourceItemID, ord, RelationshipID) - перемещает отношение с данным ИД отношения после отношения с указанным значением «порядок». Отношению может быть присвоено новое значение «порядок», находящееся между ord и OrdNext, неисключительно.
Согласно отмеченному выше, каждая Статья должна быть членом Папки статей. Применительно к Отношениям, каждая Статья должна иметь отношение в Папке статей. В нескольких вариантах осуществления настоящего изобретения, определенные отношения представлены Отношениями, существующими между Статьями.
В реализациях, предусмотренных различными вариантами осуществления настоящего изобретения, Отношение обеспечивает направленное бинарное отношение, которое «проходит» от одной Статьи (источника) к другой Статье (цели). Отношение является собственностью исходной статьи (статьи, от которой оно проходит) и таким образом удаляется при удалении источника (например, Отношение удаляется при удалении исходной статьи). Кроме того, в некоторых случаях Отношением может одновременно владеть (совладеющая) целевая статья, и такое владение может быть отражено в свойстве IsOwned («владение») (или эквивалентном ему) Отношения (как показано на фиг.7 для типа свойства Отношения). В этих вариантах осуществления создание нового Отношения IsOwned автоматически увеличивает отсчет ссылок на целевой статье, и удаление такого Отношения может уменьшить отсчет ссылок на целевой статье. Для этих конкретных вариантов осуществления Статьи продолжают существовать, если они имеют отсчет ссылок больший нуля, и автоматически удаляются, если отсчет достигает нуля. Опять же Папка статей является Статьей, которая имеет (или способна иметь) множество Отношений с другими Статьями, причем эти другие Статьи имеют членство в Папке статей. Другие фактические реализации Отношений возможны и предусмотрены настоящим изобретением для обеспечения описанных здесь функций.
Вне зависимости от фактической реализации Отношение является избирательным соединением от одного объекта к другому. Способность Статьи принадлежать более чем одной Папке статей, а также одной или более Категориям, независимо от того, являются ли эти Статьи, Папки и Категории общедоступными или приватными, определяется смысловыми значениями существования (или отсутствия) в структуре на основе Статей. Эти логические Отношения являются смысловыми значениями, присвоенными множеству Отношений, независимо от физической реализации, которые конкретно применяются для достижения описанных здесь функциональных возможностей. Логические Отношения устанавливаются между Статьей и ее Папкой(ами) статей или Категориями (и наоборот), поскольку, в сущности, Папки статей и Категории являются особым типом Статьи. Следовательно, над Папками статей и Категориями можно совершать такие же действия, как над любыми другими Статьями, - копирование, добавление к сообщению электронной почты, внедрение в документ и т.д. без ограничения, и Папки статей и Категории можно сериализовать и десериализовать (импортировать и экспортировать) с использованием тех же механизмов, что и для других Статей. (Например, в XML все Статьи могут иметь формат сериализации, и этот формат применяется в равной степени к Папкам статей, Категориям и Статьям.)
Вышеупомянутые Отношения, которые представляют отношение между Статьей и ее Папкой(ами) статей, могут логически продолжаться от Статьи к Папке статей, от Папки статей к Статье или в обоих направлениях. Отношение, которое логически продолжается от статьи к Папке статей, указывает, что Папка статей является общедоступной по отношению к этой Статье и совместно с этой Статьей использует свою информацию членства; напротив, отсутствие логического Отношения от Статьи к Папке статей указывает, что Папка статей является приватной по отношению к этой Статье и не использует совместно с этой Статьей свою информацию членства. Аналогично отношение, которое логически продолжается от Папки статей к Статье, указывает, что статья является общедоступной и совместно используемой по отношению к этой Папке статей, тогда как отсутствие логического Отношения от Папки статей к статье указывает, что Статья является приватной и не совместно используемой. Следовательно, когда Папка статей экспортируется в другую систему, именно «общедоступные» Статьи совместно используются в новом контексте, и когда Статья осуществляет поиск в своих Папках статей других, совместно используемых Статей, именно «общедоступные» Папки статей предоставляют Статье информацию, касающуюся принадлежащих им совместно используемых Статей.
На фиг.9 показана блок-схема, иллюстрирующая Папку статей (которая опять же сама является Статьей), входящие в нее Статьи и Отношения, связывающие между собой Папку статей и входящие в нее Статьи. Папка 900 статей имеет в качестве членов совокупность Статей 902, 904 и 906. Папка 900 статей имеет Отношение 912 от себя к Статье 902, которое указывает, что Статья 902 является публичной и совместно используемой по отношению к Папке 900 статей, ее членам 904 и 906 и любым другим Папкам статей, Категориям или Статьям (не показаны), которые могут обращаться к Папке 900 статей. Однако не существует Отношения от Статьи 902 к Папке 900 статей, и это указывает, что Папка 900 статей является приватной по отношению к Статье 902 и не использует совместно свою информацию членства со Статьей 902. С другой стороны, Статья 904 имеет Отношение 924 от себя к Папке 900 статей, и это указывает, что Папка 900 статей является общедоступной и совместно использует свою информацию членства со Статьей 904. Однако не существует Отношения от Папки 900 статей к Статье 904, и это указывает, что Статья 904 является приватной и не совместно используемой по отношению к Папке 900 статей, ее членам 902 и 906 и любым другим Папкам статей, Категориям или Статьям (не показаны), которые могут обращаться к Папке 900 статей. В отличие от Отношений (или их отсутствию) к Статьям 902 и 904 Папка 900 статей имеет Отношение 916 от себя к Статье 906, и Статья 906 имеет Отношение 926 обратно к Папке 900 статей, которые совместно указывают, что Статья 906 является общедоступной и совместно используемой по отношению к Папке 900 статей, ее членам 902 и 904 и любым другим Папкам статей, Категориям или Статьям (не показаны), которые могут обращаться к Папке 900 статей, и что Папка 900 статей является общедоступной и совместно использует свою информацию членства со Статьей 906.
Согласно рассмотренному ранее, Статьи в Папке статей не обязаны совместно использовать общность, поскольку Папки статей не «описаны». С другой стороны, Категории описаны общностью, которая является общей по отношению ко всем входящим в нее Статьям. Поэтому членство в Категории внутренне ограничено Статьями, имеющими описанную общность, и в некоторых вариантах осуществления все Статьи, отвечающие описанию Категории автоматически становятся членами Категории. Таким образом, в то время как Папки статей допускают представление тривиальных структур типов посредством их членства, Категории допускают членство на основании определенной общности.
Конечно, описания Категорий являются по природе своей логическими и потому Категорию можно описывать с помощью любого логического представления типов, свойств и/или значений. Например, логическим представлением для Категории может служить условие членства в ней, согласно которому Статья должна иметь одно из двух свойств или оба. Если эти описанные свойства для Категории обозначить «А» и «В», то членами Категории могут быть Статьи, имеющие свойство А, но не В, Статьи, имеющие свойство В, но не А, и Статьи, имеющие оба свойства А и В. Это логическое представление свойств описывается логическим оператором ИЛИ, где множество членов, описанное Категорией, представляет собой Статьи, имеющие свойство А или В. Аналогичные логические операторы (в том числе без ограничения И, ИСКЛЮЧАЮЩЕЕ ИЛИ и НЕ по отдельности или в комбинации) также можно использовать для описания категории, что очевидно специалистам в данной области.
Несмотря на различие между Папками статей (неописанными) и Категориями (описанными), Отношение от Категорий к Статьям и Отношение от Статей к Категориям производится, по существу, такие же, как описано выше для Папок статей и Статей во многих вариантах осуществления настоящего изобретения.
На фиг.10 показана блок-схема, иллюстрирующая Категорию (которая опять же сама является Статьей), входящие в нее Статьи и Отношения, связывающие между собой Категорию и входящие в нее Статьи. Категория 1000 имеет в качестве членов совокупность Статей 1002, 1004 и 1006, которые все совместно используют некоторую комбинацию общих свойств, значений или типов 1008, которые описаны (описание общности 1008') Категорией 1000. Категория 1000 имеет Отношение 1012 от себя к Статье 1002, которое указывает, что Статья 1002 является общедоступной и совместно используемой по отношению к Категории 1000, ее членам 1004 и 1006 и любым другим Категориям, Папкам статей или Статьям (не показаны), которые могут обращаться к Категории 1000. Однако не существует Отношения от Статьи 1002 к Категории 1000, и это указывает, что Категория 1000 является приватной по отношению к Статье 1002 и не использует совместно свою информацию членства со Статьей 1002. С другой стороны, Статья 1004 имеет Отношение 1024 от себя к Категории 1000, и это указывает, что Категория 1000 является общедоступной и совместно использует свою информацию членства со Статьей 1004. Однако не существует Отношения, продолжающегося от Категории 1000 к Статье 1004, и это указывает, что Статья 1004 является приватной и не совместно используемой по отношению к Категории 1000, другим ее членам 1002 и 1006 и любым другим Категориям, Папкам статей или Статьям (не показаны), которые могут обращаться к Категории 1000. В отличие от своих Отношений (или их отсутствия) со Статьями 1002 и 1004 Категория 1000 имеет Отношение 1016 от себя к Статье 1006, и Статья 1006 имеет Отношение 1026 обратно к Категории 1000, которые совместно указывают, что Статья 1006 является общедоступной и совместно используемой по отношению к Категории 1000, ее членам-Статьям и любым другим Категориям, Папкам статей или Статьям (не показаны), которые могут обращаться к Категории 1000, и что Категория 1000 является общедоступной и совместно использует свою информацию членства со Статьей 1006.
Наконец, поскольку Категории и Папки статей сами являются Статьями, и Статьи могут иметь Отношения друг к другу, Категории могут иметь Отношения к Папкам статей и наоборот, и Категории, Папки статей и Статьи могут иметь Отношения с другими Категориями, Папками статей и Статьями соответственно в определенных альтернативных вариантах осуществления. Однако в различных вариантах осуществления в структурах Папок статей и/или в структурах Категорий запрещены циклы на уровне системы аппаратно-программного интерфейса. Когда структуры Папок статей и Категорий сродни ориентированным графам, варианты осуществления, которые запрещают циклы, сродни ориентированным ациклическим графам (ОАГ), которые согласно математическому определению в области теории графов являются ориентированными графами, в которых ни один путь не может начинаться и оканчиваться в одной и той же вершине.
6. Расширяемость
Платформа хранения должна быть снабжена начальным множеством схем 340, которые описаны выше. Кроме того, согласно, по меньшей мере, некоторым вариантам осуществления, платформа хранения позволяет потребителям, в том числе независимым продавцам программных продуктов (НПП) создавать новые схемы 344 (т.е. новые типы Статей и Вложенных элементов). В этом разделе рассматривается механизм создания таких схем путем расширения типов Статьи и типов Вложенного элемента (или просто типов «элемента»), заданных в начальном множестве схем 340.
Предпочтительно расширение начального множества типов Статей и Вложенных элементов ограничивается следующим образом:
- НПП разрешается вводить новые типы Статьи, т.е. подтип Base.Item;
- НПП разрешается вводить новые расширения, т.е. подтип Base.NestedElement; но
- НПП не может выделять подтипы ни в каких типах (типах Статьи, Вложенного элемента или расширения), определенных начальным множеством схем 340 платформы хранения.
Поскольку тип Статьи или тип Вложенного элемента, определенный начальным множеством схем платформы хранения, может не целиком отвечать потребности приложения НПП, необходимо чтобы НПП могли переделывать тип. Это возможно с помощью понятия Расширений. Расширения - это строго типизированные экземпляры, но (а) они не могут существовать независимо и (b) они должны быть присоединены к Статье или Вложенному элементу.
Помимо решения вопроса расширяемости схемы Расширения также призваны решать вопрос «многотипности». Поскольку в некоторых вариантах осуществления платформа хранения может не поддерживать множественное наследование или перекрытие подтипов, приложения могут использовать Расширения как способ моделирования перекрывающихся экземпляров типов (например, Документ является юридическим документом и одновременно защищенным документом).
а) Расширения статьи
Для обеспечения расширяемости Статьи модель данных дополнительно задает абстрактный тип по имени Base.Extension. Это корневой тип для иерархии типов расширения. Приложения могут выделять подтипы в Base.Extension для создания особых типов расширения.
Тип Base.Extension задан в Базовой схеме следующим образом:
<Type Name="Base.Extension" IsAbstract="True">
<Propety Name="ItemID"
Type="the storage
platformTypes.uniqueidentified"
Nullable="false"
MultiValued="false"/>
<Property Name="ExtensionID"
Type="the storage
platformTypes.uniqueidentified"
Nullable="false"
MultiValued="false"/>
</Type>
Поле ItemID содержит ИД статьи для статьи, с которой связано расширение. Статья с этим ИД статьи должна существовать. Расширение нельзя создать, если статьи с данным ИД статьи не существует. При удалении Статьи все расширения с тем же ИД статьи удаляются. Кортеж (ItemID,ExtensionID) уникальным образом идентифицирует экземпляр расширения.
Структура типа расширения подобна структуре типов статьи:
- Типы расширения имеют поля;
- Поля могут быть примитивными типами или типами вложенного элемента;
- Типы расширения можно подразделять на подтипы.
К типам расширения применяются следующие ограничения:
- Расширения не могут быть источниками и целями отношений;
- Экземпляры типа расширения не могут существовать независимо от статьи;
- Типы расширения нельзя использовать как типы полей в определениях типов платформы хранения.
Не существует ограничений по типам расширений, которые можно связать с данным типом Статьи. Любой тип расширения может расширять любой тип статьи. Когда к статье присоединено несколько экземпляров расширения, они не зависят друг от друга по структуре и поведению.
Сохранение экземпляров расширения и доступ к ним осуществляется независимо от статьи. Все экземпляры типа расширения доступны из глобального вида расширения. Можно составить эффективный запрос, который будет возвращать все экземпляры данного типа расширения независимо от типа статьи, с которой они связаны. API платформы хранения обеспечивает программную модель, которая может сохранять, извлекать и изменять расширения на статьях.
Типы расширения могут быть получены выделением подтипов с использованием модели единичного наследования платформы хранения. Вывод из типа расширения создает новый тип расширения. Структура или поведение расширения не может подменять или заменять структуру или поведения иерархии типов статьи. По аналогии с типами Статьи, к Экземплярам типа расширения можно иметь непосредственный доступ через вид, связанный с типом расширения. ИД статьи для расширения указывает, какой статье они принадлежат и какую статью можно использовать для извлечения соответствующего объекта Статьи из глобального вида Статьи. Расширения рассматриваются как часть статьи в целях операционной согласованности. Копирование/перемещение, резервирование/восстановление и другие общие операции, которые задает платформа хранения, могут действовать на расширениях как на части статьи.
Рассмотрим следующий пример. В множестве типов Windows задан тип «контакт» (Contact).
<Type Name="Contact" BaseType=“Base.Item”>
<Property Name="Name"
Type="String"
Nullable="false"
MultiValued="false"/>
<Property Name="Address"
Type="Address"
Nullable="true"
MultiValued="false"/>
</Type>
Разработчику приложения CRM [управление взаимодействия с потребителями] может понадобиться присоединить расширение приложения CRM к контактам, хранящимся в платформе хранения. Разработчик приложения задает расширение CRM, которое содержит дополнительную структуру данных, которой может манипулировать приложение.
<Type Name="CRMExtension" BaseType="Base.Extension">
<Property Name="CustomerID"
Type="String"
Nullable="false"
MultiValued="false"/>
…
</Type>
Разработчик приложения HR может пожелать также присоединить к «контакту» дополнительные данные. Эти данные не зависят от данных приложения CRM. Разработчик приложения опять же может создать расширение.
<Type Name="HRExtension" EBaseType="Base.Extension">
<Property Name="EmployeeID"
Type="String"
Nullable="false"
MultiValued="false"/>
…
</Type>
CRMExtension и HRExtension представляют собой два независимых расширения, которые можно присоединять к статьям «контакт». Их создание и доступ к ним осуществляется независимо друг от друга.
В вышеприведенном примере поля и методы типа CRMExtension не могут подменять поля или методы иерархии «контактов». Следует отметить, что экземпляры типа CRMExtension можно присоединять к типам Статьи, отличным от «контакта».
При извлечении статьи «контакт» автоматически извлекаются ее расширения статьи. Для данной статьи «контакт», к связанным с ней расширениям статьи можно осуществлять доступ, запрашивая глобальный вид расширения на предмет расширений с тем же ИД статьи.
Ко всем расширениям CRMExtension в системе можно осуществлять доступ через вид типов CRMExtension, независимо от того, какой статье они принадлежат. Все расширения статьи для статьи совместно используют один и тот же ИД статьи. В вышеприведенном примере экземпляр статьи «контакт» и присоединенные CRMExtension и HRExtension ссылаются на один и тот же ИД статьи.
В нижеприведенной таблице приведены сходства и различия между типами Статьи, Расширения и Вложенного элемента:
b) Расширение типов Вложенного элемента
Типы Вложенного элемента не расширяются с помощью того же механизма, что и типы Статьи. Сохранение расширений вложенных элементов и доступ к ним осуществляется с помощью тех же механизмов, что и для полей типов вложенного элемента.
Модель данных определяет корень для типов вложенного элемента под именем Элемент:
<Type Name="Element"
IsAbstract="True">
<Property Name="ElementID"
Type="the storage
platformTypes.uniqueidentifier"
Nullable="false"
MultiValued="false"/>
</Type>
Тип NestedElement наследует от этого типа. Тип элемента «вложенный элемент» дополнительно определяет поле, которое является мультимножеством Элементов.
<Type Name="NestedElement" BaseType="Base.Element"
IsAbstract="True">
<Property Name="Extensions"
Type="Base.Element"
Nullable="false"
MultiValued="true"/>
</Type>
Расширения Вложенного элемента отличаются от расширений статьи по следующим признакам:
- Расширения вложенного элемента не являются типами расширения. Они не принадлежат иерархии типов расширения, корнем которой является тип Base.Extension;
- Расширения вложенного элемента хранятся совместно с другими полями статьи и не являются глобально доступными - нельзя составить запрос, извлекающий все экземпляры данного типа расширения;
- Эти расширения сохраняются таким же образом, как и другие вложенные элементы (статьи). Как и другие вложенные множества, расширения NestedElement хранятся в ТОП. Они доступны через поле «Расширения» (Extensions) типа вложенного элемента.
- Коллекция интерфейсов, используемая для доступа к многозначным свойствам, также используется для доступа и итерации по множеству расширений типов.
В нижеследующей таблице приведены существенные характеристики и различия Расширений статьи и расширений Вложенного элемента.
F. Машина базы данных
Согласно отмеченному выше, хранилище данных реализуется на машине базы данных. В данном варианте осуществления машина базы данных содержит машину реляционной базы данных, которая реализует язык запросов SQL, например машину Microsoft SQL Server, с объектными реляционными расширениями. Этот раздел описывает отображение модели данных, которую реализует хранилище данных, в реляционное хранилище и предоставляет информацию о логическом API, потребляемом клиентами платформы хранения, согласно данному варианту осуществления. Однако понятно, что при использовании разных машин базы данных можно использовать разные отображения. Действительно, помимо реализации концептуальной модели данных платформы хранения на машине реляционной базы данных она также может быть реализована на других типах баз данных, например объектно-ориентированных базах данных или базах данных XML.
Объектно-ориентированная (OO) система баз данных обеспечивает персистентность и транзакции для объектов языка программирования (например, C++, Java). Понятие «статья» платформы хранения хорошо отображается в «объект» в объектно-ориентированных системах, хотя внедренные коллекции придется добавлять к Объектам. Другие концепции типов платформы хранения, например наследование и типы вложенного элемента, также отображаются в объектно-ориентированные системы типов. Объектно-ориентированные системы обычно уже поддерживают идентификацию объектов. Поведения (операции) статей хорошо отображаются в объектные методы. Однако для объектно-ориентированных систем характерен недостаток организационных возможностей и слабые средства поиска. Кроме того, объектно-ориентированные системы не обеспечивают поддержку неструктурированных или частично структурированных данных. Для поддержки описанной здесь полной модели данных платформы хранения в объектную модель данных нужно добавить такие концепции, как отношения, папки и расширения. Кроме того, необходимо реализовать такие механизмы, как продвижения, синхронизации, уведомления и безопасности.
По аналогии с объектно-ориентированными системами базы данных XML, основанные на XSD (определение схемы XML), поддерживают систему типов на основе единичного наследования. Система типов статьи, отвечающая настоящему изобретению, может отображаться в модель типов XSD. XSD также не обеспечивают поддержку поведений. XSD для статей должны дополняться поведениями статей. Базы данных XML имеют дело с единичными документами XSD и испытывают недостаток возможностей организации и широкого поиска. Как и с объектно-ориентированной базой данных, для поддержки описанной здесь модели данных в такие базы данных XML нужно внедрить другие концепции, как-то отношения и папки; кроме того, должны быть реализованы такие механизмы, как синхронизации, уведомления и безопасности.
В отношении нижеследующих подразделов, предусмотрено несколько иллюстраций, облегчающих раскрытие общей информации: на фиг.13 показана схема, иллюстрирующая механизм уведомления. На фиг.14 показана схема, иллюстрирующая пример, в котором две транзакции вставляют новую запись в одно и то же Б-дерево. Фиг.15 иллюстрирует процесс обнаружения изменения данных. На фиг.16 показано иллюстративное дерево директории. На фиг.17 показан пример, в котором существующая папка файловой системы на основе директорий перемещается в хранилище данных платформы хранения.
