Настоящая заявка испрашивает приоритет по заявке на патент США №10/692,515 (номер в реестре поверенного MSFT-2844), поданной 24 октября 2004, озаглавленной "SYSTEMS AND METHODS FOR PROVIDING SYNCHRONIZATION SERVICES FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; заявке на патент США №10/646,575 (номер в реестре поверенного MSFT-2733), поданной 21 августа 2003, озаглавленной "SYSTEMS AND METHODS FOR INTERFACING APPLICATION PROGRAMS WITH AN ITEM-BASED STORAGE PLATFORM"; и международной заявке №PCT/US 03/26150 (номер в реестре поверенного 2777), поданной 21 августа 2003, озаглавленной "SYSTEMS AND METHODS FOR INTERFACING APPLICATION PROGRAMS WITH AN ITEM-BASED STORAGE PLATFORM"; раскрытия которых включены в описание по ссылке в их полном содержании.
Настоящая заявка связана объектом изобретения с изобретениями, раскрытыми в следующих заявках, права на которые обычным образом переданы, содержание которых тем самым включено в эту настоящую заявку в их полноте (и частично кратко изложены для удобства): заявка на патент США №10/647,058 (номер в реестре поверенного MSFT-1748), поданная 21 августа 2003, озаглавленная "SYSTEMS AND METHODS FOR REPRESENTING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM BUT INDEPENDENT OF PHYSICAL REPRESENTATION"; заявка на патент США №10/646,941 (номер в реестре поверенного MSFT-1749), поданная 21 августа 2003, озаглавленная "SYSTEMS AND METHODS FOR SEPARATING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM FROM THEIR PHYSICAL ORGANIZATION"; заявка на патент США №10/646,940 (номер в реестре поверенного MSFT-1750), поданная 21 августа 2003, озаглавленная "SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A BASE SCHEMA FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; заявка на патент США №10/646,632 (номер в реестре поверенного MSFT-1751), поданная 21 августа 2003, озаглавленная "SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A CORE SCHEMA FOR PROVIDING A TOP-LEVEL STRUCTURE FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; заявка на патент США №10/646,645 (номер в реестре поверенного MSFT-1752), поданная 21 августа 2003, озаглавленная "SYSTEMS AND METHOD FOR REPRESENTING RELATIONSHIPS BETWEEN UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; заявка на патент США №10/646,646 (номер в реестре поверенного MSFT-2734), поданная 21 августа 2003, озаглавленная "STORAGE PLATFORM FOR ORGANIZING, SEARCHING, AND SHARING DATA"; заявка на патент США №10/646,580 (номер в реестре поверенного MSFT-2735), поданная 21 августа 2003, озаглавленная "SYSTEMS AND METHODS FOR DATA MODELING IN AN ITEM-BASED STORAGE PLATFORM"; заявка на патент США №10/692,779 (номер в реестре поверенного MSFT-2829), поданная 24 октября 2003, озаглавленная "SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A DIGITAL IMAGES SCHEMA FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; заявка на патент США №10/692,508 (номер в реестре поверенного MSFT-2845), поданная 24 октября 2003, озаглавленная "SYSTEMS AND METHODS FOR PROVIDING RELATIONAL AND HIERARCHICAL SYNCHRONIZATION SERVICES FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; заявка на патент США №10/693,362 (номер в реестре поверенного MSFT-2846), поданная 24 октября 2003, озаглавленная "SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A SYNCHRONIZATION SCHEMAS FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM"; и заявка на патент США №10/693,574 (номер в реестре поверенного MSFT-2847), поданная 24 октября 2003, озаглавленная "SYSTEMS AND METHODS FOR EXTENSIONS AND INHERITANCE FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM".
Область техники
Настоящее изобретение в целом относится к области хранения и извлечения информации и, более конкретно, к активной платформе хранения для организации, поиска и совместного использования различных типов данных в компьютеризированной системе.
Предшествующий уровень техники
Объем отдельного диска возрастал приблизительно на семьдесят процентов (70%) в год в течение последнего десятилетия. Закон Мура точно предсказал огромное увеличение мощности центрального блока обработки (ЦПУ), которая произошла за эти годы. Проводные и беспроводные технологии обеспечили огромную связность и пропускную способность. Предположение текущих тенденций продолжается, в пределах нескольких лет средний портативный компьютер будет обладать приблизительно одним терабайтом (Тb) памяти и содержать миллионы файлов, и диски емкостью 500 гигабайт (Гбайт) станут обыденными.
Потребители используют свои компьютеры прежде всего для связи и организации персональной информации, является ли она традиционными данными стиля для персонального администратора информации (PIM) или аудиовизуальной информацией типа цифровой музыки или фотографий. Объем цифрового содержимого (контента) и способность сохранять необработанные байты увеличились чрезвычайно; однако способы, доступные потребителям для организации и объединения этих данных, не сохраняют этого темпа. Квалифицированные работники тратят огромное количество времени на управление и совместное использование информации, и некоторые исследования оценивают, что квалифицированные работники тратят 15-25% своего времени на непроизводительные действия, связанные с информацией. Другие исследования оценивают, что типичный квалифицированный работник тратит приблизительно 2,5 часа в день на поиск информации.
Отделы разработки и информационной технологии (IT) затрачивают значительные количества времени и денег на построение своих собственных хранилищ данных для общих абстракций памяти, чтобы представить такие вещи, как люди, места, времена и события. Мало того, что это приводит к дублированию работы, но это также создает “островки” общих данных без механизмов для общего поиска или совместного использования этих данных. Стоит рассмотреть, сколько записных книжек (Address book) могут существовать сегодня на компьютере, на котором выполняется операционная система Microsoft Windows. Много прикладных программ, типа клиентов электронной почты и персональных финансовых программ, хранят индивидуальные записные книжки, и имеется мало совместного использования среди прикладных программ данных записной книжки, которые индивидуально поддерживает каждая такая программа. Следовательно, финансовая программа (подобная Microsoft Money) совместно не использует адреса для получателей платежа с адресами, поддерживаемыми в папке контактов электронной почты (подобно как в Microsoft Outlook). Действительно, много пользователей имеют множество устройств и логически должны синхронизировать свои персональные данные между собой и с широким разнообразием дополнительных источников, включая сотовые телефоны, с коммерческими службами типа MSN и AOL; однако, совместная работа совместно используемых документов в значительной степени достигается посредством прикрепления документов к сообщениям электронной почты - то есть вручную и неэффективно.
Одна из причин для этого недостатка сотрудничества заключается в том, что традиционные подходы к организации информации в компьютерных системах фокусировались на использовании систем, основанных на файле-папке-каталоге ("файловые системы") для организации множества файлов в иерархию каталогов папок, на основании абстракции физической организации носителя данных, используемого для хранения файлов. Операционную систему Multics, разработанную в течение 1960-х годов, можно назвать пионерской в использовании файлов, папок и каталогов для управления сохраняемыми блоками данных на уровне операционной системы. В частности, Multics использовала символические адреса в пределах иерархии файлов (таким образом, представляя идею пути файла), где физические адреса файлов не были прозрачны для пользователя (прикладных программ и конечных пользователей). Эта файловая система была полностью незаинтересованной относительно формата файла любого индивидуального файла, и отношения среди и между файлами считались иррелевантными на уровне операционной системы (то есть, в отличие от расположения файла в иерархии). Начиная с появления Multics, сохраняемые данные были организованы в файлы, папки и каталоги на уровне операционной системы. Эти файлы обычно включают в себя саму иерархию файлов ("каталог"), воплощенную в специальном файле, поддерживаемом файловой системой. Этот каталог, в свою очередь, поддерживает список входов (записей), соответствующих всем другим файлам в этом каталоге, и узловое расположение таких файлов в иерархии (здесь упоминаемые как папки). Таково было состояние уровня техники в течение приблизительно сорока лет.
Однако при обеспечении разумного представления информации, постоянно находящейся в системе физической памяти компьютера, файловая система является тем не менее абстракцией этой системы физической памяти, и поэтому использование файлов требует уровня отклонения (интерпретации) между тем, чем пользователь управляет (модули, имеющие контекст, особенности и отношения к другим модулям), и тем, что операционная система обеспечивает (файлы, папки и каталоги). Следовательно, пользователи (прикладные программы и/или конечные пользователи) не имеют никакого выбора, кроме как включать блоки информации в структуру файловой системы, даже делая это так неэффективно, противоречиво или иным нежелательным образом. Кроме того, существующие файловые системы немного знают о структуре данных, сохраненных в отдельных файлах, и из-за этого большая часть информации остается "запертой" в файлах, к которым можно только обращаться (и постигать) прикладным программам, которые их записали. Следовательно, этот недостаток схематического описания информации и механизмов для управления информацией ведет к созданию бункеров данных с малой степенью совместного использования данных для индивидуальных бункеров. Например, много пользователей персональных компьютеров (PC) имеют более чем пять различных хранилищ, которые содержат информацию относительно людей, с которыми они взаимодействует на некотором уровне - например. Outlook Contacts, адреса интерактивного выставления счетов, записную книжку (Address Book) Windows, Quicken Payees, и список приятелей для мгновенной передачи сообщений (IM) - потому что организация файлов представляет существенный вызов этим пользователям PC. Поскольку большинство существующих файловых систем используют метафору “вложенной папки” для организации файлов и папок, когда число файлов увеличивается, то усилие, необходимое для обслуживания схемы организации, которая должна быть гибкой и эффективной, становится весьма устрашающим. В таких ситуациях было бы очень полезно иметь множество классификаций одиночного файла; однако, использование жестких или мягких связей в существующих файловых системах тяжело и трудно для обслуживания.
Несколько неудачных попыток разрешить недостатки файловых систем были сделаны в прошлом. Некоторые из этих предыдущих попыток включали в себя использование памяти с адресацией по контенту, чтобы обеспечить механизм, посредством которого к данным можно было бы обращаться по контенту вместо физического адреса. Однако, эти усилия были доказаны как неудачные, потому что в то время как память с адресацией по контенту доказала пользу для использования устройствами малого масштаба, типа кэша, и модулей управления памятью, крупномасштабное использование для устройств типа физических носителей данных еще не было возможно по ряду причин, и таким образом такое решение просто не существует. Были сделаны другие попытки, использующие системы объектно-ориентированных баз данных (OODB), но эти попытки, показывая хорошие характеристики базы данных и хорошие не-файловые представления, не были эффективны в обработке представлений файлов и не могли воспроизводить на уровне аппаратной/программной интерфейсной системы быстродействие, эффективность и простоту иерархической структуры, основанной на файлах и папках. Другие усилия, типа тех, которые попытались использовать SmallTalk (и другие производные), оказались весьма эффективными при обработке файловых и не-файловых представлений, но испытывали недостаток в наличии базы данных, необходимой для эффективной организации и использования отношений, которые существуют между различными файлами данных, и таким образом общая эффективность таких систем была неприемлема. Другие попытки использовать ВеОS (и другое такое исследование операционных систем) оказались неадекватными при обработке нефайловых представлений - тот же самый основной недостаток традиционных файловых систем - несмотря на способность соответственно представить файлы, в то же время обеспечивая некоторые необходимые особенности базы данных.
Технология баз данных - другая область, в которой имеют место подобные проблемы. Например, в то время как реляционная модель базы данных была большим коммерческим успехом, по правде говоря, независимые продавцы программ (ISV) обычно реализовывали маленькую часть функциональных возможностей, доступных в программных продуктах реляционной базы данных (типа Microsoft SQL Server). Вместо этого, большинство взаимодействий прикладной программы с таким продуктом находится в форме простых (операций) "получить" и "поместить". В то время как имеется ряд очевидных причин для этого - типа, являющегося платформой или агностиком базы данных, - одна ключевая причина, которая часто бывает незамеченной, заключается в том, что база данных не обязательно обеспечивает точные абстракции, в которых продавец главного бизнес-приложения действительно нуждается. Например, в то время как реальный мир имеет понятие "элементы", такие как "заказчики" или "заказы" (наряду с внедренными "элементами строки" заказа в качестве элементов внутри себя и самих себя), реляционные базы данных оперируют только с терминами таблиц и строк. Поэтому, в то время как прикладная программа может желать иметь аспекты последовательности, блокировки, защиты, и/или спусковых механизмов (триггеров, инициаторов) на уровне элементов (названо несколько), обычно базы данных обеспечивают эти особенности только на уровне таблиц/строк. В то время как это может работать прекрасно, если каждый элемент отображается в одиночную строку в некоторой таблице в базе данных, в случае множества элементов строки могут существовать причины, почему элемент фактически отображается на множество таблиц, и когда это имеет место, простая система реляционной базы данных не совсем обеспечивает правильные абстракции. Следовательно, прикладная программа должна строить логику поверх базы данных, чтобы обеспечить эти основные абстракции. Другими словами, основная реляционная модель не обеспечивает достаточную платформу для хранения данных, над которыми могут легко быть разработаны прикладные программы более высокого уровня, потому что основная реляционная модель требует уровня отклонения (варьирования) между прикладной программой и системой хранения - где семантическая структура данных в некоторых случаях могла бы быть только видима в прикладной программе. В то время как некоторые продавцы баз данных строят функциональные возможности более высокого уровня в своих продуктах - таких как обеспечение объектных реляционных способностей, новых организационных моделей и т.п. - ни один (из них) все же не обеспечивает вид всестороннего необходимого решения, где истинно всестороннее решение является тем, которое обеспечивает обе полезные абстракции модели данных (типа "Порции данных", "Расширения", "Отношения" и так далее) для полезных абстракций области (применения) (типа "Люди", "Расположения", "События" и т.д.).
Ввиду предшествующих недостатков в существующих технологиях хранения данных и баз данных, имеется потребность в новой платформе памяти (хранения), которая обеспечивает улучшенную способность организовывать, искать и совместно использовать все типы данных в компьютерной системе - платформе хранения, которая расширяет и “распространяет” платформу данных за пределы существующих файловых систем и систем базы данных, и которая предназначена, чтобы быть хранилищем для всех типов данных. Настоящее изобретение вместе со связанными изобретениями, включенными по ссылке, упомянутыми выше, удовлетворяет эту потребность.
Сущность изобретения
Нижеследующее изложение обеспечивает краткий обзор различных аспектов изобретения, описанного в контексте связанных изобретений, включенных ранее по ссылке ("связанные изобретения"). Это изложение не предназначено ни для обеспечения исчерпывающего описания всех важных аспектов изобретения, ни для определения объема изобретения. Скорее, это изложение предназначено, чтобы служить как введение в подробное описание и чертежи, которые описаны ниже
Настоящее изобретение, так же как связанные изобретения, все вместе посвящены платформе памяти (хранения) для организации, поиска и совместного использования данных. Платформа хранения согласно настоящему изобретению расширяет и распространяет концепцию хранения данных вне существующих файловых систем и систем баз данных, и предназначена, чтобы быть хранилищем для всех типов данных, включающих в себя структурированные, неструктурированные или полу-структурированные данные.
Платформа хранения согласно настоящему изобретению содержит хранилище данных, реализованное на механизме базы данных. Механизм базы данных содержит механизм реляционной базы данных с реляционными расширениями объектов. Хранилище данных реализует модель данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных. Специфические типы данных описаны в схемах, и платформа обеспечивает механизм для расширения набора схем для определения новых типов данных (по существу подтипов основных типов, обеспеченных схемами). Возможность синхронизации облегчает совместное использование данных для пользователей или систем. Обеспечиваются возможности, подобные файловой системе, которые позволяют обеспечить взаимодействие хранилища данных с существующими файловыми системами, но без ограничения таких традиционных файловых систем. Механизм отслеживания изменений обеспечивает возможность отслеживания изменений для хранилища данных. Платформа хранения дополнительно содержит набор интерфейсов прикладных программ, которые дают возможность прикладным программам обращаться ко всем из предшествующих возможностей платформы хранения и обращаться к данным, описанным в схемах.
Модель данных, реализованная хранилищем данных, определяет модули хранения данных в терминах порций данных (Items), элементов (elements) и отношений (relationship). Порция данных (Item) - блок данных, сохраняемых в хранилище данных и который может содержать один или более элементов и отношений. Элемент - экземпляр такого типа, который содержит одно или более полей (также называемых как свойство). Отношение - связь между двумя порциями данных. (Используемые здесь эти и другие специфические термины могут быть напечатаны прописными буквами, чтобы отличить их от других терминов, используемых в близком смысле; однако обычно не имеется никакого намерения отличать напечатанный прописными буквами термин, например "Порция данных" (Item), и тот же самый термин, не напечатанный прописными буквами, например, "порция данных" (item), и никакое такое различие не должно предполагаться или подразумеваться.)
Компьютерная система также содержит множество Порций данных (Items), где каждая Порция данных образует дискретную сохраняемую единицу информации, которой можно манипулировать аппаратной/программной интерфейсной системой; множество Папок Порций данных (Item Folders), которые образуют организационную структуру для упомянутых Порций данных; и аппаратная/программная интерфейсная система для манипулирования множеством Порций данных и в которой каждая Порция данных принадлежит по меньшей мере одной Папке Порций данных и может принадлежать более чем одной Папке Порций данных.
Порция данных или некоторые из значений свойств Порции данных могут быть вычислены динамически в противоположность получению (его) из постоянного (персистентного) хранилища. Другими словами, аппаратная/программная интерфейсная система не требует, чтобы Порция данных была сохранена, и поддерживаются некоторые операции, такие как возможность перенумеровать текущий набор Порции данных или возможность извлечь Порцию данных, заданную ее идентификатором (которые более полностью описаны в разделах, которые описывают интерфейс прикладного программирования, или API) платформы хранения - например. Порция данных может быть текущим местоположением сотового телефона или температурой, считываемой датчиком температуры. Аппаратная/программная интерфейсная система может манипулировать множеством Порций данных и может дополнительно содержать Порции данных, связанные множеством Отношений (Relationship), управляемых аппаратной/программной интерфейсной системой.
Аппаратная/программная интерфейсная система для компьютерной системы дополнительно содержит основную схему, чтобы определить набор основных Порций данных, которые упомянутая аппаратная/программная интерфейсная система понимает и может непосредственно обрабатывать заранее определенным и предсказуемым способом. Чтобы манипулировать множеством Порций данных, компьютерная система связывает упомянутые Порции данных с множеством Отношений и управляет упомянутыми Отношениями на уровне аппаратной/программной интерфейсной системы.
API платформы хранения обеспечивает классы данных для каждой порции данных, расширения порции данных и отношение, определенное в наборе схем платформы хранения. Кроме того, интерфейс прикладного программирования обеспечивает набор классов инфраструктуры, которые определяют общий набор поведений для классов данных и которые вместе с классами данных обеспечивают основную модель программирования для API платформы хранения. API платформы хранения обеспечивает упрощенную модель запросов, которая дает возможность программистам приложения формировать запросы на основании различных свойств порций данных в хранилище данных таким способом, который изолирует программиста приложения от подробностей языка запросов, лежащего в основе механизма базы данных. API платформы хранения также собирает изменения для порции данных, сделанные прикладной программой, и затем объединяет их в корректные обновления, требуемые механизмом базы данных (или любым видом механизма хранения), на котором реализовано хранилище данных. Это дает возможность программистам приложения делать изменения для порции данных в памяти, в то же время оставляя сложности, связанные с обновлениями хранилища данных, для API.
Посредством своей общей основы хранения и схематизированных данных платформа хранения согласно настоящему изобретению допускает более эффективную разработку приложений для потребителей, специалистов и предприятий. Она предлагает богатый и расширяемый интерфейс прикладного программирования, который не только делает доступным возможности, свойственные ее модели данных, но также и охватывает и расширяет существующую файловую систему и методы доступа к базам данных.
В качестве части этой перекрывающейся структуры взаимосвязанных изобретений (описанной подробно в разделе II подробного описания) настоящее изобретение конкретно посвящено API синхронизации (описанный подробно в Разделе III подробного описания). Другие признаки и преимущества изобретения очевидны из нижеследующего подробного описания изобретения и сопроводительных чертежей.
Краткое описание чертежей
Предшествующее краткое изложение, так же как нижеследующее подробное описание изобретения, станет более понятно при рассмотрении вместе с прилагаемыми чертежами. С целью иллюстрирования изобретения на чертежах показаны примерные варианты осуществления различных аспектов изобретения; однако изобретение не ограничено конкретными способами и раскрытыми реализациями.
На чертежах:
Фиг.1 изображает схематическую диаграмму, представляющую компьютерную систему, в которую могут быть включены аспекты настоящего изобретения;
Фиг.2 изображает схематическую диаграмму, иллюстрирующую компьютерную систему, разделенную на три группы компонентов:
аппаратный компонент, аппаратный/программный компонент интерфейсной системы и компонент прикладных программ;
Фиг.2А иллюстрирует традиционную древовидную иерархическую структуру для файлов, сгруппированных в папках в каталоге в основанной на файлах операционной системе;
Фиг.3 изображает схематическую диаграмму, иллюстрирующую платформу хранения;
Фиг.4 иллюстрирует структурные отношения между Порциями данных. Папками Порций данных и Категориями;
Фиг.5А изображает схематическую диаграмму, иллюстрирующую структуру Порции данных;
Фиг.5 В изображает схематическую диаграмму, иллюстрирующую составные типы свойств Порции данных из Фиг.5А;
Фиг.5С изображает схематическую диаграмму, иллюстрирующую Порцию данных "Расположение", в которой дополнительно описаны ее составные типы (явно перечислены);
Фиг.6А иллюстрирует Порцию данных как подтип Порции данных, найденной в Базовой Схеме;
Фиг.6В изображает схематическую диаграмму, иллюстрирующую подтип Порции данных из Фиг.6А, в которой ее унаследованные типы явно перечислены (в дополнение к ее непосредственным свойствам);
Фиг.7 изображает схематическую диаграмму, иллюстрирующую Базовую Схему, включающую в себя ее два типа классов верхнего уровня. Item и PropertyBase, и дополнительные типы Базовой Схемы, полученные из них;
Фиг.8А изображает схематическую диаграмму, иллюстрирующую Порции данных в Основной Схеме;
Фиг.8В изображает схематическую диаграмму, иллюстрирующую типы свойств в Основной Схеме;
Фиг.9 изображает схематическую диаграмму, иллюстрирующую Папку Порций данных, ее элементы - Порции данных, и взаимосвязь Отношений между Папкой Порций данных и ее элементами - Порциями данных;
Фиг.10 изображает схематическую диаграмму, иллюстрирующую Категорию (которая снова сама является Порцией данных), ее элементы - Порции данных и взаимосвязь Отношений между Категорией и ее элементом - Порцией данных;
Фиг.11 изображает диаграмму, иллюстрирующую иерархию ссылочных типов модели данных платформы хранения;
Фиг.12 изображает диаграмму, иллюстрирующую, как классифицированы отношения;
Фиг.13 изображает диаграмму, иллюстрирующую механизм уведомления;
Фиг.14 изображает диаграмму, иллюстрирующую пример, в котором две транзакции вставляют новую запись в одно и то же В-дерево;
Фиг.15 иллюстрирует процесс обнаружения изменения данных;
Фиг.16 иллюстрирует пример дерева каталогов;
Фиг.17 показывает пример, в котором существующая папка основанной на каталогах файловой системы перемещена в хранилище данных платформы хранения;
Фиг.18 иллюстрирует концепцию Папок Включения;
Фиг.19 иллюстрирует основную архитектуру API платформы хранения;
Фиг.20 схематично представляет различные компоненты стека API платформы хранения;
Фиг.21А изображает графическое представление примерной схемы Порции данных "Контакты";
Фиг.21В изображает графическое представление Элементов для примерной схемы Порции данных "Контакты" на фиг.21А;
Фиг.22 иллюстрирует инфраструктуру выполнения API платформы хранения;
Фиг.23 иллюстрирует выполнение операции "FindAll";
Фиг.24 иллюстрирует процесс, посредством которого классы API платформы хранения генерируются из Схемы платформы хранения;
Фиг.25 иллюстрирует схему, на которой основан API File;
Фиг.26 изображает диаграмму, иллюстрирующую формат маски доступа, используемый с целью защиты данных;
Фиг.27 (части а, b, и с) изображает новую идентично защищенную область защиты, вырезанную из существующей области защиты;
Фиг.28 изображает диаграмму, иллюстрирующую концепцию представления поиска Порции данных;
Фиг.29 изображает диаграмму, иллюстрирующую примерную иерархию Порций данных;
Фиг.30А иллюстрирует интерфейс Interface1 как канал, через который связываются первый и второй сегменты кода;
Фиг.30В иллюстрирует интерфейс как содержащий объекты I1 и I2 интерфейсы, которые дают возможность первому и второму сегментам кода системы обмениваться через среду М;
Фиг.31А иллюстрирует, как функция, обеспеченная интерфейсом Interface1, может быть подразделена для преобразования обменов интерфейса в множество интерфейсов Interface1A, Interface1B, Interface1C;
Фиг.31В иллюстрирует, как функция, обеспеченная интерфейсом II, может быть подразделена на множество интерфейсов 11а, 11b, 11 с;
Фиг.32А иллюстрирует сценарий, где ненужная точность параметра может быть игнорирована или заменена произвольным параметром;
Фиг.32В иллюстрирует сценарий, где интерфейс заменен заменяющим интерфейсом, который определен для игнорирования или добавления параметров к интерфейсу;
Фиг.33А иллюстрирует сценарий, где 1-й и 2-й Сегменты Кода объединены в модуль, содержащий их оба;
Фиг.33В иллюстрирует сценарий, где часть или весь интерфейс могут быть вписаны в другой интерфейс, чтобы формировать объединенный интерфейс.
Фиг.34А иллюстрирует, как одна или более частей промежуточного программного обеспечения может преобразовывать обмены по первому интерфейсу для приведения их в соответствие с одним или более отличным интерфейсом;
Фиг.34В иллюстрирует, как сегмент кода может быть введен в интерфейс для приема обмена информацией от одного интерфейса, но передавать функциональные возможности второму и третьему интерфейсам;
Фиг.35А иллюстрирует, как динамический компилятор (JIT) может преобразовывать обмены информацией из одного сегмента кода в другой сегмент кода;
Фиг.35В иллюстрирует JIТ-метод динамической перезаписи одного или более интерфейсов, которые могут применяться, чтобы динамически разделять или иначе изменять упомянутый интерфейс;
Фиг.36 иллюстрирует три экземпляра обычного хранилища данных и компоненты для их синхронизации; и
Фиг.37 иллюстрирует один вариант осуществления настоящего изобретения, который предполагает простой адаптер, который не осведомлен, как вычисляется состояние или обмениваются его связанные метаданные.
Подробное описание
ОГЛАВЛЕНИЕ
I. ВВЕДЕНИЕ
А. ПРИМЕРНАЯ ВЫЧИСЛИТЕЛЬНАЯ СРЕДА
В. ТРАДИЦИОННАЯ ПАМЯТЬ, ОСНОВАННАЯ НА ФАЙЛАХ
II. ПЛАТФОРМА WINFS ХРАНЕНИЯ ДЛЯ ОРГАНИЗАЦИИ, ПОИСКА И СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ ДАННЫХ
А. ГЛОССАРИЙ
В. КРАТКИЙ ОБЗОР ПЛАТФОРМЫ ХРАНЕНИЯ
С. МОДЕЛЬ ДАННЫХ
1. Порции данных
2. Идентификация Порции данных
3. Папки Порции данных и Категории
4. Схемы
a) Базовая Схема
b) Основная Схема
5. Отношения
a) Объявление Отношения
b) Отношение Хранения
c) Отношения Внедрения
d) Отношения Ссылки
e) Правила и Ограничения
f) Упорядочение Отношений
6. Расширяемость
a) Расширения Порции данных
b) Расширяющие типы NestedElement
D. МЕХАНИЗМ БАЗЫ ДАННЫХ
1. Реализация Хранилища Данных, используя UDT
2. Отображение Порции данных
3. Отображение Расширения
4. Отображение Вложенных элементов
5. Идентичность Объектов
6. Наименование SQL Объектов
7. Наименование Столбцов
8. Представления поиска
a) Порция данных
(1) Главное представление поиска Порции данных
(2) Имеющие тип представления поиска Порции данных
b) Расширения Порции данных
(1) Главное представление поиска Расширения
(2) Имеющие тип представления поиска Расширения
c) Вложенные Элементы
d) Отношения
(1) Главное представление поиска Отношения
(2) Представления поиска экземпляров Отношения
е)
9. Обновления
10. Отслеживание изменений & оповещения
a) Отслеживание изменений
(1) Отслеживание изменений в "главных" представлениях поиска
(2) Отслеживание изменений в "имеющих тип" представлениях поиска
b) Оповещения
(1) Оповещения Порции данных
(2) Оповещения Расширения
(3) Оповещение Отношений
(4) Очистка Оповещения
11. API и Функции помощника
a) Функция [System.Storage].Getltem
b) Функция [System.Storage].GetExtension
с) Функция [System.Storage].GetRelationship
12. Метаданные
a) Схема Метаданные
b) Экземпляр Метаданные
Е. ЗАЩИТА
F. УВЕДОМЛЕНИЯ И ОТСЛЕЖИВАНИЕ ИЗМЕНЕНИЯ
G. ТРАДИЦИОННАЯ ВОЗМОЖНОСТЬ ВЗАИМОДЕЙСТВИЯ ФАЙЛОВОЙ СИСТЕМЫ
Н. API ПЛАТФОРМЫ ХРАНЕНИЯ
III. API СИНХРОНИЗАЦИИ
А. КРАТКИЙ ОБЗОР СИНХРОНИЗАЦИИ
1. Синхронизация "Платформа хранения - Платформа хранения"
a) Приложения управления синхронизацией (Sync)
b) Аннотация Схемы
c) Конфигурация синхронизации
(1) Папка Сообщества - Отображения
(2) Профили
(3) Расписания
d) Обработка Конфликтов
(1) Обнаружение Конфликтов
(a) Конфликты на основе знания
(b) Конфликты на основе ограничения
(2) Обработка конфликтов
(a) Автоматическое разрешение конфликтов
(b) Регистрация конфликтов
(c) Проверка и разрешение конфликтов
(d) Сходимость точных копий и распространение
24 разрешения конфликтов
2. Синхронизация с хранилищем данных не-платформы хранения
a) Услуги синхронизации
(1) Перечисление изменений
(2) Применение изменений
(3) Разрешение конфликтов
b) Реализация адаптера
3. Защита
4. Управляемость
В. КРАТКИЙ ОБЗОР API СИНХРОНИЗАЦИИ
1. Общая Терминология
2. Принципы API Синхронизации
С. УСЛУГИ API СИНХРОНИЗАЦИИ
1. Перечисление изменений
2. Применение изменений
3. Код образца
4. Способы API синхронизации
D. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ SYNC-СХЕМЫ IV.
ЗАКЛЮЧЕНИЕ
Введение
Сущность настоящего изобретения описана с такой спецификой, чтобы выполнить установленные законом требования. Однако само описание не предназначено для ограничения объема этого патента. Скорее, изобретатели рассматривают, что заявленная сущность может быть также реализована другими способами для включения различных этапов или комбинации этапов, подобных описанным в этом документе, вместе с другими существующими или будущими технологиями. Кроме того, хотя термин "этап" может использоваться для обозначения различных элементов используемых способов, этот термин не должен интерпретироваться как предположение какого-либо конкретного порядка среди или между различными этапами, раскрытыми здесь, если только и за исключением того, когда порядок отдельных этапов описан явно.
А. Примерная вычислительная среда
Многочисленные варианты осуществления настоящего изобретения могут выполняться на компьютере. Фиг.1 и нижеследующее описание предназначены для обеспечения краткого общего описания подходящей вычислительной среды, в которой может быть осуществлено изобретение. Хотя и не требуется, различные аспекты изобретения могут быть описаны в общем контексте выполняемых компьютером команд, таких как программные модули, выполняемые компьютером, таким как клиентская рабочая станция или сервер. Обычно, программные модули включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.п., которые исполняют конкретные задачи или реализуют специфические абстрактные типы данных. Кроме того, изобретение может быть осуществлено с другими конфигурациями компьютерных систем, включающими в себя ручные устройства, многопроцессорные системы, основанную на микропроцессорах или программируемую бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры и т.п. Изобретение может также быть осуществлено в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, которые связаны через систему коммуникаций. В распределенной вычислительной среде программные модули могут быть расположены и в локальных и в удаленных запоминающих устройствах хранения.
Как показано на фиг.1, примерная вычислительная система общего назначения включает в себя обычный персональный компьютер 20 или ему подобный, включающий в себя блок 21 обработки, системную память 22 и системную шину 23, которая подсоединяет различные системные компоненты, включая системную память, к блоку 21 обработки. Системная шина 23 может быть любой из нескольких типов шинных структур, включая шину памяти или контроллер памяти, шину периферийных устройств и локальную шину, используя любую из ряда шинных архитектур. Системная память включает в себя постоянное запоминающее устройство (ПЗУ, ROM) 24 и оперативную память (ОЗУ, RAM) 25. Базовая система ввода-вывода 26 (BIOS), содержащая основные подпрограммы, которые помогают передавать информацию между элементами в персональном компьютере 20, например, во время запуска, сохранена в ROM 24. Персональный компьютер 20 может также включает в себя накопитель 27 на жестком диске для считывания с и записи на жесткий диск, не показанный, накопитель 28 на магнитном диске для считывания с или записи на сменный магнитный диск 29, и накопитель 30 на оптическом диске для считывания с или записи на сменный оптический диск 31 типа CD-ROM или другую оптическую среду. Накопитель 27 на жестком диске, накопитель 28 на магнитном диске и накопитель 30 на оптическом диске связаны с системной шиной 23 интерфейсом 32 накопителя на жестком диске, интерфейсом 33 накопителя на магнитном диске и интерфейсом 34 накопителя на оптическом диске, соответственно. Накопители и связанные с ними считываемые компьютером носители обеспечивают энергонезависимую память считываемых компьютером команд, структур данных, программных модулей и других данных для персонального компьютера 20. Хотя примерная среда, описанная здесь, использует жесткий диск, сменный магнитный диск 29 и сменный оптический диск 31, специалистам понятно, что другие типы считываемых компьютером носителей, которые могут сохранять данные, которые являются доступными компьютеру, такие как магнитные кассеты, карточки с флэш-памятью, цифровые видео диски, картриджи Бернулли, память с произвольным доступом (ОЗУ), память только для считывания (ROM, ПЗУ) и т.п., также могут использоваться в примерной среде. Аналогично, примерная среда может также включать в себя много типов устройств контроля типа датчиков теплоты и защиты или систем пожарной тревоги, и другие источники информации.
Ряд программных модулей может быть сохранен на жестком диске, магнитном диске 29, оптическом диске 31, ПЗУ 24 или ОЗУ 25, включая операционную систему 35, одну или более прикладных программ 36, другие программные модули 37 и программные данные 38. Пользователь может вводить команды и информацию в персональный компьютер 20 через устройства ввода данных типа клавиатуры 40 и устройства 42 управления позицией. Другие устройства ввода данных (не показаны) могут включать в себя микрофон, джойстик, игровую клавиатуру, спутниковую антенну, сканер и т.п. Эти и другие устройства ввода данных часто соединяются с блоком 21 обработки посредством интерфейса 46 последовательного порта, который подсоединен к системной шине, но может быть соединен с другими интерфейсами, такими как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 47 или другой тип устройства отображения также связан с системной шиной 23 через интерфейс, типа видео адаптера 48. В дополнение к монитору 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), типа динамиков и принтеров. Примерная система на фиг.1 также включает в себя контроллер 55, шину 56 Интерфейса Малых Компьютерных Систем (SCSI) и внешнее запоминающее устройство 62, связанное с шиной SCSI 56.
Персональный компьютер 20 может работать в связанной в сеть среде, используя логические соединения с одним или более удаленными компьютерами, такими как удаленный компьютер 49. Удаленный компьютер 49 может быть другим персональным компьютером, сервером, маршрутизатором, сетевым ПК, равноправным устройством или другим обычным сетевым узлом и обычно включает в себя многие или все элементы, описанные выше относительно персонального компьютера 20, хотя только запоминающее устройство 50 было иллюстрировано на фиг.1. Логические соединения, изображенные на фиг.1, включают в себя локальную сеть (LAN) 51 и глобальную сеть (WAN) 52. Такие сетевые среды являются обычными в офисах, предприятиях, глобальных компьютерных сетях, сетях предприятий и Интернет.
При использовании в локальной сети (LAN) персональный компьютер 20 связан с ЛС 51 через сетевой интерфейс или адаптер 53. При использовании в глобальной сети (WAN) персональный компьютер 20 обычно включает в себя модем 54 или другие средства для установления связи по глобальной сети 52, такой как Интернет. Модем 54, который может быть внутренним или внешним, связан с системной шиной 23 через интерфейс 46 последовательного порта. В связанной в сеть среде программные модули, изображенные относительно персонального компьютера 20 или его частей, могут быть сохранены в удаленном запоминающем устройстве. Очевидно, что показанные сетевые соединения являются примерными и могут использоваться другие средства установления линии связи между компьютерами.
Как проиллюстрировано на схематической диаграмме на Фиг.2, компьютерная система 200 может быть грубо разделена на три группы компонентов: компонент 202 аппаратных средств, аппаратный/программный компонент 204 интерфейсной системы и компонент 206 прикладных программ (также названный здесь в некоторых контекстах "пользовательским компонентом" или "программным компонентом").
В различных вариантах осуществления компьютерной системы 200 и, ссылаясь опять на фиг.1, компонент 202 аппаратных средств может содержать помимо прочего центральный блок обработки (ЦПУ) 21, память (и ROM 24, и RAM 25), базовую систему ввода/вывода (BIOS) 26 и различные устройства ввода/вывода (I/O) типа клавиатуры 40, мыши 42, монитора 47 и/или принтера (не показан). Компонент 202 аппаратных средств содержит основную физическую инфраструктуру для компьютерной системы 200.
Компонент 206 прикладных программ содержит различные программы, включая, но не ограничиваясь ими, трансляторы, системы баз данных, текстовые процессоры, бизнес-программы, видеоигры и т.д. Прикладные программы обеспечивают средства, которые компьютерные ресурсы используют, чтобы решить проблемы, обеспечивать решения и обработать данные для различных пользователей (машин, других компьютерных систем и/или конечных пользователей).
Аппаратный/программный компонент 204 интерфейсной системы содержит (и в некоторых вариантах осуществления может исключительно состоять из) операционную систему, которая в большинстве случаев непосредственно содержит оболочку и ядро. "Операционная система" (OS) - это специальная программа, которая действует как посредник между прикладными программами и компьютерными аппаратными средствами. Аппаратный/программный компонент 204 интерфейсной системы может также содержать диспетчер виртуальной машины (VMM), среду выполнения программ на различных языках (CLR) или ее функциональный эквивалент, Виртуальную Машину Java (JVM) или ее функциональный эквивалент, или другие такие программные компоненты вместо или в дополнение к операционной системе в компьютерной системе. Цель аппаратной/программной интерфейсной системы состоит в том, чтобы обеспечить среду, в которой пользователь может выполнять прикладные программы. Цель любой аппаратной/программной интерфейсной системы состоит в том, чтобы сделать компьютерную систему удобной для использования, а также использовать компьютерные аппаратные средства эффективным образом.
Аппаратная/программная интерфейсная система обычно загружается в компьютерную систему при запуске и после этого управляет всеми прикладными программами в компьютерной системе. Прикладные программы взаимодействуют с аппаратной/программной интерфейсной системой, запрашивая услуги через интерфейс прикладного программирования (API). Некоторые прикладные программы дают возможность конечным пользователям взаимодействовать с аппаратной/программной интерфейсной системой через интерфейс пользователя, такой как язык команд или графический интерфейс пользователя (GUI).
Аппаратная/программная интерфейсная система традиционно выполняет ряд услуг для прикладных программ. В многозадачной аппаратной/программной интерфейсной системе, где множество программ могут выполняться в одно и то же время, аппаратная/программная интерфейсная система определяет, какие прикладные программы должны выполниться, в каком порядке, и сколько времени нужно выделить для каждой прикладной программы перед переключением к другой прикладной программе для смены. Аппаратная/программная интерфейсная система также управляет совместным использованием внутренней памяти для множества прикладных программ и обрабатывает ввод и вывод к и от присоединенных аппаратных устройств, таких как жесткие диски, принтеры и порты модемной связи. Аппаратная/программная интерфейсная система также посылает сообщения каждой прикладной программе (и в некоторых случаях конечному пользователю) относительно состояния операций и любых ошибках, которые, возможно, произошли. Аппаратная/программная интерфейсная система может также разгрузить управление пакетных заданий (например, печать), так чтобы прикладная программа инициализации была освобождена от этой работы и могла продолжать другую обработку и/или операции. На компьютерах, которые могут обеспечивать параллельную обработку, аппаратная/программная интерфейсная система также управляет разделением программы так, чтобы она выполнялась на более чем одном процессоре одновременно.
Оболочка аппаратной/программной интерфейсной системы (просто называемая здесь как "оболочка") является интерактивным интерфейсом конечного пользователя для аппаратной/программной интерфейсной системы. (Оболочка может также быть названа как "интерпретатор команд" или в операционной системе - как "оболочка операционной системы"). Оболочка является внешним уровнем аппаратной/программной интерфейсной системы, которая является непосредственно доступной прикладным программам и/или конечным пользователям. В отличие от оболочки ядро является наиболее внутренним уровнем аппаратной/программной интерфейсной системы, который взаимодействует непосредственно с аппаратными компонентами.
