Область техники
Настоящее изобретение, в целом, относится к трансформации шкалы времени, т.е. расширению или сжатию, кадров в вокодере и, в частности, к способам трансформации шкалы времени кадров в широкополосном вокодере.
Уровень техники
Трансформация шкалы времени имеет ряд применений в сетях с коммутацией пакетов, где пакеты вокодера могут поступать асинхронно. Хотя трансформация шкалы времени может осуществляться как внутри, так и вне вокодера, его осуществление внутри вокодера обеспечивает ряд преимуществ, как то более высокое качество кадров с трансформированной шкалой времени и снижение вычислительной нагрузки.
Раскрытие изобретения
Изобретение предусматривает устройство и способ трансформации шкалы времени речевых кадров путем манипулирования речевым сигналом. Согласно одному аспекту раскрыт способ трансформации шкалы времени кадров линейного предсказания с кодовым возбуждением (CELP) и линейного предсказания с шумовым возбуждением (NELP) на широкополосном вокодере типа вокодера четвертого поколения (4GV). В частности, для кадров CELP, способ поддерживает фазу речи путем добавления или удаления периодов основного тона для расширения или сжатия речи соответственно. Согласно этому способу низкополосный сигнал можно подвергать трансформации шкалы времени в остатке, т.е. до синтеза, тогда как высокополосный сигнал может подвергаться трансформации шкалы времени после синтеза в области 8 кГц. Раскрытый способ можно применять к любому широкополосному вокодеру, который использует CELP и/или NELP для низкой полосы и/или использует метод расщепления полосы для кодирования низкой и верхней полосы по отдельности. Следует заметить, что стандарты для широкополосного 4GV называются EVRC-C.
В виду вышеизложенного описанные признаки изобретения, в целом, относятся к одной или нескольким усовершенствованным системам, способам и/или устройствам для передачи речи. В одном варианте осуществления изобретение предусматривает способ передачи речи, содержащий трансформацию шкалы времени остаточного низкополосного речевого сигнала в растянутую или сжатую версию остаточного низкополосного речевого сигнала, трансформацию шкалы времени высокополосного речевого сигнала в растянутую или сжатую версию высокополосного речевого сигнала, и объединение подвергнутых трансформации шкалы времени низкополосного и высокополосного речевых сигналов для получения полного трансформированного по шкале времени речевого сигнала. Согласно одному аспекту изобретения остаточный низкополосный речевой сигнал синтезируется после трансформации шкалы времени остаточного низкополосного сигнала, тогда как в верхней полосе синтез осуществляется до трансформации шкалы времени высокополосного речевого сигнала. Способ может дополнительно содержать этапы, на которых классифицируют сегменты речи и кодируют сегменты речи. Кодирование сегментов речи может представлять собой одно из кодирования линейного предсказания с кодовым возбуждением, кодирования линейного предсказания с шумовым возбуждением или кодирования 1/8 кадра (пауза). Низкая полоса может представлять собой частотный диапазон до приблизительно 4 кГц, и верхняя полоса может представлять собой частотный диапазон от приблизительно 3,5 кГц до приблизительно 7 кГц.
Согласно другому варианту осуществления раскрыт вокодер, имеющий, по меньшей мере, один вход и, по меньшей мере, один выход, причем вокодер содержит кодер, содержащий фильтр, имеющий, по меньшей мере, один вход, оперативно соединенный с входом вокодера, и, по меньшей мере, один выход; и декодер, содержащий синтезатор, имеющий, по меньшей мере, один вход, оперативно соединенный с, по меньшей мере, одним выходом кодера, и, по меньшей мере, один выход, оперативно соединенный с, по меньшей мере, одним выходом вокодера. В этом варианте осуществления декодер содержит память, причем декодер способен выполнять программные инструкции, хранящиеся в памяти, содержащие трансформацию шкалы времени остаточного низкополосного речевого сигнала в растянутую или сжатую версию остаточного низкополосного речевого сигнала, трансформацию шкалы времени высокополосного речевого сигнала в растянутую или сжатую версию высокополосного речевого сигнала, и объединение подвергнутых трансформации шкалы времени низкополосного и высокополосного речевых сигналов для получения полного трансформированного по шкале времени речевого сигнала. Синтезатор может содержать средство для синтеза трансформированного по шкале времени остаточного низкополосного речевого сигнала и средство для синтеза высокополосного речевого сигнала до его трансформации шкалы времени. Кодер содержит память и может выполнять программные инструкции, хранящиеся в памяти, содержащие классификацию сегментов речи как 1/8 кадра (пауза), линейного предсказания с кодовым возбуждением или линейного предсказания с шумовым возбуждением.
Дополнительный объем применимости настоящего изобретения явствует из нижеследующего подробного описания, формулы изобретения и чертежей. Однако следует понимать, что подробное описание и конкретные примеры, хотя и указывают предпочтительные варианты осуществления изобретения, приведены исключительно в порядке иллюстрации, поскольку специалисту в данной области техники будут ясны различные изменения и модификации в рамках сущности и объема изобретения.