1. Реализация хранилища данных с использованием ТОП
В данном варианте осуществления машина 314 реляционной базы данных, которая согласно одному варианту осуществления содержит машину Microsoft SQL Server, поддерживает встроенные скалярные типы. Встроенные скалярные типы являются «собственными» и «простыми». Они являются собственными в том смысле, что пользователь не может задавать свои собственные типы, и простыми в том смысле, что они не могут инкапсулировать сложную структуру. Типы, определенные пользователем (ниже ТОП), обеспечивают механизм расширяемости типов за пределы системы собственных скалярных типов, позволяя пользователям расширять систему типов путем задания сложных, структурированных типов. Будучи заданы пользователем, ТОП могут использоваться где угодно в системе типов, где могут использоваться встроенные скалярные типы.
Согласно аспекту настоящего изобретения, схемы платформы хранения отображаются в классы ТОП в хранилище машины базы данных. Статьи хранилища данных отображаются в классы ТОП, выводимые из типа Base.Item. Наподобие Статей, Расширения также отображаются в классы ТОП и используют наследование. Корневым типом расширения является Base.Extension, из которого выводятся все типы расширения.
ТОП является классом CLR - он имеет состояние (т.е. поля данных) и поведение (т.е. процедуры). ТОП задаются с использованием любого управляемого языка - C#, VB.NET и пр. Методы и операторы ТОП можно вызывать в T-SQL в соответствии с экземпляром этого типа. ТОП может быть типом столбца в строке, типом параметра процедуры в T-SQL или типом переменной в T-SQL.
Отображение схем платформы хранения в классы ТОП довольно очевидно на высоком уровне. В общем случае, схема платформы хранения отображается в пространство имен CLR. Тип платформы хранения отображается в класс CLR. Наследование класса CLR отражает наследование типа платформы хранения, и Свойство платформы хранения отображается в свойство класса CLR.
2. Отображение статьи
Если желательно иметь возможность осуществления глобального поиска Статей и поддержки в реляционной базе данных, отвечающей данному варианту осуществления, наследования и возможности подстановки типов, то возможная реализация хранилища статей в хранилище базы данных состоит в сохранении всех Статей в единой таблице со столбцом типа Base.Item. Используя возможность подстановки типов, можно сохранять статьи всех типов, и поиски можно фильтровать по типу и подтипу Статьи с использованием оператора Юкона «относится к (типу)».
Однако в связи с проблемой избыточной нагрузки, сопряженной с таким подходом, в данном варианте осуществления, Статьи делятся по типу верхнего уровня, так что Статьи каждого «семейства» типов хранятся в отдельной таблице. В соответствии с такой схемой разбиения таблица создается для каждого типа Статьи, наследующего непосредственно от Base.Item. Типы, наследующие ниже них, сохраняются в соответствующей таблице семейства типов с использованием возможности подстановки типов, которая описана выше. Специально обрабатывается только первый уровень наследования от Base.Item.
«Теневая» таблица используется для хранения копий глобально искомых свойств для всех Статей. Эта таблица может поддерживаться методом Update() API платформы хранения, посредством которого производятся все изменения данных. В отличие от таблицы семейства типов эта глобальная таблица Статьи содержит только скалярные свойства верхнего уровня Статьи, а не полный объект Статьи ТОП. Глобальная таблица Статьи допускает навигацию к объекту Статьи, хранящемуся в таблице семейства типов, представляя ИД Статьи и ИД Типа. ИД Статьи, в общем случае, уникальным образом идентифицирует Статью в хранилище данных. ИД Типа может отображаться с использованием метаданных, которые здесь не описаны, в имя типа и вид, содержащее Статью. Поскольку отыскание Статьи по ее ИД Статьи может быть общей операцией, как в контексте глобальной таблицы Статьи, так и в противном случае, функция GetItem() обеспечивается для извлечения объекта Статьи по данному ИД статьи для Статьи.
Для удобства доступа и скрытия деталей реализации до возможной степени все запросы Статей можно делать с помощью видов, построенных на описанных здесь таблицах Статей. В частности, виды можно создавать для каждого типа Статьи с помощью соответствующей таблицы семейства типов. Эти виды типов могут выбирать все Статьи соответствующего типа, включая подтипы. Для удобства помимо объекта ТОП, виды могут представлять столбцы для всех полей верхнего уровня этого типа, включая унаследованные поля.
3. Отображение расширений
Расширения весьма похожи на Статьи и имеют некоторые из тех же требований. В качестве корневого типа, поддерживающего наследование, Расширениям свойственны многие из тех же соображений и компромиссов при хранении. Вследствие этого к Расширениям применяется аналогичное отображение семейства типов, а не подход единой таблицы. Конечно, в других вариантах осуществления можно использовать подход единой таблицы. В данном варианте осуществления Расширение связано строго с одной Статьей посредством ИД статьи и содержит ИД расширения, который является уникальным в контексте Статьи. Как и в случае статей, может быть обеспечена функция для извлечения Расширения по его идентификации, которая состоит из пары ИД статьи и ИД расширения. Вид создается для каждого Типа расширения, по аналогии с видами типов Статьи.
4. Отображение вложенных элементов
Вложенные элементы являются типами, которые могут быть внедрены в Статьи, Расширения, Отношения или другие Вложенные элементы для формирования структур с глубоким вложением. Наподобие Статей и Расширений Вложенные элементы реализованы как ТОП, но они хранятся внутри статей и расширений. Поэтому Вложенные элементы не имеют отображения хранения за пределы контейнеров их Статей и Расширений. Другими словами, в системе не существует таблиц, в которых непосредственно хранятся экземпляры типов Вложенных элементов, и нет видов, непосредственно предназначенных для Вложенных элементов.
5. Идентификация объектов
Каждая сущность в модели данных, т.е. каждая Статья, Расширение и Отношение имеет уникальное значение ключа. Статья уникальным образом идентифицируется своим ИД статьи. Расширение уникальным образом идентифицируется составным ключом (ИД статьи, ИД расширения). Отношение идентифицируется составным ключом (ИД статьи, ИД отношения). ИД статьи, ИД расширения и ИД отношения являются значениями GUID.
6. Присвоение имен объектам SQL
Все объекты, созданные в хранилище данных, могут храниться в имени схемы SQL, выведенном из имени схемы платформы хранения. Например, Базовая схема платформа хранения (часто именуемая «базой») может создавать типы в схеме SQL “[System.Storage]”, например, “[System.Storage].Item”. Генерированные имена имеют в качестве префикса спецификатор для исключения конфликтов присвоения имен. При необходимости, восклицательный знак (!) используется в качестве разделителя для каждой логической части имени. В нижеследующей таблице описано соглашение по присвоению имен, используемое для объектов в хранилище данных. Каждый элемент схемы (Статья, Расширение, Отношение и Вид) перечислен совместно с соглашением по присвоению декорированных имен, используемым для доступа к экземплярам в хранилище данных.
AuthorsFromDocument]
7. Присвоение имен столбцам
При отображении любой объектной модели в хранилище возникает возможность конфликтов присвоения имен в связи с дополнительной информацией, сохраняемой совместно с объектом приложения. Во избежание конфликтов присвоения имен все столбцы, не зависящие от типа (столбцы, которые не отображаются напрямую в именованное Свойство в объявлении типа) должны снабжаться префиксом в виде символа подчеркивания (_). В данном варианте осуществления символы подчеркивания (_) запрещены в качестве начального символа любого свойства идентификатора. Кроме того, для унификации присвоения имен между CLR и хранилищем данных все свойства типов платформы хранения или элемента схемы (отношения и пр.) должны начинаться с заглавной буквы.
8. Поисковые виды
Виды обеспечиваются платформой хранения для поиска сохраненного содержимого. Вид SQL предусмотрен для каждой Статьи и Типа расширения. Кроме того, виды предусмотрены для поддержки Отношений и Видов (заданных в Модели данных). Все виды SQL и нижележащие таблицы в платформе хранения доступны только для чтения. Данные можно сохранять или изменять с использованием метода Update() API платформы хранения, как описано более подробно ниже.
Каждый вид, заданный в явном виде в схеме платформы хранения (заданный разработчиком схемы, а не генерированный автоматически платформой хранения), доступен посредством именованного вида SQL [<имя схемы>].[View!<имя вида>]. Например, вид, имеющий имя “BookSales” в схеме “AcmePublisher.Books” доступен с использованием имени “[AcmePublisher.Books].[View!BookSales]”. Поскольку выходной формат вида является настраиваемым для каждого вида (определяется посредством произвольного запроса, обеспеченного стороной, определяющей вид), столбцы непосредственно отображаются на основании определения вида схемы.
Все поисковые виды SQL в хранилище данных платформы хранения используют следующее соглашение по упорядочению для столбцов:
- Логический(е) «ключевой(ые)» столбец(цы) результата вида, как то ИД статьи, ИД элемента, ИД отношения, …;
- Информация метаданных о типе результата, например ИД типа;
- Столбцы отслеживания изменений, например, «создать версию», «обновить версию», …;
- Столбец(цы), зависящий(е) от типа (Свойства объявленного типа);
- Виды, зависящие от типа (виды семейства), также содержат столбец объектов, который возвращает объект.
Члены каждого семейства типов можно искать с использованием последовательности видов Статьи, причем в хранилище данных на каждый тип Статьи приходится один вид. На фиг.28 показана схема, иллюстрирующая концепцию поискового вида Статьи.
а) Статья
Каждый поисковый вид Статьи содержит строку для каждого экземпляра Статьи определенного типа или его подтипов. Например, вид для Документа может возвращать экземпляры Документа, Юридического документа и Обзорного Документа. Согласно этому примеру, виды Статьи можно концептуализировать, как показано на фиг.29.
(1) Главный поисковый вид Статьи
Каждый экземпляр хранилища данных платформы хранения задает особый вид Статьи, именуемый Главным видом статьи. Этот вид обеспечивает основную информацию о каждой Статье в хранилище данных. Вид обеспечивает по одному столбцу для каждого свойства типа Статьи, столбец, описывающий тип Статьи, и несколько столбцов, которые используются для обеспечения информации отслеживания изменений и синхронизации. Главный вид статьи идентифицируется в хранилище данных с использованием имени “[System.Storage].[Master!Item]”.
(2) Типизированные поисковые виды Статьи
Каждый тип Статьи также имеет поисковый вид. Хотя он и аналогичен корневому виду Статьи, этот вид также обеспечивает доступ к объекту Статьи через столбец “_Item”. Каждый типизированный поисковый вид Статьи идентифицируется в хранилище данных с использованием имени [имя схемы].[имя типа статьи]. Например, [AcmeCorp.Doc].[OfficeDoc].
b) Расширения статьи
Все расширения статьи в хранилище WinFS также доступны с использованием поисковых видов.
(1) Главный поисковый вид расширения
Каждый экземпляр хранилища данных определяет особый вид Расширения, именуемый Главным видом расширения. Этот вид обеспечивает основную информацию о каждом Расширении в хранилище данных. Вид имеет по одному столбцу на свойство Расширения, столбец, описывающий тип Расширения, и несколько столбцов, которые используются для обеспечения информации отслеживания изменений и синхронизации. Главный вид расширения идентифицируется в хранилище данных с использованием имени “[System.Storage].[Master!Extension]”.
(2) Типизированные поисковые виды расширения
Каждый Тип расширения также имеет поисковый вид. Хотя он и аналогичен главному виду расширения, этот вид также обеспечивает доступ к объекту Статьи через столбец _Extension. Каждый типизированный поисковый вид расширения идентифицируется в хранилище данных с использованием имени [имя схемы].[Extension!имя типа расширения]. Например, [AcmeCorp.Doc].[Extension!OfficeDocExt].
c) Вложенные элементы
Все вложенные элементы хранятся в экземплярах Статей, Расширений или Отношений. Как таковые они доступны путем запрашивания поискового вида соответствующей Статьи, Расширения или Отношения.
d) Отношения
Согласно описанному выше, Отношения образуют основной блок связи между Статьями в хранилище данных платформы хранения.
(1) Главный поисковый вид отношения
Каждое хранилище данных обеспечивает Главный вид отношения. Этот вид обеспечивает информацию обо всех экземплярах отношения в хранилище данных. Главный вид отношения идентифицируется в хранилище данных с использованием имени “[System.Storage].[Master!Relationship]”.
(2) Поисковые виды экземпляра отношения
Каждое декларированное Отношение также имеет поисковый вид, который возвращает все экземпляры конкретного отношения. Хотя он и аналогичен главному виду отношения, этот вид также обеспечивает именованные столбцы для каждого свойства данных отношения. Каждый поисковый вид экземпляра отношения идентифицируется в хранилище данных с использованием имени [имя схемы].[Relationship!имя отношения]. Например, [AcmeCorp.Doc].[Relationship!DocumentAuthor].
9. Обновления
Все виды в хранилище данных платформы хранения предназначены только для чтения. Для создания нового экземпляра элемента модели данных (статьи, расширения или отношения) или для обновления существующего экземпляра следует использовать методы ProcessOperation или ProcessUpdategram API платформы хранения. Метод ProcessOperation - это одиночная сохраненная процедура, определенная хранилищем данных, которая потребляет «операцию», детализирующую действие, подлежащее выполнению. Метод ProcessUpdategram - это сохраненная процедура, которая берет упорядоченное множество операций, именуемое «апдейтграммой», которые совместно детализируют множество действий, подлежащих выполнению.
Формат операции является расширяемым и обеспечивает различные операции над элементами схемы. Некоторые общие операции включают в себя:
1. Операции над статьями:
а. CreateItem (создает новую статью в контексте отношения внедрения или поддержания);
b. UpdateItem (обновляет существующую статью).
2. Операции над отношениями:
a. CreateRelationship (создает экземпляр отношения ссылки или поддержания);
b. UpdateRelationship (обновляет экземпляр отношения);
c. DeleteRelationship (удаляет экземпляры отношения).
3. Операции над расширениями:
a. CreateExtension (добавляет расширение к существующей Статье);
b. UpdateExtension (обновляет существующее расширение);
c. DeleteExtension (удаляет расширение).
10. Отслеживание изменений и Захоронения
Сервисы отслеживания изменений и захоронения обеспечиваются хранилищем данных, что будет рассмотрено ниже более подробно. В этом разделе кратко описана информация отслеживания изменений, представляемая в хранилище данных.
a) Отслеживание изменений
Каждый поисковый вид, обеспеченный хранилищем данных, содержит столбцы, используемые для обеспечения информации отслеживания изменений; столбцы являются общими для всех видов Статьи, Расширения и Отношения. Виды схема платформы хранения, заданные в явном виде разработчиками схем, не обеспечивают автоматически информацию отслеживания изменений - такая информация обеспечивается опосредованно, через поисковые виды, на которых построен сам вид.
Для каждого элемента в хранилище данных информация отслеживания изменений доступна из двух мест - «главного» вида элемента и «типизированного» вида элемента. Например, информация отслеживания изменений по типу Статьи AcmeCorp.Document.Document доступна из Главного вида статьи “[System.Storage].[Master!Item]” и типизированного поискового вида Статьи [AcmeCorp.Document].[Document].
(1) Отслеживание изменений в “Главных” поисковых видах
Информация отслеживания изменений в главных поисковых видах обеспечивает информацию о создании и обновлении версий элемента, информацию о партнере по синхронизации, создавшем элемент, о партнере по синхронизации, последний раз обновившем элемент, и номера версий от каждого партнера для создания и обновления. Партнеры в отношениях синхронизации (описаны ниже) идентифицируются ключом партнера. Единичный объект ТОП, имеющий имя _ChangeTrackingInfo и тип [System.Storage.Store].ChangeTrackingInfo, содержит всю эту информацию. Тип задан в схеме System.Storage. _ChangeTrackingInfo доступен во всех глобальных поисковых видах для Статьи, Расширения и Отношения. Ниже приведено определение типа ChangeTrackingInfo:
<Type Name=”ChangeTrackingInfo” BaseType=”Base.NestedElement”>
<FieldProperty Name=”CreationLocalTS” Type=”SqlTypes.SqlInt64”
Nullable=”False”/>
<FieldProperty Name=”CreatingPartnerKey” Type=”SqlTypes.SqlInt32”
Nullable=”False”/>
<FieldProperty Name=”CreatingPartnerTS” Type=”SqlTypes.SqlInt64”
Nullable=”False”/>
<FieldProperty Name=”LastUpdateLocalTS” Type=”SqlTypes.SqlInt64”
Nullable=”False”/>
<FieldProperty Name=”LastUpdatingPartnerKey” Type=”SqlTypes.SqlInt32”
Nullable=”False”/>
<FieldProperty Name=”LastUpdatingPartnerTS” Type=”SqlTypes.SqlInt64”
Nullable=”False” />
</Type>
Эти свойства содержат следующую информацию:
(2) Отслеживание изменений в «типизированных» поисковых видах
Помимо обеспечения той же информации, которую обеспечивает глобальный поисковый вид, каждый типизированный поисковый вид обеспечивает дополнительную информацию, касающуюся состояния синхронизации каждого элемента в топологии синхронизации.
b) Захоронения
Хранилище данных обеспечивает информацию захоронения для Статей, Расширений и Отношений. Виды захоронения обеспечивают информацию как о живых, так и захороненных сущностях (статьях, расширениях и отношениях) в одном месте. Виды захоронения для статей и расширений не обеспечивают доступ к соответствующему объекту, тогда как вид захоронения для отношения обеспечивает доступ к объекту отношения (объект отношения равен NULL в случае «захороненного» отношения).
(1) Захоронения Статей
Захоронения Статей извлекаются из системы посредством вида [System.Storage].[Tombstone!Item].
(2) Захоронения расширений
Захоронения расширений извлекаются из системы с использованием вида [System.Storage].[Tombstone!Extension]. Информация отслеживания изменений расширения подобна той, которая обеспечивается для Статей, но дополнена свойством ИД расширения.
(3) Захоронения отношений
Захоронения расширений извлекаются из системы посредством вида [System.Storage].[Tombstone!Relationship]. Информация захоронения расширений подобна той, которая обеспечена для Расширений. Однако обеспечивается дополнительная информация ссылки на целевую статью для экземпляра отношения. Кроме того, выбирается объект отношения.
(4) Очистка захоронения
Во избежание неограниченного роста информации захоронения хранилище данных обеспечивает задание очистки захоронения. Это задание определяет, когда информацию захоронения можно аннулировать. Задание вычисляет границу локального создания/обновления версии, после чего усекает информацию захоронения, аннулируя все более ранние захороненные версии.
11. API и функции помощника
Отображение Базы также обеспечивает ряд функций помощника. Эти функции обеспечиваются в помощь общим операциям над моделью данных.
a) Функция [System.Storage].GetItem
Возвращает объект Статьи при данном ИД статьи
//
Item GetItem (ItemId ItemId)
b) Функция [System.Storage].GetExtension
// Возвращает объект расширения при данных ИД статьи и ИД расширения
//
Extension GetExtension (ItemId ItemId, ExtensionId ExtensionId)
c) Функция [System.Storage].GetRelationship
// Возвращает объект отношения при данных ИД статьи и ИД отношения
//
Relationship GetRelationship (ItemId ItemId, RelationshipId RelationshipId)
12. Метаданные
В Хранилище представлены два типа метаданных: метаданные экземпляра (тип Статьи и пр.) и метаданные типа.
a) Метаданные схемы
Метаданные схемы хранятся в хранилище данных как экземпляры типов Статьи из схемы метаданных.
b) Метаданные экземпляра
Метаданные экземпляра используются приложением для запрашивания типа Статьи и находят расширения, связанные со Статьей. При данном ИД статьи для Статьи, приложение может запросить, чтобы глобальный вид статьи возвратил тип статьи, и использовать это значение, чтобы запросить, чтобы вид Meta.Type возвратил информацию об объявленном типе Статьи. Например,
// Возвратить метаданные объекта Статьи для данного экземпляра Статьи
//
SELECT m._Item AS metadataInfoObj
FROM [System.Storage].[Item] i INNER JOIN [Meta].[Type] m ON i._TypeId=m.ItemId
WHERE i.ItemId = @ItemId
G. Безопасность
В общем случае, все защищаемые объекты организуют свои права доступа с использованием формата маски доступа, показанного на фиг.26. В этом формате 16 младших битов предназначены для прав доступа, зависящих от объекта, следующие 7 битов предназначены для стандартных прав доступа, которые применяются к большинству типов объектов, и 4 старших бита используются для задания общих прав доступа, которые каждый тип объекта может отображать в множество стандартных и зависящих от объекта прав. Бит «доступ к системной безопасности» соответствует праву доступа к SACL объекта.
В структуре маски доступа, изображенной на фиг.26, права, зависящие от статьи, размещены в секции «права, зависящие от статьи» (16 младших битов). Поскольку в данном варианте осуществления платформа хранения представляет два множества API для администрирования безопасности API Win32 и платформы хранения, права, зависящие от объекта, файловой системы следует рассматривать в порядке мотивации конструирования прав, зависящих от объекта, платформы хранения.
Модель безопасности для платформы хранения, отвечающей настоящему изобретению, полностью описана в родственных заявках, включенных в настоящее описание посредством ссылки. В этой связи на фиг.27 (части a, b и c) изображена новая идентично защищенная область безопасности, вырезанная из существующей области безопасности, согласно одному варианту осуществления модели безопасности.
Н. Уведомления и отслеживание изменений
Согласно еще одному аспекту настоящего изобретения, платформа хранения обеспечивает функцию уведомлений, которая позволяет приложениям отслеживать изменения данных. Эта особенность главным образом предназначена для приложений, которые поддерживают временные состояния или выполняют бизнес-логику на событиях изменения данных. Приложения регистрируются для уведомлений на статьях, расширениях статьи и отношений статьи. Уведомления доставляются асинхронно после совершения изменений данных. Приложения могут фильтровать уведомления по статье, расширению и типу отношения, а также типу операции.
