Настоящая заявка на патент испрашивает приоритет по предварительной заявке № 60/943558, озаглавленной «METHOD AND APPARATUS FOR MODE SELECTION IN A GENERALIZED AUDIO CODING SYSTEM INCLUDING MULTIPLE CODING MODES» («СПОСОБ И УСТРОЙСТВО ДЛЯ ВЫБОРА РЕЖИМА В ОБОБЩЕННОЙ СИСТЕМЕ КОДИРОВАНИЯ АУДИО, ВКЛЮЧАЮЩЕЙ В СЕБЯ МНОГОЧИСЛЕННЫЕ РЕЖИМЫ КОДИРОВАНИЯ»), поданной 13 июня 2007 года, права на которую принадлежат правообладателю данной заявки.
УРОВЕНЬ ТЕХНИКИ
Область техники
Это раскрытие относится к кодированию аудиосигналов.
Уровень техники
Передача аудиоинформации, такой как речь и/или музыка, посредством цифровых технологий стала широко распространенной, в частности, в телефонии дальней связи, телефонии с коммутацией пакетов, такой как передача голоса по IP (также называемая VoIP, где IP обозначает протокол сети Интернет), и цифровой радиотелефонии, такой как сотовая телефония. Такое распространение создало заинтересованность в уменьшении объема информации, используемой для передачи речевых сообщений через канал передачи, наряду с сохранением воспринимаемого качества восстановленного речевого сигнала. Например, желательно сделать эффективным использование имеющейся в распоряжении ширины полосы системы (особенно в системах беспроводной связи). Один из путей для эффективного использования ширины полосы системы состоит в том, чтобы применять технологии сжатия сигнала. Для систем, которые переносят речевые сигналы, технологии сжатия речи (или «кодирования речевого сигнала») широко применяются для этой цели.
Устройства, которые сконфигурированы для сжатия речи посредством извлечения параметров, которые относятся к модели формирования человеческой речи, часто называются аудиокодерами, голосовыми кодерами, кодеками, вокодерами или речевыми кодерами, и в нижеследующем описании эти термины используются взаимозаменяемо. Аудиокодер обычно включает в себя кодер и декодер. Кодер типично принимает цифровой аудиосигнал в качестве последовательности блоков выборок, называемых «кадрами», анализирует каждый кадр для извлечения определенных существенных параметров и квантует параметры для создания соответствующей последовательности кодированных кадров. Кодированные кадры передаются по каналу передачи (то есть проводному или беспроводному сетевому соединению) в приемник, который включает в себя декодер. В качестве альтернативы, кодированный аудиосигнал может сохраняться для повторного извлечения и декодирования в более позднее время. Декодер принимает и обрабатывает кодированные кадры, деквантует их, чтобы сформировать параметры, и воссоздает кадры речевого сигнала с использованием деквантованных параметров.
Линейное предсказание с кодовым возбуждением («CELP») является схемой кодирования, которая пытается подобрать волновой (колебательный) сигнал для исходного аудиосигнала. Может быть желательным кодировать кадры речевого сигнала, особенно вокализованные кадры, с использованием варианта CELP, который назван ослабленным CELP («RCELP»). В схеме кодирования RCELP ограничения подбора волновых сигналов ослаблены. Схема кодирования RCELP является схемой кодирования с регуляризацией основных тонов, в которой изменение между периодами основных тонов сигнала (также называемое «профилем задержки») подвергается регуляризации, обычно посредством изменения относительных положений импульсов основных тонов, чтобы подбирать или аппроксимировать более гладкий синтетический профиль задержки. Регуляризация основных тонов типично обеспечивает возможность кодировать информацию об основных тонах с меньшим количеством битов и малым и даже отсутствующим снижением воспринимаемого качества. Типично, в декодер не передается никакой информации, предписывающей величины регуляризации. Следующие документы описывают системы кодирования, которые включают в себя схему кодирования RCELP: документ C.S0030-0, v3.0, Проекта 2 партнерства третьего поколения («3GPP2»), озаглавленный «Selectable Mode Vocoder (SMV) Service Option for Wideband Spread Spectrum Communication Systems» («Вариант услуги вокодера с выбираемым режимом (SMV) для широкополосных систем связи с расширенным спектром»), январь 2004 года (имеющийся в распоряжении в режиме прямого доступа на www.3gpp.org); и документ C.S0014-C, v1.0, 3GPP2, озаглавленный «Enhanced Variable Rate Codec, Speech Service Options 3, 68, and 70 for Wideband Spread Spectrum Digital Systems» («Улучшенный кодек с переменной скоростью кодирования, Варианты 3, 60 и 70 речевой услуги для широкополосной цифровой системы с расширенным спектром»), январь 2007 года (имеющийся в распоряжении в режиме прямого доступа на www.3gpp.org). Другие схемы кодирования для вокализованных кадров, включающие в себя схемы интерполяции волновым сигналом-прототипом («PWI»), такой как период основного тона прототипа («PPP»), также могут быть реализованы в качестве PR (например, как описано в части 4.2.4.3 документа C.S0014-C 3GPP2, указанного ссылкой выше). Обычные диапазоны частоты основного тона для говорящих абонентов-мужчин включают в себя от 50 или 70 до 150 или 200 Гц, а обычные диапазоны частоты основного тона для говорящих абонентов-женщин включают в себя от 120 или 140 до 300 или 400 Гц.
Аудиосвязь по коммутируемой телефонной сети общего пользования («PSTN») традиционно была ограничена по ширине полосы частотным диапазоном 300-3400 килогерц (кГц). Более новые сети для аудиосвязи, такие как сети, которые используют сотовую телефонию и/или VoIP, могут не иметь прежних ограничений ширины полосы, и может быть желательно, чтобы устройство, использующее такие сети, имело возможность передавать и принимать аудиосообщения, которые включают в себя широкополосный частотный диапазон. Например, может быть желательно, чтобы такое устройство поддерживало аудиочастотный диапазон, который тянется вниз до 50 Гц и/или вверх до 7 или 8 кГц. Также может быть желательно, чтобы такое устройство поддерживало другие применения, такие как высококачественное воспроизведение аудио или проведение аудио/видеоконференций, доставка мультимедийных услуг, таких как музыка и/или телевидение, и т.д., которые могут содержать речевой контент в диапазонах вне традиционных ограничений PSTN.
Расширение диапазона, поддерживаемого речевым кодером, до более высоких частот может улучшить разборчивость. Например, информация в речевом сигнале, которая отличает фрикативные звуки, такие как 's' и 'f', в значительной степени находится на высоких частотах. Широкополосное расширение также может улучшить другие качества декодированного речевого сигнала, такие как эффект присутствия. Например, даже вокализованный гласный звук может иметь спектральную энергию гораздо выше частотного диапазона PSTN.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Способ обработки кадров аудиосигнала согласно общей конфигурации включает в себя кодирование первого кадра аудиосигнала согласно схеме кодирования с регуляризацией основных тонов («PR») и кодирование второго кадра аудиосигнала согласно схеме кодирования без PR. В этом способе второй кадр сопровождает и является следующим за первым кадром в аудиосигнале, а кодирование первого кадра включает в себя временное модифицирование, на основании сдвига во времени, сегмента первого сигнала, который основан на первом кадре, где временное модифицирование включает в себя одно из (A) временного сдвига сегмента первого кадра согласно сдвигу во времени и (B) изменения шкалы времени сегмента первого сигнала на основании сдвига во времени. В этом способе временное модифицирование сегмента первого сигнала включает в себя изменение положения импульса основного тона сегмента относительно другого импульса основного тона первого сигнала. В этом способе кодирование второго кадра включает в себя временное модифицирование, на основании сдвига во времени, сегмента второго сигнала, который основан на втором кадре, где временное модифицирование включает в себя одно из (A) временного сдвига сегмента второго кадра согласно сдвигу во времени и (B) изменения шкалы времени сегмента второго сигнала на основании сдвига во времени. К тому же описаны машиночитаемые носители, содержащие команды для обработки кадров аудиосигнала таким образом, а также устройство и системы для обработки кадров аудиосигнала подобным образом.
Способ обработки кадров аудиосигнала согласно еще одной общей конфигурации включает в себя кодирование первого кадра аудиосигнала согласно первой схеме кодирования и кодирование второго кадра аудиосигнала согласно схеме кодирования с PR. В этом способе второй кадр следует и является следующим за первым кадром в аудиосигнале, а первая схема кодирования является схемой кодирования без PR. В этом способе кодирование первого кадра включает в себя временное модифицирование, на основании первого сдвига во времени, сегмента первого сигнала, который основан на первом кадре, где временное модифицирование включает в себя одно из (A) временного сдвига сегмента первого сигнала согласно первому сдвигу во времени и (B) изменения шкалы времени сегмента первого сигнала на основании первого сдвига во времени. В этом способе кодирование второго кадра включает в себя временное модифицирование, на основании второго сдвига во времени, сегмента второго сигнала, который основан на втором кадре, где временное модифицирование включает в себя одно из (A) временного сдвига сегмента второго сигнала согласно второму сдвигу во времени и (B) изменения шкалы времени сегмента второго сигнала на основании второго сдвига во времени. В этом способе временное модифицирование сегмента второго сигнала включает в себя изменение положения импульса основного тона сегмента относительно другого импульса основного тона второго сигнала, а второй сдвиг во времени основан на информации из подвергнутого временному модифицированию сегмента первого сигнала. К тому же описаны машинно-читаемые носители, содержащие команды для обработки кадров аудиосигнала таким образом, а также устройство и системы для обработки кадров аудиосигнала подобным образом.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 иллюстрирует пример системы беспроводной телефонной связи.
Фиг. 2 иллюстрирует пример системы сотовой телефонии, которая сконфигурирована для поддержки передачи данных с коммутацией пакетов.
Фиг. 3a иллюстрирует структурную схему системы кодирования, которая включает в себя аудиокодер AE10 и аудиодекодер AD10.
Фиг. 3b иллюстрирует структурную схему пары систем кодирования.
Фиг. 4a иллюстрирует структурную схему многорежимной реализации AE20 аудиокодера AE10.
Фиг. 4b иллюстрирует структурную схему многорежимной реализации AD20 аудиодекодера AD10.
Фиг. 5a иллюстрирует структурную схему реализации AE22 аудиокодера AE20.
Фиг. 5b иллюстрирует структурную схему реализации AE24 аудиокодера AE20.
Фиг. 6a иллюстрирует структурную схему реализации AE25 аудиокодера AE24.
Фиг. 6b иллюстрирует структурную схему реализации AE26 аудиокодера AE20.
Фиг. 7a иллюстрирует блок-схему последовательности операций способа M10 кодирования кадра аудиосигнала.
Фиг. 7b иллюстрирует структурную схему устройства F10, сконфигурированного для кодирования кадра аудиосигнала.
Фиг. 8 иллюстрирует пример остатка до и после изменения масштаба времени по профилю задержки.
Фиг. 9 иллюстрирует пример остатка до и после кусочного модифицирования.
Фиг. 10 иллюстрирует блок-схему последовательности операций способа RM100 кодирования RCELP.
Фиг. 11 иллюстрирует блок-схему последовательности операций реализации RM110 способа RM100 кодирования RCELP.
Фиг. 12a иллюстрирует структурную схему реализации RC100 кодера 34c кадров RCELP.
Фиг. 12b иллюстрирует структурную схему реализации RC110 кодера RC100 RCELP.
Фиг. 12c иллюстрирует структурную схему реализации RC105 кодера RC100 RCELP.
Фиг. 12d иллюстрирует структурную схему реализации RC115 кодера RC110 RCELP.
Фиг. 13 иллюстрирует структурную схему реализации R12 формирователя R10 остатка.
Фиг. 14 иллюстрирует структурную схему устройства для кодирования RCELP, RF100.
Фиг. 15 иллюстрирует блок-схему последовательности операций реализации RM120 способа RM100 кодирования RCELP.
Фиг. 16 иллюстрирует три примера типичной синусоидальной формы окна для схемы кодирования MDCT.
Фиг. 17a иллюстрирует структурную схему реализации ME100 кодера 34d MDCT.
Фиг. 17b иллюстрирует структурную схему реализации ME200 кодера 34d MDCT.
Фиг. 18 иллюстрирует один из примеров технологии оконной обработки, которая является иной, чем технология оконной обработки, проиллюстрированная на фиг. 16.
Фиг. 19a иллюстрирует блок-схему последовательности операций способа M100 обработки кадров аудиосигнала согласно общей конфигурации.
Фиг. 19b иллюстрирует блок-схему последовательности операций способа для реализации T112 этапа T110.
Фиг. 19c иллюстрирует блок-схему последовательности операций способа для реализации T114 этапа T112.
Фиг. 20a иллюстрирует структурную схему реализации ME110 кодера ME100 MDCT.
Фиг. 20b иллюстрирует структурную схему реализации ME210 кодера ME200 MDCT.
Фиг. 21a иллюстрирует структурную схему реализации ME120 кодера ME100 MDCT.
Фиг. 21b иллюстрирует структурную схему реализации ME130 кодера ME100 MDCT.
Фиг. 22 иллюстрирует структурную схему реализации ME140 кодеров ME120 и ME130 MDCT.
Фиг. 23a иллюстрирует блок-схему последовательности операций способа кодирования MDCT, MM100.
Фиг. 23b иллюстрирует структурную схему устройства для кодирования MDCT, MF100.
Фиг. 24a иллюстрирует блок-схему последовательности операций способа M200 обработки кадров аудиосигнала согласно общей конфигурации.
Фиг. 24b иллюстрирует блок-схему последовательности операций способа для реализации T622 этапа T620.
Фиг. 24c иллюстрирует блок-схему последовательности операций способа для реализации T624 этапа T620.
Фиг. 24d иллюстрирует блок-схему последовательности операций способа для реализации T626 этапов T622 и T624.
Фиг. 25a иллюстрирует пример области перекрытия и сложения, которая является следствием применения окон MDCT к следующим друг за другом кадрам аудиосигнала.
Фиг. 25b иллюстрирует пример применения сдвига во времени к последовательности кадров без PR.
Фиг. 26 иллюстрирует структурную схему устройства для аудиосвязи 1108.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Системы, способы и устройство, описанные в материалах настоящей заявки, могут использоваться для поддержки повышенного воспринимаемого качества во время переходов между схемами кодирования с PR и без PR в многорежимной системе кодирования аудио, особенно для систем кодирования, которые включают в себя схему кодирования без PR с перекрытием и сложением, такую как схема кодирования с модифицированным дискретным косинусным преобразованием («MDCT»). Конфигурации, описанные ниже, предположительно располагаются в системе связи беспроводной телефонии, сконфигурированной для применения эфирного интерфейса множественного доступа с кодовым разделением («CDMA»). Тем не менее, специалистам в данной области техники было бы понятно, что способ и устройство, имеющие признаки, подобные описанным в материалах настоящей заявки, могут находиться в любой из различных систем связи, применяющих широкий диапазон технологий, известных специалистам в данной области техники, таких как системы, применяющие передачу голоса по IP («VoIP») по проводным и/или беспроводным каналам передачи (например, CDMA, TDMA (множественного доступа с временным разделением), FDMA (множественного доступа с частотным разделением), и/или TD-SCDMA (множественного доступа с синхронизированными режимами временного и кодового разделения).
В настоящей заявке явным образом предусматривается и раскрывается, что конфигурации, раскрытые в материалах заявки, могут быть приспособлены для использования в сетях, которые могут быть сетями с коммутацией пакетов (например, проводных и/или беспроводных сетях, выполненных с возможностью передачи аудио согласно протоколам, таким как VoIP) и/или с коммутацией каналов. Также в настоящей заявке явным образом предусматривается и раскрывается, что конфигурации, раскрытые в материалах заявки, могут быть приспособлены для использования в узкополосных системах кодирования (например, системах, которые кодируют аудиочастотный диапазон около четырех или пяти килогерц) и для использования в широкополосных системах кодирования (например, системах, которые кодируют аудиочастоты больше, чем пять килогерц), в том числе широкополосных системах кодирования с целиковой полосой и широкополосных системах кодирования с расщеплением полосы.
Пока иное не оговаривается явным образом контекстом, термин «сигнал» используется в материалах настоящей заявки для указания любого из его обычных значений, в том числе состояния ячейки памяти (или набора ячеек памяти), которое представлено в проводном, шинном или другом носителе передачи. Если иное не указывается явным образом контекстом, термин «формирование» используется в материалах настоящей заявки для указания любого из его обычных значений, таких как вычисление или создание иным образом. Если иное не указывается явным образом контекстом, термин «расчет» используется в материалах настоящей заявки для указания любого из его обычных значений, таких как вычисление, оценивание, сглаживание и/или выбор из множества значений. Если иное не указывается явным образом контекстом, термин «получение» используется в материалах настоящей заявки для указания любого из его обычных значений, таких как расчет, вывод, прием (например, из внешнего устройства) и/или извлечение (например, из массива элементов запоминающего устройства). В тех случаях, когда термин «содержащий» используется в настоящем описании и формуле изобретения, он не исключает другие элементы или операции. Выражение «A основано на B» используется для указания любого из его обычных значений, в том числе случаев (i) «A основано на по меньшей мере B» и (ii) «A равно B» (если уместно в конкретном контексте).
Пока не указан иной образ действий, любое раскрытие работы устройства, имеющего конкретный признак, также явным образом подразумевается как раскрытие способа, имеющего аналогичный признак (и наоборот), а любое раскрытие работы устройства согласно конкретной конфигурации также явным образом подразумевается как раскрытие способа согласно аналогичной конфигурации (и наоборот). Например, пока не указан иной образ действий, любое раскрытие аудиокодера, имеющего конкретный признак, также явным образом подразумевается как раскрытие способа кодирования аудио, имеющего аналогичный признак (и наоборот), и любое раскрытие аудиокодера согласно конкретной конфигурации также явным образом подразумевается как раскрытие способа кодирования аудио согласно аналогичной конфигурации (и наоборот).
Любое включение в состав посредством ссылки на часть документа также должно пониматься как включение в состав определений терминов или переменных, которые указываются ссылкой в этой части, в независимости от того, где такие определения появляются в настоящем документе.
Термины «кодер», «кодек» и «система кодирования» взаимозаменяемо используются для обозначения системы, которая включает в себя по меньшей мере один кодер, сконфигурированный для приема кадра аудиосигнала (возможно, после одной или более операций предварительной обработки, таких как перцепционное (воспринимаемое) взвешивание и/или другая операция фильтрации), и соответствующий декодер, сконфигурированный для создания декодированного представления кадра.
Как проиллюстрировано на фиг. 1, система беспроводной телефонной связи (например, система CDMA, TDMA, FDMA и/или TD-SCDMA) обычно включает в себя множество мобильных абонентских узлов 10, сконфигурированных для поддержания связи беспроводным образом с сетью радиодоступа, которая включает в себя множество базовых станций 12 (BS) и один или более контроллеров 14 базовых станций (BSC). Такая система также обычно включает в себя центр 16 коммутации мобильной связи (MSC), присоединенный к BSC 14, который сконфигурирован для взаимодействия сети радиодоступа с традиционной коммутируемой телефонной сетью 18 общего пользования (PSTN). Чтобы поддерживать такой интерфейс, MSC может включать в себя или иным образом поддерживать связь с медиа-шлюзом, который действует в качестве узла трансляции между сетями. Медиа-шлюз сконфигурирован для осуществления преобразований между разными форматами, такими как технологии передачи и/или кодирования (например, для преобразований между голосовым сигналом, подвергнутым мультиплексированию с временным разделением («TDM») и VoIP сигналом), и также может быть сконфигурирован для выполнения функций потоковой передачи медиа-данных, таких как эхо-подавление, двухтональный многочастотный набор («DTMF») и отправка тонов. BSC 14 присоединены к базовым станциям 12 через линии транзитных соединений. Линии транзитных соединений могут быть сконфигурированы для поддержки любого из некоторых известных интерфейсов, в том числе, например, E1/T1 (высокоскоростных цифровых магистралей 2,048/1,544 Мбит/с), ATM (асинхронного режима передачи), IP (протокола сети Интернет), PPP (протокола двухточечного соединения), Frame Relay (ретрансляции кадров), HDSL (высокоскоростной цифровой абонентской линии), ADSL (асимметричной цифровой абонентской линии), или технологии xDSL. Совокупность базовых станций 12, BSC 14, MSC 16 и медиа-шлюзов, если таковые имеют место, также упоминаются как «инфраструктура».
Каждая из базовых станций 12 может включать в себя один или более секторов, каждый сектор имеет всенаправленную антенну или антенну, направленную в конкретном направлении радиально от базовой станции 12. В качестве альтернативы, каждый сектор может содержать две или более антенн для разнесенного приема. Каждая базовая станция 12 преимущественно может быть предназначена для поддержки множества назначений частот. Пересечение сектора и назначения частоты могут упоминаться как канал CDMA. Базовые станции 12 также могут быть известны как приемопередающие подсистемы 12 базовых станций (BTS). В качестве альтернативы, термин «базовая станция» может использоваться в данной отрасли промышленности, чтобы в собирательном значении указывать на BSC 14 и одну или более BTS 12. BTS 12 также могут обозначаться «узлами сотовой связи» 12. В качестве альтернативы, отдельные секторы данной BTS 12 могут называться узлами сотовой связи. Мобильные абонентские узлы 10 типично включают в себя сотовые телефоны и/или телефоны службы персональной связи («PCS»), персональные цифровые секретари («PDA») и/или другие устройства, обладающие функциональной возможностью мобильного телефона. Такой узел 10 может включать в себя внутренние громкоговоритель и микрофон, проводную телефонную гарнитуру или гарнитуру, которая включает в себя громкоговоритель и микрофон (например, телефонную трубку USB (универсальной последовательной шины)), или беспроводную гарнитуру, которая включает в себя громкоговоритель и микрофон (например, гарнитуру, которая передает аудиоинформацию на узел с использованием варианта протокола Bluetooth, который представляется Консорциумом по технологии Bluetooth, Беллвью, штат Вашингтон). Такая система может быть сконфигурирована для использования в соответствии с одним или более вариантами стандарта IS-95 (например, IS-95, IS-95A, IS-95B, cdma2000; который опубликован Ассоциацией телекоммуникационной промышленности, Арлингтон, штат Вирджиния).
Далее описана типичная работа сотовой телефонной системы. Базовые станции 12 принимают набор сигналов обратной линии связи с набора мобильных абонентских узлов 10. Мобильные абонентские узлы 10 проводят телефонные вызовы или другой обмен информацией. Каждый сигнал обратной линии связи, принятый данной базовой станцией 12, обрабатывается в такой базовой станции 12, а получающиеся, в результате, данные пересылаются в BSC 14. BSC 14 обеспечивает выделение ресурсов вызова и функциональные возможности управления мобильностью, в том числе управление мягкими передачами обслуживания между базовыми станциями 12. BSC 14 также маршрутизируют принимаемые данные в MSC 16, который обеспечивает дополнительные услуги маршрутизации для взаимодействия с PSTN 18. Аналогично, PSTN 18 взаимодействует с MSC 16, а MSC 16 взаимодействует с BSC 14, который, в свою очередь, управляет базовыми станциями 12 для передачи наборов сигналов прямой линии связи на наборы мобильных абонентских узлов 10.
Элементы системы сотовой телефонии, как показано на фиг. 1, также могут быть сконфигурированы для поддержки передачи данных с коммутацией пакетов. Как показано на фиг. 2, поток обмена пакетными данными обычно маршрутизируется между мобильными абонентскими узлами 10 и внешней сетью 24 с коммутацией пакетов (например, сетью общего пользования, такой как сеть Интернет) с использованием узла 22 обслуживания пакетных данных (PDSN), который соединен со шлюзовым маршрутизатором, соединенным с сетью с коммутацией пакетов. PDSN 22, в свою очередь, маршрутизирует данные в одну или более функций 20 управления пакетами (PCF), каждая из которых обслуживает один или более BSC 14 и действует в качестве линии связи между сетью с коммутацией пакетов и сетью радиодоступа. Сеть 24 с коммутацией пакетов также может быть реализована так, чтобы включать в себя локальную сеть («LAN»), университетскую сеть («CAN»), региональную сеть («MAN»), глобальную сеть («WAN»), кольцевую сеть, звездообразную сеть, кольцевую сеть с маркерным доступом и т. д. Терминал пользователя, присоединенный к сети 24, может быть PDA, дорожным компьютером, персональным компьютером, игровым устройством (примеры такого устройства включают в себя XBOX и XBOX 360 (корпорация Майкрософт, Редмонд, штат Вашингтон), Playstation 3 и Playstation Portable (корпорация Сони, Токио, Япония), и Wii и DS (Нинтдендо, Кийото, Япония), и/или любое устройство, имеющее возможность аудиообработки, и может быть сконфигурирован для поддержки телефонного вызова или другой связи с использованием одного или более протоколов, таких как VoIP. Такой терминал может включать в себя внутренние громкоговоритель и микрофон, проводную гарнитуру, которая включает в себя громкоговоритель и микрофон (например, телефонную трубку USB (универсальной последовательной шины)), или беспроводную гарнитуру, которая включает в себя громкоговоритель и микрофон (например, гарнитуру, которая передает звуковую информацию на терминал с использованием варианта протокола Bluetooth, который представляется Консорциумом по технологии Bluetooth, Беллвью, штат Вашингтон). Такая система может быть сконфигурирована для передачи телефонного вызова или другой связи в качестве потока обмена пакетными данными между мобильными абонентскими узлами по разным сетям радиодоступа (например, посредством одного или более протоколов, таких как VoIP), между мобильным абонентским узлом и немобильным терминалом пользователя, или между двумя немобильными терминалами пользователей, без входа в PSTN. Мобильный абонентский узел 10 или другой терминал пользователя также может называться «терминалом доступа».
Фиг. 3a иллюстрирует аудиокодер AE10, который выполнен с возможностью принимать оцифрованный аудиосигнал S100 (например, в виде последовательности кадров) и создавать соответствующий кодированный сигнал S200 (например, в виде последовательности соответствующих кодированных кадров) для передачи по каналу C100 связи (например, проводной, оптической и/или беспроводной линии связи) в аудиодекодер AD10. Аудиодекодер AD10 выполнен с возможностью декодировать принятый вариант S300 кодированного аудиосигнала S200 и синтезировать соответствующий выходной речевой сигнал S400.
Аудиосигнал S100 представляет собой аналоговый сигнал (например, такой,как зафиксированный микрофоном), который был оцифрован и квантован в соответствии с любым из различных способов, известных в данной области техники, таких как импульсно-кодовая модуляция («ИКМ», «PCM»), компадирование с мю-характеристикой, А-характеристикой. Сигнал также может подвергаться другим операциям предварительной обработки в аналоговой и/или цифровой области, таким как подавление шумов, перцепционное взвешивание и/или другие операции фильтрации. Дополнительно или в качестве альтернативы, такие операции могут выполняться в аудиокодере AE10. Экземпляр аудиосигнала S100 также может представлять собой комбинацию аналоговых сигналов (например, как зафиксированные комплектом микрофонов), которые были оцифрованы и квантованы.
Фиг. 3b иллюстрирует первый вариант AE10a аудиокодера AE10, который выполнен с возможностью принимать первый вариант S110 оцифрованного аудиосигнала S100 и создавать соответствующий вариант S210 кодированного сигнала S200 для передачи по первому варианту C110 канала C100 связи в первый вариант AD10a аудиодекодера AD10. Аудиодекодер AD10a выполнен с возможностью декодировать принятый вариант S310 кодированного аудиосигнала S210 и синтезировать соответствующий вариант S410 выходного речевого сигнала S400.