Краткое описание чертежей
Настоящее изобретение будет лучше понятно из нижеприведенного подробного описания, прилагаемой формулы изобретения и прилагаемых чертежей, на которых:
фиг. 1 - блок-схема вокодера на основе кодирования линейного предсказания (LPC);
фиг. 2A - речевой сигнал, содержащий вокализованную речь;
фиг. 2B - речевой сигнал, содержащий невокализованную речь;
фиг. 2C - речевой сигнал, содержащий переходную речь;
фиг. 3 - блок-схема трансформации шкалы времени низкой полосы и высокой полосы;
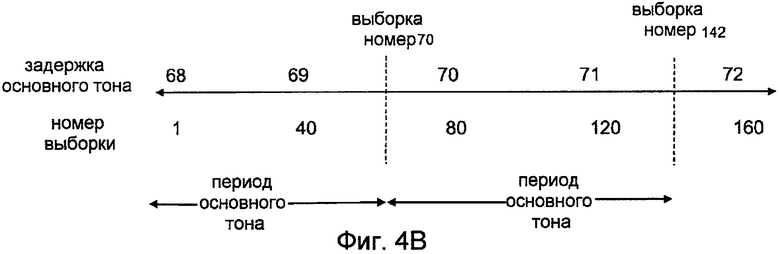
фиг. 4A - определение задержек основного тона путем интерполяции;
фиг. 4B - идентификация периодов основного тона;
фиг. 5A - представляет исходный речевой сигнал в форме периодов основного тона;
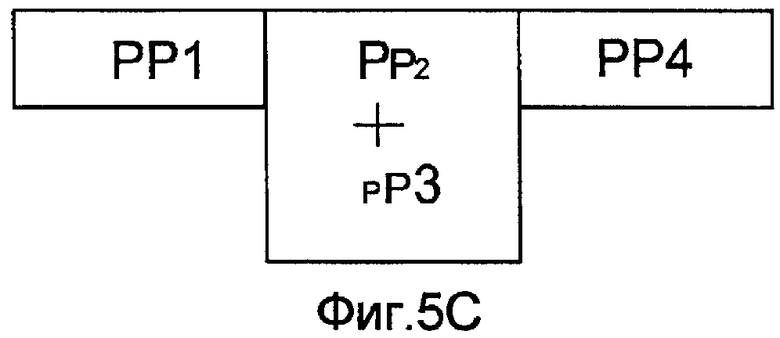
фиг. 5B - представляет речевой сигнал, растянутый с использованием перекрытия/суммирования; и
фиг. 5C представляет речевой сигнал, сжатый с использованием перекрытия/суммирования.
Осуществление изобретения
Слово “иллюстративный” используется в данном документе в смысле “служащий примером, экземпляром или иллюстрацией”. Любой вариант осуществления, описанный здесь как “иллюстративный”, не обязательно рассматривается как предпочтительный или имеющий преимущество над другими вариантами осуществления.
Трансформация шкалы времени имеет ряд применений в сетях с коммутацией пакетов, где пакеты вокодера могут поступать асинхронно. Хотя трансформация шкалы времени может осуществляться как внутри, так и вне вокодера, ее осуществление внутри вокодера обеспечивает ряд преимуществ, как то более высокое качество трансформированных по шкале времени кадров и снижение вычислительной нагрузки. Описанные здесь методы можно легко применять к другим вокодерам, в которых используются аналогичные методы, например широкополосный 4GV, стандарты которого называются EVRC-C, для кодирования речевых данных.
Описание функциональных возможностей вокодера
Человеческие голоса содержат два компонента. Один компонент содержит основные волны, чувствительные к основному тону, и другой содержит фиксированные гармоники, нечувствительные к основному тону. Воспринимаемый основной тон звука является реакцией уха на частоту, т.е. для большинства практических целей основной тон является частотой. Гармонические компоненты добавляют отличительные особенности голосу человека. Они зависят от голосовых связок и физической формы речевого тракта и называются формантами.
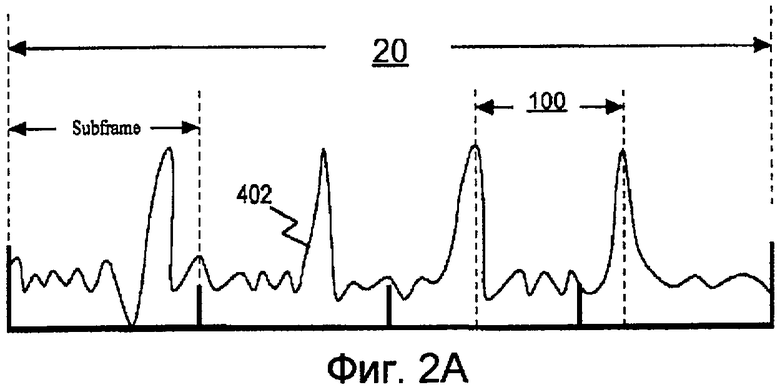
Человеческий голос можно представить цифровым сигналом s(n) 10 (см. фиг. 1). Пусть s(n) 10 это цифровой речевой сигнал, полученный в результате типичного преобразования и включающий в себя различные вокальные звуки и периоды молчания. Речевой сигнал s(n) 10 можно разделить на кадры 20, как показано на фиг. 2A-2C. Согласно одному аспекту s(n) 10 получен путем дискретизации на частоте 8 кГц. Согласно другим аспектам s(n) 10 можно дискретизировать на частоте 16 кГц или 32 кГц или на какой-либо другой частоте дискретизации.
Современные схемы кодирования сжимают оцифрованный речевой сигнал 10 в сигнал с низкой битовой скоростью путем удаления всех естественных избытков (т.е. коррелированных элементов), свойственных речи. Речь обычно демонстрирует кратковременные избытки, возникающие в результате механического действия губ и языка, долговременные избытки, возникающие в результате вибрации голосовых связок. Кодирование линейного предсказания (LPC) фильтрует речевой сигнал 10 путем удаления избытков, создавая остаточный речевой сигнал. Затем оно моделирует результирующий остаточный сигнал в виде белого гауссова шума. Дискретизированное значение речевого сигнала можно прогнозировать путем взвешенного суммирования ряда предыдущих выборок, каждая из которых умножается на коэффициент линейного предсказания. Таким образом, кодеры линейного предсказания достигают сниженной битовой скорости путем передачи коэффициентов фильтра и квантованного шума вместо речевого сигнала 10 во всей полосе.