Согласно одному варианту осуществления, API 322 платформы хранения обеспечивает два вида интерфейсов для уведомлений. Во-первых, приложения регистрируют простые события изменения данных, вызванные изменениями в статьях, расширениях статьи и отношений статьи. Во-вторых, приложения создают объекты «наблюдатель» для отслеживания множеств статей, расширений статей и отношений между статьями. Состояние объекта наблюдателя можно сохранять и повторно создавать после системной ошибки или после того, как система пребывала в автономном режиме в течение продолжительного периода времени. Одиночное уведомление может отражать множество обновлений.
Дополнительные подробности, касающиеся этой функции, описаны в родственных заявках, включенных в настоящее описание посредством ссылки.
I. Синхронизация
Согласно еще одному аспекту настоящего изобретения, платформа хранения обеспечивает сервис 330 синхронизации, который (i) позволяет множеству экземпляров платформы хранения (каждый имеет собственное хранилище 302 данных) синхронизировать части своего содержимого согласно гибкому множеству правил и (ii) предоставляет третьим сторонам инфраструктуру для синхронизации хранилища данных платформы хранения, отвечающей настоящему изобретению, с другими источниками данных, которые реализуют протоколы прав собственности.
Синхронизация между платформами хранения происходит среди группы участвующих дубликатов. Например, согласно фиг.3, может понадобиться обеспечить синхронизацию между хранилищем 302 данных платформы 300 хранения и другим удаленным хранилищем 338 данных под управлением другого экземпляра платформы хранения, возможно, действующего в другой компьютерной системе. Полное членство этой группы не обязательно известно любому данному дубликату в любой данный момент времени.
Разные дубликаты могут производить изменения независимо (т.е. параллельно). Этот процесс синхронизации по определению состоит в том, что каждому дубликату становятся известны изменения, произведенные другими дубликатами. Эта функция синхронизации по природе своей предусматривает множество задающих элементов.
Функция синхронизации согласно настоящему изобретению позволяет дубликатам:
- Определять, о каких изменениях осведомлен другой дубликат;
- Запрашивать информацию об изменениях, о которых этот дубликат не знает;
- Передавать информацию об изменениях, о которых не знает другой дубликат;
- Определять, когда два изменения конфликтуют друг с другом;
- Применять изменения локально;
- Передавать разрешения конфликтов другим дубликатам, чтобы гарантировать сходимость; и
- Разрешать конфликты на основании заданных политик для разрешения конфликтов.
1. Синхронизация между платформами хранения
Основное применение сервиса 330 синхронизации платформы хранения, отвечающей настоящему изобретению, состоит в синхронизации множества экземпляров платформы хранения (каждый из которых имеет собственное хранилище данных). Сервис синхронизации действует на уровне схем платформы хранения (а не на более низком уровне таблиц машины 314 базы данных). Так, например, «Границы» используются для определения множеств синхронизации, что рассмотрено ниже.
Сервис синхронизации действует по принципу «чистых изменений». Вместо того, чтобы записывать и отправлять отдельные операции (например, с транзакционным дублированием), сервис синхронизации отправляет конечный результат этих операций, таким образом, зачастую объединяя результаты множества операций в единое результирующее изменение.
Сервис синхронизации, в общем случае, не учитывает границы транзакции. Другими словами, если два изменения произведены в хранилище данных платформы хранения в одной транзакции, нет гарантии, что эти изменения применяются ко всем остальным дубликатам атомарно - одно может происходить без другого. Исключением из этого принципа является то, что если два изменения произведены над одной и той же Статьей в одной и той же транзакции, то эти изменения гарантированно направляются и применяются к другим дубликатам атомарно. Таким образом, Статьи являются блоками согласованности для сервиса синхронизации.
a) Приложения, управляющие синхронизацией
Любое приложение может соединяться с сервисом синхронизации и инициировать операцию синхронизации. Такое приложение обеспечивает все параметры, необходимые для осуществления синхронизации (см. профиль синхронизации ниже). Такие приложения будем называть приложениями, управляющими синхронизацией (ПУС).
При синхронизации двух экземпляров платформы хранения синхронизация инициируется, с одной стороны, ПУС. Это ПУС предписывает локальной службе синхронизации синхронизироваться с удаленным партнером. С другой стороны, сервис синхронизации активизируется сообщениями, отправленными сервисом синхронизации с машины-отправителя. Он реагирует на основании устойчивой информации конфигурации (см. отображения ниже), имеющейся на машине-получателе. Сервис синхронизации может запускаться по расписанию или в ответ на события. В этих случаях сервис синхронизации, реализующий расписание, становится ПУС.
Для обеспечения синхронизации нужно выполнить два этапа. Во-первых, разработчик схемы должен аннотировать схему платформы хранения надлежащей семантикой синхронизации (указывающей блоки изменения, согласно описанному ниже). Во-вторых, синхронизация должна быть правильно сконфигурирована на всех машинах, имеющих экземпляр платформы хранения, который должен участвовать в синхронизации (согласно описанному ниже).
b) Аннотация схемы
Основной концепцией службы синхронизации является концепция Блока изменения. Блок изменения - это мельчайший фрагмент схемы, который индивидуально отслеживается платформой хранения. Для каждого Блока изменения сервис синхронизации может иметь возможность определять, изменился ли он после последней синхронизации.
Указание Блоков изменения в схеме служит нескольким целям. Во-первых, оно определяет, в какой степени сервис синхронизации обменивается информацией. Когда в Блоке изменения производится изменение, Блок изменения целиком отправляется другим дубликатам, поскольку сервис синхронизации не знает, какая часть Блока изменения изменилась. Во-вторых, оно определяет степень дискретизации обнаружения конфликта. Когда два параллельных изменения (эти термины подробно определены в последующих разделах) производятся в одном и том же блоке изменения, сервис синхронизации создает конфликт; с другой стороны, если параллельные изменения производятся в разных блоках изменения, никакой конфликт не создается, и изменения автоматически сливаются. В-третьих, оно сильно влияет на объем метаданных, поддерживаемых системой. Большая часть метаданных сервиса синхронизации поддерживается для каждого Блока изменения; таким образом, чем мельче Блоки изменения, тем больше служебная нагрузка синхронизации.
Определение Блоков изменения требует нахождения правильных компромиссов. По этой причине сервис синхронизации позволяет разработчикам схемы участвовать в этом процессе.
В одном варианте осуществления сервис синхронизации не поддерживает Блоки изменения, которые больше элемента. Однако, он поддерживает возможность для разработчиков схемы задавать блоки изменения более мелкие, чем элемент, а именно группировать множество атрибутов элемента в отдельный Блок изменения. В этом варианте это осуществляется с использованием следующего синтаксиса:
<Type Name="Appointment" MajorVersion="1" MinorVersion="0"ExtendsType="Base.Item"
ExtendsVersion="1">
<Field Name="MeetingStatus“ Type="the storageplatformTypes.uniqueidentifier Nullable="False"/>
<Field Name="OrganizerName“ Type="the storageplatformTypes.nvarchar(512)" Nullable="False"/>
<Field Name="OrganizerEmail“ Type="the storageplatformTypes.nvarchar(512)"
TypeMajorVersion="1“ MultiValued="True"/>
…
<ChangeUnit Name=”CU_Status”>
<Field Name=”MeetingStatus”/>
</ChangeUnit>
<ChangeUnit Name=”CU_Organizer”/>
<Field Name=”OrganizerName”/>
<Field Name=”OrganizerEmail”/>
</ChangeUnit>
…
</Type>
c) Конфигурация синхронизации
Группа партнеров платформы хранения, которые желают поддерживать определенные части своих данных в синхронизме, называются сообществом синхронизации. Хотя члены сообщества хотят оставаться в синхронизме, им не обязательно представлять данные точно одинаковым образом; другими словами, партнеры по синхронизации могут преобразовывать данные, которые они синхронизируют.
В сценарии взаимодействия равноправных сущностей для равноправных сущностей нецелесообразно поддерживать отображения преобразования для всех своих партнеров. Вместо этого сервис синхронизации пользуется подходом, предусматривающим определение “папок сообщества”. Папка сообщества - это абстракция, которая представляет гипотетическую “совместно используемую папку”, с которой синхронизируются все члены сообщества.
Это понятие лучше всего проиллюстрировать на примере. Если Джо хочет поддерживать папки «My Documents» нескольких своих компьютеров в синхронизме, он задает папку сообщества под именем, например, «JoesDocuments». Затем на каждом компьютере Джо конфигурирует отображение между гипотетической папкой JoesDocuments и локальной папкой My Documents. После этого когда компьютеры Джо синхронизированы друг с другом, они взаимодействуют в терминах документов в папке JoesDocuments, а не своих локальных статей. Таким образом, все компьютеры Джо понимают друг друга без необходимости знать, кем являются другие - папка сообщества становится лингва-франка сообщества синхронизации.
Конфигурирование сервиса синхронизации состоит из трех этапов: (1) задание отображений между локальными папками и папками сообщества; (2) задание профилей синхронизации, которые определяют, что синхронизируется (например, кто с кем синхронизируется и какие подмножества нужно передавать, а какие принимать); и (3) задание расписаний, по которым должен запускаться каждый из различных профилей синхронизации, или запуск их вручную.
(1) Отображения папки сообщества
Отображения папки сообщества хранятся в файлах конфигурации XML на отдельных машинах. Каждое отображение имеет следующую схему:
/mappings/communityFolder
Этот элемент присваивает имя папке сообщества, для которой предназначено это отображение. Имя подчиняется правилам синтаксиса для Папок.
/mappings/localFolder
Этот элемент присваивает имя локальной папке, в которую преобразуется отображение. Имя подчиняется правилам синтаксиса для Папок. Чтобы отображение было действительным, папка уже должна существовать. Благодаря этому отображению статьи в этой паке считаются синхронизированными.
/mappings/transformations
Этот элемент задает, как преобразовывать статьи из папки сообщества в локальную папку и обратно. Если папка отсутствует или пуста, никаких преобразований не осуществляется. В частности, это значит, что никакие ИД не отображаются. Эта конфигурация в основном полезна для создания кэша Папки.
/mappings/transformations/mapIDs
Этот элемент запрашивает, чтобы вновь генерированные локальные ИД были присвоены всем статьям, отображенным из папки сообщества, вместо повторного использования идентификаторов сообщества. Среда выполнения синхронизации будет поддерживать отображения ИД для преобразования статей в обоих направлениях.
/mappings/transformations/localRoot
Этот элемент запрашивает, чтобы все корневые статьи в папке сообщества были сделаны дочерними по отношению к указанному корню.
/mappings/runAs
Этот элемент контролирует, под чьим началом обрабатываются запросы относительно отображения. В случае отсутствия предполагается отправитель.
/mappings/runAs/sender
Наличие этого элемента указывает, что отправитель сообщений для этого отображения должен быть неперсонифицированным и запросы обрабатываются под его ответственность.
(2) Профили
Профиль синхронизации - это полное множество параметров, необходимых для запуска синхронизации. ПУС передает его в среду выполнения синхронизации, чтобы инициализировать синхронизацию. Профили синхронизации для синхронизации между платформами хранения содержат следующую информацию:
- Локальную папку, служащую источником и пунктом назначения для изменений;
- Имя удаленной папки для синхронизации - эта Папка должна быть опубликована от удаленного партнера путем отображения согласно описанному выше;
- Направление - сервис синхронизации поддерживает синхронизацию с возможностью только отправки, только приема и отправки/приема;
- Локальный фильтр - выбирает, какую локальную информацию отправить удаленному партнеру. Выражается как запрос платформы хранения относительно локальной папки;
- Удаленный фильтр - выбирает, какую удаленную информацию извлечь из уделенного партнера - выражается как запрос платформы хранения относительно папки сообщества;
- Преобразования - задает, как преобразовывать статьи в локальный формат и из локального формата;
- Локальная безопасность - указывает, подлежат ли изменения, извлеченные из удаленной конечной точки, применению по разрешению удаленной конечной точки (неперсонифицированной) или пользователя, инициирующего синхронизацию локально; и
- Политика разрешения конфликтов - указывает, следует ли конфликты отбрасывать, регистрировать или автоматически разрешать - в последнем случае она указывает, какой механизм разрешения конфликтов использовать, а также параметры конфигурации для него.
Сервис синхронизации обеспечивает класс среды выполнения CLR, который обеспечивает возможность простого построения Профилей синхронизации. Профили также можно сериализовать в файлы XML и из них для простого сохранения (часто совместно с расписаниями). Однако в платформе хранения нет стандартного места, где хранятся все профили; ПУС предоставляется возможность построения профиля на месте даже без постоянного его сохранения. Заметим, что для инициирования синхронизации не обязательно иметь локальное отображение. В профиле может быть задана вся информация синхронизации. Однако отображение требуется для ответа на запросы синхронизации, инициированные удаленной стороной.
(3) Расписания
В одном варианте осуществления сервис синхронизации не обеспечивает свою собственную инфраструктуру диспетчеризации. Вместо этого для осуществления этой задачи он опирается на другой компонент - Windows Scheduler, входящий в состав операционной системы Microsoft Windows. Сервис синхронизации включает в себя утилиту командной строки, которая действует как ПУС и запускает синхронизацию на основании профиля синхронизации, сохраненного в файле XML. Эта утилита весьма упрощает конфигурирование Windows Scheduler для запуска синхронизации либо по расписанию либо в ответ на события, например входа пользователя в систему или его выхода.
d) Обработка конфликтов
Обработка конфликтов в сервисе синхронизации делится на три стадии: (1) обнаружение конфликта, которое происходит в момент применения изменения - этот этап определяет, можно ли безопасно применить изменение; (2) автоматическое разрешение и регистрация конфликта - на этом этапе (который осуществляется сразу после обнаружения конфликта) обращаются к автоматическим механизмам разрешения конфликтов, чтобы посмотреть, можно ли разрешить конфликт - если нет, конфликт, в необязательном порядке, можно зарегистрировать; и (3) инспектирование и разрешение конфликта - этот этап имеет место, если некоторые конфликты были зарегистрированы, и происходит вне контекста сеанса синхронизации - в это время зарегистрированные конфликты можно разрешить и удалить из журнала.
(1) Обнаружение конфликта
В данном вариант осуществления сервис синхронизации обнаруживает два типа конфликтов: на основе знания и на основе ограничения.
(а) Конфликты на основе знания
Конфликт на основе знания происходит, когда два дубликата производят независимые изменения в одном и том же Блоке изменения. Два изменения называются независимыми, если они осуществляются без знания друг о друге, иными словами, версия первого не покрывается знанием второго и наоборот. Сервис синхронизации автоматически обнаруживает все такие конфликты, основанные на знании дубликатов, что описано выше.
Иногда полезно рассматривать конфликты как вилки в истории версий для блоков изменения. Если за время жизни блоков изменения не происходит конфликтов, его история версий является простой цепью - каждое изменение происходит после предыдущего. В случае конфликта на основе знания два изменения происходят параллельно, приводя к расщеплению цепи и созданию дерева версий.
(b) Конфликты на основе ограничения
Имеются случаи, когда независимые изменения нарушают ограничение целостности при совместном применении. Например, два дубликата, создающие файл с одним и тем же именем в одной и той же директории, могут привести к возникновению такого конфликта.
Конфликт на основе ограничения предусматривает два независимых изменения (совсем как основанное на знании), но они не влияют на один и тот же блок изменения. Вместо этого они влияют на разные блоки изменения, но с ограничением, существующим между ними.
Сервис синхронизации обнаруживает нарушения ограничений в момент применения изменения и автоматически создает конфликты на основе ограничения. Разрешение конфликтов на основе ограничения обычно требует настроенного кода, который модифицирует изменения таким образом, чтобы не нарушать ограничения. Сервис синхронизации не обеспечивает механизм общего назначения, который осуществляет это.
(2) Обработка конфликта
При обнаружении конфликта сервис синхронизации может совершать одно из трех действий (выбранных инициатором синхронизации в Профиле синхронизации): (1) отменить изменение, возвратить его отправителю; (2) зарегистрировать конфликт в журнале конфликтов; или (3) автоматически разрешить конфликт.
В случае отмены изменения сервис синхронизации действует так, как если бы изменение не поступало на дубликат. Отправителю направляется отрицательное квитирование. Эта политика разрешения в основном полезна на заголовочных дубликатах (например, файловых серверах), где регистрация конфликтов невозможна. Вместо этого такие дубликаты вынуждают других иметь дело с конфликтами, отбрасывая их.
Инициаторы синхронизации конфигурируют разрешение конфликтов в своих Профилях синхронизации. Сервис синхронизации поддерживает объединение множества механизмов разрешения конфликтов в едином профиле следующими способами: во-первых, определяя список механизмов разрешения конфликтов, которые нужно пробовать один за другим, пока один из них не приведет к успеху; и во-вторых, ассоциируя механизмы разрешения конфликтов с типами конфликтов, например, направляя конфликты на основе знания между обновлениями на один механизм разрешения конфликтов, а все остальные конфликты - в журнал регистрации.
(a) Автоматическое разрешение конфликтов
Сервис синхронизации обеспечивает ряд принятых по умолчанию механизмов разрешения конфликтов. Этот список включает в себя:
- Локальные выигрыши: игнорировать входящие изменения в случае конфликта с локально сохраненными данными;
- Удаленные выигрыши: игнорировать локальные данные в случае конфликта с входящими изменениями;
- Выигрыши последнего записывающего: выбрать либо локальные выигрыши либо удаленные выигрыши для каждого блока изменения на основании метки времени изменения (заметим, что сервис синхронизации, в общем случае, не опирается на значения часов; этот механизм разрешения конфликтов является единственным исключением из этого правила);
- Детерминистический: выбрать победителя таким образом, чтобы он гарантированно был одинаковым на всех дубликатах, а в противном случае не имел смысла - один вариант осуществления сервисов синхронизации использует лексикографические сравнения ИД партнеров для реализации этой особенности.
Кроме того, НПП могут реализовывать и устанавливать свои собственные механизмы разрешения конфликтов. Специализированные механизмы разрешения конфликтов могут принимать параметры конфигурации; ПУС должно указывать такие параметры в разделе Разрешение конфликтов Профиля синхронизации.
Когда механизм разрешения конфликтов обрабатывает конфликт, он возвращает список операций, которые необходимо выполнить (вместо конфликтующего изменения) обратно в среду выполнения. Затем сервис синхронизации применяет эти операции, принадлежащей настройке удаленного знания, чтобы оно включало в себя то, что учитывается механизмом обработки конфликтов.
Возможно, что во время применения этого разрешения будет обнаружен другой конфликт. В этом случае новый конфликт должен быть разрешен до возобновления первоначальной обработки.
При рассмотрении конфликтов как ответвлений в истории версий статьи разрешения конфликтов можно рассматривать как соединения - объединение двух ветвей для образования одной точки. Таким образом, разрешения конфликтов превращают истории версий в ОНГ.
(b) Регистрация конфликтов
Очень специфический вид механизма разрешения конфликтов представляет собой Регистратор конфликтов. Сервис синхронизации регистрирует конфликты как Статьи типа ConflictRecord. Эти записи связываются со статьями, находящимися в конфликте (если сами статьи не удалены). Каждая запись конфликта содержит: входящее изменение, вызвавшее конфликт; тип конфликта: обновление-обновление, обновление-удаление, удаление-обновление, вставка-вставка или ограничение; и версию входящего изменения и знание отправившего его дубликата. Зарегистрированные конфликты доступны для инспектирования и разрешения согласно описанному выше.
(c) Инспектирование и разрешение конфликтов
Сервис синхронизации обеспечивает API для приложений, чтобы проверять журнал конфликтов и предлагать разрешения указанных в нем конфликтов. API позволяет приложению перечислять все конфликты или конфликты, относящиеся к данной Статье. Он также позволяет таким приложениям разрешать зарегистрированные конфликты одним из трех способов: (1) удаленные выигрыши - прием зарегистрированного изменения и переписывание конфликтующего локального изменения; (2) локальные выигрыши - игнорирование конфликтующих частей зарегистрированного изменения; и (3) предложение нового изменения - когда приложение предлагает слияние, которое, по его мнению, разрешает конфликт. После того как конфликты разрешены приложением, сервис синхронизации удаляет их из журнала.
(d) Сходимость дубликатов и распространение разрешений конфликтов
В сложных сценариях синхронизации один и тот же конфликт может быть обнаружен на множестве дубликатов. Если это происходит, может иметь место следующее: (1) конфликт может быть разрешен на одном дубликате, и разрешение направлено на другой; (2) конфликт автоматически разрешается на обоих дубликатах; или (3) конфликт разрешается на обоих дубликатах вручную (через API инспектирования конфликтов).
Чтобы гарантировать сходимость, сервис синхронизации пересылает разрешения конфликтов на другие дубликаты. Когда изменение, разрешающее конфликт, поступает на дубликат, сервис синхронизации автоматически находит в журнале записи любых конфликтов, которые разрешаются этим обновлением, и исключает их. В этом смысле разрешение конфликта на одном дубликате связано со всеми остальными дубликатами.
Если для одного и того же конфликта разные дубликаты выбирают разных победителей, то сервис синхронизации применяет принцип связывания разрешений конфликта и выбирает одно из двух разрешений, которое автоматически выигрывает перед другим. Победитель выбирается детерминистически, что гарантированно приводит к одним и тем же результатам каждый раз (один вариант осуществления использует лексикографические сравнения ИД дубликатов).
Если для одного и того же конфликта разные дубликаты предлагают разные «новые изменения», то сервис синхронизации обрабатывает этот новый конфликт как особый конфликт и использует Регистратор конфликтов для предотвращения его распространения на другие дубликаты. Такая ситуация обычно возникает при разрешении конфликта вручную.
2. Синхронизация с хранилищами данных платформы без хранения
Согласно одному аспекту платформы хранения, отвечающей настоящему изобретению, платформа хранения обеспечивает архитектуру для НПП для реализации Адаптеров синхронизации, которые позволяют платформе хранения синхронизироваться такими известными системами, как Microsoft Exchange, AD, Hotmail и пр. Адаптеры синхронизации пользуются многими Услугами синхронизации, предоставляемыми сервисом синхронизации, как описано ниже.