Фиг. 3b также иллюстрирует второй вариант AE10b аудиокодера AE10, который выполнен с возможностью принимать второй вариант S120 оцифрованного аудиосигнала S100 и создавать соответствующий вариант S220 кодированного сигнала S200 для передачи по второму варианту C120 канала C100 связи во второй вариант AD10b аудиодекодера AD10. Аудиодекодер AD10b выполнен с возможностью декодировать принятый вариант S320 кодированного аудиосигнала S220 и синтезировать соответствующий вариант S420 выходного речевого сигнала S400.
Аудиокодер AE10a и аудиодекодер AD10b (аналогично, аудиокодер AE10b и аудиодекодер AD10a) могут использоваться совместно в любом устройстве связи для передачи и приема речевых сигналов, в том числе, например, абонентских узлах, терминалах пользователя, медиа-шлюзах, BTS или BSC, описанных выше со ссылкой на фиг. 1 и 2. Как описано в материалах настоящей заявки, аудиокодер AE10 может быть реализован многими различными способами, и аудиокодеры AE10a и AE10b могут быть вариантами разных реализаций аудиокодера AE10. Аналогично, аудиодекодер AD10 может быть реализован многими разными способами, и аудиодекодеры AD10a и AD10b могут быть вариантами разных реализаций аудиодекодера AD10.
Аудиокодер (например, аудиокодер AE10) обрабатывает цифровые выборки аудиосигнала в качестве последовательности кадров входных данных, при этом каждый кадр содержит предопределенное количество выборок. Эта последовательность обычно реализована в качестве неперекрывающейся последовательности, хотя операция обработки кадра или сегмента кадра (также называемого подкадром) также может включать в себя сегменты одного или более соседних кадров на своем входе. Кадры аудиосигнала типично достаточно коротки, чтобы огибающая спектра сигнала могла предполагаться остающейся относительно постоянной в течение кадра. Кадр типично соответствует от пяти до тридцати пяти миллисекундам аудиосигнала (или приблизительно от сорока до двухсот отсчетам), причем двадцать миллисекунд являются обычным размером кадра для применений в телефонии. Другие примеры обычного размера кадра включают в себя десять и тридцать миллисекунд. Типично, все кадры аудиосигнала имеют одинаковую длину, и постоянная длина кадра предполагается в конкретных примерах, описанных в материалах настоящей заявки. Однако в настоящей заяке также явным образом предусматривается и раскрывается, что могут использоваться и непостоянные длины кадров.
Длина кадра в двадцать миллисекунд соответствует 140 выборкам при частоте выборки в семь килогерц (кГц), 160 выборкам при частоте выборки в восемь кГц (одной из типичных частот выборки для узкополосной системы кодирования), и 320 выборкам при частоте выборки в 16 кГц (одной из типичных частот выборки для широкополосной системы кодирования), хотя может использоваться любая частота выборки, считающаяся пригодной для конкретного применения. Еще одним примером частоты выборки, которая может использоваться для кодирования речевого сигнала, является 12,8 кГц, и дополнительные примеры включают в себя другие частоты в диапазоне от 12,8 кГц до 38,4 кГц.
В типичном сеансе аудиосвязи, таком как телефонный вызов, каждый говорящий абонент молчит приблизительно в течение шестидесяти процентов времени. Аудиокодер для такого применения обычно будет сконфигурирован для проведения различия между кадрами аудиосигналов, которые содержат речь или другую информацию («активных кадров»), и кадрами аудиосигнала, которые содержат только фоновый шум или безмолвие («неактивных кадров»). Может быть желательным реализовать аудиокодер AE10 для использования разных режимов кодирования и/или битовых скоростей для кодирования активных кадров и неактивных кадров. Например, аудиокодер AE10 может быть реализован для использования меньшего количества бит (то есть более низкой битовой скорости) для кодирования неактивного кадра, чем для кодирования активного кадра. Также может быть желательным, чтобы аудиокодер AE10 использовал разные битовые скорости для кодирования разных типов активных кадров. В таких случаях более низкие битовые скорости могут избирательно использоваться для кадров, содержащих в себе относительно меньшее количество речевой информации. Примеры битовых скоростей, обычно используемых для кодирования активных кадров, включают в себя 171 бит на кадр, восемьдесят бит на кадр и сорок бит на кадр; а примеры битовых скоростей, обычно используемых для кодирования неактивных кадров, включают в себя шестнадцать бит на кадр. В контексте систем сотовой телефонии (особенно систем, которые совместимы с временным стандартом (IS)-95, который представляется Ассоциацией телекоммуникационной промышленности, Арлингтон, штат Вирджиния, или подобным промышленным стандартом), эти четыре битовые скорости также обозначаются как «полная скорость», «половинная скорость», «четвертная скорость» и «одна восьмая скорость», соответственно.
Может быть желательным, чтобы аудиокодер AE10 классифицировал каждый активный кадр аудиосигнала в качестве одного из нескольких разных типов. Эти разные типы могут включать в себя кадры вокализованной речи (например, речи, представляющей гласный звук), переходные кадры (например, кадры, которые представляют начало или конец слова), кадры невокализованной речи (например, речи, представляющей фрикативный звук) и кадры неречевой информации (например, музыки, такой как пение и/или музыкальные инструменты, или другой аудио контент). Также может быть желательным реализовать аудиокодер AE10 для использования разных режимов кодирования для кодирования разных типов кадров. Например, кадры вокализованной речи имеют тенденцию иметь периодическую структуру, которая является долговременной (то есть продолжается в течение более чем одного периода кадров) и имеет отношение к основному тону, и типично, эффективнее кодировать вокализованные кадры (или последовательность вокализованных кадров) с использованием режима кодирования, который кодирует описание этого долговременного спектрального признака. Примеры таких режимов кодирования включают в себя линейное предсказание с кодовым возбуждением («CELP»), интерполяцию волновым сигналом-прототипом («PWI») и период основного тона прототипа («PPP»). Невокализованные кадры и неактивные кадры, с другой стороны, обычно не имеют никакого значащего долговременного спектрального признака, и аудиокодер может быть сконфигурирован для кодирования этих кадров с использованием режима кодирования, который не пытается описывать такой признак. Линейное предсказание с шумовым возбуждением («NELP») является одним из примеров такого режима кодирования. Кадры музыки обычно содержат смеси разных тонов, и аудиокодер может быть сконфигурирован для кодирования этих кадров (или остатков операций разложения LPC (кодированием с линейным предсказанием) над этими кадрами) с использованием способа, основанного на синусоидальном разложении, таком как преобразование Фурье или косинусное преобразование. Одним из таких примеров является режим кодирования, основанный на модифицированном дискретном косинусном преобразовании («MDCT»).
Аудиокодер AE10 или соответствующий способ аудио кодирования могут быть реализованы для выбора среди разных комбинаций битовых скоростей и режимов кодирования (также называемых «схемами кодирования»). Например, аудиокодер AE10 может быть реализован для использования схемы CELP полной скорости для кадров, содержащих в себе вокализованную речь и для переходных кадров, схему NELP половинной скорости для кадров, содержащих в себе невокализованную речь, схему NELP с одной восьмой скорости для неактивных кадров и схему MDCT полной скорости для многофункциональных аудиокадров (например, включающих в себя кадры, содержащие в себе музыку). В качестве альтернативы, такая реализация аудиокодера AE10 может быть сконфигурирована для использования схемы PPP полной скорости для по меньшей мере некоторых кадров, содержащих в себе вокализованную речь, особенно для высоковокализованных кадров.
Аудиокодер AE10 также может быть реализован для поддержки множества битовых скоростей для каждой из одной или более схем кодирования, таких как схемы CELP полной скорости и половинной скорости и/или схемы PPP полной скорости и четвертной скорости. Кадры в последовательности, которые включают в себя период стабильной вокализованной речи, имеют тенденцию быть в значительной степени избыточными, например, такими, что по меньшей мере некоторые из них могут кодироваться на менее чем с полной скоростью без заметной потери воспринимаемого качества.
Многорежимные аудиокодеры (включающие в себя аудиокодеры, которые поддерживают многочисленные битовые скорости и/или режимы кодирования) типично обеспечивают эффективное кодирование аудио на низких битовых скоростях. Специалистам должно быть понятно, что увеличение количества схем кодирования будет предоставлять возможность большей гибкости при выборе схемы кодирования, которая может давать, в результате, более низкую среднюю битовую скорость. Однако увеличение количества схем кодирования будет соответственно увеличивать сложность в пределах полной системы. Конкретная комбинация имеющихся в распоряжении схем, используемых в любой данной системе, будет диктоваться имеющимися в распоряжении системными ресурсами и отдельной сигнальной средой. Примеры многорежимных технологий кодирования, например, описаны в патенте США № 6691084, озаглавленном «VARIABLE RATE SPEECH CODING» («КОДИРОВАНИЕ РЕЧЕВОГО СИГНАЛА С ПЕРЕМЕННОЙ СКОРОСТЬЮ») и публикации США № 2007/0171931, озаглавленной «ARBITRARY AVERAGE DATA RATES FOR VARIABLE RATE CODERS» («ПРОИЗВОЛЬНЫЕ СРЕДНИЕ СКОРОСТИ ПЕРЕДАЧИ ДАННЫХ ДЛЯ КОДЕРОВ С ПЕРЕМЕННОЙ СКОРОСТЬЮ КОДИРОВАНИЯ»).
Фиг. 4a иллюстрирует структурную схему многорежимной реализации AE20 аудиокодера AE10. Кодер AE20 включает в себя селектор 20 схемы кодирования и множество p кодеров 30a-30p кадра. Каждый из p кодеров кадра сконфигурирован для кодирования кадра согласно соответственному режиму кодирования, и сигнал выбора схемы кодирования, вырабатываемый селектором 20 схемы кодирования, используется для управления парой селекторов 50a и 50b аудиокодера AE20, чтобы выбирать требуемый режим кодирования для текущего кадра. Селектор 20 схемы кодирования также может быть сконфигурирован для управления выбранным кодером кадра для кодирования текущего кадра при выбранной битовой скорости. Отмечено, что программная или программно-аппаратная реализация аудиокодера AE20 может использовать указание схемы кодирования, чтобы направлять поток выполнения в тот или другой из декодеров кадра, и что такая реализация может не включать в себя аналог селектора 50a и/или селектора 50b. Два или более (возможно, все) из кодеров 30a-30p кадра могут совместно использовать общую структуру, такую как вычислитель значений коэффициентов LPC (возможно, сконфигурированный для выдачи результата, имеющего разный порядок для разных схем кодирования, такой как более высокий порядок для речевых и неречевых кадров, чем для неактивных кадров) и/или формирователь остатка LPC.
Селектор 20 схемы кодирования типично включает в себя модуль решения без обратной связи, который исследует входной аудиокадр и принимает решение касательно того, какой режим или схему кодирования следует применять к кадру. Этот модуль типично сконфигурирован для классифицирования кадров в качестве активных или неактивных, и также может быть сконфигурирован для классифицирования активного кадра в качестве одного из двух или более разных типов, таких как вокализированный, невокализированный, переходный или многофункциональный звук. Классификация кадров может быть основана на одной или более характеристик текущего кадра и/или одного или более предыдущих кадров, таких как полная энергия кадра, энергия кадра в каждой из двух или более разных полос частот, отношение сигнал/шум («SNR»), периодичность и частота переходов через нуль. Селектор 20 схемы кодирования может быть реализован для расчета значений таких характеристик, для приема значений таких характеристик из одного или более других модулей аудиокодера AE20 и/или для приема значений таких характеристик из одного или более других модулей устройства, которое включает в себя аудиокодер AE20 (например, сотового телефона). Классификация кадров может включать в себя сравнение значения или модуля такой характеристики с пороговым значением и/или сравнение амплитуды изменения такого значения с пороговым значением.
Модуль решения без обратной связи может быть сконфигурирован для выбора битовой скорости, при которой следует кодировать конкретный кадр, согласно типу речи, которую содержит кадр. Такая операция называется «кодирование с переменной скоростью». Например, может быть желательным конфигурировать аудиокодер AD20 для кодирования переходного кадра на верхней битовой скорости (например, полной скорости), для кодирования невокализованного кадра на нижней битовой скорости (например, четвертичной скорости) и для кодирования вокализованного кадра на промежуточной битовой скорости (например, половинной скорости) или на верхней битовой скорости (например, полной скорости). Битовая скорость, выбранная для конкретного кадра, также может зависеть от такого критерия, как требуемая средняя битовая скорость, требуемый профиль битовых скоростей в течение последовательности кадров (который может использоваться для поддержки требуемой средней битовой скорости) и/или битовая скорость, выбранная для предыдущего кадра.
Селектор 20 схемы кодирования также может быть реализован для выполнения выбора кодирования с обратной связью, при котором один или более показателей рабочих характеристик кодирования получаются после полного или частичного кодирования с использованием выбранной без обратной связи схемы кодирования. Измерения рабочих характеристик, которые могут учитываться в тестировании с обратной связью, например, включают в себя, SNR, предсказание SNR в схемах кодирования, таких как кодер речевого сигнала PPP, SNR квантования ошибки предсказания, SNR квантования фазы, SNR квантования амплитуды, воспринимаемая SNR и нормализованная взаимная корреляция между текущим и прошлым кадрами в качестве меры стационарности. Селектор 20 схемы кодирования может быть реализован для расчета значений таких характеристик, для приема значений таких характеристик из одного или более других модулей аудиокодера AE20 и/или для приема значений таких характеристик из одного или более других модулей устройства, которое включает в себя аудиокодер AE20 (например, сотового телефона). Если показатель рабочих характеристик падает ниже порогового значения, битовая скорость и/или режим кодирования может быть изменен на тот, от которого ожидается обеспечение лучшего качества. Примеры схем классификации с обратной связью, которые могут использоваться для поддержания качества многорежимного аудиокодера с переменной скоростью, описаны в патенте США № 6330532, озаглавленном «METHOD AND APPARATUS FOR MAINTAINING A TARGET BIT RATE IN A SPEECH CODER» («СПОСОБ И УСТРОЙСТВО ДЛЯ ПОДДЕРЖАНИЯ ЦЕЛЕВОЙ БИТОВОЙ СКОРОСТИ В КОДЕРЕ РЕЧЕВОГО СИГНАЛА»), и в патенте США № 5911128, озаглавленном «METHOD AND APPARATUS FOR PERFORMING SPEECH FRAME ENCODING MODE SELECTION IN A VARIABLE RATE ENCODING SYSTEM» («СПОСОБ И УСТРОЙСТВО ДЛЯ ВЫПОЛНЕНИЯ ВЫБОРА РЕЖИМА КОДИРОВАНИЯ РЕЧЕВОГО КАДРА В СИСТЕМЕ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ»).
Фиг. 4b иллюстрирует структурную схему реализации AD20 аудиодекодера AD10, который сконфигурирован для обработки принятого кодированного аудиосигнала S300, чтобы создавать соответствующий декодированный аудиосигнал S400. Аудиодекодер AD20 включает в себя детектор 60 схемы кодирования и множество p декодеров 70a-70p кадров. Декодеры 70a-70p могут быть сконфигурированы, чтобы соответствовать кодерам аудиокодера AE20, описанного выше, таким образом, чтобы декодер 70a кадра был сконфигурирован для декодирования кадров, которые были закодированы кодером 30a кадра, и так далее. Два или более (возможно, и все) из декодеров 70a-70p кадра могут совместно использовать общую структуру, такую как фильтр синтеза, сконфигурированный согласно набору декодированных значений коэффициентов LPC. В таком случае декодеры кадра, главным образом, могут отличаться технологиями, которые они используют для формирования сигнала возбуждения, который возбуждает фильтр синтеза, чтобы создавать декодированный аудиосигнал. Аудиодекодер AD20 типично также включает в себя постфильтр, который сконфигурирован для обработки декодированного аудиосигнала S400, чтобы понижать шумы квантования (например, выделением формантных частот и/или ослаблением спектральных впадин), и также может включать в себя адаптивную регулировку усиления. Устройство, которое включает в себя аудиодекодер AD20 (например, сотовый телефон), может включать в себя цифроаналоговый преобразователь («DAC»), сконфигурированный для создания аналогового сигнала из декодированного аудиосигнала S400 для вывода на наушник, динамик или другой аудио преобразователь, и/или гнездо аудиовыхода, расположенное в пределах корпуса устройства. Такое устройство также может быть сконфигурировано для выполнения одной или более операций аналоговой обработки над аналоговым сигналом (например, фильтрацию, коррекцию и/или усиление) перед тем, как он подается на гнездо и/или преобразователь.
Детектор 60 схемы кодирования сконфигурирован для указания схемы кодирования, которая соответствует текущему кадру принятого кодированного аудиосигнала S300. Надлежащая битовая скорость кодирования и/или режим кодирования могут указываться форматом кадра. Детектор 60 схемы кодирования может быть сконфигурирован для выполнения детектирования скорости или для приема указания скорости из другой части устройства, в пределах которой встроен аудиодекодер AD20, такой как подуровень мультиплексирования. Например, детектор 60 схемы кодирования может быть сконфигурирован для приема, с подуровня мультиплексирования, индикатора типа пакета, который указывает битовую скорость. В качестве альтернативы, детектор 60 схемы кодирования может быть сконфигурирован для определения битовой скорости кодированного кадра по одному или более параметров, таких как энергия кадра. В некоторых применениях система кодирования сконфигурирована для использования только одного режима кодирования для конкретной битовой скорости, чтобы битовая скорость кодированного кадра также указывала режим кодирования. В других случаях кодированный кадр может включать в себя информацию, такую как набор из одного или более бит, которая идентифицирует режим кодирования, согласно которому закодирован кадр. Такая информация (также называемая «индекс кодирования») может указывать режим кодирования явно или неявно (например, указывая значение, которое недействительно для других возможных режимов кодирования).
Фиг. 4b иллюстрирует пример, в котором указание схемы кодирования, выработанное детектором 60 схемы кодирования, используется для управления парой селекторов 90a и 90b аудиодекодера AD20, чтобы выбирать один из декодеров 70a-70p кадра. Отмечено, что программная или программно-аппаратная реализация аудиодекодера AD20 может использовать указание схемы кодирования, чтобы направлять поток выполнения в тот или другой из декодеров кадра, и что такая реализация может не включать в себя аналог селектора 90a и/или селектора 90b.
Фиг. 5a иллюстрирует структурную схему реализации AE22 многорежимного аудиокодера AE20, который включает в себя реализации 32a, 32b кодеров 30a, 30b кадра. В этом примере реализация 22 селектора 20 схемы кодирования сконфигурирована для различения активных кадров аудиосигнала S100 от неактивных кадров. Такая операция также называется «обнаружение речевой активности», и селектор 22 схемы кодирования может быть реализован, чтобы включать в себя детектор речевой активности. Например, селектор 22 схемы кодирования может быть сконфигурирован для вывода бинарного сигнала выбора схемы кодирования, который является высоким для активных кадров (указывая выбор кодера 32a активного кадра) и низким для неактивных кадров (указывая выбор кодера 32b неактивного кадра), или наоборот. В этом примере сигнал выбора схемы кодирования, выработанный селектором 22 схемы кодирования, используется для управления реализациями 52a, 52b селекторов 50a, 50b так, чтобы каждый кадр аудиосигнала S100 кодировался выбранным одним из числа кодера 32a активного кадра (например, кодера CELP) и кодера 32b неактивного кадра (например, кодера NELP).
Селектор 22 схемы кодирования может быть сконфигурирован для выполнения обнаружения речевой активности на основании одной или более характеристик энергетического и/или спектрального содержимого кадра, такого как энергия кадра, отношение сигнал/шум («SNR»), периодичность, спектральное распределение (например, сдвиг спектра) и/или частота переходов через ноль. Селектор 22 схемы кодирования может быть реализован для расчета значений таких характеристик, для приема значений таких характеристик из одного или более других модулей аудиокодера AE22 и/или для приема значений таких характеристик из одного или более других модулей устройства, которое включает в себя аудиокодер AE22 (например, сотового телефона). Такое обнаружение может включать в себя сравнение значения или модуля такой характеристики с пороговым значением, и/или сравнение амплитуды изменения такой характеристики (например, относительно предыдущего кадра) с пороговым значением. Например, селектор 22 схемы кодирования может быть сконфигурирован для оценки энергии текущего кадра и для классификации кадра как активного, если значение энергии является меньшим, чем (в качестве альтернативы, не большим, чем) пороговое значение. Такой селектор может быть сконфигурирован для расчета энергии кадра в качестве суммы квадратов выборок кадра.
Еще одна реализация селектора 22 схемы кодирования сконфигурирована для оценки энергии текущего кадра в каждой из полосы низких частот (например, от 300 Гц до 2 кГц) и полосы высоких частот (например, от 2 кГц до 4 кГц) и для указания, что кадр является неактивным, если значение энергии для каждой полосы является меньшим, чем (в качестве альтернативы, не большим, чем) соответственное пороговое значение. Такой селектор может быть сконфигурирован для расчета энергии кадра в полосе посредством применения полосового фильтра к кадру и расчета суммы квадратов выборок подвергнутого фильтрации кадра. Один из примеров такой операции обнаружения речевой активности описан в разделе 4,7 документа C.S0014-C, v1.0 (январь 2007 года), стандартов Проекта 2 партнерства третьего поколения («3GPP2»), доступного в режиме прямого доступа на www.3gpp2.org.
Дополнительно или в качестве альтернативы, операция обнаружения речевой активности может быть основана на информации из одного или более предыдущих кадров и/или одного или более последующих кадров. Например, может быть желательным конфигурировать селектор 22 схемы кодирования для классифицирования кадра как активного или неактивного на основании значения характеристики кадра, которая усреднена по двум или более кадрам. Может быть желательным конфигурировать селектор 22 схемы кодирования для классифицирования кадра с использованием порогового значения, которое основано на информации из предыдущего кадра (например, уровне фонового шума, SNR). Также может быть желательным конфигурировать селектор 22 схемы кодирования для классифицирования в качестве активного одного или более первых кадров, которые следуют за переходом в аудиосигнале S100 с активных кадров на неактивные кадры. Действие продолжения предыдущего состояния классификации подобным образом после перехода также называется «затягивание».
Фиг. 5b иллюстрирует структурную схему реализации AE24 многорежимного аудиокодера AE20, который включает в себя реализации 32c, 32d кодеров 30c, 30d кадра. В этом примере реализация 24 селектора 20 схемы кодирования сконфигурирована для различения речевых кадров аудиосигнала S100 от неречевых кадров (например, музыки). Например, селектор 24 схемы кодирования может быть сконфигурирован для вывода бинарного сигнала выбора схемы кодирования, который является высоким для речевых кадров (указывая выбор кодера 32c речевого кадра, такого как кодер CELP) и низким для неречевых кадров (указывая выбор кодера 32d неречевого кадра, такого как кодер MDCT), или наоборот. Такая классификация может быть основана на одной или более характеристиках энергетического и/или спектрального содержимого кадра, таких как энергия кадра, основной тон, периодичность, спектральное распределение (например, коэффициенты косинусного преобразования Фурье, коэффициенты LPC, линейные спектральные частоты («LSF»)) и/или частота переходов через ноль. Селектор 24 схемы кодирования может быть реализован для расчета значений таких характеристик, для приема значений таких характеристик из одного или более других модулей аудиокодера AE24 и/или для приема значений таких характеристик из одного или более других модулей устройства, которое включает в себя аудиокодер AE24 (например, сотового телефона). Такая классификация может включать в себя сравнение значения или модуля такой характеристики с пороговым значением и/или сравнение амплитуды изменения такой характеристики (например, относительно предыдущего кадра) с пороговым значением. Такая классификация может быть основана на информации из одного или более предыдущих кадров и/или одного или более последующих кадров, которая может использоваться для обновления модели с множеством состояний (такой как скрытая модель Маркова).
В этом примере сигнал выбора схемы кодирования, выработанный селектором 24 схемы кодирования, используется для управления селекторами 52a, 52b, чтобы каждый кадр аудиосигнала S100 кодировался выбранным одним из числа кодера 32c речевого кадра и кодера 32d неречевого кадра. Фиг. 6a иллюстрирует структурную схему реализации AE25 аудиокодера AE24, который включает в себя реализацию 34c RCELP кодера 32c речевого кадра и реализацию 34d MDCT кодера 32d неречевого кадра.
Фиг. 6b иллюстрирует структурную схему реализации AE26 многорежимного аудиокодера AE20, который включает в себя реализации 32b, 32d, 32e, 32f кодеров 30b, 30d, 30e, 30f кадра. В этом примере реализация 26 селектора 20 схемы кодирования сконфигурирована для классифицирования кадров аудиосигнала S100 в качестве вокализированных речевых, невокализированных речевых, неактивных речевых и неречевых. Такая классификация может быть основана на одной или более характеристиках энергетического и/или спектрального содержимого кадра, как упомянуто выше, может включать в себя сравнение значения или модуля такой характеристики с пороговым значением и/или сравнение амплитуды изменения такой характеристики (например, относительно предшествующего кадра) с пороговым значением, и может быть основана на информации из одного или более предыдущих кадров и/или одного или более последующих кадров. Селектор 26 схемы кодирования может быть реализован для расчета значений таких характеристик, для приема значений таких характеристик из одного или более других модулей аудиокодера AE26 и/или для приема значений таких характеристик из одного или более других модулей устройства, которое включает в себя аудиокодер AE26 (например, сотового телефона). В этом примере сигнал выбора схемы кодирования, выработанный селектором 26 схемы кодирования, используется для управления реализациями 54a, 54b селекторов 50a, 50b, чтобы каждый кадр аудиосигнала S100 кодировался выбранным одним из кодера 32e вокализованного кадра (например, кодера CELP или ослабленного CELP («RCELP»)), кодера 32f невокализованного кадра (например, кодера NELP), кодера 32d неречевого кадра и кодера 32b неактивного кадра (например, кодера NELP низкой скорости).
Кодированный кадр, который создается аудиокодером AE10, типично содержит в себе набор значений параметров, по которому может быть реконструирован соответствующий кадр аудиосигнала. Этот набор значений параметров типично включает в себя спектральную информацию, такую как описание распределения энергии в пределах кадра по частотному спектру. Такое распределение энергии также называется «огибающей частот» или «огибающей спектра» кадра. Описание огибающей спектра кадра может иметь разную форму и/или длину в зависимости от конкретной схемы кодирования, используемой для кодирования соответствующего кадра. Аудиокодер AE10 может быть реализован, чтобы включать в себя формирователь пакетов (не показан), который сконфигурирован для компоновки набора значений параметров в пакет так, чтобы размер, формат и содержимое пакета соответствовали конкретной схеме кодирования, выбранной для такого кадра. Соответствующая реализация аудиодекодера AD10 может быть осуществлена так, чтобы включать в себя восстановитель данных из пакетов (не показан), который сконфигурирован для отделения набора значений параметров от другой информации в пакете, такой как заголовок и/или другая информация о маршрутизации.
Аудиокодер, такой как аудиокодер AE10, типично сконфигурирован для расчета описания огибающей спектра кадра в качестве упорядоченной последовательности значений. В некоторых реализациях аудиокодер AE10 сконфигурирован для расчета упорядоченной последовательности, чтобы каждое значение указывало амплитуду или модуль сигнала на соответствующей частоте или в соответствующей области спектра. Одним из примеров такого описания является упорядоченная последовательность коэффициентов преобразования Фурье или дискретного косинусного преобразования.
В других реализациях аудиокодер AE10 сконфигурирован для расчета описания огибающей спектра в качестве упорядоченной последовательности значений параметров модели кодирования, такой как набор значений коэффициентов разложения кодированием с линейным предсказанием («LPC»). Значения коэффициентов LPC указывают резонансы аудиосигнала, также называемые «формантами». Упорядоченная последовательность значений коэффициентов LPC типично скомпонована в качестве одного или более векторов, и аудиокодер может быть реализован для расчета этих значений в качестве коэффициентов фильтра или в качестве коэффициентов отражения. Количество значений коэффициентов в наборе также называется «порядком» разложения LPC, и примеры типичного порядка разложения LPC, которое выполняется аудиокодером устройства связи (такого как сотовый телефон), включают в себя четыре, шесть, восемь, десять, 12, 16, 20, 24, 28 и 32.