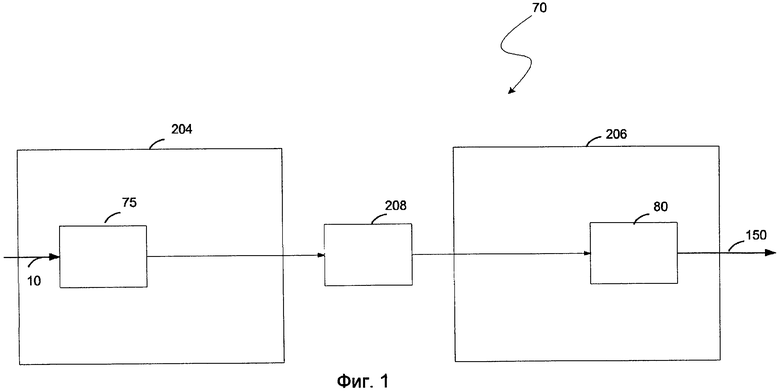
На фиг. 1 показана блок-схема одного варианта осуществления LPC-вокодера 70. Функция LPC состоит в минимизации суммы квадратов разностей между исходным речевым сигналом и оценочным речевым сигналом на конечном интервале. Это позволяет создавать уникальное множество коэффициентов предсказания, которые обычно оцениваются для каждого кадра 20. Кадр 20 обычно имеет длительность 20 мс. Передаточную функцию переменного по времени цифрового фильтра 75 можно задать в виде:
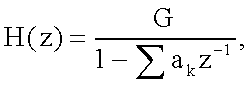
где коэффициенты предсказания можно представить как a k, и коэффициент усиления как G.
Суммирование производится от k = 1 до k = p. Если используется метод LPC-10, то p = 10. Это значит, что только первые 10 коэффициентов передаются на синтезатор LPC 80. Два наиболее часто используемых метода вычисления коэффициентов - это метод ковариаций и метод автокорреляции, без ограничения ими.
Типичные вокодеры создают кадры 20 длительностью 20 мс, включающие в себя 160 выборок на предпочтительной частоте 8 кГц или 320 выборок на частоте 16 кГц. Версия этого кадра 20, трансформированная по шкале времени со сжатием, имеет длительность менее 20 мс, тогда как версия, трансформированная по шкале времени с растяжением, имеет длительность более 20 мс. Трансформация шкалы времени речевых данных имеет значительные преимущества при передаче речевых данных по сетям с коммутацией пакетов, которые вносят дрожание задержки в передачу речевых пакетов. В таких сетях трансформация шкалы времени может использоваться для ослабления таких эффектов, как дрожание задержки, и для создания речевого потока, который выглядит “синхронным”.
Варианты осуществления изобретения относятся к устройству и способу для трансформации шкалы времени кадров 20 на вокодере 70 за счет манипулирования остаточным речевым сигналом. В одном варианте осуществления настоящие способ и устройство используется в широкополосном 4GV. Раскрытые варианты осуществления содержат способы и устройства или системы для растяжения/сжатия разных типов сегментов речи широкополосного 4GV, закодированных с использованием кодирования на основе линейного предсказания с кодовым возбуждением (CELP) или линейного предсказания с шумовым возбуждением (NELP).
Термин “вокодер” 70 обычно относится к устройствам, которые сжимают вокализованную речь путем извлечения параметров на основании модели генерации человеческой речи. Вокодеры 70 включают в себя кодер 204 и декодер 206. Кодер 204 анализирует входной речевой сигнал и извлекает нужные параметры. В одном варианте осуществления кодер содержит фильтр 75. Декодер 206 синтезирует речевой сигнал с использованием параметров, которые он принимает от кодера 204, по каналу связи 208. В одном варианте осуществления декодер содержит синтезатор 80. Речевой сигнал 10 часто делится на кадры 20 данных и блок, обрабатываемый вокодером 70.
Специалистам в данной области техники очевидно, что человеческую речь можно классифицировать многими разными способами. Три традиционных разновидности речи представляют собой вокализованные, невокализованные звуки и переходную речь.
На фиг. 2A показан вокализованный речевой сигнал s(n) 402. На фиг. 2A показано измеримое общее свойство вокализованного речевого сигнала, известное как период 100 основного тона.
На фиг. 2B показан невокализованный речевой сигнал s(n) 404. Невокализованный речевой сигнал 404 напоминает окрашенный шум.
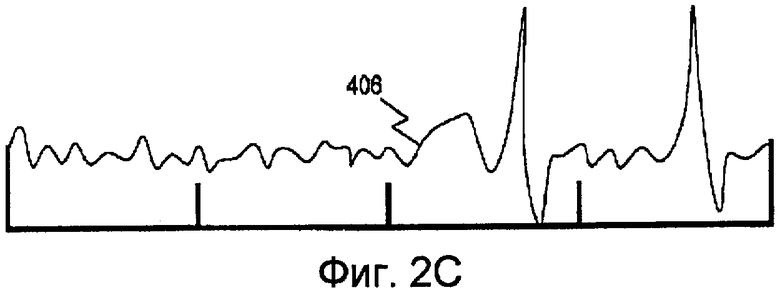
На фиг. 2C показан переходный речевой сигнал s(n) 406, т.е. речь, которая не является ни вокализованной, ни невокализованной. Пример переходной речи 406, показанной на фиг. 2C, может представлять собой сигнал s(n), промежуточный между невокализованной речью и вокализованной речью. Эти три разновидности не являются исключительными. Существует много других разновидностей речи, которые можно реализовать согласно описанным здесь способам для достижения сравнимых результатов.
Широкополосный вокодер 4GV
Вокодер четвертого поколения (4GV) обеспечивает привлекательные признаки для использования в беспроводных сетях, которые дополнительно описаны в совместно рассматриваемой патентной заявке № 11/123,467, поданной 5 мая 2005 г., под названием “Time Warping Frames Inside the Vocoder by Modifying the Residual”, которая полностью включена в настоящий документ посредством ссылки. Некоторые из этих признаков включают в себя возможность компромисса между качеством и битовой скоростью, повышения отказоустойчивости речевого кодирования при наличии повышенной частоты пакетной ошибки (PER), улучшения маскирования стираний и т.д. В настоящем изобретении раскрыт широкополосный вокодер 4GV, который кодирует речевой сигнал с использованием метода расщепления полосы, т.е. низкая и верхняя полосы кодируются по отдельности.