Несмотря на название, Адаптеры синхронизации не обязательно реализовать как модули, внедряемые в некоторую архитектуру платформы хранения. При желании, “адаптером синхронизации” может быть просто любое приложение, которое использует интерфейсы среды выполнения сервиса синхронизации для получения таких услуг, как перечисление и применение изменений.
Чтобы другим было проще конфигурировать и запускать синхронизацию с данной машиной базы данных, предпочтительно, чтобы создатели Адаптеров синхронизации представляли стандартный интерфейс Адаптера синхронизации, который запускает синхронизацию с учетом Профиля синхронизации, как описано выше. Профиль предоставляет адаптеру информацию конфигурации, часть которой адаптеры передают среде выполнения синхронизации для управления сервисами среды выполнения (например, Папка, подлежащая синхронизации).
a) Услуги синхронизации
Сервис синхронизации предоставляет создателям адаптеров ряд услуг синхронизации. Для оставшейся части этого раздела удобно называть машину, на которой платформа хранения осуществляет синхронизацию, «клиентом», а машину базы данных платформы без хранения - «сервером».
(1) Перечисление изменений
На основании данных отслеживания изменений, которыми манипулирует сервис синхронизации, Перечисление изменений позволяет адаптерам синхронизации легко перечислять изменения, произошедшие в Папке хранилища данных с того времени, как последний раз была предпринята попытка синхронизации с этим партнером.
Изменения перечисляются на основании концепции «анкера» - непрозрачной структуры, которая представляет информацию о последней синхронизации. Анкер принимает форму Знания платформы хранения согласно описанному в следующих разделах. Адаптеры синхронизации, использующие услуги перечисления изменений, делятся на две обширные категории: те, которые используют «сохраненные анкеры», и те, которые используют «подаваемые анкеры».
Разница состоит в том, где хранится информация о последней синхронизации - на клиенте или на сервере. Адаптерам часто проще хранить эту информацию на клиенте - машина базы данных часто неспособна с удобством сохранять эту информацию. С другой стороны, если множество клиентов синхронизируются с одной и той же машиной базы данных, сохранение этой информации на клиенте неэффективно и в некоторых случаях некорректно - один клиент может не знать об изменениях, которые другой клиент уже протолкнул на сервер. Если адаптер хочет использовать анкер серверного хранения, то адаптеру нужно подать его обратно на платформу хранения во время перечисления изменений.
Чтобы платформа хранения поддерживала анкер (либо для локального либо для удаленного хранения), платформе хранения должно быть известно об изменениях, успешно примененных на сервере. Эти и только эти изменения могут быть включены в анкер. В ходе перечисления изменений Адаптеры синхронизации используют интерфейс квитирования, чтобы сообщать, какие изменения успешно применены. В конце синхронизации адаптеры, использующие поданные анкеры, должны считывать новый анкер (который включает в себя все успешно примененные изменения) и передавать их своей машине базы данных.
Зачастую адаптерам приходится сохранять данные, относящиеся к адаптеру, совместно со статьями, которые представляют для них интерес, в хранилище данных платформы хранения. Общими примерами таких данных являются удаленные ИД и удаленные версии (метки времени). Служба синхронизации обеспечивает механизм хранения этих данных, и Перечисление изменений обеспечивает механизм приема этих дополнительных данных совместно с возвращаемыми изменениями. Это в большинстве случаев исключает необходимость для адаптеров в повторном запрашивании базы данных.
(2) Применение изменений
Применение изменений позволяет Адаптерам синхронизации применять изменения, принятые от их машины базы данных, к локальным платформам хранения. Адаптеры выполняются для преобразования изменений в схему платформы хранения. На фиг.24 проиллюстрирован процесс, посредством которого из схемы платформы хранения генерируются классы API платформы хранения.
Основная функция применения изменений состоит в автоматическом обнаружении конфликтов. Как и в случае синхронизации между Платформами хранения, конфликт определяется как два перекрывающихся изменения, произведенных без знания друг о друге. Когда адаптеры используют Применение изменений, они должны указывать анкер по отношению к которому осуществляется обнаружение конфликта. Применение изменений создает конфликт в случае обнаружения перекрывающегося локального изменения, не покрытого знанием адаптера. По аналогии с Перечислением изменений адаптеры могут использовать либо сохраненные либо подаваемые анкеры. Применение изменений поддерживает эффективное сохранение метаданных, относящихся к адаптеру. Такие данные могут присоединяться адаптером к применяемым изменениям и могут сохраняться сервисом синхронизации. Данные могут возвращаться при следующем перечислении изменений.
(3) Разрешение конфликтов
Описанные выше механизмы Разрешения конфликтов (опции регистрации и автоматического разрешения) доступны также и адаптерам синхронизации. Адаптеры синхронизации могут определять стратегию разрешения конфликтов при применении изменений. После определения конфликты могут передаваться указанному манипулятору конфликтов и разрешаться (если возможно). Конфликты также могут регистрироваться. Возможно, что адаптер может обнаруживать конфликт при попытке применения локального изменения к машине базы данных. В этом случае адаптер может по-прежнему передавать конфликт среде выполнения синхронизации для его разрешения в соответствии со стратегией. Кроме того, Адаптеры синхронизации могут запрашивать, чтобы любые конфликты, обнаруженные сервисом синхронизации, передавались им обратно для обработки. Это особенно удобно в случае, когда машина базы данных способна сохранять или разрешать конфликты.
b) Реализация адаптера
Хотя некоторые «адаптеры» являются просто приложениями, использующими интерфейсы среды выполнения, предпочтительно, чтобы адаптеры реализовали стандартные интерфейсы адаптера. Эти интерфейсы позволяют Приложениям, управляющим синхронизацией, запрашивать, чтобы адаптер осуществлял синхронизацию согласно данному Профилю синхронизации; отменял действующую синхронизацию; и принимал отчет о ходе выполнения (процент выполнения) для действующей синхронизации.
3. Безопасность
Сервис синхронизации стремится как можно меньше изменять модель безопасности, реализованную платформой хранения. Вместо того чтобы определять новые права на синхронизацию, используются существующие права. В частности,
- Всякий, кто может читать Статью хранилища данных, может перечислять изменения для этой статьи;
- Всякий, кто может записывать в Статью хранилища данных, может применять изменения к этой Статье; и
- Всякий, кто может расширять Статью хранилища данных, может ассоциировать с этой статьей метаданные синхронизации.
Сервис синхронизации не поддерживает защищенную информацию авторства. Когда изменения производятся на дубликате A пользователем U и пересылаются дубликату B, тот факт, что изменение первоначально произведено на А (или произведено U), утрачивается. Если В пересылает это изменение дубликату C, это производится от имени В, а не от имени А. Это приводит к следующему ограничению: если дубликату не доверено делать свои собственные изменения в статье, он не может пересылать изменения, сделанные другими.
При инициировании сервиса синхронизации это делается Приложением, управляющим синхронизацией. Сервис синхронизации имитирует идентификацию ПУС и осуществляет все операции (как локально, так и удаленно) от его имени. Для примера заметим, что пользователь U не может заставить локальный сервис синхронизации извлечь изменения из удаленной платформы хранения для статей, к которым пользователь U не имеет доступа для чтения.
4. Управляемость
Контроль распределенной общности дубликатов является сложной проблемой. Сервис синхронизации может использовать алгоритм «заметания» для сбора и распределения информации о статусе дубликатов. Свойства алгоритма заметания гарантируют, что информация обо всех сконфигурированных дубликатах в конечном счете будет собрана и что сбойные (неотвечающие) дубликаты будут обнаружены.
Эта информация контроля в масштабах сообщества делается доступной на каждом дубликате. Инструменты контроля можно запускать на произвольно выбранном дубликате, чтобы проверять эту информацию контроля и принимать административные решения. Любые изменения конфигурации должны производиться непосредственно на задействованных дубликатах.
J. Возможность взаимодействия с традиционной файловой системой
Согласно отмеченному выше платформа хранения, отвечающая настоящему изобретению, согласно, по меньшей мере, некоторым вариантам осуществления реализована как неотъемлемая часть системы аппаратно-программного интерфейса компьютерной системы. Например, платформа хранения, отвечающая настоящему изобретению, может быть реализована как неотъемлемая часть операционной системы, например, семейства операционных систем Microsoft Windows. В этом случае API платформы хранения становится частью API операционной системы, посредством которых прикладные программы взаимодействуют с операционной системой. Таким образом, платформа хранения становится средством, с помощью которого прикладные программы сохраняют информацию в операционной системе, и, следовательно, модель данных, основанная на статьях, платформы хранения заменяет традиционную файловую систему такой операционной системы. Например, будучи реализованной в семействе операционных систем Microsoft Windows, платформа хранения может заменить файловую систему NTFS, реализованную в этой операционной системе. В настоящее время прикладные программы обращаются к службам файловой системы NTFS через API Win32, представляемые семейством операционных систем Windows.
Однако осознавая, что полная замена файловой системы NTFS платформой хранения, отвечающей настоящему изобретению, потребует записи существующих прикладных программ на основе Win32, и что такая запись может быть нежелательна, было бы предпочтительно, чтобы платформа хранения, отвечающая настоящему изобретению, обеспечивала некоторую возможность взаимодействия с существующими файловыми системами, например NTFS. Поэтому в одном варианте осуществления настоящего изобретения платформа хранения позволяет прикладным программам, которые опираются на программную модель Win32, обращаться к содержимому хранилища данных как платформы хранения, так и традиционной файловой системы NTFS. Для этого платформа хранения использует соглашение по присвоению имен, которое является супермножеством соглашений по присвоению имен Win32, для облегчения возможности взаимодействия. Кроме того, платформа хранения поддерживает доступ к файлам и директориям, хранящимся в томе платформы хранения, через API Win32.
Дополнительные подробности, касающиеся этой функции, можно найти в родственных заявках, включенных в настоящее описание посредством ссылки.
К. API платформы хранения
Платформа хранения содержит API, который позволяет прикладным программам обращаться к особенностям и возможностям платформы хранения, рассмотренным выше, и обращаться к статьям, хранящимся в хранилище данных. В этом разделе описан один вариант осуществления API платформы хранения для платформы хранения, отвечающей настоящему изобретению. Подробности, касающиеся этой функции, можно найти в родственных заявках, включенных в настоящее описание посредством ссылки, но для удобства часть этой информации кратко приведена ниже.
Согласно фиг.18 папка Включения является статьей, которая содержит отношения поддержания с другими Статьями, и является эквивалентом общего понятия папки файловой системы. Каждая Статья «содержится» в, по меньшей мере, одной папке включения.
Фиг.19 иллюстрирует базовую архитектуру API платформы хранения, согласно данному варианту осуществления. API платформы хранения использует SQLClient 1900 для общения с локальным хранилищем 302 данных и может также использовать SQLClient 1900 для общения с удаленными хранилищами данных (например, хранилищем данных 340). Локальное хранилище 302 также может общаться с удаленным хранилищем 340 данных либо с использованием РПЗ (распределенным процессором запросов) либо через вышеописанный сервис синхронизации платформы хранения. API 322 платформы хранения также действует как мостовой API для уведомлений хранилища данных, передавая подписки приложения машине 332 уведомлений и маршрутизируя уведомления к приложению (например, приложению 350a, 350b или 350c), что также описано выше. В одном варианте осуществления API 322 платформы хранения может также задавать ограниченную архитектуру «поставщика», что позволяет ему обращаться к данным в Microsoft Exchange и AD.
На фиг.20 схематически представлены различные компоненты API платформы хранения. API платформы хранения состоит из следующих компонентов: (1) классов 2002 данных, которые представляют типы элементов и статей платформы хранения, (2) структуры 2004 среды выполнения, которая управляет сохранением объектов и обеспечивает поддержку классов 2006; и (3) инструменты 2008, которые используются для генерации классов CLR из схем платформы хранения.
Иерархия классов, получающаяся из данной схемы, непосредственно отражает иерархию типов в этой схеме. Для примера рассмотрим типы Статьи, определенные в схеме «контакты», показанные на фиг.21А и фиг.21В.
Фиг.22 иллюстрирует структуру среды выполнения в действии. Структура среды выполнения действует следующим образом:
1. Приложение 350a, 350b или 350c связывается со статьей в платформе хранения.
2. Структура 2004 создает объект 2202 ItemContext, соответствующий статье границы и возвращает его приложению.
3. Приложение применяет Find к этому ItemContext, чтобы получить коллекцию Статей; возвращенная коллекция концептуально является графом 2204 объектов (в силу отношений).
4. Приложение изменяет, удаляет и вставляет данные.
5. Приложение сохраняет изменения, вызывая метод Update().
Фиг.23 иллюстрирует выполнение операции “FindAll”.
Фиг.24 иллюстрирует процесс, посредством которого классы API платформы хранения генерируются из схемы платформы хранения.
Фиг.25 иллюстрирует схему, на которой базируется API файлов. API платформы хранения включает в себя пространство имен отработки объектов файлов. Это пространство имен называется System.Storage.Files. Данные - члены классов в System.Storage.Files непосредственно отражают информацию, хранящуюся в хранилище платформы хранения; эта информация «продвигается» из объектов файловой системы или может создаваться внутренне с использованием API Win32. Пространство имен System.Storage.Files имеет два класса: FileItem и DirectoryItem. Члены этих классов и их методы можно представить себе, взглянув на схему, изображенную на фиг.25. FileItem и DirectoryItem можно только считывать из API платформы хранения. Чтобы изменять их, нужно использовать API Win32 или классы в System.IO.
Что касается API, программный интерфейс (или просто интерфейс) можно рассматривать как любой механизм, процесс, протокол, позволяющий одному или нескольким сегменту(ам) кода связываться или обращаться к функциям, обеспечиваемым одним или несколькими другим(и) сегментом(ами) кода. Альтернативно программный интерфейс можно рассматривать как один или несколько механизм(ов), метод(ов), функциональный(х) вызов(ов), модуль(ей), объект(ов) и т.д. компонента системы, способных общаться с одним или несколькими механизм(ами), метод(ами), функциональный(ыми) вызов(ами), модуль(ями), объект(ами) и т.д. другого(их) компонента(ов). Термин «сегмент кода» в предыдущем предложении призван включать в себя одну или несколько команд или строк кода и включает в себя, например, модули кода, объекты, подпрограммы, функции и т.д. независимо от применяемой терминологии или от того, компилированы ли сегменты кода по отдельности, или обеспечены ли сегменты кода как исходный, промежуточный или объектный код, используются ли сегменты кода в системе среды выполнения или в процессе, или размещены ли они на одной и той же или разных машинах или распределены по множеству машин, или являются ли функциональные возможности, представленные сегментами кода, реализованными полностью программными средствами, полностью аппаратными средствами или комбинацией аппаратных и программных средств.
Примечательно, что программный интерфейс можно рассматривать в общем виде, как показано на фиг.30А или фиг.30В. Фиг.30А иллюстрирует интерфейс Интерфейс1 как канал, через который сообщаются первый и второй сегменты кода. Фиг.30В иллюстрирует интерфейс как содержащий объекты интерфейса I1 и I2 (которые могут быть или не быть частью первого и второго сегментов кода), что позволяет первому и второму сегментам кода системы сообщаться между собой через среду М. Согласно фиг.30В объекты интерфейса I1 и I2 можно рассматривать как отдельные интерфейсы одной и той же системы, и можно также считать, что объекты I1 и I2 плюс среда М образуют интерфейс. Хотя на фиг.30A и 30B показан двунаправленный поток и интерфейсы по обе стороны потока, определенные реализации могут иметь информационный поток только в одном направлении (или вообще не иметь информационного потока, как описано ниже) или могут иметь объект интерфейса только с одной стороны. В порядке примера, но не ограничения, такие термины, как программный интерфейс приложения (API), точка ввода, метод, функция, подпрограмма, вызов удаленной процедуры и интерфейс модели компонентных объектов (COM) подпадают под определение программного интерфейса.
Аспекты такого программного интерфейса могут включать в себя метод, посредством которого первый сегмент кода передает информацию (где «информация» используется в самом широком смысле и включает в себя данные, команды, запросы и пр.) второму сегменту кода; метод, посредством которого второй сегмент кода принимает информацию; и структуру, последовательность, синтаксис, организацию, схему, хронирование и содержимое информации. В этой связи сама по себе базовая транспортная среда может быть не важна для работы интерфейса, а именно, является ли среда проводной или беспроводной или комбинацией обеих, поскольку способ транспортировки информации определяется интерфейсом. В определенных ситуациях информация может не передаваться в одном или обоих направлениях в традиционном смысле, поскольку перенос информации может либо осуществляться через другой механизм (например, информация, помещенная в буфер, файл и т.д. отдельно от информационного потока между сегментами кода) либо не существовать, например, когда один сегмент кода просто обращается к функциям, осуществляемым вторым сегментом кода. Какие-либо или все из этих аспектов могут быть важны в данной ситуации, например, в зависимости от того, являются ли сегменты кода частью системы в свободно связанной или тесно связанной конфигурации, и потому этот список следует рассматривать в порядке иллюстрации, но не ограничения.
Это понятие программного интерфейса известно специалистам в данной области и поясняется в вышеизложенном подробном описании изобретения. Однако возможны и другие способы реализации программного интерфейса, которые, если явно не исключены, охватываются формулой изобретения, приведенной в конце этого описания изобретения. Такие другие способы могут показаться более изощренными или сложными, чем упрощенный вид на фиг.30А и 30В, но они, тем не менее, осуществляют аналогичную функцию для достижения того же общего результата. Ниже кратко описаны некоторые альтернативные реализации программного интерфейса.
Разложение: Связь от одного сегмента кода к другому может осуществляться косвенно, путем разбиения канала связи на несколько дискретных каналов связи. Это схематически изображено на фиг.31А и 31В. Показано, что некоторые интерфейсы можно описать в терминах делимых множеств функций. Таким образом, функции интерфейса, показанного на фиг.30А и 30В, можно разложить для достижения того же результата, наподобие разложения на множители числа 24 в виде 2 умножить на 2 умножить на 3 умножить на 2. Соответственно, как показано на фиг.31А, функцию, обеспечиваемую интерфейсом Интерфейс1, можно разложить для преобразования каналов связи интерфейса в множество интерфейсов Интерфейс1A, Интерфейс 1B, Интерфейс 1C и т.д. с получением того же результата. Как показано на фиг.31В, функцию, обеспечиваемую интерфейсом I1, можно разложить в множество интерфейсов I1a, I1b, I1c и т.д. с получением того же результата. Аналогично интерфейс I2 второго сегмента кода, который принимает информацию от первого сегмента кода, можно разложить в множество интерфейсов I2a, I2b, I2c и т.д. При разложении количество интерфейсов, включенных с 1-м сегментом кода, не совпадает с количеством интерфейсов, включенных со 2-м сегментом кода. В любом из случаев, представленных на фиг.31А и 31В, смысл разложения интерфейсов Интерфейс1 и I1 остается таким же, как для фиг.30А и 30В соответственно. Разложение интерфейсов может также подчиняться законам ассоциативности, коммутативности и другим математическим законам, так что разложение может быть трудно распознать. Например, порядок операций может быть не важен и, следовательно, функция, выполняемая интерфейсом, может выполняться до достижения интерфейса, другим участком кода или интерфейса или выполняться отдельным компонентом системы. Кроме того, специалисту в данной области очевидно, что существуют разные способы осуществления вызовов разных функций, которые приводят к одному и тому же результату.
Переопределение: В некоторых случаях может представиться возможность игнорировать, добавлять или переопределять определенные аспекты (например, параметры) программного интерфейса, тем не менее, получая нужный результат. Это проиллюстрировано на фиг.32А и 32В. Например, пусть интерфейс Интерфейс1, показанный на фиг.30А, включает в себя функциональный вызов Square(input, precision, output), вызов, включающий в себя три параметра: input (вход), precision (точность) и output (выход), который выдается 1-м Сегментом кода на 2-й Сегмент кода. Если средний параметр «точность» не важен в данном сценарии, как показано на фиг.32А, его можно просто игнорировать или даже заменить бессмысленным (в этой ситуации) параметром. Можно также добавить дополнительный параметр, который ничего не значит. В любом случае функция square (квадрат) может быть реализована, если возвращается output (выход) после того, как input (вход) будет возведен в квадрат вторым сегментом кода. Precision (точность) может быть значимым параметром для некоторой последующей в цепи выполнения или другой части вычислительной системы; однако поскольку понятно, что для узкой цели вычисления квадрата точность не обязательна, ее можно заменить или игнорировать. Например, вместо передачи действительного значения точности можно передать бессмысленное значение, например дату рождения, и это не повлияет неблагоприятно на результат. Аналогично, как показано на фиг.32А, интерфейс I1 заменен интерфейсом I1', переопределенным на игнорирование или добавление параметров к интерфейсу. Интерфейс I2 можно аналогично переопределить как интерфейс I2', переопределенный на игнорирование необязательных параметров или параметров, которые можно обрабатывать в другом месте. Смысл в том, что в некоторых случаях программный интерфейс может включать в себя аспекты, например параметры, которые не нужны для некоторых целей, и поэтому их можно игнорировать или переопределять или обрабатывать в другом месте для других целей.