Устройство, которое включает в себя реализацию аудиокодера AE10, типично сконфигурировано для передачи описания огибающей спектра через канал передачи в квантованной форме (например, в качестве одного или более индексов к соответствующим справочным таблицам или «словарям кодов»). Соответственно, может быть желательным, чтобы аудиокодер AE10 рассчитывал набор значений коэффициентов LPC в виде, который может эффективно квантоваться, таком как набор значений линейных спектральных пар («LSP»), LSF, спектральных пар иммитансов («ISP»), спектральных частот иммитансов («ISF»), коэффициентов косинусного преобразования Фурье или логарифмических соотношений площадей. Аудиокодер AE10 также может быть сконфигурирован для выполнения одного или более других операций обработки, таких как перцепционное взвешивание или другие операции фильтрации, над упорядоченной последовательностью значений до преобразования и/или квантования.
В некоторых случаях описание огибающей спектра кадра также включает в себя описание временной информации кадра (например, как в упорядоченной последовательности коэффициентов преобразования Фурье или дискретного косинусного преобразования). В других случаях набор параметров пакета также может включать в себя описание временной информации кадра. Форма описания временной информации может зависеть от конкретного режима кодирования, используемого для кодирования кадра. Для некоторых режимов кодирования (например, для режима кодирования CELP или PPP или для некоторых режимов кодирования MDCT) описание временной информации может включать в себя описание сигнала возбуждения, который должен использоваться аудиодекодером для возбуждения модели LPC (например, фильтра синтеза, сконфигурированного согласно описанию огибающей спектра). Описание сигнала возбуждения обычно основано на остатке операции разложения LPC над кадром. Описание сигнала возбуждения типично появляется в пакете в квантованной форме (например, в качестве одного или более индексов к соответствующим словарям кодов) и может включать в себя информацию, относящуюся к по меньшей мере одной составляющей основного тона сигнала возбуждения. Для режима кодирования PPP, например, кодированная временная информация может включать в себя описание прототипа, который должен использоваться аудиокодером для воспроизведения составляющей основного тона сигнала возбуждения. Что касается режима кодирования RCELP или PPP, кодированная временная информация может включать в себя одну или более оценок периода основных тонов. Описание информации, относящейся к составляющей основного тона, типично появляется в пакете в квантованной форме (например, в качестве одного или более индексов к соответствующим словарям кодов).
Различные элементы реализации аудиокодера AE10 могут быть воплощены в любой комбинации аппаратных средств, программного обеспечения и/или аппаратно-программного обеспечения, которые считаются пригодными для предполагаемого применения. Например, такие элементы могут быть изготовлены в качестве электронных и/или оптических устройств, например, находящихся в одной и той же микросхеме или среди двух или более микросхем в наборе микросхем. Одним из примеров такого устройства является фиксированная или программируемая матрица логических элементов, таких как транзисторы или логические вентили, и любой из этих элементов может быть реализован в качестве одной или более таких матриц. Любые два или более, или даже все, из этих элементов могут быть реализованы в пределах одной и той же матрицы или матриц. Такая матрица или матрицы могут быть реализованы в пределах одной или более микросхем (например, в пределах набора микросхем, включающего в себя две или более микросхем). То же самое применимо для различных элементов реализации соответствующего аудиодекодера AD10.
Один или более элементов различных реализаций аудиокодера AE10, описанного в материалах настоящей заявки, также могут быть реализованы, целиком или частично, в качестве одного или более наборов команд, выполненных с возможностью исполнения их в одной или более фиксированных или программируемых матриц логических элементов, таких как микропроцессоры, встроенные процессоры, IP-ядра, цифровые сигнальные процессоры, программируемые вентильные матрицы («FPGA»), специализированные стандартные изделия («ASSP») и специализированные интегральные схемы («ASIC»). Любые из различных элементов реализации аудиокодера AE10 также могут быть осуществлены в качестве одного или более компьютеров (например, машин, включающих в себя одну или более матриц, запрограммированных для выполнения одного или более наборов последовательностей команд, также называемых «процессорами»), и любые два или более, или даже все, из этих элементов могут быть реализованы в пределах одного и того же такого компьютера или компьютеров. То же самое применимо к элементам различных реализаций соответствующего аудиодекодера AD10.
Различные элементы реализации аудиокодера AE10 могут быть включены в устройство проводной и/или беспроводной связи, такое как сотовый телефон или другое устройство, имеющее такую возможность связи. Такое устройство может быть сконфигурировано для поддержания связи с сетями с коммутацией каналов и/или с коммутацией пакетов (например, используя один или более протоколов, таких как VoIP). Такое устройство может быть сконфигурировано для выполнения операций над сигналом, несущим кодированные кадры, таких как перемежение, прореживание, сверточное кодирование, кодирование с исправлением ошибок, кодирование одного или более уровней сетевого протокола (например, Ethernet, TCP/IP, cdma2000), модуляция одной или более радиочастотных (РЧ, RF) и/или оптических несущих, и/или передача одной или более модулированных несущих по каналу.
Различные элементы реализации аудиодекодера AD10 могут быть заключены в устройстве для проводной и/или беспроводной связи, таком как сотовый телефон или другое устройство, имеющее подобную возможность связи. Такое устройство может быть сконфигурировано для поддержания связи с сетями с коммутацией каналов и/или с коммутацией пакетов (например, используя один или более протоколов, таких как VoIP). Такое устройство может быть сконфигурировано для выполнения операций над сигналом, несущим кодированные кадры, таких как обращенное перемежение, устранение прореживания, сверточное декодирование, декодирование с исправлением ошибок, декодирование одного или более уровней сетевого протокола (например, Ethernet, TCP/IP, cdma2000), демодуляция одной или более РЧ и/или оптических несущих, и/или прием одной или более модулированных несущих по каналу.
Возможно, чтобы один или более элементов реализации аудиокодера AE10 использовались для выполнения этапов или исполнения других наборов команд, которые не имеют непосредственного отношения к работе устройства, таких как этап, относящийся к другой операции устройства или системы, в которую встроено устройство. Также возможно, чтобы один или более элементов реализации аудиокодера AE10 имели общую структуру (например, процессор, используемый для выполнения участков управляющей программы, соответствующих разным элементам в разные моменты времени, набор команд, исполняемых для выполнения этапов, соответствующих разным элементам в разные моменты времени, или компоновку электронных и/или оптических устройств, выполняющих операции для разных элементов в разные моменты времени). То же самое применимо к элементам различных реализаций соответствующего аудиодекодера AD10. В одном из таких примеров селектор 20 схемы кодирования и кодеры 30a-30p кадров реализованы как наборы команд, предназначенные для выполнения на одном и том же процессоре. В еще одном таком примере детектор 60 схемы кодирования и декодеры 70a-70p кадра реализованы как наборы команд, предназначенные для выполнения на одном и том же процессоре. Два или более из числа кодеров 30a-30p кадра могут быть реализованы для совместного использования одного или более наборов команд, выполняющихся в разные моменты времени; то же самое применимо к декодерам 70a-70p кадра.
Фиг. 7a иллюстрирует блок-схему последовательности операций способа кодирования кадра аудиосигнала M10. Способ M10 включает в себя этап TE10, где рассчитываются значения характеристик кадра, как описано выше, таких как энергетические и/или спектральные характеристики. На основании рассчитанных значений этап TE20 выбирает схему кодирования (например, как описано выше со ссылкой на различные реализации селектора 20 схемы кодирования). Этап TE30 кодирует кадр согласно выбранной схеме кодирования (например, как описано в материалах настоящей заявки со ссылкой на различные реализации кодеров 30a-30p кадра) для создания кодированного кадра. Необязательный этап TE40 формирует пакет, который включает в себя кодированный кадр. Способ M10 может быть сконфигурирован (например, повторяться) для кодирования каждого в последовательности кадров аудиосигнала.
В типичном применении реализации способа M10 матрица логических элементов (например, логических вентилей) сконфигурирована для выполнения одного, более чем одного, или даже всех из различных этапов способа. Один или более (возможно, все) из этапов также могут быть реализованы как управляющая программа (например, один или более наборов команд), воплощенная в компьютерном программном продукте (например, в одном или более носителей хранения данных, таких как диски, флэш-память или другие карты энергонезависимой памяти, микросхемы полупроводниковой памяти и т. д.), которая является считываемой и/или исполняемой машиной (например, процессором, микропроцессором, микроконтроллером или другим конечным автоматом). Этапы реализации способа M10 также могут выполняться более чем одной такой матрицей или машиной. В этих или других реализациях этапы могут выполняться в устройстве беспроводной связи, таком как сотовый телефон или другое устройство, имеющее такую возможность связи. Такое устройство может быть сконфигурировано для поддержания связи с сетями с коммутацией каналов и/или с коммутацией пакетов (например, используя один или более протоколов, таких как VoIP). Например, такое устройство может включать в себя РЧ-схему, сконфигурированную для приема кодированных кадров.
Фиг. 7b иллюстрирует структурную схему устройства F10, которое сконфигурировано для кодирования кадра аудиосигнала. Устройство F10 включает в себя средство для расчета значений характеристик кадра, FE10, таких как энергетические и/или спектральные характеристики, как описанные выше. Устройство F10 также включает в себя средство для выбора схемы FE20 кодирования на основании рассчитанных значений (например, как описано выше со ссылкой на различные реализации селектора 20 схемы кодирования). Устройство F10 также включает в себя средство для кодирования кадра согласно выбранной схеме FE30 кодирования (например, как описано в материалах настоящей заявки со ссылкой на различные реализации кодеров 30a-30p кадра) для создания кодированного кадра. Устройство F10 также включает в себя необязательное средство для формирования пакета, который включает в себя кодированный кадр FE40. Устройство F10 может быть сконфигурировано для кодирования каждого в последовательности кадров аудиосигнала.
В типичной реализации схемы кодирования с PR, такой как схема кодирования RCELP, или реализации с PR схемы кодирования PPP, период основного тона оценивается, один раз для каждого кадра или подкадра, с использованием операции оценки основного тона, которая может быть основана на корреляции. Может быть желательным центрировать окно оценки основного тона по границе кадра или подкадра. Типичные разделения кадра на подкадры включают в себя три подкадра на кадр (например, 53, 53 и 54 выборки для каждого из неперекрывающихся подкадров кадра в 160 выборок), четыре подкадра на кадр, и пять подкадров на кадр (например, пять неперекрывающихся подкадров в 32 выборки в кадре в 160 выборок). Также может быть желательным осуществлять проверку на совместимость среди оцененных периодов основных тонов, чтобы избегать ошибок, таких как деление основного тона пополам, удвоение основного тона, утроение основного тона и т.д. Между обновлениями оценки основного тона период основного тона интерполируется для создания синтетического профиля задержки. Такая интерполяция может выполняться по выборкам или менее часто (например, по каждой второй или третьей выборке) или более часто (например, с разрешением по подвыборкам). Усовершенствованный кодек с переменной скоростью кодирования («EVRC»), описанный в документе C.S0014-C 3GPP2, упомянутом выше, например, использует синтезированный профиль задержки, который подвергнут восьмикратной избыточной дискретизации. Типично, интерполяция является линейной или билинейной интерполяцией, и она может выполняться с использованием одного или более фильтров многофазной интерполяции или другой приходной технологии. Схема кодирования с PR, такая как RCELP, типично сконфигурирована для кодирования кадров на полной скорости или половинной скорости, хотя реализации, которые осуществляют кодирование на других скоростях, таких как четвертная скорость, также возможны.
Использование непрерывного профиля основных тонов с невокализованными кадрами может вызывать нежелательные артефакты, такие как гудение. Для невокализованных кадров, поэтому, может быть желательным использовать постоянный период основного тона в пределах каждого подкадра, с резким переключением на другой постоянный период основного тона на границе подкадра. Типичные примеры такой технологии используют псевдослучайную последовательность периодов основных тонов, которые находятся в диапазоне от 20 выборок до 40 выборок (при частоте выборки в 8 кГц), которая повторяется каждые 50 миллисекунд. Операция обнаружения речевой активности («VAD»), как описано выше, может быть сконфигурирована для различения вокализованных кадров от невокализованных кадров, и такая операция типично используется на основании таких факторов, как автокорреляция речевого сигнала и/или остатка, частота переходов через ноль и/или коэффициент первого отражения.
Схема кодирования с PR (например, RCELP) выполняет изменение масштаба шкалы времени речевого сигнала. В этой операции изменения масштаба времени, которая также называется «модифицирование сигнала», разные сдвиги во времени применяются к разным сегментам сигнала, чтобы менялись исходные временные соотношения между признаками сигнала (например, импульсами основных тонов). Например, может быть желательным изменять шкалу времени сигнала, чтобы его профиль периода основного тона отображался в синтетический профиль периода основного тона. Значение сдвига во времени типично находится в диапазоне от нескольких положительных миллисекунд до нескольких отрицательных миллисекунд. Является типичным, чтобы кодер с PR (например, кодер RCELP) предпочтительнее модифицировал остаток, чем речевой сигнал, поскольку может быть желательным избегать изменения в положениях формант. Однако в настоящей заявке явным образом подразумевается и раскрывается, что компоновки, заявленные ниже, также могут быть осуществлены на практике с использованием кодера с PR (например, кодера RCELP), который сконфигурирован для модифицирования речевого сигнала.
Может ожидаться, что наилучшие результаты были бы получены модифицированием остатка с использованием непрерывного изменения масштаба времени. Такое изменение масштаба времени выполняется на повыборочной основе или посредством сжатия и расширения сегментов остатка (например, подкадров или периодов основных тонов).
Фиг. 8 иллюстрирует пример остатка до (волновой сигнал A) и после изменения масштаба времени по профилю задержки (волновой сигнал B). В этом примере интервалы между вертикальными пунктирными линиями указывают постоянный период основного тона.
Непрерывное изменение масштаба времени может характеризоваться слишком большим объемом вычислений для практического осуществления в портативных, встроенных, работающих в реальном времени и/или работающих от аккумулятора применениях. Поэтому более типично, чтобы RCELP или другой кодер с PR выполнял кусочное модифицирование остатка посредством временного сдвига сегментов остатка, чтобы величина сдвига во времени была постоянной на каждом сегменте (хотя в настоящей заявке явным образом подразумевается и раскрывается, что компоновки, заявленные ниже, также могут быть осуществлены на практике с использованием RCELP или другого кодера с PR, который сконфигурирован для модифицирования речевого сигнала или для модифицирования остатка с использованием непрерывного изменения масштаба времени). Такая операция может быть сконфигурирована для модифицирования текущего остатка посредством сдвига сегментов, так что каждый импульс основного тона отображается в соответствующий импульс основного тона в целевом остатке, где целевой остаток основан на модифицированном остатке из предыдущего кадра, подкадра, сдвигового кадра или другого сегмента сигнала.
Фиг. 9 иллюстрирует пример остатка до (волновой сигнал A) и после кусочного модифицирования (волновой сигнал B). На этом чертеже пунктирные линии иллюстрируют, каким образом сегмент, показанный полужирным, сдвигается вправо относительно оставшейся части остатка. Может быть желательным, чтобы длина каждого сегмента была меньшей, чем период основного тона (например, так, чтобы каждый сдвиговый сегмент содержал в себе не более чем один импульс основного тона). Также может быть желательным предохранять границы сегмента от попадания на импульсы основных тонов (например, чтобы локализовать границы сегмента областями низкой энергии остатка).
Процедура кусочного модифицирования типично включает в себя выбор сегмента, который включает в себя импульс основного тона (также называемый «сдвиговым кадром»). Один из примеров такой операции описан в разделе 4.11.6.2 (стр. с 4-95 по 4-99) документа C.S0014-C EVRC, упомянутого выше, данный раздел настоящим включен в состав настоящей заявки посредством ссылки в качестве примера. Типично, последняя модифицированная выборка (или первая немодифицированная выборка) выбирается в качестве начала сдвигового кадра. В примере EVRC операция выбора сегмента отыскивает текущий остаток подкадра для импульса, который должен быть сдвинут (например, первый импульс основного тона в области подкадра, который еще не был модифицирован), и устанавливает конец сдвигового кадра относительно положения этого импульса. Подкадр может содержать множество сдвиговых кадров, так что операция выбора сдвигового кадра (и последующие операции процедуры кусочного модифицирования) может выполняться несколько раз для одиночного подкадра.
Процедура кусочного модифицирования типично включает в себя операцию для отображения остатка в синтетический профиль задержки. Один из примеров такой операции описан в разделе 4.11.6.3 (стр. с 4-99 по 4-101) документа C.S0014-C EVRC, упомянутого выше, такой раздел настоящим включен в состав посредством ссылки в качестве примера. Этот пример формирует целевой остаток извлечением модифицированного остатка предыдущего подкадра из буфера и отображением его в профиль задержки (например, как описано в разделе 4.11.6.1 (стр. 4-95) документа C.S0014-C EVRC, упомянутого выше, данный раздел настоящим включен в состав настоящей заявки посредством ссылки в качестве примера). В этом примере операция отображения формирует подвергнутый временному модифицированию остаток посредством сдвига копии выбранного сдвигового кадра, определения оптимального сдвига согласно корреляции между подвергнутым временному модифицированию остатком и целевым остатком и расчета сдвига во времени на основании оптимального сдвига. Сдвиг во времени типично является накопленным значением, так что операция расчета сдвига во времени включает в себя обновление накопленного сдвига во времени на основании оптимального сдвига (например, как описано в части 4.11.6.3.4 раздела 4.11.6.3, включенного в состав посредством ссылки, приведенной выше).
Для каждого сдвигового кадра текущего остатка кусочное модифицирование достигается применением соответствующего рассчитанного сдвига во времени к сегменту текущего остатка, который соответствует сдвигу во времени. Один из примеров такой операции модифицирования описан в разделе 4.11.6.4 (стр. 4-101) документа C.S0014-C EVRC, упомянутого выше, такой раздел настоящим включен в состав посредством ссылки в качестве примера. Типично, сдвиг во времени имеет значение, которое является дробным, чтобы процедура модифицирования выполнялась с разрешением, более высоким, чем частота выборки. В таком случае может быть желательным применять сдвиг во времени к соответствующему сегменту остатка с использованием интерполяции, такой как линейная или билинейная интерполяция, которая может выполняться с использованием одного или более фильтров многофазной интерполяции или другой подходящей технологии.
Фиг. 10 иллюстрирует блок-схему последовательности операций способа кодирования RCELP, RM100, согласно основной конфигурации (например, реализации RCELP этапа TE30 способа M10). Способ RM100 включает в себя этап RT10, где рассчитывается остаток текущего кадра. Этап RT10 типично обеспечивает прием дискретного аудиосигнала (который может быть предварительно обработан), такого как аудиосигнал S100. Этап RT10 типично включает в себя операцию разложения кодированием с линейным предсказанием («LPC») и может быть сконфигурирован для создания набора параметров LPC, такого как линейные спектральные пары («LSP»). Этап RT10 также может включать в себя другие операции обработки, такие как одно или более перцепционных взвешиваний, и/или другие операции фильтрации.
Способ RM100 также включает в себя этап RT20, где рассчитывается синтетический профиль задержки аудиосигнала, этап RT30, где выбирается сдвиговый кадр по сформированному остатку, этап RT40, где рассчитывается сдвиг во времени на основании информации из выбранного сдвигового кадра и профиля задержки, и этап RT50, где модифицируется остаток текущего кадра на основании рассчитанного сдвига во времени.
Фиг. 11 иллюстрирует блок-схему последовательности операций реализации RM110 способа RM100 кодирования RCELP. Способ RM110 включает в себя реализацию RT42 этапа RT40 расчета сдвига во времени. Этап RT42 включает в себя этап RT60, где модифицированный остаток предыдущего подкадра отображается в синтетический профиль задержки текущего подкадра, этап RT70, где формируется подвергнутый временному модифицированию остаток (например, на основании выбранного сдвигового кадра), и этап RT80, где обновляется сдвиг во времени (например, на основании корреляции между подвергнутым временному модифицированию остатком и соответствующим сегментом отображенного прошлого модифицированного остатка). Реализация способа RM100 может быть включена в реализацию способа M10 (например, в пределах этапа TE30 кодирования), и, как отмечено выше, матрица логических элементов (например, логических вентилей) может быть сконфигурирована для выполнения одного, более чем одного или даже всех из различных этапов способа.
Фиг. 12a иллюстрирует структурную схему реализации RC100 кодера 34c кадров RCELP. Кодер RC100 включает в себя формирователь R10 остатка, сконфигурированный для расчета остатка текущего кадра (например, на основании операции разложения LPC), и вычислитель R20 профиля задержки, сконфигурированный для расчета синтетического контура задержки аудиосигнала S100 (например, на основании текущей и последней оценок основных тонов). Кодер RC100 также включает в себя селектор 30 сдвигового кадра, сконфигурированный для выбора сдвигового кадра текущего остатка, вычислитель R40 сдвига во времени, сконфигурированный для расчета сдвига во времени (например, для обновления сдвига во времени на основании подвергнутого временному модифицированию остатка), и модификатор R50 остатка, сконфигурированный для модифицирования остатка согласно сдвигу во времени (например, для применения рассчитанного сдвига во времени к сегменту остатка, который соответствует сдвиговому кадру).
Фиг. 12b иллюстрирует структурную схему реализации RC110 кодера RC100 RCELP, который включает в себя реализацию R42 вычислителя R40 сдвига во времени. Вычислитель R42 включает в себя блок R60 отображения прошлого модифицированного остатка, сконфигурированный для отображения модифицированного остатка предыдущего подкадра в синтетический профиль задержки текущего подкадра, формирователь R70 подвергнутого временному модифицированию остатка, сконфигурированный для формирования подвергнутого временному модифицированию остатка на основании выбранного сдвигового кадра, и блок R80 обновления сдвига во времени, сконфигурированный для расчета (например, обновления) сдвига во времени на основании корреляции между подвергнутым временному модифицированию остатком и соответствующим сегментом отображенного прошлого модифицированного остатка. Каждый из элементов кодеров RC100 и RC110 может быть реализован соответствующим модулем, таким как набор логических вентилей и/или команд для выполнения одним или более процессоров. Многорежимный кодер, такой как аудиокодер AE20, может включать в себя вариант кодера RC100 или его реализацию, и, в таком случае, один или более элементов кодера кадра RCELP (например, формирователь R10 остатка) могут совместно использоваться кодерами кадра, которые сконфигурированы для выполнения других режимов кодирования.
Фиг. 13 иллюстрирует структурную схему реализации R12 формирователя R10 остатка. Формирователь R12 включает в себя модуль 210 разложения LPC, сконфигурированный для расчета набора значений коэффициентов LPC на основании текущего кадра аудиосигнала S100. Блок 220 преобразования сконфигурирован для преобразования набора значений коэффициентов LPC в набор LSF, а квантователь 230 сконфигурирован для квантования LSF (например, в качестве одного или более индексов словаря кодов), чтобы вырабатывать параметры SL10 LPC. Обратный квантователь 240 конфигурируется для получения набора декодированных LSF из квантованных параметров SL10 LPC, а блок 250 обратного преобразования конфигурируется для получения набора декодированных значений коэффициентов LPC из набора декодированных LSF. Отбеливающий фильтр 260 (также называемый фильтром разложения), который конфигурируется согласно набору декодированных значений коэффициентов LPC, обрабатывает аудиосигнал S100 для создания остатка SR10 LPC. Формирователь R10 остатка также может быть реализован согласно любой другой конструкции, считающейся пригодной для конкретного применения.
Когда значение сдвига во времени изменяется с одного сдвига во времени на следующий, может возникать зазор или перекрытие на границе между сдвиговыми кадрами, и может быть желательным, чтобы модификатор R50 остатка или этап RT50 повторяли или опускали часть сигнала в этой области надлежащим образом. Также может быть желательным реализовать кодер RC100 или способ RM100 для сохранения модифицированного остатка в буфер (например, в качестве источника для формирования целевого остатка, который должен использоваться при выполнении процедуры кусочного модифицирования над остатком последующего кадра). Такой буфер может быть выполнен с возможностью для выдачи входного сигнала в вычислитель R40 сдвига во времени (например, в блок R60 отображения прошлого модифицированного остатка) или этап RT40 расчета сдвига во времени (например, в этап RT60 отображения).
Фиг. 12c иллюстрирует структурную схему реализации RC105 кодера RC100 RCELP, который включает в себя такой буфер R90 модифицированного остатка и реализацию R44 вычислителя R40 сдвига во времени, которая сконфигурирована для расчета сдвига во времени на основании информации из буфера R90. Фиг. 12d иллюстрирует структурную схему реализации RC115 кодера RC105 RCELP и кодера RC110 RCELP, которая включает в себя вариант буфера R90 и реализацию R62 модуля R60 отображения прошлого модифицированного остатка, который сконфигурирован для приема прошлого модифицированного остатка из буфера R90.
Фиг. 14 иллюстрирует структурную схему устройства RF100 для кодирования RCELP кадра аудиосигнала (например, реализацию RCELP средства FE30 устройства F10). Устройство RF100 включает в себя средство для формирования остатка, RF10, (например, остатка LPC) и средство для расчета профиля задержки, RF20, (например, посредством выполнения линейной или билинейной интерполяции между текущей и предыдущей оценкой основного тона). Устройство RF100 также включает в себя средство для выбора сдвигового кадра RF30 (например, посредством определения местоположения следующего импульса основного тона), средство для расчета сдвига во времени, RF40, (например, посредством обновления сдвига во времени согласно корреляции между подвергнутым временному модифицированию остатком и отображенным прошлым модифицированным остатком), и средство для модифицирования остатка, RF50 (например, посредством временного сдвига сегмента остатка, который соответствует сдвиговому кадру).
Модифицированный остаток типично используется для расчета вклада фиксированного словаря кодов в сигнал возбуждения для текущего кадра. Фиг. 15 иллюстрирует блок-схему последовательности операций реализации RM120 способа RM100 кодирования RCELP, которая включает в себя дополнительные этапы для поддержки такой операции. Этап RT90 изменяет масштаб времени адаптивного словаря кодов («ACB»), который хранит копию декодированного сигнала возбуждения из предыдущего кадра, отображая его в профиль задержки. Этап RT100 применяет фильтр разложения LPC, основанный на текущих значениях коэффициентов LPC, к подвергнутому изменению масштаба времени ACB, чтобы получить вклад ACB в области восприятия, а этап RT110 применяет фильтр разложения LPC, основанный на текущих значениях коэффициентов LPC, к текущему модифицированному остатку, чтобы получать текущий модифицированный остаток в области восприятия. Может быть желательным, чтобы этап RT100 и/или этап RT110 применяли фильтр разложения LPC, который основан на наборе взвешенных значений коэффициентов LPC, например, как описано в разделе 4.11.4.5 (стр. с 4-84 по 4-86) документа C.S0014-C EVRC 3GPP2, упомянутого выше. Этап RT120 рассчитывает разность между двумя сигналами области восприятия для получения цели для поиска по фиксированному словарю кодов («FCB»), а этап RT130 выполняет поиск по FCB для получения вклада FCB в сигнал возбуждения. Как отмечено выше, матрица логических элементов (например, логических вентилей) может быть сконфигурирована для выполнения одного, более чем одного, или даже всех из различных этапов этой реализации способа RM100.