В одном варианте осуществления входной сигнал представляет широкополосный речевой сигнал, дискретизированный на частоте 16 кГц. Банк фильтров анализа предусмотрен для генерации узкополосного (низкополосного) сигнала, дискретизированного на частоте 8 кГц, и высокополосного сигнала, дискретизированного на частоте 7 кГц. Этот высокополосный сигнал представляет полосу от примерно 3,5 кГц до примерно 7 кГц во входном сигнале, тогда как низкополосный сигнал представляет полосу до примерно 4 кГц, и окончательно реконструированный широкополосный сигнал будет ограничен полосой до примерно 7 кГц. Заметим, что существует перекрытие примерно на 500 Гц между низкой и высокой полосами, допускающее более плавный переход между полосами.
В одном аспекте узкополосный сигнал кодируется с использованием модифицированной версии узкополосного речевого кодера EVRC-B, который является CELP-кодером с размером кадра 20 миллисекунд. Несколько сигналов от узкополосного кодера используются для анализа и синтеза высокой полосы; это: (1) сигнал возбуждения (т.е. квантованный остаток) от узкополосного кодера; (2) квантованный первый коэффициент отражения (в качестве индикатора спектрального наклона узкополосного сигнала); (3) квантованный коэффициент усиления адаптивной кодовой книги; и (4) квантованное отставание основного тона.
Модифицированный узкополосный кодер EVRC-B, используемый в широкополосном 4GV, кодирует речевые данные каждого кадра в один из трех разных типов кадра: линейного предсказания с кодовым возбуждением (CELP); линейного предсказания с шумовым возбуждением (NELP); или кадр паузы 1/8 скорости.
CELP используется для кодирования большинства речевых сигналов, которые включают в себя речь, которая является периодической, а также которая обладает слабой периодичностью. Обычно около 75% кадров, не содержащих пауз, кодируются модифицированным узкополосным кодером EVRC-B с использованием CELP.
NELP используется для кодирования речевого сигнала, сходного с шумом. Шумоподобный характер таких сегментов речи можно реконструировать путем генерации случайных сигналов на декодере и применения к ним соответствующих коэффициентов усиления.
Кадры 1/8 скорости используются для кодирования фонового шума, т.е. периодов, когда пользователь не говорит.
Трансформация шкалы времени кадров широкополосного 4GV
Поскольку широкополосный вокодер 4GV кодирует нижнюю и верхнюю полосы по отдельности, тот же подход применяется к трансформации шкалы времени кадров. Нижняя полоса трансформируется по шкале времени с использованием метода, аналогичного описанному в вышеупомянутой совместно рассматриваемой патентной заявке под названием “Time Warping Frames Inside the Vocoder by Modifying the Residual”.
На фиг. 3 показана трансформация 32 в нижней полосе, которая применяется к остаточному сигналу 30. Основная причина для осуществления трансформации 32 шкалы времени остаточного сигнала состоит в том, что это позволяет применять LPC-синтез 34 к подвернутому трансформации шкалы времени остаточному сигналу. Коэффициенты LPC играют важную роль в том, как звучит речь, и применение синтеза 34 после трансформации 32 гарантирует, что в сигнале поддерживается верная информация LPC. Если, с другой стороны, трансформация шкалы времени осуществляется после декодера, LPC-синтез уже произведен до трансформации шкалы времени. Таким образом, процедура трансформации может изменять информацию LPC сигнала, в особенности, если оценка периода основного тона не очень точна.
Трансформация шкалы времени остаточного сигнала, когда сегмент речи является CELP
Для трансформации остатка декодер использует информацию задержки основного тона, содержащуюся в кодированном кадре. Эта задержка основного тона фактически является задержкой основного тона в конце кадра. Заметим, что даже в периодическом кадре задержка основного тона может немного изменяться. Задержки основного тона в любой точке кадра можно оценить путем интерполяции между задержкой основного тона в конце последнего кадра и в конце текущего кадра. Это показано на фиг. 4. Когда задержки основного тона во всех точках кадра известны, кадр можно разделить на периоды основного тона. Границы периодов основного тона определяются с использованием задержек основного тона в различных точках кадра.
На фиг. 4A показан пример деления кадра на его периоды основного тона. Например, выборка номер 70 имеет задержку основного тона около 70 и выборка номер 142 имеет задержку основного тона около 72. Таким образом, периоды основного тона составляют [1-70] и [71-142]. Это показано на фиг. 4B.
Когда кадр разделен на периоды основного тона, эти периоды основного тона можно затем перекрывать/суммировать для увеличения/уменьшения размера остатка. Метод перекрытия/суммирования является известным методом, и на фиг. 5A-5C показано, как он используется для растяжения/сжатия остатка.
Альтернативно, периоды основного тона можно повторять, если необходимо растянуть речевой сигнал. Например, на фиг. 5B, период основного тона PP1 можно повторять (вместо перекрытия-суммирования с PP2) для создания дополнительного периода основного тона.
Кроме того, перекрытие/суммирование и/или повторение периодов основного тона можно производить необходимое число раз для обеспечения необходимой величины растяжения/сжатия.
На фиг. 5A показан исходный речевой сигнал, содержащий 4 периода основного тона (PP). На фиг. 5B показано, как этот речевой сигнал можно растянуть с использованием перекрытия/суммирования. Согласно фиг. 5B периоды основного тона PP2 и PP1 перекрываются/суммируются так, чтобы вклад PP2 уменьшался, и чтобы вклад PP1 увеличивался. На фиг. 5C показано, как используется перекрытие/суммирование для сжатия остатка.
В случаях, когда период основного тона изменяется, метод перекрытия-суммирования может требовать объединения двух периодов основного тона неравной длины. В этом случае лучшее объединение может достигаться путем выравнивания пиков двух периодов основного тона до их перекрытия/суммирования.