Встроенное кодирование: Также может представиться возможность слияния некоторых или всех функциональных возможностей двух отдельных модулей кода, в результате чего “интерфейс” между ними меняет форму. Например, функцию, изображенную на фиг.30А и 30В, можно преобразовать в функцию, изображенную на фиг.33А и 33В соответственно. На фиг.33А предыдущие 1-й и 2-й Сегменты кода, показанные на фиг.30А, сливаются в модуль, содержащий оба из них. В этом случае сегменты кода могут по-прежнему сообщаться друг с другом, но интерфейс может быть адаптирован к форме, которая больше подходит к одиночному модулю. Так, например, формальные операторы Call и Return могут быть уже не нужны, но аналогичная обработка или отклик(и) в соответствии с интерфейсом Интерфейс1 все еще могут действовать. Аналогично, как показано на фиг.33В, интерфейс I2, показанный на фиг.30В, частично (или полностью) можно записать внутри интерфейса I1, чтобы сформировать интерфейс I1”. Показано, что интерфейс I2 делится на I2a и I2b, и часть I2a интерфейса закодирована совместно с интерфейсом I1 для образования интерфейса I1”. В качестве конкретного примера предположим, что интерфейс I1, показанный на фиг.30В, осуществляет функциональный вызов square(input, output), который принимается интерфейсом I2, который после обработки значения, переданного с input (для возведения его в квадрат) вторым сегментом кода, передает результат возведения в квадрат обратно с output. В этом случае обработка, осуществляемая вторым сегментом кода (возведения input в квадрат), может осуществляться первым сегментом кода без вызова интерфейса.
Разъединение: Связь от одного сегмента кода к другому может осуществляться косвенно путем разбиения канала связи на несколько дискретных каналов связи. Это схематически изображено на фиг.34А и 34В. Как показано на фиг.34А, один или несколько фрагментов промежуточного программного обеспечения (Интерфейс(ы) разъединения, поскольку они отделяют функциональные возможности и/или функции интерфейса от исходного интерфейса), предусмотрены для преобразования каналов связи на первом интерфейсе, Интерфейс1, для согласования их с другим интерфейсом, в данном случае интерфейсами Интерфейс2A, Интерфейс2B и Интерфейс2C. Это может происходить, например, когда установлена база приложений, предназначенных для связи, скажем, с операционной системой в соответствии с протоколом Интерфейс1, но затем операционная система изменилась для использования другого интерфейса, в данном случае интерфейсов Интерфейс2A, Интерфейс2B и Интерфейс2C. Смысл в том, что первоначальный интерфейс, используемый 2-м Сегментом кода, изменился, в результате чего он перестал быть совместимым с интерфейсом, используемым 1-м Сегментом кода, и поэтому для обеспечения совместимости старого и нового интерфейсов используется посредник. Аналогично, как показано на фиг.34В, может быть введен третий сегмент кода с интерфейсом разъединения DI1 для приема информации от интерфейса I1 и с интерфейсом разъединения DI2 для передачи функций интерфейса, например интерфейсам I2a и I2b, перестроенными для работы с DI2, но обеспечивающими тот же функциональный результат. Аналогично, DI1 и DI2 могут действовать совместно, чтобы транслировать функциональные возможности интерфейсов I1 и I2, показанных на фиг.30В, в новую операционную систему, обеспечивая тот же или аналогичный функциональный результат.
Переписывание: Еще один возможный вариант заключается в динамическом переписывании кода для замены функциональных возможностей интерфейса какими-то другими, дающими, тем не менее, тот же общий результат. Например, может существовать система, в которой сегмент кода, представленный на промежуточном языке (например, Microsoft IL, Java ByteCode и т.д.), поступает на оперативный компилятор (JIT) или интерпретатор в среде выполнения (например, обеспечиваемом структурой .Net, средой выполнения Java или другими с аналогичными типами среды выполнения). JIT-компилятор может быть написан так, чтобы динамически преобразовывать передачи от 1-го Сегмента кода на 2-й Сегмент кода, т.е. согласовывать их с другим интерфейсом, который может понадобиться 2-му Сегменту кода (либо исходному, либо другому 2-му Сегменту кода). Это изображено на фиг.35А и 35В. Согласно фиг.35А этот подход аналогичен вышеописанному сценарию разъединения. Это может происходить, например, когда установленная база приложений способна связываться с операционной системой в соответствии с протоколом Интерфейс 1, но затем операционная система изменяется для использования другого интерфейса. JIT-компилятор можно использовать для оперативного согласования каналов связи от установленных базовых приложений к новому интерфейсу операционной системы. Согласно фиг.35В этот подход динамического переписывания интерфейса(ов) можно применять для динамического разложения или иного изменения интерфейса(ов).
Заметим также, что вышеописанные сценарии для достижения того же или аналогичного результата, что и интерфейс, посредством альтернативных вариантов осуществления можно также объединять различными способами, последовательно и/или параллельно или с другими промежуточными кодами. Таким образом, представленные выше альтернативные варианты осуществления не являются взаимоисключающими и могут смешиваться, согласовываться и комбинироваться для создания сценариев, идентичных или аналогичных общим сценариям, представленным на фиг.30А и 30В. Следует также заметить, что в большинстве случаев конфликтов программирования существуют другие аналогичные способы достижения таких же или аналогичных функциональных возможностей интерфейса, которые здесь не описаны, но, тем не менее, представлены сущностью и объемом изобретения, т.е. по меньшей мере, частично, функциональные возможности, представленные интерфейсом, и преимущественные результаты, обеспеченные интерфейсом, составляют основу интерфейса.
III. Расширения и наследование
Основная идея настоящего изобретения состоит в использовании Статей, которые в определенной степени моделируют объекты практического применения со сложными структурой, поведениями и операциями, описываемыми схемами и воплощаемыми системой аппаратно-программного интерфейса. Для обеспечения богатых функциональных возможностей выделения подтипов и согласно различным вариантам осуществления настоящего изобретения система аппаратно-программного интерфейса (которую для удобства мы будем называть далее просто WinFS) может обеспечивать механизм, посредством которого можно расширять Статьи (и типы Статьи) с использованием «Расширений». Расширения обеспечивают дополнительные структуры данных (Свойства, Отношения и пр.) к уже существующим структурам типов Статей.
Согласно рассмотренному выше (и конкретно рассмотренному в Разделах II.E.6.(a) и II.F.3), хотя предполагается обеспечение платформы хранения с начальным набором схем, согласно, по меньшей мере, некоторым вариантам осуществления платформа хранения позволяет потребителям, включая независимых продавцов программных продуктов (НПП), создавать новые схемы (т.е. новые типы Статьи и Вложенного элемента). Поскольку тип Статьи или тип Вложенного элемента, заданный начальным набором схем платформы хранения, может не в точности отвечать нуждам приложения НПП, необходимо позволить НПП самим создавать нужные им типы. Такую возможность предоставляет понятие Расширений. Расширения являются строго типизированными экземплярами, но (а) они не могут существовать независимо и (b) они должны присоединяться к Статье или Вложенному элементу. Кроме того, помимо решения вопроса необходимости в расширяемости схем Расширения также призваны решать вопросы «многотипности». Поскольку в некоторых вариантах осуществления платформа хранения может не поддерживать множественного наследования или перекрывающихся подтипов, приложения могут использовать Расширения как способ моделирования экземпляров перекрывающихся типов (например, Документ может быть «юридическим документом» и одновременно «защищенным документом»).
А. Система типов
В различных вариантах осуществления настоящего изобретения система типов WinFS обеспечивает механизм для задания структур данных. Система типов используется для представления данных, хранящихся в WinFS. Тип WinFS декларируется в схеме WinFS. Схема WinFS задает пространство имен, которое служит для логического группирования множества типов и других элементов схемы WinFS. Схемы WinFS можно декларировать с использованием «языка определения схем» (SDL), который может использовать формат XML. Ниже приведен пример возможного определения схемы:
<Schema Namespace="System.Storage" >
Определения типов
</Schema>
Схемы WinFS также служат блоками для контроля версий типов. WinFS задает несколько системных схем, которые обеспечивают самонастройку системы. Имеется пространство имен схем System.Storage, которое содержит декларации типов для корневых типов в системе, и пространство имен схем System.Storage.WinFS, которое декларирует все примитивные скалярные типы в системе.
Система типов WinFS декларирует множество простых скалярных типов. Эти типы используются как наиболее примитивные строительные блоки для всех остальных типов в системе типов WinFS. Эти типы декларируются в пространстве имен схем System.Storage.WinFS. В нижеследующей таблице определено множество примитивных типов.
В хранилище точность всегда равна 28 цифр и масштаб равен 0.
Перечисление WinFS - это скалярный тип, который декларирует множество именованных констант, именуемое списком значений. Перечислительный тип можно использовать в любом месте, где можно использовать скалярный тип. Ниже приведен пример декларирования перечисления:
<Enumeration Name="Gender">
<Value Name="Male"/>
<Value Name="Female"/>
</Enumeration>
Значения перечисления имеют базовое значение нуль. В вышеприведенном примере Gender.Male представляет значение 0, и Gender.Female представляет значение 1.
Сложный тип задается именем и множеством свойств. Свойство это поле члена типа и задается именем и типом. Тип Свойства может быть либо скалярным (включая перечислительный тип) либо другим сложным типом. Тип WinFS, который можно использовать как тип Свойства, называется вложенным типом. Экземпляр вложенного типа может существовать только как значение Свойства сложного типа WinFS - экземпляр вложен в экземпляр сложного типа. Вложенный тип декларируется с использованием элемента NestedType схемы. Ниже приведены примеры деклараций действительных типов:
<NestedType Name="Address"BaseType="System.Storage.NestedObject">
<Property Name="Street" Type="WinFS.String" Size="256"
Nullable="false"/>
<Property Name="City" Type=" WinFS.String" Size="256"
Nullable="false" />
<Property Name="State" Type=" WinFS.String" Size="256"
Nullable="false" />
<Property Name="Country" Type="WinFSString" Size="256"
Nullable="false" />
</NestedType>
<ItemType Name="Person" BaseType="System.Storage.Item">
<Property Name="Name" Type="WinFS.String" Size="256"
Nullable="false"/>
<Property Name="Age" Type="WinFS.Int32"
Nullable="false" Default="1"/>
<Property Name="Picture" Type="WinFS.Binary" Size="max"/>
<Property Name="Addresses" Type="MultiSet"MultiSetOfType="Address"/>
</ItemType>
Для свойств типа String (строка) и Binary (двоичный) должен быть задан атрибут Size (размер). Этот атрибут определяет максимальный размер значений, содержащихся в Свойстве. Свойство может, в необязательном порядке, декларировать ограничение обнуляемости с использованием атрибута Nullable. Значение «ложно» для этого атрибута указывает, что приложение должно обеспечивать значение при создании экземпляра типа. Еще один необязательный атрибут Свойства представляет собой атрибут Default, который определяет значение по умолчанию для Свойства. Это значение будет присвоено Свойству в момент создания экземпляра, если приложение не обеспечило его.
Свойство «адреса» в вышеприведенном примере относится к типу MultiSet. Свойство типа MultiSet также называют многозначным свойством. В примере MultiSet содержит множество экземпляра типа Address. MultiSet подобен коллекции. Он может содержать нуль или более экземпляров сложного типа. Тип экземпляра в MultiSet должен быть сложного вложенного типа. Тип MultiSet не поддерживает экземпляры скалярных типов WinFS (включая перечислительные типы). Свойства типа MultiSet не могут быть обнуляемыми и не могут иметь значения по умолчанию.
WinFS поддерживает единичное наследование типов. Все типы WinFS должны наследовать от одного и только одного типа WinFS. Наследующий тип называется производным типом, а тип, из которого выведен этот тип, называется базовым типом. Базовый тип является атрибутом BaseType элементов декларации типа WinFS. Пусть тип А выводится из базового типа B, который, в свою очередь, выводится из типа С. Тип С является типом-предком для типов А и В. Тип А является типом-потомком для типов В и С. Экземпляр данных, хранящийся в WinFS, всегда является экземпляром единичного типа. Однако можно обрабатывать этот экземпляр данных как экземпляр множества типов, содержащего тип и все его типы-предки. Для экземпляра данных, который является экземпляром такого множества типов, тип, который не является предком любого другого типа в множестве, называется последним производным типом. Однотипный экземпляр данных является экземпляром в точности одного последнего производного типа. В общем случае, последний производный тип однотипного элемента будет называться его типом. Производный тип наследует все свойства, декларированные в его базовом типе. Производный тип может декларировать новые свойства, но не может подменять свойства, заданные в базовом типе. Свойство, декларированное в производном типе, не должно использовать то же имя, что и Свойство базового типа.
Главное преимущество наследования в модели данных обусловлено возможностью подстановки унаследованных типов. Рассмотрим следующий пример:
<NestedType Name="Name" BaseType="System.Storage.NestedObject">
<Property Name="FirstName" Type="WinFS.String"/>
<Property Name="LastName" Type="WinFS.String"/>
</Nestedype>
<NestedType Name="NameWithMiddleInitial" BaseType="Name">
<Property Name="MiddleInitial" Type=“WinFS.String"/>
</NestedType>
<NestedType Name="Person" BaseType="System.Storage.Item">
<Property Name="RealName" Type="Name"/>
<Property Name="OtherNames" Type="MultiSet"MultiSetOfType="Name"/>
</NestedType>
В вышеприведенном примере тип Person имеет Свойство RealName типа Name и Свойство OtherNames, которое является множеством типов Name. Обычно требуется, чтобы Свойство RealName имело только экземпляры, типом которых является Name. Однако благодаря наследованию значением RealName могут быть однозначные значения, поскольку тип Name является одним из предков последнего производного типа этого элемента. Поэтому экземпляр NameWithMiddleInitial может быть значением Свойства RealName.
То же правило распространяется на множество свойств. Свойство OtherNames содержит множество элементов. Для каждого однотипного экземпляра, который является членом этого множества, последний производный тип этого экземпляра должен иметь Name в качестве одного из своих предков. Поэтому некоторые из экземпляров в множестве OtherNames могут быть экземплярами типа Name, тогда как другие могут быть экземплярами типа NameWithMiddleInitial.
Наследование также позволяет удобно осуществлять запрашивание, поскольку в системе WinFS можно найти все экземпляры определенного типа. При поиске всех экземпляров типа машина запросов будет также возвращать все экземпляры, последние производные типы которых являются потомками этого типа. Однако эти операции поддерживаются только для Статьи, Расширения и Типов отношения (не Типов свойства). Для вложенных типов (например, Вложенных элементов, Свойства или сложных типов свойства) операция поддерживается только для экземпляров, содержащихся в единичном Свойстве «мультимножество».
В. Семейства типов
В сущности, система типов WinFS задает четыре различных семейства типов:
- Типы Вложенного элемента (например, Вложенные типы или Типы свойств);
- Типы Статьи;
- Типы отношения;
- Типы расширения.
Каждое семейство типов имеет отдельное множество свойств и использование в системе типов WinFS. Пространство имен схемы System.Storage декларирует четыре типа, которые служат корневыми типами для каждого из семейств типов. В нижеследующих разделах подробно описаны семейства типов.
1. Типы вложенного элемента
В отличие от других семейств типов WinFS вложенные типы можно использовать как типы свойств сложных типов WinFS. Экземпляры вложенного типа могут быть вложены только в экземпляр другого сложного типа. Однако экземпляры вложенных типов не могут запрашиваться глобально, т.е. приложения не могут составить простой запрос, который возвращает все экземпляры данного вложенного типа в хранилище WinFS.
2. Типы статьи
Статья WinFS является экземпляром типа, предком которого является тип System.Storage.Item. Этот тип является сложным типом, который является корнем семейства типов Статьи. System.Storage.Item декларирует Свойство имени ItemId типа Guid. Это особое свойство статьи, которое служит главным ключом Статьи. Значение этого Свойства гарантированно является уникальным для Статей в данном хранилище WinFS. Это свойство является необнуляемым и должно назначаться приложением при создании экземпляра типа Статьи. Свойство ItemId также является неизменяемым - оно никогда не должно изменяться и не подлежит повторному использованию.
Машина запросов может возвращать экземпляры данного типа Статьи в хранилище WinFS. Этот запрос может возвращать все экземпляры типа и все типы-потомки этого типа. Ниже описана главная роль, которую статьи играют в семантике операций системы WinFS.
3. Типы отношения
Типы отношения обеспечивают существование Отношений между Статьями. Типы отношения WinFS описывают бинарные отношения, где одна Статья играет роль источника, а другая Статья играет роль цели. Отношение является экземпляром типа, предком которого является тип System.Storage.Relationship. Этот тип является корнем иерархии Типов отношения.
Тип System.Storage.Relationship объявляет следующие свойства:
- SourceItemId - ItemId Статьи, которая является источником Экземпляра отношения;
- RelationshipId - уникальный идентификатор Отношения по отношению к исходной статье; пара (SourceItemId, RelationshipId) образует главный ключ для Типов отношения в WinFS;
- TargetItemId - ItemId цели Отношения;
- Mode - один из 3 возможных режимов Экземпляров отношения: поддержания (Holding), внедрения (Embedding) или ссылки (Reference);
- Name - содержит имя Отношения для отношений поддержания;
- IsHidden - булев атрибут, который приложения могут использовать в необязательном порядке для фильтрации Отношений, которые не нужно отображать;
Значения свойств SourceItemId, RelationshipId, TargetItemId и Mode являются неизменяемыми. Они назначаются в момент создания Экземпляра отношения и не подлежат изменению.
Тип Отношения объявляется как сложный тип со следующими дополнительными ограничениями:
- Указанием исходной и целевой конечных точек: каждая конечная точка указывает имя и тип Статьи, к которой она относится;
- Допустимыми режимами экземпляров Типа отношения: Экземпляр отношения не может иметь значение для Свойства Mode, которое не является разрешенным в декларации Отношения.
Ниже приведен пример декларации Отношения:
<RelationshipType Name="DocumentAuthor"
BaseType="System.Storage.Relationship"
AllowsHolding="true"
AllowsEmbedding="false"
AllowsReference="true">
<Source Name="Document" Type="Core.Document"/>
<Target Name="Author" Type="Core.Contact"/>
<Property Name="Role" Type="WinFS.String"/>
<Property Name="DisplayName" Type="WinFS.String"/>
</RelationshipType>
Отношение DocumentAuthor («автор документа») декларируется с ограничениями экземпляров для режимов поддержания и ссылки. Это значит, что экземпляр Отношения DocumentAuthor может иметь экземпляры со значением Mode=”Reference” или Mode=”Holding”. Экземпляры со значением Mode=”Embedding” не разрешены.
Отношение декларирует исходную конечную точку под именем “Document” с типом Статьи “Core.Document” и целевую конечную точку типа “Core.Contact”. Отношение также декларирует два дополнительных свойства. Экземпляры отношения подлежат хранению и доступу отдельно от Статьи. Все экземпляры Типа отношения доступны из глобального вида расширения. Можно составить запрос, который будет возвращать все экземпляры данного типа Расширения.
Для данной Статьи, все Отношения, для которой Статья является источником, можно перечислить на основании Свойства SourceItemId Отношения. Аналогично для данной Статьи, все Отношения в одном и том же хранилище, для которого Статья является целью, можно перечислить с использованием Свойства TargetItemId Отношения.
a) Семантика отношения
В нижеследующих разделах описана семантика различных режимов Экземпляра отношения:
Отношения поддержания: Отношения поддержания используются для моделирования управления временем жизни целевых статей на основании счетчика ссылок. Статья может быть исходной конечной точкой для нуля или более Отношений со Статьями. Статья, которая не является внедренной статьей, может быть целью одного или нескольких отношений поддержания. Целевая статья должна находиться в том же хранилище, что и Экземпляр отношения.
Отношения поддержания реализуют управление временем жизни целевой конечной точки. Создание экземпляра отношения поддержания и Статьи, для которого она является целью, является атомарной операцией. Можно создавать дополнительные экземпляры отношения поддержания, для которых та же Статья является целью. При удалении последнего экземпляра отношения поддержания с данной Статьей в качестве целевой конечной точки, целевая статья также подлежит удалению.
Типы Статей-конечных точек, указанные в декларации Отношения, реализуются при создании экземпляра Отношения. Типы Статей-конечных точек не подлежат изменению после установления Отношения.
Отношения поддержания играют ключевую роль в формировании пространства имен Статей WinFS. Все отношения поддержания участвуют в декларации пространства имен. Свойство «имя» в декларации Отношения задает имя целевой статьи относительно исходной статьи. Это относительное имя уникально для всех отношений поддержания, для которых данная Статья является источником, и не может быть обнулено. Упорядоченный список этих относительных имен от корневой Статьи до данной Статьи образует полное имя Статьи.
Отношения поддержания образуют ориентированный ациклический граф (ОАГ). При создании отношения поддержания система гарантирует, что цикл не создается, и таким образом гарантирует, что пространство имен Статей WinFS образует ОАГ. За дополнительной информацией о пространстве имен WinFS и путях статей следует обратиться к описанию «Пространство имен WinFS».
Отношения внедрения: Отношения внедрения моделируют концепцию исключительного управления временем жизни целевой статьи. Они реализуют концепцию составных статей. Создание экземпляра отношения внедрения и Статьи, которая является его целью, является атомарной операцией. Статья может быть источником нуля или более отношений внедрения. Однако Статья может быть целью одного и только одного отношения внедрения. Статья, которая является целью отношения внедрения, не может быть целью отношения поддержания. Целевая статья должна находиться в том же хранилище, что и Экземпляр отношения.
Типы Статей-конечных точек, указанные в декларации Отношения, реализуются при создании экземпляра Отношения. После установления Отношения типы Статей-конечных точек не подлежат изменению. Отношения внедрения не участвуют в пространстве имен WinFS. Значение Свойства «имя» отношения внедрения должно быть нулевым.
Отношения ссылки: Отношения ссылки не управляют временем жизни статьи, на которую они ссылаются. Отношения ссылки не гарантируют существование цели, а также не гарантируют тип цели, что указано в декларации Отношения. Это значит, что отношения ссылки могут повисать. Кроме того, отношение ссылки может ссылаться на Статьи в других хранилищах WinFS.