Современная система многорежимного кодирования, которая включает в себя схему кодирования RCELP (например, система кодирования, включающая в себя реализацию аудиокодера AE25), типично также будет включать в себя одну или более схем кодирования без RCELP, таких как линейное предсказание с шумовым возбуждением («NELP»), которое типично используется для невокализованных кадров (например, проговариваемых фрикативных звуков) и кадров, которые содержат в себе только фоновый шум. Другие примеры схем кодирования без RCELP включают в себя интерполяцию волновым сигналом-прототипом («PWI») и ее варианты, такие как период основного тона прототипа («PPP»), которые типично используются для высоковокализованных кадров. Когда схема кодирования RCELP используется для кодирования кадра аудиосигнала, а схема кодирования без RCELP используется для кодирования соседнего кадра аудиосигнала, возможно, что может возникать разрывность в колебательном сигнале синтеза.
Может быть желательным кодировать кадр с использованием выборок соседнего кадра. Кодирование по границам кадра, таким образом, имеет тенденцию снижать воспринимаемые действия артефактов, которые могут возникать между кадрами вследствие таких факторов, как ошибка квантования, усечение, округление, отбрасывание лишних коэффициентов и т.п. Одним из примеров такой схемы кодирования является схема кодирования модифицированным дискретным косинусным преобразованием (MDCT).
Схема кодирования MDCT является схемой кодирования без PR, которая широко используется для кодирования музыки и других неречевых звуков. Например, перспективный аудиокодек («AAC»), который специфицирован в документе 14496-3:1999 Международной организации по стандартизации (ISO)/Международной электротехнической комиссии (IEC), также известный как часть 3 MPEG-4, является схемой кодирования MDCT. Раздел 4.13 (страницы с 4-145 по 4-151) документа C.S0014-C EVRC 3GPP2, упомянутого выше, описывает другую схему кодирования MDCT, и этот раздел настоящим включен в состав настоящей заявки посредством ссылки в качестве примера. Схема кодирования MDCT кодирует аудиосигнал в частотной области скорее как смесь синусоид, чем сигнал, чья структура основана на периоде основного тона, и является более подходящей для кодирования пения, музыки и других смесей синусоид.
Схема кодирования MDCT использует окно кодирования, которое продолжается (то есть перекрывает) по двум или более следующим друг за другом кадрам. Для длины кадра M MDCT создает M коэффициентов на основании ввода 2M выборок. Поэтому один из признаков схемы кодирования MDCT состоит в том, что она обеспечивает протяженность окна преобразования через одну или более границ кадров, не увеличивая количество коэффициентов преобразования, необходимых для представления кодированного кадра. Когда такая схема кодирования с перекрытием используется для кодирования кадра, смежного с кадром, кодированным с использованием схемы кодирования с PR, однако может возникать разрывность в соответствующем декодированном кадре.
Расчет M коэффициентов MDCT может быть выражен как:

где,
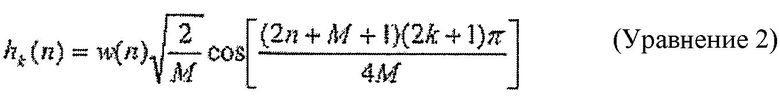
для k = 0, 1,..., M-1. Функция w(n) типично выбирается, чтобы быть окном, которое удовлетворяет условию w 2 (n) + w 2 (n + M) = 1 (также называемому условием Принсена-Брэдли).
Соответствующая операция обратного MDCT может быть выражена как:

для n=0, 1,..., 2M-1, где 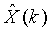 - M принятых коэффициентов MDCT, а
- M принятых коэффициентов MDCT, а 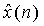 - 2M декодированных выборок.
- 2M декодированных выборок.
Фиг. 16 иллюстрирует три примера типичной синусоидальной формы окна для схемы кодирования MDCT. Эта форма окна, которая удовлетворяет условию Принсена-Брэдли, может быть выражена как

для 0 ≤n<2M, где n=0 указывает первую выборку текущего кадра.
Как показано на чертеже, окно 804 MDCT, используемое для кодирования текущего кадра (кадра p), содержит ненулевые значения на протяжении кадра p и кадра (p+1), а в остальном имеет нулевые значения. Окно 802 MDCT, используемое для кодирования предыдущего кадра (кадра (p-1)), содержит ненулевые значения на протяжении кадра (p-1) и кадра p и остальные нулевые значения, и окно 806 MDCT, используемое для кодирования следующего кадра (кадра (p+1)) скомпоновано аналогичным образом. В декодере декодированные последовательности перекрываются таким же образом, как входные последовательности, и складываются. Фиг. 25a иллюстрирует один из примеров области перекрытия и сложения, которая является следствием применения окон MDCT к следующим друг за другом кадрам аудиосигнала. Операция перекрытия и сложения нейтрализует ошибки, обусловленные преобразованием, и обеспечивает возможность точного восстановления (когда w(n) удовлетворяет условию Принсена-Брэдли и при отсутствии ошибки квантования). Даже если MDCT использует оконную функцию с перекрытием, она является критично дискретной гребенкой фильтров, так как после перекрытия и сложения количество входных выборок на кадр является таким же, как количество коэффициентов MDCT на кадр.
Фиг. 17a иллюстрирует структурную схему реализации ME100 кодера 34d кадра MDCT. Формирователь D10 остатка может быть сконфигурирован для формирования остатка с использованием квантованных параметров LPC (например, квантованных LSP, как описано в части 4.13.2 раздела 4.13 документа C.S0014-C EVRC 3GPP2, включенной в состав настоящей заявки посредством ссылки, приведенной выше). В качестве альтернативы, формирователь D10 остатка может быть сконфигурирован для формирования остатка с использованием неквантованных параметров LPC. В многорежимном кодере, который включает в себя реализации кодера RC100 RCELP и кодера ME100 MDCT, формирователь R10 остатка и формирователь D10 остатка могут быть реализованы как одна структура.
Кодер 100 ME также включает в себя модуль D20 MDCT, который сконфигурирован для расчета коэффициентов MDCT (например, согласно выражению для X(k), как изложено выше в EQ. 1). Кодер ME100 также включает в себя квантователь D30, который сконфигурирован для обработки коэффициентов MDCT, чтобы вырабатывать квантованный сигнал S30 кодированного остатка. Квантователь D30 может быть сконфигурирован для выполнения факториального кодирования коэффициентов MDCT с использованием вычислений точных функций. В качестве альтернативы, квантователь может быть сконфигурирован для выполнения факториального кодирования коэффициентов MDCT с использованием вычислений приближенных функций, например, как описано в «Low Complexity Factorial Pulse Coding of MDCT Coefficients Using Approximation of Combinatorial Functions» («Факториальное импульсное кодирование низкой сложности коэффициентов MDCT с использованием приближения комбинаторных функций»), У. Миттел и др., IEEE ICASSP 2007, стр. с 1-289 по 1-292, и в части 4.13.5 раздела 4.13 документа C.S0014-C EVRC 3GPP2, включенного в состав настоящей заявки посредством ссылки, приведенной выше. Как показано на фиг. 17a, кодер ME100 MDCT также может включать в себя необязательный модуль D40 обратного MDCT (IMDCT), который сконфигурирован для расчета декодированных выборок на основании квантованного сигнала (например, согласно выражению для x(n), как изложено выше в EQ. 3).
В некоторых случаях может быть желательным выполнять операцию MDCT над аудиосигналом S100 предпочтительнее, чем над остатком аудиосигнала S100. Хотя разложение LPC хорошо пригодно для кодирования резонансов человеческой речи, оно может не быть настолько эффективным для кодирования признаков неречевых сигналов, таких как музыка. Фиг. 17b иллюстрирует структурную схему реализации ME200 кодера 34d кадра MDCT, в котором модуль D20 MDCT сконфигурирован для приема кадров аудиосигнала S100 в качестве входных данных.
Стандартная схема перекрытия MDCT, как показано на фиг. 16, требует 2M выборок, которые должны иметься, прежде чем сможет выполняться преобразование. Такая схема эффективно принудительно применяет ограничение по задержке в 2M выборок к системе кодирования (то есть M выборок текущего кадра плюс M выборок опережения). Другие режимы кодирования многорежимного кодера, такие как CELP, RCELP, NELP, PWI и/или PPP, типично сконфигурированы для оперирования более коротким ограничением по задержке (например, M выборок текущего кадра плюс M/2, M/3 и M/4 выборок опережения). В современных многорежимных кодерах (например, EVRC, SMV, AMR) переключение между режимами кодирования выполняется автоматически и может происходить даже несколько раз за одну секунду. Может быть желательным, чтобы режимы кодирования такого кодера действовали с одной и той же задержкой, особенно для приложений с коммутацией каналов, что может потребовать передатчика, который включает в себя кодеры для формирования пакетов с конкретной частотой.
Фиг. 18 иллюстрирует один из примеров оконной функции w(n), которая может применяться модулем D20 MDCT (например, вместо функции w(n), которая проиллюстрирована на фиг. 16), чтобы предоставлять возможность интервала опережения, который короче, чем M. В конкретном примере, показанном на фиг. 18, интервал опережения имеет длину в M/2 выборок, но такая технология может быть реализована, чтобы предоставлять возможность произвольного опережения в L выборок, где L имеет любое значение от 0 до M. В этой технологии (примеры которой описаны в части 4.13.4 (стр. 4-147) раздела 4.13 документа C.S0014-C EVRC 3GPP2, включенного в состав настоящей заявки посредством ссылки, приведенной выше, и в публикации США № 2008/0027719, озаглавленной «SYSTEMS AND METHODS FOR MODIFYING A WINDOW WITH A FRAME ASSOCIATED WITH AN AUDIO SIGNAL» («СИСТЕМЫ И СПОСОБЫ ДЛЯ МОДИФИЦИРОВАНИЯ ОКНА С КАДРОМ, АССОЦИИРОВАННЫМ С АУДИОСИГНАЛОМ»)), окно MDCT начинается и заканчивается областями заполнения нулями длиной в (M-L)/2, а w(n) удовлетворяет условию Принстона-Брэдли. Одна из реализаций такой оконной функции может быть выражена, как изложено ниже:
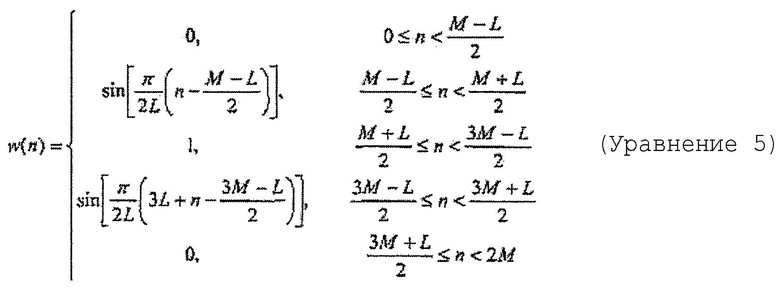
где 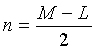 - первая выборка текущего кадра p, а
- первая выборка текущего кадра p, а 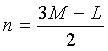 - первая выборка следующего кадра (p+1). Сигнал, кодированный согласно такой технологии, сохраняет свойство точного восстановления (при отсутствии ошибок квантования и численных ошибок). Отмечено, что для случая L=M эта оконная функция является такой же, как проиллюстрированная на фиг. 16, а для функции L = 0, w(n) = 1 для
- первая выборка следующего кадра (p+1). Сигнал, кодированный согласно такой технологии, сохраняет свойство точного восстановления (при отсутствии ошибок квантования и численных ошибок). Отмечено, что для случая L=M эта оконная функция является такой же, как проиллюстрированная на фиг. 16, а для функции L = 0, w(n) = 1 для 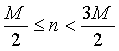 и является нулевой в ином случае, так что отсутствует перекрытие.
и является нулевой в ином случае, так что отсутствует перекрытие.
В многорежимном кодере, который включает в себя схемы кодирования с PR и без PR, может быть желательным гарантировать, что волновой сигнал синтеза является непрерывным на границе кадра, в котором текущий режим кодирования переключается с режима кодирования с PR на режим кодирования без PR (или наоборот). Селектор режима кодирования может осуществлять переключение с одной схемы кодирования на другую несколько раз за секунду, и желательно предусмотреть воспринимаемый гладкий переход между такими схемами. К сожалению, период основного тона, который охватывает границу между подвергнутым регуляризации кадром и не подвергнутым регуляризации кадром, может быть необыкновенно большим или малым, так что переключение между схемами кодирования с PR и без PR может вызывать слышимый щелчок или другую разрывность в декодированном сигнале. Дополнительно, как отмечено выше, схема кодирования без PR может кодировать кадр аудиосигнала с использованием окна перекрытия и сложения, которое тянется по следующим друг за другом кадрам, и может быть желательным избегать изменения сдвига во времени на границе между этими следующими друг за другом кадрами. В этих случаях может быть желательным модифицировать не подвергнутые регуляризации кадры согласно сдвигу во времени, применяемому схемой кодирования с PR.
Фиг. 19a иллюстрирует блок-схему последовательности операций способа M100 обработки кадров аудиосигнала согласно общей конфигурации. Способ M100 включает в себя этап T110, где кодируется первый кадр согласно схеме кодирования с PR (например, схеме кодирования RCELP). Способ M100 также включает в себя этап T210, где кодируется второй кадр аудиосигнала согласно схеме кодирования без PR (например, схеме кодирования MDCT). Как отмечено выше, один или более из первого и второго кадров могут перцепционно взвешиваться и/или обрабатываться иным образом до и/или после такого кодирования.
Этап T110 включает в себя подэтап T120, который осуществляет временное модифицирование сегмента первого сигнала согласно сдвигу T во времени, где первый сигнал основан на первом кадре (например, первый сигнал является первым кадром или остатком первого кадра). Временное модифицирование может выполняться посредством временного сдвига или посредством изменения масштаба времени. В одной из реализаций этап T120 осуществляет временной сдвиг сегмента, перемещая полный сегмент вперед или назад во времени (то есть относительно другого сегмента кадра или аудиосигнала) согласно значению T. Такая операция может включать в себя интерполяцию значений выборок, для того чтобы выполнять фрагментарный сдвиг во времени. В еще одной реализации этап T120 изменяет масштаб времени сегмента на основании сдвига T во времени. Такая операция может включать в себя перемещение одной выборки сегмента (например, первой выборки) согласно значению T и перемещение другой выборки сегмента (например, последней выборки) на значение, имеющее модуль, меньший, чем величина T.
Этап T210 включает в себя подэтап T220, где осуществляется временное модифицирование сегмента второго сигнала согласно сдвигу T во времени, где второй сигнал основан на втором кадре (например, второй сигнал является вторым кадром или остатком второго кадра). В одной из реализаций этап T220 осуществляет временной сдвиг сегмента, перемещая полный сегмент вперед или назад во времени (то есть относительно другого сегмента кадра или аудиосигнала) согласно значению T. Такая операция может включать в себя интерполяцию значений выборок, для того чтобы выполнять фрагментарный сдвиг во времени. В еще одной реализации этап T220 изменяет масштаб времени сегмента на основании сдвига T во времени. Такая операция может включать в себя отображение сегмента в профиль задержки. Например, такая операция может включать в себя перемещение одной выборки сегмента (например, первой выборки) согласно значению T и перемещение другой выборки сегмента (например, последней выборки) на значение, имеющее модуль, меньший, чем величина T. Например, этап T120 может изменять масштаб времени кадра или другого сегмента, отображая его в соответствующий временной интервал, который был укорочен на значение сдвига T во времени (например, удлинен, в случае отрицательного значения T), в таком случае значение T может сбрасываться в ноль на конце подвергаемого изменению масштаба времени сегмента.
Сегмент, временное модифицирование которого осуществляется на этапе T220, может включать в себя полный второй сигнал, или сегмент может быть более короткой частью такого сигнала, такой как подкадр остатка (например, начальный подкадр). Типично, этап T220 осуществляет временное модифицирование сегмента неквантованного остаточного сигнала (например, после фильтрации обратным LPC аудиосигнала S100), такого как выходной сигнал формирователя D10 остатка, как показано на фиг. 17a. Однако этап T220 также может быть реализован для временного модифицирования сегмента декодированного остатка (например, после обработки MDCT-IMDCT), такого как сигнал S40, как показано на фиг. 17a, или сегмента аудиосигнала S100.
Может быть желательным, чтобы сдвиг T во времени был последним сдвигом во времени, который использовался для модифицирования первого сигнала. Например, сдвиг T во времени может быть сдвигом во времени, который применялся к последнему подвергнутому временному сдвигу сегменту остатка первого кадра, и/или значением, являющимся результатом самого последнего обновления накопленного сдвига во времени. Реализация кодера RC100 RCELP может быть сконфигурирована для выполнения этапа T110, в таком случае сдвиг T во времени может быть значением последнего сдвига во времени, рассчитанным блоком R40 или блоком R80 во время кодирования первого кадра.
Фиг. 19b иллюстрирует блок-схему последовательности операций способа для реализации T112 этапа T110. Этап T112 включает в себя подэтап T130, где рассчитывается сдвиг во времени на основании информации из остатка предыдущего подкадра, такого как модифицированный остаток самого последнего подкадра. Как обсуждено выше, может быть желательным, чтобы схема кодирования RCELP формировала целевой остаток, который основан на модифицированном остатке предыдущего подкадра, и рассчитывала сдвиг во времени согласно отображению между выбранным сдвигом во времени и соответствующим сегментом целевого остатка.
Фиг. 19c иллюстрирует блок-схему последовательности операций способа для реализации T114 этапа T112, который включает в себя реализацию T132 этапа T130. Этап T132 включает в себя этап T140, где выборки предыдущего остатка отображаются в профиль задержки. Как обсуждалось выше, может быть желательным, чтобы схема кодирования RCELP формировала целевой остаток, отображая модифицированный остаток предыдущего подкадра в синтетический профиль задержки текущего подкадра.
Может быть желательным конфигурировать этап T210, чтобы осуществлялся временной сдвиг второго сигнала, а также участка последующего кадра, который используется в качестве опережения для кодирования второго кадра. Например, может быть желательным, чтобы этап T210 применял сдвиг T во времени к остатку второго кадра (без PR), а также к любой части остатка последующего кадра, который используется в качестве опережения для кодирования второго кадра (например, как описано выше со ссылкой на окна MDCT и с перекрытием). Также может быть желательным конфигурировать этап T210, чтобы применялся сдвиг T во времени к остаткам любых последующих, идущих друг за другом кадров, которые кодируются с использованием схемы кодирования без PR (например, схемы кодирования MDCT) и к любым сегментам опережения, соответствующим таким кадрам.
Фиг. 25b иллюстрирует пример, в котором каждая из последовательности кадров без PR между двумя кадрами с PR сдвинута на сдвиг во времени, который применялся к последнему сдвиговому кадру первого кадра с PR. На этом череже сплошные линии указывают положения исходных кадров во времени, пунктирные линии указывают сдвинутые положения кадров, а пунктирные линии показывают соответствие между исходными и сдвинутыми границами. Более длинные вертикальные линии указывают границы кадров, первая короткая вертикальная линия указывает начало последнего сдвигового кадра у первого кадра с PR (где пик указывает импульс основного тона сдвигового кадра), а последняя короткая вертикальная линия указывает конец сегмента опережения для конечного кадра без PR последовательности. В одном из примеров кадры с PR являются кадрами RCELP, а кадры без PR являются кадрами MDCT. В еще одном примере кадры с PR являются кадрами RCELP, некоторые из кадров без PR являются кадрами MDCT, а другие из кадров без PR являются кадрами NELP или PWI.
Способ M100 может быть пригоден для случая, в котором никакая оценка основного тона не имеется в распоряжении для текущего кадра без PR. Однако может быть желательным выполнять способ M100, даже если оценка основного тона имеется в распоряжении для текущего кадра без PR. В схеме кодирования без PR, которая влечет за собой перекрытие и сложение между следующими друг за другом кадрами (такие как с окном MDCT), может быть желательным сдвигать следующие друг за другом кадры, любые соответствующие опережения, и любые области перекрытия между кадрами, на одно и то же значение сдвига. Такое постоянство может помочь избежать ухудшения качества восстановленного аудиосигнала. Например, может быть желательным использовать одно и то же значение сдвига во времени для обоих из кадров, которые осуществляют вклад в область перекрытия, такую как окно MDCT.
Фиг. 21a иллюстрирует структурную схему реализации ME110 кодера ME100 MDCT. Кодер ME110 включает в себя временной модификатор TM10, который выполнен с возможностью для временного модифицирования сегмента остаточного сигнала, сформированного формирователем D10 остатка, чтобы вырабатывать подвергнутый временному модифицированию остаточный сигнал S20. В одной из реализаций временной модификатор TM10 сконфигурирован для временного сдвига сегмента посредством перемещения полного сегмента вперед или назад согласно значению T. Такая операция может включать в себя интерполяцию значений выборок, для того, чтобы выполнять фрагментарный сдвиг во времени. В еще одной реализации временной модификатор TM10 сконфигурирован для изменения масштаба времени сегмента на основании сдвига T во времени. Такая операция может включать в себя отображение сегмента в профиль задержки. Например, такая операция может включать в себя перемещение одной выборки сегмента (например, первой выборки) согласно значению T и перемещение другой выборки (например, последней выборки) на значение, имеющее модуль, меньший, чем величина T. Например, этап T120 может изменять масштаб времени кадра или другого сегмента, отображая его в соответствующий временной интервал, который был укорочен на значение сдвига T во времени (например, удлинен, в случае отрицательного значения T), в таком случае значение T может сбрасываться в ноль на конце подвергаемого изменению масштаба времени сегмента. Как отмечено выше, сдвиг T во времени может быть сдвигом во времени, который применялся самый последний раз к подвергнутому временному сдвигу сегменту схемой кодирования с PR, и/или значением, являющимся результатом самого последнего обновления накопленного сдвига во времени посредством схемы кодирования с PR. В реализации аудиокодера AE10, которая включает в себя реализации кодера RC105 RCELP и кодера ME110 MDCT, кодер ME110 также может быть сконфигурирован для сохранения подвергнутого временному модифицированию остаточного сигнала S20 в буфер R90.
Фиг. 20b иллюстрирует структурную схему реализации ME210 кодера ME200 MDCT. Кодер ME200 включает в себя вариант временного модификатора TM10, который выполнен с возможностью для временного модифицирования сегмента аудиосигнала S100, чтобы вырабатывать подвергнутый временному модифицированию аудиосигнал S25. Как отмечено выше, аудиосигнал S100 может быть перцепционно взвешенным и/или иным образом фильтрованным цифровым сигналом. В реализации аудиокодера AE10, которая включает в себя реализации кодера RC105 RCELP и кодера ME210 MDCT, кодер ME210 также может быть сконфигурирован для сохранения подвергнутого временному модифицированию остаточного сигнала S20 в буфер R90.
Фиг. 21a иллюстрирует структурную схему реализации ME120 кодера ME110 MDCT, которая включает в себя модуль D50 добавления шума. Модуль D50 добавления шума сконфигурирован для замещения шумом наделенных нулевым значением элементов квантованного кодированного остаточного сигнала S30 в пределах предопределенного частотного диапазона (например, согласно технологии, которая описана в части 4.13.7 (стр. 4-150) раздела 4.13 документа C.S0014-C EVRC 3GPP2, включенного в состав посредством ссылки, приведенной выше). Такая операция может улучшать качество аудио уменьшением восприятия тональных артефактов, которые могут возникать во время находящегося под моделированием остаточного линейчатого спектра.
Фиг. 21b иллюстрирует структурную схему реализации ME130 кодера ME100 MDCT. Кодер ME130 включает в себя модуль D60 назначения формант, сконфигурированный для выполнения перцепционного взвешивания областей низкочастотных формант остаточного сигнала S20 (например, согласно технологии, которая описана в части 4.13.3 (стр. 4-147) раздела 4.13 документа C.S0014-C EVRC 3GPP2, включенной в состав настоящей заявки посредством ссылки, приведенной выше), и модуль D70 устранения формант, сконфигурированный для устранения перцепционного взвешивания (например, согласно технологии, которая описана в части 4.13.9 (стр. 4-151) раздела 4.13 документа C.S0014-C EVRC 3GPP2).
Фиг. 22 иллюстрирует структурную схему реализации ME140 кодеров ME120 и ME130 MDCT. Другие реализации кодера MD110 MDCT могут быть сконфигурированы, чтобы включать одну или более дополнительных операций в тракт обработки между формирователем D10 остатка и декодированным остаточным сигналом S40.
Фиг. 23a иллюстрирует блок-схему последовательности операций способа кодирования MDCT, MM100, согласно основной конфигурации (например, реализации MDCT этапа TE30 способа M10). Способ MM100 включает в себя этап MT10, где формируется остаток кадра. Этап MT10 типично выполнен с возможностью для приема кадра дискретного аудиосигнала (который может быть предварительно обработан), такого как аудиосигнал S100. Этап MT10 типично реализован так, чтобы включать в себя операцию разложения кодированием с линейным предсказанием («LPC») и может быть сконфигурирован для создания набора параметров LPC, такого как линейные спектральные пары («LSP»). Этап MT10 также может включать в себя другие операции обработки, такие как одна или более операции перцепционного взвешивания, и/или другой фильтрации.
Способ MM100 включает в себя этап MT20, где осуществляется временное модифицирование сформированного остатка. В одной из реализаций этап MT20 осуществляет временное модифицирование остатка посредством временного сдвига сегмента остатка, перемещая полный сегмент вперед или назад согласно значению T. Такая операция может включать в себя интерполяцию значений выборок, для того, чтобы выполнять фрагментарный сдвиг во времени. В еще одной реализации этап MT220 осуществляет временное модифицирование остатка посредством изменения масштаба времени сегмента остатка на основании сдвига T во времени. Такая операция может включать в себя отображение сегмента в профиль задержки. Например, такая операция может включать в себя перемещение одной выборки сегмента (например, первой выборки) согласно значению T и перемещение другой выборки (например, последней выборки) на значение, имеющее модуль, меньший, чем T. Сдвиг T во времени может быть сдвигом во времени, который применялся самый последний раз к подвергнутому временному сдвигу сегменту схемой кодирования с PR, и/или значением, являющимся результатом самого последнего обновления накопленного сдвига во времени посредством схемы кодирования с PR. В реализации способа M10 кодирования, который включает в себя реализации способа RM100 кодирования RCELP и способа MM100 кодирования MDCT, этап MT20 также может быть сконфигурирован для сохранения подвергнутого временному модифицированию остаточного сигнала S20 в буфере модифицированного остатка (например, для возможного использования способом RM100 для формирования целевого остатка для следующего кадра).
Способ MM100 включает в себя этап MT30, где выполняется операция MDCT над подвергнутым временному модифицированию остатком (например, согласно выражению для X(k), как изложено выше), чтобы создать набор коэффициентов MDCT. Этап MT30 может применять оконную функцию w(n), такую, как описанная в материалах настоящей заявки (например, как показано на фиг. 16 или 18), или может использовать другую оконную функцию или алгоритм для выполнения операции MDCT. Способ MM40 включает в себя этап MT40, где квантуются коэффициенты MDCT с использованием факториального кодирования, комбинаторной аппроксимации, усечения, округления и/или любой другой операции квантования, считающейся пригодной для конкретного применения. В этом примере способ MM 100 также включает в себя необязательный этап MT50, который сконфигурирован для выполнения операции IMDCT над квантованными коэффициентами для получения набора декодированных выборок (например, согласно выражению для 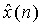 , как изложено выше).
, как изложено выше).
Реализация способа MM100 может быть включена в реализацию способа M10 (например, в пределах этапа TE30 кодирования) и, как отмечено выше, матрица логических элементов (например, логических вентилей) может быть сконфигурирована для выполнения одного, более чем одного, или даже всех из различных этапов способа. Для случая, в котором способ M10 включает в себя реализации обоих, способа MM100 и способа RM100, этап RT10 расчета остатка и этап MT10 формирования остатка могут совместно использовать общие операции (например, могут отличаться только порядком операции LPC) или даже могут быть реализованы в качестве одного и того же этапа.