Наконец, растянутый/сжатый остаток проходит через LPC-синтез.
После трансформации шкалы нижней полосы верхняя полоса должна быть подвергнута трансформации шкалы с использованием периода основного тона из нижней полосы, т.е. для растяжения, период основного тона выборок добавляется, а для сжатия период основного тона удаляется.
Процедура трансформации шкалы верхней полосы отличается от соответствующей процедуры для нижней полосы. Согласно фиг. 3 верхняя полоса не подвергается трансформации шкалы в остаточном сигнале, но зато трансформация 38 шкалы производится после синтеза 36 верхнеполосных выборок. Причина этого в том, что верхняя полоса дискретизируется на частоте 7 кГц, тогда как нижняя полоса дискретизируется на частоте 8 кГц. Таким образом, период основного тона нижней полосы (дискретизированной на частоте 8 кГц) может содержать дробное количество выборок, когда частота дискретизации равна 7 кГц, как в верхней полосе. Например, если период основного тона равен 25 в нижней полосе, в остаточной области верхней полосы, это потребует добавления/удаления 25·7/8 = 21,875 выборок из остатка верхней полосы. Очевидно, поскольку невозможно сгенерировать дробное количество выборок, верхняя полоса трансформируется 38 после ее повторной дискретизации на 8 кГц, что имеет место после синтеза 36.
После трансформации шкалы нижней полосы 32 нижнеполосное возбуждение без трансформации шкалы (состоящее из 160 выборок) передается на высокополосный декодер. С использованием этого низкополосного возбуждения без трансформации шкалы высокополосный декодер создает 140 выборок высокой полосы на частоте 7 кГц. Эти 140 выборок затем проходят через фильтр синтеза 36 и повторно дискретизируются на 8 кГц с образованием 160 верхнеполосных выборок.
Эти 160 выборок на частоте 8 кГц затем подвергаются трансформации 38 шкалы времени с использованием периода основного тона из нижней полосы и метода перекрытия/суммирования, используемого для трансформации шкалы низкополосного сегмента речи CELP.
Наконец, верхняя и нижняя полосы суммируются или объединяются для получения полного трансформированного по шкале времени сигнала.
Трансформация шкалы времени остаточного сигнала, когда сегмент речи является NELP
Для сегментов речи NELP кодер кодирует только информацию LPC, а также коэффициенты усиления разных частей сегмента речи для нижней полосы. Коэффициенты усиления можно кодировать в “сегменты” по 16 выборок PCM в каждом. Таким образом, нижнюю полосу можно представить в виде 10 кодированных значений коэффициента усиления (по одному на каждые 16 выборок речевого сигнала).
Декодер генерирует низкополосный остаточный сигнал путем генерации случайных значений с последующим применением к ним соответствующих коэффициентов усиления. В этом случае концепция периода основного тона не применяется, и поэтому растяжение/сжатие нижней полосы не связано с разбиением на периоды основного тона.
Для растяжения/сжатия нижней полосы кадра, кодированного на основе NELP, декодер может генерировать количество сегментов, большее/меньшее, чем 10. Растяжение/сжатие нижней полосы в этом случае кратно 16 выборкам, что дает N = 16·n выборок, где n - количество сегментов. В случае растяжения дополнительно добавляемые сегменты могут принимать коэффициенты усиления некоторой функции первых 10 сегментов. Например, дополнительные сегменты могут принимать коэффициент усиления 10-го сегмента.
Альтернативно, декодер может растягивать/сжимать нижнюю полосу кадра, кодированного на основе NELP, применяя 10 декодированных коэффициентов усиления к множествам из y (вместо 16) выборок для генерации растянутого (y>16) или сжатого (y<16) низкополосного остатка.
Затем растянутый/сжатый остаток проходит через LPC-синтез для создания низкополосного подвергнутого трансформации шкалы сигнала.
После трансформации шкалы нижней полосы нижнеполосное возбуждение без трансформации шкалы (состоящее из 160 выборок) передается на высокополосный декодер. С использованием этого низкополосного возбуждения без трансформации шкалы высокополосный декодер создает 140 выборок верхней полосы на частоте 7 кГц. Эти 140 выборок затем проходят через фильтр синтеза и повторно дискретизируются на 8 кГц с образованием 160 верхнеполосных выборок.
Эти 160 выборок на частоте 8 кГц затем подвергаются трансформации шкалы времени по аналогии с верхнеполосной трансформацией шкалы сегментов речи CELP, т.е. с использованием перекрытия/суммирования. При использовании перекрытия/ суммирования для высокополосного NELP величина сжатия/ растяжения такая же, как величина, используемая для нижней полосы. Другими словами, “перекрытие”, используемое для метода перекрытия/суммирования, предполагается равным величине растяжения/сжатия в нижней полосе. Например, если нижняя полоса создала 192 выборок после трансформации шкалы, период перекрытия, используемый в методе перекрытия/суммирования, равен 192-160=32 выборкам.
Наконец, верхняя и нижняя полосы суммируются для обеспечения полного трансформированного по шкале времени сегмента речи NELP.
Специалистам в данной области техники будет очевидно, что информацию и сигналы можно представить с использованием разнообразных технологий и методов. Например, данные, инструкции, команды, информация, сигналы, биты, символы и элементарные сигналы, которые могли быть упомянуты в вышеприведенном описании, можно представить напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями, или частицами, или любой их комбинацией.
Специалистам в данной области техники будет очевидно, что различные иллюстративные логические блоки, модули, схемы и этапы алгоритма, описанные в связи с раскрытыми здесь вариантами осуществления, можно реализовать в виде электронного оборудования, компьютерного программного обеспечения или их комбинации. Чтобы отчетливо проиллюстрировать эту взаимозаменяемость оборудования и программного обеспечения, различные иллюстративные компоненты, блоки, модули, схемы и этапы были описаны выше, в целом, в отношении их функций. Реализовать ли такие функции в виде оборудования или программного обеспечения, зависит от конкретного применения и конструкционных ограничений, налагаемых на систему в целом. Специалисты могут реализовать описанные функции по-разному для каждого конкретного применения, но такие решения по реализации не следует интерпретировать как вызывающие отход от объема настоящего изобретения.