В WinFS отношения ссылки будут использоваться для моделирования большинства Отношений между Статьями без управления временем жизни. Поскольку существование цели не гарантировано, отношение ссылки удобно для моделирования слабосвязанных Отношений. Отношение ссылки можно использовать применительно к целевым статьям в других хранилищах WinFS, включая хранилища на других машинах. Отношения внедрения не участвуют в пространстве имен WinFS. Значение Свойства «имя» отношения внедрения должно быть нулевым.
b) Правила и ограничения для отношений
К Отношениям применяются следующие дополнительные правила и ограничения:
- Статья должна быть целью (в точности одного отношения внедрения) или (одного или нескольких отношений поддержания). Единственным исключением является корневая Статья. Статья может быть целью нуля или более отношений ссылки;
- Статья, которая является целью отношения внедрения, не может быть источником отношений поддержания. Она может быть источником отношений ссылки;
- Статья не может быть источником отношения поддержания, если она продвинута из файла. Она может быть источником отношений внедрения и отношений ссылки;
- Статья, продвинутая из файла, не может быть целью отношения внедрения.
Когда Тип отношения A является производным от базового Типа отношения B, применяются следующие правила:
- Тип отношения A может дополнительно ограничивать типы конечной точки. Типы конечной точки должны быть подтипами соответствующего типа конечной точки в базовом отношении B. Если конечная точка дополнительно ограничена, должно декларироваться новое имя конечной точки. Если конечная точка не ограничена, то описание конечной точки является необязательным;
- Тип отношения A может дополнительно ограничивать разрешенные режимы экземпляра, декларированные в базовом отношении. Ограниченное множество режимов экземпляра должно быть подмножеством множества базовых типов или разрешенных типов экземпляров;
- Имена конечных точек обрабатываются как имена Свойств: они не могут совпадать с именем Свойства или именем конечной точки типа или его базового типа;
- Исходный и целевой элементы являются необязательными, если соответствующий тип конечной точки не ограничен дополнительно производным Отношением.
Ниже приведен пример декларирования Типа отношения, который является производным от Отношения DocumentAuthor, заданного выше:
<RelationshipType Name="LegalDocumentAuthor"
BaseType="Core.DocumentAuthor"
AllowsHolding="false"
AllowsEmbedding="false"
AllowsReference="true" >
<Source Name="LegalDocument" Type="Legal.Document"/>
<Property Name="CaseNumber" Type="WinFS.String"/>
</RelationshipType>
Отношение LegalDocumentAuthor дополнительно ограничивает исходную конечную точку, но не целевую конечную точку. Типом исходной конечной точки является Legal.Document, который выводится из Core.Document.
В этом случае целевая конечная точка не подлежит дополнительному ограничению, поэтому целевой элемент опущен.
Отношение также накладывает дополнительные ограничения на режимы экземпляра. Оно запрещает режим поддержания, поэтому остается единственный разрешенный режим - ссылки.
4. Типы расширения
Расширение WinFS является экземпляром типа, предком которого является тип System.Storage.Extension. Этот тип является сложным типом, который является корнем семейства Типов расширения.
System.Storage.Extension определяет два свойства:
- ItemId - ИД Статьи для статьи, с которой связано Расширение;
- ExtensionId - уникальный идентификатор для Расширения по отношению к ИД статьи. Пара (ItemId, ExtensionId) уникально идентифицирует Экземпляр расширения.
К Типам расширения применяются следующие ограничения:
- Экземпляры типа расширения могут существовать независимо от Статьи; Экземпляр типа Статьи с тем же ItemId, что и ItemId Расширения должен существовать в хранилище до создания Экземпляра типа расширения. Расширение не может быть создано, если статьи с данным ItemId не существует. При удалении Статьи все Расширения с тем же ItemId удаляются;
- С отдельной статьей можно связать самое большее один экземпляр данного последнего производного Типа расширения;
- Расширения не могут быть источниками и целями Отношений.
Не существует ограничений на типы Расширений, которые можно связать с данным типом Статьи. Любой Тип расширения разрешен для расширения любого типа Статьи. Если к Статье присоединено множество экземпляров различных Типов расширения, то они не зависят друг от друга в отношении структуры и поведения. Экземпляры расширения подлежат хранению и доступу отдельно от статьи. Все Экземпляры типа расширения доступны из глобального вида расширения. Можно составить запрос, который будет возвращать все экземпляры данного типа Расширения независимо от типа Статьи, с которой они связаны. ItemId Расширения указывает, к какой Статье они принадлежат, и может использоваться для извлечения соответствующего объекта Статьи из глобального вида Статьи. Кроме того, для данной Статьи все Экземпляры расширения, связанные со Статьей, можно перечислять с использованием Свойства ItemId Расширения.
С. Расширенные функциональные возможности
В нескольких вариантах осуществления настоящего изобретения система аппаратно-программного интерфейса использует Расширения и Наследование для формализации отношений между различными Статьями и таким образом улучшения возможностей запрашивания совокупности Статей.
1. Наследование
Фиг.36 иллюстрирует ряд взаимосвязанных Статей и подмножество их Отношений. Статья 3502 «документ» и статья 3604 «контакт» непосредственно связаны назначенным отношением 3606, которое в данном случае является «отношением авторства», т.е. Контакт 3604 является «автором» Документа 3602. В этом примере статья 3622 «изображение», статья 36724 «музыка» и статья 3626 «особая» наследуют от статьи 3602 «документ», поскольку тип Статьи является подтипом типа Статьи «документ». Аналогично статья 3642 «лицо» и статья 3644 «организация» наследуют от статьи 3604 «контакт». В нескольких вариантах осуществления настоящего изобретения эти наследующие Статьи (Изображение 3622, Музыка 3624, Особая 3626, Лицо 3642 и Организация 3644) не только наследуют свойства соответствующих родительских статей (Документа 3602 и Контакта 3604), но также наследуют назначенные Отношения между этими родительскими Статьями. Например, Изображение 3622 наследует отношение 3662 с Контактом 3604, отношение 3664 с Лицом 3642 и отношение 3666 с Организацией 3644. Аналогичное множество Отношений также наследуется каждой из других показанных Статей.
Однако важно отметить, что наследование отношений не является автоматическим и не происходит в каждом контексте. Например, атрибуты, которые описывают, когда тип может наследоваться (т.е. средства управления наследованием), сами не являются наследуемыми. Параметры наследования поддерживаются и регулируются системой аппаратно-программного интерфейса.
2. Расширения