Фиг. 23b иллюстрирует структурную схему устройства MF100 для кодирования MDCT кадра аудиосигнала (например, реализацию MDCT средства FE30 устройства F10). Устройство MF100 включает в себя средство для формирования остатка кадра FM10 (например, посредством выполнения реализации этапа MT10, как описано выше). Устройство MF100 включает в себя средство для временного модифицирования сформированного остатка кадра FM20 (например, посредством выполнения реализации этапа MT20, как описано выше). В реализации устройства F10 кодирования, которое включает в себя реализации устройства RF100 кодирования RCELP и устройства MF100 кодирования MDCT, средство FM20 также может быть сконфигурировано для сохранения подвергнутого временному модифицированию остаточного сигнала S20 в буфере модифицированного остатка (например, для возможного использования устройством RF100 для формирования целевого остатка для следующего кадра). Устройство MF100 также включает в себя средство для выполнения операции MDCT над подвергнутым временному модифицированию остатком FM30, чтобы получать набор коэффициентов MDCT (например, посредством выполнения реализации этапа MT30, как описано выше), и средство для квантования коэффициентов MDCT, FM40, (например, посредством выполнения реализации этапа MT40, как описано выше). Устройство MF100 также включает в себя необязательное средство для выполнения операции IMDCT над квантованными коэффициентами, FM50, (например, посредством выполнения этапа MT50, как описано выше).
Фиг. 24a иллюстрирует блок-схему последовательности операций способа M200 обработки кадров аудиосигнала согласно еще одной общей конфигурации. Этап T510 способа M200 кодирует первый кадр согласно схеме кодирования без PR (например, схеме кодирования MDCT). Этап T610 способа M200 кодирует второй кадр аудиосигнала согласно схеме кодирования с PR (например, схеме кодирования RCELP).
Этап T510 включает в себя подэтап T520, где осуществляется временное модифицирование сегмента первого сигнала согласно первому сдвигу T во времени, где первый сигнал основан на первом кадре (например, первый сигнал является первым кадром (без PR) или остатком первого кадра). В одном из примеров сдвиг T во времени является значением (например, последним обновленным значением) накопленного сдвига во времени, которое рассчитывается во время кодирования RCELP кадра, который предшествует первому кадру в аудиосигнале. Сегмент, временное модифицирование которого осуществляется на этапе T520, может включать в себя полный первый сигнал, или сегмент может быть более короткой частью такого сигнала, такой как подкадр остатка (например, конечный подкадр). Типично на этапе T520 осуществляется временное модифицирование неквантованного остаточного сигнала (например, после фильтрации обратным LPC аудиосигнала S100), такого как выходной сигнал формирователя D10 остатка, как показано на фиг. 17a. Однако этап T520 также может быть реализован для временного модифицирования сегмента декодированного остатка (например, после обработки MDCT-IMDCT), такого как сигнал S40, как показано на фиг. 17a, или сегмента аудиосигнала S100.
В одной из реализаций этап T520 осуществляет временной сдвиг сегмента, перемещая полный сегмент вперед или назад во времени (то есть относительно другого сегмента кадра или аудиосигнала) согласно значению T. Такая операция может включать в себя интерполяцию значений выборок, чтобы выполнять фрагментарный сдвиг во времени. В еще одной реализации этап T520 изменяет масштаб времени сегмента на основании сдвига T во времени. Такая операция может включать в себя отображение сегмента в профиль задержки. Например, такая операция может включать в себя перемещение одной выборки сегмента (например, первой выборки) согласно значению T и перемещение другой выборки сегмента (например, последней выборки) на значение, имеющее модуль, меньший, чем величина T.
Этап T520 может быть сконфигурирован для сохранения подвергнутого временному модифицированию сигнала в буфер (например, буфер модифицированного остатка) для возможного использования задачей T620, описанной ниже (например, чтобы формировать целевой остаток для следующего кадра). Этап T520 также может быть сконфигурирован для обновления другой памяти состояний этапа кодирования с PR. Одна из таких реализаций этапа T520 сохраняет декодированный квантованный остаточный сигнал, такой как декодированный остаточный сигнал S40, в памяти адаптивного словаря кодов («ACB») и состоянии фильтра реакции при нулевом входном сигнале этапа кодирования с PR (например, способа RM120 кодирования RCELP).
Этап T610 включает в себя подэтап T620, где изменяется масштаб времени второго сигнала на основании информации из подвергнутого временному модифицированию сегмента, где второй сигнал основан на втором кадре (например, второй сигнал является вторым кадром с PR или остатком второго кадра). Например, схема кодирования с PR может быть схемой кодирования RCELP, сконфигурированной для кодирования второго кадра, как описанный выше, посредством использования остатка первого кадра, включающего в себя подвергнутый временному модифицированию (например, временному сдвигу) сегмент, вместо прошлого модифицированного остатка.
В одной из реализаций этап T620 применяет второй сдвиг во времени к сегменту, перемещая полный сегмент вперед или назад во времени (то есть относительно другого сегмента кадра или аудиосигнала). Такая операция может включать в себя интерполяцию значений выборок, чтобы выполнять фрагментарный сдвиг во времени. В еще одной реализации этап T620 изменяет масштаб времени сегмента, что может включать в себя отображение сегмента в профиль задержки. Например, такая операция может включать в себя перемещение одной выборки сегмента (например, первой выборки) согласно сдвигу во времени и перемещение другой выборки сегмента (например, последней выборки) на меньший сдвиг во времени.
Фиг. 24b иллюстрирует блок-схему последовательности операций способа для реализации T622 этапа T620. Этап T622 включает в себя подэтап T630, где рассчитывается второй сдвиг во времени на основании информации из подвергнутого временному модифицированию сегмента. Этап T622 также включает в себя подэтап T640, который применяет второй сдвиг во времени к сегменту второго сигнала (в этом примере к остатку второго кадра).
Фиг. 24c иллюстрирует блок-схему последовательности операций способа для реализации T624 этапа T620. Этап T624 включает в себя подэтап T650, где выборки подвергнутого временному модифицированию сегмента отображаются в профиль задержки аудиосигнала. Как обсуждено выше, может быть желательным, чтобы схема кодирования RCELP формировала целевой остаток, отображая модифицированный остаток предыдущего подкадра в синтетический профиль задержки текущего подкадра. В этом случае схема кодирования RCELP может быть сконфигурирована для выполнения этапа T650 посредством формирования целевого остатка, который основан на остатке первого кадра (без RCELP), включающего в себя подвергнутый временному модифицированию сегмент.
Например, такая схема кодирования RCELP может быть сконфигурирована для формирования целевого остатка посредством отображения остатка первого кадра (без RCELP), включающего в себя подвергнутый временному модифицированию сегмент, в синтезированный профиль задержки текущего кадра. Схема кодирования RCELP также может быть сконфигурирована для расчета сдвига во времени на основании целевого сигнала и для использования рассчитанного сдвига во времени для изменения шкалы времени остатка второго кадра, как обсуждено выше. Фиг. 24d иллюстрирует блок-схему последовательности операций способа реализации T626 этапов T622 и T624, которая включает в себя этап T650, реализацию T632 этапа T630, где рассчитывается второй сдвиг во времени на основании информации из отображенных выборок подвергнутого временному модифицированию сегмента, и этап T640.
Как отмечено выше, может быть желательным передавать и принимать аудиосигнал, имеющий частотный диапазон, который превышает частотный диапазон PSTN в приблизительно 300-3400 Гц. Одним из подходов к кодированию такого сигнала является технология «цельной полосы», которая кодирует весь расширенный частотный диапазон, как единый частотный диапазон (например, посредством масштабирования системы кодирования для диапазона PSTN для покрытия расширенного частотного диапазона). Еще один подход состоит в том, чтобы экстраполировать информацию из сигнала PSTN на расширенный частотный диапазон (например, экстраполировать сигнал возбуждения для широкополосного диапазона выше диапазона PSTN на основании информации из аудиосигнала с диапазоном PSTN). Дополнительным подходом является технология «расщепленной полосы», в которой отдельно кодируется информация аудиосигнала, который находится вне диапазона PSTN (например, информацию для широкополосного частотного диапазона, такого как 3500-7000 или 3500-8000 Гц). Описания технологий кодирования с PR расщепленной полосы может быть найдена в документах, таких как публикация США № 2008/0052065, озаглавленная «TIME-WARPING FRAMES OF WIDEBAND VOCODER» («ИЗМЕРЕНИЕ ШКАЛЫ ВРЕМЕНИ КАДРОВ ШИРОКОПОЛОСНОГО ВОКОДЕРА»), и № 2006/0282263, озаглавленная «SYSTEMS, METHODS, AND APPARATUS FOR HIGHBAND TIME WARPING» («СИСТЕМЫ, СПОСОБЫ И УСТРОЙСТВО ДЛЯ ШИРОКОПОЛОСНОГО ИЗМЕНЕНИЯ МАСШТАБА ВРЕМЕНИ»). Может быть желательным расширить технологию кодирования расщепленной полосы для включения реализаций способа M100 и/или M200 в обеих, узкополосной и широкополосной, частях аудиосигнала.