Различные иллюстративные логические блоки, модули и схемы, описанные в связи с раскрытыми здесь вариантами осуществления, можно реализовать или осуществлять посредством процессора общего назначения, цифрового сигнального процессора (ЦСП), специализированной интегральной схемы (СИС), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства, дискретной вентильной или транзисторной логики, дискретных аппаратных компонентов или любой их комбинации, предназначенных для осуществления описанных здесь функций. Процессор общего назначения может представлять собой микропроцессор, но, альтернативно, процессор может представлять собой любой традиционный процессор, контроллер, микроконтроллер или конечный автомат. Процессор также может быть реализован как комбинация вычислительных устройств, например комбинация ЦСП и микропроцессора, совокупность микропроцессоров, один или несколько микропроцессоров в сочетании с ядром ЦСП или любая другая подобная конфигурация.
Этапы способа или алгоритма, описанные в связи с раскрытыми здесь вариантами осуществления, могут быть реализованы непосредственно в оборудовании, в программном модуле, выполняемом процессором, или в их комбинации. Программный модуль может размещаться в оперативной памяти (ОЗУ), флэш-памяти, постоянной памяти (ПЗУ), электронно-программируемом ПЗУ (ЭППЗУ), электрически стираемом программируемом ПЗУ (ЭСППЗУ), в регистрах, на жестком диске, сменном диске, CD-ROM, или носителе данных любого другого типа, известного в технике. Иллюстративный носитель данных подключен к процессору, в результате чего процессор может считывать с него информацию и записывать на него информацию. Альтернативно, носитель данных может образовывать с процессором единое целое. Процессор и носитель данных могут размещаться в СИС (специализированная интегральная схема). СИС может находиться в абонентской станции. Альтернативно, процессор и носитель данных могут размещаться в абонентской станции как дискретные компоненты.
Вышеприведенное описание раскрытых вариантов осуществления предоставлено, чтобы специалист в данной области мог использовать настоящее изобретение. Специалисту в данной области должны быть очевидны различные модификации этих вариантов осуществления, и что раскрытые здесь общие принципы можно применять к другим вариантам осуществления, не выходя за рамки сущности и объема изобретения. Таким образом, настоящее изобретение не ограничивается показанными здесь вариантами осуществления, но подлежит рассмотрению в широчайшем объеме, согласующемся с раскрытыми здесь принципами и новыми признаками.




Изобретение относится к трансформации шкалы времени, т.е. расширению или сжатию, кадров в вокодере и, в частности, к способам трансформации шкалы времени кадров в широкополосном вокодере. Техническим результатом является повышение качества трансформированных по шкале времени кадров и снижение вычислительной нагрузки. Указанный технический результат достигается тем, что способ передачи речи включает трансформацию шкалы времени остаточного низкополосного речевого сигнала в растянутую или сжатую версию остаточного низкополосного речевого сигнала, трансформацию шкалы времени высокополосного речевого сигнала в растянутую или сжатую версию высокополосного речевого сигнала и объединение подвергнутых трансформации шкалы времени низкополосного и высокополосного речевых сигналов для получения полного трансформированного по шкале времени речевого сигнала. Трансформация шкалы времени высокополосного речевого сигнала содержит определение множества периодов основного тона из низкополосного речевого сигнала, использование периодов основного тона из низкополосного речевого сигнала и перекрытие/суммирование одного или нескольких периодов основного тона, если высокополосный речевой сигнал сжат, и перекрытие/суммирование или повторение одного или нескольких периодов основного тона, если высокополосный речевой сигнал растянут. Способ может дополнительно содержать этапы, на которых классифицируют сегменты речи и осуществляют кодирование линейного предсказания с кодовым возбуждением, линейного предсказания с шумовым возбуждением или кодирования 1/8 кадра (паузы). 2 н. и 49 з.п. ф-лы, 5 ил.
1. Способ передачи речи, содержащий:
трансформацию шкалы времени остаточного низкополосного речевого сигнала в растянутую или сжатую версию остаточного низкополосного речевого сигнала,
трансформацию шкалы времени высокополосного речевого сигнала в растянутую или сжатую версию высокополосного речевого сигнала, причем трансформация шкалы времени высокополосного речевого сигнала содержит:
определение множества периодов основного тона из низкополосного речевого сигнала,
использование периодов основного тона из низкополосного речевого сигнала,
перекрытие/суммирование одного или нескольких периодов основного тона, если высокополосный речевой сигнал сжат, и перекрытие/суммирование или повторение одного или нескольких периодов основного тона, если высокополосный речевой сигнал растянут, и
объединение подвергнутых трансформации шкалы времени низкополосного и высокополосного речевых сигналов для получения полного трансформированного по шкале времени речевого сигнала.
2. Способ по п.1, дополнительно содержащий синтезирование трансформированного по шкале времени остаточного низкополосного речевого сигнала.
3. Способ по п.2, дополнительно содержащий синтезирование высокополосного речевого сигнала до его трансформации шкалы времени.
4. Способ по п.3, дополнительно содержащий:
классифицирование сегментов речи и
кодирование сегментов речи.
5. Способ по п.4, в котором кодирование сегментов речи включает в себя использование линейного предсказания с кодовым возбуждением, линейное предсказание с шумовым возбуждением или кодирование 1/8 кадра.
6. Способ по п.4, в котором кодирование является кодированием линейного предсказания с кодовым возбуждением.
7. Способ по п.4, в котором кодирование является кодированием линейного предсказания с шумовым возбуждением.