В то время как предполагается, что многочисленные варианты осуществления настоящего изобретения особенно хорошо подходят для компьютеризированных систем, ничто в этом документе не предназначено, чтобы ограничить изобретение такими вариантами осуществления. Напротив, используемый здесь термин "компьютерная система" предназначен для охвата любого и всех устройств, способных к сохранению и обработке информации и/или способных к использованию сохраненной информации, чтобы управлять поведением или выполнением самого устройства независимо от того, являются ли такие устройства электронными, механическими, логическими или виртуальными по природе.
В. Традиционное хранение, основанное на файлах
Сегодня в большинстве компьютерных систем "файлы" являются единицами сохраняемой информации, которые могут включать в себя аппаратную/программную интерфейсную систему, а также прикладные программы, наборы данных и т.д. Во всех современных аппаратных/программных интерфейсных системах (Windows, Unix, Linux, Mac OS, системах виртуальных машин и т.д.), файлы являются основными дискретными (сохраняемыми и извлекаемыми) блоками информации (например, данными, программами и т.д.), которыми может манипулировать аппаратная/программная интерфейсная система. Группы файлов обычно организовываются в "папки". В Microsoft Windows, Macintosh OS и других аппаратных/программных интерфейсных системах папка является коллекцией (совокупностью) файлов, которые могут быть извлечены, перемещены и которыми можно иным образом манипулировать в качестве одиночных блоков информации. Эти папки, в свою очередь, организованы в древовидную иерархическую структуру, называемую "каталогом" (описана более подробно ниже). В некоторых других аппаратных/программных интерфейсных системах, таких как DOS, z/OS и большинство Unix-основанных операционных систем, термины "каталог" и/или "папка" являются взаимозаменяемыми и ранние компьютерные системы Apple (например, Apple lie) использовали термин "каталог" вместо директории; однако считается, что все эти используемые в настоящем описании термины являются синонимами и взаимозаменяемыми и предназначены, чтобы дополнительно включить в себя все другие эквивалентные термины для иерархических структур хранения информации и ссылки на них и их компонентов папок и файлов.
Традиционно, каталог (известный под именем "каталог папок") является древовидной иерархической структурой, в которой файлы сгруппированы в папки, и папки, в свою очередь, располагаются согласно относительным узловым местоположениям, которые составляют дерево каталогов. Например, как проиллюстрировано на фиг.2А, базовая папка 212 файловой системы, основанной на DOS (или "корневая директория" (каталог)), может содержать множество папок 214, каждая из которых может также содержать дополнительные папки (в качестве "подпапки" этой конкретной папки) 216, и каждая из них может также содержать дополнительные папки 218 до бесконечности. Каждая из этих папок может иметь один или более файлов, хотя на уровне аппаратной/программной интерфейсной системы, отдельные файлы в папке не имеют ничего другого общего, кроме их расположения в древовидной иерархии. Не удивительно, что этот подход организации файлов в иерархии папок косвенно отражает физическую организацию типичных носителей данных, используемых для сохранения этих файлов (например, жесткие диски, гибкие диски, CD-ROM и т.д.).
В дополнение к предшествующему, каждая папка является контейнером для его подпапок и его файлов, то есть каждая папка имеет свои подпапки и файлы. Например, когда папка удаляется аппаратной/программной интерфейсной системой, эти подпапки и файлы в папке также удаляются (которая, в случае каждой подпапки, дополнительно включает в себя свои собственные подпапки и файлы рекурсивно). Аналогично, каждый файл обычно принадлежит только одной папке и, хотя файл может быть скопирован и копия расположена в отличной папке, копия файла является самостоятельным отличным и отдельным модулем, который не имеет никакой непосредственной связи с оригиналом (например, изменения по отношению к первоначальному файлу не отражены в копии файла на уровне аппаратной/программной интерфейсной системы). Поэтому в этом отношении файлы и папки являются характерно "физическими" по природе, потому что папки обрабатываются подобно физическим контейнерам, и файлы обрабатываются как дискретные и отдельные физические элементы внутри этих контейнеров.
II. Платформа WINFS хранения для организации, поиска и совместного использования данных
Настоящее изобретение в комбинации со связанными изобретениями, включенными посредством ссылок, как описано выше, посвящено платформе хранения для организации, поиска и совместного использования данных. Платформа хранения согласно настоящему изобретению расширяет и распространяет платформу данных вне видов существующих файловых систем и систем баз данных, описанных выше, и предназначена, чтобы быть хранилищем для всех типов данных, включая новую форму данных, названную "Порция данных" ("Item").
А. Глоссарии
Используемые в описании и формуле изобретения следующие термины имеют следующие значения:
"Порция данных" (Item) - единица сохраняемой информации, доступная для аппаратной/программной интерфейсной системы, которая, в отличие от простого файла, является объектом, имеющим базовый набор свойств, которые обычно поддерживаются для всех объектов, открытых оболочкой аппаратной/программной интерфейсной системы конечному пользователю. Порции данных также имеют свойства и отношения, которые обычно поддерживаются для всех типов Порции данных, включая особенности, которые позволяют вводить новые свойства и отношения (описаны более подробно ниже).
"Операционная система" (OS) - специальная программа, которая действует как посредник между прикладными программами и компьютерными аппаратными средствами. Операционная система в большинстве случаев содержит оболочку и ядро.
"Аппаратная/программная интерфейсная система" является программным обеспечением или комбинацией аппаратных средств и программного обеспечения, которые служат как интерфейс между лежащими в основе компонентами аппаратных средств компьютерной системы и прикладными программами, которые выполняются на компьютерной системе. Аппаратная/программная интерфейсная система обычно содержит (и в некоторых вариантах осуществления может состоять исключительно из) операционную систему. Аппаратная/программная интерфейсная система может также содержать диспетчер виртуальной машины (VMM), среду выполнения программ на различных языках (CLR) или ее функциональный эквивалент. Виртуальную Машину Java (JVM) или ее функциональный эквивалент, или другие такие программные компоненты вместо или в дополнение к операционной системе в компьютерной системе. Цель аппаратной/программной интерфейсной системы состоит в том, чтобы обеспечить среду, в которой пользователь может выполнять прикладные программы. Цель любой аппаратной/программной интерфейсной системы состоит в том, чтобы сделать компьютерную систему удобной для использования, а также использовать компьютерные аппаратные средства эффективным образом.
В. Краткий обзор платформы хранения
Со ссылками на Фиг.3, платформа 300 хранения содержит хранилище 302 данных, осуществленное на механизме 314 базы данных. В одном варианте осуществления механизм базы данных содержит механизм реляционной базы данных с реляционными расширениями объектов. В одном варианте осуществления механизм 314 реляционной базы данных содержит механизм Microsoft SQL Server реляционной базы данных. Хранилище 302 данных реализует модель 304 данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных. Специфические типы данных описаны в схемах, таких как схемы 340, и платформа 300 хранения обеспечивает инструментальные средства 346 для развертывания этих схем, а также для расширения этих схем, как описано более подробно ниже.
Механизм 306 отслеживания изменений, реализованный в хранилище 302 данных, обеспечивает возможность отслеживания изменений для хранилища данных. Хранилище 302 данных также обеспечивает возможности 308 защиты и возможности 310 развития/препятствования, обе из которых описаны более полно ниже. Хранилище 302 данных также обеспечивает набор 312 интерфейсов прикладных программ, чтобы предоставить возможности хранилища 302 данных другим компонентам платформы хранения и прикладным программам (например, прикладным программам 350а, 350b и 350 с), которые используют эту платформу хранения. Платформа хранения согласно настоящему изобретению дополнительно содержит интерфейс прикладного программирования (API) 322, который позволяет прикладным программам, таким как прикладные программы 350а, 350b и 350с, обращаться ко всем предшествующим возможностям платформы хранения и обращаться к данным, описанным в схемах. API 322 платформы хранения может использоваться прикладными программами в комбинации с другим API, типа OLE-DB API 324 и API 326 Microsoft Windows Win32.
Платформа 300 хранения из настоящего изобретения может обеспечивать ряд услуг 328 к прикладным программам, включая службу 330 синхронизации, которая облегчает совместное использование данных для пользователей или систем. Например, служба 330 синхронизации может разрешать меж-взаимодействия с другими хранилищами 340 данных, имеющих тот же самый формат, что и хранилище 302 данных, а также доступ к хранилищу 342 данных, имеющему другие форматы. Платформа 300 хранения также обеспечивает возможности файловой системы, которые допускают взаимодействие хранилища 302 данных с существующими файловыми системами, типа файловой системы 318 NTFS Windows. По меньшей мере в некоторых вариантах осуществления платформа 320 хранения может также обеспечивать прикладные программы дополнительными возможностями для предоставления данных, над которыми нужно осуществлять действия, и для предоставления взаимодействия с другими системами. Эти возможности могут быть воплощены в форме дополнительных услуг 328, типа службы 334 Агента Информации (Info Agent), и службы 332 уведомления, а также в форме других утилит 336.
По меньшей мере в некоторых вариантах осуществления платформа хранения воплощена, или формирует неотъемлемую часть ее, в аппаратной/программной интерфейсной системе компьютерной системы. Например, и без ограничения, платформа хранения согласно настоящему изобретению может быть воплощена, или формировать неотъемлемую часть, в операционной системе, диспетчере виртуальной машины (VMM), среде выполнения программ на различных языках (CLR) или ее функциональном эквиваленте, или Виртуальной Машине Java (JVM) или ее функциональном эквиваленте. Благодаря своей общей основе хранения и схематизированным данным, платформа хранения согласно настоящему изобретению допускает более эффективную разработку приложений для потребителей, специалистов и предприятий. Она предлагает богатую и расширяемую область поверхности программирования, которая не только делает доступными возможности, свойственные ее модели данных, но также и охватывает и расширяет существующую файловую систему и способы доступа к базам данных.
В нижеследующем описании и на различных чертежах платформа 300 хранения согласно настоящему изобретению может быть упомянута как "WinFS". Однако использование этого названия для ссылки на платформу хранения служит исключительно для удобства описания и не предназначено, чтобы ограничить его каким-либо способом.
С. Модель данных
Хранилище 302 данных из платформы 300 хранения согласно настоящему изобретению реализует модель данных, которая поддерживает организацию, поиск, совместное использование, синхронизацию и защиту данных, которые находятся в хранилище. В модели данных согласно настоящему изобретению "Порция данных" (Item) является основной единицей информации хранения. Модель данных обеспечивает механизм для объявления Порций данных и расширений Порции данных и для установления отношений между Порциями данных и для организации Порций данных в Папках с Порциями данных и в Категориях, как описано более подробно ниже.
Модель данных основана на двух примитивных механизмах, Типах и Отношениях. Типы - представляют собой структуры, которые обеспечивают формат, который управляет формой экземпляра Типа. Формат выражен как упорядоченный набор Свойств. Свойство является именем для значения или набором значений для заданного Типа. Например, тип USPostalAddress может означать свойства Street (Улица), City (Город), Zip (Почтовый индекс). State (Государство), в котором Street, City и State имеет тип String (Строка), и Zip имеет тип Int32. Street может быть многозначным (то есть набором значений), позволяя адресу иметь более одного значения для свойства Street. Система определяет некоторые примитивные типы, которые могут использоваться в конструкции других типов - они включают в себя String (Строка), Binary (Двоичный), Boolean (Логический), Intl6, Int32, Int64, Single (Одинарная точность). Double (Удвоенная точность). Byte (Байт), DateTime (Дата-Время), Decimal (Десятичное) и GUID (Глобально уникальный идентификатор). Свойства Типа могут быть определены, используя любой из примитивных типов или (с некоторыми ограничениями, отмеченными ниже) любой из созданных типов. Например, Тип Location (Расположение) может быть определен так, что имеет Свойства Coordinate (Координата) и Address (Адрес), где Свойство Address имеет Тип USPostalAddress, как описано выше. Свойства могут также быть требуемыми (обязательными) или необязательными.
Отношения могут быть объявлены и представлять отображение между наборами экземпляров двух типов. Например, может иметь место Отношение, объявленное между Типом Person (Человек) и Типом Location (Расположение), названное LivesAt, которое определяет, какие люди живут в каком месте. Отношение имеет имя, две оконечных точки, а именно оконечную точку - источник и оконечную точку - Адресат. Отношения могут также иметь упорядоченный набор свойств. И Источник и Адресат - оконечные точки - имеют Имя (Name) и Тип (Type). Например, Отношение LivesAt имеет Источник, названный Occupant (Житель) Типа Person (Человек) и Адресат по имени Dwelling (Жилье) Типа Location (Расположение) и кроме того, имеют свойства StartDate и EndDate, указывающие период времени, в течение которого житель жил в жилье. Следует заметить, что Person (Человек) может жить во множестве жилищ через какое-то время, и жилье может иметь множество жителей, так что наиболее вероятное место, куда поместить информацию StartDate и EndDate, находится в самом отношении.
Отношения определяют отображение между экземплярами, которые ограничены типами, заданными как типы оконечной точки. Например, отношение LivesAt не может быть отношением, в котором
Автомобиль является Жителем, потому что Автомобиль - не Человек.
Модель данных допускает определение отношений подтип-супертип между типами. Отношение подтип-супертип, также известное как отношение ВазеТуре (Базовый Тип), определено таким образом, что если Тип А имеет ВазеТуре для Типа В, должен иметь место случай, когда каждый экземпляр В также является экземпляром А. Другой путь выражения этого состоит в том, что каждый экземпляр, который соответствует В, должен также соответствовать А. Если, например, А имеет свойство Name (Имя) Типа String (Строка), в то время как В имеет свойство Age
(Возраст) Типа Intl6, из этого следует, что любой экземпляр В должен иметь и Имя и Возраст.Эта иерархия типов может быть предусмотрена как дерево с одиночным супертипом в корне. Ветви от корня обеспечивают подтипы первого уровня, ветви на этом уровне обеспечивают подтипы второго уровня и так далее к подтипам крайних листьев, которые сами не имеют никаких подтипов. Это дерево не ограничено тем, что может быть однородной глубины, но не может содержать какие-либо циклы. Заданный Тип может иметь ноль или много подтипов и ноль или один тип из супертипов. Заданный экземпляр может соответствовать самое большее одному типу вместе с типами этого супертипа. Чтобы поместить это другим образом, для заданного экземпляра на любом уровне в дереве экземпляр может соответствовать самое большее одному подтипу на этом уровне. Тип, считается как Abstract (Абстрактный), если экземпляры этого типа также были экземпляром подтипа этого типа.
1. Порции данных
Порция данных (Item) является единицей сохраняемой информации, которая, в отличие от простого файла, является объектом, имеющим базовый набор свойств, которые обычно поддерживаются для всех объектов, открытых платформой хранения конечному пользователю. Порции данных также имеют свойства и отношения, которые обычно поддерживаются для всех типов Порции данных, включая особенности, которые позволяют вводить новые свойства и отношения, как описано ниже.
Порции данных являются объектами для обычных операций, таких как копирование, удаление, перемещение, открытие, печать, резервное копирование, восстановление, дублирование и т.д. Порции данных являются единицами, которые могут быть сохранены и извлечены, и все формы сохраняемой информации, которой манипулирует платформа хранения, существуют как Порции данных, свойства Порций данных, или Отношения между Порциями данных, каждое из которых описано более подробно ниже.
Порции данных предназначены для представления существующих в реальном мире и легко понятных единиц данных, подобных Контактам, Людям, Услугам, Местоположениям, Документам (всех различных видов) и так далее. Фиг.5А изображает схематическую диаграмму, иллюстрирующую структуру Порции данных. Неквалифицированным именем Порции данных является Location ("Местоположение"). Составным (квалифицированным) именем Порции данных является "Core.Location", которое указывает, что структура этой Порции данных (Item) определена как специфический тип Порции данных в Core Schema (Основной Схеме). (Основная
Схема описана более подробно ниже)
Порция данных Location имеет множество свойств, включающих в себя EAddresses, MetropolitanRegion, Neighborhood и PostalAddresses. Конкретный тип свойства для каждого обозначен непосредственно после имени свойства и отделен от имени свойства двоеточием (":"). Справа от имени типа, число значений, разрешенных для этого типа свойства, обозначено между скобками ("[]"), причем звездочка ("*") справа от двоеточия (":") указывает незаданное и/или неограниченное число ("много"). "1" справа от двоеточия указывает, что может существовать самое большее одно значение. Ноль ("0") слева от двоеточия указывает, что свойство необязательно (может не иметь никакого значения вообще). "1" слева от двоеточия указывает, что должно существовать по меньшей мере одно значение (свойство является требуемым). Neighborhood и MetropolitanRegion - оба имеют тип "nvarchar" (или эквивалент), который является заранее определенным типом данных или "простым типом" (и обозначены здесь отсутствием преобразования букв в прописные). EAddresses и PostalAddresses, однако, являются свойствами определенных типов или "составными типами" (как обозначено здесь преобразованием букв в прописные) типов EAddress и PostalAddress соответственно. Составной тип является типом, который получен из одного или более простых типов данных и/или из других составных типов. Составные типы для свойств Порции данных также составляют "вложенные элементы", так как подробности составного типа вложены в следующую Порцию данных для определения ее свойств, и информация, относящаяся к этим составным типам, поддерживается Порцией данных, которая имеет эти свойства (в границе Порции данных, как описано ниже). Эти концепции распределения типов известны и легко понятны специалистам.
Фиг.5В изображает схематическую диаграмму, иллюстрирующую составные типы свойств PostalAddress и EAddress. Тип свойства PostalAddress определяет, что Порция данных с типом PostalAddress свойств может иметь ноль или одно значения City, ноль или одно значения CountryCode, ноль или одно значение MailStop и любое количество (ноль для многих) PostalAddressTypes, и т.д., и т.п.Таким образом, форма данных для конкретного свойства в Порции данных тем самым определена. Тип свойства EAddress подобно определен, как показано. Хотя и необязательный для использования в настоящей заявке, другой способ представлять составные типы в Порции данных Location заключается в выведении Порции данных с индивидуальными свойствами каждого составного типа, перечисленных в ней. Фиг.5С изображает схематическую диаграмму, иллюстрирующую Порцию данных Location, в которой ее составные типы описаны далее. Однако, должно быть понятно, что это альтернативное представление Порции данных Location на этой Фиг.5С приводится для той же самой Порции данных, проиллюстрированной на фиг.5А. Платформа хранения согласно настоящему изобретению также допускает подтипы, посредством чего один тип свойства может быть подтипом другого (где один тип свойств наследует свойства другого, родительского типа свойств).
Аналогично, но в отличие от свойств и их типов свойства, Порции данных (Items) неотъемлемо представляют свои собственные Типы Порции данных, которые могут также быть предметом обладания подтипами. Другими словами, платформа хранения в нескольких вариантах осуществления настоящего изобретения позволяет Порции данных быть подтипом другой Порции данных (посредством чего одна Порция данных наследует свойства другой, родительской. Порции данных). Кроме того, для различных вариантов осуществления настоящего изобретения каждая Порция данных является подтипом типа "Item" Порции данных, который является первым и основополагающим типом Item, имеющимся в Базовой Схеме (Base Schema) (Базовая Схема также описана подробно ниже.) Фиг.6А иллюстрирует Порцию данных (Item), Порцию данных Location в этом Экземпляре (Instance), как являющуюся подтипом типа Item Порции данных, имеющимся в Базовой Схеме. На этом чертеже стрелка указывает, что Порция данных Расположение (Location) (подобно всем другим Порциям данных) является подтипом типа Item Порции данных. Тип Item Порции данных как основополагающей Порции данных, из которой получены все другие Порции данных, имеет ряд важных свойств, таких как Itemid и различные метки времени (timestamps), и таким образом определяет стандартные свойства всех Порций данных в операционной системе. На данном чертеже эти свойства типа Item Порции данных унаследованы Location и таким образом становятся свойствами для Location.
Другой способ представления свойств в Порции данных Расположение (Location), унаследованных от типа Item Порции данных, состоит в том, чтобы вывести (получить) Location с индивидуальными свойствами каждого типа свойства из родительской Порции данных, перечисленной в ней. Фиг.6В изображает схематическую диаграмму, иллюстрирующую Порцию данных Location, в которой ее унаследованные типы описаны в дополнение к ее последующим свойствам. Должно быть отмечено и понятно, что эта Порция данных является той же самой Порцией данных, проиллюстрированной на фиг.5А, хотя в данном чертеже Location проиллюстрирована со всеми ее свойствами и последующими показанными на этом чертеже и на Фиг.5А - и унаследованными -показанными на этом чертеже, но не на Фиг.5А (в то время как на фиг.5А эти свойства упомянуты указанием стрелкой, что Порция данных Location является подтипом типа Item Порции данных).
Порции данных (Items) являются автономными объектами; таким образом, если удаляется Порция данных, все последующие и унаследованные свойства Порции данных также удаляются. Точно так же при извлечении Порции данных то, что принимается, является Порцией данных и всеми ее последующими и унаследованными свойствами (включая информацию, относящуюся к ее составным типам свойств). Некоторые варианты осуществления настоящего изобретения могут давать возможность запросить поднабор свойств при извлечении конкретной Порции данных; однако по умолчанию для многих таких вариантов осуществления должна обеспечиваться Порция данных со всеми ее последующими и унаследованными свойствами при извлечении. Кроме того, свойства Порций данных могут также быть расширены добавлением новых свойств к существующим свойствам типа этой Порции данных. Эти “расширения” являются подлинными свойствами Порции данных и подтипы этого типа Порции данных могут автоматически включать в себя свойства расширения.
"Граница" Порции данных представлена ее свойствами (включая составные типы свойств, расширения и т.д.). Граница Порции данных также представляет предел операции, выполненной над Порцией данных, такой как копирование, удаление, перемещение, создание и так далее. Например, в нескольких вариантах осуществления настоящего изобретения, когда Порция данных копируется, все в границах этой Порции данных также копируется. Для каждой Порции данных граница охватывает следующее:
* Тип Item Порции данных и, если Порция данных является подтипом другой Порции данных (как это имеет место в нескольких вариантах осуществления настоящего изобретения, где все Порции данных получены из одной Порции данных и Типа Порции данных в Базовой Схеме), - любую применимую информацию подтипа (то есть информацию, имеющую отношение к родительскому Типу Порции данных). Если первоначальная копируемая Порция данных является подтипом другой Порции данных, копия может также быть подтипом этой же Порций данных.
* Свойства Порции данных составного типа и Расширения, если есть. Если первоначальная Порция данных имеет свойства составных типов (собственный или расширенный), копия может также иметь те же самые составные типы.
* Записи Порции данных относительно "отношений собственности", то есть собственный список Порции данных того, что другие Порции данных ("Целевые Порции данных") принадлежат данной Порции данных ("Обладание Порцией данных"). Это особенно уместно в отношении Папок Порций данных (Item Folders), описанных более подробно ниже, и правила, приведенного ниже, что все Порции данных должны принадлежать по меньшей мере одной Папке Порций данных. Кроме того, в отношении внедренных порций данных - описанных более подробно ниже - внедренная порция данных рассматривается как являющаяся частью Порции данных, в которую она внедрена, для операций типа копирования, удаления и т.п.
2. Идентификация Порции данных
Порции данных уникально идентифицированы посредством ItemID (идентификатором Порций данных) в пределах глобального пространства Порций данных. Тип Base.Item определяет поле ItemID типа GUID, которое хранит идентификационную информацию для Порции данных. Порция данных должна иметь точно одну идентификационную информацию (экземпляр) в хранилище 302 данных.
Ссылка (Reference) Порции данных является структурой данных, которая содержит информацию для определения местоположения и идентификации Порции данных. В модели данных абстрактный тип определен названным ItemReference, из которого получают все ссылочные типы Порции данных. Тип ItemReference определяет виртуальный метод, названный Resolve (Решение). Метод Resolve разрешает ItemReference и возвращает Порцию данных. Этот метод отменяется конкретными подтипами ItemReference, которые реализуют функцию, которая извлекает Порцию данных, заданную ссылкой. Метод Resolve вызывается как часть API 322 платформы хранения.
ItemIDReference является подтипом ItemReference. Он определяет Locator (указатель местоположения) и поле ItemID. Поле Locator называет (то есть идентифицирует) область Порции данных. Она обрабатывается методом разрешения указателя местоположения, который может определять (разрешать) значение Locator для области Порции данных. Поле ItemID имеет тип ItemID.
ItemPathReference является специализацией ItemReference, которая определяет Locator и поле Path (Путь). Поле Locator идентифицирует область Порции данных. Она обрабатывается методом разрешения указателя местоположения, который может разрешать значение Locator для области Порции данных. Поле Path содержит (относительный) путь в пространстве имен платформы хранения с корнем в области Порций данных, обеспеченной указателем местоположения (Locator).
Этот тип ссылки не может использоваться в операции установки. Ссылка должна обычно разрешаться посредством процесса разрешения пути. Метод Resolve API 322 платформы хранения обеспечивает эти функциональные возможности.
Формы ссылки, описанные выше, представлены иерархией типов ссылок, иллюстрированной на фиг.11. Дополнительные ссылочные типы, которые наследуются из этих типов, могут быть определены в схемах. Они могут использоваться в объявлении отношений как тип целевого поля.
3. Папки Порция данных и Категории
Как описано более подробно ниже, группы Порций данных могут быть организованы в специальные Порции данных по имени Папки Порции данных (Item Folders) (которые не следует путать с папками файлов). Несмотря на то, что в большинстве файловых систем, однако, Порция данных (Item) может принадлежать более чем одной Папке Порций данных, так что, когда к Порции данных обращаются в одной Папке Порций данных и просматривают, к этой просматриваемой Порции данных можно затем обращаться непосредственно из другой папки Порции данных. В сущности, хотя доступ к Порции данных может происходить из различных Папок Порции данных, то, к чему фактически обращаются, фактически является одной и той же Порцией данных. Однако Папка Порции данных не обязательно обладает всеми ее элементами - Порциями данных, или может просто совместно обладать Порциями данных вместе с другими папками, так что удаление Папки Порции данных не обязательно приводит к удалению Порции данных. Тем не менее, в нескольких вариантах осуществления настоящего изобретения Порция данных должна принадлежать по меньшей мере одной Папке Порций данных так, чтобы, если единственная Папка Порции данных для конкретной Порции данных была удалена, то для некоторых вариантов осуществления, Порция данных автоматически удаляется или, в альтернативных вариантах осуществления Порция данных автоматически становится элементом заданной по умолчанию Папки Порции данных (например. Папка Порции данных "Trush Can" концептуально аналогична аналогично названным папкам, используемым в различных системах, основанных на файлах-и-папках).
Как также описано более подробно ниже, Порция данных может также принадлежать Категориям, основанным на общей описанной характеристике, такой как (а) Тип (или Типы) Порции данных, (b) специфическое непосредственное или унаследованное свойство (или свойства), или (с) конкретное значение (или значения), соответствующие свойству Порции данных. Например, Порция данных, содержащая специфические свойства для персональной информации о контактах, может автоматически принадлежать Категории Контактов (Contact Category), и любая Порция данных, имеющая свойства информации о контактах, будет аналогично автоматически принадлежать этой Категории. Аналогично, любая Порция данных, имеющая свойство местоположения со значением New York City ("Город Нью-Йорк"), может автоматически принадлежать Категории NewYorkCity.
Категории являются концептуально отличными от Папок Порции данных в том, что в то время как Папки Порции данных могут содержать Порции данных, которые не находятся во взаимосвязи (то есть, без общей описанной характеристики), каждая Порция данных в Категории имеет общие тип, свойство или значение ("общность"), которые описаны для этой Категории, и именно эта общность формирует основание для ее отношений с и среди других Порций данных в Категории. Кроме того, в то время как членство Порции данных в конкретной Папке не обязательно основано на каком-либо конкретном аспекте этой Порции данных, для некоторых вариантов осуществления все Порции данных, имеющие общность, категориально относящейся к Категории, могут автоматически стать элементом Категории на уровне аппаратной/программной интерфейсной системы. Концептуально, Категории можно также представить как виртуальные Папки Порции данных, чье членство основано на результатах конкретного запроса (например, в контексте базы данных), и Порции данных, которые удовлетворяют условиям этого запроса (определенный общностями Категории), таким образом будут содержать членство Категории.
Фиг.4 иллюстрирует структурные отношения между Порциями данных, Папками Порции данных и Категориями. Множество Порций данных 402, 404, 406, 408, 410, 412, 414, 416, 418 и 420 являются членами различных Папок Порции данных 422, 424, 426, 428, и 430. Некоторые Порции данных могут принадлежать более чем одной Папке Порций данных, например, Порция данных 402 принадлежит Папкам 422 и 424 Порции данных. Некоторые Порции данных, например, Порция данных 402, 404, 406, 408, 410 и 412 также являются членами одной или более Категорий 432, 434 и 436, в то время как другие, например, Порции данных 414, 416, 418 и 420, не могут принадлежать каким-либо Категориям (хотя это в значительной степени маловероятно в некоторых вариантах осуществления, где владение любым свойством автоматически подразумевает членство в Категории, и таким образом Порция данных должна быть полностью лишена характерных черт, чтобы не быть элементом какой-либо категории в таком варианте осуществления). В отличие от иерархической структуры папок, и Категории и Папки Порции данных имеют структуры, более родственные к направленным графам, как показано. В любом случае, Порции данных, Папки Порции данных и Категории - все являются Порциями данных (хотя из различных Типов Порции данных).
В отличие от файлов, папок и каталогов, Порции данных (Items), Папки Порции (Item Folders) данных и Категории (Categories) согласно настоящему изобретению не являются характерно "физическими" по природе, потому что они не имеют концептуальных эквивалентов физических контейнеров, и поэтому Порции данных могут существовать в более чем одном таком местоположении. Возможность для Порций данных существовать в более чем одном местоположении Папки Порции данных, а также быть организованной в Категории обеспечивает усовершенствованную и обогащенную степень манипуляции данными и возможностями структуры хранения на уровне аппаратного/программного интерфейса, кроме тех, что в настоящее время доступны.
4. Схемы
а) Базовая Схема
Чтобы обеспечивать универсальную основу для создания и использования Порций данных, различные варианты осуществления платформы хранения согласно настоящему изобретению содержат Базовую Схему (Base Schema), которая устанавливает концептуальную инфраструктуру для создания и организации Порций данных и свойств. Базовая Схема определяет некоторые специальные типы Порций данных и свойств и особенности этих специальных основополагающих типов, из которых подтипы могут быть далее получены. Использование этой Базовой Схемы позволяет программисту концептуально отличать Порции данных (и их соответствующие типы) от свойств (и их соответствующих типов). Кроме того, Базовая Схема устанавливает основополагающий набор свойств, которыми все Порции данных могут обладать, когда все Порции данных (и их соответствующие Типы Порции данных) получены из этой основополагающей Порции данных в Базовой Схеме (и ее соответствующем Типе Порции данных).
Как проиллюстрировано на фиг.7 и в отношении нескольких вариантов осуществления настоящего изобретения, Базовая Схема определяет три типа верхнего уровня: Порция данных (Item), Расширение (Extension) и Базовое Свойство (PropertyBase). Как показано, тип Item определен свойствами этого основополагающего типа "Item" Порции данных. Напротив, тип свойств "PropertyBase" верхнего уровня не имеет никаких заранее определенных свойств и является просто анкером (средством привязки), из которого получены все другие типы свойства и посредством которого все полученные типы свойства находятся во взаимосвязи (обычно получаемые из одного типа свойств). Свойства типа Extension определяют, какая Порция данных расширяет это расширение, а также идентификацию, чтобы отличить одно расширение от другого, поскольку Порция данных может иметь множество расширений.
ItemFolder является подтипом типа Item Порции данных, который, в дополнение к свойствам, унаследованным от Порции данных, указывает Отношение (Relationship) для установления ссылок к ее членам (если есть), в то время как и IdentityKey и Properties являются подтипами PropertyBase. CategoryRef, в свою очередь, является подтипом IdentityKey.
b) Основная Схема
Различные варианты осуществления платформы хранения согласно настоящему изобретению также содержат Основную Схему (Core Schema), которая обеспечивает концептуальную инфраструктуру для структур типа Порций данных верхнего уровня. Фиг.8А изображает схематическую диаграмму, иллюстрирующую Порции данных в Основной Схеме, и Фиг.8В изображает схематическую диаграмму, иллюстрирующую типы свойств в Основной Схеме. Различие, сделанное между файлами с различными расширениями (*.com, *.exe, *.bat, *.sys, и т.д.) и другими такими критериями в системе, основанной на файлах-и-папках, аналогично этой функции Основной Схемы. В основанной на Порции данных аппаратной/программной интерфейсной системе Основная Схема определяет набор основных типов Порции данных, которые непосредственно (посредством типа Item (Порции данных)) или косвенно (посредством подтипа Порции данных) характеризуют все Порции данных в одном или более типах Порции данных Основной Схемы, которые основанная на Порции данных аппаратная/программная интерфейсная система понимает и может непосредственно обрабатывать заранее определенным и предсказуемым способом. Заранее определенные типы Порции данных отражают наиболее общие Порции данных в основанной на Порции данных аппаратной/программной интерфейсной системе, и таким образом достигается уровень эффективности посредством основанной на Порции данных аппаратной/программной интерфейсной системы, понимающей эти заранее определенные типы Порции данных, которые содержат Основную Схему.
В некоторых вариантах осуществления Основная Схема является не расширяемой - то есть никакие дополнительные типы Порции данных не могут быть выведены в качестве подтипа непосредственно из типа Порции данных в Основной Схеме, за исключением специфических заранее определенных полученных типов Порции данных, которые являются частью Основной Схемы. Предотвращая расширения для Основной Схемы (то есть, предотвращая дополнение новых Порций данных к Основной Схеме), платформа хранения обеспечивает использование типов Порции данных Основной Схемы, так как каждый последующий тип Порции данных обязательно является подтипом типа Порции данных Основной Схемы. Эта структура допускает разумную степень гибкости в определении дополнительных типов Порции данных, в то же время сохраняя выгоды от наличия заранее определенного набора основных типов Порции данных.
Для различных вариантов осуществления настоящего изобретения и со ссылками на Фиг.8А конкретные типы Порции данных, поддерживаемые Основной Схемой, могут включать в себя одно или более из следующего:
* Категории: Порции данных этого Типа Порции данных (и подтипы, полученные из него) представляют достоверные Категории в основанной на Порции данных аппаратной/программной интерфейсной системе.
* Предметы потребления: Порции данных, которые являются идентифицируемыми ценными вещами.
* Устройства: Порции данных, имеющие логическую структуру, которая поддерживает возможности обработки информации.
* Документы: Порции данных с содержимым, которое не интерпретируется основанной на Порции данных аппаратной/программной интерфейсной системой, но вместо этого интерпретируются прикладной программой, соответствующей типу документа.
* События: Порции данных, которые записывают некоторые случаи в среде.
* Местоположения: Порции данных, представляющие физические местоположения (например, географические местоположения).
* Сообщения: Порции данных связи между двумя или больше принципалами (определенными ниже).
* Принципалы: Порции данных, имеющие по меньшей мере одну определенно доказуемую информацию идентичности (идентичность) кроме Itemid (например, идентификационная информация человека, организации, группы, домашнего хозяйства, полномочия, службы и т.д.).
* Формулировки: Порции данных, имеющие специальную информацию относительно среды, включающие, без ограничения, политики, подписки, мандаты и т.д.
Аналогично и со ссылками на Фиг.8В, специфические типы свойств, поддерживаемые Основной Схемой, могут включать в себя одно или более из следующего:
*Сертификаты (полученные из основополагающего типа PropertyBase в Базовой Схеме)
* Ключи идентичности принципалов (полученные из типа IdentityKey в Базовой Схеме)
* Почтовый Адрес (полученный из типа Properties (Свойства) в Базовой Схеме)
* Обогащенный Текст (полученный из типа Properties в Базовой Схеме)
* EAddress (полученный из типа Properties в Базовой Схеме)
* IdentitySecurityPackage (полученный из типа Relationship (Отношения) в Базовой Схеме)
* RoleOccupancy (полученный из типа Relationship в Базовой Схеме)
* BasicPresence (полученный из типа Relationship в Базовой Схеме)
Эти Порции данных и Свойства далее описаны их соответствующими свойствами, приведенными на фиг.8А и Фиг.8В.
5. Отношения
Отношения (Relationships) являются двоичными отношениями, где одна Порция данных обозначена как источник, а другая Порция данных - как адресат (целевая). Исходная Порция данных и целевая Порция данных связаны отношением. Исходная Порция данных обычно управляет "продолжительностью жизни" отношения. То есть, когда исходная Порция данных удаляется, отношение между Порциями данных также удаляется.
Отношения классифицируются на: отношения Включение (Containment) и Ссылка (Reference). Отношения включения управляют продолжительностью жизни целевых Порций данных, в то время как отношения ссылки не обеспечивают никакой семантики управления продолжительностью жизни. Фиг.12 иллюстрирует способ, которым классифицируются отношения.
Типы отношения Включение далее классифицируются на отношения Хранение (Holding) и Внедрение (Embedding). Когда все отношения хранения для Порции данных удалены, Порция данных удаляется. Отношения Хранение управляют "продолжительностью жизни" адресата посредством механизма эталонного счета. Отношения внедрения разрешают моделирование составных Порций данных, и можно говорить как об исключительных отношениях Хранения. Порция данных может быть адресатом одного или более отношений Хранения; но Порция данных может быть адресатом только одного отношения внедрения. Порция данных, которая является адресатом отношения внедрения, не может быть адресатом любого другого из отношений хранения или внедрения.
Отношения Ссылки не управляют "продолжительностью жизни" целевой Порции данных (адресата). Они могут быть висящими, целевая Порция данных может не существовать. Отношения Ссылки могут быть использованы для примерных (модельных) ссылок на Порции данных в любом месте в глобальном пространстве имен Порции данных (то есть, включая удаленные хранилища данных).
Выборка Порции данных автоматически не выбирает ее отношения. Прикладные программы должны явно запросить отношения Порции данных. Кроме того, изменение отношения не изменяет Порцию данных - источник или целевую Порцию данных; точно так же добавление отношения не влияет на Порцию данных источник/адресат.
а) Объявление Отношения
Явные типы отношений определены со следующими элементами:
* Имя отношения определено в атрибуте Name (Имя).
* Тип Отношения, один из следующих: Хранение, Внедрение, Ссылка. Это задано в атрибуте Type (Тип).
* Исходная и целевая оконечные точки. Каждая оконечная точка определяет имя и тип упомянутой Порции данных.
* Поле исходной оконечной точки имеет обычно тип ItemID (не объявленный), и оно должно ссылаться на Порцию данных в том же хранилище данных, что и экземпляр отношения.
* Для отношений Хранение и Внедрение, поле целевой оконечной точки должно иметь тип ItemIDReference, и оно должно ссылаться на Порцию данных в том же хранилище, что и экземпляр отношения. Для отношений Ссылки целевая оконечная точка может иметь любой тип ItemReference и может ссылаться на Порцию данных в других хранилищах данных платформы хранения.
* Необязательно может быть объявлено одно или более полей скалярного или типа PropertyBase. Эти поля могут содержать данные, связанные с отношениями.
* Экземпляры Отношения сохраняют в глобальной таблице отношений.
* Каждый экземпляр отношения уникально идентифицирован комбинацией (ItemID источника, ID (идентификатор) отношения). ID отношения является уникальным в пределах заданного источника ItemID для всех отношений, начинающихся в заданной Порции данных независимо от их типа.
Порция данных - источник является владельцем отношения. В то время как Порция данных, обозначенная как владелец, управляет "продолжительностью жизни" отношения, сами отношения отделены от Порций данных, которые они связывают. API 322 платформы хранения обеспечивает механизмы для демонстрации отношений, связанных с Элементом.
Ниже приведен пример объявления отношения:

Это является примером отношения Ссылка. Отношение не может быть создано, если персональная Порция данных (Порция данных в отношении человека), которая упомянута исходной ссылкой, не существует. Также, если персональная Порция данных удалена, экземпляры отношения между человеком и организацией удаляются. Однако, если Порция данных Организации удаляется, отношение не удаляется, и оно является повисшим.
b) Отношение Хранения
Отношение Хранения используется для основанного на примерном (модельном) эталонном подсчете управления "продолжительностью жизни" целевых Порций данных.
Порция данных может быть оконечной точкой - источником для нуля или более отношений для Порций данных. Порция данных, которая не является внедренной Порцией данных, может быть адресатом в одном или более отношений хранения.
Ссылочный тип целевой оконечной точки должен быть ItemIDReference, и он должен ссылаться на Порцию данных в том же хранилище, что и экземпляр отношения.
Отношение Хранения вводит управление продолжительностью жизни целевой оконечной точки. Создание экземпляра отношения хранения и Порции данных, которая является целевой, является элементарной операцией. Могут быть созданы дополнительные экземпляры отношения хранения, для которых целевой является та же самая Порция данных. Когда последний экземпляр отношения хранения с данной Порцией данных в качестве целевой оконечной точки удаляется, целевая Порция данных также удаляется.
Типы Порций данных оконечной точки, указанных в объявлении отношения, будут обычно предписываться, когда создан экземпляр отношения. Типы Порций данных оконечной точки не могут быть изменены после того, как отношение установлено.
Отношения Хранения играют ключевую роль в формировании пространства имен Порции данных. Они содержат свойство "Имя" (Name), которое определяет имя целевой Порции данных относительно исходной Порции данных. Это относительное имя уникально для всех отношений хранения, исходящих из данной Порции данных. Упорядоченный список этих относительных имен, начиная от корневой Порции данных до заданной Порции данных, формирует полное имя для Порции данных.
Отношения хранения формируют направленный ациклический граф (НАГ, DAG). Когда отношения хранения созданы, система гарантирует, что цикл не создан, таким образом гарантируя, что пространство имен Порции данных формирует DAG.
Хотя отношение хранения управляет продолжительностью жизни целевой Порции данных, оно не управляет операционной непротиворечивостью целевой Порции данных оконечной точки. Целевая Порция данных операционно независима от Порции данных, которая владеет ей посредством отношения хранения. Копирование, Перемещение, Резервное Копирование и другие операции над Порцией данных, которая является источником отношения хранения, не влияет на Порцию данных, которая является адресатом того же самого отношения - например, резервное копирование Порции данных Папки автоматически не резервирует все Порции данных в папке (адресаты отношения FolderMember).
Ниже представлен пример отношений хранения:

Отношение FolderMembers допускает концепции Папки в качестве родовой коллекции Порций данных.
с) Отношения Внедрения
Отношения Внедрения моделируют концепцию исключительного управления продолжительностью жизни целевой Порции данных. Они допускают концепцию составных Порций данных.
Создание экземпляра отношения внедрения и Порции данных, которую оно указывает в качестве адресата, является элементарной операцией. Порция данных может быть источником нуля или более отношений внедрения. Однако Порция данных может быть адресатом одного и только одного отношения внедрения. Порция данных, которая является адресатом отношения внедрения, не может быть адресатом отношения хранения.
Ссылочный тип целевой оконечной точки должен быть ItemIDReference, и он должен ссылаться на Порцию данных в том же хранилище данных, что и экземпляр отношения.
Типы Порций данных оконечной точки, заданных в объявлении отношения, будут обычно предписываться, когда создан экземпляр отношения. Типы Порций данных оконечной точки не могут быть изменены после того, как отношение установлено.
Отношения внедрения управляют операционной непротиворечивостью целевой оконечной точки. Например, операция преобразования в последовательную форму Порции данных может включать в себя преобразование в последовательную форму всех отношений внедрения, которые исходят из этой Порции данных, а также всех их адресатов; копирование Порции данных также копирует все ее внедренные Порции данных. Ниже представлен пример объявления:

d) Отношения Ссылки
Отношение Ссылки не управляет продолжительностью жизни Порции данных, на которую оно ссылается. Даже больше, отношения Ссылки не гарантируют существование адресата, и при этом они не гарантируют тип адресата, как задано в объявлении отношения. Это означает, что отношения Ссылки могут быть повисшими. Также, отношение Ссылки может ссылаться на Порции данных в других хранилищах данных. Отношения Ссылки можно представить как концепцию, подобную ссылкам на Web-страницах.
Пример объявления отношения Ссылки приведен ниже:

Любой ссылочный тип разрешен в целевой оконечной точке. Порции данных, которые участвуют в отношении Ссылки, могут иметь любой тип Порции данных (Item).
Отношения Ссылки используются для моделирования большинства отношений управления, не связанных с продолжительностью жизни, между Порциями данных. Так как существование адресата не предписано, отношения Ссылки удобны для моделирования слабо связанных отношений. Отношение Ссылки может быть использовано для целевых Порций данных в других хранилищах данных, включая хранилища на других компьютерах.
e) Правила и Ограничения
Следующие дополнительные правила и ограничения применяются для отношений:
* Порция данных должна быть адресатом для (только одно отношение внедрения) или (одно или более отношений хранения). Одним исключением является корневая Порция данных. Порция данных может быть адресатом нуля или более отношений Ссылки.
* Порция данных, которая является адресатом отношения внедрения, не может быть источником отношения хранения. Она может быть источником отношений Ссылки.
* Порция данных не может быть источником отношения хранения, если она промотируется (выдвигается) из файла. Она может быть источником отношений внедрения и отношений Ссылки.
* Порция данных, которая промотируется (выдвигается) из файла, не может быть адресатом отношения внедрения.
f) Упорядочение Отношений
По меньшей мере в одном варианте осуществления Платформа хранения согласно настоящему изобретению поддерживает упорядочение отношений. Упорядочение достигается посредством свойства, названного "Порядок" (Order), в базовом определении отношения. Не имеется никакого ограничения уникальности на поле Order. Порядок отношений с одним и тем же значением свойства "order" не гарантируется, однако гарантируется, что они могут быть упорядочены после отношений с более низким значением "order" и перед отношениями с более высоким значением поля "order".
Прикладные программы могут получить отношения в заданном по умолчанию порядке посредством упорядочения, выполняемом над комбинацией (SourceItemID, RelationshipID, Order). Все экземпляры отношений, исходящие из данной Порции данных, являются упорядоченными как одиночная коллекция независимо от типа отношений в этой коллекции. Это, однако, гарантирует, что все отношения заданного типа (например, FolderMembers) являются упорядоченным поднабором коллекции отношений для заданной Порции данных.
API 312 хранилища данных для управления отношениями реализует набор операций, которые поддерживают упорядочение отношений. Нижеследующие термины представлены для пояснения описания операций:
* RelFirst - первое отношение в упорядоченной коллекции со значением OrdFirst порядка;
* RelLast - последнее отношение в упорядоченной коллекции со значением OrdLast порядка;
* RelX - заданное отношение в коллекции со значением OrdX порядка;
* RelPrev - ближайшее отношение в коллекции для RelX со значением OrdPrev порядка, меньшим, чем OrdX; и
* RelNext - ближайшее отношение в коллекции для RelX со значением OrdNext порядка, большим, чем OrdX.
Операции включают в себя, но не ограничиваются ими:
* InsertBeforeFirst (SourceItemID, Relationship) вставляет отношение в качестве первого отношения в коллекции. Значение свойства "Order" нового отношения может быть меньшим, чем OrdFirst.
* InsertAfterLast (SourceItemID, Relationship) вставляет отношение в качестве последнего отношения в коллекции. Значение свойства "Order" нового отношения может быть большим, чем OrdLast.
* InsertAt (SourceItemID, ord. Relationship) вставляет отношение с заданным значением для свойства "Order".
* InsertBefore (SourceItemID, ord. Relationship) вставляет отношение перед отношением с заданным значением порядка. Новое отношение может быть присвоенным значением "Order", которое находится между OrdPrev и ord, не-включительно.
* InsertAfter (SourceItemID, ord. Relationship) вставляет отношение после отношения с заданным значением порядка. Новое отношение может быть присвоенным значением "Order", которое находится между ord и OrdNext, не-включительно.
* MoveBefore (SourceItemID, ord, RelationshipID) перемещает отношение с заданным идентификатором отношения перед отношением с заданным значением "Order". Отношение может быть присвоенным новым значением "Order", которое находится между OrdPrev и ord, не-включительно.
* MoveAfter (SourceItemID, ord, RelationshipID) перемещает отношение с заданным идентификатором отношения после отношения с указанным значением "Order". Отношение может быть присвоенным новым значением порядка, которое находится между ord и OrdNext, не-включительно.
Как упомянуто выше, каждая Порция данных должна быть членом Папки Порции данных. В терминах Отношений, каждая Порция данных должна иметь отношение с Папкой Порции данных. В нескольких вариантах осуществления настоящего изобретения некоторые отношения представлены Отношениями (Relationships), существующими между Порциями данных (Items).
Как реализовано для различных вариантов осуществления настоящего изобретения, Отношение обеспечивает направленные бинарные отношения, которые "распространяются" одной Порцией данных (источником) на другую Порцию данных (адресат). Отношение принадлежит исходной Порции данных (Порция данных, которая “распространила” его), и таким образом Отношение удаляется, если удаляется источник (например, Отношение удаляется, когда исходная Порция данных удаляется). Кроме того, в некоторых случаях Отношение может совместно использовать собственность (со-собственных) целевой Порции данных, и такая собственность может быть отражена в свойстве IsOwned (или его эквиваленте) Отношения (как показано на фиг.7 для типа свойства Relationship "Отношение"). В этих вариантах осуществления создание нового Отношения IsOwned автоматически увеличивает подсчет Ссылок на целевой Порции данных, а удаление такого Отношения может уменьшить подсчет Ссылок на целевой Порции данных. Для этих конкретных вариантов осуществления Порции данных продолжают существовать, если они имеют подсчет Ссылок, больший нуля, и автоматически удаляются, если и когда этот подсчет (значение подсчета) достигает нуля. Снова, Папка Порции данных является Порцией данных, которая имеет (или способна иметь) набор Отношений с другими Порциями данных, причем эти другие Порции данных содержат членство Папки Порции данных. Другие фактические реализации Отношений возможны и ожидаемы настоящим изобретением для достижения описанных здесь функциональных возможностей.
Независимо от фактического выполнения Отношение является выбираемым соединением от одного объекта к другому. Возможность для Порции данных принадлежать более чем одной Папке Порций данных, а также одной или более Категориям, и то, являются ли эти Порции данных, Папки и Категории общими или частными, определяется значениями, заданными для существования (или отсутствия) в структуре, основанной на Порциях данных. Эти логические Отношения являются значениями, присвоенными набору Отношений, независимо от физического выполнения, которые специально используются, чтобы достичь функциональных возможностей, описанных здесь. Логические Отношения устанавливаются между Порцией данных и ее Папкой(ами) Порции данных или Категориями (и наоборот) потому что, в сущности, Папки Порции данных и Категории каждая являются специальным типом Порции данных. Следовательно, над папками Порции данных и Категориями можно выполнять действия тем же самым образом, как над любой другой Порцией данных - копировать, добавлять к сообщению электронной почты, внедрять в документ и т.д. без ограничения - и Папки Порции данных и Категории могут быть преобразованы в последовательную форму и обратно преобразованы из последовательной формы (импортированы и экспортированы), используя те же механизмы, которые касаются других Порций данных. (Например, в XML все Порции данных могут иметь формат преобразования в последовательную форму, и этот формат применяется одинаково к Папкам Порции данных, Категориям и Порциям данных).
Вышеупомянутые Отношения, которые представляют отношение между Порцией данных и ее Папкой(ками) Порции данных, могут логически простираться от Порции данных до Папки Порции данных, от Папки Порции данных до Порции данных или согласно обоим вариантам. Отношение, которое логически распространяется от Порции данных до Папки Порции данных, обозначает, что Папка Порции данных является общей (public) для этой Порции данных и совместно использует информацию ее членства с этой Порцией данных; и наоборот, отсутствие логического Отношения от Порции данных до Папки Порции данных означает, что Папка Порции данных является частной (private) для этой Порции данных и не использует совместно информацию ее членства с этой Порцией данных. Точно так же Отношение, которое логически распространяется от Папки Порции данных до Порции данных, означает, что Порция данных является общей и может быть совместно использована для этой Папки Порций данных, в то время как отсутствие логического Отношения из Папки Порции данных к Порции данных означает, что Порция данных является частной и не является совместно используемой. Следовательно, когда Папка Порции данных экспортируется в другую систему, это "общественные" (public) Порции данных, которые совместно используются в новом контексте, и когда Порция данных осуществляет поиск в своих Папках Порций данных другой совместно используемой Порции данных, это "общественные" Папки Порции данных, которые обеспечивают Порцию данных информацией относительно совместно используемых Порций данных, которые принадлежат ей.
Фиг.9 изображает схематическую диаграмму, иллюстрирующую Папку Порции данных (которая, снова, сама является Порцией данных), ее элементы-Порции данных и межсоединение Отношений между Папкой Порции данных и ее элементами-Порциями данных. Папка 900 Порции данных имеет в качестве членов множество Порций данных 902, 904 и 906. Папка 900 Порции данных имеет Отношение 912 от самой себя к Порции данных 902, что означает, что Порция данных 902 является общественной и совместно используемой для Папки 900 Порций данных, ее членов 904 и 906 и любых других Папок Порций данных, Категорий или Порций данных (не показаны), которые могут обращаться к Папке 900 Порций данных. Однако не имеется никакого Отношения из Порции данных 902 к Папке 900 Порций данных, что означает, что Папка 900 Порции данных является частной для Порции данных 902 и совместно не использует ее информацию членства с Порцией данных 902. Порция данных 904, с другой стороны, имеет Отношение 924 из самой себя к Папке 900 Порции данных, что означает, что Папка 900 Порции данных является общественной и совместно использует ее информацию членства с Порцией данных 904. Однако не имеется никакого Отношения от Папки 900 Порции данных к Порции данных 904, что означает, что Порция данных 904 - частная и не является совместно используемой для Папки 900 Порций данных, ее других членов 902 и 906 и любых других Папок Порции данных, Категорий или Порции данных (не показаны), которые могут обращаться к Папке 900 Порций данных. В отличие от ее Отношений (или их отсутствия) к Порциям данных 902 и 904 Папка 900 Порции данных имеет Отношение 916 из самой себя к Порции данных 906, и Порция данных 906 имеет Отношение 926 назад к Папке 900 Порций данных, что вместе означает, что Порция данных 906 является общественной и совместно используемой для Папки 900 Порций данных, ее членов 902 и 904 и любых других Папок Порции данных, Категорий или Порций данных (не показаны), которые могут обращаться к Папке 900 Порций данных, и эта Папка 900 Порции данных является общественной и совместно использует ее информацию членства с Порцией данных 906.
Как описано выше, Порции данных в Папке Порций данных не должны совместно использовать общность, потому что Папки Порции данных не "описаны". Категории, с другой стороны, описаны общностью, которая является общей для всех ее элементов-Порций данных. Следовательно, членство Категории неотъемлемо ограничено Порциями данных, имеющими описанную общность и в некоторых вариантах осуществления все Порции данных, удовлетворяющие описанию Категории, автоматически сделаны членами Категории. Таким образом, в то время как Папки Порции данных позволяют тривиальным структурам типа быть представленными их членством, Категории допускают членство, основанное на определенной общности.
Конечно, описания Категории являются логическими по природе, и поэтому Категория может быть описана любым логическим представлением типов, свойств и/или значений. Например, логическим представлением для Категории может быть ее членство, чтобы содержать Порции данных, которые имеют одно из двух свойств или оба. Если этими описанными свойствами для Категории являются "А" и "В", то членство Категорий может содержать Порции данных, имеющие свойство А, но не В, Порции данных, имеющие свойство В, но не А, и Порции данных, имеющие оба свойства А и В. Это логическое представление свойств описано логическим оператором "OR", где набор членов, описанных Категорией, является Порцией данных, имеющей свойство А ИЛИ В. Аналогичные логические операнды (включая без ограничения "И", "ИСКЛЮЧАЮЩЕЕ ИЛИ" и "НЕ" - один или в комбинации) могут также использоваться для описания категории, как очевидно специалистам.
Несмотря на различие между Папками Порции данных (не описаны) и Категориями (описаны), Отношение Категорий к Порциям данных и Отношение Порций данных к Категориям по существу аналогично тому, как раскрыто выше для Папок Порции данных и Порций данных во многих вариантах осуществления настоящего изобретения.
Фиг.10 изображает схематическую диаграмму, иллюстрирующую Категорию (которая снова сама является Порцией данных), ее элементы-Порции данных и соединяющие Отношения между Категорией и ее элементами-Порциями данных. Категория 1000 имеет в качестве членов множество Порций данных 1002, 1004 и 1006, все из которых совместно используют некоторую комбинацию общих свойств, значений или типов 1008, как описано (описание общности для 1008) Категорией 1000. Категория 1000 имеет Отношение 1012 из себя к Порции данных 1002, что означает, что Порция данных 1002 является общественной и совместно используемой для Категории 1000, ее членов 1004 и 1006 и любых других Категорий, Папок Порций данных или Порций данных (не показаны), которые могут обращаться к категории 1000. Однако не имеется никакого Отношения из Порции данных 1002 к Категории 1000, что означает, что Категория 1000 является частной для Порции данных 1002 и совместно не использует ее информацию членства с Порцией данных 1002. Порция данных 1004, с другой стороны, имеет Отношение 1024 от себя к Категории 1000, что означает, что Категория 1000 является общественной и совместно использует ее информацию членства с Порцией данных 1004. Однако не имеется никакого Отношения, распространяющегося от Категории 1000 к Порции данных 1004, что означает, что Порция данных 1004 является частной и не совместно используемой для Категории 1000, ее других членов 1002 и 1006 и любых других Категорий, Папок Порций данных или Порций данных (не показаны), которые могут обращаться к категории 1000. В отличие от ее Отношений (или их отсутствия) с Порциями данных 1002 и 1004 Категория 1000 имеет Отношение 1016 от себя к Порции данных 1006, и Порция данных 1006 имеет Отношение 1026 назад к Категории 1000, что в целом означает, что Порция данных 1006 является общественной и совместно используемой для Категории 1000, ее членов 1002 и 1004 Порции данных и любых других Категорий, Папок Порции данных или Порций данных (не показаны), которые могут обращаться к категории 1000, и что Категория 1000 является общественной и совместно использует ее информацию членства с Порцией данных 1006.
Наконец, так как Категории и Папки Порции данных сами являются Порциями данных, и Порции данных могут иметь отношение друг с другом. Категории могут иметь отношение к Папкам Порции данных и наоборот, и Категории, Папки Порций данных и Порции данных могут иметь Отношение к другим Категориям, Папкам Порции данных и Порциям данных соответственно в некоторых альтернативных вариантах осуществления. Однако в различных вариантах осуществления для структур Папки Порции данных (Item Folder) и/или структуры Категории (Category) запрещено на уровне аппаратной/программной интерфейсной системы содержать циклы. Где структуры Папки Порций данных и Категории являются родственными направленным графам, варианты осуществления, которые запрещают циклы, являются родственными направленным нециклическим графам (DAG), которые по математическому определению в области теории графов являются направленными графами, в которых никакие пути не начинаются и не заканчиваются в одной и той же вершине.
6. Расширяемость
Платформа хранения должна быть обеспечена начальным набором схем 340, как описано выше. Кроме того, однако, по меньшей мере в некоторых вариантах осуществления Платформа хранения позволяет заказчикам, включая независимых продавцов программ (ISV, НПП), создавать новые схемы 344 (то есть новые типы Порции данных (Item) и Вложенных элементов). Этот раздел описывает механизм для создания таких схем, расширяя типы Порции данных и Типы Вложенный Элемент (Nested Element) (или просто типы "Элементы"), определенные в начальном наборе схем 340.
Предпочтительно расширение начального набора типов Порции данных (Item) и Вложенный Элемент (Nested Element) ограничено следующим образом:
* для ISV позволено вводить новые типы Порции данных, то есть подтипы Base.Item;
* для ISV позволено вводить новые типы Вложенный Элемент, то есть подтип Base.NestedElement;
* для ISV позволено вводить новые Расширения, то есть подтип Base.NestedElement; но,
* ISV не может задавать подтип какого-либо типа (типы Item, Nested Element или Extension), определенный начальным набором схем 340 платформы хранения.
Так как тип Item или тип Nested Element (Вложенный Элемент), определенный начальным набором схем платформы хранения, не может точно соответствовать потребности прикладной программы продавца ISV, необходимо позволить продавцам ISV настраивать тип. Это разрешается нотацией Расширений (Extensions). Расширения являются строго типизированными экземплярами, но: (а) они не могут существовать независимо, и (b) они должны быть присоединены к Item или Nested Element.
В дополнение к разрешению потребности в расширяемости схемы. Расширения также предназначены, чтобы решить проблему "множества типов". Так как в некоторых вариантах осуществления Платформа хранения не может поддерживать множество подтипов многократного наследования или наложения, прикладные программы могут использовать Расширения как путь для моделирования экземпляров накладывающихся типов (например, документ является юридическим документом, а также безопасным документом).
i) Расширение Порции данных
Чтобы обеспечить расширяемость Порции данных, модель данных далее определяет абстрактный тип, названный Base.Extention. Это корневой тип для иерархии типов Расширения. Прикладные программы могут (использовать) подтип Base.Extention, чтобы создать специфические типы расширения.
Тип Base.Extention определен в Базовой схеме следующим образом:

Поле ItemID содержит ItemID порции данных, с которой связано расширение. Должна существовать Порция данных с этим ItemID. Расширение не может быть создано, если порция данных с заданным ItemID не существует. Когда Порция данных удаляется, все Расширения с тем же самым ItemID удаляются. Кортеж (ItemID, ExtensionID) уникально идентифицирует экземпляр Расширения.
Структура типа Расширения подобна таковому для типа Порции данных:
* Типы Расширения имеют поля;
* Поля могут быть примитивными (элементарными) или типа вложенного элемента; и
* Для типов Расширения могут быть созданы подтипы.
Следующие ограничения применяются для типов расширения:
* Расширения не могут быть источниками и адресатами отношений;
* Экземпляры типа Расширения не могут существовать независимо от Порции данных; и
* Типы Расширения не могут использоваться как типы поля в определениях типов платформы хранения.
Не имеется никаких ограничений на типы расширений, которые могут быть связаны с заданным типом Порции данных. Любому типу расширения разрешено расширять любой тип элемента. Когда множество экземпляров расширения присоединены к порции данных, они являются независимыми друг от друга и в структуре, и в поведении.
Экземпляры расширения сохранены и доступны отдельно от Порции данных. Все экземпляры типа расширения доступны из глобального представления расширения. Может быть составлен эффективный запрос, который возвратит все экземпляры заданного типа расширения независимо от того, с каким типом Порции данных они связаны. API платформы хранения обеспечивают модель программирования, которая может сохранять, извлекать и изменять расширения относительно Порций данных.
Для типов Расширения могут быть созданы подтипы типа, используя единую модель наследования платформы хранения. Операция произведения (получения) от типа расширения создает новый тип расширения. Структура или поведение расширения не могут отменять или заменять структуру или поведения иерархии типов Порций данных. Аналогично типам Порции данных к экземплярам типа расширения можно непосредственно обращаться через представление, связанное с типом расширения. ItemID расширения указывает, какому элементу они принадлежат и могут использоваться для извлечения соответствующего объекта Порции данных из глобального представления Порции данных. Расширения рассматриваются частью Порции данных для целей операционной совместимости. Копирование/перемещение, Резервное копирование/Восстановление и другие обычные операции, которые определяет Платформа хранения, могут работать над расширениями как частью Порции данных.
Рассмотрим следующий пример. Тип Контакта определен в наборе Типов Windows.

Разработчик прикладной программы CRM хотел бы присоединить расширение прикладной программы CRM к Контактам (Contacts), сохраненным в платформе хранения. Разработчик приложения может определить CRM расширение, которое будет содержать дополнительную структуру данных, которой прикладная программа может манипулировать.

Разработчик прикладной программы HR может хотеть также присоединить дополнительные данные к Контакту (Contact). Эти данные независимы от данных прикладной программы CRM. Снова прикладной разработчик может создавать расширение

CRMExtension и HRExtension - два независимых расширения, которые могут быть присоединены к Порции данных Contact. Они созданы и обращаются независимо друг от друга.
В вышеупомянутом примере поля и методы типа CRMExtension не могут отменять поля или методы иерархии Контакта (Contact). Следует отметить, что экземпляры типа CRMExtension могут быть присоединены к типам Порции данных, отличным от Контакта.
Когда Порция данных Контакта извлечена, его расширения Порции данных автоматически не извлекаются. При заданной Порции данных Контакта к его связанным расширениям Порции данных можно обращаться, запрашивая глобальное представление расширения для расширений с одним и тем же Itemld.
Ко всем расширениям CRMExtension в системе можно обращаться через представление типа CRMExtension, независимо от того, какому элементу они принадлежат. Расширение всех Порций данных для Порции данных совместно использует один и тот же идентификатор Itemld. В вышеупомянутом примере экземпляры Порции данных Контакта и присоединенные экземпляры CRMExtension и HRExtension используют один и тот же ItemID.
Следующая таблица суммирует сходства и различия между типами Item, Extension и NestedElement:
Item в зависимости от ItemExtension в зависимости от NestedElement
Данных
а) Расширяющие типы NestedElement
Типы Nested Element (Вложенный Элемент) не расширяется тем же самым механизмом, как типы Item (Порции данных). Расширения вложенных элементов сохранены и доступны посредством тех же механизмов, что и поля типов вложенных элементов.
Модель данных определяет корень для типов вложенных элементов, названный Element (Элемент):

Тип NestedElement наследуется из этого типа. Тип элемента NestedElement дополнительно определяет поле, которое является мультинабором Элементов.