Способ M100 и/или M200 может выполняться в пределах реализации способа M10. Например, этапы T110 и T210 (аналогично, этапы T510 и T610) могут выполняться следующими друг за другом итерациями этапа TE30 по мере того, как способ M10 выполняется для обработки следующих друг за другом кадров аудиосигнала S100. Способ M100 и/или M200 также может выполняться реализацией устройства F10 и/или устройства AE10 (например, устройства AE20 или AE25). Как отмечено выше, такое устройство может быть включено в портативное устройство связи, такое как сотовый телефон. Такие способы и/или устройство также могут быть реализованы в инфраструктурном оборудовании, таком как медиа-шлюз.
Предшествующее представление описанных конфигураций приведено, чтобы дать любому специалисту в данной области техники возможность изготовить или использовать способы и другие конструкции, раскрытые в материалах настоящей заявки. Блок-схемы последовательности операций способов, структурные схемы, графы состояний и другие структуры, показанные и описанные в материалах настоящей заявки, являются только примерами, и другие варианты этих структур также находятся в пределах объема раскрытия. Возможны различные модификации в отношении этих конфигураций, и общие принципы, представленные в материалах настоящей заявки, также могут быть применены к другим конфигурациям. Таким образом, настоящее раскрытие не подразумевается ограниченным конфигурациями, показанными выше, а скорее должно рассматриваться в самом широком объеме, совместимом с принципами и новыми признаками, раскрытыми в материалах настоящей заявки, в том числе в прилагаемой формуле изобретения, как подано, которая является частью первоначального раскрытия.
В дополнение к кодекам EVRC и SMV, упомянутым выше, примеры кодеков, которые могут быть использованы или приспособлены для использования с кодерами речи, способами кодирования речи, декодерами речи и/или способами декодирования речи, как описано в материалах настоящей заявки, включают в себя адаптивный многоскоростной («AMR») речевой кодек, как описано в документе ETSI TS 126092, V6.0.0, (Европейский институт стандартов по телекоммуникациям («ETSI»), Sophia Antipolis Cedex, Франция, декабрь 2004 года); и широкополосный речевой кодек AMR, как описано в документе ETSI TS 126192, V6.0.0, (ETSI, декабрь 2004 года).
Специалистам в данной области техники должно быть понятно, что информация и сигналы могут быть представлены с использованием любой из многообразия разных технологий и методик. Например, данные, команды, директивы, информация, сигналы, биты и символы, которые могли упоминаться на всем протяжении вышеприведенного описания, могут быть представлены напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами, или любой их комбинацией.
Специалисты, кроме того, приняли бы во внимание, что различные иллюстративные логические блоки, модули, схемы и операции, описанные в связи с конфигурациями, раскрытыми в материалах настоящей заявки, могут быть реализованы в виде электронных аппаратных средств, компьютерного программного обеспечения или их комбинаций. Такие логические блоки, модули, схемы и операции могут быть реализованы или выполняться с помощью процессора общего применения, цифрового сигнального процессора (DSP), ASIC, ASSP, FPGA или другого программируемого логического устройства, дискретной вентильной или транзисторной логики, дискретных компонентов аппаратных средств или любой их комбинации, предназначенной для выполнения функций, описанных в материалах настоящей заявки. Процессором общего применения может быть микропроцессор, но в альтернативном варианте процессор может быть любым традиционным процессором, контроллером, микроконтроллером или конечным автоматом. Процессор также может быть реализован в виде комбинации вычислительных устройств, например, сочетания DSP и микропроцессора, множества микропроцессоров, одного или более микропроцессоров в соединении с DSP-ядром или любой другой такой конфигурации.
Этапы способов или алгоритмов, описанные в материалах настоящей заявки, могут быть осуществлены непосредственно в аппаратных средствах, в модуле программного обеспечения, выполняемом процессором, или в их комбинации. Модуль программного обеспечения может находиться в оперативном запоминающем устройстве (ОЗУ, RAM), постоянном запоминающем устройстве (ПЗУ, ROM), энергонезависимом ОЗУ (NVRAM), таком как ОЗУ флэш-памяти, стираемом программируемом ПЗУ (СППЗУ, EPROM), электрическом стираемом программируемом ПЗУ (ЭСППЗУ, EEPROM), регистрах, жестком диске, съемном диске, CD-ROM (ПЗУ на компакт диске) или любом другом виде запоминающего носителя, известном в данной области техники. Иллюстративный носитель записи является соединенным с процессором, и такой процессор может считывать информацию и записывать информацию на носитель записи. В альтернативном варианте носитель записи может составлять одно целое с процессором. Процессор и носитель записи могут находиться в ASIC. ASIC может находиться в пользовательском терминале. В альтернативном варианте процессор и носитель записи могут находиться, в виде дискретных компонентов, в пользовательском терминале.
Каждая из конфигураций, описанных в материалах настоящей заявки, может быть реализована, по меньшей мере частично, как аппаратная схема, схемная конфигурация, скомпонованная в специализированную интегральную схему, или как аппаратно реализованная программа, загруженная в энергонезависимое запоминающее устройство, либо программно реализованная программа, загружаемая с/на носитель хранения данных в виде машиночитаемой управляющей программы, причем такая управляющая программа является набором команд, выполняемых матрицей логических элементов, такой как микропроцессор или другой узел цифровой сигнальной обработки. Носитель хранения данных может быть матрицей запоминающих элементов, такой как полупроводниковая память (которая может включать в себя, без ограничения, динамическое или статическое ОЗУ, ПЗУ и/или ОЗУ на флэш-памяти), или ферроэлектрической, магниторезистивной, полимерной памятью, либо памятью на элементах Овшинского или на фазовых переходах; или дисковым носителем, таким как магнитный или оптический диск. Понятно, что термин «программное обеспечение» включает в себя программу на исходном языке, программу на языке ассемблера, машинный код, двоичный код, программно-аппаратное обеспечение, макрокод, микрокод, любые один или более наборов или последовательностей команд, выполняемых матрицей логических элементов, и любой комбинацией таких примеров.
Реализации способов M10, RM100, MM100, M100 и M200, раскрытых в материалах настоящей заявки, также могут быть вещественно осуществлены (например, в одном или более носителей хранения данных, которые перечислены выше), как один или более наборов команд, считываемых и/или выполняемых машиной, включающей в себя матрицу логических элементов (например, процессор, микропроцессор, микроконтроллер или другой конечный автомат). Таким образом, настоящее раскрытие не подразумевается ограниченным конфигурациями, показанными выше, а скорее должно быть согласовано с самым широким объемом, совместимым с принципами и новыми признаками, раскрытыми любым образом в материалах настоящей заявки, в том числе в прилагаемой формуле изобретения, как подано, которая образует часть первоначального раскрытия.
Элементы различных реализаций устройства, описанного в материалах настоящей заявки (например, AE10, AD10, RC100, RF100, ME100, ME200, MF100), могут быть изготовлены как электронные и/или оптические устройства, например, находящиеся на одной и той же микросхеме или в числе двух или более микросхем в наборе микросхем. Одним из примеров такого устройства является фиксированная или программируемая матрица логических элементов, таких как транзисторы или вентили. Один или более элементов различных реализаций описанного устройства также могут быть реализованы, целиком или частично, как один или более наборов команд, предназначенных для исполнения в одной или более фиксированных или программируемых матрицах логических элементов, таких как микропроцессоры, встроенные процессоры, IP-ядра, цифровые сигнальные процессоры, FPGA, ASSP и ASIC.