8. Способ по п.7, в котором кодирование содержит кодирование информации кодирования линейного предсказания в качестве коэффициентов усиления разных частей речевого кадра.
9. Способ по п.8, в котором коэффициенты усиления кодируются для наборов выборок речи.
10. Способ по п.9, дополнительно содержащий генерацию остаточного низкополосного сигнала путем генерации случайных значений и затем применения коэффициентов усиления к случайным значениям.
11. Способ по п.9, дополнительно содержащий представление информации кодирования линейного предсказания в виде 10 кодированных значений коэффициента усиления для остаточного низкополосного речевого сигнала, причем каждое кодированное значение коэффициента усиления представляет 16 выборок речи.
12. Способ по п.7, дополнительно содержащий генерацию 140 выборок высокополосного речевого сигнала из не трансформированного по шкале низкополосного сигнала возбуждения.
13. Способ по п.7, в котором трансформация шкалы времени низкополосного речевого сигнала содержит генерацию большего/меньшего количества выборок и применение некоторой функции декодированных коэффициентов усиления частей речевого кадра к остатку с последующим его синтезированием.
14. Способ по п.13, в котором применение некоторой функции декодированных коэффициентов усиления частей речевого кадра к остатку содержит применение коэффициента усиления последнего сегмента речи к дополнительным выборкам, когда низкая полоса растянута.
15. Способ по п.7, в котором трансформация шкалы времени высокополосного речевого сигнала содержит:
перекрытие/суммирование того же количества выборок, которое было сжато в низкой полосе, если высокополосный речевой сигнал сжат, и
перекрытие/суммирование того же количества выборок, которое было растянуто в низкой полосе, если высокополосный речевой сигнал растянут.
16. Способ по п.6, в котором трансформация шкалы времени остаточного низкополосного речевого сигнала содержит:
оценивание, по меньшей мере, одного периода основного тона, и
прибавление или вычитание, по меньшей мере, одного периода основного тона после приема остаточного низкополосного речевого сигнала.
17. Способ по п.6, в котором трансформация шкалы времени остаточного низкополосного речевого сигнала содержит:
оценивание задержки основного тона,
деление речевого кадра на периоды основного тона, причем границы периодов основного тона определяются с использованием задержки основного тона в различных точках речевого кадра,
перекрытие/суммирование периодов основного тона, если остаточный низкополосный речевой сигнал сжат, и
перекрытие/суммирование или повторение одного или нескольких из периодов основного тона, если остаточный низкополосный речевой сигнал растянут.
18. Способ по п.17, в котором оценивание задержки основного тона включает в себя вычисление интерполяции между задержками основного тона в конце последнего кадра и в конце текущего кадра.
19. Способ по п.17, в котором перекрытие/суммирование или повторение одного или нескольких из периодов основного тона включает в себя объединение сегментов речи.
20. Способ по п.17, в котором перекрытие/суммирование или повторение одного или нескольких из периодов основного тона, если остаточный низкополосный речевой сигнал растянут, включает в себя добавление дополнительного периода основного тона, созданного из первого сегмента периода основного тона и второго сегмента периода основного тона.
21. Способ по п.19, дополнительно содержащий выбор аналогичных сегментов речи, причем аналогичные сегменты речи объединяются.
22. Способ по п.19, дополнительно содержащий определение корреляции между сегментами речи и выбор тем самым аналогичных сегментов речи.
23. Способ по п.20, в котором добавление дополнительного периода основного тона, созданного из первого сегмента периода основного тона и второго сегмента периода основного тона, включает в себя добавление первого и второго сегментов основного тона таким образом, чтобы вклад первого сегмента периода основного тона возрастал, а вклад второго сегмента периода основного тона убывал.
24. Способ по п.1, в котором низкая полоса представляет полосу до 4 кГц включительно.
25. Способ по п.1, в котором верхняя полоса представляет полосу от приблизительно 3,5 кГц до приблизительно 7 кГц.
26. Вокодер, имеющий, по меньшей мере, один вход и, по меньшей мере, один выход, содержащий:
кодер, содержащий фильтр, имеющий, по меньшей мере, один вход, оперативно соединенный с входом вокодера, и, по меньшей мере, один выход, и
декодер, содержащий:
синтезатор, имеющий, по меньшей мере, один вход, оперативно соединенный с, по меньшей мере, одним выходом кодера, и, по меньшей мере, один выход, оперативно соединенный с, по меньшей мере, одним выходом вокодера, и
память, причем декодер способен выполнять программные инструкции, сохраненные в памяти, содержащие:
трансформацию шкалы времени остаточного низкополосного речевого сигнала в растянутую или сжатую версию остаточного низкополосного речевого сигнала,
трансформацию шкалы времени высокополосного речевого сигнала в растянутую или сжатую версию высокополосного речевого сигнала, причем программная инструкция трансформации шкалы времени высокополосного речевого сигнала содержит определение множества периодов основного тона из низкополосного речевого сигнала, использование периодов основного тона из низкополосного речевого сигнала, перекрытие/суммирование одного или нескольких периодов основного тона, если высокополосный речевой сигнал сжат, и перекрытие/суммирование или повторение одного или нескольких периодов основного тона, если высокополосный речевой сигнал растянут, и
объединение подвергнутых трансформации шкалы времени низкополосного и высокополосного речевых сигналов для получения полного трансформированного по шкале времени речевого сигнала.
27. Вокодер по п.26, в котором синтезатор содержит средство для синтеза трансформированного по шкале времени остаточного низкополосного речевого сигнала.
28. Вокодер по п.27, в котором синтезатор дополнительно содержит средство для синтеза высокополосного речевого сигнала до его трансформации шкалы времени.
29. Вокодер по п.26, в котором кодер содержит память, и кодер способен выполнять программные инструкции, сохраненные в памяти, содержащие классификацию сегментов речи согласно 1/8 кадра, линейного предсказания с кодовым возбуждением или линейного предсказания с шумовым возбуждением.