Расширения NestedElement отличаются от расширений Порции данных следующими чертами:
* Расширения Вложенных элементов не являются типами расширения. Они не принадлежат иерархии типов расширений, которая имеет корень в типе Base.Extension.
* Расширения Вложенных элементов сохраняются наряду с другими полями Порции данных и не являются глобально доступными, не может быть составлен запрос, который извлекает все экземпляры типа заданного расширения.
* Эти Расширения сохранены так же, как сохранены и другие вложенные элементы (для Порции данных). Подобно другим вложенным наборам, расширения NestedElement сохранены в UDT. Они доступны через поле Extensions типа вложенного элемента.
* Интерфейсы коллекции, используемые для обращения к многозначным свойствам, также используются для доступа и выполнения итераций по набору расширений типа.
Следующая таблица суммирует и сравнивает расширения Порции данных и Расширения NestedElement.
Расширения Порции данных в зависимости от расширений NestedElement
D. МЕХАНИЗМ БАЗЫ ДАННЫХ
Как упомянуто выше, хранилище данных реализовано на механизме базы данных. В существующем варианте осуществления механизм базы данных содержит механизм реляционной базы данных, который реализует язык запросов SQL, типа механизма Microsoft SQL Server, с объектными реляционными расширениями. Настоящий раздел описывает отображение модели данных, которое хранилище данных реализует для реляционного хранения и обеспечивает информацию относительно логического API, использованного клиентами платформы хранения, в соответствии с настоящим вариантом осуществления. Понятно, однако, что отличное отображение может быть использовано, когда используется отличный механизм базы данных. Действительно, в дополнение к осуществлению концептуальной модели данных платформы хранения на механизме реляционной базы данных, она может также быть реализована на других типах баз данных, например объектно-ориентированных и XML базах данных.
Объектно-ориентированная (OO) система базы данных обеспечивает персистентность и транзакции для объектов языка программирования (например, C++, Java). Понятие "Порции данных" в платформы хранения хорошо соответствует "Объекту" в объектно-ориентированных системах, хотя внедренные коллекции могут быть добавлены к Объектам. Другие концепции типа платформы хранения, подобные наследованию и типам вложенных элементов, также соответствуют системам объектно-ориентированного типа. Объектно-ориентированные системы обычно уже поддерживают идентичность объектов; следовательно, идентичность Порции данных может быть отображена на идентичность объекта. Поведения (операции) Порции данных хорошо соответствуют объектным методам. Однако объектно-ориентированные системы обычно испытывают недостаток организационных возможностей и слабы в поиске. Также объектно-ориентированные системы не обеспечивают поддержку для неструктурированных и полуструктурированных данных. Чтобы поддерживать полную модель данных платформы хранения, описанную здесь, концепции, подобные отношениям, папкам и расширениям, нужно было бы добавить к объектной модели данных. Кроме того, должны быть реализованы механизмы, подобные промотированию, синхронизации, уведомлениям и защите.
Подобно объектно-ориентированным системам, XML базы данных, основанные на XSD (Определение XML Схемы), поддерживают систему типов, основанную на одиночном наследовании. Система типов Порции данных по настоящему изобретению может быть отображена на модель типа XSD. XSD также не обеспечивают поддержку для поведений. XSD для Порций данных должны быть дополнены поведениями Порции данных. XML базы данных имеют дело с единственными документами и испытывают недостаток в организации и широких возможностях поиска. Как и с объектно-ориентированными базами данных, чтобы поддержать модель данных, описанную здесь, другие концепции подобно отношениям и папкам должны быть включены в такие XML базы данных; также должны быть осуществлены механизмы, подобные синхронизации, уведомлениям и защите.
В отношении следующих подразделов обеспечиваются несколько иллюстраций, чтобы облегчить общую раскрытую информацию: Фиг.13 - диаграмма, иллюстрирующая механизм уведомления. Фиг.14 - диаграмма, иллюстрирующая пример, в который две транзакции обе вставляют новую запись в одно и то же Б-дерево. Фиг.15 иллюстрирует процесс обнаружения изменения данных. Фиг.16 иллюстрирует примерное дерево каталогов. Фиг.17 иллюстрирует пример, в котором существующая папка основанной на каталогах файловой системы перемещена в хранилище данных платформы хранения.
1. Реализация Хранилища данных с использованием UDT
В настоящем варианте осуществления механизм 314 реляционной базы данных, который в одном варианте осуществления содержит механизм Microsoft SQL Server, поддерживает встроенные скалярные типы. Встроенные скалярные типы являются "родными" (собственными) и "простыми". Они являются родными в том смысле, что пользователь не может определять свои собственные типы, и они просты в том, что они не могут инкапсулировать сложную структуру. Определяемые пользователем типы (ОПТ) (в дальнейшем: UDT) обеспечивают механизм для расширяемости типа сверх и вне родной системы скалярных типов, позволяя пользователям расширять систему типов, определяя составные структурированные типы. После того как он определен пользователем, UDT может использоваться где-нибудь в этой системе типов, так что может быть использован встроенный скалярный тип.
В соответствии с аспектом настоящего изобретения схемы платформы хранения отображаются в классы UDT в хранилище механизма базы данных. Порции данных хранилища данных отображаются на классы UDT, производных от типа Base.Item. Подобно Порциям данных, Расширения также отображаются на классы UDT и используют наследование. Корневым типом расширения является Base.Extension, из которого получены все типы Расширения.
UDT является CLR-классом - он имеет состояние (то есть поля данных) и поведение (то есть подпрограммы). UDT определены, используя любой из поддерживаемых языков - С#, VB.NET и т.д. Методы и операторы UDT могут быть вызваны в Т-SQL для экземпляра этого типа. UDT может быть: типом столбца в строке, типом параметра подпрограммы в T-SQL или типом переменной в T-SQL
Отображение схем платформы хранения в классы UDT непосредственно справедливо на высоком уровне. Обычно Схема платформы хранения отображается в пространство имен CLR. Тип платформы хранения отображается в класс CLR. Наследование класса CLR отражает наследование Типа платформы хранения, и свойство платформы хранения отображается в свойство класса CLR.
2. Отображение Порция данных
Учитывая желательность для Порций данных быть глобально доступными для поиска и поддержки в реляционной базе данных согласно настоящему варианту осуществления для наследования и заменяемости типов, одна из возможных реализации для памяти Порции данных в хранилище базы данных должна сохранять все Порции данных в одной таблице со столбцом типа Base.Item. Используя заменяемость типов, Порции данных всех типов могут быть сохранены, и поиски могут быть отфильтрованы по типу Порции данных и подтипу, используя оператор Юкона "имеет (Тип)" ("is of (Type)").
Однако из-за проблем накладных расходов, связанных с таким подходом, в существующем варианте осуществления Порции данных разделены по типу высокого уровня, так что Порции данных каждого типа "семейным образом" сохранены в отдельной таблице. Согласно этой схеме разделения, создается таблица для каждого типа Порции данных, наследуя непосредственно от Base.Item. Типы, наследующиеся ниже них, сохраняются в соответствующей таблице семейства типов, используя подставимость типов, как описано выше. Только первый уровень наследования от Base.Item обрабатывается специальным образом.
"Теневая" таблица используется для сохранения копий глобально доступных свойств для поиска для всех Порций данных. Эта таблица может поддерживаться методом Update() из API платформы хранения, посредством которого делают все изменения данных. В отличие от таблиц семейства типов эта глобальная таблица Порции данных содержит только скалярные свойства высокого уровня для Порции данных, а не полный UDT-объект Порции данных. Глобальная таблица Порции данных (Item) позволяет осуществить навигацию к объекту Item, сохраненному в таблице семейства типов, открывая ItemID и TypeID. ItemID будет обычно уникально идентифицировать Порцию данных в хранилище данных. TypeID может быть отображен, используя метаданные, которые не здесь описаны, на имя типа и представление, содержащее Порцию данных. Так как обнаружение Порции данных по ее ItemID может быть обычной операцией, и в контексте глобальной таблицы Порции данных, и в другом случае обеспечивается функция GetItem() для извлечения объекта Item при заданном ItemID Порции данных.
Для удобного доступа и скрытия деталей реализации до возможной степени все запросы Порций данных могут быть для представлений, построенных на таблицах Порции данных, описанных выше. В частности, представления могут быть созданы для каждого типа Порции данных в зависимости от соответствующей таблицы семейства типов. Эти представления типов могут выбирать все Порции данных связанного типа, включая подтипы. Для удобства в дополнение к объекту UDT представления могут открывать столбцы для всех полей высокого уровня этого типа, включая унаследованные поля.
3. Отображение Расширения
Расширения очень подобны Порциям данных и имеют некоторые из тех же самых требований. В качестве другого корневого типа, поддерживающего наследование, Расширения подчинены многим из тех же самых соображений и компромиссов при сохранении. Из-за этого подобное отображение семейства типов применяется к Расширениям, вместо подхода с одиночной таблицей. Конечно, в других вариантах осуществления может использоваться подход с одиночной таблицей. В существующем варианте осуществления Расширение связано точно с одной Порцией данных посредством ItemID и содержит ExtensionID, который является уникальным в контексте Порции данных. Как и с Порциями данных, может быть обеспечена функция для извлечения Расширения, заданного его идентичностью (информация идентичности), которая состоит из пары ExtensionID и ItemID. Создается представление для каждого типа Расширения, подобно представлениям типа Item.
4. Отображение Вложенных элементов
Вложенные Элементы являются типами, которые могут быть внедрены в Порции данных, Расширения, Отношения или другие Вложенные Элементы для формирования глубоко вложенных структур. Подобно Порциям данных и Расширениям, Вложенные Элементы реализованы как UDT, но они сохранены в Порциях данных и Расширениях. Поэтому Вложенные Элементы не имеют никакого отображения хранения, кроме их контейнеров Порции данных и Расширения. Другими словами, не имеется никаких таблиц в системе, которые непосредственно сохраняют экземпляры типов NestedElement, и не имеется никаких представлений, выделенных специально для Вложенных Элементов.
5. Идентичность Объектов
Каждый объект в модели данных, то есть каждое из Порции данных, Расширения и Отношения, имеет уникальное ключевое значение. Порция данных уникально идентифицируется ее Itemld. Расширение уникально идентифицируется составным ключом (Itemld, Extensionid). Отношение идентифицируется составным ключом (Itemld, Relationshipid). Itemld, Extensionid и Relationshipid являются значениями QUID.
6. Наименование SQL Объектов
Все объекты, созданные в хранилище данных, могут быть сохранены в SQL схеме с именем, полученным из имени схемы платформы хранения. Например, Базовая схема платформы хранения (часто называемой "Базой") может производить типы в SQL схеме "[System.Storage]", например "[System.Storage].Item". Сгенерированные имена имеют в качестве префикса спецификатор, чтобы устранить конфликты обозначений. Там, где приемлемо, символ (!) восклицания используется как разделитель для каждой логической части имени. Таблица ниже приводит соглашение о наименовании, используемое для объектов в хранилище данных. Каждый элемент схемы (Порция данных, Расширение, Отношения и Представление) перечислен наряду с декорированным соглашением о наименовании, используемым для обращения к экземплярам в хранилище данных.
Name
AufhorsFromDocument]
7. Наименования столбцов
При отображении любой объектной модели в хранилище возможность конфликтов наименований происходит из-за дополнительной информации, сохраненной наряду с объектом приложения. Чтобы избежать конфликтов наименований, все не относящиеся к какому-либо типу столбцы (столбцы, которые не отображаются непосредственно на наименованное Свойство в объявлении типа), снабжаются префиксом с символом подчеркивания (_). В существующем варианте осуществления символы подчеркивания (_) запрещены в качестве начального символа какого-либо свойства идентификатора. Далее, чтобы унифицировать наименования между CLR и хранилищем данных, все свойства типов платформы хранения или элемента схемы (отношение и т.д.) должны иметь набранный прописными буквами первый символ.
8. Представления Поиска
Виды (Представления) обеспечиваются платформой хранения для поиска сохраненного содержимого. SQL-представление (SQL-вид) обеспечивается для каждого типа Порции данных и Расширения. Далее, представления обеспечиваются, чтобы поддержать Отношения (Relationships) и Представления (Views) (как определено Моделью Данных). Все SQL-представления и лежащие в основе таблицы в платформе хранения предназначены только для считывания. Данные могут быть сохранены или изменены, используя метод Update() API платформы хранения, как описано более подробно ниже.
Каждое представление (вид), явно определенное в схеме платформы хранения (определенной проектировщиком схемы, а не автоматически сгенерированный платформой хранения), доступно посредством наименованного SQL-вида [<имя схемы>].[View!<Haзвание вида>]. Например, представление, названное "BookSales" в схеме "Acme Publisher.Books", может быть доступно, используя имя
"[AcmePublisher.Books].[View! BookSales]". Так как выходной формат представления является настраиваемым на основе предварительного просмотра (определенного произвольным запросом, обеспеченным стороной, определяющей представление), столбцы непосредственно отображаются на основании определения представления схемы.
Все представления SQL-поиска в хранилище данных платформы хранения используют следующее соглашение упорядочения для столбцов:
* Логический "ключевой" столбец(цы) результата представления, такой как Itemid, Elementid, Relationshipid,...
* Информацию метаданных относительно типа результата, такую как Typeld.
* Столбцы отслеживания изменений, такие как CreateVersion, UpdateVersion,...
* Столбец(цы) специального типа (Properties (Свойства) объявленного типа).
* Представления специального типа (представления семейства) также содержат объектный столбец, который возвращает этот объект.
Члены каждого семейства типов доступны для поиска, используя последовательность представлений Порции данных, по одному представлению на тип Порции данных в хранилище данных. Фиг.28 - диаграмма, иллюстрирующая концепцию представления поиска Порции данных.
а) Порция данных
Каждый вид поиска Порции данных содержит строку для каждого экземпляра Порции данных конкретного типа или его подтипов. Например, вид (представление) для Документа может возвращать экземпляры Document, LegalDocument и ReviewDocument. Для данного примера виды Порции данных могут быть концептуализированы, как показано на фиг.29.
(1) Главное представление поиска Порции данных
Каждый экземпляр хранилища данных платформы хранения определяет специальное представление Порции данных, называемое Главным представлением Порции данных (Master Item View). Это представление обеспечивает суммированную информацию относительно каждой Порции данных в хранилище данных. Представление обеспечивает один столбец на (каждое) свойство типа Item (Порции данных), столбец, который описывает тип Порции данных, и нескольких столбцов, которые используются, чтобы обеспечить отслеживание изменений и информацию синхронизации. Главное представление Порции данных идентифицируется в хранилище данных, используя имя "[System.Storage].[Master!Item]".
(2) Имеющие тип представления поиска Порции данных
Каждый тип Порции данных также имеет представление поиска. Хотя и подобно корневому представлению Порции данных, это представление также обеспечивает доступ к объекту Item через столбец "_Item". Каждое имеющее тип представление поиска элемента идентифицировано в хранилище данных, используя имя [schemaName].[ItemTypeName].
Например, [AcmeCorp.Документ].[OfficeDoc].
данных
b) Расширения Порции данных
Все Расширения Порции данных в хранилище WinFS также доступны, используя представления поиска.
(1) Главное представление поиска Расширения
Каждый экземпляр хранилища данных определяет специальное представление Расширения, называемое Главным Представлением Расширения (Master Extension View). Это представление обеспечивает суммированную информацию относительно каждого Расширения в хранилище данных. Представление имеет столбец на (каждое) свойство Расширения, столбец, который описывает тип Расширения, и нескольких столбцов, которые используются, чтобы обеспечить отслеживание изменений и информацию синхронизации. Главное представление Расширения идентифицировано в хранилище данных, используя имя "[System.Storage].[Master!Extension]".
(2) Имеющие тип представления поиска Расширения
Каждый тип Расширения также имеет представление поиска. Хотя и подобно главному представлению Расширения, это представление также обеспечивает доступ к объекту Item через столбец Extension. Каждое имеющее тип представление поиска Расширения идентифицировано в хранилище данных, используя имя [schemaName].[Extension!ExtensionTypeName]. Например [AcmeCorp.Doc]. [Extension!OfficeDocExt]
c) Вложенные Элементы
Все вложенные элементы сохранены в экземплярах Порций данных, Расширений или Отношений. Как таковые, к ним обращаются, запрашивая соответствующее представление поиска Порций данных, Расширения или Отношения.
d) Отношения
Как описано выше, Отношения формируют основную единицу связывания между Порциями данных в хранилище данных платформы хранения.
(1) Главное представление поиска Отношения
Каждое хранилище данных обеспечивает Главное Представление Отношений (Master Relationship View). Это представление обеспечивает информацию относительно всех экземпляров отношений в хранилище данных. Главное представление отношения идентифицировано в хранилище данных, используя имя "[System.Storage].[Master'Relationship]".
(2) Представления поиска экземпляра Отношения
Каждое объявленное Отношение также имеет представление поиска, которое возвращает все экземпляры конкретного отношения. Хотя подобно главному представлению отношения, это представление также обеспечивает именованные столбцы для каждого свойства данных отношения. Каждое представление поиска экземпляра отношений идентифицировано в хранилище данных, используя имя [schemaName].[Relationship!relationshlpName]. Например, [AcmeCorp.Doc].[Relationship!DocumentAuthor].
е) 9. Обновления
Все представления в хранилище данных платформы хранения доступны только для считывания. Чтобы создавать новый экземпляр элемента модели данных (Порция данных, расширение или отношение) или обновить существующий экземпляр, должны использоваться методы ProcessOperation или ProcessUpdategram из API платформы хранения. Метод ProcessOperation - единственная сохраненная процедура, определенная хранилищем данных, которая использует "операцию", которая детализирует действие, которое должно быть выполнено. Метод ProcessUpdategram - сохраненная процедура, которая берет упорядоченный набор операций, известный как "updategram", которые все вместе детализируют набор действий, которые должны быть выполнены.
Формат операции является расширяемым и обеспечивает различные операции над элементами схемы. Некоторые обычные операции включают в себя:
1. Операции Порции данных:
A. Createltem (Создает новую Порцию данных в контексте отношений внедрения или хранения)
В. Updateltem (обновляет существующую Порцию данных)
2. Операции Отношения:
A. CreateRelationship (создает экземпляр отношения Ссылки или хранения)
В. UpdateRelationship (обновляет экземпляр отношения)
C. DeleteRelationship (удаляет экземпляры отношения)
3. Операции Расширения:
A. CreateExtension (добавляет расширение к существующей Порции данных)
В. UpdateExtension (обновляет существующее расширение)
С. DeleteExtension (удаляет расширение)
10. Отслеживание изменений и оповещения
Услуги отслеживания изменений и оповещения обеспечиваются хранилищем данных, как описано более подробно ниже. Этот раздел обеспечивает обзор информации отслеживания изменений, открытой в хранилище данных.
а) Отслеживание изменений
Каждое представление поиска, обеспеченное хранилищем данных, содержит столбцы, используемые для обеспечения информации отслеживания изменений; столбцы являются общими для всех представлений Порции данных. Расширения и Отношения. Представления Схемы платформы хранения, определенные явно проектировщиками схемы, автоматически не обеспечивают информацию отслеживания изменений - такая информация обеспечивается косвенно через представления поиска, на которых построено само представление.
Для каждого элемента в хранилище данных информация отслеживания изменений доступна из двух мест - "главное" представление элемента и "имеющее тип" представление элемента. Например, информация отслеживания изменений относительно типа Порции данных AcmeCorp.Document.Document доступна из Главного Представления Порции данных (Master Item View) "[System.Storage].[Master!Item]" и имеющего тип представления поиска Порции данных [AcmeCorp.Document].[Document].
(1) Отслеживание изменений в "главных" представлениях поиска
Информация отслеживания изменений в главных представлениях поиска обеспечивает информацию относительно создания и версий обновления элемента, причем информация о том, какой sync-партнер (партнер синхронизации) создал элемент, какой sync-партнер последний обновил элемент, и номера версии от каждого партнера для создания и модификации. Партнеры в отношениях синхронизации (sync-отношениях) (описаны ниже) идентифицированы ключом партнера (partner key). Одиночный UDT-объект, названный _ChangeTrackingInfo типа [System.Storage.Store].Change Trackinglnfo, содержит всю эту информацию. Тип определен в Схеме System.Storage. _ChangeTrackingInfo доступен во всех представлениях глобального поиска для Порции данных, Расширения и Отношения. Определением типов ChangeTrackingInfo является:
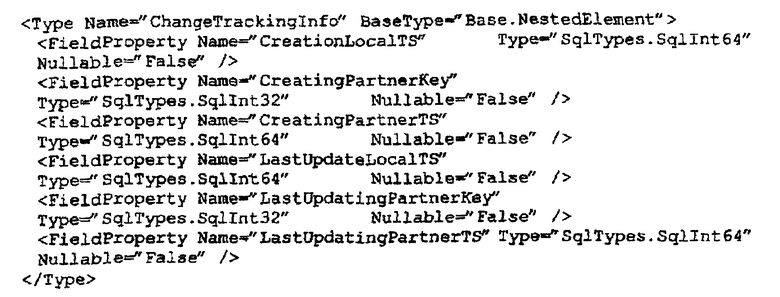
Эти свойства содержат следующую информацию:
(2) Отслеживание изменений в "имеющих тип" представлениях Поиска
В дополнение к обеспечению одной и той же информации как глобального представления поиска, каждое имеющее тип представление поиска обеспечивает запись дополнительной информации состояния синхронизации каждого элемента в топологии синхронизации.
b) Оповещения
Хранилище данных обеспечивает информацию оповещения для Порций данных, Расширений и Отношений. Представления (Views) оповещения обеспечивают информацию относительно и живых и удаленных (tombstoned) объектов (элементов, расширений и отношений) в одном месте. Представления оповещения Порции данных и Расширения не обеспечивают доступ к соответствующему объекту, в то время как представление оповещения отношения обеспечивает доступ к объекту отношения (объектом отношений есть NULL (ПУСТОЙ) в случае удаленных (tombstoned) отношений).
(1) Оповещения порции данных
Оповещения Порции данных извлекаются из системы через представление [System.Storage].[Tombstone!Item].
(2) Оповещения Расширения
Оповещения Расширения извлекают из системы, используя представление [System.Storage].[Tombstone!Extension]. Информация отслеживания изменений для Расширения аналогична таковой, предусмотренной для Порции данных с дополнением свойства Extensionld.
(3) Оповещение Отношения
Оповещения Отношения извлекают из системы через представление [System.Storage].[Tombstone!Relationship]. Информация оповещения для Отношений подобна таковой, предусмотренной для Расширений. Однако дополнительная информация обеспечивается на целевом ItemRef экземпляра отношения. Кроме того, объект отношений также является выбранным.
(4) Очистка Оповещения
Чтобы предотвращать неограниченный рост информации оповещения, хранилище данных обеспечивает задачу очистки оповещения. Эта задача определяет, когда информация оповещения может быть отброшена. Задача вычисляет связь для локальной, созданной/обновленной версии и затем усекает информацию оповещения, отказываясь от всех более ранних версий оповещения.
11. Помощник API и Функции
Отображение Базы (Base) также обеспечивает ряд функций помощника. Эти функции предоставлены для помощи обычным операциям над моделью данных.
a) Функция [System. Storage].Getltem
Возвращает объект Item, заданный посредством Itemid
// Item Getltem (Itemid Itemid)
b) Функция [System.Storage.GetExtension
// Возвращает объект расширения, заданный Itemid и Extensionid
// Extension GetExtension (Itemid Itemid, Extensionid Extensionid)
c) Функция [Systern.Storage.GetRelationship
// Возвращает объект отношения, заданный Itemid и Relationshipid //
Relationship GetRelationship (Itemid Itemid, Relationshipid Relationshipid)
12. Метаданные
Имеются два типа метаданных, представленных в Хранилище: метаданные экземпляра (тип Item и т.д.) и метаданные типа.
a) Схема Метаданные
Схема метаданные (metadata) сохранена в хранилище данных как экземпляры типов Item из схемы Мета.
b) Экземпляр Metadata
Экземпляр метаданных (metadata) используется прикладной программой для запроса типа Порции данных и находит Расширения, связанные с Порцией данных. При заданном Itemid для Порции данных прикладная программа может сделать запрос глобального представления Порции данных, чтобы возвратить тип Порции данных и использовать это значение, чтобы запросить представление Meta.Type, чтобы возвратить информацию относительно объявленного типа Порции данных. Например,
// Возвратить объект Item metadata для данного экземпляра Порции данных //
SELECT m._Item AS metadataInfoObj
FROM [System.Storage].[Item] i INNER JOIN [Meta].[Type] m ON i._TypeId=m.Itemid
WHERE i.Itemid=@ltemld
E. ЗАЩИТА
Обычно все защищаемые объекты организуют свои права доступа, используя формат маски доступа, показанный на фиг.26. В этом формате 16 младших бит предназначены для специфичных для объекта прав доступа, следующие 7 бит - для стандартных прав доступа, которые применяются к большинству типов объектов, и 4 старших бита используются, чтобы определить родовые права доступа, которые каждый тип объекта может отображать на набор стандартных и специфичных для объекта прав. Бит ACCESS_SYSTEM_SECURITY соответствует праву доступа к SACL объекта.
В структуре маски доступа по Фиг.26 специфические права Порции данных помещены в раздел Прав Специфических Объектов (младшие 16 бит). Поскольку в настоящем варианте осуществления Платформа хранения предоставляет два набора API, чтобы управлять защитой, - Win32 и API платформы хранения, специфичные для объекта файловой системы права должны быть рассмотрены, чтобы мотивировать строение прав, специфичных для объекта файловой системы.
Модель защиты для платформы хранения согласно настоящему изобретению изобретения полностью описана в родственных заявках, включенных по ссылке в настоящее описание. В этом отношении Фиг.27 (части a, b и с) изображает новую идентично защищенную область защиты, вырезаемую из существующей области защиты, в соответствии с одним вариантом осуществления модели защиты.
F. УВЕДОМЛЕНИЯ И ОТСЛЕЖИВАНИЕ ИЗМЕНЕНИЙ
Согласно другому аспекту настоящего изобретения Платформа хранения обеспечивает возможность уведомлений, которая позволяет прикладным программам отслеживать изменения данных. Эта особенность прежде всего предназначена для прикладных программ, которые поддерживают энергозависимое состояние или выполняют бизнес-логику в отношении событий изменения данных. Прикладные программы регистрируют уведомления для Порций данных, расширений Порций данных и отношений Порции данных. Уведомления доставляются асинхронно после того, как были сделаны изменения данных. Прикладные программы могут фильтровать уведомления по Порции данных, Расширению и типу отношения, а также типу операции.
Согласно одному варианту осуществления, API 322 платформы хранения обеспечивает два вида интерфейсов для уведомлений. Первый - прикладные программы регистрируют простые события изменения данных, вызванные изменениями в Порциях данных, Расширениях Порций данных и отношениях Порции данных. Второй - прикладные программы создают объекты - "наблюдатели" для контроля Порций данных, расширений Порций данных и отношений между Порциями данных. Состояние объекта-наблюдателя может быть сохранено и создано заново после системного отказа или после того, как система вошла в автономный режим на длительный период времени. Одиночное уведомление может отражать множество обновлений.
Дополнительные детали относительно этих функциональных возможностей могут быть найдены в родственных заявках, включенных выше в настоящее описание по ссылке.
G. ВОЗМОЖНОСТЬ К ВЗАИМОДЕЙСТВИЮ ТРАДИЦИОННОЙ ФАЙЛОВОЙ СИСТЕМЫ
Как упомянуто выше, Платформа хранения согласно настоящему изобретению, по меньшей мере в некоторых вариантах осуществления предназначена для реализации в качестве неотъемлемой части аппаратной/программной интерфейсной системы для компьютерной системы. Например, Платформа хранения согласно настоящему изобретению может быть воплощена как неотъемлемая часть операционной системы, такой как семейство операционных систем Microsoft Windows. При наличии такой возможности API платформы хранения становится частью интерфейсов API операционной системы, через которые прикладные программы взаимодействуют с операционной системой. Таким образом, Платформа хранения становится средством, посредством которого прикладные программы сохраняют информацию относительно операционной системы, и основанная на Порции данных модель данных платформы хранения поэтому заменяет традиционные файловые системы такой операционной системы. Например, как воплощено в семействе операционных систем Microsoft Windows, Платформа хранения может заменить файловую систему NTFS, осуществленную в этой операционной системе. В настоящее время прикладные программы обращаются к службам файловой системы NTFS через интерфейсы API Win32, предоставленные семейством операционных систем Windows.
Признавая, однако, что полностью замена файловой системы NTFS платформой хранения настоящего изобретения требовала бы перекодирования существующих основанных на Win32 прикладных программ и что такое перекодирование может быть нежелательно, было бы выгодно для платформы хранения согласно настоящему изобретению обеспечить некоторую возможность к взаимодействию с существующими файловыми системами типа NTFS. В одном варианте осуществления настоящего изобретения поэтому Платформа хранения позволяет прикладным программам, которые полагаются на модель программирования Win32, обращаться к содержанию и хранилища данных платформы хранения, и традиционной файловой системы NTFS. С этой целью Платформа хранения использует соглашение о наименованиях, которое является супернабором соглашений о наименованиях Win32, чтобы облегчить простую возможность к взаимодействию. Далее, платформа хранения поддерживает обращение к файлам и каталогам, сохраненным в объеме платформы хранения, через API Win32.
Дополнительные детали относительно этих функциональных возможностей могут быть найдены в родственных заявках, включенных по ссылке выше.
H. API ПЛАТФОРМЫ ХРАНЕНИЯ
Платформа хранения содержит API, который дает возможность прикладным программам обращаться к особенностям и возможностям платформы хранения, описанным выше, и обращаться к элементам, сохраненным в хранилище данных. Этот раздел описывает один вариант осуществления API платформы хранения настоящего изобретения. Детали относительно этих функциональных возможностей могут быть найдены в родственных заявках, включенных по ссылке выше, причем часть этой информации суммирована ниже для удобства.
Что касается Фиг.18, Папка Включения является порцией данных, которая содержит Отношения хранения к другим Порциям данных и является эквивалентом обычной концепции папки файловой системы. Каждая Порция данных "содержится" в по меньшей мере одной папке включения.
Фиг.19 иллюстрирует основную архитектуру API платформы хранения в соответствии с настоящим вариантом осуществления. API платформы хранения использует SQLClient 1900 для общения с локальным хранилищем 302 данных и может также использовать SQLClient 1900 для общения с удаленным хранилищем данных (например, хранилищем данных 340). Локальное хранилище 302 может также обмениваться с удаленным хранилищем 340 данных, используя или DQP (Процессор Распределенного Запроса) или посредством службы синхронизации ("Sync") платформы хранения, описанной ниже. API 322 платформы хранения также действует как мост API для уведомлений из хранилища данных, пропуская подписки прикладной программы на механизм 332 уведомления и направляя уведомления прикладной программе (например, прикладной программе 350а, 350b или 350 с), как также описано выше. В одном варианте осуществления API 322 платформы хранения может также определять ограниченную архитектуру "проводника" так, чтобы он мог обращаться к данным в Microsoft Exchange и AD (продукт Active Directoty от Microsoft).
Фиг.20 схематично представляет различные компоненты API платформы хранения. API платформы хранения состоит из следующих компонентов: (1) классы 2002 данных, которые представляют элемент платформы хранения и типы Порции данных, (2) инфраструктуру 2004 выполнения, которая управляет персистентностью объектов и обеспечивает классы 2006 поддержки; и (3) инструментальные средства 2008, которые используются для генерирования CLR-классов из схем платформы хранения.
Иерархия классов, получающихся из заданной схемы, непосредственно отражает иерархию типов в этой схеме. В качестве примера следует рассмотреть типы Порции данных, определенные в схеме Контакты (Contacts), как показано на фиг.21А и Фиг.21 В.
Фиг.22 иллюстрирует инфраструктуру выполнения в работе. Инфраструктура выполнения работает следующим образом:
1. Прикладная программа 350а, 350b или 350с связывается с Порцией данных в платформе хранения.
2. Инфраструктура 2004 создает объект 2202 ItemContext, соответствующий связанной Порции данных, и возвращает его прикладной программе.
3. Прикладная программа представляет Find (найти) в отношении этого ItemContext, чтобы получить коллекцию Порций данных; возвращенная коллекция концептуально является объектным графом 2204 (из-за отношений).
4. Прикладная программа изменяет, удаляет и вставляет данные.
5. Прикладная программа сохраняет изменения, вызывая метод Update().
Фиг.23 иллюстрирует выполнение операции "FindAll".
Фиг.24 иллюстрирует процесс, посредством которого классы API платформы хранения генерируются из Схемы (Schema) платформы хранения.
Фиг.25 иллюстрирует схему, на котором основан API File (Файл). API платформы хранения включает в себя пространство имен для работы с объектами-файлами. Это пространство имен называется System.Storage.Files. Члены данных классов в System.Storage.Files непосредственно отражают информацию, сохраненную в памяти платформы хранения; эта информация "промотируется" из объектов файловой системы или может быть создана собственно, используя API Win32. Пространство System.Storage.Files имен имеет два класса: Fileltem и Directoryltem. Члены этих классов и их методы могут быть легко предсказаны из схематической диаграммы на фиг.25. Fileltem и Directoryltem доступны только для считывания из API платформы хранения. Чтобы изменять их, необходимо использовать API Win32 или классы в System.10.
В отношении API интерфейс программирования (или более просто, интерфейс) может быть рассмотрен как любой механизм, процесс, протокол для предоставления одного или более сегмента(ов) кода для осуществления обмена или обращения к функциональным возможностям, обеспеченным одним или более другим(и) сегмента(ми) кода. Альтернативно, интерфейс программирования может быть рассмотрен как один или более механизм(ов), метод(ов), вызов(ов) функции, модуль(ей), объект(ов) и т.д. компонента системы, способной соединяться с возможностью обмена с одним или более механизмом(ами), методом(ами), вызовом(ами) функции, модулем(ями) и т.д. другим(и) компонентом(ами). Термин "сегмент кода" в предыдущем предложении означает включение в себя одного или более команд или строк кода и включает в себя, например, модули кода, объекты, подпрограммы, функции и так далее, независимо от применяемой терминологии или того, откомпилированы ли сегменты кода отдельно, или обеспечиваются ли сегменты кода как источник, промежуточное звено или объектный код, используются ли сегменты кода в системе или процессе во время выполнения, или расположены ли они на одной и той же или различных машинах или распределены среди множества машин, или осуществлены ли функциональные возможности, представленные сегментами кода, полностью в программном обеспечении, полностью в аппаратных средствах или комбинации аппаратных средств и программного обеспечения.
С точки зрения нотации интерфейс программирования может быть просмотрен в общем виде, как показано на фиг.30А или Фиг.30 В. Фиг.30А иллюстрирует интерфейс Interfacel как канал, через который первый и второй сегменты кода обмениваются информацией. Фиг.30 В иллюстрирует интерфейс как содержащий объекты I1 и I2 интерфейса (которые могут быть или могут не быть частью первого и второго сегментов кода), которые дают возможность первому и второму сегментам кода системы обмениваться через среду М. Ввиду Фиг.30В можно рассматривать объекты I1 и I2 интерфейса как отдельные интерфейсы одной и той же системы и можно также рассматривать, что объекты I1 и I2 плюс среда М составляют интерфейс. Хотя Фиг.30А и 30 В показывают двунаправленный поток и интерфейсы на каждой стороне потока, некоторые реализации могут иметь информационный поток только в одном направлении (или никакого информационного потока, как описано ниже) или могут только иметь интерфейсный объект на одной стороне. Посредством примера, а не ограничения, такие термины, как “интерфейс прикладного программирования” (API), точка входа, метод, функция, подпрограмма, удаленный вызов процедуры и интерфейс объектной модели компонента (СОМ), используются в пределах определения интерфейса программирования.
Аспекты такого интерфейса программирования могут включать в себя метод, посредством которого первый сегмент кода передает информацию (где "информация" используется в ее самом широком смысле и включает в себя данные, команды, запросы и т.д.) ко второму сегменту кода; метод, посредством которого второй сегмент кода принимает информацию; и структуру, последовательность, синтаксис, организацию, схему, тактирование и содержание (контент) информации. В этом отношении для самой лежащей в основе транспортной среды может быть не важны работа интерфейса, является ли среда проводной или беспроводной или их комбинацией, пока информация передается способом, определенным интерфейсом. В некоторых ситуациях информацию нельзя пропускать в одном или обоих направлениях в обычном смысле, поскольку передача информации может быть или через другой механизм (например, информация, помещенная в буфер, файл и т.д. отдельной от информационного потока между сегментами кода) или несуществующей, как в случае, когда один сегмент кода просто обращается к функциональным возможностям, выполняемым вторым сегментом кода. Любой или все эти аспекты могут быть важны в заданной ситуации, например, в зависимости от того, являются ли сегменты кода частью системы в нежестко связанной или жестко связанной конфигурации, и так что этот список должен рассматриваться как иллюстративный и не ограничивающий.
Это понятие интерфейса программирования известно специалистам и понятно из предшествующего подробного описания изобретения. Имеются, однако, другие способы реализовать интерфейс программирования, и, если явно не исключено, они также охватываются формулой изобретения, сформулированной в конце этого описания. Такие другие способы могут показаться более изощренными или сложными, чем упрощенное представление на Фиг.30А и 30В, но они, тем не менее, выполняют аналогичную функцию для достижения одного и того общего результата. Ниже кратко описаны некоторые иллюстративные альтернативные реализации интерфейса программирования.
Разложение на элементарные операции: связь (обмен информацией) от одного сегмента кода с другим может быть реализована косвенно, преобразуя связь в множество дискретных связей (обменов). Это изображено схематично на фиг.31А и 31 В. Как показано, некоторые интерфейсы могут быть описаны в терминах делимых наборов функциональных возможностей. Таким образом, функциональные возможности интерфейса на Фиг.30А и 30В могут быть разложены на элементарные операции, чтобы достичь того же самого результата, как можно математически получить 24, перемножая 2 на 2 на 3 на 2. Соответственно, как проиллюстрировано на фиг.31А, функция, обеспеченная интерфейсом Interfacel, может быть подразделена для преобразования обменов интерфейса во множество интерфейсов InterfacelA, Интерфейс 1В, Интерфейс 1С и т.д. при достижении того же самого результата. Как проиллюстрировано на фиг.31В, функция, обеспеченная интерфейсом I1, может быть подразделена во множество интерфейсов I1а, I1b, I1e и т.д. при достижении того же самого результата. Точно так же интерфейс 12 второго сегмента кода, который принимает информацию от первого сегмента кода, может быть разложен на множество интерфейсов I2a, I2b, I2с и т.д. При разложении число интерфейсов, включенных в 1-й сегмент кода, не должно совпадать с числом интерфейсов, включенных во 2-й сегмент кода. В любом из случаев на Фиг.31А и 31В функциональная сущность интерфейсов Interfacel и I1 остается той же самой, как на Фиг.30А и 30В соответственно. Разложение интерфейсов может также следовать ассоциативным, коммутативным и другим математическим свойствам, так что разложение может быть трудным для распознавания. Например, упорядочение операций может не быть важным, и, следовательно, функция, выполняемая интерфейсом, может быть выполнена перед достижением интерфейса другой частью кода или интерфейса или выполнена отдельным компонентом системы. Кроме того, специалисту ясно, что имеется ряд путей создания различных вызовов функции, которые достигают того же самого результата.
Переопределение: В некоторых случаях возможно игнорировать, добавлять или переопределять некоторые аспекты (например, параметры) интерфейса программирования, в то же время выполняя заданный результат. Это проиллюстрировано на фиг.32А и 32В. Например, предположим, что интерфейс Interfacel на Фиг.30А включает в себя вызов функции “возведение в квадрат” Square(input. Precision, output), причем вызов включает в себя три параметра - входные данные, точность, выходные данные, и который выдан из 1-го Сегмента Кода ко 2-му Сегменту Кода. Если средний параметр “точность” не имеет никакого значения в данном сценарии, как показано на фиг.32А, он может точно так же игнорироваться или даже быть заменен бессмысленным (в этой ситуации) параметром. Можно также добавлять дополнительный не относящийся параметр. В любом случае функциональные возможности возведения в квадрат могут быть достигнуты, пока выдается результат после возведения в квадрат входных данных вторым сегментом кода. Точность может быть существенным значащим параметром для некоторой последующей (по ходу обработки) или другой части вычислительной системы; однако, как только признано, что точность не необходима для узких целей вычисления квадрата значения, она может быть заменена или игнорироваться. Например, вместо принятия допустимого значения точности, бессмысленное значение типа даты рождения может быть принято без негативного влияния на результат. Точно так же, как показано на фиг.32В, интерфейс I1 заменен интерфейсом I1', переопределенным, чтобы игнорировать или добавить параметры для этого интерфейса. Интерфейс I2 может аналогично быть переопределен как интерфейс I2', переопределенный так, чтобы игнорировать ненужные параметры или параметры, которые могут быть обработаны в другом месте. Следует заметить, что в некоторых случаях интерфейс программирования может включать в себя аспекты, такие как параметры, которые не необходимы для некоторой цели, и поэтому они могут игнорироваться, или переопределяться, или обрабатываться в другом месте для других целей.
Встроенное Кодирование: может также быть выполнимо для объединения некоторых или всех функциональных возможностей двух отдельных модулей кода так, что "интерфейс" между ними изменяет форму. Например, функциональные возможности на Фиг.30А и 30В могут быть преобразованы в функциональные возможности на Фиг.33А и 33В соответственно. На фиг.33А, предыдущие 1-й и 2-й Сегменты Кода на Фиг.30А объединены в модуль, содержащий оба из них. В этом случае сегменты кода могут все еще поддерживать связь друг с другом, но интерфейс может быть адаптирован к форме, которая является более подходящей для одного модуля.
Таким образом, например, формальные инструкции Call и Return могут быть больше не необходимы, но подобная обработка или ответ(ы) в соответствии с интерфейсом Interfacel может быть в действительности. Точно так же, как показано на фиг.33В, часть (или весь) интерфейса 12 на Фиг.30 В может быть написана встроенной в интерфейс I1, чтобы сформировать интерфейс I1". Как проиллюстрировано, интерфейс I2 разделен на I2а и I2b и часть I2а интерфейса кодирована в качестве встроенной в интерфейс I1, чтобы сформировать интерфейс I1". Для конкретного примера рассмотрим, что интерфейс II на Фиг.30В исполняет вызов функции возведения в квадрат Square (input, output), который принимается интерфейсом 12, который после обработки значения, поступившего со входа (для его возведения в квадрат), вторым сегментом кода передает назад результат возведения в квадрат в качестве выходного значения. В таком случае обработка, выполненная вторым сегментом кода (возведение в квадрат входного значения), может быть выполнена первым сегментом кода без запроса к интерфейсу.
Отделение: передача от одного сегмента кода к другому может быть выполнена косвенно, разбивая передачу на множество дискретных связей. Это изображено схематично на фиг.34А и 34В. Как показано на фиг.34А, обеспечиваются одна или более частей промежуточного программного обеспечения (middleware) (Интерфейс(ы) Отделения, так как они отделяют функциональные возможности и/или интерфейсные функции от первоначального интерфейса), чтобы преобразовать связь на первом интерфейсе, Interfacel, так, чтобы они были приспособлены к отличающемуся интерфейсу, в этом случае интерфейсам Interface2A, Interface2B и Interface2C. Это могло бы быть сделано, например, там, где имеется установленная база прикладных программ, предназначенных для обмена, например, с операционной системой, в соответствии с протоколом Interface1, но затем операционная система стала использовать отличный интерфейс, в этом случае - интерфейсы Interface2A, Interface2B и Interface2C. Особенность в том, что первоначальный интерфейс, используемый 2-м Сегментом Кода изменен так, что он более не совместим с интерфейсом, используемым 1-м Сегментом Кода, и поэтому используется посредник, чтобы сделать старый и новый интерфейсы совместимыми. Точно так же, как показано на фиг.34В, третий сегмент кода может быть представлен с отдельным интерфейсом DI1, чтобы принимать информацию от интерфейса I1, и с отдельным интерфейсом DI2, чтобы передавать функциональные возможности интерфейса, например, к интерфейсам I2а и I2b, переработанным так, чтобы работать с DI2, но обеспечивать один и тот же функциональный результат. Аналогично, DI1 и DI2 могут работать вместе для преобразования функциональных возможностей интерфейсов I1 и I2 согласно Фиг.30В для новой операционной системы при обеспечении одного и того же или аналогичного функционального результата.
Перезапись: Еще одним возможным вариантом является динамическая перезапись кода, чтобы заменить функциональные возможности интерфейса чем-то еще, но при этом достигается тот же самый общий результат. Например, может иметь место система, в которой сегмент кода, представленный на промежуточном языке (например, Microsoft IL, Java ByteCode, и т.д.), передают на динамичный (JIT) компилятор или интерпретатор в среде выполнения (такой как обеспечиваемый инфраструктурой.Net, средой выполнения Java или других подобных средах выполнения такого типа). JIT-компилятор может быть написан, чтобы динамически преобразовывать передачи информации от 1-го Сегмента Кода ко 2-му Сегменту Кода, то есть приспосабливать их к отличному интерфейсу, который может потребоваться 2-м Сегментом Кода (или оригинальным или отличным 2-м Сегментом Кода). Это изображено на фиг.35А и 35В. Как можно видеть из фиг.35А, этот подход подобен сценарию отделения, описанному выше. Это может быть реализовано, например, когда установленная база прикладных программ предназначена для обмена с операционной системой в соответствии с протоколом Интерфейса 1, но затем операционная система стала использовать отличный интерфейс. ЛТ-компилятор может использоваться для приспособления обменов “на лету” от установленных базовых прикладных программ к новому интерфейсу операционной системы. Как изображено на фиг.35В, этот подход динамической перезаписи интерфейса(ов) может применяться, чтобы динамически разделить или также иным образом изменить интерфейс(ы).
Должно также быть отмечено, что описанные выше сценарии для достижения одного и того же или аналогичного результата, как у интерфейса, посредством альтернативных вариантов осуществления могут также быть объединены различными способами, последовательно и/или параллельно или с другим промежуточным кодом. Таким образом, альтернативные варианты осуществления, представленные выше, не являются взаимоисключающими и могут быть смешаны, согласованы и объединены, чтобы получить одинаковые или эквивалентные сценарии для общих сценариев, представленных на фиг.30А и 30В. Также следует отметить, что, как с большинством конструкций программирования, имеются другие подобные пути достижения одних и тех же или аналогичных функциональных возможностей интерфейса, которые могут быть здесь не описаны, но тем не менее охватываются объемом и контекстом изобретения, то есть следует отметить, что раскрыты, по меньшей мере частично, функциональные возможности и выгодные результаты, представленные и допускаемые интерфейсом, которые лежат в основе значимости интерфейса.
III. СИНХРОНИЗАЦИЯ API
Несколько подходов к синхронизации возможны в основанной на Порции данных аппаратной/программной интерфейсной системе. Раздел А раскрывает несколько вариантов осуществления настоящего изобретения, в то время как Раздел В посвящен различным вариантам осуществления API для синхронизации.
А. КРАТКИЙ ОБЗОР СИНХРОНИЗАЦИИ
Для нескольких вариантов осуществления настоящего изобретения и в отношении Фиг.3 Платформа хранения обеспечивает службу 330 синхронизации, которая (i) допускает множество экземпляров платформы хранения (каждый с его собственным хранилищем 302 данных), чтобы синхронизировать части их содержания (контента) согласно гибкому набору правил, и (ii) обеспечивает инфраструктуру для третьих лиц, чтобы синхронизировать хранилище данных платформы хранения согласно настоящему изобретению с другими источниками данных, которые реализуют составляющие собственность протоколы.
Синхронизация "Платформа хранения - платформа хранения" имеет место среди группы участвующих "точных копий" (replicas). Например, со ссылкой на Фиг.3, может быть желательно обеспечить синхронизацию между хранилищем 302 данных платформы 300 хранения с другим удаленным хранилищем 338 данных под управлением другого экземпляра платформы хранения, возможно выполняющимся на отличной компьютерной системе. Полное членство этой группы не обязательно известно любой заданной точной копии в любое заданное время.
Различные точные копии могут делать изменения независимо (то есть одновременно). Процесс синхронизации определяется как создание каждой точной копии, “знающей” об изменениях, сделанных другими точными копиями. Эта возможность синхронизации является по существу синхронизацией с многими основными копиями.
Возможность синхронизации согласно настоящему изобретению позволяет точным копиям:
* определить, о каких изменениях другая точная копия осведомлена;
* запросить информацию об изменениях, о которых эта точная копия не осведомлена;
* передать информацию об изменениях, о которых другая точная копия не осведомлена;
* определить, когда два изменения находятся в конфликте друг с другом;
* применить изменения локально;
* передать разрешения конфликта другим точным копиям, чтобы гарантировать сходимость; и
* разрешить конфликты на основании заданной политики разрешения конфликтов.
1. Синхронизация "платформа хранения - платформе хранения"
Первичная прикладная программа службы 330 синхронизации платформы хранения согласно настоящему изобретению должна синхронизировать множество экземпляров платформы хранения (каждый со своим собственным хранилищем данных). Служба синхронизации работает на уровне схем платформы хранения (вместо лежащих в основе таблиц механизма 314 базы данных). Таким образом, например, "Контексты" (Scopes) используются, чтобы определить синхронизацию, установленную, как описано ниже.
Служба синхронизации работает на основе принципа "чистовые изменения". Вместо записи и посылки индивидуальных операций (таких как с транзакционным ответом) Служба синхронизации посылает конечный результат этих операций, таким образом часто объединяя результаты множества операций в единое результирующее изменение.
Служба синхронизации действует не в общих границах соответствующей транзакции. Другими словами, если два изменения сделаны в хранилище данных платформы хранения в одной транзакции, то не имеется никакой гарантии, что эти изменения применяются во всех других точных копиях поэлементно - одна может обнаруживаться без другой. Исключение из этого принципа заключается в том, что если два изменения сделаны в одной и той же Порции данных в одной и той же транзакции, то гарантируется, что эти изменения будут посланы и применены к другим точным копиям поэлементно. Таким образом, Порции данных являются непротиворечивыми единицами службы синхронизации.
а) Приложения управления синхронизацией (Sync)
Любая прикладная программа (приложение) может соединяться со службой синхронизации и инициализировать операцию sync (синхронизации). Такая прикладная программа обеспечивает все параметры, необходимые для выполнения синхронизации (см. профиль sync ниже). Такие прикладные программы упомянуты здесь как Приложения управления синхронизацией (Sync) (SCA, ПУС).
При синхронизации двух экземпляров платформы хранения синхронизация инициализируется на одной стороне посредством SCA. Это SCA информирует локальную службу синхронизации для синхронизации с удаленным партнером. С другой стороны, Служба синхронизации вызывается сообщениями, посланными службой синхронизации от исходной (инициирующей) машины. Она отвечает на основании персистентной информации конфигурации (см. “отображения” ниже), присутствующей на машине адресата. Служба синхронизации может быть запущена на основе расписания или в ответ на события. В этих случаях Служба синхронизации, реализующая расписание, становится SCA.
Чтобы разрешить синхронизацию, должны быть предприняты два этапа. Сначала проектировщик схемы должен аннотировать схему платформы хранения с соответствующей семантикой sync (синхронизации) (обозначающей блоки изменений, как описано ниже). Во-вторых, синхронизация должна быть должным образом сконфигурирована на всех машинах, имеющих экземпляр платформы хранения, которая должна участвовать в синхронизации (как описано ниже).
b) Аннотация Схемы
Фундаментальной концепцией службы синхронизации является концепция Блока Изменений (Change Unit). Блок изменений - самая малая часть схемы, которая индивидуально отслеживается платформой хранения. Для каждого Блока изменений Служба синхронизации может быть способна определить, изменен ли он или не изменен с момента последней синхронизации (sync).
Обозначение Блоков изменений в схеме служит нескольким целям. Во-первых, оно определяет, как часто Служба синхронизации вызывается. Когда изменение сделано внутри Блока изменений, полный Блок изменений посылают другим точным копиям, так как Служба синхронизации не знает, какая часть Блока изменений была изменена. Во-вторых, оно определяет степень детализации обнаружения конфликтов. Когда два параллельных изменения (эти термины подробно определены в последующих разделах) сделаны в отношении одного и того же Блока изменений, Служба синхронизации устанавливает факт конфликта; с другой стороны, если параллельные изменения сделаны в различных Блоках Изменений, то никакой конфликт не устанавливается и изменения автоматически объединяют. В-третьих, это сильно влияет на объем метаданных, хранимых системой. Многие из метаданных службы синхронизации сохраняются для каждого Блока изменений; таким образом, обеспечение Блоков Изменений меньшими по размеру увеличивает накладные расходы на синхронизацию.
Определение Блоков изменений требует обнаружения компромиссов прав. По этой причине Служба синхронизации позволяет проектировщикам схемы участвовать в процессе.
В одном варианте осуществления Служба синхронизации не поддерживает Блоки изменений, которые являются большими, чем элемент. Однако она поддерживает возможность для проектировщиков схемы определять меньшие Блоки изменений, чем элемент - а именно, группируя множественные атрибуты элемента в отдельный Блок изменений. В этом варианте осуществления это выполняется, используя следующий синтаксис:

с) Конфигурация синхронизации
Группа партнеров платформы хранения, которые желают сохранить некоторые части своих данных синхронными, называется sync-сообществом. В то время как члены сообщества желают остаться синхронными, они не обязательно представляют данные в точности одинаковым образом; другими словами, sync-партнеры (партнеры по синхронизации) могут преобразовать данные, которые они синхронизируют.
В одноранговом сценарии для равноправных сторон непрактично поддерживать отображения преобразования для всех их партнеров. Вместо этого служба синхронизации принимает подход определения "Папки Сообщества". Папка сообщества является абстракцией, которая представляет гипотетическую "совместно используемую папку", с которой все члены сообщества являются синхронизированными.
Это понятие лучше иллюстрируется примером. Если Джо хочет сохранить папки “Мои Документы” на его нескольких компьютерах синхронизированными, Джо определяет папку сообщества, называемую, скажем, JoesDocuments. Тогда на каждом компьютере Джо конфигурирует отображение между гипотетической папкой JoesDocuments и локальной папкой “Мои Документы”. С этого момента, когда компьютеры Джо синхронизируются друг с другом, они обмениваются в терминах документов в JoesDocuments, вместо своих локальных Порций данных. Таким образом, все компьютеры Джо понимают друг друга без необходимости знания, кто эти другие есть - Папка Сообщества становится лингва-франка для sync-сообщества.
Конфигурирование службы синхронизации состоит из трех этапов: (1) отображения определения между локальными папками и папками сообщества; (2) определение sync-профилей (профилей синхронизации), которые определяют то, что синхронизируется (например, с кем осуществлена синхронизация, каким подмножествам необходимо посылать (информацию) и какие должны принимать); и (3) определение расписаний, на основании которых различные sync-профили должны выполняться или выполнять их вручную.
(1) Папка Сообщества - Отображения
Отображения Папки Сообщества сохранены как XML файлы конфигурации на отдельных машинах. Каждое отображение имеет следующую схему:
/mappings/community Folder
Этот элемент называет папку сообщества, для которой это отображение предназначено. За именем следуют правила синтаксиса Папок.
/mappings/local Folder
Этот элемент называет локальную папку, в которую отображение осуществляет преобразование. За именем следуют правила синтаксиса Папок. Папка должна уже существовать для отображения, чтобы быть допустимой. Порции данных в этой папке рассматриваются для синхронизации для этого отображения.
/mappings/transformations
Этот элемент определяет, как преобразовать Порции данных из папки сообщества в локальную папку и обратно. Если отсутствует или пусто, никакие преобразования не выполняются. В частности, это означает, что никакие идентификаторы не отображаются. Эта конфигурация прежде всего полезна для создания кэша Папки.
/mappings/transformations/mapIDs
Этот элемент требует, чтобы заново сгенерированные локальные идентификаторы были назначены всем Порциям данных, отображенных из папки сообщества, вместо повторного использования идентификаторов сообщества. Выполнение синхронизации (Sync Runtime) поддерживает отображения идентификатора, чтобы преобразовывать порции данных назад и вперед.
/mappings/transformations/local Root
Этот элемент требует, чтобы все корневые порции данных в папке сообщества были сделаны дочерними указанного корня.
/mappings/runAs
Этот элемент управляет тем, под чьими полномочиями обрабатываются запросы этого отображения. Если отсутствует, принимается отправитель.
/mappings/runAs/sender
Присутствие этого элемента указывает, что отправитель сообщений для этого отображения должен играть чужую роль и запросы должны быть обработаны под его мандатом (полномочиями).
(2) Профили
Профиль синхронизации (Sync-Profile) является полным набором параметров, необходимых, чтобы начать синхронизацию. Он подается посредством SCA к Sync Runtime (выполнению синхронизации), чтобы инициализировать синхронизацию. Профиль синхронизации для синхронизации “платформы хранения - платформа хранения” содержит следующую информацию:
* Локальная Папка служит как источник и адресат для изменений;
* Имя Удаленной Папки для синхронизации с ней - эта Папка должна быть опубликована от удаленного партнера посредством отображения, как определено выше;
* Направление - служба синхронизации поддерживает только синхронизацию “только послать”, “только получить” и “послать -получить”;
* Локальный Фильтр - выбирает какую локальную информацию послать удаленному партнеру. Выражен как запрос платформы хранения для локальной папки;
* Удаленный Фильтр - выбирает, какую удаленную информацию извлечь из удаленного партнера - выражен как запрос платформы хранения для папки сообщества;
* Преобразования - определяют, как преобразовать элементы в и из локального формата;
* Локальная защита - определяет, должны ли быть изменения, извлеченные из удаленной оконечной точки, применены согласно разрешениям удаленной оконечной точки (исполняющей роль) или пользователя, инициирующего синхронизацию локально; и
* Политика разрешения конфликтов - определяет, должны ли конфликты быть отклонены, зарегистрированы или автоматически разрешены - в последнем случае она определяет, какой использовать блок разрешения конфликтов, а также параметры конфигурации для него.
Служба синхронизации обеспечивает CLR-класс выполнения, который позволяет простое формирование Профиля синхронизации. Профили могут быть также последовательно направлены к и от XML-файлов для простого хранения (часто рядом с расписаниями). Однако не имеется никакого стандартного места в платформе хранения, где сохранены все профили; SCA приглашается для конструирования профиля на месте без когда-либо продолжения его существования. Следует заметить, что не имеется никакой потребности иметь локальное отображение, чтобы инициализировать синхронизацию. Вся информация о синхронизации может быть определена в профиле. От отображения, однако, требуется, чтобы оно отвечало на запросы синхронизации, инициализированные удаленной стороной.
(3) Расписания
В одном варианте осуществления служба синхронизации не обеспечивает свою собственную инфраструктуру планирования. Вместо этого она полагается на другой компонент для выполнения этой задачи - Планировщик Windows (Windows Sheduler), доступный с операционной системой Microsoft Windows. Служба синхронизации включает в себя утилиту командной строки, которая действует как SCA и инициирует синхронизацию, основанную на профиле синхронизации, сохраненной в XML файле. Эта утилита делает очень простым конфигурирование планировщика Windows для запуска синхронизации или по расписанию, или в ответ на события, такие как вход пользователя в систему или выход из системы.
d) Обработка конфликтов
Обработка Конфликтов в службе синхронизации разделена на три стадии: (1) обнаружение конфликта, которое имеет место во время изменения прикладной программы - этот этап определяет, может ли изменение быть безопасно применено; (2) автоматическое разрешение конфликта и регистрация - в течение этого этапа (который имеет место немедленно после того, как конфликт обнаружен) блок автоматического разрешения конфликтов опрашивается, чтобы видеть, может ли конфликт быть разрешен, если нет, конфликт может быть необязательно зарегистрирован; и (3) проверка конфликта и разрешение - этот этап имеет место, если некоторые конфликты были зарегистрированы, и происходит вне контекста сеанса синхронизации - в это время зарегистрированные конфликты могут быть разрешены и удалены из файла регистрации.
(1) Обнаружение конфликтов
В существующем варианте осуществления Служба синхронизации обнаруживает два типа конфликтов: на основе знания и на основе ограничения.
(a) Конфликты на основе знания
Конфликт на основе знания происходит, когда две точные копии делают независимые изменения в одном и том же Блоке Изменений. Два изменения называются независимыми, если они сделаны без знания друг о друге - другими словами, версия первая не охвачена знанием о второй и наоборот. Служба синхронизации автоматически обнаруживает все такие конфликты, основанные на знании точных копий, как описано выше.
Иногда полезно думать о конфликтах как ветвлениях в хронологии (истории) версий Блока изменений. Если никакие конфликты не происходят в жизни Блока изменений, его история версий является простой цепочкой - каждое изменение встречается после предыдущей. В случае конфликта на основе знания два изменения происходят параллельно, вызывая разрыв цепочки и создание дерева версий.
(b) Конфликты, основанные на отграничении
Имеются случаи, когда независимые изменения нарушают ограничение целостности, когда они применяются вместе. Например, две точные копии, создающие файл с одним и тем же именем в одном и том же каталоге, могут вызвать такой конфликт.
Конфликт, основанный на ограничении, включает два независимых изменения (точно так же, как на основе знания), но они не затрагивают один и тот же Блок изменений. Вместо этого, они затрагивают различные Блоки изменений, но с ограничением, существующим между ними.
Служба синхронизации обнаруживает нарушения ограничения во время изменения прикладной программы и устанавливает факт конфликтов, основанных на ограничении, автоматически. Разрешение конфликтов, основанных на ограничении, обычно требует специального кода, который модифицирует изменения так, чтобы не нарушать ограничение; служба синхронизации не обеспечивает механизм общего назначения для такого выполнения.
(2) Обработка конфликтов
Когда конфликт обнаружен, служба синхронизации может предпринимать одно из трех действий (выбираемое инициатором синхронизации в Профиле синхронизации): (1) отклонить изменение, возвращая его обратно отправителю; (2) регистрировать конфликт в файле регистрации конфликтов; или (3) разрешить конфликт автоматически.
Если изменение отклонено, служба синхронизации действует так, как будто изменение не достигло точной копии. Отрицательное подтверждение посылают назад источнику. Эта политика разрешения прежде всего полезна на автономных (лишенных руководства) точных копиях (таких как файл-серверы), где регистрация конфликтов невыполнима. Вместо этого, такие точные копии вынуждают другие иметь дело с конфликтами, отклоняя их.
Инициаторы синхронизации конфигурируют разрешение конфликтов в своих Профилях синхронизации. Служба синхронизации поддерживает объединение множества блоков разрешения конфликтов в одном профиле следующими способами - первый, определяя список блоков разрешения конфликтов, которые один за другим должны пытаться (разрешить конфликт), до первого из них, который успешно разрешит; и второй, связывая блоки разрешения конфликтов с типами конфликтов, например направляя конфликты обновление-обновление на основе знания к одному блоку разрешения конфликтов, а все другие конфликты - на регистрацию.
(а) Автоматическое разрешение конфликтов
Служба синхронизации обеспечивает ряд заданных по умолчанию блоков разрешения конфликтов. Этот список включает в себя:
* Локальный выиграл: игнорировать поступающие изменения, если они находятся в конфликте с локально сохраненными данными;
* Удаленный выиграл: игнорировать локальные данные, если они находятся в конфликте с поступающими изменениями;
* Последний записывающий выиграл: выбрать или “Локальный выиграл”, или “Удаленный выиграл” для Блока изменений, на основании отметки времени изменения (следует заметить, что Служба синхронизации обычно не полагается на значения часов;
этот блок разрешения конфликтов - единственное исключение из этого правила);
* Детерминированный: выбор победителя способом, который, как гарантируется, будет одним и тем же на всех точных копиях, но не иначе имеющим значение - один вариант осуществления услуг синхронизации использует лексикографические сравнения идентификаторов партнеров, чтобы осуществить эту особенность.
Кроме того, ISV могут реализовывать и устанавливать свои собственные блоки разрешения конфликтов. Настраиваемые блоки разрешения конфликтов могут принимать параметры конфигурации;
такие параметры должны быть определены посредством SCA в разделе Разрешения конфликтов в Профиле синхронизации.
Когда блок разрешения конфликтов обрабатывает конфликт, он возвращает список операций, которые должны быть выполнены (вместо конфликтующего изменения) назад на выполнение. Служба синхронизации затем применяет эти операции, должным образом скорректировав удаленное знание, чтобы включить в себя то, что рассмотрел обработчик конфликта.
Возможно, что другой конфликт обнаружен во время выполнения разрешения. В этом случае новый конфликт должен быть разрешен перед тем, как оригинальная обработка продолжится.
При рассмотрении конфликтов в качестве ветвей в истории версий Порции данных разрешения конфликтов могут быть просмотрены как объединения - объединяя две ветви, чтобы сформировать одиночный пункт. Таким образом, разрешения конфликта возвращают истории версий в DAG.
(b) Регистрация конфликтов
Очень специфический вид блока разрешения конфликтов Регистратор Конфликтов. Служба синхронизации регистрирует конфликты в качестве Порции данных типа ConflictRecord. Эти записи обратно связаны с Порциями данных, которые находятся в конфликте (если только сами Порции данных не были удалены). Каждая запись о конфликте содержит: входящее изменение, которое вызвало конфликт; тип конфликта: обновление-обновление, обновление-удаление, удаление-обновление, вставка-вставка или ограничение; и версия входящего изменения и знание о точной копии, посылающей его. Зарегистрированные конфликты доступны для проверки и разрешения, как описано ниже.
(c) Проверка конфликтов и разрешение
Служба синхронизации обеспечивает API для прикладных программ, чтобы исследовать файл регистрации конфликтов и предложить разрешения конфликтов в нем. API позволяет прикладной программе перенумеровать (перечислить) все конфликты, или конфликты, относящиеся к заданной Порции данных. Он также позволяет таким прикладным программам разрешать зарегистрированные конфликты одним из трех способов: (1) удаленный выиграл - принятие зарегистрированного изменения и перезапись конфликтующего локального изменения; (2) локальный выиграл - игнорирование конфликтующих частей зарегистрированного изменения; и (3) предложение нового изменения - когда прикладная программа предлагает слияние, которое, по ее мнению, разрешает конфликт. Как только конфликты разрешены прикладной программой, служба синхронизации удаляет их из файла регистрации.
(d) Сходимость точных копий и распространения разрешения конфликтов
В сложных сценариях синхронизации один и тот же конфликт может быть обнаружен в множестве точных копий. Если это происходит, несколько случаев могут иметь место: (1) конфликт может быть разрешен на одной точной копии, и разрешения посланы другим; (2) конфликт разрешен на обеих точных копиях автоматически; или (3) конфликт разрешен на обеих точных копиях вручную (посредством API проверки конфликтов).
Чтобы гарантировать сходимость, служба синхронизации передает разрешения конфликтов другим точным копиям. Когда изменение, которое разрешает конфликт, достигает точной копии, служба синхронизации автоматически находит любые записи о конфликте в файле регистрации, которые разрешены этим обновлением, и устраняет их. В этом смысле разрешение конфликтов в одной точной копии является связывающим для всех других точных копий.
Если различные победители выбраны различными точными копиями для одного и того же конфликта, служба синхронизации применяет принцип связывающего разрешения конфликтов и выбирает одно из этих двух разрешений, чтобы автоматически разрешить другие. Победитель выбирают детерминированным способом, который, как гарантируется, обеспечивает всегда одни и те же результаты (один вариант осуществления использует лексикографические сравнения идентификатора точной копии).
Если различные "новые изменения" предложены различными точными копиями для одного и того же конфликта, служба синхронизации обрабатывает этот новый конфликт как специальный конфликт и использует Регистратор конфликта, чтобы предотвратить его от размножения на другие точные копии. Такая ситуация обычно возникает с ручным разрешением конфликта.
2. Синхронизация с хранилищем данных не-платформы хранения
Согласно другому аспекту платформы хранения согласно настоящему изобретению платформа хранения обеспечивает архитектуру для ISV (НПП), чтобы реализовать Sync Adapters (Адаптеры синхронизации), которые позволяют платформе хранения синхронизироваться с системами наследования, такими как Microsoft Exchange, AD, Hotmail и т.д. Адаптеры синхронизации приносят пользу от многих Услуг синхронизации, обеспеченных службой синхронизации, как описано ниже.
Несмотря на имя, Адаптеры синхронизации не должны быть реализованы как съемные модули (plug-in) в некоторую архитектуру платформы хранения. Если желательно, "адаптером синхронизации" может быть просто любая прикладная программа, которая использует интерфейсы выполнения службы синхронизации, чтобы получить услуги, такие как перечисления изменений и прикладная программа.
Чтобы сделать для других более простое конфигурирование и выполнение синхронизации с заданной серверной частью, авторы Адаптера синхронизации предоставили стандартный интерфейс Адаптера синхронизации, который выполняет синхронизацию, заданную Профилем синхронизации, как описано выше. Профиль выдает информацию конфигурации на адаптер, часть которой адаптеры передают к Sync Runtime (Выполнению синхронизации), чтобы управлять услугами выполнения (например, Папка для синхронизации).
а) Услуги синхронизации
Служба синхронизации обеспечивает ряд услуг синхронизации редактору адаптера. Для остальной части этого раздела удобно обратиться к машине, на которой Платформа хранения выполняет синхронизацию в качестве "клиента", и серверной части неплатформы хранения, с которой адаптер обменивается в качестве "сервера".
(1) Перечисление изменений
Основанное на отслеживании изменений данных, поддерживаемых службой синхронизации, Перечисление (перенумерация) изменений позволяет адаптерам синхронизации легко перечислять изменения, которые произошли, в Папку хранения данных, с тех пор как была предпринята последняя синхронизация с этим партнером.
Изменения перечисляют на основании концепции "анкера" непрозрачной структуры, которая представляет информацию относительно последней синхронизации. Анкер принимает форму платформы хранения "Знание", как описано в последующих разделах. Адаптеры синхронизации, использующие услуги перечисления изменений, попадают в две широких категории: те, что используют "сохраненный анкер", и те, что используют "подаваемый анкер".
Различие основано на том, где сохранена информация относительно последней синхронизации - на клиенте или на сервере. Часто для адаптеров проще сохранить эту информацию на клиенте - серверная часть часто не способна удобно сохранять эту информацию. С другой стороны, если множество клиентов синхронизируется с одной и той же серверной частью, сохранение этой информации на клиенте неэффективно и в некоторых случаях неправильно - это делает одного клиента не осведомленным об изменениях, которые другой клиент уже выдал на сервер. Если адаптер хочет использовать сохраненный сервером анкер, адаптер должен выдать его назад платформе хранения во время перечисления изменений.
Чтобы платформа хранения могла поддержать анкер (или для локального или удаленного хранения), Платформа хранения должна быть оповещена об изменениях, которые успешно применены на сервере. Эти и только эти изменения могут быть включены в анкер. В течение перечисления изменений Адаптеры синхронизации используют интерфейс Подтверждения, чтобы сообщить, какие изменения были успешно применены. В конце синхронизации адаптеры, использующие поданные анкеры, должны считывать новый анкер (который включает все успешно примененные изменения) и посылать его на свою серверную часть.
Часто Адаптеры должны сохранить специфические для адаптера данные наряду с Порциями данных, которые они вставляют в хранилище данных платформы хранения. Обычным примером таких данных являются удаленные идентификаторы и удаленные версии (отметки времени, timestamps). Служба синхронизации обеспечивает механизм для сохранения этих данных, и Перечисление изменений обеспечивает механизм приема этих дополнительных данных наряду с возвращаемыми изменениями. Это устраняет необходимость для адаптеров заново запрашивать базы данных в большинстве случаев.
(2) Применение изменения
Применение изменений позволяет Адаптерам синхронизации применять изменения, полученные от их серверной части, к локальной платформе хранения. Адаптеры, как ожидается, преобразуют изменения к схеме платформы хранения. Фиг.24 иллюстрирует процесс, посредством которого классы API платформы хранения сгенерированы из Схемы платформы хранения.
Первичная функция применения изменений - автоматически обнаружить конфликты. Как в случае синхронизации "Платформа хранения - платформа хранения", конфликт определяется как два накладывающихся изменения, сделанные без знания друг о друге. Когда адаптеры используют Применение Изменений, они должны задать анкер, относительно которого выполняется обнаружение конфликтов. Применение Изменений устанавливает факт конфликта, если обнаружено накладывающееся локальное изменение, которое не охвачено знанием адаптера. Подобно Перечислению Изменений, адаптеры могут использовать или сохраненный, или подаваемый анкер. Применение Изменений поддерживает эффективное хранение метаданных, специфических для адаптера. Такие данные могут быть присоединены адаптером к применяемым изменениям и могут быть сохранены службой синхронизации. Данные могут быть возвращены при следующем перечислении изменения.
(3) Разрешение конфликтов
Механизмы Разрешения Конфликтов, описанные выше (регистрация и опции автоматического разрешения) также доступны адаптерам синхронизации. Адаптеры синхронизации могут определить политику для разрешения конфликтов при применении изменений. Если задано, конфликты могут быть переданы на заданный обработчик конфликтов и разрешены (если возможно). Конфликты могут также быть зарегистрированы. Возможно, что адаптер может обнаруживать конфликт при попытке применить локальное изменение к серверной части. В таком случае адаптер может все еще передавать конфликт к Выполнению синхронизации (Sync Runtime) для разрешения согласно политике. Кроме того, Адаптеры синхронизации могут требовать, чтобы любые конфликты, обнаруженные службой синхронизации, были посланы назад к ним для обработки. Это особенно удобно в случае, когда серверная часть способна к сохранению или разрешению конфликтов.
b) Реализация адаптера
В то время как некоторые "адаптеры" являются просто прикладными программами, использующими интерфейсы выполнения, адаптеры призваны реализовать стандартные интерфейсы адаптера. Эти интерфейсы позволяют Прикладным программам Управления синхронизацией требовать, чтобы адаптер выполнил синхронизацию согласно данному Профилю синхронизации; отменил продолжающуюся синхронизацию и принял сообщение о выполнении (процент завершения) относительно продолжающейся синхронизации.
3. Защита
Служба синхронизации стремится вводить как можно меньше в модель защиты, реализованную платформой хранения. Вместо определения новых прав для синхронизации используются существующие права. В частности,
* Любой, кто может считывать Порцию данных сохранения данных, может перечислять изменения для этой Порции данных;
* Любой, кто может записывать в Порцию данных сохранения данных, может применять изменения к этой Порции данных; и
* Любой, кто может расширять Порцию данных сохранения данных, может ассоциировать метаданные синхронизации с этой Порцией данных.
Служба синхронизации не поддерживает информацию авторства защиты. Когда изменение сделано в точной копии А пользователем U и направлено к точной копии В, факт, что изменение было первоначально сделано в А (или U) теряется. Если В направило это изменение к точной копии С, это делается под полномочиями В, но не А. Это ведет к следующему ограничению: если точной копии не доверяют, чтобы сделать свои собственные изменения в Порции данных, нельзя направлять изменения, сделанные другими.
Когда Служба синхронизации инициируется, это делается Прикладной программой Управления синхронизацией. Служба синхронизации исполняет роль идентичности SCA и выполняет все операции (и локально, и удаленно) под этой информацией идентичности. Для иллюстрации заметим, что пользователь U не может вынудить локальную службу синхронизации извлекать изменения из удаленной платформы хранения для Порций данных, для которых пользователь U не имеет прав доступа для считывания.
4. Контролируемость
Контроль распределенного сообщества точных копий является сложной проблемой. Служба синхронизации может использовать алгоритм "зачистки" для сбора и распределения информации относительно состояния точных копий. Свойства алгоритма зачистки гарантируют, что информация относительно всех конфигурированных точных копий в конечном счете собрана и что обнаружены сбойные (не отзывающиеся) точные копии.
Эта информация контроля по сообществу сделана доступной в каждой точной копии. Инструментальные средства контроля могут быть выполнены в произвольно выбранной точной копии, чтобы исследовать эту информацию контроля и принять административные решения. Любые изменения конфигурации должны быть сделаны непосредственно в подвергающихся воздействию точных копиях.
В. КРАТКИЙ ОБЗОР API СИНХРОНИЗАЦИИ
Во все более и более распределенном цифровом мире индивидуалы и рабочие группы часто сохраняют информацию и данные в ряде различных устройств и местоположений. Это способствовало развитию услуг синхронизации данных, которые могут сохранять информацию в эти отдельные, часто несоизмеримые, хранилища данных, синхронизированные всегда, с минимальным вмешательством пользователя.
Платформа синхронизации согласно настоящему изобретению, которая является частью богатой платформы хранения, описанной в Разделе II (иначе называемой "WinFS"), преследует три главные цели:
* Позволить прикладным программам и услугам эффективно синхронизировать данные между различными хранилищами "WinFS".
* Дать возможность разработчикам строить богатые решения для синхронизации данных между "WinFS" и He-"WinFS" хранилищами.
* Обеспечить разработчиков соответствующими интерфейсами, чтобы настроить опыт пользователя синхронизации.
1. Общая Терминология
Ниже приведены некоторые дополнительные усовершенствованные определения и ключевые концепции, относящиеся к последующему описанию в Разделе III.В: Sync Replica (Точная копия синхронизации): Большинство прикладных программ заинтересовано только в отслеживании, перечислении и изменении синхронизации с заданным поднабором Порций данных в хранилище WinFS. Набор Порций данных, который принимает участие в операции синхронизации, назван как Точная копия синхронизации. Точная копия определена в терминах Порций данных, содержащихся в заданной иерархии включений WinFS (обычно корневой в Порции данных Папки). Все услуги синхронизации выполняются в пределах контекста заданной точной копии. Синхронизация WinFS обеспечивает механизм для определения, управления и очистки точных копий. Каждая точная копия имеет идентификатор GUID, который уникально идентифицирует ее в пределах данного хранилища WinFS.
Sync Partner (Партнер синхронизации): партнер синхронизации определен как объект, способный к воздействию на изменения относительно Порций данных, расширениях и отношениях WinFS. Таким образом, каждое хранилище WinFS может быть названо как партнер синхронизации. При синхронизации с не-WinFS хранилищем внешний источник данных (ВИД, EDS) также назван как партнер синхронизации. Каждый партнер имеет GUID-идентификатор, который уникально идентифицирует его.
Sync Community (Сообщество синхронизации): сообщество синхронизации определено как коллекция точных копий, которые сохраняются синхронизированными посредством одноранговых операций синхронизации. Эти точные копии могут все находиться в одном и том же хранилище WinFS, различных хранилищах WinFS или даже проявлять себя как виртуальные точные копии на не-WinFS хранилищах. WinFS синхронизация не предписывает или не уполномочивает никакой специальной топологии для сообщества, особенно, если только операции синхронизации выполняются в сообществе через службу WinFS Sync (WinFS адаптер). Адаптеры Синхронизации (определены ниже) могут представлять свои собственные ограничения топологии.
Change Traking, Change Units и Versions (Отслеживание Изменений, Блоки изменений и Версии): Каждое хранилище WinFS отслеживает изменения для всех локальных Порций данных, Расширений и Отношений WinFS. Изменения отслеживают на уровне степени детализации блока изменений, определенной в схеме. Поля верхнего уровня любого из типов Порции данных, Расширения и Отношения могут быть подразделены проектировщиком схемы на блоки изменений с самой маленькой степенью детализации, являющейся одним полем верхнего уровня. Для целей отслеживания изменений каждому блоку изменений назначена Версия, где версия является парой - идентификатор партнера синхронизации и номер версии (номер версии - определенный партнером монотонно увеличивающийся номер). Версии обновляются, когда в хранилище случаются изменения локально или когда они получены от других точных копий.
Sync Knowledge (Знание синхронизации): Знание представляет состояние заданной точной копии синхронизации в любой момент, то есть оно инкапсулирует метаданные относительно всех изменений, о которых осведомлена данная точная копия, или локальных или от других точных копий. WinFS синхронизация поддерживает и обновляет знание для точных копий синхронизации для операций синхронизации. Важно отметить, что представление Знания позволяет его интерпретировать относительно всего сообщества, а не только относительно конкретной точной копии, где знание сохранено.
SyncAdapters (Адаптеры синхронизации): адаптер синхронизации - управляемая прикладная программа кода, которая обращается к услуге WinFS Sync через API Sync Runtime и разрешает синхронизацию WinFS данных с не-WinFS хранилищем данных. В зависимости от требований сценария, это дело разработчика адаптера относительно какого поднабора WinFS данных и какие типы WinFS данных синхронизировать. Адаптер ответствен за связь с EDS, преобразовывая WinFS схемы к и из схем, поддерживающих EDS, и определяя и управляя его собственной конфигурацией и метаданными. Адаптеры настоятельно призываются реализовывать WinFS Sync Adapter API, чтобы воспользоваться преимуществом общей конфигурации и инфраструктуры управления для адаптеров, обеспеченных группой WinFS Sync. Для более полной информации см. спецификацию WinFS Sync Adapter API [SADP] и спецификацию WinFS Sync Controller API [SCTRL].
Для адаптеров, которые синхронизируют WinFS-данные с внешним не-WinFS хранилищем и не могут производить или поддерживать знание в формате WinFS, WinFS Sync обеспечивает услуги для получения удаленного знания, которое может использоваться для последующих операций перечисления изменений или применения. В зависимости от возможностей хранилища серверной части адаптер может желать сохранить это удаленное знание на серверной части или на локальном хранилище WinFS.
Для простоты, "точная копия" синхронизации - это структура, которая представляет набор данных в хранилище "WinFS", которая существует в одиночном логическом местоположении, в то время как данные относительно не-"WinFS" хранилища называются "источник данных" и обычно требуют использования адаптера.
Remote Knowledge (Удаленное Знание): Когда заданная точная копия синхронизации желает получить изменения от другой точной копии, она обеспечивает свое собственное знание как базовую линию, относительно которой другая точная копия перечисляет изменения. Точно так же, когда данная точная копия желает послать изменения к другой точной копии, она обеспечивает свое собственное знание как базовую линию, которая может использоваться удаленной точной копией для обнаружения конфликтов. Это знание относительно другой точной копии, которая предоставлена в течение перечисления изменений синхронизации и прикладной программы, названо Удаленным Знанием.
2. Принципы API Синхронизации
Для некоторых вариантов осуществления API синхронизации делится на две части: API конфигурации синхронизации и API контроллера синхронизации. API конфигурации синхронизации дает возможность прикладным программам конфигурировать синхронизацию и задавать параметры для конкретного сеанса синхронизации между двумя точными копиями. Для заданного сеанса синхронизации параметры конфигурации включают в себя набор Порций данных, подлежащих синхронизации, тип синхронизации (односторонний или двухсторонний), информацию относительно удаленного источника данных и политику разрешения конфликтов. API контроллера синхронизации инициализирует сеанс синхронизации, отменяет синхронизацию и получает информацию о ходе и ошибках продолжающейся синхронизации. Кроме того, для конкретных вариантов осуществления, где синхронизация должна быть выполнена по заранее определенному расписанию, такие системы могут включать в себя механизм планирования, чтобы настроить планирование.
Несколько вариантов осуществления настоящего изобретения используют адаптеры синхронизации для синхронизации информации между "WinFS" и He-"WinFS" источниками данных. Примеры адаптеров включают в себя адаптер, который синхронизирует информацию записной книжки (Address book) между папкой контактов "WinFS" и “почтовым ящиком” не-WinFS. В этих случаях разработчики адаптера могут использовать API основной службы синхронизации "WinFS", описанный здесь для доступа к услугам, предоставленным платформой синхронизации "WinFS", чтобы разработать код преобразования схемы между "WinFS"-cxeмoй и нe-"WinFS"-cxeмoй источника данных. Дополнительно, разработчик адаптера обеспечивает поддержку протокола для обмена изменениями с не-"WinFS" источником данных. Адаптер синхронизации вызывается и управляется, используя API контроллера синхронизации, и сообщает о ходе выполнения и ошибках, используя этот API.
Однако для некоторых вариантов осуществления настоящего изобретения при синхронизации "WinFS" хранилища данных с другим "WinFS" хранилищем данных адаптер синхронизации может быть не нужен, если услуги синхронизации "WinFS"-"WinFS" интегрированы в аппаратной/программной интерфейсной системе. В любом случае несколько таких вариантов осуществления обеспечивают набор услуг синхронизации и для "WinFS"-"WinFS", и для решений адаптера синхронизации, которые включают в себя:
- Отслеживание изменений для Порций данных, Расширений и отношений "WinFS".
- Поддержка для эффективного возрастающего перечисления изменений, начиная с заданного прошлого состояния.
- Применение внешних изменений к "WinFS".
- Обработка конфликтов в течение применения изменений.
На Фиг.36 иллюстрируются три экземпляра обычного хранилища данных и компоненты для их синхронизации. Первая система 3602 имеет WinFS хранилище 3612 данных, содержащее услуги 3622 синхронизации WinFS-K-WinFS Sync и основные услуги 3624 синхронизации (Core Sync) для синхронизации WinFS-K-He-WinFS, которое предоставляет 3646 Sync API 3652 для использования. Аналогично первой системе 3602, вторая система 3604 имеет WinFS хранилище 3614 данных, содержащее услуги 3632 синхронизации WinFS-K-WinFS Sync и основные услуги 3634 синхронизации (Core Sync), для синхронизации WinFS-K-He-WinFS, которая предоставляет 3646 Sync API 3652 для использования. Первая система 3602 и вторая система 3604 синхронизируются 3642 через их соответствующие услуги 3622 и 3632 WinFS-K-WinFS Sync. Третья система 3606, которая не является WinFS системой, имеет прикладную программу для использования WinFS Sync 3666, чтобы поддерживать источник данных в сообществе синхронизации с точными копиями WinFS. Эта прикладная программа может использовать или услугу 3664 WinFS Sync Config/Control (конфигурации синхронизации/управления), чтобы непосредственно взаимодействовать 3644 с WinFS-хранилищем данных 3612 через услуги 3622 синхронизации WinFS-WinFS (если она сама так способна виртуализироваться как WinFS хранилище данных) или через Sync Адаптер 3662, который взаимодействует 3648 с Sync API 3652.
Как иллюстрировано на этом чертеже, первая система 3602 знает и непосредственно синхронизируется и со второй системой 3604 и третьей системой 3606. Однако ни вторая система 3604, ни третья система 3606 не знают друг друга и, таким образом, не синхронизируют свои изменения непосредственно друг с другом, но вместо этого изменения, которые происходят на одной системе, должны распространяться через первую систему 3602.
С. УСЛУГИ API СИНХРОНИЗАЦИИ
Несколько вариантов осуществления настоящего изобретения посвящены услугам синхронизации, содержащим две основополагающие услуги: Перечисление изменений и применение изменений.
1. Перечисление изменений
Как описано выше, Перечисление изменений позволяет адаптерам синхронизации легко перечислять изменения, которые произошли с Папкой хранилища данных с того момента, как синхронизация с этим партнером была предпринята последний раз, на основании отслеживания изменений данных, поддерживаемых службой синхронизации. В отношении перечисления изменений, несколько вариантов осуществления настоящего изобретения посвящены этому:
* Эффективное перечисление изменений в Порциях данных, Расширениях и Отношениях в данной точной копии относительно специфического экземпляра Знания.
* Перечисление изменений на уровне степени детализации блока изменений, указанной в WinFS схемах.
* Группировка перечисленных изменений в терминах составных Порций данных. Составная порция данных состоит из порции данных, всех ее расширений, всех отношений хранения для Порции данных и всех составных порций данных, соответствующих ее внедренным порциям данных. Изменения в ссылочных отношениях между порциями данных перечисляются отдельно.
* Пакетирование перечисления изменений. Степень детализации пакета является составной порцией данных или изменением отношений (для ссылочных отношений).
* Спецификация фильтров по порциям данных в точной копии во время перечисления изменений, например, точная копия состоит из всех Порций данных в данной папке, но для этого конкретного перечисления изменений прикладная программа хотела бы только перечислить изменения во всех Порциях данных Контактов, где имя начинается с '@' (эта поддержка будет добавлена после В-промежуточного этапа разработки).
* Использование удаленного знания для перечислимых изменений с возможностью записывать индивидуальные блоки изменений (или целиком порции данных, Расширения или отношения) как неспособные к синхронизации в знании, чтобы иметь их перечисленными в следующий раз.
* Использование расширенных адаптеров, которые могут быть способны к пониманию метаданных WinFS Sync посредством возвращения метаданных наряду с изменениями во время перечисления изменений.
2. Применение изменений
Как описано выше, применение изменений позволяет Адаптерам синхронизации применять изменения, полученные от их серверной части, к локальной платформе хранения, так как адаптеры, как ожидается, преобразуют изменения в схему платформы хранения. В отношении применения изменений несколько вариантов осуществления настоящего изобретения посвящены следующему:
* Применение инкрементальных (связанных с приращением) изменений от других точных копий (или не-WinFS хранилищ) с соответствующими обновлениями для метаданных изменений WinFS.
* Обнаружение конфликтов при применении изменений со степенью детализации блока изменений.
* Сообщение об успешном выполнении, неудачном выполнении и конфликтах на уровне отдельного модуля изменений при применении изменений так, чтобы прикладные программы (включая адаптеры и приложения управления синхронизацией) могли использовать эту информацию для сообщения о ходе выполнения, ошибках и состоянии и для обновления состояния их серверной части, если есть.
* Обновления удаленного знания во время применения изменений, чтобы предотвращать "отражение" прикладной программы, снабженной изменениями, в течение следующей операции перечисления изменений.
* Использование расширенных адаптеров, которые способны к пониманию и обеспечению метаданных синхронизации WinFS Sync наряду с изменениями.
3. Типовой Код
Ниже представлен код для иллюстрации того, как FOO Sync адаптер может взаимодействовать с Sync Runtime (где все специфичные для адаптера функции снабжены префиксом FOO):
ItemContext ctx=new ItemContext ("\.\System\UserData\dshah\My Contacts", true);
// Получить идентификатор порции данных точной копии и удаленный // идентификатор партнера из профиля.
// Большинство адаптеров может получить эту информацию из профиля // синхронизации
Guid replicaltemid=FOO_GetRephcaId();
Guid remotePartnerId=FOO Get_RemotePartnerId();
//
// Просмотр сохраненного знания в хранилище, используя сохраненный
// идентификатор storedKnowledgeId аналогично вышеупомянутому.
//
ReplicaKnowledge remoteKnowledge=...;
//
// Инициализировать ReplicaSynchronizer
//
ctx.ReplicaSynchronizer=new ReplicaSynchronizer(replicaltemid, remotePartnerId);
ctx. ReplicaSynchronizer. RemoteKnowledge=remoteKnowledge;
ChangeReader reader=ctx.ReplicaSynchronizer. GetChangeReaderQ;
//
// Перечислить изменения и обработать их
//
bool bChangesToRead=true;
while (bChangesToRead)
{
ChangeCollection<object>changes=null;
bChangesToRead=reader.ReadChanges(10, out changes);
foreach (object change in changes)
{
// Обработать перечисленный объект, адаптер выполняет свое собственное
// преобразование схемы и отображение идентификатора. Он может даже
// извлекать дополнительные объекты из Ctx для этой цели и изменять
// метаданные адаптера после того, как
// изменения применены к удаленному хранилищу
ChangeStatus status=FOOProcessAndApplyToRemoteStore(change);
// Обновить изученное знание с помощью состояния reader.AcknowledgeChange (changeStatus);
}
}
remoteKnowledge=ctx.ReplicaSynchronizer.GetUpdatedRemoteKnowledgeQ;
reader. Close();
// // Сохранить обновленное знание и метаданные адаптера, если есть
// ctx.Update();
//
// Выборка для применения изменений, сначала инициализирует удаленное
// знание, используя StoredKnowledgeId как прежде.
// remoteKnowledge=...;
ctx.ReplicaSynchronizer.ConflictPolicy=conflictPolicy;
ctx.ReplicaSynchronizer.RemotePartnerId=remotePartnerid;
ctx.ReplicaSynchronizer.RemoteKnowledge=remoteKnowledge;
ctx.ReplicaSynchronizer.ChangeStatusEvent+=FOO OnChangeStatusEvent;
//
// Получить изменения от удаленного хранилища. Адаптер ответствен за
// извлечение метаданных, специфичных для его серверной части,
// из хранилища. Это может быть расширением относительно точной копии.
//
object remoteAnchor=FOO GetRemoteAnchorFromStoreQ;
FOORemoteChangeCollection remoteChanges=FOOGetRemoteChanges(remoteAnchor);
//
// Заполнить коллекцию изменений
//
foreach(FOO_RemoteChange change in remoteChanges)
{
// Адаптер, ответственный за выполнение отображения идентификатора
Guid localld=FOO_MapRemoteId (change);
// Можно сказать, что мы - синхронизированные персональные объекты ItemSearcher searcher=Person. GetSearcher(ctx);
searcher.Filters.Add("Personld=@localld");
searcher.Parameters["PersonId"]=localld;
Person person=searcher.FindOneQ;
//
// Адаптер преобразовывает удаленные изменения в обновления
// относительно персонального объекта. Как часть этого адаптер
// может даже делать изменения в метаданных, специфических для серверной
// части уровня порции данных для удаленного объекта.
//
FOO_TransformRemoteToLocal(remoteChange, person);
ctx.Update();
//
// Сохранить новый удаленный анкер (это может быть расширение
// относительно точной копии)
//
FOO_SaveRemoteAnchor();
// // Это - регулярное WinFS API сохранение, так как удаленное знание - не
// синхронизировано.
//
remoteKnowledge=ctx.ReplicaSynchronizer. GetUpdatedRemoteKnowledge();
ctx.Update();
ctx.Close();
//
// Обратный вызов Адаптера для обработки Обратных вызовов состояния
// приложения
//
void FOO_OnEntitySaved(object sender, ChangeStatusEventArgs args)
{
remoteAnchor.AcceptChange(args.ChangeStatus);
}
4. Способы API Синхронизации
В одном варианте осуществления настоящего изобретения синхронизация между WinFS хранилищем и не-WinFS хранилищем может быть выполнена посредством API Синхронизации, предоставленным аппаратной/программной интерфейсной системой, основанной на WinFS.
В одном варианте осуществления требуются все адаптеры синхронизации, чтобы реализовать API адаптера синхронизации, API, управляемый единой средой выполнения программ на разных языках программирования (CLR) так, чтобы они могли быть последовательно развернуты, инициализированы и управляемыми. API Адаптера обеспечивает:
Стандартный механизм, чтобы регистрировать адаптеры посредством инфраструктуры синхронизации аппаратной/программной интерфейсной системы.
Стандартный механизм для адаптеров, чтобы объявить их возможности и тип информации конфигурации, необходимой, чтобы инициализировать адаптер.
Стандартный механизм для передачи информации инициализации на адаптер.
Механизм для адаптеров, чтобы сообщать о состоянии хода выполнения обратно к прикладным программам, вызывающим синхронизацию.
Механизм, чтобы сообщить о любых ошибках, которые происходят в течение синхронизации.
Механизм, чтобы запросить отмену выполняющейся операции синхронизации.
Имеются две потенциальных модели обработки для адаптеров в зависимости от требований сценария. Адаптер может выполняться в одном и том же пространстве процесса, что и прикладная программа, его вызывающая, или в отдельном процессе совершенно отдельно. Чтобы выполняться в своем собственном отдельном процессе, адаптер определяет свой собственный класс из фабрики, который используется для инициализации адаптера. Фабрика может возвращать экземпляр адаптера в том же самом процессе, что и вызывающая прикладная программа, или возвращать удаленный экземпляр адаптера в отличную область или процесс единой среды выполнения программ на разных языках программирования от Microsoft. Обеспечивается заданная по умолчанию реализация фабрики, которая инициализирует адаптер в том же самом процессе. Практически, множество адаптеров выполняются в одном и том же процессе, что и вызывающая прикладная программа. Модель вне процесса обычно требуется по одной или обоим из следующих причин:
- Цель Защиты. Адаптер должен выполниться в пространстве процесса некоторого процесса или службы.
- Адаптер должен обработать запросы из других источников - например, поступающие сетевые запросы - в дополнение к обработке запросов от вызывающих прикладных программ.
Со ссылками на Фиг.37 один вариант осуществления настоящего изобретения предполагает простой адаптер, который не осведомлен о том, как вычисляется состояние или как обмениваются соответствующие метаданные. В этом варианте осуществления синхронизация достигается точной копией в отношении источника данных, с которым он хочет синхронизироваться, во-первых, на этапе 3702 определяя, какие изменения произошли с тех пор, как он был синхронизирован с упомянутым источником данных, и точная копия затем передает появившиеся (возрастающие) изменения, которые произошли со времени этой последней синхронизации, на основании ее текущей информации о состоянии, и эта текущая информация о состоянии и возрастающие изменения передаются к источнику данных через адаптер. На этапе 3704 адаптер после получения данных об изменениях от точной копии на предыдущем этапе реализует столько изменений для источника данных, насколько возможно, отслеживает, какие изменения являются успешными и какие были неудачными, и передает информацию "успех-и-неудача" назад к WinFS (точной копии). Аппаратная/программная интерфейсная система для точной копии (WinFS) на этапе 3706 после получения информации "успех-и-неудача" от точной копии затем вычисляет новую информацию о состоянии для источника данных, сохраняет эту информацию для будущего использования его точной копией и передает эту новую информацию о состоянии назад к источнику данных, то есть на адаптер, для сохранения и последующего использования адаптером.
D. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ СХЕМЫ СИНХРОНИЗАЦИИ
Ниже представлены дополнительные (или более специфичные) аспекты схемы синхронизации для различных вариантов осуществления настоящего изобретения.
* Каждая точная копия - это определенный поднабор данных синхронизации из полноты хранилища данных - срез данных, имеющих множество экземпляров.
* Политика разрешения конфликтов обрабатывается каждой точной копией (и комбинацией адаптер/источник данных) индивидуально - то есть каждая точная копия способна разрешить конфликты на основании ее собственных критериев и схемы разрешения конфликтов. Кроме того, в то время как различия в каждом экземпляре хранилища данных могут иметь место и вести к дополнительным будущим конфликтам, возрастающее и последовательное перечисление конфликтов, как отражено в обновляемой информации о состоянии, невидимо для других точных копий, которые получают эту обновленную информацию о состоянии.
* В корне схемы синхронизации находится точная копия, которая имеет базовый тип, чтобы определить корневую папку (фактически, корневая Порция данных), которая имеет уникальный идентификатор, идентификатор для сообщества синхронизации, в котором она является членом, и необходимы ли или желательны фильтры и другие элементы для этой конкретной точной копии.
* "Отображение" каждой точной копии поддерживается в пределах этой точной копии, и как таковое отображение для любой конкретной точной копии ограничено другими точными копиями, о которых такая точная копия знает. В то время как это отображение может только содержать поднабор полного сообщества синхронизации, изменения упомянутой точной копии будут все же распространяться ко всему сообществу синхронизации обычно через совместно используемые точные копии (хотя любая конкретная точная копия не осведомлена, какие другие точные копии обычно совместно используются с неизвестной точной копией).
* Схема синхронизации включает в себя и множество заранее определенных обработчиков конфликтов, доступных всем точным копиям, а также возможность (наличия) определенных пользователем/разработчиком заказных обработчиков конфликтов. Схема также может включать в себя три специальных "блока разрешения конфликтов": (а) "фильтр" конфликтов, который разрешает различные конфликты на основании различных способов, например, (i) как обрабатывать, когда один и тот же блок изменений изменен в двух местах, (ii) как обрабатывать, когда блок изменений изменен в одном месте, но удален в другом; и (iii) как обрабатывать, когда два различных блока изменений имеют одно и то же имя в двух различных местоположениях; (b) "список обработчиков" конфликтов, где каждый элемент списка задает ряд действий по осуществлению попыток, пока конфликт не будет успешно разрешен; и (с) "пустой" (“ничего не делать”) файл регистрации, который отслеживает конфликт, но не предпринимает никаких дальнейших действий без вмешательства пользователя.
* Схема синхронизации и использование точных копий допускают верно распределенное одноранговое сообщество синхронизации со многими основными (копиями). Кроме того, не имеется никакого типа сообщества синхронизации, но сообщество синхронизации существует просто как значение в поле сообщества самих точных копий.
* Каждая точная копия имеет свои собственные метаданные для отслеживания возрастающего перечисления изменений и сохранения информации о состоянии для других точных копий, которые известны в сообществе синхронизации.
* Блоки изменений имеют свои собственные метаданные, содержащие: версию, содержащую ключ партнера плюс номер изменения партнера; версии Item/Extension/Relationship для каждого блока изменений; знание относительно изменений, которые точная копия увидела/получила от сообщества синхронизации; GUID и идентификатор локальной конфигурации; и GUID, сохраненный относительно ссылочного отношения для очистки.
II. ЗАКЛЮЧЕНИЕ
Как проиллюстрировано выше, настоящее изобретение посвящено платформе хранения для организации, поиска и совместного использования данных. Платформа хранения согласно настоящему изобретению расширяет и распространяет концепцию хранения данных за пределы существующих файловых систем и систем базы данных и предназначена, чтобы быть хранилищем для всех типов данных, включая структурированные, неструктурированные или полуструктурированные данные, типа реляционных (табличных) данных, XML и новые формы данных, названные Порцией данных. Посредством своей обычной основы хранения и схематизированных данных Платформа хранения согласно настоящему изобретению позволяет выполнять более эффективную разработку приложений для потребителей, специалистов и предприятий. Она предлагает богатый и расширяемый интерфейс прикладного программирования, который не только делает доступным возможности, свойственные его модели данных, но также и охватывает и расширяет существующую файловую систему и способы доступа к базе данных. Понятно, что к вариантам осуществления, описанным выше, могут быть сделаны изменения без отрыва от их широких изобретательных концепций. Соответственно, настоящее изобретение не ограничено конкретными раскрытыми вариантами осуществления, а предназначено, чтобы охватить все модификации, которые находятся в объеме и контексте изобретения, которое определено прилагаемой формулой изобретения.
Как очевидно из вышесказанного, все или части различных систем, способов и аспектов настоящего изобретения могут быть воплощены в форме программного кода (то есть командах). Этот программный код может быть сохранен на считываемом компьютером носителе типа магнитного, электрического или оптического носителя данных, включая в себя без ограничения гибкую дискету, CD-ROM, CD-RW, DVD-ROM, DVD-RAM, магнитную ленту, флэш-память, накопитель на жестком диске или любой другой машинно-считываемый носитель данных, в котором, когда программный код загружают и выполняют машиной, такой как компьютер или сервер, эта машина становится устройством для осуществления изобретения.
Настоящее изобретение может также быть воплощено в форме программного кода, который передают по некоторой среде передачи, например по электрическим проводам или кабельному соединению, волоконно-оптическому кабелю, по сети, включая Интернет или интранет, или посредством любой другой формы передачи, в которой, когда программный код получен и загружен и выполнен машиной, такой как компьютер, эта машина становится устройством для осуществления изобретения. При реализации на процессоре общего назначения программный код объединяется с процессором, чтобы обеспечить уникальное устройство, которое работает аналогично специализированным логическим схемам.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СИСТЕМЫ И СПОСОБЫ РАСШИРЕНИЙ И НАСЛЕДОВАНИЯ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО-ПРОГРАММНОГО ИНТЕРФЕЙСА | 2004 |
|
RU2412475C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| ОТОБРАЖЕНИЕ МОДЕЛИ ФАЙЛОВОЙ СИСТЕМЫ В ОБЪЕКТ БАЗЫ ДАННЫХ | 2006 |
|
RU2409847C2 |
| СИСТЕМЫ И СПОСОБЫ МАНИПУЛИРОВАНИЯ ДАННЫМИ В СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2413984C2 |
| СИСТЕМА И СПОСОБ ПРЕДСТАВЛЕНИЯ ДЛЯ ПОЛЬЗОВАТЕЛЯ ВЗАИМОСВЯЗАННЫХ ЭЛЕМЕНТОВ | 2004 |
|
RU2358312C2 |
| ФАЙЛОВАЯ СИСТЕМА, ПРЕДСТАВЛЕННАЯ ВНУТРИ БАЗЫ ДАННЫХ | 2006 |
|
RU2398275C2 |
| МЕХАНИЗМЫ ОБНАРУЖИВАЕМОСТИ И ПЕРЕЧИСЛЕНИЯ В ИЕРАРХИЧЕСКИ ЗАЩИЩЕННОЙ СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2408070C2 |
| ИНТЕРФЕЙС ПРИКЛАДНОГО ПРОГРАММИРОВАНИЯ ХРАНИЛИЩА ДЛЯ ОБЩЕЙ ПЛАТФОРМЫ ДАННЫХ | 2006 |
|
RU2408061C2 |
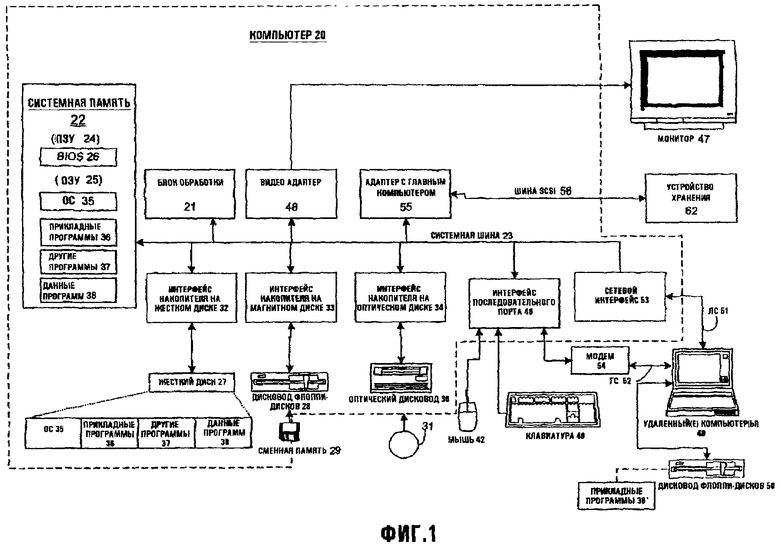
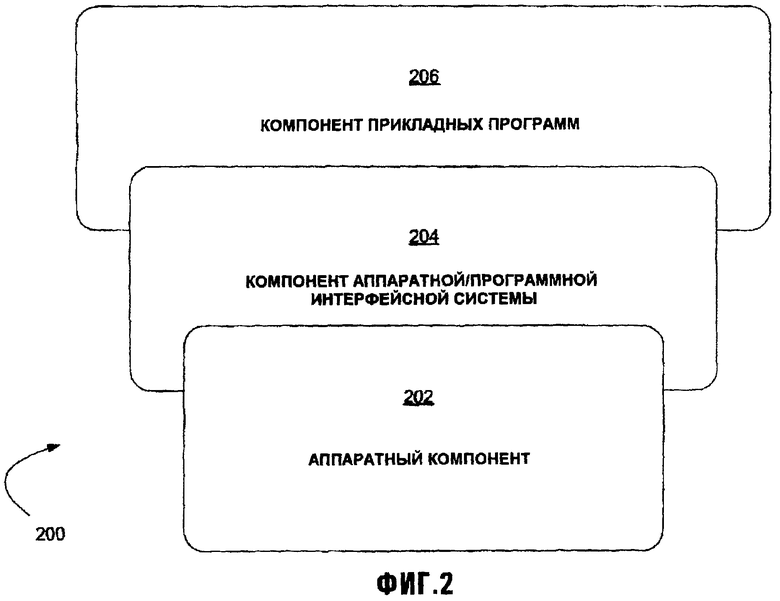
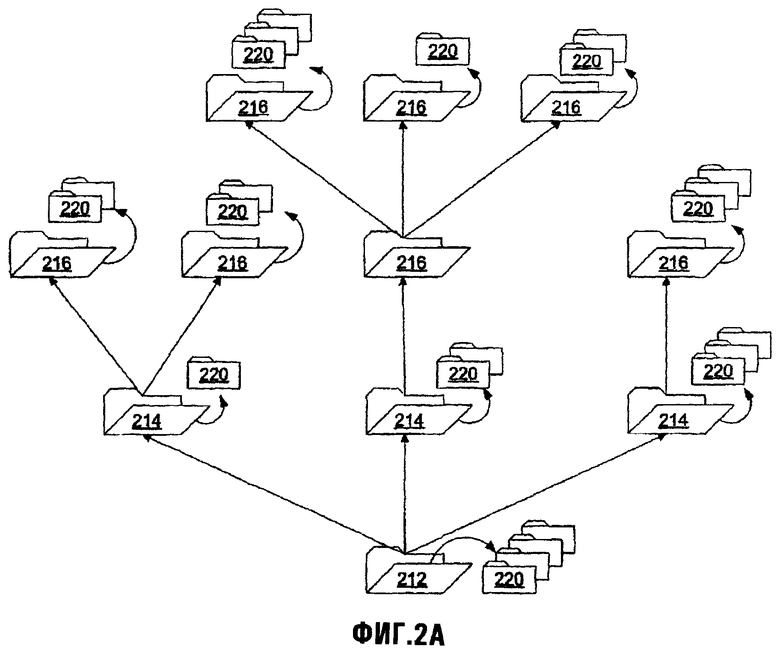
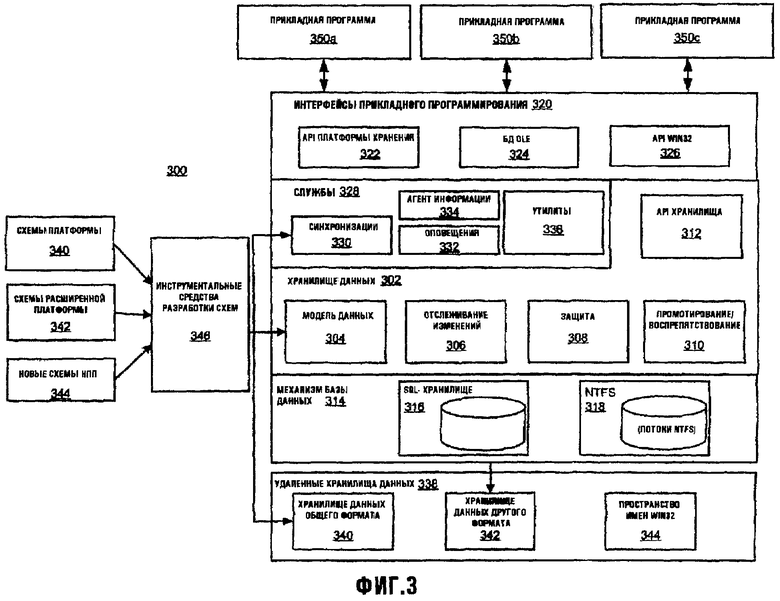
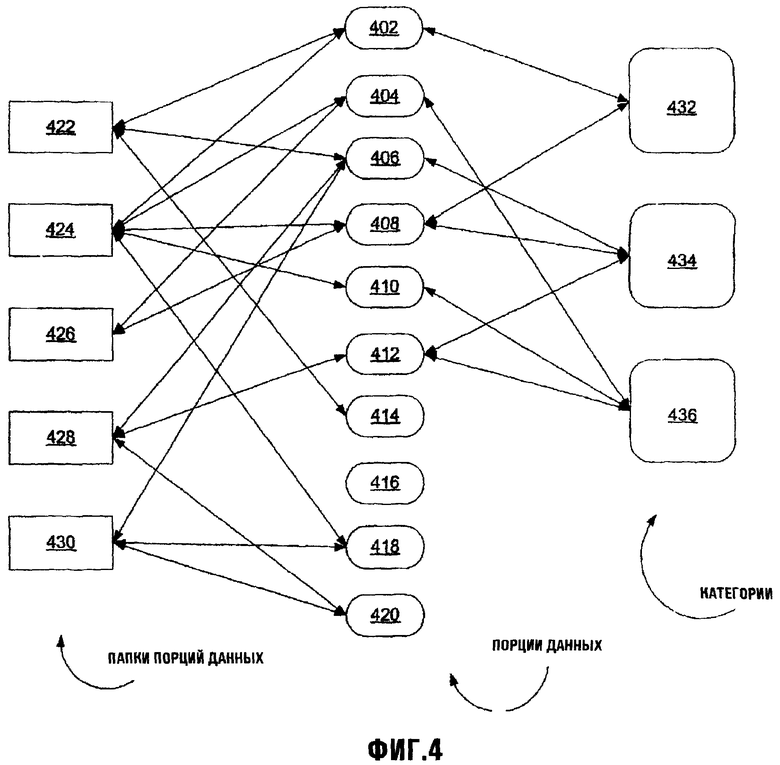