Фиг.37А иллюстрирует недостатки стандартного выделения подтипов Статьи для применения в конкретных целях. На этом чертеже Контакт доступен для четырех приложений, Пр1, Пр2, ПрХ и ПрY. Пр1 и Пр2 обращаются к стандартному Контакту, но каждому из ПрХ и ПрY нужен расширенный объект контакта (с добавлением дополнительных полей), и таким образом они выводят Контакт' и Контакт'', каждый из которых наследует от Контакта. Однако проблема состоит в том, что появляются три новых экземпляра исходной Статьи: «контакт» - один в Контакте, один - в Контакте' и один - в Контакте''.
Частичное решение этой проблемы, проиллюстрированной на фиг.37В, заключается в расширении свойств Контакта для включения полей, необходимых приложению, которое их требует. В этом случае Контакт расширяется для включения Дополнительных полей, необходимых для ПрХ. Однако непосредственное расширение полей Статьи, например «контакт», можно произвести только один раз, и таким образом ПрY не может использовать этот способ.
В одном варианте осуществления настоящего изобретения, более универсальное решение состоит в расширении Контакта с помощью Расширения, которое отличается и отделено от самого Контакта, как показано на фиг.37С. Таким образом, ПрХ может расширить Контакт для включения своих Дополнительных полей ПрХ, тогда как ПрY может также отдельно расширить Контакт для включения своих Дополнительных полей ПрY. Эти Расширения сами являются искомыми и запрашиваемыми и таким образом эти Расширения обеспечивают форму многотипности для системы аппаратно-программного интерфейса.
IV. Заключение
Согласно проиллюстрированному выше, настоящее изобретение относится к платформе хранения для организации, поиска и совместного использования данных. Платформа хранения, отвечающая настоящему изобретению, продолжает и расширяет концепцию хранения данных за пределы существующих файловых систем и систем баз данных, и предназначена быть хранилищем для всех типов данных, включая структурированные, неструктурированные или частично структурированные данные, например реляционных (табличных) данных, XML и новой формы данных, именуемой Статьями. Посредством общей основы хранения и схематизированных данных платформа хранения, отвечающая настоящему изобретению, обеспечивает более эффективную разработку приложений для потребителей, специалистов в сфере информационных технологий и предпринимателей. Она обеспечивает богатый и расширяемый программный интерфейс приложения, который не только делает доступными возможности, присущие ее модели данных, но также охватывает и расширяет существующую файловую систему и методы доступа к данным. Понятно, что можно вносить изменения в вышеописанные варианты осуществления, не выходя за рамки сущности изобретения. Соответственно настоящее изобретение не ограничено конкретными раскрытыми вариантами осуществления, но призвано охватывать все модификации, отвечающие сущности и объему изобретения, заданному в прилагаемой формуле изобретения.
Из вышеприведенного описания явствует, что различные системы, способы и аспекты настоящего изобретения полностью или частично можно реализовать в виде программного кода (т.е. команд). Этот программный код может храниться в компьютерно-считываемой среде, например магнитной, электрической или оптической среде хранения, включая, без ограничения, флоппи-диск, CD-ROM, CD-RW, DVD-ROM, DVD-RAM, магнитную ленту, флэш-память, жесткий диск или любой другой машиночитаемый носитель, в которой при загрузке программного кода в машину и его выполнении машиной, например компьютером или сервером, машина становится устройством для практического осуществления изобретения. Настоящее изобретение также можно реализовать в виде программного кода, который передается по некоторой среде передачи, например по электрическим проводам или кабелям, по оптическим волокнам, по сети, включая интернет и интрасеть, или посредством любой другой формы передачи, в которой при приеме и загрузки программного кода в машину и его выполнении машиной, например компьютером, машина становится устройством для практического осуществления изобретения. Будучи реализован на процессоре общего назначения, программный код объединяется с процессором для обеспечения уникального устройства, которое действует аналогично конкретным логическим схемам.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ УСЛУГ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ АППАРАТНОЙ/ПРОГРАММНОЙ ИНТЕРФЕЙСНОЙ СИСТЕМОЙ | 2004 |
|
RU2377646C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ ЭЛЕМЕНТОВ, СОХРАНЕННЫХ НА КОМПЬЮТЕРЕ | 2004 |
|
RU2377647C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ ЭЛЕМЕНТОВ ПОЛЬЗОВАТЕЛЮ С ИСПОЛЬЗОВАНИЕМ КОНТЕКСТНОГО ПРЕДСТАВЛЕНИЯ | 2004 |
|
RU2369896C2 |
| СИСТЕМА И СПОСОБ ПРЕДСТАВЛЕНИЯ ДЛЯ ПОЛЬЗОВАТЕЛЯ ВЗАИМОСВЯЗАННЫХ ЭЛЕМЕНТОВ | 2004 |
|
RU2358312C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| БЕЗОПАСНОСТЬ В ПРИЛОЖЕНИЯХ СИНХРОНИЗАЦИИ РАВНОПРАВНЫХ УЗЛОВ | 2006 |
|
RU2421799C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2365972C2 |
| ОТОБРАЖЕНИЕ МОДЕЛИ ФАЙЛОВОЙ СИСТЕМЫ В ОБЪЕКТ БАЗЫ ДАННЫХ | 2006 |
|
RU2409847C2 |
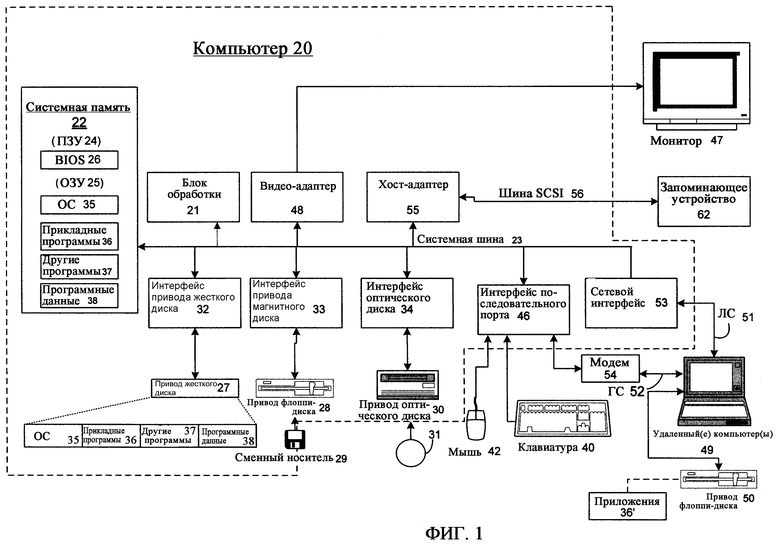
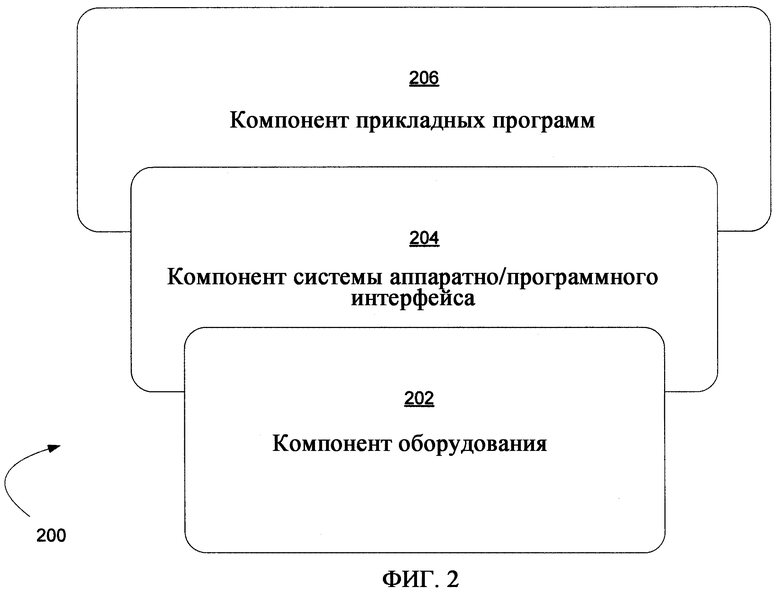
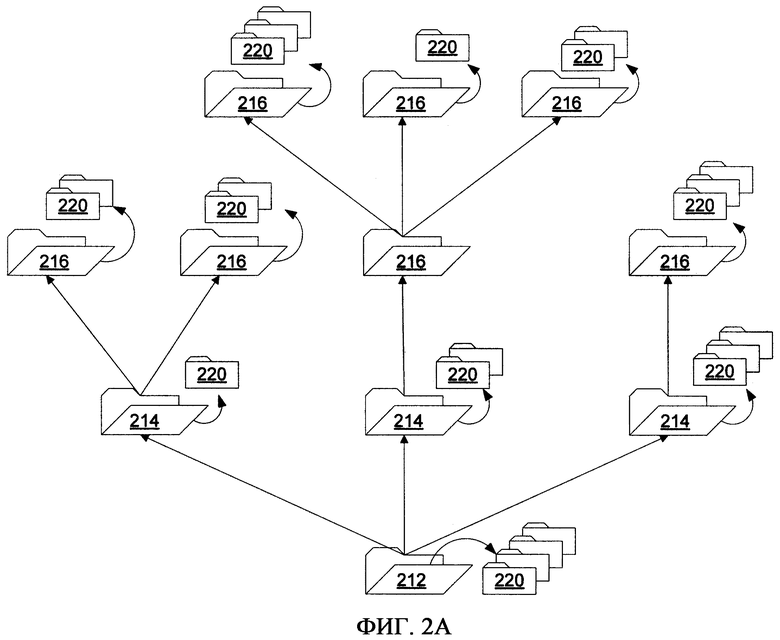

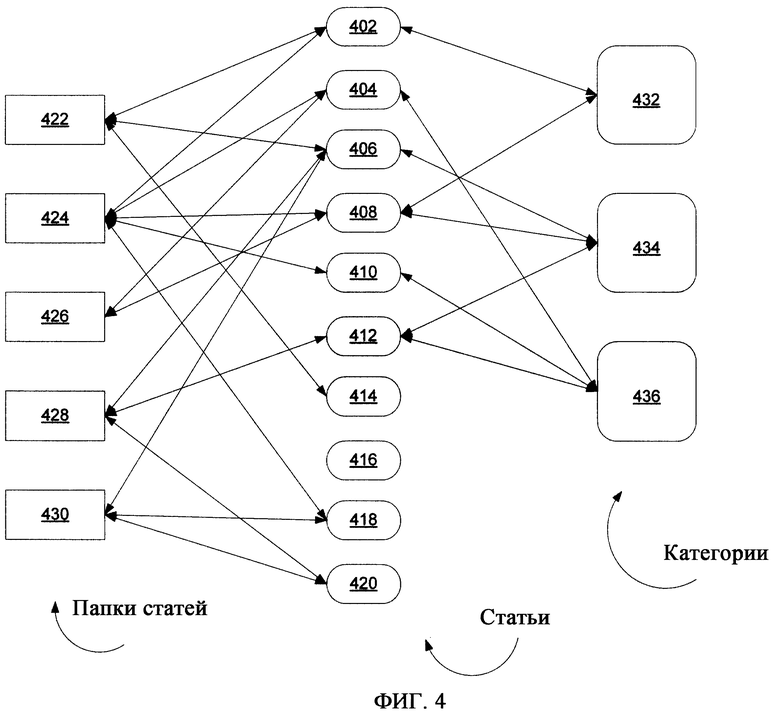

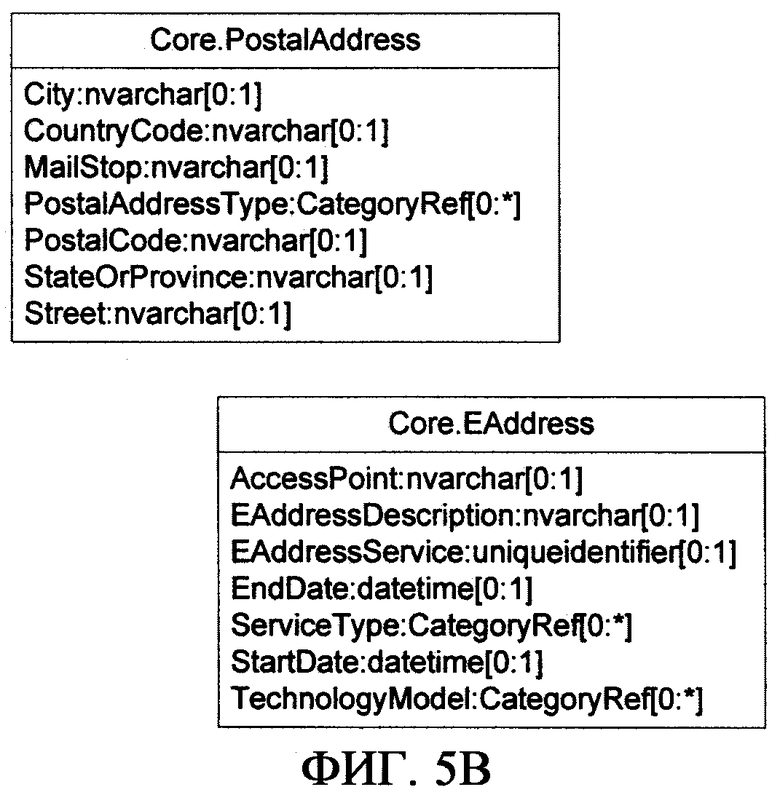




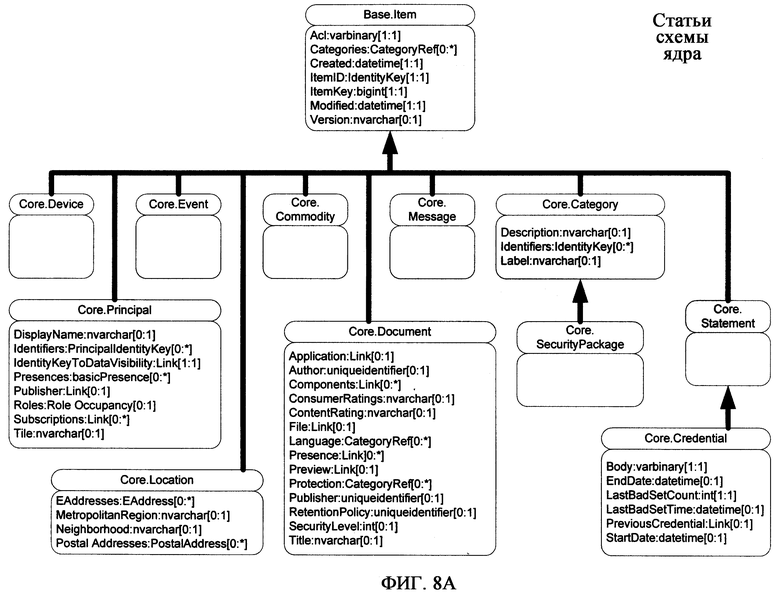
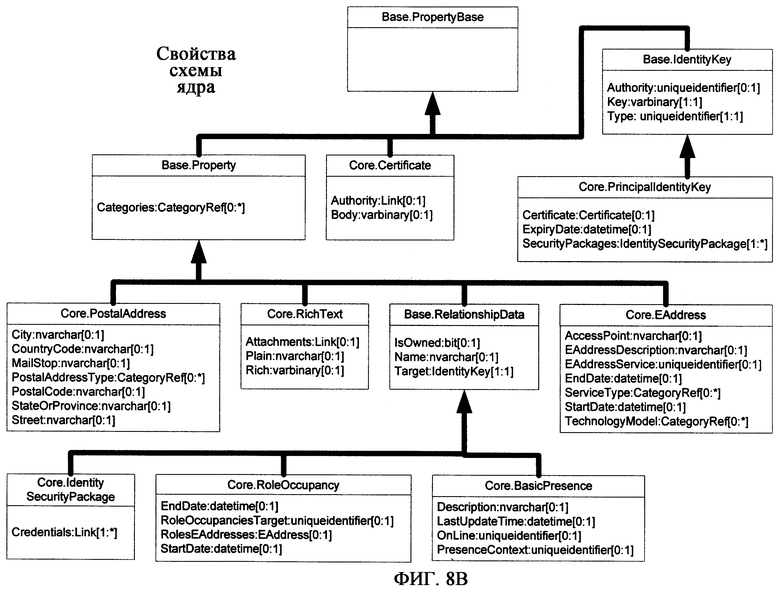
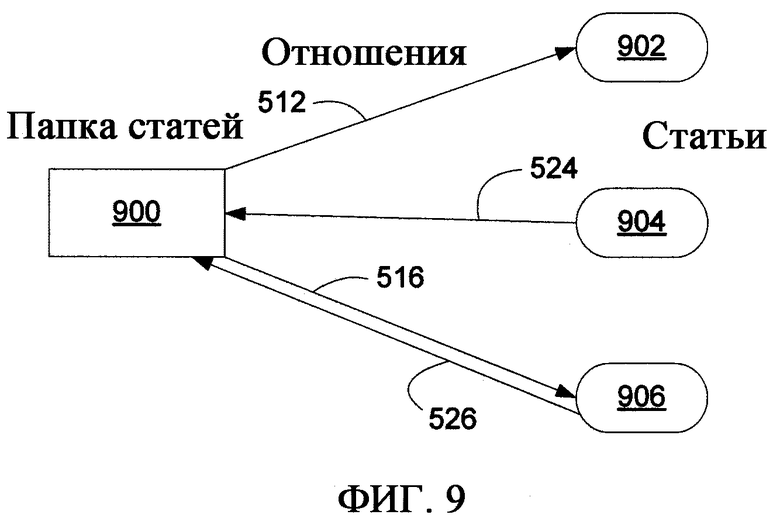
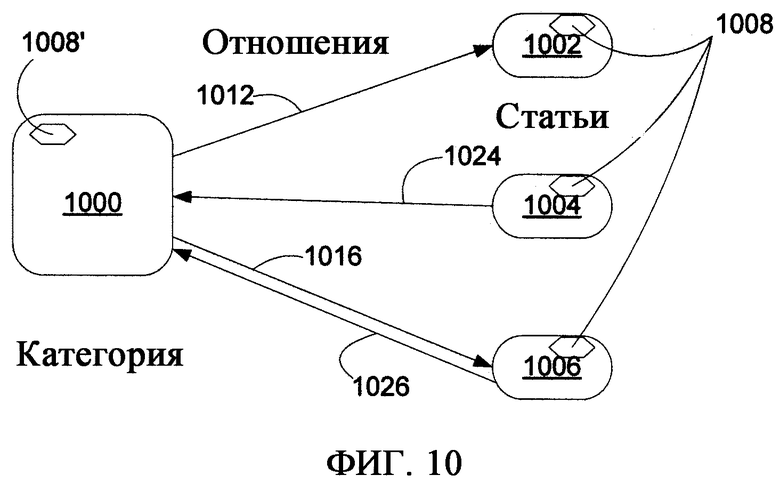

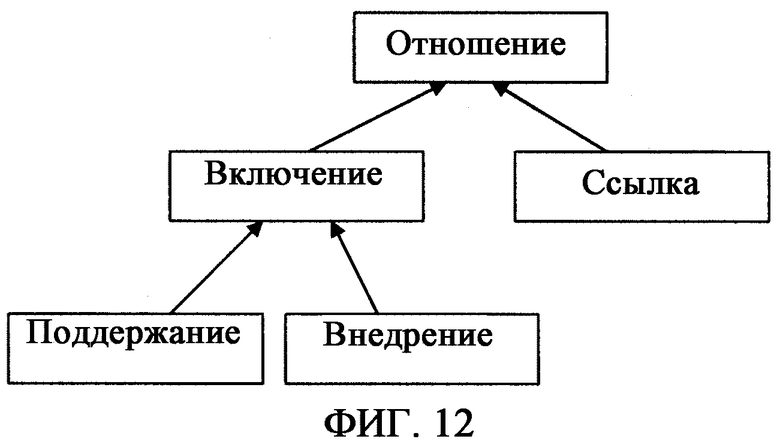
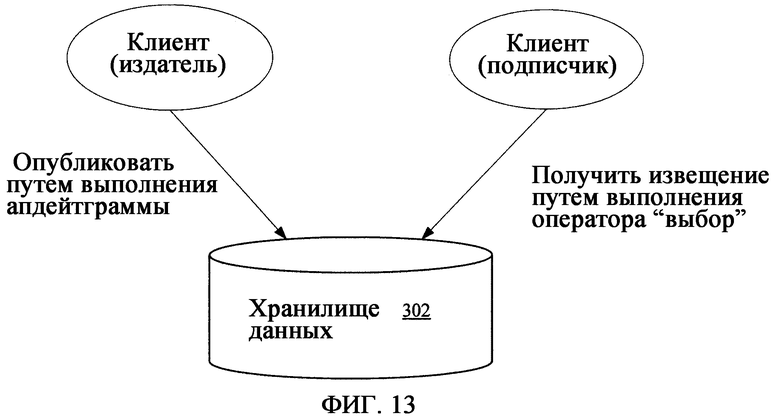

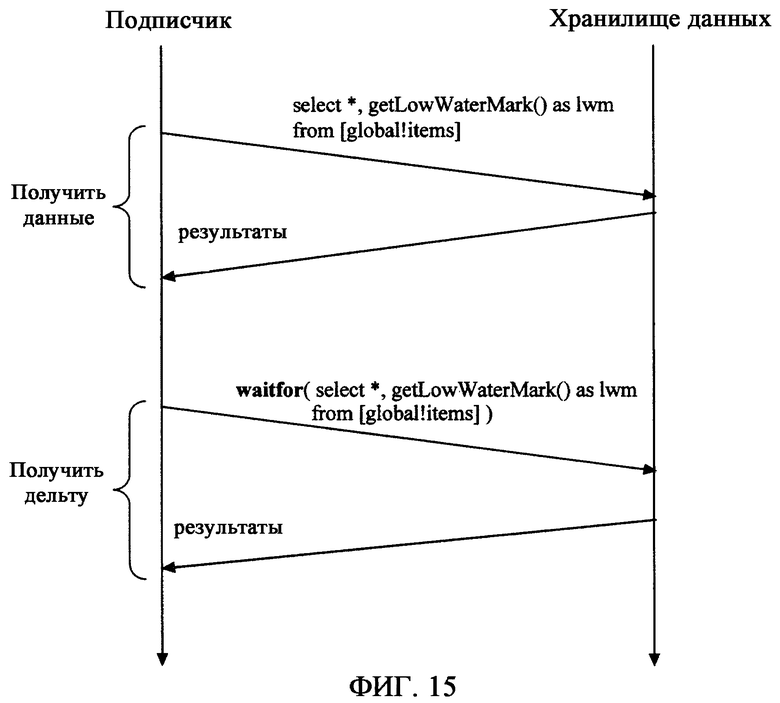
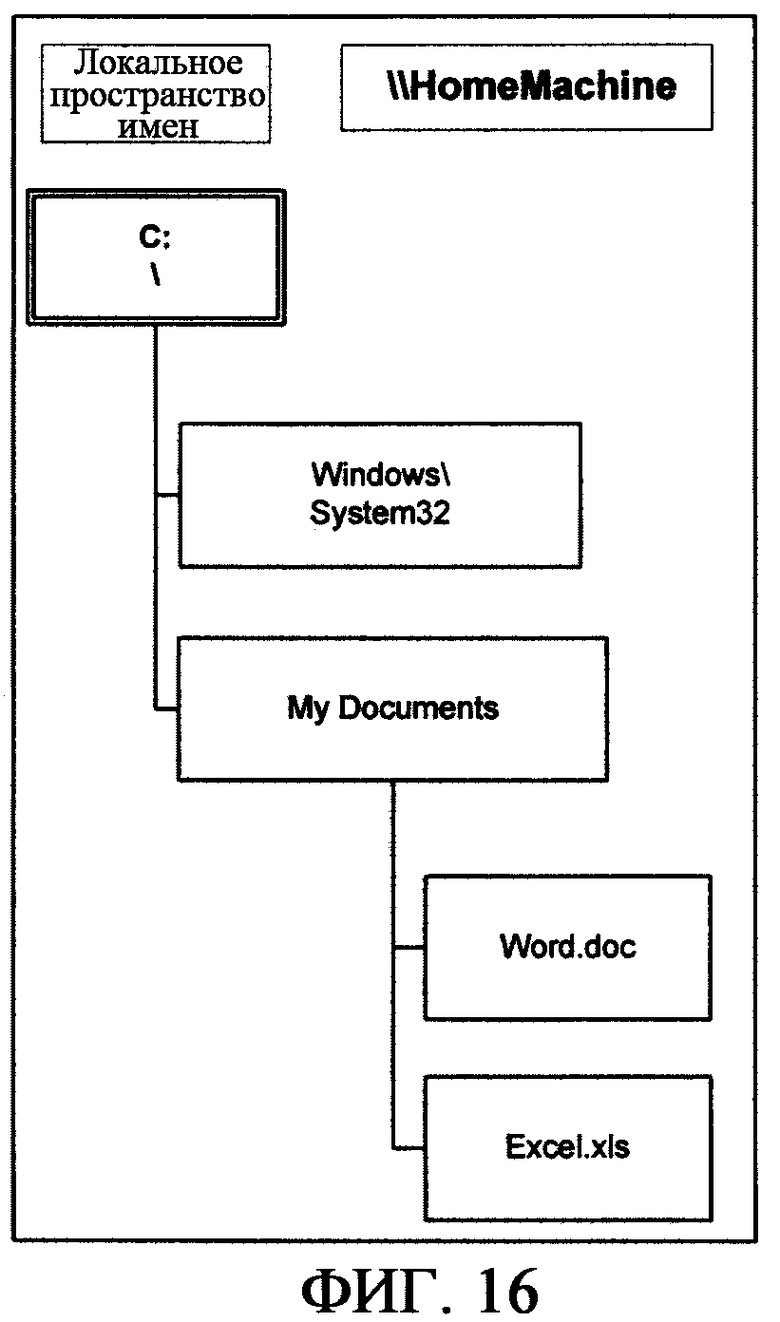



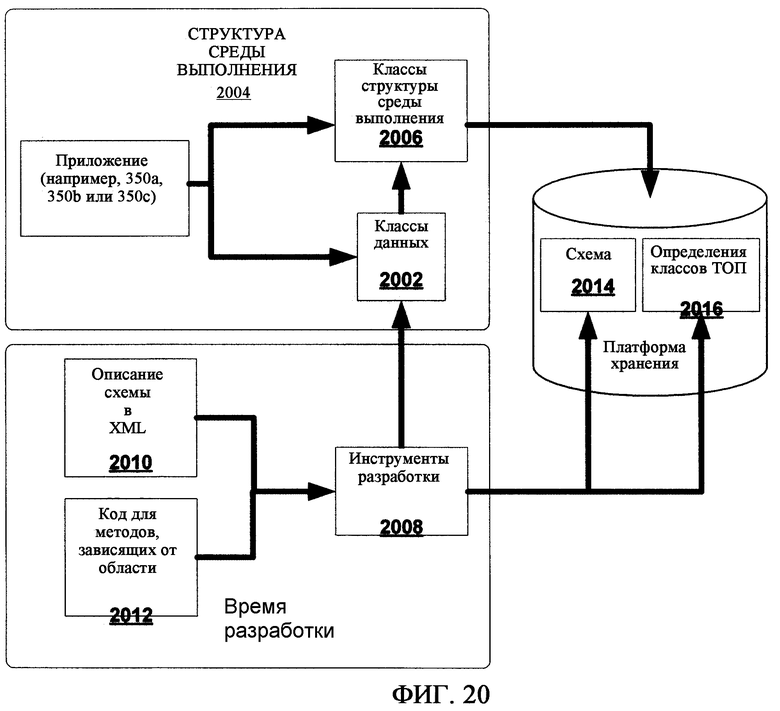

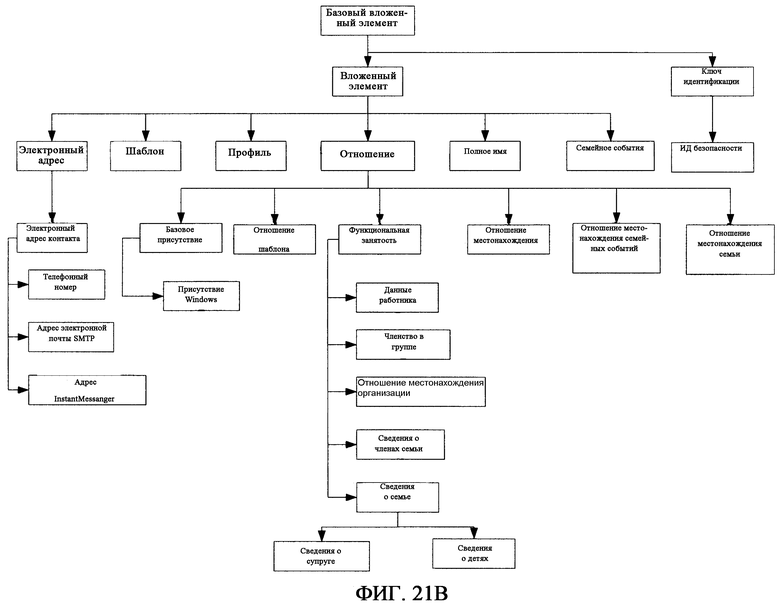

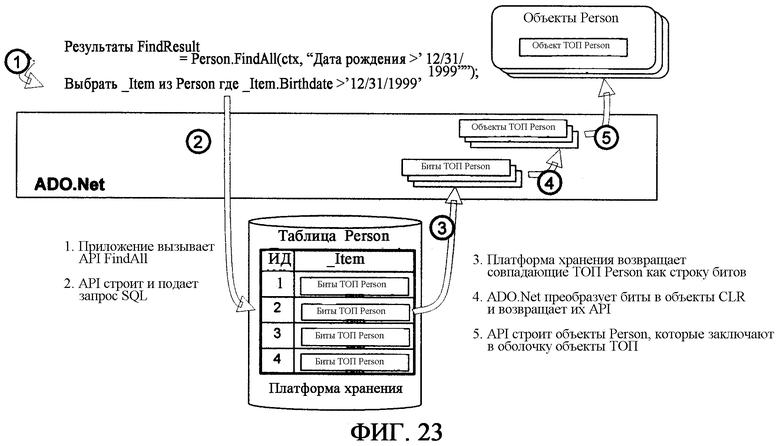



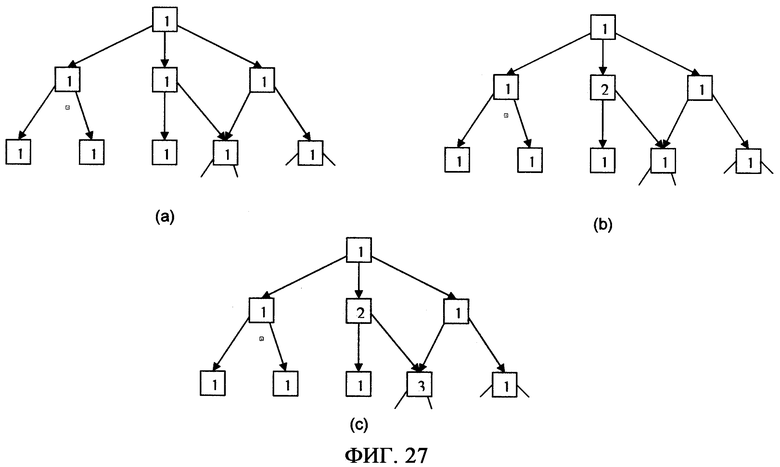
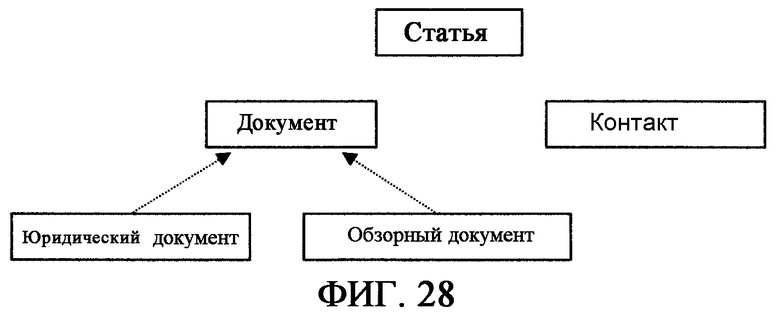
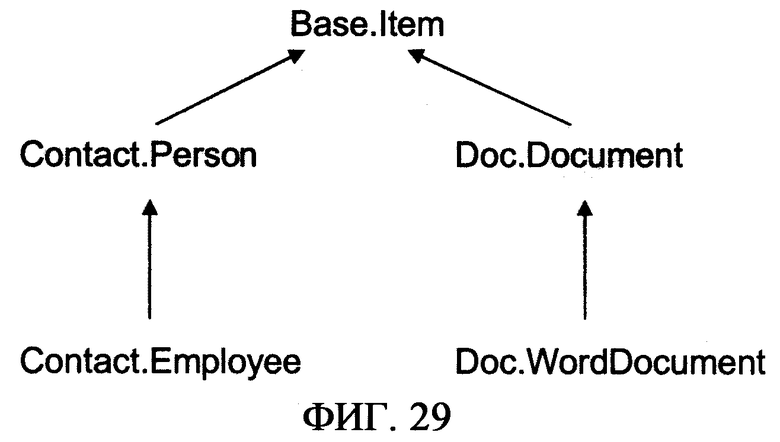
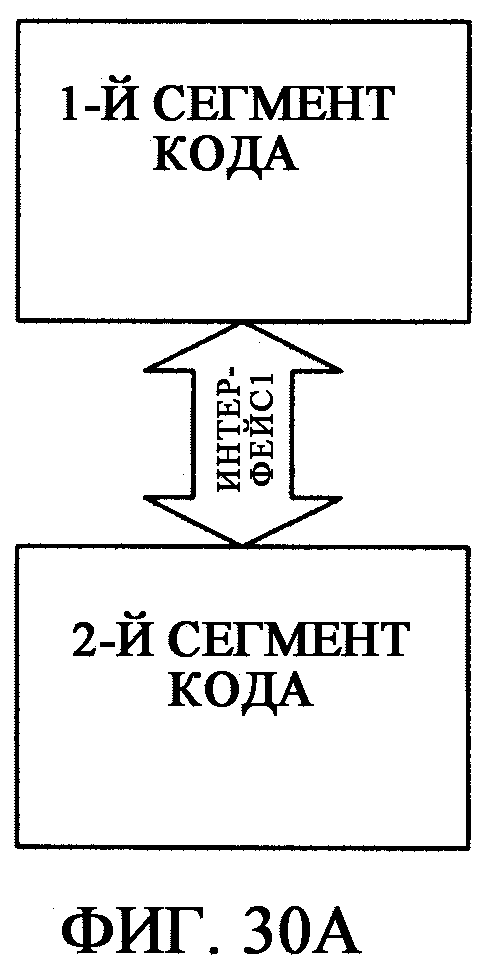
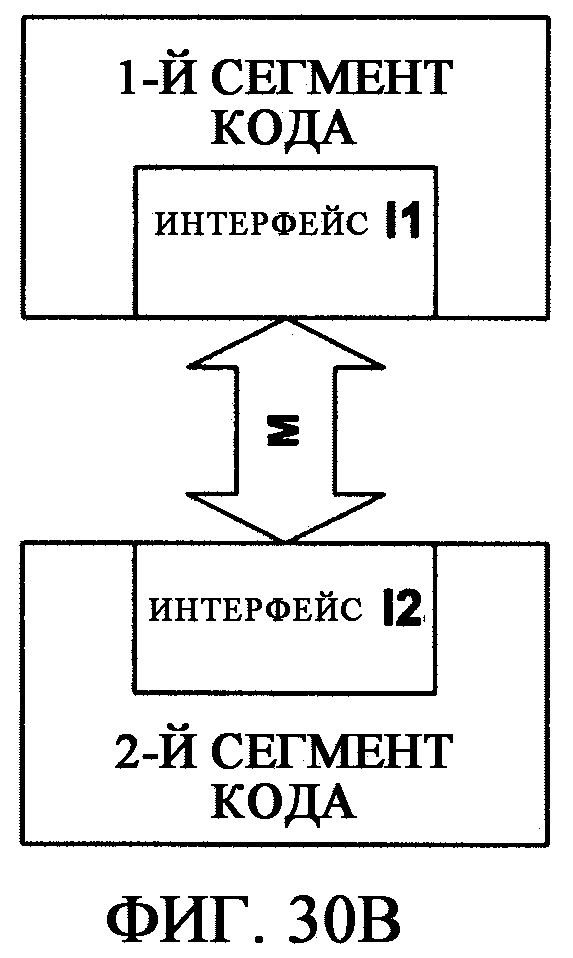
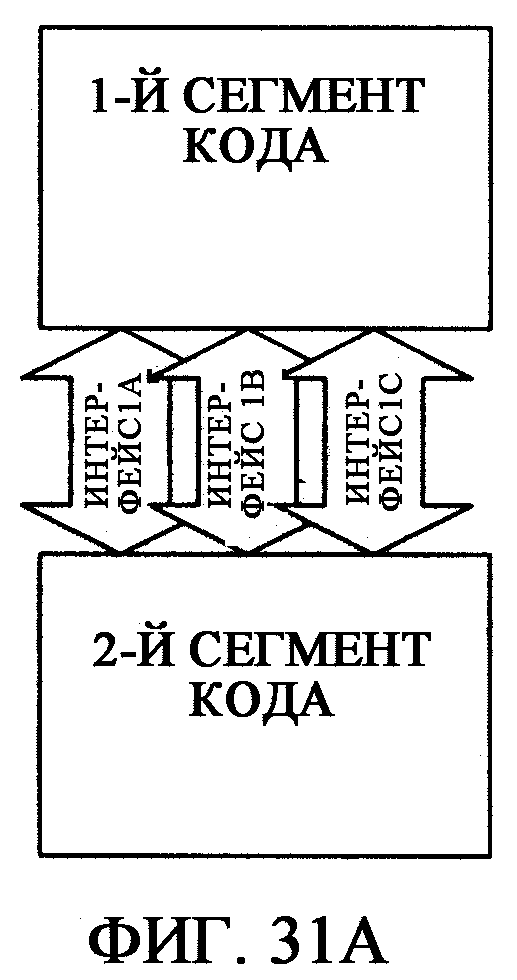


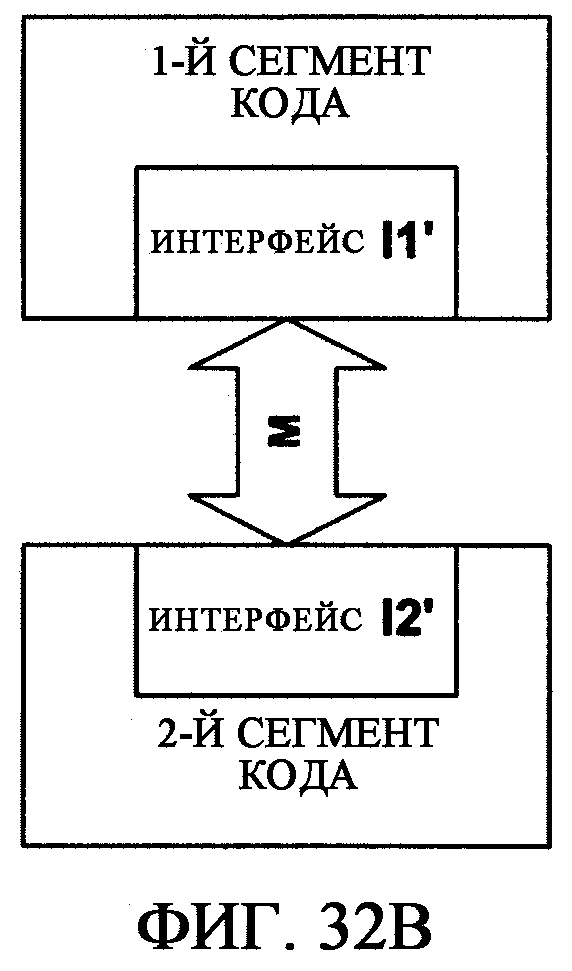
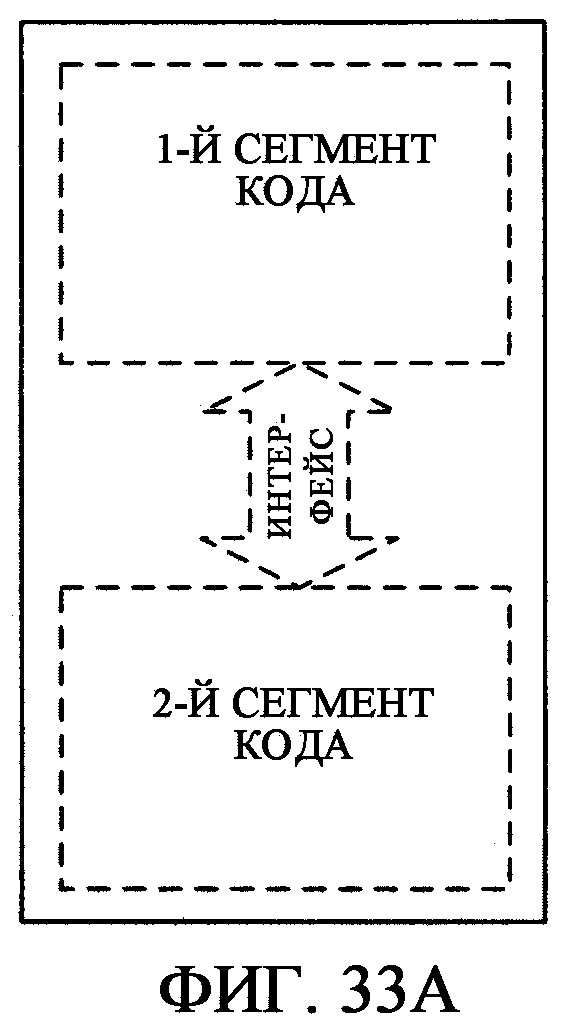
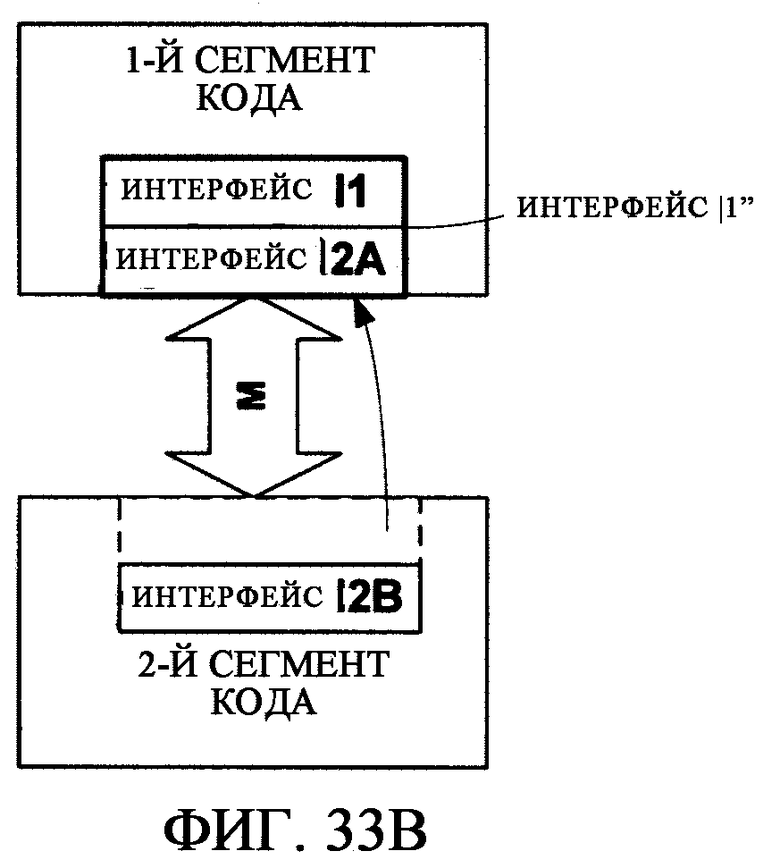


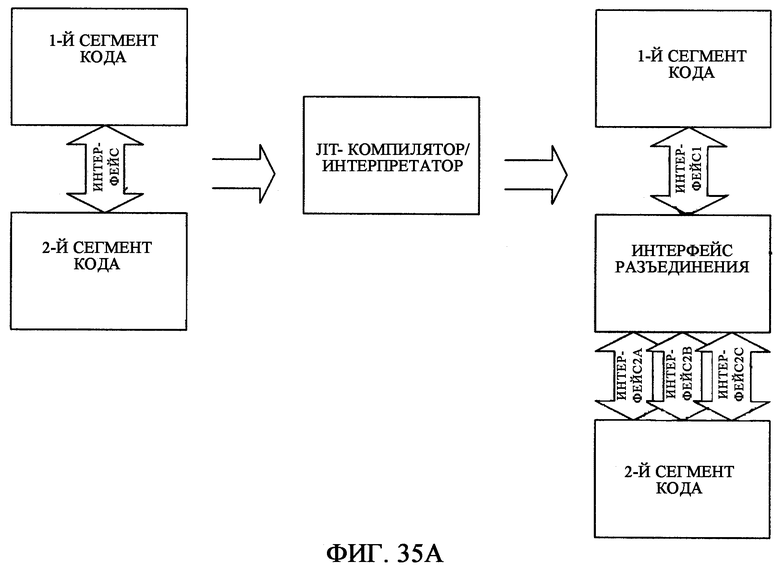
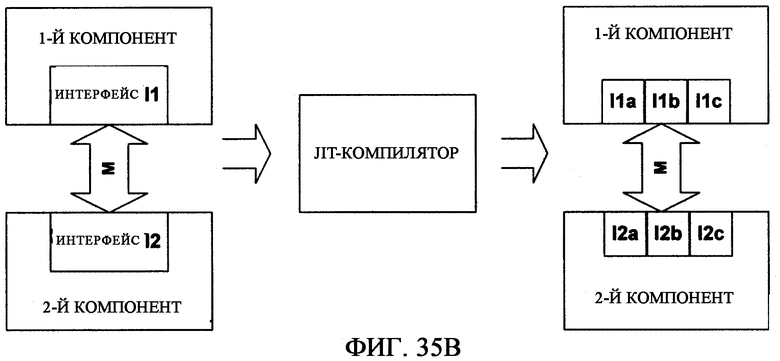
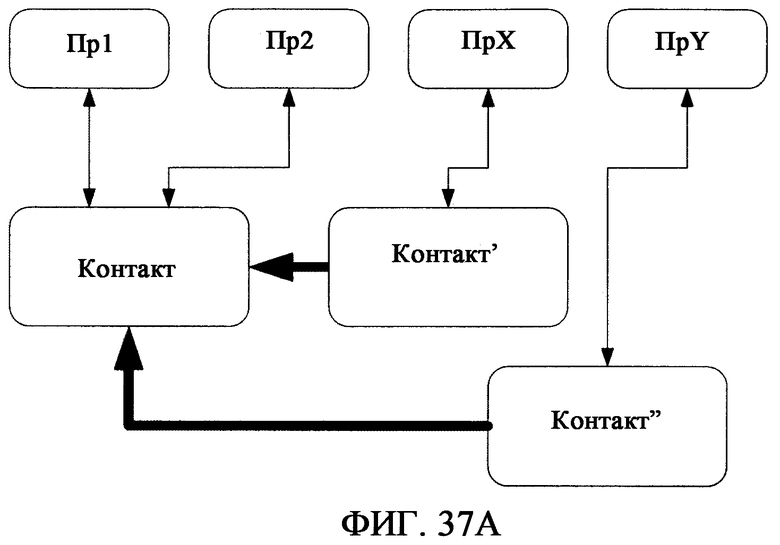
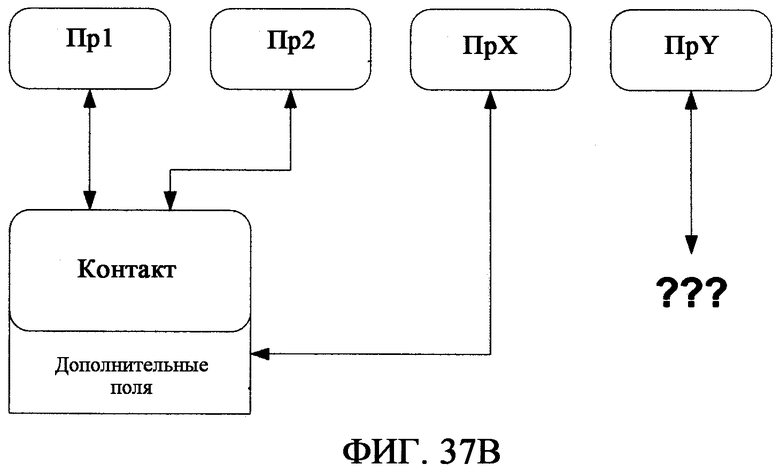
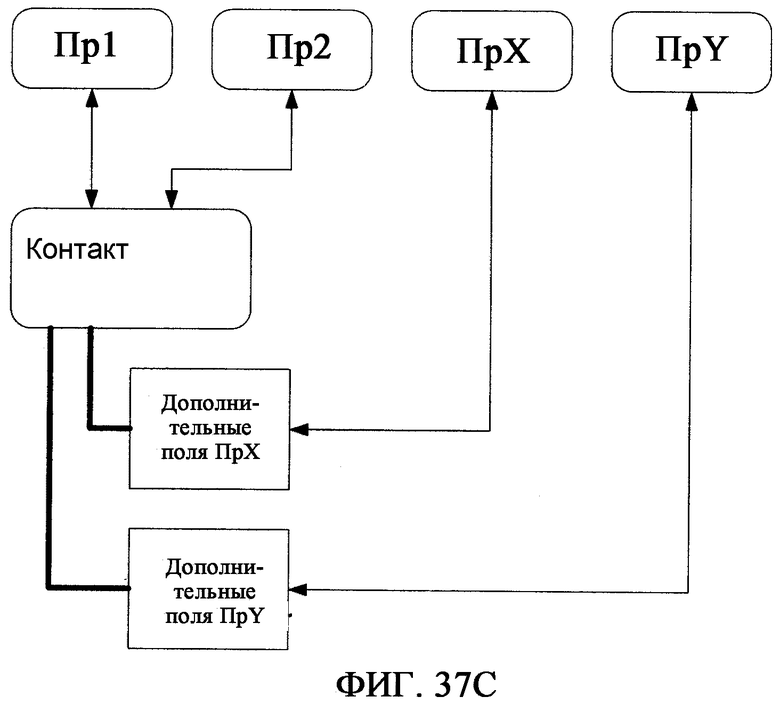
Изобретение относится к области хранения и извлечения информации. Технический результат - расширение функциональных возможностей выделения подтипов путем расширения Статей (и типов Статьи) с использованием Расширений, которые обеспечивают дополнительные структуры данных (Свойства, Отношения и пр.) для уже существующих структур типов Статей. Расширения являются строго типизированными экземплярами, которые не могут существовать независимо и должны присоединяться к Статье или Вложенному элементу. Расширения также призваны решать вопросы многотипности, допуская перекрытие экземпляров типов (например, Документ может быть юридическим документом и одновременно защищенным документом). 3 н. 13 з. и ф-лы, 37 ил.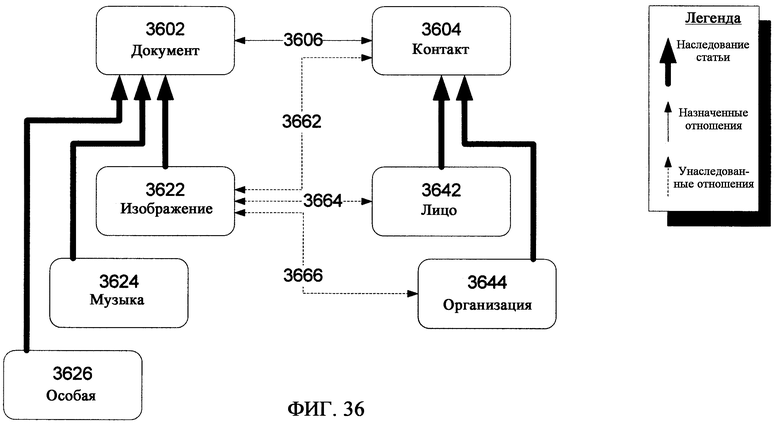