Возможно, чтобы один или более элементов реализации устройства, которое описано в материалах настоящей заявки, использовались для выполнения этапов или исполнения других наборов команд, которые не имеют непосредственного отношения к работе устройства, таких как этап, относящийся к другой операции устройства или системы, в которую встроено устройство. Также возможно, чтобы один или более элементов реализации такого устройства имели общую структуру (например, процессор, используемый для выполнения участков управляющей программы, соответствующих разным элементам в разные моменты времени, набор команд, исполняемых для выполнения этапов, соответствующих разным элементам в разные моменты времени, или компоновку электронных и/или оптических устройств, выполняющих операции для разных элементов в разные моменты времени).
Фиг. 26 иллюстрирует структурную схему одного из примеров устройства для аудиосвязи, 1108, которое может использоваться в качестве терминала доступа с системами и способами, описанными в материалах настоящей заявки. Устройство 1108 включает в себя процессор 1102, сконфигурированный для управления работой устройства 1108. Процессор 1102 может быть сконфигурирован для управления устройством 1108 для реализации способа M100 или M200. Устройство 1108 также включает в себя память 1104, которая сконфигурирована для выдачи команд и данных в процессор 1102 и может включать в себя ПЗУ, ОЗУ и/или NVRAM. Устройство 1108 также включает в себя корпус 1122, который содержит в себе приемопередатчик 1120. Приемопередатчик 1120 включает в себя передатчик 1110 и приемник 1112, которые поддерживают передачу и прием данных между устройством 1108 и удаленным местоположением. Антенна 1118 устройства 1108 прикреплена к корпусу 1122 и электрически соединена с приемопередатчиком 1120.
Устройство 1108 включает в себя детектор 1106 сигналов, сконфигурированный для детектирования и измерения уровней сигналов, принимаемых приемопередатчиком 1120. Например, детектор 1106 сигналов может быть сконфигурирован для расчета значений параметров, таких как полная энергия, энергия контрольного сигнала на символ псевдошумовой последовательности (также выражаемой как Eb/No) и/или спектральная плотность мощности. Устройство 1108 включает в себя систему 1126 шин, сконфигурированную для соединения различных компонентов устройства 1108 вместе. В дополнение к шине данных, система 1126 шин может включать в себя шину питания, шину управляющих сигналов и/или шину сигналов состояния. Устройство 1108 также включает в себя DSP 1116, сконфигурированный для обработки сигналов, принимаемых и/или передаваемых приемопередатчиком 1120.
В этом примере устройство 1108 сконфигурировано для работы в любом одном из нескольких разных состояний и включает в себя переключатель 1114 состояний, сконфигурированный для управления состоянием устройства 1108 на основании текущего состояния устройства и сигналов, принятых приемопередатчиком 1120 и детектированных детектором 1106 сигналов. В этом примере устройство 1108 также включает в себя определитель 1124 системы, сконфигурированный для определения, что текущий поставщик услуг не отвечает требованиям, и для управления устройством 1108 для переключения на другого поставщика услуг.
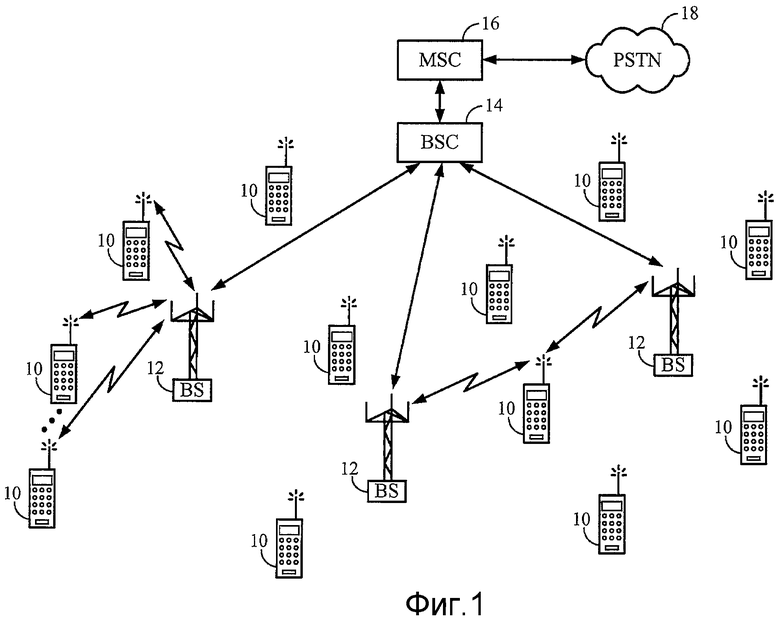
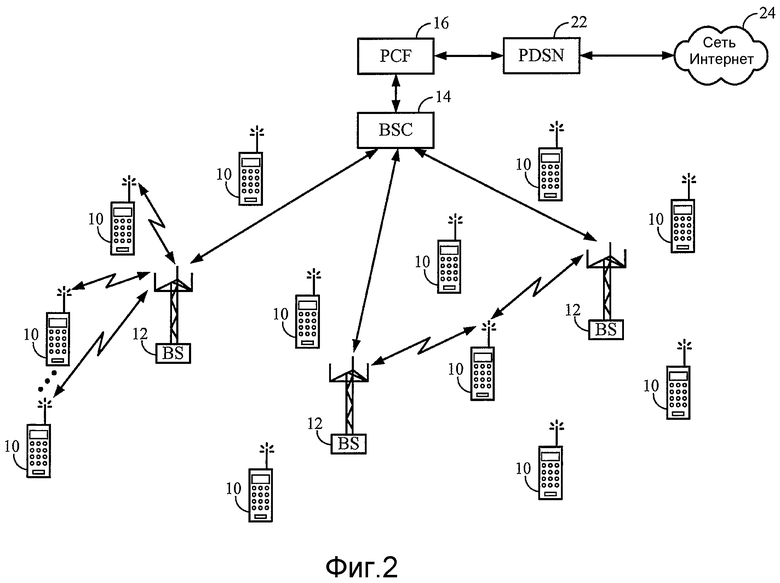

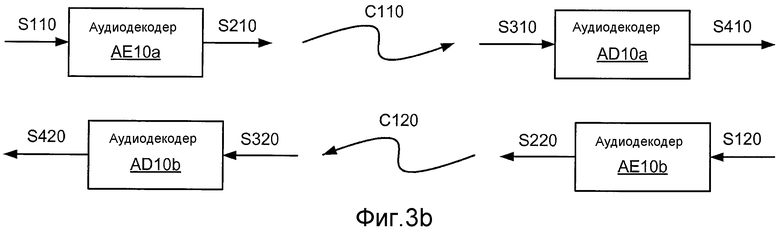
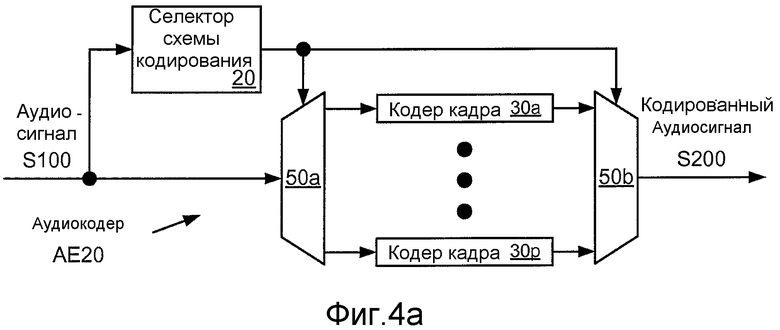
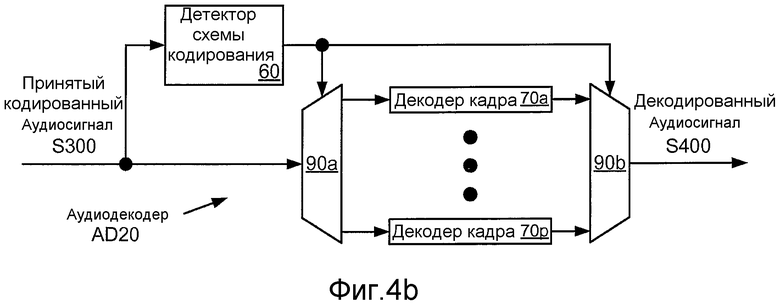
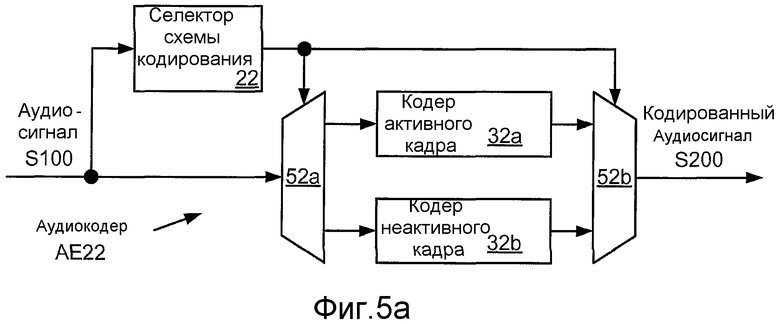
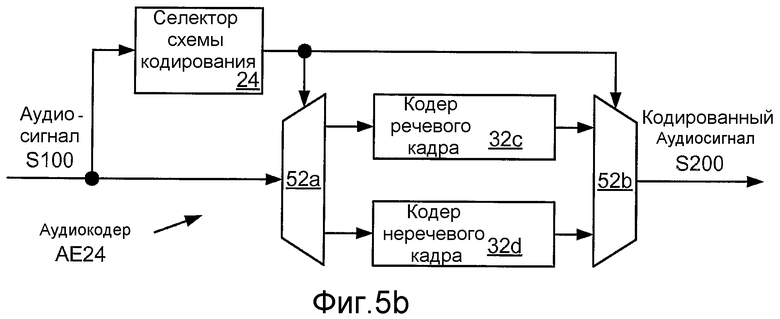
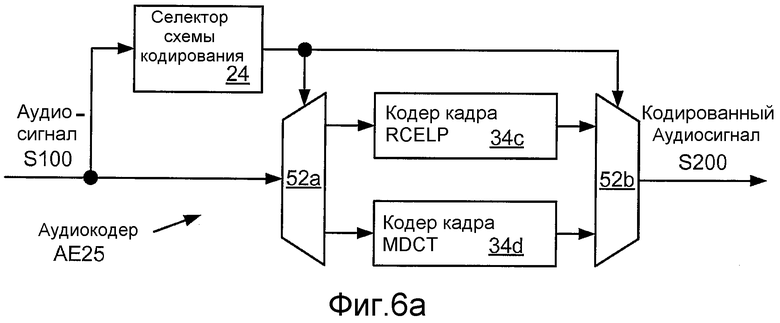
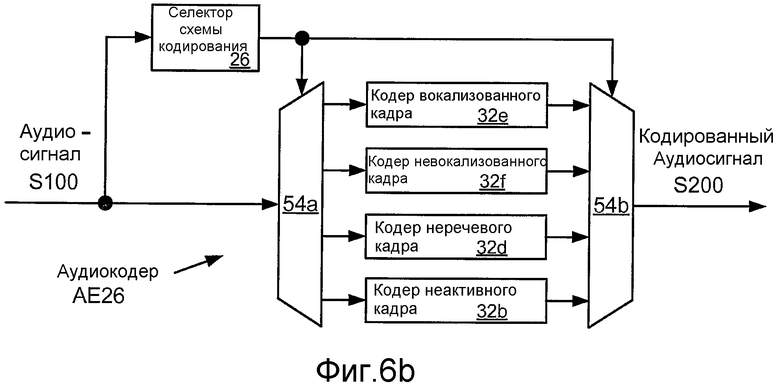
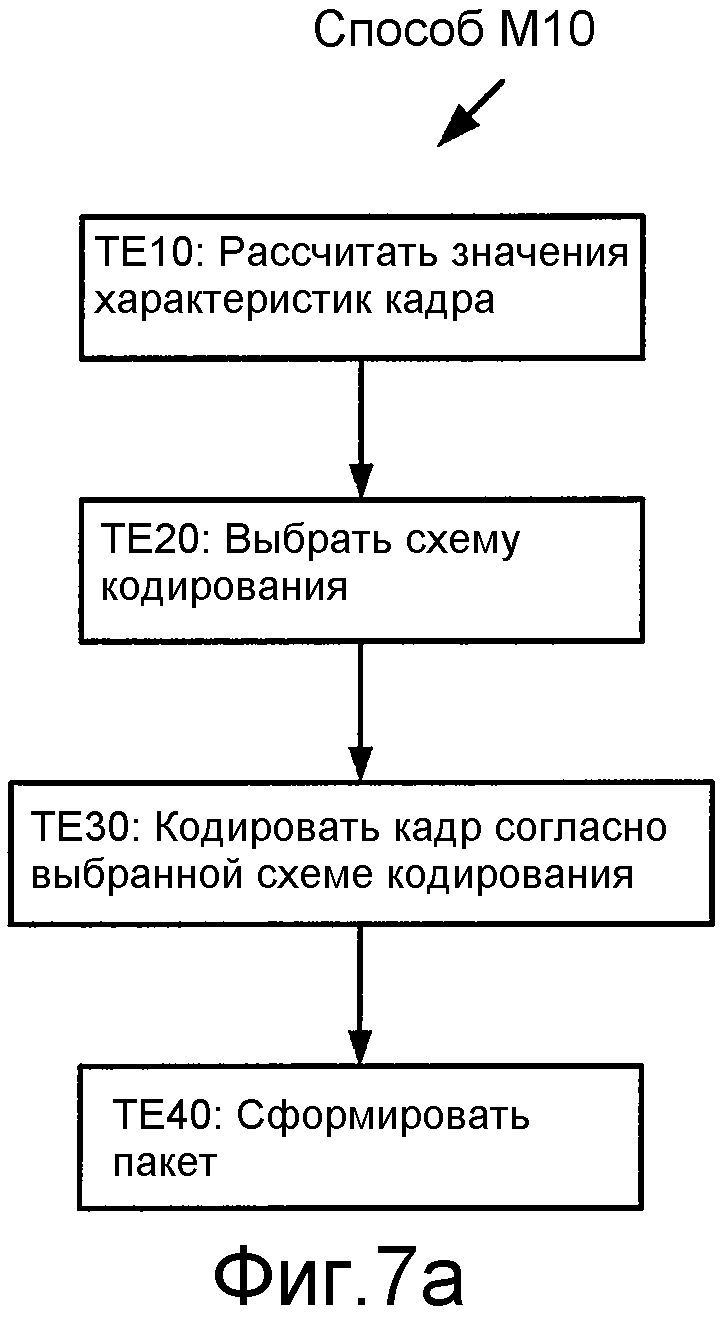
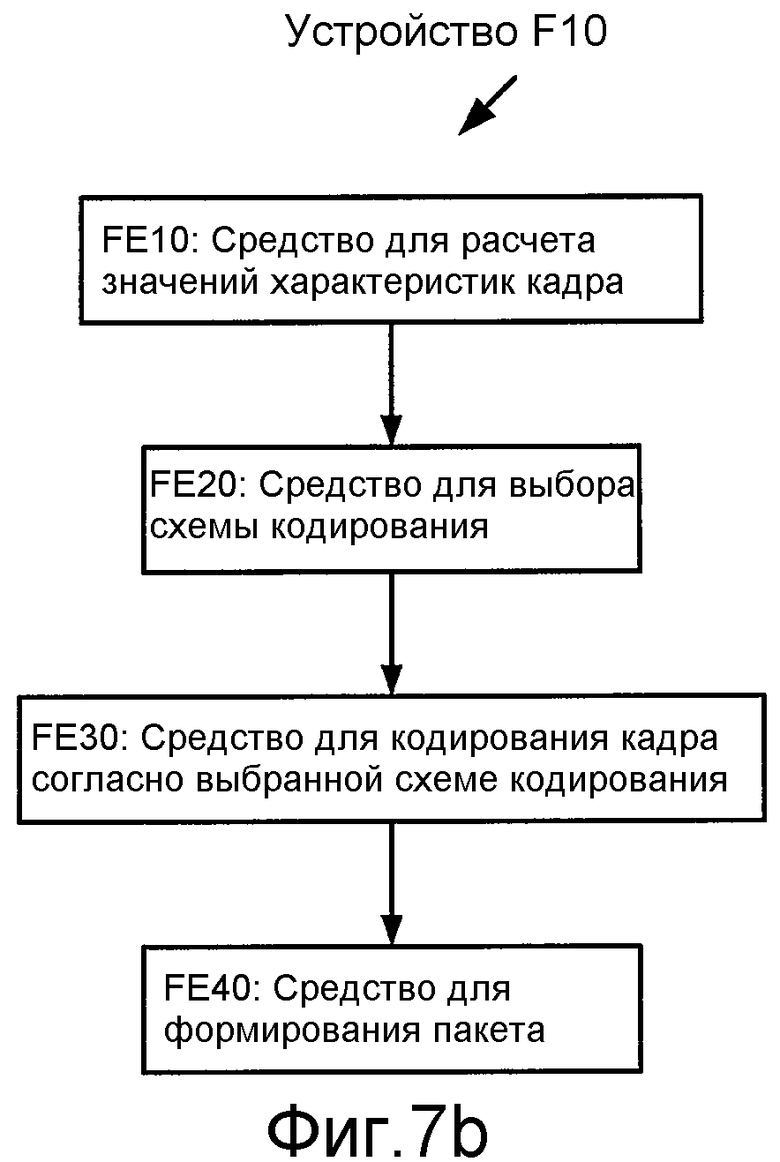
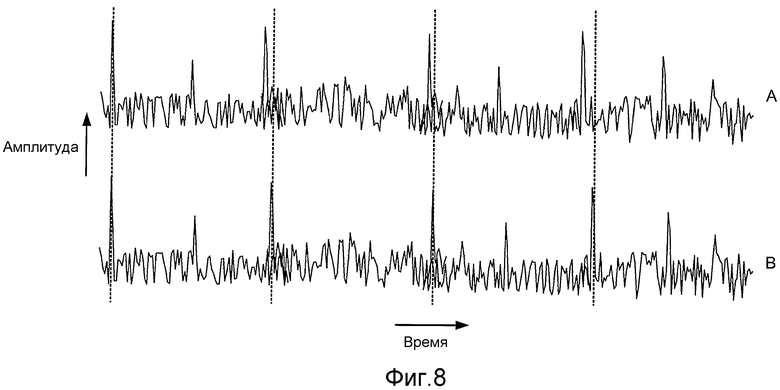
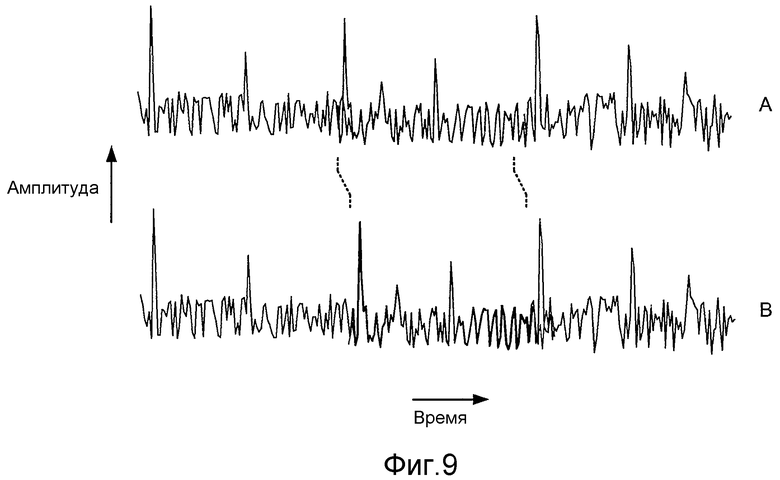
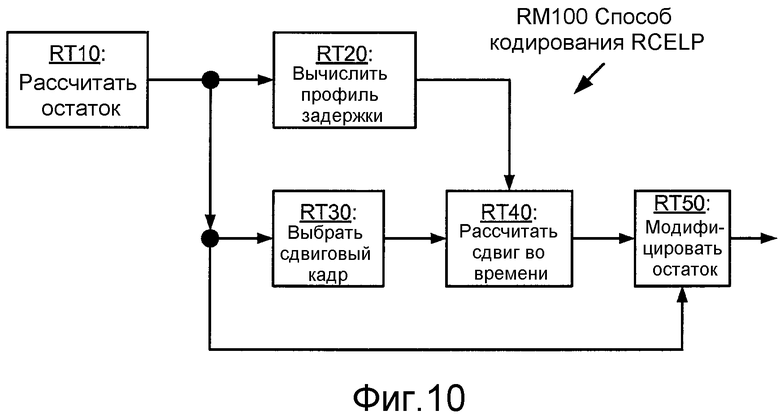
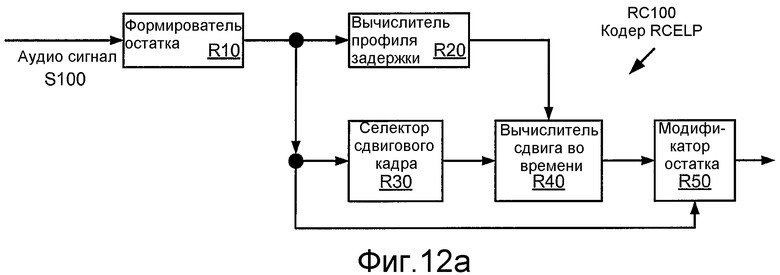
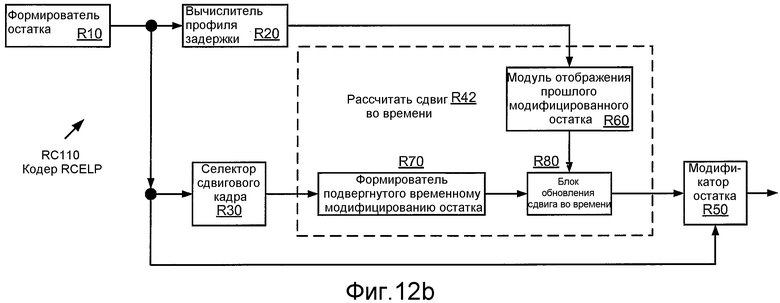
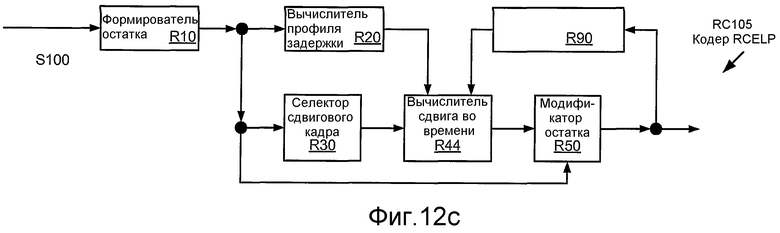

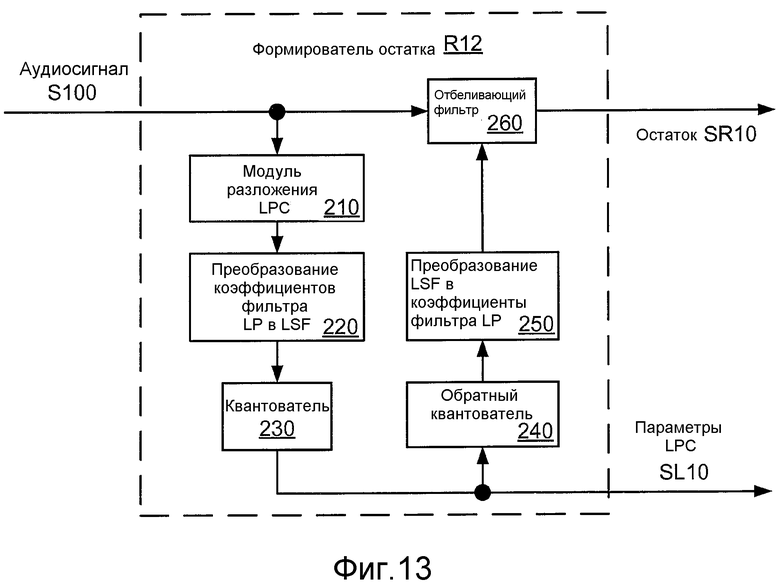
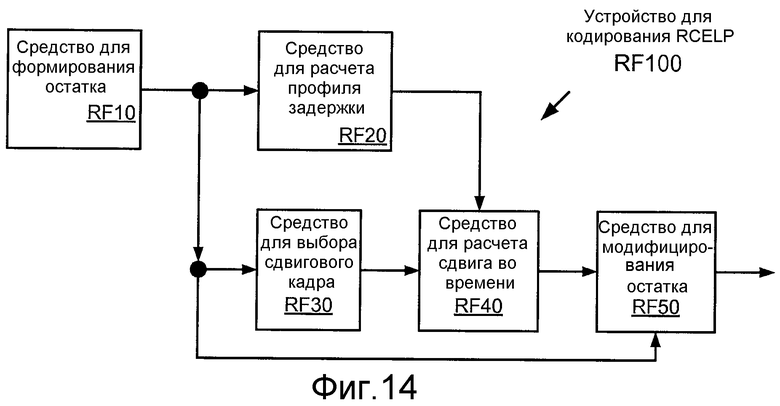
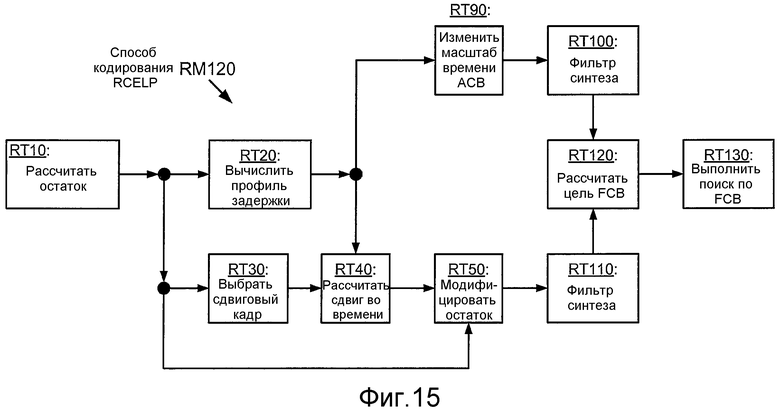
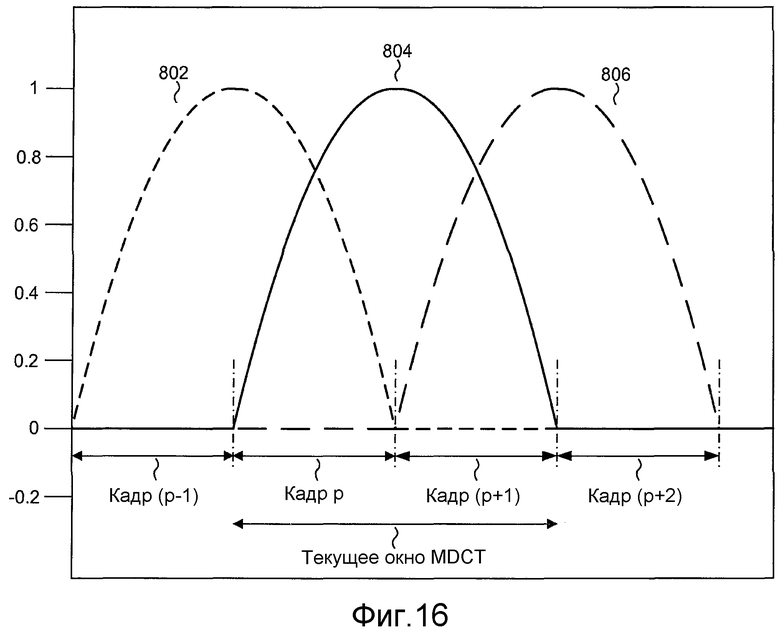
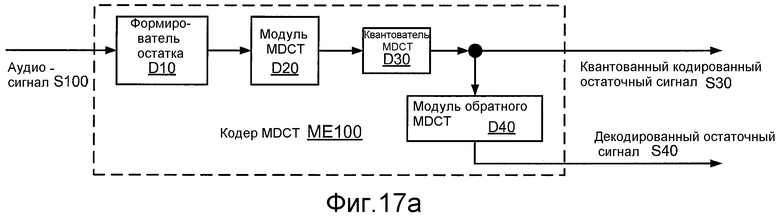
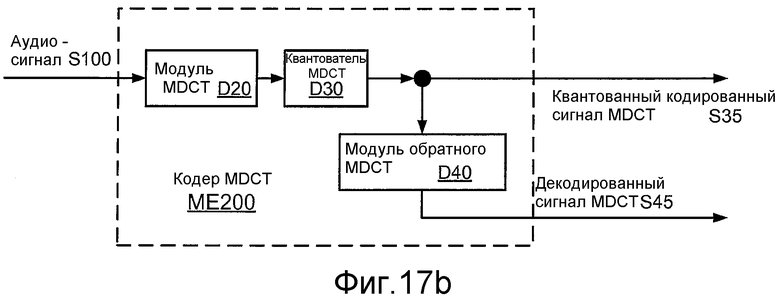
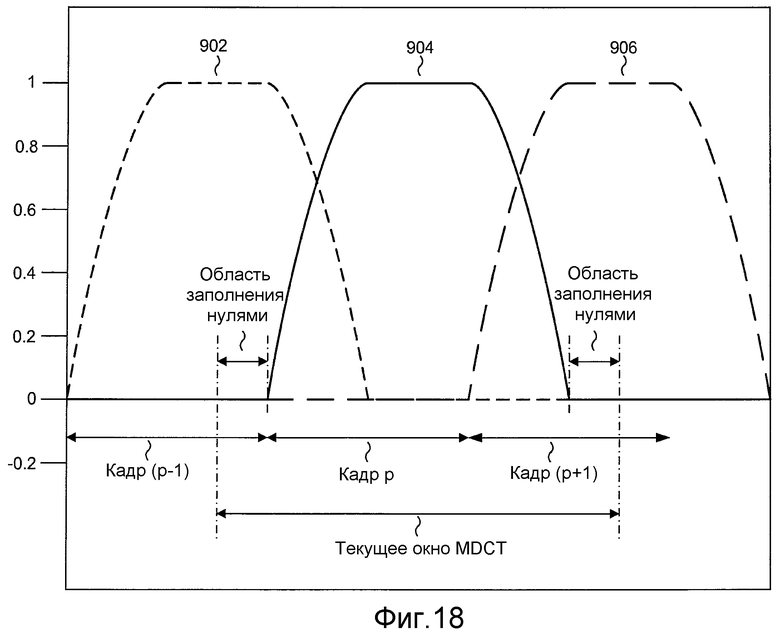
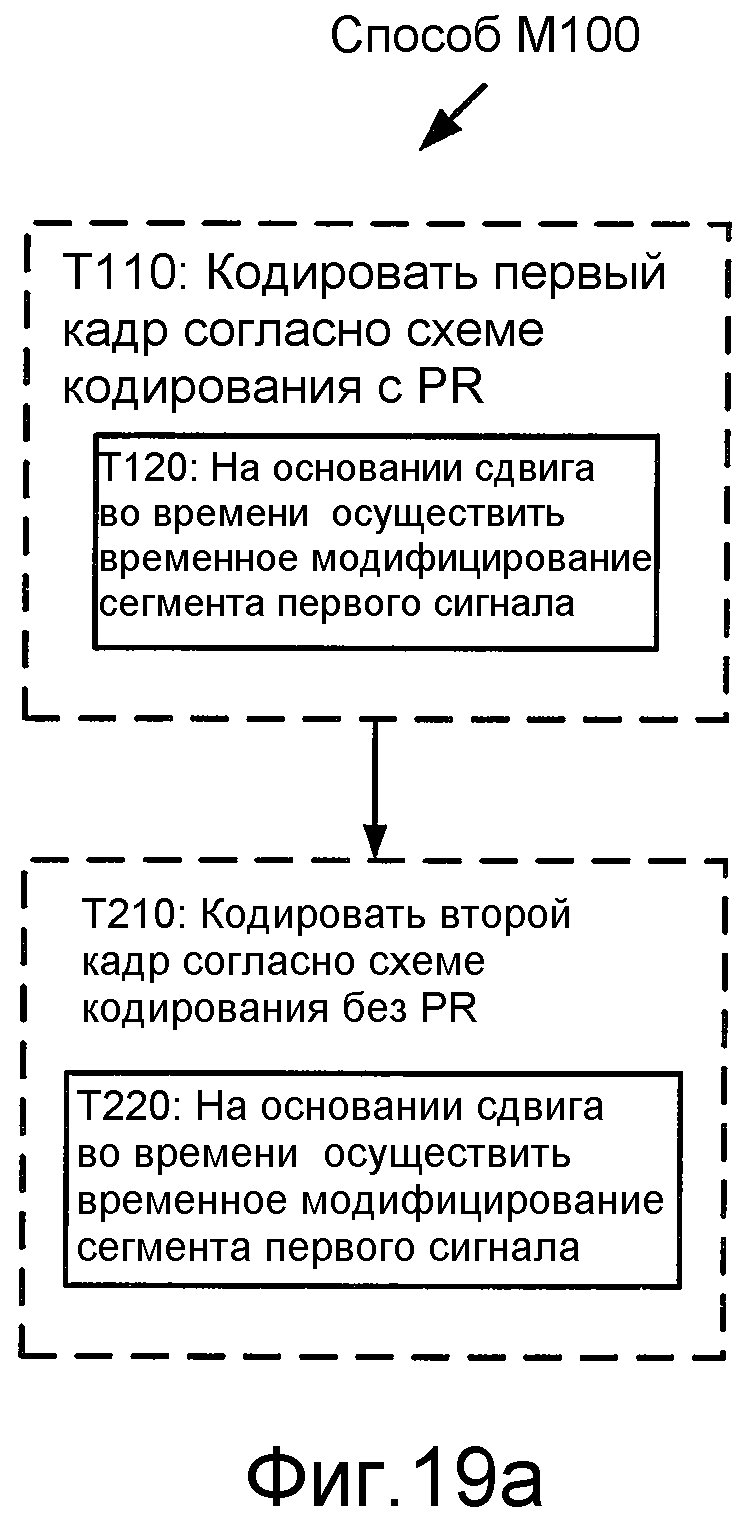
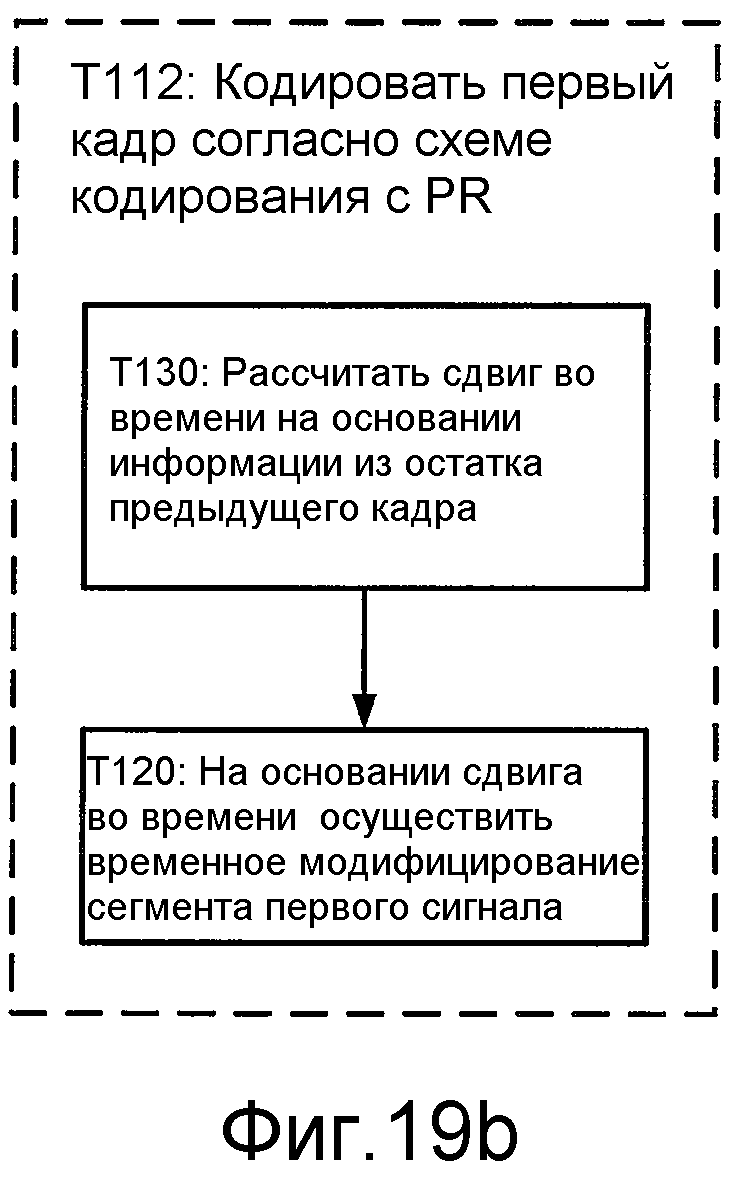
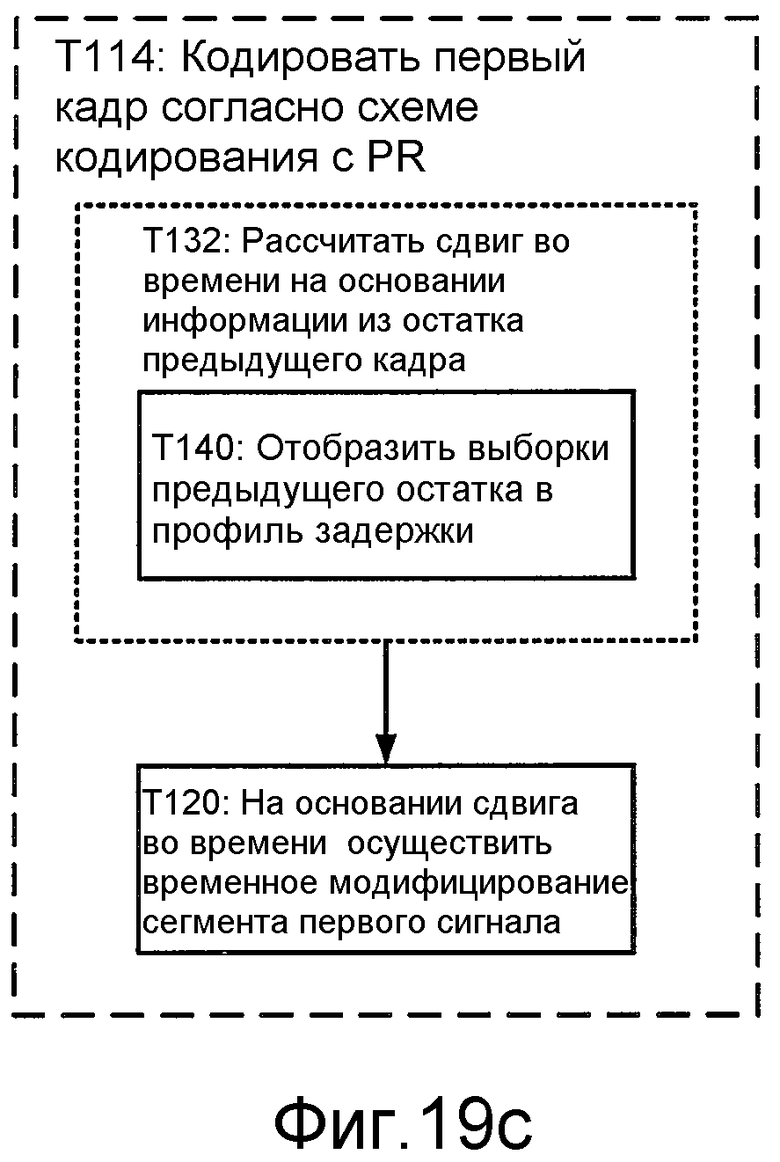
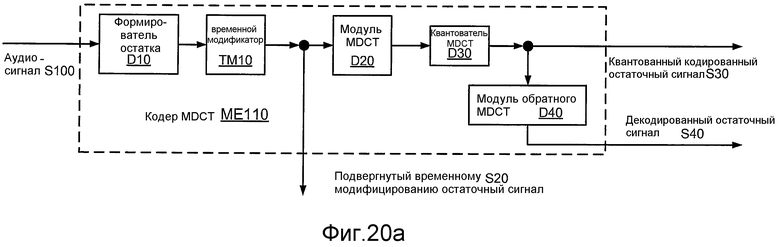
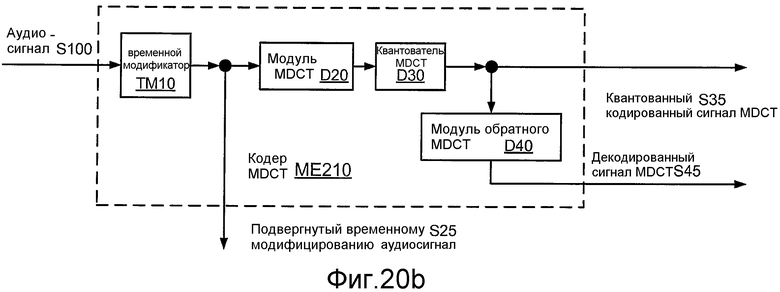
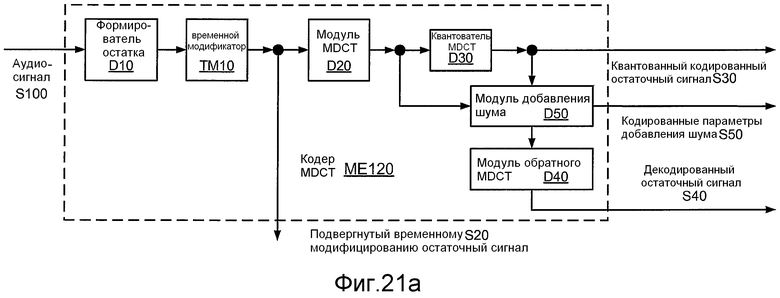
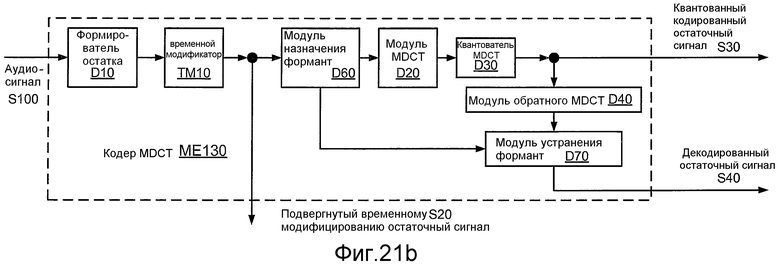
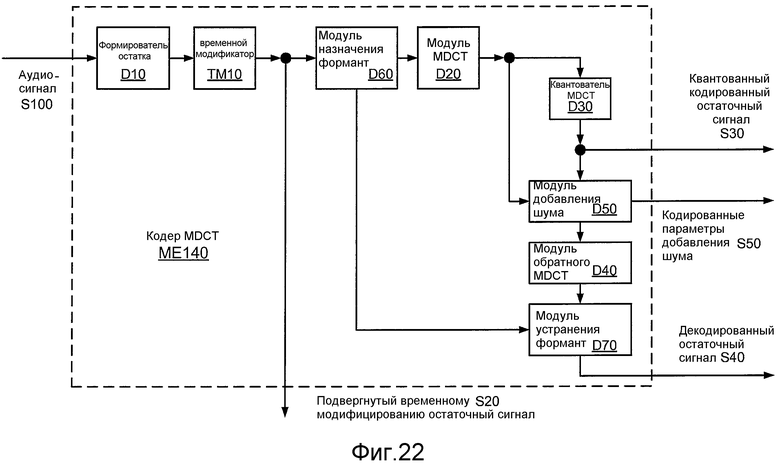
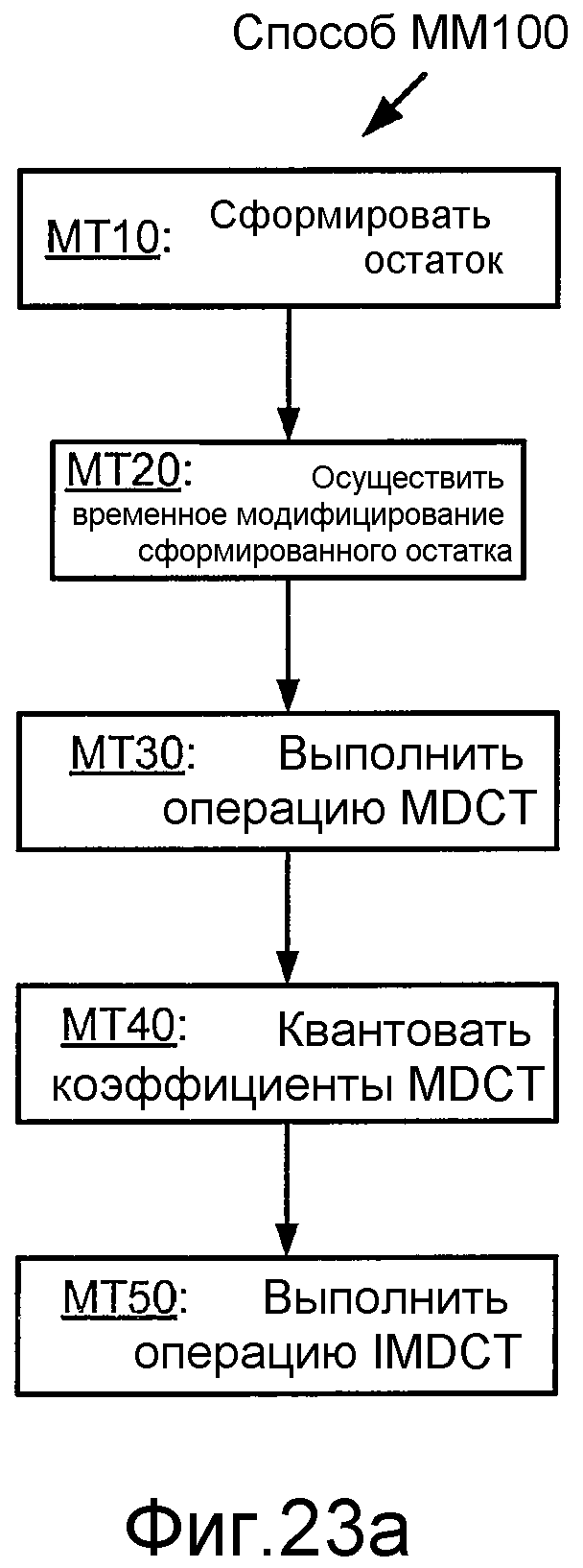
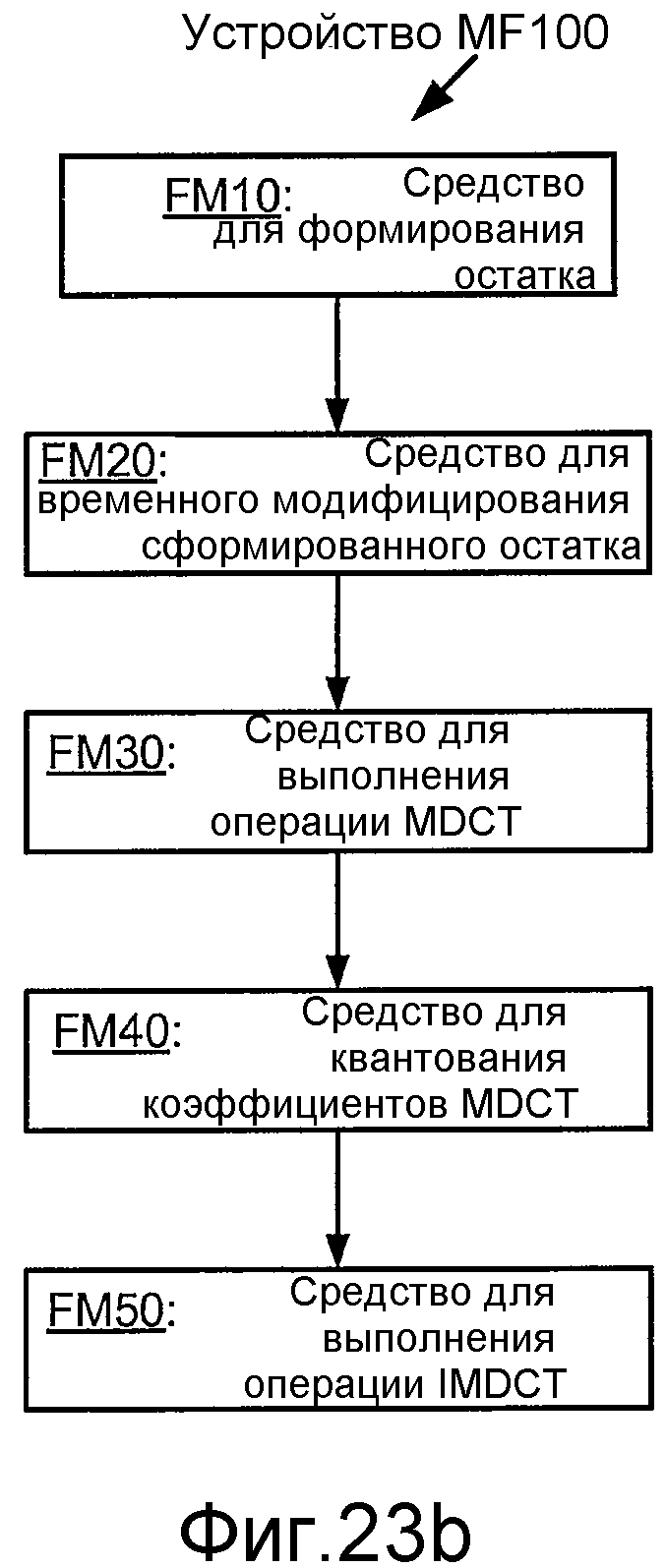
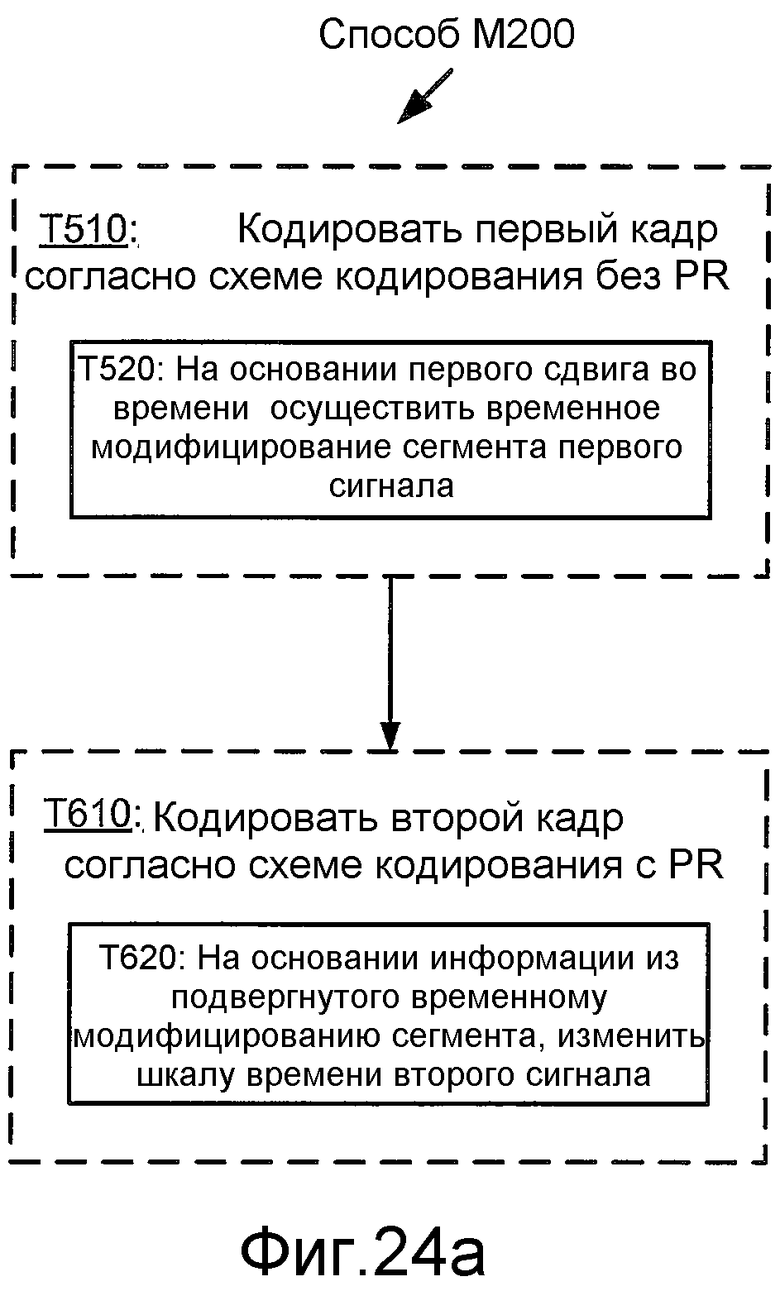
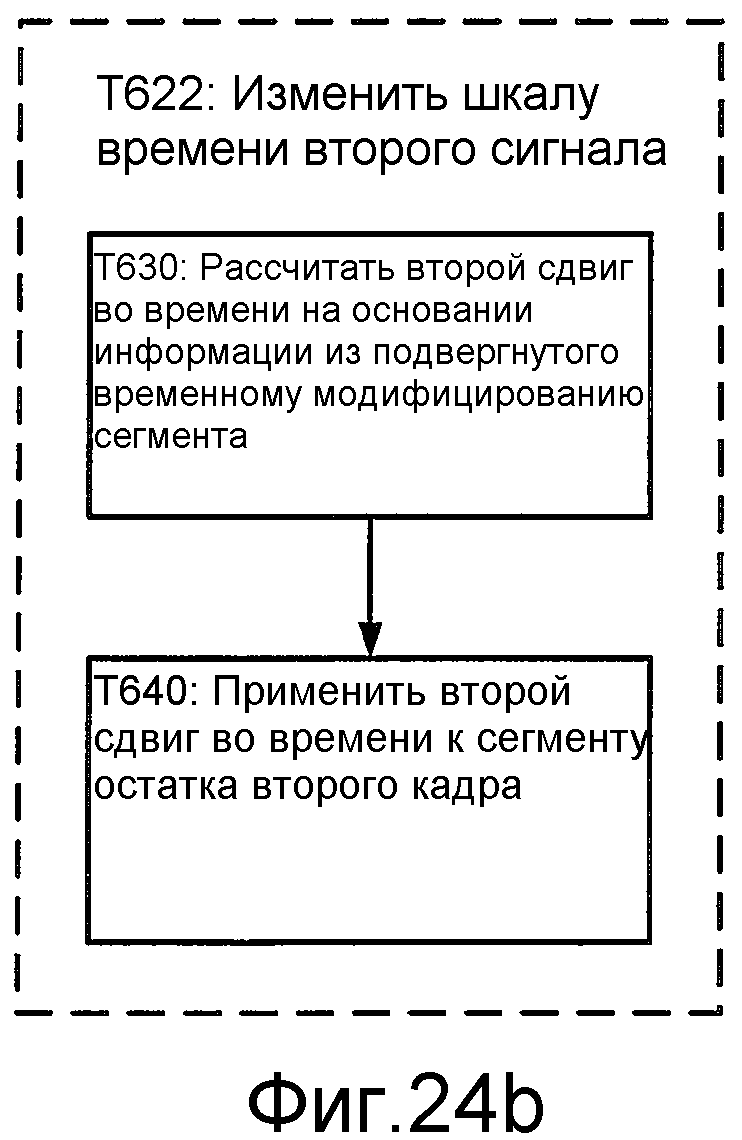
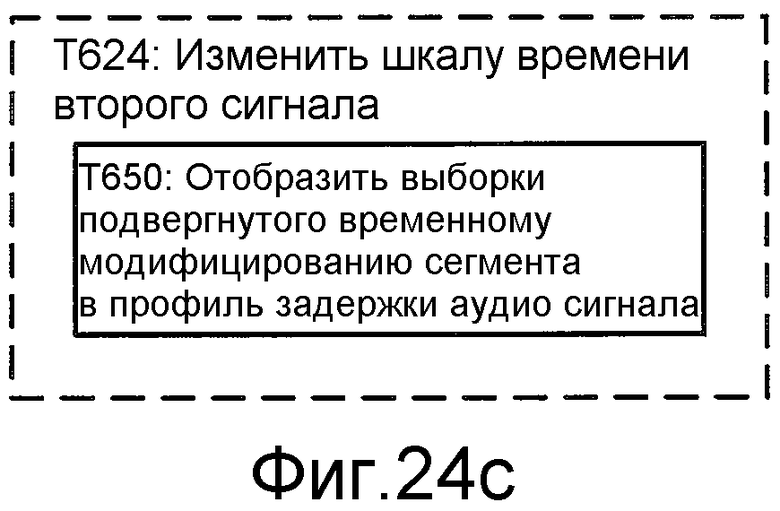
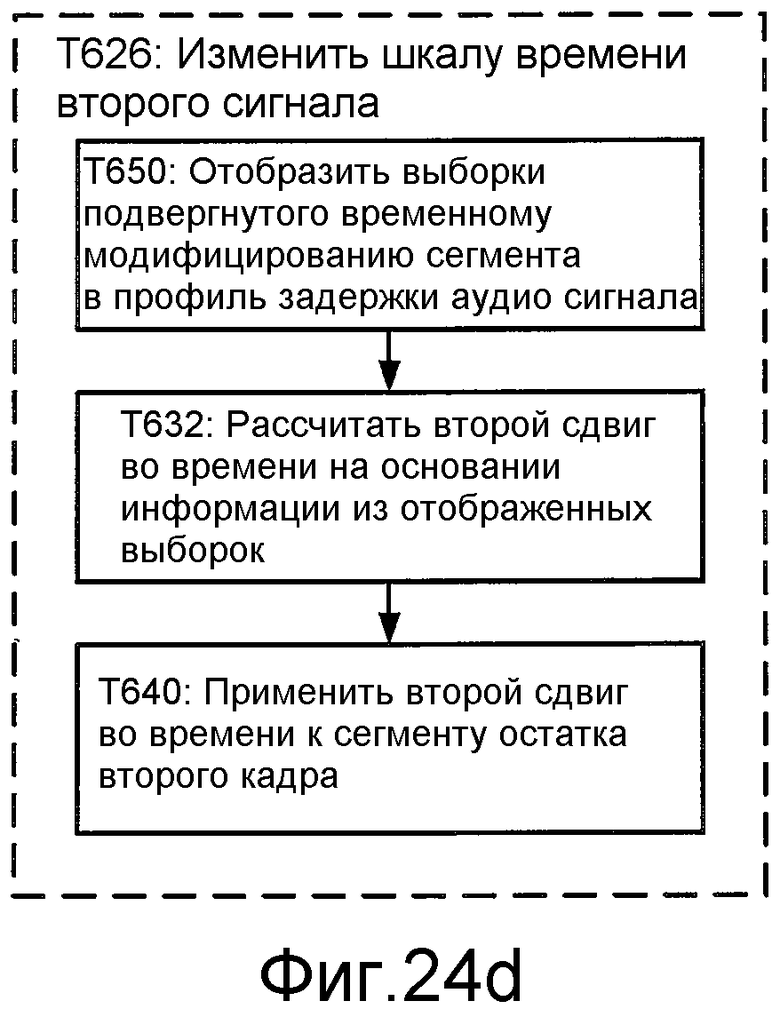
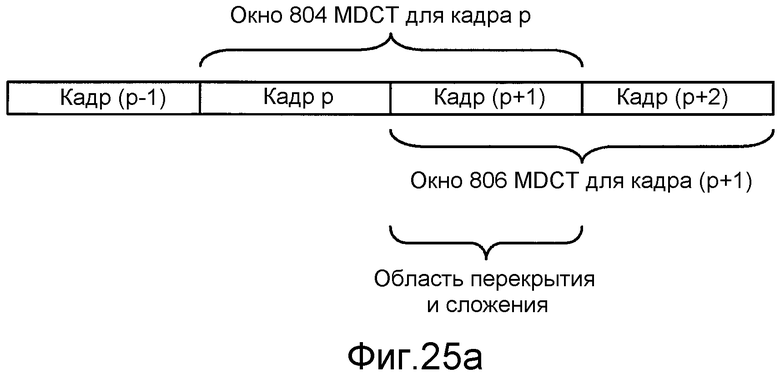
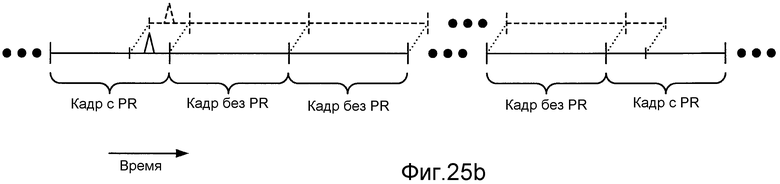
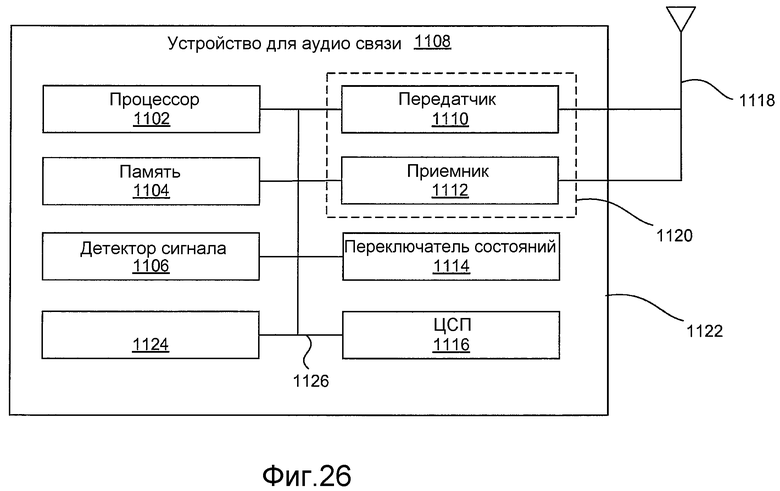
Изобретение относится к кодированию аудиосигналов, в частности к кодированию сигнала с использованием кодирования с регуляризацией основных тонов (PR) и без PR. Сущность кодирования состоит в том, что первый кадр аудиосигнала кодируют согласно схеме кодирования с PR, второй кадр, следующий за первым кадром в аудиосигнале, кодируют согласно схеме кодирования без PR. Кодирование первого кадра включает в себя временное модифицирование, на основании сдвига во времени, сегмента первого сигнала, основанного на первом кадре. Временное модифицирование включает в себя одно из (А) временного сдвига сегмента первого кадра согласно сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании сдвига во времени. Временное модифицирование сегмента первого сигнала включает в себя изменение положения импульса основного тона сегмента относительно другого импульса основного тона первого сигнала. Кодирование второго кадра включает в себя временное модифицирование, на основании сдвига во времени, сегмента второго сигнала, основанного на втором кадре. Временное модифицирование включает в себя одно из (А) временного сдвига сегмента второго кадра согласно сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании сдвига во времени. Технический результат - повышение воспринимаемого качества аудиосигнала во время переходов между схемами кодирования с PR и без PR в многорежимной системе кодирования аудио. 8 н. и 63 з.п. ф-лы, 44 ил.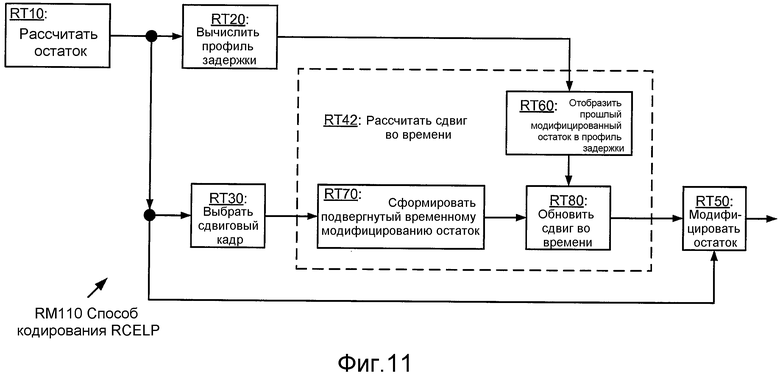
1. Способ обработки кадров аудиосигнала, причем упомянутый способ содержит этапы, на которых:
кодируют первый кадр аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR); и
кодируют второй кадр аудиосигнала согласно схеме кодирования без PR,
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом упомянутое кодирование первого кадра включает в себя временное модифицирование, на основании сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутое временное модифицирование включает в себя одно из (А) временного сдвига сегмента первого кадра согласно упомянутому сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании упомянутого сдвига во времени, и
при этом упомянутое временное модифицирование сегмента первого сигнала включает в себя изменение положения импульса основного тона сегмента относительно другого импульса основного тона первого сигнала, и
при этом упомянутое кодирование второго кадра включает в себя временное модифицирование, на основании сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутое временное модифицирование включает в себя одно из (А) временного сдвига сегмента второго кадра согласно упомянутому сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании упомянутого сдвига во времени.
2. Способ по п.1, в котором упомянутое кодирование первого кадра включает в себя создание первого кодированного кадра, который основан на подвергнутом временному модифицированию сегменте первого сигнала, и
при этом упомянутое кодирование второго кадра включает в себя создание второго кодированного кадра, который основан на подвергнутом временному модифицированию сегменте второго сигнала.
3. Способ по п.1, в котором первый сигнал является остатком первого кадра, и при этом второй сигнал является остатком второго кадра.
4. Способ по п.1, в котором первый и второй сигналы являются взвешенными аудиосигналами.
5. Способ по п.1, в котором упомянутое кодирование первого кадра включает в себя расчет сдвига во времени на основании информации из остатка третьего кадра, который предшествует первому кадру в аудиосигнале.
6. Способ по п.5, в котором упомянутый расчет сдвига во времени включает в себя отображение выборок остатка третьего кадра в профиль задержки аудиосигнала.
7. Способ по п.6, в котором упомянутое кодирование первого кадра включает в себя вычисление профиля задержки на основании информации, относящейся к периоду основного тона аудиосигнала.
8. Способ по п.1, в котором схема кодирования PR является схемой кодирования ослабленного линейного предсказания с кодовым возбуждением, и
при этом схема кодирования без PR является одной из (А) схемы кодирования линейного предсказания с шумовым возбуждением, (В) схемы кодирования с модифицированным дискретным косинусным преобразованием и (С) схемы кодирования с интерполяцией волновым сигналом-прототипом.
9. Способ по п.1, в котором схема кодирования без PR является схемой кодирования с модифицированным дискретным косинусным преобразованием.