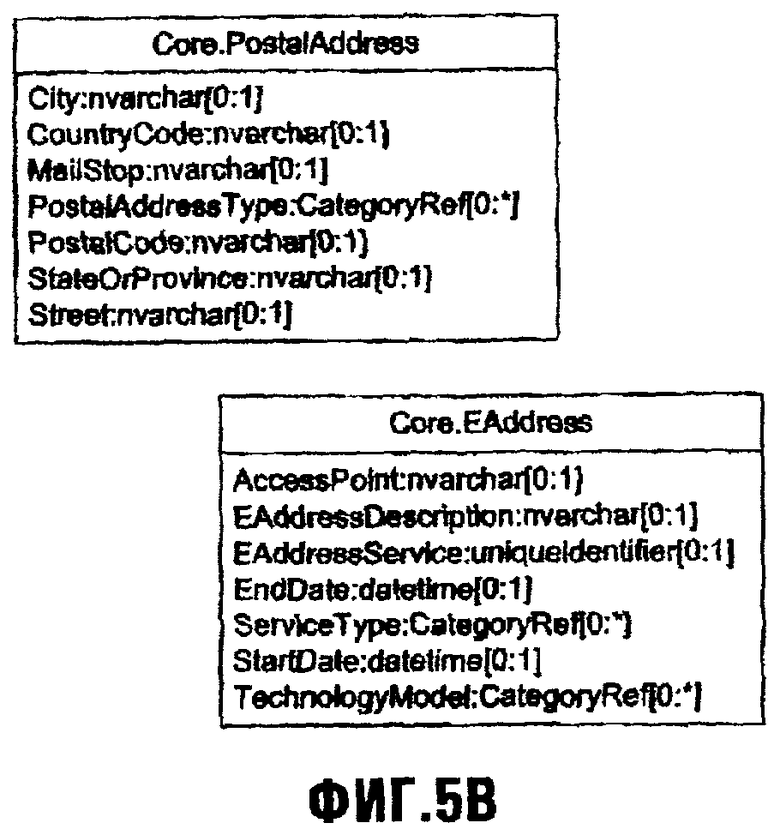

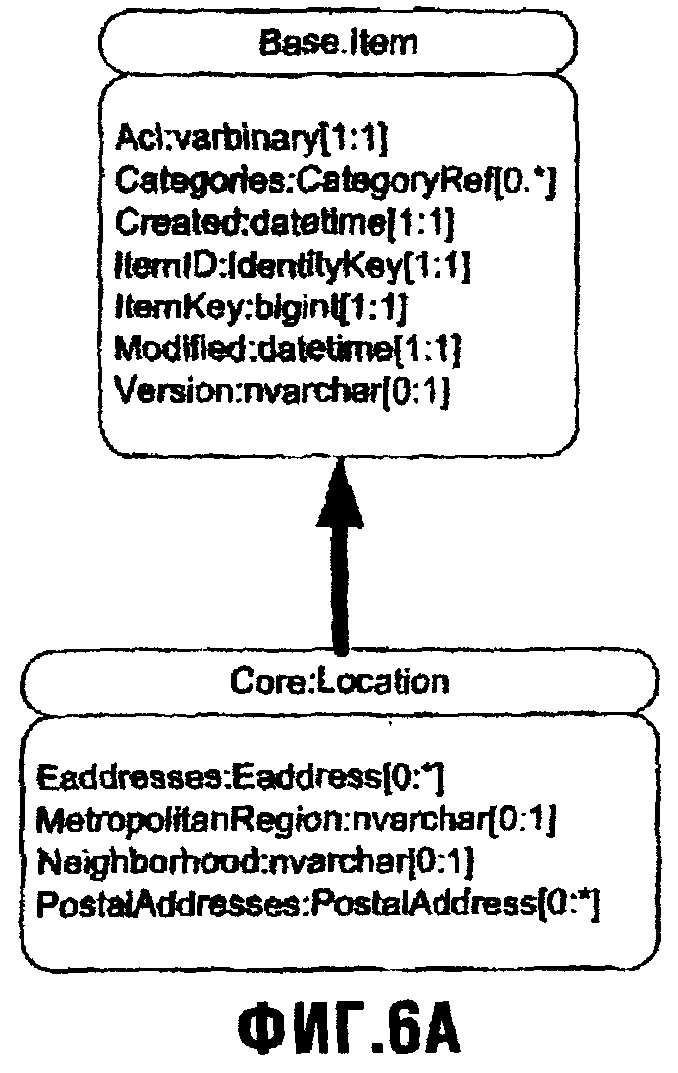

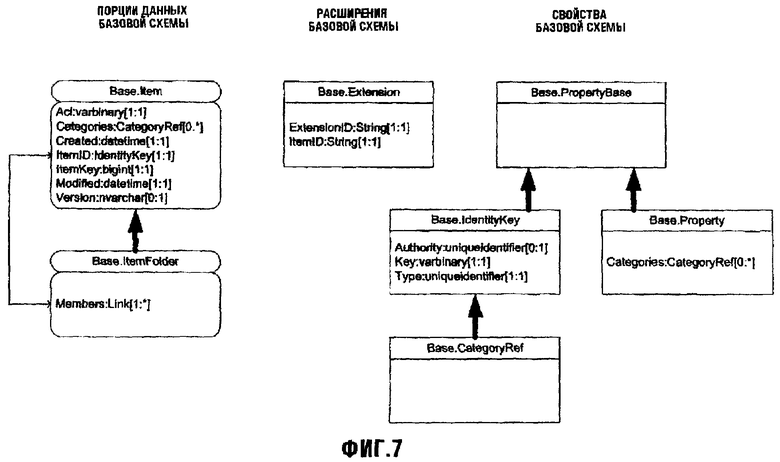
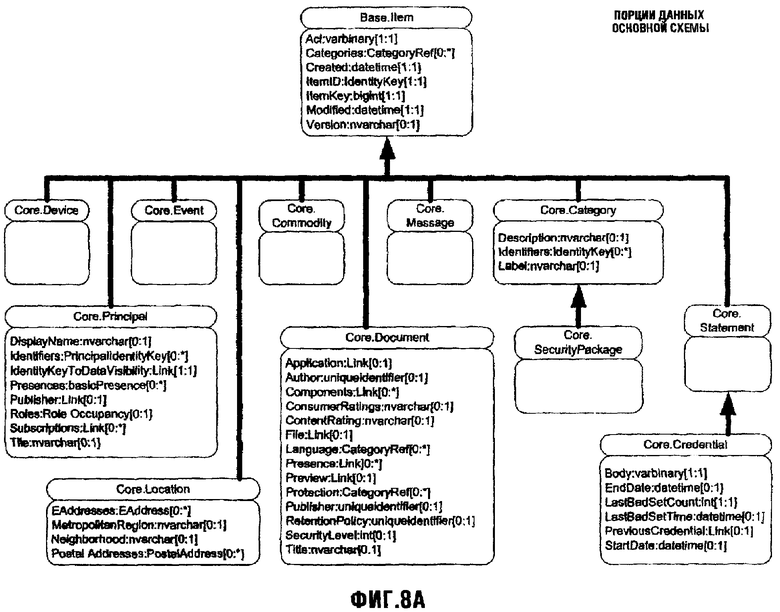
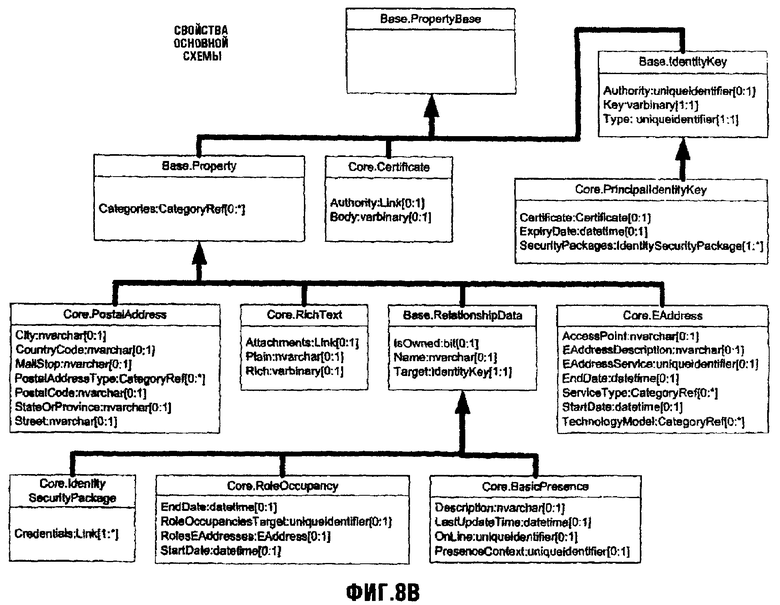
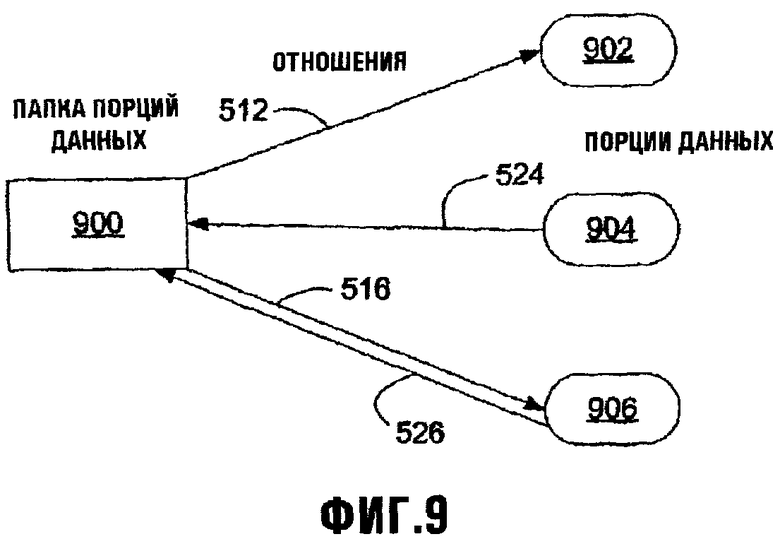
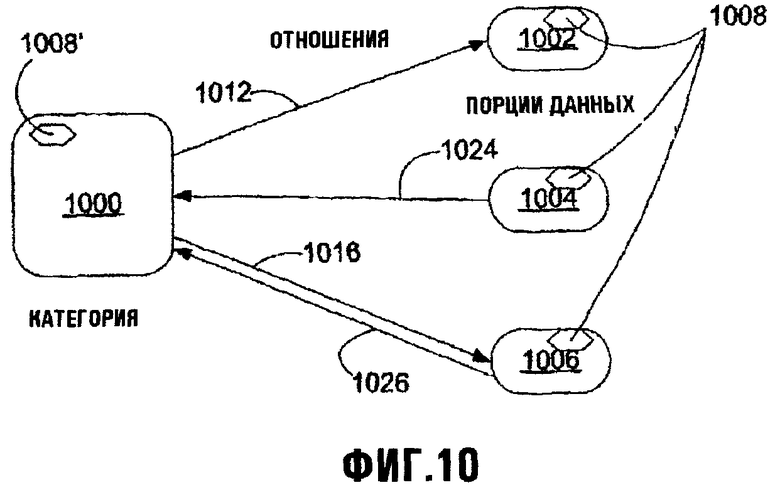
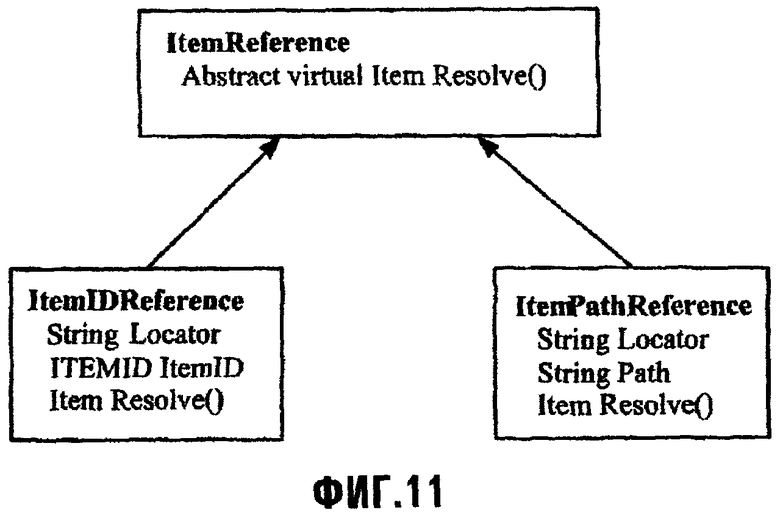
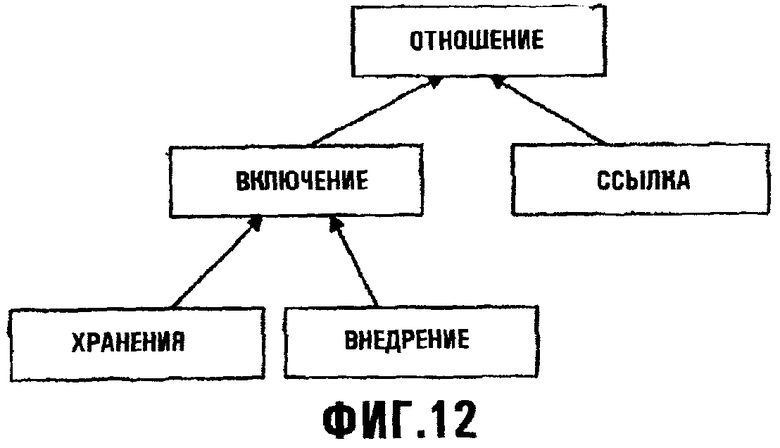
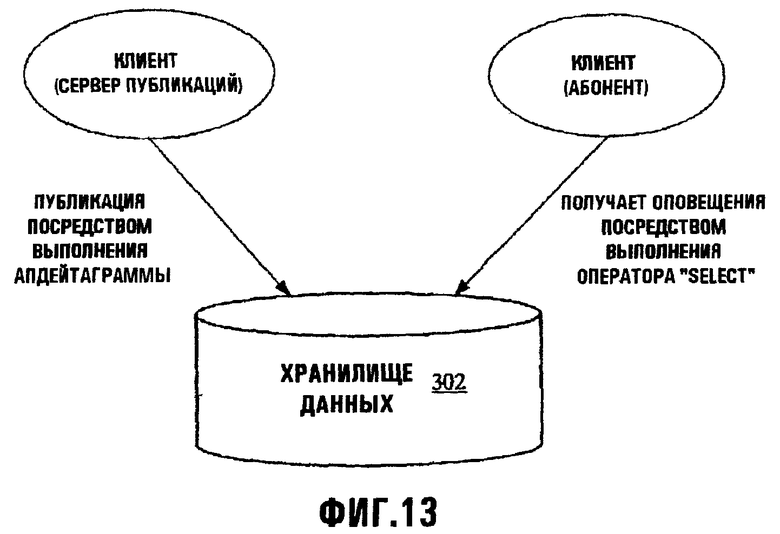
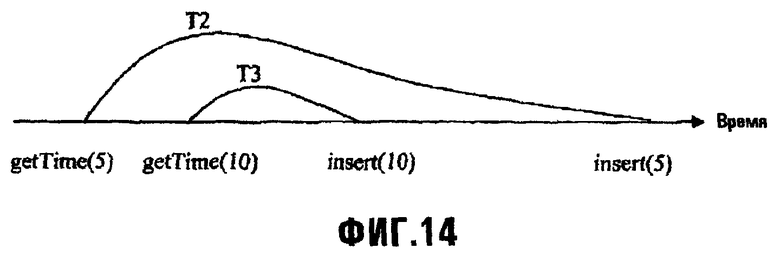
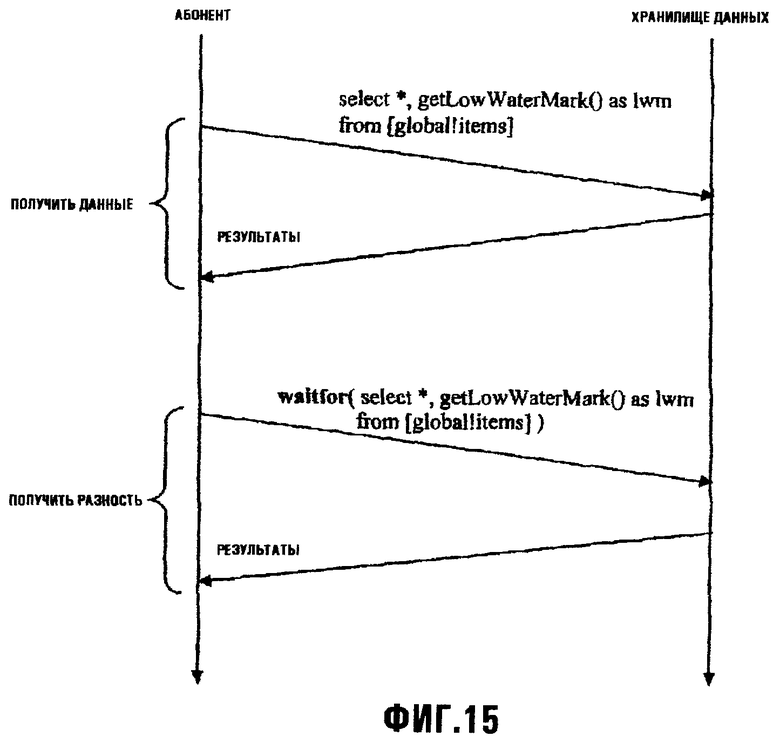
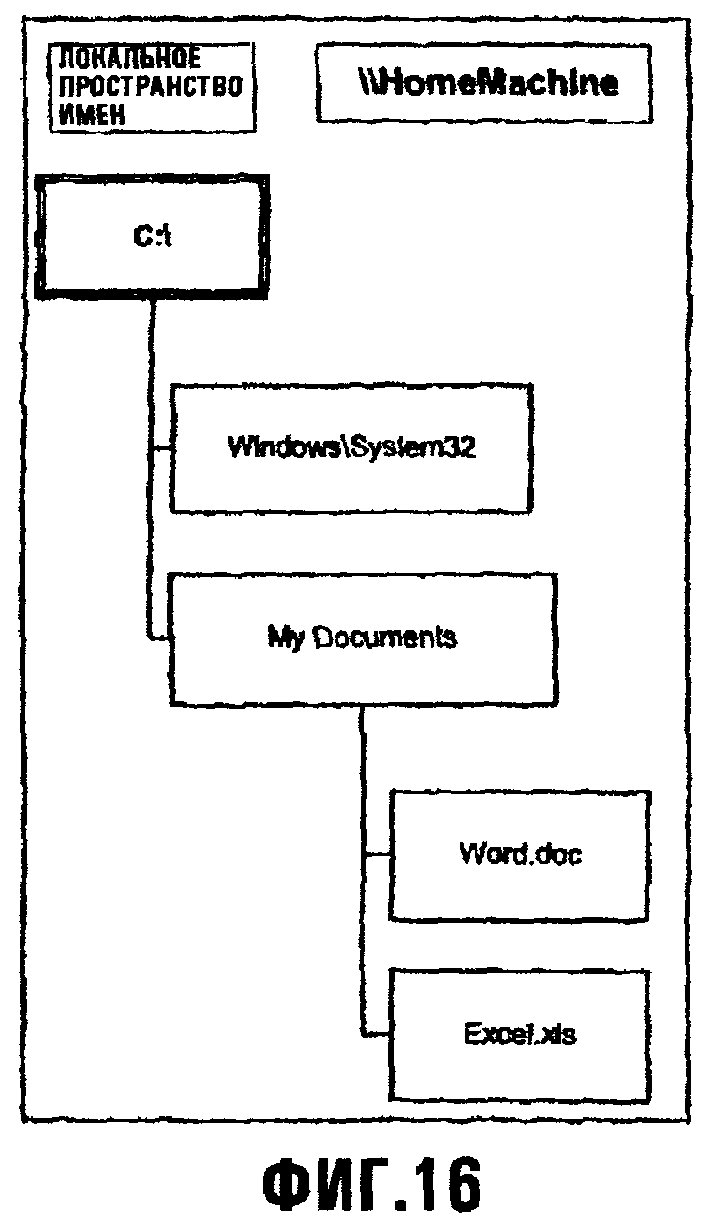
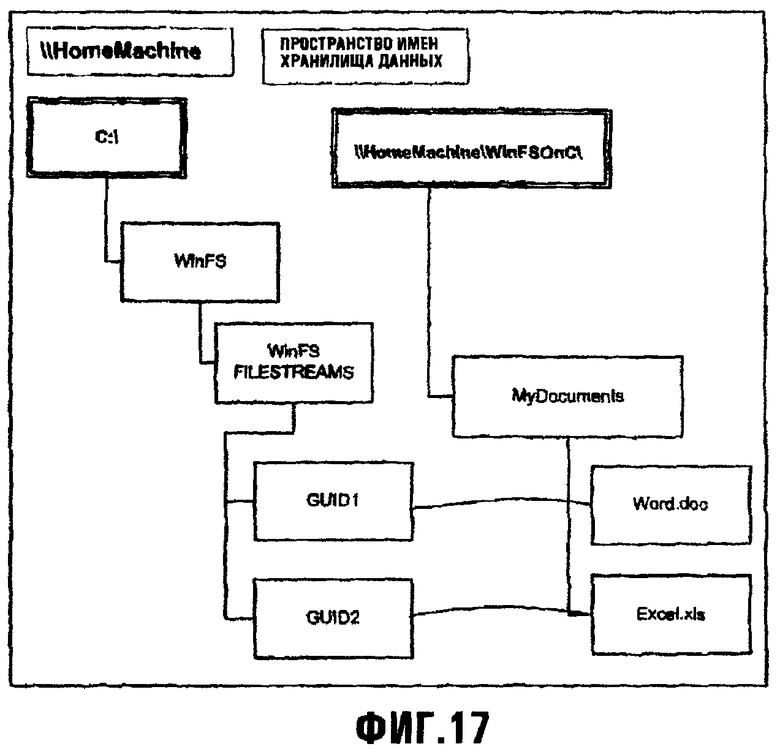
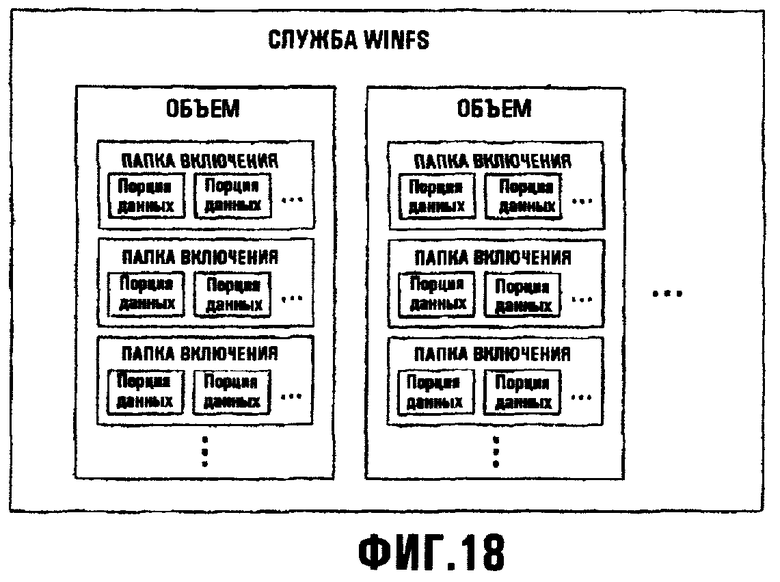