1. В платформе хранения, содержащей хранилище данных, реализующее модель данных, которая представляет информацию посредством дискретных сохраняемых блоков, и систему аппаратно-программного интерфейса, способ настройки дискретного сохраняемого блока информации, реализуемый посредством платформы хранения, содержащий следующие этапы:
осуществление доступа к хранилищу данных для определения исходного дискретного сохраняемого блока информации, имеющего типизированную структуру и первый идентификатор;
определение расширения, характерного для желательной дополнительной структуры данных;
определение экземпляра расширения, имеющего тип расширения, причем экземпляр расширения идентифицируется первым идентификатором и идентификатором расширения, хранится и доступен отдельно от дискретного сохраняемого блока информации; и
создание настроенного дискретного сохраняемого блока информации в хранилище данных, который хранится и доступен отдельно от дискретного сохраняемого блока информации, причем создание настроенного дискретного сохраняемого блока информации содержит присоединение экземпляра расширения, имеющего тип расширения, к дискретному сохраняемому блоку информации.
2. Способ по п.1, в котором упомянутое расширение не может существовать независимо от упомянутой типизированной структуры упомянутого настроенного дискретного сохраняемого блока информации.
3. Способ по п.1, дополнительно содержащий следующие этапы:
определение совокупности расширений, причем каждое расширение является характерным для желательной дополнительной структуры данных; и
присоединение расширений к типизированной структуре исходного дискретного сохраняемого блока информации.
4. Способ по п.3, в котором совокупность расширений используют для моделирования перекрывающихся экземпляров типов.
5. Способ по п.1, в котором дискретный сохраняемый блок информации является статьей.
6. Способ по п.1, в котором дискретный сохраняемый блок информации является вложенным элементом.
7. Способ по п.1, в котором расширение представляет определенное свойство.
8. Способ по п.1, в котором расширение представляет определенное отношение.
9. Система аппаратно-программного интерфейса для манипулирования совокупностью дискретных сохраняемых блоков информации посредством осуществления доступа к платформе хранения, содержащей хранилище данных, реализующее модель данных, которая представляет информацию посредством дискретных сохраняемых блоков, причем упомянутая система содержит
процессор, выполненный с возможностью выполнения исполняемых процессором инструкций;
запоминающее устройство, соединенное с возможностью обмена данными с процессором, хранящее исполняемые процессором инструкции, которые при выполнении процессором, реализуют подсистему для
определения исходных дискретных сохраняемых блоков информации, имеющих типизированную структуру и соответствующие первые идентификаторы;
определения по меньшей мере одного типа расширения, характерного для желательной дополнительной структуры данных;
определения по меньшей мере одного экземпляра расширения по меньшей мере одного типа расширения, причем по меньшей мере один экземпляр расширения идентифицируется соответствующим первым идентификатором дискретного сохраняемого блока информации, к которому присоединяется по меньшей мере один экземпляр расширения, и соответствующим идентификатором расширения, при этом по меньшей мере один экземпляр расширения хранится и доступен отдельно от дискретных сохраняемых блоков информации; и
присоединения расширений к типизированной структуре исходных дискретных сохраняемых блоков информации и
создания настроенных дискретных сохраняемых блоков информации в платформе хранения, которые хранятся и доступны отдельно от дискретных сохраняемых блоков информации, причем создание настроенных дискретных сохраняемых блоков информации содержит присоединение по меньшей мере одного экземпляра расширения по меньшей мере одного типа расширения к дискретным сохраняемым блокам информации.
10. Система аппаратно-программного интерфейса по п.9, в которой по меньшей мере одно расширение не может существовать независимо от упомянутой типизированной структуры настроенных дискретных сохраняемых блоков информации.
11. Система аппаратно-программного интерфейса по п.9, дополнительно содержащая подсистему для определения совокупности расширений, причем каждое расширение является характерным для желательной дополнительной структуры данных; и присоединения расширений к типизированной структуре исходных дискретных сохраняемых блоков информации.
12. Система аппаратно-программного интерфейса по п.9, в которой дискретные сохраняемые блоки информации являются статьями.
13. Система аппаратно-программного интерфейса по п.9, в которой дискретные сохраняемые блоки информации являются вложенными элементами.
14. Система аппаратно-программного интерфейса по п.9, в которой расширения представляют определенное свойство.
15. Система аппаратно-программного интерфейса по п.9, в которой расширения представляют определенное отношение.
16. Машиночитаемый носитель, содержащий считываемые компьютером команды, которые при исполнении процессором инструктируют платформу хранения:
осуществлять доступ к хранилищу данных для определения исходного дискретного сохраняемого блока информации, имеющего типизированную структуру и первый идентификатор;
определять по меньшей мере первый тип расширения и второй тип расширения, причем первый тип расширения является характерным для первой желательной дополнительной структуры данных, требуемой первым приложением, а второй тип расширения является характерным для второй желательной дополнительной структуры данных, требуемой вторым приложением;
определять первый экземпляр расширения первого типа расширения, причем первый экземпляр расширения идентифицируется первым идентификатором и первым идентификатором расширения;
определять второй экземпляр расширения второго типа расширения, причем второй экземпляр расширения идентифицируется первым идентификатором и вторым идентификатором расширения, при этом первый экземпляр расширения и второй экземпляр расширения хранятся и доступны отдельно от дискретного сохраняемого блока информации; и
создавать по меньшей мере два настроенных дискретных сохраняемых блока информации, которые хранятся и доступны отдельно от дискретного сохраняемого блока информации, причем создание по меньшей мере двух настроенных дискретных сохраняемых блоков информации содержит присоединение первого экземпляра расширения первого типа расширения к дискретному сохраняемому блоку информации для создания первого настроенного дискретного сохраняемого блока информации и, отдельно, присоединение второго экземпляра расширения второго типа расширения к дискретному сохраняемому блоку информации для создания настроенного дискретного сохраняемого блока информации.
| US 2002198891 A1, 24.12.2002 | |||
| US 2003110189 A1, 12.06.2003 | |||
| СПОСОБ ПЕРЕДАЧИ И ОБРАБОТКИ ГРУППОВЫХ СООБЩЕНИЙ В СИСТЕМЕ ЭЛЕКТРОННОЙ ПОЧТЫ | 1997 |
|
RU2144274C1 |
| US 6377953 B1, 15.01.2002 | |||
| US 6418448 B1, 10.07.2002. | |||