10. Способ по п.1, в котором упомянутое кодирование второго кадра включает в себя этапы, на которых:
выполняют операцию модифицированного дискретного косинусного преобразования (MDCT) над остатком второго кадра, чтобы получить кодированный остаток; и
выполняют операцию обратного MDCT над сигналом, который основан на кодированном остатке, чтобы получить декодированный остаток, при этом второй сигнал основан на декодированном остатке.
11. Способ по п.1, в котором упомянутое кодирование второго кадра включает в себя этапы, на которых:
формируют остаток второго кадра, при этом второй сигнал является сформированным остатком;
вслед за упомянутым временным модифицированием сегмента второго сигнала выполняют операцию модифицированного дискретного косинусного преобразования над сформированным остатком, включающим в себя подвергнутый временному модифицированию сегмент для получения кодированного остатка; и создают второй кодированный кадр на основании кодированного остатка.
12. Способ по п.1, при этом упомянутый способ содержит осуществление временного сдвига, согласно упомянутому сдвигу во времени, сегмента остатка кадра, который следует за вторым кадром в аудиосигнале.
13. Способ по п.1, при этом упомянутый способ включает в себя временное модифицирование, на основании упомянутого сдвига во времени, сегмента третьего сигнала, который основан на третьем кадре аудиосигнала, который следует за вторым кадром, и
при этом упомянутое кодирование второго кадра включает в себя выполнение операции модифицированного дискретного косинусного преобразования (MDCT) над окном, которое включает в себя выборки подвергнутых временному модифицированию сегментов второго и третьего сигналов.
14. Способ по п.13, в котором второй сигнал имеет длину в М выборок, и третий сигнал имеет длину в М выборок, и
при этом упомянутое выполнение операции MDCT включает в себя создание набора из М коэффициентов MDCT, который основан на (А) М выборках второго сигнала, включающего в себя подвергнутый временному модифицированию сегмент, и (В) не более чем 3М/4 выборках третьего сигнала.
15. Способ по п.13, в котором второй сигнал имеет длину в М выборок, и третий сигнал имеет длину в М выборок, и
при этом упомянутое выполнение операции MDCT включает в себя создание набора из М коэффициентов MDCT, который основан на последовательности из 2М выборок, которая (А) включает в себя М выборок второго сигнала, включающего в себя подвергнутый временному модифицированию сегмент, (В) начинается с последовательности из по меньшей мере М/8 выборок с нулевым значением и (С) заканчивается последовательностью из по меньшей мере М/8 выборок с нулевым значением.
16. Устройство для обработки кадров аудиосигнала, причем упомянутое устройство содержит:
средство для кодирования первого кадра аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR); и средство для кодирования второго кадра аудиосигнала согласно схеме кодирования без PR,
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом упомянутое средство для кодирования первого кадра включает в себя средство для временного модифицирования, на основании сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутое средство для временного модифицирования сконфигурировано для выполнения одного из (А) временного сдвига сегмента первого кадра согласно упомянутому сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании упомянутого сдвига во времени, и
при этом упомянутое средство для временного модифицирования сегмента первого сигнала сконфигурировано для изменения положения импульса основного тона сегмента относительно другого импульса основного тона первого сигнала, и
при этом упомянутое средство для кодирования второго кадра включает в себя средство для временного модифицирования, на основании сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутое средство для временного модифицирования сконфигурировано для выполнения одного из (А) временного сдвига сегмента второго кадра согласно упомянутому сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании упомянутого сдвига во времени.
17. Устройство по п.16, при этом первый сигнал является остатком первого кадра, и при этом второй сигнал является остатком второго кадра.
18. Устройство по п.16, при этом первый и второй сигналы являются взвешенными аудиосигналами.
19. Устройство по п.16, в котором упомянутое средство для кодирования первого кадра включает в себя средство для расчета сдвига во времени на основании информации из остатка третьего кадра, который предшествует первому кадру в аудиосигнале.
20. Устройство по п.16, в котором упомянутое средство для кодирования второго кадра включает в себя:
средство для формирования остатка второго кадра, при этом второй сигнал является сформированным остатком; и
средство для выполнения операции модифицированного дискретного косинусного преобразования над сформированным остатком, включающим в себя подвергнутый временному модифицированию сегмент, чтобы получить кодированный остаток,
при этом упомянутое средство для кодирования второго кадра сконфигурировано для создания второго кодированного кадра на основании кодированного остатка.
21. Устройство по п.16, в котором упомянутое средство для временного модифицирования сегмента второго сигнала сконфигурировано для осуществления временного сдвига, согласно упомянутому сдвигу во времени, сегмента остатка кадра, который следует за вторым кадром в аудиосигнале.
22. Устройство по п.16, в котором упомянутое средство для временного модифицирования сегмента второго сигнала сконфигурировано для временного модифицирования, на основании упомянутого сдвига во времени, сегмента третьего сигнала, который основан на третьем кадре аудиосигнала, который следует за вторым кадром, и
при этом упомянутое средство для кодирования второго кадра включает в себя средство для выполнения операции модифицированного дискретного косинусного преобразования (MDCT) в окне, которое включает в себя выборки подвергнутых временному модифицированию сегментов второго и третьего сигналов.
23. Устройство по п.22, при этом второй сигнал имеет длину в М выборок, и третий сигнал имеет длину в М выборок, и
при этом упомянутое средство для выполнения операции MDCT сконфигурировано для создания набора из М коэффициентов MDCT, который основан на (А) М выборках второго сигнала, включающего в себя подвергнутый временному модифицированию сегмент, и (В) не более чем 3М/4 выборках третьего сигнала.
24. Устройство для обработки кадров аудиосигнала, причем упомянутое устройство содержит:
кодер первого кадра, сконфигурированный для кодирования первого кадра аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR); и
кодер второго кадра, сконфигурированный для кодирования второго кадра аудиосигнала согласно схеме кодирования без PR, при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом упомянутый кодер первого кадра включает в себя первый временной модификатор, сконфигурированный для временного модифицирования, на основании сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутый первый временной модификатор сконфигурирован для выполнения одного из (А) временного сдвига сегмента первого кадра согласно упомянутому сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании упомянутого сдвига во времени, и
при этом упомянутый первый временной модификатор сконфигурирован для изменения положения импульса основного тона сегмента относительно другого импульса основного тона первого сигнала, и
при этом упомянутый кодер второго кадра включает в себя второй временной модификатор, сконфигурированный для временного модифицирования, на основании сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутый второй временной модификатор сконфигурирован для выполнения одного из (А) временного сдвига сегмента второго кадра согласно упомянутому сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании упомянутого сдвига во времени.
25. Устройство по п.24, при этом первый сигнал является остатком первого кадра, и при этом второй сигнал является остатком второго кадра.
26. Устройство по п.24, при этом первый и второй сигналы являются взвешенными аудиосигналами.
27. Устройство по п.24, в котором упомянутый кодер первого кадра включает в себя вычислитель сдвига во времени, сконфигурированный для расчета сдвига во времени на основании информации из остатка третьего кадра, который предшествует первому кадру в аудиосигнале.
28. Устройство по п.24, в котором упомянутый кодер второго кадра включает в себя:
формирователь остатка, сконфигурированный для формирования остатка второго кадра, при этом второй сигнал является сформированным остатком; и
модуль модифицированного дискретного косинусного преобразования (MDCT), сконфигурированный для выполнения операции MDCT над сформированным остатком, включающим в себя подвергнутый временному модифицированию сегмент, чтобы получить кодированный остаток,
при этом упомянутый кодер второго кадра сконфигурирован для создания второго кодированного кадра на основании кодированного остатка.
29. Устройство по п.24, в котором упомянутый второй временной модификатор сконфигурирован для осуществления временного сдвига, согласно упомянутому сдвигу во времени, сегмента остатка кадра, который следует за вторым кадром в аудиосигнале.
30. Устройство по п.24, в котором упомянутый второй временной модификатор сконфигурирован для временного модифицирования, на основании упомянутого сдвига во времени, сегмента третьего сигнала, который основан на третьем кадре аудиосигнала, который следует за вторым кадром, и
при этом упомянутый кодер второго кадра включает в себя модуль модифицированного дискретного косинусного преобразования (MDCT), сконфигурированный для выполнения операции MDCT в окне, которое включает в себя выборки подвергнутых временному модифицированию сегментов второго и третьего сигналов.
31. Устройство по п.30, при этом второй сигнал имеет длину в М выборок, и третий сигнал имеет длину в М выборок, и
при этом упомянутый модуль MDCT сконфигурирован для создания набора из М коэффициентов MDCT, который основан на (А) М выборках второго сигнала, включающего в себя подвергнутый временному модифицированию сегмент, и (В) не более чем 3М/4 выборках третьего сигнала.
32. Машиночитаемый носитель, содержащий команды, которые, при исполнении их процессором, побуждают процессор:
кодировать первый кадр аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR); и
кодировать второй кадр аудиосигнала согласно схеме кодирования без PR,
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом упомянутые команды, которые, при их исполнении, побуждают процессор кодировать первый кадр, включают в себя команды для временного модифицирования, на основании сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутые команды для временного модифицирования включают в себя одно из (А) команд для временного сдвига сегмента первого кадра согласно упомянутому сдвигу во времени и (В) команд для изменения шкалы времени сегмента первого сигнала на основании упомянутого сдвига во времени, и
при этом упомянутые команды для временного модифицирования сегмента первого сигнала включают в себя команды для изменения положения импульса основного тона сегмента относительно другого импульса основного тона первого сигнала, и
при этом упомянутые команды, которые, при их исполнении, побуждают процессор кодировать второй кадр, включают в себя команды для временного модифицирования, на основании сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутые команды для временного модифицирования включают в себя одно из (А) команд для временного сдвига сегмента второго кадра согласно упомянутому сдвигу во времени и (В) команд для изменения шкалы времени сегмента второго сигнала на основании упомянутого сдвига во времени.
33. Способ обработки кадров аудиосигнала, причем упомянутый способ содержит этапы, на которых:
кодируют первый кадр аудиосигнала согласно первой схеме кодирования; и
кодируют второй кадр аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR),
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом первая схема кодирования является схемой кодирования без PR, и
при этом упомянутое кодирование первого кадра включает в себя временное модифицирование, на основании первого сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутое временное модифицирование включает в себя одно из (А) временного сдвига сегмента первого сигнала согласно первому сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании первого сдвига во времени; и
при этом упомянутое кодирование второго кадра включает в себя временное модифицирование, на основании второго сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутое временное модифицирование включает в себя одно из (А) временного сдвига сегмента второго сигнала согласно второму сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании второго сдвига во времени,
при этом упомянутое временное модифицирование сегмента второго сигнала включает в себя изменение положения импульса основного тона сегмента относительно другого импульса основного тона второго сигнала, и
при этом второй сдвиг во времени основан на информации из подвергнутого временному модифицированию сегмента первого сигнала.
34. Способ по п.33, в котором упомянутое кодирование первого кадра включает в себя создание первого кодированного кадра, который основан на подвергнутом временному модифицированию сегменте первого сигнала, и
при этом упомянутое кодирование второго кадра включает в себя создание второго кодированного кадра, который основан на подвергнутом временному модифицированию сегменте второго сигнала.
35. Способ по п.33, в котором первый сигнал является остатком первого кадра, и при этом второй сигнал является остатком второго кадра.
36. Способ по п.33, в котором первый и второй сигналы являются взвешенными аудиосигналами.
37. Способ по п.33, в котором упомянутое временное модифицирование сегмента второго сигнала включает в себя расчет второго сдвига во времени на основании информации из подвергнутого временному модифицированию сегмента первого сигнала, и
при этом упомянутый расчет второго сдвига во времени включает в себя отображение подвергнутого временному модифицированию сегмента первого сигнала в профиль задержки, который основан на информации из второго кадра.
38. Способ по п.37, в котором упомянутый второй сдвиг во времени основан на корреляции между выборками отображенного сегмента и выборками подвергнутого временному модифицированию остатка, и
при этом подвергнутый временному модифицированию остаток основан на (А) выборках остатка второго кадра и (В) первом сдвиге во времени.
39. Способ по п.33, в котором второй сигнал является остатком второго кадра, и
при этом упомянутое временное модифицирование сегмента второго сигнала включает в себя временной сдвиг первого сегмента остатка согласно второму сдвигу во времени, и при этом упомянутый способ содержит этапы, на которых:
рассчитывают третий сдвиг во времени, который является иным, чем второй сдвиг во времени, на основании информации из подвергнутого временному модифицированию сегмента первого сигнала; и
осуществляют временной сдвиг второго сегмента остатка согласно третьему сдвигу во времени.
40. Способ по п.33, в котором второй сигнал является остатком второго кадра, и
при этом упомянутое временное модифицирование сегмента второго сигнала включает в себя временной сдвиг первого сегмента остатка согласно второму сдвигу во времени, и при этом упомянутый способ содержит этапы, на которых:
рассчитывают третий сдвиг во времени, который является иным, чем второй сдвиг во времени, на основании информации из подвергнутого временному модифицированию первого сегмента остатка; и
осуществляют временной сдвиг второго сегмента остатка согласно третьему сдвигу во времени.
41. Способ по п.33, в котором упомянутое временное модифицирование сегмента второго сигнала включает в себя отображение выборок подвергнутого временному модифицированию сегмента первого сигнала в профиль задержки, который основан на информации из второго кадра.
42. Способ по п.33, причем упомянутый способ содержит этапы, на которых:
сохраняют последовательность, основанную на подвергнутом временному модифицированию сегменте первого сигнала, в буфер адаптивного словаря кодов; и
вслед за упомянутым сохранением отображают выборки буфера адаптивного словаря кодов в профиль задержки, который основан на информации из второго кадра.
43. Способ по п.33, в котором второй сигнал является остатком второго кадра, и при этом упомянутое временное модифицирование сегмента второго сигнала включает в себя изменение шкалы времени остатка второго кадра, и
при этом упомянутый способ содержит изменение шкалы времени остатка третьего кадра аудиосигнала на основании информации из подвергнутого изменению шкалы времени остатка второго кадра, при этом третий кадр является следующим за вторым кадром в аудиосигнале.
44. Способ по п.33, в котором второй сигнал является остатком второго кадра, и при этом упомянутое временное модифицирование сегмента второго сигнала включает в себя расчет второго сдвига во времени на основании (А) информации из подвергнутого временному модифицированию сегмента первого сигнала и (В) информации из остатка второго кадра.
45. Способ по п.33, в котором схема кодирования с PR является схемой кодирования ослабленного линейного предсказания с кодовым возбуждением, и при этом схема кодирования без PR является одной из (А) схемы кодирования линейного предсказания с шумовым возбуждением, (В) схемы кодирования с модифицированным дискретным косинусным преобразованием и (С) схемы кодирования с интерполяцией волновым сигналом-прототипом.
46. Способ по п.33, в котором схема кодирования без PR является схемой кодирования модифицированного дискретного косинусного преобразования.
47. Способ по п.33, в котором упомянутое кодирование первого кадра включает в себя этапы, на которых:
выполняют операцию модифицированного дискретного косинусного преобразования (MDCT) над остатком первого кадра, чтобы получить кодированный остаток; и
выполняют операцию обратного MDCT над сигналом, который основан на кодированном остатке, чтобы получить декодированный остаток,
при этом первый сигнал основан на декодированном остатке.
48. Способ по п.33, в котором упомянутое кодирование первого кадра включает в себя этапы, на которых:
формируют остаток первого кадра, при этом первый сигнал является сформированным остатком;
вслед за упомянутым временным модифицированием сегмента первого сигнала выполняют операцию модифицированного дискретного косинусного преобразования над сформированным остатком, включающим в себя подвергнутый временному модифицированию сегмент, для получения кодированного остатка; и
создают первый кодированный кадр на основании кодированного остатка.
49. Способ по п.33, в котором первый сигнал имеет длину в М выборок, и второй сигнал имеет длину в М выборок, и
при этом упомянутое кодирование первого кадра включает в себя создание набора из М коэффициентов модифицированного дискретного косинусного преобразования (MDCT), который основан на М выборках первого сигнала, включающего в себя подвергнутый временному модифицированию сегмент, и не более чем 3М/4 выборках второго сигнала.
50. Способ по п.33, в котором первый сигнал имеет длину в М выборок, и второй сигнал имеет длину в М выборок, и
при этом упомянутое кодирование первого кадра включает в себя создание набора из М коэффициентов модифицированного дискретного косинусного преобразования (MDCT), который основан на последовательности 2М выборок, которая (А) включает в себя М выборок первого сигнала, включающего в себя подвергнутый временному модифицированию сегмент, (В) начинается с последовательности из по меньшей мере М/8 выборок с нулевым значением и (С) заканчивается последовательностью из по меньшей мере М/8 выборок с нулевым значением.
51. Устройство для обработки кадров аудиосигнала, причем упомянутое устройство содержит:
средство для кодирования первого кадра аудиосигнала согласно первой схеме кодирования; и
средство для кодирования второго кадра аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR),
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом первая схема кодирования является схемой кодирования без PR, и
при этом упомянутое средство для кодирования первого кадра включает в себя средство для временного модифицирования, на основании первого сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутое средство для временного модифицирования сконфигурировано для выполнения одного из (А) временного сдвига сегмента первого сигнала согласно первому сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании первого сдвига во времени; и
при этом упомянутое средство для кодирования второго кадра включает в себя средство для временного модифицирования, на основании второго сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутое средство для временного модифицирования сконфигурировано для выполнения одного из (А) временного сдвига сегмента второго сигнала согласно второму сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании второго сдвига во времени,
при этом упомянутое средство для временного модифицирования сегмента второго сигнала сконфигурировано для изменения положения импульса основного тона сегмента относительно другого импульса основного тона второго сигнала, и
при этом второй сдвиг во времени основан на информации из подвергнутого временному модифицированию сегмента первого сигнала.
52. Устройство по п.51, при этом первый сигнал является остатком первого кадра, и при этом второй сигнал является остатком второго кадра.
53. Устройство по п.51, при этом первый и второй сигналы являются взвешенными аудиосигналами.
54. Устройство по п.51, в котором упомянутое средство для временного модифицирования сегмента второго сигнала включает в себя средство для расчета второго сдвига во времени на основании информации из подвергнутого временному модифицированию сегмента первого сигнала, и
при этом упомянутое средство для расчета второго сдвига во времени включает в себя средство для отображения подвергнутого временному модифицированию сегмента первого сигнала в профиль задержки, который основан на информации из второго кадра.
55. Устройство по п.54, при этом упомянутый второй сдвиг во времени основан на корреляции между выборками отображенного сегмента и выборками подвергнутого временному модифицированию остатка, и
при этом подвергнутый временному модифицированию остаток основан на (А) выборках остатка второго кадра и (В) первом сдвиге во времени.
56. Устройство по п.51, в котором второй сигнал является остатком второго кадра, и
при этом упомянутое средство для временного модифицирования сегмента второго сигнала сконфигурировано для временного сдвига первого сегмента остатка согласно второму сдвигу во времени, и при этом упомянутый способ содержит:
средство для расчета третьего сдвига во времени, который является иным, чем второй сдвиг во времени, на основании информации из подвергнутого временному модифицированию первого сегмента остатка; и
средство для временного сдвига второго сегмента остатка согласно третьему сдвигу во времени.
57. Устройство по п.51, при этом второй сигнал является остатком второго кадра, и при этом упомянутое средство для временного модифицирования сегмента второго сигнала включает в себя средство для расчета второго сдвига во времени на основании (А) информации из подвергнутого временному модифицированию сегмента первого сигнала и (В) информации из остатка второго кадра.
58. Устройство по п.51, в котором упомянутое средство для кодирования первого кадра включает в себя:
средство для формирования остатка первого кадра, при этом первый сигнал является сформированным остатком; и
средство для выполнения операции модифицированного дискретного косинусного преобразования над сформированным остатком, включающим в себя подвергнутый временному модифицированию сегмент, чтобы получить кодированный остаток, и
при этом упомянутое средство для кодирования первого кадра сконфигурировано для создания первого кодированного кадра на основании кодированного остатка.
59. Устройство по п.51, в котором первый сигнал имеет длину в М выборок, и второй сигнал имеет длину в М выборок, и
при этом упомянутое средство для кодирования первого кадра включает в себя средство для создания набора из М коэффициентов модифицированного дискретного косинусного преобразования (MDCT), который основан на М выборках первого сигнала, включающего в себя подвергнутый временному модифицированию сегмент, и не более чем 3М/4 выборках второго сигнала.
60. Устройство по п.51, в котором первый сигнал имеет длину в М выборок, и второй сигнал имеет длину в М выборок, и
при этом упомянутое средство для кодирования первого кадра включает в себя средство для создания набора из М коэффициентов модифицированного дискретного косинусного преобразования (MDCT), который основан на последовательности из 2М выборок, которая (А) включает в себя М выборок первого сигнала, включающего в себя подвергнутый временному модифицированию сегмент, (В) начинается с последовательности из по меньшей мере М/8 выборок с нулевым значением и (С) заканчивается последовательностью из по меньшей мере М/8 выборок с нулевым значением.
61. Устройство для обработки кадров аудиосигнала, причем упомянутое устройство содержит:
кодер первого кадра, сконфигурированный для кодирования первого кадра аудиосигнала согласно первой схеме кодирования; и
кодер второго кадра, сконфигурированный для кодирования второго кадра аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR),
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом первая схема кодирования является схемой кодирования без PR, и
при этом упомянутый кодер первого кадра включает в себя первый временной модификатор, сконфигурированный для временного модифицирования, на основании первого сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутый первый временной модификатор сконфигурирован для выполнения одного из (А) временного сдвига сегмента первого сигнала согласно первому сдвигу во времени и (В) изменения шкалы времени сегмента первого сигнала на основании первого сдвига во времени; и
при этом упомянутый кодер второго кадра включает в себя второй временной модификатор, сконфигурированный для временного модифицирования, на основании второго сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутый второй временной модификатор сконфигурирован для выполнения одного из (А) временного сдвига сегмента второго сигнала согласно второму сдвигу во времени и (В) изменения шкалы времени сегмента второго сигнала на основании второго сдвига во времени,
при этом упомянутый второй временной модификатор сконфигурирован для изменения положения импульса основного тона сегмента второго сигнала относительно другого импульса основного тона второго сигнала, и
при этом второй сдвиг во времени основан на информации из подвергнутого временному модифицированию сегмента первого сигнала.
62. Устройство по п.61, при этом первый сигнал является остатком первого кадра, и при этом второй сигнал является остатком второго кадра.
63. Устройство по п.61, при этом первый и второй сигналы являются взвешенными аудиосигналами.
64. Устройство по п.61, в котором упомянутый второй временной модификатор включает в себя вычислитель сдвига во времени, сконфигурированный для расчета второго сдвига во времени на основании информации из подвергнутого временному модифицированию сегмента первого сигнала, и
при этом упомянутый вычислитель сдвига во времени включает в себя модуль отображения, сконфигурированный для отображения подвергнутого временному модифицированию сегмента первого сигнала в профиль задержки, который основан на информации из второго кадра.
65. Устройство по п.64, при этом упомянутый второй сдвиг во времени основан на корреляции между выборками отображенного сегмента и выборками подвергнутого временному модифицированию остатка, и
при этом подвергнутый временному модифицированию остаток основан на (А) выборках остатка второго кадра и (В) первом сдвиге во времени.
66. Устройство по п.61, в котором второй сигнал является остатком второго кадра, и
при этом упомянутый второй временной модификатор сконфигурирован для временного сдвига первого сегмента остатка согласно второму сдвигу во времени, и
при этом упомянутый вычислитель сдвига во времени сконфигурирован для расчета третьего сдвига во времени, который является иным, чем второй сдвиг во времени, на основании информации из подвергнутого временному модифицированию первого сегмента остатка, и
при этом упомянутый второй временной модификатор сконфигурирован для временного сдвига второго сегмента остатка согласно третьему сдвигу во времени.
67. Устройство по п.61, в котором второй сигнал является остатком второго кадра, и при этом упомянутый второй временной модификатор включает в себя вычислитель сдвига во времени, сконфигурированный для расчета второго сдвига во времени на основании (А) информации из подвергнутого временному модифицированию сегмента первого сигнала и (В) информации из остатка второго кадра.
68. Устройство по п.61, в котором упомянутый кодер первого кадра включает в себя:
формирователь остатка, сконфигурированный для формирования остатка первого кадра, при этом первый сигнал является сформированным остатком; и
модуль модифицированного дискретного косинусного преобразования (MDCT), сконфигурированный для выполнения операции MDCT над сформированным остатком, включающим в себя подвергнутый временному модифицированию сегмент, чтобы получить кодированный остаток, и
при этом упомянутый кодер первого кадра сконфигурирован для создания первого кодированного кадра на основании кодированного остатка.
69. Устройство по п.61, в котором первый сигнал имеет длину в М выборок, и второй сигнал имеет длину в М выборок, и
при этом упомянутый кодер первого кадра включает в себя модуль модифицированного дискретного косинусного преобразования (MDCT), сконфигурированный для создания набора из М коэффициентов MDCT, который основан на М выборках первого сигнала, включающего в себя подвергнутый временному модифицированию сегмент, и не более чем 3М/4 выборках второго сигнала.
70. Устройство по п.61, в котором первый сигнал имеет длину в М выборок, и второй сигнал имеет длину в М выборок, и
при этом упомянутый кодер первого кадра включает в себя модуль модифицированного дискретного косинусного преобразования (MDCT);
сконфигурированный для создания набора из М коэффициентов MDCT, который основан на последовательности из 2М выборок, которая (А) включает в себя М выборок первого сигнала, включающего в себя подвергнутый временному модифицированию сегмент, (В) начинается с последовательности из по меньшей мере М/8 выборок с нулевым значением и (С) заканчивается последовательностью из по меньшей мере М/8 выборок с нулевым значением.
71. Машиночитаемый носитель, содержащий команды, которые, при исполнении их процессором, побуждают процессор:
кодировать первый кадр аудиосигнала согласно первой схеме кодирования; и
кодировать второй кадр аудиосигнала согласно схеме кодирования с регуляризацией основных тонов (PR),
при этом второй кадр следует и является последующим за первым кадром в аудиосигнале, и
при этом первая схема кодирования является схемой кодирования без PR, и
при этом упомянутые команды, которые, при исполнении их процессором, побуждают процессор кодировать первый кадр, включают в себя команды для временного модифицирования, на основании первого сдвига во времени, сегмента первого сигнала, который основан на первом кадре, причем упомянутые команды для временного модифицирования включают в себя одно из (А) команд для временного сдвига сегмента первого сигнала согласно первому сдвигу во времени и (В) команд для изменения шкалы времени сегмента первого сигнала на основании первого сдвига во времени; и
при этом упомянутые команды, которые, при исполнении их процессором, побуждают процессор кодировать второй кадр, включают в себя команды для временного модифицирования, на основании второго сдвига во времени, сегмента второго сигнала, который основан на втором кадре, причем упомянутые команды для временного модифицирования включают в себя одно из (А) команд для временного сдвига сегмента второго сигнала согласно второму сдвигу во времени и (В) команд для изменения шкалы времени сегмента второго сигнала на основании второго сдвига во времени,
при этом упомянутые команды для временного модифицирования сегмента второго сигнала включают в себя команды для изменения положения импульса основного тона сегмента относительно другого импульса основного тона второго сигнала, и
при этом второй сдвиг во времени основан на информации из подвергнутого временному модифицированию сегмента первого сигнала.
| US 2007088558 A1, 19.04.2007 | |||
| US 20050065782 A, 24.03.2005 | |||
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| Ручной ковроткацкий станок | 1990 |
|
SU1758101A1 |
| RU 2005104122 A, 10.08.2005 | |||
| Термопреобразователь сопротивления | 1985 |
|
SU1420391A1 |
| Опрыскиватель с автоматической дозировкой компонентов | 1985 |
|
SU1271471A1 |