30. Вокодер по п.28, в котором кодер содержит память, и кодер способен выполнять программные инструкции, сохраненные в памяти, содержащие кодирование сегментов речи с использованием кодирования линейного предсказания с кодовым возбуждением.
31. Вокодер по п.28, в котором кодер содержит память, и кодер способен выполнять программные инструкции, сохраненные в памяти, содержащие кодирование сегментов речи с использованием кодирования линейного предсказания с шумовым возбуждением.
32. Вокодер по п.31, в котором программная инструкция кодирования сегментов речи с использованием кодирования линейного предсказания с шумовым возбуждением содержит кодирование информации кодирования линейного предсказания в качестве коэффициентов усиления разных частей сегмента речи.
33. Вокодер по п.32, в котором коэффициенты усиления кодируются для наборов выборок речи.
34. Вокодер по п.33, в котором инструкция трансформации шкалы времени остаточного низкополосного речевого сигнала дополнительно содержит генерацию остаточного низкополосного речевого сигнала путем генерации случайных значений с последующим применением коэффициентов усиления к случайным значениям.
35. Вокодер по п.33, в котором инструкция трансформации шкалы времени остаточного низкополосного речевого сигнала дополнительно содержит представление информации кодирования линейного предсказания в виде 10 кодированных значений коэффициента усиления для остаточного низкополосного речевого сигнала, причем каждое кодированное значение коэффициента усиления представляет 16 выборок речи.
36. Вокодер по п.31, дополнительно содержащий создание 140 выборок высокополосного речевого сигнала из не трансформированного по шкале низкополосного сигнала возбуждения.
37. Вокодер по п.31, в котором программная инструкция трансформации шкалы времени низкополосного речевого сигнала содержит генерацию большего/меньшего количества выборок и применение некоторой функции декодированных коэффициентов усиления частей речевого кадра к остатку с последующим его синтезированием.
38. Вокодер по п.37, в котором применение некоторой функции декодированных коэффициентов усиления частей речевого кадра к остатку содержит применение коэффициента усиления последнего сегмента речи к дополнительным выборкам, когда низкая полоса растянута.
39. Вокодер по п.30, в котором программная инструкция трансформации шкалы времени высокополосного речевого сигнала содержит:
перекрытие/суммирование того же количества выборок, которое было сжато в низкой полосе, если высокополосный речевой сигнал сжат, и
перекрытие/суммирование того же количества выборок, которое было растянуто в низкой полосе, если высокополосный речевой сигнал растянут.
40. Вокодер по п.30, в котором программная инструкция трансформации шкалы времени остаточного низкополосного речевого сигнала содержит:
оценивание, по меньшей мере, одного периода основного тона, и
прибавление или вычитание, по меньшей мере, одного периода основного тона после приема остаточного низкополосного речевого сигнала.
41. Вокодер по п.30, в котором программная инструкция трансформации шкалы времени остаточного низкополосного речевого сигнала содержит:
оценивание задержки основного тона,
деление речевого кадра на периоды основного тона, причем границы периодов основного тона определяются с использованием задержки основного тона в различных точках речевого кадра,
перекрытие/суммирование периодов основного тона, если остаточный речевой сигнал сжат, и
перекрытие/суммирование или повторение одного или нескольких периодов основного тона, если остаточный речевой сигнал растянут.
42. Вокодер по п.41, в котором инструкция перекрытия/суммирования периодов основного тона, если остаточный низкополосный речевой сигнал сжат, содержит:
сегментирование входной последовательности выборок на блоки выборок,
удаление сегментов остаточного сигнала с регулярными временными интервалами,
объединение удаленных сегментов и
замену удаленных сегментов объединенным сегментом.
43. Вокодер по п.41, в котором инструкция оценивания задержки основного тона содержит интерполяцию между задержками основного тона в конце последнего кадра и в конце текущего кадра.
44. Вокодер по п.41, в котором инструкция перекрытия/суммирования или повторения одного или нескольких из периодов основного тона содержит объединение сегментов речи.
45. Вокодер по п.41, в котором инструкция перекрытия/суммирования или повторения одного или нескольких из периодов основного тона, если остаточный низкополосный речевой сигнал растянут, содержит добавление дополнительного периода основного тона, созданного из первого сегмента периода основного тона и второго сегмента периода основного тона.
46. Вокодер по п.42, в котором инструкция объединения удаленных сегментов содержит увеличение вклада первого сегмента периода основного тона и уменьшение вклада второго сегмента периода основного тона.
47. Вокодер по п.44, дополнительно содержащий выбор аналогичных сегментов речи, причем аналогичные сегменты речи объединяются.
48. Вокодер по п.44, в котором инструкция трансформации шкалы времени остаточного низкополосного речевого сигнала дополнительно содержит вычисление корреляции между сегментами речи, причем таким образом выбираются аналогичные сегменты речи.
49. Вокодер по п.45, в котором инструкция добавления дополнительного периода основного тона, созданного из первого и второго сегментов периода основного тона, содержит добавление первого и второго сегментов периода основного тона таким образом, чтобы вклад первого сегмента периода основного тона возрастал, и вклад второго сегмента периода основного тона убывал.
50. Вокодер по п.26, в котором низкая полоса представляет собой полосу до 4 кГц включительно.
51. Вокодер по п.26, в котором верхняя полоса представляет собой полосу от приблизительно 3,5 кГц до приблизительно 7 кГц.
| TAN R.K.C., LIN A.H.J., A time-scale modification algorithm based on the subband time-domain technique for broad-band signal applications, Journal of the audio engineering society, Audio engineering society, New York, NY, US, vol.48, №5, 05.2000 | |||
| US 2001023399 A1, 20.09.2001 | |||
| Огнегасительная смесь | 1958 |
|
SU122403A1 |
| Устройство для торможения приемоподающего узла лентопротяжного механизма магнитофона | 1978 |
|
SU680033A1 |
| US 2005137730 | |||