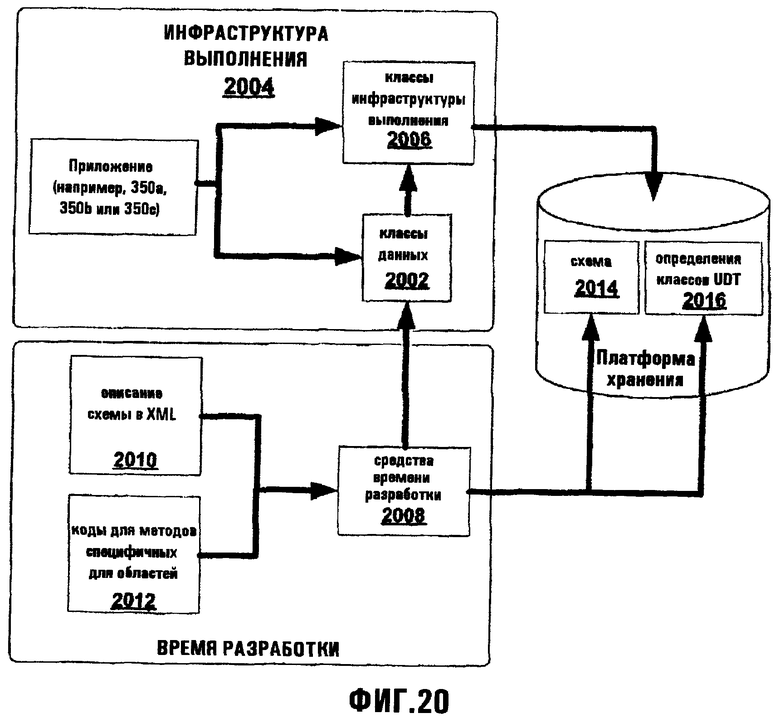
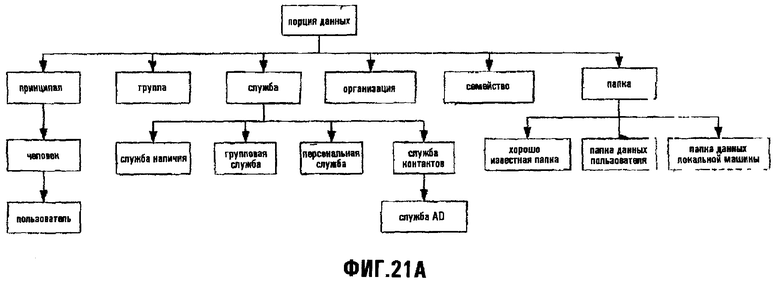
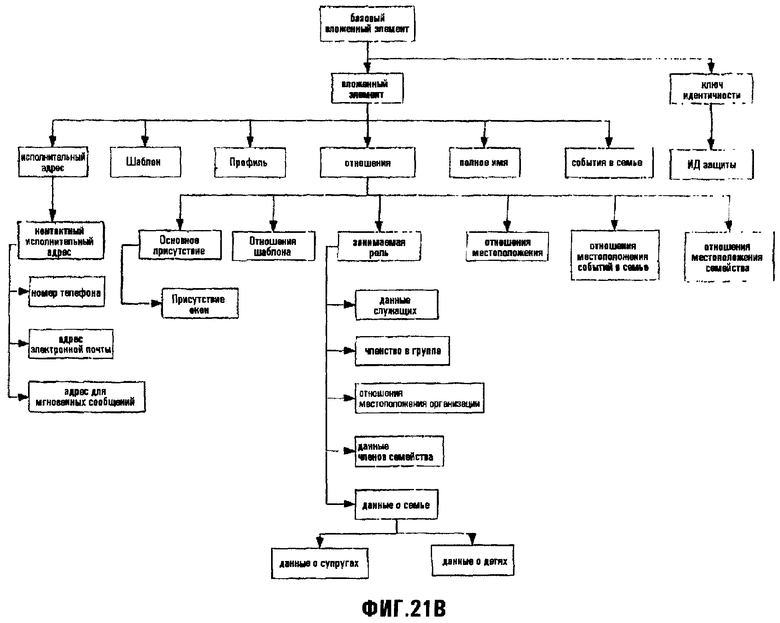
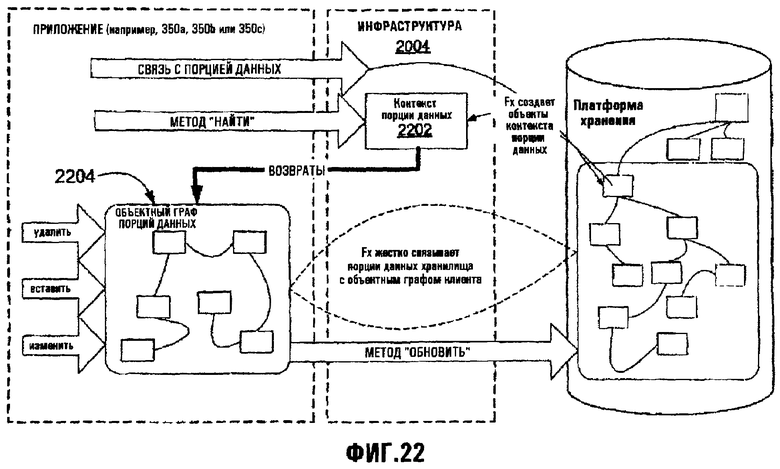
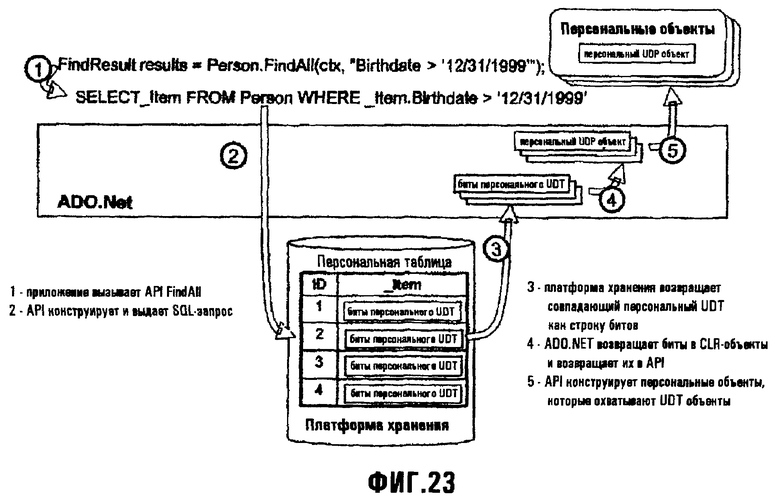
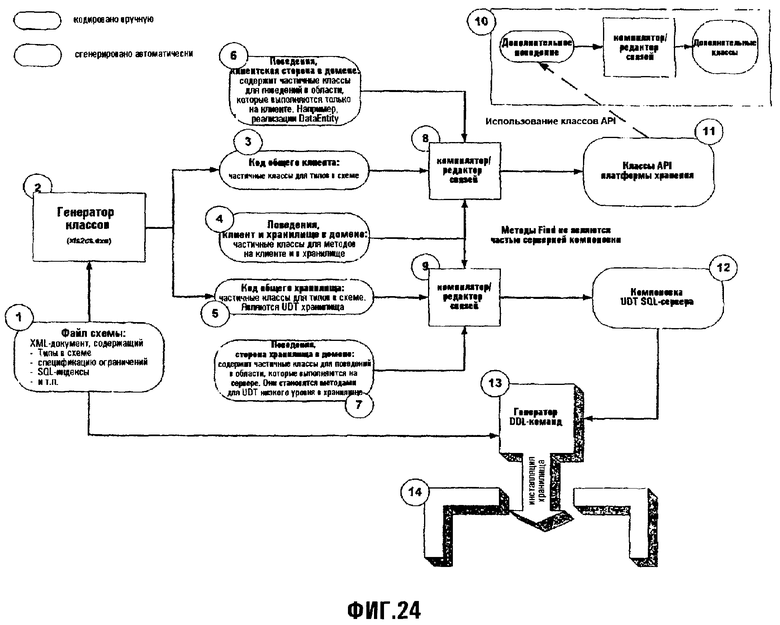
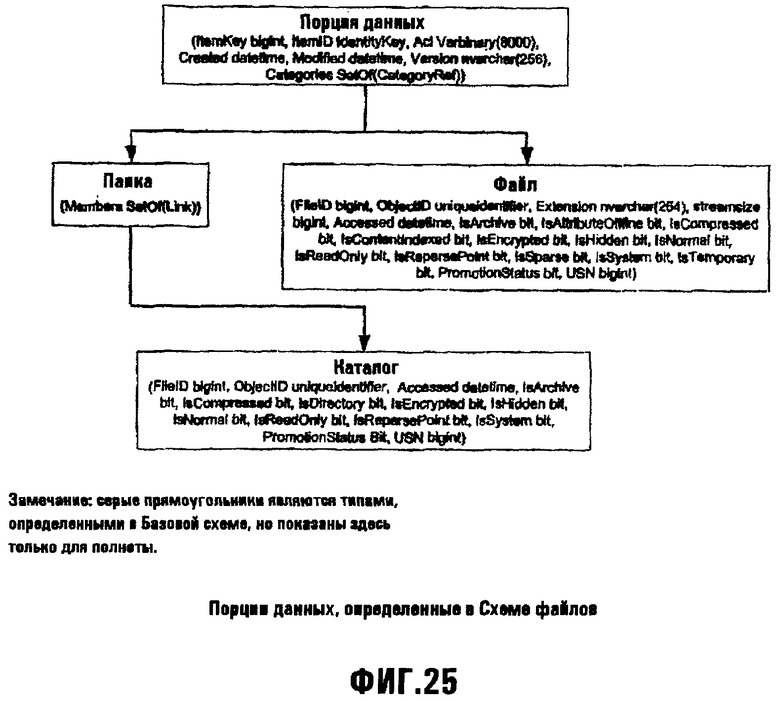
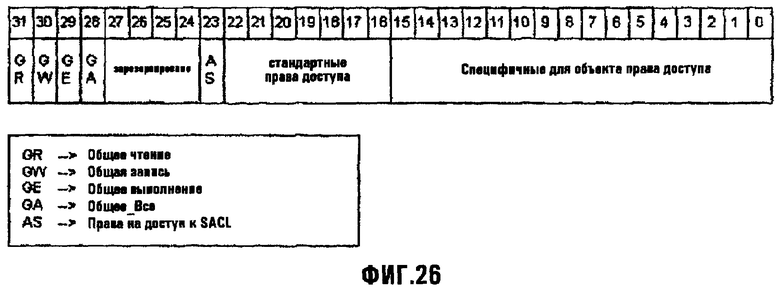
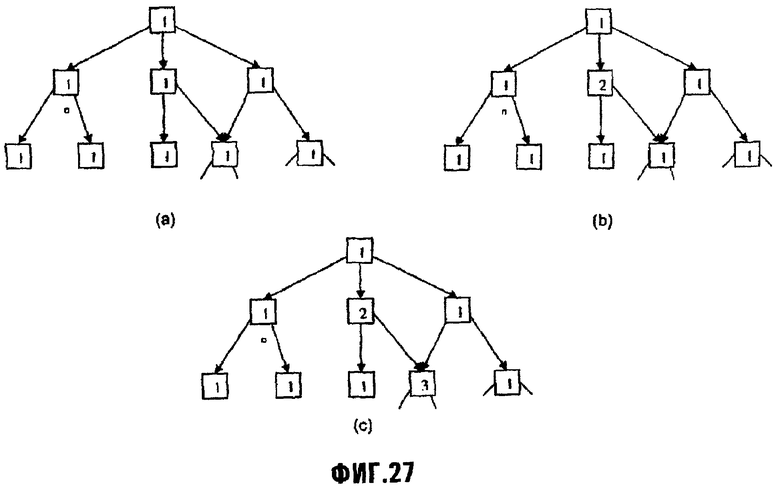
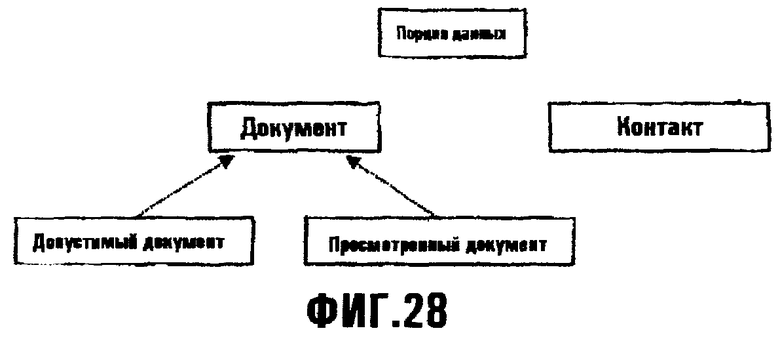
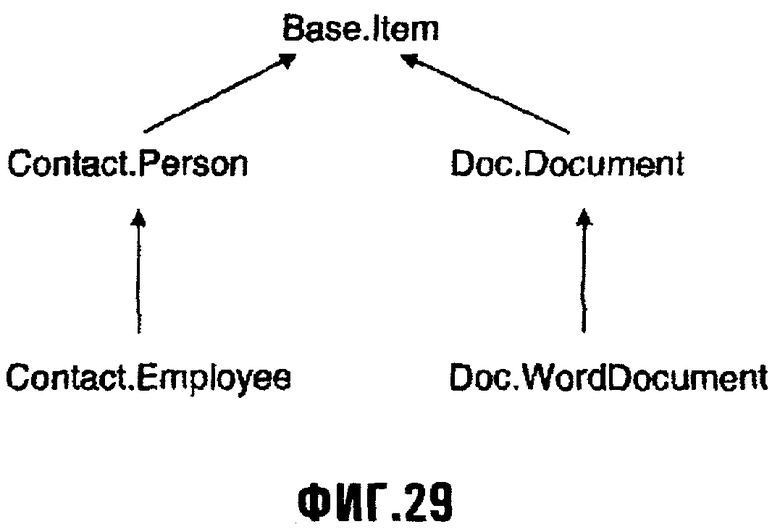
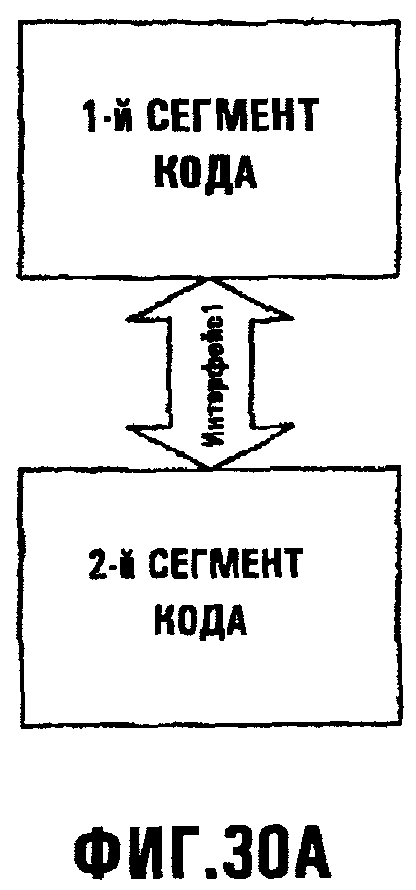
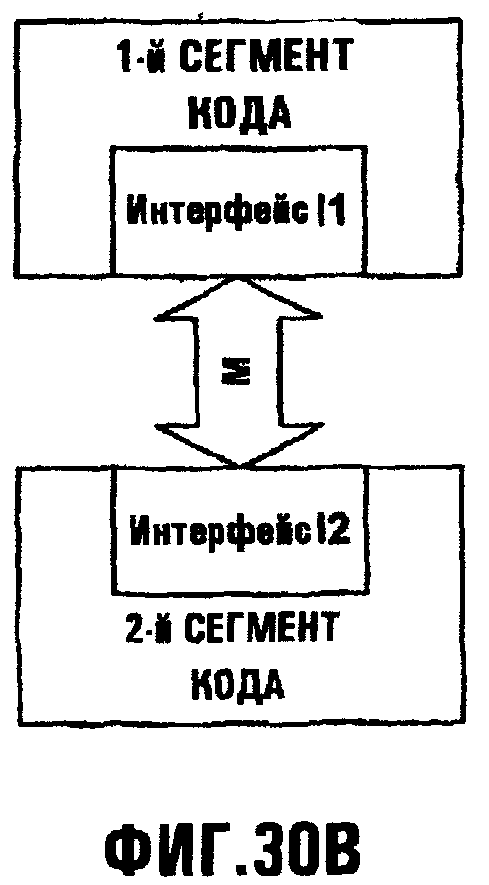
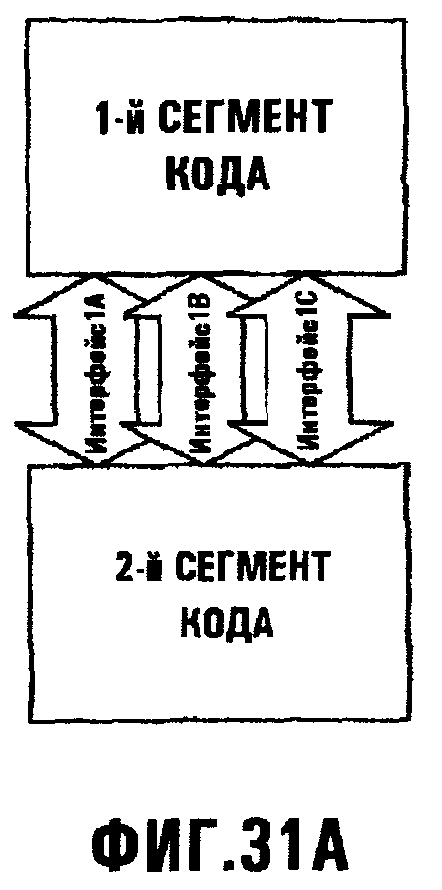
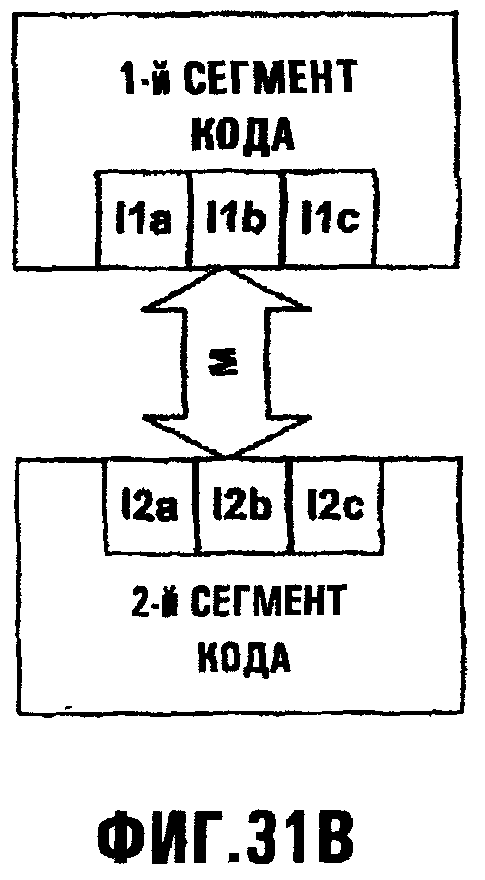
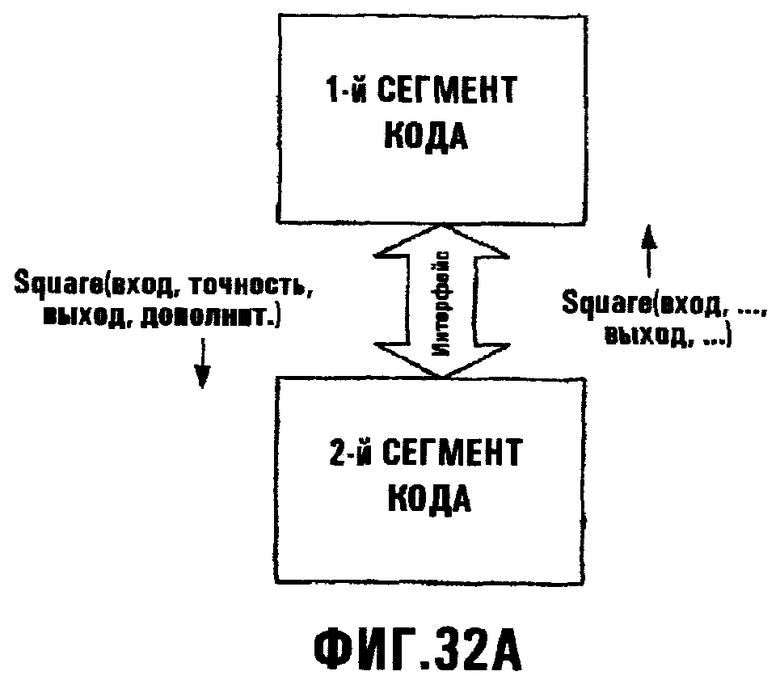
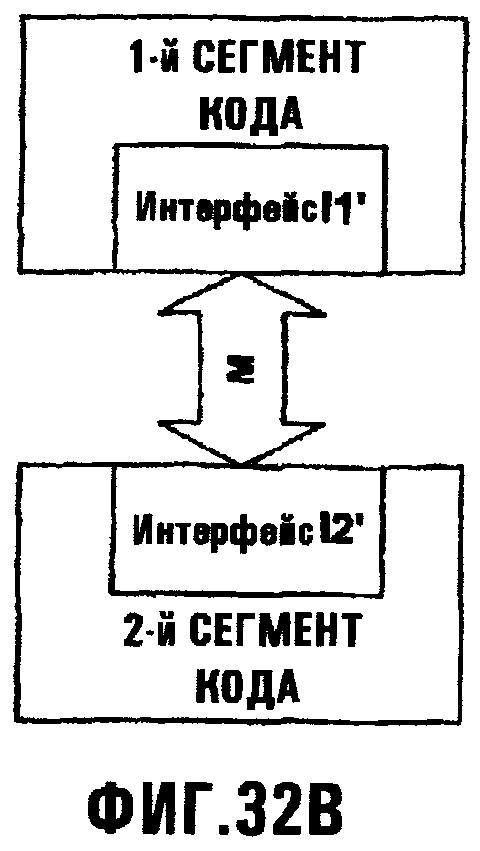
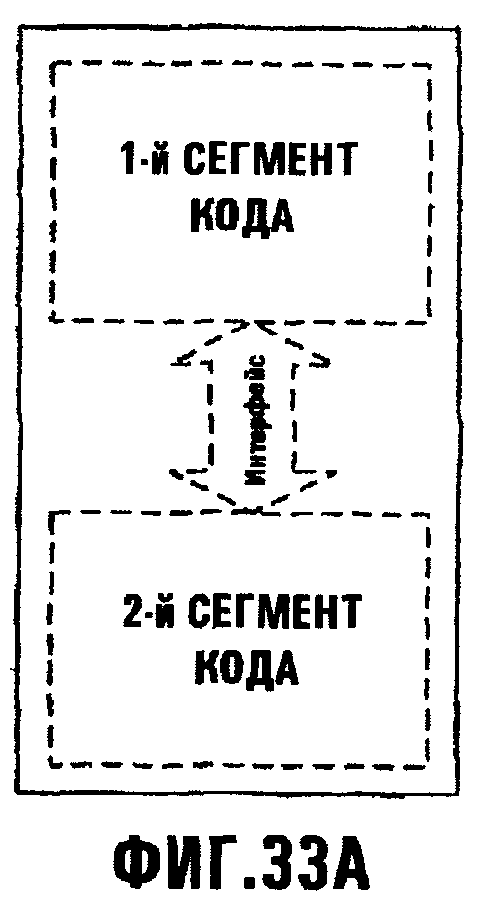
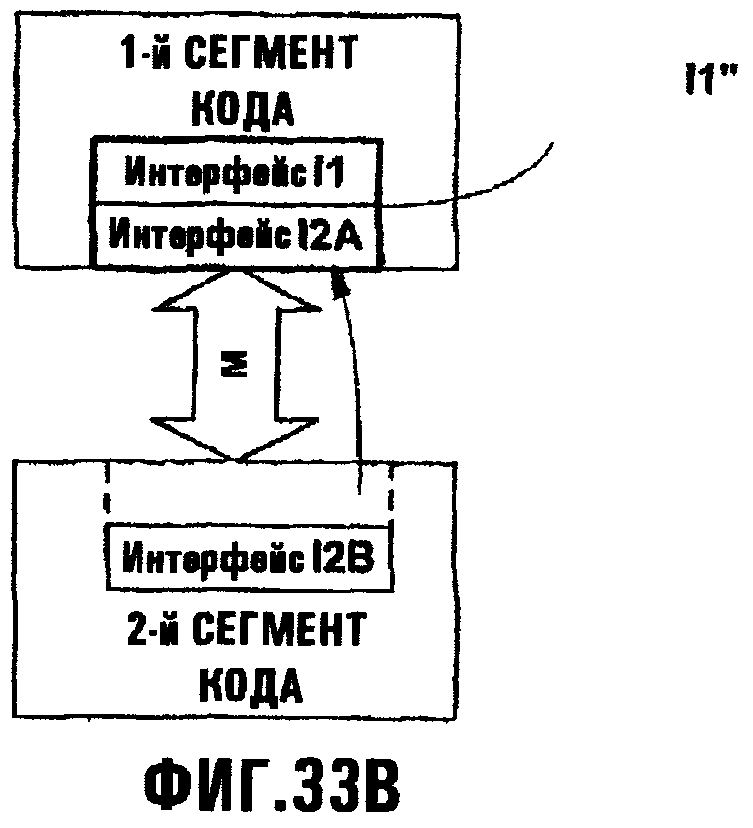
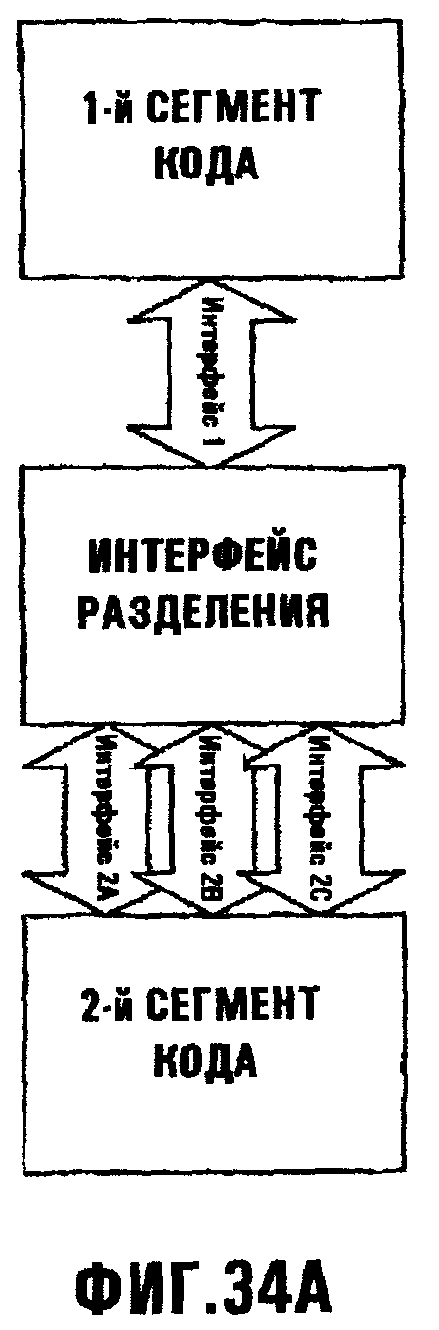
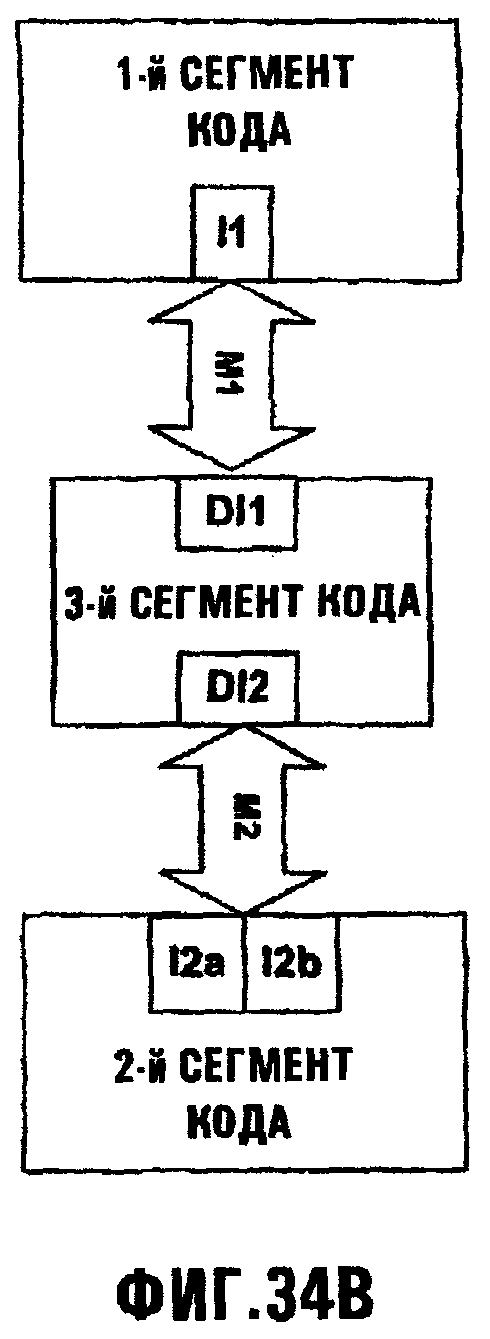
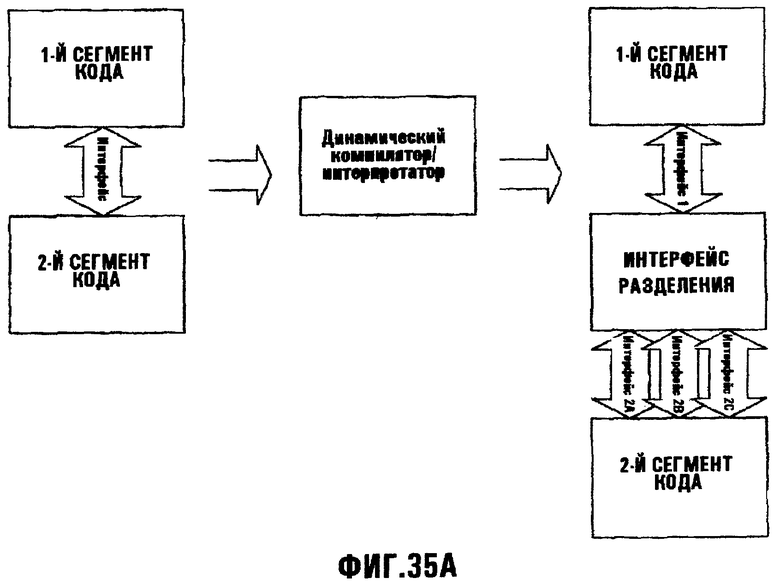
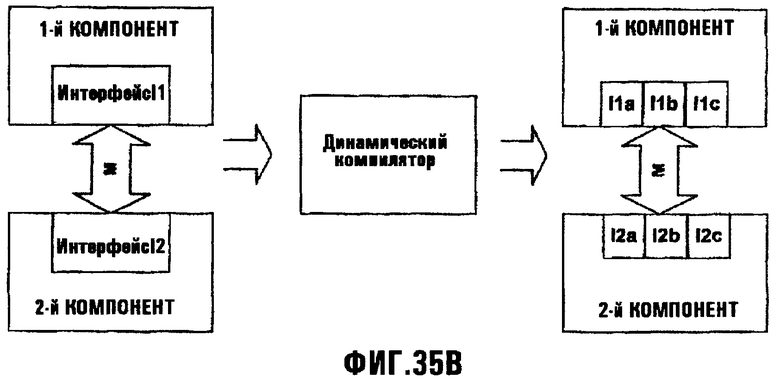

Настоящее изобретение относится к области хранения и извлечения информации. Изобретение обеспечивает платформу хранения, которая расширяет платформу данных за пределы существующих файловых систем и систем базы данных и которая служит хранилищем для всех типов данных. Несколько вариантов осуществления настоящего изобретения используют адаптеры синхронизации для синхронизации информации между "WinFS" и не-"WinFS" источниками данных. Примеры адаптеров включают в себя адаптер, который синхронизирует информацию записной книжки между папкой контактов "WinFS" и "почтовым ящиком" не-WinFS. В этих случаях разработчики адаптера могут использовать API основных услуг синхронизации "WinFS" для доступа к услугам, обеспеченным платформой синхронизации "WinFS" с тем, чтобы разработать код преобразования схемы между "WinFS" схемой и не-"WinFS" схемой источника данных. Кроме того, разработчик адаптера обеспечивает поддержку протокола для обмена изменениями с не-"WinFS" источником данных. Адаптер синхронизации вызывается и управляется при помощи API контроллера синхронизации и сообщает о ходе выполнения и ошибках при помощи этого API. 6 н. и 22 з.п. ф-лы, 49 ил.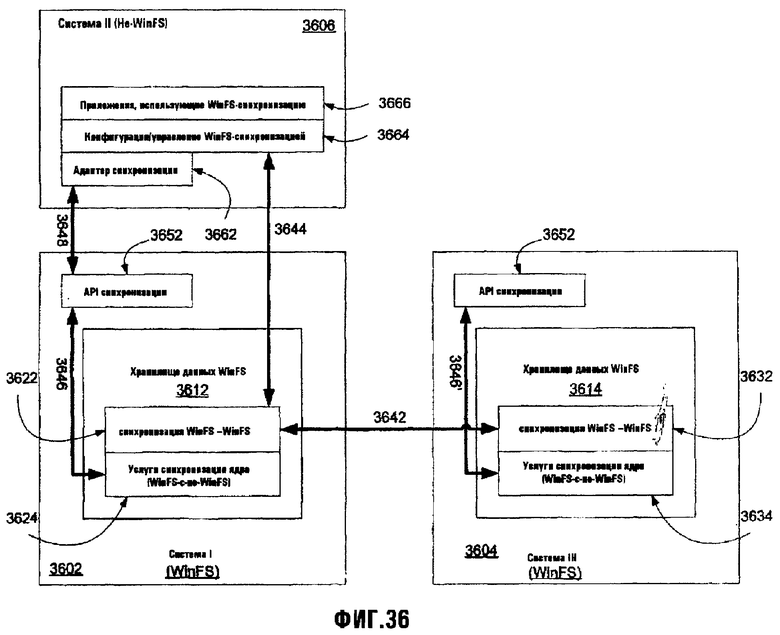
1. Компьютерная система, содержащая
операционную систему, содержащую систему управления базой данных, причем система управления базой данных интегрирована с файловой системой, система управления базой данных хранит данные, упомянутые данные разделяются на программно-определенные блоки изменений;
подсистему синхронизации, собственную для операционной системы, которая позволяет операционной системе выполнять операцию синхронизации для синхронизации данных, сохраненных в системе управления базой данных с данными, сохраненными в удаленных системах управления базами данных, на основе изменений, которые являются последовательно перечисленными и отслеженными из расчета на каждый блок изменений.
2. Система по п.1, в которой подсистема синхронизации синхронизирует только поднабор данных из общего числа данных в упомянутой системе управления базой данных в течение операции синхронизации.
3. Система по п.1, в которой система управления базой данных является точной копией, выполняющейся в операционной системе, которая имеет подсистему синхронизации, и удаленная система управления базой данных является источником данных, выполняющимся в операционной системе, которая не имеет подсистемы синхронизации.
4. Система по п.3, в которой синхронизация между точной копией и источником данных обеспечивается адаптером синхронизации, который виртуализирует источник данных посредством взаимодействия с интерфейсом прикладного программирования операционной системы этой точной копии.
5. Система по п.1, в которой конфликты в синхронизации автоматически обнаруживаются и разрешаются на основании заранее определенных детерминируемых критериев.
6. Система по п.5, в которой некоторые из упомянутых конфликтов разрешаются посредством регистрации для ручного разрешения конечным пользователем.
7. Система по п.1, в которой подсистема синхронизации отслеживает состояние предыдущих синхронизаций с партнером синхронизации, и посредством этого синхронизирует только те блоки изменений с этим партнером, которые изменились с момента последней синхронизации.
8. Способ синхронизации данных, сохраненных во множестве систем управления базой данных, объединенных с файловой системой операционных систем, причем упомянутый способ содержит этапы:
разделяют упомянутые данные, сохраненные в системе управления базой данных, на программно-определенные блоки изменений;
последовательно перечисляют изменения к указанным данным и отслеживают упомянутые изменения из расчета на каждый блок изменений;
для каждой системы управления базой данных отслеживают состояние изменений для этой системы управления базой данных, а также состояние изменений для удаленной системы управления базой данных; и идентифицируют новые изменения для выполнения синхронизации, сравнивая перечисленные изменения для конкретной системы управления базой данных с состоянием изменений для этой системы управления базой данных.
9. Способ по п.8, в котором первую систему управления базой данных - точную копию - инициализируют на операционной системе, которая непосредственно поддерживает основанную на Порции данных синхронизацию, и в котором удаленную систему управления базой данных - источник данных - инициализируют на операционной системе, которая непосредственно не поддерживает основанную на Порции данных синхронизацию, причем упомянутый способ дополнительно содержит этап использования адаптера для виртуализации удаленной системы управления базой данных посредством интерфейса прикладного программирования синхронизации.
10. Способ по п.9, дополнительно содержащий этап обнаружения конфликтов синхронизации на уровне степени детализации блока изменений.
11. Способ по п.9, дополнительно содержащий этап на котором
выдают сообщения из упомянутых систем управления базой данных об успехе, неудаче и/или конфликтах на уровне индивидуального блока изменений относительно применения изменений; и используют прикладными программами данные синхронизации для обновления состояния серверной части.
12. Способ синхронизации точной копии с источником данных, в котором и упомянутая точная копия и упомянутый источник данных имеют информацию о состоянии изменений, которая поддерживается каждым партнером синхронизации, и в котором упомянутый источник данных использует адаптер, чтобы осуществлять взаимодействие с аппаратной/программной интерфейсной системой упомянутой точной копии, причем упомянутый способ содержит этапы на которых
посылают из упомянутой точной копии к упомянутому адаптеру обновленную информацию о состоянии для упомянутой точной копии, которая на основании последней информации о состоянии для упомянутого источника данных отражает изменения, которые были сделаны с момента последней синхронизации, как отражено в упомянутой последней информации о состоянии для упомянутого источника данных; и
принимают посредством упомянутого адаптера упомянутую обновленную информацию о состоянии для упомянутой точной копии и упомянутые новые изменения, применяя политику разрешения конфликтов, выбранную из множества политик разрешения конфликтов, реализуют столько изменений в источнике данных, насколько возможно в отношении конкретной политики разрешения конфликтов, и отслеживают успех или неудачу для каждого изменения относительно блока изменений по принципу - блок изменений за блоком изменений, при этом изменения являются последовательно перечисленными и отслеженными из расчета на каждый блок изменений.
13. Способ по п.12, дополнительно содержащий этапы:
вычисляют посредством упомянутого адаптера новое состояние источника данных на основании успеха или неудачи для каждого изменения по принципу - блок изменений за блоком изменений, сохраняют эту информацию о новом состоянии и передают эту информацию о новом состоянии к аппаратной/программной интерфейсной системе точной копии, и
сохраняют посредством упомянутой аппаратной/программной интерфейсной системы точной копии упомянутую информацию о новом состоянии для упомянутого источника данных для будущего использования упомянутой точной копией.
14. Способ по п.12, дополнительно содержащий этапы:
передают от упомянутого адаптера к аппаратной/программной интерфейсной системе точной копии успех или неудачу для каждого изменения по принципу - блок изменений за блоком изменений;
вычисляют в упомянутой аппаратной/программной интерфейсной системе точной копии информацию о новом состоянии для источника данных на основании успеха или неудачи для каждого изменения в источнике данных по принципу - блок изменений за блоком изменений;
передают на адаптер посредством упомянутой аппаратной/программной интерфейсной системой точной копии информацию о новом состоянии и сохраняют упомянутую информацию о новом состоянии для будущего использования упомянутой точной копией; и принимают на упомянутом адаптере, и сохраняют упомянутую информацию о новом состоянии.
15. Считываемый компьютером носитель, содержащий записанные на нем считываемые компьютером команды для компьютерной системы, содержащей операционную систему, которая содержит систему управления базой данных, интегрированную с файловой системой, при этом команды служат для синхронизации посредством операционной системы данных, сохраненных в системе управления базой данных, с данными, сохраненными в удаленных системах управления базами данных, где сохраненные данные разделены на программно-определенные блоки изменений на основании изменений, которые являются последовательно перечисленными и отслеженными из расчета на каждый блок изменений.
16. Считываемый компьютером носитель по п.15, в котором подсистема синхронизации синхронизирует только поднабор данных из всех данных в упомянутой системе управления базой данных в течение операции синхронизации.
17. Считываемый компьютером носитель по п.15, в котором система управления базой данных является точной копией, выполняющейся в операционной системе, которая имеет подсистему синхронизации, и удаленная система управления базой данных является источником данных, выполняющимся в операционной системе, которая не имеет подсистемы синхронизации.
18. Считываемый компьютером носитель по п.17, в котором синхронизация между точной копией и источником данных обеспечивается адаптером синхронизации, который виртуализирует удаленную систему управления базой данных посредством взаимодействия с интерфейсом прикладного программирования операционной системы, имеющей подсистему синхронизации.
19. Считываемый компьютером носитель по п.15, в котором конфликты синхронизации автоматически обнаруживаются и разрешаются на основании заранее определенных детерминированных критериев.
20. Считываемый компьютером носитель по п.19, в котором некоторые из упомянутых конфликтов разрешают посредством регистрации для ручного разрешения конечным пользователем.
21. Считываемый компьютером носитель по п.15, в котором подсистема синхронизации отслеживает состояние предыдущих синхронизаций с партнером синхронизации и посредством этого синхронизирует блоки изменений только с тем партнером, который изменился с момента последней синхронизации.
22. Считываемый компьютером носитель, содержащий считываемые компьютером команды для синхронизации данных, сохраненных во множестве удаленных систем управления базами данных, интегрированных с файловой системой для операционных систем, причем упомянутые считываемые компьютером команды содержат команды для
деления упомянутых данных, сохраненных в упомянутых системах управления базами данных, на программно-определенные блоки изменений;
последовательно перечисляют изменения к упомянутым данным и отслеживают упомянутые изменения из расчета на каждый блок изменений;
для каждой удаленной системы управления базой данных отслеживают состояние изменений сохраненных в ней данных, а также состояние изменений для множества других систем управления базой данных в сообществе синхронизации; и
с целью синхронизации идентифицируют новые изменения, сравнивая перечисленные изменения для конкретной системы управления базой данных с состоянием изменений для этой системы управления базой данных.
23. Считываемый компьютером носитель по п.22, дополнительно содержащий команды, посредством которых первая система управления базой данных - точная копия - инициализируется в операционной системе, которая непосредственно поддерживает основанную на Порциях данных синхронизацию, и при этом удаленная система управления базой данных - источник данных - инициализируется в операционной системе, которая непосредственно не поддерживает основанную на Порциях данных синхронизацию, причем упомянутый способ дополнительно содержит использование адаптера для виртуализации удаленной системы управления базой данных посредством интерфейса прикладного программирования синхронизации.
24. Считываемый компьютером носитель по п.23, дополнительно содержащий обнаружение конфликтов синхронизации на уровне степени детализации блока изменений.
25. Считываемый компьютером носитель по п.23, дополнительно содержащий
сообщение экземплярами об успехе, неудаче и/или конфликтах на уровне индивидуального блока изменений относительно применения изменений; и использование прикладными программами данных синхронизации для обновления состояния серверной части.
26. Считываемый компьютером носитель, содержащий считываемые компьютером команды для синхронизации точной копии с источником данных, в котором и упомянутая точная копия и упомянутый источник данных имеют информацию состояния об изменениях, которая поддерживается каждым партнером синхронизации, и в котором упомянутый источник данных использует адаптер для взаимодействия с аппаратной/программной интерфейсной системой упомянутой точной копии, причем упомянутые считываемые компьютером команды содержат команды для упомянутой точной копии для посылки упомянутому адаптеру обновленной информации о состоянии для упомянутой точной копии, которая на основании последней информации о состоянии для упомянутого источника данных отражает изменения, которые были сделаны с момента последней синхронизации, как отражено в упомянутой последней информации о состоянии для упомянутого источника данных, так что упомянутый адаптер, принимая упомянутую обновленную информацию о состоянии для упомянутой точной копии и упомянутые новые изменения, может применять политику разрешения конфликтов, выбранную из множества политик разрешения конфликтов, может реализовать столько изменений в источнике данных насколько возможно в отношении конкретной политики разрешения конфликтов, и отслеживать успех или неудачу для каждого изменения по принципу - блок изменений за блоком изменений.
27. Считываемый компьютером носитель по п.26, дополнительно содержащий команды для упомянутой аппаратной/программной интерфейсной системы точной копии, хранящей упомянутую информацию о новом состоянии для упомянутого источника данных для будущего использования упомянутой точной копией, при условии, что упомянутый адаптер вычислил новое состояние источника данных на основании успеха или неудачи для каждого изменения по принципу - блок изменений за блоком изменений, и имея эту информацию о новом состоянии, передал эту информацию о новом состоянии к аппаратной/программной интерфейсной системе точной копии.
28. Считываемый компьютером носитель по п.26, в котором упомянутый адаптер передает к аппаратной/программной интерфейсной системе точной копии успех или неудачу для каждого изменения по принципу - блок изменений за блоком изменений, дополнительно содержащие команды для
упомянутой аппаратной/программной интерфейсной системы точной копии для вычисления информации о новом состоянии для источника данных, основываясь на успехе или неудаче для каждого изменения источника данных на основании - блок изменений за блоком изменений;
упомянутой аппаратной/программной интерфейсной системы точной копии для передачи информации о новом состоянии на адаптер и сохранения упомянутой информации о новом состоянии для будущего использования упомянутой точной копией, так чтобы упомянутый адаптер мог принимать и сохранять упомянутую информацию о новом состоянии.
| US 6553391 B1, 22.04.2003 | |||
| СПОСОБ ОБРАЩЕНИЯ К ДАННЫМ, ХРАНИМЫМ В КОМПЬЮТЕРНОЙ СИСТЕМЕ, СПОСОБ АРХИВИРОВАНИЯ ДАННЫХ И КОМПЬЮТЕРНАЯ СИСТЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБОВ | 1995 |
|
RU2182360C2 |
| US 5774717 A, 30.06.1998 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 6088694 A, 11.07.2000. | |||

